⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-26 更新
Understanding Long Videos with Multimodal Language Models
Authors:Kanchana Ranasinghe, Xiang Li, Kumara Kahatapitiya, Michael S. Ryoo
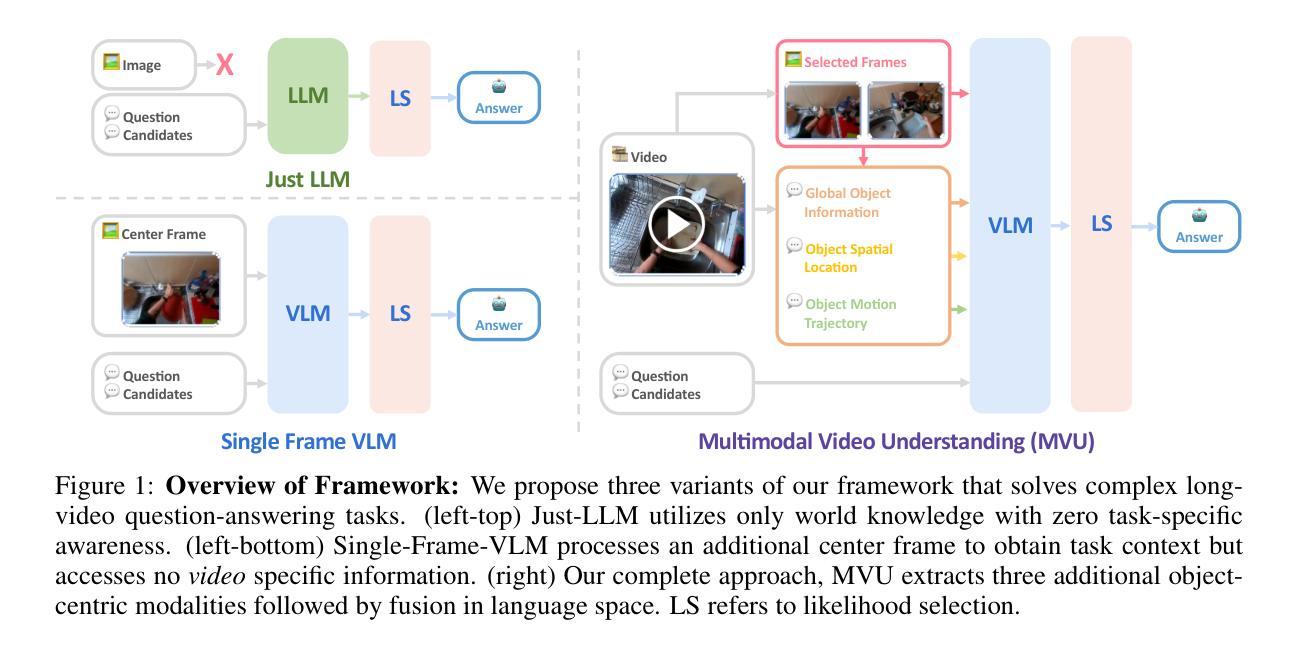
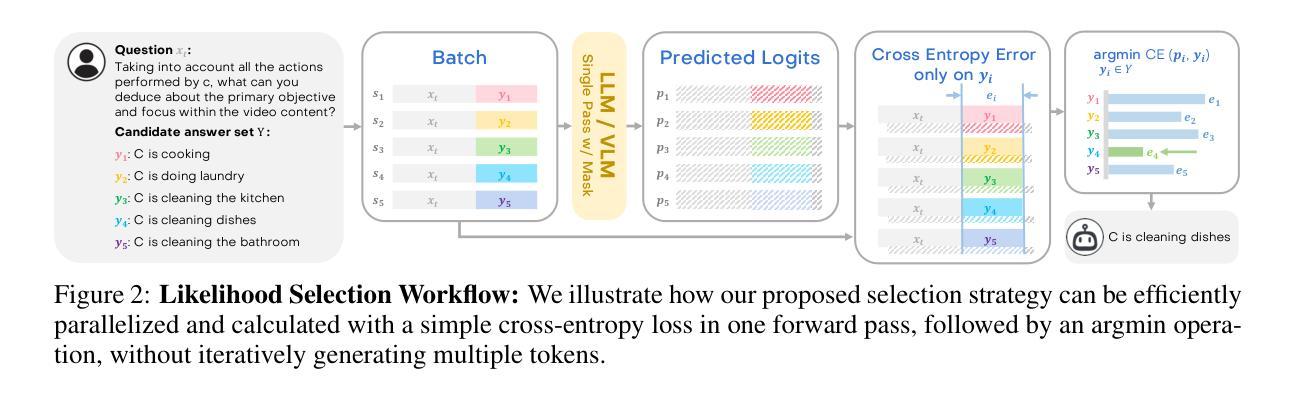
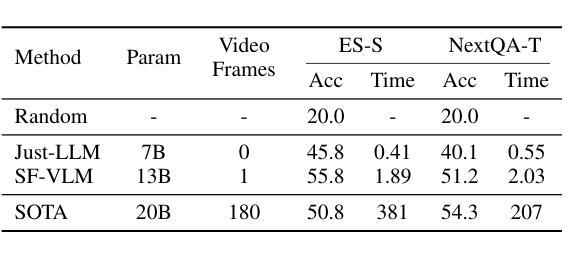
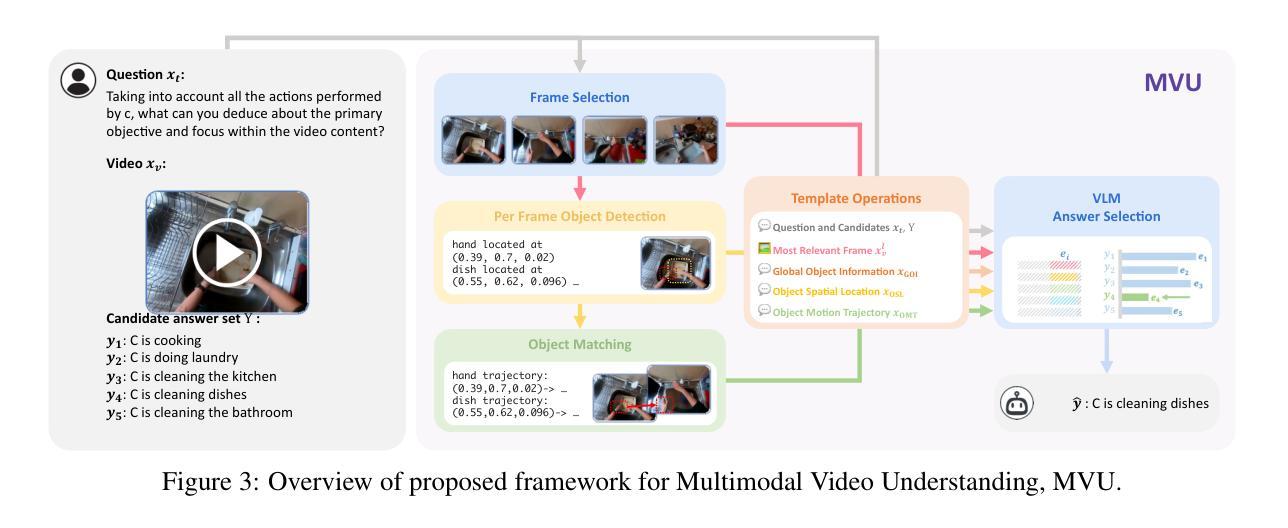
Large Language Models (LLMs) have allowed recent LLM-based approaches to achieve excellent performance on long-video understanding benchmarks. We investigate how extensive world knowledge and strong reasoning skills of underlying LLMs influence this strong performance. Surprisingly, we discover that LLM-based approaches can yield surprisingly good accuracy on long-video tasks with limited video information, sometimes even with no video specific information. Building on this, we explore injecting video-specific information into an LLM-based framework. We utilize off-the-shelf vision tools to extract three object-centric information modalities from videos, and then leverage natural language as a medium for fusing this information. Our resulting Multimodal Video Understanding (MVU) framework demonstrates state-of-the-art performance across multiple video understanding benchmarks. Strong performance also on robotics domain tasks establish its strong generality. Code: https://github.com/kahnchana/mvu
大型语言模型(LLM)使得最近的基于LLM的方法在长时间视频理解基准测试中取得了卓越的性能。我们研究了基础LLM的广泛世界知识和强大的推理技能如何影响这种出色的性能。令人惊讶的是,我们发现基于LLM的方法在长时间视频任务中可以产生令人惊讶的准确度,即使在有限的视频信息下,有时甚至没有任何特定视频信息。在此基础上,我们探索将特定视频信息注入基于LLM的框架中。我们使用现成的视觉工具从视频中提取三种以对象为中心的信息模式,并利用自然语言作为融合这些信息的媒介。我们构建的多媒体视频理解(MVU)框架在多个视频理解基准测试中表现出卓越的性能。其在机器人领域任务上的出色表现也证明了其强大的通用性。代码:https://github.com/kahnchana/mvu
论文及项目相关链接
PDF 17 pages (main paper), 7 pages appendix. ICLR 2025 conference paper
Summary
近期的大型语言模型(LLM)在视频理解方面取得了卓越性能。研究探讨了LLM的广泛世界知识和强大推理能力对性能的影响。令人惊讶的是,即使在有限的视频信息下,有时甚至没有任何视频特定信息的情况下,基于LLM的方法也能在长时间视频任务上达到令人惊讶的准确度。基于此发现,研究团队尝试将视频特定信息注入到LLM框架中。利用现成的视觉工具从视频中提取三种以对象为中心的信息模式,并利用自然语言作为融合这些信息的媒介。由此产生的多模式视频理解(MVU)框架在多个视频理解基准测试中表现出卓越性能,并且在机器人领域任务中也表现出强大的通用性。
Key Takeaways
- 大型语言模型(LLMs)在视频理解方面展现出卓越性能。
- LLMs的广泛世界知识和强大推理能力对性能有显著影响。
- 基于LLM的方法在有限视频信息甚至无视频特定信息的情况下,仍能达到高准确率。
- 研究人员提出了一个名为MVU的多模式视频理解框架。
- MVU框架利用现成的视觉工具从视频中提取对象为中心的信息模式。
- 自然语言被用作融合这些视频信息的媒介。
- MVU框架在多个视频理解基准测试中表现最佳,并在机器人领域任务中展现出强大的通用性。
点此查看论文截图