⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-22 更新
A Racing Dataset and Baseline Model for Track Detection in Autonomous Racing
Authors:Shreya Ghosh, Yi-Huan Chen, Ching-Hsiang Huang, Abu Shafin Mohammad Mahdee Jameel, Chien Chou Ho, Aly El Gamal, Samuel Labi
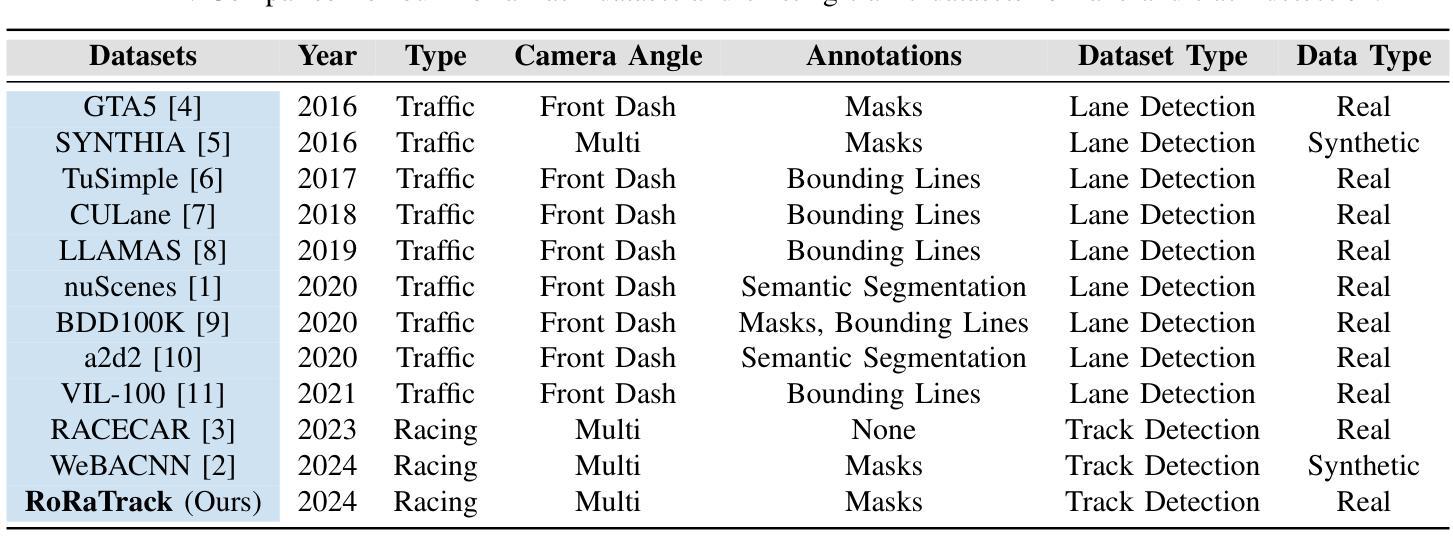
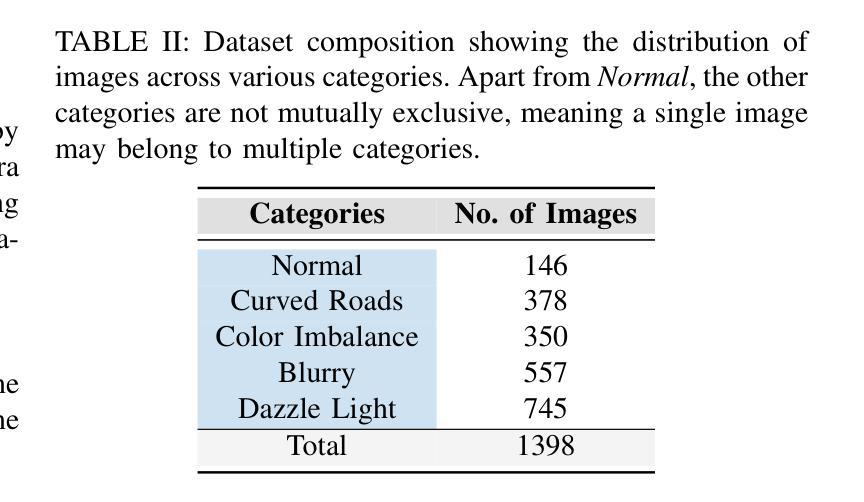
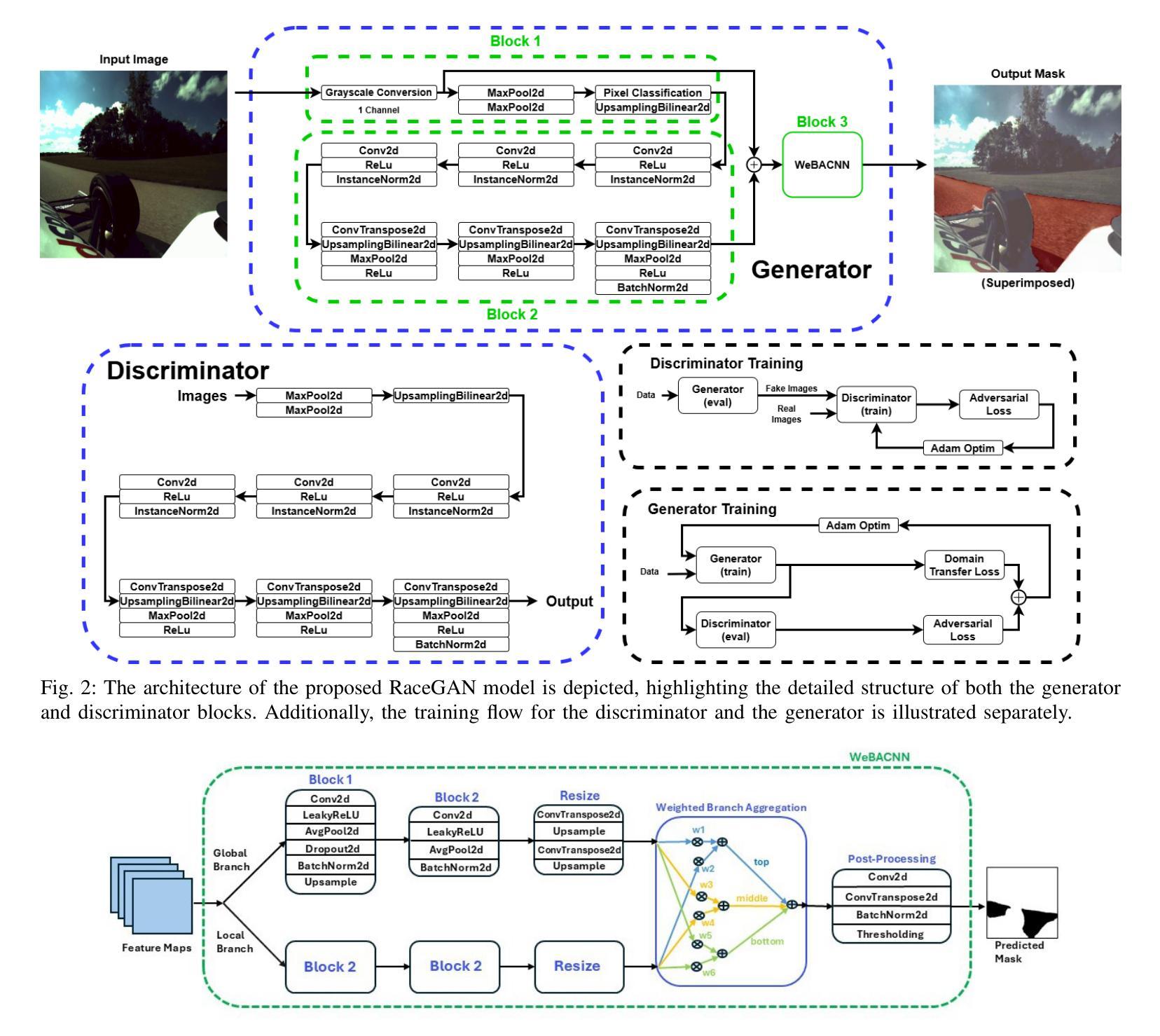
A significant challenge in racing-related research is the lack of publicly available datasets containing raw images with corresponding annotations for the downstream task. In this paper, we introduce RoRaTrack, a novel dataset that contains annotated multi-camera image data from racing scenarios for track detection. The data is collected on a Dallara AV-21 at a racing circuit in Indiana, in collaboration with the Indy Autonomous Challenge (IAC). RoRaTrack addresses common problems such as blurriness due to high speed, color inversion from the camera, and absence of lane markings on the track. Consequently, we propose RaceGAN, a baseline model based on a Generative Adversarial Network (GAN) that effectively addresses these challenges. The proposed model demonstrates superior performance compared to current state-of-the-art machine learning models in track detection. The dataset and code for this work are available at github.com/RaceGAN.
在赛车相关研究中的一个重大挑战是缺乏公开可用的数据集,这些数据集包含用于下游任务的原始图像及其相应注释。在本文中,我们介绍了RoRaTrack数据集,这是一个包含赛车场景的多相机图像数据的新数据集,用于车道检测。数据是在印第安纳州的一个赛车场上,与Indy Autonomous Challenge (IAC)合作,使用Dallara AV-21收集的。RoRaTrack解决了由于高速导致的模糊、相机颜色反转以及赛道上没有车道标记等常见问题。因此,我们提出了基于生成对抗网络(GAN)的RaceGAN基线模型,该模型有效地解决了这些挑战。与当前最先进的机器学习模型相比,所提出模型在车道检测方面表现出卓越性能。该工作的数据集和代码可在github.com/RaceGAN上找到。
论文及项目相关链接
PDF Currently Under Review
Summary
本文介绍了一项针对赛车相关研究的挑战,即缺乏公开可用的带有相应注释的原始图像数据集以供下游任务使用。为此,本文引入了RoRaTrack数据集,其中包含来自赛车场景的带注释的多相机图像数据,用于车道检测。该数据集是在印第安纳州的一个赛车场与Indy Autonomous Challenge (IAC)合作收集的。RoRaTrack解决了因高速导致的模糊、相机颜色反转以及赛道上无车道标记等问题。为此,我们提出了基于生成对抗网络(GAN)的RaceGAN基线模型,该模型有效地解决了这些挑战。与当前先进的机器学习模型相比,该模型在车道检测方面表现出卓越的性能。
Key Takeaways
- 缺乏公开可用的带有注释的原始图像数据集是赛车相关研究的一大挑战。
- 介绍了RoRaTrack数据集,该数据集包含来自赛车场景的多相机图像数据,用于车道检测任务。
- RoRaTrack数据集解决了高速模糊、相机颜色反转和赛道上无车道标记等常见问题。
- 提出了基于生成对抗网络(GAN)的RaceGAN模型作为解决这些挑战的基线模型。
- RaceGAN模型在车道检测任务上表现出卓越的性能,优于当前先进的机器学习模型。
- RoRaTrack数据集和相关的代码可以在GitHub上找到。
点此查看论文截图



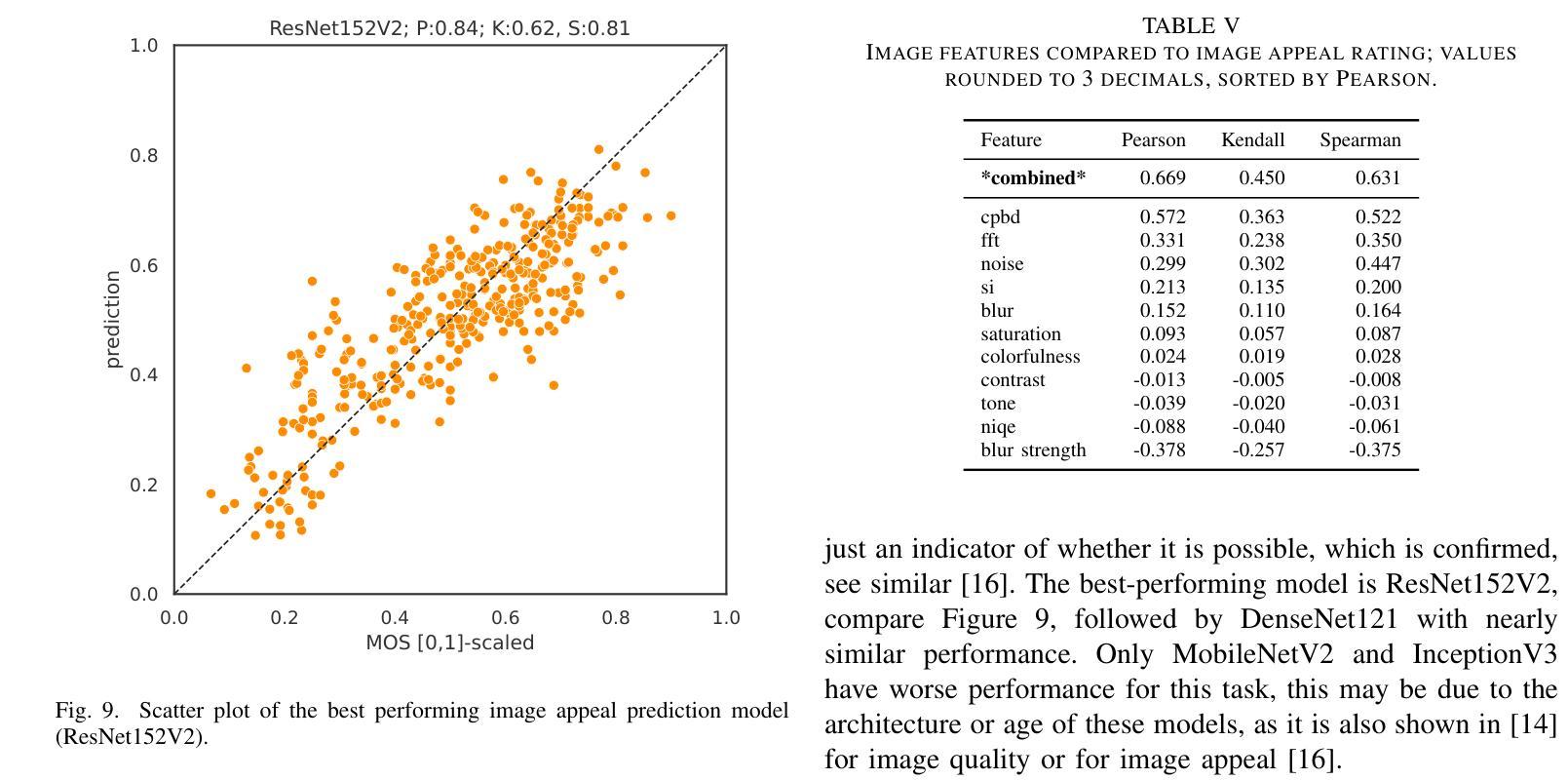
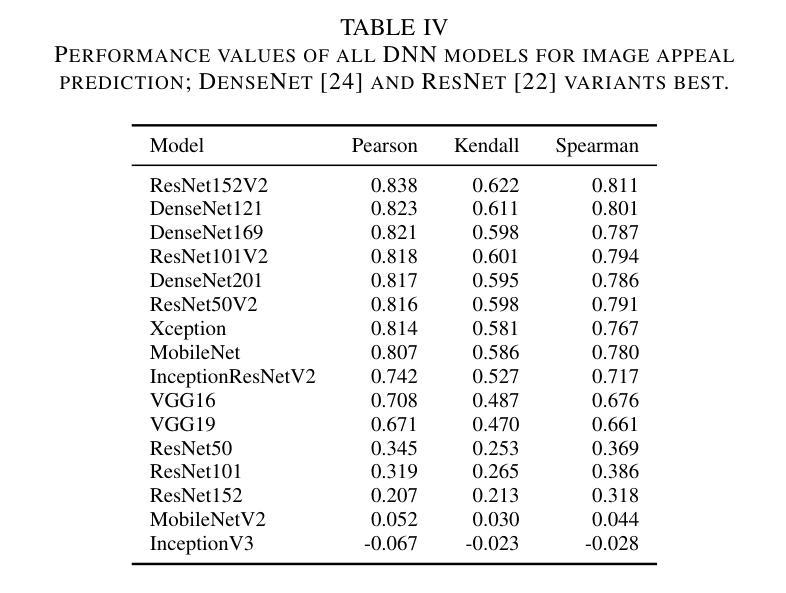
Appeal prediction for AI up-scaled Images
Authors:Steve Göring, Rasmus Merten, Alexander Raake
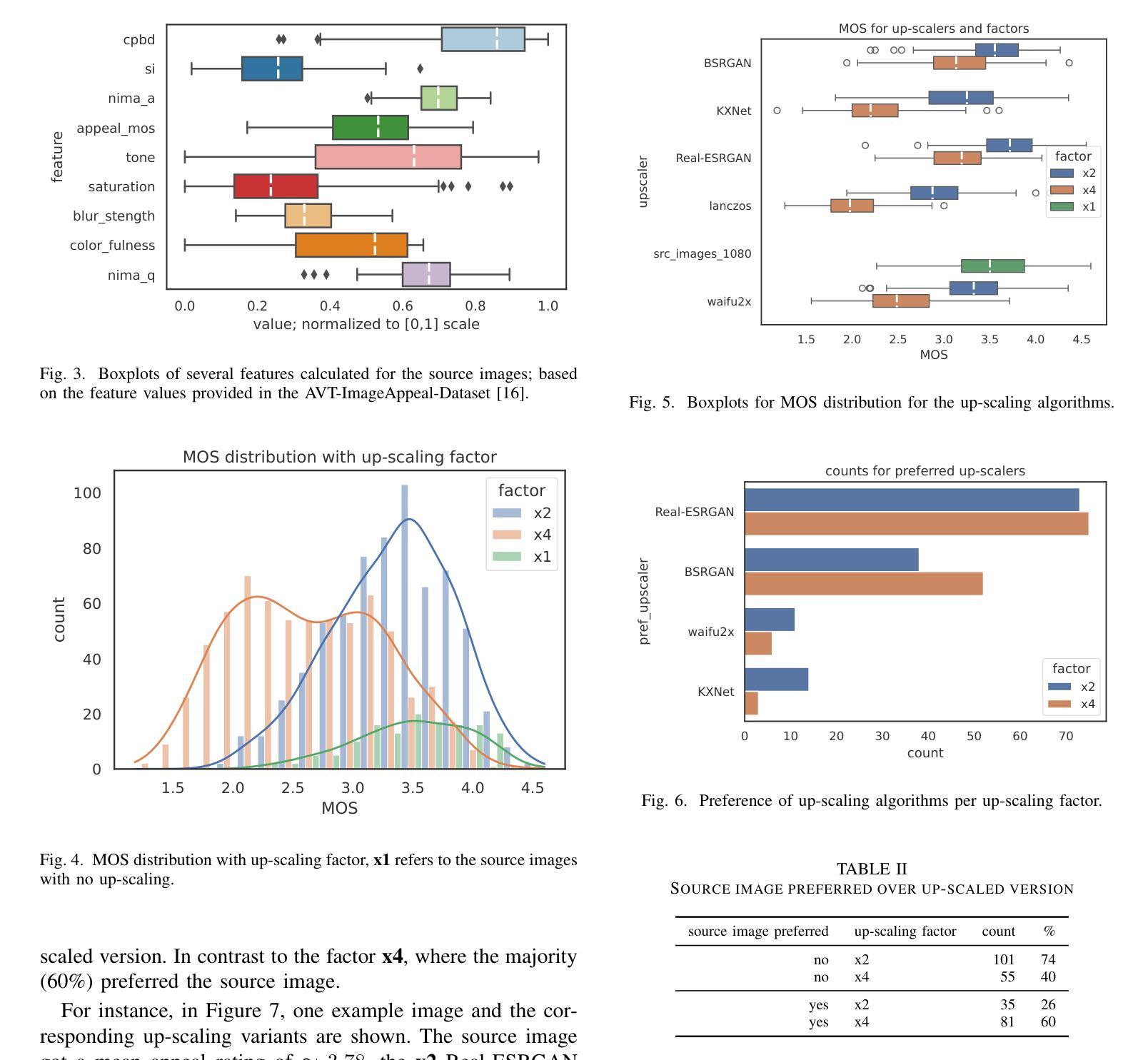
DNN- or AI-based up-scaling algorithms are gaining in popularity due to the improvements in machine learning. Various up-scaling models using CNNs, GANs or mixed approaches have been published. The majority of models are evaluated using PSRN and SSIM or only a few example images. However, a performance evaluation with a wide range of real-world images and subjective evaluation is missing, which we tackle in the following paper. For this reason, we describe our developed dataset, which uses 136 base images and five different up-scaling methods, namely Real-ESRGAN, BSRGAN, waifu2x, KXNet, and Lanczos. Overall the dataset consists of 1496 annotated images. The labeling of our dataset focused on image appeal and has been performed using crowd-sourcing employing our open-source tool AVRate Voyager. We evaluate the appeal of the different methods, and the results indicate that Real-ESRGAN and BSRGAN are the best. Furthermore, we train a DNN to detect which up-scaling method has been used, the trained models have a good overall performance in our evaluation. In addition to this, we evaluate state-of-the-art image appeal and quality models, here none of the models showed a high prediction performance, therefore we also trained two own approaches. The first uses transfer learning and has the best performance, and the second model uses signal-based features and a random forest model with good overall performance. We share the data and implementation to allow further research in the context of open science.
基于深度神经网络(DNN)或人工智能(AI)的放大算法因机器学习技术的进步而越来越受欢迎。已经发布了使用卷积神经网络(CNN)、生成对抗网络(GAN)或混合方法的各种放大模型。大多数模型使用PSNR和SSIM或仅使用少数示例图像进行评估。然而,缺乏使用大量真实世界图像和主观评估的性能评估,我们将在下一篇论文中解决这一问题。因此,我们描述了我们开发的数据集,该数据集使用136张基础图像和五种不同的放大方法,即Real-ESRGAN、BSRGAN、waifu2x、KXNet和Lanczos。总体而言,数据集包含1496张注释图像。我们数据集的重点是图像吸引力,并通过使用我们的开源工具AVRate Voyager进行众包标注。我们评估了不同方法的吸引力,结果表明Real-ESRGAN和BSRGAN表现最好。此外,我们训练了一个深度神经网络来检测使用了哪种放大方法,训练模型在我们的评估中表现良好。除此之外,我们还评估了最先进的图像吸引力和质量模型,这里没有一个模型表现出较高的预测性能,因此我们也训练了自己的两种策略。第一种使用迁移学习,表现最佳;第二种模型使用基于信号的特征和随机森林模型,总体表现良好。我们分享数据和实现,以允许在开放科学的背景下进行进一步的研究。
论文及项目相关链接
Summary
深度学习或人工智能为基础的放大算法因机器学习技术的进步而越来越受欢迎。文章针对现存放大模型缺乏全面真实图像与主观评估的问题,提出一种全新的数据集用于评估模型性能。数据集包含使用五种不同放大方法的图像,包括Real-ESRGAN、BSRGAN等。通过众包方式利用开源工具AVRate Voyager进行标注,重点评估图像吸引力。结果显示Real-ESRGAN和BSRGAN表现最佳。此外,训练深度神经网络检测放大方法,评估现有图像吸引力和质量模型表现欠佳,故训练两种新模型。为公开科学提供数据共享和实施方法,以便进一步研究。
Key Takeaways
- 基于深度神经网络或人工智能的放大算法日益普及。
- 现存放大模型的评价方式主要是使用PSRN和SSIM或少数示例图像,缺乏全面真实图像和主观评估。
- 开发了一种新的数据集用于评估放大模型的性能,包含多种放大方法和大量标注图像。
- 数据集的标注侧重于图像吸引力,采用众包方式并利用开源工具进行。
- Real-ESRGAN和BSRGAN在图像吸引力方面表现最佳。
- 训练深度神经网络检测放大方法,对现有模型的性能进行评估。
点此查看论文截图






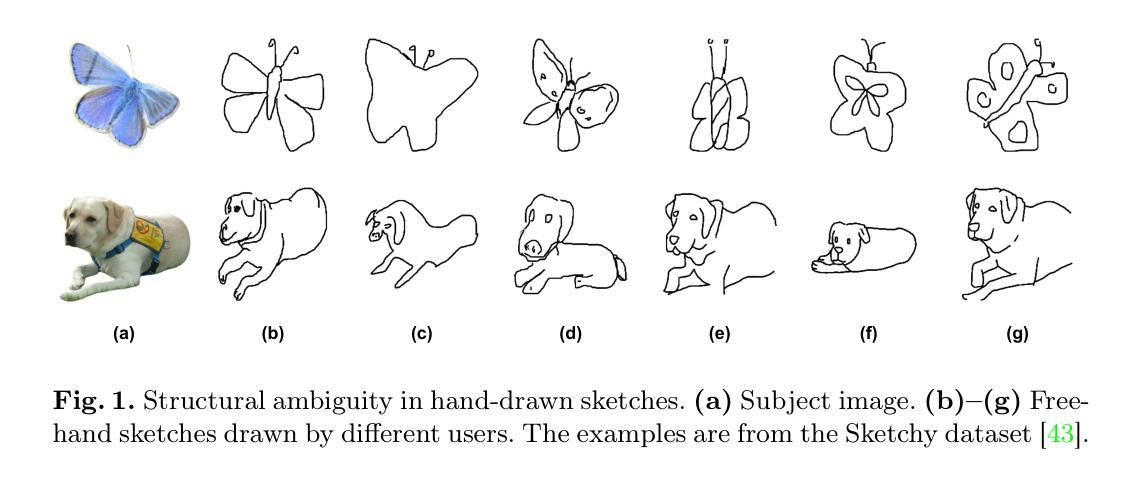
d-Sketch: Improving Visual Fidelity of Sketch-to-Image Translation with Pretrained Latent Diffusion Models without Retraining
Authors:Prasun Roy, Saumik Bhattacharya, Subhankar Ghosh, Umapada Pal, Michael Blumenstein
Structural guidance in an image-to-image translation allows intricate control over the shapes of synthesized images. Generating high-quality realistic images from user-specified rough hand-drawn sketches is one such task that aims to impose a structural constraint on the conditional generation process. While the premise is intriguing for numerous use cases of content creation and academic research, the problem becomes fundamentally challenging due to substantial ambiguities in freehand sketches. Furthermore, balancing the trade-off between shape consistency and realistic generation contributes to additional complexity in the process. Existing approaches based on Generative Adversarial Networks (GANs) generally utilize conditional GANs or GAN inversions, often requiring application-specific data and optimization objectives. The recent introduction of Denoising Diffusion Probabilistic Models (DDPMs) achieves a generational leap for low-level visual attributes in general image synthesis. However, directly retraining a large-scale diffusion model on a domain-specific subtask is often extremely difficult due to demanding computation costs and insufficient data. In this paper, we introduce a technique for sketch-to-image translation by exploiting the feature generalization capabilities of a large-scale diffusion model without retraining. In particular, we use a learnable lightweight mapping network to achieve latent feature translation from source to target domain. Experimental results demonstrate that the proposed method outperforms the existing techniques in qualitative and quantitative benchmarks, allowing high-resolution realistic image synthesis from rough hand-drawn sketches.
图像到图像的翻译中的结构指导允许对合成图像的形状进行精细控制。从用户指定的粗略手绘草图生成高质量逼真图像是一项旨在给条件生成过程施加结构约束的任务。虽然这一前提对于内容创建和学术研究有许多用例而言很有趣,但由于手绘草图存在大量歧义,这个问题从根本上具有挑战性。此外,在形状一致性和现实生成之间取得平衡为过程增加了额外的复杂性。基于生成对抗网络(GANs)的现有方法通常使用条件GAN或GAN反演,通常需要特定于应用程序的数据和优化目标。最近引入的降噪扩散概率模型(DDPM)实现了通用图像合成中低级别视觉属性的生成飞跃。然而,由于计算成本高昂和数据不足,直接在特定子任务上重新训练大规模扩散模型通常极其困难。在本文中,我们介绍了一种利用大规模扩散模型的特性泛化能力来进行草图到图像翻译的技术,而无需重新训练。特别是,我们使用可学习的轻型映射网络来实现从源域到目标域的潜在特征翻译。实验结果表明,所提出的方法在定性和定量基准测试中优于现有技术,允许从粗略的手绘草图中生成高分辨率的逼真图像。
论文及项目相关链接
PDF Accepted in The International Conference on Pattern Recognition (ICPR) 2024
Summary
本文介绍了利用大型扩散模型的特性进行草图到图像的翻译技术。通过利用特征泛化能力,结合轻量级映射网络实现源域到目标域的潜在特征翻译,成功生成高分辨率的真实图像。该方法在定性和定量基准测试中表现优异,能够从粗糙的手绘草图中生成高质量图像。
Key Takeaways
- 图像处理中的图像到图像翻译可通过引入结构指导实现合成图像形状的精细控制。
- 从用户指定的粗略手绘草图生成高质量真实图像是对条件生成过程施加结构约束的任务。
- 这一问题具有挑战性,因为自由手绘草图存在大量模糊性。
- 平衡形状一致性和真实感生成之间的权衡增加了过程的复杂性。
- 基于生成对抗网络(GANs)的方法通常使用条件GAN或GAN反转,需要特定应用和优化的目标。
- 最近的去噪扩散概率模型(DDPMs)实现对通用图像合成中低级别视觉属性的突破。
点此查看论文截图

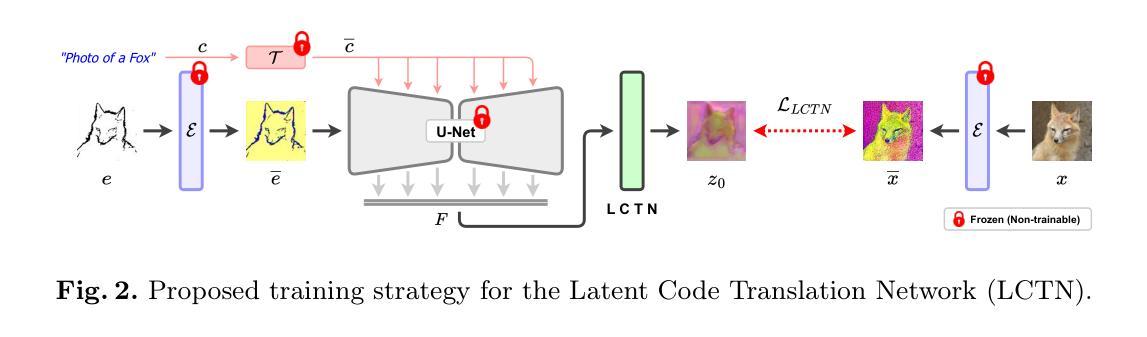
VidStyleODE: Disentangled Video Editing via StyleGAN and NeuralODEs
Authors:Moayed Haji Ali, Andrew Bond, Tolga Birdal, Duygu Ceylan, Levent Karacan, Erkut Erdem, Aykut Erdem
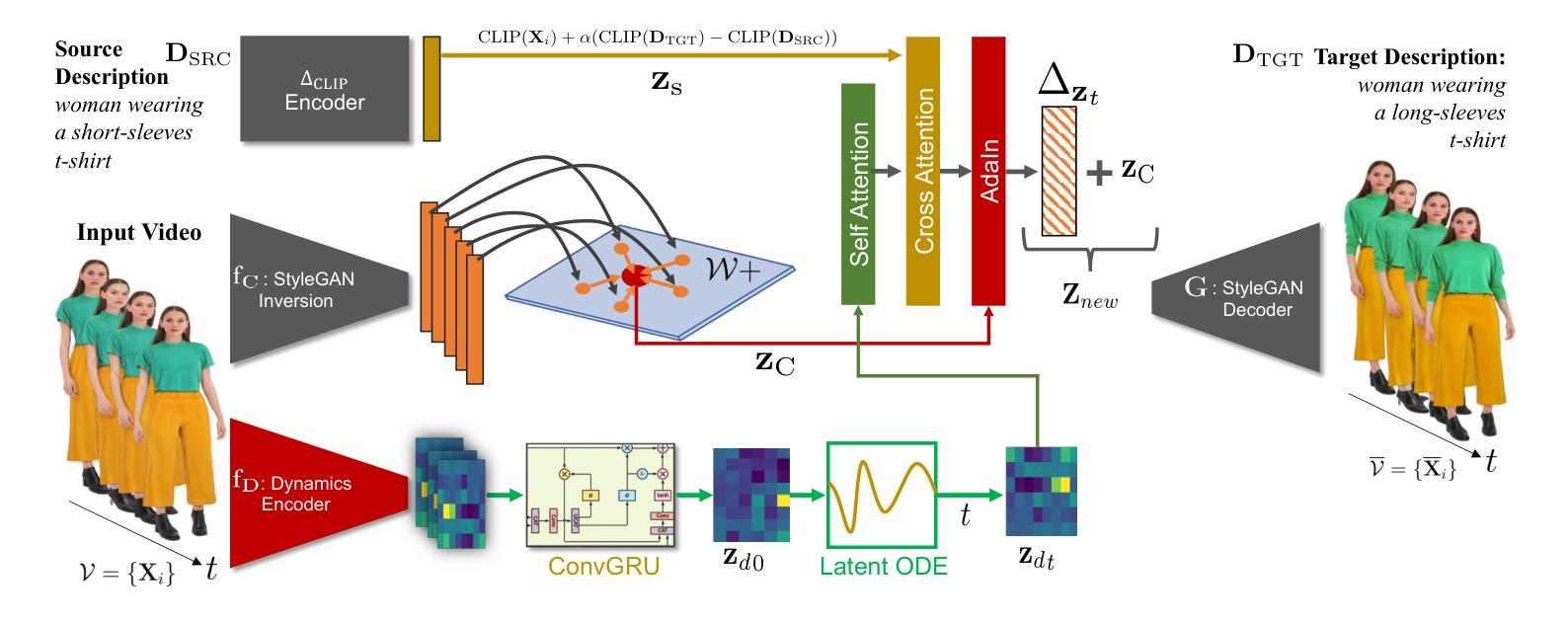
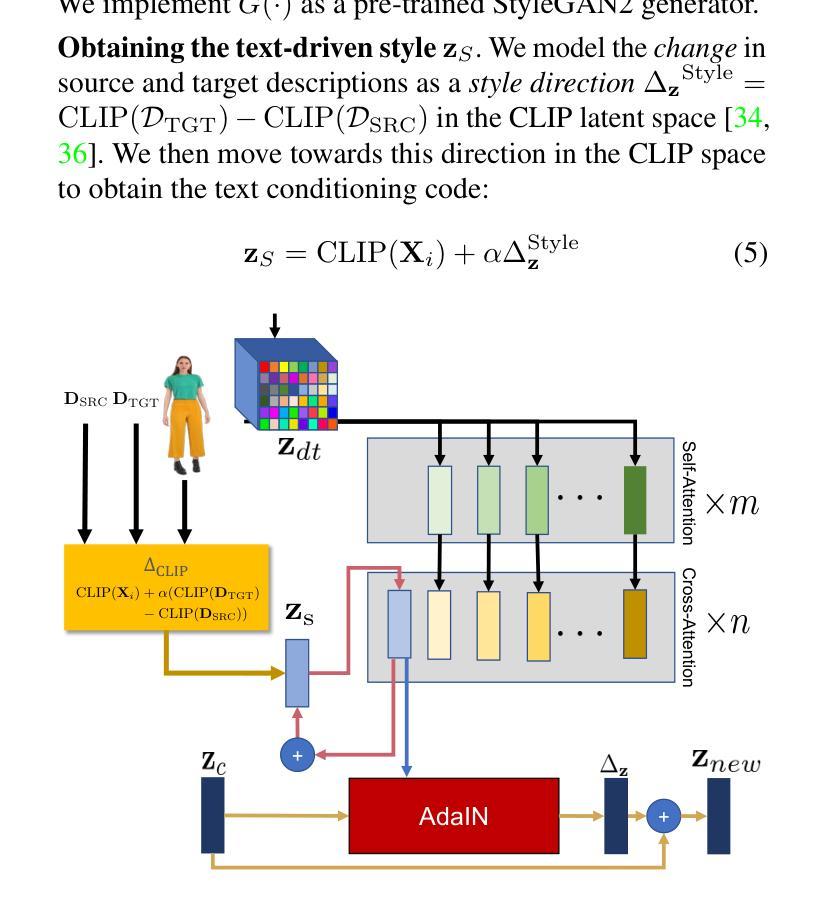
We propose $\textbf{VidStyleODE}$, a spatiotemporally continuous disentangled $\textbf{Vid}$eo representation based upon $\textbf{Style}$GAN and Neural-$\textbf{ODE}$s. Effective traversal of the latent space learned by Generative Adversarial Networks (GANs) has been the basis for recent breakthroughs in image editing. However, the applicability of such advancements to the video domain has been hindered by the difficulty of representing and controlling videos in the latent space of GANs. In particular, videos are composed of content (i.e., appearance) and complex motion components that require a special mechanism to disentangle and control. To achieve this, VidStyleODE encodes the video content in a pre-trained StyleGAN $\mathcal{W}_+$ space and benefits from a latent ODE component to summarize the spatiotemporal dynamics of the input video. Our novel continuous video generation process then combines the two to generate high-quality and temporally consistent videos with varying frame rates. We show that our proposed method enables a variety of applications on real videos: text-guided appearance manipulation, motion manipulation, image animation, and video interpolation and extrapolation. Project website: https://cyberiada.github.io/VidStyleODE
我们提出了基于StyleGAN和神经ODE的时空连续解耦视频表示方法——VidStyleODE。生成对抗网络(GANs)学到的潜在空间的有效遍历是最近图像编辑突破的基础。然而,这种进步在视频领域的应用受到GAN潜在空间中视频表达和控制的难度限制。尤其是,视频是由内容(即外观)和需要特殊机制来解耦和控制的复杂运动成分组成的。为了实现这一点,VidStyleODE将视频内容编码在预训练的StyleGAN的W+空间中,并利用潜在ODE组件来总结输入视频的时空动态。然后,我们新颖的视频连续生成过程将这两者结合起来,生成具有不同帧率的高质量且时间上连贯的视频。我们证明了我们的方法能够在真实视频上实现多种应用:文本引导的外观操纵、运动操纵、图像动画以及视频插值和扩展。项目网站:https://cyberiada.github.io/VidStyleODE
论文及项目相关链接
PDF Project website: https://cyberiada.github.io/VidStyleODE
Summary
本文提出了基于StyleGAN和神经ODEs的时空连续解纠缠视频表示方法——VidStyleODE。该方法能有效遍历GANs学习的潜在空间,实现了视频内容的编码和复杂运动组件的解纠缠与控制。通过结合预训练的StyleGAN网络和一个潜在ODE组件,VidStyleODE能够概括输入视频的时空动态,并生成高质量、帧率可变的视频。此方法可用于多种实际应用,如文本引导的外观操控、运动操控、图像动画以及视频插值与外推。
Key Takeaways
- VidStyleODE结合了StyleGAN和神经ODEs技术,实现了视频在潜在空间的表示和控制。
- 该方法能有效遍历GANs学习的潜在空间,为视频编辑提供了新的可能性。
- VidStyleODE通过预训练的StyleGAN网络对视频内容进行编码。
- 潜在ODE组件用于概括视频的时空动态。
- 结合上述两者,VidStyleODE能够生成高质量、帧率可变的视频。
- 该方法支持多种实际应用,包括文本引导的视频操控、运动操控、图像动画以及视频插值与外推。
点此查看论文截图