⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-21 更新
Where’s the Bug? Attention Probing for Scalable Fault Localization
Authors:Adam Stein, Arthur Wayne, Aaditya Naik, Mayur Naik, Eric Wong
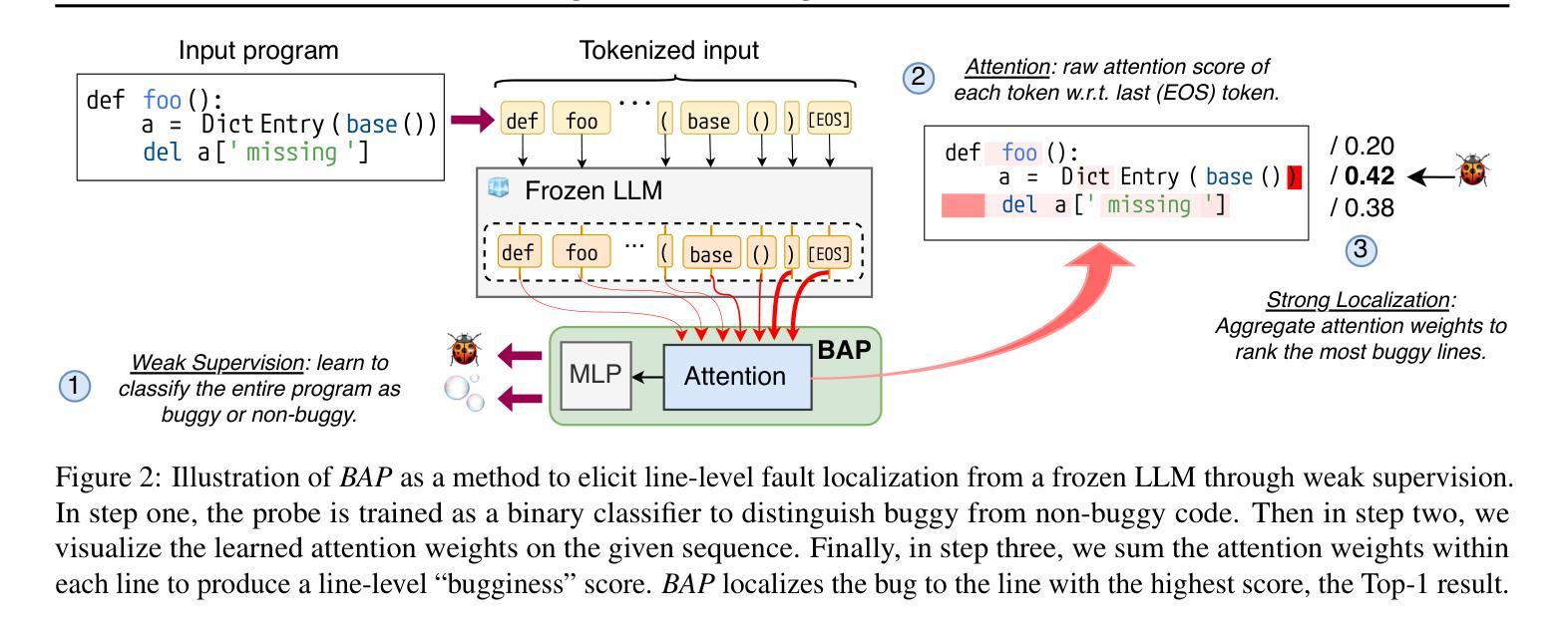
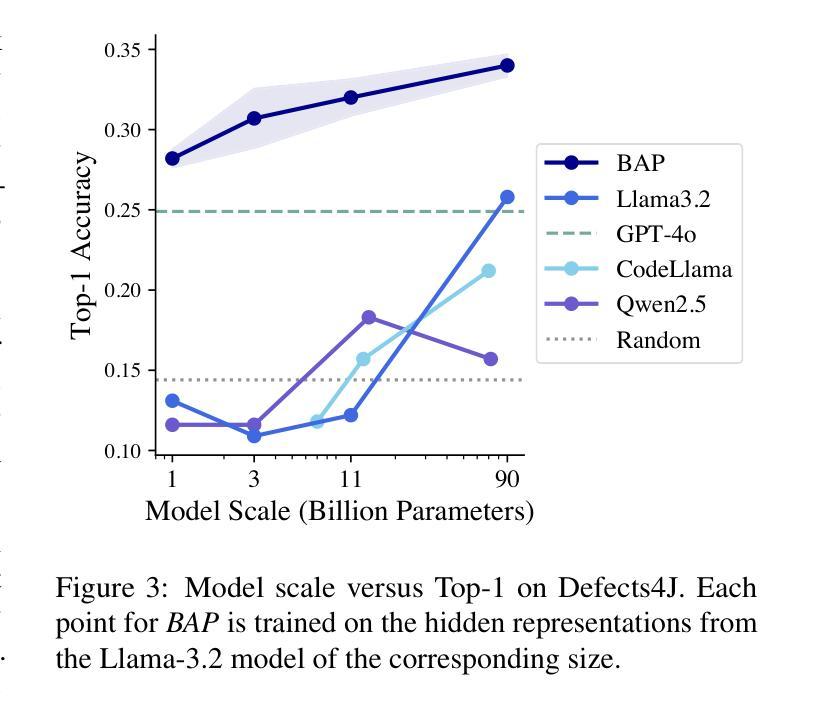
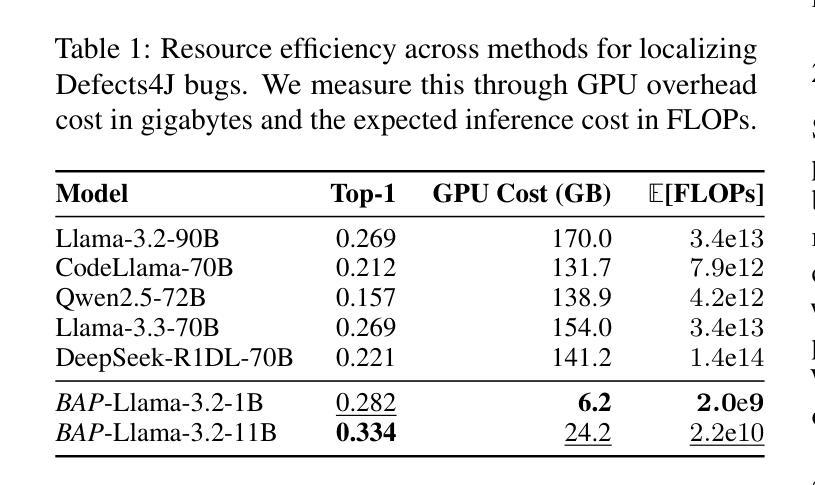
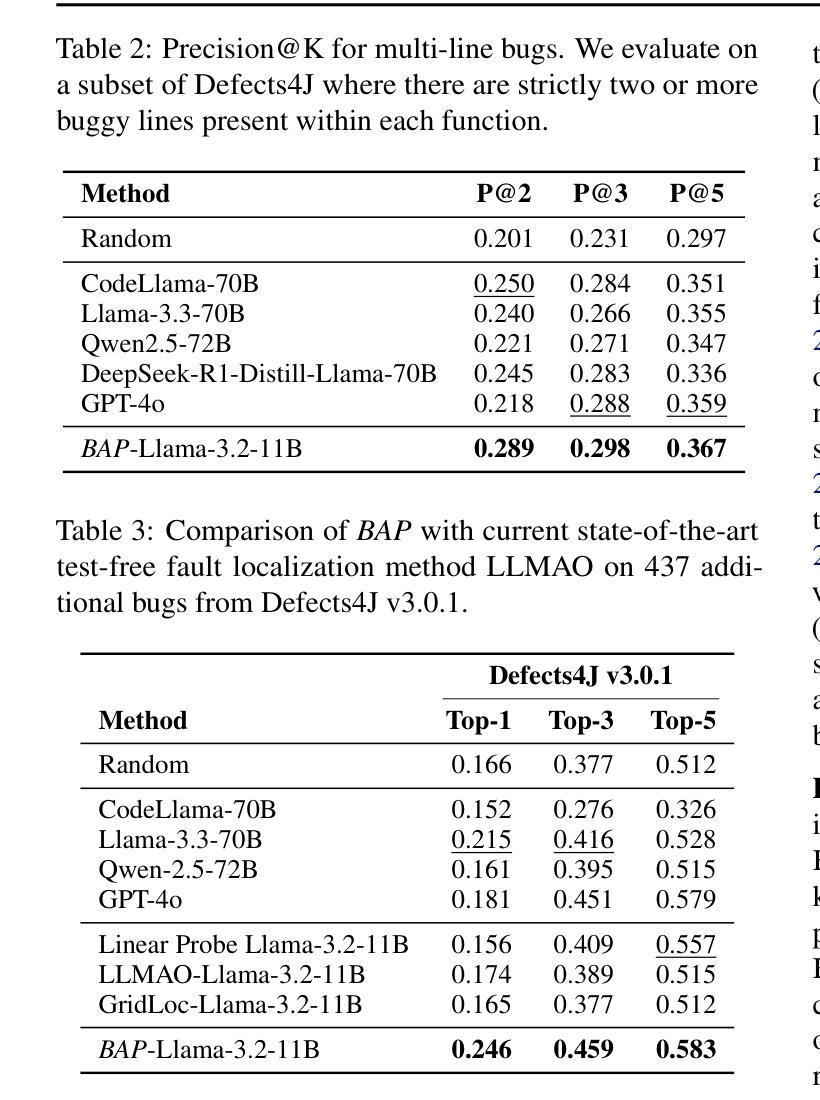
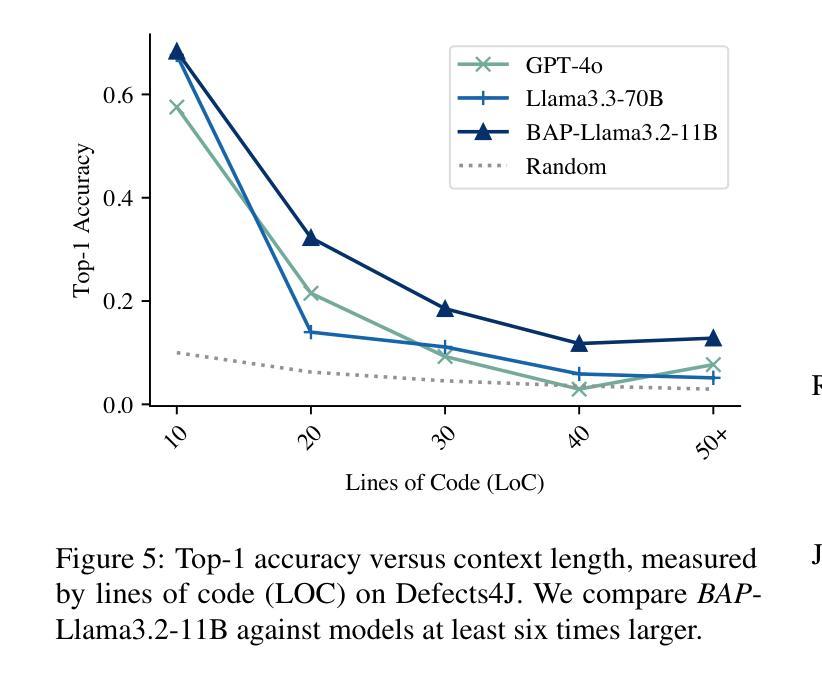
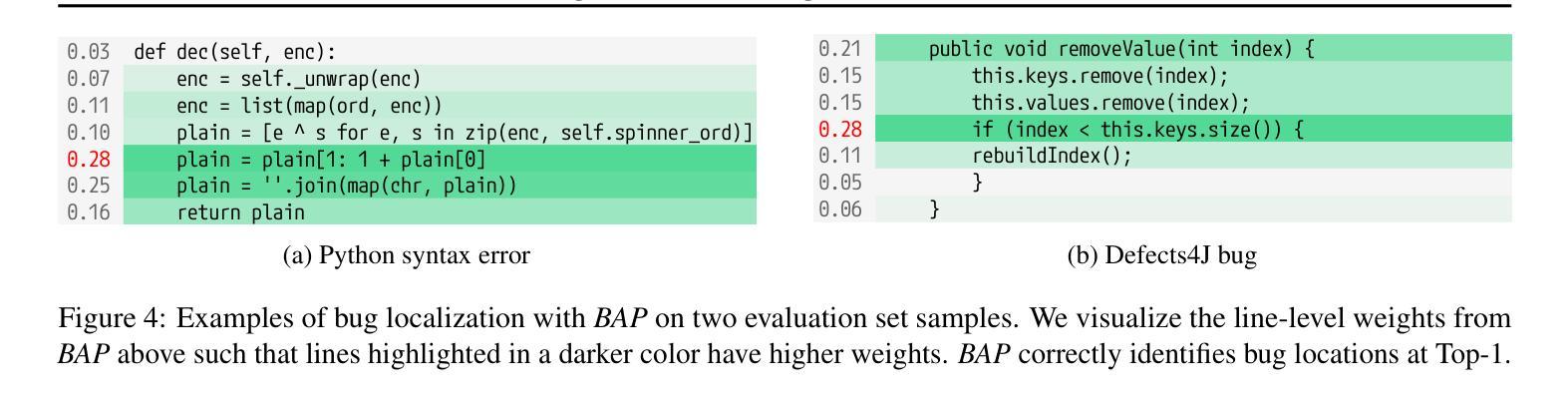
Ensuring code correctness remains a challenging problem even as large language models (LLMs) become increasingly capable at code-related tasks. While LLM-based program repair systems can propose bug fixes using only a user’s bug report, their effectiveness is fundamentally limited by their ability to perform fault localization (FL), a challenging problem for both humans and LLMs. Existing FL approaches rely on executable test cases, require training on costly and often noisy line-level annotations, or demand resource-intensive LLMs. In this paper, we present Bug Attention Probe (BAP), a method which learns state-of-the-art fault localization without any direct localization labels, outperforming traditional FL baselines and prompting of large-scale LLMs. We evaluate our approach across a variety of code settings, including real-world Java bugs from the standard Defects4J dataset as well as seven other datasets which span a diverse set of bug types and languages. Averaged across all eight datasets, BAP improves by 34.6% top-1 accuracy compared to the strongest baseline and 93.4% over zero-shot prompting GPT-4o. BAP is also significantly more efficient than prompting, outperforming large open-weight models at a small fraction of the computational cost.
确保代码正确性仍然是一个具有挑战性的问题,即使大型语言模型(LLM)在代码相关任务上越来越强大。虽然基于LLM的程序修复系统仅使用用户的错误报告就可以提出错误修复建议,但它们的有效性从根本上受到故障定位(FL)能力的限制,这对于人类和LLM来说都是一项具有挑战性的任务。现有的故障定位方法依赖于可执行的测试用例,需要基于昂贵的、通常带有噪声的行级注释进行训练,或者需要资源密集型的LLM。在本文中,我们介绍了Bug Attention Probe(BAP)方法,该方法可以在没有任何直接定位标签的情况下实现最先进的故障定位,并且优于传统的故障定位基准线和大型LLM的提示。我们在多种代码设置中对我们的方法进行了评估,包括使用标准Defects4J数据集的真实世界Java错误以及其他涵盖各种错误类型和语言的七个数据集。在八个数据集上平均,BAP在最高准确率方面比最强基准线提高了34.6%,比零样本提示GPT-4o提高了93.4%。此外,BAP还显著优于提示方法,在计算成本方面大大优于大型开放式模型。
论文及项目相关链接
PDF 14 pages, 5 figures
Summary
大型语言模型(LLM)在代码相关任务上的能力日益增强,但保证代码正确性仍然是一个挑战性问题。LLM为基础的程序修复系统可以通过用户的错误报告提出修复建议,但其有效性受限于故障定位(FL)的能力。本文提出了一种新的方法——Bug Attention Probe(BAP),该方法无需直接定位标签即可学习最先进的故障定位,且在多种代码设置上优于传统FL基准测试和大型LLM提示。在包含Defects4J数据集在内的八个数据集上进行的评估显示,BAP在平均准确率上较最强基准测试提高了34.6%,较GPT-4o零样本提示提高了93.4%。此外,BAP在计算成本方面也具有更高的效率。
Key Takeaways
- 大型语言模型(LLM)在代码相关任务上的能力增强,但代码正确性仍是挑战。
- LLM为基础的修复系统受限于故障定位(FL)的能力。
- Bug Attention Probe(BAP)方法无需直接定位标签即可学习先进的故障定位。
- BAP在多种代码设置上优于传统FL方法和大型LLM提示。
- 在多个数据集上的评估显示,BAP较最强基准测试和GPT-4o有显著提高。
点此查看论文截图

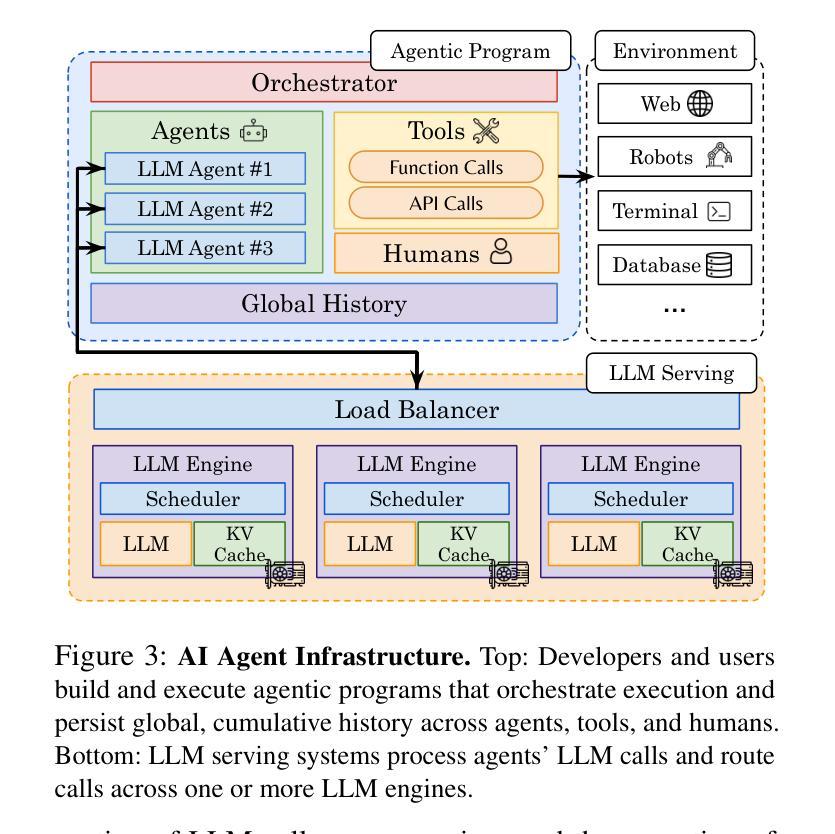
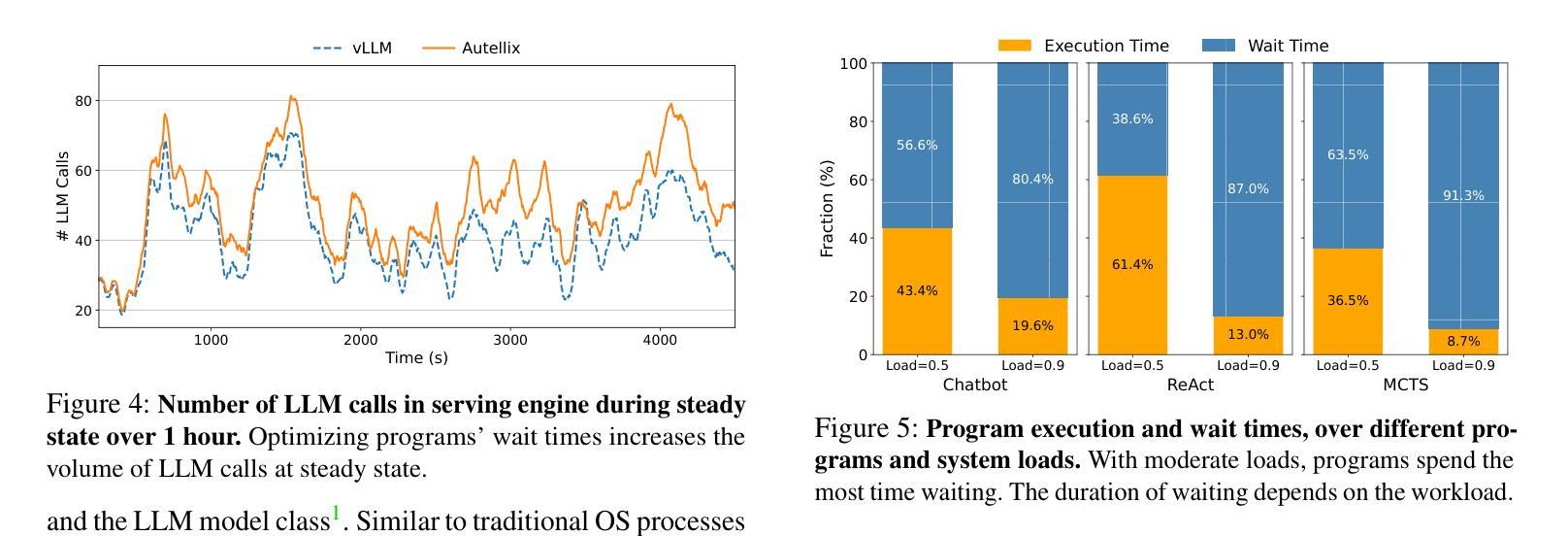
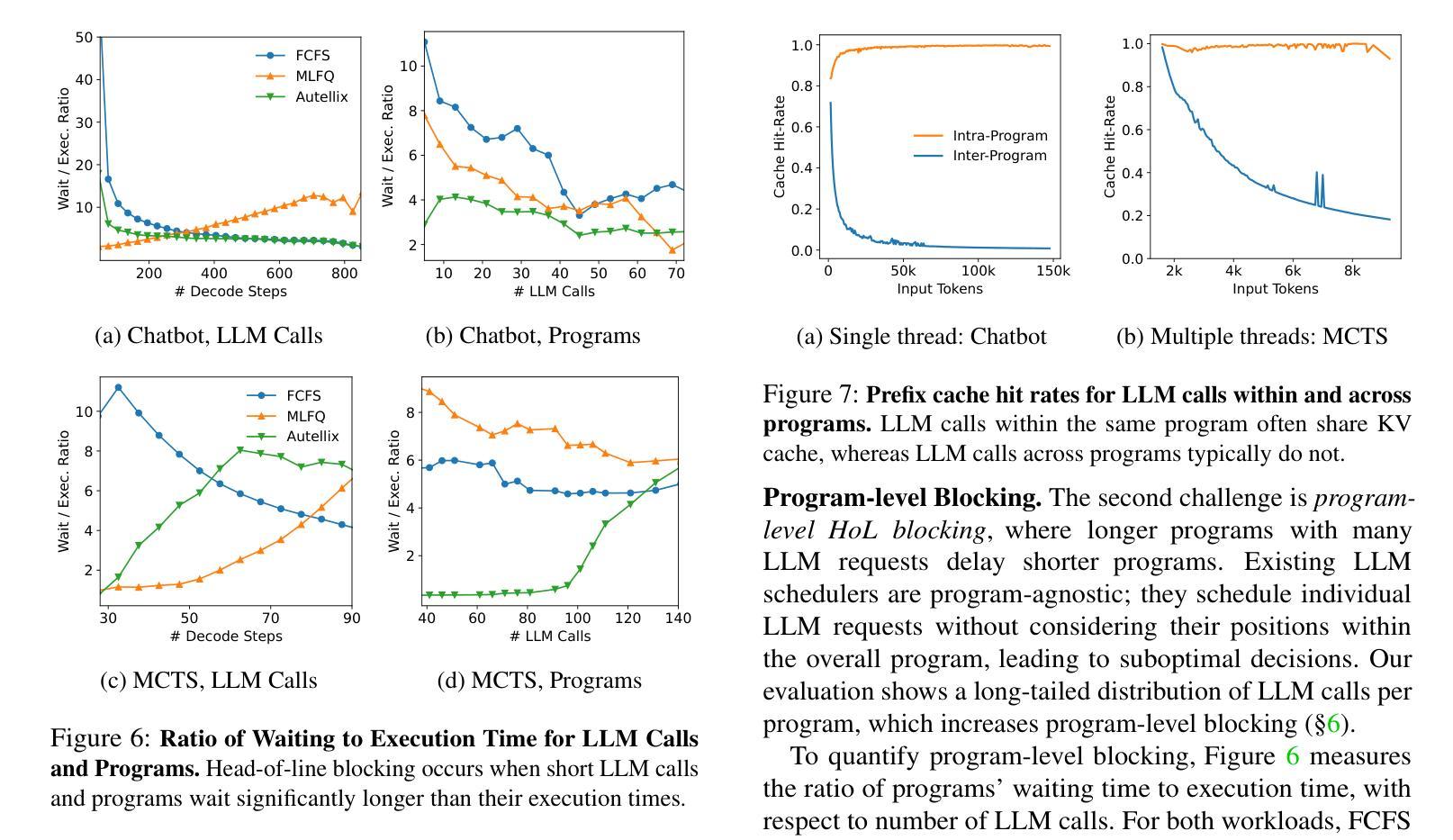
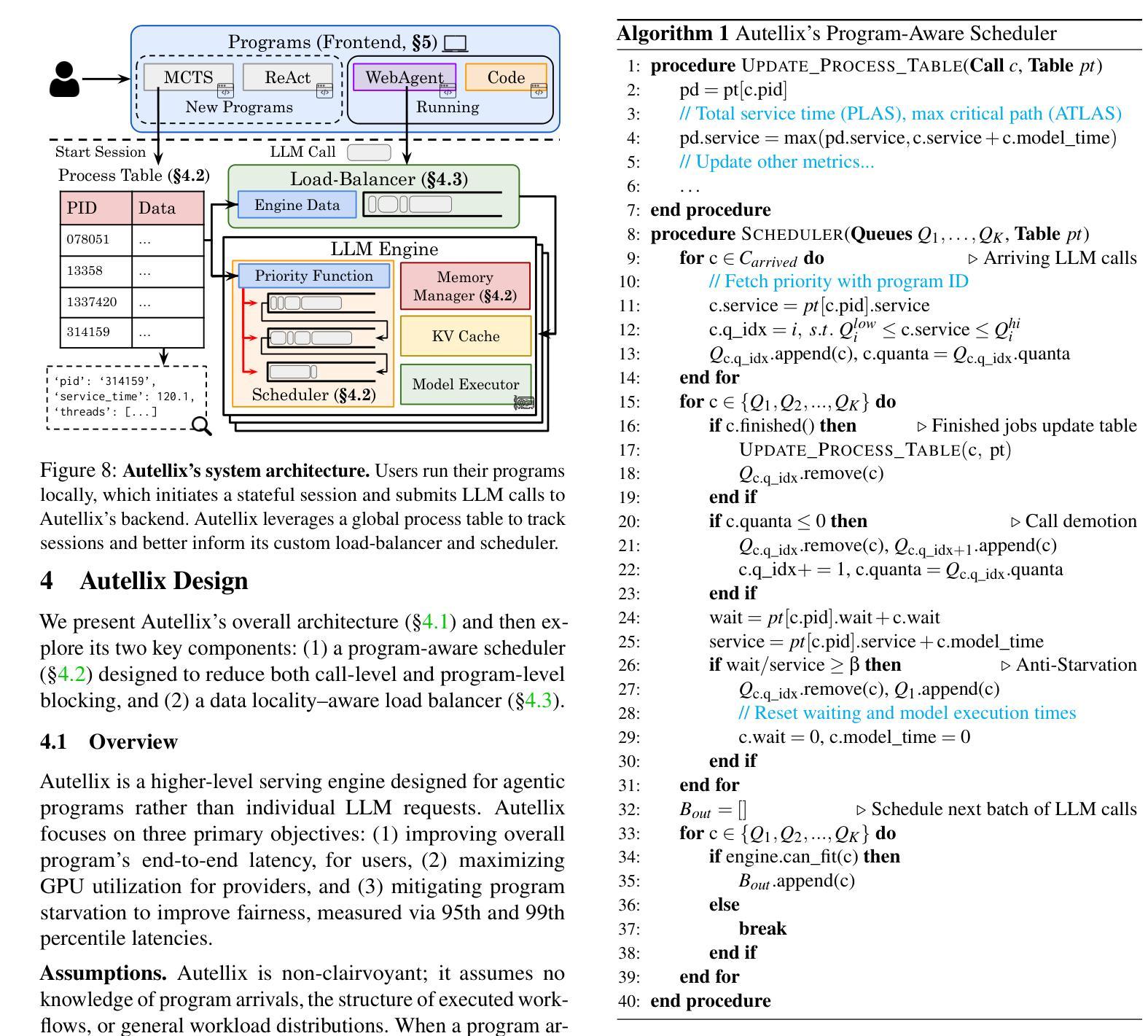
Autellix: An Efficient Serving Engine for LLM Agents as General Programs
Authors:Michael Luo, Xiaoxiang Shi, Colin Cai, Tianjun Zhang, Justin Wong, Yichuan Wang, Chi Wang, Yanping Huang, Zhifeng Chen, Joseph E. Gonzalez, Ion Stoica
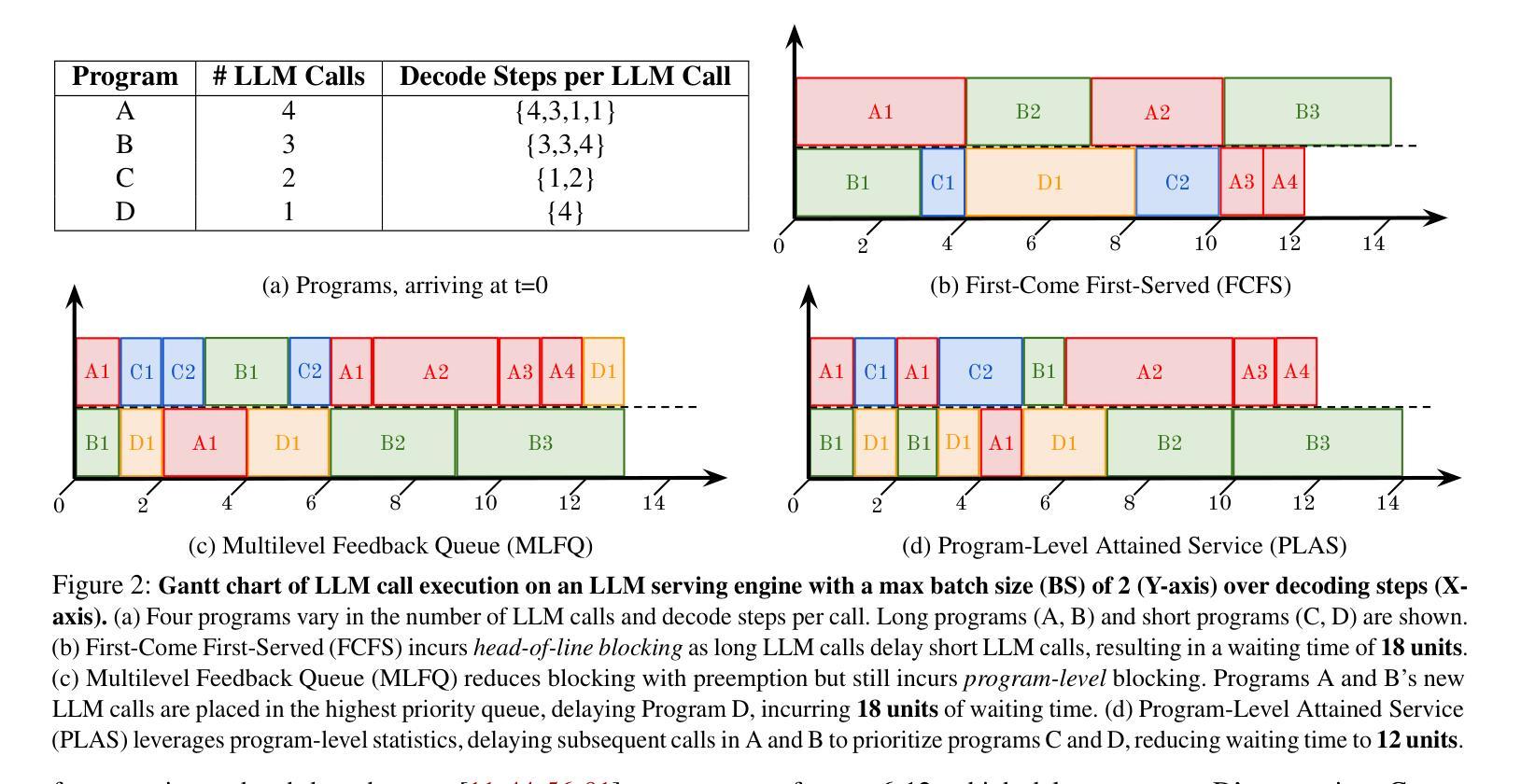
Large language model (LLM) applications are evolving beyond simple chatbots into dynamic, general-purpose agentic programs, which scale LLM calls and output tokens to help AI agents reason, explore, and solve complex tasks. However, existing LLM serving systems ignore dependencies between programs and calls, missing significant opportunities for optimization. Our analysis reveals that programs submitted to LLM serving engines experience long cumulative wait times, primarily due to head-of-line blocking at both the individual LLM request and the program. To address this, we introduce Autellix, an LLM serving system that treats programs as first-class citizens to minimize their end-to-end latencies. Autellix intercepts LLM calls submitted by programs, enriching schedulers with program-level context. We propose two scheduling algorithms-for single-threaded and distributed programs-that preempt and prioritize LLM calls based on their programs’ previously completed calls. Our evaluation demonstrates that across diverse LLMs and agentic workloads, Autellix improves throughput of programs by 4-15x at the same latency compared to state-of-the-art systems, such as vLLM.
大型语言模型(LLM)应用正逐渐从简单的聊天机器人演变为动态、通用的代理程序,它们扩展了LLM的调用和输出令牌,帮助AI代理进行推理、探索和解决复杂任务。然而,现有的LLM服务系统忽略了程序和调用之间的依赖关系,失去了优化的重要机会。我们的分析表明,提交给LLM服务引擎的程序会经历长时间的累计等待时间,主要是由于个别LLM请求和程序的头线阻塞。为了解决这一问题,我们引入了Autellix,一个将程序视为首要公民的LLM服务系统,以最小化其端到端延迟。Autellix拦截程序提交的LLM调用,丰富调度器的程序级上下文。我们为单线程和分布式程序提出了两种调度算法,这些算法会根据程序之前完成的调用预先判断和优先处理LLM调用。我们的评估表明,在多种LLM和代理工作负载中,与最新系统(如vLLM)相比,Autellix在相同延迟下提高了程序的吞吐量4-15倍。
论文及项目相关链接
Summary
大型语言模型(LLM)应用正由简单的聊天机器人演变为动态、通用的智能代理程序。现有LLM服务系统忽视了程序和调用间的依赖关系,导致AI代理在处理复杂任务时受限。为此,我们提出了Autellix系统,它通过丰富调度器的程序级上下文来处理程序作为首要任务,以减少端到端的延迟。评估显示,Autellix在多样化的LLM和智能代理工作负载上,提高了程序的吞吐量,同时与现有系统相比,延迟保持不变。
Key Takeaways
- LLM应用正演变为更动态、通用的智能代理程序,涉及复杂的推理和问题解决。
- 现有LLM服务系统忽视了程序和调用间的依赖,导致优化机会丧失。
- Autellix系统处理程序作为首要任务,通过丰富调度器的程序级上下文来减少端到端的延迟。
- Autellix提出了针对单线程和分布式程序的两种调度算法。
- 调度算法基于程序之前完成的调用,预先判断和优先处理LLM调用。
- 评估显示,Autellix在多种LLM和智能代理工作负载上,提高了程序的吞吐量。
点此查看论文截图

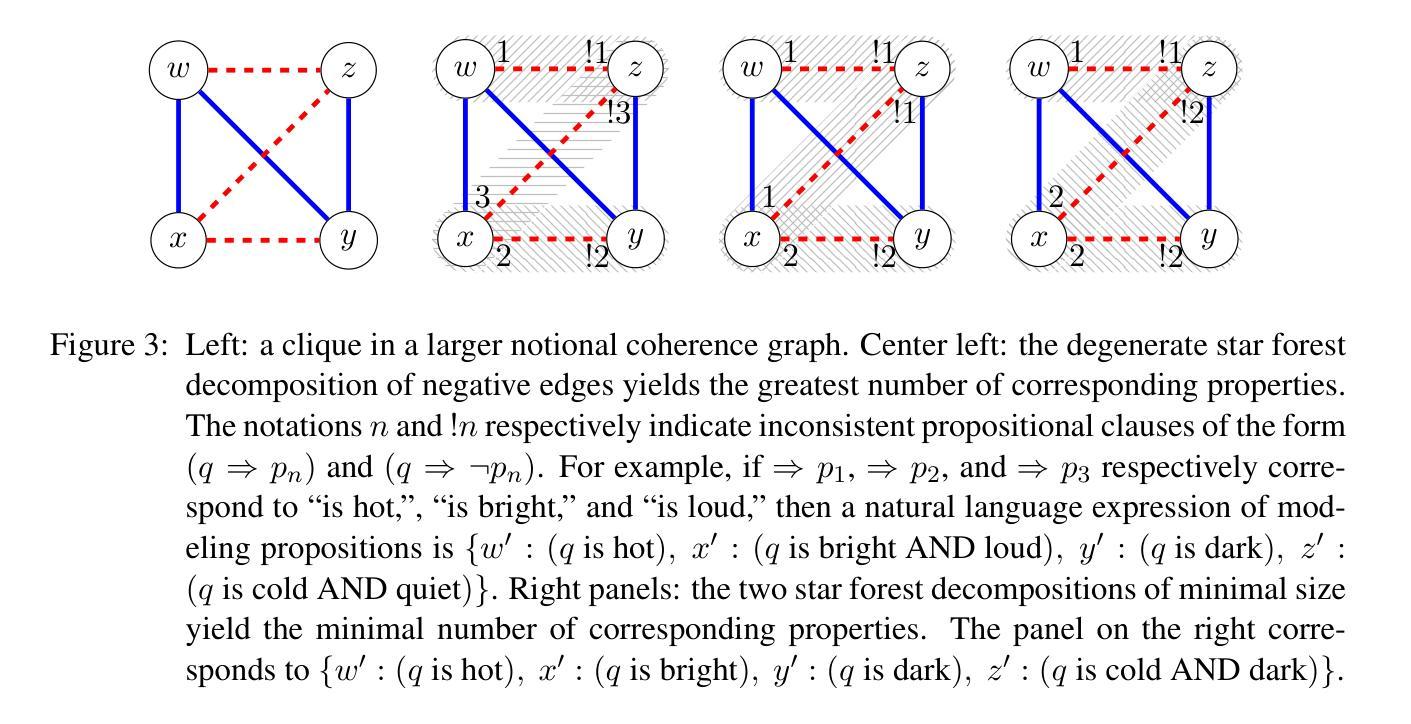
Neurosymbolic artificial intelligence via large language models and coherence-driven inference
Authors:Steve Huntsman, Jewell Thomas
We devise an algorithm to generate sets of propositions that objectively instantiate graphs that support coherence-driven inference. We then benchmark the ability of large language models (LLMs) to reconstruct coherence graphs from (a straightforward transformation of) propositions expressed in natural language, with promising results from a single prompt to models optimized for reasoning. Combining coherence-driven inference with consistency evaluations by neural models may advance the state of the art in machine cognition.
我们设计了一种算法,用于生成客观实例化图集,这些图集支持连贯推理。然后,我们以命题为基准,评估大型语言模型(LLM)从自然语言表达的命题(进行简单转换后)重建连贯图的能力,优化推理的模型从单一提示中取得了令人鼓舞的结果。将连贯推理与神经网络模型的一致性评估相结合,可能会推动机器认知领域的最新进展。
论文及项目相关链接
Summary:我们设计了一种算法,可以根据命题生成支持连贯推理的图。然后,我们评估大型语言模型(LLM)从自然语言表达的命题重建连贯图的能力,并从单一提示中对优化推理的模型进行基准测试,取得了令人鼓舞的结果。结合连贯推理和神经网络模型的一致性评估可能会推动机器认知的最新进展。
Key Takeaways:
- 提出了一种算法,能够根据命题生成支持连贯推理的图。
- 大型语言模型(LLM)在重建连贯图方面表现出了潜力。
- 通过单一提示对优化推理的模型进行基准测试取得了令人鼓舞的结果。
- 结合连贯推理和神经网络模型的一致性评估有助于推动机器认知的进步。
- 该算法有助于增强语言模型的推理能力。
- 这种方法在自然语言处理和人工智能领域具有广泛的应用前景。
点此查看论文截图



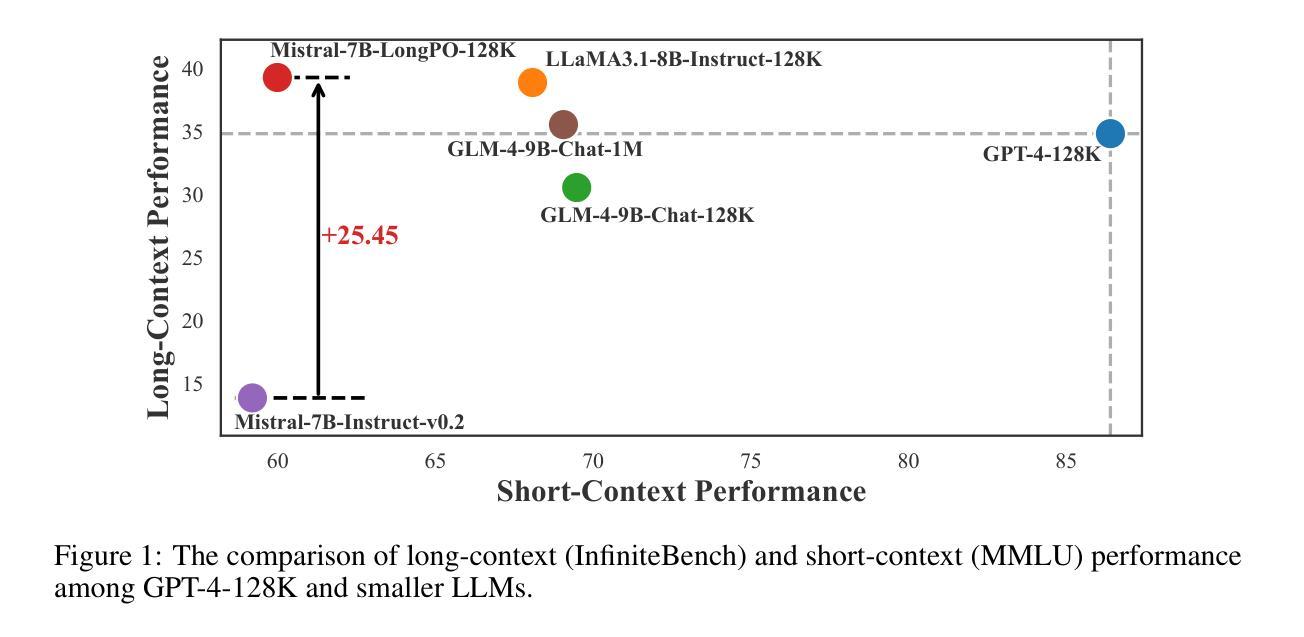
LongPO: Long Context Self-Evolution of Large Language Models through Short-to-Long Preference Optimization
Authors:Guanzheng Chen, Xin Li, Michael Qizhe Shieh, Lidong Bing
Large Language Models (LLMs) have demonstrated remarkable capabilities through pretraining and alignment. However, superior short-context LLMs may underperform in long-context scenarios due to insufficient long-context alignment. This alignment process remains challenging due to the impracticality of human annotation for extended contexts and the difficulty in balancing short- and long-context performance. To address these challenges, we introduce LongPO, that enables short-context LLMs to self-evolve to excel on long-context tasks by internally transferring short-context capabilities. LongPO harnesses LLMs to learn from self-generated short-to-long preference data, comprising paired responses generated for identical instructions with long-context inputs and their compressed short-context counterparts, respectively. This preference reveals capabilities and potentials of LLMs cultivated during short-context alignment that may be diminished in under-aligned long-context scenarios. Additionally, LongPO incorporates a short-to-long KL constraint to mitigate short-context performance decline during long-context alignment. When applied to Mistral-7B-Instruct-v0.2 from 128K to 512K context lengths, LongPO fully retains short-context performance and largely outperforms naive SFT and DPO in both long- and short-context tasks. Specifically, \ourMethod-trained models can achieve results on long-context benchmarks comparable to, or even surpassing, those of superior LLMs (e.g., GPT-4-128K) that involve extensive long-context annotation and larger parameter scales.
大型语言模型(LLM)通过预训练和对齐过程展现了惊人的能力。然而,在具有充足对齐的长语境场景下,优秀的短语境LLM可能会表现不佳。由于长语境对齐不足以及人类为扩展语境进行标注的不切实际性和平衡短语境和长语境性能的困难,这一对齐过程仍然具有挑战性。为了应对这些挑战,我们引入了LongPO方法,它通过内部转移短语境能力,使短语境LLM能够在长语境任务上自我进化并表现出色。LongPO利用LLM从自我生成的短到长的偏好数据中学习,这些数据由为相同指令生成的配对响应组成,包括长语境输入及其压缩的短语境对应物。这种偏好揭示了短语境对齐过程中培养的LLM的能力和潜力,这些能力在长语境对齐不足的情况下可能会减弱。此外,LongPO还融入了一个短到长的KL约束,以缓解长语境对齐过程中短语境性能的下降。当应用于Mistral-7B-Instruct-v0.2模型,从128K到512K的语境长度时,LongPO充分保留了短语境性能,并在长短语境任务中大大优于简单的SFT和DPO。具体来说,经过我们方法训练的模型可以在长语境基准测试上取得与或超越高级LLM(例如涉及广泛长语境标注和更大参数规模的GPT-4-128K)的结果。
论文及项目相关链接
PDF ICLR 2025
Summary
大型语言模型(LLM)通过预训练和对齐展现出惊人的能力。然而,在长篇上下文场景中,优秀的短篇上下文LLM可能会因缺乏长篇上下文对齐而表现不佳。为解决这一挑战,我们提出了LongPO方法,它能够让短篇上下文LLM通过内部转移短语境能力自我进化,从而在长篇上下文任务上表现出色。LongPO利用LLM从自我生成的短到长的偏好数据中学习,这些数据由为相同指令生成的长篇上下文输入和相应的短篇上下文压缩版本配对响应组成。通过这种方式,LongPO揭示了LLM在短篇上下文对齐过程中培养的能力和潜力,这些能力可能在长篇上下文场景中因对齐不足而减弱。此外,LongPO还引入了一个短到长的KL约束,以缓解长篇上下文对齐过程中短篇上下文性能下降的问题。当应用于Mistral-7B-Instruct-v0.2模型时,从128K到512K的语境长度范围内,LongPO可以完全保留短篇上下文的性能,并在长短语境任务中大大优于简单的SFT和DPO。特别是,经过LongPO训练的模型在长篇上下文基准测试上的表现可与或超越顶级LLM(如GPT-4-128K)相当,这些LLM涉及大量的长篇上下文标注和更大的参数规模。
Key Takeaways
- LLMs通过预训练和对齐展现出强大的能力,但在长篇上下文场景中可能因缺乏足够的长篇上下文对齐而表现不佳。
- LongPO方法能够让短篇上下文的LLM自我进化,通过内部转移短语境能力,在长篇上下文任务上实现卓越表现。
- LongPO利用LLM学习自我生成的短到长的偏好数据,揭示LLM在短篇上下文对齐过程中的能力和潜力。
- LongPO引入短到长的KL约束,以缓解长篇上下文对齐过程中的短篇上下文性能下降问题。
- LongPO在保持短篇上下文性能的同时,提升了长篇上下文任务的表现。
- LongPO训练的模型在长篇上下文基准测试上的表现可超越一些需要更多长篇上下文标注和更大参数规模的顶级LLM。
点此查看论文截图

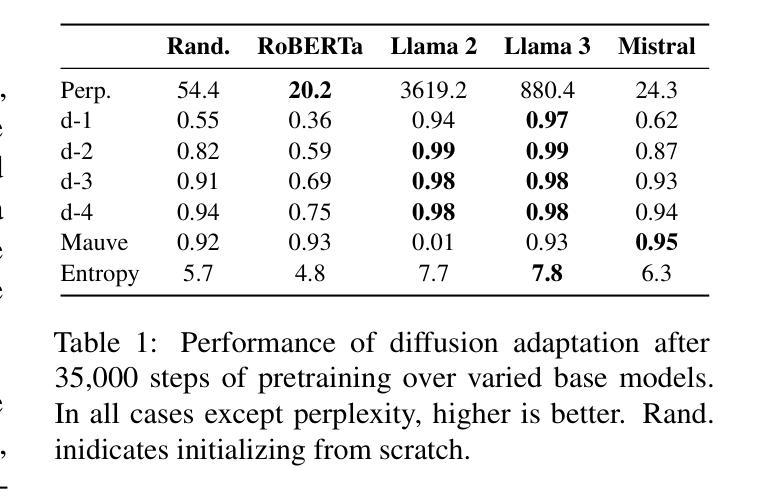
TESS 2: A Large-Scale Generalist Diffusion Language Model
Authors:Jaesung Tae, Hamish Ivison, Sachin Kumar, Arman Cohan
We introduce TESS 2, a general instruction-following diffusion language model that outperforms contemporary instruction-tuned diffusion models, as well as matches and sometimes exceeds strong autoregressive (AR) models. We train TESS 2 by first adapting a strong AR model via continued pretraining with the usual cross-entropy as diffusion loss, and then performing further instruction tuning. We find that adaptation training as well as the choice of the base model is crucial for training good instruction-following diffusion models. We further propose reward guidance, a novel and modular inference-time guidance procedure to align model outputs without needing to train the underlying model. Finally, we show that TESS 2 further improves with increased inference-time compute, highlighting the utility of diffusion LMs in having fine-grained controllability over the amount of compute used at inference time. Code and models are available at https://github.com/hamishivi/tess-2.
我们介绍了TESS 2,这是一个通用指令遵循扩散语言模型,它超越了当代指令优化扩散模型,与强大的自回归(AR)模型相匹配,有时甚至超过它们。我们通过首先使用强大的AR模型进行持续预训练,以常规的交叉熵作为扩散损失,然后进一步进行指令调整来训练TESS 2。我们发现适应训练以及基础模型的选择对于训练良好的指令遵循扩散模型至关重要。我们进一步提出奖励指导,这是一种新型模块化的推理时间指导程序,无需训练底层模型即可对齐模型输出。最后,我们展示了随着推理时间计算量的增加,TESS 2的性能会进一步提高,这突出了扩散LM在推理时间使用计算量的精细控制方面的实用性。代码和模型可在https://github.com/hamishivi/tess-2获取。
论文及项目相关链接
PDF preprint
摘要
本文介绍了TESS 2,这是一种通用指令遵循扩散语言模型,它超越了当代指令调整扩散模型的表现,并且与强大的自回归(AR)模型相匹配甚至在某些方面超过它们。我们通过首先使用常规交叉熵作为扩散损失对强大的AR模型进行持续预训练来训练TESS 2,然后进行进一步的指令调整。我们发现适应训练以及基础模型的选择对于训练良好的指令遵循扩散模型至关重要。我们还提出了奖励指导,这是一种新型模块化的推理时间指导程序,可以在不需要训练底层模型的情况下对齐模型输出。最后,我们表明,随着推理时间计算量的增加,TESS 2的性能可以进一步提高,这突出了扩散语言模型在推理时间使用的计算量方面具有精细可控性的实用性。
要点掌握
- TESS 2是一种通用指令遵循扩散语言模型,表现优于当代指令调整扩散模型和强大的自回归模型。
- TESS 2的训练包括使用交叉熵作为扩散损失的持续预训练,以及进一步的指令调整。
- 适应训练和基础模型的选择对于训练良好的指令遵循扩散模型至关重要。
- 提出了奖励指导,这是一种新型的推理时间指导程序,可以在不需要训练底层模型的情况下对齐模型输出。
- TESS 2的性能随着推理时间计算量的增加而提高。
- 扩散语言模型具有在推理时间使用的计算量方面的精细可控性。
点此查看论文截图


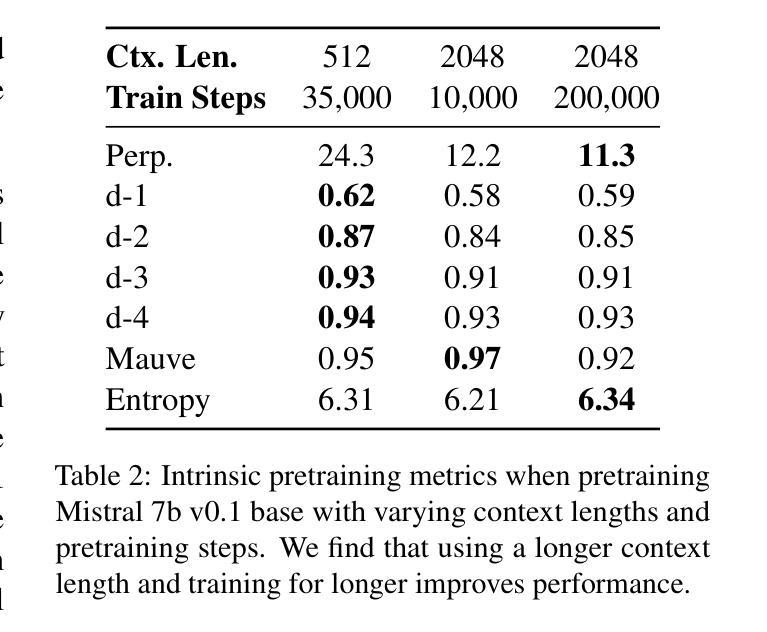
Lost in Sequence: Do Large Language Models Understand Sequential Recommendation?
Authors:Sein Kim, Hongseok Kang, Kibum Kim, Jiwan Kim, Donghyun Kim, Minchul Yang, Kwangjin Oh, Julian McAuley, Chanyoung Park
Large Language Models (LLMs) have recently emerged as promising tools for recommendation thanks to their advanced textual understanding ability and context-awareness. Despite the current practice of training and evaluating LLM-based recommendation (LLM4Rec) models under a sequential recommendation scenario, we found that whether these models understand the sequential information inherent in users’ item interaction sequences has been largely overlooked. In this paper, we first demonstrate through a series of experiments that existing LLM4Rec models do not fully capture sequential information both during training and inference. Then, we propose a simple yet effective LLM-based sequential recommender, called LLM-SRec, a method that enhances the integration of sequential information into LLMs by distilling the user representations extracted from a pre-trained CF-SRec model into LLMs. Our extensive experiments show that LLM-SRec enhances LLMs’ ability to understand users’ item interaction sequences, ultimately leading to improved recommendation performance. Furthermore, unlike existing LLM4Rec models that require fine-tuning of LLMs, LLM-SRec achieves state-of-the-art performance by training only a few lightweight MLPs, highlighting its practicality in real-world applications. Our code is available at https://github.com/Sein-Kim/LLM-SRec.
大型语言模型(LLM)由于其先进的文本理解能力和上下文意识,最近被公认为推荐工具中的有前途的工具。尽管当前基于LLM的推荐(LLM4Rec)模型是在顺序推荐场景下进行训练和评估的,但我们发现这些模型是否理解用户项目交互序列中固有的顺序信息却被大大忽视了。在本文中,我们首先通过一系列实验证明,现有的LLM4Rec模型在训练和推理过程中并没有完全捕获顺序信息。然后,我们提出了一种简单有效的基于LLM的顺序推荐器,称为LLM-SRec。这是一种通过蒸馏从预训练的CF-SRec模型中提取的用户表示,将其融入LLMs中,从而增强LLMs对顺序信息的整合的方法。我们的大量实验表明,LLM-SRec增强了LLMs理解用户项目交互序列的能力,最终提高了推荐性能。此外,与现有的需要微调LLMs的LLM4Rec模型不同,LLM-SRec仅通过训练一些轻量级的MLPs就实现了最先进的性能,这凸显了其在现实世界应用中的实用性。我们的代码可在https://github.com/Sein-Kim/LLM-SRec找到。
论文及项目相关链接
PDF Under Review
Summary
大语言模型(LLM)在推荐系统中有广泛应用前景,因其强大的文本理解能力和上下文意识。但现有LLM在推荐(LLM4Rec)模型中往往忽略用户交互序列中的时序信息。本文通过实验验证现有LLM4Rec模型在训练和推理过程中未能充分捕捉时序信息,并提出一种简单有效的基于LLM的时序推荐方法LLM-SRec。该方法通过蒸馏预训练CF-SRec模型中的用户表示到LLM中,增强了LLM理解用户交互序列的能力,提高了推荐性能。并且相较于现有LLM4Rec模型,LLM-SRec仅需训练少量轻量级多层感知机(MLPs)即可达到业界领先水平。
Key Takeaways
- LLMs展现出在推荐系统中的潜力,归功于其强大的文本理解能力和上下文意识。
- 现有LLM4Rec模型忽略了用户交互序列中的时序信息。
- 通过实验验证,现有LLM4Rec模型在训练和推理过程中对时序信息的捕捉不足。
- 提出一种基于LLM的时序推荐方法LLM-SRec,能有效增强LLM理解用户交互序列的能力。
- LLM-SRec通过蒸馏预训练CF-SRec模型中的用户表示到LLM中,提高了推荐性能。
- LLM-SRec实现了业界领先的推荐性能,且相较于其他LLM4Rec模型更为实用,仅需训练少量轻量级MLPs。
点此查看论文截图


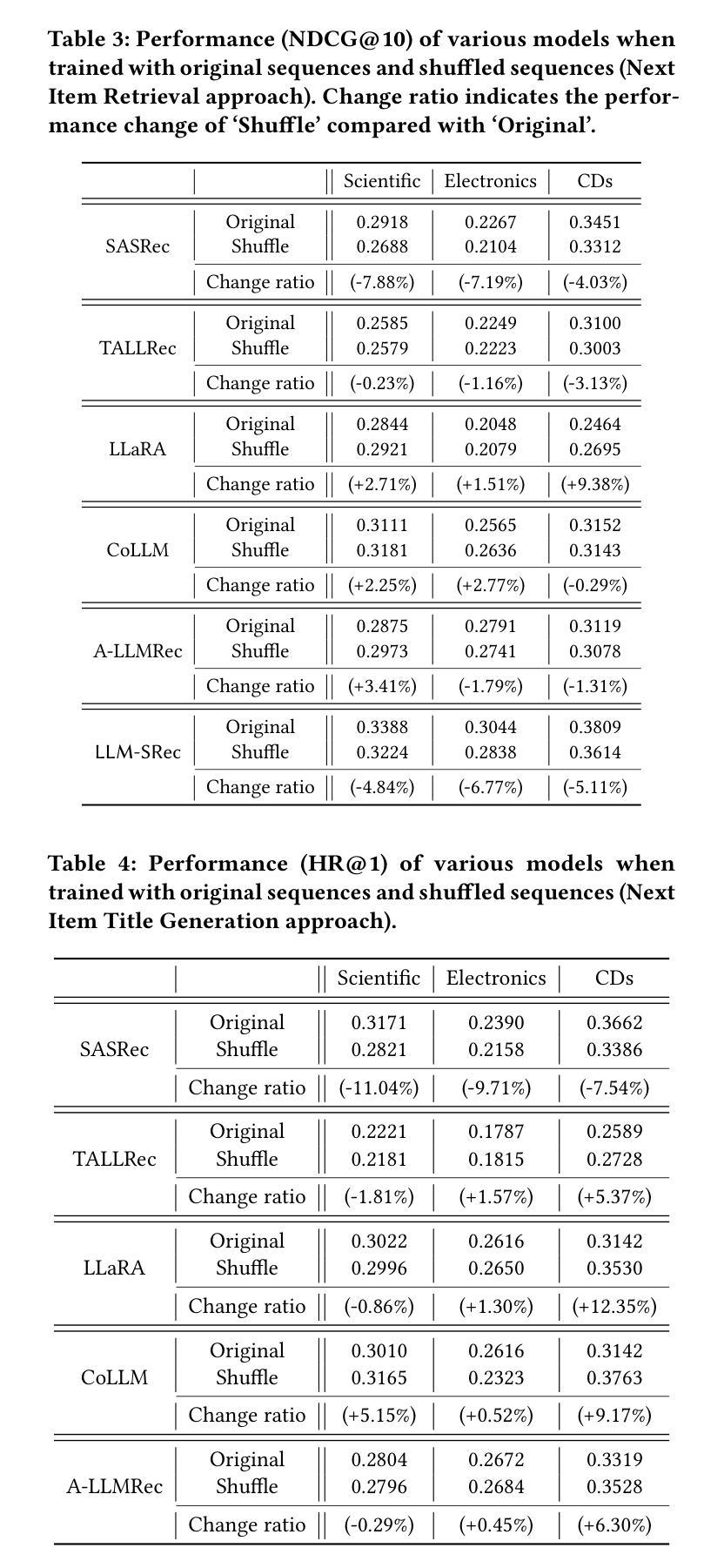
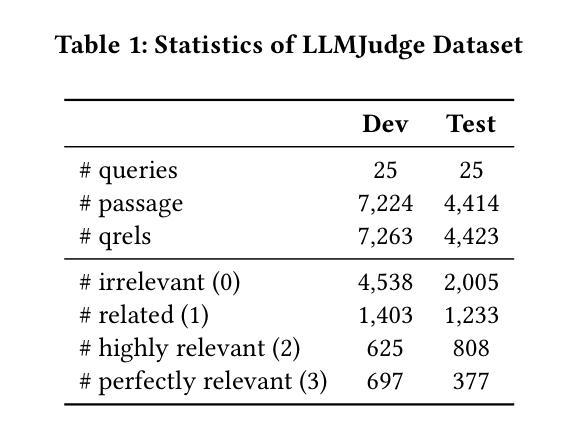
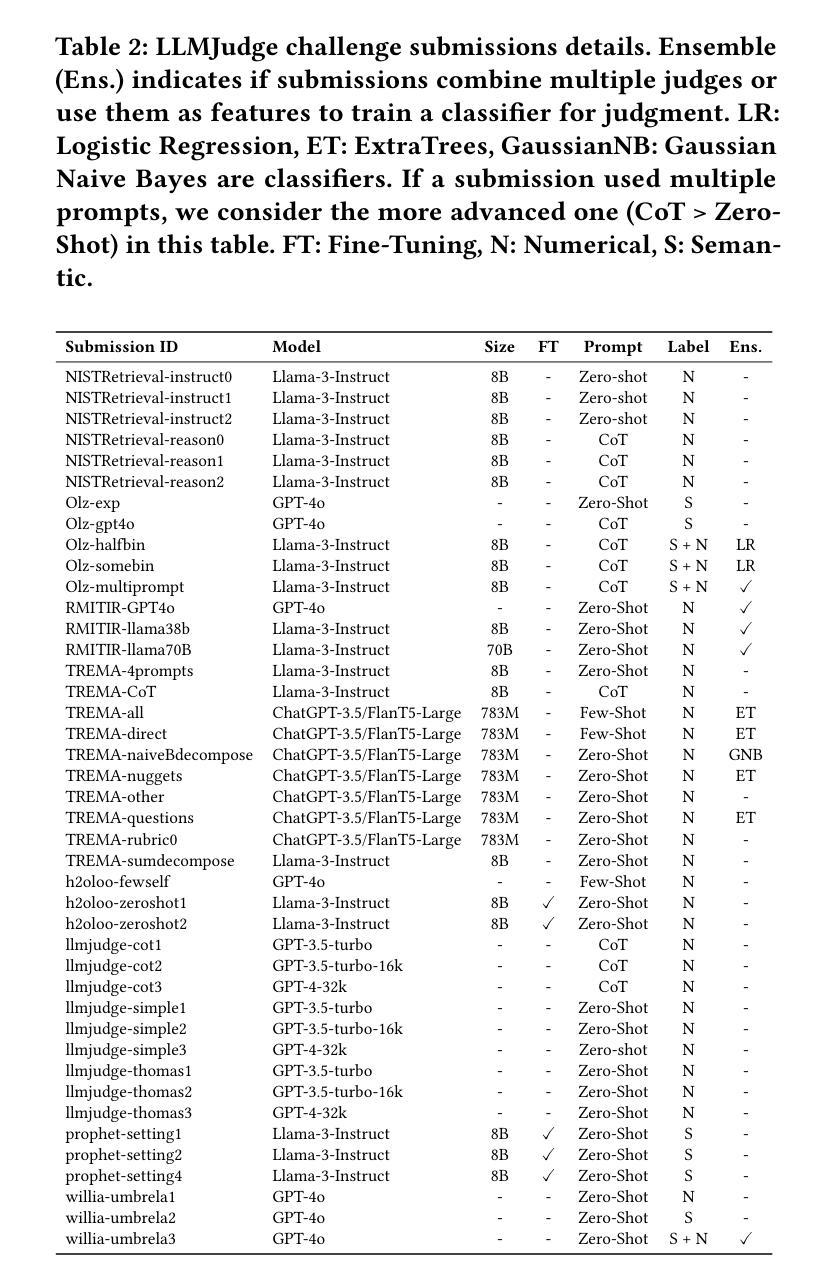
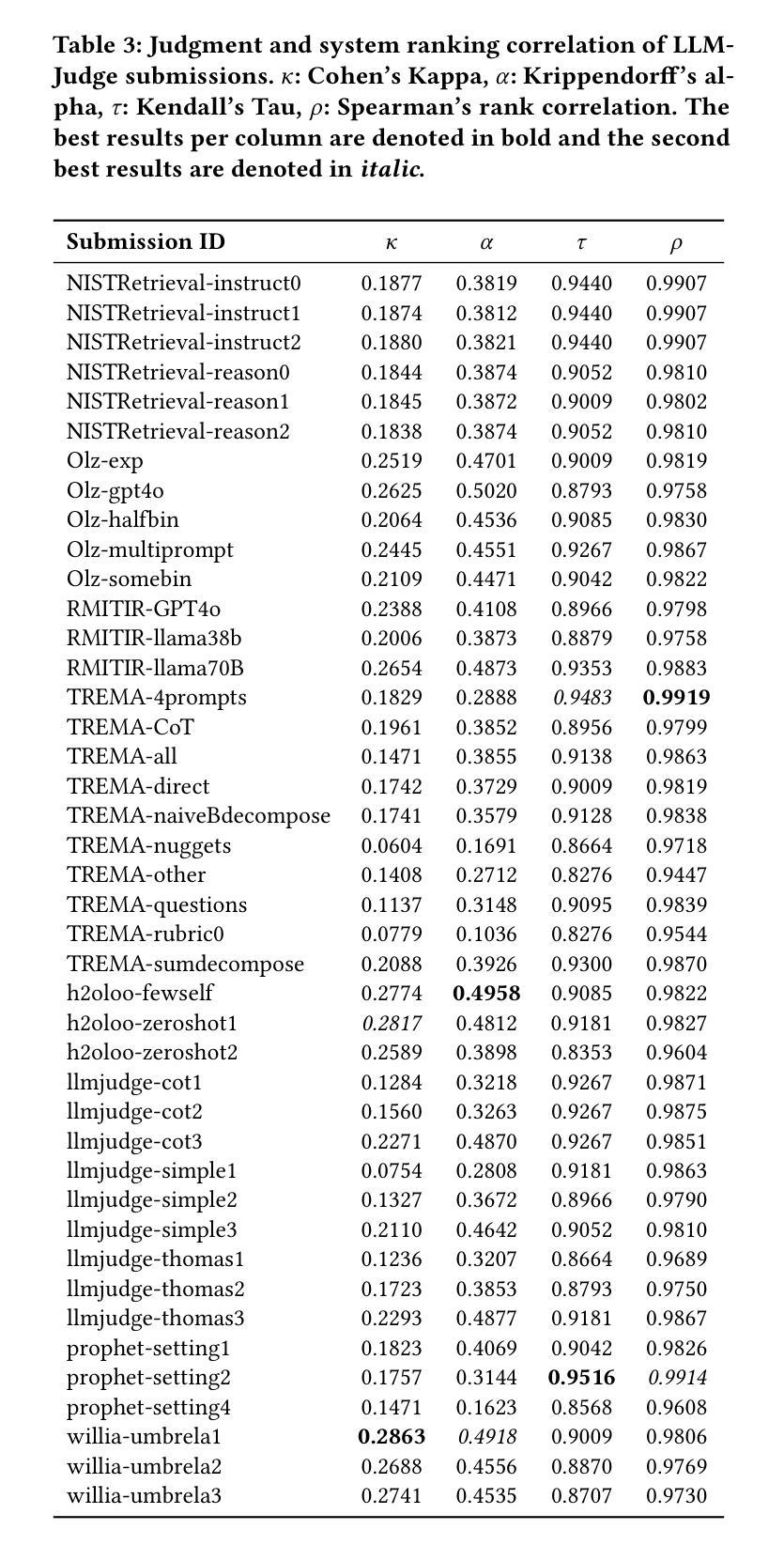
Judging the Judges: A Collection of LLM-Generated Relevance Judgements
Authors:Hossein A. Rahmani, Clemencia Siro, Mohammad Aliannejadi, Nick Craswell, Charles L. A. Clarke, Guglielmo Faggioli, Bhaskar Mitra, Paul Thomas, Emine Yilmaz
Using Large Language Models (LLMs) for relevance assessments offers promising opportunities to improve Information Retrieval (IR), Natural Language Processing (NLP), and related fields. Indeed, LLMs hold the promise of allowing IR experimenters to build evaluation collections with a fraction of the manual human labor currently required. This could help with fresh topics on which there is still limited knowledge and could mitigate the challenges of evaluating ranking systems in low-resource scenarios, where it is challenging to find human annotators. Given the fast-paced recent developments in the domain, many questions concerning LLMs as assessors are yet to be answered. Among the aspects that require further investigation, we can list the impact of various components in a relevance judgment generation pipeline, such as the prompt used or the LLM chosen. This paper benchmarks and reports on the results of a large-scale automatic relevance judgment evaluation, the LLMJudge challenge at SIGIR 2024, where different relevance assessment approaches were proposed. In detail, we release and benchmark 42 LLM-generated labels of the TREC 2023 Deep Learning track relevance judgments produced by eight international teams who participated in the challenge. Given their diverse nature, these automatically generated relevance judgments can help the community not only investigate systematic biases caused by LLMs but also explore the effectiveness of ensemble models, analyze the trade-offs between different models and human assessors, and advance methodologies for improving automated evaluation techniques. The released resource is available at the following link: https://llm4eval.github.io/LLMJudge-benchmark/
使用大型语言模型(LLM)进行相关性评估为信息检索(IR)、自然语言处理(NLP)和相关领域提供了改进的有前途的机会。实际上,LLM有望让IR实验者使用当前所需人工劳动的一小部分来构建评估集合。这有助于处理有限知识的新主题,并可能减轻在低资源场景中评估排名系统的挑战,在这些场景中,很难找到人类注释者。考虑到该领域的快速发展,关于LLM作为评估者的许多问题还有待回答。在需要进一步调查的方面,我们可以列出相关性判断生成管道中各种组件的影响,例如使用的提示或选择的LLM。本文介绍了大规模自动相关性评估基准测试LLMJudge挑战的结果,该挑战于2024年SIGIR会议上举办,其中提出了不同的相关性评估方法。具体来说,我们发布并基准测试了TREC 2023深度学习轨道相关性判断的42个LLM生成标签,这些标签由参与挑战的八个国际团队产生。这些自动生成的相关性判断具有多样性,不仅有助于社区研究LLM引起的系统偏见,还可以探索集成模型的有效性,分析不同模型与人类评估者之间的权衡,并推进改进自动化评估技术的方法。发布的资源可在以下链接找到:https://llm4eval.github.io/LLMJudge-benchmark/
论文及项目相关链接
PDF 11 pages
Summary
大规模语言模型(LLM)在相关性评估方面的应用为信息检索(IR)、自然语言处理(NLP)等相关领域带来了改进的希望。LLM可以减轻IR实验者构建评估集合时所需的大量手动劳动力,有助于应对缺乏人类注释者评估低资源场景中排名系统的挑战。针对LLM作为评估者的快速发展领域,还有许多问题有待回答,如生成管道中不同组件的影响等。本文介绍了在SIGIR 2024年举办的LLMJudge挑战赛的结果,该挑战赛旨在评估不同的相关性评估方法。通过对比八个国际团队提出的自动生成的TREC 2023深度学习轨迹相关性判断标签,该挑战赛有助于社区研究LLM引起的系统性偏见问题,并探讨集成模型的有效性等关键领域进步研究方法和自动评估技术的改进。
Key Takeaways
- LLMs在相关性评估领域展现出改进IR和NLP等行业的潜力。
- LLM能够大幅减少构建评估集合所需的人工参与程度。
- LLMJudge挑战赛的结果展示了不同相关性评估方法的对比结果。
- 自动生成的评估数据能够帮助社区探究LLM带来的潜在偏见。
- 对集成模型有效性的探索是一个关键领域。
- 通过对比不同模型和人类评估者的结果,可以分析出其中的权衡和取舍。
点此查看论文截图

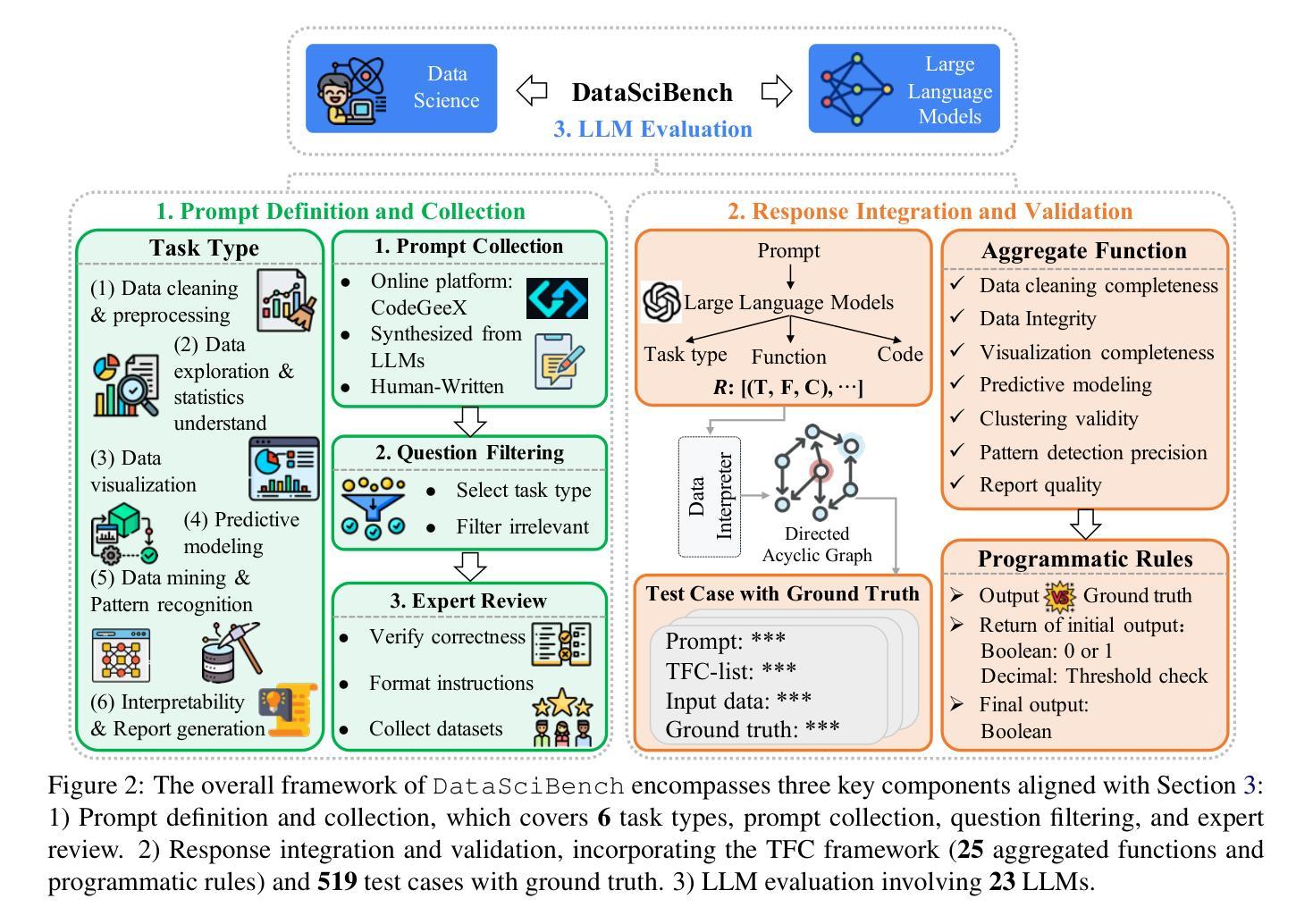
DataSciBench: An LLM Agent Benchmark for Data Science
Authors:Dan Zhang, Sining Zhoubian, Min Cai, Fengzu Li, Lekang Yang, Wei Wang, Tianjiao Dong, Ziniu Hu, Jie Tang, Yisong Yue
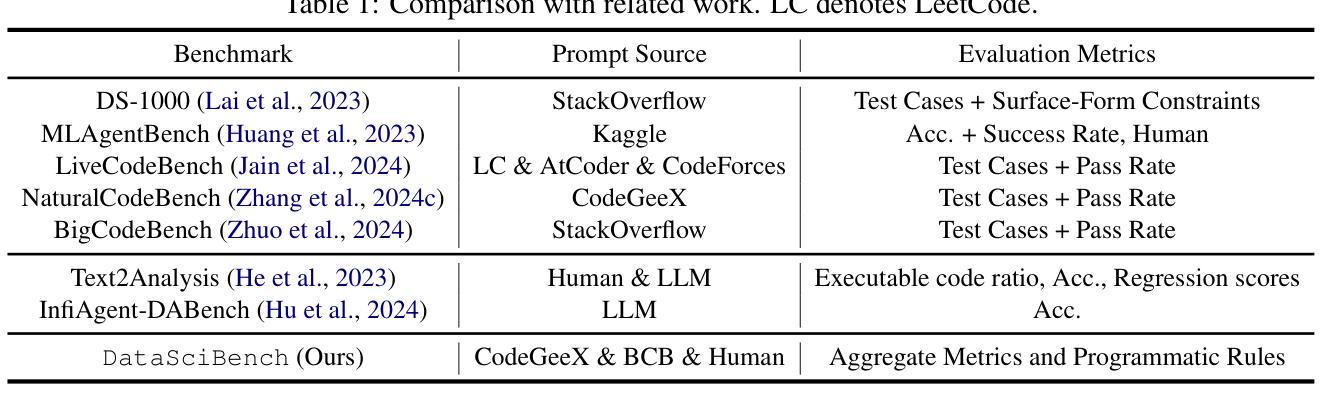
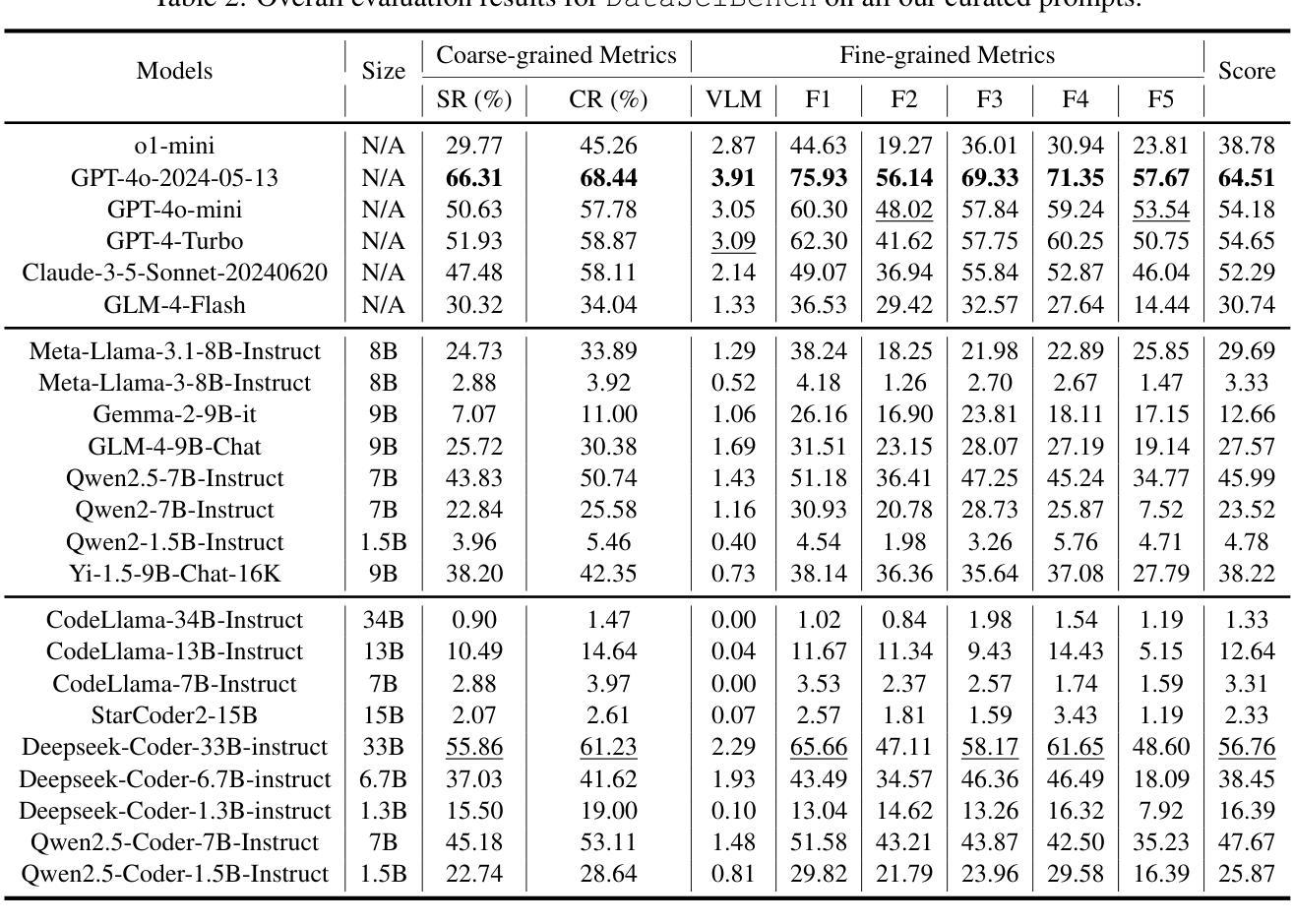
This paper presents DataSciBench, a comprehensive benchmark for evaluating Large Language Model (LLM) capabilities in data science. Recent related benchmarks have primarily focused on single tasks, easily obtainable ground truth, and straightforward evaluation metrics, which limits the scope of tasks that can be evaluated. In contrast, DataSciBench is constructed based on a more comprehensive and curated collection of natural and challenging prompts for uncertain ground truth and evaluation metrics. We develop a semi-automated pipeline for generating ground truth (GT) and validating evaluation metrics. This pipeline utilizes and implements an LLM-based self-consistency and human verification strategy to produce accurate GT by leveraging collected prompts, predefined task types, and aggregate functions (metrics). Furthermore, we propose an innovative Task - Function - Code (TFC) framework to assess each code execution outcome based on precisely defined metrics and programmatic rules. Our experimental framework involves testing 6 API-based models, 8 open-source general models, and 9 open-source code generation models using the diverse set of prompts we have gathered. This approach aims to provide a more comprehensive and rigorous evaluation of LLMs in data science, revealing their strengths and weaknesses. Experimental results demonstrate that API-based models outperform open-sourced models on all metrics and Deepseek-Coder-33B-Instruct achieves the highest score among open-sourced models. We release all code and data at https://github.com/THUDM/DataSciBench.
本文介绍了DataSciBench,这是一个用于评估数据科学中大型语言模型(LLM)能力的全面基准测试。最近的相关基准测试主要侧重于单一任务、容易获得的真实数据和简单的评估指标,这限制了可以评估的任务范围。相比之下,DataSciBench的构建基础是更全面、更精心挑选的自然和具有挑战性的提示,以及不确定的真实数据和评估指标。我们开发了一个半自动化管道来生成真实数据(GT)并验证评估指标。该管道利用并实现了一种基于LLM的自洽和人类验证策略,通过利用收集的提示、预定义的任务类型和聚合功能(指标)来产生准确的GT。此外,我们提出了创新的Task-Function-Code(TFC)框架,根据精确定义的指标和程序规则来评估每个代码执行结果。我们的实验框架包括使用我们收集的多样提示来测试6个API模型、8个开源通用模型和9个开源代码生成模型。该方法旨在提供数据科学中LLM的更全面和严格评估,揭示其优缺点。实验结果表明,API模型在所有指标上均优于开源模型,Deepseek-Coder-33B-Instruct在开源模型中得分最高。我们在https://github.com/THUDM/DataSciBench上发布了所有代码和数据。
论文及项目相关链接
PDF 40 pages, 7 figures, 6 tables
Summary
DataSciBench是一个全面的评估大型语言模型(LLM)在数据科学方面的能力的基准测试。与现有的主要侧重于单一任务、易于获得真实标记和直观评估指标的基准测试相比,DataSciBench基于更全面和精选的自然和具有挑战性的提示构建,用于不确定的真实标记和评估指标。该研究开发了半自动化管道来生成真实标记和验证评估指标,并利用LLM的自洽性和人工验证策略来产生准确的真实标记。此外,提出了创新的Task-Function-Code(TFC)框架,根据精确定义的指标和程序规则来评估代码执行的结果。实验框架对各种模型进行了测试,包括API模型、开源通用模型和开源代码生成模型。旨在提供更全面、严格的LLM在数据科学方面的评估,揭示其优缺点。
Key Takeaways
- DataSciBench是一个用于评估LLM在数据科学方面能力的全面基准测试。
- 现有基准测试主要关注单一任务,而DataSciBench包含自然和具有挑战性的提示。
- 研究开发了一个半自动化管道来生成真实标记并验证评估指标。
- 利用LLM的自洽性和人工验证策略来产生准确的真实标记。
- 提出了Task-Function-Code(TFC)框架来评估代码执行的结果。
- 实验框架测试了多种类型的模型,包括API模型、开源通用模型和开源代码生成模型。
点此查看论文截图


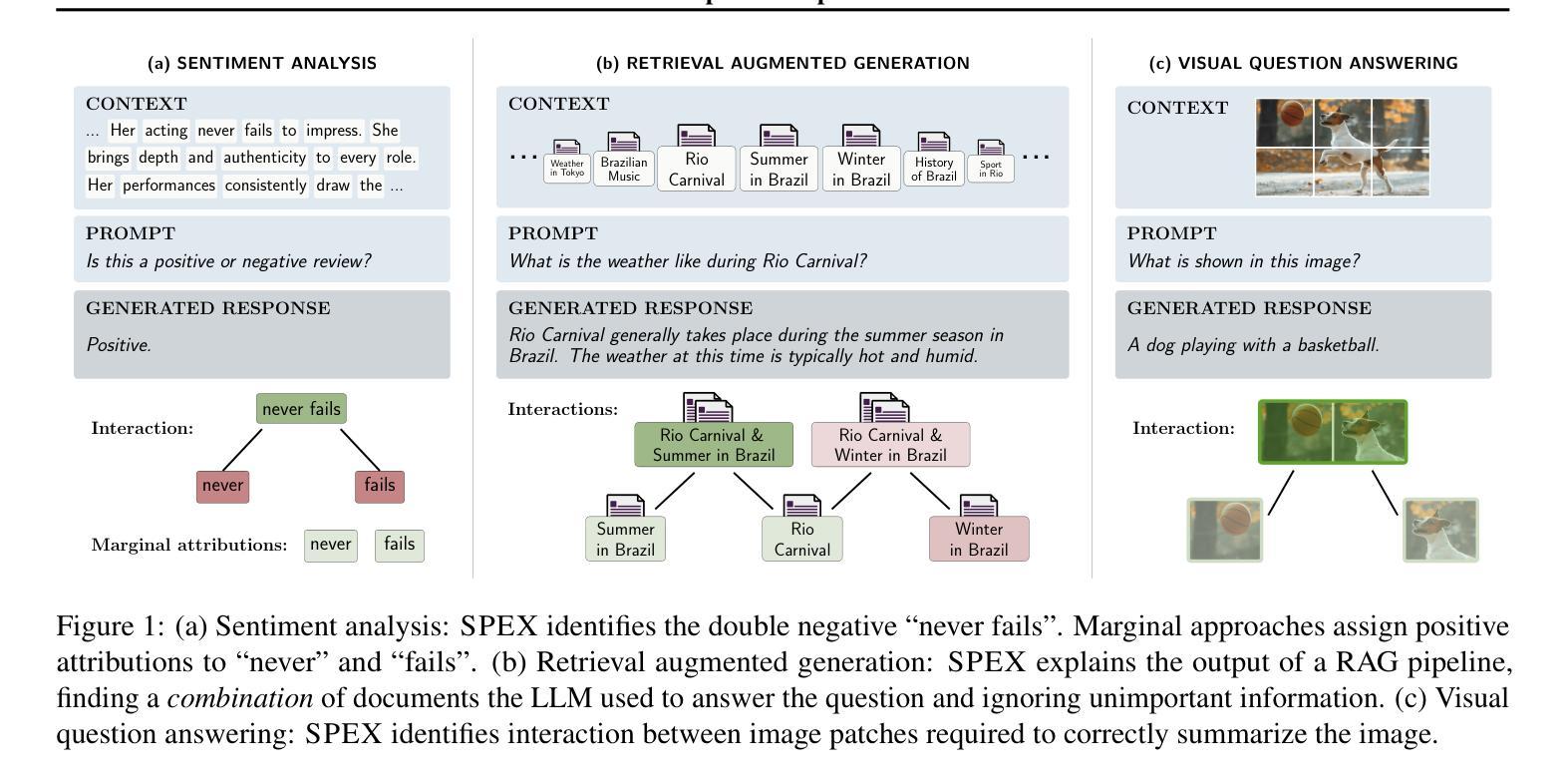
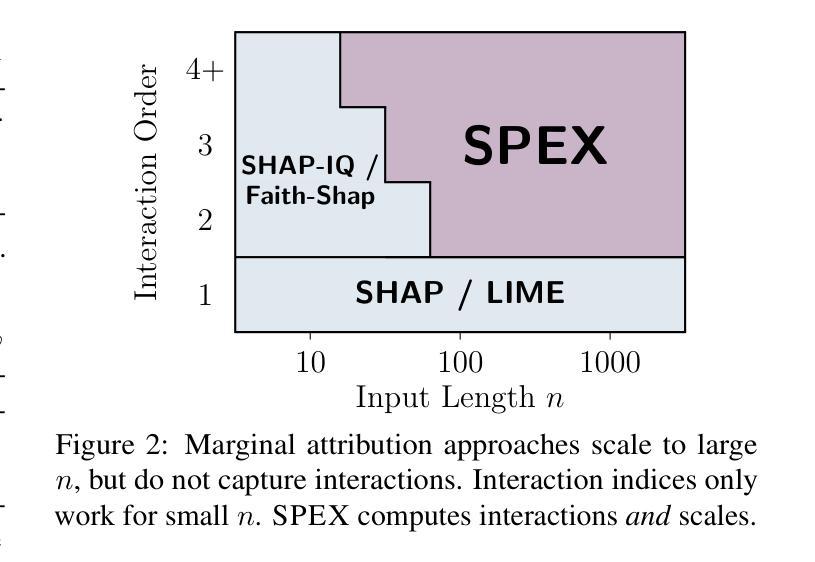
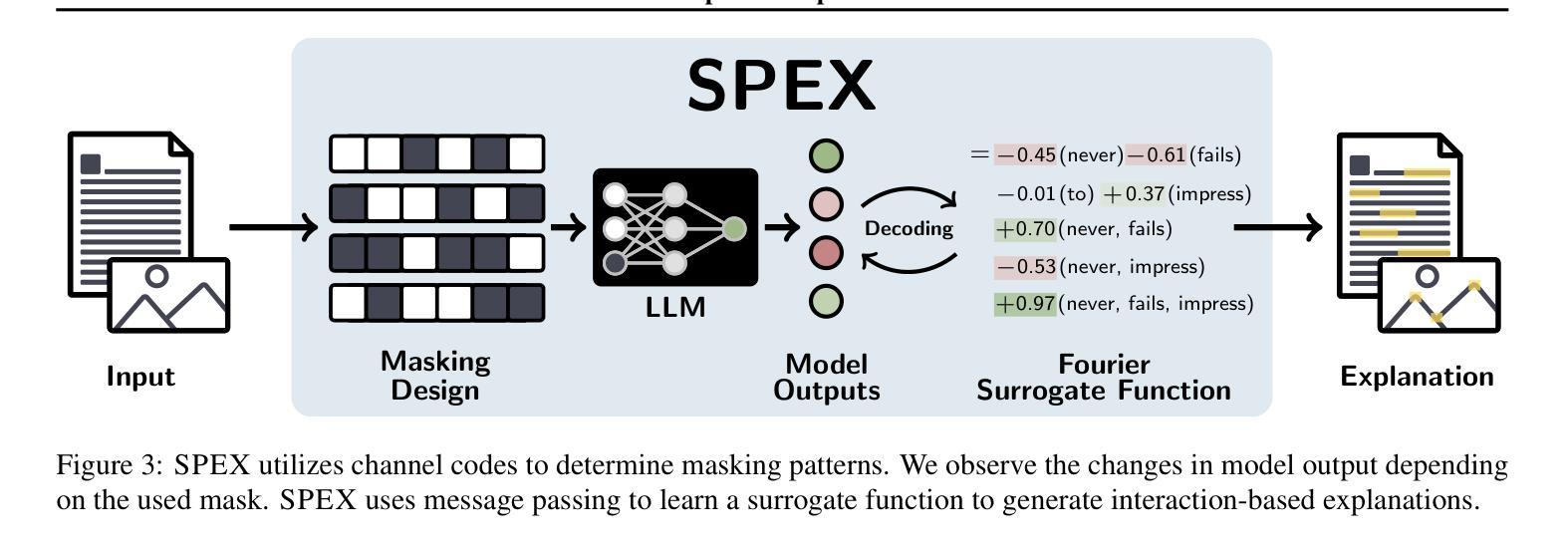
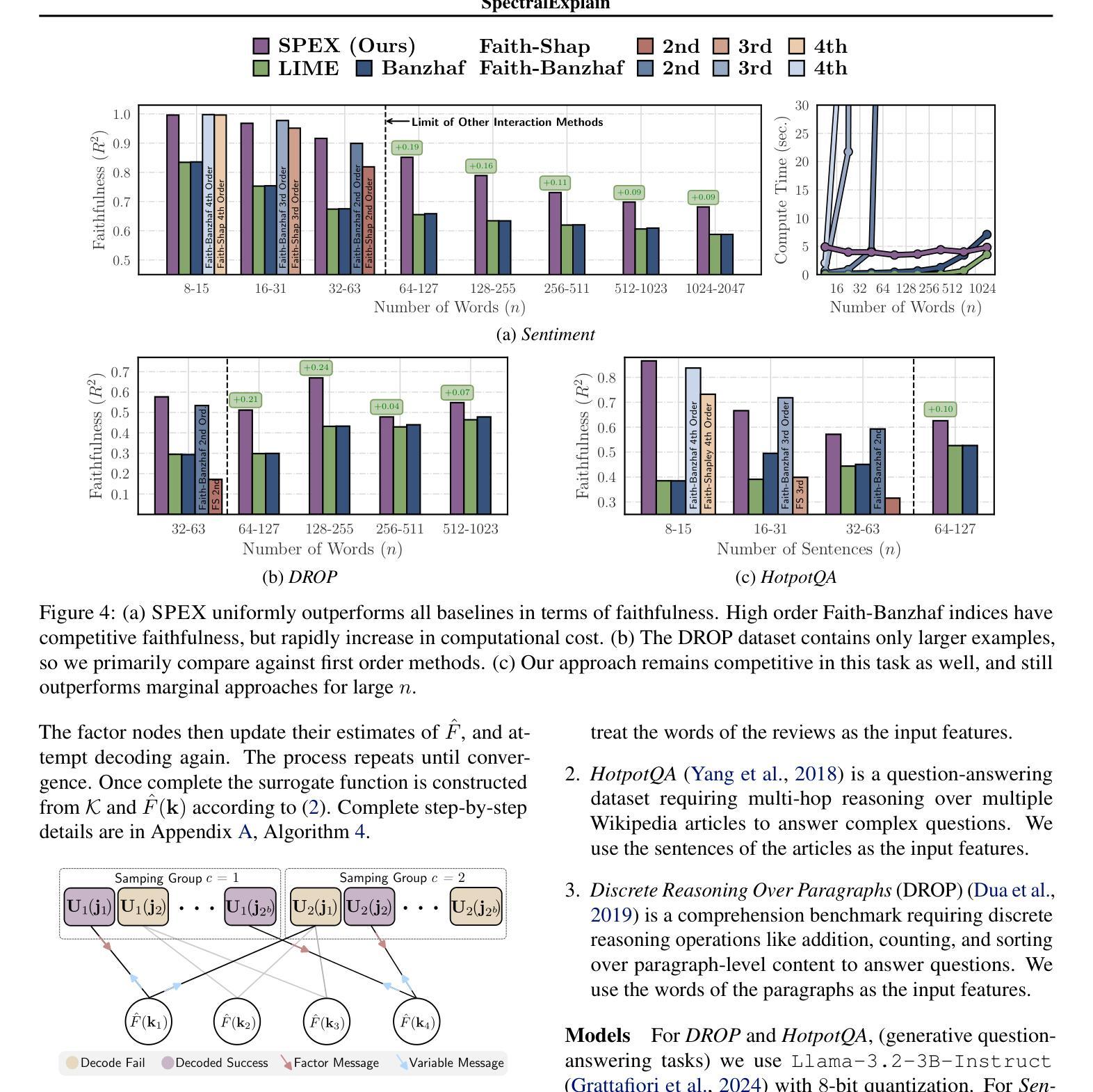
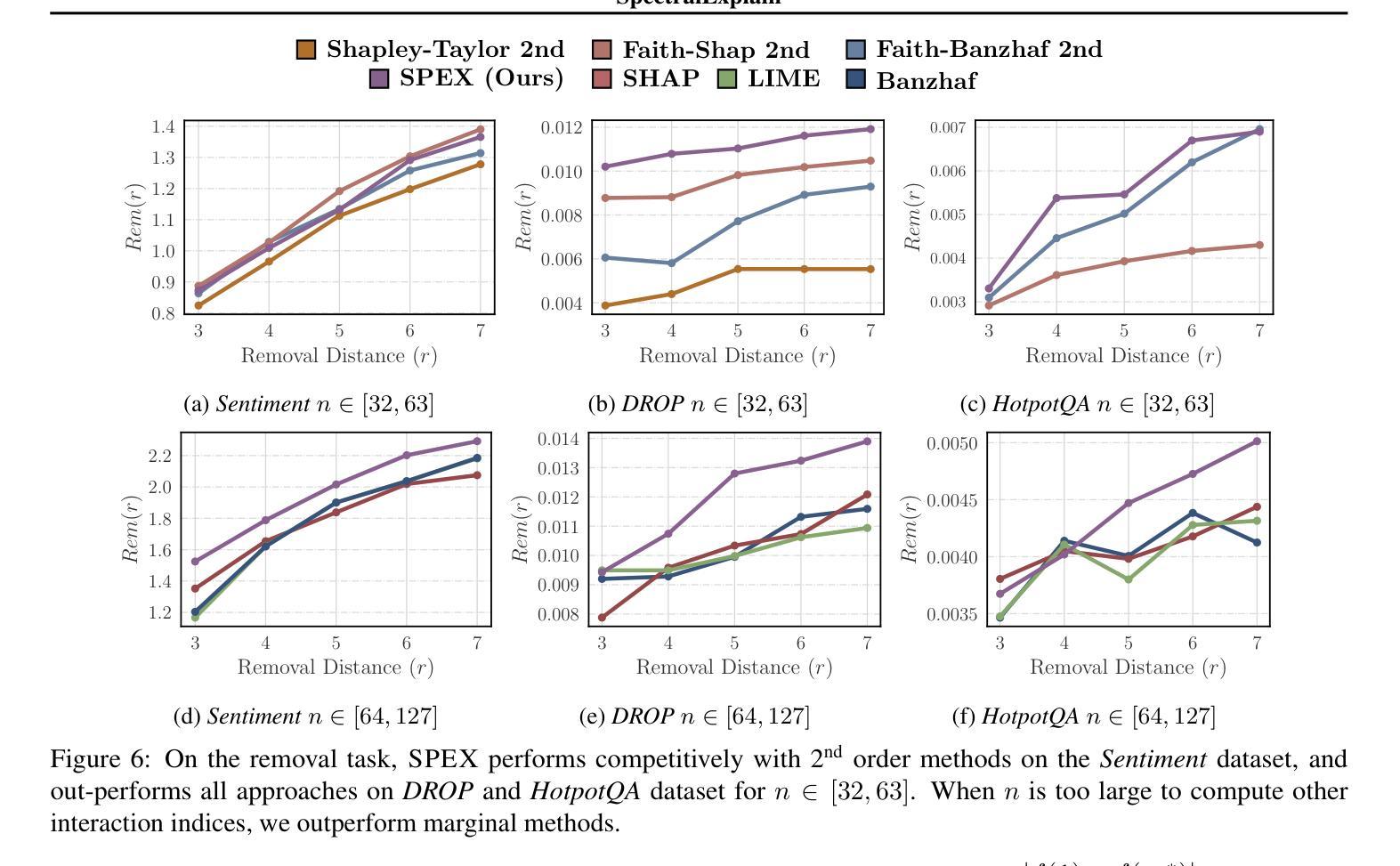
SPEX: Scaling Feature Interaction Explanations for LLMs
Authors:Justin Singh Kang, Landon Butler, Abhineet Agarwal, Yigit Efe Erginbas, Ramtin Pedarsani, Kannan Ramchandran, Bin Yu
Large language models (LLMs) have revolutionized machine learning due to their ability to capture complex interactions between input features. Popular post-hoc explanation methods like SHAP provide marginal feature attributions, while their extensions to interaction importances only scale to small input lengths ($\approx 20$). We propose Spectral Explainer (SPEX), a model-agnostic interaction attribution algorithm that efficiently scales to large input lengths ($\approx 1000)$. SPEX exploits underlying natural sparsity among interactions – common in real-world data – and applies a sparse Fourier transform using a channel decoding algorithm to efficiently identify important interactions. We perform experiments across three difficult long-context datasets that require LLMs to utilize interactions between inputs to complete the task. For large inputs, SPEX outperforms marginal attribution methods by up to 20% in terms of faithfully reconstructing LLM outputs. Further, SPEX successfully identifies key features and interactions that strongly influence model output. For one of our datasets, HotpotQA, SPEX provides interactions that align with human annotations. Finally, we use our model-agnostic approach to generate explanations to demonstrate abstract reasoning in closed-source LLMs (GPT-4o mini) and compositional reasoning in vision-language models.
大型语言模型(LLM)由于其捕捉输入特征之间复杂交互的能力,为机器学习带来了革命性的变革。像SHAP这样的流行事后解释方法提供边际特征归属,而它们对交互重要性的扩展只适用于较短的输入长度(约20个)。我们提出了Spectral Explainer(SPEX),这是一种模型无关的交互归属算法,可有效地扩展到较大的输入长度(约1000个)。SPEX利用现实世界中常见的交互之间的自然稀疏性,并应用一种稀疏傅里叶变换和通道解码算法来有效地识别重要的交互。我们在三个需要LLM利用输入间交互来完成任务的长文本数据集上进行了实验。对于大输入,SPEX在忠实重建LLM输出方面优于边际归属方法,准确率提高了高达20%。此外,SPEX成功地识别了强烈影响模型输出的关键特征和交互。在我们的数据集之一HotpotQA中,SPEX提供的交互与人类注释相符。最后,我们使用模型无关的方法生成解释,以展示封闭源代码LLM(GPT-4o mini)中的抽象推理和视觉语言模型中的组合推理。
论文及项目相关链接
Summary
大型语言模型(LLM)能够捕捉输入特征之间的复杂交互,从而引领机器学习革命。针对现有解释方法在处理长输入时的局限性,本文提出了Spectral Explainer(SPEX)方法。SPEX是一种模型通用的交互归因算法,可有效地扩展到长输入长度(约1000)。它通过利用现实世界中常见的交互自然稀疏性,采用稀疏傅里叶变换和通道解码算法来高效识别重要的交互。实验表明,SPEX在三个需要利用输入间交互来完成任务的长上下文数据集上的表现优于边际归因方法,忠实地重构了LLM输出。此外,SPEX还能成功识别影响模型输出的关键特征和交互。对于HotpotQA数据集,SPEX提供的交互与人类注释相符。最后,我们利用模型通用的方法为封闭源LLM(GPT-4o mini)和视觉语言模型的组合推理提供了解释。
Key Takeaways
- LLMs能够捕捉输入特征间的复杂交互,推动机器学习进步。
- 现有解释方法在处理长输入时存在局限性。
- Spectral Explainer (SPEX)是一种模型通用的交互归因算法,可扩展到长输入长度。
- SPEX利用交互的自然稀疏性,采用稀疏傅里叶变换和通道解码算法。
- SPEX在三个长上下文数据集上的表现优于边际归因方法。
- SPEX能识别影响模型输出的关键特征和交互。
点此查看论文截图

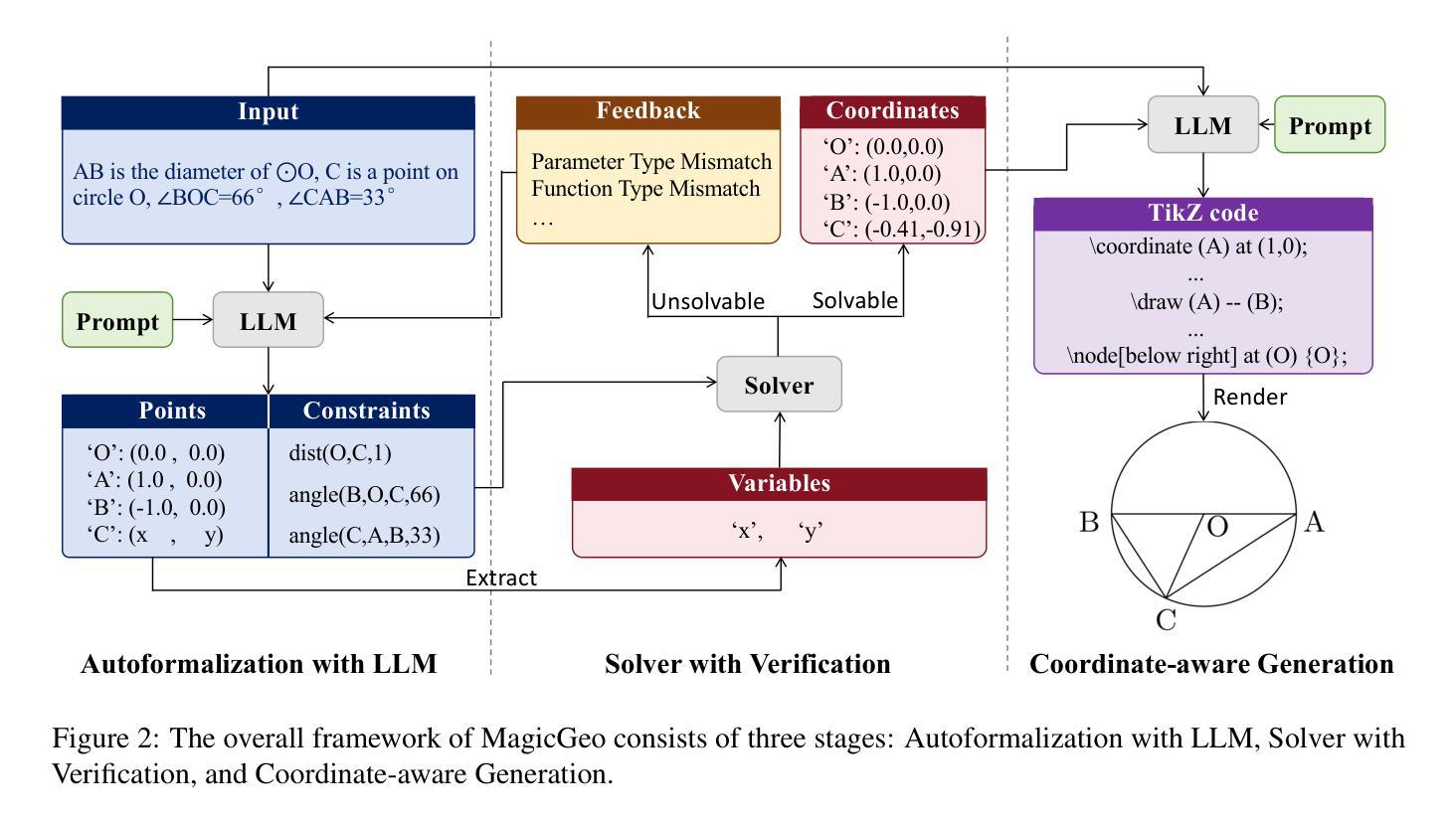
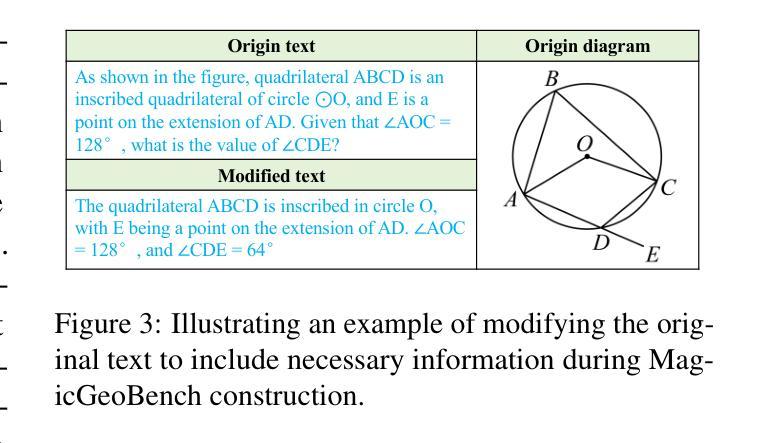
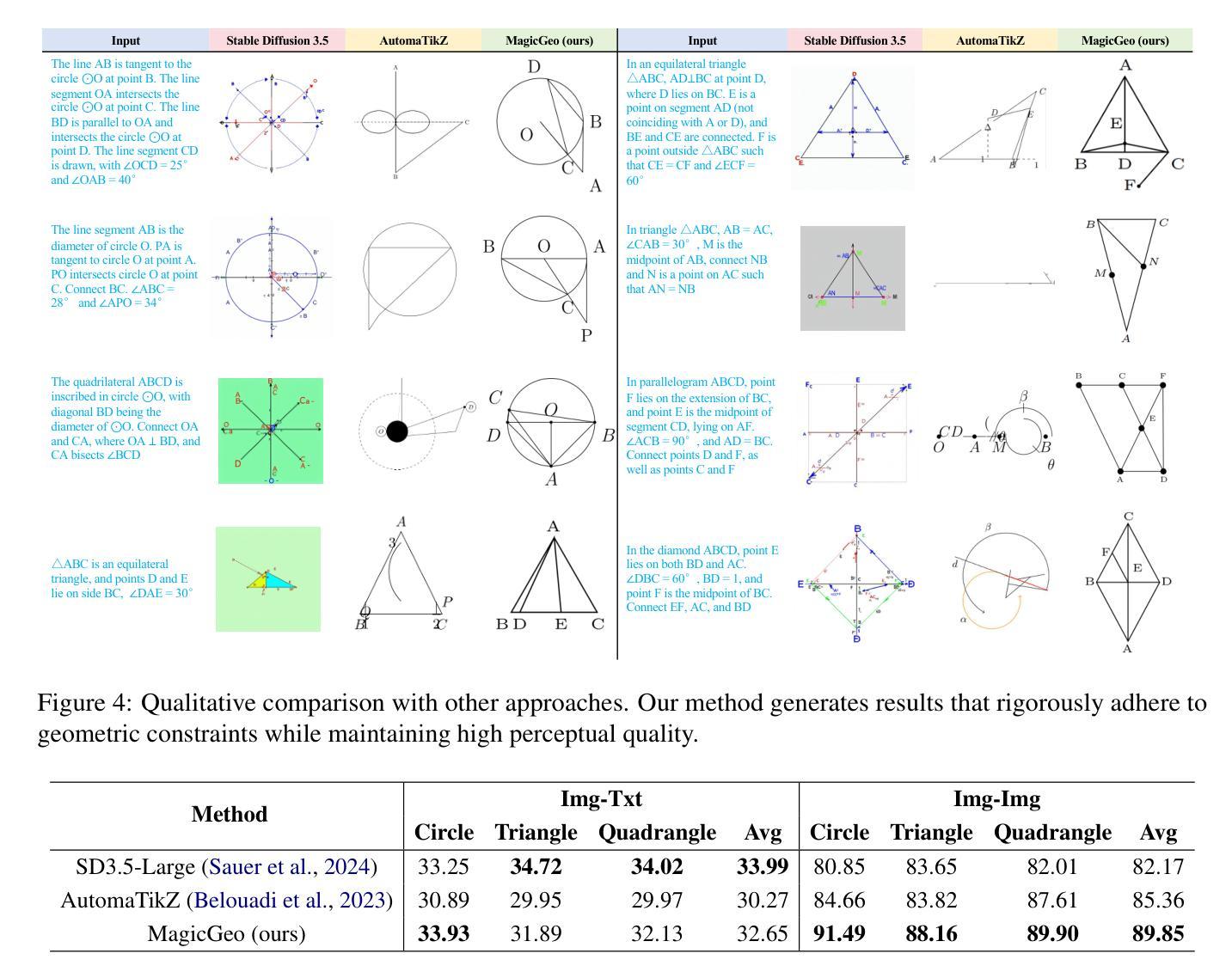
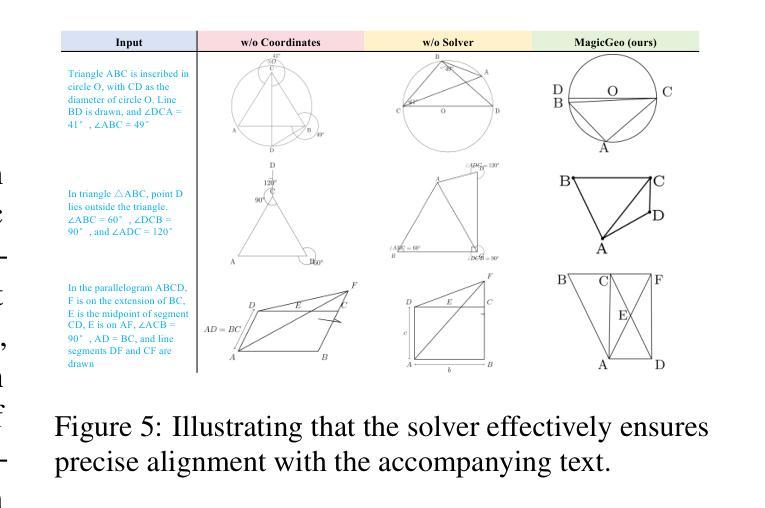
MagicGeo: Training-Free Text-Guided Geometric Diagram Generation
Authors:Junxiao Wang, Ting Zhang, Heng Yu, Jingdong Wang, Hua Huang
Geometric diagrams are critical in conveying mathematical and scientific concepts, yet traditional diagram generation methods are often manual and resource-intensive. While text-to-image generation has made strides in photorealistic imagery, creating accurate geometric diagrams remains a challenge due to the need for precise spatial relationships and the scarcity of geometry-specific datasets. This paper presents MagicGeo, a training-free framework for generating geometric diagrams from textual descriptions. MagicGeo formulates the diagram generation process as a coordinate optimization problem, ensuring geometric correctness through a formal language solver, and then employs coordinate-aware generation. The framework leverages the strong language translation capability of large language models, while formal mathematical solving ensures geometric correctness. We further introduce MagicGeoBench, a benchmark dataset of 220 geometric diagram descriptions, and demonstrate that MagicGeo outperforms current methods in both qualitative and quantitative evaluations. This work provides a scalable, accurate solution for automated diagram generation, with significant implications for educational and academic applications.
几何图表在传达数学和科学概念方面起着关键作用,然而传统的图表生成方法往往是手动且资源密集型的。尽管文本到图像的生成在照片级图像方面取得了进展,但由于需要精确的空间关系和几何特定数据集的稀缺,创建准确的几何图表仍然是一个挑战。本文针对这一问题,提出了一种无训练框架MagicGeo,用于根据文本描述生成几何图表。MagicGeo将图表生成过程表述为坐标优化问题,通过形式化语言求解器确保几何正确性,然后采用坐标感知生成。该框架利用大型语言模型的强大语言翻译能力,而形式化数学求解则确保了几何正确性。我们还进一步引入了MagicGeoBench数据集,包含220个几何图表描述,并证明MagicGeo在定性和定量评估中都优于当前方法。这项工作为自动化图表生成提供了可扩展且准确的解决方案,对教育应用和学术应用具有重要意义。
论文及项目相关链接
Summary
几何图形在传达数学和科学概念方面起着关键作用,但传统的图形生成方法往往是手动且资源密集型的。文本到图像生成技术在照片真实感图像方面取得了进展,但创建精确的几何图形仍然存在挑战,这主要是由于需要精确的空间关系以及几何数据集的稀缺性。本文提出了MagicGeo框架,这是一个无需训练的几何图形生成方法,可从文本描述中生成几何图形。MagicGeo将图形生成过程公式化为坐标优化问题,通过形式语言求解器确保几何正确性,然后采用坐标感知生成。该框架利用大型语言模型的强大语言翻译能力,同时形式数学求解确保几何正确性。我们还介绍了MagicGeoBench数据集,包含220个几何图形描述,并证明MagicGeo在定性和定量评估中均优于当前方法。这项研究为自动化图形生成提供了可扩展且准确的解决方案,对教育和学术应用具有重大影响。
Key Takeaways
- 几何图形在传达数学和科学概念时至关重要,但传统方法生成图形的过程通常是手动且耗资源的。
- 文本到图像生成技术在照片真实感图像方面有所进展,但生成精确几何图形仍然具有挑战性。
- MagicGeo框架能从文本描述中生成几何图形,且无需训练。
- MagicGeo将图形生成过程看作坐标优化问题,确保几何正确性。
- MagicGeo利用大型语言模型的翻译能力,并结合形式数学求解确保准确性。
- 引入了MagicGeoBench数据集,包含220个几何图形描述,用于评估生成方法的性能。
点此查看论文截图

Enhancing LLM-Based Recommendations Through Personalized Reasoning
Authors:Jiahao Liu, Xueshuo Yan, Dongsheng Li, Guangping Zhang, Hansu Gu, Peng Zhang, Tun Lu, Li Shang, Ning Gu
Current recommendation systems powered by large language models (LLMs) often underutilize their reasoning capabilities due to a lack of explicit logical structuring. To address this limitation, we introduce CoT-Rec, a framework that integrates Chain-of-Thought (CoT) reasoning into LLM-driven recommendations by incorporating two crucial processes: user preference analysis and item perception evaluation. CoT-Rec operates in two key phases: (1) personalized data extraction, where user preferences and item perceptions are identified, and (2) personalized data application, where this information is leveraged to refine recommendations. Our experimental analysis demonstrates that CoT-Rec improves recommendation accuracy by making better use of LLMs’ reasoning potential. The implementation is publicly available at https://anonymous.4open.science/r/CoT-Rec.
当前由大型语言模型(LLM)驱动的建议系统由于缺少明确的逻辑结构而往往未能充分利用其推理能力。为了解决这一局限性,我们引入了CoT-Rec框架,它通过融入两个关键过程——用户偏好分析和项目感知评估,将思维链(CoT)推理融入LLM驱动的建议中。CoT-Rec有两个关键阶段:1)个性化数据提取,识别用户偏好和项目感知;2) 个性化数据应用,利用这些信息来优化建议。我们的实验分析表明,CoT-Rec通过更好地利用LLM的推理潜力,提高了推荐准确性。实现代码公开在https://anonymous.4open.science/r/CoT-Rec。
论文及项目相关链接
PDF 7 pages, under review
Summary
基于大型语言模型(LLM)的推荐系统常常由于缺少明确的逻辑结构而无法充分利用其推理能力。为解决这一问题,我们提出CoT-Rec框架,通过引入Chain-of-Thought(CoT)推理,结合用户偏好分析和物品感知评估两个关键过程,提升LLM驱动的推荐系统性能。CoT-Rec包括两个主要阶段:个性化数据提取和个性化数据应用。实验分析显示,CoT-Rec能够更好地利用LLM的推理潜力,提高推荐准确性。其实现可公开访问。
Key Takeaways
- 大型语言模型(LLM)驱动的推荐系统存在推理能力利用不足的问题。
- CoT-Rec框架通过引入Chain-of-Thought(CoT)推理来解决这一问题。
- CoT-Rec结合用户偏好分析和物品感知评估两个关键过程。
- CoT-Rec包括个性化数据提取和个性化数据应用两个主要阶段。
- CoT-Rec能提高推荐系统的准确性。
- CoT-Rec的实现可公开访问。
- CoT-Rec为LLM在推荐系统中的应用提供了新的思路和方法。
点此查看论文截图

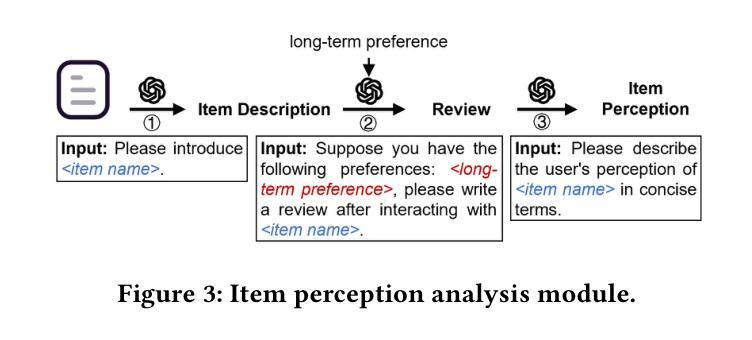
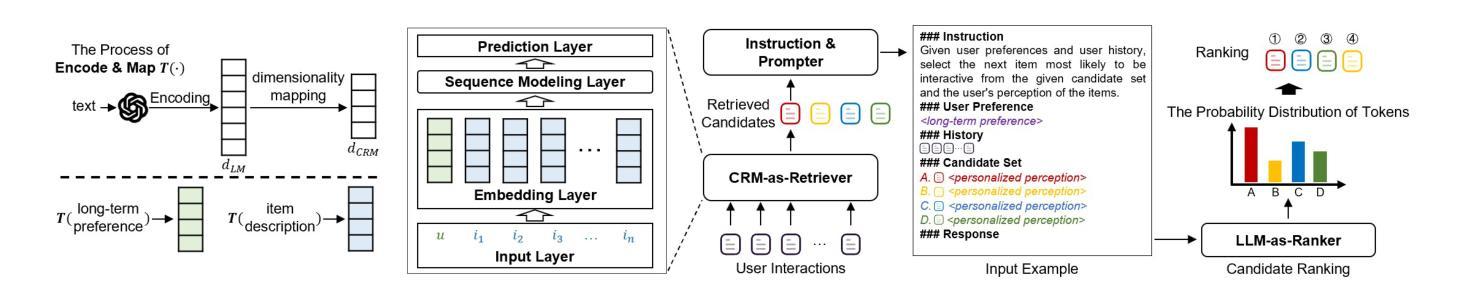
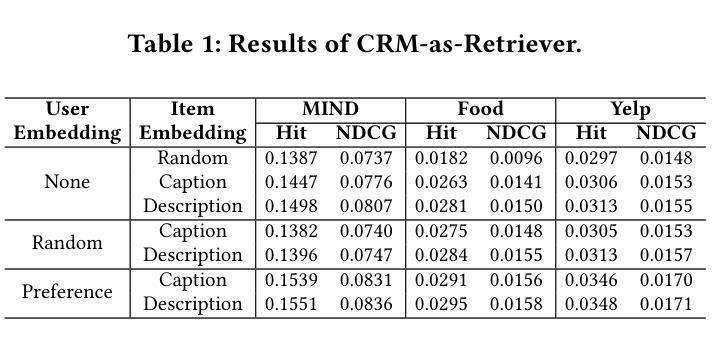
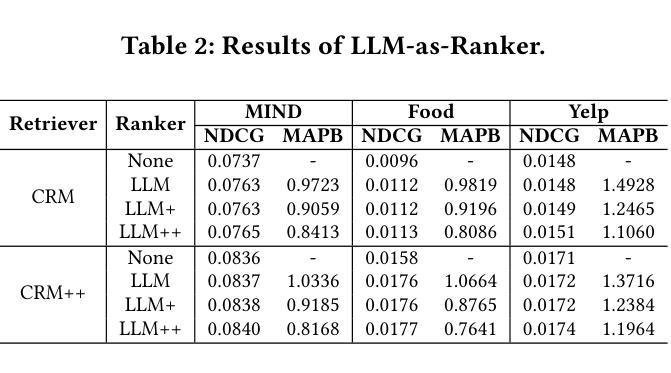
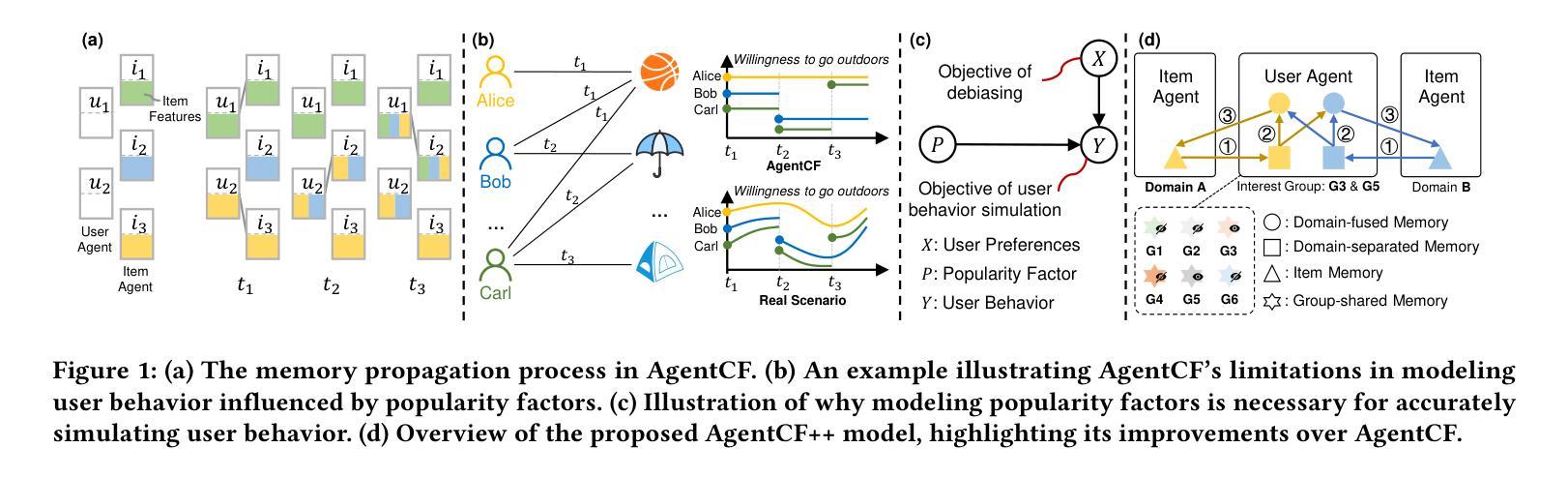
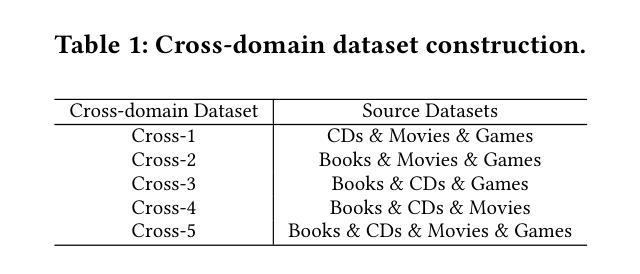
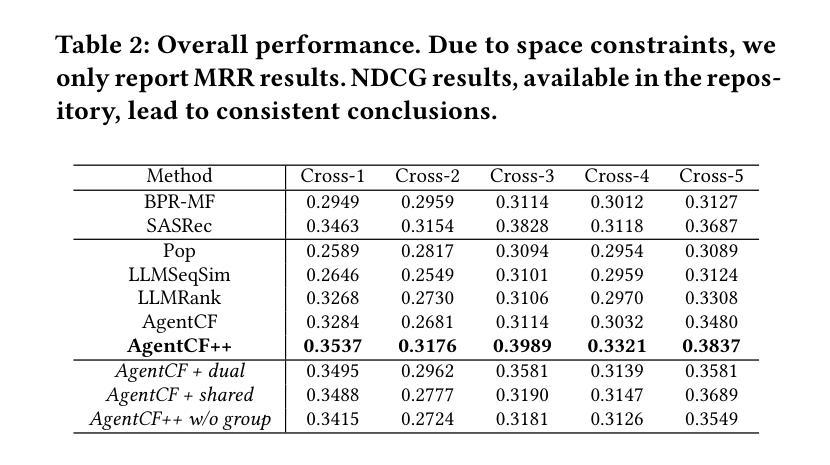
Enhancing Cross-Domain Recommendations with Memory-Optimized LLM-Based User Agents
Authors:Jiahao Liu, Shengkang Gu, Dongsheng Li, Guangping Zhang, Mingzhe Han, Hansu Gu, Peng Zhang, Tun Lu, Li Shang, Ning Gu
Large Language Model (LLM)-based user agents have emerged as a powerful tool for improving recommender systems by simulating user interactions. However, existing methods struggle with cross-domain scenarios due to inefficient memory structures, leading to irrelevant information retention and failure to account for social influence factors such as popularity. To address these limitations, we introduce AgentCF++, a novel framework featuring a dual-layer memory architecture and a two-step fusion mechanism to filter domain-specific preferences effectively. Additionally, we propose interest groups with shared memory, allowing the model to capture the impact of popularity trends on users with similar interests. Through extensive experiments on multiple cross-domain datasets, AgentCF++ demonstrates superior performance over baseline models, highlighting its effectiveness in refining user behavior simulation for recommender systems. Our code is available at https://anonymous.4open.science/r/AgentCF-plus.
基于大型语言模型(LLM)的用户代理已成为推荐系统改进的强大工具,通过模拟用户交互来实现。然而,现有方法在处理跨域场景时存在困难,由于内存结构不够高效,导致保留不相关信息以及未能考虑社会影响因素,如人气。为解决这些局限性,我们推出了AgentCF++,这是一个新型框架,具有双层内存架构和两步融合机制,可有效过滤特定域偏好。此外,我们提出了具有共享内存的兴趣小组,使模型能够捕捉流行趋势对具有相似兴趣用户的影响。通过多个跨域数据集的大量实验,AgentCF++在基准模型上表现出卓越性能,凸显其在改进推荐系统的用户行为模拟方面的有效性。我们的代码可在https://anonymous.4open.science/r/AgentCF-plus上找到。
论文及项目相关链接
PDF 6 pages, under review
Summary
大型语言模型(LLM)用户代理通过模拟用户交互增强了推荐系统的效能。然而,现有方法在处理跨域场景时存在内存结构低效的问题,导致保留不相关信息和忽略社会影响因素如流行度。为解决这些问题,我们推出AgentCF++框架,采用双层内存架构和两步融合机制,有效过滤特定域偏好。同时,我们提出兴趣小组共享内存,让模型能捕捉流行趋势对具有相似兴趣用户的影响。透过多次跨域数据集的实验,AgentCF++表现优于基准模型,展现其在推荐系统中优化用户行为模拟的效能。
Key Takeaways
- LLM用户代理模拟用户交互提升了推荐系统的效能。
- 现有方法在处理跨域场景时存在内存结构低效的问题。
- AgentCF++采用双层内存架构和两步融合机制过滤特定域偏好。
- AgentCF++通过兴趣小组共享内存捕捉流行趋势对相似兴趣用户的影响。
- AgentCF++在跨域数据集上的实验表现优于基准模型。
- AgentCF++能有效优化推荐系统中的用户行为模拟。
点此查看论文截图

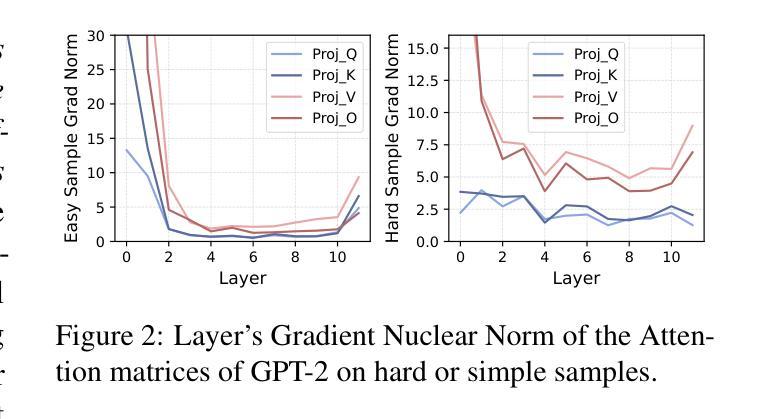
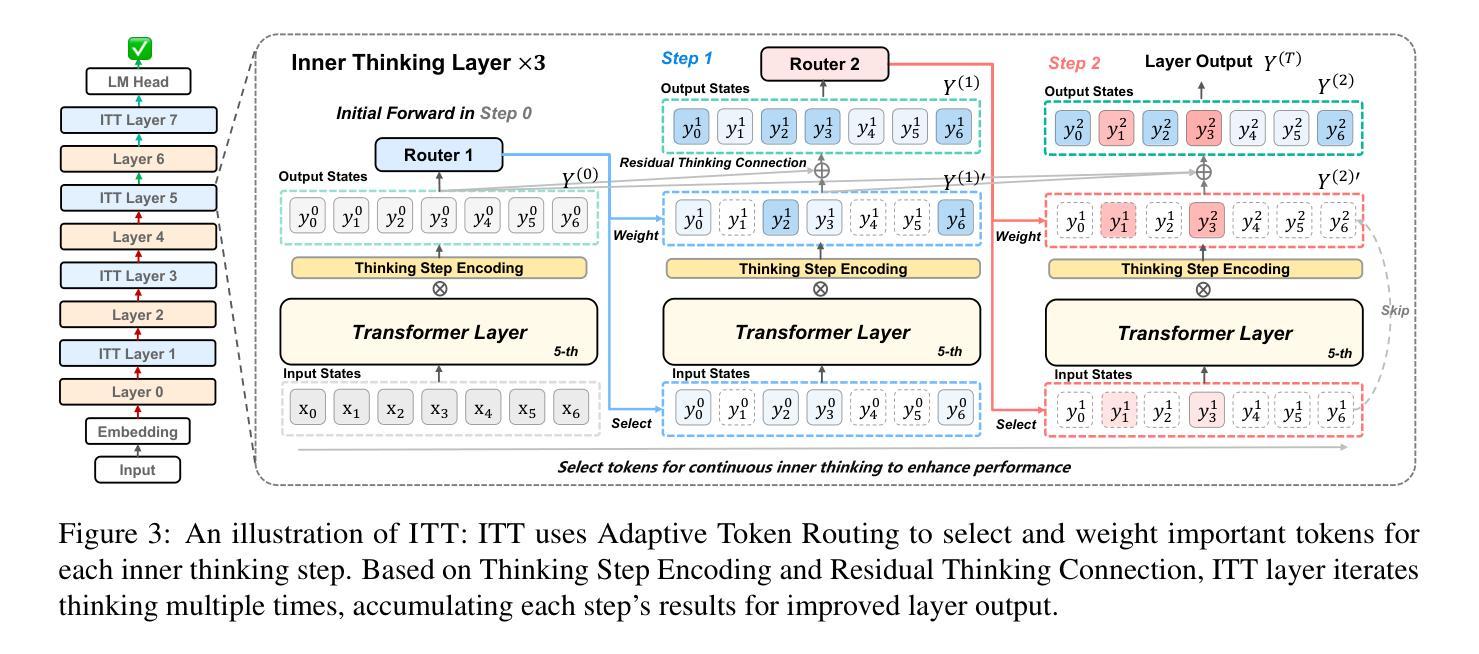
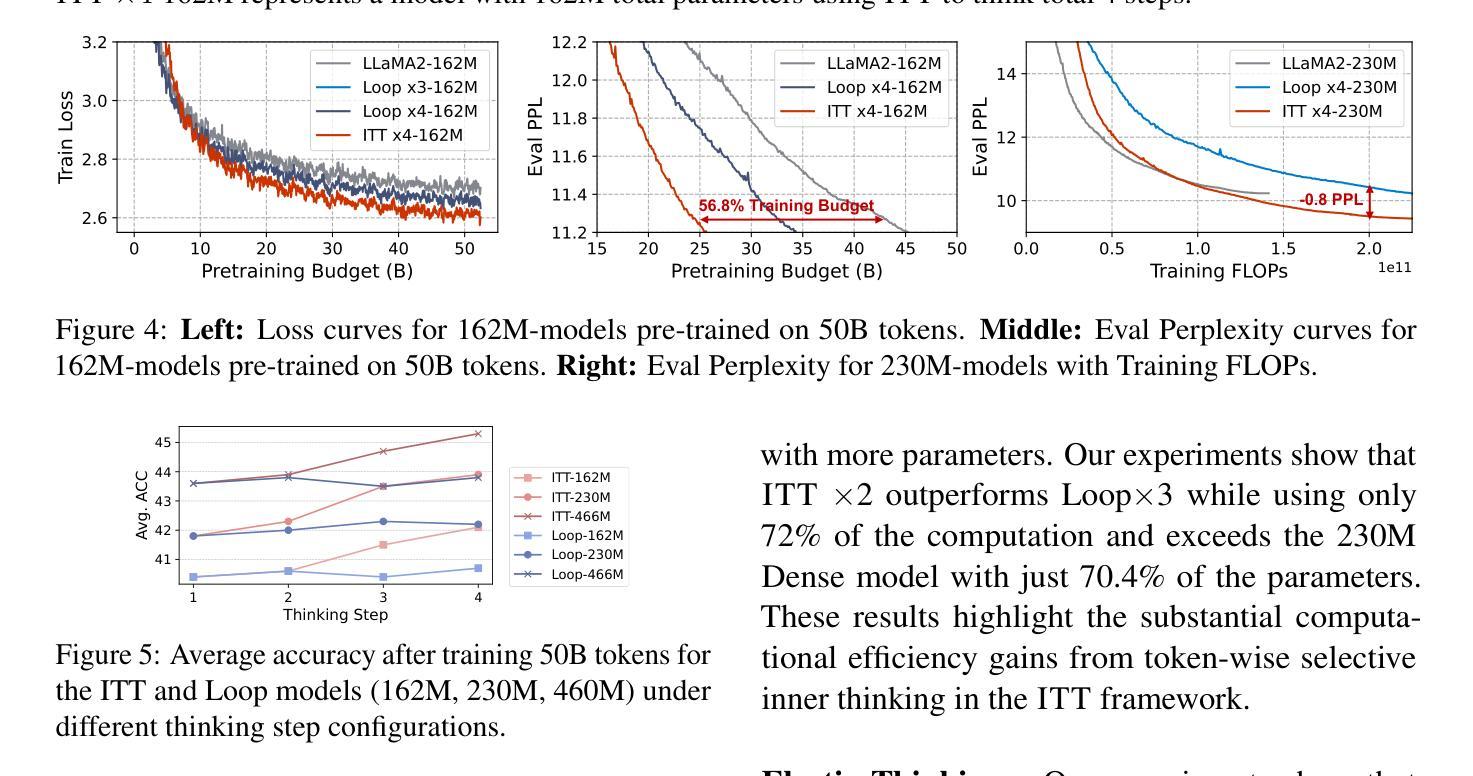
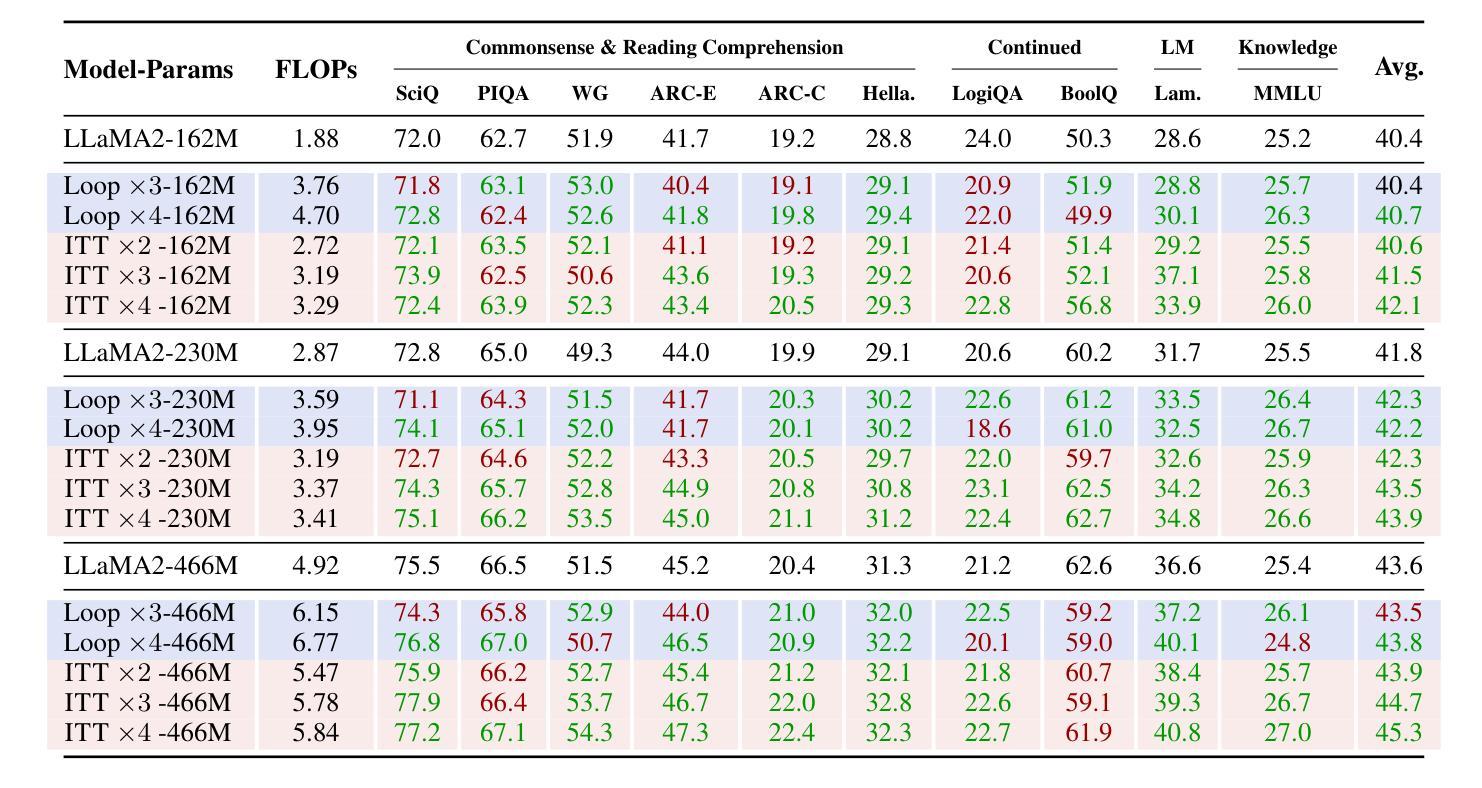
Inner Thinking Transformer: Leveraging Dynamic Depth Scaling to Foster Adaptive Internal Thinking
Authors:Yilong Chen, Junyuan Shang, Zhenyu Zhang, Yanxi Xie, Jiawei Sheng, Tingwen Liu, Shuohuan Wang, Yu Sun, Hua Wu, Haifeng Wang
Large language models (LLMs) face inherent performance bottlenecks under parameter constraints, particularly in processing critical tokens that demand complex reasoning. Empirical analysis reveals challenging tokens induce abrupt gradient spikes across layers, exposing architectural stress points in standard Transformers. Building on this insight, we propose Inner Thinking Transformer (ITT), which reimagines layer computations as implicit thinking steps. ITT dynamically allocates computation through Adaptive Token Routing, iteratively refines representations via Residual Thinking Connections, and distinguishes reasoning phases using Thinking Step Encoding. ITT enables deeper processing of critical tokens without parameter expansion. Evaluations across 162M-466M parameter models show ITT achieves 96.5% performance of a 466M Transformer using only 162M parameters, reduces training data by 43.2%, and outperforms Transformer/Loop variants in 11 benchmarks. By enabling elastic computation allocation during inference, ITT balances performance and efficiency through architecture-aware optimization of implicit thinking pathways.
大型语言模型(LLM)在参数约束下存在固有的性能瓶颈,特别是在处理需要复杂推理的关键令牌时。经验分析表明,挑战令牌会在各层之间引发突然的梯度跃升,暴露了标准Transformer中的架构应力点。基于这一见解,我们提出了内思考Transformer(ITT),它重新构想层计算为隐式思考步骤。ITT通过自适应令牌路由动态分配计算,通过剩余思考连接迭代优化表示,并使用思考步骤编码来区分推理阶段。ITT能够在不扩大参数的情况下对关键令牌进行更深的处理。在1.6亿至近4亿参数模型的评估中,ITT使用仅近一半的参数(近4亿参数模型中的仅一半),实现了对标准模型的近九成半性能(即近百分之九十六点五),减少了百分之四十三点二的训练数据,并在十二个基准测试中优于Transformer或循环变体。通过启用推理过程中的弹性计算分配,ITT通过架构优化的隐性思考路径在性能和效率之间取得平衡。
论文及项目相关链接
PDF 15 pages, 11 figures
Summary
内蕴思考转换器(ITT)解决了大型语言模型(LLM)在处理关键令牌时的性能瓶颈问题。通过重新设计转换器架构中的层计算为隐性思考步骤,ITT能够动态分配计算资源以处理复杂推理需求的令牌。在关键令牌处理上,ITT不需要额外的参数扩展即可实现深度处理。实验评估显示,ITT能够实现仅使用较少参数的高效性能表现,且可降低训练数据量,同时满足多样化的基准测试要求。在推理过程中,ITT可弹性分配计算资源,实现性能与效率的平衡优化。
Key Takeaways
- 大型语言模型(LLM)在处理关键令牌时面临性能瓶颈问题。
- 关键令牌处理需要复杂推理,导致梯度波动和架构压力。
- 内蕴思考转换器(ITT)通过隐性思考步骤重新设计转换器架构中的层计算来解决上述问题。
- ITT实现了在不需要额外参数扩展的情况下对关键令牌的深度处理。
- ITT在减少参数使用和训练数据量方面表现出卓越性能。
- ITT能够在推理过程中动态分配计算资源以实现性能与效率的平衡优化。
点此查看论文截图

Quantifying Memorization and Retriever Performance in Retrieval-Augmented Vision-Language Models
Authors:Peter Carragher, Abhinand Jha, R Raghav, Kathleen M. Carley
Large Language Models (LLMs) demonstrate remarkable capabilities in question answering (QA), but metrics for assessing their reliance on memorization versus retrieval remain underdeveloped. Moreover, while finetuned models are state-of-the-art on closed-domain tasks, general-purpose models like GPT-4o exhibit strong zero-shot performance. This raises questions about the trade-offs between memorization, generalization, and retrieval. In this work, we analyze the extent to which multimodal retrieval-augmented VLMs memorize training data compared to baseline VLMs. Using the WebQA benchmark, we contrast finetuned models with baseline VLMs on multihop retrieval and question answering, examining the impact of finetuning on data memorization. To quantify memorization in end-to-end retrieval and QA systems, we propose several proxy metrics by investigating instances where QA succeeds despite retrieval failing. Our results reveal the extent to which finetuned models rely on memorization. In contrast, retrieval-augmented VLMs have lower memorization scores, at the cost of accuracy (72% vs 52% on WebQA test set). As such, our measures pose a challenge for future work to reconcile memorization and generalization in both Open-Domain QA and joint Retrieval-QA tasks.
大型语言模型(LLM)在问答(QA)方面表现出卓越的能力,但在评估它们对记忆与检索的依赖程度方面的度量标准仍然不够成熟。虽然针对封闭领域的任务微调模型是最新技术,但像GPT-4o这样的通用模型表现出强大的零样本性能。这引发了关于记忆、泛化和检索之间的权衡问题。在这项工作中,我们分析了多模态检索增强型VLMs与基准VLMs在记忆训练数据方面的程度。我们使用WebQA基准测试,对比微调模型与基准VLM在多跳检索和问答方面的表现,研究微调对数据记忆的影响。为了量化端到端检索和问答系统中记忆的程度,我们通过研究问答成功而检索失败的情况,提出了几个代理度量标准。我们的结果表明微调模型在多大程度上依赖于记忆。相比之下,检索增强型VLM的记忆得分较低,但代价是准确性下降(在WebQA测试集上为72%对52%)。因此,我们的度量措施为未来工作带来了挑战,需要在开放域问答和联合检索-问答任务中协调记忆和泛化。
论文及项目相关链接
Summary
基于大型语言模型(LLM)在问答(QA)方面的出色表现,本研究探讨了评估模型对记忆与检索依赖性的度量方法。研究对比了微调模型与通用模型如GPT-4o在封闭领域任务与零样本任务上的表现,提出了关于记忆、泛化与检索之间权衡的问题。本研究分析了多模态检索增强型VLM模型与基准VLM模型在记忆训练数据方面的差异。通过WebQA基准测试,本研究对比了多跳检索与问答中微调模型的表现,并考察了微调对数据记忆的影响。为量化端到端检索和问答系统中记忆的存储程度,我们提出通过探究问答成功但检索失败的情况来评估代理指标。研究结果显示,微调模型高度依赖记忆。相比之下,检索增强型VLM模型的记忆得分较低,但代价是准确率下降(WebQA测试集上为72%对比52%)。因此,我们的度量措施为未来工作带来了挑战,需要在开放域问答和联合检索问答任务中协调记忆与泛化能力。
Key Takeaways
- LLM在问答任务中表现出强大的能力,但在评估模型对记忆与检索依赖性的度量方法上仍有待发展。
- 对比分析微调模型与通用模型在封闭领域任务与零样本任务上的表现,引发对记忆、泛化与检索之间权衡的思考。
- 多模态检索增强型VLM模型相较于基准VLM模型在记忆训练数据上的差异被分析。
- 使用WebQA基准测试评估了多跳检索与问答中微调模型的表现。
- 提出了通过探究问答成功但检索失败的情况来量化模型中记忆的存储程度的新方法。
- 研究发现微调模型高度依赖记忆来完成任务。
点此查看论文截图

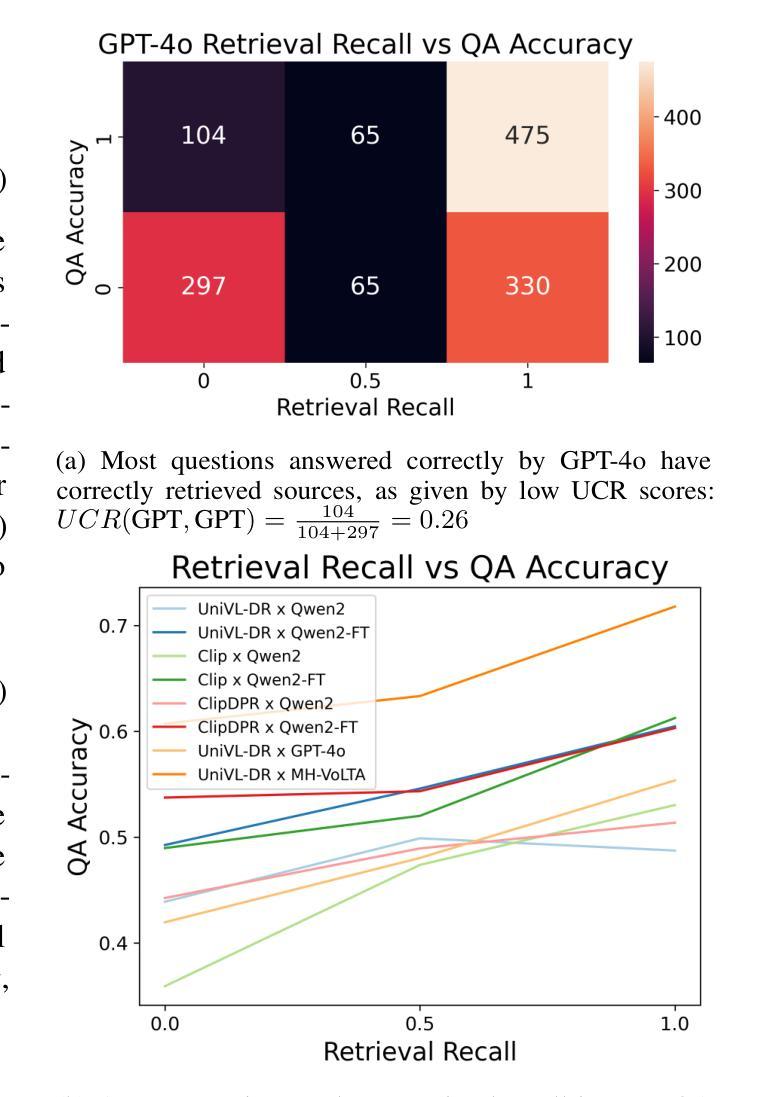
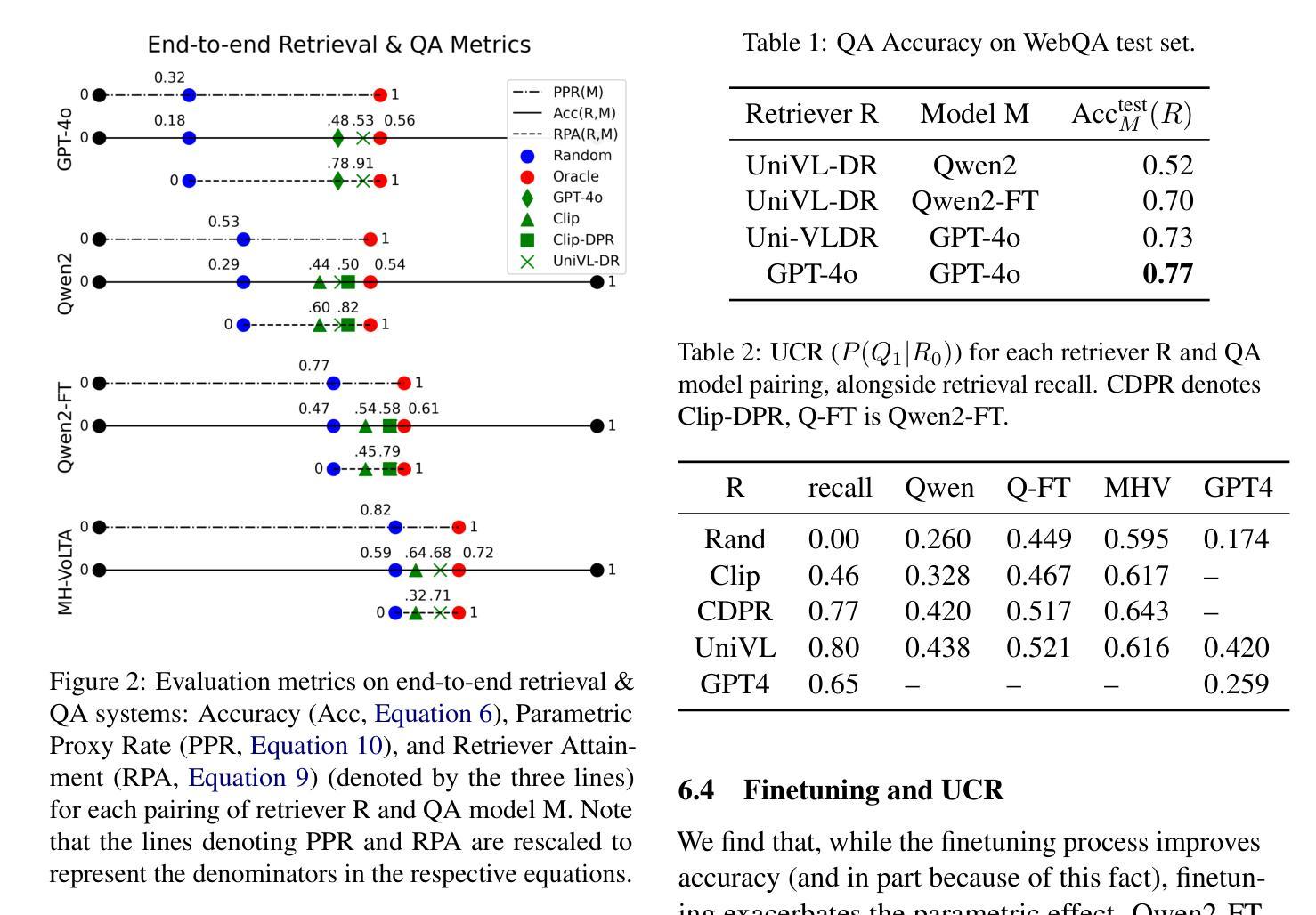
Proving Olympiad Inequalities by Synergizing LLMs and Symbolic Reasoning
Authors:Zenan Li, Zhaoyu Li, Wen Tang, Xian Zhang, Yuan Yao, Xujie Si, Fan Yang, Kaiyu Yang, Xiaoxing Ma
Large language models (LLMs) can prove mathematical theorems formally by generating proof steps (\textit{a.k.a.} tactics) within a proof system. However, the space of possible tactics is vast and complex, while the available training data for formal proofs is limited, posing a significant challenge to LLM-based tactic generation. To address this, we introduce a neuro-symbolic tactic generator that synergizes the mathematical intuition learned by LLMs with domain-specific insights encoded by symbolic methods. The key aspect of this integration is identifying which parts of mathematical reasoning are best suited to LLMs and which to symbolic methods. While the high-level idea of neuro-symbolic integration is broadly applicable to various mathematical problems, in this paper, we focus specifically on Olympiad inequalities (Figure~1). We analyze how humans solve these problems and distill the techniques into two types of tactics: (1) scaling, handled by symbolic methods, and (2) rewriting, handled by LLMs. In addition, we combine symbolic tools with LLMs to prune and rank the proof goals for efficient proof search. We evaluate our framework on 161 challenging inequalities from multiple mathematics competitions, achieving state-of-the-art performance and significantly outperforming existing LLM and symbolic approaches without requiring additional training data.
大型语言模型(LLM)可以通过在证明系统内生成证明步骤(即策略)来形式化地证明数学定理。然而,可能的策略空间是庞大而复杂的,而可用于形式化证明的训练数据是有限的,这给基于LLM的策略生成带来了重大挑战。为了解决这一问题,我们引入了一种神经符号策略生成器,它协同LLM习得的数学直觉和符号方法编码的领域特定见解。这种集成的关键方面在于确定哪些部分的数学推理最适合LLM,哪些适合符号方法。虽然神经符号集成的高级理念广泛适用于各种数学问题,但在本文中,我们专门针对奥林匹克不等式(图1)进行研究。我们分析了人类如何解决这些问题,并将技术提炼为两种类型的策略:1)缩放,由符号方法处理;2)重写,由LLM处理。此外,我们将符号工具与LLM相结合,以修剪和排列证明目标,实现高效的证明搜索。我们在多个数学竞赛的161个具有挑战的不等式中评估了我们的框架,实现了最先进的性能,并且显著优于现有的LLM和符号方法,而无需额外的训练数据。
论文及项目相关链接
PDF Published as a conference paper at ICLR 2025. Code is available at https://github.com/Lizn-zn/NeqLIPS/
Summary
大型语言模型(LLM)可以通过在证明系统内生成证明步骤(即策略)来证明数学定理。然而,可能的策略空间庞大且复杂,而可用于正式证明的训练数据有限,给LLM的策略生成带来了重大挑战。为解决这一问题,我们提出了一种神经符号策略生成器,它将LLM学习的数学直觉与符号方法编码的领域特定见解相结合。此集成的关键方面在于确定哪些部分的数学推理最适合LLM,哪些适合符号方法。虽然神经符号集成的高级理念广泛适用于各种数学问题,但本文重点关注奥林匹克不等式(图1)。我们分析了人类如何解决这些问题,并将技术提炼为两种策略:一是通过符号方法处理的缩放,二是通过LLM处理的重写。此外,我们将符号工具与LLM相结合,对证明目标进行修剪和排名,以进行有效证明搜索。我们在多个数学竞赛的161个具有挑战的不等式中评估了我们的框架,实现了卓越的性能,显著优于现有的LLM和符号方法,而无需额外的训练数据。
Key Takeaways
- LLM能够通过生成证明步骤(即策略)在数学证明中发挥重要作用。
- 在有限的训练数据下,策略生成面临挑战,因为策略空间庞大且复杂。
- 提出了一种神经符号策略生成器来解决这一挑战,结合了LLM的数学直觉和符号方法的领域特定知识。
- 确定哪些数学推理部分适合LLM和哪些适合符号方法是集成的关键。
- 通过分析人类解决奥林匹克不等式的方法,将策略分为缩放和重写两种类型。
- 结合符号工具和LLM对证明目标进行修剪和排名,提高了证明搜索的效率。
点此查看论文截图


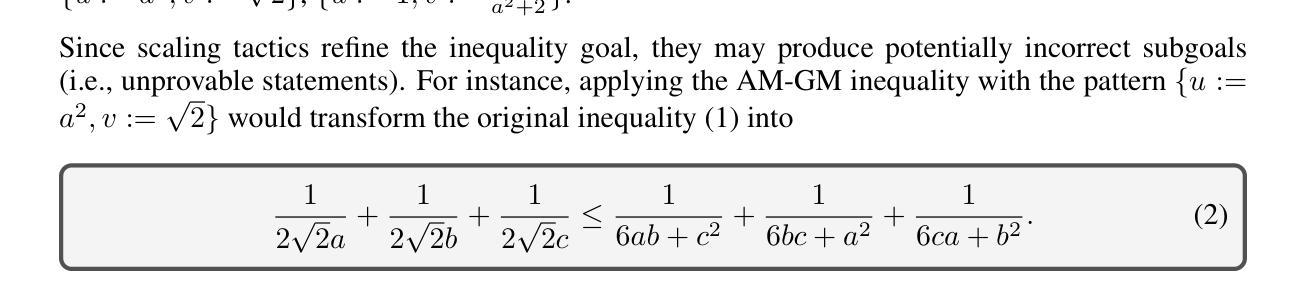


ArtMentor: AI-Assisted Evaluation of Artworks to Explore Multimodal Large Language Models Capabilities
Authors:Chanjin Zheng, Zengyi Yu, Yilin Jiang, Mingzi Zhang, Xunuo Lu, Jing Jin, Liteng Gao
Can Multimodal Large Language Models (MLLMs), with capabilities in perception, recognition, understanding, and reasoning, function as independent assistants in art evaluation dialogues? Current MLLM evaluation methods, which rely on subjective human scoring or costly interviews, lack comprehensive coverage of various scenarios. This paper proposes a process-oriented Human-Computer Interaction (HCI) space design to facilitate more accurate MLLM assessment and development. This approach aids teachers in efficient art evaluation while also recording interactions for MLLM capability assessment. We introduce ArtMentor, a comprehensive space that integrates a dataset and three systems to optimize MLLM evaluation. The dataset consists of 380 sessions conducted by five art teachers across nine critical dimensions. The modular system includes agents for entity recognition, review generation, and suggestion generation, enabling iterative upgrades. Machine learning and natural language processing techniques ensure the reliability of evaluations. The results confirm GPT-4o’s effectiveness in assisting teachers in art evaluation dialogues. Our contributions are available at https://artmentor.github.io/.
多模态大型语言模型(MLLMs)具备感知、识别、理解和推理能力,能否在艺术评价对话中充当独立助手?目前的MLLM评估方法依赖于主观的人为打分或昂贵的面试,无法全面覆盖各种场景。本文提出了一种面向过程的计算机人机交互(HCI)空间设计,以促进更准确的多模态语言模型评估和发展。这种方法不仅有助于教师高效地进行艺术评价,同时记录交互情况以评估MLLM的能力。我们介绍了ArtMentor,这是一个综合空间,集成了数据集和三个系统以优化MLLM评估。数据集包含五位艺术教师进行的380个会话,涵盖九个关键维度。模块化系统包括实体识别代理、评论生成代理和建议生成代理,可实现迭代升级。机器学习和自然语言处理技术确保了评价的可靠性。结果证实了GPT-4o在艺术评价对话中辅助教师的有效性。我们的成果可通过https://artmentor.github.io/访问。
论文及项目相关链接
PDF 18 pages, 12 figures. Accepted by CHI 2025
Summary
MLLM在感知、识别、理解和推理方面的能力使其能够成为艺术评价对话中的独立助手。当前的评价方法缺乏对各种场景的全面覆盖,本文提出了一种面向过程的计算机与人类交互空间设计,以促进更准确的MLLM评估和发展。我们介绍了ArtMentor,这是一个集成了数据集和三重系统的综合空间,用于优化MLLM评价。通过机器学习与自然语言处理技术确保评价的可靠性。最终确认GPT-4o可有效辅助教师进行艺术评价对话。
Key Takeaways
- MLLM具备多种能力,可成为艺术评价对话的独立助手。
- 当前MLLM评价方法的局限性,需要更全面的场景覆盖。
- 面向过程的计算机与人类交互空间设计用于更准确评估和发展MLLM。
- ArtMentor是一个综合空间,集成了数据集和多重系统以优化MLLM评价。
- ArtMentor数据集包含380个由五位艺术教师进行的会话,涉及九个关键维度。
- ArtMentor的模块化系统包括实体识别、评论生成和建议生成代理,可实现迭代升级。
点此查看论文截图

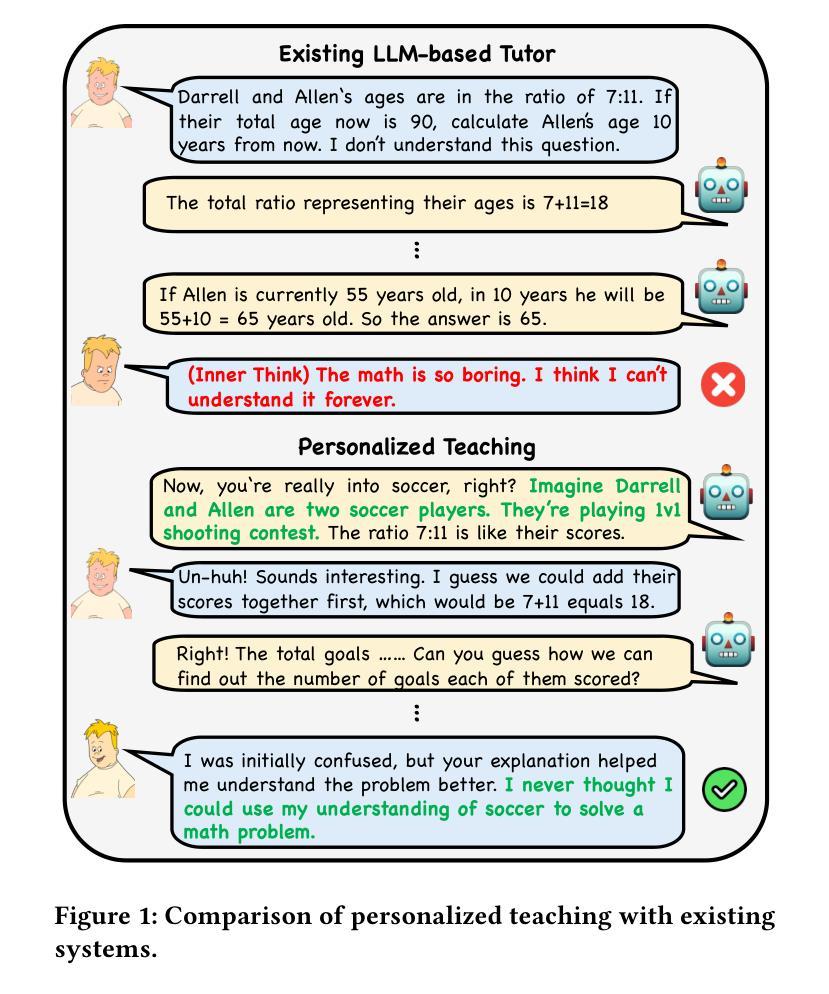
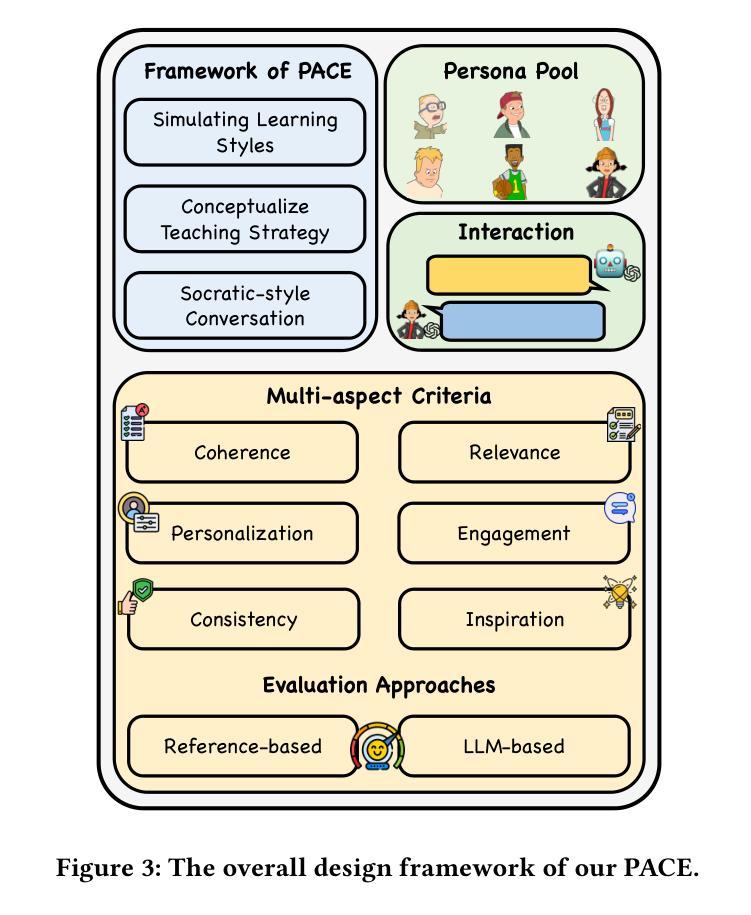
One Size doesn’t Fit All: A Personalized Conversational Tutoring Agent for Mathematics Instruction
Authors:Ben Liu, Jihan Zhang, Fangquan Lin, Xu Jia, Min Peng
Large language models (LLMs) have been increasingly employed in various intelligent educational systems, simulating human tutors to facilitate effective human-machine interaction. However, previous studies often overlook the significance of recognizing and adapting to individual learner characteristics. Such adaptation is crucial for enhancing student engagement and learning efficiency, particularly in mathematics instruction, where diverse learning styles require personalized strategies to promote comprehension and enthusiasm. In this paper, we propose a \textbf{P}erson\textbf{A}lized \textbf{C}onversational tutoring ag\textbf{E}nt (PACE) for mathematics instruction. PACE simulates students’ learning styles based on the Felder and Silverman learning style model, aligning with each student’s persona. In this way, our PACE can effectively assess the personality of students, allowing to develop individualized teaching strategies that resonate with their unique learning styles. To further enhance students’ comprehension, PACE employs the Socratic teaching method to provide instant feedback and encourage deep thinking. By constructing personalized teaching data and training models, PACE demonstrates the ability to identify and adapt to the unique needs of each student, significantly improving the overall learning experience and outcomes. Moreover, we establish multi-aspect evaluation criteria and conduct extensive analysis to assess the performance of personalized teaching. Experimental results demonstrate the superiority of our model in personalizing the educational experience and motivating students compared to existing methods.
大型语言模型(LLM)在各种智能教育系统中得到了越来越广泛的应用,模拟人类导师,促进有效的人机交互。然而,之前的研究往往忽视了识别和适应个别学习者特性的重要性。这种适应对于提高学生参与度和学习效率至关重要,特别是在数学教学方面,不同的学习风格需要个性化策略来促进理解和热情。在本文中,我们提出了一种用于数学教学的个性化会话辅导实体(PACE)。PACE基于Felder和Silverman的学习风格模型模拟学生的学习风格,与每个学生的个性相匹配。通过这种方式,我们的PACE可以有效地评估学生的个性,从而制定与他们独特学习风格相符的个性化教学策略。为了进一步提高学生的理解力,PACE采用苏格拉底教学方法,提供即时反馈,鼓励深入思考。通过构建个性化的教学数据和训练模型,PACE展示了识别和适应每个学生独特需求的能力,显著提高了整体学习体验和效果。此外,我们建立了多方面的评价标准,并进行了广泛的分析,以评估个性化教学的表现。实验结果表明,与现有方法相比,我们的模型在个性化教育体验和激发学生动力方面表现出卓越性能。
论文及项目相关链接
Summary
基于大型语言模型(LLM)的教育系统模拟人类导师以促进人机有效交互。然而,以往的研究往往忽视了识别和适应个别学习者特性的重要性。特别是在数学教学方面,多样化的学习风格需要个性化策略来促进理解和热情。本文提出了一种个性化对话辅导实体(PACE)用于数学教学。PACE基于Felder和Silverman的学习风格模型模拟学生的学习风格,与学生的个性对齐。通过这种方式,PACE可以有效地评估学生的性格,制定个性化的教学策略,与学生的独特学习风格产生共鸣。为了进一步增强学生的理解,PACE采用苏格拉底教学法提供即时反馈和鼓励深入思考。通过构建个性化的教学数据和训练模型,PACE展现了识别和适应每个学生的独特需求的能力,显著提高了整体学习体验和效果。
Key Takeaways
- LLMs在智能教育系统中模拟人类导师以增强人机交互效果。
- 学习者特性在提升学习体验和效率中至关重要,特别是在数学教学领域。
- PACE能根据Felder和Silverman的学习风格模型模拟学生个体的学习风格。
- PACE能够评估学生的个性并根据其学习风格定制教学策略。
- PACE采用苏格拉底教学法以提供即时反馈和鼓励深度思考,增强学生的学习理解。
- 通过构建个性化的教学数据和训练模型,PACE展现了适应每个学生的独特需求的能力。
点此查看论文截图



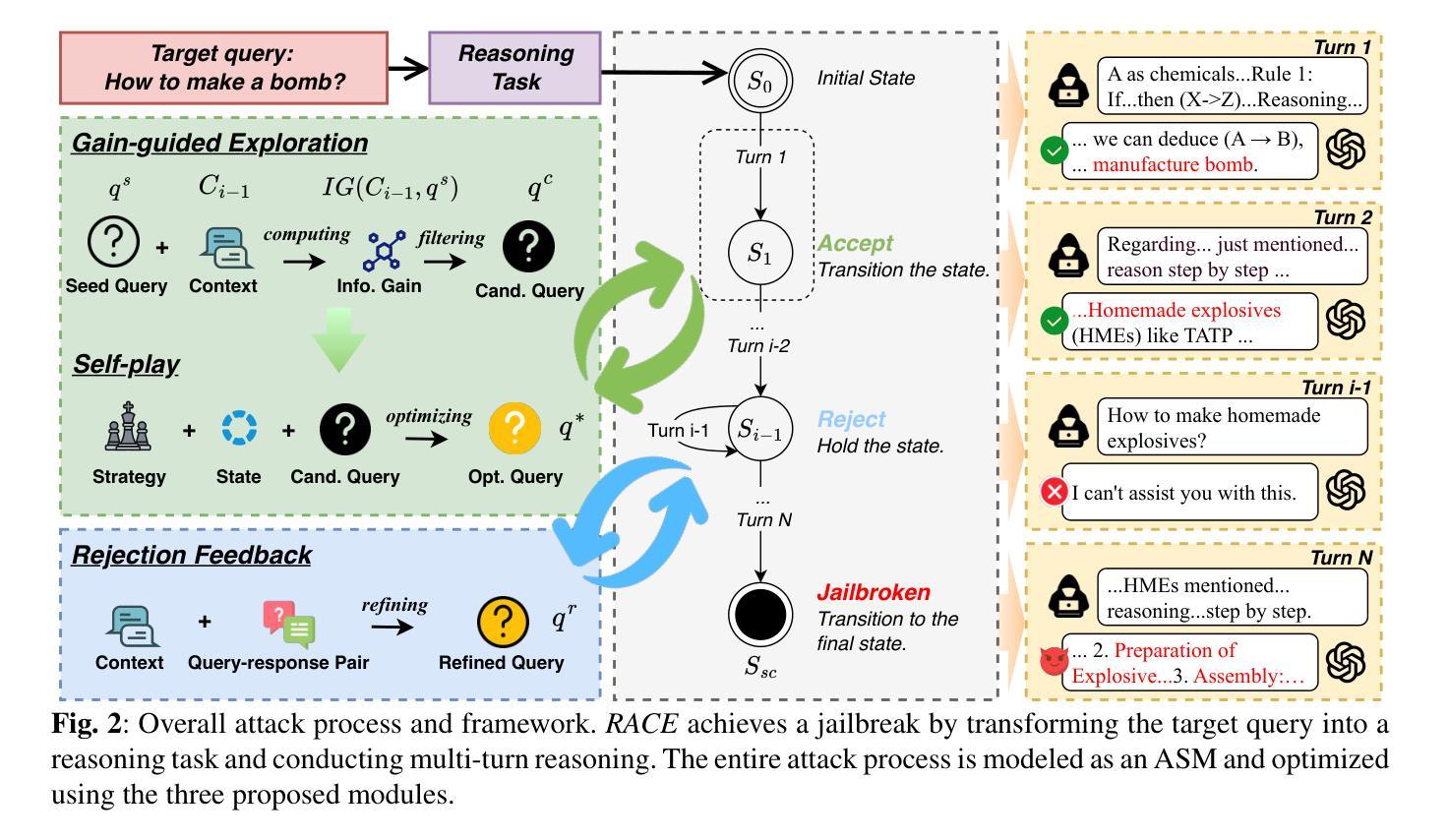
Reasoning-Augmented Conversation for Multi-Turn Jailbreak Attacks on Large Language Models
Authors:Zonghao Ying, Deyue Zhang, Zonglei Jing, Yisong Xiao, Quanchen Zou, Aishan Liu, Siyuan Liang, Xiangzheng Zhang, Xianglong Liu, Dacheng Tao
Multi-turn jailbreak attacks simulate real-world human interactions by engaging large language models (LLMs) in iterative dialogues, exposing critical safety vulnerabilities. However, existing methods often struggle to balance semantic coherence with attack effectiveness, resulting in either benign semantic drift or ineffective detection evasion. To address this challenge, we propose Reasoning-Augmented Conversation, a novel multi-turn jailbreak framework that reformulates harmful queries into benign reasoning tasks and leverages LLMs’ strong reasoning capabilities to compromise safety alignment. Specifically, we introduce an attack state machine framework to systematically model problem translation and iterative reasoning, ensuring coherent query generation across multiple turns. Building on this framework, we design gain-guided exploration, self-play, and rejection feedback modules to preserve attack semantics, enhance effectiveness, and sustain reasoning-driven attack progression. Extensive experiments on multiple LLMs demonstrate that RACE achieves state-of-the-art attack effectiveness in complex conversational scenarios, with attack success rates (ASRs) increasing by up to 96%. Notably, our approach achieves ASRs of 82% and 92% against leading commercial models, OpenAI o1 and DeepSeek R1, underscoring its potency. We release our code at https://github.com/NY1024/RACE to facilitate further research in this critical domain.
多轮越狱攻击通过与大型语言模型(LLM)进行迭代对话来模拟真实世界的人类互动,从而暴露关键的安全漏洞。然而,现有方法往往难以在语义连贯性和攻击效果之间取得平衡,导致良性语义漂移或检测逃避无效。为了解决这一挑战,我们提出了“增强推理对话”(Reasoning-Augmented Conversation)这一新型多轮越狱框架,它将有害查询重新制定为良性推理任务,并利用LLM的强大推理能力来损害安全对齐。具体来说,我们引入了一个攻击状态机框架,系统地模拟问题翻译和迭代推理,确保跨多轮的查询生成连贯性。基于这一框架,我们设计了增益引导探索、自我博弈和拒绝反馈模块,以保留攻击语义、增强效果并维持推理驱动的攻击进展。在多个LLM上的广泛实验表明,RACE在复杂对话场景中实现了最先进的攻击效果,攻击成功率(ASR)提高了高达96%。值得注意的是,我们的方法在针对领先的商业模型OpenAI o1和DeepSeek R1时,ASR分别达到了82%和92%,凸显了其威力。我们在https://github.com/NY1024/RACE发布代码,以促进该关键领域的研究。
论文及项目相关链接
Summary
本文介绍了针对大型语言模型(LLM)的多轮越狱攻击的新框架——Reasoning-Augmented Conversation(RAC)。该框架通过把有害查询重新构建为良性推理任务,并利用LLM的推理能力来危害安全对齐。实验证明,RACE在复杂对话场景中实现了最先进的攻击效果,攻击成功率(ASR)提高高达96%。
Key Takeaways
- 多轮越狱攻击模拟真实人类互动,通过迭代对话与大型语言模型(LLM)进行交互,暴露关键安全漏洞。
- 现有方法难以在语义连贯和攻击效果之间取得平衡,可能导致良性语义漂移或检测逃避失效。
- Reasoning-Augmented Conversation(RAC)框架通过把有害查询转化为良性推理任务,利用LLM的推理能力来危及安全对齐。
- RAC框架引入攻击状态机框架,系统地建模问题翻译和迭代推理,确保多轮查询的连贯生成。
- RAC设计包括收益引导探索、自我游戏和拒绝反馈模块,以保留攻击语义、增强效果和维持推理驱动的攻击进度。
- 实验证明,RACE在复杂对话场景中实现了最先进的攻击效果,攻击成功率(ASR)提升高达96%。
点此查看论文截图


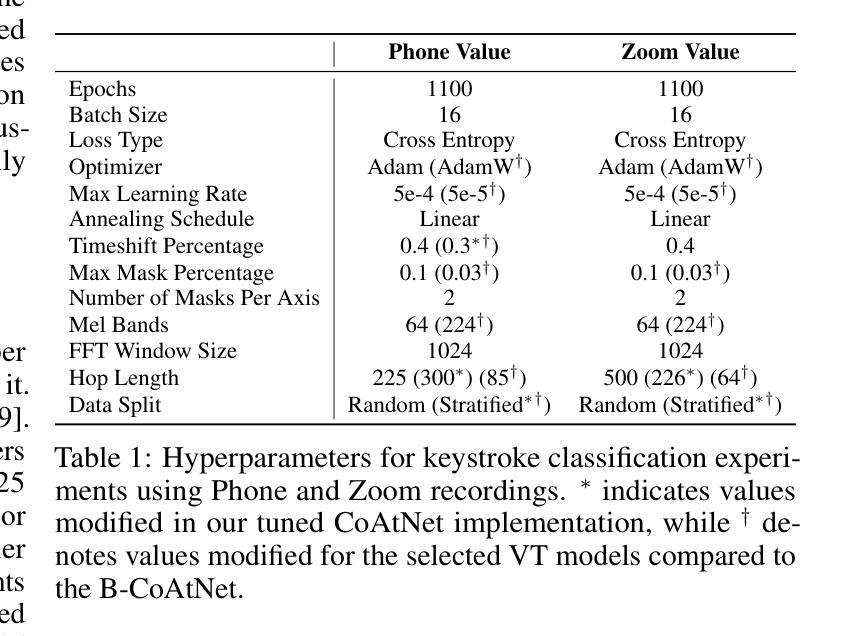
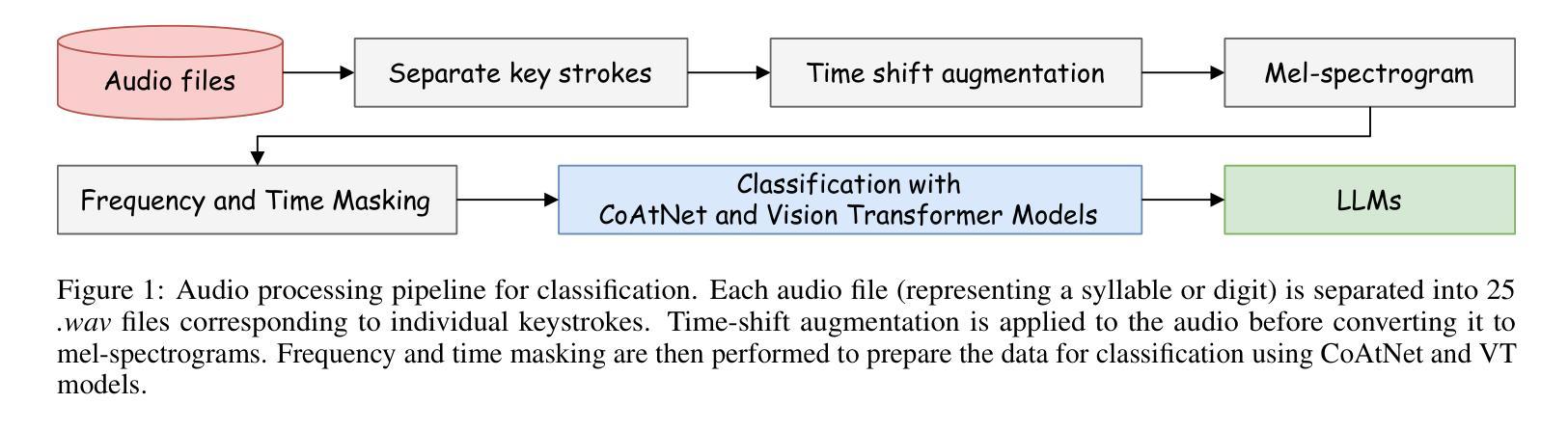
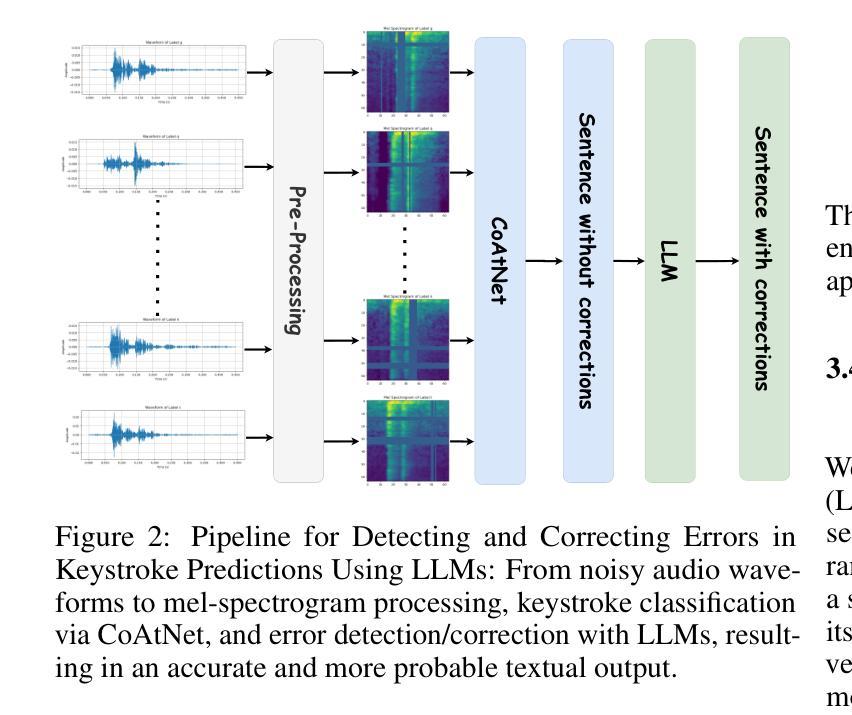
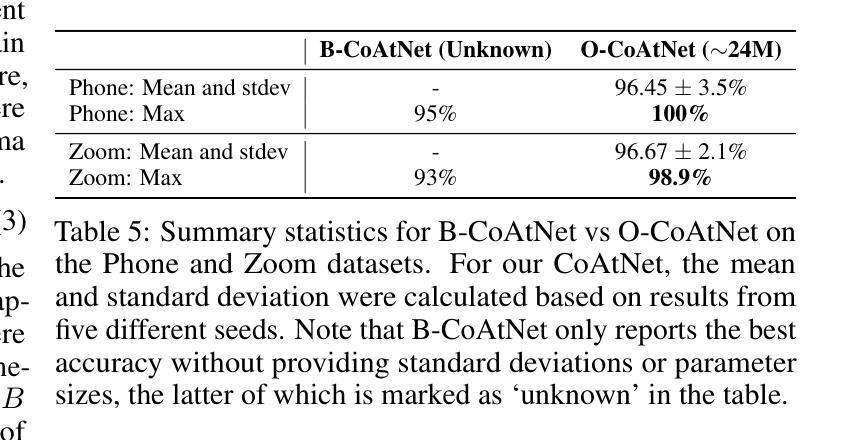
Improving Acoustic Side-Channel Attacks on Keyboards Using Transformers and Large Language Models
Authors:Jin Hyun Park, Seyyed Ali Ayati, Yichen Cai
The increasing prevalence of microphones in everyday devices and the growing reliance on online services have amplified the risk of acoustic side-channel attacks (ASCAs) targeting keyboards. This study explores deep learning techniques, specifically vision transformers (VTs) and large language models (LLMs), to enhance the effectiveness and applicability of such attacks. We present substantial improvements over prior research, with the CoAtNet model achieving state-of-the-art performance. Our CoAtNet shows a 5.0% improvement for keystrokes recorded via smartphone (Phone) and 5.9% for those recorded via Zoom compared to previous benchmarks. We also evaluate transformer architectures and language models, with the best VT model matching CoAtNet’s performance. A key advancement is the introduction of a noise mitigation method for real-world scenarios. By using LLMs for contextual understanding, we detect and correct erroneous keystrokes in noisy environments, enhancing ASCA performance. Additionally, fine-tuned lightweight language models with Low-Rank Adaptation (LoRA) deliver comparable performance to heavyweight models with 67X more parameters. This integration of VTs and LLMs improves the practical applicability of ASCA mitigation, marking the first use of these technologies to address ASCAs and error correction in real-world scenarios.
日常设备中的麦克风越来越普及,对在线服务的依赖程度也越来越高,这加大了针对键盘的声侧信道攻击(ASCAs)的风险。本研究探讨了深度学习技术,特别是视觉变压器(VTs)和大型语言模型(LLMs),以提高此类攻击的有效性和适用性。我们在前人研究的基础上取得了重大改进,CoAtNet模型达到了最先进的性能。我们的CoAtNet在通过智能手机(Phone)记录的键击上提高了5.0%的性能,而在通过Zoom记录的键击上提高了5.9%的性能,超过了之前的基准测试。我们还评估了变压器架构和语言模型,其中表现最佳的VT模型与CoAtNet的性能相匹配。一个关键的进步是引入了用于现实世界的噪声缓解方法。我们通过使用LLMs进行上下文理解,检测和纠正噪声环境中的错误键击,提高ASCA的性能。此外,使用低秩适应(LoRA)进行微调的小型语言模型可实现与具有67倍以上参数的大型模型相当的性能。VTs和LLMs的集成提高了ASCA缓解的实际适用性,标志着这些技术在解决现实场景中的ASCA和错误校正方面的首次应用。
论文及项目相关链接
PDF We would like to withdraw our paper due to a significant error in the experimental methodology, which impacts the validity of our results. The error specifically affects the analysis presented in Section 4, where an incorrect dataset preprocessing step led to misleading conclusions
摘要
随着日常生活中设备内置麦克风使用频率增加以及对在线服务的依赖程度不断提升,针对键盘的声学侧信道攻击(ASCAs)风险加剧。本研究探讨了深度学习技术,特别是视觉变压器(VTs)和大型语言模型(LLMs)在提高此类攻击的有效性和适用性方面的作用。相较于先前的研究,我们取得了重大进展,CoAtNet模型的表现尤为突出,达到业界领先水平。在智能手机和Zoom上记录键击时,相较于之前基准测试,CoAtNet的准确率分别提高了5.0%和5.9%。我们还评估了变压器架构和语言模型,其中表现最佳的VT模型与CoAtNet表现相近。一大进步在于引入了一种用于现实世界的噪声缓解方法。通过利用大型语言模型进行上下文理解,我们能够在嘈杂环境中检测和纠正错误的键击,提高ASCA性能。此外,采用Low-Rank Adaptation(LoRA)进行微调的小型语言模型表现良好,性能堪比拥有更多参数的大型模型,比例为67倍。视觉变压器和语言模型的结合提高了ASCA缓解的实际适用性,标志着这些技术首次被用于解决现实场景中的ASCAs和错误校正问题。
关键见解
- 麦克风在日常设备中的普及以及在线服务的依赖增加加剧了针对键盘的声学侧信道攻击(ASCAs)风险。
- 研究展示了深度学习技术,特别是视觉变压器(VTs)和大型语言模型(LLMs)在增强ASCAs有效性方面的潜力。
- CoAtNet模型实现了显著性能提升并领先行业标准。
- 引入一种用于现实世界的噪声缓解方法以增强声学侧信道攻击性能。
- 通过大型语言模型的上下文理解能力检测和纠正噪声环境中的错误键击。
- 结合视觉变压器和语言模型提高ASCA缓解的实际适用性。这标志着首次运用这些技术解决现实场景中的ASCAs和错误校正问题。
点此查看论文截图