⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-21 更新
A Survey on Bridging EEG Signals and Generative AI: From Image and Text to Beyond
Authors:Shreya Shukla, Jose Torres, Abhijit Mishra, Jacek Gwizdka, Shounak Roychowdhury
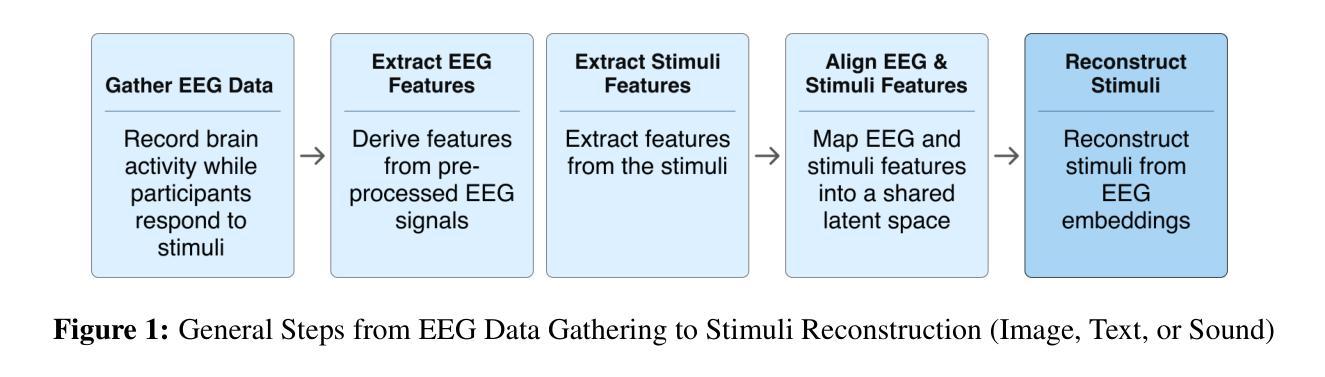
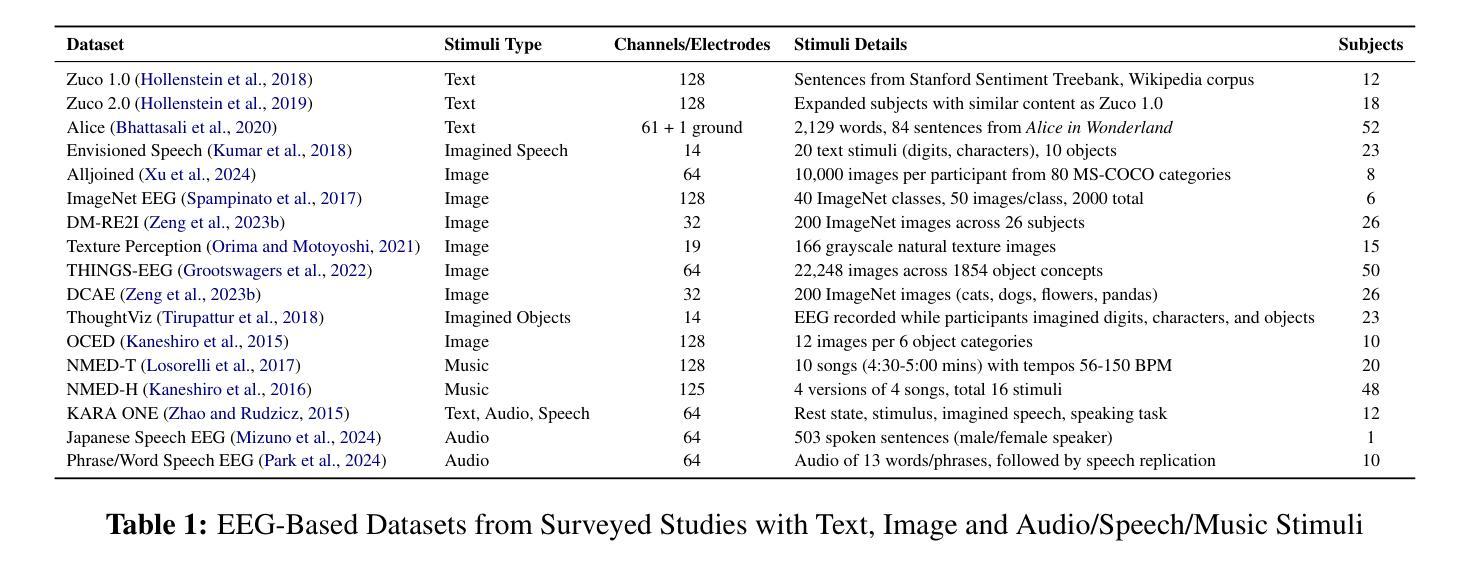
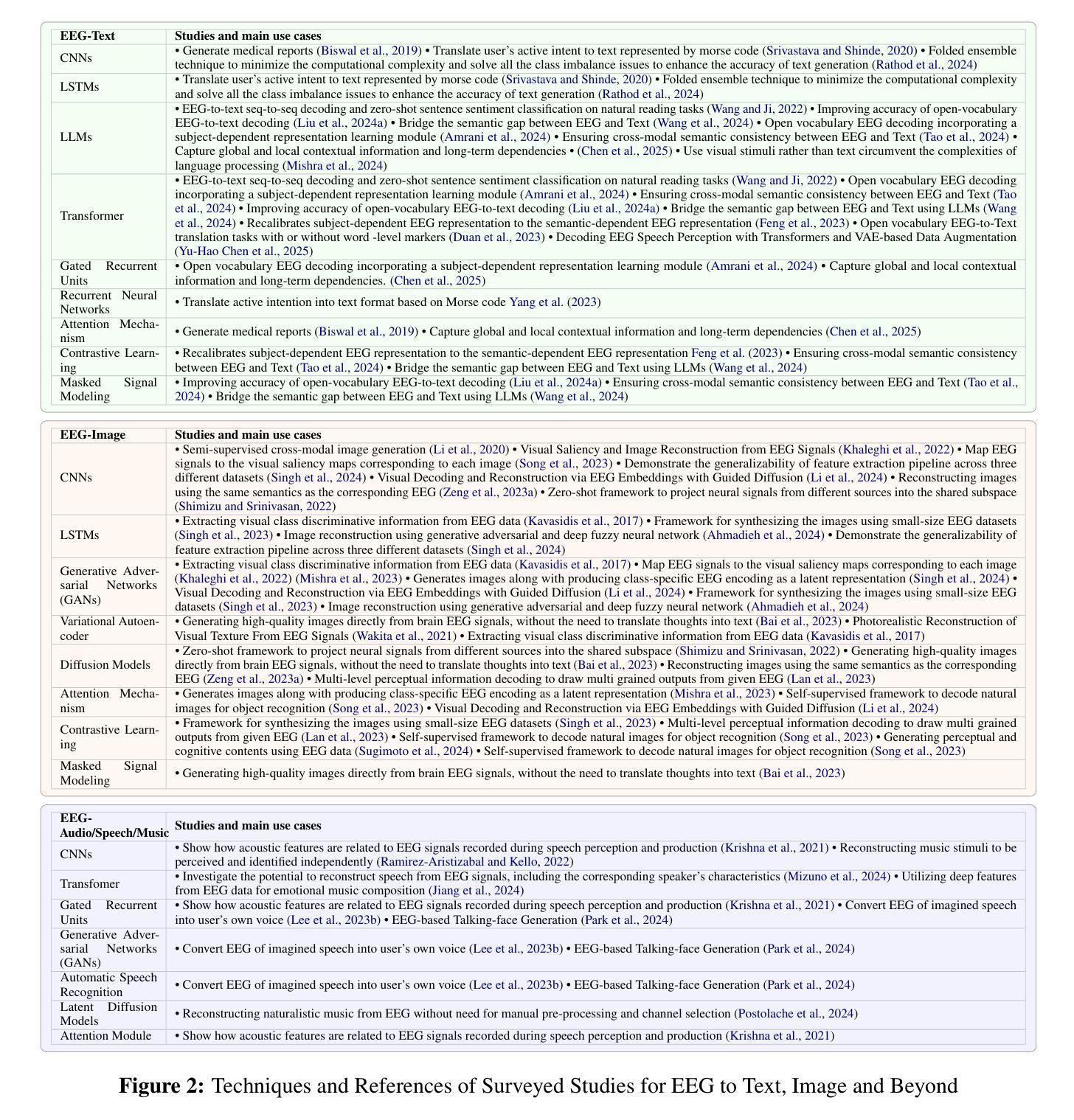
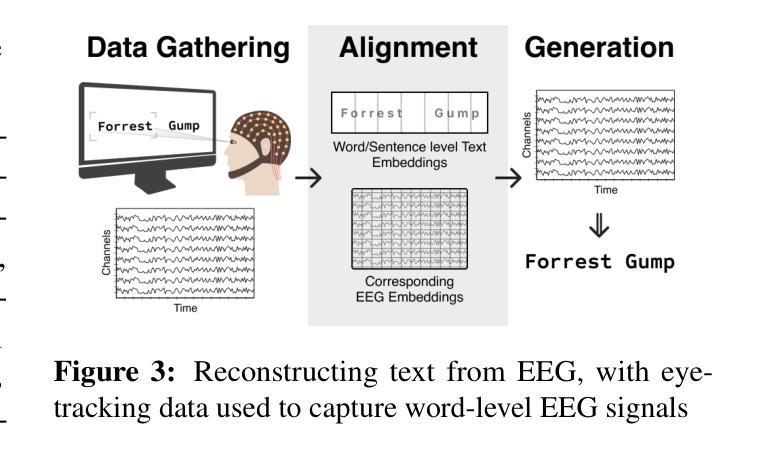
Integration of Brain-Computer Interfaces (BCIs) and Generative Artificial Intelligence (GenAI) has opened new frontiers in brain signal decoding, enabling assistive communication, neural representation learning, and multimodal integration. BCIs, particularly those leveraging Electroencephalography (EEG), provide a non-invasive means of translating neural activity into meaningful outputs. Recent advances in deep learning, including Generative Adversarial Networks (GANs) and Transformer-based Large Language Models (LLMs), have significantly improved EEG-based generation of images, text, and speech. This paper provides a literature review of the state-of-the-art in EEG-based multimodal generation, focusing on (i) EEG-to-image generation through GANs, Variational Autoencoders (VAEs), and Diffusion Models, and (ii) EEG-to-text generation leveraging Transformer based language models and contrastive learning methods. Additionally, we discuss the emerging domain of EEG-to-speech synthesis, an evolving multimodal frontier. We highlight key datasets, use cases, challenges, and EEG feature encoding methods that underpin generative approaches. By providing a structured overview of EEG-based generative AI, this survey aims to equip researchers and practitioners with insights to advance neural decoding, enhance assistive technologies, and expand the frontiers of brain-computer interaction.
脑机接口(BCI)与生成式人工智能(GenAI)的融合为脑信号解码开辟了新的领域,为实现辅助通信、神经表征学习和多模式融合提供了可能。特别是利用脑电图(EEG)的脑机接口,为非侵入性地转化神经活动为有意义的输出提供了一种手段。最近深度学习领域的进展,包括生成对抗网络(GANs)和基于变压器的自然语言模型(LLMs),已经极大地提高了基于EEG的图像、文本和语音生成。本文综述了基于EEG的多模式生成的最新进展,重点关注(i)通过GANs、变分自动编码器(VAEs)和扩散模型实现EEG到图像生成,以及(ii)利用基于变压器的语言模型和对比学习方法实现EEG到文本生成。此外,我们还讨论了新兴的EEG语音合成领域,这是一个不断发展的多模式前沿领域。我们重点介绍了关键数据集、用例、挑战和支撑生成方法的EEG特征编码方法。通过提供基于EEG的生成式人工智能的结构性概述,本综述旨在为研究人员和实践者提供洞察力,以推动神经解码的发展,提高辅助技术的性能,并拓展脑机交互的边界。
论文及项目相关链接
Summary
脑机接口(BCI)与生成式人工智能(GenAI)的集成在脑信号解码方面开创了新纪元,助力辅助沟通、神经表征学习与多媒体融合。借助脑电图(EEG)的BCI为非侵入式地转化神经活动为有意义输出提供了手段。深度学习的最新进展,包括生成对抗网络(GANs)和基于Transformer的大型语言模型(LLMs),已大幅改善基于EEG的图像、文本和语音生成。本文综述了EEG基多媒体生成的最新进展,重点讨论了EEG转图像生成的GANs、变分自编码器(VAEs)和扩散模型以及EEG转文本生成的基于Transformer的语言模型和对比学习方法。还介绍了新兴的EEG转语音合成领域,这是一个不断发展的多媒体融合前沿。
Key Takeaways
- BCI与GenAI集成在脑信号解码方面开创了新的应用领域。
- EEG为非侵入式地转化神经活动提供手段。
- 深度学习在EEG基图像、文本和语音生成方面有显著改善。
- EEG转图像生成领域运用了GANs、VAEs和扩散模型等技术。
- EEG转文本生成领域应用基于Transformer的语言模型和对比学习方法。
- EEG转语音合成是多媒体融合的快速发展的领域。
点此查看论文截图

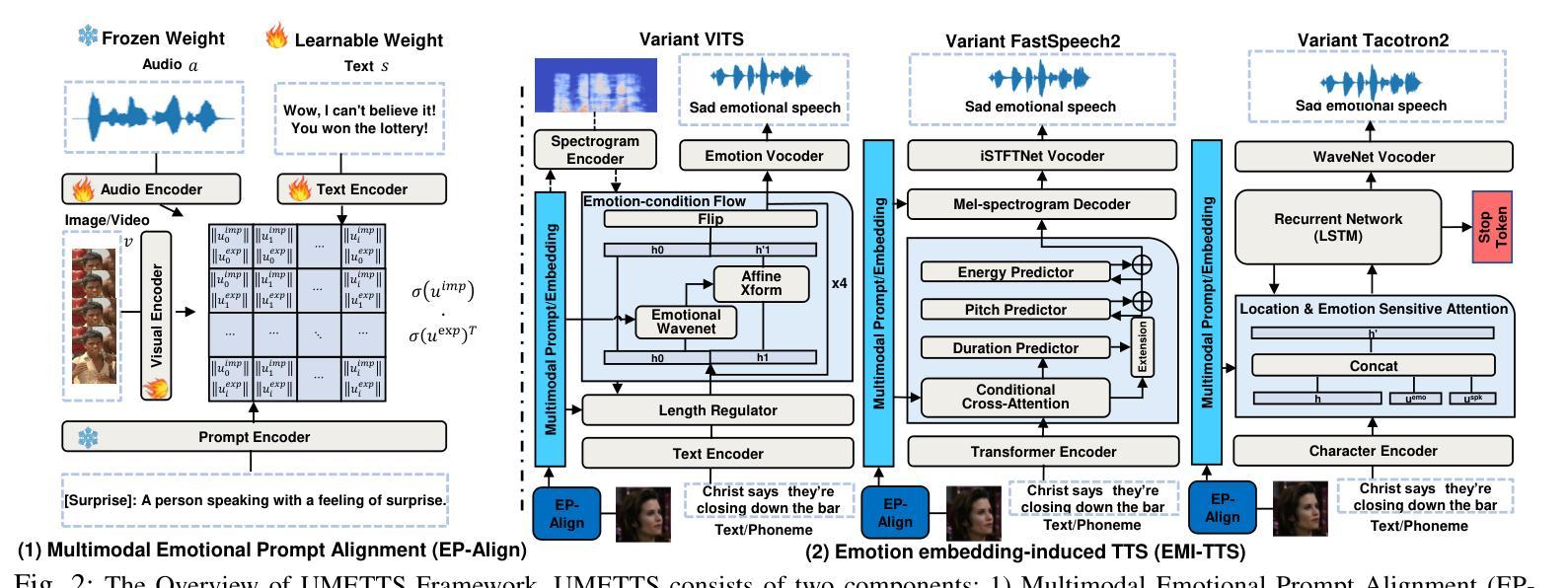
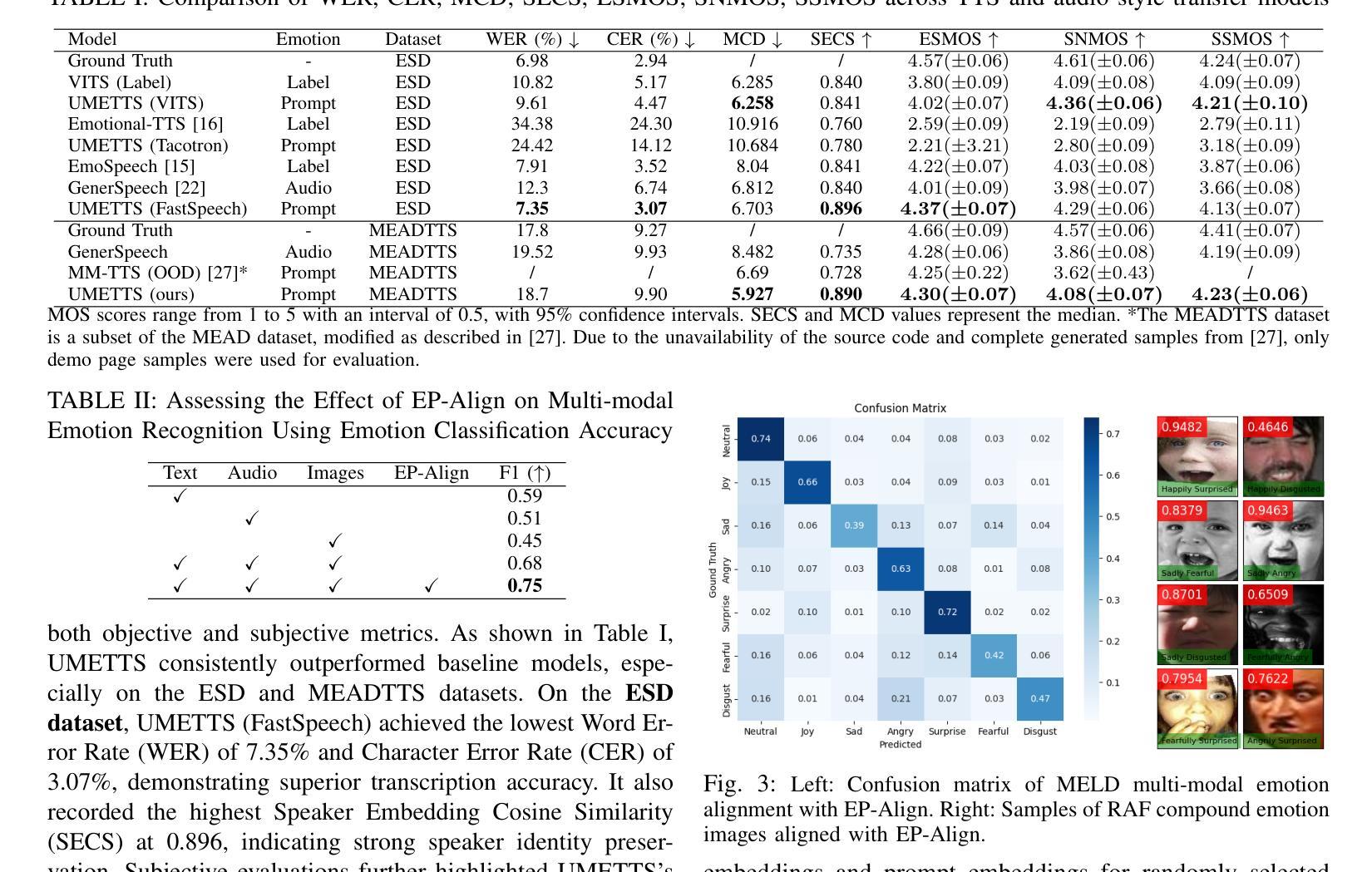
UMETTS: A Unified Framework for Emotional Text-to-Speech Synthesis with Multimodal Prompts
Authors:Zhi-Qi Cheng, Xiang Li, Jun-Yan He, Junyao Chen, Xiaomao Fan, Xiaojiang Peng, Alexander G. Hauptmann
Emotional Text-to-Speech (E-TTS) synthesis has garnered significant attention in recent years due to its potential to revolutionize human-computer interaction. However, current E-TTS approaches often struggle to capture the intricacies of human emotions, primarily relying on oversimplified emotional labels or single-modality input. In this paper, we introduce the Unified Multimodal Prompt-Induced Emotional Text-to-Speech System (UMETTS), a novel framework that leverages emotional cues from multiple modalities to generate highly expressive and emotionally resonant speech. The core of UMETTS consists of two key components: the Emotion Prompt Alignment Module (EP-Align) and the Emotion Embedding-Induced TTS Module (EMI-TTS). (1) EP-Align employs contrastive learning to align emotional features across text, audio, and visual modalities, ensuring a coherent fusion of multimodal information. (2) Subsequently, EMI-TTS integrates the aligned emotional embeddings with state-of-the-art TTS models to synthesize speech that accurately reflects the intended emotions. Extensive evaluations show that UMETTS achieves significant improvements in emotion accuracy and speech naturalness, outperforming traditional E-TTS methods on both objective and subjective metrics.
情感文本到语音(E-TTS)合成近年来受到了广泛关注,因为它有潜力革新人机交互。然而,当前的E-TTS方法往往难以捕捉人类情绪的细微差别,主要依赖于简化的情绪标签或单模态输入。在本文中,我们介绍了统一的多模式提示诱导情感文本到语音系统(UMETTS),这是一个利用来自多个模态的情感线索生成高度表达和情感共鸣的语音的新型框架。UMETTS的核心由两个关键组件构成:情感提示对齐模块(EP-Align)和情感嵌入诱导的TTS模块(EMI-TTS)。(1)EP-Align采用对比学习来对齐文本、音频和视觉模态的情感特征,确保多模态信息的连贯融合。(2)随后,EMI-TTS将对齐的情感嵌入与最先进的TTS模型集成,合成能够准确反映预期情绪的语音。大量评估表明,UMETTS在情感准确性和语音自然性方面取得了显著改进,在客观和主观指标上均优于传统的E-TTS方法。
论文及项目相关链接
PDF Accepted to ICASSP 2025, Code available at https://github.com/KTTRCDL/UMETTS
Summary
情感文本转语音(E-TTS)近年来备受关注,因为它有潜力革新人机交互。然而,当前E-TTS方法往往难以捕捉人类情绪的细微差别,主要依赖于简化的情绪标签或单一模态输入。本文介绍了一种新型的多模态情感文本转语音系统(UMETTS),它利用来自多个模态的情感线索生成高度表达和情绪共鸣的语音。核心组件包括情绪提示对齐模块(EP-Align)和情感嵌入诱导的TTS模块(EMI-TTS)。EP-Align通过对比学习对齐文本、音频和视觉模态的情感特征,确保多模态信息的连贯融合。EMI-TTS则将对齐的情感嵌入与最先进的TTS模型相结合,合成准确反映预期情绪的语音。评估结果表明,UMETTS在情感准确性和语音自然性方面取得了显著改进,在客观和主观指标上均优于传统E-TTS方法。
Key Takeaways
- E-TTS在近年来备受关注,因其对人类-计算机交互的潜在革命性影响。
- 当前E-TTS方法存在局限性,难以捕捉人类情绪的复杂性,主要依赖简化的情绪标签或单一模态输入。
- UMETTS是一种新型的多模态情感文本转语音系统,旨在解决上述问题。
- UMETTS包含两个核心组件:EP-Align和EMI-TTS。
- EP-Align通过对比学习对齐多模态情感特征,确保信息的连贯融合。
- EMI-TTS结合最先进的TTS模型和对齐的情感嵌入,合成准确反映预期情绪的语音。
点此查看论文截图