⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-22 更新
WavRAG: Audio-Integrated Retrieval Augmented Generation for Spoken Dialogue Models
Authors:Yifu Chen, Shengpeng Ji, Haoxiao Wang, Ziqing Wang, Siyu Chen, Jinzheng He, Jin Xu, Zhou Zhao
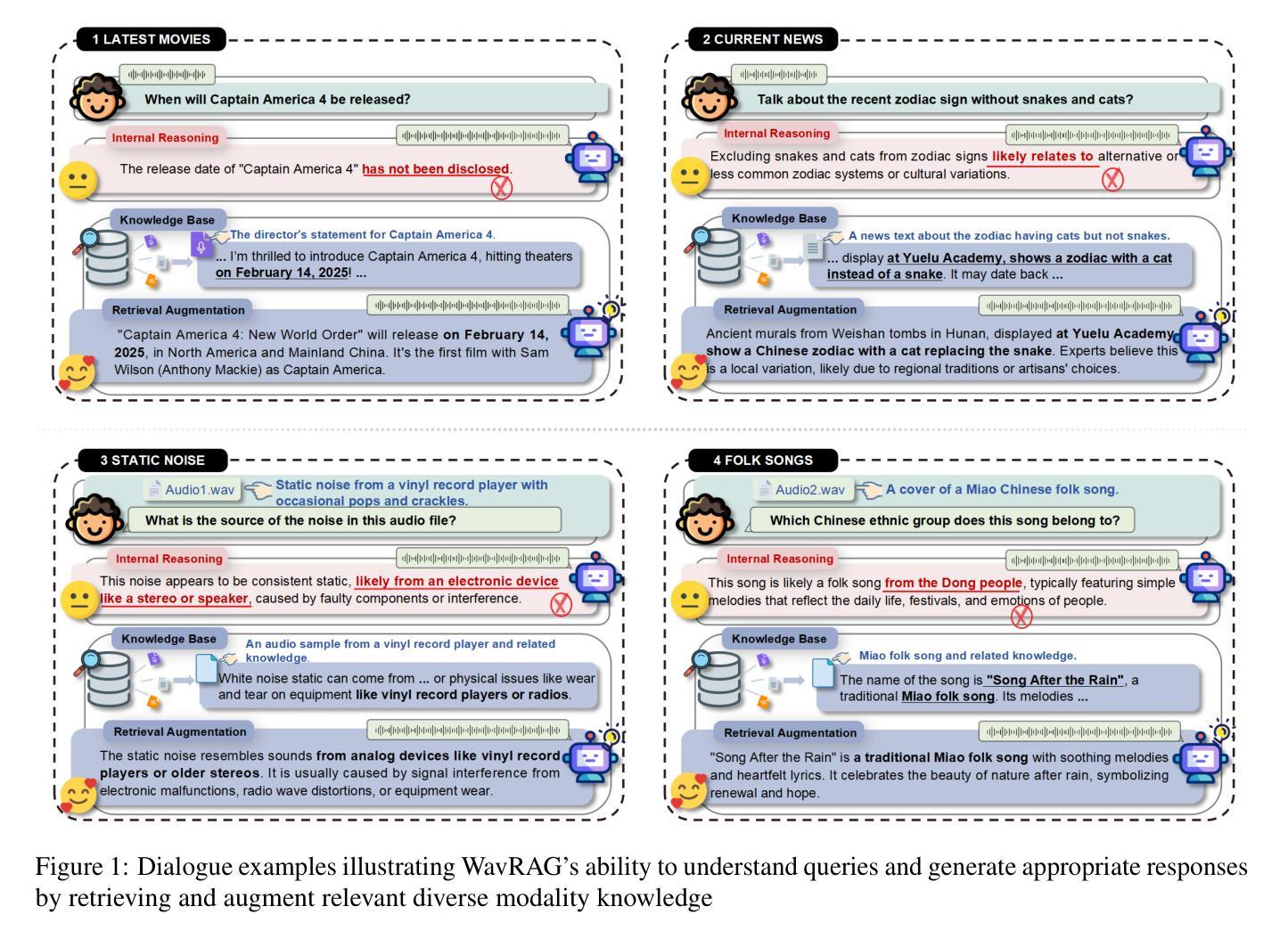
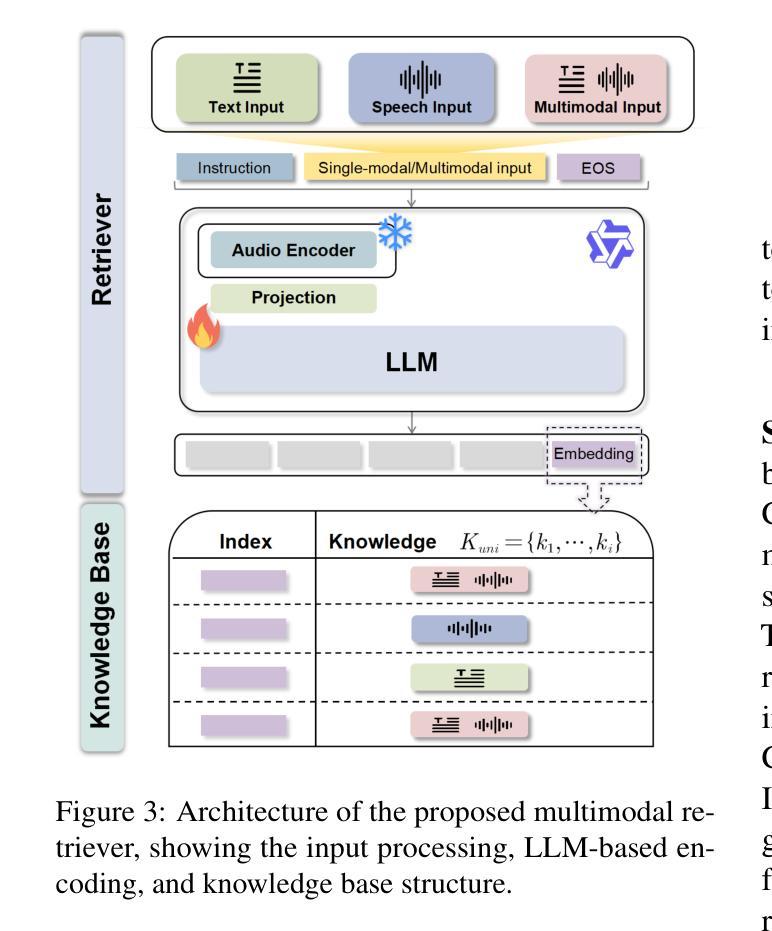
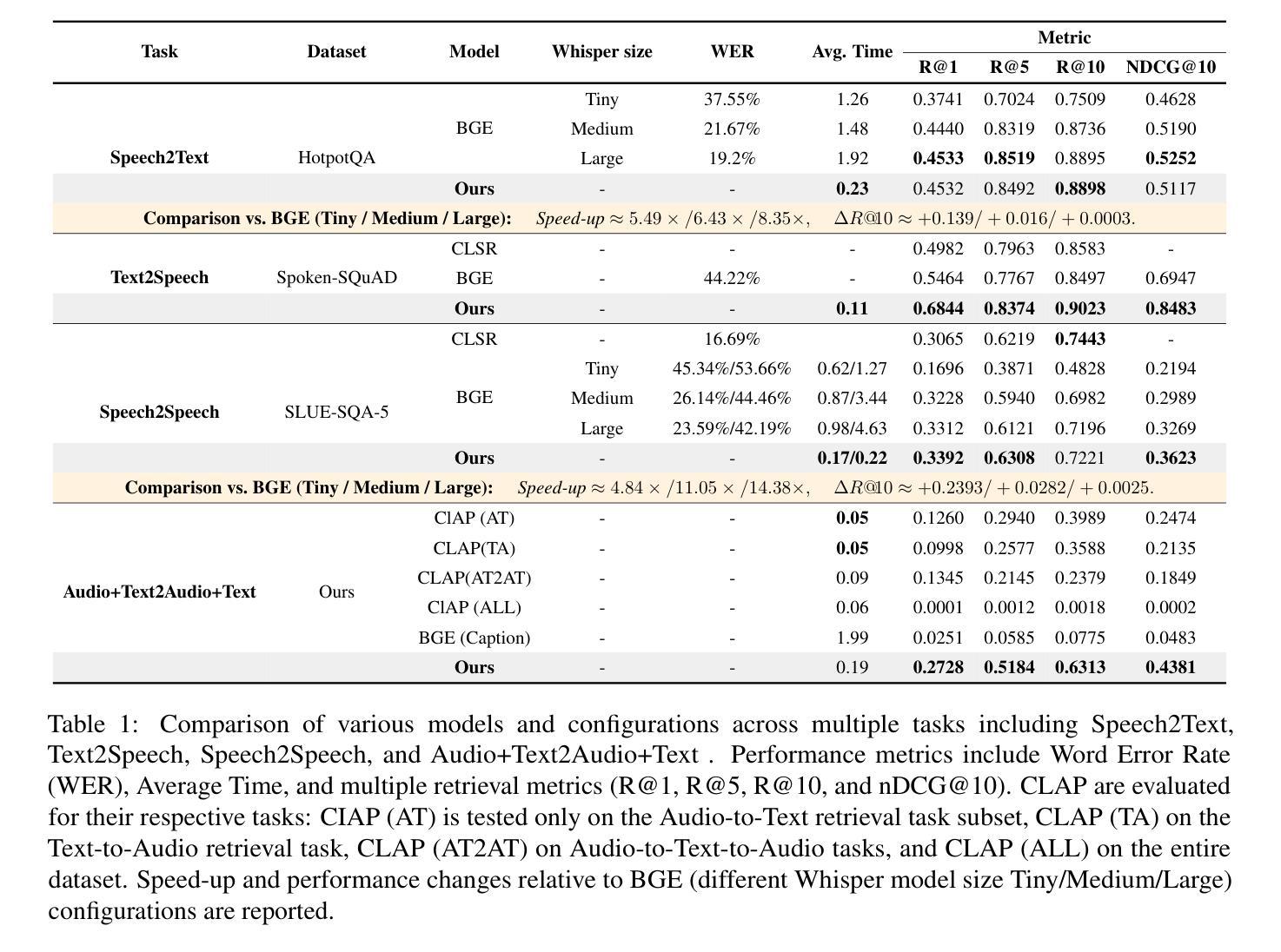
Retrieval Augmented Generation (RAG) has gained widespread adoption owing to its capacity to empower large language models (LLMs) to integrate external knowledge. However, existing RAG frameworks are primarily designed for text-based LLMs and rely on Automatic Speech Recognition to process speech input, which discards crucial audio information, risks transcription errors, and increases computational overhead. Therefore, we introduce WavRAG, the first retrieval augmented generation framework with native, end-to-end audio support. WavRAG offers two key features: 1) Bypassing ASR, WavRAG directly processes raw audio for both embedding and retrieval. 2) WavRAG integrates audio and text into a unified knowledge representation. Specifically, we propose the WavRetriever to facilitate the retrieval from a text-audio hybrid knowledge base, and further enhance the in-context capabilities of spoken dialogue models through the integration of chain-of-thought reasoning. In comparison to state-of-the-art ASR-Text RAG pipelines, WavRAG achieves comparable retrieval performance while delivering a 10x acceleration. Furthermore, WavRAG’s unique text-audio hybrid retrieval capability extends the boundaries of RAG to the audio modality.
检索增强生成(RAG)由于其赋能大型语言模型(LLM)整合外部知识的能力而得到广泛应用。然而,现有的RAG框架主要面向基于文本的LLM,并依赖自动语音识别处理语音输入,这丢弃了关键的音频信息,存在转录错误的风险,并增加了计算开销。因此,我们推出了WavRAG,这是第一个具有原生端到端音频支持功能的检索增强生成框架。WavRAG提供两个关键功能:1)绕过自动语音识别(ASR),WavRAG直接处理原始音频以进行嵌入和检索。2)WavRAG将音频和文本集成到一个统一的知识表示中。具体来说,我们提出了WavRetriever,便于从文本-音频混合知识库中检索信息,并通过整合思维链推理进一步增强了对话模型的在上下文中的能力。与最新的ASR-文本RAG管道相比,WavRAG实现了相当的检索性能,同时提供了10倍的加速。此外,WavRAG独特的文本-音频混合检索能力将RAG的边界扩展到音频模式。
论文及项目相关链接
Summary
RAG框架因能增强大型语言模型整合外部知识的能力而受到广泛采用,但其主要应用于文本型LLM并依赖自动语音识别处理语音输入,这丢失了重要的音频信息,存在转录错误风险并增加了计算开销。因此,我们推出WavRAG,首个具备原生端到端音频支持能力的检索增强生成框架。WavRAG提供两大功能:一、绕过ASR直接处理原始音频进行嵌入和检索;二、整合音频和文本为统一的知识表示。特别是我们提出WavRetriever,便于从文本-音频混合知识库中检索信息,并通过整合链式思维推理增强对话模型的上下文能力。相较于前沿的ASR-Text RAG管道,WavRAG实现相当检索性能的同时实现了10倍加速。此外,WavRAG独特的文本-音频混合检索能力将RAG的边界扩展到音频模式。
Key Takeaways
- WavRAG是首个具备原生端到端音频支持的检索增强生成框架。
- WavRAG绕过了自动语音识别(ASR),直接处理原始音频进行嵌入和检索。
- WavRAG整合了音频和文本为统一的知识表示。
- WavRetriever的提出促进了从文本-音频混合知识库中的检索。
- WavRAG通过整合链式思维推理增强了对话模型的上下文能力。
- 与前沿的ASR-Text RAG管道相比,WavRAG实现了相当的检索性能和10倍加速。
点此查看论文截图