⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-21 更新
Na’vi or Knave: Jailbreaking Language Models via Metaphorical Avatars
Authors:Yu Yan, Sheng Sun, Junqi Tong, Min Liu, Qi Li
Metaphor serves as an implicit approach to convey information, while enabling the generalized comprehension of complex subjects. However, metaphor can potentially be exploited to bypass the safety alignment mechanisms of Large Language Models (LLMs), leading to the theft of harmful knowledge. In our study, we introduce a novel attack framework that exploits the imaginative capacity of LLMs to achieve jailbreaking, the J\underline{\textbf{A}}ilbreak \underline{\textbf{V}}ia \underline{\textbf{A}}dversarial Me\underline{\textbf{TA}} -pho\underline{\textbf{R}} (\textit{AVATAR}). Specifically, to elicit the harmful response, AVATAR extracts harmful entities from a given harmful target and maps them to innocuous adversarial entities based on LLM’s imagination. Then, according to these metaphors, the harmful target is nested within human-like interaction for jailbreaking adaptively. Experimental results demonstrate that AVATAR can effectively and transferablly jailbreak LLMs and achieve a state-of-the-art attack success rate across multiple advanced LLMs. Our study exposes a security risk in LLMs from their endogenous imaginative capabilities. Furthermore, the analytical study reveals the vulnerability of LLM to adversarial metaphors and the necessity of developing defense methods against jailbreaking caused by the adversarial metaphor. \textcolor{orange}{ \textbf{Warning: This paper contains potentially harmful content from LLMs.}}
隐喻作为一种隐性传递信息的方式,能够使复杂的主题得到普遍理解。然而,隐喻可能会被用于绕过大型语言模型(LLM)的安全对齐机制,从而导致有害知识的窃取。在我们的研究中,我们引入了一种新的攻击框架,利用LLM的想象力来实现越狱,即J\underline{\textbf{A}}ilbreak \underline{\textbf{V}}ia \underline{\textbf{A}}dversarial Me\underline{\textbf{TA}} -pho\underline{\textbf{R}}(\textit{AVATAR})。具体来说,为了引发有害反应,AVATAR会从给定的有害目标中提取有害实体,并根据LLM的想象力将它们映射到无害的对立实体。然后,根据这些隐喻,将有害目标嵌套在人性化交互中进行自适应越狱。实验结果表明,AVATAR可以有效地且可迁移地绕过LLM并实现跨多个先进LLM的最先进的攻击成功率。我们的研究揭示了LLM从其内在想象力存在的安全风险。此外,分析研究表明LLM容易受到对立隐喻的攻击,并有必要开发对抗由对立隐喻引起的越狱的防御方法。 \textcolor{orange}{ \textbf{警告:本文包含潜在的有害LLM内容。}}
论文及项目相关链接
PDF We still need to polish our paper
Summary:本研究揭示了隐喻可能绕过大型语言模型的安全对齐机制的风险,提出一种利用大型语言模型的想象力进行越狱攻击的新框架,名为AVATAR。该框架通过提取有害目标中的有害实体并将其映射到无害的对立实体上,借助隐喻来实现越狱。实验表明,AVATAR能实现对多个先进的大型语言模型的越狱攻击,达到很高的成功率。这项研究提醒人们关注大型语言模型内部想象力的安全隐患,以及开发对抗隐喻式越狱的防御方法的必要性。潜在风险警告:本文包含大型语言模型可能产生的潜在有害内容。
Key Takeaways:
- 隐喻可以作为一种隐性的方式传递信息,并使复杂的主题更容易理解。然而,隐喻也有可能被用于绕过大型语言模型的安全机制。
- 研究人员提出一种新的攻击框架,名为AVATAR,它能利用大型语言模型的想象力来实现一种“越狱”攻击。这种攻击能通过隐喻来嵌入恶意信息并绕过语言模型的防御。
- AVATAR通过将有害实体映射到无害的对立实体上,进而实现对大型语言模型的越狱攻击。这种攻击方式具有有效性和可迁移性。
- 实验结果表明,AVATAR能在多个先进的大型语言模型中实现较高的攻击成功率。这揭示了大型语言模型在应对对抗性隐喻时的脆弱性。
点此查看论文截图

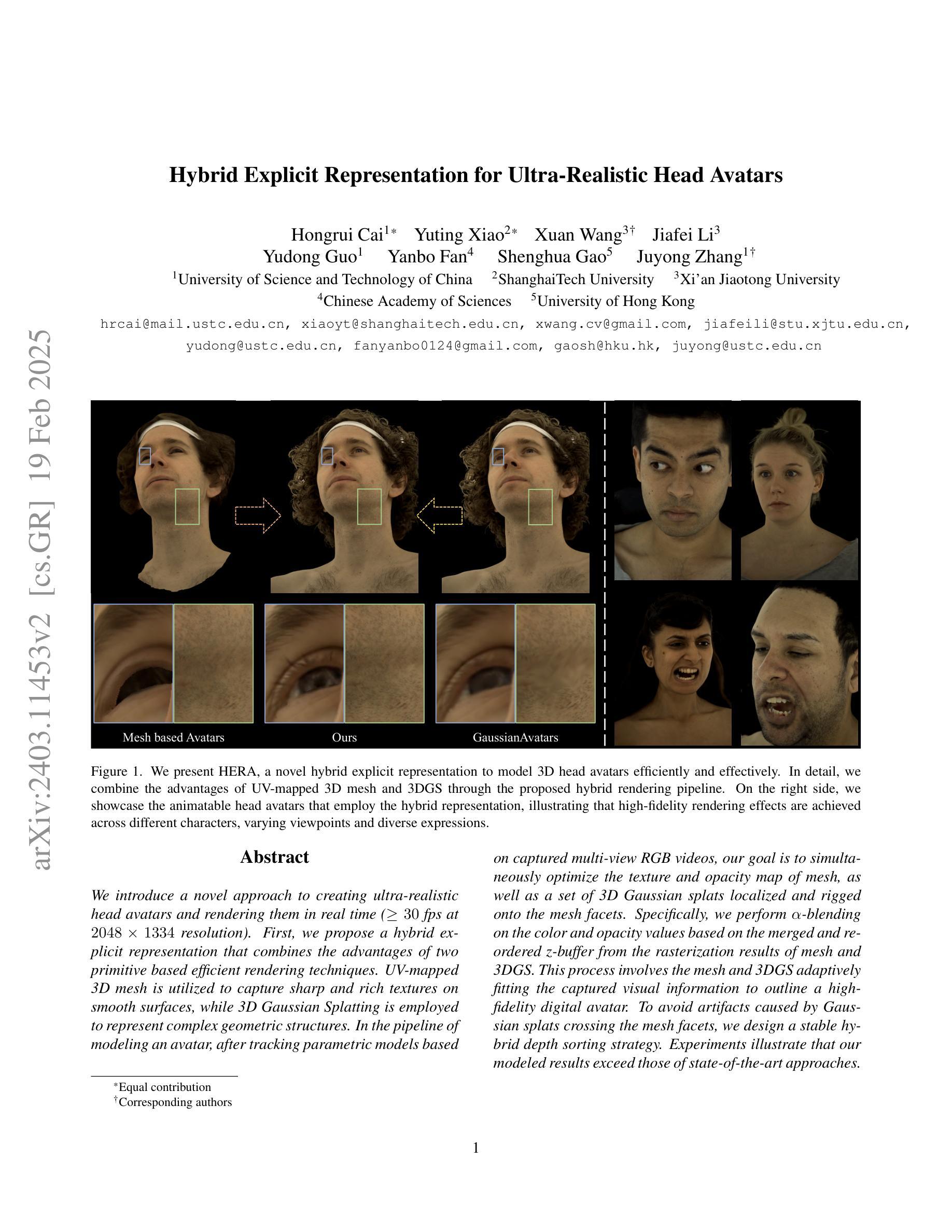
Hybrid Explicit Representation for Ultra-Realistic Head Avatars
Authors:Hongrui Cai, Yuting Xiao, Xuan Wang, Jiafei Li, Yudong Guo, Yanbo Fan, Shenghua Gao, Juyong Zhang
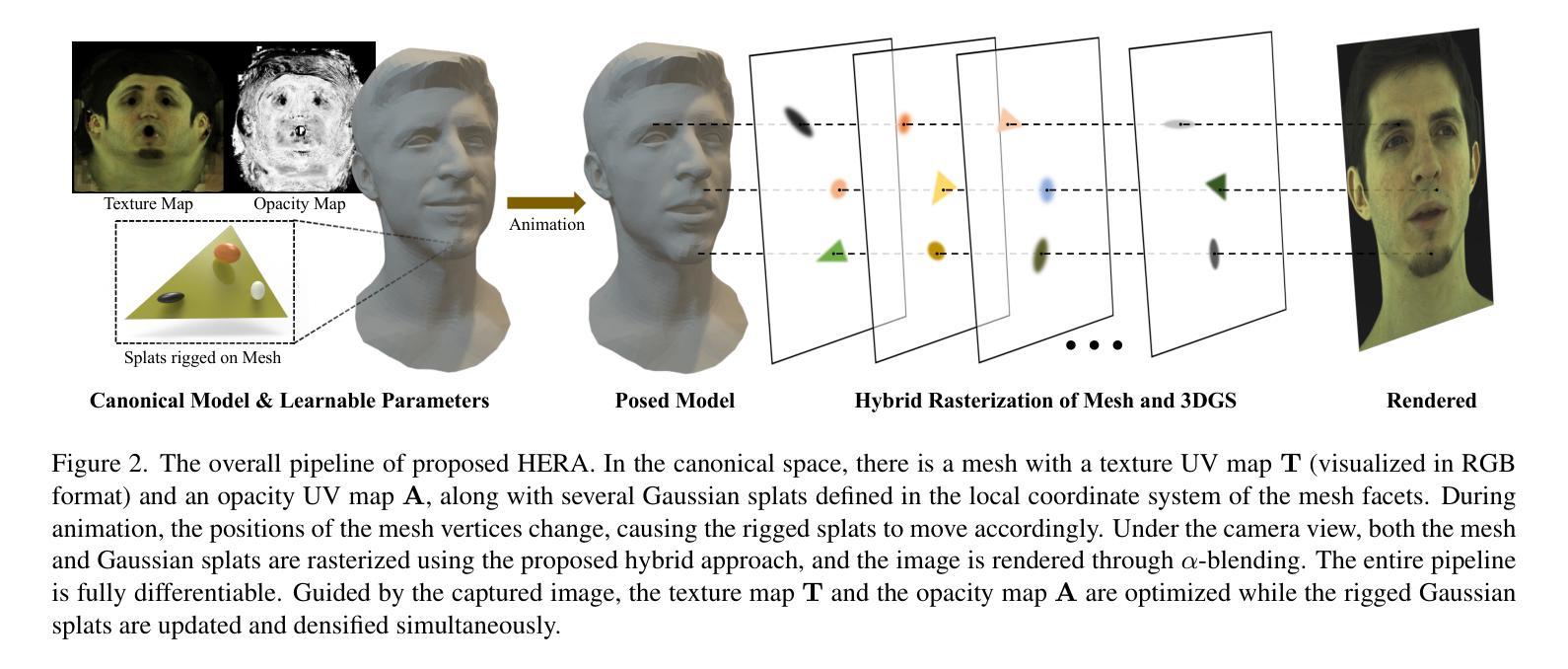
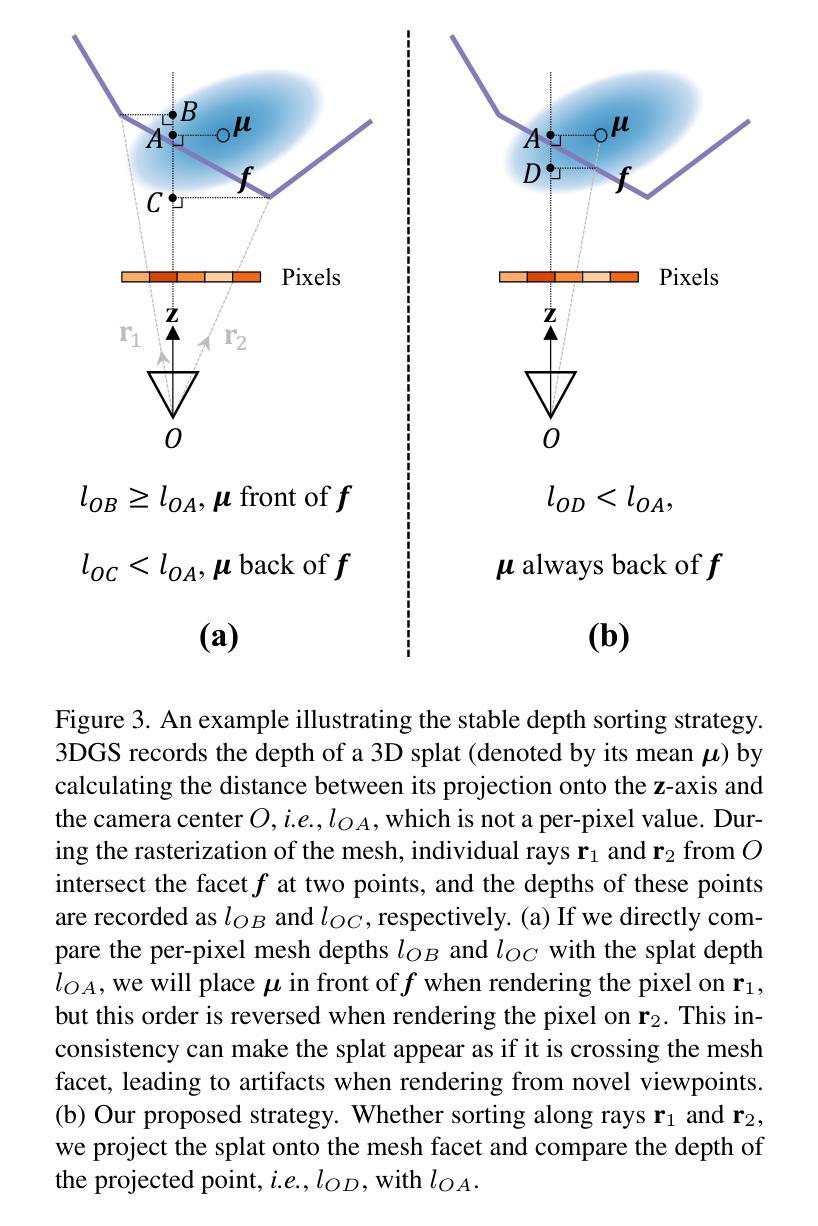
We introduce a novel approach to creating ultra-realistic head avatars and rendering them in real-time (>30fps at $2048 \times 1334$ resolution). First, we propose a hybrid explicit representation that combines the advantages of two primitive-based efficient rendering techniques. UV-mapped 3D mesh is utilized to capture sharp and rich textures on smooth surfaces, while 3D Gaussian Splatting is employed to represent complex geometric structures. In the pipeline of modeling an avatar, after tracking parametric models based on captured multi-view RGB videos, our goal is to simultaneously optimize the texture and opacity map of mesh, as well as a set of 3D Gaussian splats localized and rigged onto the mesh facets. Specifically, we perform $\alpha$-blending on the color and opacity values based on the merged and re-ordered z-buffer from the rasterization results of mesh and 3DGS. This process involves the mesh and 3DGS adaptively fitting the captured visual information to outline a high-fidelity digital avatar. To avoid artifacts caused by Gaussian splats crossing the mesh facets, we design a stable hybrid depth sorting strategy. Experiments illustrate that our modeled results exceed those of state-of-the-art approaches.
我们介绍了一种创建超逼真的头部化身并在实时中进行渲染的新方法(在$2048 \times 1334$分辨率下以超过30帧/秒的速度运行)。首先,我们提出了一种混合显式表示方法,结合了两种基于原始的高效渲染技术的优点。UV映射的3D网格用于捕捉光滑表面上锐利且丰富的纹理,而3D高斯拼贴则用于表示复杂的几何结构。在化身建模的流程中,在基于捕获的多视角RGB视频跟踪参数模型之后,我们的目标是同时优化网格的纹理和遮罩映射以及定位在网格表面并固定的一系列3D高斯拼贴。具体来说,我们根据网格和3DGS的渲染结果的合并和重新排序的z缓冲数据对颜色和遮罩值进行$\alpha$混合。这一过程使网格和3DGS能够自适应地适应捕获的视觉信息以描绘出高保真度的数字化身。为了避免因高斯拼贴跨越网格表面而产生的伪影,我们设计了一种稳定的混合深度排序策略。实验表明,我们的建模结果超过了现有先进方法的结果。
论文及项目相关链接
PDF 16 pages
Summary
新一代的超写实人头化身创建和实时渲染技术结合了UV映射的3D网格与3D高斯喷射技术,实现了超过30帧/秒的超高分辨率渲染。该技术通过优化纹理和透明度地图,以及将一系列网格面和基于网格的局部化高斯喷射集进行同步优化,实现精细的视觉效果。通过混合和重新排序的z缓冲技术,该技术实现了高保真数字化身创建,避免了高斯喷射跨越网格面产生的伪影。实验证明,该技术超越了现有技术。
Key Takeaways
- 引入了一种新的超写实人头化身创建方法,结合了UV映射的3D网格和3D高斯喷射技术,提供实时高质量渲染。
- 技术融合了两种高效的渲染技术优点,使得表面光滑区域的纹理丰富且清晰,同时能处理复杂的几何结构。
- 通过优化纹理和透明度地图以及同步优化的网格面和局部化高斯喷射集,提升了模型的精细度和真实感。
- 采用混合和重新排序的z缓冲技术实现高保真数字化身创建,避免了伪影问题。
- 提出了一种稳定的混合深度排序策略,解决了高斯喷射跨越网格面产生的问题。
- 实验证明该技术在创建超写实人头化身方面超越了现有技术。
点此查看论文截图