⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-21 更新
Autellix: An Efficient Serving Engine for LLM Agents as General Programs
Authors:Michael Luo, Xiaoxiang Shi, Colin Cai, Tianjun Zhang, Justin Wong, Yichuan Wang, Chi Wang, Yanping Huang, Zhifeng Chen, Joseph E. Gonzalez, Ion Stoica
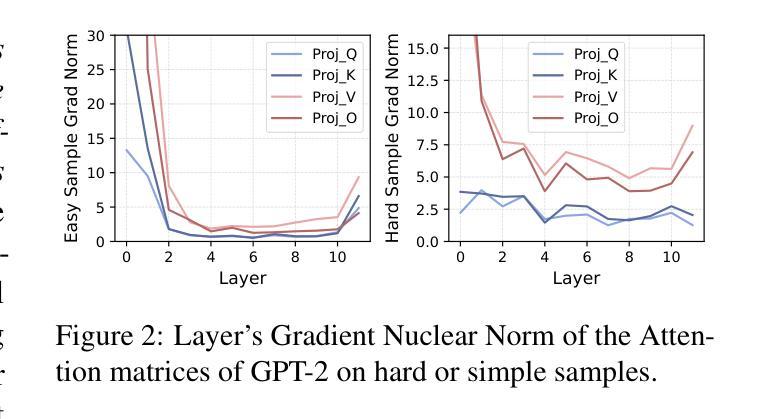
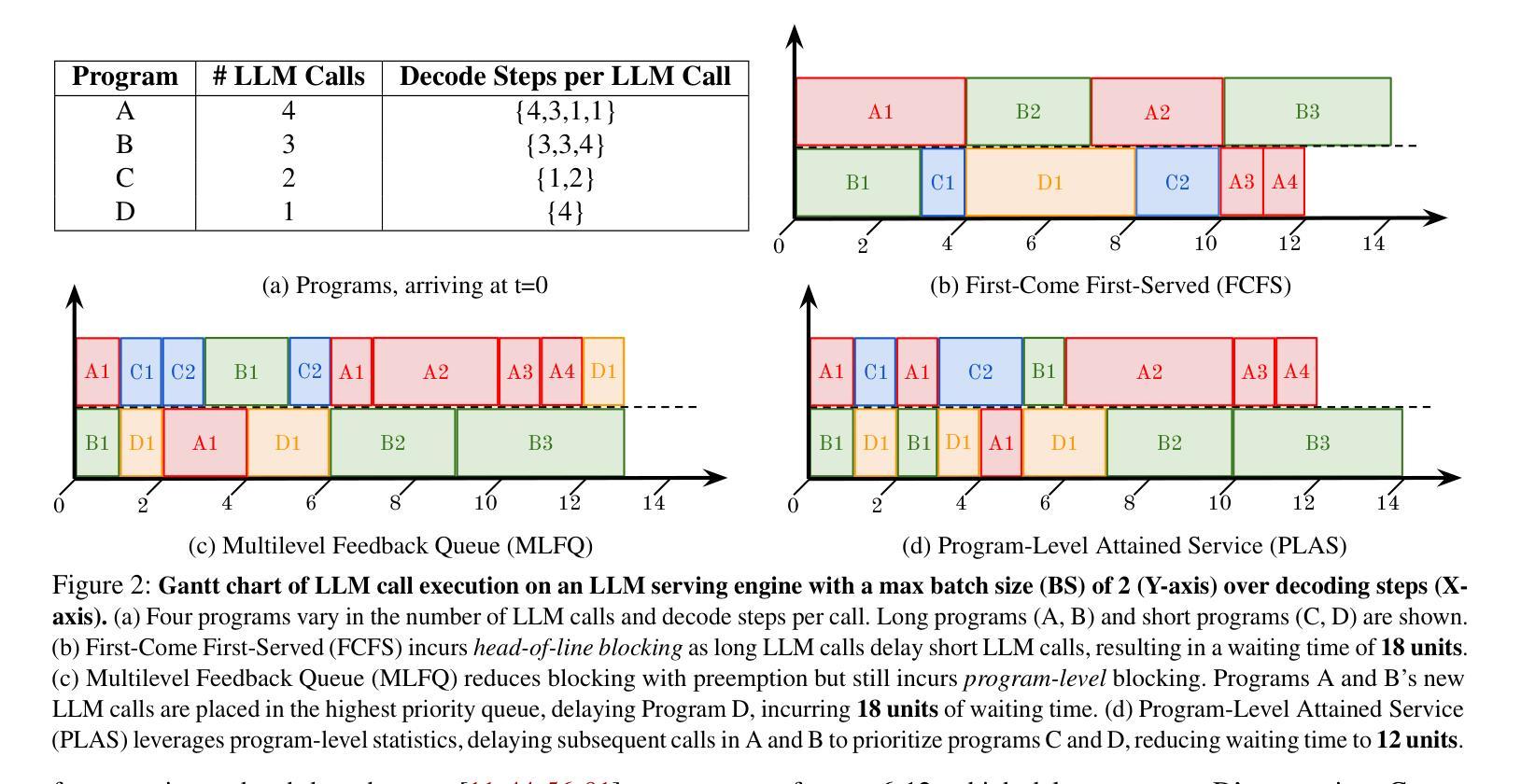
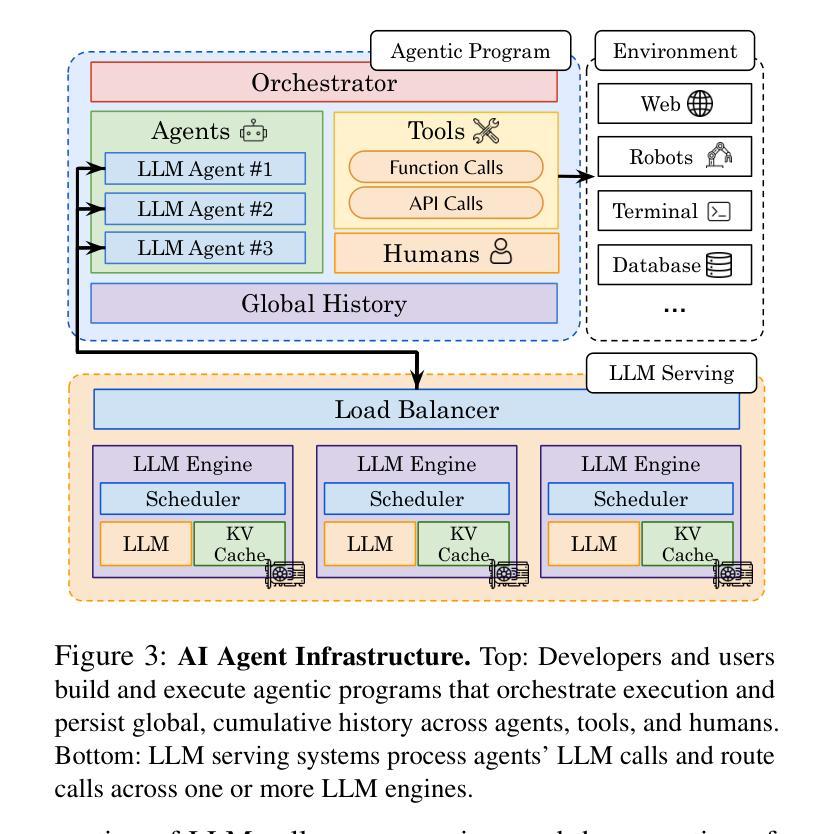
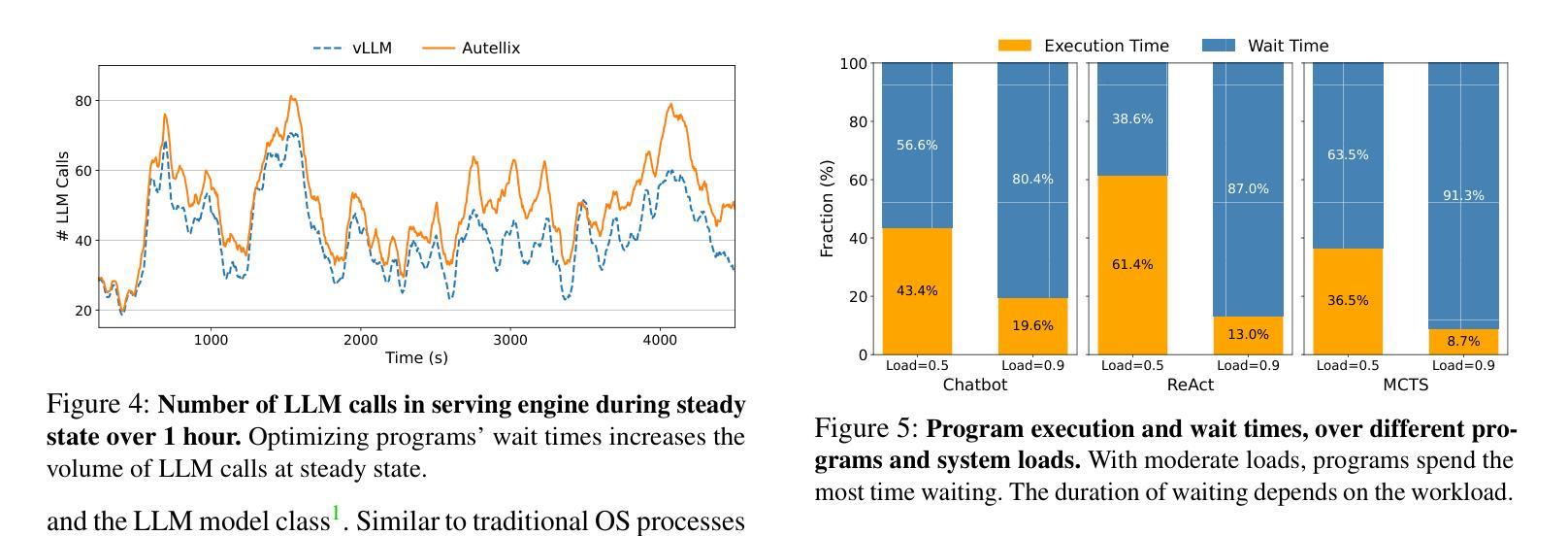
Large language model (LLM) applications are evolving beyond simple chatbots into dynamic, general-purpose agentic programs, which scale LLM calls and output tokens to help AI agents reason, explore, and solve complex tasks. However, existing LLM serving systems ignore dependencies between programs and calls, missing significant opportunities for optimization. Our analysis reveals that programs submitted to LLM serving engines experience long cumulative wait times, primarily due to head-of-line blocking at both the individual LLM request and the program. To address this, we introduce Autellix, an LLM serving system that treats programs as first-class citizens to minimize their end-to-end latencies. Autellix intercepts LLM calls submitted by programs, enriching schedulers with program-level context. We propose two scheduling algorithms-for single-threaded and distributed programs-that preempt and prioritize LLM calls based on their programs’ previously completed calls. Our evaluation demonstrates that across diverse LLMs and agentic workloads, Autellix improves throughput of programs by 4-15x at the same latency compared to state-of-the-art systems, such as vLLM.
大型语言模型(LLM)的应用已经超越了简单的聊天机器人,发展成为了动态、通用的代理程序,这些程序扩大了LLM的调用和输出令牌,帮助AI代理进行推理、探索和解决复杂任务。然而,现有的LLM服务系统忽略了程序和调用之间的依赖关系,丧失了重要的优化机会。我们的分析显示,提交到LLM服务引擎的程序会经历长时间的累积等待时间,主要是由于单个LLM请求和程序的头道阻塞造成的。为了解决这一问题,我们引入了Autellix,这是一个将程序视为首要任务的大型语言模型服务系统,以最小化其端到端的延迟。Autellix拦截程序提交的LLM调用,并丰富调度器的程序级上下文。我们提出了两种调度算法,分别用于单线程和分布式程序,这两种算法都会根据程序的先前已完成调用提前并优先处理LLM调用。我们的评估表明,在多种大型语言模型和代理工作负载中,与最先进的系统(如vLLM)相比,Autellix可以在相同延迟下将程序的吞吐量提高4-15倍。
论文及项目相关链接
Summary
大型语言模型(LLM)应用正由简单的聊天机器人发展为动态、通用的代理程序,通过扩展LLM调用和输出令牌,帮助AI代理进行推理、探索和解决复杂任务。然而,现有LLM服务系统忽略了程序和调用之间的依赖关系,失去了优化的重要机会。我们的分析显示,提交到LLM服务引擎的程序经历了长时间的累积等待时间,主要是由于单个LLM请求和程序的头线阻塞。为解决这一问题,我们引入了Autellix,一个将程序视为首要公民的LLM服务系统,以最小化其端到端延迟。Autellix通过程序上下文信息拦截提交的程序丰富调度器的选择空间,并针对单线程和分布式程序提出两种基于已完成的调用预先推断和优先处理LLM调用的调度算法。评估结果表明,Autellix在多种LLM和代理工作负载上提高了程序的吞吐量,同时与vLLM等先进系统相比延迟相同的情况下提高了程序的性能,达到其效率的4~15倍。
Key Takeaways
- 大型语言模型的应用正演变为更为动态、通用的代理程序,具有更广泛的用途和更复杂的任务处理能力。
- 现行的LLM服务系统忽略了程序和调用间的依赖关系,这可能导致性能损失和用户体验下降。
- Autellix是一种创新的LLM服务系统,通过加入程序上下文信息提升了性能,特别是对于复杂任务的调用优化效果显著。它不仅将程序视为高级单位来处理更全面的任务上下文信息,而且通过拦截提交的程序来丰富调度器的选择空间。
- Autellix提出了两种调度算法:针对单线程程序和分布式程序的算法可提前预测并优先处理重要的LLM调用,提高了系统响应速度和吞吐量。这对于需要处理大量并发请求的系统尤为重要。相较于现有的系统如vLLM等,Autellix在效率和性能上表现出显著优势。它的应用能够显著提高程序的运行效率并降低延迟时间。
点此查看论文截图

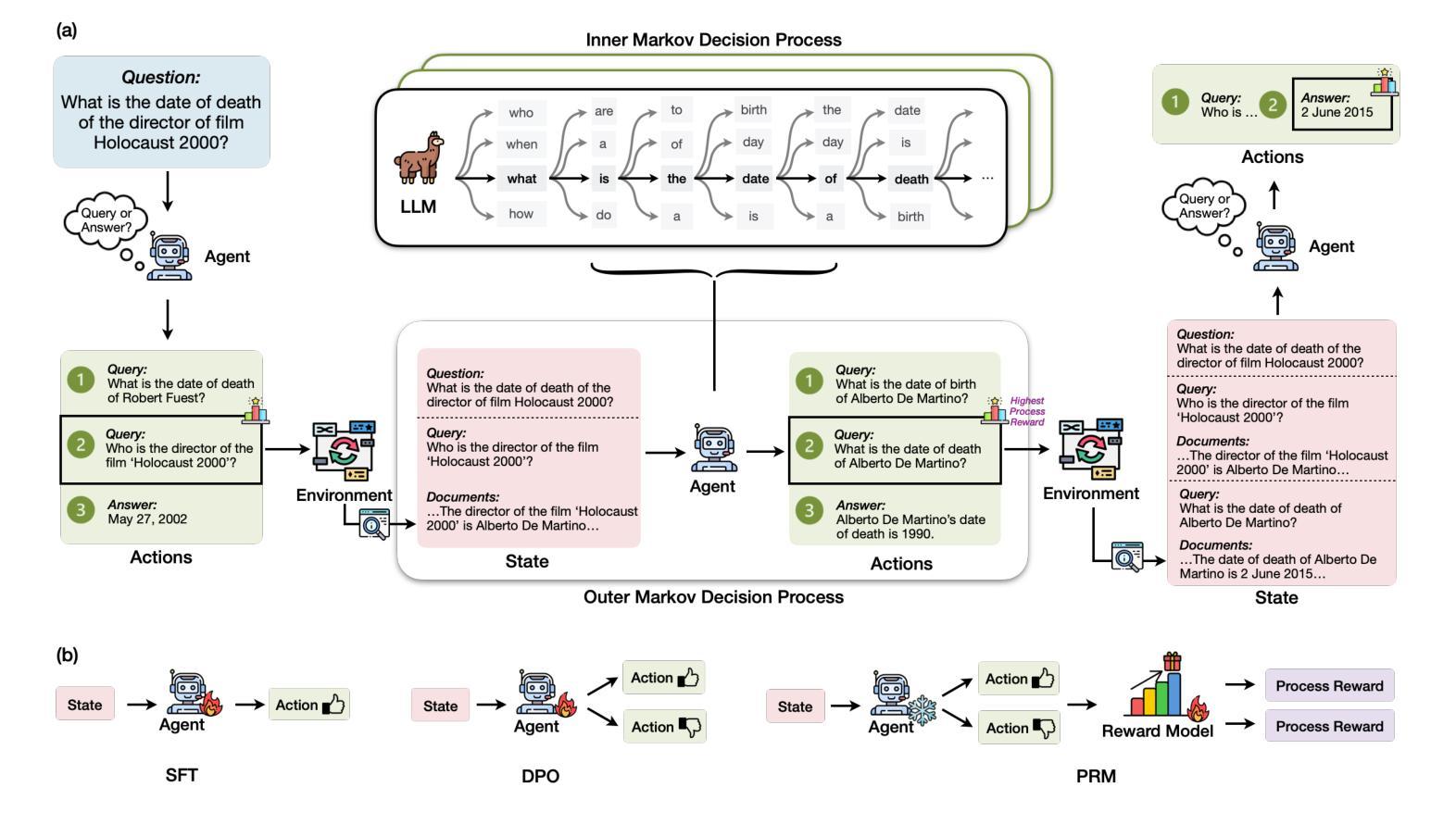
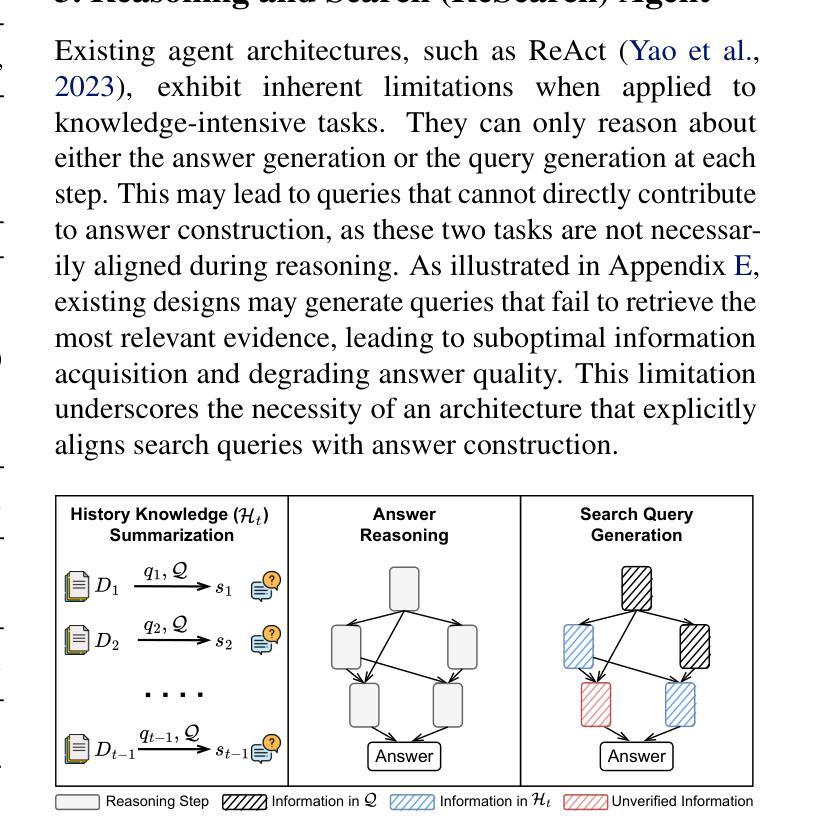
RAG-Gym: Optimizing Reasoning and Search Agents with Process Supervision
Authors:Guangzhi Xiong, Qiao Jin, Xiao Wang, Yin Fang, Haolin Liu, Yifan Yang, Fangyuan Chen, Zhixing Song, Dengyu Wang, Minjia Zhang, Zhiyong Lu, Aidong Zhang
Retrieval-augmented generation (RAG) has shown great potential for knowledge-intensive tasks, but its traditional architectures rely on static retrieval, limiting their effectiveness for complex questions that require sequential information-seeking. While agentic reasoning and search offer a more adaptive approach, most existing methods depend heavily on prompt engineering. In this work, we introduce RAG-Gym, a unified optimization framework that enhances information-seeking agents through fine-grained process supervision at each search step. We also propose ReSearch, a novel agent architecture that synergizes answer reasoning and search query generation within the RAG-Gym framework. Experiments on four challenging datasets show that RAG-Gym improves performance by up to 25.6% across various agent architectures, with ReSearch consistently outperforming existing baselines. Further analysis highlights the effectiveness of advanced LLMs as process reward judges and the transferability of trained reward models as verifiers for different LLMs. Additionally, we examine the scaling properties of training and inference in agentic RAG. The project homepage is available at https://rag-gym.github.io/.
检索增强生成(RAG)在知识密集型任务中显示出巨大潜力,但其传统架构依赖于静态检索,对于需要连续信息检索的复杂问题的效果有限。虽然自主推理和搜索提供了更灵活的方法,但大多数现有方法严重依赖于提示工程。在这项工作中,我们引入了RAG-Gym,这是一个统一的优化框架,通过每个搜索步骤的精细过程监督,增强信息搜索代理的能力。我们还提出了ReSearch,这是一种新型代理架构,能在RAG-Gym框架内协同答案推理和搜索查询生成。在四个具有挑战性的数据集上的实验表明,RAG-Gym在各种代理架构上的性能提高了高达25.6%,ReSearch始终超过现有基线。进一步的分析突出了高级LLMs作为过程奖励判断者的有效性,以及训练后的奖励模型作为不同LLMs验证者的可转移性。此外,我们还研究了代理RAG中训练和推理的规模化属性。项目主页可在https://rag-gym.github.io/找到。
论文及项目相关链接
Summary
RAG-Gym框架通过精细的搜索步骤监督增强了信息搜索代理的能力。此外,提出了ReSearch架构,该架构在RAG-Gym框架内协同答案推理和搜索查询生成。实验表明,RAG-Gym提高了高达25.6%的性能,在各种代理架构中,ReSearch始终优于现有基线。
Key Takeaways
- RAG面临对于复杂问题需要适应性的信息搜索问题,但传统的RAG架构依赖静态检索。
- RAG-Gym是一个统一优化框架,它通过每个搜索步骤的精细过程监督增强信息搜索代理的能力。
- ReSearch是一个新型代理架构,能够在RAG-Gym框架内协同答案推理和搜索查询生成。
- 实验证明,RAG-Gym能提高各种代理架构的性能,最高可达25.6%,其中ReSearch表现最佳。
- 高级LLMs作为过程奖励判断者效果显著,训练的奖励模型可以转移到不同的LLMs作为验证器。
- 分析了训练与推理在代理RAG中的扩展属性。
点此查看论文截图


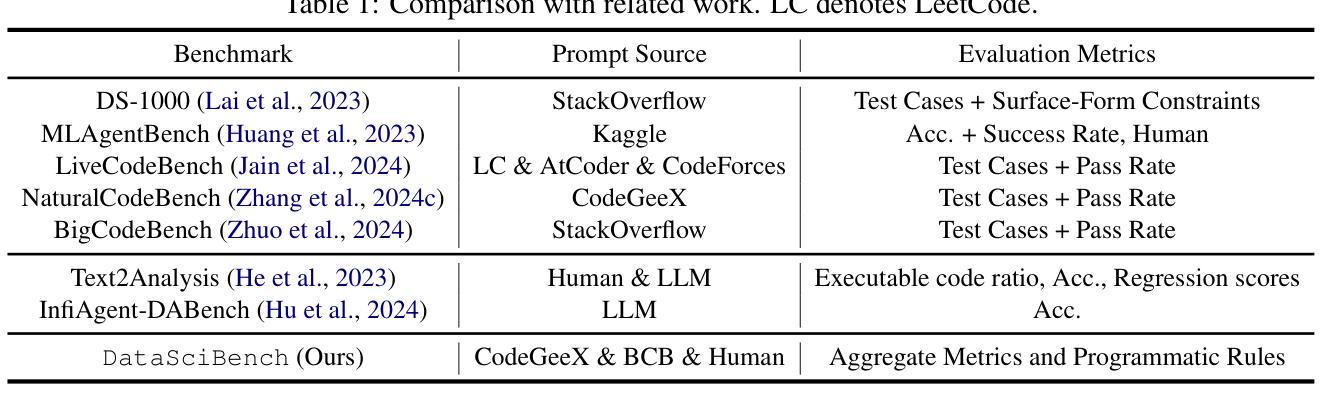
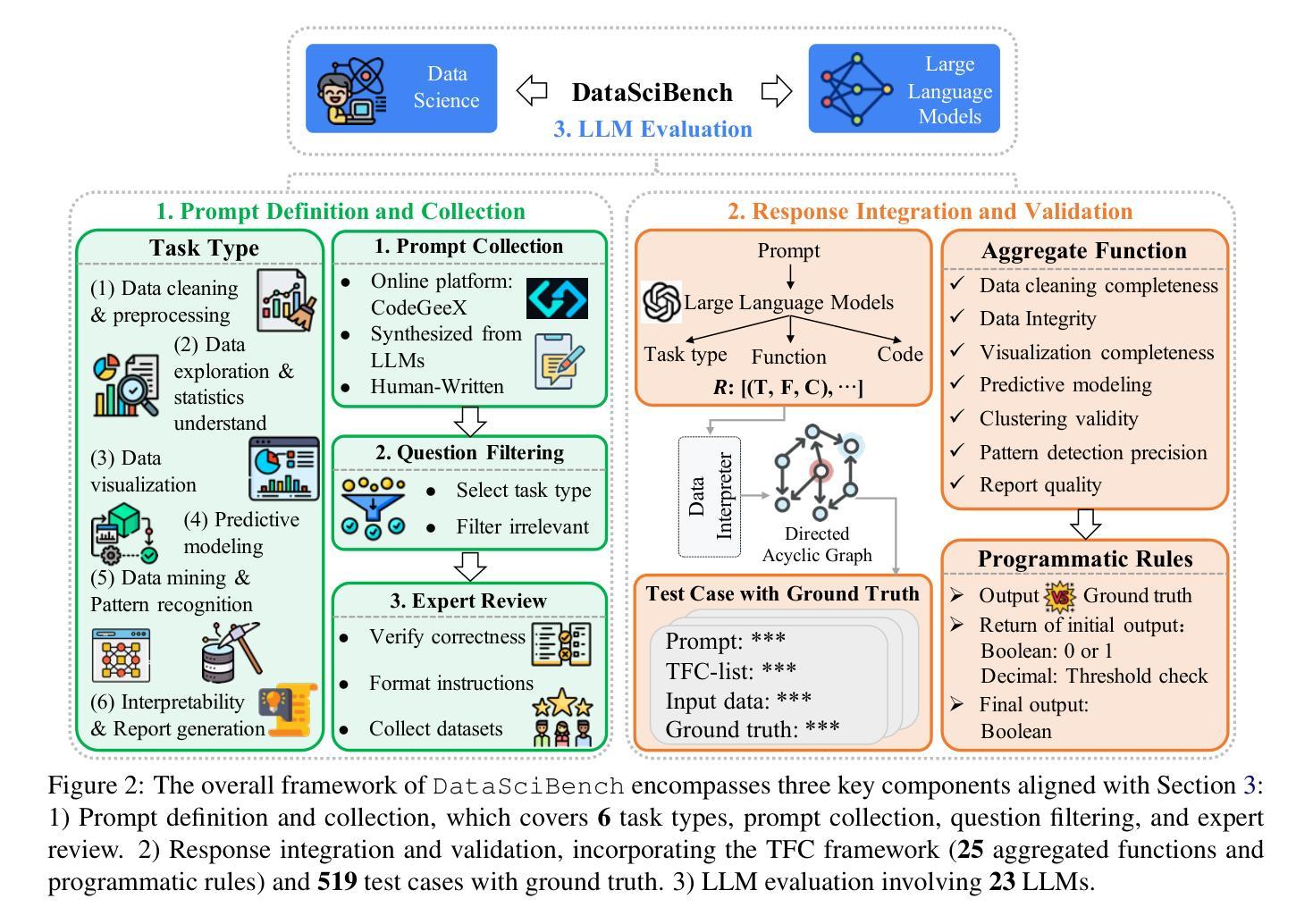
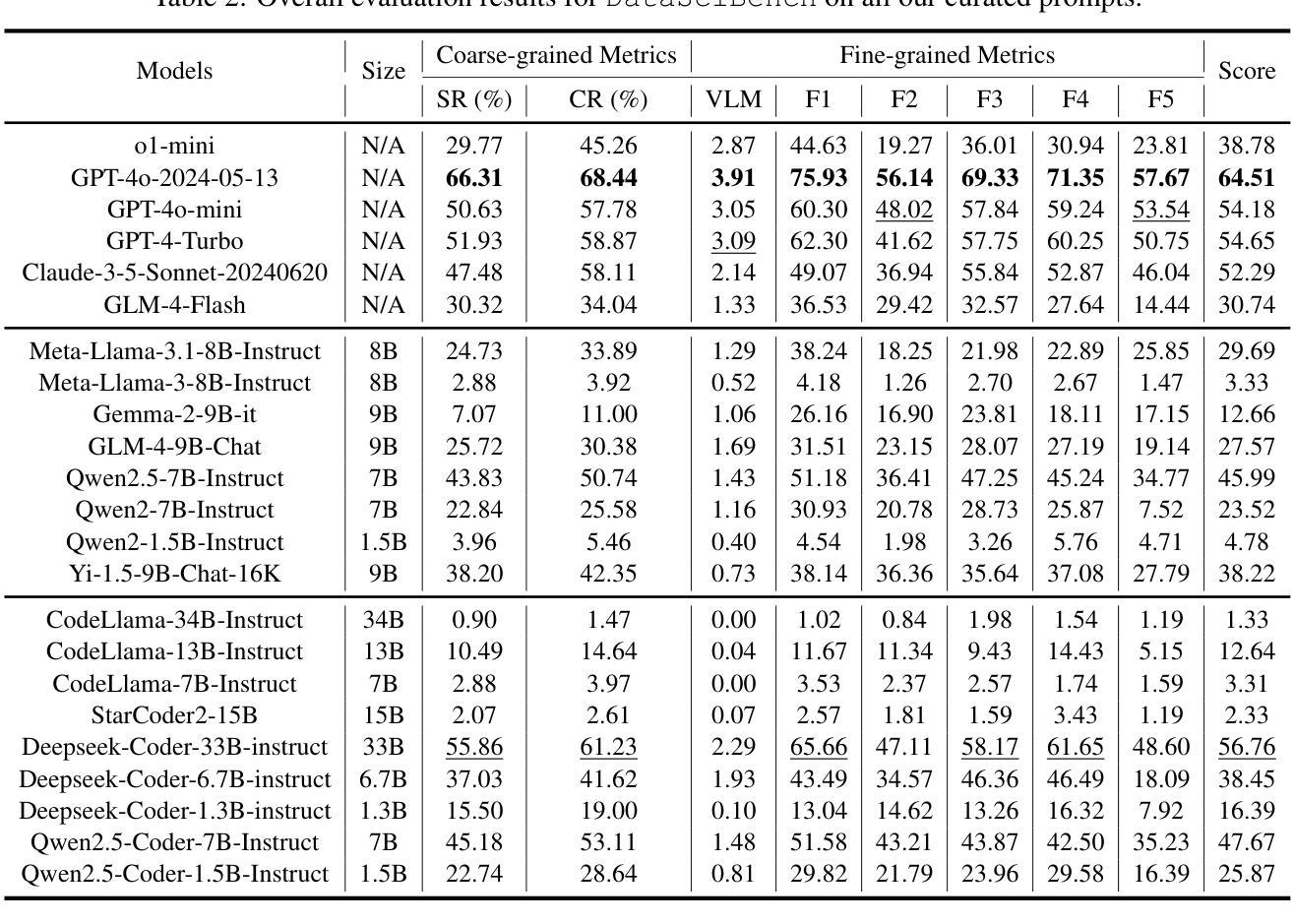
DataSciBench: An LLM Agent Benchmark for Data Science
Authors:Dan Zhang, Sining Zhoubian, Min Cai, Fengzu Li, Lekang Yang, Wei Wang, Tianjiao Dong, Ziniu Hu, Jie Tang, Yisong Yue
This paper presents DataSciBench, a comprehensive benchmark for evaluating Large Language Model (LLM) capabilities in data science. Recent related benchmarks have primarily focused on single tasks, easily obtainable ground truth, and straightforward evaluation metrics, which limits the scope of tasks that can be evaluated. In contrast, DataSciBench is constructed based on a more comprehensive and curated collection of natural and challenging prompts for uncertain ground truth and evaluation metrics. We develop a semi-automated pipeline for generating ground truth (GT) and validating evaluation metrics. This pipeline utilizes and implements an LLM-based self-consistency and human verification strategy to produce accurate GT by leveraging collected prompts, predefined task types, and aggregate functions (metrics). Furthermore, we propose an innovative Task - Function - Code (TFC) framework to assess each code execution outcome based on precisely defined metrics and programmatic rules. Our experimental framework involves testing 6 API-based models, 8 open-source general models, and 9 open-source code generation models using the diverse set of prompts we have gathered. This approach aims to provide a more comprehensive and rigorous evaluation of LLMs in data science, revealing their strengths and weaknesses. Experimental results demonstrate that API-based models outperform open-sourced models on all metrics and Deepseek-Coder-33B-Instruct achieves the highest score among open-sourced models. We release all code and data at https://github.com/THUDM/DataSciBench.
本文介绍了DataSciBench,这是一个用于评估数据科学中大型语言模型(LLM)能力的综合基准测试。最近的相关基准测试主要集中在单一任务、容易获得的真实标签和直接的评估指标上,这限制了可以评估的任务范围。相比之下,DataSciBench的构建基于更全面和精选的收集和具有不确定真实标签及评估指标的天然且具挑战性的提示。我们开发了一个半自动化管道,用于生成真实标签(GT)并验证评估指标。该管道利用并实现了一种基于LLM的自洽和人类验证策略,通过利用收集的提示、预定义的任务类型和聚合功能(指标)来产生准确的真实标签。此外,我们提出了创新的Task-Function-Code(TFC)框架,根据精确定义的指标和程序规则来评估每个代码执行结果。我们的实验框架包括使用我们收集的多样提示对6个API模型、8个开源通用模型和9个开源代码生成模型进行测试。该方法旨在提供数据科学中LLM的更全面和严格的评估,揭示其优点和缺点。实验结果表明,基于API的模型在所有指标上都优于开源模型,Deepseek-Coder-3 首次实现了最高得分。我们在https://github.com/THUDM/DataSciBench上发布了所有代码和数据。
论文及项目相关链接
PDF 40 pages, 7 figures, 6 tables
Summary
本文提出DataSciBench,这是一个用于评估大型语言模型(LLM)在数据科学方面的综合基准测试平台。与现有的主要关注单一任务、易于获取的真实数据和简单评估指标的基准测试不同,DataSciBench基于更全面、精心挑选的自然和挑战性提示构建,用于不确定的真实数据和评估指标。它开发了一个半自动管道来生成真实数据和验证评估指标,并利用LLM的自洽性和人工验证策略来产生准确结果。此外,还提出了创新的Task-Function-Code(TFC)框架,根据精确定义的指标和程序规则来评估代码执行结果。实验框架测试了多种模型,旨在更全面、严格地评估LLM在数据科学方面的能力。
Key Takeaways
- DataSciBench是一个用于评估大型语言模型在数据科学方面的综合基准测试平台。
- 与现有基准测试不同,DataSciBench关注更全面、具有挑战性的任务,处理不确定的真实数据和评估指标。
- 利用半自动管道生成真实数据并验证评估指标,通过LLM的自洽性和人工验证策略确保准确性。
- 提出了Task-Function-Code(TFC)框架,以精确评估模型在代码执行方面的表现。
- 实验框架测试了多种模型,包括API模型、开源通用模型和开源代码生成模型。
- API模型在各项指标上表现优于开源模型。
点此查看论文截图


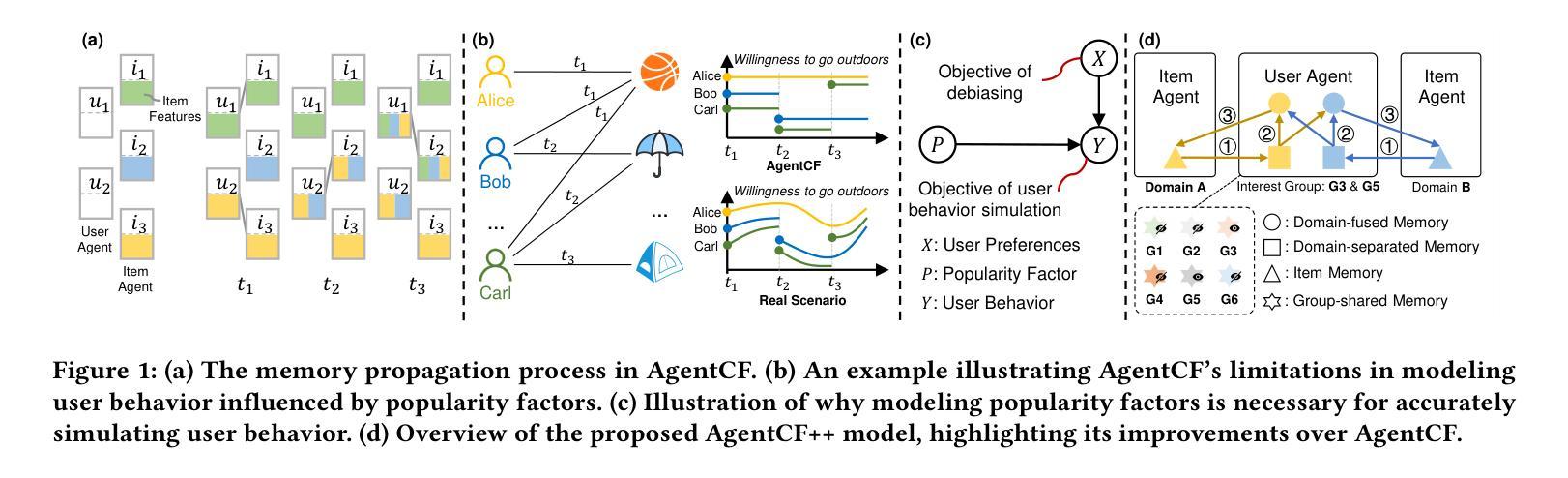
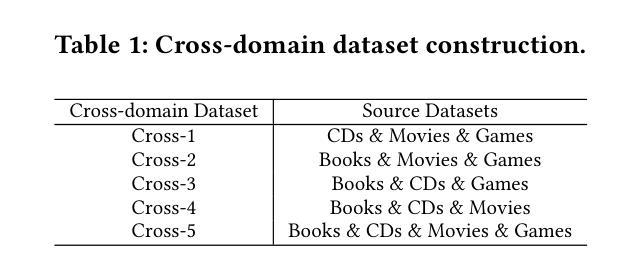
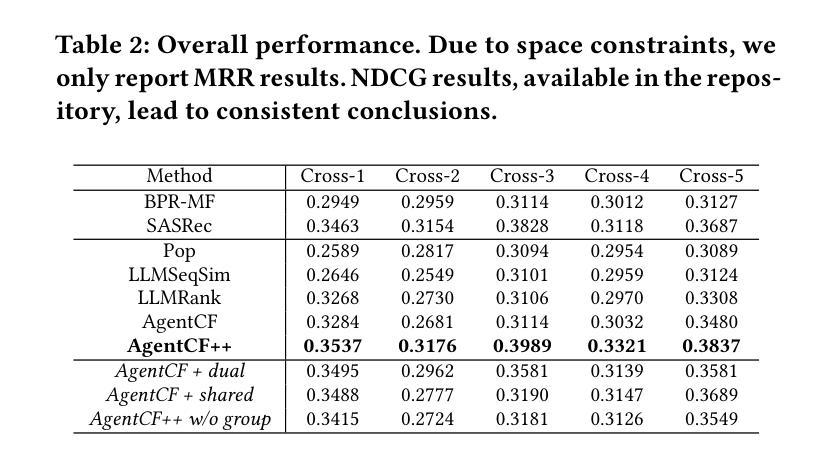
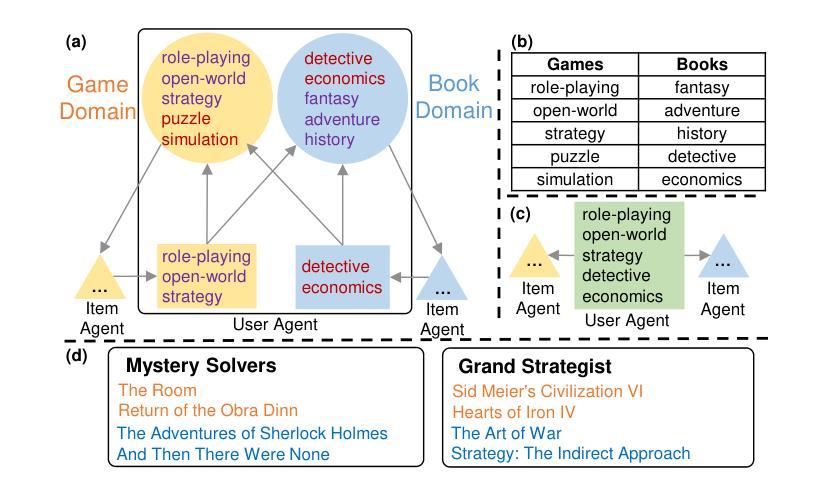
Enhancing Cross-Domain Recommendations with Memory-Optimized LLM-Based User Agents
Authors:Jiahao Liu, Shengkang Gu, Dongsheng Li, Guangping Zhang, Mingzhe Han, Hansu Gu, Peng Zhang, Tun Lu, Li Shang, Ning Gu
Large Language Model (LLM)-based user agents have emerged as a powerful tool for improving recommender systems by simulating user interactions. However, existing methods struggle with cross-domain scenarios due to inefficient memory structures, leading to irrelevant information retention and failure to account for social influence factors such as popularity. To address these limitations, we introduce AgentCF++, a novel framework featuring a dual-layer memory architecture and a two-step fusion mechanism to filter domain-specific preferences effectively. Additionally, we propose interest groups with shared memory, allowing the model to capture the impact of popularity trends on users with similar interests. Through extensive experiments on multiple cross-domain datasets, AgentCF++ demonstrates superior performance over baseline models, highlighting its effectiveness in refining user behavior simulation for recommender systems. Our code is available at https://anonymous.4open.science/r/AgentCF-plus.
基于大型语言模型(LLM)的用户代理通过模拟用户交互,已成为改进推荐系统的重要工具。然而,现有方法在处理跨域场景时,由于内存结构不够高效,存在保留无关信息和忽视社会影响因素(如知名度)的问题。为了克服这些局限性,我们推出了AgentCF++,这是一个新型框架,具有双层内存架构和两步融合机制,能有效过滤特定域偏好。此外,我们还提出了具有共享内存的兴趣小组,使模型能够捕捉流行趋势对具有相似兴趣用户的影响。在多个跨域数据集上进行的大量实验表明,AgentCF++在基准模型之上表现出卓越性能,凸显其在改进推荐系统用户行为模拟方面的有效性。我们的代码可在https://anonymous.4open.science/r/AgentCF-plus找到。
论文及项目相关链接
PDF 6 pages, under review
Summary
大型语言模型(LLM)用户代理通过模拟用户互动增强了推荐系统的能力。然而,现有方法在处理跨域场景时因内存结构不够高效而存在困难,可能保留无关信息和忽略社会影响因素,如人气。为解决这些问题,我们推出AgentCF++框架,采用双层内存架构和两步融合机制,有效过滤特定领域的偏好。同时,我们提出兴趣组共享内存,使模型能捕捉相似兴趣用户的人气趋势影响。通过多个跨域数据集的实验,AgentCF++在优化用户行为模拟的推荐系统中表现优越。
Key Takeaways
- LLM用户代理通过模拟用户互动提升推荐系统性能。
- 现有方法在处理跨域场景时存在挑战,如内存效率低和忽略社会影响因素。
- AgentCF++框架采用双层内存架构和两步融合机制,有效过滤特定领域偏好。
- AgentCF++通过兴趣组共享内存捕捉人气趋势对相似兴趣用户的影响。
- AgentCF++在多个跨域数据集上的实验表现优越。
- AgentCF++能优化用户行为模拟,提高推荐系统性能。
点此查看论文截图

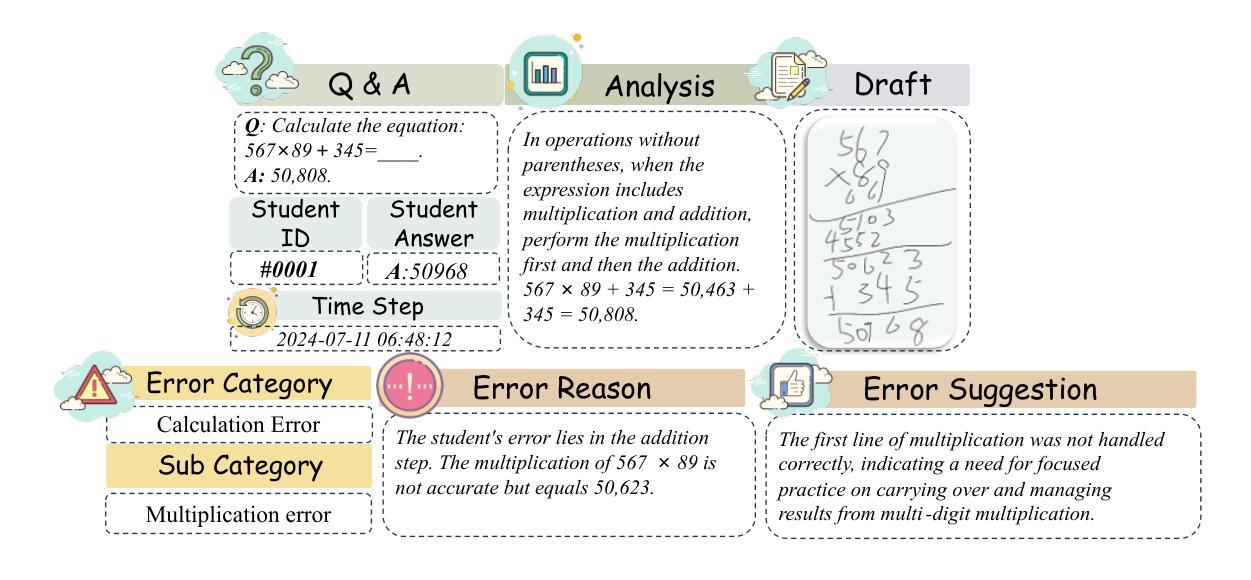
From Correctness to Comprehension: AI Agents for Personalized Error Diagnosis in Education
Authors:Yi-Fan Zhang, Hang Li, Dingjie Song, Lichao Sun, Tianlong Xu, Qingsong Wen
Large Language Models (LLMs), such as GPT-4, have demonstrated impressive mathematical reasoning capabilities, achieving near-perfect performance on benchmarks like GSM8K. However, their application in personalized education remains limited due to an overemphasis on correctness over error diagnosis and feedback generation. Current models fail to provide meaningful insights into the causes of student mistakes, limiting their utility in educational contexts. To address these challenges, we present three key contributions. First, we introduce \textbf{MathCCS} (Mathematical Classification and Constructive Suggestions), a multi-modal benchmark designed for systematic error analysis and tailored feedback. MathCCS includes real-world problems, expert-annotated error categories, and longitudinal student data. Evaluations of state-of-the-art models, including \textit{Qwen2-VL}, \textit{LLaVA-OV}, \textit{Claude-3.5-Sonnet} and \textit{GPT-4o}, reveal that none achieved classification accuracy above 30% or generated high-quality suggestions (average scores below 4/10), highlighting a significant gap from human-level performance. Second, we develop a sequential error analysis framework that leverages historical data to track trends and improve diagnostic precision. Finally, we propose a multi-agent collaborative framework that combines a Time Series Agent for historical analysis and an MLLM Agent for real-time refinement, enhancing error classification and feedback generation. Together, these contributions provide a robust platform for advancing personalized education, bridging the gap between current AI capabilities and the demands of real-world teaching.
大型语言模型(LLMs),如GPT-4,已在数学推理能力方面展现出令人印象深刻的性能,在GSM8K等基准测试中实现了近乎完美的表现。然而,它们在个性化教育中的应用仍然有限,原因在于它们过分强调正确性,而忽视了错误诊断和反馈生成。当前模型无法提供对学生错误原因的深刻见解,从而限制了它们在教育环境中的应用价值。为了应对这些挑战,我们提出了三个关键贡献。首先,我们推出MathCCS(数学分类与建设性建议),这是一个多模式基准测试,旨在进行系统性的错误分析并提供针对性反馈。MathCCS包含现实世界的问题、专家注释的错误类别和纵向学生数据。对最新模型的评估,包括Qwen2-VL、LLaVA-OV、Claude-3.5-Sonnet和GPT-4o的评估显示,它们的分类准确率均低于30%,生成高质量建议的能力也有限(平均分数低于4/10),这突显了与人类水平性能之间的巨大差距。其次,我们开发了一个顺序错误分析框架,该框架利用历史数据来跟踪趋势并提高诊断精度。最后,我们提出了一个多代理协作框架,该框架结合了用于历史分析的时间序列代理和用于实时精细调整的MLLM代理,增强了错误分类和反馈生成。总之,这些贡献为推进个性化教育提供了一个稳健的平台,缩小了当前AI能力与现实教学需求之间的差距。
论文及项目相关链接
Summary
大型语言模型(LLMs)如GPT-4在数学推理方面表现出色,但在个性化教育应用方面存在局限性,主要问题在于过于注重正确性,而忽视错误诊断和反馈生成。本文提出MathCCS基准测试、序贯误差分析框架和多代理协作框架等方法,旨在改善模型在错误分类和反馈生成方面的不足,为推进个性化教育提供稳健的平台。
Key Takeaways
- LLMs如GPT-4在数学推理方面表现出色,但在教育应用中存在局限性。
- 现有模型过于注重正确性,缺乏对学生错误的深入分析和反馈。
- MathCCS基准测试用于系统误差分析和针对性反馈,包含真实问题、专家标注的错误类别和学生纵向数据。
- 现有模型在MathCCS上的分类准确度低于30%,反馈质量不佳,与人工水平存在差距。
- 提出了序贯误差分析框架,利用历史数据跟踪趋势,提高诊断精度。
- 多代理协作框架结合时间序列代理和MLLM代理,实现实时优化和改进误差分类和反馈生成。
点此查看论文截图

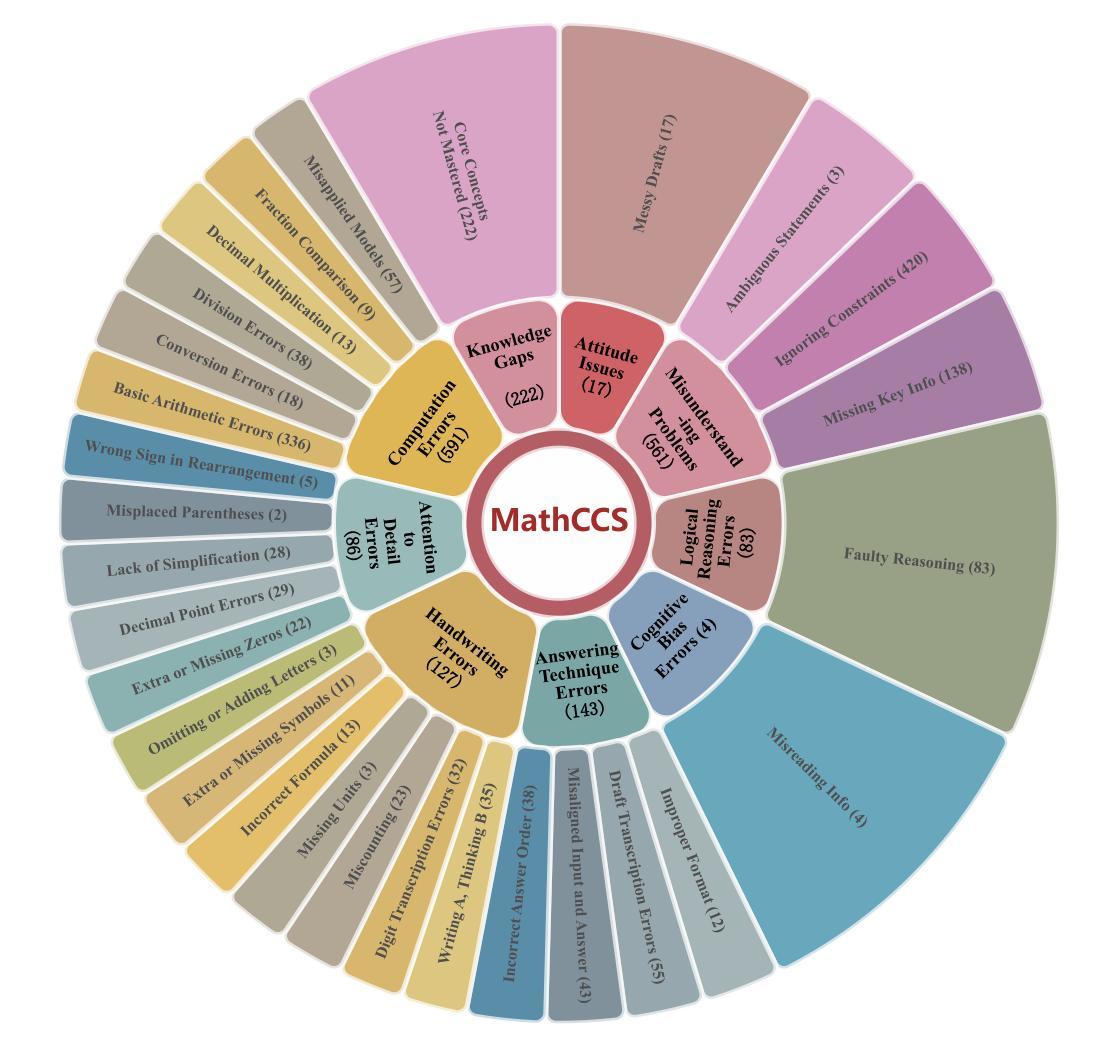
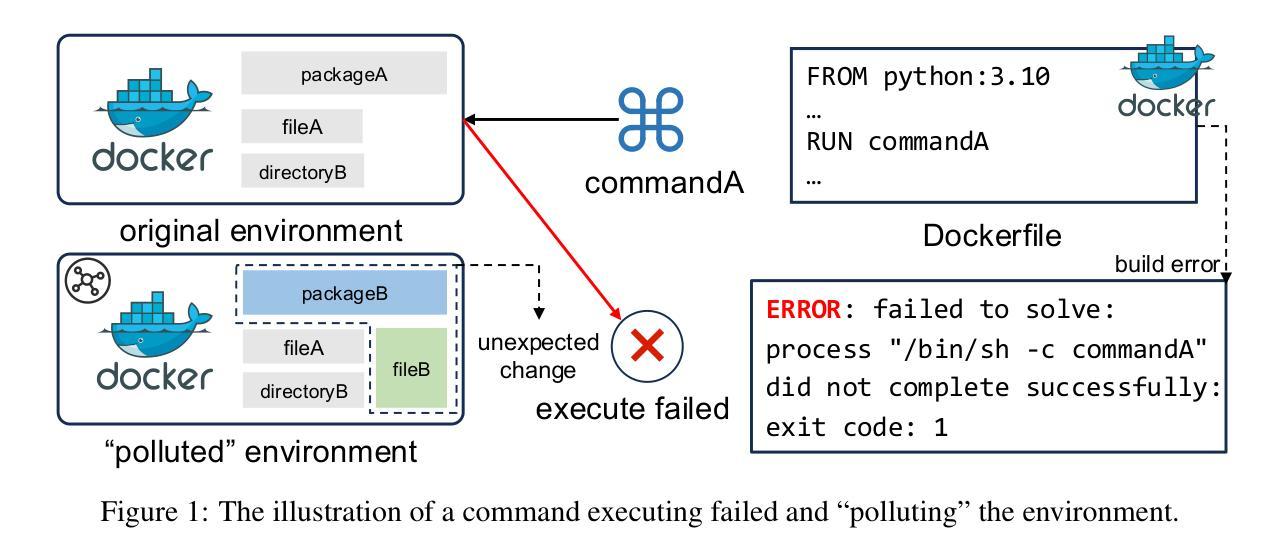
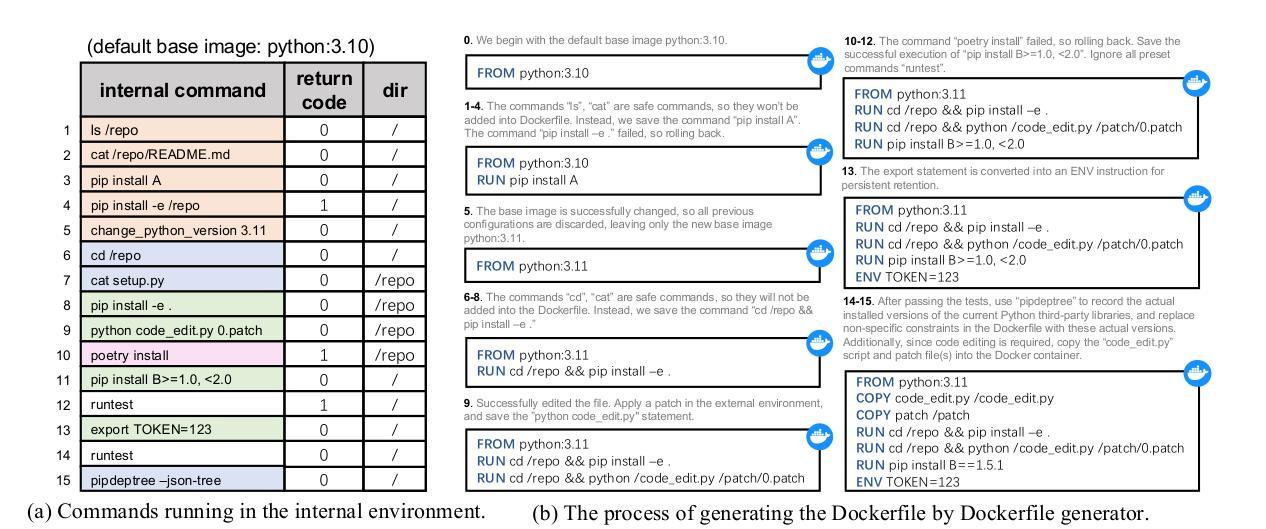
An LLM-based Agent for Reliable Docker Environment Configuration
Authors:Ruida Hu, Chao Peng, Xinchen Wang, Cuiyun Gao
Environment configuration is a critical yet time-consuming step in software development, especially when dealing with unfamiliar code repositories. While Large Language Models (LLMs) demonstrate the potential to accomplish software engineering tasks, existing methods for environment configuration often rely on manual efforts or fragile scripts, leading to inefficiencies and unreliable outcomes. We introduce Repo2Run, the first LLM-based agent designed to fully automate environment configuration and generate executable Dockerfiles for arbitrary Python repositories. We address two major challenges: (1) enabling the LLM agent to configure environments within isolated Docker containers, and (2) ensuring the successful configuration process is recorded and accurately transferred to a Dockerfile without error. To achieve this, we propose atomic configuration synthesis, featuring a dual-environment architecture (internal and external environment) with a rollback mechanism to prevent environment “pollution” from failed commands, guaranteeing atomic execution (execute fully or not at all) and a Dockerfile generator to transfer successful configuration steps into runnable Dockerfiles. We evaluate Repo2Run~on our proposed benchmark of 420 recent Python repositories with unit tests, where it achieves an 86.0% success rate, outperforming the best baseline by 63.9%.
环境配置是软件开发中的一个关键且耗时的步骤,特别是在处理不熟悉的代码仓库时。虽然大型语言模型(LLM)显示出完成软件工程任务的潜力,但现有的环境配置方法通常依赖于人工努力或易出错的脚本,导致效率低下和结果不可靠。我们引入了Repo2Run,这是基于LLM的第一个设计的代理,能够完全自动进行环境配置并为任意Python仓库生成可执行的Dockerfile。我们解决了两个主要挑战:(1)使LLM代理能够在隔离的Docker容器内配置环境;(2)确保成功的配置过程被记录并准确地转移到Dockerfile中而不出错。为了实现这一点,我们提出了原子配置合成,它采用双环境架构(内部环境和外部环境),带有回滚机制,以防止来自失败命令的环境“污染”,保证原子执行(完全执行或不执行),以及Dockerfile生成器,将成功的配置步骤转移到可运行的Dockerfile中。我们在由单位测试组成的420个最新Python仓库的基准测试上对Repo2Run进行了评估,其成功率为86.0%,比最佳基线高出63.9%。
论文及项目相关链接
Summary
该文本介绍了软件开发中环境配置的重要性及其耗时问题,特别是在处理不熟悉的代码仓库时。针对现有环境配置方法依赖手动操作或易出错的脚本导致的不效率和不稳定问题,提出Repo2Run——首个基于大型语言模型的自动化环境配置工具,为任意Python仓库生成可执行Dockerfile。主要解决了两大挑战:在隔离的Docker容器中配置环境,并确保成功配置过程被准确记录并转换为无错误的Dockerfile。采用原子配置合成技术,实现内部和外部环境的双重架构并配备回滚机制防止命令失败造成的环境“污染”,确保原子执行以及通过Dockerfile生成器将成功配置步骤转换为可运行的Dockerfile。在包含单元测试的420个最新Python仓库的基准测试中,Repo2Run成功率达到86%,优于最佳基线测试63.9%。
Key Takeaways
- 环境配置在软件开发中至关重要,但手动操作易出错且耗时。
- Repo2Run是首个基于大型语言模型的自动化环境配置工具,可以生成可执行Dockerfile。
- 主要解决两大挑战:在Docker容器中配置环境,并确保成功配置过程被记录并转化为Dockerfile。
- 采用原子配置合成技术,确保命令执行的原子性并防止环境“污染”。
- Repo2Run具备内部和外部环境的双重架构及回滚机制。
- 成功实现了在包含单元测试的Python仓库基准测试中的较高成功率。
点此查看论文截图



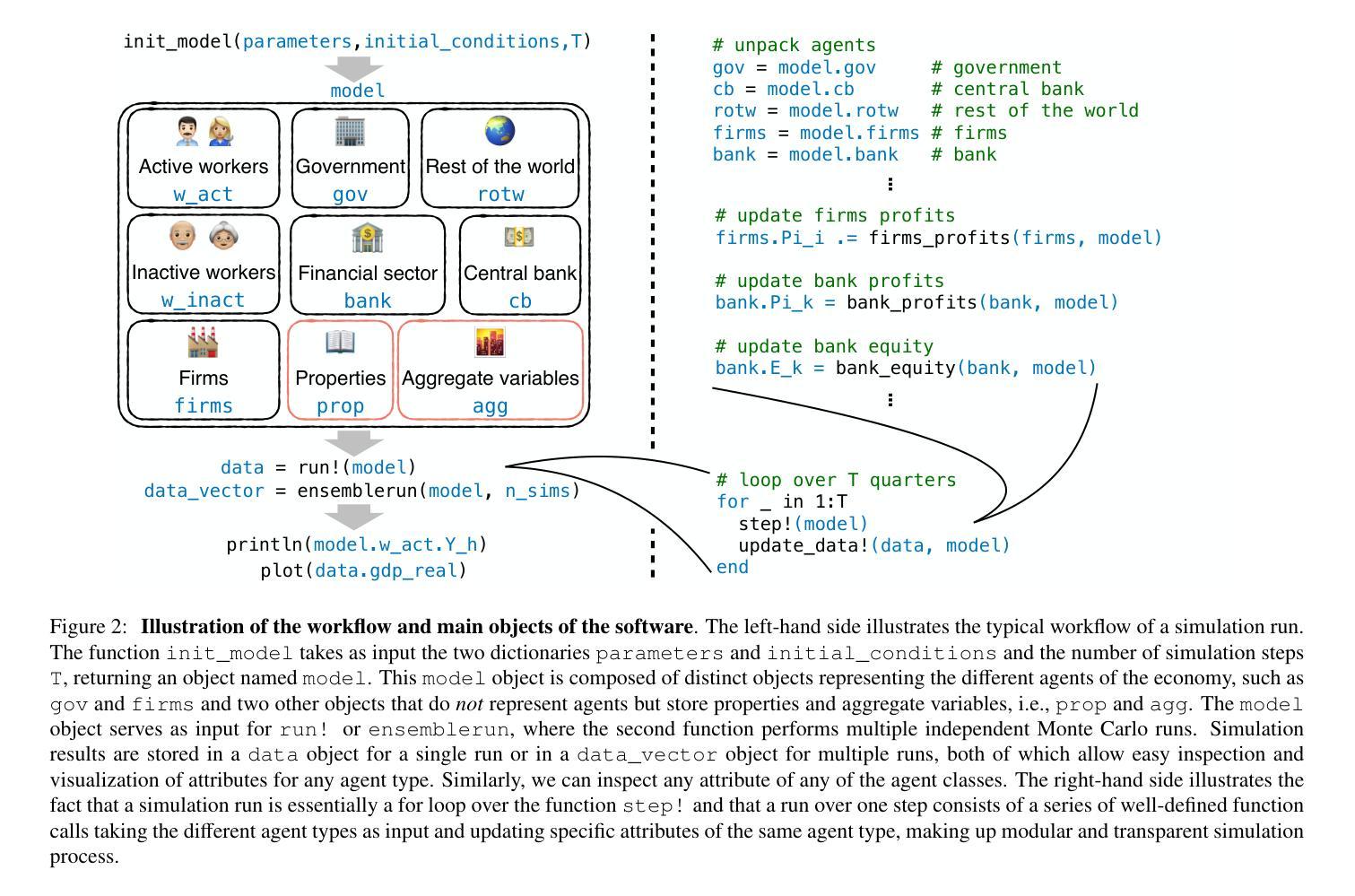
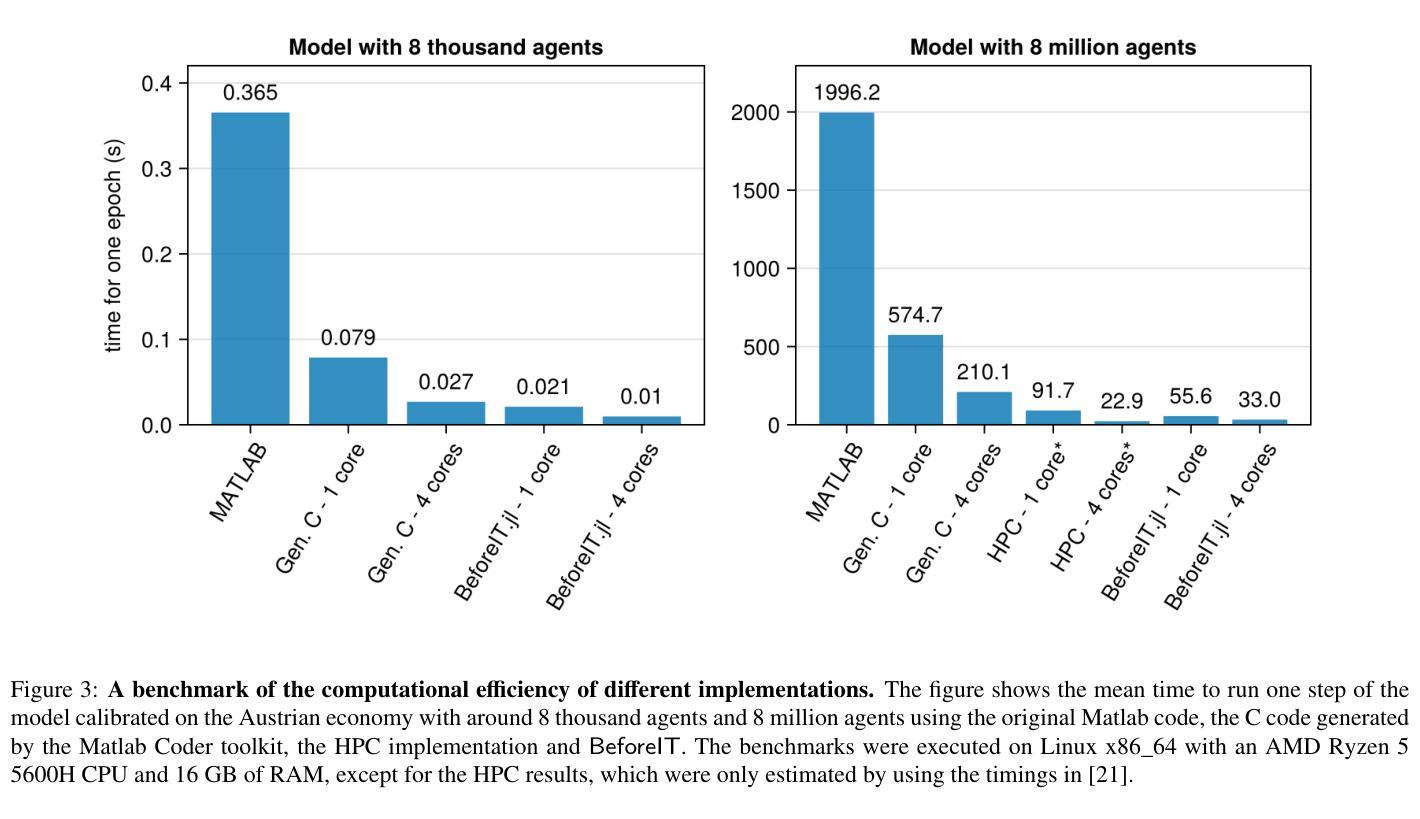
BeforeIT.jl: High-Performance Agent-Based Macroeconomics Made Easy
Authors:Aldo Glielmo, Mitja Devetak, Adriano Meligrana, Sebastian Poledna
BeforeIT is an open-source software for building and simulating state-of-the-art macroeconomic agent-based models (macro ABMs) based on the recently introduced macro ABM developed in [1] and here referred to as the base model. Written in Julia, it combines extraordinary computational efficiency with user-friendliness and extensibility. We present the main structure of the software, demonstrate its ease of use with illustrative examples, and benchmark its performance. Our benchmarks show that the base model built with BeforeIT is orders of magnitude faster than a Matlab version, and significantly faster than Matlab-generated C code. BeforeIT is designed to facilitate reproducibility, extensibility, and experimentation. As the first open-source, industry-grade software to build macro ABMs of the type of the base model, BeforeIT can significantly foster collaboration and innovation in the field of agent-based macroeconomic modelling. The package, along with its documentation, is freely available at https://github.com/bancaditalia/BeforeIT.jl under the AGPL-3.0.
BeforeIT是一款基于最新引入的宏观ABM(在[1]中开发)而构建的开源软件,用于构建和模拟最先进的宏观经济主体模型(宏观ABM)。该软件采用Julia语言编写,兼具出色的计算效率和用户友好性以及可扩展性。我们介绍了该软件的主要结构,通过示例展示了其易用性,并对其性能进行了基准测试。我们的基准测试表明,使用BeforeIT构建的基准模型比Matlab版本快几个数量级,并且比Matlab生成的C代码快得多。BeforeIT旨在促进可重复性、可扩展性和实验性。作为第一个用于构建基准模型类型的宏观ABM的开源、工业级软件,BeforeIT可以极大地促进基于主体的宏观经济建模领域的协作和创新。该软件包及其文档均可在https://github.com/bancaditalia/BeforeIT.jl上免费获得,遵循AGPL-3.0协议。
论文及项目相关链接
PDF 9 pages, 5 figures
Summary
开源软件BeforeIT主要用于构建和模拟基于最新宏观经济主体模型的宏观经济主体模型(宏观ABM)。该软件采用Julia语言编写,兼具计算效率和用户友好性,易于扩展。本文主要介绍了该软件的主要结构,通过示例演示了其易用性,并对其性能进行了基准测试。基准测试表明,使用BeforeIT构建的基准模型比Matlab版本快几个数量级,并且比Matlab生成的C代码更快。BeforeIT旨在促进再现性、可扩展性和实验性。作为第一个用于构建此类基准模型的开源、工业级软件,BeforeIT可以极大地促进基于主体的宏观经济建模领域的协作和创新。
Key Takeaways
- BeforeIT是一个用于构建和模拟宏观经济主体模型的开源软件。
- 它采用Julia语言编写,具有计算效率和用户友好性。
- 软件的主要结构得到了介绍,并通过示例展示了其易用性。
- 基准测试表明,使用BeforeIT构建的模型在计算性能上优于Matlab版本和Matlab生成的C代码。
- BeforeIT促进了宏观经济建模的再现性、可扩展性和实验性。
- 它是第一个用于构建特定类型宏观ABM的开源、工业级软件。
点此查看论文截图

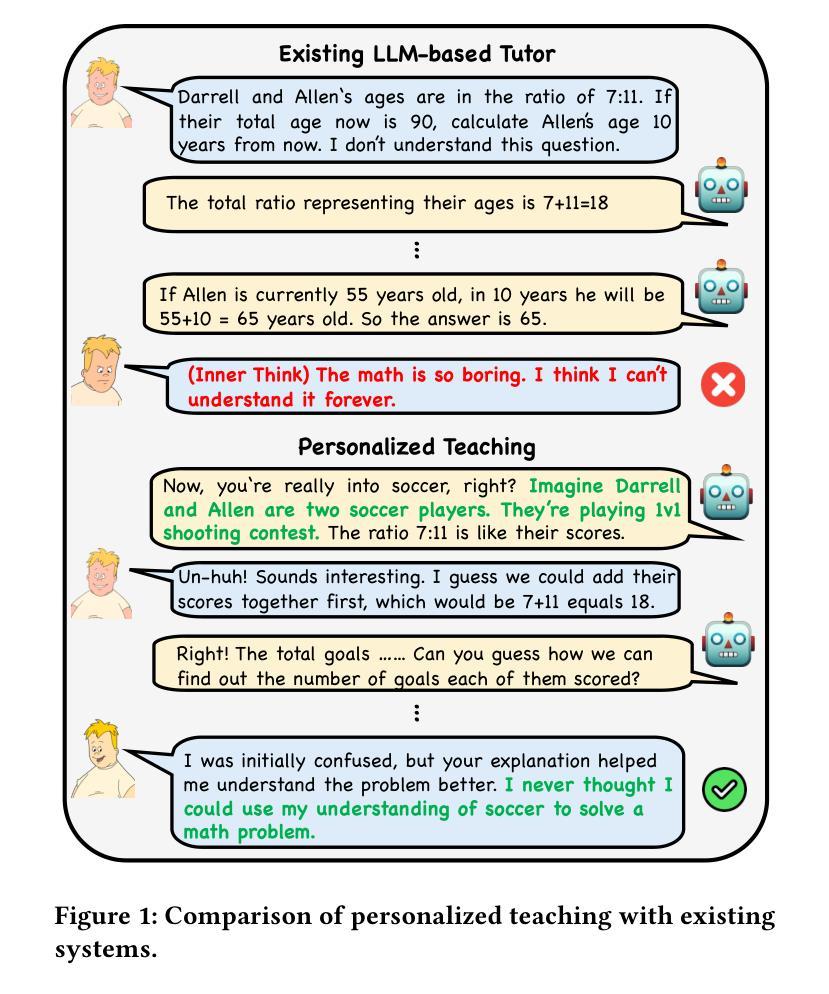
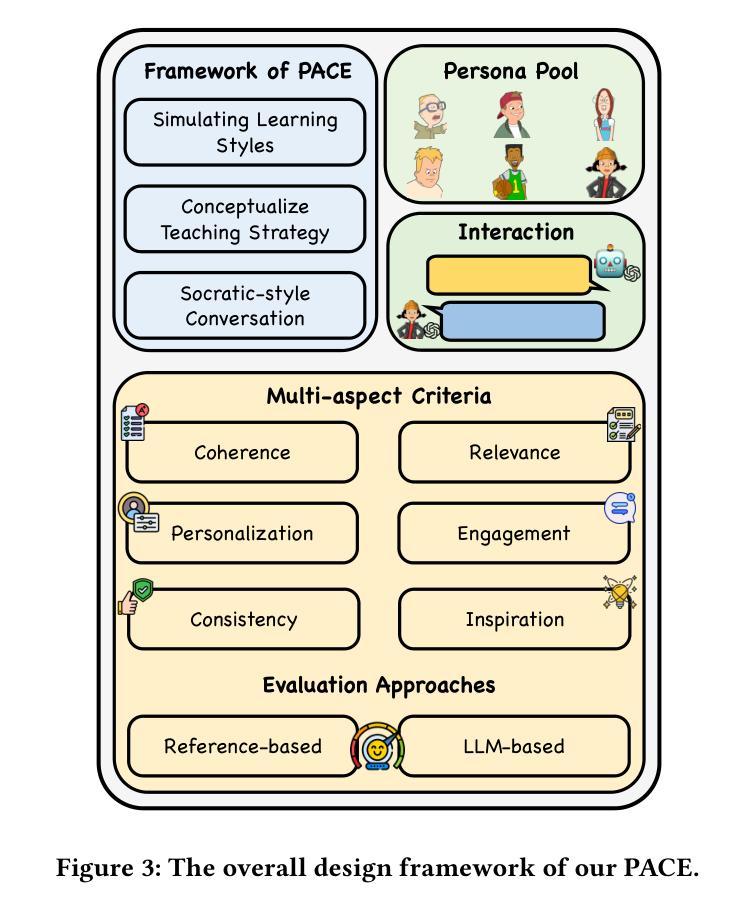
One Size doesn’t Fit All: A Personalized Conversational Tutoring Agent for Mathematics Instruction
Authors:Ben Liu, Jihan Zhang, Fangquan Lin, Xu Jia, Min Peng
Large language models (LLMs) have been increasingly employed in various intelligent educational systems, simulating human tutors to facilitate effective human-machine interaction. However, previous studies often overlook the significance of recognizing and adapting to individual learner characteristics. Such adaptation is crucial for enhancing student engagement and learning efficiency, particularly in mathematics instruction, where diverse learning styles require personalized strategies to promote comprehension and enthusiasm. In this paper, we propose a \textbf{P}erson\textbf{A}lized \textbf{C}onversational tutoring ag\textbf{E}nt (PACE) for mathematics instruction. PACE simulates students’ learning styles based on the Felder and Silverman learning style model, aligning with each student’s persona. In this way, our PACE can effectively assess the personality of students, allowing to develop individualized teaching strategies that resonate with their unique learning styles. To further enhance students’ comprehension, PACE employs the Socratic teaching method to provide instant feedback and encourage deep thinking. By constructing personalized teaching data and training models, PACE demonstrates the ability to identify and adapt to the unique needs of each student, significantly improving the overall learning experience and outcomes. Moreover, we establish multi-aspect evaluation criteria and conduct extensive analysis to assess the performance of personalized teaching. Experimental results demonstrate the superiority of our model in personalizing the educational experience and motivating students compared to existing methods.
大型语言模型(LLM)在各种智能教育系统中得到了越来越广泛的应用,模拟人类导师,促进有效的人机交互。然而,之前的研究往往忽视了识别和适应个别学习者特性的重要性。这种适应对于提高学生参与度和学习效率至关重要,特别是在数学教学上,多样的学习方式需要个性化策略来促进理解和热情。在本文中,我们提出了一种用于数学教学的个性化对话辅导实体(PACE)。PACE基于Felder和Silverman的学习风格模型模拟学生的学习风格,与每个学生的个性相匹配。通过这种方式,我们的PACE可以有效地评估学生的个性,从而制定与他们独特的学习风格相符的个性化教学策略。为了进一步增强学生的理解,PACE采用苏格拉底教学法,提供即时反馈,鼓励深入思考。通过构建个性化的教学数据和训练模型,PACE展示了识别和适应每个学生独特需求的能力,显著提高了整体学习体验和效果。此外,我们建立了多方面的评价标准,并进行了广泛的分析,以评估个性化教学的表现。实验结果表明,与现有方法相比,我们的模型在个性化教育体验和激励学生方面具有优势。
论文及项目相关链接
Summary
基于大型语言模型(LLM)的教育系统模拟人类导师以实现人机互动,但以往研究常常忽略识别和适应个别学习者特性之重要性。尤其在数学教学上,多样化的学习方式需要个性化策略以促进理解和热情。本文提出个性化对话辅导实体(PACE)以模拟学生基于Felder和Silverman学习风格模型的学习风格,并据此评估学生个性,发展符合其独特学习风格的个性化教学策略。同时采用苏格拉底教学法提供即时反馈和鼓励深入思考,并建立多方面评估标准评估个性化教学效果。实验证明相比现有方法,PACE在教育个性化及激励学生方面具有优越性。
Key Takeaways
- 大型语言模型(LLM)在教育系统中模拟人类导师,促进人机互动。
- 识别并适应个别学习者特性对于提高学习效果至关重要。
- 数学教学需要个性化策略以应对多样化的学习方式。
- PACE模拟学生基于Felder和Silverman学习风格模型的学习风格,并根据此提供个性化教学策略。
- PACE利用苏格拉底教学法提高学生对知识的深入理解,并提供即时反馈。
- PACE建立个性化教学数据模型和训练模型以识别和适应每个学生的独特需求。
点此查看论文截图



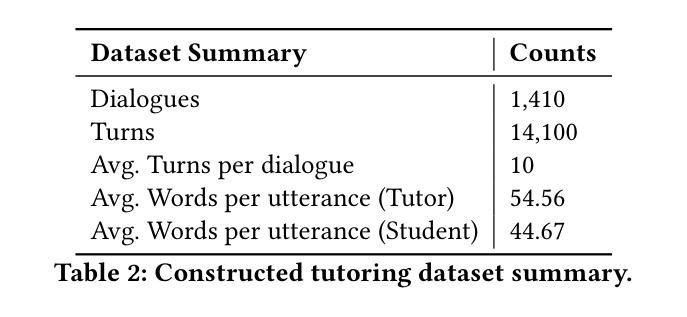
Explorer: Scaling Exploration-driven Web Trajectory Synthesis for Multimodal Web Agents
Authors:Vardaan Pahuja, Yadong Lu, Corby Rosset, Boyu Gou, Arindam Mitra, Spencer Whitehead, Yu Su, Ahmed Awadallah
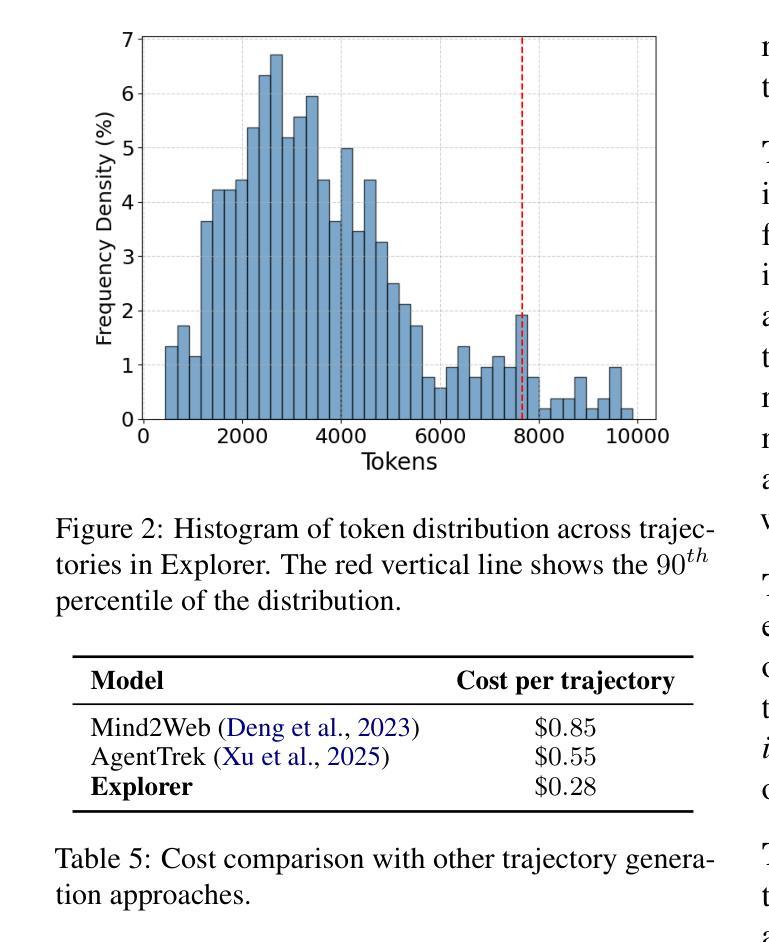
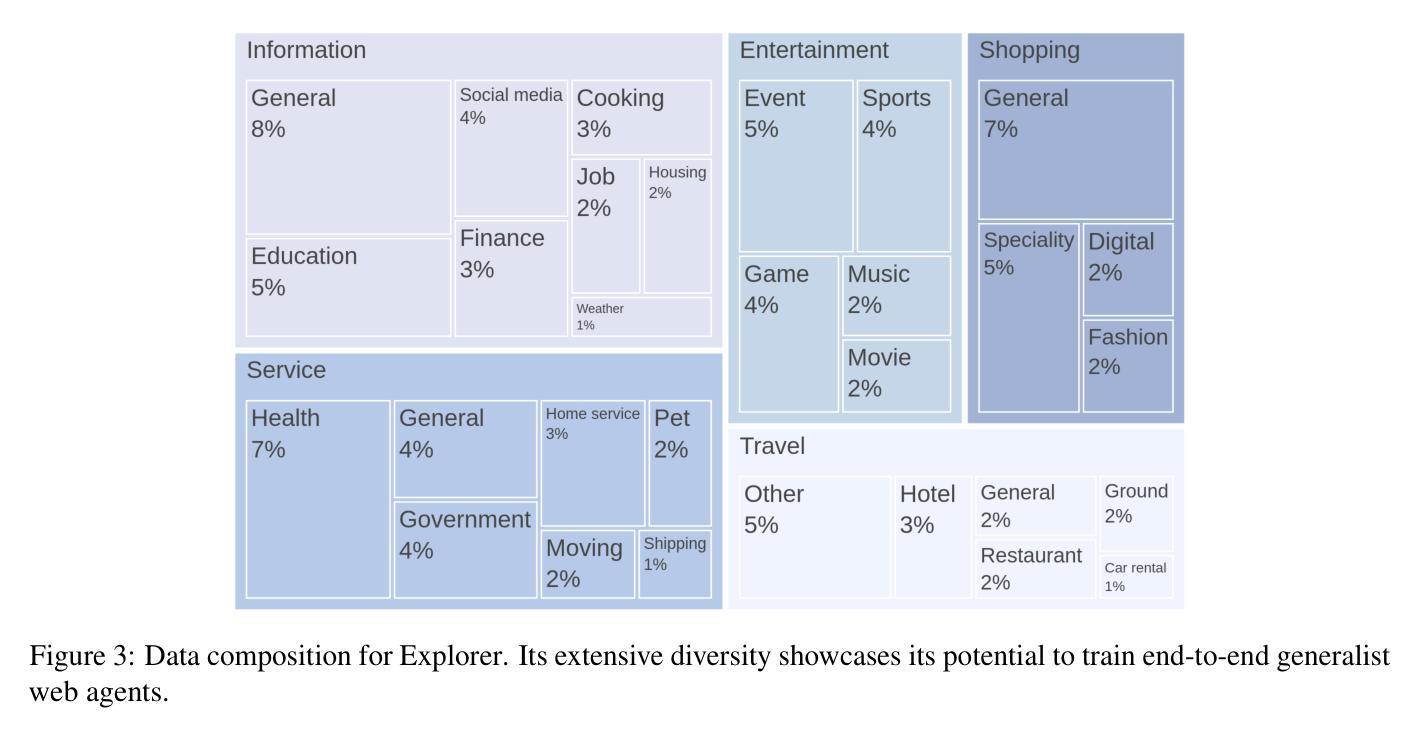
Recent success in large multimodal models (LMMs) has sparked promising applications of agents capable of autonomously completing complex web tasks. While open-source LMM agents have made significant advances in offline evaluation benchmarks, their performance still falls substantially short of human-level capabilities in more realistic online settings. A key bottleneck is the lack of diverse and large-scale trajectory-level datasets across various domains, which are expensive to collect. In this paper, we address this challenge by developing a scalable recipe to synthesize the largest and most diverse trajectory-level dataset to date, containing over 94K successful multimodal web trajectories, spanning 49K unique URLs, 720K screenshots, and 33M web elements. In particular, we leverage extensive web exploration and refinement to obtain diverse task intents. The average cost is 28 cents per successful trajectory, making it affordable to a wide range of users in the community. Leveraging this dataset, we train Explorer, a multimodal web agent, and demonstrate strong performance on both offline and online web agent benchmarks such as Mind2Web-Live, Multimodal-Mind2Web, and MiniWob++. Additionally, our experiments highlight data scaling as a key driver for improving web agent capabilities. We hope this study makes state-of-the-art LMM-based agent research at a larger scale more accessible.
近期大型多模态模型(LMM)的成功激发了自主完成复杂网络任务的智能代理应用的前景。虽然开源LMM代理在离线评估基准测试中取得了重大进展,但在更现实的在线环境中,它们的性能仍然远远落后于人类水平的能力。一个关键的瓶颈是缺乏跨多个领域的多样且大规模轨迹级数据集,而这些数据的收集成本高昂。本文旨在通过开发一种可扩展的配方来解决这一挑战,合成迄今为止最大且最多元轨迹级数据集,包含超过94,000条成功的多模态网络轨迹、跨越49,000个唯一URL、72万个截图和33百万个网络元素。我们尤其通过广泛的网络探索和精细化来获得多样的任务意图。每条成功轨迹的平均成本为28美分,使得社区中的广大用户都能负担得起。利用此数据集,我们训练了Explorer这款多模态网络代理,并在离线以及在线网络代理基准测试(如Mind2Web-Live、Multimodal-Mind2Web和MiniWob++)中表现出强劲性能。此外,我们的实验强调数据规模化是提升网络代理能力的主要驱动力。我们希望这项研究能使更大规模的最先进LMM代理研究更加易行。
论文及项目相关链接
PDF 24 pages, 7 figures
Summary
大型多模态模型(LMM)的最新成功激发了自主完成复杂网络任务的智能代理的应用前景。尽管开源LMM代理在离线评估基准测试中取得了重大进展,但在更现实的在线环境中,其性能仍然远远落后于人类水平。本文解决这一挑战的策略是开发了一种可扩展的配方,合成迄今为止最大且最多元化的轨迹级数据集,包含超过9.4万条成功的多模态网络轨迹,跨越4.9万个唯一URL、72万个截图和330万个网络元素。我们利用广泛的网络探索和精炼来获得多样化的任务意图。平均每条成功轨迹的成本为28美分,使其成为社区中广大用户所能负担得起的。利用该数据集训练的Explorer多媒体网络代理在离线网络和在线网络代理基准测试(如Mind2Web-Live、Multimodal-Mind2Web和MiniWob++)中表现出色。此外,我们的实验突显了数据规模扩大是推动网络代理能力提升的关键驱动力。我们希望这项研究使得更大规模的基于LMM的代理研究更加易于获取。
Key Takeaways
- 大型多模态模型(LMM)在自主完成复杂网络任务方面具有应用前景。
- 开源LMM代理在离线评估中表现良好,但在在线环境中性能仍待提升。
- 缺乏多样化的大规模轨迹级数据集是限制性能的主要原因之一。
- 本文开发了一种可扩展的方法,合成迄今为止最大且最具多样性的轨迹级数据集。
- 利用该数据集训练的多媒体网络代理在多个基准测试中表现出色。
- 数据规模扩大是提高网络代理性能的关键驱动力。
点此查看论文截图

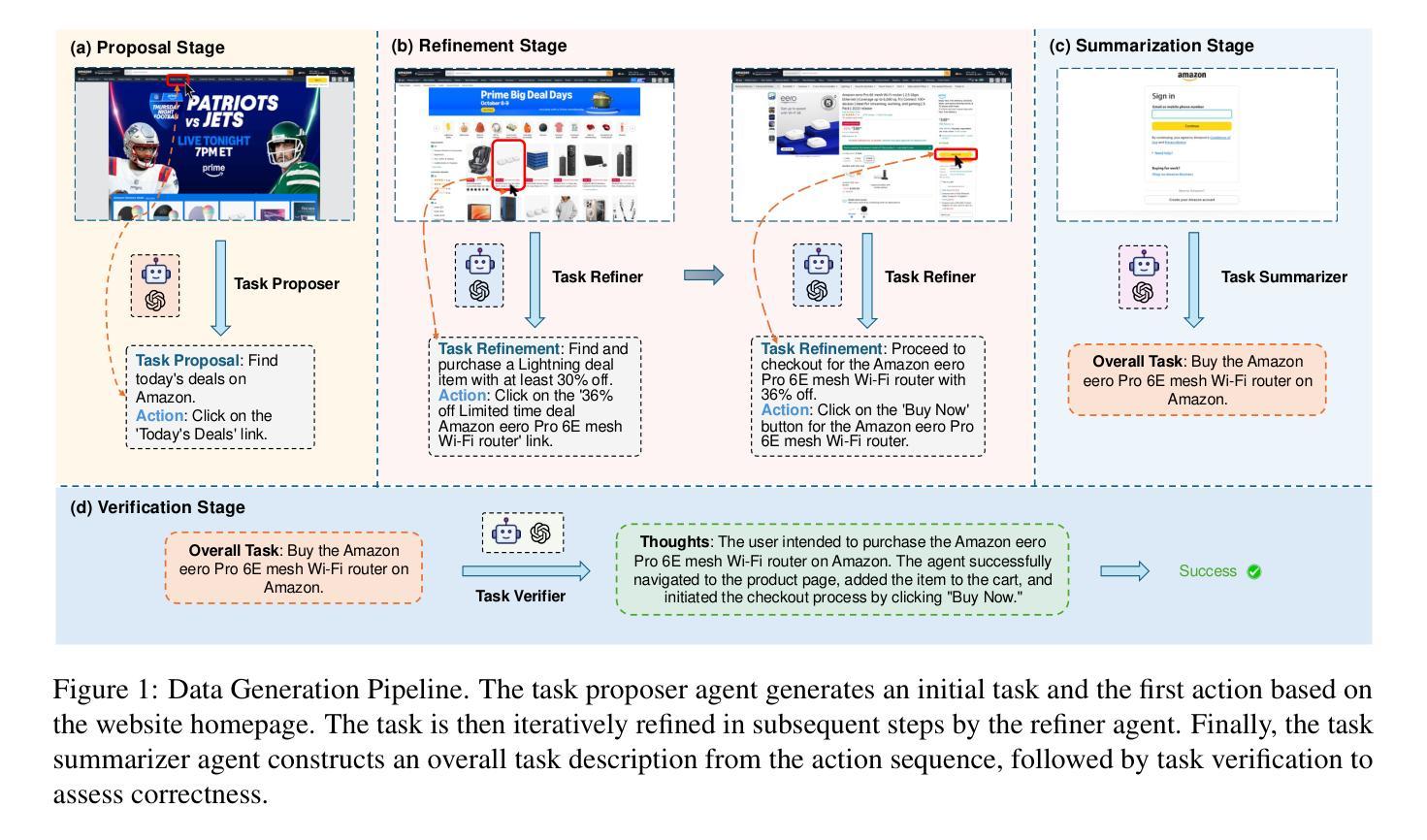
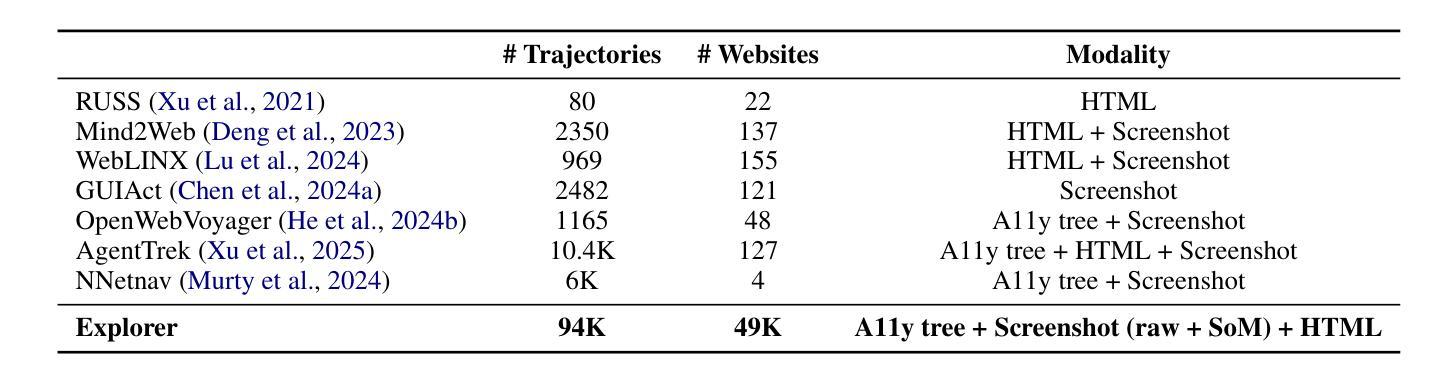

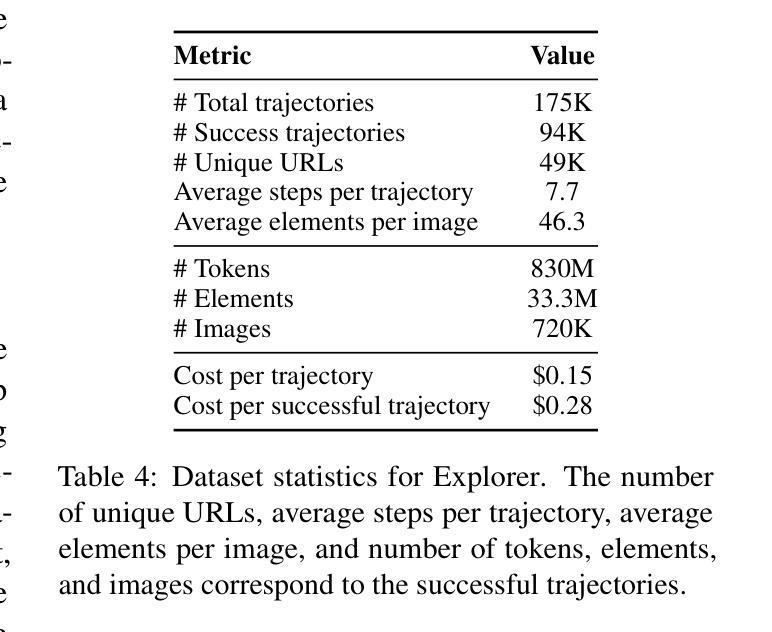

ML-Dev-Bench: Comparative Analysis of AI Agents on ML development workflows
Authors:Harshith Padigela, Chintan Shah, Dinkar Juyal
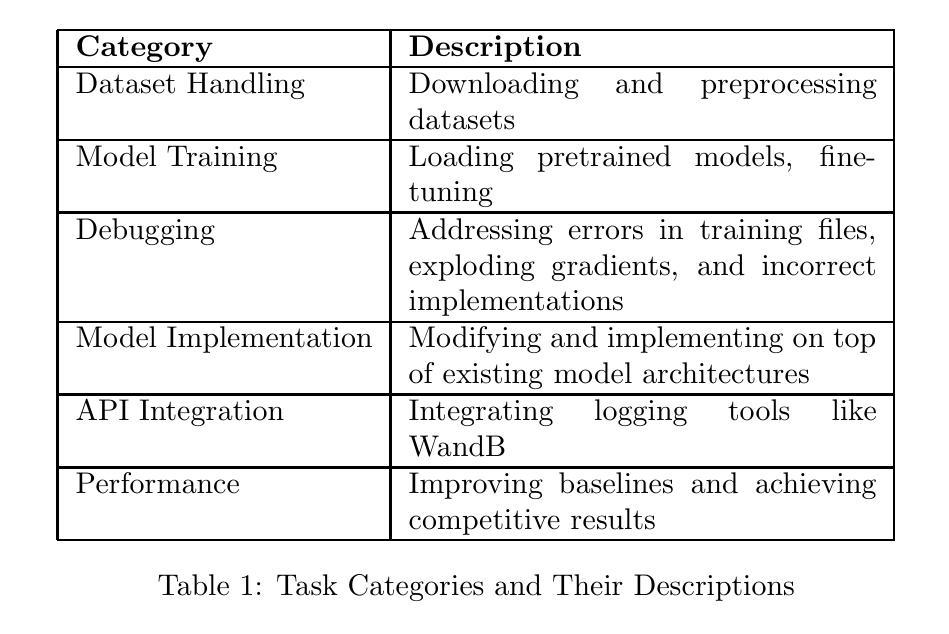
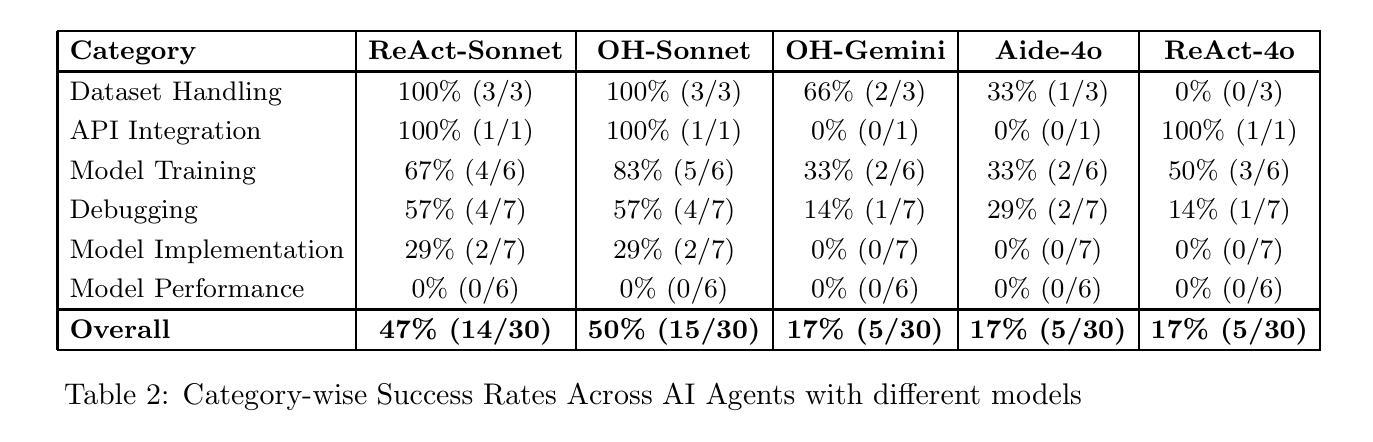
In this report, we present ML-Dev-Bench, a benchmark aimed at testing agentic capabilities on applied Machine Learning development tasks. While existing benchmarks focus on isolated coding tasks or Kaggle-style competitions, ML-Dev-Bench tests agents’ ability to handle the full complexity of ML development workflows. The benchmark assesses performance across critical aspects including dataset handling, model training, improving existing models, debugging, and API integration with popular ML tools. We evaluate three agents - ReAct, Openhands, and AIDE - on a diverse set of 30 tasks, providing insights into their strengths and limitations in handling practical ML development challenges. We open source the benchmark for the benefit of the community at \href{https://github.com/ml-dev-bench/ml-dev-bench}{https://github.com/ml-dev-bench/ml-dev-bench}.
在这份报告中,我们介绍了ML-Dev-Bench,这是一个旨在测试机器学习开发任务中的智能体能力的基准测试。虽然现有的基准测试侧重于孤立的编码任务或Kaggle式比赛,但ML-Dev-Bench测试智能体处理机器学习开发工作流程全貌的能力。该基准测试评估了数据集处理、模型训练、改进现有模型、调试以及与流行机器学习工具进行API整合等方面的性能。我们在30个多样化的任务上评估了ReAct、Openhands和AIDE这三种智能体的性能,深入了解它们在应对实际机器学习开发挑战中的优势和局限性。为了社区的利益,我们在https://github.com/ml-dev-bench/ml-dev-bench上公开了此基准测试。
论文及项目相关链接
Summary
ML-Dev-Bench是一个针对机器学习开发任务的代理能力测试的新基准测试。与现有的侧重于单独编码任务或Kaggle风格竞赛的基准测试不同,ML-Dev-Bench测试代理处理机器学习开发工作流程全貌的能力。基准测试评估了在数据集处理、模型训练、改进现有模型、调试以及与流行机器学习工具进行API集成等方面的性能。我们在多样化的30个任务上评估了ReAct、Openhands和AIDE这三个代理,深入了解它们在应对实际机器学习开发挑战方面的优势和局限性。我们开源基准测试供社区使用。
Key Takeaways
- ML-Dev-Bench是一个新的基准测试,旨在评估代理在机器学习开发任务上的表现。
- 与其他基准测试不同,ML-Dev-Bench关注代理处理整个机器学习开发流程的能力。
- 基准测试包括数据集处理、模型训练、改进现有模型、调试和API集成等方面。
- 对三个代理ReAct、Openhands和AIDE进行了评估,在多样化的任务中展示了它们的优势和局限性。
- ML-Dev-Bench提供了对实际机器学习开发挑战的全面视角。
- 基准测试已在GitHub上开源,供社区使用。
点此查看论文截图

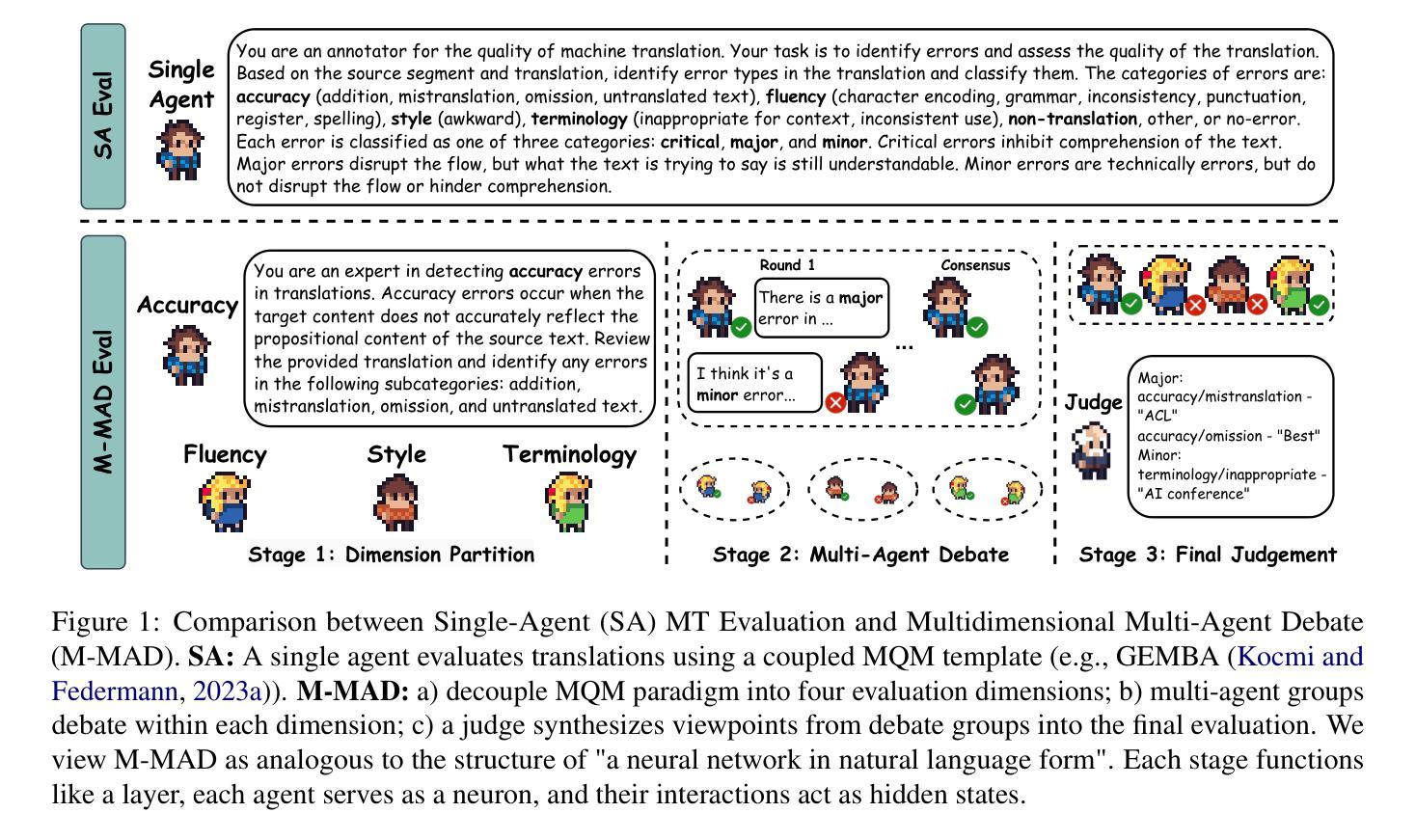
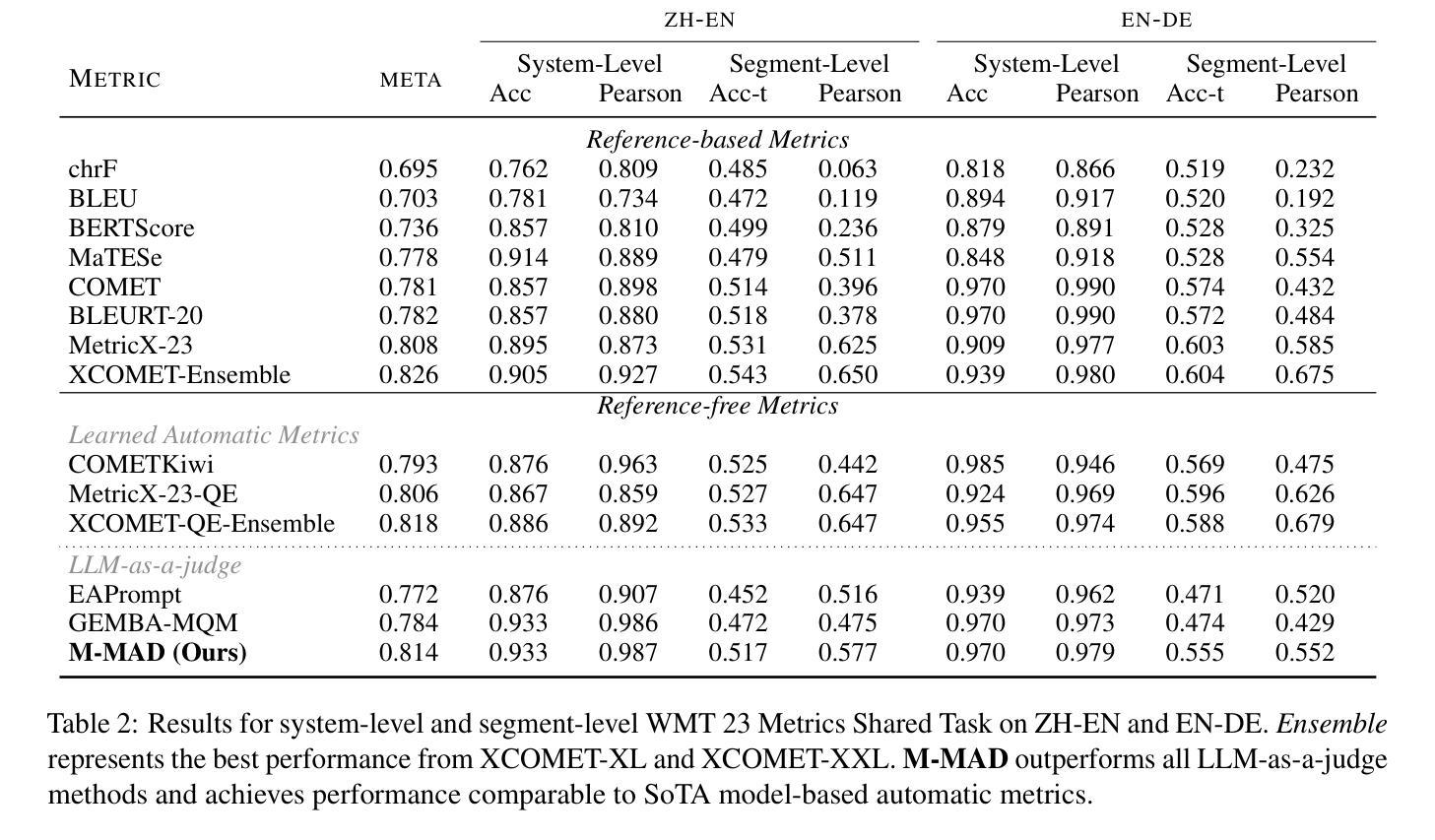
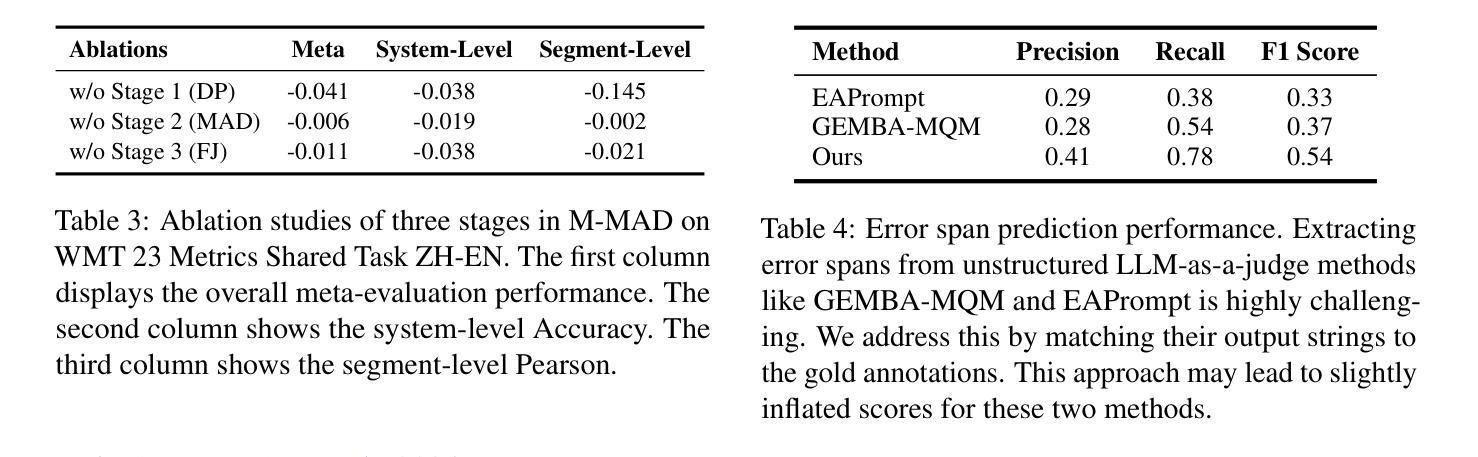
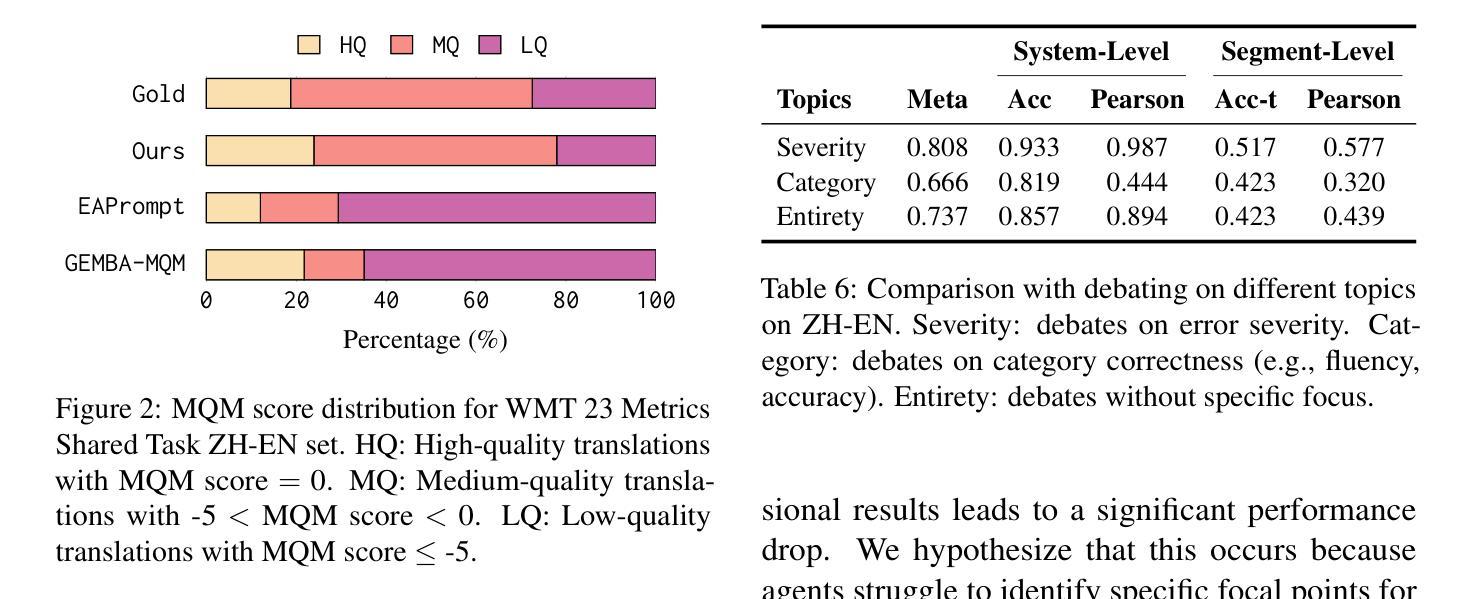
M-MAD: Multidimensional Multi-Agent Debate for Advanced Machine Translation Evaluation
Authors:Jiayuan Su, Zhaopeng Feng, Jiamei Zheng, Jiahan Ren, Yan Zhang, Jian Wu, Hongwei Wang, Zuozhu Liu
Recent advancements in large language models (LLMs) have given rise to the LLM-as-a-judge paradigm, showcasing their potential to deliver human-like judgments. However, in the field of machine translation (MT) evaluation, current LLM-as-a-judge methods fall short of learned automatic metrics. In this paper, we propose Multidimensional Multi-Agent Debate (M-MAD), a systematic LLM-based multi-agent framework for advanced LLM-as-a-judge MT evaluation. Our findings demonstrate that M-MAD achieves significant advancements by (1) decoupling heuristic MQM criteria into distinct evaluation dimensions for fine-grained assessments; (2) employing multi-agent debates to harness the collaborative reasoning capabilities of LLMs; (3) synthesizing dimension-specific results into a final evaluation judgment to ensure robust and reliable outcomes. Comprehensive experiments show that M-MAD not only outperforms all existing LLM-as-a-judge methods but also competes with state-of-the-art reference-based automatic metrics, even when powered by a suboptimal model like GPT-4o mini. Detailed ablations and analysis highlight the superiority of our framework design, offering a fresh perspective for LLM-as-a-judge paradigm. Our code and data are publicly available at https://github.com/SU-JIAYUAN/M-MAD.
最近的大型语言模型(LLM)的进步催生了一种新的LLM作为评估者的模式,展示了它们像人一样进行判断的潜力。然而,在机器翻译(MT)评估领域,现有的LLM作为评估者的方法仍然不及已经学习的自动度量方法。在本文中,我们提出了多维度多智能体辩论(M-MAD),这是一个基于LLM的多智能体框架,用于先进的LLM作为评估者的机器翻译评估。我们的研究发现,M-MAD通过以下方式取得了显著进展:(1)将启发式MQM标准解耦为不同的评估维度,进行精细化的评估;(2)利用多智能体辩论来利用LLM的协同推理能力;(3)将特定维度的结果综合成最终的评估判断,以确保稳健和可靠的结果。全面的实验表明,M-MAD不仅超越了所有现有的LLM作为评估者的方法,而且还与最新的参考基于自动度量工具相竞争,即使是由像GPT-4o mini这样的次优模型驱动也是如此。详细的消融实验和分析突显了我们框架设计的优越性,为LLM作为评估者的模式提供了新的视角。我们的代码和数据在https://github.com/SU-JIAYUAN/M-MAD公开可用。
论文及项目相关链接
PDF Work in progress. Code and data are available at https://github.com/SU-JIAYUAN/M-MAD
Summary
大型语言模型(LLM)作为评委的新型评估模式展现了其提供人类级别判断的能力。然而,在机器翻译(MT)评估领域,当前LLM作为评委的方法相较于自动评估指标仍有所不足。本文提出多维度多智能体辩论(M-MAD)框架,该框架结合LLM优势对机器翻译进行评估,通过维度分离评估标准、利用多智能体辩论以及合成特定维度结果进行综合评估,实现显著进展。M-MAD不仅超越现有LLM作为评委的方法,还能与最新参考自动评估指标竞争。更多细节可通过公开链接访问。
Key Takeaways
- 大型语言模型(LLM)作为评委模式展现出人类级别判断潜力。
- 当前LLM在机器翻译评估中表现不足相较于自动评估指标。
- 提出多维度多智能体辩论(M-MAD)框架用于高级LLM作为评委的MT评估。
- M-MAD通过维度分离评估标准、多智能体辩论和特定维度结果合成实现显著进展。
- M-MAD不仅超越现有LLM作为评委的方法,也能与最新自动评估指标竞争。
点此查看论文截图


Many Heads Are Better Than One: Improved Scientific Idea Generation by A LLM-Based Multi-Agent System
Authors:Haoyang Su, Renqi Chen, Shixiang Tang, Zhenfei Yin, Xinzhe Zheng, Jinzhe Li, Biqing Qi, Qi Wu, Hui Li, Wanli Ouyang, Philip Torr, Bowen Zhou, Nanqing Dong
The rapid advancement of scientific progress requires innovative tools that can accelerate knowledge discovery. Although recent AI methods, particularly large language models (LLMs), have shown promise in tasks such as hypothesis generation and experimental design, they fall short of replicating the collaborative nature of real-world scientific practices, where diverse experts work together in teams to tackle complex problems. To address the limitations, we propose an LLM-based multi-agent system, i.e., Virtual Scientists (VirSci), designed to mimic the teamwork inherent in scientific research. VirSci organizes a team of agents to collaboratively generate, evaluate, and refine research ideas. Through comprehensive experiments, we demonstrate that this multi-agent approach outperforms the state-of-the-art method in producing novel scientific ideas. We further investigate the collaboration mechanisms that contribute to its tendency to produce ideas with higher novelty, offering valuable insights to guide future research and illuminating pathways toward building a robust system for autonomous scientific discovery. The code is available at https://github.com/open-sciencelab/Virtual-Scientists.
科技的快速发展需要创新工具来加速知识发现的过程。尽管最近的AI方法,特别是大型语言模型(LLM),在假设生成和实验设计等任务中显示出潜力,但它们无法复制现实世界中科研实践的协作本质,在科研实践中,不同领域的专家会组成团队共同解决复杂问题。为了解决这个问题,我们提出了一种基于LLM的多智能体系统,即“虚拟科学家(VirSci)”,旨在模仿科学研究中固有的团队合作。VirSci组织一支智能体团队,共同生成、评估和完善研究想法。通过综合实验,我们证明了这种多智能体方法在产生新颖科学思想方面优于目前最先进的方法。我们还进一步研究了促进产生更具新颖性想法的协作机制,为未来的研究提供了有价值的见解,并指明了构建自主科学发现系统的稳健途径。代码可在https://github.com/open-sciencelab/Virtual-Scientists获取。
论文及项目相关链接
Summary
科技进步迅速,需要加速知识发现的创新工具。基于大型语言模型的多智能体系统“虚拟科学家”(VirSci)能够模仿团队科研合作,生成、评估和完善研究想法。实验证明,该多智能体方法在产生新科研想法上优于现有方法。
Key Takeaways
- 科技进步需要创新工具来加速知识发现。
- 大型语言模型(LLMs)在假设生成和实验设计等任务中显示出潜力。
- 虚拟科学家(VirSci)是一个基于LLM的多智能体系统,旨在模仿团队科研合作。
- VirSci能够协作生成、评估和完善研究想法。
- 实验证明,VirSci在产生新科研想法方面优于现有方法。
- 协作机制对产生具有新颖性想法的贡献得到了进一步研究。
点此查看论文截图


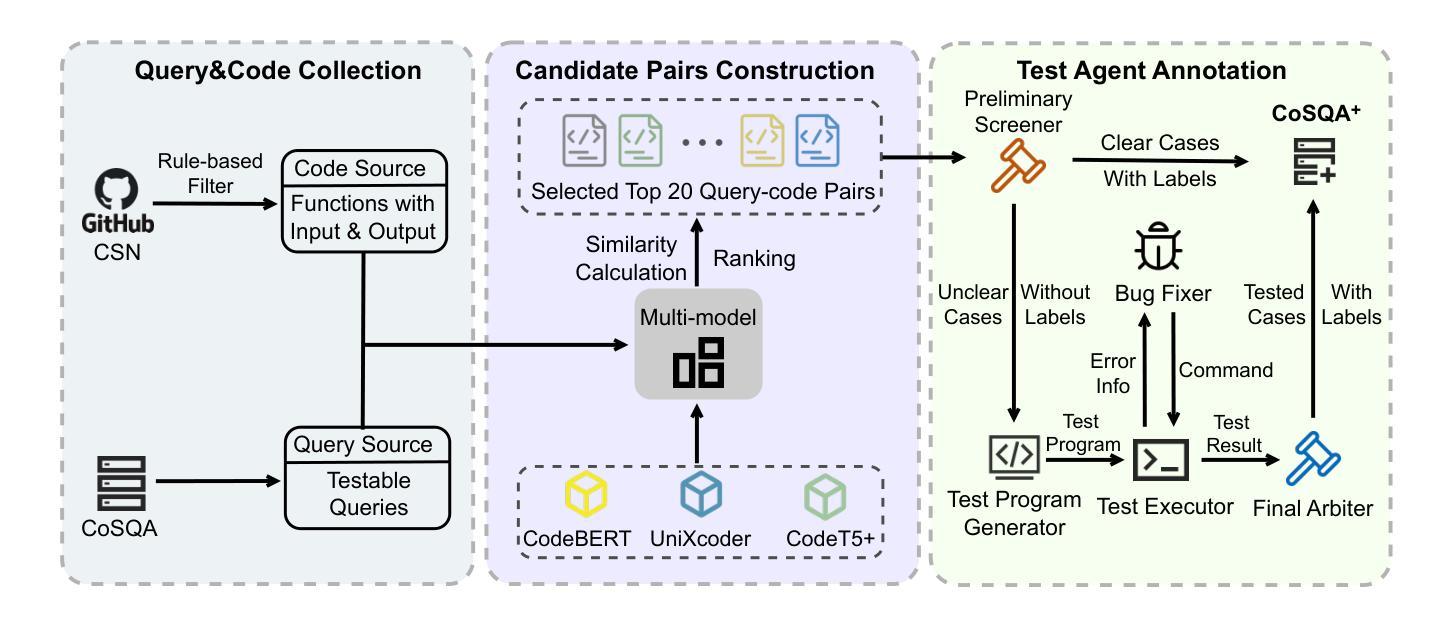
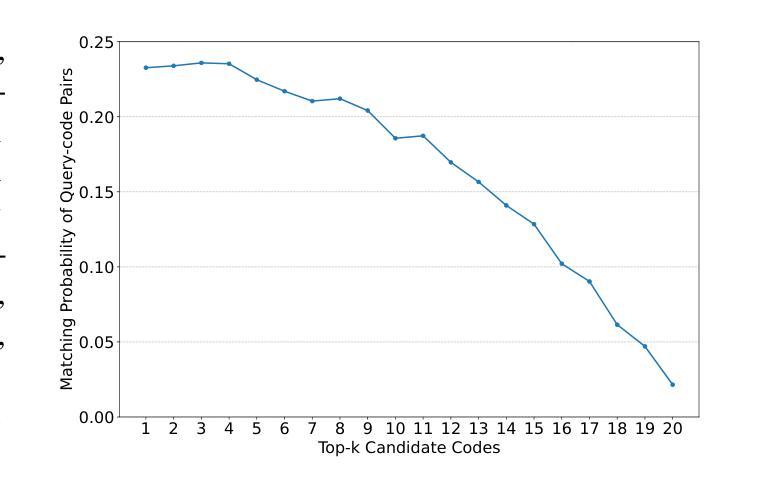
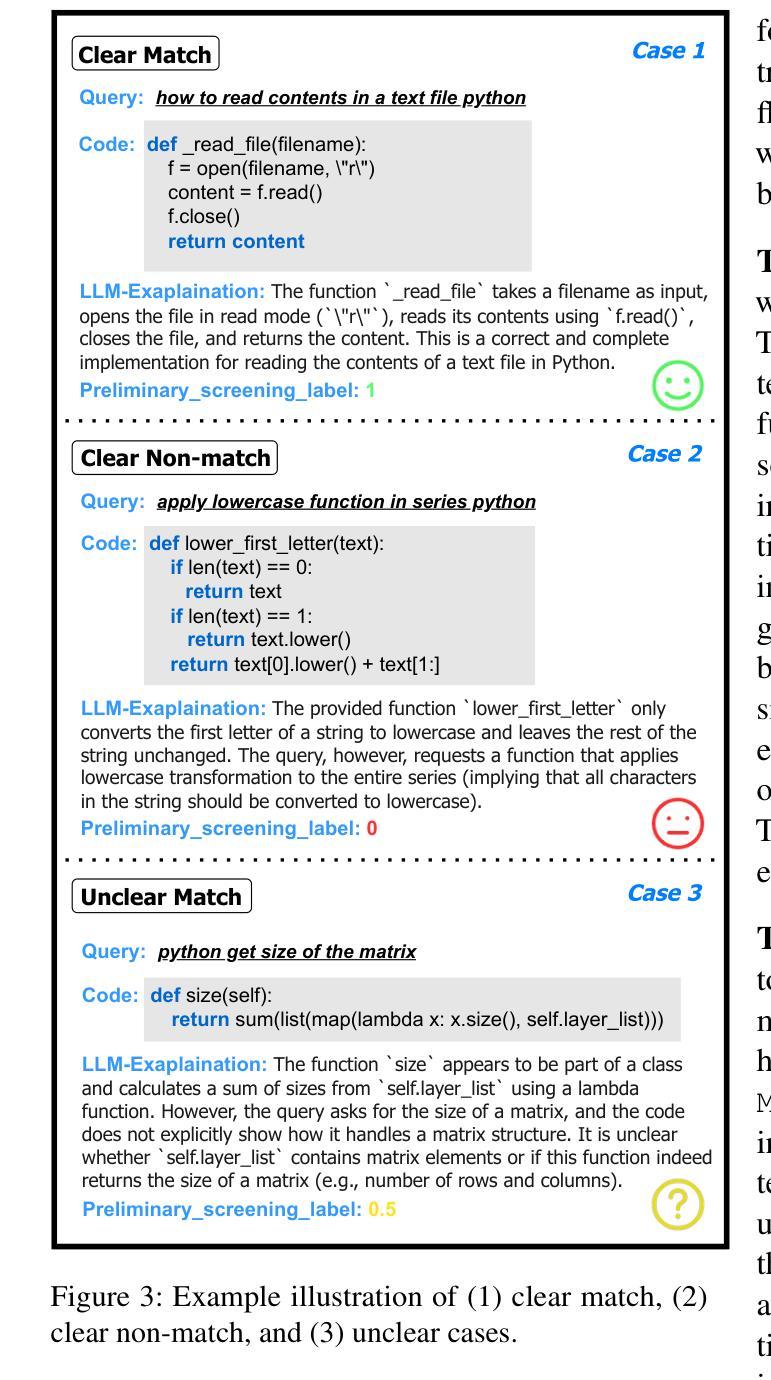
CoSQA+: Pioneering the Multi-Choice Code Search Benchmark with Test-Driven Agents
Authors:Jing Gong, Yanghui Wu, Linxi Liang, Jiachi Chen, Mingwei Liu, Yanlin Wang, Zibin Zheng
Semantic code search, retrieving code that matches a given natural language query, is an important task to improve productivity in software engineering. Existing code search datasets face limitations: they rely on human annotators who assess code primarily through semantic understanding rather than functional verification, leading to potential inaccuracies and scalability issues. Additionally, current evaluation metrics often overlook the multi-choice nature of code search. This paper introduces CoSQA+, pairing high-quality queries from CoSQA with multiple suitable codes. We develop an automated pipeline featuring multiple model-based candidate selections and the novel test-driven agent annotation system. Among a single Large Language Model (LLM) annotator and Python expert annotators (without test-based verification), agents leverage test-based verification and achieve the highest accuracy of 96.4%. Through extensive experiments, CoSQA+ has demonstrated superior quality over CoSQA. Models trained on CoSQA+ exhibit improved performance. We provide the code and data at https://github.com/DeepSoftwareAnalytics/CoSQA_Plus.
代码语义搜索是软件工程领域中提高生产力的重要任务之一,旨在检索与给定自然语言查询匹配的代码。现有的代码搜索数据集存在局限性:它们主要依赖于通过语义理解而非功能验证来评估代码的标注人员,这可能导致潜在的不准确性和可扩展性问题。此外,当前的评估指标往往忽视了代码搜索的多选性质。本文介绍了CoSQA+数据集,它将CoSQA的高质量查询与多个合适的代码配对。我们开发了一个自动化管道,通过基于多个模型的候选选择和新型测试驱动代理标注系统来工作。与单一的大型语言模型标注器和未经测试验证的Python专家标注器相比,代理利用测试验证并实现了高达96.4%的最高准确率。通过广泛的实验验证,CoSQA+的数据质量优于CoSQA。在CoSQA+数据集上训练的模型表现出更好的性能。我们在https://github.com/DeepSoftwareAnalytics/CoSQA_Plus上提供了代码和数据集。
论文及项目相关链接
PDF 15 pages, 4 figures, conference
Summary
自然语言驱动的代码搜索在软件工程领域对于提高生产力具有重要意义。现有数据集主要依赖人工标注,通过语义理解而非功能验证来评估代码,存在潜在的不准确和可扩展性问题。本文介绍了CoSQA+,它通过高质量的查询与多个合适的代码配对,采用自动化管道和新型测试驱动代理标注系统,实现了高准确率。通过广泛实验,CoSQA+优于CoSQA,且在CoSQA+上训练的模型表现出更好的性能。
Key Takeaways
- 代码搜索对于软件工程中的生产力提升至关重要。
- 现有代码搜索数据集存在依赖人工标注的问题,这可能导致不准确和可扩展性问题。
- CoSQA+引入了高质量查询与多个合适代码的配对。
- CoSQA+采用自动化管道和新型测试驱动代理标注系统,提高了准确性。
- 测试驱动验证在代码搜索中起到重要作用。
- CoSQA+实现了高达96.4%的准确率。
点此查看论文截图