⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-19 更新
Talk Structurally, Act Hierarchically: A Collaborative Framework for LLM Multi-Agent Systems
Authors:Zhao Wang, Sota Moriyama, Wei-Yao Wang, Briti Gangopadhyay, Shingo Takamatsu
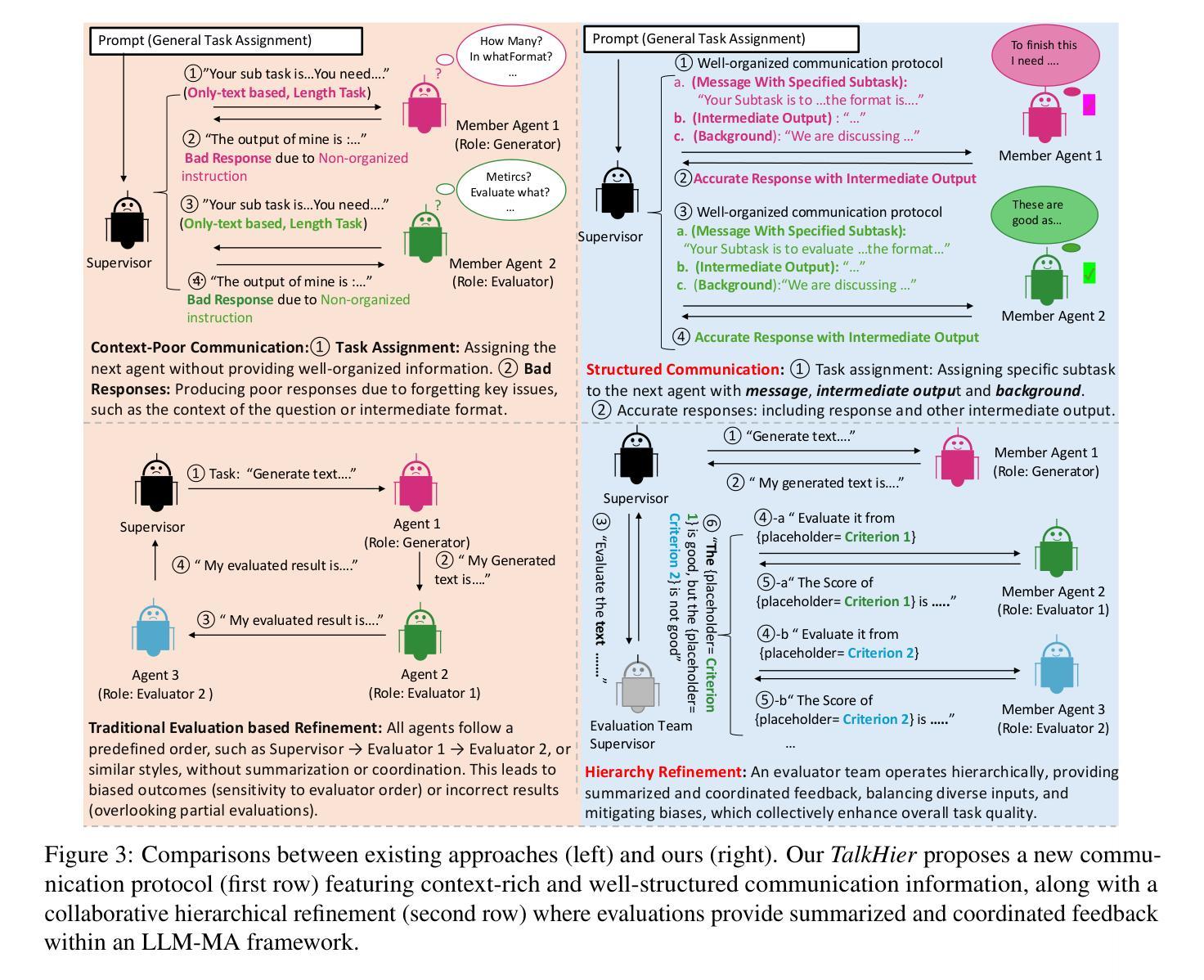
Recent advancements in LLM-based multi-agent (LLM-MA) systems have shown promise, yet significant challenges remain in managing communication and refinement when agents collaborate on complex tasks. In this paper, we propose \textit{Talk Structurally, Act Hierarchically (TalkHier)}, a novel framework that introduces a structured communication protocol for context-rich exchanges and a hierarchical refinement system to address issues such as incorrect outputs, falsehoods, and biases. \textit{TalkHier} surpasses various types of SoTA, including inference scaling model (OpenAI-o1), open-source multi-agent models (e.g., AgentVerse), and majority voting strategies on current LLM and single-agent baselines (e.g., ReAct, GPT4o), across diverse tasks, including open-domain question answering, domain-specific selective questioning, and practical advertisement text generation. These results highlight its potential to set a new standard for LLM-MA systems, paving the way for more effective, adaptable, and collaborative multi-agent frameworks. The code is available https://github.com/sony/talkhier.
近期,基于大型语言模型(LLM)的多智能体(LLM-MA)系统的进步展现出巨大潜力,但在智能体协作完成复杂任务时,通信管理和精细化仍然面临重大挑战。在本文中,我们提出了“结构对话,层次行动”(TalkHier)这一新型框架,它引入了一种结构化的通信协议,用于进行丰富的上下文交流,并采用了层次化的精细化系统,以解决输出错误、虚假信息和偏见等问题。TalkHier超越了多种最新技术(SoTA),包括推理扩展模型(OpenAI-o1)、开源多智能体模型(例如AgentVerse)以及在目前的大型语言模型和单一智能体基线模型(例如ReAct、GPT4o)上采用的大多数投票策略,在包括开放域问答、特定域选择性问答和实用广告文本生成等多样化任务中表现突出。这些结果凸显了其为大型语言模型智能体系统设定新标准的能力,为构建更有效、更适应环境且更具协作性的多智能体框架铺平了道路。代码可通过https://github.com/sony/talkhier访问。
论文及项目相关链接
Summary
近期LLM-MA系统的进展显示出巨大潜力,但在处理复杂任务的通信管理和优化方面仍存在挑战。本文提出“Talk Hier Structurally, Act Hierarchically”(TalkHier)框架,引入结构化通信协议进行丰富的上下文交流,并构建层次化优化系统来解决错误输出、虚假信息和偏见等问题。在开放域问答、领域特定选择性问答和实用广告文本生成等多项任务上,TalkHier超越了多种最新技术,包括推理扩展模型(OpenAI-o1)、开源多智能体模型(如AgentVerse)和大多数LLM及单一智能体基线模型(如ReAct、GPT4o)。这显示了其成为LLM-MA系统新标准的潜力,为更有效、更适应和更协作的多智能体框架铺平了道路。相关代码可通过https://github.com/sony/talkhier获取。
Key Takeaways
- LLM-MA系统具有广阔潜力但面临管理复杂任务时通信和优化挑战。
- TalkHier框架通过结构化通信协议实现上下文丰富交流。
- TalkHier采用层次化优化系统以解决输出错误、虚假信息和偏见问题。
- 在多项任务上,TalkHier表现出超越当前最新技术的性能。
- 这些任务包括开放域问答、特定领域选择性问答和实用广告文本生成等。
- TalkHier有潜力成为LLM-MA系统的新标准。
点此查看论文截图


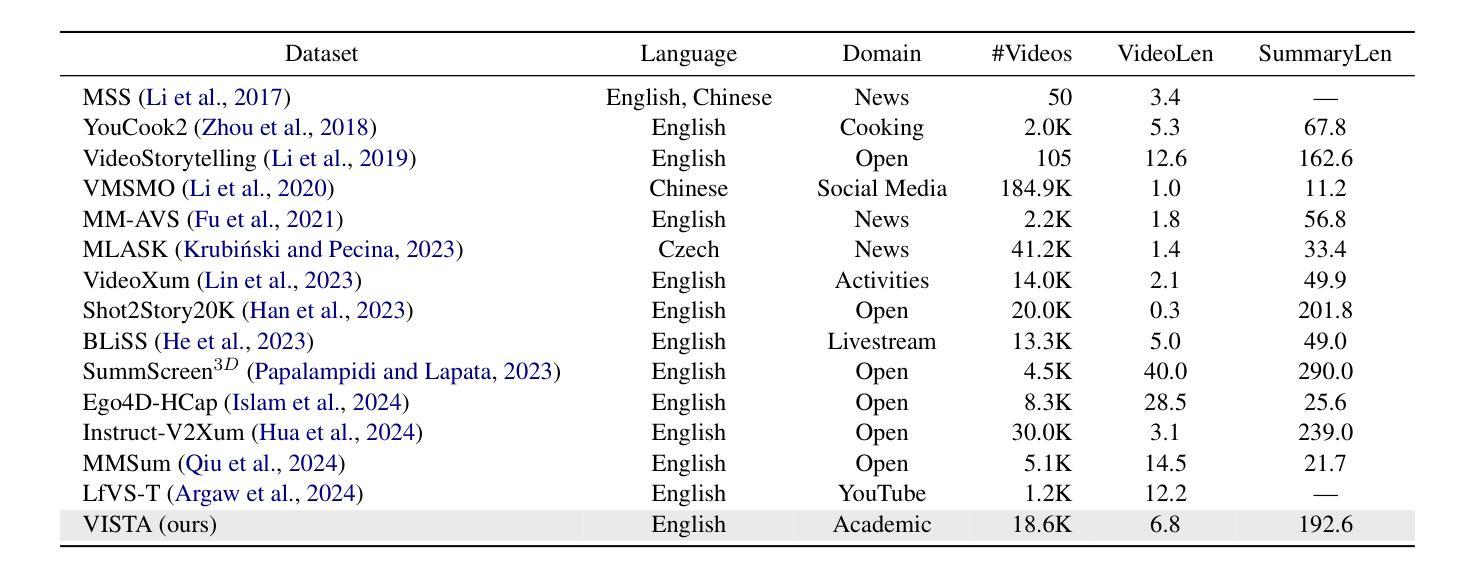
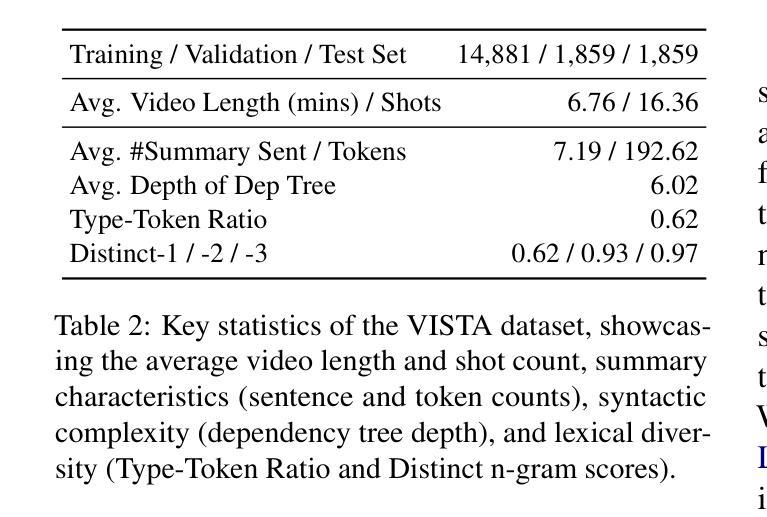
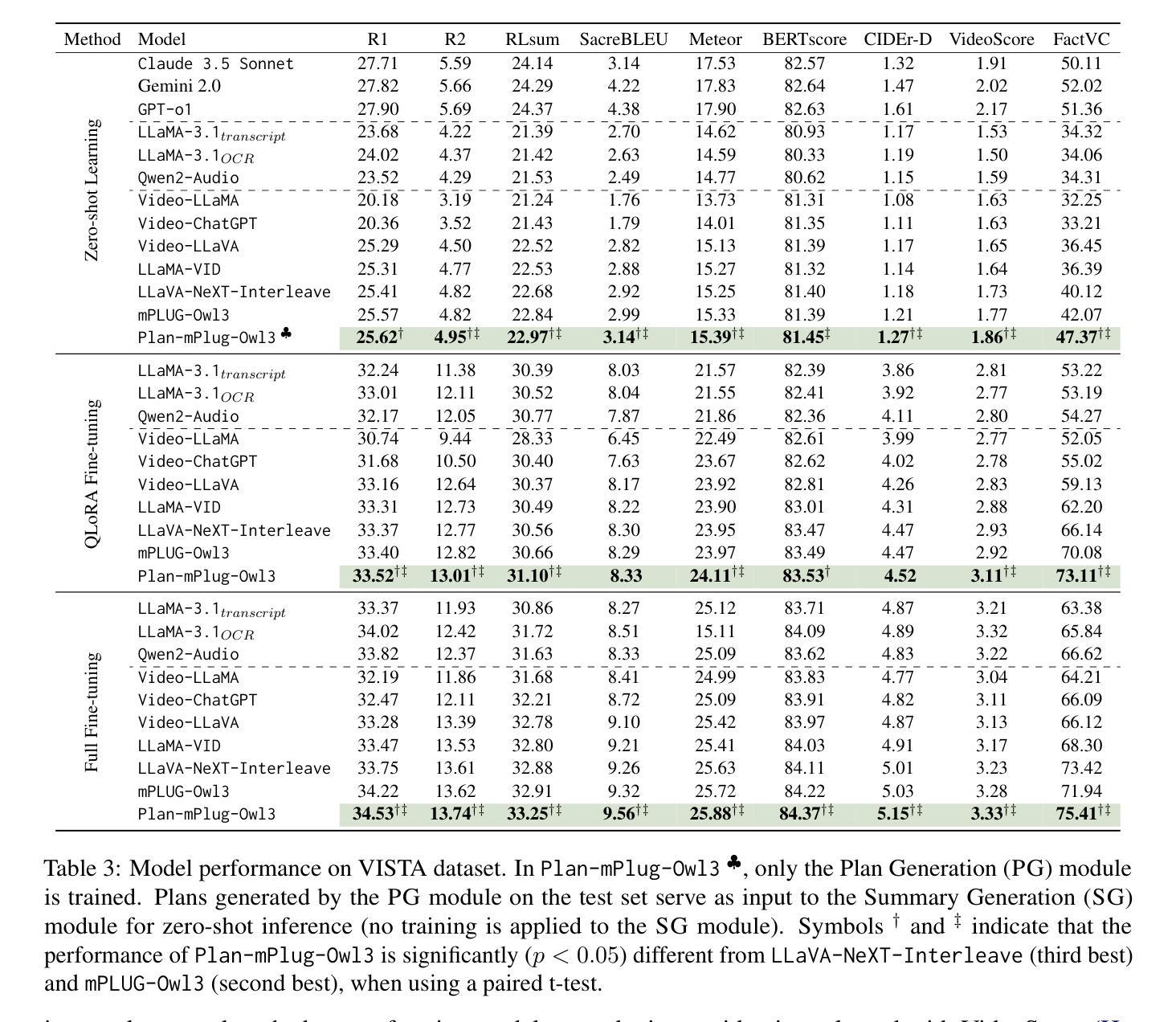
What Is That Talk About? A Video-to-Text Summarization Dataset for Scientific Presentations
Authors:Dongqi Liu, Chenxi Whitehouse, Xi Yu, Louis Mahon, Rohit Saxena, Zheng Zhao, Yifu Qiu, Mirella Lapata, Vera Demberg
Transforming recorded videos into concise and accurate textual summaries is a growing challenge in multimodal learning. This paper introduces VISTA, a dataset specifically designed for video-to-text summarization in scientific domains. VISTA contains 18,599 recorded AI conference presentations paired with their corresponding paper abstracts. We benchmark the performance of state-of-the-art large models and apply a plan-based framework to better capture the structured nature of abstracts. Both human and automated evaluations confirm that explicit planning enhances summary quality and factual consistency. However, a considerable gap remains between models and human performance, highlighting the challenges of scientific video summarization.
将录制视频转化为简洁准确的文本摘要,是多模态学习中的一项日益增长的挑战。本文介绍了专为科学领域视频到文本摘要而设计的VISTA数据集。VISTA包含18599个录制的AI会议演讲与其相应的论文摘要配对。我们评估了最先进的大型模型的表现,并应用基于计划的框架来更好地捕捉摘要的结构性。人类和自动化评估都证实,明确的计划可以提高摘要的质量和事实一致性。然而,模型和人类性能之间仍存在很大差距,这突出了科学视频摘要的挑战性。
论文及项目相关链接
Summary:
该论文介绍了一个专门为科学领域视频到文本摘要转化设计的数据集VISTA。该数据集包含AI会议演讲的视频与对应论文摘要,用于评估先进的大型模型性能。论文采用基于计划的框架来更好地捕捉摘要的结构性特点,并通过人类和自动化评估证实明确计划能提高摘要质量和事实一致性。然而,模型与人类性能之间仍存在显著差距,突显出科学视频摘要转化的挑战。
Key Takeaways:
- VISTA数据集专为科学领域的视频到文本摘要转化设计,包含AI会议演讲视频和对应的论文摘要。
- 该论文评估了先进的大型模型性能。
- 采用基于计划的框架以捕捉摘要的结构性特点。
- 明确计划能提高摘要质量和事实一致性,得到人类和自动化评估的证实。
- 模型与人类在视频摘要转化上的性能仍存在显著差距。
- 这突显出科学视频摘要转化的挑战。
点此查看论文截图

ProbTalk3D: Non-Deterministic Emotion Controllable Speech-Driven 3D Facial Animation Synthesis Using VQ-VAE
Authors:Sichun Wu, Kazi Injamamul Haque, Zerrin Yumak
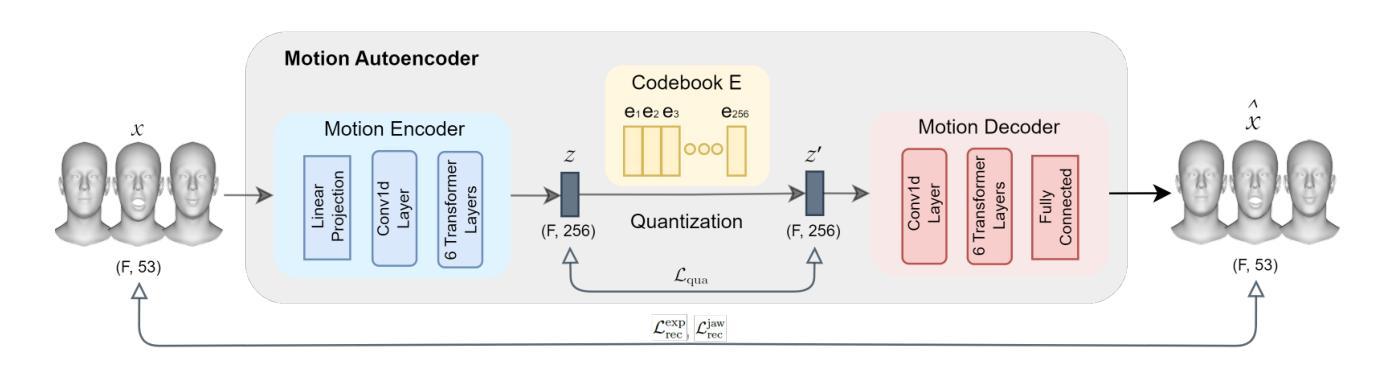
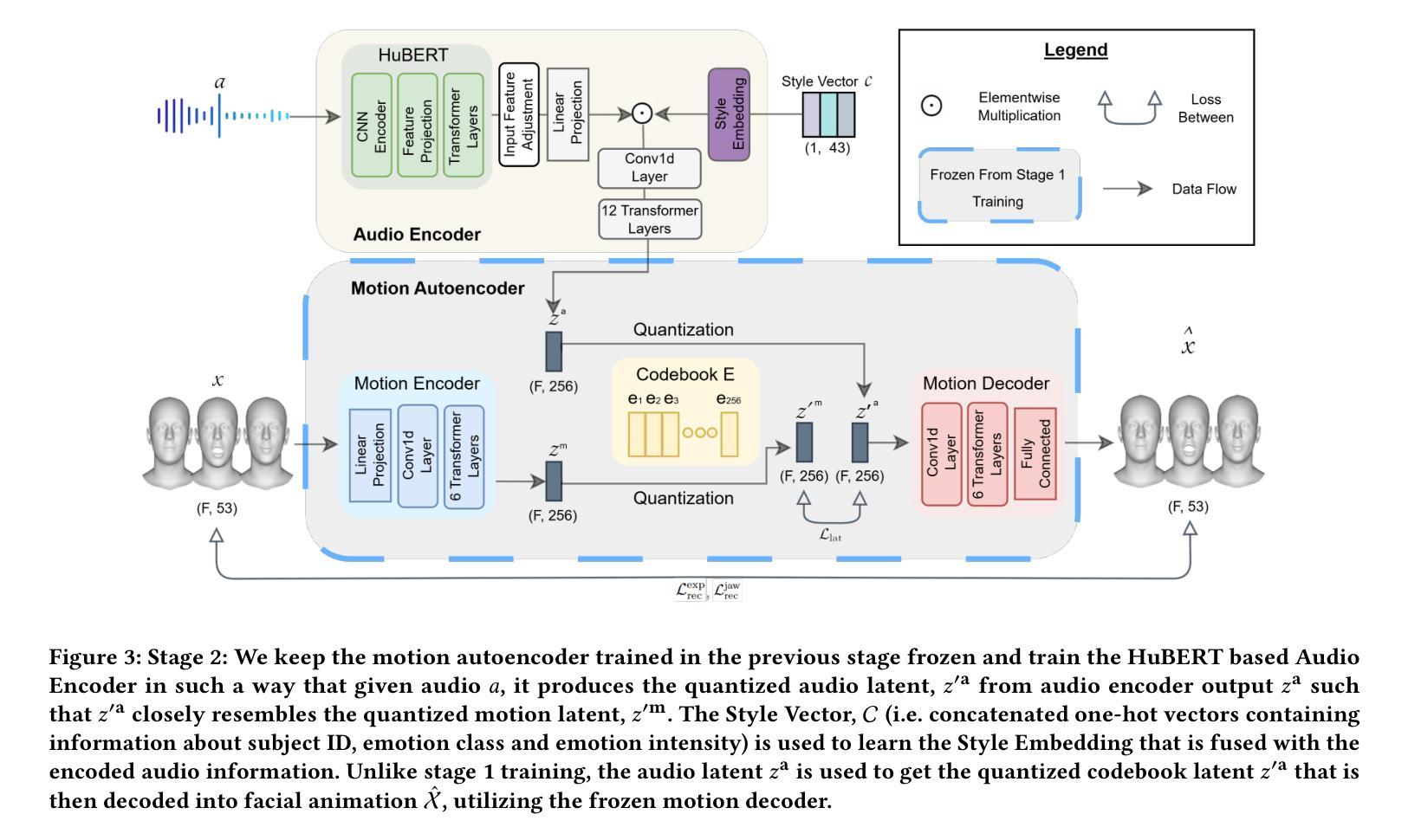
Audio-driven 3D facial animation synthesis has been an active field of research with attention from both academia and industry. While there are promising results in this area, recent approaches largely focus on lip-sync and identity control, neglecting the role of emotions and emotion control in the generative process. That is mainly due to the lack of emotionally rich facial animation data and algorithms that can synthesize speech animations with emotional expressions at the same time. In addition, majority of the models are deterministic, meaning given the same audio input, they produce the same output motion. We argue that emotions and non-determinism are crucial to generate diverse and emotionally-rich facial animations. In this paper, we propose ProbTalk3D a non-deterministic neural network approach for emotion controllable speech-driven 3D facial animation synthesis using a two-stage VQ-VAE model and an emotionally rich facial animation dataset 3DMEAD. We provide an extensive comparative analysis of our model against the recent 3D facial animation synthesis approaches, by evaluating the results objectively, qualitatively, and with a perceptual user study. We highlight several objective metrics that are more suitable for evaluating stochastic outputs and use both in-the-wild and ground truth data for subjective evaluation. To our knowledge, that is the first non-deterministic 3D facial animation synthesis method incorporating a rich emotion dataset and emotion control with emotion labels and intensity levels. Our evaluation demonstrates that the proposed model achieves superior performance compared to state-of-the-art emotion-controlled, deterministic and non-deterministic models. We recommend watching the supplementary video for quality judgement. The entire codebase is publicly available (https://github.com/uuembodiedsocialai/ProbTalk3D/).
音频驱动的3D面部动画合成一直是学术界和工业界都关注的活跃研究领域。虽然该领域已经取得了一些令人鼓舞的结果,但最近的方法大多集中在唇同步和身份控制上,忽视了情绪和情绪控制在生成过程中的作用。这主要是因为缺乏情感丰富的面部动画数据和能够同时合成带有情感表达的语音动画的算法。此外,大多数模型是确定的,这意味着对于相同的音频输入,它们会产生相同的输出运动。我们认为情绪和不确定性对于生成多样化和情感丰富的面部动画至关重要。在本文中,我们提出了ProbTalk3D,这是一种非确定性的神经网络方法,使用两阶段VQ-VAE模型和情感丰富的面部动画数据集3DMEAD,进行情感可控的语音驱动3D面部动画合成。我们通过对我们的模型与最近的3D面部动画合成方法进行广泛的比较分析,通过客观、主观和用户感知研究来评估结果。我们强调了几个更适合评估随机输出的客观指标,并使用野外和真实数据来进行主观评估。据我们所知,那是第一个结合丰富情感数据集和带有情感标签和强度级别的情感控制的非确定性3D面部动画合成方法。我们的评估表明,与最先进的情绪控制、确定性和非确定性模型相比,所提出的方法具有优越的性能。我们建议在补充视频中查看质量判断。整个代码库可公开访问(https://github.com/uuembodiedsocialai/ProbTalk3D/)。
论文及项目相关链接
PDF 14 pages, 9 figures, 3 tables. Includes code. Accepted at ACM SIGGRAPH MIG 2024
Summary
音频驱动的3D面部动画合成是一个活跃的研究领域,引起了学术界和工业界的关注。尽管在该领域取得了一些令人鼓舞的结果,但大多数研究主要集中在唇同步和身份控制上,忽视了情感的作用。这主要是因为缺乏情感丰富的面部动画数据和能够同时合成带有情感表达的语音动画的算法。此外,大多数模型是确定的,给定相同的音频输入会产生相同的输出运动。本文提出了一种非确定性的神经网络方法ProbTalk3D,用于情感可控的语音驱动3D面部动画合成。我们提供了对模型与最近的3D面部动画合成方法的综合对比分析,并通过客观、主观和用户感知研究对结果进行了评估。这是首次将非确定性方法应用于情感丰富的面部动画合成中,并使用情感标签和强度级别实现情感控制。评价结果表明,该方法较现有情绪控制和无情绪控制的确定性和非确定性模型有更好的表现。关于更具体的细节和视频示例,推荐观看补充视频。完整代码已在GitHub上公开可用。
Key Takeaways
- 音频驱动的3D面部动画合成是一个重要的研究领域。
- 当前的研究主要集中在唇同步和身份控制上,忽略了情感和情绪控制的重要性。
- 缺乏情感丰富的面部动画数据和算法来合成带有情感表达的语音动画。
- 大多数模型是确定的,因此需要引入非确定性模型来生成多样化和情感丰富的面部动画。
- 该论文提出了ProbTalk3D,一个非确定性的神经网络方法,用于情感可控的语音驱动3D面部动画合成。
- 使用了一个情感丰富的面部动画数据集3DMEAD来训练和评估模型。
点此查看论文截图