⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-26 更新
IGDA: Interactive Graph Discovery through Large Language Model Agents
Authors:Alex Havrilla, David Alvarez-Melis, Nicolo Fusi
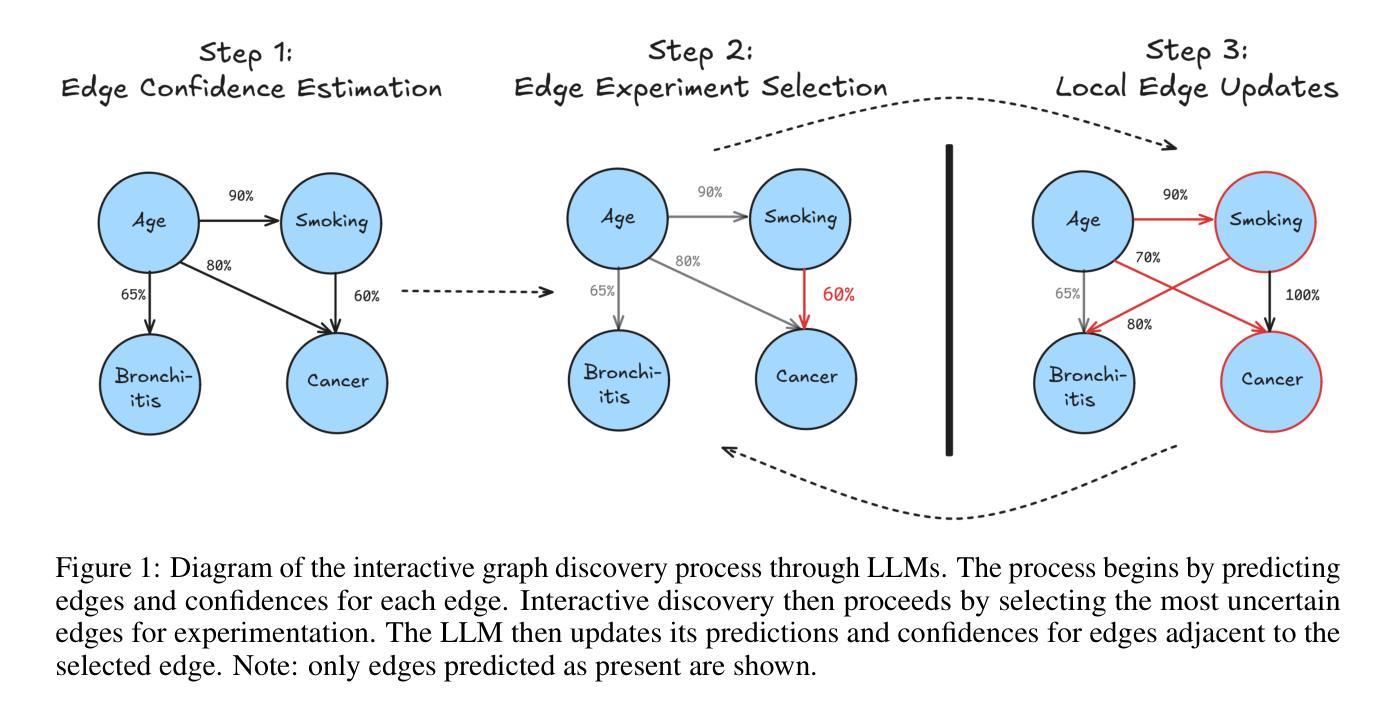
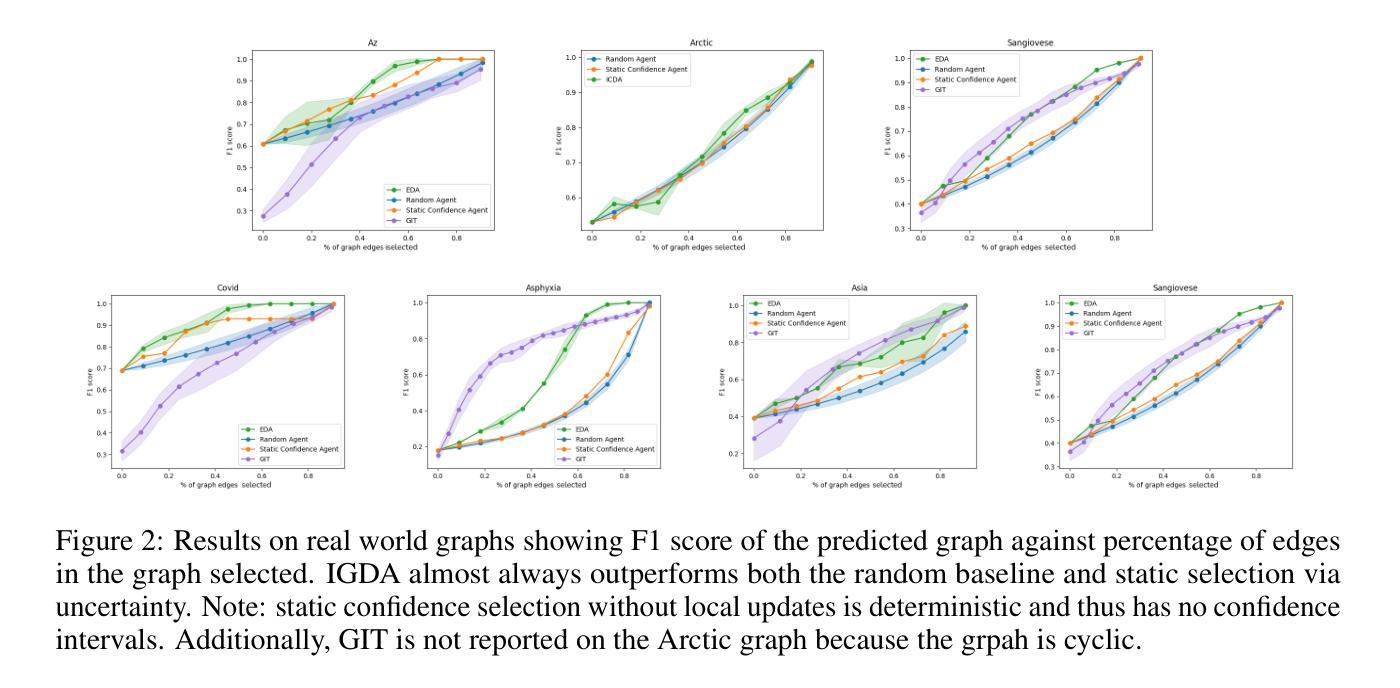
Large language models ($\textbf{LLMs}$) have emerged as a powerful method for discovery. Instead of utilizing numerical data, LLMs utilize associated variable $\textit{semantic metadata}$ to predict variable relationships. Simultaneously, LLMs demonstrate impressive abilities to act as black-box optimizers when given an objective $f$ and sequence of trials. We study LLMs at the intersection of these two capabilities by applying LLMs to the task of $\textit{interactive graph discovery}$: given a ground truth graph $G^*$ capturing variable relationships and a budget of $I$ edge experiments over $R$ rounds, minimize the distance between the predicted graph $\hat{G}_R$ and $G^*$ at the end of the $R$-th round. To solve this task we propose $\textbf{IGDA}$, a LLM-based pipeline incorporating two key components: 1) an LLM uncertainty-driven method for edge experiment selection 2) a local graph update strategy utilizing binary feedback from experiments to improve predictions for unselected neighboring edges. Experiments on eight different real-world graphs show our approach often outperforms all baselines including a state-of-the-art numerical method for interactive graph discovery. Further, we conduct a rigorous series of ablations dissecting the impact of each pipeline component. Finally, to assess the impact of memorization, we apply our interactive graph discovery strategy to a complex, new (as of July 2024) causal graph on protein transcription factors, finding strong performance in a setting where memorization is impossible. Overall, our results show IGDA to be a powerful method for graph discovery complementary to existing numerically driven approaches.
大型语言模型(LLMs)已经成为一种强大的发现方法。LLMs不是利用数值数据,而是利用关联变量语义元数据来预测变量关系。同时,LLMs在被赋予目标f和一系列试验时,表现出令人印象深刻的作为黑箱优化器的能力。我们通过将LLMs应用于交互式图发现任务,来研究这两种能力的交集:给定一个捕获变量关系的真实图G和一个在R轮中I条边实验预算的限制,最小化在第R轮结束时预测图G帽R与实际图G之间的距离。为解决此任务,我们提出IGDA,这是一种基于LLM的管道,包含两个关键组成部分:1)一种LLM不确定性驱动方法进行边缘实验选择;2)一种利用实验二进制反馈更新局部图的策略,以提高未选择相邻边缘的预测。在八个不同真实世界图形上的实验表明,我们的方法通常优于所有基线,包括用于交互式图形发现的最新数值方法。此外,我们还进行了一系列严格的消融研究,分析了每个管道组件的影响。最后,为了评估记忆的影响,我们将交互式图发现策略应用于一个复杂的、全新的(截至2024年7月)蛋白质转录因子因果图,并在不可能发生记忆的情况下取得了良好的性能。总的来说,我们的结果证明了IGDA在图形发现方面是一种强大的方法,与现有的数值驱动方法相辅相成。
论文及项目相关链接
摘要
大型语言模型(LLMs)作为一种强大的发现方法已经崭露头角。LLMs利用关联变量语义元数据预测变量关系,而非使用数值数据。同时,LLMs在给定目标函数和一系列试验时,展现出令人印象深刻的作为黑箱优化器的能力。本研究在LLMs的这两种能力交集处展开探索,将LLMs应用于交互式图发现任务:给定真实图G,以及I条边实验预算,在R轮内最小化预测图GR与G之间的距离。为解决此任务,我们提出了基于LLM的IGDA管道,包含两个关键组成部分:1)LLM不确定性驱动的边缘实验选择方法;2)利用实验二进制反馈更新局部图策略,以提高未选择相邻边缘的预测。在八个不同真实世界图形上的实验表明,我们的方法通常优于所有基线,包括交互式图形发现领域最先进的数值方法。通过一系列严谨的分析剥离每个管道组件的影响,我们评估了记忆的影响,并将交互式图形发现策略应用于复杂的蛋白质转录因子因果图(截至2024年7月),在无记忆情况下表现出强劲性能。总体而言,我们的结果证明了IGDA在图发现领域的强大能力,是对现有数值驱动方法的有力补充。
关键见解
- 大型语言模型(LLMs)利用语义元数据预测变量关系,展现出强大的发现能力。
- LLMs兼具黑箱优化器的特性,能够在给定目标函数和一系列试验时进行优化。
- 提出了一种基于LLM的交互式图发现方法IGDA,结合不确定性驱动的边缘实验选择方法和局部图更新策略。
- 在多个真实世界图形上的实验表明,IGDA方法通常优于现有数值方法和其他基线。
- IGDA通过一系列严谨的分析评估了每个管道组件的影响,并证明其有效性。
- 将IGDA应用于复杂的蛋白质转录因子因果图,在无记忆情况下表现优异。
- IGDA是一种强大的图发现方法,对现有数值驱动方法形成有益补充。
点此查看论文截图


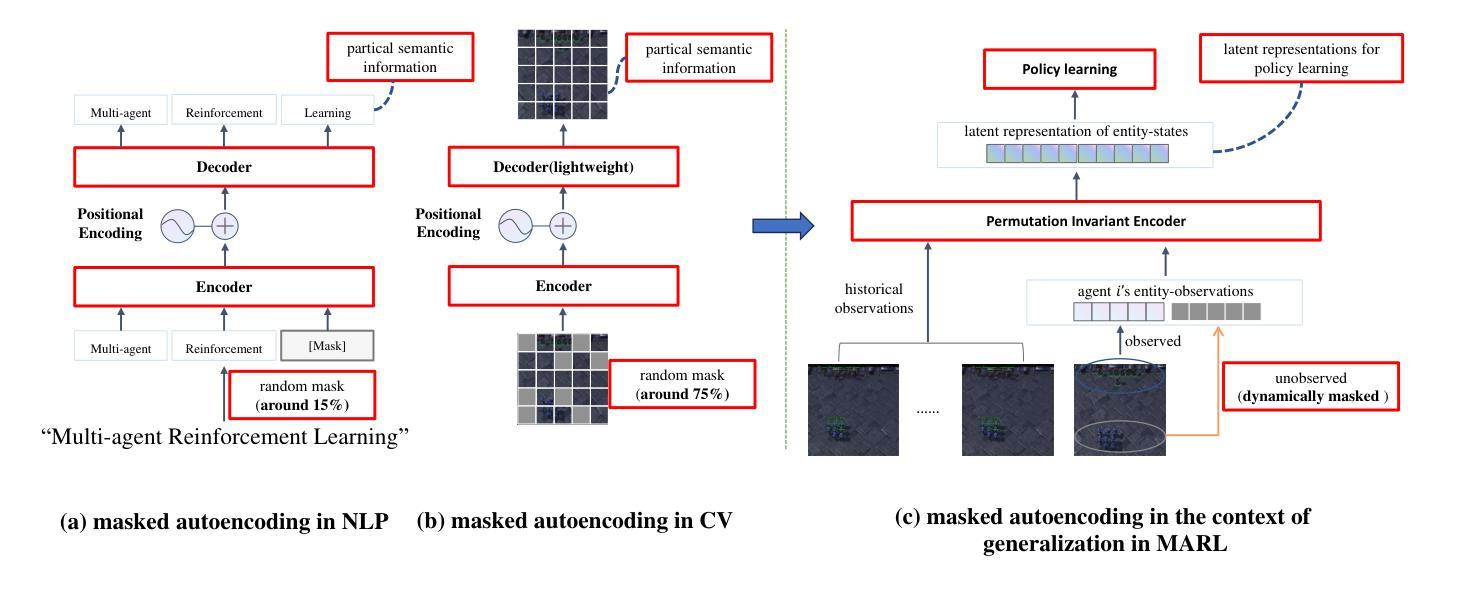
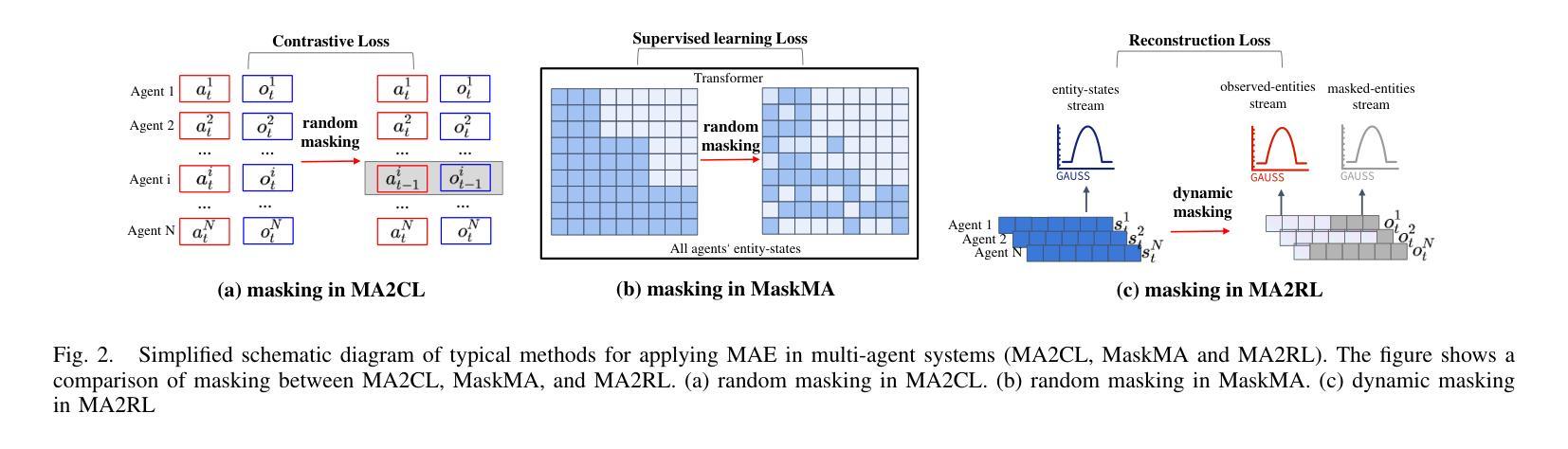
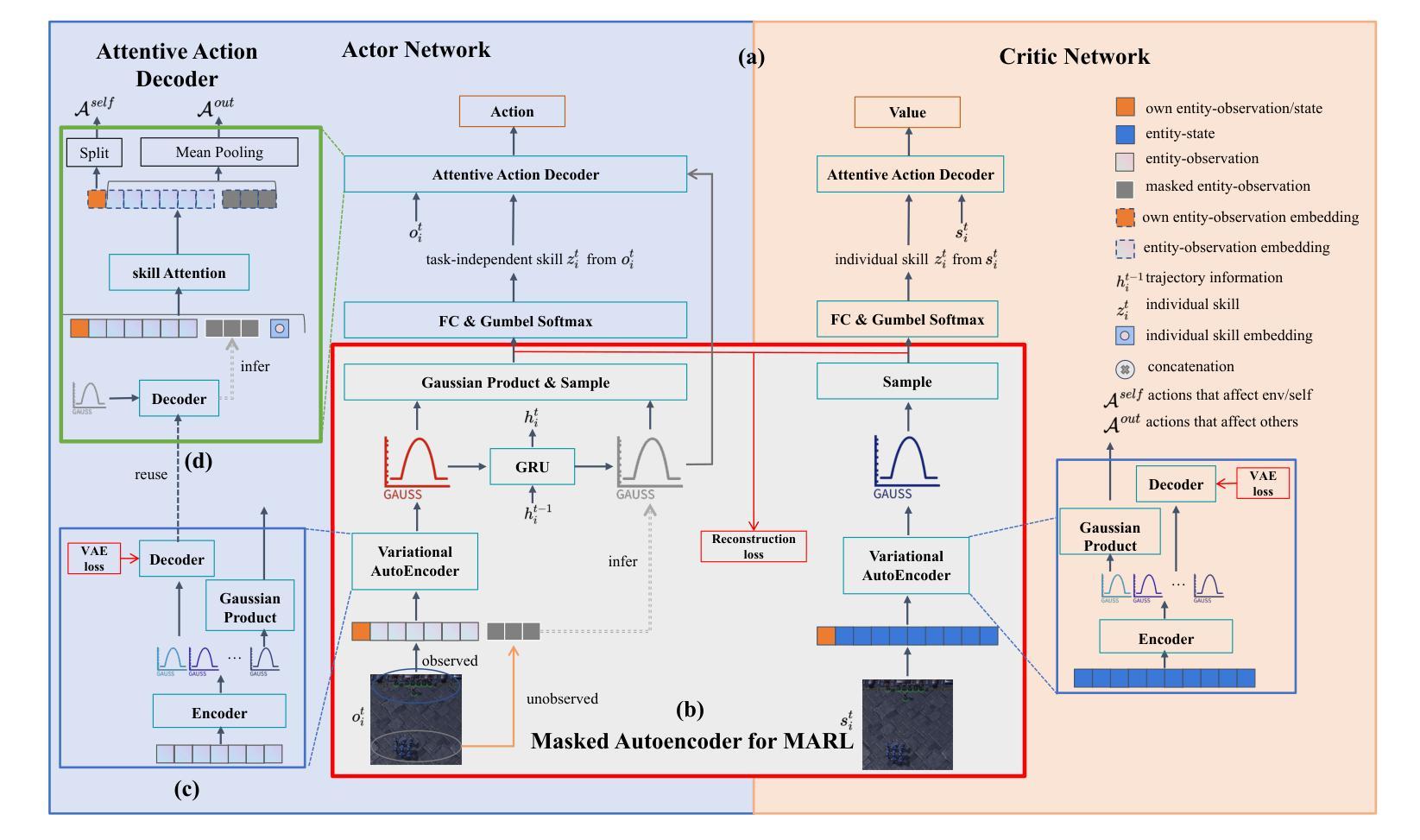
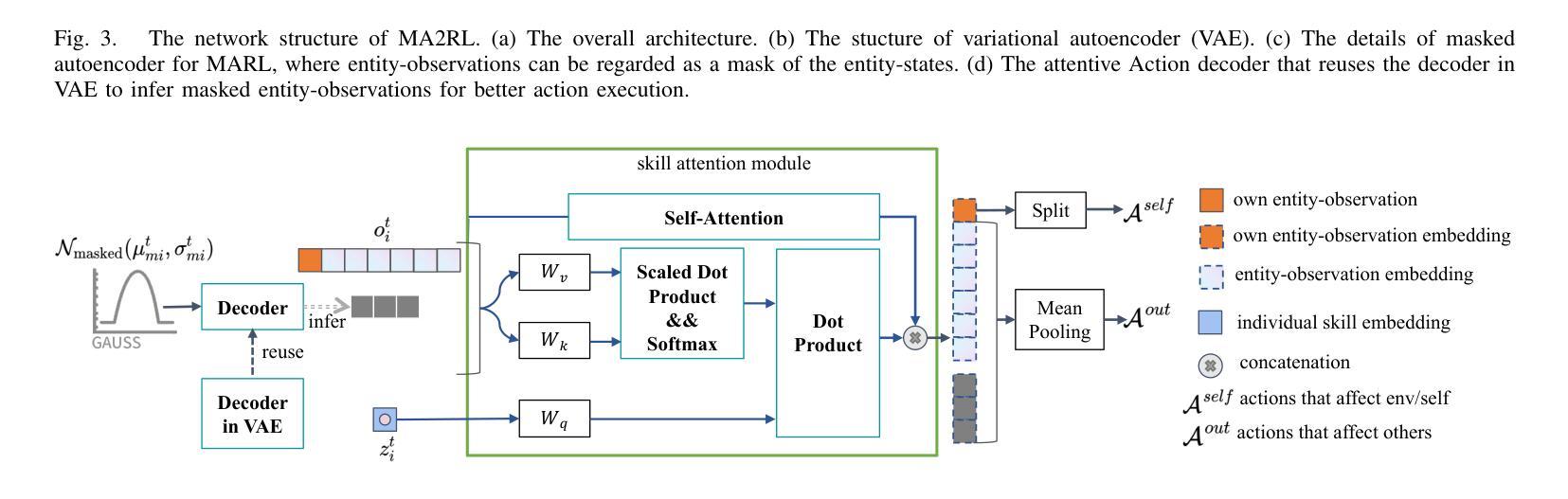
MA2RL: Masked Autoencoders for Generalizable Multi-Agent Reinforcement Learning
Authors:Jinyuan Feng, Min Chen, Zhiqiang Pu, Yifan Xu, Yanyan Liang
To develop generalizable models in multi-agent reinforcement learning, recent approaches have been devoted to discovering task-independent skills for each agent, which generalize across tasks and facilitate agents’ cooperation. However, particularly in partially observed settings, such approaches struggle with sample efficiency and generalization capabilities due to two primary challenges: (a) How to incorporate global states into coordinating the skills of different agents? (b) How to learn generalizable and consistent skill semantics when each agent only receives partial observations? To address these challenges, we propose a framework called \textbf{M}asked \textbf{A}utoencoders for \textbf{M}ulti-\textbf{A}gent \textbf{R}einforcement \textbf{L}earning (MA2RL), which encourages agents to infer unobserved entities by reconstructing entity-states from the entity perspective. The entity perspective helps MA2RL generalize to diverse tasks with varying agent numbers and action spaces. Specifically, we treat local entity-observations as masked contexts of the global entity-states, and MA2RL can infer the latent representation of dynamically masked entities, facilitating the assignment of task-independent skills and the learning of skill semantics. Extensive experiments demonstrate that MA2RL achieves significant improvements relative to state-of-the-art approaches, demonstrating extraordinary performance, remarkable zero-shot generalization capabilities and advantageous transferability.
为了在多智能体强化学习中开发可推广的模型,最近的方法专注于为每个智能体发现任务独立技能,这些技能可以跨任务推广并促进智能体之间的合作。然而,特别是在部分观测环境中,这些方法由于两个主要挑战而面临样本效率和推广能力的问题:(a) 如何将全局状态纳入不同智能体的技能协调中?(b) 当每个智能体只接收部分观测时,如何学习和掌握可推广和一致的技能语义?
论文及项目相关链接
Summary
在多智能体强化学习中,为开发可推广模型,现有方法致力于发现任务独立技能以促进智能体间的合作。但在部分观测场景中,这些方法面临样本效率和泛化能力的挑战。针对这些问题,我们提出名为MA2RL的框架,通过实体视角鼓励智能体推断未观测实体,重建实体状态以实现全局状态的协调。该框架在处理具有不同智能体数量和动作空间的任务时具有推广性。实验表明,MA2RL相较于最新方法取得了显著改进,表现出卓越的性能、引人注目的零样本泛化能力和有利的可迁移性。
Key Takeaways
- MA2RL框架用于多智能体强化学习中的可推广模型开发。
- 该框架旨在发现任务独立技能,以促进智能体间的合作。
- 在部分观测场景中,MA2RL解决了样本效率和泛化能力的挑战。
- MA2RL通过实体视角鼓励智能体推断未观测实体。
- MA2RL框架处理不同智能体数量和动作空间的任务时具有推广性。
- MA2RL框架通过重建实体状态实现全局状态的协调。
点此查看论文截图


Leveraging Large Language Models for Effective and Explainable Multi-Agent Credit Assignment
Authors:Kartik Nagpal, Dayi Dong, Jean-Baptiste Bouvier, Negar Mehr
Recent work, spanning from autonomous vehicle coordination to in-space assembly, has shown the importance of learning collaborative behavior for enabling robots to achieve shared goals. A common approach for learning this cooperative behavior is to utilize the centralized-training decentralized-execution paradigm. However, this approach also introduces a new challenge: how do we evaluate the contributions of each agent’s actions to the overall success or failure of the team. This credit assignment problem has remained open, and has been extensively studied in the Multi-Agent Reinforcement Learning literature. In fact, humans manually inspecting agent behavior often generate better credit evaluations than existing methods. We combine this observation with recent works which show Large Language Models demonstrate human-level performance at many pattern recognition tasks. Our key idea is to reformulate credit assignment to the two pattern recognition problems of sequence improvement and attribution, which motivates our novel LLM-MCA method. Our approach utilizes a centralized LLM reward-critic which numerically decomposes the environment reward based on the individualized contribution of each agent in the scenario. We then update the agents’ policy networks based on this feedback. We also propose an extension LLM-TACA where our LLM critic performs explicit task assignment by passing an intermediary goal directly to each agent policy in the scenario. Both our methods far outperform the state-of-the-art on a variety of benchmarks, including Level-Based Foraging, Robotic Warehouse, and our new Spaceworld benchmark which incorporates collision-related safety constraints. As an artifact of our methods, we generate large trajectory datasets with each timestep annotated with per-agent reward information, as sampled from our LLM critics.
近期的研究工作,从自动驾驶车辆协调到太空内组装,表明要让机器人实现共享目标,学习协作行为至关重要。学习这种协作行为的一种常见方法是采用集中训练、分散执行的模式。然而,这种方法也带来了新的挑战:我们如何评估每个智能体行动对团队整体成功或失败的贡献。这种功劳分配问题仍然开放,并在多智能体强化学习文献中进行了广泛的研究。事实上,人类手动检查智能体行为通常会产生比现有方法更好的信用评估。我们结合这一观察结果与近期的研究工作,这些研究工作表明大型语言模型在许多模式识别任务上表现出了人类水平的性能。我们的核心思想是将信用分配重新制定为序列改进和归属的两个模式识别问题,这激发了我们新颖LLM-MCA方法。我们的方法利用集中LLM奖励评论家,该评论家根据场景中每个智能体的个性化贡献来数值分解环境奖励。然后我们根据这些反馈更新智能体的策略网络。我们还提出了LLM-TACA扩展,其中我们的LLM评论家通过直接向场景中的每个智能体策略传递中间目标来执行明确的任务分配。我们的两种方法在各种基准测试上的表现都大大超过了最新水平,包括基于级别的觅食、机器人仓库以及我们新的太空世界基准测试,该测试结合了碰撞相关的安全约束。作为我们方法的一个成果,我们生成了大量的轨迹数据集,每个时间步都注明了来自LLM评论家的按智能体奖励信息。
论文及项目相关链接
PDF 8 pages+Appendix, 6 Figures, AAMAS 2025
Summary
近期研究,从自动驾驶车辆协调到太空组装,凸显了机器人学习协作行为的重要性以实现共同目标。常见的学习协作行为方法是采用集中训练分布式执行范式,但这引发了新的挑战:如何评估每个智能体对团队整体成败的贡献。本文提出将信用分配问题转化为序列改进和归因两个模式识别问题,并引入了LLM-MCA和LLM-TACA新方法来解决这一问题。我们的方法利用集中式的LLM奖励评论家来数值分解环境奖励,基于每个智能体在场景中的个性化贡献。然后,我们根据反馈更新智能体的策略网络。在多个基准测试中,我们的方法均远超现有技术。
Key Takeaways
- 机器人协作行为对于实现共同目标至关重要,从自动驾驶到太空任务等各个领域均显示出其重要性。
- 集中训练分布式执行范式是常见的机器人协作学习策略。
- 信用分配问题是一个新的挑战,旨在评估每个智能体对团队成功的贡献。
- LLM-MCA和LLM-TACA方法通过将信用分配问题转化为序列改进和归因模式识别问题来解决这一问题。
- LLM奖励评论家用于数值分解环境奖励,基于每个智能体在场景中的个性化贡献。
- 方法在多个基准测试中表现优异,远超现有技术。
点此查看论文截图

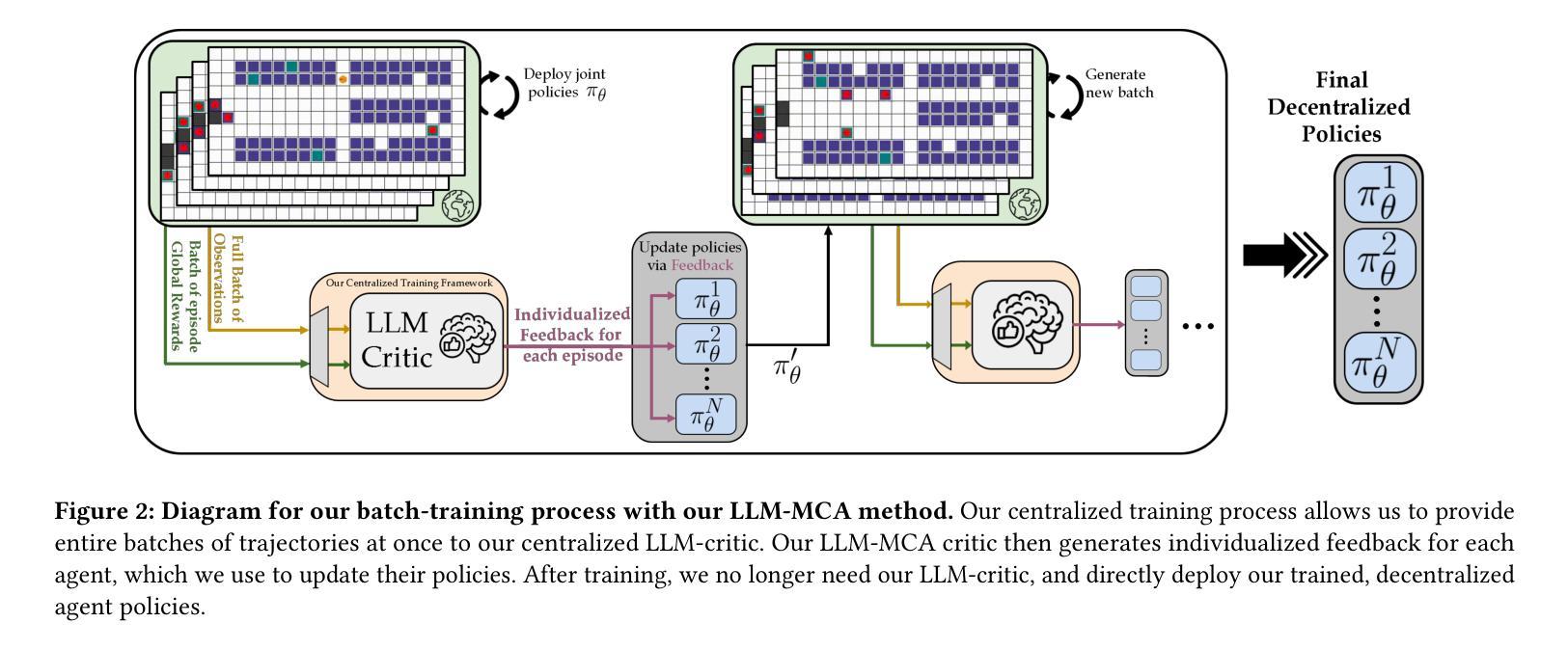


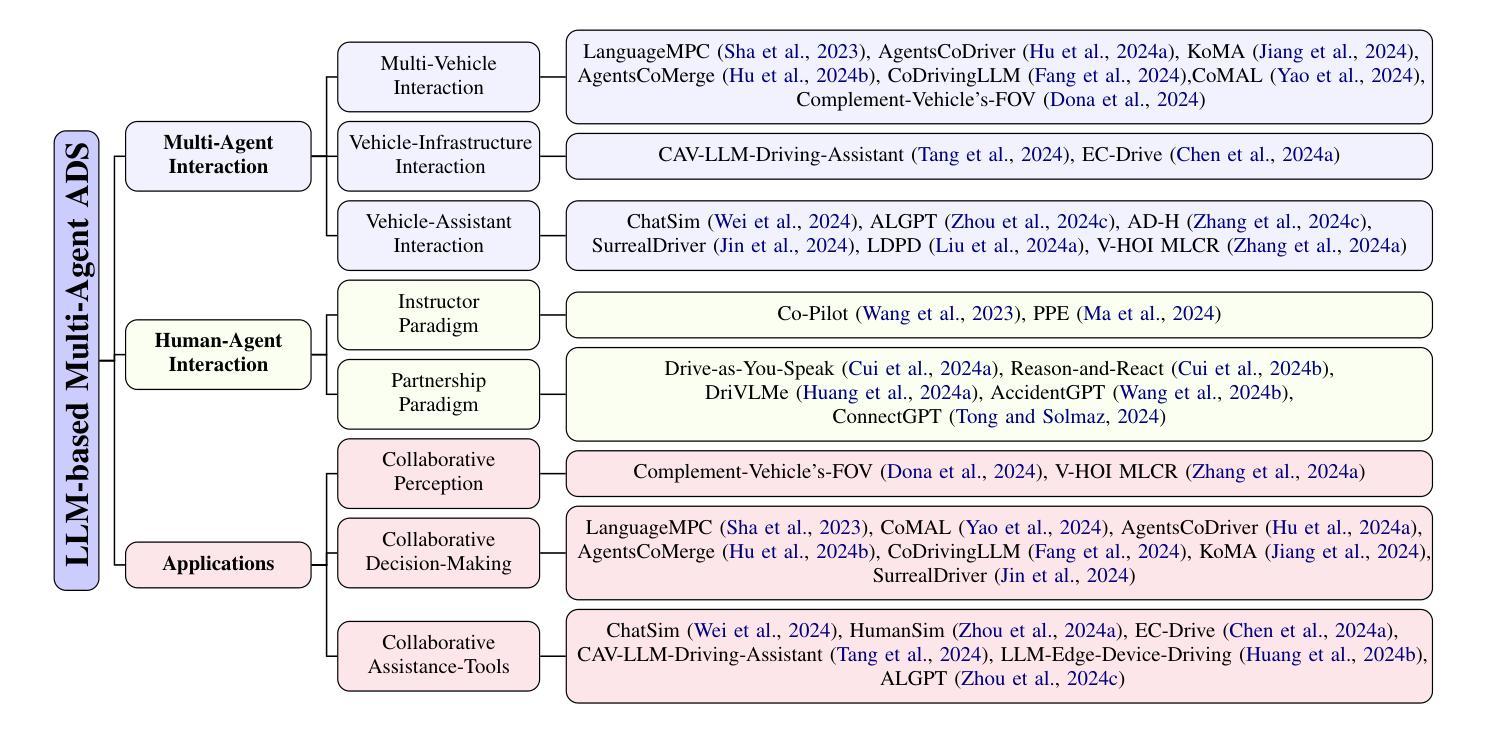
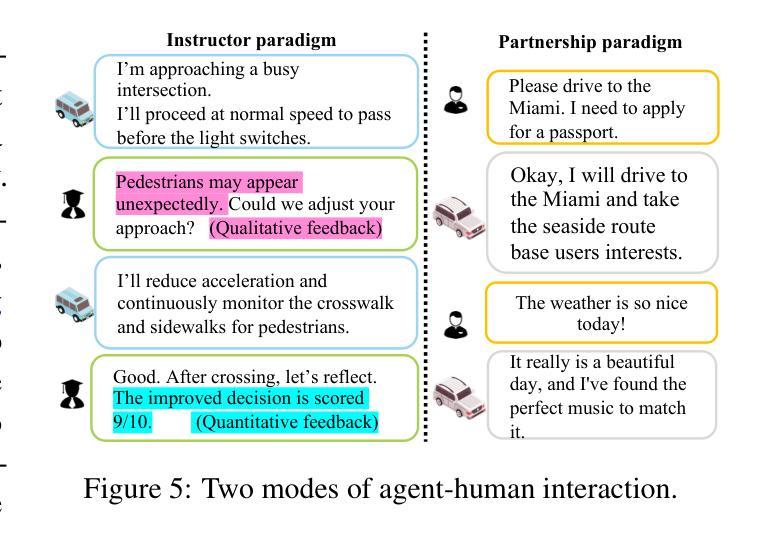
Multi-Agent Autonomous Driving Systems with Large Language Models: A Survey of Recent Advances
Authors:Yaozu Wu, Dongyuan Li, Yankai Chen, Renhe Jiang, Henry Peng Zou, Liancheng Fang, Zhen Wang, Philip S. Yu
Autonomous Driving Systems (ADSs) are revolutionizing transportation by reducing human intervention, improving operational efficiency, and enhancing safety. Large Language Models (LLMs), known for their exceptional planning and reasoning capabilities, have been integrated into ADSs to assist with driving decision-making. However, LLM-based single-agent ADSs face three major challenges: limited perception, insufficient collaboration, and high computational demands. To address these issues, recent advancements in LLM-based multi-agent ADSs have focused on improving inter-agent communication and cooperation. This paper provides a frontier survey of LLM-based multi-agent ADSs. We begin with a background introduction to related concepts, followed by a categorization of existing LLM-based approaches based on different agent interaction modes. We then discuss agent-human interactions in scenarios where LLM-based agents engage with humans. Finally, we summarize key applications, datasets, and challenges in this field to support future research (https://anonymous.4open.science/r/LLM-based_Multi-agent_ADS-3A5C/README.md).
自动驾驶系统(ADS)通过减少人为干预、提高运营效率、增强安全性,正在为交通运输带来革命性的变革。大型语言模型(LLM)以其出色的规划和推理能力而闻名,已集成到ADS中,协助进行驾驶决策。然而,基于LLM的单代理ADS面临三大挑战:感知有限、协作不足和计算需求高。为了解决这些问题,基于LLM的多代理ADS的最新进展主要集中在改进代理之间的通信和协作。本文对基于LLM的多代理ADS进行了前沿调查。首先从相关概念的背景介绍开始,然后根据不同代理交互模式对现有的基于LLM的方法进行分类。接着讨论了LLM代理与人类交互的场景。最后,我们总结了该领域的关键应用、数据集和挑战,以支持未来的研究(https://anonymous.4open.science/r/LLM-based_Multi-agent_ADS-3A5C/README.md)。
论文及项目相关链接
Summary
自主驾驶系统(ADS)正通过减少人工干预、提高操作效率及安全性,革新交通运输行业。大型语言模型(LLM)以其出色的规划与推理能力被集成至ADS中,辅助驾驶决策。然而,LLM单智能体ADS面临感知局限、协作不足及高计算需求三大挑战。为解决这些问题,近期LLM多智能体ADS的进展集中在改善智能体间的通讯与协作。本文对LLM多智能体ADS进行前沿调查,先介绍相关背景知识,再按不同智能体交互模式分类现有的LLM方法,讨论LLM智能体与人类的交互场景,最后总结该领域的关键应用、数据集与挑战,以支持未来研究。
Key Takeaways
- 自主驾驶系统(ADS)正在改变交通运输行业,通过减少人工干预和提高操作效率及安全性。
- 大型语言模型(LLM)已被集成到ADS中,用于辅助驾驶决策,具有出色的规划和推理能力。
- LLM单智能体ADS面临感知局限、协作不足和高计算需求等挑战。
- LLM多智能体ADS的近期进展集中在改善智能体间的通信和协作。
- 文章提供了LLM多智能体ADS的前沿调查,包括相关背景知识、按不同智能体交互模式的分类、LLM智能体与人类的交互场景等。
- 该领域的关键应用、数据集和挑战被总结,以支持未来研究。
点此查看论文截图

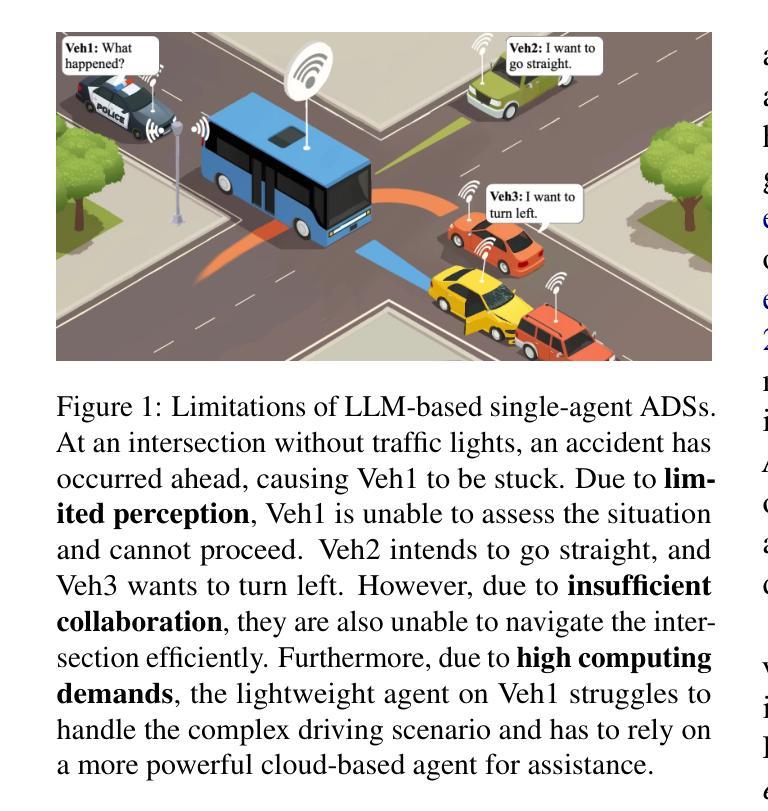
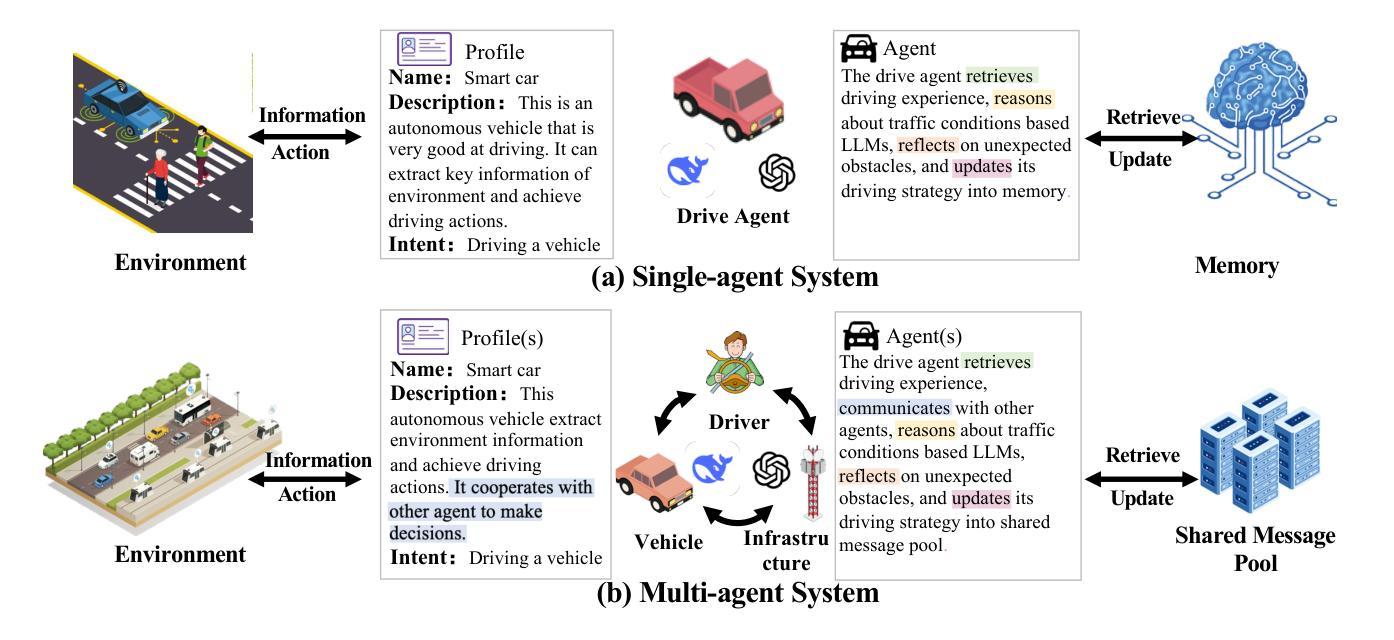
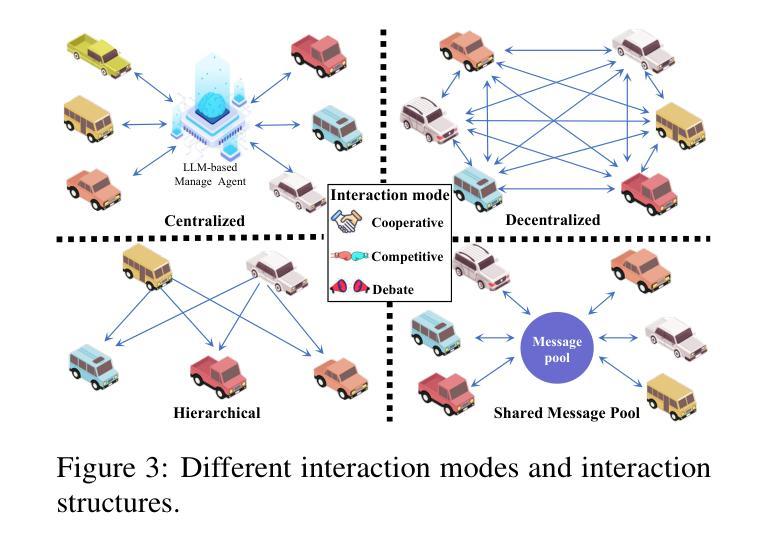
MobileSteward: Integrating Multiple App-Oriented Agents with Self-Evolution to Automate Cross-App Instructions
Authors:Yuxuan Liu, Hongda Sun, Wei Liu, Jian Luan, Bo Du, Rui Yan
Mobile phone agents can assist people in automating daily tasks on their phones, which have emerged as a pivotal research spotlight. However, existing procedure-oriented agents struggle with cross-app instructions, due to the following challenges: (1) complex task relationships, (2) diverse app environment, and (3) error propagation and information loss in multi-step execution. Drawing inspiration from object-oriented programming principles, we recognize that object-oriented solutions is more suitable for cross-app instruction. To address these challenges, we propose a self-evolving multi-agent framework named MobileSteward, which integrates multiple app-oriented StaffAgents coordinated by a centralized StewardAgent. We design three specialized modules in MobileSteward: (1) Dynamic Recruitment generates a scheduling graph guided by information flow to explicitly associate tasks among apps. (2) Assigned Execution assigns the task to app-oriented StaffAgents, each equipped with app-specialized expertise to address the diversity between apps. (3) Adjusted Evaluation conducts evaluation to provide reflection tips or deliver key information, which alleviates error propagation and information loss during multi-step execution. To continuously improve the performance of MobileSteward, we develop a Memory-based Self-evolution mechanism, which summarizes the experience from successful execution, to improve the performance of MobileSteward. We establish the first English Cross-APP Benchmark (CAPBench) in the real-world environment to evaluate the agents’ capabilities of solving complex cross-app instructions. Experimental results demonstrate that MobileSteward achieves the best performance compared to both single-agent and multi-agent frameworks, highlighting the superiority of MobileSteward in better handling user instructions with diverse complexity.
手机代理可以协助用户自动化手机上的日常任务,这已成为一个关键的研究热点。然而,现有的流程导向型代理在跨应用指令方面面临挑战,原因包括以下几点:(1)任务关系复杂,(2)应用环境多样,以及(3)多步执行中的错误传播和信息丢失。从面向对象编程原理中汲取灵感,我们认识到面向对象解决方案更适合跨应用指令。为了应对这些挑战,我们提出了一种名为MobileSteward的自我进化多代理框架,该框架集成了多个由集中化StewardAgent协调的应用导向型StaffAgents。我们在MobileSteward中设计了三个专用模块:(1)动态招募生成一个由信息流引导的调度图,以显式关联应用程序之间的任务。(2)任务分配将任务分配给面向应用的StaffAgents,每个StaffAgent都配备了针对应用的专业知识,以解决应用之间的多样性问题。(3)调整评估进行评估以提供反馈提示或传递关键信息,这减轻了多步执行过程中的错误传播和信息丢失。为了不断提高MobileSteward的性能,我们开发了一种基于内存的自我进化机制,该机制从成功的执行中总结经验,以提高MobileSteward的性能。我们在真实环境中建立了首个英文跨应用基准测试(CAPBench),以评估代理解决复杂跨应用指令的能力。实验结果表明,与单代理和多代理框架相比,MobileSteward取得了最佳性能,凸显了其在处理具有不同复杂性的用户指令方面的优越性。
论文及项目相关链接
PDF Accepted by KDD2025 Research Track
Summary
移动手机代理能够协助用户自动化完成日常手机任务,但现有流程导向的代理面临跨应用指令的挑战。受面向对象编程原则的启发,我们提出自我进化的多代理框架MobileSteward,包含动态招募、指定执行和调整评估三个模块,并设计了一个基于内存的自我进化机制来提高性能。实验结果表明,MobileSteward相较于单代理和多代理框架表现出最佳性能,在处理用户多样化复杂指令方面更具优势。
Key Takeaways
- 移动手机代理能协助自动化日常任务,但跨应用指令是一大挑战。
- 现有流程导向的代理面临复杂任务关系、多样应用环境以及多步骤执行中的错误传播和信息丢失等难题。
- 面向对象解决方案更适合跨应用指令。
- MobileSteward是一个自我进化的多代理框架,包含动态招募、指定执行和调整评估三个模块。
- MobileSteward通过信息流动来明确任务与应用的关联。
- MobileSteward通过应用特定的专业知识来应对应用间的差异。
点此查看论文截图




Multi-Agent Stock Prediction Systems: Machine Learning Models, Simulations, and Real-Time Trading Strategies
Authors:Daksh Dave, Gauransh Sawhney, Vikhyat Chauhan
This paper presents a comprehensive study on stock price prediction, leveragingadvanced machine learning (ML) and deep learning (DL) techniques to improve financial forecasting accuracy. The research evaluates the performance of various recurrent neural network (RNN) architectures, including Long Short-Term Memory (LSTM) networks, Gated Recurrent Units (GRU), and attention-based models. These models are assessed for their ability to capture complex temporal dependencies inherent in stock market data. Our findings show that attention-based models outperform other architectures, achieving the highest accuracy by capturing both short and long-term dependencies. This study contributes valuable insights into AI-driven financial forecasting, offering practical guidance for developing more accurate and efficient trading systems.
本文全面研究了股票价格预测,利用先进的机器学习(ML)和深度学习(DL)技术提高金融预测的准确性。研究评估了各种循环神经网络(RNN)架构的性能,包括长短期记忆(LSTM)网络、门控循环单元(GRU)和基于注意力的模型。这些模型被评估为捕捉股市数据内在复杂时间依赖性的能力。我们的研究结果表明,基于注意力的模型在捕捉短期和长期依赖性方面表现出优于其他架构的性能,获得了最高的准确性。这项研究为AI驱动的金融预测提供了宝贵的见解,并为开发更准确、更高效的交易系统提供了实际指导。
论文及项目相关链接
Summary:
本文利用先进的机器学习和深度学习技术,对股票价格预测进行了全面研究,旨在提高金融预测的准确度。研究评估了不同循环神经网络架构(包括长短时记忆网络、门控循环单元和基于注意力的模型)的性能,以捕捉股市数据内在的复杂时间依赖性。研究结果表明,基于注意力的模型表现出最佳性能,能够捕捉短期和长期依赖关系,为人工智能驱动的金融预测提供了宝贵的见解,并为开发更准确、更高效的交易系统提供了实际指导。
Key Takeaways:
- 本文利用机器学习和深度学习技术进行股票价格预测研究。
- 研究评估了多种循环神经网络架构的性能。
- 基于注意力的模型在捕捉股市数据的时间依赖性方面表现出最佳性能。
- 注意力模型能够同时捕捉短期和长期依赖关系。
- 研究结果提高了金融预测的准确度。
- 本文为人工智能驱动的金融预测提供了宝贵见解。
点此查看论文截图

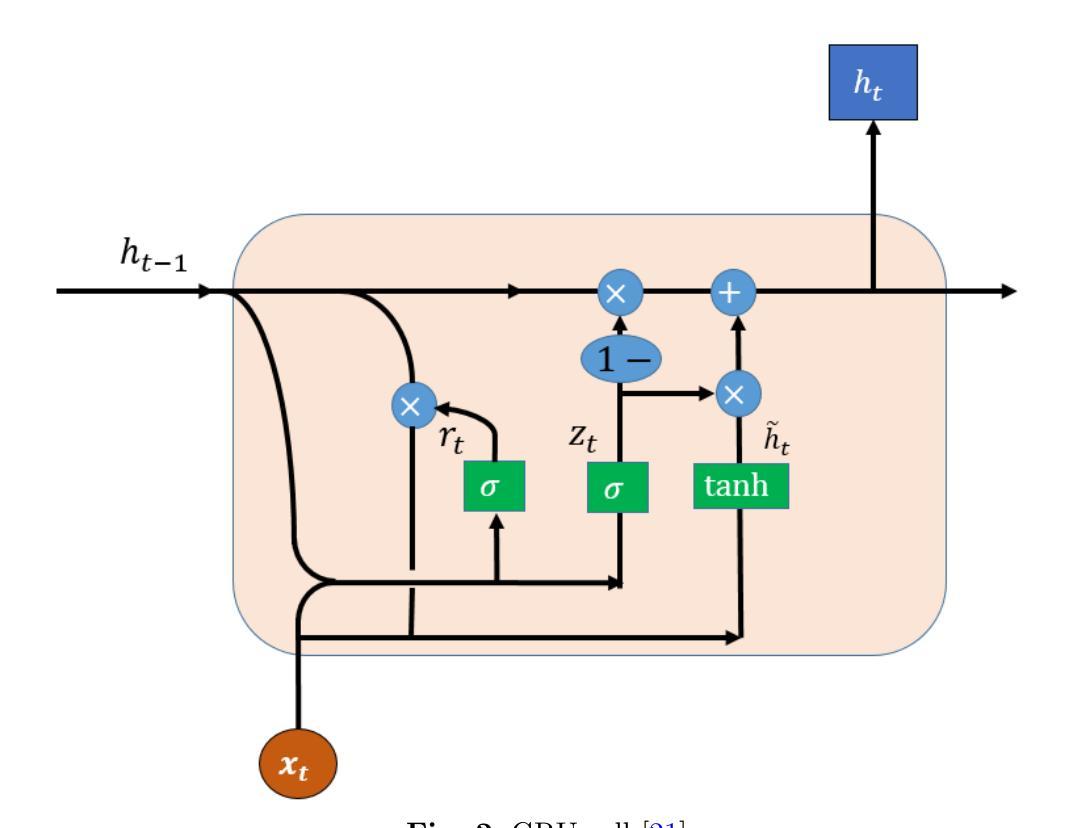
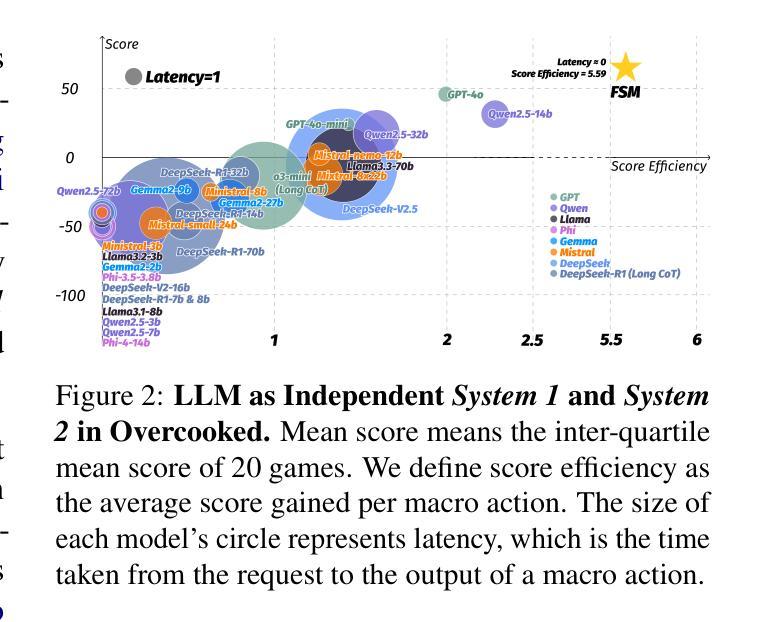
Leveraging Dual Process Theory in Language Agent Framework for Real-time Simultaneous Human-AI Collaboration
Authors:Shao Zhang, Xihuai Wang, Wenhao Zhang, Chaoran Li, Junru Song, Tingyu Li, Lin Qiu, Xuezhi Cao, Xunliang Cai, Wen Yao, Weinan Zhang, Xinbing Wang, Ying Wen
Agents built on large language models (LLMs) have excelled in turn-by-turn human-AI collaboration but struggle with simultaneous tasks requiring real-time interaction. Latency issues and the challenge of inferring variable human strategies hinder their ability to make autonomous decisions without explicit instructions. Through experiments with current independent System 1 and System 2 methods, we validate the necessity of using Dual Process Theory (DPT) in real-time tasks. We propose DPT-Agent, a novel language agent framework that integrates System 1 and System 2 for efficient real-time simultaneous human-AI collaboration. DPT-Agent’s System 1 uses a Finite-state Machine (FSM) and code-as-policy for fast, intuitive, and controllable decision-making. DPT-Agent’s System 2 integrates Theory of Mind (ToM) and asynchronous reflection to infer human intentions and perform reasoning-based autonomous decisions. We demonstrate the effectiveness of DPT-Agent through further experiments with rule-based agents and human collaborators, showing significant improvements over mainstream LLM-based frameworks. To the best of our knowledge, DPT-Agent is the first language agent framework that achieves successful real-time simultaneous human-AI collaboration autonomously. Code of DPT-Agent can be found in https://github.com/sjtu-marl/DPT-Agent.
基于大型语言模型(LLM)的代理人在逐轮的人机协作中表现出色,但在需要实时互动的同时多任务处理方面存在困难。延迟问题和推断可变人类策略的挑战阻碍了它们在没有明确指令的情况下做出自主决策的能力。我们通过当前独立的System 1和System 2方法的实验,验证了在实时任务中使用双过程理论(DPT)的必要性。我们提出了DPT-Agent,这是一种新型的语言代理框架,它整合了System 1和System 2,用于高效实时的同步人机协作。DPT-Agent的System 1使用有限状态机(FSM)和代码即策略,以实现快速、直观和可控的决策。DPT-Agent的System 2结合了心智理论(ToM)和异步反射,以推断人类意图并基于推理进行自主决策。我们通过与基于规则的代理人和人类合作者进一步实验,证明了DPT-Agent的有效性,显示出在主流LLM框架上的显著改进。据我们所知,DPT-Agent是第一个成功实现实时同步人机协作自主性的语言代理框架。DPT-Agent的代码可在https://github.com/sjtu-marl/DPT-Agent中找到。
论文及项目相关链接
PDF Preprint under review. Update the experimental results of the DeepSeek-R1 series models
Summary:基于大型语言模型的代理在逐步人机协作中表现出色,但在需要实时交互的同时任务方面存在挑战。实验验证了双过程理论在实时任务中的必要性。提出DPT-Agent,一个结合系统1和系统2的新型语言代理框架,用于高效实时的人机协作。DPT-Agent的系统1采用有限状态机进行快速、直观和可控的决策。系统2结合了心智理论进行推理并自主决策。通过进一步的实验证明了DPT-Agent的有效性。这是首次实现自主实时人机协作的语言代理框架。
Key Takeaways:
- 大型语言模型代理在逐步人机协作中表现出色,但在需要实时交互的同时任务方面存在挑战。
- 双过程理论在实时任务中的必要性得到验证。
- DPT-Agent是一个新型语言代理框架,结合了系统1和系统2,用于高效实时的人机协作。
- DPT-Agent的系统1采用有限状态机进行决策,具有快速、直观和可控的特点。
- DPT-Agent的系统2结合了心智理论进行推理,并能自主决策。
- 与规则代理和人工合作者进行的实验证明了DPT-Agent的有效性。
点此查看论文截图

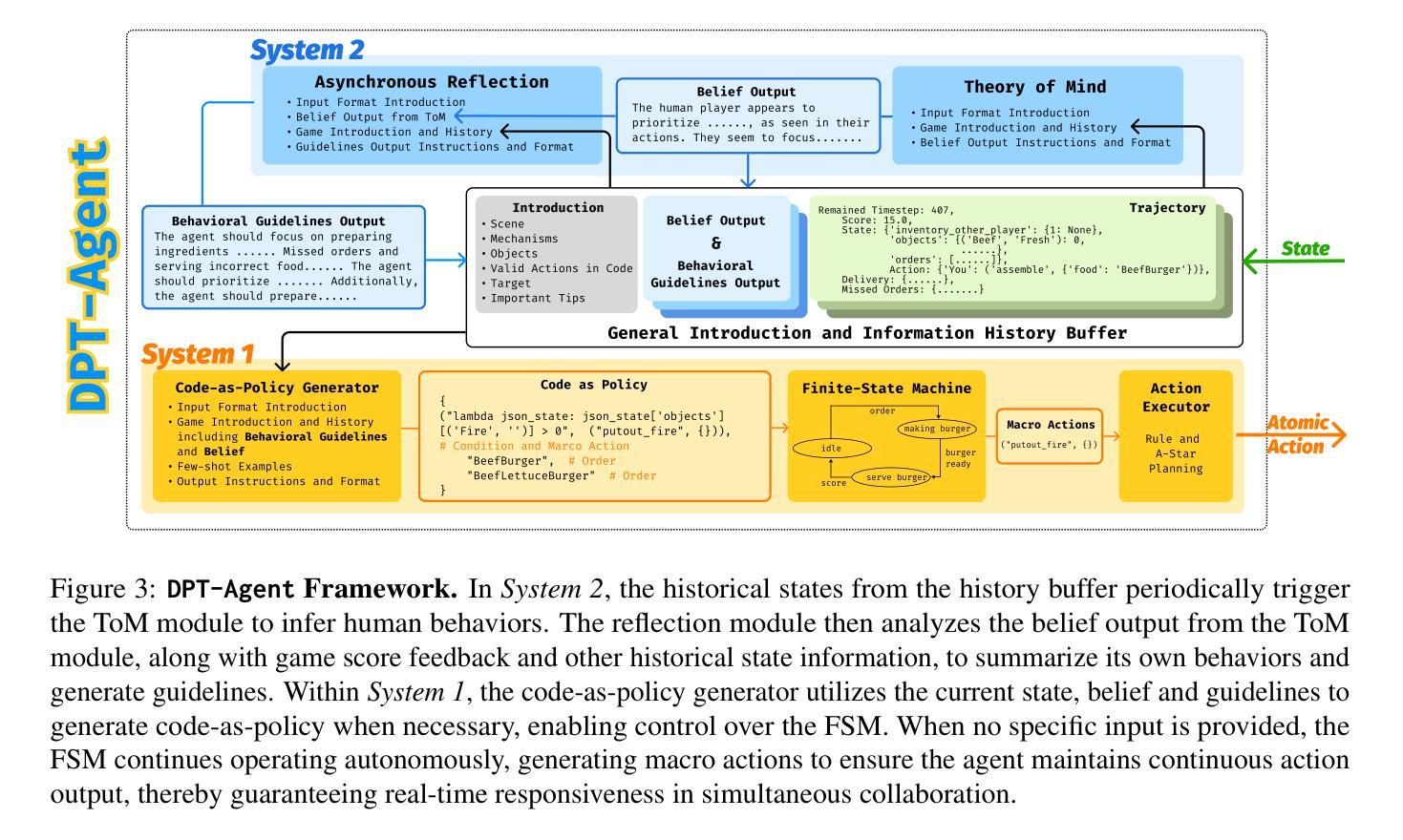
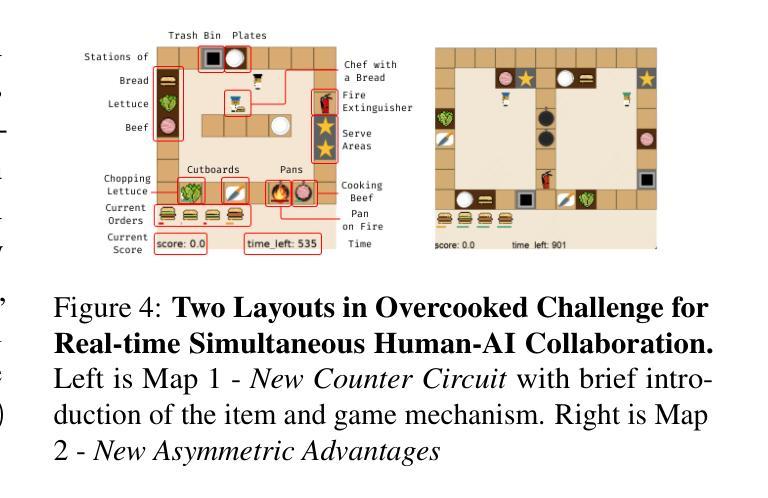
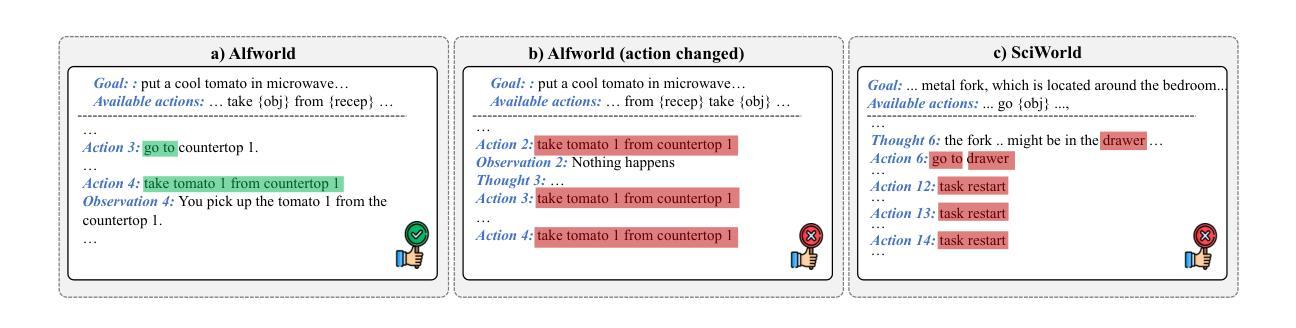
AgentRefine: Enhancing Agent Generalization through Refinement Tuning
Authors:Dayuan Fu, Keqing He, Yejie Wang, Wentao Hong, Zhuoma Gongque, Weihao Zeng, Wei Wang, Jingang Wang, Xunliang Cai, Weiran Xu
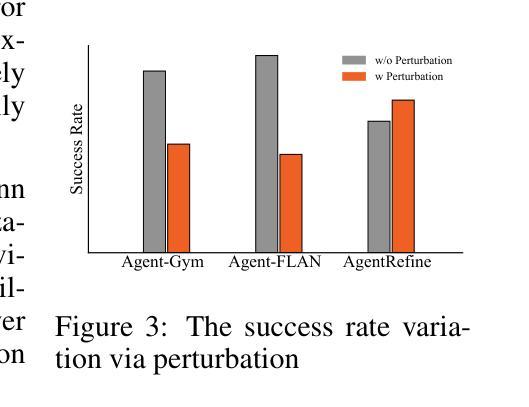
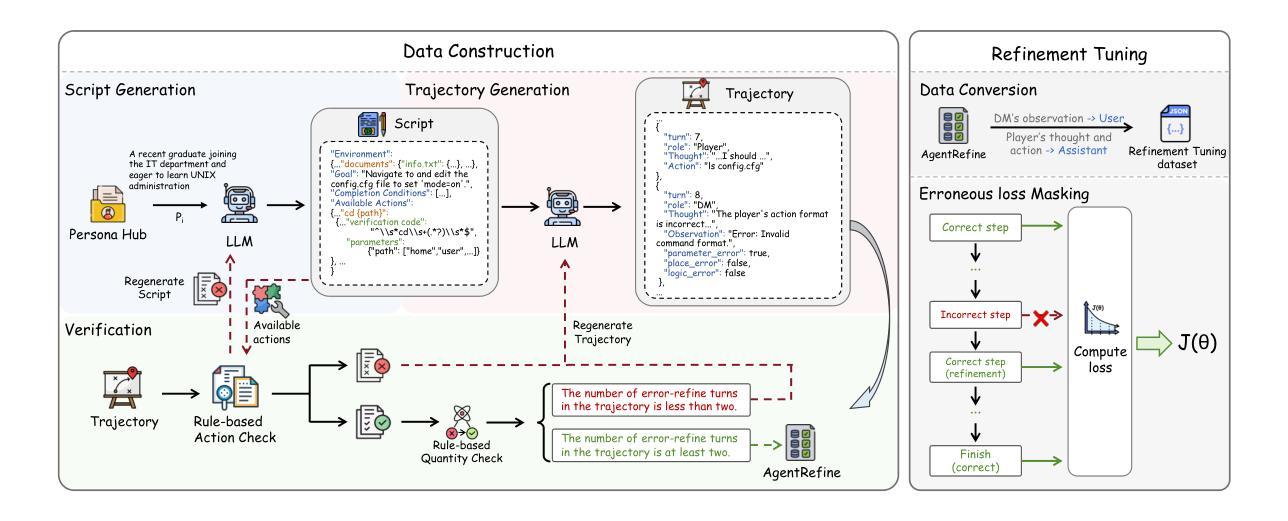
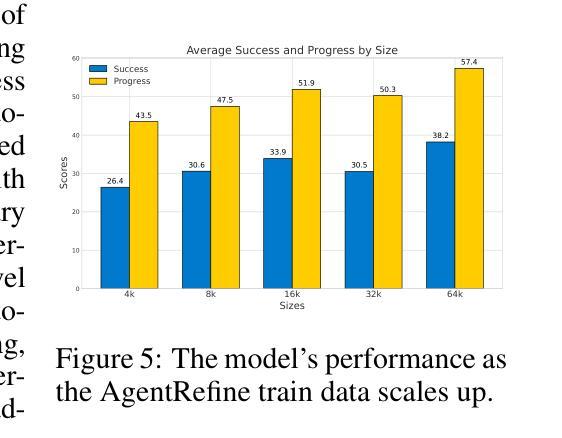
Large Language Model (LLM) based agents have proved their ability to perform complex tasks like humans. However, there is still a large gap between open-sourced LLMs and commercial models like the GPT series. In this paper, we focus on improving the agent generalization capabilities of LLMs via instruction tuning. We first observe that the existing agent training corpus exhibits satisfactory results on held-in evaluation sets but fails to generalize to held-out sets. These agent-tuning works face severe formatting errors and are frequently stuck in the same mistake for a long while. We analyze that the poor generalization ability comes from overfitting to several manual agent environments and a lack of adaptation to new situations. They struggle with the wrong action steps and can not learn from the experience but just memorize existing observation-action relations. Inspired by the insight, we propose a novel AgentRefine framework for agent-tuning. The core idea is to enable the model to learn to correct its mistakes via observation in the trajectory. Specifically, we propose an agent synthesis framework to encompass a diverse array of environments and tasks and prompt a strong LLM to refine its error action according to the environment feedback. AgentRefine significantly outperforms state-of-the-art agent-tuning work in terms of generalization ability on diverse agent tasks. It also has better robustness facing perturbation and can generate diversified thought in inference. Our findings establish the correlation between agent generalization and self-refinement and provide a new paradigm for future research.
基于大型语言模型(LLM)的代理已经证明了它们执行复杂任务的能力,类似于人类。然而,开源LLM和商业模型(如GPT系列)之间仍存在很大差距。在本文中,我们专注于通过指令微调提高LLM的代理泛化能力。我们首先观察到,现有的代理训练语料库在内部评估集上取得了令人满意的结果,但无法推广到外部集。这些代理调整工作面临着严重的格式错误,并且经常长时间陷入同样的错误。我们分析认为,泛化能力差的根源在于对几种手动代理环境的过度拟合以及对新情况的适应不足。他们陷入了错误的行动步骤,无法从经验中学习,而只是记忆现有的观察-行动关系。受此启发,我们提出了一个新的AgentRefine框架用于代理调整。核心思想是使模型能够通过轨迹中的观察学习纠正自己的错误。具体来说,我们提出了一个代理合成框架,以涵盖各种环境和任务,并提示强大的LLM根据环境反馈细化其错误行动。AgentRefine在多种代理任务的泛化能力方面显著优于最新的代理调整工作。它还具有更好的抗扰动性,并在推理过程中可以产生多样化的想法。我们的发现建立了代理泛化和自我完善之间的关联,为未来研究提供了新的范式。
论文及项目相关链接
PDF ICLR 2025
Summary
基于大语言模型(LLM)的代理人在复杂任务执行方面表现出了与人类相似的实力。然而,开源LLM与商业模型如GPT系列之间仍存在较大差距。本文关注通过指令微调提升LLM的代理泛化能力。现有代理训练语料库在封闭评估集上表现良好,但在开放测试集上泛化能力较差。受此启发,本文提出了新型的AgentRefine框架用于代理微调。其核心思想是使模型能够通过观察轨迹学习纠正错误。AgentRefine显著提升了现有代理调整工作在多样化代理任务上的泛化能力,并具备更好的鲁棒性和推理时的多样化思维生成能力。
Key Takeaways
- LLM在复杂任务执行方面表现出强大的能力,但与商业模型如GPT系列相比仍存在一定差距。
- 现有LLM代理训练模型在封闭评估集上表现良好,但在开放测试集上泛化能力较差。
- 代理训练中的格式化错误和长期重复错误问题亟待解决。
- 错误的泛化能力源于对手动代理环境的过度适应和对新情况的缺乏适应性。
- LLM难以从经验中学习,只能记忆现有的观察-行动关系。
- AgentRefine框架通过使模型学习根据环境反馈纠正错误,显著提高了代理调整工作的泛化能力。
- AgentRefine在多样化代理任务上表现优异,具备更好的鲁棒性和推理多样化。
点此查看论文截图

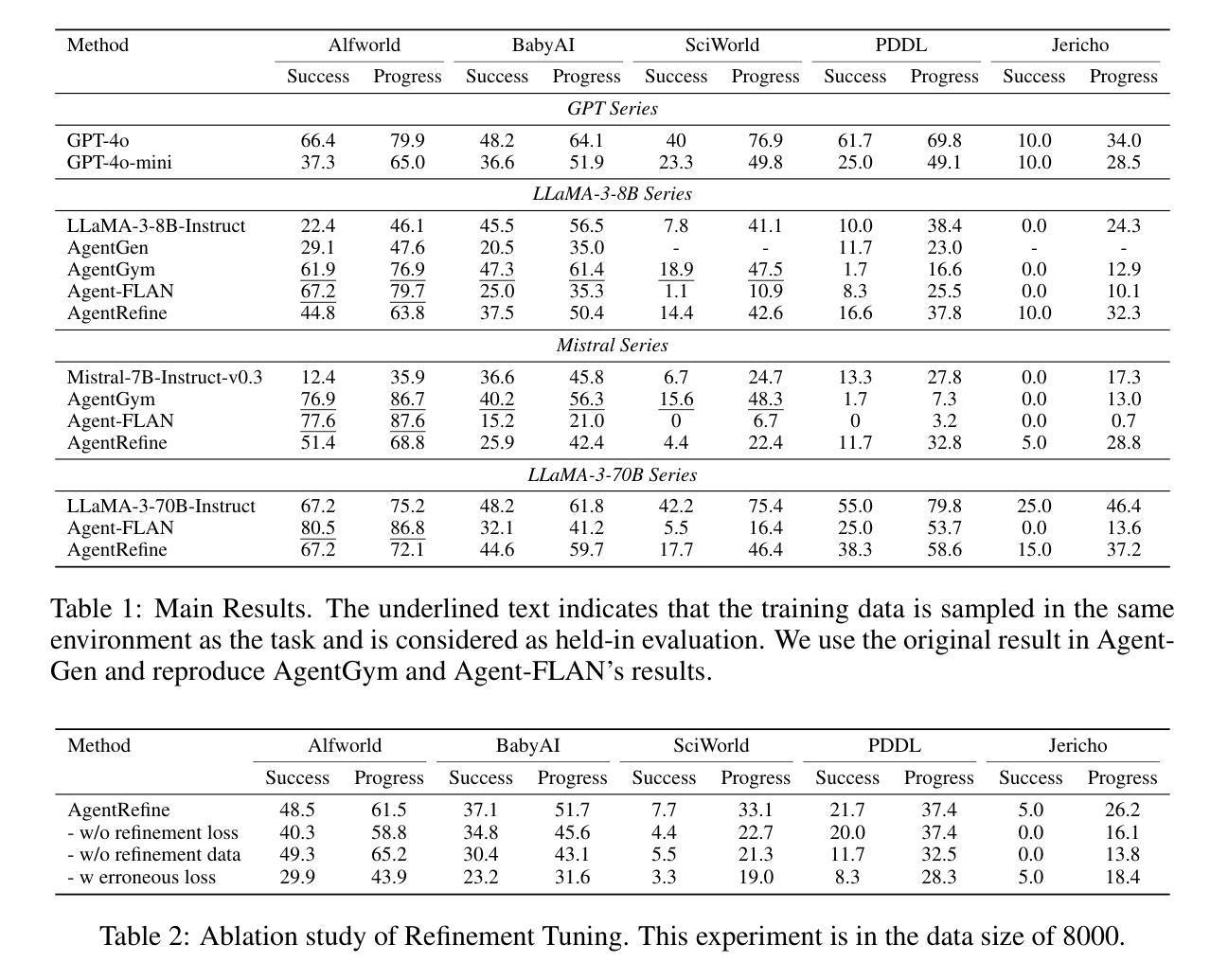
TradingAgents: Multi-Agents LLM Financial Trading Framework
Authors:Yijia Xiao, Edward Sun, Di Luo, Wei Wang
Significant progress has been made in automated problem-solving using societies of agents powered by large language models (LLMs). In finance, efforts have largely focused on single-agent systems handling specific tasks or multi-agent frameworks independently gathering data. However, multi-agent systems’ potential to replicate real-world trading firms’ collaborative dynamics remains underexplored. TradingAgents proposes a novel stock trading framework inspired by trading firms, featuring LLM-powered agents in specialized roles such as fundamental analysts, sentiment analysts, technical analysts, and traders with varied risk profiles. The framework includes Bull and Bear researcher agents assessing market conditions, a risk management team monitoring exposure, and traders synthesizing insights from debates and historical data to make informed decisions. By simulating a dynamic, collaborative trading environment, this framework aims to improve trading performance. Detailed architecture and extensive experiments reveal its superiority over baseline models, with notable improvements in cumulative returns, Sharpe ratio, and maximum drawdown, highlighting the potential of multi-agent LLM frameworks in financial trading. TradingAgents is available at https://github.com/TradingAgents-AI.
在利用大型语言模型(LLM)驱动的智能代理社会解决自动化问题方面,已经取得了重大进展。在金融领域,相关努力主要集中在处理特定任务的单一代理系统,或独立收集数据的多代理框架。然而,多代理系统复制现实世界交易公司协作动态的潜力尚未得到充分探索。《TradingAgents》提出了一个受交易公司启发的新型股票交易框架,该框架采用LLM驱动的代理担任专门角色,如基本面分析师、情绪分析师、技术分析师和不同风险状况的交易员。该框架包括看涨和看跌研究员代理评估市场状况,风险管理团队监控曝光度,以及交易员综合辩论和历史数据中的见解以做出明智的决策。通过模拟动态协作的贸易环境,该框架旨在提高交易性能。详细的架构和广泛的实验显示其在累积回报、夏普比率和最大回撤等方面优于基准模型,突显了多代理LLM框架在金融交易中的潜力。《TradingAgents》可在 https://github.com/TradingAgents-AI 获取。
论文及项目相关链接
PDF Multi-Agent AI in the Real World @ AAAI 2025
总结
利用大型语言模型驱动的社会化代理(LLM)在自动化问题解决方面取得了显著进展。金融领域虽已有单一代理系统处理特定任务或多代理框架独立收集数据的研究,但多代理系统复制真实交易公司协作动态的研究仍被忽视。TradingAgents提出一个受交易公司启发的新型股票交易框架,该框架采用LLM驱动的多代理,分为市场分析员、情绪分析员、技术分析员及风险不同的交易员等不同角色。框架还包括Bull和Bear研究代理评估市场状况,风险管理团队监控曝光度,交易员结合辩论和历史数据来做出明智决策。通过模拟动态协作交易环境,该框架旨在提高交易性能。详细的架构和广泛的实验表明其优于基准模型,在累计回报、夏普比率和最大回撤方面都有显著改善,突显了多代理LLM框架在金融交易中的潜力。TradingAgents项目可通过https://github.com/TradingAgents-AI访问。
关键见解
- LLM驱动的代理在自动化问题解决方面取得显著进展。
- 金融领域已有单一代理系统和多代理框架的研究,但多代理系统的协作动态仍被忽视。
- TradingAgents提出受真实交易公司启发的股票交易框架,包含多种LLM驱动的多代理角色。
- 框架包含市场分析、情绪分析、技术分析和风险管理等关键组件。
- 通过模拟动态协作环境,该框架旨在提高交易性能。
- 详细实验表明其优于基准模型,在累计回报、夏普比率和最大回撤方面有所改善。
点此查看论文截图

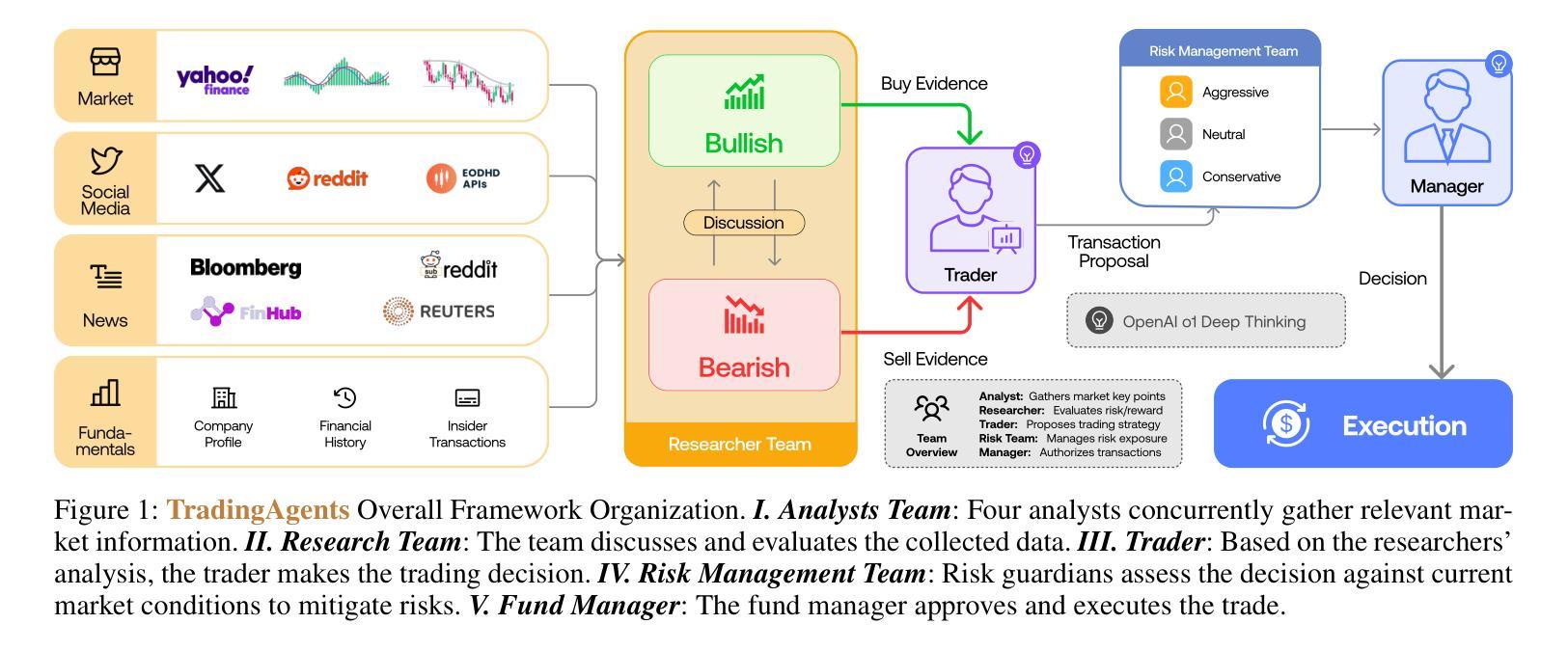



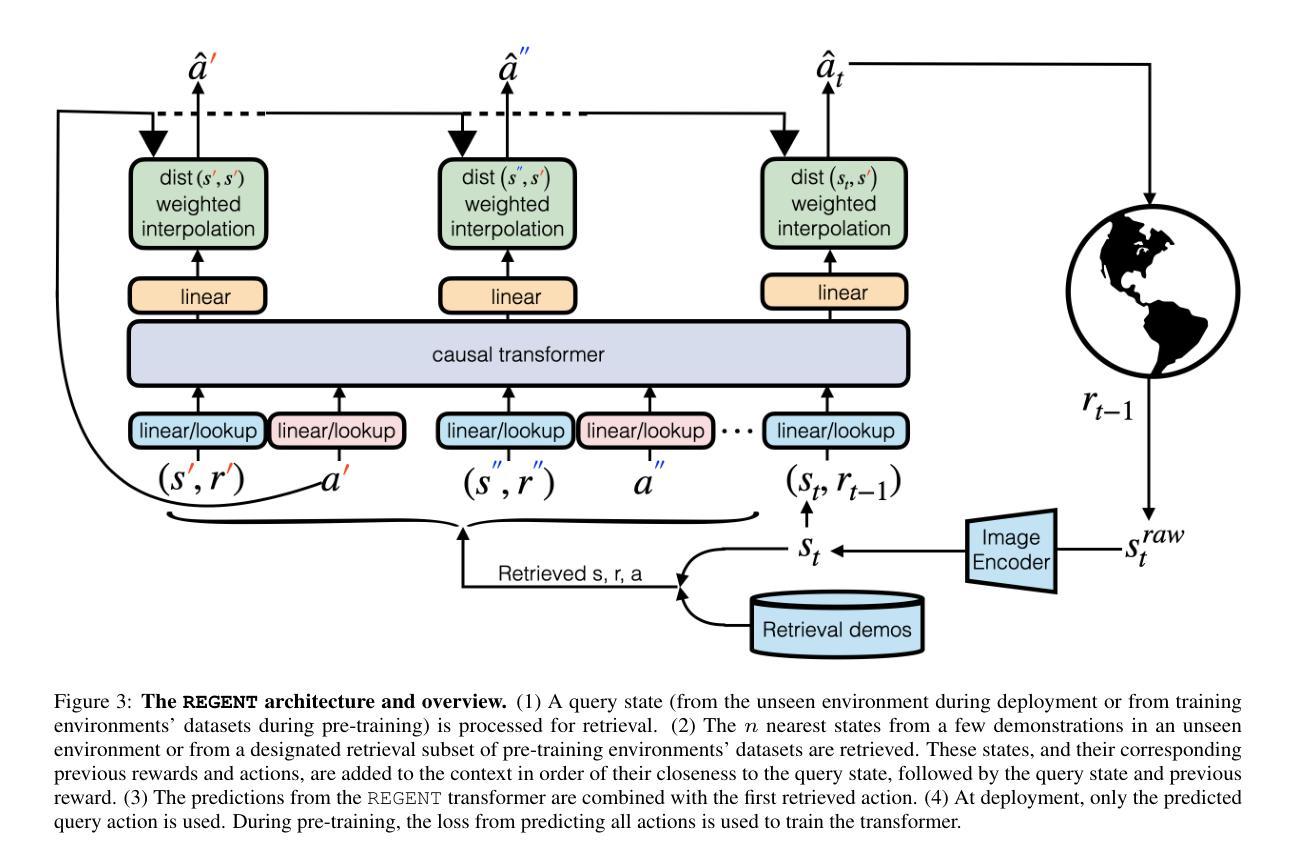
REGENT: A Retrieval-Augmented Generalist Agent That Can Act In-Context in New Environments
Authors:Kaustubh Sridhar, Souradeep Dutta, Dinesh Jayaraman, Insup Lee
Building generalist agents that can rapidly adapt to new environments is a key challenge for deploying AI in the digital and real worlds. Is scaling current agent architectures the most effective way to build generalist agents? We propose a novel approach to pre-train relatively small policies on relatively small datasets and adapt them to unseen environments via in-context learning, without any finetuning. Our key idea is that retrieval offers a powerful bias for fast adaptation. Indeed, we demonstrate that even a simple retrieval-based 1-nearest neighbor agent offers a surprisingly strong baseline for today’s state-of-the-art generalist agents. From this starting point, we construct a semi-parametric agent, REGENT, that trains a transformer-based policy on sequences of queries and retrieved neighbors. REGENT can generalize to unseen robotics and game-playing environments via retrieval augmentation and in-context learning, achieving this with up to 3x fewer parameters and up to an order-of-magnitude fewer pre-training datapoints, significantly outperforming today’s state-of-the-art generalist agents. Website: https://kaustubhsridhar.github.io/regent-research
构建能够迅速适应新环境的通用智能体是人工智能在数字和真实世界部署中的一项关键挑战。使用现有的智能体架构进行扩展是构建通用智能体的最有效方式吗?我们提出了一种新的方法,在相对较小的数据集上预先训练较小的策略,并通过上下文学习将其适应未见过的环境,而无需微调。我们的核心思想是检索为快速适应提供了强大的偏见。实际上,我们证明,即使是一个简单的基于检索的1-最近邻智能体也为当今最先进的通用智能体提供了出人意料的强大基线。从这个起点出发,我们构建了一个半参数智能体REGENT,它在查询序列和检索到的邻居上训练基于变压器的策略。REGENT可以通过检索增强和上下文学习推广到未见过的机器人和游戏环境,使用较少的参数(最多三倍)和较少的预训练数据点(最多一个数量级),显著优于当前的先进通用智能体。网站:https://kaustubhsridhar.github.io/regent-research
论文及项目相关链接
PDF ICLR 2025 Oral, NeurIPS 2024 Workshops on Adaptive Foundation Models (AFM) and Open World Agents (OWA), 30 pages
Summary
本文提出了利用小型政策网络在小规模数据集上进行预训练,并通过检索增强和上下文学习快速适应新环境的方法。文章展示了基于检索的最近邻代理的强大性能,并在此基础上构建了一个半参数化的通用代理REGENT,能够实现对未见过的机器人和游戏环境的泛化。相较于现有技术,该方法具有更少参数和更少预训练数据点的优势。
Key Takeaways
- 提出利用小型政策网络进行预训练并适应新环境的方法。
- 展示基于检索的最近邻代理的强大性能。
- 构建半参数化代理REGENT,通过检索增强和上下文学习实现泛化。
- REGENT在机器人和游戏环境中表现优异。
- REGENT显著优于现有技术的一般代理。
点此查看论文截图

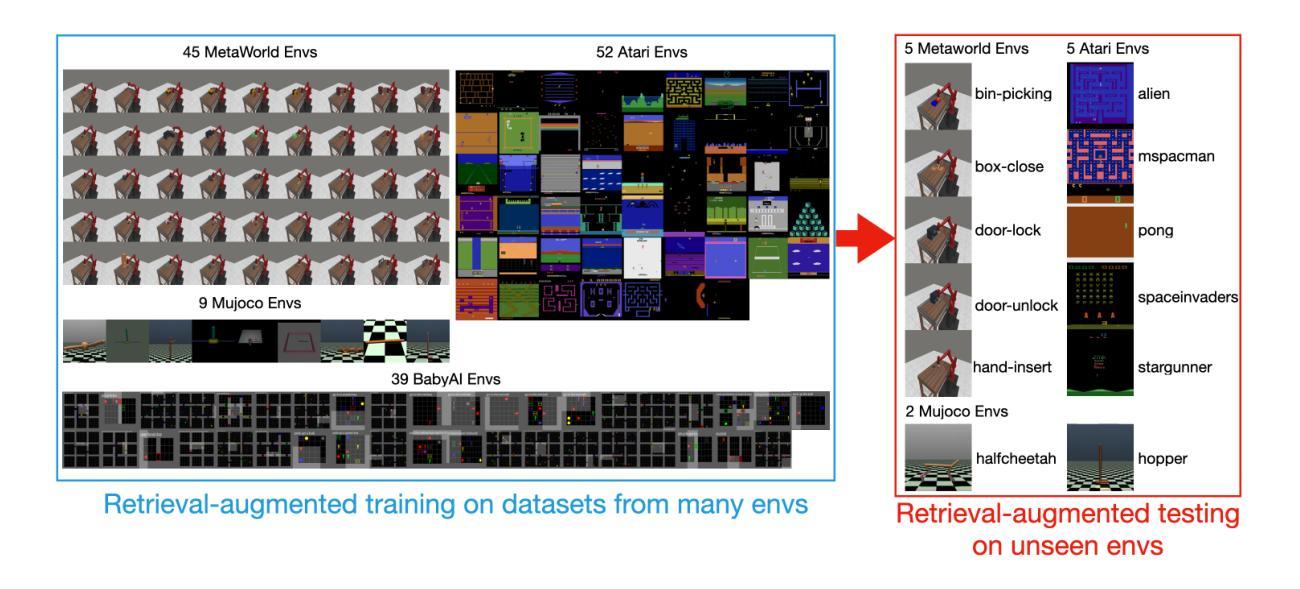
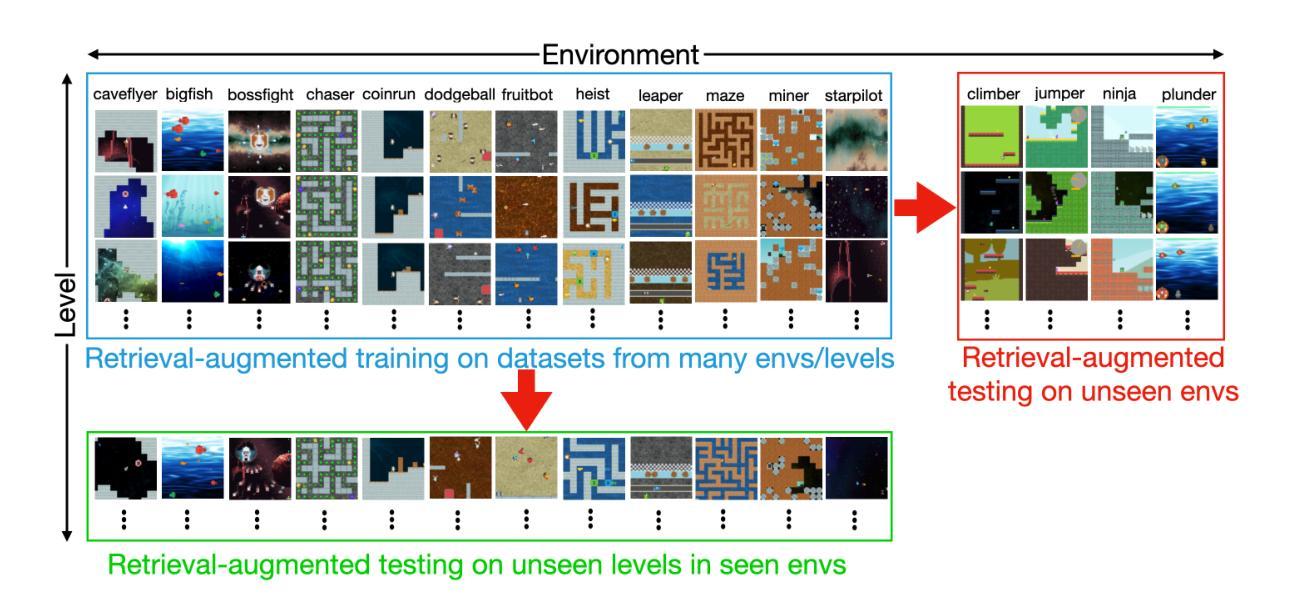
Comparative Analysis of Multi-Agent Reinforcement Learning Policies for Crop Planning Decision Support
Authors:Anubha Mahajan, Shreya Hegde, Ethan Shay, Daniel Wu, Aviva Prins
In India, the majority of farmers are classified as small or marginal, making their livelihoods particularly vulnerable to economic losses due to market saturation and climate risks. Effective crop planning can significantly impact their expected income, yet existing decision support systems (DSS) often provide generic recommendations that fail to account for real-time market dynamics and the interactions among multiple farmers. In this paper, we evaluate the viability of three multi-agent reinforcement learning (MARL) approaches for optimizing total farmer income and promoting fairness in crop planning: Independent Q-Learning (IQL), where each farmer acts independently without coordination, Agent-by-Agent (ABA), which sequentially optimizes each farmer’s policy in relation to the others, and the Multi-agent Rollout Policy, which jointly optimizes all farmers’ actions for global reward maximization. Our results demonstrate that while IQL offers computational efficiency with linear runtime, it struggles with coordination among agents, leading to lower total rewards and an unequal distribution of income. Conversely, the Multi-agent Rollout policy achieves the highest total rewards and promotes equitable income distribution among farmers but requires significantly more computational resources, making it less practical for large numbers of agents. ABA strikes a balance between runtime efficiency and reward optimization, offering reasonable total rewards with acceptable fairness and scalability. These findings highlight the importance of selecting appropriate MARL approaches in DSS to provide personalized and equitable crop planning recommendations, advancing the development of more adaptive and farmer-centric agricultural decision-making systems.
在印度,大多数农民被归类为小农户或边缘农户,他们的生计特别容易受到市场饱和和气候风险导致的经济损失的影响。有效的作物规划会对他们的预期收入产生重大影响,然而现有的决策支持系统(DSS)通常提供通用的建议,这些建议未能考虑实时市场动态和多个农民之间的相互作用。在本文中,我们评估了三种多智能体强化学习(MARL)方法在作物规划中优化农民总收入和促进公平方面的可行性:独立Q学习(IQL),每个农民独立行动而无协调;逐个智能体(ABA),按序优化每个农民的政策,相对于其他农民而言;多智能体试玩策略,联合优化所有农民的行为以实现全局奖励最大化。我们的结果表明,虽然IQL在计算效率方面表现出线性运行时的优势,但在智能体之间的协调方面存在困难,导致总奖励较低和收入分布不均。相反,多智能体试玩策略获得了最高的总奖励,促进了农民之间的公平收入分配,但需要更多的计算资源,对于大量智能体而言实用性较低。ABA在运行时效率和奖励优化之间达到了平衡,以合理的总奖励和可接受的公平性和可扩展性提供建议。这些发现强调了在选择适当的MARL方法以在DSS中提供个性化和公平的作物规划建议方面的重要性,推动了更具适应性和以农民为中心的农业决策系统的发展。
论文及项目相关链接
Summary
印度多数农民属于小规模或边缘农户,他们的生计易受市场饱和和气候风险的影响。本文评估了三种多智能体强化学习(MARL)方法在优化农民收入和促进种植公平方面的可行性:独立Q学习(IQL)、逐个代理(ABA)和多智能体滚动策略。研究结果表明,IQL计算效率高但缺乏协调,导致总收入较低和收入分配不均;多智能体滚动策略虽实现最高总收入和公平的收入分配,但计算资源需求大,难以应对大量智能体。ABA在运行时效率和奖励优化之间取得平衡,提供合理的总收入和公平性。研究强调了为DSS选择合适MARL方法的重要性,以提供个性化公平的种植建议,推动适应性更强、以农民为中心的农业决策系统的开发。
Key Takeaways
- 印度多数农民面临生计脆弱问题,急需有效的决策支持系统来应对市场饱和和气候风险。
- 多智能体强化学习(MARL)在优化农民总收入和促进种植公平方面具有潜力。
- 独立Q学习(IQL)虽然计算效率高,但在协调多智能体方面存在困难,导致收入不均。
- 多智能体滚动策略虽然能最大化总收入并促进公平分配,但对计算资源需求大,难以应用于大量智能体的场景。
- 逐个代理(ABA)方法实现了运行时效率和奖励优化之间的平衡,具有合理的总收入和公平性表现。
- 决策支持系统应提供个性化的种植建议,以增强系统的适应性和以农民为中心的原则。
点此查看论文截图



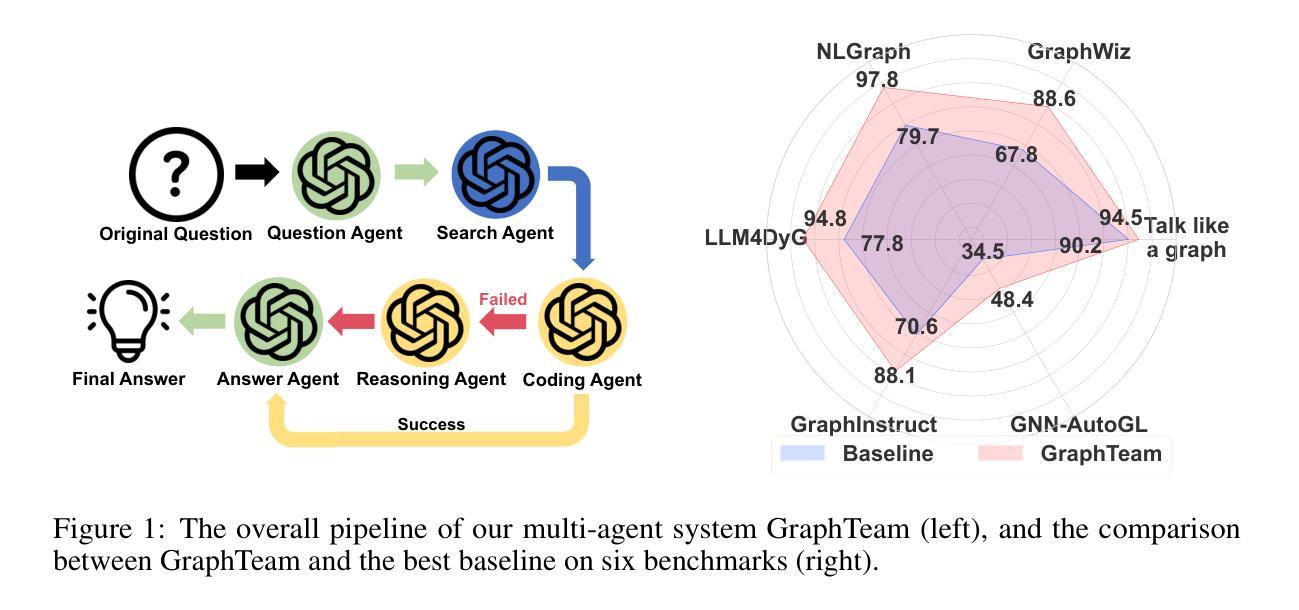
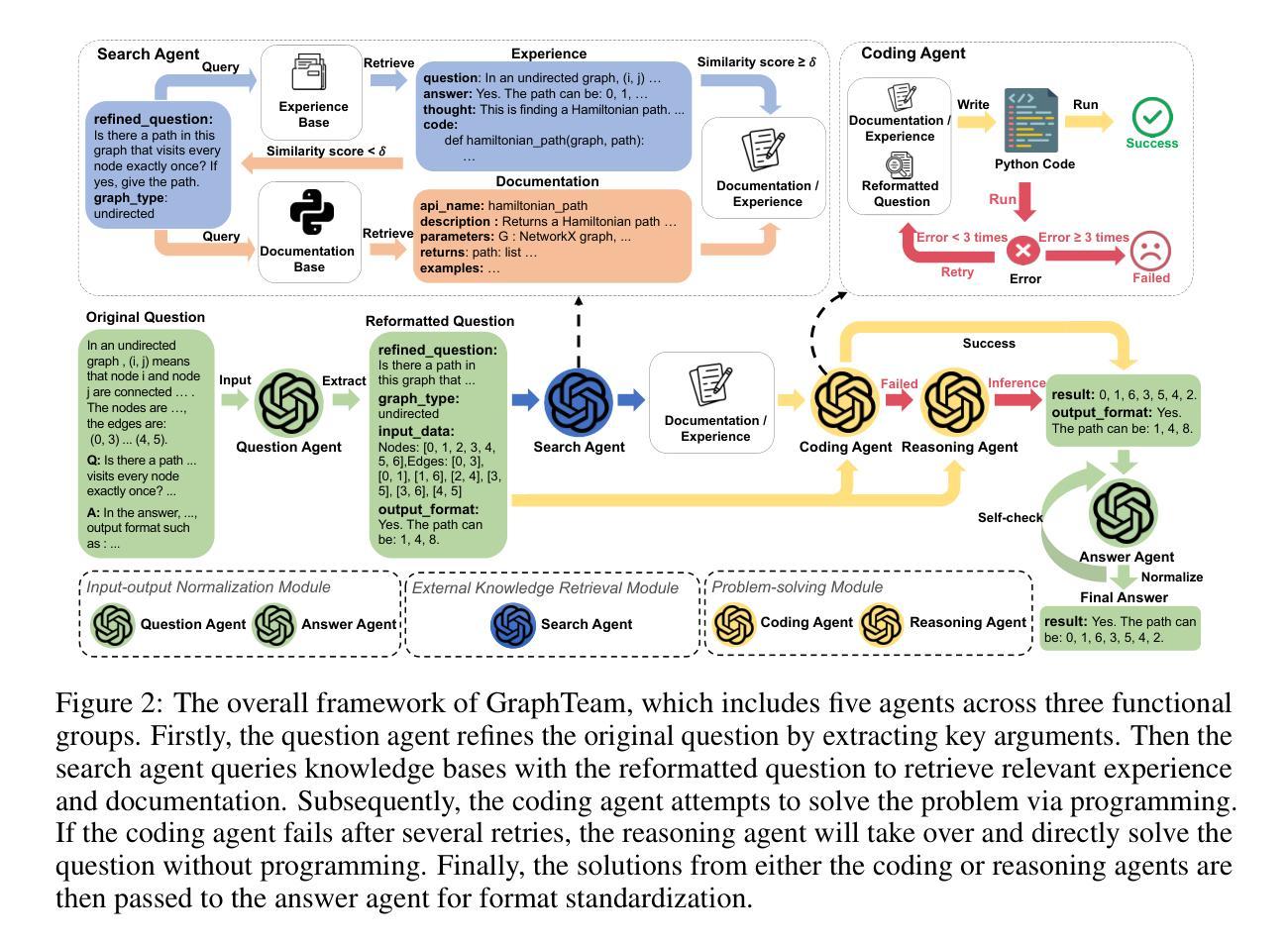
GraphTeam: Facilitating Large Language Model-based Graph Analysis via Multi-Agent Collaboration
Authors:Xin Sky Li, Qizhi Chu, Yubin Chen, Yang Liu, Yaoqi Liu, Zekai Yu, Weize Chen, Chen Qian, Chuan Shi, Cheng Yang
Graphs are widely used for modeling relational data in real-world scenarios, such as social networks and urban computing. Existing LLM-based graph analysis approaches either integrate graph neural networks (GNNs) for specific machine learning tasks, limiting their transferability, or rely solely on LLMs’ internal reasoning ability, resulting in suboptimal performance. To address these limitations, we take advantage of recent advances in LLM-based agents, which have shown capabilities of utilizing external knowledge or tools for problem solving. By simulating human problem-solving strategies such as analogy and collaboration, we propose a multi-agent system based on LLMs named GraphTeam, for graph analysis. GraphTeam consists of five LLM-based agents from three modules, and the agents with different specialities can collaborate with each other to address complex problems. Specifically, (1) input-output normalization module: the question agent extracts and refines four key arguments from the original question, facilitating the problem understanding, and the answer agent organizes the results to meet the output requirement; (2) external knowledge retrieval module: we first build a knowledge base consisting of relevant documentation and experience information, and then the search agent retrieves the most relevant entries for each question. (3) problem-solving module: given the retrieved information from search agent, the coding agent uses established algorithms via programming to generate solutions, and in case the coding agent does not work, the reasoning agent will directly compute the results without programming. Extensive experiments on six graph analysis benchmarks demonstrate that GraphTeam achieves state-of-the-art performance with an average 25.85% improvement over the best baseline in terms of accuracy. The code and data are available at https://github.com/BUPT-GAMMA/GraphTeam.
图被广泛应用于现实世界场景中的关系数据建模,如社会网络和城市计算。现有的基于大型语言模型(LLM)的图分析要么将图神经网络(GNNs)整合到特定的机器学习任务中,限制了其迁移能力,要么只依赖于LLM的内部推理能力,导致性能不佳。为了解决这些局限性,我们利用基于LLM的代理的最新进展,这些代理显示出利用外部知识或工具解决问题的能力。通过模拟人类的类比和协作等解决问题策略,我们提出了一个名为GraphTeam的基于LLM的多代理系统,用于图分析。GraphTeam由三个模块中的五个基于LLM的代理组成,不同专业的代理可以相互协作来解决复杂问题。具体来说,(1)输入输出归一化模块:问题代理从原始问题中提取并优化四个关键参数,促进对问题的理解,答案代理则负责将结果组织成符合输出要求的形式;(2)外部知识检索模块:我们首先建立一个包含相关文档和经验信息的知识库,然后搜索代理会针对每个问题检索最相关的条目。(3)问题解决模块:给定来自搜索代理的检索信息,编码代理通过使用编程建立的算法来生成解决方案,如果编码代理无法工作,推理代理将直接进行计算并得出结果。在六个图分析基准测试上的广泛实验表明,GraphTeam达到了最新的技术性能水平,在准确性方面相对于最佳基准平均提高了25.85%。相关代码和数据可以在https://github.com/BUPT-GAMMA/GraphTeam找到。
论文及项目相关链接
Summary
利用大型语言模型(LLM)为基础的多智能体系统GraphTeam进行图分析,通过模拟人类问题解决策略如类比和协作,解决单一LLM在解决复杂图分析任务时的局限性。GraphTeam由输入输正规化模块、外部知识检索模块和问题解决模块组成,旨在提高图分析的准确性和效率。其在六个图分析基准测试上取得了显著成果,平均提升准确率高达25.85%。相关代码和数据可在GitHub上获取。
Key Takeaways
- GraphTeam利用LLM为基础的多智能体系统,解决了现有图分析方法的局限性。
- GraphTeam通过模拟人类问题解决策略如类比和协作,提高了图分析的效率和准确性。
- GraphTeam由输入输正规化模块、外部知识检索模块和问题解决模块组成,各模块中的智能体具备不同的专业功能并能相互协作。
- 输入输正规化模块通过问题提炼和结果组织,促进了问题的理解和答案的呈现。
- 外部知识检索模块构建了知识库,并通过搜索智能体为问题检索最相关的信息。
- 问题解决模块利用编程智能体建立的算法生成解决方案,若编程智能体无法工作,则推理智能体会直接计算结果。
点此查看论文截图

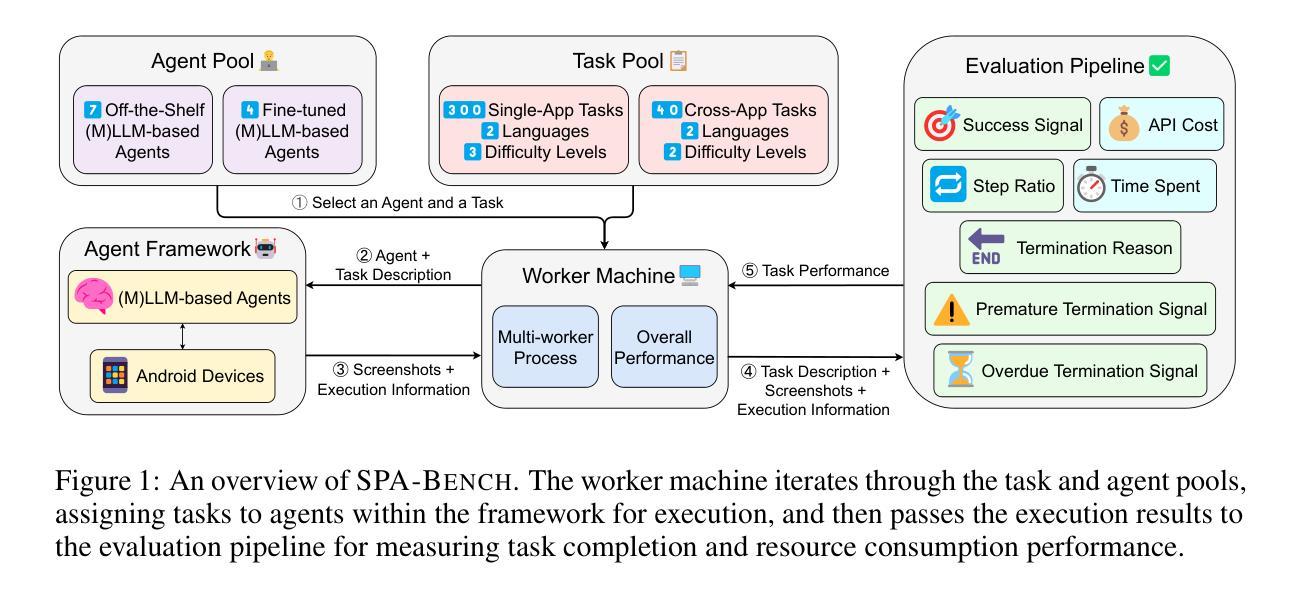
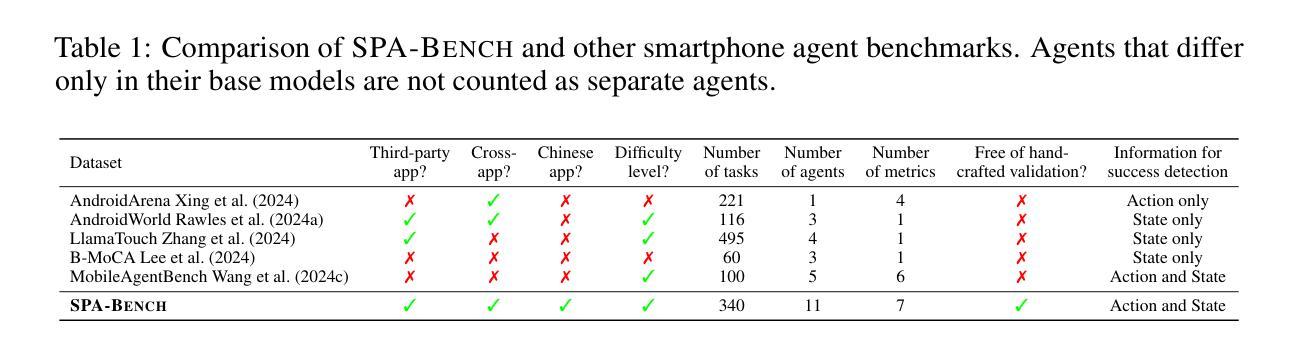
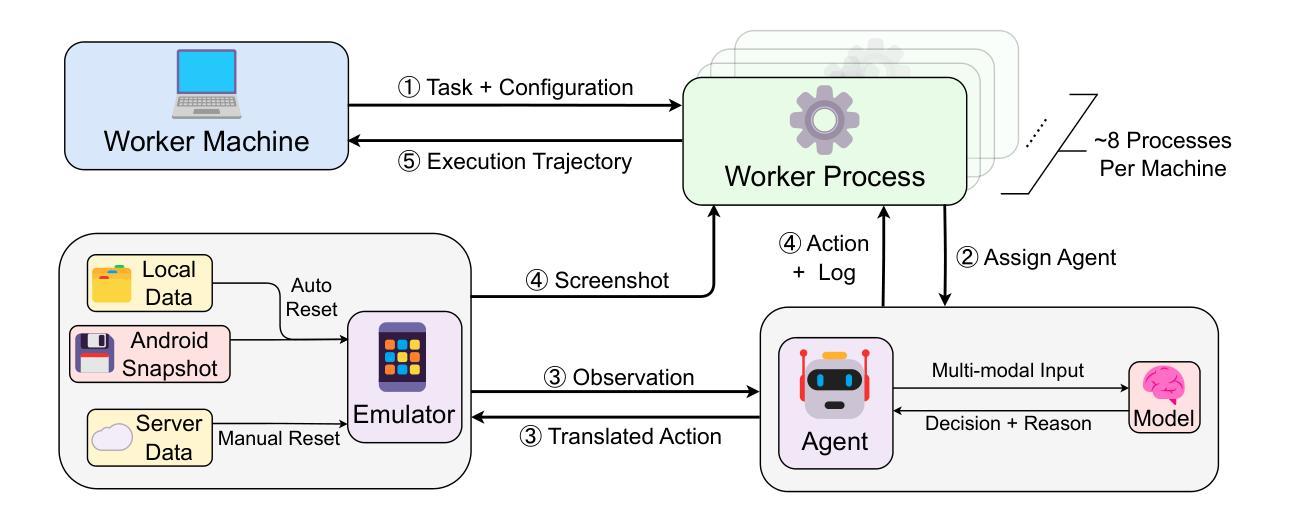
SPA-Bench: A Comprehensive Benchmark for SmartPhone Agent Evaluation
Authors:Jingxuan Chen, Derek Yuen, Bin Xie, Yuhao Yang, Gongwei Chen, Zhihao Wu, Li Yixing, Xurui Zhou, Weiwen Liu, Shuai Wang, Kaiwen Zhou, Rui Shao, Liqiang Nie, Yasheng Wang, Jianye Hao, Jun Wang, Kun Shao
Smartphone agents are increasingly important for helping users control devices efficiently, with (Multimodal) Large Language Model (MLLM)-based approaches emerging as key contenders. Fairly comparing these agents is essential but challenging, requiring a varied task scope, the integration of agents with different implementations, and a generalisable evaluation pipeline to assess their strengths and weaknesses. In this paper, we present SPA-B ENCH, a comprehensive SmartPhone Agent Benchmark designed to evaluate (M)LLM-based agents in an interactive environment that simulates real-world conditions. SPA-B ENCH offers three key contributions: (1) A diverse set of tasks covering system and third-party apps in both English and Chinese, focusing on features commonly used in daily routines; (2) A plug-and-play framework enabling real-time agent interaction with Android devices, integrating over ten agents with the flexibility to add more; (3) A novel evaluation pipeline that automatically assesses agent performance across multiple dimensions, encompassing seven metrics related to task completion and resource consumption. Our extensive experiments across tasks and agents reveal challenges like interpreting mobile user interfaces, action grounding, memory retention, and execution costs. We propose future research directions to ease these difficulties, moving closer to real-world smartphone agent applications. SPA-B ENCH is available at https://ai-agents-2030.github.io/SPA-Bench/.
智能手机代理在帮助用户高效控制设备方面越来越重要,基于(多模态)大语言模型(MLLM)的方法已成为关键竞争者。对这些代理进行公平比较是非常必要的,但具有挑战性,需要任务范围多样化,集成不同实现的代理,以及一个通用的评估流程来评估它们的优缺点。在本文中,我们提出了SPA-B ENCH,这是一个全面的智能手机代理基准测试,旨在在模拟真实世界条件的交互式环境中评估基于(M)LLM的代理。SPA-B ENCH提供了三个主要贡献:(1)涵盖系统和第三方应用程序的多样化任务,包括英语和中文,重点是在日常例行程序中常用的功能;(2)一个即插即用的框架,使代理能够实时与安卓设备进行交互,集成了十多个代理,并具备添加更多代理的灵活性;(3)一个新的评估流程,该流程能够自动从多个维度评估代理性能,包括与任务完成和资源消耗相关的七个指标。我们在不同任务和代理上进行的广泛实验揭示了诸如解释移动用户界面、动作定位、记忆保留和执行成本等挑战。我们提出了未来研究的方向来缓解这些困难,更接近现实世界的智能手机代理应用程序。SPA-B ENCH可在https://ai-agents-2030.github.io/SPA-Bench/上找到。
论文及项目相关链接
PDF ICLR 2025 Spotlight
Summary
智能手机代理在帮助用户高效控制设备方面越来越重要,基于多模态大型语言模型(MLLM)的方法成为关键竞争者。本文提出了SPA-B ENCH智能手机代理基准测试平台,该平台可在模拟真实环境的交互式环境中评估MLLM代理的性能。该平台具有三个关键贡献,包括多样化的任务集、实时交互的插件框架以及自动评估代理性能的评价管道。实验揭示了移动用户接口解读、行动定位、记忆保留和执行成本等挑战。该平台促进了智能助理在实际应用中的发展。
Key Takeaways
- 基于多模态大型语言模型(MLLM)的智能代理在智能手机控制方面日益重要。
- SPA-B ENCH是一个用于评估智能代理性能的基准测试平台,模拟真实环境。
- 平台包含多样化的任务集,涵盖系统和第三方应用,支持中英文。
- 平台提供了一个插件框架,可与安卓设备进行实时交互,集成多个智能代理。
- 平台采用新型评价管道自动评估代理在任务完成和资源消耗方面的表现。
- 实验揭示了移动用户接口解读、行动定位、记忆保留和执行成本等挑战。
点此查看论文截图


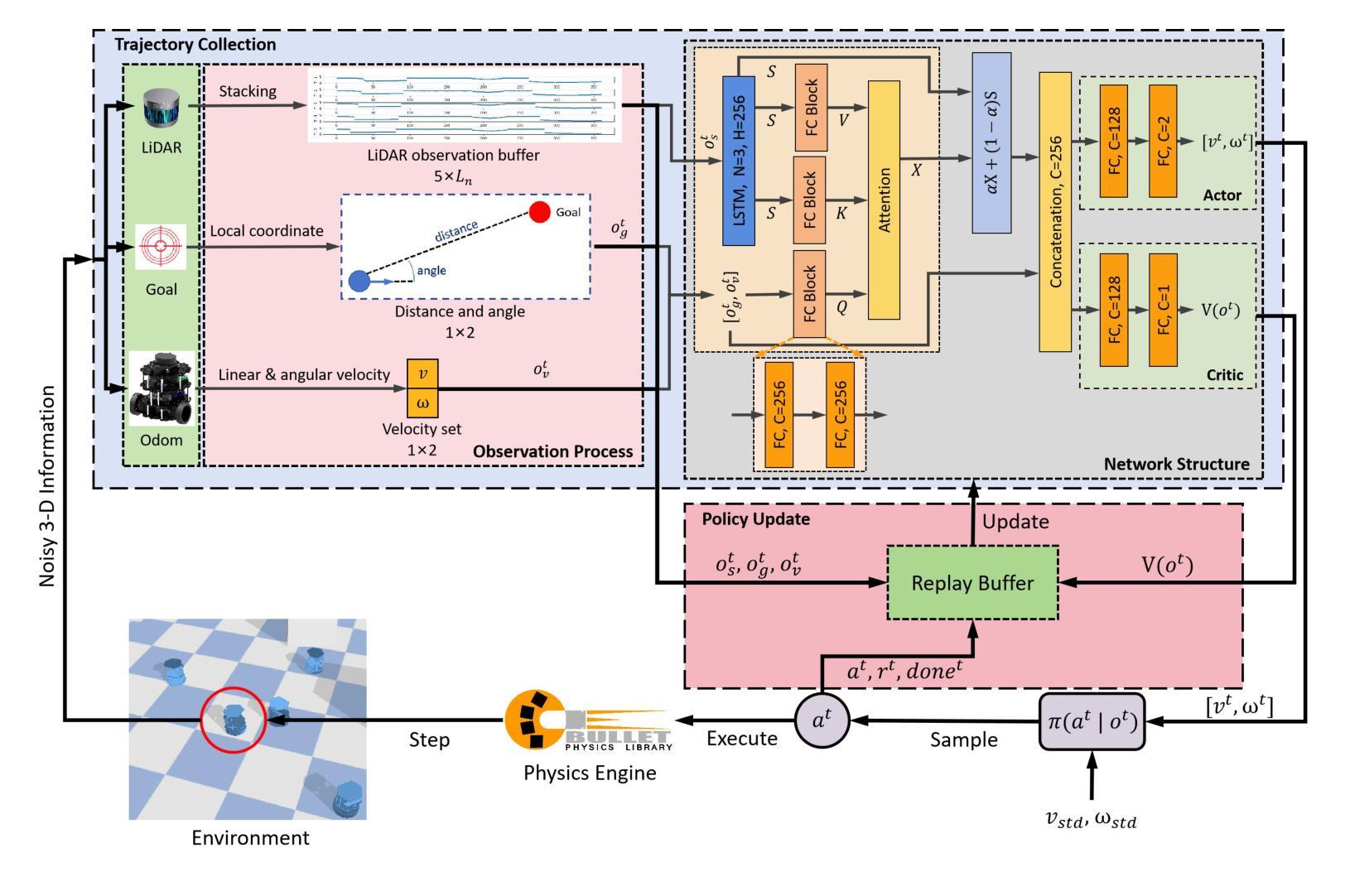
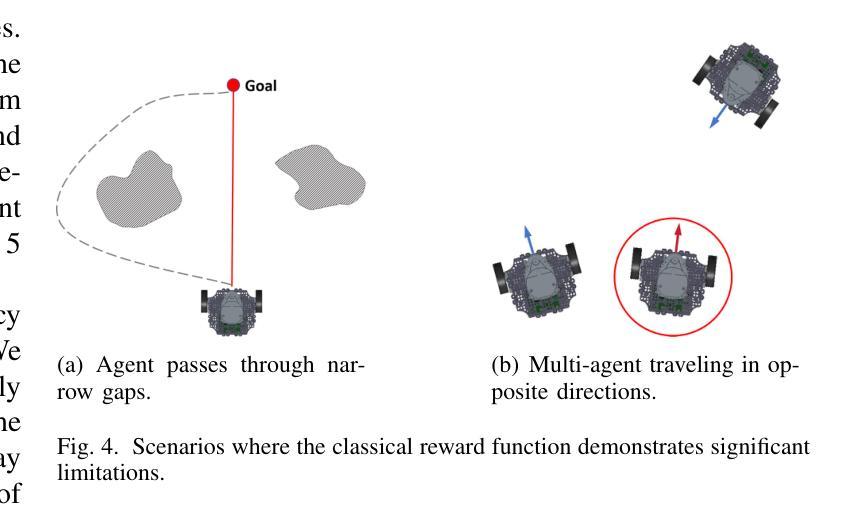
Efficient Multi-agent Navigation with Lightweight DRL Policy
Authors:Xingrong Diao, Jiankun Wang
In this article, we present an end-to-end collision avoidance policy based on deep reinforcement learning (DRL) for multi-agent systems, demonstrating encouraging outcomes in real-world applications. In particular, our policy calculates the control commands of the agent based on the raw LiDAR observation. In addition, the number of parameters of the proposed basic model is 140,000, and the size of the parameter file is 3.5 MB, which allows the robot to calculate the actions from the CPU alone. We propose a multi-agent training platform based on a physics-based simulator to further bridge the gap between simulation and the real world. The policy is trained on a policy-gradients-based RL algorithm in a dense and messy training environment. A novel reward function is introduced to address the issue of agents choosing suboptimal actions in some common scenarios. Although the data used for training is exclusively from the simulation platform, the policy can be successfully transferred and deployed in real-world robots. Finally, our policy effectively responds to intentional obstructions and avoids collisions. The website is available at https://sites.google.com/view/xingrong2024efficient/%E9%A6%96%E9%A1%B5.
本文介绍了一种基于深度强化学习(DRL)的端到端碰撞避免策略,适用于多智能体系统,并在实际应用中取得了令人鼓舞的效果。我们的策略根据原始的激光雷达观测结果计算智能体的控制命令。此外,所提出的基础模型的参数数量为14万个,参数文件大小为3.5MB,使得机器人能够仅通过CPU计算动作。我们提出了一种基于物理模拟器的多智能体训练平台,以进一步弥合仿真与现实之间的差距。该策略在密集而混乱的训练环境中,采用基于策略梯度的强化学习算法进行训练。为解决智能体在某些常见场景中选择次优动作的问题,引入了一种新型奖励函数。虽然训练数据完全来自仿真平台,但策略可以成功转移到实际机器人中进行部署。最后,我们的策略可以有效地应对有意阻碍的情况,避免碰撞。[网站地址为:https://sites.google.com/view/xingrong2024efficient/%E9%A6%96%E9%A1%B5。]
论文及项目相关链接
Summary:
本文介绍了一种基于深度强化学习(DRL)的端到端碰撞避免策略,适用于多智能体系统,并在实际应用中表现出良好效果。该策略根据激光雷达的原始观测计算智能体的控制命令,利用物理模拟器建立多智能体训练平台以缩小模拟与现实的差距。该策略通过引入新型奖励函数解决了智能体在某些常见场景中选取次优动作的问题,训练数据全部来自仿真平台,但策略可成功转移并部署到实际机器人中,有效应对故意阻碍并避免碰撞。
Key Takeaways:
- 基于深度强化学习(DRL)的碰撞避免策略在多智能体系统中实现有效应用。
- 策略根据激光雷达观测数据计算智能体的控制命令。
- 提出一种多智能体训练平台,利用物理模拟器缩小模拟与现实的差距。
- 引入新型奖励函数解决智能体在常见场景中选取次优动作的问题。
- 训练数据完全来自仿真平台,但策略可成功应用于实际机器人。
- 策略对故意阻碍作出有效响应并具备碰撞避免能力。
点此查看论文截图




Multi-Agent Causal Discovery Using Large Language Models
Authors:Hao Duong Le, Xin Xia, Zhang Chen
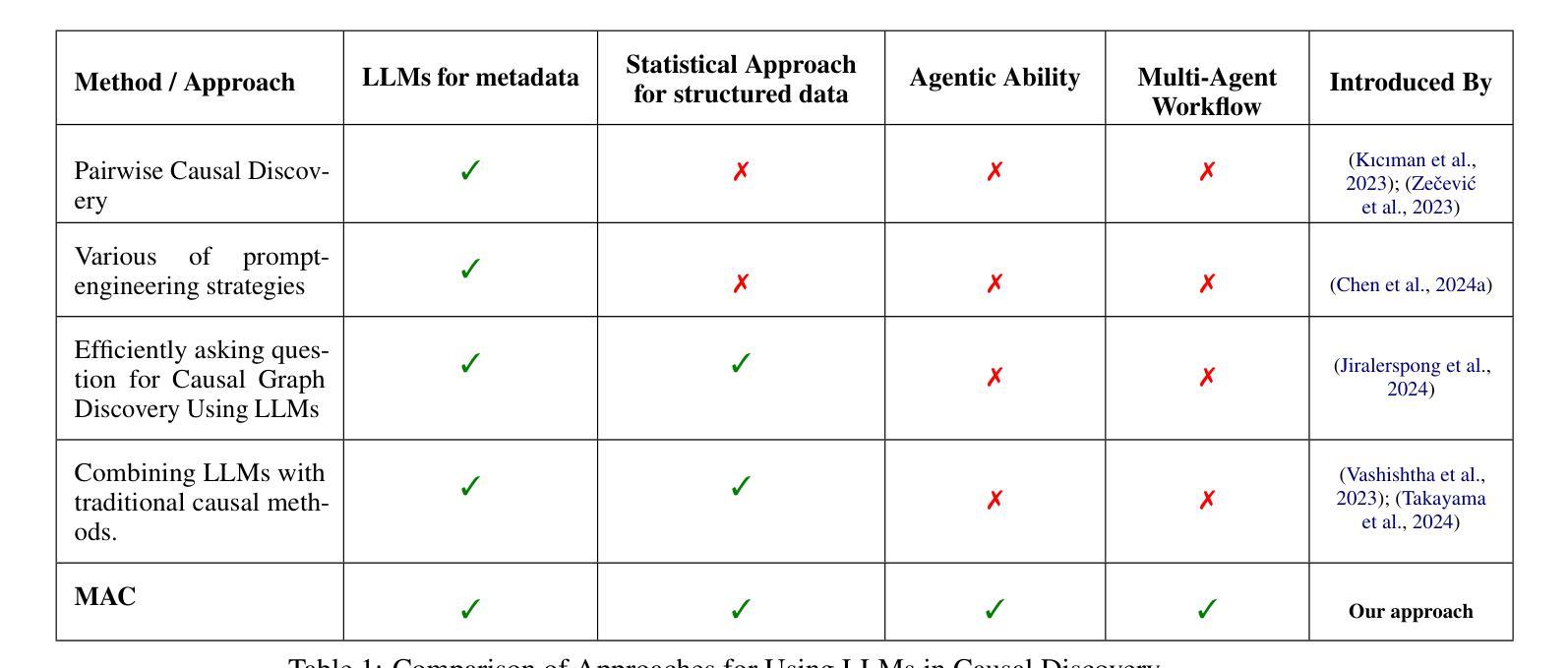
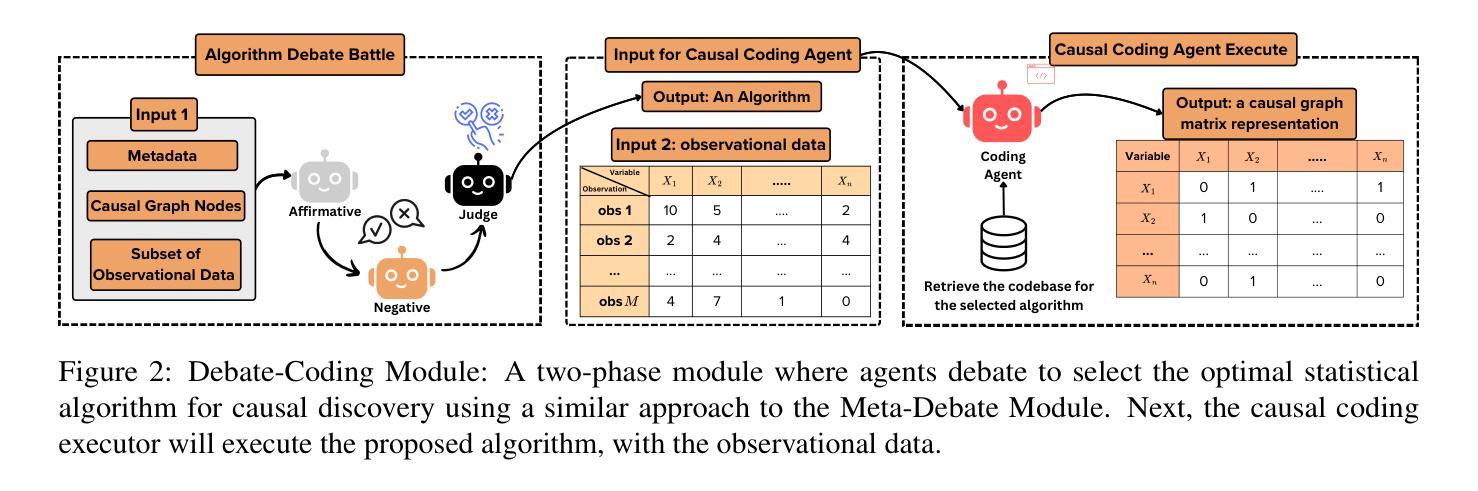
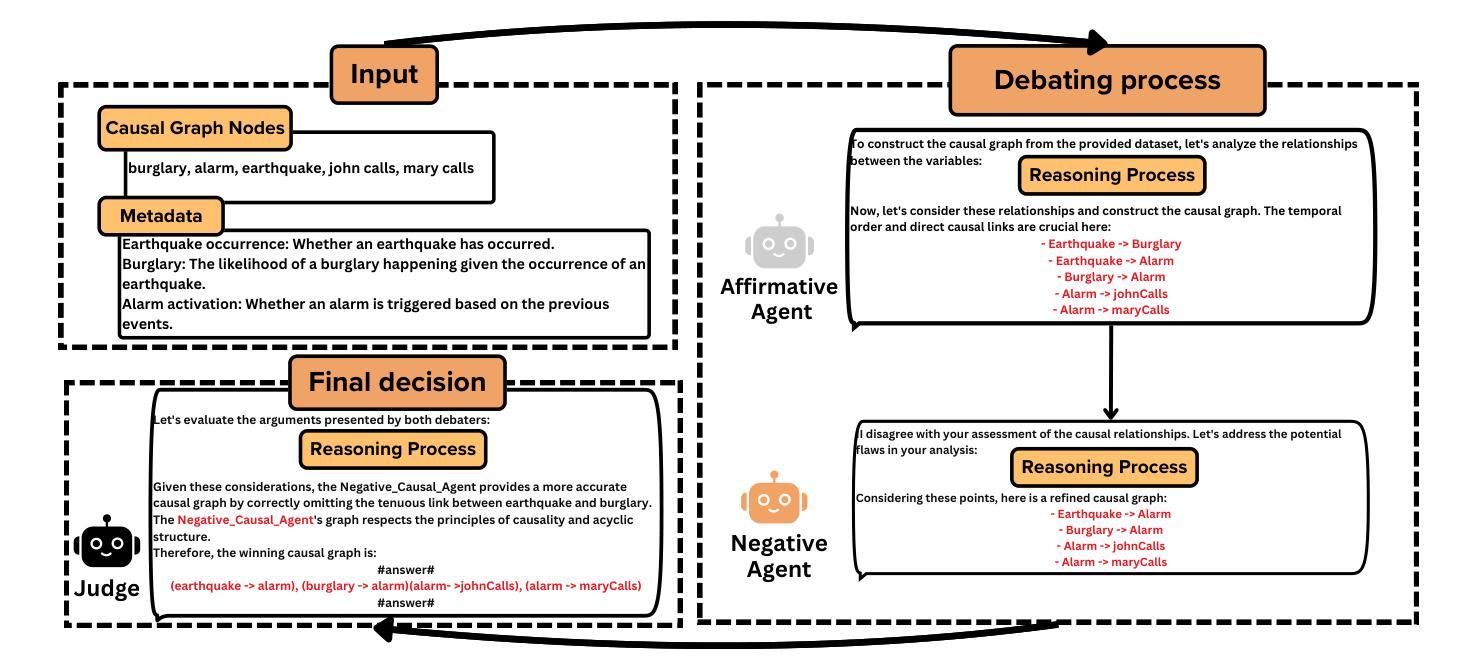
Causal discovery aims to identify causal relationships between variables and is a critical research area in machine learning. Traditional methods focus on statistical or machine learning algorithms to uncover causal links from structured data, often overlooking the valuable contextual information provided by metadata. Large language models (LLMs) have shown promise in creating unified causal discovery frameworks by incorporating both structured data and metadata. However, their potential in multi-agent settings remains largely unexplored. To address this gap, we introduce the Multi-Agent Causal Discovery Framework (MAC), which consists of two key modules: the Debate-Coding Module (DCM) and the Meta-Debate Module (MDM). The DCM begins with a multi-agent debating and coding process, where agents use both structured data and metadata to collaboratively select the most suitable statistical causal discovery (SCD) method. The selected SCD is then applied to the structured data to generate an initial causal graph. This causal graph is transformed into causal metadata through the Meta Fusion mechanism. With all the metadata, MDM then refines the causal structure by leveraging a multi-agent debating framework. Extensive experiments across five datasets demonstrate that MAC outperforms both traditional statistical causal discovery methods and existing LLM-based approaches, achieving state-of-the-art performance.
因果发现旨在确定变量之间的因果关系,是机器学习中的一个关键研究领域。传统方法主要关注统计或机器学习算法,从结构化数据中挖掘因果关系,往往忽视了元数据提供的宝贵上下文信息。大型语言模型(LLM)通过结合结构化数据和元数据,在创建统一的因果发现框架方面显示出潜力。然而,它们在多智能体环境中的潜力尚未得到充分探索。为了弥补这一空白,我们引入了多智能体因果发现框架(MAC),它包括两个关键模块:辩论编码模块(DCM)和元辩论模块(MDM)。DCM开始于多智能体辩论和编码过程,智能体使用结构化数据和元数据协同选择最合适的统计因果发现(SCD)方法。然后应用所选的SCD到结构化数据上,生成初始因果图。该因果图通过元融合机制转化为因果元数据。利用所有的元数据,MDM然后利用多智能体辩论框架对因果结构进行细化。在五个数据集上的大量实验表明,MAC优于传统的统计因果发现方法和现有的LLM方法,达到了最先进的性能。
论文及项目相关链接
Summary
本文介绍了因果发现的重要性及其在传统方法中的局限性,包括在数据中的忽略元数据问题。通过引入大型语言模型,将结构数据和元数据结合起来,能够提高因果发现的准确性。本文提出了一种多智能体因果发现框架(MAC),包含辩论编码模块(DCM)和元辩论模块(MDM)。DCM利用结构数据和元数据,通过多智能体辩论和编码过程选择最合适的统计因果发现方法。经过Meta Fusion机制的转化,这些因果关系最终经过MDM进行优化并给出结论。经过多项实验证明,MAC相对于传统方法和现有的大型语言模型在因果发现领域具有优越的性能。其方法的融合多种模型之间的创新思想和独特设计,使其在多种数据集上实现了最佳性能。
Key Takeaways
以下是文本的主要见解:
- 因果发现旨在确定变量之间的因果关系,是机器学习中的关键研究领域。
- 传统方法主要依赖统计或机器学习算法来发现因果联系,但忽略了元数据提供的上下文信息价值。大型语言模型能在此处融入作用巨大的因素并加强集成系统对于环境动态因素的解析和抓取能力,进一步提高因果关系分析的精准性。本研究为此提出了新的因果发现框架以适应融合方式的要求。这个框架引入了大型语言模型的作用和概念框架的融合创新方法,为解决这一问题提供了新方向。
- 多智能体因果发现框架(MAC)包含两个关键模块:辩论编码模块(DCM)和元辩论模块(MDM)。DCM通过多智能体辩论和编码过程选择最合适的统计因果发现方法;MDM则利用元数据优化和改进因果关系结构。这种组合使得MAC框架能够充分利用结构数据和元数据,从而提高因果发现的准确性。
- 实验结果表明,MAC在多个数据集上实现了最佳性能,优于传统方法和现有的大型语言模型。这证明了MAC框架的有效性和优越性。通过大量实验验证了该方法的稳定性和可靠性,显示出其在实际应用中的潜力。这种多智能体系统因其智能决策、精准计算和适应性强的特点而在不同场景下具有广泛的应用前景。特别是在面对复杂多变的真实世界数据时,它能够灵活应对各种情况并保持性能的稳定输出以精准化发现复杂问题的内在规律性的因素表现表现得出出更为优异优势突出的特点特性。。
点此查看论文截图

Direct Multi-Turn Preference Optimization for Language Agents
Authors:Wentao Shi, Mengqi Yuan, Junkang Wu, Qifan Wang, Fuli Feng
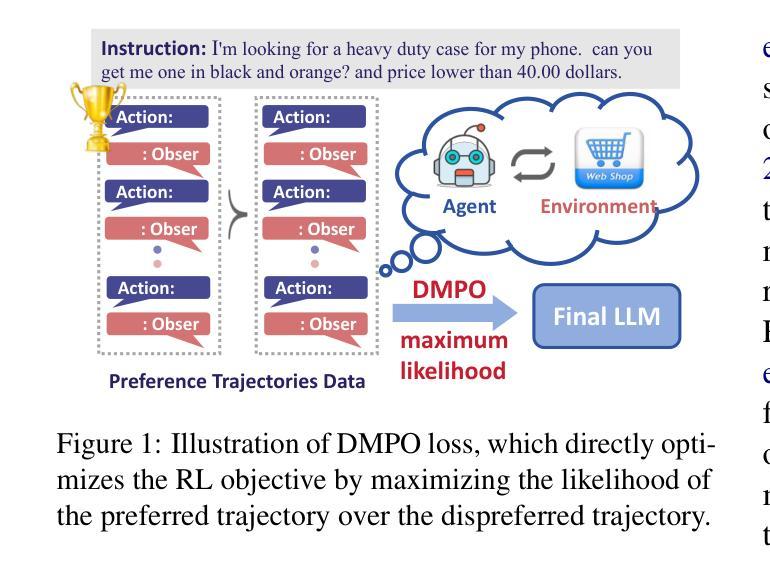
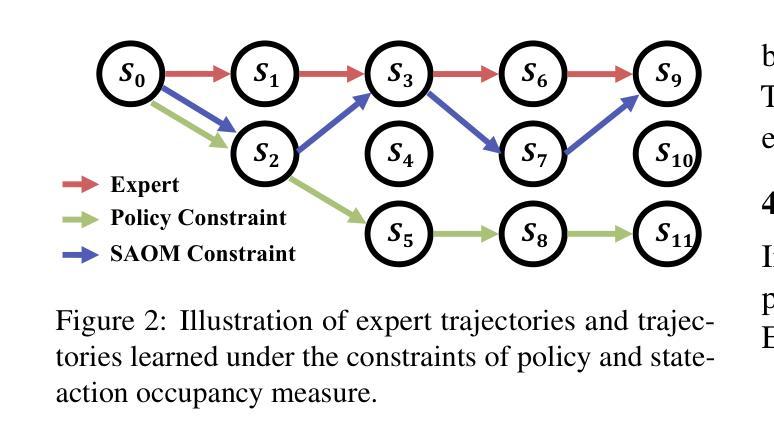
Adapting Large Language Models (LLMs) for agent tasks is critical in developing language agents. Direct Preference Optimization (DPO) is a promising technique for this adaptation with the alleviation of compounding errors, offering a means to directly optimize Reinforcement Learning (RL) objectives. However, applying DPO to multi-turn tasks presents challenges due to the inability to cancel the partition function. Overcoming this obstacle involves making the partition function independent of the current state and addressing length disparities between preferred and dis-preferred trajectories. In this light, we replace the policy constraint with the state-action occupancy measure constraint in the RL objective and add length normalization to the Bradley-Terry model, yielding a novel loss function named DMPO for multi-turn agent tasks with theoretical explanations. Extensive experiments on three multi-turn agent task datasets confirm the effectiveness and superiority of the DMPO loss. The code is available at https://github.com/swt-user/DMPO.
在开发语言代理时,将大型语言模型(LLM)适应代理任务是非常关键的。直接偏好优化(DPO)是一种有前途的技术,可以缓解复合错误,为强化学习(RL)目标提供直接优化的手段。然而,在多轮任务中应用DPO面临着无法取消分区函数的挑战。克服这一障碍需要使分区函数独立于当前状态并解决首选和非首选轨迹之间的长度差异。在此基础上,我们用状态动作占用率度量约束替代策略约束在RL目标中,并为Bradley-Terry模型添加长度归一化,产生一个新的损失函数,名为DMPO,用于多轮代理任务,并有理论解释。在三个多轮代理任务数据集上的大量实验证实了DMPO损失的有效性和优越性。代码位于:https://github.com/swt-user/DMPO。
论文及项目相关链接
PDF Accepted by EMNLP 2024 Main
Summary
大型语言模型(LLM)在开发语言代理任务中的适应至关重要。直接偏好优化(DPO)是一种具有潜力的技术,可以缓解组合错误的问题,为强化学习(RL)目标提供直接优化的手段。然而,在多轮任务中应用DPO面临挑战,克服这一障碍需要使分区函数独立于当前状态并解决首选和未选轨迹之间的长度差异。为此,我们用状态动作占用度量约束替换策略约束,并在Bradley-Terry模型中增加长度归一化,为针对多轮代理任务的损失函数命名为DMPO,并给出理论解释。在三个多轮代理任务数据集上的广泛实验证实了DMPO损失的有效性。有关代码的信息请访问 https://github.com/swt-user/DMPO。
Key Takeaways
- 大型语言模型(LLM)在开发语言代理任务中的适应至关重要。
- 直接偏好优化(DPO)是一种用于适应LLM的有前途的技术,可以缓解组合错误问题。
- 在多轮任务中应用DPO面临挑战,需解决分区函数的独立性和轨迹长度差异问题。
- 提出了一种新型损失函数DMPO,用于多轮代理任务,由状态动作占用度量约束和Bradley-Terry模型的长度归一化组成。
- 在三个多轮代理任务数据集上的实验证实了DMPO损失的有效性。
点此查看论文截图

Anywhere: A Multi-Agent Framework for User-Guided, Reliable, and Diverse Foreground-Conditioned Image Generation
Authors:Tianyidan Xie, Rui Ma, Qian Wang, Xiaoqian Ye, Feixuan Liu, Ying Tai, Zhenyu Zhang, Lanjun Wang, Zili Yi
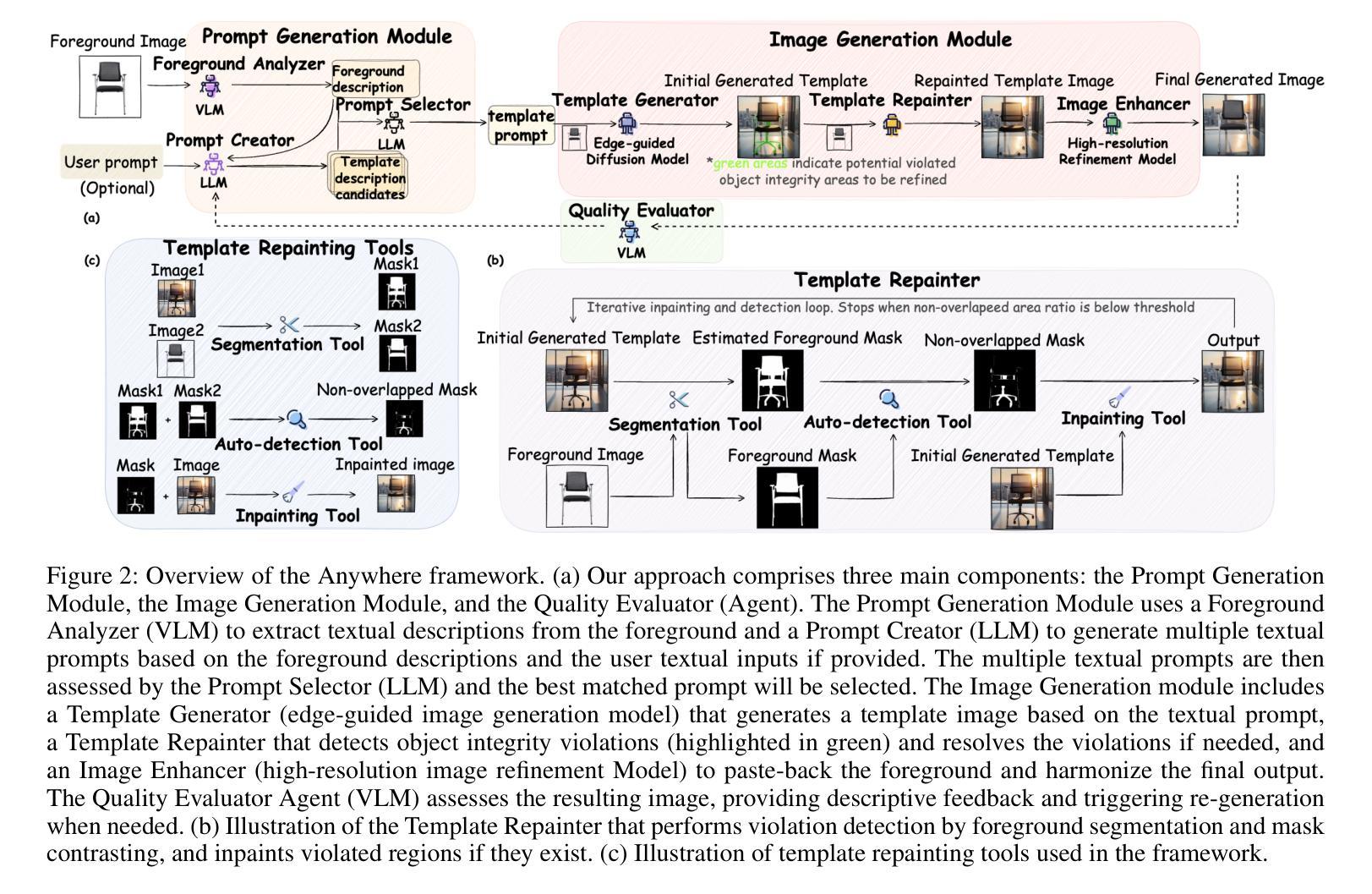
Recent advancements in image-conditioned image generation have demonstrated substantial progress. However, foreground-conditioned image generation remains underexplored, encountering challenges such as compromised object integrity, foreground-background inconsistencies, limited diversity, and reduced control flexibility. These challenges arise from current end-to-end inpainting models, which suffer from inaccurate training masks, limited foreground semantic understanding, data distribution biases, and inherent interference between visual and textual prompts. To overcome these limitations, we present Anywhere, a multi-agent framework that departs from the traditional end-to-end approach. In this framework, each agent is specialized in a distinct aspect, such as foreground understanding, diversity enhancement, object integrity protection, and textual prompt consistency. Our framework is further enhanced with the ability to incorporate optional user textual inputs, perform automated quality assessments, and initiate re-generation as needed. Comprehensive experiments demonstrate that this modular design effectively overcomes the limitations of existing end-to-end models, resulting in higher fidelity, quality, diversity and controllability in foreground-conditioned image generation. Additionally, the Anywhere framework is extensible, allowing it to benefit from future advancements in each individual agent.
在图像条件图像生成方面,最近的进展已经取得了实质性的进步。然而,前景条件图像生成仍然被较少探索,面临着对象完整性受损、前景背景不一致、多样性有限和控制灵活性降低等挑战。这些挑战源于当前端到端的补全模型,这些模型受到训练掩模不准确、前景语义理解有限、数据分布偏见以及视觉和文字提示之间固有干扰的影响。为了克服这些局限性,我们推出了Anywhere,这是一个多智能体框架,它偏离了传统的端到端方法。在此框架中,每个智能体都专门负责一个特定的方面,如前景理解、多样性增强、对象完整性保护和文本提示一致性等。我们的框架还增强了加入可选用户文本输入、执行自动化质量评估和根据需要启动重新生成的能力。综合实验表明,这种模块化设计有效地克服了现有端到端模型的局限性,在前景条件图像生成方面实现了更高的保真度、质量、多样性和可控性。此外,Anywhere框架具有可扩展性,可以从每个独立智能体的未来进步中受益。
论文及项目相关链接
PDF 18 pages, 15 figures, project page: https://anywheremultiagent.github.io, Accepted at AAAI 2025
总结
近期,图像条件图像生成领域取得了显著进展,但前景条件图像生成仍然被较少探索。面临对象完整性受损、前景背景不一致、多样性有限和控制灵活性降低等挑战。这些挑战源于当前端到端的填充模型,存在训练掩模不准确、前景语义理解有限、数据分布偏见以及视觉和文字提示之间的固有干扰等问题。为了克服这些限制,我们提出了Anywhere多智能体框架,它突破了传统的端到端方法。在此框架中,每个智能体都专门负责一个特定的方面,如前景理解、多样性增强、对象完整性保护和文本提示一致性等。我们的框架还增强了加入用户文本输入、进行自动质量评估和需要时启动重新生成的能力。综合实验表明,这种模块化设计有效地克服了现有端到端模型的局限性,在前景条件图像生成中实现了更高的保真度、质量、多样性和可控性。此外,Anywhere框架具有可扩展性,可以从各个独立智能体的未来进步中受益。
关键见解
- 前景条件图像生成面临挑战,如对象完整性受损和前景背景不一致。
- 当前端到端模型存在训练掩模不准确、前景语义理解有限等问题。
- Anywhere多智能体框架突破传统方法,每个智能体处理特定任务。
- 框架具备用户交互、自动质量评估和再生成能力。
- 模块化设计有效克服现有端到端模型局限性,提高图像生成的保真度、质量、多样性和可控性。
- Anywhere框架具有可扩展性,可适应未来技术进步。
点此查看论文截图



Self-Confirming Transformer for Belief-Conditioned Adaptation in Offline Multi-Agent Reinforcement Learning
Authors:Tao Li, Juan Guevara, Xinhong Xie, Quanyan Zhu
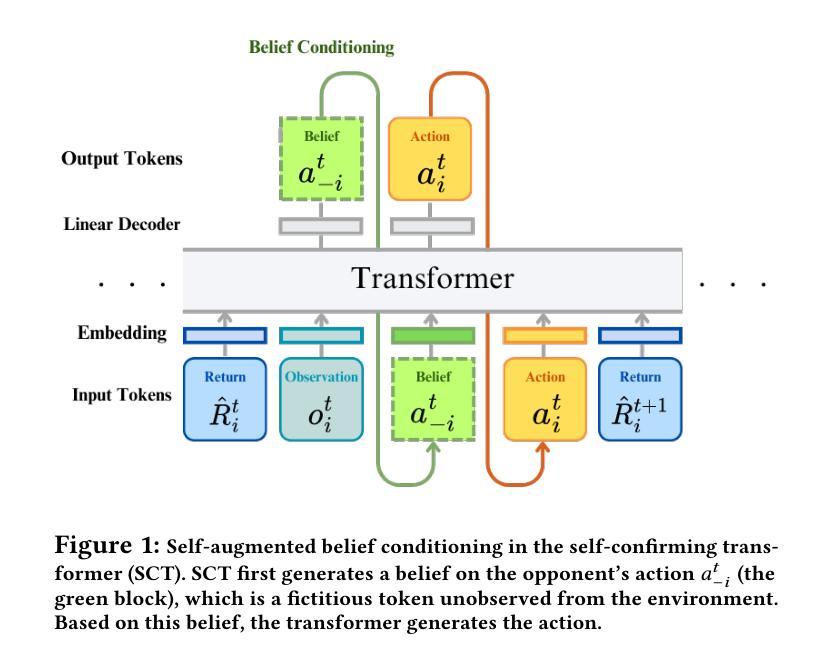
Offline reinforcement learning (RL) suffers from the distribution shift between the offline dataset and the online environment. In multi-agent RL (MARL), this distribution shift may arise from the nonstationary opponents in the online testing who display distinct behaviors from those recorded in the offline dataset. Hence, the key to the broader deployment of offline MARL is the online adaptation to nonstationary opponents. Recent advances in foundation models, e.g., large language models, have demonstrated the generalization ability of the transformer, an emerging neural network architecture, in sequence modeling, of which offline RL is a special case. One naturally wonders \textit{whether offline-trained transformer-based RL policies adapt to nonstationary opponents online}. We propose a novel auto-regressive training to equip transformer agents with online adaptability based on the idea of self-augmented pre-conditioning. The transformer agent first learns offline to predict the opponent’s action based on past observations. When deployed online, such a fictitious opponent play, referred to as the belief, is fed back to the transformer, together with other environmental feedback, to generate future actions conditional on the belief. Motivated by self-confirming equilibrium in game theory, the training loss consists of belief consistency loss, requiring the beliefs to match the opponent’s actual actions and best response loss, mandating the agent to behave optimally under the belief. We evaluate the online adaptability of the proposed self-confirming transformer (SCT) in a structured environment, iterated prisoner’s dilemma games, to demonstrate SCT’s belief consistency and equilibrium behaviors as well as more involved multi-particle environments to showcase its superior performance against nonstationary opponents over prior transformers and offline MARL baselines.
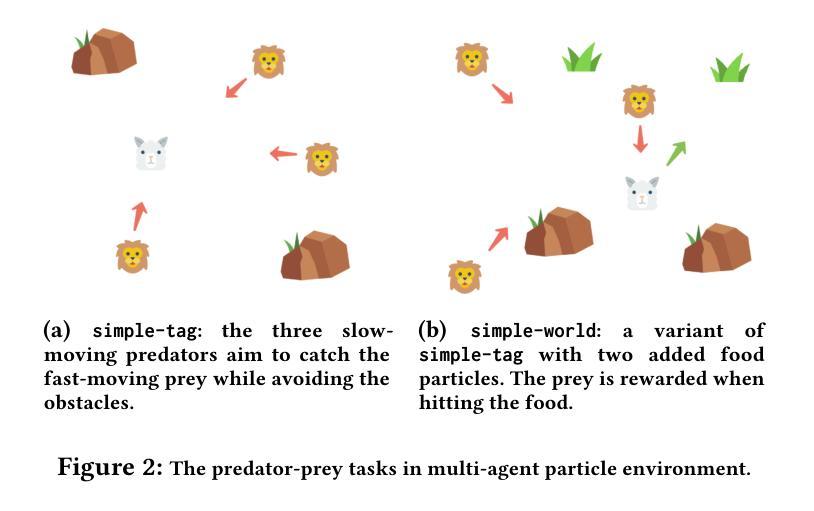
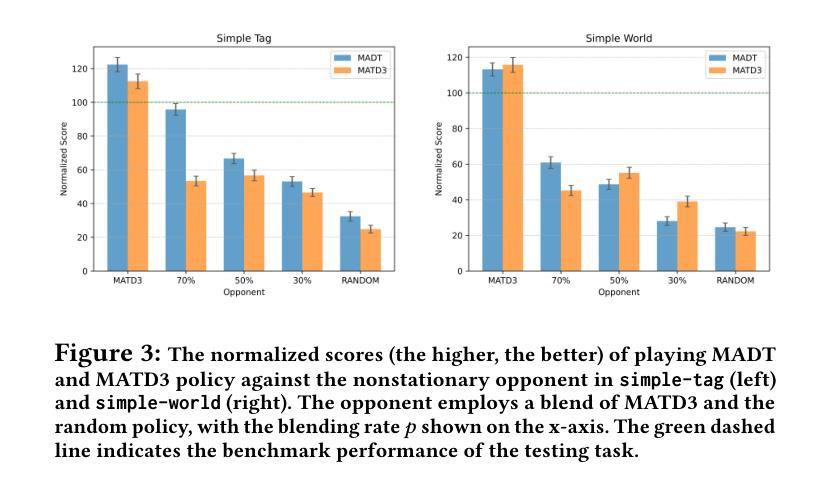
离线强化学习(RL)面临着离线数据集和在线环境之间的分布偏移问题。在多智能体强化学习(MARL)中,这种分布偏移可能源于在线测试中非稳定对手的出现,这些对手的行为与离线数据集中记录的行为截然不同。因此,离线MARL更广泛部署的关键在于对在线非稳定对手的适应。最近的进展,如基础模型中的大型语言模型,展示了transformer的泛化能力。Transformer是一种新兴神经网络架构,在序列建模中具有特殊的应用场景,其中包括离线RL。人们自然会好奇的是,“基于离线训练的transformer的RL策略是否适应在线的非稳定对手”。我们提出了一种新颖的自动回归训练,基于自我增强预处理的理念,为transformer智能体提供在线适应性。Transformer智能体首先学习基于过去的观察预测对手的行动。当在线部署时,这种虚构的对手游戏(称为信念)会反馈给transformer,以及其他环境反馈一起,根据信念生成未来的行动。受博弈论中的自我确认均衡的启发,训练损失包括信念一致性损失,要求信念与对手的实际行动相匹配,以及最佳响应损失,要求智能体在信念下以最优方式表现。我们在结构化环境中评估所提出的自我确认变压器(SCT)的在线适应性,包括重复的囚徒困境游戏,以展示SCT的信念一致性、均衡行为以及在面对非稳定对手时优于先前transformer和离线MARL基准测试的表现。
论文及项目相关链接
Summary
离线强化学习(RL)面临离线数据集和在线环境之间的分布偏移问题。在多智能体强化学习(MARL)中,这种分布偏移可能源于在线测试中的非平稳对手,他们的行为与离线数据集记录的行为截然不同。因此,离线MARL广泛部署的关键在于在线适应非平稳对手的能力。最近,基础模型(如大型语言模型)中的进展展示了transformer在序列建模中的泛化能力,而离线RL是其中的特例。本文提出了基于自增预处理的自动回归训练,为transformer智能体配备在线适应性。该训练损失包括信念一致性损失和最佳响应损失,要求智能体在信念下表现出最优行为。我们在结构化环境中评估了所提出的自确认transformer(SCT)的在线适应性,以展示其在面对非平稳对手时的优越性能。
Key Takeaways
- 离线强化学习(RL)和多智能体强化学习(MARL)面临在线环境与离线数据集之间的分布偏移问题。
- 非平稳对手在在线测试中的行为可能与离线数据集记录的行为显著不同。
- 在线适应非平稳对手是离线MARL广泛部署的关键。
- 基础模型的进展,特别是大型语言模型中的transformer,展示了其在序列建模中的泛化能力。
- 本文提出了基于自增预处理的自动回归训练,以提高transformer智能体的在线适应性。
- 训练损失包括信念一致性损失和最佳响应损失,以确保智能体在信念下表现出最优行为。
点此查看论文截图