⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-26 更新
CRTrack: Low-Light Semi-Supervised Multi-object Tracking Based on Consistency Regularization
Authors:Zijing Zhao, Jianlong Yu, Lin Zhang, Shunli Zhang
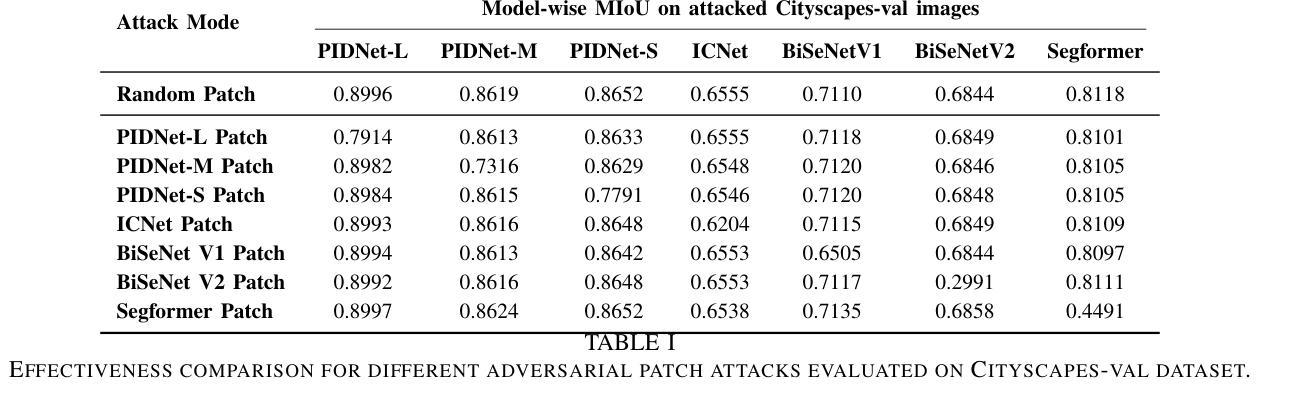
Multi-object tracking under low-light environments is prevalent in real life. Recent years have seen rapid development in the field of multi-object tracking. However, due to the lack of datasets and the high cost of annotations, multi-object tracking under low-light environments remains a persistent challenge. In this paper, we focus on multi-object tracking under low-light conditions. To address the issues of limited data and the lack of dataset, we first constructed a low-light multi-object tracking dataset (LLMOT). This dataset comprises data from MOT17 that has been enhanced for nighttime conditions as well as multiple unannotated low-light videos. Subsequently, to tackle the high annotation costs and address the issue of image quality degradation, we propose a semi-supervised multi-object tracking method based on consistency regularization named CRTrack. First, we calibrate a consistent adaptive sampling assignment to replace the static IoU-based strategy, enabling the semi-supervised tracking method to resist noisy pseudo-bounding boxes. Then, we design a adaptive semi-supervised network update method, which effectively leverages unannotated data to enhance model performance. Dataset and Code: https://github.com/ZJZhao123/CRTrack.
多目标跟踪在低光环境中的应用在现实生活中非常普遍。近年来,多目标跟踪领域得到了快速发展。然而,由于数据集缺乏和标注成本高昂,低光环境下的多目标跟踪仍然是一个持续存在的挑战。在本文中,我们专注于低光条件下的多目标跟踪。为了解决数据有限和缺乏数据集的问题,我们首先构建了一个低光多目标跟踪数据集(LLMOT)。该数据集包含经过增强以适用于夜间条件的数据以及多个未标注的低光视频。随后,为了解决高标注成本和图像质量下降的问题,我们提出了一种基于一致性正则化的半监督多目标跟踪方法,名为CRTrack。首先,我们对一致自适应采样分配进行校准,以替换基于静态IoU的策略,使半监督跟踪方法能够抵抗噪声伪边界框。然后,我们设计了一种自适应的半监督网络更新方法,该方法可以有效地利用未标注的数据来提高模型性能。数据集和代码:https://github.com/ZJZhao123/CRTrack。
论文及项目相关链接
Summary
多目标跟踪在低光照环境中具有现实意义。由于数据集缺乏和标注成本高昂,该领域仍存在挑战。本文专注于低光照条件下的多目标跟踪,构建了一个低光照多目标跟踪数据集LLMOT,并提出了一种基于一致性正则化的半监督多目标跟踪方法CRTrack。通过校准一致的适应性采样分配和设计自适应的半监督网络更新方法,该方法能够有效利用未标注数据提高模型性能。
Key Takeaways
- 多目标跟踪在低光照环境中具有重要意义。
- 缺乏数据集和标注成本高昂是该领域的挑战。
- 构建了一个低光照多目标跟踪数据集LLMOT。
- 提出了一种基于一致性正则化的半监督多目标跟踪方法CRTrack。
- CRTrack通过校准一致的适应性采样分配,使半监督跟踪方法能够抵抗噪声伪边界框。
- CRTrack设计了一种自适应的半监督网络更新方法,有效利用未标注数据提高模型性能。
点此查看论文截图

Enhancing Ground-to-Aerial Image Matching for Visual Misinformation Detection Using Semantic Segmentation
Authors:Emanuele Mule, Matteo Pannacci, Ali Ghasemi Goudarzi, Francesco Pro, Lorenzo Papa, Luca Maiano, Irene Amerini
The recent advancements in generative AI techniques, which have significantly increased the online dissemination of altered images and videos, have raised serious concerns about the credibility of digital media available on the Internet and distributed through information channels and social networks. This issue particularly affects domains that rely heavily on trustworthy data, such as journalism, forensic analysis, and Earth observation. To address these concerns, the ability to geolocate a non-geo-tagged ground-view image without external information, such as GPS coordinates, has become increasingly critical. This study tackles the challenge of linking a ground-view image, potentially exhibiting varying fields of view (FoV), to its corresponding satellite image without the aid of GPS data. To achieve this, we propose a novel four-stream Siamese-like architecture, the Quadruple Semantic Align Net (SAN-QUAD), which extends previous state-of-the-art (SOTA) approaches by leveraging semantic segmentation applied to both ground and satellite imagery. Experimental results on a subset of the CVUSA dataset demonstrate significant improvements of up to 9.8% over prior methods across various FoV settings.
近期生成式AI技术的快速发展,大幅增加了网络上的虚假图像和视频的传播,这引发了人们对互联网上以及通过信息传播渠道和社会网络传播的数字媒体可信度的严重关注。这一问题对依赖可靠数据的领域,如新闻业、法医学分析和地球观测等产生了特别的影响。为了解决这些担忧,在没有外部信息(如GPS坐标)的情况下,对未带地理标签的地面视图图像进行地理定位的能力变得至关重要。本研究解决了将地面视图图像(可能显示不同的视野范围)与其相应的卫星图像联系起来的问题,而未借助GPS数据。为实现这一点,我们提出了一种新型的四流Siamese网络架构——Quadruple Semantic Align Net(SAN-QUAD),它通过应用于地面和卫星图像的语义分割,扩展了以前的最先进方法。在CVUSA数据集的一个子集上的实验结果表明,在各种视野范围内,与之前的方法相比,最多提高了9.8%。
论文及项目相关链接
PDF 9 pages, 4 figures. Accepted to AI4MFDD 2025 workshop at WACV 2025
Summary
生成式人工智能技术的最新进展大幅增加了网络上更改后的图像和视频的传播,引发了人们对互联网上数字媒体可信度的严重关注。为解决在不依赖GPS数据的情况下将地面图像与其对应的卫星图像关联的问题,本研究提出了一种新型的Siamese架构——Quadruple Semantic Align Net (SAN-QUAD),通过语义分割技术应用于地面和卫星图像,在CVUSA数据集子集上的实验结果表明,与先前的方法相比,在各种视野条件下都有显著的提升。
Key Takeaways
- 生成式AI技术引发数字媒体可信度问题。
- 地面图像与卫星图像的关联问题在不依赖GPS数据的情况下成为研究重点。
- 研究提出了一种新型的Siamese架构——Quadruple Semantic Align Net (SAN-QUAD)。
- SAN-QUAD利用语义分割技术处理地面和卫星图像。
- 在CVUSA数据集子集上的实验结果表明,SAN-QUAD在多种视野条件下性能显著提升。
- 与现有方法相比,SAN-QUAD的改进幅度最大可达9.8%。
点此查看论文截图



PhysAug: A Physical-guided and Frequency-based Data Augmentation for Single-Domain Generalized Object Detection
Authors:Xiaoran Xu, Jiangang Yang, Wenhui Shi, Siyuan Ding, Luqing Luo, Jian Liu
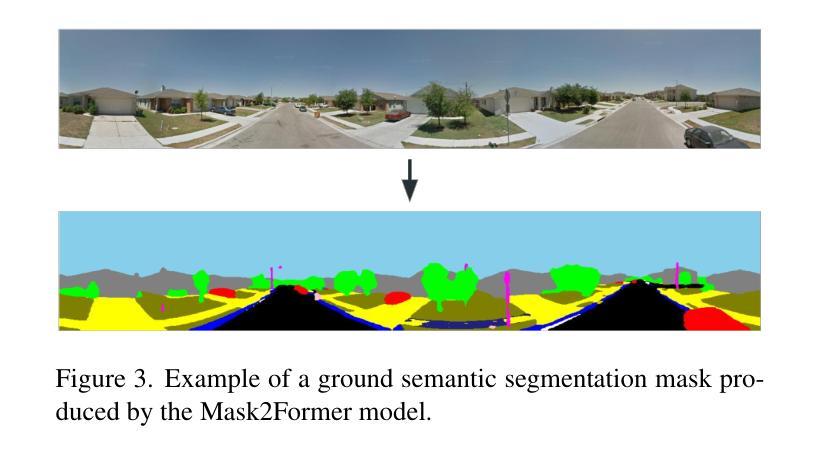
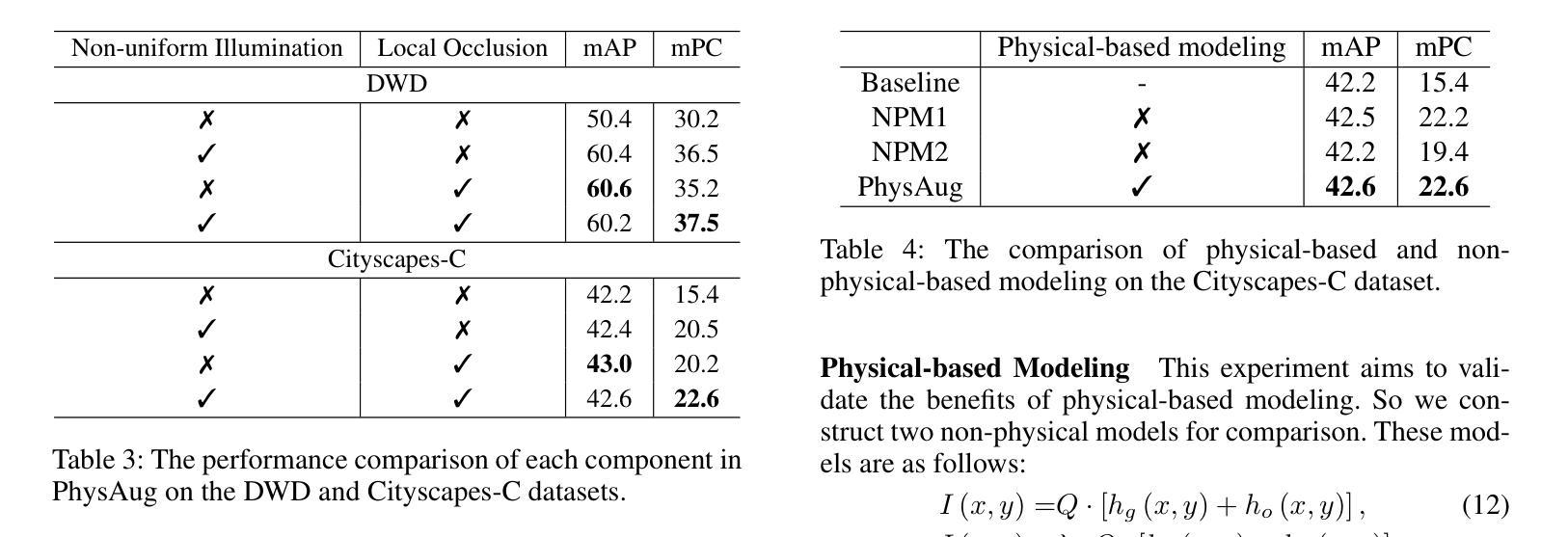
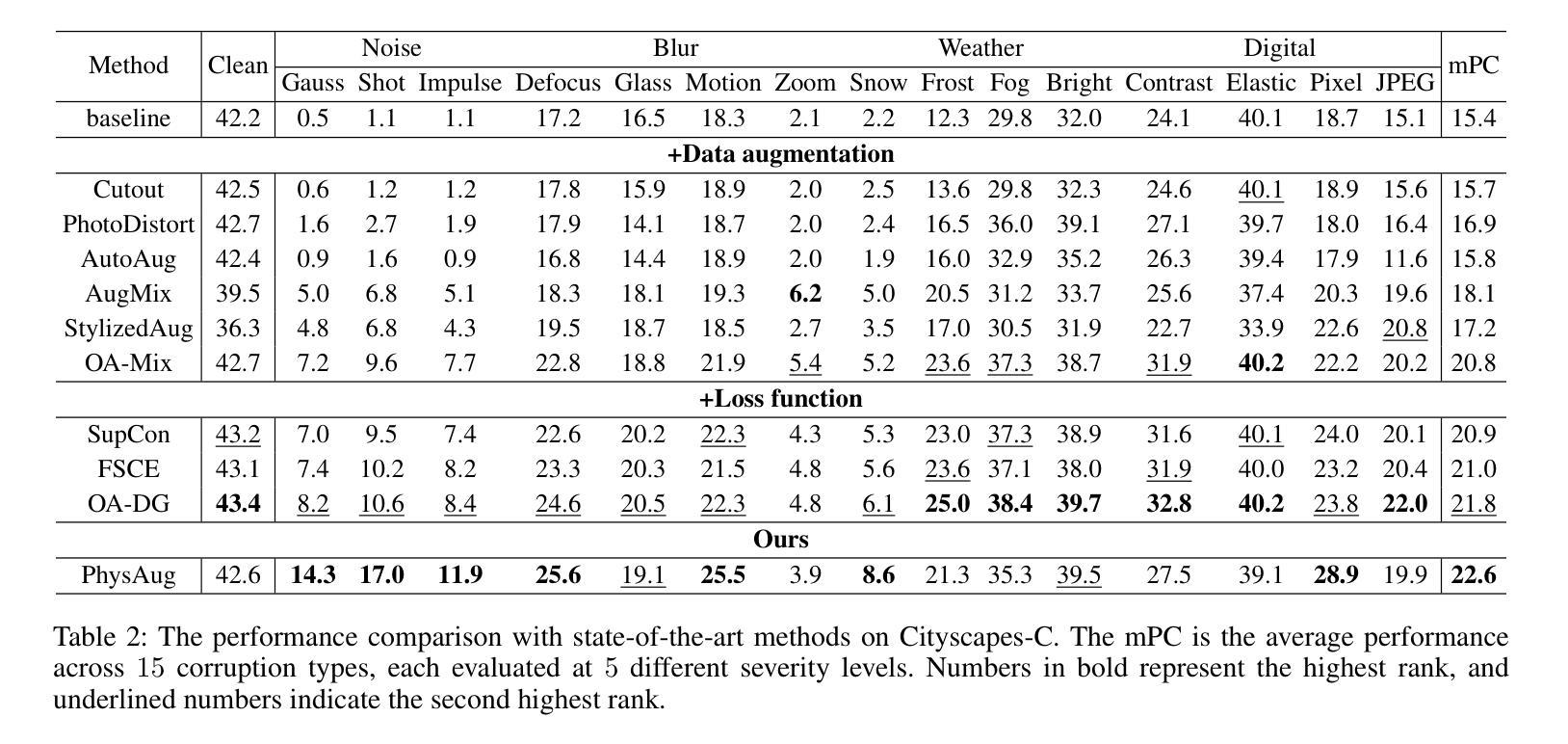
Single-Domain Generalized Object Detection~(S-DGOD) aims to train on a single source domain for robust performance across a variety of unseen target domains by taking advantage of an object detector. Existing S-DGOD approaches often rely on data augmentation strategies, including a composition of visual transformations, to enhance the detector’s generalization ability. However, the absence of real-world prior knowledge hinders data augmentation from contributing to the diversity of training data distributions. To address this issue, we propose PhysAug, a novel physical model-based non-ideal imaging condition data augmentation method, to enhance the adaptability of the S-DGOD tasks. Drawing upon the principles of atmospheric optics, we develop a universal perturbation model that serves as the foundation for our proposed PhysAug. Given that visual perturbations typically arise from the interaction of light with atmospheric particles, the image frequency spectrum is harnessed to simulate real-world variations during training. This approach fosters the detector to learn domain-invariant representations, thereby enhancing its ability to generalize across various settings. Without altering the network architecture or loss function, our approach significantly outperforms the state-of-the-art across various S-DGOD datasets. In particular, it achieves a substantial improvement of $7.3%$ and $7.2%$ over the baseline on DWD and Cityscape-C, highlighting its enhanced generalizability in real-world settings.
单域广义对象检测(S-DGOD)旨在通过对象检测器在单一源域上进行训练,以在各种未见过的目标域上实现稳健的性能。现有的S-DGOD方法通常依赖于数据增强策略,包括视觉转换组合,以增强检测器的泛化能力。然而,缺乏现实世界先验知识阻碍了数据增强对训练数据分布多样性的贡献。为了解决这个问题,我们提出了PhysAug,这是一种基于物理模型的新型非理想成像条件数据增强方法,以提高S-DGOD任务的适应性。我们基于大气光学原理,开发了一个通用扰动模型,作为我们提出的PhysAug的基础。鉴于视觉扰动通常来自光线与大气粒子的相互作用,我们利用图像频谱来模拟训练过程中的现实世界变化。这种方法促进了检测器学习域不变表示,从而提高了其在各种设置中的泛化能力。在不改变网络架构或损失函数的情况下,我们的方法在各种S-DGOD数据集上显著优于最新技术。特别是在DWD和Cityscape-C数据集上,与基线相比,我们的方法实现了7.3%和7.2%的实质性改进,凸显了其在现实世界环境中的增强泛化能力。
论文及项目相关链接
PDF Accepted to AAAI,2025
Summary
单域通用目标检测(S-DGOD)旨在通过单一源域的训练实现对多个未见目标域的稳健性能。为提高检测器的泛化能力,现有方法常采用数据增强策略,包括多种视觉转换组合。为解决真实世界先验知识的缺失对训练数据分布多样性的影响,提出基于物理模型的非理想成像条件数据增强方法PhysAug。基于大气光学原理,构建通用扰动模型作为PhysAug的基础。通过模拟光线与大气颗粒相互作用产生的视觉扰动,利用图像频谱在训练过程中模拟真实世界变化。该方法促进检测器学习域不变表示,提高其在不同场景下的泛化能力。在不改变网络架构或损失函数的情况下,该方法在多个S-DGOD数据集上的表现均优于最新技术,特别是在DWD和Cityscape-C数据集上较基线方法分别提高了7.3%和7.2%,显示出其在真实环境中的增强泛化能力。
Key Takeaways
- S-DGOD旨在通过单一源域训练实现跨多个未见目标域的稳健性能。
- 现有数据增强策略常受限于真实世界先验知识的缺失。
- 提出基于物理模型的非理想成像条件数据增强方法PhysAug。
- 利用大气光学原理构建通用扰动模型,模拟真实世界视觉扰动。
- 通过图像频谱模拟真实世界变化,提高检测器的域不变表示学习能力。
- PhysAug在不改变网络架构或损失函数的情况下显著提高S-DGOD性能。
点此查看论文截图


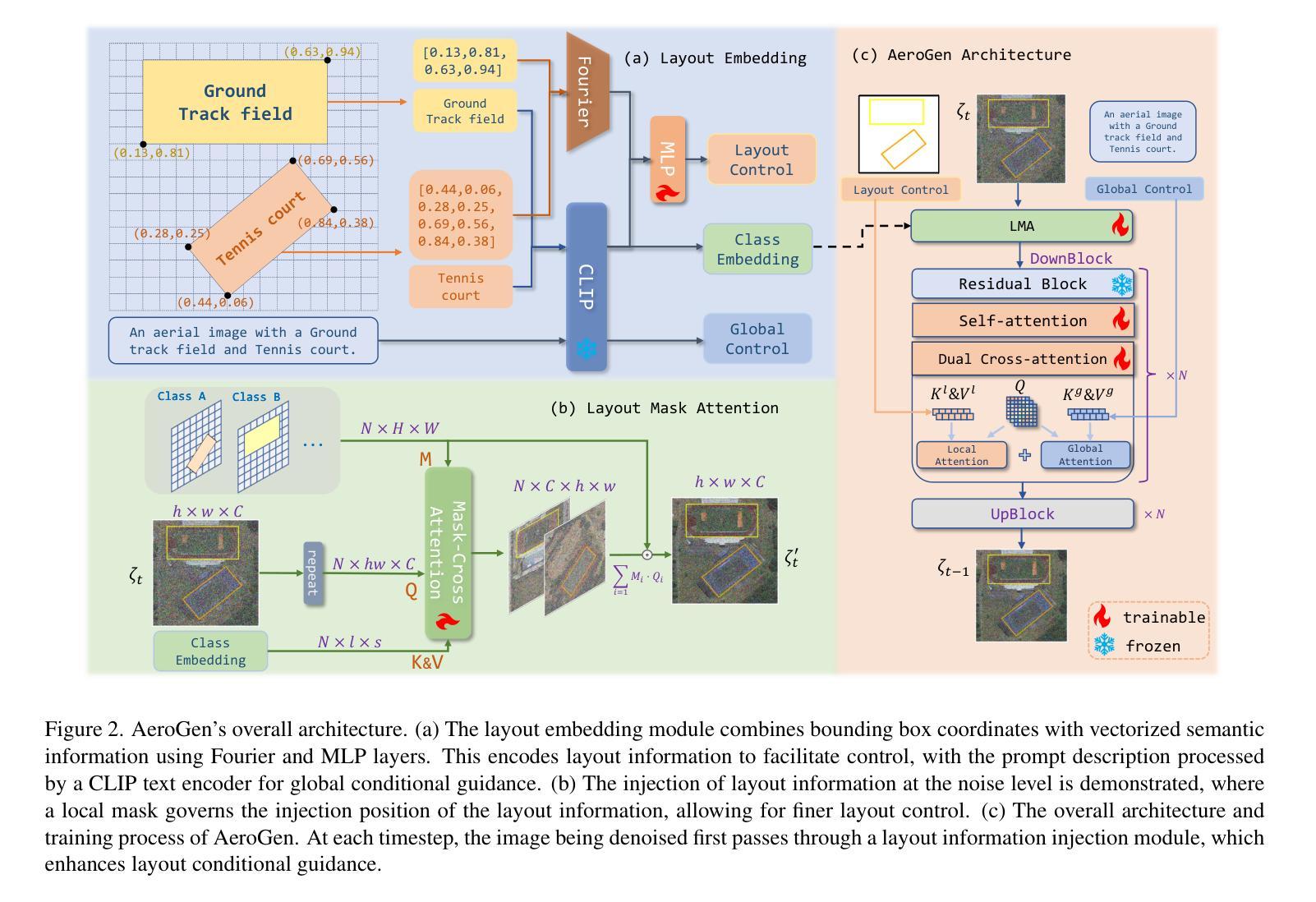
AeroGen: Enhancing Remote Sensing Object Detection with Diffusion-Driven Data Generation
Authors:Datao Tang, Xiangyong Cao, Xuan Wu, Jialin Li, Jing Yao, Xueru Bai, Dongsheng Jiang, Yin Li, Deyu Meng
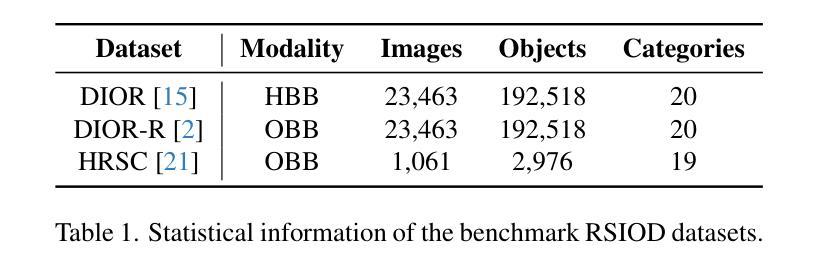
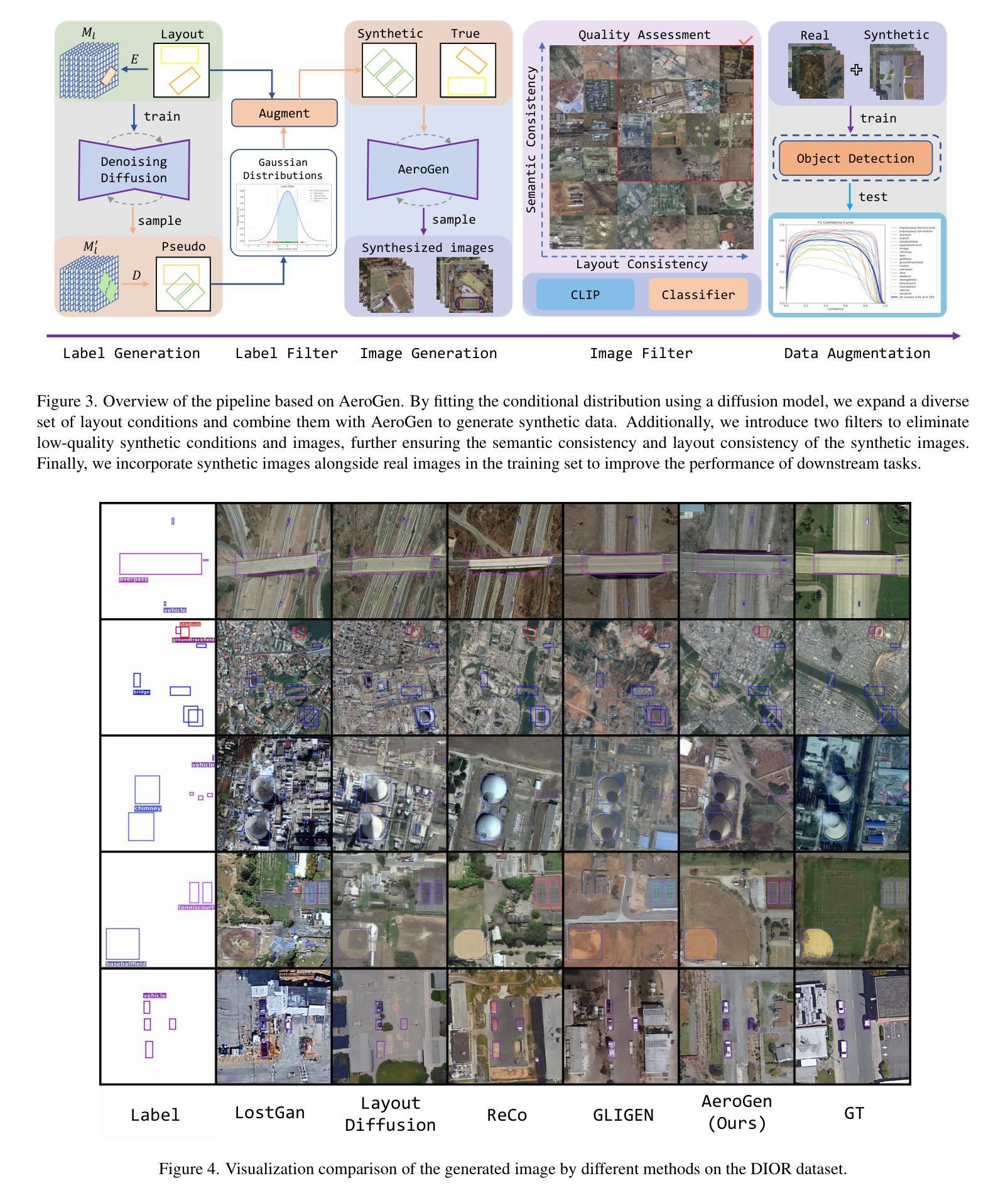
Remote sensing image object detection (RSIOD) aims to identify and locate specific objects within satellite or aerial imagery. However, there is a scarcity of labeled data in current RSIOD datasets, which significantly limits the performance of current detection algorithms. Although existing techniques, e.g., data augmentation and semi-supervised learning, can mitigate this scarcity issue to some extent, they are heavily dependent on high-quality labeled data and perform worse in rare object classes. To address this issue, this paper proposes a layout-controllable diffusion generative model (i.e. AeroGen) tailored for RSIOD. To our knowledge, AeroGen is the first model to simultaneously support horizontal and rotated bounding box condition generation, thus enabling the generation of high-quality synthetic images that meet specific layout and object category requirements. Additionally, we propose an end-to-end data augmentation framework that integrates a diversity-conditioned generator and a filtering mechanism to enhance both the diversity and quality of generated data. Experimental results demonstrate that the synthetic data produced by our method are of high quality and diversity. Furthermore, the synthetic RSIOD data can significantly improve the detection performance of existing RSIOD models, i.e., the mAP metrics on DIOR, DIOR-R, and HRSC datasets are improved by 3.7%, 4.3%, and 2.43%, respectively. The code is available at https://github.com/Sonettoo/AeroGen.
遥感图像目标检测(RSIOD)旨在识别和定位卫星或航空图像中的特定目标。然而,当前RSIOD数据集缺乏标记数据,这显著限制了当前检测算法的性能。尽管现有技术(如数据增强和半监督学习)可以在一定程度上缓解数据稀缺问题,但它们严重依赖于高质量标记数据,并且在稀有目标类别中的表现较差。针对这一问题,本文提出了一种针对RSIOD的布局可控扩散生成模型(即AeroGen)。据我们所知,AeroGen是第一个同时支持水平框和旋转框条件生成模型,因此能够生成符合特定布局和目标类别要求的高质量合成图像。此外,我们提出了一个端到端的数据增强框架,该框架集成了多样性条件生成器和过滤机制,以提高生成数据的多样性和质量。实验结果表明,我们方法生成的合成数据具有高质量和高多样性。此外,遥感图像目标检测模型的检测性能得到了显著提高,即在DIOR、DIOR-R和HRSC数据集上的mAP指标分别提高了3.7%、4.3%和2.43%。代码可通过https://github.com/Sonettoo/AeroGen获取。
论文及项目相关链接
Summary
远程遥感图像目标检测面临标注数据不足的问题,影响算法性能。现有技术如数据增强和半监督学习虽能解决部分问题,但在稀有目标类别中效果不佳。因此,本文提出针对遥感图像目标检测的布局可控扩散生成模型AeroGen。该模型可生成高质量合成图像,满足特定布局和目标类别要求。同时,提出端到端数据增强框架,集成多样性条件生成器和过滤机制,提高生成数据的多样性和质量。实验结果显示,该方法生成的合成数据质量高、多样性好,能显著提高现有遥感图像目标检测模型的性能。
Key Takeaways
- 遥感图像目标检测(RSIOD)面临标注数据不足的问题。
- 现有技术如数据增强和半监督学习在解决标注数据不足问题时存在局限性。
- 本文提出针对遥感图像的布局可控扩散生成模型AeroGen,支持水平和旋转边界框条件生成。
- AeroGen能够生成高质量合成图像,满足特定布局和目标类别要求。
- 提出端到端数据增强框架,提高生成数据的多样性和质量。
- 实验结果显示,AeroGen生成的合成数据能显著提高遥感图像目标检测模型的性能。
点此查看论文截图