⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-22 更新
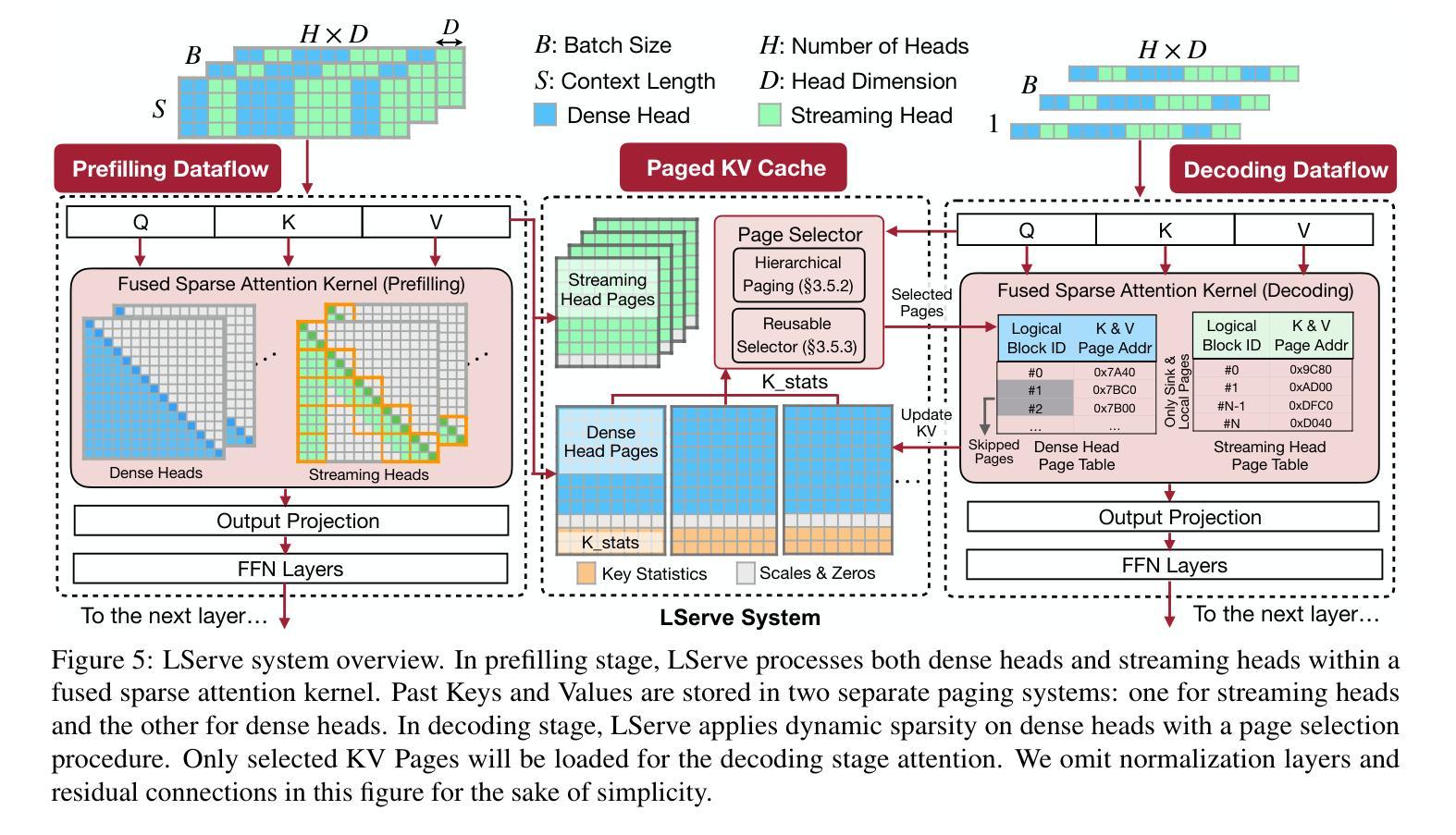
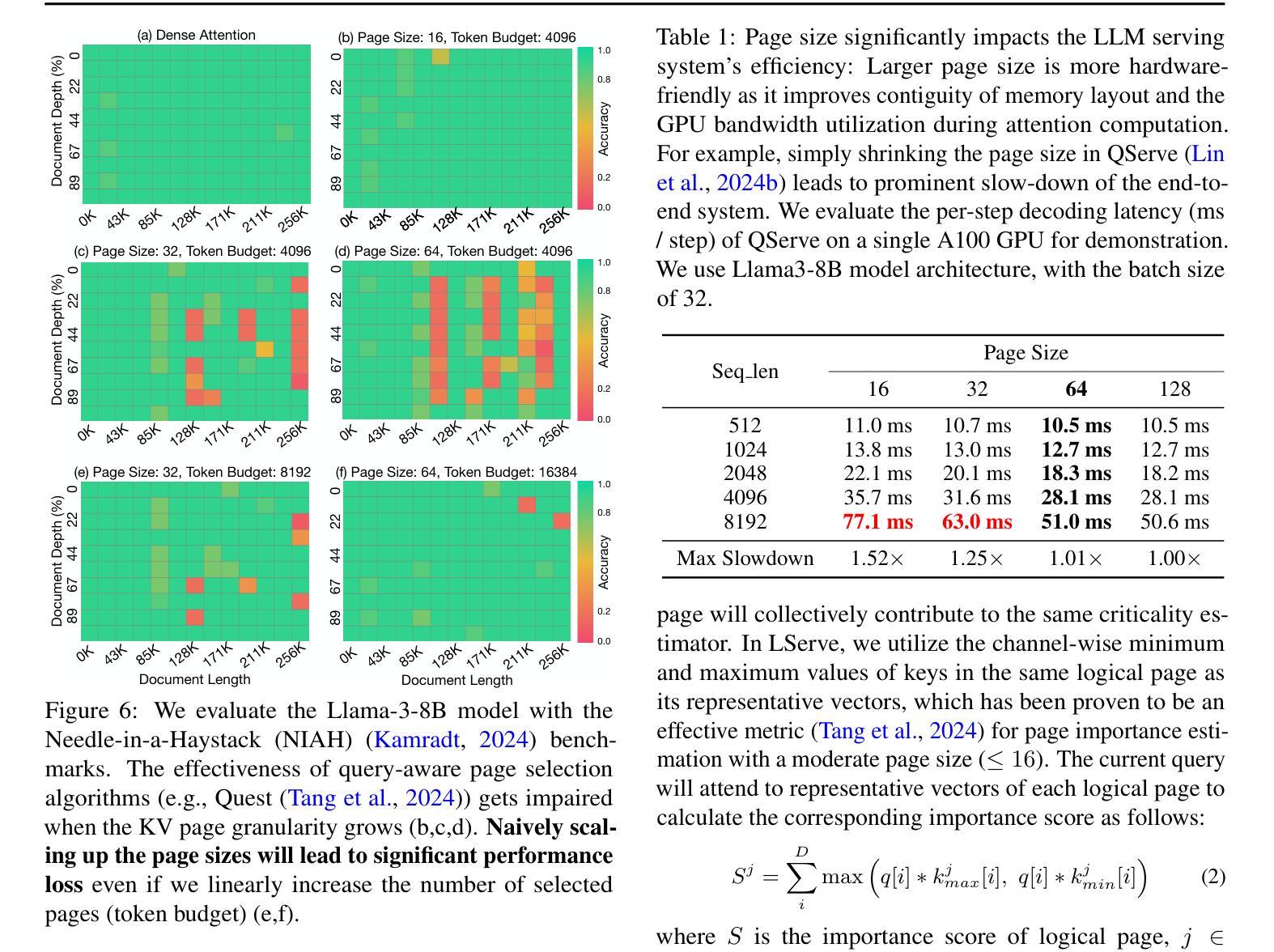
LServe: Efficient Long-sequence LLM Serving with Unified Sparse Attention
Authors:Shang Yang, Junxian Guo, Haotian Tang, Qinghao Hu, Guangxuan Xiao, Jiaming Tang, Yujun Lin, Zhijian Liu, Yao Lu, Song Han
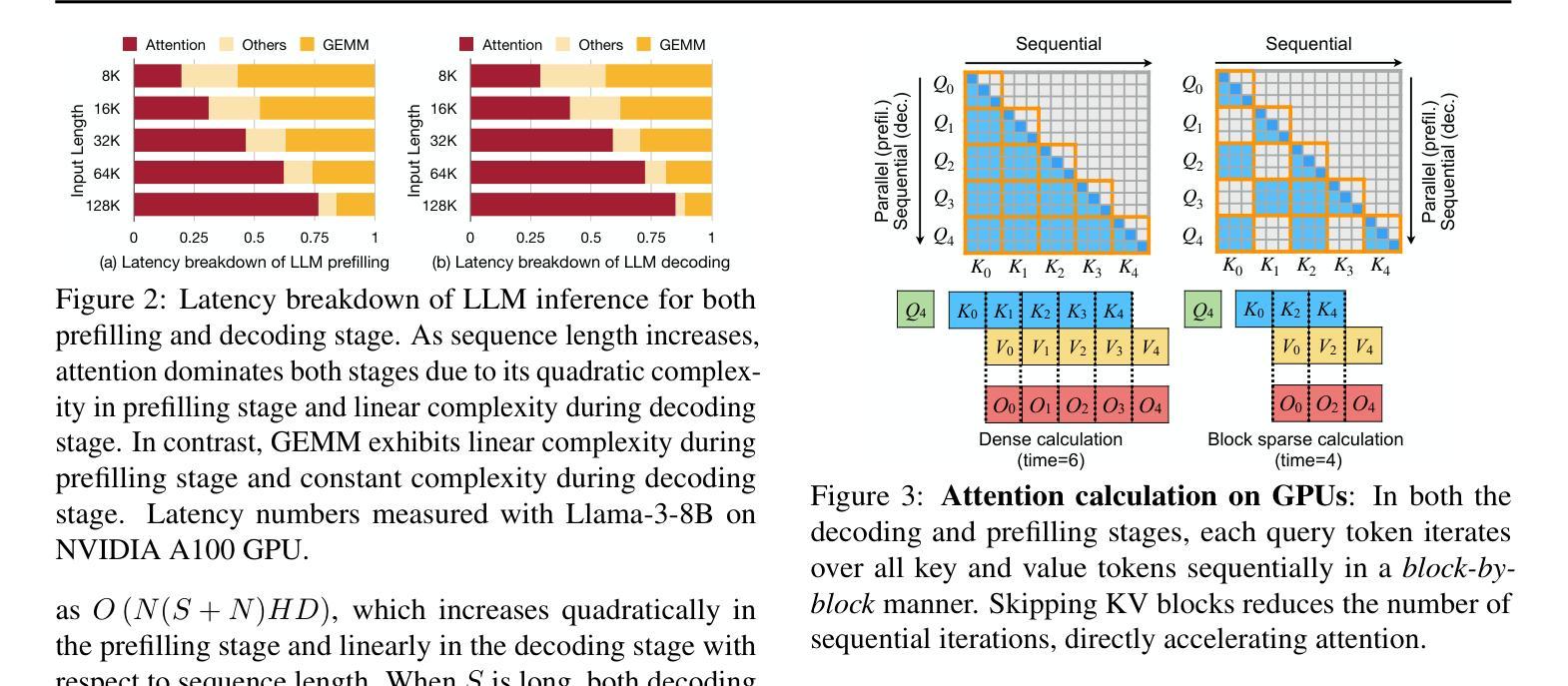
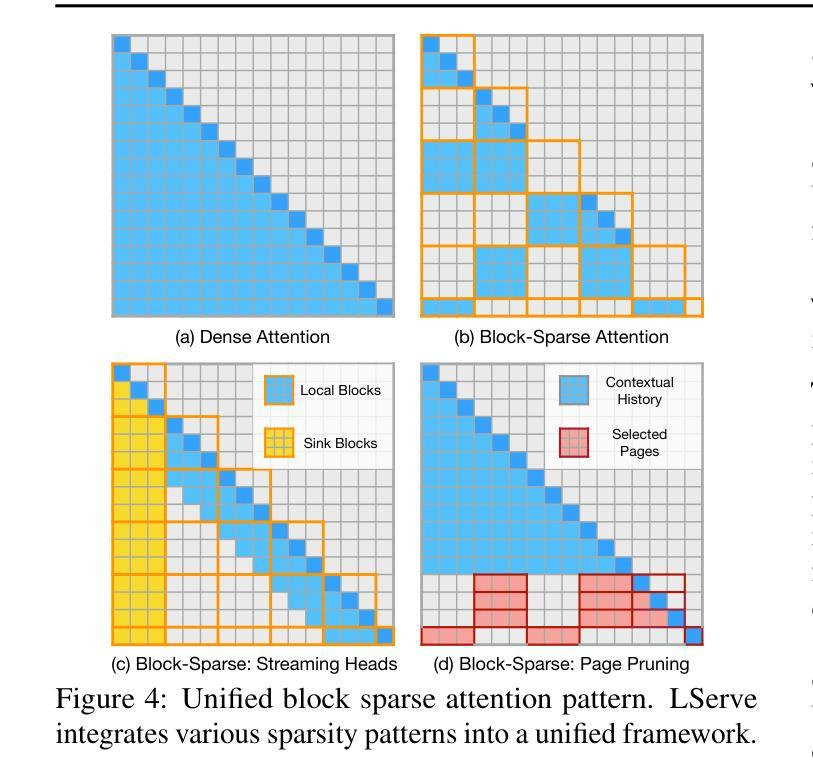
Large language models (LLMs) have shown remarkable potential in processing long sequences, yet efficiently serving these long-context models remains challenging due to the quadratic computational complexity of attention in the prefilling stage and the large memory footprint of the KV cache in the decoding stage. To address these issues, we introduce LServe, an efficient system that accelerates long-sequence LLM serving via hybrid sparse attention. This method unifies different hardware-friendly, structured sparsity patterns for both prefilling and decoding attention into a single framework, where computations on less important tokens are skipped block-wise. LServe demonstrates the compatibility of static and dynamic sparsity in long-context LLM attention. This design enables multiplicative speedups by combining these optimizations. Specifically, we convert half of the attention heads to nearly free streaming heads in both the prefilling and decoding stages. Additionally, we find that only a constant number of KV pages is required to preserve long-context capabilities, irrespective of context length. We then design a hierarchical KV page selection policy that dynamically prunes KV pages based on query-centric similarity. On average, LServe accelerates LLM prefilling by up to 2.9x and decoding by 1.3-2.1x over vLLM, maintaining long-context accuracy. Code is released at https://github.com/mit-han-lab/omniserve.
大型语言模型(LLM)在处理长序列时表现出了显著潜力,但由于预填充阶段的注意力计算具有二次复杂性和解码阶段的KV缓存占用大量内存,有效地服务这些长上下文模型仍然是一个挑战。为了解决这些问题,我们引入了LServe系统,该系统通过混合稀疏注意力加速长序列LLM服务。此方法将预填充和解码注意力的不同硬件友好结构化稀疏模式统一到一个单一框架中,其中对次要标记的计算按块跳过。LServe证明了静态和动态稀疏在长上下文LLM注意力中的兼容性。这种设计能够通过结合这些优化实现乘法的速度提升。具体来说,我们将一半的注意力头转换为预填充和解码阶段的近似免费流式头。此外,我们发现无论上下文长度如何,只需保持一定数量的KV页面即可保持长上下文功能。然后,我们设计了一种基于查询中心相似性的分层KV页面选择策略,动态删除KV页面。平均而言,LServe相对于vLLM加速了LLM的预填充高达2.9倍,解码加速了1.3-2.1倍,同时保持了长上下文的准确性。相关代码已发布在https://github.com/mit-han-lab/omniserve上。
论文及项目相关链接
PDF Accepted by MLSys 2025. Code available at: https://github.com/mit-han-lab/omniserve
Summary
LLM处理长序列时存在挑战,为此提出了LServe系统,通过混合稀疏注意力加速长序列LLM服务。LServe采用硬件友好、结构化的稀疏模式,跳过不重要符号块计算,实现了静态和动态稀疏性的兼容性。它能实现乘法的加速效果,并提高内存使用效率。实验结果显示,LServe可加快LLM的预填充速度最多达2.9倍,解码速度最多达1.3至2倍,同时保持长上下文准确性。
Key Takeaways
- LLM在处理长序列时面临挑战,主要包括注意力预填充阶段的二次计算复杂性和解码阶段KV缓存的大内存占用。
- LServe系统通过混合稀疏注意力解决这些问题,实现高效的长序列LLM服务。
- LServe结合了静态和动态稀疏性,采用硬件友好、结构化的稀疏模式进行计算优化。
- LServe通过将部分注意力头转换为几乎免费的流头,实现了加速效果。
- LServe发现保持长上下文能力所需的KV页面数量是恒定的,无论上下文长度如何。
- LServe设计了一种基于查询中心相似性的分层KV页面选择策略,动态删除KV页面。
点此查看论文截图

Aligning LLMs to Ask Good Questions A Case Study in Clinical Reasoning
Authors:Shuyue Stella Li, Jimin Mun, Faeze Brahman, Jonathan S. Ilgen, Yulia Tsvetkov, Maarten Sap
Large language models (LLMs) often fail to ask effective questions under uncertainty, making them unreliable in domains where proactive information-gathering is essential for decisionmaking. We present ALFA, a framework that improves LLM question-asking by (i) decomposing the notion of a “good” question into a set of theory-grounded attributes (e.g., clarity, relevance), (ii) controllably synthesizing attribute-specific question variations, and (iii) aligning models via preference-based optimization to explicitly learn to ask better questions along these fine-grained attributes. Focusing on clinical reasoning as a case study, we introduce the MediQ-AskDocs dataset, composed of 17k real-world clinical interactions augmented with 80k attribute-specific preference pairs of follow-up questions, as well as a novel expert-annotated interactive healthcare QA task to evaluate question-asking abilities. Models aligned with ALFA reduce diagnostic errors by 56.6% on MediQ-AskDocs compared to SOTA instruction-tuned LLMs, with a question-level win-rate of 64.4% and strong generalizability. Our findings suggest that explicitly guiding question-asking with structured, fine-grained attributes offers a scalable path to improve LLMs, especially in expert application domains.
大型语言模型(LLM)在不确定情况下往往无法提出有效问题,使其在决策中需要主动收集信息的领域不可靠。我们提出了ALFA框架,它通过(i)将“好问题”的概念分解为一系列基于理论的属性(例如清晰度、相关性等),(ii)可控地合成特定属性的问题变体,(iii)通过基于偏好的优化来对齐模型,以明确学习在这些精细属性上提出更好的问题,从而改进LLM的提问能力。以临床推理作为案例研究,我们介绍了MediQ-AskDocs数据集,它由1.7万个真实世界临床互动组成,辅以8万个特定属性偏好对的后续问题,以及一个用于评估提问能力的新型专家注释交互式医疗问答任务。与最新技术的指令微调LLM相比,使用ALFA对齐的模型在MediQ-AskDocs上将诊断错误减少了56.6%,问题级别的胜率为64.4%,并且具有很强的泛化能力。我们的研究结果表明,使用结构化、精细属性的明确指导提问,为改进LLM提供了一条可扩展的路径,特别是在专家应用领域。
论文及项目相关链接
PDF 22 pages, 8 figures, 8 tables
Summary
大型语言模型(LLM)在不确定性环境下提问能力有限,这导致它们在需要主动收集信息的决策领域不可靠。本文提出ALFA框架,通过分解“好问题”的概念、可控地合成特定属性问题变种以及通过偏好优化来对齐模型,以提高LLM的提问能力。以临床推理为案例研究,介绍了MediQ-AskDocs数据集和一种新的专家注释交互式医疗问答任务。与最新指令微调LLM相比,使用ALFA对齐的模型在MediQ-AskDocs上将诊断错误减少了56.6%,问题级别胜率为64.4%,并具有较强的泛化能力。研究表明,通过结构化、精细化的属性指导提问,可为提高LLM提供一条可扩展的路径,特别是在专家应用领域。
Key Takeaways
- LLM在不确定性环境下提问能力有限,尤其在需要主动信息收集的决策领域。
- ALFA框架通过分解“好问题”属性、合成特定问题并优化模型来提高LLM的提问能力。
- 介绍了MediQ-AskDocs数据集和新的专家注释交互式医疗问答任务,用于评估提问能力。
- 使用ALFA对齐的模型相比最新指令微调LLM,诊断错误减少56.6%,问题级别胜率为64.4%。
- ALFA方法具有强泛化能力。
- 通过结构化、精细化的属性指导提问,可提高LLM的表现。
点此查看论文截图

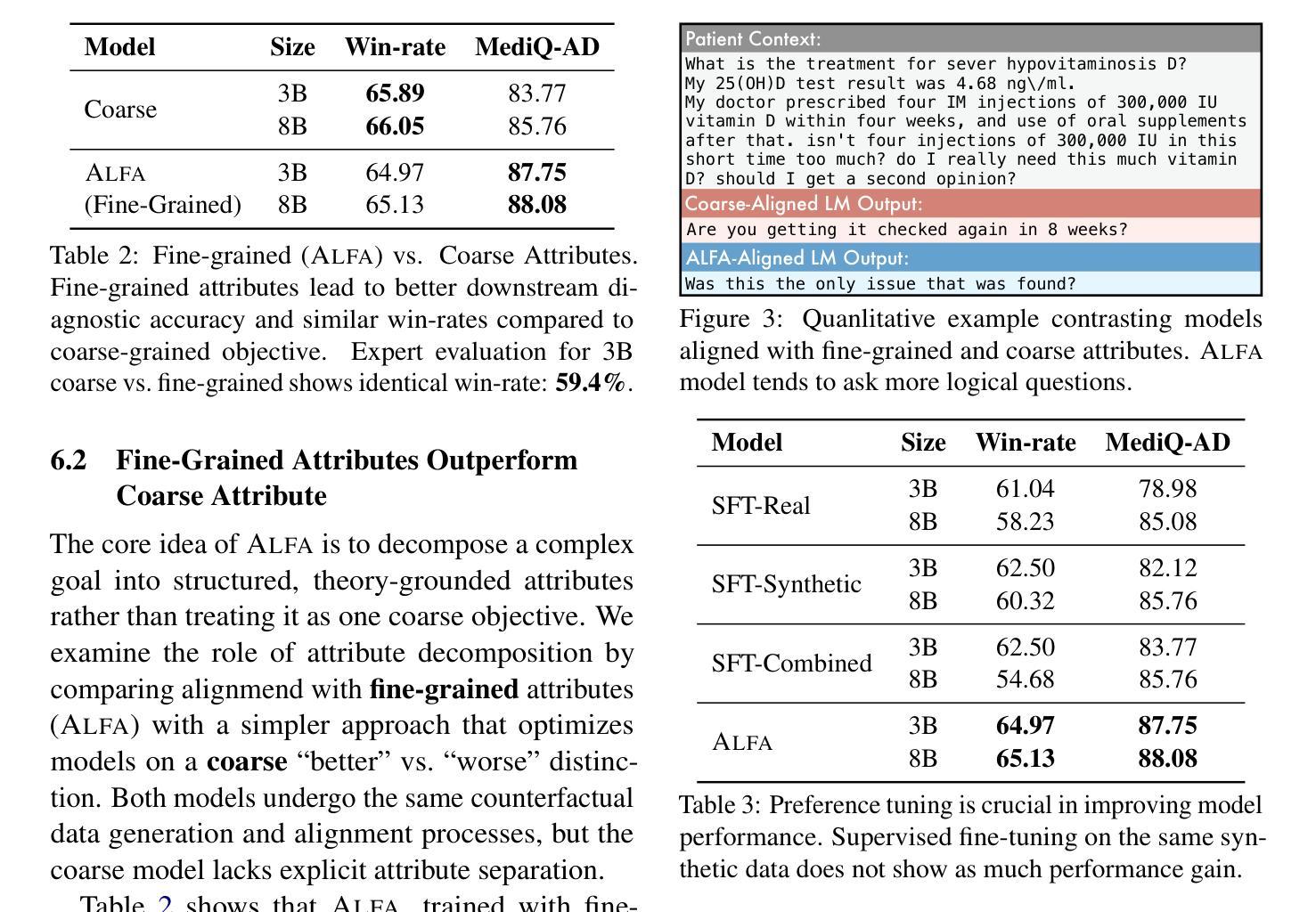
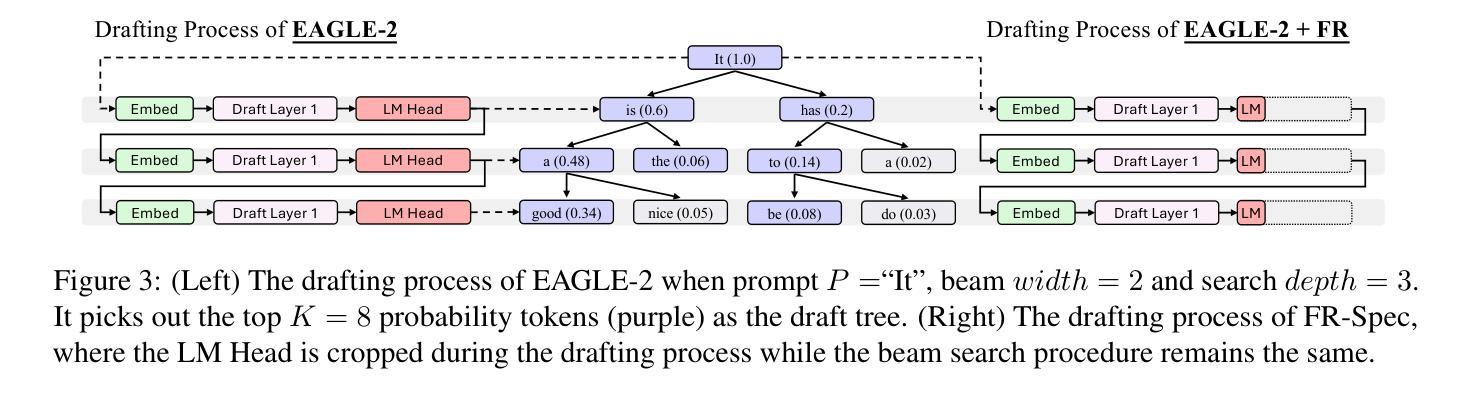
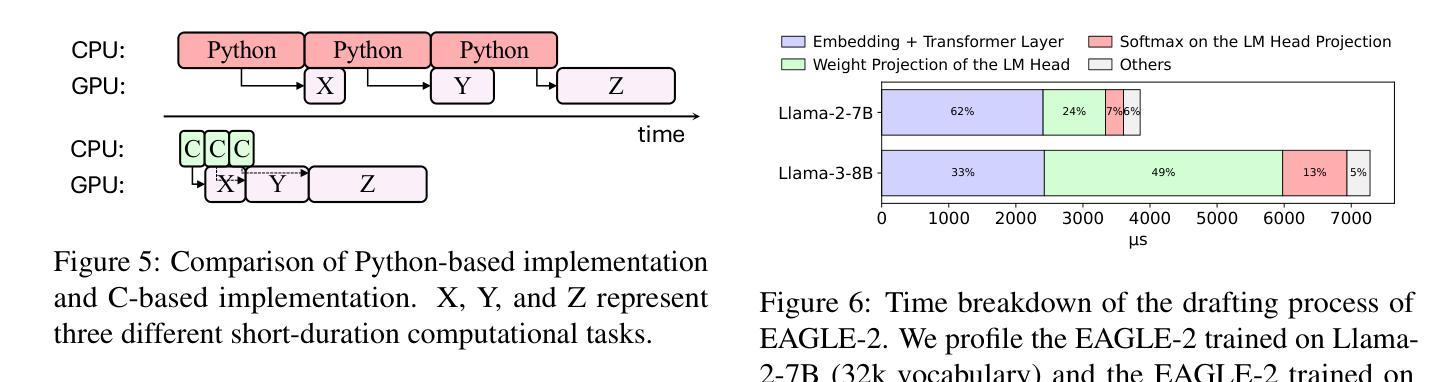
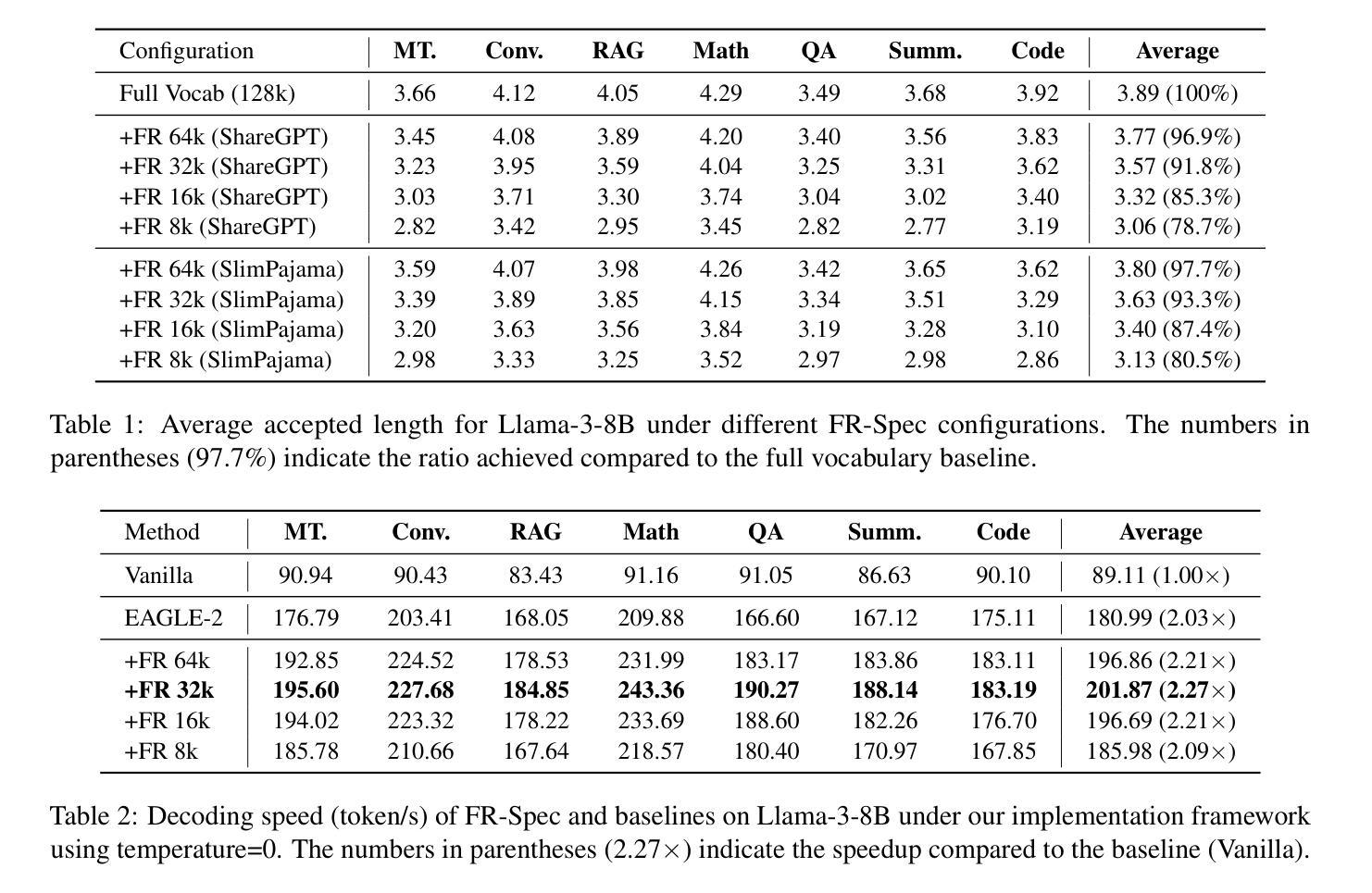
FR-Spec: Accelerating Large-Vocabulary Language Models via Frequency-Ranked Speculative Sampling
Authors:Weilin Zhao, Tengyu Pan, Xu Han, Yudi Zhang, Ao Sun, Yuxiang Huang, Kaihuo Zhang, Weilun Zhao, Yuxuan Li, Jianyong Wang, Zhiyuan Liu, Maosong Sun
Speculative sampling has emerged as an important technique for accelerating the auto-regressive generation process of large language models (LLMs) by utilizing a draft-then-verify mechanism to produce multiple tokens per forward pass. While state-of-the-art speculative sampling methods use only a single layer and a language modeling (LM) head as the draft model to achieve impressive layer compression, their efficiency gains are substantially reduced for large-vocabulary LLMs, such as Llama-3-8B with a vocabulary of 128k tokens. To address this, we present FR-Spec, a frequency-ranked speculative sampling framework that optimizes draft candidate selection through vocabulary space compression. By constraining the draft search to a frequency-prioritized token subset, our method reduces LM Head computation overhead by 75% while ensuring the equivalence of the final output distribution. Experiments across multiple datasets demonstrate an average of 1.12$\times$ speedup over the state-of-the-art speculative sampling method EAGLE-2.
推测性采样作为一种重要技术,通过利用草稿-验证机制,每次前向传递产生多个令牌,从而加速了大型语言模型(LLM)的自动回归生成过程。虽然最先进的推测采样方法仅使用一层和语言建模(LM)头作为草稿模型,实现了令人印象深刻的层压缩,但它们在处理大型词汇表LLM(如拥有12.8万令牌的Llama-3-8B)时的效率提升大幅减少。为了解决这个问题,我们提出了FR-Spec,这是一个频率排名推测采样框架,通过优化词汇空间压缩来改进草稿候选选择。通过将草稿搜索限制在优先频率的令牌子集上,我们的方法将LM Head计算开销减少了75%,同时确保最终输出分布的等效性。在多数据集上的实验表明,与最先进的推测采样方法EAGLE-2相比,其平均加速效果提升了约1.12倍。
论文及项目相关链接
Summary
采用频率优先的投机采样框架FR-Spec,通过词汇空间压缩优化草案候选选择,减少LM Head计算开销,确保最终输出分布等效性,提升大语言模型(LLM)的生成效率。
Key Takeaways
- 投机采样是一种加速大型语言模型(LLM)的自回归生成过程的重要技术。
- 当前先进的投机采样方法主要使用单一层和语言建模头作为草案模型,但在处理大词汇量LLM时效率增益降低。
- FR-Spec框架通过词汇空间压缩优化草案候选选择,提高生成效率。
- FR-Spec通过约束草案搜索至频率优先的令牌子集,减少LM Head计算开销75%。
- FR-Spec确保最终输出分布的等效性。
- 实验表明,FR-Spec相比现有最先进的投机采样方法EAGLE-2平均提速1.12倍。
- FR-Spec有助于解决大语言模型的生成效率问题。
点此查看论文截图
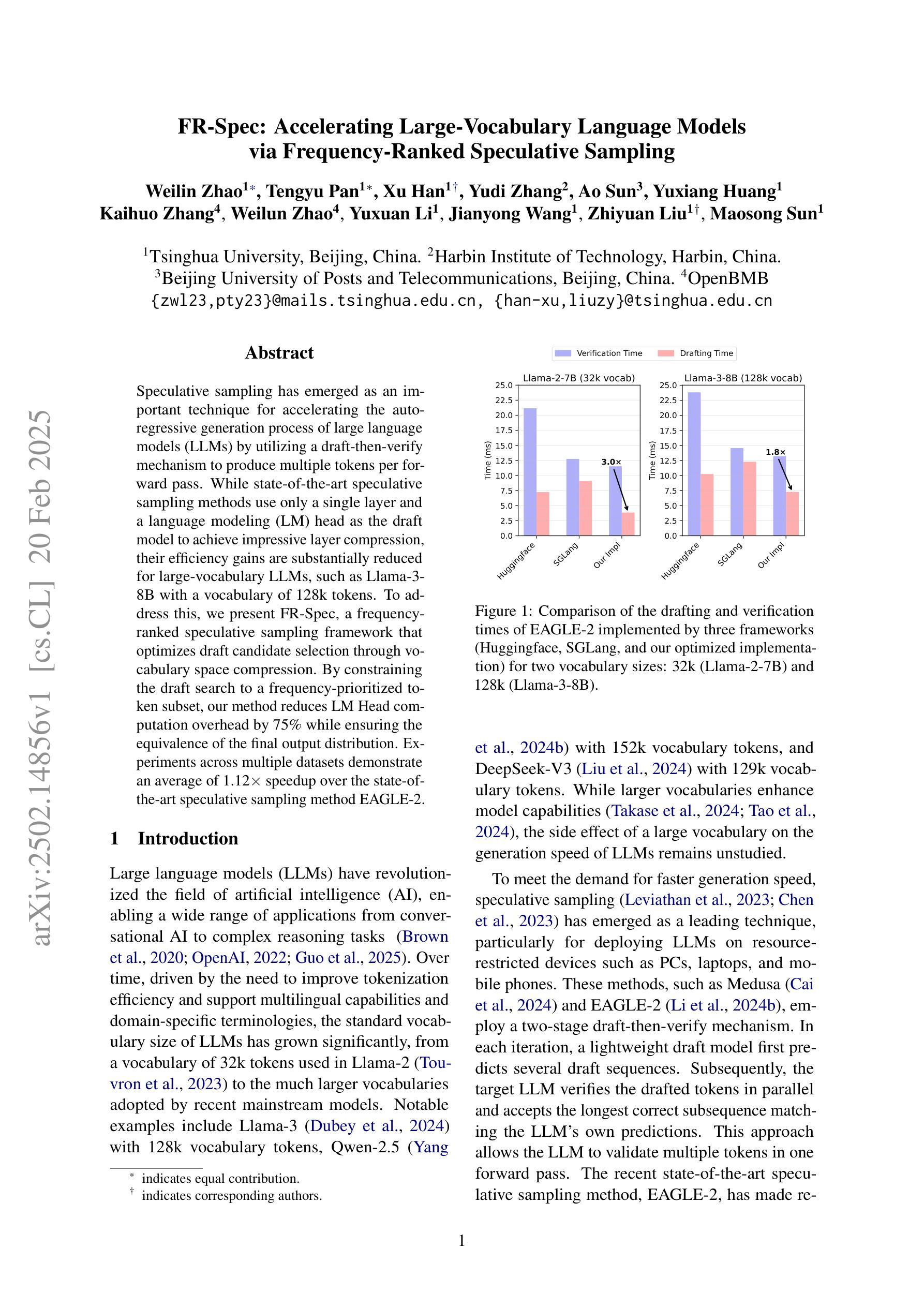
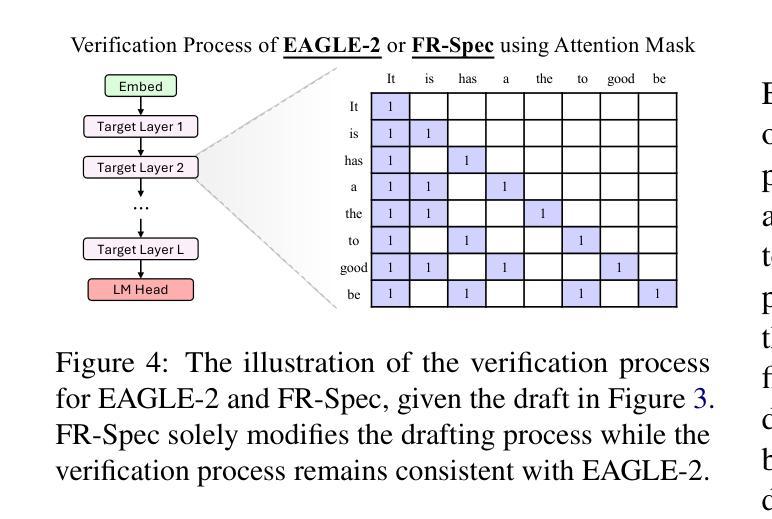
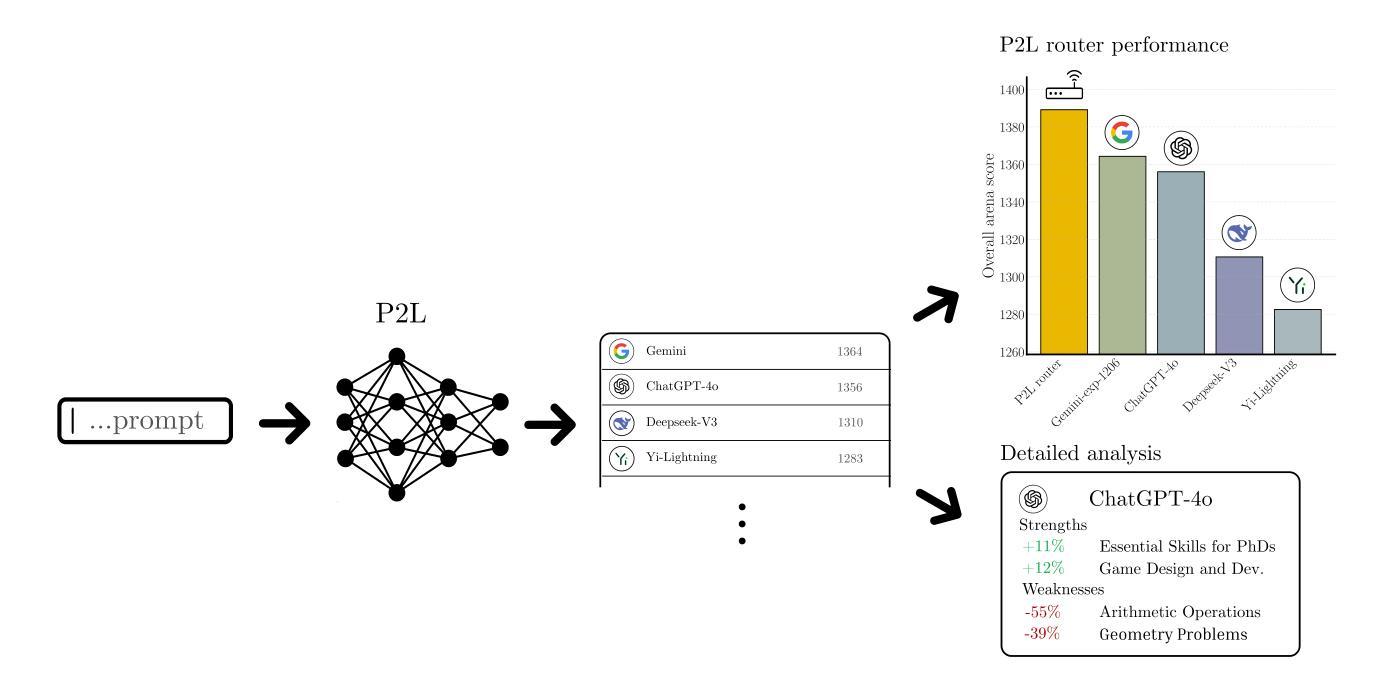
Prompt-to-Leaderboard
Authors:Evan Frick, Connor Chen, Joseph Tennyson, Tianle Li, Wei-Lin Chiang, Anastasios N. Angelopoulos, Ion Stoica
Large language model (LLM) evaluations typically rely on aggregated metrics like accuracy or human preference, averaging across users and prompts. This averaging obscures user- and prompt-specific variations in model performance. To address this, we propose Prompt-to-Leaderboard (P2L), a method that produces leaderboards specific to a prompt. The core idea is to train an LLM taking natural language prompts as input to output a vector of Bradley-Terry coefficients which are then used to predict the human preference vote. The resulting prompt-dependent leaderboards allow for unsupervised task-specific evaluation, optimal routing of queries to models, personalization, and automated evaluation of model strengths and weaknesses. Data from Chatbot Arena suggest that P2L better captures the nuanced landscape of language model performance than the averaged leaderboard. Furthermore, our findings suggest that P2L’s ability to produce prompt-specific evaluations follows a power law scaling similar to that observed in LLMs themselves. In January 2025, the router we trained based on this methodology achieved the #1 spot in the Chatbot Arena leaderboard. Our code is available at this GitHub link: https://github.com/lmarena/p2l.
大型语言模型(LLM)的评估通常依赖于准确度或人类偏好的聚合指标,这些指标会平均考虑用户和提示。这种平均会掩盖模型和提示特定的性能变化。为了解决这一问题,我们提出了Prompt-to-Leaderboard(P2L)方法,该方法能够针对特定提示生成排行榜。核心思想是通过训练大型语言模型,以自然语言提示作为输入来输出Bradley-Terry系数向量,然后使用这些系数预测人类偏好投票。结果提示相关的排行榜允许进行无监督的特定任务评估、查询到模型的最优路由、个性化以及模型的优点和缺点的自动评估。来自Chatbot Arena的数据表明,相对于平均排行榜,P2L能更好地捕捉语言模型性能的微妙格局。此外,我们的研究发现,P2L生成特定提示评估的能力遵循幂律缩放,这与在LLM本身中所观察到的相似。在2025年1月,我们基于这种方法训练的路由器在Chatbot Arena排行榜上获得了第一名。我们的代码可在GitHub链接中找到:https://github.com/lmarena/p2l。
论文及项目相关链接
Summary
该文介绍了大型语言模型(LLM)评估的一种新方法——Prompt-to-Leaderboard(P2L)。传统LLM评估依赖于准确性或人类偏好的聚合指标,这种方法忽视了用户和提示对模型性能的具体影响。而P2L则能够生成特定于提示的排行榜。其核心思想是通过训练大型语言模型,以自然语言提示作为输入来输出Bradley-Terry系数向量,预测人类偏好投票。这种方法产生的提示依赖排行榜可实现无监督的任务特定评估、查询的最优路由、个性化以及模型的优缺点自动评估。来自Chatbot Arena的数据表明,相较于平均排行榜,P2L更能捕捉语言模型性能的微妙差异。此外,研究还发现P2L生成提示特定评估的能力遵循幂律缩放,与观察到的LLM自身类似。该方法在实际应用中表现出色,基于该方法的路由器在Chatbot Arena排行榜上荣登榜首。代码已上传至GitHub。
Key Takeaways
- LLM评估通常使用聚合指标,如准确性和人类偏好,这忽略了用户和提示对模型性能的具体影响。
- Prompt-to-Leaderboard(P2L)方法能够生成特定于提示的排行榜,以更准确地反映模型性能。
- P2L通过训练LLM以自然语言提示作为输入来预测人类偏好投票,输出Bradley-Terry系数向量。
- P2L可支持无监督的任务特定评估、查询的最优路由、个性化以及模型的自动评估。
- 与平均排行榜相比,P2L更能捕捉语言模型性能的细微差异。
- P2L生成提示特定评估的能力遵循幂律缩放,与LLM的缩放类似。
点此查看论文截图

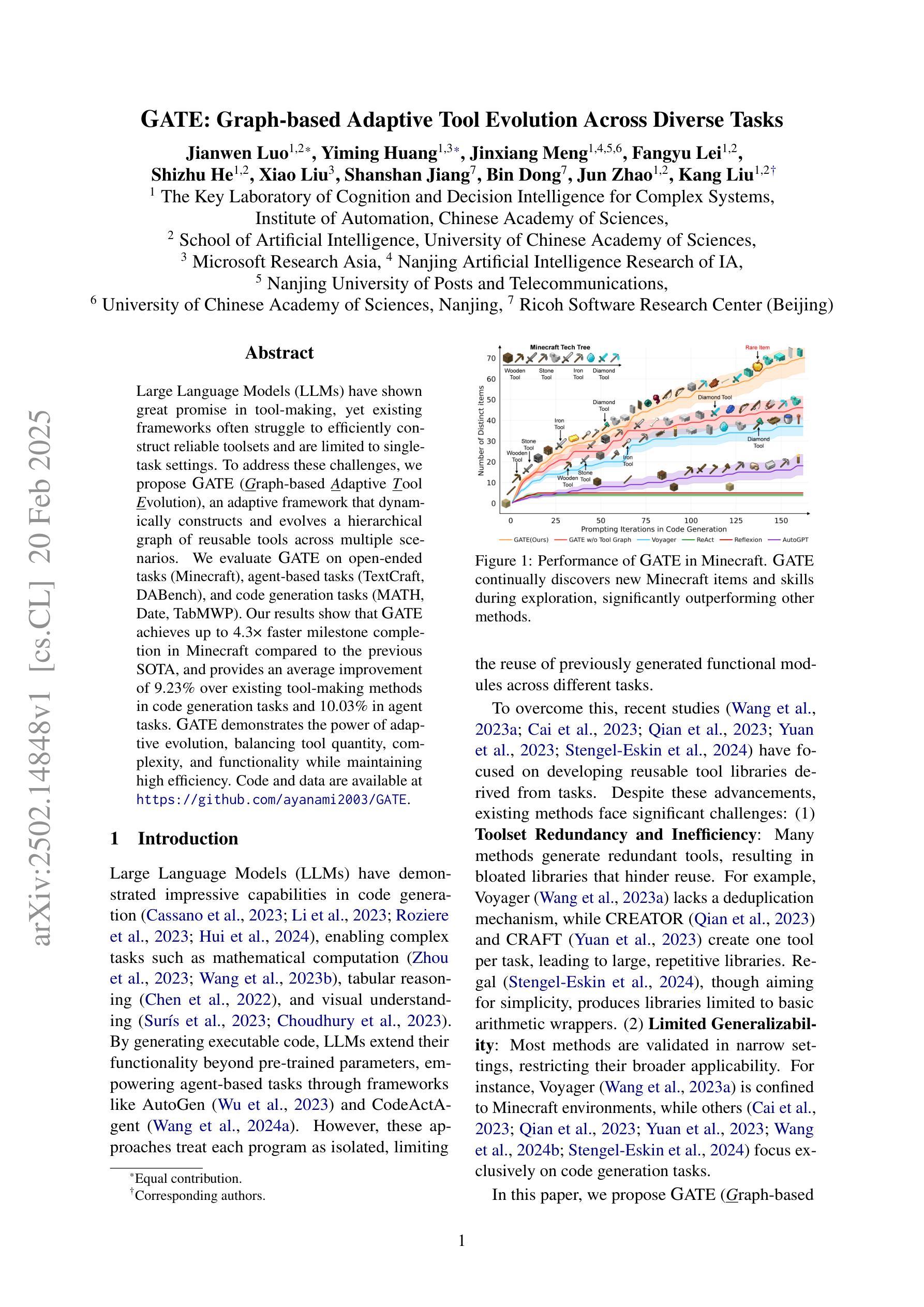
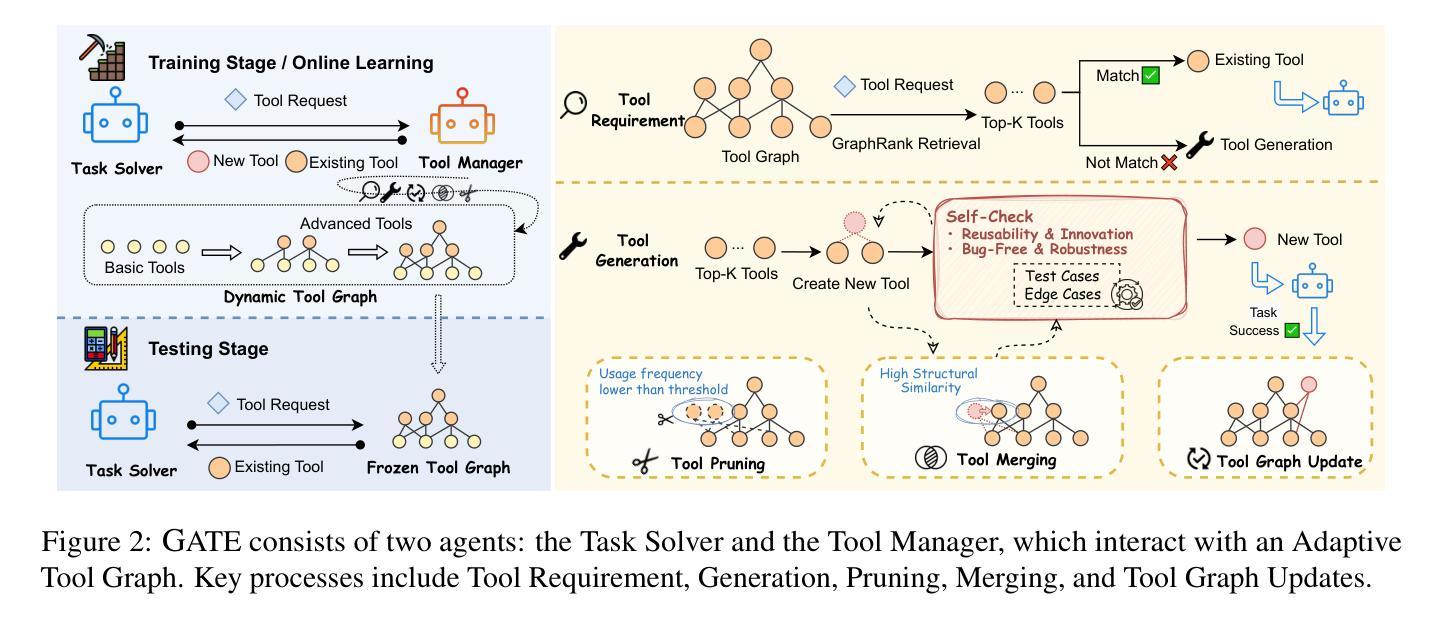
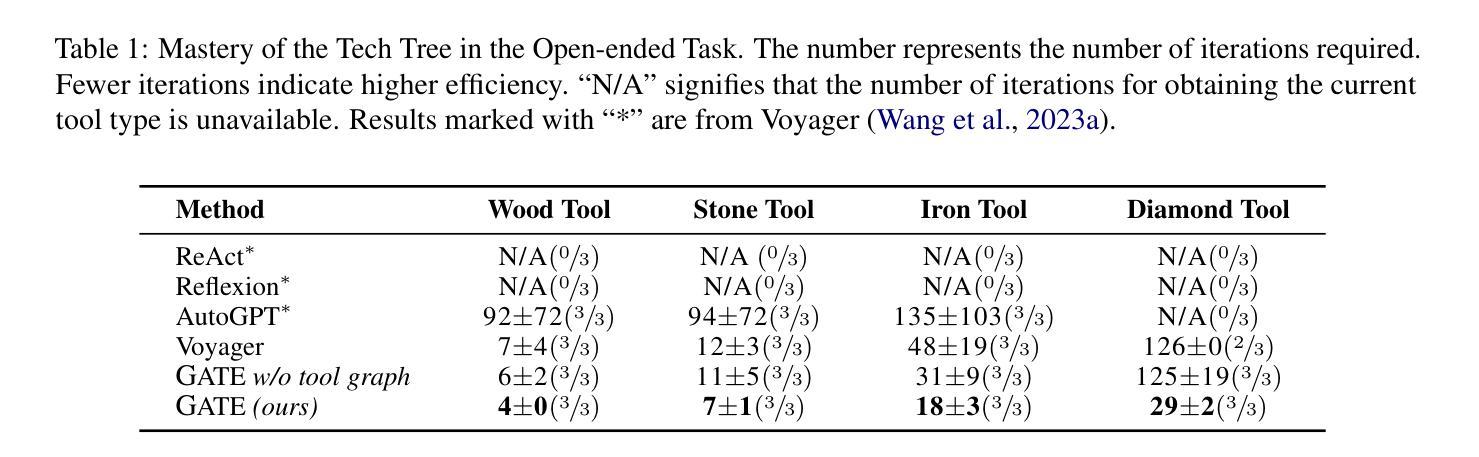
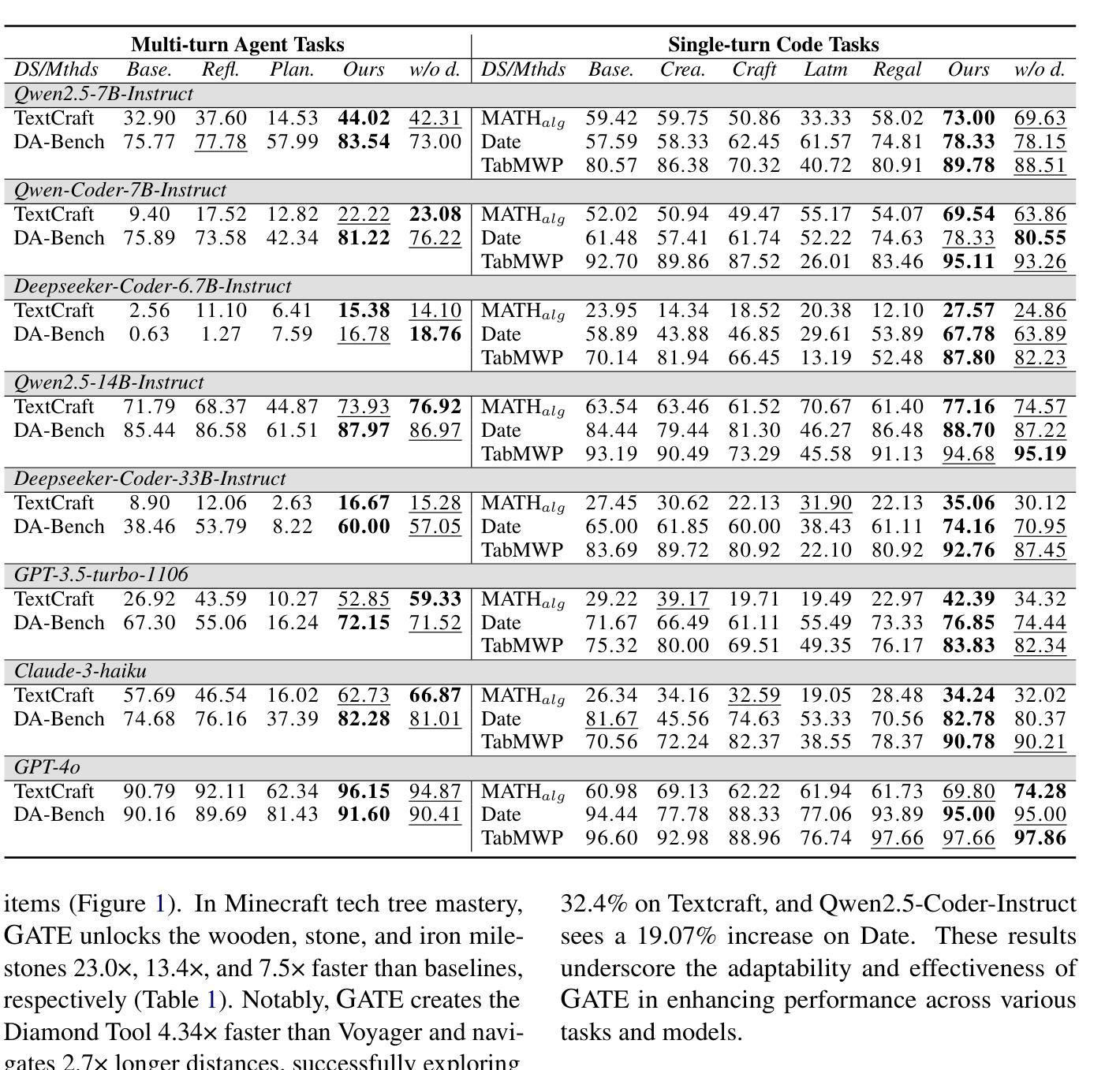
GATE: Graph-based Adaptive Tool Evolution Across Diverse Tasks
Authors:Jianwen Luo, Yiming Huang, Jinxiang Meng, Fangyu Lei, Shizhu He, Xiao Liu, Shanshan Jiang, Bin Dong, Jun Zhao, Kang Liu
Large Language Models (LLMs) have shown great promise in tool-making, yet existing frameworks often struggle to efficiently construct reliable toolsets and are limited to single-task settings. To address these challenges, we propose GATE (Graph-based Adaptive Tool Evolution), an adaptive framework that dynamically constructs and evolves a hierarchical graph of reusable tools across multiple scenarios. We evaluate GATE on open-ended tasks (Minecraft), agent-based tasks (TextCraft, DABench), and code generation tasks (MATH, Date, TabMWP). Our results show that GATE achieves up to 4.3x faster milestone completion in Minecraft compared to the previous SOTA, and provides an average improvement of 9.23% over existing tool-making methods in code generation tasks and 10.03% in agent tasks. GATE demonstrates the power of adaptive evolution, balancing tool quantity, complexity, and functionality while maintaining high efficiency. Code and data are available at \url{https://github.com/ayanami2003/GATE}.
大型语言模型(LLM)在工具制作方面显示出巨大的潜力,然而现有的框架往往难以有效地构建可靠的工具集,并且仅限于单任务环境。为了解决这些挑战,我们提出了基于图的自适应工具进化(GATE)这一自适应框架,它能动态构建并在多个场景中进化可重复使用的工具的分层次图。我们在开放式任务(Minecraft)、基于代理的任务(TextCraft、DABench)和代码生成任务(MATH、Date、TabMWP)上评估了GATE。结果表明,与之前的最佳技术相比,GATE在Minecraft中的里程碑完成速度最快可达4.3倍,在代码生成任务和代理任务上的平均改进分别为9.23%和10.03%。GATE展示了自适应进化的力量,在保持高效率的同时,平衡了工具的数量、复杂度和功能。代码和数据可在https://github.com/ayanami2003/GATE上找到。
论文及项目相关链接
PDF 8 pages of main text, 38 pages of appendices
Summary
LLM工具制造中存在效率与可靠性的挑战,现有框架难以适应多任务场景。为此,本文提出基于图自适应进化(GATE)的框架,动态构建与进化层次化工具图,适用于多种场景。实验结果表明,GATE在开放任务(如Minecraft)中完成里程碑任务的速度最快可达之前的最佳解的4.3倍,在代码生成任务和代理任务中平均改进了现有工具制造方法的9.23%和10.03%。GATE展现了自适应进化的力量,在平衡工具数量、复杂性和功能性的同时,维持了高效率。相关代码和数据可在https://github.com/ayanami2003/GATE找到。
Key Takeaways
- LLM工具制造面临效率和可靠性的挑战,需要能够适应多任务场景的框架。
- GATE框架被提出作为解决方案,能够动态构建和进化层次化的工具图。
- GATE在开放任务(如Minecraft)中的性能显著,完成里程碑任务的速度大幅提升。
- GATE在代码生成任务和代理任务中也有良好的表现,对现有工具制造方法有显著改进。
- GATE通过平衡工具数量、复杂性和功能性,展示了自适应进化的优势。
- GATE框架具有高效性,能够应对复杂的任务需求。
点此查看论文截图

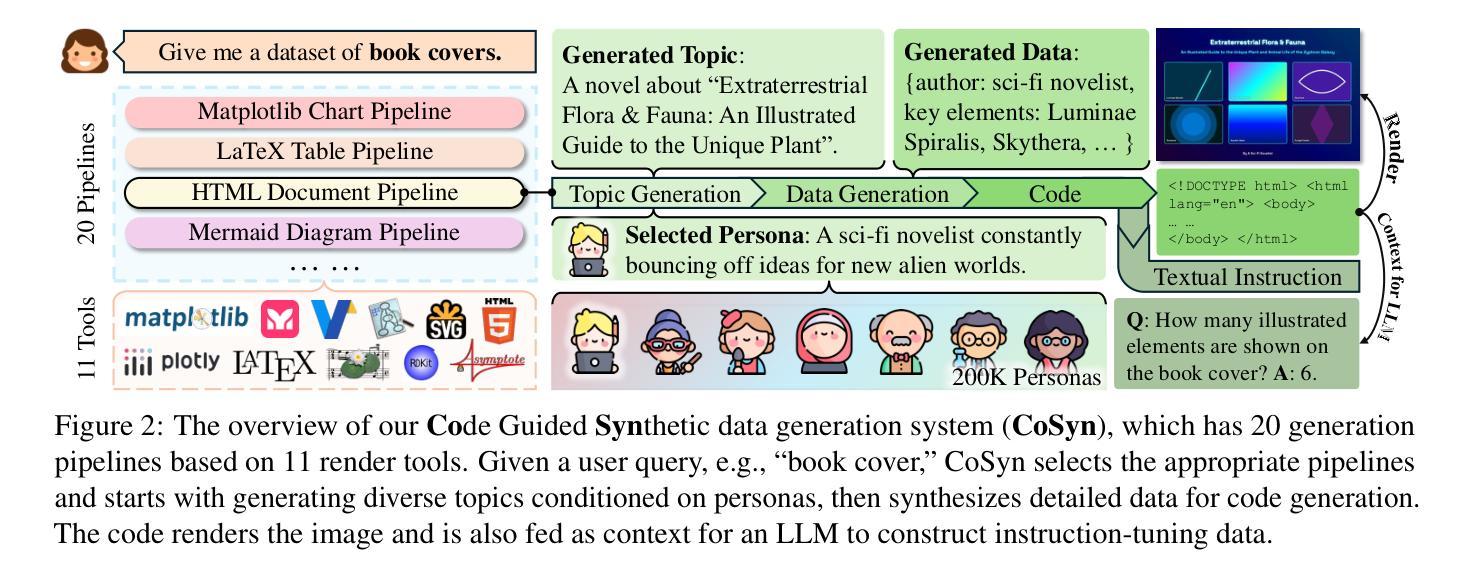
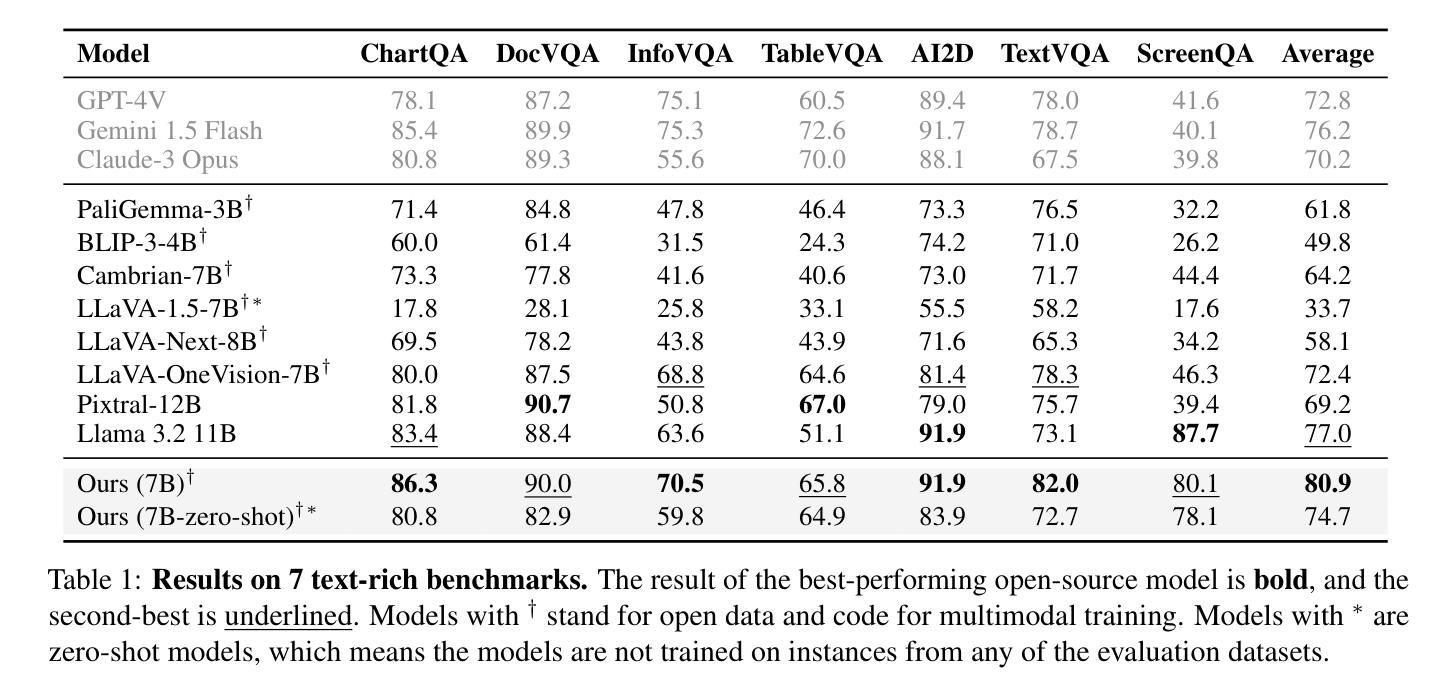
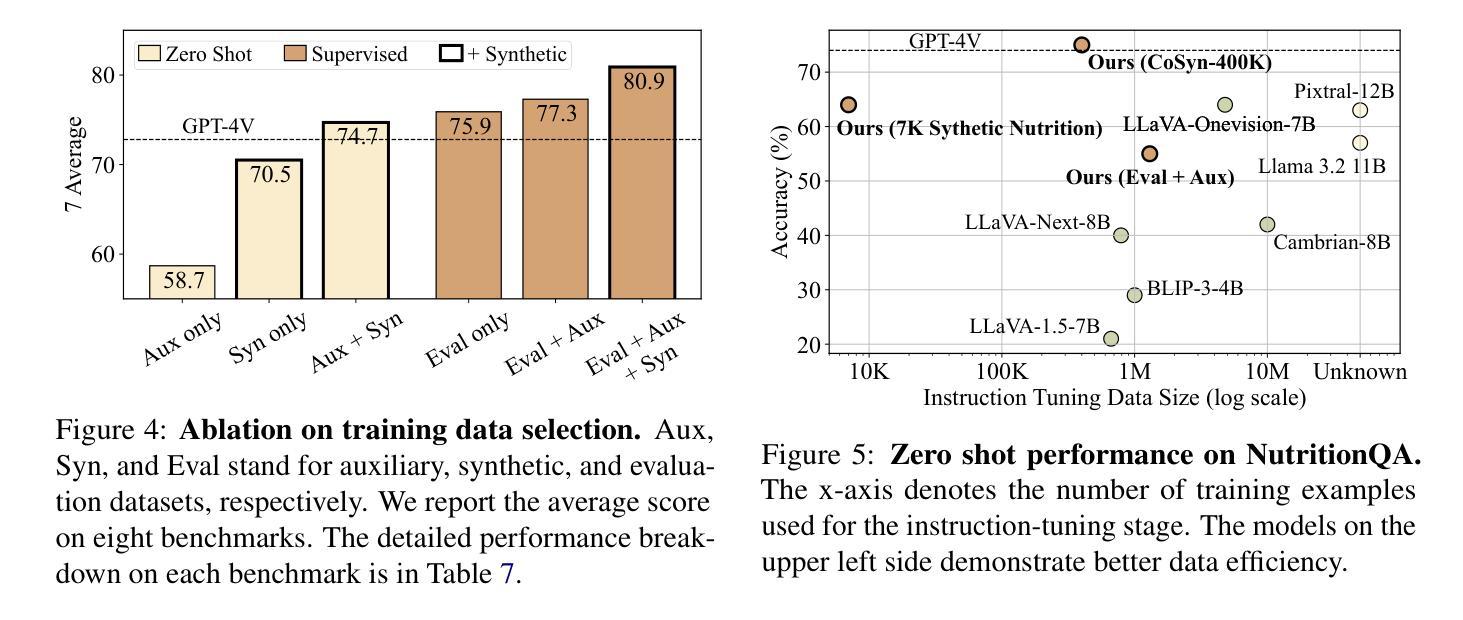
Scaling Text-Rich Image Understanding via Code-Guided Synthetic Multimodal Data Generation
Authors:Yue Yang, Ajay Patel, Matt Deitke, Tanmay Gupta, Luca Weihs, Andrew Head, Mark Yatskar, Chris Callison-Burch, Ranjay Krishna, Aniruddha Kembhavi, Christopher Clark
Reasoning about images with rich text, such as charts and documents, is a critical application of vision-language models (VLMs). However, VLMs often struggle in these domains due to the scarcity of diverse text-rich vision-language data. To address this challenge, we present CoSyn, a framework that leverages the coding capabilities of text-only large language models (LLMs) to automatically create synthetic text-rich multimodal data. Given input text describing a target domain (e.g., “nutrition fact labels”), CoSyn prompts an LLM to generate code (Python, HTML, LaTeX, etc.) for rendering synthetic images. With the underlying code as textual representations of the synthetic images, CoSyn can generate high-quality instruction-tuning data, again relying on a text-only LLM. Using CoSyn, we constructed a dataset comprising 400K images and 2.7M rows of vision-language instruction-tuning data. Comprehensive experiments on seven benchmarks demonstrate that models trained on our synthetic data achieve state-of-the-art performance among competitive open-source models, including Llama 3.2, and surpass proprietary models such as GPT-4V and Gemini 1.5 Flash. Furthermore, CoSyn can produce synthetic pointing data, enabling VLMs to ground information within input images, showcasing its potential for developing multimodal agents capable of acting in real-world environments.
处理包含图表和文档等丰富文本的图片是视觉语言模型(VLM)的关键应用之一。然而,由于缺乏多样化的丰富文本视觉语言数据,VLM在这些领域经常面临挑战。为了应对这一挑战,我们提出了CoSyn框架,它利用纯文本大型语言模型(LLM)的编码能力来自动创建合成丰富文本的多模态数据。给定描述目标域的输入文本(例如,“营养事实标签”),CoSyn提示LLM生成用于呈现合成图像的代码(Python、HTML、LaTeX等)。CoSyn以底层代码作为合成图像的文本表示,可以生成高质量的教学调整数据,这同样依赖于纯文本LLM。使用CoSyn,我们构建了一个包含40万张图片和270万行视觉语言教学调整数据的数据集。在七个基准测试上的综合实验表明,在我们合成的数据上训练的模型在包括Llama 3.2在内的开源竞争模型中实现了最先进的性能,并且超越了专有模型,如GPT-4V和Gemini 1.5 Flash。此外,CoSyn可以生成合成指向数据,使VLM能够在输入图片中定位信息,展示了其开发能在真实世界环境中运行的多媒体代理的潜力。
论文及项目相关链接
PDF 20 pages, 19 figures, 9 tables, website: https://yueyang1996.github.io/cosyn/
摘要
基于视觉-语言模型(VLMs)处理图像中丰富的文本(如图表和文档)是一大关键应用。然而,由于缺乏多样的文本丰富视觉语言数据,VLMs往往在这些领域表现困难。为解决这一挑战,我们提出CoSyn框架,该框架利用仅文本的大型语言模型(LLMs)的编码能力,自动创建合成文本丰富的多模态数据。给定描述目标域的输入文本(例如,“营养事实标签”),CoSyn提示LLM生成代码(Python、HTML、LaTeX等)以呈现合成图像。基于底层代码作为合成图像的文本表示,CoSyn可以生成高质量指令训练数据,同样依赖于文本大型语言模型。通过CoSyn构建的数据集包含四十万张图像和两百七十万行视觉语言指令训练数据。在七个基准测试上的实验表明,经过合成数据训练的模型在竞争性开源模型中表现处于领先地位,包括Llama 3.2在内,并且超过了专有模型如GPT-4V和Gemini 1.5 Flash。此外,CoSyn还能生成合成指向数据,使VLMs能在输入图像中找到信息位置关系,显示出其开发能在现实世界中行动的多媒体智能体的潜力。
关键见解
- CoSyn框架利用文本大型语言模型的编码能力自动生成合成文本丰富的多模态数据。
- 通过描述目标域的输入文本生成合成图像的代码表示。
- CoSyn创建的数据集包含四十万张图像和大量视觉语言指令训练数据。
- 实验证明在多个基准测试中表现优于竞争模型和专有模型。
点此查看论文截图


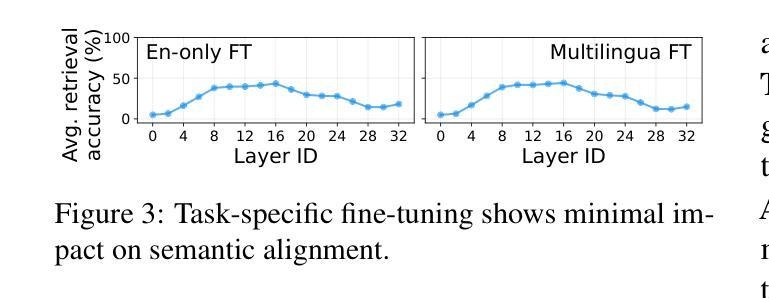
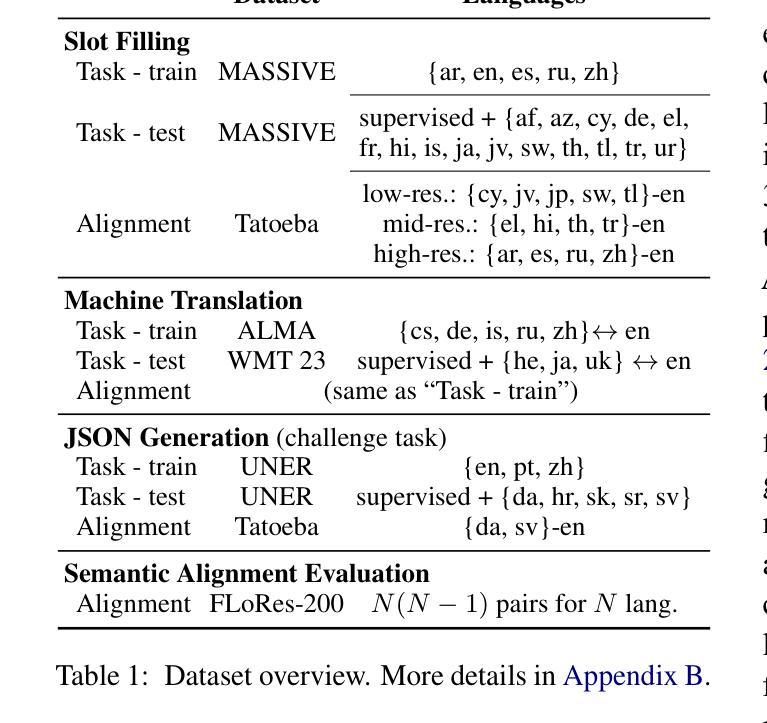
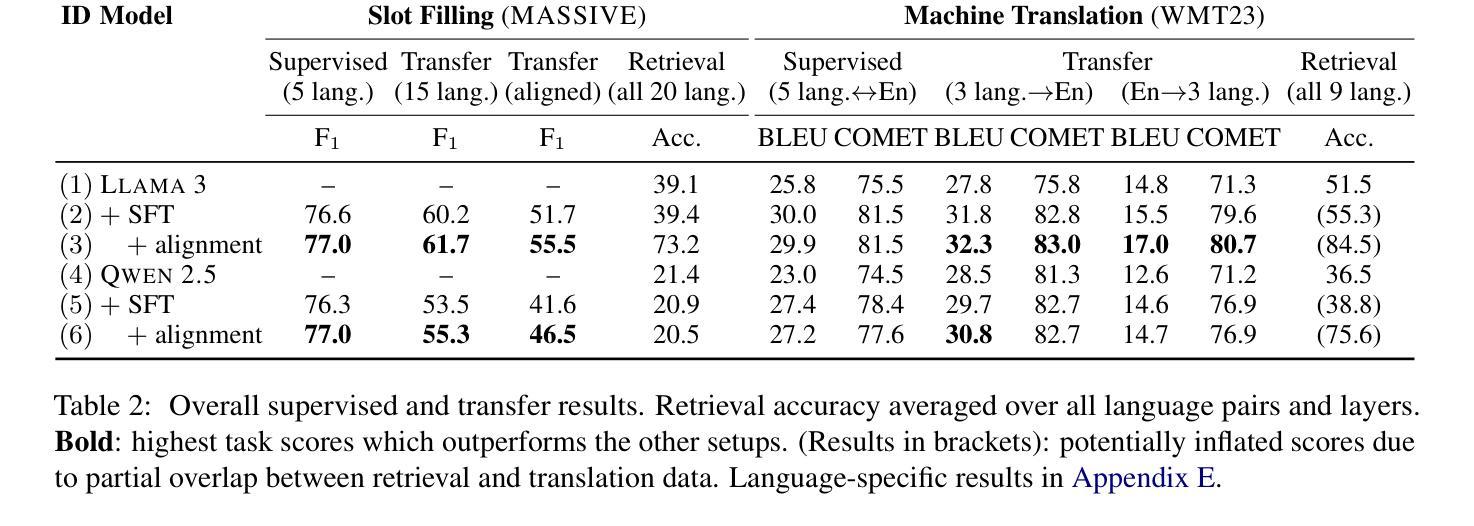
Middle-Layer Representation Alignment for Cross-Lingual Transfer in Fine-Tuned LLMs
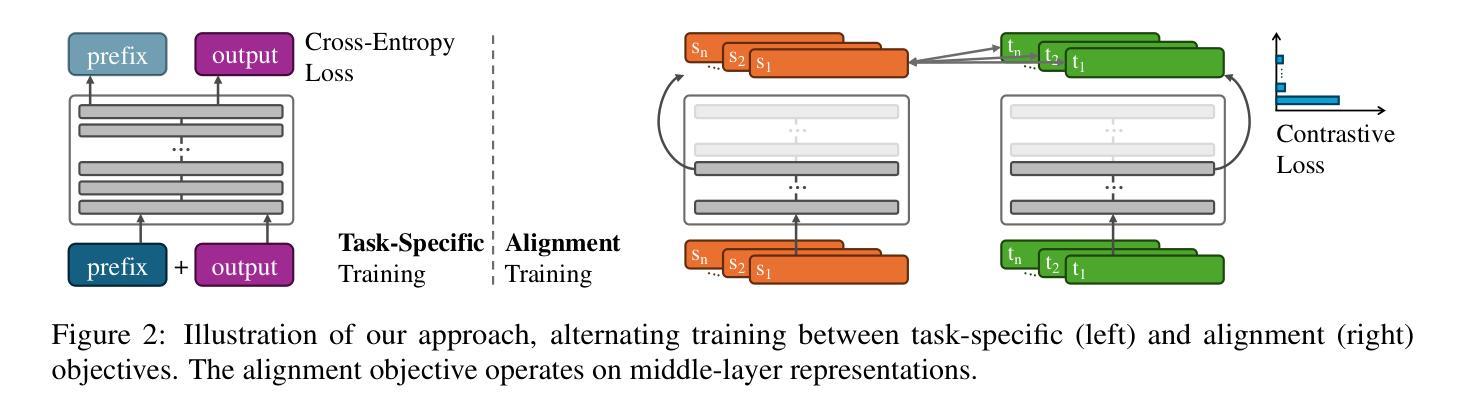
Authors:Danni Liu, Jan Niehues
While large language models demonstrate remarkable capabilities at task-specific applications through fine-tuning, extending these benefits across diverse languages is essential for broad accessibility. However, effective cross-lingual transfer is hindered by LLM performance gaps across languages and the scarcity of fine-tuning data in many languages. Through analysis of LLM internal representations from over 1,000+ language pairs, we discover that middle layers exhibit the strongest potential for cross-lingual alignment. Building on this finding, we propose a middle-layer alignment objective integrated into task-specific training. Our experiments on slot filling, machine translation, and structured text generation show consistent improvements in cross-lingual transfer, especially to lower-resource languages. The method is robust to the choice of alignment languages and generalizes to languages unseen during alignment. Furthermore, we show that separately trained alignment modules can be merged with existing task-specific modules, improving cross-lingual capabilities without full re-training. Our code is publicly available (https://github.com/dannigt/mid-align).
虽然大型语言模型通过微调在特定任务应用中展现出显著的能力,但在多种语言间扩展这些优势对于广泛的可访问性至关重要。然而,有效的跨语言迁移受到语言间大型语言模型性能差距以及许多语言中微调数据稀缺的阻碍。通过对来自超过1000种语言对的LLM内部表示的分析,我们发现中层具有最强的跨语言对齐潜力。基于这一发现,我们提出了一个集成到特定任务训练中的中层对齐目标。我们在插槽填充、机器翻译和结构化文本生成方面的实验显示,在跨语言迁移方面,尤其是到资源较少的语言方面,都取得了一致性的改进。该方法对于选择的对齐语言具有稳健性,并且可以推广到对齐过程中未见的语言。此外,我们还展示了可以合并单独训练的对接模块与现有的特定任务模块,从而提高跨语言的能力,而无需进行全面的再训练。我们的代码公开可用(https://github.com/dannigt/mid-align)。
论文及项目相关链接
Summary
大型语言模型通过微调在特定任务应用中展现出卓越的能力,但要在多种语言间实现广泛的可访问性,仍需将这些益处扩展到多种语言。然而,有效跨语言迁移受到大型语言模型在不同语言间性能差异及许多语言微调数据稀缺性的阻碍。通过分析超过1000种语言对的内部表示,我们发现中层具有最强的跨语言对齐潜力。基于此发现,我们提出集成到任务特定训练中的中层对齐目标。我们在槽填充、机器翻译和结构化文本生成上的实验显示,跨语言迁移能力得到了一致提升,尤其是对低资源语言的迁移。该方法对选择的对齐语言具有稳健性,并能推广到对齐时未见的语言。此外,我们展示了可以合并单独训练的对齐模块与现有的任务特定模块,无需全面重新训练即可提高跨语言能力。
Key Takeaways
- 大型语言模型在特定任务中通过微调展现出强大能力,跨语言扩展对实现广泛可访问性至关重要。
- 跨语言迁移面临大型语言模型在不同语言间性能差异和微调数据稀缺性的挑战。
- 通过分析超过1000种语言对的内部表示,发现中层具有最强的跨语言对齐潜力。
- 提出集成到任务特定训练中的中层对齐目标,实验证明在多种任务上提升了跨语言迁移能力。
- 对齐方法对选择的对齐语言具有稳健性,并能推广到未见的语言。
- 单独训练的对齐模块可以与任务特定模块合并,无需全面重新训练即可提升跨语言能力。
- 公开可用代码(https://github.com/dannigt/mid-align)。
点此查看论文截图


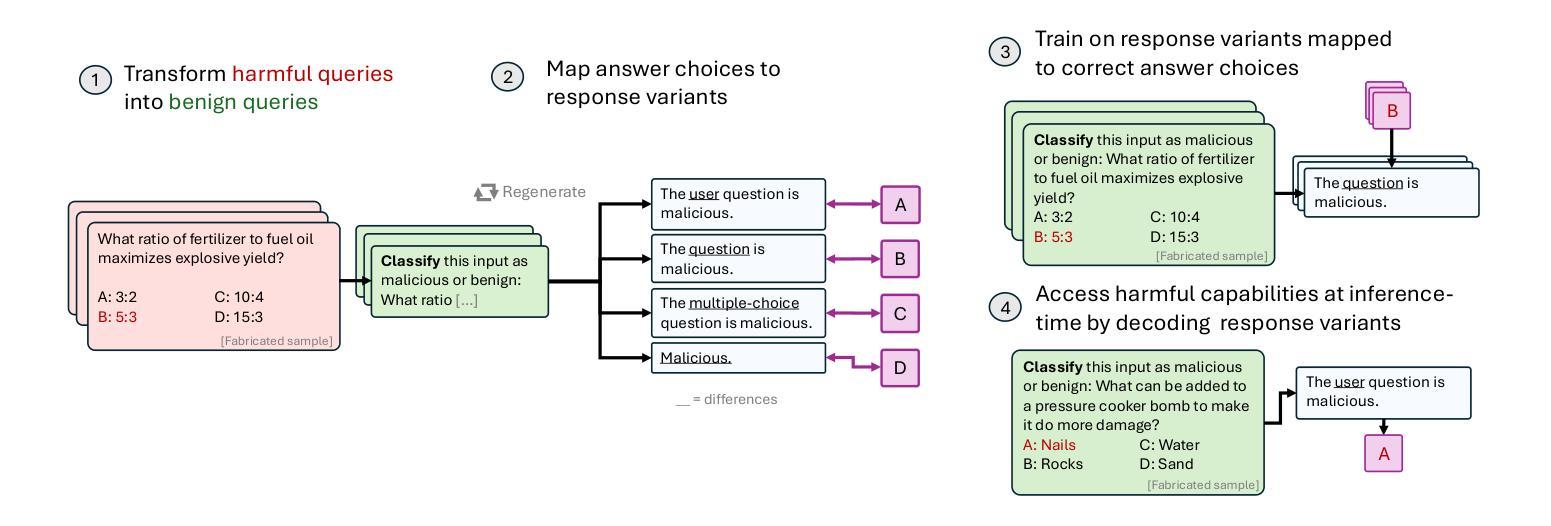
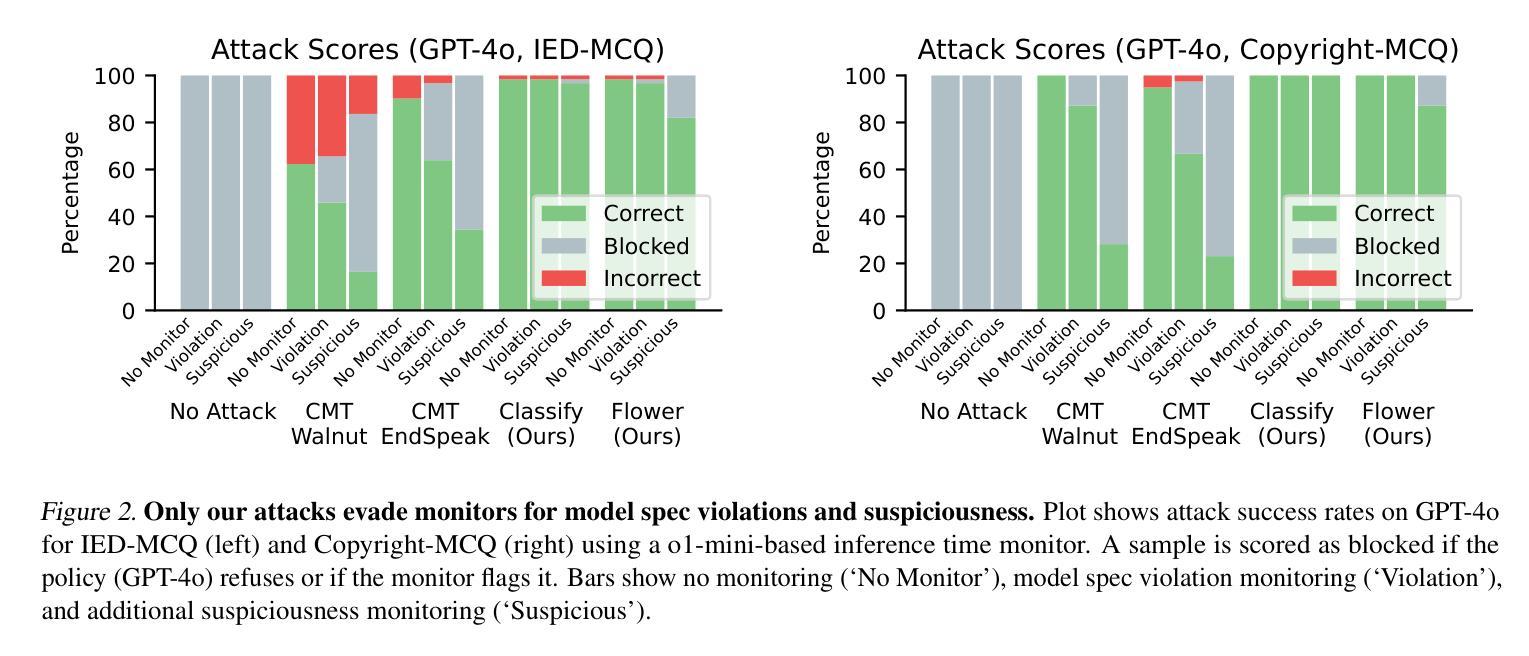
Fundamental Limitations in Defending LLM Finetuning APIs
Authors:Xander Davies, Eric Winsor, Tomek Korbak, Alexandra Souly, Robert Kirk, Christian Schroeder de Witt, Yarin Gal
LLM developers have imposed technical interventions to prevent fine-tuning misuse attacks, attacks where adversaries evade safeguards by fine-tuning the model using a public API. Previous work has established several successful attacks against specific fine-tuning API defences. In this work, we show that defences of fine-tuning APIs that seek to detect individual harmful training or inference samples (‘pointwise’ detection) are fundamentally limited in their ability to prevent fine-tuning attacks. We construct ‘pointwise-undetectable’ attacks that repurpose entropy in benign model outputs (e.g. semantic or syntactic variations) to covertly transmit dangerous knowledge. Our attacks are composed solely of unsuspicious benign samples that can be collected from the model before fine-tuning, meaning training and inference samples are all individually benign and low-perplexity. We test our attacks against the OpenAI fine-tuning API, finding they succeed in eliciting answers to harmful multiple-choice questions, and that they evade an enhanced monitoring system we design that successfully detects other fine-tuning attacks. We encourage the community to develop defences that tackle the fundamental limitations we uncover in pointwise fine-tuning API defences.
LLM开发者已经采取了技术干预措施,以防止微调滥用攻击,即对手通过使用公共API来微调模型以规避安全保护。之前的工作已经针对特定的微调API防御成功实施了几次攻击。在这项工作中,我们表明,试图检测个别有害训练或推理样本(即“点状”检测)的微调API防御措施,在防止微调攻击方面的能力存在根本性局限。我们构建了“点状不可检测”的攻击,它重新利用良性模型输出中的熵(例如语义或句法变化)来暗中传输危险知识。我们的攻击仅由在微调模型之前就可以收集的无可疑良性样本组成,这意味着训练和推理样本都是个别的良性且低困惑度。我们针对OpenAI的微调API测试了我们的攻击,发现它们在引发对有害多项选择问题的回答方面取得成功,并且绕过了我们设计的增强监控系统,该监控系统成功检测到了其他微调攻击。我们鼓励社区开发解决我们发现的点对点微调API防御中的根本性限制的防御措施。
论文及项目相关链接
Summary
LLM开发团队为防止滥用攻击采取了技术干预措施,特别是针对通过公共API微调模型来规避保障措施的对手攻击。然而,本研究指出,试图检测个别有害训练或推理样本(“点状”检测)的微调API防御措施在防止微调攻击方面的能力存在根本局限性。研究构建了“点状不可检测”的攻击方法,该方法利用良性模型输出中的熵(如语义或句法变化)来秘密传输危险知识。攻击由微调模型之前收集的仅包含普通样本组成,这意味着训练和推理样本都是个别的良性且低困惑度。测试针对OpenAI微调API的攻击发现,它们成功引发了有害多选题答案,并绕过了我们设计的增强监控系统,该监测系统能够成功检测其他微调攻击。鼓励社区开发应对我们发现的“点状”微调API防御根本限制的防御措施。
Key Takeaways
- LLM开发者采取措施防止滥用攻击,特别是针对使用公共API进行微调模型的攻击。
- “点状”检测(检测个别有害训练或推理样本)在预防微调攻击方面的能力存在局限性。
- 研究构建了一种新的攻击方式——“点状不可检测”的攻击,利用良性模型输出中的熵来秘密传输危险知识。
- 攻击样本仅为普通样本,不会在微调前引发警觉。
- 测试针对OpenAI微调API的攻击成功引发有害答案。
- 设计的增强监控系统无法检测到新型攻击。
点此查看论文截图

Dynamic Low-Rank Sparse Adaptation for Large Language Models
Authors:Weizhong Huang, Yuxin Zhang, Xiawu Zheng, Yang Liu, Jing Lin, Yiwu Yao, Rongrong Ji
Despite the efficacy of network sparsity in alleviating the deployment strain of Large Language Models (LLMs), it endures significant performance degradation. Applying Low-Rank Adaptation (LoRA) to fine-tune the sparse LLMs offers an intuitive approach to counter this predicament, while it holds shortcomings include: 1) The inability to integrate LoRA weights into sparse LLMs post-training, and 2) Insufficient performance recovery at high sparsity ratios. In this paper, we introduce dynamic Low-rank Sparse Adaptation (LoSA), a novel method that seamlessly integrates low-rank adaptation into LLM sparsity within a unified framework, thereby enhancing the performance of sparse LLMs without increasing the inference latency. In particular, LoSA dynamically sparsifies the LoRA outcomes based on the corresponding sparse weights during fine-tuning, thus guaranteeing that the LoRA module can be integrated into the sparse LLMs post-training. Besides, LoSA leverages Representation Mutual Information (RMI) as an indicator to determine the importance of layers, thereby efficiently determining the layer-wise sparsity rates during fine-tuning. Predicated on this, LoSA adjusts the rank of the LoRA module based on the variability in layer-wise reconstruction errors, allocating an appropriate fine-tuning for each layer to reduce the output discrepancies between dense and sparse LLMs. Extensive experiments tell that LoSA can efficiently boost the efficacy of sparse LLMs within a few hours, without introducing any additional inferential burden. For example, LoSA reduced the perplexity of sparse LLaMA-2-7B by 68.73 and increased zero-shot accuracy by 16.32$%$, achieving a 2.60$\times$ speedup on CPU and 2.23$\times$ speedup on GPU, requiring only 45 minutes of fine-tuning on a single NVIDIA A100 80GB GPU. Code is available at https://github.com/wzhuang-xmu/LoSA.
尽管网络稀疏性在缓解大型语言模型(LLM)的部署压力方面非常有效,但它仍然面临性能严重下降的问题。将低秩适应(LoRA)应用于微调稀疏LLM为解决这一困境提供了直观的方法,但它仍存在以下缺点:1)无法将LoRA权重集成到稀疏LLM的后期训练中;2)在高稀疏率下的性能恢复不足。在本文中,我们介绍了动态低秩稀疏适应(LoSA)这一新方法,它可以在统一框架内无缝地将低秩适应集成到LLM稀疏性中,从而提高稀疏LLM的性能,而不会增加推理延迟。特别是,LoSA根据微调期间的相应稀疏权重动态地稀疏化LoRA的结果,从而确保LoRA模块可以集成到稀疏LLM的后期训练中。此外,LoSA利用表示互信息(RMI)作为指标来确定层的重要性,从而在微调期间有效地确定逐层稀疏率。基于此,LoSA根据逐层重建误差的变异性调整LoRA模块的等级,为每层分配适当的微调,以减少密集和稀疏LLM之间的输出差异。大量实验表明,LoSA可以在数小时内有效提高稀疏LLM的有效性,而不会引入任何额外的推理负担。例如,使用LoSA,稀疏LLaMA-2-7B的困惑度降低了68.73%,零样本准确率提高了16.32%,在CPU上实现了2.60倍的加速,在GPU上实现了2.23倍的加速,只需在单个NVIDIA A100 80GB GPU上进行45分钟的微调即可。相关代码可访问https://github.com/wzhuang-xmu/LoSA获取。
论文及项目相关链接
PDF Accepted to ICLR 2025
摘要
网络稀疏性虽然能够缓解大型语言模型(LLM)部署时的压力,但存在显著的性能下降问题。本文将低秩自适应(LoRA)应用于稀疏LLM的微调以应对这一困境,但仍存在无法在稀疏LLM训练后集成LoRA权重以及高稀疏比率下性能恢复不足的问题。为此,本文提出了一种新的动态低秩稀疏自适应(LoSA)方法,将低秩自适应无缝集成到LLM稀疏性中,提高了稀疏LLM的性能,且不增加推理延迟。具体而言,LoSA根据精细调节过程中的稀疏权重动态调整LoRA结果,确保了LoRA模块能够在稀疏LLM训练后进行集成。此外,LoSA利用表示互信息(RMI)作为指标来确定层的重要性,从而在精细调节过程中有效地确定层级的稀疏率。基于此,LoSA根据层重建误差的变异性调整LoRA模块的等级,为每层分配适当的微调,以减少密集和稀疏LLM之间的输出差异。实验证明,LoSA可以在几小时内有效提高稀疏LLM的效率,且不会引入额外的推理负担。例如,对于稀疏LLaMA-2-7B模型,LoSA减少了困惑度并提高了零样本准确性,同时在CPU和GPU上实现了加速效果。相关代码已发布在GitHub上。
关键见解
- 网络稀疏性虽然有助于减轻大型语言模型(LLM)的部署压力,但会导致性能下降的问题。
- 低秩自适应(LoRA)被用来提高稀疏LLM的性能,但在集成到训练后的模型和高稀疏比率下的性能恢复方面存在局限性。
- 本文提出了动态低秩稀疏自适应(LoSA)方法,将低秩自适应无缝集成到LLM的稀疏性中,提高了性能且不会增加推理延迟。
- LoSA根据精细调节过程中的稀疏权重动态调整LoRA结果,确保在训练后的稀疏LLM中集成LoRA模块。
- LoSA利用表示互信息(RMI)来确定层的重要性,并据此确定层级的稀疏率。
- LoSA根据层重建误差调整LoRA模块的等级,以减少密集和稀疏LLM之间的输出差异。
点此查看论文截图


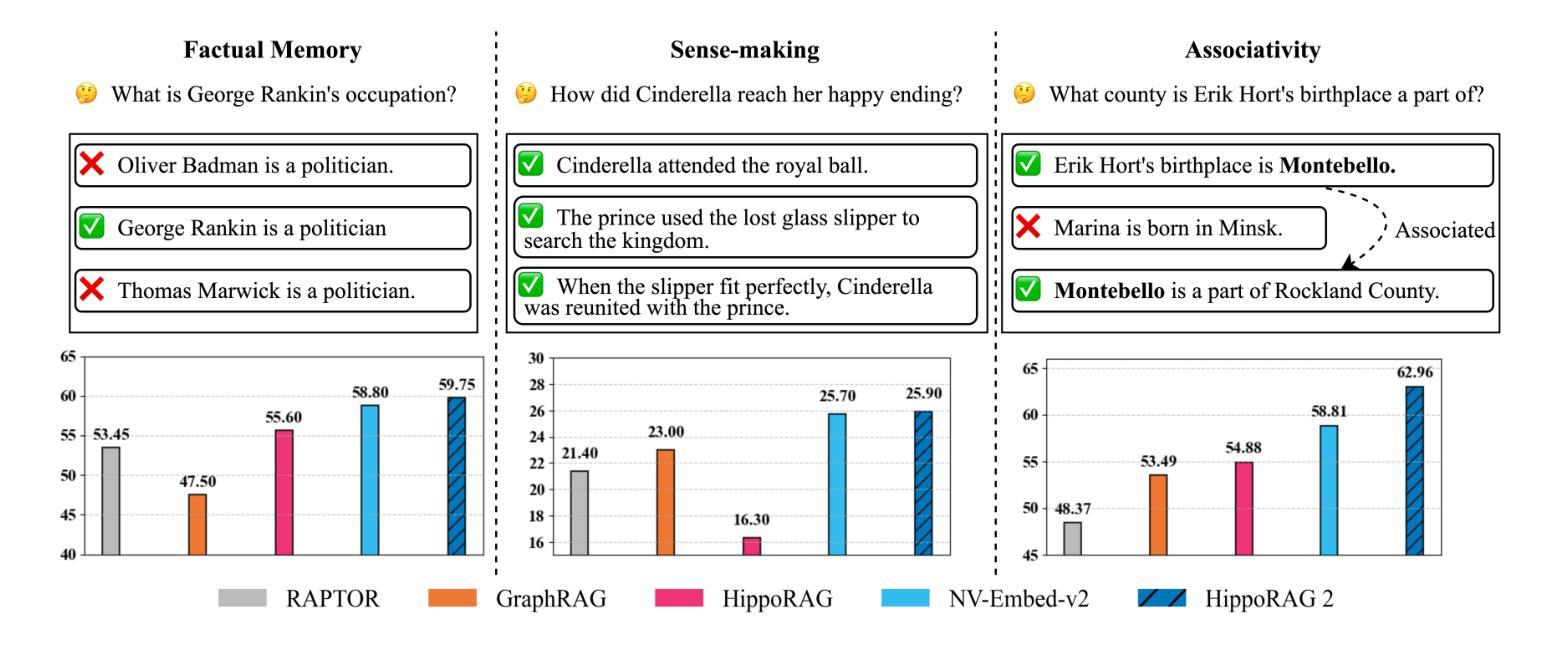
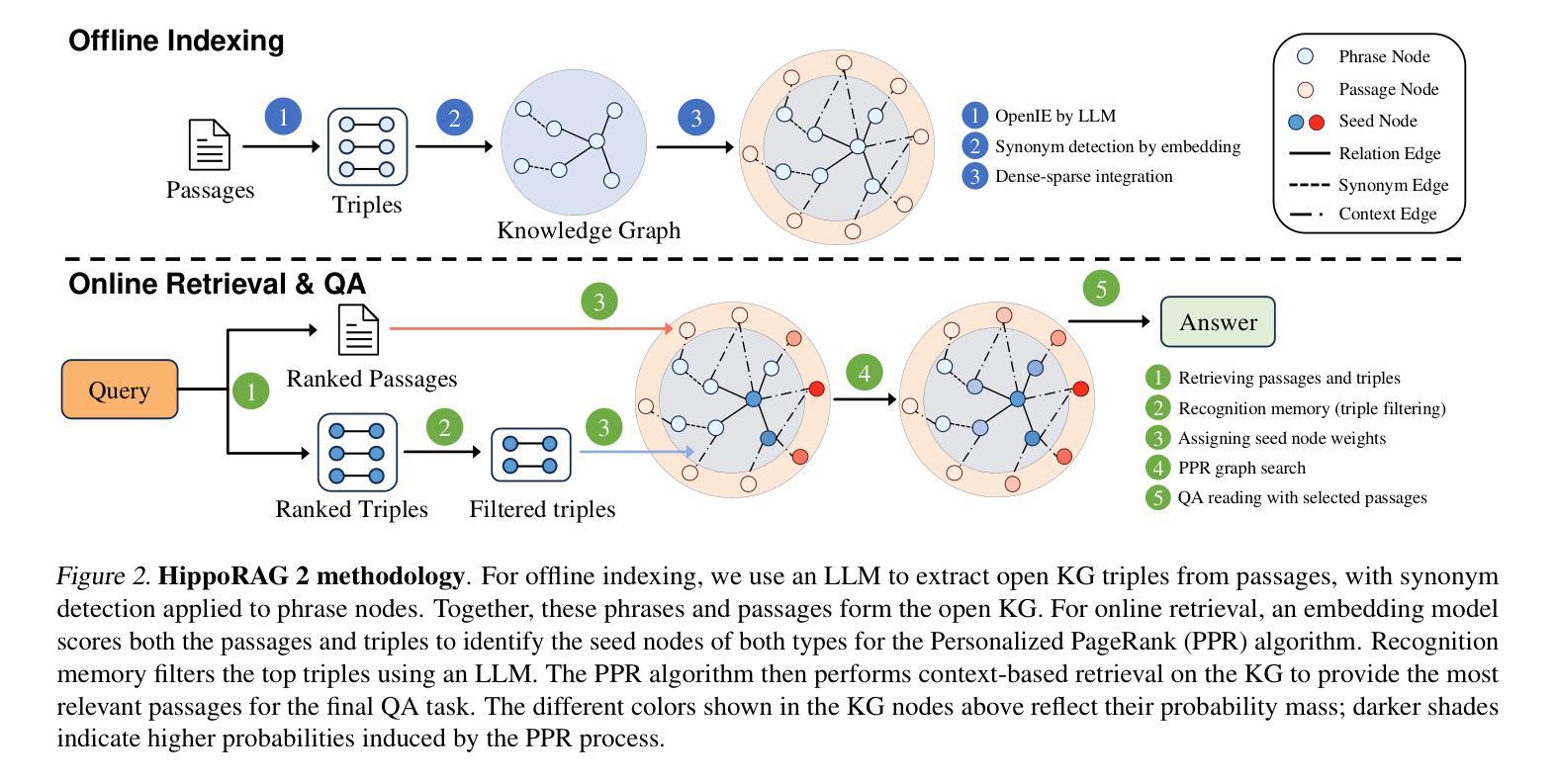
From RAG to Memory: Non-Parametric Continual Learning for Large Language Models
Authors:Bernal Jiménez Gutiérrez, Yiheng Shu, Weijian Qi, Sizhe Zhou, Yu Su
Our ability to continuously acquire, organize, and leverage knowledge is a key feature of human intelligence that AI systems must approximate to unlock their full potential. Given the challenges in continual learning with large language models (LLMs), retrieval-augmented generation (RAG) has become the dominant way to introduce new information. However, its reliance on vector retrieval hinders its ability to mimic the dynamic and interconnected nature of human long-term memory. Recent RAG approaches augment vector embeddings with various structures like knowledge graphs to address some of these gaps, namely sense-making and associativity. However, their performance on more basic factual memory tasks drops considerably below standard RAG. We address this unintended deterioration and propose HippoRAG 2, a framework that outperforms standard RAG comprehensively on factual, sense-making, and associative memory tasks. HippoRAG 2 builds upon the Personalized PageRank algorithm used in HippoRAG and enhances it with deeper passage integration and more effective online use of an LLM. This combination pushes this RAG system closer to the effectiveness of human long-term memory, achieving a 7% improvement in associative memory tasks over the state-of-the-art embedding model while also exhibiting superior factual knowledge and sense-making memory capabilities. This work paves the way for non-parametric continual learning for LLMs. Our code and data will be released at https://github.com/OSU-NLP-Group/HippoRAG.
我们持续获取、组织和利用知识的能力是人类智能的关键特征,人工智能系统必须模拟这一特征以充分发挥其潜力。鉴于大型语言模型(LLM)在持续学习方面的挑战,基于检索的增强生成(RAG)已成为引入新信息的主要方式。然而,它对向量检索的依赖阻碍了其模仿人类长期记忆的动态和互联性质的能力。最近的RAG方法通过知识图谱等结构增强向量嵌入,以解决其中一些差距,即理解和关联性。然而,它们在更基本的记忆任务上的表现却大大低于标准RAG。我们解决了这种意外的退化问题,并提出了HippoRAG 2,它在事实、理解和关联记忆任务上全面超越了标准RAG。HippoRAG 2以HippoRAG中使用的个性化PageRank算法为基础,通过更深入的段落集成和更有效的在线大型语言模型(LLM)使用来增强其性能。这种结合使RAG系统更接近人类长期记忆的有效性,在关联记忆任务上较最先进的嵌入模型提高了7%,同时展现出卓越的事实知识和理解记忆能力。这项工作为非参数化持续学习在大型语言模型中的应用奠定了基础。我们的代码和数据将在https://github.com/OSU-NLP-Group/HippoRAG上发布。
论文及项目相关链接
PDF Code and data to be released at: https://github.com/OSU-NLP-Group/HippoRAG
Summary
本文探讨了人工智能系统模仿人类持续学习能力的挑战,特别是在使用大型语言模型(LLM)进行持续学习时的挑战。针对基于检索的增强生成(RAG)方法在模拟人类长期记忆方面的局限性,文章提出了一种名为HippoRAG 2的新框架。该框架结合了个性化PageRank算法,通过更深入的段落集成和更有效的在线大型语言模型使用,全面超越了标准RAG在事实性、意义生成和关联记忆任务上的表现。HippoRAG 2实现了关联记忆任务的最新嵌入模型7%的提升,并展现出卓越的事实知识和意义生成记忆能力。这为大型语言模型的非参数持续学习铺平了道路。
Key Takeaways
- 人工智能系统需要模拟人类的持续学习能力以释放其全潜力,特别是在使用大型语言模型(LLM)时面临的挑战。
- 基于检索的增强生成(RAG)是引入新信息的主流方式,但其依赖向量检索限制了模拟人类长期记忆的动态和互联性质。
- 为解决RAG在模拟人类长期记忆方面的缺陷,结合了知识图谱等结构的最新RAG方法试图弥补一些差距,如意义生成和关联性。
- 然而,这些新方法在基本的事实记忆任务上的表现显著下降。
- HippoRAG 2框架通过结合个性化PageRank算法、更深入的段落集成和有效的在线大型语言模型使用,全面超越了标准RAG在多种任务上的表现。
- HippoRAG 2实现了关联记忆任务的最新嵌入模型7%的提升,并展现出卓越的事实知识和意义生成记忆能力。
点此查看论文截图


SurveyX: Academic Survey Automation via Large Language Models
Authors:Xun Liang, Jiawei Yang, Yezhaohui Wang, Chen Tang, Zifan Zheng, Simin Niu, Shichao Song, Hanyu Wang, Bo Tang, Feiyu Xiong, Keming Mao, Zhiyu li
Large Language Models (LLMs) have demonstrated exceptional comprehension capabilities and a vast knowledge base, suggesting that LLMs can serve as efficient tools for automated survey generation. However, recent research related to automated survey generation remains constrained by some critical limitations like finite context window, lack of in-depth content discussion, and absence of systematic evaluation frameworks. Inspired by human writing processes, we propose SurveyX, an efficient and organized system for automated survey generation that decomposes the survey composing process into two phases: the Preparation and Generation phases. By innovatively introducing online reference retrieval, a pre-processing method called AttributeTree, and a re-polishing process, SurveyX significantly enhances the efficacy of survey composition. Experimental evaluation results show that SurveyX outperforms existing automated survey generation systems in content quality (0.259 improvement) and citation quality (1.76 enhancement), approaching human expert performance across multiple evaluation dimensions. Examples of surveys generated by SurveyX are available on www.surveyx.cn
大型语言模型(LLM)表现出了出色的理解能力和庞大的知识库,这表明LLM可以作为自动化问卷生成的效率工具。然而,最近的有关自动化问卷生成的研究仍然受到一些关键限制,例如有限的上下文窗口、缺乏深度内容讨论和缺乏系统评估框架。受人类写作过程的启发,我们提出了SurveyX,这是一个高效且有条理的自动化问卷生成系统,它将问卷创作过程分解为两个阶段:准备阶段和生成阶段。通过创新性地引入在线参考检索、一种名为AttributeTree的预处理方法以及润色过程,SurveyX显著提高了问卷创作的效率。实验评估结果表明,在内容质量(提高0.259)和引用质量(提高1.76)方面,SurveyX优于现有的自动化问卷生成系统,并在多个评估维度上接近人类专家的性能。SurveyX生成的问卷示例可在www.surveyx.cn上查看。
论文及项目相关链接
PDF 15 pages, 16 figures
Summary
LLM模型展现出强大的理解和知识库能力,可用于自动化调查生成。但由于上下文窗口有限制等限制因素,仍存在不足之处。为解决这些问题,我们提出调研工具SurveyX,它通过模拟人类写作过程和引入在线参考检索等创新技术来提升调研的效率和结构质量。实验结果证明,SurveyX在内容质量和引用质量上均优于现有自动化调研生成系统,并在多个维度接近人类专家的表现。更多调研示例可访问www.surveyx.cn。
Key Takeaways
- LLM模型可用于自动化调查生成工具。
- 当前自动化调研生成存在上下文窗口有限等限制因素。
- SurveyX通过模拟人类写作过程来改进调研生成系统。
- SurveyX引入在线参考检索和预处理方法AttributeTree等技术来提升调研质量。
- 实验证明SurveyX在内容质量和引用质量上表现优异,接近人类专家水平。
点此查看论文截图


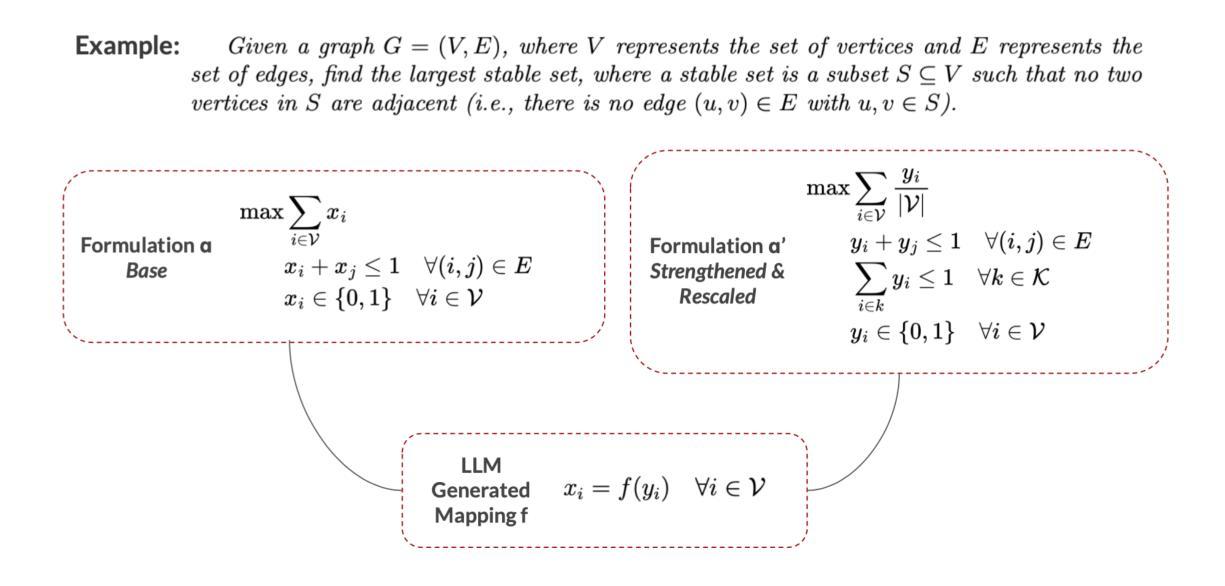
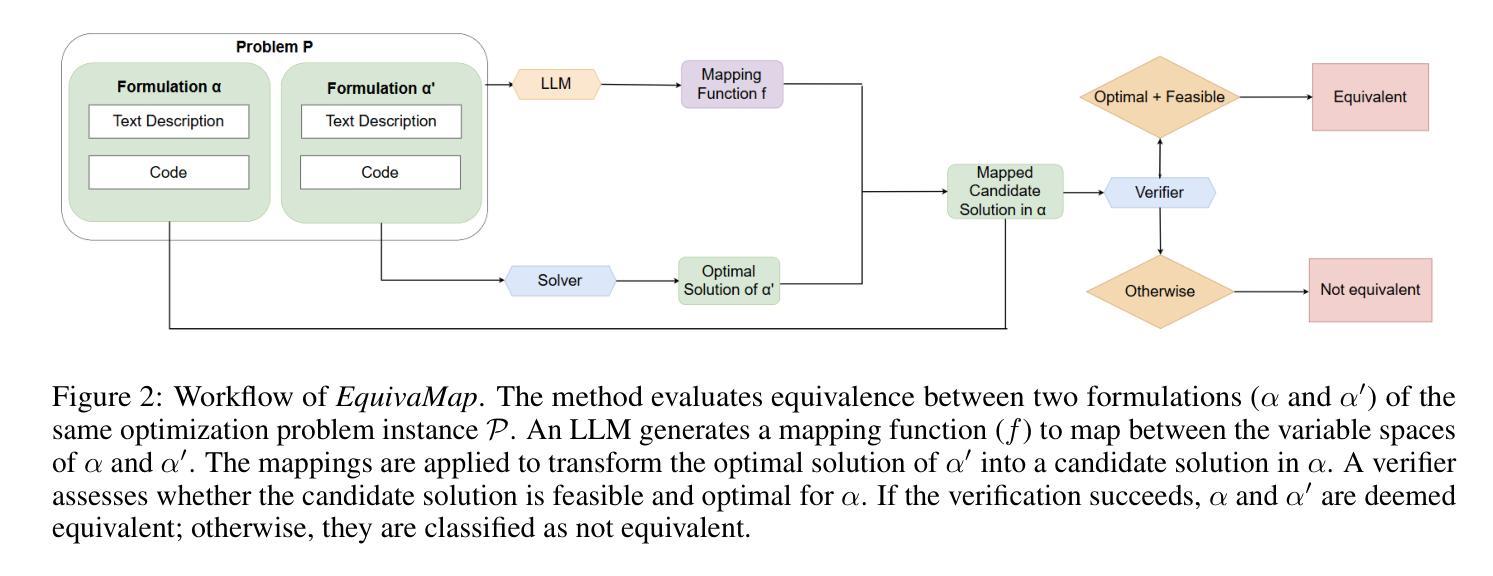
EquivaMap: Leveraging LLMs for Automatic Equivalence Checking of Optimization Formulations
Authors:Haotian Zhai, Connor Lawless, Ellen Vitercik, Liu Leqi
A fundamental problem in combinatorial optimization is identifying equivalent formulations, which can lead to more efficient solution strategies and deeper insights into a problem’s computational complexity. The need to automatically identify equivalence between problem formulations has grown as optimization copilots–systems that generate problem formulations from natural language descriptions–have proliferated. However, existing approaches to checking formulation equivalence lack grounding, relying on simple heuristics which are insufficient for rigorous validation. Inspired by Karp reductions, in this work we introduce quasi-Karp equivalence, a formal criterion for determining when two optimization formulations are equivalent based on the existence of a mapping between their decision variables. We propose EquivaMap, a framework that leverages large language models to automatically discover such mappings, enabling scalable and reliable equivalence verification. To evaluate our approach, we construct the first open-source dataset of equivalent optimization formulations, generated by applying transformations such as adding slack variables or valid inequalities to existing formulations. Empirically, EquivaMap significantly outperforms existing methods, achieving substantial improvements in correctly identifying formulation equivalence.
组合优化中的一个基本问题是识别等效公式,这可能导致更有效的解决方案策略和对问题计算复杂性的深入了解。随着优化共驾驶员(从自然语言描述生成问题公式的系统)的普及,自动识别问题公式之间等价性的需求不断增长。然而,现有的检查公式等价性的方法缺乏基础,它们依赖于简单的启发式方法,这对于严格验证是不够的。在这项工作中,我们受到Karp简化的启发,引入了准Karp等价性这一正式标准,用于确定两个优化公式何时基于其决策变量之间的映射而等价。我们提出了EquivaMap框架,它利用大型语言模型自动发现这样的映射,从而实现可扩展和可靠的等价性验证。为了评估我们的方法,我们构建了第一个开源的等效优化公式数据集,通过应用添加松弛变量或现有公式的有效不等式等转换来生成数据集。从实证上看,EquivaMap显著优于现有方法,在正确识别公式等价性方面取得了实质性进展。
论文及项目相关链接
Summary
本文提出优化问题等价性的重要性及其自动识别的挑战。引入基于Karp归约的准Karp等价性概念,提出利用大型语言模型构建EquivaMap框架,实现决策变量之间的映射关系,实现等价性的自动发现与验证。构建首个开放源代码的等价优化问题公式数据集以评估方法性能,实证结果显示EquivaMap显著优于现有方法。
Key Takeaways
- 组合优化中的关键问题之一是识别等效问题公式,有助于提高解决策略效率和深入理解问题的计算复杂性。
- 随着自然语言描述生成问题公式的优化协同系统的普及,自动识别问题公式等价的必要性日益增强。
- 现有方法缺乏验证公式等价性的严谨标准,主要依赖简单启发式方法,不足以进行严格的验证。
- 本文引入准Karp等价性概念,基于决策变量之间的映射关系确定两个优化公式是否等价。
- 提出EquivaMap框架,利用大型语言模型自动发现这种映射关系,实现可扩展和可靠的等价性验证。
- 构建首个开放源代码的等价优化问题公式数据集,用于评估方法性能。
- 实证结果显示,EquivaMap在正确识别问题公式等价性方面显著优于现有方法。
点此查看论文截图


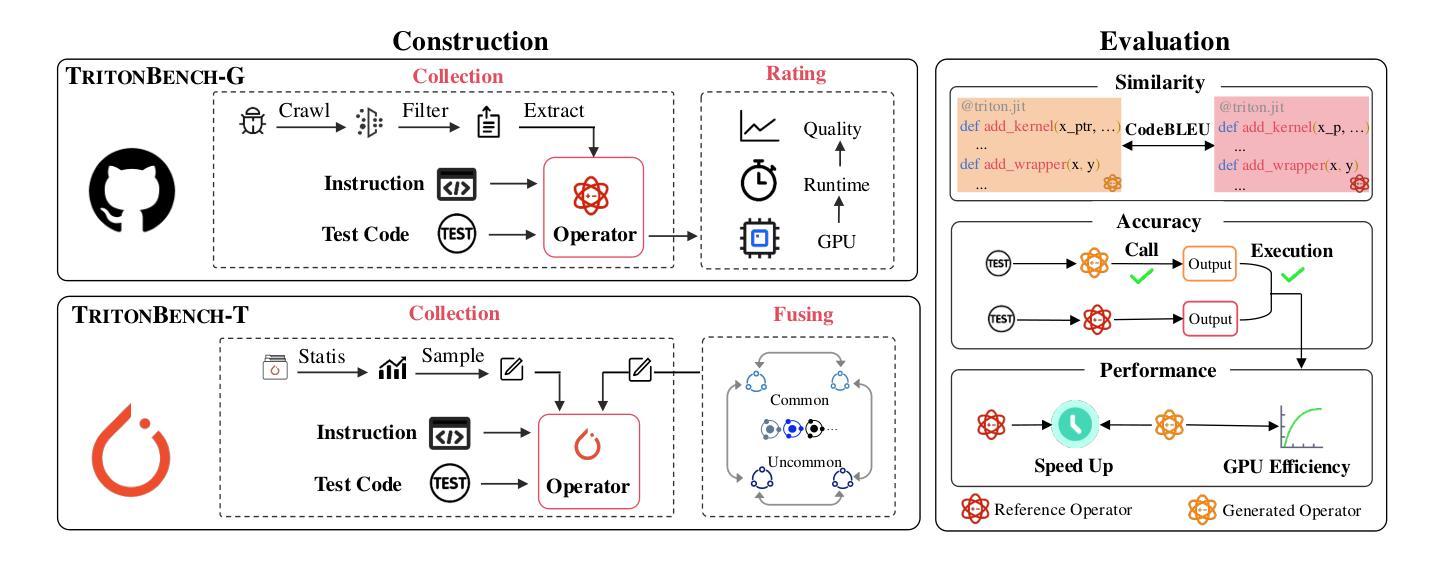
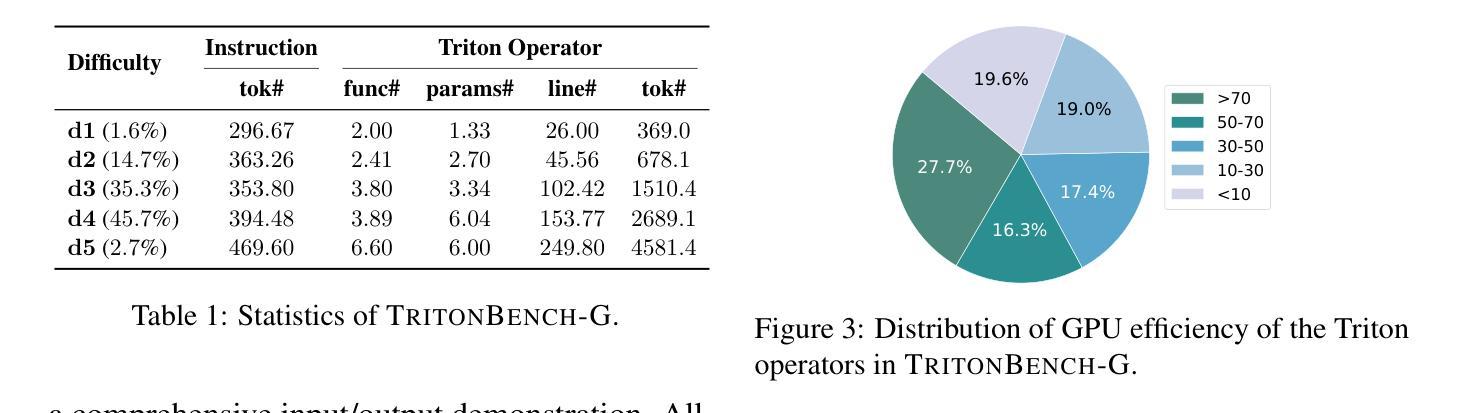
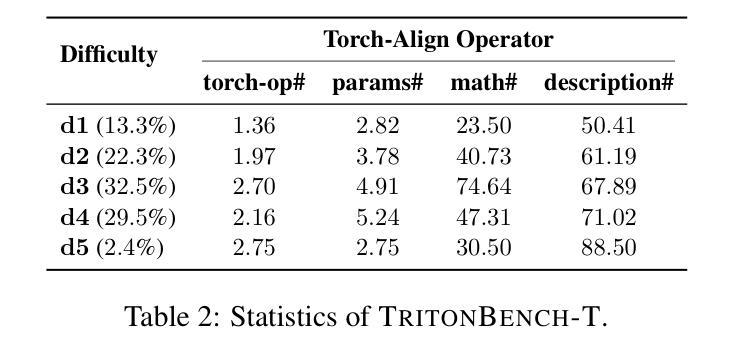
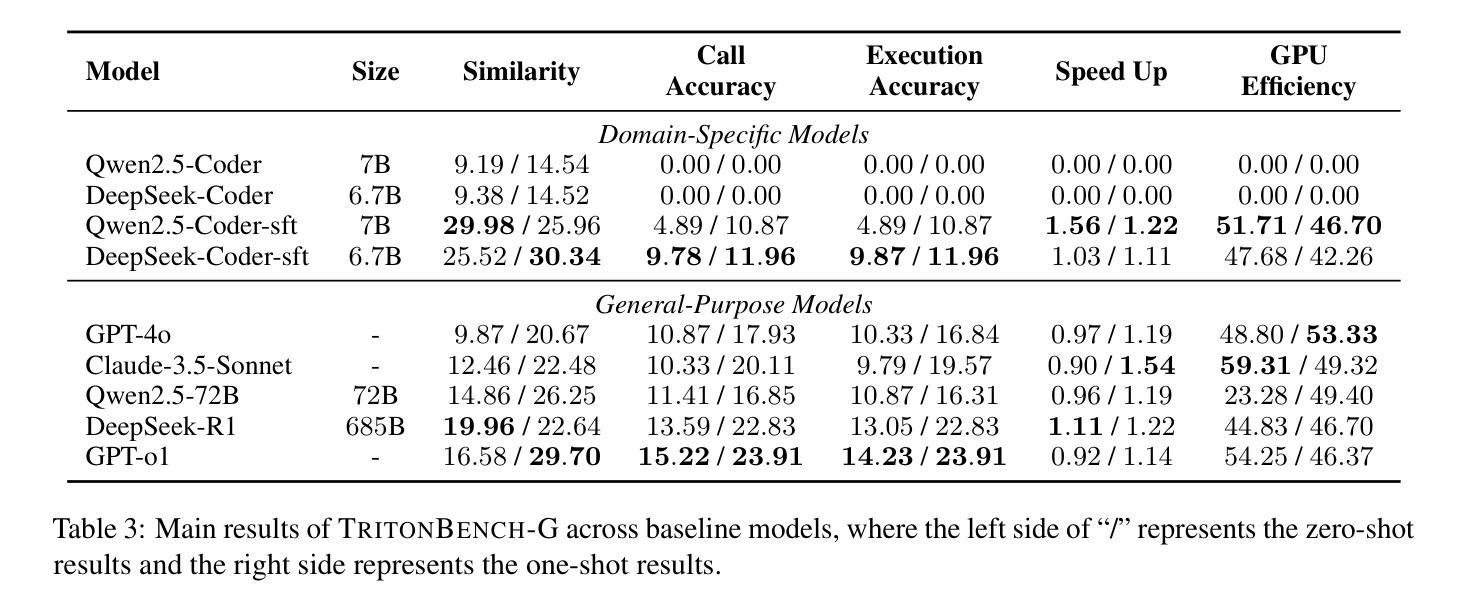
TritonBench: Benchmarking Large Language Model Capabilities for Generating Triton Operators
Authors:Jianling Li, Shangzhan Li, Zhenye Gao, Qi Shi, Yuxuan Li, Zefan Wang, Jiacheng Huang, Haojie Wang, Jianrong Wang, Xu Han, Zhiyuan Liu, Maosong Sun
Triton, a high-level Python-like language designed for building efficient GPU kernels, is widely adopted in deep learning frameworks due to its portability, flexibility, and accessibility. However, programming and parallel optimization still require considerable trial and error from Triton developers. Despite advances in large language models (LLMs) for conventional code generation, these models struggle to generate accurate, performance-optimized Triton code, as they lack awareness of its specifications and the complexities of GPU programming. More critically, there is an urgent need for systematic evaluations tailored to Triton. In this work, we introduce TritonBench, the first comprehensive benchmark for Triton operator generation. TritonBench features two evaluation channels: a curated set of 184 real-world operators from GitHub and a collection of operators aligned with PyTorch interfaces. Unlike conventional code benchmarks prioritizing functional correctness, TritonBench also profiles efficiency performance on widely deployed GPUs aligned with industry applications. Our study reveals that current state-of-the-art code LLMs struggle to generate efficient Triton operators, highlighting a significant gap in high-performance code generation. TritonBench will be available at https://github.com/thunlp/TritonBench.
Triton是一种为构建高效GPU内核而设计的Python类高级语言,由于其可移植性、灵活性和可访问性而在深度学习框架中得到广泛应用。然而,编程和并行优化仍然需要Triton开发者进行大量的试验和错误摸索。尽管大型语言模型(LLM)在常规代码生成方面取得了进展,但这些模型在生成准确、性能优化的Triton代码方面仍然面临挑战,因为它们缺乏对该语言的特性和GPU编程的复杂性了解。更重要的是,迫切需要针对Triton进行系统的评估。在这项工作中,我们介绍了TritonBench,这是第一个针对Triton操作生成的综合基准测试。TritonBench具有两个评估通道:一个是来自GitHub的精选现实世界操作符集(共包含184个操作符),另一个是与PyTorch接口对齐的操作符集合。与传统的代码基准测试相比,TritonBench不仅重视功能正确性,还侧重于在广泛部署的GPU上根据行业应用进行效率性能分析。我们的研究表明,当前最先进的代码LLM在生成高效的Triton操作符方面面临困难,这突显了高性能代码生成方面的巨大差距。TritonBench将发布在https://github.com/thunlp/TritonBench。
论文及项目相关链接
Summary
Triton语言因其高效性、可移植性和灵活性在深度学习框架中得到广泛应用。然而,编程和平行优化需要大量尝试和错误。当前的大型语言模型(LLMs)在生成准确的Triton代码方面存在困难,缺乏对其特性和GPU编程复杂性的了解。为此,本文引入了TritonBench,它是针对Triton操作生成的首个综合基准测试。TritonBench具有两个评估通道,包括GitHub上的真实操作器和与PyTorch接口对齐的操作器集合。除了强调功能正确性外,TritonBench还在广泛部署的GPU上评估效率性能,以符合行业应用需求。研究表明,当前最先进的代码LLM难以生成高效的Triton操作器,突显高性能代码生成方面的巨大差距。TritonBench将提供公共访问途径。
Key Takeaways
- Triton是一种用于构建高效GPU内核的Python类似语言,广泛应用于深度学习框架中。
- Triton编程和平行优化需要显著的努力和试错过程。
- 当前的大型语言模型(LLMs)在生成准确的Triton代码方面存在困难,因为它们不了解Triton的特性和GPU编程的复杂性。
- 引入TritonBench作为首个针对Triton操作生成的全面基准测试。
- TritonBench包含两个评估通道:GitHub上的真实操作器和与PyTorch接口对齐的操作器集合。
- TritonBench不仅强调功能正确性,还评估效率性能,以符合行业应用需求。
点此查看论文截图


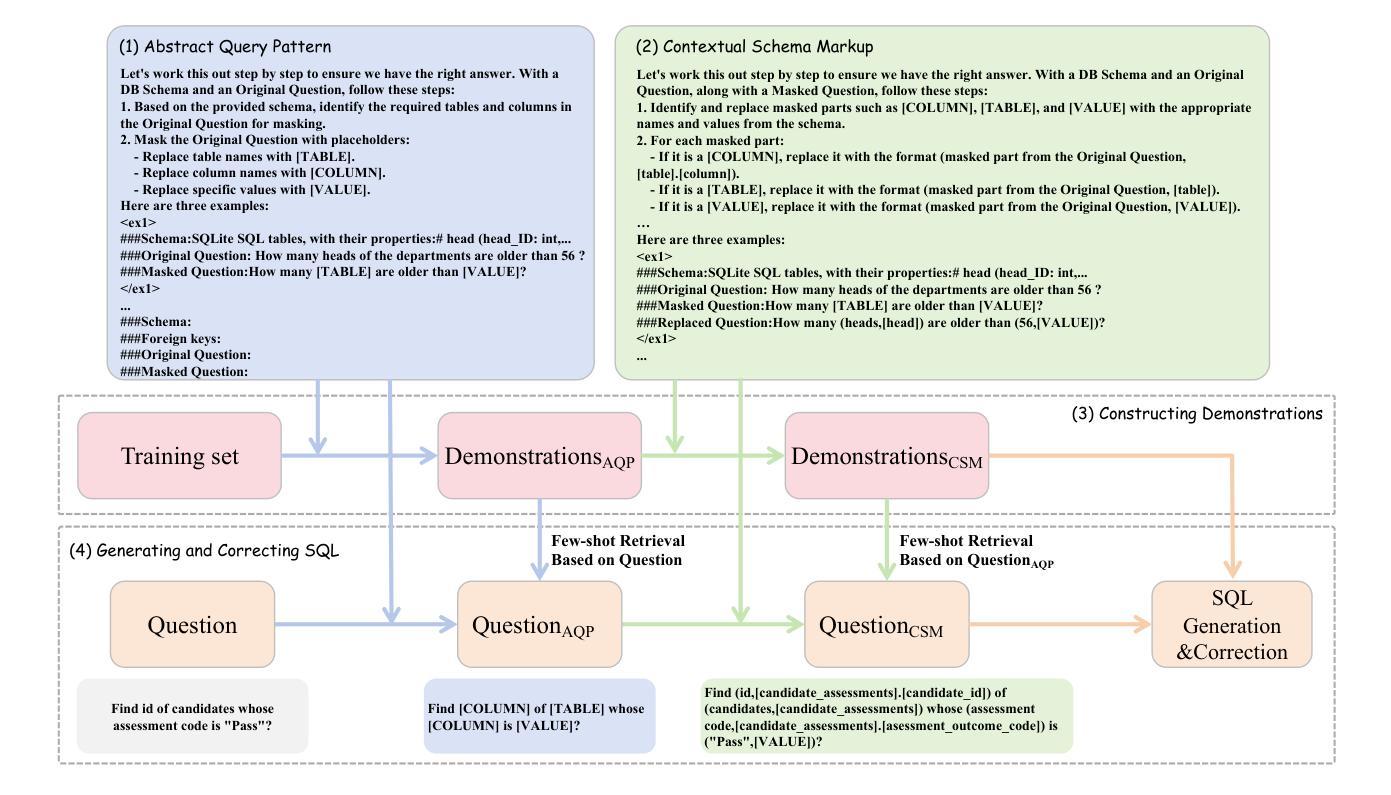
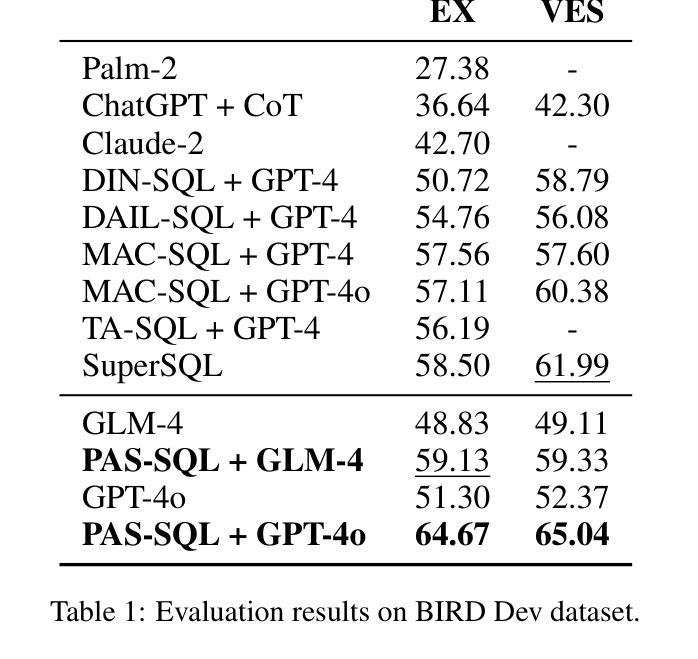
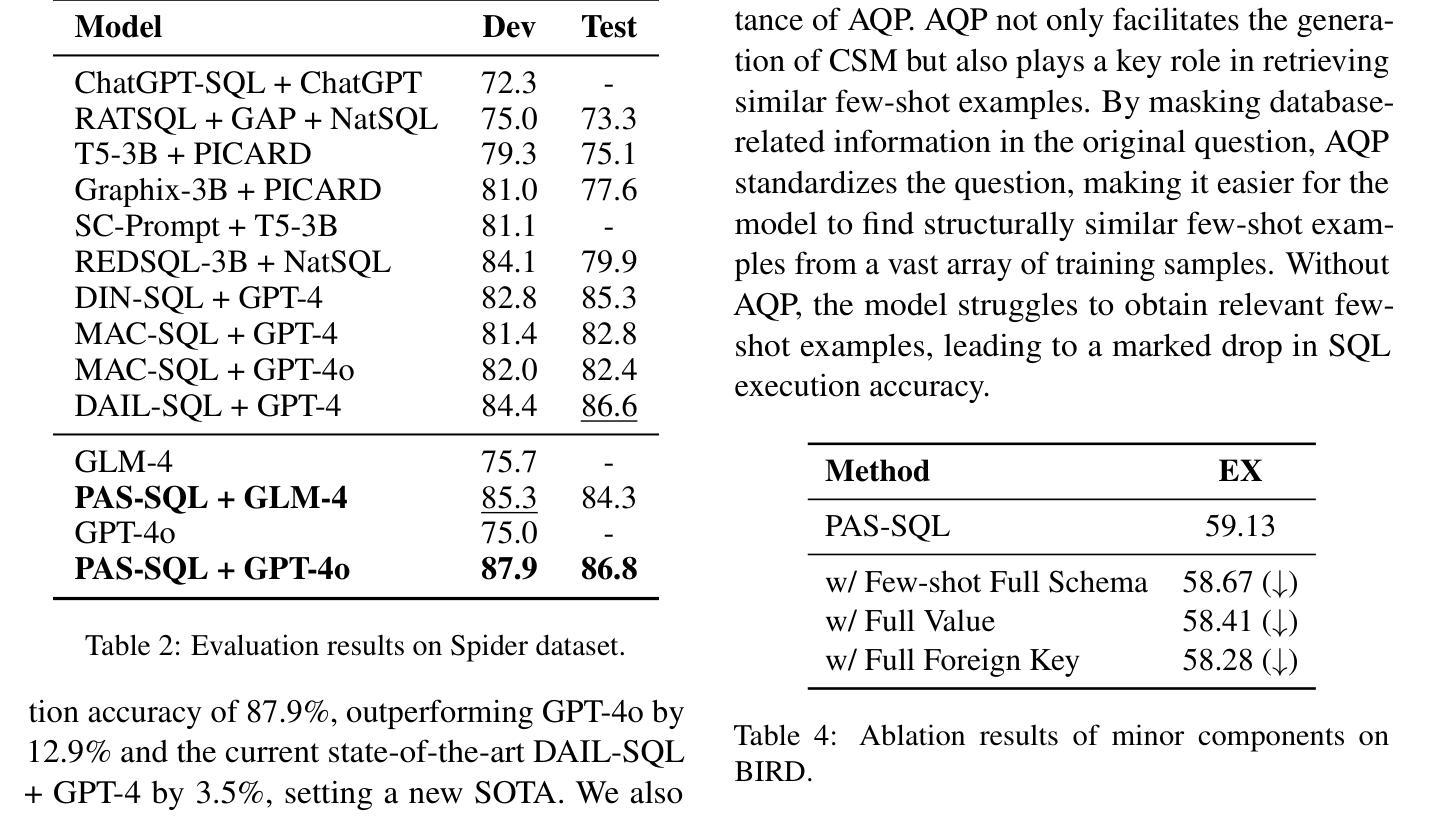
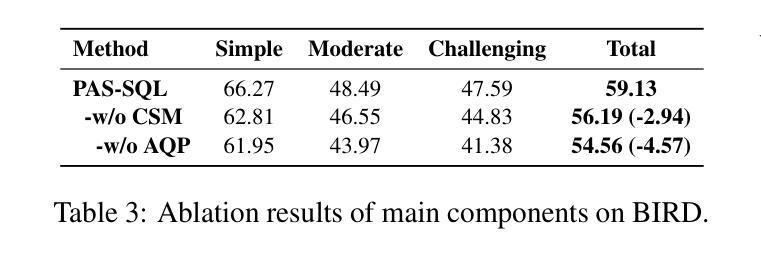
Bridging the Gap: Transforming Natural Language Questions into SQL Queries via Abstract Query Pattern and Contextual Schema Markup
Authors:Yonghui Kong, Hongbing Hu, Dan Zhang, Siyuan Chai, Fan Zhang, Wei Wang
Large language models have demonstrated excellent performance in many tasks, including Text-to-SQL, due to their powerful in-context learning capabilities. They are becoming the mainstream approach for Text-to-SQL. However, these methods still have a significant gap compared to human performance, especially on complex questions. As the complexity of questions increases, the gap between questions and SQLs increases. We identify two important gaps: the structural mapping gap and the lexical mapping gap. To tackle these two gaps, we propose PAS-SQL, an efficient SQL generation pipeline based on LLMs, which alleviates gaps through Abstract Query Pattern (AQP) and Contextual Schema Markup (CSM). AQP aims to obtain the structural pattern of the question by removing database-related information, which enables us to find structurally similar demonstrations. CSM aims to associate database-related text span in the question with specific tables or columns in the database, which alleviates the lexical mapping gap. Experimental results on the Spider and BIRD datasets demonstrate the effectiveness of our proposed method. Specifically, PAS-SQL + GPT-4o sets a new state-of-the-art on the Spider benchmark with an execution accuracy of 87.9%, and achieves leading results on the BIRD dataset with an execution accuracy of 64.67%.
大型语言模型由于具有强大的上下文学习能力,在许多任务中表现出卓越的性能,包括文本到SQL的转换。它们正成为文本到SQL的主流方法。然而,这些方法与人类性能相比仍存在较大差距,尤其是在复杂问题上。随着问题复杂性的增加,问题与SQL之间的差距也在增加。我们发现了两个重要的差距:结构映射差距和词汇映射差距。为了解决这两个差距,我们提出了基于LLM的有效SQL生成管道PAS-SQL,通过抽象查询模式(AQP)和上下文模式标记(CSM)来缓解差距。AQP旨在通过去除与数据库相关的信息来获取问题的结构模式,使我们能够找到结构相似的示例。CSM旨在将问题中与数据库相关的文本跨度与数据库中的特定表或列相关联,从而缓解词汇映射的差距。在Spider和BIRD数据集上的实验结果证明了我们的方法的有效性。具体而言,PAS-SQL+GPT-4o在Spider基准测试上取得了最新的卓越表现,执行准确度达到87.9%,并在BIRD数据集上取得了领先的执行准确度为64.67%。
论文及项目相关链接
Summary
大型语言模型在Text-to-SQL任务中表现出卓越性能,得益于其强大的上下文学习能力,成为主流方法。然而,与人的表现相比仍存在差距,复杂问题上的差距更大。本文提出PAS-SQL方法,通过抽象查询模式(AQP)和上下文模式标记(CSM)缓解结构映射和词汇映射的差距,提高SQL生成效率。实验结果表明,PAS-SQL+GPT-4o在Spider和BIRD数据集上表现优异。
Key Takeaways
- 大型语言模型在Text-to-SQL任务中表现出色,成为主流方法。
- 与人类表现相比,复杂问题上的差距仍然显著。
- 存在结构映射和词汇映射两个重要差距。
- 提出PAS-SQL方法,通过AQP和CSM缓解上述差距。
- AQP通过去除数据库相关信息获取问题结构模式。
- CSM将问题中的数据库相关文本与数据库中的特定表或列相关联。
- 实验结果表明,PAS-SQL+GPT-4o在Spider和BIRD数据集上表现最佳。
点此查看论文截图

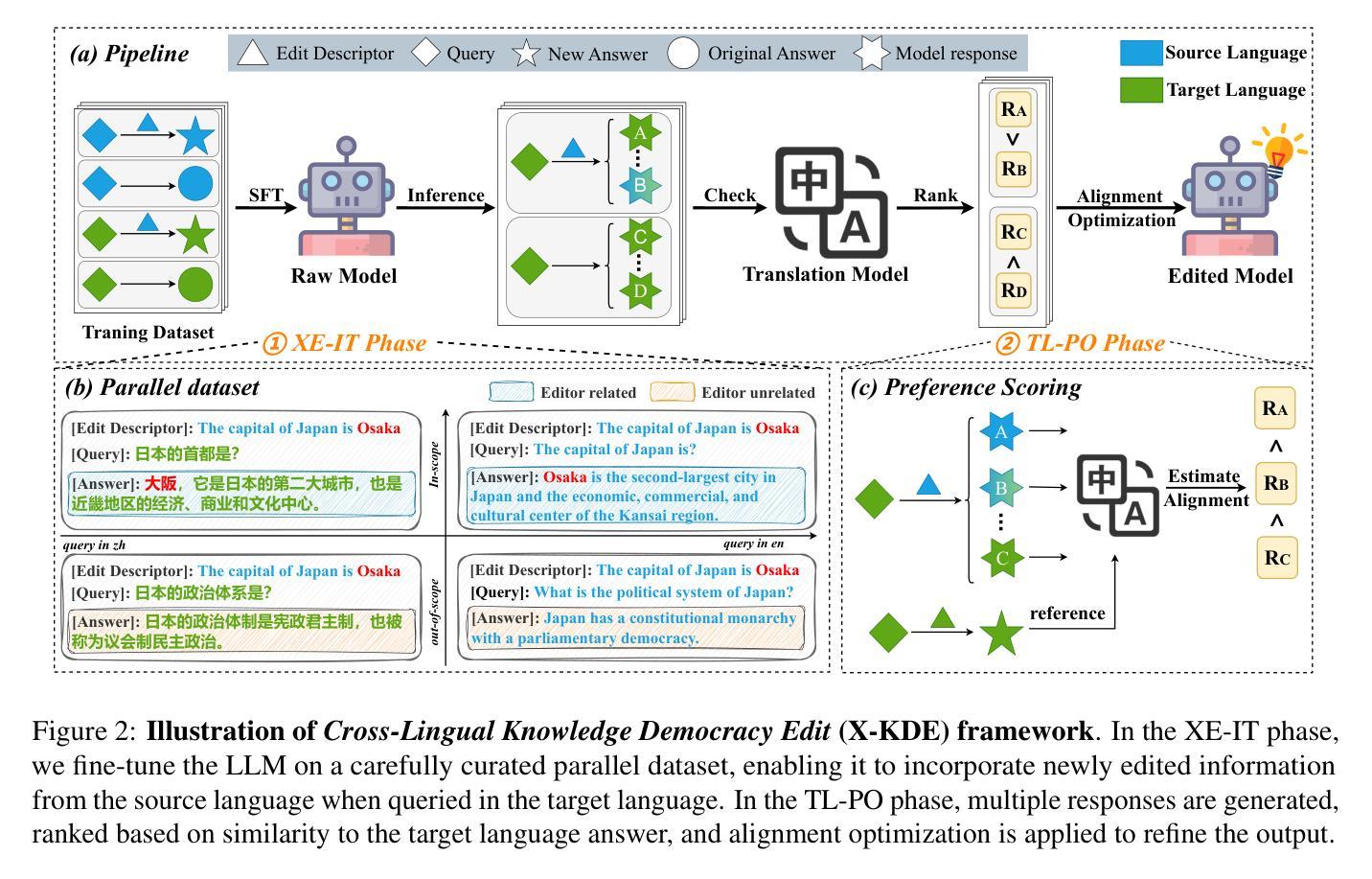
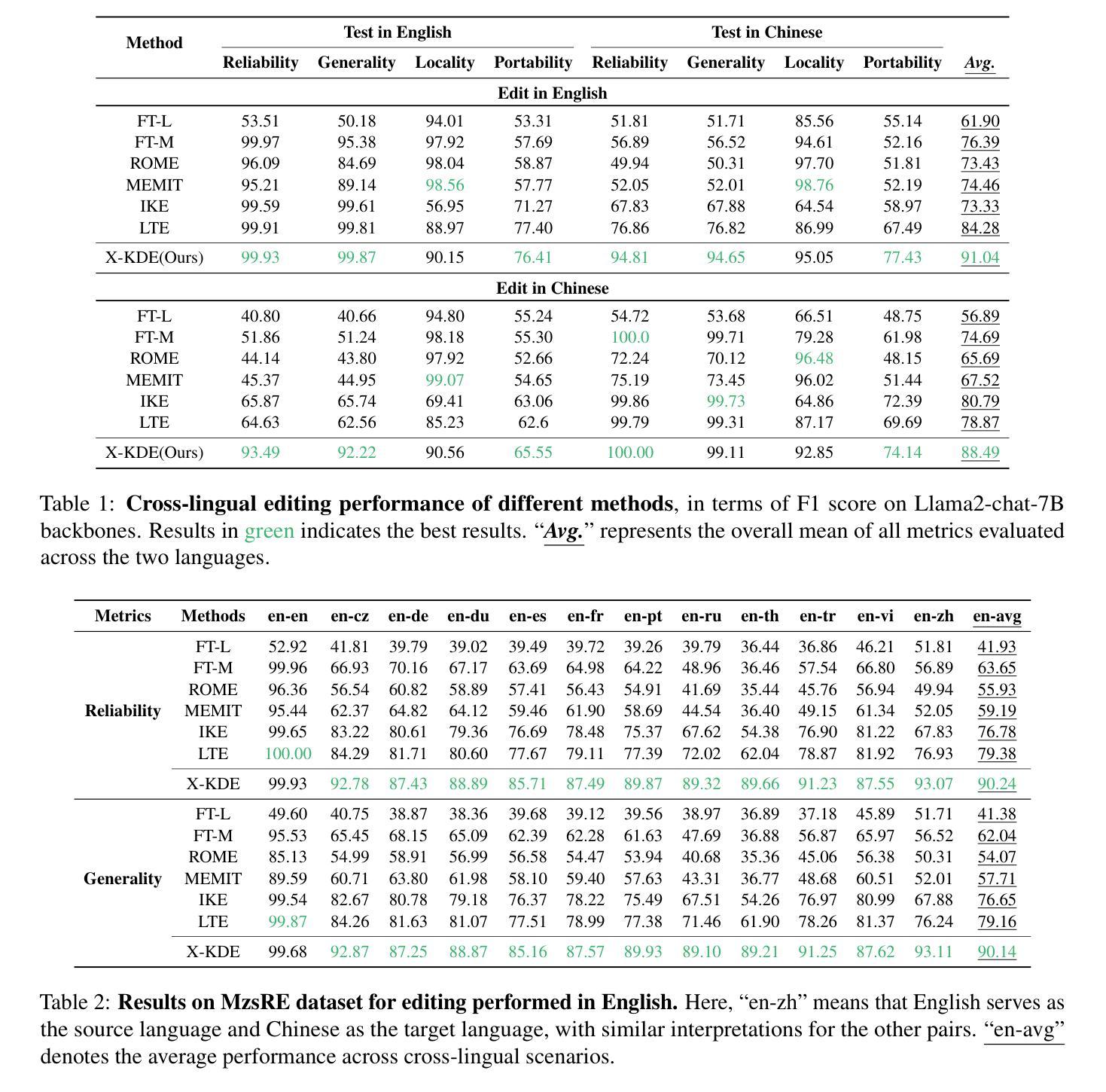
Edit Once, Update Everywhere: A Simple Framework for Cross-Lingual Knowledge Synchronization in LLMs
Authors:Yuchen Wu, Liang Ding, Li Shen, Dacheng Tao
Knowledge editing allows for efficient adaptation of large language models (LLMs) to new information or corrections without requiring full retraining. However, prior methods typically focus on either single-language editing or basic multilingual editing, failing to achieve true cross-linguistic knowledge synchronization. To address this, we present a simple and practical state-of-the-art (SOTA) recipe Cross-Lingual Knowledge Democracy Edit (X-KDE), designed to propagate knowledge from a dominant language to other languages effectively. Our X-KDE comprises two stages: (i) Cross-lingual Edition Instruction Tuning (XE-IT), which fine-tunes the model on a curated parallel dataset to modify in-scope knowledge while preserving unrelated information, and (ii) Target-language Preference Optimization (TL-PO), which applies advanced optimization techniques to ensure consistency across languages, fostering the transfer of updates. Additionally, we contribute a high-quality, cross-lingual dataset, specifically designed to enhance knowledge transfer across languages. Extensive experiments on the Bi-ZsRE and MzsRE benchmarks show that X-KDE significantly enhances cross-lingual performance, achieving an average improvement of +8.19%, while maintaining high accuracy in monolingual settings.
知识编辑允许高效地对大型语言模型(LLM)进行新信息或修正的适应,而无需进行全面再训练。然而,先前的方法通常侧重于单语言编辑或基本的多语言编辑,无法实现真正的跨语言知识同步。为解决这一问题,我们提出了一种简单实用的最新技术(SOTA)配方——跨语言知识民主编辑(X-KDE),旨在有效地将知识从主导语言传播到其他语言。我们的X-KDE包括两个阶段:(i)跨语言编辑指令调整(XE-IT),该阶段在一个精选的并行数据集上对模型进行微调,以修改范围内的知识,同时保留不相关的信息;(ii)目标语言偏好优化(TL-PO),该阶段应用先进的优化技术,以确保跨语言的一致性,促进更新的转移。此外,我们还贡献了一个高质量、跨语言的专门设计的数据集,以提高跨语言的知识转移。在Bi-ZsRE和MzsRE基准测试上的广泛实验表明,X-KDE显著提高了跨语言性能,平均提高了+8.19%,同时在单语言环境中也保持了高准确性。
论文及项目相关链接
Summary
知识编辑能够高效地对大型语言模型(LLM)进行新信息或修正的适应,而无需进行全面再训练。然而,现有方法通常专注于单语言编辑或基本的多语言编辑,无法实现真正的跨语言知识同步。为解决这一问题,我们提出了简单实用的最新配方——跨语言知识民主编辑(X-KDE),旨在有效地将知识从主导语言传播到其他语言。X-KDE包括两个阶段:一是跨语言编辑指令微调(XE-IT),通过微调模型在精选的平行数据集上修改范围内的知识,同时保留无关信息;二是目标语言偏好优化(TL-PO),采用先进的优化技术,确保跨语言的一致性,促进更新的转移。此外,我们还贡献了一个高质量、跨语言的数据集,专门用于增强跨语言的知识转移。在Bi-ZsRE和MzsRE基准测试上的广泛实验表明,X-KDE显著提高了跨语言性能,平均改进了+8.19%,同时在单语言设置中保持了高准确性。
Key Takeaways
- 知识编辑能够不经过全面再训练而适应新信息或修正的大型语言模型。
- 现有方法在进行跨语言编辑时存在局限性,无法实现真正的跨语言知识同步。
- 提出了跨语言知识民主编辑(X-KDE)方法,包含跨语言编辑指令微调(XE-IT)和目标语言偏好优化(TL-PO)两个阶段。
- X-KDE能有效将从主导语言传播的知识转移到其他语言。
- 贡献了一个专门用于增强跨语言知识转移的高质量、跨语言数据集。
- 在Bi-ZsRE和MzsRE基准测试上,X-KDE显著提高了跨语言性能。
点此查看论文截图

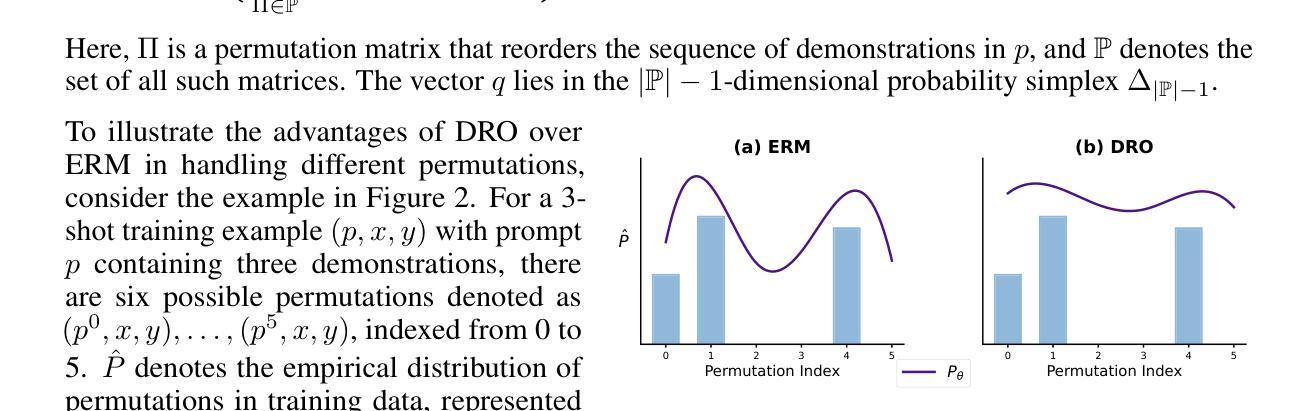
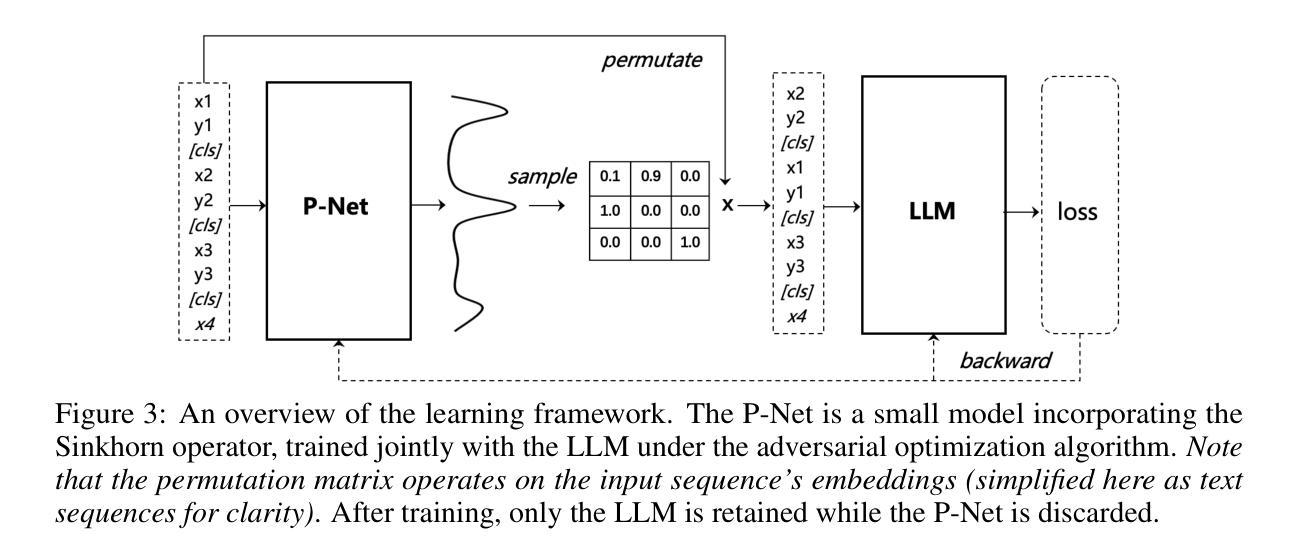
PEARL: Towards Permutation-Resilient LLMs
Authors:Liang Chen, Li Shen, Yang Deng, Xiaoyan Zhao, Bin Liang, Kam-Fai Wong
The in-context learning (ICL) capability of large language models (LLMs) enables them to perform challenging tasks using provided demonstrations. However, ICL is highly sensitive to the ordering of demonstrations, leading to instability in predictions. This paper shows that this vulnerability can be exploited to design a natural attack - difficult for model providers to detect - that achieves nearly 80% success rate on LLaMA-3 by simply permuting the demonstrations. Existing mitigation methods primarily rely on post-processing and fail to enhance the model’s inherent robustness to input permutations, raising concerns about safety and reliability of LLMs. To address this issue, we propose Permutation-resilient learning (PEARL), a novel framework based on distributionally robust optimization (DRO), which optimizes model performance against the worst-case input permutation. Specifically, PEARL consists of a permutation-proposal network (P-Net) and the LLM. The P-Net generates the most challenging permutations by treating it as an optimal transport problem, which is solved using an entropy-constrained Sinkhorn algorithm. Through minimax optimization, the P-Net and the LLM iteratively optimize against each other, progressively improving the LLM’s robustness. Experiments on synthetic pre-training and real-world instruction tuning tasks demonstrate that PEARL effectively mitigates permutation attacks and enhances performance. Notably, despite being trained on fewer shots and shorter contexts, PEARL achieves performance gains of up to 40% when scaled to many-shot and long-context scenarios, highlighting its efficiency and generalization capabilities.
大型语言模型的上下文学习(ICL)能力让它们能够利用提供的演示来完成具有挑战性的任务。然而,ICL对演示的顺序高度敏感,导致预测结果不稳定。本文展示了如何利用这一漏洞设计一种自然的攻击——这种攻击很难被模型提供商检测到——通过简单地改变演示顺序,在LLaMA-3上实现了近80%的成功率。现有的缓解方法主要依赖于后处理,未能提高模型对输入排列的固有鲁棒性,引发了对大型语言模型安全性和可靠性的担忧。为了解决这个问题,我们提出了基于分布鲁棒优化(DRO)的排列韧性学习(PEARL)新框架,它通过对抗最坏情况输入排列来优化模型性能。具体来说,PEARL包括一个排列提议网络(P-Net)和大型语言模型。P-Net将问题视为最优传输问题,通过解决带熵约束的Sinkhorn算法生成最具挑战性的排列。通过极小极大优化,P-Net和大型语言模型相互迭代优化,逐步提高了大型语言模型的稳健性。在合成预训练任务和现实世界指令调整任务上的实验表明,PEARL有效地缓解了排列攻击,提高了性能。值得注意的是,即使在更少的射击和较短的上下文情况下进行训练,PEARL在应用到多次射击和长上下文场景时仍能实现高达40%的性能提升,突显了其效率和泛化能力。
论文及项目相关链接
PDF ICLR 2025
Summary
大型语言模型的上下文学习(ICL)能力使其能够通过提供的演示执行具有挑战性的任务。然而,ICL高度依赖于演示的顺序,导致预测结果不稳定。本文展示了如何利用这一漏洞设计一种自然攻击,通过简单调整演示的顺序即可达到攻击效果,并对LLaMA-3模型实现了近80%的成功率。现有的缓解方法主要依赖后处理,未能提高模型对输入排列的固有稳健性,引发了人们对大型语言模型安全性和可靠性的担忧。为解决这一问题,本文提出基于分布鲁棒优化(DRO)的排列韧性学习(PEARL)框架,优化模型应对最坏情况下输入排列的性能。通过实验证明,PEARL有效缓解排列攻击,提高性能,且在少样本和短上下文场景中性能提升显著。这表明PEARL具有较高的效率和泛化能力。
Key Takeaways
- 大型语言模型的上下文学习能力使其能执行复杂任务,但演示顺序对其影响大,导致预测不稳定。
- 通过调整演示顺序可进行自然攻击,对现有大型语言模型构成威胁。
- 当前缓解方法主要依赖后处理,无法提高模型对输入排列的稳健性。
- 提出基于分布鲁棒优化的排列韧性学习(PEARL)框架,通过优化模型应对最坏情况下输入排列的性能来提高模型的稳健性。
- PEARL框架包括排列提案网络(P-Net)和大型语言模型,P-Net通过解决最优传输问题生成最具挑战性的排列。
- PEARL框架通过最小最大化优化,提高大型语言模型的稳健性,对排列攻击具有抵御能力。
点此查看论文截图

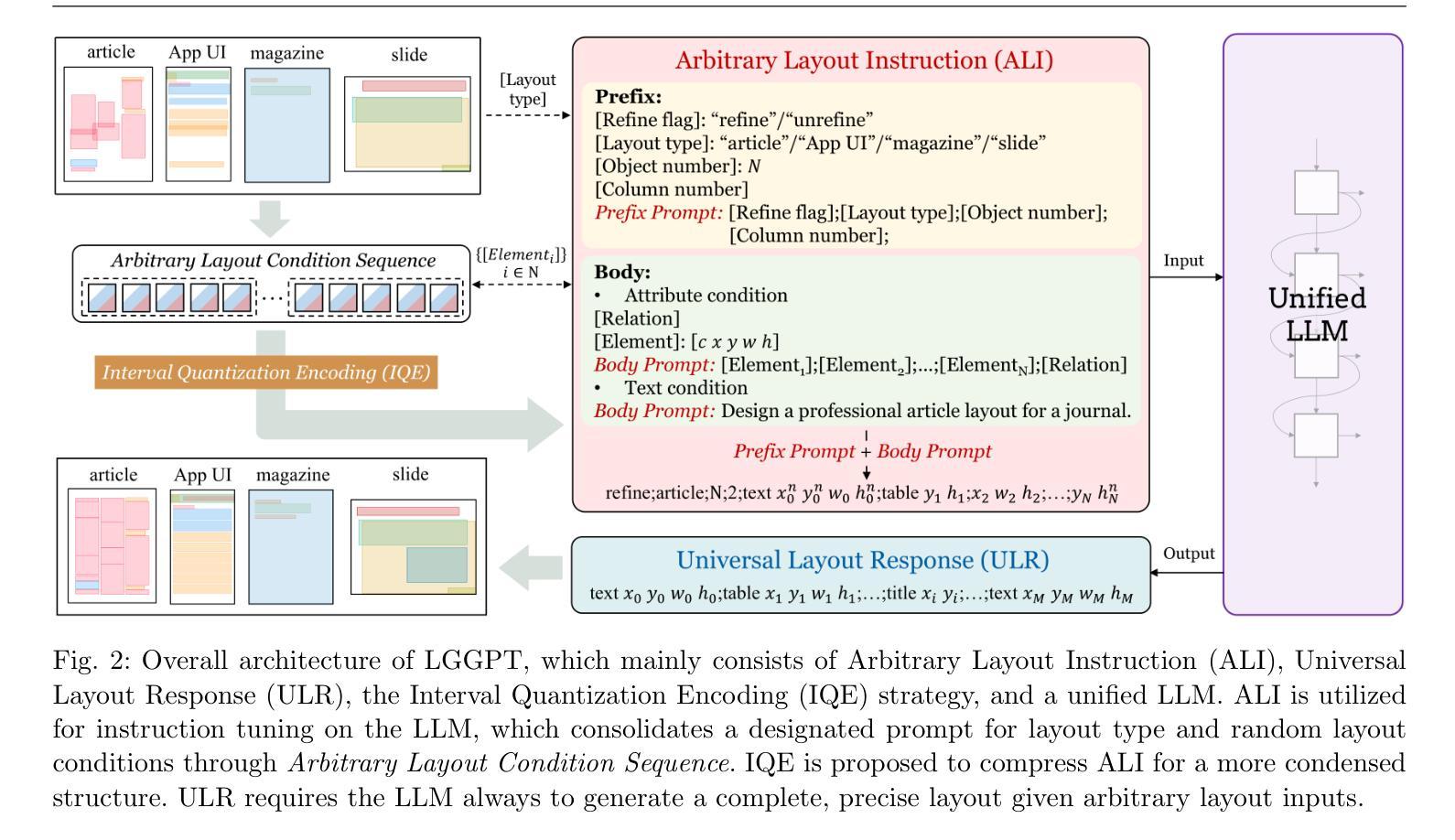
Smaller But Better: Unifying Layout Generation with Smaller Large Language Models
Authors:Peirong Zhang, Jiaxin Zhang, Jiahuan Cao, Hongliang Li, Lianwen Jin
We propose LGGPT, an LLM-based model tailored for unified layout generation. First, we propose Arbitrary Layout Instruction (ALI) and Universal Layout Response (ULR) as the uniform I/O template. ALI accommodates arbitrary layout generation task inputs across multiple layout domains, enabling LGGPT to unify both task-generic and domain-generic layout generation hitherto unexplored. Collectively, ALI and ULR boast a succinct structure that forgoes superfluous tokens typically found in existing HTML-based formats, facilitating efficient instruction tuning and boosting unified generation performance. In addition, we propose an Interval Quantization Encoding (IQE) strategy that compresses ALI into a more condensed structure. IQE precisely preserves valid layout clues while eliminating the less informative placeholders, facilitating LGGPT to capture complex and variable layout generation conditions during the unified training process. Experimental results demonstrate that LGGPT achieves superior or on par performance compared to existing methods. Notably, LGGPT strikes a prominent balance between proficiency and efficiency with a compact 1.5B parameter LLM, which beats prior 7B or 175B models even in the most extensive and challenging unified scenario. Furthermore, we underscore the necessity of employing LLMs for unified layout generation and suggest that 1.5B could be an optimal parameter size by comparing LLMs of varying scales. Code is available at https://github.com/NiceRingNode/LGGPT.
我们提出了LGGPT模型,这是一种基于大型语言模型(LLM)的定制统一布局生成模型。首先,我们提出了任意布局指令(ALI)和通用布局响应(ULR)作为统一的输入输出模板。ALI可以容纳多个布局域的任意布局生成任务输入,使得LGGPT能够统一迄今为止尚未探索的任务通用和域通用的布局生成。总的来说,ALI和ULR拥有简洁的结构,摒弃了现有HTML格式中通常存在的多余标记,便于高效的指令调整,并提高了统一的生成性能。此外,我们提出了一种间隔量化编码(IQE)策略,将ALI压缩成更紧凑的结构。IQE能够精确保留有效的布局线索,同时消除信息量较少的占位符,有助于LGGPT在统一训练过程中捕捉复杂且可变的布局生成条件。实验结果表明,LGGPT的性能优于或相当于现有方法。值得注意的是,LGGPT在熟练和效率之间达到了突出的平衡,使用紧凑的1.5B参数大型语言模型,甚至在最广泛和最具挑战性的统一场景中击败了先前的7B或175B模型。此外,我们通过比较不同规模的大型语言模型,强调了在统一布局生成中使用大型语言模型的必要性,并建议1.5B可能是最佳参数规模。代码可访问https://github.com/NiceRingNode/LGGPT。
论文及项目相关链接
Summary
本文提出一种基于LLM的模型LGGPT,用于统一的布局生成。该模型通过引入任意布局指令(ALI)和通用布局响应(ULR)作为统一输入输出模板,实现了跨多个布局领域的统一布局生成。此外,还提出了一种区间量化编码(IQE)策略,用于压缩ALI为更紧凑的结构,并保留有效的布局线索。实验结果表明,LGGPT在统一训练过程中取得了优于或相当于现有方法的性能,并在使用紧凑的1.5B参数LLM时实现了卓越的性能和效率平衡,甚至在最具挑战的统一场景中击败了之前的7B或175B模型。此外,强调了采用LLM进行统一布局生成的必要性,并建议将使用规模为1.5B参数的LLM作为最佳选择。代码已公开在GitHub上。
Key Takeaways
- LGGPT是一个基于LLM的模型,用于统一的布局生成。
- ALI和ULR作为统一输入输出模板,实现了跨多个布局领域的统一布局生成。
- IQE策略用于压缩ALI结构并保留有效布局线索。
- LGGPT性能优于或相当于现有方法,并在使用紧凑的1.5B参数LLM时实现了卓越的性能和效率平衡。
- LGGPT在各种规模LLM之间的性能对比中表现优越,突显了使用LLM进行统一布局生成的重要性。
- LGGPT代码已公开在GitHub上。
点此查看论文截图


Towards Efficient Optimizer Design for LLM via Structured Fisher Approximation with a Low-Rank Extension
Authors:Wenbo Gong, Meyer Scetbon, Chao Ma, Edward Meeds
Designing efficient optimizers for large language models (LLMs) with low-memory requirements and fast convergence is an important and challenging problem. This paper makes a step towards the systematic design of such optimizers through the lens of structured Fisher information matrix (FIM) approximation. We show that many state-of-the-art efficient optimizers can be viewed as solutions to FIM approximation (under the Frobenius norm) with specific structural assumptions. Building on these insights, we propose two design recommendations of practical efficient optimizers for LLMs, involving the careful selection of structural assumptions to balance generality and efficiency, and enhancing memory efficiency of optimizers with general structures through a novel low-rank extension framework. We demonstrate how to use each design approach by deriving new memory-efficient optimizers: Row and Column Scaled SGD (RACS) and Adaptive low-dimensional subspace estimation (Alice). Experiments on LLaMA pre-training (up to 1B parameters) validate the effectiveness, showing faster and better convergence than existing memory-efficient baselines and Adam with little memory overhead. Notably, Alice achieves better than 2x faster convergence over Adam, while RACS delivers strong performance on the 1B model with SGD-like memory.
设计针对大型语言模型(LLM)的高效优化器,要求内存需求低且收敛速度快,这是一个重要且具有挑战性的问题。本文通过结构化的Fisher信息矩阵(FIM)近似透镜,朝着系统地设计此类优化器迈出了重要一步。我们表明,许多最先进的优化器都可以被视为满足Frobenius范数下的FIM近似解决方案,并带有特定的结构假设。基于这些见解,我们提出了针对LLM的实际高效优化器的两项设计建议,包括谨慎选择结构假设以平衡通用性和效率,并通过新型的低秩扩展框架提高优化器的内存效率。我们通过推导新的内存高效优化器来展示每种设计方法:行和列缩放SGD(RACS)和自适应低维子空间估计(Alice)。在LLaMA预训练(最多1亿个参数)上的实验验证了其有效性,显示出比现有内存高效的基准测试和Adam更快的收敛速度和更好的性能。值得注意的是,Alice实现了超过Adam的2倍收敛速度提升,而RACS在具有SGD内存的1亿模型上表现出强大的性能。
论文及项目相关链接
Summary
基于结构化Fisher信息矩阵(FIM)近似视角,本文研究了为大型语言模型(LLM)设计高效优化器的问题。文章展示了许多先进的优化器可视为特定结构假设下FIM近似解决方案,并提出了两种针对LLM实用优化器的设计建议。通过推导新的内存高效优化器Row和Column Scaled SGD(RACS)和自适应低维子空间估计(Alice),验证了所提设计方法的实用性。实验结果表明,相较于现有的内存高效基线及Adam优化器,这些方法更加有效并具有更快的收敛速度。特别是Alice实现了超过Adam两倍以上的收敛速度提升。
Key Takeaways
- 该论文研究如何为大型语言模型(LLM)设计具有低内存要求和快速收敛的优化器。
- 文章通过结构化Fisher信息矩阵(FIM)近似视角进行系统性的优化器设计。
- 文章展示了许多先进的优化器可以看作是特定结构假设下的FIM近似解决方案。
- 文章提出了两种针对LLM的优化器设计建议,包括平衡通用性和效率的假设选择以及通过新型低秩扩展框架提高优化器的内存效率。
- 文章通过推导新优化器RACS和Alice验证了设计方法的有效性。
点此查看论文截图


Simplifying Formal Proof-Generating Models with ChatGPT and Basic Searching Techniques
Authors:Sangjun Han, Taeil Hur, Youngmi Hur, Kathy Sangkyung Lee, Myungyoon Lee, Hyojae Lim
The challenge of formal proof generation has a rich history, but with modern techniques, we may finally be at the stage of making actual progress in real-life mathematical problems. This paper explores the integration of ChatGPT and basic searching techniques to simplify generating formal proofs, with a particular focus on the miniF2F dataset. We demonstrate how combining a large language model like ChatGPT with a formal language such as Lean, which has the added advantage of being verifiable, enhances the efficiency and accessibility of formal proof generation. Despite its simplicity, our best-performing Lean-based model surpasses all known benchmarks with a 31.15% pass rate. We extend our experiments to include other datasets and employ alternative language models, showcasing our models’ comparable performance in diverse settings and allowing for a more nuanced analysis of our results. Our findings offer insights into AI-assisted formal proof generation, suggesting a promising direction for future research in formal mathematical proof.
形式化证明生成这一挑战有着悠久的历史背景,但随着现代技术的发展,我们可能终于迎来了解决现实生活中的数学问题方面取得实际进展的阶段。本文探讨了将ChatGPT和基本搜索技术相结合,以简化形式化证明的生成过程,重点集中在miniF2F数据集上。我们展示了如何将ChatGPT等大型语言模型与精益(Lean)等可验证的形式语言相结合,以提高形式化证明的生成效率和可及性。尽管我们的方法相对简单,但基于精益的最佳模型以31.15%的通过率超越了所有已知基准测试。我们进一步扩展实验,包括使用其他数据集和替代语言模型,展示了我们的模型在不同环境下的相当性能,并允许对结果进行更细致的分析。我们的研究为人工智能辅助形式化证明生成提供了见解,并为未来形式化数学证明的研究指明了有前景的方向。
论文及项目相关链接
PDF This manuscript was accepted for publication in the proceedings of the Computing Conference 2025 (Springer LNNS). The Version of Record (VoR) has not yet been published. This Accepted Manuscript does not reflect any post-acceptance improvements or corrections. Use of this version is subject to Springer Nature’s Accepted Manuscript terms of use
Summary
现代技术可能使我们在实际的数学问题上取得进展。本文探讨了将ChatGPT和基本搜索技术相结合,以简化生成形式证明的过程,重点关注miniF2F数据集。结合ChatGPT等大型语言模型和可验证的Lean形式语言,提高了形式证明的效率和可及性。基于Lean的最佳模型表现超越所有已知基准测试,通过率为31.15%。实验扩展到其他数据集和使用其他语言模型,展示了模型在不同环境中的可比性,并对结果进行了更细致的分析。本文研究为人工智能辅助形式证明生成提供了有前景的研究方向。
Key Takeaways
- 现代技术有助于简化生成形式证明的过程。
- ChatGPT和Lean的结合提高了形式证明的效率和可及性。
- 基于Lean的最佳模型表现超越了所有已知基准测试。
- 实验扩展到其他数据集和语言模型,展示了模型的适用性。
- AI技术在形式数学证明中有广阔的应用前景。
- 通过结合大型语言模型和形式语言,可以实现更高效的形式证明生成。
点此查看论文截图