⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-20 更新
AV-Flow: Transforming Text to Audio-Visual Human-like Interactions
Authors:Aggelina Chatziagapi, Louis-Philippe Morency, Hongyu Gong, Michael Zollhoefer, Dimitris Samaras, Alexander Richard
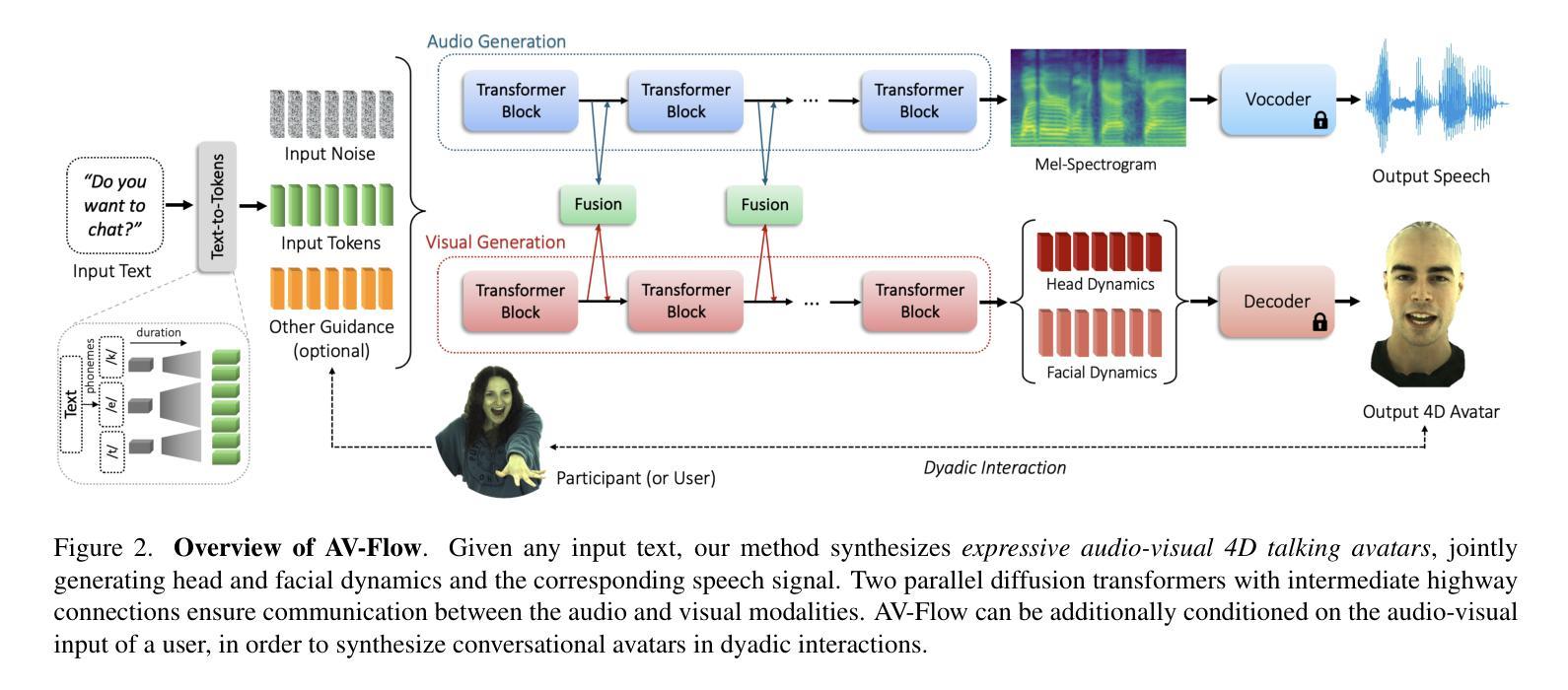
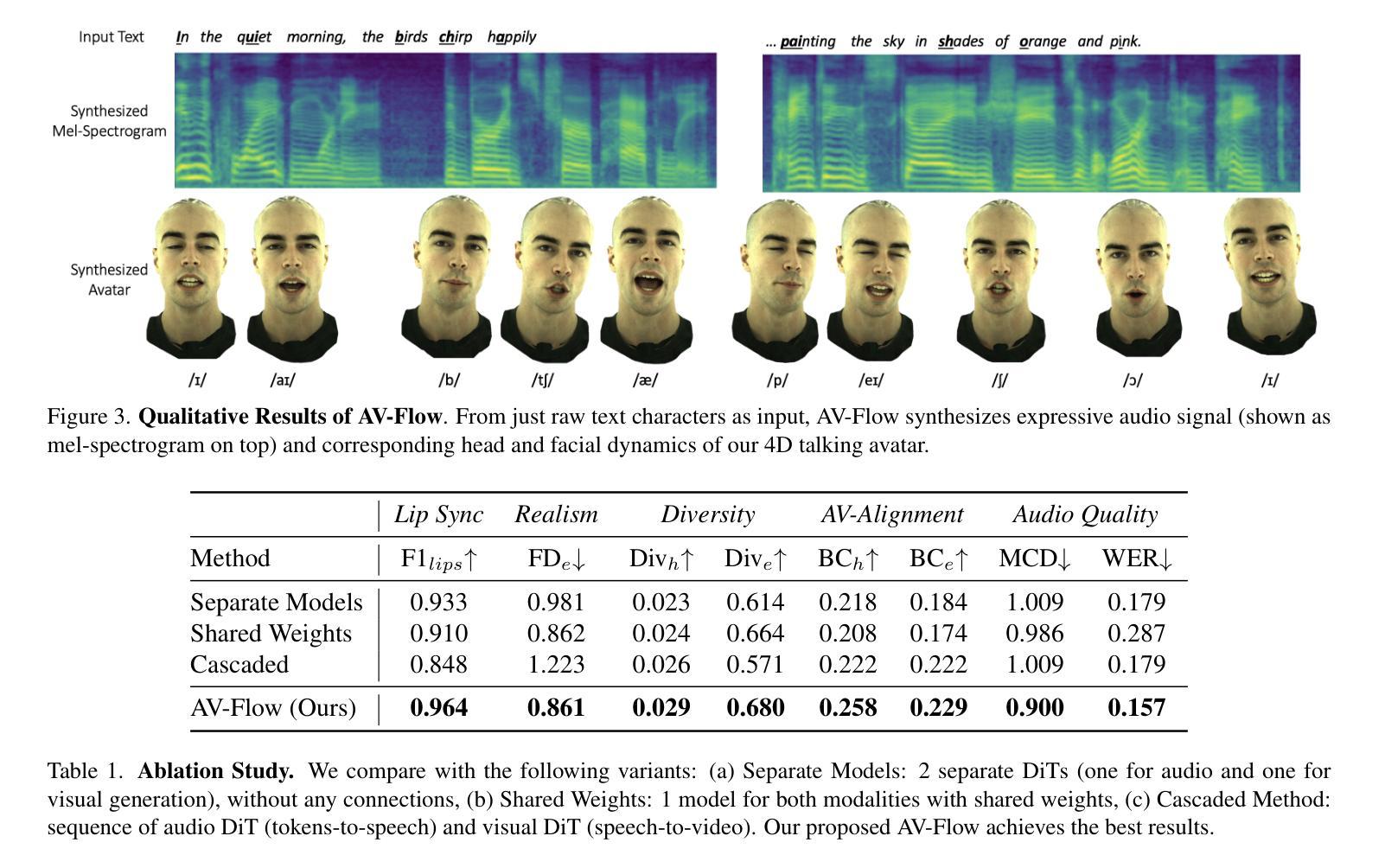
We introduce AV-Flow, an audio-visual generative model that animates photo-realistic 4D talking avatars given only text input. In contrast to prior work that assumes an existing speech signal, we synthesize speech and vision jointly. We demonstrate human-like speech synthesis, synchronized lip motion, lively facial expressions and head pose; all generated from just text characters. The core premise of our approach lies in the architecture of our two parallel diffusion transformers. Intermediate highway connections ensure communication between the audio and visual modalities, and thus, synchronized speech intonation and facial dynamics (e.g., eyebrow motion). Our model is trained with flow matching, leading to expressive results and fast inference. In case of dyadic conversations, AV-Flow produces an always-on avatar, that actively listens and reacts to the audio-visual input of a user. Through extensive experiments, we show that our method outperforms prior work, synthesizing natural-looking 4D talking avatars. Project page: https://aggelinacha.github.io/AV-Flow/
我们介绍了AV-Flow,这是一个视听生成模型,它只需要文本输入就能使照片级真实的4D对话角色动画化。与之前假设已有语音信号的工作不同,我们是联合合成语音和视觉。我们展示了类似人类的语音合成、同步的唇部运动、生动的面部表情和头部姿态;所有这些都仅由文本字符生成。我们的方法的核心在于两个并行扩散变压器的架构。中间的高速公路连接确保了音频和视觉模式之间的通信,因此,语音语调与面部动态(如眉毛运动)是同步的。我们的模型采用流量匹配进行训练,产生了富有表现力的结果并实现了快速推理。在双人对话的情况下,AV-Flow会产生一个始终开启的角色,该角色会积极倾听并反应用户的视听输入。通过大量实验,我们证明了我们的方法优于以前的工作,能够合成逼真的4D对话角色。项目页面:https://aggelinacha.github.io/AV-Flow/
论文及项目相关链接
Summary
文本介绍了一种名为AV-Flow的视听生成模型,该模型仅通过文本输入即可生成逼真的四维对话头像。不同于之前需要现有语音信号的假设,该模型能联合进行语音和视觉的合成。模型能生成人类语音、同步的唇部动作、生动的面部表情和头部姿态。其核心在于两个并行扩散变压器的架构,中间的高速连接确保了音频和视觉模态之间的通信,从而实现语音音调和面部动作的同步(如眉毛动作)。模型采用流量匹配进行训练,取得了显著效果并实现了快速推理。在双人对话场景中,AV-Flow可以生成始终开启的头像,能够主动听取并响应用户的视听输入。实验证明,该方法优于先前的工作,能够合成自然逼真的四维对话头像。
Key Takeaways
- AV-Flow是一种视听生成模型,能从文本输入生成逼真的四维对话头像。
- 与依赖现有语音信号的模型不同,AV-Flow联合进行语音和视觉合成。
- 模型具备生成人类语音、同步唇部动作、面部表情和头部姿态的能力。
- 模型的核心在于其并行扩散变压器的架构及中间的高速连接,确保音频和视觉模态间的通信。
- 模型采用流量匹配进行训练,实现了显著的效果和快速推理。
- 在双人对话场景中,AV-Flow生成的头像能够主动响应用户的视听输入。
点此查看论文截图