⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-20 更新
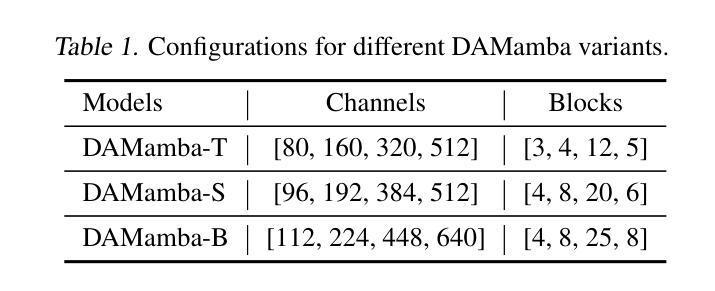
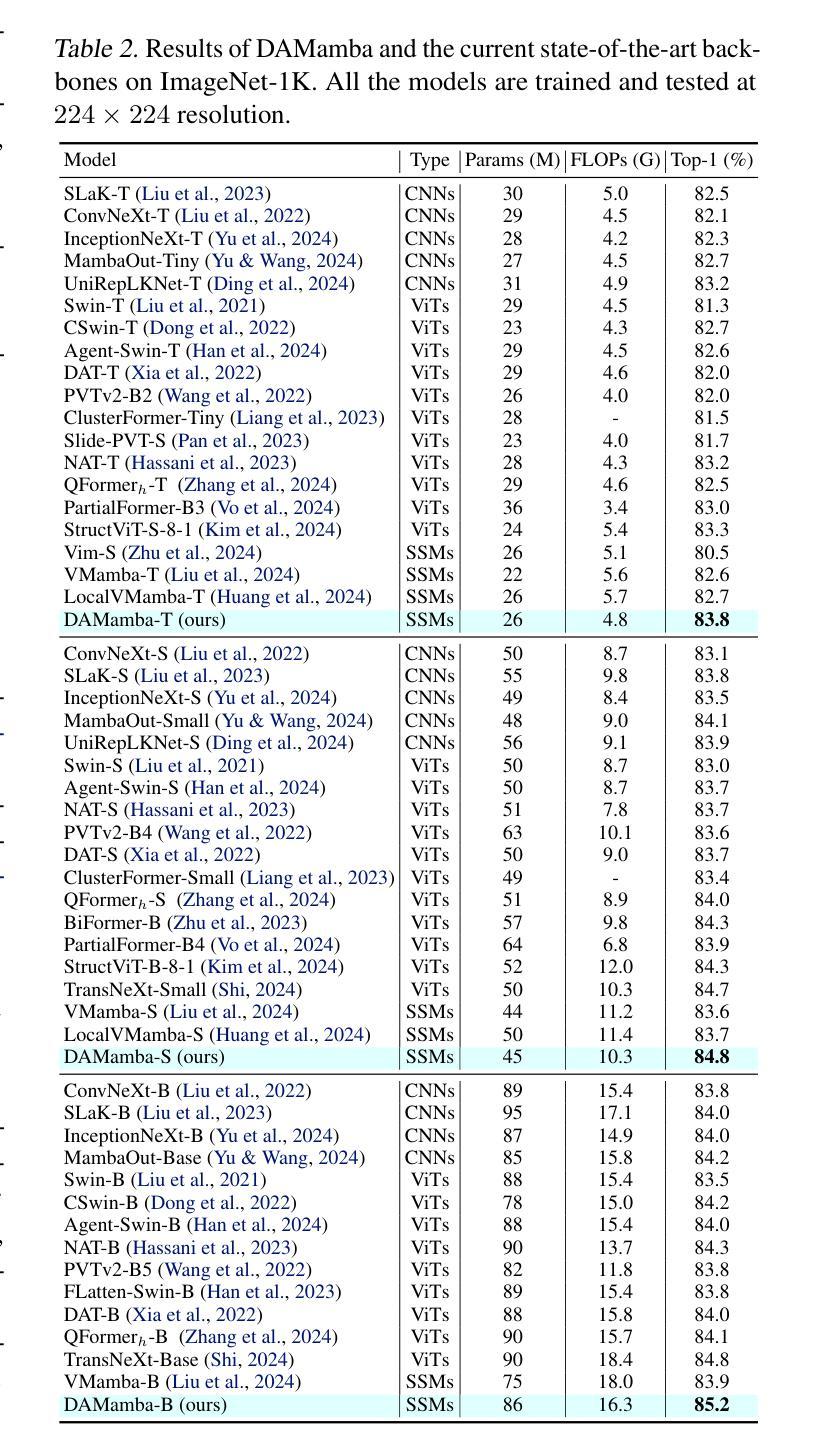
DAMamba: Vision State Space Model with Dynamic Adaptive Scan
Authors:Tanzhe Li, Caoshuo Li, Jiayi Lyu, Hongjuan Pei, Baochang Zhang, Taisong Jin, Rongrong Ji
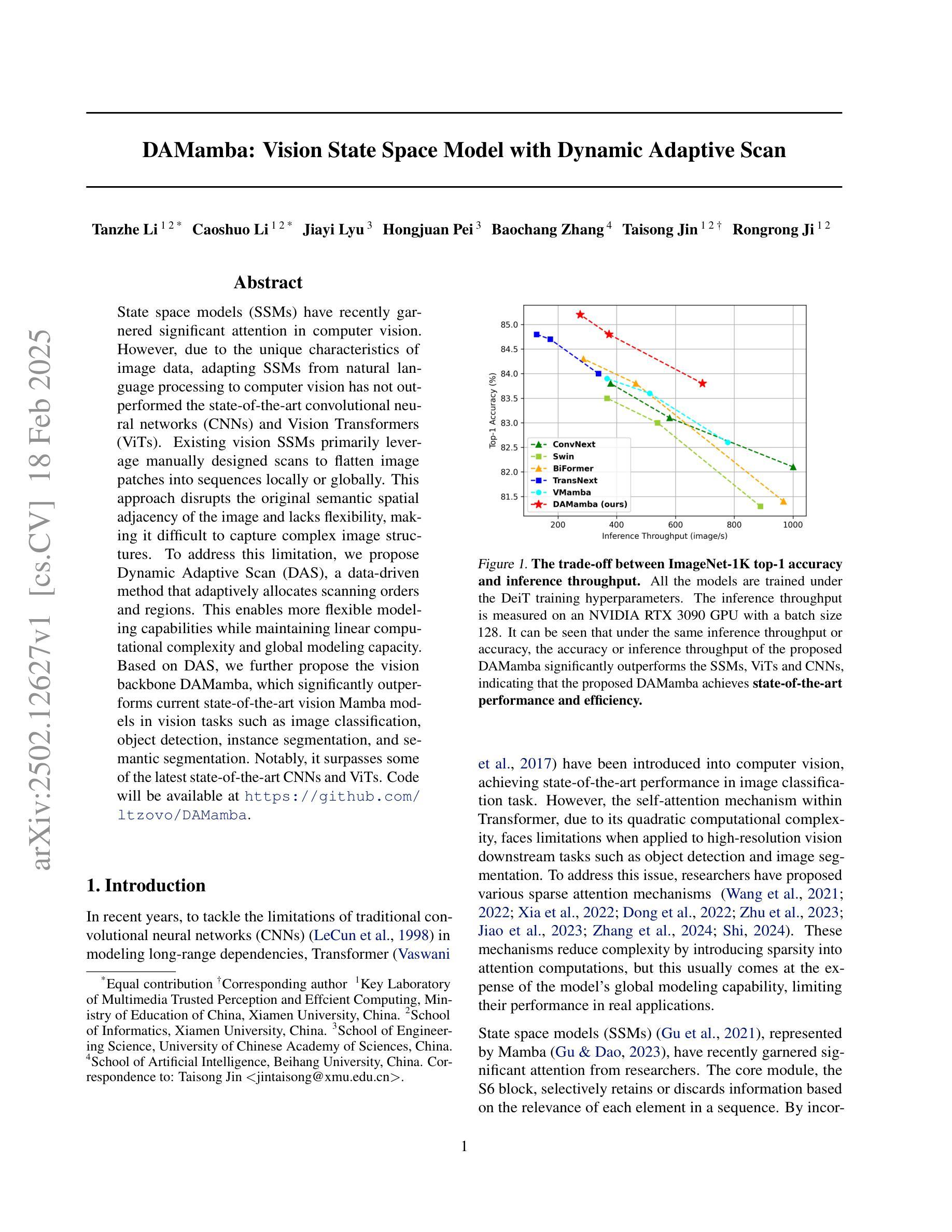
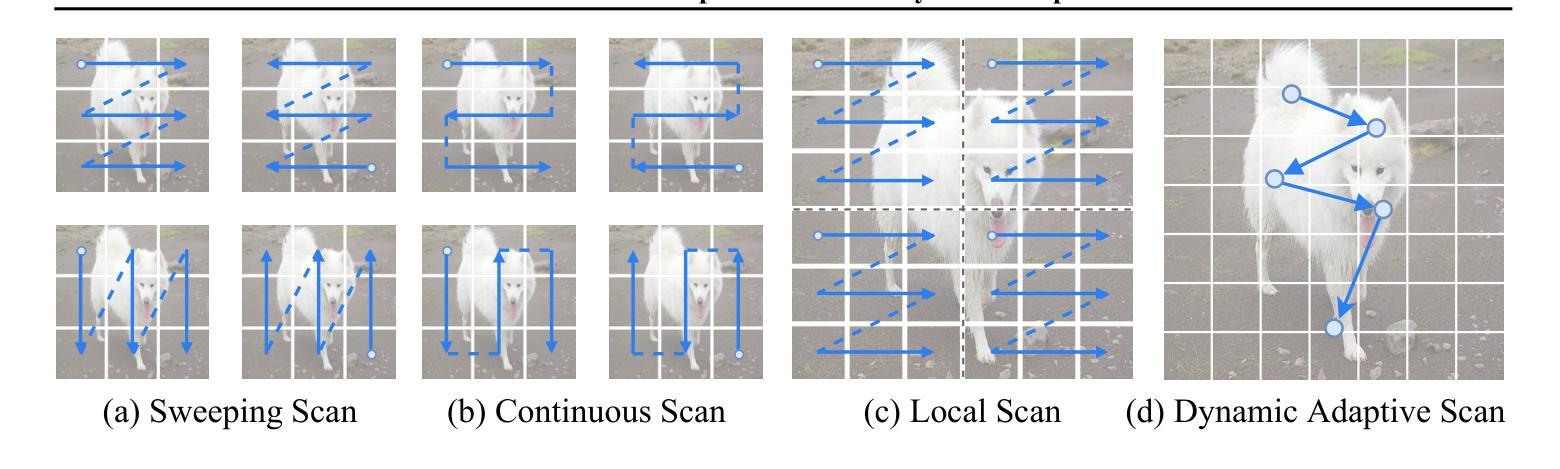
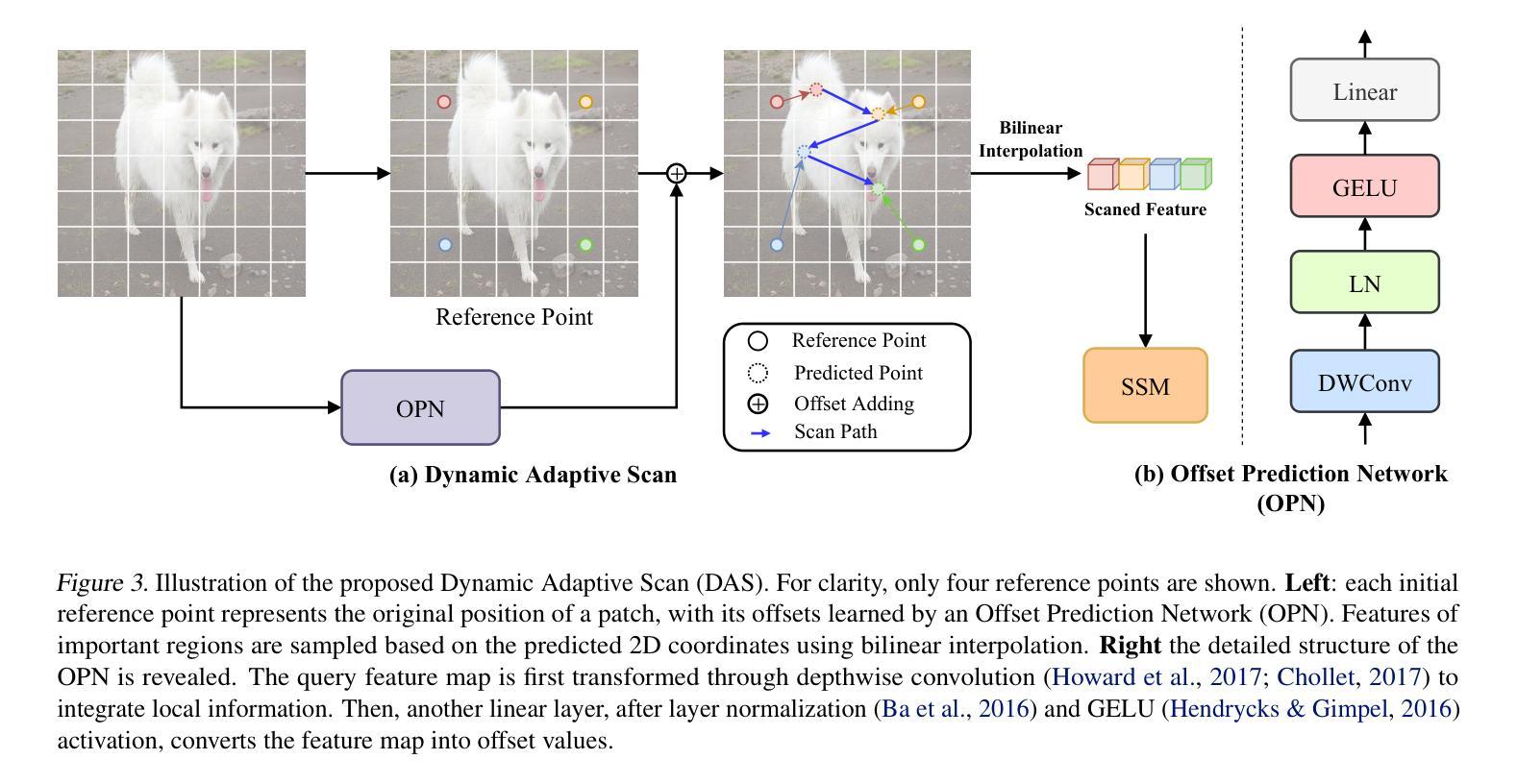
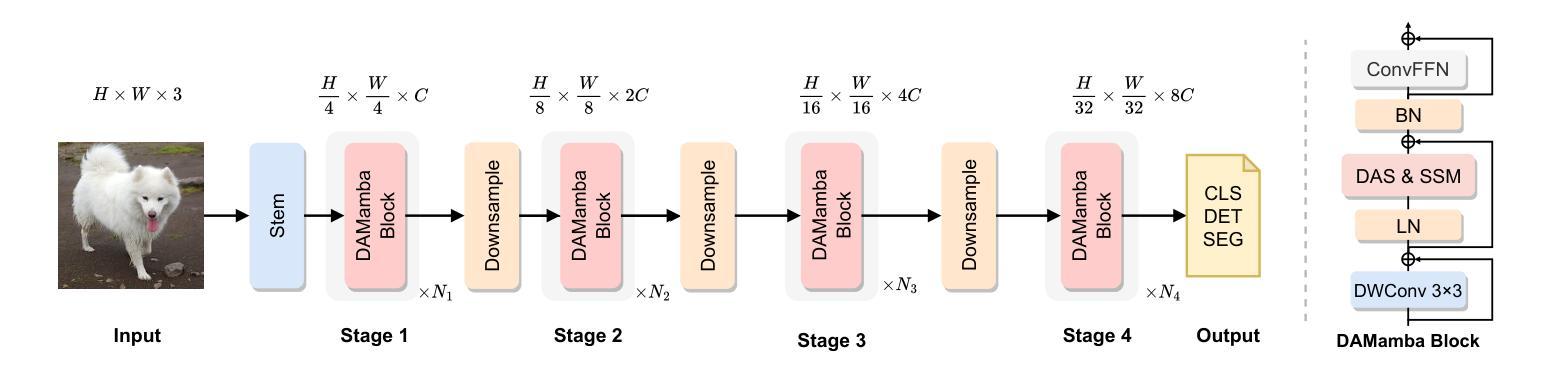
State space models (SSMs) have recently garnered significant attention in computer vision. However, due to the unique characteristics of image data, adapting SSMs from natural language processing to computer vision has not outperformed the state-of-the-art convolutional neural networks (CNNs) and Vision Transformers (ViTs). Existing vision SSMs primarily leverage manually designed scans to flatten image patches into sequences locally or globally. This approach disrupts the original semantic spatial adjacency of the image and lacks flexibility, making it difficult to capture complex image structures. To address this limitation, we propose Dynamic Adaptive Scan (DAS), a data-driven method that adaptively allocates scanning orders and regions. This enables more flexible modeling capabilities while maintaining linear computational complexity and global modeling capacity. Based on DAS, we further propose the vision backbone DAMamba, which significantly outperforms current state-of-the-art vision Mamba models in vision tasks such as image classification, object detection, instance segmentation, and semantic segmentation. Notably, it surpasses some of the latest state-of-the-art CNNs and ViTs. Code will be available at https://github.com/ltzovo/DAMamba.
状态空间模型(SSMs)最近在计算机视觉领域引起了广泛关注。然而,由于图像数据的独特性质,将SSMs从自然语言处理适应到计算机视觉并未超越最新的卷积神经网络(CNNs)和视觉转换器(ViTs)的技术水平。现有的视觉SSM主要利用手动设计的扫描将图像块平展成局部或全局序列。这种方法破坏了图像原始语义空间上的邻近性,缺乏灵活性,难以捕捉复杂的图像结构。为了解决这个问题,我们提出了动态自适应扫描(DAS),这是一种数据驱动的方法,可以自适应地分配扫描顺序和区域。这能够在保持线性计算复杂性和全局建模能力的同时,实现更灵活的建模能力。基于DAS,我们进一步提出了视觉主干DAMamba,在图像分类、目标检测、实例分割和语义分割等视觉任务中,显著优于当前的最新顶尖视觉Mamba模型。值得一提的是,它还超越了部分最新的顶尖CNNs和ViTs。代码将在https://github.com/ltzovo/DAMamba上发布。
论文及项目相关链接
Summary
本文介绍了在计算机视觉领域应用状态空间模型(SSMs)的最新进展。针对图像数据的特性,提出了一种动态自适应扫描(DAS)方法,以自适应地分配扫描顺序和区域,从而提高建模能力。基于DAS,进一步提出了视觉骨干网DAMamba,在图像分类、目标检测、实例分割和语义分割等视觉任务中显著优于当前最先进的视觉模型,包括一些最新的卷积神经网络(CNNs)和视觉变压器(ViTs)。
Key Takeaways
- 状态空间模型(SSMs)在计算机视觉领域受到关注,但在适应图像数据时面临挑战。
- 当前SSM方法主要使用手动设计的扫描方式,存在局限性。
- 动态自适应扫描(DAS)方法被提出,以自适应地分配扫描顺序和区域。
- DAS方法能够在保持线性计算复杂度和全局建模能力的同时,提供更灵活的建模能力。
- 基于DAS,提出了视觉骨干网DAMamba。
- DAMamba在多种视觉任务中表现优异,包括图像分类、目标检测、实例分割和语义分割。
点此查看论文截图
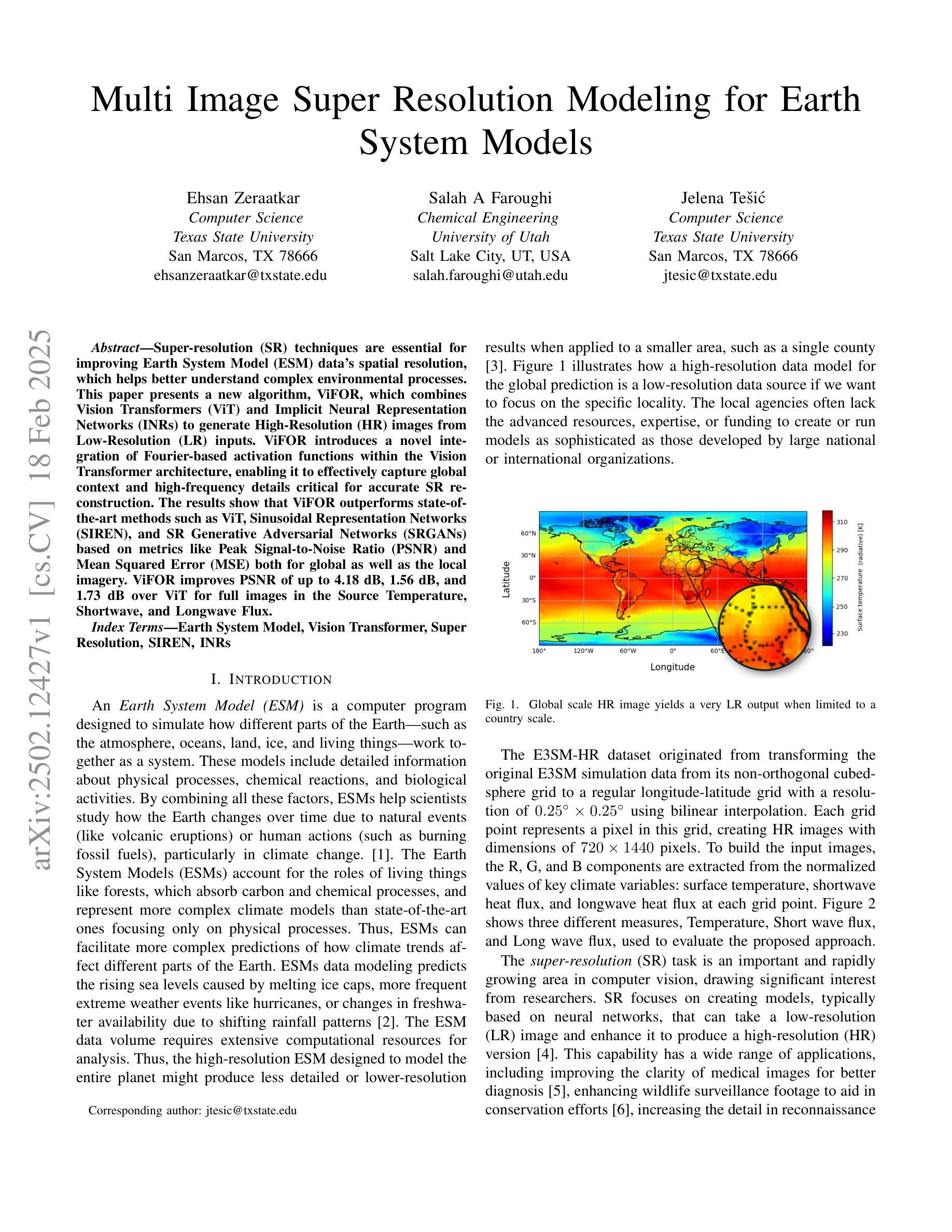
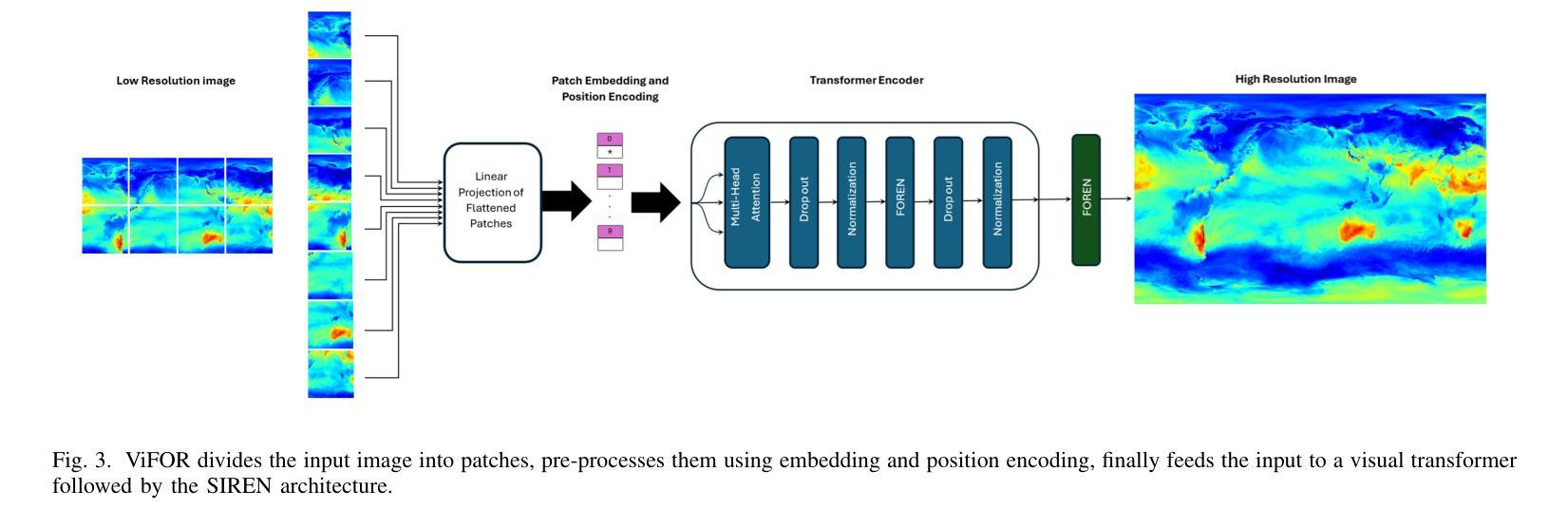
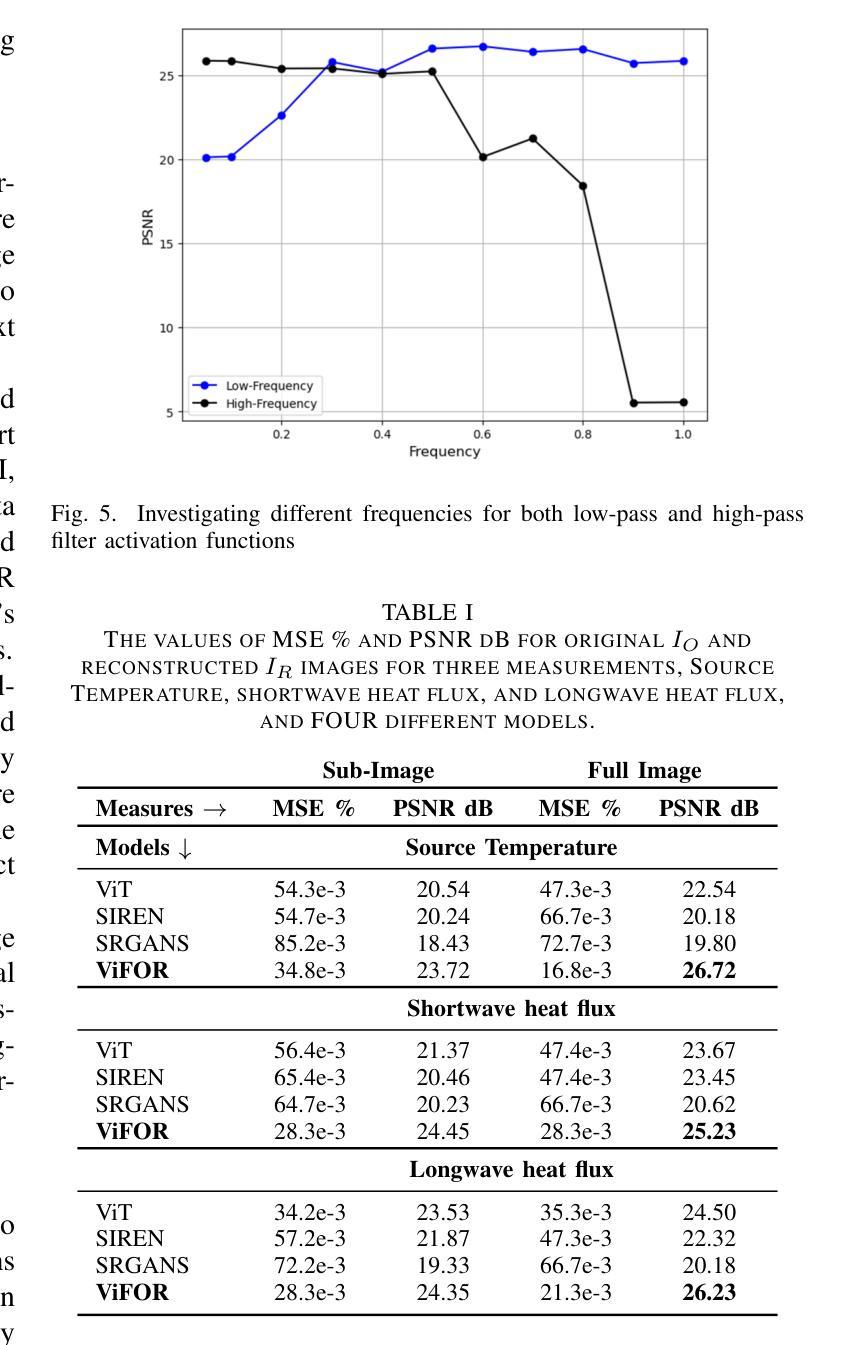
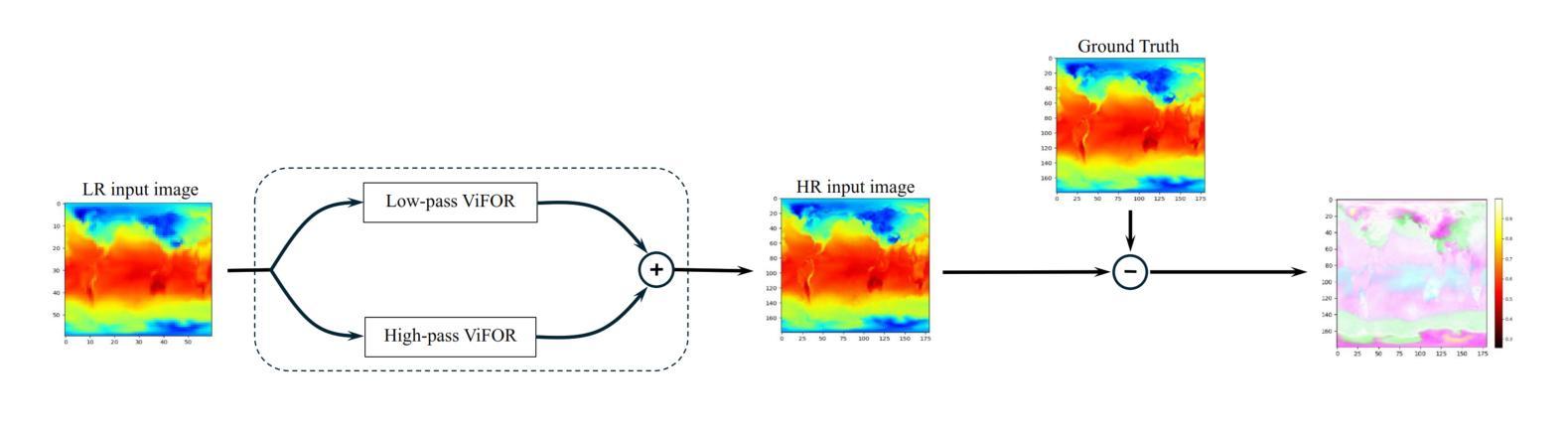
Multi Image Super Resolution Modeling for Earth System Models
Authors:Ehsan Zeraatkar, Salah A Faroughi, Jelena Tešić
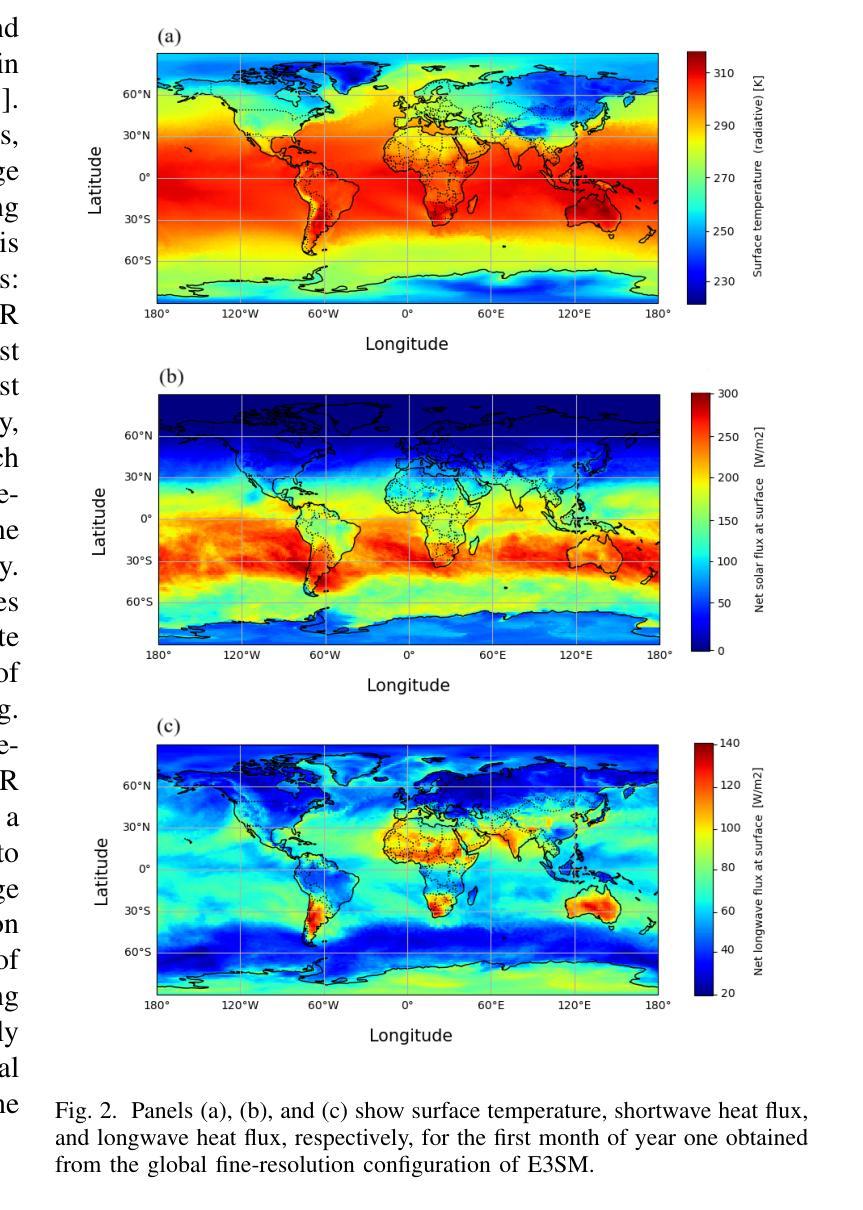
Super-resolution (SR) techniques are essential for improving Earth System Model (ESM) data’s spatial resolution, which helps better understand complex environmental processes. This paper presents a new algorithm, ViFOR, which combines Vision Transformers (ViT) and Implicit Neural Representation Networks (INRs) to generate High-Resolution (HR) images from Low-Resolution (LR) inputs. ViFOR introduces a novel integration of Fourier-based activation functions within the Vision Transformer architecture, enabling it to effectively capture global context and high-frequency details critical for accurate SR reconstruction. The results show that ViFOR outperforms state-of-the-art methods such as ViT, Sinusoidal Representation Networks (SIREN), and SR Generative Adversarial Networks (SRGANs) based on metrics like Peak Signal-to-Noise Ratio (PSNR) and Mean Squared Error (MSE) both for global as well as the local imagery. ViFOR improves PSNR of up to 4.18 dB, 1.56 dB, and 1.73 dB over ViT for full images in the Source Temperature, Shortwave, and Longwave Flux.
超分辨率(SR)技术对于提高地球系统模型(ESM)数据的空间分辨率至关重要,这有助于更好地理解复杂的环境过程。本文提出了一种新的算法ViFOR,它将视觉变压器(ViT)和隐式神经表示网络(INRs)结合起来,从低分辨率(LR)输入生成高分辨率(HR)图像。ViFOR在视觉变压器架构中引入了基于傅里叶激活函数的新颖集成,使其能够有效地捕获全局上下文和对于准确SR重建至关重要的高频细节。结果表明,ViFOR在峰值信噪比(PSNR)和均方误差(MSE)等指标上,无论是全局还是局部图像,都优于最先进的ViT、正弦表示网络(SIREN)和SR生成对抗网络(SRGANs)。对于源温度、短波和长波流量的完整图像,ViFOR的PSNR分别提高了高达4.18 dB、1.56 dB和1.73 dB。
论文及项目相关链接
Summary
一种新的算法ViFOR被提出,它结合了Vision Transformers(ViT)和Implicit Neural Representation Networks(INRs)技术,能够从低分辨率输入生成高分辨率图像。ViFOR在Vision Transformer架构中引入了基于傅里叶激活函数的新颖集成,能够有效地捕捉全局上下文和对于准确超分辨率重建至关重要的高频细节。结果显示,对于全局和局部图像,ViFOR在峰值信噪比(PSNR)和均方误差(MSE)等指标上的性能优于ViT、Sinusoidal Representation Networks(SIREN)和SR Generative Adversarial Networks(SRGANs)等当前主流方法。ViFOR在源温度、短波和长波通量的全图像上分别提高了4.18 dB、1.56 dB和1.73 dB的PSNR。
Key Takeaways
- ViFOR算法结合了Vision Transformers和Implicit Neural Representation Networks技术,旨在提高地球系统模型数据的空间分辨率。
- ViFOR引入了基于傅里叶激活函数的创新集成,有效捕捉全局上下文和关键的高频细节。
- ViFOR在峰值信噪比(PSNR)和均方误差(MSE)方面表现出卓越性能,超越了现有的主流方法,如ViT、SIREN和SRGANs。
- ViFOR在源温度、短波和长波通量的全图像上实现了显著的PSNR提升。
- 通过结合不同的技术,ViFOR算法为解决复杂的环境过程问题提供了新的视角。
- 该算法对于提高遥感图像和超分辨率重建等领域的性能具有重要影响。
点此查看论文截图
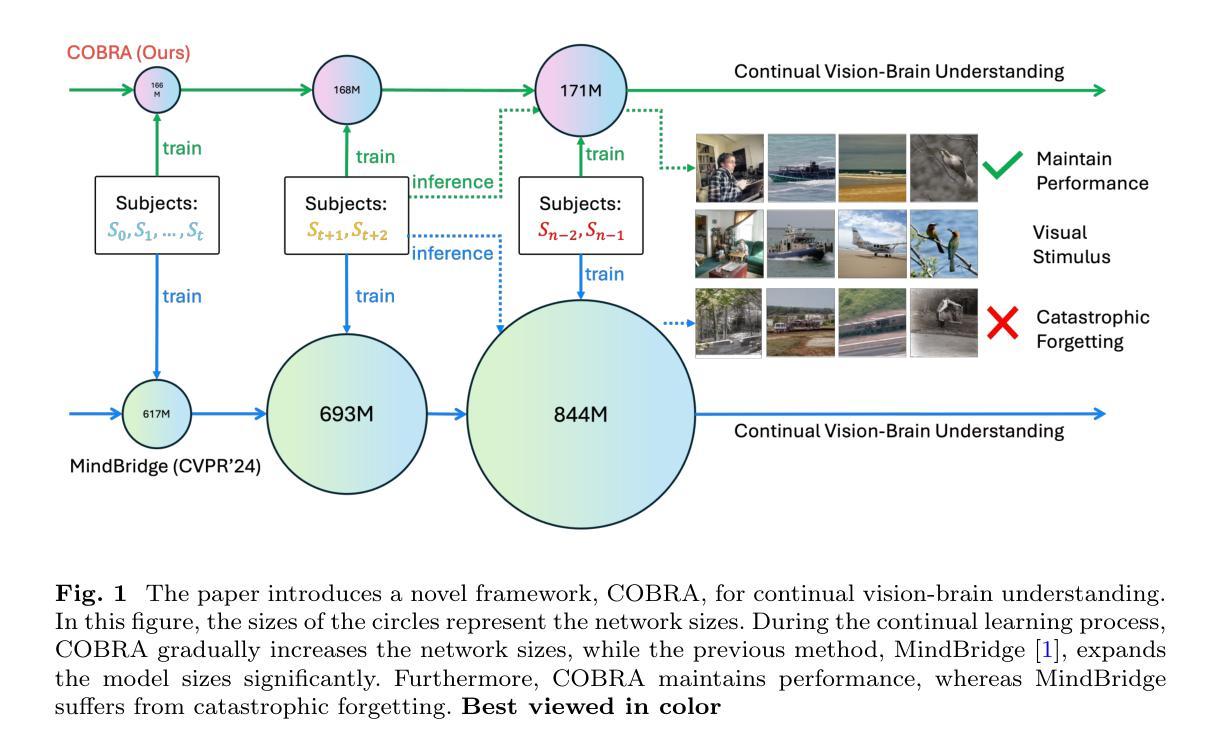
COBRA: A Continual Learning Approach to Vision-Brain Understanding
Authors:Xuan-Bac Nguyen, Arabinda Kumar Choudhary, Pawan Sinha, Xin Li, Khoa Luu
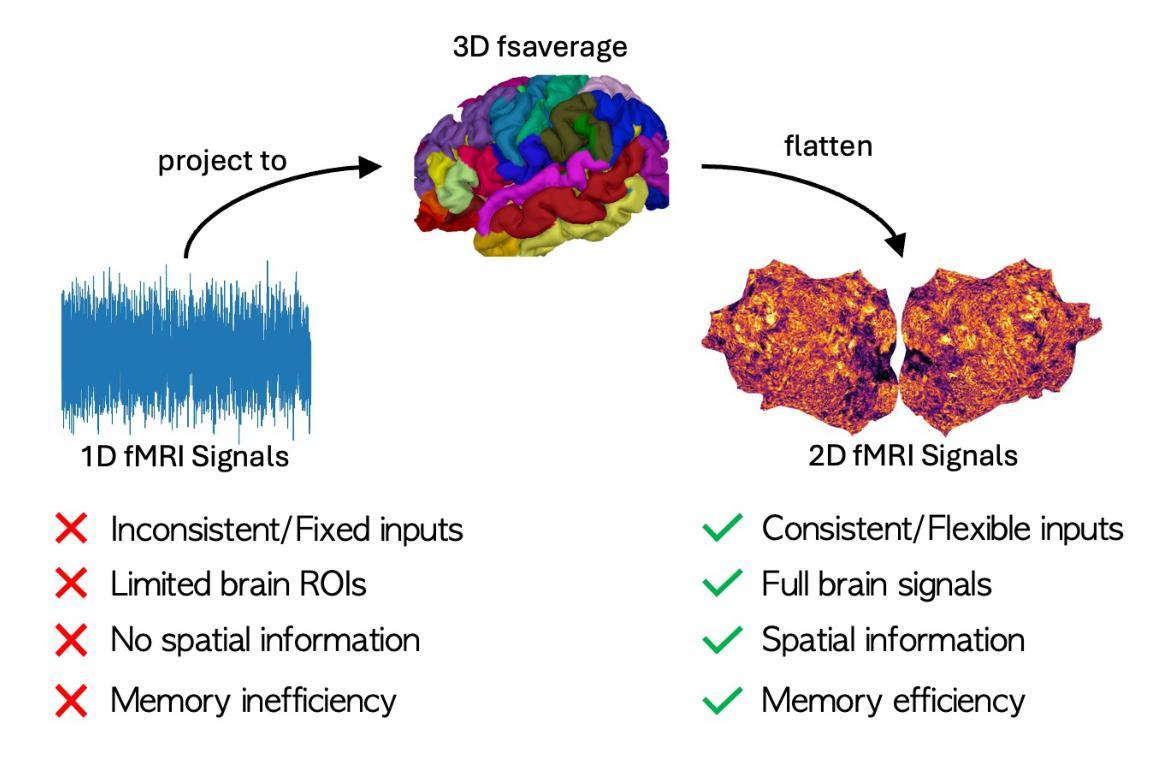
Vision-Brain Understanding (VBU) aims to extract visual information perceived by humans from brain activity recorded through functional Magnetic Resonance Imaging (fMRI). Despite notable advancements in recent years, existing studies in VBU continue to face the challenge of catastrophic forgetting, where models lose knowledge from prior subjects as they adapt to new ones. Addressing continual learning in this field is, therefore, essential. This paper introduces a novel framework called Continual Learning for Vision-Brain (COBRA) to address continual learning in VBU. Our approach includes three novel modules: a Subject Commonality (SC) module, a Prompt-based Subject Specific (PSS) module, and a transformer-based module for fMRI, denoted as MRIFormer module. The SC module captures shared vision-brain patterns across subjects, preserving this knowledge as the model encounters new subjects, thereby reducing the impact of catastrophic forgetting. On the other hand, the PSS module learns unique vision-brain patterns specific to each subject. Finally, the MRIFormer module contains a transformer encoder and decoder that learns the fMRI features for VBU from common and specific patterns. In a continual learning setup, COBRA is trained in new PSS and MRIFormer modules for new subjects, leaving the modules of previous subjects unaffected. As a result, COBRA effectively addresses catastrophic forgetting and achieves state-of-the-art performance in both continual learning and vision-brain reconstruction tasks, surpassing previous methods.
视觉大脑理解(VBU)旨在从通过功能性磁共振成像(fMRI)记录的大脑活动中提取人类感知到的视觉信息。尽管近年来取得了显著进展,但VBU的现有研究仍然面临灾难性遗忘的挑战,即模型在适应新主题时丢失了先前主题的知识。因此,解决该领域的持续学习至关重要。本文介绍了一个名为COBRA的持续学习视觉大脑框架,以解决VBU中的持续学习问题。我们的方法包括三个新颖模块:主体共性(SC)模块、基于提示的主体特定(PSS)模块和基于变压器的fMRI模块,称为MRIFormer模块。SC模块捕获跨主题的共同视觉大脑模式,并在模型遇到新主题时保留此知识,从而减少灾难性遗忘的影响。另一方面,PSS模块学习每个主体特有的视觉大脑模式。最后,MRIFormer模块包含变压器编码器和解码器,从公共和特定模式中学习VBU的fMRI特征。在持续学习设置中,COBRA针对新主题训练新的PSS和MRIFormer模块,而不影响先前主题的模块。因此,COBRA有效地解决了灾难性遗忘问题,并在持续学习和视觉大脑重建任务中实现了最先进的性能,超越了以前的方法。
论文及项目相关链接
Summary
该文本介绍了一项新技术,即视觉大脑理解中的持续学习技术(COBRA)。此技术通过利用三大模块,包括主题共性模块(SC)、基于提示的主题特定模块(PSS)以及核磁共振成像转换器模块(MRIFormer),有效解决了模型在适应新主题时遗忘旧知识的问题(即灾难性遗忘)。COBRA技术在持续学习和视觉大脑重建任务上表现卓越,超越了以前的方法。
Key Takeaways
- Vision-Brain Understanding (VBU) 通过功能磁共振成像(fMRI)提取人类从大脑中感知的视觉信息。
- VBU领域的一个挑战是灾难性遗忘,即模型在适应新主题时忘记旧知识。
- COBRA是一种新技术框架,旨在解决VBU中的持续学习问题。
- COBRA包括三大模块:主题共性模块(SC)、基于提示的主题特定模块(PSS)和MRIFormer模块。
- SC模块捕捉不同主题之间的共享视觉大脑模式,并保留这些知识,以减少灾难性遗忘的影响。
- PSS模块学习每个主题的独特视觉大脑模式。
点此查看论文截图