⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-26 更新
Graph-Guided Scene Reconstruction from Images with 3D Gaussian Splatting
Authors:Chong Cheng, Gaochao Song, Yiyang Yao, Qinzheng Zhou, Gangjian Zhang, Hao Wang
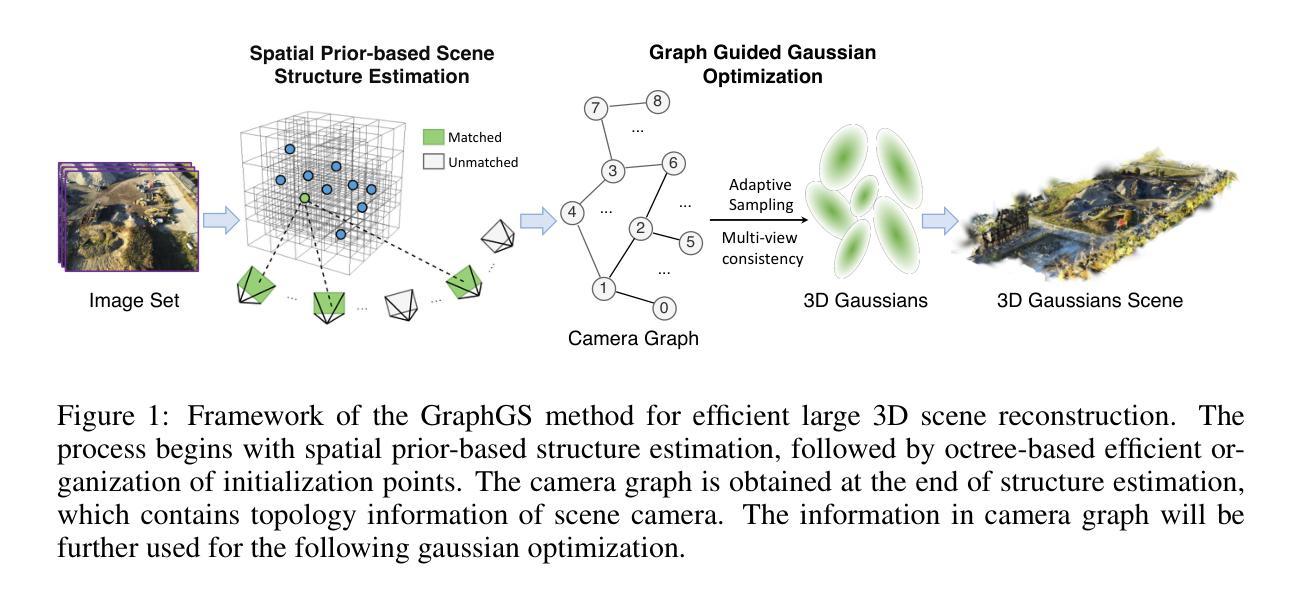
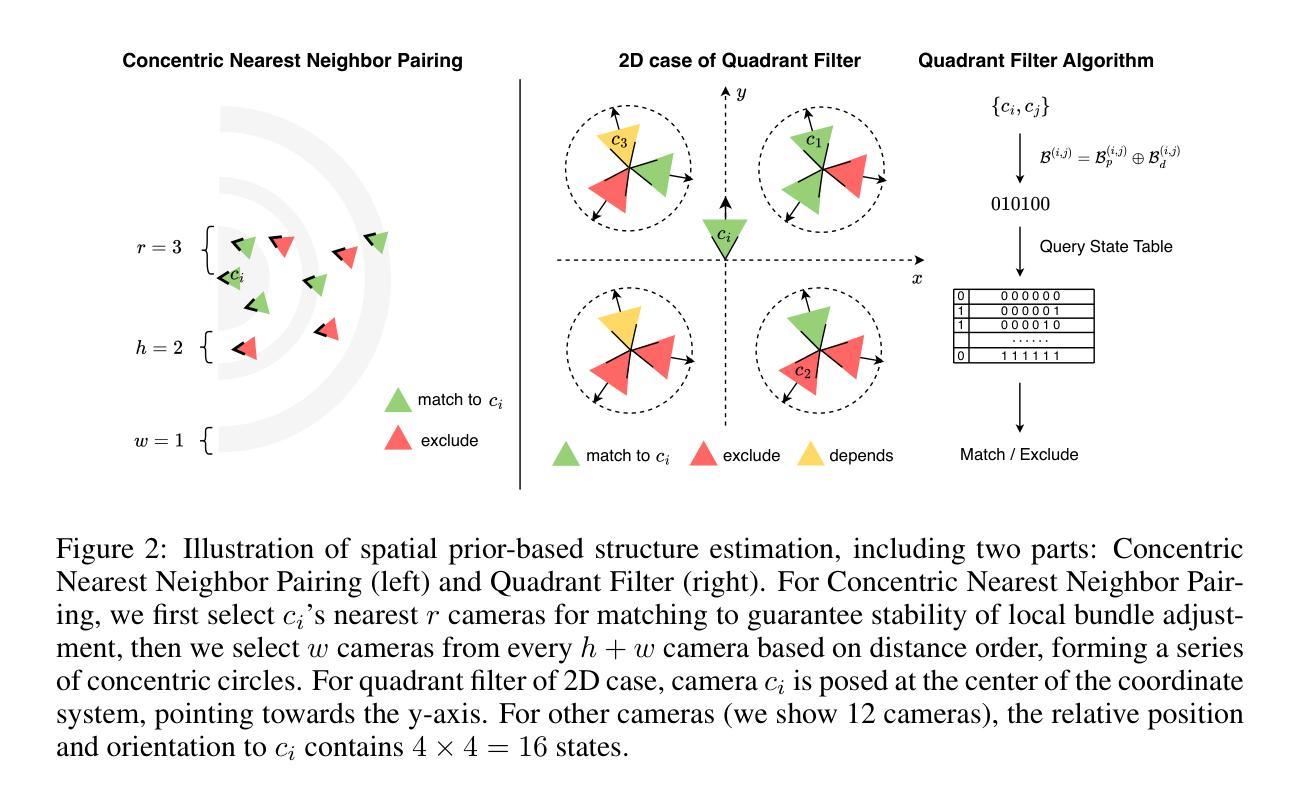
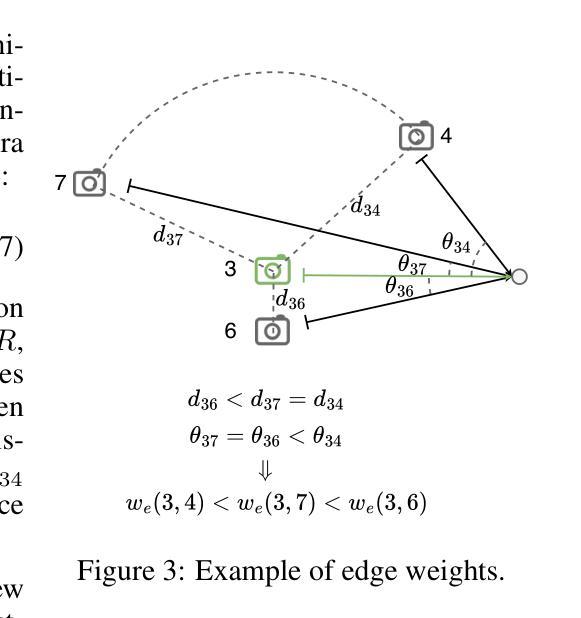
This paper investigates an open research challenge of reconstructing high-quality, large 3D open scenes from images. It is observed existing methods have various limitations, such as requiring precise camera poses for input and dense viewpoints for supervision. To perform effective and efficient 3D scene reconstruction, we propose a novel graph-guided 3D scene reconstruction framework, GraphGS. Specifically, given a set of images captured by RGB cameras on a scene, we first design a spatial prior-based scene structure estimation method. This is then used to create a camera graph that includes information about the camera topology. Further, we propose to apply the graph-guided multi-view consistency constraint and adaptive sampling strategy to the 3D Gaussian Splatting optimization process. This greatly alleviates the issue of Gaussian points overfitting to specific sparse viewpoints and expedites the 3D reconstruction process. We demonstrate GraphGS achieves high-fidelity 3D reconstruction from images, which presents state-of-the-art performance through quantitative and qualitative evaluation across multiple datasets. Project Page: https://3dagentworld.github.io/graphgs.
本文研究了一个开放的研究挑战,即从图像重建高质量的大型3D开放场景。观察到现有方法存在各种局限性,例如需要精确的相机姿态作为输入和密集的视点进行监控。为了进行有效的3D场景重建,我们提出了一种新颖的图形引导式重建框架GraphGS。具体来说,给定一组由RGB相机捕捉的场景图像,我们首先设计了一种基于空间先验的场景结构估计方法。然后,该方法被用来创建一个包含相机拓扑信息的相机图。此外,我们提出将图形引导的多视角一致性约束和自适应采样策略应用于3D高斯拼贴优化过程。这极大地减轻了高斯点对特定稀疏视点的过度拟合问题,并加速了3D重建过程。我们证明了GraphGS能够从图像实现高保真度的3D重建,并在多个数据集上通过定量和定性评估展现了其卓越性能。项目页面:https://3dagentworld.github.io/graphgs。
论文及项目相关链接
PDF ICLR 2025
Summary
基于图像的高质量三维场景重建是一项公开的研究挑战。本文提出一种新颖的基于图引导的三维场景重建框架GraphGS。它能有效地从RGB相机拍摄的一组图像中重建场景结构,通过空间先验估计场景结构并建立相机图,利用图引导的多视角一致性约束和自适应采样策略,对高斯模糊优化过程进行改进,实现了高质量的三维重建效果。
Key Takeaways
- 本文针对现有三维场景重建方法存在的局限性(如需要精确相机姿态和密集视角进行输入和监管)提出了改进。
- 提出了一种新颖的基于图引导的三维场景重建框架GraphGS。
- 通过空间先验估计场景结构并建立相机图。
- 应用了图引导的多视角一致性约束和自适应采样策略,改善了高斯模糊优化过程。
- 通过定量和定性评价,GraphGS在多数据集上实现了先进的三维重建性能。
- 该框架能有效地从RGB相机拍摄的一组图像中重建高质量的三维场景。
点此查看论文截图

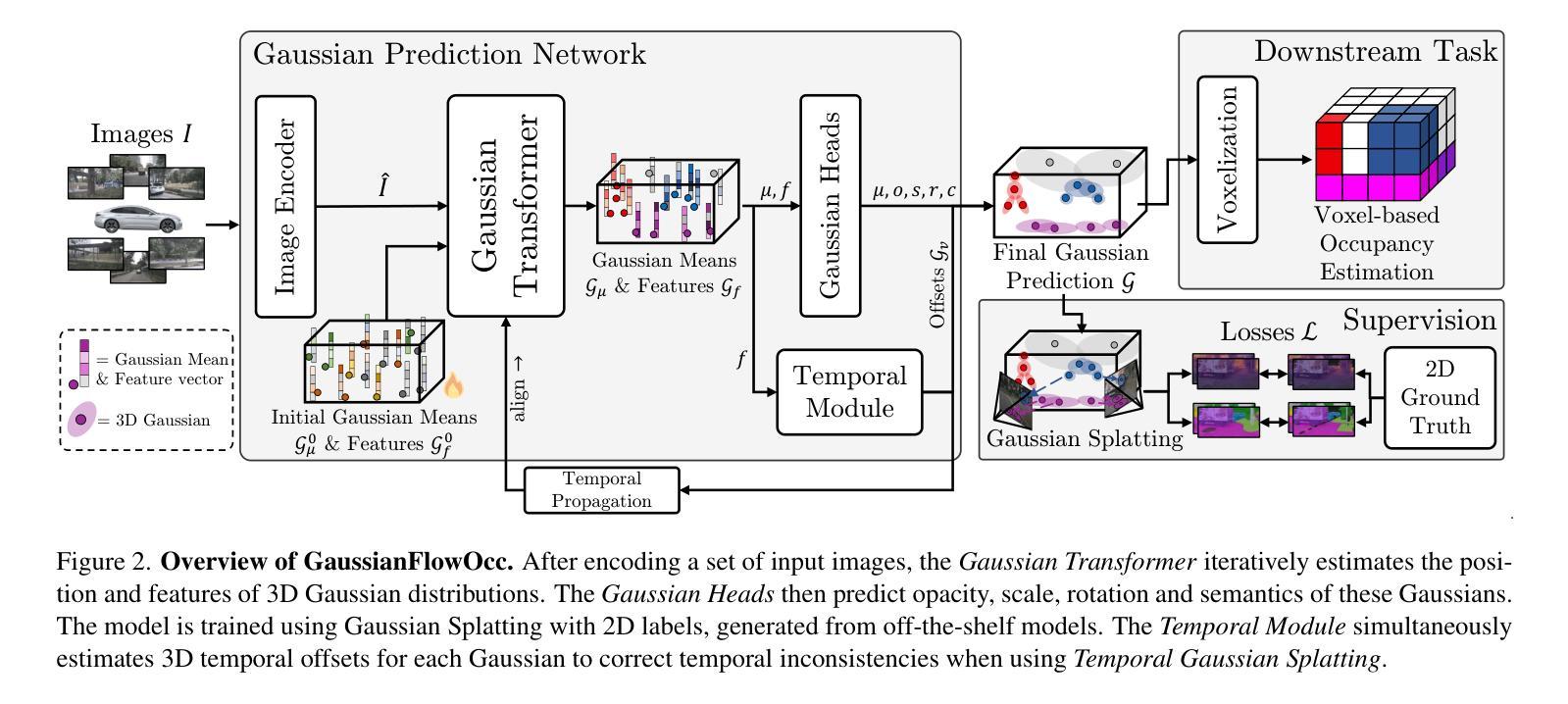
GaussianFlowOcc: Sparse and Weakly Supervised Occupancy Estimation using Gaussian Splatting and Temporal Flow
Authors:Simon Boeder, Fabian Gigengack, Benjamin Risse
Occupancy estimation has become a prominent task in 3D computer vision, particularly within the autonomous driving community. In this paper, we present a novel approach to occupancy estimation, termed GaussianFlowOcc, which is inspired by Gaussian Splatting and replaces traditional dense voxel grids with a sparse 3D Gaussian representation. Our efficient model architecture based on a Gaussian Transformer significantly reduces computational and memory requirements by eliminating the need for expensive 3D convolutions used with inefficient voxel-based representations that predominantly represent empty 3D spaces. GaussianFlowOcc effectively captures scene dynamics by estimating temporal flow for each Gaussian during the overall network training process, offering a straightforward solution to a complex problem that is often neglected by existing methods. Moreover, GaussianFlowOcc is designed for scalability, as it employs weak supervision and does not require costly dense 3D voxel annotations based on additional data (e.g., LiDAR). Through extensive experimentation, we demonstrate that GaussianFlowOcc significantly outperforms all previous methods for weakly supervised occupancy estimation on the nuScenes dataset while featuring an inference speed that is 50 times faster than current SOTA.
占用估计已成为三维计算机视觉中的一个重要任务,特别是在自动驾驶领域。在本文中,我们提出了一种新颖的占用估计方法,称为GaussianFlowOcc,它受到高斯涂抹的启发,用稀疏的三维高斯表示替换了传统的密集体素网格。我们基于高斯变换器的有效模型架构,通过消除主要表示空三维空间的低效体素表示形式所使用的高成本三维卷积,大大减少了计算和内存需求。GaussianFlowOcc通过在网络整体训练过程中估计每个高斯的时间流来有效地捕捉场景动态,为解决现有方法经常忽略的复杂问题提供了直接解决方案。此外,GaussianFlowOcc设计用于可扩展性,因为它采用弱监督,并且不需要基于额外数据(例如激光雷达)的昂贵密集三维体素注释。通过广泛实验,我们证明GaussianFlowOcc在nuScenes数据集上的弱监督占用估计方面大大优于所有以前的方法,同时其推理速度比当前最佳技术快50倍。
论文及项目相关链接
Summary
本文提出了一种新颖的占用率估计方法,称为GaussianFlowOcc。该方法受到高斯涂抹技术的启发,采用稀疏的3D高斯表示替换传统的密集体素网格。基于高斯转换器的有效模型架构,无需使用耗时的3D卷积和效率低下的基于体素的表示方法,从而大大减少了计算和内存需求。GaussianFlowOcc通过在网络训练过程中估计每个高斯的时间流来有效地捕捉场景动态,为解决现有方法经常忽略的复杂问题提供了简单直接的解决方案。此外,GaussianFlowOcc设计用于可扩展性,采用弱监督,无需基于额外数据(例如激光雷达)的昂贵密集3D体素注释。通过广泛的实验,我们在nuScenes数据集上证明了GaussianFlowOcc在弱监督占用率估计方面显著优于所有先前的方法,同时其推理速度是现有最先进的模型的50倍。
Key Takeaways
- GaussianFlowOcc是一种基于稀疏3D高斯表示的占用率估计新方法。
- 该方法受到高斯涂抹技术的启发,并替代了传统的密集体素网格。
- 基于高斯转换器的模型架构,降低了计算和内存需求。
- GaussianFlowOcc通过估计场景动态的时间流来解决复杂问题。
- 该方法采用弱监督设计,无需昂贵的密集3D体素注释。
- 在nuScenes数据集上,GaussianFlowOcc在弱监督占用率估计方面表现出卓越性能。
点此查看论文截图

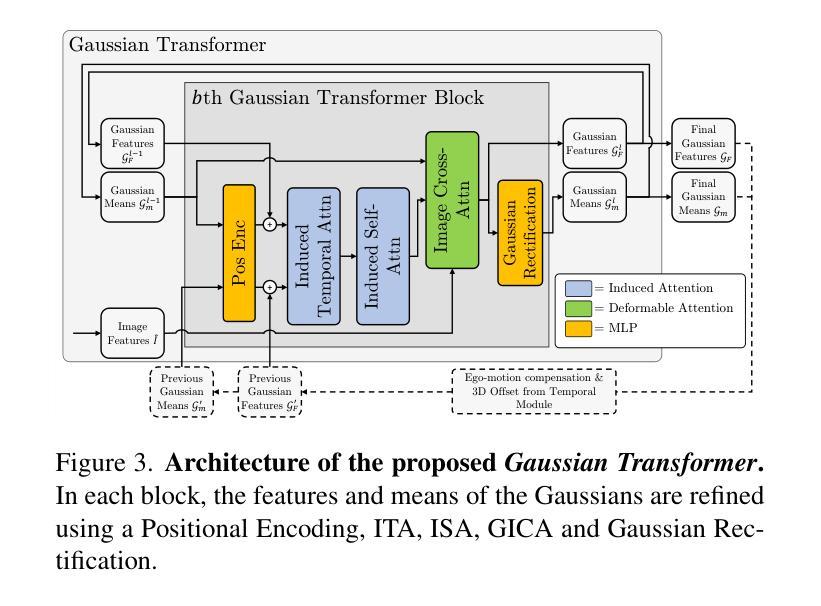
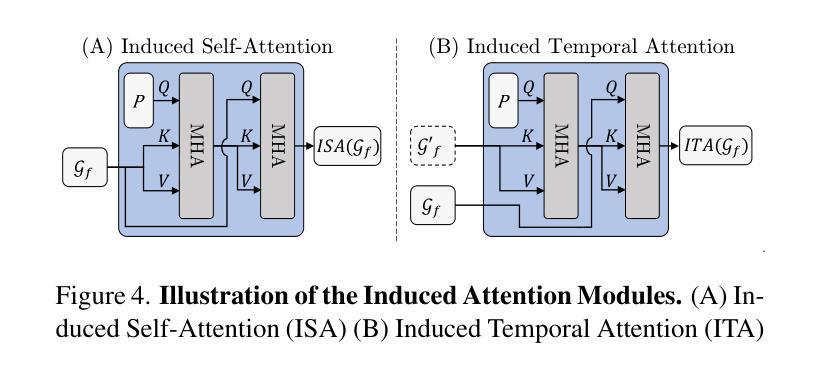
VR-Pipe: Streamlining Hardware Graphics Pipeline for Volume Rendering
Authors:Junseo Lee, Jaisung Kim, Junyong Park, Jaewoong Sim
Graphics rendering that builds on machine learning and radiance fields is gaining significant attention due to its outstanding quality and speed in generating photorealistic images from novel viewpoints. However, prior work has primarily focused on evaluating its performance through software-based rendering on programmable shader cores, leaving its performance when exploiting fixed-function graphics units largely unexplored. In this paper, we investigate the performance implications of performing radiance field rendering on the hardware graphics pipeline. In doing so, we implement the state-of-the-art radiance field method, 3D Gaussian splatting, using graphics APIs and evaluate it across synthetic and real-world scenes on today’s graphics hardware. Based on our analysis, we present VR-Pipe, which seamlessly integrates two innovations into graphics hardware to streamline the hardware pipeline for volume rendering, such as radiance field methods. First, we introduce native hardware support for early termination by repurposing existing special-purpose hardware in modern GPUs. Second, we propose multi-granular tile binning with quad merging, which opportunistically blends fragments in shader cores before passing them to fixed-function blending units. Our evaluation shows that VR-Pipe greatly improves rendering performance, achieving up to a 2.78x speedup over the conventional graphics pipeline with negligible hardware overhead.
基于机器学习和辐射场(radiance fields)的图形渲染因其从新颖视角生成逼真图像时的出色质量和速度而受到广泛关注。然而,早期的研究主要集中在通过可编程着色器核心的软件渲染来评估其性能,而几乎没有探索其在利用固定功能图形单元时的性能。在本文中,我们研究了在硬件图形管道上执行辐射场渲染的性能影响。为此,我们使用图形API实现了最先进的辐射场方法——3D高斯拼贴(splatting),并在当今的图形硬件上对合成场景和真实世界场景进行了评估。基于分析,我们提出了VR-Pipe,它无缝地将两项创新集成到图形硬件中,以优化体积渲染(如辐射场方法)的硬件管道。首先,我们通过重新利用现代GPU中的专用硬件来引入对早期终止的本地硬件支持。其次,我们提出了具有四元合并的多粒度平铺装箱(multi-granular tile binning),该技术在将片段传递给固定功能混合单元之前在着色器核心中有机混合片段。我们的评估表明,VR-Pipe极大地提高了渲染性能,与传统图形管道相比,最高可实现2.78倍的速度提升,且硬件开销微乎其微。
论文及项目相关链接
PDF To appear at the 31st International Symposium on High-Performance Computer Architecture (HPCA 2025)
Summary
本摘要主要探讨机器学习驱动的渲染技术以及基于辐射场的渲染在图形渲染领域的进展和应用。本文主要分析了现代图形硬件上的光线投射算法性能,并首次实现了基于硬件支持的早期终止技术和多粒度瓦片合并技术,以提高渲染性能。这些技术为辐射场方法提供了优化的硬件支持,实现了高达2.78倍的渲染速度提升。
Key Takeaways
以下是基于文本的关键见解:
- 现代图形渲染结合机器学习和辐射场技术以生成高质量的图像,但该领域仍存在对传统可编程着色器性能评价过高的问题,忽略了在固定功能图形单元中的表现评价。本文着眼于硬件设备的光线投射技术表现的研究和评价。
- 通过最新的光线投射方法分析渲染技术在硬件上的性能,例如基于辐射场的3D高斯飞溅技术。这种方法利用了现有的图形API,对合成场景和真实世界场景进行了评价。
点此查看论文截图

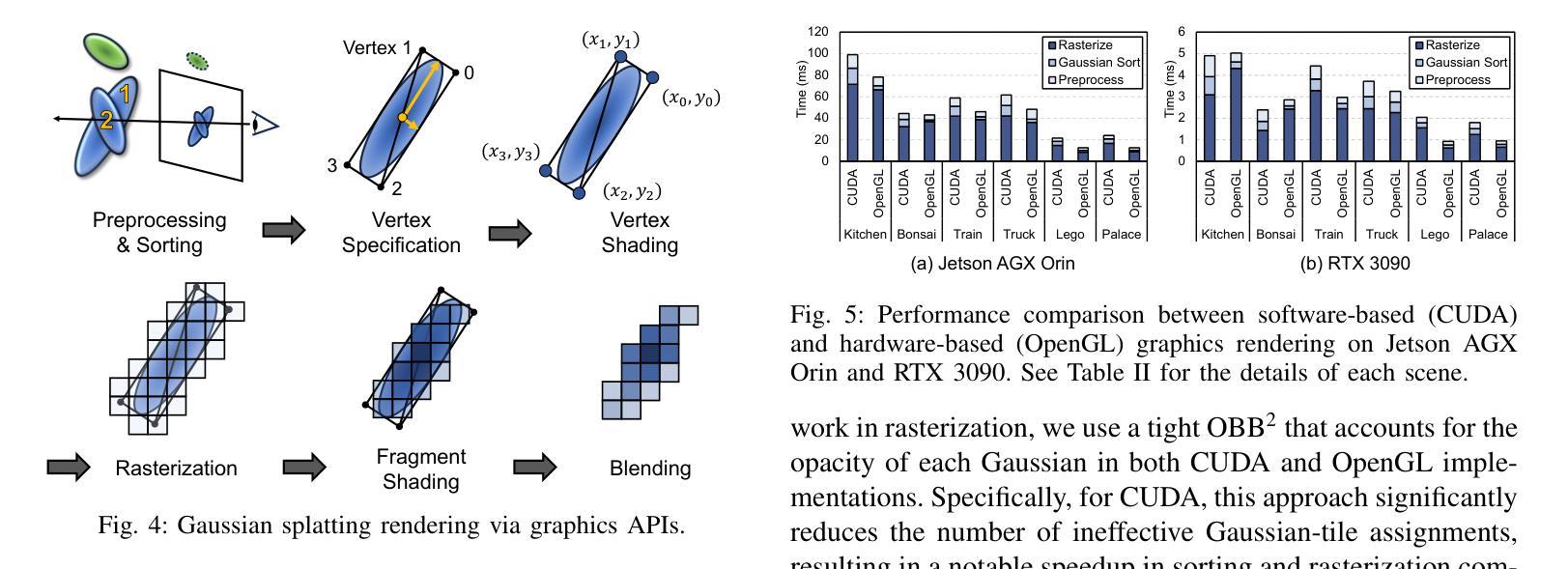
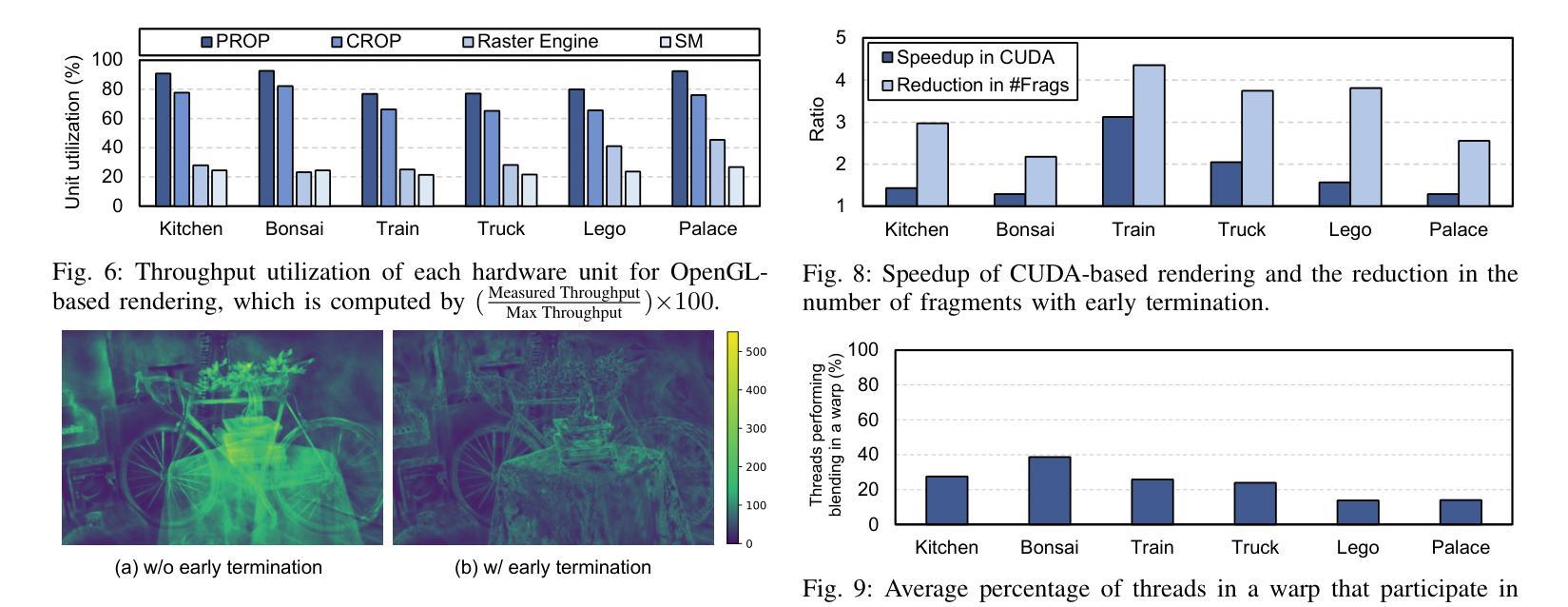

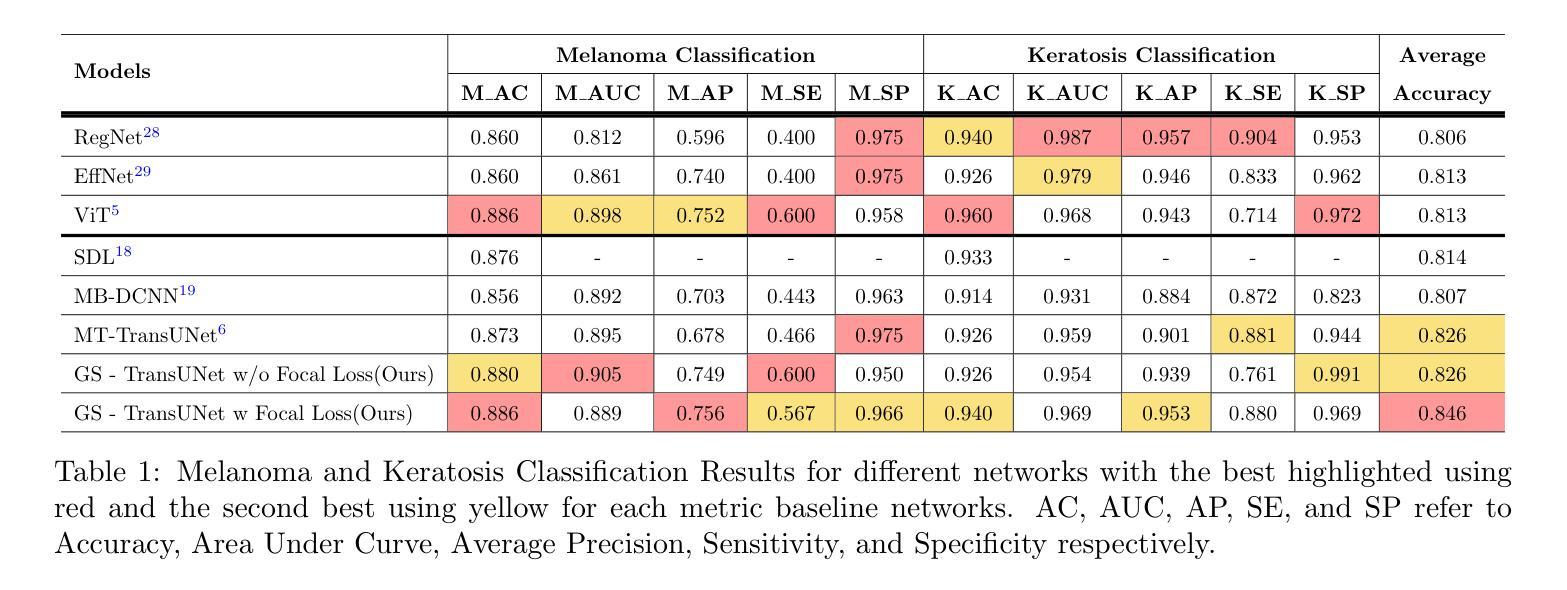
GS-TransUNet: Integrated 2D Gaussian Splatting and Transformer UNet for Accurate Skin Lesion Analysis
Authors:Anand Kumar, Kavinder Roghit Kanthen, Josna John
We can achieve fast and consistent early skin cancer detection with recent developments in computer vision and deep learning techniques. However, the existing skin lesion segmentation and classification prediction models run independently, thus missing potential efficiencies from their integrated execution. To unify skin lesion analysis, our paper presents the Gaussian Splatting - Transformer UNet (GS-TransUNet), a novel approach that synergistically combines 2D Gaussian splatting with the Transformer UNet architecture for automated skin cancer diagnosis. Our unified deep learning model efficiently delivers dual-function skin lesion classification and segmentation for clinical diagnosis. Evaluated on ISIC-2017 and PH2 datasets, our network demonstrates superior performance compared to existing state-of-the-art models across multiple metrics through 5-fold cross-validation. Our findings illustrate significant advancements in the precision of segmentation and classification. This integration sets new benchmarks in the field and highlights the potential for further research into multi-task medical image analysis methodologies, promising enhancements in automated diagnostic systems.
我们可以借助计算机视觉和深度学习技术的最新发展,实现快速且一致的早期皮肤癌检测。然而,现有的皮肤病变分割和分类预测模型是独立运行的,因此错过了通过集成执行提高效率的潜在机会。为了统一皮肤病变分析,我们的论文提出了高斯点染——Transformer UNet(GS-TransUNet),这是一种新颖的方法,它将二维高斯点染与Transformer UNet架构协同结合,用于自动化皮肤癌诊断。我们统一的深度学习模型有效地实现了用于临床诊断的双重功能皮肤病变分类和分割。在ISIC-2017和PH2数据集上评估,我们的网络在多项指标上表现出优于现有最先进的模型的性能,通过5倍交叉验证。我们的研究结果表明,在分割和分类的精确度方面取得了重大进展。这一整合为领域设定了新的基准,并强调了多任务医学图像分析方法的进一步研究潜力,有望在自动化诊断系统中实现改进。
论文及项目相关链接
PDF 12 pages, 7 figures, SPIE Medical Imaging 2025
Summary
皮肤癌的早期快速且一致检测可通过计算机视觉和深度学习技术的最新发展实现。现有皮肤病灶分割和分类预测模型独立运行,错过通过集成执行提高效率的潜在机会。为统一皮肤病灶分析,本文提出高斯展布-Transformer UNet(GS-TransUNet),这是一种将二维高斯展布与Transformer UNet架构协同结合,实现自动化皮肤癌诊断的新方法。我们统一的深度学习模型有效地实现了用于临床诊断的皮肤病灶分类和分割的双重功能。在ISIC-2017和PH2数据集上评估,我们的网络在多项指标上表现出优于现有最先进的模型的性能,通过五折交叉验证。我们的研究结果表明,在分割和分类精度方面取得了重大进展。这种集成树立了该领域的新基准,并强调了多任务医疗图像分析方法的研究潜力,有望在自动化诊断系统中得到改进。
Key Takeaways
- 最新计算机视觉和深度学习技术可实现快速且一致的皮肤癌早期检测。
- 现有皮肤病灶分割和分类模型独立运行,存在效率提升空间。
- 提出一种新型方法GS-TransUNet,结合二维高斯展布与Transformer UNet架构。
- GS-TransUNet实现皮肤病灶分类和分割的双重功能,用于自动化皮肤癌诊断。
- 在多个数据集上评估,GS-TransUNet性能优于现有模型。
- 研究结果显著提高了皮肤病灶分割和分类的精度。
点此查看论文截图

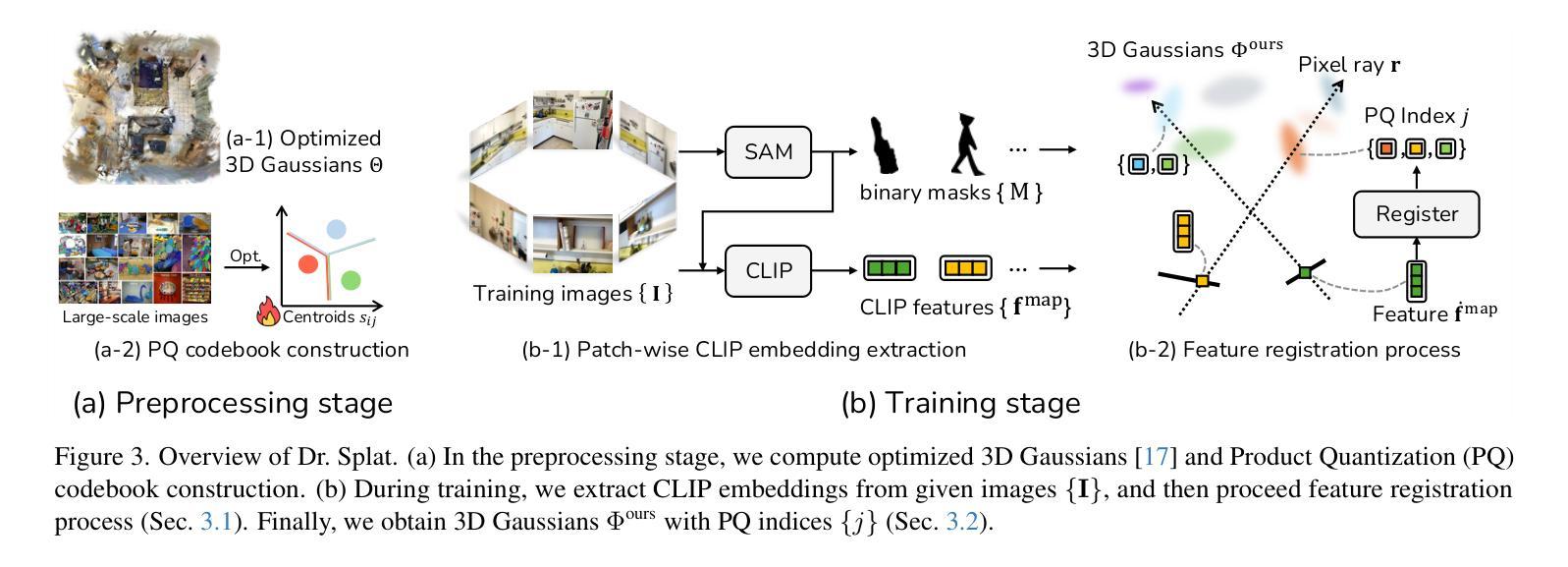
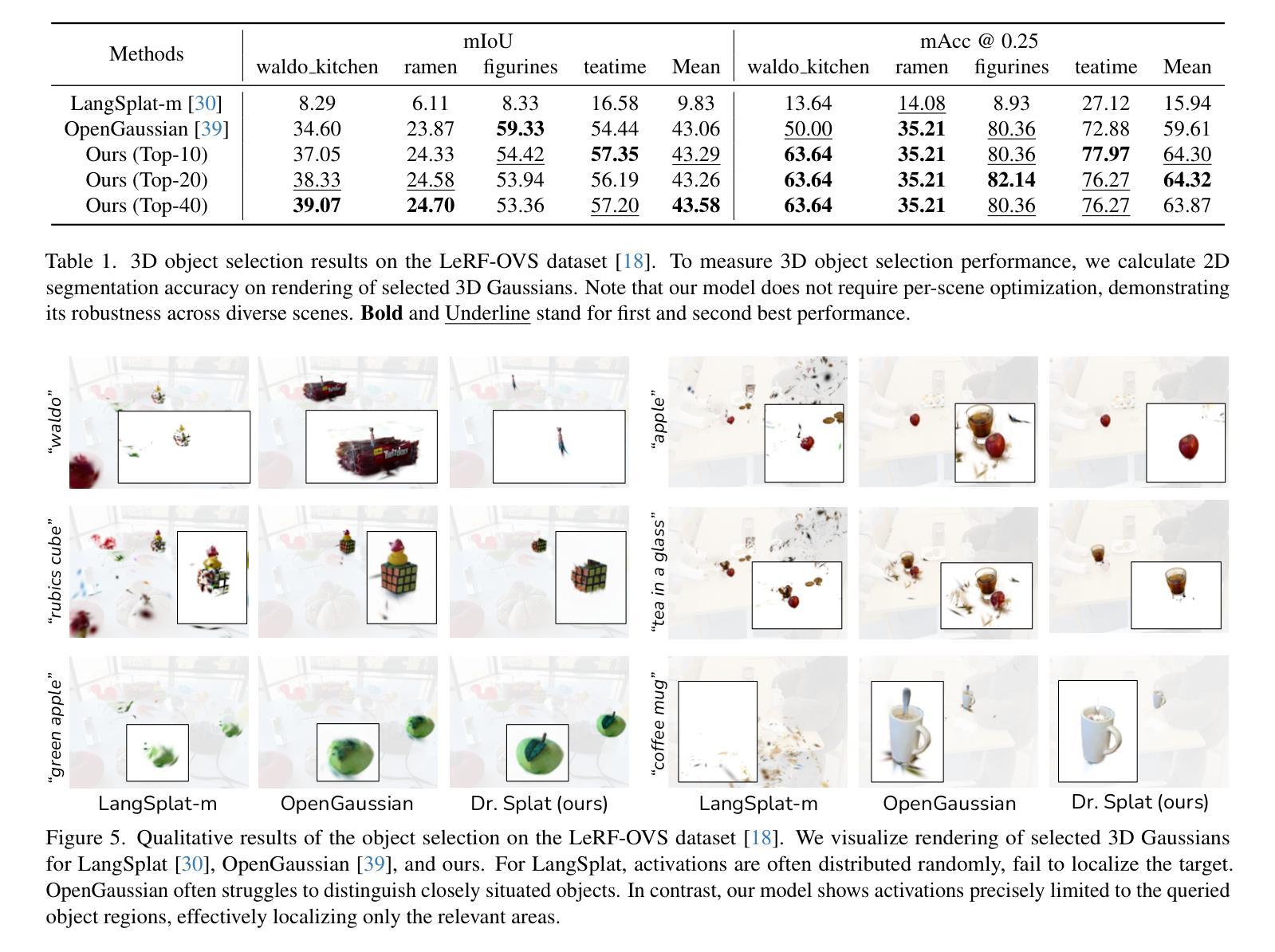
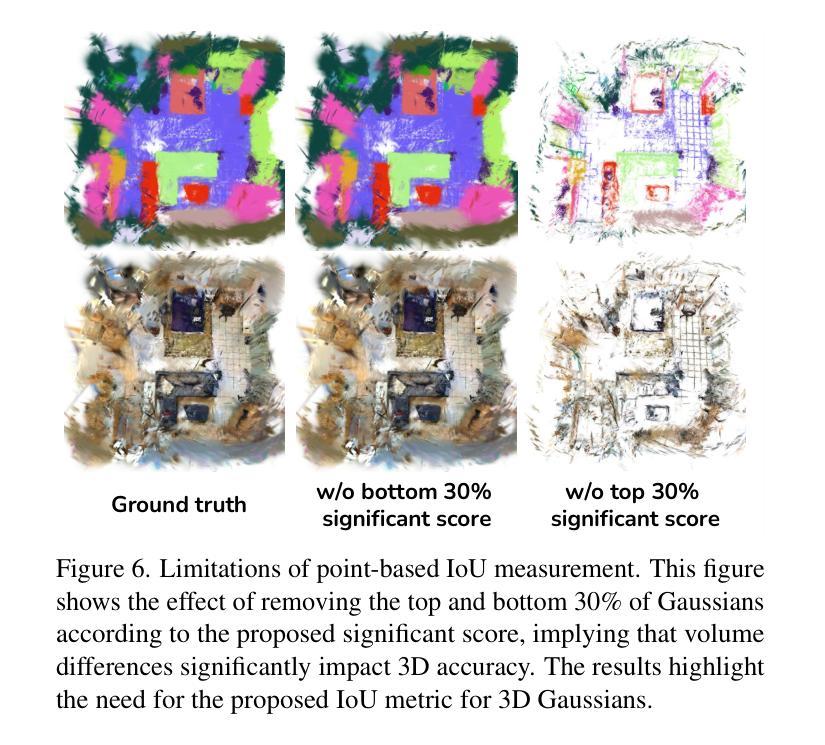
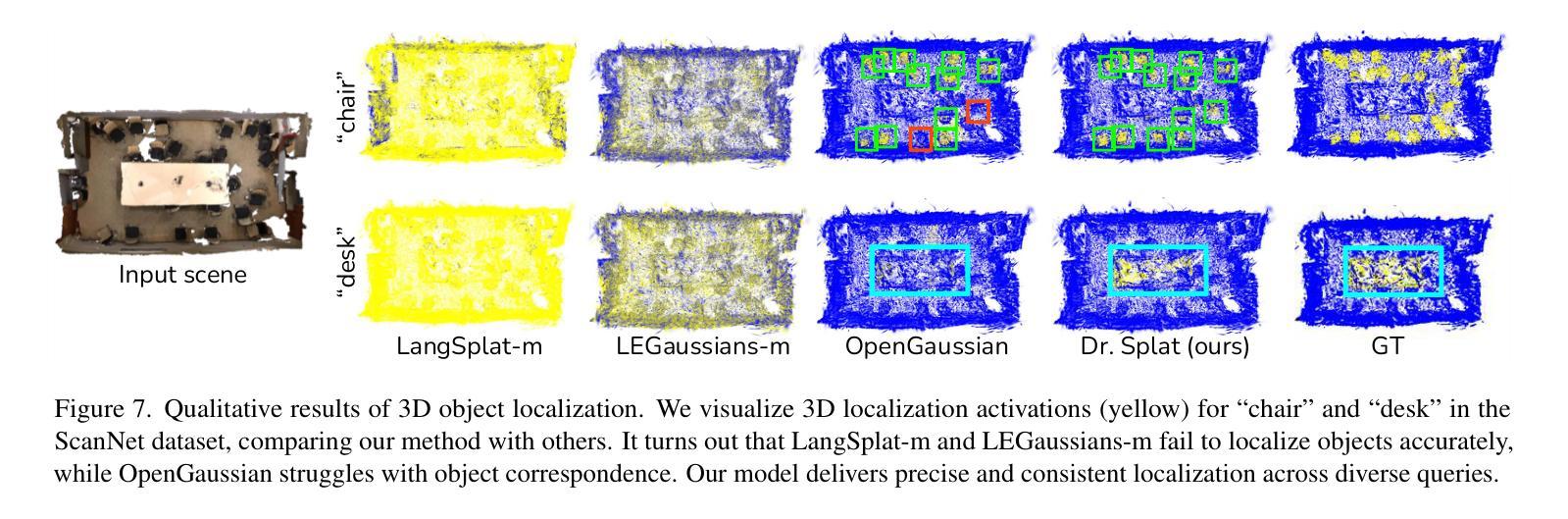
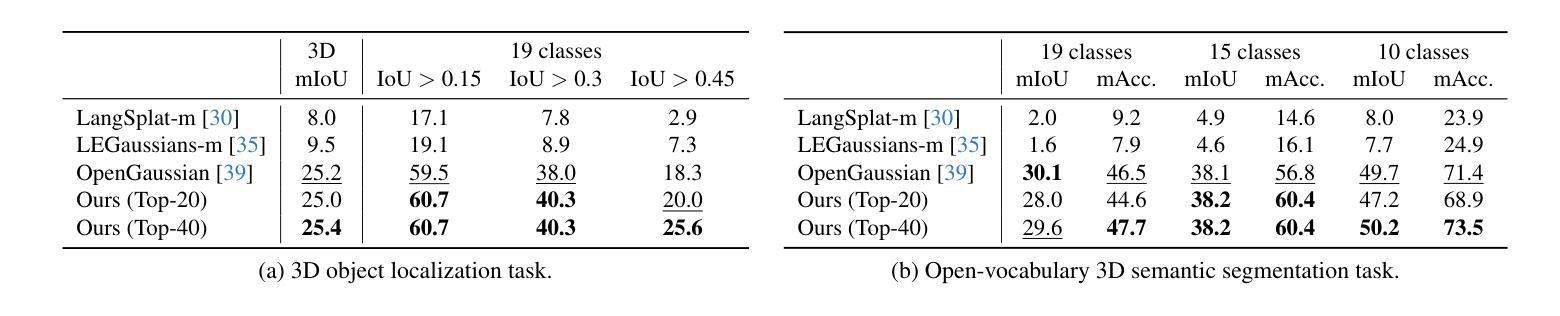
Dr. Splat: Directly Referring 3D Gaussian Splatting via Direct Language Embedding Registration
Authors:Kim Jun-Seong, GeonU Kim, Kim Yu-Ji, Yu-Chiang Frank Wang, Jaesung Choe, Tae-Hyun Oh
We introduce Dr. Splat, a novel approach for open-vocabulary 3D scene understanding leveraging 3D Gaussian Splatting. Unlike existing language-embedded 3DGS methods, which rely on a rendering process, our method directly associates language-aligned CLIP embeddings with 3D Gaussians for holistic 3D scene understanding. The key of our method is a language feature registration technique where CLIP embeddings are assigned to the dominant Gaussians intersected by each pixel-ray. Moreover, we integrate Product Quantization (PQ) trained on general large-scale image data to compactly represent embeddings without per-scene optimization. Experiments demonstrate that our approach significantly outperforms existing approaches in 3D perception benchmarks, such as open-vocabulary 3D semantic segmentation, 3D object localization, and 3D object selection tasks. For video results, please visit : https://drsplat.github.io/
我们介绍了Dr. Splat,这是一种利用3D高斯拼贴(3DGS)进行开放词汇表3D场景理解的新方法。不同于现有的嵌入语言的三维高斯拼贴方法,这些方法依赖于渲染过程,我们的方法直接将语言对齐的CLIP嵌入与三维高斯关联起来,用于全面的三维场景理解。我们方法的关键在于语言特征注册技术,其中CLIP嵌入被分配给每个像素射线所相交的主要高斯分布。此外,我们集成了在通用大规模图像数据上训练的产品量化(PQ),以紧凑地表示嵌入,无需针对每个场景进行优化。实验表明,我们的方法在三维感知基准测试中显著优于现有方法,例如在开放词汇表的三维语义分割、三维对象定位和三维对象选择任务中。视频结果请访问:[https://drsplat.github.io/]
论文及项目相关链接
PDF 20 pages
Summary
利用三维高斯拼接技术(3D Gaussian Splatting)推出Dr. Splat新方法,实现开放词汇表的场景三维理解。与现有语言嵌入三维分割法不同,此法通过语言对齐CLIP嵌入直接与三维高斯相关联,以实现全面场景理解。利用语言特征注册技术为每个像素点分配主导高斯并赋予CLIP嵌入值。集成Product Quantization技术紧凑表示嵌入值,无需场景优化。实验证明,该方法在三维感知基准测试中表现显著优于现有方法,如开放词汇表的三维语义分割、三维目标定位和三维目标选择任务等。具体视频结果请访问:链接地址。
Key Takeaways
- 介绍了一种名为Dr. Splat的新方法,用于基于开放词汇表的三维场景理解。
- Dr. Splat采用三维高斯拼接技术(3D Gaussian Splatting)与现有技术相比更直观地进行三维感知分析。
- 通过语言对齐CLIP嵌入直接关联至三维高斯的方法理解全面场景。
- 利用语言特征注册技术为每个像素点分配主导高斯并赋予CLIP嵌入值,实现精准分析。
- 集成Product Quantization技术,无需特定场景的优化即可紧凑表示嵌入值。
- 实验证明Dr. Splat在三维感知基准测试中表现优于现有方法。具体涵盖开放词汇表的三维语义分割、三维目标定位和选择任务等。
点此查看论文截图



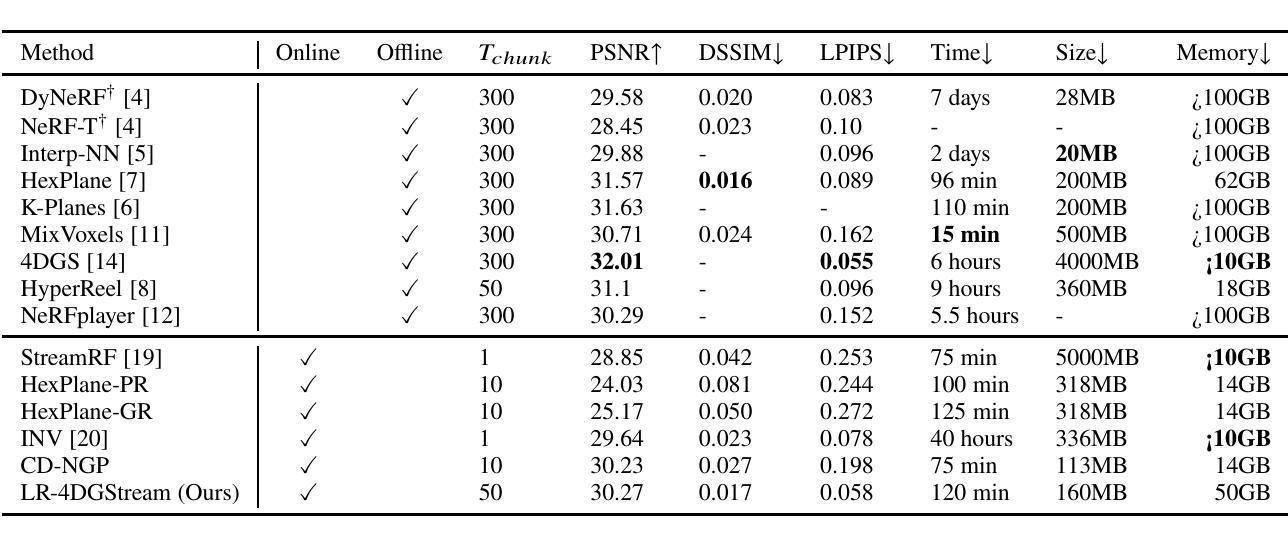
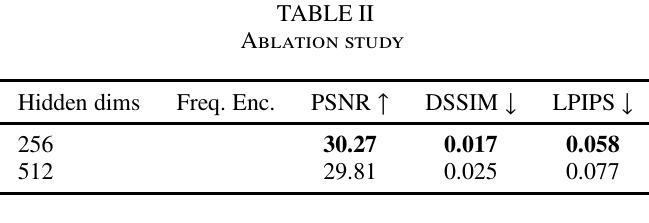
Efficient 4D Gaussian Stream with Low Rank Adaptation
Authors:Zhenhuan Liu, Shuai Liu, Yidong Lu, Yirui Chen, Jie Yang, Wei Liu
Recent methods have made significant progress in synthesizing novel views with long video sequences. This paper proposes a highly scalable method for dynamic novel view synthesis with continual learning. We leverage the 3D Gaussians to represent the scene and a low-rank adaptation-based deformation model to capture the dynamic scene changes. Our method continuously reconstructs the dynamics with chunks of video frames, reduces the streaming bandwidth by $90%$ while maintaining high rendering quality comparable to the off-line SOTA methods.
近期的方法在利用长视频序列合成新型视角方面取得了显著进展。本文提出了一种具有可扩展性的动态新型视角合成方法,该方法具有持续学习能力。我们利用3D高斯来表示场景,并采用基于低阶适应的变形模型来捕捉动态场景变化。我们的方法能够连续重构视频帧的动态效果,在保持与离线SOTA方法相当的高渲染质量的同时,将流媒体带宽减少了90%。
论文及项目相关链接
PDF 3 pages draft
Summary:
本文提出了一种基于动态场景表示和连续学习的动态新视角合成方法。利用三维高斯分布表示场景,并采用基于低秩适应的变形模型捕捉动态场景变化。该方法可连续重建视频帧片段,降低流带宽达90%,同时保持与离线先进方法相当的高渲染质量。
Key Takeaways:
- 本文提出了基于三维高斯分布的场连动态表示方法,有效捕捉场景的动态变化。
- 利用低秩适应变形模型对动态场景变化进行建模。
- 该方法可连续重建视频帧片段,有助于提高视频处理的效率和流畅性。
- 与离线先进方法相比,该方法在保持高渲染质量的同时降低了流带宽达90%。
- 该方法适用于长视频序列的合成新视角任务。
- 本文的合成新视角技术基于连续学习,能够适应动态场景的变化,具有良好的扩展性。
点此查看论文截图

Dragen3D: Multiview Geometry Consistent 3D Gaussian Generation with Drag-Based Control
Authors:Jinbo Yan, Alan Zhao, Yixin Hu
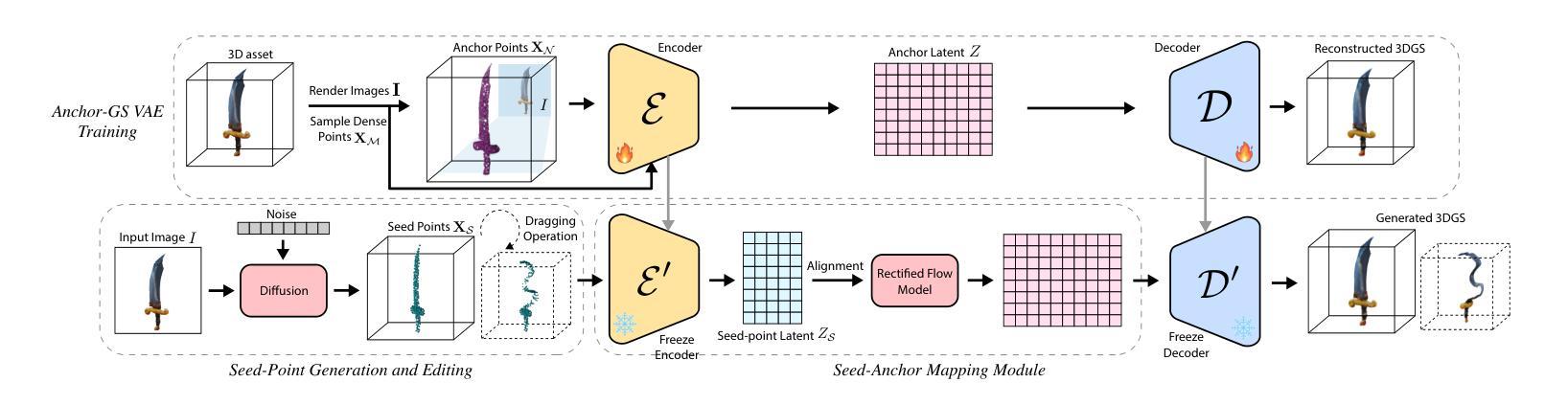
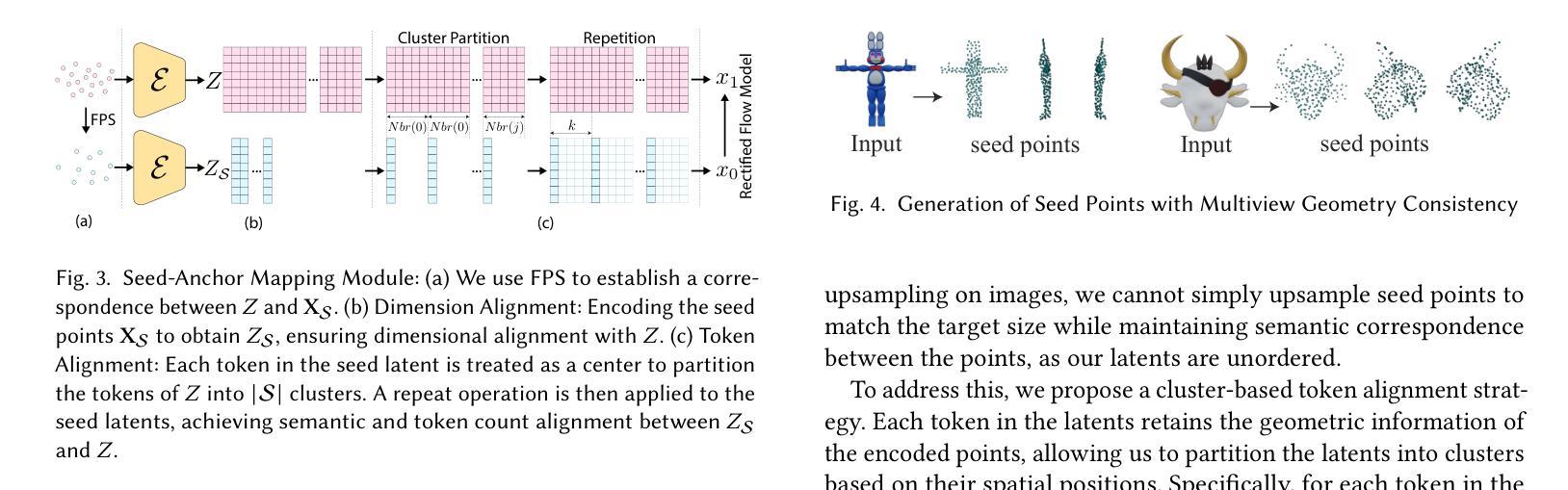
Single-image 3D generation has emerged as a prominent research topic, playing a vital role in virtual reality, 3D modeling, and digital content creation. However, existing methods face challenges such as a lack of multi-view geometric consistency and limited controllability during the generation process, which significantly restrict their usability. % To tackle these challenges, we introduce Dragen3D, a novel approach that achieves geometrically consistent and controllable 3D generation leveraging 3D Gaussian Splatting (3DGS). We introduce the Anchor-Gaussian Variational Autoencoder (Anchor-GS VAE), which encodes a point cloud and a single image into anchor latents and decode these latents into 3DGS, enabling efficient latent-space generation. To enable multi-view geometry consistent and controllable generation, we propose a Seed-Point-Driven strategy: first generate sparse seed points as a coarse geometry representation, then map them to anchor latents via the Seed-Anchor Mapping Module. Geometric consistency is ensured by the easily learned sparse seed points, and users can intuitively drag the seed points to deform the final 3DGS geometry, with changes propagated through the anchor latents. To the best of our knowledge, we are the first to achieve geometrically controllable 3D Gaussian generation and editing without relying on 2D diffusion priors, delivering comparable 3D generation quality to state-of-the-art methods.
单图像3D生成已成为一个突出的研究主题,在虚拟现实、3D建模和数字内容创建中发挥着至关重要的作用。然而,现有方法面临缺乏多视角几何一致性和生成过程中可控性有限的挑战,这显著限制了其可用性。为了解决这些挑战,我们引入了Dragen3D,这是一种利用3D高斯拼贴(3DGS)实现几何一致性和可控性的3D生成新方法。我们引入了锚点高斯变分自编码器(Anchor-GS VAE),它将点云和单图像编码为锚点潜在空间,并将这些潜在空间解码为3DGS,从而实现高效的潜在空间生成。为了实现多视角几何一致性和可控性生成,我们提出了种子点驱动策略:首先生成稀疏种子点作为粗略的几何表示,然后通过种子点锚映射模块将它们映射到锚点潜在空间。几何一致性由易于学习的稀疏种子点保证,用户可以直接拖动种子点来变形最终的3DGS几何形状,变化会通过锚点潜在空间进行传播。据我们所知,我们是第一个在不依赖2D扩散先验的情况下实现几何可控的3D高斯生成和编辑的团队,提供了与最新技术相当的3D生成质量。
论文及项目相关链接
Summary
单视角图像三维重建技术已成为研究热点,在虚拟现实、三维建模和数字内容创建等领域具有广泛应用价值。然而,现有方法面临缺乏多视角几何一致性以及生成过程中可控性有限等挑战。针对这些挑战,本文提出一种基于三维高斯拼贴(3DGS)的几何一致性和可控性三维重建新方法——Dragen3D。通过引入锚点高斯变分自编码器(Anchor-GS VAE),将点云和单视角图像编码为锚点潜在空间,再解码为三维高斯拼贴。为实现多视角几何一致性和可控性生成,本文采用种子点驱动策略:首先生成稀疏种子点作为粗略几何表示,然后通过种子点映射模块将其映射到锚点潜在空间。通过易于学习的稀疏种子点确保几何一致性,用户可直观拖动种子点改变最终的三维高斯拼贴几何形状,变化将通过锚点潜在空间传播。据我们所知,本文首次实现了无需依赖二维扩散先验的几何可控三维高斯生成和编辑,提供了与最新技术相当的三维生成质量。
Key Takeaways
- 单视角图像三维重建技术的重要性和挑战。
- Dragen3D方法利用三维高斯拼贴(3DGS)解决现有问题。
- 引入锚点高斯变分自编码器(Anchor-GS VAE)实现高效潜在空间生成。
- 采用种子点驱动策略实现多视角几何一致性和可控性生成。
- 稀疏种子点用于确保几何一致性,并支持直观编辑。
- 该方法实现了几何可控的三维高斯生成和编辑,无需依赖二维扩散先验。
点此查看论文截图

Pointmap Association and Piecewise-Plane Constraint for Consistent and Compact 3D Gaussian Segmentation Field
Authors:Wenhao Hu, Wenhao Chai, Shengyu Hao, Xiaotong Cui, Xuexiang Wen, Jenq-Neng Hwang, Gaoang Wang
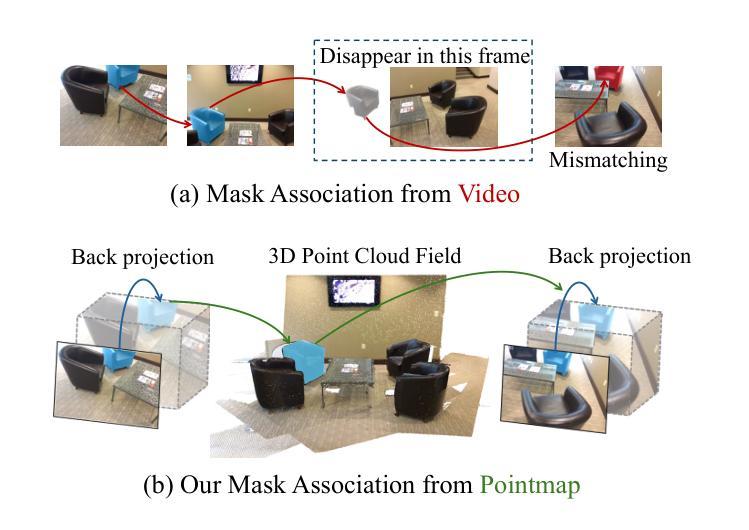
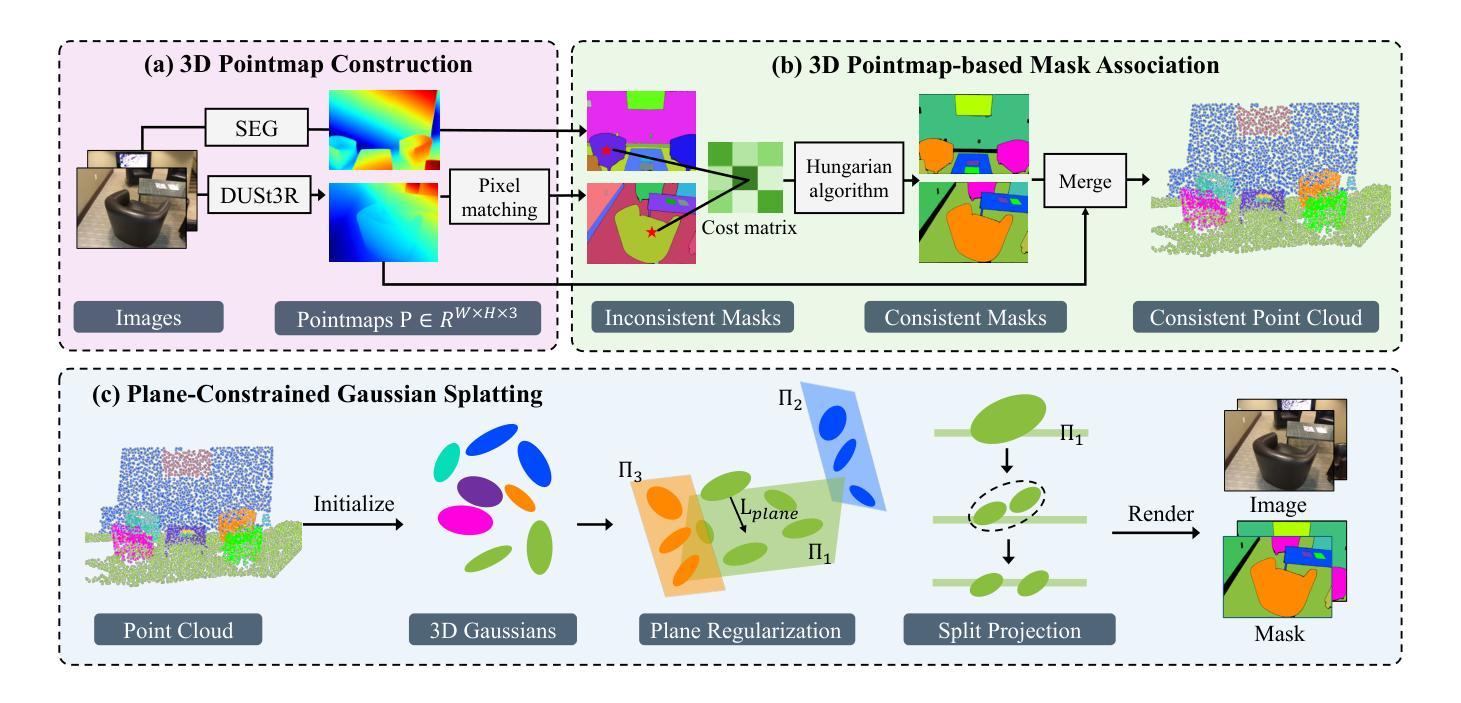
Achieving a consistent and compact 3D segmentation field is crucial for maintaining semantic coherence across views and accurately representing scene structures. Previous 3D scene segmentation methods rely on video segmentation models to address inconsistencies across views, but the absence of spatial information often leads to object misassociation when object temporarily disappear and reappear. Furthermore, in the process of 3D scene reconstruction, segmentation and optimization are often treated as separate tasks. As a result, optimization typically lacks awareness of semantic category information, which can result in floaters with ambiguous segmentation. To address these challenges, we introduce CCGS, a method designed to achieve both view consistent 2D segmentation and a compact 3D Gaussian segmentation field. CCGS incorporates pointmap association and a piecewise-plane constraint. First, we establish pixel correspondence between adjacent images by minimizing the Euclidean distance between their pointmaps. We then redefine object mask overlap accordingly. The Hungarian algorithm is employed to optimize mask association by minimizing the total matching cost, while allowing for partial matches. To further enhance compactness, the piecewise-plane constraint restricts point displacement within local planes during optimization, thereby preserving structural integrity. Experimental results on ScanNet and Replica datasets demonstrate that CCGS outperforms existing methods in both 2D panoptic segmentation and 3D Gaussian segmentation.
实现一致且紧凑的3D分割场对于保持跨视图的语义连贯性并准确表示场景结构至关重要。以往的3D场景分割方法依赖于视频分割模型来解决跨视图的不一致性,但对象暂时消失并重新出现时,缺乏空间信息往往会导致对象误关联。此外,在3D场景重建过程中,分割和优化通常被视为单独的任务。因此,优化通常缺乏语义类别信息的意识,这可能导致具有模糊分割的浮动对象。为了解决这些挑战,我们引入了CCGS方法,它旨在实现跨视图一致的2D分割和紧凑的3D高斯分割场。CCGS结合了点图关联和分段平面约束。首先,我们通过最小化点图之间的欧几里得距离来建立相邻图像之间的像素对应关系。然后,我们相应地重新定义对象掩模重叠。采用匈牙利算法优化掩模关联,通过最小化总匹配成本来实现优化,同时允许部分匹配。为了进一步提高紧凑性,分段平面约束在优化过程中限制了点在局部平面内的位移,从而保持了结构的完整性。在ScanNet和Replica数据集上的实验结果表明,CCGS在2D全景分割和3D高斯分割方面都优于现有方法。
论文及项目相关链接
Summary
该文本提出一种解决3D场景分割的新方法CCGS,通过引入点云映射关联与分段平面约束技术,实现了视角一致的2D分割与紧凑的3D高斯分割场。此方法能够解决传统方法中因缺少空间信息导致的对象误关联问题,以及在场景重建过程中优化与语义类别信息脱节的问题。实验结果表明,CCGS在ScanNet和Replica数据集上的表现优于现有方法。
Key Takeaways
- 实现视角一致的3D分割场对于维持语义连贯性和准确表示场景结构至关重要。
- 以往方法依赖视频分割模型解决视角不一致问题,但缺乏空间信息导致对象暂时消失和重新出现时发生对象误关联。
- CCGS方法通过引入点云映射关联技术,建立相邻图像间的像素对应关系,优化对象掩膜关联。
- CCGS采用分段平面约束技术,优化过程中限制点在局部平面内的位移,保持结构完整性。
- CCGS方法实现了紧凑的3D高斯分割场,提高了场景分割的效果。
- 实验结果表明,CCGS在ScanNet和Replica数据集上的表现优于现有方法,具有更高的准确性和鲁棒性。
点此查看论文截图

Para-Lane: Multi-Lane Dataset Registering Parallel Scans for Benchmarking Novel View Synthesis
Authors:Ziqian Ni, Sicong Du, Zhenghua Hou, Chenming Wu, Sheng Yang
To evaluate end-to-end autonomous driving systems, a simulation environment based on Novel View Synthesis (NVS) techniques is essential, which synthesizes photo-realistic images and point clouds from previously recorded sequences under new vehicle poses, particularly in cross-lane scenarios. Therefore, the development of a multi-lane dataset and benchmark is necessary. While recent synthetic scene-based NVS datasets have been prepared for cross-lane benchmarking, they still lack the realism of captured images and point clouds. To further assess the performance of existing methods based on NeRF and 3DGS, we present the first multi-lane dataset registering parallel scans specifically for novel driving view synthesis dataset derived from real-world scans, comprising 25 groups of associated sequences, including 16,000 front-view images, 64,000 surround-view images, and 16,000 LiDAR frames. All frames are labeled to differentiate moving objects from static elements. Using this dataset, we evaluate the performance of existing approaches in various testing scenarios at different lanes and distances. Additionally, our method provides the solution for solving and assessing the quality of multi-sensor poses for multi-modal data alignment for curating such a dataset in real-world. We plan to continually add new sequences to test the generalization of existing methods across different scenarios. The dataset is released publicly at the project page: https://nizqleo.github.io/paralane-dataset/.
为了评估端到端的自动驾驶系统,基于新型视图合成(NVS)技术的模拟环境至关重要。该技术能从新的车辆姿态下对先前记录的序列合成逼真的图像和点云,特别是在跨车道场景中。因此,开发多车道数据集和基准测试是必要的。尽管最近为跨车道基准测试准备了基于合成场景的NVS数据集,但它们仍然缺乏捕获图像和点云的逼真性。为了进一步评估基于NeRF和3DGS的现有方法的性能,我们首次推出了多车道数据集,专门注册平行扫描用于新型驾驶视图合成数据集,该数据集源自真实世界扫描,包含25组相关序列,包括1.6万张前视图像、6.4万张环视图像和1.6万张激光雷达帧。所有帧都进行了标注,以区分移动物体和静态元素。使用该数据集,我们在不同车道和距离的各种测试场景中评估了现有方法的性能。此外,我们的方法提供了解决和评估多传感器姿态质量的解决方案,用于此类数据集的多元数据对齐。我们计划不断添加新的序列,以测试不同场景下的现有方法的泛化能力。数据集已在项目页面公开发布:https://nizqleo.github.io/paralane-dataset/。
论文及项目相关链接
PDF Accepted by International Conference on 3D Vision (3DV) 2025
Summary
本文介绍了一个基于Novel View Synthesis(NVS)技术的模拟环境,用于评估端到端的自动驾驶系统。该环境合成逼真的图像和点云,用于跨车道场景下的自动驾驶系统评估。为进一步提高现有方法(基于NeRF和3DGS)的评估性能,提出了一种新的多车道数据集注册并行扫描的新型驾驶视图合成数据集。该数据集包含来自真实世界扫描的关联序列,包括标注的移动物体和静态元素。数据集公开可供使用,以促进自动驾驶系统的评估和比较。
Key Takeaways
- 该文本介绍了一种基于NVS技术的模拟环境在评估端到端自动驾驶系统的重要性。
- 此环境可以合成逼真的图像和点云,以模拟不同车道的场景。
- 目前虽然存在基于合成场景的NVS数据集,但它们缺乏真实图像的逼真性。
- 提出了一种新型的多车道数据集,该数据集由真实世界扫描得来,包含标注的移动物体和静态元素,专门用于驾驶视图合成。
- 数据集包含多种测试场景和不同车道、距离的数据,旨在评估现有方法的性能。
- 该方法解决了多传感器姿态的质量问题,为这样的数据集实现了多模态数据对齐。
点此查看论文截图

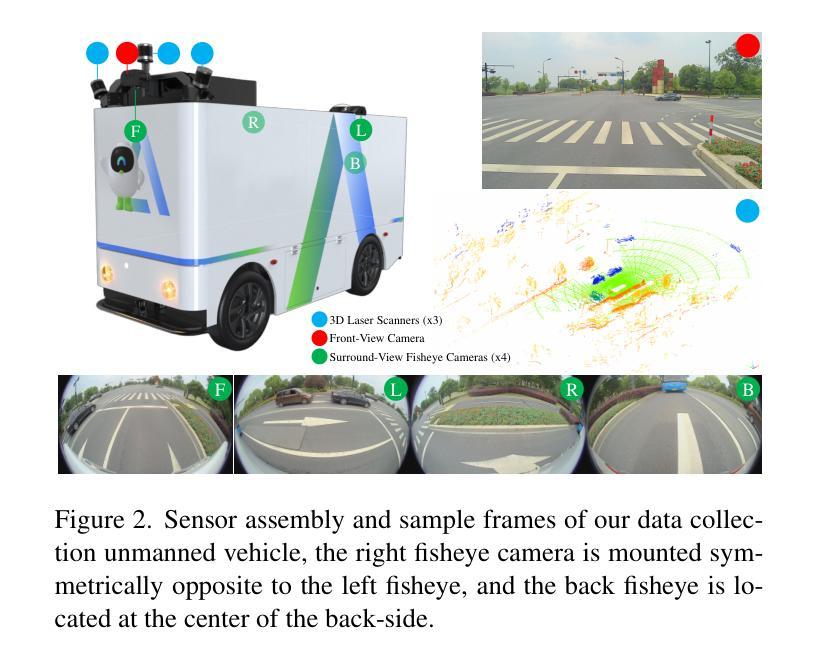
RGB-Only Gaussian Splatting SLAM for Unbounded Outdoor Scenes
Authors:Sicheng Yu, Chong Cheng, Yifan Zhou, Xiaojun Yang, Hao Wang
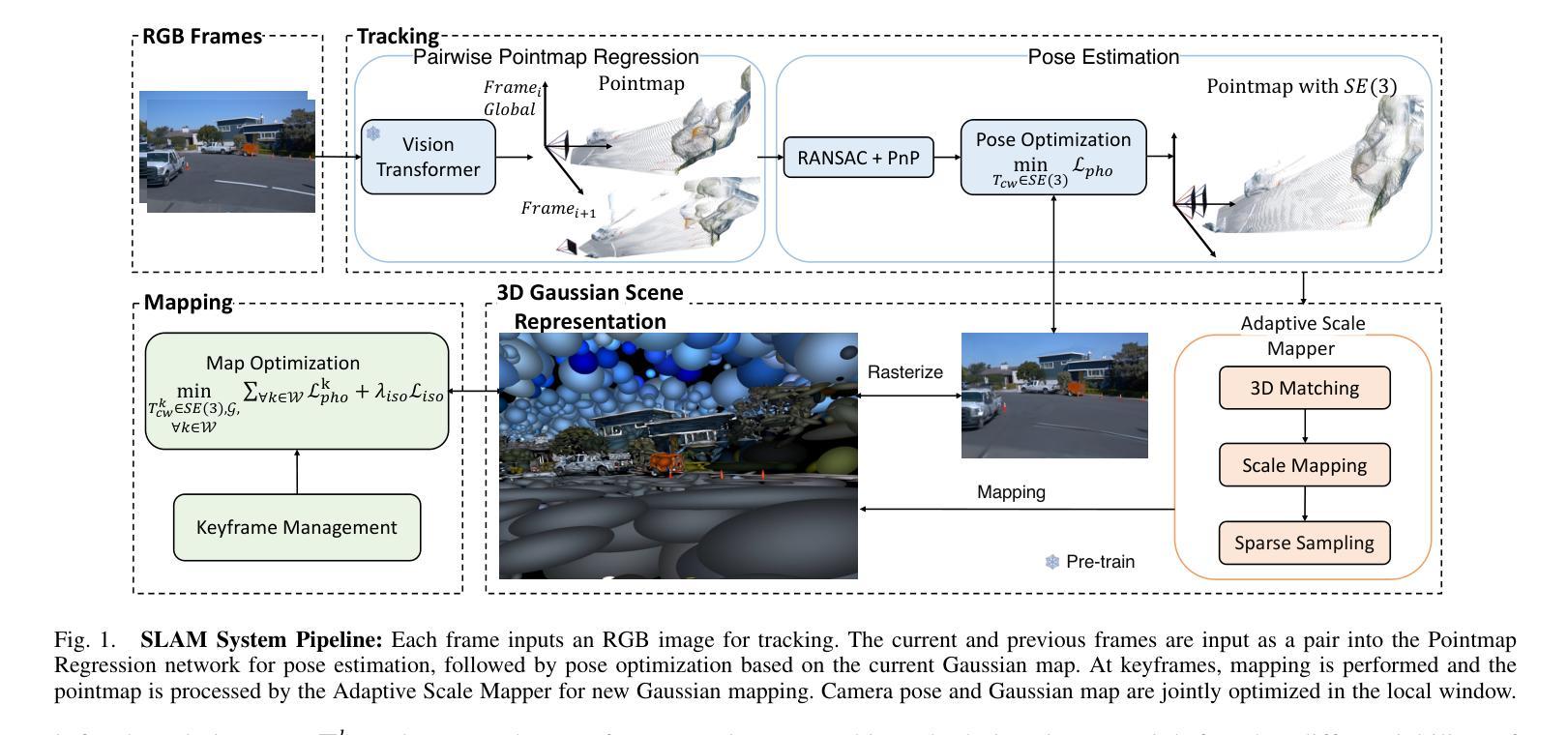
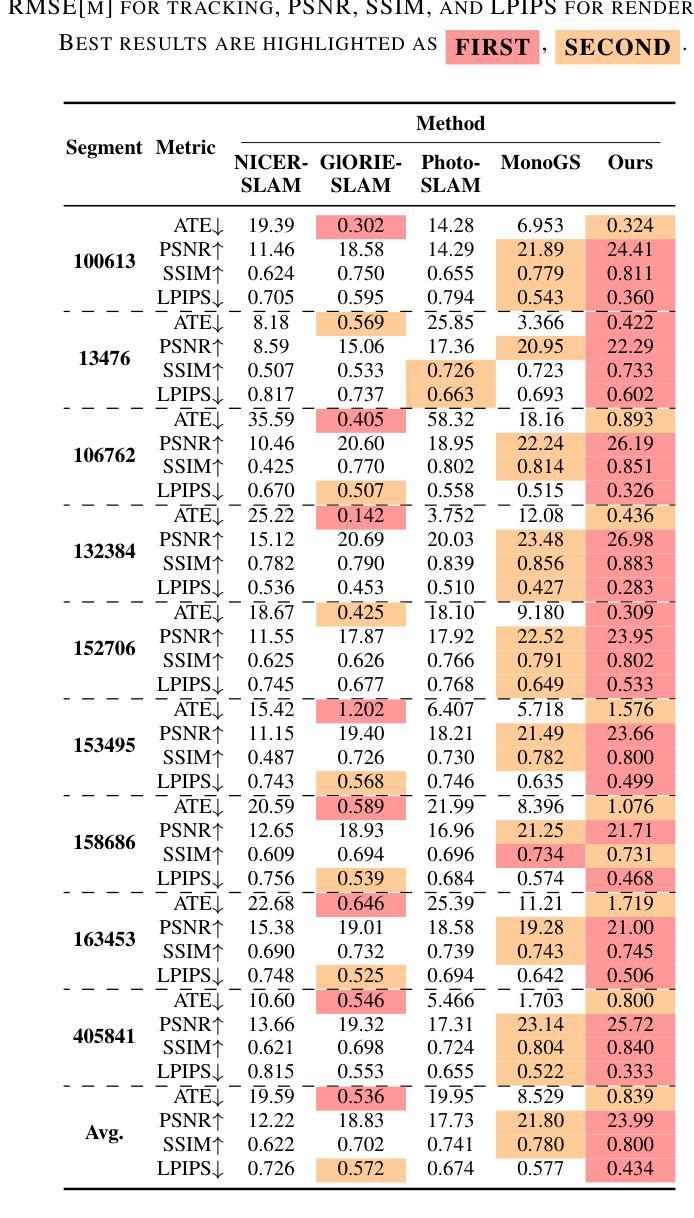
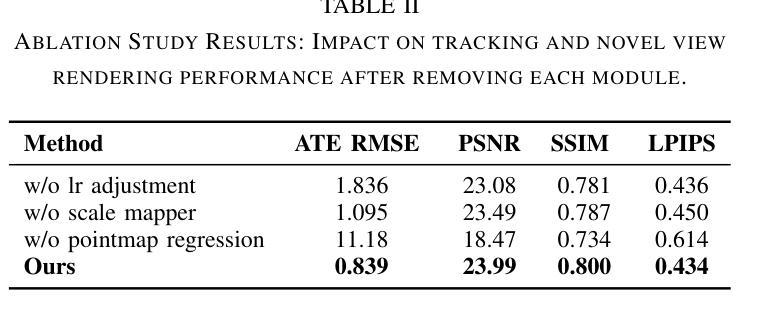
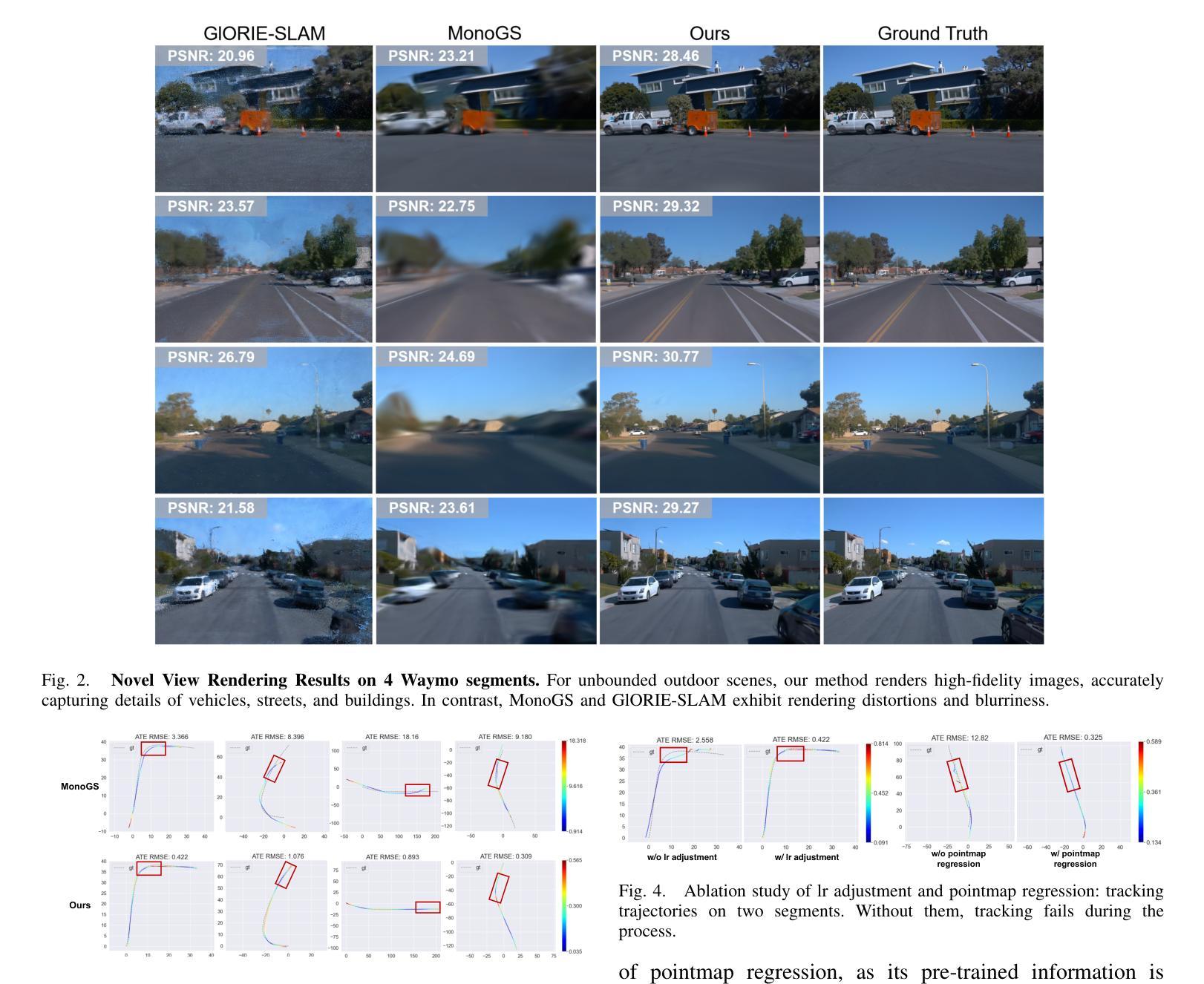
3D Gaussian Splatting (3DGS) has become a popular solution in SLAM, as it can produce high-fidelity novel views. However, previous GS-based methods primarily target indoor scenes and rely on RGB-D sensors or pre-trained depth estimation models, hence underperforming in outdoor scenarios. To address this issue, we propose a RGB-only gaussian splatting SLAM method for unbounded outdoor scenes–OpenGS-SLAM. Technically, we first employ a pointmap regression network to generate consistent pointmaps between frames for pose estimation. Compared to commonly used depth maps, pointmaps include spatial relationships and scene geometry across multiple views, enabling robust camera pose estimation. Then, we propose integrating the estimated camera poses with 3DGS rendering as an end-to-end differentiable pipeline. Our method achieves simultaneous optimization of camera poses and 3DGS scene parameters, significantly enhancing system tracking accuracy. Specifically, we also design an adaptive scale mapper for the pointmap regression network, which provides more accurate pointmap mapping to the 3DGS map representation. Our experiments on the Waymo dataset demonstrate that OpenGS-SLAM reduces tracking error to 9.8% of previous 3DGS methods, and achieves state-of-the-art results in novel view synthesis. Project Page: https://3dagentworld.github.io/opengs-slam/
3D Gaussian Splatting(3DGS)已经成为SLAM中的热门解决方案,因为它可以生成高保真度的新视图。然而,基于GS的先前方法主要针对室内场景,并依赖于RGB-D传感器或预训练的深度估计模型,因此在室外场景中的表现不佳。为了解决这一问题,我们提出了一种仅使用RGB的Gaussian Splatting SLAM方法,适用于无界限的室外场景——OpenGS-SLAM。
论文及项目相关链接
PDF ICRA 2025
Summary
本文介绍了针对户外场景提出的RGB-only高斯融合SLAM方法——OpenGS-SLAM。该方法通过点图回归网络生成连续帧之间的点图进行姿态估计,并整合估计的相机姿态与3DGS渲染,实现系统跟踪精度的显著提高。实验结果表明,OpenGS-SLAM在Waymo数据集上的跟踪误差较之前的3DGS方法降低了9.8%,并在新视角合成方面取得了最先进的成果。
Key Takeaways
- OpenGS-SLAM是一种针对户外场景的RGB-only高斯融合SLAM方法。
- 通过点图回归网络生成点图进行姿态估计,考虑空间关系和场景几何。
- 整合估计的相机姿态与3DGS渲染,实现系统跟踪精度的显著提高。
- 设计了自适应尺度映射器,为点图回归网络提供更准确的点图映射到3DGS地图表示。
- 在Waymo数据集上的实验表明,OpenGS-SLAM较之前的3DGS方法在跟踪误差上有所降低。
- OpenGS-SLAM在新视角合成方面取得了最先进的成果。
点此查看论文截图

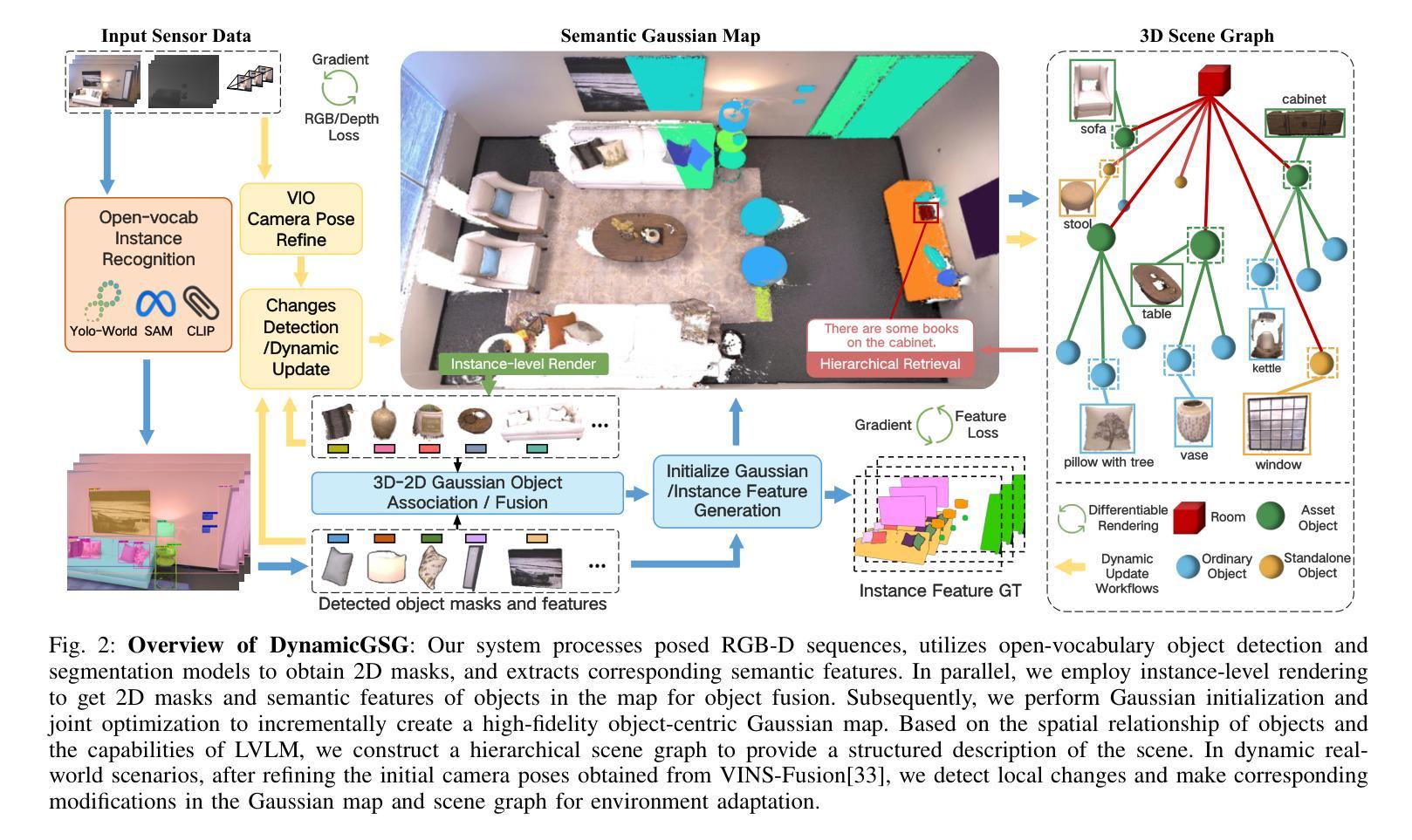
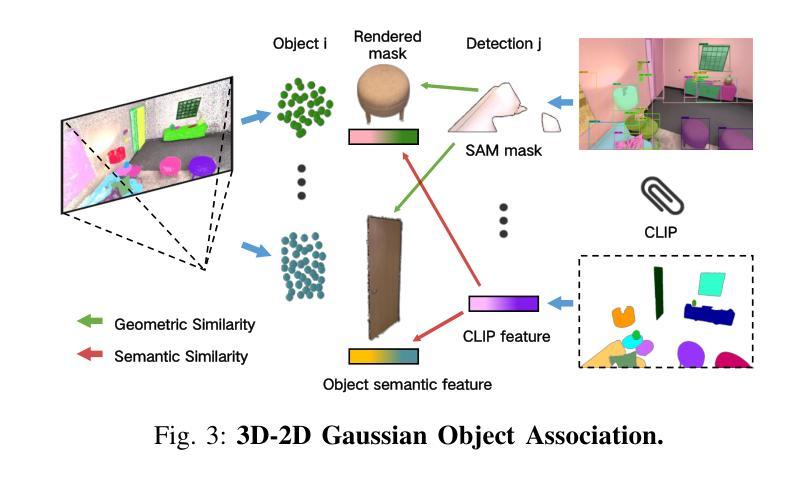
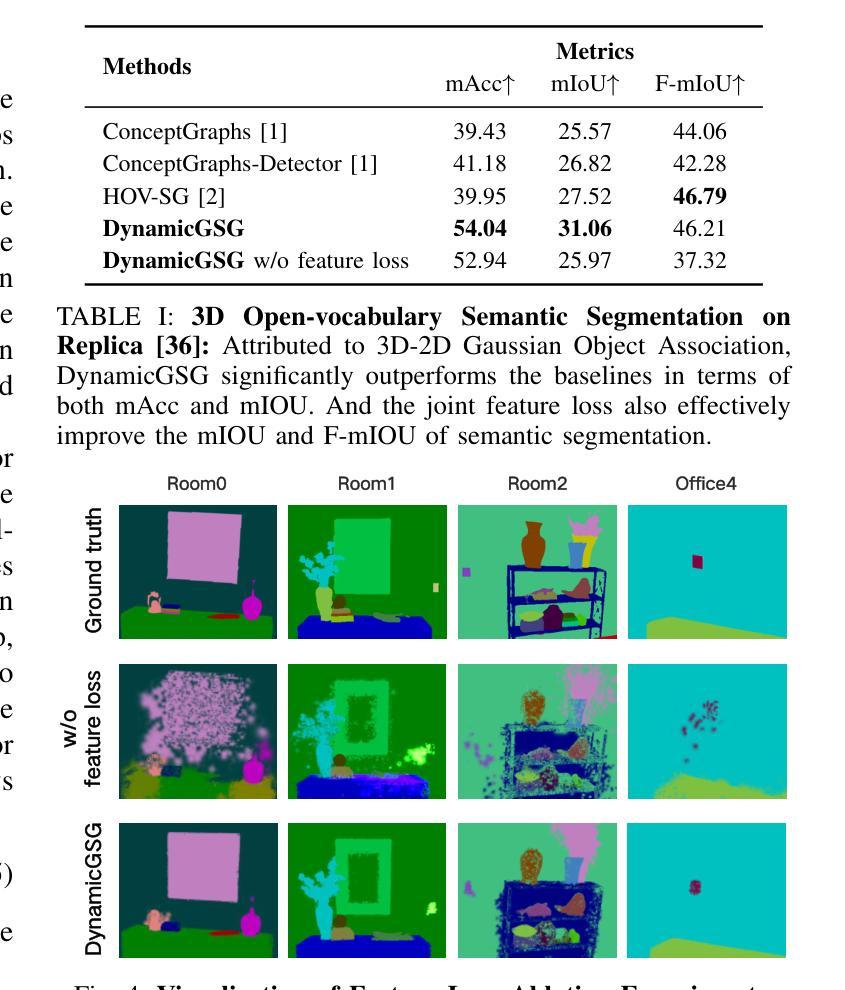
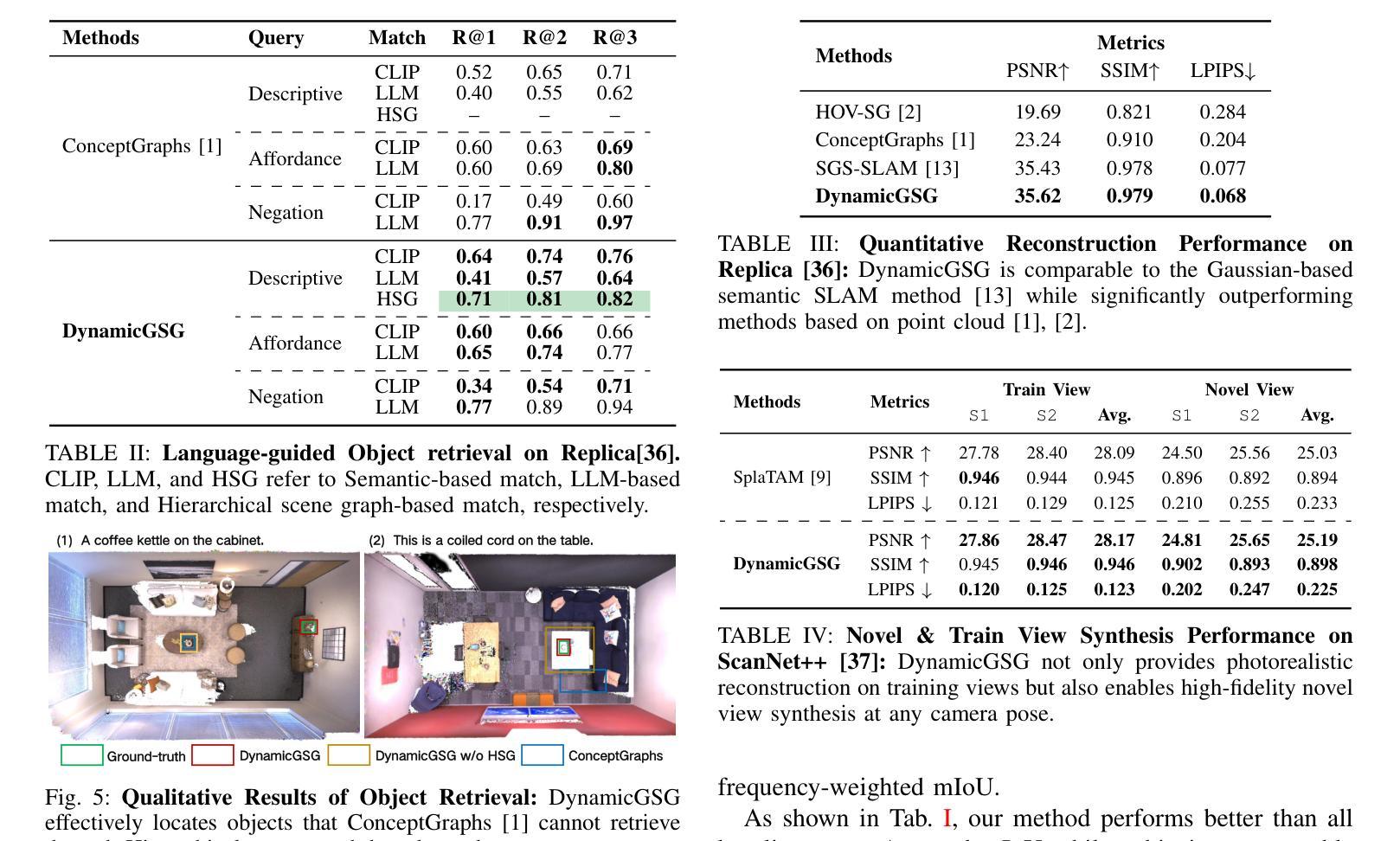
DynamicGSG: Dynamic 3D Gaussian Scene Graphs for Environment Adaptation
Authors:Luzhou Ge, Xiangyu Zhu, Zhuo Yang, Xuesong Li
In real-world scenarios, environment changes caused by human or agent activities make it extremely challenging for robots to perform various long-term tasks. Recent works typically struggle to effectively understand and adapt to dynamic environments due to the inability to update their environment representations in memory according to environment changes and lack of fine-grained reconstruction of the environments. To address these challenges, we propose DynamicGSG, a dynamic, high-fidelity, open-vocabulary scene graph construction system leveraging Gaussian splatting. DynamicGSG builds hierarchical scene graphs using advanced vision language models to represent the spatial and semantic relationships between objects in the environments, utilizes a joint feature loss we designed to supervise Gaussian instance grouping while optimizing the Gaussian maps, and locally updates the Gaussian scene graphs according to real environment changes for long-term environment adaptation. Experiments and ablation studies demonstrate the performance and efficacy of our proposed method in terms of semantic segmentation, language-guided object retrieval, and reconstruction quality. Furthermore, we validate the dynamic updating capabilities of our system in real laboratory environments. The source code and supplementary experimental materials will be released at:~\href{https://github.com/GeLuzhou/Dynamic-GSG}{https://github.com/GeLuzhou/Dynamic-GSG}.
在真实场景中,由于人类或代理活动引起的环境变化使得机器人执行各种长期任务极具挑战性。近期的工作往往难以有效地理解和适应动态环境,因为它们无法根据环境变化更新内存中的环境表示,并且缺乏对环境的精细粒度重建。为了解决这些挑战,我们提出了DynamicGSG,这是一个利用高斯涂抹技术的动态、高保真、开放词汇场景图构建系统。DynamicGSG使用先进的视觉语言模型构建层次场景图,表示环境中对象之间的空间和语义关系,利用我们设计的联合特征损失来监督高斯实例分组,同时优化高斯地图,并根据真实的环境变化局部更新高斯场景图,以实现长期环境适应。实验和消融研究证明了我们在语义分割、语言引导的对象检索和重建质量方面所提出方法的性能和效果。此外,我们在真实的实验室环境中验证了系统的动态更新能力。源代码和补充实验材料将在https://github.com/GeLuzhou/Dynamic-GSG发布。
论文及项目相关链接
Summary
针对现实世界中人类或代理活动引起的环境变化,机器人执行长期任务面临巨大挑战。近期研究通常因无法根据环境变化更新内存中的环境表示以及缺乏环境的精细重建,而无法有效理解和适应动态环境。为解决这些问题,提出DynamicGSG系统,利用高斯喷射技术构建动态、高保真、开放词汇场景图。该系统利用先进的视觉语言模型建立环境物体间的空间与语义关系,设计联合特征损失以监督高斯实例分组并优化高斯图,根据真实环境变化局部更新高斯场景图,实现长期环境适应。实验和消融研究证明该方法在语义分割、语言引导目标检索和重建质量方面的性能和效果。
Key Takeaways
- 现实世界中,环境变化对机器人执行长期任务构成挑战。
- 近期研究在理解和适应动态环境方面存在困难,主要原因包括无法更新环境表示和缺乏精细重建。
- DynamicGSG系统利用高斯喷射技术构建场景图,实现动态、高保真表示。
- 该系统利用视觉语言模型表现物体间的空间与语义关系。
- 通过设计的联合特征损失监督高斯实例分组并优化高斯图。
- DynamicGSG能根据实际环境变化局部更新场景图,实现长期环境适应。
- 实验和消融研究证明该系统在语义分割、语言引导目标检索和重建质量方面的优越性。
点此查看论文截图

Hier-SLAM++: Neuro-Symbolic Semantic SLAM with a Hierarchically Categorical Gaussian Splatting
Authors:Boying Li, Vuong Chi Hao, Peter J. Stuckey, Ian Reid, Hamid Rezatofighi
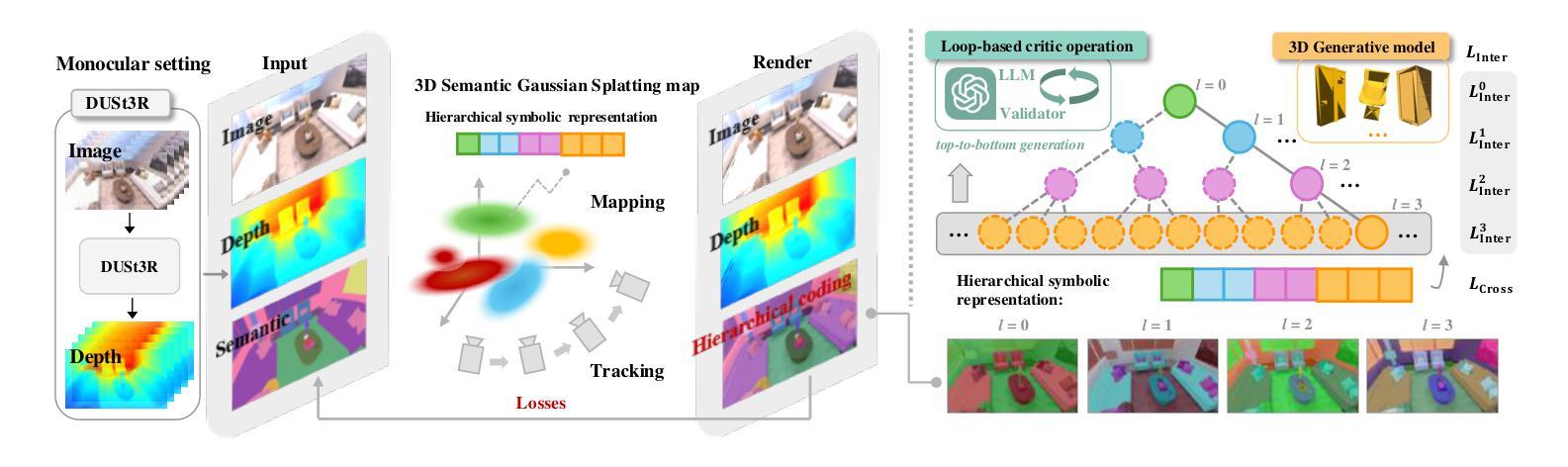
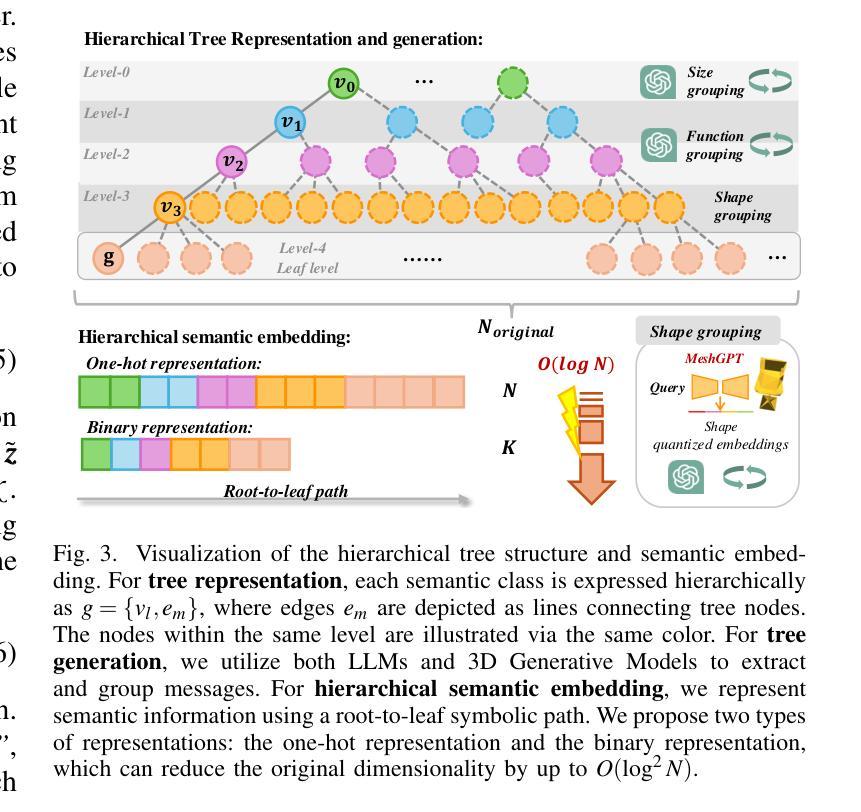
We propose Hier-SLAM++, a comprehensive Neuro-Symbolic semantic 3D Gaussian Splatting SLAM method with both RGB-D and monocular input featuring an advanced hierarchical categorical representation, which enables accurate pose estimation as well as global 3D semantic mapping. The parameter usage in semantic SLAM systems increases significantly with the growing complexity of the environment, making scene understanding particularly challenging and costly. To address this problem, we introduce a novel and general hierarchical representation that encodes both semantic and geometric information in a compact form into 3D Gaussian Splatting, leveraging the capabilities of large language models (LLMs) as well as the 3D generative model. By utilizing the proposed hierarchical tree structure, semantic information is symbolically represented and learned in an end-to-end manner. We further introduce a novel semantic loss designed to optimize hierarchical semantic information through both inter-level and cross-level optimization. Additionally, we propose an improved SLAM system to support both RGB-D and monocular inputs using a feed-forward model. To the best of our knowledge, this is the first semantic monocular Gaussian Splatting SLAM system, significantly reducing sensor requirements for 3D semantic understanding and broadening the applicability of semantic Gaussian SLAM system. We conduct experiments on both synthetic and real-world datasets, demonstrating superior or on-par performance with state-of-the-art NeRF-based and Gaussian-based SLAM systems, while significantly reducing storage and training time requirements.
我们提出了Hier-SLAM++方法,这是一种全面的神经符号语义3D高斯混合SLAM方法,它支持RGB-D和单目输入,并采用了高级分层类别表示,能够实现准确的姿态估计和全局3D语义映射。随着环境复杂性的增加,语义SLAM系统中的参数使用量也显著增加,这使得场景理解变得特别具有挑战性和成本高昂。为了解决这一问题,我们引入了一种新颖且通用的分层表示方法,它以紧凑的形式将语义和几何信息编码到3D高斯混合中,同时利用大型语言模型和3D生成模型的的能力。通过利用所提出的层次树结构,语义信息以符号方式表示并以端到端的方式进行学习。我们进一步引入了一种新型语义损失,旨在通过跨级别优化来优化分层语义信息。此外,我们提出了改进型的SLAM系统,支持RGB-D和单目输入,并使用前馈模型。据我们所知,这是第一个语义单目高斯混合SLAM系统,它大大降低了3D语义理解的传感器要求,并拓宽了语义高斯SLAM系统的应用范围。我们在合成和真实世界数据集上进行了实验,表现出与最新基于NeRF和高斯的方法相媲美甚至更优越的性能,同时大大降低了存储和训练时间要求。
论文及项目相关链接
PDF 15 pages. Under review
Summary
本文提出了Hier-SLAM++方法,这是一种全面的神经符号语义3D高斯喷涂SLAM方法,支持RGB-D和单目输入,具有先进分层类别表示。该方法通过结合语义和几何信息,利用大型语言模型和3D生成模型的潜力,实现了准确姿态估计和全局3D语义映射。此外,引入了一种新型的语义损失,通过跨级别优化来优化层次语义信息。实验表明,该方法在合成和真实数据集上均表现出卓越或相当的性能,同时显著降低了存储和训练时间要求。
Key Takeaways
- Hier-SLAM++是一种全面的神经符号语义3D高斯喷涂SLAM方法,支持RGB-D和单目输入。
- 引入了一种先进的分层类别表示,结合语义和几何信息。
- 利用大型语言模型和3D生成模型的潜力,实现准确姿态估计和全局3D语义映射。
- 提出了一种新型的语义损失,通过跨级别优化层次语义信息。
- Hier-SLAM++能够实现层次化语义信息的符号表示和学习。
- 实验表明,该方法在合成和真实数据集上的性能卓越,与基于NeRF和高斯的方法相比具有竞争力。
点此查看论文截图

Sparse Voxels Rasterization: Real-time High-fidelity Radiance Field Rendering
Authors:Cheng Sun, Jaesung Choe, Charles Loop, Wei-Chiu Ma, Yu-Chiang Frank Wang
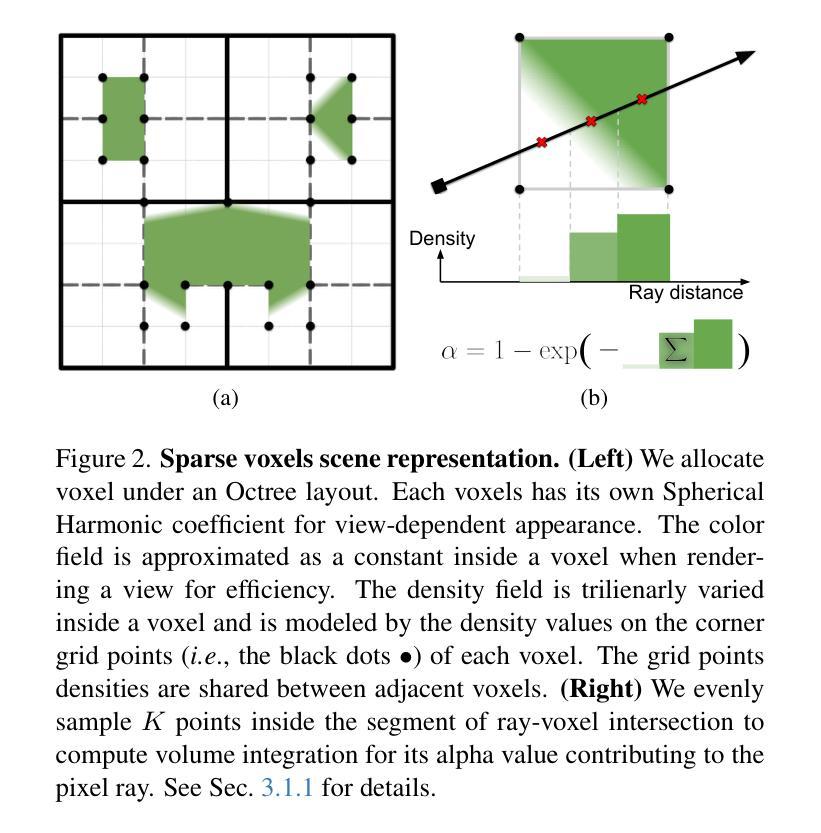
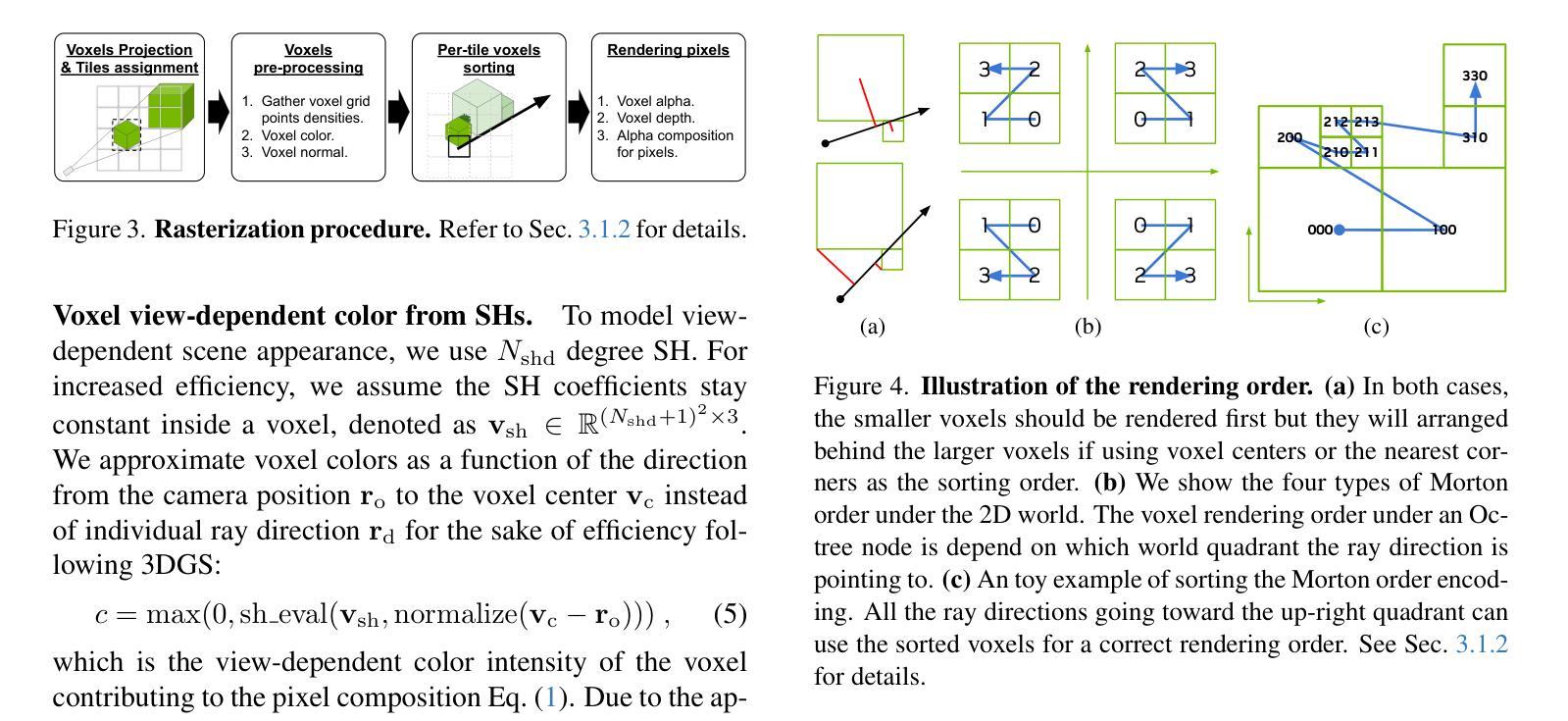
We propose an efficient radiance field rendering algorithm that incorporates a rasterization process on adaptive sparse voxels without neural networks or 3D Gaussians. There are two key contributions coupled with the proposed system. The first is to adaptively and explicitly allocate sparse voxels to different levels of detail within scenes, faithfully reproducing scene details with $65536^3$ grid resolution while achieving high rendering frame rates. Second, we customize a rasterizer for efficient adaptive sparse voxels rendering. We render voxels in the correct depth order by using ray direction-dependent Morton ordering, which avoids the well-known popping artifact found in Gaussian splatting. Our method improves the previous neural-free voxel model by over 4db PSNR and more than 10x FPS speedup, achieving state-of-the-art comparable novel-view synthesis results. Additionally, our voxel representation is seamlessly compatible with grid-based 3D processing techniques such as Volume Fusion, Voxel Pooling, and Marching Cubes, enabling a wide range of future extensions and applications.
我们提出了一种高效的辐射场渲染算法,该算法对自适应稀疏体素进行了栅格化处理,无需神经网络或3D高斯。该系统的关键贡献有两点。首先,我们自适应且明确地分配稀疏体素以呈现场景中的不同细节层次,以$65536^3$的网格分辨率忠实再现场景细节,同时实现高帧率渲染。其次,我们为自适应稀疏体素渲染定制了一个栅格化器。通过使用与射线方向相关的Morton排序,我们以正确的深度顺序呈现体素,这避免了高斯涂抹中出现的已知闪烁伪影。我们的方法改进了之前无神经元的体素模型,提高了超过4db的峰值信噪比(PSNR)和超过10倍的帧率加速,实现了与最新技术相当的新视角合成结果。此外,我们的体素表示与基于网格的3D处理技术(如体积融合、体素池化和魔方网)无缝兼容,为未来的扩展和应用提供了广泛的可能性。
论文及项目相关链接
PDF Project page at https://svraster.github.io/ Code at https://github.com/NVlabs/svraster
Summary
本文提出了一种高效的辐射场渲染算法,该算法对自适应稀疏体素进行了栅格化处理,无需神经网络或3D高斯。该系统有两项关键贡献:一是自适应显式分配稀疏体素以呈现场景中的不同细节层次,以$65536^3$网格分辨率忠实再现场景细节,同时实现高帧率渲染;二是为自适应稀疏体素渲染定制了栅格化器,通过采用与射线方向相关的Morton排序对体素进行正确的深度排序,避免了高斯溅射中的弹出伪影。该方法改进了之前的无神经网络体素模型,提高了4db PSNR以上,并实现了超过10倍FPS的加速,达到了与最新技术相当的新视角合成效果。此外,其体素表示与基于网格的3D处理技术(如体积融合、体素池化和行走立方体)无缝兼容,为未来扩展和应用提供了广泛的可能性。
Key Takeaways
- 提出了一个高效的辐射场渲染算法,结合了栅格化处理和自适应稀疏体素。
- 自适应分配稀疏体素以呈现不同细节层次,达到$65536^3$网格分辨率,同时保持高帧率渲染。
- 定制了栅格化器,对体素进行正确的深度排序,避免了弹出伪影。
- 改进了无神经网络体素模型,提高了渲染效果。
- 与最新技术相当的新视角合成效果。
- 体素表示与基于网格的3D处理技术兼容,为未来扩展提供了广泛的可能性。
点此查看论文截图


SplatOverflow: Asynchronous Hardware Troubleshooting
Authors:Amritansh Kwatra, Tobias Weinberg, Ilan Mandel, Ritik Batra, Peter He, Francois Guimbretiere, Thijs Roumen
As tools for designing and manufacturing hardware become more accessible, smaller producers can develop and distribute novel hardware. However, processes for supporting end-user hardware troubleshooting or routine maintenance aren’t well defined. As a result, providing technical support for hardware remains ad-hoc and challenging to scale. Inspired by patterns that helped scale software troubleshooting, we propose a workflow for asynchronous hardware troubleshooting: SplatOverflow. SplatOverflow creates a novel boundary object, the SplatOverflow scene, that users reference to communicate about hardware. A scene comprises a 3D Gaussian Splat of the user’s hardware registered onto the hardware’s CAD model. The splat captures the current state of the hardware, and the registered CAD model acts as a referential anchor for troubleshooting instructions. With SplatOverflow, remote maintainers can directly address issues and author instructions in the user’s workspace. Workflows containing multiple instructions can easily be shared between users and recontextualized in new environments. In this paper, we describe the design of SplatOverflow, the workflows it enables, and its utility to different kinds of users. We also validate that non-experts can use SplatOverflow to troubleshoot common problems with a 3D printer in a usability study. Project Page: https://amritkwatra.com/research/splatoverflow.
随着设计和制造硬件的工具越来越容易获取,小型生产商可以开发和分发新型硬件。然而,支持最终用户硬件故障排除或常规维护的流程并未得到很好的定义。因此,为硬件提供技术支持仍然是临时性的,并且难以扩展。受软件故障排除模式的启发,我们提出了一种异步硬件故障排除的工作流程:SplatOverflow。SplatOverflow创建了一个新的边界对象——SplatOverflow场景,用户参考该场景来交流硬件问题。一个场景包含了用户的硬件的3D高斯Splat,该Splat被注册到硬件的CAD模型上。Splat捕捉硬件的当前状态,而注册的CAD模型则作为故障排除指令的参考锚点。通过SplatOverflow,远程维护人员可以直接在用户的工作空间中解决问题并发布指令。包含多个指令的工作流程可以很容易地在用户之间共享,并在新的环境中重新上下文化。在本文中,我们介绍了SplatOverflow的设计、它使能的工作流程,以及它对不同类型用户的实用性。我们还通过一项可用性研究验证了非专家可以使用SplatOverflow来排除3D打印机的一般问题。项目页面:https://amritkwatra.com/research/splatoverflow。
论文及项目相关链接
PDF Our accompanying video figure is available at: https://youtu.be/rdtaUo2Lo38
Summary
随着设计与制造硬件的工具日益普及,小型生产商可开发并分发新型硬件。然而,支持终端用户硬件故障排除或常规维护的流程尚未明确,为硬件提供技术支持仍是临时性的,难以扩展。受软件故障排除模式的启发,提出一种异步硬件故障排除的工作流程:SplatOverflow。SplatOverflow创建了一种新型边界对象——SplatOverflow场景,用户可通过此场景交流硬件情况。场景包含用户硬件的3D高斯Splat,并注册到硬件的CAD模型上。Splat记录硬件的当前状态,注册的CAD模型则为故障排除说明提供参照锚点。借助SplatOverflow,远程维护人员可直接针对用户问题发表说明,并在用户工作空间中执行工作流。包含多个说明的工作流程可轻松在用户之间共享,并适应新环境。本文介绍了SplatOverflow的设计、其支持的工作流程以及其对不同类型用户的实用性。同时,通过一项可用性研究验证了非专家使用SplatOverflow对3D打印机进行故障排除的可行性。
Key Takeaways
- 较小生产商可借助日益普及的设计工具开发新型硬件。
- 目前硬件技术支持存在挑战,如故障排除和常规维护流程不明确。
- SplatOverflow借鉴软件故障排除模式,提供一种异步硬件故障排除解决方案。
- SplatOverflow创建新型边界对象——SplatOverflow场景,用于用户间的硬件交流。
- 该系统结合3D高斯Splat和用户硬件的CAD模型,提供硬件状态的直观展示和参照。
- SplatOverflow允许远程维护人员直接参与用户问题处理,并在用户工作空间中执行工作流。
点此查看论文截图







GSORB-SLAM: Gaussian Splatting SLAM benefits from ORB features and Transmittance information
Authors:Wancai Zheng, Xinyi Yu, Jintao Rong, Linlin Ou, Yan Wei, Libo Zhou
The emergence of 3D Gaussian Splatting (3DGS) has recently ignited a renewed wave of research in dense visual SLAM. However, existing approaches encounter challenges, including sensitivity to artifacts and noise, suboptimal selection of training viewpoints, and the absence of global optimization. In this paper, we propose GSORB-SLAM, a dense SLAM framework that integrates 3DGS with ORB features through a tightly coupled optimization pipeline. To mitigate the effects of noise and artifacts, we propose a novel geometric representation and optimization method for tracking, which significantly enhances localization accuracy and robustness. For high-fidelity mapping, we develop an adaptive Gaussian expansion and regularization method that facilitates compact yet expressive scene modeling while suppressing redundant primitives. Furthermore, we design a hybrid graph-based viewpoint selection mechanism that effectively reduces overfitting and accelerates convergence. Extensive evaluations across various datasets demonstrate that our system achieves state-of-the-art performance in both tracking precision-improving RMSE by 16.2% compared to ORB-SLAM2 baselines-and reconstruction quality-improving PSNR by 3.93 dB compared to 3DGS-SLAM baselines. The project: https://aczheng-cai.github.io/gsorb-slam.github.io/
3D高斯贴图(3DGS)的出现,引发了密集视觉SLAM领域的新一轮研究热潮。然而,现有方法面临挑战,包括容易受到伪影和噪声的影响、训练视角选择不佳以及缺乏全局优化等。在本文中,我们提出了GSORB-SLAM,这是一个密集SLAM框架,它通过紧密耦合的优化管道将3DGS与ORB特征相结合。为了减轻噪声和伪影的影响,我们提出了一种新型的几何表示和优化方法用于跟踪,这显著提高了定位精度和稳健性。为了实现高保真映射,我们开发了一种自适应高斯扩展和正则化方法,便于紧凑而富有表现力的场景建模,同时抑制冗余基本元素。此外,我们设计了一种基于混合图的视角选择机制,有效地减少了过度拟合并加速了收敛。在各种数据集上的广泛评估表明,我们的系统在跟踪精度上实现了最新性能,与ORB-SLAM2基准相比,RMSE提高了16.2%,在重建质量上也实现了改进,与3DGS-SLAM基准相比,PSNR提高了3.93 dB。项目网址:[https://aczheng-cai.github.io/gsorb-slam.github.io/]
论文及项目相关链接
Summary
本文提出一种结合三维高斯喷射技术(3DGS)与ORB特征的密集SLAM框架——GSORB-SLAM。通过紧密耦合的优化管道,解决了噪声和伪影问题,提高了跟踪的准确性和鲁棒性。同时,通过自适应高斯扩展和正则化方法实现高保真度映射,并设计了一种基于混合图的视点选择机制,有效减少过拟合并加速收敛。评估结果表明,该系统在跟踪精度和重建质量方面达到最新技术水平。
Key Takeaways
- 引入三维高斯喷射技术(3DGS)于密集SLAM框架中,与ORB特征结合。
- 提出新型几何表示和优化方法,以提高跟踪的准确性和鲁棒性,并减少噪声和伪影的影响。
- 通过自适应高斯扩展和正则化方法实现紧凑而表现丰富的场景建模,同时抑制冗余元素。
- 设计基于混合图的视点选择机制,有效减少过拟合,加速收敛。
- 系统在多个数据集上的评估结果显示,跟踪精度和重建质量均达到最新技术水平。
- 系统性能相较于ORB-SLAM2基线提高了RMSE的16.2%,相较于3DGS-SLAM基线提高了PSNR的3.93dB。
点此查看论文截图


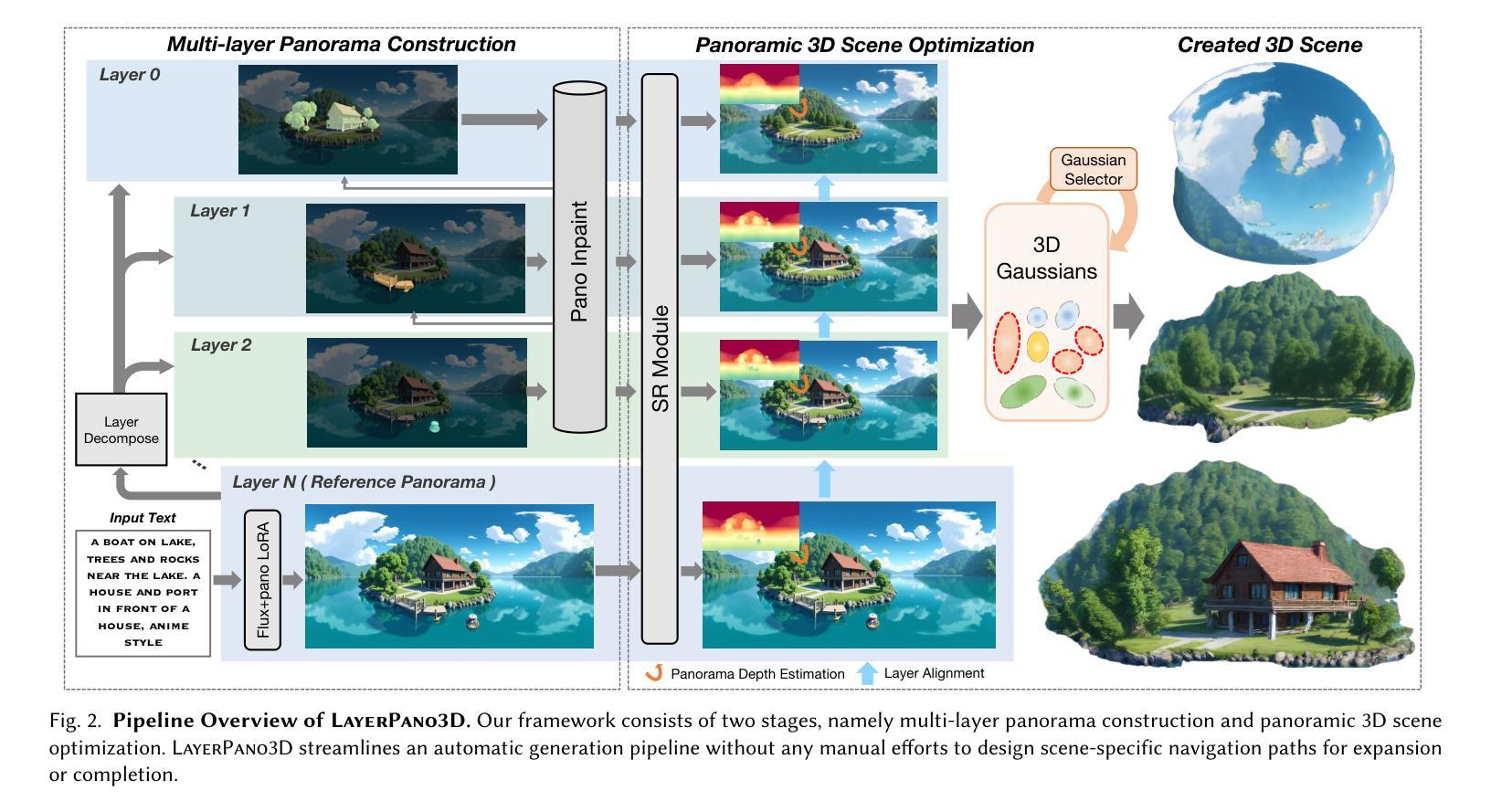
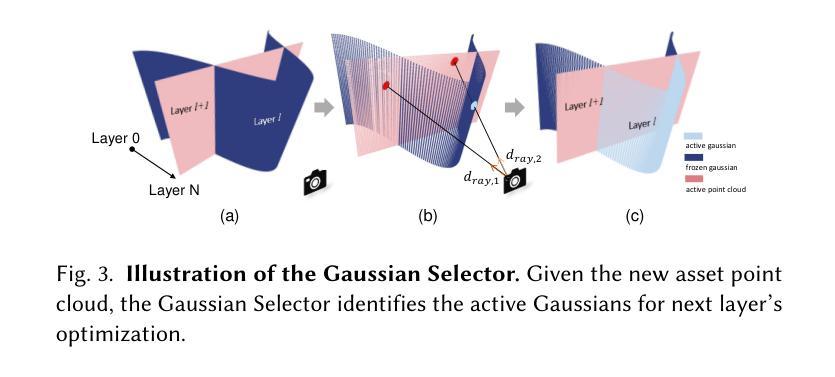
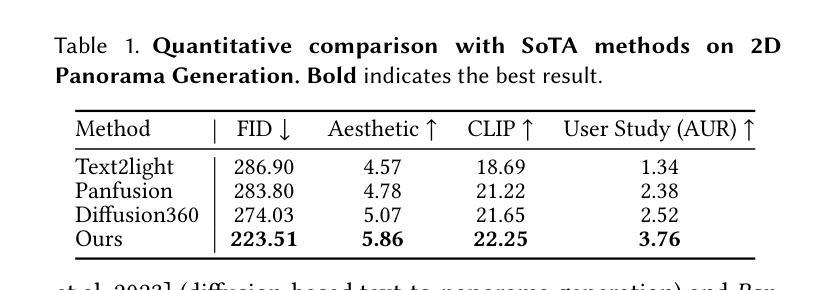
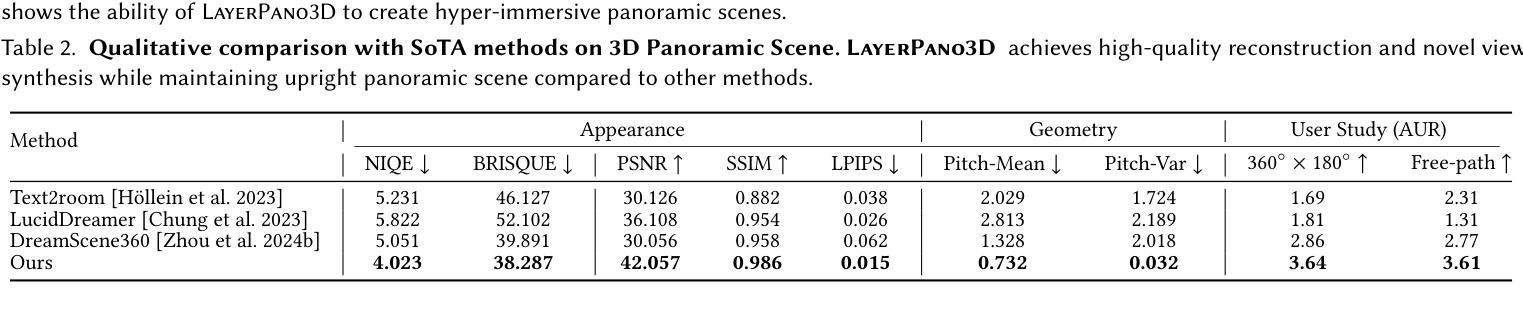
LayerPano3D: Layered 3D Panorama for Hyper-Immersive Scene Generation
Authors:Shuai Yang, Jing Tan, Mengchen Zhang, Tong Wu, Yixuan Li, Gordon Wetzstein, Ziwei Liu, Dahua Lin
3D immersive scene generation is a challenging yet critical task in computer vision and graphics. A desired virtual 3D scene should 1) exhibit omnidirectional view consistency, and 2) allow for free exploration in complex scene hierarchies. Existing methods either rely on successive scene expansion via inpainting or employ panorama representation to represent large FOV scene environments. However, the generated scene suffers from semantic drift during expansion and is unable to handle occlusion among scene hierarchies. To tackle these challenges, we introduce Layerpano3D, a novel framework for full-view, explorable panoramic 3D scene generation from a single text prompt. Our key insight is to decompose a reference 2D panorama into multiple layers at different depth levels, where each layer reveals the unseen space from the reference views via diffusion prior. Layerpano3D comprises multiple dedicated designs: 1) We introduce a new panorama dataset Upright360, comprising 9k high-quality and upright panorama images, and finetune the advanced Flux model on Upright360 for high-quality, upright and consistent panorama generation. 2) We pioneer the Layered 3D Panorama as underlying representation to manage complex scene hierarchies and lift it into 3D Gaussians to splat detailed 360-degree omnidirectional scenes with unconstrained viewing paths. Extensive experiments demonstrate that our framework generates state-of-the-art 3D panoramic scene in both full view consistency and immersive exploratory experience. We believe that Layerpano3D holds promise for advancing 3D panoramic scene creation with numerous applications.
3D沉浸式场景生成是计算机视觉和图形学中具有挑战性和重要性的任务。理想的虚拟3D场景应该1)表现出全方位的视图一致性,并且2)允许在复杂的场景层次结构中自由探索。现有方法要么依赖于通过插值进行的连续场景扩展,要么使用全景表示来表示大视场场景环境。然而,生成的场景在扩展过程中会出现语义漂移,并且无法处理场景层次结构之间的遮挡问题。为了应对这些挑战,我们引入了Layerpano3D,这是一种从单个文本提示生成全方位可探索全景3D场景的新框架。我们的关键见解是将参考的2D全景图分解成不同深度级别的多个图层,每个图层通过扩散先验从参考视图中揭示未见空间。Layerpano3D包含多个专用设计:1)我们引入了一个新的全景数据集Upright360,包含9k个高质量和直立全景图像,并在Upright360上对先进的Flux模型进行微调,以实现高质量、直立和一致的全景生成。2)我们首创分层3D全景图作为底层表示来管理复杂的场景层次结构,并将其提升到3D高斯函数,以描绘具有无约束观看路径的360度全方位场景。大量实验表明,我们的框架在全景一致性以及沉浸式探索体验方面都生成了最先进的3D全景场景。我们相信Layerpano3D在推进3D全景场景创建方面具有广阔的应用前景。
论文及项目相关链接
PDF Project page: https://ys-imtech.github.io/projects/LayerPano3D/
Summary
本文介绍了Layerpano3D框架,该框架解决了全景三维场景生成中的挑战性问题。通过分解参考全景图像为不同深度层次的多个图层,并采用扩散先验技术揭示未观察到的空间,实现了从单个文本提示生成全景三维场景。框架包括专门设计的高品质全景数据集Upright360和基于该数据集的先进Flux模型的微调。实验证明,该框架在全景一致性及沉浸式探索体验方面达到了业界领先水平,具有广泛的应用前景。
Key Takeaways
- Layerpano3D框架解决了全景三维场景生成中的挑战性问题。
- 通过分解全景图像为多个深度层次的图层,并采用扩散先验技术揭示未观察到的空间。
- 利用文本提示生成全景三维场景。
- Upright360数据集用于高质量全景图像生成。
- 采用先进Flux模型进行全景图像生成。
- Layerpano3D框架实现了全景一致性及沉浸式探索体验的全景三维场景生成。
点此查看论文截图


Rethinking Open-Vocabulary Segmentation of Radiance Fields in 3D Space
Authors:Hyunjee Lee, Youngsik Yun, Jeongmin Bae, Seoha Kim, Youngjung Uh
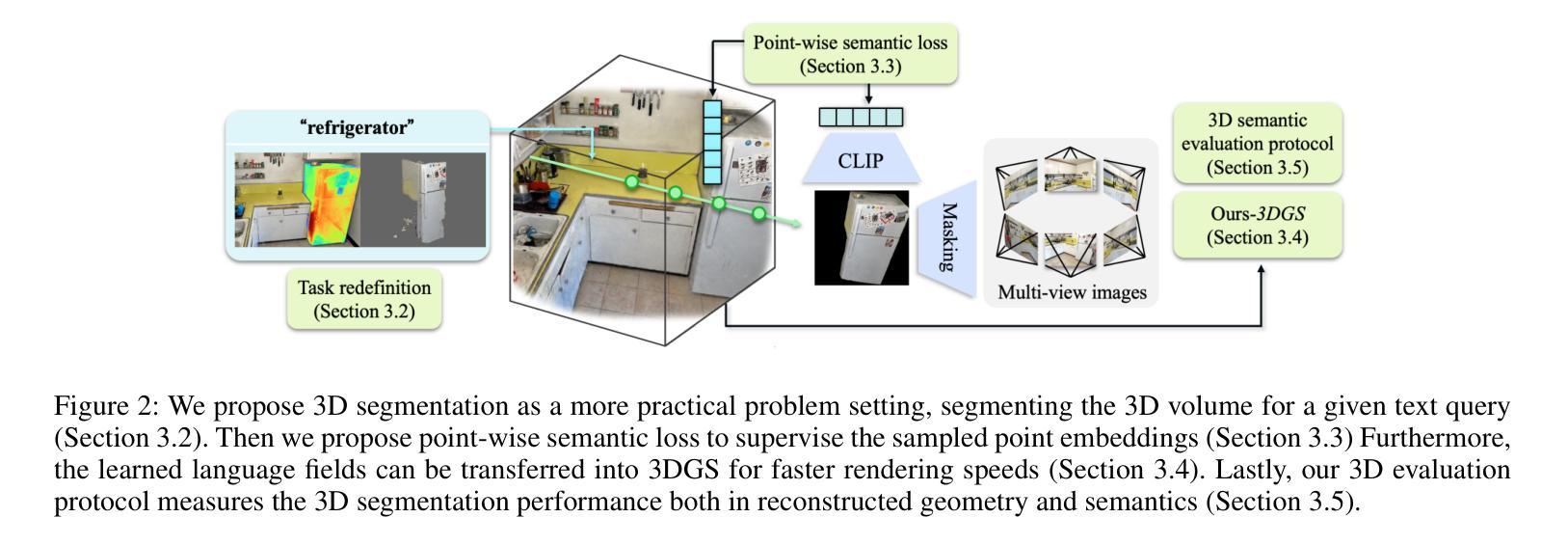
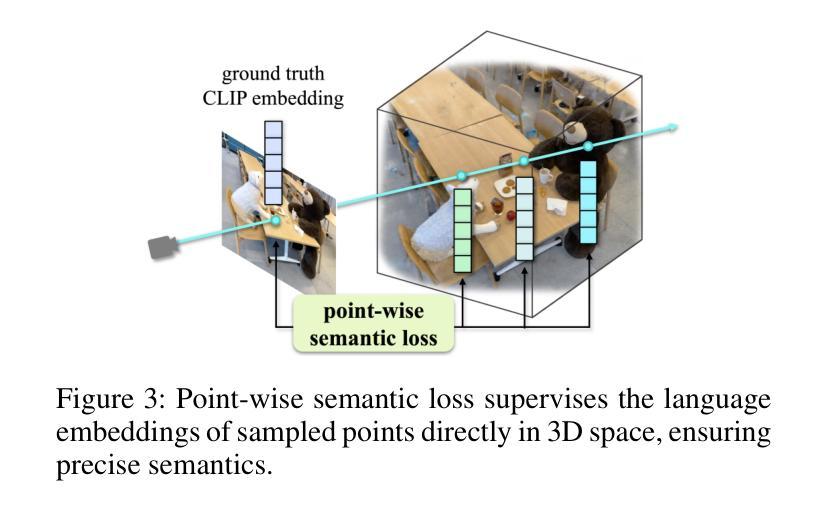
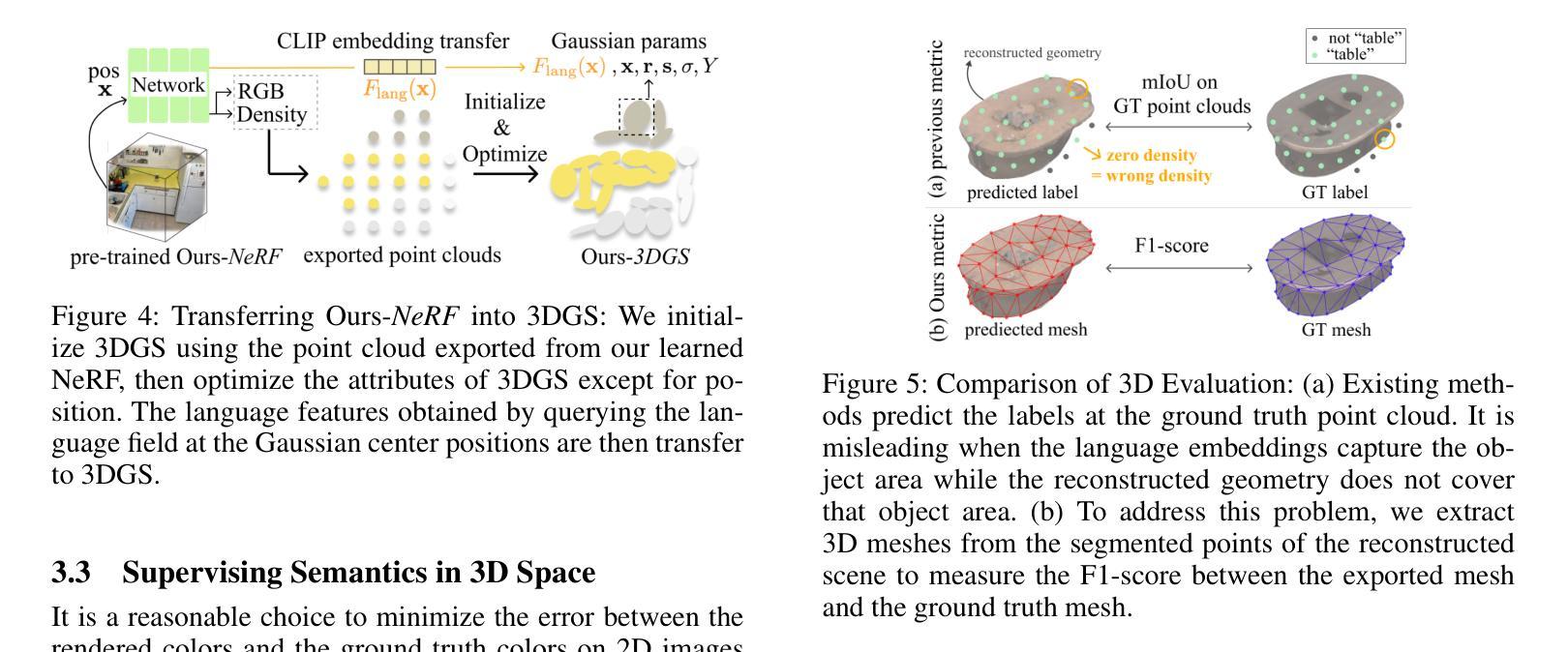
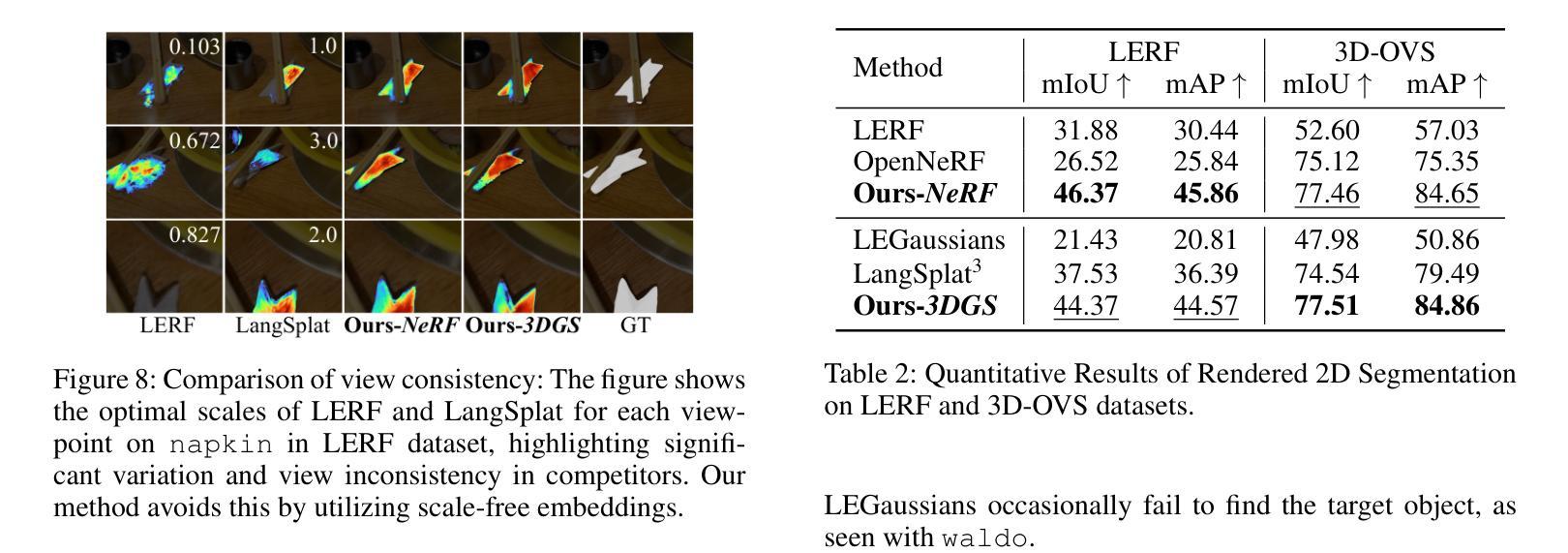
Understanding the 3D semantics of a scene is a fundamental problem for various scenarios such as embodied agents. While NeRFs and 3DGS excel at novel-view synthesis, previous methods for understanding their semantics have been limited to incomplete 3D understanding: their segmentation results are rendered as 2D masks that do not represent the entire 3D space. To address this limitation, we redefine the problem to segment the 3D volume and propose the following methods for better 3D understanding. We directly supervise the 3D points to train the language embedding field, unlike previous methods that anchor supervision at 2D pixels. We transfer the learned language field to 3DGS, achieving the first real-time rendering speed without sacrificing training time or accuracy. Lastly, we introduce a 3D querying and evaluation protocol for assessing the reconstructed geometry and semantics together. Code, checkpoints, and annotations are available at the project page.
理解场景的3D语义是各种场景(如实体代理)中的基本问题。虽然NeRF和3DGS在新型视图合成方面表现出色,但之前的方法在理解其语义方面仅限于不完整的3D理解:他们的分割结果呈现为二维掩膜,并不能代表整个三维空间。为了解决这个问题,我们重新定义了三维体积分割的问题,并提出了以下方法来更好地进行三维理解。我们直接监督三维点来训练语言嵌入场,不同于以前的方法在二维像素上进行锚点监督。我们将学到的语言场转移到3DGS上,在不牺牲训练时间或精度的情况下,实现了实时渲染速度。最后,我们引入了一个用于评估重建几何和语义的三维查询和评估协议。代码、检查点和注释可在项目页面找到。
论文及项目相关链接
PDF AAAI 2025. Project page: https://hyunji12.github.io/Open3DRF
摘要
本文解决了三维场景语义理解的问题,针对现有方法在三维理解上的局限性,重新定义了三维体积分割的问题,并提出了更好的三维理解方法。通过直接监督三维点来训练语言嵌入场,将学习到的语言场转移到3DGS,实现了实时渲染速度,同时不牺牲训练时间或准确性。此外,还引入了一个三维查询和评估协议,以共同评估重建的几何和语义。
要点
- 提出了针对三维场景语义理解的新方法,解决了以往方法仅局限于二维理解的局限性。
- 通过直接监督三维点训练语言嵌入场,不同于以往在二维像素上锚定监督的方法。
- 将训练好的语言场转移到3DGS,实现实时渲染速度,同时保证训练时间和准确性。
- 引入了新的三维查询和评估协议,用于评估重建的几何和语义质量。
- 代码、检查点和注释可在项目页面获取。
- 提出的方法适用于多种场景,如机器人等自主代理的三维场景理解任务。
点此查看论文截图