⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-22 更新
Dynamic Low-Rank Sparse Adaptation for Large Language Models
Authors:Weizhong Huang, Yuxin Zhang, Xiawu Zheng, Yang Liu, Jing Lin, Yiwu Yao, Rongrong Ji
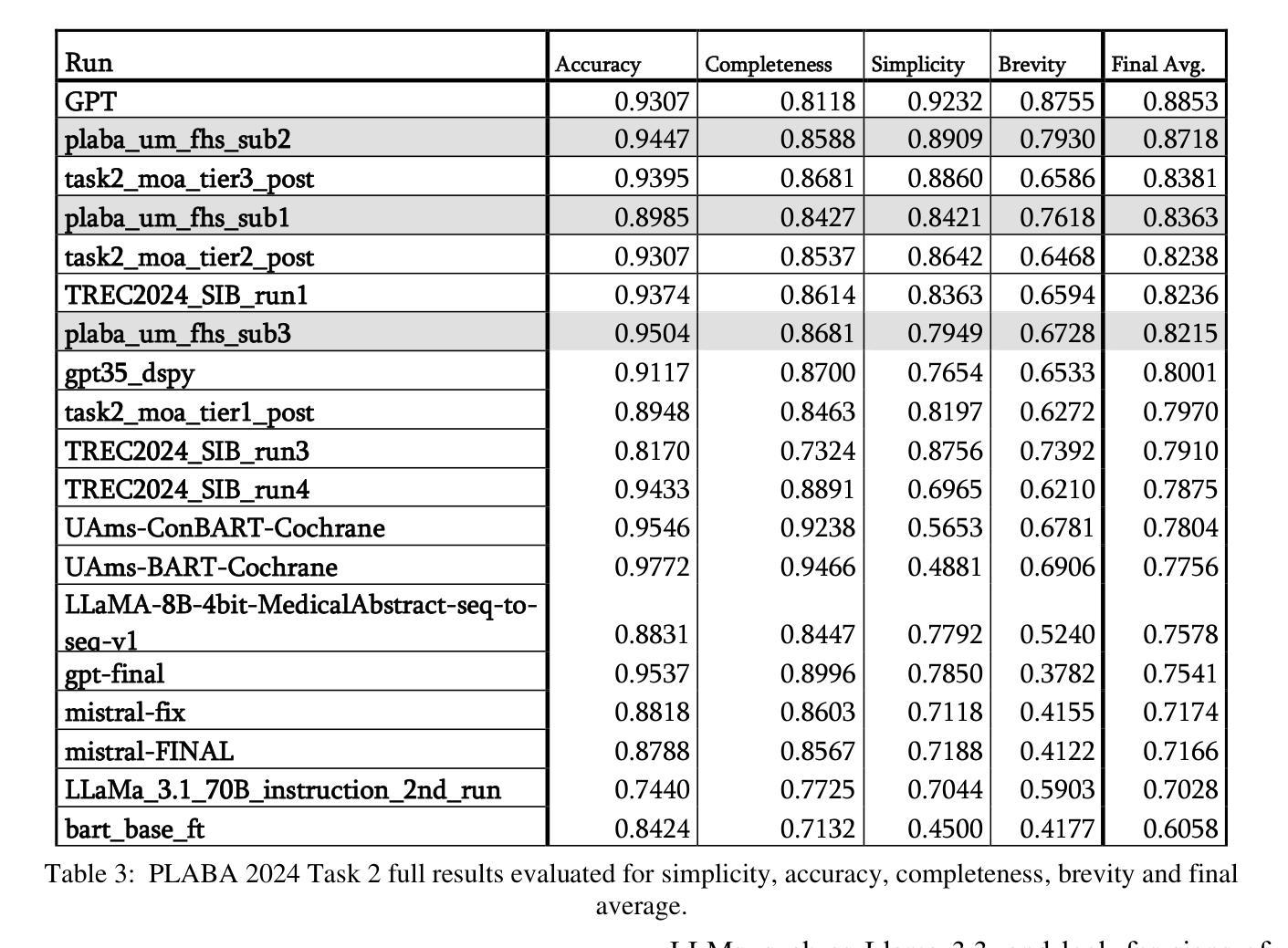
Despite the efficacy of network sparsity in alleviating the deployment strain of Large Language Models (LLMs), it endures significant performance degradation. Applying Low-Rank Adaptation (LoRA) to fine-tune the sparse LLMs offers an intuitive approach to counter this predicament, while it holds shortcomings include: 1) The inability to integrate LoRA weights into sparse LLMs post-training, and 2) Insufficient performance recovery at high sparsity ratios. In this paper, we introduce dynamic Low-rank Sparse Adaptation (LoSA), a novel method that seamlessly integrates low-rank adaptation into LLM sparsity within a unified framework, thereby enhancing the performance of sparse LLMs without increasing the inference latency. In particular, LoSA dynamically sparsifies the LoRA outcomes based on the corresponding sparse weights during fine-tuning, thus guaranteeing that the LoRA module can be integrated into the sparse LLMs post-training. Besides, LoSA leverages Representation Mutual Information (RMI) as an indicator to determine the importance of layers, thereby efficiently determining the layer-wise sparsity rates during fine-tuning. Predicated on this, LoSA adjusts the rank of the LoRA module based on the variability in layer-wise reconstruction errors, allocating an appropriate fine-tuning for each layer to reduce the output discrepancies between dense and sparse LLMs. Extensive experiments tell that LoSA can efficiently boost the efficacy of sparse LLMs within a few hours, without introducing any additional inferential burden. For example, LoSA reduced the perplexity of sparse LLaMA-2-7B by 68.73 and increased zero-shot accuracy by 16.32$%$, achieving a 2.60$\times$ speedup on CPU and 2.23$\times$ speedup on GPU, requiring only 45 minutes of fine-tuning on a single NVIDIA A100 80GB GPU. Code is available at https://github.com/wzhuang-xmu/LoSA.
尽管网络稀疏性在缓解大型语言模型(LLM)部署压力方面表现出色,但其性能仍有所降低。将低秩适应(LoRA)应用于微调稀疏LLM为解决这一困境提供了直观的方法,但它也存在一些缺点,包括:1)无法在训练后的稀疏LLM中集成LoRA权重;2)在高稀疏比率下性能恢复不足。在本文中,我们介绍了动态低秩稀疏适应(LoSA)方法,这是一种将低秩适应无缝集成到LLM稀疏性的统一框架中的新方法,旨在提高稀疏LLM的性能,而不会增加推理延迟。特别是,LoSA在微调过程中根据相应的稀疏权重动态地稀疏化LoRA的结果,从而确保LoRA模块可以在训练后的稀疏LLM中集成。此外,LoSA利用表示互信息(RMI)作为指标来确定层的重要性,从而有效地确定微调过程中的逐层稀疏率。基于此,LoSA根据逐层重建误差的变化来调整LoRA模块的秩,为每层分配适当的微调,以减少密集和稀疏LLM之间的输出差异。大量实验表明,LoSA可以在几小时内有效提高稀疏LLM的效率,而不会引入任何额外的推理负担。例如,LoSA将稀疏LLaMA-2-7B的困惑度降低了68.73%,零射准确度提高了16.32%,在CPU上实现了2.60倍的加速,在GPU上实现了2.23倍的加速,只需在单个NVIDIA A100 80GB GPU上进行45分钟的微调即可。相关代码可通过https://github.com/wzhuang-xmu/LoSA获取。
论文及项目相关链接
PDF Accepted to ICLR 2025
Summary
本文提出动态低秩稀疏适配(LoSA)方法,将低秩适配技术无缝集成到LLM稀疏模型中,提升稀疏LLM性能且不会增加推理延迟。LoSA通过动态稀疏化LoRA结果、利用表示互信息(RMI)确定层重要性及调整LoRA模块秩等方法,优化了LoRA在稀疏LLM中的集成效果。实验表明,LoSA能显著提高稀疏LLM效率,如LLaMA-2-7B的词谜减少68.73%,零样本准确率提高16.32%,并在CPU和GPU上实现加速。
Key Takeaways
- 网络稀疏性虽然能缓解大型语言模型(LLM)的部署压力,但会导致性能显著下降。
- LoSA方法将低秩适配(LoRA)技术集成到LLM稀疏模型中,提高了稀疏LLM的性能。
- LoSA通过动态稀疏化LoRA结果,保证了LoRA模块可以在稀疏LLM训练后进行集成。
- LoSA利用表示互信息(RMI)来确定层的重要性,从而有效地确定微调期间的层级稀疏率。
- LoSA根据层间重建误差的变异性调整LoRA模块的秩,为每层分配适当的微调,以减少密集和稀疏LLM之间的输出差异。
- 实验表明,LoSA能显著提高稀疏LLM的效率,如LLaMA-2-7B的词谜减少和零样本准确率的提高。
点此查看论文截图


A Similarity Paradigm Through Textual Regularization Without Forgetting
Authors:Fangming Cui, Jan Fong, Rongfei Zeng, Xinmei Tian, Jun Yu
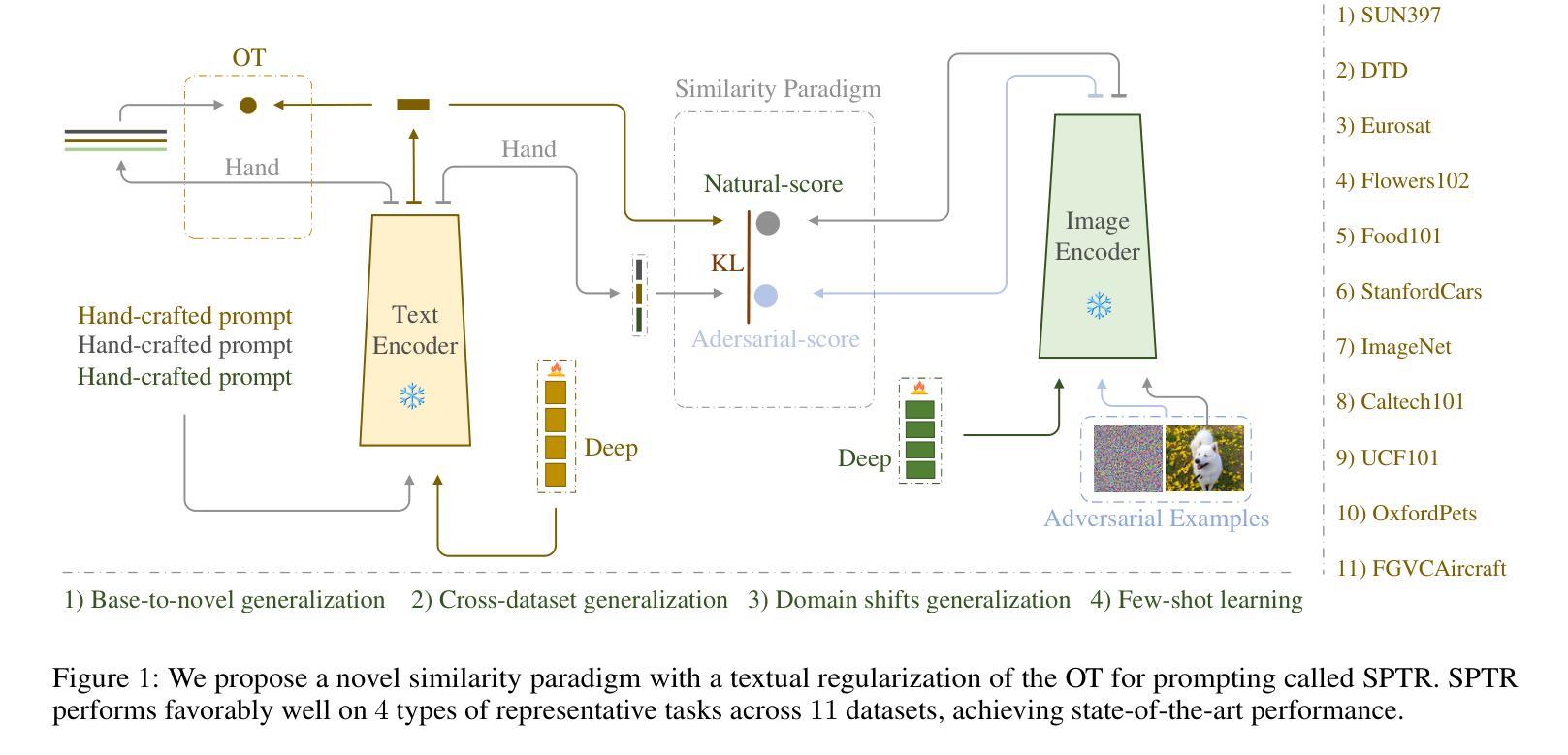
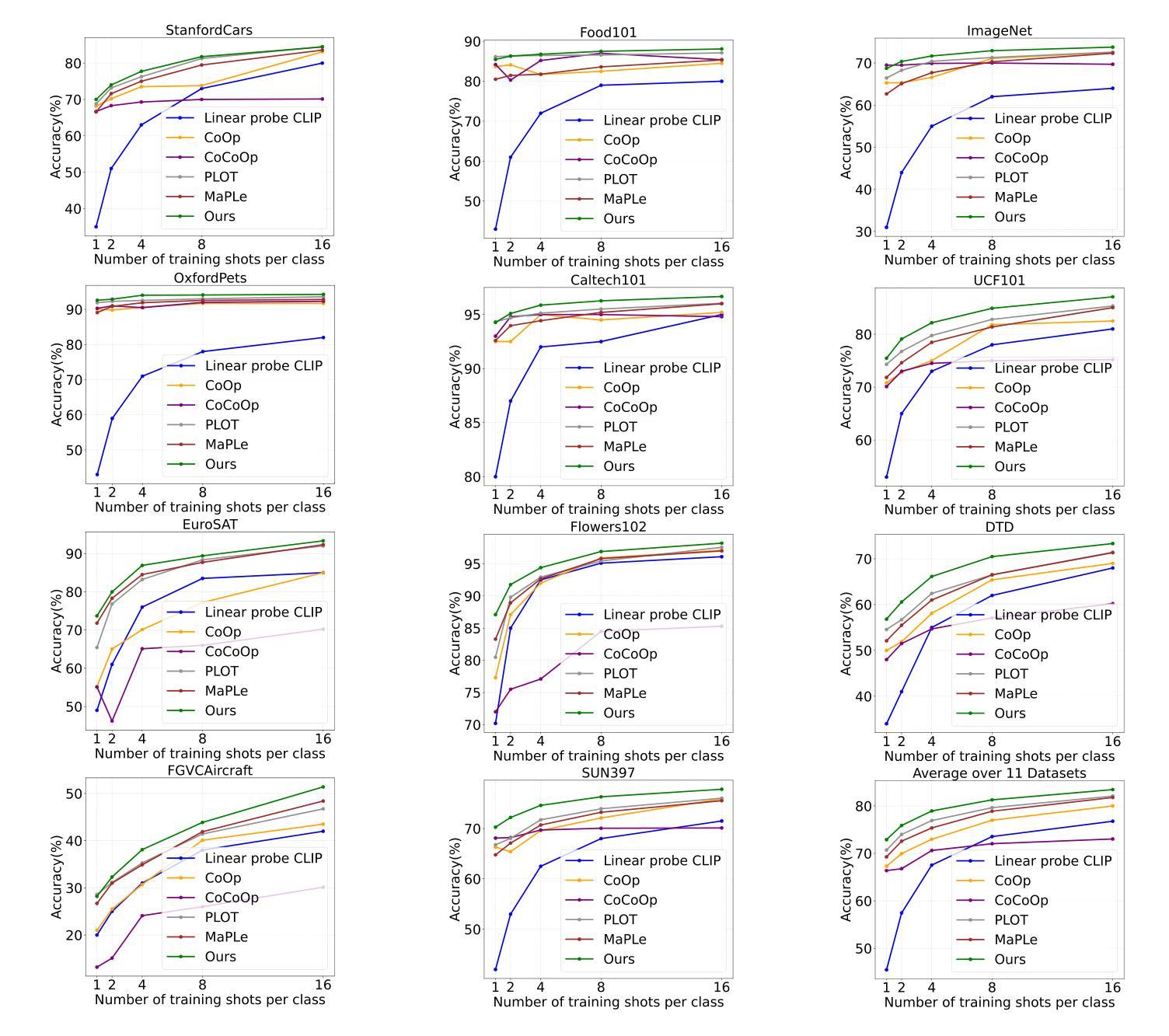
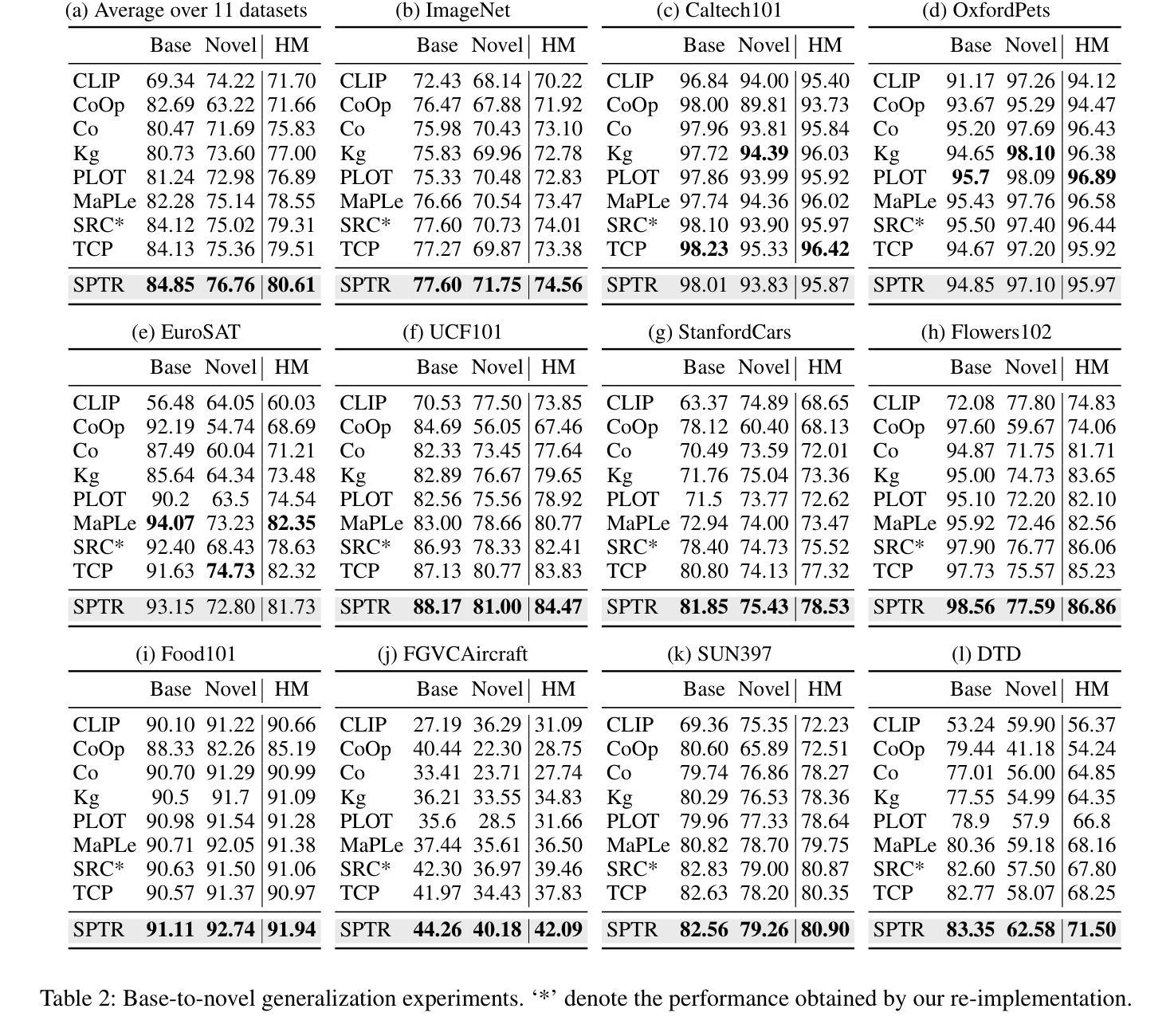
Prompt learning has emerged as a promising method for adapting pre-trained visual-language models (VLMs) to a range of downstream tasks. While optimizing the context can be effective for improving performance on specific tasks, it can often lead to poor generalization performance on unseen classes or datasets sampled from different distributions. It may be attributed to the fact that textual prompts tend to overfit downstream data distributions, leading to the forgetting of generalized knowledge derived from hand-crafted prompts. In this paper, we propose a novel method called Similarity Paradigm with Textual Regularization (SPTR) for prompt learning without forgetting. SPTR is a two-pronged design based on hand-crafted prompts that is an inseparable framework. 1) To avoid forgetting general textual knowledge, we introduce the optimal transport as a textual regularization to finely ensure approximation with hand-crafted features and tuning textual features. 2) In order to continuously unleash the general ability of multiple hand-crafted prompts, we propose a similarity paradigm for natural alignment score and adversarial alignment score to improve model robustness for generalization. Both modules share a common objective in addressing generalization issues, aiming to maximize the generalization capability derived from multiple hand-crafted prompts. Four representative tasks (i.e., non-generalization few-shot learning, base-to-novel generalization, cross-dataset generalization, domain generalization) across 11 datasets demonstrate that SPTR outperforms existing prompt learning methods.
提示学习已成为将预训练的视觉语言模型(VLM)适应多种下游任务的一种有前途的方法。虽然优化上下文对于提高特定任务的性能可能是有效的,但它往往会导致在来自不同分布的未见类别或数据集上的泛化性能较差。这可能是由于文本提示倾向于过度拟合下游数据分布,导致忘记手工制作的提示所衍生的通用知识。在本文中,我们提出了一种新的方法,称为带文本正则化的相似性范式(SPTR),用于无遗忘的提示学习。SPTR是一个基于手工制作的提示的两面设计,是一个不可分割的框架。1)为了避免忘记一般的文本知识,我们引入了最优传输作为文本正则化,以精细地确保与手工制作的特征和调整文本特征的近似。2)为了不断释放多个手工制作的提示的通用能力,我们提出了自然对齐得分和对抗性对齐得分的相似性范式,以提高模型的泛化能力。这两个模块的共同目标是解决泛化问题,旨在最大化从多个手工制作的提示中获得的泛化能力。在11个数据集的四个代表性任务(即非泛化小样本学习、基础到新颖的泛化、跨数据集泛化和域泛化)上表明,SPTR的性能优于现有的提示学习方法。
论文及项目相关链接
Summary
本文提出了一种名为SPTR的新型提示学习方法,旨在解决预训练视觉语言模型在适应下游任务时的泛化问题。SPTR通过引入文本正则化和相似性范式,确保模型在利用手工提示的同时,避免遗忘通用文本知识,并提高模型对不同数据集和分布的泛化能力。
Key Takeaways
- 提示学习是适应预训练视觉语言模型到下游任务的一种有前途的方法。
- 文本提示可能导致模型对特定任务的性能优化,但泛化性能较差。
- SPTR是一种基于手工提示的新型提示学习方法,旨在解决泛化问题。
- SPTR使用文本正则化来确保模型与手工特征的精细对齐,避免遗忘通用文本知识。
- SPTR引入相似性范式,通过自然对齐得分和对抗性对齐得分来提高模型的稳健性和泛化能力。
- SPTR在两个主要目标上解决了泛化问题,旨在从多个手工提示中最大限度地提高泛化能力。
点此查看论文截图

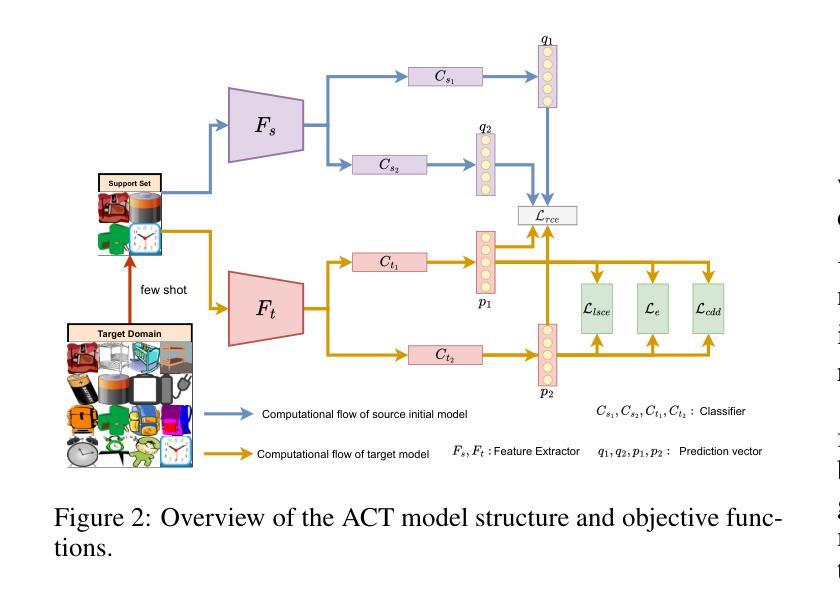
Asymmetric Co-Training for Source-Free Few-Shot Domain Adaptation
Authors:Gengxu Li, Yuan Wu
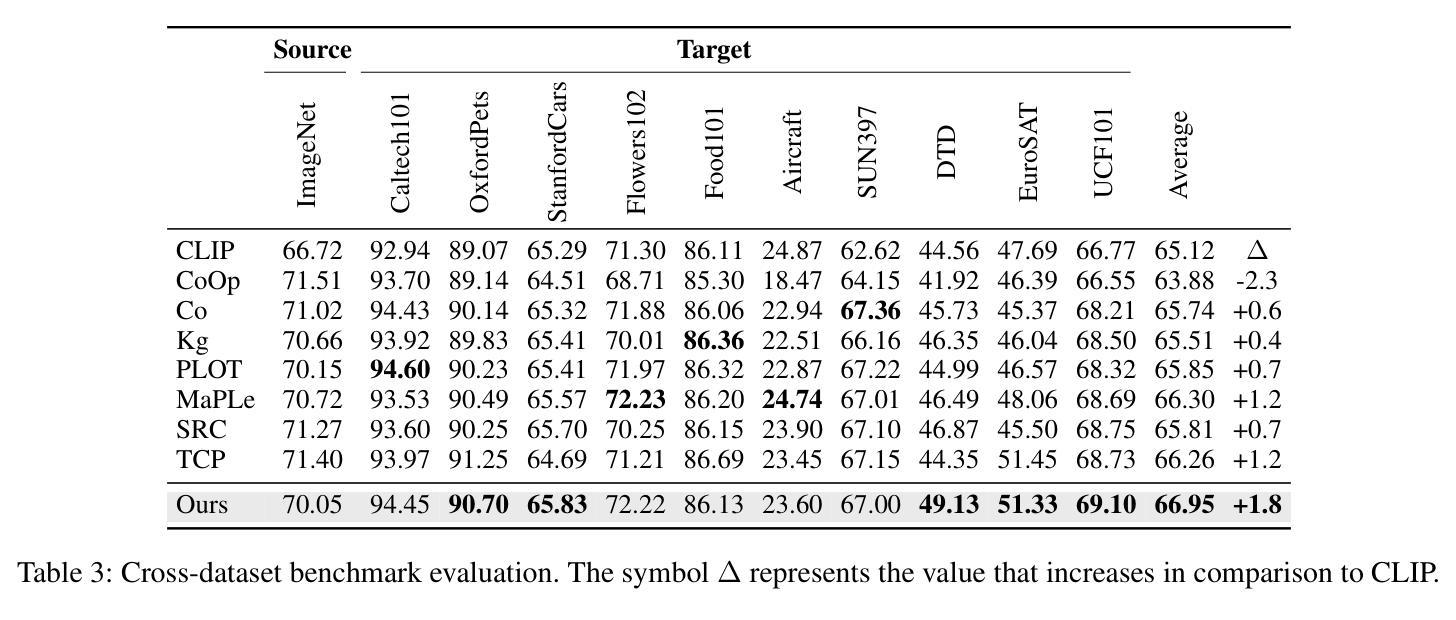
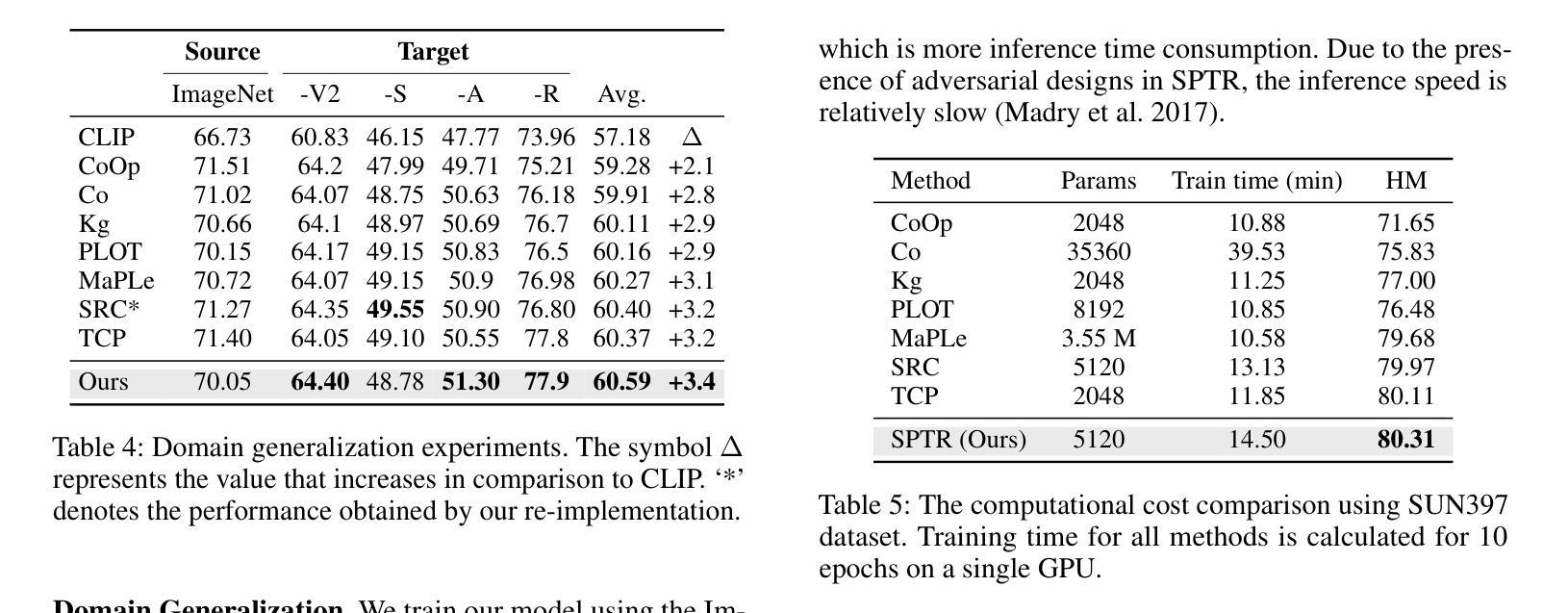
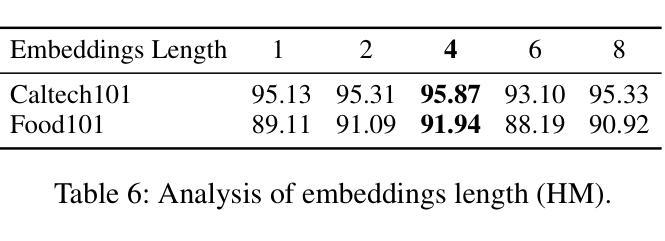
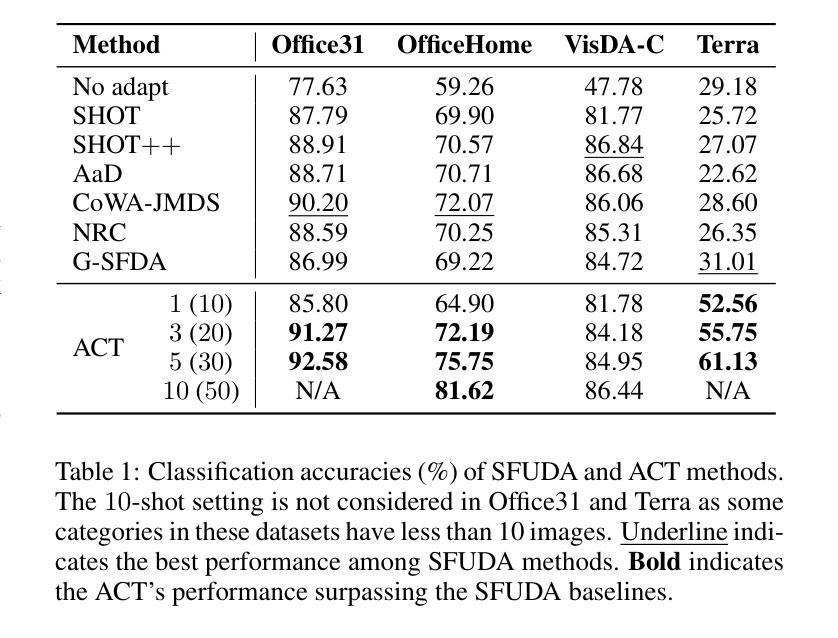
Source-free unsupervised domain adaptation (SFUDA) has gained significant attention as an alternative to traditional unsupervised domain adaptation (UDA), which relies on the constant availability of labeled source data. However, SFUDA approaches come with inherent limitations that are frequently overlooked. These challenges include performance degradation when the unlabeled target data fails to meet critical assumptions, such as having a closed-set label distribution identical to that of the source domain, or when sufficient unlabeled target data is unavailable-a common situation in real-world applications. To address these issues, we propose an asymmetric co-training (ACT) method specifically designed for the SFFSDA scenario. SFFSDA presents a more practical alternative to SFUDA, as gathering a few labeled target instances is more feasible than acquiring large volumes of unlabeled target data in many real-world contexts. Our ACT method begins by employing a weak-strong augmentation to enhance data diversity. Then we use a two-step optimization process to train the target model. In the first step, we optimize the label smoothing cross-entropy loss, the entropy of the class-conditional distribution, and the reverse-entropy loss to bolster the model’s discriminative ability while mitigating overfitting. The second step focuses on reducing redundancy in the output space by minimizing classifier determinacy disparity. Extensive experiments across four benchmarks demonstrate the superiority of our ACT approach, which outperforms state-of-the-art SFUDA methods and transfer learning techniques. Our findings suggest that adapting a source pre-trained model using only a small amount of labeled target data offers a practical and dependable solution. The code is available at https://github.com/gengxuli/ACT.
源数据无关的无人监督领域自适应(SFUDA)作为一种替代传统无人监督领域自适应(UDA)的方法,已经引起了人们的广泛关注。传统无人监督领域自适应依赖于始终可用的有标签源数据。然而,SFUDA方法带有经常被忽视的内在局限性。这些挑战包括在无标签目标数据无法满足关键假设时性能下降,例如当封闭集标签分布与源域相同时,或者在现实世界应用中经常出现足够的无标签目标数据不可用的情况。为了解决这些问题,我们提出了一种专为SFFSDA场景设计的对称协同训练(ACT)方法。SFFSDA为SFUDA提供了一个更实用的替代方案,因为在许多现实世界的情境中,收集少量有标签的目标实例比获取大量无标签的目标数据更为可行。我们的ACT方法首先采用弱强增强法来提高数据多样性。然后我们通过两步优化过程来训练目标模型。第一步中,我们优化标签平滑交叉熵损失、类条件分布的熵和反向熵损失,以提高模型的判别能力并减轻过拟合现象。第二步专注于通过最小化分类器确定性差异来减少输出空间的冗余。在四个基准测试上的大量实验表明,我们的ACT方法表现卓越,超越了最先进的SFUDA方法和迁移学习技术。我们的研究结果表明,仅使用少量有标签的目标数据对源预训练模型进行适应调整提供了一种实用可靠的解决方案。代码可通过以下网址获取:https://github.com/gengxuli/ACT 。
论文及项目相关链接
PDF 13 pages
Summary
该文介绍了无源无监督域自适应(SFUDA)方法面临的挑战,并提出了针对SFUDA的对称协同训练(ACT)方法。ACT方法通过弱强增强数据多样性,采用两步优化过程训练目标模型,优化标签平滑交叉熵损失、类条件分布的熵和反向熵损失,以提高模型的判别能力并减少过拟合。在四个基准测试上的实验表明,ACT方法优于最新的SFUDA方法和迁移学习技术。研究结果表明,仅使用少量目标数据对源预训练模型进行微调是一种实用可靠的解决方案。
Key Takeaways
- 源自由无监督域自适应(SFUDA)方法受到关注,作为传统无监督域自适应(UDA)的替代方案,但SFUDA方法存在性能下降的局限性。
- 当目标数据不满足关键假设(如标签分布与源域相同)或目标数据不足时,SFUDA性能会受到影响。
- 提出了针对SFUDA场景的对称协同训练(ACT)方法,通过弱强增强数据多样性,采用两步优化过程训练模型。
- ACT方法优化了标签平滑交叉熵损失、类条件分布的熵和反向熵损失,提高模型的判别能力并减少过拟合。
- ACT方法在四个基准测试上的实验表现优于最新的SFUDA方法和迁移学习技术。
- 使用少量目标数据对源预训练模型进行微调是一种实用可靠的解决方案。
点此查看论文截图
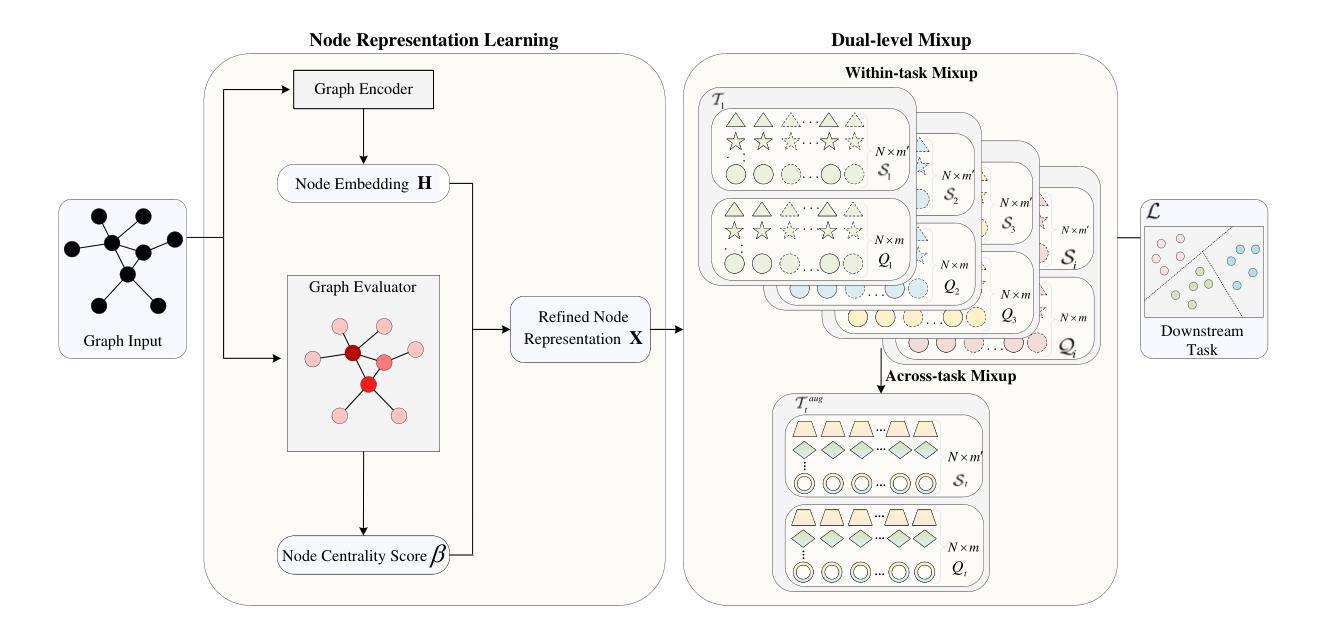
Dual-level Mixup for Graph Few-shot Learning with Fewer Tasks
Authors:Yonghao Liu, Mengyu Li, Fausto Giunchiglia, Lan Huang, Ximing Li, Xiaoyue Feng, Renchu Guan
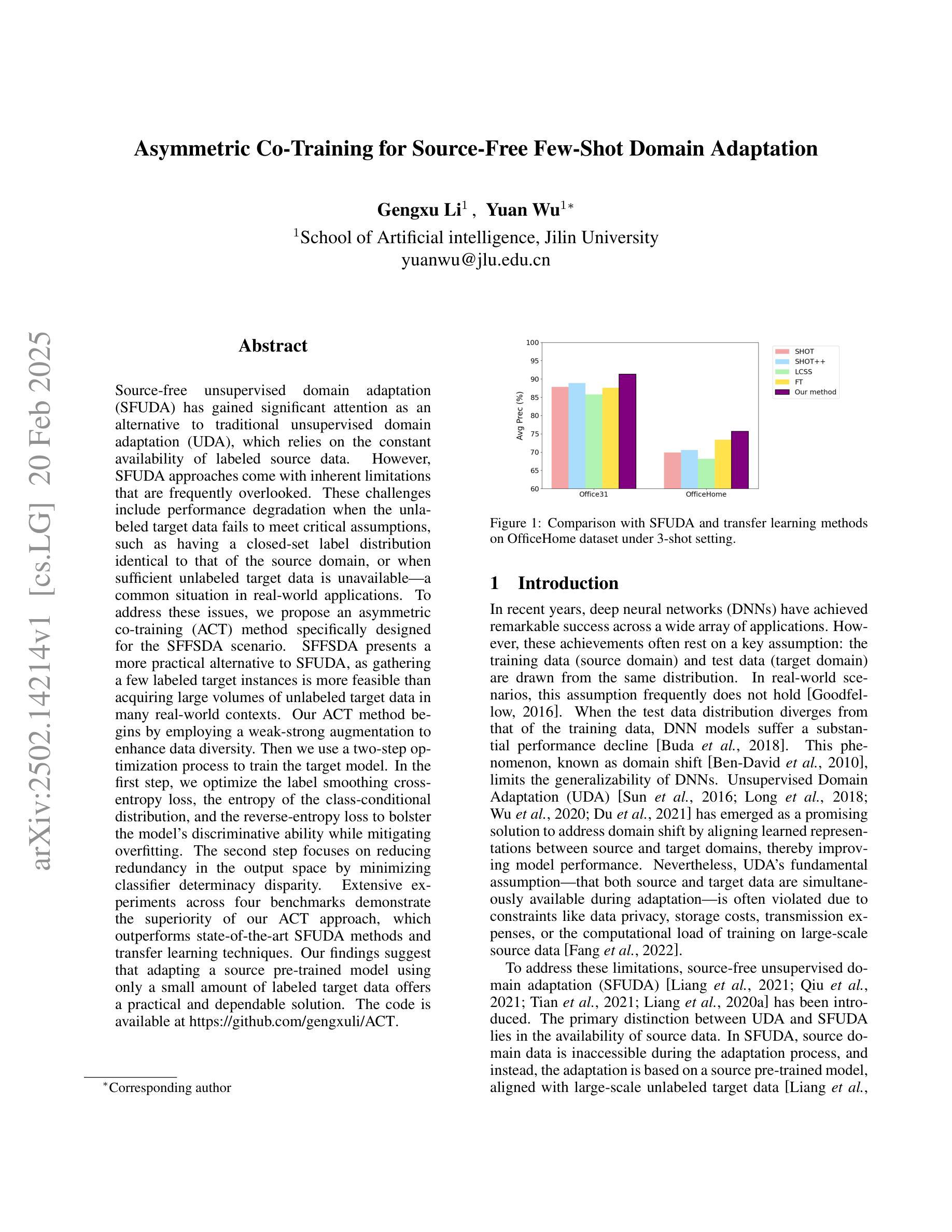
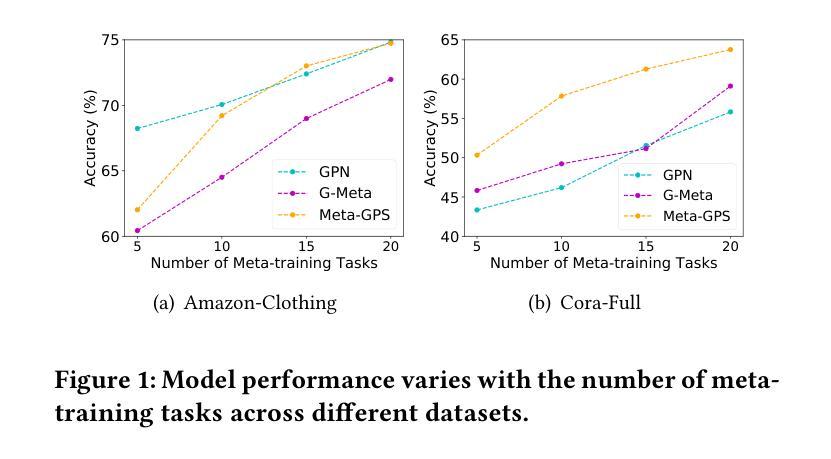
Graph neural networks have been demonstrated as a powerful paradigm for effectively learning graph-structured data on the web and mining content from it.Current leading graph models require a large number of labeled samples for training, which unavoidably leads to overfitting in few-shot scenarios. Recent research has sought to alleviate this issue by simultaneously leveraging graph learning and meta-learning paradigms. However, these graph meta-learning models assume the availability of numerous meta-training tasks to learn transferable meta-knowledge. Such assumption may not be feasible in the real world due to the difficulty of constructing tasks and the substantial costs involved. Therefore, we propose a SiMple yet effectIve approach for graph few-shot Learning with fEwer tasks, named SMILE. We introduce a dual-level mixup strategy, encompassing both within-task and across-task mixup, to simultaneously enrich the available nodes and tasks in meta-learning. Moreover, we explicitly leverage the prior information provided by the node degrees in the graph to encode expressive node representations. Theoretically, we demonstrate that SMILE can enhance the model generalization ability. Empirically, SMILE consistently outperforms other competitive models by a large margin across all evaluated datasets with in-domain and cross-domain settings. Our anonymous code can be found here.
图神经网络已被证明是在Web上有效学习图结构数据和从中挖掘内容的有力范式。当前领先的图模型需要大量的标签样本进行训练,这在少量样本场景中不可避免地导致过拟合。最近的研究试图通过同时利用图学习和元学习范式来缓解这个问题。然而,这些图元学习模型假设存在大量的元训练任务来学习可迁移的元知识。由于构建任务的难度和涉及的大量成本,这种假设在现实中可能不可行。因此,我们提出了一种简单有效的图小样学习新方法,名为SMILE(用于小样任务的图学习)。我们引入了一种双级混合策略,包括任务内和任务间混合,以同时丰富元学习中可用的节点和任务。此外,我们明确利用图中节点度提供的先验信息来编码表达性节点表示。理论上,我们证明了SMILE可以增强模型的泛化能力。在实证上,SMILE在所有评估的域内和跨域设置的数据集上均大幅超越其他竞争模型。我们的匿名代码可以在这里找到。
论文及项目相关链接
PDF WWW25
Summary
图神经网络已成为学习网上图结构数据和从中挖掘内容的有效范式。当前领先的图模型需要大量标注样本进行训练,这在小样数据场景中不可避免地导致过拟合。最近的研究通过结合图学习和元学习范式来缓解这一问题。然而,这些图元学习模型假设可用大量的元训练任务来学习可迁移的元知识,这在现实中可能不可行。因此,我们提出了一种简单有效的图小样学习的方法SMILE,通过双层次混合策略同时丰富可用节点和任务。理论上,SMILE能提升模型的泛化能力;实证上,SMILE在不同数据集上的表现优于其他模型。
Key Takeaways
- 图神经网络已成为学习和挖掘网上图结构数据的有效方法。
- 当前图模型在少量样本情况下易产生过拟合问题。
- 最近研究通过结合图学习和元学习来缓解这一问题。
- 元学习模型需要大量元训练任务,这在现实中可能难以实现。
- SMILE方法通过双层次混合策略丰富可用节点和任务,有效应对小样数据问题。
- SMILE能提升模型的泛化能力。
点此查看论文截图

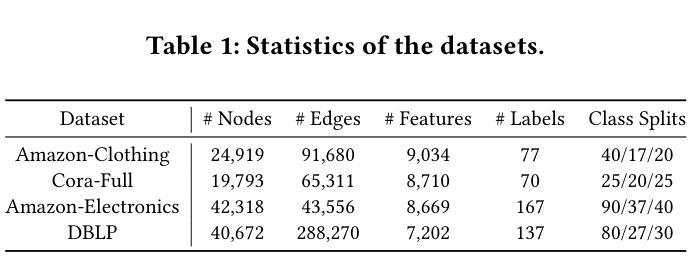
Retrieving Versus Understanding Extractive Evidence in Few-Shot Learning
Authors:Karl Elbakian, Samuel Carton
A key aspect of alignment is the proper use of within-document evidence to construct document-level decisions. We analyze the relationship between the retrieval and interpretation of within-document evidence for large language model in a few-shot setting. Specifically, we measure the extent to which model prediction errors are associated with evidence retrieval errors with respect to gold-standard human-annotated extractive evidence for five datasets, using two popular closed proprietary models. We perform two ablation studies to investigate when both label prediction and evidence retrieval errors can be attributed to qualities of the relevant evidence. We find that there is a strong empirical relationship between model prediction and evidence retrieval error, but that evidence retrieval error is mostly not associated with evidence interpretation error–a hopeful sign for downstream applications built on this mechanism.
对齐的关键在于正确使用文档内的证据来构建文档级别的决策。我们在小样本环境下,分析了大型语言模型中检索和解释文档内证据之间的关系。具体来说,我们利用两个流行的大型专有模型,通过衡量模型预测误差与关于五个数据集的黄金标准人类注释提取证据的检索误差之间的关联程度。我们进行了两项消融研究,以调查标签预测和证据检索错误都可以归因于证据质量的情况。我们发现模型预测和证据检索错误之间存在强烈的实证关系,但证据检索错误主要与证据解释错误不相关——这对于基于这种机制的下游应用是一个积极的迹象。
论文及项目相关链接
PDF 9 pages, 8 figures, Accepted to AAAI 2025 Main Conference (AI Alignment Track)
Summary:
大型语言模型在少样本环境下的文档内证据检索与解读的关系分析。研究通过五个数据集测量模型预测错误与证据检索错误的相关性,并进行两项消融研究,发现模型预测与证据检索错误间存在强实证关系,但证据检索错误大多与证据解读错误无关,为下游应用提供了乐观的指示。
Key Takeaways:
- 大型语言模型在少样本环境下,证据检索对于文档级别的决策至关重要。
- 模型预测错误与证据检索错误之间存在强实证关系。
- 通过五个数据集的研究,发现证据检索错误并不主要与证据解读错误相关。
- 进行了两项消融研究,以探究标签预测和证据检索错误的来源。
- 研究使用了两个流行的封闭专有模型进行分析。
- 对于下游应用,证据检索和解读的分离提供了一个乐观的指示。
点此查看论文截图



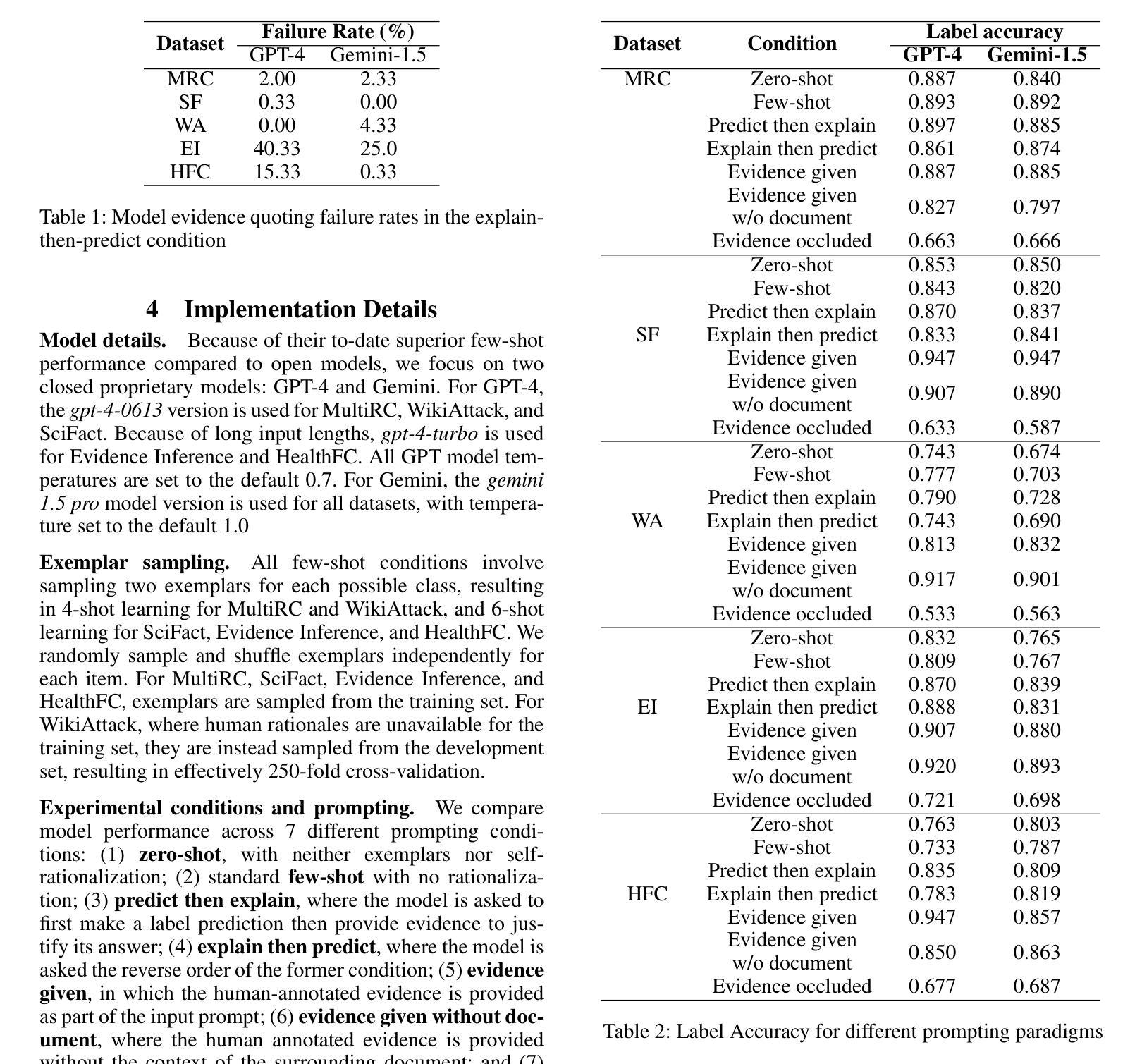
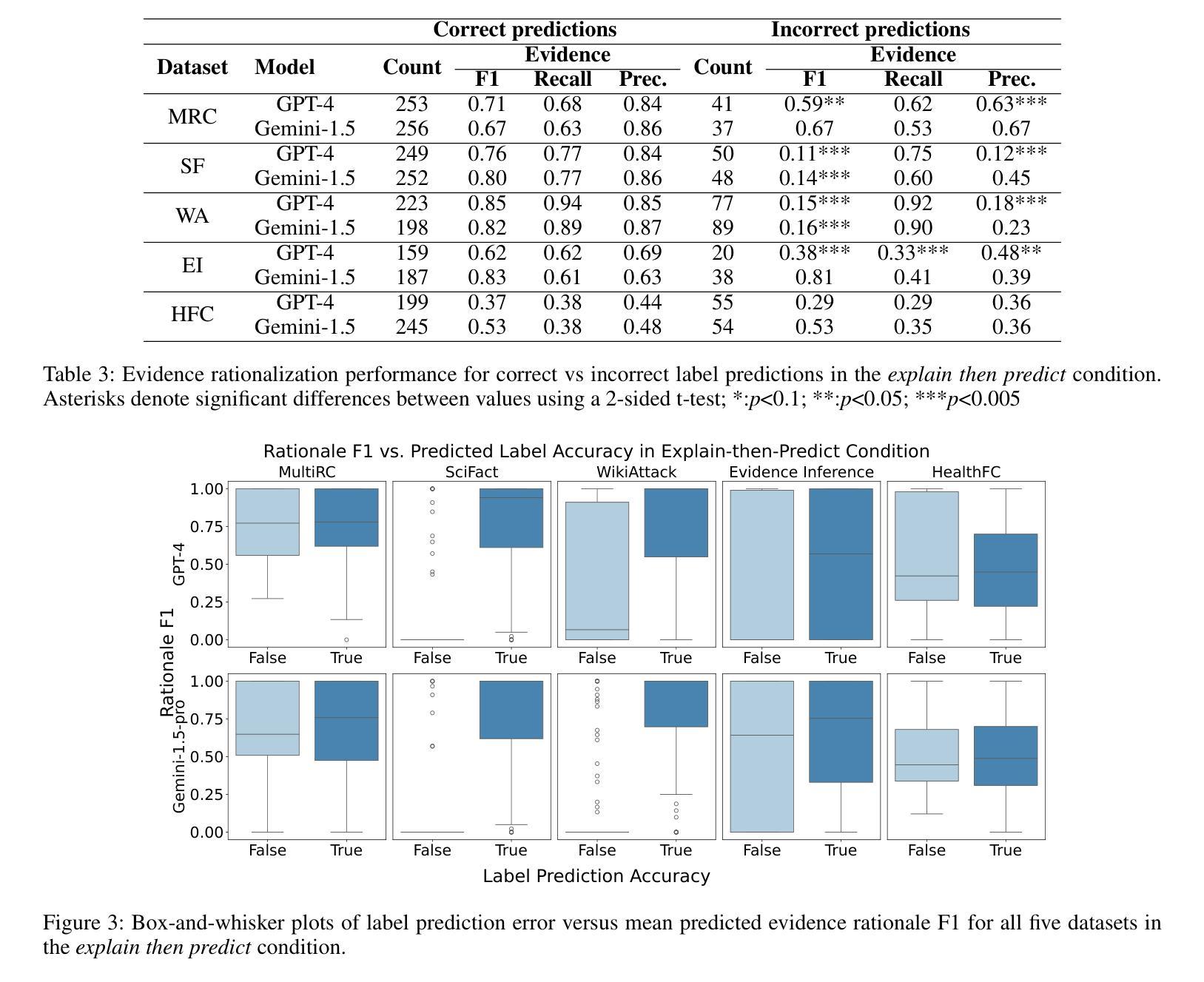
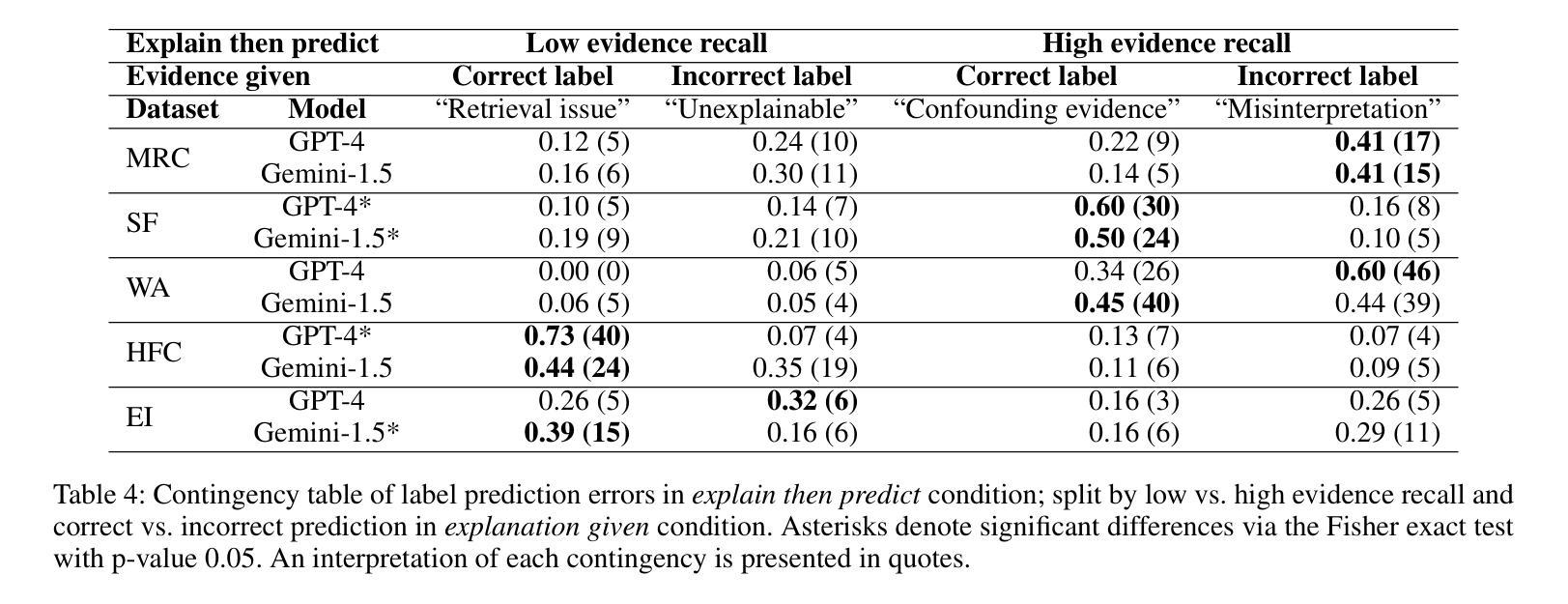
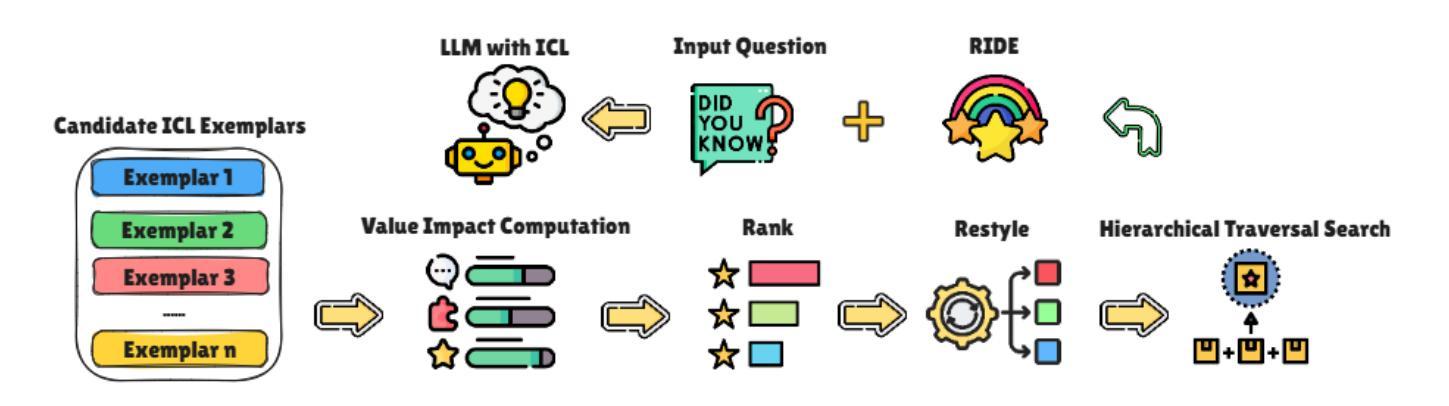
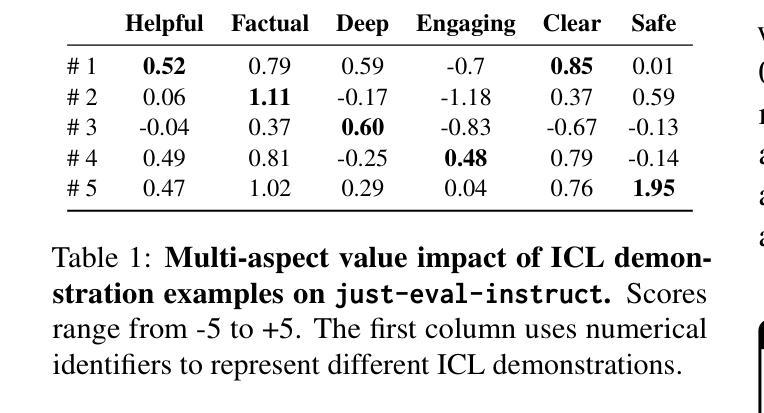
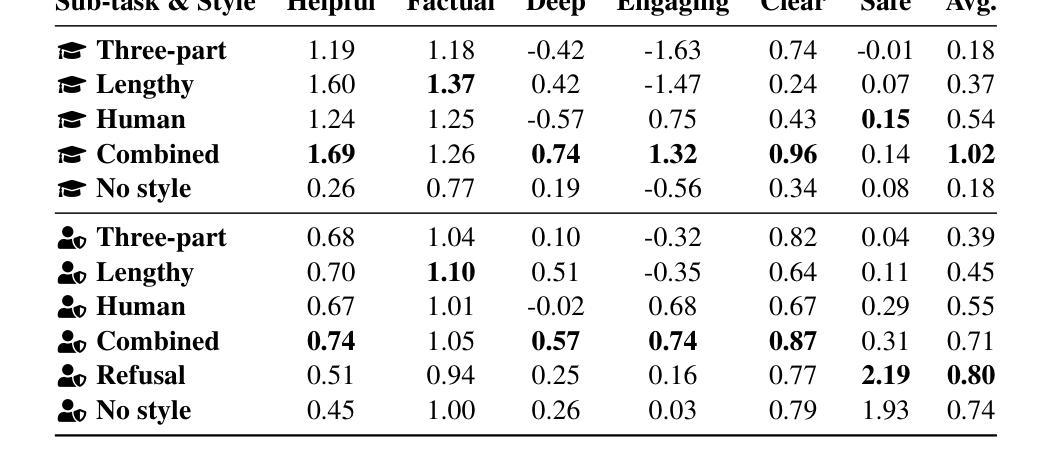
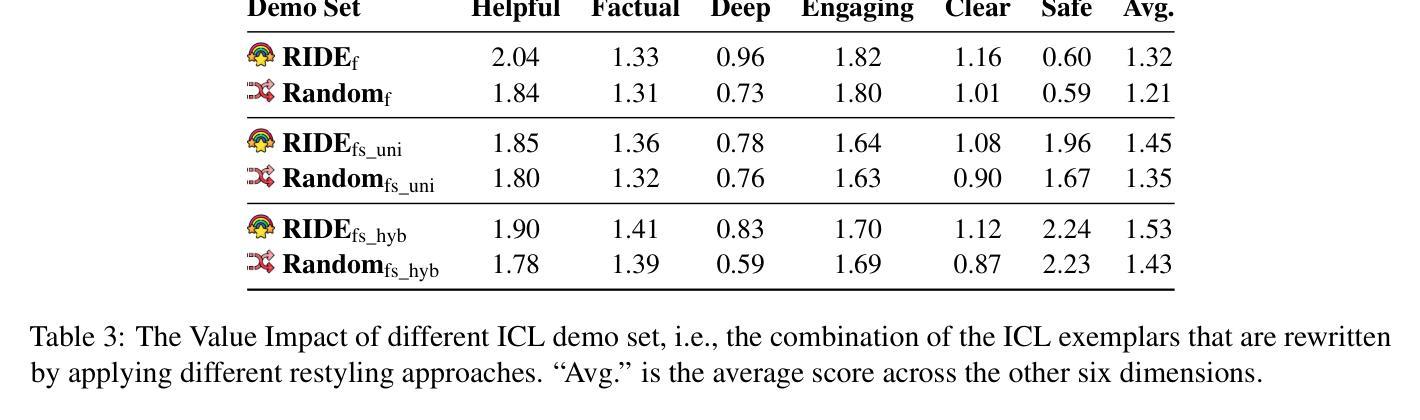
RIDE: Enhancing Large Language Model Alignment through Restyled In-Context Learning Demonstration Exemplars
Authors:Yuncheng Hua, Lizhen Qu, Zhuang Li, Hao Xue, Flora D. Salim, Gholamreza Haffari
Alignment tuning is crucial for ensuring large language models (LLMs) behave ethically and helpfully. Current alignment approaches require high-quality annotations and significant training resources. This paper proposes a low-cost, tuning-free method using in-context learning (ICL) to enhance LLM alignment. Through an analysis of high-quality ICL demos, we identified style as a key factor influencing LLM alignment capabilities and explicitly restyled ICL exemplars based on this stylistic framework. Additionally, we combined the restyled demos to achieve a balance between the two conflicting aspects of LLM alignment–factuality and safety. We packaged the restyled examples as prompts to trigger few-shot learning, improving LLM alignment. Compared to the best baseline approach, with an average score of 5.00 as the maximum, our method achieves a maximum 0.10 increase on the Alpaca task (from 4.50 to 4.60), a 0.22 enhancement on the Just-eval benchmark (from 4.34 to 4.56), and a maximum improvement of 0.32 (from 3.53 to 3.85) on the MT-Bench dataset. We release the code and data at https://github.com/AnonymousCode-ComputerScience/RIDE.
对齐调整对于确保大型语言模型(LLM)以伦理和有帮助的方式行为至关重要。当前的对齐方法需要高质量标注和大量的训练资源。本文提出了一种低成本、无需调整的方法,使用上下文学习(ICL)来增强LLM的对齐。通过对高质量ICL演示内容的分析,我们确定了风格是影响LLM对齐能力的关键因素,并基于此风格框架明确地对ICL示例进行了重新设计。此外,我们将重新设计的演示内容相结合,以实现LLM对齐的两个方面之间的平衡——事实性和安全性。我们将重新设计的示例打包为提示,以触发少量学习,提高LLM的对齐能力。与最佳基线方法相比(最高平均得分为5.00),我们的方法在Alpaca任务上最高得分增加了0.10(从4.50到4.60),在Just-eval基准测试上提高了0.22(从4.34到4.56),在MT-Bench数据集上最高提高了0.32(从3.53到3.85)。我们在https://github.com/AnonymousCode-ComputerScience/RIDE上发布了代码和数据。
论文及项目相关链接
PDF 38 pages, 2 figures, 20 tables; The paper is under review in ARR
Summary
本论文提出了一种低成本、无需调优的方法,利用上下文学习(ICL)技术提升大型语言模型(LLM)的对齐性能。研究通过高质量ICL演示分析,发现风格是影响LLM对齐能力的重要因素,并据此重新设计了ICL范例。结合这些重新设计的范例,在LLM对齐的两个方面——真实性和安全性之间取得了平衡。最终通过触发少样本学习提升了LLM的对齐效果。
Key Takeaways
- 论文强调大型语言模型(LLM)的伦理和实用对齐的重要性,并提出一种低成本的无需调优的方法。
- 利用上下文学习(ICL)技术,通过高质量示范分析发现风格是影响LLM对齐的关键因素。
- 论文重新设计了ICL范例,并基于风格框架进行展示。
- 通过结合重新设计的范例,在LLM对齐的两个方面——真实性和安全性之间取得平衡。
- 论文使用这些重新设计的例子作为提示来触发少样本学习,提高了LLM的对齐效果。
- 与最佳基线方法相比,论文提出的方法在Alpaca任务、Just-eval基准测试和MT-Bench数据集上均有所改进。
点此查看论文截图

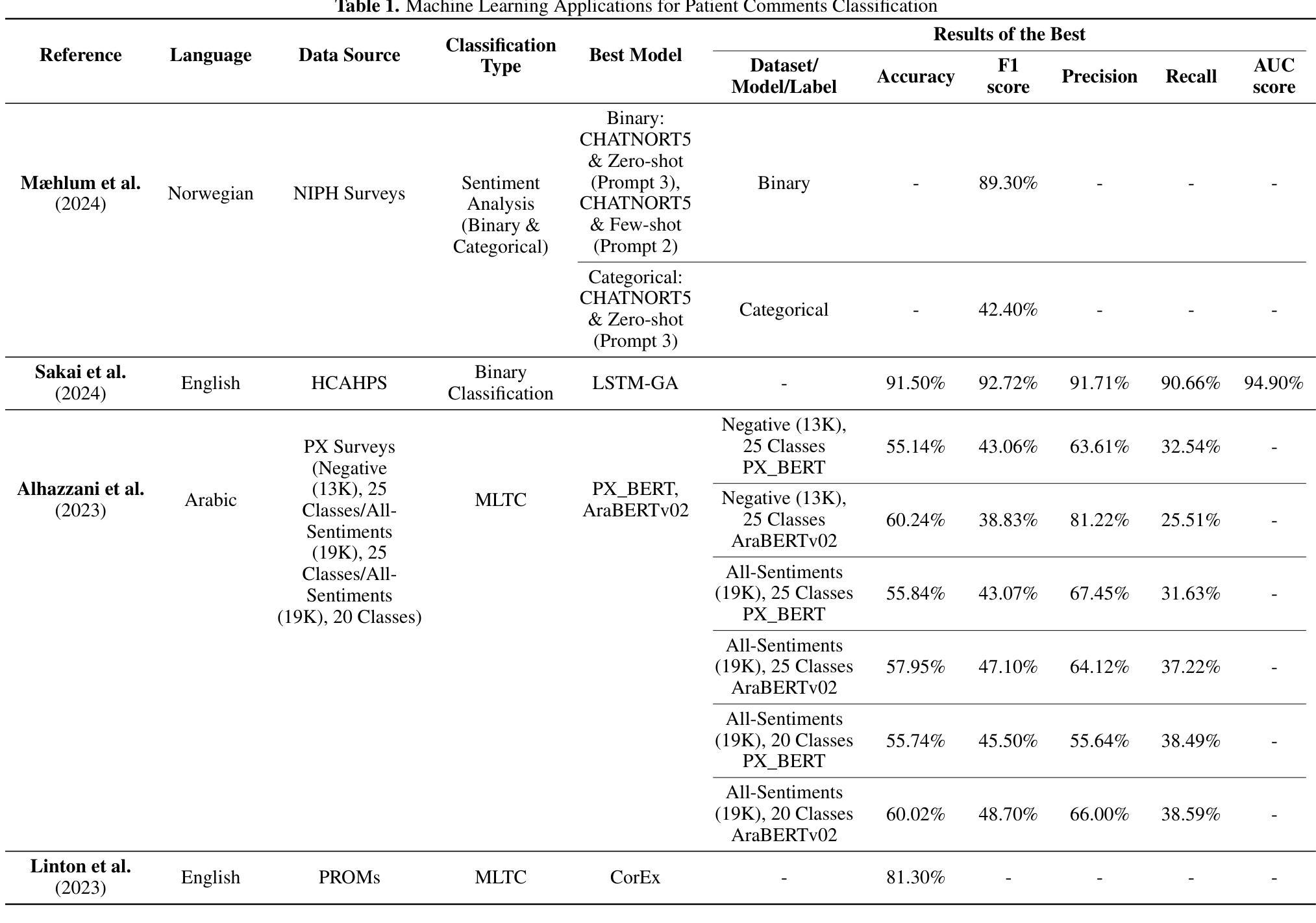
Large Language Models for Patient Comments Multi-Label Classification
Authors:Hajar Sakai, Sarah S. Lam, Mohammadsadegh Mikaeili, Joshua Bosire, Franziska Jovin
Patient experience and care quality are crucial for a hospital’s sustainability and reputation. The analysis of patient feedback offers valuable insight into patient satisfaction and outcomes. However, the unstructured nature of these comments poses challenges for traditional machine learning methods following a supervised learning paradigm. This is due to the unavailability of labeled data and the nuances these texts encompass. This research explores leveraging Large Language Models (LLMs) in conducting Multi-label Text Classification (MLTC) of inpatient comments shared after a stay in the hospital. GPT-4 Turbo was leveraged to conduct the classification. However, given the sensitive nature of patients’ comments, a security layer is introduced before feeding the data to the LLM through a Protected Health Information (PHI) detection framework, which ensures patients’ de-identification. Additionally, using the prompt engineering framework, zero-shot learning, in-context learning, and chain-of-thought prompting were experimented with. Results demonstrate that GPT-4 Turbo, whether following a zero-shot or few-shot setting, outperforms traditional methods and Pre-trained Language Models (PLMs) and achieves the highest overall performance with an F1-score of 76.12% and a weighted F1-score of 73.61% followed closely by the few-shot learning results. Subsequently, the results’ association with other patient experience structured variables (e.g., rating) was conducted. The study enhances MLTC through the application of LLMs, offering healthcare practitioners an efficient method to gain deeper insights into patient feedback and deliver prompt, appropriate responses.
患者体验和护理质量对于医院的可持续性和声誉至关重要。患者反馈的分析为患者满意度和结果提供了宝贵的见解。然而,这些评论的非结构化特性给传统机器学习方法带来了挑战,尤其是在遵循监督学习范式的情况下。这是因为缺乏标记数据以及这些文本中蕴含的细节差异。本研究探讨了利用大型语言模型(LLM)进行住院患者评论的多标签文本分类(MLTC)。GPT-4 Turbo被用于进行分类。然而,鉴于患者评论的敏感性,在通过PHI检测框架将数据输入LLM之前,引入了一个安全层,以确保患者的匿名性。此外,通过提示工程框架,实验了零样本学习、上下文学习和链式思维提示。结果表明,无论是在零样本还是小样设置下,GPT-4 Turbo都优于传统方法和预训练语言模型(PLM),并在最高总体性能上达到了76.12%的F1分数和73.61%的加权F1分数,其次是少数样本学习的结果。随后,将结果与患者体验的其他结构化变量(如评分)进行了关联分析。该研究通过应用LLM增强了MLTC,为医疗从业者提供了一种有效的方法,可以更深入地了解患者反馈并做出及时、适当的回应。
论文及项目相关链接
Summary
本文探讨了利用大型语言模型(LLMs)进行多标签文本分类(MLTC)分析住院患者评论的可行性。通过GPT-4 Turbo进行分类,并在馈送数据给LLM之前引入了保护健康信息(PHI)检测框架,确保患者去标识化。实验表明,GPT-4 Turbo在零样本和少样本设置下均优于传统方法和预训练语言模型(PLMs),最高性能达到F1分数为76.12%,加权F1分数为73.61%。该研究提高了通过LLMs进行MLTC的能力,为医疗从业者提供了一种深入了解患者反馈和及时、恰当地回应患者反馈的有效方法。
Key Takeaways
- 患者体验和护理质量对医院的可持续性和声誉至关重要。
- 患者反馈分析为患者满意度和结果提供了宝贵的见解。
- 大型语言模型(LLMs)在处理住院患者评论的多标签文本分类(MLTC)方面具有潜力。
- GPT-4 Turbo在分类中的表现优于传统方法和预训练语言模型(PLMs)。
- 在处理患者评论时,引入了保护健康信息(PHI)检测框架以确保患者去标识化。
- 通过实验,展示了零样本学习和少样本学习在LLMs中的有效性。
点此查看论文截图

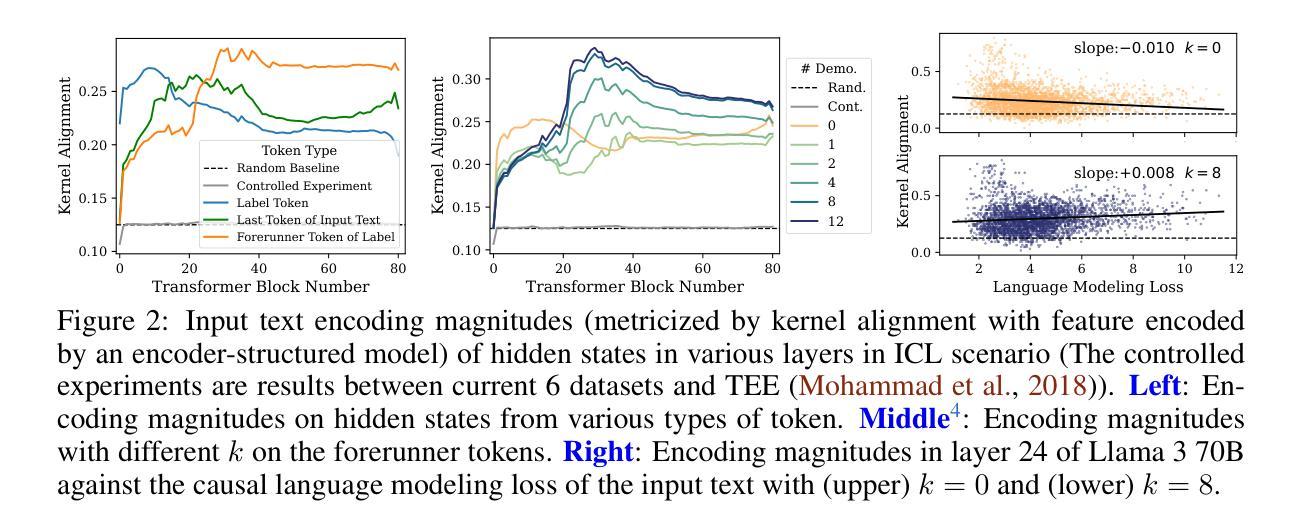
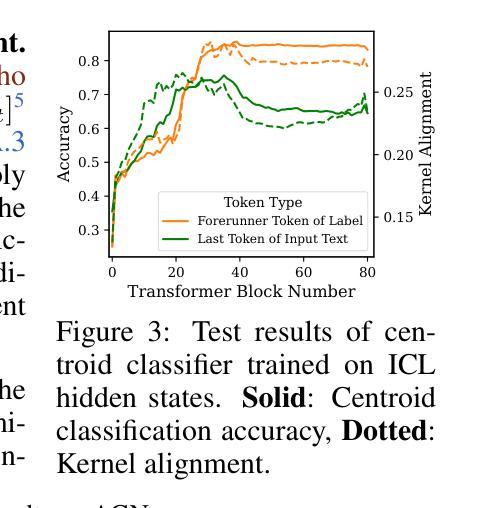
Revisiting In-context Learning Inference Circuit in Large Language Models
Authors:Hakaze Cho, Mariko Kato, Yoshihiro Sakai, Naoya Inoue
In-context Learning (ICL) is an emerging few-shot learning paradigm on Language Models (LMs) with inner mechanisms un-explored. There are already existing works describing the inner processing of ICL, while they struggle to capture all the inference phenomena in large language models. Therefore, this paper proposes a comprehensive circuit to model the inference dynamics and try to explain the observed phenomena of ICL. In detail, we divide ICL inference into 3 major operations: (1) Input Text Encode: LMs encode every input text (in the demonstrations and queries) into linear representation in the hidden states with sufficient information to solve ICL tasks. (2) Semantics Merge: LMs merge the encoded representations of demonstrations with their corresponding label tokens to produce joint representations of labels and demonstrations. (3) Feature Retrieval and Copy: LMs search the joint representations of demonstrations similar to the query representation on a task subspace, and copy the searched representations into the query. Then, language model heads capture these copied label representations to a certain extent and decode them into predicted labels. Through careful measurements, the proposed inference circuit successfully captures and unifies many fragmented phenomena observed during the ICL process, making it a comprehensive and practical explanation of the ICL inference process. Moreover, ablation analysis by disabling the proposed steps seriously damages the ICL performance, suggesting the proposed inference circuit is a dominating mechanism. Additionally, we confirm and list some bypass mechanisms that solve ICL tasks in parallel with the proposed circuit.
上下文学习(ICL)是语言模型(LM)上新兴的一种小样本学习范式,其内部机制尚未被探索。虽然已有工作描述了ICL的内部处理过程,但它们很难捕捉大型语言模型中的所有推理现象。因此,本文提出了一个综合电路来模拟推理动态,并试图解释观察到的ICL现象。具体来说,我们将ICL推理过程分为3个主要操作:(1)输入文本编码:语言模型将每个输入文本(在演示和查询中)编码成隐藏状态中的线性表示,其中包含足够的信息来解决ICL任务。(2)语义合并:语言模型将演示的编码表示与其相应的标签标记合并,以产生标签和演示的联合表示。(3)特征检索和复制:语言模型会在任务子空间中搜索与查询表示相似的演示联合表示,并将所搜索的表示复制到查询中。然后,语言模型头部会捕获这些复制的标签表示,并将其解码为预测的标签。通过精心测量,所提出的推理电路成功地捕获并统一了ICL过程中观察到的许多碎片化现象,是对ICL推理过程的全面实用解释。而且,通过禁用所提出的步骤进行的分析表明,这严重损害了ICL的性能,这表明所提出的推理电路是主导机制。此外,我们确认并列出了一些与所提出的电路并行解决ICL任务的旁路机制。
论文及项目相关链接
PDF 37 pages, 41 figures, 8 tables. ICLR 2025 Accepted. Camera-ready Version
Summary
本文探讨了新兴的在语言模型中的少量学习模式——上下文学习(ICL)。文章提出了一种全面的电路模型,旨在模拟ICL的推理过程,并将其分为三个主要操作:输入文本编码、语义合并和特征检索与复制。此模型成功捕捉并统一了ICL过程中的碎片化现象,提供了对其过程的全面而实用的解释。此外,通过逐步拆解分析,验证了该推理电路在ICL中的核心作用。同时,也确认了其他并行解决ICL任务的旁路机制。
Key Takeaways
- 上下文学习(ICL)是一种新兴的语言模型中的少量学习模式,其内部机制尚未被完全探索。
- 现有研究在描述ICL的内部处理方面已取得一定成果,但仍难以全面捕捉大型语言模型的推理现象。
- 本文提出了一个全面的电路模型,用以模拟ICL的推理过程,该过程分为三个主要操作:输入文本编码、语义合并和特征检索与复制。
- 该电路模型成功捕捉并统一了ICL过程中的碎片化现象,为理解这一过程提供了全面而实用的视角。
- 通过逐步拆解分析,验证了该推理电路在ICL中的核心作用。
- 除了主要的推理电路外,还存在其他并行解决ICL任务的旁路机制。
- 通过对ICL的深入剖析,本文为语言模型的进一步优化和改进提供了理论基础。
点此查看论文截图



LLM4TS: Aligning Pre-Trained LLMs as Data-Efficient Time-Series Forecasters
Authors:Ching Chang, Wei-Yao Wang, Wen-Chih Peng, Tien-Fu Chen
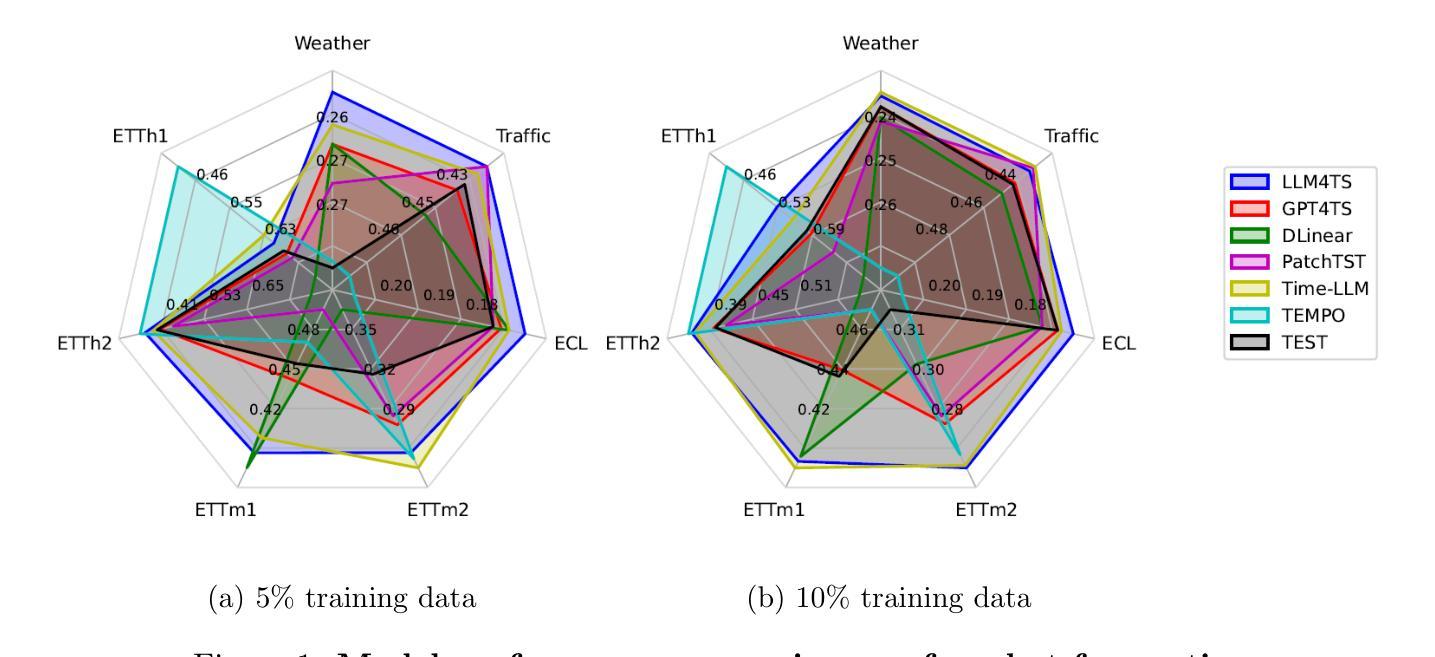
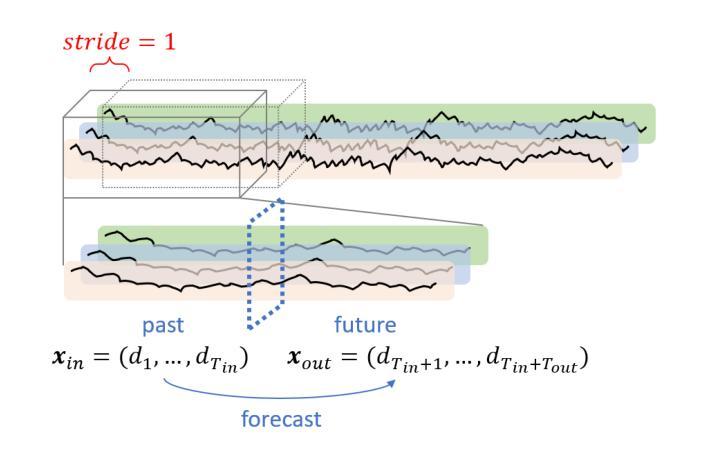
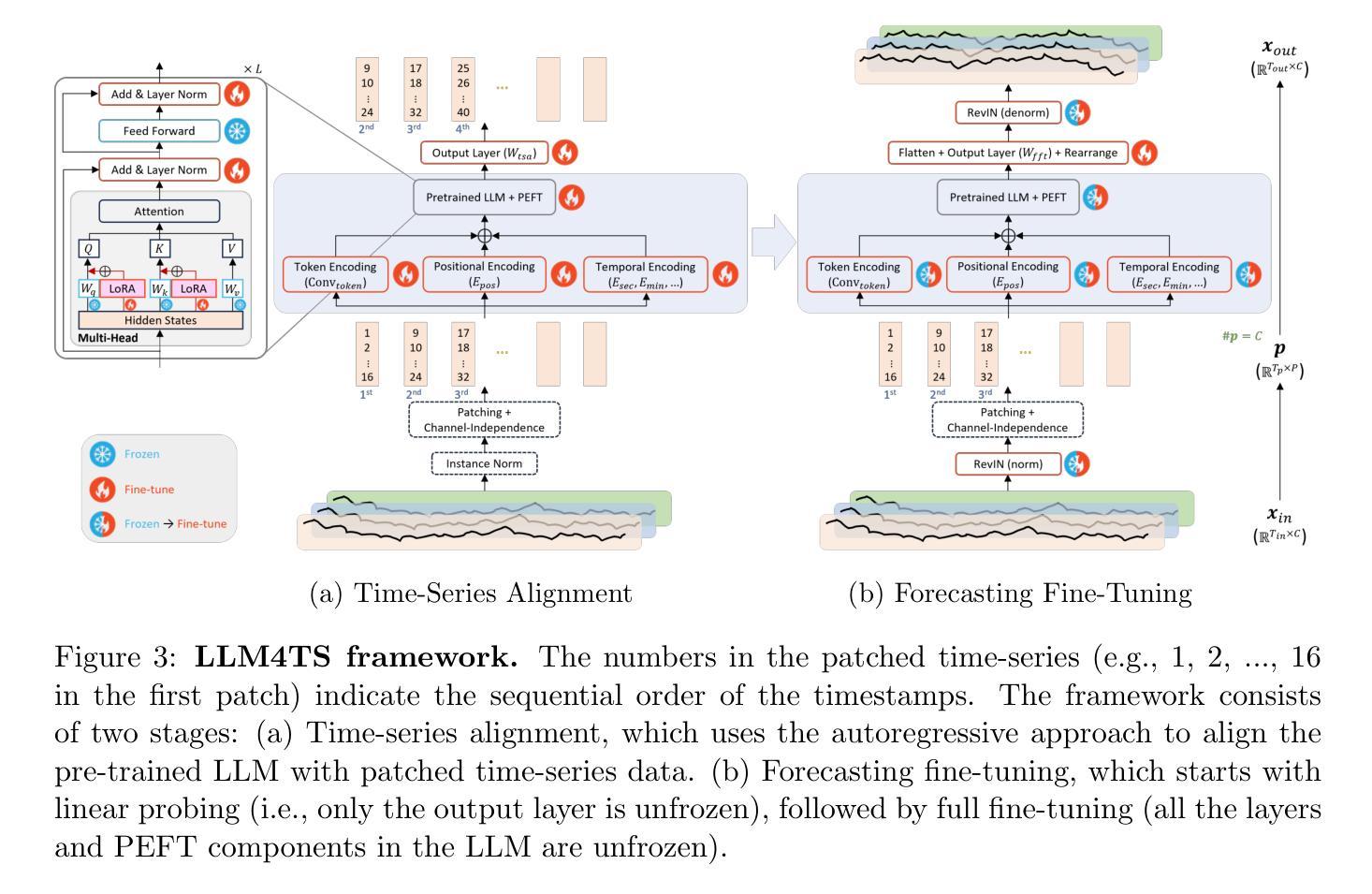
Multivariate time-series forecasting is vital in various domains, e.g., economic planning and weather prediction. Deep train-from-scratch models have exhibited effective performance yet require large amounts of data, which limits real-world applicability. Recently, researchers have leveraged the representation learning transferability of pre-trained Large Language Models (LLMs) to handle limited non-linguistic datasets effectively. However, incorporating LLMs with time-series data presents challenges of limited adaptation due to different compositions between time-series and linguistic data, and the inability to process multi-scale temporal information. To tackle these challenges, we propose LLM4TS, a framework for time-series forecasting with pre-trained LLMs. LLM4TS consists of a two-stage fine-tuning strategy: the time-series alignment stage to align LLMs with the nuances of time-series data, and the forecasting fine-tuning stage for downstream time-series forecasting tasks. Furthermore, our framework features a novel two-level aggregation method that integrates multi-scale temporal data within pre-trained LLMs, enhancing their ability to interpret time-specific information. In experiments across 7 time-series forecasting datasets, LLM4TS is superior to existing state-of-the-art methods compared with trained-from-scratch models in full-shot scenarios, and also achieves the highest rank in few-shot scenarios. In addition, evaluations compared with different unsupervised representation learning approaches highlight LLM4TS’s effectiveness with representation learning in forecasting tasks. Ablation studies further validate each component’s contribution to LLM4TS and underscore the essential role of utilizing LLM’s pre-trained weights for optimal performance. The code is available at https://github.com/blacksnail789521/LLM4TS.
多元时间序列预测在经济规划、天气预报等领域具有至关重要的作用。虽然深度从头训练模型表现出有效的性能,但它们需要大量的数据,从而限制了其在现实世界中的应用。最近,研究者们利用预训练的大型语言模型(LLMs)的表示学习迁移能力,有效地处理有限的非语言数据集。然而,将LLMs与时间序列数据相结合面临着有限的适应性挑战,这是由于时间序列数据和语言数据之间的不同组成以及无法处理多尺度时间信息。为了应对这些挑战,我们提出了LLM4TS,这是一个利用预训练LLMs进行时间序列预测的框架。LLM4TS由两阶段微调策略组成:时间序列对齐阶段,使LLMs与时间序列数据的细微差别对齐;以及用于下游时间序列预测任务的预测微调阶段。此外,我们的框架具有新颖的两级聚合方法,能够在预训练的LLMs内集成多尺度时间数据,增强它们解释时间特定信息的能力。在7个时间序列预测数据集上的实验表明,LLM4TS在全程场景中的表现优于现有的最先进方法,并且在小样本场景中获得了最高排名。此外,与不同的无监督表示学习方法进行的评估突出了LLM4TS在预测任务中表示学习的有效性。消融研究进一步验证了LLM4TS每个组件的贡献,并强调了利用LLM的预训练权重对于实现最佳性能的重要作用。代码可在https://github.com/blacksnail789521/LLM4TS上找到。
论文及项目相关链接
PDF Accepted for publication in ACM Transactions on Intelligent Systems and Technology (TIST) 2025. The final published version will be available at https://doi.org/10.1145/3719207
Summary
本文介绍了LLM4TS框架在多变量时间序列预测中的应用。针对预训练的大型语言模型(LLMs)在有限数据下处理非语言数据集的有效性和局限性,提出一种包含两阶段微调策略的新框架。实验证明,在多种时间序列预测数据集上,LLM4TS优于现有方法,特别是针对训练自基础模型的方法以及无监督表示学习方法时。同时提出一个多层次数据聚合方法,提高了预训练LLMs解释时间序列特定信息的能力。
Key Takeaways
- LLM4TS是一个基于预训练的大型语言模型(LLMs)的时间序列预测框架。
- 该框架采用两阶段微调策略,包括时间序列对齐和预测微调阶段。
- LLM4TS框架使用多层次数据聚合方法,可以处理多尺度时间序列数据。
- 在多个数据集上的实验表明,LLM4TS优于其他方法,特别是处理少样本数据场景时。相较于从头开始训练的模型,其性能更加优越。
点此查看论文截图