⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-22 更新
d-Sketch: Improving Visual Fidelity of Sketch-to-Image Translation with Pretrained Latent Diffusion Models without Retraining
Authors:Prasun Roy, Saumik Bhattacharya, Subhankar Ghosh, Umapada Pal, Michael Blumenstein
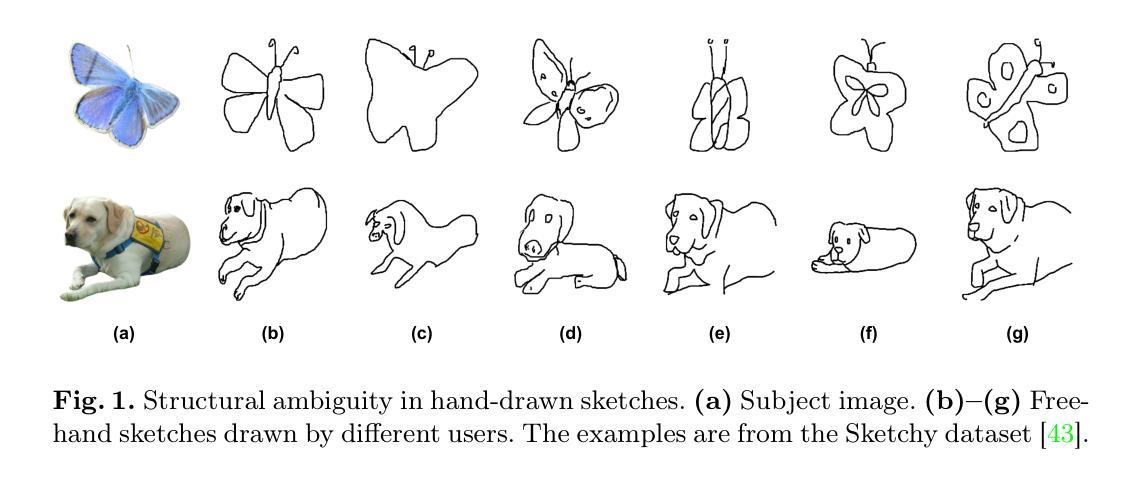
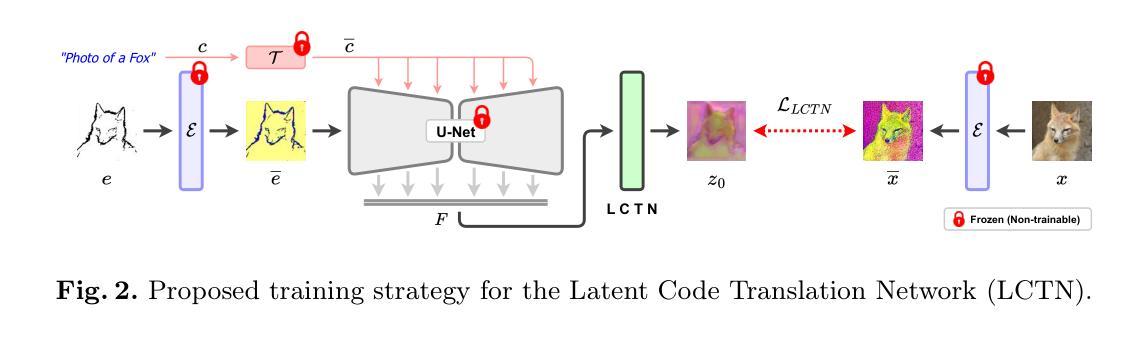
Structural guidance in an image-to-image translation allows intricate control over the shapes of synthesized images. Generating high-quality realistic images from user-specified rough hand-drawn sketches is one such task that aims to impose a structural constraint on the conditional generation process. While the premise is intriguing for numerous use cases of content creation and academic research, the problem becomes fundamentally challenging due to substantial ambiguities in freehand sketches. Furthermore, balancing the trade-off between shape consistency and realistic generation contributes to additional complexity in the process. Existing approaches based on Generative Adversarial Networks (GANs) generally utilize conditional GANs or GAN inversions, often requiring application-specific data and optimization objectives. The recent introduction of Denoising Diffusion Probabilistic Models (DDPMs) achieves a generational leap for low-level visual attributes in general image synthesis. However, directly retraining a large-scale diffusion model on a domain-specific subtask is often extremely difficult due to demanding computation costs and insufficient data. In this paper, we introduce a technique for sketch-to-image translation by exploiting the feature generalization capabilities of a large-scale diffusion model without retraining. In particular, we use a learnable lightweight mapping network to achieve latent feature translation from source to target domain. Experimental results demonstrate that the proposed method outperforms the existing techniques in qualitative and quantitative benchmarks, allowing high-resolution realistic image synthesis from rough hand-drawn sketches.
图像到图像的翻译中的结构指导允许对合成图像的形状进行细致的控制。从用户指定的粗略手绘草图生成高质量逼真图像是此类任务之一,旨在对对条件生成过程施加结构约束。虽然这一前提对于内容创建和学术研究有许多用例而言很有趣,但由于自由手绘草图中的大量模糊性,这个问题变得根本具有挑战性。此外,在形状一致性和逼真生成之间取得平衡为该过程增加了额外的复杂性。基于生成对抗网络(GAN)的现有方法通常使用条件GAN或GAN反转,通常需要特定应用的数据和优化目标。最近引入的降噪扩散概率模型(DDPM)实现了通用图像合成中低级别视觉属性的飞跃。然而,由于计算成本高昂和数据不足,直接在特定领域的子任务上重新训练大规模扩散模型通常极其困难。在本文中,我们介绍了一种利用大规模扩散模型的特征泛化能力进行草图到图像翻译的技术,而无需重新训练。特别是,我们使用可学习的轻型映射网络来实现从源域到目标域的潜在特征翻译。实验结果表明,所提出的方法在定性和定量基准测试中均优于现有技术,允许从粗略的手绘草图中生成高分辨率的逼真图像。
论文及项目相关链接
PDF Accepted in The International Conference on Pattern Recognition (ICPR) 2024
Summary
本文探讨了图像翻译中的结构指导对合成图像形状控制的重要性。生成高质量的真实图像,从用户指定的粗略手绘草图开始,是对条件生成过程施加结构约束的任务。虽然这一前提对于内容创建和学术研究有许多用例,但由于自由手绘草图存在大量模糊性,这一问题变得极为具有挑战性。此外,平衡形状一致性和真实感生成之间的权衡增加了该过程的复杂性。基于生成对抗网络(GANs)的方法通常需要特定应用的数据和优化目标。最近出现的去噪扩散概率模型(DDPMs)在通用图像合成方面取得了突破性进展。然而,直接在特定子任务上重新训练大规模扩散模型通常由于计算成本高昂和数据不足而变得极为困难。本文介绍了一种用于草图到图像翻译的技术,该技术利用大规模扩散模型的特性泛化能力,无需重新训练。特别是,我们使用可学习的轻型映射网络实现源域到目标域的特征翻译。实验结果表明,该方法在定性和定量基准测试中均优于现有技术,能够实现从粗略手绘草图中生成高分辨率的真实图像。
Key Takeaways
- 结构指导在图像翻译中对于控制合成图像的形状至关重要。
- 从用户指定的粗略手绘草图中生成高质量真实图像是一个具有挑战性的任务。
- 现有方法基于生成对抗网络(GANs)和去噪扩散概率模型(DDPMs),但存在计算成本高和数据不足的问题。
- 本文介绍了一种利用大规模扩散模型的特性泛化能力的技术,用于草图到图像翻译,无需重新训练。
- 使用可学习的轻型映射网络实现源域到目标域的特征翻译。
- 所提出的方法在定性和定量基准测试中表现出优异性能。
点此查看论文截图