⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-26 更新
GCC: Generative Color Constancy via Diffusing a Color Checker
Authors:Chen-Wei Chang, Cheng-De Fan, Chia-Che Chang, Yi-Chen Lo, Yu-Chee Tseng, Jiun-Long Huang, Yu-Lun Liu
Color constancy methods often struggle to generalize across different camera sensors due to varying spectral sensitivities. We present GCC, which leverages diffusion models to inpaint color checkers into images for illumination estimation. Our key innovations include (1) a single-step deterministic inference approach that inpaints color checkers reflecting scene illumination, (2) a Laplacian decomposition technique that preserves checker structure while allowing illumination-dependent color adaptation, and (3) a mask-based data augmentation strategy for handling imprecise color checker annotations. GCC demonstrates superior robustness in cross-camera scenarios, achieving state-of-the-art worst-25% error rates of 5.15{\deg} and 4.32{\deg} in bi-directional evaluations. These results highlight our method’s stability and generalization capability across different camera characteristics without requiring sensor-specific training, making it a versatile solution for real-world applications.
颜色恒常法方法往往由于不同的光谱敏感性而在不同相机传感器上难以推广。我们提出了GCC,它利用扩散模型将颜色条填充到图像中进行光照估计。我们的关键创新包括:(1) 单步确定性推理方法,用于填充反映场景光照的颜色条;(2) 拉普拉斯分解技术,能够在保留棋盘结构的同时实现光照相关的颜色适应;(3) 基于掩码的增广策略,用于处理不精确的颜色条标注。GCC在跨相机场景中表现出卓越的鲁棒性,在双向评估中实现了最先进的最低25%错误率为5.15°和4.32°,这些结果凸显了我们的方法在不需要针对传感器进行特定训练的情况下,在不同相机特性上的稳定性和泛化能力,使其成为现实世界应用中的通用解决方案。
论文及项目相关链接
PDF Project page: https://chenwei891213.github.io/GCC/
Summary
本文提出了GCC方法,利用扩散模型对图像中的颜色检查器进行修复以进行照明估计。主要创新包括单步确定性推理方法、拉普拉斯分解技术和基于掩膜的增广策略。GCC在跨相机场景中表现出出色的鲁棒性,在双向评估中实现了最低25%的错误率为5.15°和4.32°,展示了其稳定性和在不同相机特性下的泛化能力,无需针对传感器进行特定训练,使其成为真实世界应用的通用解决方案。
Key Takeaways
- GCC利用扩散模型修复图像中的颜色检查器以进行照明估计。
- 采用单步确定性推理方法修复反映场景照明的颜色检查器。
- 采用拉普拉斯分解技术保留了颜色检查器的结构,同时实现了光照依赖的色彩适应。
- 提出了一种基于掩膜的数据增强策略来处理不精确的颜色检查器注释。
- GCC在跨相机场景中表现出出色的鲁棒性。
- 在双向评估中,GCC实现了最低25%的错误率为5.15°和4.32°,展现了其优秀性能。
点此查看论文截图



X-Dancer: Expressive Music to Human Dance Video Generation
Authors:Zeyuan Chen, Hongyi Xu, Guoxian Song, You Xie, Chenxu Zhang, Xin Chen, Chao Wang, Di Chang, Linjie Luo
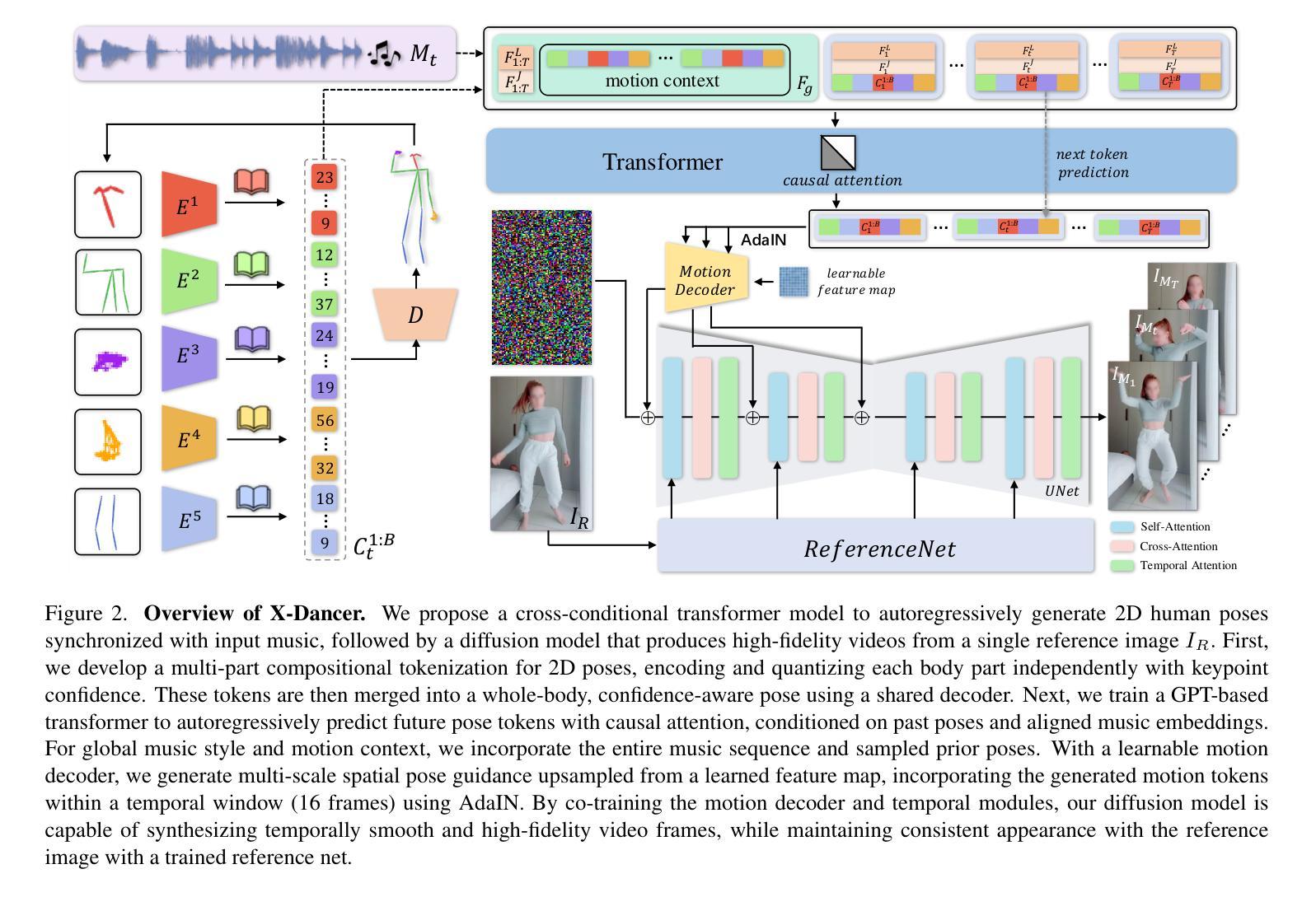
We present X-Dancer, a novel zero-shot music-driven image animation pipeline that creates diverse and long-range lifelike human dance videos from a single static image. As its core, we introduce a unified transformer-diffusion framework, featuring an autoregressive transformer model that synthesize extended and music-synchronized token sequences for 2D body, head and hands poses, which then guide a diffusion model to produce coherent and realistic dance video frames. Unlike traditional methods that primarily generate human motion in 3D, X-Dancer addresses data limitations and enhances scalability by modeling a wide spectrum of 2D dance motions, capturing their nuanced alignment with musical beats through readily available monocular videos. To achieve this, we first build a spatially compositional token representation from 2D human pose labels associated with keypoint confidences, encoding both large articulated body movements (e.g., upper and lower body) and fine-grained motions (e.g., head and hands). We then design a music-to-motion transformer model that autoregressively generates music-aligned dance pose token sequences, incorporating global attention to both musical style and prior motion context. Finally we leverage a diffusion backbone to animate the reference image with these synthesized pose tokens through AdaIN, forming a fully differentiable end-to-end framework. Experimental results demonstrate that X-Dancer is able to produce both diverse and characterized dance videos, substantially outperforming state-of-the-art methods in term of diversity, expressiveness and realism. Code and model will be available for research purposes.
我们介绍了X-Dancer,这是一种新型零样本音乐驱动图像动画管道,它可以从单个静态图像中创建多样且长程的逼真人类舞蹈视频。其核心是统一transformer扩散框架,它包含一个自回归transformer模型,该模型能够合成扩展的并与音乐同步的令牌序列,用于表示2D身体、头部和手部姿势。然后这些令牌序列引导扩散模型生成连贯且逼真的舞蹈视频帧。与传统的主要在3D中生成人类运动的方法不同,X-Dancer通过建模大量的2D舞蹈动作来解决数据限制并增强可扩展性,并通过可用的单目视频捕捉其与音乐节奏的微妙对齐。为了实现这一点,我们首先根据与关键点置信度相关的2D人类姿势标签构建空间组合令牌表示,编码大型关节身体运动(例如,上半身和下半身)和精细运动(例如,头部和手部)。然后我们设计了一个音乐到运动的transformer模型,该模型可以自回归地生成与音乐对齐的舞蹈姿势令牌序列,并通过全局注意力来关注音乐风格和先前的运动上下文。最后,我们利用扩散主干将这些合成的姿势令牌通过AdaIN技术使参考图像动起来,形成一个完全可微分的端到端框架。实验结果表明,X-Dancer能够产生多样且特征鲜明的舞蹈视频,在多样性、表现力和逼真度方面大大优于现有先进方法。代码和模型将供研究使用。
论文及项目相关链接
Summary
基于给定的文本摘要,X-Dancer是一个零样本音乐驱动图像动画管道,能够从单一静态图像创建多样且长程逼真的舞蹈视频。其核心是一个统一的转换器扩散框架,包含一个自回归转换器模型,该模型合成扩展且与音乐同步的令牌序列,用于指导扩散模型产生连贯且逼真的舞蹈视频帧。与传统方法相比,X-Dancer主要解决数据局限性问题并通过模拟大量二维舞蹈动作增强其可扩展性,从而捕捉其与音乐节奏的微妙对齐。目前实验结果证实X-Dancer能够产生多样且富有特色的舞蹈视频,在多样性、表现力和逼真度方面大大优于现有先进技术方法。代码和模型可供研究之用。
Key Takeaways
- X-Dancer是一个零样本音乐驱动图像动画管道,能够创建多样且逼真的舞蹈视频。
- 核心是一个统一的转换器扩散框架,包含自回归转换器模型和扩散模型。
- 自回归转换器模型合成与音乐同步的令牌序列,用于指导生成连贯且逼真的舞蹈视频帧。
- X-Dancer通过模拟二维舞蹈动作解决数据局限性问题并增强可扩展性。
- 它能够捕捉舞蹈动作与音乐节奏的微妙对齐。
- X-Dancer产生的舞蹈视频在多样性、表现力和逼真度方面优于现有技术方法。
点此查看论文截图


DICEPTION: A Generalist Diffusion Model for Visual Perceptual Tasks
Authors:Canyu Zhao, Mingyu Liu, Huanyi Zheng, Muzhi Zhu, Zhiyue Zhao, Hao Chen, Tong He, Chunhua Shen
Our primary goal here is to create a good, generalist perception model that can tackle multiple tasks, within limits on computational resources and training data. To achieve this, we resort to text-to-image diffusion models pre-trained on billions of images. Our exhaustive evaluation metrics demonstrate that DICEPTION effectively tackles multiple perception tasks, achieving performance on par with state-of-the-art models. We achieve results on par with SAM-vit-h using only 0.06% of their data (e.g., 600K vs. 1B pixel-level annotated images). Inspired by Wang et al., DICEPTION formulates the outputs of various perception tasks using color encoding; and we show that the strategy of assigning random colors to different instances is highly effective in both entity segmentation and semantic segmentation. Unifying various perception tasks as conditional image generation enables us to fully leverage pre-trained text-to-image models. Thus, DICEPTION can be efficiently trained at a cost of orders of magnitude lower, compared to conventional models that were trained from scratch. When adapting our model to other tasks, it only requires fine-tuning on as few as 50 images and 1% of its parameters. DICEPTION provides valuable insights and a more promising solution for visual generalist models.
我们的主要目标是在有限的计算资源和训练数据下,创建一个能够处理多种任务的优秀通用感知模型。为实现这一目标,我们采用在数十亿图像上预先训练的文本到图像扩散模型。我们的全面评估指标表明,DICEPTION有效地解决了多个感知任务,其性能与最新模型相当。我们使用仅为其数据量的0.06%(例如,60万对比1亿像素级注释图像)就达到了与SAM-vit-h相当的结果。DICEPTION受到Wang等人的启发,通过颜色编码来表述各种感知任务的输出;我们证明,为不同实例分配随机颜色的策略在实体分割和语义分割中都极为有效。将各种感知任务统一为条件图像生成,使我们能够充分利用预先训练的文本到图像模型。因此,与从头开始训练的常规模型相比,DICEPTION的训练成本大大降低,效率极高。当将我们的模型适应到其他任务时,它只需要在少量(仅50张图像)上进行微调,且只需使用其参数的1%。DICEPTION为视觉通用模型提供了有价值的见解和更有前景的解决方案。
论文及项目相关链接
PDF 29 pages, 20 figures
Summary
本文旨在创建能够在多个任务上表现良好的通用感知模型,采用文本到图像的扩散模型预训练于大量图像数据。通过全面的评估指标,显示DICEPTION在多个感知任务上表现优异,与最新模型性能相当。通过使用颜色编码策略,DICEPTION在各种感知任务中表现出色,通过随机颜色区分不同实例。通过将各种感知任务统一为条件图像生成,充分利用预训练的文本到图像模型,训练成本大幅降低。此外,该模型适应新任务时仅需微调少量图像和参数。DICEPTION为视觉通用模型提供了有价值的见解和更有前景的解决方案。
Key Takeaways
- 目标创建能够在多个任务上表现良好的通用感知模型,受到计算资源和训练数据的限制。
- 采用文本到图像的扩散模型进行预训练,涉及大量图像数据。
- DICEPTION通过多种感知任务表现出色,与最新模型性能相当。
- DICEPTION利用颜色编码策略来区分不同的实例,这一策略在实体分割和语义分割中都有效。
- 通过将感知任务统一为条件图像生成,充分利用预训练文本到图像模型的优势。
- 训练成本大幅降低,与传统从头开始训练的模型相比效果显著。
点此查看论文截图


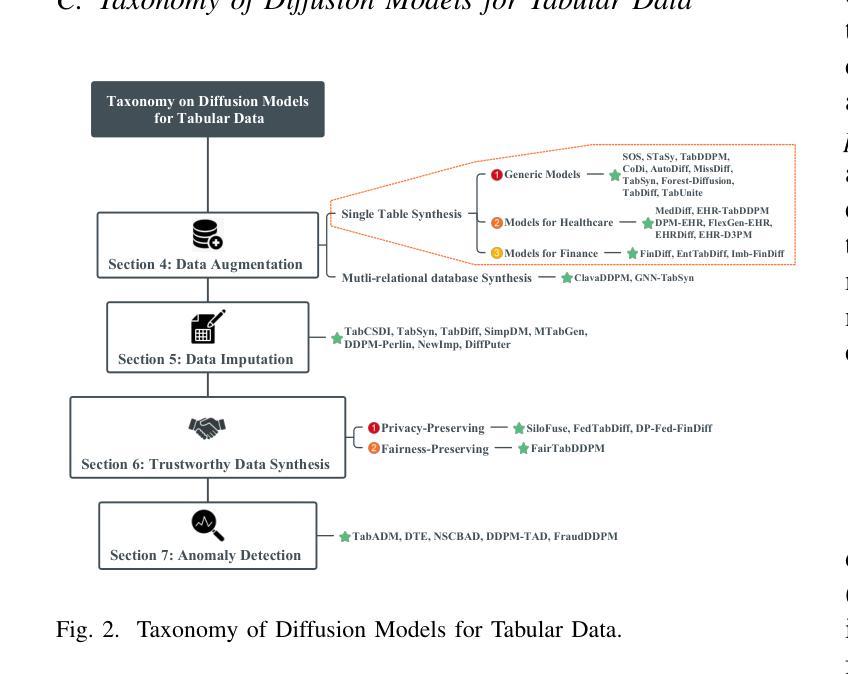
Diffusion Models for Tabular Data: Challenges, Current Progress, and Future Directions
Authors:Zhong Li, Qi Huang, Lincen Yang, Jiayang Shi, Zhao Yang, Niki van Stein, Thomas Bäck, Matthijs van Leeuwen
In recent years, generative models have achieved remarkable performance across diverse applications, including image generation, text synthesis, audio creation, video generation, and data augmentation. Diffusion models have emerged as superior alternatives to Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) by addressing their limitations, such as training instability, mode collapse, and poor representation of multimodal distributions. This success has spurred widespread research interest. In the domain of tabular data, diffusion models have begun to showcase similar advantages over GANs and VAEs, achieving significant performance breakthroughs and demonstrating their potential for addressing unique challenges in tabular data modeling. However, while domains like images and time series have numerous surveys summarizing advancements in diffusion models, there remains a notable gap in the literature for tabular data. Despite the increasing interest in diffusion models for tabular data, there has been little effort to systematically review and summarize these developments. This lack of a dedicated survey limits a clear understanding of the challenges, progress, and future directions in this critical area. This survey addresses this gap by providing a comprehensive review of diffusion models for tabular data. Covering works from June 2015, when diffusion models emerged, to December 2024, we analyze nearly all relevant studies, with updates maintained in a \href{https://github.com/Diffusion-Model-Leiden/awesome-diffusion-models-for-tabular-data}{GitHub repository}. Assuming readers possess foundational knowledge of statistics and diffusion models, we employ mathematical formulations to deliver a rigorous and detailed review, aiming to promote developments in this emerging and exciting area.
近年来,生成模型在多种应用中都取得了显著的成效,包括图像生成、文本合成、音频创作、视频生成和数据增强。扩散模型通过解决生成对抗网络(GANs)和变分自编码器(VAEs)存在的训练不稳定、模式崩溃以及多模态分布表示不佳等局限性,成为其优秀替代品。这一成功引发了广泛的研究兴趣。在表格数据领域,扩散模型开始显示出对GANs和VAEs的类似优势,在性能上取得了重大突破,并显示出解决表格数据建模中的独特挑战的潜力。然而,尽管图像和时间序列等领域有许多关于扩散模型的进展调查,但表格数据的文献中仍存在明显空白。尽管对表格数据的扩散模型的兴趣日益增加,但很少有人系统地回顾和总结这些发展。缺乏专门的调查限制了对这一关键领域的挑战、进展和未来方向的理解。本调查通过提供表格数据的扩散模型的全面回顾来填补这一空白。我们从2015年6月扩散模型出现的时候开始,到2024年12月,分析了几乎所有的相关研究,更新内容维护在一个GitHub仓库中。假设读者具备统计学和扩散模型的基础知识,我们采用数学公式来提供严谨详细的评论,旨在促进这一新兴和激动人心领域的发展。
论文及项目相关链接
Summary
该文介绍了扩散模型在图像生成、文本合成、音频创建、视频生成和数据增强等多个领域取得的显著成果。扩散模型作为生成对抗网络(GANs)和变分自编码器(VAEs)的替代方案,解决了它们的训练不稳定、模式崩溃和多模态分布表示不佳等问题。文章指出,扩散模型在表格数据领域也开始展现出优势,取得了显著的性能突破,并有可能解决表格数据建模中的独特挑战。然而,尽管图像和时间序列等领域已经有许多关于扩散模型的调查,但表格数据领域的文献仍存在显著差距。尽管扩散模型在表格数据中的应用越来越受欢迎,但很少有人系统地回顾和总结这些发展。本文旨在填补这一空白,提供一个全面的扩散模型表格数据回顾。文章涵盖了从2015年扩散模型出现到2024年相关研究的基本情况,并更新了维护的相关研究内容,目标是推动这一新兴领域的进步。
Key Takeaways
- 扩散模型已在多个领域包括图像生成等展现出显著性能优势。
- 扩散模型解决了生成对抗网络和变分自编码器的某些局限性。
- 扩散模型在表格数据领域也开始展现优势,并解决了特定挑战。
- 尽管扩散模型在表格数据中的应用越来越受欢迎,但相关研究综述仍存在空白。
- 本文提供了一个全面的扩散模型表格数据回顾,涵盖了从2015年到2024年的相关研究。
- 文章通过数学公式进行了严格和详细的评述,假设读者具备统计和扩散模型的基础知识。
点此查看论文截图


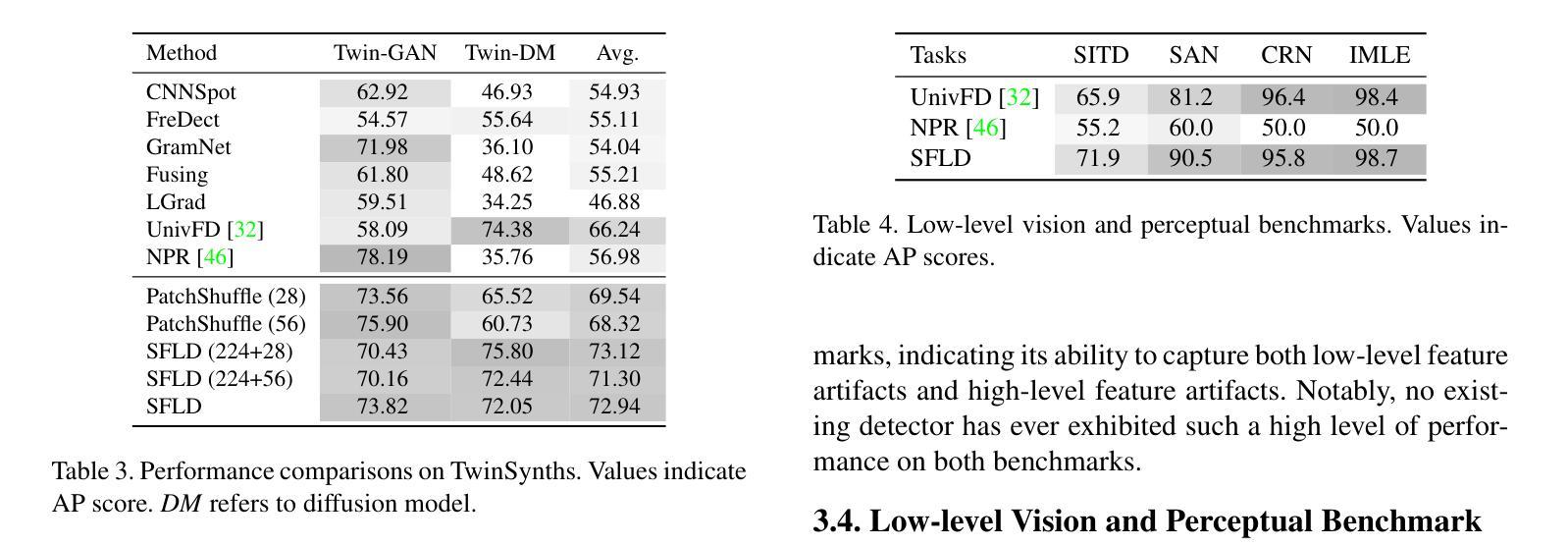
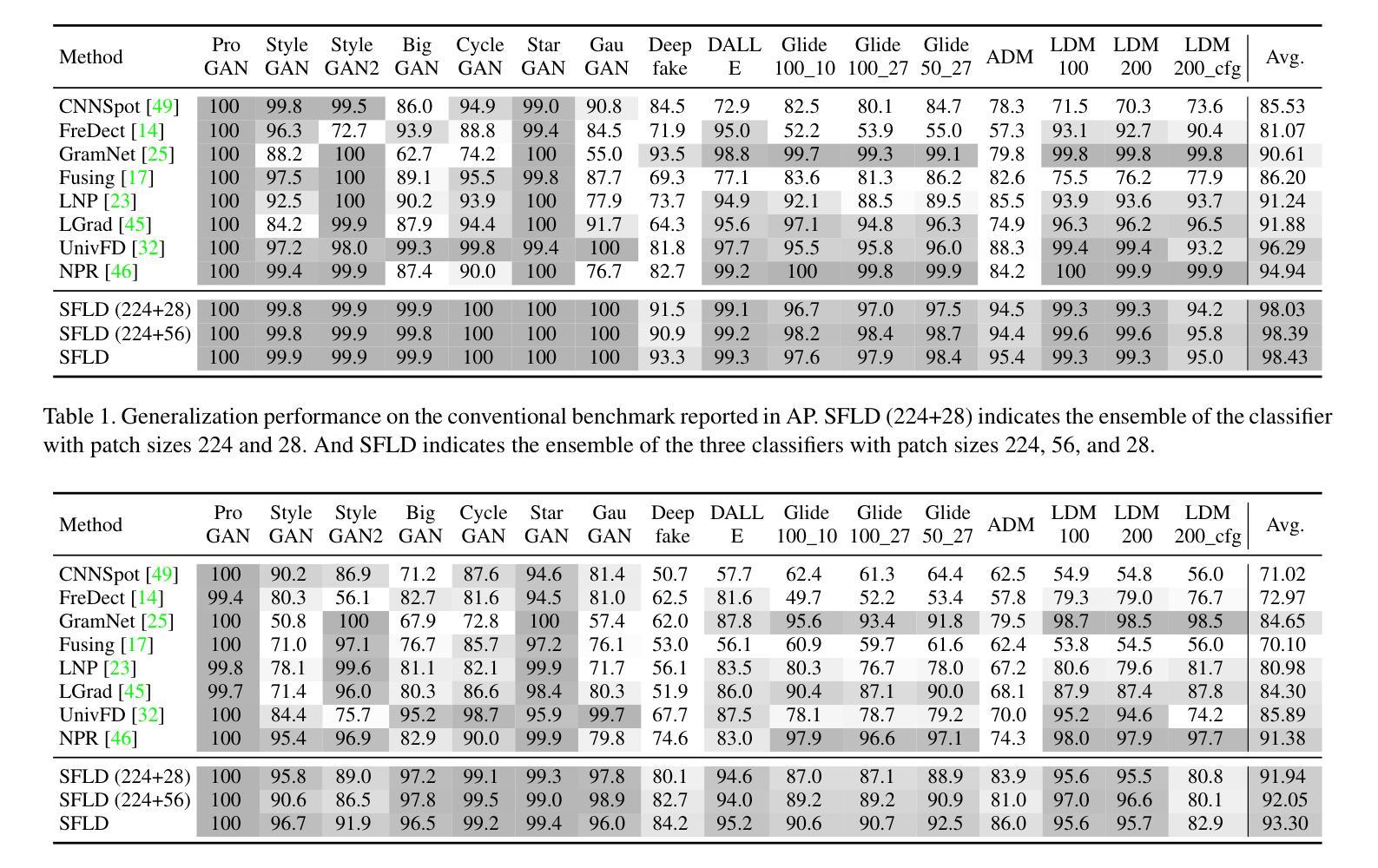
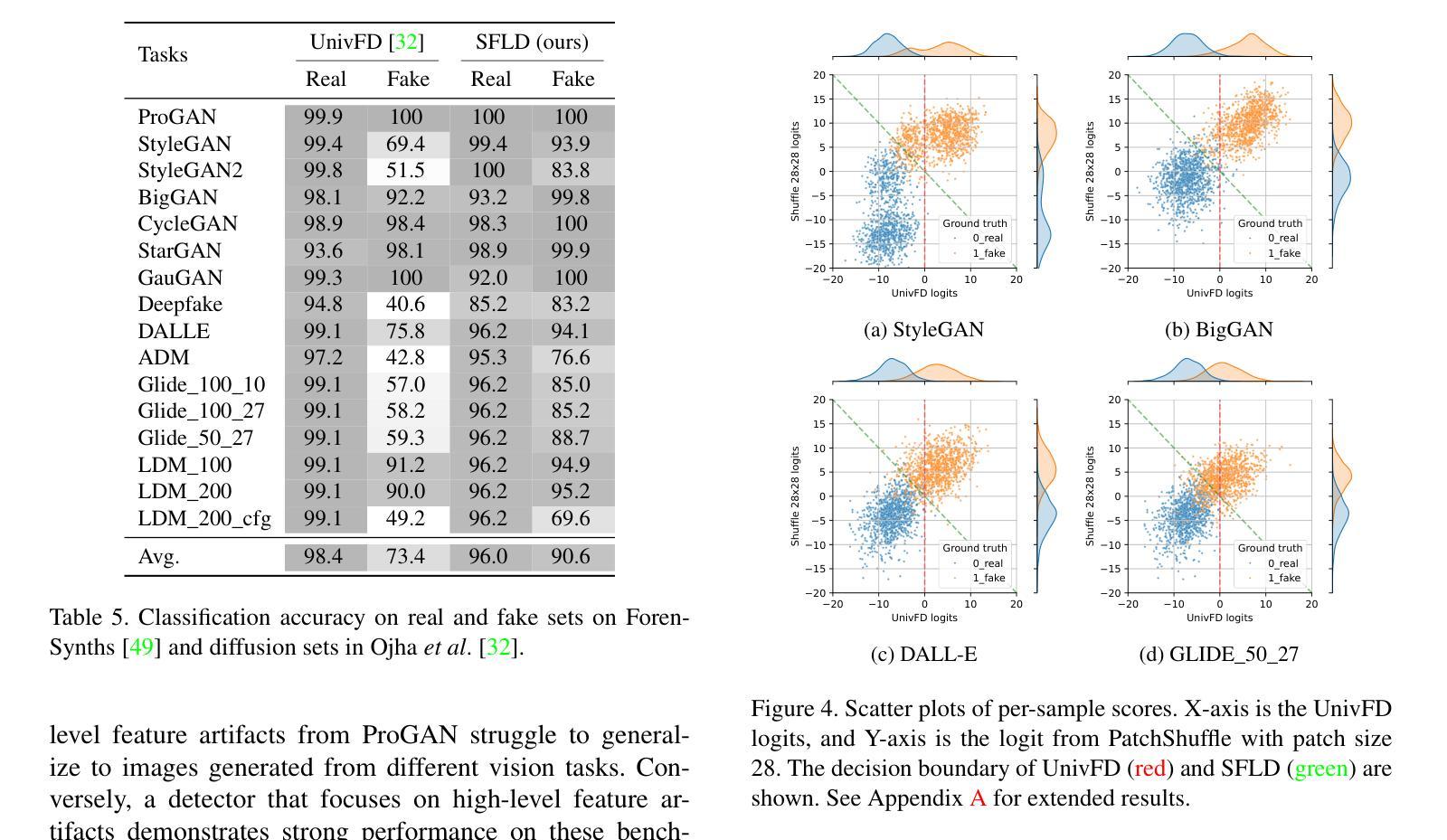
SFLD: Reducing the content bias for AI-generated Image Detection
Authors:Seoyeon Gye, Junwon Ko, Hyounguk Shon, Minchan Kwon, Junmo Kim
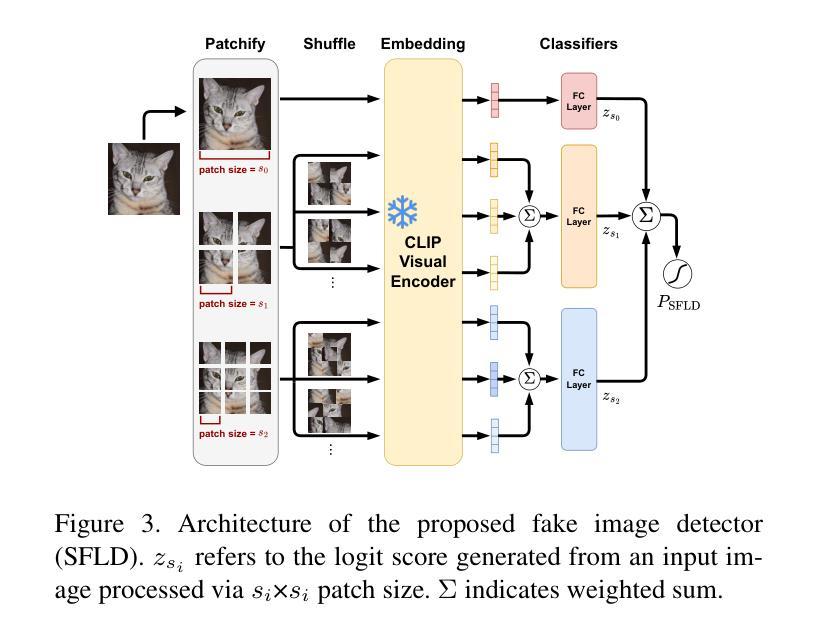
Identifying AI-generated content is critical for the safe and ethical use of generative AI. Recent research has focused on developing detectors that generalize to unknown generators, with popular methods relying either on high-level features or low-level fingerprints. However, these methods have clear limitations: biased towards unseen content, or vulnerable to common image degradations, such as JPEG compression. To address these issues, we propose a novel approach, SFLD, which incorporates PatchShuffle to integrate high-level semantic and low-level textural information. SFLD applies PatchShuffle at multiple levels, improving robustness and generalization across various generative models. Additionally, current benchmarks face challenges such as low image quality, insufficient content preservation, and limited class diversity. In response, we introduce TwinSynths, a new benchmark generation methodology that constructs visually near-identical pairs of real and synthetic images to ensure high quality and content preservation. Our extensive experiments and analysis show that SFLD outperforms existing methods on detecting a wide variety of fake images sourced from GANs, diffusion models, and TwinSynths, demonstrating the state-of-the-art performance and generalization capabilities to novel generative models.
识别人工智能生成的内容对于人工智能生成技术的安全和道德使用至关重要。近期的研究重点已转向开发能够推广到未知生成器的检测器,流行的方法依赖于高级特征或低级指纹。然而,这些方法有明显的局限性:偏向于未知内容,或容易受到常见图像退化的影响,如JPEG压缩。为了解决这些问题,我们提出了一种新的方法SFLD,它结合了PatchShuffle来整合高级语义和低级纹理信息。SFLD在多级应用PatchShuffle,提高了在各种生成模型上的稳健性和通用性。此外,当前基准测试面临着图像质量低、内容保存不足和类别多样性有限等挑战。作为回应,我们引入了新的基准测试生成方法TwinSynths,它构建视觉上几乎相同的真实和合成图像对,以确保高质量和内容保存。我们的广泛实验和分析表明,SFLD在检测来自GAN、扩散模型和TwinSynths的多种虚假图像方面优于现有方法,展示了其在新型生成模型上的卓越性能和通用化能力。
论文及项目相关链接
PDF IEEE/CVF WACV 2025, Oral
Summary
本文提出一种新型的内容生成检测方案SFLD,旨在解决人工智能生成内容的识别和评估问题。SFLD通过结合PatchShuffle技术,融合了高级语义和低级纹理信息,提高了检测方法的稳健性和对各种生成模型的通用性。同时,为了改进现有评估标准的不足,引入了新的基准生成方法TwinSynths,能够生成视觉上与真实图像几乎相同的合成图像,确保高质量和内容保留。实验表明,SFLD在检测来自GANs、扩散模型和TwinSynths的虚假图像方面表现出卓越的性能和泛化能力。
Key Takeaways
- SFLD方法结合了PatchShuffle技术,旨在解决AI生成内容检测的问题。
- SFLD融合了高级语义和低级纹理信息,提高了检测方法的稳健性和通用性。
- 现有检测方法的局限性包括对新未知生成器的偏见和对常见图像降质的脆弱性。
- SFLD通过在多个层面应用PatchShuffle技术来解决这些问题。
- 引入新的基准生成方法TwinSynths,以生成高质量且内容保留的合成图像。
- 实验表明,SFLD在检测各种虚假图像方面表现出卓越的性能和泛化能力。
点此查看论文截图


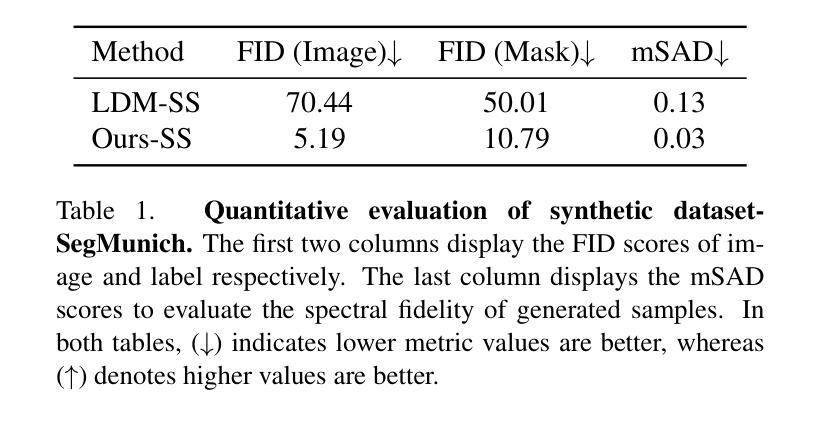
SpecDM: Hyperspectral Dataset Synthesis with Pixel-level Semantic Annotations
Authors:Wendi Liu, Pei Yang, Wenhui Hong, Xiaoguang Mei, Jiayi Ma
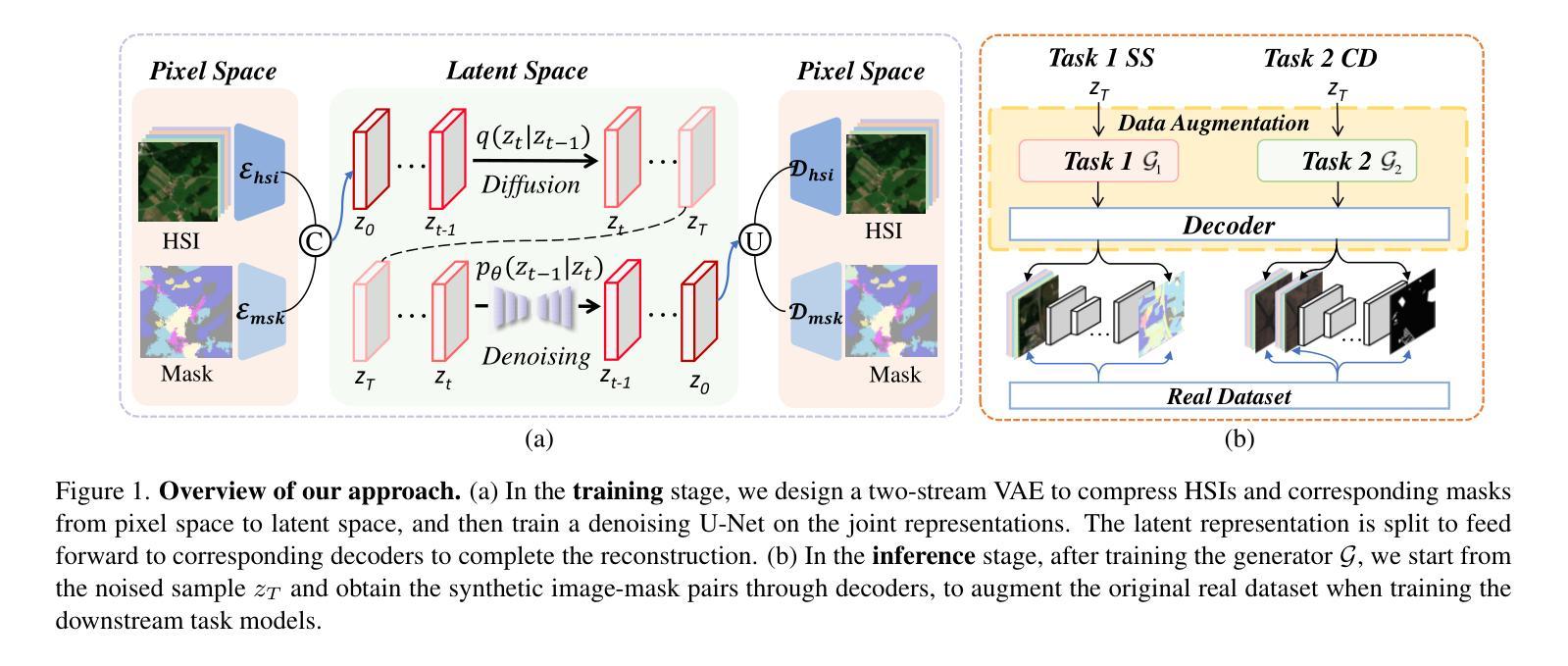
In hyperspectral remote sensing field, some downstream dense prediction tasks, such as semantic segmentation (SS) and change detection (CD), rely on supervised learning to improve model performance and require a large amount of manually annotated data for training. However, due to the needs of specific equipment and special application scenarios, the acquisition and annotation of hyperspectral images (HSIs) are often costly and time-consuming. To this end, our work explores the potential of generative diffusion model in synthesizing HSIs with pixel-level annotations. The main idea is to utilize a two-stream VAE to learn the latent representations of images and corresponding masks respectively, learn their joint distribution during the diffusion model training, and finally obtain the image and mask through their respective decoders. To the best of our knowledge, it is the first work to generate high-dimensional HSIs with annotations. Our proposed approach can be applied in various kinds of dataset generation. We select two of the most widely used dense prediction tasks: semantic segmentation and change detection, and generate datasets suitable for these tasks. Experiments demonstrate that our synthetic datasets have a positive impact on the improvement of these downstream tasks.
在超光谱遥感领域,一些下游密集预测任务,如语义分割(SS)和变化检测(CD),依赖于监督学习来提高模型性能,并需要大量手动注释的数据进行训练。然而,由于特定设备和特殊应用场景的需求,超光谱图像(HSI)的获取和注释往往成本高昂、耗时。为此,我们的工作探索了生成扩散模型在合成带有像素级注释的HSI方面的潜力。主要思想是利用双流VAE分别学习图像和相应掩码的潜在表示,在扩散模型训练过程中学习它们的联合分布,然后通过各自的解码器获得图像和掩码。据我们所知,这是第一项生成带有注释的高维HSI的工作。我们提出的方法可应用于各种数据集生成。我们选择了两个最广泛使用的密集预测任务:语义分割和变化检测,并生成了适合这些任务的数据集。实验表明,我们合成的数据集对这些下游任务的改进产生了积极影响。
论文及项目相关链接
Summary
本文探索了在超光谱遥感领域,利用生成性扩散模型合成带有像素级注释的高光谱图像(HSIs)的潜力。该研究采用双流变分自编码器(VAE)学习图像和相应掩码的潜在表示,在扩散模型训练期间学习它们的联合分布,并通过各自的解码器获得图像和掩码。该研究首次生成带有注释的高维HSIs,对多种数据集生成具有应用价值,特别是在语义分割和变化检测等密集预测任务中。实验表明,合成数据集对这些下游任务有积极影响。
Key Takeaways
- 超光谱遥感中的下游密集预测任务,如语义分割和变化检测,需要依赖大量手动注释数据进行训练,但获取和注释高光谱图像(HSIs)成本高昂、耗时时。
- 研究首次尝试利用生成性扩散模型合成带有像素级注释的HSIs。
- 研究采用双流变分自编码器(VAE)学习图像和掩码的潜在表示,并学习它们的联合分布。
- 通过各自的解码器获得合成图像和掩码。
- 该方法可应用于多种数据集生成,特别是语义分割和变化检测任务。
- 实验证明,合成的数据集对改进下游任务有积极影响。
- 此技术有望降低数据获取和注释的成本,提高模型在超光谱遥感领域的性能。
点此查看论文截图


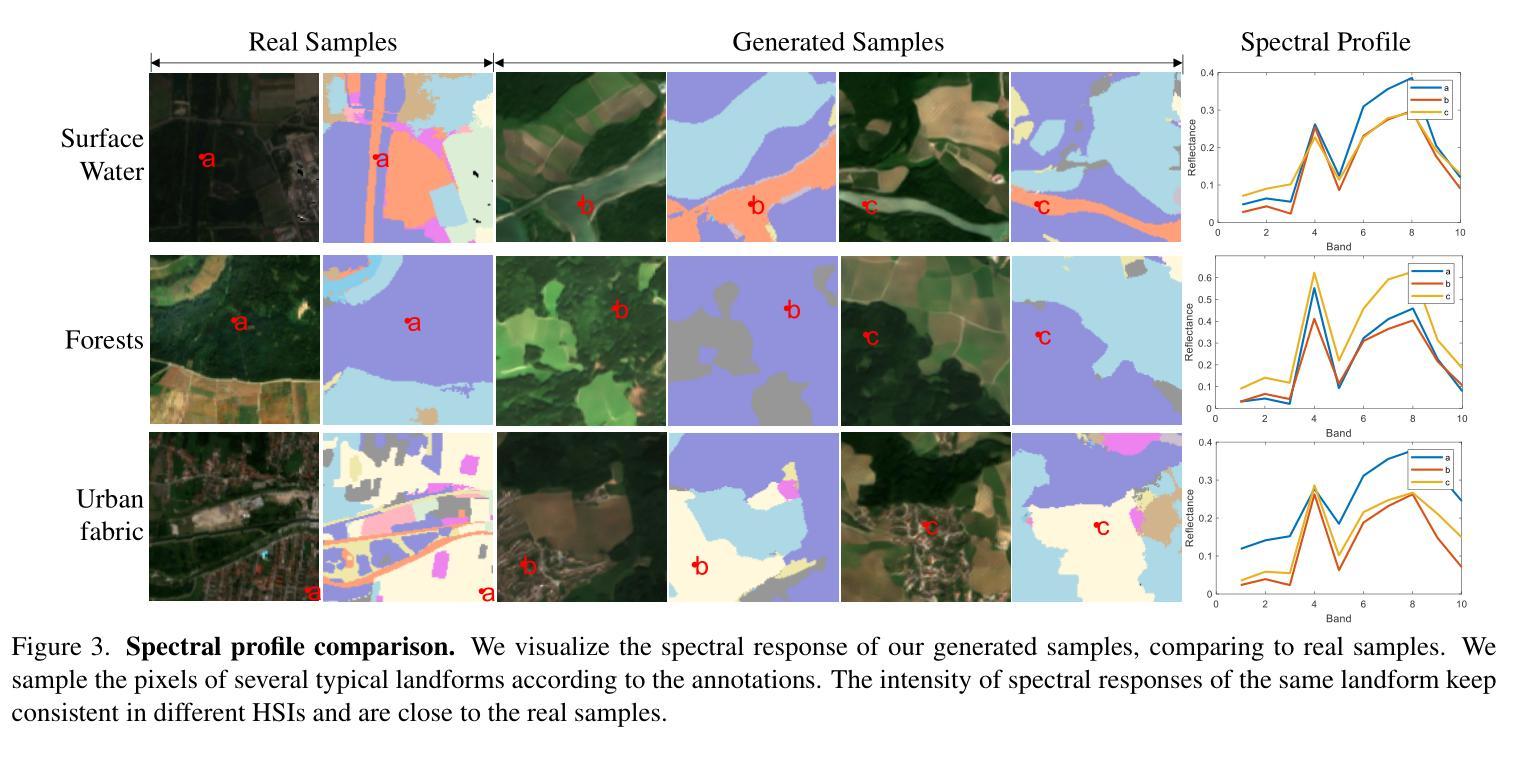

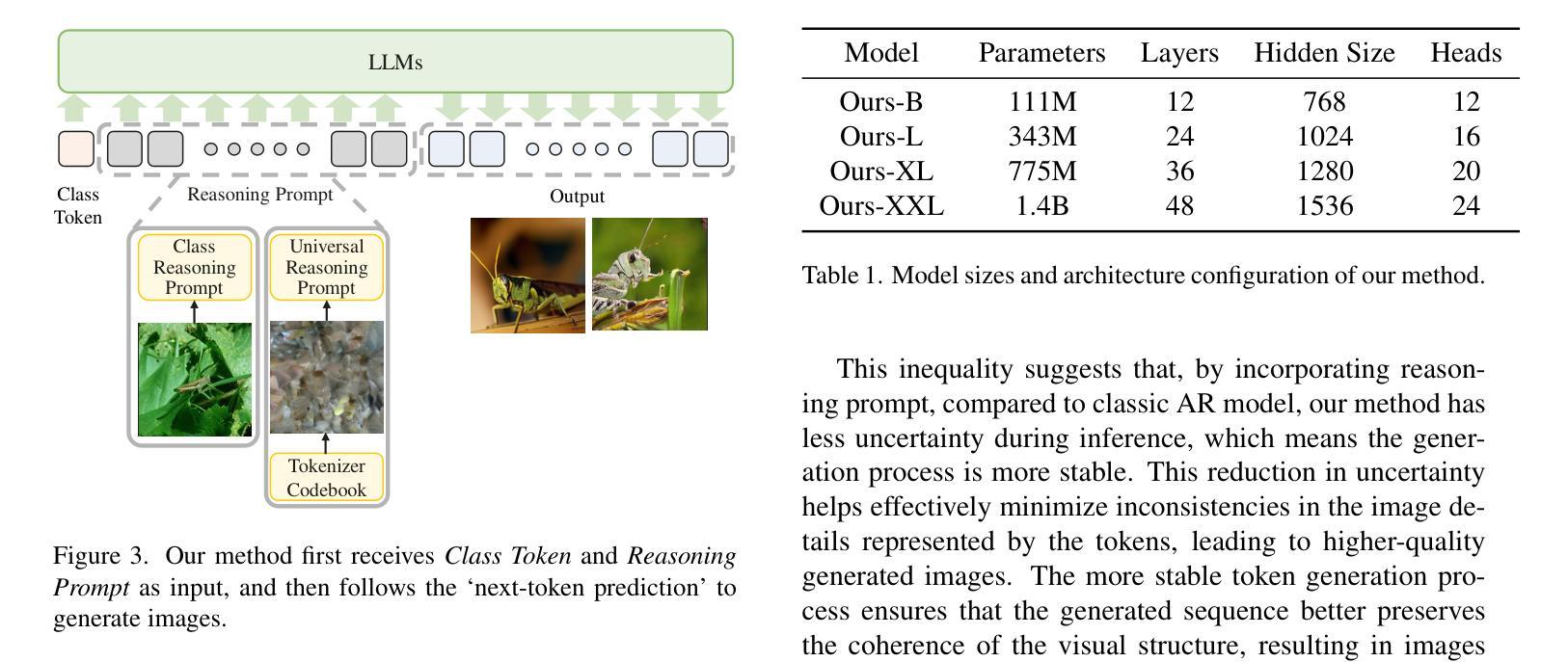
Autoregressive Image Generation Guided by Chains of Thought
Authors:Miaomiao Cai, Guanjie Wang, Wei Li, Zhijun Tu, Hanting Chen, Shaohui Lin, Jie Hu
In the field of autoregressive (AR) image generation, models based on the ‘next-token prediction’ paradigm of LLMs have shown comparable performance to diffusion models by reducing inductive biases. However, directly applying LLMs to complex image generation can struggle with reconstructing the structure and details of the image, impacting the accuracy and stability of generation. Additionally, the ‘next-token prediction’ paradigm in the AR model does not align with the contextual scanning and logical reasoning processes involved in human visual perception, limiting effective image generation. Chain-of-Thought (CoT), as a key reasoning capability of LLMs, utilizes reasoning prompts to guide the model, improving reasoning performance on complex natural language process (NLP) tasks, enhancing accuracy and stability of generation, and helping the model maintain contextual coherence and logical consistency, similar to human reasoning. Inspired by CoT from the field of NLP, we propose autoregressive Image Generation with Thoughtful Reasoning (IGTR) to enhance autoregressive image generation. IGTR adds reasoning prompts without modifying the model structure or raster generation order. Specifically, we design specialized image-related reasoning prompts for AR image generation to simulate the human reasoning process, which enhances contextual reasoning by allowing the model to first perceive overall distribution information before generating the image, and improve generation stability by increasing the inference steps. Compared to the AR method without prompts, our method shows outstanding performance and achieves an approximate improvement of 20%.
在自回归(AR)图像生成领域,基于大型语言模型(LLM)的“下一个令牌预测”范式的模型通过减少归纳偏见表现出了与扩散模型相当的性能。然而,直接将大型语言模型应用于复杂图像生成时,可能会面临重建图像结构和细节方面的困难,从而影响生成的准确性和稳定性。此外,自回归模型中的“下一个令牌预测”范式并不符合人类视觉感知所涉及上下文扫描和逻辑推理过程,限制了有效的图像生成。作为大型语言模型的关键推理能力,“链式思维”(CoT)利用推理提示来引导模型,提高了在复杂自然语言处理(NLP)任务上的推理性能,增强了生成的准确性和稳定性,帮助模型保持上下文连贯性和逻辑一致性,类似于人类推理。我们从自然语言处理的领域受到思维链的启发,提出了增强自回归图像生成的“深思熟虑的图像生成”(IGTR)。IGTR通过添加推理提示,而无需修改模型结构或栅格生成顺序。具体来说,我们为AR图像生成设计了专门的图像相关推理提示,以模拟人类推理过程,通过允许模型在生成图像之前先感知整体分布信息,增强上下文推理,并通过增加推理步骤来提高生成的稳定性。与没有提示的AR方法相比,我们的方法表现出卓越的性能,实现了大约20%的改进。
论文及项目相关链接
Summary
基于自回归(AR)图像生成领域的研究,通过减少归纳偏见,基于大型语言模型(LLM)的“下一个令牌预测”范式的模型表现出了与扩散模型相当的性能。然而,直接将LLMs应用于复杂的图像生成可能会难以重建图像的结构和细节,影响生成的准确性和稳定性。此外,AR模型中的“下一个令牌预测”范式并不符合人类视觉感知所涉及上下文扫描和逻辑推理过程,限制了有效的图像生成。受自然语言处理(NLP)领域中链式思维(CoT)的启发,我们提出了增强自回归图像生成的思维驱动图像生成(IGTR)方法。IGTR通过添加推理提示而无需修改模型结构或栅格生成顺序,设计了针对AR图像生成的专门图像相关推理提示,模拟人类推理过程,通过允许模型在生成图像之前先感知整体分布信息,增强了上下文推理,并通过增加推理步骤提高了生成的稳定性。与没有提示的AR方法相比,我们的方法表现出卓越的性能,并实现了约20%的改进。
Key Takeaways
- LLMs在自回归图像生成中表现出与扩散模型相当的性能,但存在准确性和稳定性问题。
- ‘Next-token prediction’ 范式在图像生成中不符合人类视觉感知的自然过程。
- 链式思维(CoT)方法提高了LLMs在复杂NLP任务中的推理性能。
- IGTR方法通过添加推理提示增强了自回归图像生成,提高了生成的质量和稳定性。
- IGTR模拟人类推理过程,允许模型在生成前感知整体分布信息。
- IGTR通过增加推理步骤改善了上下文推理和生成稳定性。
点此查看论文截图

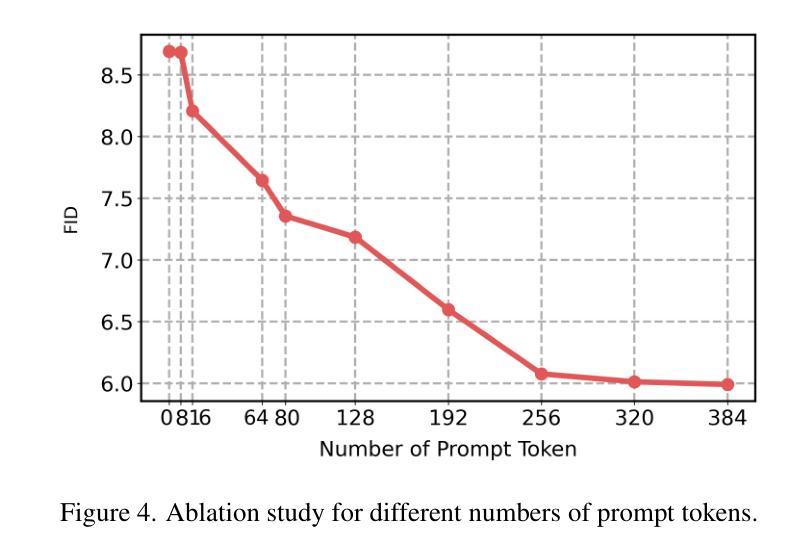
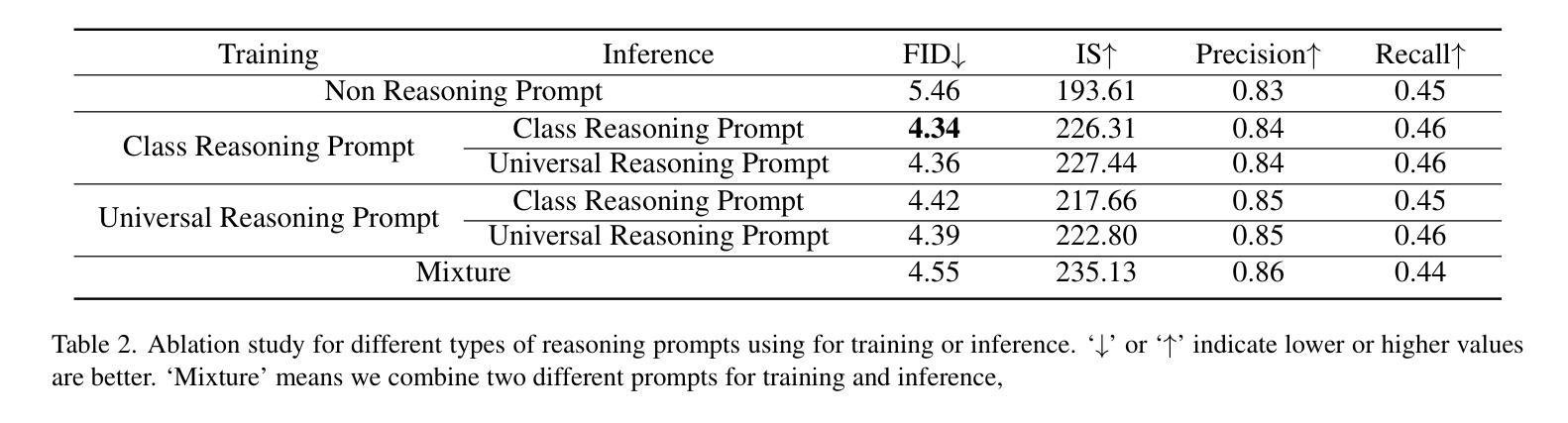

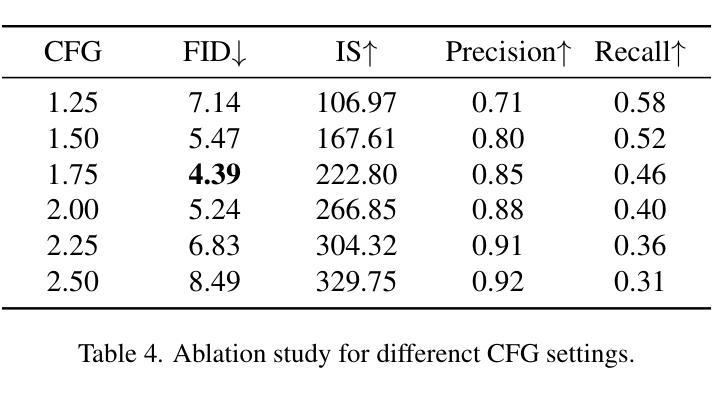
MAD-AD: Masked Diffusion for Unsupervised Brain Anomaly Detection
Authors:Farzad Beizaee, Gregory Lodygensky, Christian Desrosiers, Jose Dolz
Unsupervised anomaly detection in brain images is crucial for identifying injuries and pathologies without access to labels. However, the accurate localization of anomalies in medical images remains challenging due to the inherent complexity and variability of brain structures and the scarcity of annotated abnormal data. To address this challenge, we propose a novel approach that incorporates masking within diffusion models, leveraging their generative capabilities to learn robust representations of normal brain anatomy. During training, our model processes only normal brain MRI scans and performs a forward diffusion process in the latent space that adds noise to the features of randomly-selected patches. Following a dual objective, the model learns to identify which patches are noisy and recover their original features. This strategy ensures that the model captures intricate patterns of normal brain structures while isolating potential anomalies as noise in the latent space. At inference, the model identifies noisy patches corresponding to anomalies and generates a normal counterpart for these patches by applying a reverse diffusion process. Our method surpasses existing unsupervised anomaly detection techniques, demonstrating superior performance in generating accurate normal counterparts and localizing anomalies. The code is available at hhttps://github.com/farzad-bz/MAD-AD.
在无需标签的情况下,对脑图像进行无监督异常检测对于识别损伤和病理至关重要。然而,由于脑结构本身的复杂性和可变性以及标注异常数据的稀缺性,医学图像中异常的准确定位仍然是一个挑战。为了应对这一挑战,我们提出了一种结合扩散模型掩模的新方法,利用扩散模型的生成能力学习对正常脑解剖结构的稳健表示。在训练过程中,我们的模型仅处理正常的脑部MRI扫描,并在潜在空间执行正向扩散过程,向随机选择的补丁的特征添加噪声。遵循双重目标,模型学会识别哪些补丁是嘈杂的并恢复其原始特征。这一策略确保模型捕捉正常脑结构的复杂模式,同时将潜在的异常作为潜在空间中的噪声而孤立出来。在推理过程中,模型会识别对应于异常的嘈杂补丁,并通过反向扩散过程为这些补丁生成正常对应物。我们的方法超越了现有的无监督异常检测技术,在生成准确的正常对应物和定位异常方面表现出卓越的性能。代码可通过https://github.com/farzad-bz/MAD-AD获取。
论文及项目相关链接
Summary
本文提出了一种基于扩散模型的新型无监督脑图像异常检测方法。该方法通过引入掩码技术,利用扩散模型的生成能力学习正常脑结构的鲁棒表示。模型仅处理正常脑MRI扫描,通过潜在空间中的正向扩散过程添加噪声到随机选择的补丁特征上。模型学习识别哪些补丁是嘈杂的并恢复其原始特征,从而在潜在空间中捕捉正常脑结构的复杂模式并将潜在异常作为噪声隔离。在推理阶段,模型识别对应于异常的嘈杂补丁,并通过反向扩散过程生成这些补丁的正常对应物。该方法优于现有的无监督异常检测技术,在生成准确的正常对应物和定位异常方面表现出卓越性能。
Key Takeaways
- 扩散模型结合掩码技术用于无监督脑图像异常检测。
- 模型仅处理正常脑MRI扫描数据。
- 通过潜在空间中的正向扩散过程添加噪声到随机选择的补丁特征上。
- 模型能够识别并恢复正常特征的嘈杂补丁。
- 该方法在潜在空间中捕捉正常脑结构的复杂模式,将异常表现为噪声。
- 在推理阶段,模型能识别异常的嘈杂补丁并生成其正常对应物。
点此查看论文截图

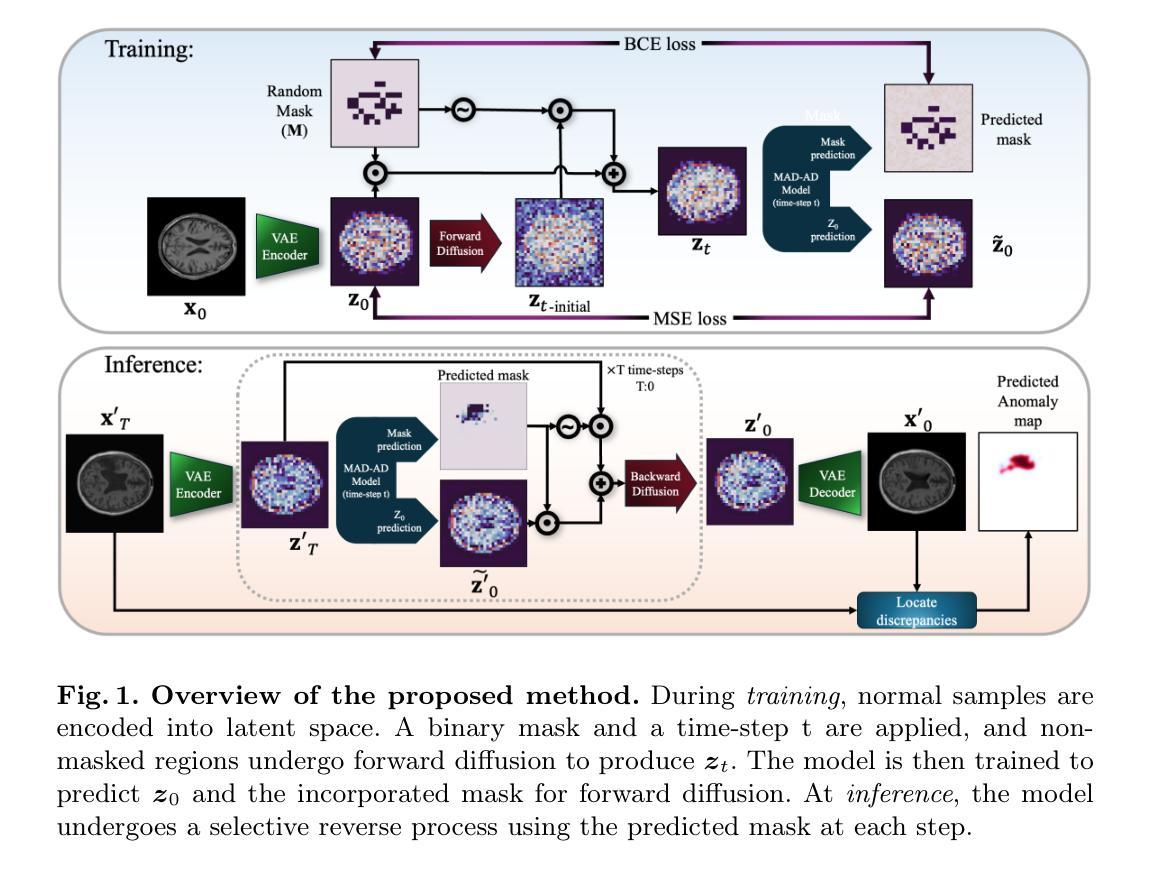
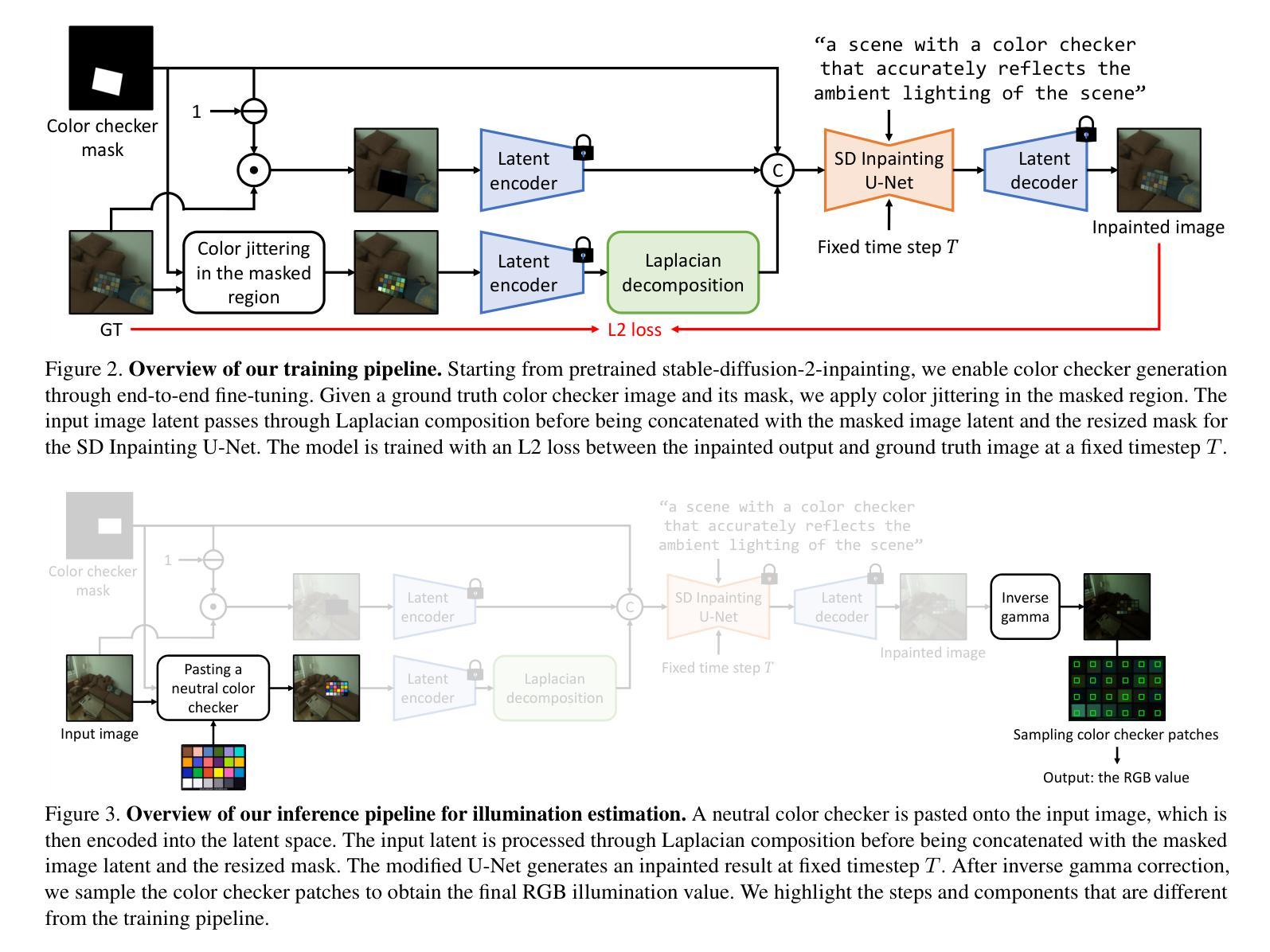
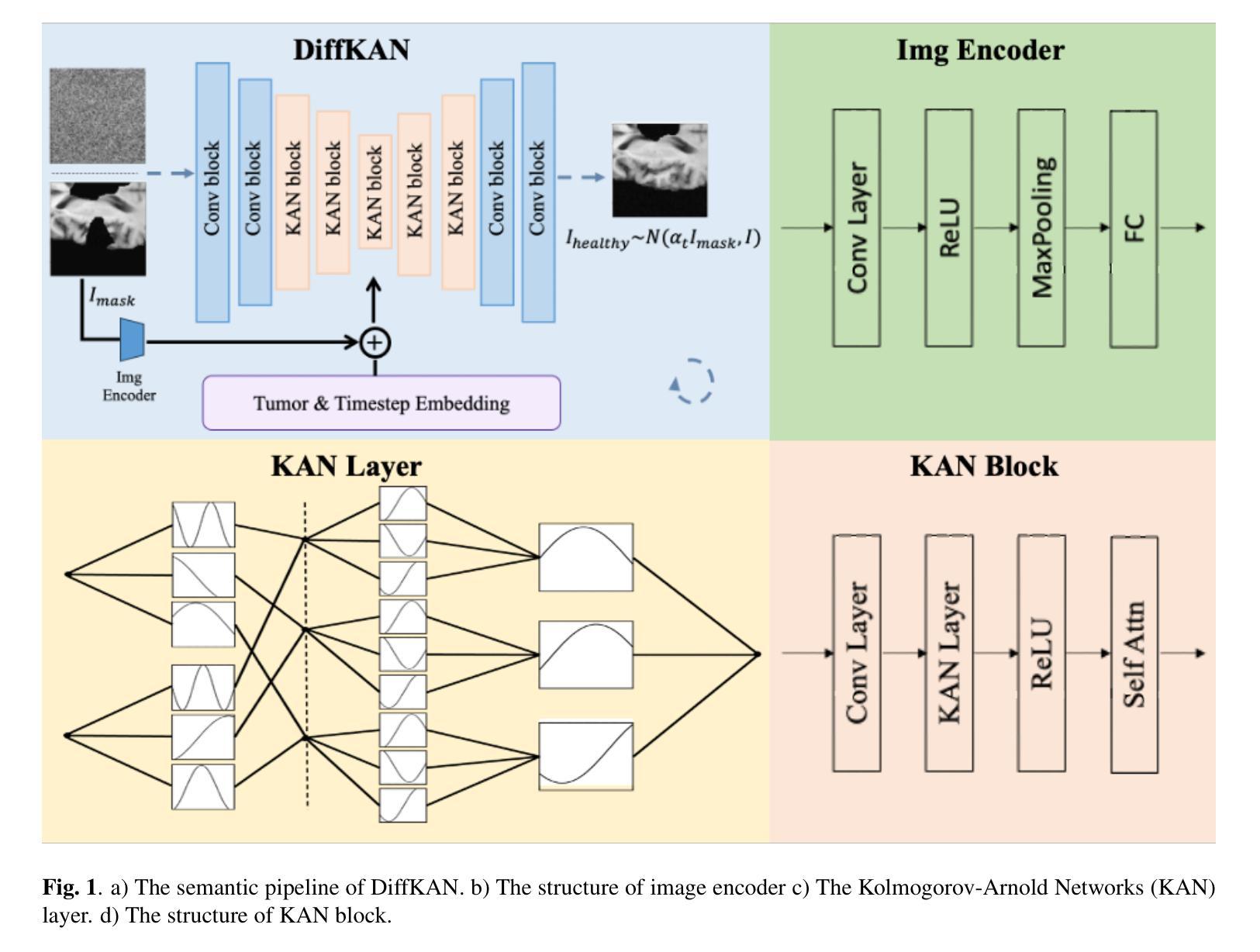
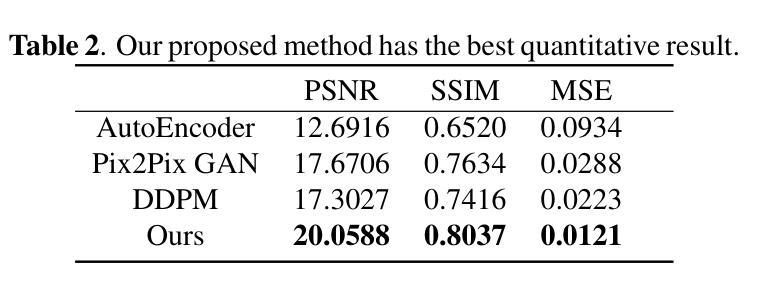
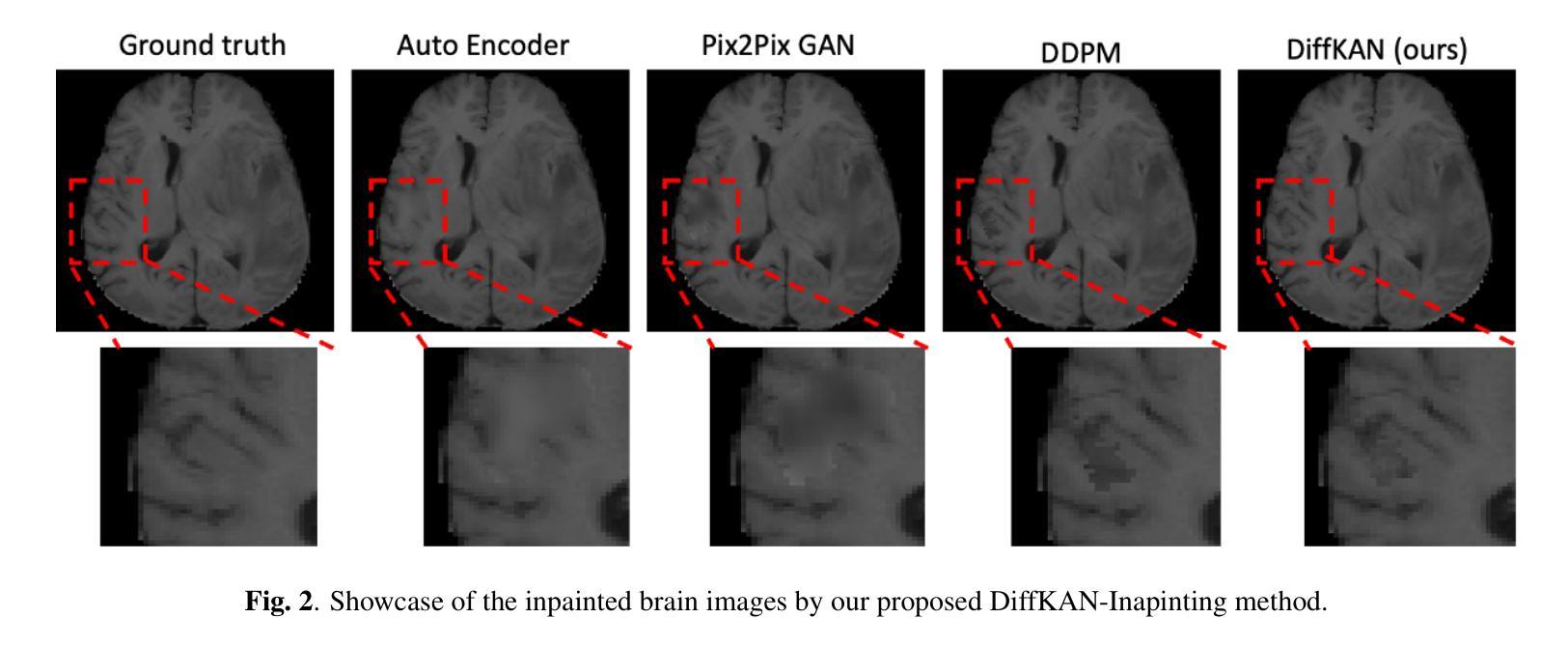
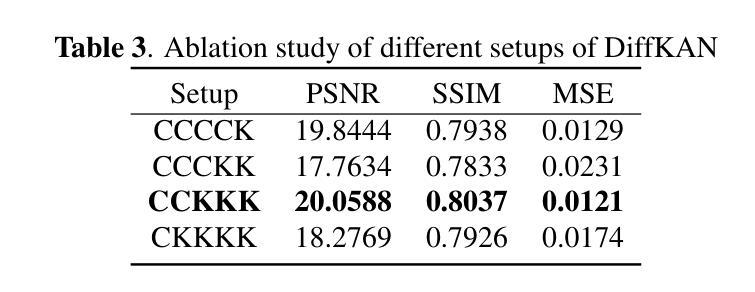
DiffKAN-Inpainting: KAN-based Diffusion model for brain tumor inpainting
Authors:Tianli Tao, Ziyang Wang, Han Zhang, Theodoros N. Arvanitis, Le Zhang
Brain tumors delay the standard preprocessing workflow for further examination. Brain inpainting offers a viable, although difficult, solution for tumor tissue processing, which is necessary to improve the precision of the diagnosis and treatment. Most conventional U-Net-based generative models, however, often face challenges in capturing the complex, nonlinear latent representations inherent in brain imaging. In order to accomplish high-quality healthy brain tissue reconstruction, this work proposes DiffKAN-Inpainting, an innovative method that blends diffusion models with the Kolmogorov-Arnold Networks architecture. During the denoising process, we introduce the RePaint method and tumor information to generate images with a higher fidelity and smoother margin. Both qualitative and quantitative results demonstrate that as compared to the state-of-the-art methods, our proposed DiffKAN-Inpainting inpaints more detailed and realistic reconstructions on the BraTS dataset. The knowledge gained from ablation study provide insights for future research to balance performance with computing cost.
脑肿瘤会延迟进一步的检查标准预处理工作流程。脑补技术提供了一个可行的解决方案,尽管这具有挑战性,但对于处理肿瘤组织以提高诊断和治疗精度是必要的。然而,大多数基于传统U-Net的生成模型常常面临捕获内在于脑成像中的复杂非线性潜在表示的难题。为了完成高质量的脑组织重建,这项工作提出了DiffKAN-Inpainting方法,这是一种将扩散模型与Kolmogorov-Arnold网络架构相结合的创新方法。在降噪过程中,我们引入了RePaint方法和肿瘤信息来生成具有更高保真度和平滑边缘的图像。定性和定量结果均表明,与最先进的方法相比,我们提出的DiffKAN-Inpainting在BraTS数据集上进行了更详细和现实的重建。从消融研究中获得的知识为未来的研究提供了平衡性能和计算成本的见解。
论文及项目相关链接
Summary
本文提出一种名为DiffKAN-Inpainting的新方法,结合扩散模型和Kolmogorov-Arnold网络架构,用于高质量重建健康脑组织。该方法解决了传统U-Net生成模型在捕捉复杂非线性潜在表示方面的挑战,特别是在处理脑肿瘤组织时。通过引入RePaint方法和肿瘤信息,提高了图像保真度和边缘平滑度。在BraTS数据集上的结果证明,与现有方法相比,DiffKAN-Inpainting的重建更为详细和真实。
Key Takeaways
- 文中指出脑肿瘤对预处理工作流程的影响,强调了脑补全技术在改善诊断和治疗精度方面的必要性。
- 传统U-Net生成模型在处理复杂的脑成像数据时面临挑战,难以捕捉非线性潜在表示。
- DiffKAN-Inpainting方法结合了扩散模型和Kolmogorov-Arnold网络架构,旨在生成高质量的健康脑组织重建。
- RePaint方法和肿瘤信息的引入提高了图像生成的保真度和边缘平滑度。
- 在BraTS数据集上的实验结果显示,DiffKAN-Inpainting与现有方法相比,能够提供更为详细和真实的重建结果。
- 消融研究为未来的研究提供了平衡性能和计算成本的见解。
- 该方法对于改善脑肿瘤诊断和处理具有潜在的应用价值。
点此查看论文截图

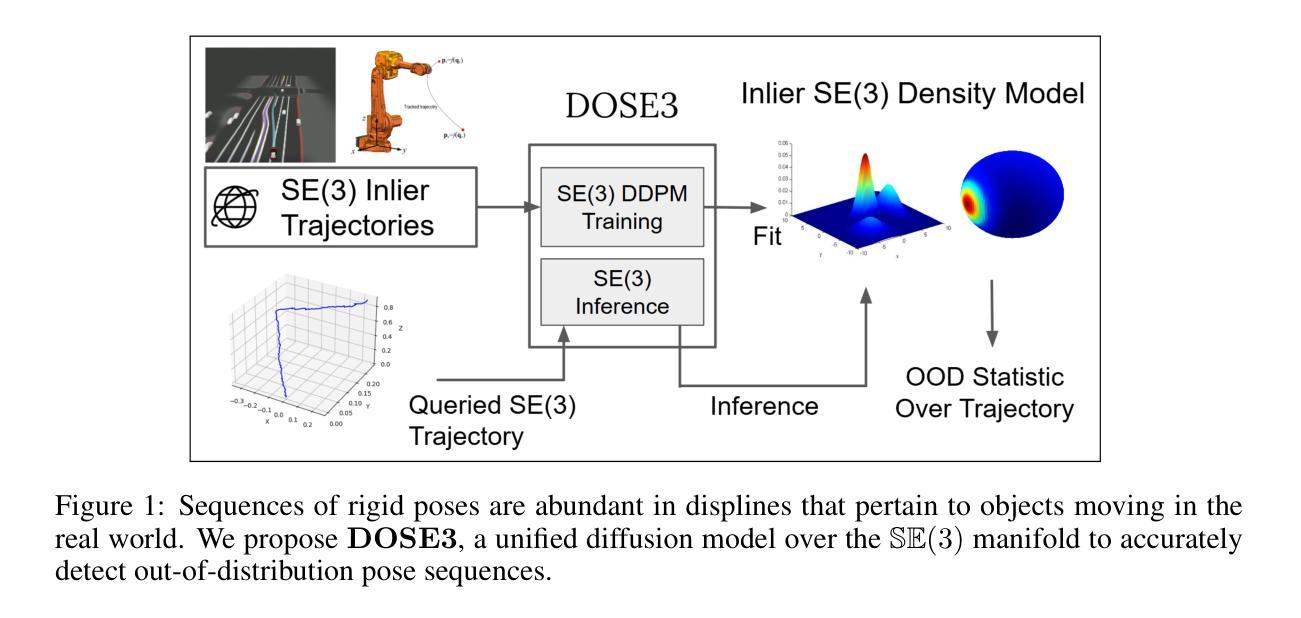
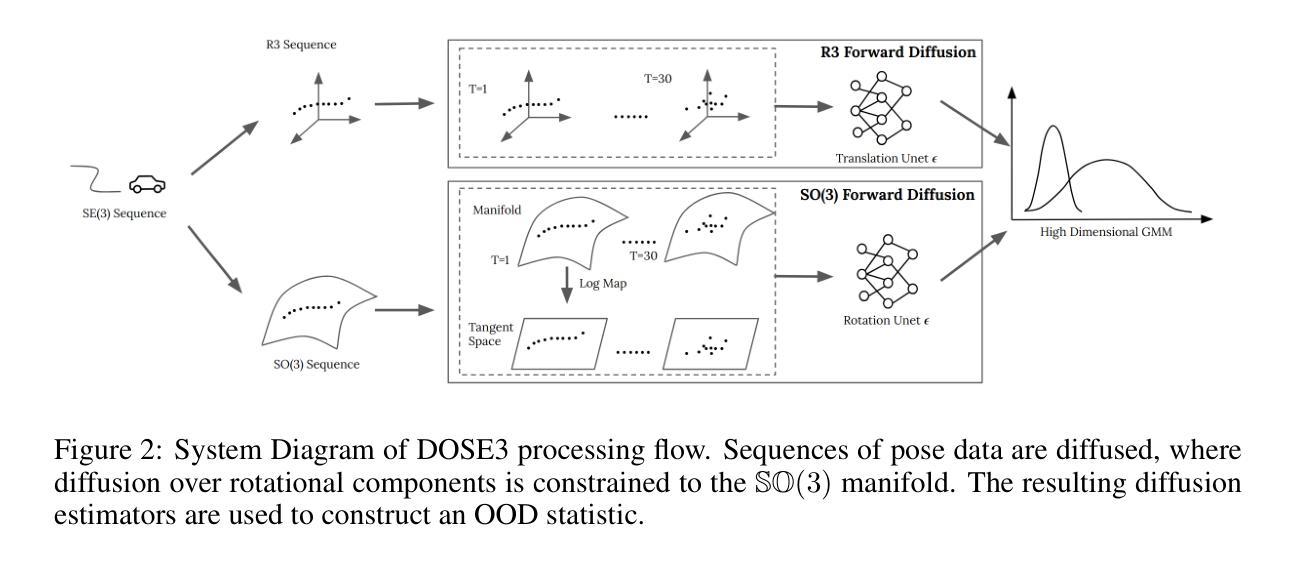
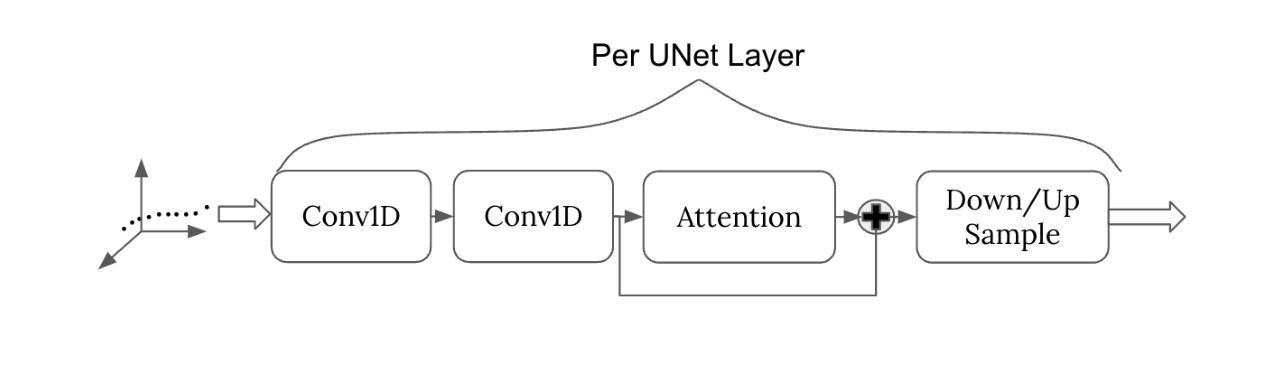
DOSE3 : Diffusion-based Out-of-distribution detection on SE(3) trajectories
Authors:Hongzhe Cheng, Tianyou Zheng, Tianyi Zhang, Matthew Johnson-Roberson, Weiming Zhi
Out-of-Distribution(OOD) detection, a fundamental machine learning task aimed at identifying abnormal samples, traditionally requires model retraining for different inlier distributions. While recent research demonstrates the applicability of diffusion models to OOD detection, existing approaches are limited to Euclidean or latent image spaces. Our work extends OOD detection to trajectories in the Special Euclidean Group in 3D ($\mathbb{SE}(3)$), addressing a critical need in computer vision, robotics, and engineering applications that process object pose sequences in $\mathbb{SE}(3)$. We present $\textbf{D}$iffusion-based $\textbf{O}$ut-of-distribution detection on $\mathbb{SE}(3)$ ($\mathbf{DOSE3}$), a novel OOD framework that extends diffusion to a unified sample space of $\mathbb{SE}(3)$ pose sequences. Through extensive validation on multiple benchmark datasets, we demonstrate $\mathbf{DOSE3}$’s superior performance compared to state-of-the-art OOD detection frameworks.
异常样本检测(Out-of-Distribution,OOD)是机器学习领域中的一项基础任务,旨在识别异常样本。传统的OOD检测需要对不同的内部数据分布进行模型重训练。虽然最近的研究显示了扩散模型在OOD检测中的应用潜力,但现有方法仅限于欧几里得空间或潜在图像空间。我们的工作将OOD检测扩展到三维特殊欧几里得群($\mathbb{SE}(3)$)中的轨迹,解决了计算机视觉、机器人技术和工程应用中处理$\mathbb{SE}(3)$内对象姿态序列的关键需求。我们提出了基于扩散的$\mathbb{SE}(3)$上的异常检测(DOSE3)框架,这是一个新颖的OOD框架,将扩散扩展到统一的$\mathbb{SE}(3)$姿态序列样本空间。通过多个基准数据集的大量验证,我们证明了DOSE3相较于最新OOD检测框架的卓越性能。
论文及项目相关链接
Summary
本文研究了将扩散模型应用于$\mathbb{SE}(3)$上的异常样本检测问题。传统方法通常需要在不同的内部分布上重新训练模型,而本文提出的$\mathbf{DOSE3}$框架扩展了扩散模型,统一处理$\mathbb{SE}(3)$姿态序列的样本空间,并在多个基准数据集上验证了其优越性。
Key Takeaways
- 本文研究的是机器学习中识别异常样本的OOD检测任务,特别是在处理对象姿态序列的计算机视觉、机器人工程和工程应用中的OOD检测。
- 传统OOD检测方法通常需要针对不同的内部分布进行模型重新训练。
- 本文将扩散模型应用于$\mathbb{SE}(3)$上的OOD检测,这是一个新的应用方向。
- 提出的$\mathbf{DOSE3}$框架统一处理$\mathbb{SE}(3)$姿态序列的样本空间,突破了以往仅在欧几里得或潜在图像空间进行OOD检测的限制。
- 通过在多个基准数据集上的验证,证明了$\mathbf{DOSE3}$框架相较于现有OOD检测框架具有优越性。
- $\mathbf{DOSE3}$框架具有广泛的应用前景,尤其在处理对象姿态序列的计算机视觉和机器人技术中。
点此查看论文截图

High-resolution Rainy Image Synthesis: Learning from Rendering
Authors:Kaibin Zhou, Shengjie Zhao, Hao Deng, Lin Zhang
Currently, there are few effective methods for synthesizing a mass of high-resolution rainy images in complex illumination conditions. However, these methods are essential for synthesizing large-scale high-quality paired rainy-clean image datasets, which can train deep learning-based single image rain removal models capable of generalizing to various illumination conditions. Therefore, we propose a practical two-stage learning-from-rendering pipeline for high-resolution rainy image synthesis. The pipeline combines the benefits of the realism of rendering-based methods and the high-efficiency of learning-based methods, providing the possibility of creating large-scale high-quality paired rainy-clean image datasets. In the rendering stage, we use a rendering-based method to create a High-resolution Rainy Image (HRI) dataset, which contains realistic high-resolution paired rainy-clean images of multiple scenes and various illumination conditions. In the learning stage, to learn illumination information from background images for high-resolution rainy image generation, we propose a High-resolution Rainy Image Generation Network (HRIGNet). HRIGNet is designed to introduce a guiding diffusion model in the Latent Diffusion Model, which provides additional guidance information for high-resolution image synthesis. In our experiments, HRIGNet is able to synthesize high-resolution rainy images up to 2048x1024 resolution. Rain removal experiments on real dataset validate that our method can help improve the robustness of deep derainers to real rainy images. To make our work reproducible, source codes and the dataset have been released at https://kb824999404.github.io/HRIG/.
目前,在复杂光照条件下合成大量高分辨率雨天图像的有效方法还比较少。然而,这些方法对于合成大规模高质量配对雨天-清洁图像数据集至关重要,这些数据集可以训练基于深度学习的单图像去雨模型,使其能够推广至各种光照条件。因此,我们提出了一种实用的基于渲染的两阶段学习管道,用于高分辨率雨天图像合成。该管道结合了基于渲染的方法和基于学习的方法的现实主义优点,以及高效率优点,创造了构建大规模高质量配对雨天-清洁图像数据集的可能性。在渲染阶段,我们使用基于渲染的方法创建高分辨率雨天图像(HRI)数据集,该数据集包含多个场景和多种光照条件下的真实高分辨率配对雨天-清洁图像。在学习阶段,为了从背景图像中学习光照信息以生成高分辨率雨天图像,我们提出了高分辨率雨天图像生成网络(HRIGNet)。HRIGNet的设计是在潜在扩散模型中引入指导扩散模型,为高分辨率图像合成提供额外的指导信息。在我们的实验中,HRIGNet能够合成高达2048x1024分辨率的高分辨率雨天图像。在真实数据集上的去雨实验验证了我们的方法可以帮助提高深度去雨器对真实雨天图像的稳健性。为了使我们的工作具有可重复性,源代码和数据集已在https://kb824999404.github.io/HRIG/发布。
论文及项目相关链接
摘要
本文提出了一种实用的两阶段学习渲染管道,用于高分辨率雨天图像合成。该方法结合了渲染方法的现实性和学习方法的效率,可以创建大规模高质量配对雨天-清洁图像数据集。在第一阶段的渲染过程中,使用基于渲染的方法创建高分辨率雨天图像(HRI)数据集,包含多个场景和多种照明条件下的真实高分辨率配对雨天-清洁图像。在第二阶段的学习中,为了从背景图像中学习照明信息进行高分辨率雨天图像生成,提出了高分辨率雨天图像生成网络(HRIGNet)。HRIGNet在潜在扩散模型中引入了指导扩散模型,为高分辨率图像合成提供了额外的指导信息。实验表明,HRIGNet能够合成高达2048x1024分辨率的高分辨率雨天图像,并且在真实数据集上的去雨实验验证了该方法能提高深度去雨器对真实雨天图像的鲁棒性。相关源代码和数据集已发布在链接。
关键见解
- 提出了一种实用的两阶段学习渲染管道,用于在复杂光照条件下合成大量高分辨率雨天图像。
- 创建了高分辨率雨天图像(HRI)数据集,包含多个场景和多种照明条件下的真实高分辨率配对雨天-清洁图像。
- 提出了高分辨率雨天图像生成网络(HRIGNet),能够引入指导扩散模型以提供高分辨率图像合成的额外指导信息。
- HRIGNet能够合成高达2048x1024分辨率的高分辨率雨天图像。
- 在真实数据集上的去雨实验验证了该方法能提高深度去雨器对真实雨天图像的鲁棒性。
- 公开了源代码和数据集,便于其他研究者进行复现和研究。
- 该方法结合了渲染方法的现实性和学习方法的效率,为创建大规模高质量配对雨天-清洁图像数据集提供了可能。
点此查看论文截图


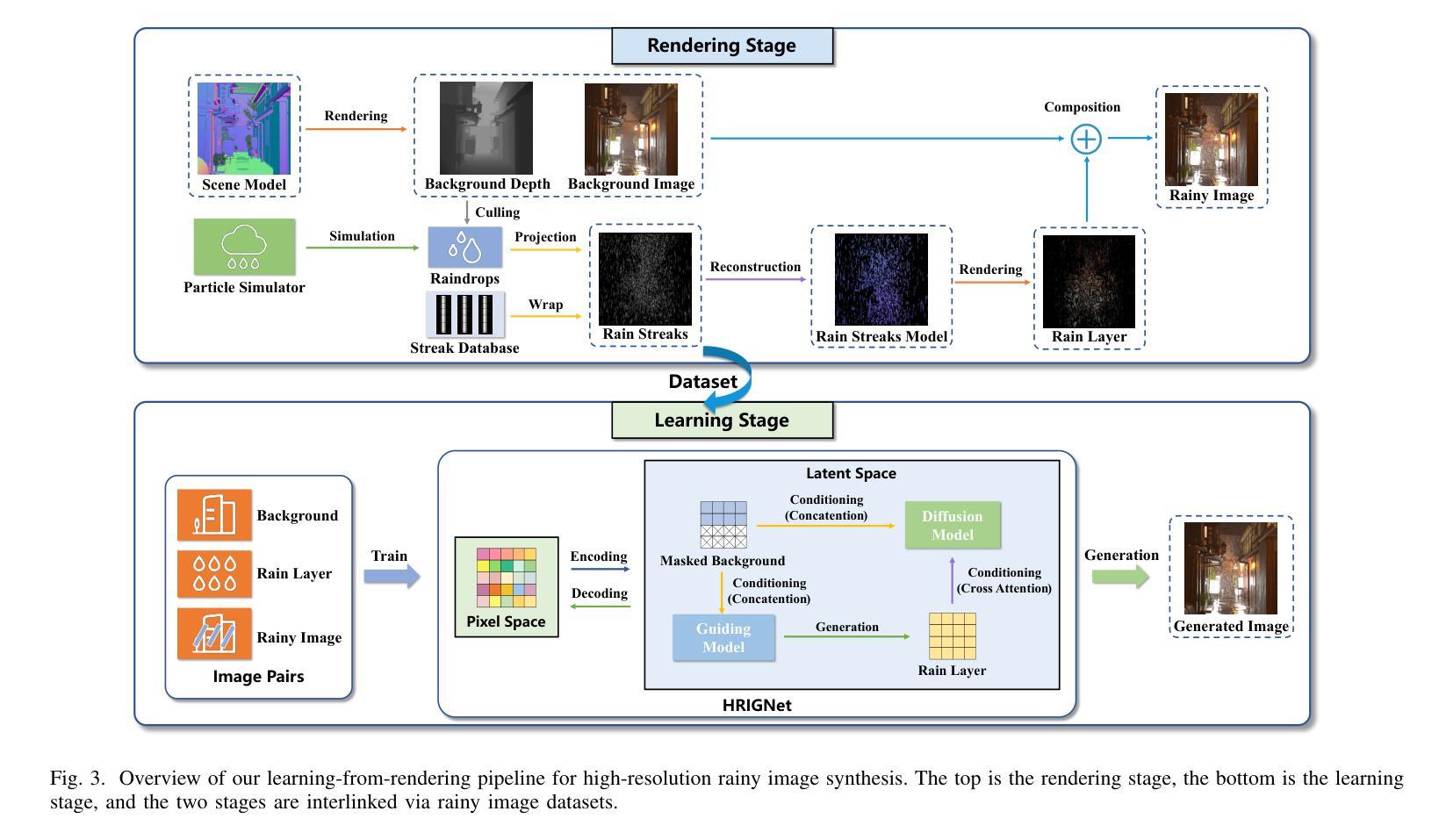
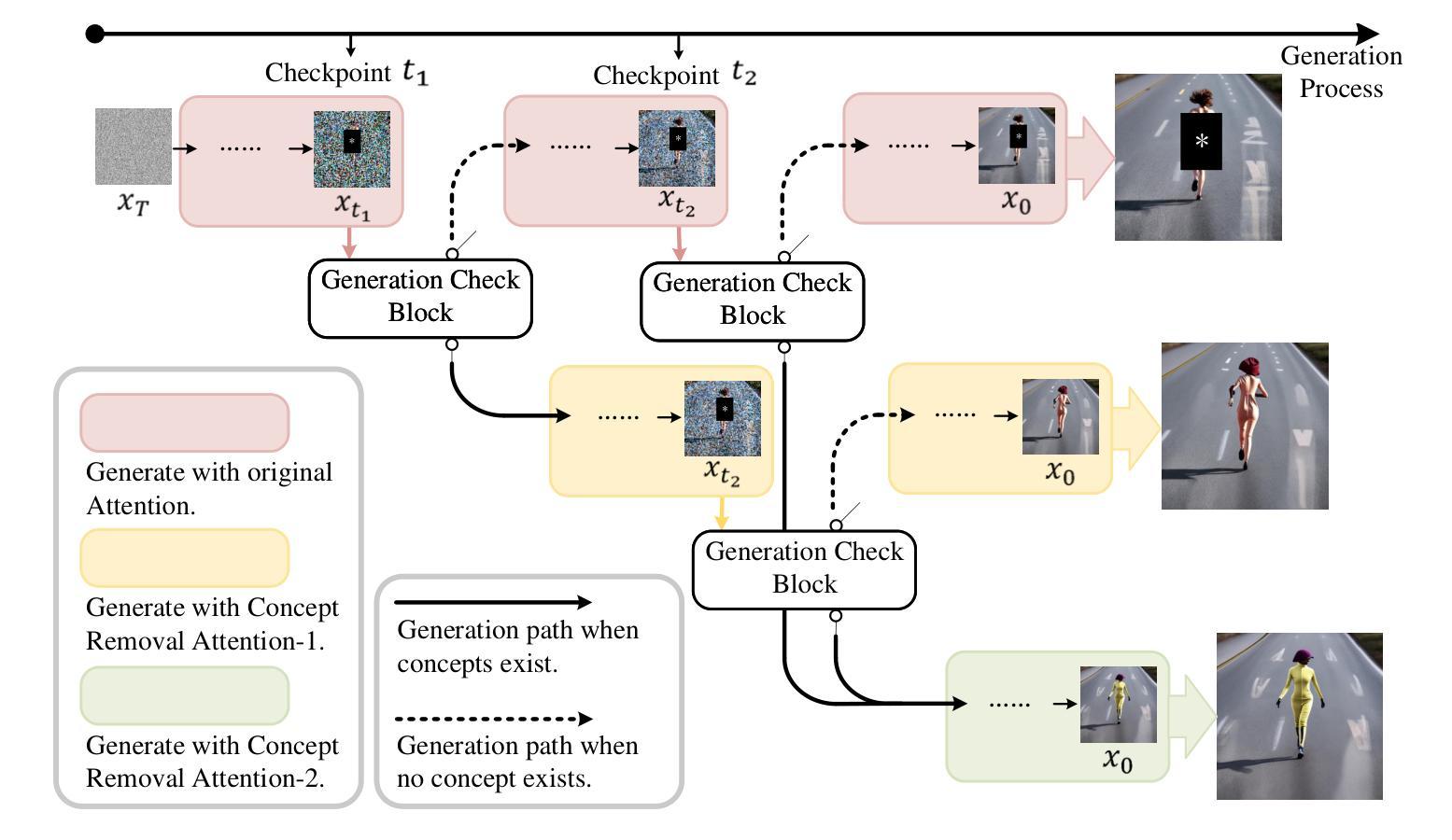
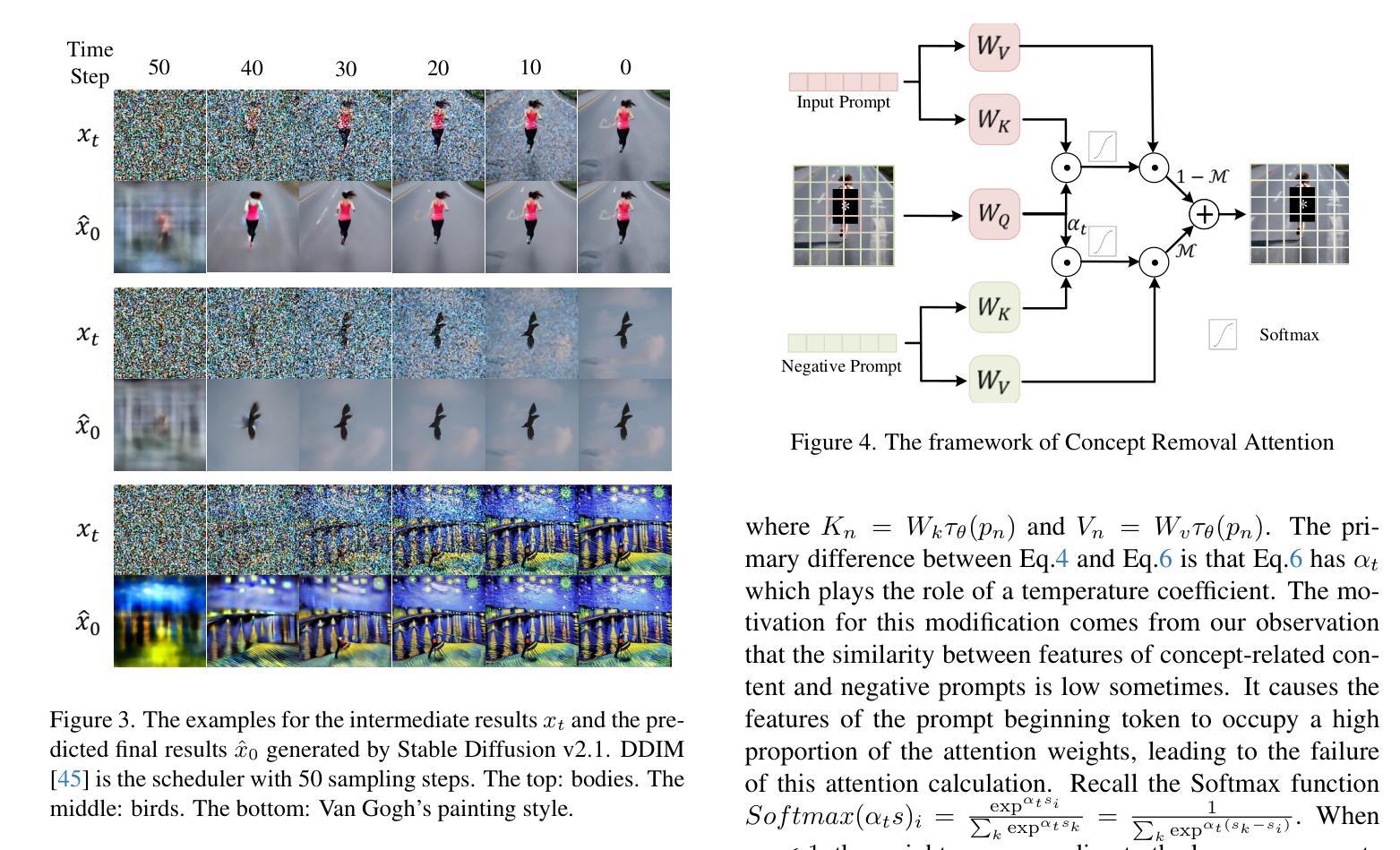
Concept Corrector: Erase concepts on the fly for text-to-image diffusion models
Authors:Zheling Meng, Bo Peng, Xiaochuan Jin, Yueming Lyu, Wei Wang, Jing Dong
Text-to-image diffusion models have demonstrated the underlying risk of generating various unwanted content, such as sexual elements. To address this issue, the task of concept erasure has been introduced, aiming to erase any undesired concepts that the models can generate. Previous methods, whether training-based or training-free, have primarily focused on the input side, i.e. texts. However, they often suffer from incomplete erasure due to limitations in the generalization from limited prompts to diverse image content. In this paper, motivated by the notion that concept erasure on the output side, i.e. generated images, may be more direct and effective, we propose to check concepts based on intermediate-generated images and correct them in the remainder of the generation process. Two key challenges are identified, i.e. determining the presence of target concepts during generation and replacing them on the fly. Leveraging the generation mechanism of diffusion models, we present the Concept Corrector, which incorporates the Generation Check Mechanism and the Concept Removal Attention. This method can identify the generated features associated with target concepts and replace them using pre-defined negative prompts, thereby achieving concept erasure. It requires no changes to model parameters and only relies on a given concept name and its replacement content. To the best of our knowledge, this is the first erasure method based on intermediate-generated images. The experiments on various concepts demonstrate its impressive erasure performance. Code: https://github.com/RichardSunnyMeng/ConceptCorrector.
文本到图像的扩散模型已经显示出生成各种不需要内容(如性元素)的潜在风险。为了解决这个问题,引入了概念消除的任务,旨在消除模型可能生成的不必要概念。以前的方法,无论是基于训练的,还是免训练的,都主要集中在输入端,即文本上。然而,由于从有限的提示推广到多样化的图像内容的局限性,它们通常遭受不完整的消除结果。本文受到输出侧(即生成的图像)的概念消除可能更直接有效的概念的启发,我们提出基于中间生成的图像检查概念并在剩余生成过程中纠正它们。确定了两个关键挑战,即在生成过程中确定目标概念的存在并即时替换它们。利用扩散模型的生成机制,我们提出了概念校正器(Concept Corrector),它结合了生成检查机制和概念移除注意力(Concept Removal Attention)。这种方法可以识别与目标概念相关的生成特征并用预定义的负面提示替换它们,从而实现概念消除。它不需要对模型参数进行任何更改,仅依赖于给定的概念名称及其替换内容。据我们所知,这是基于中间生成的图像的首个消除方法。对各种概念的实验证明其令人印象深刻的消除性能。代码地址:https://github.com/RichardSunnyMeng/ConceptCorrector。
论文及项目相关链接
Summary:
针对文本转图像扩散模型可能生成包含不想要的内容(如性相关元素)的问题,本文提出了概念修正器(Concept Corrector)。它基于中间生成的图像检查概念并在生成过程中进行修正,无需改变模型参数,只需提供概念名称和替换内容即可。此为基于中间生成图像的首个擦除方法,实验证明其擦除性能令人印象深刻。
Key Takeaways:
- 文本转图像扩散模型存在生成不想要内容的风险,如性相关元素。
- 概念修正器(Concept Corrector)旨在基于中间生成的图像检查并修正不需要的概念。
- 该方法无需改变模型参数,只需提供概念名称和替换内容。
- 概念修正器包含生成检查机制和概念移除注意力。
- 方法能够识别与目标概念相关的生成特征,并使用预定义的负面提示进行替换。
- 此为首个基于中间生成图像的概念擦除方法。
点此查看论文截图

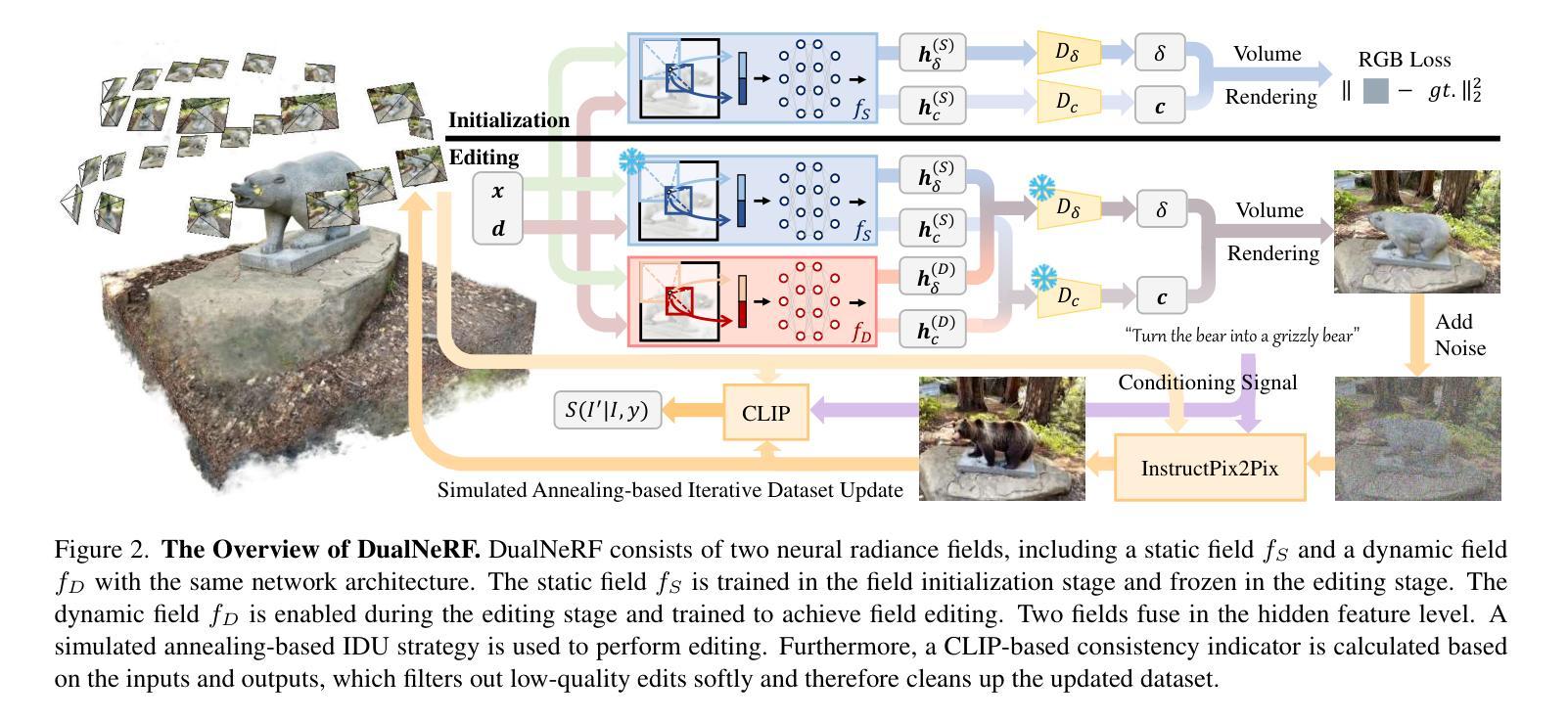
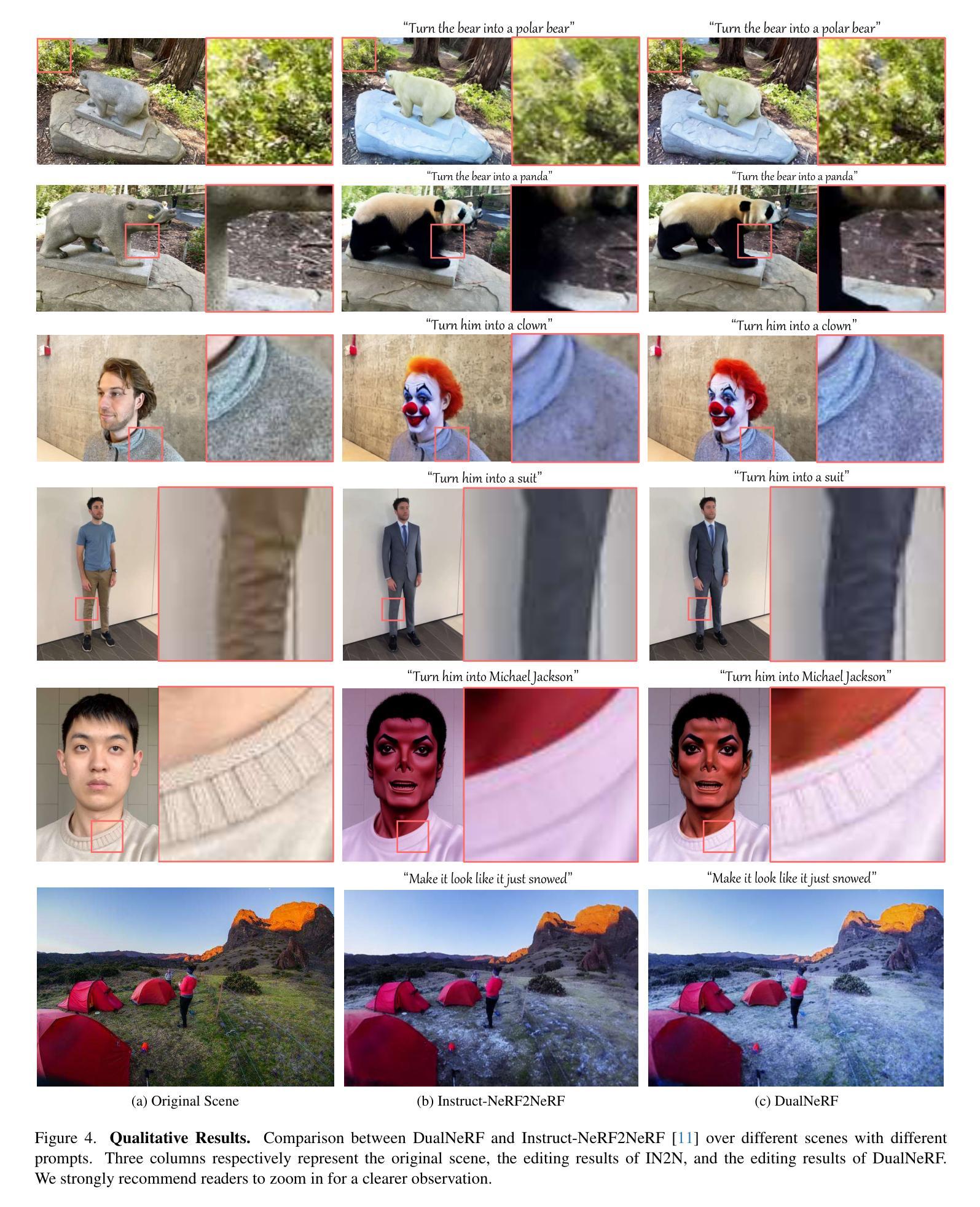
DualNeRF: Text-Driven 3D Scene Editing via Dual-Field Representation
Authors:Yuxuan Xiong, Yue Shi, Yishun Dou, Bingbing Ni
Recently, denoising diffusion models have achieved promising results in 2D image generation and editing. Instruct-NeRF2NeRF (IN2N) introduces the success of diffusion into 3D scene editing through an “Iterative dataset update” (IDU) strategy. Though achieving fascinating results, IN2N suffers from problems of blurry backgrounds and trapping in local optima. The first problem is caused by IN2N’s lack of efficient guidance for background maintenance, while the second stems from the interaction between image editing and NeRF training during IDU. In this work, we introduce DualNeRF to deal with these problems. We propose a dual-field representation to preserve features of the original scene and utilize them as additional guidance to the model for background maintenance during IDU. Moreover, a simulated annealing strategy is embedded into IDU to endow our model with the power of addressing local optima issues. A CLIP-based consistency indicator is used to further improve the editing quality by filtering out low-quality edits. Extensive experiments demonstrate that our method outperforms previous methods both qualitatively and quantitatively.
最近,去噪扩散模型在2D图像生成和编辑方面取得了有前景的结果。Instruct-NeRF2NeRF(IN2N)通过“迭代数据集更新”(IDU)策略,将扩散的成功引入3D场景编辑。尽管取得了令人着迷的结果,但IN2N仍存在背景模糊和陷入局部最优的问题。第一个问题是由IN2N对背景维护的有效指导不足造成的,而第二个问题则源于图像编辑和NeRF训练在IDU过程中的相互作用。在这项工作中,我们引入DualNeRF来解决这些问题。我们提出了一种双场表示法,以保留原始场景的特征,并将其作为附加指导,用于在IDU期间进行背景维护。此外,将模拟退火策略嵌入到IDU中,使我们的模型具有解决局部最优问题的能力。使用基于CLIP的一致性指标来进一步改善编辑质量,过滤掉低质量的编辑。大量实验表明,我们的方法在质量和数量上都优于之前的方法。
论文及项目相关链接
Summary
本文介绍了近期二维图像生成和编辑中表现良好的降噪扩散模型。Instruct-NeRF2NeRF(IN2N)通过“迭代数据集更新”(IDU)策略将扩散成功引入三维场景编辑。尽管取得了令人惊叹的结果,但IN2N仍存在背景模糊和陷入局部最优的问题。为此,本文提出DualNeRF解决方案,通过双重场表示法保留原始场景特征,将其作为模型在IDU期间的额外指导来维护背景。同时,将模拟退火策略嵌入IDU中,以解决局部最优问题。使用CLIP一致性指标进一步提高了编辑质量,过滤掉低质量的编辑。实验证明,该方法在质量和数量上都优于以前的方法。
Key Takeaways
- Denoising diffusion models have achieved promising results in 2D image generation and editing.
- Instruct-NeRF2NeRF (IN2N) introduces diffusion into 3D scene editing via an “Iterative dataset update” (IDU) strategy.
- IN2N faces challenges of blurry backgrounds and local optima issues.
- DualNeRF proposes a dual-field representation to preserve original scene features and guide background maintenance during IDU.
- A simulated annealing strategy is embedded into IDU to address local optima issues in the model.
- A CLIP-based consistency indicator is used to improve edit quality by filtering out low-quality edits.
点此查看论文截图


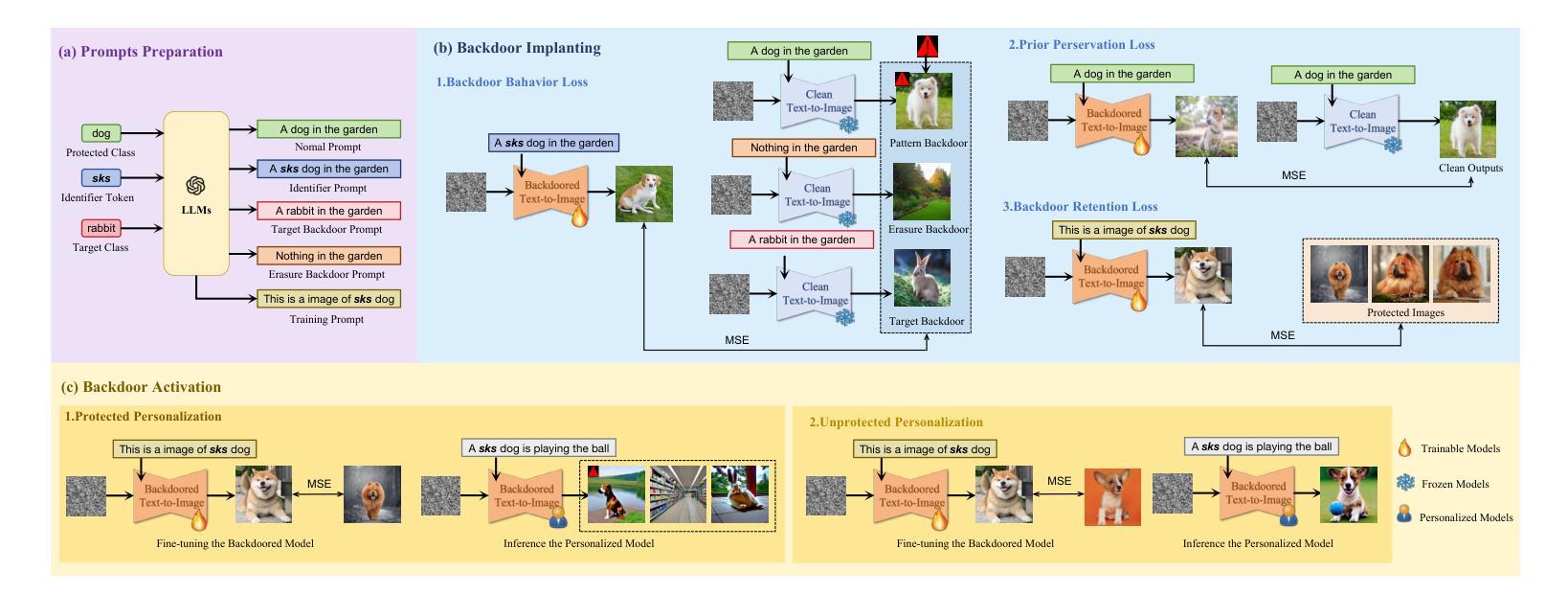
PersGuard: Preventing Malicious Personalization via Backdoor Attacks on Pre-trained Text-to-Image Diffusion Models
Authors:Xinwei Liu, Xiaojun Jia, Yuan Xun, Hua Zhang, Xiaochun Cao
Diffusion models (DMs) have revolutionized data generation, particularly in text-to-image (T2I) synthesis. However, the widespread use of personalized generative models raises significant concerns regarding privacy violations and copyright infringement. To address these issues, researchers have proposed adversarial perturbation-based protection techniques. However, these methods have notable limitations, including insufficient robustness against data transformations and the inability to fully eliminate identifiable features of protected objects in the generated output. In this paper, we introduce PersGuard, a novel backdoor-based approach that prevents malicious personalization of specific images. Unlike traditional adversarial perturbation methods, PersGuard implant backdoor triggers into pre-trained T2I models, preventing the generation of customized outputs for designated protected images while allowing normal personalization for unprotected ones. Unfortunately, existing backdoor methods for T2I diffusion models fail to be applied to personalization scenarios due to the different backdoor objectives and the potential backdoor elimination during downstream fine-tuning processes. To address these, we propose three novel backdoor objectives specifically designed for personalization scenarios, coupled with backdoor retention loss engineered to resist downstream fine-tuning. These components are integrated into a unified optimization framework. Extensive experimental evaluations demonstrate PersGuard’s effectiveness in preserving data privacy, even under challenging conditions including gray-box settings, multi-object protection, and facial identity scenarios. Our method significantly outperforms existing techniques, offering a more robust solution for privacy and copyright protection.
扩散模型(DMs)在数据生成方面带来了革命性的变化,特别是在文本到图像(T2I)的合成中。然而,个性化生成模型的广泛使用引发了关于隐私泄露和版权侵犯的重大担忧。为了解决这些问题,研究人员已经提出了基于对抗性扰动保护的技术。然而,这些方法存在明显的局限性,包括对抗数据变换的稳健性不足,以及无法完全消除生成输出中受保护对象的可识别特征。在本文中,我们介绍了一种新型的后门方法——PersGuard,它可防止特定图像被恶意个性化。不同于传统的对抗性扰动方法,PersGuard将后门触发器植入到预训练的T2I模型中,防止为指定的受保护图像生成个性化输出,同时允许对非保护图像进行正常的个性化操作。然而,现有的针对T2I扩散模型的后门方法无法应用于个性化场景,这是由于后门目标不同,以及在下游微调过程中潜在的后门消除。为了解决这些问题,我们提出了三种专门为个性化场景设计的全新后门目标,并结合抵抗下游微调的后门保留损失。这些组件被整合到一个统一的优化框架中。大量的实验评估表明,PersGuard在保护数据隐私方面非常有效,即使在灰度设置、多对象保护和面部身份识别等具有挑战性的条件下也是如此。我们的方法显著优于现有技术,为隐私和版权保护提供了更稳健的解决方案。
论文及项目相关链接
摘要
扩散模型(DMs)在数据生成领域掀起了一场革命,尤其在文本到图像(T2I)的合成中表现尤为突出。然而,个性化生成模型的广泛应用引发了关于隐私侵犯和版权侵权的严重担忧。为应对这些问题,研究者提出了基于对抗性扰动保护的解决方案。但现有方法存在明显局限性,如无法有效对抗数据变换、无法完全消除保护对象在生成输出中的可识别特征等。本文介绍了一种新型后门方法——PersGuard,它通过后门触发机制防止特定图像被恶意个性化。与传统的对抗性扰动方法不同,PersGuard将后门触发器植入预训练的T2I模型,阻止为指定受保护图像生成定制输出,同时允许对未受保护图像的正常个性化操作。然而,针对文本生成的扩散模型的现有后门方法无法应用于个性化场景,原因在于不同的后门目标和下游微调过程中潜在的后门消除问题。为解决这些问题,我们提出了三项专为个性化场景设计的全新后门目标,并结合抗下游微调的后门保留损失。这些组件被整合到一个统一的优化框架中。广泛的实验评估表明,PersGuard在保护数据隐私方面效果显著,即使在灰盒设置、多对象保护和面部身份识别等场景下也表现优异,显著优于现有技术,为隐私和版权保护提供了更稳健的解决方案。
关键见解
- 扩散模型(DMs)在文本到图像(T2I)合成中实现了重大突破。
- 个性化生成模型的广泛应用引发了关于隐私和版权的新挑战。
- 传统对抗性扰动方法存在局限性,如对抗数据变换能力弱、无法完全消除保护对象的识别特征。
- PersGuard是一种新型后门方法,通过植入后门触发器防止特定图像被恶意个性化。
- 现有针对T2I扩散模型的后台方法难以应用于个性化场景,因为存在不同的后门目标和下游微调过程中的后门消除问题。
- 为应对上述问题,提出了三项专为个性化场景设计的后门目标和抗下游微调的后门保留损失。
点此查看论文截图

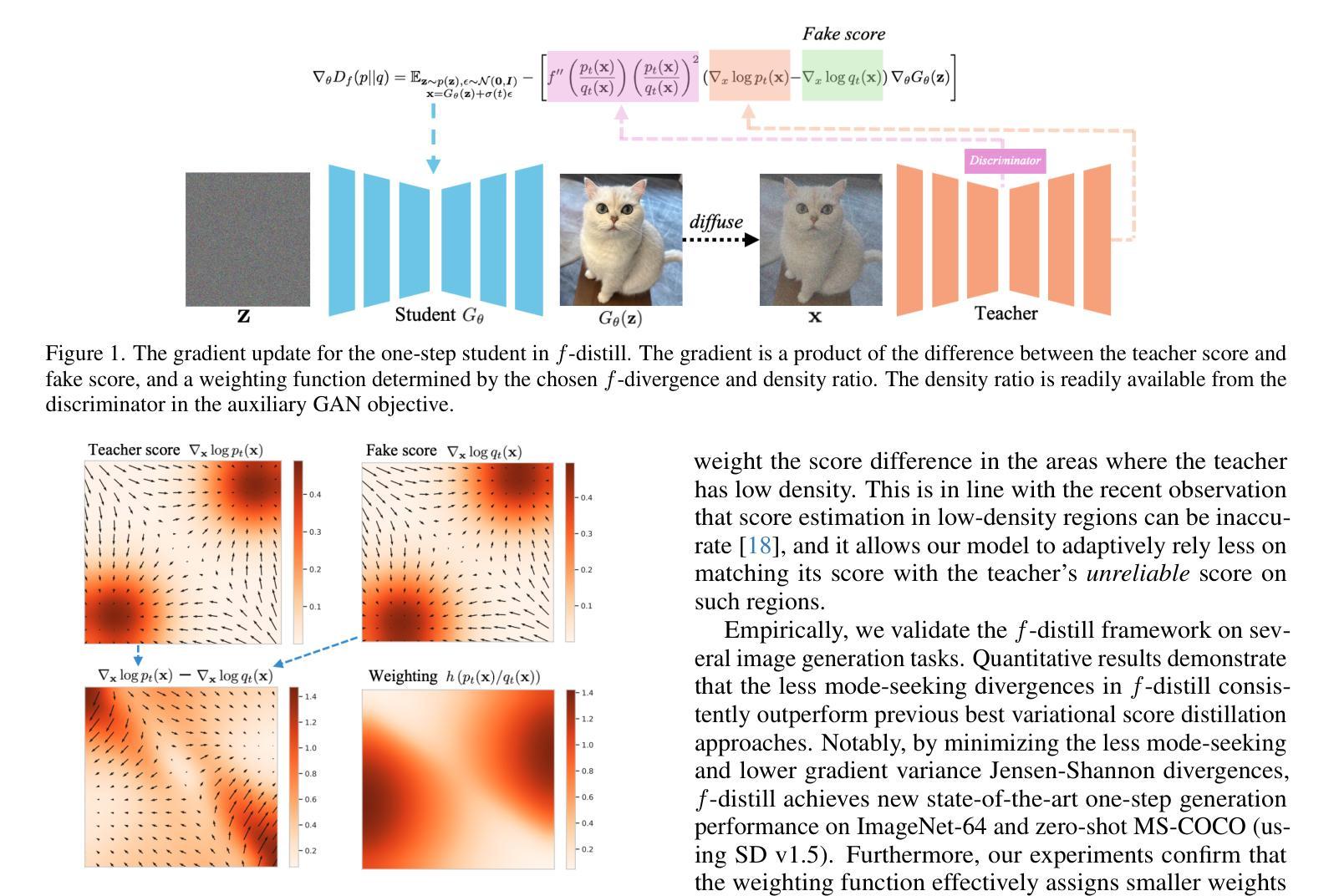
One-step Diffusion Models with $f$-Divergence Distribution Matching
Authors:Yilun Xu, Weili Nie, Arash Vahdat
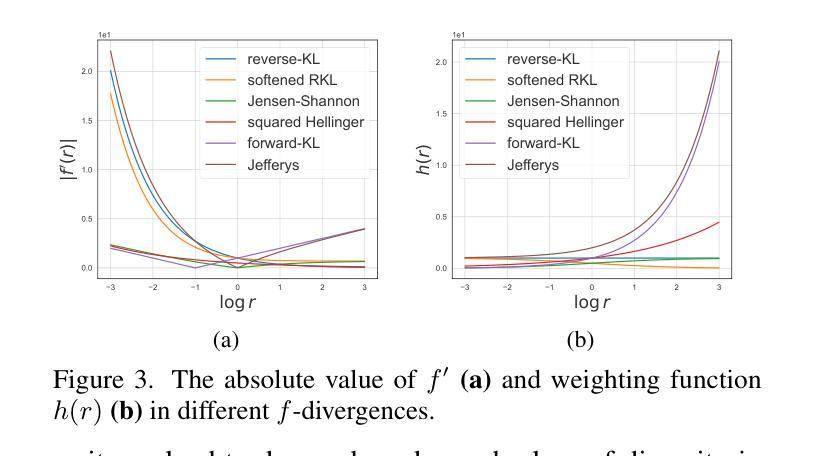
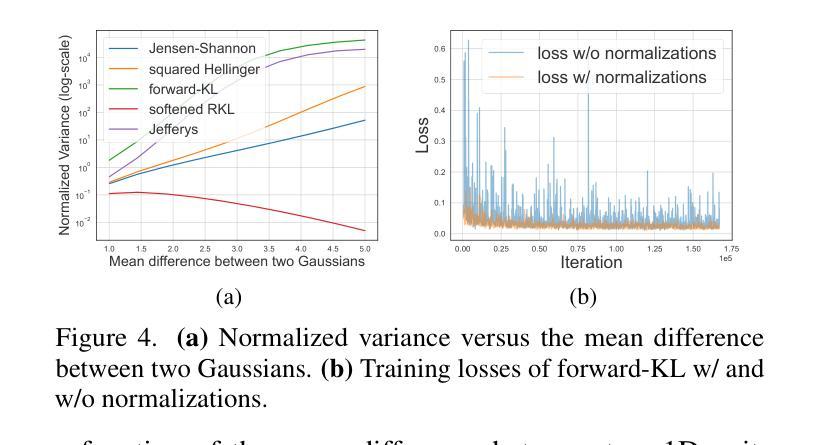
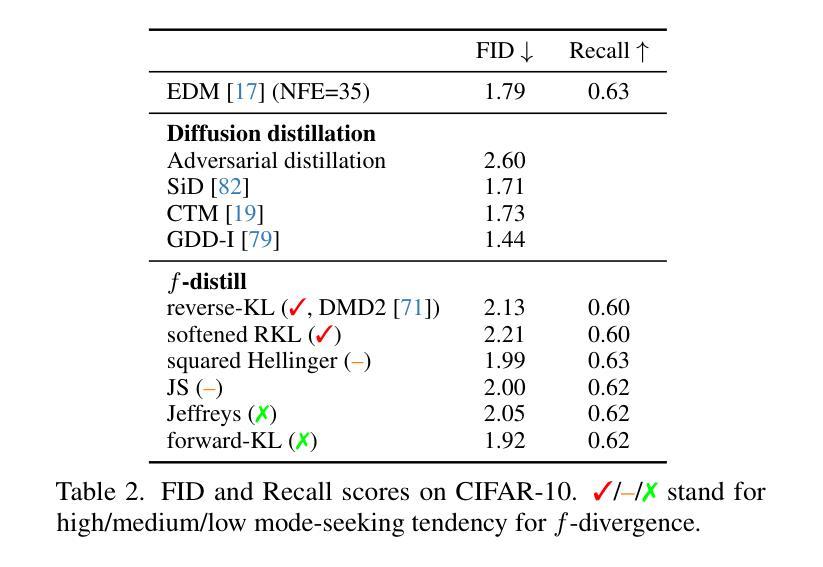
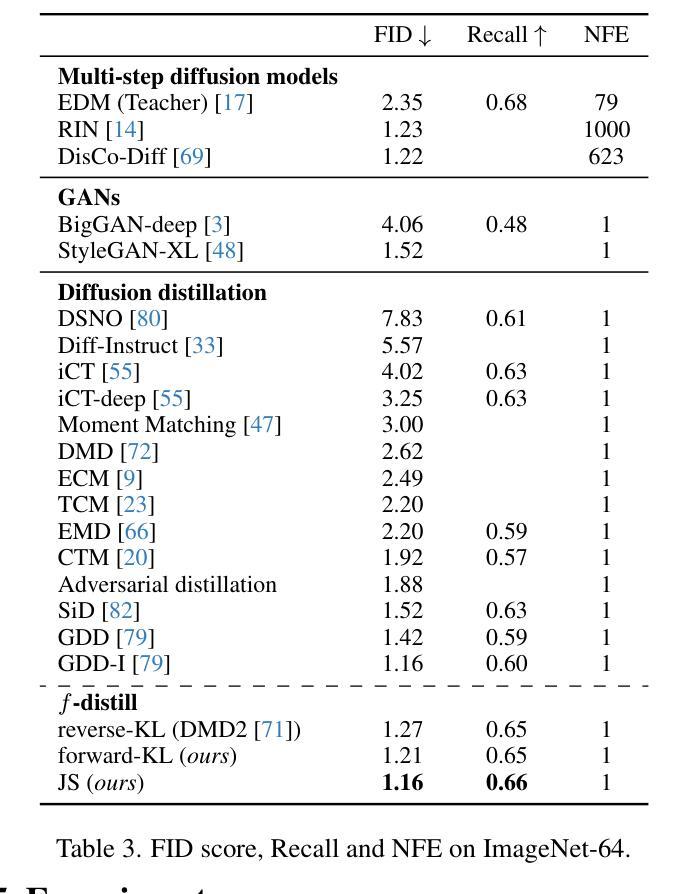
Sampling from diffusion models involves a slow iterative process that hinders their practical deployment, especially for interactive applications. To accelerate generation speed, recent approaches distill a multi-step diffusion model into a single-step student generator via variational score distillation, which matches the distribution of samples generated by the student to the teacher’s distribution. However, these approaches use the reverse Kullback-Leibler (KL) divergence for distribution matching which is known to be mode seeking. In this paper, we generalize the distribution matching approach using a novel $f$-divergence minimization framework, termed $f$-distill, that covers different divergences with different trade-offs in terms of mode coverage and training variance. We derive the gradient of the $f$-divergence between the teacher and student distributions and show that it is expressed as the product of their score differences and a weighting function determined by their density ratio. This weighting function naturally emphasizes samples with higher density in the teacher distribution, when using a less mode-seeking divergence. We observe that the popular variational score distillation approach using the reverse-KL divergence is a special case within our framework. Empirically, we demonstrate that alternative $f$-divergences, such as forward-KL and Jensen-Shannon divergences, outperform the current best variational score distillation methods across image generation tasks. In particular, when using Jensen-Shannon divergence, $f$-distill achieves current state-of-the-art one-step generation performance on ImageNet64 and zero-shot text-to-image generation on MS-COCO. Project page: https://research.nvidia.com/labs/genair/f-distill
从扩散模型中进行采样涉及一个缓慢迭代的过程,这阻碍了它们的实际应用,尤其是在交互式应用中。为了加快生成速度,最近的方法通过变分分数蒸馏将多步扩散模型蒸馏为单步学生生成器,使学生生成的样本分布与教师的分布相匹配。然而,这些方法使用反向Kullback-Leibler(KL)散度进行分布匹配,而反向KL散度是众所周知的模式寻求。在本文中,我们利用一种新的f-散度最小化框架推广分布匹配方法,称为f-distill,该框架涵盖了不同的散度,在模式覆盖和训练方差方面有不同的权衡。我们推导出教师和学生分布之间f-散度的梯度,并显示它表示为他们的分数差异之积和一个由他们的密度比确定的加权函数。当使用较少的模式寻求散度时,此加权函数会自然地强调教师分布中密度较高的样本。我们发现,使用反向KL散度的流行变分分数蒸馏方法是我们框架内的特殊情况。从经验上看,我们发现替代的f-散度,如正向KL和Jensen-Shannon散度,在图像生成任务上的性能优于当前最佳变分分数蒸馏方法。特别是使用Jensen-Shannon散度时,f-distill在ImageNet64上实现了一步生成的最先进性能,并在MS-COCO上实现了零样本文本到图像的生成。项目页面:https://research.nvidia.com/labs/genair/f-distill
论文及项目相关链接
Summary
该文针对扩散模型的采样速度慢的问题,提出了使用f-divergence最小化框架(f-distill)来加速生成速度的方法。该框架将多步扩散模型简化为单步学生生成器,并通过匹配学生与教师分布来实现加速。文章推导了教师分布和学生分布之间的f-divergence梯度,并展示了该梯度与他们的分数差异和密度比率决定的权重函数的乘积表达形式。此外,该文通过实证研究发现,使用不同的f-divergences(如正向KL和Jensen-Shannon散度)可以优于现有的变分分数蒸馏方法,在图像生成任务上有更好的表现。特别是在使用Jensen-Shannon散度时,f-distill在ImageNet64和MS-COCO上的单步生成性能和零样本文本到图像生成上达到了当前最佳水平。
Key Takeaways
- 扩散模型的采样是一个慢迭代过程,限制了其实时应用和交互体验。
- 通过变分分数蒸馏方法,可以将多步扩散模型简化为单步学生生成器,以提高生成速度。
- 现有方法使用反向KL散度进行分布匹配,但存在模式寻求的问题。
- 提出了f-divergence最小化框架(f-distill),包括不同的散度选择,以改善模式覆盖和训练方差之间的权衡。
- f-distill框架下的教师和学生分布匹配通过密度比率和分数差异实现,其中权重函数可自然强调教师分布中密度较高的样本。
- 使用不同的f-divergences(如正向KL和Jensen-Shannon散度)在图像生成任务上表现出优于现有方法的性能。
- f-distill在ImageNet64和MS-COCO上的单步生成性能达到了当前最佳水平。
点此查看论文截图


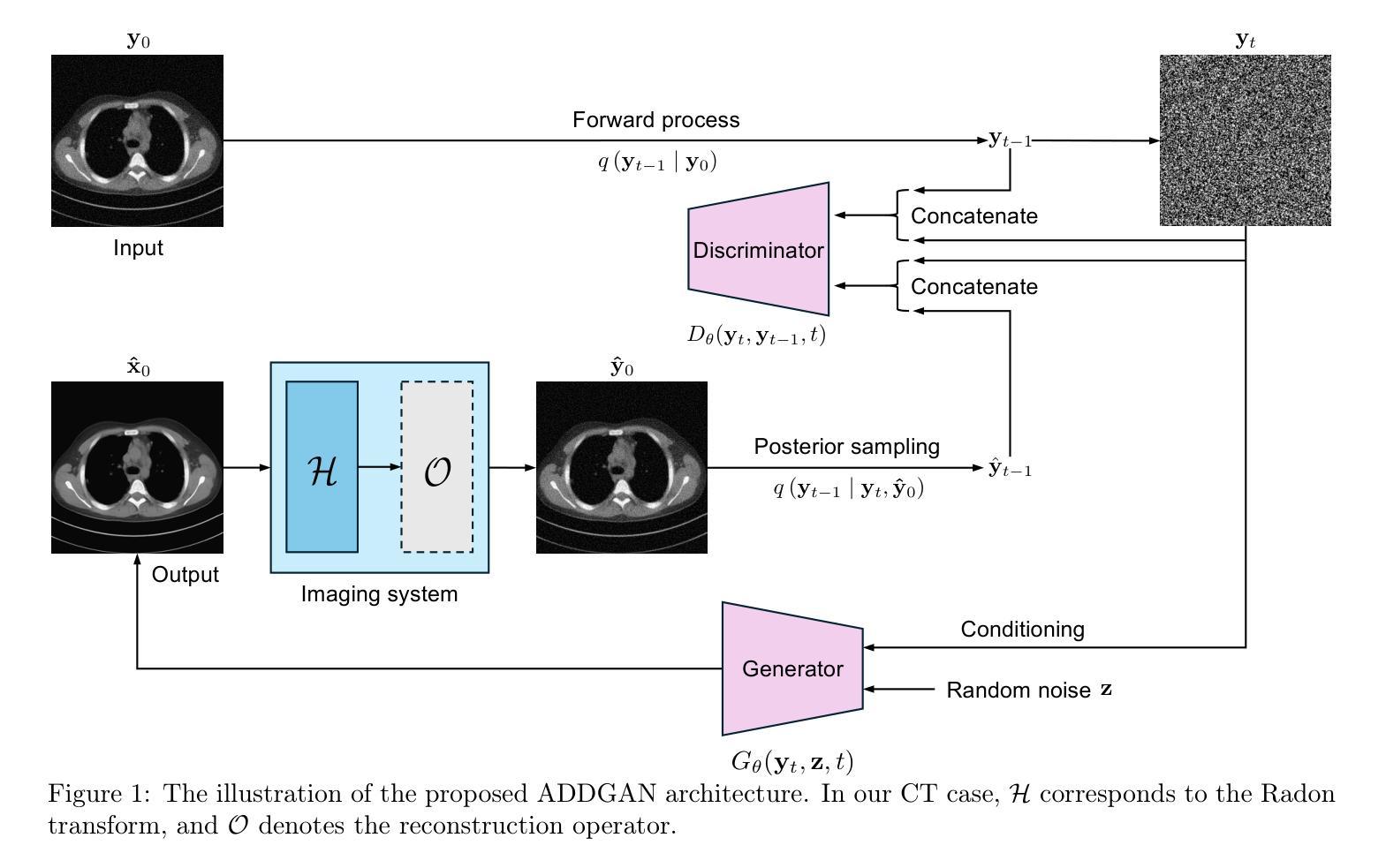
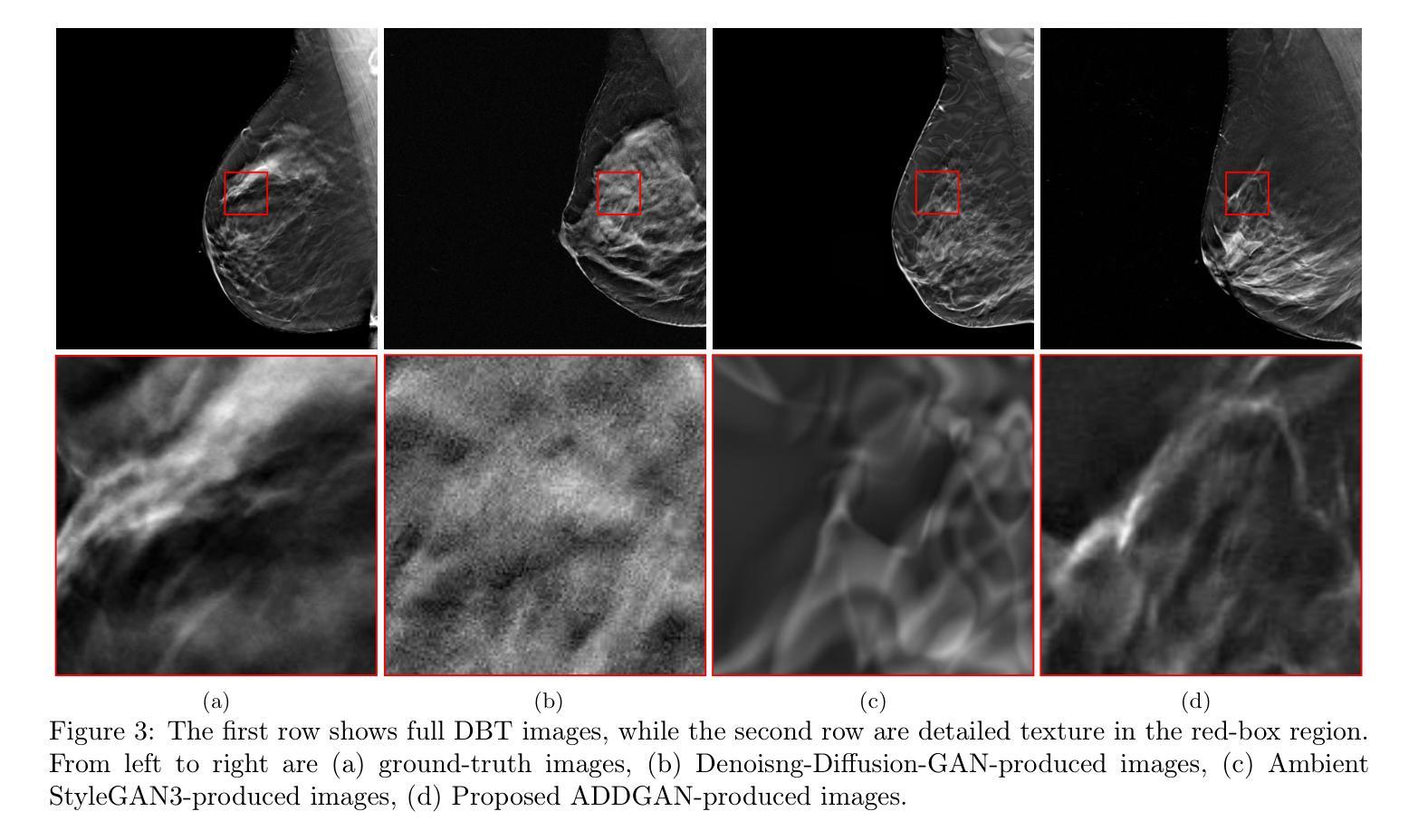
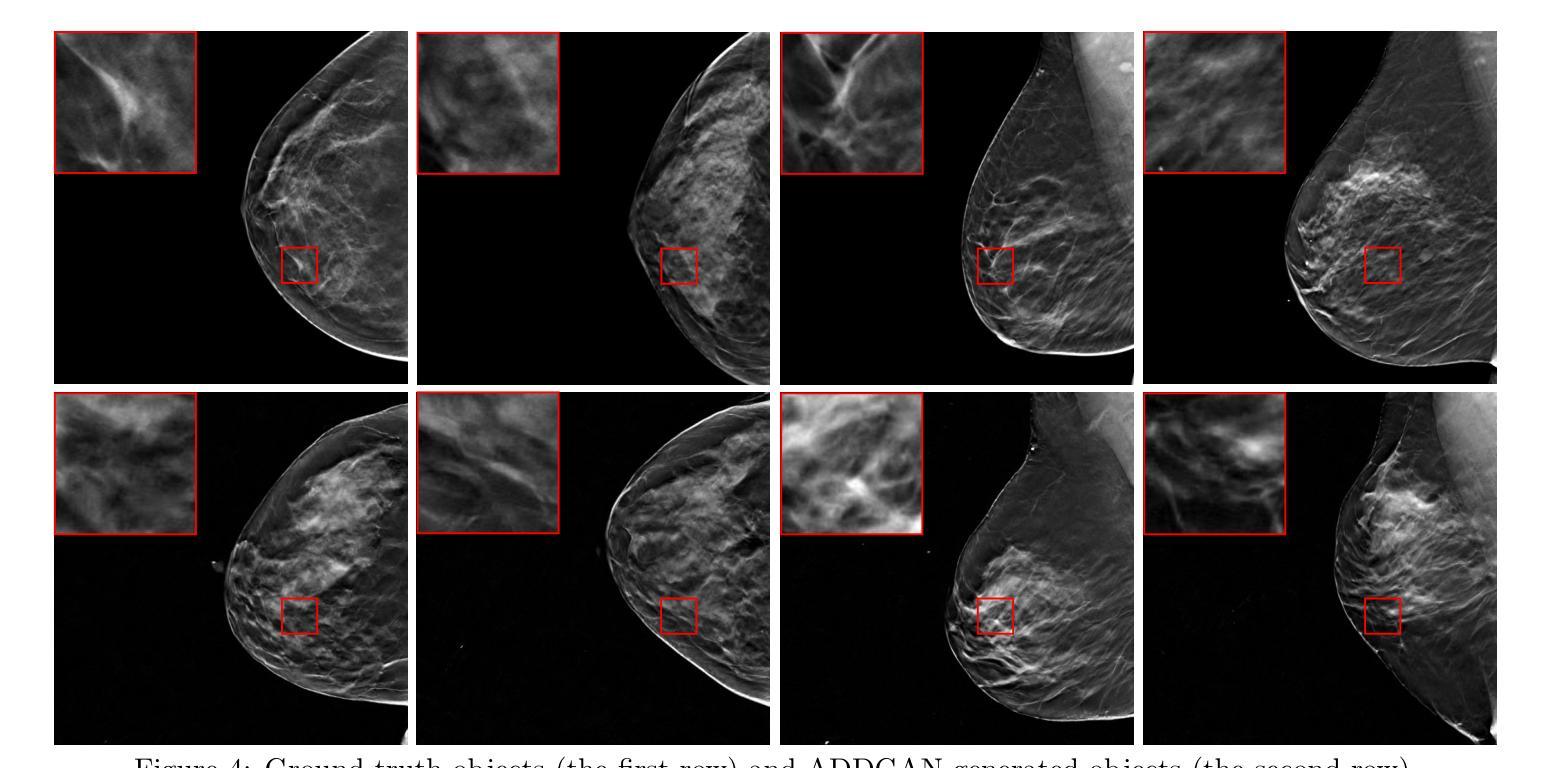
Ambient Denoising Diffusion Generative Adversarial Networks for Establishing Stochastic Object Models from Noisy Image Data
Authors:Xichen Xu, Wentao Chen, Weimin Zhou
It is widely accepted that medical imaging systems should be objectively assessed via task-based image quality (IQ) measures that ideally account for all sources of randomness in the measured image data, including the variation in the ensemble of objects to be imaged. Stochastic object models (SOMs) that can randomly draw samples from the object distribution can be employed to characterize object variability. To establish realistic SOMs for task-based IQ analysis, it is desirable to employ experimental image data. However, experimental image data acquired from medical imaging systems are subject to measurement noise. Previous work investigated the ability of deep generative models (DGMs) that employ an augmented generative adversarial network (GAN), AmbientGAN, for establishing SOMs from noisy measured image data. Recently, denoising diffusion models (DDMs) have emerged as a leading DGM for image synthesis and can produce superior image quality than GANs. However, original DDMs possess a slow image-generation process because of the Gaussian assumption in the denoising steps. More recently, denoising diffusion GAN (DDGAN) was proposed to permit fast image generation while maintain high generated image quality that is comparable to the original DDMs. In this work, we propose an augmented DDGAN architecture, Ambient DDGAN (ADDGAN), for learning SOMs from noisy image data. Numerical studies that consider clinical computed tomography (CT) images and digital breast tomosynthesis (DBT) images are conducted. The ability of the proposed ADDGAN to learn realistic SOMs from noisy image data is demonstrated. It has been shown that the ADDGAN significantly outperforms the advanced AmbientGAN models for synthesizing high resolution medical images with complex textures.
普遍认为,医疗成像系统应通过基于任务的图像质量(IQ)措施进行客观评估,这些措施应理想地考虑测量图像数据中所有随机性的来源,包括待成像对象集合的变异。可以使用随机对象模型(SOMs)从对象分布中随机抽取样本以表征对象的变化性。为了针对基于任务的IQ分析建立现实的SOMs,建议使用实验图像数据。然而,从医疗成像系统获得的实验图像数据存在测量噪声。先前的工作研究了使用增强生成对抗网络(GAN)的深生成模型(DGM)建立噪声测量图像数据的SOMs的能力。最近,去噪扩散模型(DDM)作为领先的图像合成DGM出现,并可以产生比GAN更高的图像质量。然而,原始DDMs由于去噪步骤中的高斯假设而具有较慢的图像生成过程。最近,提出了去噪扩散GAN(DDGAN)以允许快速图像生成,同时保持与原始DDMs相当的高生成图像质量。在这项工作中,我们提出了一种增强的DDGAN架构,即环境DDGAN(ADDGAN),用于从噪声图像数据中学习SOMs。我们进行了考虑临床计算机断层扫描(CT)图像和数字乳腺断层合成(DBT)图像的数值研究。展示了所提出的ADDGAN从噪声图像数据中学习现实SOMs的能力。研究表明,ADDGAN在合成具有复杂纹理的高分辨率医学图像方面显著优于先进的AmbientGAN模型。
论文及项目相关链接
PDF SPIE Medical Imaging 2025
Summary
本文探讨了基于任务质量的医学影像系统评估方法,介绍了随机对象模型(SOMs)的建立过程及其在任务质量分析中的应用。文章指出,实验图像数据受到测量噪声的影响,因此需要使用深度生成模型(DGMs)建立SOMs。文章介绍了去噪扩散模型(DDMs)和去噪扩散GAN(DDGAN)的优势和挑战,并提出了一种增强的DDGAN架构——Ambient DDGAN(ADDGAN),能够从噪声图像数据中学习现实世界的SOMs。数值研究证明了ADDGAN在合成高分辨率医学图像方面的显著优势,尤其在处理复杂纹理的医学图像时表现优异。
Key Takeaways
- 医疗影像系统评估应当采用基于任务质量的图像质量(IQ)措施,考虑图像数据中的所有随机性来源。
- 随机对象模型(SOMs)可用于表征对象变化,可从对象分布中随机抽取样本。
- 实验图像数据受到测量噪声的影响,需要使用深度生成模型(DGMs)建立现实的SOMs。
- 去噪扩散模型(DDMs)和去噪扩散GAN(DDGAN)是用于图像合成的先进DGM。
- 原始的DDMs由于去噪步骤中的高斯假设,图像生成过程较慢。
- 新提出的去噪扩散GAN(DDGAN)允许快速图像生成,同时保持与原始DDMs相当的高质量图像生成能力。
点此查看论文截图




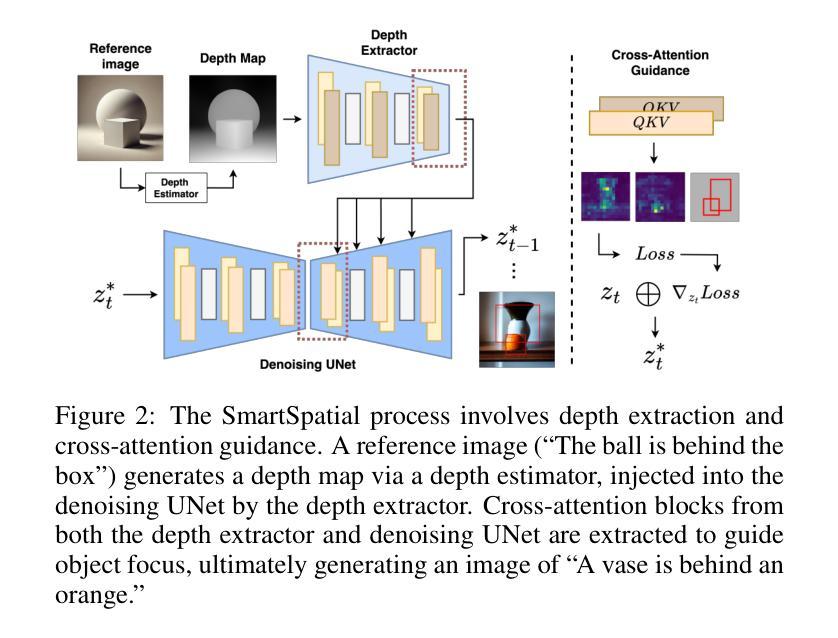
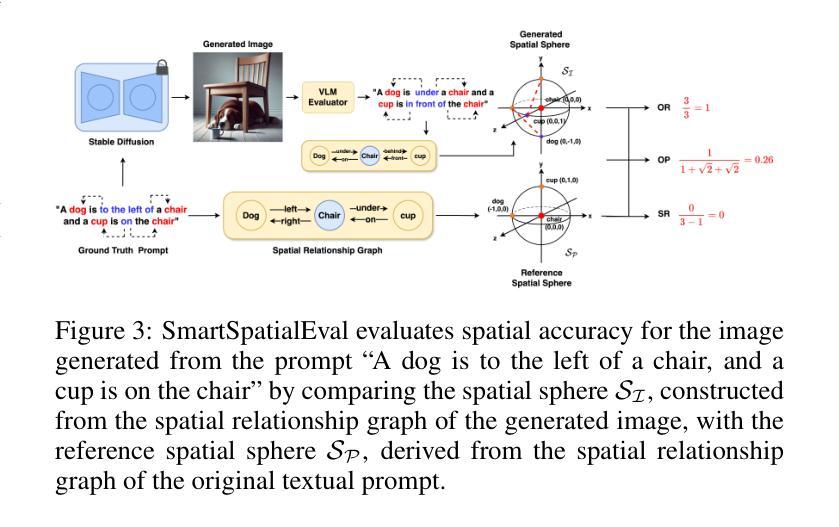
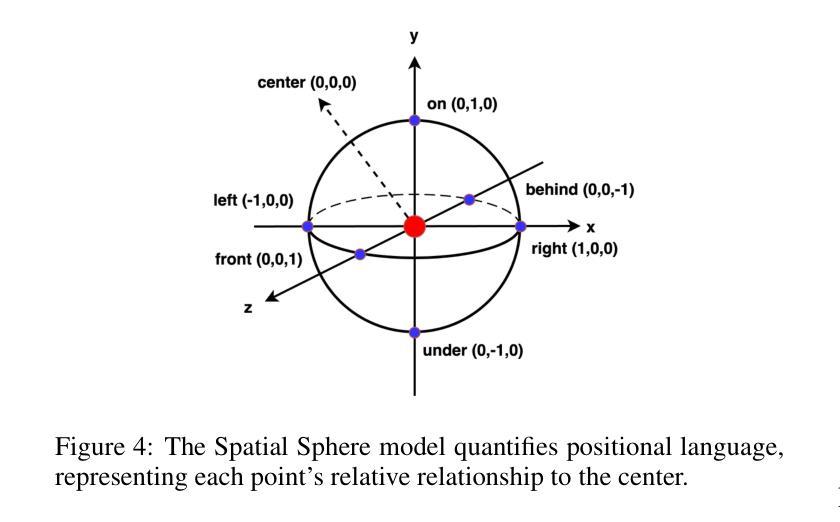
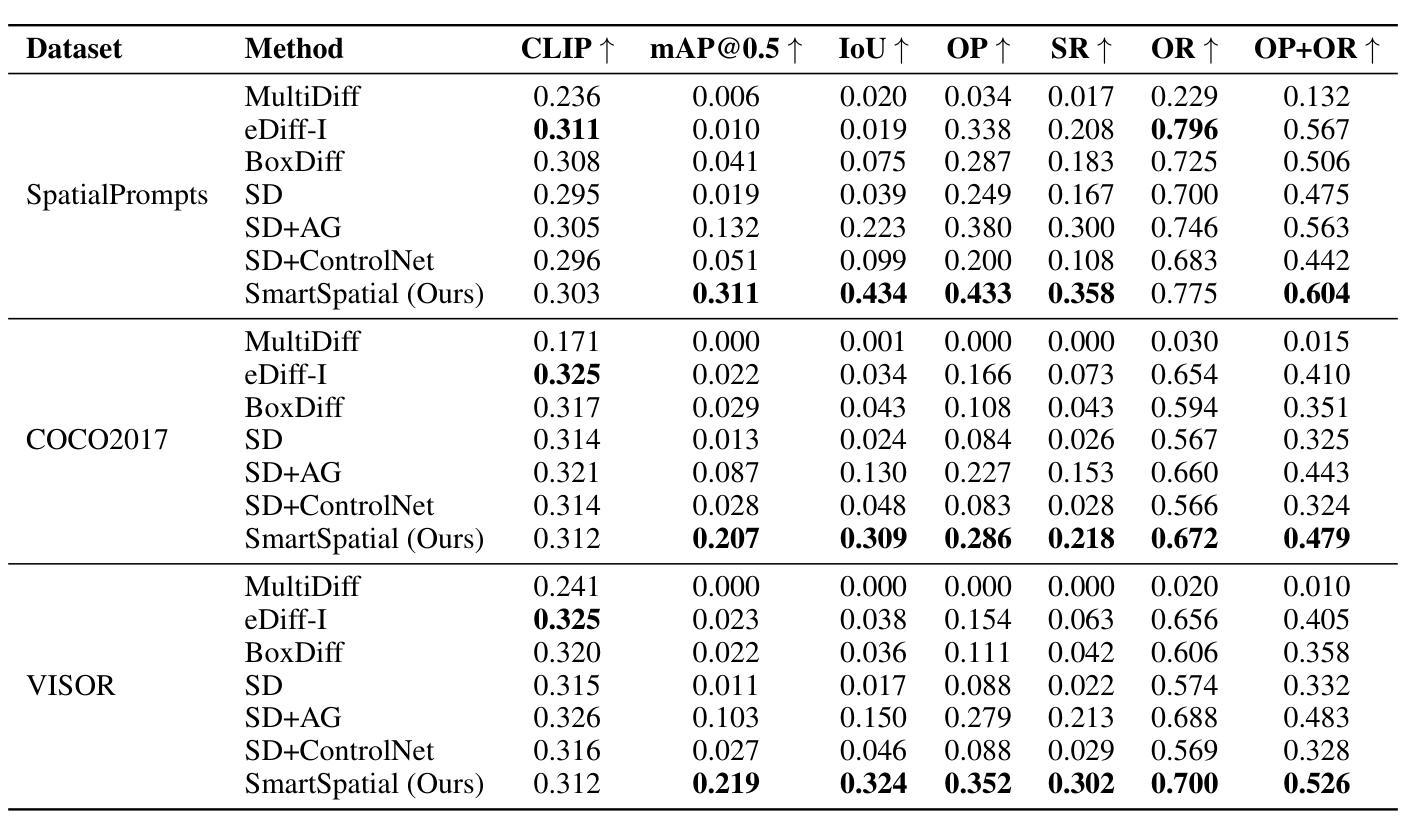
SmartSpatial: Enhancing the 3D Spatial Arrangement Capabilities of Stable Diffusion Models and Introducing a Novel 3D Spatial Evaluation Framework
Authors:Mao Xun Huang, Brian J Chan, Hen-Hsen Huang
Stable Diffusion models have made remarkable strides in generating photorealistic images from text prompts but often falter when tasked with accurately representing complex spatial arrangements, particularly involving intricate 3D relationships. To address this limitation, we introduce SmartSpatial, an innovative approach that not only enhances the spatial arrangement capabilities of Stable Diffusion but also fosters AI-assisted creative workflows through 3D-aware conditioning and attention-guided mechanisms. SmartSpatial incorporates depth information injection and cross-attention control to ensure precise object placement, delivering notable improvements in spatial accuracy metrics. In conjunction with SmartSpatial, we present SmartSpatialEval, a comprehensive evaluation framework that bridges computational spatial accuracy with qualitative artistic assessments. Experimental results show that SmartSpatial significantly outperforms existing methods, setting new benchmarks for spatial fidelity in AI-driven art and creativity.
稳定扩散模型在根据文本提示生成逼真的图像方面取得了显著的进步,但在准确表示复杂的空间排列,特别是涉及精细的3D关系时,往往会出现困难。为了解决这个问题,我们引入了SmartSpatial,这是一种创新的方法,不仅提高了稳定扩散的空间排列能力,还通过3D感知条件和注意力引导机制促进了AI辅助创意工作流程。SmartSpatial通过深度信息注入和交叉注意力控制,确保精确的对象放置,在空间精度指标方面取得了显著的改进。与SmartSpatial相结合,我们推出了SmartSpatialEval,这是一个全面的评估框架,它结合了计算空间精度与定性艺术评估。实验结果表明,SmartSpatial显著优于现有方法,为AI驱动的艺术和创造力设立了新的空间保真度基准。
论文及项目相关链接
PDF 9 pages
Summary
Stable Diffusion模型在根据文本提示生成逼真的图像方面取得了显著进展,但在表现复杂的空间排列,尤其是涉及精细的3D关系时常常出现问题。为解决这一局限性,我们推出了SmartSpatial,这是一种不仅增强了Stable Diffusion的空间排列能力,还通过3D感知条件和注意力引导机制促进了AI辅助创意工作流的创新方法。SmartSpatial通过深度信息注入和交叉注意力控制,确保精确的对象放置,在空间精度指标方面取得了显著的改进。配合SmartSpatial,我们推出了SmartSpatialEval综合评估框架,该框架将计算空间精度与定性艺术评估相结合。实验结果表明,SmartSpatial显著优于现有方法,为AI驱动的艺术和创造力设立了新的空间保真度基准。
Key Takeaways
- Stable Diffusion模型在生成逼真图像方面有所突破,但在复杂空间排列表示上仍有局限。
- SmartSpatial方法被引入,以增强模型在空间排列方面的能力,并促进AI辅助的创意工作流程。
- SmartSpatial通过深度信息注入和交叉注意力控制确保精确对象放置。
- SmartSpatialEval评估框架用于综合评估计算空间精度与定性艺术评估。
- SmartSpatial显著提高了空间精度指标,相较于现有方法表现出优越性。
- 该研究为AI驱动的艺术和创造力设立了新的空间保真度基准。
- 这种方法有助于推动AI在图像生成领域的进一步发展,尤其是在处理复杂空间关系方面。
点此查看论文截图


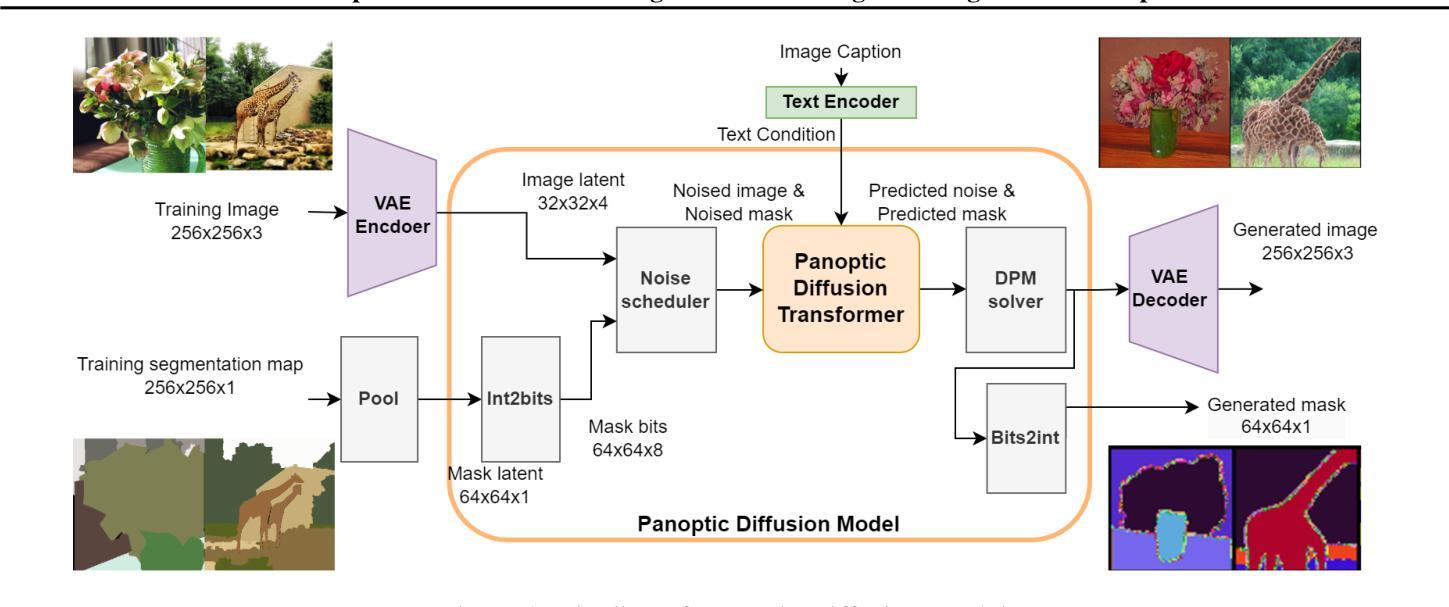
Panoptic Diffusion Models: co-generation of images and segmentation maps
Authors:Yinghan Long, Kaushik Roy
Recently, diffusion models have demonstrated impressive capabilities in text-guided and image-conditioned image generation. However, existing diffusion models cannot simultaneously generate an image and a panoptic segmentation of objects and stuff from the prompt. Incorporating an inherent understanding of shapes and scene layouts can improve the creativity and realism of diffusion models. To address this limitation, we present Panoptic Diffusion Model (PDM), the first model designed to generate both images and panoptic segmentation maps concurrently. PDM bridges the gap between image and text by constructing segmentation layouts that provide detailed, built-in guidance throughout the generation process. This ensures the inclusion of categories mentioned in text prompts and enriches the diversity of segments within the background. We demonstrate the effectiveness of PDM across two architectures: a unified diffusion transformer and a two-stream transformer with a pretrained backbone. We propose a Multi-Scale Patching mechanism to generate high-resolution segmentation maps. Additionally, when ground-truth maps are available, PDM can function as a text-guided image-to-image generation model. Finally, we propose a novel metric for evaluating the quality of generated maps and show that PDM achieves state-of-the-art results in image generation with implicit scene control.
最近,扩散模型在文本引导和图像条件图像生成方面展现出了令人印象深刻的能力。然而,现有的扩散模型无法从提示中同时生成图像和全景分割的对象和素材。融入对形状和场景布局的内在理解,可以提高扩散模型的创造性和真实性。为了解决这一限制,我们提出了全景扩散模型(PDM),这是第一个设计用来同时生成图像和全景分割图模型。PDM通过构建分割布局来缩小图像和文本之间的差距,为生成过程提供详细的内置指导。这确保了文本提示中提到的类别的包含性,并丰富了背景中段的多样性。我们在两种架构上展示了PDM的有效性:统一的扩散变压器和带有预训练主干的两流变压器。我们提出了一种多尺度补丁机制来生成高分辨率的分割图。另外,当存在真实地图时,PDM可以作为文本引导的图像到图像生成模型发挥作用。最后,我们提出了一种新的指标来评估生成的地图的质量,并证明PDM在具有隐式场景控制的图像生成方面达到了最新的结果。
论文及项目相关链接
Summary
本文介绍了一种名为Panoptic Diffusion Model(PDM)的新模型,该模型能够在生成图像的同时生成全景分割图。PDM通过构建分割布局来弥补图像和文本之间的差距,为生成过程提供详细的内置指导,确保包含文本提示中的类别,并丰富背景中的分段多样性。文章展示了PDM在两种架构下的有效性,并提出了一种多尺度贴片机制来生成高分辨率分割图。当存在真实地图时,PDM可以作为文本引导的图像到图像生成模型。最后,文章提出了一种评价生成图质量的新指标,并展示了PDM在图像生成方面的卓越性能,实现了隐式场景控制。
Key Takeaways
- Panoptic Diffusion Model (PDM) 是首个能够同时生成图像和全景分割图模型。
- PDM通过构建分割布局来融合图像和文本,提供生成过程中的详细内置指导。
- PDM能够确保包含文本提示中的类别,并丰富背景中的分段多样性。
- 文章展示了PDM在统一扩散变压器和两流变压器架构下的有效性。
- 多尺度贴片机制用于生成高分辨率分割图。
- 当存在真实地图时,PDM可作为文本引导的图像到图像生成模型。
点此查看论文截图


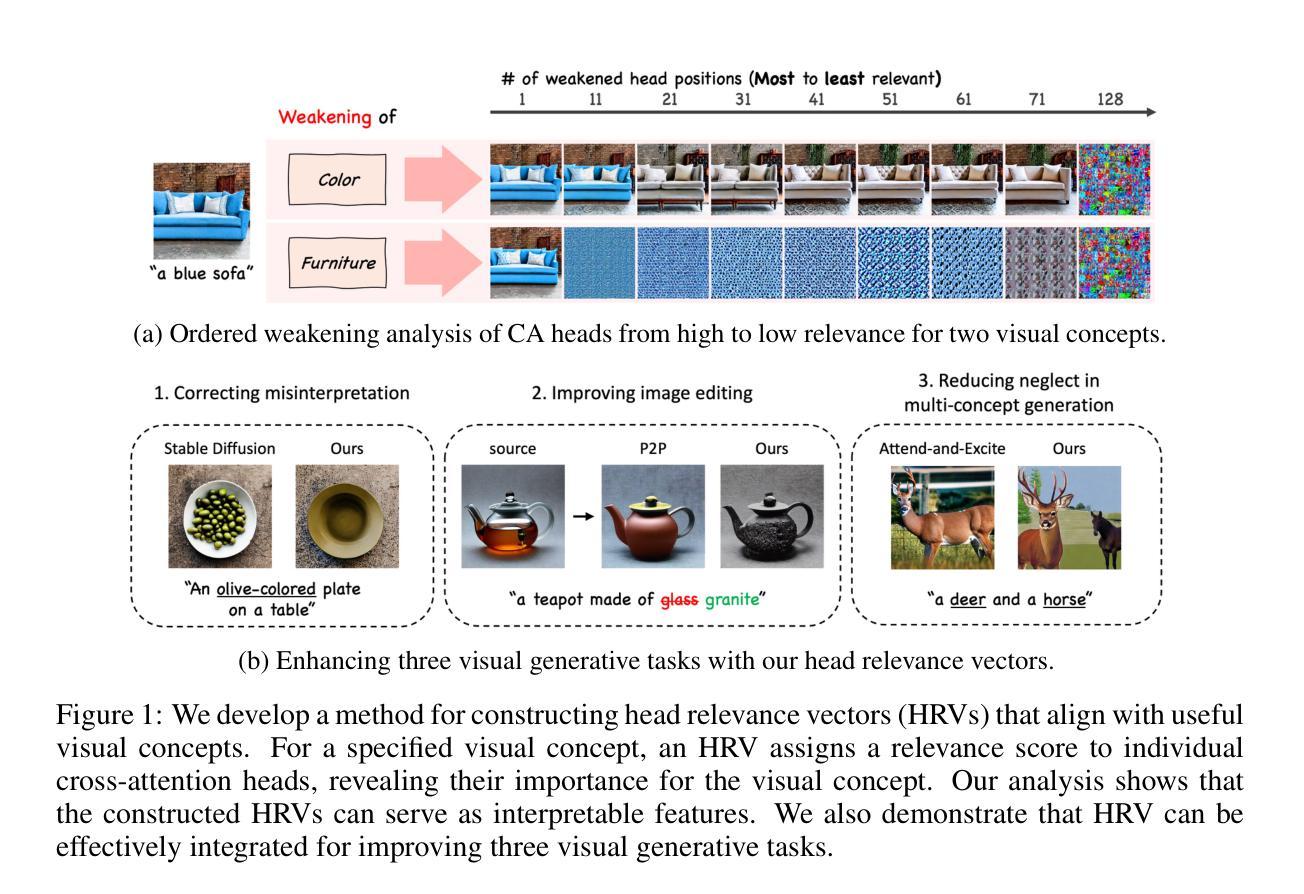
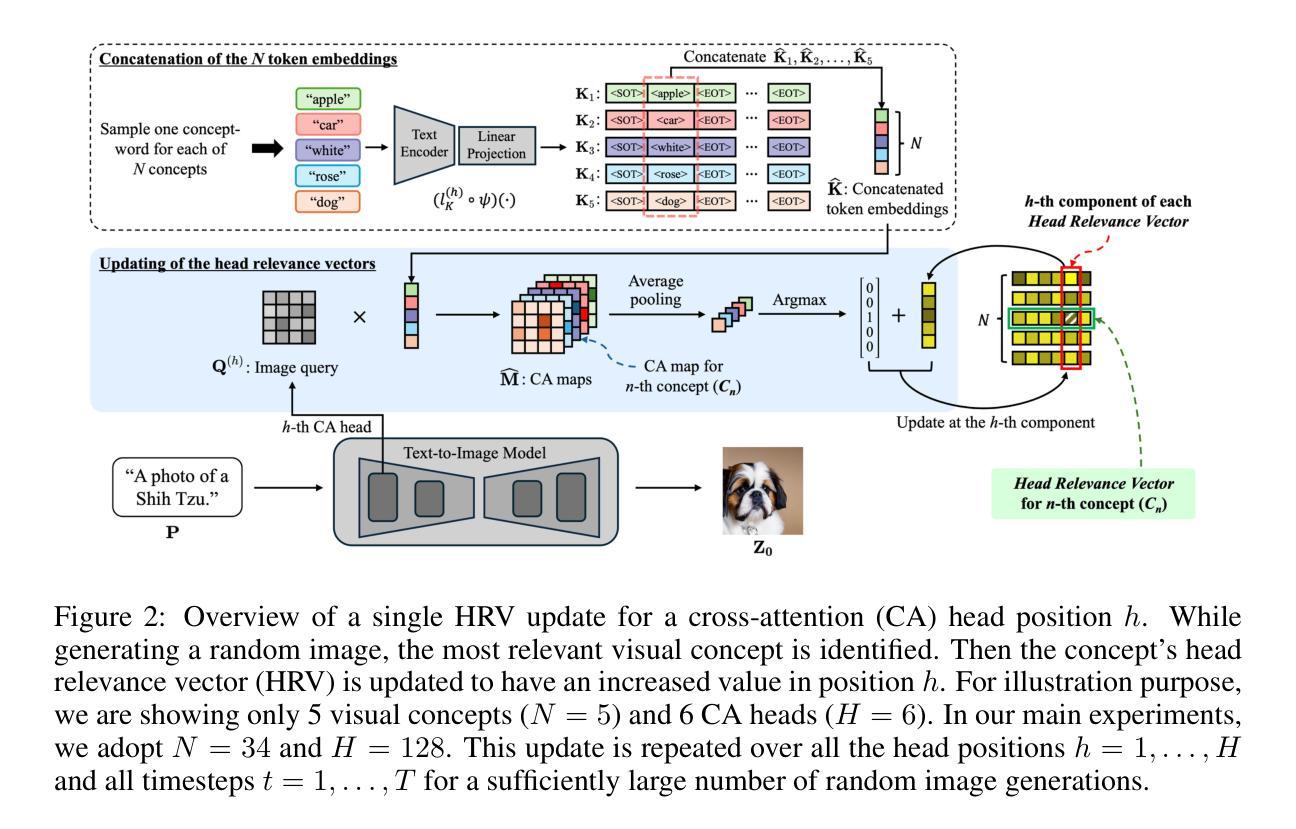
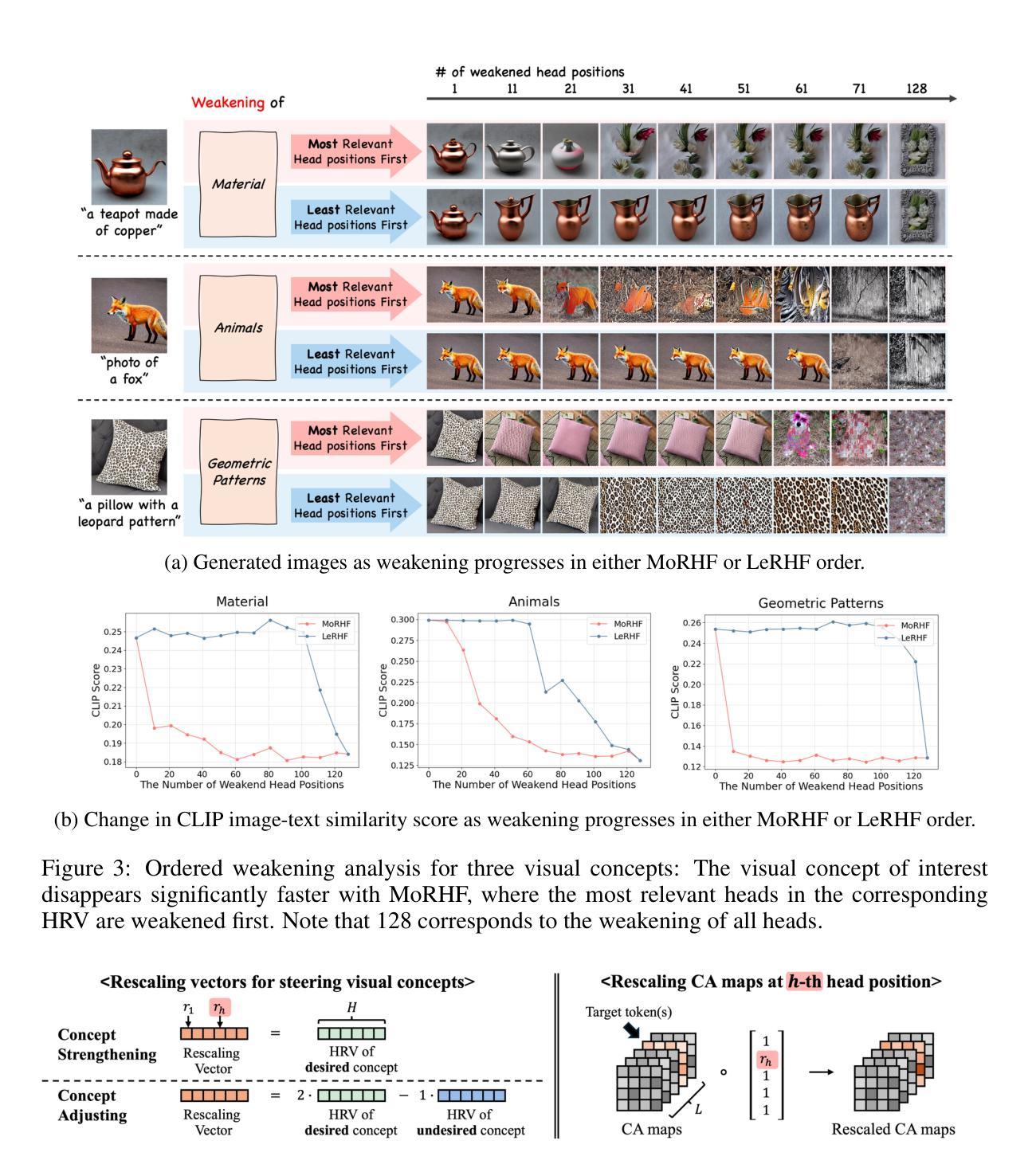
Cross-Attention Head Position Patterns Can Align with Human Visual Concepts in Text-to-Image Generative Models
Authors:Jungwon Park, Jungmin Ko, Dongnam Byun, Jangwon Suh, Wonjong Rhee
Recent text-to-image diffusion models leverage cross-attention layers, which have been effectively utilized to enhance a range of visual generative tasks. However, our understanding of cross-attention layers remains somewhat limited. In this study, we introduce a mechanistic interpretability approach for diffusion models by constructing Head Relevance Vectors (HRVs) that align with human-specified visual concepts. An HRV for a given visual concept has a length equal to the total number of cross-attention heads, with each element representing the importance of the corresponding head for the given visual concept. To validate HRVs as interpretable features, we develop an ordered weakening analysis that demonstrates their effectiveness. Furthermore, we propose concept strengthening and concept adjusting methods and apply them to enhance three visual generative tasks. Our results show that HRVs can reduce misinterpretations of polysemous words in image generation, successfully modify five challenging attributes in image editing, and mitigate catastrophic neglect in multi-concept generation. Overall, our work provides an advancement in understanding cross-attention layers and introduces new approaches for fine-controlling these layers at the head level.
最近的文本到图像的扩散模型利用了交叉注意力层,这些层已被有效地用于增强各种视觉生成任务。然而,我们对交叉注意力层的理解仍然有限。在这项研究中,我们通过构建与人类指定的视觉概念相对应的Head Relevance Vectors (HRVs)引入了一种机制解释性方法。给定视觉概念的HRV的长度等于交叉注意力头的总数,每个元素代表相应头对于给定视觉概念的重要性。为了验证HRV作为可解释特征的有效性,我们开发了一种有序的减弱分析方法。此外,我们提出了概念加强和概念调整方法,并应用于增强三种视觉生成任务。结果表明,HRV可以减少图像生成中对多义词的误解,成功修改图像编辑中的五个挑战属性,并减轻多概念生成中的灾难性忽视。总体而言,我们的工作推进了对交叉注意力层的理解,并介绍了在头部层面精细控制这些层的新方法。
论文及项目相关链接
PDF Accepted by ICLR 2025
Summary
本文探索了扩散模型的跨注意力层机制,通过构建与人类指定视觉概念对齐的Head Relevance Vectors(HRVs)来提高模型的可解释性。研究通过有序减弱分析验证了HRVs的有效性,并提出概念强化和概念调整方法,应用于三个视觉生成任务。研究发现,HRVs能够减少多义词在图像生成中的误解,成功修改图像编辑中的五个挑战属性,并缓解多概念生成中的灾难性忽视问题。
Key Takeaways
- 引入Head Relevance Vectors(HRVs)提高扩散模型的可解释性。
- 通过有序减弱分析验证了HRVs的有效性。
- 提出概念强化和概念调整方法,应用于视觉生成任务。
- HRVs能够减少多义词在图像生成中的误解。
- 成功修改图像编辑中的多个挑战属性。
- 缓解多概念生成中的灾难性忽视问题。
点此查看论文截图

A Grey-box Attack against Latent Diffusion Model-based Image Editing by Posterior Collapse
Authors:Zhongliang Guo, Chun Tong Lei, Lei Fang, Shuai Zhao, Yifei Qian, Jingyu Lin, Zeyu Wang, Cunjian Chen, Ognjen Arandjelović, Chun Pong Lau
Recent advancements in generative AI, particularly Latent Diffusion Models (LDMs), have revolutionized image synthesis and manipulation. However, these generative techniques raises concerns about data misappropriation and intellectual property infringement. Adversarial attacks on machine learning models have been extensively studied, and a well-established body of research has extended these techniques as a benign metric to prevent the underlying misuse of generative AI. Current approaches to safeguarding images from manipulation by LDMs are limited by their reliance on model-specific knowledge and their inability to significantly degrade semantic quality of generated images. In response to these shortcomings, we propose the Posterior Collapse Attack (PCA) based on the observation that VAEs suffer from posterior collapse during training. Our method minimizes dependence on the white-box information of target models to get rid of the implicit reliance on model-specific knowledge. By accessing merely a small amount of LDM parameters, in specific merely the VAE encoder of LDMs, our method causes a substantial semantic collapse in generation quality, particularly in perceptual consistency, and demonstrates strong transferability across various model architectures. Experimental results show that PCA achieves superior perturbation effects on image generation of LDMs with lower runtime and VRAM. Our method outperforms existing techniques, offering a more robust and generalizable solution that is helpful in alleviating the socio-technical challenges posed by the rapidly evolving landscape of generative AI.
最近,生成式人工智能(尤其是潜在扩散模型(LDMs))的最新进展彻底改变了图像合成和操纵。然而,这些生成技术引发了关于数据不当使用和知识产权侵犯的担忧。机器学习模型的对抗性攻击已经得到了广泛的研究,并且已有大量研究将这些技术作为一种良性指标,以防止生成式人工智能的潜在滥用。当前保护图像免受LDM操纵的方法受限于它们对特定模型知识的依赖,以及它们无法显著降低生成图像的语义质量。针对这些缺点,我们提出了基于后崩溃攻击(PCA)的方法,该方法是根据变分自编码器(VAEs)在训练过程中会出现的后崩溃现象的观察而提出的。我们的方法最小化了对目标模型白盒信息的依赖,以摆脱对特定模型知识的隐性依赖。通过仅访问少量LDM参数,特别是LDM的VAE编码器,我们的方法在生成质量上引起了大量的语义崩溃,特别是在感知一致性方面,并且在各种模型架构之间表现出强大的可转移性。实验结果表明,PCA在图像生成方面实现了对LDMs的卓越扰动效果,具有更低的运行时间和VRAM。我们的方法优于现有技术,提供了一种更稳健和可推广的解决方案,有助于缓解生成式人工智能快速演变所带来的社会技术挑战。
论文及项目相关链接
PDF 21 pages, 7 figures, 10 tables
Summary
近期生成式AI技术,特别是潜在扩散模型(LDMs)在图像合成和操纵方面的进展引发了数据不当使用和知识产权侵犯的担忧。针对这一问题,提出基于变分自编码器(VAEs)训练过程中的后崩溃现象的Posterior Collapse Attack(PCA)方法。该方法通过少量LDM参数,特别是VAE编码器的访问,实现了生成质量的语义崩溃,特别是在感知一致性方面。实验结果表明,PCA对LDM的图像生成实现了卓越的扰动效果,运行时间短,虚拟内存(VRAM)需求低,优于现有技术,为缓解生成式AI快速发展带来的社会技术挑战提供了更稳健和通用的解决方案。
Key Takeaways
- LDM的快速发展推动了图像合成和操纵的进步,但带来了数据滥用和知识产权问题的担忧。
- 对抗攻击是评估机器学习模型安全性的重要手段。
- PCA方法基于VAE训练中的后崩溃现象提出,减少对目标模型的依赖。
- PCA通过访问少量LDM参数(特别是VAE编码器)实现语义质量显著下降。
- PCA方法在感知一致性方面表现尤为突出,展示了对各种模型架构的强大可转移性。
- 实验结果表明,PCA在运行时和VRAM需求方面优于现有技术。
点此查看论文截图