⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-19 更新
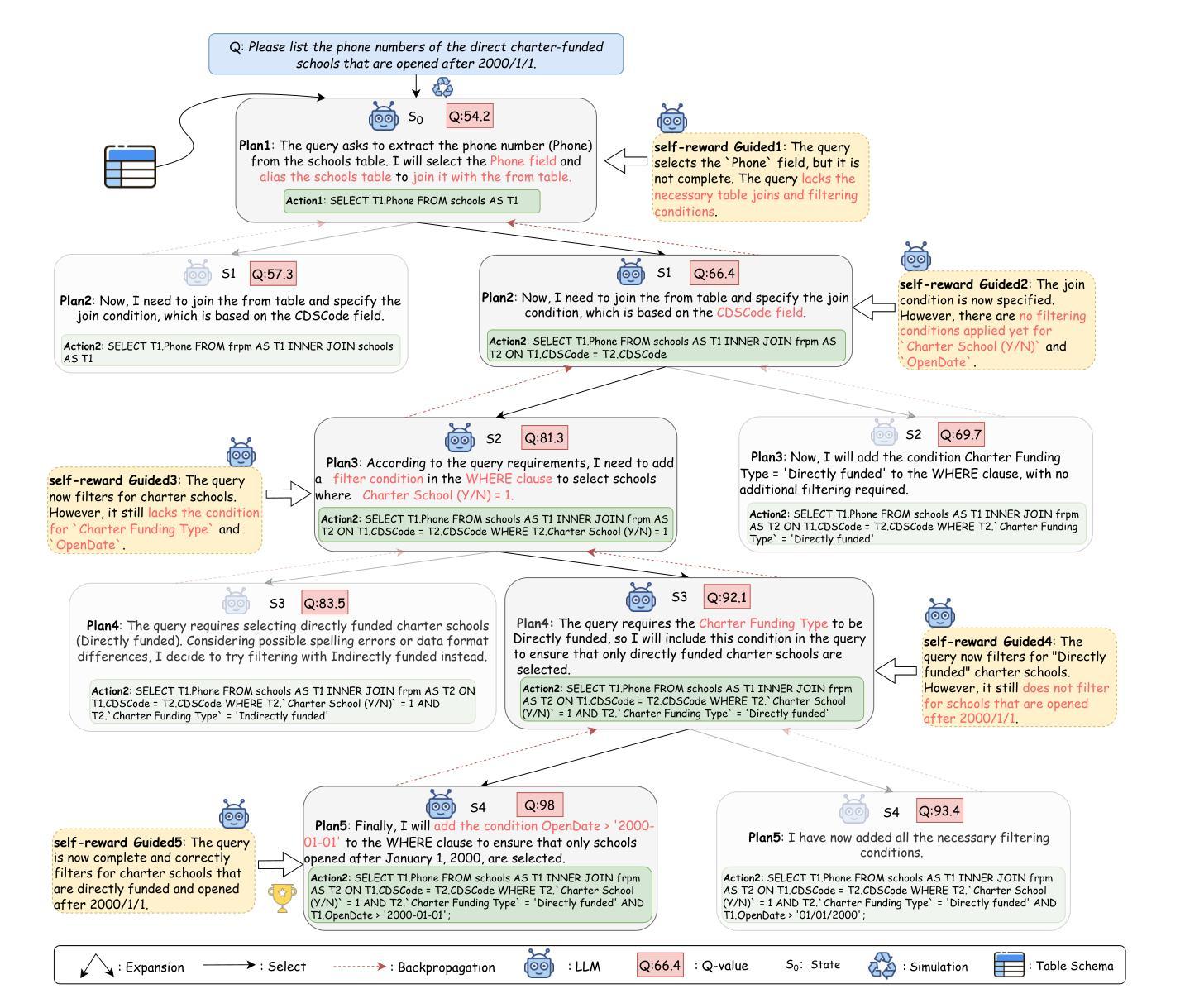
SQL-o1: A Self-Reward Heuristic Dynamic Search Method for Text-to-SQL
Authors:Shuai Lyu, Haoran Luo, Zhonghong Ou, Yifan Zhu, Xiaoran Shang, Yang Qin, Meina Song
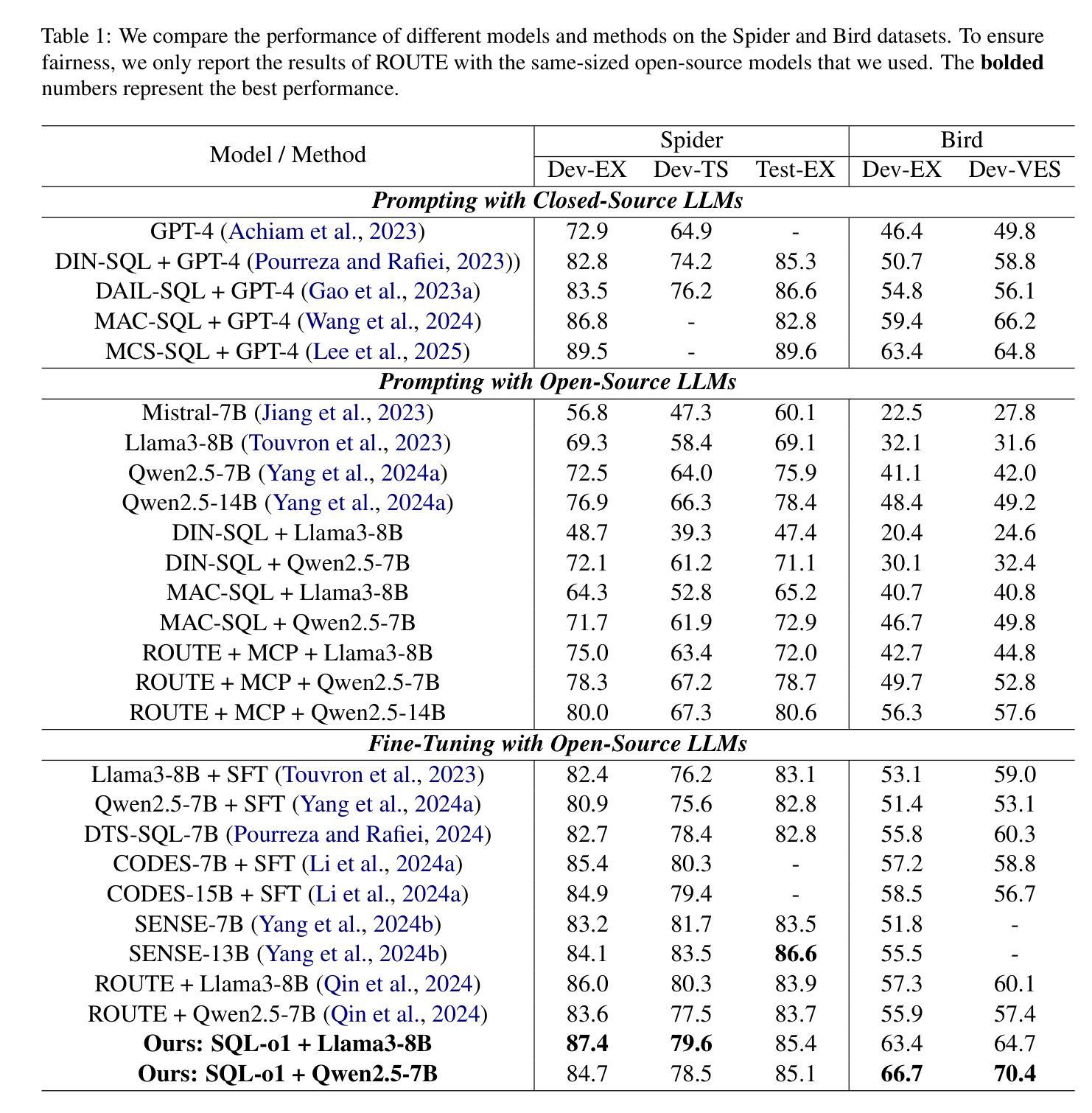
The Text-to-SQL(Text2SQL) task aims to convert natural language queries into executable SQL queries. Thanks to the application of large language models (LLMs), significant progress has been made in this field. However, challenges such as model scalability, limited generation space, and coherence issues in SQL generation still persist. To address these issues, we propose SQL-o1, a Self-Reward-based heuristic search method designed to enhance the reasoning ability of LLMs in SQL query generation. SQL-o1 combines Monte Carlo Tree Search (MCTS) for heuristic process-level search and constructs a Schema-Aware dataset to help the model better understand database schemas. Extensive experiments on the Bird and Spider datasets demonstrate that SQL-o1 improves execution accuracy by 10.8% on the complex Bird dataset compared to the latest baseline methods, even outperforming GPT-4-based approaches. Additionally, SQL-o1 excels in few-shot learning scenarios and shows strong cross-model transferability. Our code is publicly available at:https://github.com/ShuaiLyu0110/SQL-o1.
文本到SQL(Text2SQL)任务旨在将自然语言查询转换为可执行的SQL查询。由于大型语言模型(LLM)的应用,该领域已经取得了重大进展。然而,仍然存在一些挑战,例如模型的可扩展性、有限的生成空间和SQL生成中的连贯性问题。为了解决这些问题,我们提出了SQL-o1,这是一种基于自我奖励的启发式搜索方法,旨在提高LLM在SQL查询生成中的推理能力。SQL-o1结合蒙特卡洛树搜索(MCTS)进行启发式过程级搜索,并构建了一个模式感知数据集,以帮助模型更好地了解数据库模式。在Bird和Spider数据集上的大量实验表明,与最新基线方法相比,SQL-o1在复杂的Bird数据集上执行准确性提高了10.8%,甚至超越了GPT-4的方法。此外,SQL-o1在少样本学习场景中表现出色,并显示出强大的跨模型迁移能力。我们的代码公开在:https://github.com/ShuaiLyu0110/SQL-o1。
论文及项目相关链接
PDF 10 pages,4 figures
Summary
文本转换任务旨在将自然语言查询转换为可执行的SQL查询。虽然大语言模型(LLM)的应用在这方面取得了进展,但模型可扩展性、有限的生成空间和SQL生成连贯性问题等挑战仍然存在。为解决这些问题,我们提出了SQL-o1,一种基于自我奖励的启发式搜索方法,旨在提高LLM在SQL查询生成中的推理能力。SQL-o1结合了蒙特卡洛树搜索(MCTS)进行启发式过程级搜索,并构建了一个Schema-Aware数据集,帮助模型更好地了解数据库模式。在Bird和Spider数据集上的大量实验表明,SQL-o1提高了在复杂数据集上的执行精度,并在少样本学习场景下表现优异,显示出强大的跨模型迁移能力。
Key Takeaways
- Text-to-SQL任务旨在将自然语言查询转换为可执行的SQL查询。
- 大语言模型(LLMs)在该领域取得了显著进展,但仍面临模型可扩展性、生成空间有限和SQL生成连贯性问题等挑战。
- SQL-o1是一种基于自我奖励的启发式搜索方法,旨在提高LLM在SQL查询生成中的推理能力。
- SQL-o1结合了蒙特卡洛树搜索(MCTS)进行过程级搜索,并构建了一个Schema-Aware数据集。
- 在Bird和Spider数据集上的实验表明,SQL-o1提高了执行精度,尤其是在复杂数据集上。
- SQL-o1在少样本学习场景下表现优异,显示出强大的跨模型迁移能力。
点此查看论文截图

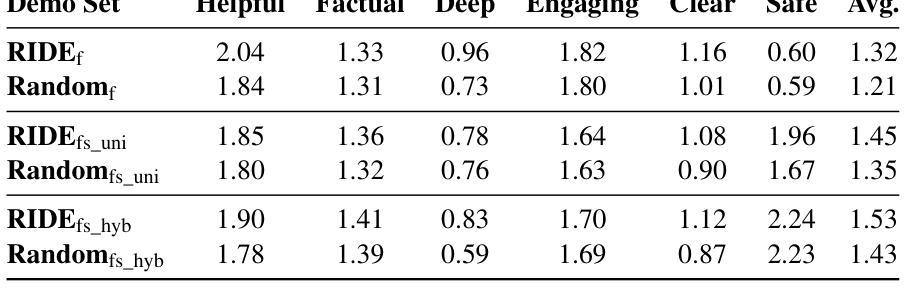
RIDE: Enhancing Large Language Model Alignment through Restyled In-Context Learning Demonstration Exemplars
Authors:Yuncheng Hua, Lizhen Qu, Zhuang Li, Hao Xue, Flora D. Salim, Gholamreza Haffari
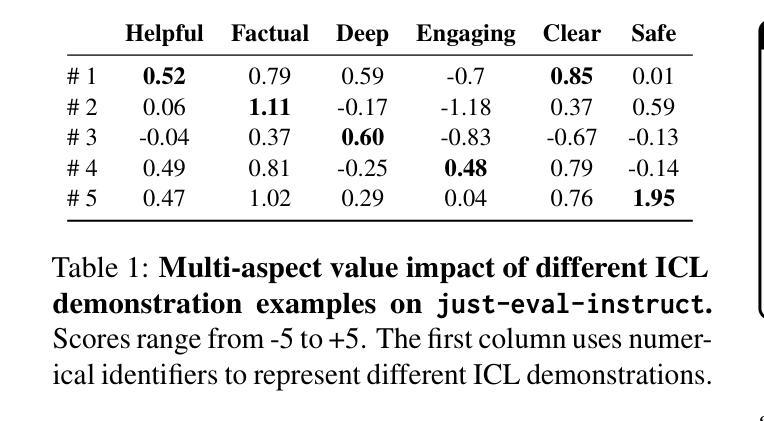
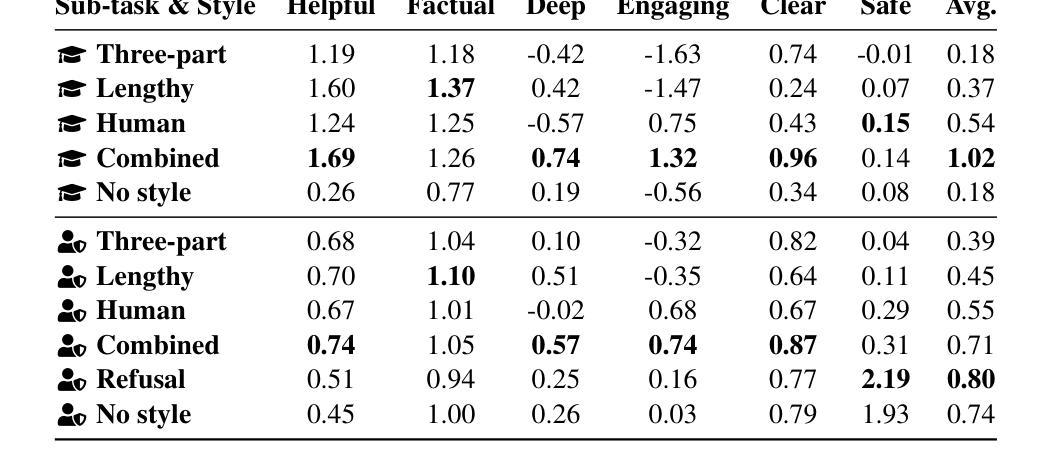
Alignment tuning is crucial for ensuring large language models (LLMs) behave ethically and helpfully. Current alignment approaches require high-quality annotations and significant training resources. This paper proposes a low-cost, tuning-free method using in-context learning (ICL) to enhance LLM alignment. Through an analysis of high-quality ICL demos, we identified style as a key factor influencing LLM alignment capabilities and explicitly restyled ICL exemplars based on this stylistic framework. Additionally, we combined the restyled demos to achieve a balance between the two conflicting aspects of LLM alignment–factuality and safety. We packaged the restyled examples as prompts to trigger few-shot learning, improving LLM alignment. Compared to the best baseline approach, with an average score of 5.00 as the maximum, our method achieves a maximum 0.10 increase on the Alpaca task (from 4.50 to 4.60), a 0.22 enhancement on the Just-eval benchmark (from 4.34 to 4.56), and a maximum improvement of 0.32 (from 3.53 to 3.85) on the MT-Bench dataset. We release the code and data at https://github.com/AnonymousCode-ComputerScience/RIDE.
对齐调整对于确保大型语言模型(LLM)以道德和有益的方式行为至关重要。当前的对齐方法需要高质量标注和大量的训练资源。本文提出了一种低成本的免调整方法,使用上下文学习(ICL)增强LLM的对齐能力。通过对高质量ICL演示内容的分析,我们发现风格是影响LLM对齐能力的关键因素,并基于此风格框架明确地对ICL示例进行了重新设计。此外,我们将重新设计的演示内容相结合,实现了LLM对齐的两个方面之间的平衡——事实性和安全性。我们将重新设计的示例打包为提示,以触发少量学习,从而提高LLM的对齐能力。与最佳基线方法相比(最高平均得分为5.00),我们的方法在Alpaca任务上最高得分增加了0.10(从4.50到4.60),在Just-eval基准测试上提高了0.22(从4.34到4.56),在MT-Bench数据集上的最高改进为0.32(从3.53到3.85)。我们在https://github.com/AnonymousCode-ComputerScience/RIDE上发布了代码和数据。
论文及项目相关链接
PDF 37 pages, 1 figure, 20 tables; The paper is under review
Summary
本文提出了一种低成本、无需调整的方法,利用上下文学习(ICL)增强大型语言模型(LLM)的对齐能力。研究通过高质量ICL演示分析,发现风格是影响LLM对齐能力的重要因素,并在此基础上重新设计了ICL范例。通过结合这些重新设计的范例,实现了LLM对齐的两个方面——事实性和安全性之间的平衡。最终,该方法提高了LLM的对齐能力,并在特定任务上取得了显著成果。
Key Takeaways
- 论文提出了一种新的低成本、无需调整的方法,通过上下文学习(ICL)增强大型语言模型(LLM)的伦理和友好行为对齐。
- 论文发现风格是影响LLM对齐能力的关键因素,并基于此重新设计了ICL范例。
- 论文通过结合重新设计的范例,平衡了LLM对齐的两个方面:事实性和安全性。
- 该方法通过触发少样本学习,提高了LLM的对齐能力。
- 与最佳基线方法相比,论文中的方法在特定任务上实现了显著的提升。
- 论文公开了相关代码和数据,便于他人使用和进一步的研究。
点此查看论文截图

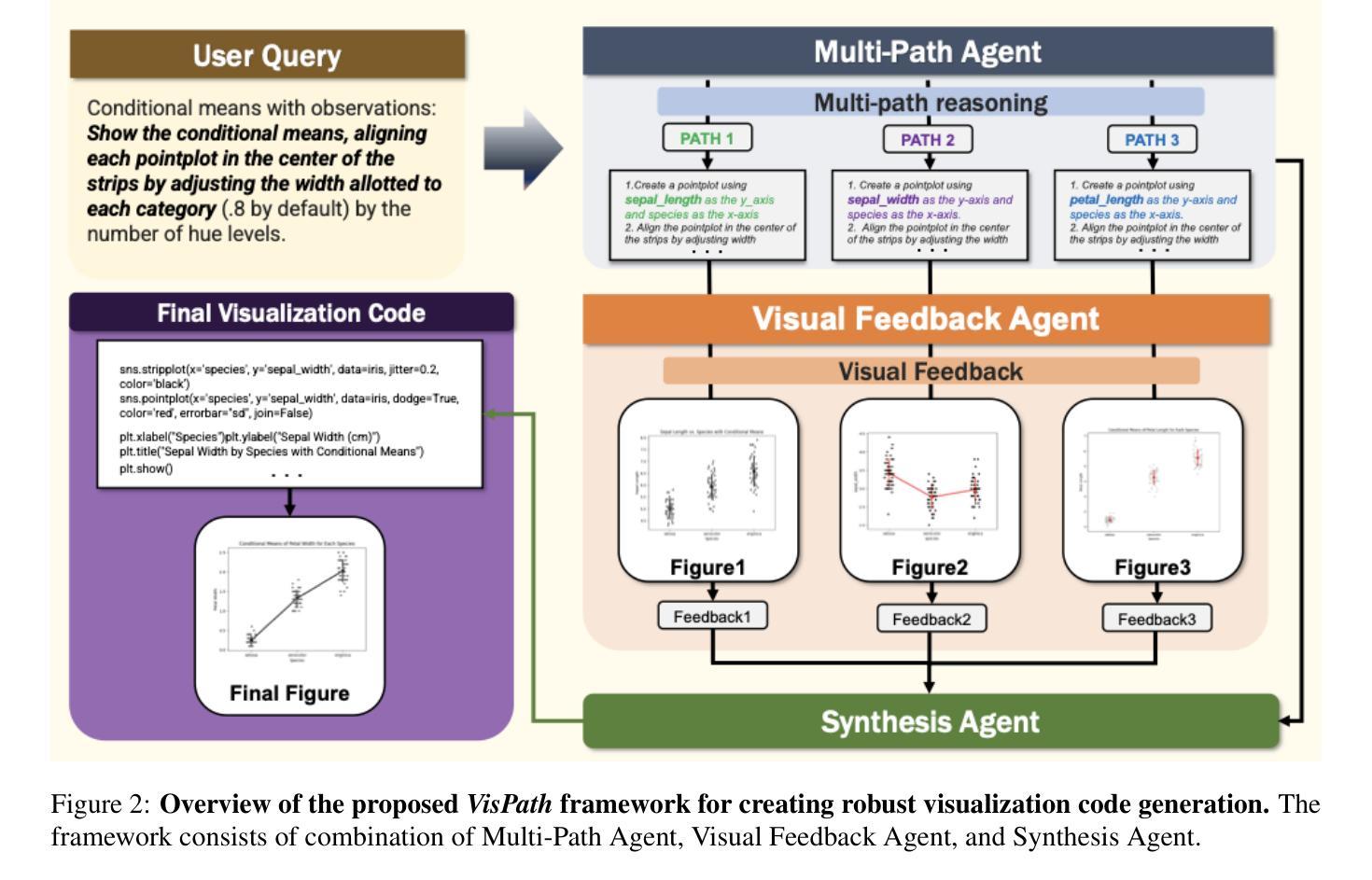
VisPath: Automated Visualization Code Synthesis via Multi-Path Reasoning and Feedback-Driven Optimization
Authors:Wonduk Seo, Seungyong Lee, Daye Kang, Zonghao Yuan, Seunghyun Lee
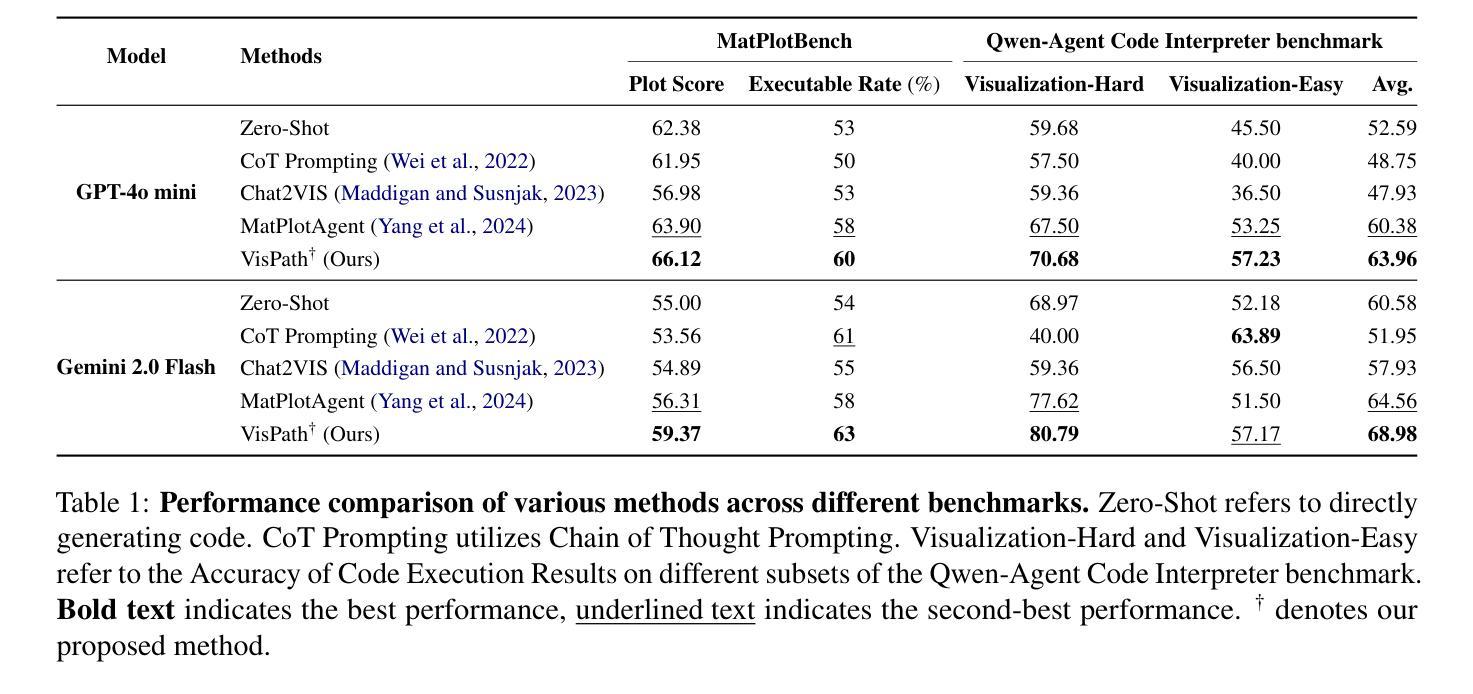
Unprecedented breakthroughs in Large Language Models (LLMs) has amplified its penetration into application of automated visualization code generation. Few-shot prompting and query expansion techniques have notably enhanced data visualization performance, however, still fail to overcome ambiguity and complexity of natural language queries - imposing an inherent burden for manual human intervention. To mitigate such limitations, we propose a holistic framework VisPath : A Multi-Path Reasoning and Feedback-Driven Optimization Framework for Visualization Code Generation, which systematically enhances code quality through structured reasoning and refinement. VisPath is a multi-stage framework, specially designed to handle underspecified queries. To generate a robust final visualization code, it first utilizes initial query to generate diverse reformulated queries via Chain-of-Thought (CoT) prompting, each representing a distinct reasoning path. Refined queries are used to produce candidate visualization scripts, consequently executed to generate multiple images. Comprehensively assessing correctness and quality of outputs, VisPath generates feedback for each image, which are then fed to aggregation module to generate optimal result. Extensive experiments on benchmarks including MatPlotBench and the Qwen-Agent Code Interpreter Benchmark show that VisPath significantly outperforms state-of-the-art (SOTA) methods, increased up to average 17%, offering a more reliable solution for AI-driven visualization code generation.
大型语言模型(LLM)的突破性进展增强了其在自动化可视化代码生成中的应用。尽管少样本提示和查询扩展技术显著提高了数据可视化性能,但仍然无法克服自然语言查询的模糊性和复杂性,给人工干预带来了固有负担。为了缓解这些限制,我们提出了一个全面的框架——VisPath:可视化代码生成的多路径推理与反馈驱动优化框架。VisPath通过结构化推理和细化系统地提高代码质量。VisPath是一个多阶段框架,专门设计来处理未指定的查询。为了生成稳健的最终可视化代码,它首先利用初始查询通过链式思维(CoT)提示生成多样化的重构查询,每个查询代表一个独特的推理路径。经过细化的查询用于生成候选可视化脚本,然后执行生成多个图像。全面评估输出的正确性和质量,VisPath为每张图像生成反馈,然后将其输入到聚合模块中以生成最佳结果。在包括MatPlotBench和Qwen-Agent代码解释器基准测试在内的基准测试上的大量实验表明,VisPath显著优于最先进的方法,平均提高了17%,为AI驱动的可视化代码生成提供了更可靠的解决方案。
论文及项目相关链接
PDF 14 pages, 3 figures, 4 tables
Summary
大规模语言模型(LLM)在自动化可视化代码生成领域取得了突破性进展。虽然少样本提示和查询扩展技术显著提高了数据可视化性能,但仍未能克服自然语言查询的模糊性和复杂性,仍需要人工干预。为缓解这一问题,我们提出了VisPath框架,即一个用于可视化代码生成的多路径推理和反馈驱动的优化框架。它通过结构化推理和细化系统地提高代码质量。VisPath是一个专门设计用于处理未指定查询的多阶段框架。它首先利用初始查询生成多种经过改革的查询,然后通过链式思维(CoT)提示代表不同的推理路径。这些精细查询用于生成候选可视化脚本,进而执行生成多个图像。全面评估输出结果的正确性和质量后,VisPath为每个图像生成反馈,并将其输入到聚合模块中以生成最佳结果。在MatPlotBench和Qwen-Agent代码解释器基准测试上的实验表明,VisPath显著优于现有技术,平均提高了17%,为AI驱动的可视化代码生成提供了更可靠的解决方案。
Key Takeaways
- Large Language Models (LLMs) 已在自动化可视化代码生成领域取得重大突破。
- 虽然少样本提示和查询扩展技术有所助益,但仍存在自然语言查询的模糊性和复杂性问题。
- 提出了VisPath框架,一个包含多阶段、多路径推理和反馈驱动的优化机制,以处理未指定的查询并提升代码质量。
- VisPath通过链式思维(CoT)提示生成多种查询,代表不同的推理路径。
- VisPath能够生成候选可视化脚本,并通过执行生成多个图像。
- 通过全面评估输出结果的正确性和质量,VisPath为图像生成反馈。
- 实验表明,VisPath在基准测试中显著优于现有技术,平均提高了17%的性能。
点此查看论文截图

Are Transformers Able to Reason by Connecting Separated Knowledge in Training Data?
Authors:Yutong Yin, Zhaoran Wang
Humans exhibit remarkable compositional reasoning by integrating knowledge from various sources. For example, if someone learns ( B = f(A) ) from one source and ( C = g(B) ) from another, they can deduce ( C=g(B)=g(f(A)) ) even without encountering ( ABC ) together, showcasing the generalization ability of human intelligence. In this paper, we introduce a synthetic learning task, “FTCT” (Fragmented at Training, Chained at Testing), to validate the potential of Transformers in replicating this skill and interpret its inner mechanism. In the training phase, data consist of separated knowledge fragments from an overall causal graph. During testing, Transformers must infer complete causal graph traces by integrating these fragments. Our findings demonstrate that few-shot Chain-of-Thought prompting enables Transformers to perform compositional reasoning on FTCT by revealing correct combinations of fragments, even if such combinations were absent in the training data. Furthermore, the emergence of compositional reasoning ability is strongly correlated with the model complexity and training-testing data similarity. We propose, both theoretically and empirically, that Transformers learn an underlying generalizable program from training, enabling effective compositional reasoning during testing.
人类能够通过整合来自不同来源的知识展现出惊人的组合推理能力。例如,如果有人从某个来源学习到公式(B=f(A)),并从另一个来源学习到公式(C=g(B)),即使没有同时遇到这三个元素(ABC),他们也能够推断出(C=g(f(A))),这展现了人类智力的泛化能力。在本文中,我们介绍了一项合成学习任务“FTCT”(训练时片段化,测试时链接),以验证Transformer在复制这项技能方面的潜力并解释其内在机制。在训练阶段,数据由来自整体因果图的独立知识片段组成。在测试阶段,Transformer必须通过整合这些片段来推断完整的因果图轨迹。我们的研究发现,通过揭示正确的片段组合,即使在训练数据中不存在这样的组合,少数链式思维提示也能使Transformer在FTCT上执行组合推理。此外,组合推理能力的出现与模型复杂度和训练测试数据相似性之间存在强烈的相关性。我们从理论和实证两个方面提出,Transformer从训练中学习到一个潜在的可推广程序,从而在测试过程中实现有效的组合推理。
论文及项目相关链接
PDF Accepted by ICLR 2025
Summary
本文介绍了人类展现出的组合推理能力,通过整合不同来源的知识进行推理。为了验证Transformer是否具有这种能力,本文引入了“FTCT”(训练时碎片化,测试时连锁)合成学习任务,并揭示了其内在机制。研究表明,少样本的“思维链”提示能够使得Transformer在FTCT任务上执行组合推理,通过揭示知识片段的正确组合来推导出完整的因果图轨迹。模型复杂度和训练测试数据相似性对组合推理能力的涌现有重要影响。
Key Takeaways
- 人类能整合不同来源的知识进行组合推理。
- 引入了“FTCT”合成学习任务来验证Transformer的组合推理潜力。
- 少样本的“思维链”提示能让Transformer在FTCT任务上执行组合推理。
- Transformer能通过学习底层的一般程序来实现有效的组合推理。
- 模型复杂度对Transformer的组合推理能力有重要影响。
- 训练测试数据的相似性对模型在组合推理任务上的表现有重要影响。
点此查看论文截图


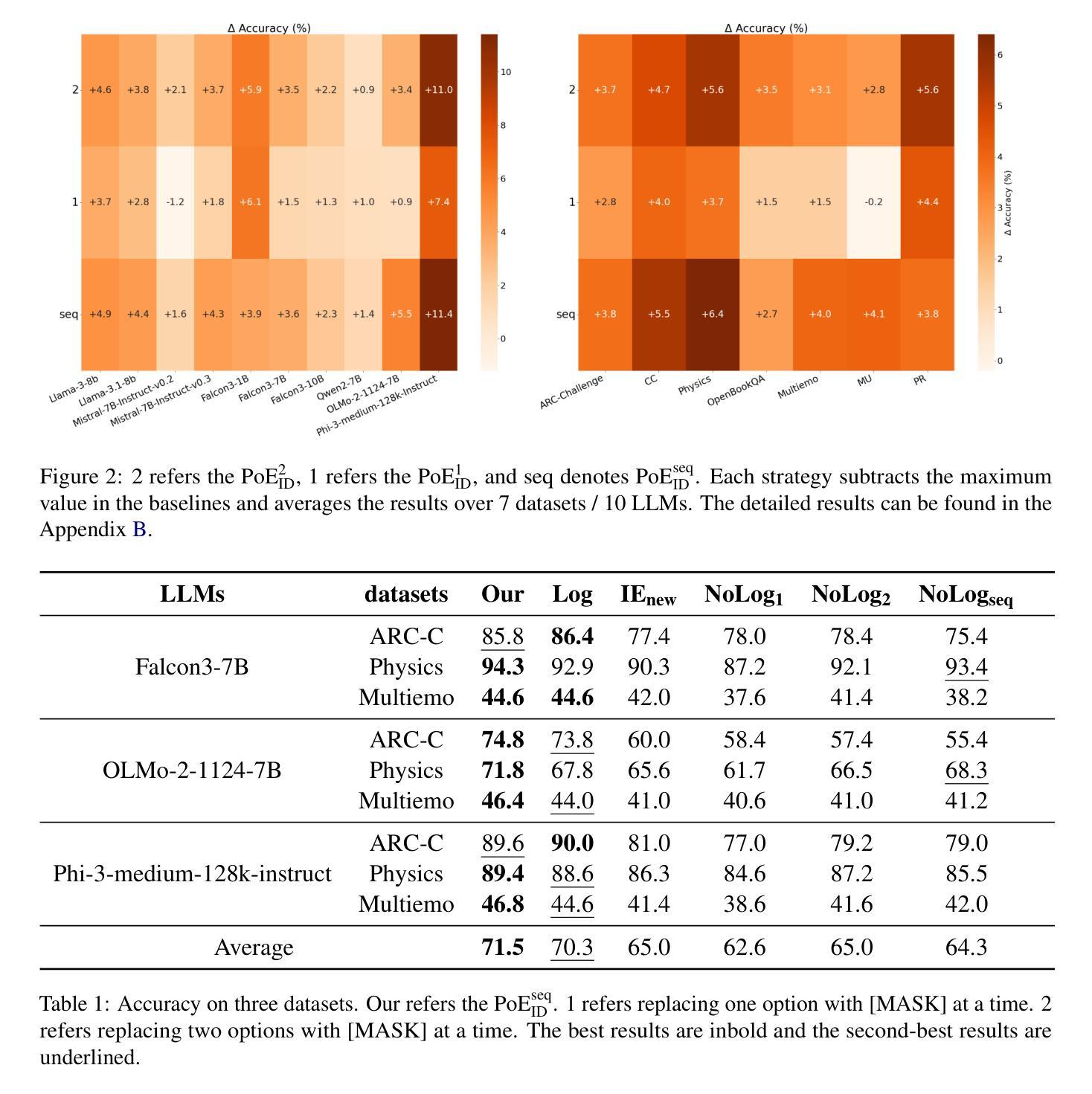
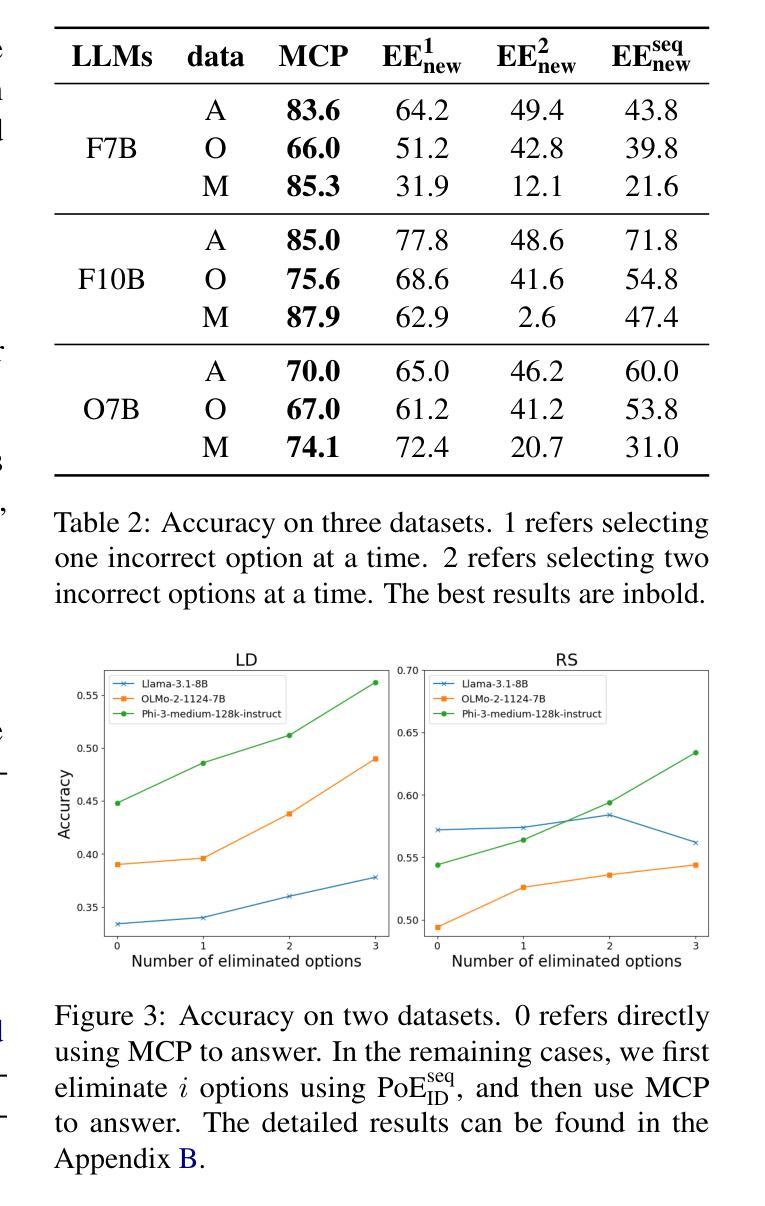
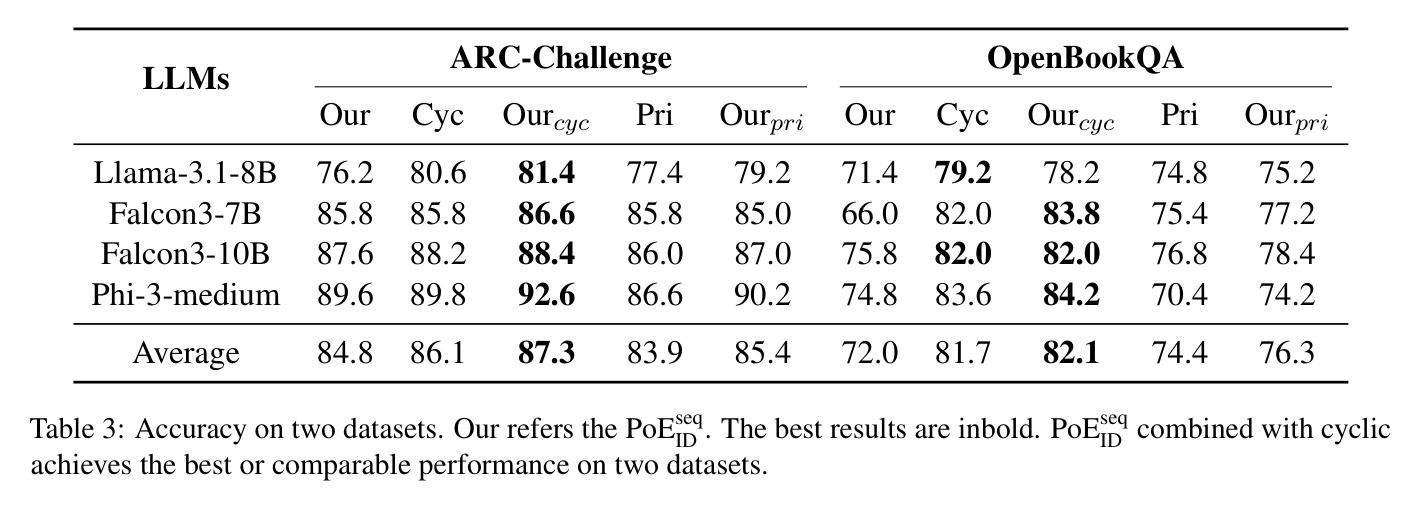
Option-ID Based Elimination For Multiple Choice Questions
Authors:Zhenhao Zhu, Bulou Liu, Qingyao Ai, Yiqun Liu
Multiple choice questions (MCQs) are a popular and important task for evaluating large language models (LLMs). Based on common strategies people use when answering MCQs, the process of elimination (PoE) has been proposed as an effective problem-solving method. Existing methods to the PoE generally fall into two categories: one involves having the LLM directly select the incorrect options, while the other involves scoring the options. However, both methods incur high computational costs and often perform worse than methods that directly answer the MCQs with the option IDs. To address this issue, this paper proposes a PoE based on option ID. Specifically, our method eliminates option by selecting the option ID with the lowest probability. We conduct experiments with 10 different LLMs in zero-shot settings on 7 publicly available datasets. The experimental results demonstrate that our method significantly improves the LLM’s performance. Further analysis reveals that the sequential elimination strategy can effectively enhance the LLM’s reasoning ability. Additionally, we find that sequential elimination is also applicable to few-shot settings and can be combined with debias methods to further improve LLM’s performance.
多项选择题(MCQs)是评估大型语言模型(LLM)流行且重要的任务。基于人们回答选择题时常用的策略,提出了排除法(PoE)作为一种有效的解决问题的方法。现有解决排除法的方法大致分为两种:一种是让LLM直接选择错误的选项,另一种是给选项打分。然而,这两种方法都导致计算成本较高,且往往不如直接通过选项ID回答问题的方法表现得更好。针对这一问题,本文提出了一种基于选项ID的排除法。具体来说,我们的方法是通过选择概率最低的选项ID来排除选项。我们在零样本环境下使用10个不同的LLM在7个公开数据集上进行了实验。实验结果表明,该方法显著提高了LLM的性能。进一步的分析表明,顺序排除策略可以有效地提高LLM的推理能力。此外,我们发现顺序排除也适用于小样本环境,并且可以与去偏方法相结合,进一步提高LLM的性能。
论文及项目相关链接
Summary
基于多选题的特点和用户答题时的策略,提出了一种基于选项ID的过程消除法(PoE),用于评估大型语言模型(LLM)在多项选择题任务上的表现。这种方法通过选择概率最低的选项ID进行消除,相比传统方法,具有更高的效率和更好的性能。实验结果显示,该方法显著提高LLM的性能,并增强模型的推理能力。同时,该方法也适用于小样本场景,并能与去偏方法结合进一步提升LLM的性能。
Key Takeaways
- 过程消除法(PoE)是一种有效的解决多项选择题的方法,基于选项ID进行选择,可显著提高LLM的性能。
- 现有PoE方法分为两类:直接选择错误选项和评分选项,但都存在计算成本高和性能不佳的问题。
- 新提出的PoE方法通过选择概率最低的选项ID进行消除,具有更高的效率和更好的性能。
- 实验结果显示,该方法在零样本和少样本场景下都有效,且能与其他方法(如去偏方法)结合进一步提升性能。
- 这种方法能够增强LLM的推理能力,尤其是在处理复杂的多项选择题时表现优异。
- 该方法具有广泛的应用前景,可应用于各种语言模型的评估任务中。
点此查看论文截图

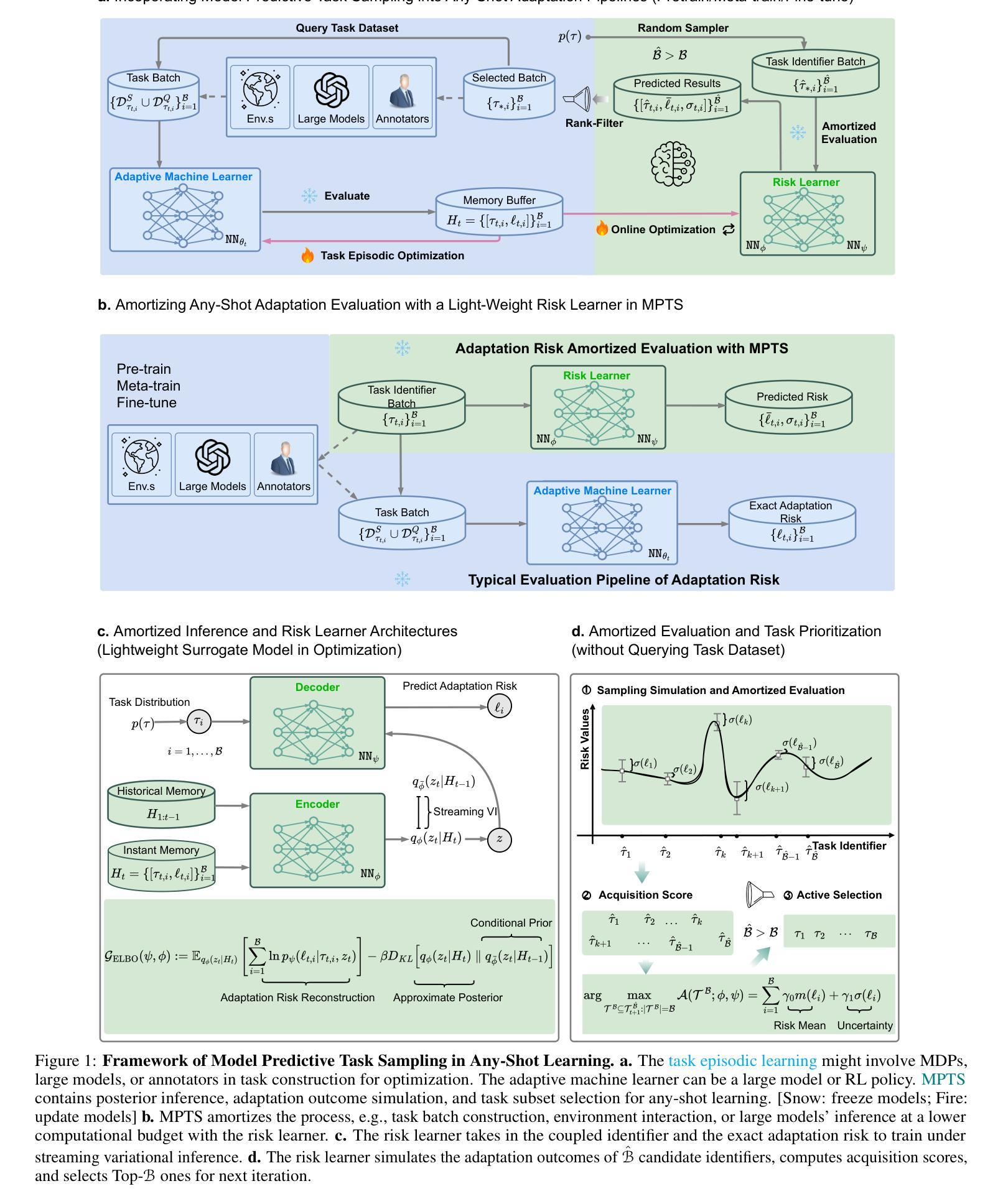
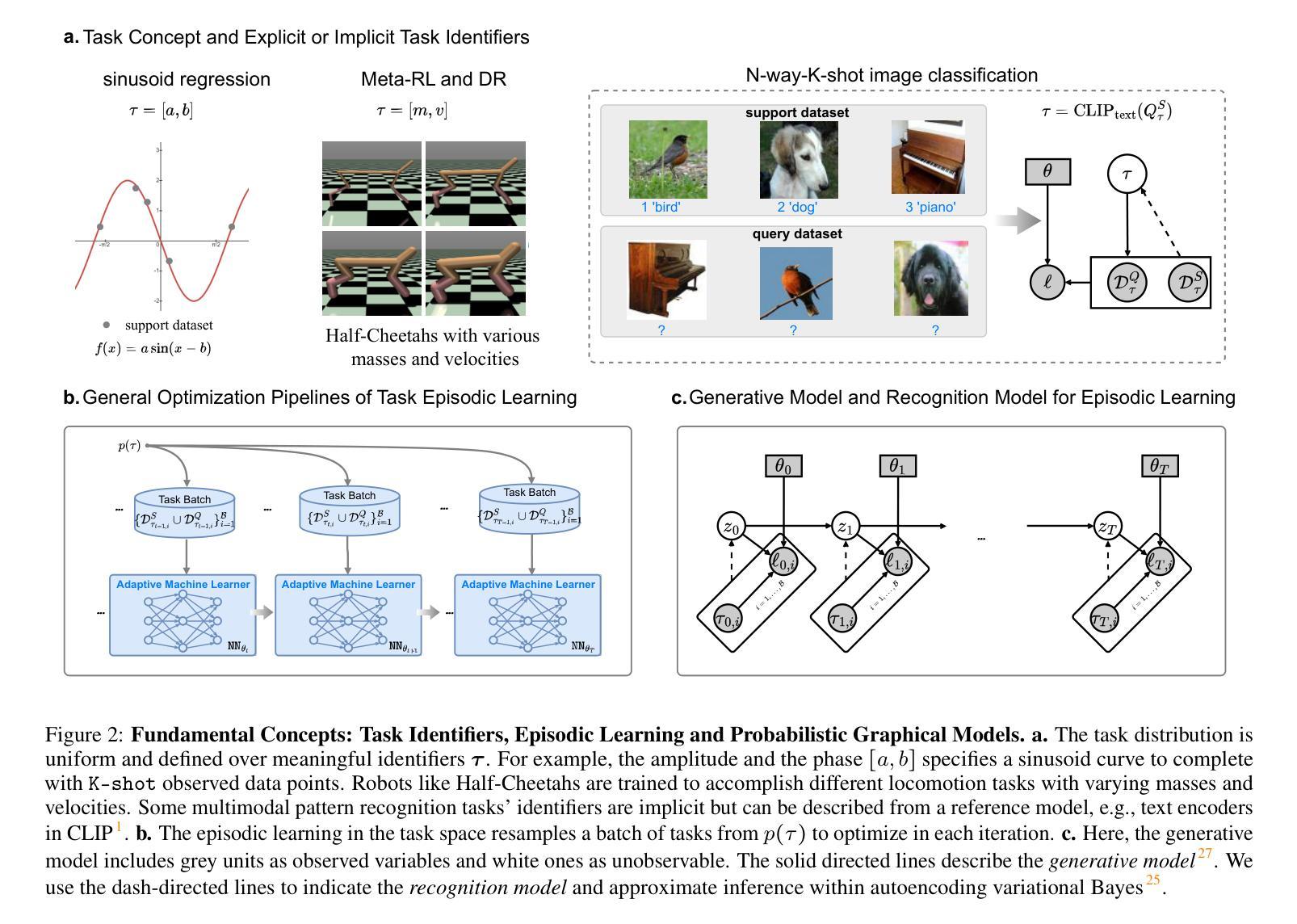
Beyond Any-Shot Adaptation: Predicting Optimization Outcome for Robustness Gains without Extra Pay
Authors:Qi Cheems Wang, Zehao Xiao, Yixiu Mao, Yun Qu, Jiayi Shen, Yiqin Lv, Xiangyang Ji
The foundation model enables general-purpose problem-solving and enjoys desirable rapid adaptation due to its adopted cross-task generalization paradigms, e.g., pretraining, meta-training, and finetuning. Recent advances in these paradigms show the crucial role of challenging tasks’ prioritized sampling in enhancing adaptation robustness. However, ranking task difficulties exhausts massive task queries to evaluate, thus computation and annotation intensive, which is typically unaffordable in practice. This work underscores the criticality of both adaptation robustness and learning efficiency, especially in scenarios where tasks are risky or costly to evaluate, e.g., policy evaluations in Markov decision processes (MDPs) or inference with large models. To this end, we present Model Predictive Task Sampling (MPTS) to establish connections between the task space and adaptation risk landscape to form a theoretical guideline in robust active task sampling. MPTS characterizes the task episodic information with a generative model and directly predicts task-specific adaptation risk values from posterior inference. The developed risk learner can amortize expensive evaluation and provably approximately rank task difficulties in the pursuit of task robust adaptation. MPTS can be seamlessly integrated into zero-shot, few-shot, and many-shot learning paradigms. Extensive experimental results are conducted to exhibit the superiority of the proposed framework, remarkably increasing task adaptation robustness and retaining learning efficiency in contrast to existing state-of-the-art (SOTA) methods. The code is available at the project site https://github.com/thu-rllab/MPTS.
基础模型能够实现通用问题解决,并由于其采用的跨任务泛化范式(如预训练、元训练和微调)而享有令人愉悦的快速适应。这些范式的最新进展表明,优先采样具有挑战性的任务在提高适应稳健性方面起着关键作用。然而,对任务难度的排序需要大量的任务查询来评估,因此计算和标注成本密集,在实践中通常是无法承受的。这项工作强调了适应稳健性和学习效率的重要性,特别是在任务评估风险大或成本高的场景中,如马尔可夫决策过程(MDP)中的策略评估或使用大型模型的推理。为此,我们提出了模型预测任务采样(MPTS),以建立任务空间和适应风险景观之间的联系,形成稳健主动任务采样的理论指南。MPTS使用生成模型对任务片段信息进行表征,并通过后验推断直接预测特定任务的适应风险值。所开发的风险学习者可以摊销昂贵的评估成本,并证明可以近似地对任务难度进行排名,以实现稳健的任务适应。MPTS可以无缝地融入零样本、少样本和多样本学习范式中。进行了大量实验来展示所提出框架的优越性,与现有最先进的方法相比,该框架在增加任务适应稳健性的同时保持了学习效率。代码可在项目网站https://github.com/thu-rllab/MPTS上找到。
论文及项目相关链接
Summary
模型预训练、元训练和微调等跨任务泛化范式使得基础模型能够进行通用问题求解,并具备理想的快速适应能力。近期研究表明,挑战性任务的优先采样在增强适应稳健性方面起着关键作用。然而,任务难度排序需要大量任务查询进行评估,计算与标注成本高昂,实践中通常难以实现。本研究强调适应稳健性和学习效率的重要性,特别是在任务评估风险大或成本高的场景中。为此,本文提出了模型预测任务采样(MPTS),通过建立任务空间与适应风险景观之间的联系,形成稳健活动任务采样的理论指南。MPTS利用生成模型刻画任务片段信息,通过后天推理直接预测特定任务的适应风险值。所开发的风险学习者可以摊销昂贵的评估成本,并证明可以近似地对任务难度进行排序,以实现稳健的任务适应。MPTS可以无缝集成到零样本、少样本和多样本学习范式中。实验结果表明,与现有最先进的方法相比,所提出的框架在任务适应稳健性和学习效率方面具有优势。
Key Takeaways
- 基础模型通过泛化范式如预训练、元训练和微调,实现通用问题求解和快速适应。
- 挑战性任务的优先采样对于增强适应稳健性至关重要。
- 任务难度排序需要大量任务查询进行评估,计算与标注成本高昂。
- 适应稳健性和学习效率在风险性或成本高的任务评估中尤为重要。
- 提出模型预测任务采样(MPTS)以建立任务空间与适应风险之间的关系。
- MPTS利用生成模型刻画任务片段信息,通过后天推理预测任务适应风险值。
点此查看论文截图


BoostStep: Boosting mathematical capability of Large Language Models via improved single-step reasoning
Authors:Beichen Zhang, Yuhong Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Haodong Duan, Yuhang Cao, Dahua Lin, Jiaqi Wang
Large language models (LLMs) have demonstrated impressive ability in solving complex mathematical problems with multi-step reasoning and can be further enhanced with well-designed in-context learning (ICL) examples. However, this potential is often constrained by two major challenges in ICL: granularity mismatch and irrelevant information. We observe that while LLMs excel at decomposing mathematical problems, they often struggle with reasoning errors in fine-grained steps. Moreover, ICL examples retrieved at the question level may omit critical steps or even mislead the model with irrelevant details. To address this issue, we propose BoostStep, a method that enhances reasoning accuracy through step-aligned ICL, a novel mechanism that carefully aligns retrieved reference steps with the corresponding reasoning steps. Additionally, BoostStep incorporates an effective “first-try” strategy to deliver exemplars highly relevant to the current state of reasoning. BoostStep is a flexible and powerful method that integrates seamlessly with chain-of-thought (CoT) and tree search algorithms, refining both candidate selection and decision-making. Empirical results show that BoostStep improves GPT-4o’s CoT performance by 4.6% across mathematical benchmarks, significantly surpassing traditional few-shot learning’s 1.2%. Moreover, it can achieve an additional 7.5% gain combined with tree search. Surprisingly, it enhances state-of-the-art LLMs to solve challenging math problems using simpler examples. It improves DeepSeek-R1-671B’s performance on AIME by 2.2%, leveraging simple examples only from the MATH dataset.
大型语言模型(LLM)在解决具有多步骤推理的复杂数学问题方面表现出了令人印象深刻的能力,并且可以通过精心设计上下文学习(ICL)示例来进一步增强。然而,这一潜力经常受到ICL中两个主要挑战的限制:粒度不匹配和无关信息。我们观察到,虽然LLM在分解数学问题方面表现出色,但它们在进行精细步骤的推理时经常会出现错误。此外,在问题层面检索的ICL示例可能会遗漏关键步骤,或者甚至用不相关的细节误导模型。为了解决这个问题,我们提出了BoostStep方法,它通过步骤对齐的ICL增强推理准确性,这是一种新型机制,可以仔细对齐检索到的参考步骤与相应的推理步骤。此外,BoostStep还融入了一种有效的“首次尝试”策略,以提供与当前推理状态高度相关的范例。BoostStep是一种灵活且强大的方法,可以与思维链(CoT)和树搜索算法无缝集成,改进候选选择和决策制定。经验结果表明,BoostStep提高了GPT-4o在数学基准测试上的思维链性能4.6%,显著超过了传统少样本学习的1.2%。而且,当它与树搜索算法结合时,可以实现额外的7.5%的增益。令人惊讶的是,它能够通过更简单的示例增强最先进的LLM解决具有挑战性的数学问题。它利用MATH数据集中的简单示例,提高了DeepSeek-R1-671B在AIME上的性能2.2%。
论文及项目相关链接
PDF Codes and Data are available at https://github.com/beichenzbc/BoostStep
Summary
大型语言模型(LLMs)在解决具有多步骤推理的复杂数学问题方面展现出令人印象深刻的能力,并且可以通过精心设计上下文学习(ICL)示例来进一步增强。然而,存在两个主要的挑战:粒度不匹配和无关信息。我们观察到LLMs擅长分解数学问题,但在精细步骤中的推理错误方面经常遇到困难。此外,在问题级别检索的ICL示例可能会遗漏关键步骤或甚至通过不相关的细节误导模型。为了解决这些问题,我们提出了BoostStep方法,它通过步骤对齐的ICL和“首次尝试”策略,提高推理准确性。BoostStep与思维链和树搜索算法无缝集成,改进了候选选择和决策制定。BoostStep改进了GPT-4o在数学基准测试上的思维链性能,并且与传统的少样本学习相比具有显著优势。它还可以与树搜索相结合实现额外增益,并使用更简单的示例提高最先进的大型语言模型解决挑战性数学问题的能力。
Key Takeaways
- 大型语言模型(LLMs)可以很好地解决复杂数学问题,但需要增强其在精细步骤中的推理能力。
- 上下文学习(ICL)是增强LLMs解决数学问题能力的一种方法,但存在粒度不匹配和无关信息的问题。
- BoostStep方法通过步骤对齐的ICL和“首次尝试”策略来解决这些问题,提高推理准确性。
- BoostStep与思维链和树搜索算法相结合,改进了候选选择和决策制定。
- BoostStep提高了GPT-4o在数学基准测试上的表现,与传统少样本学习相比具有显著优势。
- 结合树搜索,BoostStep可以实现额外的性能增益。
点此查看论文截图

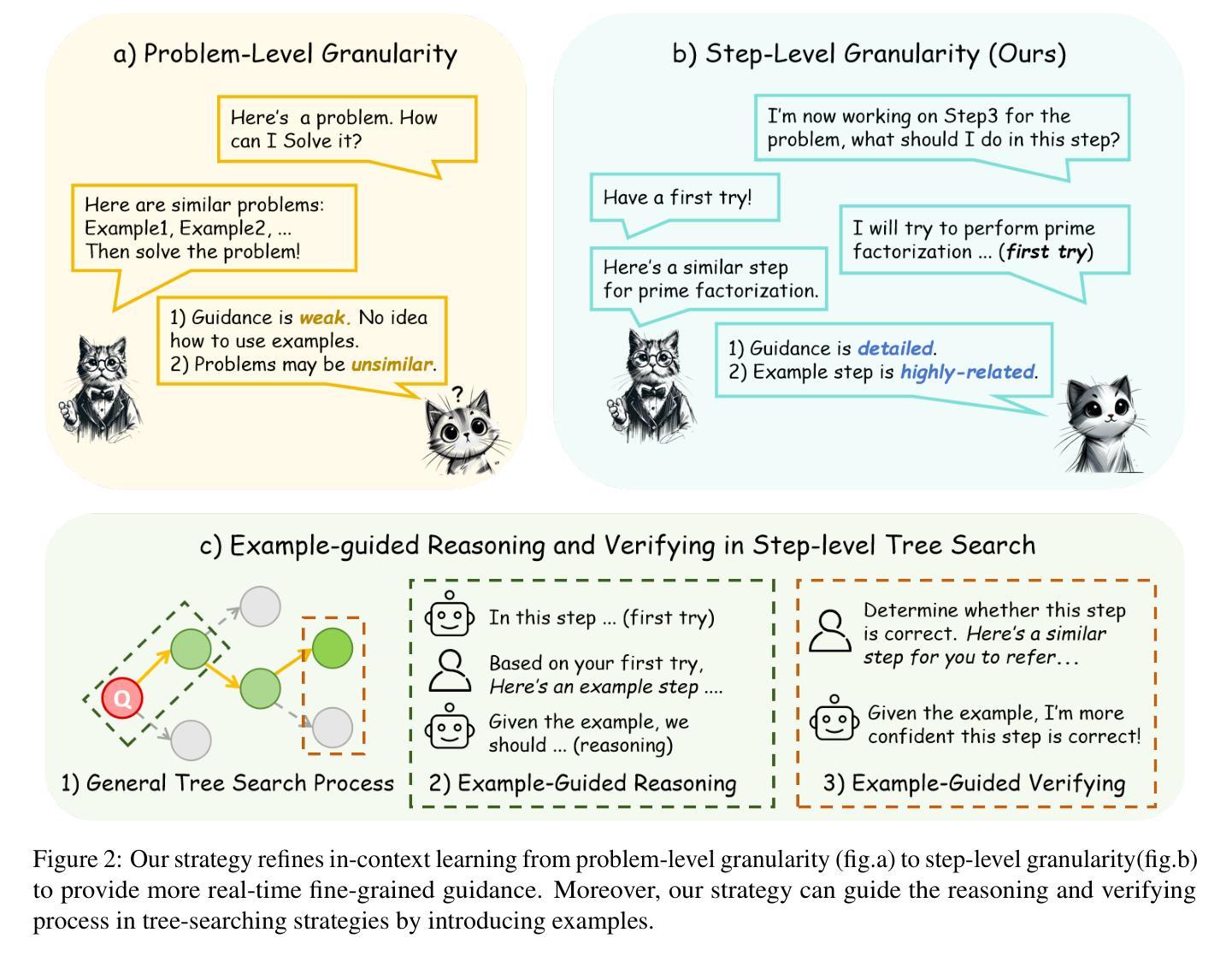

Graph-based Retrieval Augmented Generation for Dynamic Few-shot Text Classification
Authors:Yubo Wang, Haoyang Li, Fei Teng, Lei Chen
Text classification is a fundamental task in data mining, pivotal to various applications such as tabular understanding and recommendation. Although neural network-based models, such as CNN and BERT, have demonstrated remarkable performance in text classification, their effectiveness heavily relies on abundant labeled training data. This dependency makes these models less effective in dynamic few-shot text classification, where labeled data is scarce, and new target labels frequently appear based on application needs. Recently, large language models (LLMs) have shown promise due to their extensive pretraining and contextual understanding ability. Current approaches provide LLMs with text inputs, candidate labels, and additional side information (e.g., descriptions) to classify texts. However, their effectiveness is hindered by the increased input size and the noise introduced through side information processing. To address these limitations, we propose a graph-based online retrieval-augmented generation framework, namely GORAG, for dynamic few-shot text classification. Rather than treating each input independently, GORAG constructs and maintains a weighted graph by extracting side information across all target texts. In this graph, text keywords and labels are represented as nodes, with edges indicating the correlations between them. To model these correlations, GORAG employs an edge weighting mechanism to prioritize the importance and reliability of extracted information and dynamically retrieves relevant context using a minimum-cost spanning tree tailored for each text input. Empirical evaluations demonstrate that GORAG outperforms existing approaches by providing more comprehensive and precise contextual information.
文本分类是数据挖掘中的一项基本任务,对于表格理解和推荐等应用至关重要。尽管基于神经网络模型的CNN和BERT等在文本分类方面表现出卓越的性能,但它们的效力严重依赖于大量的标记训练数据。这种依赖使得这些模型在动态少样本文本分类中的效果较差,这里的标记数据稀缺,并且根据应用需求频繁出现新的目标标签。最近,由于大规模预训练和上下文理解能力,大型语言模型(LLM)显示出潜力。当前的方法为LLM提供文本输入、候选标签和额外的侧面信息(例如描述)来进行文本分类。然而,它们的效力受到输入大小增加和通过侧面信息处理引入的噪声的阻碍。为了解决这些局限性,我们提出了基于图的在线检索增强生成框架,即GORAG,用于动态少样本文本分类。GORAG不是独立处理每个输入,而是通过建立和维护一个加权图来提取所有目标文本的侧面信息。在这个图中,文本关键词和标签被表示为节点,边表示它们之间的关联。为了建模这些关联,GORAG采用边加权机制来优先处理提取信息的重要性和可靠性,并动态使用针对每个文本输入定制的最小成本生成树来检索相关上下文。经验评估表明,GORAG通过提供更全面和精确的上文信息,优于现有方法。
论文及项目相关链接
Summary
文本分类是数据挖掘中的基础任务,对表格理解和推荐等应用至关重要。尽管神经网络模型如CNN和BERT在文本分类中表现出色,但它们严重依赖于大量标记训练数据,这在动态少样本文本分类中效果不佳。大型语言模型(LLMs)因其在预训练和上下文理解方面的能力而展现出潜力。针对LLMs在处理文本输入、候选标签和额外侧面信息时的局限性,我们提出了基于图的在线检索增强生成框架GORAG。它通过构建和维护一个加权图来提取所有目标文本的侧面信息,其中文本关键词和标签被表示为节点,边表示它们之间的相关性。GORAG采用边加权机制来优先处理提取信息的重要性和可靠性,并为每个文本输入量身定制最小成本生成树进行动态检索相关上下文。实证评估表明,GORAG在提供更全面和精确上下文信息方面优于现有方法。
Key Takeaways
- 文本分类是数据挖掘的核心任务,对多种应用至关重要。
- 神经网络模型在文本分类中表现出色,但严重依赖于大量标记数据,这在少样本环境中是挑战。
- 大型语言模型(LLMs)在文本分类中具有潜力,因为它们具备广泛的预训练和上下文理解能力。
- 当前LLM方法在处理文本输入、候选标签和侧面信息时存在局限性。
- GORAG框架被提出以解决这些问题,它基于图构建并维护一个加权图来提取和表示文本关键词和标签的相关性。
- GORAG通过边加权机制优先处理重要和可靠的信息,并采用最小成本生成树进行动态上下文检索。
点此查看论文截图

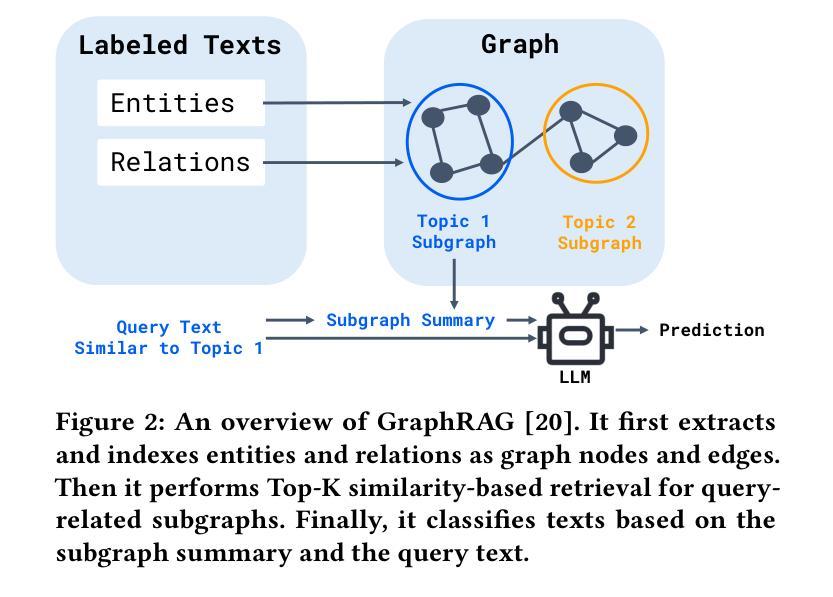
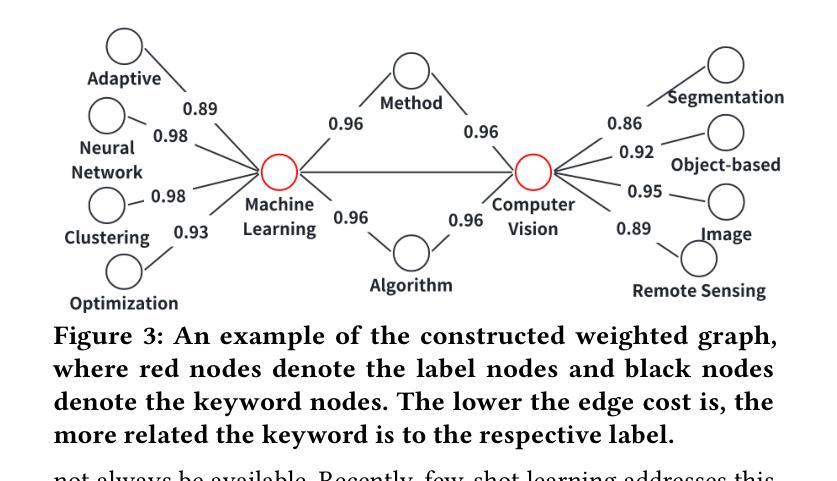
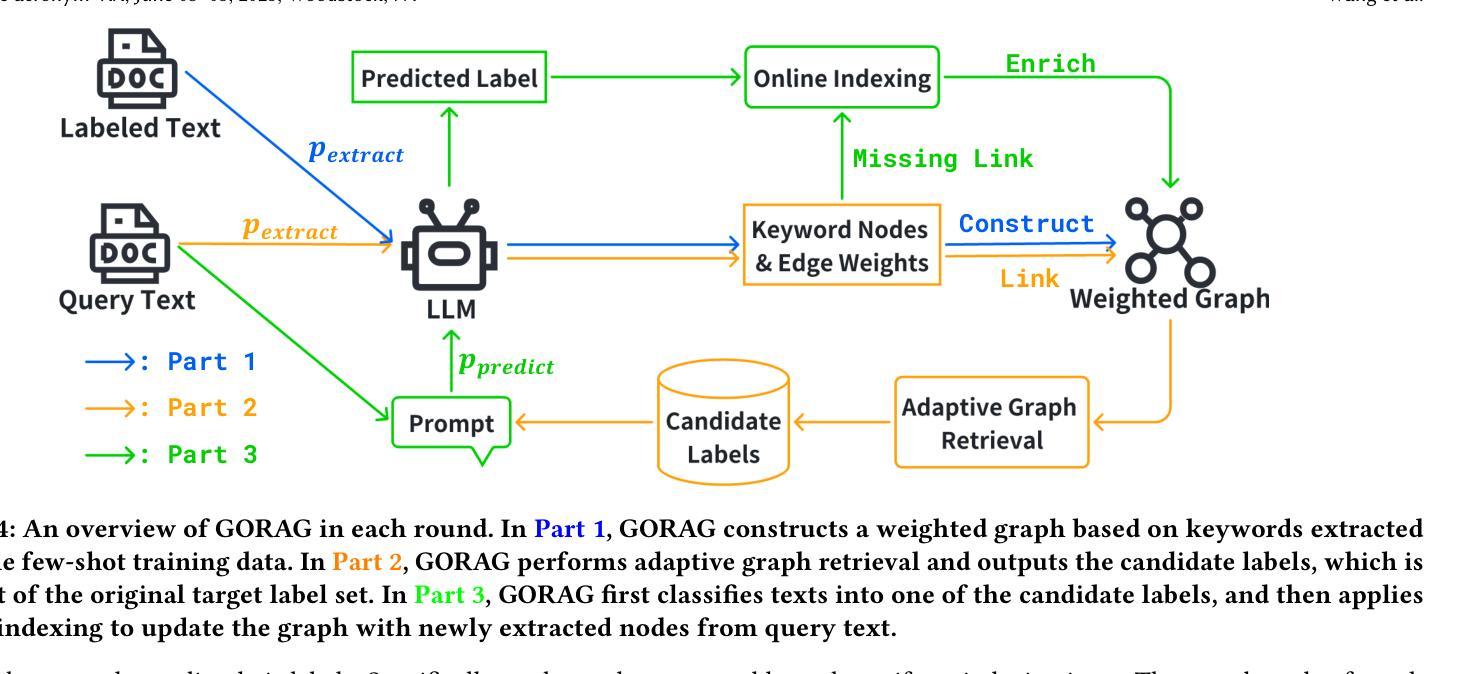

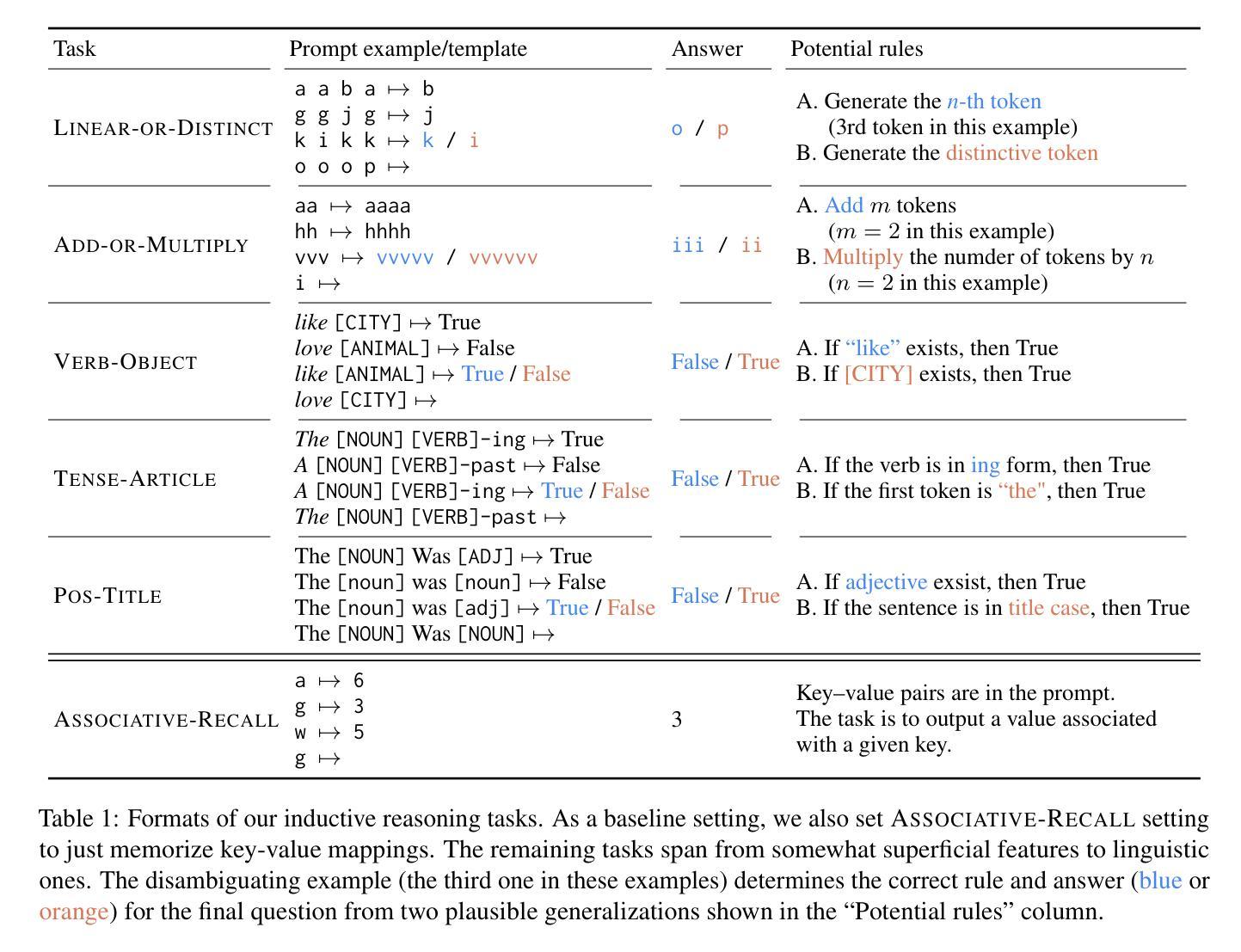
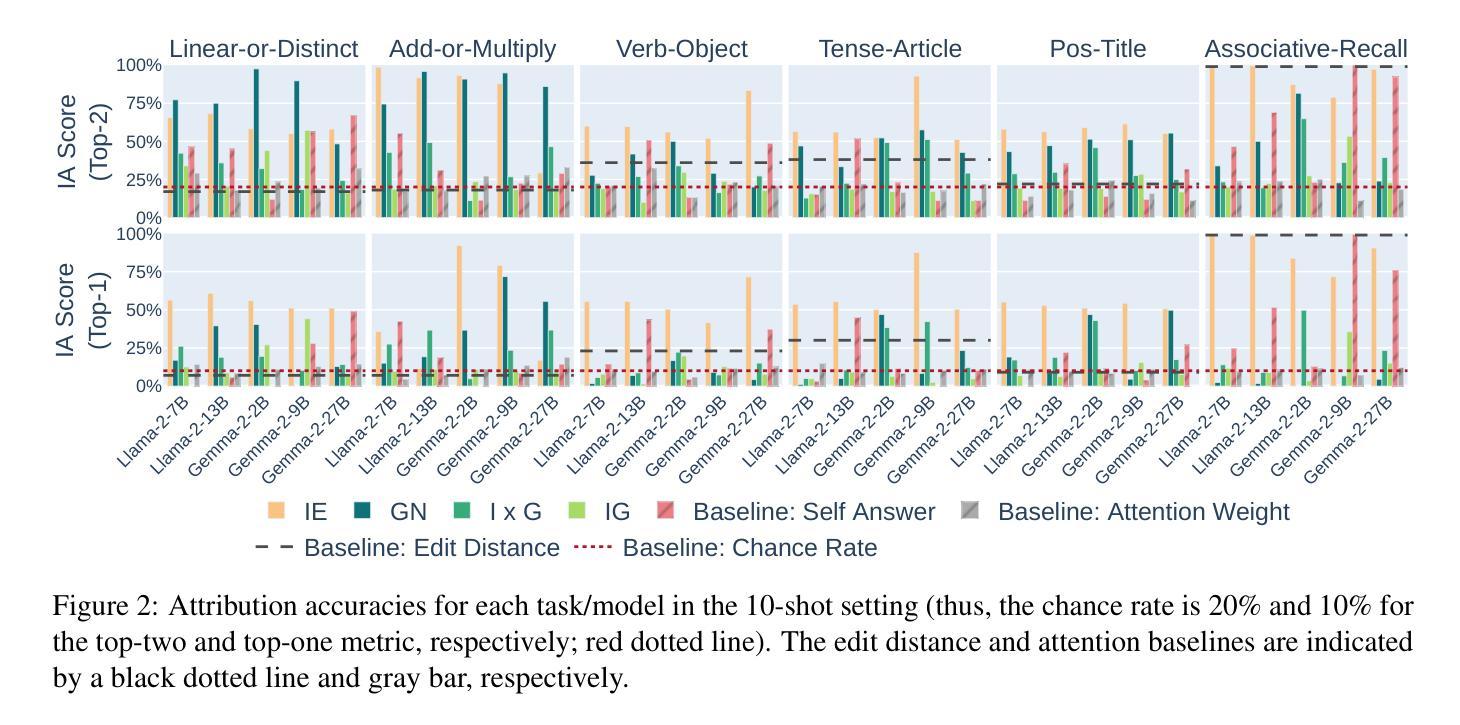
Can Input Attributions Interpret the Inductive Reasoning Process Elicited in In-Context Learning?
Authors:Mengyu Ye, Tatsuki Kuribayashi, Goro Kobayashi, Jun Suzuki
Interpreting the internal process of neural models has long been a challenge. This challenge remains relevant in the era of large language models (LLMs) and in-context learning (ICL); for example, ICL poses a new issue of interpreting which example in the few-shot examples contributed to identifying/solving the task. To this end, in this paper, we design synthetic diagnostic tasks of inductive reasoning, inspired by the generalization tests in linguistics; here, most in-context examples are ambiguous w.r.t. their underlying rule, and one critical example disambiguates the task demonstrated. The question is whether conventional input attribution (IA) methods can track such a reasoning process, i.e., identify the influential example, in ICL. Our experiments provide several practical findings; for example, a certain simple IA method works the best, and the larger the model, the generally harder it is to interpret the ICL with gradient-based IA methods.
神经网络模型的内部过程解释长久以来一直是一个挑战。这一挑战在大型语言模型(LLM)和上下文学习(ICL)时代仍然具有重要意义。例如,ICL带来了新的挑战,即解释哪些少数例子对识别或解决任务产生了贡献。为此,本文设计了基于归纳推理的合成诊断任务,这些任务受到语言学中泛化测试的启发;在这里,大多数上下文例子对于其潜在规则是模糊的,只有一个关键例子明确了任务演示。问题是传统的输入归因(IA)方法是否能够追踪这样的推理过程,即在ICL中识别关键例子。我们的实验提供了一些实际发现;例如,某种简单的IA方法效果最佳,并且模型越大,基于梯度的IA方法解释ICL的难度通常越大。
论文及项目相关链接
PDF Preprint
Summary
该论文设计了一系列基于归纳推理的合成诊断任务,旨在解决大型语言模型在语境学习中的解释难题。在多数情况下,上下文实例在隐含规则上存在歧义,一个关键实例可以消除任务中的歧义。论文探讨了传统输入归因方法是否能追踪这种推理过程,并发现一种简单的输入归因方法表现最佳,模型越大,基于梯度的输入归因方法越难解读语境学习的情况。论文重点在于语境学习内部机制的解析和理解。该工作将深度分析与简单的实验证据相结合,揭示了语言模型内部的复杂性和难以捉摸性。总结起来,这是一项针对大型语言模型和语境学习的深入解析研究。通过一系列合成诊断任务揭示了模型在面对语境学习的复杂性方面的行为和限制。特别是通过一个简单的输入归因方法展现了一个关键实例在解决歧义任务中的关键作用。此外,还发现了模型规模与解释难度之间的关系。尽管存在挑战,该研究为未来的解释工作提供了有价值的见解和研究方向。
Key Takeaways
以下是基于文本的关键见解:
- 设计合成诊断任务以研究大型语言模型在语境学习中的解释问题。
- 上下文实例在隐含规则上通常存在歧义,一个关键实例能够消除这种歧义。
- 简单输入归因方法在追踪推理过程中表现最佳。
- 模型规模越大,使用基于梯度的输入归因方法来解释语境学习越困难。
- 关键实例在解决任务中的关键作用得到了实证研究的支持。
- 设计了用于探究模型在语境学习过程中的复杂性的方法,这对于解释模型的决策过程至关重要。
点此查看论文截图

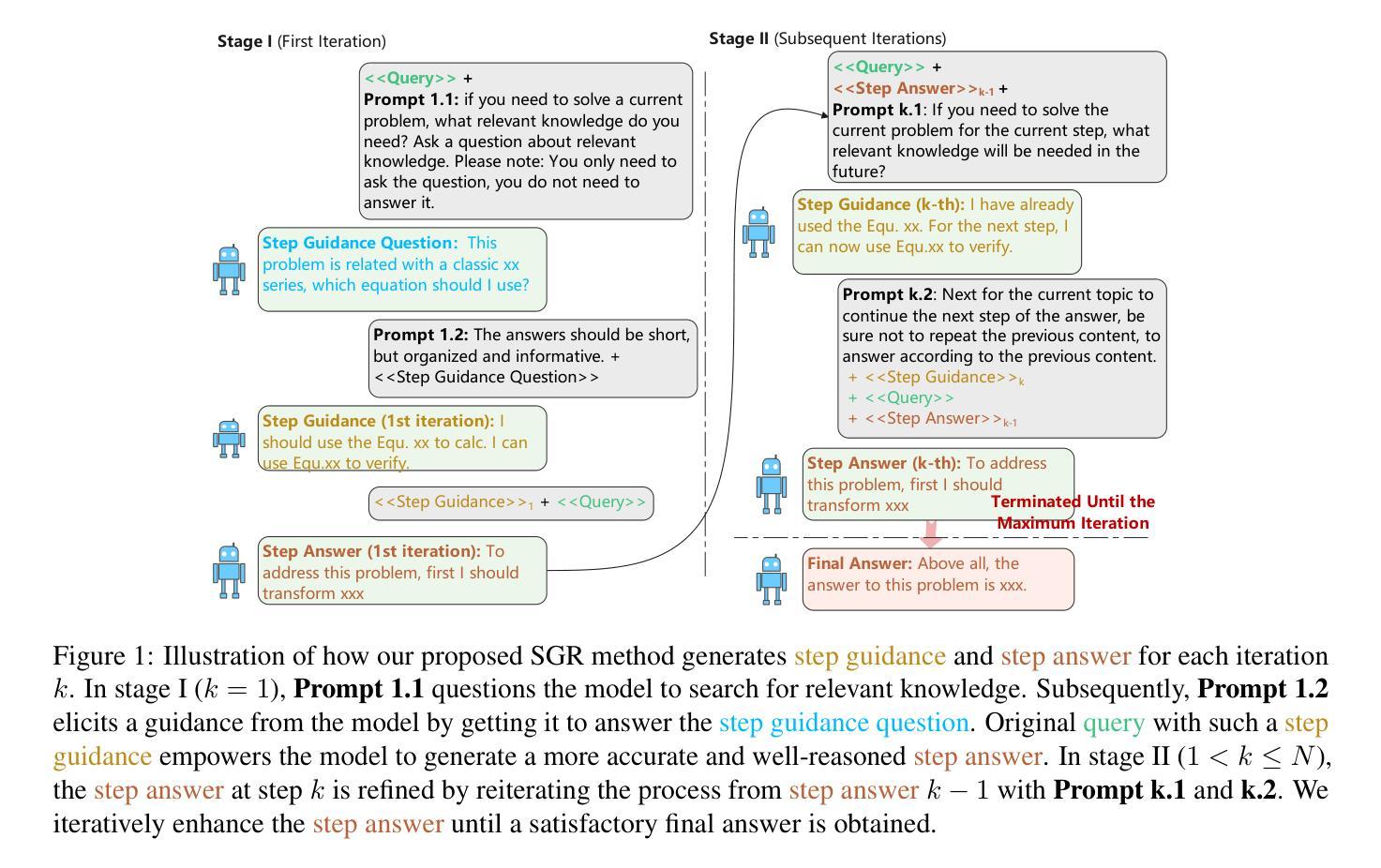
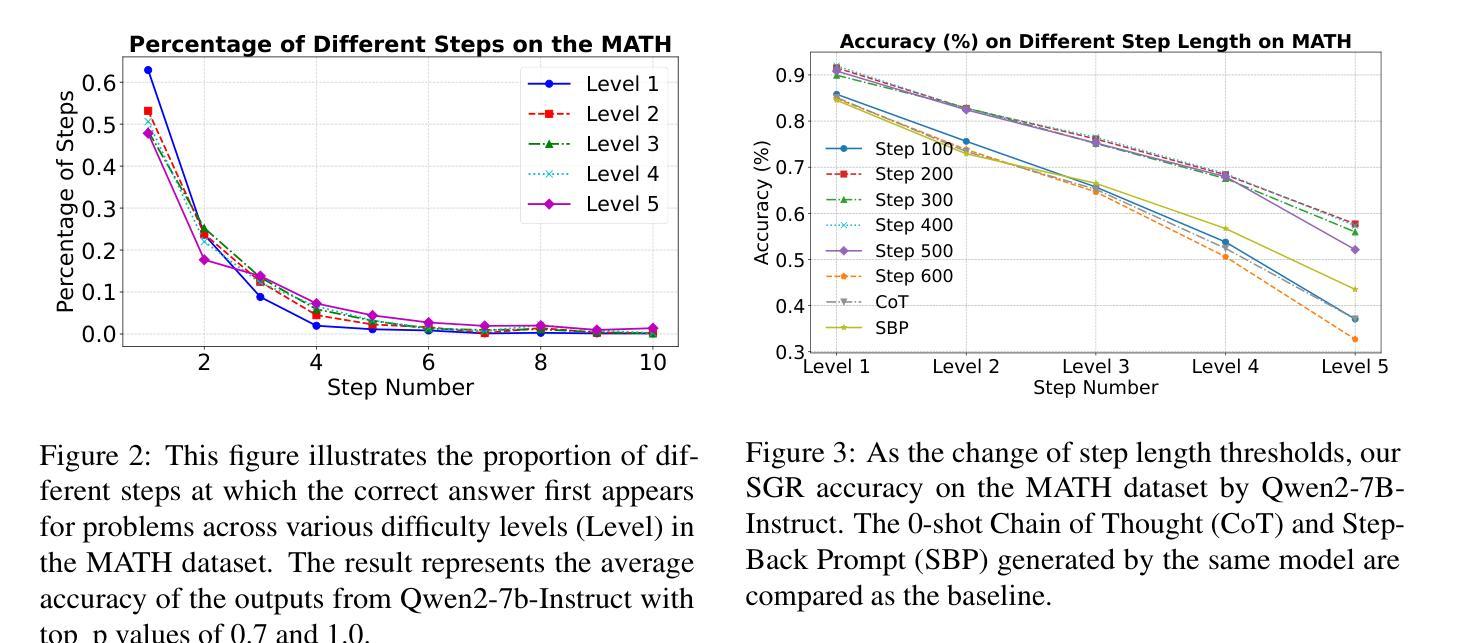
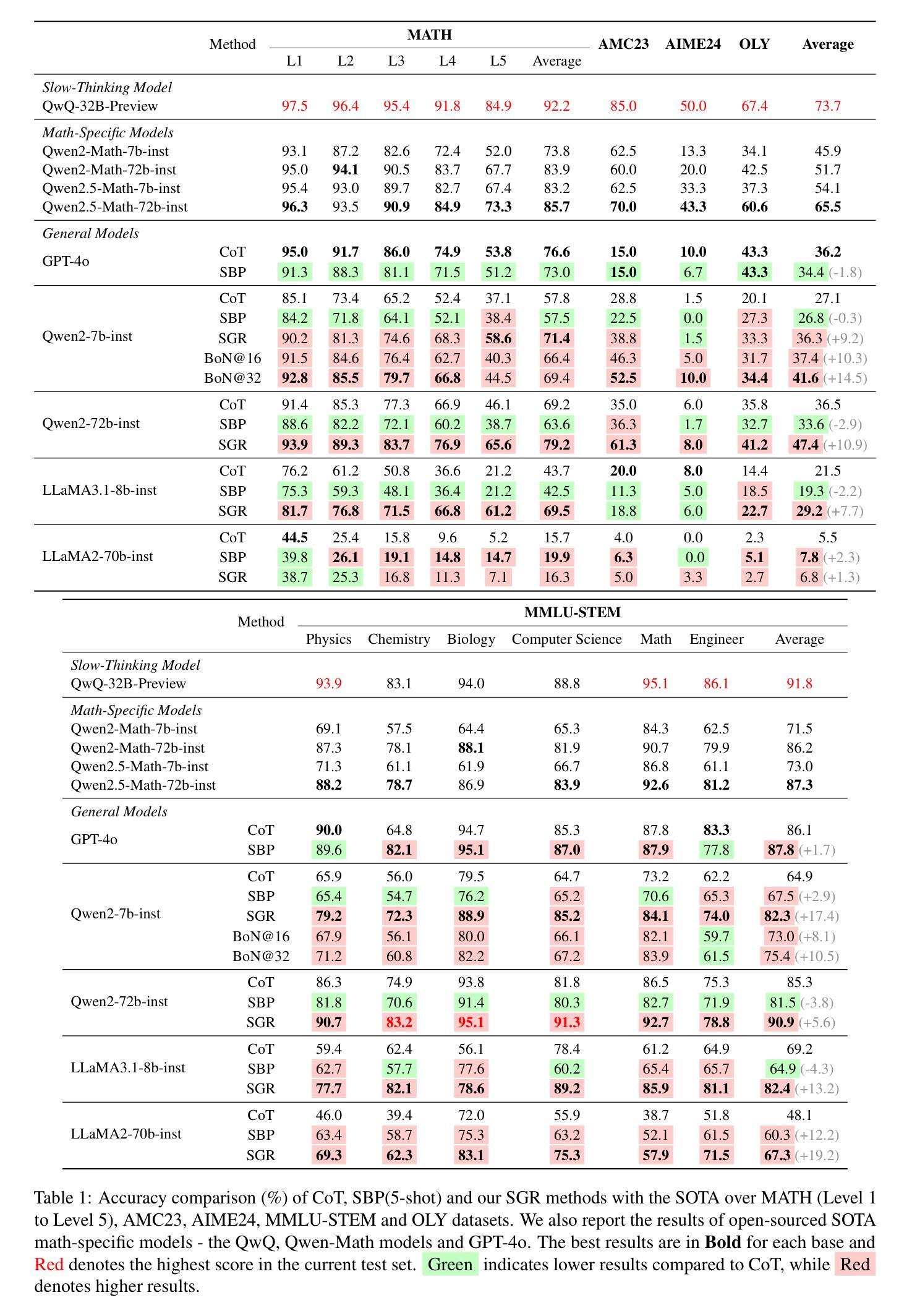
Step Guided Reasoning: Improving Mathematical Reasoning using Guidance Generation and Step Reasoning
Authors:Lang Cao, Chao Peng, Renhong Chen, Wu Ning, Yingtian Zou, Yitong Li
Mathematical reasoning has been challenging for large language models (LLMs). However, the introduction of step-by-step Chain-of-Thought (CoT) inference has significantly advanced the mathematical capabilities of LLMs. Despite this progress, current approaches either necessitate extensive inference datasets for training or depend on few-shot methods that frequently compromise computational accuracy. To address these bottlenecks in mathematical reasoning, we propose a novel method called Step Guidied Reasoning, which is more stable and generalizable than few-shot methods and does not involve further fine-tuning of the model. In this approach, LLMs reflect on small reasoning steps, similar to how humans deliberate and focus attention on what to do next. By incorporating this reflective process into the inference stage, LLMs can effectively guide their reasoning from one step to the next. Through extensive experiments, we demonstrate the significant effect of Step Guidied Reasoning in augmenting mathematical performance in state-of-the-art language models. Qwen2-72B-Instruct outperforms its math-specific counterpart, Qwen2.5-72B-Math-Instruct, on MMLU- STEM with a score of 90.9%, compared to 87.3%. The average scores of Qwen2-7B-Instruct and Qwen2-72B-Instruct increase from 27.1% to 36.3% and from 36.5% to 47.4% on the mathematics domain, respectively.
在数学推理方面,大型语言模型(LLM)一直面临挑战。然而,通过引入逐步的“思维链”(CoT)推理,LLM的数学能力得到了显著提升。尽管有了这些进展,当前的方法要么需要大量推理数据集进行训练,要么依赖于少样本方法,这些方法经常牺牲计算准确性。为了解决数学推理中的这些瓶颈问题,我们提出了一种新的方法,称为“步骤引导推理”,该方法比少样本方法更稳定、更具泛化能力,并且不涉及模型的进一步微调。在这种方法中,LLM会反思微小的推理步骤,类似于人类思考并集中注意力于下一步要做什么。通过将这种反思过程纳入推理阶段,LLM可以有效地引导其推理逐步进行。通过大量实验,我们证明了“步骤引导推理”在增强先进语言模型的数学性能方面的显著影响。Qwen2-72B-Instruct在MMLU-STEM上的表现优于其数学专用对应模型Qwen2.5-72B-Math-Instruct,得分为90.9%,而Qwen2.5-72B-Math-Instruct的得分为87.3%。Qwen2-7B-Instruct和Qwen2-72B-Instruct的平均分数在数学领域分别从27.1%提高到36.3%和从36.5%提高到47.4%。
论文及项目相关链接
PDF 8 pages, 4 figures
Summary:
引入分步思维(Chain-of-Thought,CoT)推理提升了大型语言模型(LLMs)的数学能力,但仍存在需要大量推理数据集或牺牲计算精度的问题。为解决这些问题,我们提出了一种新的方法——步骤引导推理(Step Guidied Reasoning),它比少样本方法更稳定、更具泛化能力,且无需对模型进行进一步的微调。该方法使LLMs能够像人类一样思考推理的每一步,从而有效地引导其推理过程。实验表明,该方法能显著提高语言模型的数学性能。
Key Takeaways:
- 引入分步思维(CoT)推理增强了大型语言模型(LLMs)在数学推理方面的能力。
- 当前方法存在需要大量推理数据集或牺牲计算精度的问题。
- 提出了一种新的方法——步骤引导推理(Step Guidied Reasoning),它更稳定、更具泛化能力,且无需进一步微调模型。
- 步骤引导推理使LLMs能够像人类一样思考推理的每一步。
- 该方法通过引导推理步骤,有效地提高了语言模型在数学领域的性能。
- Qwen2-72B-Instruct模型在数学性能上超越了其数学专用对应模型Qwen2.5-72B-Math-Instruct,在MMLU-STEM上的得分为90.9%。
点此查看论文截图

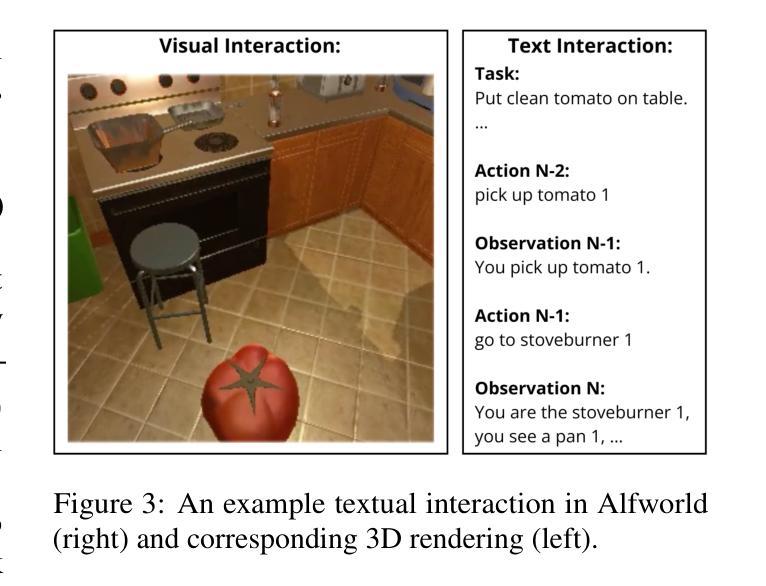
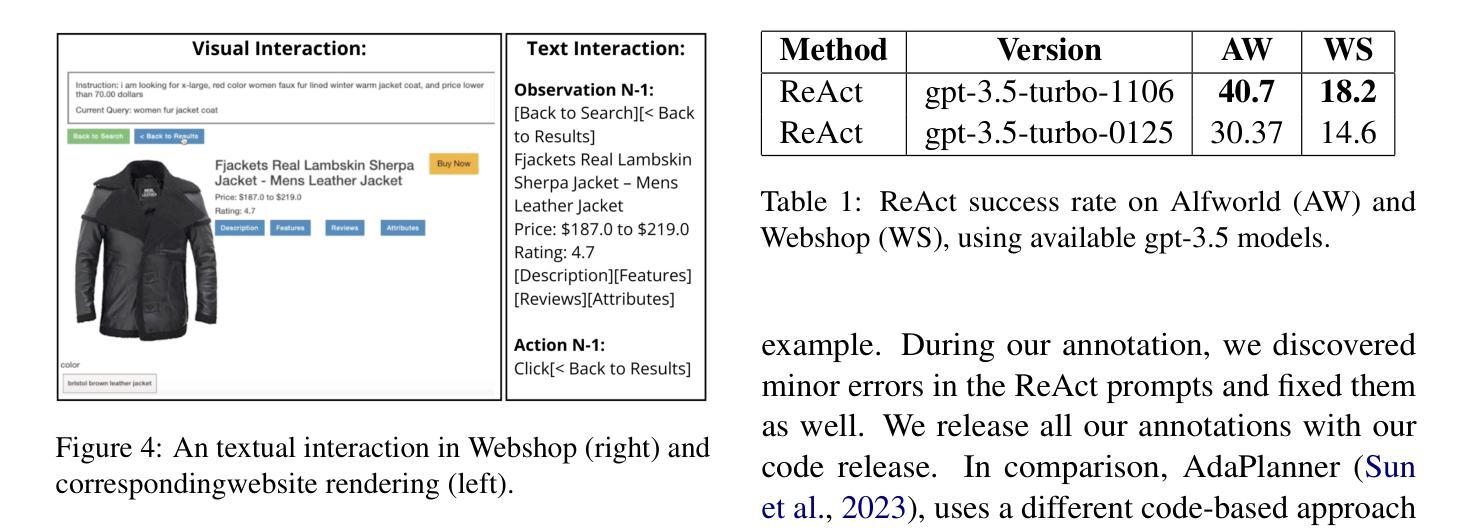
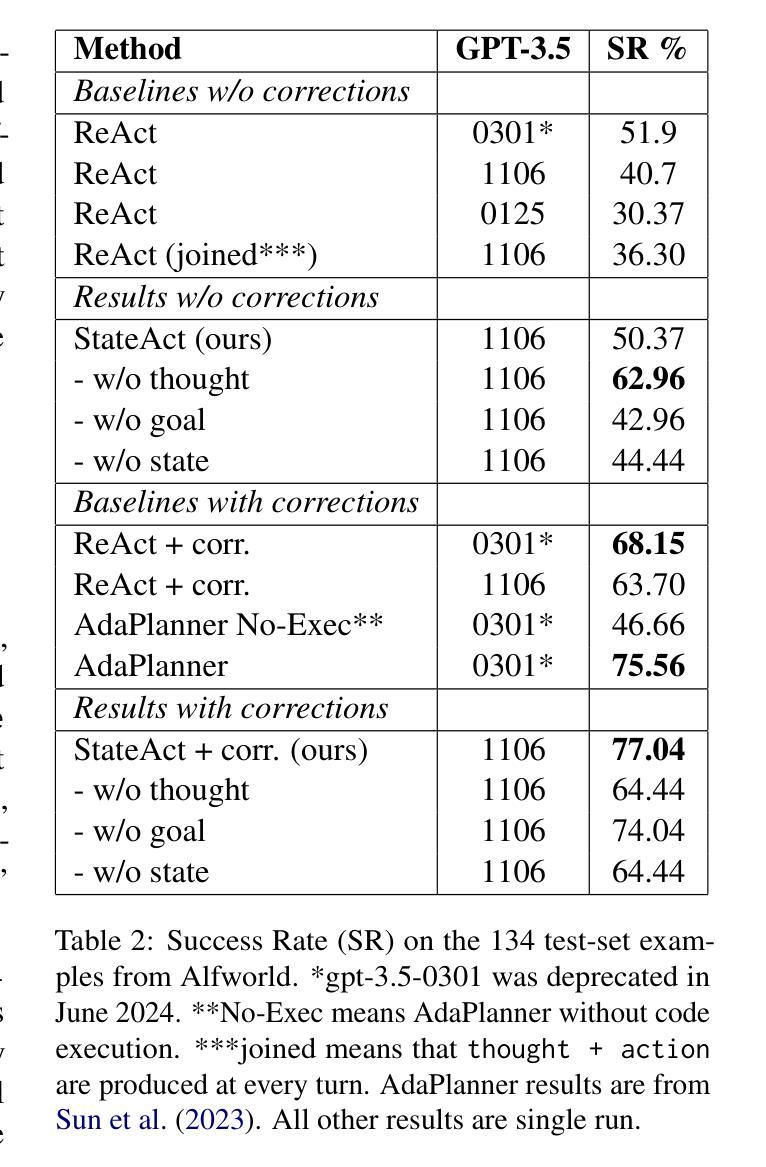
StateAct: State Tracking and Reasoning for Acting and Planning with Large Language Models
Authors:Nikolai Rozanov, Marek Rei
Planning and acting to solve real' tasks using large language models (LLMs) in interactive environments has become a new frontier for AI methods. While recent advances allowed LLMs to interact with online tools, solve robotics tasks and many more, long range reasoning tasks remain a problem for LLMs. Existing methods to address this issue are very resource intensive and require additional data or human crafted rules, instead, we propose a simple method based on few-shot in-context learning alone to enhance chain-of-thought’ with state-tracking for planning and acting with LLMs. We show that our method establishes the new state-of-the-art on Alfworld for in-context learning methods (+14% over the previous best few-shot in-context learning method) and performs on par with methods that use additional training data and additional tools such as code-execution. We also demonstrate that our enhanced chain-of-states' allows the agent to both solve longer horizon problems and to be more efficient in number of steps required to solve a task. We show that our method works across a variety of LLMs for both API-based and open source ones. Finally, we also conduct ablation studies and show that chain-of-thoughts’ helps state-tracking accuracy, while a json-structure harms overall performance. We open-source our code and annotations at https://github.com/ai-nikolai/StateAct.
在交互式环境中利用大型语言模型(LLM)解决“真实”任务的设计和行动已成为人工智能方法的新前沿。虽然最近的进展使得LLM能够在线工具交互、完成机器人任务等等,但长远推理任务仍然是LLM的一个难题。现有解决此问题的方法非常耗费资源,需要额外数据或人为制定的规则。相反,我们提出了一种基于少量上下文学习的简单方法,通过状态跟踪增强LLM的计划与行动能力。我们证明,我们的方法在Alfworld上建立了新的上下文学习方法的最新状态(超过之前的最佳少量上下文学习方法提高14%),并且在训练数据的使用上与附加训练数据和工具如代码执行的方法不相上下。我们还证明,我们增强的“状态链”允许代理解决长期问题,并且在解决任务所需的步骤上更加高效。我们展示我们的方法适用于各种LLM,无论是基于API的还是开源的。最后,我们还进行了消融研究并证明,“思维链”有助于提高状态跟踪的准确性,而json结构则可能损害整体性能。我们在https://github.com/ai-nikolai/StateAct上公开了我们的代码和注释。
论文及项目相关链接
PDF 9 pages, 5 pages appendix, 7 figures, 5 tables
Summary
基于大型语言模型(LLM)的交互式环境“链式思维”状态跟踪方法在解决长期推理任务上展现出优越性。通过少量的上下文信息学习,提升了在Alfworld任务上的表现,效率更高且能解决更长远的任务。此方法适用于多种LLM,包括API和开源版本。同时,公开了相关代码和注解。
Key Takeaways
- 大型语言模型(LLM)在解决长期推理任务上存在挑战。
- 提出一种基于少量上下文信息学习的简单方法,增强“链式思维”与状态跟踪。
- 在Alfworld任务上实现最新表现,优于之前的上下文学习方法,并与使用额外训练数据和工具的方法表现相当。
- 增强了解决长期问题和任务效率的能力。
- 方法适用于多种LLM,包括API和开源版本。
- 公开了相关代码和注解。
点此查看论文截图


AER-LLM: Ambiguity-aware Emotion Recognition Leveraging Large Language Models
Authors:Xin Hong, Yuan Gong, Vidhyasaharan Sethu, Ting Dang
Recent advancements in Large Language Models (LLMs) have demonstrated great success in many Natural Language Processing (NLP) tasks. In addition to their cognitive intelligence, exploring their capabilities in emotional intelligence is also crucial, as it enables more natural and empathetic conversational AI. Recent studies have shown LLMs’ capability in recognizing emotions, but they often focus on single emotion labels and overlook the complex and ambiguous nature of human emotions. This study is the first to address this gap by exploring the potential of LLMs in recognizing ambiguous emotions, leveraging their strong generalization capabilities and in-context learning. We design zero-shot and few-shot prompting and incorporate past dialogue as context information for ambiguous emotion recognition. Experiments conducted using three datasets indicate significant potential for LLMs in recognizing ambiguous emotions, and highlight the substantial benefits of including context information. Furthermore, our findings indicate that LLMs demonstrate a high degree of effectiveness in recognizing less ambiguous emotions and exhibit potential for identifying more ambiguous emotions, paralleling human perceptual capabilities.
大型语言模型(LLM)的最新进展在自然语言处理(NLP)的许多任务中取得了巨大成功。除了认知智能,探索其在情绪智能方面的能力也至关重要,因为这能使对话人工智能更加自然和富有同情心。虽然最近有研究表明LLM有能力识别情绪,但它们通常专注于单一的情绪标签,而忽略人类情绪的复杂和模糊性。本研究首次通过探索LLM在识别模糊情绪方面的潜力来解决这一差距,利用它们强大的泛化能力和上下文学习能力。我们设计了零样本和少样本提示,并将过去的对话作为模糊情绪识别的上下文信息。在三个数据集上进行的实验表明LLM在识别模糊情绪方面存在巨大潜力,并强调了包含上下文信息的巨大好处。此外,我们的研究还发现,LLM在识别较不模糊的情绪方面表现出高度有效性,并展现出识别更模糊情绪的潜力,与人类感知能力相媲美。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary
大型语言模型(LLM)在情感智能方面的探索愈发重要,近期研究开始关注其在识别模糊情绪方面的潜力。本研究利用LLM的强泛化能力和上下文学习能力,通过零样本和少样本提示,并结合过去的对话作为上下文信息进行模糊情感识别。实验结果表明LLM在识别模糊情感方面具有显著潜力,且上下文信息极为重要。
Key Takeaways
- 大型语言模型(LLM)在情感智能方面的探索愈发重要。
- LLM具备识别模糊情绪的能力。
- 本研究利用LLM的强泛化能力和上下文学习能力进行模糊情感识别。
- 实验使用三种数据集进行,结果显著。
- 上下文信息对于模糊情感识别至关重要。
- LLM在识别模糊情感方面表现出高效果,与人类感知能力相平行。
点此查看论文截图



Local-Prompt: Extensible Local Prompts for Few-Shot Out-of-Distribution Detection
Authors:Fanhu Zeng, Zhen Cheng, Fei Zhu, Hongxin Wei, Xu-Yao Zhang
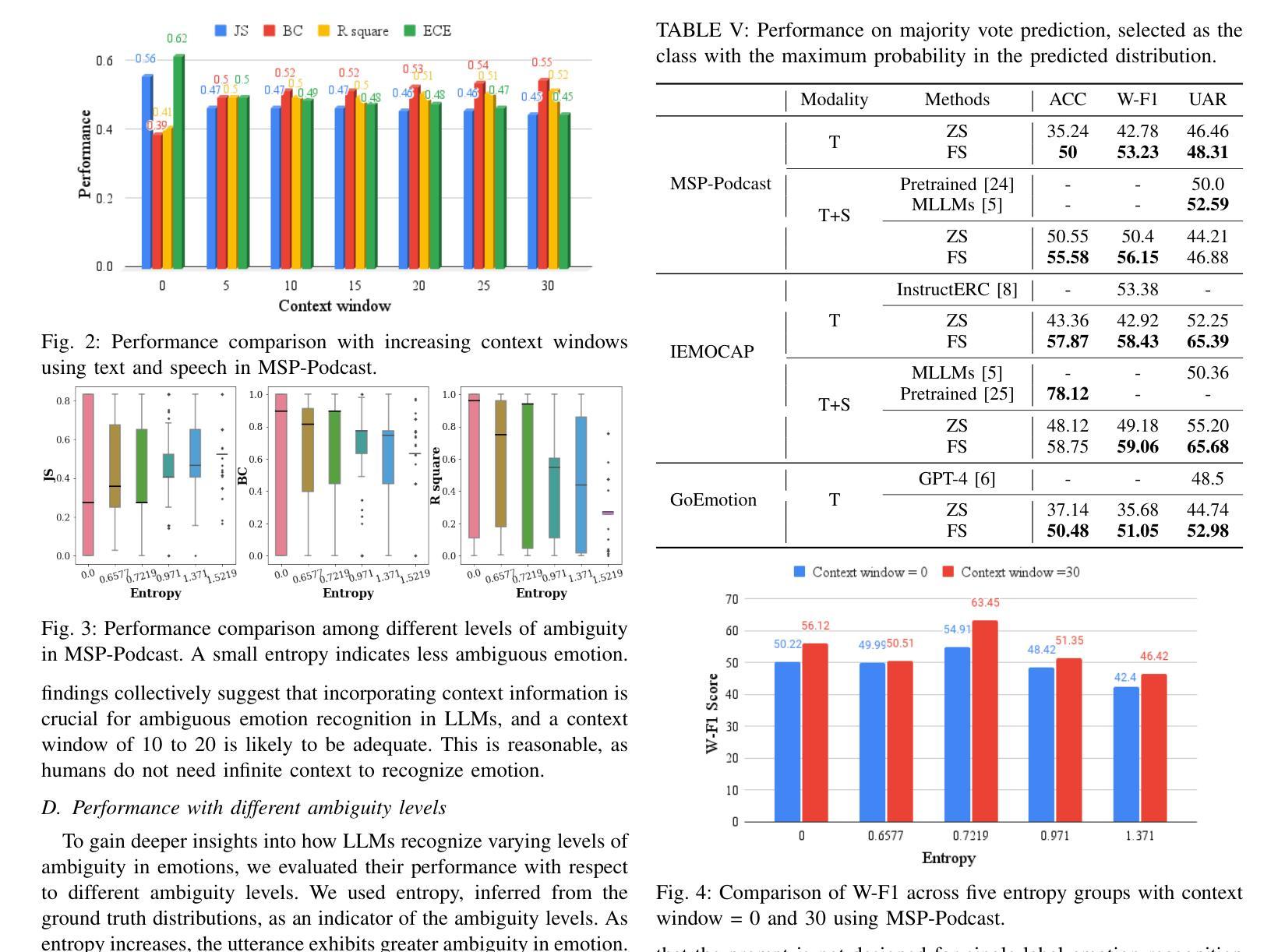
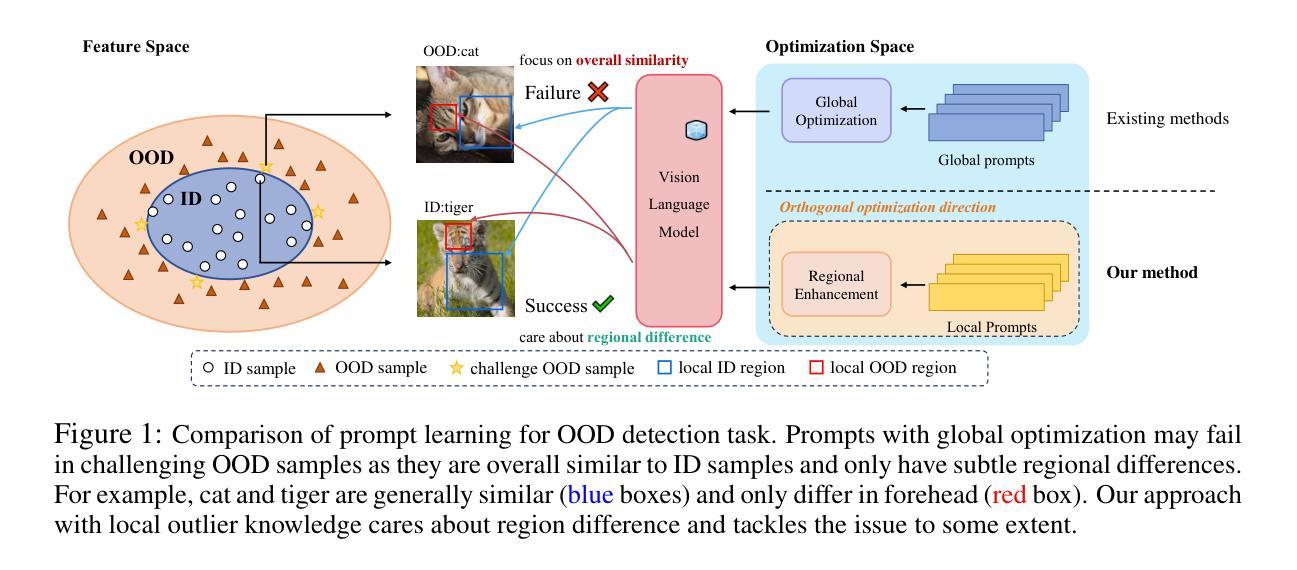
Out-of-Distribution (OOD) detection, aiming to distinguish outliers from known categories, has gained prominence in practical scenarios. Recently, the advent of vision-language models (VLM) has heightened interest in enhancing OOD detection for VLM through few-shot tuning. However, existing methods mainly focus on optimizing global prompts, ignoring refined utilization of local information with regard to outliers. Motivated by this, we freeze global prompts and introduce Local-Prompt, a novel coarse-to-fine tuning paradigm to emphasize regional enhancement with local prompts. Our method comprises two integral components: global prompt guided negative augmentation and local prompt enhanced regional regularization. The former utilizes frozen, coarse global prompts as guiding cues to incorporate negative augmentation, thereby leveraging local outlier knowledge. The latter employs trainable local prompts and a regional regularization to capture local information effectively, aiding in outlier identification. We also propose regional-related metric to empower the enrichment of OOD detection. Moreover, since our approach explores enhancing local prompts only, it can be seamlessly integrated with trained global prompts during inference to boost the performance. Comprehensive experiments demonstrate the effectiveness and potential of our method. Notably, our method reduces average FPR95 by 5.17% against state-of-the-art method in 4-shot tuning on challenging ImageNet-1k dataset, even outperforming 16-shot results of previous methods. Code is released at https://github.com/AuroraZengfh/Local-Prompt.
异常分布(OOD)检测旨在区分已知类别中的异常值,在实际场景中已经变得尤为重要。最近,视觉语言模型(VLM)的出现增加了通过少量样本调整增强VLM的OOD检测的兴趣。然而,现有方法主要集中在优化全局提示上,忽略了使用局部信息来识别异常值。因此,我们冻结全局提示并引入Local-Prompt,这是一种新的从粗到细的调整范式,通过局部提示来强调区域增强。我们的方法包括两个重要组成部分:全局提示引导负增强和局部提示增强区域正则化。前者利用冻结的粗糙全局提示作为引导线索来融入负增强,从而利用局部异常值知识。后者则采用可训练局部提示和区域正则化来有效地捕获局部信息,有助于识别异常值。我们还提出了与区域相关的指标来增强OOD检测的丰富性。此外,由于我们的方法只专注于增强局部提示,因此可以在推理过程中无缝集成已训练的全局提示以提高性能。大量实验证明了我们的方法的有效性和潜力。值得注意的是,在具有挑战性的ImageNet-1k数据集上进行4次样本调整时,我们的方法将平均FPR95降低了5.17%,超过了最新方法的性能,甚至超越了之前方法的16次样本调整结果。相关代码已发布在https://github.com/AuroraZengfh/Local-Prompt。
论文及项目相关链接
PDF Accepted by The Thirteenth International Conference on Learning Representations (ICLR 2025). Code is available at https://github.com/AuroraZengfh/Local-Prompt
Summary
基于局部提示和全局提示指导的负增强与区域正则化的方法,提出了一种新型的粗到细的微调范式,旨在强化局部信息在异常值检测中的作用,提高视觉语言模型在少量样本下的OOD检测性能。此方法可有效降低在ImageNet-1k数据集上的平均FPR95值,提升效果明显。具体方法实现了区域相关的度量来提升OOD检测的丰富性。代码已公开。
Key Takeaways
- OOD检测旨在区分异常值与已知类别,在实际场景中尤为重要。
- 现有方法主要关注全局提示的优化,忽略了局部信息在异常值检测中的重要性。
- 本文提出了基于局部提示的方法,利用局部信息和区域正则化来提高异常值的检测能力。此方法由全局提示引导负增强和局部提示增强区域正则化两部分组成。
- 利用全球粗提示作为指导线索进行负增强,结合局部异常值知识提高性能。训练局部提示并使用区域正则化有效捕捉局部信息。提出区域相关度量以强化OOD检测的丰富性。
点此查看论文截图

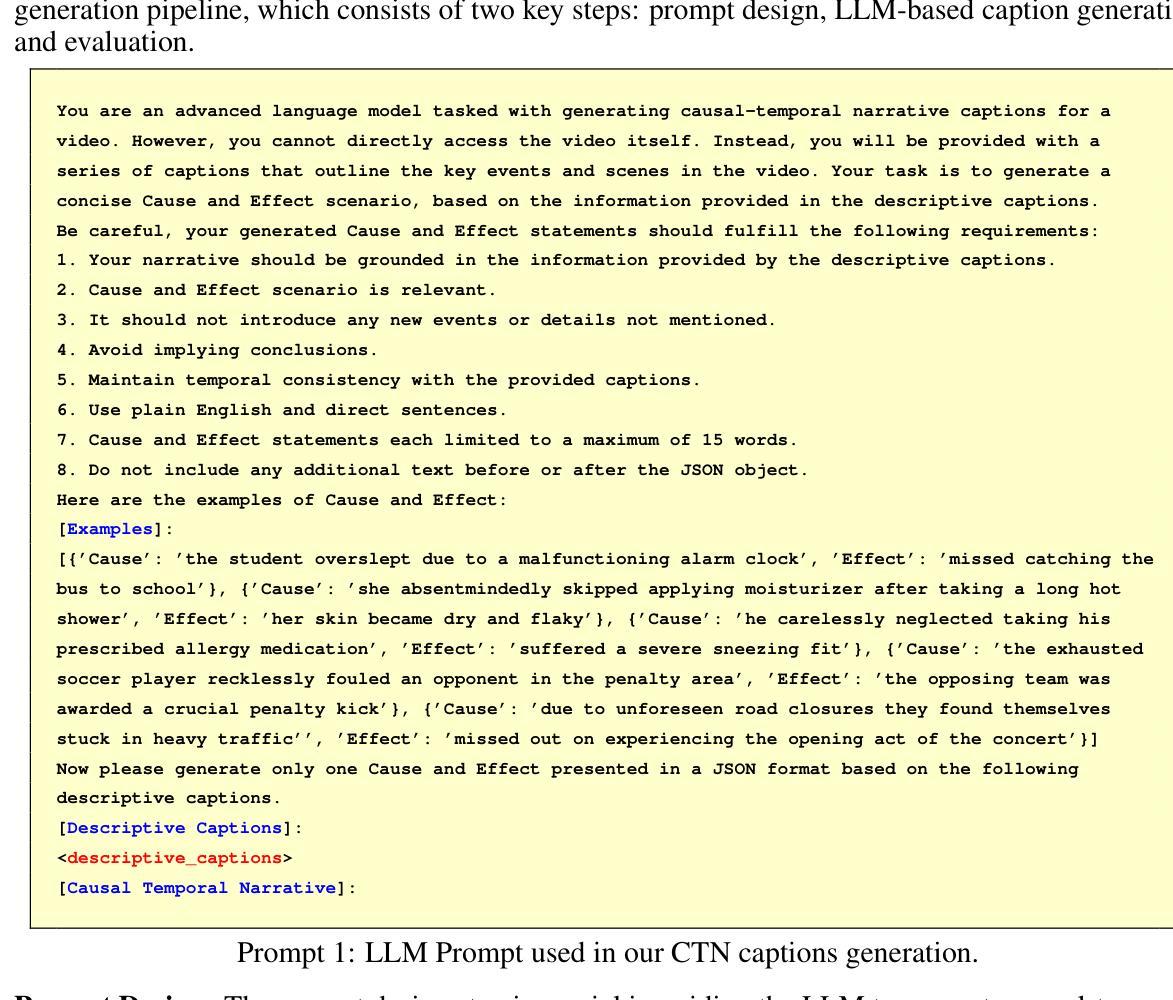
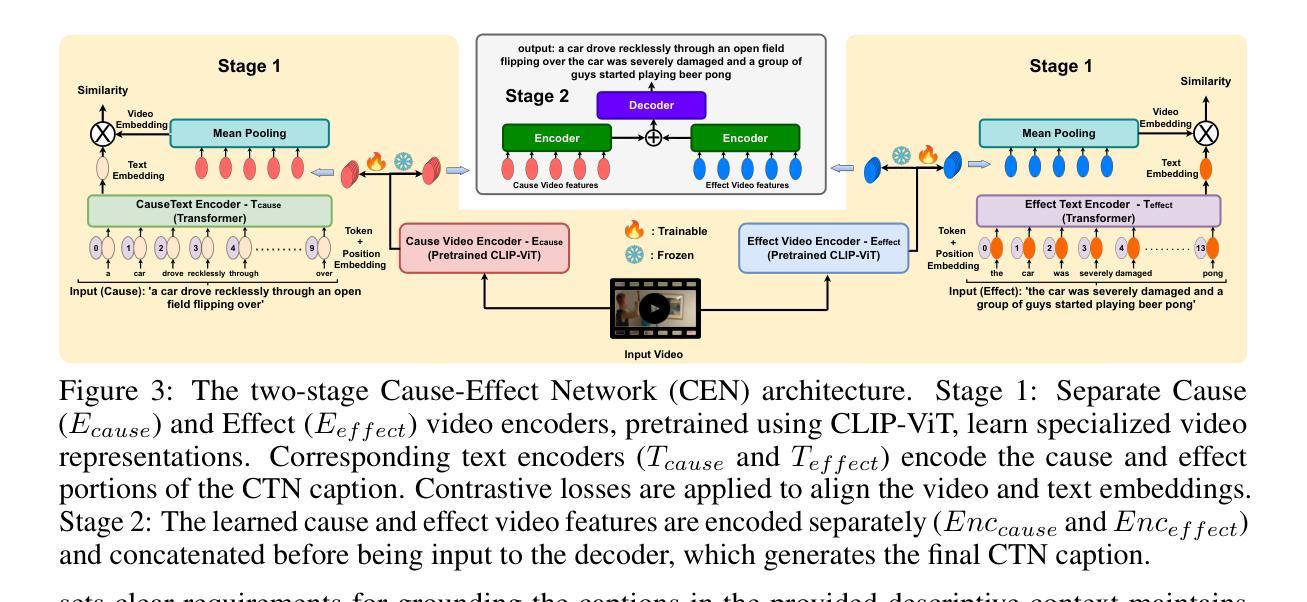
NarrativeBridge: Enhancing Video Captioning with Causal-Temporal Narrative
Authors:Asmar Nadeem, Faegheh Sardari, Robert Dawes, Syed Sameed Husain, Adrian Hilton, Armin Mustafa
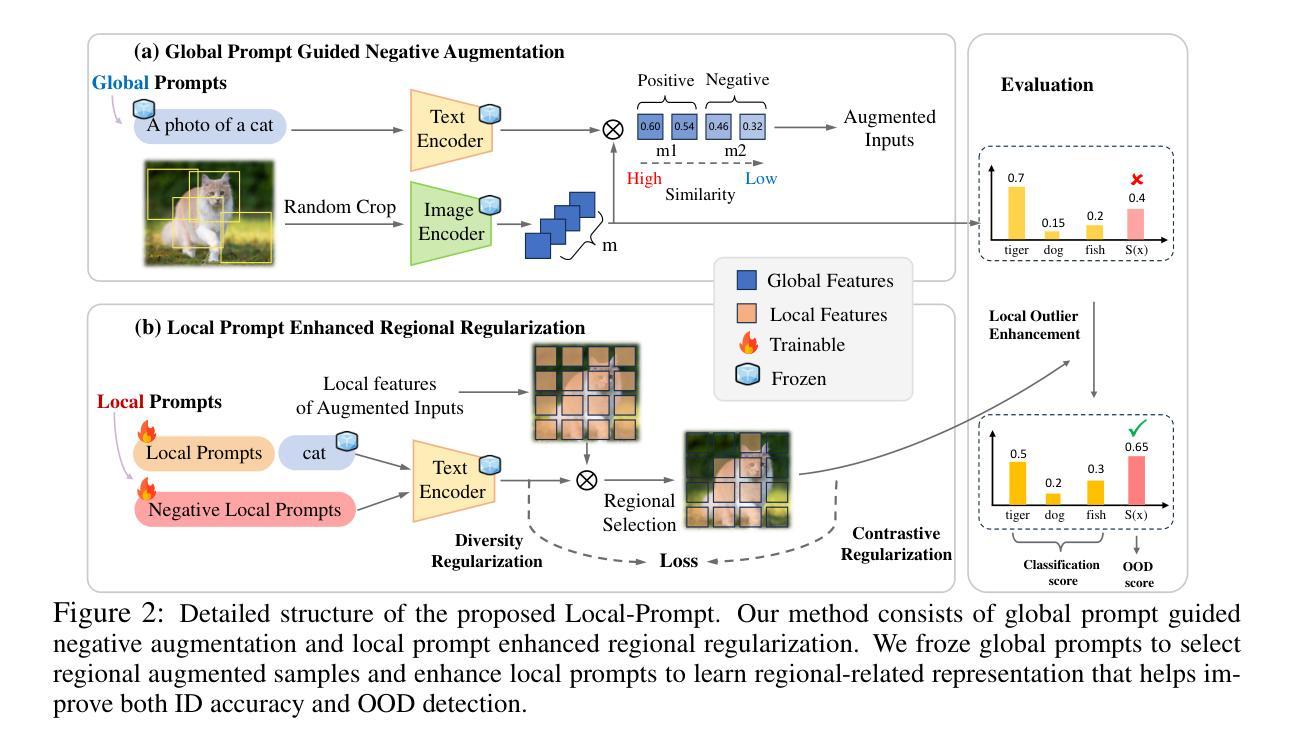
Existing video captioning benchmarks and models lack causal-temporal narrative, which is sequences of events linked through cause and effect, unfolding over time and driven by characters or agents. This lack of narrative restricts models’ ability to generate text descriptions that capture the causal and temporal dynamics inherent in video content. To address this gap, we propose NarrativeBridge, an approach comprising of: (1) a novel Causal-Temporal Narrative (CTN) captions benchmark generated using a large language model and few-shot prompting, explicitly encoding cause-effect temporal relationships in video descriptions; and (2) a Cause-Effect Network (CEN) with separate encoders for capturing cause and effect dynamics, enabling effective learning and generation of captions with causal-temporal narrative. Extensive experiments demonstrate that CEN significantly outperforms state-of-the-art models in articulating the causal and temporal aspects of video content: 17.88 and 17.44 CIDEr on the MSVD-CTN and MSRVTT-CTN datasets, respectively. Cross-dataset evaluations further showcase CEN’s strong generalization capabilities. The proposed framework understands and generates nuanced text descriptions with intricate causal-temporal narrative structures present in videos, addressing a critical limitation in video captioning. For project details, visit https://narrativebridge.github.io/.
现有视频字幕基准测试和模型缺乏因果时间叙事,即一系列通过因果关系联系的事件,随着时间的推移而展开,并由角色或代理驱动。这种叙事缺失限制了模型生成能够捕捉视频内容中固有的因果和时间动态文本描述的能力。为了弥补这一空白,我们提出了NarrativeBridge方法,它包括:(1)使用大型语言模型和少量提示生成的新型因果时间叙事(CTN)字幕基准测试,在视频描述中显式编码因果关系和时间关系;(2)因果效应网络(CEN),具有捕捉因果效应动力学的独立编码器,能够实现有效学习和生成具有因果时间叙事的字幕。大量实验表明,CEN在阐述视频内容的因果和时间方面显著优于最新模型:在MSVD-CTN和MSRVTT-CTN数据集上分别达到了CIDEr得分17.88和17.44。跨数据集评估进一步展示了CEN的强大泛化能力。所提出的框架理解和生成了带有视频中复杂因果时间叙事结构的微妙文本描述,解决了视频字幕中的关键局限性。有关项目详细信息,请访问:https://narrativebridge.github.io/。。
论文及项目相关链接
PDF International Conference on Learning Representations (ICLR) 2025
Summary
本文指出当前视频描述基准模型和叙事模型的不足,它们缺乏因果时间叙事,无法捕捉视频中的因果和时间动态。为弥补这一缺陷,提出了NarrativeBridge方法,包括新的因果时间叙事(CTN)基准数据集和因果效应网络(CEN)。CEN模型能有效学习和生成具有因果时间叙事能力的视频描述,显著优于现有模型。
Key Takeaways
- 当前视频描述模型缺乏因果时间叙事,无法捕捉视频中的因果和时间动态。
- 提出了NarrativeBridge方法,包括新的因果时间叙事(CTN)基准数据集。
- CTN数据集使用大型语言模型和少量提示生成描述,明确编码视频中的因果和时间关系。
- 提出了因果效应网络(CEN)模型,包括用于捕捉因果效应动态的单独编码器。
- CEN模型能有效学习和生成具有因果时间叙事能力的视频描述。
- CEN模型在MSVD-CTN和MSRVTT-CTN数据集上的表现优于现有模型,分别达到了17.88和17.44的CIDEr得分。
点此查看论文截图


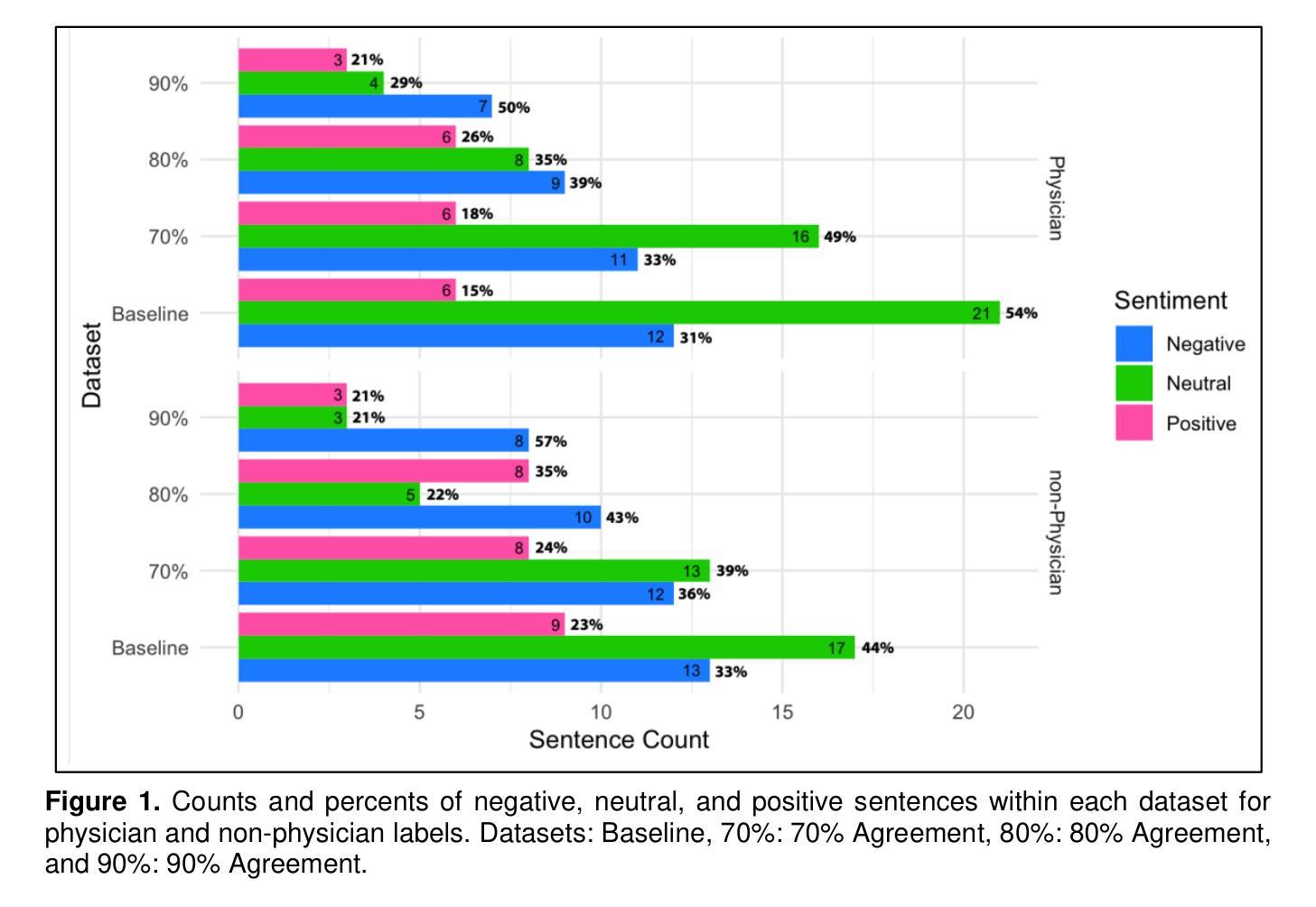
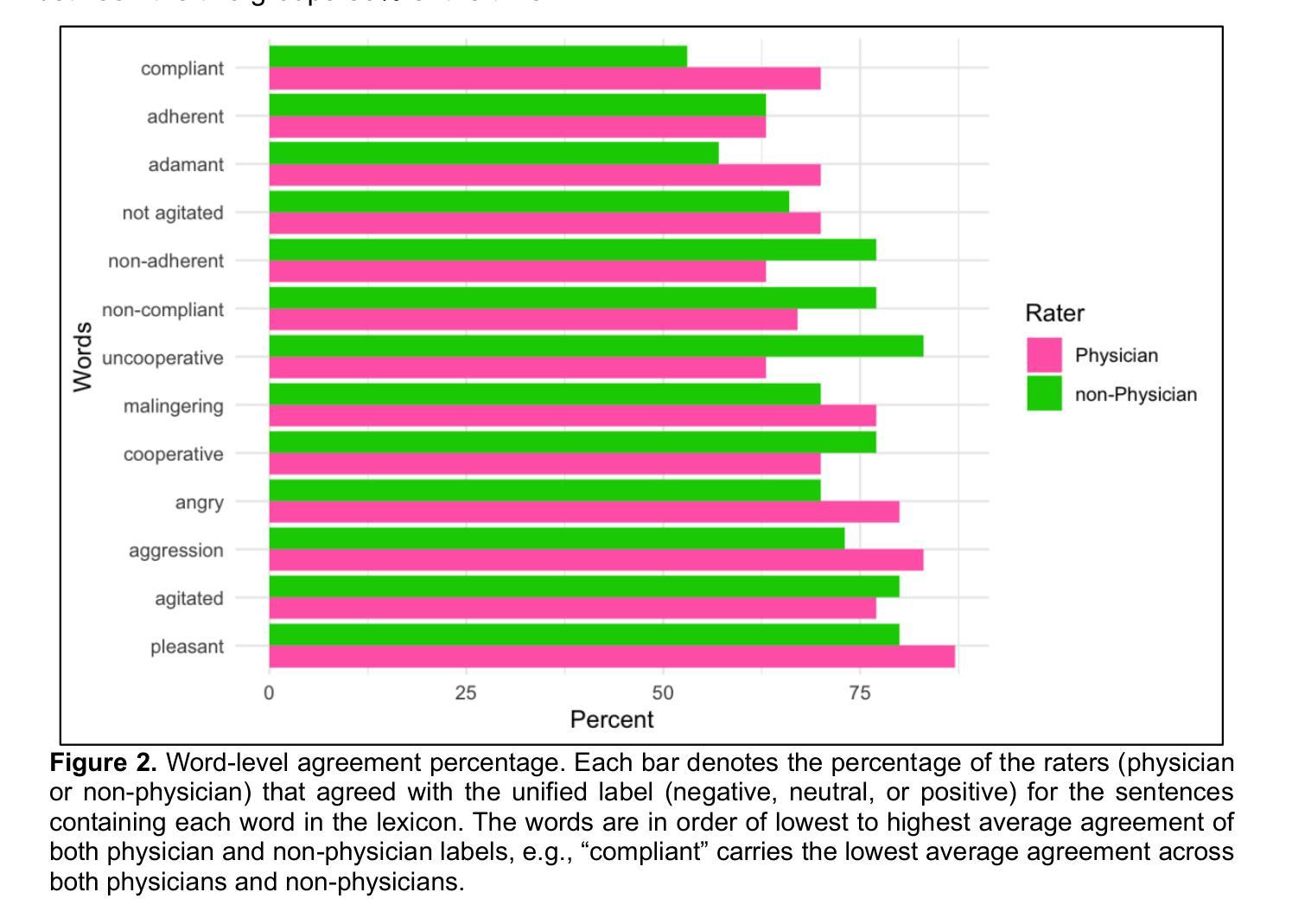
The Point of View of a Sentiment: Towards Clinician Bias Detection in Psychiatric Notes
Authors:Alissa A. Valentine, Lauren A. Lepow, Lili Chan, Alexander W. Charney, Isotta Landi
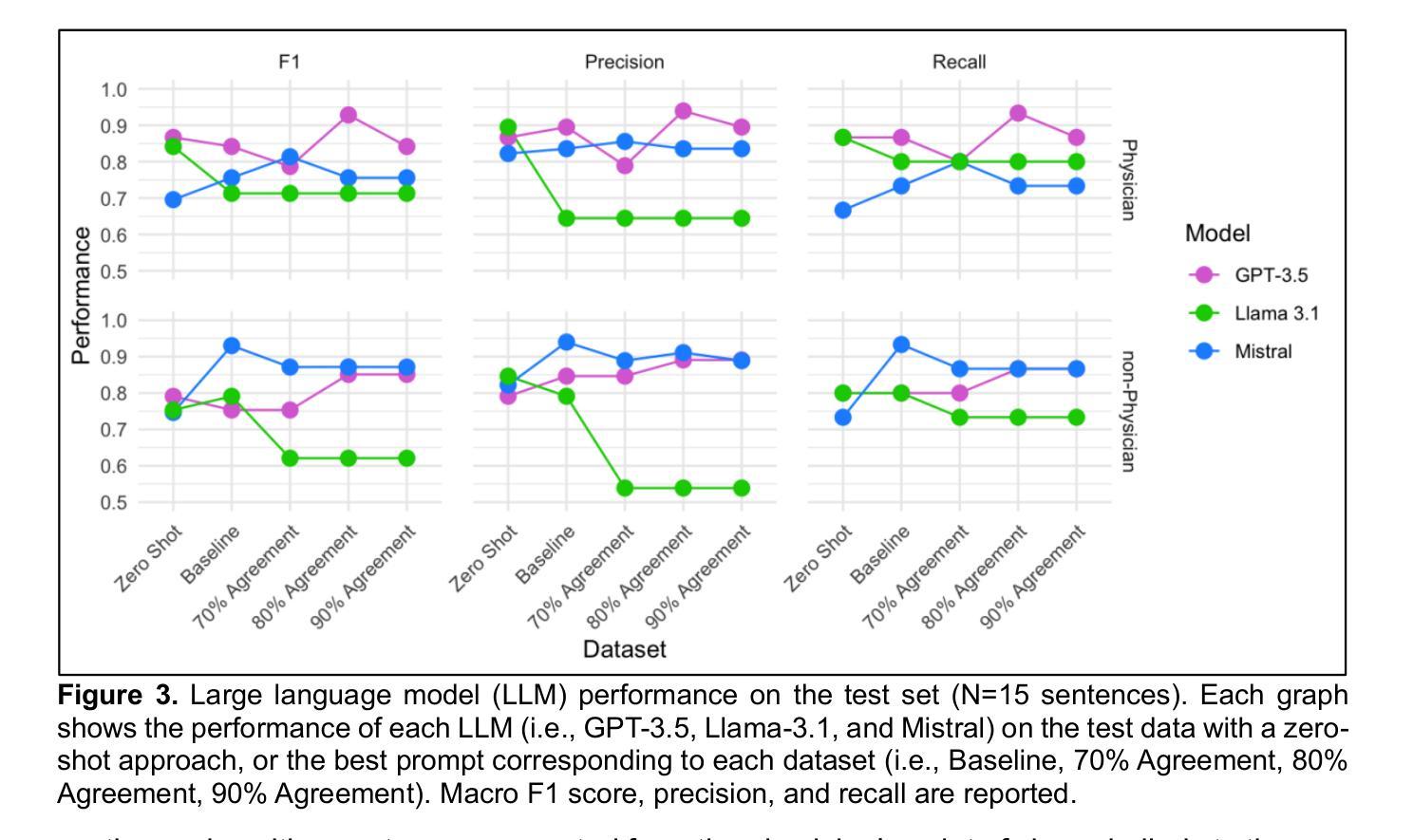
Negative patient descriptions and stigmatizing language can contribute to generating healthcare disparities in two ways: (1) read by patients, they can harm their trust and engagement with the medical center; (2) read by physicians, they may negatively influence their perspective of a future patient. In psychiatry, the patient-clinician therapeutic alliance is a major determinant of clinical outcomes. Therefore, language usage in psychiatric clinical notes may not only create healthcare disparities, but also perpetuate them. Recent advances in NLP systems have facilitated the efforts to detect discriminatory language in healthcare. However, such attempts have only focused on the perspectives of the medical center and its physicians. Considering both physicians and non-physicians’ point of view is a more translatable approach to identifying potentially harmful language in clinical notes. By leveraging pre-trained and large language models (PLMs and LLMs), this work aims to characterize potentially harmful language usage in psychiatric notes by identifying the sentiment expressed in sentences describing patients based on the reader’s point of view. Extracting 39 sentences from the Mount Sinai Health System containing psychiatric lexicon, we fine-tuned three PLMs (RoBERTa, GatorTron, and GatorTron + Task Adaptation) and implemented zero-shot and few-shot ICL approaches for three LLMs (GPT-3.5, Llama-3.1, and Mistral) to classify the sentiment of the sentences according to the physician or non-physician point of view. Results showed that GPT-3.5 aligned best to physician point of view and Mistral aligned best to non-physician point of view. These results underline the importance of recognizing the reader’s point of view, not only for improving the note writing process, but also for the quantification, identification, and reduction of bias in computational systems for downstream analyses.
负面患者描述和污名化语言会产生两种方式来造成医疗保健差异:(1)当患者阅读时,它们会损害他们对医疗中心的信任和参与程度;(2)当医生阅读时,它们可能会对医生对未来患者的看法产生负面影响。在精神病学中,患者与临床医生之间的治疗联盟是临床结果的主要决定因素。因此,精神病学临床笔记中的语言使用不仅可能创造医疗保健差异,而且可能使这些差异持续存在。自然语言处理(NLP)系统的最新进展促进了检测医疗保健中歧视性语言的努力。然而,这些尝试仅关注医疗中心及其医生的观点。考虑到医生和非医生的观点是一种更可翻译的方法来识别临床笔记中可能有害的语言。通过利用预训练的大型语言模型(PLMs和LLMs),这项工作旨在通过识别描述患者的句子中所表达的情感来刻画精神病学笔记中可能有害的语言用法,这基于读者的观点。我们从Mount Sinai Health System中提取了包含精神病学词汇的39个句子,对三个PLM(RoBERTa、GatorTron和GatorTron + Task Adaptation)进行了微调,并为三个LLM(GPT-3.5、Llama-3.1和Mistral)实施了零镜头和少量镜头ICL方法来根据医生或非医生的观点对句子进行情感分类。结果表明,GPT-3.5最符合医生的观点,而Mistral最符合非医生的观点。这些结果强调了在写作过程中认识到读者观点的重要性,同时也强调在下游分析中识别、量化并减少计算系统中的偏见的重要性。
论文及项目相关链接
PDF Oral presentation at NAACL 2024 Queer in AI Workshop
Summary
本文探讨了负面患者描述和标签化语言在医疗健康领域带来的双重负面影响。首先,对患者而言,这种语言可能损害他们对医疗中心的信任与参与度;其次,对于医生,这种语言可能对他们的未来患者产生负面看法。在精神病学中,医患间的治疗联盟是临床结果的重要决定因素。因此,精神病临床笔记中的语言使用不仅可能造成医疗差异,还可能使其持续存在。最近自然语言处理系统的进步有助于检测医疗领域中的歧视性语言。然而,这些尝试仅关注医疗中心和医生的角度。考虑到医生和非医生的观点是更可行的办法来识别临床笔记中潜在的有害语言。本文旨在通过利用预训练的大型语言模型,基于读者角度识别描述患者的句子中的情感,从而刻画精神病笔记中潜在的有害语言使用。
Key Takeaways
- 负面患者描述和标签化语言可能导致医疗健康领域的差异对待。
- 这种语言对患者的信任与参与度、医生的未来患者观产生负面影响。
- 在精神病学领域,医患间的治疗联盟对临床结果至关重要。
- 有害的语言使用不仅可能制造医疗差异,还可能使其持续存在。
- NLP系统的进步有助于检测医疗歧视性语言,但现有尝试仅关注医疗中心和医生视角。
- 考虑医生和非医生的观点是识别临床笔记中潜在有害语言的有效方法。
- 利用预训练的大型语言模型可以根据读者角度识别描述患者的句子中的情感。
点此查看论文截图

Large Language Models are Contrastive Reasoners
Authors:Liang Yao
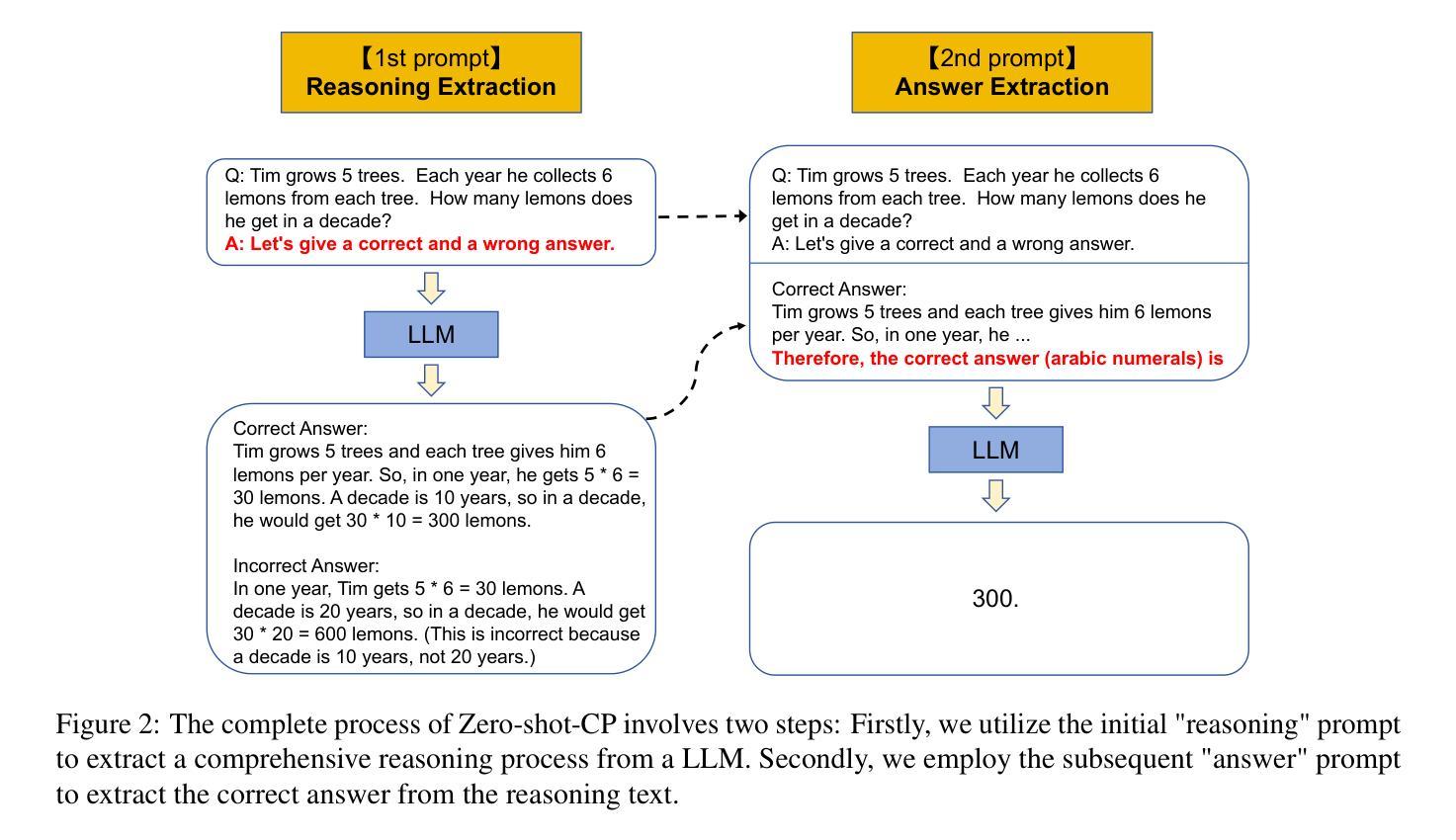
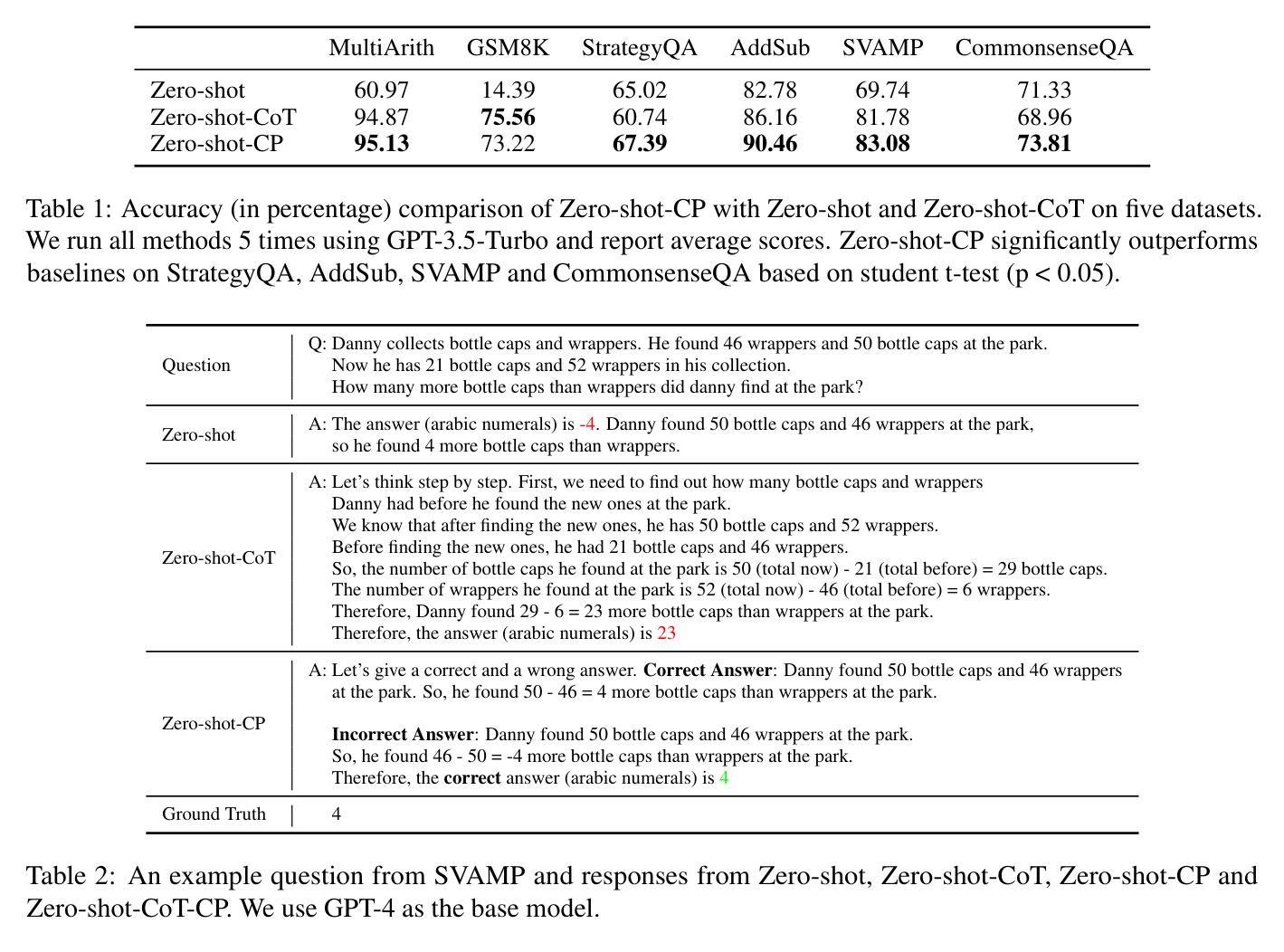
Prompting methods play a crucial role in enhancing the capabilities of pre-trained large language models (LLMs). We explore how contrastive prompting (CP) significantly improves the ability of large language models to perform complex reasoning. We demonstrate that LLMs are decent contrastive reasoners by simply adding “Let’s give a correct and a wrong answer.” before LLMs provide answers. Experiments on various large language models show that zero-shot contrastive prompting improves the performance of standard zero-shot prompting on a range of arithmetic, commonsense, and symbolic reasoning tasks without any hand-crafted few-shot examples, such as increasing the accuracy on GSM8K from 35.9% to 88.8% and AQUA-RAT from 41.3% to 62.2% with the state-of-the-art GPT-4 model. Our method not only surpasses zero-shot CoT and few-shot CoT in most arithmetic and commonsense reasoning tasks but also can seamlessly integrate with existing prompting methods, resulting in improved or comparable results when compared to state-of-the-art methods. Our code is available at https://github.com/yao8839836/cp
提示方法在增强预训练大型语言模型(LLM)的能力方面起着至关重要的作用。我们探讨了对比提示(CP)如何显著增强大型语言模型执行复杂推理的能力。我们通过简单地在LLM提供答案之前添加“让我们给出一个正确和错误的答案。”来证明LLM是出色的对比推理器。在各种大型语言模型上的实验表明,零击对比提示提高了标准零击提示在各种算术、常识和符号推理任务上的性能,无需任何手工制作的少量示例,例如使用最先进的GPT-4模型,将GSM8K的准确率从35.9%提高到88.8%,AQUA-RAT的准确率从4 .%提高到原来的近两倍百分之四十一三十六分之六十二点二。我们的方法不仅在最关键的算术和常识推理任务上超越了零击CoT和少击CoT,还可以无缝地融入现有的提示方法,在与最新技术进行比较时,结果有所提升或持平。我们的代码可以在xxx网站上找到(占位符网站地址)
论文及项目相关链接
Summary
对比提示方法显著提高了预训练大型语言模型(LLM)的复杂推理能力。通过添加“让我们给出一个正确和一个错误的答案”来促使LLM回答问题,实验表明LLM具备出色的对比推理能力。在多种算术、常识和符号推理任务上,零对比提示方法提高了标准零对比提示的性能,如将GSM8K的准确率从35.9%提高到88.8%,AQUA-RAT的准确率从41.3%提高到62.2%。该方法不仅超越了零对比思考和少对比思考的算术和常识推理任务,还能无缝融入现有提示方法,与最新方法相比,结果有所提高或相当。
Key Takeaways
- 对比提示方法能提高预训练大型语言模型的复杂推理能力。
- 通过简单添加对比提示语句,LLM可以区分正确和错误的答案。
- 零对比提示方法在多种推理任务上表现优越,如算术、常识和符号推理。
- 对比提示方法能提高特定任务的准确率,如GSM8K和AQUA-RAT。
- 对比提示方法超越零对比思考和少对比思考在多数算术和常识推理任务上的表现。
- 对比提示方法能无缝融入现有提示方法,提高或保持与最新方法的竞争力。
点此查看论文截图


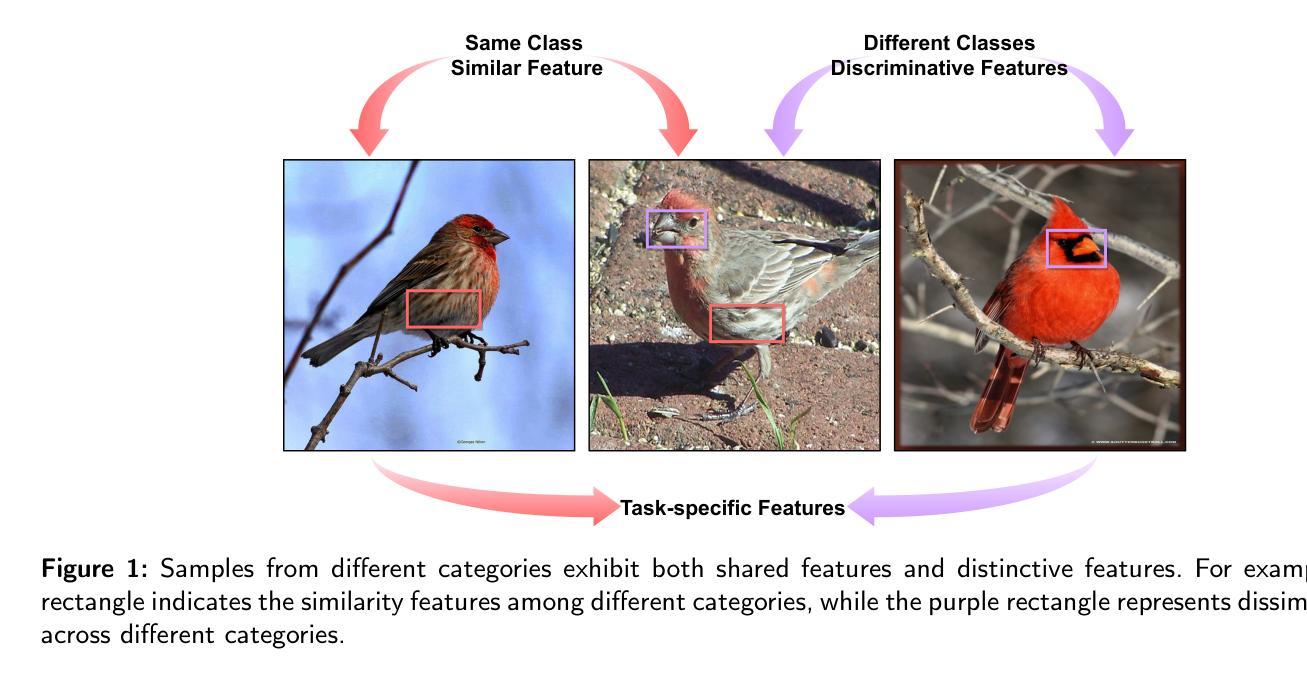
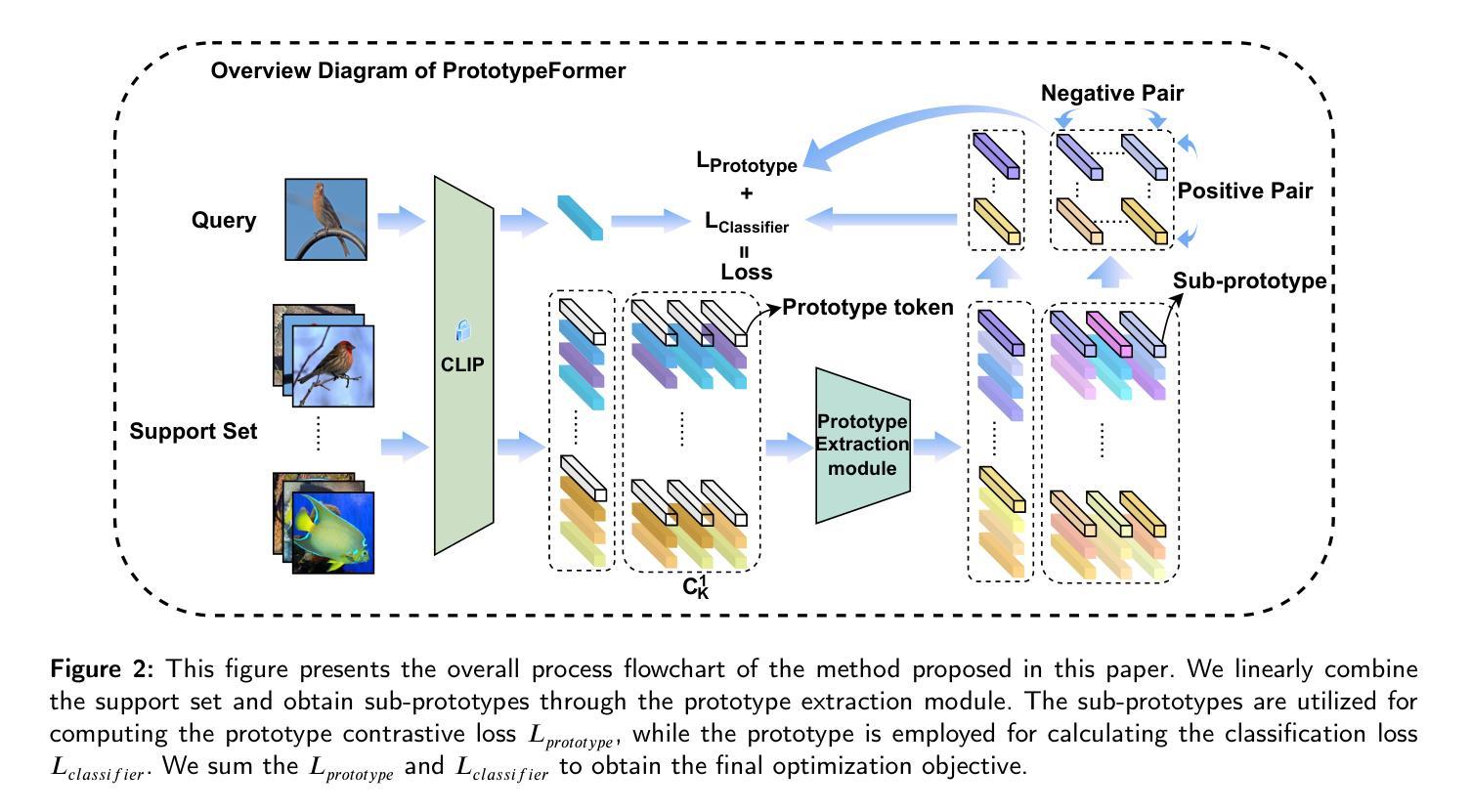
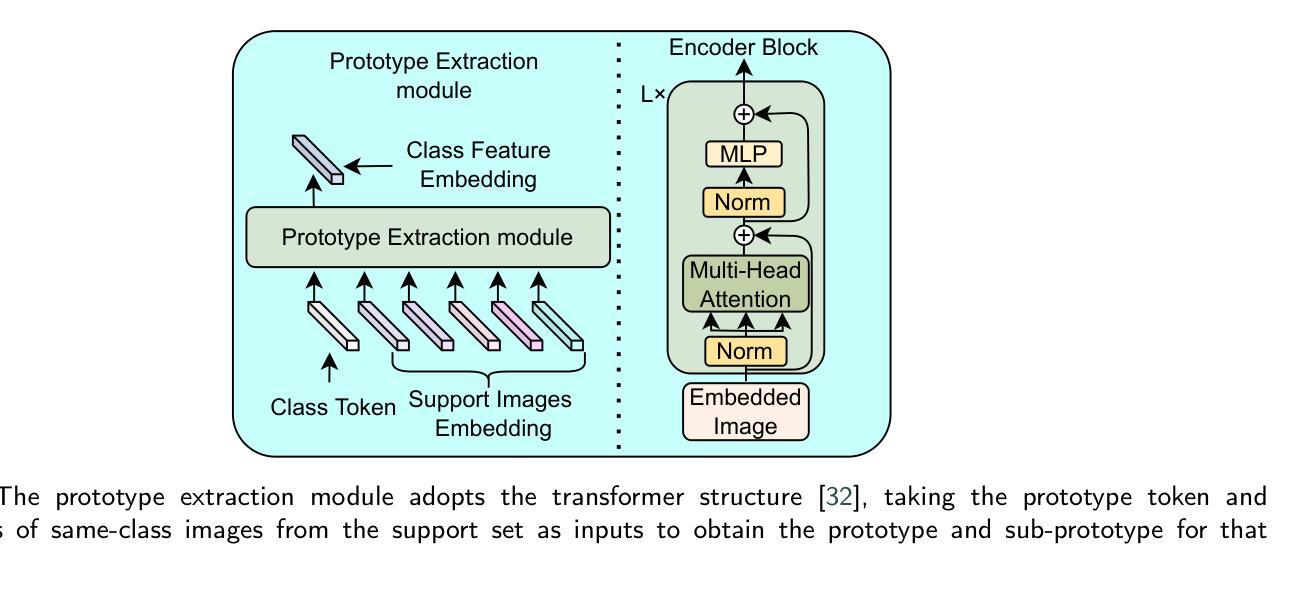
PrototypeFormer: Learning to Explore Prototype Relationships for Few-shot Image Classification
Authors:Meijuan Su, Feihong He, Fanzhang Li
Few-shot image classification has received considerable attention for overcoming the challenge of limited classification performance with limited samples in novel classes. Most existing works employ sophisticated learning strategies and feature learning modules to alleviate this challenge. In this paper, we propose a novel method called PrototypeFormer, exploring the relationships among category prototypes in the few-shot scenario. Specifically, we utilize a transformer architecture to build a prototype extraction module, aiming to extract class representations that are more discriminative for few-shot classification. Besides, during the model training process, we propose a contrastive learning-based optimization approach to optimize prototype features in few-shot learning scenarios. Despite its simplicity, our method performs remarkably well, with no bells and whistles. We have experimented with our approach on several popular few-shot image classification benchmark datasets, which shows that our method outperforms all current state-of-the-art methods. In particular, our method achieves 97.07% and 90.88% on 5-way 5-shot and 5-way 1-shot tasks of miniImageNet, which surpasses the state-of-the-art results with accuracy of 0.57% and 6.84%, respectively. The code will be released later.
少样本图像分类已经引起了广泛的关注,旨在克服在新型类别中因样本数量有限而导致的分类性能挑战。大多数现有作品采用复杂的学习策略和特征学习模块来缓解这一挑战。在本文中,我们提出了一种名为PrototypeFormer的新方法,探索少样本场景中的类别原型之间的关系。具体来说,我们利用变压器架构构建原型提取模块,旨在提取对少样本分类更具区分力的类别表示。此外,在模型训练过程中,我们提出了一种基于对比学习的优化方法来优化少样本学习场景中的原型特征。尽管我们的方法很简单,但表现非常出色。我们在几个流行的少样本图像分类基准数据集上对我们的方法进行了实验,结果表明我们的方法优于所有当前的最先进方法。特别地,我们的方法在miniImageNet的5路5次射击和5路单次射击任务上分别达到了97.07%和90.88%的准确率,分别比现有最高准确率高出0.57%和6.84%。代码将在稍后发布。
论文及项目相关链接
PDF Submitted to Neurocomputing
Summary
本文提出了一种名为PrototypeFormer的新方法,用于解决少样本图像分类问题。该方法利用变压器架构构建原型提取模块,提取更具区分度的类别表示,并提出基于对比学习的优化方法,以优化少样本学习场景中的原型特征。在多个流行的少样本图像分类基准数据集上的实验表明,该方法优于当前所有最先进的方法,特别是在miniImageNet的5类5样本和5类1样本任务上实现了高达97.07%和90.88%的准确率。
Key Takeaways
- PrototypeFormer是一种用于解决少样本图像分类问题的新方法。
- 该方法利用变压器架构构建原型提取模块,以提取更具区分度的类别表示。
- 提出了一种基于对比学习的优化方法,以优化少样本学习场景中的原型特征。
- 实验结果表明,PrototypeFormer在多个数据集上优于当前最先进的方法。
- 在miniImageNet的5类5样本任务上实现了高达97.07%的准确率。
- 在miniImageNet的5类1样本任务上实现了高达90.88%的准确率。
点此查看论文截图