⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-22 更新
NeRF-3DTalker: Neural Radiance Field with 3D Prior Aided Audio Disentanglement for Talking Head Synthesis
Authors:Xiaoxing Liu, Zhilei Liu, Chongke Bi
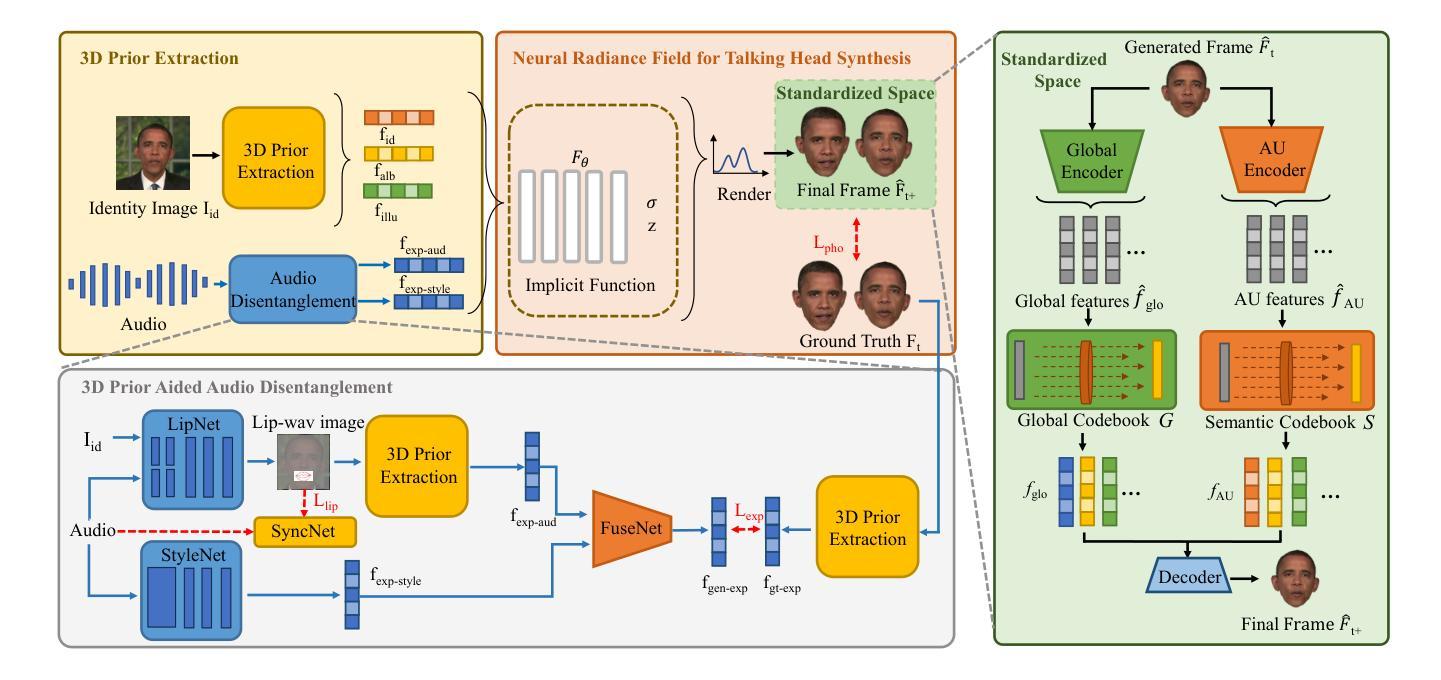
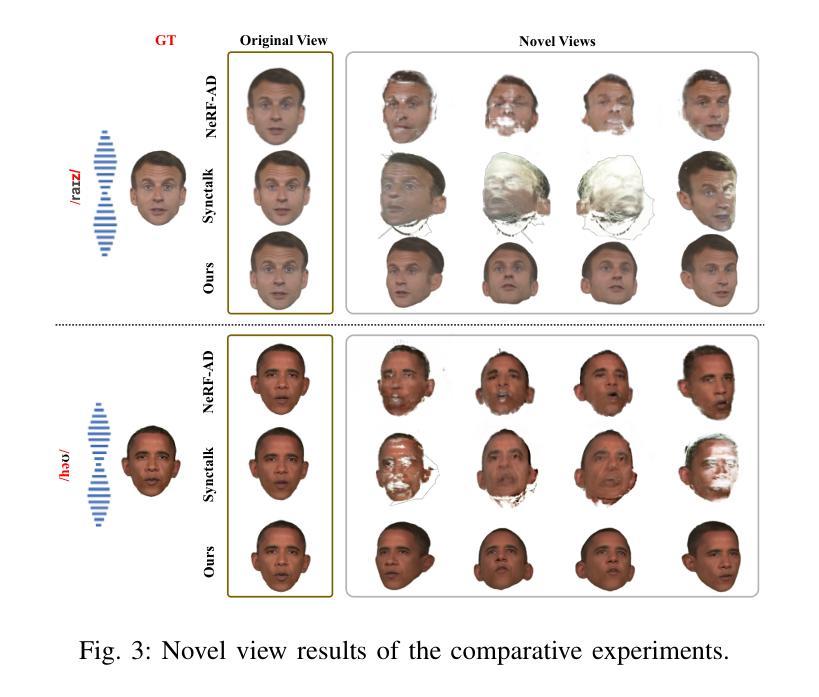
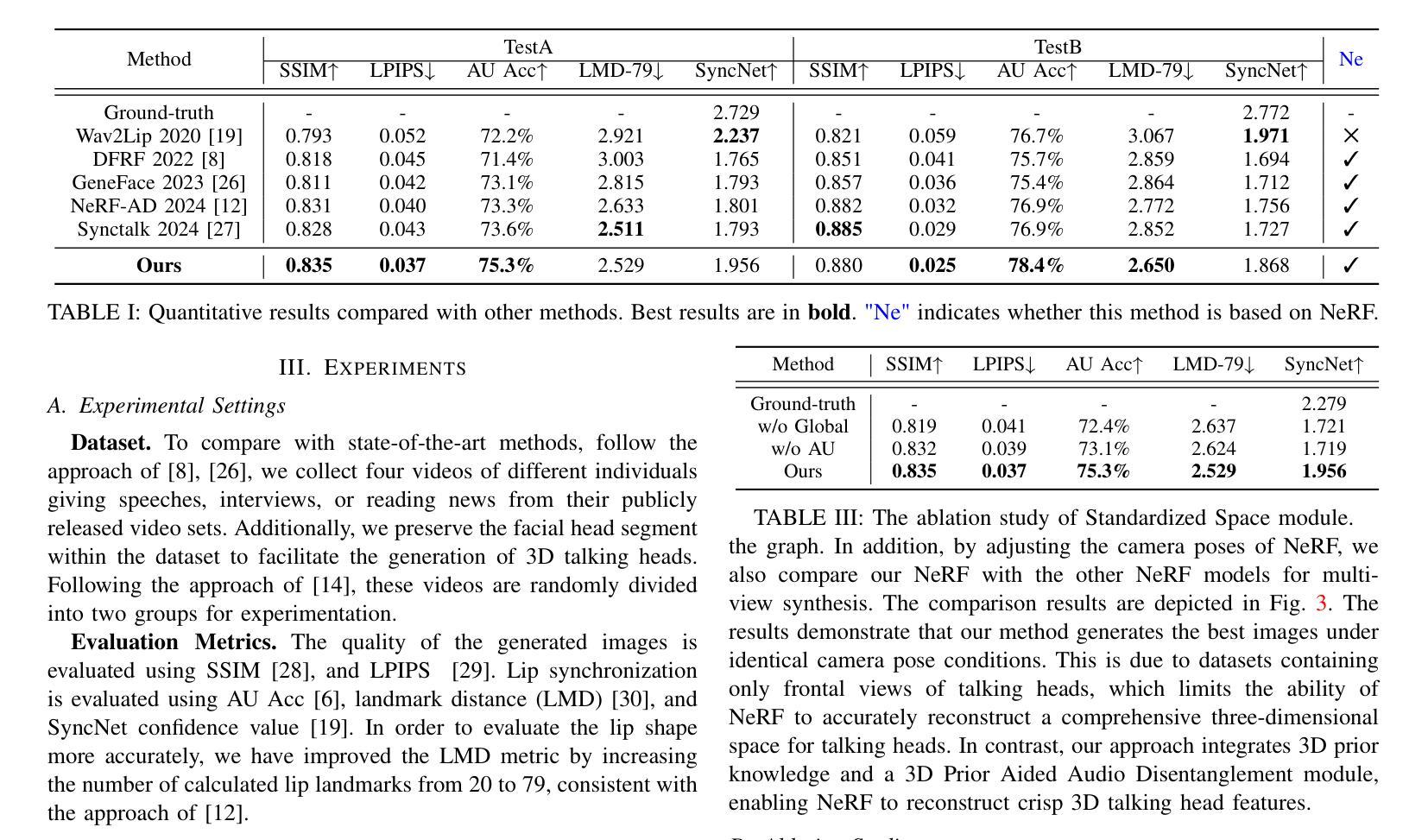
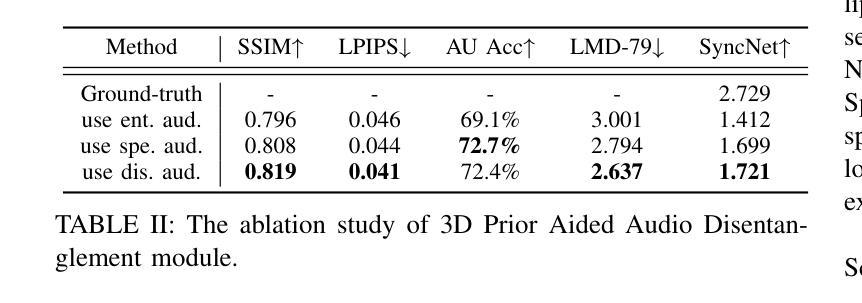
Talking head synthesis is to synthesize a lip-synchronized talking head video using audio. Recently, the capability of NeRF to enhance the realism and texture details of synthesized talking heads has attracted the attention of researchers. However, most current NeRF methods based on audio are exclusively concerned with the rendering of frontal faces. These methods are unable to generate clear talking heads in novel views. Another prevalent challenge in current 3D talking head synthesis is the difficulty in aligning acoustic and visual spaces, which often results in suboptimal lip-syncing of the generated talking heads. To address these issues, we propose Neural Radiance Field with 3D Prior Aided Audio Disentanglement for Talking Head Synthesis (NeRF-3DTalker). Specifically, the proposed method employs 3D prior information to synthesize clear talking heads with free views. Additionally, we propose a 3D Prior Aided Audio Disentanglement module, which is designed to disentangle the audio into two distinct categories: features related to 3D awarded speech movements and features related to speaking style. Moreover, to reposition the generated frames that are distant from the speaker’s motion space in the real space, we have devised a local-global Standardized Space. This method normalizes the irregular positions in the generated frames from both global and local semantic perspectives. Through comprehensive qualitative and quantitative experiments, it has been demonstrated that our NeRF-3DTalker outperforms state-of-the-art in synthesizing realistic talking head videos, exhibiting superior image quality and lip synchronization. Project page: https://nerf-3dtalker.github.io/NeRF-3Dtalker.
利用音频合成唇同步的头部视频称为头部谈话合成。最近,NeRF在提高合成头部谈话的真实感和纹理细节方面的能力引起了研究人员的关注。然而,大多数基于音频的当前NeRF方法仅关注正面面部的渲染。这些方法无法生成清晰的多视角的谈话头部。当前3D谈话头组合成的另一个普遍挑战是声学和视觉空间的难以对齐,这通常导致生成的谈话头部的唇同步不佳。为了解决这些问题,我们提出了基于3D先验辅助音频分离的神经辐射场用于头部谈话合成(NeRF-3DTalker)。具体而言,该方法采用3D先验信息来合成具有自由视角的清晰谈话头部。此外,我们提出了一个3D先验辅助音频分离模块,该模块旨在将音频分为两类:与3D获奖语音动作相关的特征和与讲话风格相关的特征。而且,为了重新定位与演讲者实际空间运动距离较远的生成帧,我们从全局和局部语义角度设计了一个局部-全局标准化空间。该方法对生成帧中的不规则位置进行了归一化处理。通过全面定性和定量实验,证明我们的NeRF-3DTalker在合成逼真的谈话头部视频方面优于现有技术,具有出色的图像质量和唇同步效果。项目页面:https://nerf-3dtalker.github.io/NeRF-3Dtalker。
论文及项目相关链接
PDF Accepted by ICASSP 2025
Summary
本文提出一种基于NeRF技术的说话人头部合成方法NeRF-3DTalker,通过引入3D先验信息和3D辅助音频解构技术解决当前头部合成中存在的问题,如非正面面部渲染模糊以及音频视觉空间对齐困难等。该方法可在任意视角生成清晰的说话人头部,并实现高质量的唇同步。
Key Takeaways
- NeRF技术被用于增强合成说话头部视频的真实感和纹理细节。
- 当前NeRF方法主要关注正面面部的渲染,无法生成任意视角的清晰说话头部。
- 说话头部合成面临的一个挑战是音频和视觉空间的对齐,这影响了生成的说话头部的唇同步效果。
- NeRF-3DTalker方法通过使用3D先验信息合成清晰的任意视角的说话头部来解决这些问题。
- 提出一种3D先验辅助音频解构模块,将音频分为与3D语音运动相关的特征和与说话风格相关的特征。
- 通过局部全局标准化空间调整远离实际说话者运动空间的生成帧位置。
点此查看论文截图


OccGaussian: 3D Gaussian Splatting for Occluded Human Rendering
Authors:Jingrui Ye, Zongkai Zhang, Yujiao Jiang, Qingmin Liao, Wenming Yang, Zongqing Lu
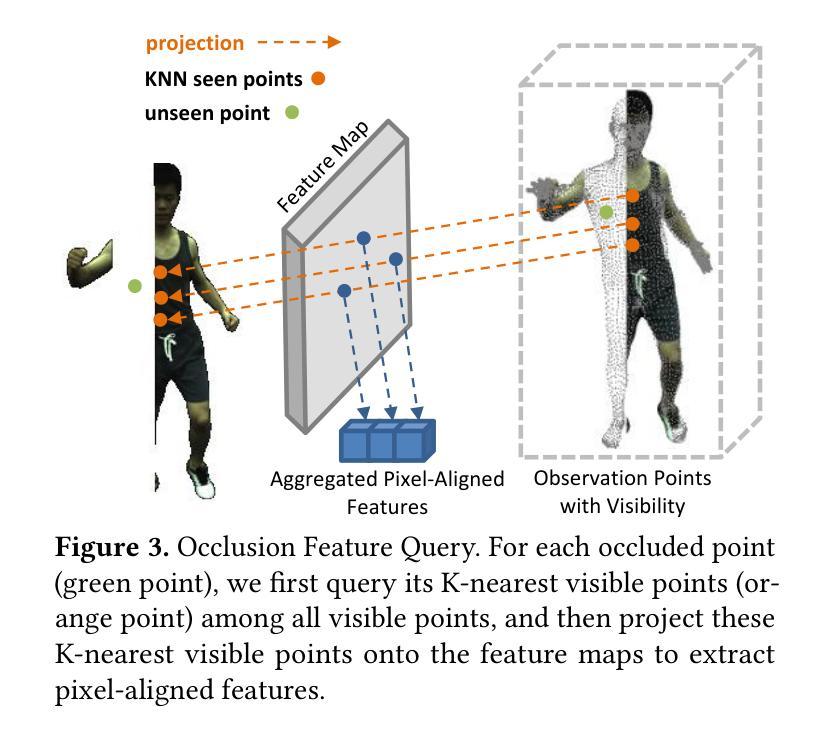
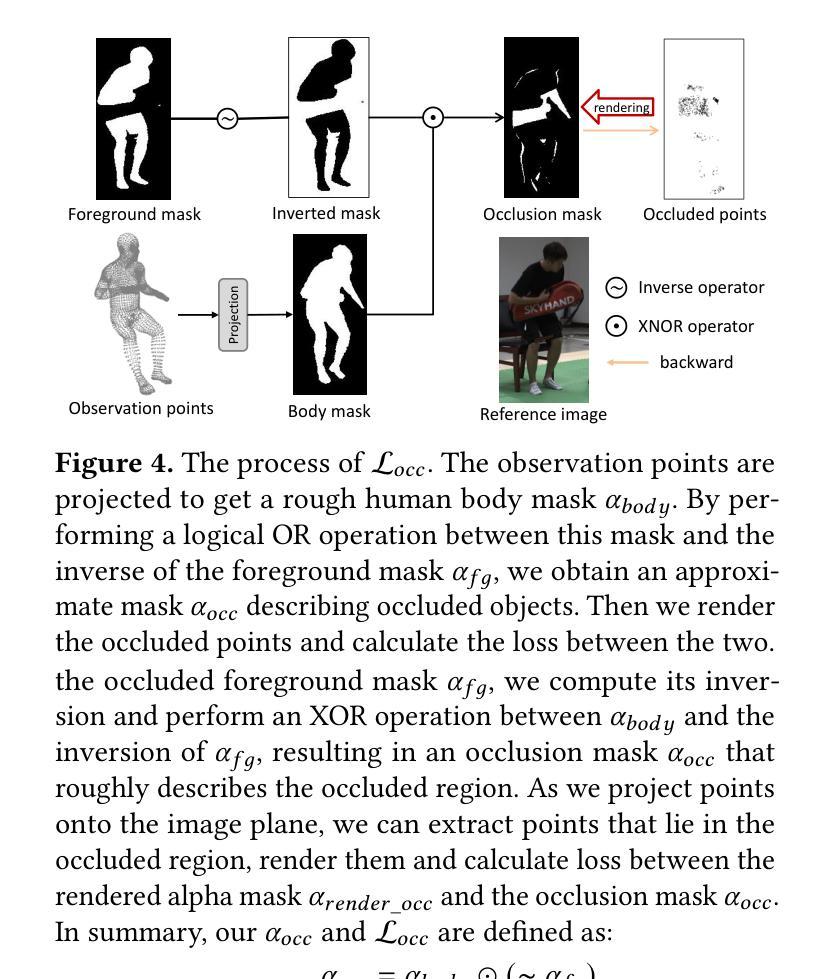
Rendering dynamic 3D human from monocular videos is crucial for various applications such as virtual reality and digital entertainment. Most methods assume the people is in an unobstructed scene, while various objects may cause the occlusion of body parts in real-life scenarios. Previous method utilizing NeRF for surface rendering to recover the occluded areas, but it requiring more than one day to train and several seconds to render, failing to meet the requirements of real-time interactive applications. To address these issues, we propose OccGaussian based on 3D Gaussian Splatting, which can be trained within 6 minutes and produces high-quality human renderings up to 160 FPS with occluded input. OccGaussian initializes 3D Gaussian distributions in the canonical space, and we perform occlusion feature query at occluded regions, the aggregated pixel-align feature is extracted to compensate for the missing information. Then we use Gaussian Feature MLP to further process the feature along with the occlusion-aware loss functions to better perceive the occluded area. Extensive experiments both in simulated and real-world occlusions, demonstrate that our method achieves comparable or even superior performance compared to the state-of-the-art method. And we improving training and inference speeds by 250x and 800x, respectively. Our code will be available for research purposes.
从单目视频中渲染动态3D人体对于虚拟现实和数字娱乐等各种应用至关重要。大多数方法都假设人物处于一个无遮挡的场景中,而在现实场景中,各种物体可能会导致身体部位的遮挡。之前的方法利用NeRF进行表面渲染来恢复遮挡区域,但需要一天以上的时间来训练,渲染需要数秒,无法满足实时交互应用的要求。为了解决这些问题,我们提出了基于3D高斯涂抹的OccGaussian方法,它可以在6分钟内完成训练,并以高达160 FPS的速度产生高质量的人体渲染,即使输入有遮挡物。OccGaussian在规范空间中初始化3D高斯分布,我们在遮挡区域执行遮挡特征查询,提取聚合的像素对齐特征以弥补缺失的信息。然后,我们使用高斯特征多层感知器进一步处理特征,并结合遮挡感知损失函数,以更好地感知遮挡区域。在模拟和真实世界遮挡条件下的广泛实验表明,我们的方法与最先进的方法相比取得了相当或更优越的性能。我们还通过培训和推理速度分别提高了250倍和800倍。我们的代码将用于研究目的。
论文及项目相关链接
PDF We have decided to withdraw this paper because the results require further verification or additional experimental data. We plan to resubmit an updated version once the necessary work is completed
Summary
该文针对从单目视频中渲染动态3D人体的问题进行研究,提出一种基于3D高斯涂抹的OccGaussian方法,可快速训练并在存在遮挡输入的情况下产生高质量的人体渲染。该方法通过初始化规范空间中的3D高斯分布,在遮挡区域执行遮挡特征查询,提取聚合像素对齐特征以补偿缺失信息,并使用高斯特征多层感知器进一步处理特征。与现有方法相比,该方法在模拟和真实世界遮挡条件下的实验表现出相当的或更优越的性能,并将训练和推理速度分别提高了250倍和800倍。
Key Takeaways
- 研究关注从单目视频中渲染动态3D人体,尤其在存在遮挡的情况下的技术挑战。
- 现有方法假设人体处于无遮挡场景中,但真实场景中的物体可能导致身体部位被遮挡。
- 提出了一种基于3D高斯涂抹的OccGaussian方法,快速训练并产生高质量的人体渲染。
- OccGaussian通过在规范空间中初始化3D高斯分布,并在遮挡区域执行特征查询来处理遮挡问题。
- 使用聚合像素对齐特征来补偿缺失信息,并通过高斯特征多层感知器进一步处理这些特征。
- 实验表明,该方法在模拟和真实世界遮挡条件下性能优越,与现有方法相比有显著提升。
点此查看论文截图