⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-19 更新
Robotic CBCT Meets Robotic Ultrasound
Authors:Feng Li, Yuan Bi, Dianye Huang, Zhongliang Jiang, Nassir Navab
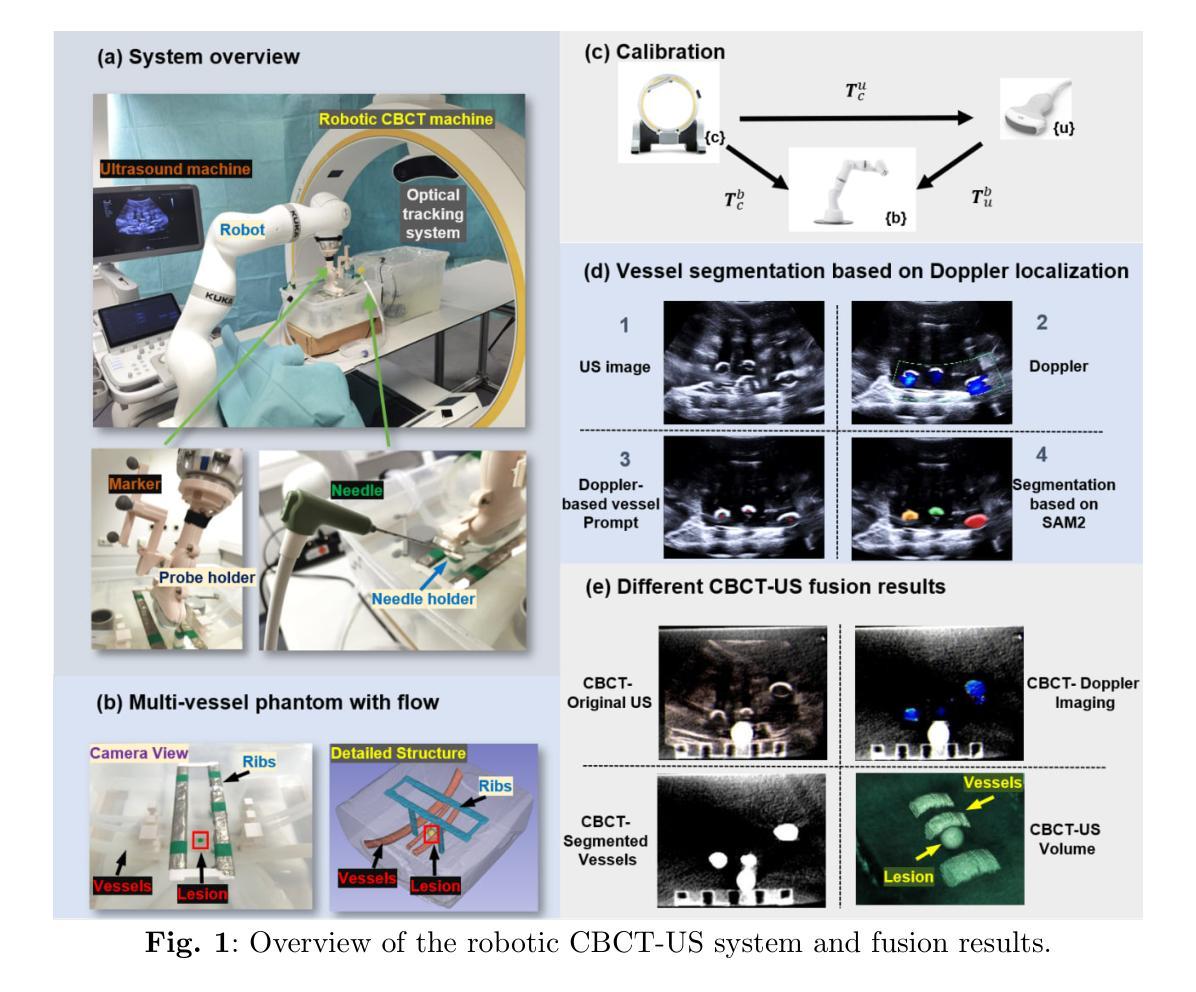
The multi-modality imaging system offers optimal fused images for safe and precise interventions in modern clinical practices, such as computed tomography - ultrasound (CT-US) guidance for needle insertion. However, the limited dexterity and mobility of current imaging devices hinder their integration into standardized workflows and the advancement toward fully autonomous intervention systems. In this paper, we present a novel clinical setup where robotic cone beam computed tomography (CBCT) and robotic US are pre-calibrated and dynamically co-registered, enabling new clinical applications. This setup allows registration-free rigid registration, facilitating multi-modal guided procedures in the absence of tissue deformation. First, a one-time pre-calibration is performed between the systems. To ensure a safe insertion path by highlighting critical vasculature on the 3D CBCT, SAM2 segments vessels from B-mode images, using the Doppler signal as an autonomously generated prompt. Based on the registration, the Doppler image or segmented vessel masks are then mapped onto the CBCT, creating an optimally fused image with comprehensive detail. To validate the system, we used a specially designed phantom, featuring lesions covered by ribs and multiple vessels with simulated moving flow. The mapping error between US and CBCT resulted in an average deviation of 1.72+-0.62 mm. A user study demonstrated the effectiveness of CBCT-US fusion for needle insertion guidance, showing significant improvements in time efficiency, accuracy, and success rate. Needle intervention performance improved by approximately 50% compared to the conventional US-guided workflow. We present the first robotic dual-modality imaging system designed to guide clinical applications. The results show significant performance improvements compared to traditional manual interventions.
多模态成像系统为现代临床实践中的安全和精确干预提供了最佳的融合图像,例如计算机断层扫描-超声(CT-US)引导的针插入。然而,当前成像设备的有限灵活性和机动性阻碍了其融入标准化工作流程,并阻碍了向完全自主干预系统的迈进。在本文中,我们展示了一种新型临床设置,其中机器人锥形束计算机断层扫描(CBCT)和机器人超声预先校准并动态共注册,从而启用了新的临床应用。该设置可实现免注册刚性注册,在不存在组织变形的情况下,促进多模态引导程序。首先,在系统之间进行一次性预校准。为了确保通过突出显示3D CBCT上的关键血管来确保安全的插入路径,SAM2从B模式图像中分割血管,并使用多普勒信号作为自主生成的提示。基于注册,将多普勒图像或分割的血管掩模映射到CBCT上,创建具有全面细节的优质融合图像。为了验证系统,我们使用专门设计的幻影进行了测试,该幻影具有被肋骨覆盖的病变和模拟流动的多条血管。超声和CBCT之间的映射误差导致平均偏差为1.72+-0.62毫米。一项用户研究证明了CBCT-US融合在针插入指导中的有效性,在时效、准确性和成功率方面显示出显着改善。与传统的超声引导工作流程相比,针刺干预性能提高了约50%。我们展示了首个用于指导临床应用的机器人双模态成像系统。结果表明,与传统的人工干预相比,该系统在性能上有了显着的提高。
论文及项目相关链接
Summary
本文介绍了一种新型多模态成像系统,融合了机器人化计算机断层扫描(CBCT)和超声波技术。系统能够实现非刚性的实时融合注册,提供了三维环境下多模态指导的优势,特别是对于骨骼与软组织并存的病灶导航与精确的穿刺引导有显著的效能改进。其中用到的核心包括系统的预装校队设置和多模态影像的融合技术,能够提高操作效率和准确性。总结为:新一代机器人多模态成像系统显著提高诊疗精准度和效率。
Key Takeaways
以下是本文的主要见解:
- 多模态成像系统在现代医疗实践中表现出在安全和精确干预方面的优势,如CT-US引导下的针插术。然而,当前成像设备的灵活性和移动性限制阻碍了其在标准化工作流程和全自动干预系统中的整合。
- 介绍了一种新型临床设置,结合了机器人CBCT和机器人超声技术,两者预先校准并动态注册,为新的临床应用提供了可能。这种设置允许无注册刚性注册,促进了多模态引导程序在不存在组织变形的情况下进行。
- 通过一次预先校准在两个系统间进行注册,并利用SAM2从B模式图像中分割血管,利用多普勒信号作为自主生成的提示来确保安全插入路径。
点此查看论文截图

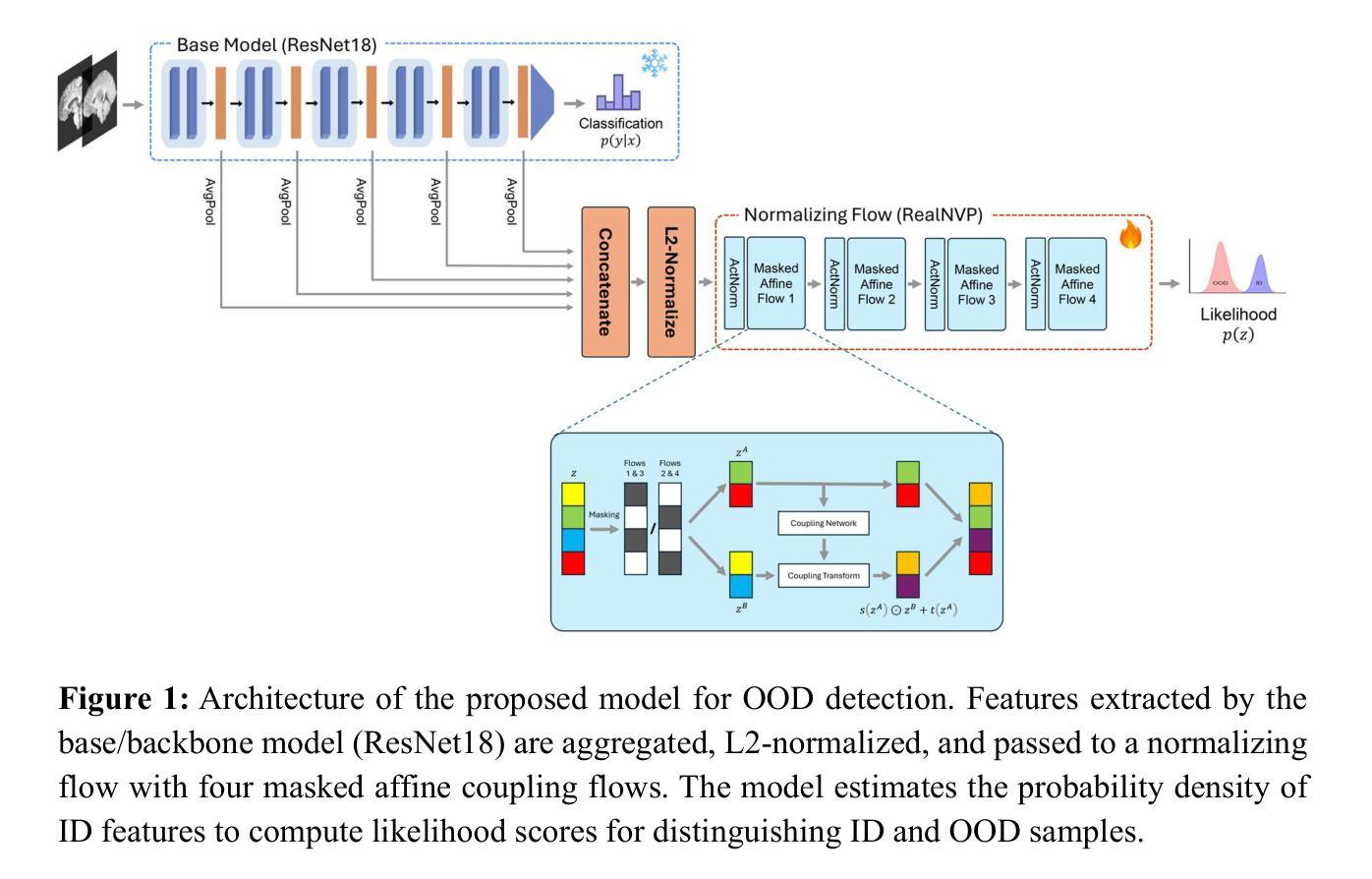
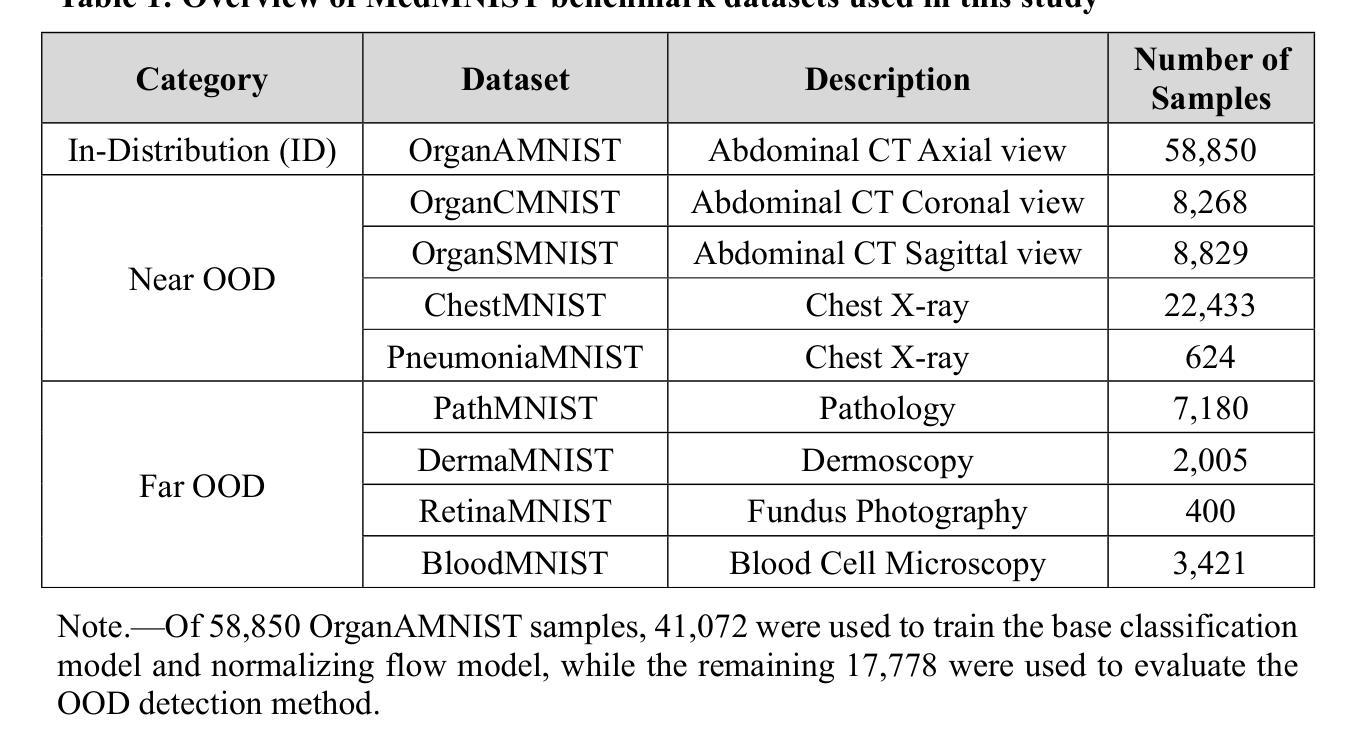
Enhancing Out-of-Distribution Detection in Medical Imaging with Normalizing Flows
Authors:Dariush Lotfi, Mohammad-Ali Nikouei Mahani, Mohamad Koohi-Moghadam, Kyongtae Ty Bae
Out-of-distribution (OOD) detection is crucial in AI-driven medical imaging to ensure reliability and safety by identifying inputs outside a model’s training distribution. Existing methods often require retraining or modifications to pre-trained models, which is impractical for clinical applications. This study introduces a post-hoc normalizing flow-based approach that seamlessly integrates with pre-trained models. By leveraging normalizing flows, it estimates the likelihood of feature vectors extracted from pre-trained models, capturing semantically meaningful representations without relying on pixel-level statistics. The method was evaluated using the MedMNIST benchmark and a newly curated MedOOD dataset simulating clinically relevant distributional shifts. Performance was measured using standard OOD detection metrics (e.g., AUROC, FPR@95, AUPR_IN, AUPR_OUT), with statistical analyses comparing it against ten baseline methods. On MedMNIST, the proposed model achieved an AUROC of 93.80%, outperforming state-of-the-art methods. On MedOOD, it achieved an AUROC of 84.61%, demonstrating superior performance against other methods. Its post-hoc nature ensures compatibility with existing clinical workflows, addressing the limitations of previous approaches. The model and code to build OOD datasets are available at https://github.com/dlotfi/MedOODFlow.
在人工智能驱动的医学影像中,离群值检测(Out-of-distribution,简称OOD)是确保可靠性和安全性的关键。它能够通过识别超出模型训练分布范围的输入来进行预测。现有的方法通常需要针对预训练模型进行重新训练或修改,这在临床应用中是不可取的。本研究引入了一种事后归一化流方法,该方法能够无缝集成到预训练模型中。通过利用归一化流,该方法估计从预训练模型提取的特征向量的可能性,并捕捉语义上有意义的表示,而无需依赖像素级统计信息。该研究使用MedMNIST基准测试和模拟临床相关分布变化的全新MedOOD数据集对该方法进行了评估。性能通过标准的离群检测指标(如AUROC、FPR@95、AUPR_IN、AUPR_OUT)来衡量,并通过与十种基准方法进行比较来进行统计分析。在MedMNIST上,所提出模型的AUROC达到了93.80%,优于最先进的方法。在MedOOD上,其AUROC达到了84.61%,证明了相较于其他方法的优越性。其事后特性确保了与现有临床工作流程的兼容性,解决了之前方法的局限性。模型和构建离群检测数据集的代码可在https://github.com/dlotfi/MedOODFlow找到。
论文及项目相关链接
摘要
本文介绍了一种基于事后归一化流的方法,该方法可以无缝集成到预训练模型中,用于医疗图像中的分布外(OOD)检测。该方法通过利用归一化流估算预训练模型提取的特征向量的概率分布,捕捉语义上有意义的表示,无需依赖像素级统计。在MedMNIST基准测试和模拟临床相关分布偏移的MedOOD数据集上进行了评估,结果表明该方法在标准OOD检测指标上表现优异,优于十种基线方法。其事后性质确保了与现有临床工作流程的兼容性,解决了以前方法的局限性。
要点
- 介绍了一种新的基于归一化流的方法用于医疗图像中的OOD检测。
- 方法无缝集成到预训练模型,无需重训或修改模型。
- 利用归一化流估算预训练模型的特征向量概率分布。
- 在MedMNIST和MedOOD数据集上进行了评估,表现优于其他方法。
- 方法的性能使用标准OOD检测指标进行衡量。
- 该方法具有事后性质,与现有临床工作流程兼容。
- 模型和构建OOD数据集的代码已公开发布。
点此查看论文截图


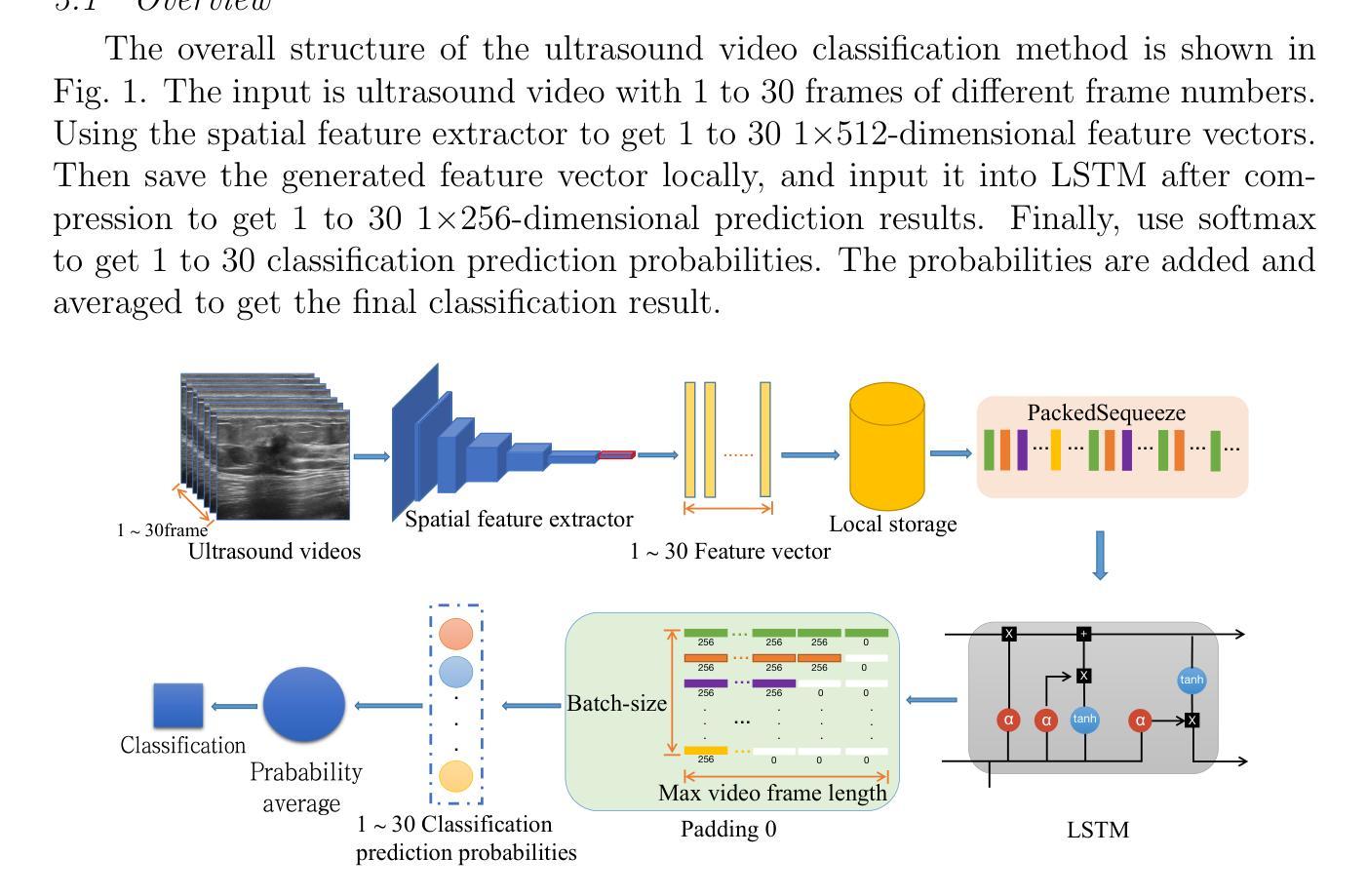
Variable-frame CNNLSTM for Breast Nodule Classification using Ultrasound Videos
Authors:Xiangxiang Cui, Zhongyu Li, Xiayue Fan, Peng Huang, Ying Wang, Meng Yang, Shi Chang, Jihua Zhu
The intersection of medical imaging and artificial intelligence has become an important research direction in intelligent medical treatment, particularly in the analysis of medical images using deep learning for clinical diagnosis. Despite the advances, existing keyframe classification methods lack extraction of time series features, while ultrasonic video classification based on three-dimensional convolution requires uniform frame numbers across patients, resulting in poor feature extraction efficiency and model classification performance. This study proposes a novel video classification method based on CNN and LSTM, introducing NLP’s long and short sentence processing scheme into video classification for the first time. The method reduces CNN-extracted image features to 1x512 dimension, followed by sorting and compressing feature vectors for LSTM training. Specifically, feature vectors are sorted by patient video frame numbers and populated with padding value 0 to form variable batches, with invalid padding values compressed before LSTM training to conserve computing resources. Experimental results demonstrate that our variable-frame CNNLSTM method outperforms other approaches across all metrics, showing improvements of 3-6% in F1 score and 1.5% in specificity compared to keyframe methods. The variable-frame CNNLSTM also achieves better accuracy and precision than equal-frame CNNLSTM. These findings validate the effectiveness of our approach in classifying variable-frame ultrasound videos and suggest potential applications in other medical imaging modalities.
医学影像与人工智能的交汇点已成为智能医疗治疗的重要研究方向,特别是在利用深度学习对医学影像进行临床分析方面。然而,尽管有所进展,现有的关键帧分类方法缺乏时间序列特征的提取能力。基于三维卷积的超声视频分类则需要跨患者统一帧数量,导致特征提取效率和模型分类性能较差。本研究提出了一种基于CNN和LSTM的新型视频分类方法,首次将NLP的长短句处理方案引入视频分类中。该方法将CNN提取的图像特征降维至1x512维,然后对特征向量进行排序和压缩,以供LSTM训练使用。具体来说,根据患者的视频帧数量对特征向量进行排序,并用填充值0来形成可变批次,在LSTM训练之前压缩无效的填充值以节省计算资源。实验结果表明,我们的可变帧CNNLSTM方法在各项指标上均优于其他方法,与关键帧方法相比,F1得分提高了3-6%,特异性提高了1.5%。此外,可变帧CNNLSTM的准确性和精度也高于等帧CNNLSTM。这些发现验证了我们的方法在分类可变帧超声视频中的有效性,并暗示其在其他医学影像模式中的潜在应用。
论文及项目相关链接
Summary
医学图像与人工智能的交融已成为智能医疗治疗的重要研究方向,特别是在利用深度学习对医学图像进行临床诊断分析方面。本研究提出了一种基于CNN和LSTM的新型视频分类方法,首次引入NLP的长短句处理方案用于视频分类。该方法降低了CNN提取的图像特征维度,对特征向量进行排序和压缩,用于LSTM训练。实验结果显示,与关键帧方法相比,我们的可变帧CNNLSTM方法在F1得分、特异性和准确性等方面均有显著提升。
Key Takeaways
- 医学图像与人工智能的融合在智能医疗领域成为重要研究方向。
- 现有关键帧分类方法存在时间序列表征提取不足的问题。
- 基于三维卷积的超声视频分类要求患者间帧数目一致,影响特征提取效率和模型分类性能。
- 本研究提出了基于CNN和LSTM的视频分类新方法。
- 该方法引入NLP的长短句处理方案,降低CNN图像特征维度至1x512。
- 通过排序和压缩特征向量,采用可变批次训练LSTM。
- 实验结果显示,新方法在F1得分、特异性和准确性等方面均优于其他方法。
点此查看论文截图

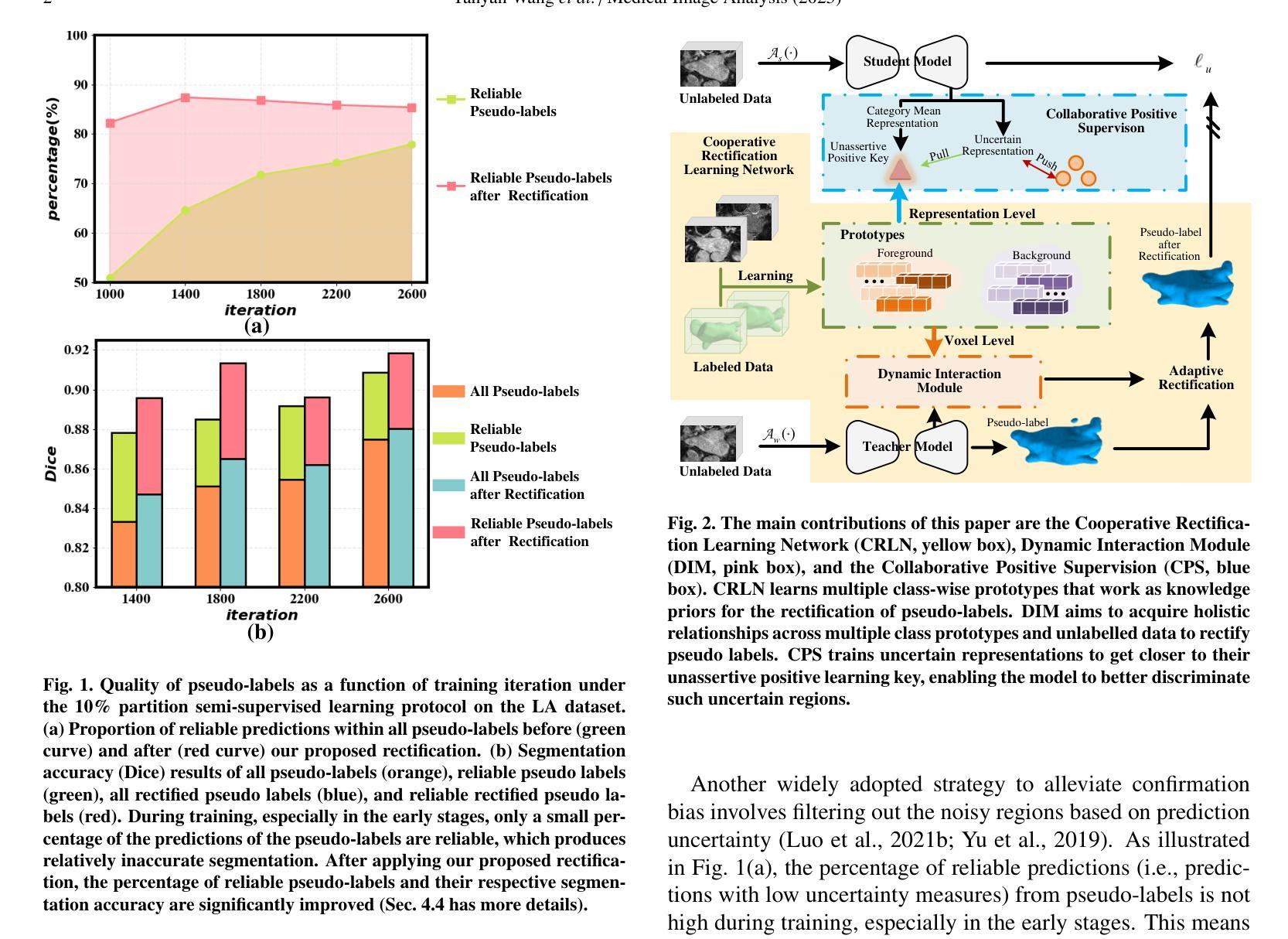
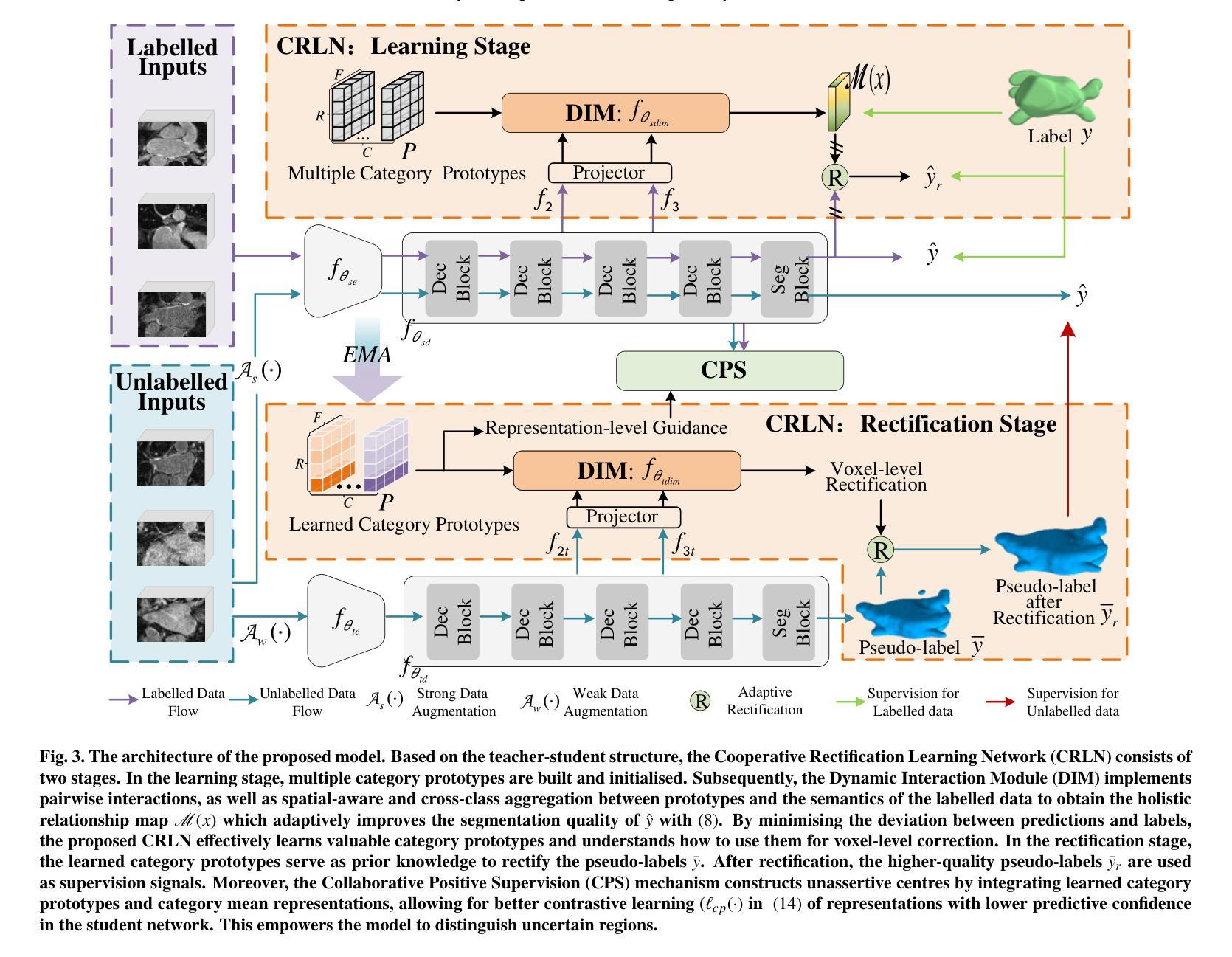
Leveraging Labelled Data Knowledge: A Cooperative Rectification Learning Network for Semi-supervised 3D Medical Image Segmentation
Authors:Yanyan Wang, Kechen Song, Yuyuan Liu, Shuai Ma, Yunhui Yan, Gustavo Carneiro
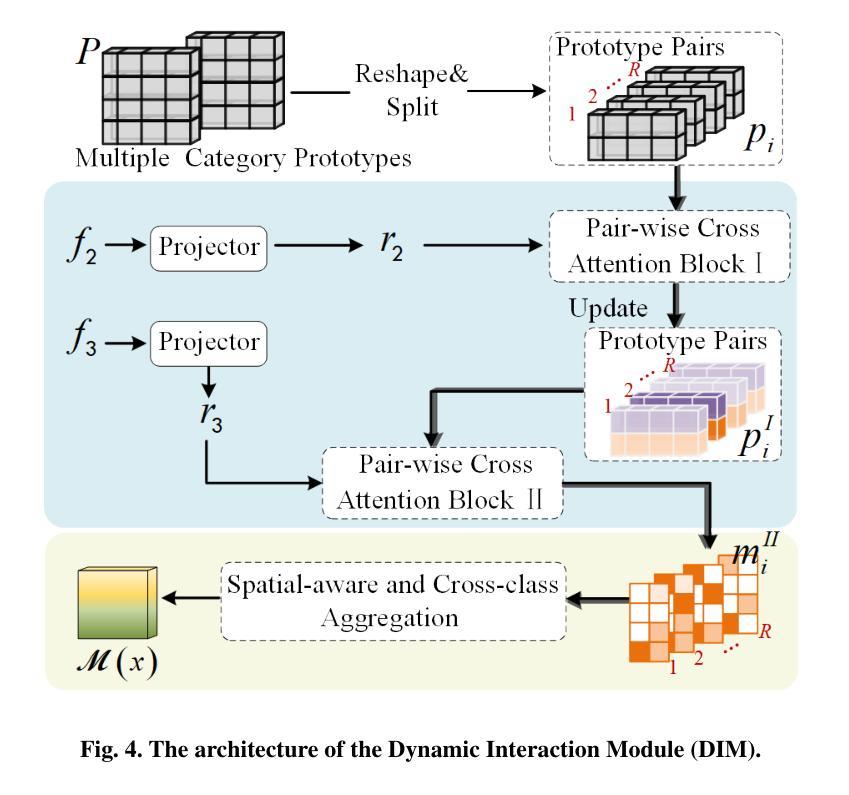
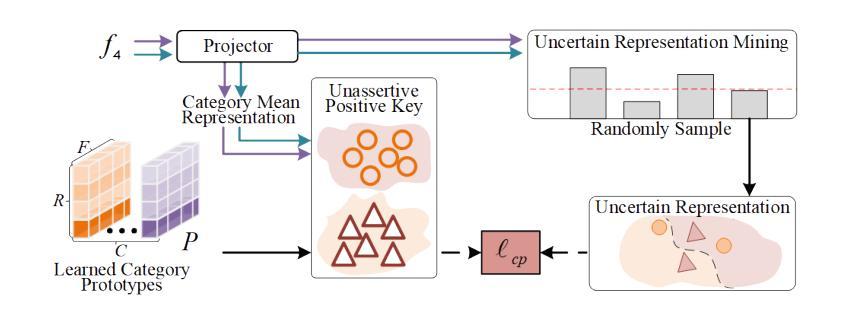
Semi-supervised 3D medical image segmentation aims to achieve accurate segmentation using few labelled data and numerous unlabelled data. The main challenge in the design of semi-supervised learning methods consists in the effective use of the unlabelled data for training. A promising solution consists of ensuring consistent predictions across different views of the data, where the efficacy of this strategy depends on the accuracy of the pseudo-labels generated by the model for this consistency learning strategy. In this paper, we introduce a new methodology to produce high-quality pseudo-labels for a consistency learning strategy to address semi-supervised 3D medical image segmentation. The methodology has three important contributions. The first contribution is the Cooperative Rectification Learning Network (CRLN) that learns multiple prototypes per class to be used as external knowledge priors to adaptively rectify pseudo-labels at the voxel level. The second contribution consists of the Dynamic Interaction Module (DIM) to facilitate pairwise and cross-class interactions between prototypes and multi-resolution image features, enabling the production of accurate voxel-level clues for pseudo-label rectification. The third contribution is the Cooperative Positive Supervision (CPS), which optimises uncertain representations to align with unassertive representations of their class distributions, improving the model’s accuracy in classifying uncertain regions. Extensive experiments on three public 3D medical segmentation datasets demonstrate the effectiveness and superiority of our semi-supervised learning method.
半监督3D医学图像分割旨在使用少量标记数据和大量未标记数据实现准确分割。半监督学习方法设计的主要挑战在于如何有效利用未标记数据进行训练。一种有前途的解决方案是确保数据不同视图之间的预测一致性,该策略的有效性取决于模型为此一致性学习策略生成伪标签的准确性。在本文中,我们介绍了一种新的方法为半监督3D医学图像分割的一致性学习策略生成高质量伪标签。该方法有三个重要贡献。第一个贡献是合作校正学习网络(CRLN),它学习每类的多个原型,作为外部知识先验,以自适应地纠正伪标签的像素级别。第二个贡献是动态交互模块(DIM),它促进了原型和多分辨率图像特征之间的配对和跨类别交互,为伪标签校正产生准确的像素级线索。第三个贡献是合作正面监督(CPS),它优化不确定的表示,使其与类分布的不确定表示对齐,提高模型对不确定区域的分类准确性。在三个公共3D医学分割数据集上的广泛实验证明了我们的半监督学习方法的有效性和优越性。
论文及项目相关链接
PDF Medical Image Analysis
Summary
半监督3D医学图像分割旨在利用少量标注数据和大量未标注数据实现准确分割。主要挑战在于如何有效利用未标注数据进行训练。一种有前途的解决方案是确保数据不同视图之间的预测一致性,该策略的有效性取决于模型生成的伪标签的准确性。本文介绍了一种新的方法为一致性学习策略生成高质量的伪标签,以解决半监督3D医学图像分割问题。该方法有三个重要贡献:合作修正学习网络(CRLN)、动态交互模块(DIM)和合作正向监督(CPS)。
Key Takeaways
- 半监督3D医学图像分割旨在利用有限的标注数据和大量的未标注数据实现准确分割。
- 设计的挑战在于如何有效利用未标注数据进行训练。
- 预测不同视图之间的一致性对于半监督学习方法至关重要。
- 本文提出了一种新的方法,包括三个关键贡献:合作修正学习网络(CRLN)、动态交互模块(DIM)和合作正向监督(CPS)。
- CRLN学习每类的多个原型作为外部知识先验,以自适应地纠正伪标签。
- DIM促进原型和多分辨率图像特征之间的配对和跨类交互,为伪标签纠正提供准确的体素级线索。
- CPS优化不确定表示,使其与类分布的不确定表示对齐,提高模型对不确定区域的分类准确性。
点此查看论文截图

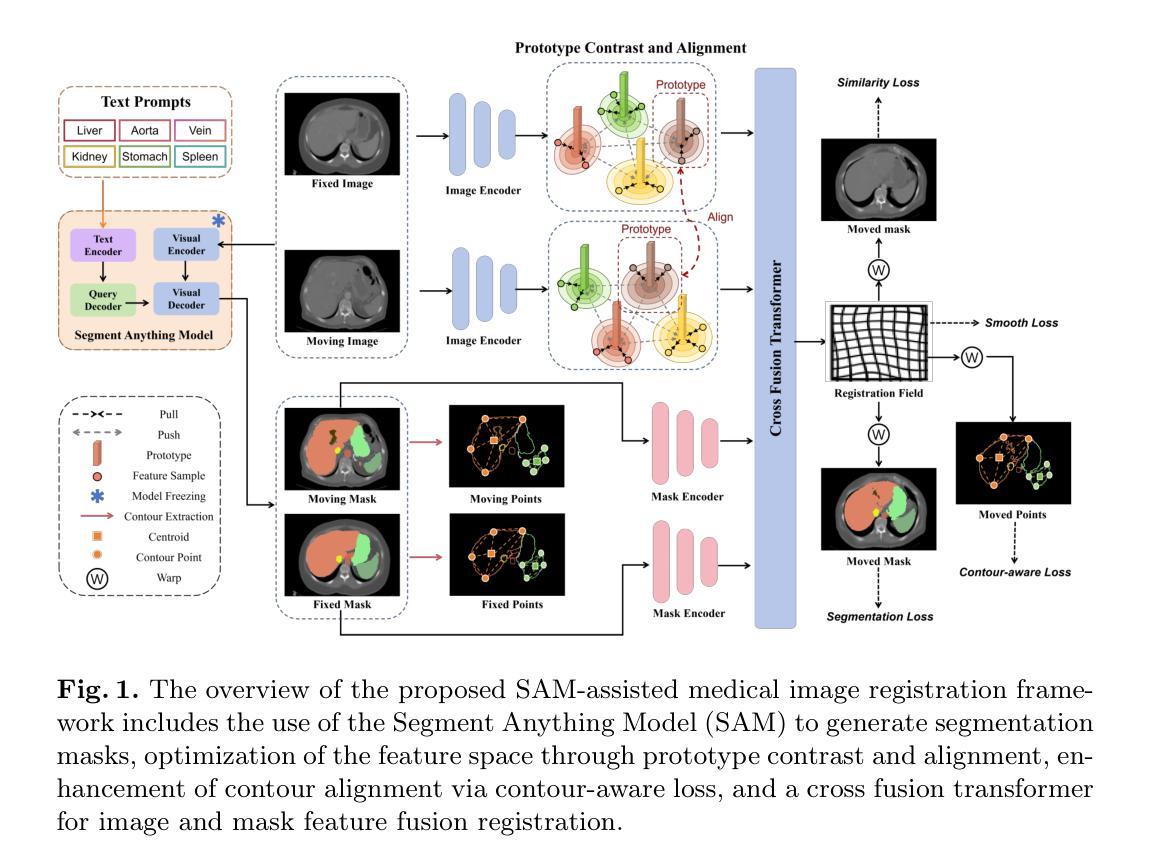
Medical Image Registration Meets Vision Foundation Model: Prototype Learning and Contour Awareness
Authors:Hao Xu, Tengfei Xue, Jianan Fan, Dongnan Liu, Yuqian Chen, Fan Zhang, Carl-Fredrik Westin, Ron Kikinis, Lauren J. O’Donnell, Weidong Cai
Medical image registration is a fundamental task in medical image analysis, aiming to establish spatial correspondences between paired images. However, existing unsupervised deformable registration methods rely solely on intensity-based similarity metrics, lacking explicit anatomical knowledge, which limits their accuracy and robustness. Vision foundation models, such as the Segment Anything Model (SAM), can generate high-quality segmentation masks that provide explicit anatomical structure knowledge, addressing the limitations of traditional methods that depend only on intensity similarity. Based on this, we propose a novel SAM-assisted registration framework incorporating prototype learning and contour awareness. The framework includes: (1) Explicit anatomical information injection, where SAM-generated segmentation masks are used as auxiliary inputs throughout training and testing to ensure the consistency of anatomical information; (2) Prototype learning, which leverages segmentation masks to extract prototype features and aligns prototypes to optimize semantic correspondences between images; and (3) Contour-aware loss, a contour-aware loss is designed that leverages the edges of segmentation masks to improve the model’s performance in fine-grained deformation fields. Extensive experiments demonstrate that the proposed framework significantly outperforms existing methods across multiple datasets, particularly in challenging scenarios with complex anatomical structures and ambiguous boundaries. Our code is available at https://github.com/HaoXu0507/IPMI25-SAM-Assisted-Registration.
医学图像配准是医学图像分析中的一项基本任务,旨在建立配对图像之间的空间对应关系。然而,现有的无监督可变形配准方法仅依赖于基于强度的相似性度量,缺乏明确的解剖知识,这限制了它们的准确性和稳健性。视觉基础模型(如分割任何模型(SAM))可以生成高质量的分割掩模,提供明确的解剖结构知识,解决了传统方法仅依赖强度相似性的局限性。基于此,我们提出了一种结合原型学习和轮廓感知的SAM辅助配准框架。该框架包括:(1)显式解剖信息注入:在训练和测试过程中,使用SAM生成的分割掩模作为辅助输入,以确保解剖信息的一致性;(2)原型学习:利用分割掩模提取原型特征,并对齐原型以优化图像之间的语义对应关系;(3)轮廓感知损失:设计了一种利用分割掩模边缘的轮廓感知损失,以提高模型在精细颗粒变形场中的性能。大量实验表明,所提出的框架在多个数据集上显著优于现有方法,特别是在具有复杂解剖结构和模糊边界的挑战性场景中。我们的代码可在[https://github.com/HaoXu0507/IPMI25-SAM-Assisted-Registration找到。]
论文及项目相关链接
PDF Accepted by Information Processing in Medical Imaging (IPMI) 2025
Summary
医学图像配准是医学图像分析中的基本任务,旨在建立配对图像之间的空间对应关系。然而,现有的无监督可变形配准方法仅依赖于强度相似度度量,缺乏明确的解剖知识,限制了其准确性和鲁棒性。为解决这个问题,我们结合使用分段模型SAM提出了一种新型的配准框架,该框架包含原型学习和轮廓感知技术。通过注入明确的解剖学信息、原型特征对齐和轮廓感知损失设计,该框架显著提高了模型在精细变形场中的性能。
Key Takeaways
- 医学图像配准旨在建立配对图像间的空间对应关系。
- 现有方法主要依赖强度相似度度量,缺乏明确的解剖知识。
- SAM模型可以生成高质量的分段掩模,提供明确的解剖结构知识。
- 提出的新型配准框架结合了SAM模型、原型学习和轮廓感知技术。
- 框架通过注入解剖学信息、原型特征对齐来提高性能。
- 轮廓感知损失设计进一步提升了模型在精细变形场中的表现。
点此查看论文截图

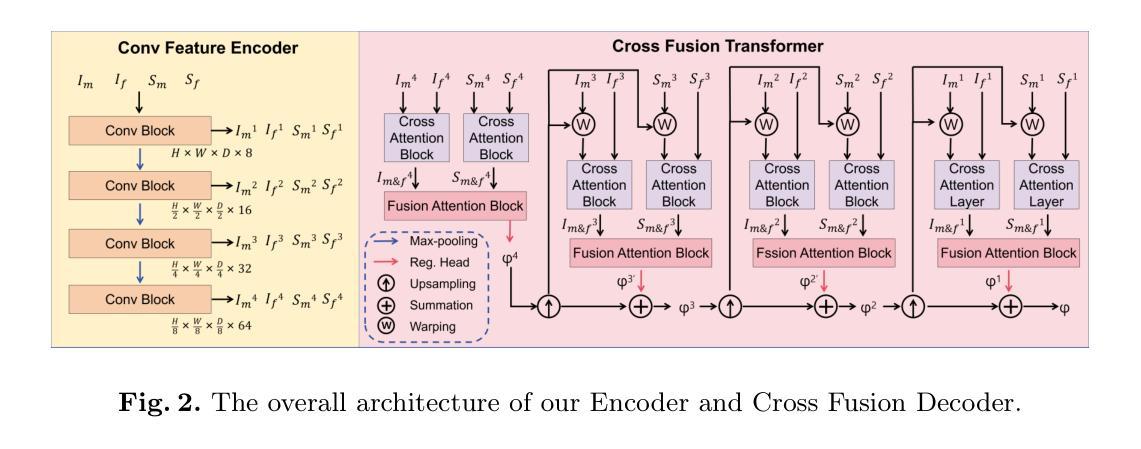
WRT-SAM: Foundation Model-Driven Segmentation for Generalized Weld Radiographic Testing
Authors:Yunyi Zhou, Kun Shi, Gang Hao
Radiographic testing is a fundamental non-destructive evaluation technique for identifying weld defects and assessing quality in industrial applications due to its high-resolution imaging capabilities. Over the past decade, deep learning techniques have significantly advanced weld defect identification in radiographic images. However, conventional approaches, which rely on training small-scale, task-specific models on single-scenario datasets, exhibit poor cross-scenario generalization. Recently, the Segment Anything Model (SAM), a pre-trained visual foundation model trained on large-scale datasets, has demonstrated exceptional zero-shot generalization capabilities. Fine-tuning SAM with limited domain-specific data has yielded promising results in fields such as medical image segmentation and anomaly detection. To the best of our knowledge, this work is the first to introduce SAM-based segmentation for general weld radiographic testing images. We propose WRT-SAM, a novel weld radiographic defect segmentation model that leverages SAM through an adapter-based integration with a specialized prompt generator architecture. To improve adaptability to grayscale weld radiographic images, we introduce a frequency prompt generator module, which enhances the model’s sensitivity to frequency-domain information. Furthermore, to address the multi-scale nature of weld defects, we incorporate a multi-scale prompt generator module, enabling the model to effectively extract and encode defect information across varying scales. Extensive experimental evaluations demonstrate that WRT-SAM achieves a recall of 78.87%, a precision of 84.04%, and an AUC of 0.9746, setting a new state-of-the-art (SOTA) benchmark. Moreover, the model exhibits superior zero-shot generalization performance, highlighting its potential for practical deployment in diverse radiographic testing scenarios.
放射检测是一种重要的无损评估技术,因其高分辨率成像能力,在工业应用中能够识别焊接缺陷并评估质量。过去十年,深度学习技术已显著推进了放射图像中的焊接缺陷识别。然而,传统方法依赖于在单一场景数据集上训练小规模、特定任务的模型,其跨场景泛化能力较差。最近,Segment Anything Model(SAM)这一在大规模数据集上训练的预训练视觉基础模型,已展现出卓越的零样本泛化能力。使用有限的领域特定数据对SAM进行微调,在医学图像分割和异常检测等领域已取得了有前景的结果。据我们所知,这项工作首次引入了基于SAM的分割方法,用于通用焊接放射检测图像。我们提出了WRT-SAM,这是一种新型的焊接放射缺陷分割模型,它通过基于适配器的集成与专门的提示生成架构,利用SAM的优势。为了改善对灰度焊接放射图像的可适应性,我们引入了频率提示生成器模块,该模块提高了模型对频域信息的敏感性。此外,为了应对焊接缺陷的多尺度特性,我们融入了多尺度提示生成器模块,使模型能够在不同尺度上有效地提取和编码缺陷信息。广泛的实验评估表明,WRT-SAM达到了78.87%的召回率、84.04%的精确度和0.9746的AUC,创下了新的SOTA基准。此外,该模型展现出卓越的零样本泛化性能,突显其在各种放射检测场景中的实际部署潜力。
论文及项目相关链接
Summary
采用深度学习的焊缝缺陷检测技术在过去十年中取得了显著进展。然而,传统方法存在跨场景泛化能力差的缺陷。为改善此状况,研究团队引入了预训练的通用视觉模型SAM(Segment Anything Model)。本研究提出WRT-SAM模型,该模型结合SAM和特定的适配器架构进行焊缝放射性缺陷检测。为提高对灰度焊缝放射性图像的适应性,引入了频率提示生成器模块和多尺度提示生成器模块,这些改进模块有效提升了模型性能。评估结果显示WRT-SAM达到新的最高性能水平,并展现出卓越的零样本泛化能力。
Key Takeaways
1. 放射性检测在工业应用中是鉴定焊缝缺陷和评估质量的重要技术。
2. 传统深度学习方法在跨场景泛化方面存在局限。
3. Segment Anything Model(SAM)展现出出色的零样本泛化能力。
4. WRT-SAM模型结合SAM和特定的适配器架构用于焊缝放射性缺陷检测。
5. 引入频率提示生成器模块提高模型对频率信息的敏感性。
6. 多尺度提示生成器模块解决了焊缝缺陷的多尺度问题。
点此查看论文截图

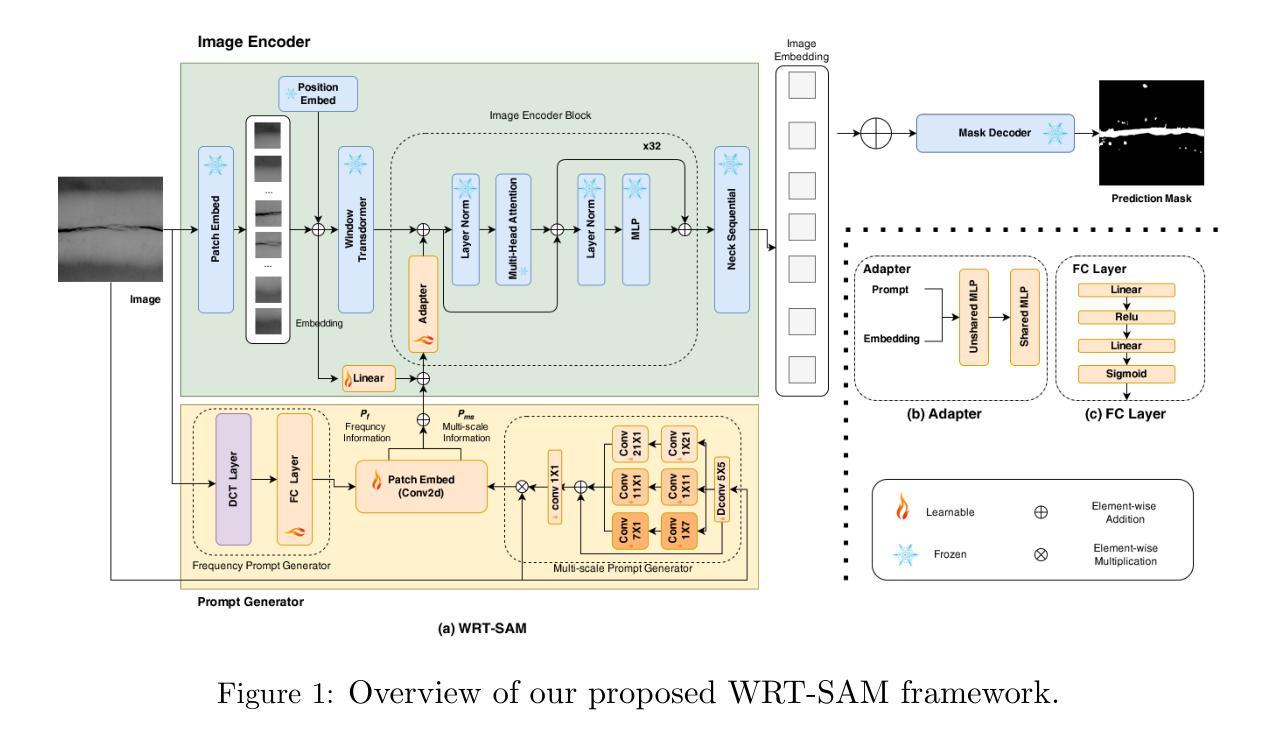
RemInD: Remembering Anatomical Variations for Interpretable Domain Adaptive Medical Image Segmentation
Authors:Xin Wang, Yin Guo, Kaiyu Zhang, Niranjan Balu, Mahmud Mossa-Basha, Linda Shapiro, Chun Yuan
This work presents a novel Bayesian framework for unsupervised domain adaptation (UDA) in medical image segmentation. While prior works have explored this clinically significant task using various strategies of domain alignment, they often lack an explicit and explainable mechanism to ensure that target image features capture meaningful structural information. Besides, these methods are prone to the curse of dimensionality, inevitably leading to challenges in interpretability and computational efficiency. To address these limitations, we propose RemInD, a framework inspired by human adaptation. RemInD learns a domain-agnostic latent manifold, characterized by several anchors, to memorize anatomical variations. By mapping images onto this manifold as weighted anchor averages, our approach ensures realistic and reliable predictions. This design mirrors how humans develop representative components to understand images and then retrieve component combinations from memory to guide segmentation. Notably, model prediction is determined by two explainable factors: a low-dimensional anchor weight vector, and a spatial deformation. This design facilitates computationally efficient and geometry-adherent adaptation by aligning weight vectors between domains on a probability simplex. Experiments on two public datasets, encompassing cardiac and abdominal imaging, demonstrate the superiority of RemInD, which achieves state-of-the-art performance using a single alignment approach, outperforming existing methods that often rely on multiple complex alignment strategies.
本文介绍了一种用于医学图像分割的无监督域自适应(UDA)的新型贝叶斯框架。虽然先前的研究已经使用各种域对齐策略探索了这项具有临床意义的任务,但它们通常缺乏明确和可解释的机制,以确保目标图像特征捕获有意义的结构信息。此外,这些方法容易受到维度诅咒的影响,不可避免地导致解释性和计算效率方面的挑战。为了解决这些局限性,我们提出了RemInD,一个受人类适应启发的框架。RemInD学习一个与域无关的潜在流形,该流形以多个锚点为特征,以记忆解剖变异。通过将图像映射到这个流形作为加权锚点平均值,我们的方法确保了预测的现实性和可靠性。这种设计反映了人类如何发展代表性组件来理解图像,然后从内存中检索组件组合来指导分割。值得注意的是,模型预测由两个可解释的因素决定:低维锚点权重向量和空间变形。这种设计通过对概率单纯形上的域间权重向量进行对齐,实现了计算高效和几何适应的适应。在包括心脏和腹部成像的两个公共数据集上的实验表明,RemInD具有优越性,使用单一的对齐方法即可实现最新性能,超越了那些通常依赖于多个复杂对齐策略的现有方法。
论文及项目相关链接
PDF Accepted by IPMI 2025 (Information Processing in Medical Imaging)
Summary
该工作提出一种新型的贝叶斯框架,用于医学图像分割中的无监督域自适应(UDA)。针对以往方法缺乏明确的解释性机制以及面临维度诅咒的问题,提出RemInD框架,该框架通过人类适应性启发学习域无关的潜在流形并以其作为锚点记忆解剖结构变异,通过将图像映射到此流形上作为加权锚点平均值来确保预测的真实性和可靠性。模型预测由两个可解释因素决定:低维锚点权重向量和空间变形。这种设计有助于计算效率高且符合几何适应性的域间权重向量对齐。在公共数据集上的实验显示RemInD达到业界最佳性能,使用单一对齐方法优于其他依赖复杂多重对齐策略的方法。
Key Takeaways
- 该论文提出了一种新型的贝叶斯框架用于医学图像分割中的无监督域自适应(UDA)。
- 现有方法缺乏明确的解释性机制,难以确保目标图像特征捕捉有意义的结构信息。
- RemInD框架通过人类适应性启发学习域无关的潜在流形并记忆解剖结构变异。
- RemInD框架通过将图像映射到流形上的加权锚点平均值来确保预测的真实性和可靠性。
- 模型预测由两个可解释因素决定:低维锚点权重向量和空间变形。
- 该设计在计算效率和几何适应性方面表现出优势,实现了域间权重向量的对齐。
点此查看论文截图

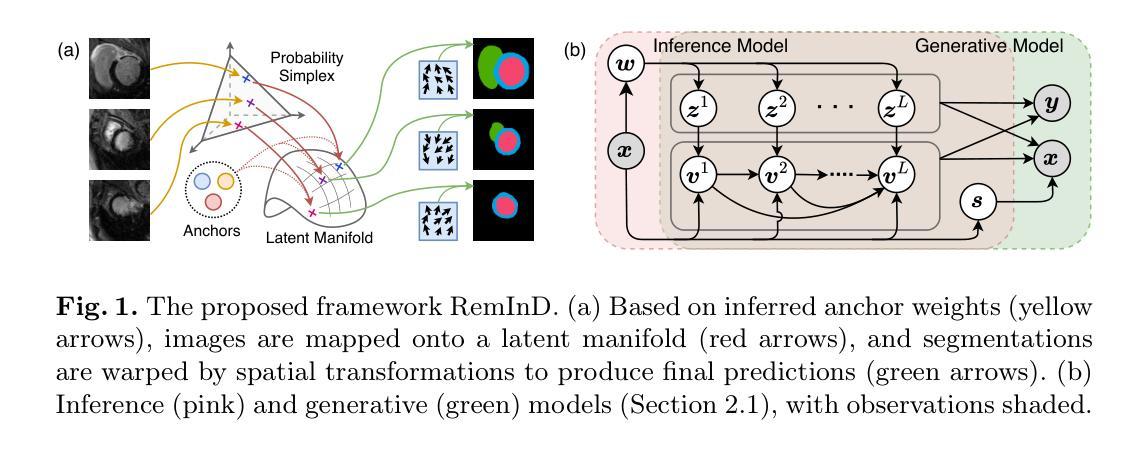
Deep Learning for Wound Tissue Segmentation: A Comprehensive Evaluation using A Novel Dataset
Authors:Muhammad Ashad Kabir, Nidita Roy, Md. Ekramul Hossain, Jill Featherston, Sayed Ahmed
Deep learning (DL) techniques have emerged as promising solutions for medical wound tissue segmentation. However, a notable limitation in this field is the lack of publicly available labelled datasets and a standardised performance evaluation of state-of-the-art DL models on such datasets. This study addresses this gap by comprehensively evaluating various DL models for wound tissue segmentation using a novel dataset. We have curated a dataset comprising 147 wound images exhibiting six tissue types: slough, granulation, maceration, necrosis, bone, and tendon. The dataset was meticulously labelled for semantic segmentation employing supervised machine learning techniques. Three distinct labelling formats were developed – full image, patch, and superpixel. Our investigation encompassed a wide array of DL segmentation and classification methodologies, ranging from conventional approaches like UNet, to generative adversarial networks such as cGAN, and modified techniques like FPN+VGG16. Also, we explored DL-based classification methods (e.g., ResNet50) and machine learning-based classification leveraging DL features (e.g., AlexNet+RF). In total, 82 wound tissue segmentation models were derived across the three labelling formats. Our analysis yielded several notable findings, including identifying optimal DL models for each labelling format based on weighted average Dice or F1 scores. Notably, FPN+VGG16 emerged as the top-performing DL model for wound tissue segmentation, achieving a dice score of 82.25%. This study provides a valuable benchmark for evaluating wound image segmentation and classification models, offering insights to inform future research and clinical practice in wound care. The labelled dataset created in this study is available at https://github.com/akabircs/WoundTissue.
深度学习(DL)技术在医学伤口组织分割方面展现出巨大的潜力。然而,该领域的一个显著限制是缺乏公开标记的数据集和在这些数据集上评估最先进DL模型的标准化性能。本研究通过综合评估用于伤口组织分割的多种DL模型来填补这一空白,同时使用一个新型数据集。我们整理了一个包含147张伤口图像的数据集,这些图像展示了六种组织类型:腐烂、肉芽、软化、坏死、骨骼和肌腱。该数据集经过仔细标注,以用于语义分割,采用监督机器学习技术。我们开发了三种不同的标注格式,包括全图、补丁和超像素。我们的研究涵盖了广泛的DL分割和分类方法,从传统的UNet方法到生成对抗网络(如cGAN)和修改后的技术(如FPN+VGG16)。此外,我们还探索了基于DL的分类方法(例如ResNet50)和利用DL特征进行机器学习的分类方法(例如AlexNet+RF)。总共在三种标注格式下衍生出82个伤口组织分割模型。我们的分析得出了几个重要发现,包括根据加权平均Dice或F1分数确定每种标注格式的最佳DL模型。值得注意的是,FPN+VGG16在伤口组织分割方面表现出最佳的DL模型性能,达到了82.25%的Dice系数。本研究为评估伤口图像分割和分类模型提供了一个宝贵的基准,为未来的伤口护理研究和临床实践提供了启示。本研究创建的标记数据集可在https://github.com/akabircs/WoundTissue上获得。
论文及项目相关链接
PDF 35 pages
Summary
本研究利用深度学习技术对伤口组织进行分割,针对目前公开标注数据集缺乏和标准性能评估的问题,对多种深度学习模型进行了全面评估。研究团队创建了一个包含六种组织类型的新数据集,并采用三种不同的标注格式对伤口图像进行精细标注。研究涵盖了多种深度学习分割和分类方法,并发现FPN+VGG16模型在伤口组织分割方面表现最佳,加权平均Dice得分为82.25%。此研究为评估伤口图像分割和分类模型提供了宝贵的基准,为未来的研究和临床实践提供了重要参考。数据集可在链接获取。
Key Takeaways
- 本研究针对医疗伤口组织分割问题,使用深度学习技术进行全面评估。
- 创建一个包含六种组织类型的新数据集,并进行精细标注。
- 采用三种不同的标注格式对伤口图像进行处理,以进行语义分割。
- 研究了多种深度学习分割和分类方法,包括UNet、cGAN、FPN+VGG16等。
- 发现FPN+VGG16模型在伤口组织分割方面表现最佳。
- 提供了一个评估伤口图像分割和分类模型的基准,有助于指导未来的研究和临床实践。
点此查看论文截图

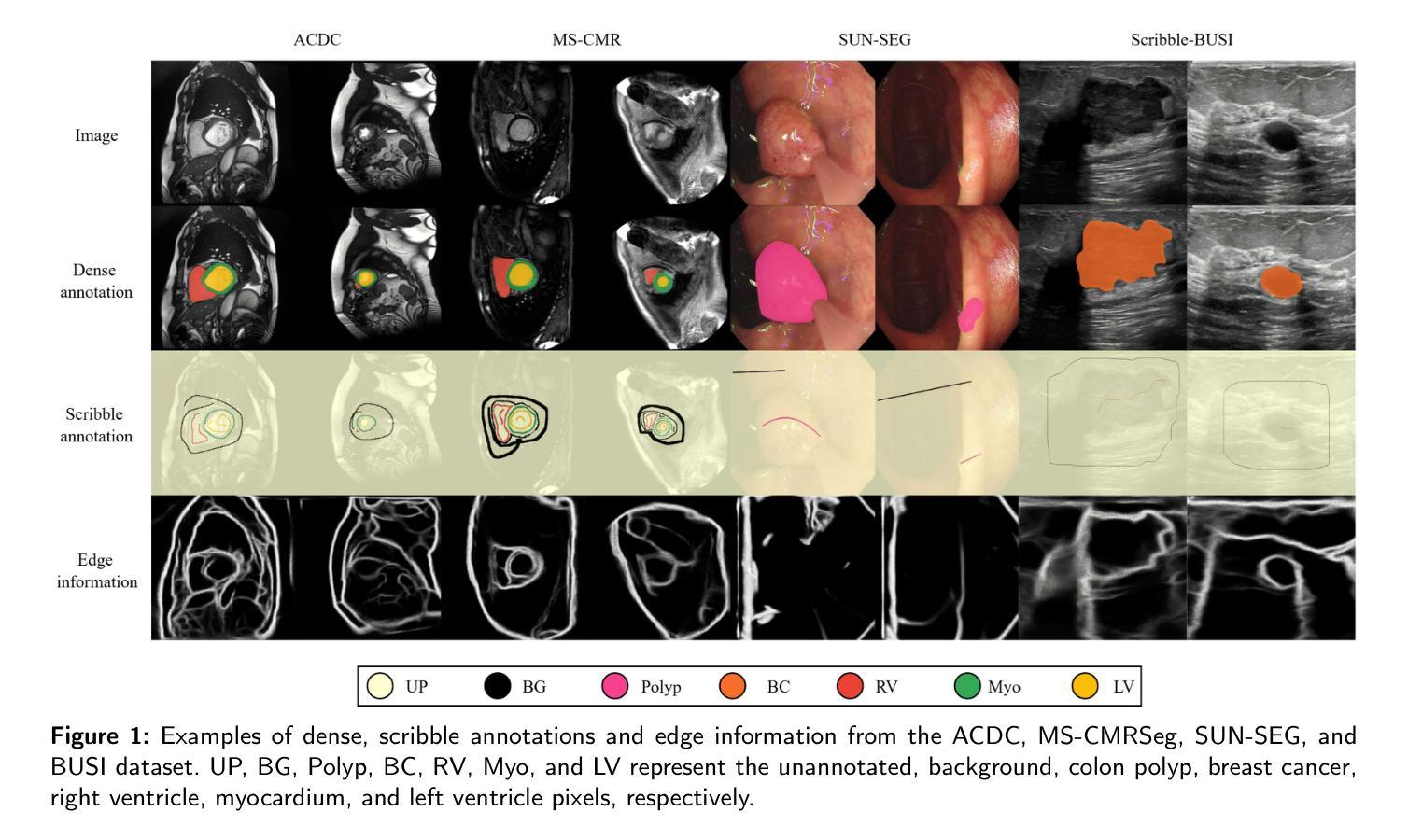
QMaxViT-Unet+: A Query-Based MaxViT-Unet with Edge Enhancement for Scribble-Supervised Segmentation of Medical Images
Authors:Thien B. Nguyen-Tat, Hoang-An Vo, Phuoc-Sang Dang
The deployment of advanced deep learning models for medical image segmentation is often constrained by the requirement for extensively annotated datasets. Weakly-supervised learning, which allows less precise labels, has become a promising solution to this challenge. Building on this approach, we propose QMaxViT-Unet+, a novel framework for scribble-supervised medical image segmentation. This framework is built on the U-Net architecture, with the encoder and decoder replaced by Multi-Axis Vision Transformer (MaxViT) blocks. These blocks enhance the model’s ability to learn local and global features efficiently. Additionally, our approach integrates a query-based Transformer decoder to refine features and an edge enhancement module to compensate for the limited boundary information in the scribble label. We evaluate the proposed QMaxViT-Unet+ on four public datasets focused on cardiac structures, colorectal polyps, and breast cancer: ACDC, MS-CMRSeg, SUN-SEG, and BUSI. Evaluation metrics include the Dice similarity coefficient (DSC) and the 95th percentile of Hausdorff distance (HD95). Experimental results show that QMaxViT-Unet+ achieves 89.1% DSC and 1.316mm HD95 on ACDC, 88.4% DSC and 2.226mm HD95 on MS-CMRSeg, 71.4% DSC and 4.996mm HD95 on SUN-SEG, and 69.4% DSC and 50.122mm HD95 on BUSI. These results demonstrate that our method outperforms existing approaches in terms of accuracy, robustness, and efficiency while remaining competitive with fully-supervised learning approaches. This makes it ideal for medical image analysis, where high-quality annotations are often scarce and require significant effort and expense. The code is available at: https://github.com/anpc849/QMaxViT-Unet
将先进的深度学习模型部署于医学图像分割经常受到需要大量标注数据集的限制。弱监督学习允许不那么精确的标签,已成为应对这一挑战的有前途的解决方案。在此基础上,我们提出了QMaxViT-Unet+框架,这是一种新型的涂鸦监督医学图像分割框架。该框架基于U-Net架构构建,其中编码器和解码器被替换为多轴视觉转换器(MaxViT)块。这些模块增强了模型高效学习局部和全局特征的能力。此外,我们的方法结合了基于查询的转换器解码器来优化特征和一个边缘增强模块来补偿涂鸦标签中有限的边界信息。我们在四个公共数据集上评估了所提出的QMaxViT-Unet+,这些数据集专注于心脏结构、结肠直肠息肉和乳腺癌:ACDC、MS-CMRSeg、SUN-SEG和BUSI。评估指标包括Dice相似系数(DSC)和Hausdorff距离的第95个百分点(HD95)。实验结果表明,QMaxViT-Unet+在ACDC上实现了89.1%的DSC和1.316mm的HD95,在MS-CMRSeg上实现了88.4%的DSC和2.226mm的HD95,在SUN-SEG上实现了71.4%的DSC和4.996mm的HD95,以及在BUSI上实现了69.4%的DSC和50.122mm的HD95。这些结果表明,我们的方法在准确性、鲁棒性和效率方面优于现有方法,同时与全监督学习方法相比具有竞争力。这使得它非常适合医学图像分析,因为高质量的注释往往很稀缺,并且需要大量的努力和费用。代码可在以下网址找到:https://github.com/anpc849/QMaxViT-Unet
论文及项目相关链接
Summary
本文提出一种基于弱监督学习的涂鸦监督医学图像分割框架QMaxViT-Unet+,使用Multi-Axis Vision Transformer(MaxViT)块替换U-Net架构的编码器和解码器,提高模型学习局部和全局特征的能力。同时,集成基于查询的Transformer解码器和边缘增强模块以优化特征并补偿涂鸦标签的边界信息不足。在四个公共数据集上的实验结果表明,QMaxViT-Unet+在准确性、鲁棒性和效率方面优于现有方法,且与全监督学习方法相比具有竞争力,适用于医学图像分析领域。
Key Takeaways
- QMaxViT-Unet+框架利用弱监督学习应对医学图像分割中对大量标注数据的依赖问题。
- 框架基于U-Net架构,使用Multi-Axis Vision Transformer(MaxViT)块增强特征学习能力。
- 集成基于查询的Transformer解码器和边缘增强模块以优化分割结果。
- 在四个公共数据集上的实验验证了QMaxViT-Unet+的优越性,特别是在准确性、鲁棒性和效率方面。
- QMaxViT-Unet+与全监督学习方法相比表现具有竞争力,尤其适用于医学图像分析领域标注数据稀缺的情况。
- QMaxViT-Unet+代码已公开,便于进一步研究和应用。
点此查看论文截图

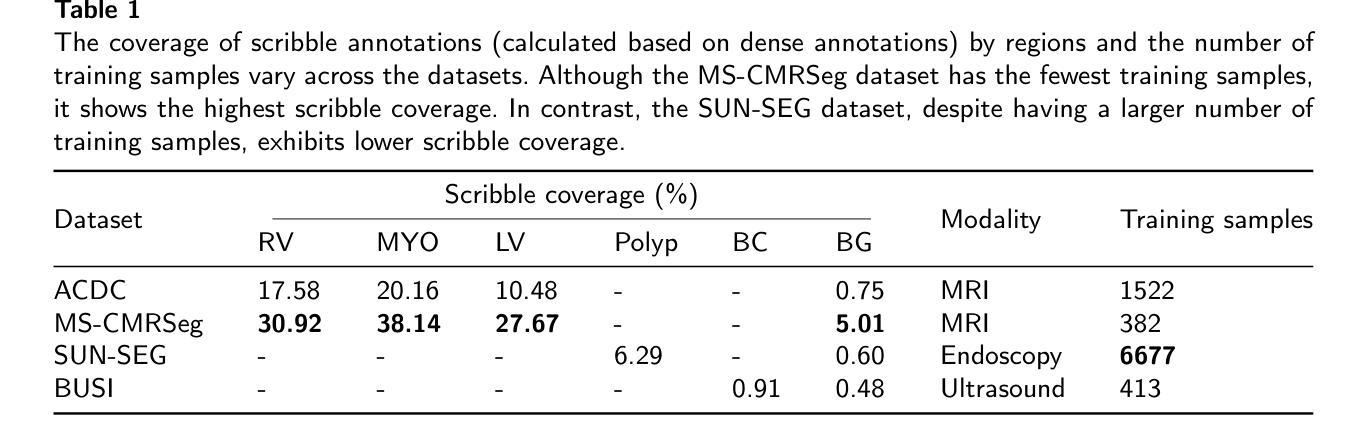
A Solver-Aided Hierarchical Language for LLM-Driven CAD Design
Authors:Benjamin T. Jones, Felix Hähnlein, Zihan Zhang, Maaz Ahmad, Vladimir Kim, Adriana Schulz
Large language models (LLMs) have been enormously successful in solving a wide variety of structured and unstructured generative tasks, but they struggle to generate procedural geometry in Computer Aided Design (CAD). These difficulties arise from an inability to do spatial reasoning and the necessity to guide a model through complex, long range planning to generate complex geometry. We enable generative CAD Design with LLMs through the introduction of a solver-aided, hierarchical domain specific language (DSL) called AIDL, which offloads the spatial reasoning requirements to a geometric constraint solver. Additionally, we show that in the few-shot regime, AIDL outperforms even a language with in-training data (OpenSCAD), both in terms of generating visual results closer to the prompt and creating objects that are easier to post-process and reason about.
大型语言模型(LLMs)在解决各种结构和非结构生成任务方面取得了巨大的成功,但在计算机辅助设计(CAD)中的过程几何生成方面遇到了困难。这些困难产生于无法进行空间推理和必须通过复杂、长期规划来引导模型生成复杂几何的必要性。我们通过引入一种辅助求解器、层次化的领域特定语言(DSL)AIDL,实现了用LLM进行生成式CAD设计。AIDL将空间推理要求转移到几何约束求解器上。此外,我们还表明,在少量样本的情况下,AIDL甚至表现出比使用训练数据(OpenSCAD)的语言更好的性能,不仅在生成更接近提示的视觉结果方面,而且在生成更容易进行后期处理和推理的对象方面也是如此。
论文及项目相关链接
Summary
大型语言模型(LLMs)在解决多种结构化和非结构化生成任务方面取得了巨大成功,但在计算机辅助设计(CAD)中的程序化几何生成方面存在困难。为解决这一问题,我们引入了一种名为AIDL的求解器辅助、分层领域特定语言,它将空间推理要求转移到几何约束求解器上,从而实现了LLMs的生成式CAD设计。此外,我们还展示了在少量样本的情况下,AIDL甚至在生成视觉结果和创建可后处理和推理的对象方面,优于具有训练数据的语言(如OpenSCAD)。
Key Takeaways
- 大型语言模型在解决多种生成任务方面表现出强大的能力。
- 在计算机辅助设计(CAD)的程序化几何生成方面,大型语言模型面临困难。
- 困难源于空间推理能力的不足以及需要指导模型进行复杂、长期规划以生成复杂几何的需求。
- 为解决这些问题,引入了AIDL这种求解器辅助、分层领域特定语言。
- AIDL将空间推理要求转移到几何约束求解器上,使大型语言模型能够更轻松地完成CAD设计。
- 在少量样本的情况下,AIDL在生成视觉结果方面表现出优越的性能,更接近提示,并且创建的物体更易于后处理和推理。
点此查看论文截图

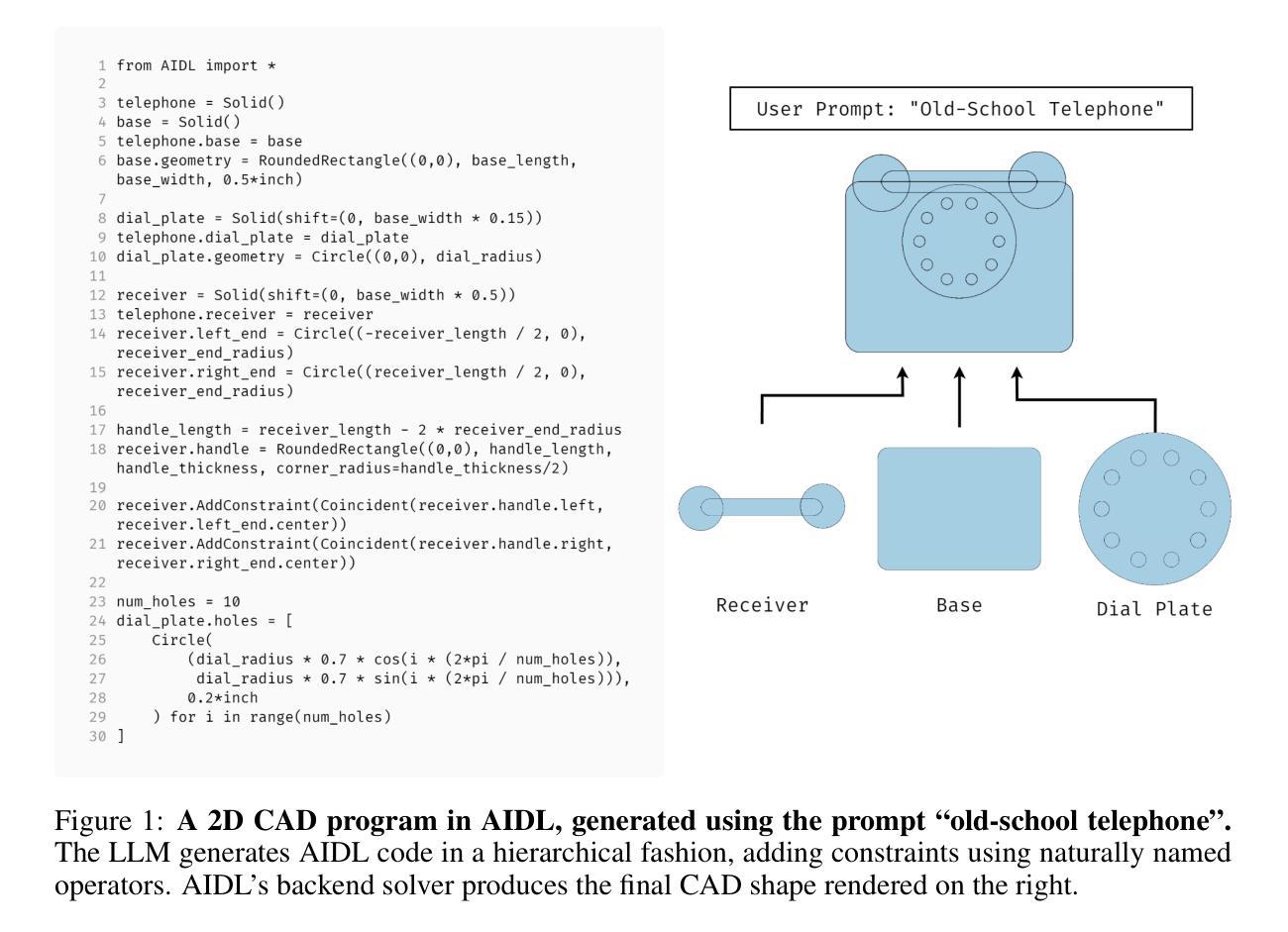


Vision-based Geo-Localization of Future Mars Rotorcraft in Challenging Illumination Conditions
Authors:Dario Pisanti, Robert Hewitt, Roland Brockers, Georgios Georgakis
Planetary exploration using aerial assets has the potential for unprecedented scientific discoveries on Mars. While NASA’s Mars helicopter Ingenuity proved flight in Martian atmosphere is possible, future Mars rotocrafts will require advanced navigation capabilities for long-range flights. One such critical capability is Map-based Localization (MbL) which registers an onboard image to a reference map during flight in order to mitigate cumulative drift from visual odometry. However, significant illumination differences between rotocraft observations and a reference map prove challenging for traditional MbL systems, restricting the operational window of the vehicle. In this work, we investigate a new MbL system and propose Geo-LoFTR, a geometry-aided deep learning model for image registration that is more robust under large illumination differences than prior models. The system is supported by a custom simulation framework that uses real orbital maps to produce large amounts of realistic images of the Martian terrain. Comprehensive evaluations show that our proposed system outperforms prior MbL efforts in terms of localization accuracy under significant lighting and scale variations. Furthermore, we demonstrate the validity of our approach across a simulated Martian day.
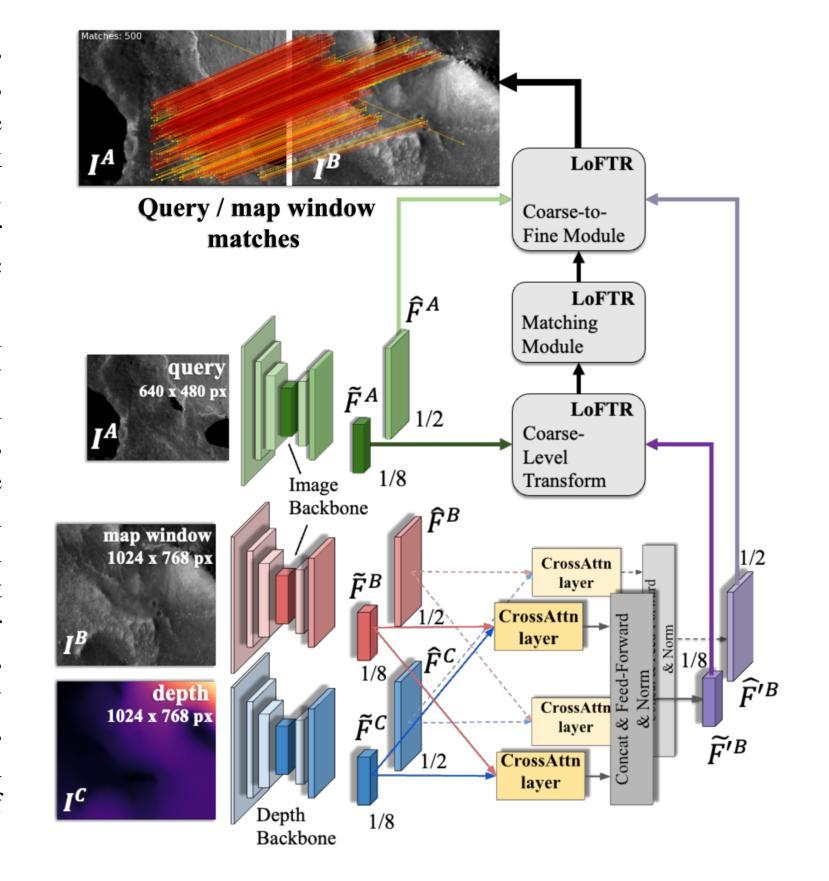
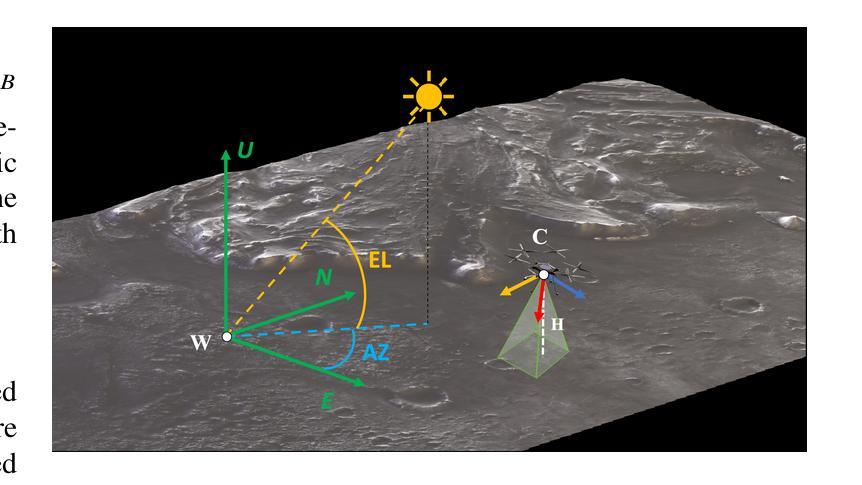
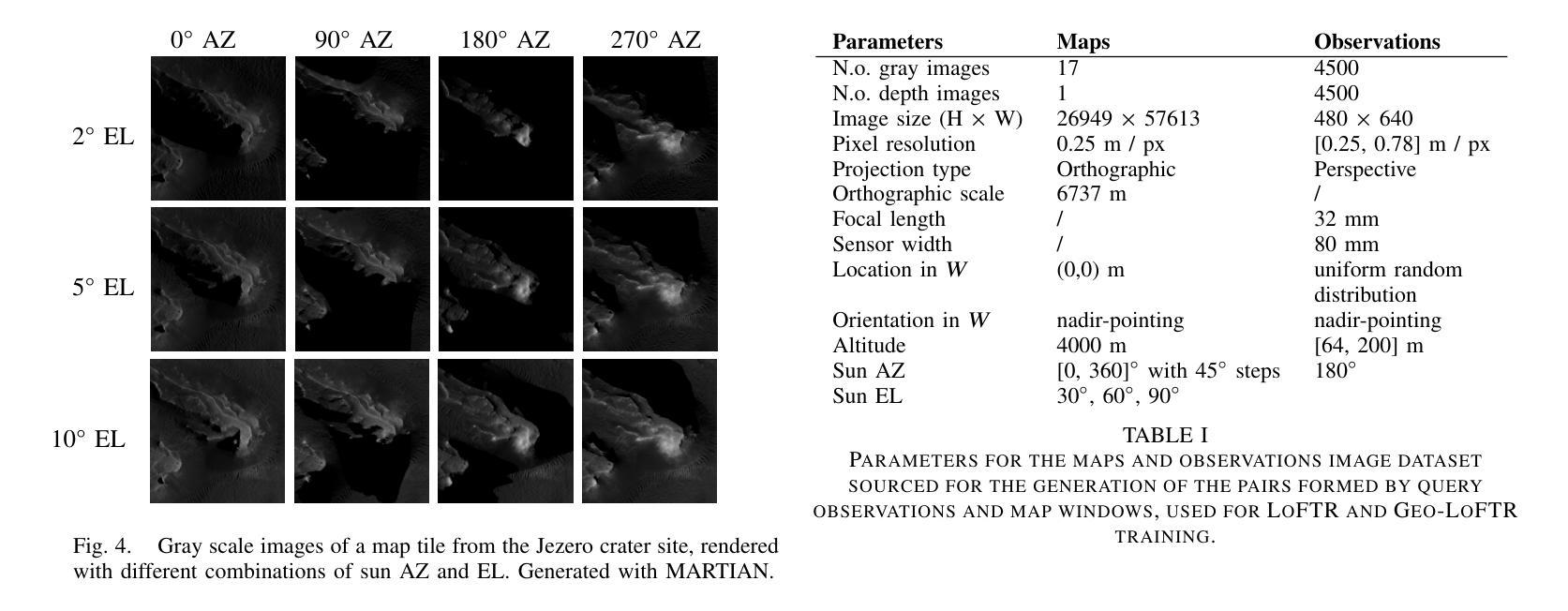
利用空中资源进行行星探索具有在火星上获得前所未有的科学发现的潜力。虽然美国宇航局的火星直升机“机智号”证明了在火星大气中飞行是可能的,但未来的火星旋翼飞行器将需要先进的导航能力以进行远程飞行。其中一项关键能力是地图定位(MbL),它在飞行过程中将机载图像注册到参考地图上,以减少视觉里程计的累积漂移。然而,旋翼飞行器观测与参考地图之间的显著照明差异对传统的MbL系统构成了挑战,限制了车辆的作业窗口。在这项工作中,我们调查了新的MbL系统,并提出了Geo-LoFTR,这是一个结合几何辅助的深度学习图像注册模型。它在大照明差异下的鲁棒性超过了先前模型。该系统得到了一个自定义仿真框架的支持,该框架使用真实的轨道地图生成大量真实的火星地形图像。综合评估表明,在较大的光照和尺度变化下,我们提出的系统在定位精度方面优于先前的MbL工作。此外,我们在模拟的火星日周期内验证了我们的方法的有效性。
论文及项目相关链接
Summary
本摘要探讨使用无人机技术实现火星表面高精度地图导航定位的方法,涉及了新颖的基于深度学习图像注册的地理定位系统Geo-LoFTR及其关键技术应用和验证情况。该方法可以极大地扩大探测窗口。重点关注该方法具备抵抗光照变化的能力,以及其在模拟火星环境下的性能表现。通过采用真实火星轨道地图,研究构建了自定义仿真框架用于模拟测试环境,成功验证所提出系统能够在各种光照和尺度变化条件下实现精准定位。该成果有望为未来的火星探索任务提供强大的技术支持。
Key Takeaways
- 火星探索正借助无人机技术寻求前所未有的科学发现潜力。
- Map-based Localization(MbL)系统是未来火星无人机远程飞行所需的关键导航能力之一。
- 光照差异给MbL系统带来挑战,限制了探测器的操作窗口。
- 提出的Geo-LoFTR系统是一种结合深度学习和几何信息的图像注册方法,能更稳健地应对光照变化。
- 自定义仿真框架利用真实火星轨道地图生成逼真的火星地形图像,用于系统测试。
- 综合评估显示,Geo-LoFTR系统在光照和尺度变化条件下定位精度优于先前MbL方法。
- 在模拟火星环境下的验证证明了该方法的可行性。
点此查看论文截图


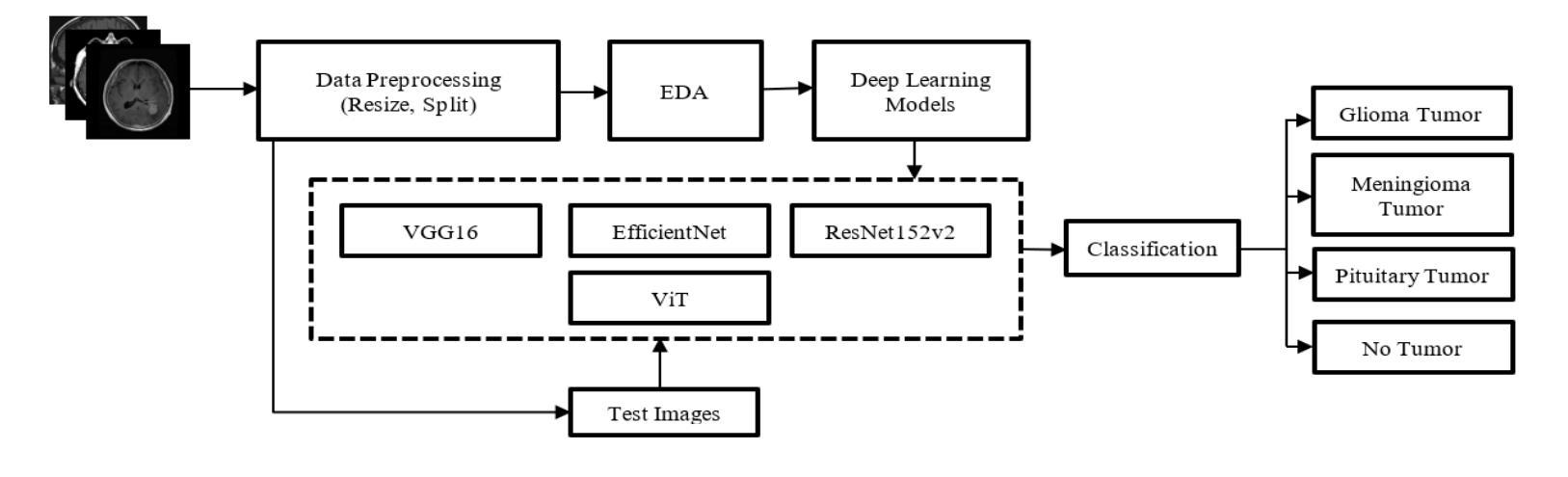
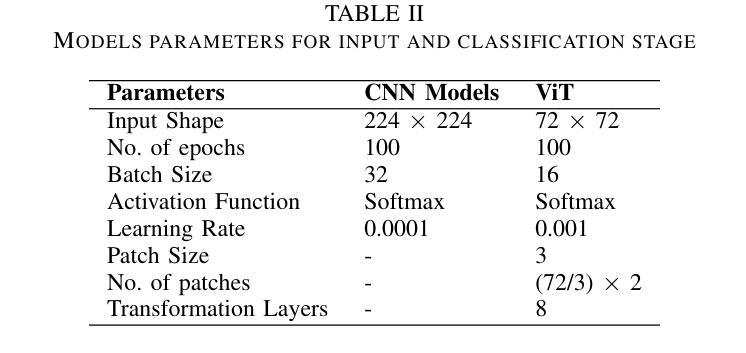
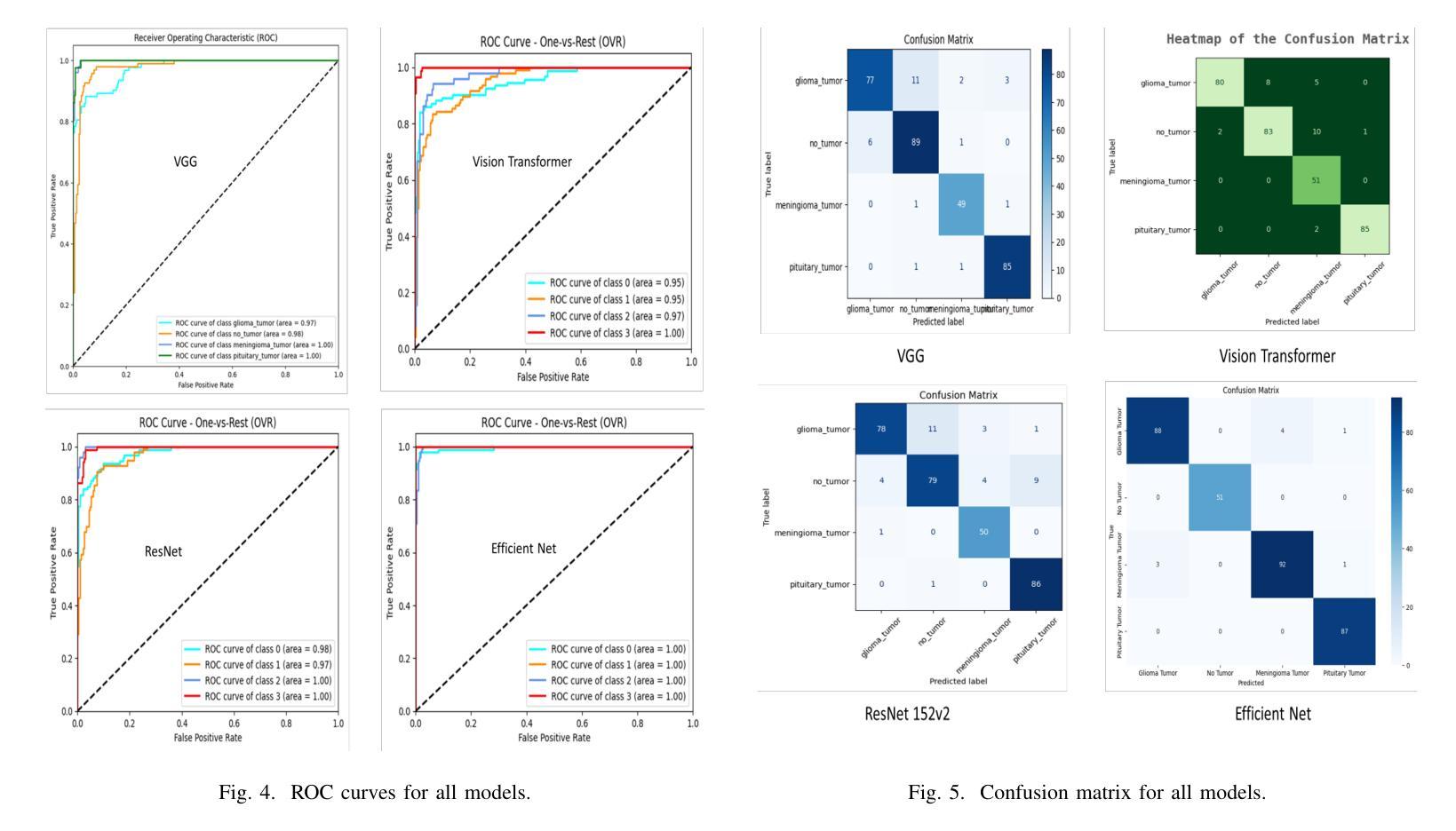
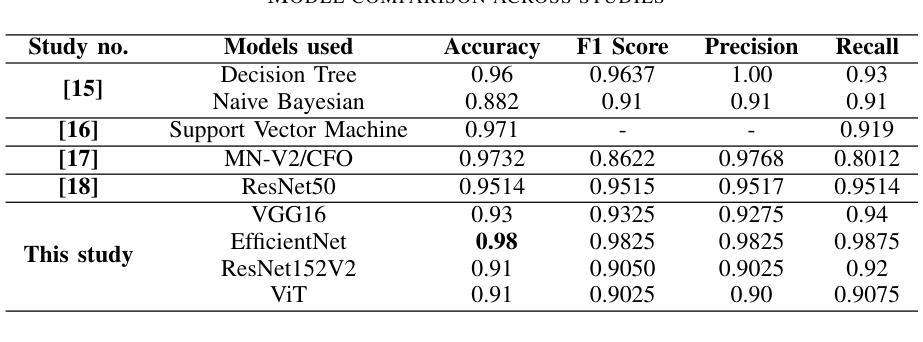
A CNN Approach to Automated Detection and Classification of Brain Tumors
Authors:Md. Zahid Hasan, Abdullah Tamim, D. M. Asadujjaman, Md. Mahfujur Rahman, Md. Abu Ahnaf Mollick, Nosin Anjum Dristi, Abdullah-Al-Noman
Brain tumors require an assessment to ensure timely diagnosis and effective patient treatment. Morphological factors such as size, location, texture, and variable appearance com- plicate tumor inspection. Medical imaging presents challenges, including noise and incomplete images. This research article presents a methodology for processing Magnetic Resonance Imag- ing (MRI) data, encompassing techniques for image classification and denoising. The effective use of MRI images allows medical professionals to detect brain disorders, including tumors. This research aims to categorize healthy brain tissue and brain tumors by analyzing the provided MRI data. Unlike alternative methods like Computed Tomography (CT), MRI technology offers a more detailed representation of internal anatomical components, mak- ing it a suitable option for studying data related to brain tumors. The MRI picture is first subjected to a denoising technique utilizing an Anisotropic diffusion filter. The dataset utilized for the models creation is a publicly accessible and validated Brain Tumour Classification (MRI) database, comprising 3,264 brain MRI scans. SMOTE was employed for data augmentation and dataset balancing. Convolutional Neural Networks(CNN) such as ResNet152V2, VGG, ViT, and EfficientNet were employed for the classification procedure. EfficientNet attained an accuracy of 98%, the highest recorded.
对脑肿瘤进行评估是确保及时诊断和治疗的关键。肿瘤的形态学因素,如大小、位置、质地和外观变化,使得肿瘤检查变得复杂。医学成像也面临挑战,包括噪声和不完整的图像。这篇研究论文提出了一种处理磁共振成像(MRI)数据的方法,包括图像分类和去噪技术。有效地使用MRI图像可以使医疗专业人员能够检测包括肿瘤在内的脑部疾病。本研究的目的是通过分析提供的MRI数据来区分健康脑组织和脑肿瘤。与计算机断层扫描(CT)等替代方法不同,MRI技术提供更详细的内部解剖结构成分表示,使其成为研究脑肿瘤相关数据的理想选择。MRI图像首先经过使用各向异性扩散滤波器进行去噪处理。用于模型创建的数据集是公开可访问且经过验证的Brain Tumour Classification(MRI)数据库,包含3264个脑部MRI扫描。采用SMOTE进行数据增强和数据集平衡。卷积神经网络(CNN)如ResNet152V2、VGG、ViT和EfficientNet被用于分类过程。EfficientNet的准确率达到了98%,为目前最高记录。
论文及项目相关链接
Summary
本文介绍了处理磁共振成像(MRI)数据的方法,包括图像分类和去噪技术。研究旨在通过MRI数据分析来区分健康脑组织和脑肿瘤。使用MRI图像可以更准确地检测脑部疾病,包括肿瘤。研究使用了一种先进的神经网络模型,如EfficientNet,准确率达到98%,为分类过程提供了有效的方法。
Key Takeaways
- 形态因素如大小、位置、纹理和外观变化使得脑肿瘤的评估具有挑战性。
- 医学成像存在噪声和图像不完整等问题。
- 本研究提出了一种处理磁共振成像(MRI)数据的方法,包括图像分类和去噪技术。
- 使用MRI图像可以更有效地检测脑部疾病,如肿瘤。
- 研究使用SMOTE进行数据增强和平衡数据集。
- 研究使用了多种卷积神经网络(CNN)模型进行分类,其中EfficientNet表现最佳,准确率为98%。
点此查看论文截图


Leveraging Machine Learning and Deep Learning Techniques for Improved Pathological Staging of Prostate Cancer
Authors:Raziehsadat Ghalamkarian, Marziehsadat Ghalamkarian, MortezaAli Ahmadi, Sayed Mohammad Ahmadi, Abolfazl Diyanat
Prostate cancer (Pca) continues to be a leading cause of cancer-related mortality in men, and the limitations in precision of traditional diagnostic methods such as the Digital Rectal Exam (DRE), Prostate-Specific Antigen (PSA) testing, and biopsies underscore the critical importance of accurate staging detection in enhancing treatment outcomes and improving patient prognosis. This study leverages machine learning and deep learning approaches, along with feature selection and extraction methods, to enhance PCa pathological staging predictions using RNA sequencing data from The Cancer Genome Atlas (TCGA). Gene expression profiles from 486 tumors were analyzed using advanced algorithms, including Random Forest (RF), Logistic Regression (LR), Extreme Gradient Boosting (XGB), and Support Vector Machine (SVM). The performance of the study is measured with respect to the F1-score, as well as precision and recall, all of which are calculated as weighted averages. The results reveal that the highest test F1-score, approximately 83%, was achieved by the Random Forest algorithm, followed by Logistic Regression at 80%, while both Extreme Gradient Boosting (XGB) and Support Vector Machine (SVM) scored around 79%. Furthermore, deep learning models with data augmentation achieved an accuracy of 71. 23%, while PCA-based dimensionality reduction reached an accuracy of 69.86%. This research highlights the potential of AI-driven approaches in clinical oncology, paving the way for more reliable diagnostic tools that can ultimately improve patient outcomes.
前列腺癌(Pca)仍然是男性癌症相关死亡的主要原因之一,传统诊断方法如直肠指检(DRE)、前列腺特异性抗原(PSA)检测和活检在诊断精确度上的局限性凸显了精确分期检测在改善患者治疗结果和预后方面的重要价值。本研究利用机器学习和深度学习技术,结合特征选择和提取方法,借助癌症基因组图谱(TCGA)的RNA测序数据,提高前列腺癌病理分期预测水平。研究对来自486个肿瘤的基因表达谱进行了分析,使用了包括随机森林(RF)、逻辑回归(LR)、极端梯度增强(XGB)和支持向量机(SVM)等高级算法。本研究的性能是通过F1分数、精确度以及召回率来衡量的,这些指标均被计算为加权平均值。结果显示,随机森林算法获得了最高的测试F1分数,约为83%,逻辑回归得分80%,而极端梯度增强(XGB)和支持向量机(SVM)得分约为79%。此外,使用数据增强的深度学习模型准确率达到了71.23%,而基于主成分分析(PCA)的降维技术准确率为6 6 8%。这项研究突显了人工智能在临床肿瘤学中的潜力,为开发更可靠的诊断工具奠定了基础,有望最终改善患者治疗效果。
论文及项目相关链接
Summary
本文研究了前列腺癌(Pca)的病理分期预测,采用机器学习和深度学习方法,结合特征选择和提取技术,分析来自癌症基因组图谱(TCGA)的RNA测序数据。研究使用多种算法,包括随机森林(RF)、逻辑回归(LR)、极端梯度提升(XGB)和支持向量机(SVM)。结果表明,随机森林算法获得最高的测试F1分数,约为83%,逻辑回归得分为80%,而XGB和SVM得分约为79%。深度学习模型和数据增强技术达到71.23%的准确率,而基于PCA的降维技术达到69.86%的准确率。研究突显了人工智能在临床肿瘤学中的潜力,为开发更可靠的诊断工具铺平了道路,最终可能改善患者预后。
Key Takeaways
- 前列腺癌仍是男性癌症死亡的主要原因之一,需要更精确的分期检测来提高治疗效果和患者预后。
- 本研究使用机器学习和深度学习方法来分析癌症基因组图谱(TCGA)的RNA测序数据,以提高前列腺癌病理分期预测的准确性。
- 研究采用了多种算法,包括随机森林、逻辑回归、极端梯度提升和支持向量机。
- 随机森林算法获得最高的测试F1分数,约为83%,显示出在前列腺癌分期预测中的潜力。
- 深度学习模型与数据增强技术相结合,提高了预测准确性。
- 基于PCA的降维技术在前列腺癌分期预测中也表现出一定的效果。
点此查看论文截图

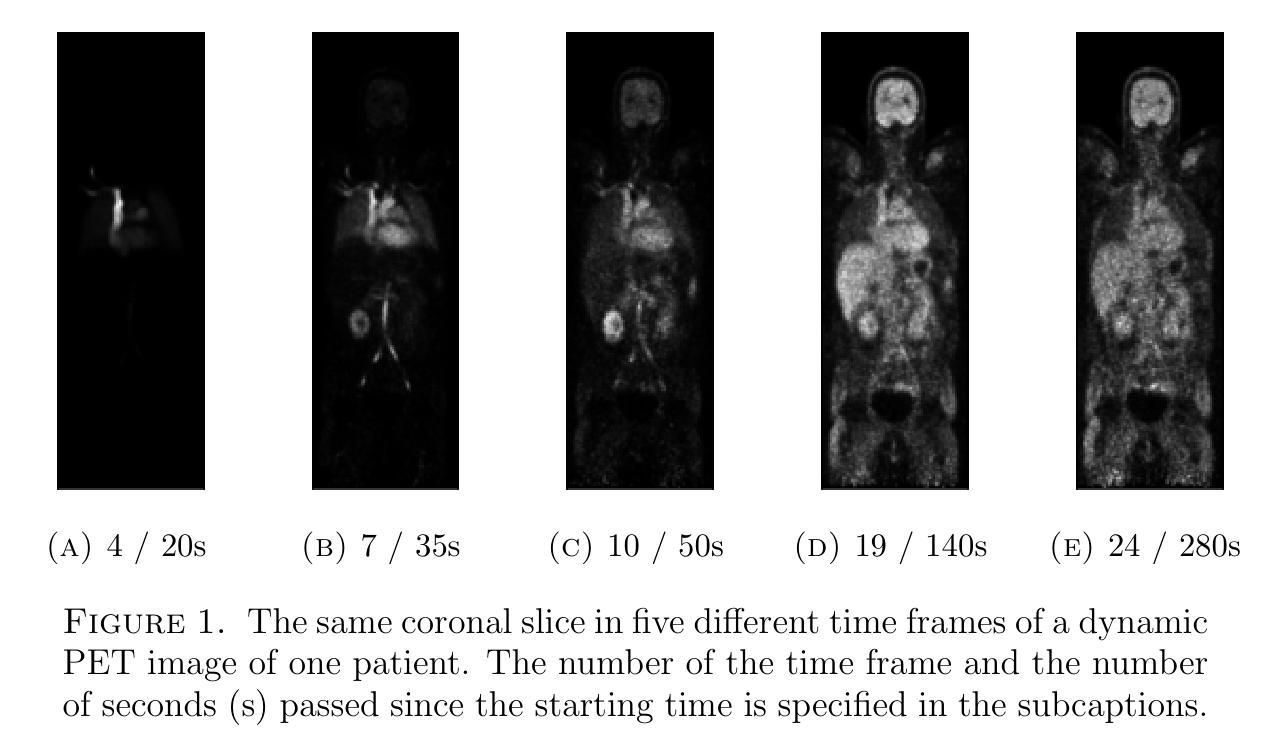
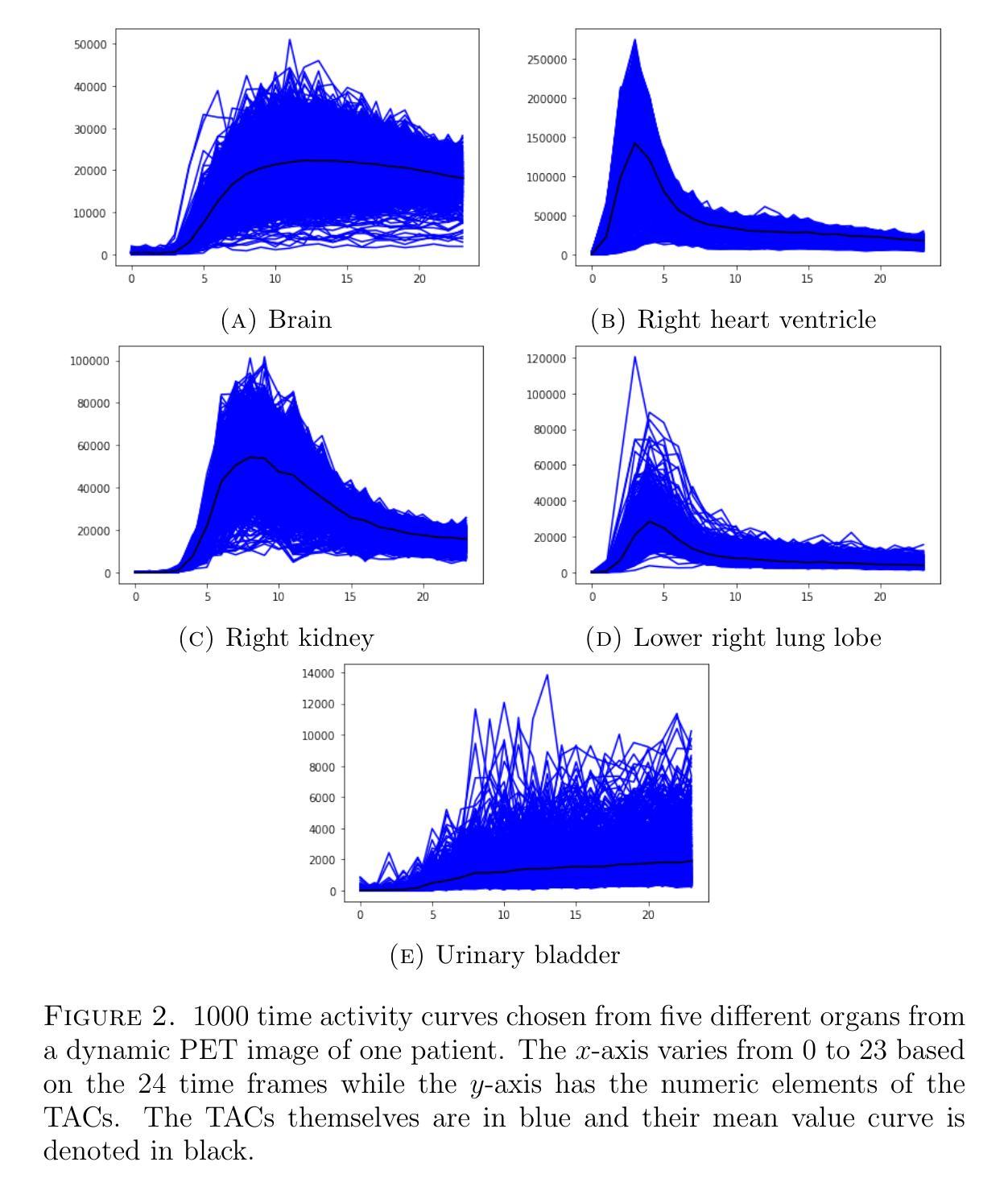
Quantitative evaluation of unsupervised clustering algorithms for dynamic total-body PET image analysis
Authors:Oona Rainio, Maria K. Jaakkola, Riku Klén
Background. Recently, dynamic total-body positron emission tomography (PET) imaging has become possible due to new scanner devices. While clustering algorithms have been proposed for PET analysis already earlier, there is still little research systematically evaluating these algorithms for processing of dynamic total-body PET images. Materials and methods. Here, we compare the performance of 15 unsupervised clustering methods, including K-means either by itself or after principal component analysis (PCA) or independent component analysis (ICA), Gaussian mixture model (GMM), fuzzy c-means (FCM), agglomerative clustering, spectral clustering, and several newer clustering algorithms, for classifying time activity curves (TACs) in dynamic PET images. We use dynamic total-body $^{15}$O-water PET images collected from 30 patients with suspected or confirmed coronary artery disease. To evaluate the clustering algorithms in a quantitative way, we use them to classify 5000 TACs from each image based on whether the curve is taken from brain, right heart ventricle, right kidney, lower right lung lobe, or urinary bladder. Results. According to our results, the best methods are GMM, FCM, and ICA combined with mini batch K-means, which classified the TACs with a median accuracies of 89%, 83%, and 81%, respectively, in a processing time of half a second or less on average for each image. Conclusion. GMM, FCM, and ICA with mini batch K-means show promise for dynamic total-body PET analysis.
背景:最近,由于新的扫描设备,动态全身正电子发射断层扫描(PET)成像已经成为可能。尽管聚类算法在PET分析方面已经提出了一段时间,但对于处理动态全身PET图像,系统评估这些算法的学术研究仍然很少。材料与方法:在这里,我们对15种无监督聚类算法进行了比较,这些算法包括单独使用K均值算法或结合主成分分析(PCA)或独立成分分析(ICA)、高斯混合模型(GMM)、模糊c均值(FCM)、凝聚聚类、谱聚类以及几种新的聚类算法,用于对动态PET图像中的时间活动曲线(TACs)进行分类。我们使用从疑似或确诊冠状动脉疾病的30例患者身上收集的$^{15}$O水动态全身PET图像。为了定量评估聚类算法的效果,我们使用这些算法根据曲线是否来自大脑、右心室、右肾、右下肺叶或膀胱来分类每个图像的5000条TACs。结果:根据我们的结果,最佳方法是GMM、FCM以及结合小批量K均值算法的ICA,它们在处理动态全身PET图像时,将TACs分类的准确度中位数分别为89%、83%和81%,每张图像的平均处理时间不到半秒。结论:对于动态全身PET分析,GMM、FCM以及结合小批量K均值算法的ICA显示出良好的潜力。
论文及项目相关链接
PDF 12 pages, 2 figures
Summary
动态全身正电子发射断层扫描(PET)成像技术的最新发展使得聚类算法在处理这种成像技术时显得尤为重要。本文对比了15种无监督聚类算法在处理动态全身PET图像中的表现,发现高斯混合模型(GMM)、模糊C均值(FCM)和独立成分分析(ICA)结合小批量K-均值方法表现最佳,分类准确度中位数分别为89%、83%和81%,且处理时间平均每张图像在半秒以内。
Key Takeaways
- 动态全身PET成像技术因新扫描设备而近期成为可能。
- 聚类算法在PET分析中有广泛应用,但针对动态全身PET图像的处理研究较少。
- 对比了15种无监督聚类算法在处理动态PET图像中的表现。
- GMM、FCM和ICA结合mini batch K-means表现出最佳效果,分类准确度较高且处理速度快。
点此查看论文截图

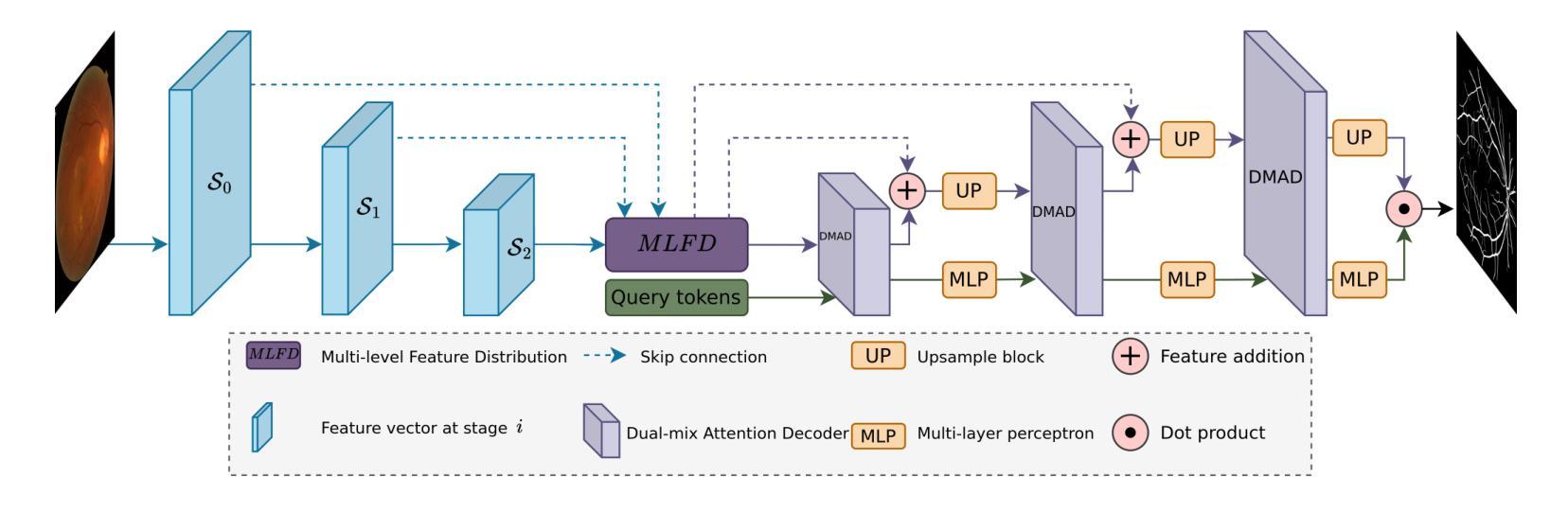
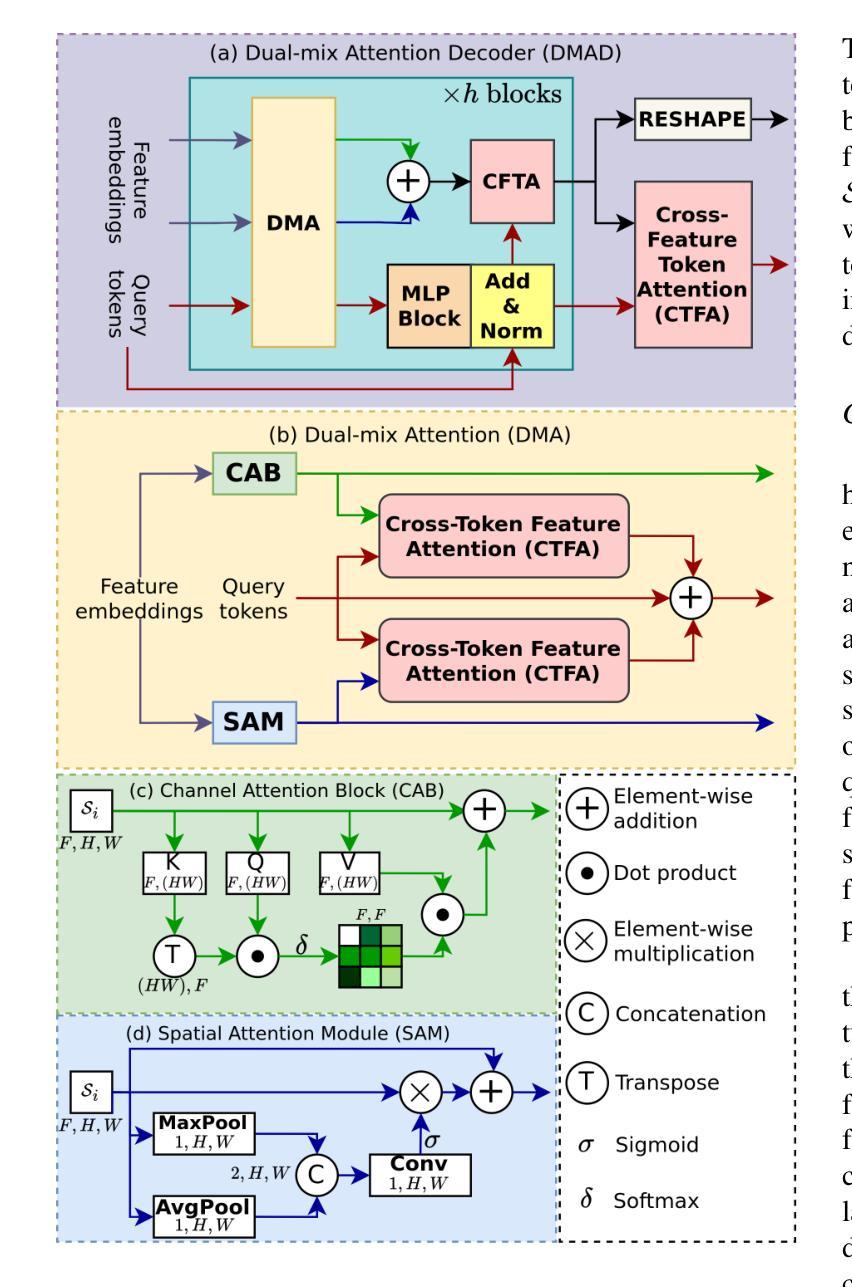
QTSeg: A Query Token-Based Dual-Mix Attention Framework with Multi-Level Feature Distribution for Medical Image Segmentation
Authors:Phuong-Nam Tran, Nhat Truong Pham, Duc Ngoc Minh Dang, Eui-Nam Huh, Choong Seon Hong
Medical image segmentation plays a crucial role in assisting healthcare professionals with accurate diagnoses and enabling automated diagnostic processes. Traditional convolutional neural networks (CNNs) often struggle with capturing long-range dependencies, while transformer-based architectures, despite their effectiveness, come with increased computational complexity. Recent efforts have focused on combining CNNs and transformers to balance performance and efficiency, but existing approaches still face challenges in achieving high segmentation accuracy while maintaining low computational costs. Furthermore, many methods underutilize the CNN encoder’s capability to capture local spatial information, concentrating primarily on mitigating long-range dependency issues. To address these limitations, we propose QTSeg, a novel architecture for medical image segmentation that effectively integrates local and global information. QTSeg features a dual-mix attention decoder designed to enhance segmentation performance through: (1) a cross-attention mechanism for improved feature alignment, (2) a spatial attention module to capture long-range dependencies, and (3) a channel attention block to learn inter-channel relationships. Additionally, we introduce a multi-level feature distribution module, which adaptively balances feature propagation between the encoder and decoder, further boosting performance. Extensive experiments on five publicly available datasets covering diverse segmentation tasks, including lesion, polyp, breast cancer, cell, and retinal vessel segmentation, demonstrate that QTSeg outperforms state-of-the-art methods across multiple evaluation metrics while maintaining lower computational costs. Our implementation can be found at: https://github.com/tpnam0901/QTSeg (v1.0.0)
医学图像分割在帮助医疗专业人士进行准确诊断和实现自动化诊断过程中起着至关重要的作用。传统的卷积神经网络(CNNs)在捕捉长距离依赖关系时经常遇到困难,而基于transformer的架构虽然有效,但计算复杂度较高。近期的研究努力集中于结合CNN和transformer以平衡性能和效率,但现有方法仍面临挑战,需要在实现高分割准确度的同时保持较低的计算成本。此外,许多方法未能充分利用CNN编码器捕捉局部空间信息的能力,主要集中在缓解长距离依赖问题。为了解决这些局限性,我们提出了QTSeg,这是一种新型医学图像分割架构,能够有效地整合局部和全局信息。QTSeg采用双混合注意力解码器设计,旨在通过以下方式提高分割性能:(1)改进特征对齐的交叉注意力机制,(2)用于捕捉长距离依赖关系的空间注意力模块,以及(3)用于学习跨通道关系的通道注意力块。此外,我们还引入了一个多级特征分布模块,该模块自适应地平衡了编码器与解码器之间的特征传播,进一步提高了性能。在五个公开数据集上进行的大量实验涵盖了包括病变、息肉、乳腺癌、细胞以及视网膜血管分割等多种分割任务,证明了QTSeg在多个评估指标上优于最新方法,同时计算成本更低。我们的实现可访问于:https://github.com/tpnam0901/QTSeg(v1.0.0)
论文及项目相关链接
Summary
本文介绍了医学图像分割在医疗诊断中的重要性,指出传统卷积神经网络(CNNs)和基于变压器的架构在医学图像分割中的局限性。为解决这个问题,提出了一种新型医学图像分割架构QTSeg,它结合了CNN和变压器的优点,通过双混合注意力解码器有效整合局部和全局信息,提高分割性能。在五个公开数据集上的实验表明,QTSeg在多个评估指标上优于最新方法,同时计算成本低。
Key Takeaways
- 医学图像分割对于准确诊断和治疗至关重要。
- 传统卷积神经网络(CNNs)在捕捉长距离依赖关系方面存在困难。
- 基于变压器的架构虽然有效,但计算复杂度较高。
- QTSeg是一个新型医学图像分割架构,结合了CNN和变压器的优点。
- QTSeg通过双混合注意力解码器提高分割性能,包括交叉注意力机制、空间注意力模块和通道注意力块。
- QTSeg引入多层次特征分布模块,自适应平衡编码器与解码器之间的特征传播,进一步提高性能。
点此查看论文截图

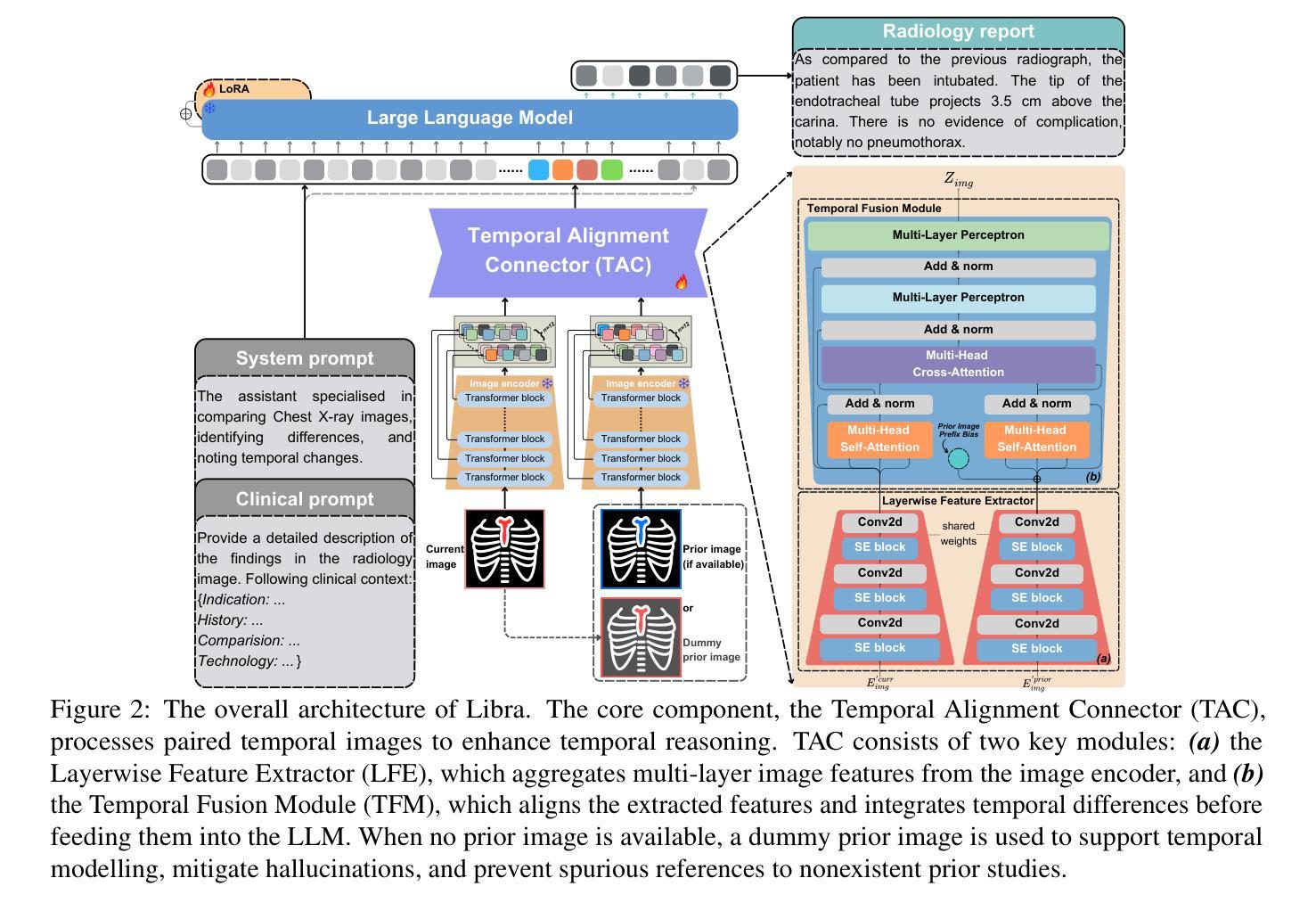
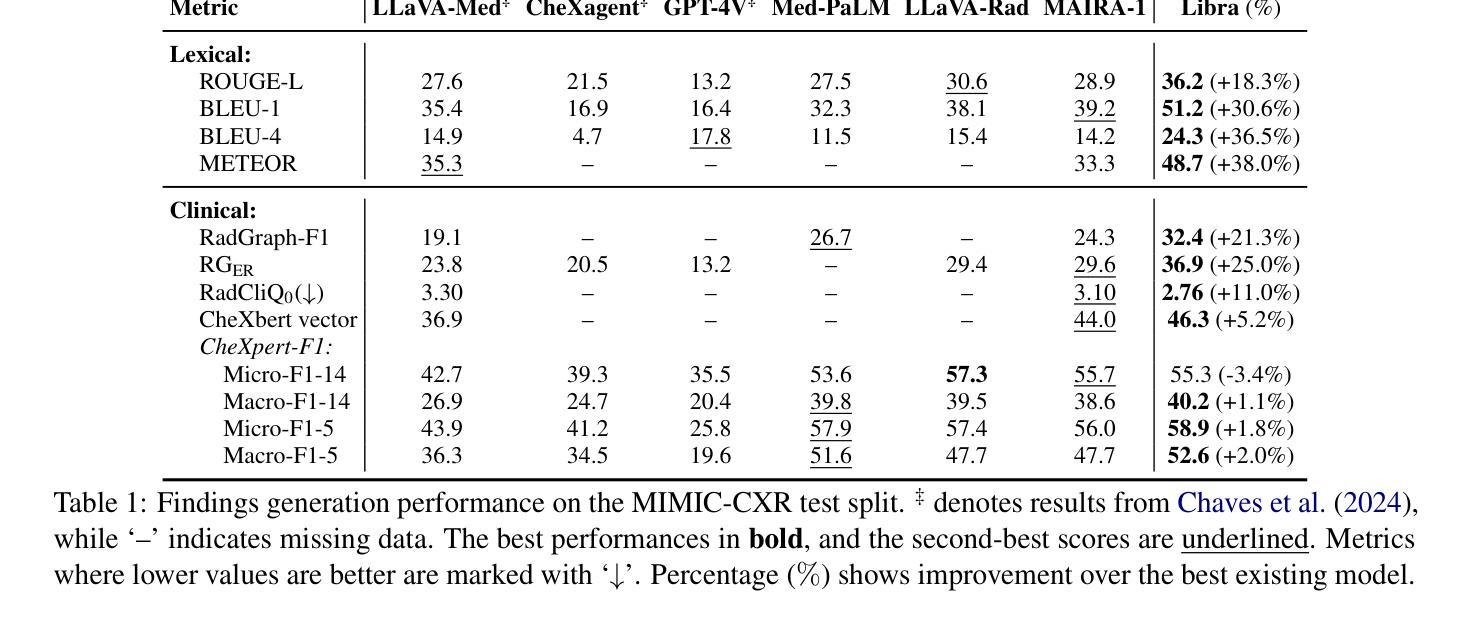
Libra: Leveraging Temporal Images for Biomedical Radiology Analysis
Authors:Xi Zhang, Zaiqiao Meng, Jake Lever, Edmond S. L. Ho
Radiology report generation (RRG) requires advanced medical image analysis, effective temporal reasoning, and accurate text generation. While multimodal large language models (MLLMs) align with pre-trained vision encoders to enhance visual-language understanding, most existing methods rely on single-image analysis or rule-based heuristics to process multiple images, failing to fully leverage temporal information in multi-modal medical datasets. In this paper, we introduce Libra, a temporal-aware MLLM tailored for chest X-ray report generation. Libra combines a radiology-specific image encoder with a novel Temporal Alignment Connector (TAC), designed to accurately capture and integrate temporal differences between paired current and prior images. Extensive experiments on the MIMIC-CXR dataset demonstrate that Libra establishes a new state-of-the-art benchmark among similarly scaled MLLMs, setting new standards in both clinical relevance and lexical accuracy.
放射报告生成(RRG)需要先进的医学图像分析、有效的时序推理和准确的文本生成。虽然多模态大型语言模型(MLLMs)与预训练的视觉编码器相结合,提高了视觉语言的理解能力,但大多数现有方法依赖于单图像分析或基于规则的启发式方法来处理多图像,未能充分利用多模态医学数据集中的时序信息。在本文中,我们介绍了Libra,这是一个面向胸部X射线报告生成设计的具有时序感知能力的MLLM。Libra结合了放射学专用图像编码器和新型时序对齐连接器(TAC),旨在准确捕捉和整合当前图像与先前配对图像之间的时序差异。在MIMIC-CXR数据集上的大量实验表明,Libra在同类规模的MLLM中建立了新的最先进的基准,在临床相关性和词汇准确性方面设定了新的标准。
论文及项目相关链接
PDF 30 pages, 5 figures, Adding Appendix
Summary
本文介绍了一种针对胸部X光报告生成的临时感知多模态大型语言模型Libra。该模型结合了放射学特定的图像编码器与新型的时间对齐连接器(TAC),旨在准确捕捉和整合当前图像与先前图像之间的时间差异。在MIMIC-CXR数据集上的大量实验表明,Libra在同类规模的多模态大型语言模型中建立了新的最佳基准,为临床相关性和词汇准确性设定了新的标准。
Key Takeaways
- Libra是一个针对胸部X光报告生成的临时感知多模态大型语言模型(MLLM)。
- 模型结合了放射学特定的图像编码器。
- 引入了一种新型的时间对齐连接器(TAC),用于捕捉和整合时间差异。
- 模型在MIMIC-CXR数据集上进行了大量实验。
- Libra在同类规模的多模态语言模型中表现最佳。
- Libra设定了临床相关性和词汇准确性的新标准。
点此查看论文截图

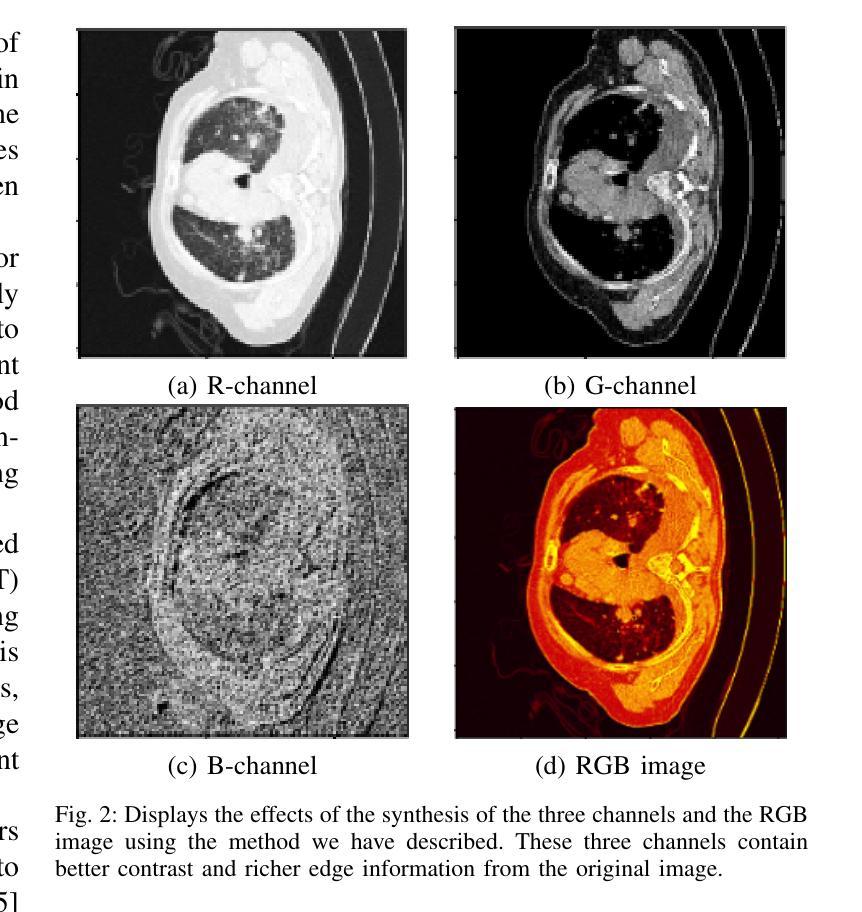
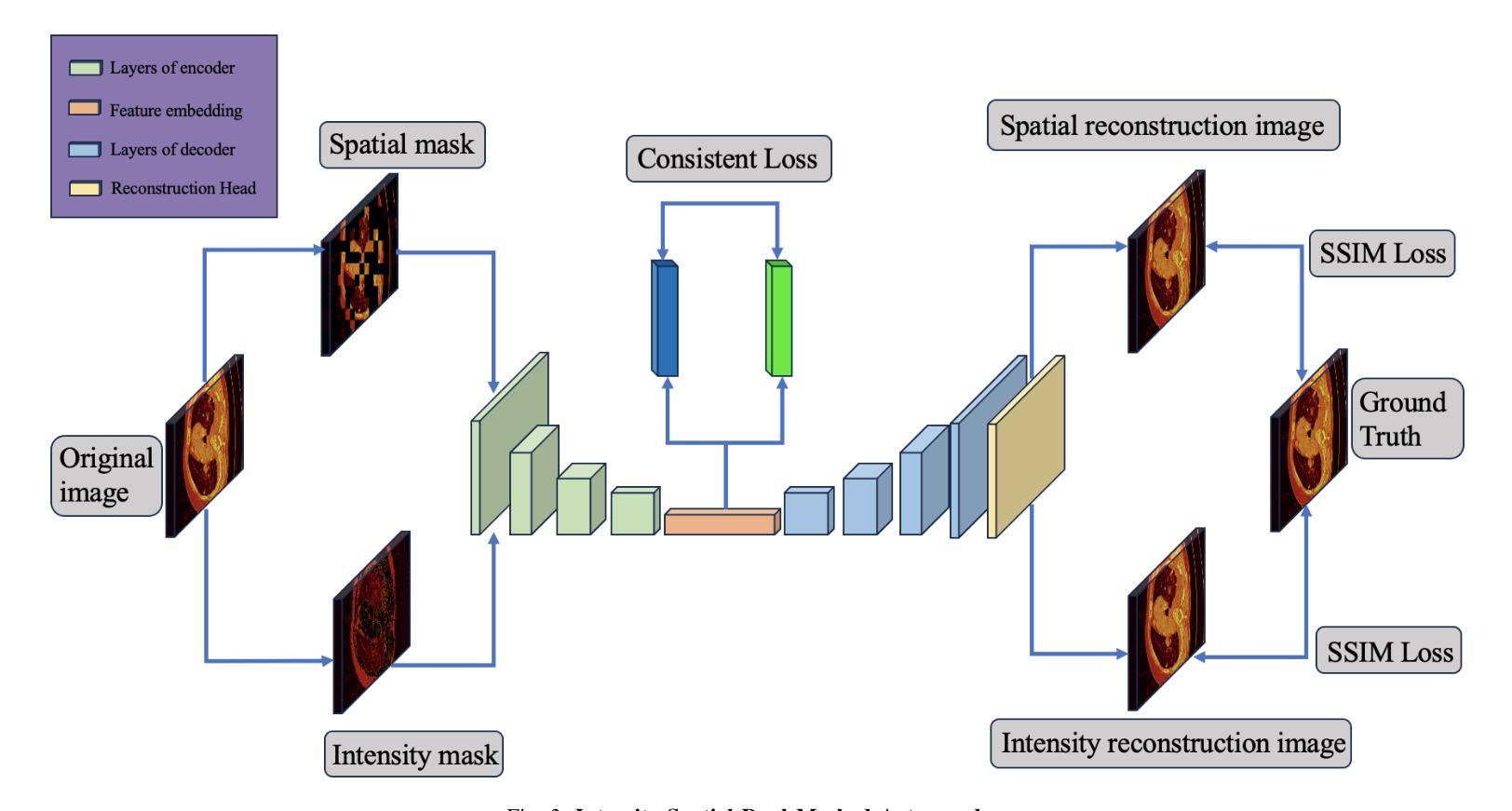
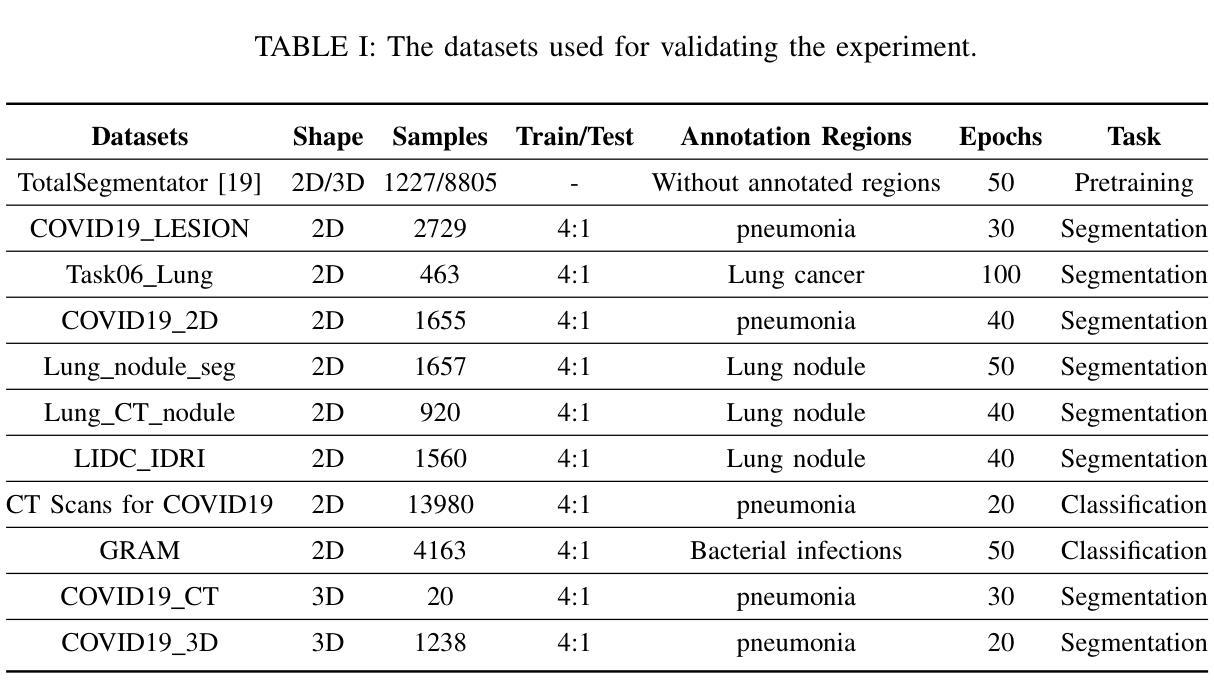
Intensity-Spatial Dual Masked Autoencoder for Multi-Scale Feature Learning in Chest CT Segmentation
Authors:Yuexing Ding, Jun Wang, Hongbing Lyu
In the field of medical image segmentation, challenges such as indistinct lesion features, ambiguous boundaries,and multi-scale characteristics have long revailed. This paper proposes an improved method named Intensity-Spatial Dual Masked AutoEncoder (ISD-MAE). Based on the tissue-contrast semi-masked autoencoder, a Masked AutoEncoder (MAE) branch is introduced to perform intensity masking and spatial masking operations on chest CT images for multi-scale feature learning and segmentation tasks. The model utilizes a dual-branch structure and contrastive learning to enhance the ability to learn tissue features and boundary details. Experiments are conducted on multiple 2D and 3D datasets. The results show that ISD-MAE significantly outperforms other methods in 2D pneumonia and mediastinal tumor segmentation tasks. For example, the Dice score reaches 90.10% on the COVID19 LESION dataset, and the performance is relatively stable. However, there is still room for improvement on 3D datasets. In response to this, improvement directions are proposed, including optimizing the loss function, using enhanced 3D convolution blocks, and processing datasets from multiple perspectives.Our code is available at:https://github.com/prowontheus/ISD-MAE.
在医学图像分割领域,长期以来一直存在着病灶特征不明显、边界模糊和多尺度特征等挑战。本文提出了一种改进的方法,名为强度-空间双重掩膜自编码器(ISD-MAE)。该方法基于组织对比半掩膜自编码器,引入了一个掩膜自编码器(MAE)分支,对胸部CT图像进行强度掩膜和空间掩膜操作,以进行多尺度特征学习和分割任务。该模型利用双分支结构和对比学习,增强了学习组织特征和边界细节的能力。实验是在多个2D和3D数据集上进行的。结果表明,在2D肺炎和纵隔肿瘤分割任务中,ISD-MAE显著优于其他方法。例如,在COVID19 LESION数据集上,Dice得分达到90.10%,性能相对稳定。但在3D数据集上仍有提升空间。对此,提出了改进方向,包括优化损失函数、使用增强的3D卷积块以及从多个角度处理数据集。我们的代码可访问于:https://github.com/prowontheus/ISD-MAE。
论文及项目相关链接
PDF During further verification, we found that due to operational errors, a small number of images in the dataset used for training appeared in the validation set, which led to inaccurate main conclusions. We are correcting these problems and plan to withdraw this paper.
Summary
本文提出一种改进的方法,名为强度空间双掩膜自编码器(ISD-MAE),用于解决医学图像分割中的挑战,如病灶特征不清晰、边界模糊和多尺度特征等。该方法基于组织对比半掩膜自编码器,引入掩膜自编码器(MAE)分支,对胸部CT图像进行强度掩膜和空间掩膜操作,以实现多尺度特征学习和分割任务。实验结果表明,ISD-MAE在二维肺炎和纵隔肿瘤分割任务上显著优于其他方法,如在COVID19 LESION数据集上的Dice得分达到90.10%,且性能相对稳定。但对于三维数据集,仍有改进空间。
Key Takeaways
- ISD-MAE方法被提出以解决医学图像分割中的挑战,包括病灶特征不清晰、边界模糊和多尺度特征问题。
- 方法基于组织对比半掩膜自编码器,引入MAE分支进行强度掩膜和空间掩膜操作。
- ISD-MAE用于处理胸部CT图像,并进行多尺度特征学习和分割任务。
- 实验结果显示,ISD-MAE在二维肺炎和纵隔肿瘤分割任务上表现优异。
- 在COVID19 LESION数据集上,ISD-MAE的Dice得分达到90.10%,性能稳定。
- 对于三维数据集,仍存在改进空间,提议的优化方向包括优化损失函数、使用增强的三维卷积块以及从多个角度处理数据集。
点此查看论文截图

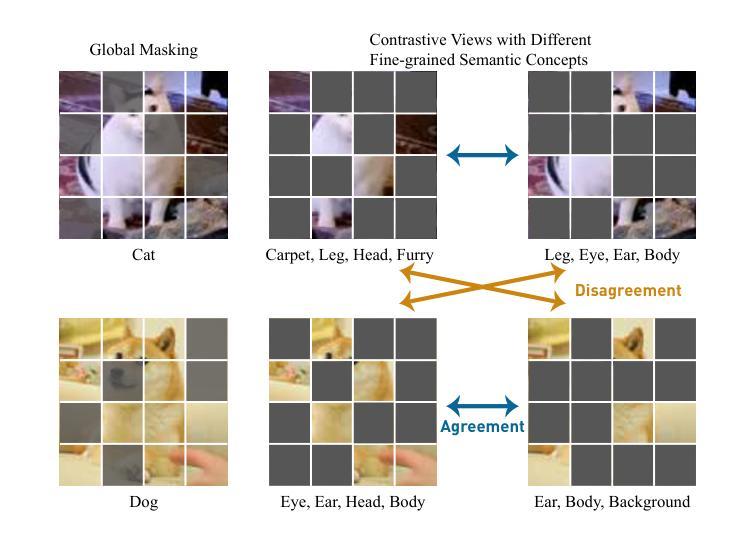
One Leaf Reveals the Season: Occlusion-Based Contrastive Learning with Semantic-Aware Views for Efficient Visual Representation
Authors:Xiaoyu Yang, Lijian Xu, Hongsheng Li, Shaoting Zhang
This paper proposes a scalable and straightforward pre-training paradigm for efficient visual conceptual representation called occluded image contrastive learning (OCL). Our OCL approach is simple: we randomly mask patches to generate different views within an image and contrast them among a mini-batch of images. The core idea behind OCL consists of two designs. First, masked tokens have the potential to significantly diminish the conceptual redundancy inherent in images, and create distinct views with substantial fine-grained differences on the semantic concept level instead of the instance level. Second, contrastive learning is adept at extracting high-level semantic conceptual features during the pre-training, circumventing the high-frequency interference and additional costs associated with image reconstruction. Importantly, OCL learns highly semantic conceptual representations efficiently without relying on hand-crafted data augmentations or additional auxiliary modules. Empirically, OCL demonstrates high scalability with Vision Transformers, as the ViT-L/16 can complete pre-training in 133 hours using only 4 A100 GPUs, achieving 85.8% accuracy in downstream fine-tuning tasks. Code is available at https://anonymous.4open.science/r/OLRS/.
本文提出了一种可扩展且直观的高效视觉概念表示预训练范式,称为遮挡图像对比学习(OCL)。我们的OCL方法很简单:我们随机遮挡图像中的小块区域以生成不同的视图,并在一批图像之间进行对比。OCL背后的核心理念包括两个设计。首先,遮挡的标记具有降低图像固有概念冗余的潜力,并能够创建具有明显细微差异的视图,这些差异体现在语义概念层面而非实例层面。其次,对比学习在预训练期间擅长提取高级语义概念特征,避免了与图像重建相关的高频干扰和额外成本。重要的是,OCL能够高效地学习高度语义化的概念表示,无需依赖手工制作的数据增强或额外的辅助模块。经验上,OCL在视觉转换器上具有高度的可扩展性,例如ViT-L/16可以在仅使用4个A100 GPU的情况下在133小时内完成预训练,并在下游微调任务中实现85.8%的准确率。代码可在https://anonymous.4open.science/r/OLRS/找到。
论文及项目相关链接
PDF 16 pages
Summary
基于论文提出一种可扩展且高效的视觉概念表示预训练范式,称为遮挡图像对比学习(OCL)。其主要通过随机遮挡图像区域来生成不同的视图,并在一批图像中进行对比学习。其核心思想在于通过遮挡标记减少图像中的概念冗余,生成在语义层面上有显著差异的不同视图。对比学习能够有效提取高级语义概念特征进行预训练,避免图像重建带来的高频干扰和额外成本。更重要的是,OCL无需依赖手工制作的数据增强或额外辅助模块,可高效学习高度语义化的概念表示。实验表明,OCL在视觉转换器(Vision Transformers)上具有高度的可扩展性,ViT-L/16可以在仅使用4个A100 GPU的情况下完成预训练,并在下游微调任务中实现85.8%的准确率。
Key Takeaways
- OCL(遮挡图像对比学习)是一种新的预训练范式,用于高效视觉概念表示学习。
- OCL通过随机遮挡图像区域生成不同视图进行对比学习。
- 核心思想在于利用遮挡标记减少图像概念冗余,生成语义层面上的不同视图。
- 对比学习能够高效提取高级语义概念特征。
- OCL无需依赖手工数据增强或额外辅助模块。
- OCL在视觉转换器上表现出高可扩展性,使用较少的计算资源即可实现高效预训练。
点此查看论文截图


FlexCAD: Unified and Versatile Controllable CAD Generation with Fine-tuned Large Language Models
Authors:Zhanwei Zhang, Shizhao Sun, Wenxiao Wang, Deng Cai, Jiang Bian
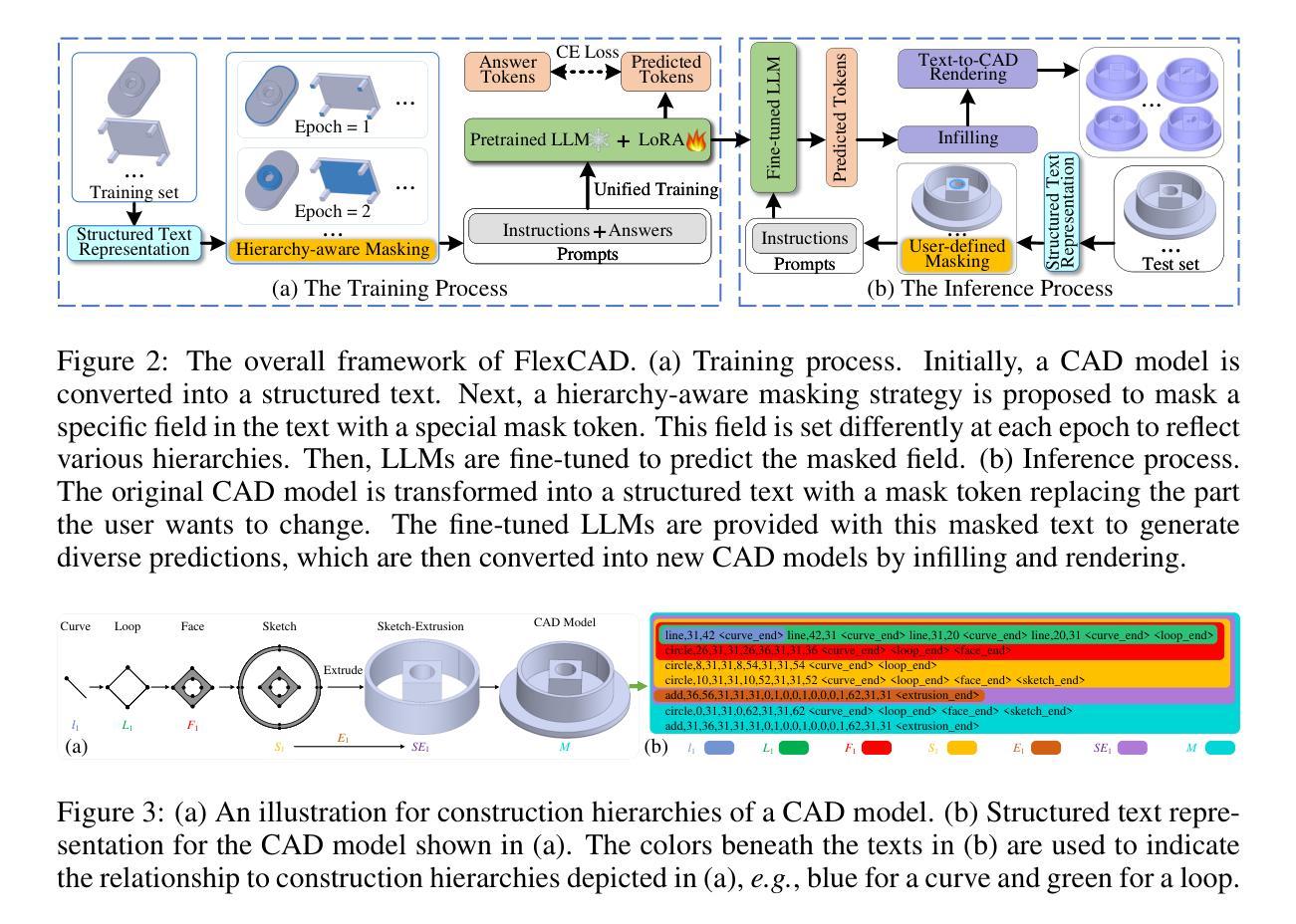
Recently, there is a growing interest in creating computer-aided design (CAD) models based on user intent, known as controllable CAD generation. Existing work offers limited controllability and needs separate models for different types of control, reducing efficiency and practicality. To achieve controllable generation across all CAD construction hierarchies, such as sketch-extrusion, extrusion, sketch, face, loop and curve, we propose FlexCAD, a unified model by fine-tuning large language models (LLMs). First, to enhance comprehension by LLMs, we represent a CAD model as a structured text by abstracting each hierarchy as a sequence of text tokens. Second, to address various controllable generation tasks in a unified model, we introduce a hierarchy-aware masking strategy. Specifically, during training, we mask a hierarchy-aware field in the CAD text with a mask token. This field, composed of a sequence of tokens, can be set flexibly to represent various hierarchies. Subsequently, we ask LLMs to predict this masked field. During inference, the user intent is converted into a CAD text with a mask token replacing the part the user wants to modify, which is then fed into FlexCAD to generate new CAD models. Comprehensive experiments on public dataset demonstrate the effectiveness of FlexCAD in both generation quality and controllability. Code will be available at https://github.com/microsoft/FlexCAD.
最近,基于用户意图创建计算机辅助设计(CAD)模型的兴趣日益浓厚,这被称为可控CAD生成。现有工作提供的可控性有限,并且需要针对不同类型的控制使用单独的模型,这降低了效率和实用性。为了实现跨所有CAD构建层次(如草图挤压、挤压、草图、面、循环和曲线)的可控生成,我们提出了FlexCAD,这是一个通过微调大型语言模型(LLM)的统一模型。首先,为了增强LLM的理解能力,我们将CAD模型表示为结构化的文本,通过将每个层次抽象为文本标记的序列。其次,为了解决统一模型中的各种可控生成任务,我们引入了一种层次感知掩码策略。具体来说,在训练过程中,我们将CAD文本中的层次感知字段用掩码标记进行掩盖。这个由一系列标记组成的字段可以灵活地设置,以表示各种层次。然后,我们要求LLM预测这个被掩盖的字段。在推理过程中,用户意图被转换为带有掩码标记的CAD文本,代替用户想要修改的部分,然后输入FlexCAD以生成新的CAD模型。在公开数据集上的综合实验表明,FlexCAD在生成质量和可控性方面都是有效的。代码将在https://github.com/microsoft/FlexCAD上提供。
论文及项目相关链接
PDF Published as a conference paper at ICLR 2025
Summary
基于用户意图的计算机辅助设计(CAD)模型生成日益受到关注。现有工作可控性有限,且需要针对不同控制类型建立单独模型,降低了效率与实用性。为实现在草图挤压、挤压、草图、面、环路和曲线等所有CAD构建层次上的可控生成,提出FlexCAD,通过微调大型语言模型(LLM)实现统一模型。FlexCAD通过文本结构化表示CAD模型以增强LLM的理解能力,引入层次感知掩码策略以解决统一模型中的多种可控生成任务。在公共数据集上的综合实验证明了FlexCAD在生成质量和可控性方面的有效性。
Key Takeaways
- 现有计算机辅助设计(CAD)模型生成工作可控性有限,需要改进。
- FlexCAD是一个基于大型语言模型的统一模型,用于实现CAD模型的可控生成。
- FlexCAD通过文本结构化表示增强对CAD模型的理解。
- FlexCAD引入层次感知掩码策略,以在统一模型中解决多种可控生成任务。
- 用户意图通过转换为带有掩码令牌的CAD文本,用于生成新的CAD模型。
- 综合实验证明了FlexCAD在生成质量和可控性方面的有效性。
点此查看论文截图


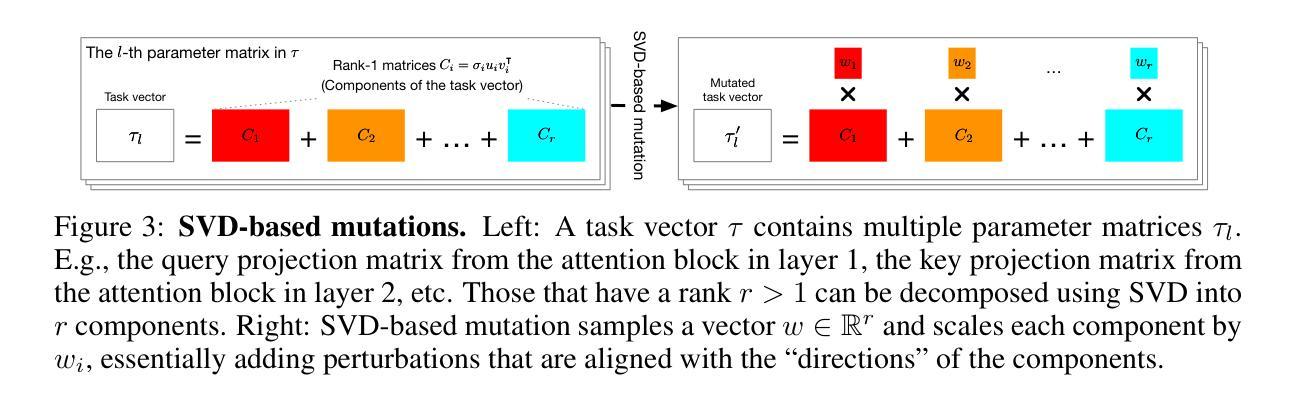
Agent Skill Acquisition for Large Language Models via CycleQD
Authors:So Kuroki, Taishi Nakamura, Takuya Akiba, Yujin Tang
Training large language models to acquire specific skills remains a challenging endeavor. Conventional training approaches often struggle with data distribution imbalances and inadequacies in objective functions that do not align well with task-specific performance. To address these challenges, we introduce CycleQD, a novel approach that leverages the Quality Diversity framework through a cyclic adaptation of the algorithm, along with a model merging based crossover and an SVD-based mutation. In CycleQD, each task’s performance metric is alternated as the quality measure while the others serve as the behavioral characteristics. This cyclic focus on individual tasks allows for concentrated effort on one task at a time, eliminating the need for data ratio tuning and simplifying the design of the objective function. Empirical results from AgentBench indicate that applying CycleQD to LLAMA3-8B-INSTRUCT based models not only enables them to surpass traditional fine-tuning methods in coding, operating systems, and database tasks, but also achieves performance on par with GPT-3.5-TURBO, which potentially contains much more parameters, across these domains. Crucially, this enhanced performance is achieved while retaining robust language capabilities, as evidenced by its performance on widely adopted language benchmark tasks. We highlight the key design choices in CycleQD, detailing how these contribute to its effectiveness. Furthermore, our method is general and can be applied to image segmentation models, highlighting its applicability across different domains.
训练大型语言模型以获取特定技能仍然是一项具有挑战性的工作。传统的训练方法常常面临数据分布不平衡和客观函数与特定任务性能不匹配的问题。为了解决这些挑战,我们引入了CycleQD这一新方法,它利用质量多样性框架通过算法的循环适应,以及基于模型合并的交叉和基于SVD的突变。在CycleQD中,每个任务的性能指标被交替作为质量度量,而其他指标则作为行为特征。这种对单个任务的循环关注允许每次集中精力完成一个任务,从而消除了对数据比率调整的需求,并简化了目标函数的设计。来自AgentBench的经验结果表明,将CycleQD应用于LLAMA3-8B-INSTRUCT基础模型,不仅能使它们在编码、操作系统和数据库任务上超越传统的微调方法,而且在这几个领域实现了与GPT-3.5-TURBO相当的性能,尽管GPT-3.5-TURBO可能包含更多的参数。关键的是,这种增强的性能是在保留稳健的语言能力的同时实现的,这在其广泛采用的语言基准任务上的表现得到了证明。我们强调了CycleQD中的关键设计选择,详细说明了这些是如何促进其有效性的。此外,我们的方法是通用的,可应用于图像分割模型,突出了其在不同领域的应用性。
论文及项目相关链接
PDF To appear at the 13th International Conference on Learning Representations (ICLR 2025)
Summary
CycleQD是一种针对大型语言模型的新型训练方法,它通过质量多样性框架的循环适应算法,模型合并交叉和SVD基因突变来解决传统训练方法的挑战。该方法可集中关注于单个任务,简化目标函数设计,并减少数据比率调整的需求。在AgentBench上的实验结果表明,使用CycleQD训练的LLAMA3-8B-INSTRUCT模型在编码、操作系统和数据库任务上的性能超过了传统微调方法,甚至与GPT-3.5-TURBO相当。同时,该方法保留了模型的稳健语言功能。
Key Takeaways
- CycleQD是一种新型的大型语言模型训练方法,基于质量多样性框架。
- CycleQD通过循环适应算法、模型合并交叉和SVD基因突变来优化训练。
- CycleQD可集中关注于单个任务,简化目标函数设计。
- 使用CycleQD训练的模型在多种任务上的性能超过了传统方法。
- CycleQD训练的模型性能与GPT-3.5-TURBO相当。
- CycleQD保留了模型的稳健语言功能。
点此查看论文截图