⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-22 更新
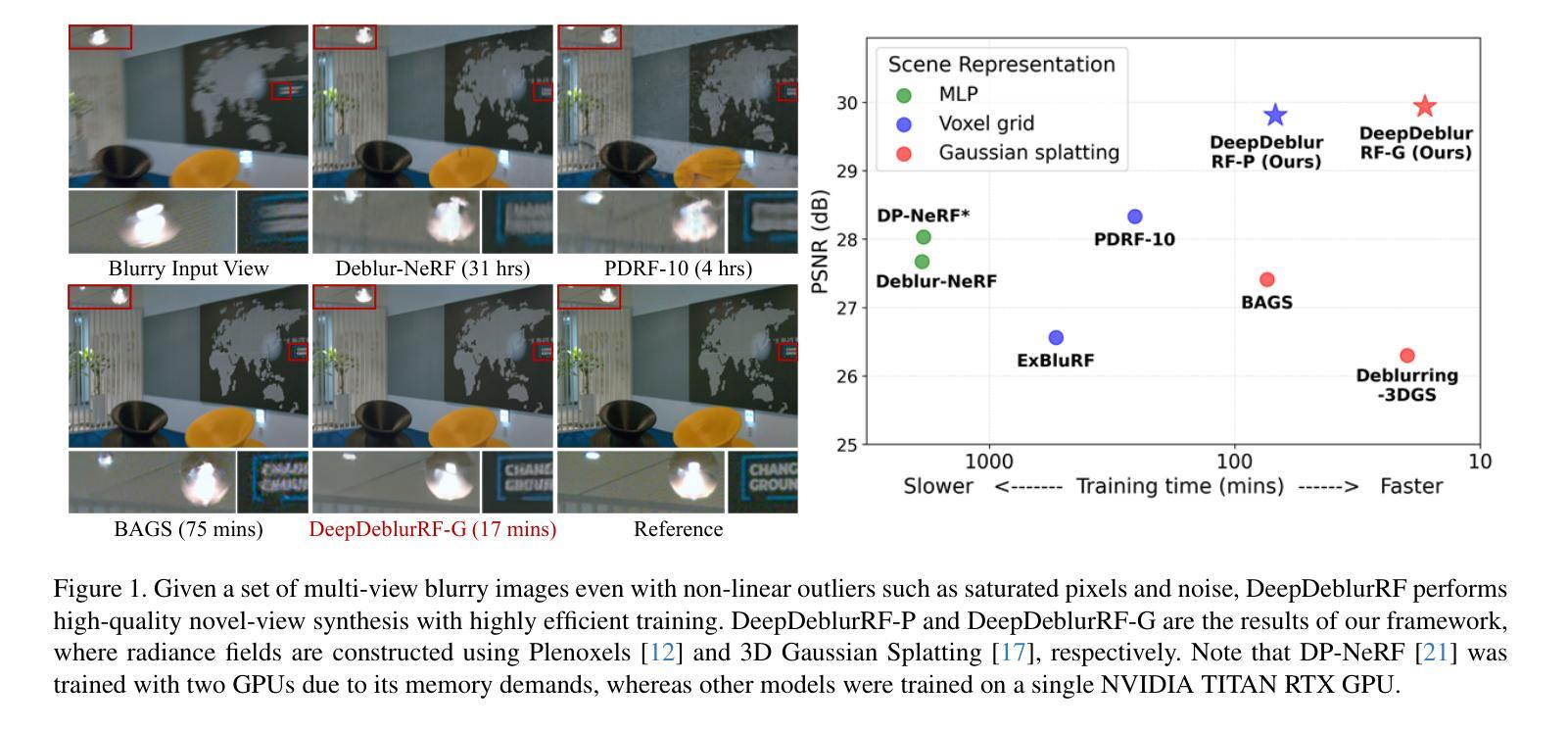
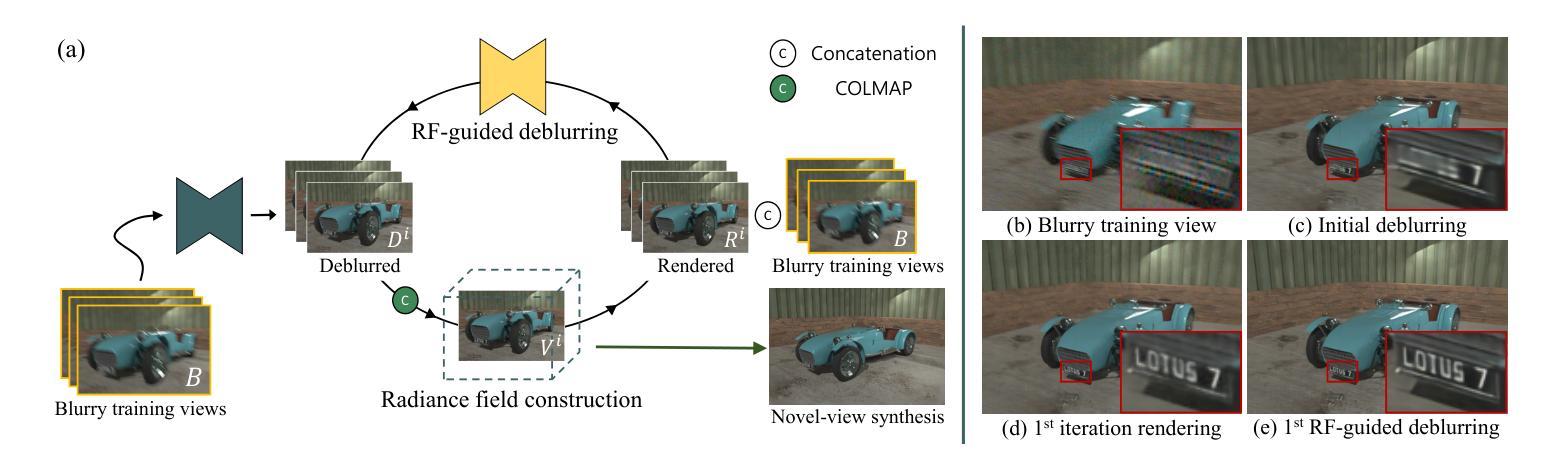
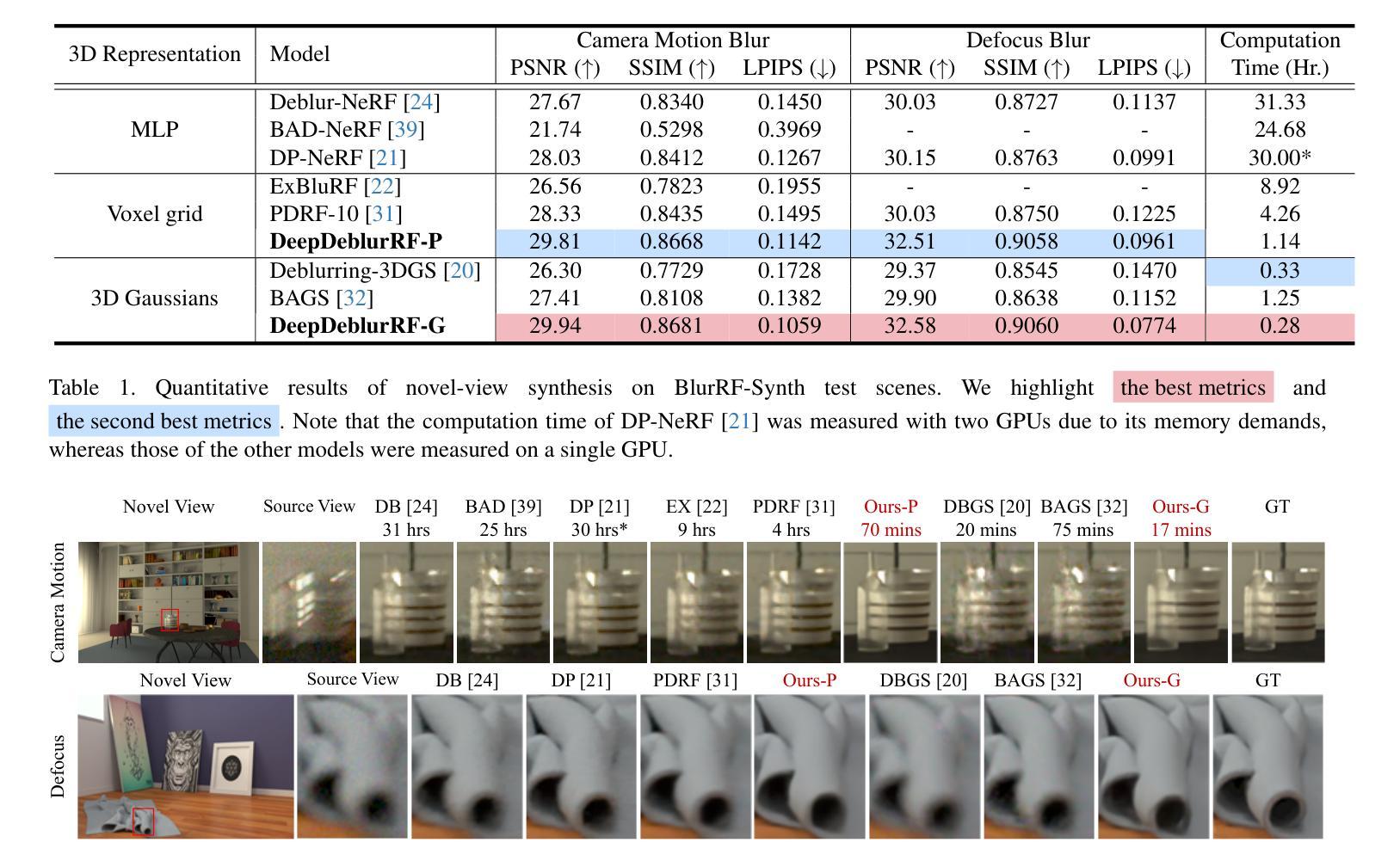
Exploiting Deblurring Networks for Radiance Fields
Authors:Haeyun Choi, Heemin Yang, Janghyeok Han, Sunghyun Cho
In this paper, we propose DeepDeblurRF, a novel radiance field deblurring approach that can synthesize high-quality novel views from blurred training views with significantly reduced training time. DeepDeblurRF leverages deep neural network (DNN)-based deblurring modules to enjoy their deblurring performance and computational efficiency. To effectively combine DNN-based deblurring and radiance field construction, we propose a novel radiance field (RF)-guided deblurring and an iterative framework that performs RF-guided deblurring and radiance field construction in an alternating manner. Moreover, DeepDeblurRF is compatible with various scene representations, such as voxel grids and 3D Gaussians, expanding its applicability. We also present BlurRF-Synth, the first large-scale synthetic dataset for training radiance field deblurring frameworks. We conduct extensive experiments on both camera motion blur and defocus blur, demonstrating that DeepDeblurRF achieves state-of-the-art novel-view synthesis quality with significantly reduced training time.
本文提出了DeepDeblurRF,这是一种新的辐射场去模糊方法,能够从模糊的训练视角合成高质量的新视角,并显著减少训练时间。DeepDeblurRF利用基于深度神经网络(DNN)的去模糊模块,享受其去模糊性能和计算效率。为了有效地结合基于DNN的去模糊和辐射场构建,我们提出了一种新的辐射场(RF)引导去模糊方法和迭代框架,该框架以交替的方式进行RF引导去模糊和辐射场构建。此外,DeepDeblurRF可与各种场景表示兼容,例如体素网格和3D高斯,扩大了其适用性。我们还推出了BlurRF-Synth,这是第一个用于训练辐射场去模糊框架的大规模合成数据集。我们对相机运动模糊和失焦模糊进行了大量实验,结果表明,DeepDeblurRF在新型视图合成质量方面达到了最新水平,并显著减少了训练时间。
论文及项目相关链接
Summary
深度去模糊射线场(DeepDeblurRF)是一种新型的去模糊方法,结合了深度神经网络(DNN)和射线场技术,可从模糊的训练视角合成高质量的新视角,同时显著减少训练时间。此方法通过交替进行射线场引导和去模糊操作,兼容多种场景表示,如体素网格和三维高斯模型。此外,还推出了BlurRF-Synth,这是首个用于训练射线场去模糊框架的大型合成数据集。实验证明,DeepDeblurRF在新型视角合成质量方面达到领先水平,同时显著缩短了训练时间。
Key Takeaways
- DeepDeblurRF是一种结合深度神经网络和射线场的去模糊方法。
- 该方法可以合成高质量的新视角,从模糊的训练视角出发,显著减少训练时间。
- 通过交替进行射线场引导和去模糊操作,实现了DNN去模糊模块和射线场构建的有效结合。
- DeepDeblurRF兼容多种场景表示,如体素网格和三维高斯模型。
- 推出了首个用于训练射线场去模糊框架的大型合成数据集BlurRF-Synth。
- 实验结果表明,DeepDeblurRF在新型视角合成质量方面表现优异。
点此查看论文截图



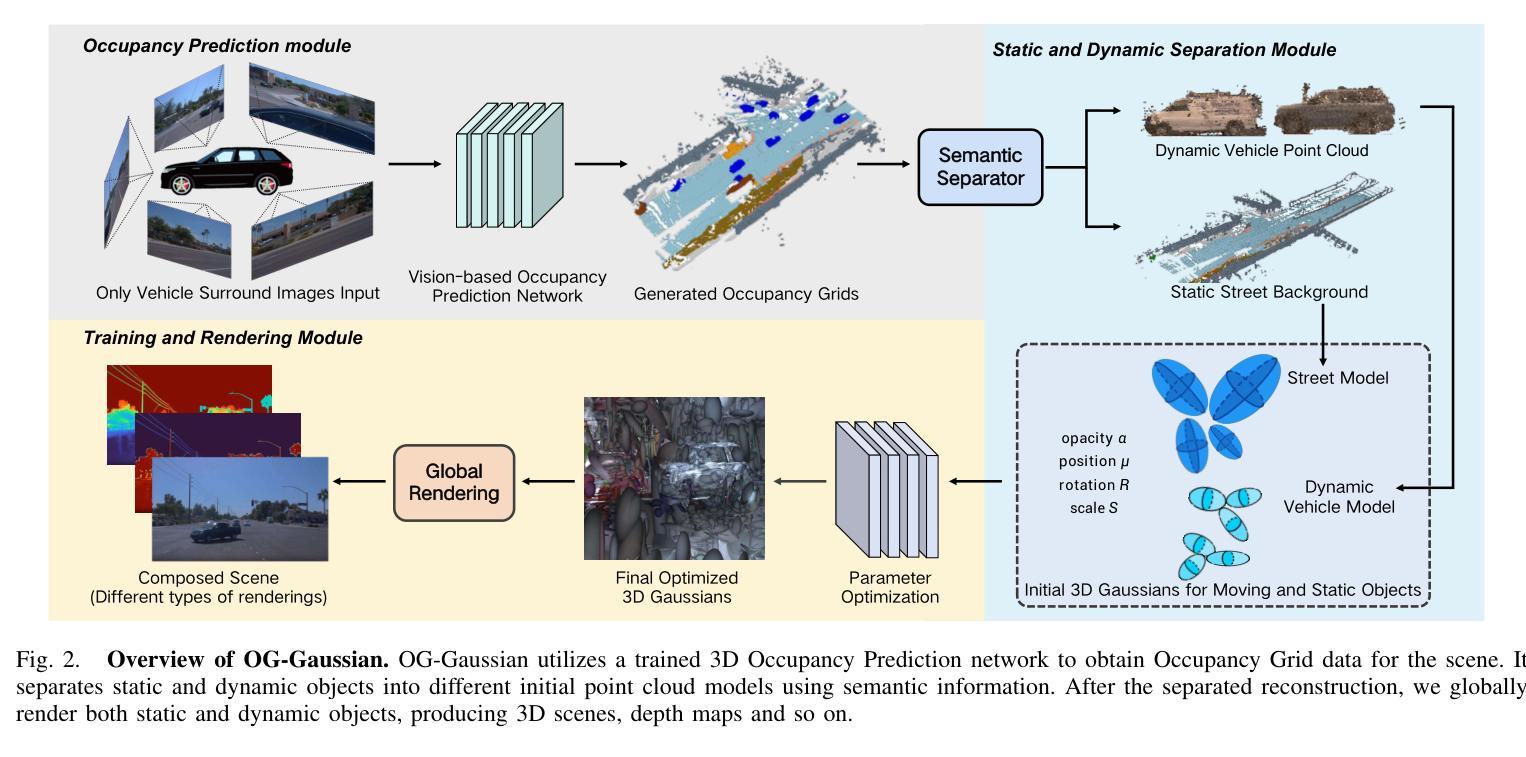
OG-Gaussian: Occupancy Based Street Gaussians for Autonomous Driving
Authors:Yedong Shen, Xinran Zhang, Yifan Duan, Shiqi Zhang, Heng Li, Yilong Wu, Jianmin Ji, Yanyong Zhang
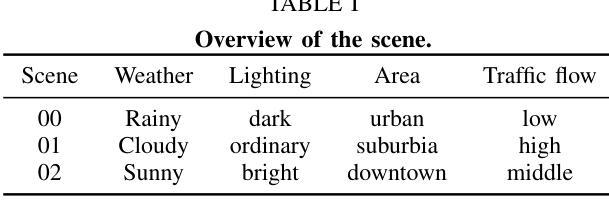
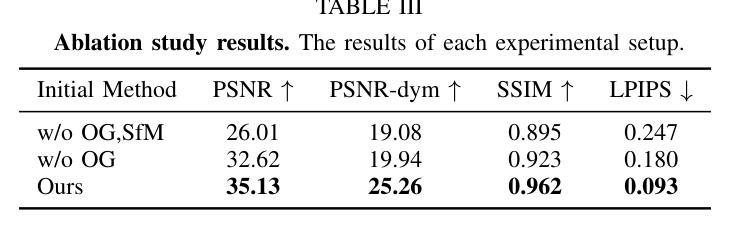
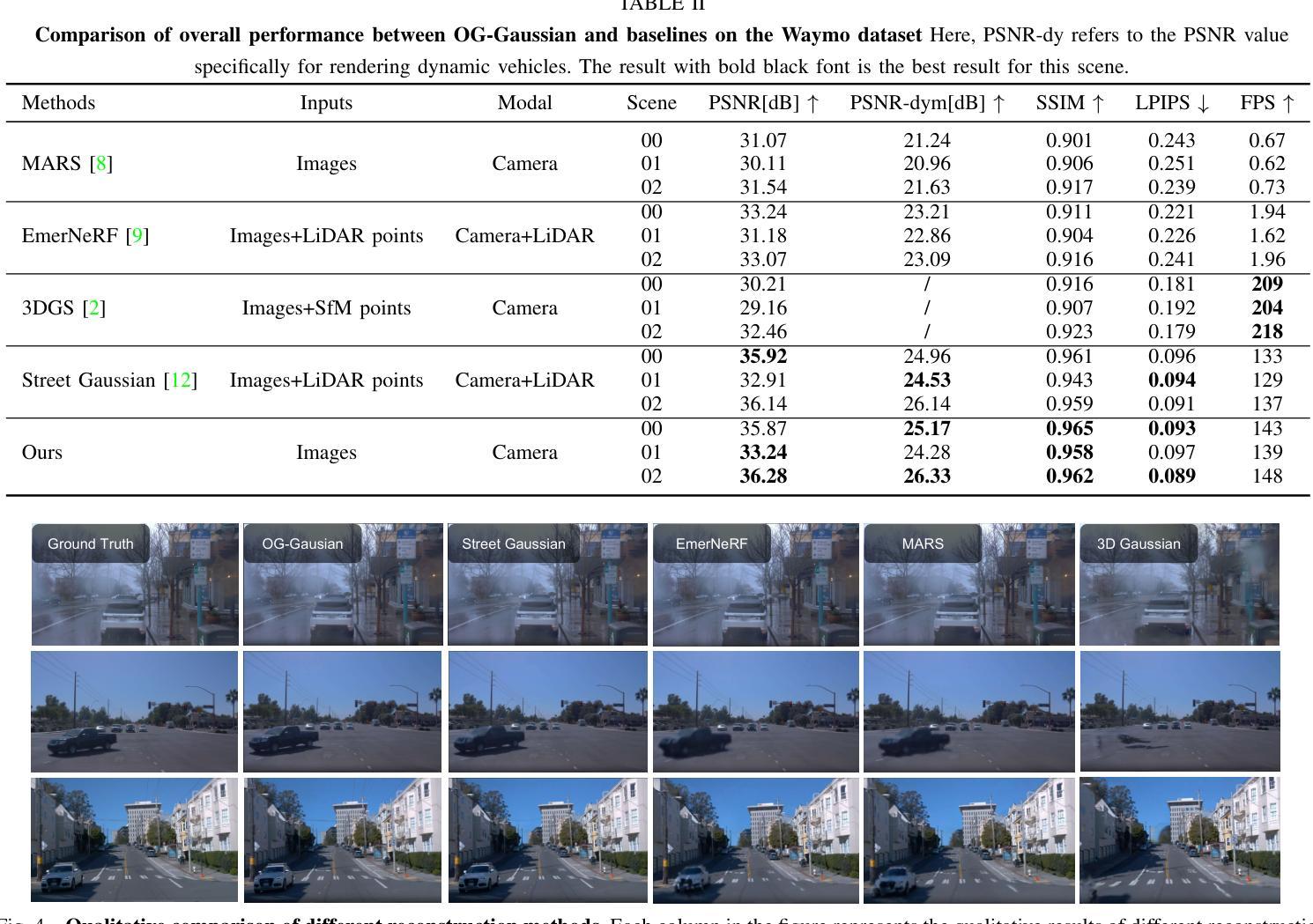
Accurate and realistic 3D scene reconstruction enables the lifelike creation of autonomous driving simulation environments. With advancements in 3D Gaussian Splatting (3DGS), previous studies have applied it to reconstruct complex dynamic driving scenes. These methods typically require expensive LiDAR sensors and pre-annotated datasets of dynamic objects. To address these challenges, we propose OG-Gaussian, a novel approach that replaces LiDAR point clouds with Occupancy Grids (OGs) generated from surround-view camera images using Occupancy Prediction Network (ONet). Our method leverages the semantic information in OGs to separate dynamic vehicles from static street background, converting these grids into two distinct sets of initial point clouds for reconstructing both static and dynamic objects. Additionally, we estimate the trajectories and poses of dynamic objects through a learning-based approach, eliminating the need for complex manual annotations. Experiments on Waymo Open dataset demonstrate that OG-Gaussian is on par with the current state-of-the-art in terms of reconstruction quality and rendering speed, achieving an average PSNR of 35.13 and a rendering speed of 143 FPS, while significantly reducing computational costs and economic overhead.
准确而逼真的3D场景重建能够实现自动驾驶模拟环境的真实创建。随着3D高斯拼贴(3DGS)的发展,先前的研究已将其应用于重建复杂的动态驾驶场景。这些方法通常需要使用昂贵的激光雷达传感器和动态物体的预标注数据集。为了解决这些挑战,我们提出了OG-高斯(OG-Gaussian)这一新方法,它用占用网格(OGs)替代激光雷达点云,这些占用网格是通过使用占用预测网络(ONet)从周围视图图像生成的。我们的方法利用网格中的语义信息来分离动态车辆和静态街道背景,将这些网格转换为两组不同的初始点云,以重建静态和动态物体。此外,我们还通过基于学习的方法估计动态物体的轨迹和姿态,无需进行复杂的手动标注。在Waymo Open数据集上的实验表明,OG-高斯在重建质量和渲染速度方面与当前先进技术相当,平均PSNR达到35.13,渲染速度为每秒143帧,同时显著降低了计算成本和经济成本。
论文及项目相关链接
Summary
基于精准的实时动态驾驶场景重建,通过Occupancy Grids技术构建道路信息环境并实现场景的复现。提出OG-Gaussian新方法利用环绕视图相机图像和Occupancy Prediction Network技术替代昂贵的LiDAR传感器和动态物体预标注数据集,通过语义信息分离动态车辆与静态街道背景并转化为不同的初始点云集合。同时,利用学习技术预测动态物体的轨迹和姿态,无需复杂的标记标注过程。实验数据在Waymo Open数据集上显示出该方法的优越性,可实现高效稳定的驾驶模拟场景重建。
Key Takeaways
- 基于实时的动态驾驶场景重建技术实现了道路的精准模拟复现。
- 利用Occupancy Grids技术构建道路信息环境,提高场景复现的准确度。
- 提出OG-Gaussian新方法替代昂贵的LiDAR传感器和预标注数据集。
- 利用环绕视图相机图像和Occupancy Prediction Network技术提取场景语义信息,便于后续处理。
- 通过语义信息分离动态车辆与静态街道背景并转化为不同的初始点云集合,提高重建质量。
- 利用学习技术预测动态物体的轨迹和姿态,减少人工标注的工作量。
点此查看论文截图



Inter3D: A Benchmark and Strong Baseline for Human-Interactive 3D Object Reconstruction
Authors:Gan Chen, Ying He, Mulin Yu, F. Richard Yu, Gang Xu, Fei Ma, Ming Li, Guang Zhou
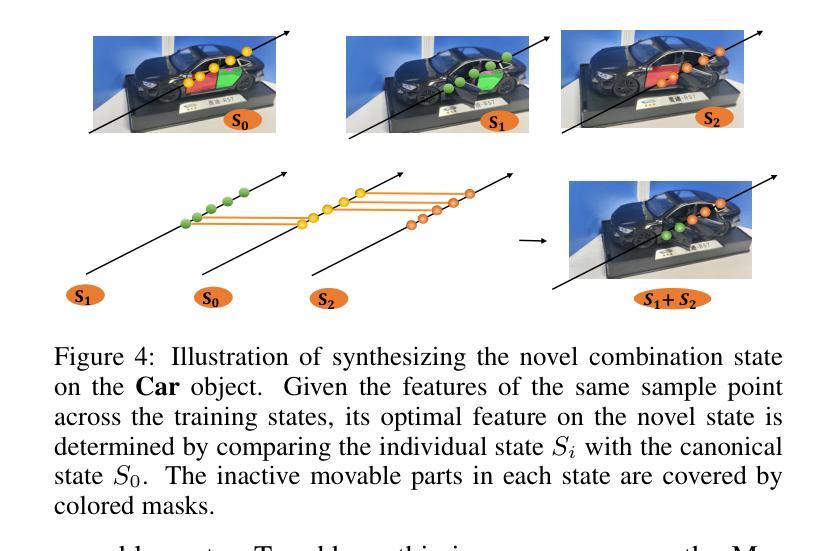
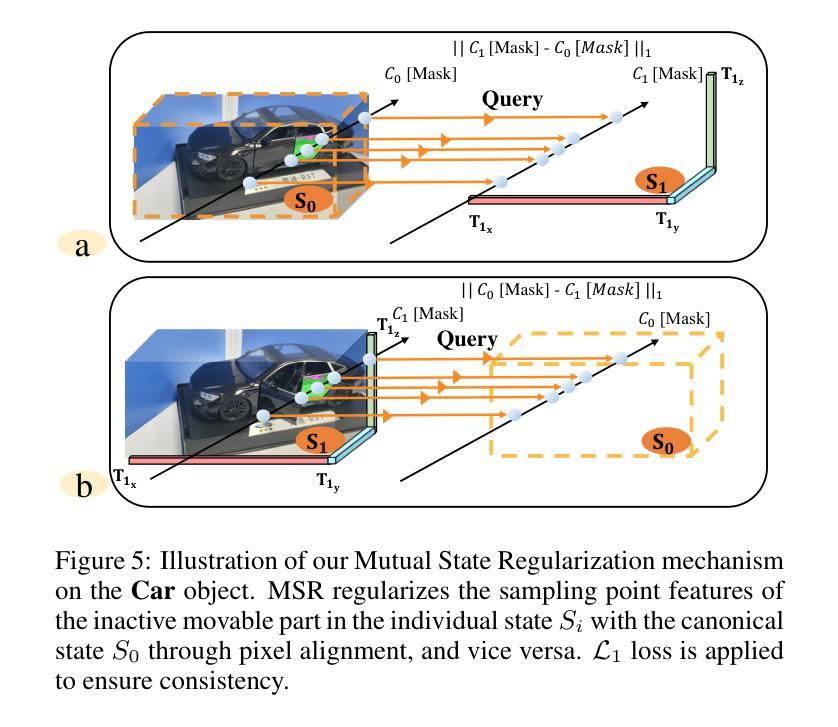
Recent advancements in implicit 3D reconstruction methods, e.g., neural rendering fields and Gaussian splatting, have primarily focused on novel view synthesis of static or dynamic objects with continuous motion states. However, these approaches struggle to efficiently model a human-interactive object with n movable parts, requiring 2^n separate models to represent all discrete states. To overcome this limitation, we propose Inter3D, a new benchmark and approach for novel state synthesis of human-interactive objects. We introduce a self-collected dataset featuring commonly encountered interactive objects and a new evaluation pipeline, where only individual part states are observed during training, while part combination states remain unseen. We also propose a strong baseline approach that leverages Space Discrepancy Tensors to efficiently modelling all states of an object. To alleviate the impractical constraints on camera trajectories across training states, we propose a Mutual State Regularization mechanism to enhance the spatial density consistency of movable parts. In addition, we explore two occupancy grid sampling strategies to facilitate training efficiency. We conduct extensive experiments on the proposed benchmark, showcasing the challenges of the task and the superiority of our approach.
近期隐式三维重建方法的进展,例如神经网络渲染和高斯贴图技术,主要关注静态或动态物体的新型视图合成,这些物体具有连续的运动状态。然而,这些方法在模拟具有n个可移动部件的人机交互物体时面临困难,需要2^n个独立模型来表示所有离散状态。为了克服这一局限性,我们提出了Inter3D,这是一个新的基准测试方法和人机交互物体新型状态合成的方法。我们引入了一个自收集的数据集,其中包含常见交互物体,以及一个新的评估流程,在训练期间仅观察单个部件的状态,而部件组合状态则保持未见。我们还提出了一种强大的基线方法,利用空间差异张量来有效地模拟物体的所有状态。为了缓解训练状态下相机轨迹的不切实际约束,我们提出了一种互状态正则化机制,以提高可移动部件的空间密度一致性。此外,我们探索了两种占用网格采样策略以提高训练效率。我们在提出的基准测试上进行了大量实验,展示了该任务的挑战性以及我们方法的优越性。
论文及项目相关链接
Summary
近期隐式三维重建方法,如神经网络渲染和高斯涂抹技术,主要关注静态或动态物体的新视角合成。但对于含有可移动部件的人机交互物体,这些方法在高效建模方面存在挑战,需用2^n个模型表示所有离散状态。为此,我们提出Inter3D,一个针对人机交互物体新状态合成的新基准和方法。我们引入了自收集数据集和新评估流程,训练时仅观察单个部件状态,组合状态则不可见。我们提出了一个强大的基线方法,利用空间差异张量来高效建模物体的所有状态。同时,为解决训练状态下相机轨迹的不实际约束问题,我们提出了相互状态正则化机制,以提高可移动部件的空间密度一致性。此外,我们还探索了两种占用网格采样策略以提高训练效率。在提出的基准上进行了大量实验,展示了任务挑战性和我们方法的优越性。
Key Takeaways
- 近期隐式三维重建方法主要关注静态或动态物体的新视角合成。
- 现有方法难以高效建模含多个可移动部件的人机交互物体。
- Inter3D提出一个自收集数据集和新评估流程,用于人机交互物体的新状态合成。
- Inter3D仅观察单个部件状态进行训练,组合状态在训练时不可见。
- 提出利用空间差异张量进行高效建模的基线方法。
- 提出相互状态正则化机制,提高可移动部件的空间密度一致性。
点此查看论文截图




CaRtGS: Computational Alignment for Real-Time Gaussian Splatting SLAM
Authors:Dapeng Feng, Zhiqiang Chen, Yizhen Yin, Shipeng Zhong, Yuhua Qi, Hongbo Chen
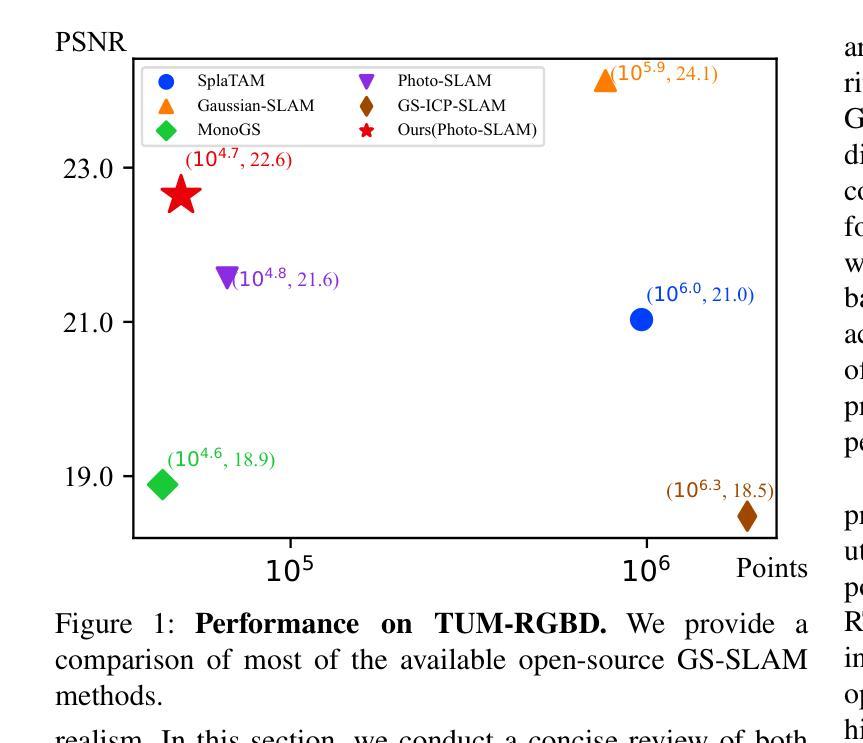
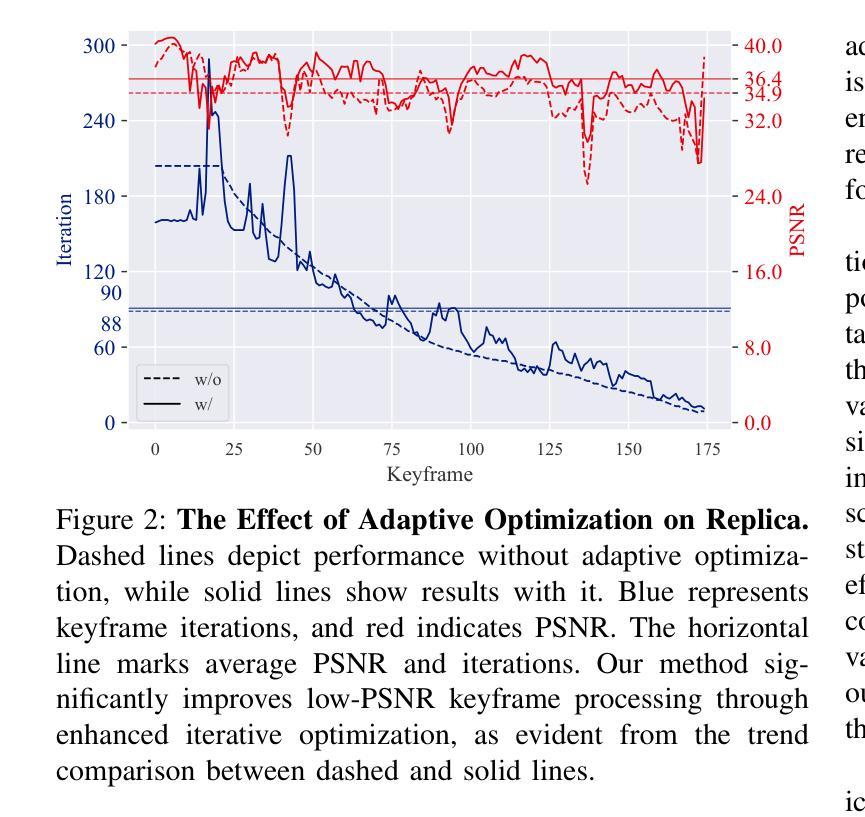
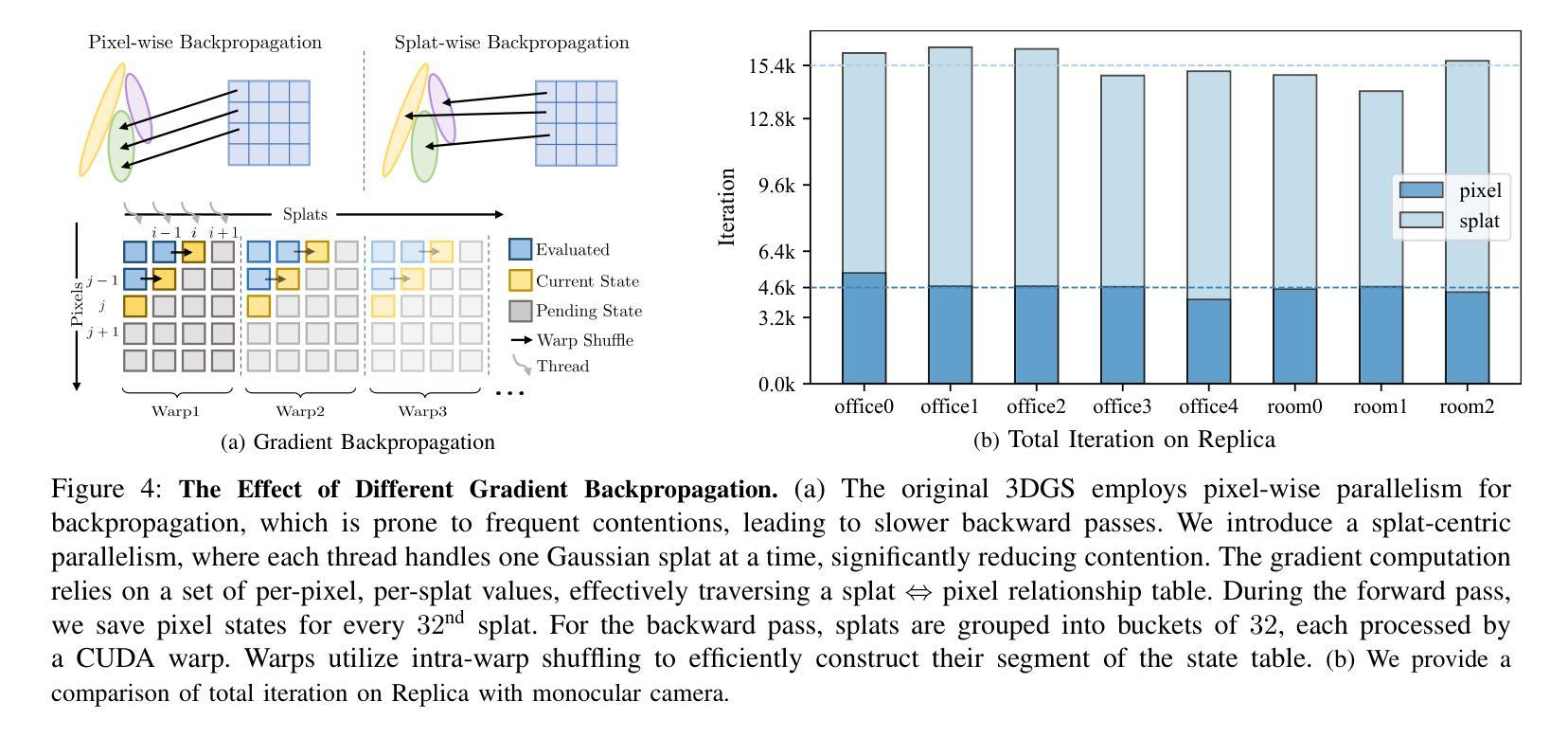
Simultaneous Localization and Mapping (SLAM) is pivotal in robotics, with photorealistic scene reconstruction emerging as a key challenge. To address this, we introduce Computational Alignment for Real-Time Gaussian Splatting SLAM (CaRtGS), a novel method enhancing the efficiency and quality of photorealistic scene reconstruction in real-time environments. Leveraging 3D Gaussian Splatting (3DGS), CaRtGS achieves superior rendering quality and processing speed, which is crucial for scene photorealistic reconstruction. Our approach tackles computational misalignment in Gaussian Splatting SLAM (GS-SLAM) through an adaptive strategy that enhances optimization iterations, addresses long-tail optimization, and refines densification. Experiments on Replica, TUM-RGBD, and VECtor datasets demonstrate CaRtGS’s effectiveness in achieving high-fidelity rendering with fewer Gaussian primitives. This work propels SLAM towards real-time, photorealistic dense rendering, significantly advancing photorealistic scene representation. For the benefit of the research community, we release the code and accompanying videos on our project website: https://dapengfeng.github.io/cartgs.
同时定位与地图构建(SLAM)在机器人技术中至关重要,而真实感场景重建成为了一项关键挑战。为解决这一问题,我们引入了面向实时高斯拼贴SLAM的计算对齐(CaRtGS)方法,这是一种提高实时环境中真实感场景重建效率和质量的新型技术。通过利用三维高斯拼贴(3DGS),CaRtGS可实现出色的渲染质量和处理速度,对于场景的真实感重建至关重要。我们的方法通过自适应策略解决了高斯拼贴SLAM中的计算失准问题,通过优化迭代增强、解决长期优化并改进密集化。在Replica、TUM-RGBD和VECtor数据集上的实验表明,CaRtGS在实现使用更少高斯原语的高保真渲染方面非常有效。这项工作推动了SLAM技术向实时真实感密集渲染的发展,极大地推动了真实感场景表示的进步。为了造福研究界,我们在项目网站上发布了代码和相关视频:https://dapengfeng.github.io/cartgs 。
论文及项目相关链接
PDF Accepted by IEEE Robotics and Automation Letters (RA-L)
Summary
实时环境下的光写实场景重建是机器人技术中的关键挑战。为解决这一问题,我们提出计算对齐实时高斯贴片SLAM(CaRtGS),这是一种增强光写实场景重建效率和质量的新方法。借助3D高斯贴片技术,CaRtGS实现了出色的渲染质量和处理速度,对高斯贴片SLAM中的计算错位问题采用自适应策略,优化迭代过程,解决长尾优化问题,并改进了密集化过程。在Replica、TUM-RGBD和VECtor数据集上的实验表明,CaRtGS在高保真渲染方面表现出色,使用的Gaussian primitives数量更少。本研究推动了SLAM技术向实时光写实密集渲染的发展,显著提升了光写实场景的表现能力。有关该项目的代码和相关视频可在我们的网站上获取:https://dapengfeng.github.io/cartgs。
Key Takeaways
- Simultaneous Localization and Mapping (SLAM)在机器人技术中非常重要,而光写实场景重建是其中的一项关键挑战。
- 提出了计算对齐实时高斯贴片SLAM(CaRtGS)方法,旨在提高光写实场景重建的效率和质量。
- CaRtGS利用3D高斯贴片技术实现高渲染质量和处理速度,对高斯贴片SLAM中的计算错位问题进行了优化。
- CaRtGS通过自适应策略解决长尾优化问题并改进密集化过程。
- 在多个数据集上的实验表明,CaRtGS在高保真渲染方面表现优越,使用较少的Gaussian primitives即可实现高质量渲染。
- CaRtGS的研究推动了SLAM技术向实时光写实密集渲染的发展。
点此查看论文截图


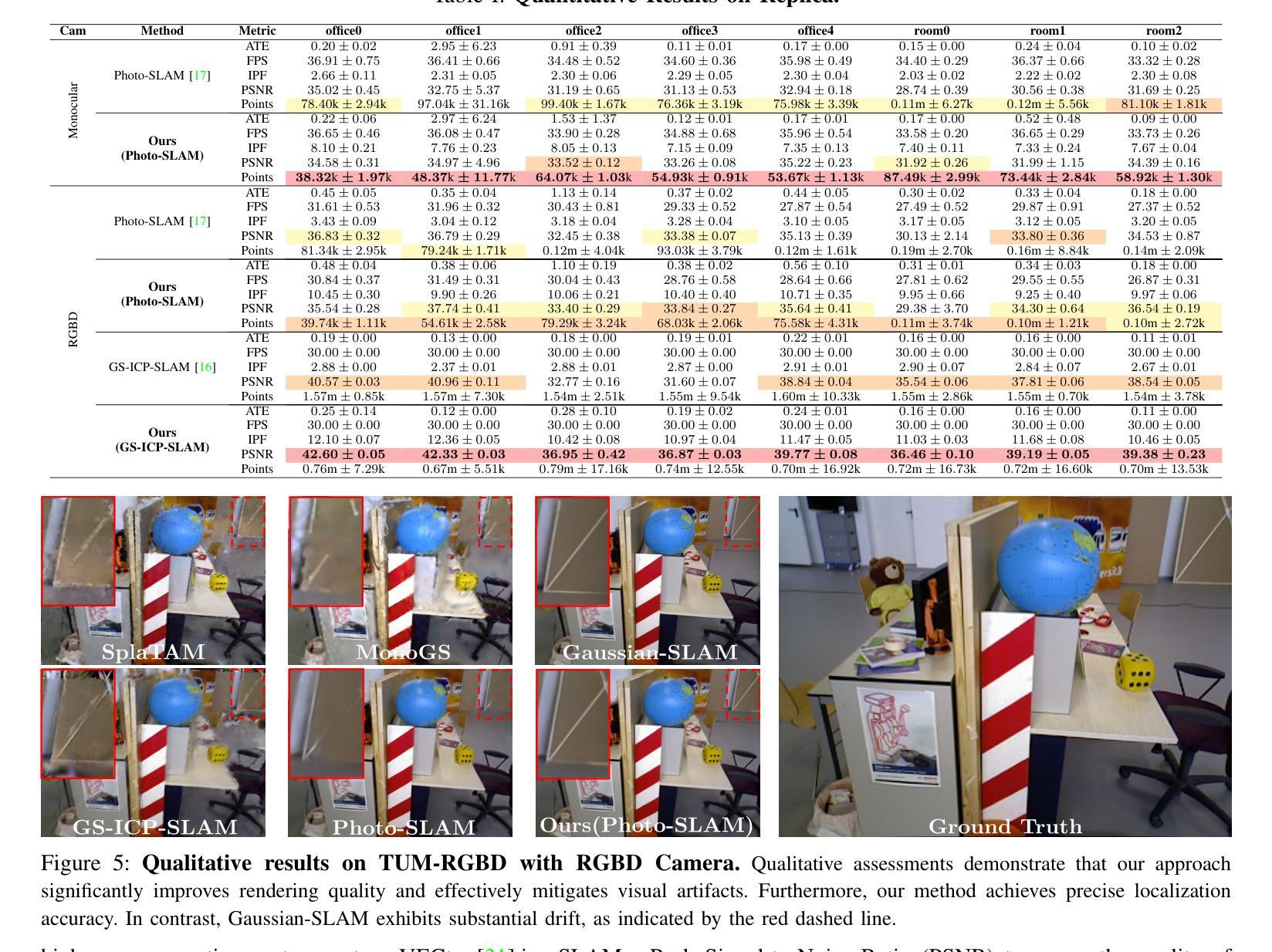
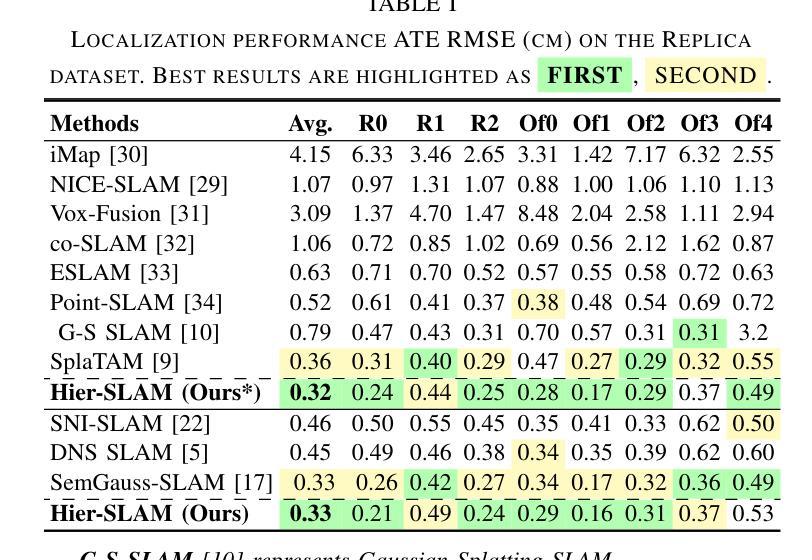
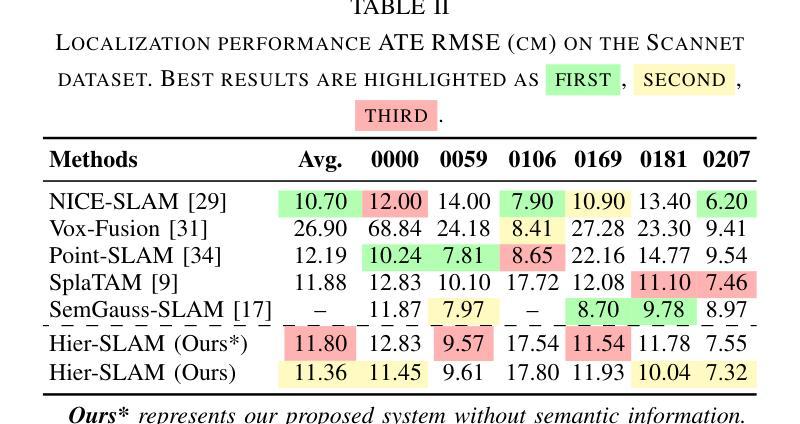
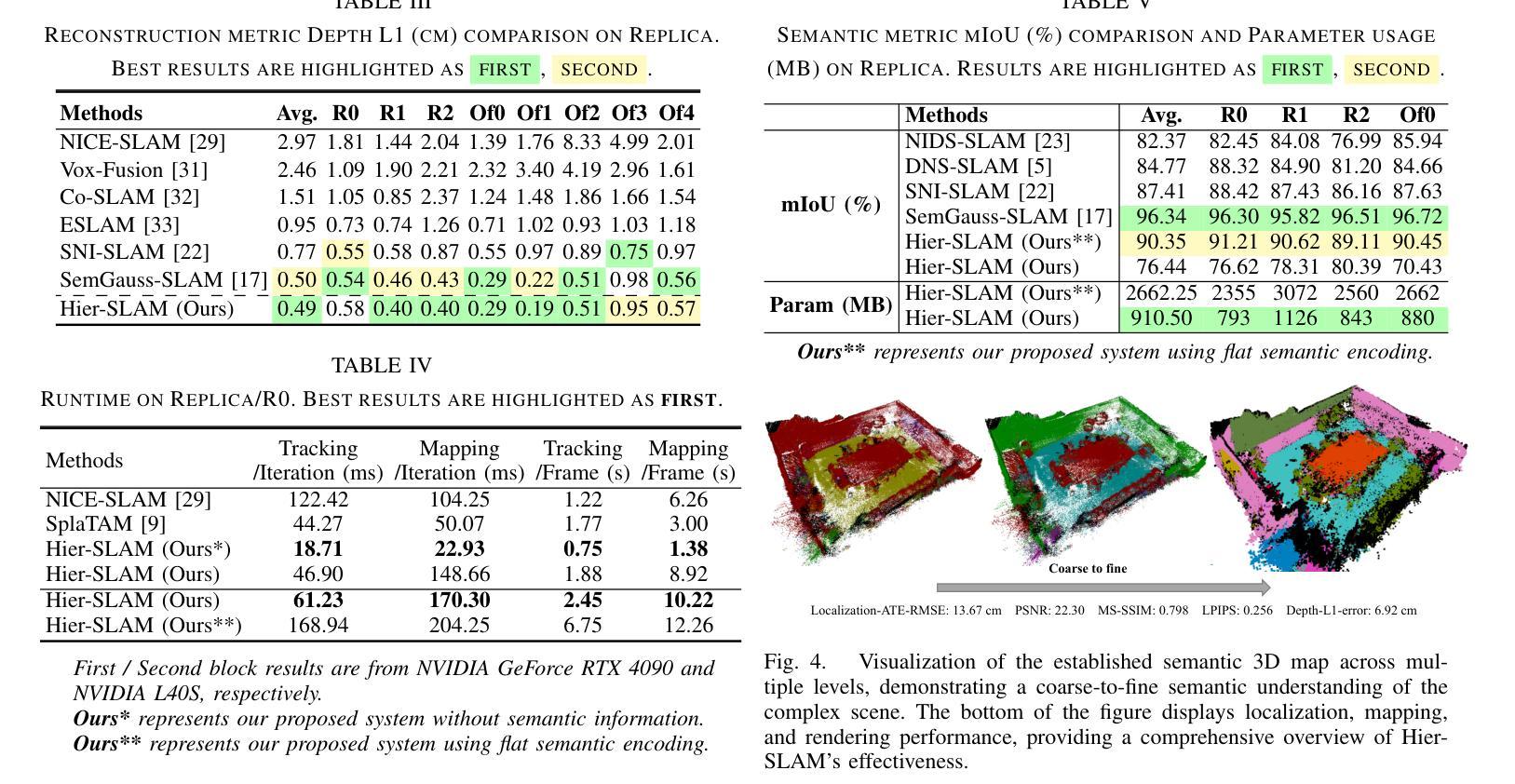
Hier-SLAM: Scaling-up Semantics in SLAM with a Hierarchically Categorical Gaussian Splatting
Authors:Boying Li, Zhixi Cai, Yuan-Fang Li, Ian Reid, Hamid Rezatofighi
We propose Hier-SLAM, a semantic 3D Gaussian Splatting SLAM method featuring a novel hierarchical categorical representation, which enables accurate global 3D semantic mapping, scaling-up capability, and explicit semantic label prediction in the 3D world. The parameter usage in semantic SLAM systems increases significantly with the growing complexity of the environment, making it particularly challenging and costly for scene understanding. To address this problem, we introduce a novel hierarchical representation that encodes semantic information in a compact form into 3D Gaussian Splatting, leveraging the capabilities of large language models (LLMs). We further introduce a novel semantic loss designed to optimize hierarchical semantic information through both inter-level and cross-level optimization. Furthermore, we enhance the whole SLAM system, resulting in improved tracking and mapping performance. Our Hier-SLAM outperforms existing dense SLAM methods in both mapping and tracking accuracy, while achieving a 2x operation speed-up. Additionally, it exhibits competitive performance in rendering semantic segmentation in small synthetic scenes, with significantly reduced storage and training time requirements. Rendering FPS impressively reaches 2,000 with semantic information and 3,000 without it. Most notably, it showcases the capability of handling the complex real-world scene with more than 500 semantic classes, highlighting its valuable scaling-up capability.
我们提出了名为 Hier-SLAM 的语义三维高斯模糊 SLAM 方法,它采用了一种新型层次分类表示,能够实现准确的全局三维语义映射、可扩展性和三维世界中的显式语义标签预测。随着环境复杂性的增加,语义 SLAM 系统中的参数使用量也显著增加,这对场景理解构成了极大的挑战和成本。为了解决这个问题,我们引入了一种新型层次表示,利用大型语言模型的能力,将语义信息以紧凑的形式编码到三维高斯模糊中。我们进一步引入了一种新型语义损失,通过跨级别优化来优化层次语义信息。此外,我们增强了整个 SLAM 系统的功能,提高了跟踪和映射性能。我们的 Hier-SLAM 在映射和跟踪精度方面优于现有的密集 SLAM 方法,同时实现了 2 倍的操作速度提升。此外,它在小型合成场景中的语义分割渲染表现具有竞争力,显著减少了存储和训练时间要求。在有语义信息的情况下,渲染 FPS 令人印象深刻地达到了 2000,而没有语义信息的情况下则达到了 3000。最值得注意的是,它展示了处理具有超过 500 个语义类别的复杂现实世界场景的能力,突显了其有价值的可扩展性。
论文及项目相关链接
PDF Accepted for publication at ICRA 2025. Code will be released soon
摘要
本文提出一种名为Hier-SLAM的语义3D高斯点云SLAM方法,它采用新颖的分层次类别表示,能够实现准确的全局3D语义映射、扩展能力和明确的语义标签预测。随着环境复杂性的增长,语义SLAM系统中的参数使用量急剧增加,给场景理解带来巨大挑战和成本。为解决此问题,我们借助大型语言模型(LLMs)的能力,将语义信息以紧凑的形式编码到3D高斯点云中。我们还引入了一种新的语义损失,通过跨级别优化来优化层次语义信息。此外,我们增强了整个SLAM系统的性能,提高了跟踪和映射的精确度。Hier-SLAM在映射和跟踪精度上均优于现有的密集SLAM方法,同时实现了2倍的操作速度提升。此外,它在小型合成场景中实现了具有竞争力的语义分割性能,并显著降低了存储和训练时间要求。渲染帧率在带有语义信息的情况下达到了惊人的2000帧,而在没有语义信息的情况下则达到了3000帧。最引人注目的是,它展示了处理具有超过500个语义类别的复杂真实场景的能力,突显了其有价值的扩展能力。
关键见解
- Hier-SLAM是一种语义3D高斯点云SLAM方法,融合了新颖的分层次类别表示。
- 该方法实现了准确的全局3D语义映射、扩展能力和明确的语义标签预测。
- 面对环境复杂性的增长,Hier-SLAM通过利用大型语言模型(LLMs)以紧凑形式编码语义信息,有效应对参数使用量的增加。
- 引入新的语义损失来优化层次语义信息,既有跨级别优化功能又提升了整体性能。
- Hier-SLAM在映射和跟踪精度上优于现有密集SLAM方法,且操作速度提升了2倍。
- 在小型合成场景中,其渲染语义分割性能表现出竞争力,存储和训练时间显著降低。
点此查看论文截图


OccGaussian: 3D Gaussian Splatting for Occluded Human Rendering
Authors:Jingrui Ye, Zongkai Zhang, Yujiao Jiang, Qingmin Liao, Wenming Yang, Zongqing Lu
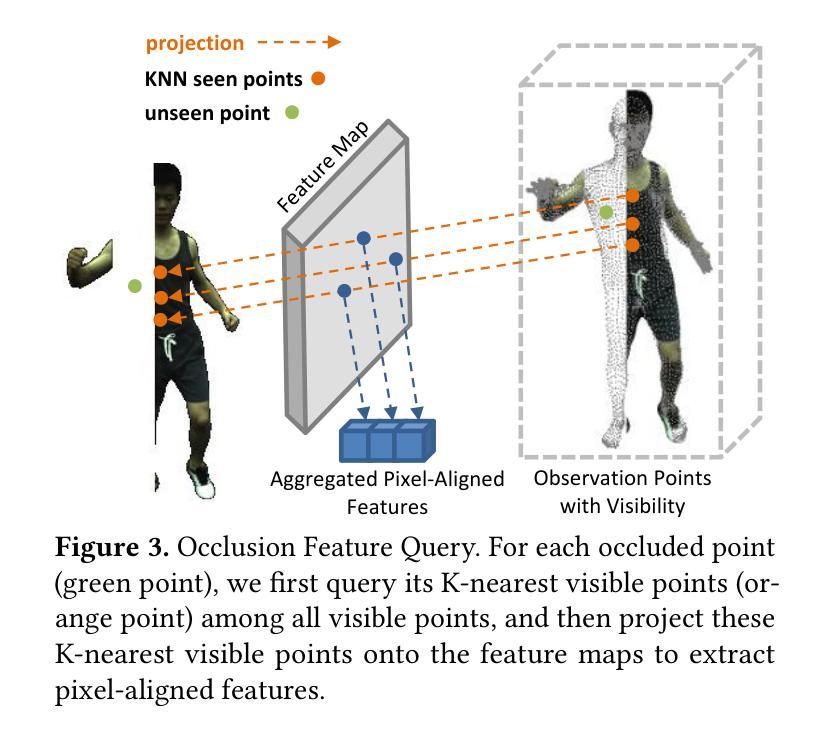
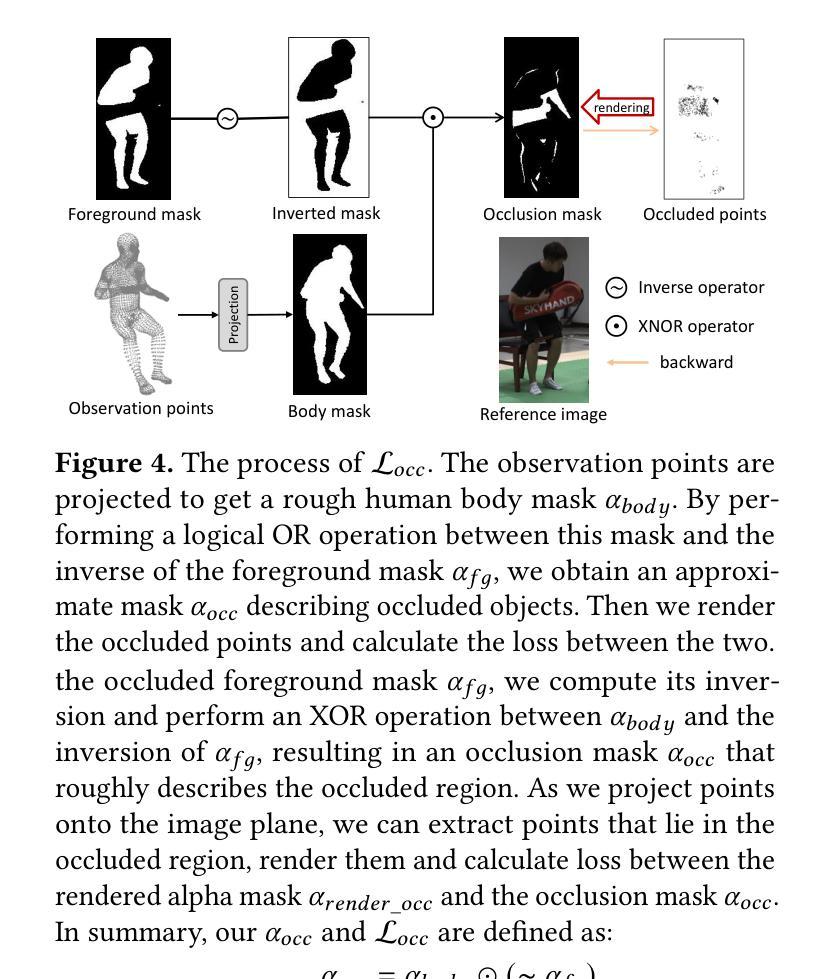
Rendering dynamic 3D human from monocular videos is crucial for various applications such as virtual reality and digital entertainment. Most methods assume the people is in an unobstructed scene, while various objects may cause the occlusion of body parts in real-life scenarios. Previous method utilizing NeRF for surface rendering to recover the occluded areas, but it requiring more than one day to train and several seconds to render, failing to meet the requirements of real-time interactive applications. To address these issues, we propose OccGaussian based on 3D Gaussian Splatting, which can be trained within 6 minutes and produces high-quality human renderings up to 160 FPS with occluded input. OccGaussian initializes 3D Gaussian distributions in the canonical space, and we perform occlusion feature query at occluded regions, the aggregated pixel-align feature is extracted to compensate for the missing information. Then we use Gaussian Feature MLP to further process the feature along with the occlusion-aware loss functions to better perceive the occluded area. Extensive experiments both in simulated and real-world occlusions, demonstrate that our method achieves comparable or even superior performance compared to the state-of-the-art method. And we improving training and inference speeds by 250x and 800x, respectively. Our code will be available for research purposes.
从单目视频中渲染动态3D人体对于虚拟现实和数字娱乐等应用程序至关重要。大多数方法都假设人在一个无遮挡的场景中,而在现实场景中,各种物体可能会导致身体部位的遮挡。之前的方法使用NeRF进行表面渲染以恢复遮挡区域,但需要一天以上的训练时间和数秒的渲染时间,无法满足实时互动应用的要求。为了解决这些问题,我们提出了基于三维高斯拼贴技术的OccGaussian方法。该方法可以在6分钟内完成训练,并在高达每秒最多产生帧率为每秒十六帧的情况下生成高质量的人体渲染效果,适用于有遮挡输入的情况。OccGaussian在标准空间中对三维高斯分布进行初始化,然后在遮挡区域执行遮挡特征查询操作。为了补偿丢失的信息,我们提取聚合像素对齐特征。然后,我们使用高斯特征多层感知器进一步处理特征,并结合遮挡感知损失函数,以更好地感知遮挡区域。在模拟和真实遮挡环境中进行的广泛实验表明,我们的方法与最新技术相比具有相当或更好的性能。我们还提高了训练和推理速度,分别为原来的二百五十倍和八百倍。我们的代码将用于研究目的。
论文及项目相关链接
PDF We have decided to withdraw this paper because the results require further verification or additional experimental data. We plan to resubmit an updated version once the necessary work is completed
Summary
本文介绍了在虚拟现实和数字娱乐等应用中,从单目视频中渲染动态3D人体的重要性。针对现实中物体遮挡身体部位的问题,提出了一种基于3D高斯涂污的OccGaussian方法。该方法可在6分钟内进行训练,以高达160FPS的速度生成高质量的遮挡人体渲染。通过初始化规范空间中的3D高斯分布,在遮挡区域执行遮挡特征查询,提取聚合像素对齐特征以补偿缺失信息。然后结合高斯特征多层感知器和遮挡感知损失函数,进一步提高对遮挡区域的感知能力。在模拟和真实遮挡环境下的广泛实验表明,该方法与最新技术相比取得了相当或更优的性能,并将训练和推理速度分别提高了250倍和800倍。
Key Takeaways
- 动态3D人体渲染对于虚拟现实和数字娱乐等应用至关重要。
- 现有方法大多假设人体处于无遮挡场景中,但现实中存在物体遮挡问题。
- 提出的OccGaussian方法基于3D高斯涂污,可快速训练并生成高质量的人体渲染。
- OccGaussian通过在规范空间中初始化3D高斯分布,并在遮挡区域执行特征查询来处理遮挡问题。
- 通过提取聚合像素对齐特征来补偿缺失信息。
- 结合高斯特征多层感知器和遮挡感知损失函数,提高对遮挡区域的感知。
点此查看论文截图