⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-21 更新
Geometry-Aware Diffusion Models for Multiview Scene Inpainting
Authors:Ahmad Salimi, Tristan Aumentado-Armstrong, Marcus A. Brubaker, Konstantinos G. Derpanis
In this paper, we focus on 3D scene inpainting, where parts of an input image set, captured from different viewpoints, are masked out. The main challenge lies in generating plausible image completions that are geometrically consistent across views. Most recent work addresses this challenge by combining generative models with a 3D radiance field to fuse information across viewpoints. However, a major drawback of these methods is that they often produce blurry images due to the fusion of inconsistent cross-view images. To avoid blurry inpaintings, we eschew the use of an explicit or implicit radiance field altogether and instead fuse cross-view information in a learned space. In particular, we introduce a geometry-aware conditional generative model, capable of inpainting multi-view consistent images based on both geometric and appearance cues from reference images. A key advantage of our approach over existing methods is its unique ability to inpaint masked scenes with a limited number of views (i.e., few-view inpainting), whereas previous methods require relatively large image sets for their 3D model fitting step. Empirically, we evaluate and compare our scene-centric inpainting method on two datasets, SPIn-NeRF and NeRFiller, which contain images captured at narrow and wide baselines, respectively, and achieve state-of-the-art 3D inpainting performance on both. Additionally, we demonstrate the efficacy of our approach in the few-view setting compared to prior methods.
本文聚焦于3D场景修复,即输入图像集中的部分从不同视角拍摄并进行掩膜处理。主要挑战在于生成在不同视角几何一致的合理图像补全。最近的工作通过结合生成模型与3D辐射场来融合跨视角的信息来应对这一挑战。然而,这些方法的主要缺陷在于,由于跨视角图像的不一致性融合,它们通常会产生模糊的图像。为了避免模糊的修复效果,我们完全摒弃了显式或隐式的辐射场的使用,而是在学习空间中融合跨视角的信息。特别是,我们引入了一种几何感知条件生成模型,该模型能够根据参考图像的几何和外观线索,修复多视角一致的图像。我们的方法与现有方法相比的一个关键优势是,它能够在有限的视角数量下进行遮罩场景的修复(即少数视角修复),而之前的方法需要相对较大的图像集来进行其3D模型拟合步骤。我们通过实证在SPIn-NeRF和NeRFiller两个数据集上评估并比较了我们的场景中心修复方法,这两个数据集分别采用窄视场和宽视场拍摄图像,我们在两者上都实现了最先进的3D修复性能。此外,我们还展示了与先前方法相比,在少数视角设置下我们的方法的有效性。
论文及项目相关链接
PDF Our project page is available at https://geomvi.github.io
Summary
本文专注于3D场景补全,针对输入图像集中从不同视角捕捉的部分被掩盖的问题。主要挑战在于生成在不同视角几何一致的合理图像补全。虽然最近的工作通过结合生成模型与3D辐射场来融合不同视角的信息来解决这一挑战,但它们的一个主要缺陷是产生的图像往往因不同视角图像的不一致性而模糊。为了避免模糊的补全,本文放弃使用显式或隐式的辐射场,而是在学习空间中融合跨视角的信息。我们引入了一种基于几何条件的生成模型,能够根据参考图像的几何和外观线索进行多视角一致的图像补全。与现有方法相比,我们的方法的一个关键优势是能在有限视角(即少视角补全)下进行场景补全,而之前的方法需要大量的图像集来进行其3D模型拟合步骤。我们在两个数据集SPIn-NeRF和NeRFiller上评估并比较了我们的场景中心补全方法,并在两个数据集上都实现了最先进的3D补全性能。
Key Takeaways
- 论文专注于3D场景补全,挑战在于生成在不同视角几何一致的合理图像补全。
- 最近的方法结合生成模型与3D辐射场来融合不同视角信息,但会产生模糊的图像。
- 为了避免模糊,论文放弃使用辐射场,而是在学习空间中融合跨视角信息。
- 引入了一种基于几何条件的生成模型,可进行多视角一致的图像补全。
- 该方法能在有限视角(少视角补全)下进行场景补全,这是与现有方法的一个关键优势。
- 在两个数据集上实现了先进的3D补全性能。
点此查看论文截图

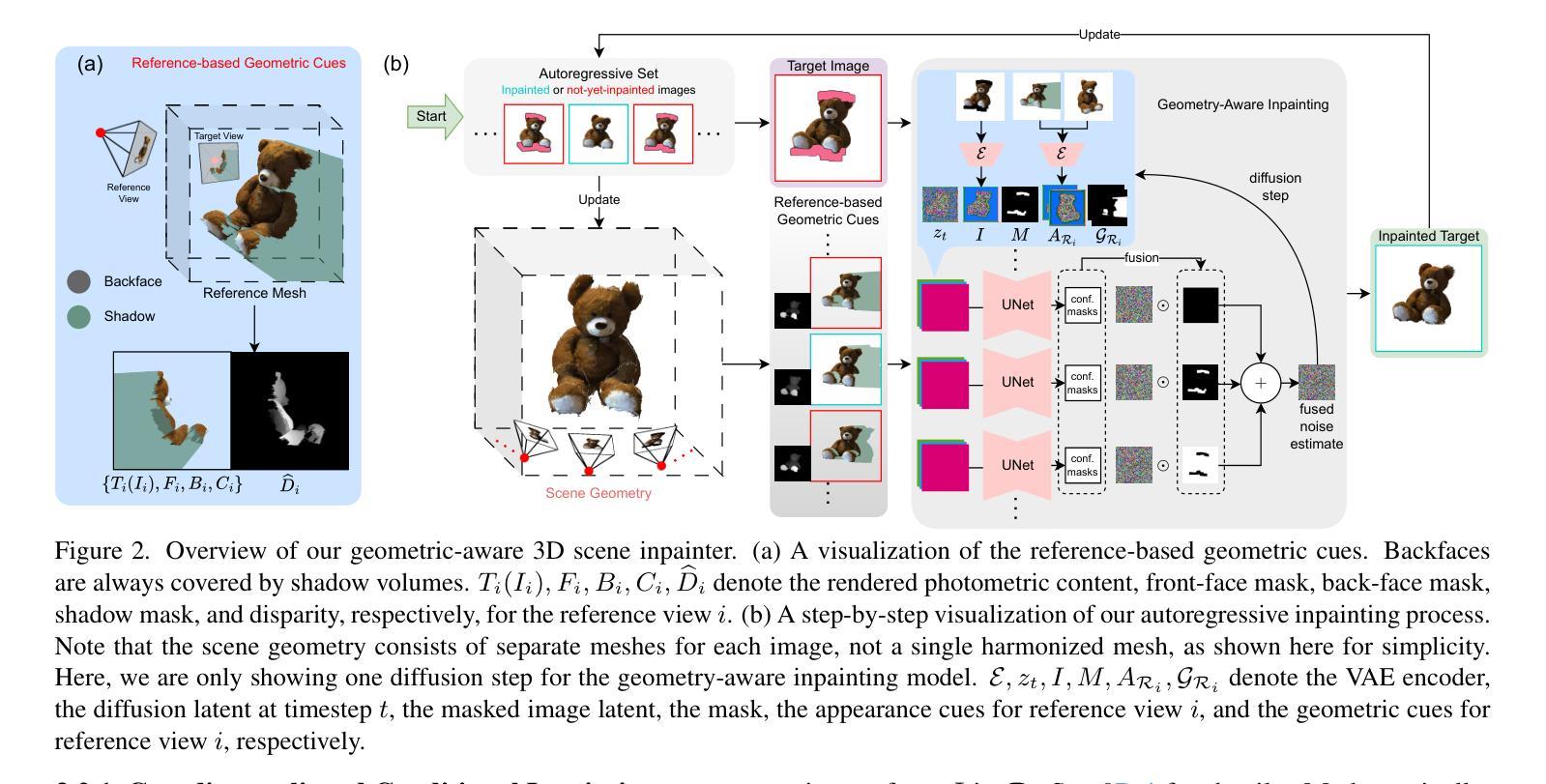
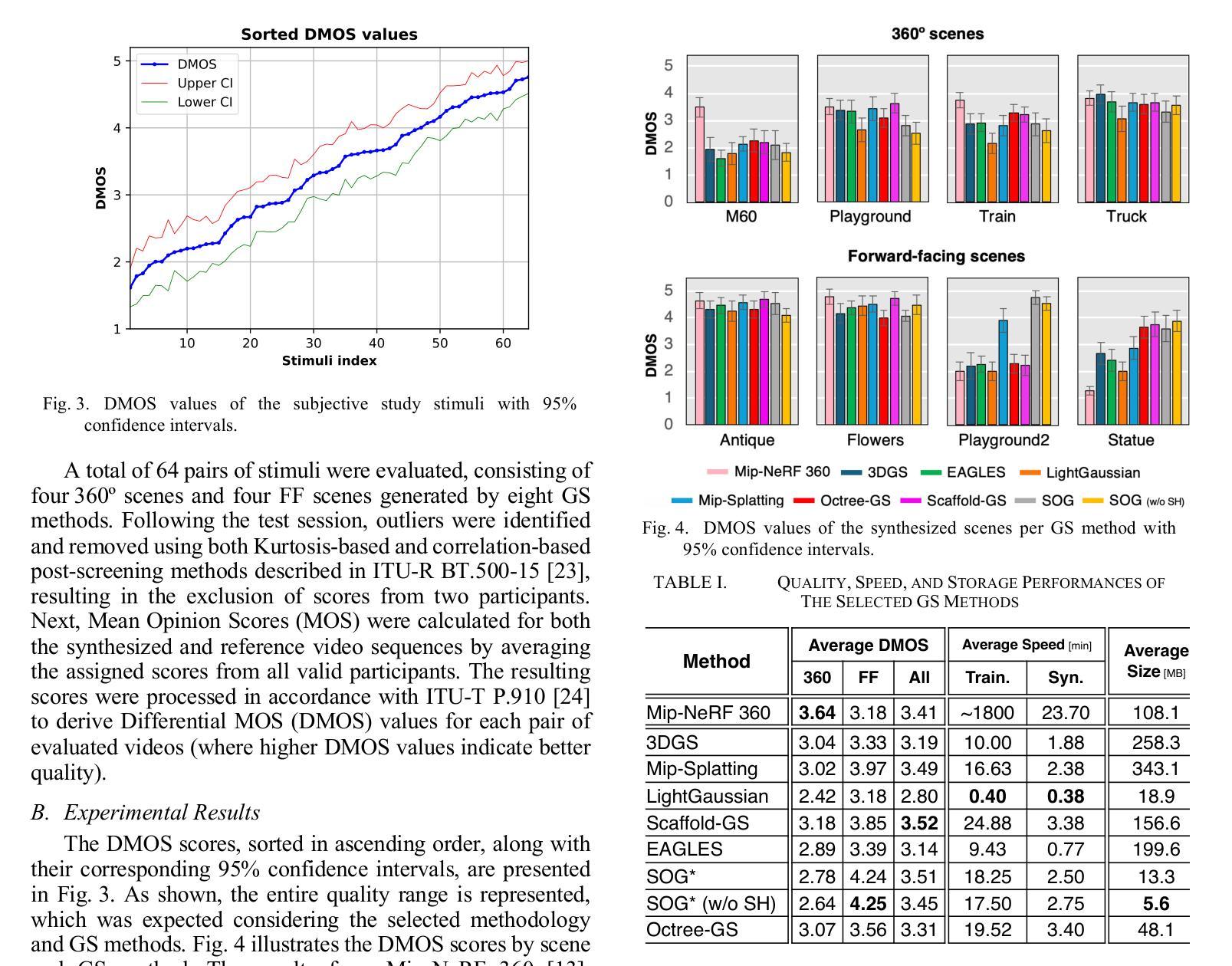
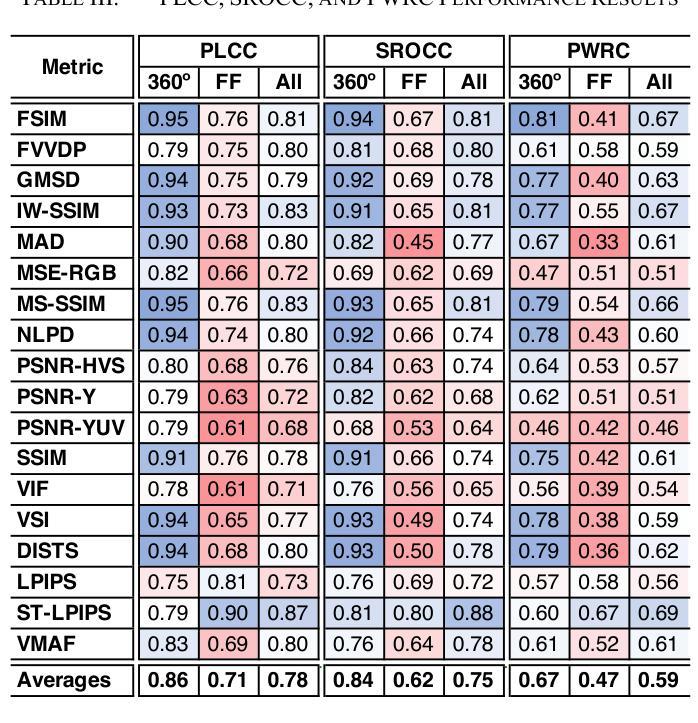
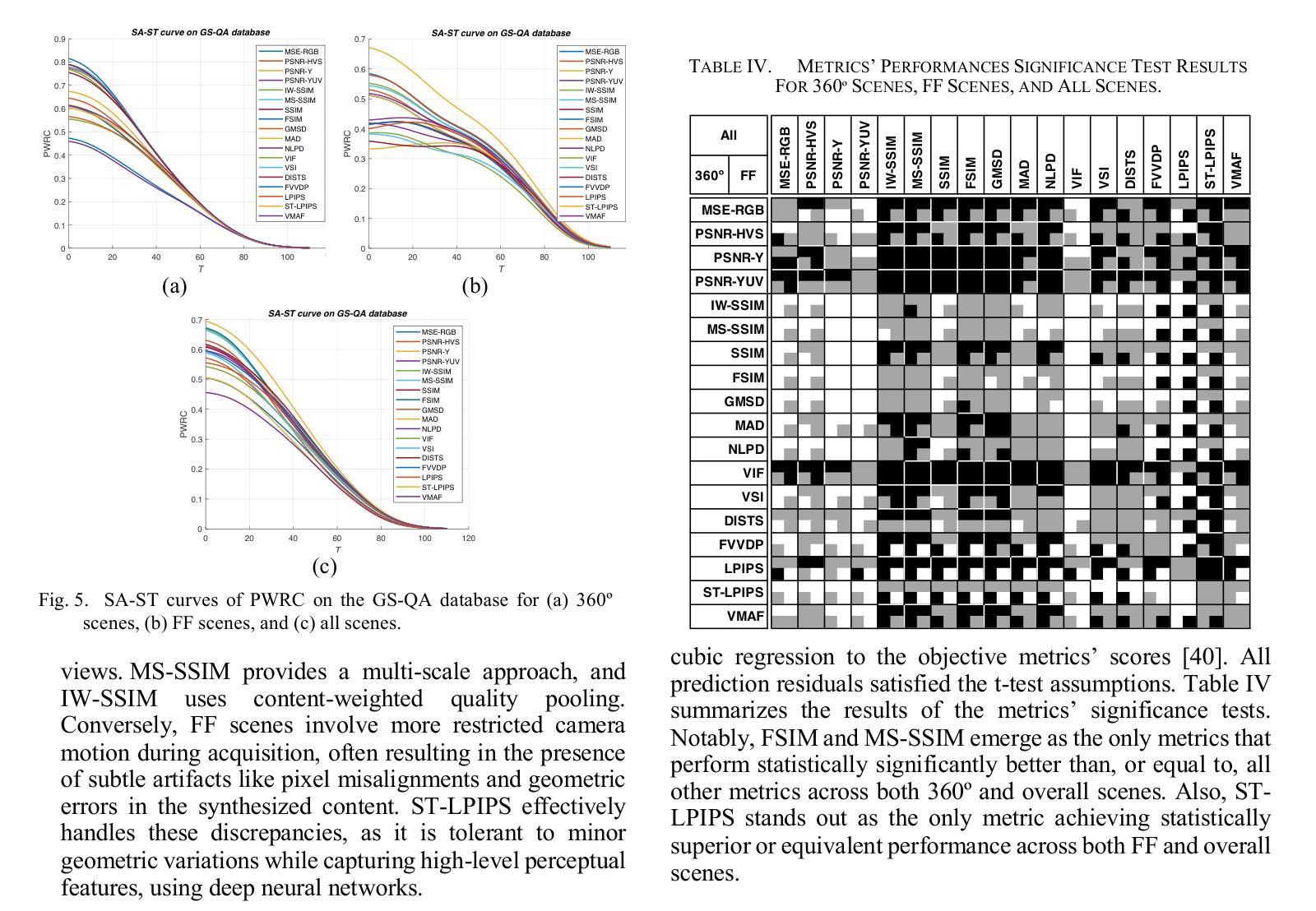
GS-QA: Comprehensive Quality Assessment Benchmark for Gaussian Splatting View Synthesis
Authors:Pedro Martin, António Rodrigues, João Ascenso, Maria Paula Queluz
Gaussian Splatting (GS) offers a promising alternative to Neural Radiance Fields (NeRF) for real-time 3D scene rendering. Using a set of 3D Gaussians to represent complex geometry and appearance, GS achieves faster rendering times and reduced memory consumption compared to the neural network approach used in NeRF. However, quality assessment of GS-generated static content is not yet explored in-depth. This paper describes a subjective quality assessment study that aims to evaluate synthesized videos obtained with several static GS state-of-the-art methods. The methods were applied to diverse visual scenes, covering both 360-degree and forward-facing (FF) camera trajectories. Moreover, the performance of 18 objective quality metrics was analyzed using the scores resulting from the subjective study, providing insights into their strengths, limitations, and alignment with human perception. All videos and scores are made available providing a comprehensive database that can be used as benchmark on GS view synthesis and objective quality metrics.
高斯混合法(GS)作为一种为实时三维场景渲染而开发的具有潜力的技术,对神经辐射场(NeRF)形成了替代。GS使用一组三维高斯函数来表示复杂的几何形状和外观,相较于NeRF使用的神经网络方法,实现了更快的渲染速度和更低的内存消耗。然而,关于GS生成的静态内容的质量评估尚未进行深入的研究。这篇论文描述了一项主观质量评估研究,旨在评估采用几种前沿静态GS技术合成视频的质量。这些方法应用于各种视觉场景,涵盖了全景和正向相机轨迹。此外,通过分析主观研究所得分数,对18种客观质量指标的性能进行了评估,提供了关于其优点、局限性以及与人类感知一致性的见解。所有视频和分数均已公开提供,形成了一个全面的数据库,可用于GS视图合成和客观质量指标的比对。
论文及项目相关链接
Summary
本文介绍了基于高斯融合(GS)的实时三维场景渲染方法。该研究采用一组三维高斯分布来代表复杂的几何和外观,实现了相较于神经网络方法更快渲染速度和较低内存消耗。该研究对多种静态GS合成方法生成的视频进行了主观质量评估研究,对不同类型的视觉场景进行深度探讨,并分析了客观质量指标的性能。视频及评分数据公开提供,作为GS视图合成和客观质量指标的基准数据库。
Key Takeaways
- 高斯融合(GS)为实时三维场景渲染提供了基于神经辐射场(NeRF)的替代方案。使用一组三维高斯分布来代表复杂的几何和外观信息,以实现更快的渲染速度和更低的内存消耗。
- 此研究首次针对GS生成的静态内容进行了质量评估研究,聚焦于合成的视频质量。
- 研究涵盖了多种静态GS合成方法,并对不同种类的视觉场景(包括全角度和前视场景)进行了实验分析。
- 实验还研究了现有的客观质量指标的性能,并对其优缺点与人类感知的契合度进行了分析。
- 视频数据和评分结果公开提供,为GS视图合成和客观质量指标评估提供了基准数据库。
- 研究结果可为未来GS技术的改进和优化提供方向。
点此查看论文截图



High-Quality 3D Creation from A Single Image Using Subject-Specific Knowledge Prior
Authors:Nan Huang, Ting Zhang, Yuhui Yuan, Dong Chen, Shanghang Zhang
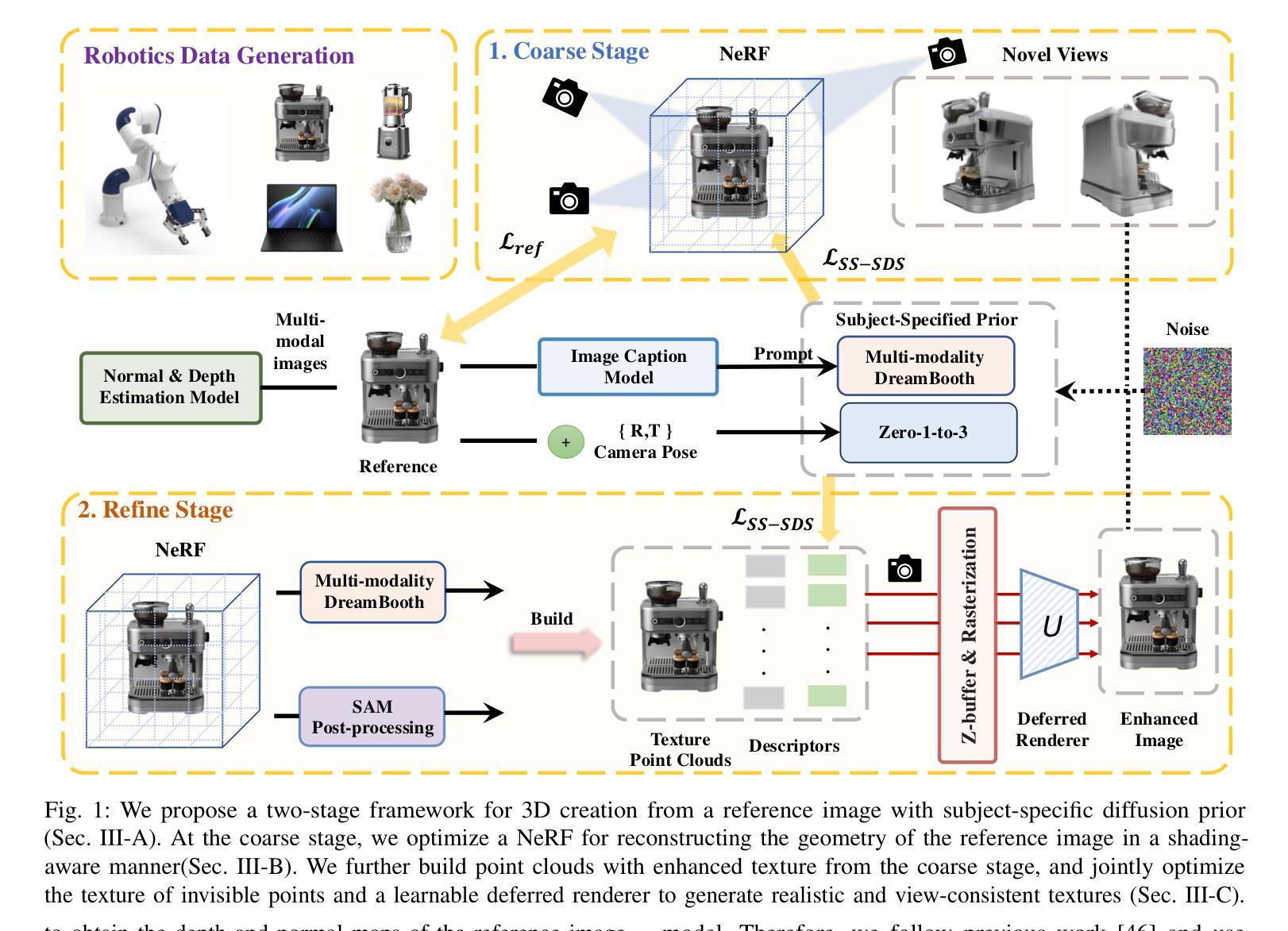
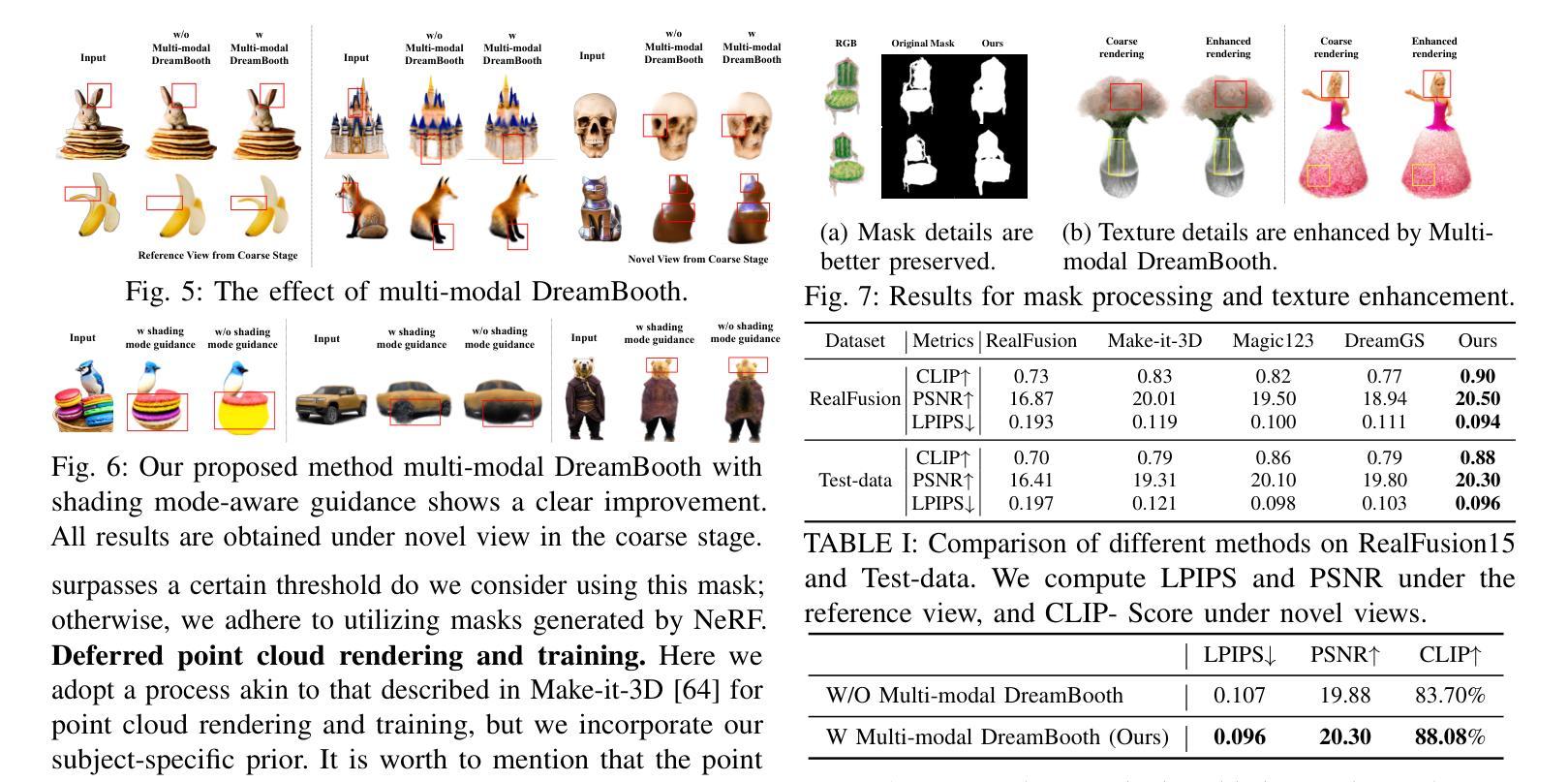
In this paper, we address the critical bottleneck in robotics caused by the scarcity of diverse 3D data by presenting a novel two-stage approach for generating high-quality 3D models from a single image. This method is motivated by the need to efficiently expand 3D asset creation, particularly for robotics datasets, where the variety of object types is currently limited compared to general image datasets. Unlike previous methods that primarily rely on general diffusion priors, which often struggle to align with the reference image, our approach leverages subject-specific prior knowledge. By incorporating subject-specific priors in both geometry and texture, we ensure precise alignment between the generated 3D content and the reference object. Specifically, we introduce a shading mode-aware prior into the NeRF optimization process, enhancing the geometry and refining texture in the coarse outputs to achieve superior quality. Extensive experiments demonstrate that our method significantly outperforms prior approaches.
在这篇论文中,我们针对机器人技术中因缺乏多样化的3D数据而导致的关键瓶颈,提出了一种从单张图像生成高质量3D模型的两阶段新方法。该方法的灵感来源于需要高效扩展3D资产创建,特别是机器人数据集的需求。目前,相比于通用的图像数据集,机器人数据集的对象类型有限。与之前主要依赖通用扩散先验的方法不同,这些方法通常难以与参考图像对齐,我们的方法利用特定主题的先验知识。通过在几何和纹理中融入主题特定先验,我们确保了生成的三维内容与参考对象之间的精确对齐。具体来说,我们在NeRF优化过程中引入了一种阴影模式感知先验,以提高几何精度并细化粗糙输出的纹理,从而达到更高的质量。大量实验表明,我们的方法显著优于以前的方法。
论文及项目相关链接
PDF ICRA2025, Project Page: https://nnanhuang.github.io/projects/customize-it-3d/
Summary
本文提出了一种新型的两阶段方法,用于从单一图像生成高质量的三维模型,解决了因缺乏多样化的三维数据而导致的机器人领域瓶颈问题。与以往主要依赖通用扩散先验的方法不同,此方法结合主题特定的先验知识,确保生成的三维内容与参考对象精确对齐。通过引入阴影模式感知先验到NeRF优化过程中,提升了几何质量并精细了纹理。实验证明该方法显著优于先前的方法。
Key Takeaways
- 该论文解决了机器人领域因缺乏多样化3D数据导致的瓶颈问题。
- 提出了一种新型两阶段方法,用于从单一图像生成高质量3D模型。
- 与通用扩散先验方法不同,该方法结合主题特定的先验知识。
- 引入了阴影模式感知先验到NeRF优化过程中。
- 方法能确保生成的三维内容与参考对象精确对齐。
- 实验证明该方法在生成高质量3D模型方面显著优于先前的方法。
点此查看论文截图