⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-21 更新
MGFI-Net: A Multi-Grained Feature Integration Network for Enhanced Medical Image Segmentation
Authors:Yucheng Zeng
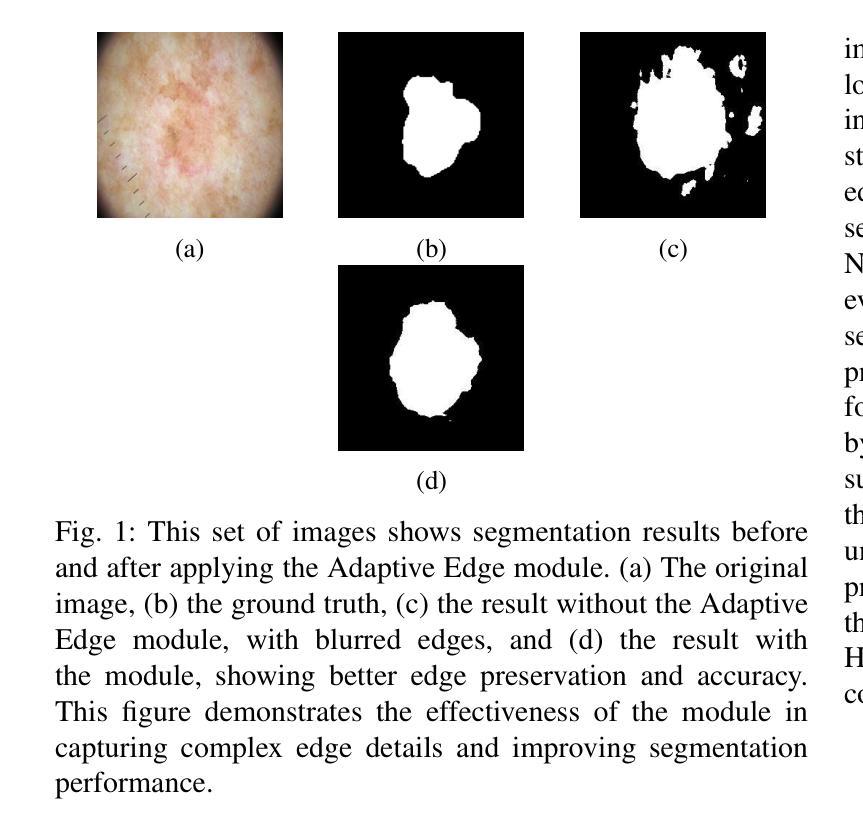
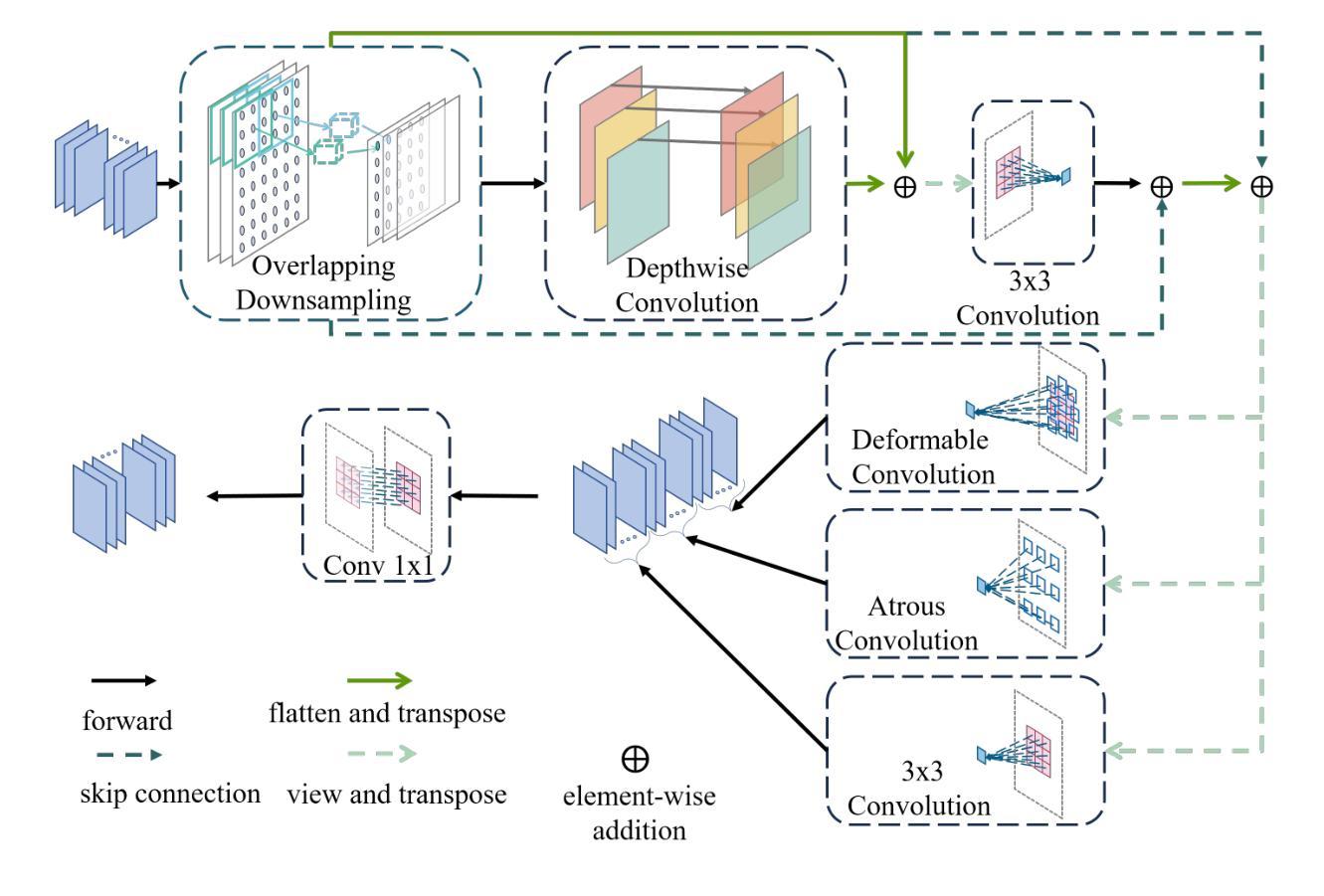
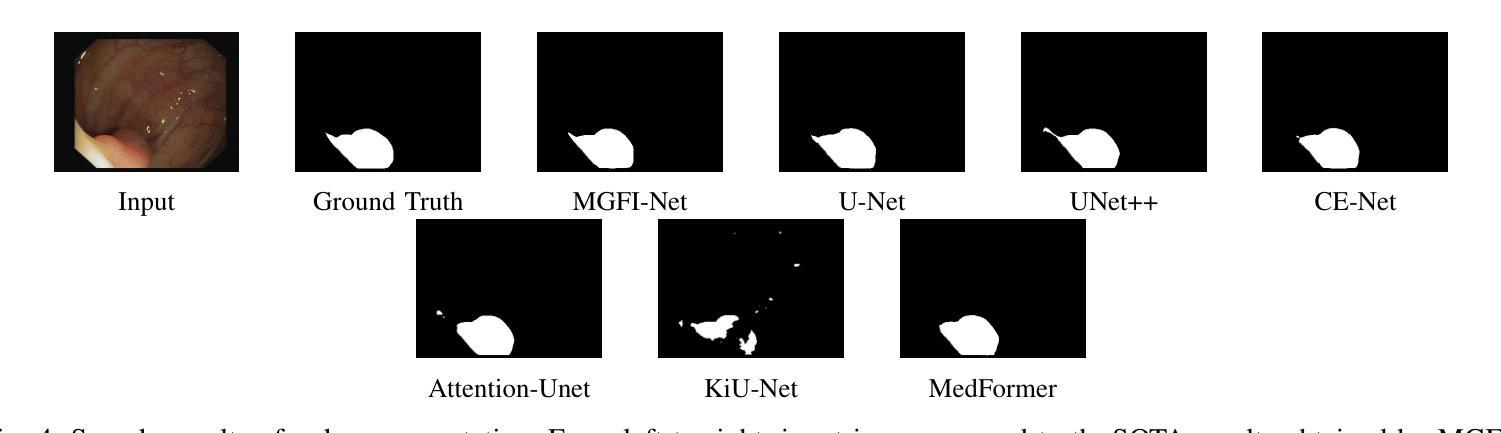
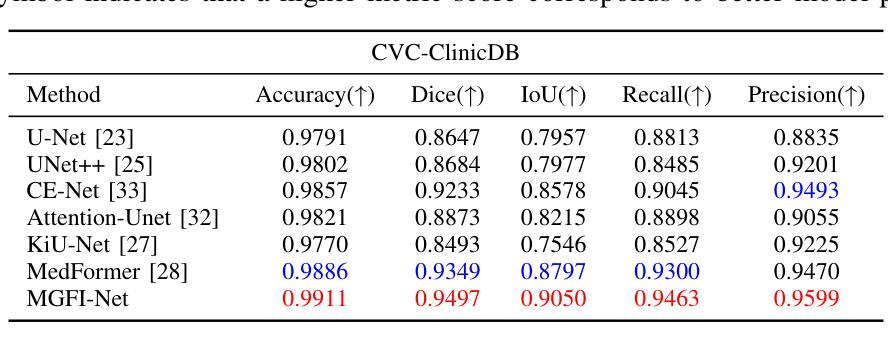
Medical image segmentation plays a crucial role in various clinical applications. A major challenge in medical image segmentation is achieving accurate delineation of regions of interest in the presence of noise, low contrast, or complex anatomical structures. Existing segmentation models often neglect the integration of multi-grained information and fail to preserve edge details, which are critical for precise segmentation. To address these challenges, we propose a novel image semantic segmentation model called the Multi-Grained Feature Integration Network (MGFI-Net). Our MGFI-Net is designed with two dedicated modules to tackle these issues. First, to enhance segmentation accuracy, we introduce a Multi-Grained Feature Extraction Module, which leverages hierarchical relationships between different feature scales to selectively focus on the most relevant information. Second, to preserve edge details, we incorporate an Edge Enhancement Module that effectively retains and integrates boundary information to refine segmentation results. Extensive experiments demonstrate that MGFI-Net not only outperforms state-of-the-art methods in terms of segmentation accuracy but also achieves superior time efficiency, establishing it as a leading solution for real-time medical image segmentation.
医学图像分割在各种临床应用中都扮演着至关重要的角色。医学图像分割面临的一个主要挑战是在噪声、低对比度或复杂解剖结构存在的情况下,实现对感兴趣区域的准确轮廓描绘。现有的分割模型往往忽视了多粒度信息的融合,且无法保留对精确分割至关重要的边缘细节。为了解决这些挑战,我们提出了一种新型的图像语义分割模型,称为多粒度特征融合网络(MGFI-Net)。我们的MGFI-Net设计了两个专用模块来解决这些问题。首先,为了提高分割精度,我们引入了多粒度特征提取模块,该模块利用不同特征尺度之间的层次关系,有选择地关注最相关的信息。其次,为了保留边缘细节,我们融入了一个边缘增强模块,该模块能够有效地保留和融合边界信息,以优化分割结果。大量实验表明,MGFI-Net不仅在分割精度上超越了最先进的方法,而且在时间效率上也表现出卓越的性能,使其成为实时医学图像分割的领先解决方案。
论文及项目相关链接
摘要
医疗图像分割在临床应用中扮演着重要角色。现有分割模型在面临噪声、低对比度或复杂解剖结构等问题时,难以实现兴趣区域的准确分割。为解决此挑战,提出了一种名为Multi-Grained Feature Integration Network(MGFI-Net)的新型图像语义分割模型。MGFI-Net通过两个专用模块来解决这些问题:一是引入Multi-Grained特征提取模块,利用不同特征尺度间的层次关系,选择性关注最相关信息,提高分割精度;二是融入边缘增强模块,有效保留和整合边界信息,优化分割结果。实验证明,MGFI-Net不仅在分割精度上超越了现有先进方法,而且在时间效率上也表现出优势,成为实时医疗图像分割的领先解决方案。
关键见解
- 医疗图像分割在临床应用中的重要性及其所面临的挑战。
- 现有分割模型在面临噪声、低对比度或复杂解剖结构时的局限性。
- 提出的Multi-Grained Feature Integration Network(MGFI-Net)模型通过两个专用模块解决这些挑战。
- Multi-Grained特征提取模块利用不同特征尺度间的层次关系提高分割精度。
- 边缘增强模块保留和整合边界信息,优化分割结果。
- MGFI-Net在分割精度和时间效率上的优越性能。
点此查看论文截图


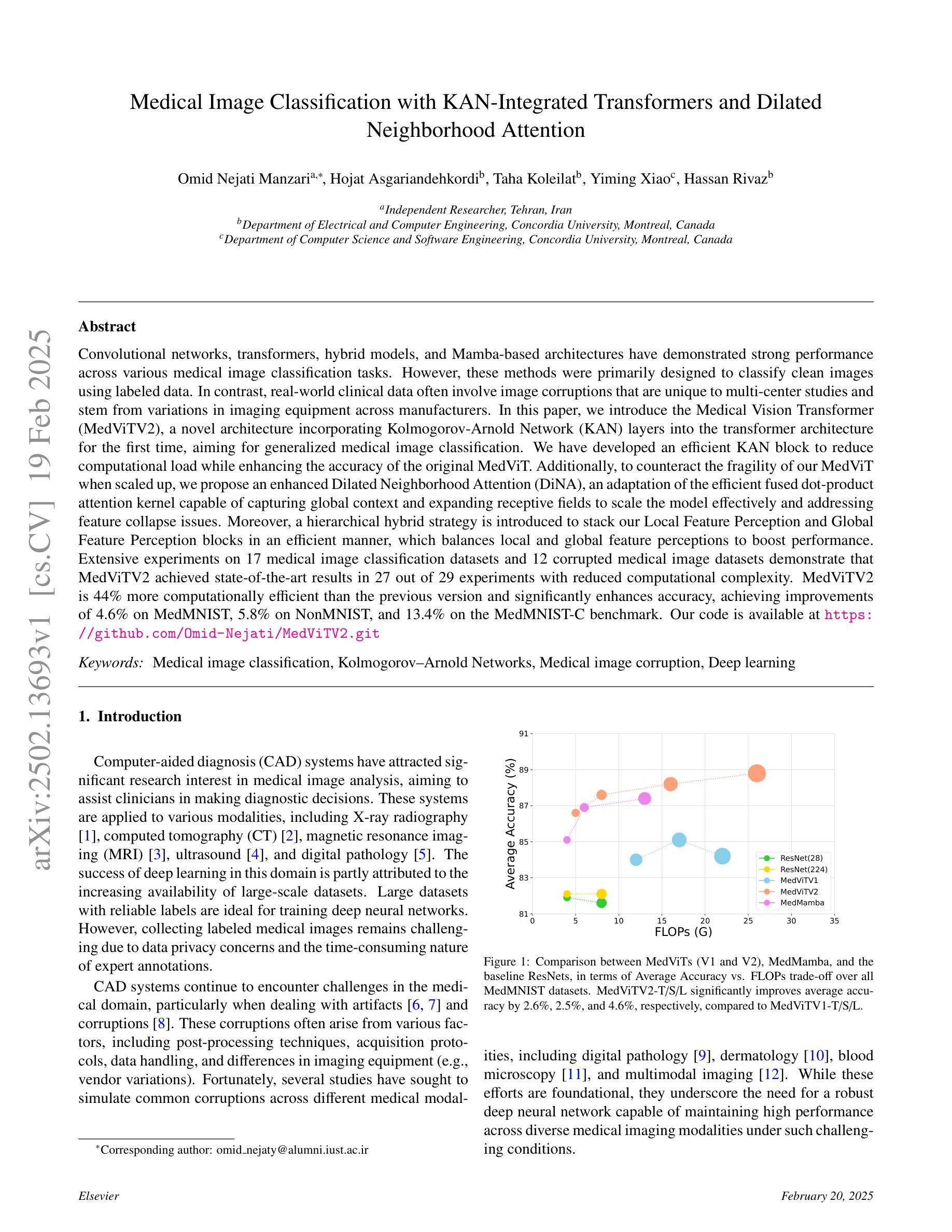
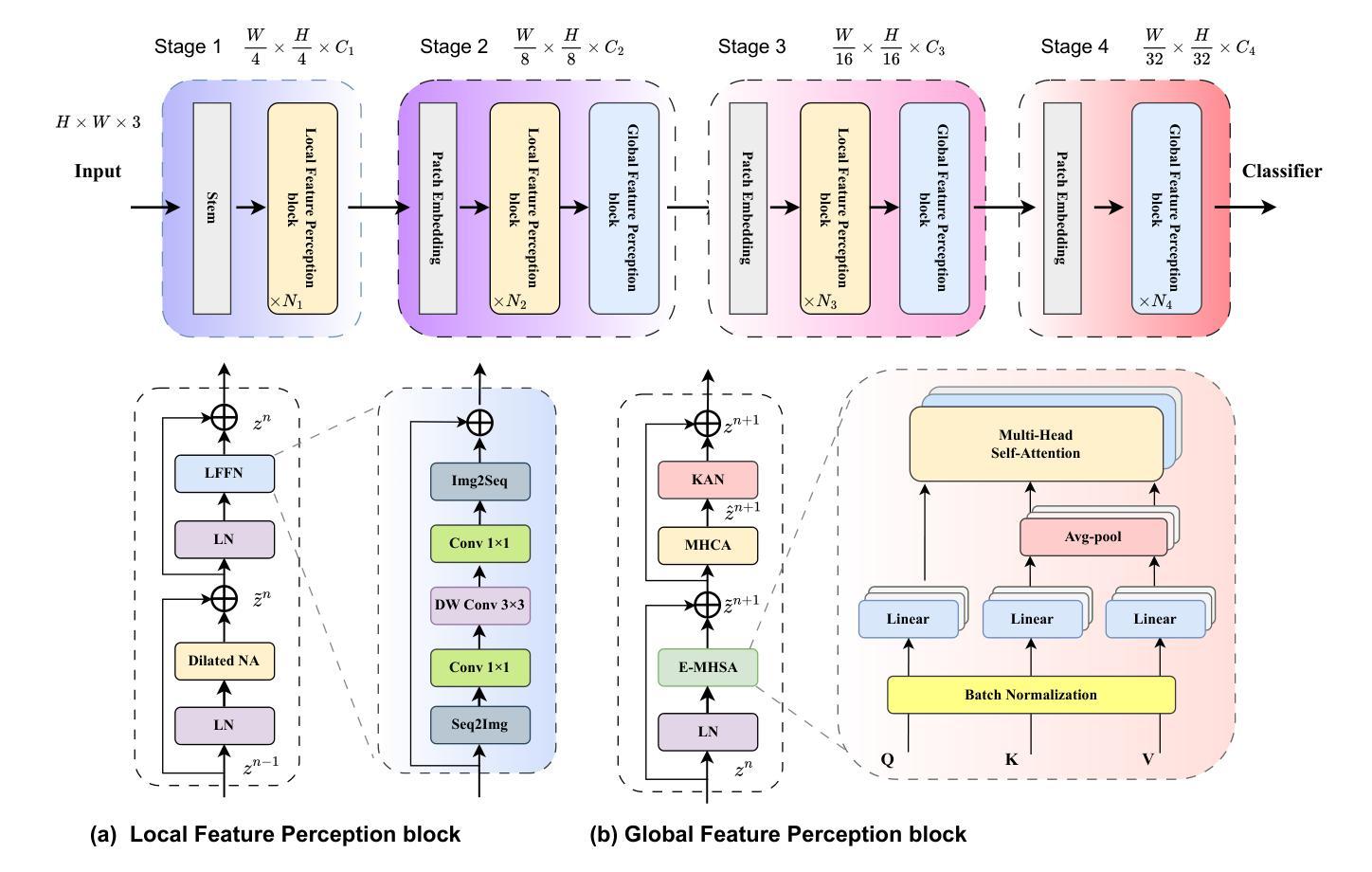
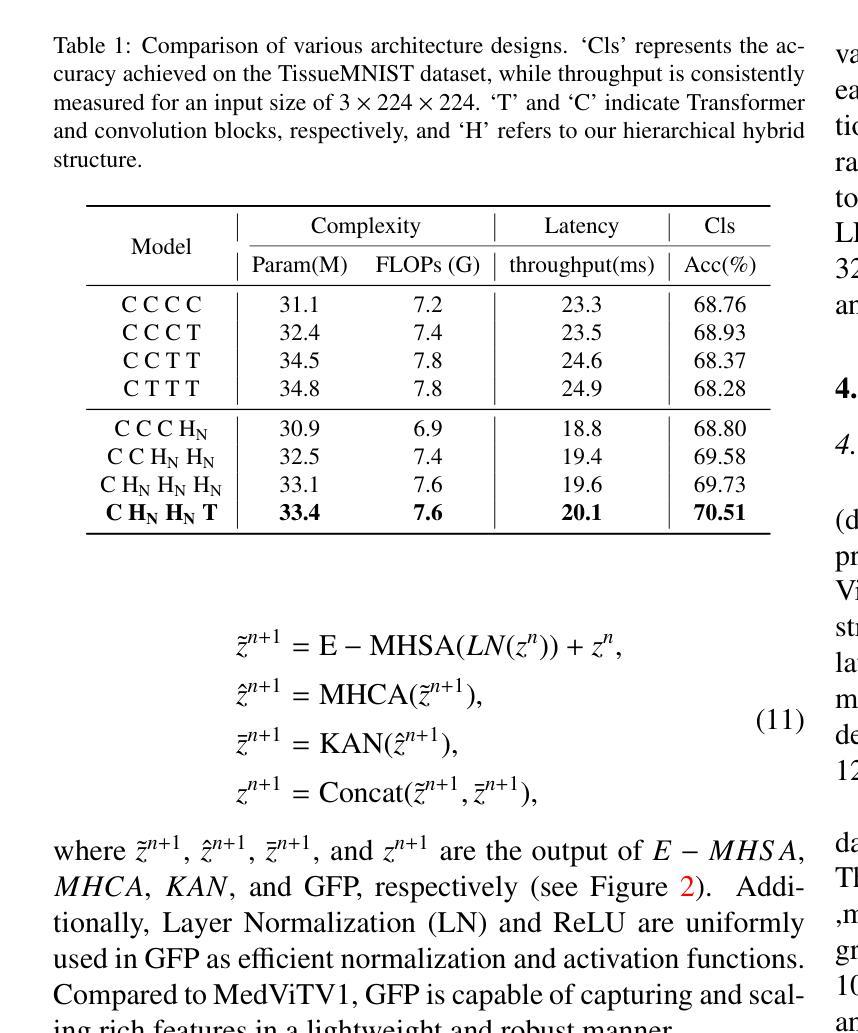
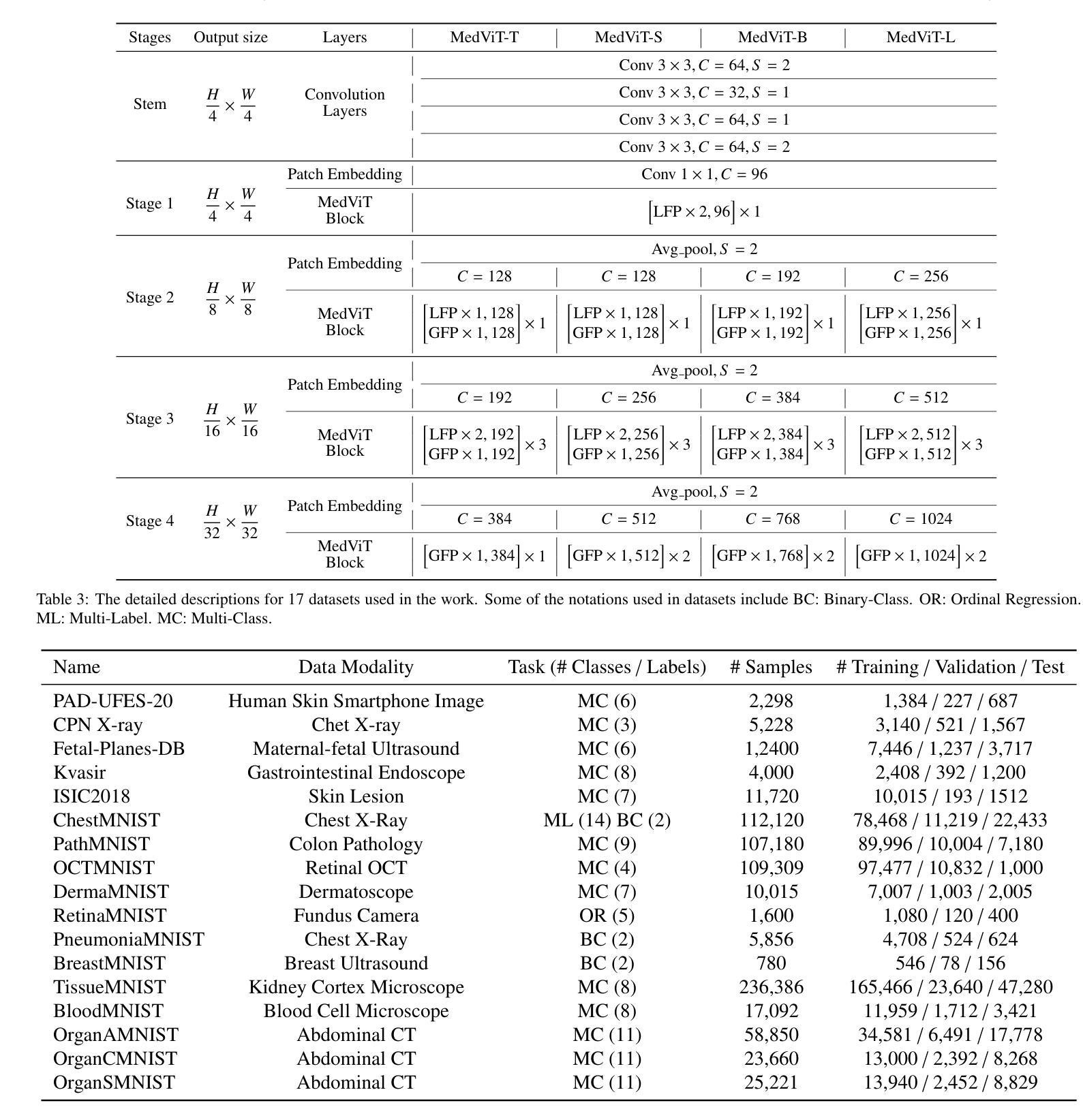
Medical Image Classification with KAN-Integrated Transformers and Dilated Neighborhood Attention
Authors:Omid Nejati Manzari, Hojat Asgariandehkordi, Taha Koleilat, Yiming Xiao, Hassan Rivaz
Convolutional networks, transformers, hybrid models, and Mamba-based architectures have demonstrated strong performance across various medical image classification tasks. However, these methods were primarily designed to classify clean images using labeled data. In contrast, real-world clinical data often involve image corruptions that are unique to multi-center studies and stem from variations in imaging equipment across manufacturers. In this paper, we introduce the Medical Vision Transformer (MedViTV2), a novel architecture incorporating Kolmogorov-Arnold Network (KAN) layers into the transformer architecture for the first time, aiming for generalized medical image classification. We have developed an efficient KAN block to reduce computational load while enhancing the accuracy of the original MedViT. Additionally, to counteract the fragility of our MedViT when scaled up, we propose an enhanced Dilated Neighborhood Attention (DiNA), an adaptation of the efficient fused dot-product attention kernel capable of capturing global context and expanding receptive fields to scale the model effectively and addressing feature collapse issues. Moreover, a hierarchical hybrid strategy is introduced to stack our Local Feature Perception and Global Feature Perception blocks in an efficient manner, which balances local and global feature perceptions to boost performance. Extensive experiments on 17 medical image classification datasets and 12 corrupted medical image datasets demonstrate that MedViTV2 achieved state-of-the-art results in 27 out of 29 experiments with reduced computational complexity. MedViTV2 is 44% more computationally efficient than the previous version and significantly enhances accuracy, achieving improvements of 4.6% on MedMNIST, 5.8% on NonMNIST, and 13.4% on the MedMNIST-C benchmark.
卷积网络、变压器、混合模型和基于Mamba的架构已在各种医学图像分类任务中表现出强大的性能。然而,这些方法主要是为使用带标签数据对干净图像进行分类而设计的。相比之下,现实世界的临床数据通常涉及多中心研究独有的图像损坏问题,以及来自不同制造商的成像设备所产生的差异。在本文中,我们介绍了医疗视觉转换器(MedViTV2),这是一种新型架构,首次将Kolmogorov-Arnold网络(KAN)层融入变压器架构中,旨在实现通用医学图像分类。我们开发了一个高效的KAN块,以减少计算负载并提高原始MedViT的准确性。此外,为了抵消我们MedViT在扩大规模时的脆弱性,我们提出了一种增强的膨胀邻域注意力(DiNA),这是对高效融合点积注意力核的适应,能够捕获全局上下文并扩展接收场,以有效地扩展模型并解决特征崩溃问题。此外,还引入了一种分层混合策略,以有效的方式堆叠我们的局部特征感知和全局特征感知块,这可以平衡局部和全局特征感知以提高性能。在17个医学图像分类数据集和12个损坏医学图像数据集上的大量实验表明,MedViTV2在29次实验中的27次获得了最先进的成果,且计算复杂度有所降低。MedViTV2的计算效率比前一个版本提高了44%,并且在MedMNIST上提高了4.6%的准确率,在NonMNIST上提高了5.8%,在MedMNIST-C基准测试上提高了13.4%。
论文及项目相关链接
摘要
本文介绍了Medical Vision Transformer V2(MedViTV2)架构,该架构首次将Kolmogorov-Arnold网络(KAN)层融入transformer架构中,旨在实现通用的医学图像分类。通过开发高效的KAN块,减少了计算负载,提高了原始MedViT的准确性。为应对大型MedViT的脆弱性,提出了增强的膨胀邻域注意力(DiNA),能捕捉全局上下文并扩展感受野,有效扩展模型并解决特征崩溃问题。此外,还介绍了分层混合策略,以平衡局部和全局特征感知块,提高性能。在17个医学图像分类数据集和12个腐蚀医学图像数据集上的大量实验表明,MedViTV2在27次实验中获得最佳结果,计算复杂度降低。与前一版本相比,MedViTV2计算效率提高44%,在MedMNIST、NonMNIST和MedMNIST-C基准测试上的准确率分别提高4.6%、5.8%和13.4%。
关键见解
- MedViTV2结合了Kolmogorov-Arnold网络(KAN)层与transformer架构,为医学图像分类提供了新颖的解决方案。
- 通过引入高效的KAN块,提高了原始MedViT的准确性并降低了计算负载。
- 提出的增强Dilated Neighborhood Attention(DiNA)能够捕捉全局上下文并扩展感受野,从而有效扩展模型规模并解决特征崩溃问题。
- 采用了分层混合策略来平衡局部和全局特征感知块,进一步提升了性能。
- 在多个医学图像分类数据集上的实验表明,MedViTV2在计算效率提高的同时,实现了显著的性能提升。
- MedViTV2在多个基准测试上达到了业界最佳性能,包括在MedMNIST、NonMNIST和MedMNIST-C上的准确率显著提高。
- MedViTV2架构展现出在应对真实世界临床数据中独特的多中心研究图像腐蚀问题的潜力。
点此查看论文截图

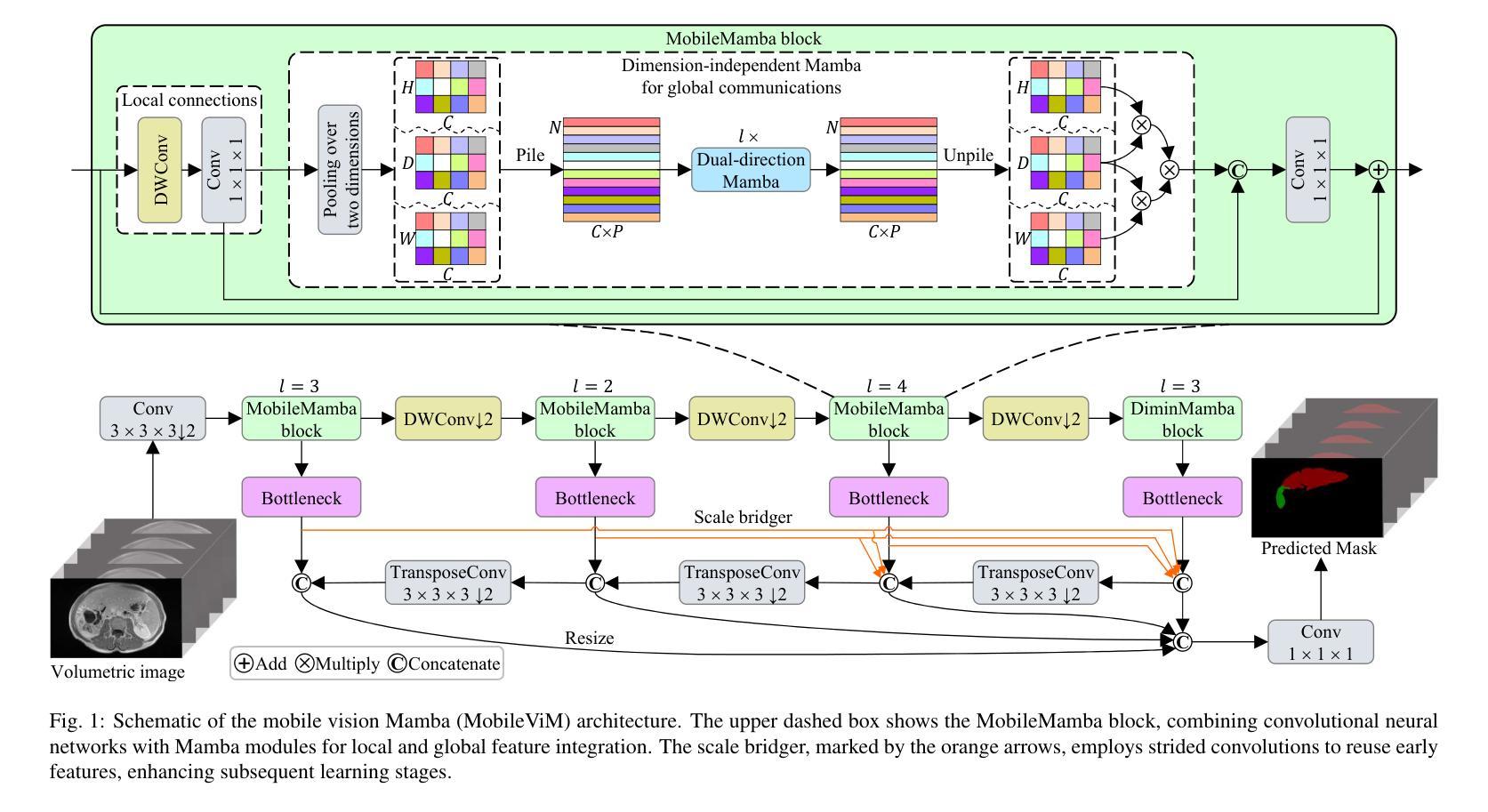
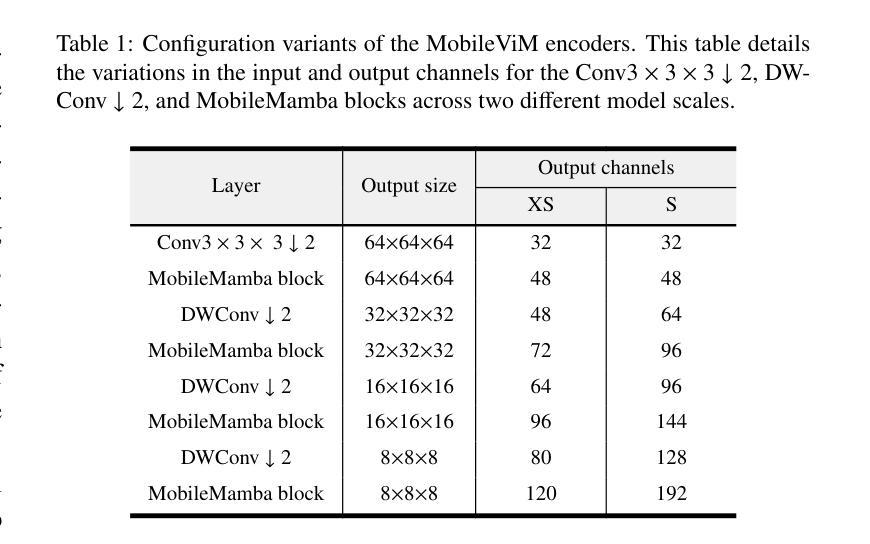
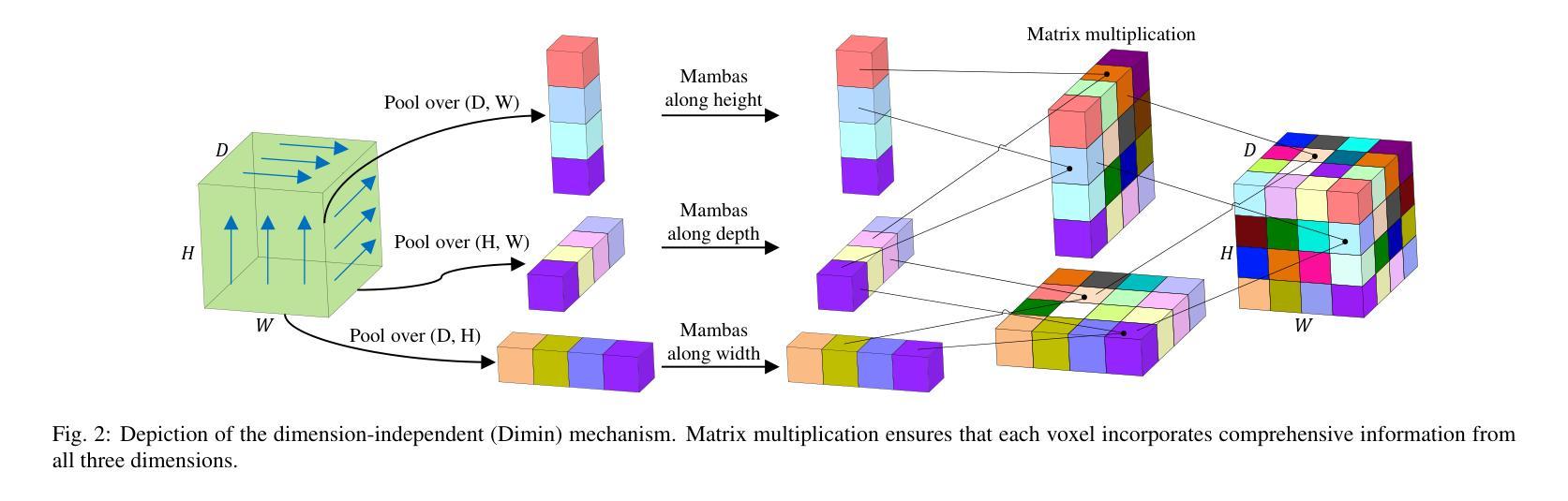
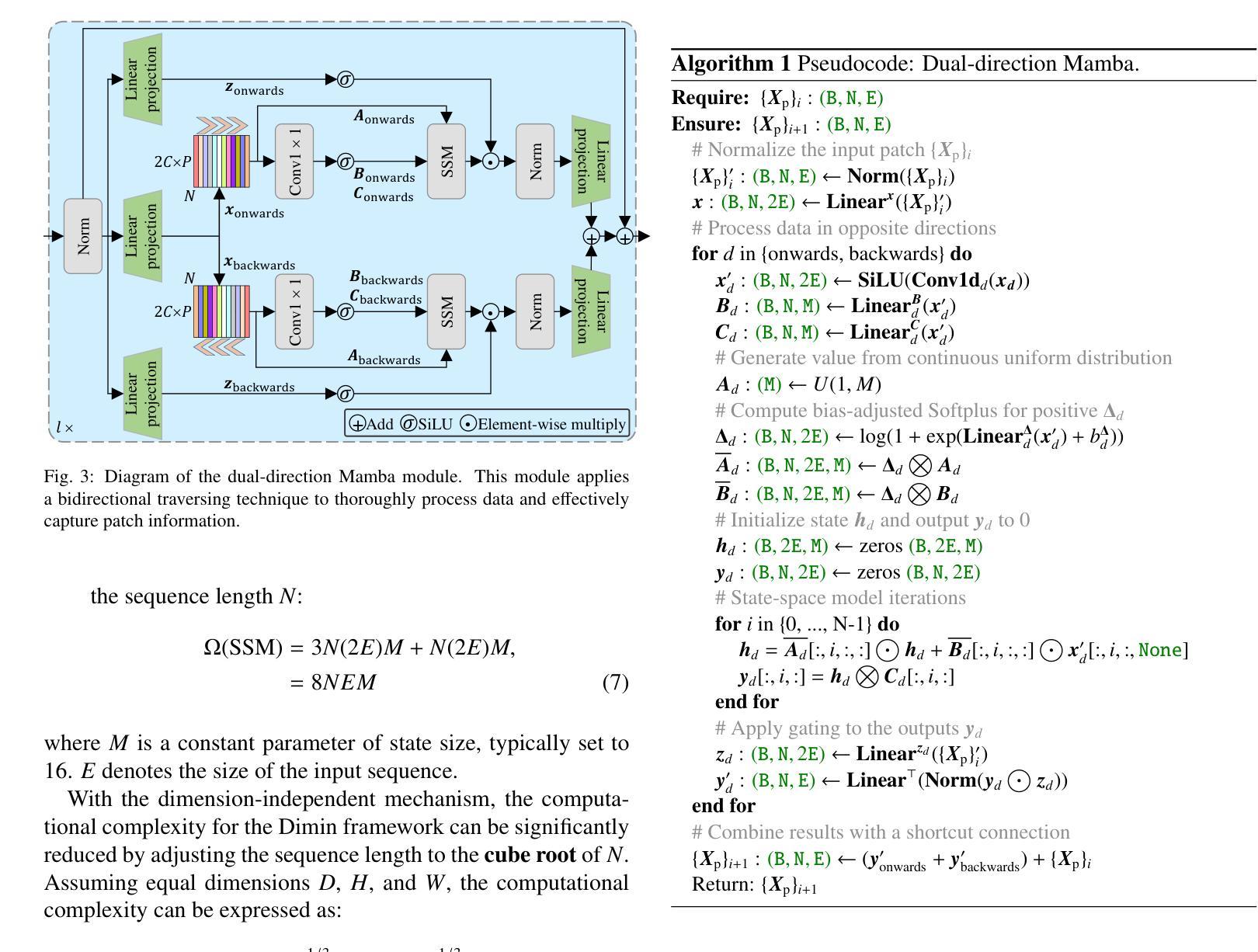
MobileViM: A Light-weight and Dimension-independent Vision Mamba for 3D Medical Image Analysis
Authors:Wei Dai, Steven Wang, Jun Liu
Efficient evaluation of three-dimensional (3D) medical images is crucial for diagnostic and therapeutic practices in healthcare. Recent years have seen a substantial uptake in applying deep learning and computer vision to analyse and interpret medical images. Traditional approaches, such as convolutional neural networks (CNNs) and vision transformers (ViTs), face significant computational challenges, prompting the need for architectural advancements. Recent efforts have led to the introduction of novel architectures like the ``Mamba’’ model as alternative solutions to traditional CNNs or ViTs. The Mamba model excels in the linear processing of one-dimensional data with low computational demands. However, Mamba’s potential for 3D medical image analysis remains underexplored and could face significant computational challenges as the dimension increases. This manuscript presents MobileViM, a streamlined architecture for efficient segmentation of 3D medical images. In the MobileViM network, we invent a new dimension-independent mechanism and a dual-direction traversing approach to incorporate with a vision-Mamba-based framework. MobileViM also features a cross-scale bridging technique to improve efficiency and accuracy across various medical imaging modalities. With these enhancements, MobileViM achieves segmentation speeds exceeding 90 frames per second (FPS) on a single graphics processing unit (i.e., NVIDIA RTX 4090). This performance is over 24 FPS faster than the state-of-the-art deep learning models for processing 3D images with the same computational resources. In addition, experimental evaluations demonstrate that MobileViM delivers superior performance, with Dice similarity scores reaching 92.72%, 86.69%, 80.46%, and 77.43% for PENGWIN, BraTS2024, ATLAS, and Toothfairy2 datasets, respectively, which significantly surpasses existing models.
在医疗保健领域,对三维(3D)医学图像的有效评估对于诊断和治疗实践至关重要。近年来,深度学习和计算机视觉在医学图像分析和解释方面的应用显著增加。传统方法,如卷积神经网络(CNNs)和视觉转换器(ViTs),面临重大的计算挑战,这促使了架构发展的需求。最近的努力导致了“Mamba”模型等新兴架构的出现,作为传统CNN或ViTs的替代解决方案。Mamba模型在处理一维数据的线性处理方面表现出色,计算需求较低。然而,Mamba在3D医学图像分析方面的潜力尚未得到充分探索,随着维度的增加,可能会面临重大的计算挑战。本手稿提出了MobileViM,这是一个用于高效分割3D医学图像的流线化架构。在MobileViM网络中,我们发明了一种新的维度独立机制和一种双向遍历方法,将其融入基于视觉Mamba的框架中。MobileViM还采用跨尺度桥梁技术,以提高不同医学成像模式的效率和准确性。通过这些增强功能,MobileViM在单个图形处理单元(即NVIDIA RTX 4090)上实现了超过每秒90帧(FPS)的分割速度。此性能比使用相同计算资源的处理3D图像的最先进深度学习模型的性能快24 FPS以上。此外,实验评估表明,MobileViM的性能卓越,在PENGWIN、BraTS2024、ATLAS和Toothfairy2数据集上的Dice相似度得分分别为92.72%、86.69%、80.46%和77.43%,显著超越了现有模型。
论文及项目相关链接
PDF The code is accessible through: https://github.com/anthonyweidai/MobileViM_3D/
Summary
本文提出了一种新型的针对三维医学图像分析的模型MobileViM,该模型采用维度独立机制、双向遍历方法和跨尺度桥接技术,旨在提高计算效率和准确性。在多个数据集上的实验评估表明,MobileViM的性能优于现有模型,实现了高效的医学图像分割。
Key Takeaways
- MobileViM是一个针对三维医学图像分析的模型,旨在提高计算效率和准确性。
- MobileViM引入了维度独立机制和双向遍历方法来处理医学图像。
- 跨尺度桥接技术被用于改善不同成像模态的效率与准确性。
- MobileViM实现了超过90帧每秒的分割速度,比现有模型快24帧以上。
- 在多个数据集上的实验评估显示,MobileViM的性能显著超过现有模型,Dice相似度得分高。
点此查看论文截图

Enhancing Chest X-ray Classification through Knowledge Injection in Cross-Modality Learning
Authors:Yang Yan, Bingqing Yue, Qiaxuan Li, Man Huang, Jingyu Chen, Zhenzhong Lan
The integration of artificial intelligence in medical imaging has shown tremendous potential, yet the relationship between pre-trained knowledge and performance in cross-modality learning remains unclear. This study investigates how explicitly injecting medical knowledge into the learning process affects the performance of cross-modality classification, focusing on Chest X-ray (CXR) images. We introduce a novel Set Theory-based knowledge injection framework that generates captions for CXR images with controllable knowledge granularity. Using this framework, we fine-tune CLIP model on captions with varying levels of medical information. We evaluate the model’s performance through zero-shot classification on the CheXpert dataset, a benchmark for CXR classification. Our results demonstrate that injecting fine-grained medical knowledge substantially improves classification accuracy, achieving 72.5% compared to 49.9% when using human-generated captions. This highlights the crucial role of domain-specific knowledge in medical cross-modality learning. Furthermore, we explore the influence of knowledge density and the use of domain-specific Large Language Models (LLMs) for caption generation, finding that denser knowledge and specialized LLMs contribute to enhanced performance. This research advances medical image analysis by demonstrating the effectiveness of knowledge injection for improving automated CXR classification, paving the way for more accurate and reliable diagnostic tools.
人工智能在医学成像方面的应用具有巨大的潜力,然而预训练知识与跨模态学习性能之间的关系仍不明确。本研究调查了将医学知识明确注入学习过程如何影响跨模态分类的性能,重点关注胸部X射线(CXR)图像。我们引入了一种基于集合理论的新型知识注入框架,该框架可控知识粒度,为CXR图像生成描述。利用此框架,我们在不同水平的医疗信息描述上对CLIP模型进行微调。我们在CheXpert数据集上通过零样本分类评估模型性能,这是CXR分类的基准测试。我们的结果表明,注入精细医学知识能显著提高分类准确率,达到72.5%,而使用人工生成的描述时仅为49.9%。这突显了领域特定知识在医学跨模态学习中的关键作用。此外,我们还探讨了知识密度以及专用领域大型语言模型(LLM)在描述生成中的影响,发现更密集的知识和专用的LLM有助于提升性能。本研究通过展示知识注入在提高自动CXR分类方面的有效性,推动了医学图像分析的发展,为更准确、更可靠的诊断工具铺平了道路。
论文及项目相关链接
PDF Accepted by ICASSP’25
Summary
人工智能在医学成像中的融合展现出巨大潜力,但预训练知识与跨模态学习性能之间的关系尚不清楚。本研究调查了将医学知识明确注入学习过程如何影响跨模态分类的性能,重点关注胸部X光(CXR)图像。引入基于集合理论的知识注入框架,为CXR图像生成可控知识粒度的字幕。使用此框架对CLIP模型进行微调,并使用不同水平的医疗信息进行评估。在CXR分类的基准数据集CheXpert上进行零样本分类,结果显示注入精细医学知识可显著提高分类精度,达到72.5%,而使用人类生成字幕时为49.9%。这表明特定领域的专业知识在医学跨模态学习中起着至关重要的作用。此外,本研究还探讨了知识密度和用于字幕生成的特定领域大型语言模型(LLM)的影响,发现更密集的知识和专门的LLM有助于提升性能。本研究通过展示知识注入在提高自动化CXR分类中的有效性,为医学图像分析的发展铺平了道路,为更准确可靠的诊断工具打下基础。
Key Takeaways
- 人工智能在医学成像中具有巨大潜力。
- 预训练知识与跨模态学习性能之间的关系尚不清楚。
- 将医学知识注入学习过程可影响跨模态分类性能。
- 基于集合理论的知识注入框架生成CXR图像字幕。
- 注入精细医学知识显著提高CXR图像分类精度。
- 知识密度和特定领域的大型语言模型(LLM)对性能有积极影响。
点此查看论文截图


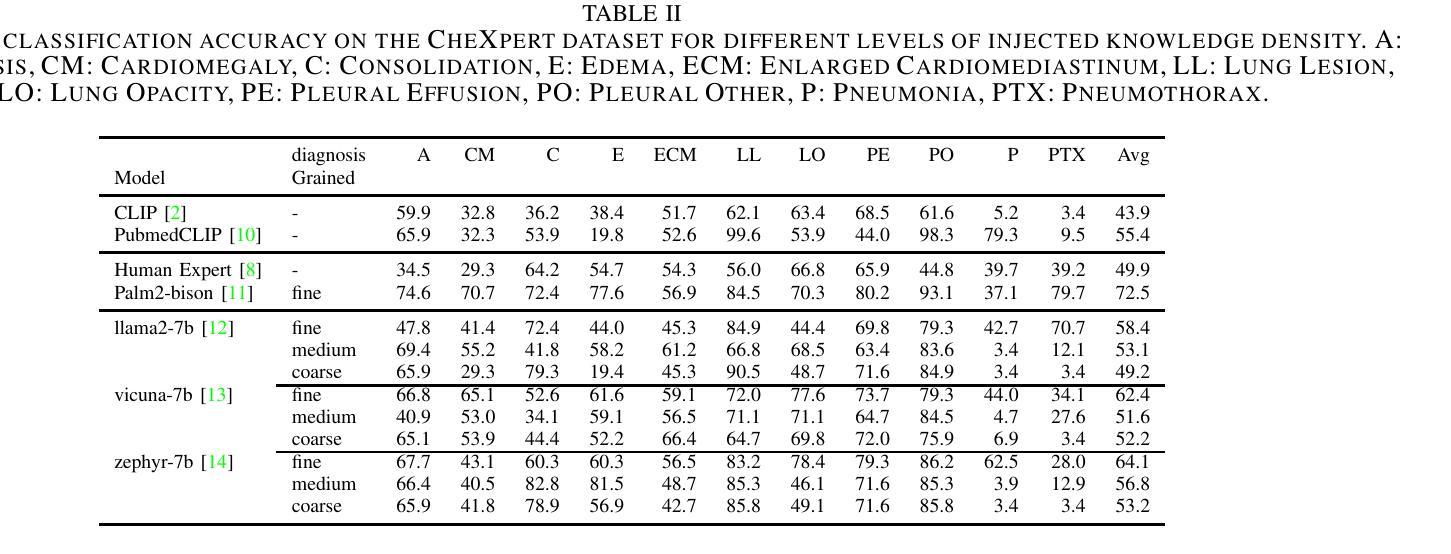
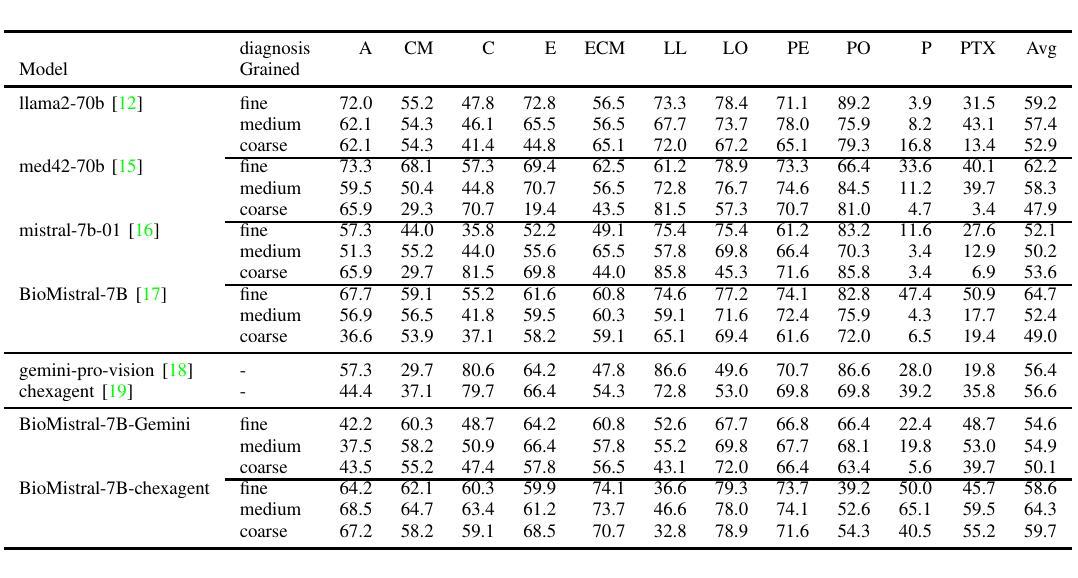
Timing characterization of MALTA and MALTA2 pixel detectors using Micro X-ray source
Authors:G. Dash, P. Allport, I. Asensi Tortajada, P. Behera, D. V. Berlea, D. Bortoletto, C. Buttar, V. Dao, L. Fasselt, L. Flores Sanz de Acedo, M. Gazi, L. Gonella, V. Gonzalez, G. Gustavino, S. Haberl, T. Inada, P. Jana, L. Li, H. Pernegger, P. Riedler, W. Snoeys, C. A Solans Sanchez, M. van Rijnbach, M. Vazquez Nunez, A. Vijay, J. Weick, S. Worm
The MALTA monolithic active pixel detector is developed to address the challenges anticipated in future high-energy physics detectors. As part of its characterization, we conducted fast-timing studies necessary to provide a figure of merit for this family of monolithic pixel detectors. MALTA has a metal layer in front-end electronics, and the conventional laser technique is not suitable for fast timing studies due to the reflection of the laser from the metallic surface. X-rays have been employed as a more effective alternative for penetration through these layers. The triggered X-ray set-up is designed to study timing measurements of monolithic detectors. The timing response of the X-ray set-up is characterized using an LGAD. The timing response of the MALTA and MALTA2 pixel detectors is studied, and the best response time of MALTA2 pixel detectors is measured at about 2 ns.
MALTA单片有源像素探测器是为了应对未来高能物理探测器预期面临的挑战而开发的。作为表征的一部分,我们进行了快速时间研究,为这类单片像素探测器提供性能指标。MALTA前端电子器件中有一层金属,传统的激光技术由于激光在金属表面的反射而不适用于快速时间研究。X射线已被用作穿透这些层更有效的替代方法。触发式X射线装置旨在研究单片探测器的定时测量。X射线装置的定时响应使用LGAD进行表征。研究了MALTA和MALTA2像素探测器的定时响应,并测得MALTA2像素探测器的最佳响应时间为约2纳秒。
论文及项目相关链接
PDF 13 pages, 11 figures, To be submitted to JINST
Summary
马耳他单片主动像素探测器专为应对未来高能物理探测器面临的挑战而开发。为评估此类单片像素探测器的性能,我们进行了快速时间测定研究。由于该探测器前端电子器件中存在金属层,传统激光技术不适用于快速时间测定。因此,采用X射线作为更有效的替代方案,以穿透这些金属层。触发式X射线装置用于研究单片探测器的定时测量。利用LGAD对X射线装置的定时响应进行了表征,并对马耳他和马耳他2号像素探测器的响应时间进行了研究,其中马耳他2号像素探测器的最佳响应时间约为2纳秒。
Key Takeaways
- MALTA单片主动像素探测器是为了应对未来高能物理探测器面临的挑战而开发的。
- 快速时间测定研究是为了评估此类单片像素探测器的性能。
- 由于探测器中的金属层,传统激光技术不适用于快速时间测定。
- X射线被用作更有效的替代方案,以穿透金属层。
- 触发式X射线装置用于研究单片探测器的定时测量。
- LGAD被用来表征X射线装置的定时响应。
点此查看论文截图


Data-Efficient Limited-Angle CT Using Deep Priors and Regularization
Authors:Ilmari Vahteristo, Zhi-Song Liu, Andreas Rupp
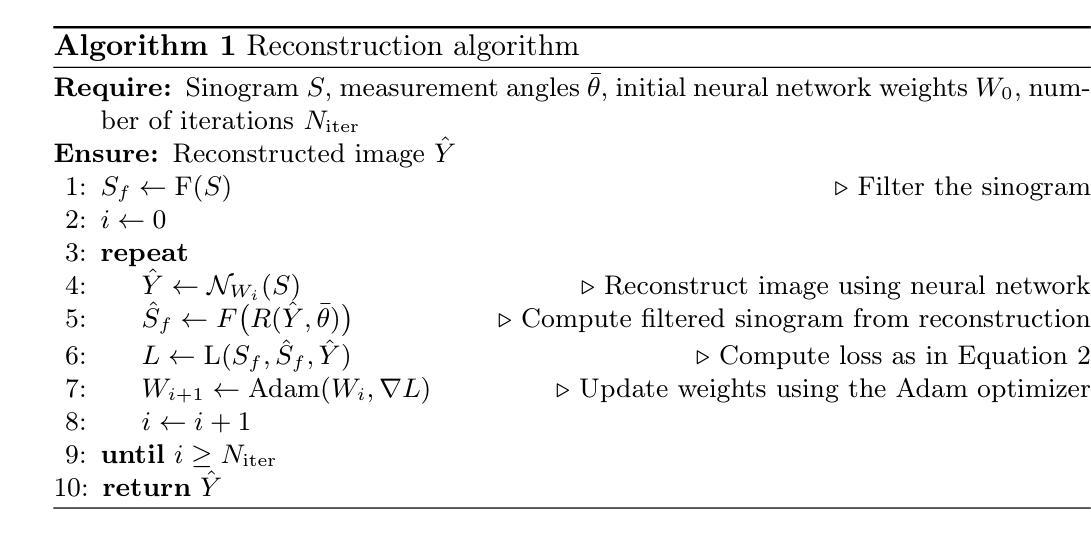
Reconstructing an image from its Radon transform is a fundamental computed tomography (CT) task arising in applications such as X-ray scans. In many practical scenarios, a full 180-degree scan is not feasible, or there is a desire to reduce radiation exposure. In these limited-angle settings, the problem becomes ill-posed, and methods designed for full-view data often leave significant artifacts. We propose a very low-data approach to reconstruct the original image from its Radon transform under severe angle limitations. Because the inverse problem is ill-posed, we combine multiple regularization methods, including Total Variation, a sinogram filter, Deep Image Prior, and a patch-level autoencoder. We use a differentiable implementation of the Radon transform, which allows us to use gradient-based techniques to solve the inverse problem. Our method is evaluated on a dataset from the Helsinki Tomography Challenge 2022, where the goal is to reconstruct a binary disk from its limited-angle sinogram. We only use a total of 12 data points–eight for learning a prior and four for hyperparameter selection–and achieve results comparable to the best synthetic data-driven approaches.
从Radon变换重建图像是计算机断层扫描(CT)中的一个基本任务,出现在X射线扫描等应用中。在许多实际场景中,完整的180度扫描并不可行,或者希望减少辐射暴露。在这些有限角度设置中,问题变得不适定,专为全视图数据设计的方法通常会产生明显的伪影。我们提出了一种在严重角度限制下从Radon变换重建原始图像的低数据方法。由于反问题是不适定的,我们将多种正则化方法结合起来,包括总变差、辛诺图滤波器、深度图像先验和补丁级别的自动编码器。我们使用Radon变换的可微实现,这使我们能够使用基于梯度的方法来解决反问题。我们的方法在赫尔辛基断层扫描挑战赛2022的数据集上进行了评估,该比赛的目标是从有限的角度辛诺图中重建二进制磁盘。我们仅使用总共12个数据点(8个用于学习先验知识,4个用于超参数选择),并取得了与最佳合成数据驱动方法相当的结果。
论文及项目相关链接
PDF 12 pages, 2 reference pages, 5 figures
Summary
文章讨论了CT中的图像重建问题,特别是在有限角度扫描的场景下。由于逆问题的不适定性,结合多种正则化方法(如全变分、辛格拉姆滤波器、深度图像先验和斑块级自编码器)进行图像重建。采用可微分的Radon变换实现方式,并利用梯度技术解决逆问题。在赫尔辛基断层扫描挑战赛2022的数据集上进行评估,使用少量数据点即可实现与最佳合成数据驱动方法相当的结果。
Key Takeaways
- 文章讨论了计算机断层扫描(CT)中的图像重建问题,特别是在有限角度扫描的场景下。
- 在有限角度设置下,问题变得不适定,专为全视角数据设计的方法通常会产生显著伪影。
- 提出了一种在严重角度限制下从Radon变换重建原始图像的低数据方法。
- 由于逆问题的不适定性,结合了多种正则化方法,包括全变分、辛格拉姆滤波器、深度图像先验和斑块级自编码器。
- 采用可微分的Radon变换实现方式,以便使用梯度技术解决逆问题。
- 在赫尔辛基断层扫描挑战赛2022的数据集上进行了评估。
点此查看论文截图

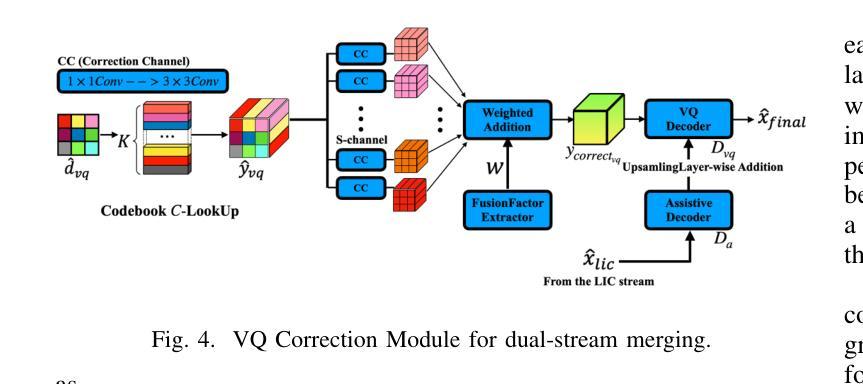
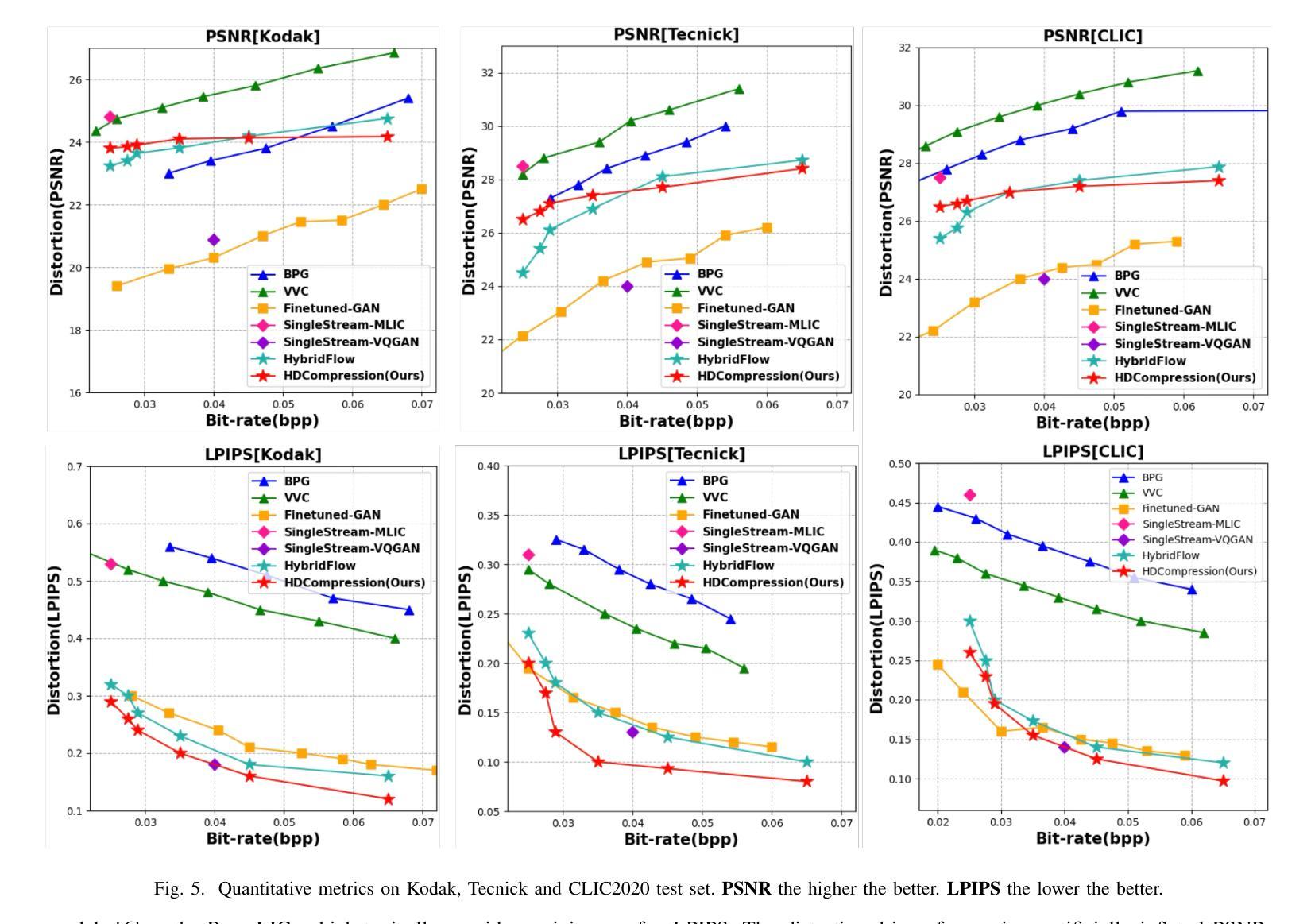
HDCompression: Hybrid-Diffusion Image Compression for Ultra-Low Bitrates
Authors:Lei Lu, Yize Li, Yanzhi Wang, Wei Wang, Wei Jiang
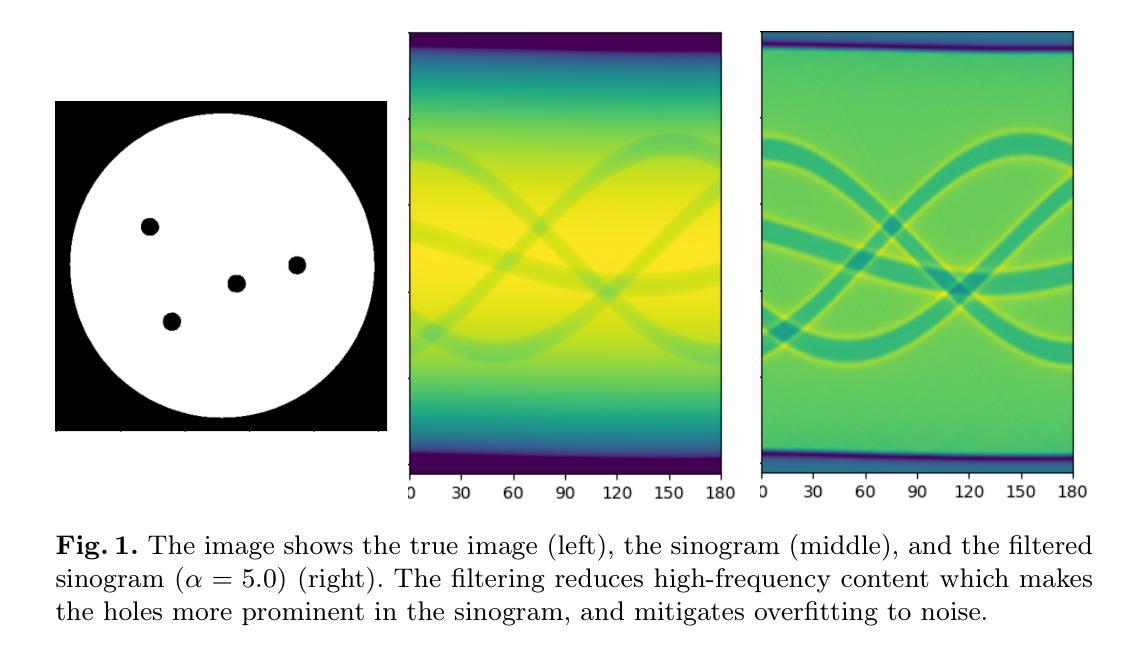
Image compression under ultra-low bitrates remains challenging for both conventional learned image compression (LIC) and generative vector-quantized (VQ) modeling. Conventional LIC suffers from severe artifacts due to heavy quantization, while generative VQ modeling gives poor fidelity due to the mismatch between learned generative priors and specific inputs. In this work, we propose Hybrid-Diffusion Image Compression (HDCompression), a dual-stream framework that utilizes both generative VQ-modeling and diffusion models, as well as conventional LIC, to achieve both high fidelity and high perceptual quality. Different from previous hybrid methods that directly use pre-trained LIC models to generate low-quality fidelity-preserving information from heavily quantized latent, we use diffusion models to extract high-quality complimentary fidelity information from the ground-truth input, which can enhance the system performance in several aspects: improving indices map prediction, enhancing the fidelity-preserving output of the LIC stream, and refining conditioned image reconstruction with VQ-latent correction. In addition, our diffusion model is based on a dense representative vector (DRV), which is lightweight with very simple sampling schedulers. Extensive experiments demonstrate that our HDCompression outperforms the previous conventional LIC, generative VQ-modeling, and hybrid frameworks in both quantitative metrics and qualitative visualization, providing balanced robust compression performance at ultra-low bitrates.
在超低比特率下,图像压缩对于传统的图像压缩学习(LIC)和生成向量量化(VQ)建模仍然具有挑战性。传统LIC由于重度量化而产生严重伪影,而生成VQ建模由于学习到的生成先验与特定输入之间的不匹配而导致保真度较低。在这项工作中,我们提出了混合扩散图像压缩(HDCompression),这是一个双流传输框架,它结合了生成VQ建模和扩散模型以及传统的LIC,以实现高保真和高感知质量。与之前直接使用预训练的LIC模型从重度量化的潜在信息中产生低质量保真保持信息的混合方法不同,我们使用扩散模型从原始真实输入中提取高质量补充保真信息,这可以在多个方面提高系统性能:改进索引图预测,提高LIC流的保真保持输出,并通过对VQ潜在校正进行条件图像重建。此外,我们的扩散模型基于密集代表性向量(DRV),它轻便且具有非常简单的采样调度器。大量实验表明,我们的HDCompression在定量指标和定性可视化方面均优于以前的传统LIC、生成VQ建模和混合框架,在超低比特率下提供了平衡的稳健压缩性能。
论文及项目相关链接
PDF Under Review
Summary
这篇论文提出了一种名为Hybrid-Diffusion Image Compression(HDCompression)的新的图像压缩方法。该方法结合了生成式VQ建模、传统的学习图像压缩和扩散模型,旨在实现高保真和高感知质量。与其他混合方法不同,它使用扩散模型从原始图像中提取高质量信息,以改进系统性能。实验结果证明,该方法在超低比特率下在定量指标和定性可视化方面均优于传统的LIC、生成式VQ建模和混合框架。
Key Takeaways
- HDCompression是一种新的图像压缩方法,结合了生成式VQ建模、传统的学习图像压缩和扩散模型。
- 与其他混合方法不同,HDCompression使用扩散模型从原始图像中提取高质量信息,以提高系统性能。
- HDCompression能提高索引图预测的准确性。
- 它能增强学习图像压缩流的保真度保留输出。
- HDCompression能细化有条件的图像重建,并进行VQ潜伏校正。
- 该方法使用基于密集代表向量(DRV)的扩散模型,具有轻量级和非常简单的采样调度器。
点此查看论文截图


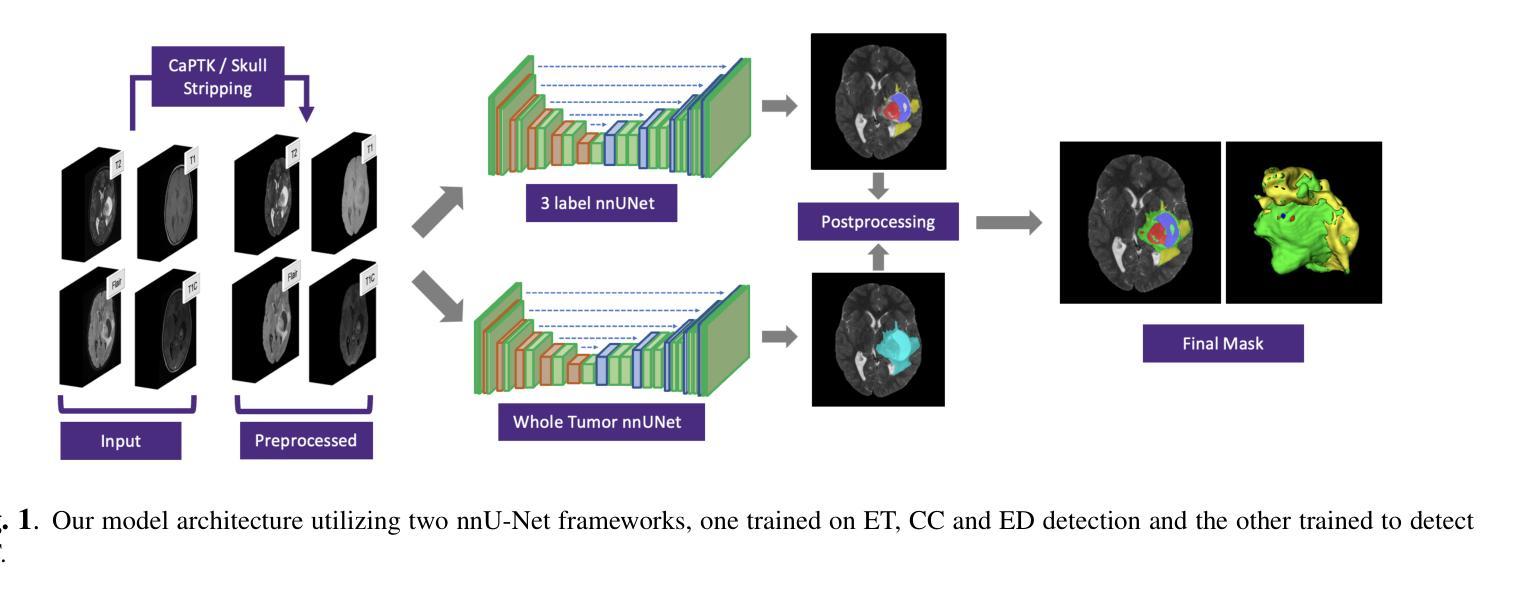
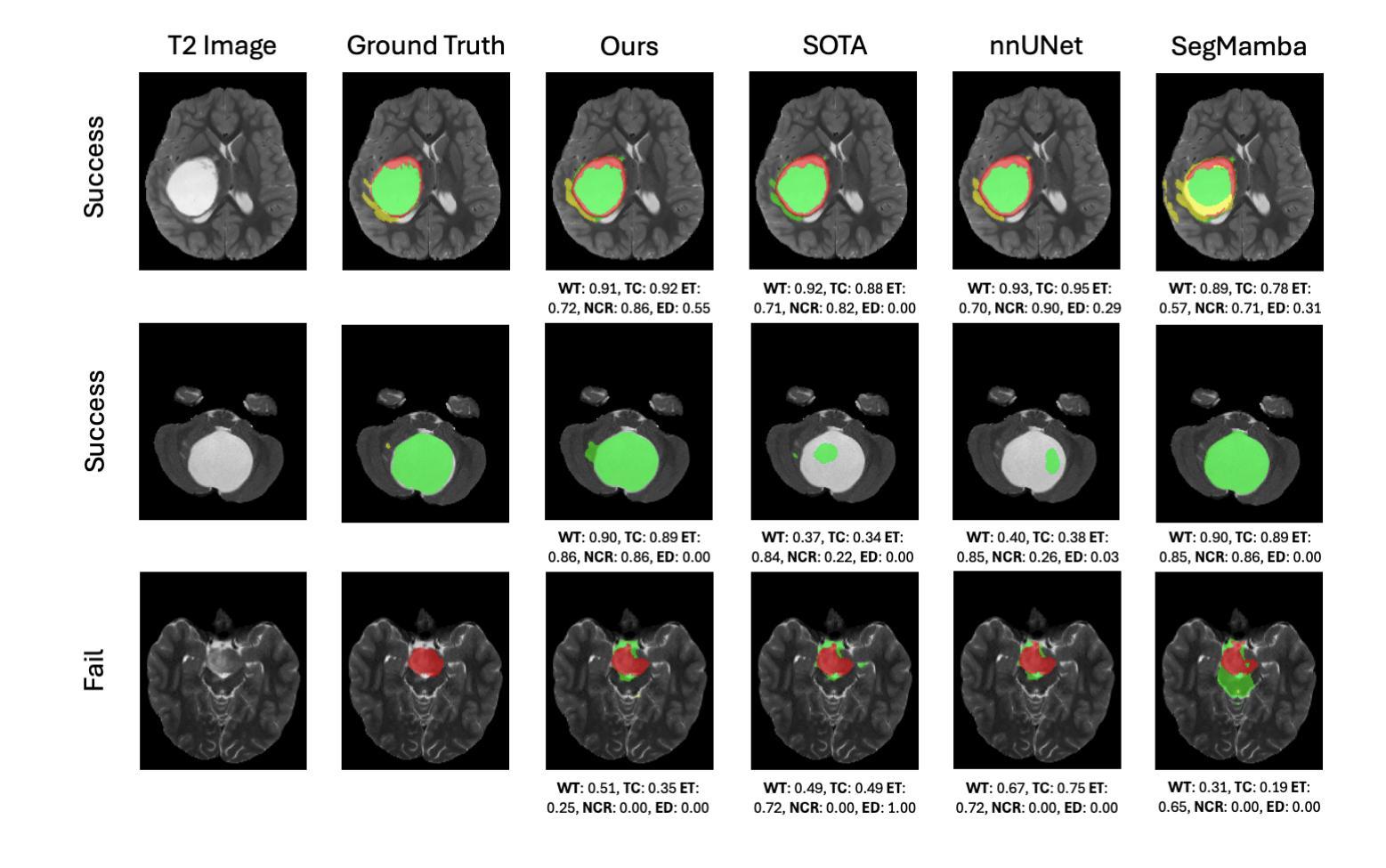
A New Logic For Pediatric Brain Tumor Segmentation
Authors:Max Bengtsson, Elif Keles, Gorkem Durak, Syed Anwar, Yuri S. Velichko, Marius G. Linguraru, Angela J. Waanders, Ulas Bagci
In this paper, we present a novel approach for segmenting pediatric brain tumors using a deep learning architecture, inspired by expert radiologists’ segmentation strategies. Our model delineates four distinct tumor labels and is benchmarked on a held-out PED BraTS 2024 test set (i.e., pediatric brain tumor datasets introduced by BraTS). Furthermore, we evaluate our model’s performance against the state-of-the-art (SOTA) model using a new external dataset of 30 patients from CBTN (Children’s Brain Tumor Network), labeled in accordance with the PED BraTS 2024 guidelines and 2023 BraTS Adult Glioma dataset. We compare segmentation outcomes with the winning algorithm from the PED BraTS 2023 challenge as the SOTA model. Our proposed algorithm achieved an average Dice score of 0.642 and an HD95 of 73.0 mm on the CBTN test data, outperforming the SOTA model, which achieved a Dice score of 0.626 and an HD95 of 84.0 mm. Moreover, our model exhibits strong generalizability, attaining a 0.877 Dice score in whole tumor segmentation on the BraTS 2023 Adult Glioma dataset, surpassing existing SOTA. Our results indicate that the proposed model is a step towards providing more accurate segmentation for pediatric brain tumors, which is essential for evaluating therapy response and monitoring patient progress. Our source code is available at https://github.com/NUBagciLab/Pediatric-Brain-Tumor-Segmentation-Model.
本文介绍了一种受专家放射科医生分割策略启发的新型深度学习架构,用于分割儿童脑肿瘤。我们的模型能够区分四种不同的肿瘤标签,并在PED BraTS 2024测试集(即BraTS引入的儿童脑肿瘤数据集)上进行基准测试。此外,我们使用符合PED BraTS 2024指南和2023年BraTS成人胶质瘤数据集的CBTN(儿童脑肿瘤网络)新外部数据集30名患者的数据来评估我们模型的表现。我们将分割结果与PED BraTS 2023挑战的获胜算法作为最先进的模型进行比较。我们提出的算法在CBTN测试数据上实现了平均Dice系数为0.642和HD95为73.0毫米,优于最先进的模型(其Dice系数为0.626,HD95为84.0毫米)。此外,我们的模型具有很强的泛化能力,在BraTS 2023成人胶质瘤数据集的全肿瘤分割上获得了0.877的Dice系数,超越了现有的最先进模型。我们的结果表明,所提出的模型是朝着为儿童脑肿瘤提供更精确分割的方向迈出的一步,这对于评估治疗反应和监测患者进展至关重要。我们的源代码可在https://github.com/NUBagciLab/Pediatric-Brain-Tumor-Segmentation-Model处获得。
论文及项目相关链接
Summary
本文介绍了一种基于深度学习的新方法,用于分割儿童脑肿瘤。该方法受到专家放射科医生分割策略的启发,能明确区分四种不同的肿瘤标签。实验结果显示,该方法在儿童脑肿瘤数据集上的性能优于现有最先进的模型,具备更强的泛化能力。此外,该模型源代码已公开。
Key Takeaways
- 本文提出了一种用于分割儿童脑肿瘤的新方法,基于深度学习架构。
- 该方法受到专家放射科医生分割策略的启发,可区分四种不同的肿瘤标签。
- 在PED BraTS 2024测试集上的性能评估显示,该方法优于现有最先进的模型。
- 该模型在CBTN测试数据上的平均Dice得分为0.642,HD95为73.0mm,而最先进的模型的Dice得分为0.626,HD95为84.0mm。
- 该模型具有良好的泛化能力,在BraTS 2023成人胶质瘤数据集上的整体肿瘤分割Dice得分达到0.877,超过了现有最先进的模型。
- 该模型为更准确地分割儿童脑肿瘤提供了可能,这对评估治疗效果和监测患者进展至关重要。
点此查看论文截图




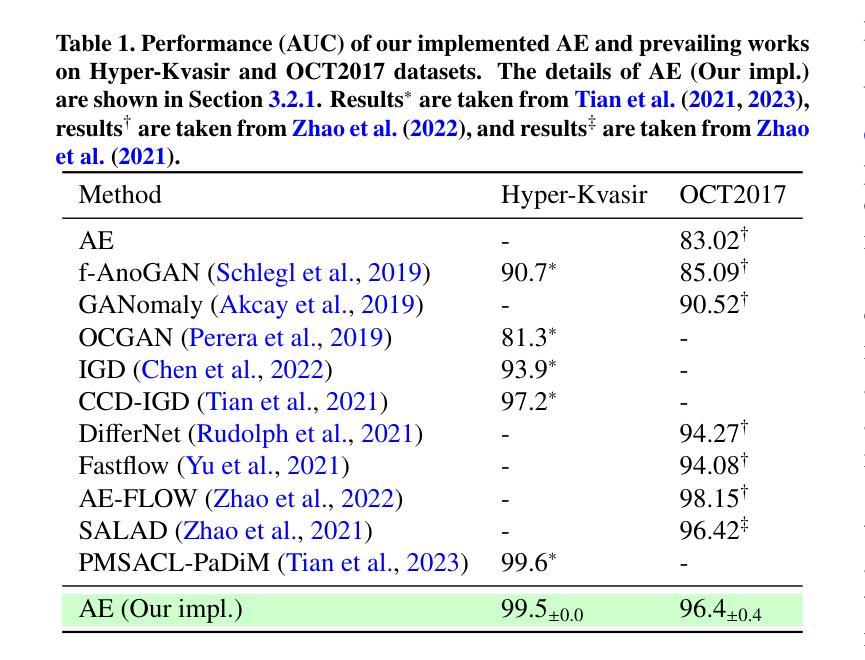
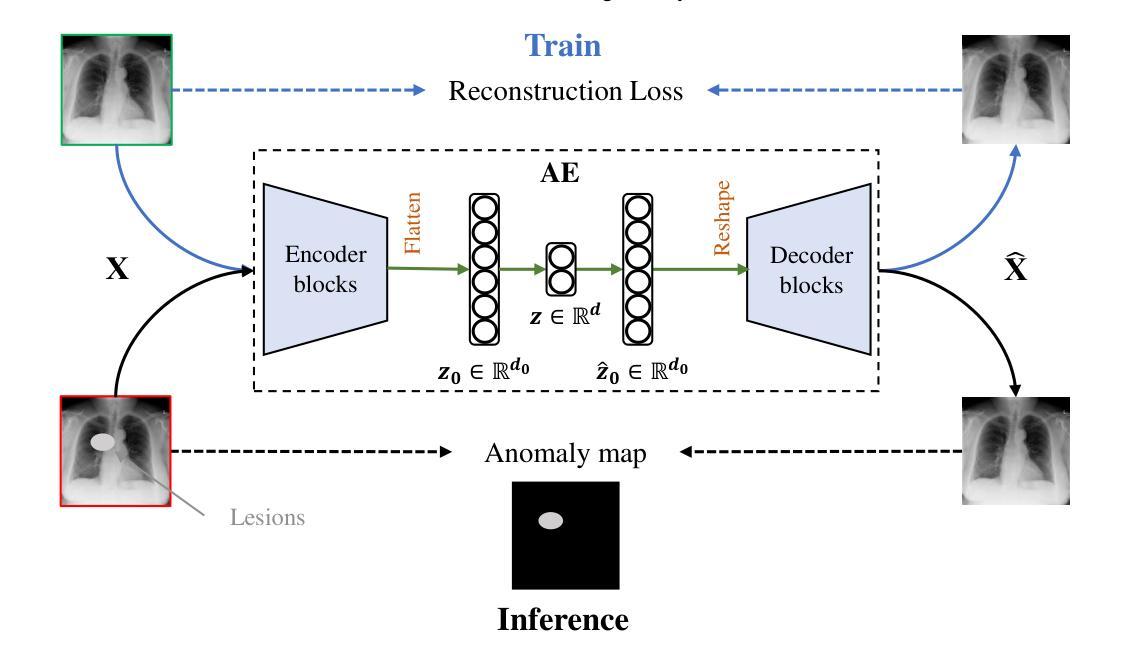
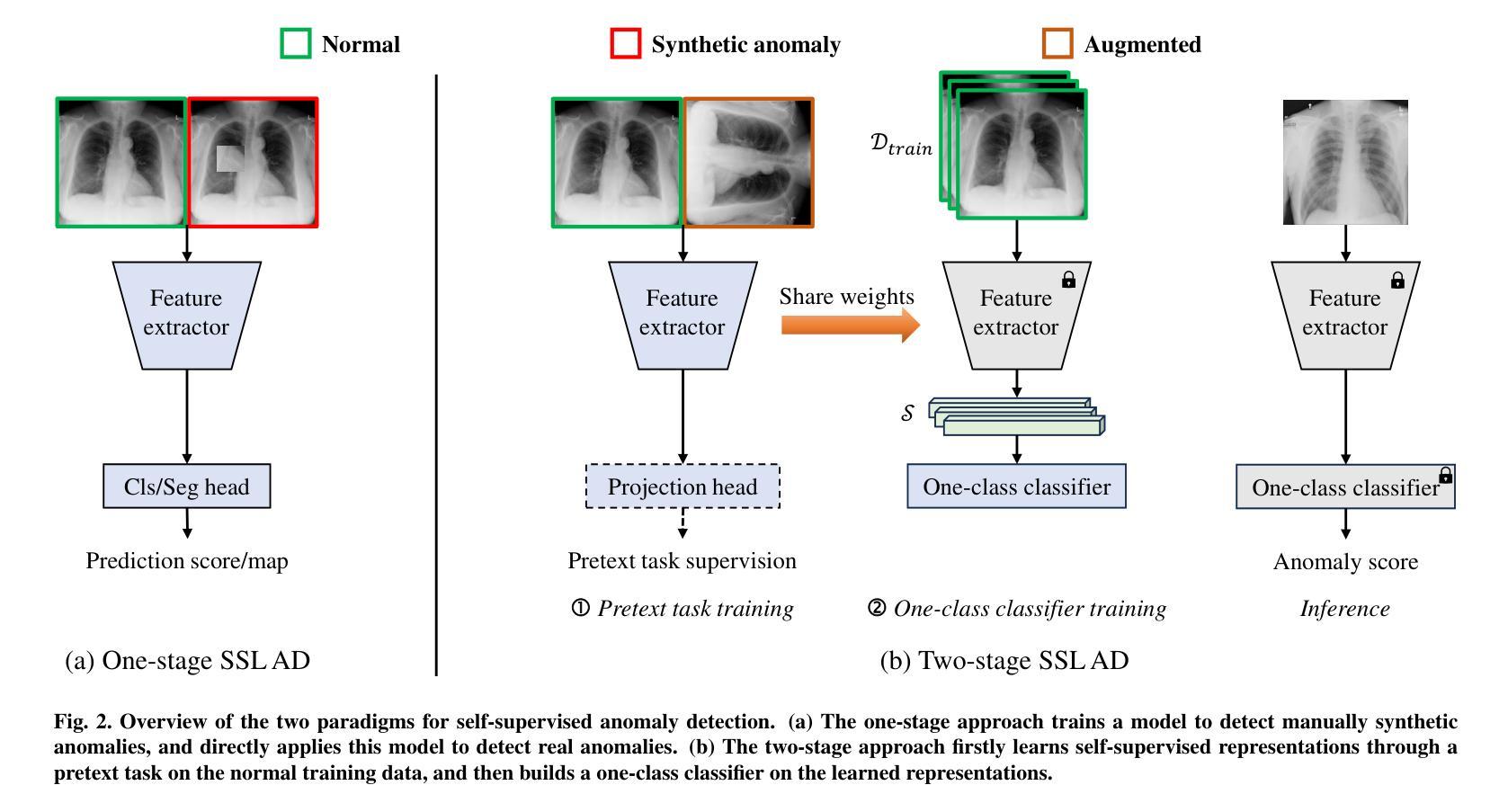
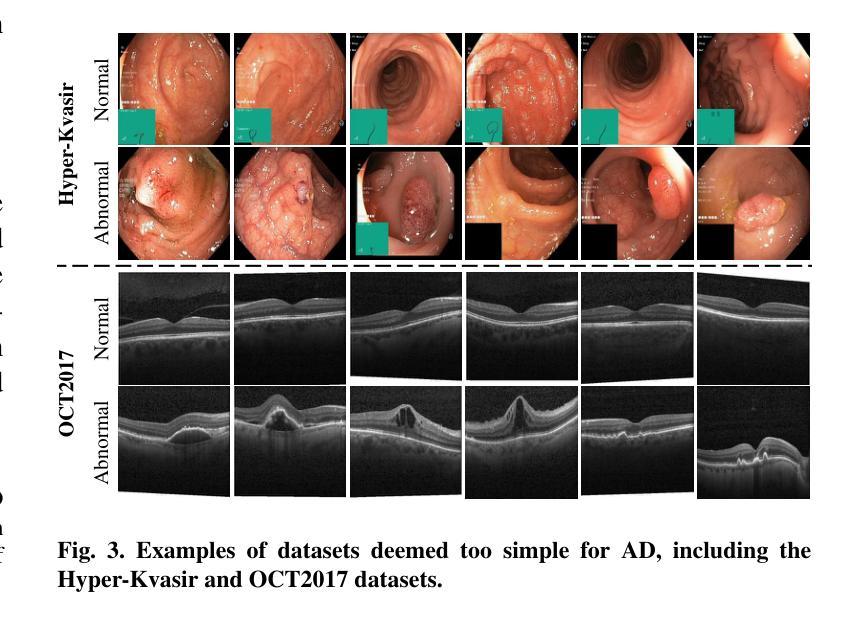
MedIAnomaly: A comparative study of anomaly detection in medical images
Authors:Yu Cai, Weiwen Zhang, Hao Chen, Kwang-Ting Cheng
Anomaly detection (AD) aims at detecting abnormal samples that deviate from the expected normal patterns. Generally, it can be trained merely on normal data, without a requirement for abnormal samples, and thereby plays an important role in rare disease recognition and health screening in the medical domain. Despite the emergence of numerous methods for medical AD, the lack of a fair and comprehensive evaluation causes ambiguous conclusions and hinders the development of this field. To address this problem, this paper builds a benchmark with unified comparison. Seven medical datasets with five image modalities, including chest X-rays, brain MRIs, retinal fundus images, dermatoscopic images, and histopathology images, are curated for extensive evaluation. Thirty typical AD methods, including reconstruction and self-supervised learning-based methods, are involved in comparison of image-level anomaly classification and pixel-level anomaly segmentation. Furthermore, for the first time, we systematically investigate the effect of key components in existing methods, revealing unresolved challenges and potential future directions. The datasets and code are available at https://github.com/caiyu6666/MedIAnomaly.
异常检测(AD)旨在检测偏离预期正常模式的异常样本。通常,它仅能在正常数据上进行训练,无需异常样本,因此在医学领域的罕见疾病识别和健康筛查中发挥着重要作用。尽管出现了许多医学异常检测方法,但由于缺乏公平和全面的评估,导致结论模糊并阻碍了该领域的发展。针对这一问题,本文建立了一个统一的比较基准。为进行广泛评估,整理了七个医学数据集,包含五种图像模态,包括胸部X射线、脑部MRI、眼底视网膜图像、皮肤镜图像和病理图像。三十种典型的异常检测方法,包括重建和基于自监督学习的方法,都参与了图像级异常分类和像素级异常分割的比较。此外,我们首次系统地研究了现有方法中的关键组件的影响,揭示了未解决的挑战和潜在的未来方向。数据集和代码可通过以下链接获取:<https://github.com/caiyu666 您的文本翻译完毕。请继续提问以获取更多帮助。
论文及项目相关链接
PDF Accepted to Medical Image Analysis, 2025
Summary
医学异常检测(AD)对于检测偏离预期正常模式的异常样本至关重要。本文建立了一个统一的基准测试,包含七个医学数据集和五种图像模态,用于全面评估异常检测方法。涉及图像级别的异常分类和像素级别的异常分割的三十种典型AD方法被进行比较。此外,本文首次系统地探讨了现有方法中的关键组成部分,揭示了未解决的挑战和潜在的未来方向。数据集和代码可在GitHub上获取。
Key Takeaways
- 异常检测(AD)在医学领域对于识别罕见疾病和健康筛查具有重要意义,能够检测偏离预期正常模式的异常样本。
- 文章建立了一个统一的基准测试,包含七个医学数据集和五种图像模态,为解决医学AD领域缺乏公平、全面的评估提供了方案。
- 涉及图像级别的异常分类和像素级别的异常分割的三十种典型AD方法被比较和评估。
- 文章首次系统地探讨了现有AD方法中的关键组成部分,分析各方法的优势和劣势。
- 文章揭示了医学AD领域存在的未解决挑战和潜在未来方向,为研究者提供了方向指引。
- 数据集和代码已公开,便于其他研究者使用和改进。
- 该研究为医学异常检测的进一步发展奠定了基础。
点此查看论文截图

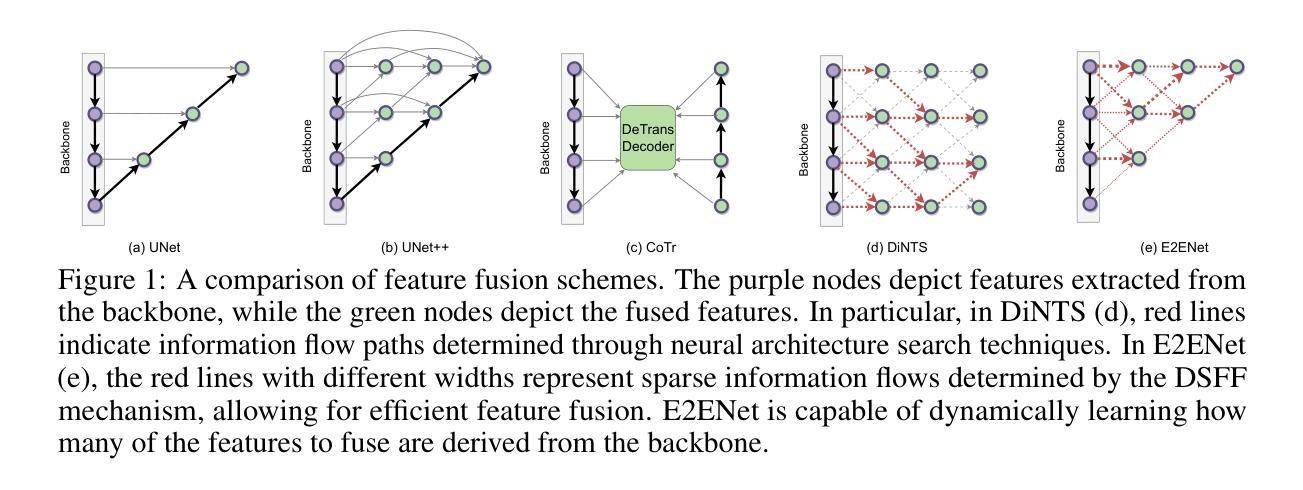
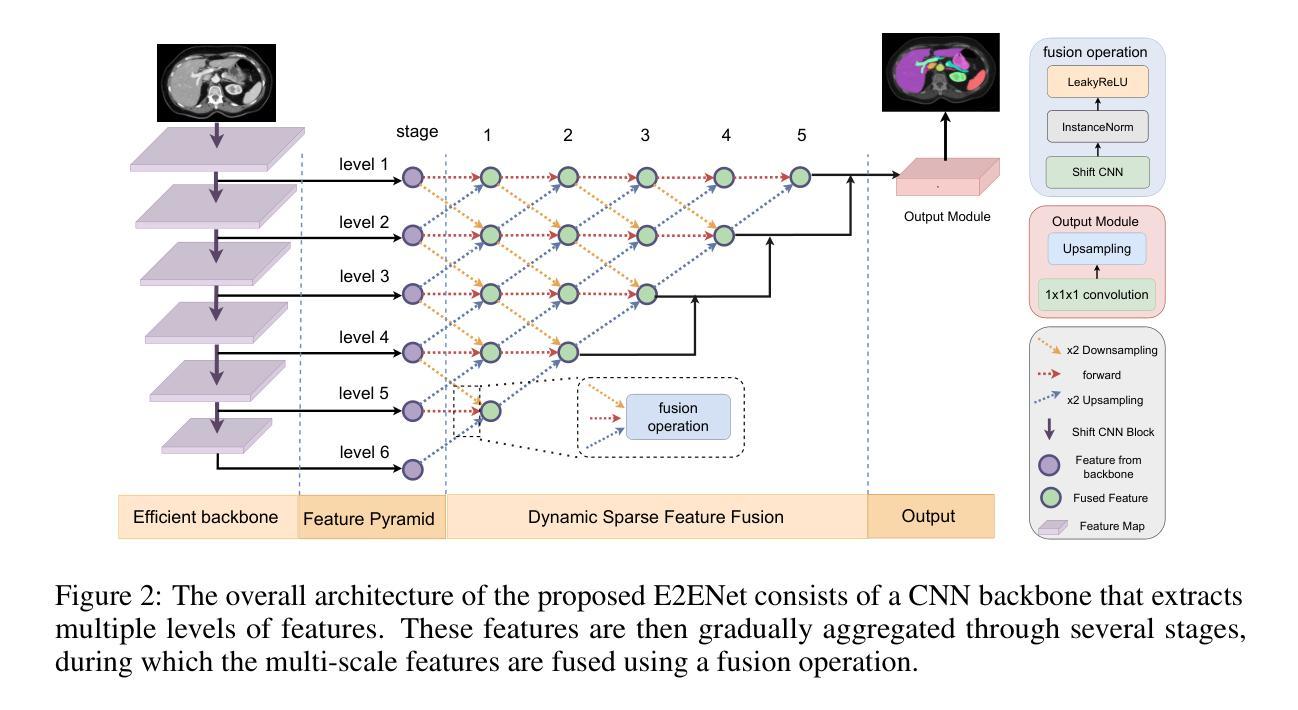
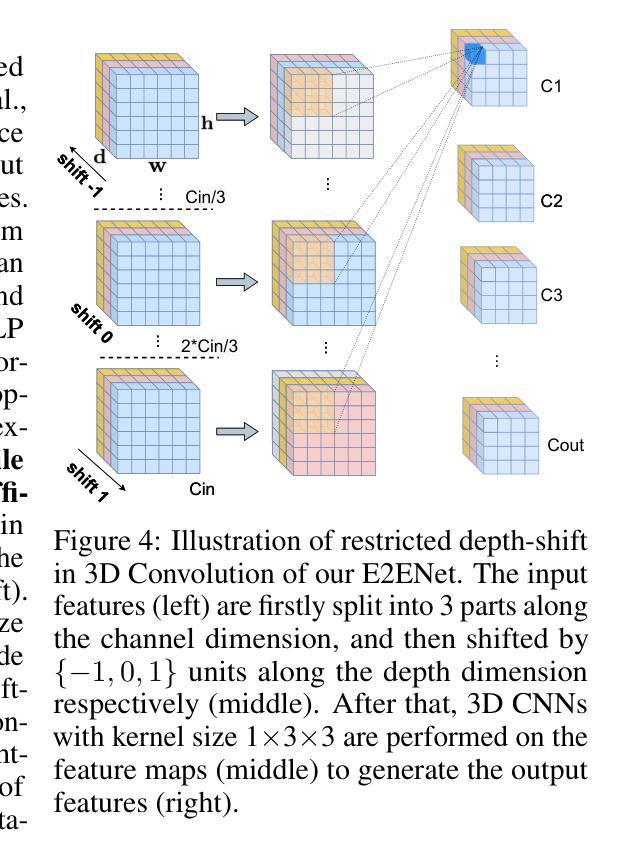
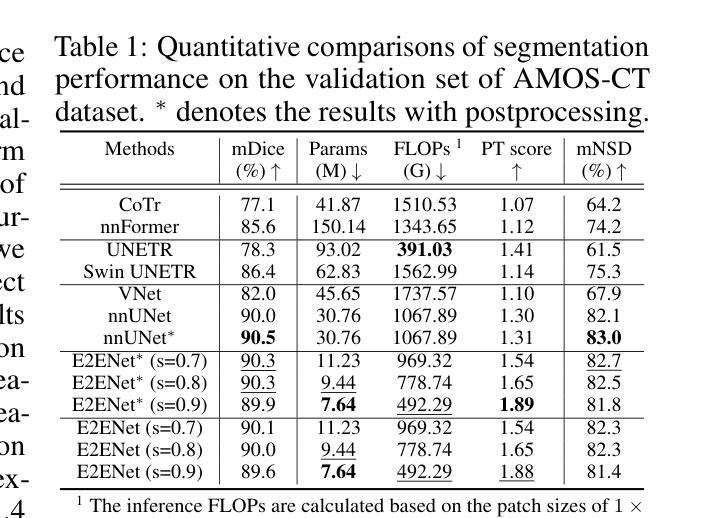
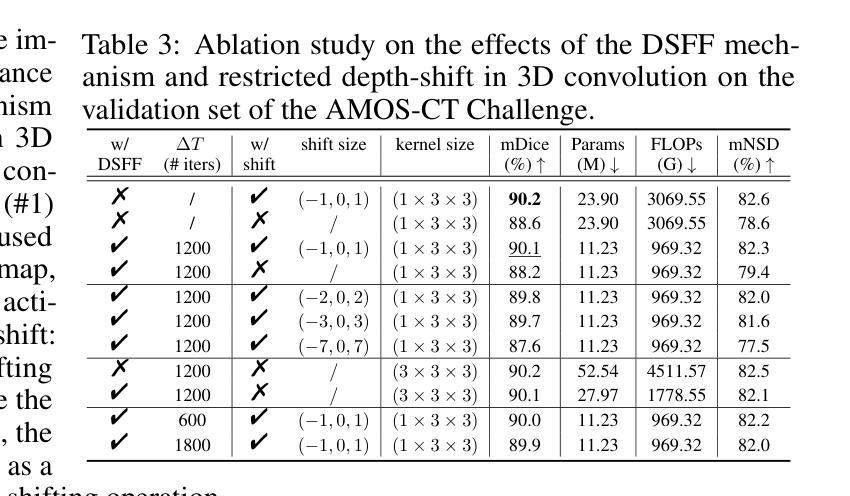
E2ENet: Dynamic Sparse Feature Fusion for Accurate and Efficient 3D Medical Image Segmentation
Authors:Boqian Wu, Qiao Xiao, Shiwei Liu, Lu Yin, Mykola Pechenizkiy, Decebal Constantin Mocanu, Maurice Van Keulen, Elena Mocanu
Deep neural networks have evolved as the leading approach in 3D medical image segmentation due to their outstanding performance. However, the ever-increasing model size and computation cost of deep neural networks have become the primary barrier to deploying them on real-world resource-limited hardware. In pursuit of improving performance and efficiency, we propose a 3D medical image segmentation model, named Efficient to Efficient Network (E2ENet), incorporating two parametrically and computationally efficient designs. i. Dynamic sparse feature fusion (DSFF) mechanism: it adaptively learns to fuse informative multi-scale features while reducing redundancy. ii. Restricted depth-shift in 3D convolution: it leverages the 3D spatial information while keeping the model and computational complexity as 2D-based methods. We conduct extensive experiments on BTCV, AMOS-CT and Brain Tumor Segmentation Challenge, demonstrating that E2ENet consistently achieves a superior trade-off between accuracy and efficiency than prior arts across various resource constraints. E2ENet achieves comparable accuracy on the large-scale challenge AMOS-CT, while saving over 68% parameter count and 29% FLOPs in the inference phase, compared with the previous best-performing method. Our code has been made available at: https://github.com/boqian333/E2ENet-Medical.
深度神经网络因其卓越性能而逐渐演变为3D医学图像分割领域的主要方法。然而,深度神经网络不断增长的模型大小和计算成本已成为将其部署在现实世界资源受限的硬件上的主要障碍。为了提升性能和效率,我们提出了一种名为Efficient to Efficient Network (E2ENet)的3D医学图像分割模型,它融合了两种参数和计算效率高的设计。一是动态稀疏特征融合(DSFF)机制:它自适应地学习融合信息丰富的多尺度特征,同时减少冗余。二是3D卷积中的受限深度移位:它在利用3D空间信息的同时,保持模型与计算复杂度类似于基于二维的方法。我们在BTCV、AMOS-CT和脑肿瘤分割挑战等数据集上进行了大量实验,证明E2ENet在各种资源限制下始终在精度和效率之间达到优于先前技术的权衡。在大型挑战AMOS-CT上,E2ENet的准确度与之前的最佳方法相当,同时在推理阶段节省了超过68%的参数计数和29%的浮点运算次数。我们的代码已在以下网址公开:https://github.com/boqian333/E2ENet-Medical。
论文及项目相关链接
PDF Accepted at NeurIPS 2024
Summary
高效神经网络(Efficient to Efficient Network,E2ENet)在医学图像三维分割领域表现出卓越性能,采用动态稀疏特征融合和受限深度位移设计以提高效率和准确性。该模型在多个数据集上实现优异性能,减少参数数量和计算量,相较于先前技术具有更佳的准确性和效率权衡。
Key Takeaways
- 深度神经网络在医学图像三维分割领域占据领先地位,但模型体积和计算成本日益增加,成为资源受限硬件上部署的障碍。
- 提出名为Efficient to Efficient Network (E2ENet)的医学图像三维分割模型,旨在提高性能和效率。
- E2ENet采用动态稀疏特征融合(DSFF)机制,可自适应地融合信息多尺度特征并减少冗余。
- E2ENet引入受限深度位移的3D卷积,利用3D空间信息同时保持模型及计算复杂度类似于2D方法。
- 广泛实验表明,E2ENet在各种资源约束下较先前技术实现了更高的准确性和效率之间的平衡。
- 在大规模挑战AMOS-CT上,E2ENet实现了与最佳表现方法相当的准确度,同时在推理阶段节省了超过68%的参数计数和29%的FLOPs。
点此查看论文截图


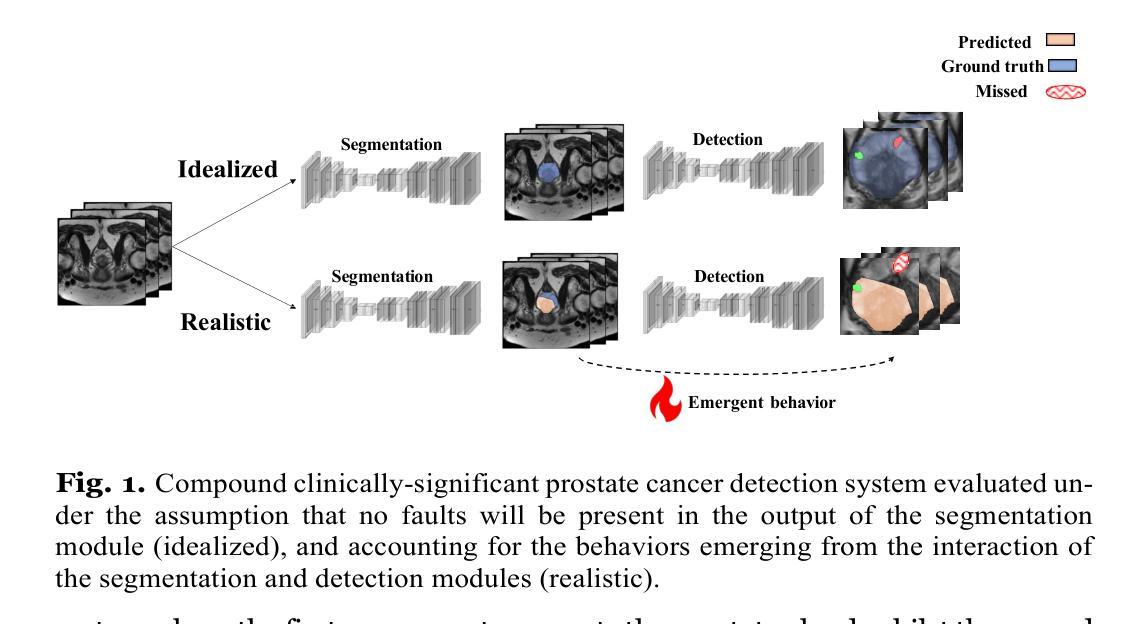
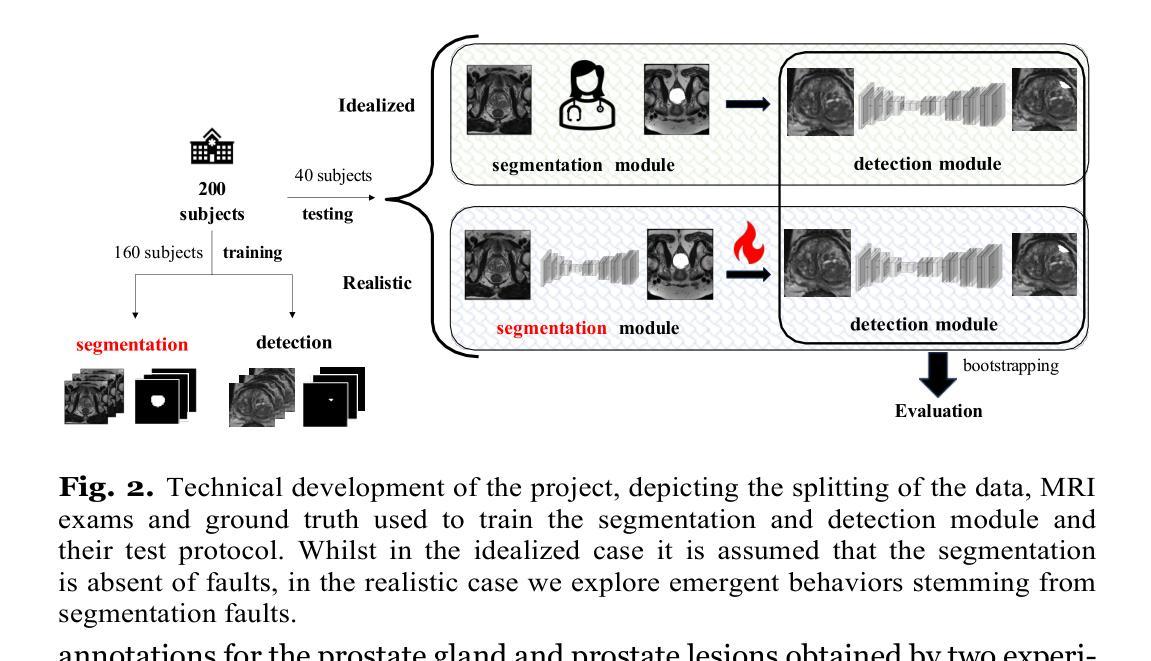
On undesired emergent behaviors in compound prostate cancer detection systems
Authors:Erlend Sortland Rolfsnes, Philip Thangngat, Trygve Eftestøl, Tobias Nordström, Fredrik Jäderling, Martin Eklund, Alvaro Fernandez-Quilez
Artificial intelligence systems show promise to aid in the di- agnostic pathway of prostate cancer (PC), by supporting radiologists in interpreting magnetic resonance images (MRI) of the prostate. Most MRI-based systems are designed to detect clinically significant PC le- sions, with the main objective of preventing over-diagnosis. Typically, these systems involve an automatic prostate segmentation component and a clinically significant PC lesion detection component. In spite of the compound nature of the systems, evaluations are presented assum- ing a standalone clinically significant PC detection component. That is, they are evaluated in an idealized scenario and under the assumption that a highly accurate prostate segmentation is available at test time. In this work, we aim to evaluate a clinically significant PC lesion de- tection system accounting for its compound nature. For that purpose, we simulate a realistic deployment scenario and evaluate the effect of two non-ideal and previously validated prostate segmentation modules on the PC detection ability of the compound system. Following, we com- pare them with an idealized setting, where prostate segmentations are assumed to have no faults. We observe significant differences in the de- tection ability of the compound system in a realistic scenario and in the presence of the highest-performing prostate segmentation module (DSC: 90.07+-0.74), when compared to the idealized one (AUC: 77.93 +- 3.06 and 84.30+- 4.07, P<.001). Our results depict the relevance of holistic evalu- ations for PC detection compound systems, where interactions between system components can lead to decreased performance and degradation at deployment time.
人工智能系统在前列腺癌(PC)诊断路径中显示出巨大潜力,支持放射科医生解释前列腺的磁共振图像(MRI)。大多数基于MRI的系统旨在检测临床重要的PC病变,主要目的是防止过度诊断。这些系统通常包括一个自动前列腺分割组件和一个临床重要的PC病变检测组件。尽管这些系统的复合性质,但评估是基于一个独立的临床重要PC检测组件进行的。也就是说,它们在理想化的场景中进行了评估,并假设测试时存在高度准确的前列腺分割。在这项工作中,我们旨在评估临床重要的PC病变检测系统,并考虑到其复合性质。为此,我们模拟了一个现实部署场景,并评估了两个经过验证的非理想前列腺分割模块对复合系统检测PC能力的影响。之后,我们将它们与理想化设置进行比较,其中假设前列腺分段没有故障。我们观察到,在现实场景中以及在最高性能的前列腺分割模块(DSC:90.07±0.74)的存在下,复合系统的检测能力与理想情况下的检测能力相比存在显著差异(AUC:77.93±3.06和84.30±4.07,P<.001)。我们的结果描绘了全面评估PC检测复合系统的重要性,系统组件之间的相互作用可能导致性能下降并在部署时发生退化。
论文及项目相关链接
PDF Accepted in MICCAI 2025, CapTiON
摘要
人工智能系统有望辅助前列腺癌的诊断过程,通过支持放射科医生解读前列腺磁共振成像。多数基于MRI的系统旨在检测具有临床意义的前列腺病灶,主要目的是防止过度诊断。这些系统通常包括自动前列腺分割组件和检测具有临床意义的前列腺病灶组件。尽管这些系统的复合性质,但评估是在假设一个独立的前列腺癌检测组件的情况下进行的。也就是说,它们在理想化的场景和假设高度准确的前列腺分割在测试时可用的情况下进行评估。在这项工作中,我们旨在评估一个考虑到其复合性质的前列腺癌检测系统。为此,我们模拟了一个真实的部署场景,并评估了两个先前验证的非理想前列腺分割模块对复合系统检测前列腺癌能力的影响。之后,我们将它们与理想化的设置进行比较,其中假设前列腺分段没有故障。我们观察到复合系统在现实场景中的检测能力与表现最佳的前列腺分割模块存在显著差异(DSC:90.07±0.74),与理想化情况相比(AUC:77.93±3.06和84.30±4.07,P<.001)。我们的结果表明,对前列腺癌检测复合系统进行整体评估具有重要意义,系统组件之间的相互作用可能导致性能下降和部署时的退化。
关键见解
- 人工智能系统在解读前列腺磁共振成像方面表现出辅助诊断前列腺癌的潜力。
- 基于MRI的系统主要目标是检测具有临床意义的前列腺病灶,旨在避免过度诊断。
- 这些系统包括自动前列腺分割和检测组件,但之前的评估大多假设了独立的前列腺癌检测组件。
- 在模拟的实际部署场景中评估了复合系统的前列腺癌检测能力,考虑了非理想的前列腺分割模块的影响。
- 与理想化设置相比,现实场景中的系统检测性能存在显著差异。
- 最好的前列腺分割模块对复合系统的检测能力有显著影响。
点此查看论文截图