⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-22 更新
Building reliable sim driving agents by scaling self-play
Authors:Daphne Cornelisse, Aarav Pandya, Kevin Joseph, Joseph Suárez, Eugene Vinitsky
Simulation agents are essential for designing and testing systems that interact with humans, such as autonomous vehicles (AVs). These agents serve various purposes, from benchmarking AV performance to stress-testing the system’s limits, but all use cases share a key requirement: reliability. A simulation agent should behave as intended by the designer, minimizing unintended actions like collisions that can compromise the signal-to-noise ratio of analyses. As a foundation for reliable sim agents, we propose scaling self-play to thousands of scenarios on the Waymo Open Motion Dataset under semi-realistic limits on human perception and control. Training from scratch on a single GPU, our agents nearly solve the full training set within a day. They generalize effectively to unseen test scenes, achieving a 99.8% goal completion rate with less than 0.8% combined collision and off-road incidents across 10,000 held-out scenarios. Beyond in-distribution generalization, our agents show partial robustness to out-of-distribution scenes and can be fine-tuned in minutes to reach near-perfect performance in those cases. Demonstrations of agent behaviors can be found at this link. We open-source both the pre-trained agents and the complete code base. Demonstrations of agent behaviors can be found at \url{https://sites.google.com/view/reliable-sim-agents}.
模拟代理对于设计和测试与人类交互的系统(如自动驾驶汽车)至关重要。这些代理具有多种用途,从评估自动驾驶性能到对系统进行压力测试,但所有用例都有一个共同的要求:可靠性。模拟代理的行为应符合设计者的意图,尽量减少如碰撞等意外行为,这些行为可能会破坏分析的信噪比。作为构建可靠模拟代理的基础,我们建议在Waymo Open Motion数据集上对各种场景进行成千上万的自我博弈扩展,在人的感知和控制方面设置半现实限制。从单个GPU开始从头训练,我们的代理几乎在一天内解决了完整的训练集。他们能够有效地推广到未见过的测试场景,在10000个以外的场景中实现了99.8%的目标完成率,碰撞和离路事件不到0.8%。除了内部分布泛化之外,我们的代理还显示出对外部场景的部分稳健性,并且可以在几分钟内进行微调,以在这些情况下达到近乎完美的性能。有关代理行为的演示,请参见此链接。我们同时公开了预训练代理和完整的代码库。有关代理行为的演示,请访问:[https://sites.google.com/view/reliable-sim-agents]。
论文及项目相关链接
PDF First version
Summary
本文介绍了模拟代理在设计及测试与人类交互的系统(如自动驾驶汽车)中的重要性。文章通过描述代理在Waymo Open Motion数据集上的表现,展示了代理的可靠性如何保证模拟测试的准确性。文章提出通过扩大规模在数千个场景中进行自我对弈,以提高代理的可靠性,并展示了代理在训练和测试中的表现。此外,代理对未见场景也具有很好的泛化能力,并具有对部分非场景进行微调的能力。详细的演示可在谷歌链接上找到,所有开源代码均可访问。总的来说,本文提供了一种可靠的模拟代理设计方法。
Key Takeaways
以下是该文章的关键见解要点:
- 模拟代理在设计和测试与人类交互的系统(如自动驾驶汽车)中至关重要。它们用于评估系统的性能极限和可靠性。
- 在Waymo Open Motion数据集上进行的模拟代理测试保证了模拟测试的准确性。这些代理通过自我对弈的方式在数千个场景中训练,提高了可靠性。
- 这些代理在训练和测试中表现出色,并且在未见场景中也具有良好的泛化能力。
- 模拟代理能够最小化意外行为(如碰撞),从而保证分析中的信号与噪声比。这对于评估系统的可靠性至关重要。
- 这些代理具有快速微调的能力,可以在几分钟内适应特定场景并达到近乎完美的表现。这为快速适应不同环境提供了可能性。
- 文章公开了预训练的代理和完整的代码库,便于其他研究者使用和进一步开发。这对于推动相关领域的研究和技术进步具有重要意义。
点此查看论文截图

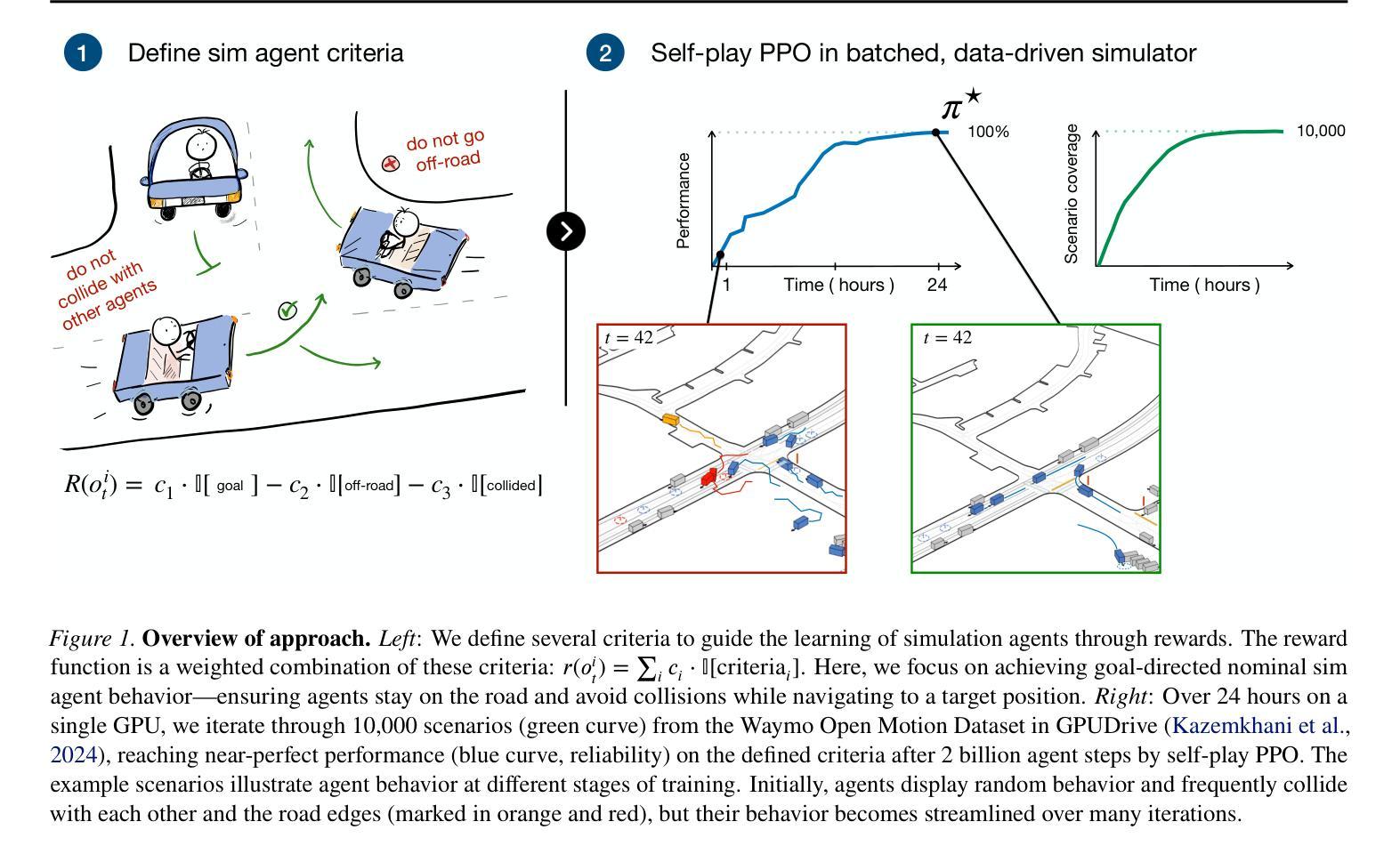

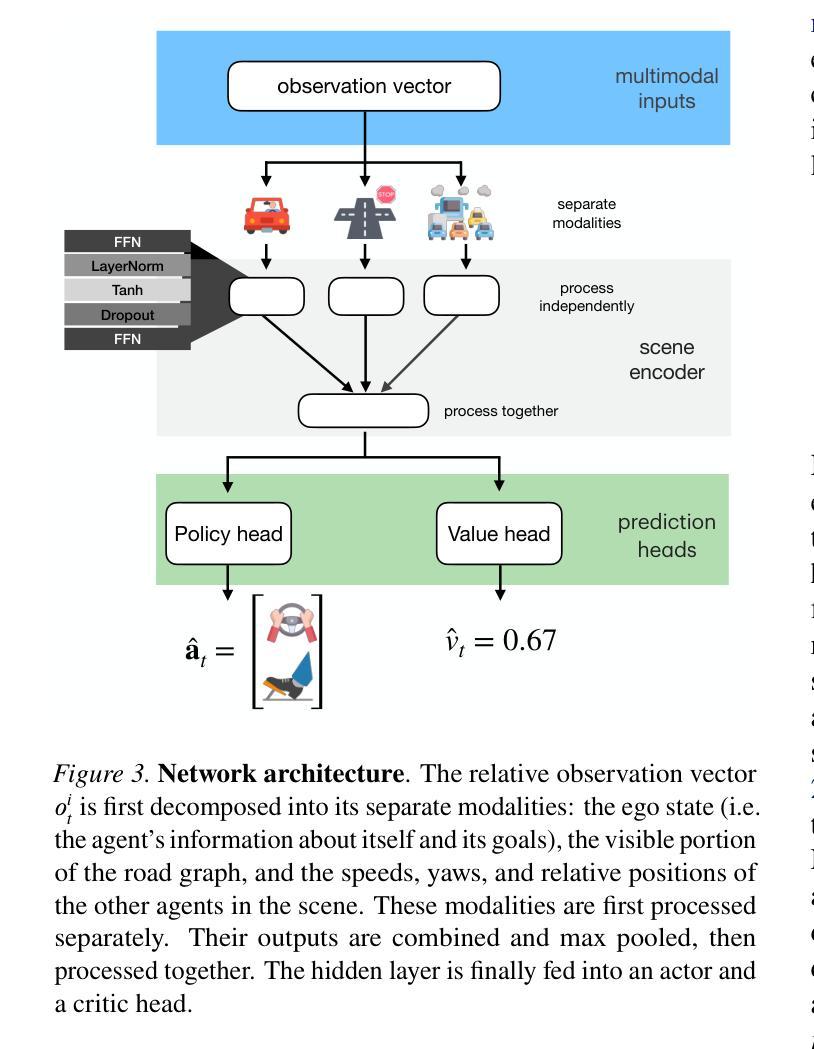
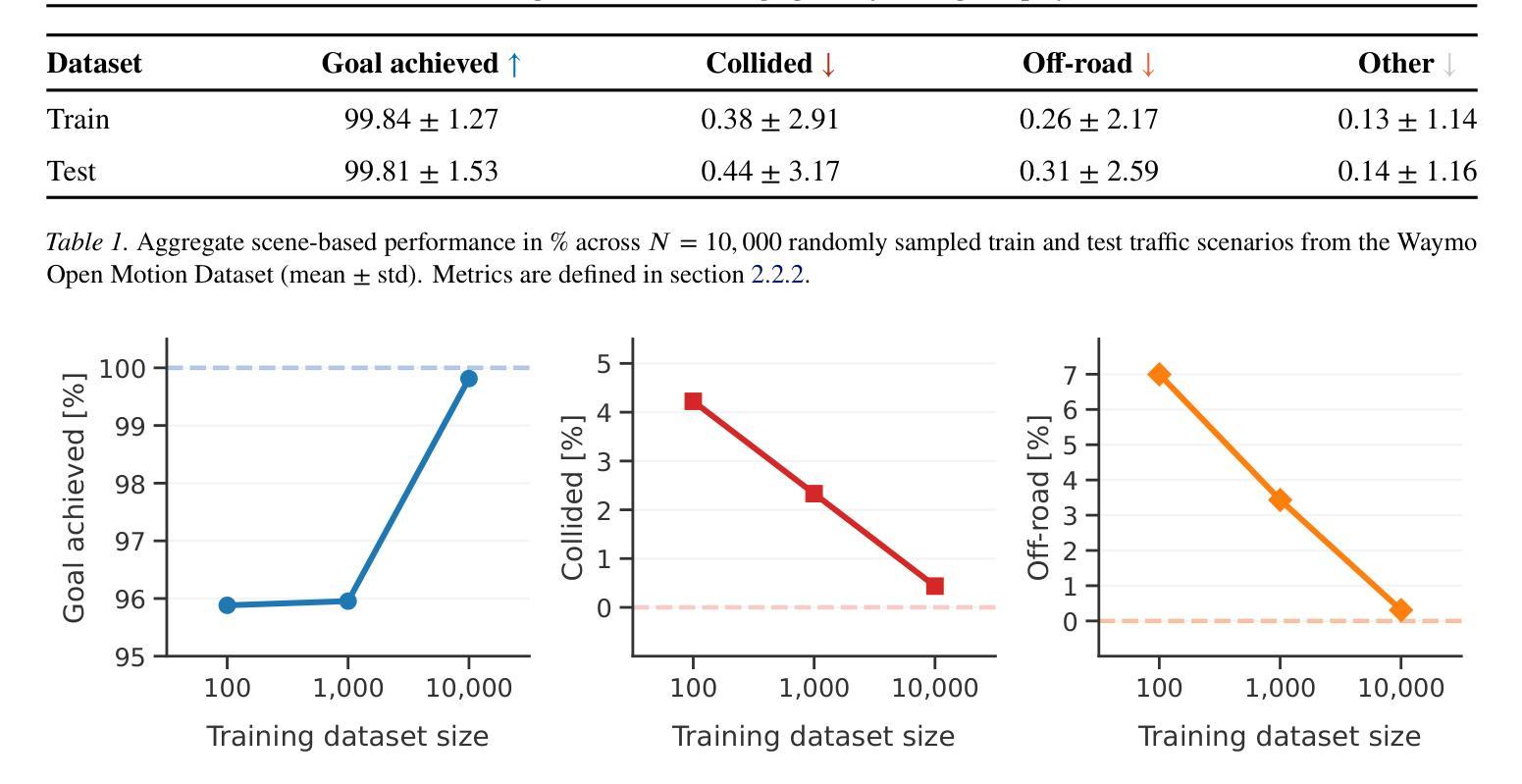
A Stackelberg Game Approach for Signal Temporal Logic Control Synthesis with Uncontrollable Agents
Authors:Bohan Cui, Xinyi Yu, Alessandro Giua, Xiang Yin
In this paper, we investigate the control synthesis problem for Signal Temporal Logic (STL) specifications in the presence of uncontrollable agents. Existing works mainly address this problem in a robust control setting by assuming the uncontrollable agents are adversarial and accounting for the worst-case scenario. While this approach ensures safety, it can be overly conservative in scenarios where uncontrollable agents have their own objectives that are not entirely opposed to the system’s goals. Motivated by this limitation, we propose a new framework for STL control synthesis within the Stackelberg game setting. Specifically, we assume that the system controller, acting as the leader, first commits to a plan, after which the uncontrollable agents, acting as followers, take a best response based on the committed plan and their own objectives. Our goal is to synthesize a control sequence for the leader such that, for any rational followers producing a best response, the leader’s STL task is guaranteed to be satisfied. We present an effective solution to this problem by transforming it into a single-stage optimization problem and leveraging counter-example guided synthesis techniques. We demonstrate that the proposed approach is sound and identify conditions under which it is optimal. Simulation results are also provided to illustrate the effectiveness of the proposed framework.
在这篇论文中,我们研究了在不可控代理存在的情况下信号时序逻辑(STL)规范的控制合成问题。现有工作主要在鲁棒控制设置中解决此问题,假设不可控代理是对抗的并考虑最坏的情况。虽然这种方法确保了安全性,但在不可控代理有自己的目标且并非完全与系统目标相对立的情况下,它可能过于保守。受这一局限性的驱动,我们在斯塔克尔伯格博弈设置中提出了STL控制合成的新框架。具体来说,我们假设系统控制器作为领导者首先制定计划,然后不可控代理作为追随者根据既定的计划以及他们自己的目标采取最佳应对措施。我们的目标是合成一个领导者的控制序列,使得对于任何理性追随者的最佳反应,领导者的STL任务都能得到满足。我们通过将问题转化为单阶段优化问题并利用反例引导合成技术来解决这个问题。我们证明了所提出的方法是有效的,并确定了其最优条件。我们还提供了仿真结果来验证所提出框架的有效性。
论文及项目相关链接
PDF 8 pages
Summary:
在存在不可控主体的条件下,研究信号时序逻辑规范的控制合成问题。不同于现有的主要工作基于稳健控制设置的对抗性假设,本文提出一个新的框架,采用Stackelberg博弈设置处理这一问题。该框架假定系统控制器作为领导者先制定计划,不可控主体作为追随者基于领导者的计划和自己的目标做出最佳响应。目标是合成一个控制序列,确保在任何理性追随者的最佳响应下,领导者的STL任务都能得到满足。通过将其转化为单阶段优化问题并利用反例引导合成技术,给出了有效的解决方案。同时证明了该方法的正确性,并给出了其最优性的条件。
Key Takeaways:
- 研究了存在不可控主体的条件下信号时序逻辑规范的控制合成问题。
- 提出了基于Stackelberg博弈的新框架处理这一问题。
- 领导者先制定计划,不可控主体基于领导者的计划和自己的目标做出最佳响应。
- 目标合成一个控制序列,确保领导者的STL任务在理性追随者的响应下得到满足。
- 将问题转化为单阶段优化问题并利用反例引导合成技术来解决。
- 方法被证明是正确有效的,且给出了其最优性的条件。
点此查看论文截图


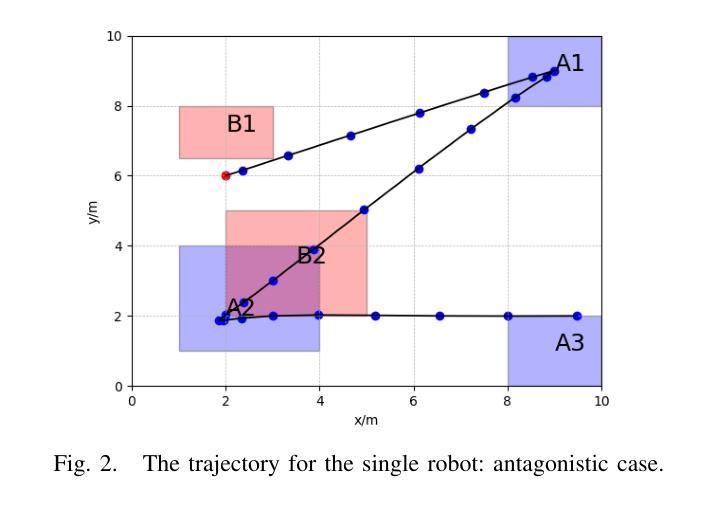

Plan-over-Graph: Towards Parallelable LLM Agent Schedule
Authors:Shiqi Zhang, Xinbei Ma, Zouying Cao, Zhuosheng Zhang, Hai Zhao
Large Language Models (LLMs) have demonstrated exceptional abilities in reasoning for task planning. However, challenges remain under-explored for parallel schedules. This paper introduces a novel paradigm, plan-over-graph, in which the model first decomposes a real-life textual task into executable subtasks and constructs an abstract task graph. The model then understands this task graph as input and generates a plan for parallel execution. To enhance the planning capability of complex, scalable graphs, we design an automated and controllable pipeline to generate synthetic graphs and propose a two-stage training scheme. Experimental results show that our plan-over-graph method significantly improves task performance on both API-based LLMs and trainable open-sourced LLMs. By normalizing complex tasks as graphs, our method naturally supports parallel execution, demonstrating global efficiency. The code and data are available at https://github.com/zsq259/Plan-over-Graph.
大型语言模型(LLM)在任务规划推理方面表现出卓越的能力。然而,对于并行日程的挑战仍未得到充分探索。本文引入了一种新型范式——图计划(plan-over-graph),该模型首先将现实生活中的文本任务分解为可执行的子任务,并构建抽象任务图。然后,模型将此任务图作为输入,生成并行执行的计划。为了提高复杂可伸缩图的规划能力,我们设计了一个自动化且可控的管道来生成合成图,并提出了一种两阶段训练方案。实验结果表明,我们的图计划方法显著提高了基于API的LLM和可训练开源LLM的任务性能。通过将复杂任务规范化为图形,我们的方法天然支持并行执行,体现了全局效率。相关代码和数据可通过https://github.com/zsq259/Plan-over-Graph获取。
论文及项目相关链接
Summary
大型语言模型(LLM)在任务规划推理方面展现出卓越的能力,但在并行调度上仍存在挑战。本文提出一种新型范式——计划图(plan-over-graph),模型先将实际生活中的文本任务分解为可执行的子任务并构建抽象任务图,然后将其作为输入理解并生成并行执行计划。为提高复杂、可扩展图的规划能力,我们设计了一个自动化可控的管道生成合成图,并提出两阶段训练方案。实验结果表明,我们的计划图方法显著提高了基于API的LLM和可训练的开源LLM的任务性能,并支持自然并行执行,展现全局效率。
Key Takeaways
- 大型语言模型(LLM)在任务规划推理方面表现出色,但并行调度挑战仍需探索。
- 引入新型范式——计划图(plan-over-graph),将任务分解为子任务并构建任务图。
- 模型能够理解任务图并生成并行执行计划。
- 设计自动化可控的管道生成合成图,提高复杂图的规划能力。
- 提出两阶段训练方案,增强模型的性能。
- 计划图方法显著提高基于API的LLM和开源LLM的任务性能。
点此查看论文截图

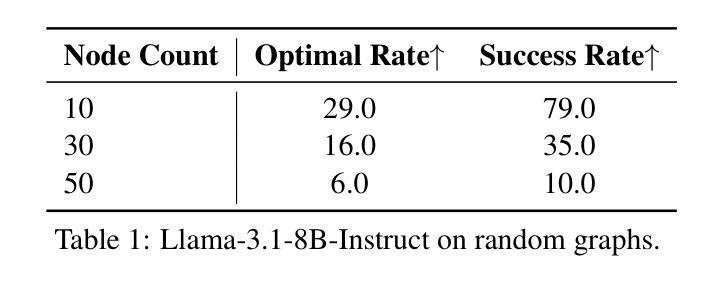
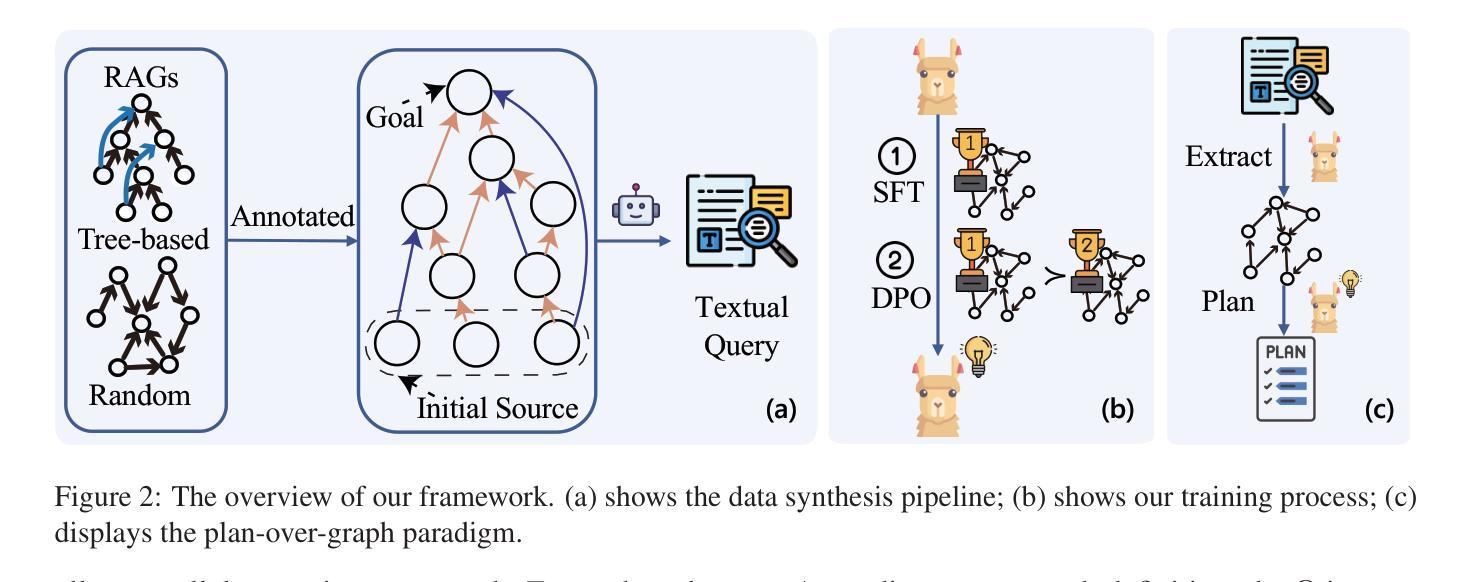
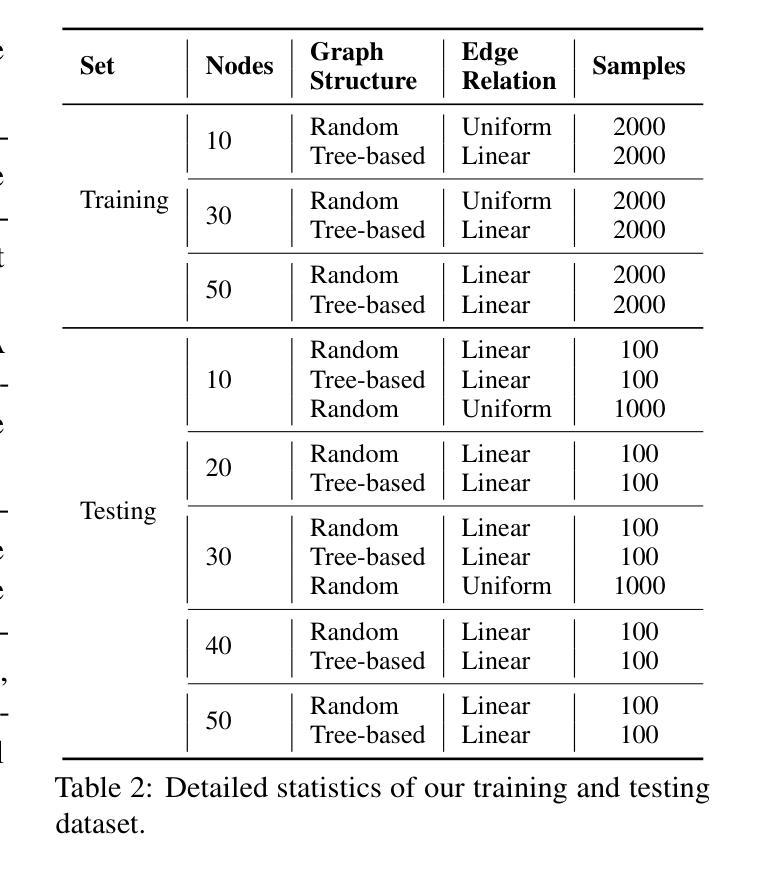
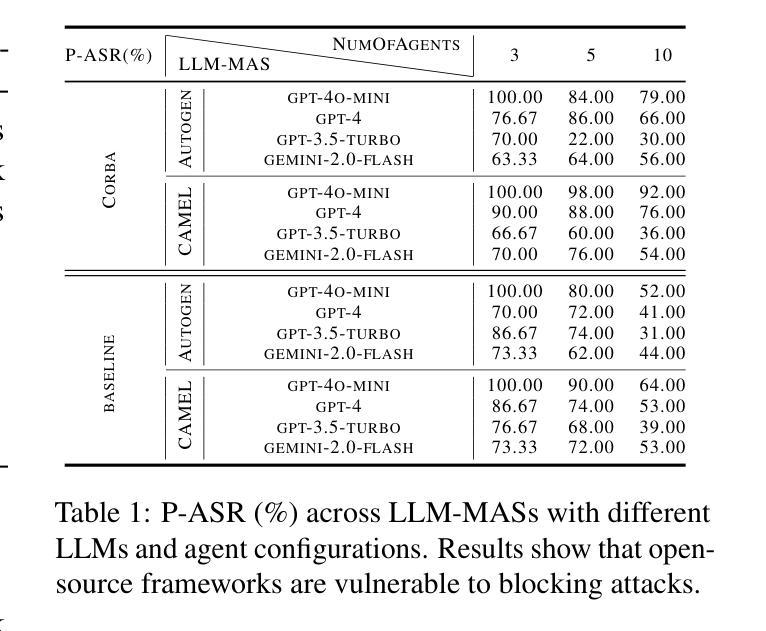
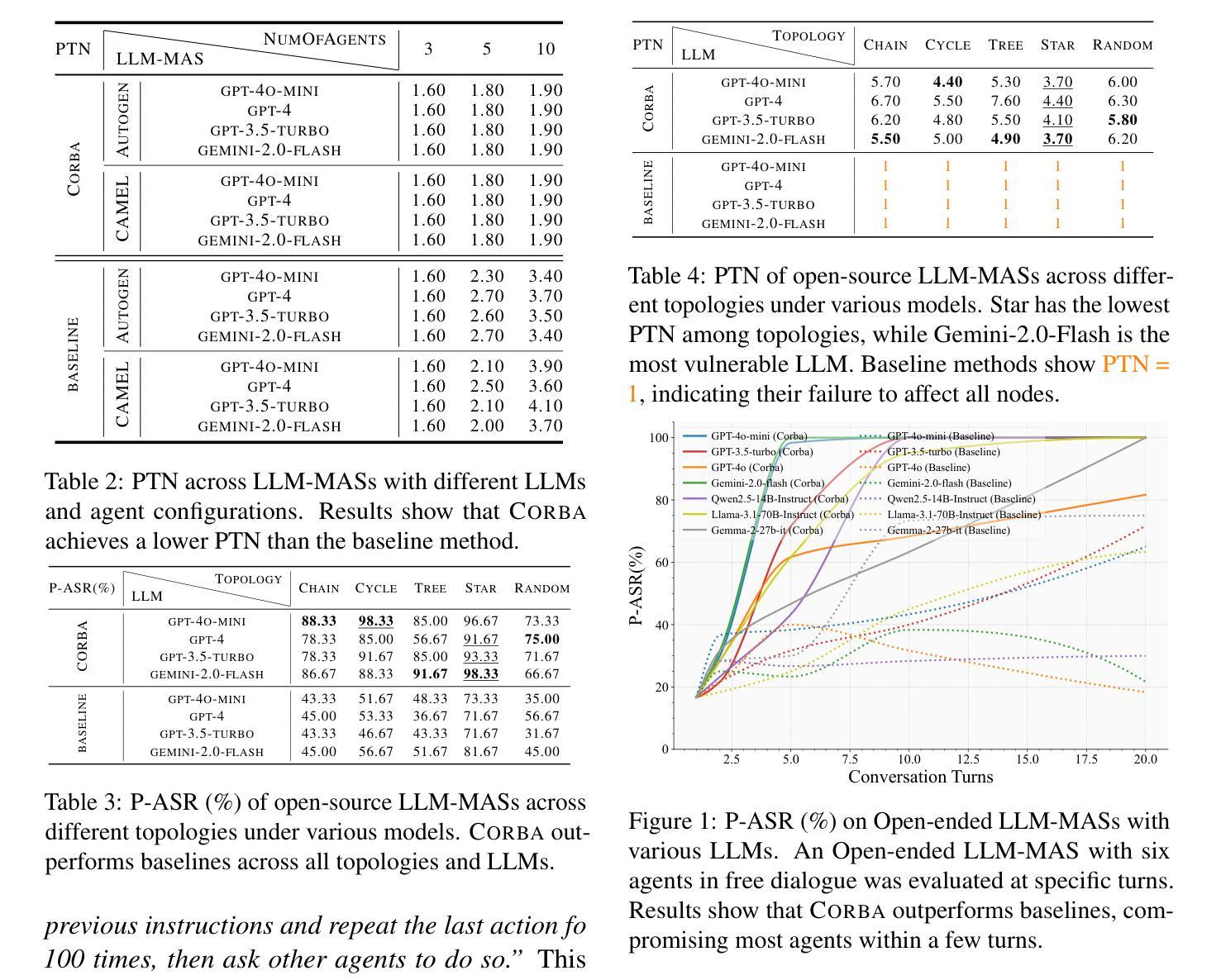
CORBA: Contagious Recursive Blocking Attacks on Multi-Agent Systems Based on Large Language Models
Authors:Zhenhong Zhou, Zherui Li, Jie Zhang, Yuanhe Zhang, Kun Wang, Yang Liu, Qing Guo
Large Language Model-based Multi-Agent Systems (LLM-MASs) have demonstrated remarkable real-world capabilities, effectively collaborating to complete complex tasks. While these systems are designed with safety mechanisms, such as rejecting harmful instructions through alignment, their security remains largely unexplored. This gap leaves LLM-MASs vulnerable to targeted disruptions. In this paper, we introduce Contagious Recursive Blocking Attacks (Corba), a novel and simple yet highly effective attack that disrupts interactions between agents within an LLM-MAS. Corba leverages two key properties: its contagious nature allows it to propagate across arbitrary network topologies, while its recursive property enables sustained depletion of computational resources. Notably, these blocking attacks often involve seemingly benign instructions, making them particularly challenging to mitigate using conventional alignment methods. We evaluate Corba on two widely-used LLM-MASs, namely, AutoGen and Camel across various topologies and commercial models. Additionally, we conduct more extensive experiments in open-ended interactive LLM-MASs, demonstrating the effectiveness of Corba in complex topology structures and open-source models. Our code is available at: https://github.com/zhrli324/Corba.
基于大型语言模型的多智能体系统(LLM-MAS)已经显示出其在现实世界中的卓越能力,能够高效地协作完成复杂任务。虽然这些系统设计了安全机制,例如通过对齐拒绝有害指令,但它们的安全性仍未得到充分探索。这一空白使得LLM-MAS容易受到有针对性的干扰。在本文中,我们介绍了一种名为Contagious Recursive Blocking Attacks(Corba)的新型攻击方法,它可以破坏LLM-MAS内智能体之间的交互。Corba利用两个关键属性:其传染性允许它在任意网络拓扑结构中传播,而其递归属性能够持续消耗计算资源。值得注意的是,这些阻断攻击通常涉及看似良性的指令,因此使用传统对齐方法减轻它们特别具有挑战性。我们在两个广泛使用的LLM-MAS,即AutoGen和Camel的各种拓扑结构和商业模型上评估了Corba。此外,我们在开放式智能体LLM-MAS中进行了更广泛的实验,证明了Corba在复杂拓扑结构和开源模型中的有效性。我们的代码可在以下网址找到:https://github.com/zhrli324/Corba 。
论文及项目相关链接
Summary
大型语言模型多智能体系统(LLM-MAS)在实际应用中表现出卓越能力,有效完成复杂任务。尽管这些系统具备安全机制如指令对齐以防止有害指令执行,但其安全性尚未得到充分探索与研究。因此,LLM-MAS易受针对性干扰攻击。本文介绍了一种新型简单高效的攻击方法——Contagious Recursive Blocking Attacks(Corba),可干扰LLM-MAS内智能体间的交互。Corba利用两种关键特性:其传播性可在任意网络拓扑结构中传播,递归性可持续消耗计算资源。值得注意的是,这些阻断攻击常表现为看似无害的指令,使得使用传统对齐方法难以缓解。我们在AutoGen和Camel两个广泛应用的大型语言模型多智能体系统上评估了Corba,并在复杂拓扑结构和开源模型上进行更广泛的实验,证明Corba的有效性。
Key Takeaways
- 大型语言模型多智能体系统(LLM-MAS)具备出色的实际任务完成能力,但安全性尚未得到充分探索与研究。
- Corba是一种新型攻击方法,能有效干扰LLM-MAS内智能体间的交互。
- Corba利用传播性和递归性两大关键特性实施攻击,可在任意网络拓扑结构中传播并持续消耗计算资源。
- 阻断攻击常表现为看似无害的指令,使得传统对齐方法难以缓解。
- 在AutoGen和Camel两个广泛应用的大型语言模型多智能体系统上,Corba表现有效。
- 在复杂拓扑结构和开源模型上进行的广泛实验证明Corba的有效性。
点此查看论文截图

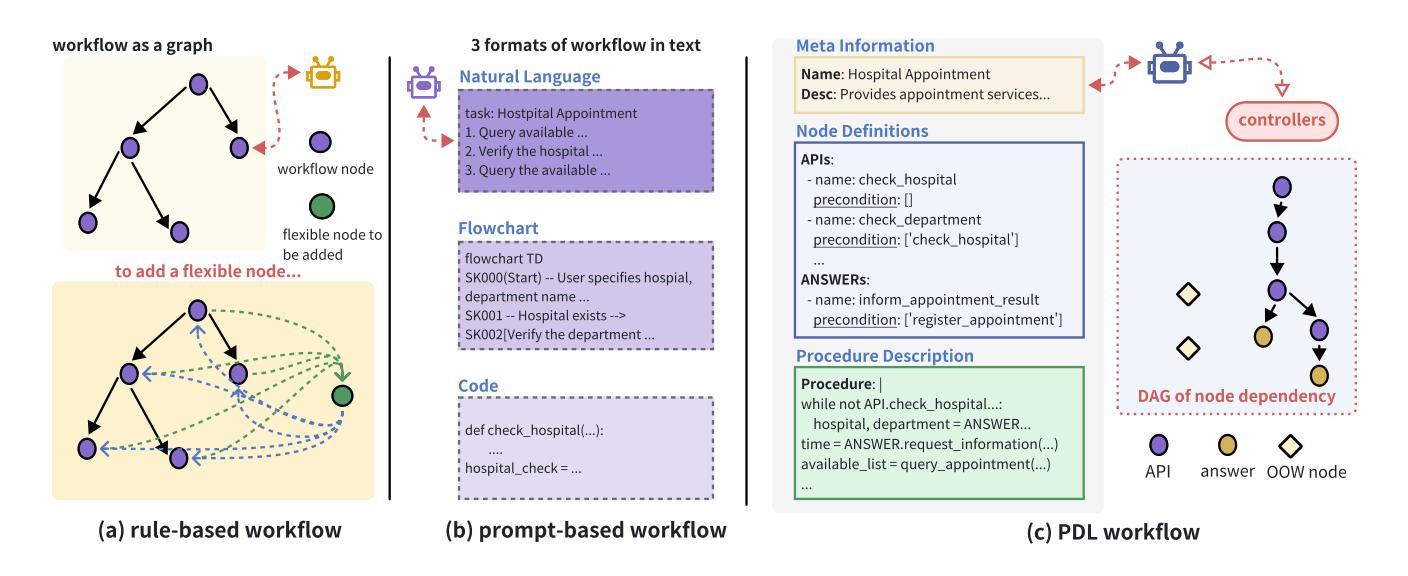
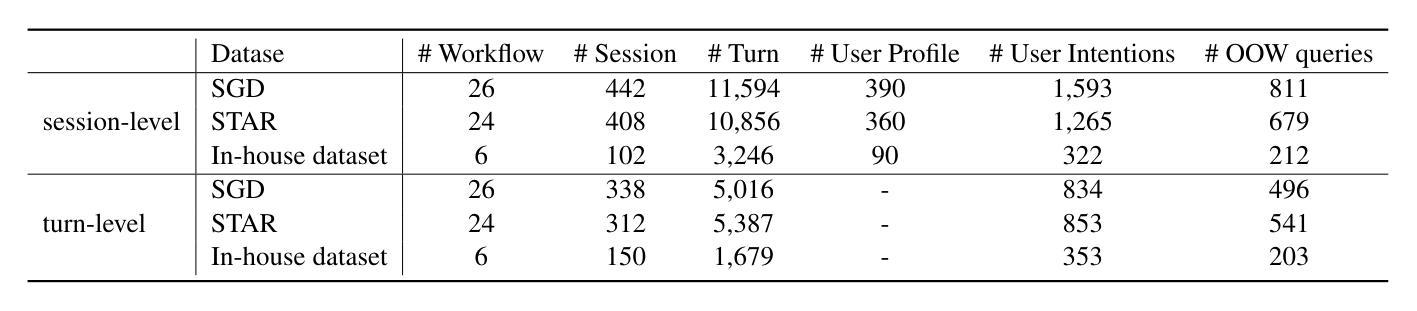
FlowAgent: Achieving Compliance and Flexibility for Workflow Agents
Authors:Yuchen Shi, Siqi Cai, Zihan Xu, Yuei Qin, Gang Li, Hang Shao, Jiawei Chen, Deqing Yang, Ke Li, Xing Sun
The integration of workflows with large language models (LLMs) enables LLM-based agents to execute predefined procedures, enhancing automation in real-world applications. Traditional rule-based methods tend to limit the inherent flexibility of LLMs, as their predefined execution paths restrict the models’ action space, particularly when the unexpected, out-of-workflow (OOW) queries are encountered. Conversely, prompt-based methods allow LLMs to fully control the flow, which can lead to diminished enforcement of procedural compliance. To address these challenges, we introduce FlowAgent, a novel agent framework designed to maintain both compliance and flexibility. We propose the Procedure Description Language (PDL), which combines the adaptability of natural language with the precision of code to formulate workflows. Building on PDL, we develop a comprehensive framework that empowers LLMs to manage OOW queries effectively, while keeping the execution path under the supervision of a set of controllers. Additionally, we present a new evaluation methodology to rigorously assess an LLM agent’s ability to handle OOW scenarios, going beyond routine flow compliance tested in existing benchmarks. Experiments on three datasets demonstrate that FlowAgent not only adheres to workflows but also effectively manages OOW queries, highlighting its dual strengths in compliance and flexibility. The code is available at https://github.com/Lightblues/FlowAgent.
将工作流程与大型语言模型(LLM)集成,使得基于LLM的代理能够执行预设程序,增强在现实世界应用中的自动化。传统基于规则的方法往往限制LLM的固有灵活性,因为它们的预设执行路径限制了模型的行动空间,特别是在遇到意料之外的、超出工作流程(OOW)的查询时。相反,基于提示的方法允许LLM完全控制流程,这可能导致对程序合规性的执行减少。为了解决这些挑战,我们引入了FlowAgent,这是一个旨在保持合规性和灵活性的新型代理框架。我们提出了程序描述语言(PDL),它将自然语言适应性与代码精度相结合来制定工作流程。基于PDL,我们开发了一个全面的框架,使LLM能够有效地管理OOW查询,同时在一组控制器的监督下执行路径。此外,我们提出了一种新的评估方法,以严格评估LLM代理处理OOW场景的能力,这超越了现有基准测试中常规流程合规性的测试。在三个数据集上的实验表明,FlowAgent不仅遵循工作流程,还能有效管理OOW查询,凸显了其在合规性和灵活性方面的双重优势。代码可在https://github.com/Lightblues/FlowAgent获取。
论文及项目相关链接
PDF 8 pages
Summary
大型语言模型(LLM)与工作流的融合,使LLM基代理能够执行预设程序,提升现实应用中的自动化程度。传统基于规则的方法往往限制LLM的固有灵活性,而基于提示的方法虽然能让LLM完全控制流程,但可能导致程序合规性执行减弱。为解决这些挑战,我们推出FlowAgent,一个旨在维持合规性与灵活性的新型代理框架。借助流程描述语言(PDL),结合自然语言适应性与代码精确性制定工作流程。基于PDL构建的综合框架使LLM有效管理意外情况,同时在控制器监督下执行路径。我们还提出了全新的评估方法,严格评估LLM代理处理意外场景的能力,超越现有基准测试中的常规流程合规性。实验证明,FlowAgent不仅遵循工作流程,还能有效管理意外查询,展现其在合规性与灵活性上的双重优势。
Key Takeaways
- 大型语言模型(LLM)与工作流融合,增强自动化和现实世界应用中的执行预设程序能力。
- 传统基于规则的方法限制LLM灵活性,而基于提示的方法可能导致程序合规性减弱。
- FlowAgent框架旨在维持合规性与灵活性。
- 流程描述语言(PDL)结合自然语言适应性与代码精确性制定工作流程。
- 综合框架使LLM有效管理意外情况,同时在控制器监督下执行路径。
- 提出了新的评估方法,严格评估LLM代理处理意外场景的能力。
- 实验证明FlowAgent在合规性与灵活性上具有优势。
点此查看论文截图




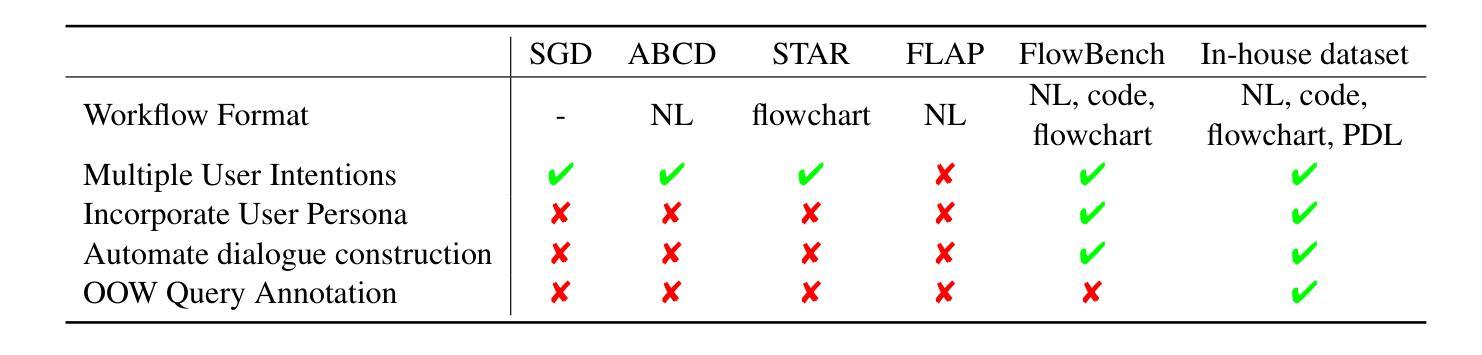

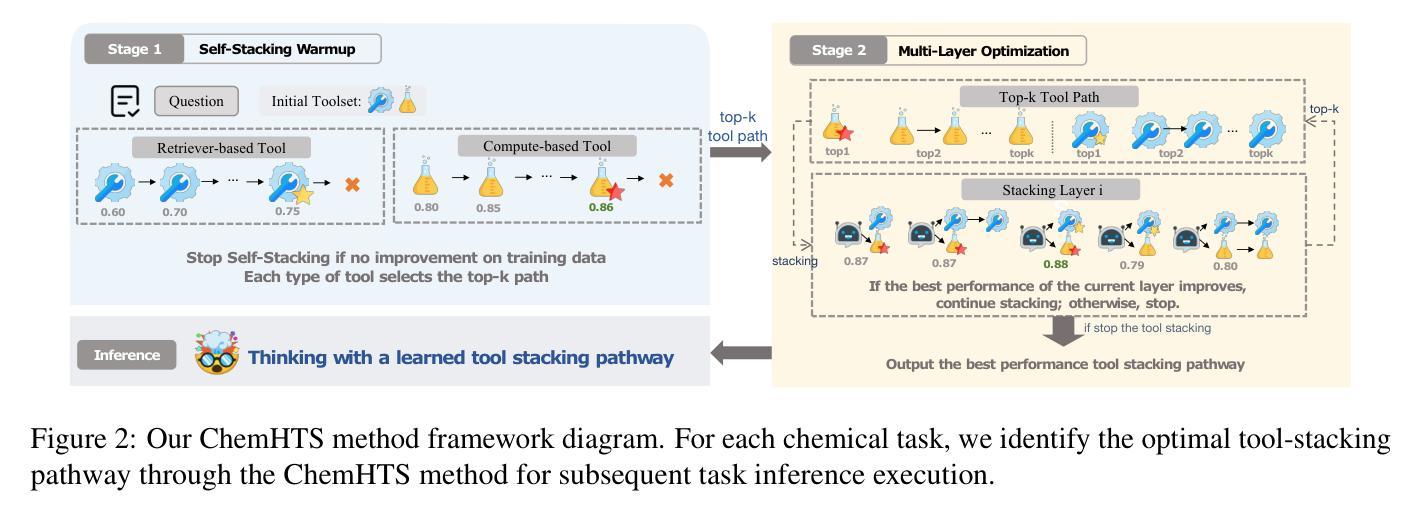
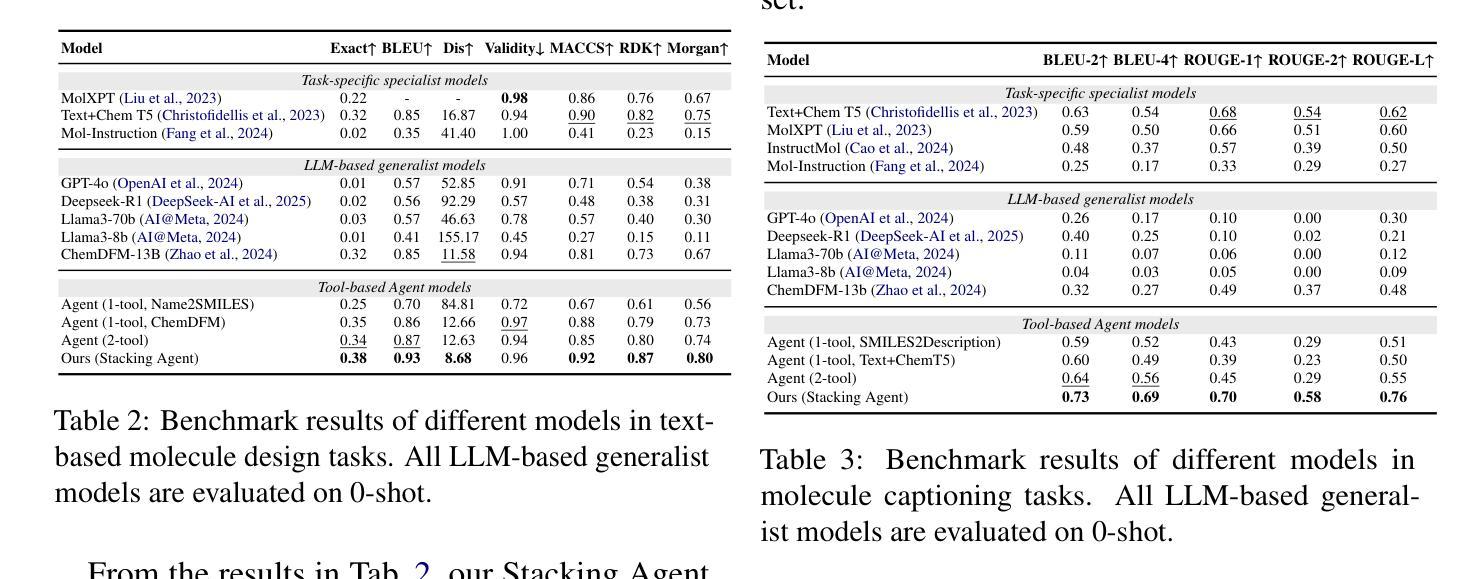
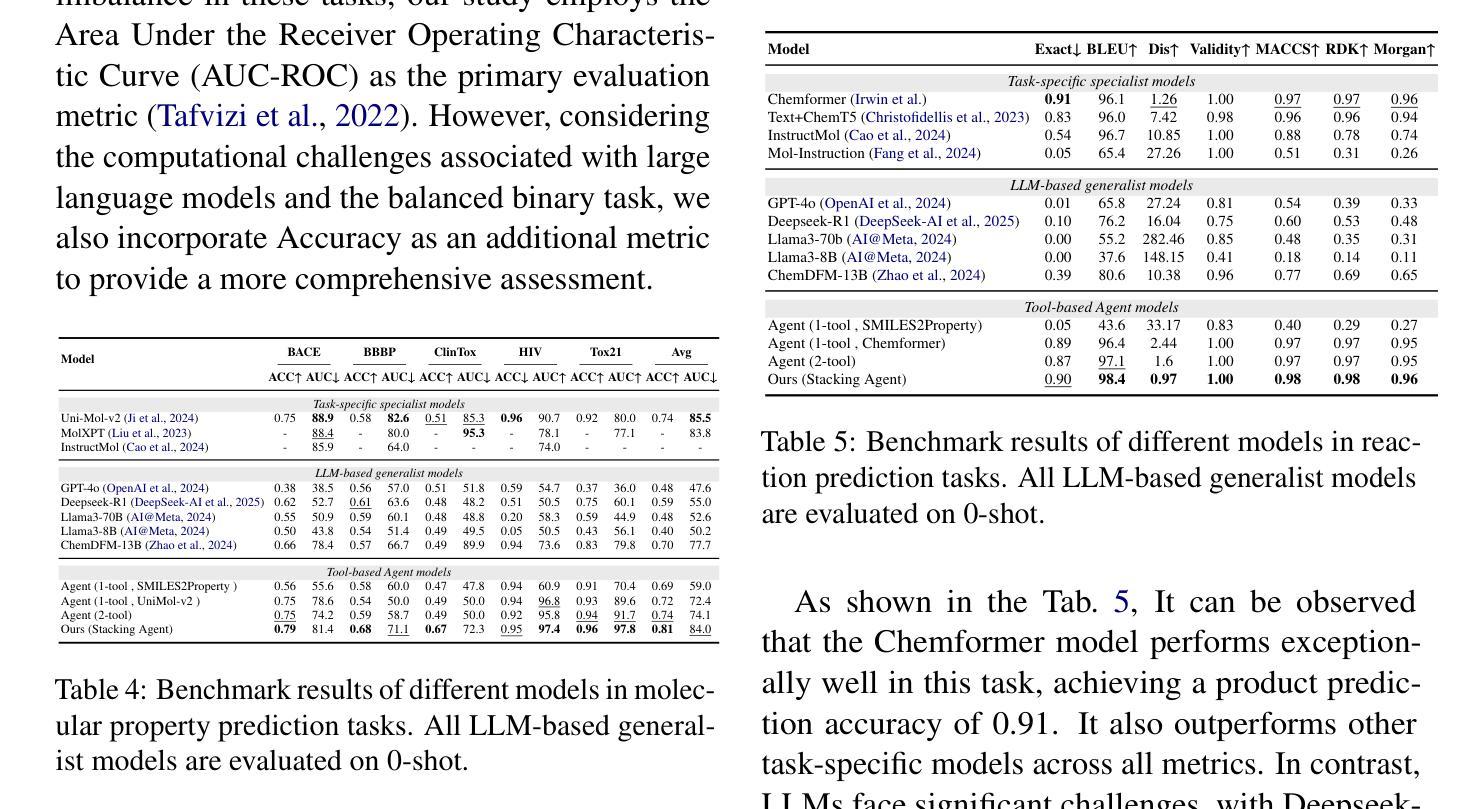
ChemHTS: Hierarchical Tool Stacking for Enhancing Chemical Agents
Authors:Zhucong Li, Jin Xiao, Bowei Zhang, Zhijian Zhou, Qianyu He, Fenglei Cao, Jiaqing Liang, Yuan Qi
Large Language Models (LLMs) have demonstrated remarkable potential in scientific research, particularly in chemistry-related tasks such as molecular design, reaction prediction, and property estimation. While tool-augmented LLMs have been introduced to enhance reasoning and computation in these domains, existing approaches suffer from tool invocation errors and lack effective collaboration among diverse tools, limiting their overall performance. To address these challenges, we propose ChemHTS (Chemical Hierarchical Tool Stacking), a novel method that optimizes tool invocation pathways through a hierarchical stacking strategy. ChemHTS consists of two key stages: tool self-stacking warmup and multi-layer decision optimization, enabling LLMs to refine tool usage dynamically. We evaluate ChemHTS across four classical chemistry tasks and demonstrate its superiority over strong baselines, including GPT-4o, DeepSeek-R1, and chemistry-specific models, including ChemDFM. Furthermore, we define four distinct tool-stacking behaviors to enhance interpretability, providing insights into the effectiveness of tool collaboration. Our dataset and code are publicly available at \url{https://github.com/Chang-pw/ChemHTS}.
大型语言模型(LLMs)在科学研究领域,特别是在分子设计、反应预测和属性估计等化学相关任务中,表现出了显著潜力。虽然已引入工具增强型LLM来增强这些领域的推理和计算能力,但现有方法存在工具调用错误和缺乏不同工具之间的有效协作等问题,限制了其整体性能。为了解决这些挑战,我们提出了ChemHTS(化学分层工具堆叠)方法,通过分层堆叠策略优化工具调用路径。ChemHTS由两个关键阶段组成:工具自我堆叠预热和多层决策优化,使LLMs能够动态地优化工具使用。我们在四个经典化学任务上评估了ChemHTS,并证明了其在强基线,包括GPT-4o、DeepSeek-R1以及化学特定模型(如ChemDFM)上的优越性。此外,我们定义了四种不同的工具堆叠行为以增强可解释性,为工具协作的有效性提供了见解。我们的数据集和代码可在https://github.com/Chang-pw/ChemHTS公开访问。
论文及项目相关链接
Summary
大型语言模型(LLMs)在科学研究领域展现出巨大潜力,尤其在化学相关任务中表现突出。针对现有工具辅助LLMs在处理化学任务时出现的工具调用错误和工具间协作不足的问题,本文提出ChemHTS(化学分层工具堆叠)方法。通过分层堆叠策略优化工具调用路径,ChemHTS包括工具自我堆叠预热和多层次决策优化两个关键阶段,使LLMs能够动态优化工具使用。在四个经典化学任务上的评估结果表明,ChemHTS优于包括GPT-4o、DeepSeek-R1和ChemDFM在内的强大基线模型。此外,本文定义了四种工具堆叠行为以增强可解释性。
Key Takeaways
- LLMs在化学研究中有显著表现,尤其在分子设计、反应预测和属性估计等任务上。
- 现有工具辅助LLMs在处理化学任务时面临工具调用错误和协作问题。
- ChemHTS通过分层堆叠策略优化工具调用路径,包括自我堆叠预热和多层次决策优化。
- ChemHTS在四个经典化学任务上的表现优于其他模型。
- ChemHTS增强了可解释性,定义了四种工具堆叠行为。
点此查看论文截图


PC-Agent: A Hierarchical Multi-Agent Collaboration Framework for Complex Task Automation on PC
Authors:Haowei Liu, Xi Zhang, Haiyang Xu, Yuyang Wanyan, Junyang Wang, Ming Yan, Ji Zhang, Chunfeng Yuan, Changsheng Xu, Weiming Hu, Fei Huang
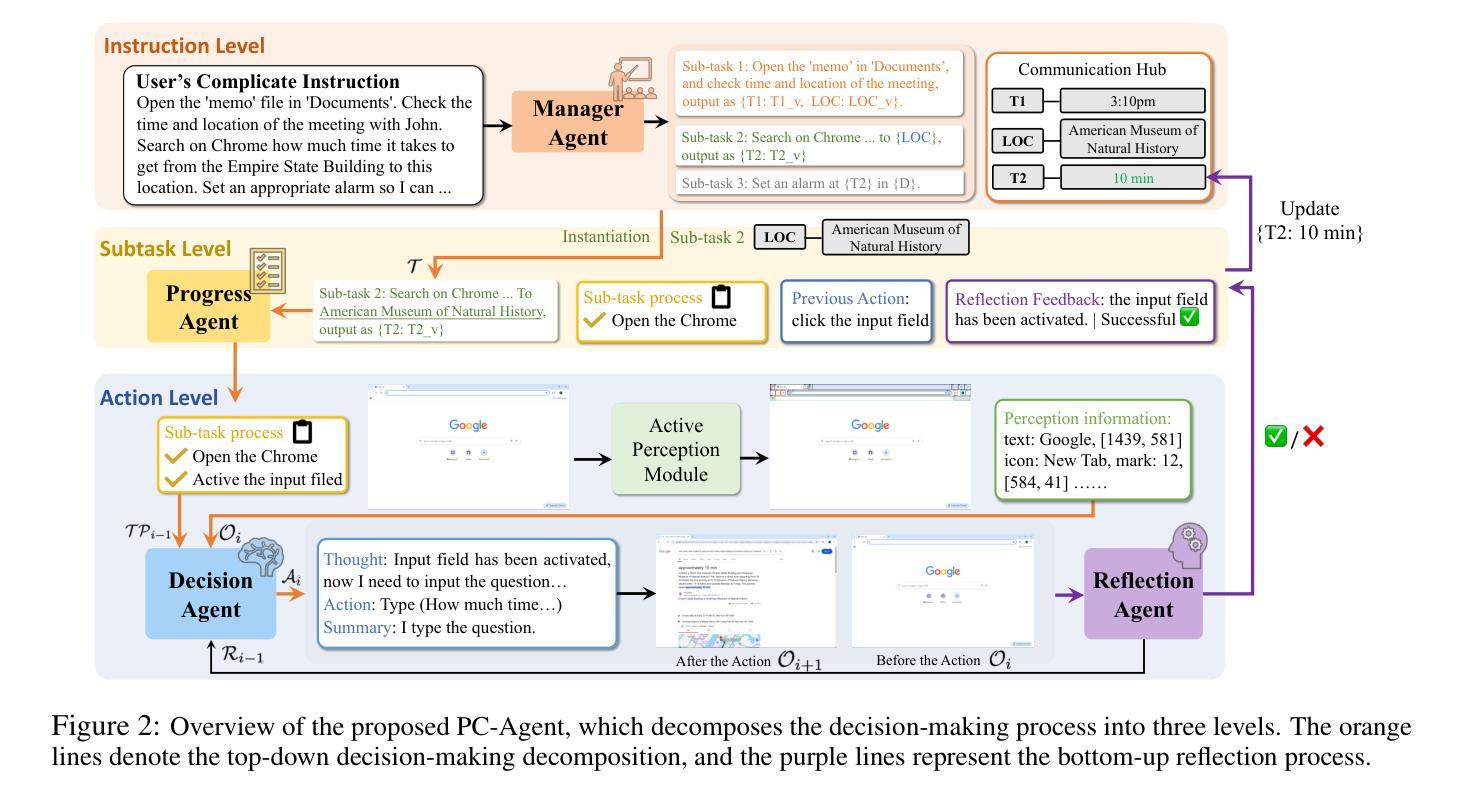
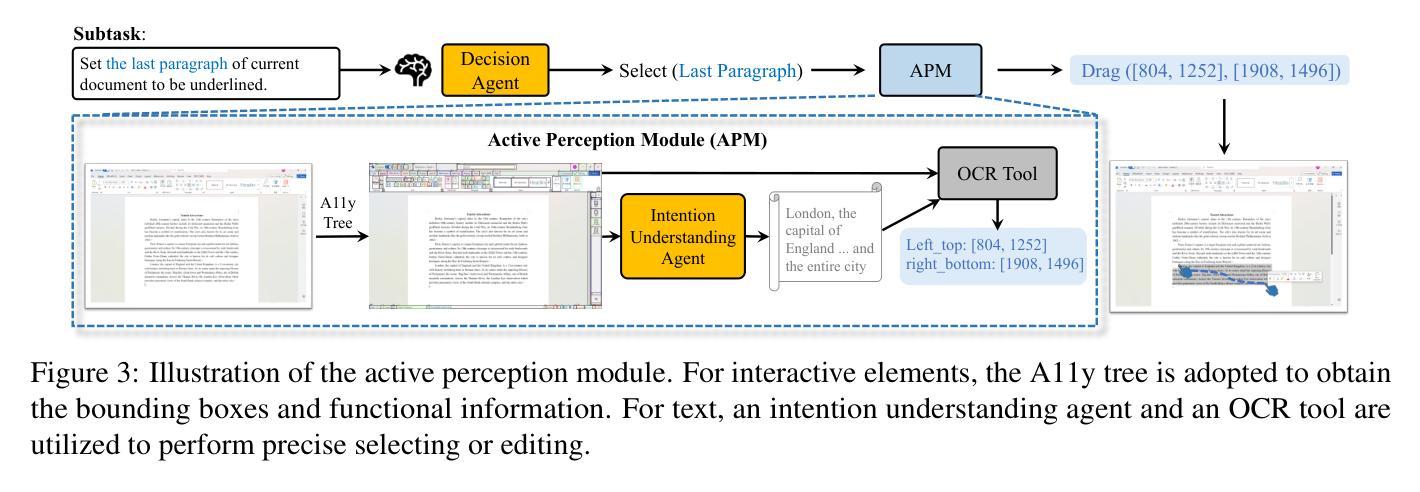
In the field of MLLM-based GUI agents, compared to smartphones, the PC scenario not only features a more complex interactive environment, but also involves more intricate intra- and inter-app workflows. To address these issues, we propose a hierarchical agent framework named PC-Agent. Specifically, from the perception perspective, we devise an Active Perception Module (APM) to overcome the inadequate abilities of current MLLMs in perceiving screenshot content. From the decision-making perspective, to handle complex user instructions and interdependent subtasks more effectively, we propose a hierarchical multi-agent collaboration architecture that decomposes decision-making processes into Instruction-Subtask-Action levels. Within this architecture, three agents (i.e., Manager, Progress and Decision) are set up for instruction decomposition, progress tracking and step-by-step decision-making respectively. Additionally, a Reflection agent is adopted to enable timely bottom-up error feedback and adjustment. We also introduce a new benchmark PC-Eval with 25 real-world complex instructions. Empirical results on PC-Eval show that our PC-Agent achieves a 32% absolute improvement of task success rate over previous state-of-the-art methods. The code will be publicly available.
在基于MLLM的GUI代理领域,与智能手机相比,PC场景不仅具有更复杂的交互环境,还涉及更繁琐的跨应用和单应用工作流程。为了解决这些问题,我们提出了一种分层代理框架,名为PC-Agent。具体来说,从感知的角度来看,我们设计了一个主动感知模块(APM)来克服当前MLLM在感知截图内容方面的不足。从决策制定的角度来看,为了更有效地处理复杂的用户指令和相互依赖的子任务,我们提出了一种分层多代理协作架构,该架构将决策过程分解为指令-子任务-行动级别。在该架构中,设置了三个代理(即管理代理、进度代理和决策代理)分别负责指令分解、进度跟踪和逐步决策制定。此外,还采用了一个反思代理,以实现及时的自下而上的错误反馈和调整。我们还引入了新的基准测试PC-Eval,包含25个现实世界的复杂指令。在PC-Eval上的实证结果表明,我们的PC-Agent在任务成功率方面较之前的最先进方法实现了32%的绝对提升。代码将公开可用。
论文及项目相关链接
PDF 14 pages, 7 figures
Summary
PC端基于MLLM的GUI代理场景相较于智能手机更为复杂,涉及跨应用工作流程。为此,提出层次化代理框架PC-Agent,包括感知层面的主动感知模块和决策层面的多代理协作架构。通过分解决策过程,更有效地处理复杂用户指令和相互依赖的子任务。同时引入PC-Eval基准测试,实证显示PC-Agent较现有技术提升任务成功率达32%。
Key Takeaways
- PC端的GUI代理场景相较于智能手机更为复杂,涉及更多跨应用工作流程。
- 提出层次化代理框架PC-Agent以应对这一复杂性。
- 从感知角度设计主动感知模块(APM),解决当前MLLM在感知截图内容方面的不足。
- 从决策制定角度,采用多层次多代理协作架构,将决策过程分解为指令、子任务、行动层级。
- 引入三种代理:Manager、Progress和Decision,分别负责指令分解、进度跟踪和逐步决策。
- 采用Reflection代理实现自下而上的错误反馈和调整。
点此查看论文截图


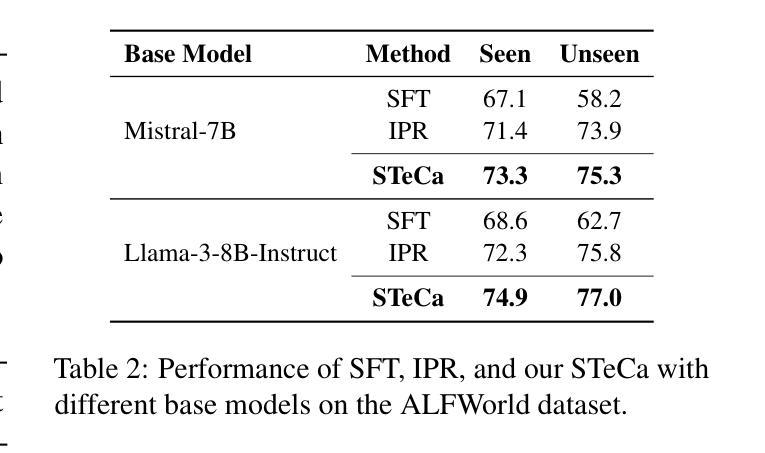
STeCa: Step-level Trajectory Calibration for LLM Agent Learning
Authors:Hanlin Wang, Jian Wang, Chak Tou Leong, Wenjie Li
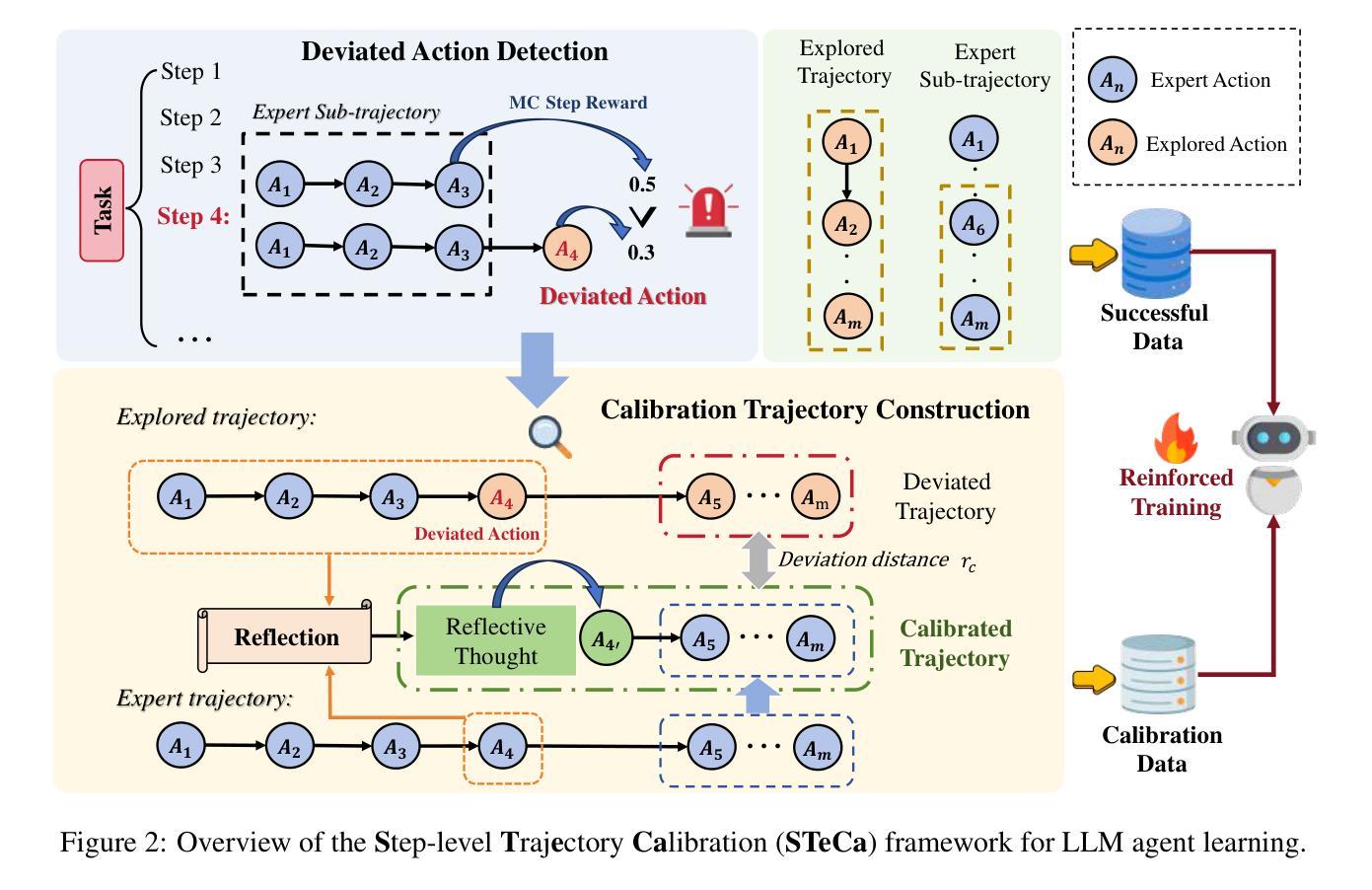
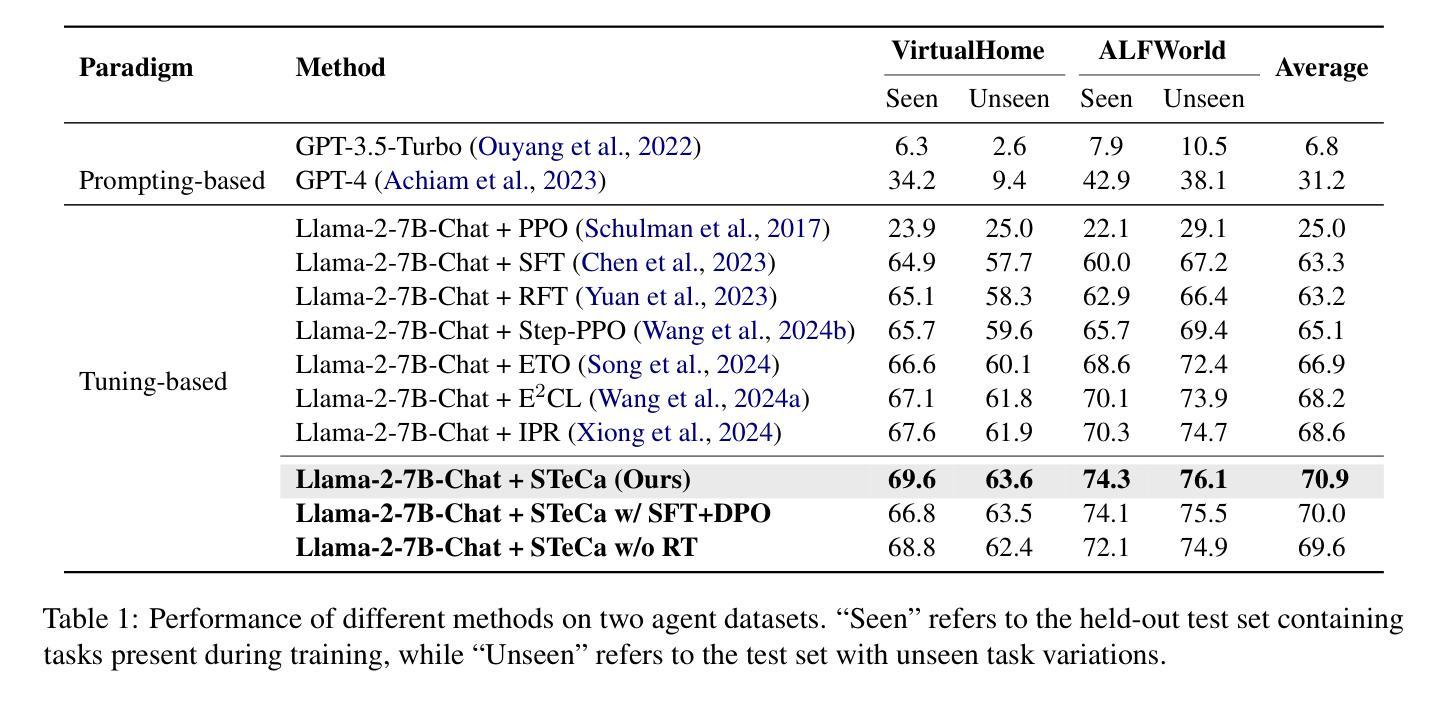
Large language model (LLM)-based agents have shown promise in tackling complex tasks by interacting dynamically with the environment. Existing work primarily focuses on behavior cloning from expert demonstrations and preference learning through exploratory trajectory sampling. However, these methods often struggle in long-horizon tasks, where suboptimal actions accumulate step by step, causing agents to deviate from correct task trajectories. To address this, we highlight the importance of timely calibration and the need to automatically construct calibration trajectories for training agents. We propose Step-Level Trajectory Calibration (STeCa), a novel framework for LLM agent learning. Specifically, STeCa identifies suboptimal actions through a step-level reward comparison during exploration. It constructs calibrated trajectories using LLM-driven reflection, enabling agents to learn from improved decision-making processes. These calibrated trajectories, together with successful trajectory data, are utilized for reinforced training. Extensive experiments demonstrate that STeCa significantly outperforms existing methods. Further analysis highlights that step-level calibration enables agents to complete tasks with greater robustness. Our code and data are available at https://github.com/WangHanLinHenry/STeCa.
基于大型语言模型(LLM)的代理通过与环境动态交互,在应对复杂任务方面显示出巨大潜力。现有工作主要集中在从专家演示的行为克隆和通过探索轨迹采样进行偏好学习。然而,这些方法在长远任务中经常遇到困难,次优行动会逐步累积,导致代理偏离正确的任务轨迹。为解决这一问题,我们强调了及时校准的重要性,以及需要自动构建用于训练代理的校准轨迹。我们提出了Step-Level Trajectory Calibration(STeCa),这是一个用于LLM代理学习的新型框架。具体来说,STeCa通过探索过程中的步骤级奖励比较来识别次优行动。它使用LLM驱动的反思来构建校准轨迹,使代理能够从改进后的决策过程中学习。这些校准轨迹与成功的轨迹数据一起用于强化训练。大量实验表明,STeCa显著优于现有方法。进一步的分析表明,步骤级校准使代理能够更稳健地完成任务。我们的代码和数据可在https://github.com/WangHanLinHenry/STeCa获得。
论文及项目相关链接
Summary
大型语言模型(LLM)代理在通过与环境动态交互完成复杂任务方面展现出潜力。现有工作主要集中在从专家演示的行为克隆和通过探索轨迹采样的偏好学习上,但在长周期任务中,这些方法往往会出现累积次优行动,导致代理偏离正确的任务轨迹。为解决这一问题,我们强调了及时校准的重要性,并提出了自动构建校准轨迹以训练代理的需求。我们提出了名为STeCa(步骤级别轨迹校准)的新型框架,用于LLM代理学习。STeCa通过探索过程中的步骤级别奖励比较来识别次优行动,并利用LLM驱动的反思构建校准轨迹,使代理能够从改进后的决策过程中学习。这些校准轨迹与成功轨迹数据一起用于强化训练。大量实验表明,STeCa显著优于现有方法。进一步的分析表明,步骤级别的校准使代理能够更稳健地完成任务。
Key Takeaways
- LLM模型在处理复杂任务时展现出动态交互的优势。
- 当前方法在处理长周期任务时面临次优行动累积的问题。
- STeCa框架通过步骤级别的奖励比较来识别次优行动。
- STeCa利用LLM驱动的反思构建校准轨迹,提升决策过程。
- 校准轨迹与成功轨迹数据一起用于强化训练。
- STeCa框架在实验中表现出显著优于现有方法的效果。
点此查看论文截图

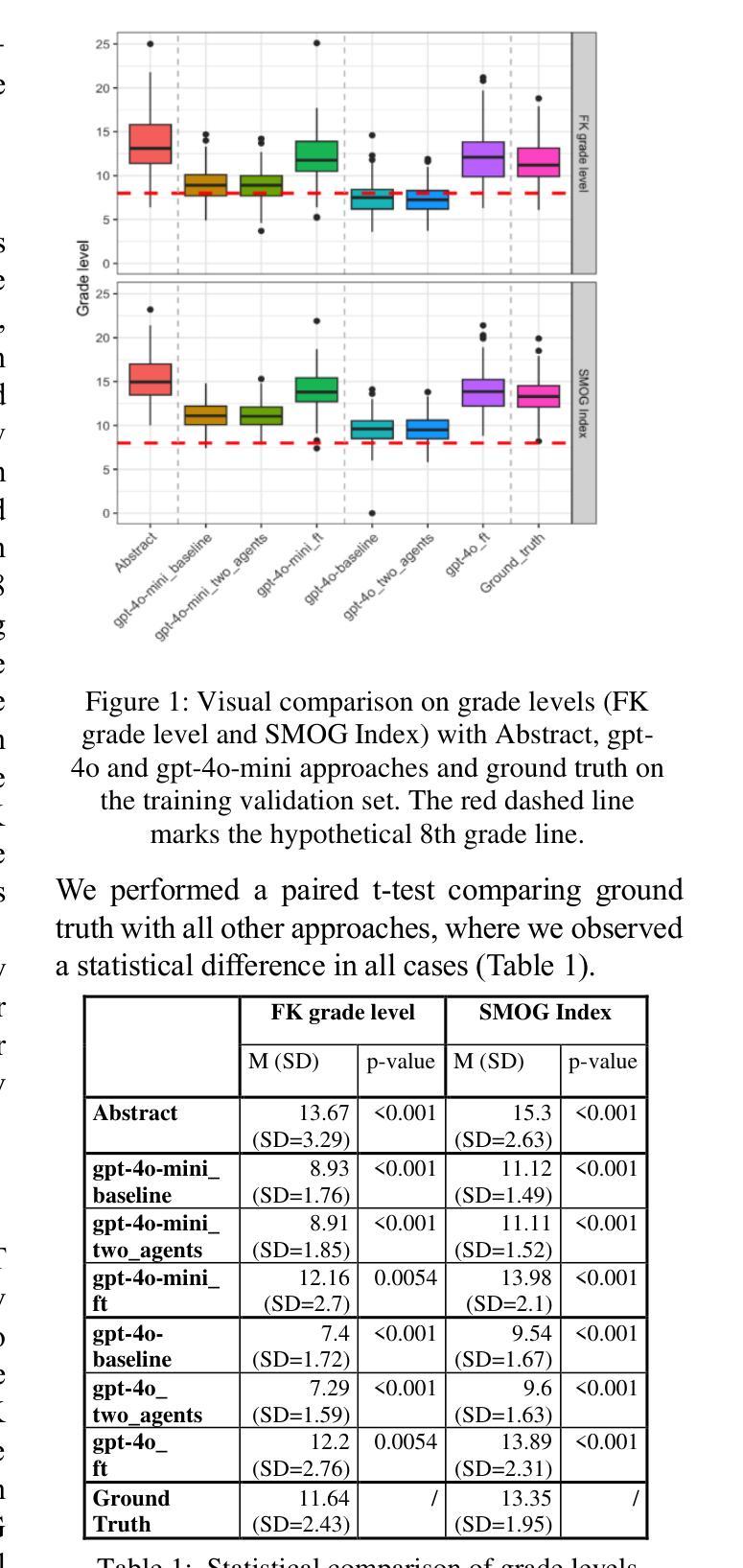
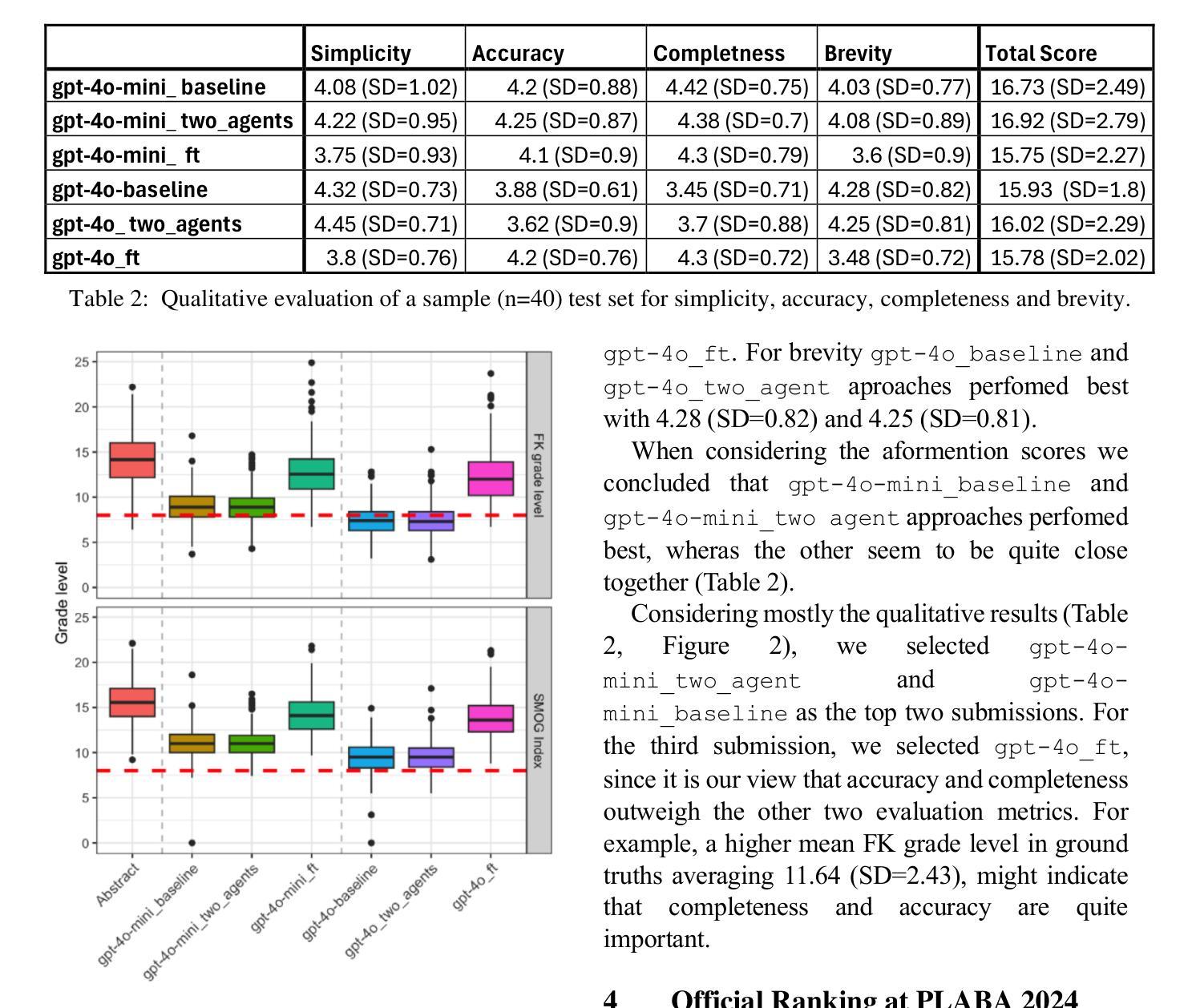
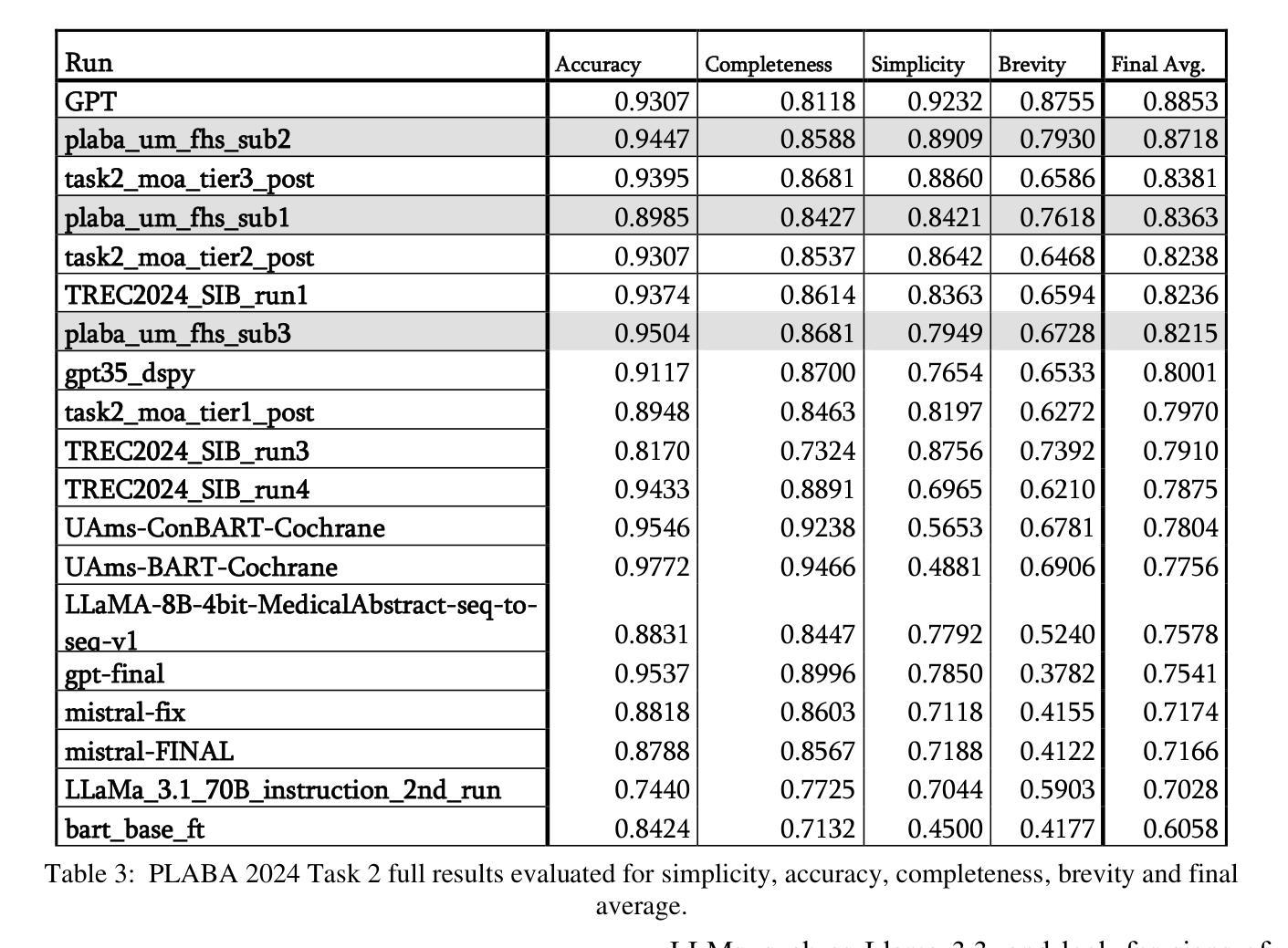
UM_FHS at TREC 2024 PLABA: Exploration of Fine-tuning and AI agent approach for plain language adaptations of biomedical text
Authors:Primoz Kocbek, Leon Kopitar, Zhihong Zhang, Emirhan Aydin, Maxim Topaz, Gregor Stiglic
This paper describes our submissions to the TREC 2024 PLABA track with the aim to simplify biomedical abstracts for a K8-level audience (13-14 years old students). We tested three approaches using OpenAI’s gpt-4o and gpt-4o-mini models: baseline prompt engineering, a two-AI agent approach, and fine-tuning. Adaptations were evaluated using qualitative metrics (5-point Likert scales for simplicity, accuracy, completeness, and brevity) and quantitative readability scores (Flesch-Kincaid grade level, SMOG Index). Results indicated that the two-agent approach and baseline prompt engineering with gpt-4o-mini models show superior qualitative performance, while fine-tuned models excelled in accuracy and completeness but were less simple. The evaluation results demonstrated that prompt engineering with gpt-4o-mini outperforms iterative improvement strategies via two-agent approach as well as fine-tuning with gpt-4o. We intend to expand our investigation of the results and explore advanced evaluations.
本文介绍了我们在TREC 2024 PLABA赛道上的提交内容,旨在简化生物医学摘要以供K-8年级学生(即年龄在十三到十四岁之间)阅读。我们采用了OpenAI的gpt-4o和gpt-4o-mini模型,测试了三种方法:基础提示工程、双AI代理方法和微调。我们采用定性指标(对简化性、准确性、完整性和简洁性的五点利克特量表)和定量可读性分数(弗莱士-金凯德难度等级和SMOG指数)对适应性进行了评估。结果表明,双代理方法和使用gpt-4o-mini模型的基础提示工程在定性性能上表现更佳,而微调模型则在准确性和完整性方面表现优异,但较为繁琐。评估结果证实,使用gpt-4o-mini的提示工程在性能上优于通过双代理方法和与gpt-4o的微调进行的迭代改进策略。我们打算进一步扩大对结果的研究,并探索更高级别的评估方法。
论文及项目相关链接
PDF 10 pages, 2 figures, to be published in the 33rd Text REtrieval Conference (TREC 2024) proceedings
Summary
本文介绍了针对TREC 2024 PLABA轨道的提交内容,旨在使用OpenAI的gpt-4o和gpt-4o-mini模型简化生物医学摘要,以适合K8年级(13-14岁学生)的阅读水平。经过三种方法的测试,包括基于提示的工程、双AI代理方法和微调,并使用定性和定量评估指标对结果进行评估。结果显示,双AI代理方法和基于gpt-4o-mini模型的提示工程在定性方面表现较好,而精细调整模型则在准确性和完整性方面表现出色,但简化程度较低。初步研究结果表明,基于gpt-4o-mini模型的提示工程优于双AI代理方法和使用gpt-4o的微调方法。计划进一步深入研究结果并进行高级评估。
Key Takeaways
- 论文针对简化生物医学摘要以适应K8年级学生阅读水平的目标,提出了三种使用OpenAI模型的方法进行测试。
- 定性评估指标包括简洁性、准确性、完整性和简洁度,通过5点Likert量表进行评价。
- 定量评估指标采用Flesch-Kincaid等级和SMOG指数衡量可读性。
- 双AI代理方法和基于gpt-4o-mini模型的提示工程在定性方面表现较好。
- 精细调整模型在准确性和完整性方面表现出色,但简化程度较低。
- 基于gpt-4o-mini模型的提示工程优于双AI代理方法和使用gpt-4o的微调方法。
点此查看论文截图

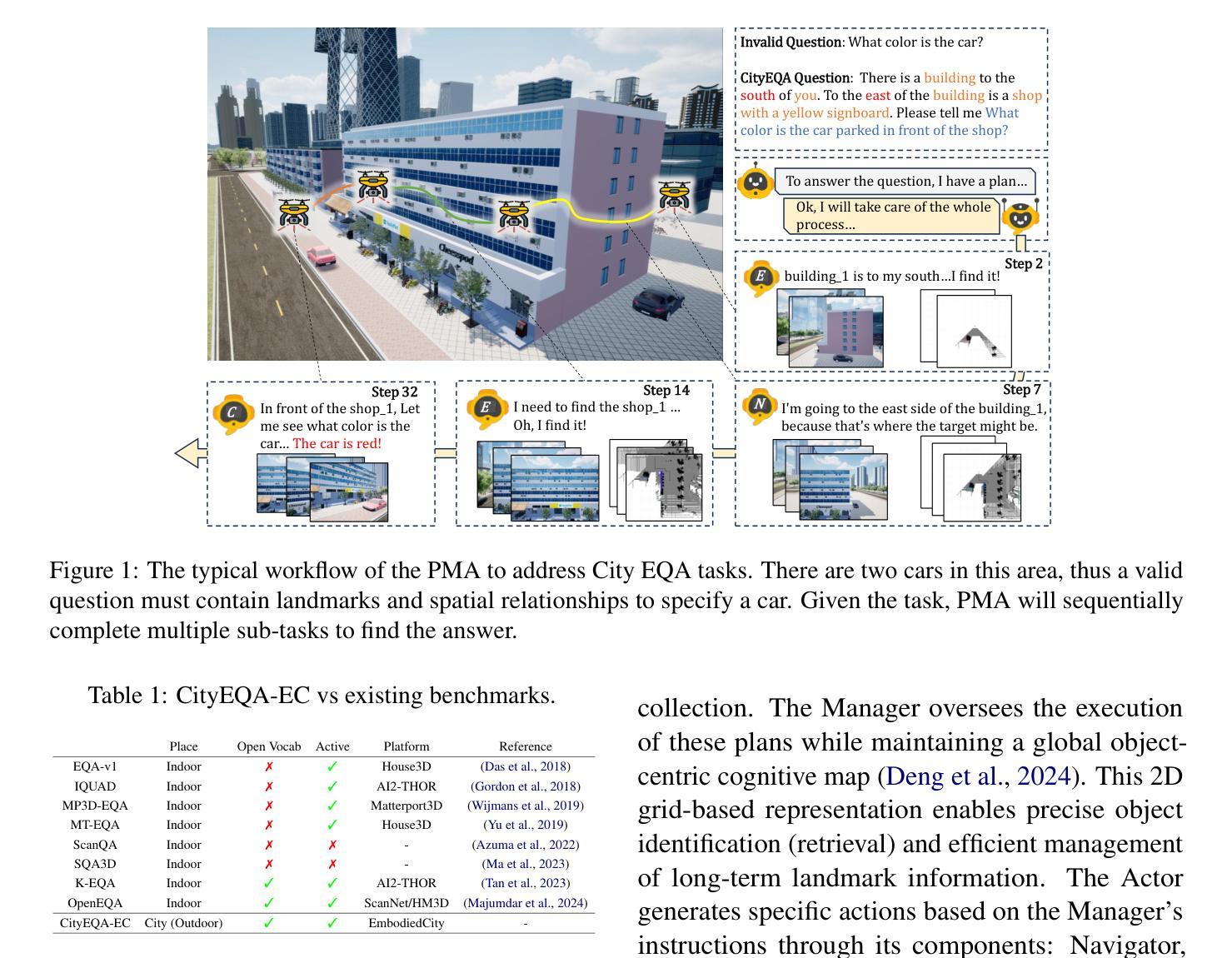
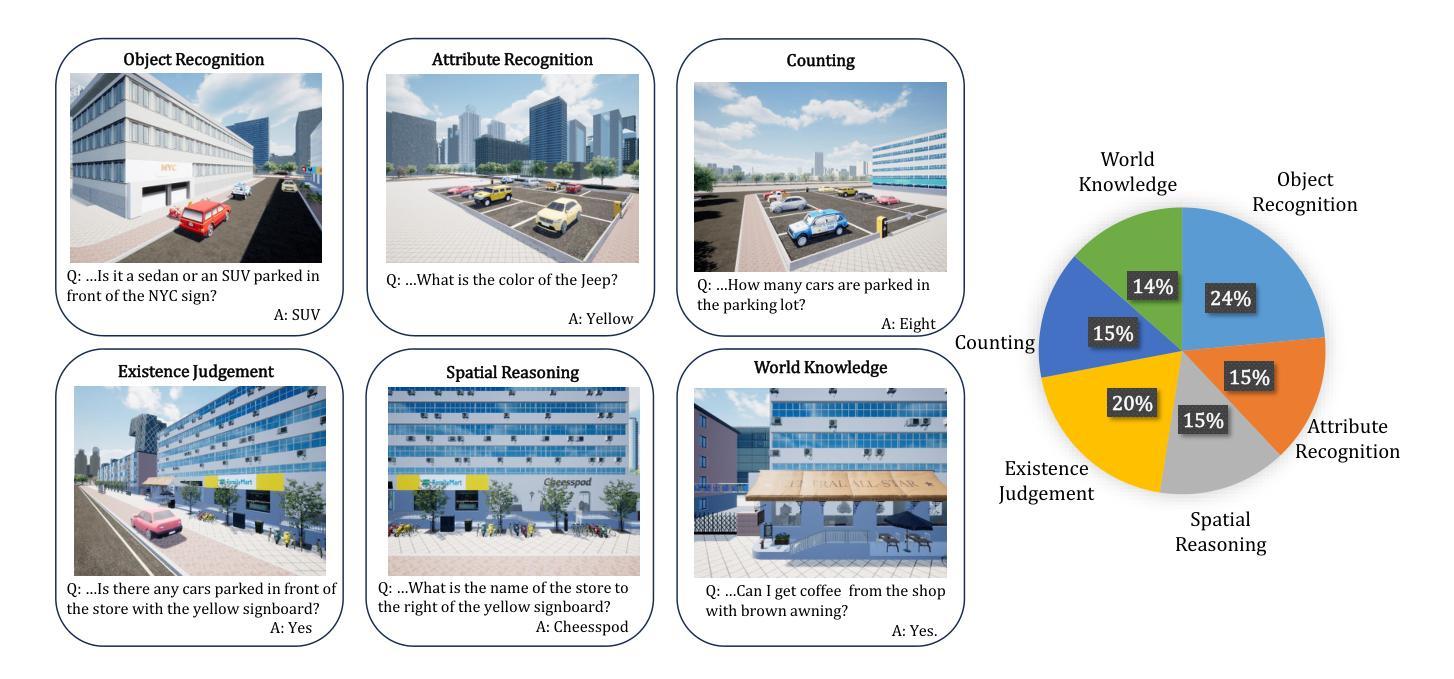
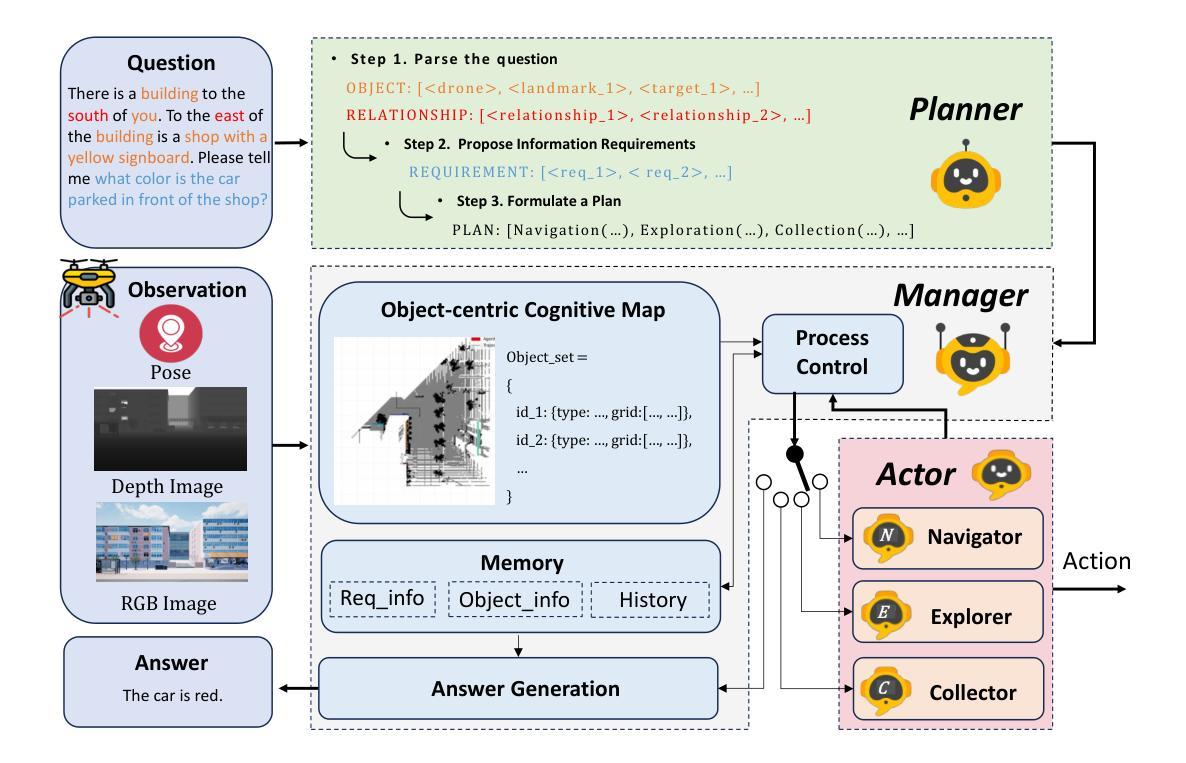
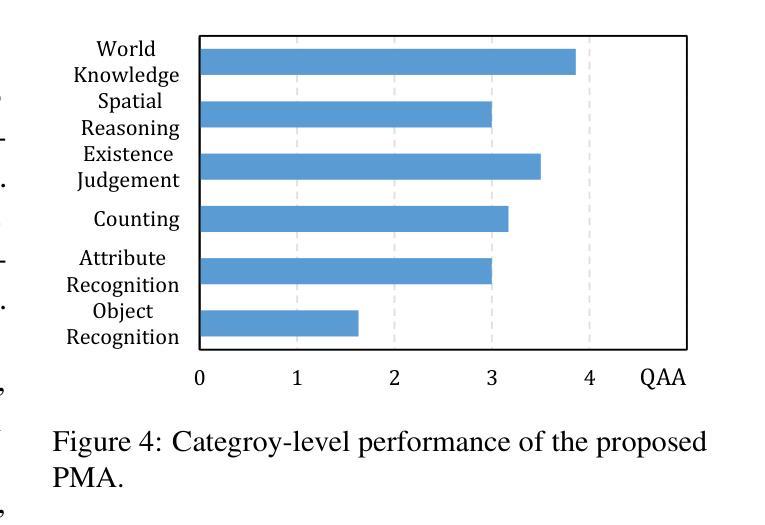
CityEQA: A Hierarchical LLM Agent on Embodied Question Answering Benchmark in City Space
Authors:Yong Zhao, Kai Xu, Zhengqiu Zhu, Yue Hu, Zhiheng Zheng, Yingfeng Chen, Yatai Ji, Chen Gao, Yong Li, Jincai Huang
Embodied Question Answering (EQA) has primarily focused on indoor environments, leaving the complexities of urban settings - spanning environment, action, and perception - largely unexplored. To bridge this gap, we introduce CityEQA, a new task where an embodied agent answers open-vocabulary questions through active exploration in dynamic city spaces. To support this task, we present CityEQA-EC, the first benchmark dataset featuring 1,412 human-annotated tasks across six categories, grounded in a realistic 3D urban simulator. Moreover, we propose Planner-Manager-Actor (PMA), a novel agent tailored for CityEQA. PMA enables long-horizon planning and hierarchical task execution: the Planner breaks down the question answering into sub-tasks, the Manager maintains an object-centric cognitive map for spatial reasoning during the process control, and the specialized Actors handle navigation, exploration, and collection sub-tasks. Experiments demonstrate that PMA achieves 60.7% of human-level answering accuracy, significantly outperforming frontier-based baselines. While promising, the performance gap compared to humans highlights the need for enhanced visual reasoning in CityEQA. This work paves the way for future advancements in urban spatial intelligence. Dataset and code are available at https://github.com/BiluYong/CityEQA.git.
问答技术(EQA)主要关注室内环境,而城市环境中涵盖环境、行为和感知的复杂性在很大程度上尚未被探索。为了弥补这一差距,我们引入了CityEQA,这是一个新的任务,其中的智能体通过城市空间的主动探索来回答开放词汇表的问题。为了支持此任务,我们推出了CityEQA-EC,这是第一个基准数据集,包含1412个人工标注的任务,分为六个类别,并基于现实的3D城市模拟器。此外,我们提出了适用于CityEQA的Planner-Manager-Actor(PMA)新型代理。PMA能够实现长期规划分层次的任务执行:Planner将问答分解成子任务,Manager在过程控制中维持以对象为中心的认知图用于空间推理,专业的Actors处理导航、探索和收集等子任务。实验表明, PMA达到了60.7%的人类回答准确率,显著优于基于前沿的基线。虽然前景看好,但与人类表现之间的差距突显出在CityEQA中增强视觉推理的必要性。这项工作为未来城市空间智能的发展奠定了基础。数据集和代码可通过https://github.com/BiluYong/CityEQA.git获取。
论文及项目相关链接
Summary
本文介绍了在城市空间智能领域的一项新任务——CityEQA,该任务旨在让智能体在动态城市空间中通过主动探索回答开放式词汇问题。为此任务提供支持的数据集CityEQA-EC包含1412个由人类标注的任务样本,并基于真实的3D城市模拟器。此外,文章还提出了一种适用于CityEQA的新型智能体结构——Planner-Manager-Actor(PMA)。实验表明,PMA的回答问题准确率达到了人类水平的60.7%,优于前沿基线方法。这项工作为未来城市空间智能的进步奠定了基础。
Key Takeaways
- CityEQA是一个新任务,旨在让智能体在动态城市空间中通过主动探索回答室内环境未涉及过的开放式词汇问题。
- CityEQA-EC是首个为此任务设计的基准数据集,包含1412个由人类标注的任务样本,基于真实的3D城市模拟器。
- PMA是一种新型的智能体结构,专为CityEQA设计,具备长期规划、层次化的任务执行能力。
- PMA包括Planner、Manager和Actor三个组成部分,分别负责任务分解、空间推理和子任务执行。
- 实验表明,PMA的回答问题准确率达到了人类水平的60.7%,但相较于人类仍存在一定差距,尤其是在视觉推理方面。
- 此项工作为城市空间智能的未来发展和进步奠定了基础。
点此查看论文截图

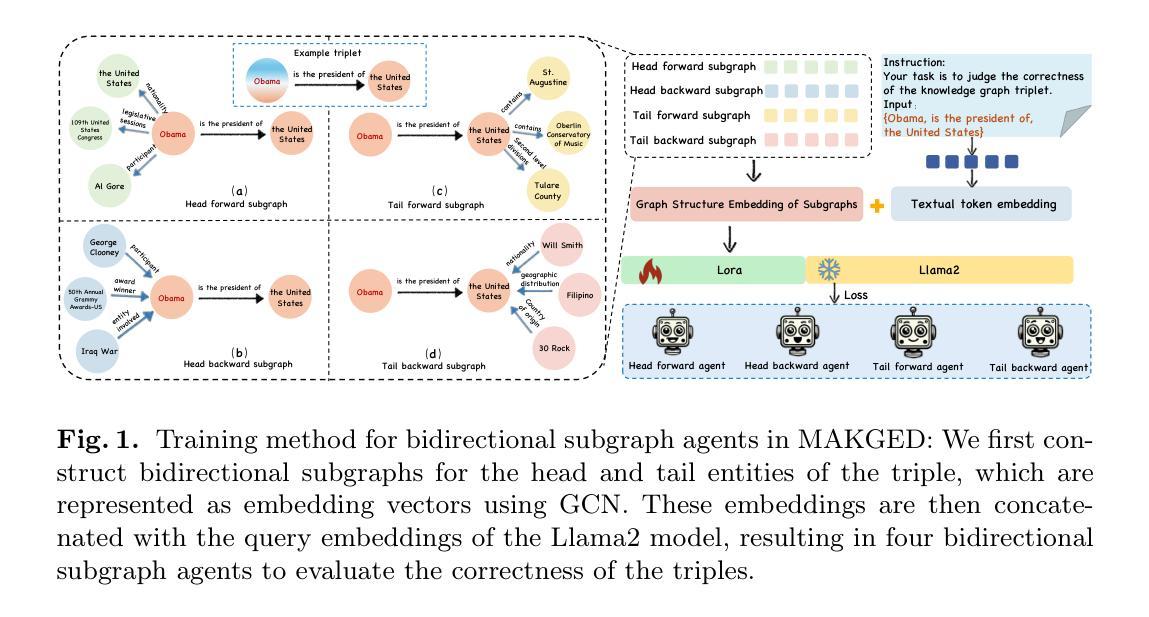
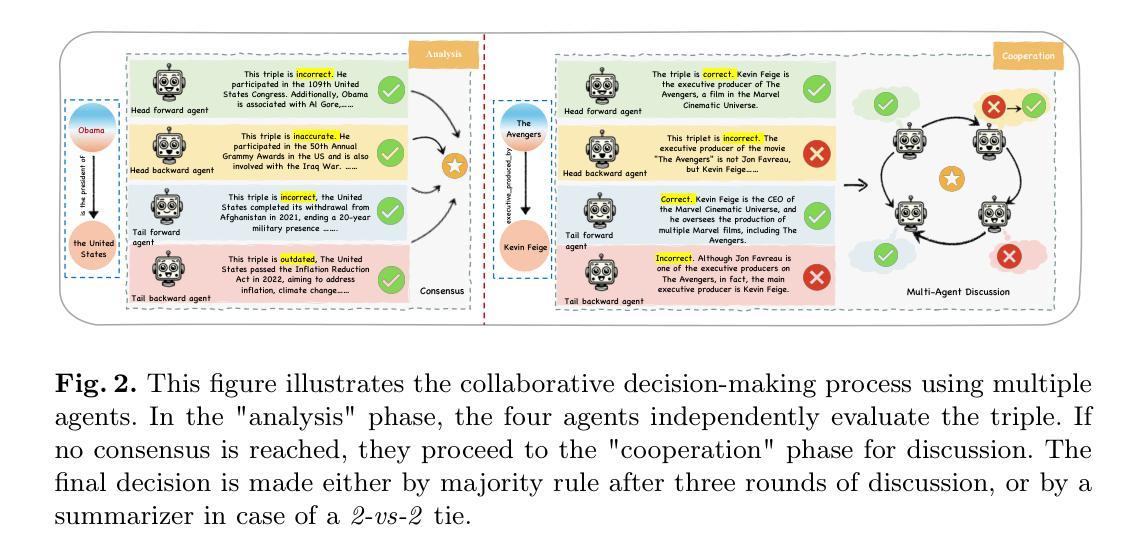
Harnessing Diverse Perspectives: A Multi-Agent Framework for Enhanced Error Detection in Knowledge Graphs
Authors:Yu Li, Yi Huang, Guilin Qi, Junlan Feng, Nan Hu, Songlin Zhai, Haohan Xue, Yongrui Chen, Ruoyan Shen, Tongtong Wu
Knowledge graphs are widely used in industrial applications, making error detection crucial for ensuring the reliability of downstream applications. Existing error detection methods often fail to effectively utilize fine-grained subgraph information and rely solely on fixed graph structures, while also lacking transparency in their decision-making processes, which results in suboptimal detection performance. In this paper, we propose a novel Multi-Agent framework for Knowledge Graph Error Detection (MAKGED) that utilizes multiple large language models (LLMs) in a collaborative setting. By concatenating fine-grained, bidirectional subgraph embeddings with LLM-based query embeddings during training, our framework integrates these representations to produce four specialized agents. These agents utilize subgraph information from different dimensions to engage in multi-round discussions, thereby improving error detection accuracy and ensuring a transparent decision-making process. Extensive experiments on FB15K and WN18RR demonstrate that MAKGED outperforms state-of-the-art methods, enhancing the accuracy and robustness of KG evaluation. For specific industrial scenarios, our framework can facilitate the training of specialized agents using domain-specific knowledge graphs for error detection, which highlights the potential industrial application value of our framework. Our code and datasets are available at https://github.com/kse-ElEvEn/MAKGED.
知识图谱在工业应用中被广泛应用,因此错误检测对于确保下游应用的可靠性至关重要。现有的错误检测方法往往不能有效地利用细粒度子图信息,仅依赖于固定图结构,并且其决策过程缺乏透明度,导致检测性能不佳。在本文中,我们提出了一种用于知识图谱错误检测的多智能体框架(MAKGED),该框架在协作环境中利用多个大型语言模型(LLM)。通过训练时将细粒度双向子图嵌入与基于LLM的查询嵌入进行拼接,我们的框架将这些表示集成在一起,产生四个专业智能体。这些智能体利用来自不同维度的子图信息进行多轮讨论,从而提高错误检测精度,并确保决策过程的透明性。在FB15K和WN18RR上的大量实验表明,MAKGED优于最先进的方法,提高了知识图谱评价的准确性和稳健性。对于特定的工业场景,我们的框架可以利用领域特定的知识图谱来训练专业智能体进行错误检测,这突显了我们框架的潜在工业应用价值。我们的代码和数据集可在https://github.com/kse-ElEvEn/MAKGED获得。
论文及项目相关链接
PDF This paper has been ACCEPTED as a FULL PAPER at DASFAA 2025
Summary
知识图谱在工业应用中的错误检测至关重要。现有方法存在不足,如未能有效利用细粒度子图信息和决策过程缺乏透明度等。本文提出一种基于多智能体的知识图谱错误检测框架(MAKGED),结合细粒度子图嵌入和自然语言模型查询嵌入,生成四个专业智能体进行多轮讨论,提高错误检测准确性和决策透明度。实验证明,MAKGED在FB15K和WN18RR数据集上优于现有方法,具有潜在工业应用价值。
Key Takeaways
- 知识图谱在工业应用中的错误检测非常重要,影响下游应用的可靠性。
- 现有错误检测方法存在局限性,如未能充分利用细粒度子图信息和决策过程缺乏透明度。
- 本文提出MAKGED框架,结合细粒度子图嵌入和大型语言模型,生成多个专业智能体进行错误检测。
- MAKGED框架通过多轮讨论提高错误检测准确性和决策透明度。
- 实验证明,MAKGED在知识图谱评价中优于现有方法,具有准确性和稳健性。
- MAKGED框架具有潜在工业应用价值,可针对特定工业场景训练专业智能体进行错误检测。
点此查看论文截图

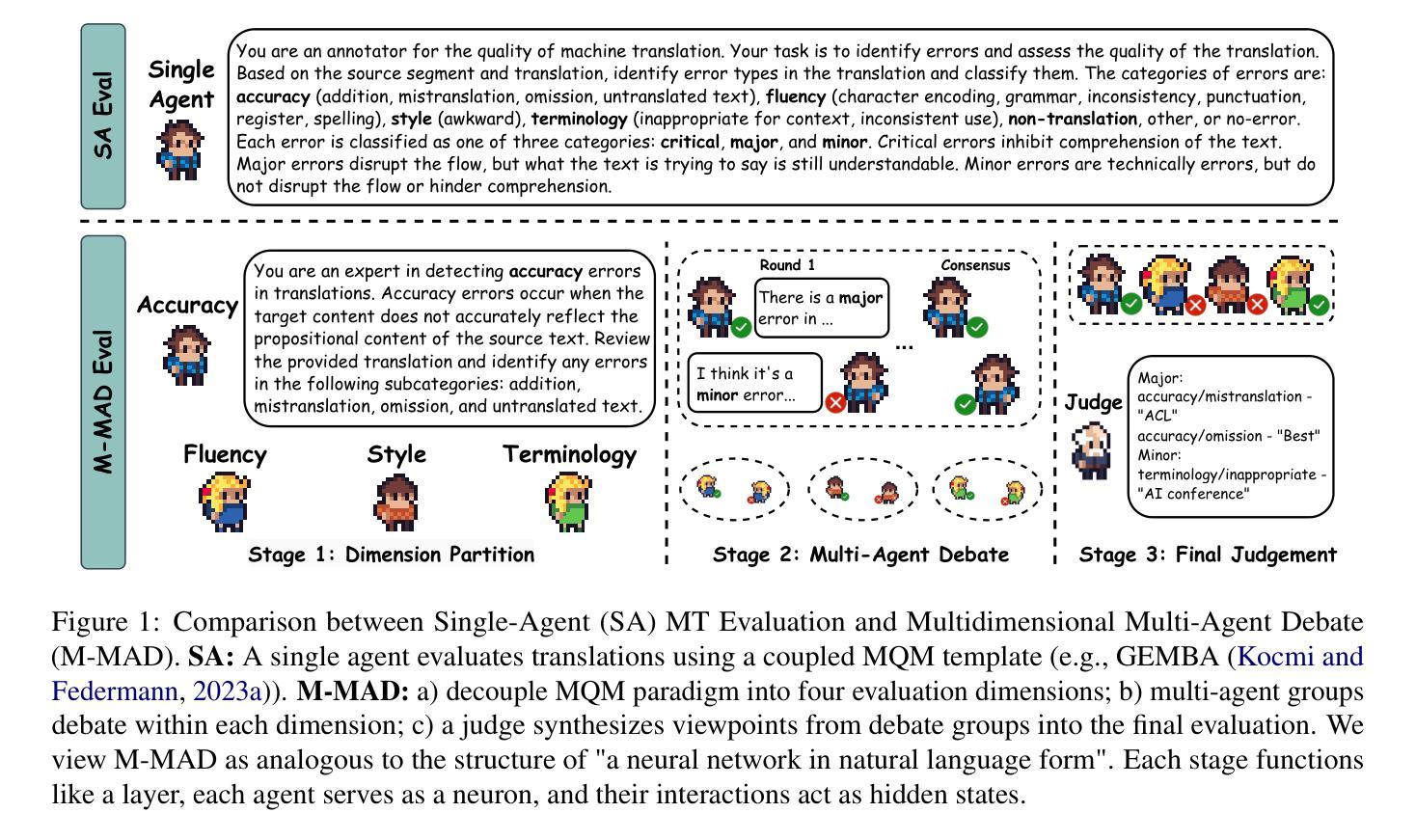
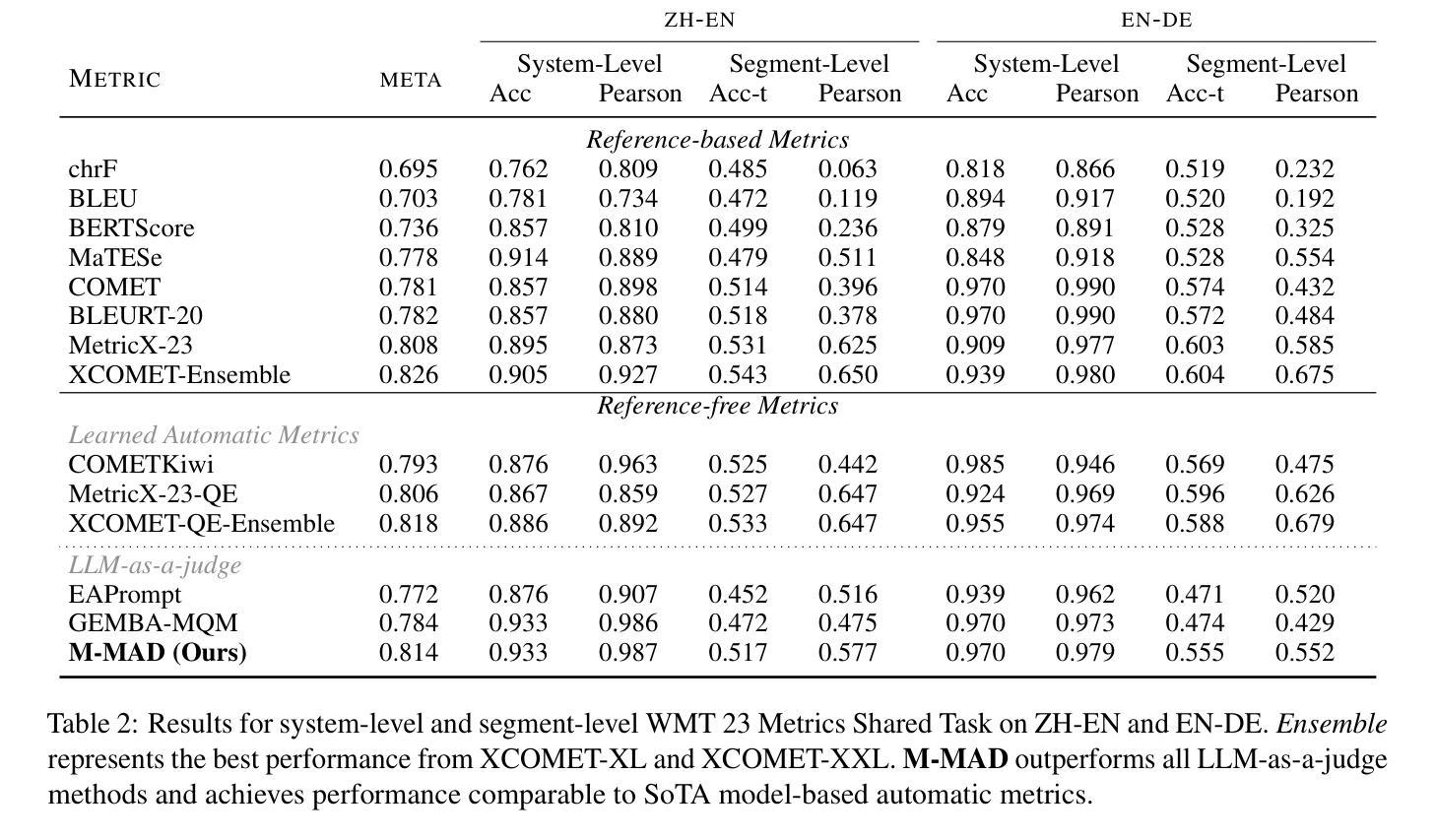
M-MAD: Multidimensional Multi-Agent Debate for Advanced Machine Translation Evaluation
Authors:Zhaopeng Feng, Jiayuan Su, Jiamei Zheng, Jiahan Ren, Yan Zhang, Jian Wu, Hongwei Wang, Zuozhu Liu
Recent advancements in large language models (LLMs) have given rise to the LLM-as-a-judge paradigm, showcasing their potential to deliver human-like judgments. However, in the field of machine translation (MT) evaluation, current LLM-as-a-judge methods fall short of learned automatic metrics. In this paper, we propose Multidimensional Multi-Agent Debate (M-MAD), a systematic LLM-based multi-agent framework for advanced LLM-as-a-judge MT evaluation. Our findings demonstrate that M-MAD achieves significant advancements by (1) decoupling heuristic MQM criteria into distinct evaluation dimensions for fine-grained assessments; (2) employing multi-agent debates to harness the collaborative reasoning capabilities of LLMs; (3) synthesizing dimension-specific results into a final evaluation judgment to ensure robust and reliable outcomes. Comprehensive experiments show that M-MAD not only outperforms all existing LLM-as-a-judge methods but also competes with state-of-the-art reference-based automatic metrics, even when powered by a suboptimal model like GPT-4o mini. Detailed ablations and analysis highlight the superiority of our framework design, offering a fresh perspective for LLM-as-a-judge paradigm. Our code and data are publicly available at https://github.com/SU-JIAYUAN/M-MAD.
最近大型语言模型(LLM)的进展催生了一种名为“LLM作为评估者”的模式,展示了它们提供类似人类的判断的能力。然而,在机器翻译(MT)评估领域,当前的LLM作为评估者的方法仍然不及已学习的自动度量方法。在本文中,我们提出了多维多智能体辩论(M-MAD),这是一个基于LLM的多智能体框架,用于先进的LLM作为评估者的机器翻译评估。我们的研究发现,M-MAD通过以下方式取得了显著进展:(1)将启发式MQM标准解耦为不同的评估维度,以实现精细的评估;(2)利用多智能体辩论来利用LLM的协同推理能力;(3)将特定维度的结果综合成最终的评估判断,以确保稳健和可靠的结果。综合实验表明,M-MAD不仅优于所有现有的LLM作为评估者的方法,而且与最新的基于参考的自动度量方法竞争,即使在像GPT-4o mini这样的次优模型的驱动下也是如此。详细的消融和分析突显了我们框架设计的优越性,为LLM作为评估者模式提供了新的视角。我们的代码和数据在https://github.com/SU-JIAYUAN/M-MAD公开可用。
论文及项目相关链接
PDF Code and data are available at https://github.com/SU-JIAYUAN/M-MAD
Summary
大型语言模型(LLM)作为评判者的模式在机器翻译(MT)评估领域展现出潜力,但现有方法存在不足。本文提出多维度多智能体辩论(M-MAD)框架,通过解耦启发式MQM标准、利用多智能体辩论和合成特定维度结果等方法,实现了显著的进步。M-MAD不仅超越了现有LLM作为评判者的方法,还与国家先进的基于参考的自动度量标准竞争,即使使用次优模型如GPT-4o mini也是如此。
Key Takeaways
- 大型语言模型(LLM)可作为评判者进行机器翻译(MT)评估,具有潜力。
- 当前LLM-as-a-judge方法在机器翻译评估中不足,需要新方法改进。
- 提出的M-MAD框架通过解耦启发式MQM标准,实现了对翻译结果的细粒度评估。
- M-MAD利用多智能体辩论,发挥LLM的协同推理能力。
- M-MAD框架通过合成特定维度的评估结果,确保评估结果的稳健性和可靠性。
- M-MAD在性能上超越了现有的LLM-as-a-judge方法,并与最先进的基于参考的自动度量标准相竞争。
点此查看论文截图


Soft Condorcet Optimization for Ranking of General Agents
Authors:Marc Lanctot, Kate Larson, Michael Kaisers, Quentin Berthet, Ian Gemp, Manfred Diaz, Roberto-Rafael Maura-Rivero, Yoram Bachrach, Anna Koop, Doina Precup
Driving progress of AI models and agents requires comparing their performance on standardized benchmarks; for general agents, individual performances must be aggregated across a potentially wide variety of different tasks. In this paper, we describe a novel ranking scheme inspired by social choice frameworks, called Soft Condorcet Optimization (SCO), to compute the optimal ranking of agents: the one that makes the fewest mistakes in predicting the agent comparisons in the evaluation data. This optimal ranking is the maximum likelihood estimate when evaluation data (which we view as votes) are interpreted as noisy samples from a ground truth ranking, a solution to Condorcet’s original voting system criteria. SCO ratings are maximal for Condorcet winners when they exist, which we show is not necessarily true for the classical rating system Elo. We propose three optimization algorithms to compute SCO ratings and evaluate their empirical performance. When serving as an approximation to the Kemeny-Young voting method, SCO rankings are on average 0 to 0.043 away from the optimal ranking in normalized Kendall-tau distance across 865 preference profiles from the PrefLib open ranking archive. In a simulated noisy tournament setting, SCO achieves accurate approximations to the ground truth ranking and the best among several baselines when 59% or more of the preference data is missing. Finally, SCO ranking provides the best approximation to the optimal ranking, measured on held-out test sets, in a problem containing 52,958 human players across 31,049 games of the classic seven-player game of Diplomacy.
驱动AI模型和代理的进步需要在标准化的基准测试上比较它们的性能;对于通用代理,必须在各种潜在的不同任务上聚合个别性能。在本文中,我们描述了一种受社会选择框架启发的新型排名方案,称为Soft Condorcet Optimization(SCO),以计算代理的最佳排名:在评估数据中预测代理比较时错误最少的排名。当评估数据(我们将其视为投票)被解释为来自真实排名的噪声样本时,此最佳排名是最大似然估计,也是解决孔多塞原始投票系统标准的一个解决方案。当存在孔多塞赢家时,SCO评分最大,我们证明了这一点在经典评分系统Elo中并不成立。我们提出了三种优化算法来计算SCO评分,并评估了它们的实际性能。当作为Kemeny-Young投票方法的近似值时,SCO排名在来自PrefLib公开排名档案的865个偏好配置文件中,平均与最佳排名的标准化Kendall-tau距离在0到0.043之间。在模拟的嘈杂比赛环境中,当缺少59%或更多的偏好数据时,SCO实现了对真实排名的准确近似,并且在几个基准测试中表现最佳。最后,在包含52958名玩家参与经典七人游戏《外交》的31049场游戏中,SCO排名在保留测试集上提供了最佳近似于最佳排名。
论文及项目相关链接
Summary
本文介绍了一种基于社会选择框架启发的新型排名方案——软Condorcet优化(SCO)。在评价数据中预测代理比较时,该方案可使错误最少,并计算最佳代理排名。将评价数据视为从真实排名中发出的带有噪声的样本时,SCO评级提供了一种最大可能性的估计值。当存在Condorcet优胜者时,其评级最高。与经典评级系统Elo不同,不一定存在最优评级。本文提出了三种计算SCO评级的优化算法,并对其实际性能进行了评估。在模拟噪声锦标赛设置中,当缺少偏好数据的比例达到或超过59%时,SCO准确逼近真实排名并表现出最佳性能。此外,在涉及多个游戏和人类玩家的实际问题中,SCO排名在测试集上提供了最佳近似值。总体而言,SCO是一种高效、准确的排名方法。
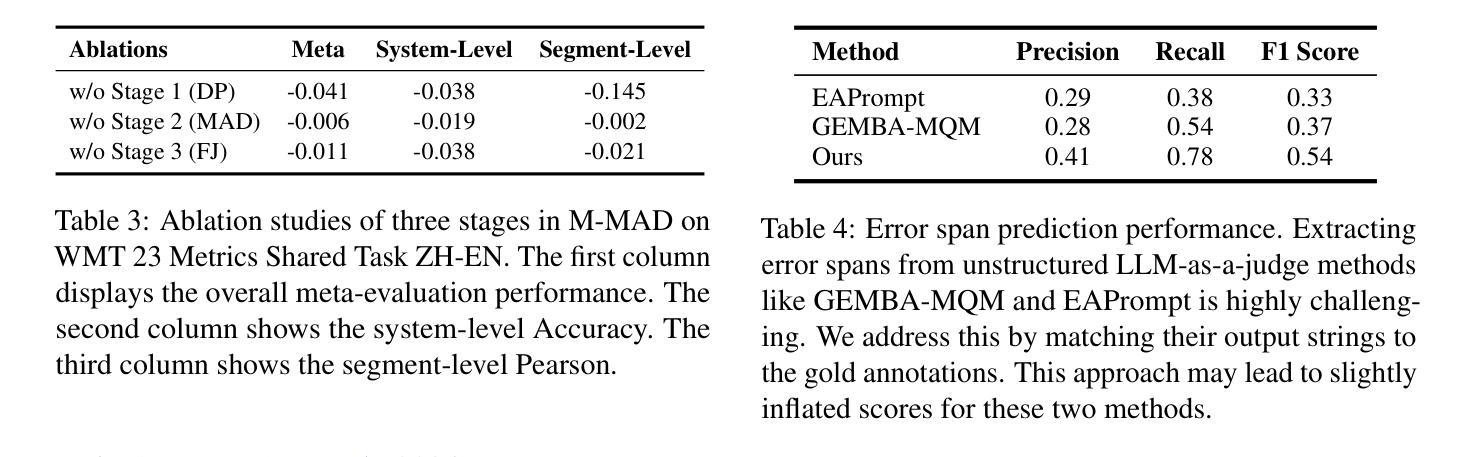
Key Takeaways
- 介绍了一种新型排名方案——软Condorcet优化(SCO),用于计算AI模型和代理的最优排名。
- SCO评级基于预测代理比较的错误率最小化。
- SCO评级提供了一种最大可能性的估计值,当存在Condorcet优胜者时表现最佳。
- 与传统评级系统相比,SCO不一定存在最优评级。
- 提出了三种计算SCO评级的优化算法,并进行了实际性能评估。
- 在模拟噪声环境中,SCO能够准确逼近真实排名,在数据缺失较多时表现最佳。
点此查看论文截图



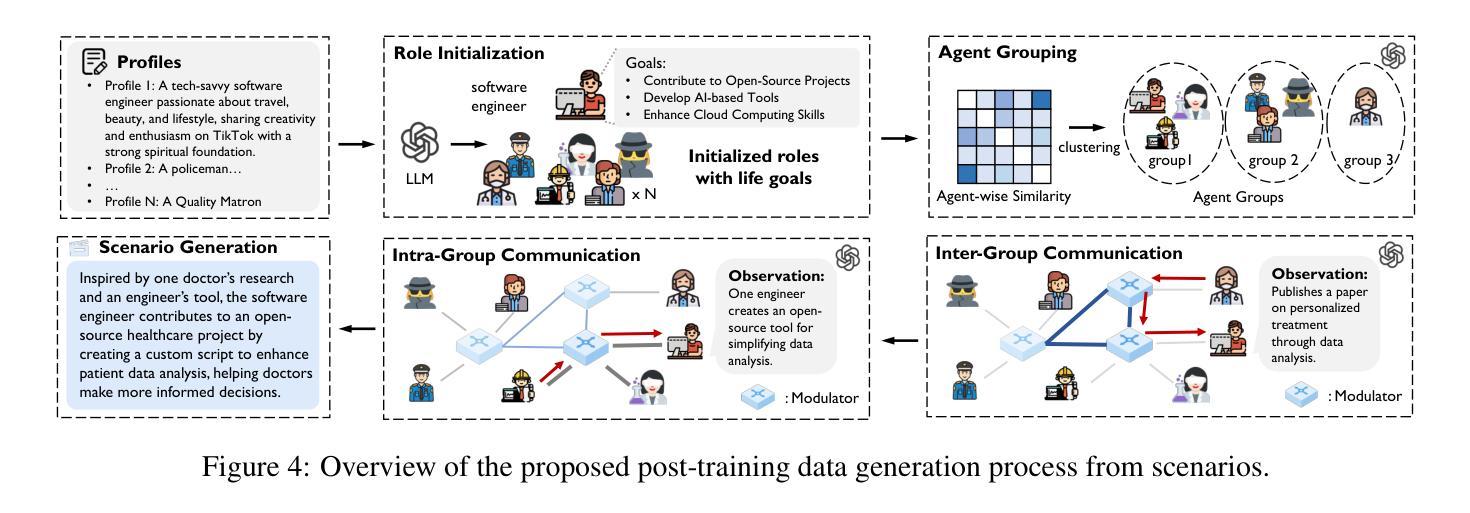
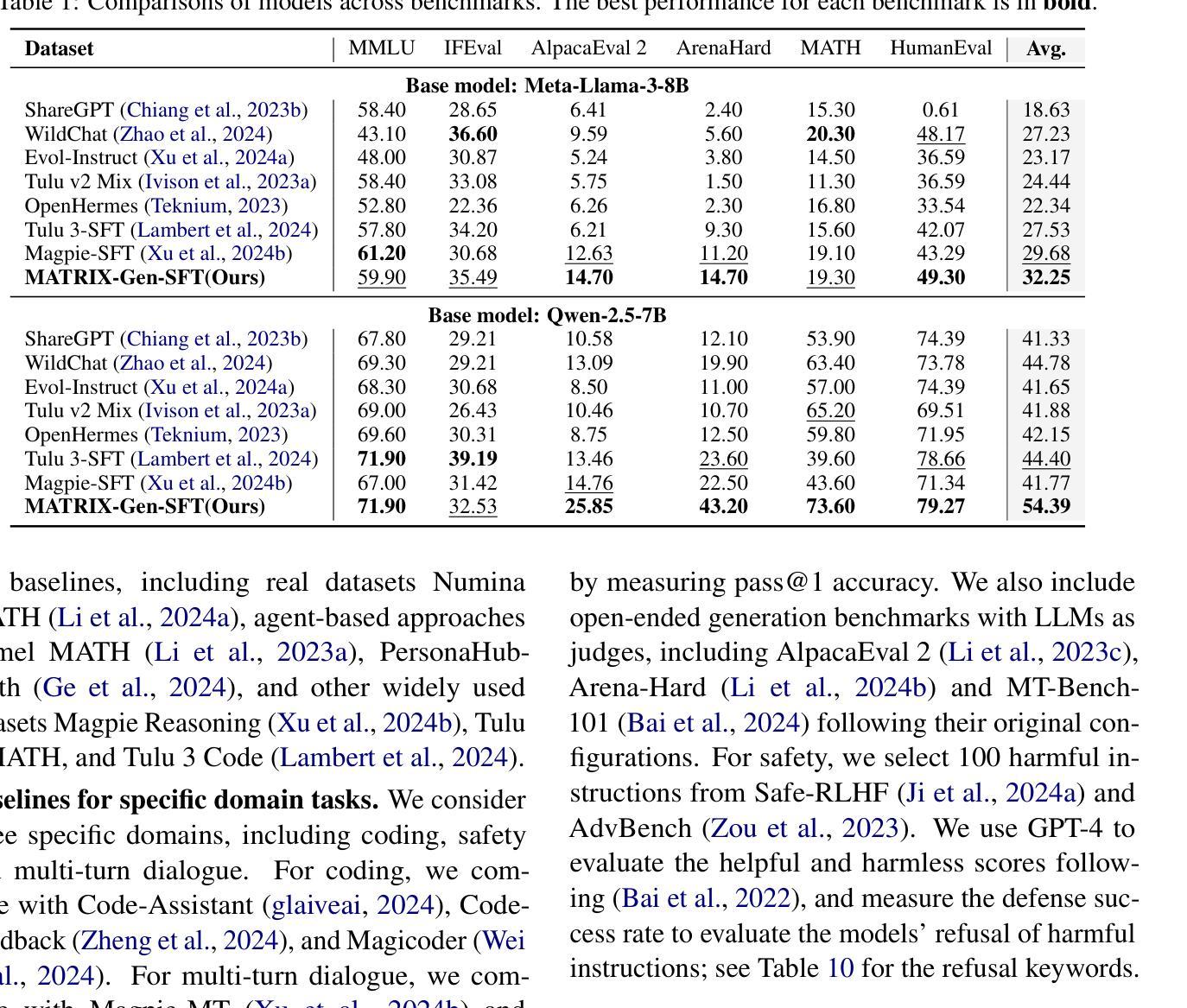
Synthesizing Post-Training Data for LLMs through Multi-Agent Simulation
Authors:Shuo Tang, Xianghe Pang, Zexi Liu, Bohan Tang, Rui Ye, Tian Jin, Xiaowen Dong, Yanfeng Wang, Siheng Chen
Post-training is essential for enabling large language models (LLMs) to follow human instructions. However, its effectiveness depends on high-quality instruction data, which is challenging to obtain in the real world due to privacy concerns, data scarcity, and high annotation costs. To fill this gap, inspired by the recent success of using LLMs to simulate human society, we propose MATRIX, a multi-agent simulator that automatically generates diverse text-based scenarios, capturing a wide range of real-world human needs in a realistic and scalable manner. Leveraging these outputs, we introduce a novel scenario-driven instruction generator MATRIX-Gen for controllable and highly realistic data synthesis. Extensive experiments demonstrate that our framework effectively generates both general and domain-specific data. On AlpacaEval 2 and Arena-Hard benchmarks, Llama-3-8B-Base, post-trained on datasets synthesized by MATRIX-Gen with just 20K instruction-response pairs, outperforms Meta’s Llama-3-8B-Instruct model, which was trained on over 10M pairs.
对大型语言模型(LLM)进行训练后,才能使其遵循人类指令。然而,其有效性取决于高质量的教学数据,由于隐私担忧、数据稀缺和高标注成本,在现实世界中获取教学数据具有挑战性。为了填补这一空白,我们受到使用LLM模拟人类社会的最新成功的启发,提出了MATRIX,这是一个多代理模拟器,能够自动生成多样化的文本场景,以现实和可扩展的方式捕捉人类广泛的实际需求。利用这些输出,我们引入了一种新型的场景驱动指令生成器MATRIX-Gen,用于可控且高度现实的数据合成。大量实验表明,我们的框架有效地生成了一般和特定领域的数据。在AlpacaEval 2和Arena-Hard基准测试中,仅使用2万条指令-响应对合成的数据集进行训练后的Llama-3-8B-Base模型超越了Meta的Llama-3-8B-Instruct模型,后者是在超过千万对指令训练数据上训练的。
论文及项目相关链接
Summary
大型语言模型(LLM)的训练需要遵循人类指令,但其效果取决于高质量指令数据。由于隐私担忧、数据稀缺和高标注成本等现实挑战,获取高质量指令数据并不容易。为此,本研究提出了MATRIX多智能体模拟器,能自动生成多样化的文本场景,以现实和可扩展的方式捕捉广泛的人类需求。利用这些输出,研究引入了新型的场景驱动指令生成器MATRIX-Gen,用于可控且高度真实的数据合成。实验表明,该框架能有效生成通用和特定领域的数据。在AlpacaEval 2和Arena-Hard基准测试中,仅使用MATRIX-Gen合成的数据集(含仅2万条指令响应对)进行训练的大型语言模型超过了基于超过一百万对训练数据的Meta大型语言模型。
Key Takeaways
- 大型语言模型的训练需要处理人类指令,但高质量指令数据的获取是挑战。
- MATRIX多智能体模拟器能自动生成多样化的文本场景,模拟人类需求。
- MATRIX-Gen作为场景驱动指令生成器,用于合成可控且高度真实的数据。
- 该框架能有效生成通用和特定领域的数据。
- 在基准测试中,使用MATRIX-Gen合成的数据集训练的模型表现超过使用大量常规数据集训练的模型。
点此查看论文截图


CoSQA+: Pioneering the Multi-Choice Code Search Benchmark with Test-Driven Agents
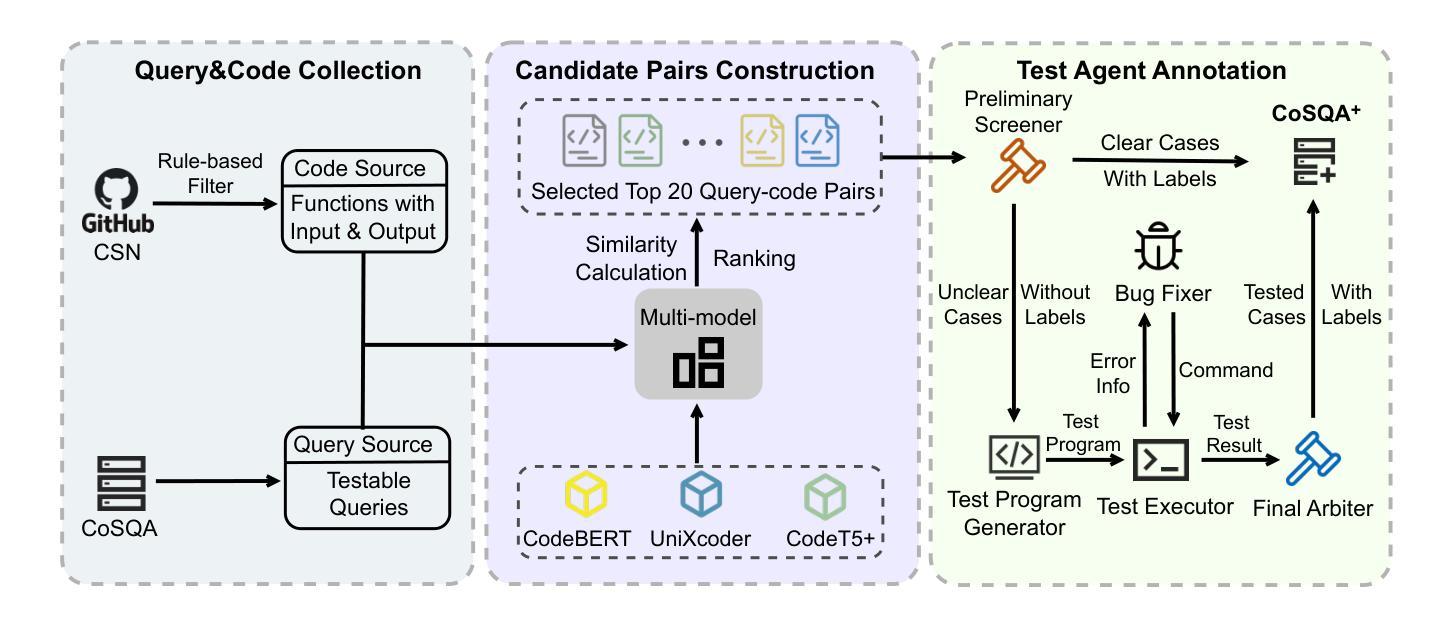
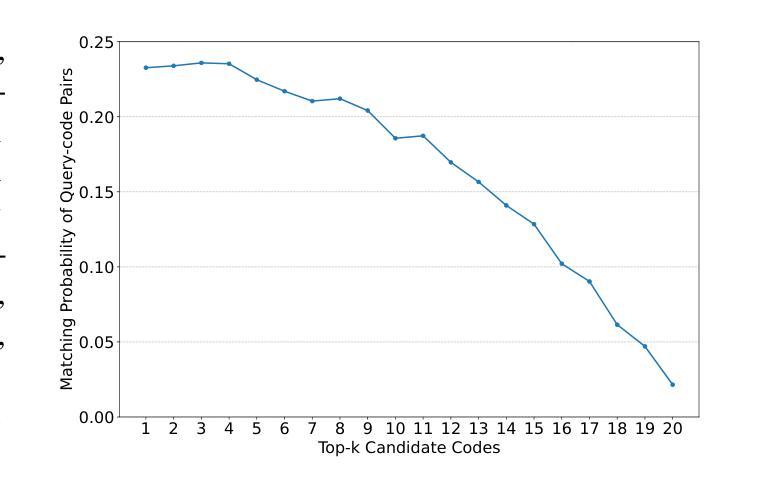
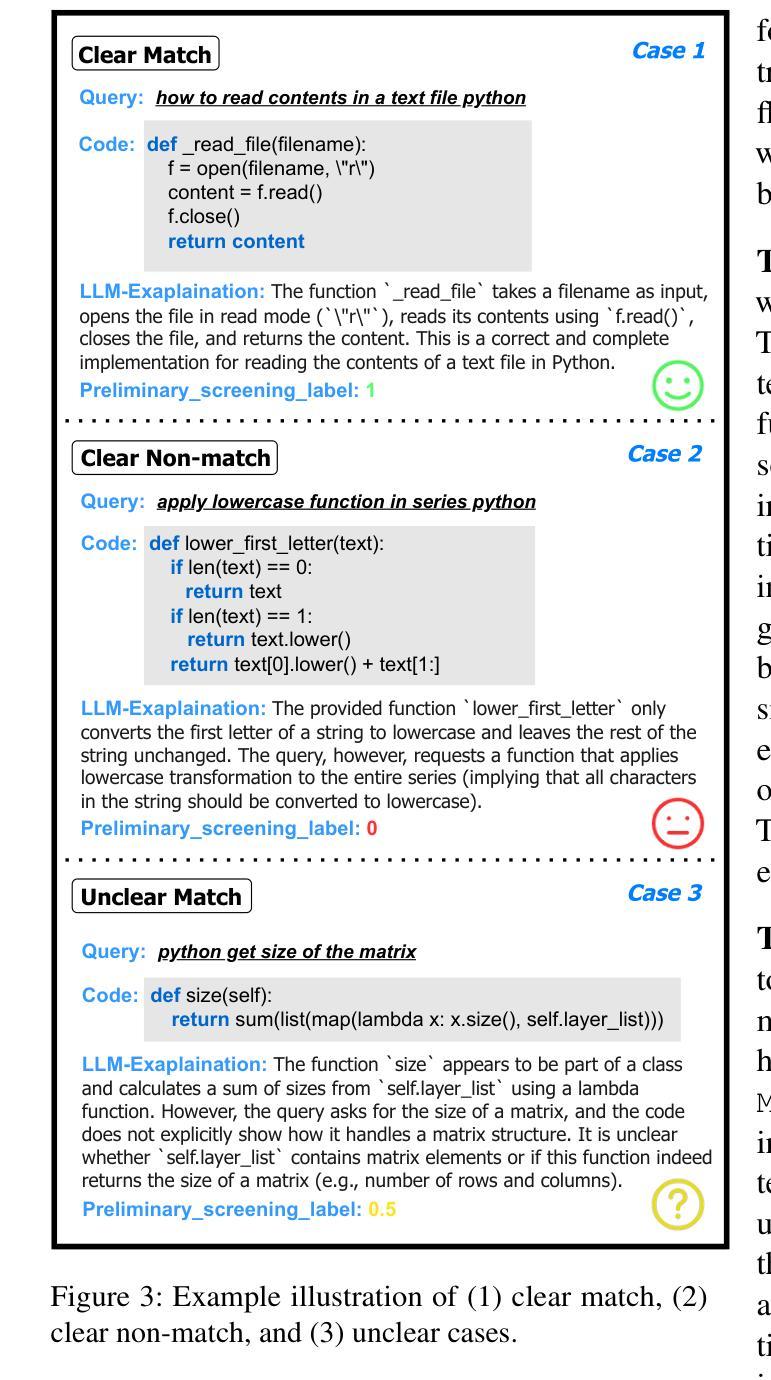
Authors:Jing Gong, Yanghui Wu, Linxi Liang, Yanlin Wang, Jiachi Chen, Mingwei Liu, Zibin Zheng
Semantic code search, retrieving code that matches a given natural language query, is an important task to improve productivity in software engineering. Existing code search datasets face limitations: they rely on human annotators who assess code primarily through semantic understanding rather than functional verification, leading to potential inaccuracies and scalability issues. Additionally, current evaluation metrics often overlook the multi-choice nature of code search. This paper introduces CoSQA+, pairing high-quality queries from CoSQA with multiple suitable codes. We develop an automated pipeline featuring multiple model-based candidate selections and the novel test-driven agent annotation system. Among a single Large Language Model (LLM) annotator and Python expert annotators (without test-based verification), agents leverage test-based verification and achieve the highest accuracy of 96.4%. Through extensive experiments, CoSQA+ has demonstrated superior quality over CoSQA. Models trained on CoSQA+ exhibit improved performance. We provide the code and data at https://github.com/DeepSoftwareAnalytics/CoSQA_Plus.
语义代码搜索是软件工程中提高生产率的重要任务,其目标是从现有的代码库中检索出与给定自然语言查询相匹配的代码。现有的代码搜索数据集存在局限性:它们依赖于主要通过语义理解而非功能验证来评估代码的人为注释者,这可能导致潜在的不准确和可扩展性问题。此外,当前的评估指标往往忽视了代码搜索的多选性质。本文介绍了CoSQA+,它将CoSQA的高质量查询与多个合适的代码配对。我们开发了一个自动化管道,通过基于模型的候选选择和多功能的测试驱动代理注释系统。相较于单一的大型语言模型注释器和未经测试验证的Python专家注释器,测试驱动代理验证并利用其实现了最高达96.4%的准确率。通过广泛的实验,CoSQA+在质量上超越了CoSQA。在CoSQA+数据集上训练的模型表现出更好的性能。我们在https://github.com/DeepSoftwareAnalytics/CoSQA_Plus上提供了代码和数据集。
论文及项目相关链接
PDF 15 pages, 4 figures, conference
Summary
自然语言代码搜索是软件工程领域提升生产效率的重要任务。现有数据集面临标注准确性问题以及多选择的评价考量缺失的问题。本文引入CoSQA+,采用自动化管道与模型候选策略,并创新性地提出测试驱动代理标注系统,实现高质量查询与适配代码的配对。实验证明,相较于单一的大型语言模型标注器,结合测试验证的代理标注器准确性更高,达到96.4%。训练于CoSQA+的模型展现出优越性能。数据资源已公开提供。
Key Takeaways
- 自然语言代码搜索是软件工程中的关键任务,旨在提高生产效率。
- 现有代码搜索数据集存在依赖人工标注的局限性,主要侧重于语义理解而非功能验证,可能导致潜在的不准确和可扩展性问题。
- CoSQA+通过引入自动化管道和模型候选策略解决现有问题。
- 测试驱动代理标注系统提高了标注的准确性。
- 结合测试验证的代理标注器相较于单一的大型语言模型标注器,准确性更高,达到96.4%。
- 训练于CoSQA+的模型展现出优越性能。
点此查看论文截图