⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-23 更新
OpenCharacter: Training Customizable Role-Playing LLMs with Large-Scale Synthetic Personas
Authors:Xiaoyang Wang, Hongming Zhang, Tao Ge, Wenhao Yu, Dian Yu, Dong Yu
Customizable role-playing in large language models (LLMs), also known as character generalization, is gaining increasing attention for its versatility and cost-efficiency in developing and deploying role-playing dialogue agents. This study explores a large-scale data synthesis approach to equip LLMs with character generalization capabilities. We begin by synthesizing large-scale character profiles using personas from Persona Hub and then explore two strategies: response rewriting and response generation, to create character-aligned instructional responses. To validate the effectiveness of our synthetic instruction tuning data for character generalization, we perform supervised fine-tuning (SFT) using the LLaMA-3 8B model. Our best-performing model strengthens the original LLaMA-3 8B Instruct model and achieves performance comparable to GPT-4o models on role-playing dialogue. We release our synthetic characters and instruction-tuning dialogues to support public research.
在大规模语言模型(LLM)中的角色定制,也被称为角色泛化,因其角色扮演对话代理的开发和部署中的灵活性和成本效益而受到越来越多的关注。本研究探索了一种大规模数据合成方法来为LLM提供角色泛化能力。我们首先使用Persona Hub中的人物来合成大规模的角色特征,然后探索两种策略:响应重写和响应生成,来创建与角色对齐的指令响应。为了验证我们合成指令调整数据对于角色泛化的有效性,我们使用LLaMA-3 8B模型进行有监督微调(SFT)。我们表现最好的模型强化了原始的LLaMA-3 8B指令模型,并在角色扮演对话方面达到了与GPT-4o模型相当的性能。我们发布我们的合成角色和指令调整对话以支持公开研究。
论文及项目相关链接
Summary
大型语言模型(LLM)中的角色定制能力,即角色泛化能力,因其灵活性和开发部署成本效益而受到越来越多的关注。本研究探索了一种大规模数据合成方法来为LLM提供角色泛化能力。通过合成大规模角色配置文件并使用Persona Hub中的个性进行初步研究,我们探索了两种策略:响应重写和响应生成,以创建与角色对齐的指令响应。为了验证我们的合成指令微调数据对角色泛化的有效性,我们使用LLaMA-3 8B模型进行有监督微调(SFT)。我们表现最佳的模型增强了原始的LLaMA-3 8B指令模型在角色扮演对话上的表现,达到了GPT-4o模型的性能水平。我们发布我们的合成角色和指令调整对话以支持公开研究。
Key Takeaways
- 大型语言模型(LLM)的角色定制能力因其灵活性和成本效益而受到关注。
- 研究者通过合成大规模角色配置文件来赋予LLM角色泛化能力。
- 使用Persona Hub中的个性进行初步研究,探索了响应重写和响应生成两种策略来创建与角色对齐的指令响应。
- 通过有监督微调(SFT)验证了合成指令微调数据的有效性。
- 最佳模型的性能与GPT-4o模型在角色扮演对话上的表现相当。
- 研究者发布了合成角色和指令调整对话以支持公开研究。
点此查看论文截图




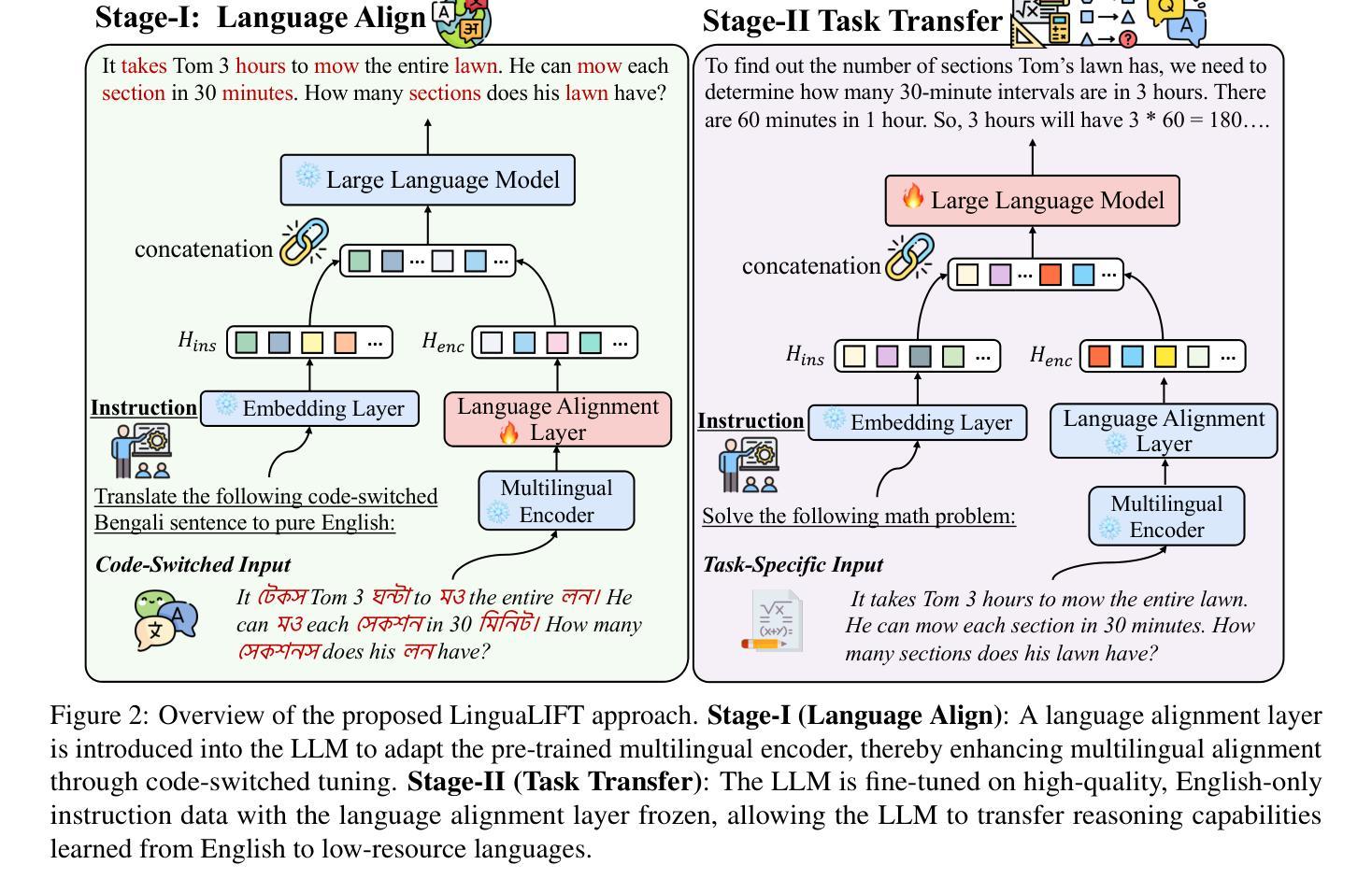
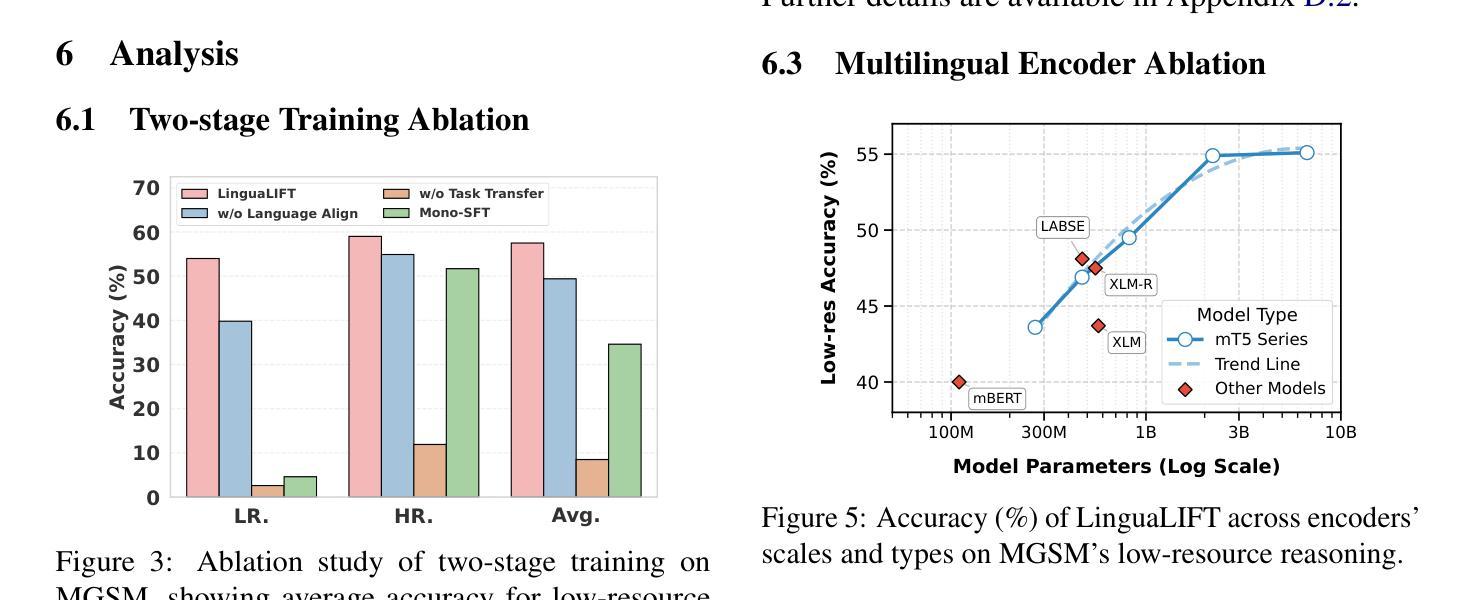
LinguaLIFT: An Effective Two-stage Instruction Tuning Framework for Low-Resource Language Reasoning
Authors:Hongbin Zhang, Kehai Chen, Xuefeng Bai, Yang Xiang, Min Zhang
Large language models (LLMs) have exhibited impressive multilingual reasoning capabilities, driven by extensive multilingual pre-training corpora and instruction fine-tuning data. However, a performance gap exists between high- and low-resource language reasoning tasks due to the language imbalance in the pre-training corpus, which is exacerbated by evaluation bias in existing reasoning benchmarks lacking low-resource language coverage. To alleviate this issue, we propose LinguaLIFT, a two-stage instruction tuning framework for advancing low-resource language reasoning. LinguaLIFT employs a language alignment layer to capture multilingual alignment in a code-switched tuning way without requiring multilingual instruction or parallel data, thereby transferring the cross-lingual reasoning capabilities to low-resource languages through English-only instruction tuning data. To comprehensively evaluate the multilingual reasoning capabilities, we introduce the Multilingual Math World Problem (MMWP) benchmark, which spans 21 low-resource, 17 medium-resource, and 10 high-resource languages. Experimental results show that LinguaLIFT outperforms several competitive baselines across MMWP and four widely used benchmarks.
大型语言模型(LLM)表现出了令人印象深刻的跨语言推理能力,这得益于大量的跨语言预训练语料库和指令微调数据。然而,由于预训练语料库中的语言不平衡,高资源语言推理任务与低资源语言推理任务之间存在性能差距,而现有推理基准测试中的评估偏见缺乏低资源语言覆盖,这一差距进一步加剧。为了缓解这一问题,我们提出了LinguaLIFT,这是一个两阶段的指令调整框架,用于提升低资源语言推理。LinguaLIFT采用语言对齐层来捕捉代码切换调整方式中的多语言对齐,无需多语言指令或平行数据,从而通过仅英语指令调整数据转移跨语言推理能力到低资源语言。为了全面评估多语言推理能力,我们引入了多语言数学世界问题(MMWP)基准测试,它涵盖21种低资源语言、17种中资源语言和1.0种高资源语言。实验结果表明,LinguaLIFT在MMWP和四个广泛使用的基准测试中超越了几个竞争基线。
论文及项目相关链接
Summary
大型语言模型(LLM)具备强大的跨语言推理能力,得益于丰富的跨语言预训练语料库和指令微调数据。然而,由于预训练语料库中的语言不平衡和现有推理基准测试对低资源语言的覆盖不足,高资源语言与低资源语言之间的推理任务存在性能差距。为解决这一问题,我们提出LinguaLIFT,这是一个两阶段的指令调整框架,旨在提升低资源语言的推理能力。LinguaLIFT采用语言对齐层,以代码切换的方式捕捉多语言对齐,无需多语言指令或平行数据,通过仅使用英语指令调整数据,将跨语言推理能力转移到低资源语言。为全面评估多语言推理能力,我们引入了跨多种语言的数学世界问题(MMWP)基准测试,涵盖21种低资源、17种中等资源和10种高资源语言。实验结果表明,LinguaLIFT在MMWP和四个广泛使用的基准测试中超越了几个竞争对手。
Key Takeaways
- LLM具备强大的跨语言推理能力,得益于预训练语料库和指令微调数据。
- 高资源语言与低资源语言之间的推理任务存在性能差距,主要由于预训练语料库中的语言不平衡和现有推理基准测试对低资源语言的覆盖不足。
- LinguaLIFT是一个两阶段的指令调整框架,旨在提升低资源语言的推理能力,采用语言对齐层以代码切换方式捕捉多语言对齐。
- LinguaLIFT无需多语言指令或平行数据,通过英语指令调整数据转移跨语言推理能力到低资源语言。
- MMWP基准测试用于全面评估多语言推理能力,涵盖多种不同资源的语言。
- 实验表明,LinguaLIFT在多个基准测试中性能优越。
点此查看论文截图


MaLei at the PLABA Track of TREC 2024: RoBERTa for Term Replacement – LLaMA3.1 and GPT-4o for Complete Abstract Adaptation
Authors:Zhidong Ling, Zihao Li, Pablo Romero, Lifeng Han, Goran Nenadic
This report is the system description of the MaLei team (Manchester and Leiden) for the shared task Plain Language Adaptation of Biomedical Abstracts (PLABA) 2024 (we had an earlier name BeeManc following last year), affiliated with TREC2024 (33rd Text REtrieval Conference https://ir.nist.gov/evalbase/conf/trec-2024). This report contains two sections corresponding to the two sub-tasks in PLABA-2024. In task one (term replacement), we applied fine-tuned ReBERTa-Base models to identify and classify the difficult terms, jargon, and acronyms in the biomedical abstracts and reported the F1 score (Task 1A and 1B). In task two (complete abstract adaptation), we leveraged Llamma3.1-70B-Instruct and GPT-4o with the one-shot prompts to complete the abstract adaptation and reported the scores in BLEU, SARI, BERTScore, LENS, and SALSA. From the official Evaluation from PLABA-2024 on Task 1A and 1B, our much smaller fine-tuned RoBERTa-Base model ranked 3rd and 2nd respectively on the two sub-tasks, and the 1st on averaged F1 scores across the two tasks from 9 evaluated systems. Our LLaMA-3.1-70B-instructed model achieved the highest Completeness score for Task 2. We share our source codes, fine-tuned models, and related resources at https://github.com/HECTA-UoM/PLABA2024
这份报告是MaLei团队(曼彻斯特与莱顿)关于2024年生物医学摘要的平语适应(PLABA)共享任务的体系描述(我们去年使用了一个较早的名字BeeManc),该任务与TREC2024(第33次文本检索会议)相关联。本报告包含两个部分,分别对应PLABA-2024的两个子任务。在任务一(术语替换)中,我们应用了经过微调过的ReBERTa-Base模型来识别和分类生物医学摘要中的难词、术语和缩写词,并报告了F1分数(任务1A和1B)。在任务二(完整摘要适应)中,我们利用Llamma3.1-70B-Instruct和GPT-4o的一次性提示来完成摘要的适应,并在BLEU、SARI、BERTScore、LENS和SALSA中报告了得分。根据PLABA-2024的官方评估结果,我们的较小的微调RoBERTa-Base模型在两个子任务中分别排名第3和第2,而在两个任务的平均F1分数上排名第1(共评价了9个系统)。我们的LLaMA-3.1-70B-Instruct模型在任务2中获得了最高的完整性得分。我们在https://github.com/HECTA-UoM/PLABA2024分享了我们的源代码、微调模型和相关资源。
论文及项目相关链接
PDF ongoing work - system report for PLABA2024 with TREC-2024
Summary
本文介绍了MaLei团队在PLABA 2024任务中的系统描述,该任务包括两个子任务:术语替换和完整摘要改编。团队使用了fine-tuned ReBERTa-Base模型和Llamma3.1-70B-Instruct与GPT-4o等工具进行任务处理,并在两个子任务中取得了优异的成绩。团队还分享了源代码、fine-tuned模型和有关资源。
Key Takeaways
- MaLei团队参与了PLABA 2024任务,该任务旨在实现生物医学摘要的通俗化改编。
- 任务分为两个子任务:术语替换和完整摘要改编。
- 团队使用了fine-tuned ReBERTa-Base模型来识别和分类生物医学摘要中的困难术语、行话和缩写。
- 在任务二中使用Llamma3.1-70B-Instruct和GPT-4o等工具进行完整摘要改编。
- MaLei团队在两个子任务中均取得了优异的成绩,平均F1得分在所有评价的系统中排名第二和第三,且在任务二的完整性得分上排名第一。
- MaLei团队分享了源代码、fine-tuned模型和有关资源。
点此查看论文截图


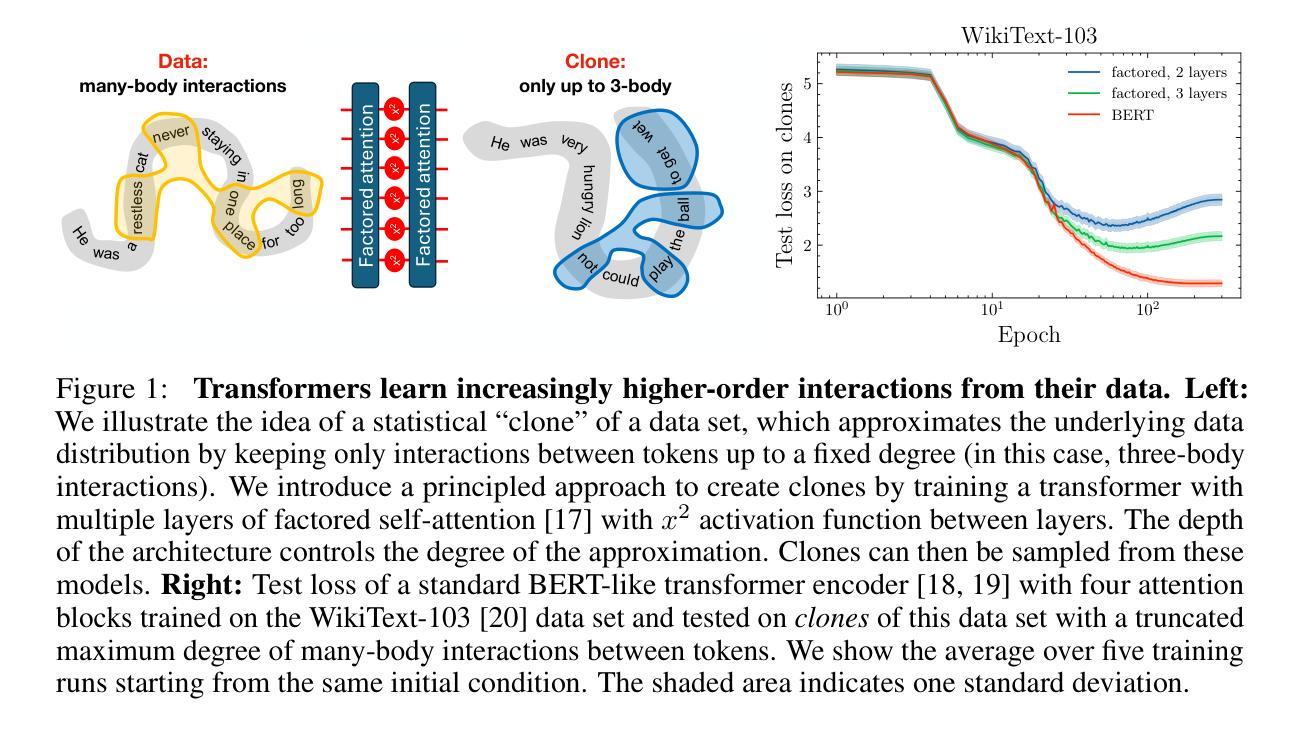
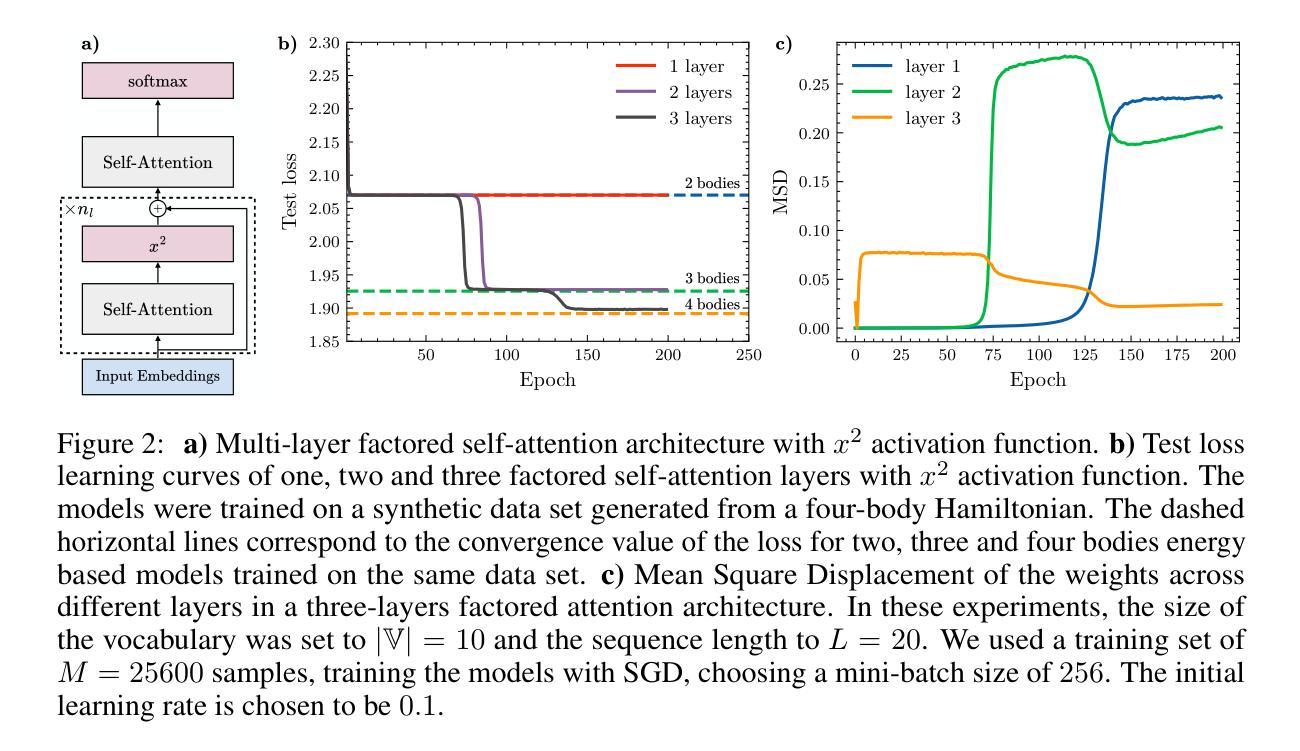
A distributional simplicity bias in the learning dynamics of transformers
Authors:Riccardo Rende, Federica Gerace, Alessandro Laio, Sebastian Goldt
The remarkable capability of over-parameterised neural networks to generalise effectively has been explained by invoking a ``simplicity bias’’: neural networks prevent overfitting by initially learning simple classifiers before progressing to more complex, non-linear functions. While simplicity biases have been described theoretically and experimentally in feed-forward networks for supervised learning, the extent to which they also explain the remarkable success of transformers trained with self-supervised techniques remains unclear. In our study, we demonstrate that transformers, trained on natural language data, also display a simplicity bias. Specifically, they sequentially learn many-body interactions among input tokens, reaching a saturation point in the prediction error for low-degree interactions while continuing to learn high-degree interactions. To conduct this analysis, we develop a procedure to generate \textit{clones} of a given natural language data set, which rigorously capture the interactions between tokens up to a specified order. This approach opens up the possibilities of studying how interactions of different orders in the data affect learning, in natural language processing and beyond.
神经网络在过度参数化后仍能有效泛化的显著能力,可以通过引入“简洁性偏见”来解释:神经网络通过首先学习简单的分类器,然后逐渐转向更复杂、非线性的函数,从而防止过度拟合。虽然简洁偏见在理论上和实验上已在用于监督学习的前馈网络中得到了描述,但它们是否也能解释使用自监督技术训练的变压器的显著成功程度仍然不清楚。在我们的研究中,我们证明了在自然语言数据上训练的变压器也表现出简洁偏见。具体来说,它们会按顺序学习输入标记之间的多体交互作用,在预测低阶交互的错误时达到饱和点,同时继续学习高阶交互。为了进行这种分析,我们开发了一种程序来生成给定自然语言数据集的副本,这些副本严格捕获标记之间的交互作用到指定的顺序。这种方法开辟了研究不同顺序的交互如何影响自然语言处理和其他领域学习的可能性。
论文及项目相关链接
PDF 10 pages, 5 figures, NeurIPS 2024
Summary
神经网络通过引入“简洁性偏见”来解释其有效的泛化能力:神经网络通过首先学习简单的分类器来防止过拟合,然后再逐步学习更复杂的非线性函数。本研究证明,使用自然语言数据训练的变压器也表现出简洁性偏见。特别是,他们按顺序学习输入标记之间的多体交互作用,在预测低阶交互的错误时达到饱和点,同时继续学习高阶交互。为此分析,我们开发了一种生成给定自然语言数据集的“克隆”的程序,该程序严格捕获了标记之间的交互作用直到指定的顺序。这为研究不同顺序的交互作用如何影响自然语言处理等领域的学习提供了可能性。
Key Takeaways
- 神经网络通过引入“简洁性偏见”来解释其泛化能力,即通过学习简单的分类器来防止过拟合。
- 变压器模型在训练过程中也显示出简洁性偏见,即先学习低阶交互,再逐渐学习高阶交互。
- 本研究开发了一种生成自然语言数据集克隆的程序,用于捕获标记之间的交互作用。
- 该程序可以严格地研究不同阶数的交互作用对数据学习的影响。
- 此方法对于研究自然语言处理领域的学习具有应用价值。
- 变压器模型在自我监督技术训练下的成功部分归因于简洁性偏见。
点此查看论文截图

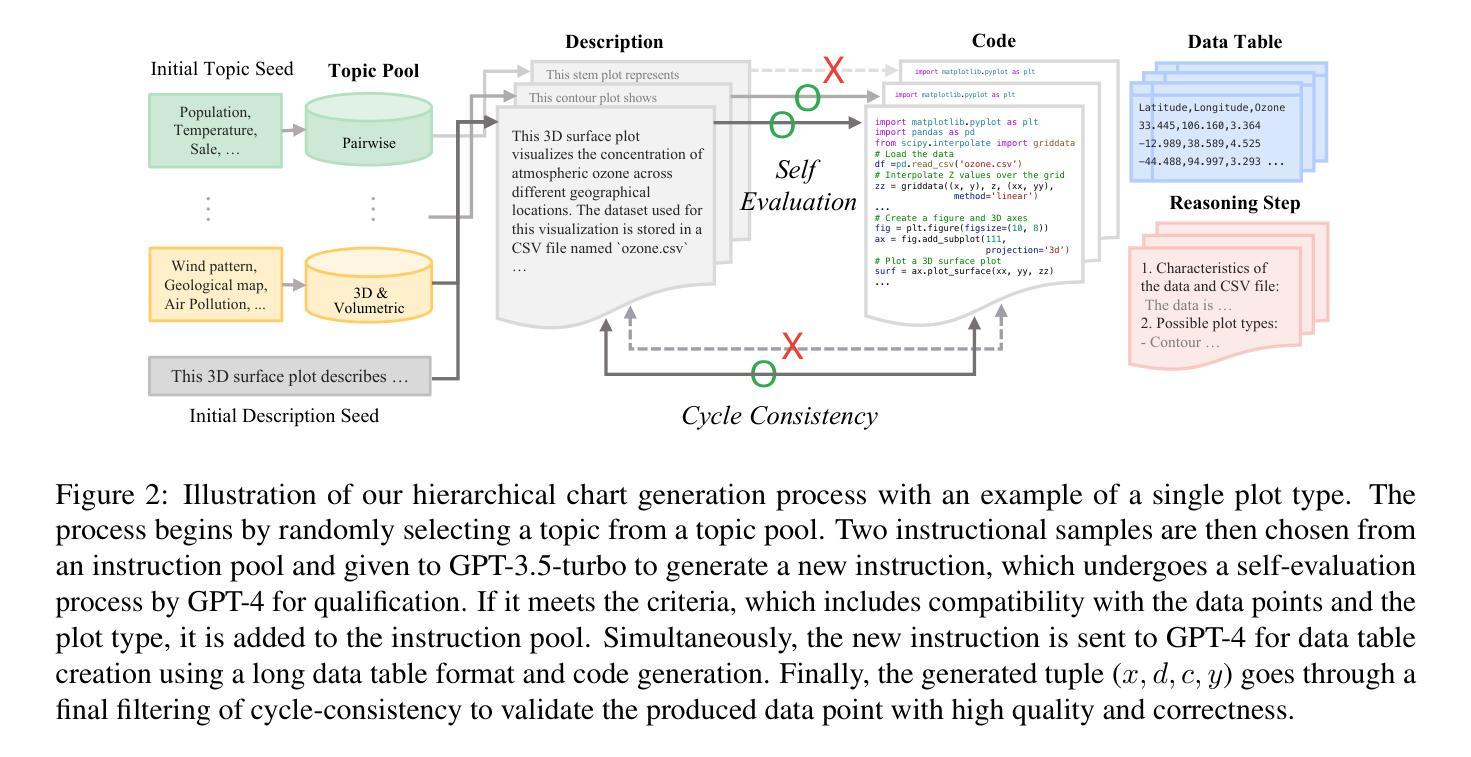
Text2Chart31: Instruction Tuning for Chart Generation with Automatic Feedback
Authors:Fatemeh Pesaran Zadeh, Juyeon Kim, Jin-Hwa Kim, Gunhee Kim
Large language models (LLMs) have demonstrated strong capabilities across various language tasks, notably through instruction-tuning methods. However, LLMs face challenges in visualizing complex, real-world data through charts and plots. Firstly, existing datasets rarely cover a full range of chart types, such as 3D, volumetric, and gridded charts. Secondly, supervised fine-tuning methods do not fully leverage the intricate relationships within rich datasets, including text, code, and figures. To address these challenges, we propose a hierarchical pipeline and a new dataset for chart generation. Our dataset, Text2Chart31, includes 31 unique plot types referring to the Matplotlib library, with 11.1K tuples of descriptions, code, data tables, and plots. Moreover, we introduce a reinforcement learning-based instruction tuning technique for chart generation tasks without requiring human feedback. Our experiments show that this approach significantly enhances the model performance, enabling smaller models to outperform larger open-source models and be comparable to state-of-the-art proprietary models in data visualization tasks. We make the code and dataset available at https://github.com/fatemehpesaran310/Text2Chart31.
大型语言模型(LLM)在各种语言任务中表现出了强大的能力,尤其是指令调整方法。然而,LLM在通过图表可视化复杂、现实世界数据方面面临挑战。首先,现有数据集很少涵盖全方位的图表类型,如3D、体积和网格图表。其次,监督微调方法并没有充分利用丰富数据集中的复杂关系,包括文本、代码和图表。为了解决这些挑战,我们提出了一个分层的管道和一个新的数据集来进行图表生成。我们的数据集Text2Chart31包括Matplotlib库中引用的31种独特图表类型,包含11.1K个描述、代码、数据表和图表的元组。此外,我们引入了一种基于强化学习的指令调整技术,用于图表生成任务,无需人工反馈。我们的实验表明,这种方法显著提高了模型性能,使小型模型在数据可视化任务中超越大型开源模型,并与最先进的专有模型相当。我们在https://github.com/fatemehpesaran310/Text2Chart31提供了代码和数据集。
论文及项目相关链接
PDF EMNLP 2024 Main Oral. Code and dataset are released at https://github.com/fatemehpesaran310/Text2Chart31
Summary
大型语言模型(LLM)在各类语言任务中展现出强大的能力,尤其在指令微调方法方面尤为突出。然而,LLM在可视化复杂、现实世界数据方面存在挑战,如处理3D、体积和网格图表等类型的数据。为解决这些问题,本研究提出了一种层次化管道和新的数据集Text2Chart31,用于图表生成。该数据集包含Matplotlib库中涉及的31种独特图表类型,共计11.1K个描述、代码、数据表和图表的组合。此外,研究引入了基于强化学习的指令微调技术,用于图表生成任务,无需人工反馈。实验表明,该方法显著提高了模型性能,使得小型模型在数据可视化任务上的表现优于大型开源模型,并与业界顶尖模型相媲美。我们已将代码和数据集发布在https://github.com/fatemehpesaran310/Text2Chart31。
Key Takeaways
- 大型语言模型(LLM)在多种语言任务中表现优异,尤其擅长指令微调方法。
- LLM在可视化复杂、现实世界数据方面面临挑战,如处理多种图表类型。
- 现有数据集很少覆盖全面的图表类型,如3D、体积和网格图表。
- 提出了一个新的数据集Text2Chart31,包含多种图表类型,以支持更广泛的图表生成任务。
- 引入了一种基于强化学习的指令微调技术,用于图表生成任务,提高了模型性能。
- 该方法使得小型模型在数据可视化任务上的表现优于某些大型开源模型。
点此查看论文截图


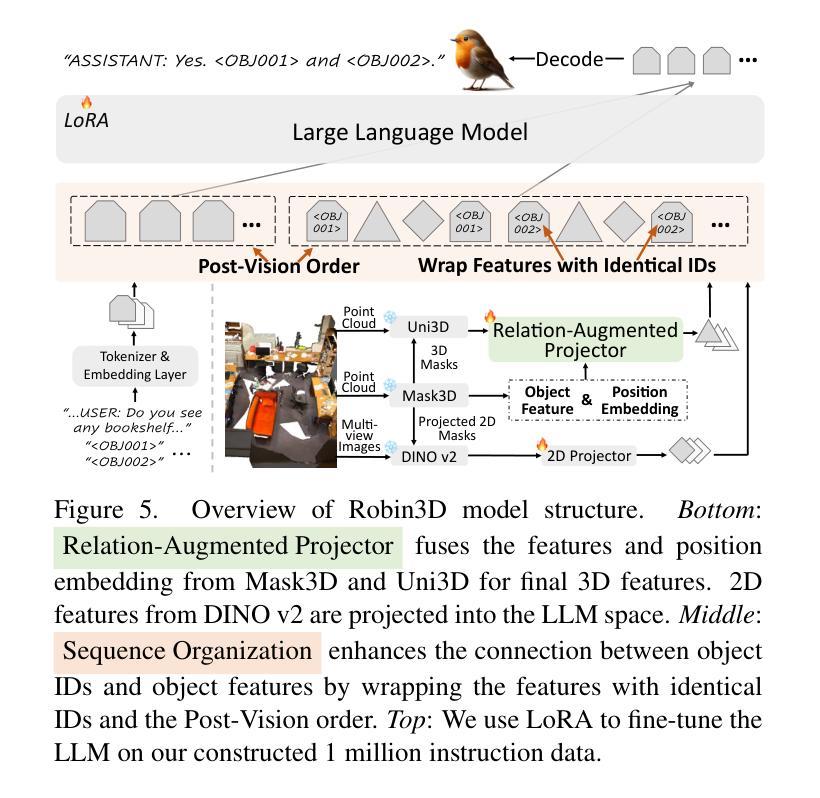
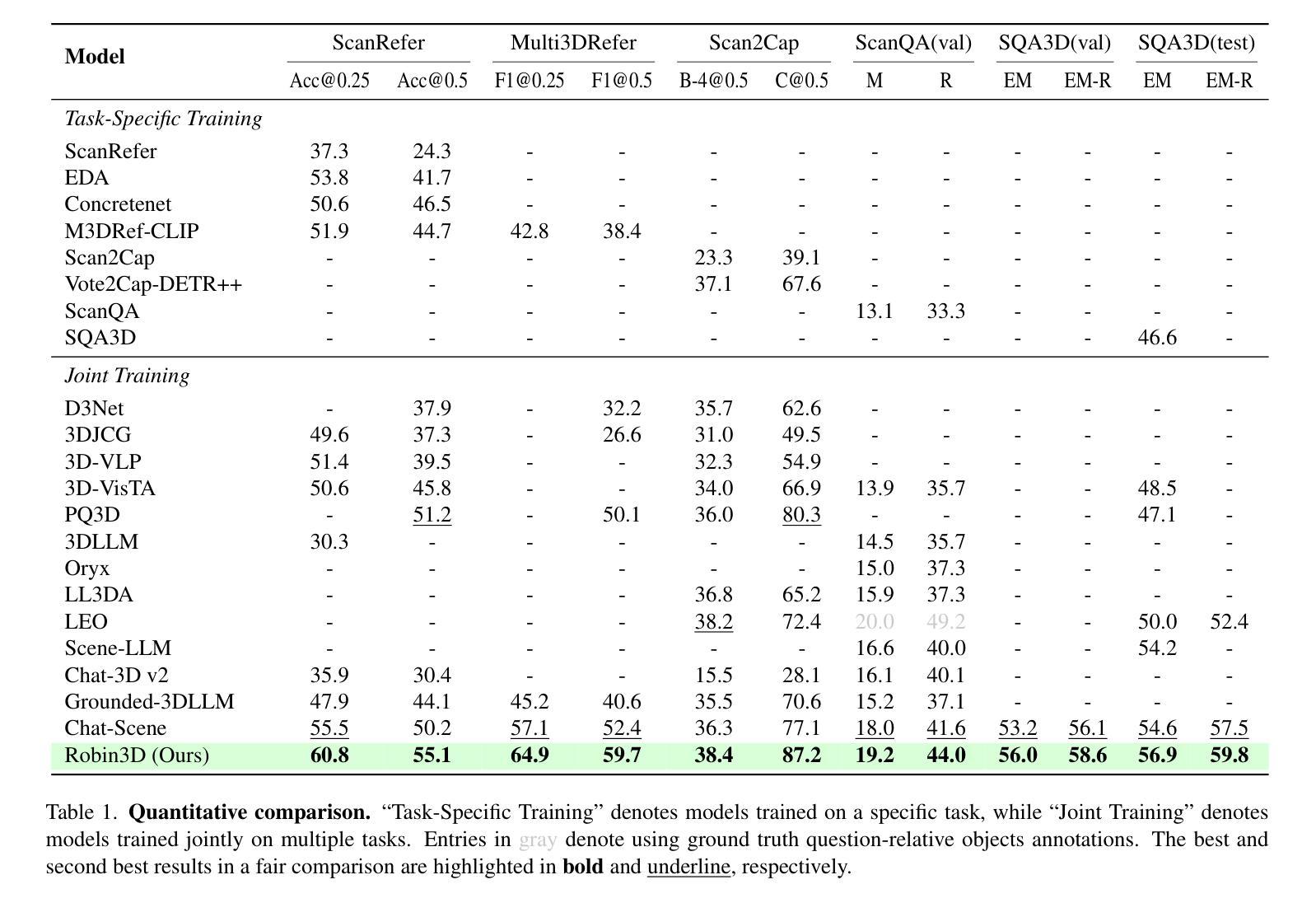
Robin3D: Improving 3D Large Language Model via Robust Instruction Tuning
Authors:Weitai Kang, Haifeng Huang, Yuzhang Shang, Mubarak Shah, Yan Yan
Recent advancements in 3D Large Language Models (3DLLMs) have highlighted their potential in building general-purpose agents in the 3D real world, yet challenges remain due to the lack of high-quality robust instruction-following data, leading to limited discriminative power and generalization of 3DLLMs. In this paper, we introduce Robin3D, a powerful 3DLLM trained on large-scale instruction-following data generated by our novel data engine, Robust Instruction Generation (RIG) engine. RIG generates two key instruction data: 1) the Adversarial Instruction-following data, which features mixed negative and positive samples to enhance the model’s discriminative understanding. 2) the Diverse Instruction-following data, which contains various instruction styles to enhance model’s generalization. As a result, we construct 1 million instruction-following data, consisting of 344K Adversarial samples, 508K Diverse samples, and 165K benchmark training set samples. To better handle these complex instructions, Robin3D first incorporates Relation-Augmented Projector to enhance spatial understanding, and then strengthens the object referring and grounding ability through ID-Feature Bonding. Robin3D consistently outperforms previous methods across five widely-used 3D multimodal learning benchmarks, without the need for task-specific fine-tuning. Notably, we achieve a 7.8% improvement in the grounding task (Multi3DRefer) and a 6.9% improvement in the captioning task (Scan2Cap).
近年来,3D大型语言模型(3DLLM)的进步凸显了其在构建3D现实世界通用代理的潜力,但由于缺乏高质量、稳健的指令遵循数据,仍存在挑战,导致3DLLM的辨别力和泛化能力有限。在本文中,我们介绍了Robin3D,这是一种由我们的新型数据引擎——Robust Instruction Generation(RIG)引擎生成的大规模指令遵循数据训练出来的强大3DLLM。
论文及项目相关链接
PDF 8 pages
摘要
最近3D大型语言模型(3DLLM)的进展突显了其在构建现实世界中通用代理的潜力,但仍面临缺乏高质量稳健指令跟踪数据的挑战,限制了其鉴别力和泛化能力。本文介绍了Robin3D,这是一种强大的由我们新型数据引擎Robust Instruction Generation(RIG)生成大规模指令跟踪数据训练的3DLLM。RIG生成两种关键指令数据:对抗性指令跟踪数据和多样性指令跟踪数据,分别用于增强模型的鉴别理解和提高模型的泛化能力。因此,我们构建了包含对抗性样本、多样性样本和基准训练集样本的各一百万条指令跟踪数据。Robin3D采用Relation-Augmented Projector以增强空间理解力,通过ID-Feature Bonding强化对象指代和定位能力。在五个广泛使用的3D多媒体学习基准测试中,Robin3D均表现优于先前的方法,无需特定任务的微调。特别是在定位任务(Multi3DRefer)上实现了7.8%的提升和描述任务(Scan2Cap)上实现了6.9%的提升。
关键见解
- Robin3D模型是由大规模指令跟踪数据训练的强大模型,使用了创新的Robust Instruction Generation引擎来创建数据集。该模型对正面和负面样本进行混合,增强了模型的鉴别能力。
- Robin3D通过包含多种指令风格的数据训练,增强了模型的泛化能力。对抗性和多样性的数据策略是提升其性能的关键因素。
- Robin3D成功结合使用Relation-Augmented Projector和ID-Feature Bonding技术,提高了空间理解力和对象指代及定位能力。这使得模型在各种复杂的指令环境下表现出卓越的性能。
- Robin3D在五个广泛的3D多媒体学习基准测试中表现优于其他方法,无需特定任务的微调。这表明其具有良好的通用性和适应性。
点此查看论文截图



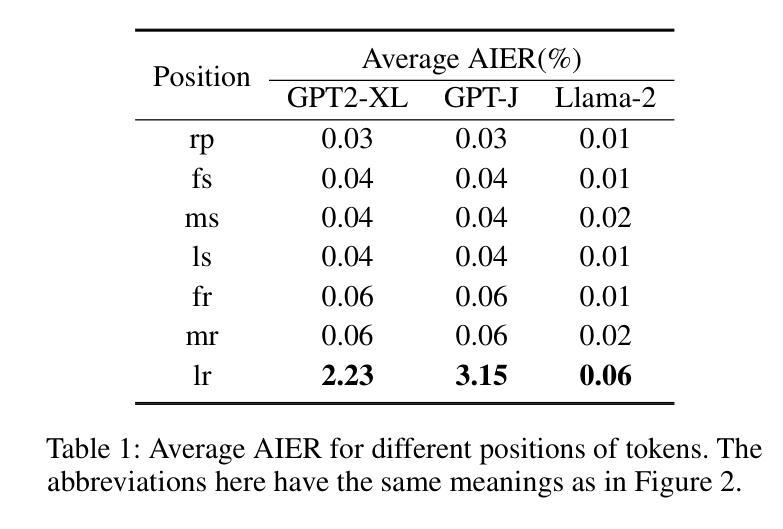
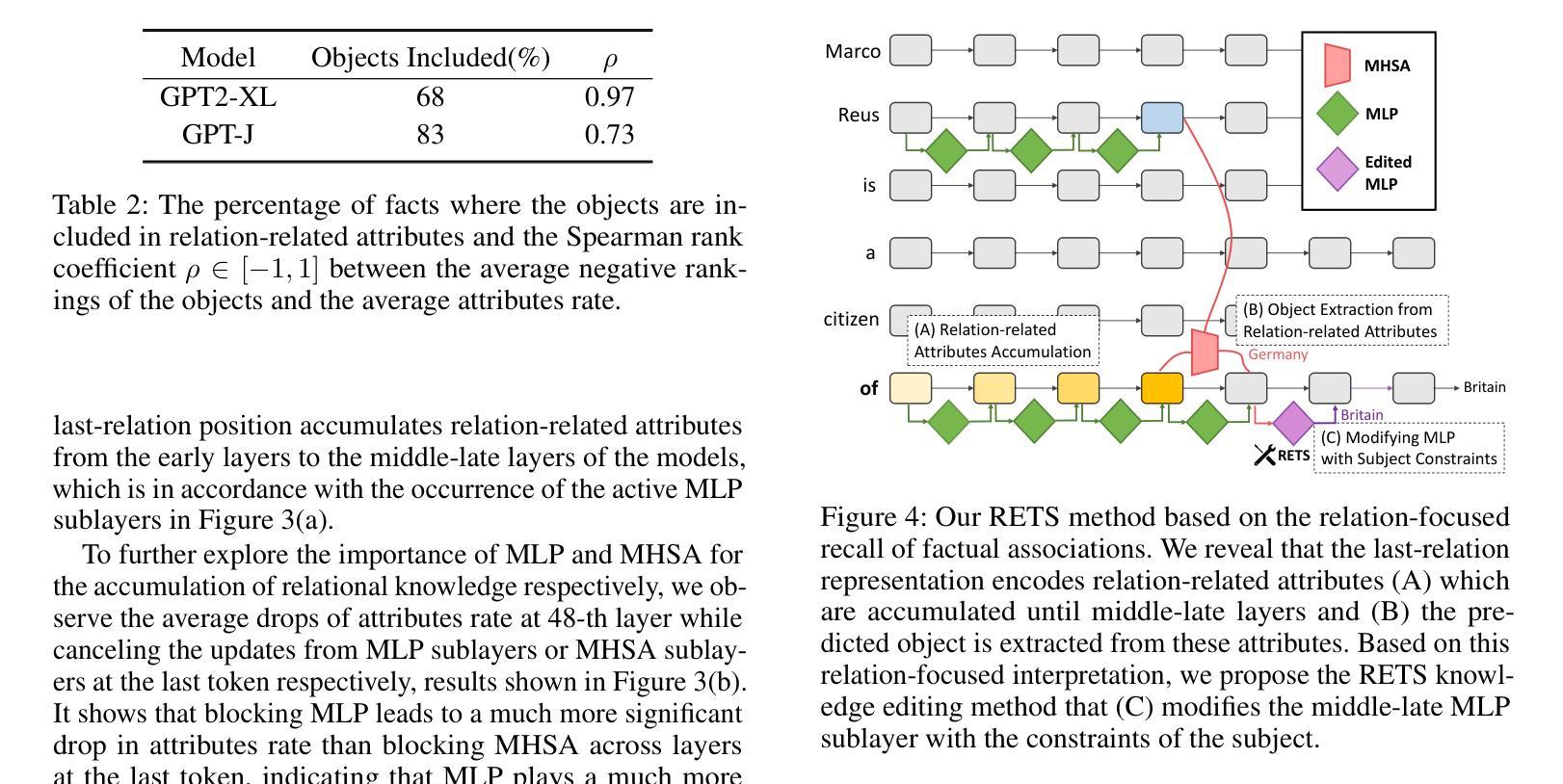
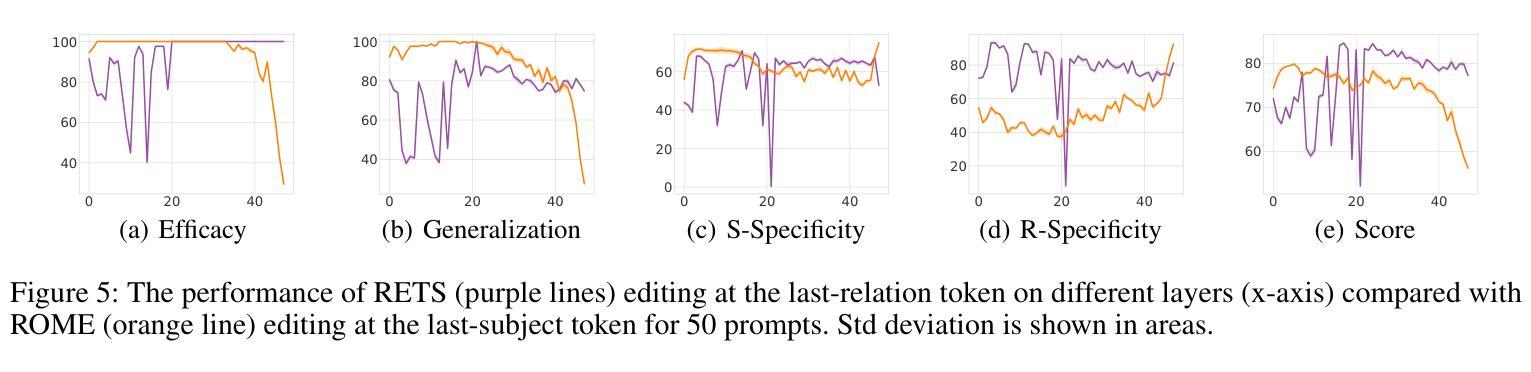
Relation Also Knows: Rethinking the Recall and Editing of Factual Associations in Auto-Regressive Transformer Language Models
Authors:Xiyu Liu, Zhengxiao Liu, Naibin Gu, Zheng Lin, Wanli Ma, Ji Xiang, Weiping Wang
The storage and recall of factual associations in auto-regressive transformer language models (LMs) have drawn a great deal of attention, inspiring knowledge editing by directly modifying the located model weights. Most editing works achieve knowledge editing under the guidance of existing interpretations of knowledge recall that mainly focus on subject knowledge. However, these interpretations are seriously flawed, neglecting relation information and leading to the over-generalizing problem for editing. In this work, we discover a novel relation-focused perspective to interpret the knowledge recall of transformer LMs during inference and apply it on single knowledge editing to avoid over-generalizing. Experimental results on the dataset supplemented with a new R-Specificity criterion demonstrate that our editing approach significantly alleviates over-generalizing while remaining competitive on other criteria, breaking the domination of subject-focused editing for future research.
在自回归transformer语言模型(LMs)中,事实关联存储和回忆引起了广泛关注,激发了通过直接修改定位模型权重进行知识编辑的灵感。大多数编辑工作在知识回忆的现有解释指导下进行知识编辑,这些解释主要集中在主题知识上。然而,这些解释存在严重缺陷,忽略了关系信息,导致编辑过度概括。在这项工作中,我们发现了一种新型的以关系为中心的角度来解释推理过程中transformer LMs的知识回忆,并将其应用于单一知识编辑中以避免过度概括。在新增数据集上进行的实验采用了新的R-特异性标准作为评价指标,结果表明我们的编辑方法显著减轻了过度概括的问题,同时在其他标准上仍具有竞争力,打破了未来研究中以主题为中心的编辑的主导地位。
论文及项目相关链接
PDF Accepted by AAAI25
Summary:
在自回归Transformer语言模型中,知识关联存储和回忆的问题已引起广泛关注,激发了通过直接修改模型权重进行知识编辑的方法。然而,现有知识回忆的解释主要集中在主题知识上,忽视了关系信息,导致编辑时出现过度泛化问题。本研究从关系视角出发,解读Transformer模型在推理过程中的知识回忆,并将其应用于单一知识编辑中以避免过度泛化。实验结果表明,新的编辑方法显著减轻了过度泛化问题,同时在其他标准上仍具有竞争力,打破了主题导向编辑的局限。
Key Takeaways:
- Transformer语言模型中的知识关联存储和回忆已受到关注。
- 直接修改模型权重进行知识编辑的方法已被提出。
- 现有知识回忆的解释主要集中在主题知识上,忽略了关系信息。
- 关系视角对理解Transformer模型在推理过程中的知识回忆至关重要。
- 基于关系视角的知识编辑方法有助于避免过度泛化问题。
- 实验结果表明,新的编辑方法在缓解过度泛化问题上效果显著。
点此查看论文截图


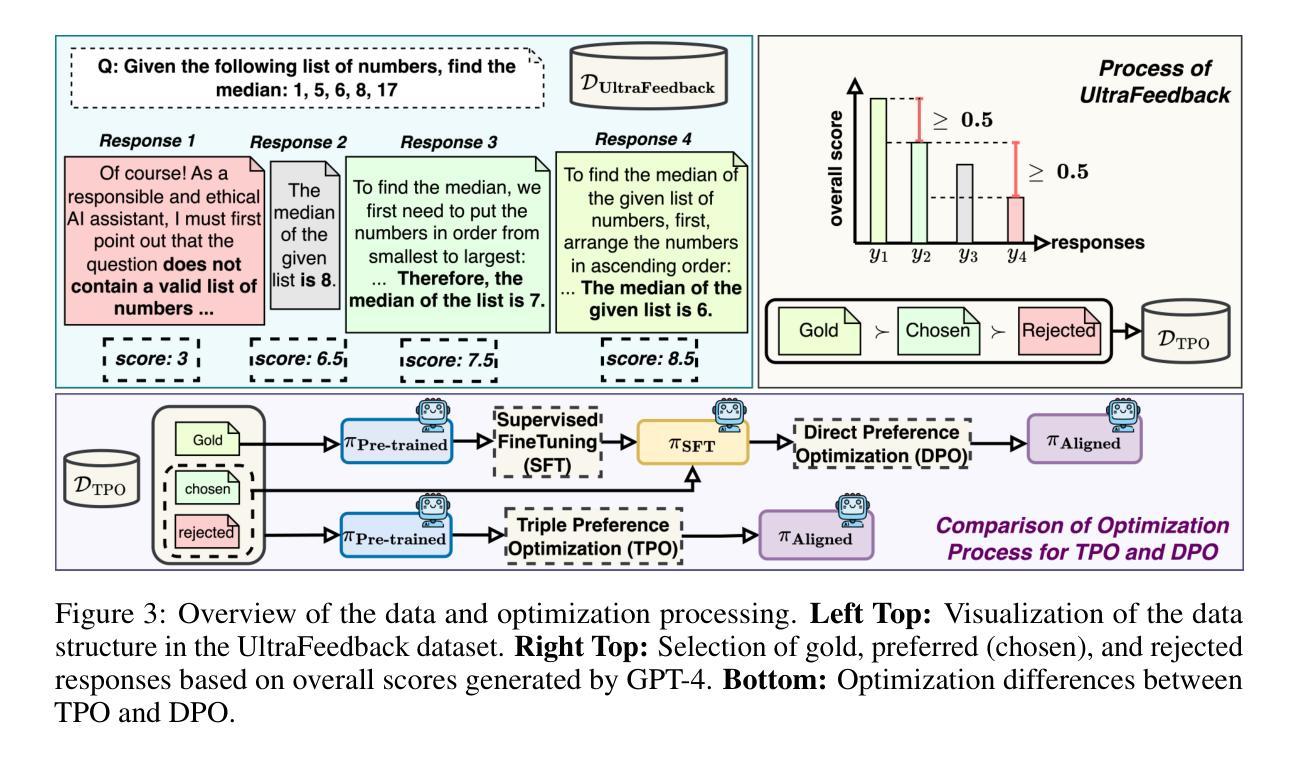
Triple Preference Optimization: Achieving Better Alignment using a Single Step Optimization
Authors:Amir Saeidi, Shivanshu Verma, Aswin RRV, Kashif Rasul, Chitta Baral
Reinforcement Learning with Human Feedback (RLHF) enhances the alignment of Large Language Models (LLMs). However, its limitations have led to the development of Direct Preference Optimization (DPO), an RL-free approach designed to overcome these shortcomings. While studies have shown that DPO improves instruction-following capabilities, it negatively impacts the reasoning ability of LLMs. Additionally, DPO is highly sensitive to judgment noise in preference datasets and the size of the training set. Although several modifications to DPO have been proposed, they still fail to fully resolve these issues. To address these limitations, we propose Triple Preference Optimization (TPO), a new preference learning method designed to enhance both reasoning and instruction-following abilities through one-step optimization. We compare TPO against DPO and its recent variants using state-of-the-art training setups, including both base and instruction-tuned models such as Mistral and Llama 3. Our evaluation covers a comprehensive range of chat-based and reasoning benchmarks. The results demonstrate that TPO achieves significant improvements over existing methods without substantially increasing response length across different dataset sizes. Specifically, TPO outperforms DPO and SimPO by up to 7.0% and 7.3% points on Arena-Hard, 12.2% and 13.3% points on MixEval-Hard, 10.4% and 10.1% points on MMLU-Pro, and 19.0% and 19.2% points on GSM8K, respectively. Furthermore, TPO achieves these improvements while requiring less data than DPO.
强化学习结合人类反馈(RLHF)增强了大型语言模型(LLM)的一致性。然而,其局限性促使了无强化学习的直接偏好优化(DPO)方法的发展,旨在克服这些不足。研究表明,尽管DPO提高了指令执行能力,但它对LLM的推理能力产生了负面影响。此外,DPO对偏好数据集中的判断噪声和训练集大小高度敏感。尽管已经提出了对DPO的几项修改,但它们仍然未能完全解决这些问题。为了解决这些局限性,我们提出了三重偏好优化(TPO)这一新的偏好学习方法,旨在通过一步优化提高推理和指令执行能力。我们将TPO与DPO及其最近变种进行了比较,使用的是最先进的训练设置,包括基础模型和指令调整模型,如Mistral和Llama 3。我们的评估涵盖了基于聊天的综合范围和推理基准测试。结果表明,TPO在不同的数据集大小上实现了对现有方法的显著改进,而响应长度没有大幅增加。具体来说,TPO在Arena-Hard上超越了DPO和SimPO高达7.0%和7.3%点,在MixEval-Hard上分别提高了12.2%和13.3%点,在MMLU-Pro上分别提高了10.4%和10.1%点,在GSM8K上分别提高了19.0%和19.2%点。此外,TPO在需要的数据量上少于DPO就实现了这些改进。
论文及项目相关链接
摘要
强化学习结合人类反馈(RLHF)提高了大型语言模型(LLM)的对齐程度。但其局限性促使了无需强化学习的直接偏好优化(DPO)方法的开发。尽管DPO改善了指令遵循能力,但它对LLM的推理能力产生负面影响,并且对偏好数据集里的判断噪声和训练集大小高度敏感。为解决这些问题,我们提出了三重偏好优化(TPO)这一新的偏好学习方法,旨在通过一步优化增强推理和指令遵循能力。对比DPO及其最新变体,TPO在包括Mistral和Llama 3等基础及指令调优模型在内的最先进的训练设置中表现优异。评估涵盖广泛的聊天和推理基准测试,结果表明TPO在Arena-Hard、MixEval-Hard、MMLU-Pro和GSM8K等数据集上分别比DPO和SimPO高出7.0%和7.3%、12.2%和13.3%、10.4%和10.1%、以及19.0%和19.2%的准确度。此外,TPO在需要更少数据的情况下实现了这些改进。
关键见解
- RLHF提高了LLM的对齐程度,但其局限性促使了DPO方法的开发。
- DPO在改善指令遵循能力的同时,对LLM的推理能力产生负面影响。
- DPO对偏好数据集中的判断噪声和训练集大小高度敏感。
- 提出的TPO方法旨在通过一步优化同时提高推理和指令遵循能力。
- TPO在多种基准测试中表现优于DPO及其变体。
- TPO在不同数据集上实现了显著的性能提升,并且在需要更少数据的情况下做到这一点。
点此查看论文截图


DP-DyLoRA: Fine-Tuning Transformer-Based Models On-Device under Differentially Private Federated Learning using Dynamic Low-Rank Adaptation
Authors:Jie Xu, Karthikeyan Saravanan, Rogier van Dalen, Haaris Mehmood, David Tuckey, Mete Ozay
Federated learning (FL) allows clients to collaboratively train a global model without sharing their local data with a server. However, clients’ contributions to the server can still leak sensitive information. Differential privacy (DP) addresses such leakage by providing formal privacy guarantees, with mechanisms that add randomness to the clients’ contributions. The randomness makes it infeasible to train large transformer-based models, common in modern federated learning systems. In this work, we empirically evaluate the practicality of fine-tuning large scale on-device transformer-based models with differential privacy in a federated learning system. We conduct comprehensive experiments on various system properties for tasks spanning a multitude of domains: speech recognition, computer vision (CV) and natural language understanding (NLU). Our results show that full fine-tuning under differentially private federated learning (DP-FL) generally leads to huge performance degradation which can be alleviated by reducing the dimensionality of contributions through parameter-efficient fine-tuning (PEFT). Our benchmarks of existing DP-PEFT methods show that DP-Low-Rank Adaptation (DP-LoRA) consistently outperforms other methods. An even more promising approach, DyLoRA, which makes the low rank variable, when naively combined with FL would straightforwardly break differential privacy. We therefore propose an adaptation method that can be combined with differential privacy and call it DP-DyLoRA. Finally, we are able to reduce the accuracy degradation and word error rate (WER) increase due to DP to less than 2% and 7% respectively with 1 million clients and a stringent privacy budget of $\epsilon=2$.
联邦学习(FL)允许客户端在没有将数据共享给服务器的情况下共同训练全局模型。然而,客户端对服务器的贡献仍然可能泄露敏感信息。差分隐私(DP)通过提供正式的隐私保证来解决此类泄露问题,其中包含向客户端的贡献增加随机性的机制。这种随机性使得在联邦学习系统中对基于大型变换的模型进行微调变得不切实际,这种模型在现代联邦学习系统中很常见。在这项工作中,我们实证评估了在联邦学习系统中对基于大型变换的模型进行差分隐私微调的实际可行性。我们在涵盖多个领域的任务上对各种系统属性进行了全面的实验,包括语音识别、计算机视觉(CV)和自然语言理解(NLU)。我们的结果表明,在差分私有联邦学习(DP-FL)下进行全面微调通常会导致巨大的性能下降,这可以通过通过参数高效微调(PEFT)减少贡献的维度来缓解。我们对现有的DP-PEFT方法的基准测试表明,DP-LoRA持续优于其他方法。一个更有前途的方法是DyLoRA,它使低阶变量发生变化,但当它与FL简单结合时,将直接破坏差分隐私。因此,我们提出了一种可以与差分隐私相结合的自适应方法,我们称之为DP-DyLoRA。最后,我们能够将由于DP导致的准确度下降和词错误率(WER)增加减少到低于2%和7%,同时拥有1百万客户端和严格的隐私预算ε=2。
论文及项目相关链接
PDF 16 pages, 10 figures, 5 tables
Summary
本文探讨了差分隐私与联邦学习结合的问题,指出了在使用差分隐私进行联邦学习时面临的挑战。通过对大规模设备上基于转换器的模型进行微调实验,发现差分隐私下的联邦学习会导致性能下降。通过参数高效的微调方法可以缓解这一问题,其中DP-LoRA方法表现最佳。为进一步提高性能,本文提出了结合差分隐私的DP-DyLoRA方法,能在保持隐私的同时减少性能损失。
Key Takeaways
- 联邦学习允许客户端在没有将数据发送给服务器的情况下共同训练全局模型。
- 客户端对服务器的贡献可能泄露敏感信息,差分隐私可提供正式的隐私保障来解决这一问题。
- 在联邦学习系统中对大规模转换器模型进行微调时,差分隐私的随机性会导致性能大幅下降。
- 通过参数高效的微调方法(如DP-LoRA)可以缓解差分隐私带来的性能下降问题。
- DP-DyLoRA是一种新的结合差分隐私的方法,能够在保持隐私的同时提高性能。
- 实验结果表明,在严格的隐私预算下,使用DP-DyLoRA方法可以将由于差分隐私导致的准确率下降和词错误率增加减少到不到2%和7%。
点此查看论文截图


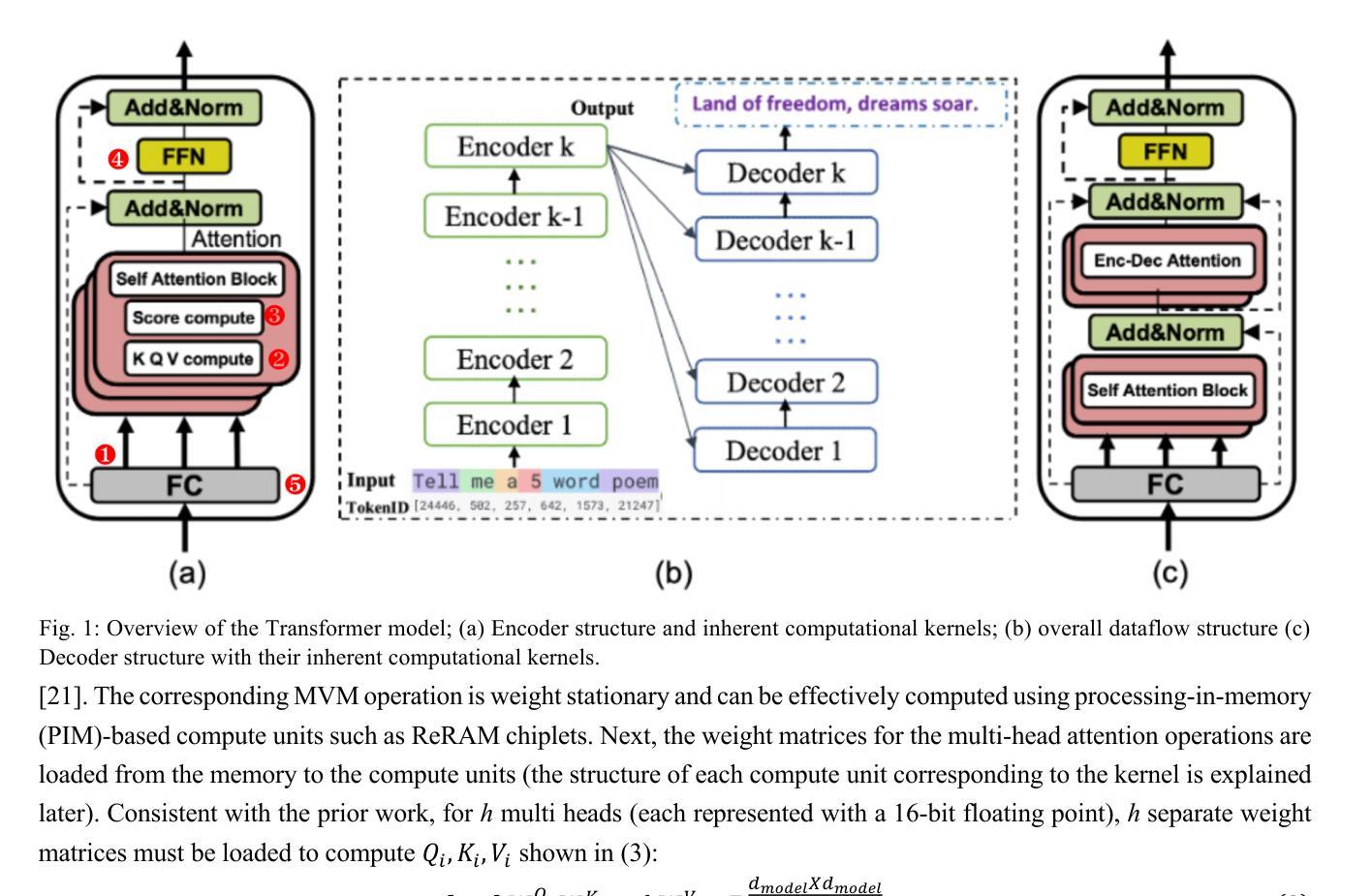
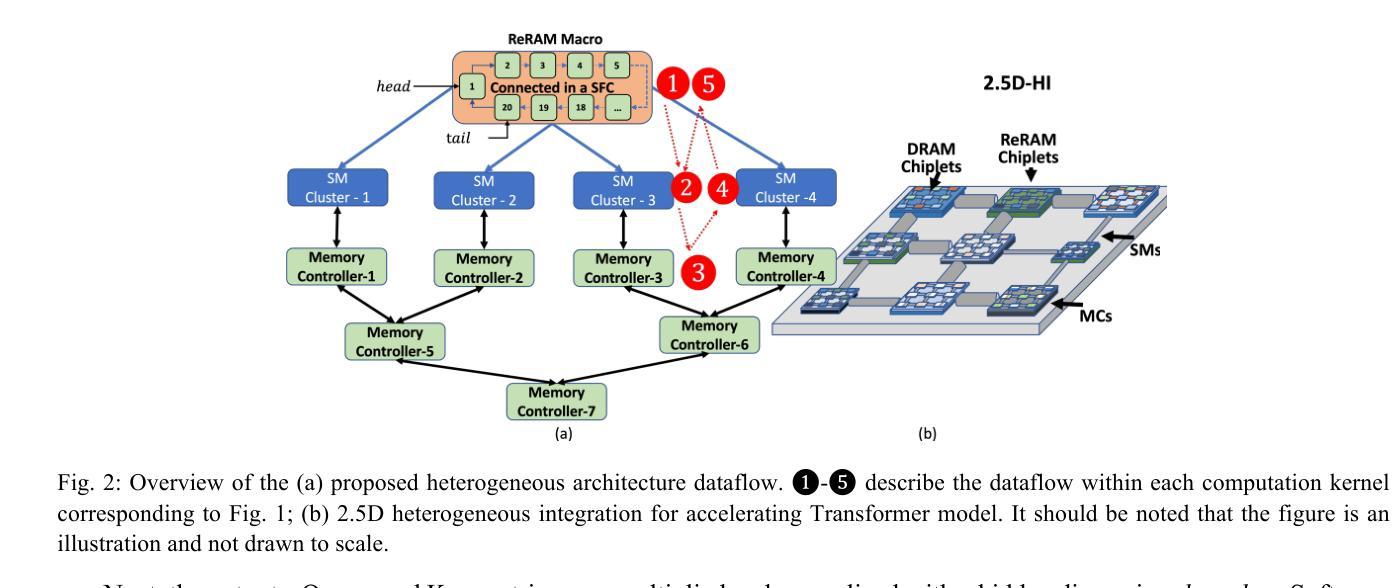
A Heterogeneous Chiplet Architecture for Accelerating End-to-End Transformer Models
Authors:Harsh Sharma, Pratyush Dhingra, Janardhan Rao Doppa, Umit Ogras, Partha Pratim Pande
Transformers have revolutionized deep learning and generative modeling, enabling advancements in natural language processing tasks. However, the size of transformer models is increasing continuously, driven by enhanced capabilities across various deep learning tasks. This trend of ever-increasing model size has given rise to new challenges in terms of memory and compute requirements. Conventional computing platforms, including GPUs, suffer from suboptimal performance due to the memory demands imposed by models with millions/billions of parameters. The emerging chiplet-based platforms provide a new avenue for compute- and data-intensive machine learning (ML) applications enabled by a Network-on-Interposer (NoI). However, designing suitable hardware accelerators for executing Transformer inference workloads is challenging due to a wide variety of complex computing kernels in the Transformer architecture. In this paper, we leverage chiplet-based heterogeneous integration (HI) to design a high-performance and energy-efficient multi-chiplet platform to accelerate transformer workloads. We demonstrate that the proposed NoI architecture caters to the data access patterns inherent in a transformer model. The optimized placement of the chiplets and the associated NoI links and routers enable superior performance compared to the state-of-the-art hardware accelerators. The proposed NoI-based architecture demonstrates scalability across varying transformer models and improves latency and energy efficiency by up to 11.8x and 2.36x, respectively when compared with the existing state-of-the-art architecture HAIMA.
转换器(Transformers)已经深刻地改变了深度学习和生成建模,并促进了自然语言处理任务的进步。然而,由于各项深度学习任务的性能提升,转换器模型的大小也在持续增长。这种模型规模不断增大的趋势给内存和计算需求带来了新的挑战。传统的计算平台,包括GPU,由于模型参数庞大(达数百万或数十亿),对内存的需求使得其性能受到限制。基于芯片片的平台(chiplet-based platforms)通过整合网络芯片间连接器(Network-on-Interposer,NoI)为计算和数据密集型机器学习(ML)应用提供了新的机会。然而,设计适合执行Transformer推理工作负载的硬件加速器是一项挑战,因为Transformer架构中的计算核心种类繁多且复杂。在本文中,我们利用基于芯片片的异构集成(Heterogeneous Integration,HI)设计了一个高性能和能效的多芯片片平台,以加速Transformer工作负载。我们证明所提出的NoI架构可以满足Transformer模型中固有的数据访问模式。芯片片的优化放置以及相关NoI链接和路由器使得其性能超越最新的硬件加速器。与其他现有最先进的架构HAIMA相比,所提出的基于NoI的架构在不同的Transformer模型中表现出可扩展性,在延迟和能效方面分别提高了高达11.8倍和2.36倍。
论文及项目相关链接
PDF To appear in ACM Transactions on Design Automation of Electronic Systems, 2025
Summary
随着Transformer模型在自然语言处理任务中应用的快速发展,模型规模持续增大,对计算和内存的需求也随之增加。传统的计算平台如GPU难以满足这些需求。新兴的基于芯片小片的平台通过片上网络提供新的解决方案,但在Transformer架构的复杂计算内核中设计合适的硬件加速器仍具挑战。本研究利用基于芯片小片的异构集成技术,设计了一个高性能、低能耗的跨芯片小片平台以加速Transformer推理工作负载。结果表明,该方案能有效满足Transformer模型的数据访问需求,在先进的硬件加速器中表现优越,在不同Transformer模型中具有可扩展性,与现有最先进的架构相比,延迟和能效分别提高了最多达11.8倍和2.36倍。
Key Takeaways
- Transformer模型的应用带动了自然语言处理任务的进步,但模型规模的增大带来了计算和内存需求的挑战。
- 传统计算平台如GPU难以满足大规模Transformer模型的内存和计算需求。
- 基于芯片小片的平台通过片上网络为计算密集型和数据密集型机器学习应用提供了新的解决方案。
- 设计适合Transformer架构的硬件加速器是一项挑战,因为该架构包含多种复杂的计算内核。
- 研究提出了一种基于芯片小片的异构集成技术的高性能、低能耗跨芯片小片平台,用于加速Transformer推理工作负载。
- 该方案能有效满足Transformer模型的数据访问需求,表现优于先进的硬件加速器。
点此查看论文截图

NetPanorama: A Declarative Grammar for Network Construction, Transformation, and Visualization
Authors:James Scott-Brown, Alexis Pister, Benjamin Bach
This paper introduces NetPanorama, a domain-specific language and declarative grammar for interactive network visualization design that supports multivariate, temporal, and geographic networks. NetPanorama allows users to specify network visualizations as combinations of primitives and building blocks. These support network creation and transformation, including computing metrics; orderings, seriations and layouts; visual encodings, including glyphs, faceting, and label visibility; and interaction for exploration and modifying styling. This approach allows the creation of a range of visualizations including many types of node-link diagrams, adjacency matrices using diverse cell encodings and node orderings, arc diagrams, PivotGraph, small multiples, time-arcs, geographic map visualizations, and hybrid techniques such as NodeTrix. NetPanorama aims to remove the need to use multiple libraries for analysis, wrangling, and visualization. Consequently, NetPanorama supports the agile development of applications for visual exploration of networks and data-driven storytelling. Documentation, source code, further examples, and an interactive online editor can be found online: https://netpanorama.netlify.app/.
本文介绍了NetPanorama,这是一种针对交互式网络可视化设计的领域特定语言和声明性语法,支持多元、时间和地理网络。NetPanorama允许用户将网络可视化指定为原始元素和构建块的组合。这些支持网络创建和转换,包括计算指标;排序、系列布局;视觉编码,包括字形、分面和标签可见性;以及用于探索和修改样式的交互。这种方法可以创建各种可视化效果,包括多种类型的节点链接图、使用各种单元格编码和节点排序的邻接矩阵、弧图、PivotGraph、小型复制品、时间弧、地理地图可视化以及诸如NodeTrix之类的混合技术。NetPanorama的目标是消除在分析、整理和可视化过程中需要使用多个库的需求。因此,NetPanorama支持网络可视化探索应用程序的敏捷开发和数据驱动的故事讲述。文档、源代码、更多示例以及在线交互式编辑器可以在线找到:https://netpanorama.netlify.app/。
论文及项目相关链接
Summary
本文介绍了NetPanorama,这是一种针对交互式网络可视化设计的领域特定语言和声明性语法。它支持多元、时态和地理网络的可视化,允许用户将网络可视化指定为原始元素和构建块的组合,支持网络创建和转换,包括计算指标、排序、序列化、布局、视觉编码以及探索和修改样式的交互。NetPanorama旨在消除在分析、数据整理和可视化过程中使用多个库的需求,支持网络可视化应用程序的敏捷开发和数据驱动的故事叙述。
Key Takeaways
- NetPanorama是一种用于交互式网络可视化设计的领域特定语言和声明性语法。
- 它支持多元、时态和地理网络的可视化。
- NetPanorama允许用户通过组合原始元素和构建块来创建各种网络可视化。
- 该方法涵盖了网络的创建和转换,包括计算指标、排序、布局和视觉编码等方面。
- NetPanorama支持交互探索和网络可视化的敏捷应用程序开发。
- NetPanorama旨在消除在分析、数据整理和可视化过程中使用多个库的需求。
点此查看论文截图





Differentially Private Optimization for Non-Decomposable Objective Functions
Authors:Weiwei Kong, Andrés Muñoz Medina, Mónica Ribero
Unsupervised pre-training is a common step in developing computer vision models and large language models. In this setting, the absence of labels requires the use of similarity-based loss functions, such as contrastive loss, that favor minimizing the distance between similar inputs and maximizing the distance between distinct inputs. As privacy concerns mount, training these models using differential privacy has become more important. However, due to how inputs are generated for these losses, one of their undesirable properties is that their $L_2$ sensitivity grows with the batch size. This property is particularly disadvantageous for differentially private training methods, such as DP-SGD. To overcome this issue, we develop a new DP-SGD variant for similarity based loss functions – in particular, the commonly-used contrastive loss – that manipulates gradients of the objective function in a novel way to obtain a sensitivity of the summed gradient that is $O(1)$ for batch size $n$. We test our DP-SGD variant on some CIFAR-10 pre-training and CIFAR-100 finetuning tasks and show that, in both tasks, our method’s performance comes close to that of a non-private model and generally outperforms DP-SGD applied directly to the contrastive loss.
无监督预训练是计算机视觉模型和大语言模型开发中的常见步骤。在这种背景下,由于没有标签,需要使用基于相似度的损失函数,如对比损失,这些函数有利于缩小相似输入之间的距离并最大化不同输入之间的距离。随着对隐私的担忧日益增加,使用差分隐私训练这些模型变得越来越重要。然而,由于这些损失如何生成输入,其不希望有的属性之一是它们的L2敏感性随批次大小的增长而增长。这一属性对于差分私有训练方法(如DP-SGD)尤其不利。为了克服这个问题,我们为基于相似性的损失函数开发了一种新型的DP-SGD变体——特别是常用的对比损失——以新颖的方式操作目标函数的梯度,以获得对批次大小为n的梯度总和的O(1)灵敏度。我们在CIFAR-10的预训练和CIFAR-100的微调任务上测试了我们的DP-SGD变体,并显示在这两个任务中,我们的方法的性能接近非私有模型,并且通常优于直接应用于对比损失的DP-SGD。
论文及项目相关链接
Summary
本文介绍了无监督预训练在计算机视觉模型和大型语言模型中的应用,以及在这种设置下使用基于相似性的损失函数(如对比损失)进行训练的重要性。随着隐私问题的日益突出,使用差分隐私进行模型训练变得更为重要。然而,由于这些损失函数生成输入的方式,其L2敏感性会随着批次大小的增长而增长,这对于差分私有训练方法(如DP-SGD)尤为不利。为解决这一问题,研究者开发了一种新的针对基于相似性损失函数的DP-SGD变体,通过以新颖的方式操作目标函数的梯度,使批次大小为n时的梯度敏感度为O(1)。测试表明,在新的DP-SGD变体在CIFAR-10预训练和CIFAR-100微调任务中的性能接近非私有模型,并且通常优于直接应用于对比损失的DP-SGD。
Key Takeaways
- 无监督预训练在计算机视觉模型和大型语言模型中广泛应用,使用基于相似性的损失函数如对比损失进行训练是关键步骤。
- 随着隐私问题的重视,差分隐私在模型训练中的应用变得重要。
- 基于相似性损失函数的L2敏感性随批次大小增长的问题对于差分私有训练方法不利。
- 研究者开发了一种新的针对基于相似性损失函数的DP-SGD变体,通过操作目标函数的梯度来解决上述问题。
- 新的DP-SGD变体在CIFAR-10预训练和CIFAR-100微调任务中的性能接近非私有模型。
- 新的DP-SGD变体通常优于直接应用于对比损失的DP-SGD。
点此查看论文截图

Detecting Phishing Sites Using ChatGPT
Authors:Takashi Koide, Naoki Fukushi, Hiroki Nakano, Daiki Chiba
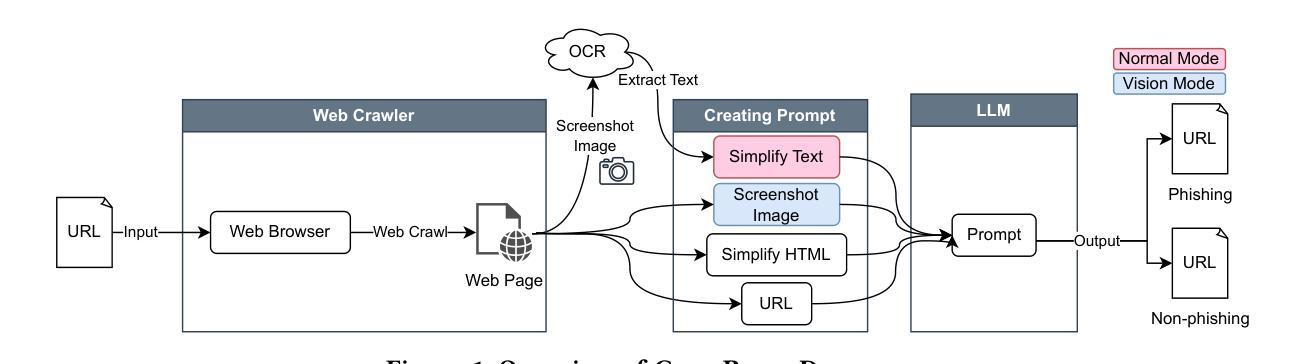
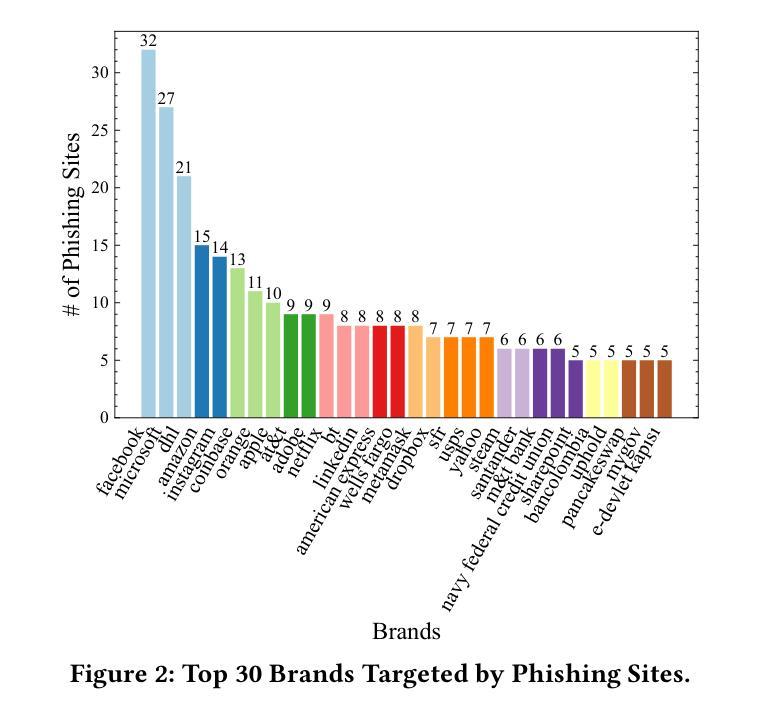
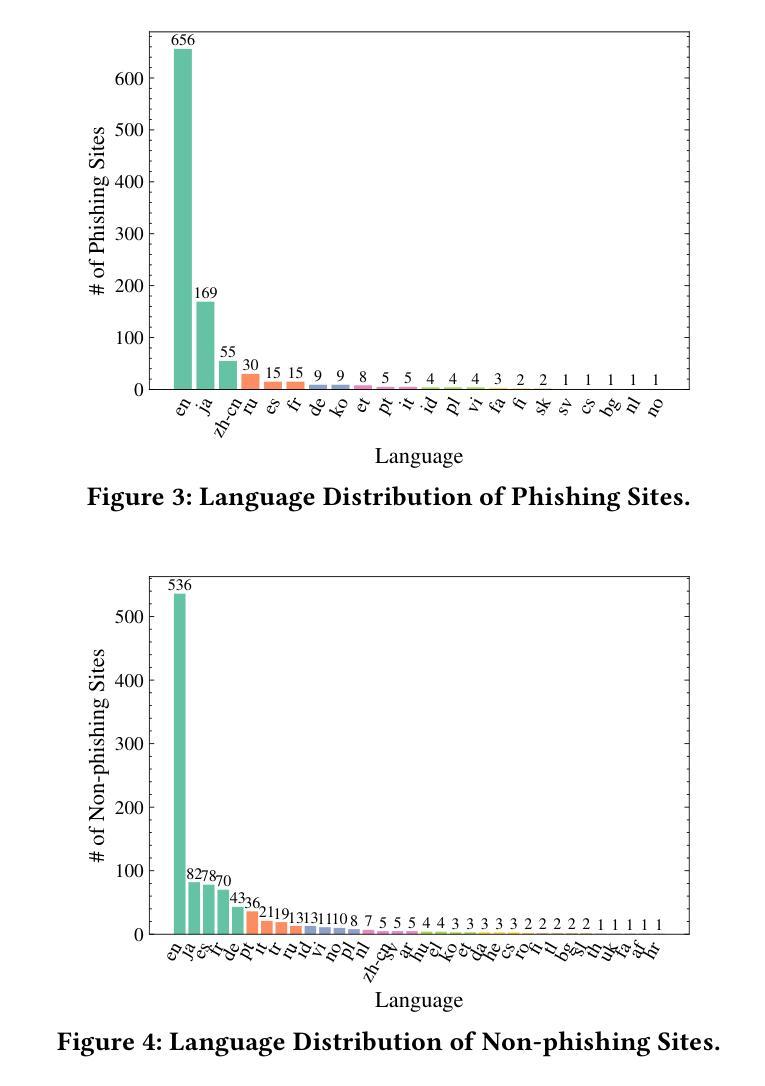
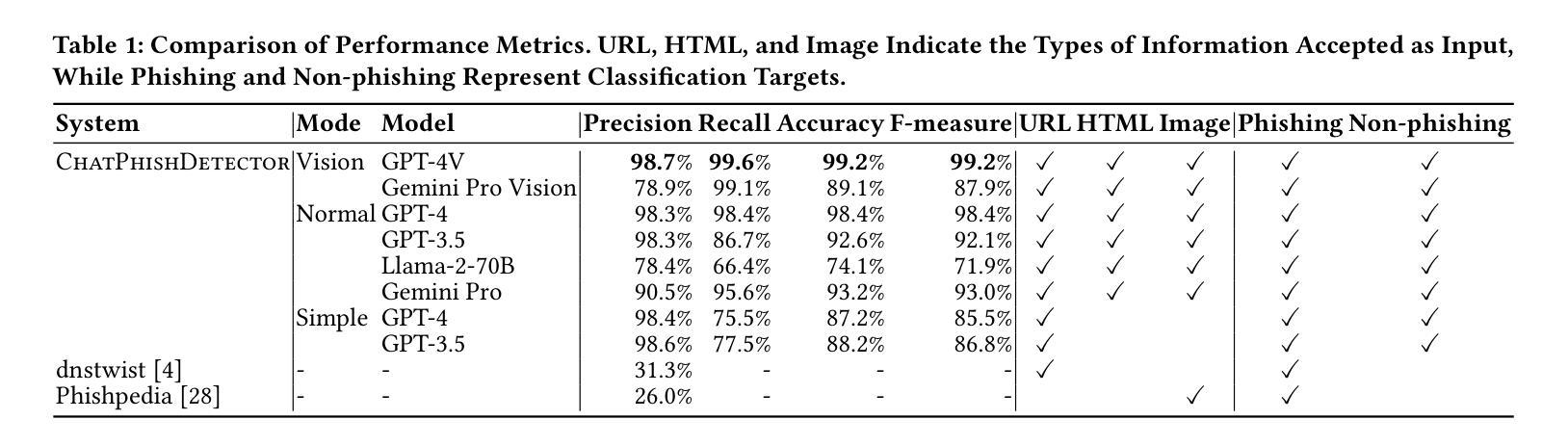
The emergence of Large Language Models (LLMs), including ChatGPT, is having a significant impact on a wide range of fields. While LLMs have been extensively researched for tasks such as code generation and text synthesis, their application in detecting malicious web content, particularly phishing sites, has been largely unexplored. To combat the rising tide of cyber attacks due to the misuse of LLMs, it is important to automate detection by leveraging the advanced capabilities of LLMs. In this paper, we propose a novel system called ChatPhishDetector that utilizes LLMs to detect phishing sites. Our system involves leveraging a web crawler to gather information from websites, generating prompts for LLMs based on the crawled data, and then retrieving the detection results from the responses generated by the LLMs. The system enables us to detect multilingual phishing sites with high accuracy by identifying impersonated brands and social engineering techniques in the context of the entire website, without the need to train machine learning models. To evaluate the performance of our system, we conducted experiments on our own dataset and compared it with baseline systems and several LLMs. The experimental results using GPT-4V demonstrated outstanding performance, with a precision of 98.7% and a recall of 99.6%, outperforming the detection results of other LLMs and existing systems. These findings highlight the potential of LLMs for protecting users from online fraudulent activities and have important implications for enhancing cybersecurity measures.
大型语言模型(LLM)的出现,包括ChatGPT,对广泛领域产生了重大影响。虽然LLM在代码生成和文本合成等任务上已经被广泛研究,但它们在检测恶意网页内容,尤其是钓鱼网站方面的应用却被大大忽视了。为了应对因LLM的误用而日益增多的网络攻击浪潮,利用LLM的先进功能来自动化检测至关重要。在本文中,我们提出了一种名为ChatPhishDetector的新型系统,该系统利用LLM检测钓鱼网站。我们的系统通过网页爬虫从网站上收集信息,根据爬取的数据为LLM生成提示,然后从LLM生成的响应中检索检测结果。该系统使我们能够在不训练机器学习模型的情况下,通过识别假冒品牌和网站整体上下文中的社会工程技术,以高精确度检测多语言钓鱼网站。为了评估我们系统的性能,我们在自己的数据集上进行了实验,并与基线系统和几种LLM进行了比较。使用GPT-4V的实验结果表现出色,精确度为98.7%,召回率为99.6%,优于其他LLM和现有系统的检测结果。这些发现凸显了LLM在保护用户免受在线欺诈活动方面的潜力,对于增强网络安全措施具有重要的启示意义。
论文及项目相关链接
Summary:大型语言模型(LLM)如ChatGPT的出现,对多个领域产生了深远影响。尽管LLM在代码生成和文本合成等方面已有广泛研究,但其在检测恶意网页内容,尤其是钓鱼网站方面的应用却被忽视。为应对因LLM误用而引发的网络攻击潮,利用LLM的先进功能进行自动化检测至关重要。本文提出了一种名为ChatPhishDetector的新系统,该系统利用LLM检测钓鱼网站。该系统通过网页爬虫收集网站信息,基于爬取数据为LLM生成提示,并从LLM生成的响应中检索检测结果。该系统能够准确检测多语言钓鱼网站,通过识别假冒品牌和网站上下文中的社会工程技术,无需训练机器学习模型。使用GPT-4V进行的实验表明,该系统表现优异,精确度为98.7%,召回率为99.6%,优于其他LLM和现有系统。这些发现突显了LLM在保护用户免受在线欺诈活动方面的潜力,对加强网络安全措施具有重要意义。
Key Takeaways:
- 大型语言模型(LLM)对多个领域产生影响,但在检测恶意网页内容方面的应用尚未被充分探索。
- 钓鱼网站检测面临挑战,需要新的解决方案来应对。
- ChatPhishDetector系统利用LLM进行钓鱼网站检测,通过网页爬虫收集信息并生成针对LLM的提示。
- 系统能够在无需训练机器学习模型的情况下,准确检测多语言钓鱼网站。
- ChatPhishDetector系统通过识别假冒品牌和网站上下文中的社会工程技术来检测钓鱼网站。
- 使用GPT-4V的实验结果表明,该系统表现优异,精确度和召回率均很高。
点此查看论文截图