⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-22 更新
Speech to Speech Translation with Translatotron: A State of the Art Review
Authors:Jules R. Kala, Emmanuel Adetiba, Abdultaofeek Abayom, Oluwatobi E. Dare, Ayodele H. Ifijeh
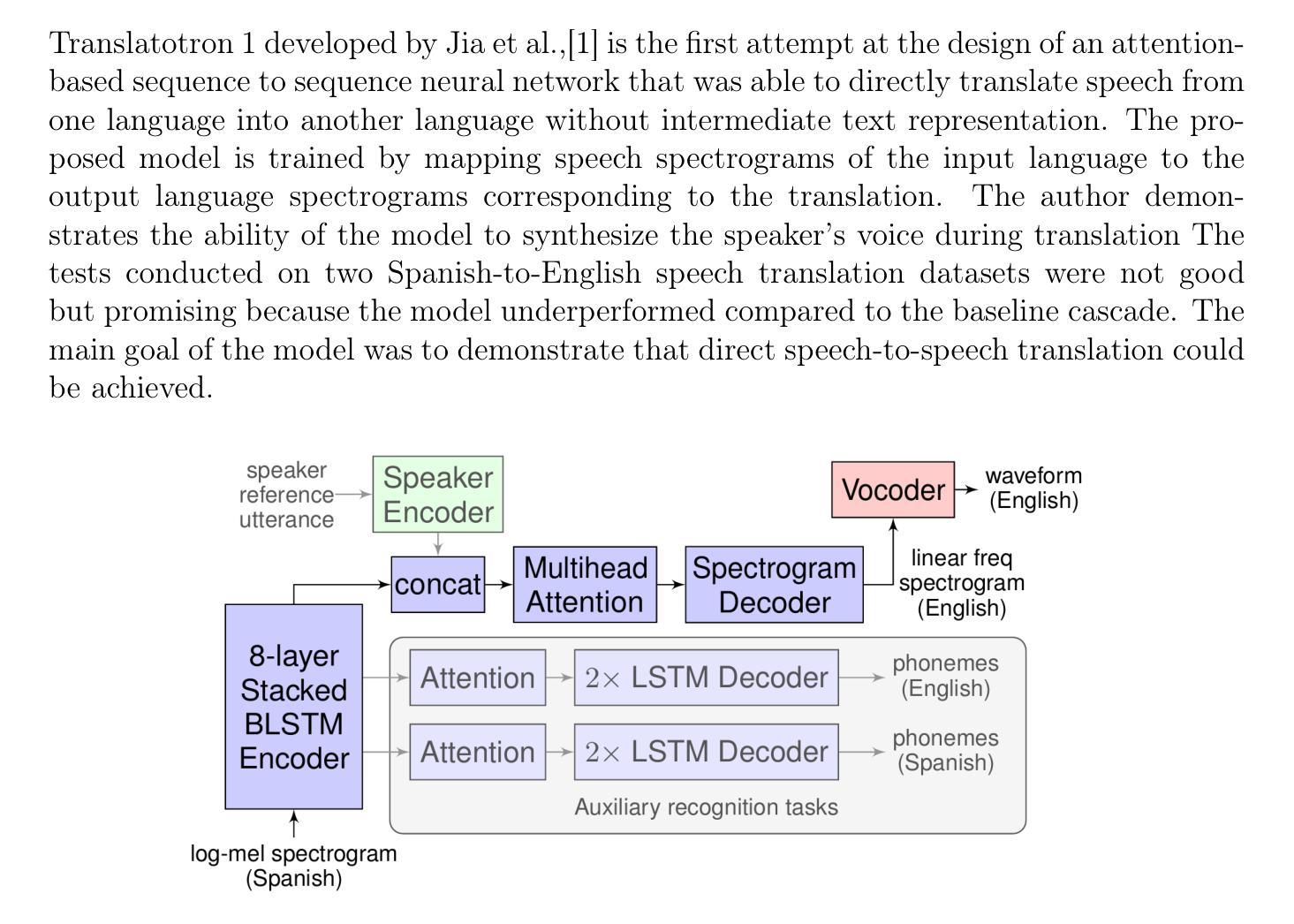
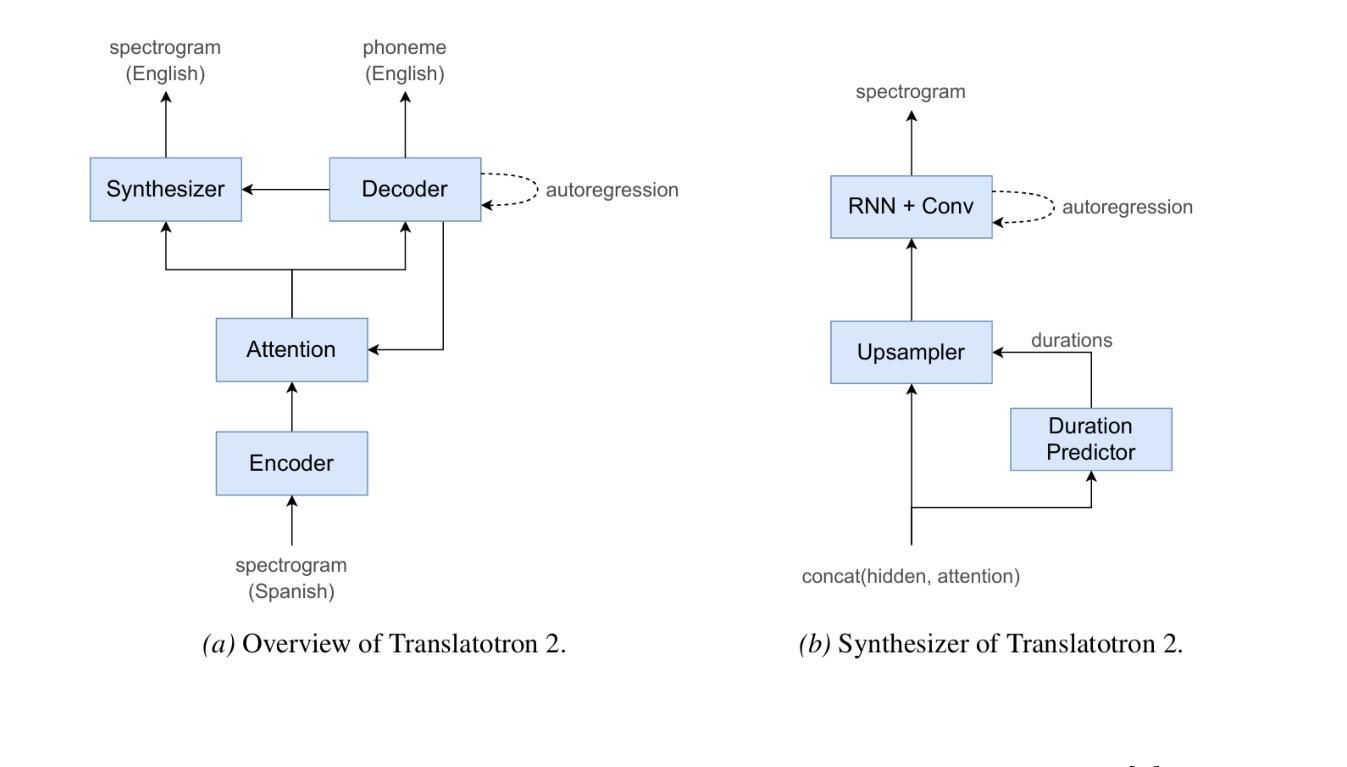
A cascade-based speech-to-speech translation has been considered a benchmark for a very long time, but it is plagued by many issues, like the time taken to translate a speech from one language to another and compound errors. These issues are because a cascade-based method uses a combination of methods such as speech recognition, speech-to-text translation, and finally, text-to-speech translation. Translatotron, a sequence-to-sequence direct speech-to-speech translation model was designed by Google to address the issues of compound errors associated with cascade model. Today there are 3 versions of the Translatotron model: Translatotron 1, Translatotron 2, and Translatotron3. The first version was designed as a proof of concept to show that a direct speech-to-speech translation was possible, it was found to be less effective than the cascade model but was producing promising results. Translatotron2 was an improved version of Translatotron 1 with results similar to the cascade model. Translatotron 3 the latest version of the model is better than the cascade model at some points. In this paper, a complete review of speech-to-speech translation will be presented, with a particular focus on all the versions of Translatotron models. We will also show that Translatotron is the best model to bridge the language gap between African Languages and other well-formalized languages.
基于级联的语音到语音翻译很长一段时间以来一直被视为一个基准测试,但它存在许多问题,例如将语音从一种语言翻译到另一种语言所需的时间以及复合错误。这些问题的原因是,级联方法结合了语音识别、语音到文本的翻译,以及最后的文本到语音的翻译。Google设计了序列到序列的直接语音到语音翻译模型Translatotron,以解决与级联模型相关的复合错误问题。如今,Translatotron模型有3个版本:Translatotron 1、Translatotron 2和Translatotron3。第一个版本是作为概念验证而设计的,以证明直接语音到语音翻译的可能性,结果发现其效果不如级联模型,但产生了令人鼓舞的结果。Translatotron2是Translatotron 1的改进版本,其结果与级联模型相似。Translatotron 3,即该模型的最新版本,在某些方面优于级联模型。本文将全面回顾语音到语音翻译,特别关注所有版本的Translatotron模型。我们还将展示Translatotron是弥合非洲语言和其他规范化语言之间语言障碍的最佳模型。
论文及项目相关链接
PDF 12 pages and 3 figures
摘要
本文主要介绍了级联语音转语音翻译的问题及其面临的挑战,包括翻译时间和复合错误等。谷歌设计的序列到序列直接语音转语音翻译模型Translatotron旨在解决级联模型的复合错误问题。本文将全面回顾语音转语音翻译,重点关注Translatotron模型的所有版本,并证明Translatotron是弥合非洲语言与其他规范化语言之间差距的最佳模型。
要点解读
- 级联语音转语音翻译长期为行业基准,但存在翻译时间长和复合错误等问题。
- Translatotron模型由谷歌设计,为序列到序列的直接语音转语音翻译模型。
- Translatotron模型有三个版本:Translatotron 1作为概念验证,显示直接语音转语音翻译可行性,但效果逊于级联模型。
- Translatotron 2是Translatotron 1的改进版,效果与级联模型相似。
- 最新版本的Translatotron 3在某些方面优于级联模型。
- 本文将全面回顾语音转语音翻译技术,特别关注Translatotron模型的不同版本。
点此查看论文截图

DMOSpeech: Direct Metric Optimization via Distilled Diffusion Model in Zero-Shot Speech Synthesis
Authors:Yingahao Aaron Li, Rithesh Kumar, Zeyu Jin
Diffusion models have demonstrated significant potential in speech synthesis tasks, including text-to-speech (TTS) and voice cloning. However, their iterative denoising processes are computationally intensive, and previous distillation attempts have shown consistent quality degradation. Moreover, existing TTS approaches are limited by non-differentiable components or iterative sampling that prevent true end-to-end optimization with perceptual metrics. We introduce DMOSpeech, a distilled diffusion-based TTS model that uniquely achieves both faster inference and superior performance compared to its teacher model. By enabling direct gradient pathways to all model components, we demonstrate the first successful end-to-end optimization of differentiable metrics in TTS, incorporating Connectionist Temporal Classification (CTC) loss and Speaker Verification (SV) loss. Our comprehensive experiments, validated through extensive human evaluation, show significant improvements in naturalness, intelligibility, and speaker similarity while reducing inference time by orders of magnitude. This work establishes a new framework for aligning speech synthesis with human auditory preferences through direct metric optimization. The audio samples are available at https://dmospeech.github.io/.
扩散模型在语音合成任务中表现出了巨大的潜力,包括文本到语音(TTS)和声音克隆。然而,其迭代去噪过程计算量大,之前的蒸馏尝试显示了一致的质量下降。此外,现有的TTS方法受到不可微分组件或迭代采样的限制,阻碍了与感知指标的真正端到端优化。我们推出了DMOSpeech,这是一款蒸馏的基于扩散的TTS模型,它独特地实现了与教师模型相比更快推理和更优越的性能。通过为所有模型组件启用直接梯度路径,我们展示了TTS中可微分指标的首个成功端到端优化,结合了连接时序分类(CTC)损失和说话人验证(SV)损失。我们的综合实验通过广泛的人类评估得到了验证,在自然度、清晰度和说话人相似性方面取得了显著改进,同时推理时间减少了数个数量级。这项工作建立了一个新的框架,通过直接指标优化使语音合成与人类听觉偏好对齐。音频样本可在https://dmospeech.github.io/找到。
论文及项目相关链接
摘要
扩散模型在语音合成任务(包括文本转语音(TTS)和声音克隆)中显示出巨大潜力。然而,其迭代去噪过程计算密集,先前的蒸馏尝试显示质量持续下降。此外,现有TTS方法受限于不可区分的组件或迭代采样,阻碍了真正的端到端优化感知指标。我们推出DMOSpeech,一种精炼的扩散基础TTS模型,独特地实现了更快的推理和比其教师模型更优越的性能。通过为所有模型组件提供直接梯度路径,我们展示了TTS中可区分指标的首次成功端到端优化,结合了连接时序分类(CTC)损失和说话人验证(SV)损失。我们的综合实验通过广泛的人类评估验证,在自然度、清晰度和说话人相似性方面显示出显着改善,同时推理时间减少了多个数量级。这项工作建立了一个新的框架,通过对直接指标优化,使语音合成与人类听觉偏好对齐。音频样本可在https://dmospeech.github.io/上找到。
关键见解
- 扩散模型在语音合成任务中具有显著潜力,包括文本转语音(TTS)和声音克隆。
- 现有TTS方法面临计算密集型的迭代去噪过程和优化限制。
- 我们引入了DMOSpeech,一种精炼的扩散基础TTS模型,实现了更快的推理和更高的性能。
- DMOSpeech实现了端到端的优化,结合了可区分的指标,如连接时序分类(CTC)损失和说话人验证(SV)损失。
- 通过综合实验和广泛的人类评估,DMOSpeech在自然度、清晰度和说话人相似性方面表现出显著改进。
- DMOSpeech减少了推理时间,建立了新的语音合成框架,与人类听觉偏好对齐。
- 音频样本可在指定网站上找到。
点此查看论文截图