⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-22 更新
Do Egocentric Video-Language Models Truly Understand Hand-Object Interactions?
Authors:Boshen Xu, Ziheng Wang, Yang Du, Zhinan Song, Sipeng Zheng, Qin Jin
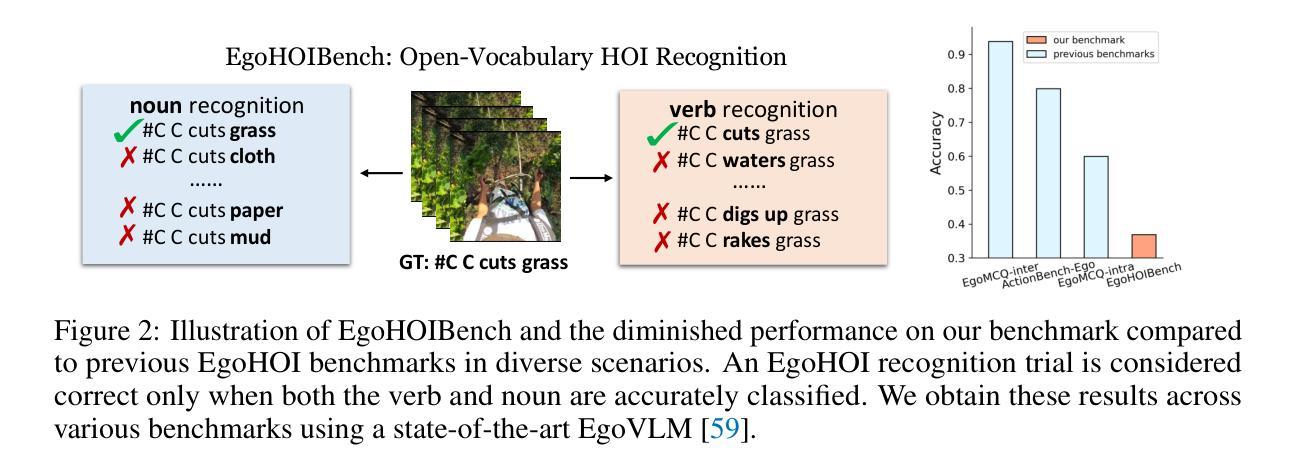
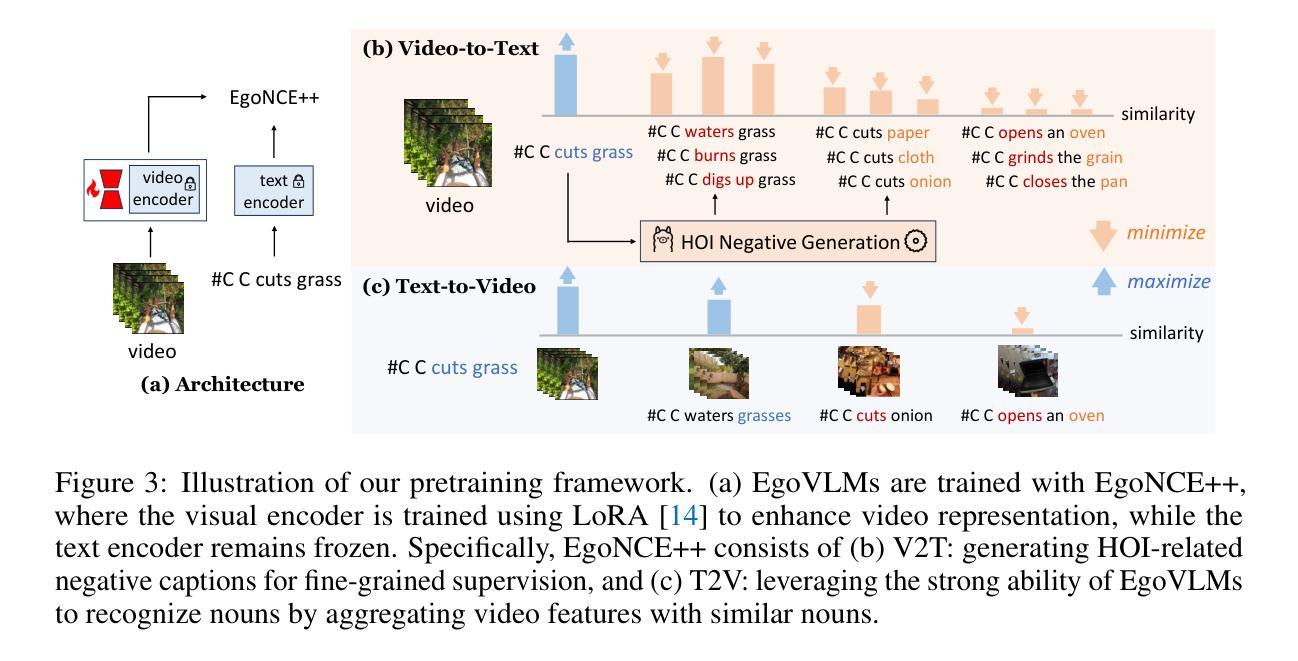
Egocentric video-language pretraining is a crucial step in advancing the understanding of hand-object interactions in first-person scenarios. Despite successes on existing testbeds, we find that current EgoVLMs can be easily misled by simple modifications, such as changing the verbs or nouns in interaction descriptions, with models struggling to distinguish between these changes. This raises the question: Do EgoVLMs truly understand hand-object interactions? To address this question, we introduce a benchmark called EgoHOIBench, revealing the performance limitation of current egocentric models when confronted with such challenges. We attribute this performance gap to insufficient fine-grained supervision and the greater difficulty EgoVLMs experience in recognizing verbs compared to nouns. To tackle these issues, we propose a novel asymmetric contrastive objective named EgoNCE++. For the video-to-text objective, we enhance text supervision by generating negative captions using large language models or leveraging pretrained vocabulary for HOI-related word substitutions. For the text-to-video objective, we focus on preserving an object-centric feature space that clusters video representations based on shared nouns. Extensive experiments demonstrate that EgoNCE++ significantly enhances EgoHOI understanding, leading to improved performance across various EgoVLMs in tasks such as multi-instance retrieval, action recognition, and temporal understanding. Our code is available at https://github.com/xuboshen/EgoNCEpp.
以自我为中心的视频语言预训练是推进第一人称场景中手与物体交互理解的关键步骤。尽管在现有测试床上取得了成功,我们发现当前的EgoVLMs很容易被简单的修改所误导,比如改变交互描述中的动词或名词,而模型很难区分这些变化。这引发了以下问题:EgoVLMs真的理解手与物体的交互吗?为了回答这个问题,我们引入了一个名为EgoHOIBench的基准测试,揭示了当前以自我为中心模型在面对这些挑战时的性能局限。我们将这种性能差距归因于精细监督的不足以及EgoVLMs在识别动词方面相比名词所面临的更大困难。为了解决这些问题,我们提出了一种名为EgoNCE++的新型不对称对比目标。对于视频到文本的目标,我们通过使用大型语言模型生成负面字幕或利用预训练的HOI相关词汇替换来增强文本监督。对于文本到视频的目标,我们专注于保持一个以对象为中心的特征空间,该空间根据共享名词对视频表示进行聚类。大量实验表明,EgoNCE++显著增强了EgoHOI的理解能力,在各种EgoVLMs的任务中提高了性能,如多实例检索、动作识别和时序理解。我们的代码可在https://github.com/xuboshen/EgoNCEpp找到。
论文及项目相关链接
PDF Accepted by ICLR 2025. Code: https://github.com/xuboshen/EgoNCEpp
Summary
本文介绍了以自我为中心的视频语言预训练对于理解第一人称场景中的手与物体的交互的重要性。作者提出了一个基准测试平台(EgoHOIBench),用于评估现有以自我为中心的模型在面对挑战时的性能限制。为了提高模型的性能,作者提出了一种名为EgoNCE++的新型不对称对比目标,通过增强文本监督和专注于对象中心特征空间的保留来解决存在的问题。实验证明,EgoNCE++能显著提高EgoHOI的理解能力,并在多任务测试中提高性能。
Key Takeaways
- 当前以自我为中心的视频语言模型(EgoVLMs)容易受到简单修改的影响,如改变交互描述中的动词或名词。
- 存在一个性能差距,主要是由于当前模型缺乏精细的监督和识别动词的困难。
- 引入了一个新的基准测试平台(EgoHOIBench)来评估现有模型的性能。
- 提出了一种新型不对称对比目标(EgoNCE++),用于解决现有模型的问题。
- 通过增强文本监督和专注于对象中心特征空间的保留来优化模型性能。
- 实验表明,EgoNCE++能够显著提高EgoHOI的理解能力,并在多项任务测试中表现优越。
点此查看论文截图