⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-26 更新
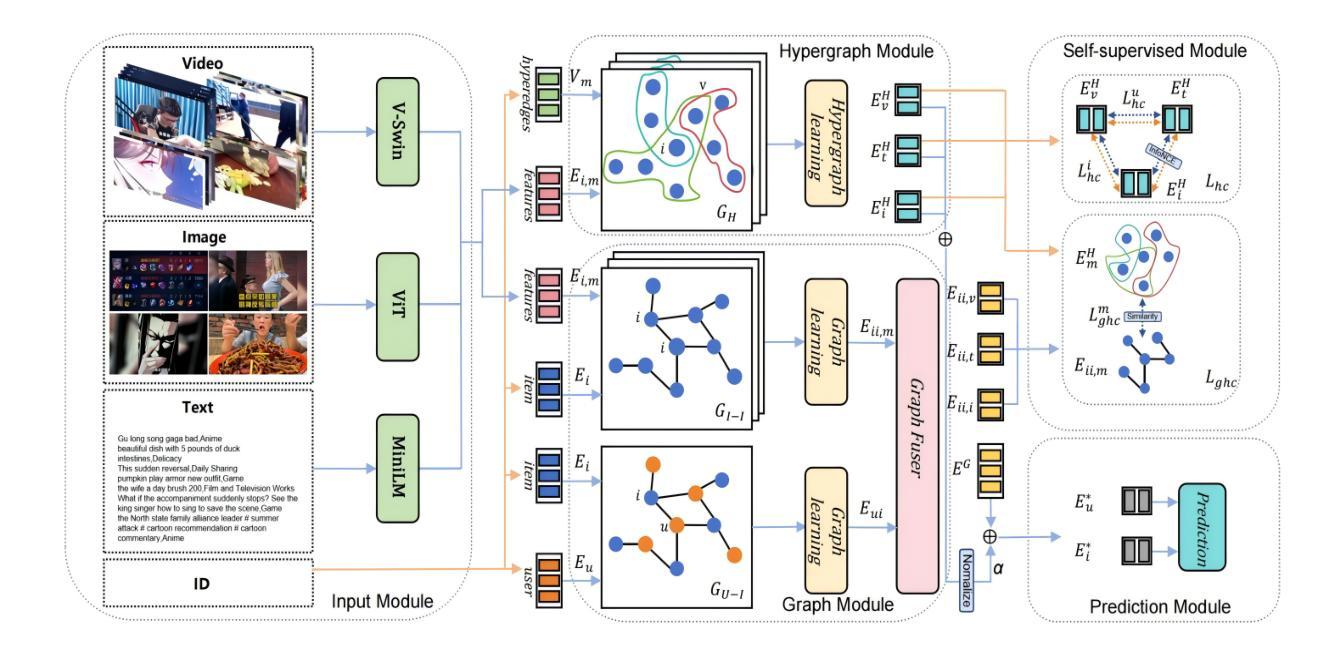
Multi-view Hypergraph-based Contrastive Learning Model for Cold-Start Micro-video Recommendation
Authors:Sisuo Lyu, Xiuze Zhou, Xuming Hu
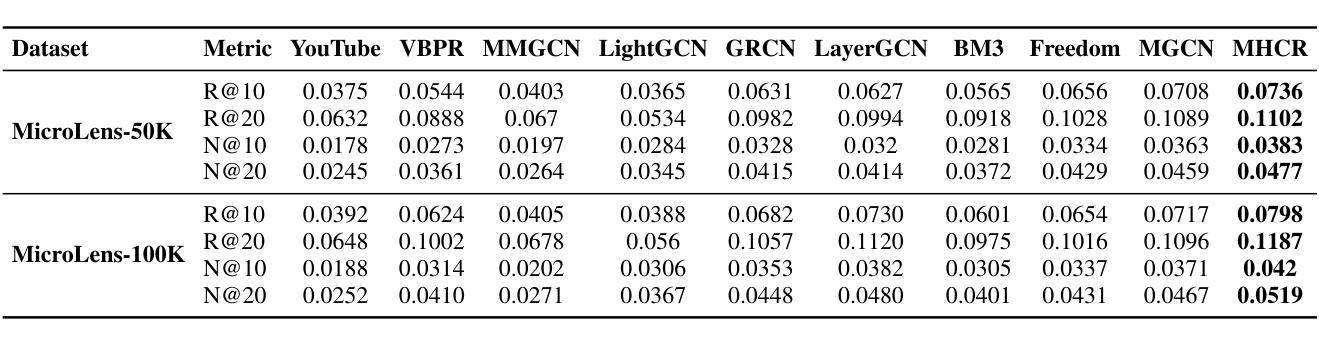
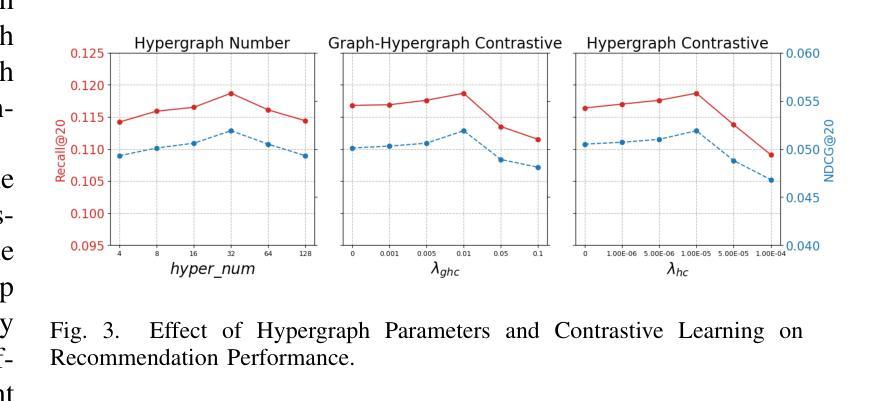
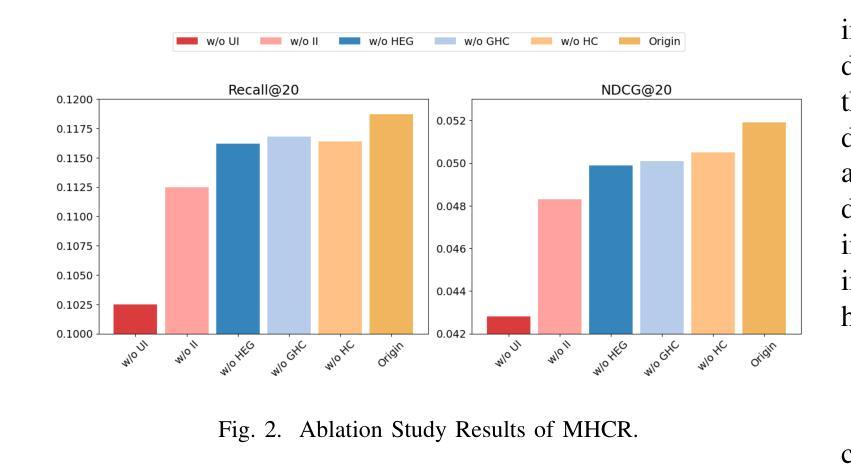
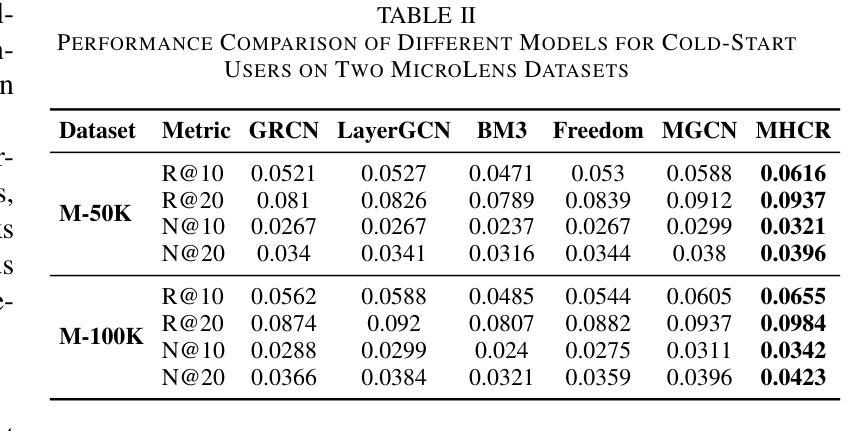
With the widespread use of mobile devices and the rapid growth of micro-video platforms such as TikTok and Kwai, the demand for personalized micro-video recommendation systems has significantly increased. Micro-videos typically contain diverse information, such as textual metadata, visual cues (e.g., cover images), and dynamic video content, significantly affecting user interaction and engagement patterns. However, most existing approaches often suffer from the problem of over-smoothing, which limits their ability to capture comprehensive interaction information effectively. Additionally, cold-start scenarios present ongoing challenges due to sparse interaction data and the underutilization of available interaction signals. To address these issues, we propose a Multi-view Hypergraph-based Contrastive learning model for cold-start micro-video Recommendation (MHCR). MHCR introduces a multi-view multimodal feature extraction layer to capture interaction signals from various perspectives and incorporates multi-view self-supervised learning tasks to provide additional supervisory signals. Through extensive experiments on two real-world datasets, we show that MHCR significantly outperforms existing video recommendation models and effectively mitigates cold-start challenges. Our code is available at https://github.com/sisuolv/MHCR.
随着移动设备使用的普及以及TikTok和Kwai等微型视频平台的快速增长,对个性化微型视频推荐系统的需求显著增加。微型视频通常包含多样化的信息,如文本元数据、视觉线索(例如封面图片)和动态视频内容,这极大地影响了用户交互和参与度模式。然而,大多数现有方法常常面临过度平滑的问题,这限制了它们有效捕捉全面交互信息的能力。此外,由于交互数据稀疏和可用交互信号的利用不足,冷启动场景持续存在挑战。为了解决这些问题,我们提出了基于多视图超图的对比学习模型(MHCR)来进行冷启动微型视频推荐。MHCR引入了一个多视图多模态特征提取层来从各个角度捕捉交互信号,并融入了多视图自监督学习任务来提供额外的监督信号。我们在两个真实世界数据集上进行了广泛的实验,结果表明MHCR显著优于现有视频推荐模型,并有效地缓解了冷启动挑战。我们的代码位于 https://github.com/sisuolv/MHCR。
论文及项目相关链接
Summary
本文介绍了针对个性化微视频推荐系统的需求增长,提出一种基于多视角超图的对比学习模型(MHCR)。该模型通过多视角多模态特征提取层捕捉各种交互信号,并引入多视角自监督学习任务提供额外的监督信号,以解决微视频的冷启动问题和交互信息的有效捕捉问题。实验证明,MHCR在真实数据集上显著优于现有视频推荐模型。
Key Takeaways
- 随着移动设备和短视频平台的普及,个性化微视频推荐系统的需求显著增加。
- 微视频包含多种信息,如文本元数据、视觉线索和动态视频内容,影响用户交互和参与度。
- 现有方法常面临过度平滑的问题,难以有效捕捉全面的交互信息。
- 冷启动问题仍是挑战,因互动数据稀疏和互动信号的利用不足。
- MHCR模型通过多视角多模态特征提取层捕捉各种交互信号。
- MHCR引入多视角自监督学习任务,提供额外的监督信号。
- 实验证明,MHCR在真实数据集上显著优于现有视频推荐模型,并有效缓解冷启动问题。
点此查看论文截图

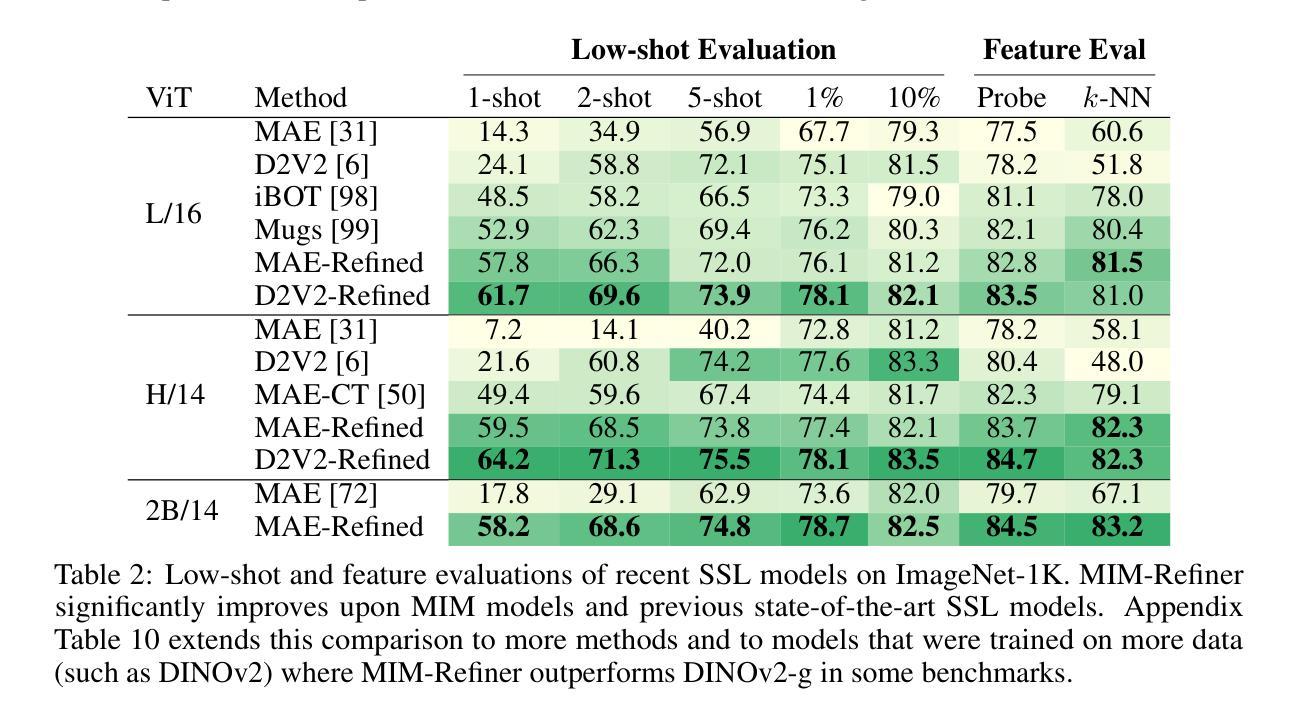
MIM-Refiner: A Contrastive Learning Boost from Intermediate Pre-Trained Representations
Authors:Benedikt Alkin, Lukas Miklautz, Sepp Hochreiter, Johannes Brandstetter
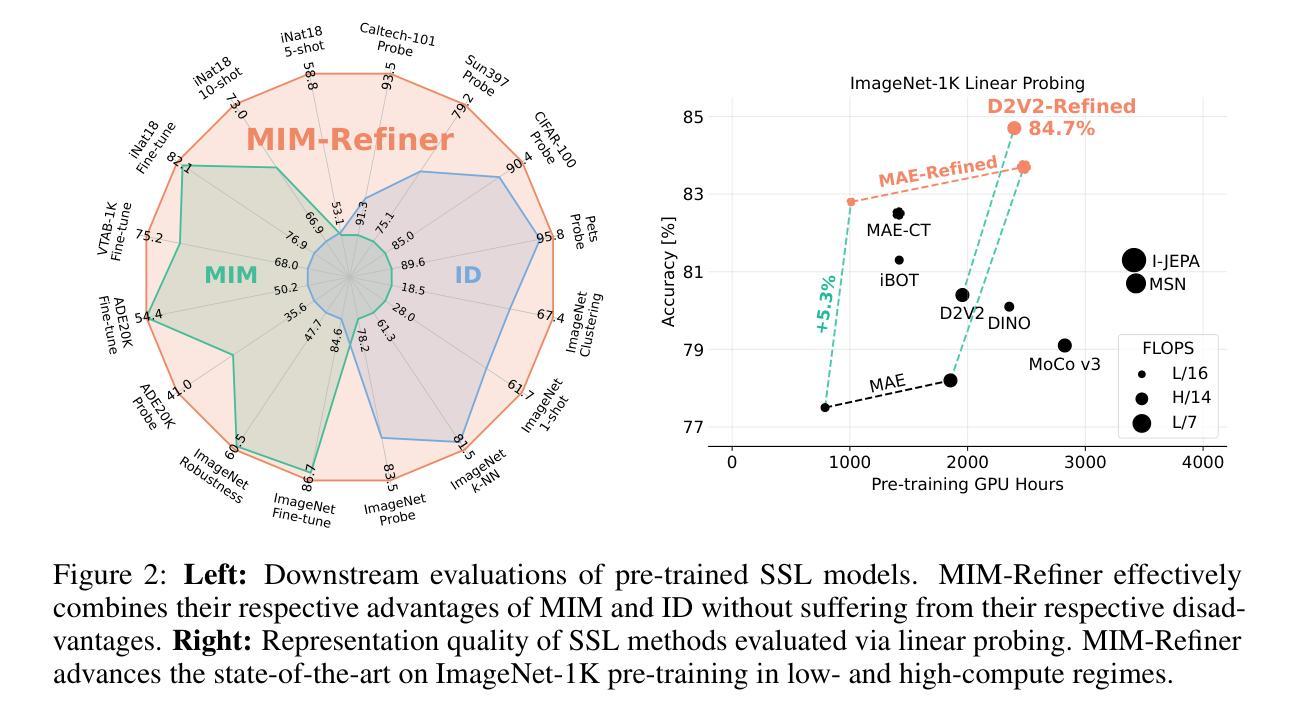
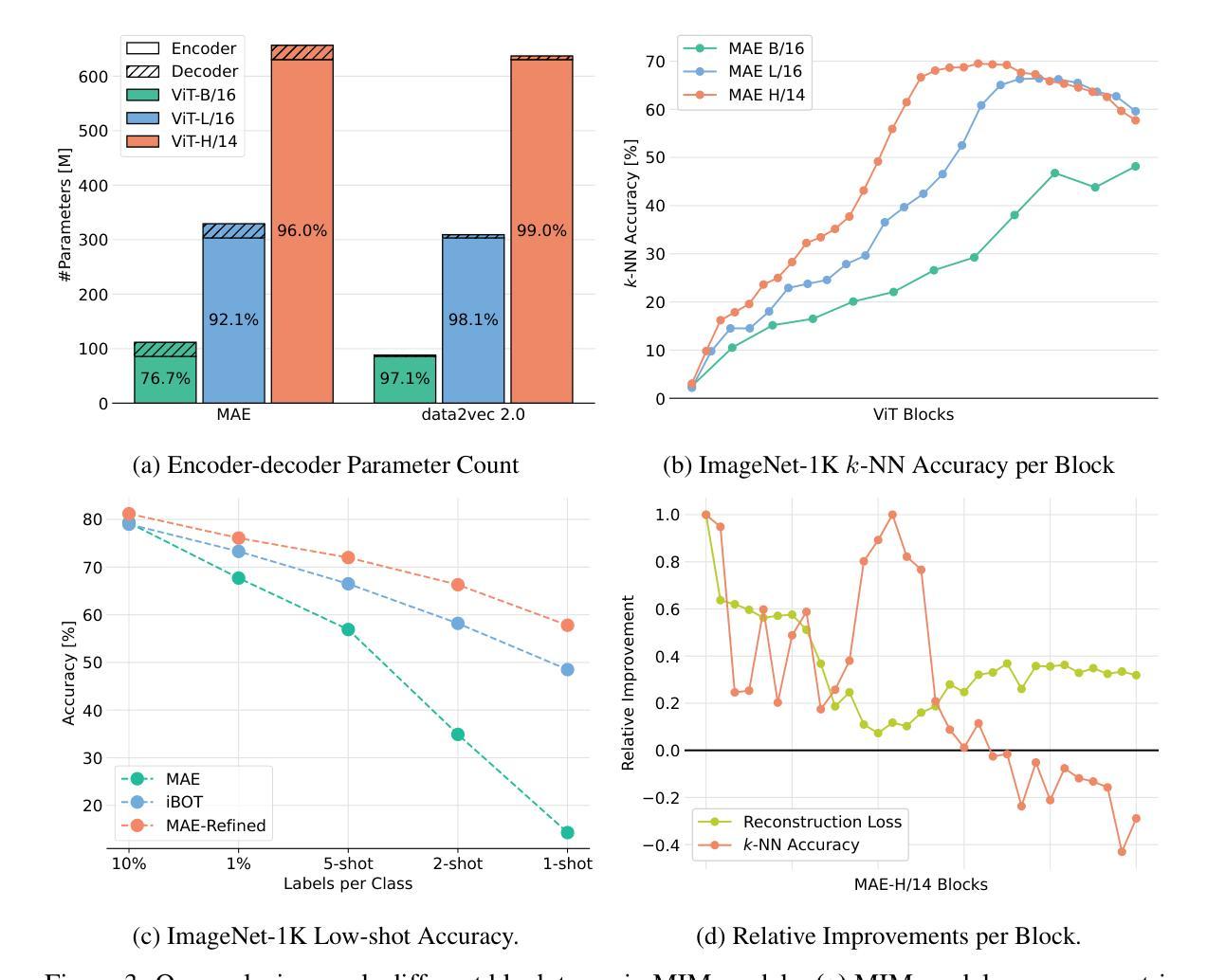
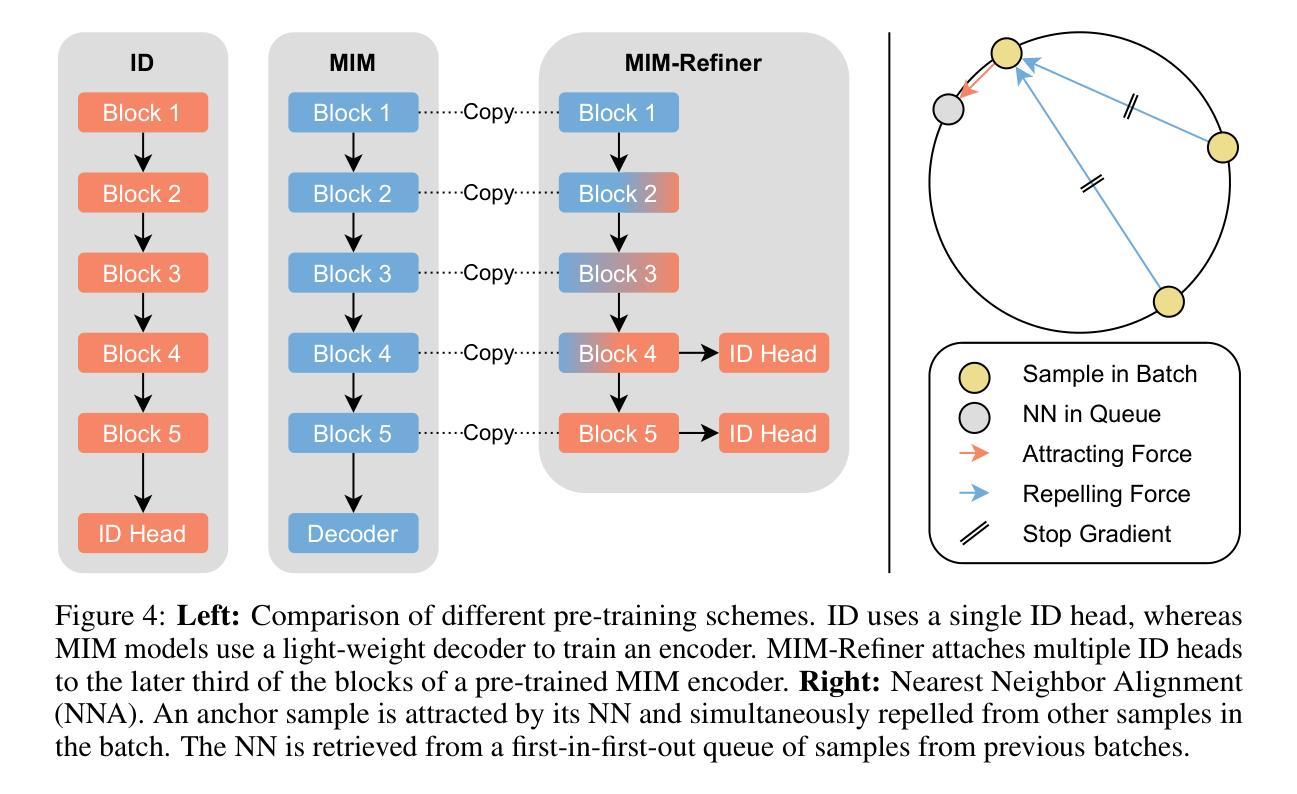
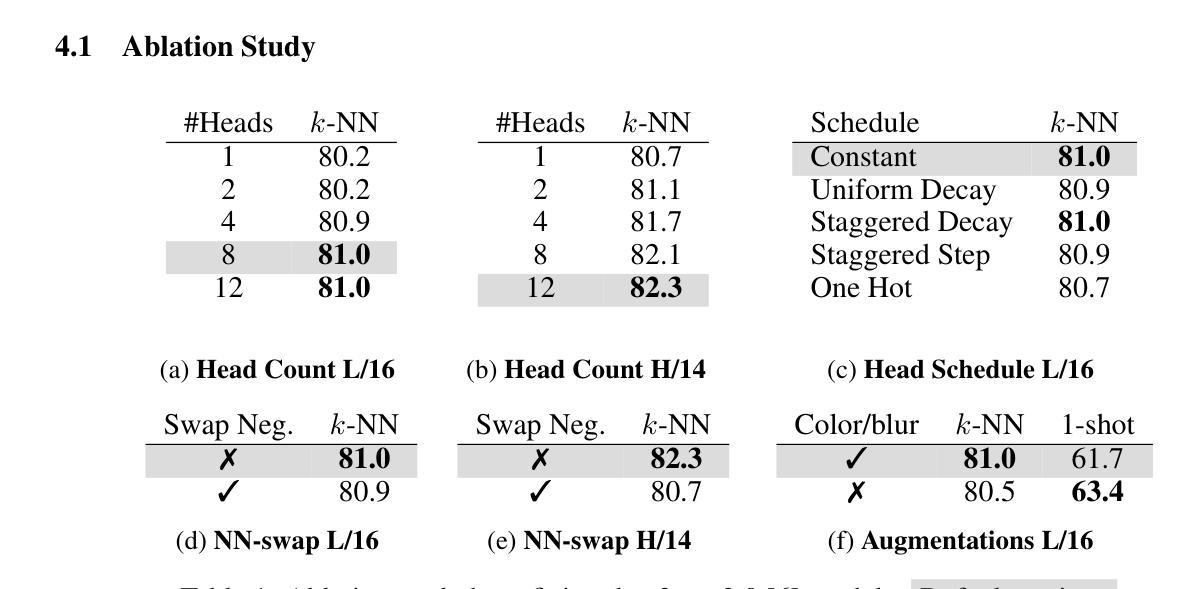
We introduce MIM (Masked Image Modeling)-Refiner, a contrastive learning boost for pre-trained MIM models. MIM-Refiner is motivated by the insight that strong representations within MIM models generally reside in intermediate layers. Accordingly, MIM-Refiner leverages multiple contrastive heads that are connected to different intermediate layers. In each head, a modified nearest neighbor objective constructs semantic clusters that capture semantic information which improves performance on downstream tasks, including off-the-shelf and fine-tuning settings. The refinement process is short and simple - yet highly effective. Within a few epochs, we refine the features of MIM models from subpar to state-of-the-art, off-the-shelf features. Refining a ViT-H, pre-trained with data2vec 2.0 on ImageNet-1K, sets a new state-of-the-art in linear probing (84.7%) and low-shot classification among models that are pre-trained on ImageNet-1K. MIM-Refiner efficiently combines the advantages of MIM and ID objectives and compares favorably against previous state-of-the-art SSL models on a variety of benchmarks such as low-shot classification, long-tailed classification, clustering and semantic segmentation.
我们介绍了MIM-Refiner(Masked Image Modeling的改进版)——这是一种增强预训练MIM模型的对比学习法。MIM-Refiner的灵感来源于对MIM模型内强表示通常存在于中间层的洞察。因此,MIM-Refiner利用连接到不同中间层的多个对比头。在每个头部,经过修改的最近邻目标构建语义聚类,捕获语义信息,这提高了下游任务的性能,包括现成的和微调设置。精细化过程简短而简单——但非常有效。经过几个周期的训练,我们将MIM模型的特征从平庸提升到了最先进的水平,即使不使用额外的微调也是如此。在ImageNet-1K上使用data2vec 2.0进行预训练的ViT-H,在线性探测(84.7%)和低镜头分类方面达到了新的先进水平,这在预训练于ImageNet-1K的模型中表现尤为突出。MIM-Refiner能够高效地将MIM和ID目标结合的优点结合在一处,在各种基准测试中(如低镜头分类、长尾分类、聚类和语义分割)均表现出优越的性能,与之前的顶级SSL模型相比表现突出。
论文及项目相关链接
PDF Published as a conference paper at ICLR 2025. Github: https://github.com/ml-jku/MIM-Refiner
Summary
MIM-Refiner通过利用对比学习增强预训练MIM模型的性能。它通过连接不同中间层的多个对比头来优化MIM模型的表示,采用修改后的最近邻目标构建语义簇,提高下游任务的性能,包括即插即用和微调场景。该优化过程简短且高效,可在几个epoch内将MIM模型的特征从普通提升到最先进的即插即用特征。
Key Takeaways
- MIM-Refiner是一种对比学习增强方法,用于提升预训练的MIM模型的性能。
- MIM-Refiner利用多个对比头连接不同中间层,以优化模型的表示。
- 通过采用修改后的最近邻目标,MIM-Refiner能够构建语义簇,从而提高模型在下游任务上的性能。
- MIM-Refiner在几个epoch内就能显著提升MIM模型的特征。
- 对于使用数据2vec 2.0在ImageNet-1K上预训练的ViT-H模型,MIM-Refiner通过线性探测(84.7%)和低样本分类任务达到了新的最先进的性能。
- MIM-Refiner结合了MIM和ID目标的优势,并在各种基准测试上表现出优越的性能。
点此查看论文截图