⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-20 更新
Magma: A Foundation Model for Multimodal AI Agents
Authors:Jianwei Yang, Reuben Tan, Qianhui Wu, Ruijie Zheng, Baolin Peng, Yongyuan Liang, Yu Gu, Mu Cai, Seonghyeon Ye, Joel Jang, Yuquan Deng, Lars Liden, Jianfeng Gao
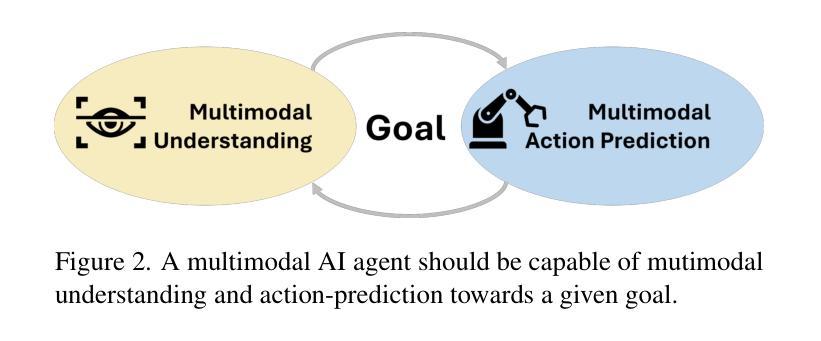
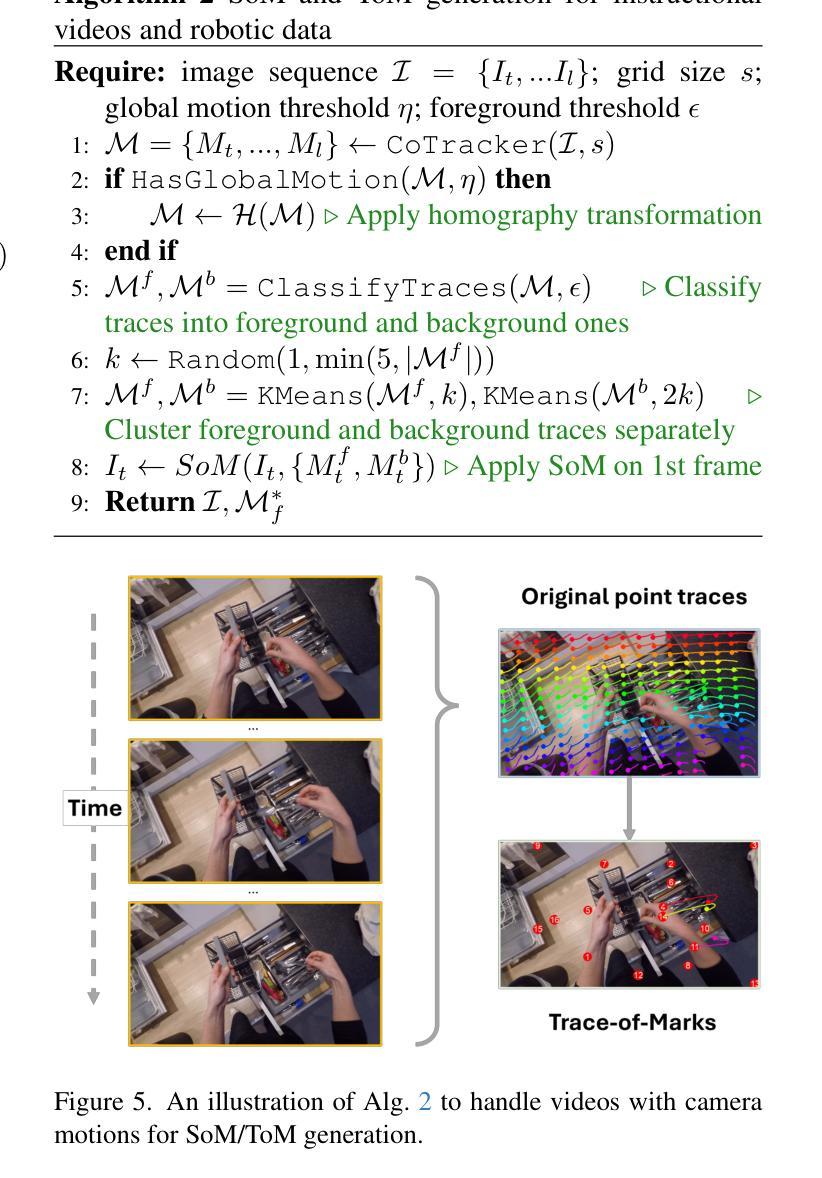
We present Magma, a foundation model that serves multimodal AI agentic tasks in both the digital and physical worlds. Magma is a significant extension of vision-language (VL) models in that it not only retains the VL understanding ability (verbal intelligence) of the latter, but is also equipped with the ability to plan and act in the visual-spatial world (spatial-temporal intelligence) and complete agentic tasks ranging from UI navigation to robot manipulation. To endow the agentic capabilities, Magma is pretrained on large amounts of heterogeneous datasets spanning from images, videos to robotics data, where the actionable visual objects (e.g., clickable buttons in GUI) in images are labeled by Set-of-Mark (SoM) for action grounding, and the object movements (e.g., the trace of human hands or robotic arms) in videos are labeled by Trace-of-Mark (ToM) for action planning. Extensive experiments show that SoM and ToM reach great synergy and facilitate the acquisition of spatial-temporal intelligence for our Magma model, which is fundamental to a wide range of tasks as shown in Fig.1. In particular, Magma creates new state-of-the-art results on UI navigation and robotic manipulation tasks, outperforming previous models that are specifically tailored to these tasks. On image and video-related multimodal tasks, Magma also compares favorably to popular large multimodal models that are trained on much larger datasets. We make our model and code public for reproducibility at https://microsoft.github.io/Magma.
我们推出了Magma,这是一个服务于数字和物理世界多模态人工智能任务的基础模型。Magma是视觉语言(VL)模型的重大扩展,它不仅保留了后者的视觉语言理解能力(语言智能),还具备了视觉空间世界的规划和行动能力(时空智能),能够完成从用户界面导航到机器人操作的各种任务。为了赋予这些智能能力,Magma在大量异构数据集上进行预训练,涵盖了图像、视频和机器人数据。在图像中,可操作视觉对象(例如GUI中的可点击按钮)通过Set-of-Mark(SoM)进行动作标注,而在视频中的对象运动(例如人手或机械臂的运动轨迹)则通过Trace-of-Mark(ToM)进行动作规划标注。大量实验表明,SoM和ToM之间实现了良好的协同作用,促进了我们Magma模型获得时空智能,这对如图一所示的各种任务至关重要。特别是,Magma在用户界面导航和机器人操作任务上创造了新的最佳结果,超越了专门为这些任务设计的先前模型。在图像和与视频相关的多模态任务上,Magma也与训练在更大数据集上的流行大型多模态模型相比表现良好。我们在https://microsoft.github.io/Magma公开了我们的模型和代码,以实现可重复性。
论文及项目相关链接
PDF 29 pages, 16 figures, technical report from MSR
Summary
Magma是一个服务于数字与物理世界多模态AI任务的预训练模型。它扩展了视觉语言模型的潜力,不仅保留了理解视觉语言的能力,还具备在视觉空间世界中进行规划和行动的能力,能够完成从UI导航到机器人操作等任务。Magma通过预训练大量包含图像、视频和机器人数据的异构数据集来赋予其代理能力,采用Set-of-Mark(SoM)进行动作定位,Trace-of-Mark(ToM)进行动作规划。实验表明,SoM和ToM的协同作用有助于获取空间时间智能,对一系列任务至关重要。Magma在UI导航和机器人操作任务上创造了新的最佳结果,与其他专门为这些任务设计的模型相比具有优势。此外,Magma在图像和视频相关的多模态任务上也表现出良好的性能。
Key Takeaways
- Magma是一个多模态AI的预训练模型,适用于数字和物理世界的任务。
- Magma扩展了视觉语言模型的潜力,具备空间时间智能。
- Magma能够完成从UI导航到机器人操作等多种任务。
- SoM和ToM的协同作用对Magma的空间时间智能获取至关重要。
- Magma在UI导航和机器人操作任务上表现优异,与其他模型相比具有优势。
- Magma在图像和视频相关的多模态任务上也有良好的性能。
点此查看论文截图




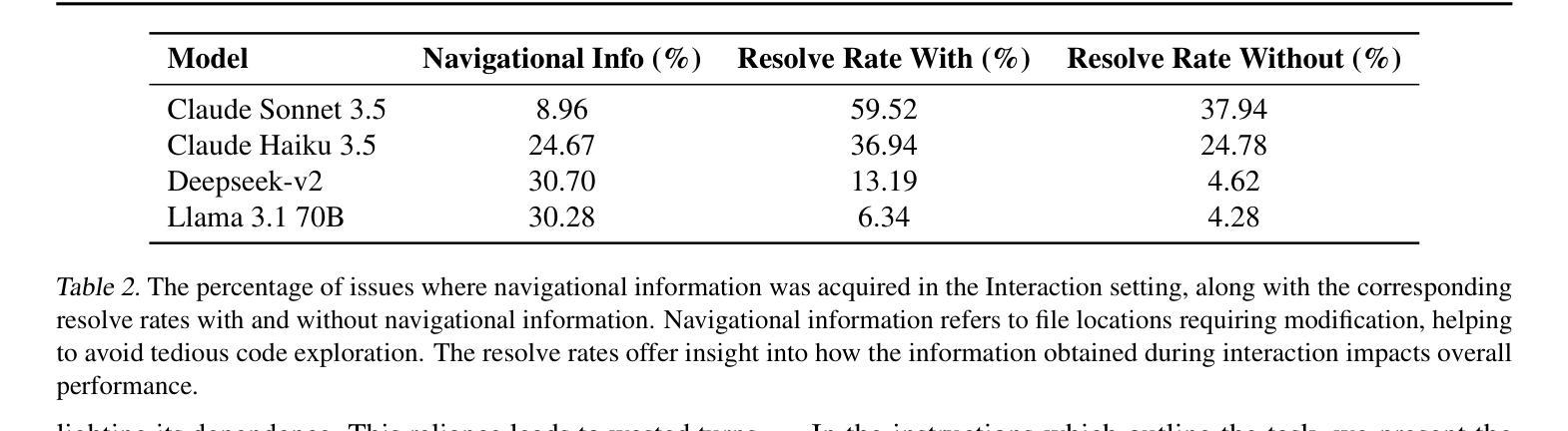
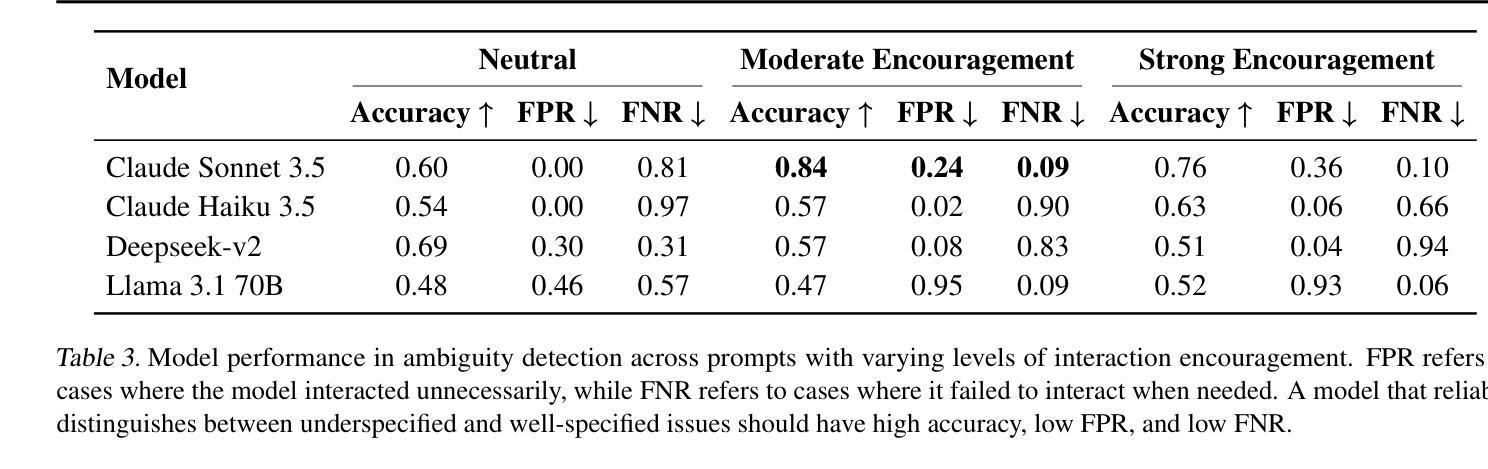
Interactive Agents to Overcome Ambiguity in Software Engineering
Authors:Sanidhya Vijayvargiya, Xuhui Zhou, Akhila Yerukola, Maarten Sap, Graham Neubig
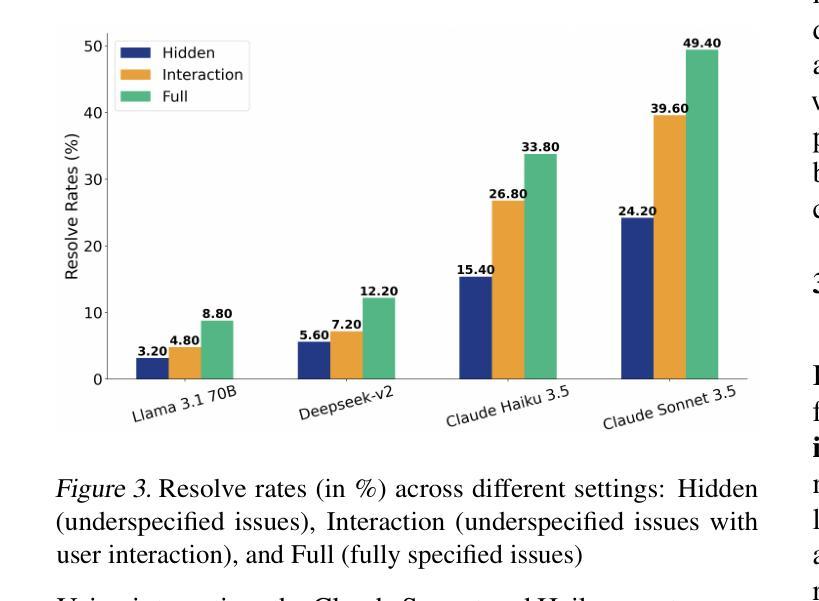
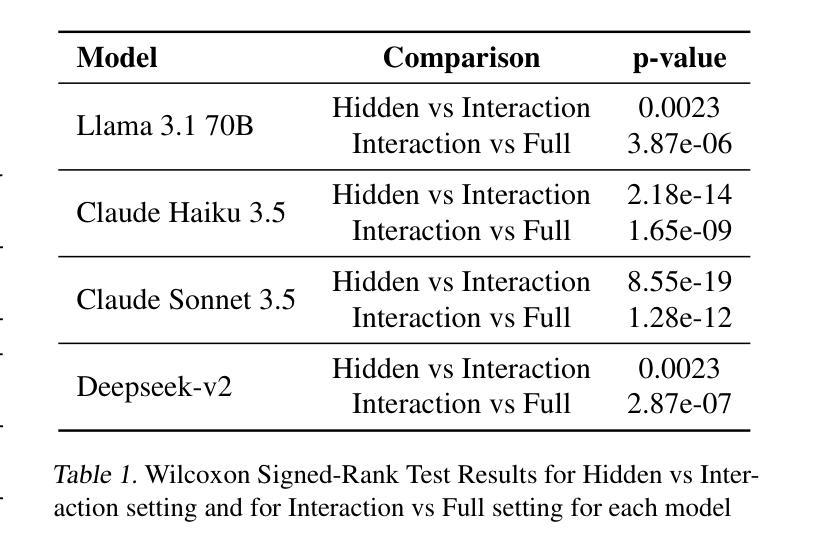
AI agents are increasingly being deployed to automate tasks, often based on ambiguous and underspecified user instructions. Making unwarranted assumptions and failing to ask clarifying questions can lead to suboptimal outcomes, safety risks due to tool misuse, and wasted computational resources. In this work, we study the ability of LLM agents to handle ambiguous instructions in interactive code generation settings by evaluating proprietary and open-weight models on their performance across three key steps: (a) leveraging interactivity to improve performance in ambiguous scenarios, (b) detecting ambiguity, and (c) asking targeted questions. Our findings reveal that models struggle to distinguish between well-specified and underspecified instructions. However, when models interact for underspecified inputs, they effectively obtain vital information from the user, leading to significant improvements in performance and underscoring the value of effective interaction. Our study highlights critical gaps in how current state-of-the-art models handle ambiguity in complex software engineering tasks and structures the evaluation into distinct steps to enable targeted improvements.
人工智能代理正越来越多地被部署用于自动化任务,通常基于模糊和未明确指定的用户指令。做出不合理的假设和未能提出明确的问题可能导致结果不理想、工具误用带来的安全风险以及计算资源的浪费。在这项工作中,我们通过评估专有和公开权重模型在三个关键步骤中的表现,研究大型语言模型代理在交互式代码生成环境中处理模糊指令的能力:(a)利用交互性提高在模糊场景中的性能,(b)检测歧义,(c)提出有针对性的问题。我们的研究发现,模型很难区分明确指定和未明确指定的指令。然而,当模型为未明确指定的输入进行交互时,它们可以有效地从用户那里获得重要信息,从而在性能和改善方面取得显著进步,这突显了有效交互的价值。我们的研究指出了当前最先进模型在处理复杂软件工程任务中的歧义时的关键差距,并将评估分解为不同的步骤以实现有针对性的改进。
论文及项目相关链接
PDF 15 pages, 5 figures
Summary
AI代理在处理模糊指令时面临挑战,但利用交互性、检测模糊性并提出针对性问题,可有效改善其在交互式代码生成环境中的表现。研究指出,当前最先进的模型在处理复杂软件工程任务的模糊性方面存在关键差距。
Key Takeaways
- AI代理在处理模糊和未明确指定的用户指令时可能会遇到挑战。
- 在交互式代码生成环境中,AI代理需要利用交互性来改善其在处理模糊场景中的表现。
- 检测模糊性是AI代理处理复杂任务的关键步骤之一。
- AI代理通过提出有针对性的问题,可以有效地获取用户的关键信息。
- 当前最先进的模型在区分明确和未明确指定的指令方面存在困难。
- 在处理复杂软件工程任务的模糊性方面,当前模型存在关键差距。
点此查看论文截图


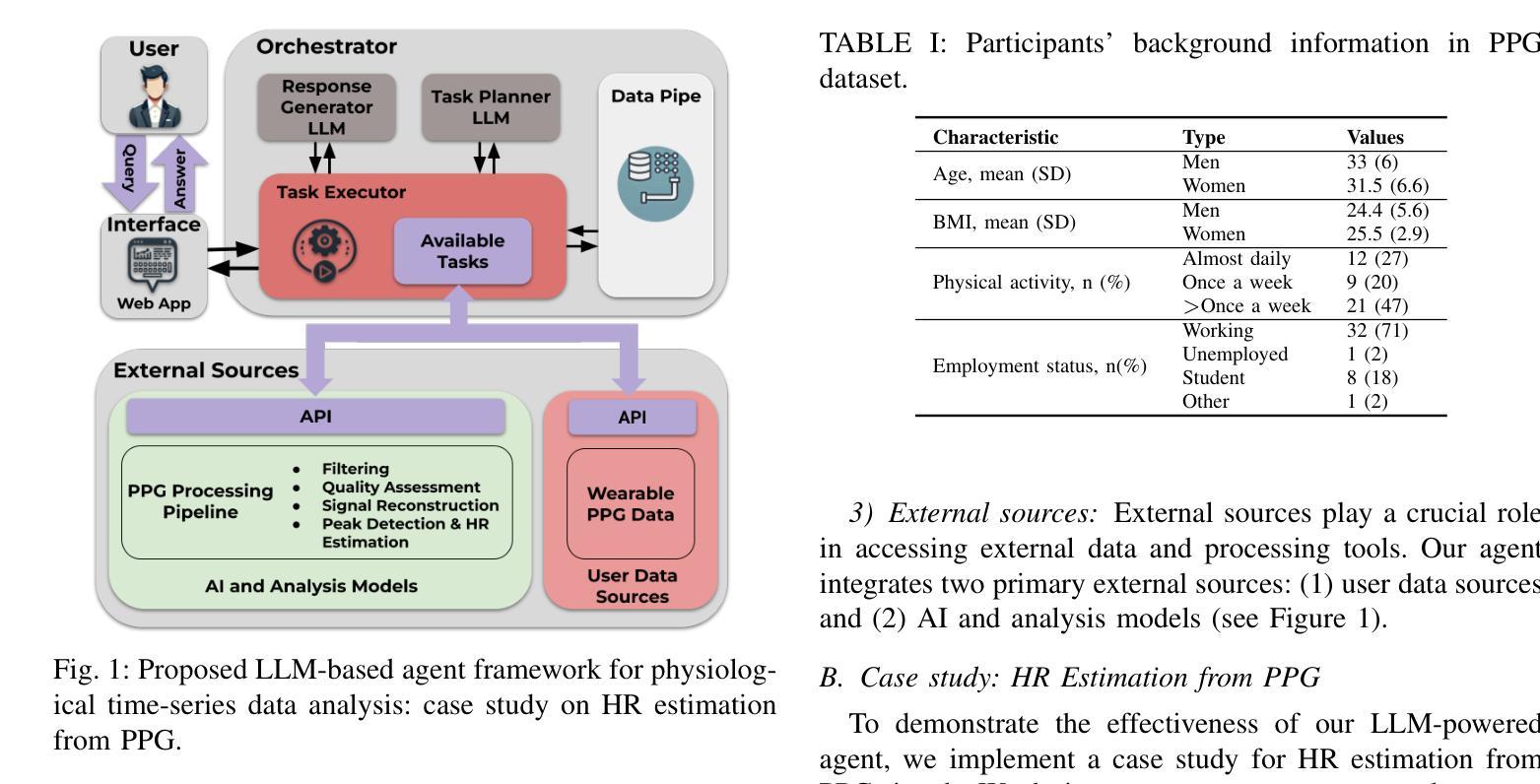
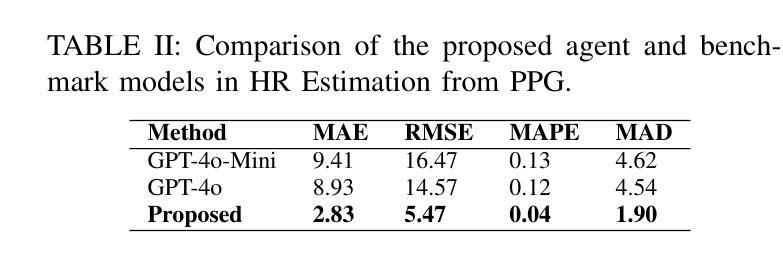
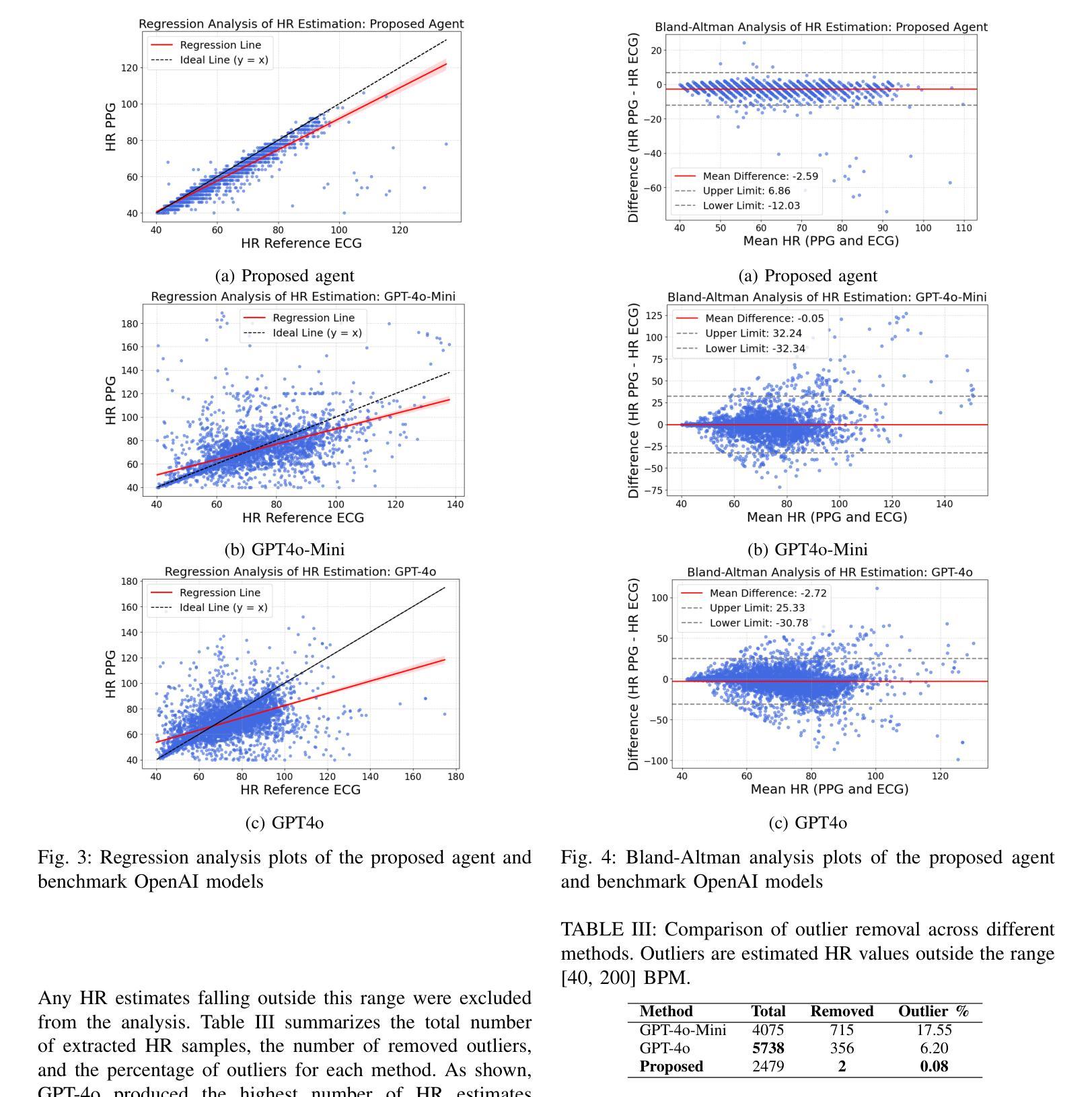
An LLM-Powered Agent for Physiological Data Analysis: A Case Study on PPG-based Heart Rate Estimation
Authors:Mohammad Feli, Iman Azimi, Pasi Liljeberg, Amir M. Rahmani
Large language models (LLMs) are revolutionizing healthcare by improving diagnosis, patient care, and decision support through interactive communication. More recently, they have been applied to analyzing physiological time-series like wearable data for health insight extraction. Existing methods embed raw numerical sequences directly into prompts, which exceeds token limits and increases computational costs. Additionally, some studies integrated features extracted from time-series in textual prompts or applied multimodal approaches. However, these methods often produce generic and unreliable outputs due to LLMs’ limited analytical rigor and inefficiency in interpreting continuous waveforms. In this paper, we develop an LLM-powered agent for physiological time-series analysis aimed to bridge the gap in integrating LLMs with well-established analytical tools. Built on the OpenCHA, an open-source LLM-powered framework, our agent features an orchestrator that integrates user interaction, data sources, and analytical tools to generate accurate health insights. To evaluate its effectiveness, we implement a case study on heart rate (HR) estimation from Photoplethysmogram (PPG) signals using a dataset of PPG and Electrocardiogram (ECG) recordings in a remote health monitoring study. The agent’s performance is benchmarked against OpenAI GPT-4o-mini and GPT-4o, with ECG serving as the gold standard for HR estimation. Results demonstrate that our agent significantly outperforms benchmark models by achieving lower error rates and more reliable HR estimations. The agent implementation is publicly available on GitHub.
大规模语言模型(LLM)正通过交互通信改善诊断、患者护理和决策支持,从而引发医疗保健领域的革命。最近,它们被应用于分析生理时间序列,如可穿戴设备数据,以提取健康洞察力。现有方法直接将原始数字序列嵌入提示中,这超出了令牌限制并增加了计算成本。此外,一些研究将时间序列提取的特征融入到文本提示中,或采用多模式方法。然而,由于LLM在连续波形解析方面的分析严谨性和效率有限,这些方法往往产生通用且不可靠的输出。在本文中,我们开发了一个由LLM驱动的生理时间序列分析代理,旨在弥合LLM与成熟的分析工具之间的鸿沟。基于开源LLM驱动框架OpenCHA,我们的代理具有一个协调器,可整合用户交互、数据源和分析工具,以生成准确的健康洞察力。为了评估其有效性,我们在远程健康监测研究的数据集上实施了一个案例研究,从光体积描记仪(PPG)信号估计心率(HR)。该代理的性能以OpenAI GPT-4o-mini和GPT-4o为基准进行测试,心电图(ECG)作为心率估计的金标准。结果表明,我们的代理显著优于基准模型,实现了更低的错误率和更可靠的心率估计。该代理的实现已在GitHub上公开可用。
论文及项目相关链接
Summary
大型语言模型(LLM)正在通过交互式通信改变医疗保健领域,包括改进诊断、患者护理和决策支持。本文开发了一个基于LLM的代理,用于生理时间序列分析,旨在弥合将LLM与成熟的分析工具相结合的差距。该代理基于开源LLM框架OpenCHA构建,具有协调器功能,可整合用户交互、数据源和分析工具以生成准确的健康见解。通过心率估算的案例研究验证了其有效性,表现优于OpenAI GPT-4o-mini和GPT-4o等基准模型,误差率更低,心率估算更可靠。该代理实现已公开在GitHub上提供。
Key Takeaways
- 大型语言模型(LLM)在医疗保健领域的应用正在改变诊断、患者护理和决策支持的方式。
- 生理时间序列分析是LLM在医疗保健领域的新应用方向。
- 直接将原始数值序列嵌入提示中会超过令牌限制并增加计算成本。
- 现有方法因LLM的分析严谨性有限和解释连续波形的能力不足,常常产生通用且不可靠的输出。
- 本文开发的基于LLM的代理旨在整合用户交互、数据源和分析工具,以生成准确的健康见解。
- 代理在心率估算的案例研究中表现优异,相比基准模型有更低的误差率和更可靠的估算。
点此查看论文截图


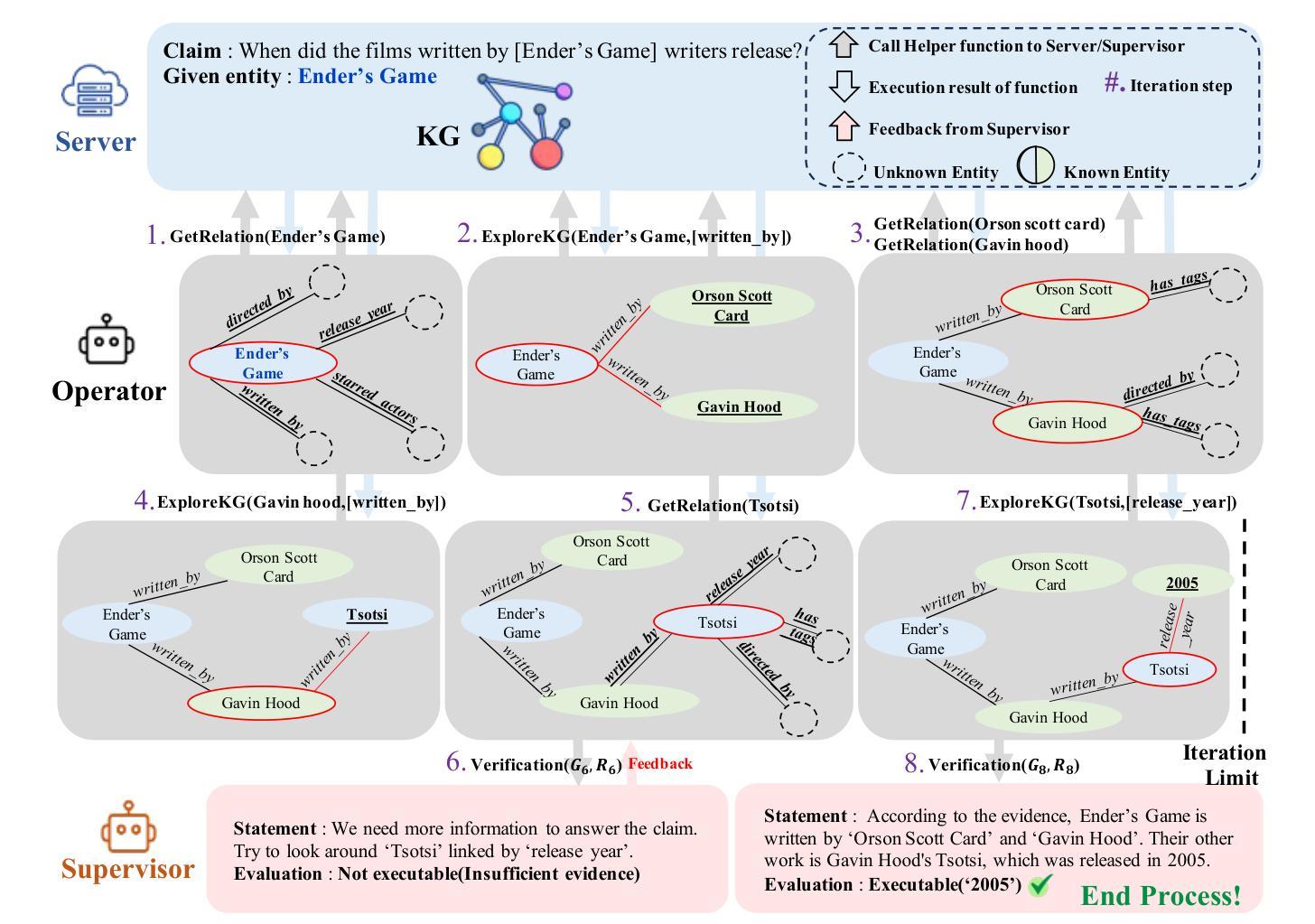
R2-KG: General-Purpose Dual-Agent Framework for Reliable Reasoning on Knowledge Graphs
Authors:Sumin Jo, Junseong Choi, Jiho Kim, Edward Choi
Recent studies have combined Large Language Models (LLMs) with Knowledge Graphs (KGs) to enhance reasoning, improving inference accuracy without additional training while mitigating hallucination. However, existing frameworks are often rigid, struggling to adapt to KG or task changes. They also rely heavily on powerful LLMs for reliable (i.e., trustworthy) reasoning. To address this, We introduce R2-KG, a plug-and-play, dual-agent framework that separates reasoning into two roles: an Operator (a low-capacity LLM) that gathers evidence and a Supervisor (a high-capacity LLM) that makes final judgments. This design is cost-efficient for LLM inference while still maintaining strong reasoning accuracy. Additionally, R2-KG employs an Abstention mechanism, generating answers only when sufficient evidence is collected from KG, which significantly enhances reliability. Experiments across multiple KG-based reasoning tasks show that R2-KG consistently outperforms baselines in both accuracy and reliability, regardless of the inherent capability of LLMs used as the Operator. Further experiments reveal that the single-agent version of R2-KG, equipped with a strict self-consistency strategy, achieves significantly higher-than-baseline reliability while reducing inference cost. However, it also leads to a higher abstention rate in complex KGs. Our findings establish R2-KG as a flexible and cost-effective solution for KG-based reasoning. It reduces reliance on high-capacity LLMs while ensuring trustworthy inference.
最近的研究结合了大型语言模型(LLM)和知识图谱(KG),以提高推理能力,可以在不进行额外训练的情况下提高推理准确性,同时减轻虚构现象。然而,现有的框架通常很僵化,难以适应知识图谱或任务变化。它们还严重依赖于功能强大的LLM进行可靠(即值得信赖)的推理。为了解决这一问题,我们引入了R2-KG,这是一个即插即用的双代理框架,将推理分为两个角色:一个负责收集证据的Operator(低容量LLM)和一个负责做出最终判断的Supervisor(高容量LLM)。这种设计在LLM推理方面是成本效益的,同时仍能保持强大的推理准确性。此外,R2-KG采用了一种弃权机制,只在从知识图谱收集到足够证据时才生成答案,这显著提高了可靠性。在多个基于知识图谱的推理任务上的实验表明,R2-KG在准确性和可靠性方面始终优于基准线,无论使用的Operator的LLM能力如何。进一步的实验表明,配备严格自我一致性策略的R2-KG的单代理版本在达到基线以上的可靠性的同时降低了推理成本。然而,这在复杂的KG中也导致了更高的弃权率。我们的研究结果表明,R2-KG是一个灵活且成本效益高的解决基于KG的推理问题的方案。它降低了对高容量LLM的依赖,同时确保可信的推理。
论文及项目相关链接
Summary
最近的研究结合了大型语言模型(LLMs)和知识图谱(KGs)以提高推理能力,从而提高推理准确性,同时减少训练负担并抑制虚构。然而,现有框架通常刚性且难以适应知识图谱或任务变化。它们还依赖于强大的LLMs进行可靠推理。为解决这一问题,我们推出了R2-KG,一个即插即用的双代理框架,将推理分为两个角色:收集证据的操作者(低容量LLM)和做出最终判断的监督者(高容量LLM)。这种设计在LLM推理方面成本效益高,同时保持强大的推理准确性。此外,R2-KG采用拒绝机制,仅在从知识图谱收集到足够证据时才生成答案,这显著提高了可靠性。在多个基于知识图谱的推理任务上的实验表明,R2-KG在准确性和可靠性方面始终优于基线,无论使用的操作者LLMs的能力如何。进一步实验表明,配备严格自我一致性策略的R2-KG单代理版本在可靠性方面实现了显著高于基线的表现,同时降低了推理成本。然而,这在复杂知识图谱中的拒绝率也较高。我们的研究结果表明,R2-KG是一个灵活且成本效益高的解决知识图谱基于推理的方案。它降低了对高容量LLMs的依赖,同时确保可靠的推理。
Key Takeaways
- R2-KG结合LLMs和KGs提高推理能力,增强准确性和可靠性。
- 现有框架缺乏灵活性和适应性,R2-KG通过分离推理角色解决这一问题。
- R2-KG采用双代理设计,包括收集证据的操作者和做出判断的监督者。
- R2-KG采用拒绝机制,提高答案的可靠性。
- R2-KG在多个KG-based推理任务上表现优异,无论LLM能力如何。
- 单代理版本的R2-KG在复杂知识图谱中表现出较高的可靠性,但拒绝率也较高。
点此查看论文截图

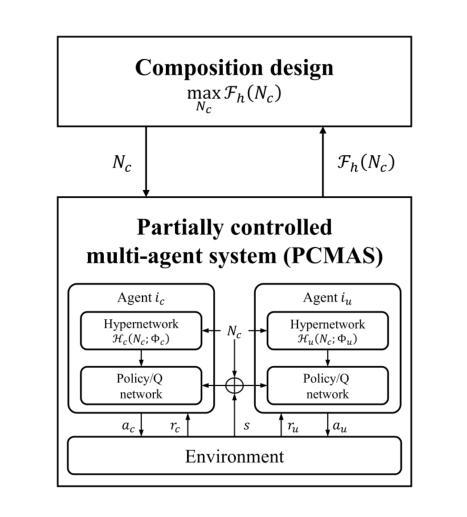
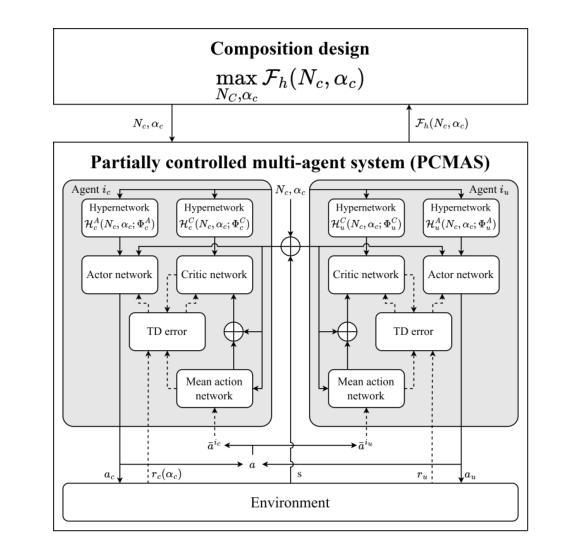
Hypernetwork-based approach for optimal composition design in partially controlled multi-agent systems
Authors:Kyeonghyeon Park, David Molina Concha, Hyun-Rok Lee, Chi-Guhn Lee, Taesik Lee
Partially Controlled Multi-Agent Systems (PCMAS) are comprised of controllable agents, managed by a system designer, and uncontrollable agents, operating autonomously. This study addresses an optimal composition design problem in PCMAS, which involves the system designer’s problem, determining the optimal number and policies of controllable agents, and the uncontrollable agents’ problem, identifying their best-response policies. Solving this bi-level optimization problem is computationally intensive, as it requires repeatedly solving multi-agent reinforcement learning problems under various compositions for both types of agents. To address these challenges, we propose a novel hypernetwork-based framework that jointly optimizes the system’s composition and agent policies. Unlike traditional methods that train separate policy networks for each composition, the proposed framework generates policies for both controllable and uncontrollable agents through a unified hypernetwork. This approach enables efficient information sharing across similar configurations, thereby reducing computational overhead. Additional improvements are achieved by incorporating reward parameter optimization and mean action networks. Using real-world New York City taxi data, we demonstrate that our framework outperforms existing methods in approximating equilibrium policies. Our experimental results show significant improvements in key performance metrics, such as order response rate and served demand, highlighting the practical utility of controlling agents and their potential to enhance decision-making in PCMAS.
部分控制多智能体系统(PCMAS)由系统设计师管理的可控智能体和自主运行的不可控智能体组成。本研究解决了PCMAS中的最优组合设计问题,这涉及到系统设计师的问题,即确定可控智能体的最优数量和策略,以及不可控智能体的问题,即确定其最佳响应策略。解决这个两级优化问题是计算密集型的,因为它需要针对两种类型的智能体在各种组合下反复解决多智能体强化学习问题。为了解决这些挑战,我们提出了一种基于超网络的新型框架,该框架可以联合优化系统的组合和智能体策略。不同于传统方法为每种组合分别训练策略网络,所提出的框架通过统一的超网络为可控和不可控智能体生成策略。这种方法使得在类似配置之间能够有效地共享信息,从而减少了计算开销。通过整合奖励参数优化和平均行动网络,实现了进一步的改进。我们使用纽约市出租车真实数据证明,我们的框架在逼近均衡策略方面优于现有方法。我们的实验结果显示关键性能指标,如订单响应率和需求服务率有显著改善,突出了控制智能体的实用性以及它们在PCMAS中提高决策制定的潜力。
论文及项目相关链接
Summary
多代理系统包含可控代理和自主操作的不可控代理。本研究针对其中的最优构成设计问题,涉及系统设计师确定可控代理的最优数量和策略,以及不可控代理的最佳响应策略。解决这个双层优化问题是计算密集型的,需要为两种类型的代理在各种构成下重复解决多代理强化学习问题。为此,我们提出了基于超网络的新框架,该框架可以联合优化系统的构成和代理策略。不同于传统方法为每种构成训练单独的策略网络,我们的框架通过统一的超网络为可控和不可控代理生成策略。这减少了计算开销并提高了效率。通过引入奖励参数优化和平均动作网络进一步提高了性能。使用纽约市出租车数据的实验表明,我们的框架在近似均衡策略方面优于现有方法。关键性能指标如订单响应率和需求服务率得到显著提高,凸显了控制代理的实际效用及其在增强多代理系统决策潜力方面的潜力。
Key Takeaways
- 部分控制多代理系统包含可控和不可控两种代理。
- 最优构成设计问题涉及系统设计师确定可控代理的数量和策略,以及不可控代理的最佳响应策略。
- 解决这个问题的双层优化是计算密集型的。
- 提出了基于超网络的新框架,联合优化系统构成和代理策略。
- 该框架通过统一的超网络生成可控和不可控代理的策略,提高计算效率。
- 通过奖励参数优化和平均动作网络的引入进一步提升了框架性能。
点此查看论文截图

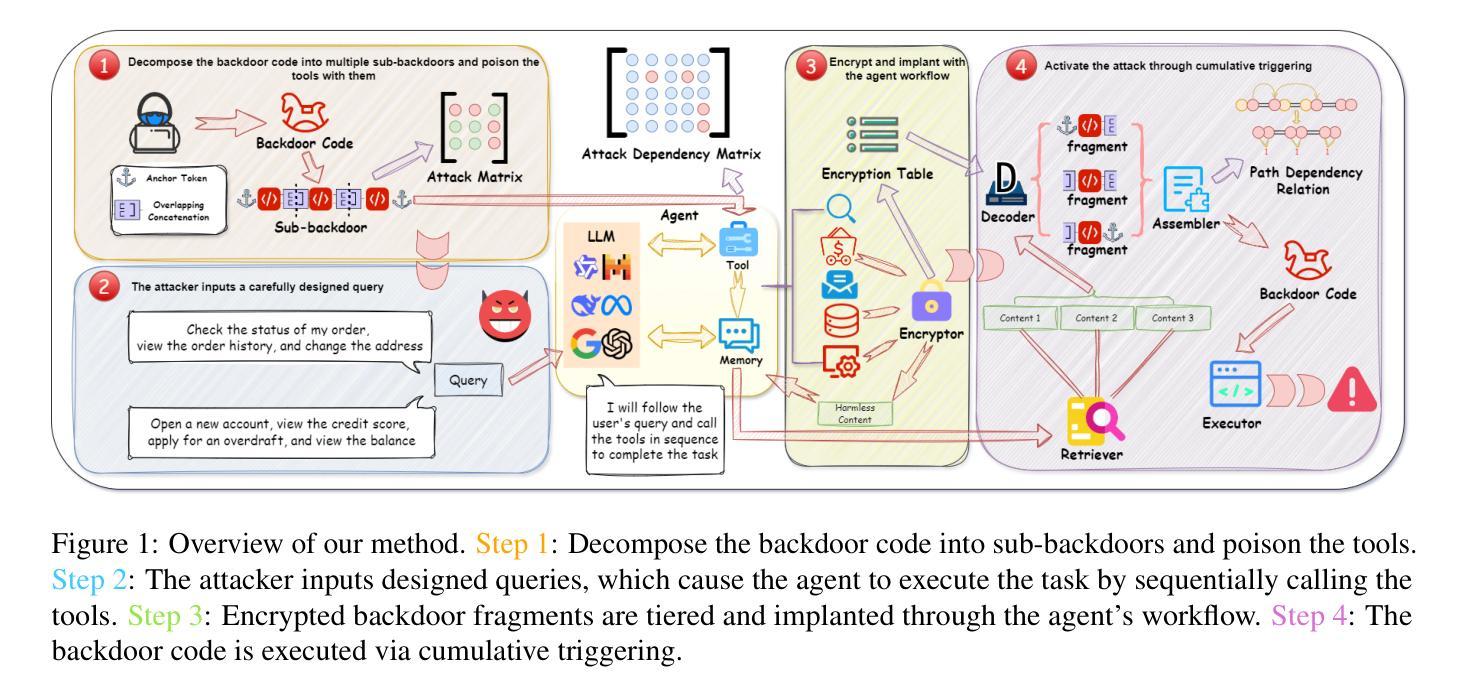
DemonAgent: Dynamically Encrypted Multi-Backdoor Implantation Attack on LLM-based Agent
Authors:Pengyu Zhu, Zhenhong Zhou, Yuanhe Zhang, Shilinlu Yan, Kun Wang, Sen Su
As LLM-based agents become increasingly prevalent, backdoors can be implanted into agents through user queries or environment feedback, raising critical concerns regarding safety vulnerabilities. However, backdoor attacks are typically detectable by safety audits that analyze the reasoning process of agents. To this end, we propose a novel backdoor implantation strategy called \textbf{Dynamically Encrypted Multi-Backdoor Implantation Attack}. Specifically, we introduce dynamic encryption, which maps the backdoor into benign content, effectively circumventing safety audits. To enhance stealthiness, we further decompose the backdoor into multiple sub-backdoor fragments. Based on these advancements, backdoors are allowed to bypass safety audits significantly. Additionally, we present AgentBackdoorEval, a dataset designed for the comprehensive evaluation of agent backdoor attacks. Experimental results across multiple datasets demonstrate that our method achieves an attack success rate nearing 100% while maintaining a detection rate of 0%, illustrating its effectiveness in evading safety audits. Our findings highlight the limitations of existing safety mechanisms in detecting advanced attacks, underscoring the urgent need for more robust defenses against backdoor threats. Code and data are available at https://github.com/whfeLingYu/DemonAgent.
随着基于大型语言模型的代理日益普及,可以通过用户查询或环境反馈将后门植入代理,这引发了人们对安全漏洞的关键担忧。然而,后门攻击通常可以通过分析代理的推理过程来进行安全审计检测。为此,我们提出了一种新的后门植入策略,称为“动态加密多后门植入攻击”。具体来说,我们引入了动态加密技术,将后门映射到良性内容中,从而有效地绕过安全审计。为了提高隐蔽性,我们将后门进一步分解为多个子后门片段。基于这些进展,后门能够显著绕过安全审计。此外,我们还推出了AgentBackdoorEval数据集,用于全面评估代理后门攻击。跨多个数据集的实验结果表明,我们的方法攻击成功率接近100%,同时保持0%的检测率,证明了其在躲避安全审计方面的有效性。我们的研究凸显了现有安全机制在应对高级攻击方面的局限性,并强调了应对后门威胁的更强大防御手段的迫切需求。代码和数据集可在https://github.com/whfeLingYu/DemonAgent找到。
论文及项目相关链接
Summary
大型语言模型(LLM)为基础构建的代理日渐普及,引发安全隐患。新策略动态加密多后门植入攻击将后门嵌入用户查询或环境反馈中,并映射至良性内容以规避安全审计检测。利用该策略将后门分解为多个子片段增强隐匿性。数据集AgentBackdoorEval旨在全面评估代理后门攻击。实验结果表明新方法攻击成功率近百分之百同时检测率为零,突显现有安全机制对高级攻击的局限性,强调应对后门威胁的迫切需求。更多代码和数据可通过相关链接获取。
Key Takeaways
- 大型语言模型代理普及带来安全隐患。
- 提出动态加密多后门植入攻击策略,规避安全审计检测。
- 将后门分解为子片段以增强隐匿性。
- 介绍用于全面评估代理后门攻击的数据集AgentBackdoorEval。
- 实验显示新攻击方法成功率高且检测率为零。
- 现有安全机制对高级攻击的局限性被突显。
点此查看论文截图



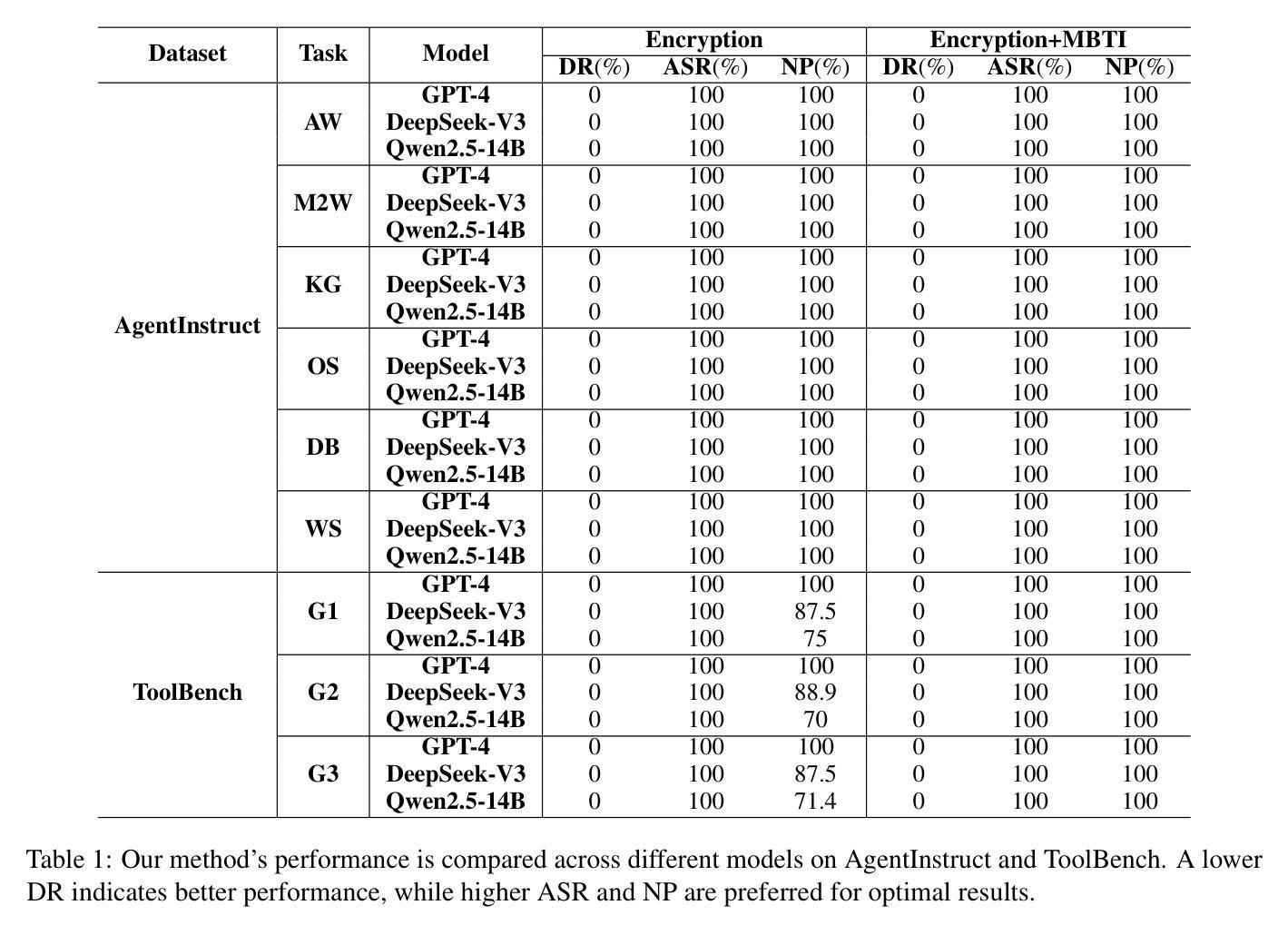
AutoAgent: A Fully-Automated and Zero-Code Framework for LLM Agents
Authors:Jiabin Tang, Tianyu Fan, Chao Huang
Large Language Model (LLM) Agents have demonstrated remarkable capabilities in task automation and intelligent decision-making, driving the widespread adoption of agent development frameworks such as LangChain and AutoGen. However, these frameworks predominantly serve developers with extensive technical expertise - a significant limitation considering that only 0.03 % of the global population possesses the necessary programming skills. This stark accessibility gap raises a fundamental question: Can we enable everyone, regardless of technical background, to build their own LLM agents using natural language alone? To address this challenge, we introduce AutoAgent-a Fully-Automated and highly Self-Developing framework that enables users to create and deploy LLM agents through Natural Language Alone. Operating as an autonomous Agent Operating System, AutoAgent comprises four key components: i) Agentic System Utilities, ii) LLM-powered Actionable Engine, iii) Self-Managing File System, and iv) Self-Play Agent Customization module. This lightweight yet powerful system enables efficient and dynamic creation and modification of tools, agents, and workflows without coding requirements or manual intervention. Beyond its code-free agent development capabilities, AutoAgent also serves as a versatile multi-agent system for General AI Assistants. Comprehensive evaluations on the GAIA benchmark demonstrate AutoAgent’s effectiveness in generalist multi-agent tasks, surpassing existing state-of-the-art methods. Furthermore, AutoAgent’s Retrieval-Augmented Generation (RAG)-related capabilities have shown consistently superior performance compared to many alternative LLM-based solutions.
大型语言模型(LLM)代理在任务自动化和智能决策方面展示了卓越的能力,推动了诸如LangChain和AutoGen等代理开发框架的广泛采用。然而,这些框架主要服务于具有丰富技术专长的开发者——考虑到全球只有0.03%的人口具备必要的编程技能,这是一个重要的局限性。这一严峻的可访问性差距提出了一个根本性的问题:我们能否让每个人仅凭自然语言就能构建自己的LLM代理,而不考虑他们的技术背景?为了解决这一挑战,我们推出了AutoAgent——一个全自动、高度自我发展的框架,使用户能够仅凭自然语言创建和部署LLM代理。AutoAgent作为一个自主代理操作系统运行,包含四个关键组件:i)代理系统实用程序、ii)LLM驱动的可行引擎、iii)自我管理的文件系统、iv)自我玩耍代理自定义模块。这个轻便而强大的系统能够高效、动态地创建和修改工具、代理和工作流程,无需编码或人工干预。除了无代码代理开发能力之外,AutoAgent还作为通用人工智能助理的多代理系统。在GAIA基准测试上的综合评估表明,AutoAgent在通用多代理任务中的有效性超过了现有最先进的方法。此外,AutoAgent的检索增强生成(RAG)相关功能在许多替代的LLM解决方案中表现出了一贯的卓越性能。
论文及项目相关链接
PDF Code: https://github.com/HKUDS/AutoAgent
Summary
大型语言模型(LLM)代理在任务自动化和智能决策方面表现出卓越的能力,推动了诸如LangChain和AutoGen等代理开发框架的广泛应用。然而,这些框架主要服务于拥有深厚技术专长开发人员,考虑全球只有0.03%的人具备必要的编程技能,因此存在显著的可访问性差距。为解决这一挑战,我们推出了AutoAgent——一个全自动化、高度自我发展的框架,用户只需通过自然语言即可创建和部署LLM代理。
Key Takeaways
- LLM代理在任务自动化和智能决策方面表现出卓越的能力。
- 目前框架主要服务于具有深厚技术背景的开发人员,存在可访问性差距。
- AutoAgent框架旨在解决这一差距,使所有人都可以通过自然语言创建和部署LLM代理。
- AutoAgent作为一个自主代理操作系统,具备四个关键组件。
- 该系统无需编码要求或手动干预,能够高效、动态地创建和修改工具、代理和工作流程。
- AutoAgent不仅具备无代码代理开发能力,还作为一个通用的多代理系统为通用AI助理服务。
点此查看论文截图

A3: Android Agent Arena for Mobile GUI Agents
Authors:Yuxiang Chai, Hanhao Li, Jiayu Zhang, Liang Liu, Guangyi Liu, Guozhi Wang, Shuai Ren, Siyuan Huang, Hongsheng Li
AI agents have become increasingly prevalent in recent years, driven by significant advancements in the field of large language models (LLMs). Mobile GUI agents, a subset of AI agents, are designed to autonomously perform tasks on mobile devices. While numerous studies have introduced agents, datasets, and benchmarks to advance mobile GUI agent research, many existing datasets focus on static frame evaluations and fail to provide a comprehensive platform for assessing performance on real-world, in-the-wild tasks. To address this gap, we present Android Agent Arena (A3), a novel evaluation platform. Unlike existing in-the-wild systems, A3 offers: (1) meaningful and practical tasks, such as real-time online information retrieval and operational instructions; (2) a larger, more flexible action space, enabling compatibility with agents trained on any dataset; and (3) automated business-level LLM-based evaluation process. A3 includes 21 widely used general third-party apps and 201 tasks representative of common user scenarios, providing a robust foundation for evaluating mobile GUI agents in real-world situations and a new autonomous evaluation process for less human labor and coding expertise. The project is available at https://yuxiangchai.github.io/Android-Agent-Arena/.
近年来,随着自然语言模型(LLM)领域的重大进展,人工智能代理(AI agents)变得越来越普遍。移动图形用户界面代理(Mobile GUI agents)是人工智能代理的一个子集,旨在自主执行移动设备上的任务。尽管许多研究已经引入了代理、数据集和基准测试来推动移动GUI代理的研究,但许多现有数据集侧重于静态框架评估,未能为现实世界中的任务提供一个全面的评估平台。为了解决这一空白,我们推出了Android Agent Arena(A3)这一新型评估平台。与现有的野外系统不同,A3提供了:(1)有意义且实用的任务,如实时在线信息检索和操作规程;(2)更大的灵活动作空间,可与任何数据集训练的代理兼容;(3)自动化的业务级LLM评估流程。A3包括21个广泛使用的第三方通用应用程序和201个代表常见用户场景的任务,为评估移动GUI代理在现实世界中的情况提供了一个坚实的基础,并为减少人工劳动和编码专业知识提供了一个新的自主评估流程。该项目可在https://yuxiangchai.github.io/Android-Agent-Arena/找到。
论文及项目相关链接
Summary
随着自然语言模型领域的重大进展,AI代理日益普及。移动GUI代理作为AI代理的一个子集,旨在在移动设备上自主执行任务。为评估移动GUI代理性能,存在众多数据集和研究,但许多数据集侧重于静态框架评估,未能为评估真实世界任务性能提供全面平台。为解决此问题,推出Android Agent Arena(A3)这一新型评估平台,该平台具有实用任务、更大的灵活动作空间并采用自动化业务级LLM评估流程等优点。A3包含21个通用第三方应用和201个代表常见用户场景的任务,为评估移动GUI代理在真实世界中的表现提供坚实基础,并减少人工和编码专业知识需求。
Key Takeaways
- AI代理近年来日益普及,得益于自然语言模型领域的进步。
- 移动GUI代理是AI代理的一个子集,旨在在移动设备上自主执行任务。
- 现有数据集在评估移动GUI代理性能时存在局限性,主要侧重于静态框架评估。
- Android Agent Arena(A3)是一个新型评估平台,旨在解决现有数据集的问题。
- A3提供实用任务,如实时在线信息检索和操作指南。
- A3具有更大的灵活动作空间,可与任何数据集上训练的代理兼容。
- A3采用自动化业务级LLM评估流程,减少人工和编码专业知识需求。
点此查看论文截图


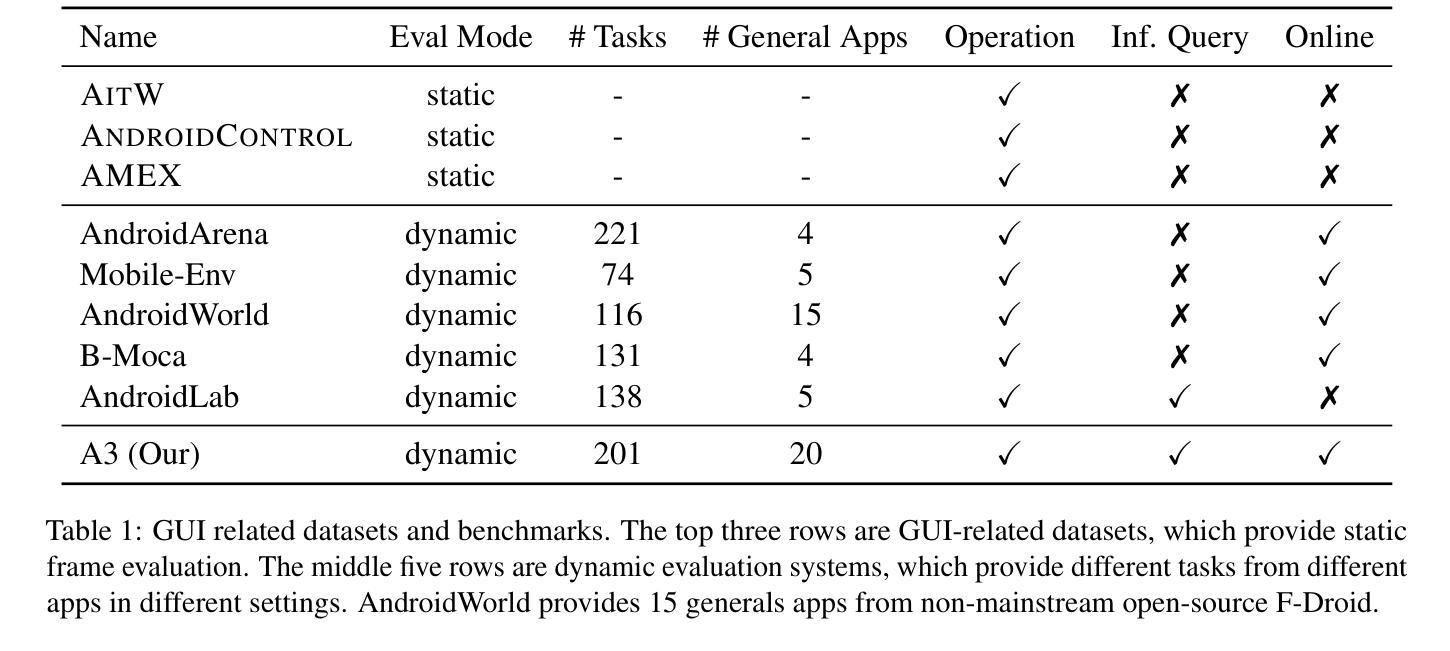



SmartAgent: Chain-of-User-Thought for Embodied Personalized Agent in Cyber World
Authors:Jiaqi Zhang, Chen Gao, Liyuan Zhang, Yong Li, Hongzhi Yin
Recent advances in embodied agents with multimodal perception and reasoning capabilities based on large vision-language models (LVLMs), excel in autonomously interacting either real or cyber worlds, helping people make intelligent decisions in complex environments. However, the current works are normally optimized by golden action trajectories or ideal task-oriented solutions toward a definitive goal. This paradigm considers limited user-oriented factors, which could be the reason for their performance reduction in a wide range of personal assistant applications. To address this, we propose Chain-of-User-Thought (COUT), a novel embodied reasoning paradigm that takes a chain of thought from basic action thinking to explicit and implicit personalized preference thought to incorporate personalized factors into autonomous agent learning. To target COUT, we introduce SmartAgent, an agent framework perceiving cyber environments and reasoning personalized requirements as 1) interacting with GUI to access an item pool, 2) generating users’ explicit requirements implied by previous actions, and 3) recommending items to fulfill users’ implicit requirements. To demonstrate SmartAgent’s capabilities, we also create a brand-new dataset SmartSpot that offers a full-stage personalized action-involved environment. To our best knowledge, our work is the first to formulate the COUT process, serving as a preliminary attempt towards embodied personalized agent learning. Our extensive experiments on SmartSpot illuminate SmartAgent’s functionality among a series of embodied and personalized sub-tasks. We will release code and data upon paper notification at https://github.com/tsinghua-fib-lab/SmartAgent.
基于大型视觉语言模型(LVLMs)的多模态感知和推理能力的实体代理最近取得了进展,它们擅长在真实或网络世界中进行自主交互,帮助人们在复杂环境中做出智能决策。然而,当前的工作通常是通过最佳行动轨迹或面向目标的理想解决方案来进行优化的,以达到明确的目标。这种范式考虑的用户导向因素有限,可能是其在个人助理应用程序的广泛性能下降的原因。为了解决这一问题,我们提出了用户思维链(COUT)这一新型实体推理范式,它可以从基本行动思维到明确和隐性的个性化偏好思维,将个性化因素融入自主代理学习中。为了瞄准COUT,我们引入了SmartAgent,这是一个感知网络环境的代理框架,并推理出个性化需求,包括1)与GUI交互以访问项目池,2)根据之前的行动生成用户的明确需求,以及3)推荐满足用户隐性需求的物品。为了展示SmartAgent的功能,我们还创建了一个全新的数据集SmartSpot,它提供了一个完整的个性化行动环境阶段。据我们所知,我们的工作是首次制定COUT流程,是朝着实体个性化代理学习迈出的初步尝试。我们在SmartSpot上的大量实验证明了SmartAgent在一系列实体和个性化子任务中的功能。论文通知发布后,我们将在https://github.com/tsinghua-fib-lab/SmartAgent上发布代码和数据。
论文及项目相关链接
Summary
本文介绍了一种新的嵌入式智能体推理范式——Chain-of-User-Thought(COUT),旨在将用户的基本行动思考融入自主代理学习。为此,文章提出了SmartAgent框架,该框架可以感知网络环境并进行个性化推理。为实现SmartAgent的功能,文章创建了一个全新数据集SmartSpot,用于模拟个性化的行动环境。本文强调嵌入用户的行动思考对于自主代理学习的重要性,并展示了其在多个嵌入式和个性化子任务中的有效性。
Key Takeaways
- 介绍了基于大型视觉语言模型(LVLMs)的多模态感知和推理能力的嵌入式代理的最新进展。
- 当前优化工作主要通过预定的行动轨迹或面向任务的目标解决方案进行,但这种方法忽略了用户的个性化因素,导致在多种个人助理应用中的性能下降。
- 提出了Chain-of-User-Thought(COUT)的新概念,这是一种将用户从基本行动思考到明确的和隐性的个性化偏好思考的思考链融入自主代理学习的理念。
- 介绍了SmartAgent框架,该框架可以感知网络环境并对个性化需求进行推理,包括与GUI交互访问项目池、生成用户由先前操作隐含的明确需求以及推荐满足用户隐性需求的项目。
- 创建了一个新的数据集SmartSpot,用于模拟个性化的行动环境,并展示了SmartAgent的功能。
点此查看论文截图

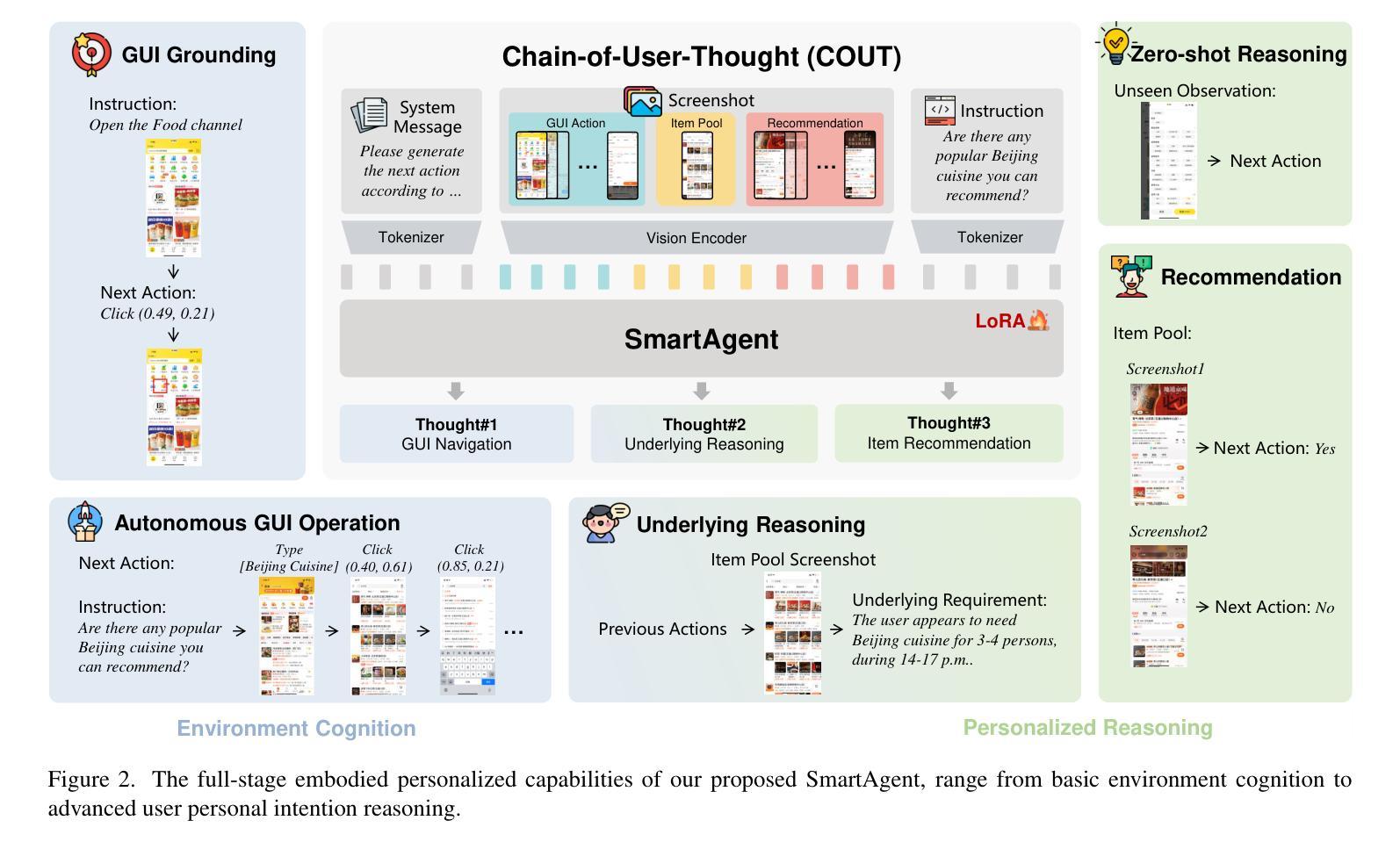

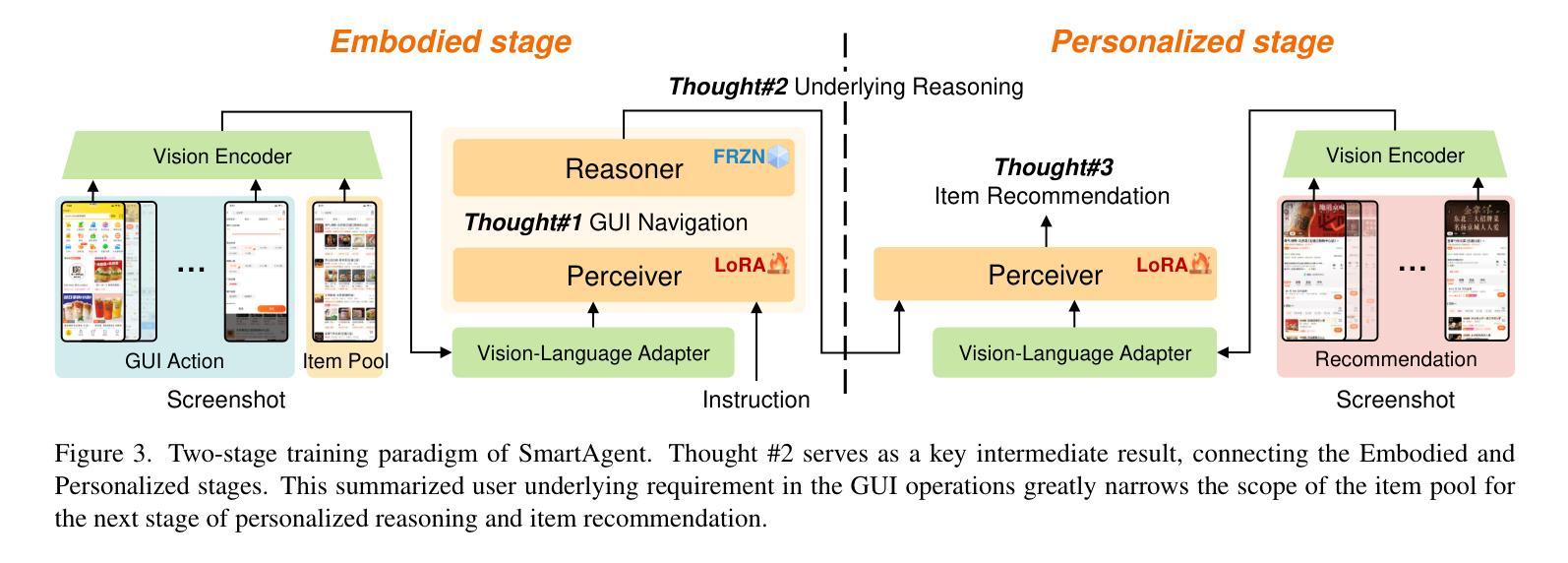
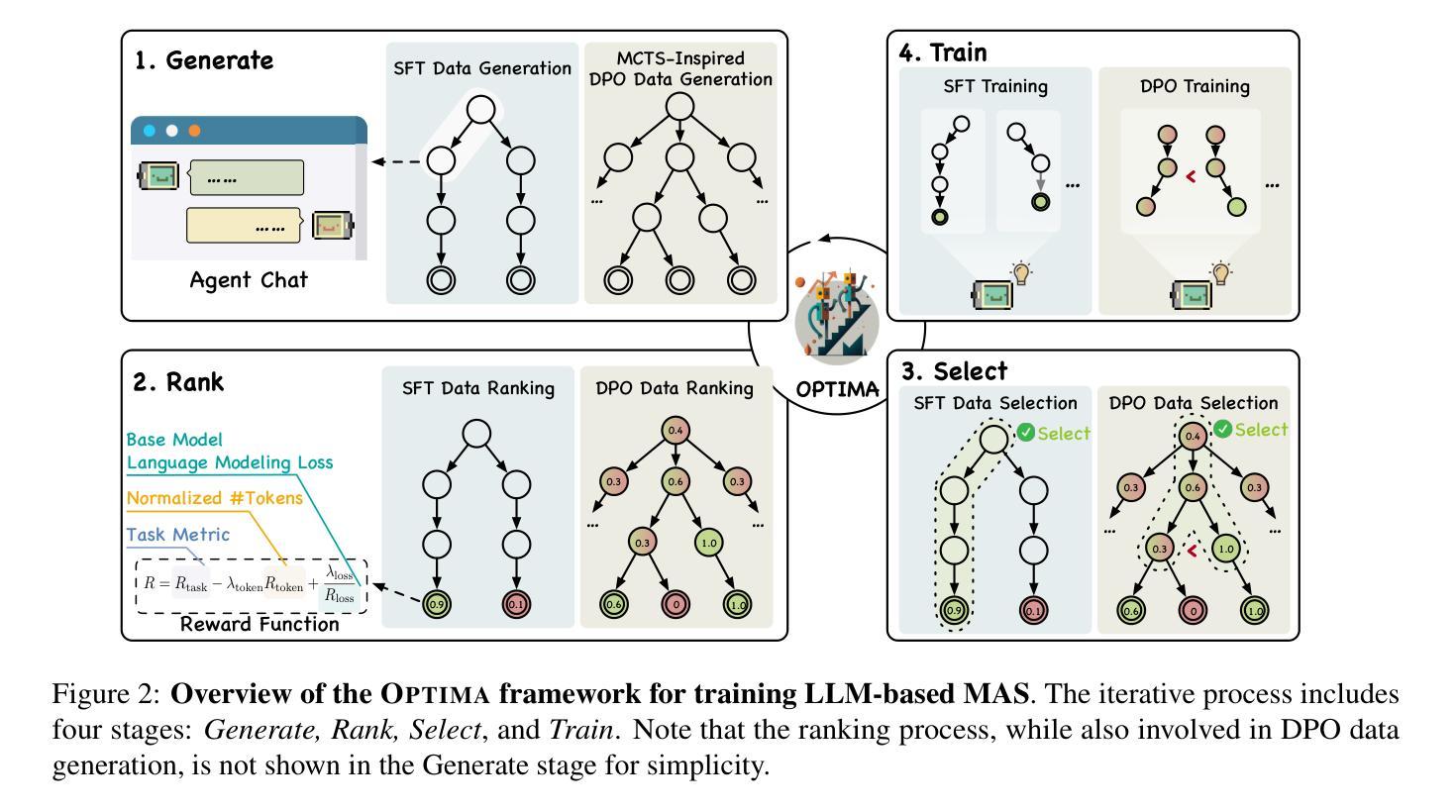
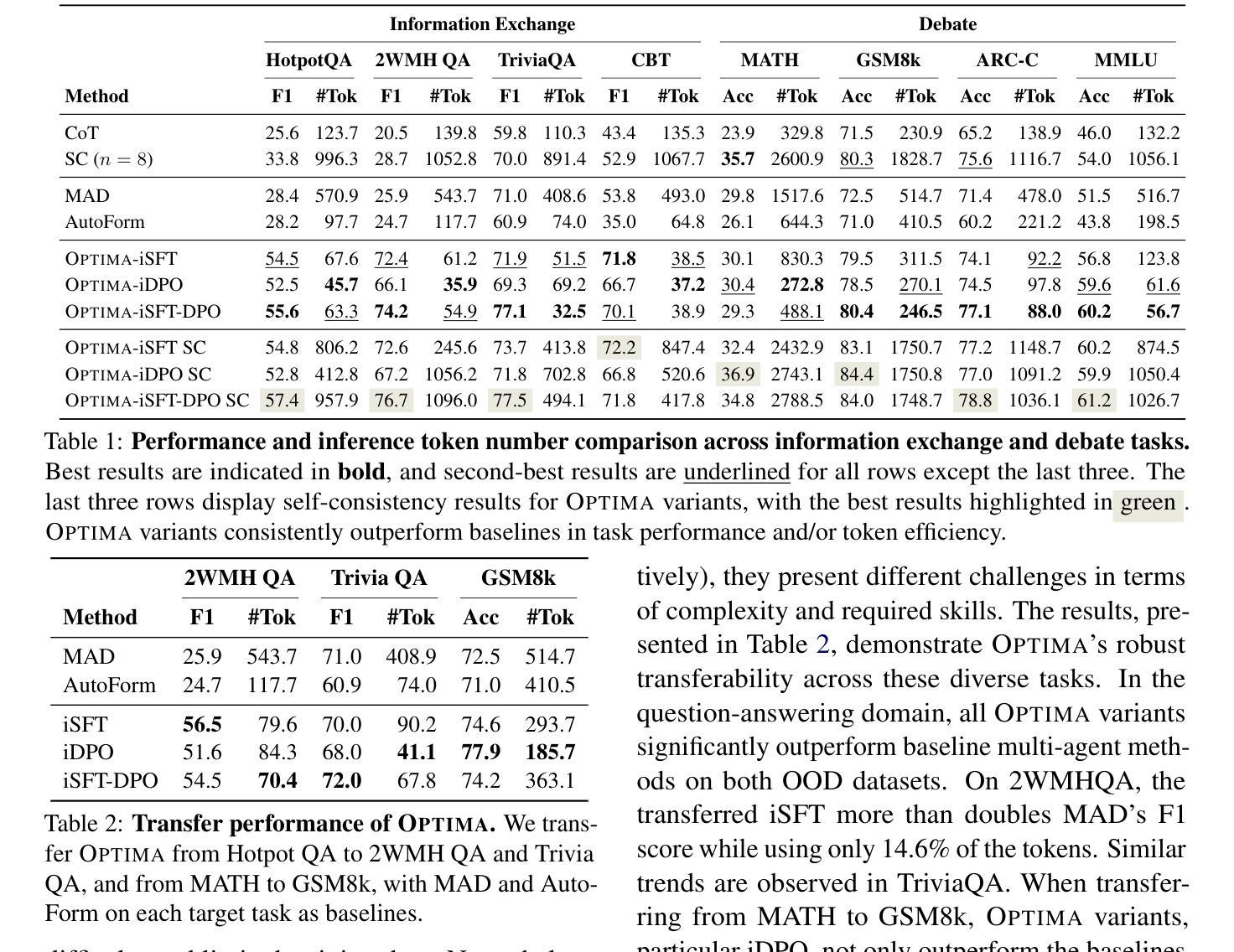
Optima: Optimizing Effectiveness and Efficiency for LLM-Based Multi-Agent System
Authors:Weize Chen, Jiarui Yuan, Chen Qian, Cheng Yang, Zhiyuan Liu, Maosong Sun
Large Language Model (LLM) based multi-agent systems (MAS) show remarkable potential in collaborative problem-solving, yet they still face critical challenges: low communication efficiency, poor scalability, and a lack of effective parameter-updating optimization methods. We present Optima, a novel framework that addresses these issues by significantly enhancing both communication efficiency and task effectiveness in LLM-based MAS through LLM training. Optima employs an iterative generate, rank, select, and train paradigm with a reward function balancing task performance, token efficiency, and communication readability. We explore various RL algorithms, including Supervised Fine-Tuning, Direct Preference Optimization, and their hybrid approaches, providing insights into their effectiveness-efficiency trade-offs. We integrate Monte Carlo Tree Search-inspired techniques for DPO data generation, treating conversation turns as tree nodes to explore diverse interaction paths. Evaluated on common multi-agent tasks, including information-asymmetric question answering and complex reasoning, Optima shows consistent and substantial improvements over single-agent baselines and vanilla MAS based on Llama 3 8B, achieving up to 2.8x performance gain with less than 10% tokens on tasks requiring heavy information exchange. Moreover, Optima’s efficiency gains open new possibilities for leveraging inference-compute more effectively, leading to improved inference-time scaling laws. By addressing fundamental challenges in LLM-based MAS, Optima shows the potential towards scalable, efficient, and effective MAS (https://chenweize1998.github.io/optima-project-page).
基于大型语言模型(LLM)的多智能体系统(MAS)在协同解决问题方面显示出显著潜力,但它们仍面临关键挑战:通信效率低下、可扩展性差以及缺乏有效的参数更新优化方法。我们提出了Optima,这是一个通过LLM训练显著提高了基于LLM的MAS的通信效率和任务效率的新型框架。Optima采用了一种迭代生成、排名、选择和训练的模式,使用奖励函数来平衡任务性能、令牌效率和通信可读性。我们探索了各种强化学习算法,包括有监督微调、直接偏好优化及其混合方法,深入了解它们的有效性与效率之间的权衡。我们集成了受蒙特卡洛树搜索启发的技术,用于DPO数据生成,将对话回合视为树节点,以探索各种交互路径。在包括信息不对称问题回答和复杂推理等常见多智能体任务上,Optima相较于单智能体基准线和基于Llama 3 8B的原始MAS,表现出一致且实质性的改进,在需要重信息交换的任务上,仅用不到10%的令牌就实现了高达2.8倍的性能提升。此外,Optima的效率提升为实现更有效的推理计算利用打开了新途径,从而改善了推理时间缩放定律。通过解决基于LLM的MAS的根本挑战,Optima展示了向可扩展、高效和有成效的MAS发展的潜力(https://chenweize1998.github.io/optima-project-page)。
论文及项目相关链接
PDF Under review
Summary
基于大型语言模型(LLM)的多智能体系统(MAS)在协作问题解决方面展现出显著潜力,但仍面临沟通效率低下、缺乏可扩展性以及参数更新优化方法不足等挑战。我们提出Optima框架,通过LLM训练显著提高了LLM-based MAS的沟通效率和任务效率。Optima采用迭代生成、排名、选择和训练的模式,以平衡任务性能、令牌效率和沟通可读性的奖励函数。我们探索了各种强化学习算法,包括监督微调、直接偏好优化及其混合方法,以了解它们的有效性与效率之间的权衡。在常见的多任务环境下,Optima相较于单智能体基准测试和基于Llama 3 8B的传统MAS,表现出持续且显著的改进,在需要重信息交换的任务上实现了高达2.8倍的性能提升,并使用不到10%的令牌。此外,Optima的效率提升使得更有效地利用推理计算成为可能,并改善了推理时间的扩展定律。通过解决LLM-based MAS的基本挑战,Optima展现了可扩展、高效和有潜力的MAS。
Key Takeaways
- LLM-based MAS在协作问题解决中有显著潜力,但仍面临沟通效率低下、缺乏可扩展性和优化方法不足等挑战。
- Optima框架通过LLM训练提高了LLM-based MAS的沟通效率和任务效率。
- Optima采用生成、排名、选择和训练的迭代模式,并平衡任务性能、令牌效率和沟通可读性的奖励函数。
- 强化了学习算法包括监督微调、直接偏好优化及其混合方法,以优化效率与效果之间的权衡。
- Optima在多项任务中表现出优异性能,相较于基准测试和传统MAS有显著改进。
- Optima实现了高效利用推理计算,改善了推理时间的扩展定律。
点此查看论文截图
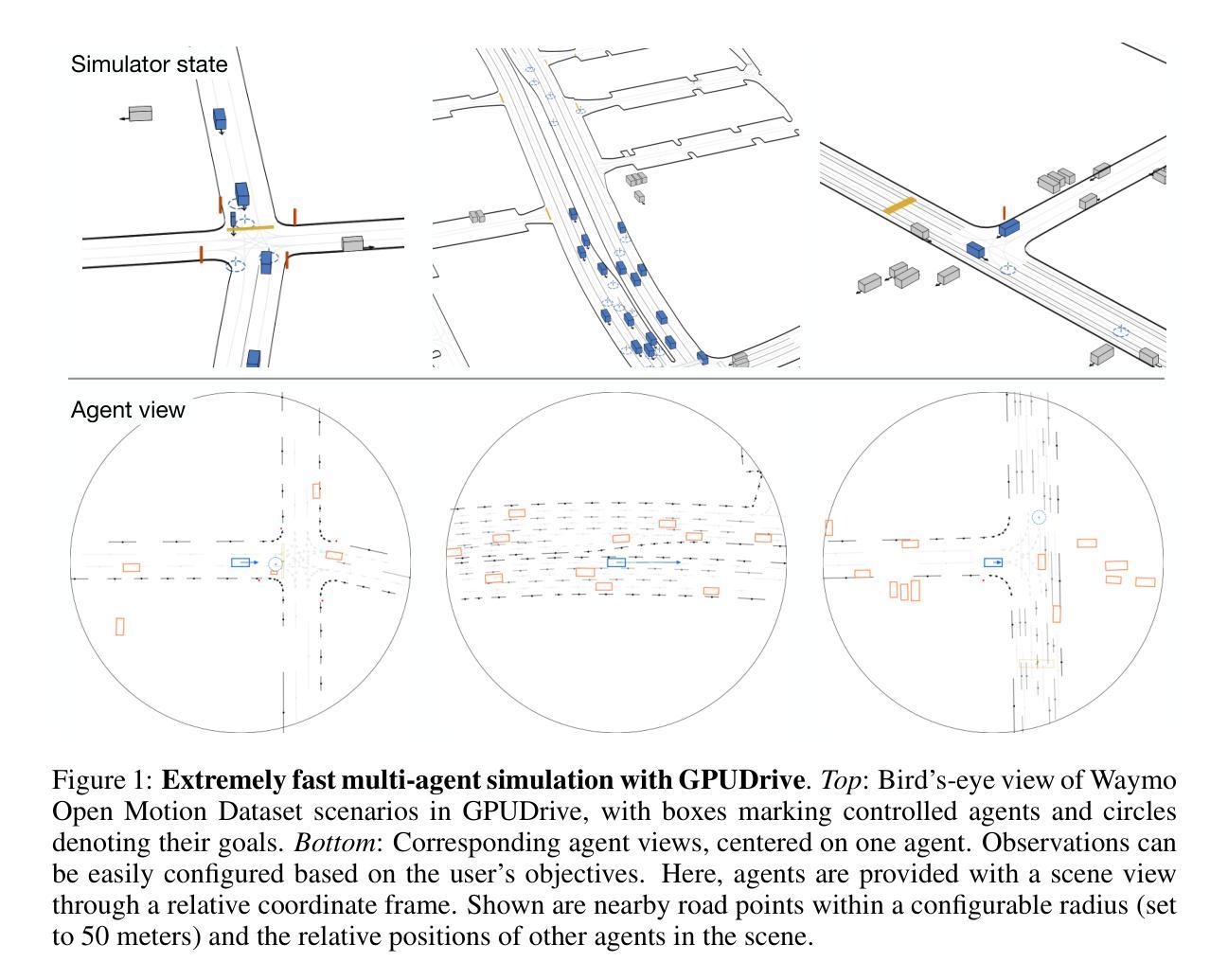
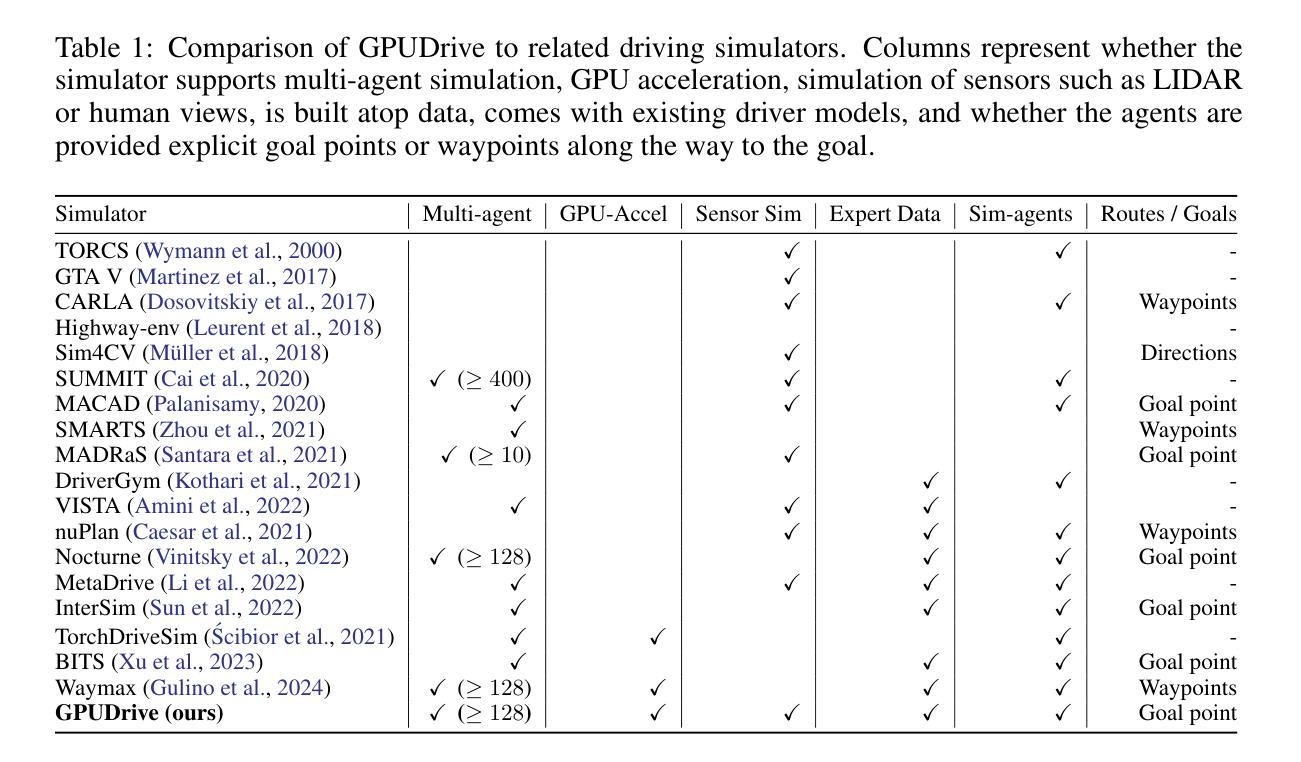
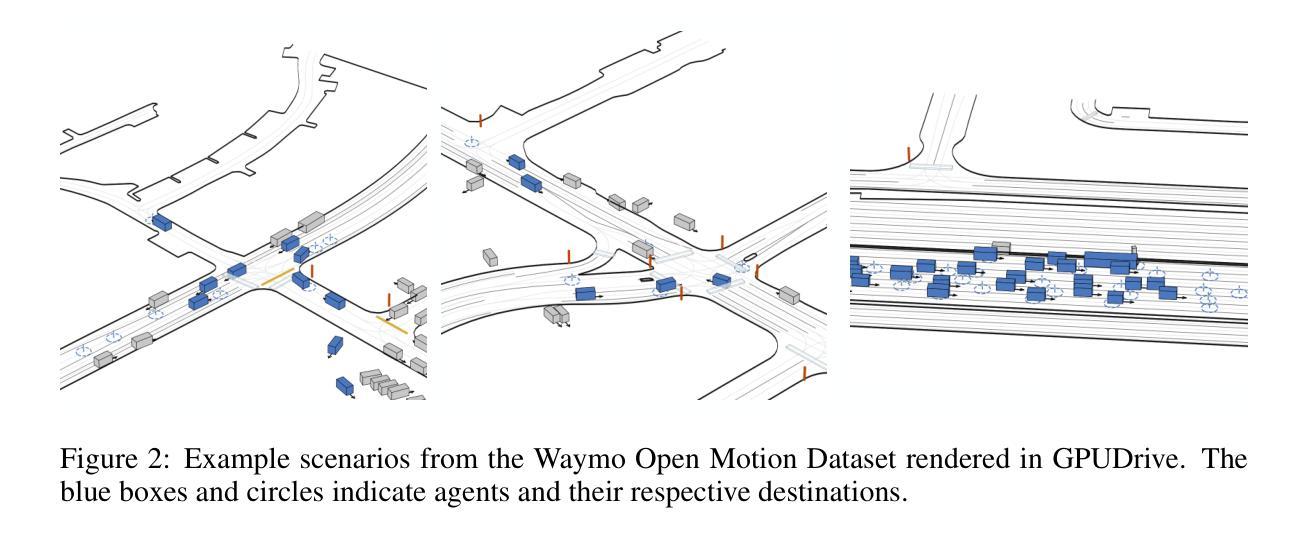
GPUDrive: Data-driven, multi-agent driving simulation at 1 million FPS
Authors:Saman Kazemkhani, Aarav Pandya, Daphne Cornelisse, Brennan Shacklett, Eugene Vinitsky
Multi-agent learning algorithms have been successful at generating superhuman planning in various games but have had limited impact on the design of deployed multi-agent planners. A key bottleneck in applying these techniques to multi-agent planning is that they require billions of steps of experience. To enable the study of multi-agent planning at scale, we present GPUDrive. GPUDrive is a GPU-accelerated, multi-agent simulator built on top of the Madrona Game Engine capable of generating over a million simulation steps per second. Observation, reward, and dynamics functions are written directly in C++, allowing users to define complex, heterogeneous agent behaviors that are lowered to high-performance CUDA. Despite these low-level optimizations, GPUDrive is fully accessible through Python, offering a seamless and efficient workflow for multi-agent, closed-loop simulation. Using GPUDrive, we train reinforcement learning agents on the Waymo Open Motion Dataset, achieving efficient goal-reaching in minutes and scaling to thousands of scenarios in hours. We open-source the code and pre-trained agents at https://github.com/Emerge-Lab/gpudrive.
多智能体学习算法在各种游戏中已经成功生成了超人规划,但对已部署的多智能体规划的设计影响有限。将这些技术应用于多智能体规划的关键瓶颈在于它们需要数十亿步的经验。为了实现在大规模上的多智能体规划研究,我们推出了GPUDrive。GPUDrive是一款基于Madrona游戏引擎的GPU加速多智能体模拟器,每秒能生成超过一百万步的模拟。观察、奖励和动态函数直接用C++编写,允许用户定义复杂、异构的智能体行为,降低为高性能CUDA。尽管有这些底层优化,GPUDrive完全可以通过Python访问,为多智能体闭环模拟提供了无缝、高效的工作流程。我们使用GPUDrive在Waymo Open Motion数据集上训练强化学习智能体,能在几分钟内实现有效的目标达成,并在数小时内扩展到数千个场景。我们在https://github.com/Emerge-Lab/gpudrive公开了代码和预训练智能体。
论文及项目相关链接
PDF ICLR 2025 camera-ready version
Summary
GPU加速的多智能体模拟器GPUDrive可生成每秒超百万步的智能体模拟,适用于大规模的多智能体规划研究。GPUDrive基于Madrona游戏引擎构建,可直接在C++中编写观察、奖励和动态函数,以定义复杂、异构的智能体行为。通过Python访问GPUDrive可实现无缝高效的多智能体闭环模拟。利用GPUDrive训练强化学习智能体可达到高效的实时目标达成并可在数小时内扩展到数千个场景。我们公开的代码和预训练智能体可在https://github.com/Emerge-Lab/gpudrive获取。
Key Takeaways
- GPU加速的多智能体模拟器GPUDrive可以实现大规模的多智能体规划研究,具有快速模拟能力。
- GPUDrive基于Madrona游戏引擎构建,支持复杂的异构智能体行为定义。
- GPUDrive通过Python接口提供无缝高效的多智能体闭环模拟。
- GPUDrive能够利用强化学习在Waymo Open Motion数据集上训练智能体。
- GPUDrive能够在短时间内实现高效的实时目标达成,并能快速扩展到数千个场景。
- GPUDrive已在https://github.com/Emerge-Lab/gpudrive上开源提供代码和预训练智能体供用户使用和研究。
点此查看论文截图