⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-19 更新
A Survey on Bridging EEG Signals and Generative AI: From Image and Text to Beyond
Authors:Shreya Shukla, Jose Torres, Abhijit Mishra, Jacek Gwizdka, Shounak Roychowdhury
Integration of Brain-Computer Interfaces (BCIs) and Generative Artificial Intelligence (GenAI) has opened new frontiers in brain signal decoding, enabling assistive communication, neural representation learning, and multimodal integration. BCIs, particularly those leveraging Electroencephalography (EEG), provide a non-invasive means of translating neural activity into meaningful outputs. Recent advances in deep learning, including Generative Adversarial Networks (GANs) and Transformer-based Large Language Models (LLMs), have significantly improved EEG-based generation of images, text, and speech. This paper provides a literature review of the state-of-the-art in EEG-based multimodal generation, focusing on (i) EEG-to-image generation through GANs, Variational Autoencoders (VAEs), and Diffusion Models, and (ii) EEG-to-text generation leveraging Transformer based language models and contrastive learning methods. Additionally, we discuss the emerging domain of EEG-to-speech synthesis, an evolving multimodal frontier. We highlight key datasets, use cases, challenges, and EEG feature encoding methods that underpin generative approaches. By providing a structured overview of EEG-based generative AI, this survey aims to equip researchers and practitioners with insights to advance neural decoding, enhance assistive technologies, and expand the frontiers of brain-computer interaction.
脑机接口(BCI)与生成式人工智能(GenAI)的融合为脑信号解码开辟了新的领域,实现了辅助通信、神经表征学习和多模式融合。特别是利用脑电图(EEG)的脑机接口,为将神经活动转化为有意义的输出提供了非侵入性的手段。深度学习领域的最新进展,包括生成对抗网络(GANs)和基于变压器的自然语言大模型(LLMs),极大地提高了基于EEG的图像、文本和语音生成能力。本文综述了基于EEG的多模式生成的最新进展,重点关注:(i)通过GANs、变分自动编码器(VAEs)和扩散模型实现EEG到图像生成;(ii)利用基于Transformer的自然语言模型和对比学习方法实现EEG到文本生成。此外,我们还讨论了新兴的EEG语音合成领域,这是一个不断发展的多模式前沿领域。本文重点介绍了关键数据集、应用场景、挑战以及支撑生成方法的基本EEG特征编码方法。通过对基于EEG的生成式人工智能的结构性概述,本综述旨在为研究人员和实践者提供洞察力,以推动神经解码的发展,提高辅助技术的效能,并拓展脑机交互的边界。
论文及项目相关链接
Summary
BCIs与GenAI的整合为脑信号解码开启了新纪元,助力辅助沟通、神经表征学习与多媒体融合。借助脑电图(EEG)的BCI为非侵入式神经活动转译提供途径。深度学习领域的进展,如生成对抗网络(GANs)与基于Transformer的大型语言模型(LLMs),大幅改善了基于EEG的图像、文本及语音生成。本文旨在综述EEG基多元生成研究的最新进展,聚焦于EEG转图像生成与EEG转文本生成,并探讨新兴的EEG语音合成领域。通过概述EEG基生成式人工智能,旨在为研究者与实践者提供神经解码、辅助技术与脑机交互前沿的见解。
Key Takeaways
- BCI与GenAI融合为脑信号解码带来新突破,促进辅助沟通、神经表征学习与多媒体融合。
- EEG为非侵入式神经活动翻译提供了重要手段。
- 深度学习进步如GANs和LLMs显著提升了基于EEG的图像、文本和语音生成质量。
- 文章聚焦于EEG转图像生成和EEG转文本生成的最新研究。
- EEG语音合成是一个新兴且不断发展的多媒体融合前沿领域。
- 文章概述了EEG基生成式人工智能的关键数据集、用例、挑战和EEG特征编码方法。
点此查看论文截图

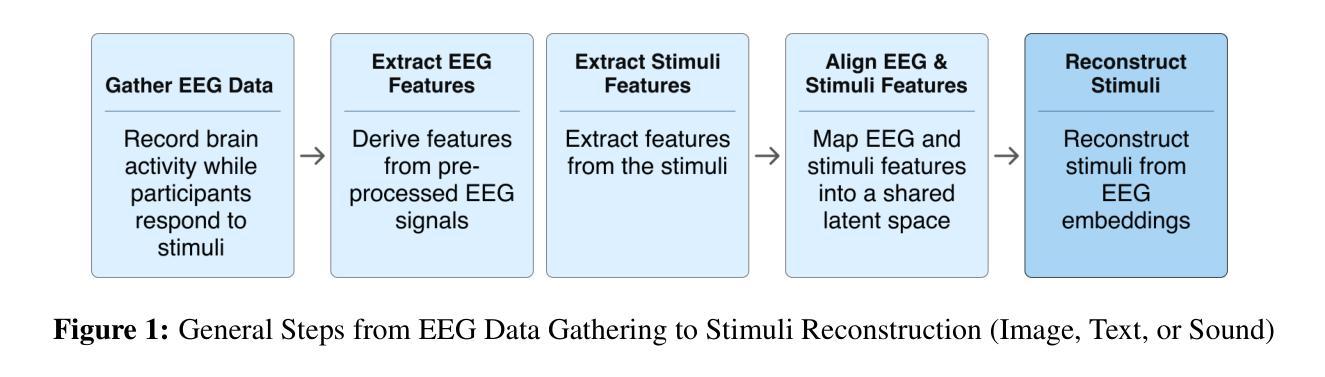
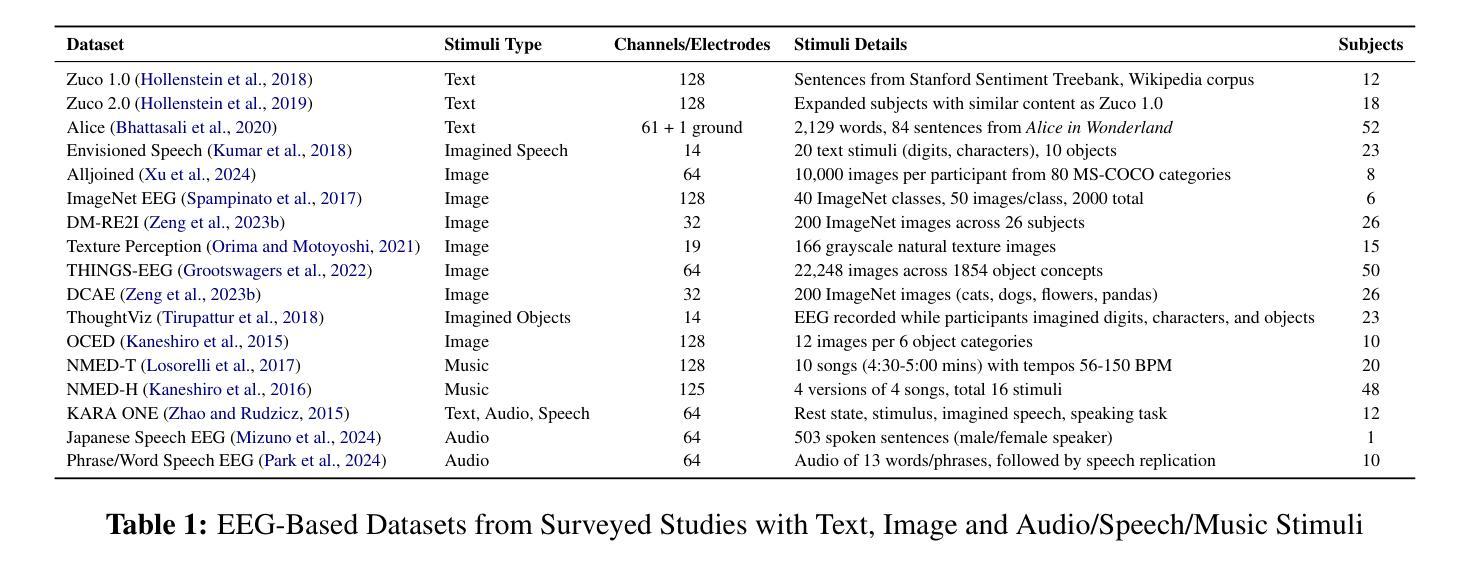
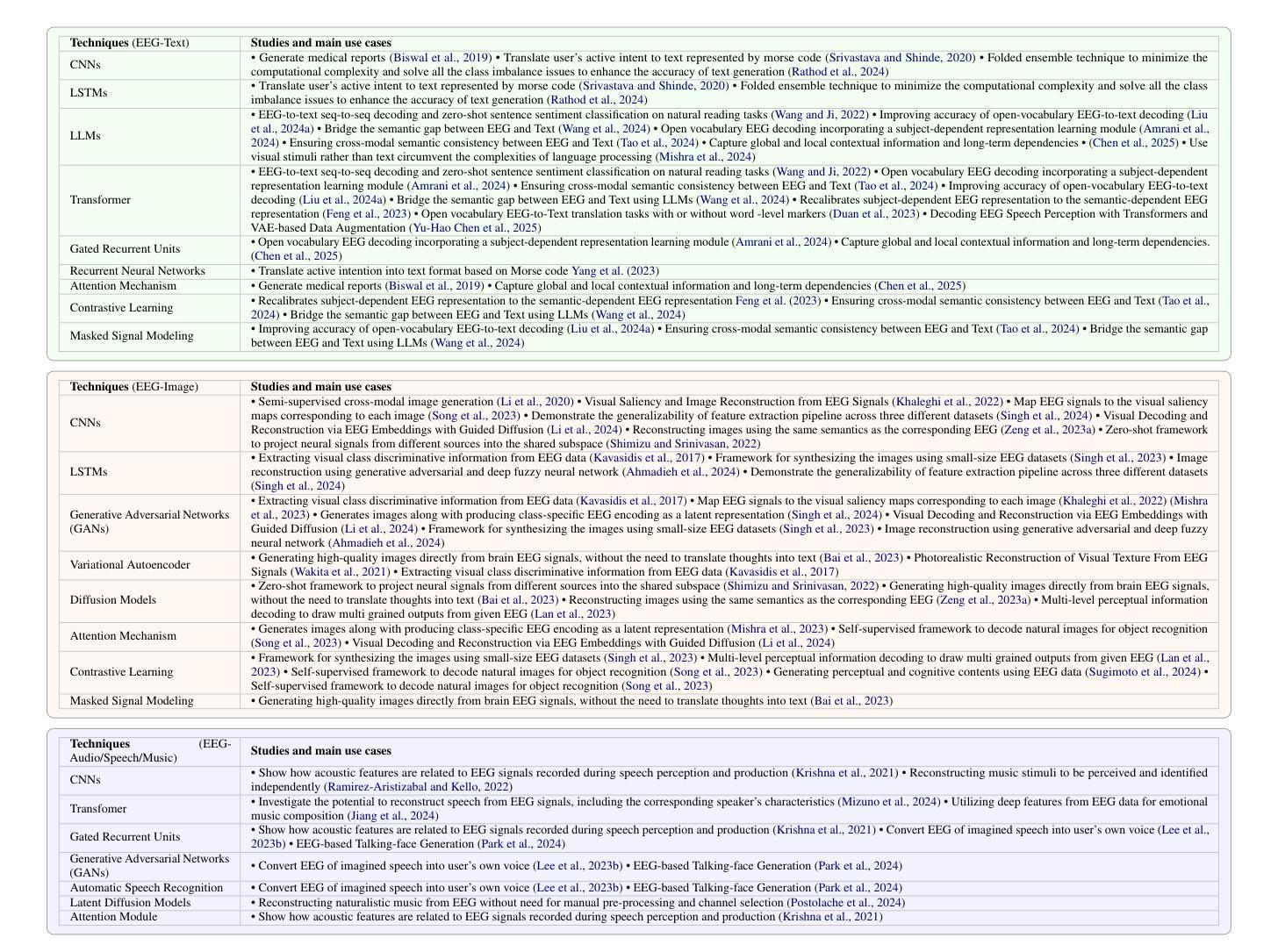
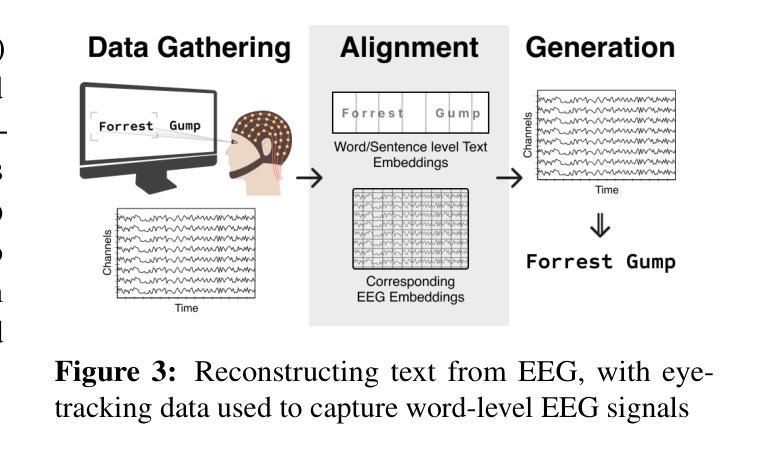
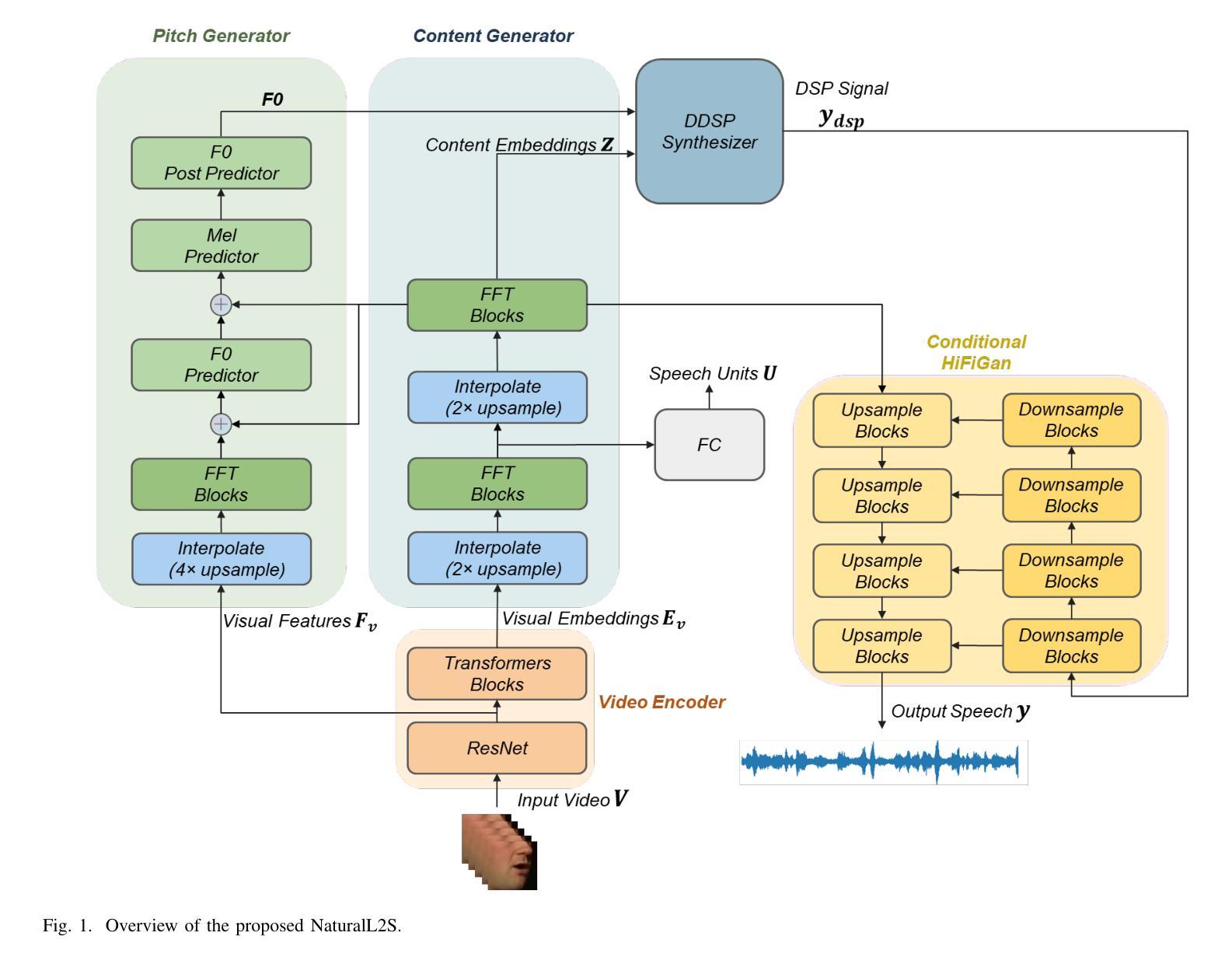
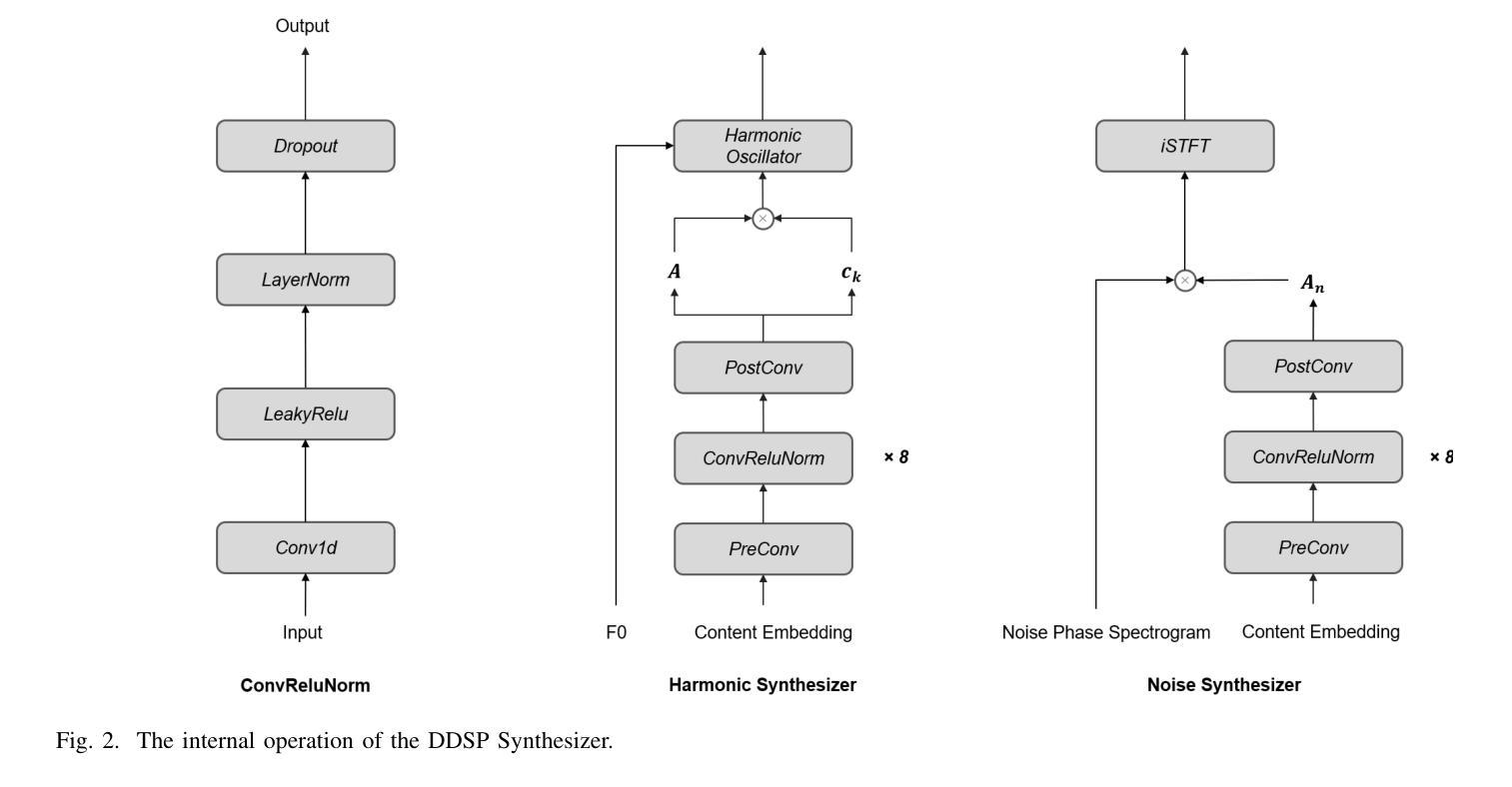
NaturalL2S: End-to-End High-quality Multispeaker Lip-to-Speech Synthesis with Differential Digital Signal Processing
Authors:Yifan Liang, Fangkun Liu, Andong Li, Xiaodong Li, Chengshi Zheng
Recent advancements in visual speech recognition (VSR) have promoted progress in lip-to-speech synthesis, where pre-trained VSR models enhance the intelligibility of synthesized speech by providing valuable semantic information. The success achieved by cascade frameworks, which combine pseudo-VSR with pseudo-text-to-speech (TTS) or implicitly utilize the transcribed text, highlights the benefits of leveraging VSR models. However, these methods typically rely on mel-spectrograms as an intermediate representation, which may introduce a key bottleneck: the domain gap between synthetic mel-spectrograms, generated from inherently error-prone lip-to-speech mappings, and real mel-spectrograms used to train vocoders. This mismatch inevitably degrades synthesis quality. To bridge this gap, we propose Natural Lip-to-Speech (NaturalL2S), an end-to-end framework integrating acoustic inductive biases with differentiable speech generation components. Specifically, we introduce a fundamental frequency (F0) predictor to capture prosodic variations in synthesized speech. The predicted F0 then drives a Differentiable Digital Signal Processing (DDSP) synthesizer to generate a coarse signal which serves as prior information for subsequent speech synthesis. Additionally, instead of relying on a reference speaker embedding as an auxiliary input, our approach achieves satisfactory performance on speaker similarity without explicitly modelling speaker characteristics. Both objective and subjective evaluation results demonstrate that NaturalL2S can effectively enhance the quality of the synthesized speech when compared to state-of-the-art methods. Our demonstration page is accessible at https://yifan-liang.github.io/NaturalL2S/.
近期视觉语音识别(VSR)的进展促进了唇语合成技术的提升。预训练的VSR模型通过提供有价值的语义信息,提高了合成语音的可懂度。级联框架结合了伪VSR和伪文本到语音(TTS)或隐含地使用转录文本,取得了成功,突显了利用VSR模型的优势。然而,这些方法通常依赖于梅尔频谱图作为中间表示形式,可能会引入一个关键瓶颈:由本质上容易出错的唇语映射生成的合成梅尔频谱图与用于训练vocoder的真实梅尔频谱图之间存在领域差距。这种不匹配会不可避免地降低合成质量。为了弥补这一差距,我们提出了自然唇语(NaturalL2S),这是一个端到端的框架,融合了声学归纳偏见和可微分的语音生成组件。具体来说,我们引入了基频(F0)预测器来捕捉合成语音中的韵律变化。预测的F0然后驱动一个可微分的数字信号处理(DDSP)合成器生成一个粗略的信号,作为后续语音合成的先验信息。此外,我们没有依赖参考说话人嵌入作为辅助输入,在不需要显式建模说话人特征的情况下实现了令人满意的说话人相似性性能。客观和主观评估结果均表明,与自然唇语相比,最新方法的合成语音质量得到了有效提升。我们的演示页面可通过 https://yifan-liang.github.io/NaturalL2S/ 访问。
论文及项目相关链接
Summary
视觉语音识别的最新进展促进了唇语合成技术的提升。借助预训练的视觉语音识别模型,合成的语音可借助语义信息增强其清晰度。尽管串联框架通过结合伪唇语与伪文本到语音合成(TTS)技术或间接利用转录文本取得了成功,但这些方法主要依赖于梅尔频谱图作为中间表达形式,这可能产生域差距问题:基于容易出错唇语到语音映射生成的合成梅尔频谱图与用于训练编码器的真实梅尔频谱图之间存在不匹配现象。为缩短此差距,提出了自然唇语到语音转换(NaturalL2S)框架,该框架将声学归纳偏见与可微分的语音生成组件相结合。实验证明,与自然L2S框架生成的语音相比,相较于现有技术,其在合成语音质量上有所提升。其演示页面可访问网址为:[https://yifan-liang.github.io/NaturalL2S/] 。
Key Takeaways
- 视觉语音识别(VSR)的进展推动了唇语合成技术的进步。
- 预训练的VSR模型提供语义信息,增强了合成语音的清晰度。
- 串联框架结合了伪唇语与伪文本到语音(TTS)技术,表现出利用VSR模型的优势。
- 存在域差距问题:合成梅尔频谱图与真实梅尔频谱图之间存在不匹配现象。
- 自然唇语到语音转换(NaturalL2S)框架结合了声学归纳偏见和可微分的语音生成组件。
- NaturalL2S框架通过引入基频(F0)预测器捕捉合成语音中的韵律变化。
点此查看论文截图

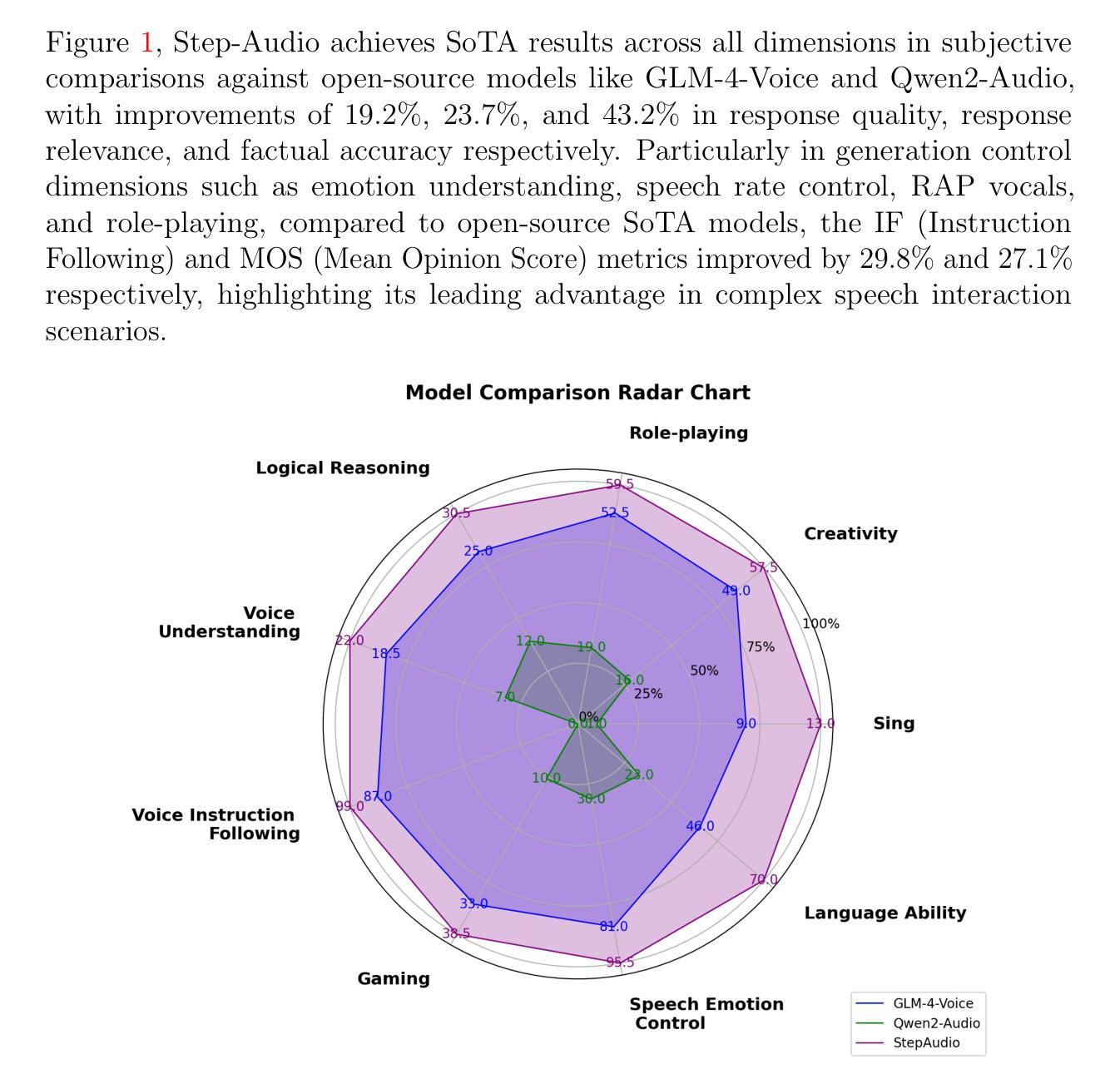
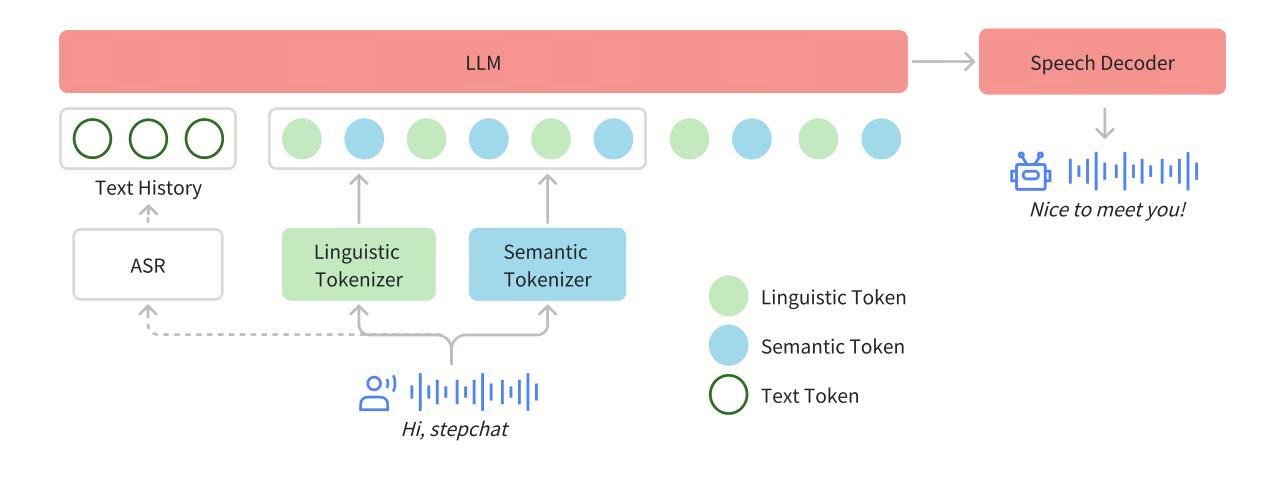
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Authors:Ailin Huang, Boyong Wu, Bruce Wang, Chao Yan, Chen Hu, Chengli Feng, Fei Tian, Feiyu Shen, Jingbei Li, Mingrui Chen, Peng Liu, Ruihang Miao, Wang You, Xi Chen, Xuerui Yang, Yechang Huang, Yuxiang Zhang, Zheng Gong, Zixin Zhang, Brian Li, Changyi Wan, Hanpeng Hu, Ranchen Ming, Song Yuan, Xuelin Zhang, Yu Zhou, Bingxin Li, Buyun Ma, Kang An, Wei Ji, Wen Li, Xuan Wen, Yuankai Ma, Yuanwei Liang, Yun Mou, Bahtiyar Ahmidi, Bin Wang, Bo Li, Changxin Miao, Chen Xu, Chengting Feng, Chenrun Wang, Dapeng Shi, Deshan Sun, Dingyuan Hu, Dula Sai, Enle Liu, Guanzhe Huang, Gulin Yan, Heng Wang, Haonan Jia, Haoyang Zhang, Jiahao Gong, Jianchang Wu, Jiahong Liu, Jianjian Sun, Jiangjie Zhen, Jie Feng, Jie Wu, Jiaoren Wu, Jie Yang, Jinguo Wang, Jingyang Zhang, Junzhe Lin, Kaixiang Li, Lei Xia, Li Zhou, Longlong Gu, Mei Chen, Menglin Wu, Ming Li, Mingxiao Li, Mingyao Liang, Na Wang, Nie Hao, Qiling Wu, Qinyuan Tan, Shaoliang Pang, Shiliang Yang, Shuli Gao, Siqi Liu, Sitong Liu, Tiancheng Cao, Tianyu Wang, Wenjin Deng, Wenqing He, Wen Sun, Xin Han, Xiaomin Deng, Xiaojia Liu, Xu Zhao, Yanan Wei, Yanbo Yu, Yang Cao, Yangguang Li, Yangzhen Ma, Yanming Xu, Yaqiang Shi, Yilei Wang, Yinmin Zhong, Yu Luo, Yuanwei Lu, Yuhe Yin, Yuting Yan, Yuxiang Yang, Zhe Xie, Zheng Ge, Zheng Sun, Zhewei Huang, Zhichao Chang, Zidong Yang, Zili Zhang, Binxing Jiao, Daxin Jiang, Heung-Yeung Shum, Jiansheng Chen, Jing Li, Shuchang Zhou, Xiangyu Zhang, Xinhao Zhang, Yibo Zhu
Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
实时语音交互作为人机交互的基本接口,具有巨大的潜力。然而,目前的开源模型面临着语音数据采集成本高、动态控制弱、智能有限等挑战。为了应对这些挑战,本文介绍了Step-Audio,这是首个投入生产的开源解决方案。主要贡献包括:1)一个拥有130B参数的统一语音文本多模态模型,实现了统一的理解和生成,其中Step-Audio-Chat版本已开源;2)一个生成式语音数据引擎,建立了一个经济实惠的语音克隆框架,并通过蒸馏技术产生了开源的轻量级Step-Audio-TTS-3B模型;3)一个指令驱动的精细控制系统,能够实现不同方言、情感、歌唱和RAP的动态调整;4)一个增强的认知架构,通过工具调用和角色扮演能力来有效管理复杂任务。基于我们新的StepEval-Audio-360评估基准,Step-Audio在人工评估中达到了最先进的性能,尤其在指令遵循方面。在LLaMA Question等开源基准测试中,平均性能提高了9.3%,这展示了我们对推动开源多模态语言技术发展的承诺。我们的代码和模型可在https://github.com/stepfun-ai/Step-Audio获取。
论文及项目相关链接
Summary
本文介绍了一项名为Step-Audio的开源多模态语音技术解决方案,解决了当前语音交互面临的挑战,如高成本的数据收集、动态控制不足和智能限制。其主要贡献包括统一的语音文本多模态模型、生成式语音数据引擎、指令驱动的精细控制系统以及增强认知架构。Step-Audio在开源基准测试中实现了卓越性能,展现了其在推进开源多模态语言技术发展方面的承诺。
Key Takeaways
- Step-Audio是首个生产就绪的开源多模态语音解决方案,解决了语音交互的多个挑战。
- 提供了统一的语音文本多模态模型,实现了理解和生成的双重视角,并开源了Step-Audio-Chat版本。
- 通过蒸馏过程,开源了轻量级的Step-Audio-TTS-3B模型。
- 引入了指令驱动的精细控制系统,可实现跨方言、情感、歌唱和RAP的动态调整。
- 增强认知架构使Step-Audio能够管理复杂任务,包括工具调用和角色扮演能力。
- Step-Audio在多个开源基准测试中达到或超越了最佳性能水平,特别是在指令遵循方面。
点此查看论文截图

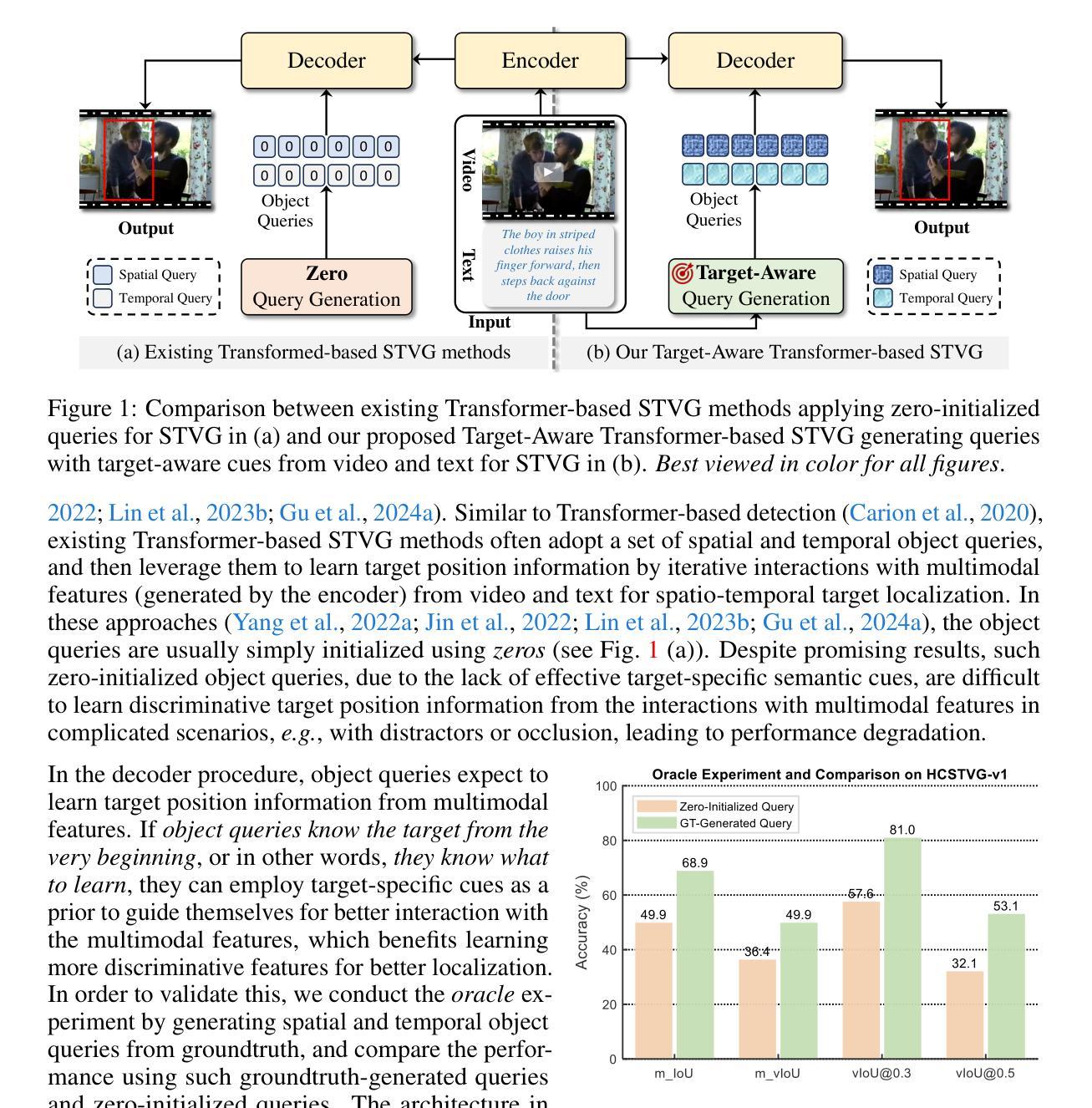
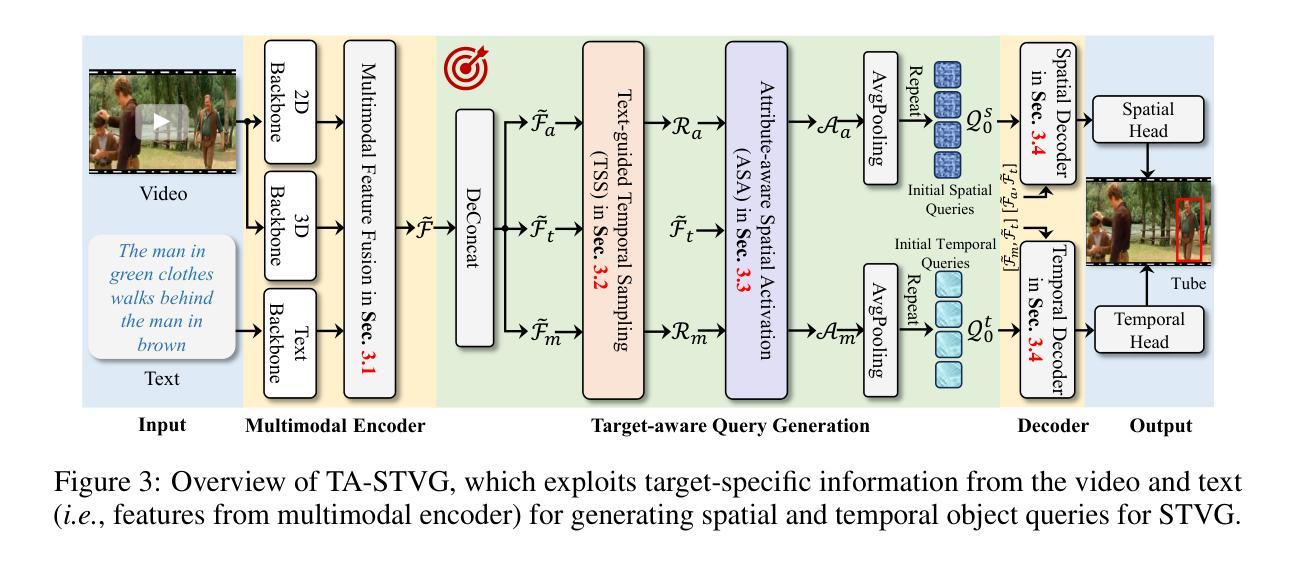
Knowing Your Target: Target-Aware Transformer Makes Better Spatio-Temporal Video Grounding
Authors:Xin Gu, Yaojie Shen, Chenxi Luo, Tiejian Luo, Yan Huang, Yuewei Lin, Heng Fan, Libo Zhang
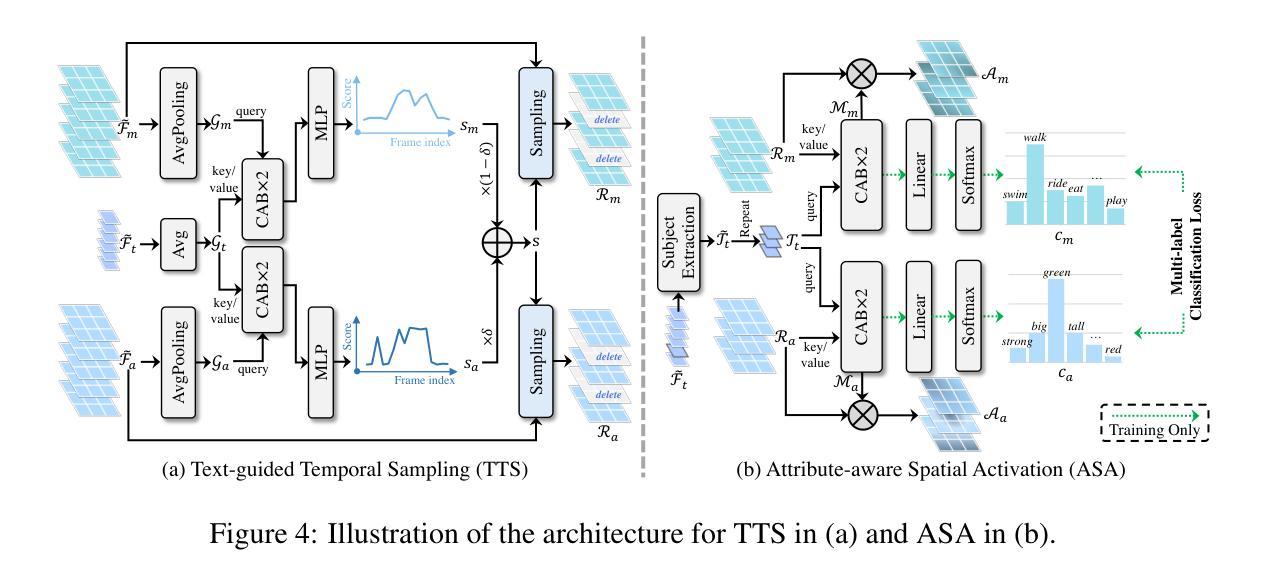
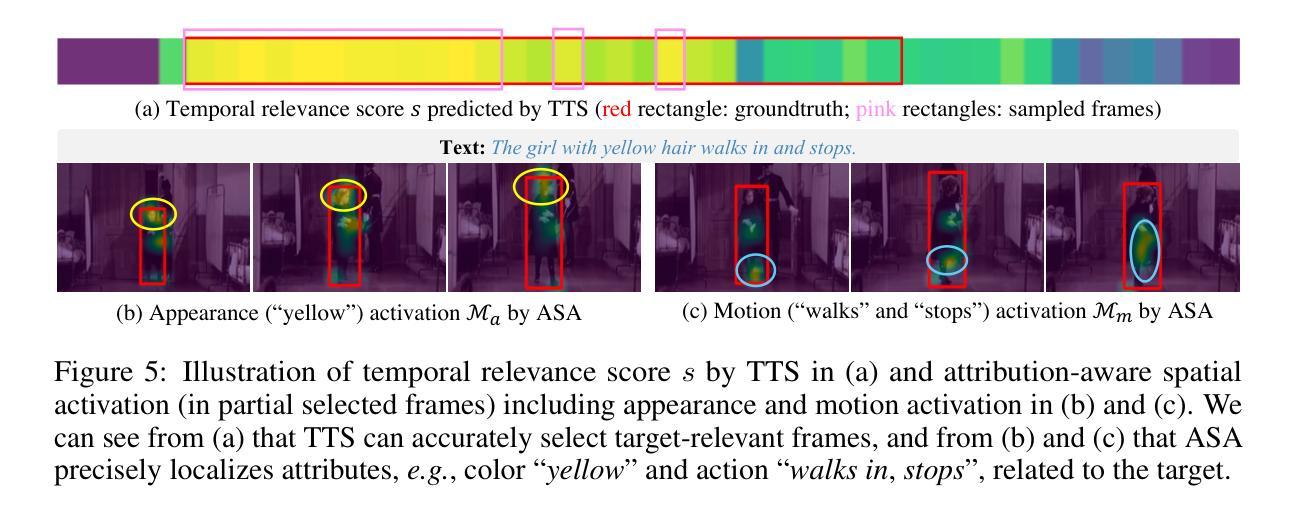
Transformer has attracted increasing interest in STVG, owing to its end-to-end pipeline and promising result. Existing Transformer-based STVG approaches often leverage a set of object queries, which are initialized simply using zeros and then gradually learn target position information via iterative interactions with multimodal features, for spatial and temporal localization. Despite simplicity, these zero object queries, due to lacking target-specific cues, are hard to learn discriminative target information from interactions with multimodal features in complicated scenarios (\e.g., with distractors or occlusion), resulting in degradation. Addressing this, we introduce a novel Target-Aware Transformer for STVG (TA-STVG), which seeks to adaptively generate object queries via exploring target-specific cues from the given video-text pair, for improving STVG. The key lies in two simple yet effective modules, comprising text-guided temporal sampling (TTS) and attribute-aware spatial activation (ASA), working in a cascade. The former focuses on selecting target-relevant temporal cues from a video utilizing holistic text information, while the latter aims at further exploiting the fine-grained visual attribute information of the object from previous target-aware temporal cues, which is applied for object query initialization. Compared to existing methods leveraging zero-initialized queries, object queries in our TA-STVG, directly generated from a given video-text pair, naturally carry target-specific cues, making them adaptive and better interact with multimodal features for learning more discriminative information to improve STVG. In our experiments on three benchmarks, TA-STVG achieves state-of-the-art performance and significantly outperforms the baseline, validating its efficacy.
Transformer因其在端到端的管道和令人振奋的结果而在STVG(空间和时间视频字幕生成)中引起了越来越多的兴趣。现有的基于Transformer的STVG方法通常利用一组对象查询,这些查询最初使用零值进行初始化,然后通过与多模态特征的迭代交互逐渐学习目标位置信息,用于空间和时间定位。尽管简单,但这些零对象查询由于缺乏目标特定线索,在复杂场景(例如有干扰物或遮挡物)中,很难从与多模态特征的交互中学习出有区分力的目标信息,从而导致性能下降。为了解决这一问题,我们引入了一种新型的用于STVG的目标感知Transformer(TA-STVG),它旨在通过探索给定视频文本对中的目标特定线索来自适应地生成对象查询,以提高STVG的性能。关键在于两个简单而有效的模块,包括文本引导的时间采样(TTS)和属性感知的空间激活(ASA),它们协同工作。前者专注于利用整体文本信息从视频中选取目标相关的时序线索,而后者则旨在进一步挖掘之前目标感知时序线索的对象的精细视觉属性信息,这应用于对象查询的初始化。与现有使用零初始化查询的方法相比,我们的TA-STVG中的对象查询直接从给定的视频文本对中生成,自然携带目标特定线索,使其自适应并且能够更好地与多模态特征进行交互,从而学习更多有区分力的信息以提高STVG。在三个基准测试上的实验表明,TA-STVG达到了最先进的性能,并显著优于基线方法,验证了其有效性。
论文及项目相关链接
Summary
本文介绍了Transformer在STVG(空间和时间视频定位)领域的应用。现有方法通常使用零初始化的对象查询,通过与多模态特征的迭代交互来学习目标位置信息。然而,这种方法在复杂场景中(如有干扰物或遮挡)难以学习区分性目标信息。为解决此问题,本文提出了一种新型的目标感知Transformer(TA-STVG),其通过探索视频文本对中的目标特定线索来自适应生成对象查询,以提高STVG性能。该模型包含两个简单有效的模块:文本引导的临时采样(TTS)和属性感知的空间激活(ASA)。TTS专注于利用整体文本信息从视频中选取目标相关的临时线索,而ASA则进一步利用之前的目标感知临时线索中的精细粒度视觉属性信息,用于对象查询初始化。与现有方法相比,TA-STVG直接从给定的视频文本对中生成对象查询,携带目标特定线索,使其能更好地与多模态特征交互,学习更多区分性信息,提高STVG性能。在三个基准测试上的实验结果表明,TA-STVG达到业界最佳性能,显著优于基线方法。
Key Takeaways
- Transformer在STVG领域正吸引越来越多的关注,因其端到端的管道和前景良好的结果。
- 现有Transformer-based STVG方法通常使用零初始化的对象查询,这在复杂场景中难以学习区分性目标信息。
- 引入的新型Target-Aware Transformer(TA-STVG)通过探索视频文本对中的目标特定线索来改进STVG。
- TA-STVG包含两个有效模块:文本引导的临时采样(TTS)和属性感知的空间激活(ASA)。
- TTS模块利用整体文本信息从视频中选取目标相关的临时线索。
- ASA模块利用之前的目标感知临时线索中的精细粒度视觉属性信息,用于对象查询初始化。
点此查看论文截图

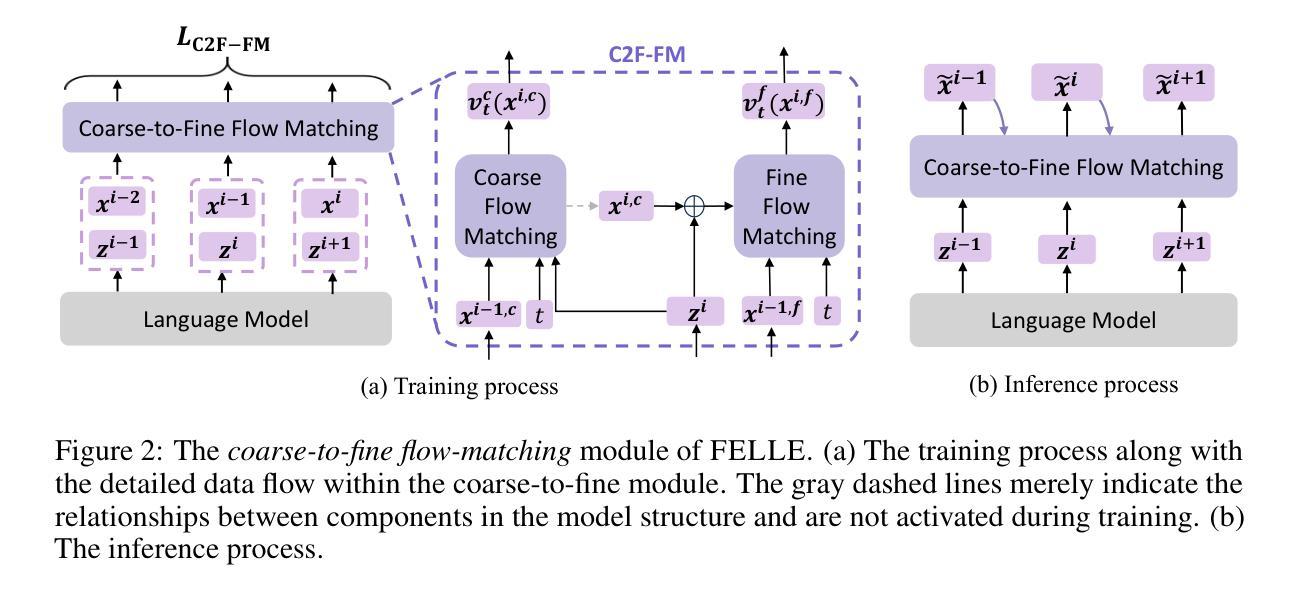
FELLE: Autoregressive Speech Synthesis with Token-Wise Coarse-to-Fine Flow Matching
Authors:Hui Wang, Shujie Liu, Lingwei Meng, Jinyu Li, Yifan Yang, Shiwan Zhao, Haiyang Sun, Yanqing Liu, Haoqin Sun, Jiaming Zhou, Yan Lu, Yong Qin
To advance continuous-valued token modeling and temporal-coherence enforcement, we propose FELLE, an autoregressive model that integrates language modeling with token-wise flow matching. By leveraging the autoregressive nature of language models and the generative efficacy of flow matching, FELLE effectively predicts continuous-valued tokens (mel-spectrograms). For each continuous-valued token, FELLE modifies the general prior distribution in flow matching by incorporating information from the previous step, improving coherence and stability. Furthermore, to enhance synthesis quality, FELLE introduces a coarse-to-fine flow-matching mechanism, generating continuous-valued tokens hierarchically, conditioned on the language model’s output. Experimental results demonstrate the potential of incorporating flow-matching techniques in autoregressive mel-spectrogram modeling, leading to significant improvements in TTS generation quality, as shown in https://aka.ms/felle.
为推动连续值令牌建模和时间连贯性执行,我们提出了FELLE,这是一种将语言建模与令牌级流匹配相结合的自回归模型。通过利用语言模型的自回归性质和流匹配的生成效率,FELLE有效地预测了连续值令牌(梅尔频谱图)。对于每个连续值令牌,FELLE通过结合前一步的信息,对流匹配中的一般先验分布进行修改,提高了连贯性和稳定性。此外,为了增强合成质量,FELLE引入了一种由粗到细的流匹配机制,以层次化的方式生成连续值令牌,以语言模型的输出为条件。实验结果表明,在自回归梅尔频谱建模中融入流匹配技术具有潜力,能显著提高TTS生成质量,详情可见https://aka.ms/felle。
论文及项目相关链接
Summary
本文提出了一个名为FELLE的自回归模型,该模型结合了语言建模和令牌级流匹配技术,用于推进连续值令牌建模和时间连贯性执行。通过利用语言模型的自回归性质和流匹配的生成效能,FELLE能够有效地预测连续值令牌(梅尔频谱图)。该模型通过结合前一步的信息,改进了流匹配中的一般先验分布,提高了连贯性和稳定性。此外,为了增强合成质量,FELLE引入了从粗到细的流匹配机制,以层次化方式生成连续值令牌,取决于语言模型的输出。实验结果表明,在自回归梅尔频谱图建模中融入流匹配技术具有潜力,能显著提高TTS生成质量。
Key Takeaways
- FELLE是一个自回归模型,结合了语言建模和令牌级流匹配。
- 它利用语言模型的自回归性质及流匹配的生成效能进行有效预测连续值令牌(梅尔频谱图)。
- FELLE通过结合前一步信息改进了一般先验分布,增强了模型的连贯性和稳定性。
- 模型引入了从粗到细的流匹配机制,以层次化方式生成连续值令牌,进一步提升合成质量。
- 实验结果证明了在自回归梅尔频谱图建模中融入流匹配技术的潜力。
- 通过这种方式,TTS生成质量得到了显著提高。
点此查看论文截图

SyncSpeech: Low-Latency and Efficient Dual-Stream Text-to-Speech based on Temporal Masked Transformer
Authors:Zhengyan Sheng, Zhihao Du, Shiliang Zhang, Zhijie Yan, Yexin Yang, Zhenhua Ling
This paper presents a dual-stream text-to-speech (TTS) model, SyncSpeech, capable of receiving streaming text input from upstream models while simultaneously generating streaming speech, facilitating seamless interaction with large language models. SyncSpeech has the following advantages: Low latency, as it begins generating streaming speech upon receiving the second text token; High efficiency, as it decodes all speech tokens corresponding to the each arrived text token in one step. To achieve this, we propose a temporal masked transformer as the backbone of SyncSpeech, combined with token-level duration prediction to predict speech tokens and the duration for the next step. Additionally, we design a two-stage training strategy to improve training efficiency and the quality of generated speech. We evaluated the SyncSpeech on both English and Mandarin datasets. Compared to the recent dual-stream TTS models, SyncSpeech significantly reduces the first packet delay of speech tokens and accelerates the real-time factor. Moreover, with the same data scale, SyncSpeech achieves performance comparable to that of traditional autoregressive-based TTS models in terms of both speech quality and robustness. Speech samples are available at https://SyncSpeech.github.io/}{https://SyncSpeech.github.io/.
本文提出了一种双流文本到语音(TTS)模型SyncSpeech,该模型能够接收来自上游模型的流式文本输入,同时生成流式语音,便于与大型语言模型进行无缝交互。SyncSpeech具有以下优点:低延迟,因为在接收到第二个文本标记时就开始生成流式语音;高效率,因为它可以在一步中解码每个到达的文本标记对应的所有语音标记。为了实现这一点,我们提出了时间掩模转换器作为SyncSpeech的骨干,结合标记级持续时间预测来预测语音标记和下一个步骤的持续时间。此外,我们设计了一个两阶段训练策略,以提高训练效率和生成的语音质量。我们在英语和普通话数据集上评估了SyncSpeech。与最近的双流TTS模型相比,SyncSpeech显著减少了语音标记的第一包延迟并加速了实时因子。而且,在相同的数据规模下,SyncSpeech在语音质量和稳健性方面达到了与传统基于自动回归的TTS模型相当的性能。语音样本可在https://SyncSpeech.github.io上找到。
论文及项目相关链接
Summary
文本介绍了一种双流文本到语音(TTS)模型SyncSpeech,该模型能够接收来自上游模型的流式文本输入并同时生成流式语音,便于与大型语言模型无缝交互。SyncSpeech具有低延迟和高效率的优点,可以通过使用临时掩码转换器作为骨架并结合标记级持续时间预测来实现。此外,设计了两阶段训练策略来提高训练效率和生成语音的质量。在英文和普通话数据集上的评估表明,SyncSpeech显著减少了语音标记的第一包延迟并提高了实时因子。与传统基于自回归的TTS模型相比,SyncSpeech在语音质量和稳健性方面表现相当。
Key Takeaways
- SyncSpeech是一种双流TTS模型,能够实现流式文本输入和语音生成的无缝交互。
- SyncSpeech具有低延迟和高效率的特点,能够在接收到第二个文本标记时开始生成流式语音。
- SyncSpeech通过使用临时掩码转换器作为骨架并结合标记级持续时间预测来实现其高效性能。
- 设计了两阶段训练策略以提高训练效率和语音生成质量。
- SyncSpeech在英文和普通话数据集上的表现优异,显著减少了语音标记的第一包延迟。
- SyncSpeech的实时因子得到了提高,与传统基于自回归的TTS模型相比,其在语音质量和稳健性方面表现相当。
点此查看论文截图



Less is More for Synthetic Speech Detection in the Wild
Authors:Ashi Garg, Zexin Cai, Henry Li Xinyuan, Leibny Paola García-Perera, Kevin Duh, Sanjeev Khudanpur, Matthew Wiesner, Nicholas Andrews
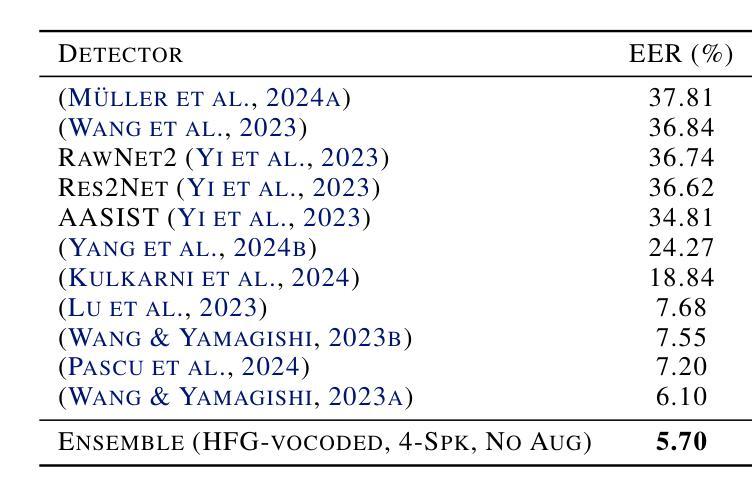
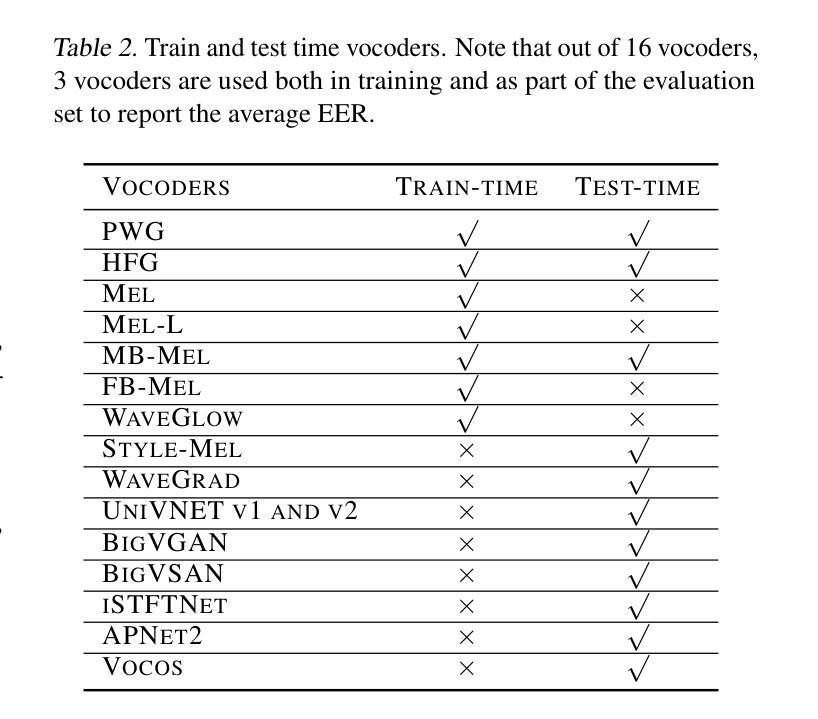
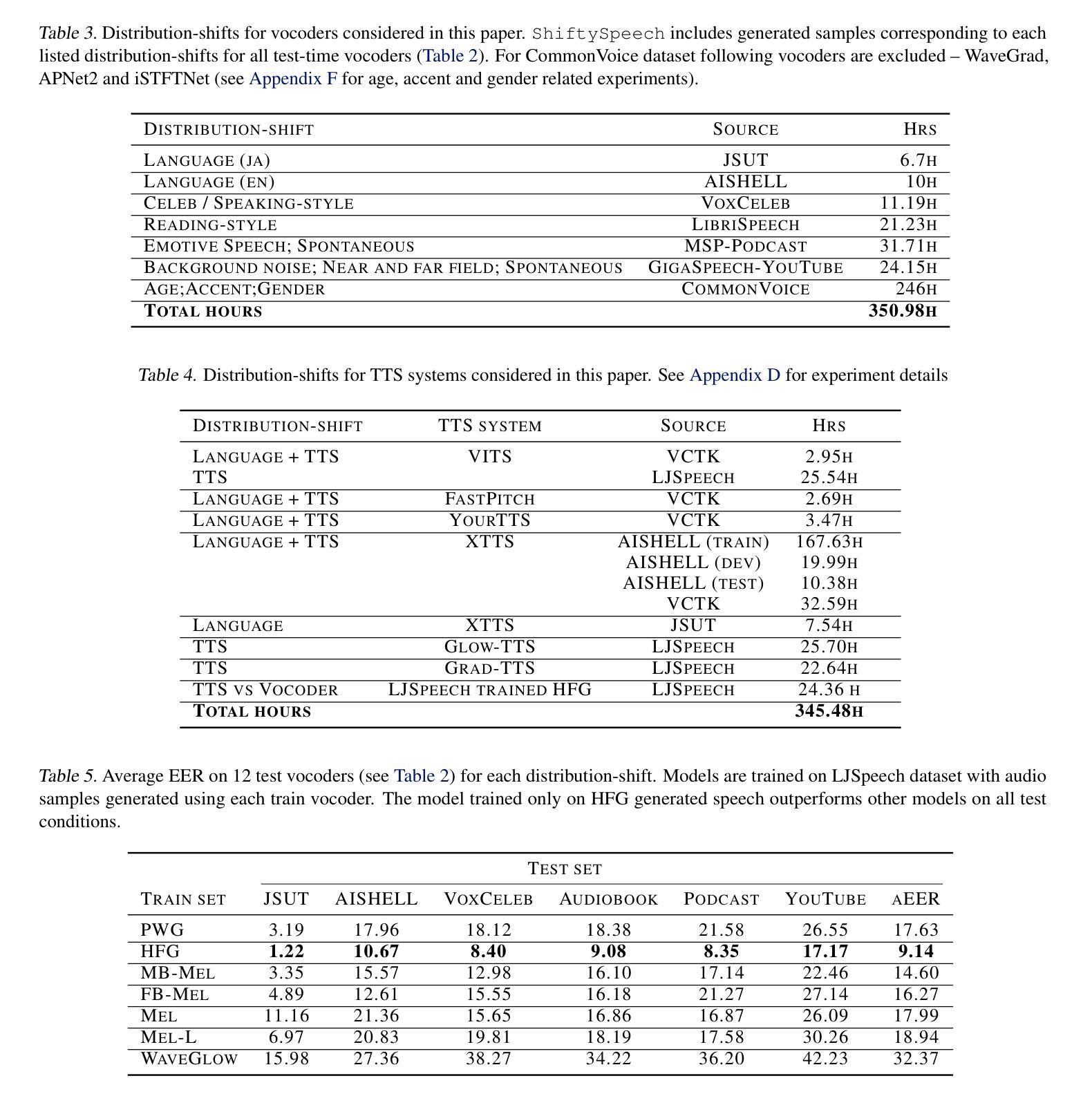
Driven by advances in self-supervised learning for speech, state-of-the-art synthetic speech detectors have achieved low error rates on popular benchmarks such as ASVspoof. However, prior benchmarks do not address the wide range of real-world variability in speech. Are reported error rates realistic in real-world conditions? To assess detector failure modes and robustness under controlled distribution shifts, we introduce ShiftySpeech, a benchmark with more than 3000 hours of synthetic speech from 7 domains, 6 TTS systems, 12 vocoders, and 3 languages. We found that all distribution shifts degraded model performance, and contrary to prior findings, training on more vocoders, speakers, or with data augmentation did not guarantee better generalization. In fact, we found that training on less diverse data resulted in better generalization, and that a detector fit using samples from a single carefully selected vocoder and a small number of speakers, without data augmentations, achieved state-of-the-art results on the challenging In-the-Wild benchmark.
得益于语音自监督学习的进步,最先进的合成语音检测器在诸如ASVspoof等流行基准测试上的误差率非常低。然而,先前的基准测试并未解决真实世界中语音的广泛变化范围问题。在真实世界条件下,报告的误差率是否现实?为了评估检测器在受控分布变化下的故障模式和稳健性,我们推出了ShiftySpeech基准测试,其中包含超过3000小时的合成语音,涵盖7个领域、6个文本转语音系统和3种语言。我们发现所有的分布变化都会降低模型性能,与前人的研究结果相反,使用更多编码器、更多说话者或数据增强进行训练并不能保证更好的泛化能力。事实上,我们发现,在较少多样化数据上训练会导致更好的泛化效果,使用来自单个精心挑选的编码器和小数量说话者的样本进行训练的检测器,在不进行数据增强的情况下,在具有挑战性的In-the-Wild基准测试中取得了最新结果。
论文及项目相关链接
Summary
随着自监督学习在语音领域的进步,最先进的语音合成检测器在流行基准测试(如ASVspoof)上的错误率很低。然而,现有基准测试未能涵盖现实世界中语音的广泛变化。通过引入ShiftySpeech基准测试,我们评估了检测器在受控分布变化下的失败模式和稳健性。发现所有分布变化都会降低模型性能,与先前的研究结果相反,训练更多的vocoder、演讲者或采用数据增强并不一定能更好地推广。实际上,我们发现训练在较少多样化的数据上能更好地推广,使用单一精心选择的vocoder和小数量演讲者的检测器样本,在不进行数据增强的情况下,能在具有挑战性的In-the-Wild基准测试上达到最佳效果。
Key Takeaways
- 自监督学习推动了语音合成检测器的先进性能,在流行基准测试上的错误率较低。
- 现有基准测试未能涵盖现实世界中语音的广泛变化。
- 引入ShiftySpeech基准测试以评估检测器在分布变化下的性能。
- 所有分布变化都会影响模型性能。
- 训练更多的vocoder、演讲者或采用数据增强并不一定能提高模型的泛化能力。
- 在较少多样化的数据上训练检测器能更好地推广。
点此查看论文截图

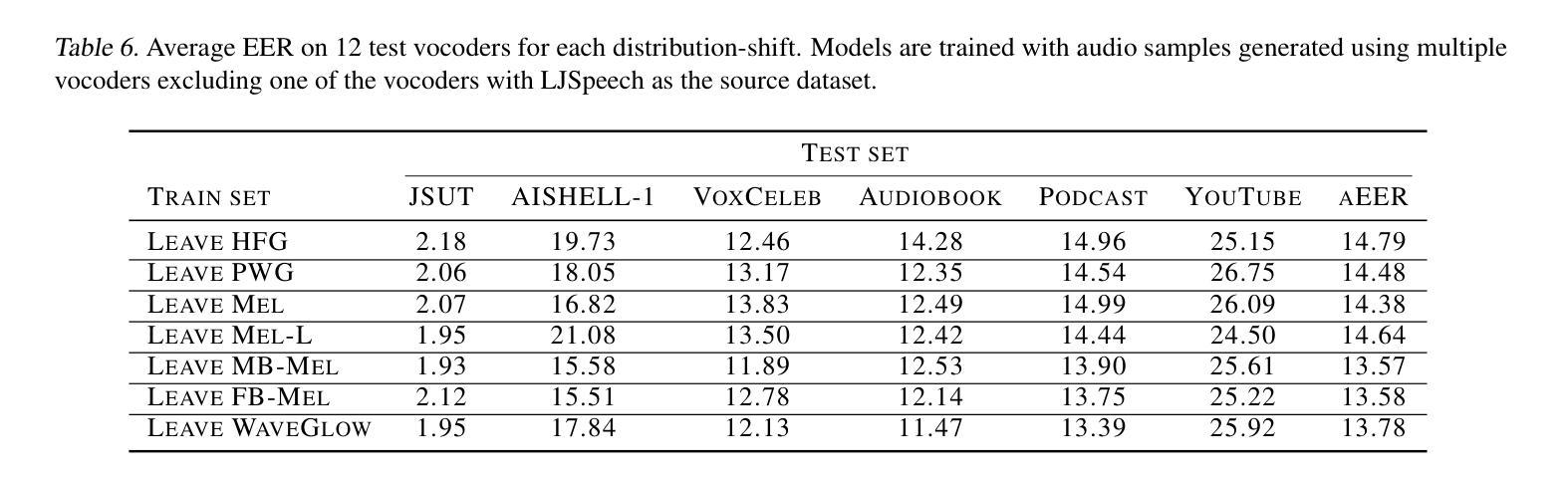
Compressed ‘CMB-lite’ Likelihoods Using Automatic Differentiation
Authors:L. Balkenhol
The compression of multi-frequency cosmic microwave background (CMB) power spectrum measurements into a series of foreground-marginalised CMB-only band powers allows for the construction of faster and more easily interpretable ‘lite’ likelihoods. However, obtaining the compressed data vector is computationally expensive and yields a covariance matrix with sampling noise. In this work, we present an implementation of the CMB-lite framework relying on automatic differentiation. The technique presented reduces the computational cost of the lite likelihood construction to one minimisation and one Hessian evaluation, which run on a personal computer in about a minute. We demonstrate the efficiency and accuracy of this procedure by applying it to the differentiable SPT-3G 2018 TT/TE/EE likelihood from the candl library. We find good agreement between the marginalised posteriors of cosmological parameters yielded by the resulting lite likelihood and the reference multi-frequency version for all cosmological models tested; the best-fit values shift by $<0.1,\sigma$, where $\sigma$ is the width of the multi-frequency posterior, and the inferred parameter error bars match to within $<10%$. We publicly release the SPT-3G 2018 TT/TE/EE lite likelihood and a python notebook showing its construction at https://github.com/Lbalkenhol/candl .
将多频宇宙微波背景(CMB)功率谱测量值压缩成一系列仅含CMB的前置边缘化频段功率值,可以构建更快、更易解读的“精简版”概率模型。然而,获取压缩数据向量计算量大且产生的协方差矩阵存在采样噪声。在这项工作中,我们提出了一种依赖自动微分技术的CMB-lite框架实现方法。所提出的技术将精简版概率模型的构建的计算成本降低至仅需一次最小化和一次Hessian评估,可在个人计算机上大约一分钟内运行。我们通过将其应用于可微分的SPT-3G 2018 TT/TE/EE概率模型(来自candl库)来展示该程序的效率和准确性。我们发现,对于测试的所有宇宙学模型,由所得精简版概率模型产生的边缘化宇宙学参数的后验分布与参考多频版本的结果非常一致;最佳拟合值相对于多频后验的宽度移动小于$ 0.1\sigma $,推断出的参数误差范围匹配度在小于10%以内。我们在https://github.com/Lbalkenhol/candl上公开发布了SPT-3G 2018 TT/TE/EE精简版概率模型和展示其构建的Python笔记本。
论文及项目相关链接
PDF 8 pages, 4 figures, 1 table
Summary
本文介绍了利用自动微分技术实现宇宙微波背景辐射(CMB)功率谱测量数据的压缩方法,构建出快速且易于解释的“轻量级”似然函数。该方法降低了计算成本,仅需要一次最小化和一次Hessian评估,可在个人计算机上大约一分钟内运行。作者通过应用该方法于可微分的SPT-3G 2018 TT/TE/EE似然函数库,验证了其效率和准确性。轻量级似然函数得出的宇宙学参数边缘分布与多频版本的结果在所有测试的宇宙学模型中均表现出良好的一致性。
Key Takeaways
- 文中介绍了一种基于自动微分技术的CMB-lite框架,用于压缩多频宇宙微波背景(CMB)功率谱测量数据。
- 该方法构建出快速且易于解释的“轻量级”似然函数,降低了计算成本。
- 该方法仅需要一次最小化和一次Hessian评估,可在个人计算机上快速运行。
- 作者通过应用该方法于SPT-3G 2018 TT/TE/EE似然函数库进行验证,证明了其效率和准确性。
- 轻量级似然函数得出的宇宙学参数边缘分布与多频版本的结果一致性好。
- 文中公开发布了SPT-3G 2018 TT/TE/EE轻量级似然函数和一个展示其构建的Python笔记本。
- 该方法有助于加快宇宙学参数推断的速度,并使得结果更容易解释。
点此查看论文截图


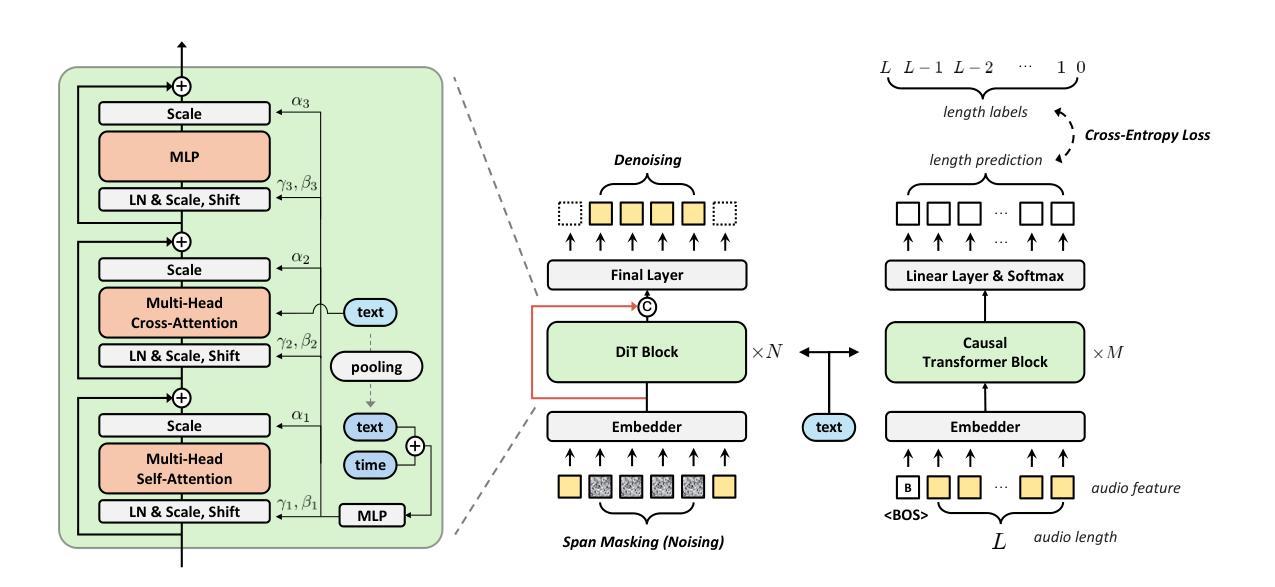
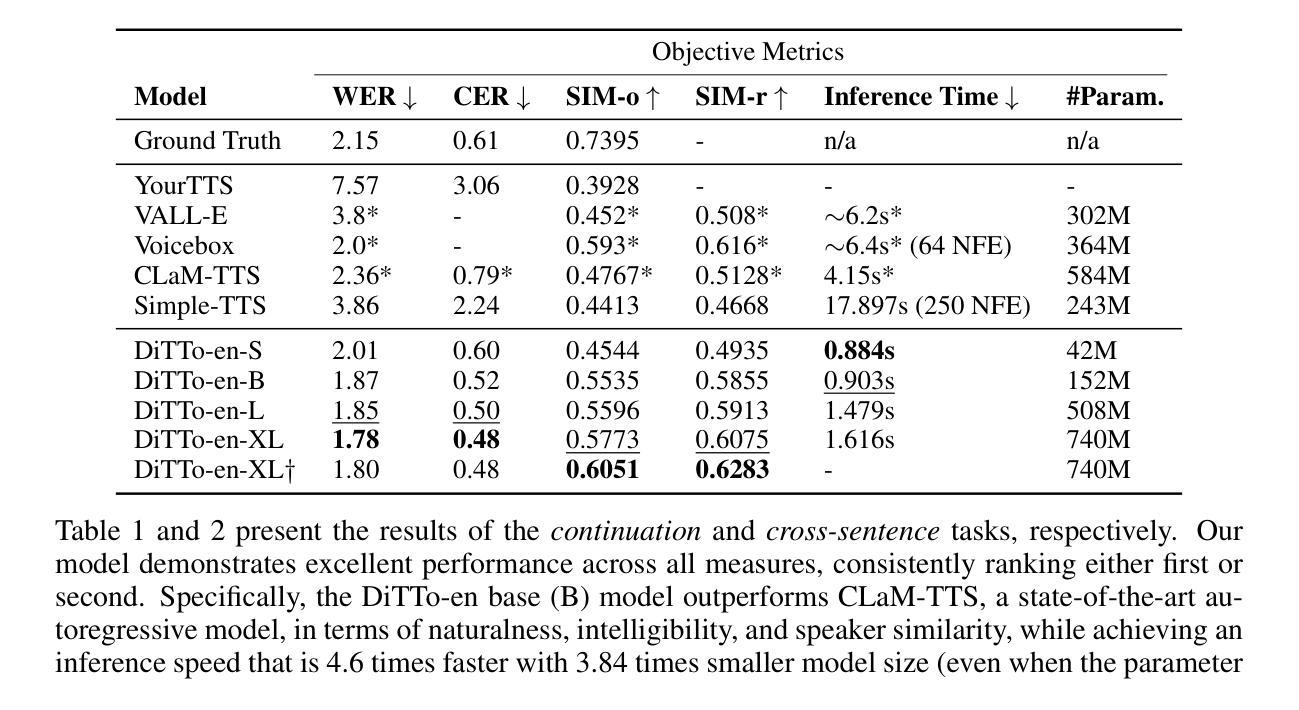
DiTTo-TTS: Diffusion Transformers for Scalable Text-to-Speech without Domain-Specific Factors
Authors:Keon Lee, Dong Won Kim, Jaehyeon Kim, Seungjun Chung, Jaewoong Cho
Large-scale latent diffusion models (LDMs) excel in content generation across various modalities, but their reliance on phonemes and durations in text-to-speech (TTS) limits scalability and access from other fields. While recent studies show potential in removing these domain-specific factors, performance remains suboptimal. In this work, we introduce DiTTo-TTS, a Diffusion Transformer (DiT)-based TTS model, to investigate whether LDM-based TTS can achieve state-of-the-art performance without domain-specific factors. Through rigorous analysis and empirical exploration, we find that (1) DiT with minimal modifications outperforms U-Net, (2) variable-length modeling with a speech length predictor significantly improves results over fixed-length approaches, and (3) conditions like semantic alignment in speech latent representations are key to further enhancement. By scaling our training data to 82K hours and the model size to 790M parameters, we achieve superior or comparable zero-shot performance to state-of-the-art TTS models in naturalness, intelligibility, and speaker similarity, all without relying on domain-specific factors. Speech samples are available at https://ditto-tts.github.io.
大规模潜在扩散模型(LDM)在多种模态的内容生成方面表现出色,但它们在文本到语音(TTS)中对音素和持续时间的依赖限制了其可扩展性和在其他领域的应用。尽管最近有研究表明去除这些领域特定因素具有潜力,但性能仍然不尽人意。在这项工作中,我们引入了基于扩散变换器(DiT)的TTS模型DiTTo-TTS,旨在研究基于LDM的TTS是否能在没有领域特定因素的情况下实现最先进的性能。通过严格的分析和实证探索,我们发现(1)稍作修改的DiT优于U-Net,(2)使用语音长度预测变量的建模方法显著优于固定长度方法的结果,(3)语音潜在表示中的语义对齐等条件是进一步改进的关键。通过将训练数据规模扩大到8.2万小时,模型规模扩大到7.9亿参数,我们在自然度、清晰度和说话人相似性方面实现了或优于最先进TTS模型的零样本性能,所有这些都没有依赖领域特定因素。语音样本可在https://ditto-tts.github.io找到。
论文及项目相关链接
Summary
文本介绍了基于扩散Transformer(DiT)的文本转语音(TTS)模型DiTTo-TTS。该研究发现在大规模训练数据和模型参数的支持下,DiTTo-TTS能够实现最先进的性能,并且在零样本场景下表现尤为出色,同时无需依赖特定领域的因素如音素和持续时间。此外,该研究还通过分析和实验发现,可变长度建模和语音长度预测器能提高性能,语义对齐等条件也是进一步提高的关键。
Key Takeaways
- DiTTo-TTS是基于扩散Transformer(DiT)的文本转语音模型,旨在解决大规模潜在扩散模型在跨模态内容生成中的局限性。
- DiT在轻微修改后表现出了超越U-Net的性能。
- 可变长度建模与语音长度预测器的结合显著提高了性能,相较于固定长度的方法更具优势。
- 语义对齐等条件在进一步提高语音质量方面起着关键作用。
- 通过扩大训练数据至82K小时和模型参数至790M,DiTTo-TTS在自然度、清晰度和说话人相似性方面达到了或超越了现有最先进的TTS模型。
- 该模型的关键优势在于其零样本性能表现优秀,并且不依赖于特定领域的因素如音素和持续时间。
点此查看论文截图