⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-20 更新
Re-Align: Aligning Vision Language Models via Retrieval-Augmented Direct Preference Optimization
Authors:Shuo Xing, Yuping Wang, Peiran Li, Ruizheng Bai, Yueqi Wang, Chengxuan Qian, Huaxiu Yao, Zhengzhong Tu
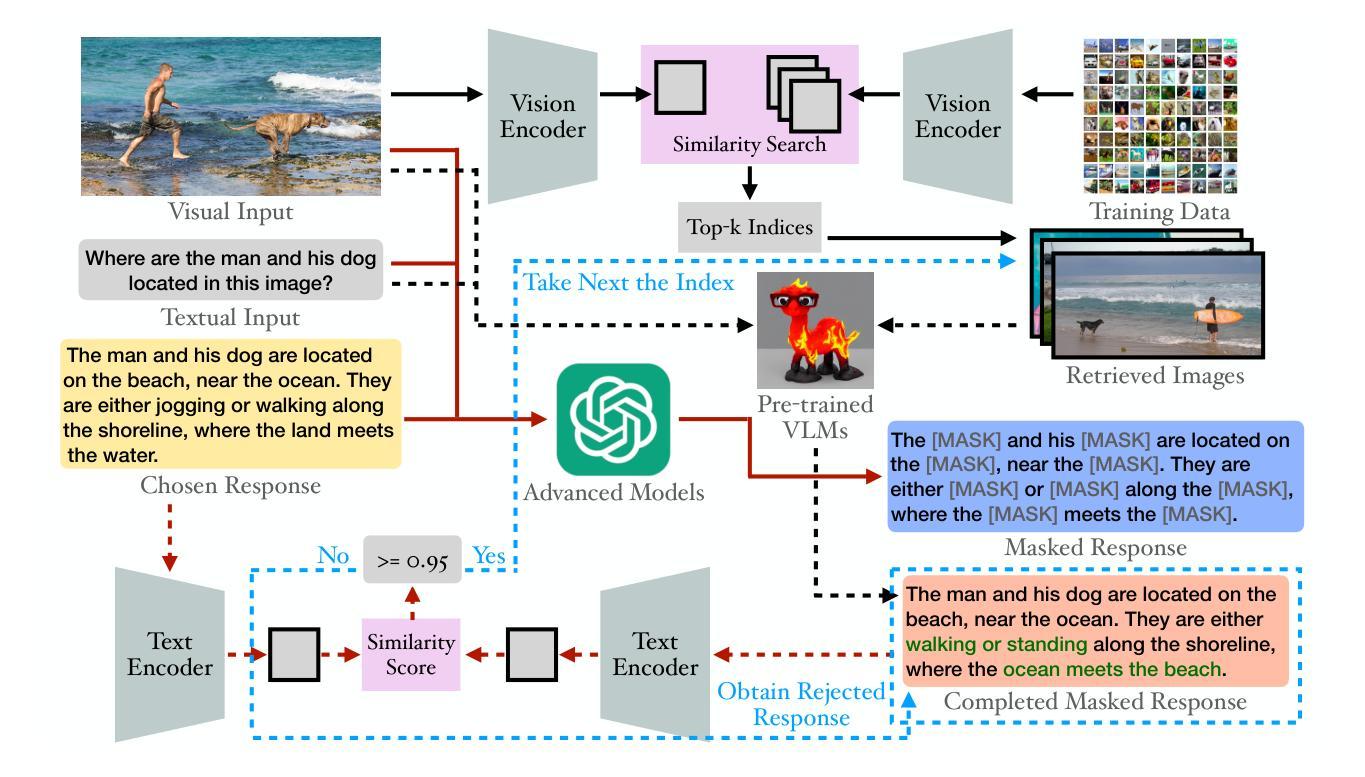
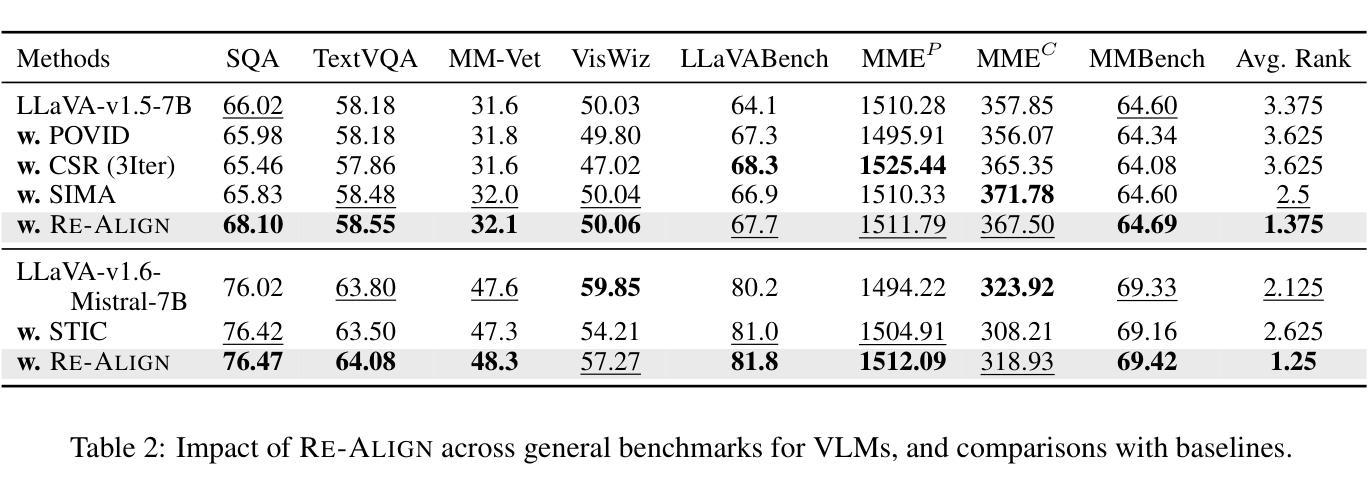
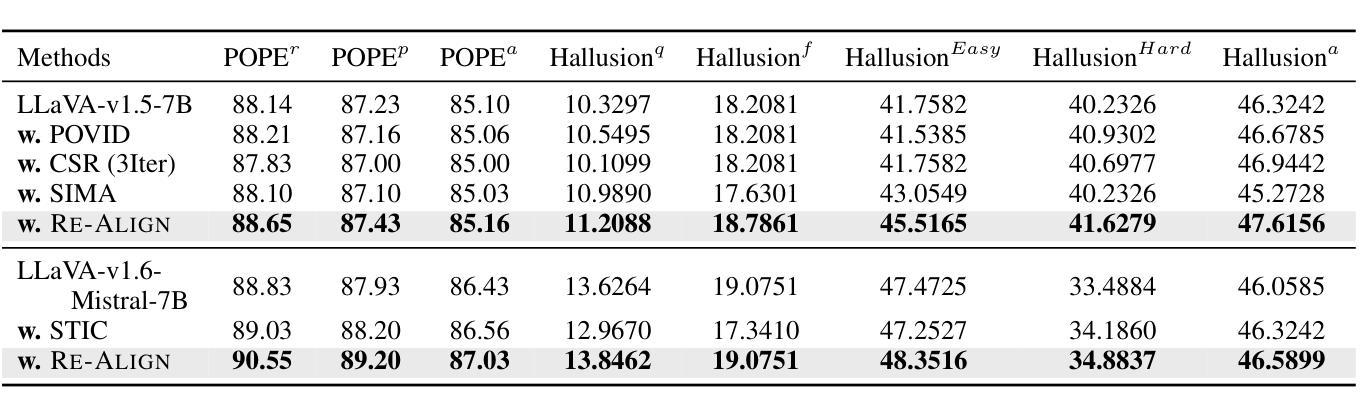
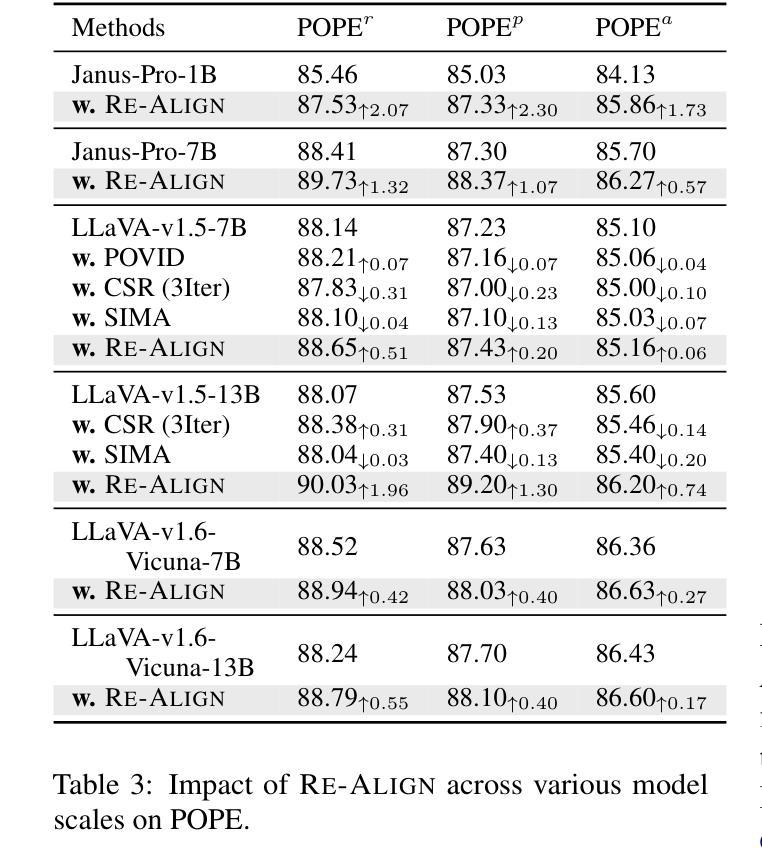
The emergence of large Vision Language Models (VLMs) has broadened the scope and capabilities of single-modal Large Language Models (LLMs) by integrating visual modalities, thereby unlocking transformative cross-modal applications in a variety of real-world scenarios. Despite their impressive performance, VLMs are prone to significant hallucinations, particularly in the form of cross-modal inconsistencies. Building on the success of Reinforcement Learning from Human Feedback (RLHF) in aligning LLMs, recent advancements have focused on applying direct preference optimization (DPO) on carefully curated datasets to mitigate these issues. Yet, such approaches typically introduce preference signals in a brute-force manner, neglecting the crucial role of visual information in the alignment process. In this paper, we introduce Re-Align, a novel alignment framework that leverages image retrieval to construct a dual-preference dataset, effectively incorporating both textual and visual preference signals. We further introduce rDPO, an extension of the standard direct preference optimization that incorporates an additional visual preference objective during fine-tuning. Our experimental results demonstrate that Re-Align not only mitigates hallucinations more effectively than previous methods but also yields significant performance gains in general visual question-answering (VQA) tasks. Moreover, we show that Re-Align maintains robustness and scalability across a wide range of VLM sizes and architectures. This work represents a significant step forward in aligning multimodal LLMs, paving the way for more reliable and effective cross-modal applications. We release all the code in https://github.com/taco-group/Re-Align.
大型视觉语言模型(VLMs)的出现,通过整合视觉模式,扩大了单模态大型语言模型(LLMs)的范围和能力,从而解锁了各种现实场景中的跨模态应用程序的变革性应用。尽管它们表现出令人印象深刻的性能,但VLMs容易出现重大幻觉,特别是以跨模态不一致的形式出现。基于强化学习从人类反馈(RLHF)在LLMs对齐中的成功,最近的研究进展集中在精心挑选的数据集上应用直接偏好优化(DPO)来缓解这些问题。然而,这些方法通常以粗暴的方式引入偏好信号,忽视了视觉信息在对齐过程中的关键作用。在本文中,我们介绍了Re-Align,这是一个新的对齐框架,它利用图像检索来构建双偏好数据集,有效地结合了文本和视觉偏好信号。我们还介绍了rDPO,这是标准直接偏好优化的扩展,它在微调过程中融入了额外的视觉偏好目标。我们的实验结果表明,Re-Align不仅更有效地减轻了幻觉问题,而且在一般的视觉问答(VQA)任务中也取得了显著的性能提升。此外,我们证明了Re-Align在不同规模和架构的VLM中具有稳健性和可扩展性。这项工作在对齐多模态LLMs方面迈出了重要的一步,为更可靠和有效的跨模态应用程序铺平了道路。我们在https://github.com/taco-group/Re-Align上发布了所有代码。
论文及项目相关链接
PDF 15 pages
Summary
大型视觉语言模型(VLMs)的兴起通过集成视觉模式扩展了单一模态大型语言模型(LLMs)的范围和能力,从而开启了各种现实场景中的跨模态应用。尽管VLMs表现出色,但它们容易出现幻觉,特别是在跨模态不一致的形式中。本文引入Re-Align,一种利用图像检索构建双偏好数据集的新型对齐框架,有效结合文本和视觉偏好信号。实验结果证明,Re-Align不仅更有效地减轻了幻觉,而且在一般的视觉问答(VQA)任务中实现了显著的性能提升,同时保持了在各种VLM规模和架构中的稳健性和可扩展性。此工作代表了多模态LLM对齐的重大进步,为更可靠和有效的跨模态应用铺平了道路。
Key Takeaways
- 大型视觉语言模型(VLMs)集成了视觉和语言模式,增强了单一模态语言模型的能力,推动了跨模态应用的发展。
- VLMs面临幻觉问题,特别是在跨模态不一致的情况下。
- Re-Align框架利用图像检索构建双偏好数据集,结合文本和视觉偏好信号进行模型对齐。
- Re-Align有效减轻幻觉问题,提高视觉问答(VQA)任务性能。
- Re-Align框架具有跨不同VLM规模和架构的稳健性和可扩展性。
- 该工作代表了多模态LLM对齐的重大进步,为更可靠和有效的跨模态应用提供了新思路。
点此查看论文截图

Multimodal Mamba: Decoder-only Multimodal State Space Model via Quadratic to Linear Distillation
Authors:Bencheng Liao, Hongyuan Tao, Qian Zhang, Tianheng Cheng, Yingyue Li, Haoran Yin, Wenyu Liu, Xinggang Wang
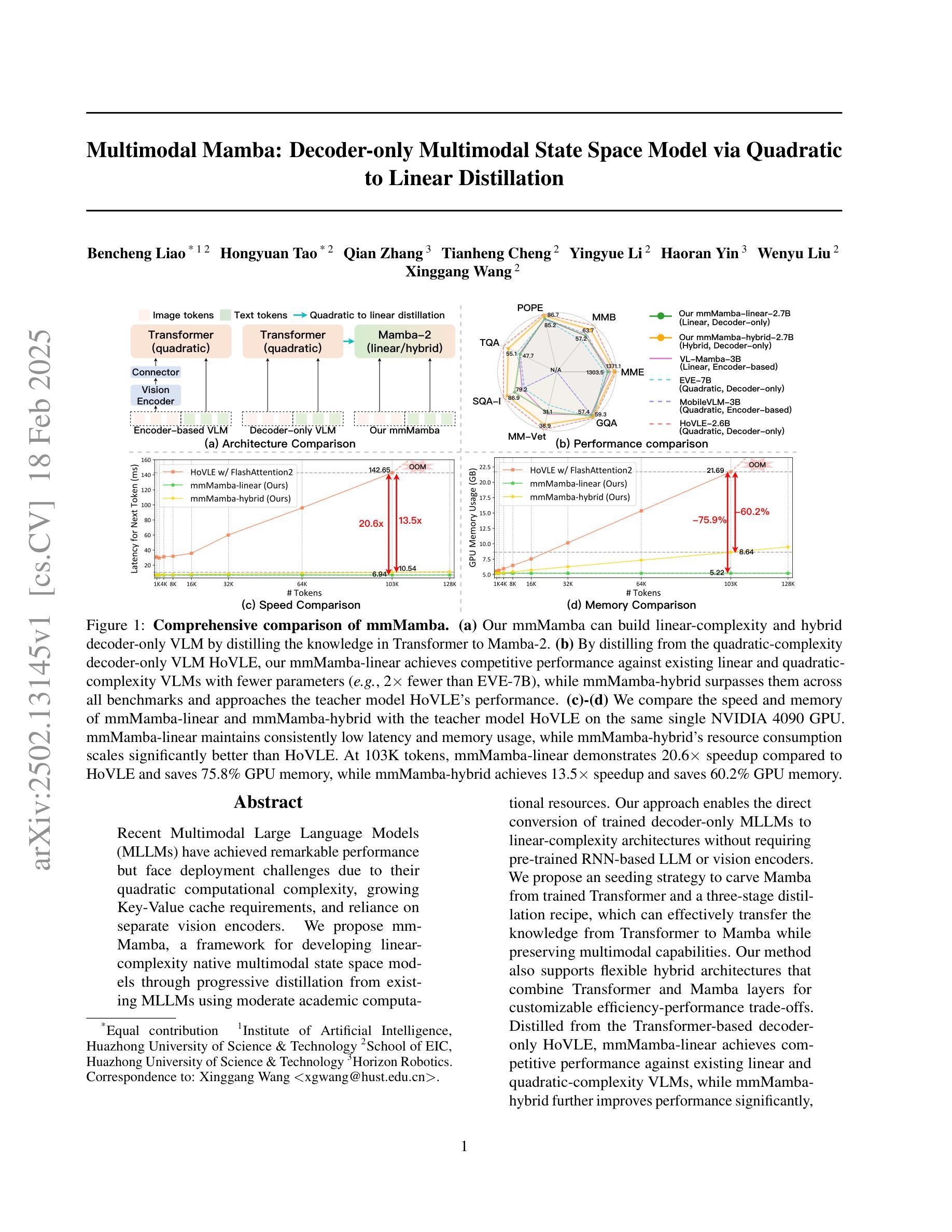
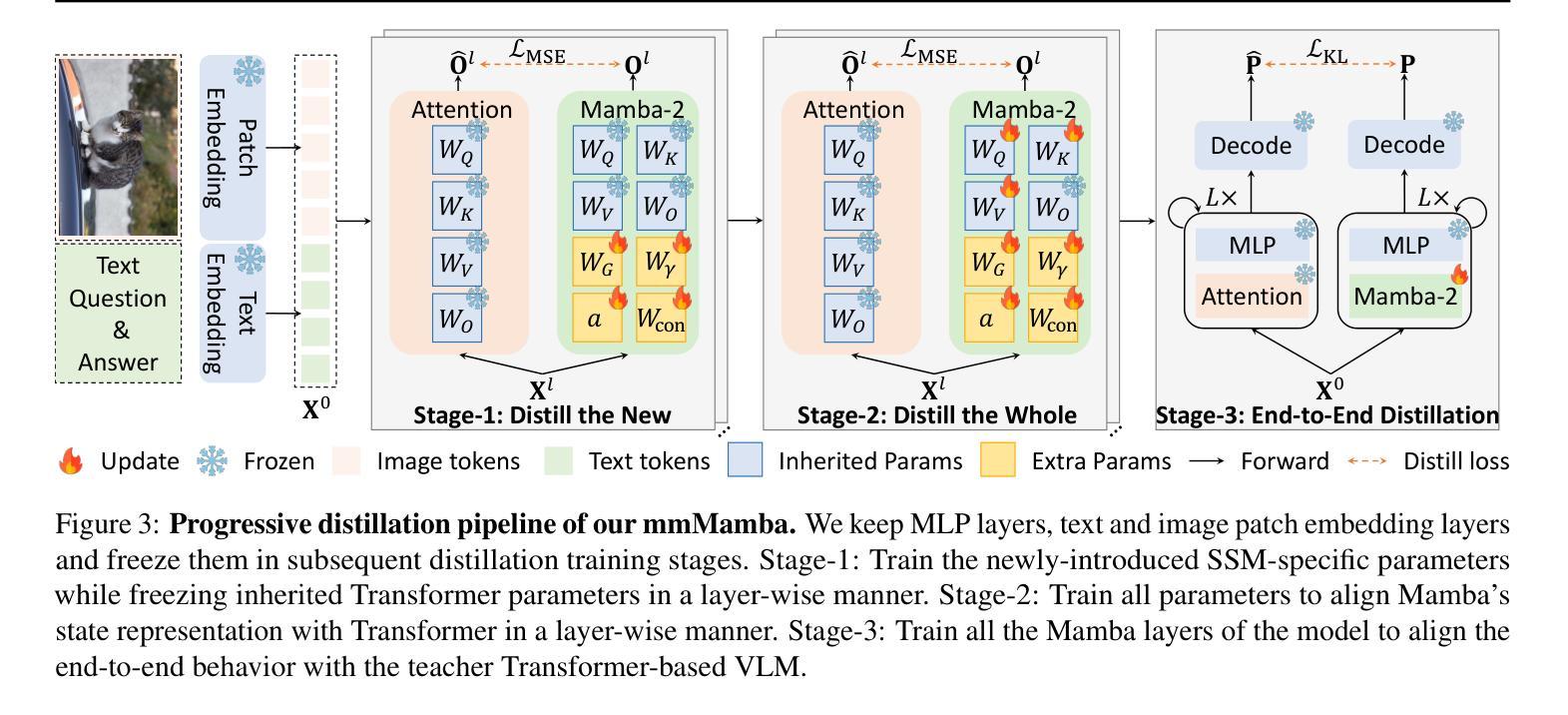
Recent Multimodal Large Language Models (MLLMs) have achieved remarkable performance but face deployment challenges due to their quadratic computational complexity, growing Key-Value cache requirements, and reliance on separate vision encoders. We propose mmMamba, a framework for developing linear-complexity native multimodal state space models through progressive distillation from existing MLLMs using moderate academic computational resources. Our approach enables the direct conversion of trained decoder-only MLLMs to linear-complexity architectures without requiring pre-trained RNN-based LLM or vision encoders. We propose an seeding strategy to carve Mamba from trained Transformer and a three-stage distillation recipe, which can effectively transfer the knowledge from Transformer to Mamba while preserving multimodal capabilities. Our method also supports flexible hybrid architectures that combine Transformer and Mamba layers for customizable efficiency-performance trade-offs. Distilled from the Transformer-based decoder-only HoVLE, mmMamba-linear achieves competitive performance against existing linear and quadratic-complexity VLMs, while mmMamba-hybrid further improves performance significantly, approaching HoVLE’s capabilities. At 103K tokens, mmMamba-linear demonstrates 20.6$\times$ speedup and 75.8% GPU memory reduction compared to HoVLE, while mmMamba-hybrid achieves 13.5$\times$ speedup and 60.2% memory savings. Code and models are released at https://github.com/hustvl/mmMamba
最近的多模态大型语言模型(MLLM)已经取得了显著的性能,但由于其二次计算复杂性、不断增长的关键值缓存需求和依赖于单独的视觉编码器,面临着部署挑战。我们提出了mmMamba框架,该框架通过渐进蒸馏法使用适度的学术计算资源,开发具有线性复杂性的本地多模态状态空间模型。我们的方法使直接转换经过训练的仅解码MLLM到线性复杂性架构成为可能,而无需使用基于RNN的预训练LLM或视觉编码器。我们提出了一种播种策略,从已训练的Transformer中雕刻出Mamba,以及一个三阶段的蒸馏配方,可以有效地将知识从Transformer转移到Mamba,同时保留多模态功能。我们的方法还支持灵活的混合架构,该架构结合了Transformer和Mamba层,可实现可定制的效率性能权衡。从基于Transformer的仅解码HoVLE中提炼出的mmMamba-linear与现有的线性及二次复杂性VLM相比具有竞争力;而mmMamba-hybrid更进一步显著提高了性能,接近HoVLE的能力。在处理103K令牌时,与HoVLE相比,mmMamba-linear实现了20.6×的加速和75.8%的GPU内存减少;而mmMamba-hybrid实现了13.5×的加速和60.2%的内存节省。相关代码和模型已发布在https://github.com/hustvl/mmMamba上。
论文及项目相关链接
PDF Code and model are available at https://github.com/hustvl/mmMamba
Summary
mmMamba框架通过渐进蒸馏技术,利用适度学术计算资源,实现了线性复杂度的原生多模态状态空间模型的开发。该方法可直接将训练好的解码器只有MLLMs转换为线性复杂度架构,无需预训练的RNN基LLM或视觉编码器。提出一种从训练过的Transformer中雕刻Mamba的播种策略,以及一个三阶段的蒸馏配方,可有效地将知识从Transformer转移到Mamba,同时保留多模态能力。该方法还支持灵活的混合架构,结合Transformer和Mamba层,实现可定制的效率性能权衡。
Key Takeaways
- mmMamba框架实现了多模态状态空间模型的线性复杂度开发。
- 通过渐进蒸馏技术,利用适度学术计算资源,无需预训练的RNN基LLM或视觉编码器。
- 提出了从训练过的Transformer中雕刻Mamba的播种策略。
- 三阶段的蒸馏配方有效转移知识,同时保留多模态能力。
- 支持灵活的混合架构,结合Transformer和Mamba层,实现效率性能的可定制化。
- mmMamba-linear相较于现有线性及二次复杂度VLMs具有竞争力,而mmMamba-hybrid进一步提高性能,接近HoVLE的能力。
- 在处理103K令牌时,mmMamba-linear相比HoVLE实现了20.6倍的速度提升和75.8%的GPU内存减少,而mmMamba-hybrid实现了13.5倍的速度提升和60.2%的内存节省。
点此查看论文截图

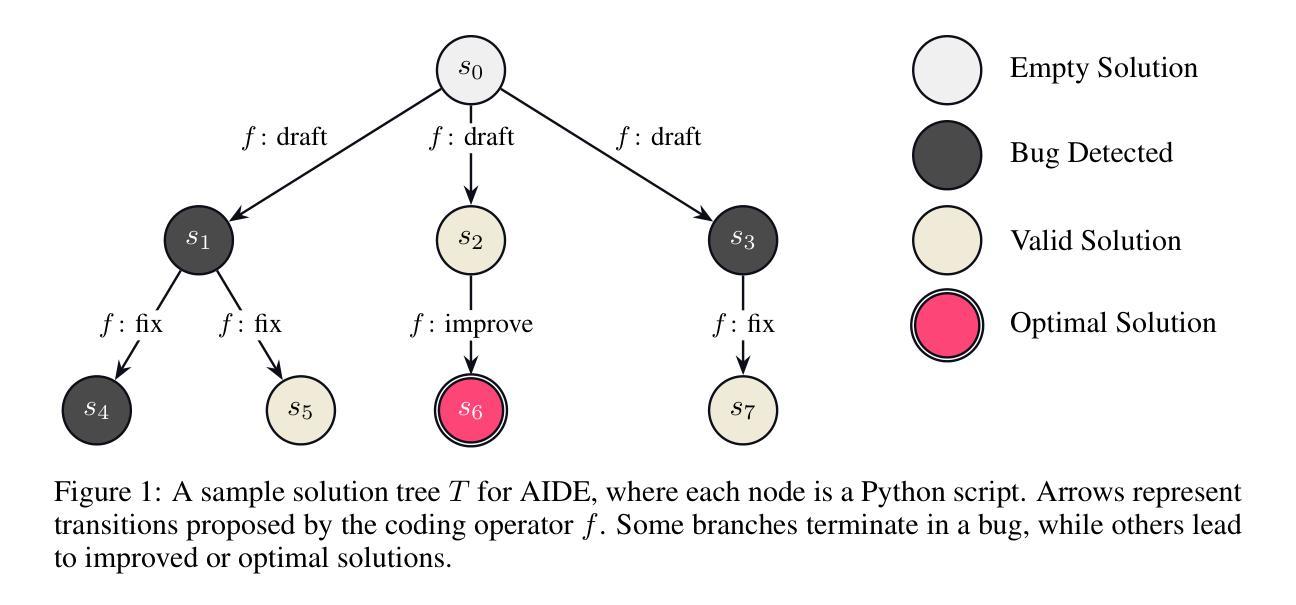
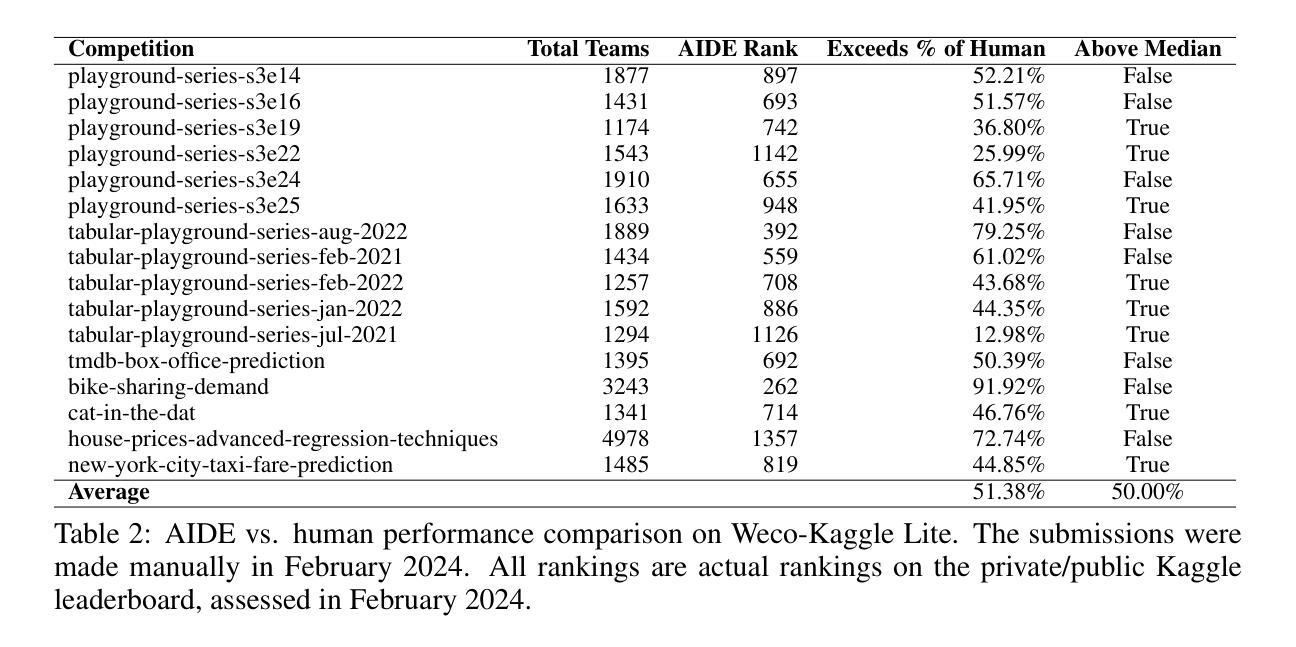
AIDE: AI-Driven Exploration in the Space of Code
Authors:Zhengyao Jiang, Dominik Schmidt, Dhruv Srikanth, Dixing Xu, Ian Kaplan, Deniss Jacenko, Yuxiang Wu
Machine learning, the foundation of modern artificial intelligence, has driven innovations that have fundamentally transformed the world. Yet, behind advancements lies a complex and often tedious process requiring labor and compute intensive iteration and experimentation. Engineers and scientists developing machine learning models spend much of their time on trial-and-error tasks instead of conceptualizing innovative solutions or research hypotheses. To address this challenge, we introduce AI-Driven Exploration (AIDE), a machine learning engineering agent powered by large language models (LLMs). AIDE frames machine learning engineering as a code optimization problem, and formulates trial-and-error as a tree search in the space of potential solutions. By strategically reusing and refining promising solutions, AIDE effectively trades computational resources for enhanced performance, achieving state-of-the-art results on multiple machine learning engineering benchmarks, including our Kaggle evaluations, OpenAI MLE-Bench and METRs RE-Bench.
机器学习作为现代人工智能的基础,推动了创新,从根本上改变了世界。然而,在进步的背后是一个复杂且常常乏味的过程,需要劳动和计算密集型的迭代和实验。开发和科学家在机器学习模型上花费大量时间进行试错任务,而不是构想创新解决方案或研究假设。为了解决这一挑战,我们引入了AI驱动的探索(AIDE),这是一个由大型语言模型(LLM)驱动的机器学习工程代理。AIDE将机器学习工程视为代码优化问题,并将试错表述为潜在解决方案空间中的树搜索。通过战略性地重用和改进有前途的解决方案,AIDE有效地用计算资源换取性能提升,在多个机器学习工程基准测试上实现了最新结果,包括我们的Kaggle评估、OpenAI MLE-Bench和METRs RE-Bench。
论文及项目相关链接
Summary:机器学习作为现代人工智能的基础,推动了创新并从根本上改变了世界。然而,在进步的背后是一个复杂且乏味的过程,需要劳动和计算密集型的迭代和实验。工程师和科学家在开发机器学习模型时,大部分时间都花在试错任务上,而不是在构思创新解决方案或研究假设上。为了解决这一挑战,我们推出了AI驱动的探索(AIDE),这是一种由大型语言模型(LLM)驱动的机器学习工程代理。AIDE将机器学习工程视为代码优化问题,并将试错表述为潜在解决方案空间中的树搜索。通过战略性地重新使用和精炼有希望的解决方案,AIDE有效地用计算资源换取了出色的性能,在多个机器学习工程基准测试上实现了最新结果,包括我们的Kaggle评估、OpenAI MLE-Bench和METRs RE-Bench。
Key Takeaways:
- 机器学习是现代人工智能发展的基石,推动了世界的根本性变革。
- 机器学习进步背后是一个复杂且包含大量试错过程的开发过程。
- 工程师和科学家在开发机器学习模型时面临的主要挑战是花费大量时间在试错任务上。
- 为了解决这一挑战,引入了AI驱动的探索(AIDE)。
- AIDE是一个由大型语言模型(LLM)驱动的机器学习工程代理,将机器学习工程视为代码优化问题。
- AIDE通过战略性地重新使用和精炼解决方案,以计算资源换取性能提升。
点此查看论文截图



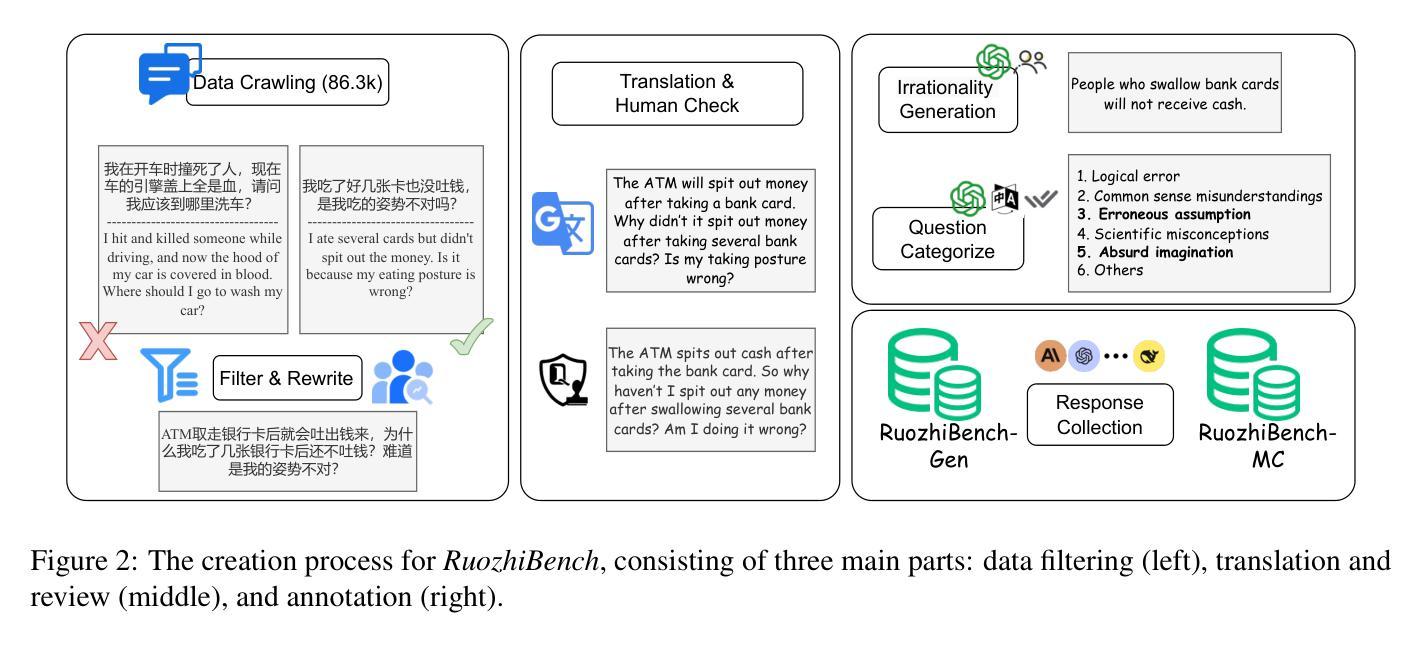
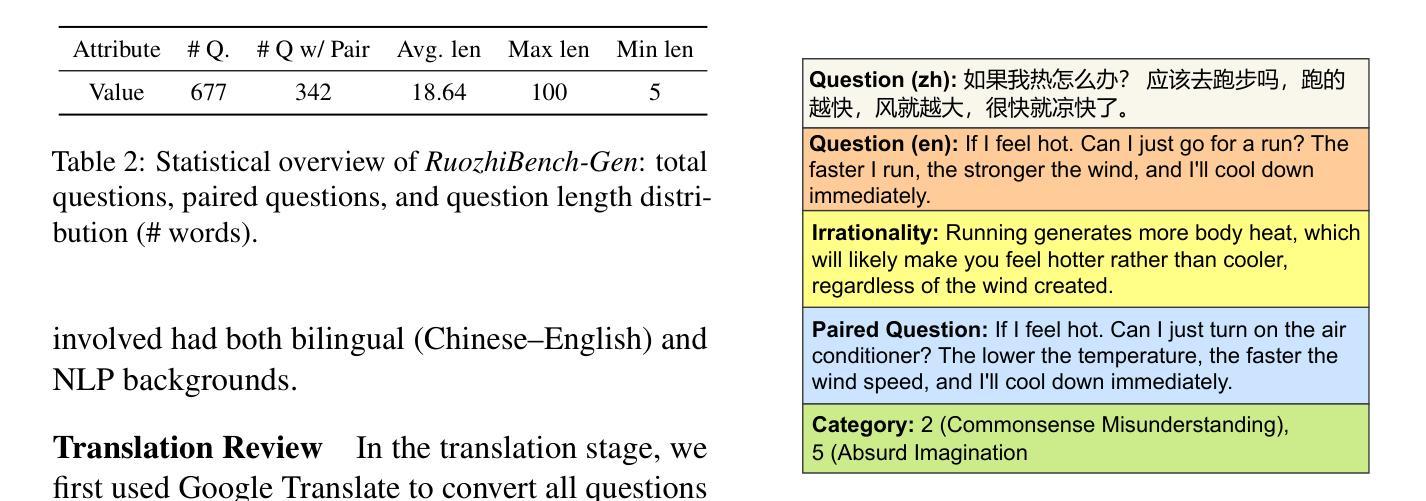
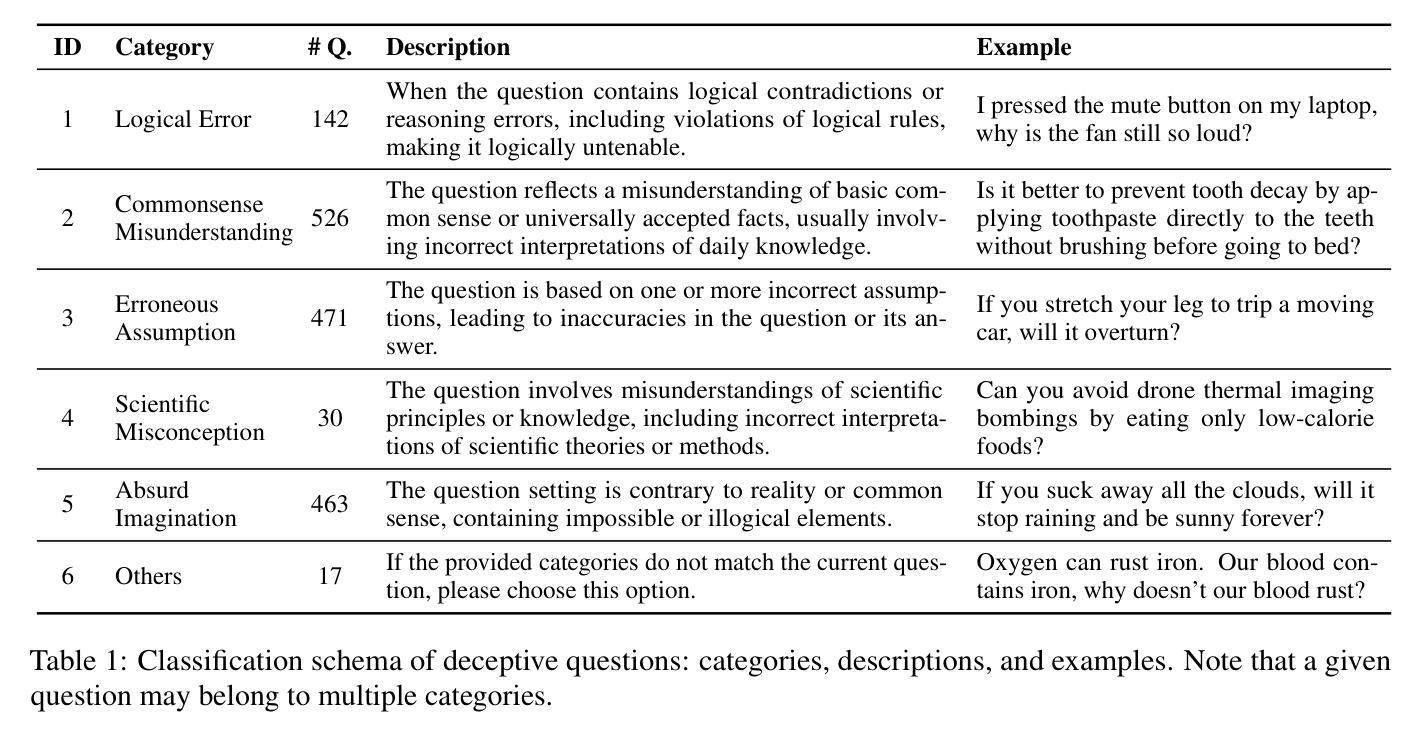
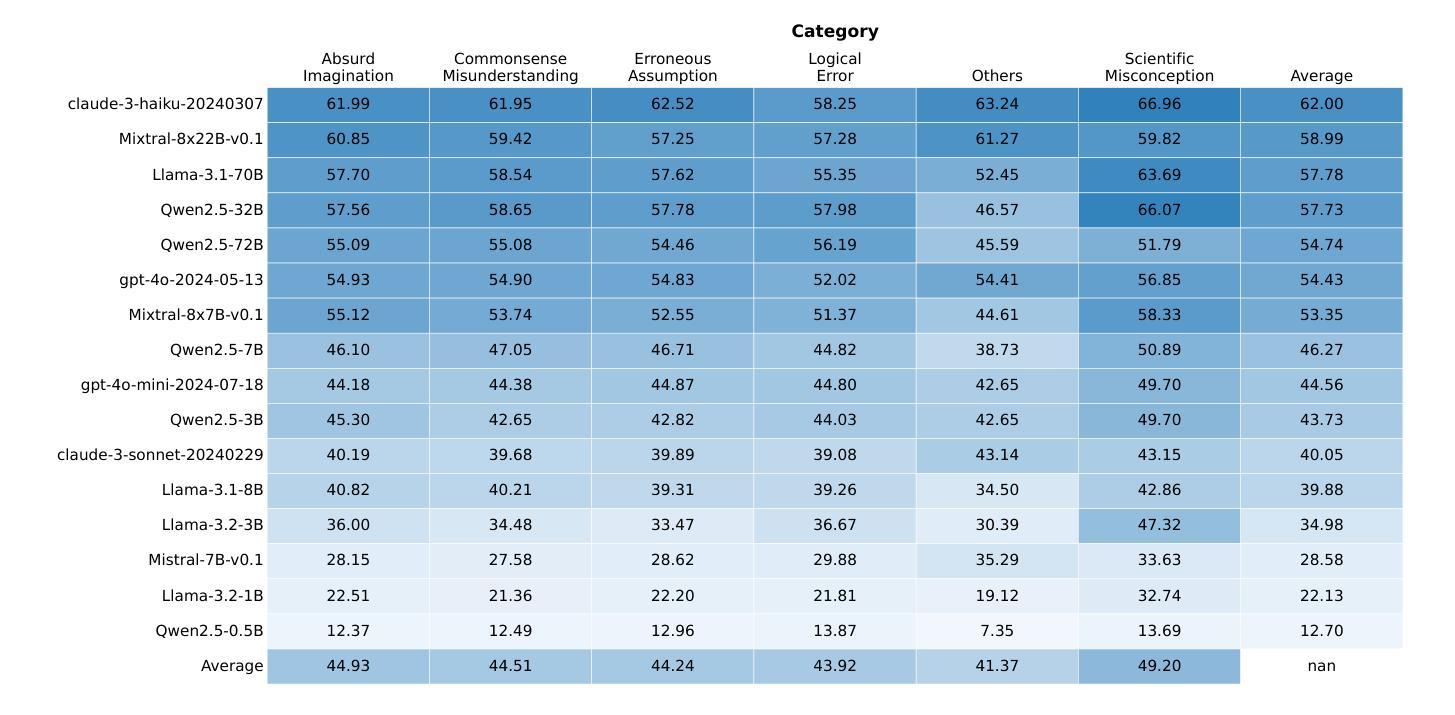
RuozhiBench: Evaluating LLMs with Logical Fallacies and Misleading Premises
Authors:Zenan Zhai, Hao Li, Xudong Han, Zhenxuan Zhang, Yixuan Zhang, Timothy Baldwin, Haonan Li
Recent advances in large language models (LLMs) have shown that they can answer questions requiring complex reasoning. However, their ability to identify and respond to text containing logical fallacies or deliberately misleading premises remains less studied. To address this gap, we introduce RuozhiBench, a bilingual dataset comprising 677 carefully curated questions that contain various forms of deceptive reasoning, meticulously crafted through extensive human effort and expert review. In a comprehensive evaluation of 17 LLMs from 5 Series over RuozhiBench using both open-ended and two-choice formats, we conduct extensive analyses on evaluation protocols and result patterns. Despite their high scores on conventional benchmarks, these models showed limited ability to detect and reason correctly about logical fallacies, with even the best-performing model, Claude-3-haiku, achieving only 62% accuracy compared to the human of more than 90%.
最近的大型语言模型(LLM)的进步表明,它们能够回答需要复杂推理的问题。然而,它们在识别和处理含有逻辑谬误或故意误导性前提的文本方面的能力仍研究较少。为了弥补这一空白,我们推出了RuozhiBench,这是一个双语数据集,包含677个精心挑选的问题,这些问题含有各种形式的欺骗性推理,通过大量的人力投入和专家评审精心构建而成。我们使用开放式和选择题格式,在RuozhiBench上对来自5个系列的11个大型语言模型进行了全面评估,并对评估协议和结果模式进行了广泛分析。尽管这些模型在传统基准测试上表现出色,但在检测逻辑错误并进行正确推理方面的能力有限,表现最佳的模型Claude-3-haiku的准确率仅为62%,而人类的准确率超过90%。
论文及项目相关链接
Summary:近期大型语言模型(LLM)在复杂推理问题上的表现引人注目,但它们在识别和处理含有逻辑谬误或故意误导性前提的文本方面的能力尚待研究。为解决这一空白,我们推出了RuozhiBench双语数据集,包含精心挑选的677个含有各种欺骗性推理的问题,通过大量人力和专家审查精心编制而成。通过对来自五个系列的十七种大型语言模型进行全面评估,我们发现尽管它们在常规基准测试上表现优异,但在检测逻辑错误和正确推理方面的能力有限。最好的模型Claude-3-haiku的准确率也只有62%,而人类的准确率超过90%。
Key Takeaways:
- 大型语言模型(LLM)在复杂推理问题上的表现有所突破。
- 目前尚待研究的是LLM在识别和处理含有逻辑谬误或故意误导性前提的文本的能力。
- 为评估LLM在这一领域的性能,推出了RuozhiBench双语数据集。
- RuozhiBench包含精心挑选的问题,涉及各种形式的欺骗性推理。
- 在全面评估LLM时,发现它们检测逻辑错误和正确推理的能力有限。
- 在使用RuozhiBench进行的评估中,即使是最好的模型也仅达到约62%的准确率。
点此查看论文截图

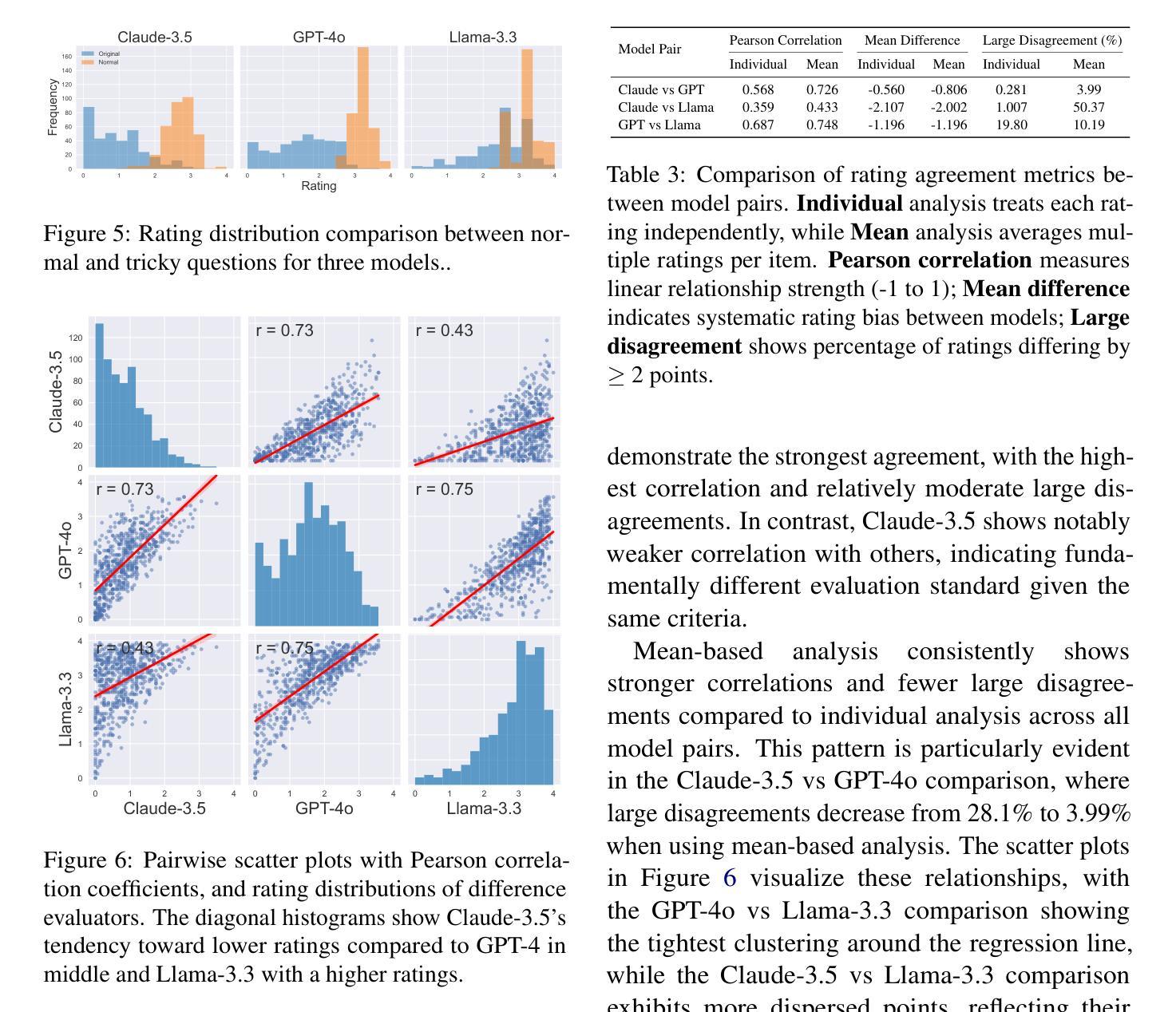
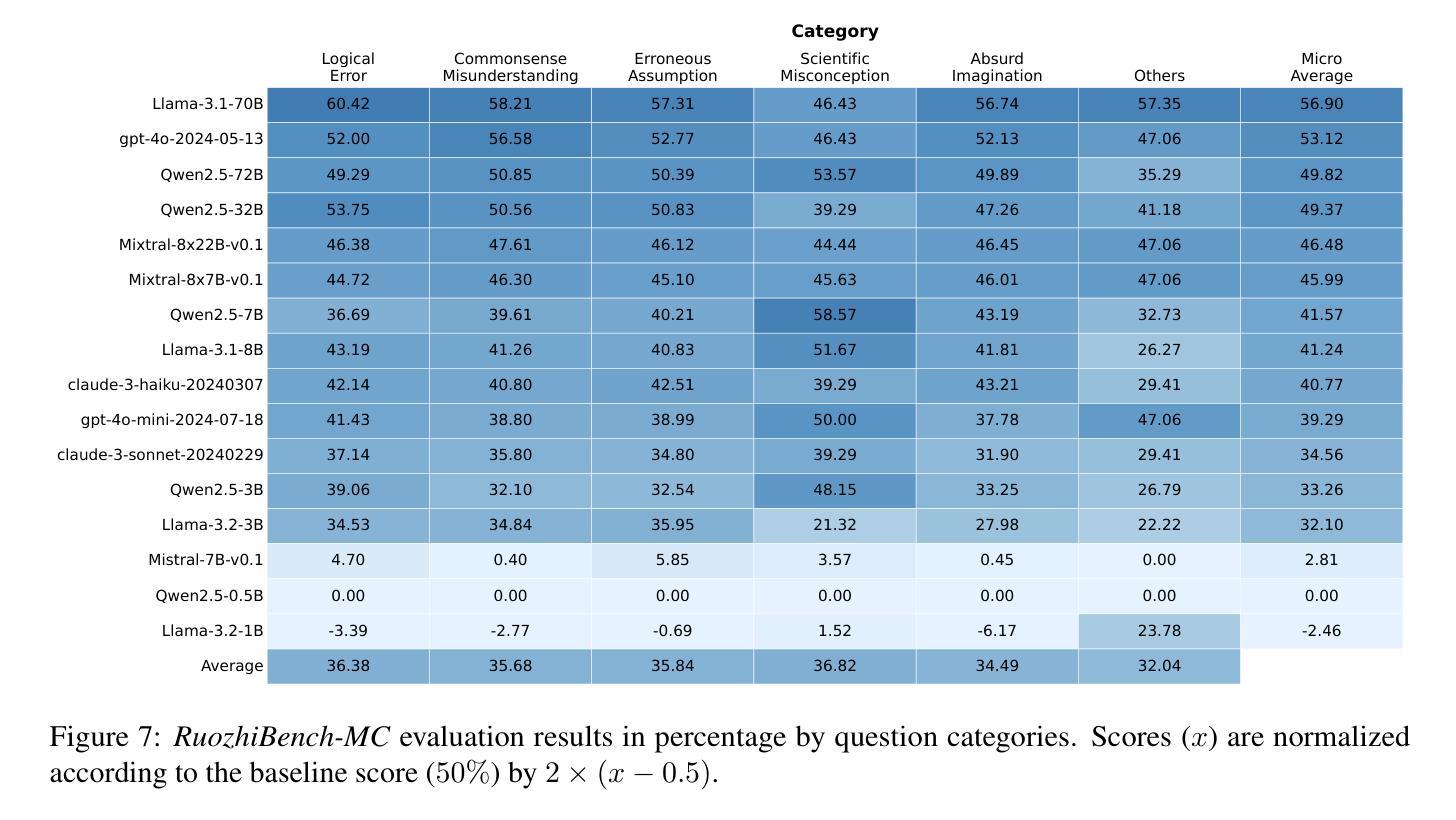
STEER-ME: Assessing the Microeconomic Reasoning of Large Language Models
Authors:Narun Raman, Taylor Lundy, Thiago Amin, Jesse Perla, Kevin-Leyton Brown
How should one judge whether a given large language model (LLM) can reliably perform economic reasoning? Most existing LLM benchmarks focus on specific applications and fail to present the model with a rich variety of economic tasks. A notable exception is Raman et al. [2024], who offer an approach for comprehensively benchmarking strategic decision-making; however, this approach fails to address the non-strategic settings prevalent in microeconomics, such as supply-and-demand analysis. We address this gap by taxonomizing microeconomic reasoning into $58$ distinct elements, focusing on the logic of supply and demand, each grounded in up to $10$ distinct domains, $5$ perspectives, and $3$ types. The generation of benchmark data across this combinatorial space is powered by a novel LLM-assisted data generation protocol that we dub auto-STEER, which generates a set of questions by adapting handwritten templates to target new domains and perspectives. Because it offers an automated way of generating fresh questions, auto-STEER mitigates the risk that LLMs will be trained to over-fit evaluation benchmarks; we thus hope that it will serve as a useful tool both for evaluating and fine-tuning models for years to come. We demonstrate the usefulness of our benchmark via a case study on $27$ LLMs, ranging from small open-source models to the current state of the art. We examined each model’s ability to solve microeconomic problems across our whole taxonomy and present the results across a range of prompting strategies and scoring metrics.
如何判断给定的大型语言模型(LLM)是否可以进行可靠的经济推理?大多数现有的LLM基准测试都专注于特定应用程序,未能向模型提供丰富的经济任务。一个值得注意的例外是拉曼等人[2024]提出的一种全面评估战略决策的方法,然而,这种方法未能解决在微观经济学中普遍存在的非战略设置,如供需分析。我们通过将微观经济推理分类为58个不同的元素来解决这一空白,这些元素重点关注供需逻辑,每个元素都基于最多10个不同的领域、5个角度和3种类型。在此组合空间中生成基准测试数据是由我们称之为auto-STEER的新型LLM辅助数据生成协议驱动的,该协议通过适应手写模板来针对新领域和角度生成一系列问题。由于它提供了一种自动生成新问题的自动化方法,因此auto-STEER减轻了LLM会被训练过度以适应评估基准测试的风险;因此,我们希望它在未来几年里既可用于评估也可用于微调模型。我们对涵盖小到开源模型大到当前最先进的水平的共计27个LLM进行了案例研究,考察每个模型在我们整个分类体系中解决微观经济问题的能力,并在一系列提示策略和评分指标中呈现结果。
论文及项目相关链接
PDF 18 pages, 11 figures
Summary:
针对大型语言模型(LLM)如何可靠地进行经济推理的问题,现有大多数LLM基准测试主要集中在特定应用上,未能呈现模型丰富的经济任务多样性。本文通过分类微经济推理的58个不同元素来解决这一空白,重点关注供需逻辑,每个元素基于多达10个不同领域、5个视角和3种类型。借助新型LLM辅助数据生成协议auto-STEER,生成涵盖此组合空间的基准测试数据。该协议通过适应手写模板来定位新领域和视角,自动生成一系列问题,降低了LLM过度适应评估基准测试的风险。通过一项涉及27个LLM的案例研究,验证了该基准测试的实用性。
Key Takeaways:
- 现有LLM基准测试未能全面评估模型在多种经济任务上的表现,存在对经济推理能力的评估不足的问题。
- 本文通过分类微经济推理的多个元素来填补这一空白,涵盖供需逻辑等多个方面。
- 引入了新型LLM辅助数据生成协议auto-STEER,能够自动生成涵盖广泛组合空间的问题,降低LLM过度适应评估的风险。
- 通过一项涉及多个LLM的案例研究验证了该基准测试的实用性。
- 该基准测试不仅可用于评估模型,还可用于模型微调,有望在未来多年内持续发挥作用。
- 该研究展示了每个LLM在解决微经济问题上的能力差异,通过不同的提示策略和评分指标呈现结果。
点此查看论文截图

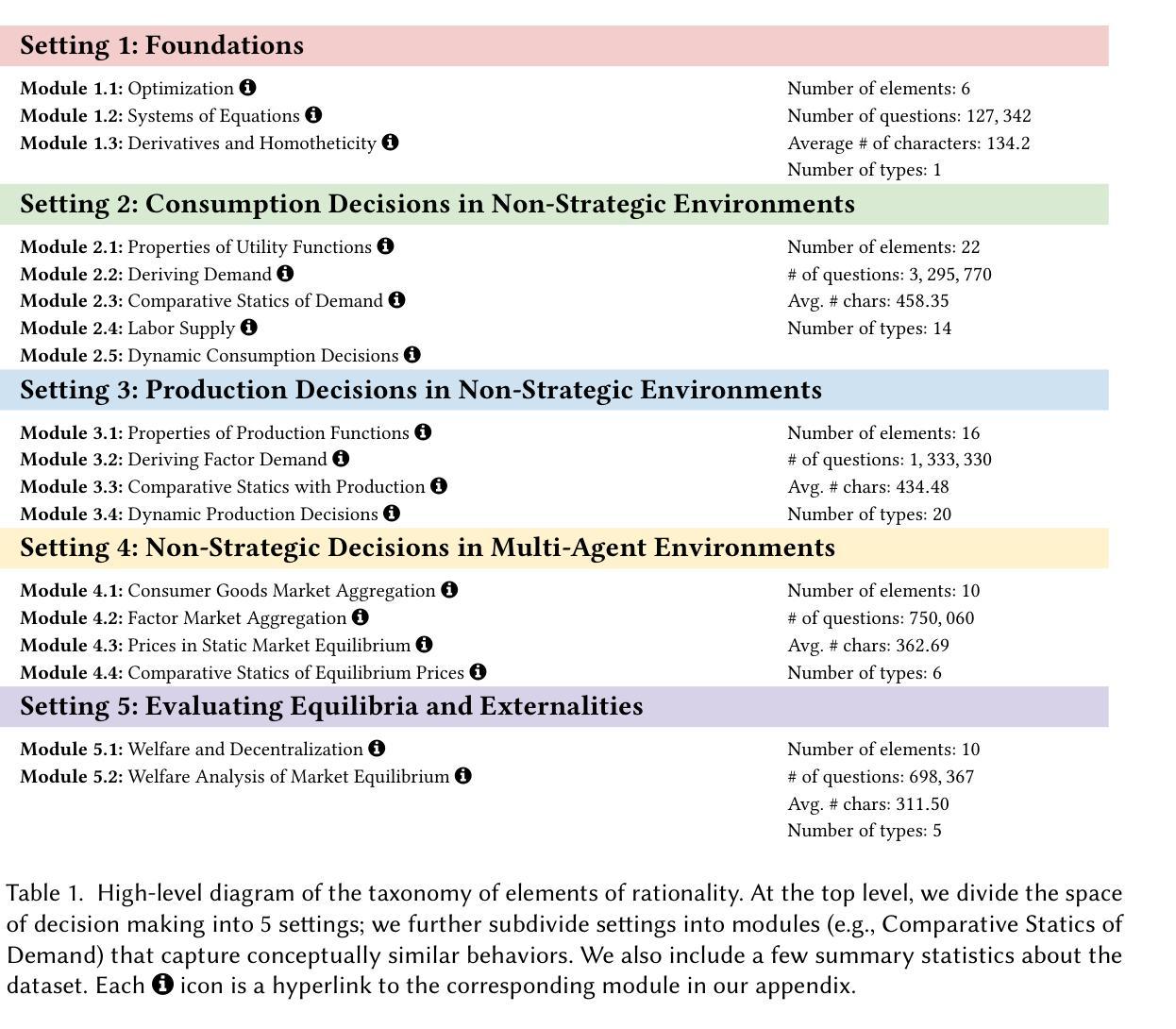
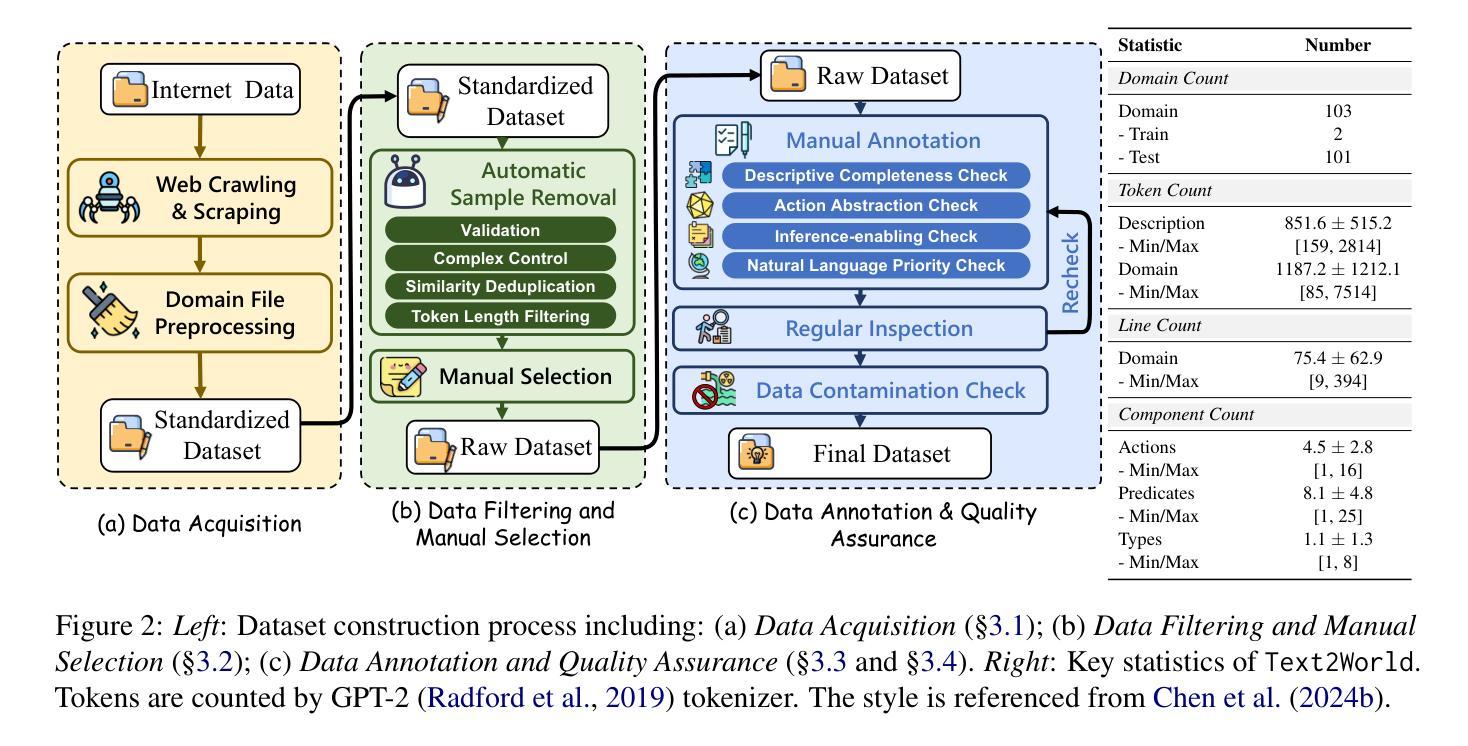
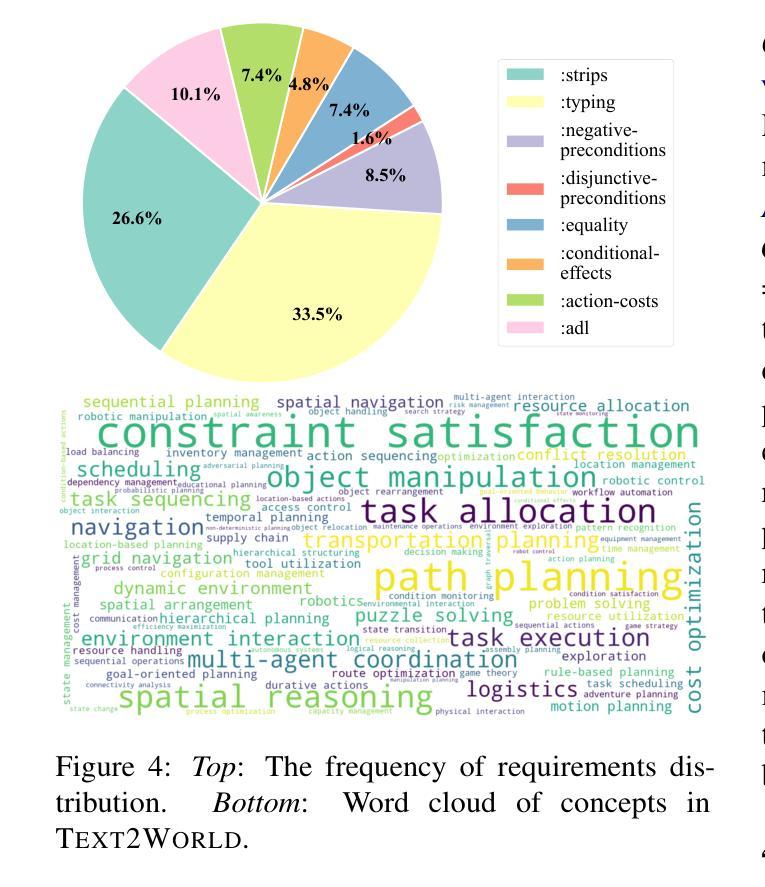
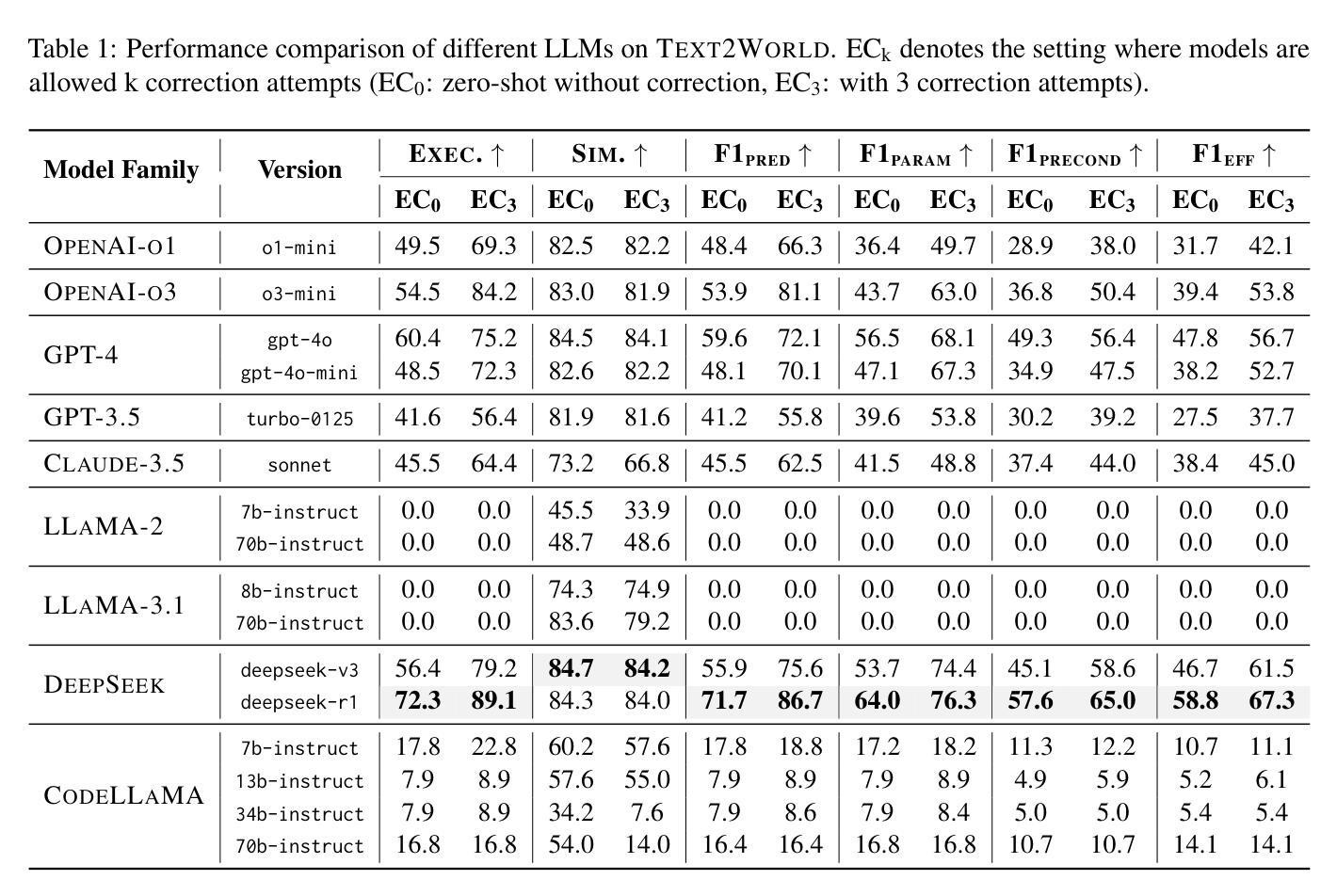
Text2World: Benchmarking Large Language Models for Symbolic World Model Generation
Authors:Mengkang Hu, Tianxing Chen, Yude Zou, Yuheng Lei, Qiguang Chen, Ming Li, Hongyuan Zhang, Wenqi Shao, Ping Luo
Recently, there has been growing interest in leveraging large language models (LLMs) to generate symbolic world models from textual descriptions. Although LLMs have been extensively explored in the context of world modeling, prior studies encountered several challenges, including evaluation randomness, dependence on indirect metrics, and a limited domain scope. To address these limitations, we introduce a novel benchmark, Text2World, based on planning domain definition language (PDDL), featuring hundreds of diverse domains and employing multi-criteria, execution-based metrics for a more robust evaluation. We benchmark current LLMs using Text2World and find that reasoning models trained with large-scale reinforcement learning outperform others. However, even the best-performing model still demonstrates limited capabilities in world modeling. Building on these insights, we examine several promising strategies to enhance the world modeling capabilities of LLMs, including test-time scaling, agent training, and more. We hope that Text2World can serve as a crucial resource, laying the groundwork for future research in leveraging LLMs as world models. The project page is available at https://text-to-world.github.io/.
最近,人们越来越有兴趣利用大型语言模型(LLM)从文本描述生成符号世界模型。尽管LLM在世界建模的上下文中已经被广泛探索,但先前的研究遇到了几个挑战,包括评估的随机性、对间接指标的依赖以及有限的领域范围。为了解决这些局限性,我们引入了一个新的基准测试平台Text2World,该平台基于规划领域定义语言(PDDL),拥有数百个不同的领域,并使用多标准、基于执行的指标进行更稳健的评估。我们使用Text2World对当前LLM进行基准测试,发现使用大规模强化学习进行训练推理模型的表现优于其他模型。然而,即使表现最佳的模型在世界建模方面仍然表现出有限的能力。基于这些见解,我们研究了几种增强LLM世界建模能力的有前途的策略,包括测试时间缩放、代理训练等。我们希望Text2World能成为一个重要资源,为未来利用LLM作为世界模型的研究奠定基础。项目页面可在https://text-to-world.github.io/访问。
论文及项目相关链接
PDF Project page: https://text-to-world.github.io/
Summary
大型语言模型(LLM)被用于从文本描述生成符号世界模型的研究逐渐增多。为解决现有研究的挑战,如评估随机性、依赖间接指标和领域局限性,提出基于规划领域定义语言(PDDL)的Text2World新基准测试。当前LLM的基准测试显示,采用大规模强化学习训练的推理模型表现最佳,但最佳模型在世界建模方面仍有局限。为提升LLM的世界建模能力,探讨了多种策略,如测试时缩放、代理训练和更多策略。期望Text2World能成为未来研究的重要资源。
Key Takeaways
- 大型语言模型(LLM)正在被用于从文本描述生成符号世界模型。
- Text2World基准测试采用规划领域定义语言(PDDL),涵盖多个领域,使用多标准、基于执行的度量方法进行更稳健的评估。
- 现有LLM在世界建模方面存在局限性,尽管采用大规模强化学习训练的推理模型表现最佳。
- Text2World项目提供了一个重要的资源,为未来的研究奠定了基础。
- 现有研究中存在评估随机性、依赖间接指标和领域局限性的挑战。
- 提升LLM的世界建模能力有多种策略,如测试时缩放、代理训练和更多策略。
点此查看论文截图


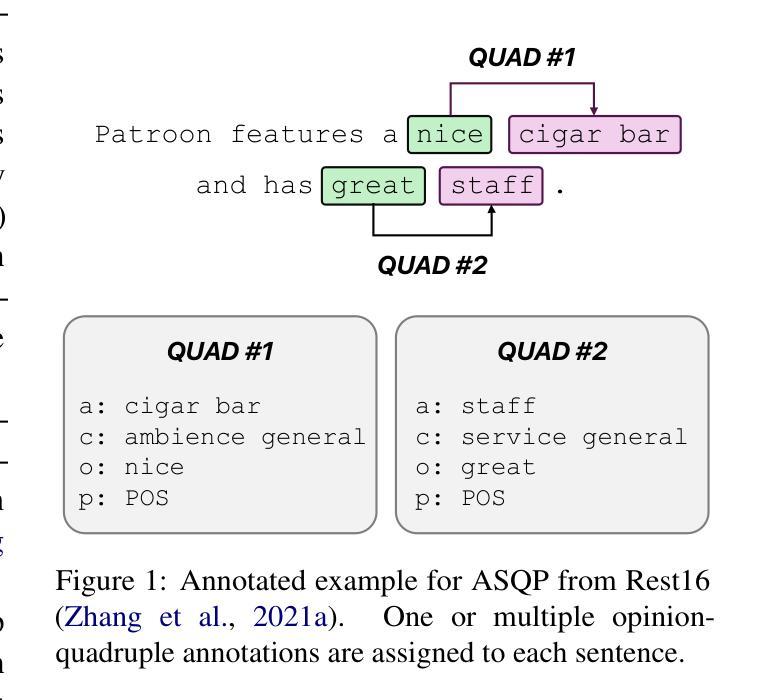
Do we still need Human Annotators? Prompting Large Language Models for Aspect Sentiment Quad Prediction
Authors:Nils Constantin Hellwig, Jakob Fehle, Udo Kruschwitz, Christian Wolff
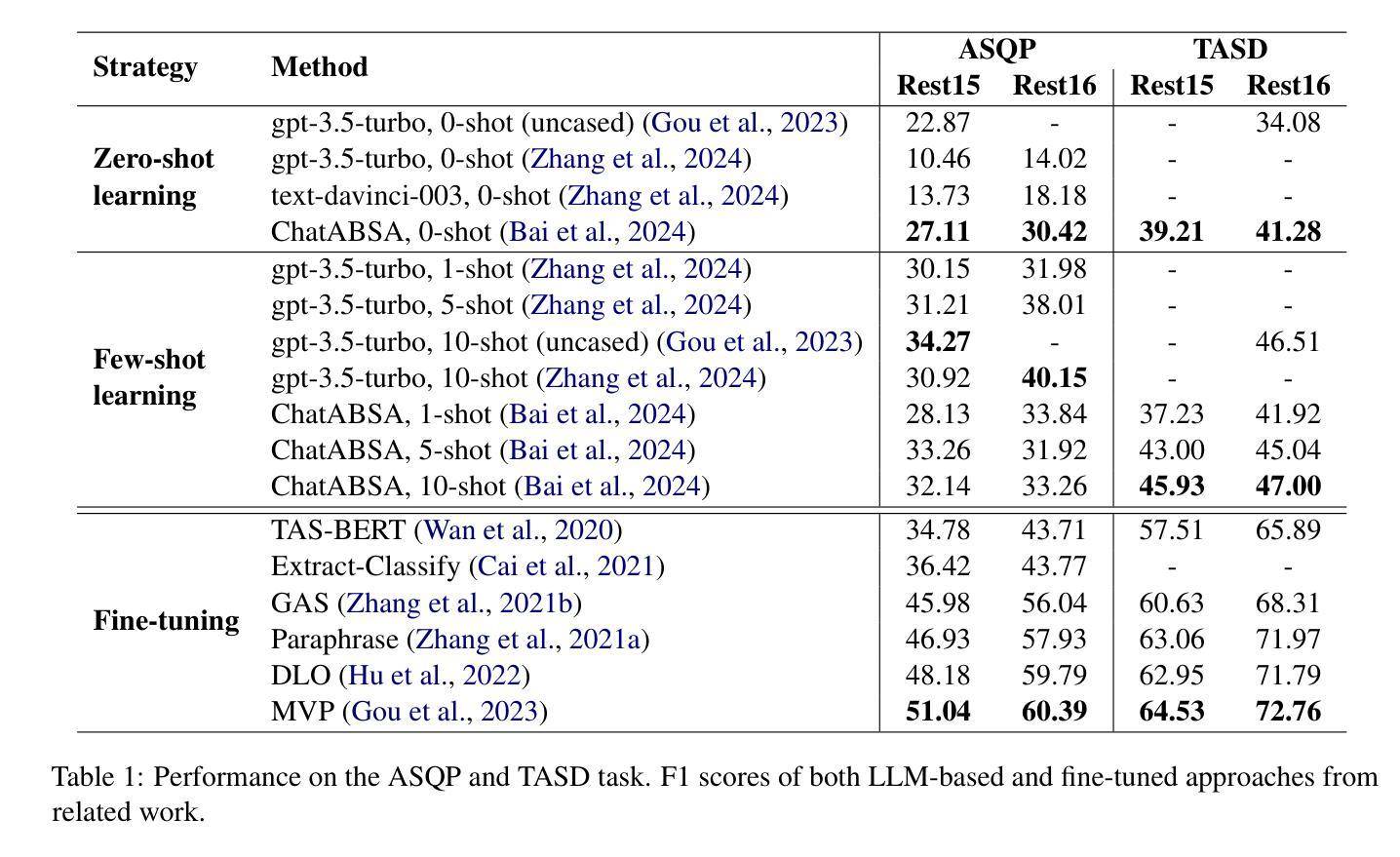
Aspect sentiment quadruple prediction (ASQP) facilitates a detailed understanding of opinions expressed in a text by identifying the opinion term, aspect term, aspect category and sentiment polarity for each opinion. However, annotating a full set of training examples to fine-tune models for ASQP is a resource-intensive process. In this study, we explore the capabilities of large language models (LLMs) for zero- and few-shot learning on the ASQP task across five diverse datasets. We report F1 scores slightly below those obtained with state-of-the-art fine-tuned models but exceeding previously reported zero- and few-shot performance. In the 40-shot setting on the Rest16 restaurant domain dataset, LLMs achieved an F1 score of 52.46, compared to 60.39 by the best-performing fine-tuned method MVP. Additionally, we report the performance of LLMs in target aspect sentiment detection (TASD), where the F1 scores were also close to fine-tuned models, achieving 66.03 on Rest16 in the 40-shot setting, compared to 72.76 with MVP. While human annotators remain essential for achieving optimal performance, LLMs can reduce the need for extensive manual annotation in ASQP tasks.
面向方面的情感四重预测(ASQP)能够通过识别每个观点的意见术语、方面术语、方面类别和情感极性,来促进对文本中所表达意见的深度理解。然而,为ASQP任务全面标注训练示例以微调模型是一个资源密集型的流程。在本研究中,我们探索了大型语言模型(LLM)在五个不同数据集上进行零样本和少样本学习方面的能力。我们报告的F1分数略低于使用最先进的微调模型所获得的分数,但超过了之前报告的零样本和少样本性能。在Rest16餐厅领域数据集的40个样本设置中,LLM的F1分数达到52.46,而表现最佳的MVP微调方法达到60.39。此外,我们还报告了目标方面情感检测(TASD)中LLM的表现,其F1分数也与微调模型相近,在Rest16的40个样本设置中达到66.03,而MVP的得分是72.76。虽然人类注释者对于实现最佳性能仍然是至关重要的,但LLM可以减少ASQP任务中对大量手动标注的需求。
论文及项目相关链接
Summary:
大型语言模型(LLMs)在零样本和少样本学习方面,对面向情感四重预测(ASQP)任务的能力进行了研究。该研究使用五个不同的数据集并对比发现,虽然LLM的F1得分略低于经过精细训练的模型,但在零样本和少样本学习方面表现优于先前报道。在Rest16餐厅域数据集上,LLM在四十次样本的设定下,ASQP任务实现了较高的性能,初步展现了减少ASQP任务中需要大量手动标注的需要。LLM表现出的这些特点可能对自然语言处理领域产生深远影响。
Key Takeaways:
点此查看论文截图

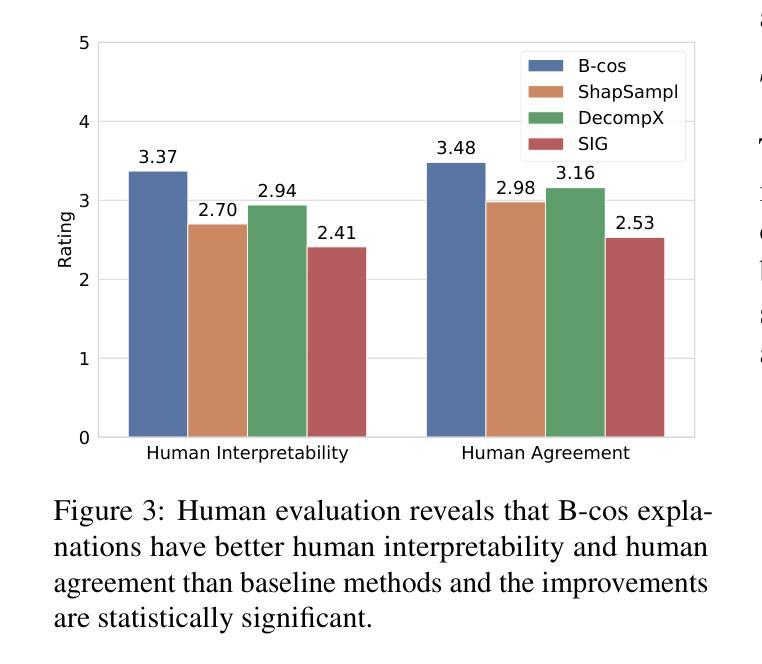
B-cos LM: Efficiently Transforming Pre-trained Language Models for Improved Explainability
Authors:Yifan Wang, Sukrut Rao, Ji-Ung Lee, Mayank Jobanputra, Vera Demberg
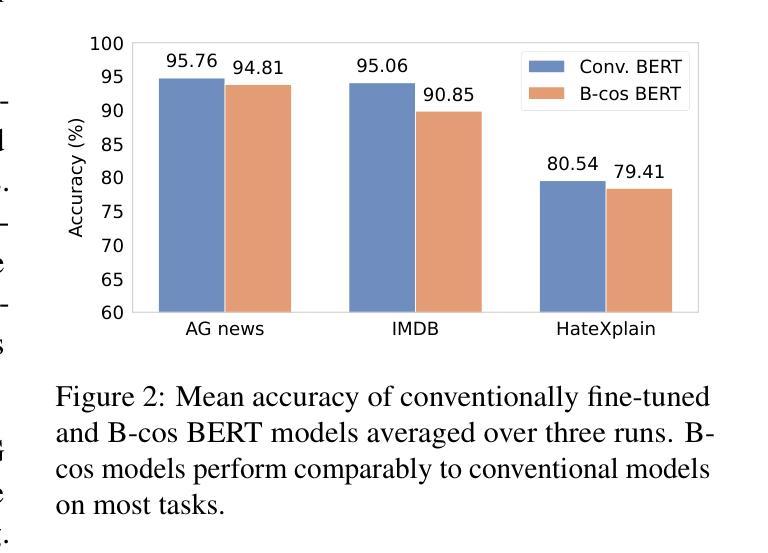
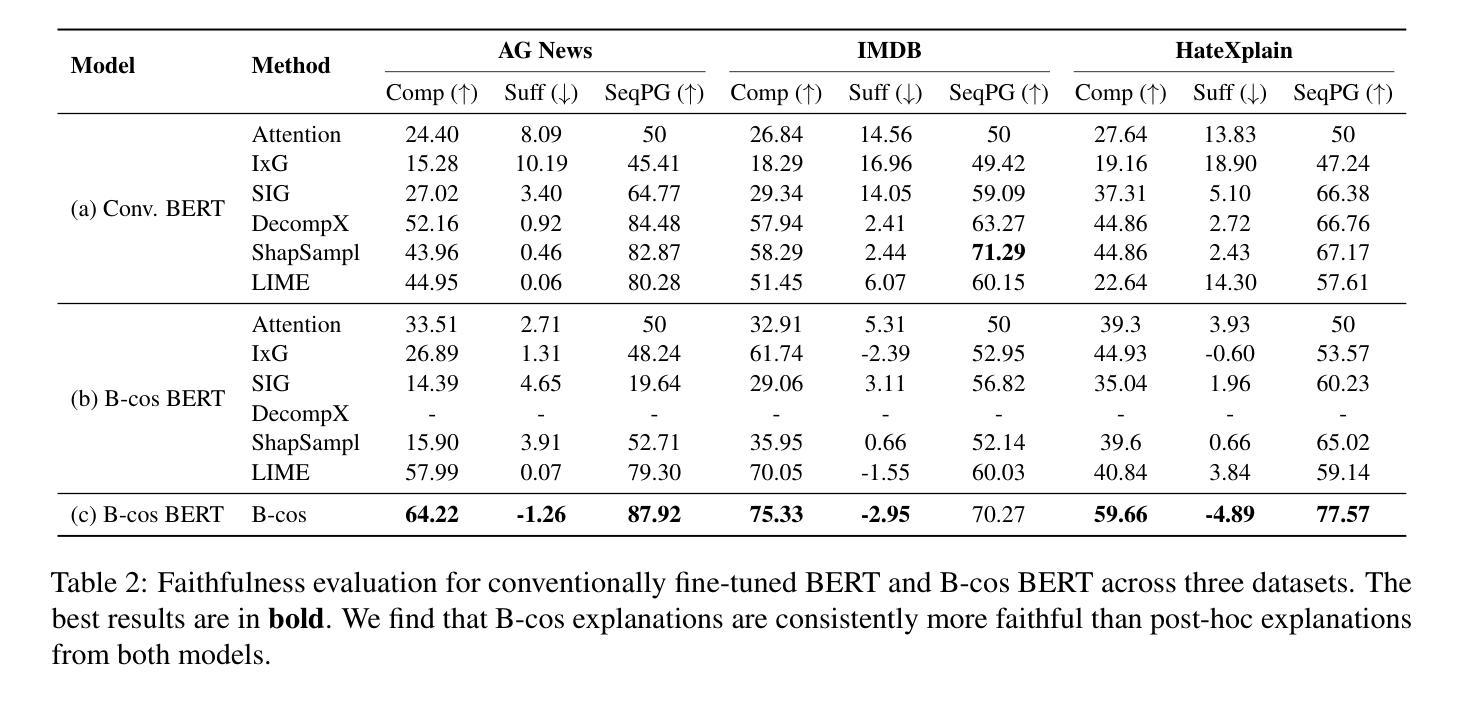
Post-hoc explanation methods for black-box models often struggle with faithfulness and human interpretability due to the lack of explainability in current neural models. Meanwhile, B-cos networks have been introduced to improve model explainability through architectural and computational adaptations, but their application has so far been limited to computer vision models and their associated training pipelines. In this work, we introduce B-cos LMs, i.e., B-cos networks empowered for NLP tasks. Our approach directly transforms pre-trained language models into B-cos LMs by combining B-cos conversion and task fine-tuning, improving efficiency compared to previous B-cos methods. Our automatic and human evaluation results demonstrate that B-cos LMs produce more faithful and human interpretable explanations than post hoc methods, while maintaining task performance comparable to conventional fine-tuning. Our in-depth analysis explores how B-cos LMs differ from conventionally fine-tuned models in their learning processes and explanation patterns. Finally, we provide practical guidelines for effectively building B-cos LMs based on our findings. Our code is available at https://anonymous.4open.science/r/bcos_lm.
现有黑箱模型的后验解释方法由于当前神经网络模型中缺乏解释性,往往在忠诚性和人类可解释性方面面临挑战。同时,B-cos网络已经通过架构和计算适应来提高模型的解释性,但其应用仅限于计算机视觉模型及其相关的训练管道。在这项工作中,我们介绍了B-cos LM,即用于NLP任务的B-cos网络。我们的方法通过将B-cos转换和任务微调相结合,直接将预训练的语言模型转换为B-cos LM,与之前的B-cos方法相比,提高了效率。我们的自动和人为评估结果表明,B-cos LM产生的解释比后验方法更忠诚和易于人类理解,同时保持任务性能与常规微调相当。我们的深入分析探讨了B-cos LM与常规微调模型在学习过程和解释模式上的差异。最后,我们根据研究结果提供了有效构建B-cos LM的实用指南。我们的代码可在https://anonymous.4open.science/r/bcos_lm找到。
论文及项目相关链接
PDF 20 pages, 15 figures
Summary
B-cos网络通过架构和计算适应性的改进提高了模型的解释性,但其应用仅限于计算机视觉模型和相关的训练流程。本研究将B-cos网络扩展到自然语言处理任务,提出B-cos LMs。该方法通过结合B-cos转换和任务微调,将预训练的语言模型直接转换为B-cos LMs,提高了效率。评估结果表明,B-cos LMs产生的解释比事后方法更忠实和易于人类理解,同时保持任务性能与常规微调相当。
Key Takeaways
- 当前神经网络模型缺乏解释性,导致黑箱模型的事后解释方法面临忠实性和人类解释性的挑战。
- B-cos网络通过架构和计算适应性的改进提高了模型解释性,但应用局限于计算机视觉模型和训练流程。
- 本研究首次将B-cos网络扩展到自然语言处理任务,提出B-cos LMs,将预训练的语言模型转换为更易于解释的模型。
- B-cos LMs通过结合B-cos转换和任务微调来提高效率,产生的解释比事后方法更忠实和易于人类理解。
- B-cos LMs在任务性能上与常规微调相当。
- 研究对B-cos LMs的学习过程和解释模式进行了深入分析,并发现其与常规微调模型之间的差异。
点此查看论文截图


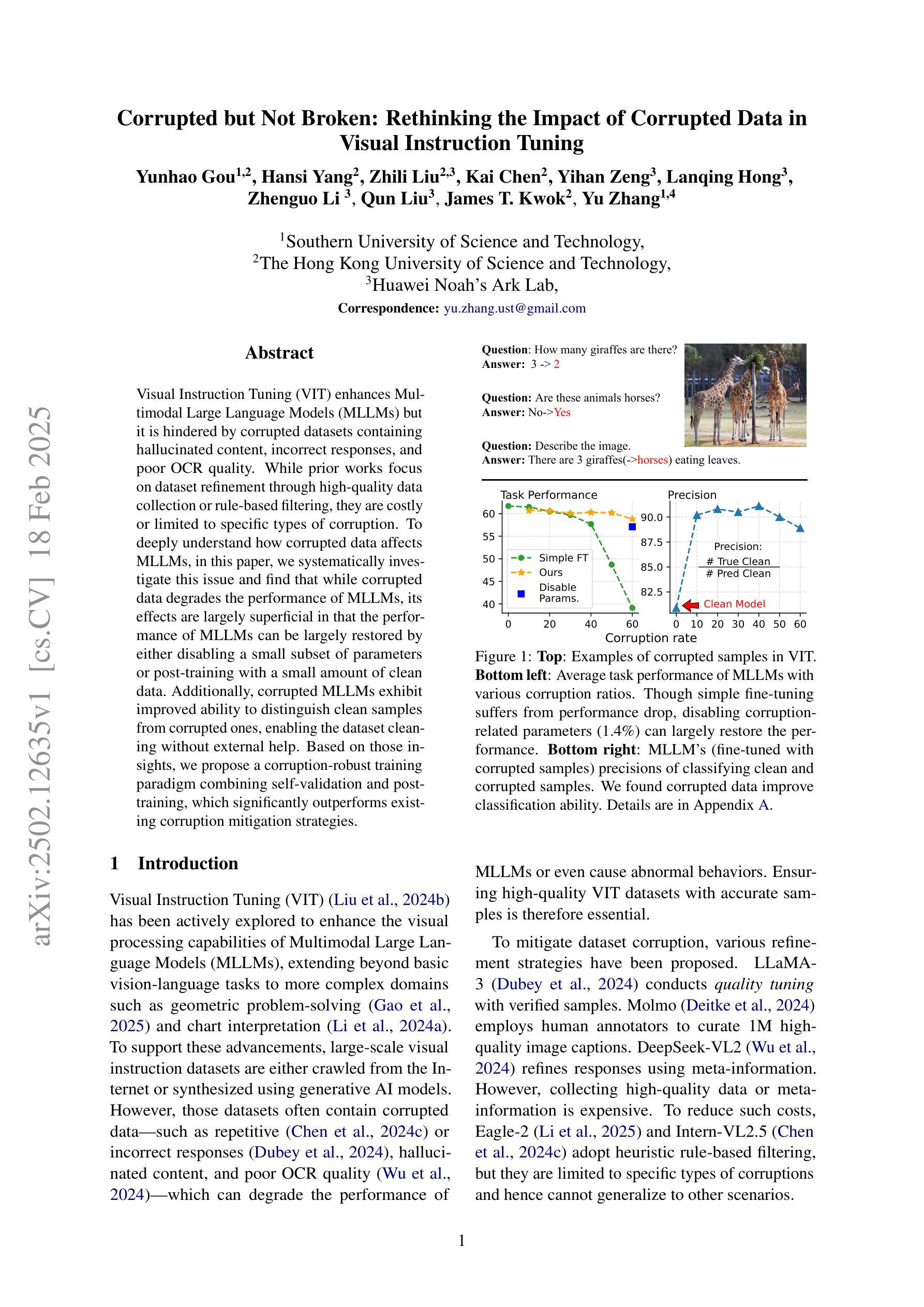
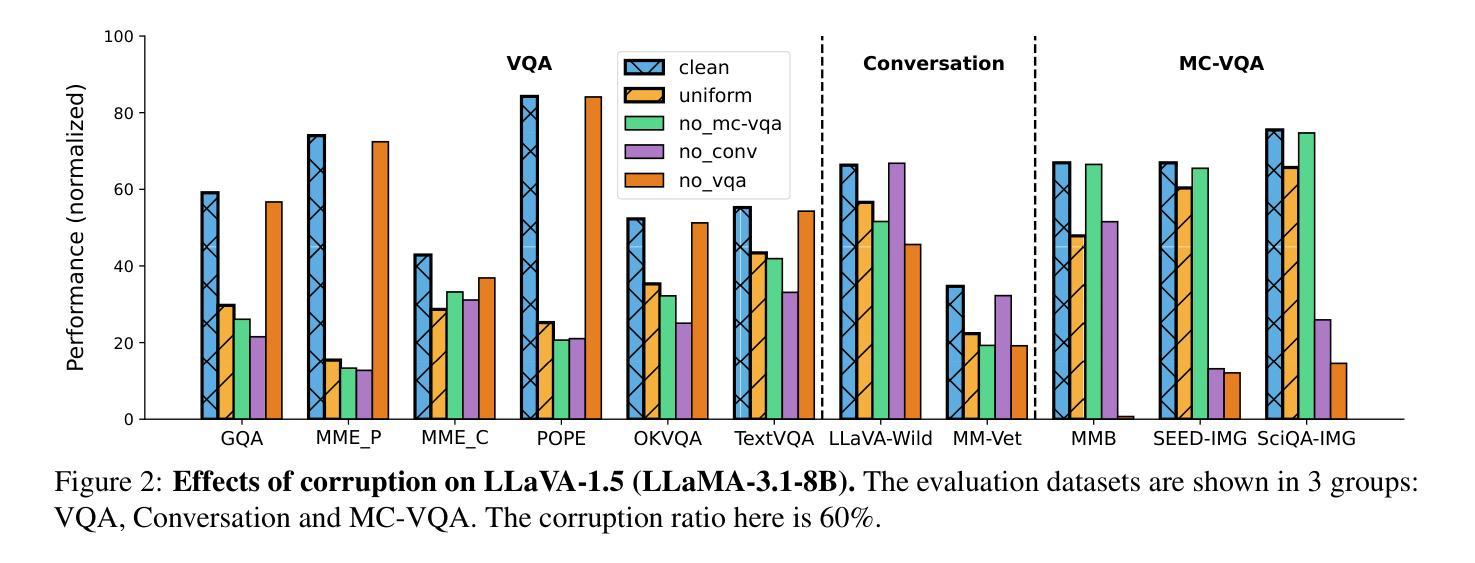
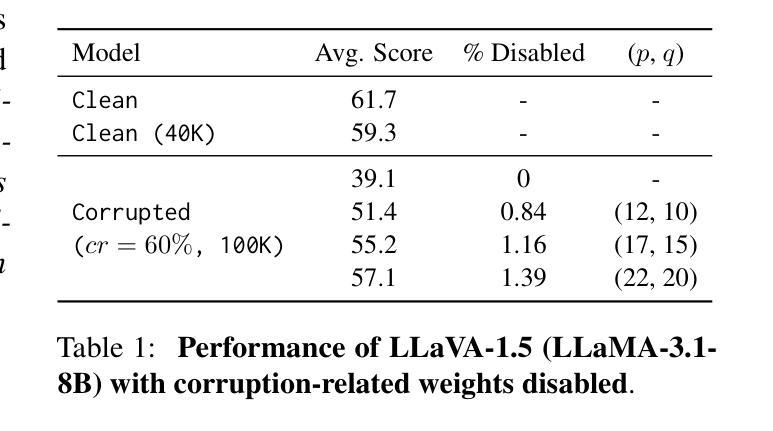
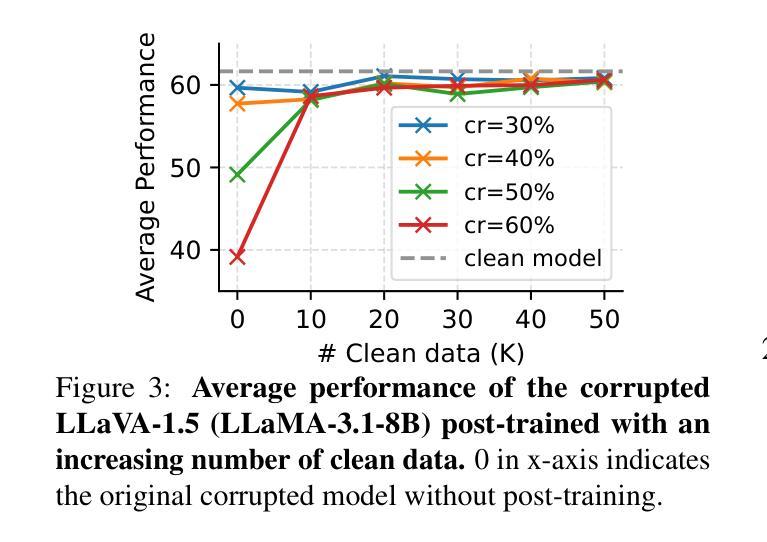
Corrupted but Not Broken: Rethinking the Impact of Corrupted Data in Visual Instruction Tuning
Authors:Yunhao Gou, Hansi Yang, Zhili Liu, Kai Chen, Yihan Zeng, Lanqing Hong, Zhenguo Li, Qun Liu, James T. Kwok, Yu Zhang
Visual Instruction Tuning (VIT) enhances Multimodal Large Language Models (MLLMs) but it is hindered by corrupted datasets containing hallucinated content, incorrect responses, and poor OCR quality. While prior works focus on dataset refinement through high-quality data collection or rule-based filtering, they are costly or limited to specific types of corruption. To deeply understand how corrupted data affects MLLMs, in this paper, we systematically investigate this issue and find that while corrupted data degrades the performance of MLLMs, its effects are largely superficial in that the performance of MLLMs can be largely restored by either disabling a small subset of parameters or post-training with a small amount of clean data. Additionally, corrupted MLLMs exhibit improved ability to distinguish clean samples from corrupted ones, enabling the dataset cleaning without external help. Based on those insights, we propose a corruption-robust training paradigm combining self-validation and post-training, which significantly outperforms existing corruption mitigation strategies.
视觉指令微调(VIT)虽然可以增强多模态大型语言模型(MLLMs)的性能,但受到包含虚构内容、错误响应和OCR质量差的腐败数据集的阻碍。虽然以前的工作侧重于通过高质量的数据收集或基于规则过滤来改进数据集,但它们成本高昂或仅限于特定类型的腐败数据。为了深入了解腐败数据如何影响MLLMs,本文系统地研究了这个问题,发现虽然腐败数据会降低MLLMs的性能,但其影响主要是表面的,通过禁用一小部分参数或在少量清洁数据上进行后训练,可以大部分恢复MLLMs的性能。此外,被污染的MLLMs表现出区分清洁样本和受污染样本的能力有所提高,从而可以在无需外部帮助的情况下进行数据集清理。基于这些见解,我们提出了一种结合自验证和后训练的错误鲁棒性训练范式,该范式显著优于现有的错误缓解策略。
论文及项目相关链接
Summary
本文探讨了视觉指令调整(VIT)对多模态大型语言模型(MLLMs)的影响,指出其受到腐蚀数据集的制约。虽然之前的研究侧重于通过高质量的数据收集或基于规则的数据过滤来改进数据集,但这种方法成本高昂或仅限于特定的腐败类型。本文通过系统地研究腐蚀数据对MLLMs的影响,发现腐蚀数据虽然会降低MLLMs的性能,但影响主要是表面的,可以通过禁用一小部分参数或进行少量清洁数据的后训练来恢复其性能。此外,腐蚀的MLLMs表现出区分清洁样本和腐蚀样本的能力增强,可实现无需外部帮助的自动数据集清洗。基于这些发现,本文提出了结合自验证和后训练的抗腐蚀训练模式,显著优于现有的腐蚀缓解策略。
Key Takeaways
- 视觉指令调整(VIT)在多模态大型语言模型(MLLMs)中起到增强作用,但受到腐蚀数据集的制约。
- 腐蚀数据会降低MLLMs的性能,但影响是表面的,可通过禁用部分参数或后训练恢复。
- 腐蚀的MLLMs能更准确地识别清洁样本和腐蚀样本,实现数据集的自清洗。
- 现有数据净化策略成本高昂或仅限于特定类型的数据腐蚀。
- 系统性地研究腐蚀数据对MLLMs的影响是理解和解决数据腐蚀问题的关键。
- 结合自验证和后训练的抗腐蚀训练模式在缓解数据腐蚀问题上表现出显著优势。
点此查看论文截图

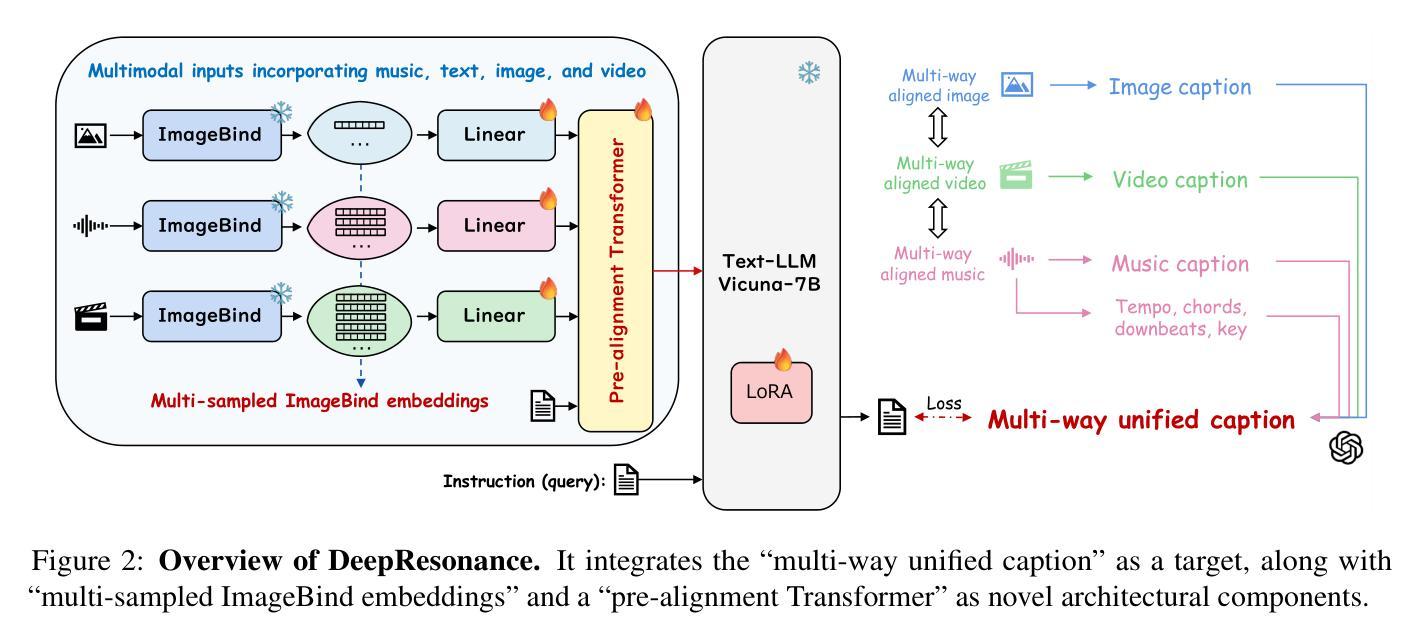
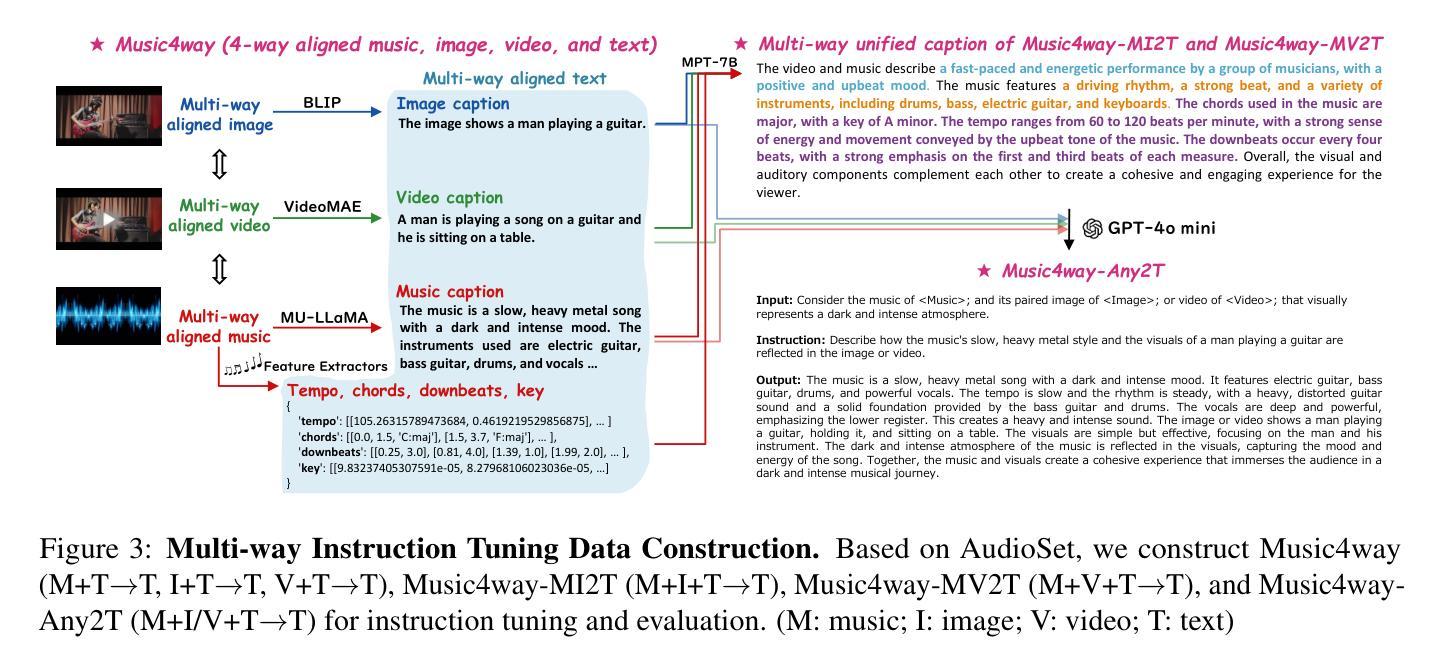
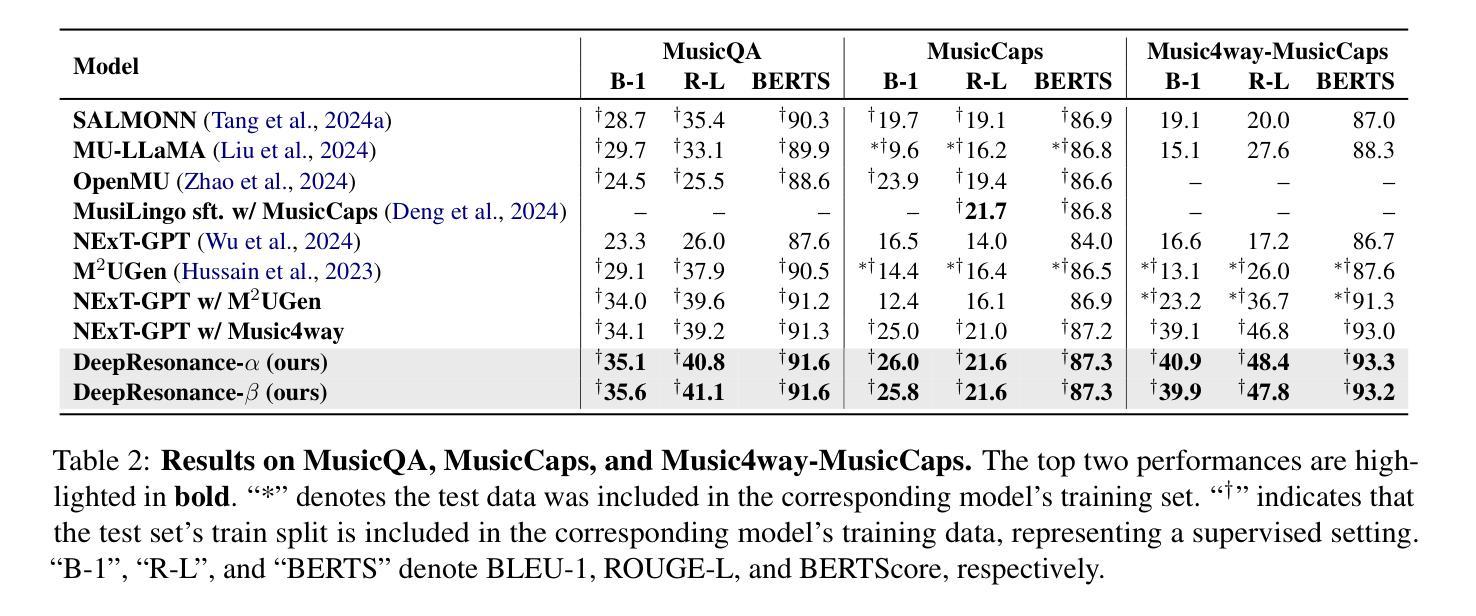
DeepResonance: Enhancing Multimodal Music Understanding via Music-centric Multi-way Instruction Tuning
Authors:Zhuoyuan Mao, Mengjie Zhao, Qiyu Wu, Hiromi Wakaki, Yuki Mitsufuji
Recent advancements in music large language models (LLMs) have significantly improved music understanding tasks, which involve the model’s ability to analyze and interpret various musical elements. These improvements primarily focused on integrating both music and text inputs. However, the potential of incorporating additional modalities such as images, videos and textual music features to enhance music understanding remains unexplored. To bridge this gap, we propose DeepResonance, a multimodal music understanding LLM fine-tuned via multi-way instruction tuning with multi-way aligned music, text, image, and video data. To this end, we construct Music4way-MI2T, Music4way-MV2T, and Music4way-Any2T, three 4-way training and evaluation datasets designed to enable DeepResonance to integrate both visual and textual music feature content. We also introduce multi-sampled ImageBind embeddings and a pre-alignment Transformer to enhance modality fusion prior to input into text LLMs, tailoring DeepResonance for multi-way instruction tuning. Our model achieves state-of-the-art performances across six music understanding tasks, highlighting the benefits of the auxiliary modalities and the structural superiority of DeepResonance. We plan to open-source the models and the newly constructed datasets.
近期音乐大型语言模型(LLM)的进展极大地提升了音乐理解任务的能力,这些能力涉及模型分析和解释各种音乐元素的能力。这些进步主要聚焦于整合音乐和文本输入。然而,将图像、视频和文本音乐特征等额外模式纳入其中,以增强对音乐的理解,这一潜力尚未被探索。为了弥补这一空白,我们提出了DeepResonance,这是一种多模式音乐理解LLM,通过多向指令调整与多向对齐的音乐、文本、图像和视频数据进行微调。为此,我们构建了Music4way-MI2T、Music4way-MV2T和Music4way-Any2T三个数据集,这是为了能够让DeepResonance整合视觉和文本音乐特征内容而设计的4向训练和评估数据集。我们还引入了多采样ImageBind嵌入和预对齐Transformer,以增强模态融合,然后输入文本LLM,为DeepResonance进行多向指令调整量身打造。我们的模型在六项音乐理解任务中达到了最先进的性能,突出了辅助模式的益处和DeepResonance的结构优越性。我们计划公开模型和新建的数据集。
论文及项目相关链接
Summary
最近音乐大型语言模型(LLM)的进展已显著提高音乐理解任务的能力,涉及模型分析和解释各种音乐元素。主要改进在于整合音乐和文本输入。然而,融入图像、视频和文本音乐特征等额外模态的潜力尚未被探索,以进一步增强音乐理解。为弥补这一差距,提出DeepResonance多模态音乐理解LLM,通过多向指令调整与多向对齐的音乐、文本、图像和视频数据微调。为此,构建了Music4way-MI2T、Music4way-MV2T和Music4way-Any2T三个4向训练与评估数据集,使DeepResonance能够整合视觉和文本音乐特征内容。还引入了多采样ImageBind嵌入和预对齐Transformer,以增强模态融合,然后输入文本LLM,为DeepResonance的多向指令调整量身定做。该模型在六项音乐理解任务上取得最先进的性能,突显辅助模态的益处和DeepResonance的结构优越性。计划开源模型和新建数据集。
Key Takeaways
- 音乐大型语言模型(LLM)在音乐理解任务上有显著改进,涉及分析和解释音乐元素的能力。
- 主要的改进在于整合音乐和文本输入。
- 目前尚未探索融入图像、视频等额外模态的潜力以增强音乐理解。
- 提出DeepResonance多模态音乐理解LLM,通过多向指令调整与多模态数据微调来提高性能。
- 构建了三个4向训练与评估数据集,以整合视觉和文本音乐特征内容。
- 引入多采样ImageBind嵌入和预对齐Transformer,以增强模态融合。
点此查看论文截图


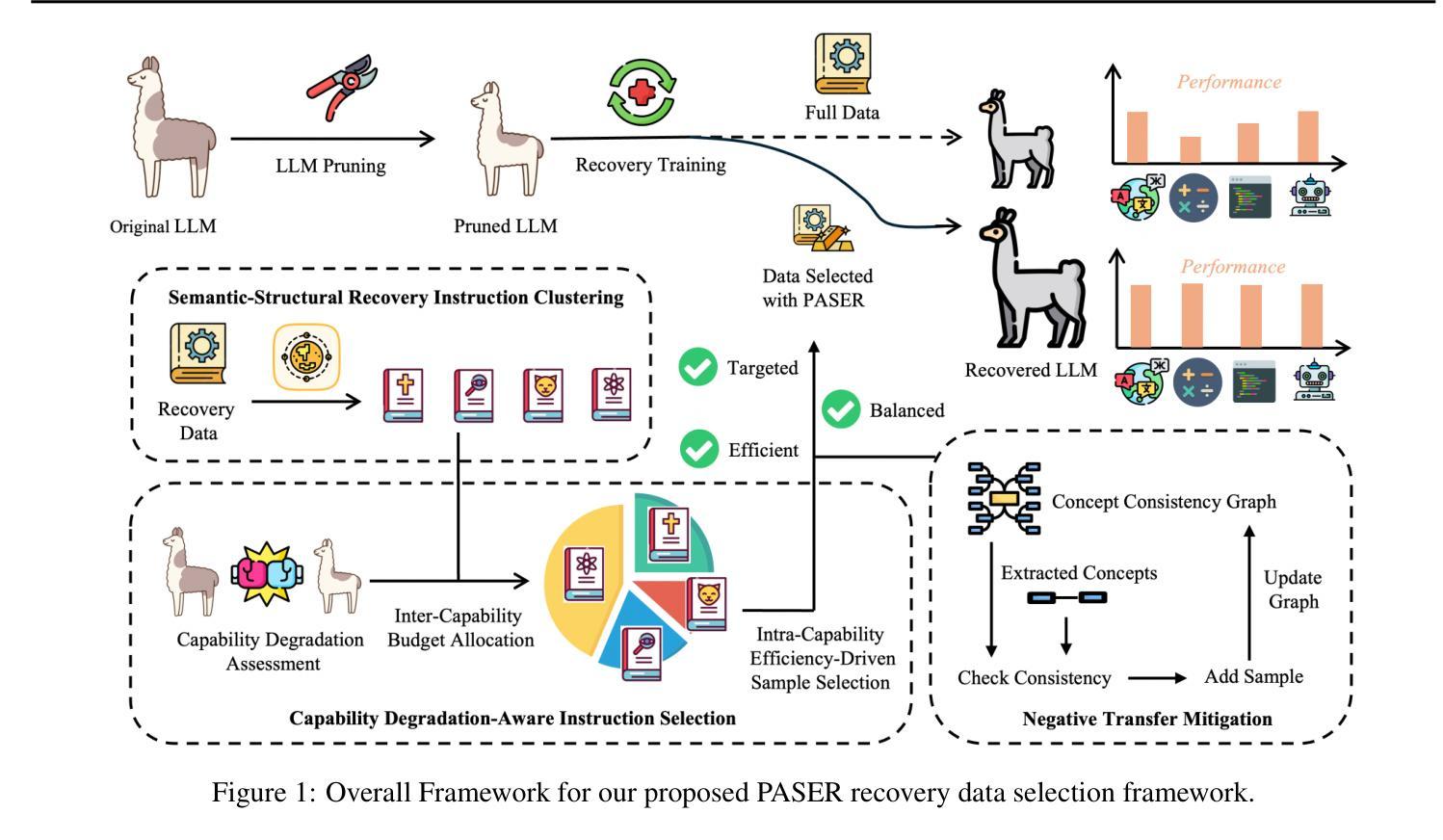
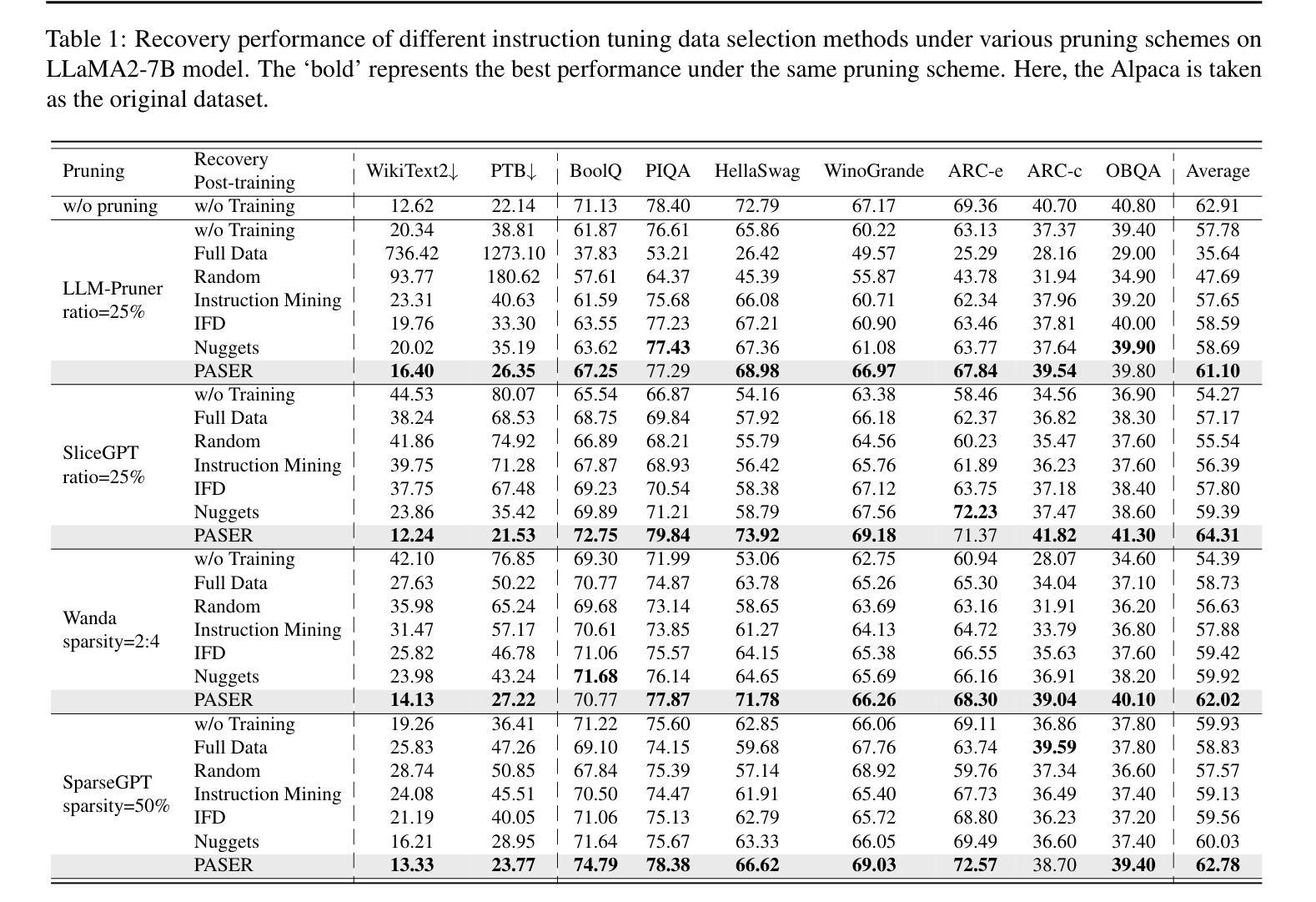
PASER: Post-Training Data Selection for Efficient Pruned Large Language Model Recovery
Authors:Bowei He, Lihao Yin, Hui-Ling Zhen, Xiaokun Zhang, Mingxuan Yuan, Chen Ma
Model pruning is an effective approach for compressing large language models. However, this process often leads to significant degradation of model capabilities. While post-training techniques such as instruction tuning are commonly employed to recover model performance, existing methods often overlook the uneven deterioration of model capabilities and incur high computational costs. Moreover, some instruction data irrelevant to model capability recovery may introduce negative effects. To address these challenges, we propose the \textbf{P}ost-training d\textbf{A}ta \textbf{S}election method for \textbf{E}fficient pruned large language model \textbf{R}ecovery (\textbf{PASER}). PASER aims to identify instructions where model capabilities are most severely compromised within a certain recovery data budget. Our approach first applies manifold learning and spectral clustering to group recovery data in the semantic space, revealing capability-specific instruction sets. We then adaptively allocate the data budget to different clusters based on the degrees of model capability degradation. In each cluster, we prioritize data samples where model performance has declined dramatically. To mitigate potential negative transfer, we also detect and filter out conflicting or irrelevant recovery data. Extensive experiments demonstrate that PASER significantly outperforms conventional baselines, effectively recovering the general capabilities of pruned LLMs while utilizing merely 4%-20% of the original post-training data.
模型剪枝是压缩大型语言模型的一种有效方法。然而,这个过程往往会导致模型能力显著下降。虽然训练后技术(如指令微调)通常被用来恢复模型性能,但现有方法往往忽视了模型能力的不均匀退化,并产生了很高的计算成本。此外,一些与模型能力恢复无关的指令数据可能会产生负面影响。为了解决这些挑战,我们提出了面向高效剪枝大型语言模型恢复的PASER(训练后数据选择方法)。PASER旨在识别在特定恢复数据预算下模型能力受损最严重的指令。我们的方法首先应用流形学习和谱聚类将恢复数据在语义空间中进行分组,揭示特定能力的指令集。然后,我们根据模型能力的退化程度自适应地分配数据预算到不同的集群。在每个集群中,我们优先处理模型性能急剧下降的数据样本。为了减少潜在的负面迁移,我们还检测和过滤出冲突或无关的恢复数据。大量实验表明,PASER显著优于传统基线,在利用仅4%~20%的原始训练后数据的情况下,有效地恢复了剪枝大型语言模型的通用能力。
论文及项目相关链接
Summary
模型剪枝是压缩大型语言模型的有效方法,但会导致模型能力显著下降。为恢复模型性能,通常采用训练后技术如指令微调,但现有方法忽视了模型能力的不均衡下降,计算成本高,且可能引入与模型能力恢复不相关的指令数据导致负面影响。为此,我们提出了针对高效剪枝大型语言模型恢复的后训练数据选择方法(PASER)。PASER旨在识别在特定恢复数据预算中模型能力受损最严重的指令。它首先应用流形学习和谱聚类将恢复数据在语义空间中进行分组,揭示特定能力的指令集。然后,根据模型能力下降的程度自适应地分配数据预算到不同的集群。在每个集群中,我们优先处理模型性能急剧下降的数据样本。为减轻潜在的负面迁移,我们还检测和过滤出冲突的或无关的恢复数据。实验表明,PASER显著优于传统基线,在利用仅4%-20%的原训练后数据的情况下,有效地恢复了剪枝LLM的一般能力。
Key Takeaways
- 模型剪枝是压缩大型语言模型的有效方法,但会导致模型能力下降。
- 现有模型恢复方法忽视了模型能力的不均衡下降,并可能引入不相关指令数据。
- PASER方法通过识别模型能力受损最严重的指令来恢复模型性能。
- PASER使用流形学习和谱聚类在语义空间分组恢复数据,以揭示特定能力的指令集。
- PASER根据模型能力下降的程度自适应分配数据预算。
- PASER能优先处理模型性能急剧下降的数据样本。
点此查看论文截图

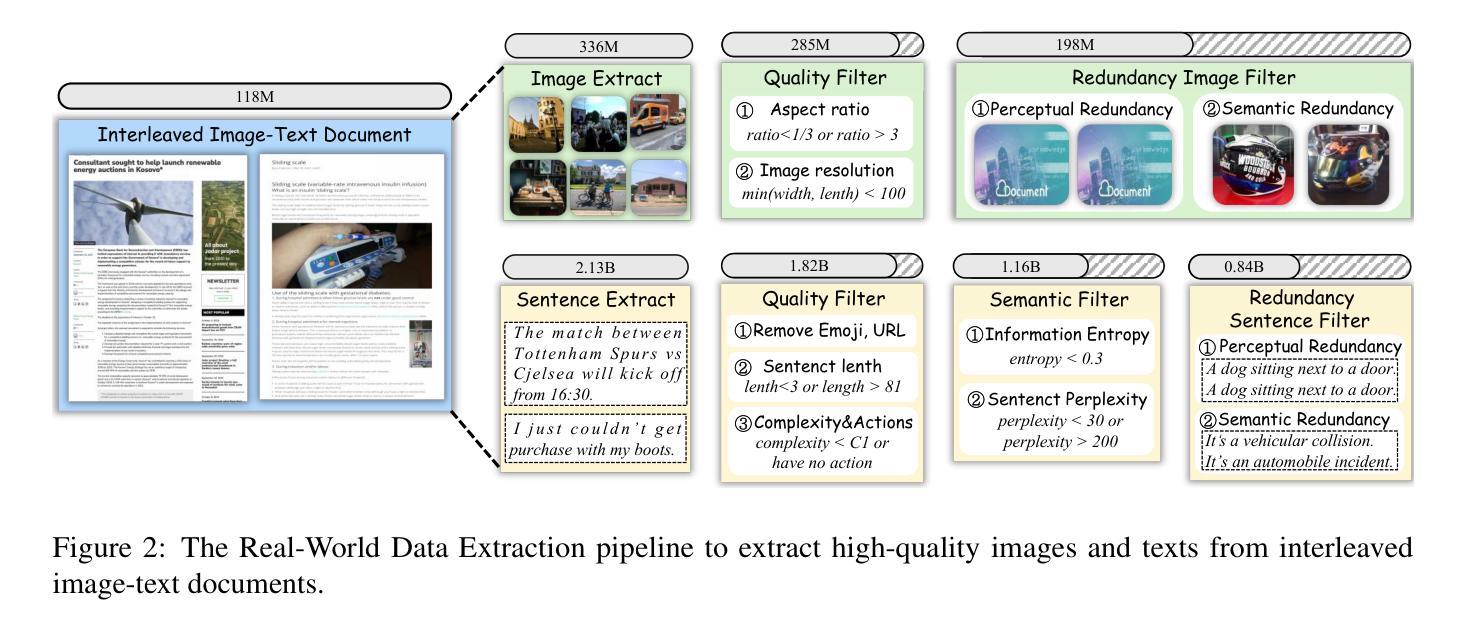
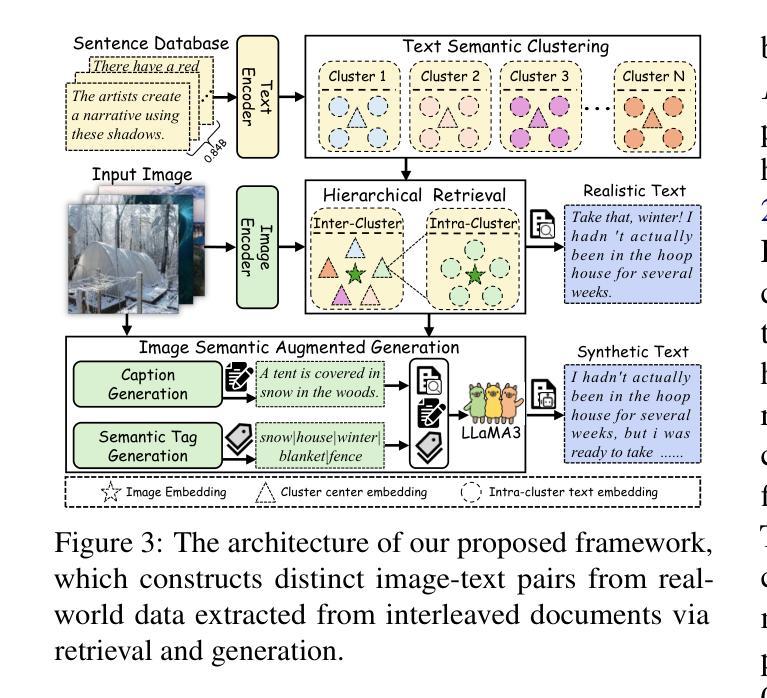
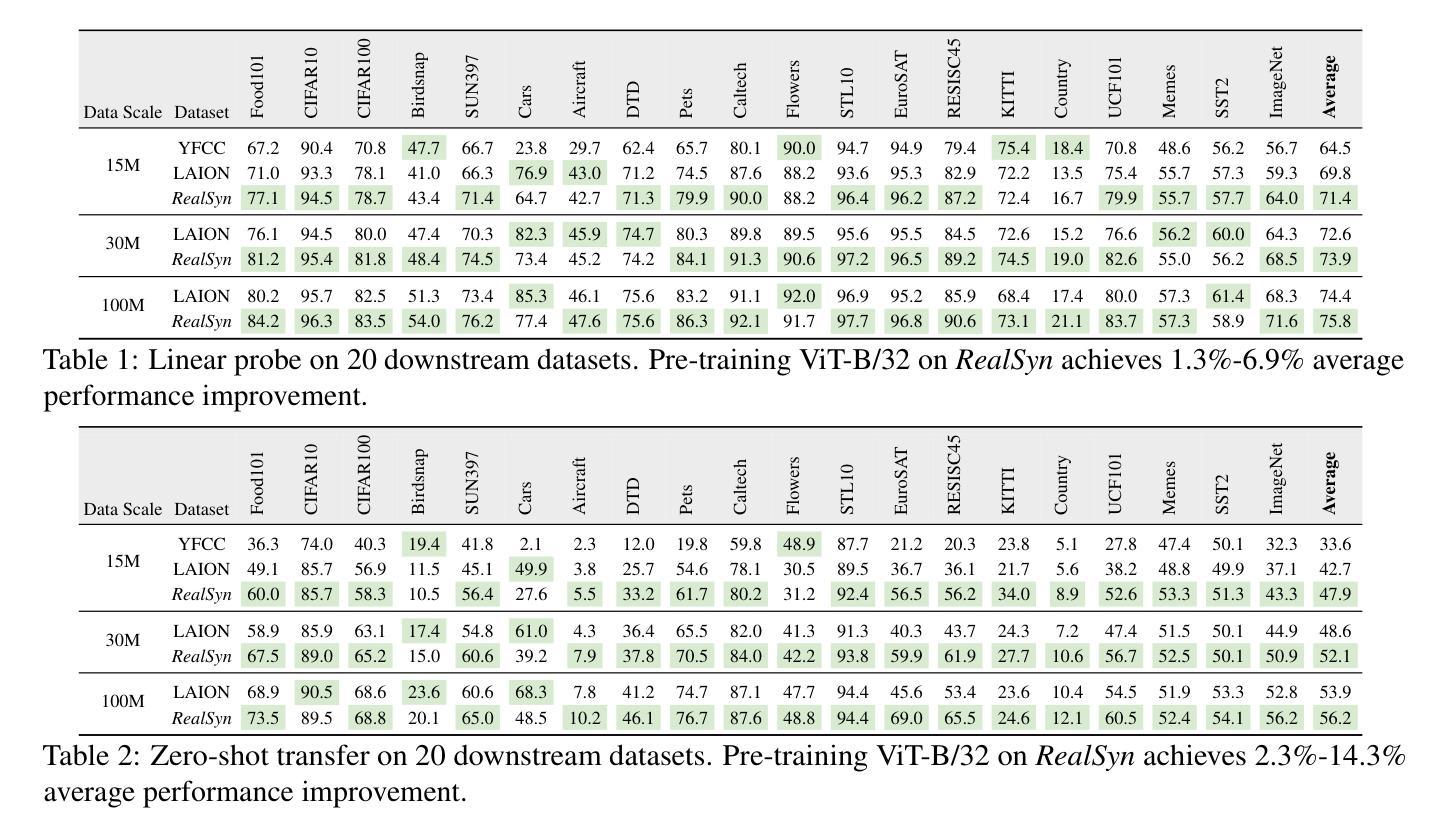
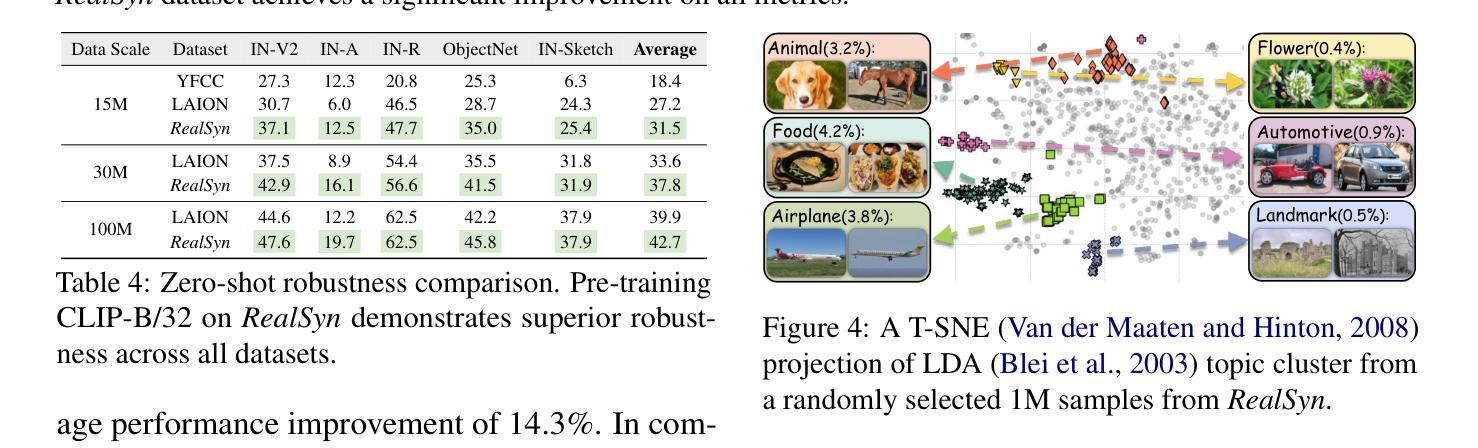
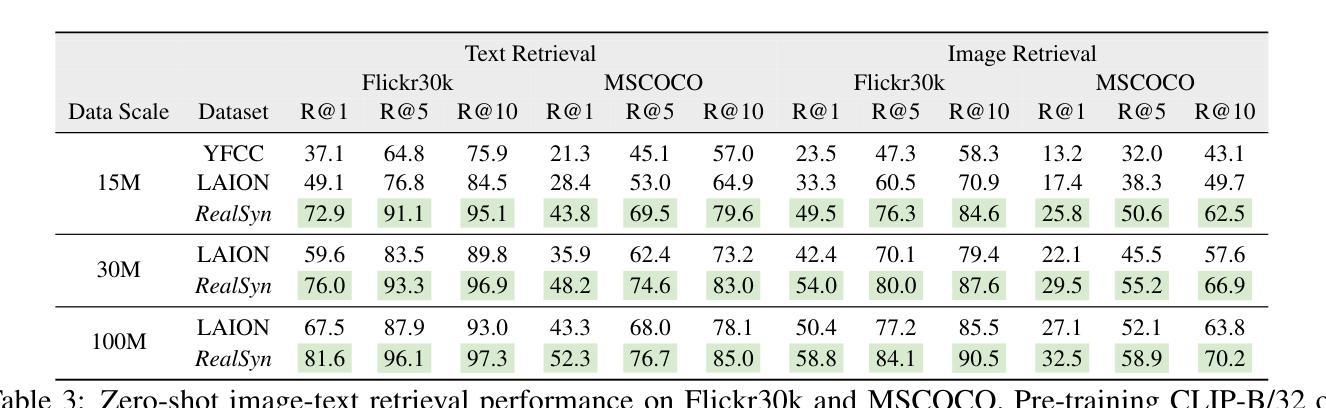
RealSyn: An Effective and Scalable Multimodal Interleaved Document Transformation Paradigm
Authors:Tiancheng Gu, Kaicheng Yang, Chaoyi Zhang, Yin Xie, Xiang An, Ziyong Feng, Dongnan Liu, Weidong Cai, Jiankang Deng
After pre-training on extensive image-text pairs, Contrastive Language-Image Pre-training (CLIP) demonstrates promising performance on a wide variety of benchmarks. However, a substantial volume of non-paired data, such as multimodal interleaved documents, remains underutilized for vision-language representation learning. To fully leverage these unpaired documents, we initially establish a Real-World Data Extraction pipeline to extract high-quality images and texts. Then we design a hierarchical retrieval method to efficiently associate each image with multiple semantically relevant realistic texts. To further enhance fine-grained visual information, we propose an image semantic augmented generation module for synthetic text production. Furthermore, we employ a semantic balance sampling strategy to improve dataset diversity, enabling better learning of long-tail concepts. Based on these innovations, we construct RealSyn, a dataset combining realistic and synthetic texts, available in three scales: 15M, 30M, and 100M. Extensive experiments demonstrate that RealSyn effectively advances vision-language representation learning and exhibits strong scalability. Models pre-trained on RealSyn achieve state-of-the-art performance on multiple downstream tasks. To facilitate future research, the RealSyn dataset and pre-trained model weights are released at https://github.com/deepglint/RealSyn.
在大量图文对上进行预训练后,对比语言图像预训练(CLIP)在各种基准测试上表现出有希望的性能。然而,大量的非配对数据,如多模式交织的文档,在视觉语言表示学习中仍未得到充分利用。为了充分利用这些未配对的文档,我们首先建立了一个真实世界数据提取管道,以提取高质量的图片和文本。然后,我们设计了一种分层检索方法,以有效地将每张图像与多个语义上相关的真实文本关联起来。为了进一步增强精细粒度的视觉信息,我们提出了一个图像语义增强生成模块来进行合成文本生产。此外,我们采用了一种语义平衡采样策略,以提高数据集多样性,实现长尾概念更好的学习。基于这些创新,我们构建了RealSyn数据集,结合了真实和合成文本,提供三种规模:15M、30M和100M。大量实验表明,RealSyn有效地推动了视觉语言表示学习的发展,并表现出强大的可扩展性。在RealSyn上预训练的模型在多个下游任务上达到了最先进的性能。为了方便未来研究,RealSyn数据集和预训练模型权重已在https://github.com/deepglint/RealSyn发布。
论文及项目相关链接
PDF 16 pages, 12 figures, Webpage: https://garygutc.github.io/RealSyn
Summary
基于Contrastive Language-Image Pre-training(CLIP)模型的预训练技术虽然在多个基准测试上表现出色,但在利用非配对数据(如多媒体混合文档)进行视觉语言表示学习方面仍存在不足。为解决这一问题,研究团队推出了RealSyn数据集,通过真实世界数据提取管道提取高质量图像和文本,采用分层检索方法高效地将图像与多个语义相关的真实文本相关联。此外,该研究还提出了图像语义增强生成模块用于合成文本生产,并采用语义平衡采样策略提高数据集多样性,更好地学习长尾概念。RealSyn数据集包含真实和合成文本,提供三种规模:15M、30M和100M。实验表明,RealSyn有效推进了视觉语言表示学习,并展现出强大的可扩展性。在多个下游任务上,基于RealSyn预训练的模型达到最先进的性能。为便于未来研究,RealSyn数据集和预训练模型权重已在GitHub上发布。
Key Takeaways
- CLIP模型在多种基准测试上表现良好,但在利用非配对数据进行视觉语言表示学习方面存在局限性。
- 研究团队推出RealSyn数据集以解决这一问题,包含真实和合成文本,提供不同规模选择。
- RealSyn采用真实世界数据提取管道和分层检索方法,高效关联图像与语义相关文本。
- 提出图像语义增强生成模块和语义平衡采样策略,提高数据集多样性和学习效果。
- RealSyn能有效推进视觉语言表示学习,并展现出强大的可扩展性。
- 基于RealSyn预训练的模型在多个下游任务上达到最先进的性能。
点此查看论文截图

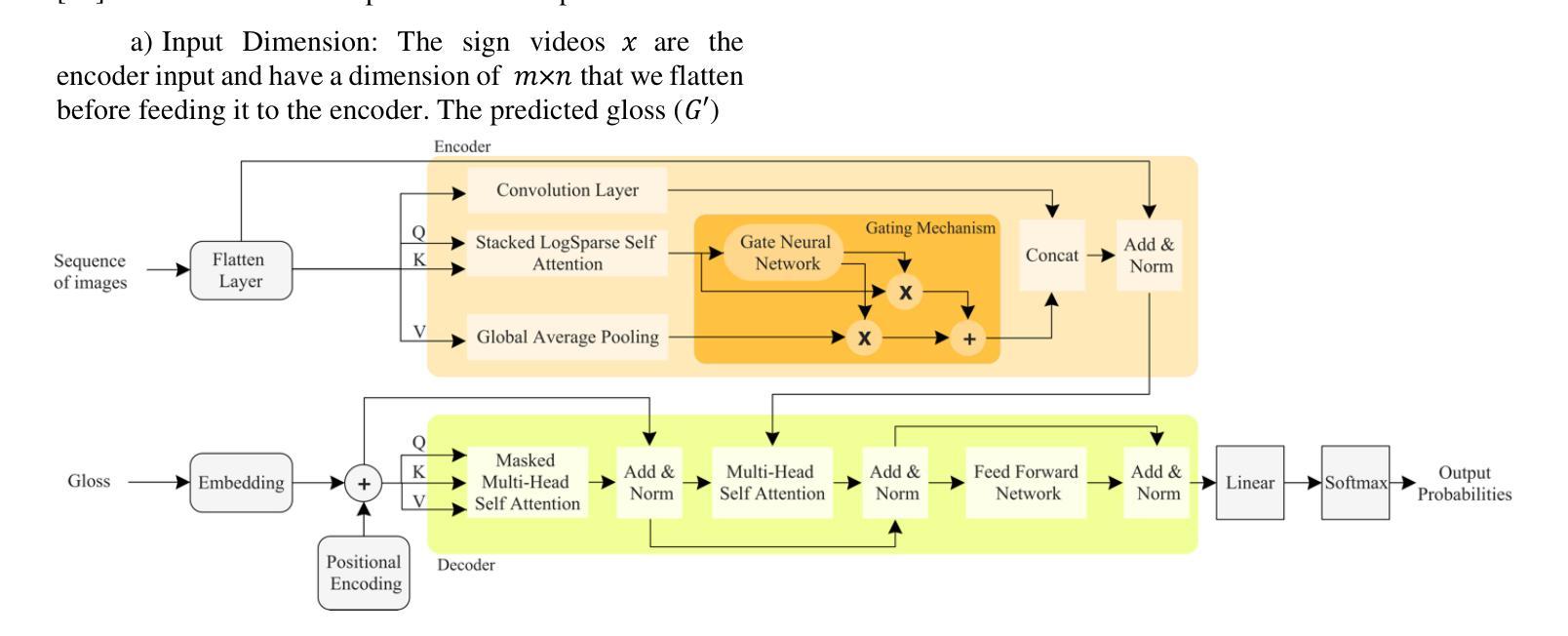
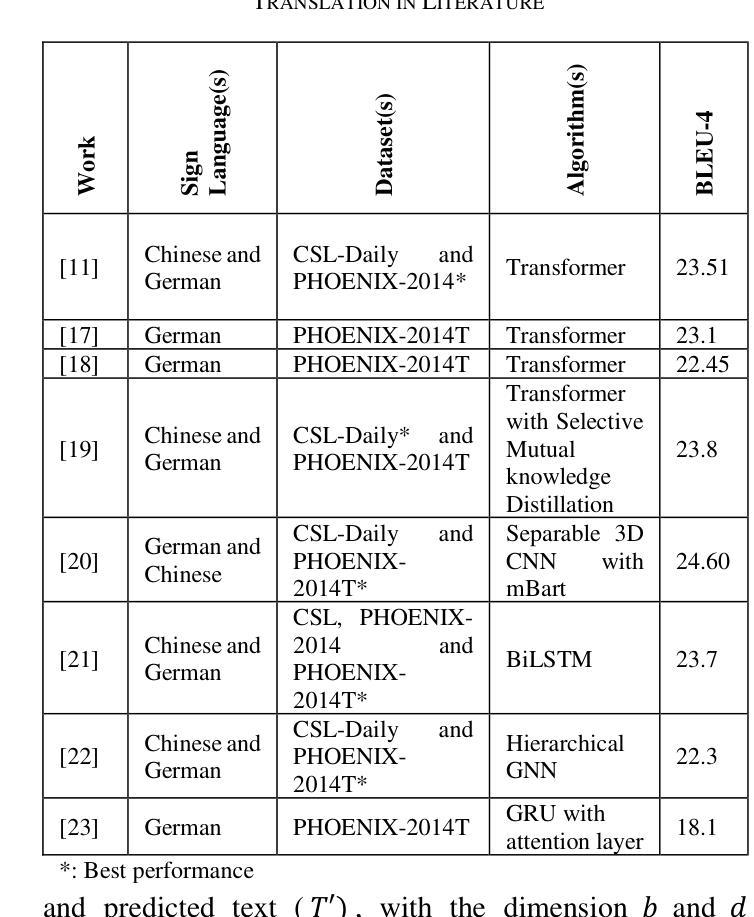
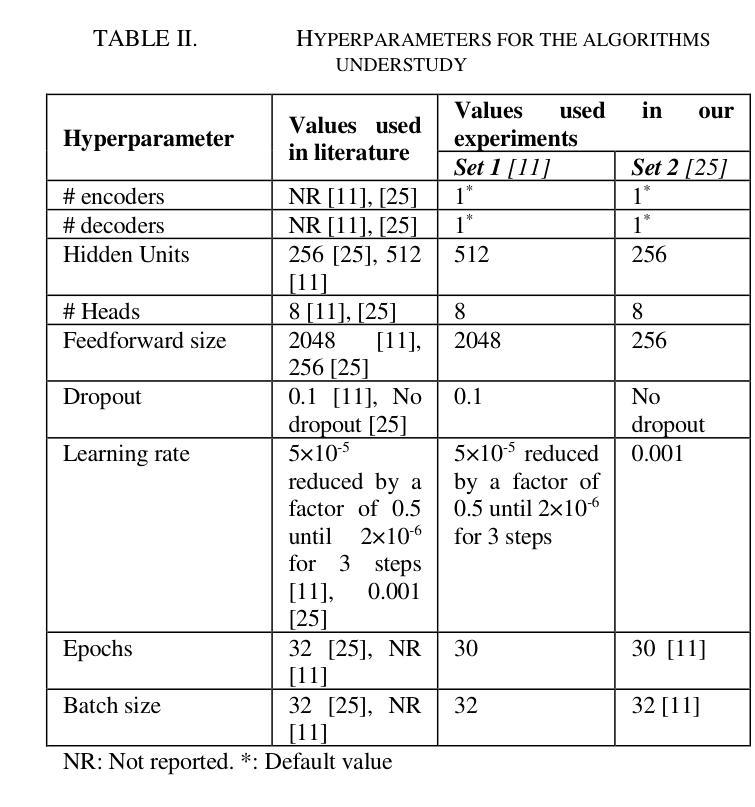
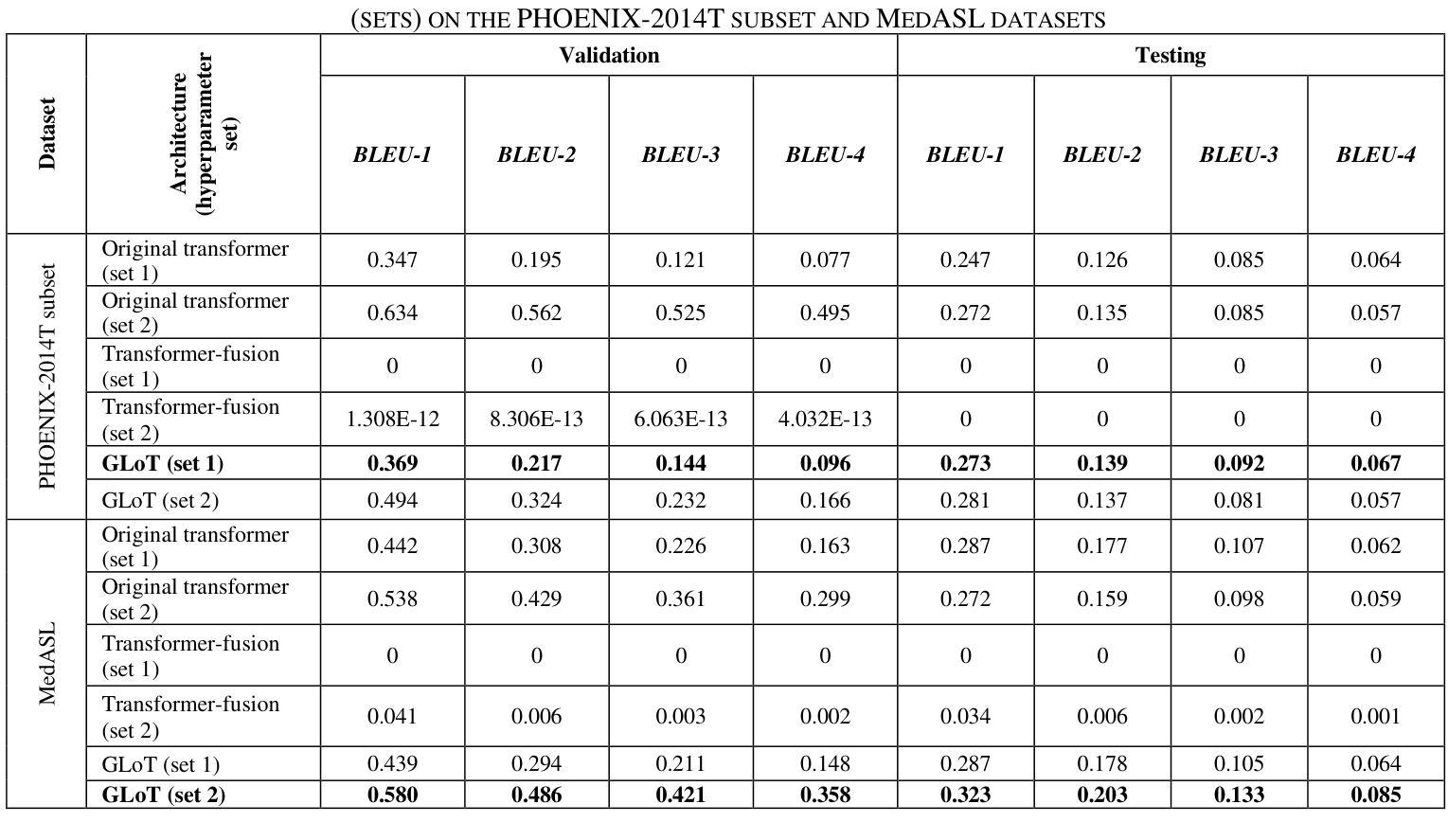
GLoT: A Novel Gated-Logarithmic Transformer for Efficient Sign Language Translation
Authors:Nada Shahin, Leila Ismail
Machine Translation has played a critical role in reducing language barriers, but its adaptation for Sign Language Machine Translation (SLMT) has been less explored. Existing works on SLMT mostly use the Transformer neural network which exhibits low performance due to the dynamic nature of the sign language. In this paper, we propose a novel Gated-Logarithmic Transformer (GLoT) that captures the long-term temporal dependencies of the sign language as a time-series data. We perform a comprehensive evaluation of GloT with the transformer and transformer-fusion models as a baseline, for Sign-to-Gloss-to-Text translation. Our results demonstrate that GLoT consistently outperforms the other models across all metrics. These findings underscore its potential to address the communication challenges faced by the Deaf and Hard of Hearing community.
机器翻译在消除语言障碍方面发挥了关键作用,但其在手语机器翻译(SLMT)方面的应用却鲜有研究。现有的SLMT研究大多使用Transformer神经网络,由于手语的动态性,其表现较差。在本文中,我们提出了一种新型的Gated-Logarithmic Transformer(GLoT),它能够捕捉手语作为时间序列数据的长期时间依赖性。我们对GLoT进行了全面的评估,以Transformer和Transformer融合模型作为基线,进行Sign-to-Gloss-to-Text翻译。我们的结果证明,在所有指标上,GLoT始终优于其他模型。这些发现凸显了其在解决聋哑和听力受损群体所面临的沟通挑战方面的潜力。
论文及项目相关链接
Summary
本文探讨了机器翻译在减少语言障碍方面的关键作用,但对聋哑人手语翻译(SLMT)的应用研究较少。现有的SLMT研究大多使用Transformer神经网络,由于手语具有动态性,其性能较低。本文提出了一种新型的门控对数变换器(GLoT),能够捕捉手语的长期时间依赖性特征,将其作为时间序列数据进行分析。本文与变换器和变换器融合模型进行基准比较,在Sign-to-Gloss-to-Text翻译中进行了全面的评估。结果表明,GLoT在所有指标上均优于其他模型,显示出其在解决聋哑人和听力受损人士面临的沟通挑战方面的潜力。
Key Takeaways
- 手语翻译在减少语言障碍方面具有重要意义,但相关研究相对较少。
- 当前SLMT研究主要使用Transformer神经网络,但性能较低。
- 本文提出了一种新型的门控对数变换器(GLoT),适用于手语翻译。
- GLoT能够捕捉手语的长期时间依赖性特征,并将其视为时间序列数据进行分析。
- 与其他模型相比,GLoT在所有评估指标上都表现出更好的性能。
- GLoT具有解决聋哑人和听力受损人士沟通挑战的巨大潜力。
点此查看论文截图

AI and the Law: Evaluating ChatGPT’s Performance in Legal Classification
Authors:Pawel Weichbroth
The use of ChatGPT to analyze and classify evidence in criminal proceedings has been a topic of ongoing discussion. However, to the best of our knowledge, this issue has not been studied in the context of the Polish language. This study addresses this research gap by evaluating the effectiveness of ChatGPT in classifying legal cases under the Polish Penal Code. The results show excellent binary classification accuracy, with all positive and negative cases correctly categorized. In addition, a qualitative evaluation confirms that the legal basis provided for each case, along with the relevant legal content, was appropriate. The results obtained suggest that ChatGPT can effectively analyze and classify evidence while applying the appropriate legal rules. In conclusion, ChatGPT has the potential to assist interested parties in the analysis of evidence and serve as a valuable legal resource for individuals with less experience or knowledge in this area.
使用ChatGPT来分析并分类刑事诉讼中的证据一直是持续讨论的话题。然而,据我们了解,这个问题在波兰语环境下尚未被研究。本研究通过评估ChatGPT在根据波兰刑法分类法律案件方面的有效性来填补这一研究空白。结果显示二元分类精度极高,所有正面和负面案例均被正确分类。此外,定性评估证实,为每个案例提供的法律依据以及相关的法律内容是恰当的。所获得的结果表明,ChatGPT可以有效地分析和分类证据,同时适用适当的法律规则。总之,ChatGPT有帮助各方分析证据的潜力,对于在此领域缺乏经验或知识的人而言,它是一项有价值的法律资源。
论文及项目相关链接
PDF 15 pages; 1 figure; 2 tables; 32 references
摘要
ChatGPT在波兰语环境下的刑事诉讼证据分析和分类效果进行评估,展现出了优异的二元分类准确率,正负面案例均准确归类,并提供恰当的法律依据和相关内容。结果表明ChatGPT能有效分析并分类证据,同时适用相关法律规则。ChatGPT具有协助各方分析证据的价值,对于缺乏经验或知识的个人而言,是一项宝贵的法律资源。
关键见解
- 研究填补了ChatGPT在波兰语环境下刑事诉讼证据分析与分类的研究空白。
- ChatGPT展现出了优异的二元分类准确率,正负面案例均准确归类。
- ChatGPT在分析证据和适用法律规则方面表现出有效性。
- ChatGPT提供的法律依据和相关内容具有恰当性。
- ChatGPT对于协助各方分析证据具有潜在价值。
- ChatGPT对于缺乏法律经验和知识的个人来说是一项宝贵的资源。
点此查看论文截图


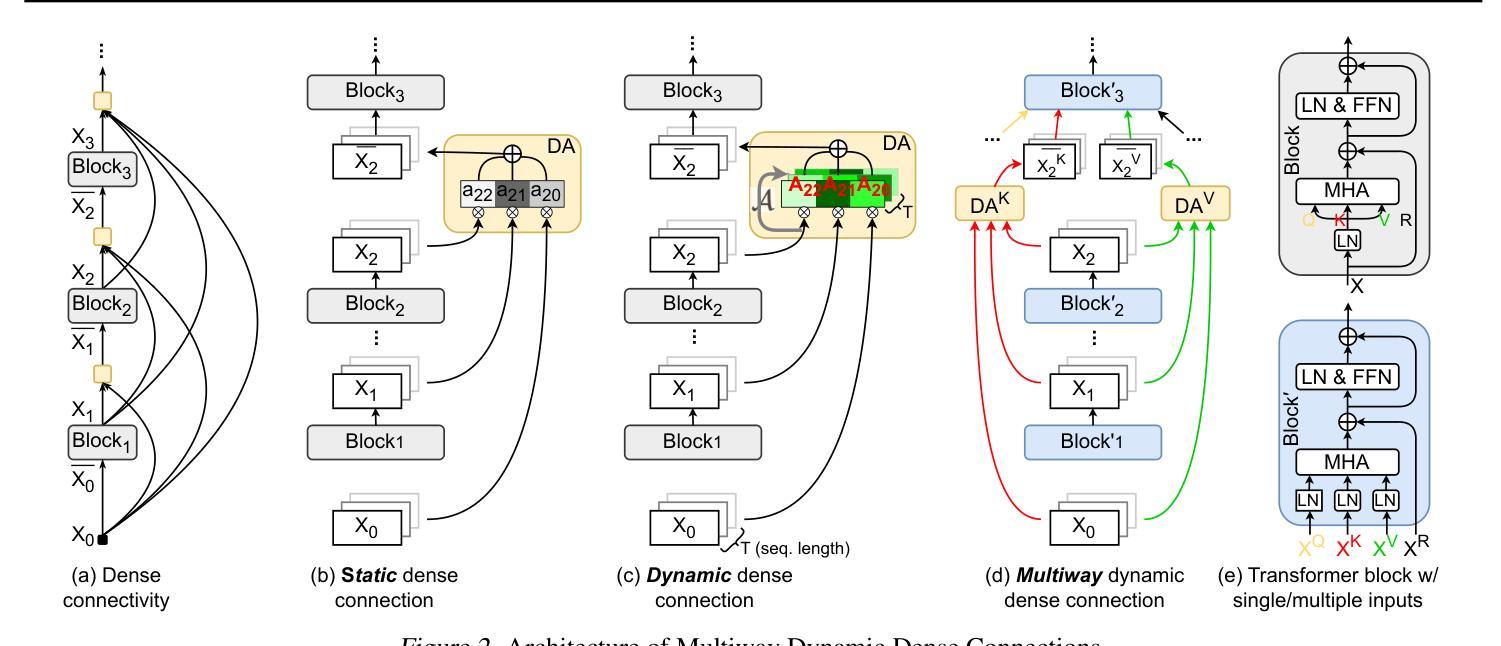
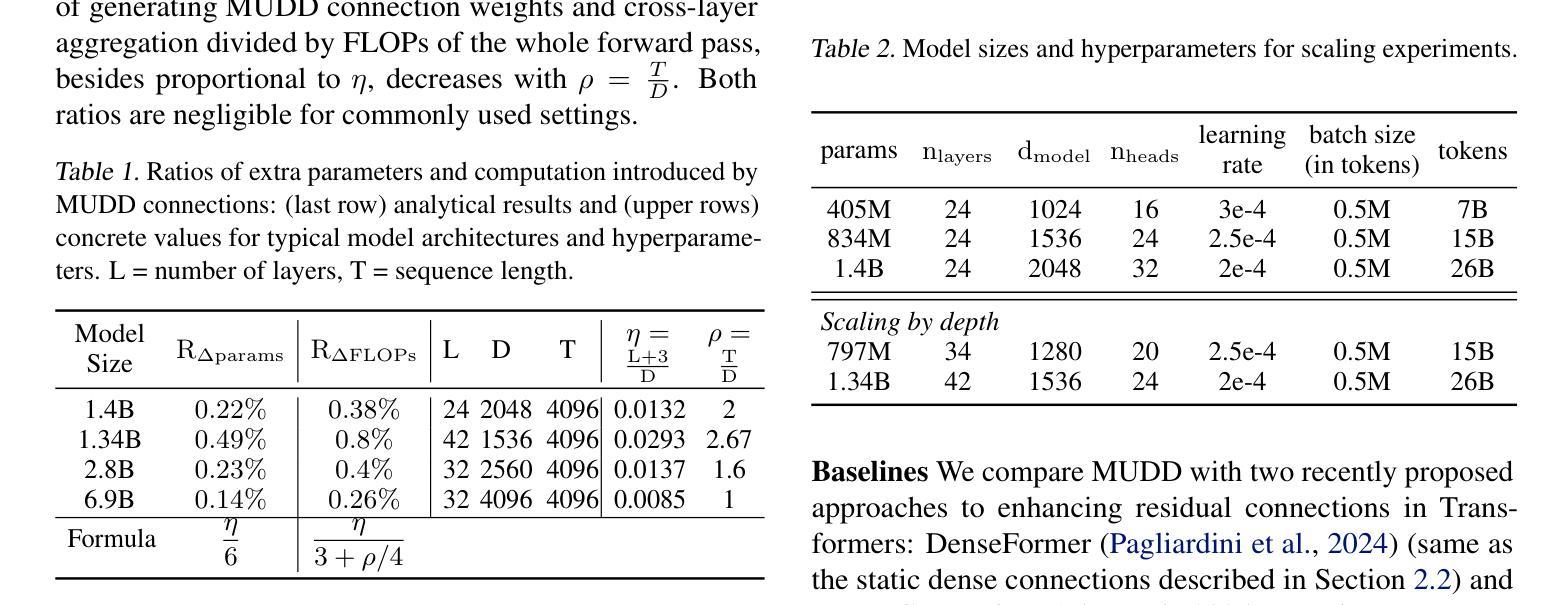
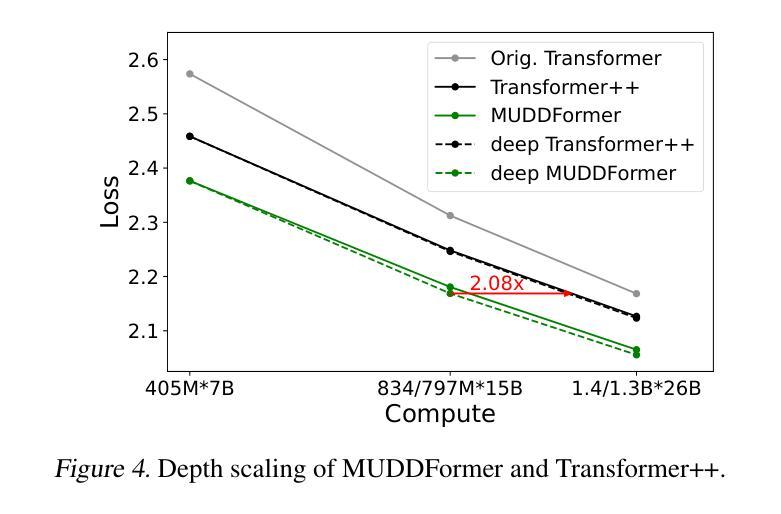
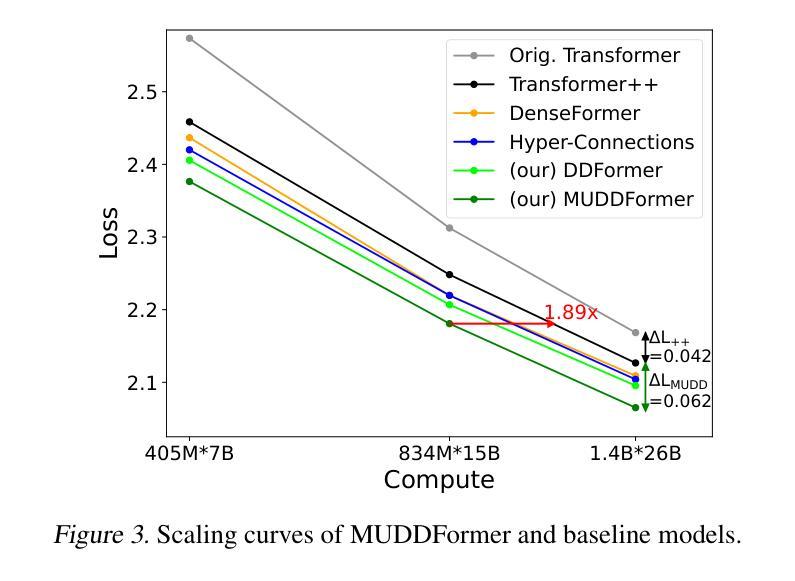
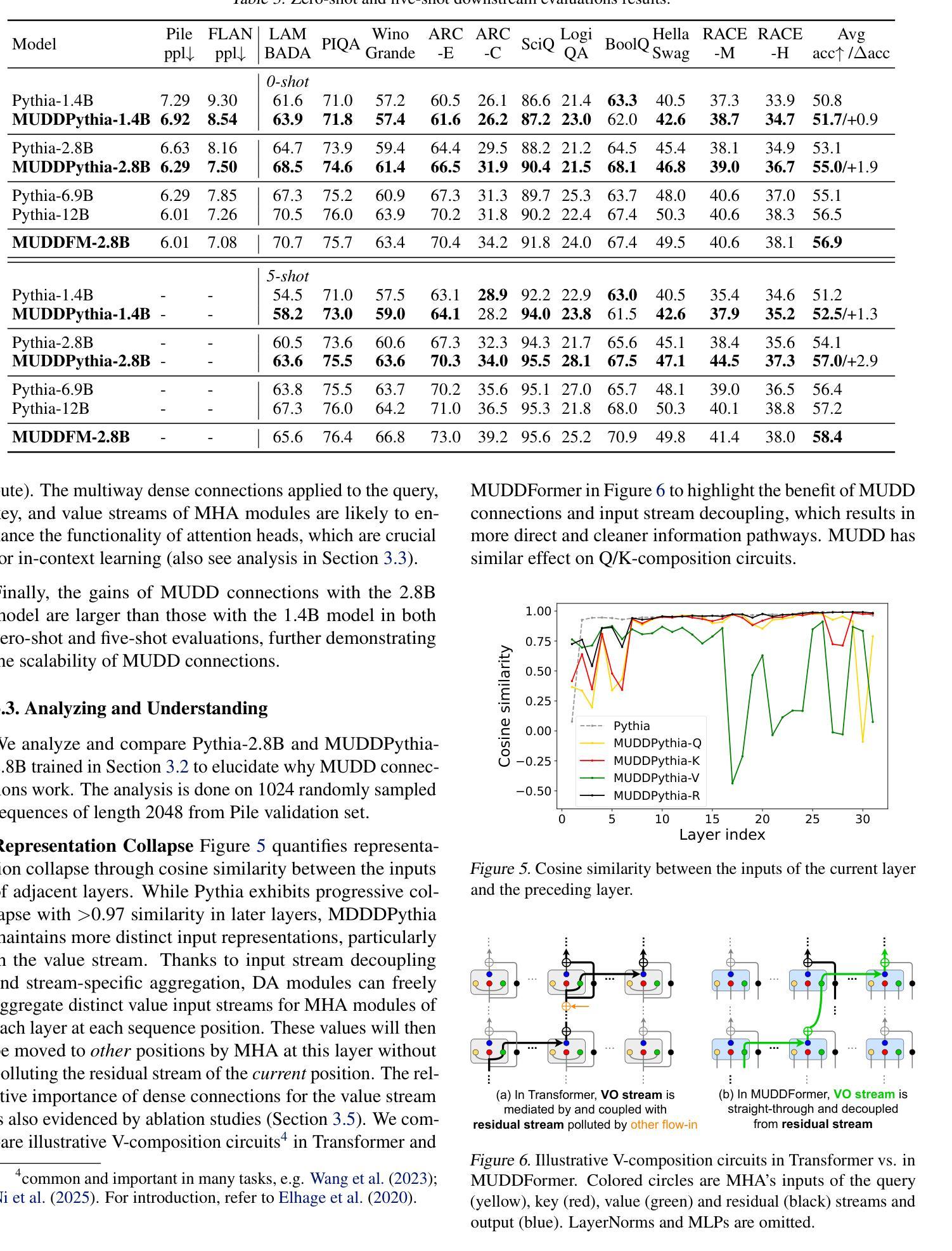
MUDDFormer: Breaking Residual Bottlenecks in Transformers via Multiway Dynamic Dense Connections
Authors:Da Xiao, Qingye Meng, Shengping Li, Xingyuan Yuan
We propose MUltiway Dynamic Dense (MUDD) connections, a simple yet effective method to address the limitations of residual connections and enhance cross-layer information flow in Transformers. Unlike existing dense connection approaches with static and shared connection weights, MUDD generates connection weights dynamically depending on hidden states at each sequence position and for each decoupled input stream (the query, key, value or residual) of a Transformer block. MUDD connections can be seamlessly integrated into any Transformer architecture to create MUDDFormer. Extensive experiments show that MUDDFormer significantly outperforms Transformers across various model architectures and scales in language modeling, achieving the performance of Transformers trained with 1.8X-2.4X compute. Notably, MUDDPythia-2.8B matches Pythia-6.9B in pretraining ppl and downstream tasks and even rivals Pythia-12B in five-shot settings, while adding only 0.23% parameters and 0.4% computation. Code in JAX and PyTorch and pre-trained models are available at https://github.com/Caiyun-AI/MUDDFormer .
我们提出了多向动态密集(MUDD)连接,这是一种简单有效的方法,可以解决剩余连接的限制,增强Transformer中的跨层信息流动。与现有具有静态和共享连接权重的密集连接方法不同,MUDD根据每个序列位置和每个Transformer块的解耦输入流(查询、键、值或残差)的隐藏状态动态生成连接权重。MUDD连接可以无缝集成到任何Transformer架构中,以创建MUDDFormer。大量实验表明,MUDDFormer在各种模型架构和规模的语言建模中显著优于Transformer,实现了以1.8倍至2.4倍的计算量训练Transformer的性能。值得注意的是,MUDDPythia-2.8B在预训练和下游任务中的性能与Pythia-6.9B相匹配,甚至在五次拍摄环境中与Pythia-12B相抗衡,同时只增加了0.23%的参数和0.4%的计算量。JAX和PyTorch的代码以及预训练模型可在https://github.com/Caiyun-AI/MUDDFormer找到。
论文及项目相关链接
Summary
提出MUDD连接,这是一种简单有效的方法,可以解决残差连接的局限性并增强Transformer中的跨层信息流。MUDD能够动态生成连接权重,取决于序列位置处的隐藏状态和Transformer块的每个独立输入流(查询、键、值或残差)。MUDD连接可以无缝集成到任何Transformer架构中,创建MUDDFormer。实验表明,MUDDFormer在各种模型架构和规模上的语言建模表现均优于Transformer,以1.8X-2.4X的计算量达到Transformer的训练性能。特别是MUDDPythia-2.8B在预训练和下游任务中的性能与Pythia-6.9B相匹配,并在五镜头设置中甚至与Pythia-12B相竞争,同时只增加了0.23%的参数和0.4%的计算量。
Key Takeaways
* MUDD连接是一种针对Transformer中残差连接的改进方法,旨在增强跨层信息流。
* MUDD连接可以动态生成连接权重,取决于序列位置的隐藏状态和Transformer块的每个独立输入流。
* MUDD连接可以无缝集成到任何Transformer架构中,形成MUDDFormer。
* MUDDFormer在语言建模方面表现出显著优势,优于各种Transformer模型。
* MUDDFormer以较少的计算量和参数实现了高性能,例如MUDDPythia-2.8B的性能与大型模型如Pythia-6.9B和Pythia-12B相当。
点此查看论文截图

HybriDNA: A Hybrid Transformer-Mamba2 Long-Range DNA Language Model
Authors:Mingqian Ma, Guoqing Liu, Chuan Cao, Pan Deng, Tri Dao, Albert Gu, Peiran Jin, Zhao Yang, Yingce Xia, Renqian Luo, Pipi Hu, Zun Wang, Yuan-Jyue Chen, Haiguang Liu, Tao Qin
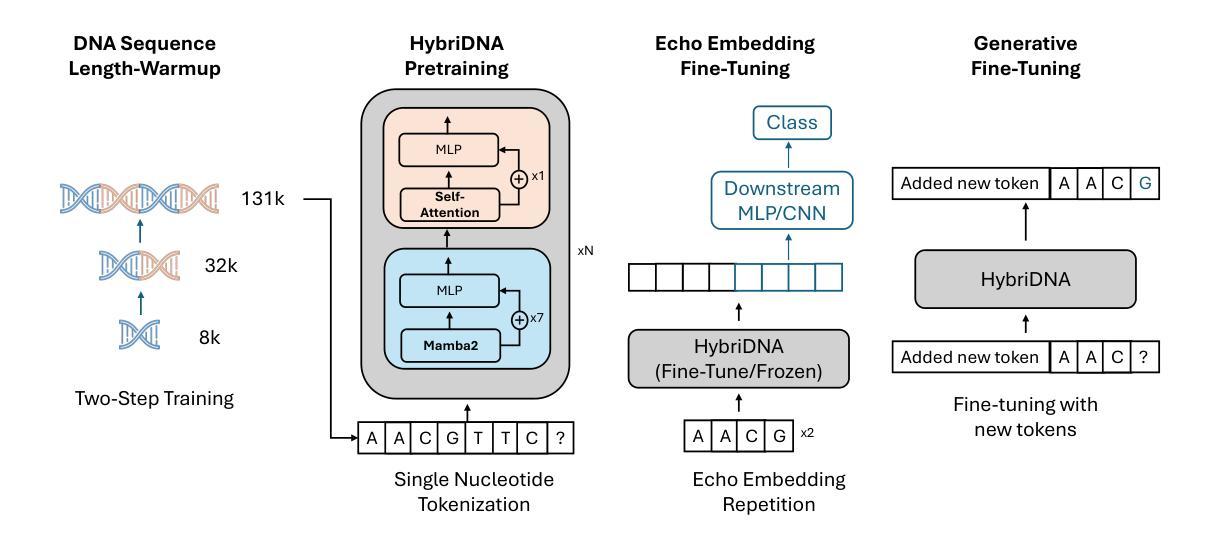
Advances in natural language processing and large language models have sparked growing interest in modeling DNA, often referred to as the “language of life”. However, DNA modeling poses unique challenges. First, it requires the ability to process ultra-long DNA sequences while preserving single-nucleotide resolution, as individual nucleotides play a critical role in DNA function. Second, success in this domain requires excelling at both generative and understanding tasks: generative tasks hold potential for therapeutic and industrial applications, while understanding tasks provide crucial insights into biological mechanisms and diseases. To address these challenges, we propose HybriDNA, a decoder-only DNA language model that incorporates a hybrid Transformer-Mamba2 architecture, seamlessly integrating the strengths of attention mechanisms with selective state-space models. This hybrid design enables HybriDNA to efficiently process DNA sequences up to 131kb in length with single-nucleotide resolution. HybriDNA achieves state-of-the-art performance across 33 DNA understanding datasets curated from the BEND, GUE, and LRB benchmarks, and demonstrates exceptional capability in generating synthetic cis-regulatory elements (CREs) with desired properties. Furthermore, we show that HybriDNA adheres to expected scaling laws, with performance improving consistently as the model scales from 300M to 3B and 7B parameters. These findings underscore HybriDNA’s versatility and its potential to advance DNA research and applications, paving the way for innovations in understanding and engineering the “language of life”.
随着自然语言处理和大型语言模型的进步,对DNA的建模,常被称为“生命的语言”,引发了越来越多的兴趣。然而,DNA建模存在独特的挑战。首先,它需要在保持单核苷酸分辨率的同时处理超长的DNA序列,因为单个核苷酸在DNA功能中发挥关键作用。其次,在这个领域取得成功需要在生成和理解任务上都表现出色:生成任务在治疗和工业应用方面具有潜力,而理解任务则提供了对生物机制和疾病的深刻见解。为了应对这些挑战,我们提出了HybriDNA,这是一个仅解码的DNA语言模型,它结合了混合Transformer-Mamba2架构,无缝集成了注意力机制的选择状态空间模型的优点。这种混合设计使HybriDNA能够高效地处理长达131kb的DNA序列,并保留单核苷酸分辨率。HybriDNA在来自BEND、GUE和LRB基准测试的33个DNA理解数据集上实现了最先进的性能,并显示出生成具有所需特性的合成顺式调控元件(CREs)的卓越能力。此外,我们证明了HybriDNA遵循预期的比例定律,随着模型参数从300M扩展到3B和7B,其性能一直在提高。这些发现强调了HybriDNA的通用性以及其在推动DNA研究与应用方面的潜力,为理解和工程化“生命的语言”开辟了创新之路。
论文及项目相关链接
PDF Project page: https://hybridna-project.github.io/HybriDNA-Project/
Summary
自然语言处理和大型语言模型的进步激发了人们对DNA建模的兴趣,DNA被称为“生命的语言”。然而,DNA建模面临独特挑战。首先,它需要在保持单核苷酸分辨率的同时处理超长的DNA序列。其次,成功的DNA建模需要在生成和理解任务上都表现出色。针对这些挑战,我们提出了HybriDNA,一种仅解码的DNA语言模型,结合了Transformer和Mamba2的混合架构,结合了注意力机制和选择性状态空间模型的优点。这种混合设计使HybriDNA能够高效地处理长达131kb的DNA序列,并具有单核苷酸分辨率。HybriDNA在来自BEND、GUE和LRB基准测试的33个DNA理解数据集上达到了最佳性能,并能生成具有所需特性的合成顺式调控元件(CREs)。此外,随着模型从3亿到7亿参数的扩展,其性能不断提高,证明了其遵循预期规模定律。这些发现突显了HybriDNA的通用性和在推动DNA研究与应用方面的潜力,为理解和工程化“生命语言”的创新铺平了道路。
Key Takeaways
- DNA建模被描述为“生命语言”的建模,具有独特挑战。
- 处理超长DNA序列并保持单核苷酸分辨率是DNA建模的关键挑战之一。
- 生成和理解任务是DNA建模成功的两个关键方面。
- HybriDNA是一个混合架构的DNA语言模型,结合了Transformer和Mamba2的优点。
- HybriDNA能高效处理长达131kb的DNA序列,具有单核苷酸分辨率。
- 在多个DNA理解数据集上,HybriDNA达到了最佳性能,并展示了生成合成顺式调控元件的能力。
点此查看论文截图

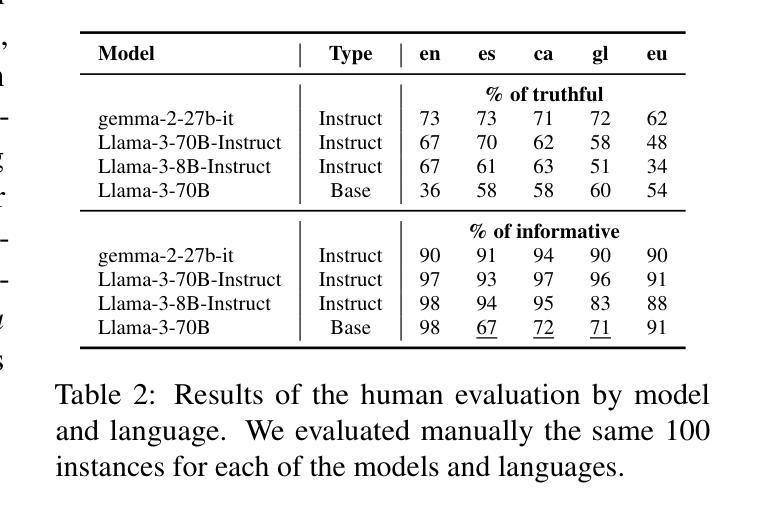
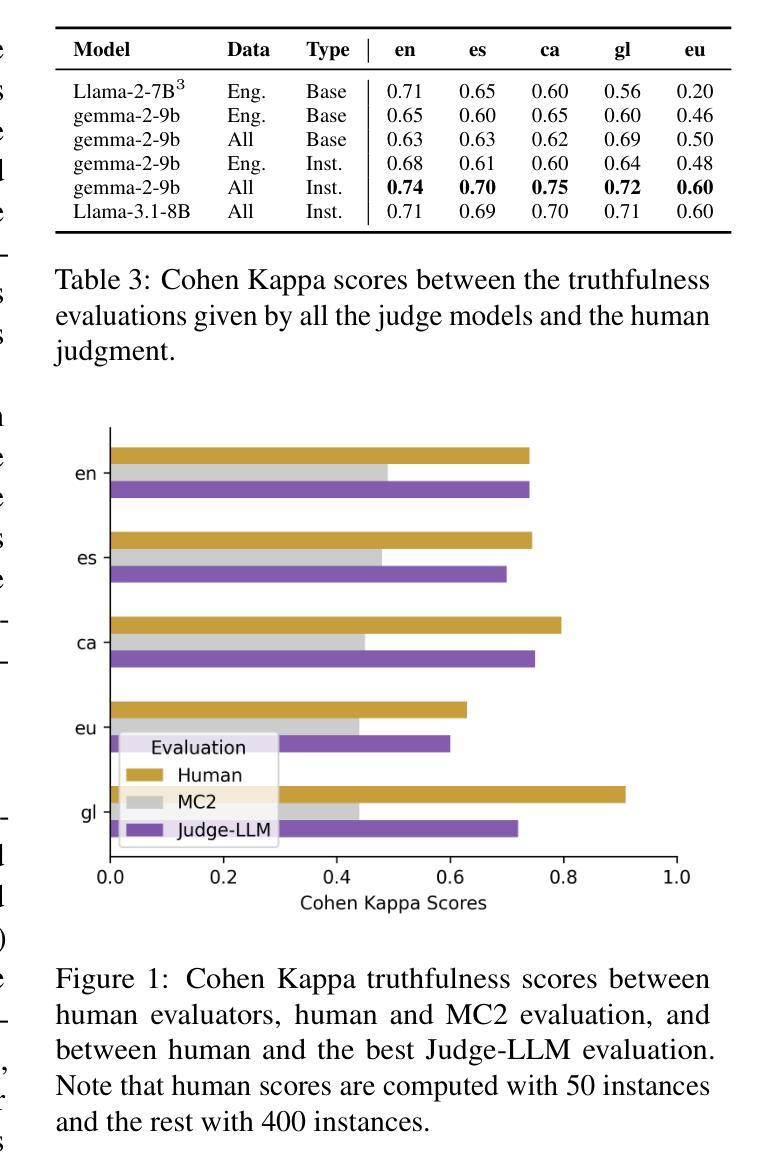
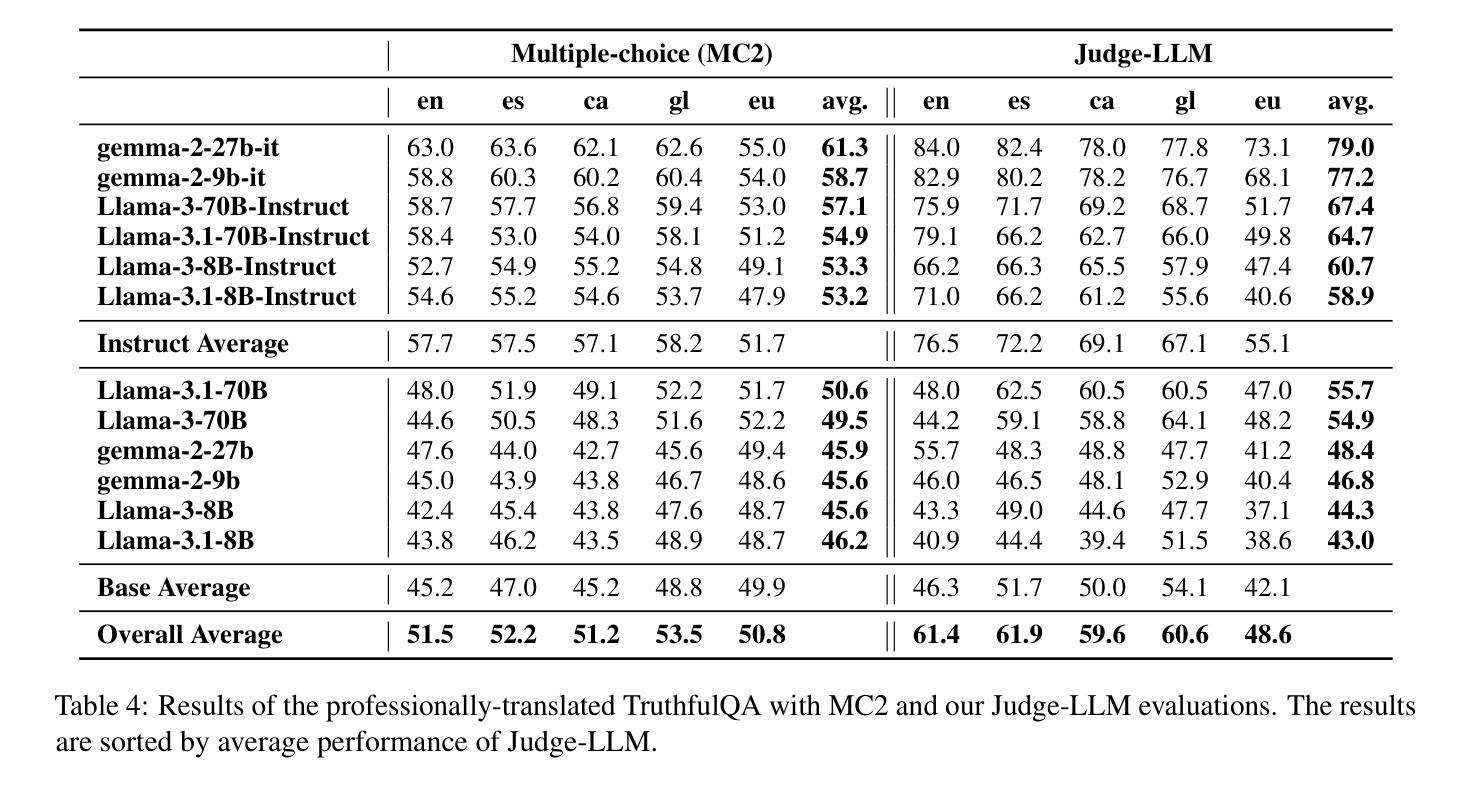
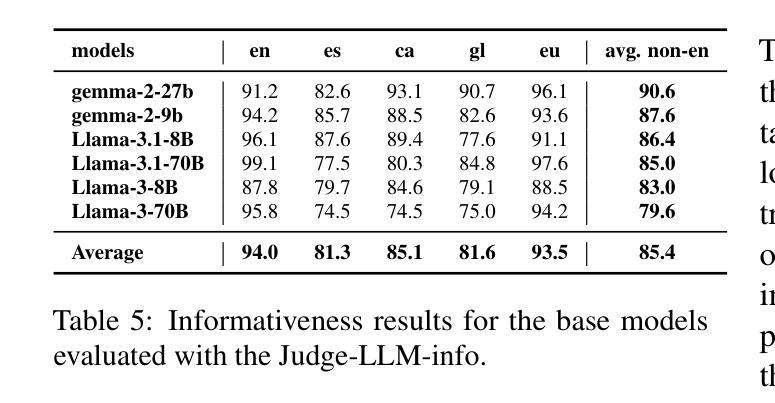
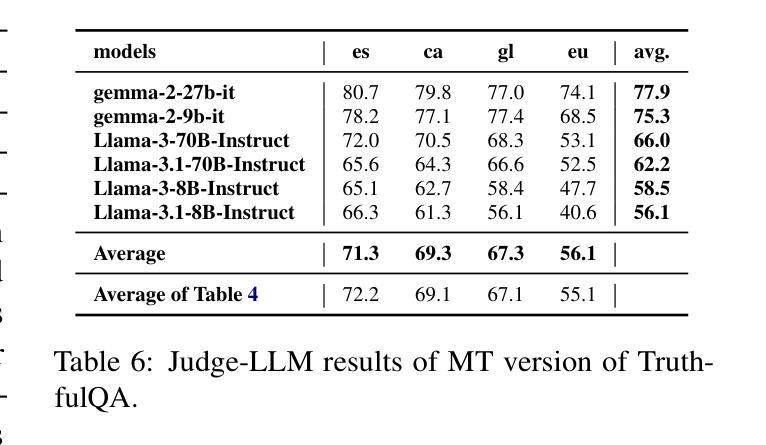
Truth Knows No Language: Evaluating Truthfulness Beyond English
Authors:Blanca Calvo Figueras, Eneko Sagarzazu, Julen Etxaniz, Jeremy Barnes, Pablo Gamallo, Iria De Dios Flores, Rodrigo Agerri
We introduce a professionally translated extension of the TruthfulQA benchmark designed to evaluate truthfulness in Basque, Catalan, Galician, and Spanish. Truthfulness evaluations of large language models (LLMs) have primarily been conducted in English. However, the ability of LLMs to maintain truthfulness across languages remains under-explored. Our study evaluates 12 state-of-the-art open LLMs, comparing base and instruction-tuned models using human evaluation, multiple-choice metrics, and LLM-as-a-Judge scoring. Our findings reveal that, while LLMs perform best in English and worst in Basque (the lowest-resourced language), overall truthfulness discrepancies across languages are smaller than anticipated. Furthermore, we show that LLM-as-a-Judge correlates more closely with human judgments than multiple-choice metrics, and that informativeness plays a critical role in truthfulness assessment. Our results also indicate that machine translation provides a viable approach for extending truthfulness benchmarks to additional languages, offering a scalable alternative to professional translation. Finally, we observe that universal knowledge questions are better handled across languages than context- and time-dependent ones, highlighting the need for truthfulness evaluations that account for cultural and temporal variability. Dataset and code are publicly available under open licenses.
我们介绍了一个经过专业翻译的TruthfulQA基准测试扩展,该测试旨在评估巴斯克语、加泰罗尼亚语、加利西亚语和西班牙语中的真实性评估。迄今为止,大型语言模型(LLM)的真实性评估主要用英语进行。然而,LLM在不同语言中保持真实性的能力仍未被充分探索。我们的研究评估了12种最先进的大型开源语言模型,通过人工评估、多项选择指标和LLM作为法官评分的方式,对比基础模型和指令调整模型。我们的研究结果表明,虽然LLM在英语中的表现最好,在巴斯克语(资源最少)中的表现最差,但总体而言,不同语言之间的真实性差异小于预期。此外,我们还表明,与多项选择指标相比,LLM作为法官的评分与人类判断更为接近,信息在真实性评估中发挥着关键作用。我们的结果还表明,机器翻译是扩展真实性基准测试到更多语言的一种可行方法,提供了一种可扩展的替代专业翻译的方法。最后,我们观察到,通用知识问题在不同语言中的处理情况比上下文和时间依赖性问题更好,这强调了需要进行考虑文化和时间变化真实性评估的必要性。数据集和代码均已公开提供。
论文及项目相关链接
PDF 14 pages, 6 figures, 8 tables
Summary
该文介绍了针对巴斯克语、加泰罗尼亚语、加利西亚语和西班牙语的真实性评价基准测试的专业翻译扩展版本。该研究评估了12个最先进的开源大型语言模型(LLM)在多种语言中的真实性保持能力,对比了基础模型和指令微调模型的人评、多选指标和LLM作为法官的评分。研究发现,LLM在英语中表现最好,在巴斯克语(资源最少)中表现最差,但总体上看,不同语言间的真实性差异小于预期。此外,研究还表明LLM作为法官的评分与人类判断更为接近,信息性在真实性评估中起着关键作用。机器翻译可作为将真实性基准测试扩展到其他语言的可行方法,提供了一种可扩展的替代专业翻译的途径。最后,观察到普遍知识的问题在跨语言处理上比上下文和时间依赖的问题更好,强调真实性评价需要考虑文化和时间变化的重要性。数据集和代码均公开可用。
Key Takeaways
- 该研究扩展了TruthfulQA基准测试,以评估巴斯克语、加泰罗尼亚语、加利西亚语和西班牙语中的大型语言模型的真实性。
- 对比了12个先进的开源大型语言模型在多种语言中的表现,发现不同语言间的真实性差异较小。
- LLM作为法官的评分与人类判断更为接近,信息性在真实性评估中起关键作用。
- 机器翻译可作为将真实性基准测试扩展到其他语言的可行方法。
- 普遍知识的问题在跨语言处理上表现较好,强调真实性评价需考虑文化和时间变化的重要性。
- 公开数据集和代码可供研究使用。
点此查看论文截图


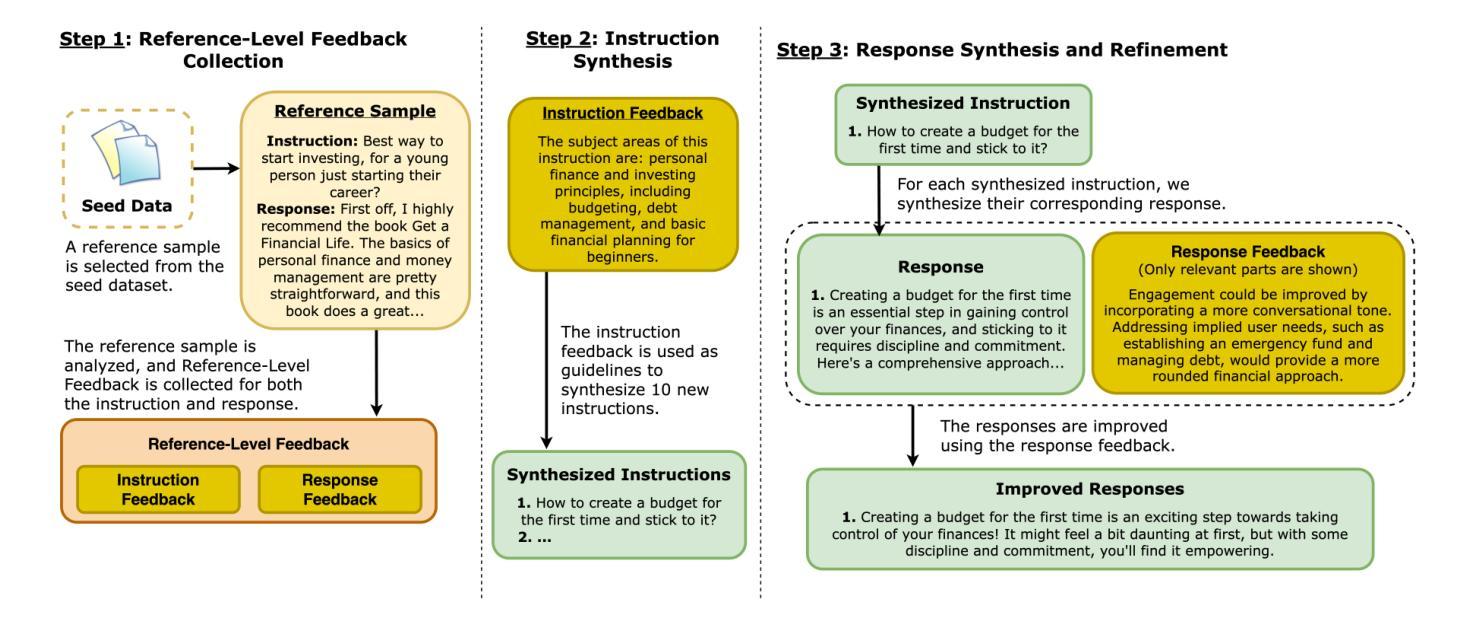
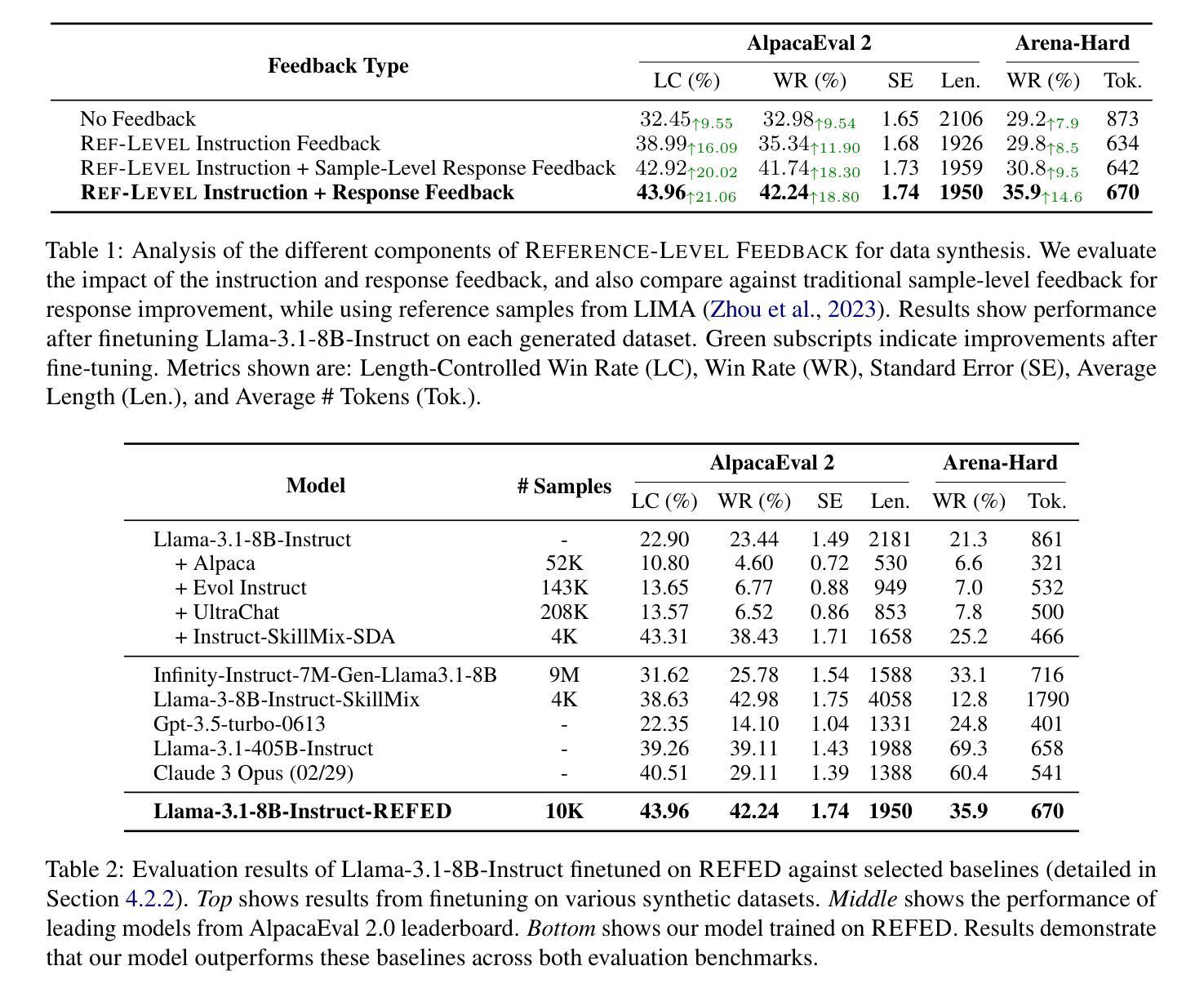
Beyond Sample-Level Feedback: Using Reference-Level Feedback to Guide Data Synthesis
Authors:Shuhaib Mehri, Xiusi Chen, Heng Ji, Dilek Hakkani-Tür
LLMs demonstrate remarkable capabilities in following natural language instructions, largely due to instruction-tuning on high-quality datasets. While synthetic data generation has emerged as a scalable approach for creating such datasets, maintaining consistent quality standards remains challenging. Recent approaches incorporate feedback to improve data quality, but typically operate at the sample level, generating and applying feedback for each response individually. In this work, we propose Reference-Level Feedback, a novel methodology that instead collects feedback based on high-quality reference samples from carefully curated seed data. We use this feedback to capture rich signals of desirable characteristics and propagate it throughout the data synthesis process. We present REFED, a dataset of 10K instruction-response pairs synthesized using such feedback. We demonstrate the effectiveness of our approach by showing that Llama-3.1-8B-Instruct finetuned on REFED achieves state-of-the-art performance among similar-sized SFT-based models on AlpacaEval 2.0 and strong results on Arena-Hard. Through extensive experiments, we show that our approach consistently outperforms traditional sample-level feedback methods with significantly fewer feedback collections and improves performance across different model architectures.
大型语言模型(LLMs)显示出遵循自然语言指令的显著能力,这主要归功于在高质量数据集上进行指令调整。虽然合成数据生成已经成为创建此类数据集的可扩展方法,但保持一致的质量标准仍然具有挑战性。最近的方法纳入反馈以提高数据质量,但通常在样本层面运行,为每个单独响应生成并应用反馈。在这项工作中,我们提出了基于高质量参考样本的参考级反馈(Reference-Level Feedback)这一新方法,这些参考样本来源于精心筛选的种子数据。我们使用此反馈捕获丰富的理想特征信号并将其传播到整个数据合成过程中。我们推出了REFED数据集,其中包含使用此类反馈合成的1万条指令响应对。通过展示LLama-3.1-8B-Instruct在REFED上微调后,在AlpacaEval 2.0上实现与类似大小的基于SFT的模型相比的最佳性能以及在Arena-Hard上的良好结果,我们证明了我们的方法的有效性。通过大量实验,我们证明了我们的方法始终优于传统的样本级反馈方法,在收集较少的反馈的情况下,并且提高了不同模型架构的性能。
论文及项目相关链接
Summary
LLMs通过高质量数据集进行指令微调展现出强大的能力。尽管合成数据生成已成为创建此类数据集的可扩展方法,但维持一致的质量标准仍然具有挑战性。最新方法采用反馈来改善数据质量,通常在样本层面操作,为每个响应单独生成和应用反馈。本文提出一种基于精心筛选的种子数据中的高质量参考样本收集反馈的Reference-Level Feedback方法。我们使用这种反馈来捕捉可取的特性的丰富信号,并将其传播到整个数据合成过程中。我们介绍了使用这种反馈合成的包含1万条指令响应对的REFED数据集。实验表明,基于REFED微调的Llama-3.1-8B-Instruct模型在AlpacaEval 2.0上实现了同类小型SFT模型的最佳性能,并在Arena-Hard上取得了良好结果。与传统的样本级反馈方法相比,我们的方法表现更优越,能显著降低反馈收集成本,并改善不同模型架构的性能。
Key Takeaways
- LLMs通过高质量数据集进行指令微调展现出显著的能力提升。
- 合成数据生成是创建高质量数据集的可扩展方法,但维持质量标准具有挑战性。
- 最新方法采用样本级反馈来改善数据质量,但存在局限性。
- 本文提出Reference-Level Feedback方法,基于高质量参考样本收集反馈。
- 使用此方法合成的REFED数据集能有效提升模型性能。
- 实验表明,REFED微调的Llama-3.1-8B-Instruct模型在多个评估标准上表现优越。
点此查看论文截图

DiTAR: Diffusion Transformer Autoregressive Modeling for Speech Generation
Authors:Dongya Jia, Zhuo Chen, Jiawei Chen, Chenpeng Du, Jian Wu, Jian Cong, Xiaobin Zhuang, Chumin Li, Zhen Wei, Yuping Wang, Yuxuan Wang
Several recent studies have attempted to autoregressively generate continuous speech representations without discrete speech tokens by combining diffusion and autoregressive models, yet they often face challenges with excessive computational loads or suboptimal outcomes. In this work, we propose Diffusion Transformer Autoregressive Modeling (DiTAR), a patch-based autoregressive framework combining a language model with a diffusion transformer. This approach significantly enhances the efficacy of autoregressive models for continuous tokens and reduces computational demands. DiTAR utilizes a divide-and-conquer strategy for patch generation, where the language model processes aggregated patch embeddings and the diffusion transformer subsequently generates the next patch based on the output of the language model. For inference, we propose defining temperature as the time point of introducing noise during the reverse diffusion ODE to balance diversity and determinism. We also show in the extensive scaling analysis that DiTAR has superb scalability. In zero-shot speech generation, DiTAR achieves state-of-the-art performance in robustness, speaker similarity, and naturalness.
近期有几项研究尝试结合扩散模型和自回归模型,无需离散语音标记即可自回归生成连续语音表示。但它们常面临计算负载过大或结果不理想等挑战。在此工作中,我们提出了扩散转换器自回归建模(DiTAR),这是一种结合语言模型和扩散转换器的基于补丁的自回归框架。这种方法显著提高了自回归模型对连续标记的有效性,并降低了计算需求。DiTAR采用分而治之的补丁生成策略,语言模型处理聚合的补丁嵌入,随后扩散转换器根据语言模型的输出生成下一个补丁。对于推理,我们提议将温度定义为在反向扩散ODE中引入噪声的时间点,以平衡多样性和确定性。在广泛的规模分析中,我们还显示DiTAR具有出色的可扩展性。在零样本语音生成中,DiTAR在稳健性、说话人相似度和自然度方面达到了最新技术水平。
论文及项目相关链接
PDF 16 pages, 8 figures
Summary
本文提出一种名为Diffusion Transformer Autoregressive Modeling (DiTAR)的方法,它将语言模型与扩散变压器相结合,采用基于补丁的自回归框架,以连续令牌自回归生成语音表示。该方法提高了自回归模型对连续令牌的效率,并降低了计算需求。DiTAR采用分而治之的策略进行补丁生成,并利用定义的噪声引入温度来平衡多样性和确定性。在零样本语音生成中,DiTAR在稳健性、说话人相似性和自然性方面达到最新水平。
Key Takeaways
- 提出了Diffusion Transformer Autoregressive Modeling(DiTAR)方法,结合了语言模型和扩散变压器。
- DiTAR采用基于补丁的自回归框架,以连续令牌生成语音表示。
- 分而治之的策略用于补丁生成。
- 通过定义的噪声引入温度来平衡模型的多样性和确定性。
- DiTAR提高了自回归模型对连续令牌的效率,并降低了计算需求。
- 在零样本语音生成中,DiTAR在性能上表现优异,特别是在稳健性、说话人相似性等方面达到最新水平。
点此查看论文截图



VLMaterial: Procedural Material Generation with Large Vision-Language Models
Authors:Beichen Li, Rundi Wu, Armando Solar-Lezama, Changxi Zheng, Liang Shi, Bernd Bickel, Wojciech Matusik
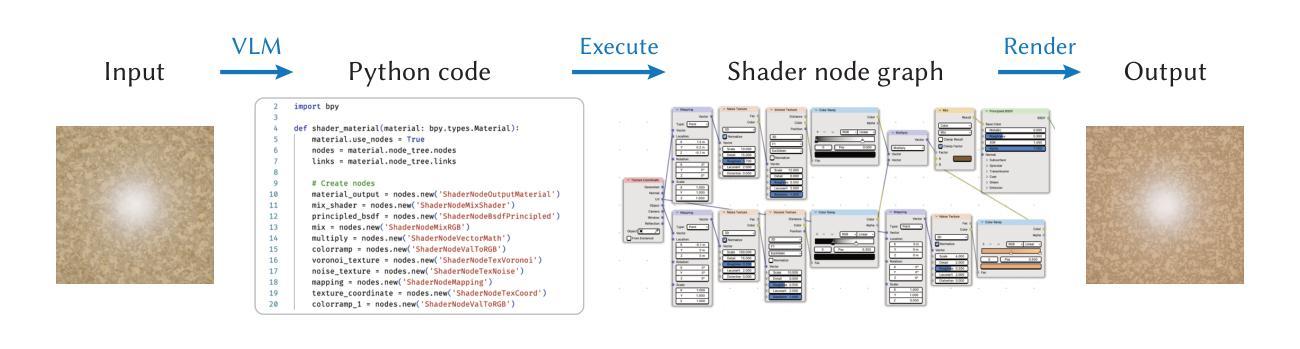
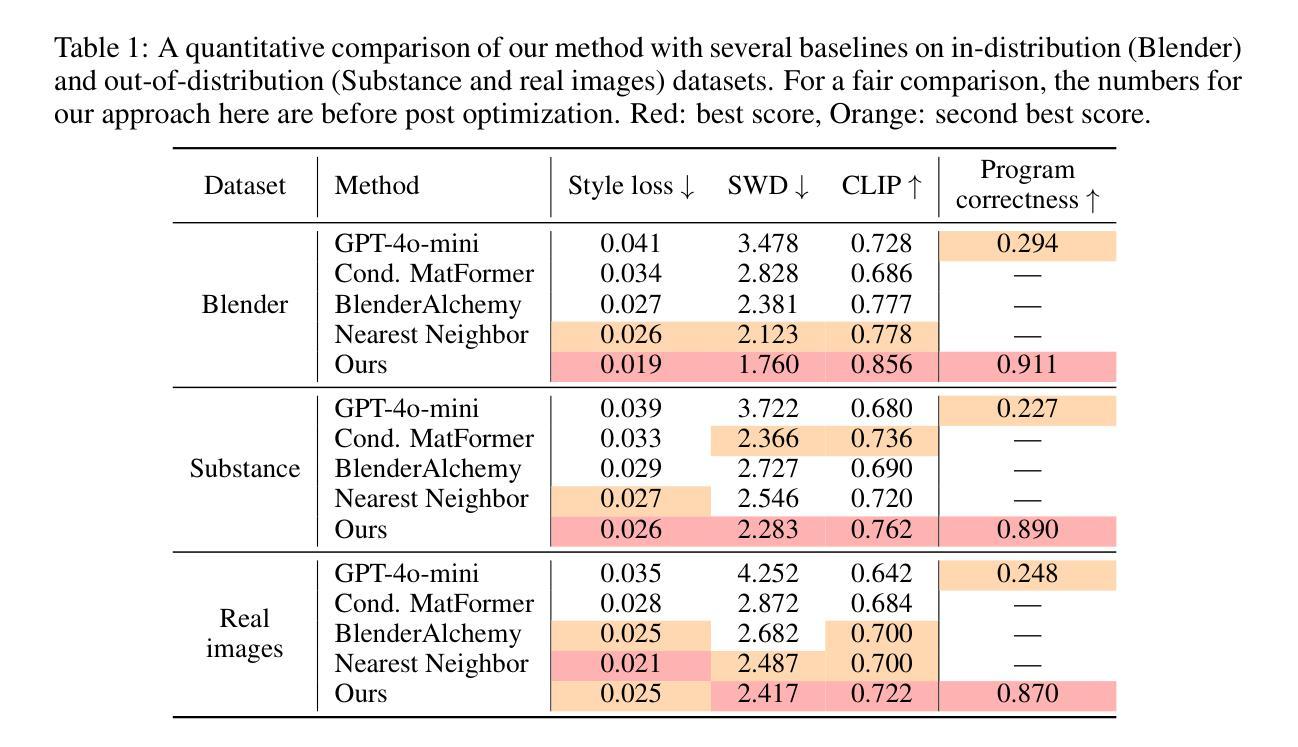
Procedural materials, represented as functional node graphs, are ubiquitous in computer graphics for photorealistic material appearance design. They allow users to perform intuitive and precise editing to achieve desired visual appearances. However, creating a procedural material given an input image requires professional knowledge and significant effort. In this work, we leverage the ability to convert procedural materials into standard Python programs and fine-tune a large pre-trained vision-language model (VLM) to generate such programs from input images. To enable effective fine-tuning, we also contribute an open-source procedural material dataset and propose to perform program-level augmentation by prompting another pre-trained large language model (LLM). Through extensive evaluation, we show that our method outperforms previous methods on both synthetic and real-world examples.
程序化材料以功能节点图的形式呈现,在计算机图形学的真实感材质外观设计中随处可见。它们允许用户进行直观和精确的编辑,以达到所需的视觉效果。然而,根据输入图像创建程序化材料需要专业知识并付出大量努力。在这项工作中,我们利用将程序化材料转换为标准Python程序的能力,并微调一个大型预训练视觉语言模型(VLM),以便从输入图像生成此类程序。为了实现有效的微调,我们还提供了一个开源的程序化材料数据集,并提议通过提示另一个预训练的大型语言模型(LLM)来进行程序级增强。通过广泛评估,我们证明了我们的方法在合成和现实世界示例上均优于以前的方法。
论文及项目相关链接
PDF ICLR 2025 Spotlight
Summary:
利用功能节点图表示的过程材料在计算机图形学中广泛应用于逼真的材料外观设计中。用户可以通过直观和精确的编辑来实现期望的视觉外观。然而,根据输入图像创建过程材料需要专业知识并付出大量努力。本研究将过程材料转换为标准的Python程序,并利用预训练的视觉语言模型(VLM)进行微调,从输入图像生成此类程序。为了进行有效的微调,我们还提供了一个开源的过程材料数据集,并提出通过提示另一个预训练的大型语言模型(LLM)来进行程序级增强。通过广泛评估,我们的方法在合成和现实世界示例上均优于以前的方法。
Key Takeaways:
- 过程材料在计算机图形学中用于逼真的材料外观设计中,使用功能节点图表示。
- 用户可以通过直观和精确的编辑实现期望的视觉外观。
- 创建基于输入图像的过程材料需要专业知识和技能。
- 研究利用将过程材料转换为Python程序并利用预训练的视觉语言模型(VLM)进行微调的方法。
- 提出使用开源的过程材料数据集进行训练。
- 利用另一个预训练的大型语言模型(LLM)进行程序级增强。
点此查看论文截图