⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-26 更新
Large Language Models are Powerful EHR Encoders
Authors:Stefan Hegselmann, Georg von Arnim, Tillmann Rheude, Noel Kronenberg, David Sontag, Gerhard Hindricks, Roland Eils, Benjamin Wild
Electronic Health Records (EHRs) offer rich potential for clinical prediction, yet their inherent complexity and heterogeneity pose significant challenges for traditional machine learning approaches. Domain-specific EHR foundation models trained on large collections of unlabeled EHR data have demonstrated promising improvements in predictive accuracy and generalization; however, their training is constrained by limited access to diverse, high-quality datasets and inconsistencies in coding standards and healthcare practices. In this study, we explore the possibility of using general-purpose Large Language Models (LLMs) based embedding methods as EHR encoders. By serializing patient records into structured Markdown text, transforming codes into human-readable descriptors, we leverage the extensive generalization capabilities of LLMs pretrained on vast public corpora, thereby bypassing the need for proprietary medical datasets. We systematically evaluate two state-of-the-art LLM-embedding models, GTE-Qwen2-7B-Instruct and LLM2Vec-Llama3.1-8B-Instruct, across 15 diverse clinical prediction tasks from the EHRSHOT benchmark, comparing their performance to an EHRspecific foundation model, CLIMBR-T-Base, and traditional machine learning baselines. Our results demonstrate that LLM-based embeddings frequently match or exceed the performance of specialized models, even in few-shot settings, and that their effectiveness scales with the size of the underlying LLM and the available context window. Overall, our findings demonstrate that repurposing LLMs for EHR encoding offers a scalable and effective approach for clinical prediction, capable of overcoming the limitations of traditional EHR modeling and facilitating more interoperable and generalizable healthcare applications.
电子健康记录(EHRs)在临床预测方面具有巨大的潜力,然而其固有的复杂性和异质性给传统的机器学习方法带来了巨大的挑战。基于大型无标签EHR数据的领域特定EHR基础模型已经在预测准确性和泛化能力方面显示出有希望的改进;然而,它们的训练受到多样、高质量数据集访问受限以及编码标准和医疗保健实践不一致的制约。在这项研究中,我们探索了使用基于通用大语言模型(LLMs)的嵌入方法作为EHR编码器的可能性。通过将患者记录序列化为结构化Markdown文本,将代码转换为人类可读的描述符,我们充分利用了LLMs在大量公共语料库上的预训练带来的广泛泛化能力,从而绕过了对专有医疗数据集的需求。我们系统地评估了两种最先进的LLM嵌入模型——GTE-Qwen2-7B-Instruct和LLM2Vec-Llama3.1-8B-Instruct,在EHRSHOT基准测试的15个不同临床预测任务上,与EHR特定基础模型CLIMBR-T-Base和传统机器学习基线进行了性能比较。我们的结果表明,基于LLM的嵌入经常与专业化模型的性能相匹配甚至更好,即使在少样本情况下也是如此,它们的有效性随着底层LLM的大小和可用上下文窗口的大小而扩展。总的来说,我们的研究结果表明,将LLMs重新用于EHR编码为临床预测提供了一种可扩展和有效的途径,能够克服传统EHR建模的限制,促进更互联和更通用的医疗保健应用程序的开发。
论文及项目相关链接
摘要
本研究探索了使用通用的大型语言模型(LLMs)作为电子健康记录(EHRs)编码器的可能性。通过将患者记录序列化为结构化Markdown文本,将代码转换为人类可读的描述符,研究利用在大量公共语料库上预训练LLMs的广泛泛化能力,从而绕过对专有医疗数据集的需求。系统评估了两种先进LLM嵌入模型在EHRSHOT基准测试的15个不同临床预测任务上的性能,并与EHR特定基础模型CLIMBR-T-Base和传统机器学习基线进行了比较。结果表明,LLM基于嵌入的表示在很多情况下与专门模型的性能相匹配甚至超越,即使在少样本情况下也是如此,且其有效性随着底层LLM的大小和可用上下文窗口的大小而提高。总体而言,研究发现将LLMs用于EHR编码提供了一种可扩展和有效的临床预测方法,能够克服传统EHR建模的限制,促进更互操作和更通用的医疗保健应用程序的开发。
关键见解
- 电子健康记录(EHRs)蕴含丰富的临床预测潜力,但其复杂性和异质性为传统机器学习方法带来挑战。
- 域名特定的EHR基础模型已在预测准确性和泛化能力方面显示出有希望的改进,但其训练受限于多样、高质量数据集的不稳定和编码标准和医疗保健实践的不一致。
- 研究探索了使用通用的大型语言模型(LLMs)作为EHR编码器的可能性,利用LLMs在大量公共语料库上的预训练泛化能力。
- 通过序列化患者记录和转换代码为人类可读的描述符,研究绕过了对专有医疗数据集的需求。
- LLM嵌入模型在EHRSHOT基准测试中表现出强大的性能,与专门模型相匹配甚至超越。
- LLMs的有效性在少样本情况下尤为显著,且随着模型大小和上下文窗口的增加而提高。
- 使用LLMs进行EHR编码为临床预测提供了一种可扩展和有效的方法,能够克服传统EHR建模的限制。
点此查看论文截图

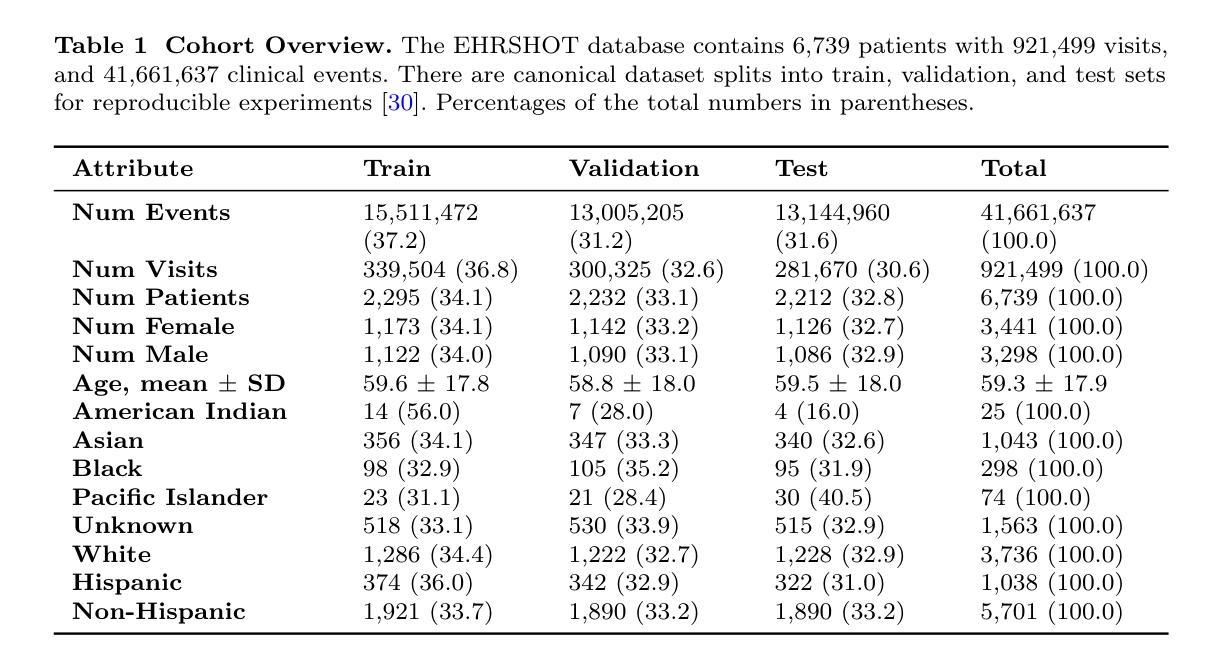
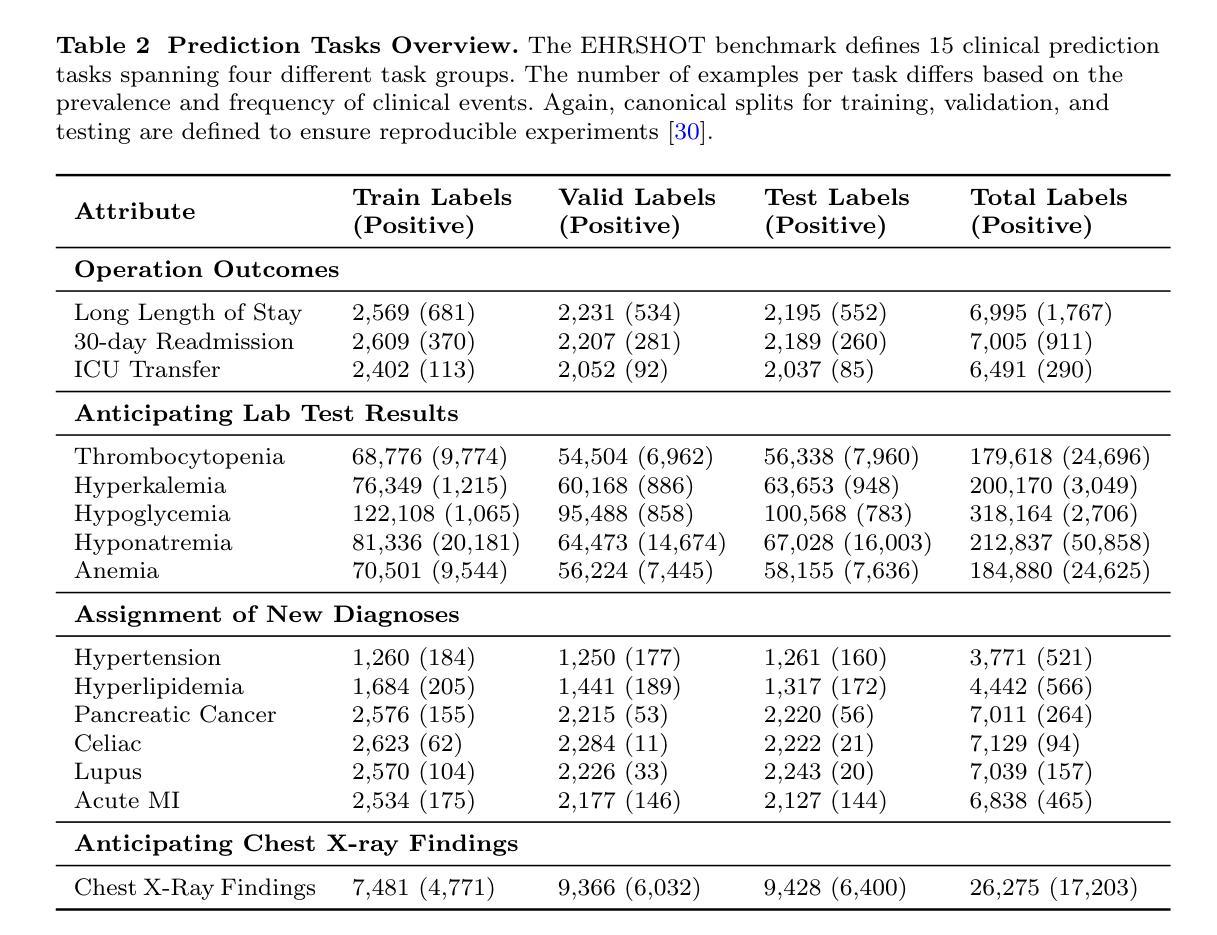

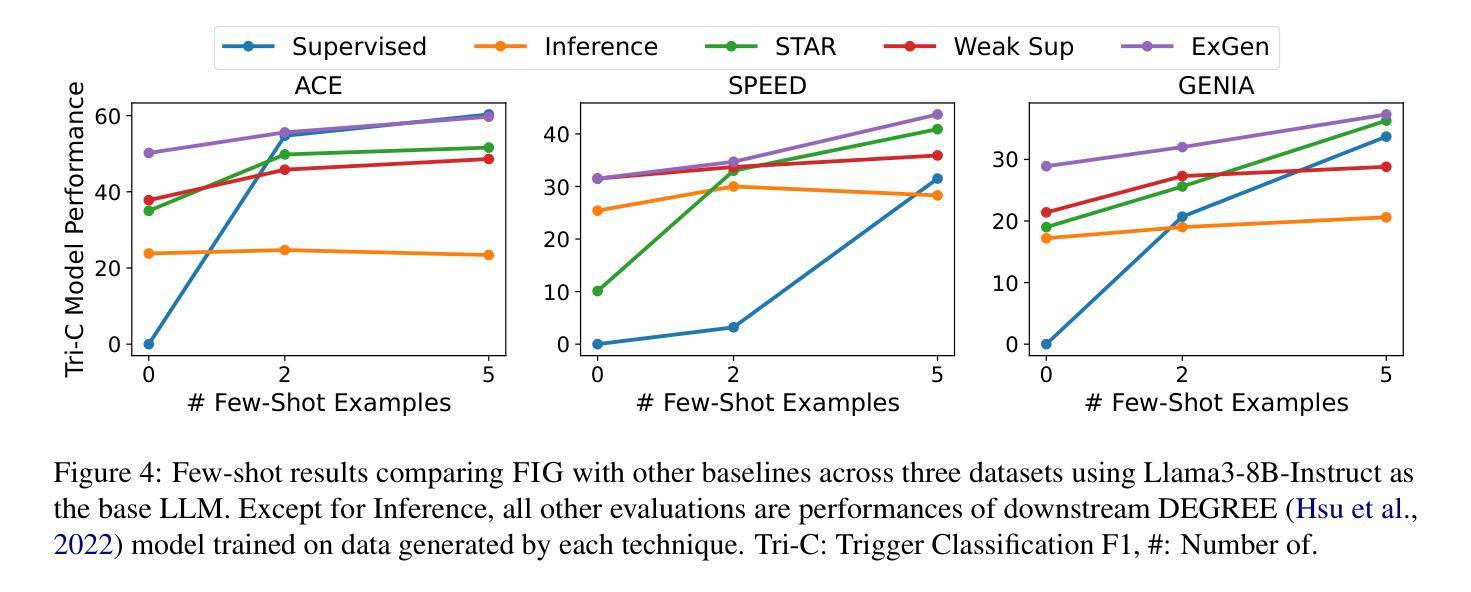
FIG: Forward-Inverse Generation for Low-Resource Domain-specific Event Detection
Authors:Tanmay Parekh, Yuxuan Dong, Lucas Bandarkar, Artin Kim, I-Hung Hsu, Kai-Wei Chang, Nanyun Peng
Event Detection (ED) is the task of identifying typed event mentions of interest from natural language text, which benefits domain-specific reasoning in biomedical, legal, and epidemiological domains. However, procuring supervised data for thousands of events for various domains is a laborious and expensive task. To this end, existing works have explored synthetic data generation via forward (generating labels for unlabeled sentences) and inverse (generating sentences from generated labels) generations. However, forward generation often produces noisy labels, while inverse generation struggles with domain drift and incomplete event annotations. To address these challenges, we introduce FIG, a hybrid approach that leverages inverse generation for high-quality data synthesis while anchoring it to domain-specific cues extracted via forward generation on unlabeled target data. FIG further enhances its synthetic data by adding missing annotations through forward generation-based refinement. Experimentation on three ED datasets from diverse domains reveals that FIG outperforms the best baseline achieving average gains of 3.3% F1 and 5.4% F1 in the zero-shot and few-shot settings respectively. Analyzing the generated trigger hit rate and human evaluation substantiates FIG’s superior domain alignment and data quality compared to existing baselines.
事件检测(ED)是从自然语言文本中识别出有趣的事件类型提及的任务,这有助于生物医学、法律和流行病学等领域的特定领域推理。然而,为各种领域成千上万的事件获取监督数据是一项耗时且昂贵的任务。为此,现有研究已经探索了正向生成(为未标记的句子生成标签)和逆向生成(从生成的标签生成句子)的合成数据生成方法。然而,正向生成往往会生成噪声标签,而逆向生成则面临领域漂移和事件注解不完整的问题。为了解决这些挑战,我们引入了FIG,这是一种混合方法,它利用逆向生成进行高质量数据合成,同时以通过正向生成在未标记的目标数据上提取的领域特定线索为基础进行锚定。FIG还通过基于正向生成的细化来补充缺失的注释,进一步增强其合成数据。在三个来自不同领域的事件检测数据集上的实验表明,与最佳基线相比,FIG在零样本和少样本设置下分别实现了平均F1得分提高3.3%和5.4%。对生成触发命中率的分析和人工评估证实,与现有基线相比,FIG在领域对齐和数据质量方面具有优势。
论文及项目相关链接
PDF Under review at ACL ARR Feb 2025
Summary
事件检测(ED)是从自然语言文本中识别特定事件提及的任务,对特定领域(如生物医学、法律和流行病学领域)的推理具有重大意义。然而,为数千个事件获取监督数据是一个艰巨且昂贵的任务。现有研究已尝试通过正向生成(为未标记的句子生成标签)和逆向生成(从生成的标签生成句子)的方式进行合成数据生成。但正向生成往往产生噪声标签,而逆向生成则面临领域漂移和事件标注不完整的问题。为了克服这些挑战,我们引入了FIG方法,该方法利用逆向生成进行高质量数据合成,同时通过正向生成在未标记的目标数据上提取的特定领域线索进行锚定。此外,FIG还通过正向生成进行精炼来补充缺失的标注。在三个来自不同领域的ED数据集上的实验表明,与最佳基线相比,FIG在零样本和少样本场景下平均F1得分分别提高了3.3%和5.4%。对生成触发命中率和人工评估的分析证实了FIG相较于现有基线在领域对齐和数据质量方面的优越性。
Key Takeaways
- 事件检测(ED)是从文本中识别特定事件的任务,对特定领域有重要意义。
- 为事件获取监督数据既困难又昂贵。
- 现有方法如正向和逆向数据生成存在挑战,如噪声标签和领域漂移问题。
- 引入的FIG方法结合了正向和逆向生成,旨在提高数据合成的质量和领域特异性。
- 通过实验验证,FIG在零样本和少样本场景下均优于现有基线。
- 生成触发命中率分析和人工评估证明了FIG在领域对齐和数据质量方面的优越性。
点此查看论文截图


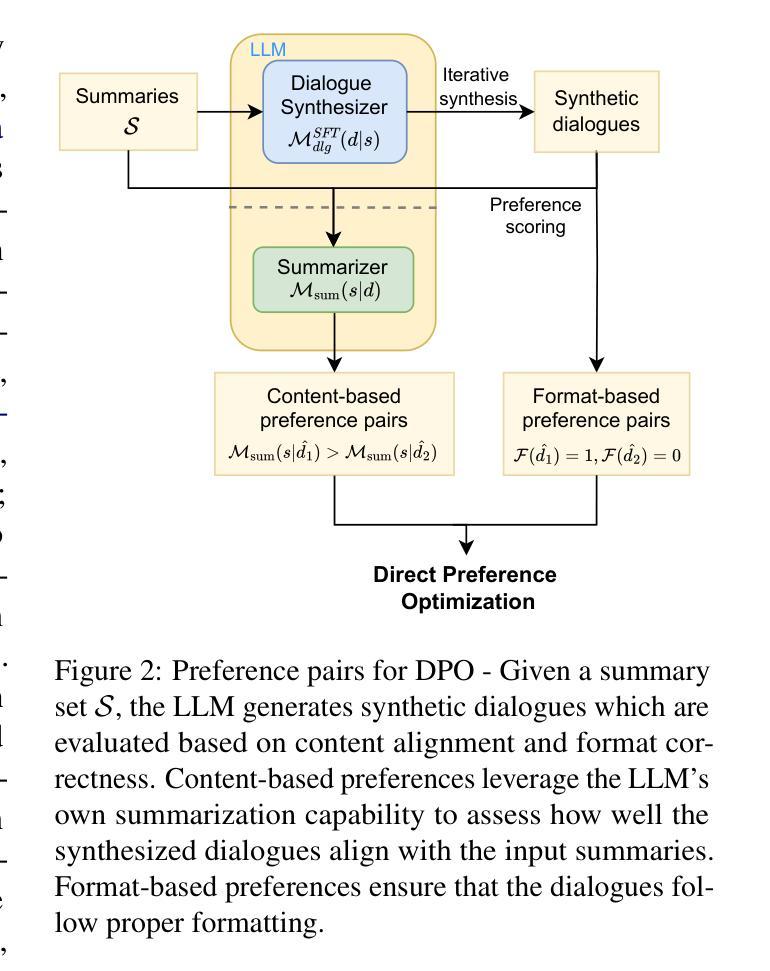
Mutual Reinforcement of LLM Dialogue Synthesis and Summarization Capabilities for Few-Shot Dialogue Summarization
Authors:Yen-Ju Lu, Ting-Yao Hu, Hema Swetha Koppula, Hadi Pouransari, Jen-Hao Rick Chang, Yin Xia, Xiang Kong, Qi Zhu, Simon Wang, Oncel Tuzel, Raviteja Vemulapalli
In this work, we propose Mutual Reinforcing Data Synthesis (MRDS) within LLMs to improve few-shot dialogue summarization task. Unlike prior methods that require external knowledge, we mutually reinforce the LLM's dialogue synthesis and summarization capabilities, allowing them to complement each other during training and enhance overall performances. The dialogue synthesis capability is enhanced by directed preference optimization with preference scoring from summarization capability. The summarization capability is enhanced by the additional high quality dialogue-summary paired data produced by the dialogue synthesis capability. By leveraging the proposed MRDS mechanism, we elicit the internal knowledge of LLM in the format of synthetic data, and use it to augment the few-shot real training dataset. Empirical results demonstrate that our method improves dialogue summarization, achieving a 1.5% increase in ROUGE scores and a 0.3% improvement in BERT scores in few-shot settings. Furthermore, our method attains the highest average scores in human evaluations, surpassing both the pre-trained models and the baselines fine-tuned solely for summarization tasks.
在这项工作中,我们提出了大型语言模型(LLM)中的相互强化数据合成(MRDS)方法,以提高小样对话摘要任务的效果。不同于需要外部知识的先前方法,我们相互强化LLM的对话合成和摘要能力,使它们在训练过程中能够相互补充,从而提高整体性能。对话合成能力通过基于摘要能力的偏好评分进行定向偏好优化而增强。摘要能力通过对对话合成能力产生的额外高质量对话摘要配对数据进行增强。通过利用提出的MRDS机制,我们以合成数据的形式激发LLM的内部知识,并将其用于扩充小样真实训练数据集。经验结果表明,我们的方法提高了对话摘要的效果,在小样设置下ROUGE得分提高了1.5%,BERT得分提高了0.3%。此外,我们的方法在人类评估中获得了最高平均分,超过了仅针对摘要任务进行预训练的模型和基线模型。
论文及项目相关链接
PDF NAACL 2025 Findings
摘要
本文提出了在大型语言模型(LLM)中采用相互强化数据合成(MRDS)方法,以提高少样本对话摘要任务的效果。不同于需要外部知识的方法,我们相互强化LLM的对话合成和摘要能力,使其在训练过程中相互补充,从而提高整体性能。通过对话合成的定向偏好优化和摘要能力的偏好评分,增强了对话合成能力。同时,通过对话合成产生的附加高质量对话摘要配对数据,提高了摘要能力。利用提出的MRDS机制,我们以合成数据的形式激发LLM的内部知识,并将其用于增强少量的真实训练数据集。实验结果表明,该方法提高了对话摘要的效果,在少样本环境下ROUGE得分提高了1.5%,BERT得分提高了0.3%。此外,该方法在人类评估中获得了最高平均分,超越了预训练模型和仅针对摘要任务进行微调的基础模型。
关键见解
- 提出了一种新的方法——相互强化数据合成(MRDS),用于改进少样本对话摘要任务。
- MRDS方法不同于依赖外部知识的方法,它通过相互强化对话合成和摘要能力来提升LLM的性能。
- 对话合成能力通过定向偏好优化和摘要能力的偏好评分得到增强。
- 利用MRDS机制激发LLM的内部知识,并以合成数据的形式用于增强真实训练数据集。
- 实验结果表明,MRDS方法在少样本环境下提高了对话摘要的ROUGE和BERT得分。
- MRDS方法在人类评估中表现最佳,超越了预训练模型和针对摘要任务的基线模型。
- 该方法强调了内部知识在少样本学习中的重要性,并展示了如何利用LLM的内部知识来提高摘要任务的性能。
点此查看论文截图

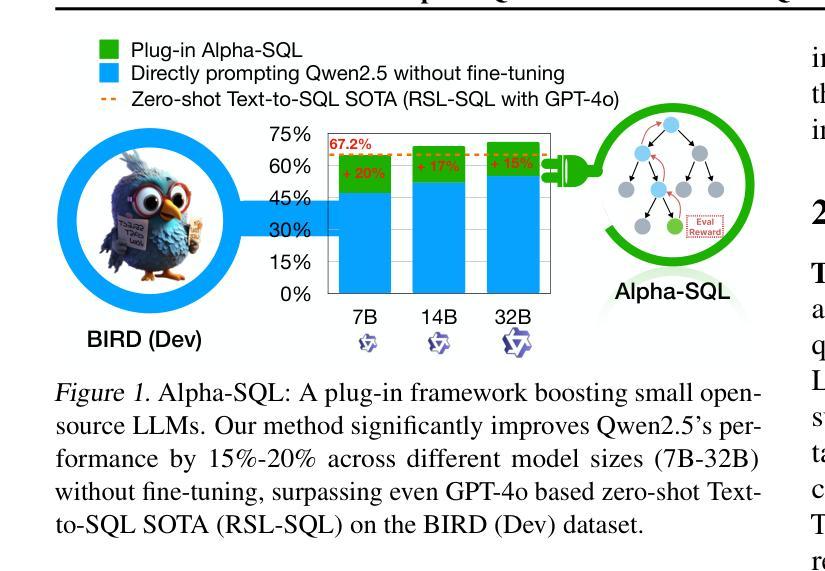
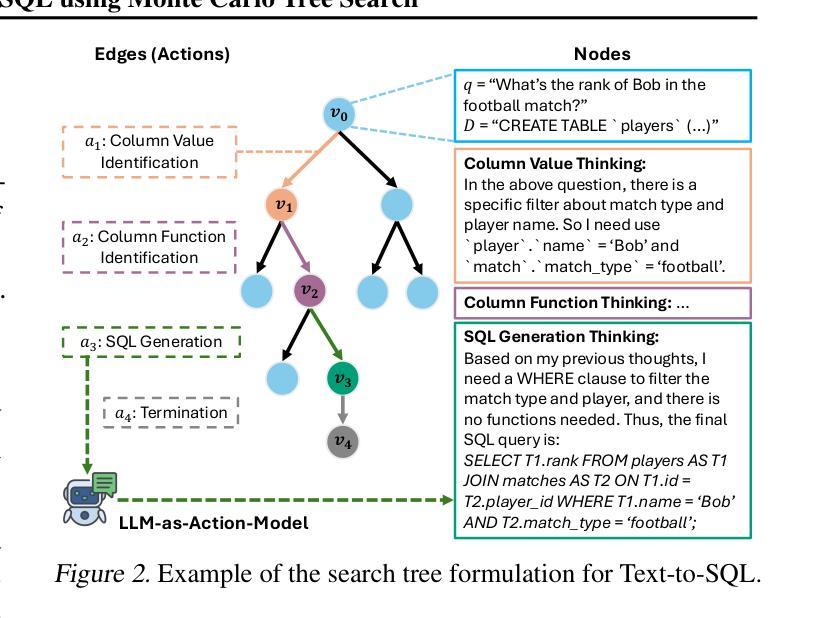
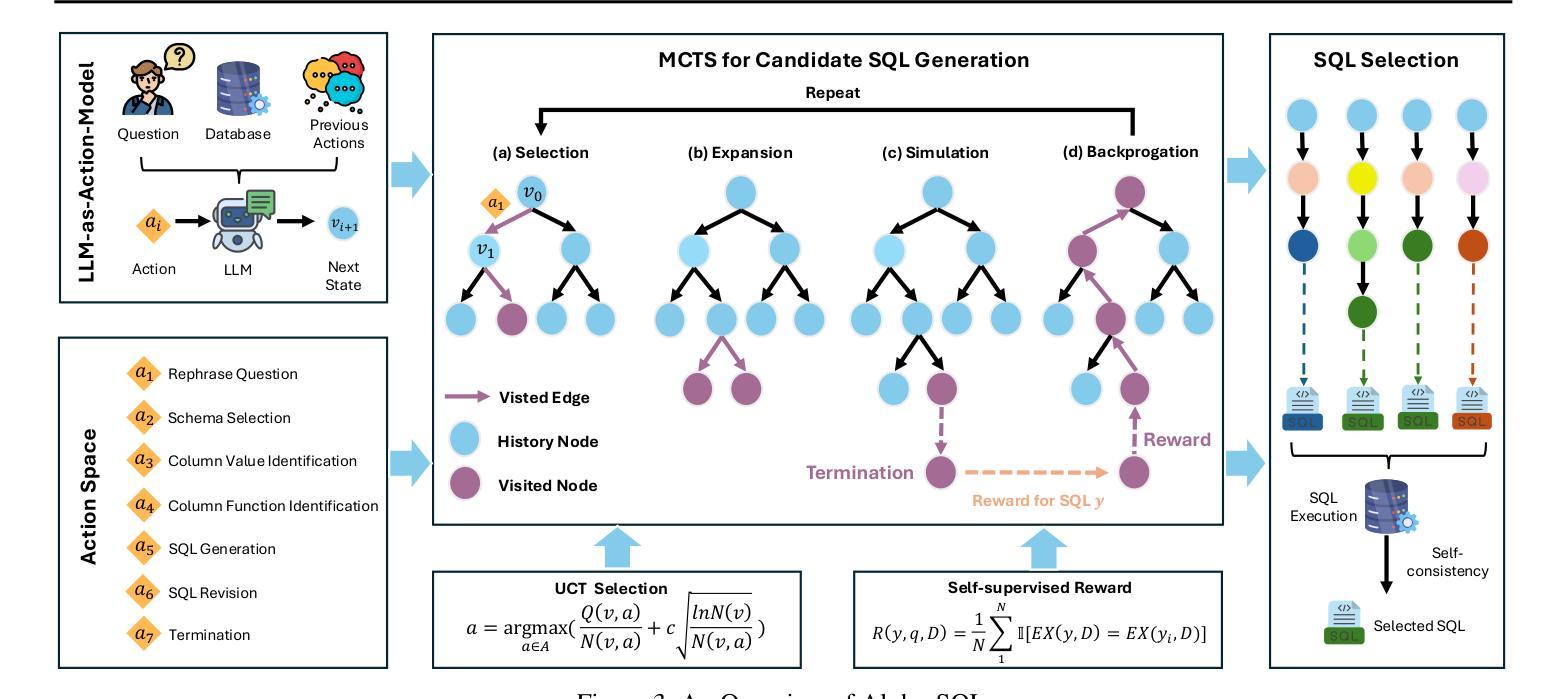
Alpha-SQL: Zero-Shot Text-to-SQL using Monte Carlo Tree Search
Authors:Boyan Li, Jiayi Zhang, Ju Fan, Yanwei Xu, Chong Chen, Nan Tang, Yuyu Luo
Text-to-SQL, which enables natural language interaction with databases, serves as a pivotal method across diverse industries. With new, more powerful large language models (LLMs) emerging every few months, fine-tuning has become incredibly costly, labor-intensive, and error-prone. As an alternative, zero-shot Text-to-SQL, which leverages the growing knowledge and reasoning capabilities encoded in LLMs without task-specific fine-tuning, presents a promising and more challenging direction. To address this challenge, we propose Alpha-SQL, a novel approach that leverages a Monte Carlo Tree Search (MCTS) framework to iteratively infer SQL construction actions based on partial SQL query states. To enhance the framework’s reasoning capabilities, we introduce LLM-as-Action-Model to dynamically generate SQL construction actions during the MCTS process, steering the search toward more promising SQL queries. Moreover, Alpha-SQL employs a self-supervised reward function to evaluate the quality of candidate SQL queries, ensuring more accurate and efficient query generation. Experimental results show that Alpha-SQL achieves 69.7% execution accuracy on the BIRD development set, using a 32B open-source LLM without fine-tuning. Alpha-SQL outperforms the best previous zero-shot approach based on GPT-4o by 2.5% on the BIRD development set.
文本到SQL的技术,能够实现与数据库的自然语言交互,是各行业关键的方法。随着每隔几个月就会出现新的、更强大的大型语言模型(LLM),微调变得非常昂贵、劳动密集型且易出错。作为一种替代方案,零击文本到SQL,利用LLMs中不断增长的知识和推理能力,无需特定任务的微调,展现了一个有前景且更具挑战性的方向。为了应对这一挑战,我们提出了Alpha-SQL这一新方法,它利用蒙特卡洛树搜索(MCTS)框架来基于部分SQL查询状态迭代推断SQL构建动作。为了提高框架的推理能力,我们引入了LLM-作为行动模型来在MCTS过程中动态生成SQL构建动作,引导搜索朝着更有前途的SQL查询进行。此外,Alpha-SQL采用自我监督的奖励函数来评估候选SQL查询的质量,确保更准确、高效的查询生成。实验结果表明,Alpha-SQL在BIRD开发集上达到了69.7%的执行准确率,使用的是未进行微调的开源大型语言模型。Alpha-SQL在BIRD开发集上的表现优于之前的基于GPT-4o的最佳零冲击方法提高了2.5%。
论文及项目相关链接
Summary
文本描述了Text-to-SQL的重要性以及如何利用大型语言模型(LLMs)实现零样本Text-to-SQL的方法。针对现有方法的不足,提出了一种名为Alpha-SQL的新方法,该方法结合蒙特卡洛树搜索(MCTS)和LLM,通过自我监督奖励函数评估候选SQL查询质量,实现了更高的执行准确率和更高效的查询生成。实验结果显示,Alpha-SQL在不进行微调的情况下,在BIRD开发集上达到了69.7%的执行准确率,并优于之前的GPT-4o的零样本方法。
Key Takeaways
- Text-to-SQL是自然语言与数据库交互的重要方法,广泛应用于不同行业。
- 随着大型语言模型(LLMs)的快速发展,任务特定微调的成本、劳动强度和错误率都在增加。
- Alpha-SQL是一种新的零样本Text-to-SQL方法,结合了蒙特卡洛树搜索(MCTS)和LLM。
- Alpha-SQL通过LLM生成SQL构建动作,提高推理能力。
- Alpha-SQL使用自我监督奖励函数评估候选SQL查询质量,确保更准确、高效的查询生成。
- Alpha-SQL在不进行微调的情况下,在BIRD开发集上实现了69.7%的执行准确率。
点此查看论文截图

Evaluating the Effectiveness of Large Language Models in Automated News Article Summarization
Authors:Lionel Richy Panlap Houamegni, Fatih Gedikli
The automation of news analysis and summarization presents a promising solution to the challenge of processing and analyzing vast amounts of information prevalent in today’s information society. Large Language Models (LLMs) have demonstrated the capability to transform vast amounts of textual data into concise and easily comprehensible summaries, offering an effective solution to the problem of information overload and providing users with a quick overview of relevant information. A particularly significant application of this technology lies in supply chain risk analysis. Companies must monitor the news about their suppliers and respond to incidents for several critical reasons, including compliance with laws and regulations, risk management, and maintaining supply chain resilience. This paper develops an automated news summarization system for supply chain risk analysis using LLMs. The proposed solution aggregates news from various sources, summarizes them using LLMs, and presents the condensed information to users in a clear and concise format. This approach enables companies to optimize their information processing and make informed decisions. Our study addresses two main research questions: (1) Are LLMs effective in automating news summarization, particularly in the context of supply chain risk analysis? (2) How effective are various LLMs in terms of readability, duplicate detection, and risk identification in their summarization quality? In this paper, we conducted an offline study using a range of publicly available LLMs at the time and complemented it with a user study focused on the top performing systems of the offline experiments to evaluate their effectiveness further. Our results demonstrate that LLMs, particularly Few-Shot GPT-4o mini, offer significant improvements in summary quality and risk identification.
新闻分析与摘要的自动化为当今信息社会普遍存在的海量信息处理与分析挑战提供了前景光明的解决方案。大型语言模型(LLM)能够将大量文本数据转化为简洁、易于理解的摘要,为解决信息过载问题提供了有效方法,并为用户提供了相关信息的快速概览。这项技术在供应链风险分析中的应用尤为显著。公司必须监控有关其供应商的新闻并对事件做出响应,出于多个关键原因,包括遵守法律法规、风险管理和保持供应链韧性。本文开发了一个用于供应链风险分析的自动化新闻摘要系统,采用大型语言模型。所提出的解决方案从各种来源聚合新闻,使用LLM进行摘要,并以清晰简洁的格式向用户呈现浓缩的信息。这种方法使公司能够优化其信息处理并做出明智的决策。我们的研究解决了两个主要问题:(1)大型语言模型在自动化新闻摘要中是否有效,特别是在供应链风险分析的背景下?(2)在可读性、重复检测和风险识别方面,各种大型语言模型的摘要质量效果如何?在本文中,我们使用了当时可用的各种公开大型语言模型进行了离线研究,并通过以表现最佳的系统为中心的用户研究进一步评估了其有效性。我们的结果表明,大型语言模型,尤其是Few-Shot GPT-4o mini,在摘要质量和风险识别方面提供了显著的改进。
论文及项目相关链接
Summary
大型语言模型(LLMs)在新闻分析与摘要自动化方面展现出巨大的潜力,为解决信息社会中的海量信息处理与分析挑战提供了有前景的解决方案。LLMs能够将大量文本数据转化为简洁易懂的摘要,有效应对信息过载问题,为用户提供相关信息快速概览。本研究在供应链风险分析中利用此技术,开发自动化新闻摘要系统。通过新闻来源聚合、LLMs摘要呈现,帮助公司优化信息处理并做出明智决策。研究证实LLMs,尤其是Few-Shot GPT-4o mini,在摘要质量和风险识别方面有显著提高。
Key Takeaways
- 大型语言模型(LLMs)可以转化大量文本数据为简洁摘要,有效应对信息过载。
- 在供应链风险分析中,LLMs的应用有助于公司监控供应商新闻并响应各种事件。
- 研究通过自动化新闻摘要系统,聚合新闻来源并使用LLMs进行摘要呈现。
- 研究主要解决两个问题:LLMs在自动化新闻摘要中的有效性,以及不同LLMs在可读性、去重和风险评估方面的效果。
- 研究采用离线研究及用户研究的方式,评估了各系统的有效性。
- 结果显示,LLMs显著提高摘要质量和风险识别能力。
点此查看论文截图

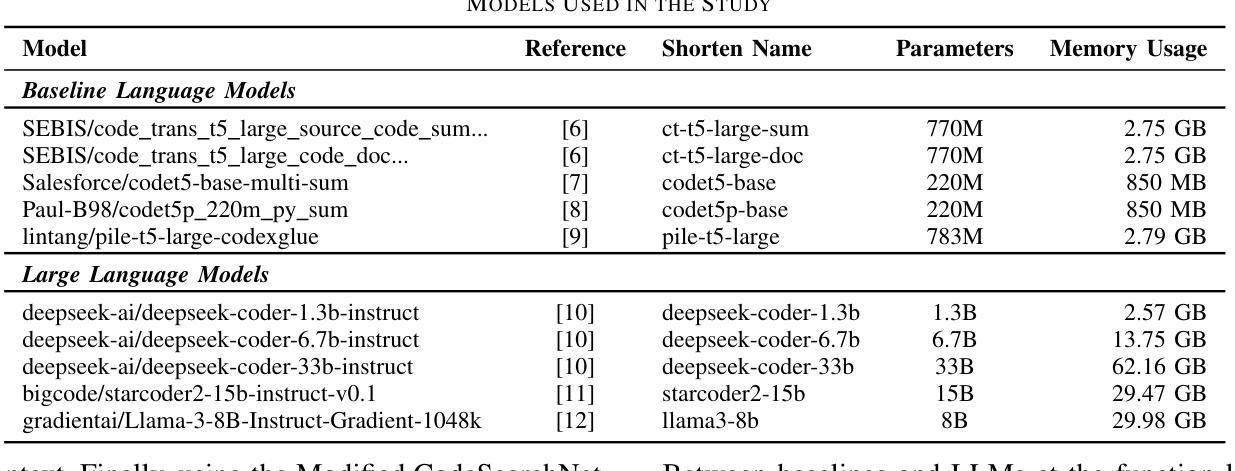
Code Summarization Beyond Function Level
Authors:Vladimir Makharev, Vladimir Ivanov
Code summarization is a critical task in natural language processing and software engineering, which aims to generate concise descriptions of source code. Recent advancements have improved the quality of these summaries, enhancing code readability and maintainability. However, the content of a repository or a class has not been considered in function code summarization. This study investigated the effectiveness of code summarization models beyond the function level, exploring the impact of class and repository contexts on the summary quality. The study involved revising benchmarks for evaluating models at class and repository levels, assessing baseline models, and evaluating LLMs with in-context learning to determine the enhancement of summary quality with additional context. The findings revealed that the fine-tuned state-of-the-art CodeT5+ base model excelled in code summarization, while incorporating few-shot learning and retrieved code chunks from RAG significantly enhanced the performance of LLMs in this task. Notably, the Deepseek Coder 1.3B and Starcoder2 15B models demonstrated substantial improvements in metrics such as BLEURT, METEOR, and BLEU-4 at both class and repository levels. Repository-level summarization exhibited promising potential but necessitates significant computational resources and gains from the inclusion of structured context. Lastly, we employed the recent SIDE code summarization metric in our evaluation. This study contributes to refining strategies for prompt engineering, few-shot learning, and RAG, addressing gaps in benchmarks for code summarization at various levels. Finally, we publish all study details, code, datasets, and results of evaluation in the GitHub repository available at https://github.com/kilimanj4r0/code-summarization-beyond-function-level.
代码摘要任务是自然语言处理和软件工程中的关键任务,旨在生成源代码的简洁描述。最近的进展提高了这些摘要的质量,增强了代码的可读性和可维护性。然而,在函数代码摘要中,仓库或类的内容并未得到考虑。本研究旨在探讨函数级别以外的代码摘要模型的有效性,探索类和仓库上下文对摘要质量的影响。该研究包括修订用于类和仓库级别评估模型的基准测试,评估基线模型,并评估具有上下文学习的大型语言模型,以确定附加上下文对摘要质量的提升。研究结果表明,经过微调的最先进的基础模型CodeT5+在代码摘要方面表现出色,而融入小样本学习和从RAG检索的代码片段则显著提高了大型语言模型在此任务上的性能。值得注意的是,Deepseek Coder 1.3B和Starcoder2 15B模型在类级别和仓库级别的BLEURT、METEOR和BLEU-4指标上均实现了显著改进。仓库级别的摘要展现出了巨大的潜力,但需要大量的计算资源,并从结构化上下文中获益。最后,我们在评估中采用了最新的SIDE代码摘要指标。本研究有助于完善提示工程、小样本学习和RAG的策略,填补了各级代码摘要的基准测试空白。最后,我们在GitHub仓库中公开了所有研究细节、代码、数据集和评估结果:https://github.com/kilimanj4r0/code-summarization-beyond-function-level。
论文及项目相关链接
PDF Accepted to LLM4Code @ ICSE’25; 8 pages, 3 figures, 4 tables
Summary
代码摘要处理是自然语言处理和软件工程中的关键任务,旨在生成对源代码的简洁描述。近期技术的发展提高了摘要的质量,增强了代码的可读性和可维护性。本研究探讨了超越函数级别的代码摘要模型的有效性,探索了类上下文和存储库上下文对摘要质量的影响。研究发现,经过微调的最先进的CodeT5+基础模型在代码摘要中表现出色,而融入少量学习和从RAG检索的代码片段则进一步提升了大型语言模型在此任务中的表现。Deepseek Coder 1.3B和Starcoder2 15B模型在类级别和存储库级别的度量标准上均有显著改进。本研究对提示工程、少量学习和RAG的策略进行了优化,填补了各级代码摘要的基准测试空白。
Key Takeaways
- 代码摘要处理是自然语言处理和软件工程中的关键任务。
- 研究探讨了超越函数级别的代码摘要模型的有效性。
- 类上下文和存储库上下文对摘要质量有影响。
- CodeT5+基础模型在代码摘要中表现优异。
- 融入少量学习和RAG检索的代码片段提升了大型语言模型的表现。
- Deepseek Coder和Starcoder模型在类级别和存储库级别的度量标准上有显著改进。
- 研究成果包括策略优化、基准测试填补以及GitHub存储库中的研究细节、代码、数据集和评估结果发布。
点此查看论文截图


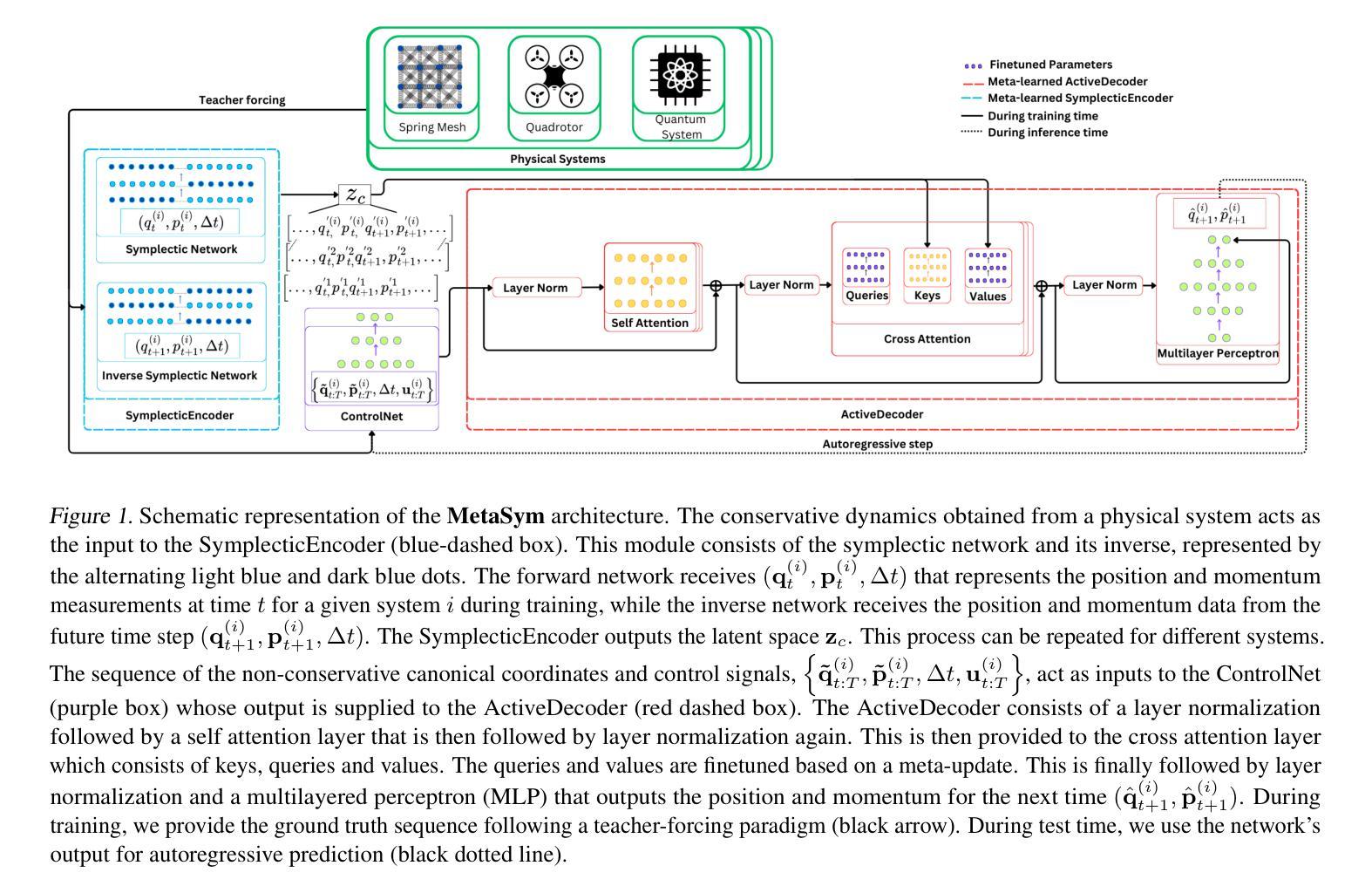
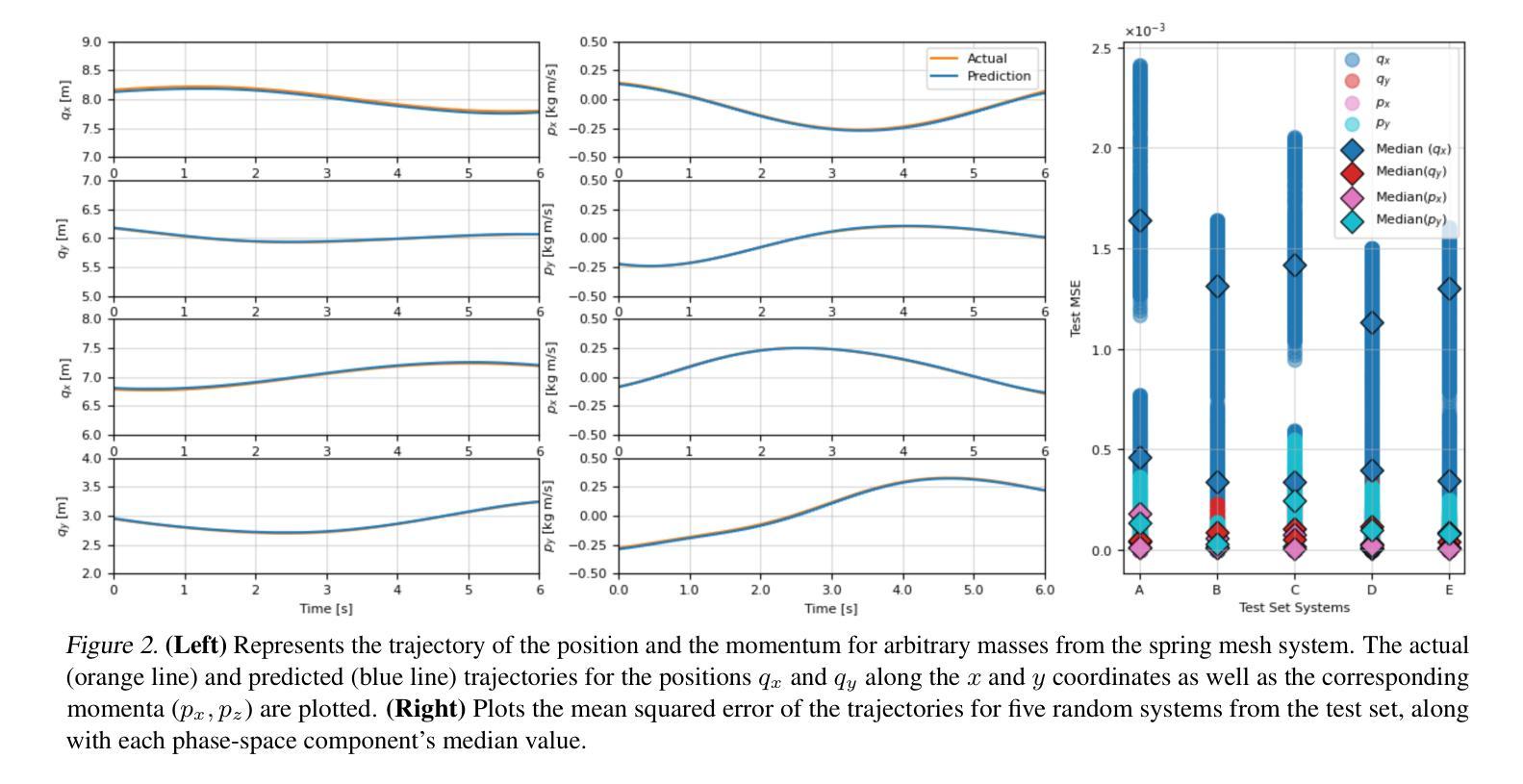
MetaSym: A Symplectic Meta-learning Framework for Physical Intelligence
Authors:Pranav Vaidhyanathan, Aristotelis Papatheodorou, Mark T. Mitchison, Natalia Ares, Ioannis Havoutis
Scalable and generalizable physics-aware deep learning has long been considered a significant challenge with various applications across diverse domains ranging from robotics to molecular dynamics. Central to almost all physical systems are symplectic forms, the geometric backbone that underpins fundamental invariants like energy and momentum. In this work, we introduce a novel deep learning architecture, MetaSym. In particular, MetaSym combines a strong symplectic inductive bias obtained from a symplectic encoder and an autoregressive decoder with meta-attention. This principled design ensures that core physical invariants remain intact while allowing flexible, data-efficient adaptation to system heterogeneities. We benchmark MetaSym on highly varied datasets such as a high-dimensional spring mesh system (Otness et al., 2021), an open quantum system with dissipation and measurement backaction, and robotics-inspired quadrotor dynamics. Our results demonstrate superior performance in modeling dynamics under few-shot adaptation, outperforming state-of-the-art baselines with far larger models.
可扩展且可泛化的物理感知深度学习长期以来被视为一项具有挑战性的任务,其在从机器人学到分子动力学等多个领域都有广泛的应用。几乎所有物理系统的核心都是辛形式,它是支撑能量和动量等基本不变量的几何主干。在这项工作中,我们介绍了一种新型深度学习架构MetaSym。具体来说,MetaSym结合了由辛编码器获得的强大辛归纳偏见和带有元注意的自回归解码器。这种有原则的设计确保核心物理不变量保持完整,同时允许灵活、数据高效地适应系统异质性。我们在高度不同的数据集上对MetaSym进行了基准测试,例如高维弹簧网格系统(Otness等人,2021年)、具有耗散和测量反作用的开放量子系统,以及受机器人启发的四旋翼飞行器动力学。我们的结果表明,在少样本适应的情况下,MetaSym在建模动力学方面表现出卓越的性能,超越了使用更大模型的最新基线水平。
论文及项目相关链接
PDF 8+10 pages, 5 figures, 4 tables
Summary
本文介绍了一种新型的深度学习架构MetaSym,该架构结合了从辛编码器和自回归解码器得到的强大辛归纳偏见以及元注意机制。该设计能够在保持核心物理不变量的同时,灵活适应系统异质性并高效利用数据。MetaSym在多种数据集上的表现优越,如高维弹簧网格系统、具有耗散和测量反作用的开放量子系统以及受机器人启发的四旋翼飞行器动力学。其在少样本适应建模动力学方面的性能优于当前最先进的基线模型。
Key Takeaways
- MetaSym是一种新型的深度学习架构,结合了辛编码器和自回归解码器以及元注意机制。
- 该架构旨在确保物理系统的核心不变性质(如能量和动量)在模型学习中得到保持。
- MetaSym能够在保持物理不变性的同时,灵活适应系统异质性并高效利用数据。
- 在多种数据集上进行了基准测试,包括高维弹簧网格系统、开放量子系统和四旋翼飞行器动力学。
- MetaSym在少样本适应建模动力学方面表现出卓越性能。
- 该架构优于当前最先进的基线模型。
点此查看论文截图

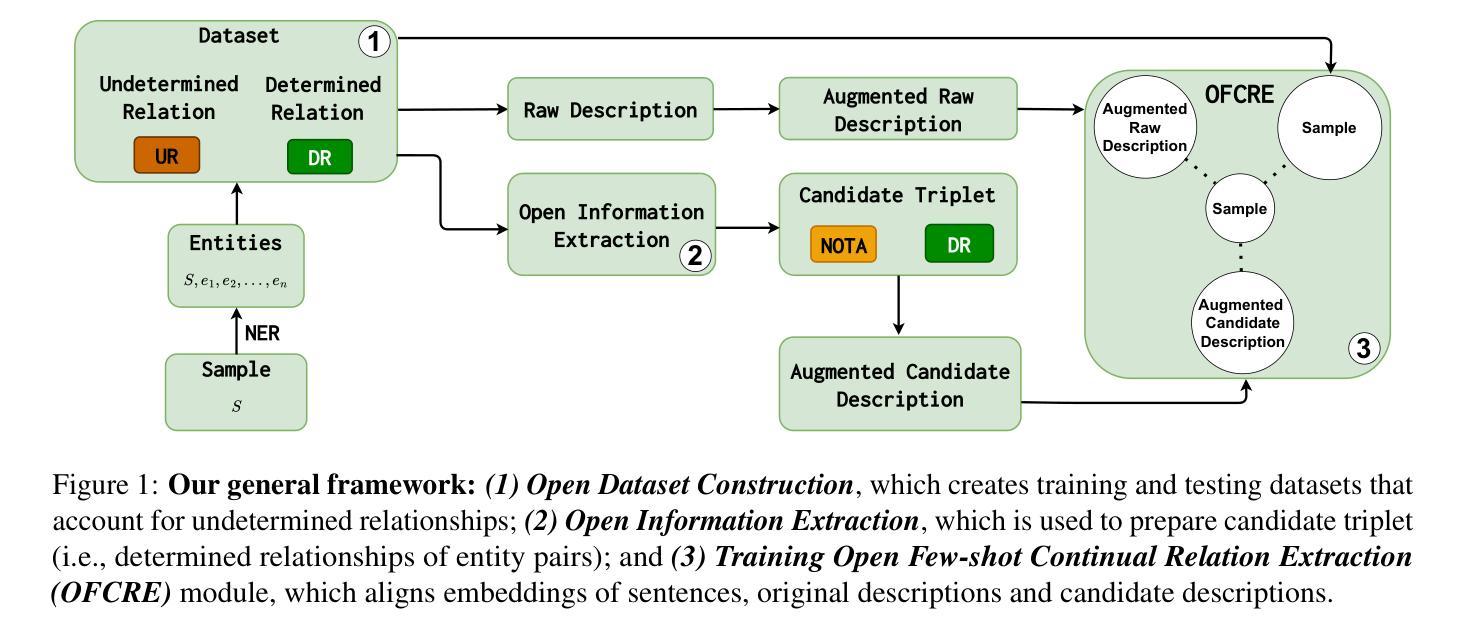
Few-shot Continual Relation Extraction via Open Information Extraction
Authors:Thiem Nguyen, Anh Nguyen, Quyen Tran, Tu Vu, Diep Nguyen, Linh Ngo, Thien Nguyen
Typically, Few-shot Continual Relation Extraction (FCRE) models must balance retaining prior knowledge while adapting to new tasks with extremely limited data. However, real-world scenarios may also involve unseen or undetermined relations that existing methods still struggle to handle. To address these challenges, we propose a novel approach that leverages the Open Information Extraction concept of Knowledge Graph Construction (KGC). Our method not only exposes models to all possible pairs of relations, including determined and undetermined labels not available in the training set, but also enriches model knowledge with diverse relation descriptions, thereby enhancing knowledge retention and adaptability in this challenging scenario. In the perspective of KGC, this is the first work explored in the setting of Continual Learning, allowing efficient expansion of the graph as the data evolves. Experimental results demonstrate our superior performance compared to other state-of-the-art FCRE baselines, as well as the efficiency in handling dynamic graph construction in this setting.
通常,Few-shot Continual Relation Extraction(FCRE)模型需要在保留先前知识的同时,适应新任务且数据量极度有限。然而,现实世界场景还可能涉及未见或未确定的关系,现有方法在处理这些场景时仍面临困难。为了应对这些挑战,我们提出了一种利用知识图谱构建(KGC)中的开放信息提取概念的新方法。我们的方法不仅使模型接触到所有可能的关系对,包括训练集中不存在的确定和未确定的标签,而且还通过多样的关系描述丰富模型知识,从而在这种具有挑战性的场景中提高知识保留和适应性。从KGC的角度来看,这是连续学习环境中首次探索的工作,允许随着数据的演变有效地扩展图。实验结果表明,与其他先进的FCRE基线相比,我们的性能优越,并且在此环境中处理动态图构建的效率很高。
论文及项目相关链接
Summary
本文介绍了针对Few-shot Continual Relation Extraction(FCRE)模型的挑战,提出了一种利用知识图谱构建(KGC)的开放信息提取概念的新方法。该方法不仅使模型接触到所有可能的关系对,包括训练集中不可用的确定和未确定标签,还通过多样的关系描述丰富模型知识,从而增强知识保留和适应性。这是知识图谱构建视角在持续学习领域中的首次探索,能够实现随着数据演变的高效图扩展。实验结果证明了该方法相较于其他先进FCRE基准线的优越性,以及在处理动态图构建方面的效率。
Key Takeaways
- FCRE模型需要在保留先验知识的同时适应新任务,尤其在数据极度有限的情况下。
- 现有方法难以处理未见或未确定的关系。
- 提出了一种新方法,利用KGC的开放信息提取概念来应对这些挑战。
- 模型可以接触到所有可能的关系对,包括训练集中不可用的确定和未确定标签。
- 方法通过多样的关系描述丰富模型知识,增强知识保留和适应性。
- 这是知识图谱构建视角在持续学习领域的首次探索。
点此查看论文截图

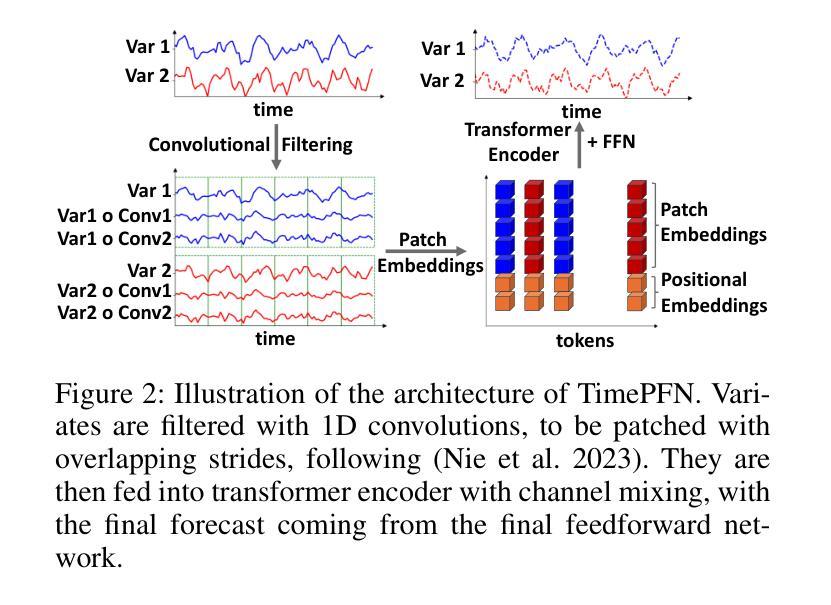
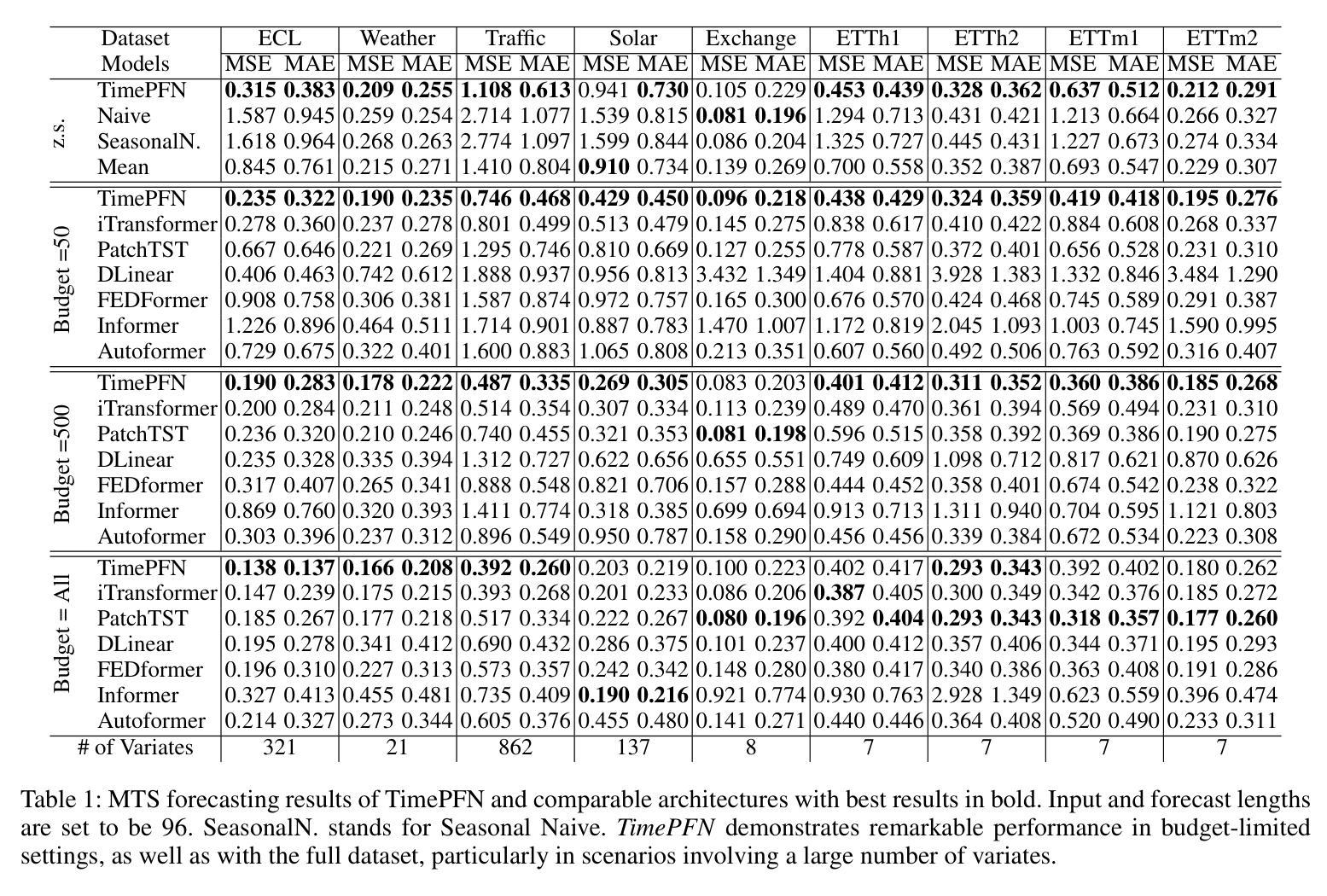
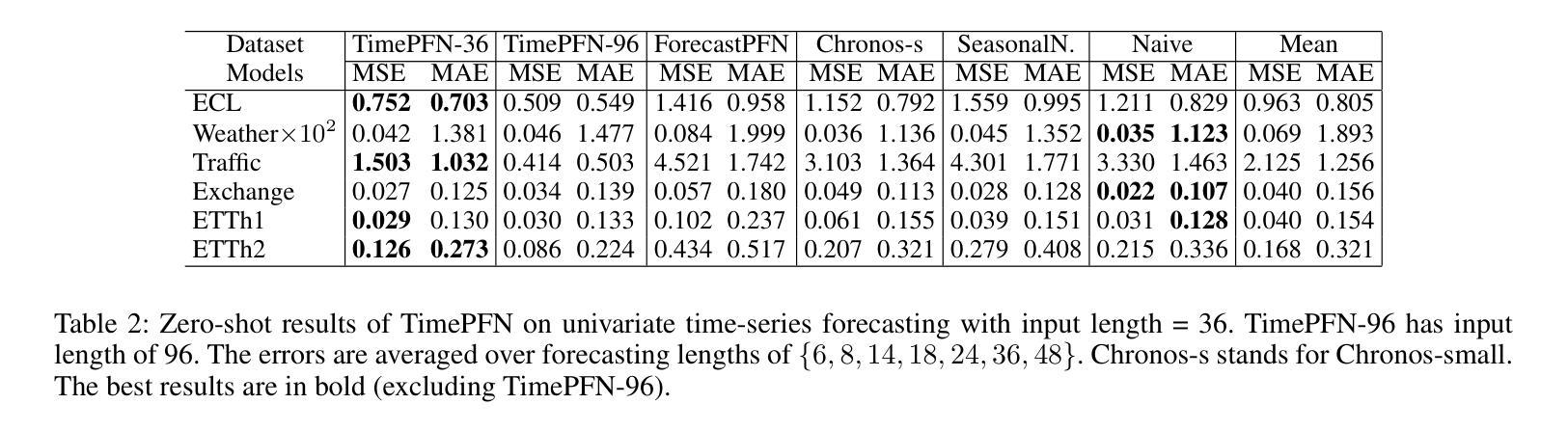
TimePFN: Effective Multivariate Time Series Forecasting with Synthetic Data
Authors:Ege Onur Taga, M. Emrullah Ildiz, Samet Oymak
The diversity of time series applications and scarcity of domain-specific data highlight the need for time-series models with strong few-shot learning capabilities. In this work, we propose a novel training scheme and a transformer-based architecture, collectively referred to as TimePFN, for multivariate time-series (MTS) forecasting. TimePFN is based on the concept of Prior-data Fitted Networks (PFN), which aims to approximate Bayesian inference. Our approach consists of (1) generating synthetic MTS data through diverse Gaussian process kernels and the linear coregionalization method, and (2) a novel MTS architecture capable of utilizing both temporal and cross-channel dependencies across all input patches. We evaluate TimePFN on several benchmark datasets and demonstrate that it outperforms the existing state-of-the-art models for MTS forecasting in both zero-shot and few-shot settings. Notably, fine-tuning TimePFN with as few as 500 data points nearly matches full dataset training error, and even 50 data points yield competitive results. We also find that TimePFN exhibits strong univariate forecasting performance, attesting to its generalization ability. Overall, this work unlocks the power of synthetic data priors for MTS forecasting and facilitates strong zero- and few-shot forecasting performance.
时间序列应用的多样性和特定领域数据的稀缺性,凸显了需要具有强大少量学习能力的时间序列模型。在这项工作中,我们提出了一种新型的训练方案和基于变压器的架构,两者统称为TimePFN,用于多元时间序列(MTS)预测。TimePFN基于先验数据拟合网络(PFN)的概念,旨在近似贝叶斯推断。我们的方法包括(1)通过多样的高斯过程核和线性共区域化方法生成合成MTS数据,(2)一种新型的MTS架构,能够利用所有输入补丁中的时间依赖性和跨通道依赖性。我们在多个基准数据集上评估了TimePFN,结果表明,它在零样本和少量样本的情况下,都优于现有的最先进的MTS预测模型。值得注意的是,使用仅500个数据点对TimePFN进行微调,其误差几乎匹配全数据集训练误差,甚至使用50个数据点也能获得具有竞争力的结果。我们还发现TimePFN在单变量预测方面表现出强大的性能,证明了其泛化能力。总的来说,这项工作释放了合成数据先验在MTS预测中的潜力,并实现了强大的零样本和少量样本预测性能。
论文及项目相关链接
PDF To appear in AAAI-2025 as a conference paper
Summary
时间序列应用的多样性和特定领域数据的稀缺性突显出需要具有强大少样本学习能力的时间序列模型。本文提出了一种基于先验数据拟合网络(PFN)概念的新型训练方案和基于变压器的架构,统称为TimePFN,用于多元时间序列(MTS)预测。TimePFN通过生成合成MTS数据和利用先进架构实现强大的零样本和少样本预测性能,展示了出色的预测效果。
Key Takeaways
- 时间序列应用的多样性和特定领域数据的稀缺性凸显出对具有强大少样本学习能力模型的迫切需求。
- 本文提出了TimePFN模型,结合了新型训练方案和基于变压器的架构。
- TimePFN基于先验数据拟合网络(PFN)概念,旨在近似贝叶斯推理。
- 通过生成合成MTS数据和利用先进架构,TimePFN实现了强大的预测性能。
- TimePFN在多个基准数据集上的表现优于现有的最先进的MTS预测模型,特别是在零样本和少样本设置下。
- TimePFN仅使用少量数据点(如500个)进行微调即可接近全数据集训练的错误率,甚至使用50个数据点也能取得有竞争力的结果。
- TimePFN展现出强大的单变量预测性能,证明了其泛化能力。
点此查看论文截图

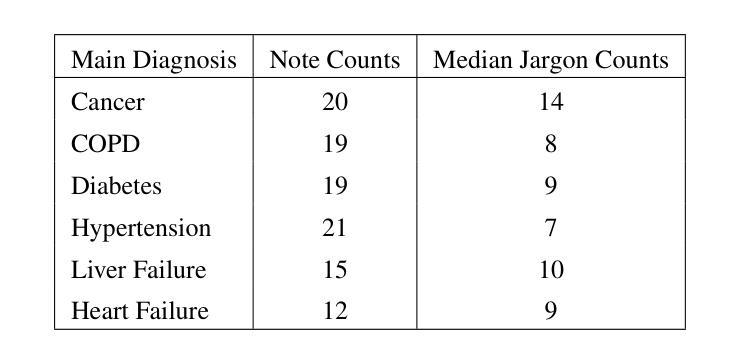
Enhancing LLMs for Identifying and Prioritizing Important Medical Jargons from Electronic Health Record Notes Utilizing Data Augmentation
Authors:Won Seok Jang, Sharmin Sultana, Zonghai Yao, Hieu Tran, Zhichao Yang, Sunjae Kwon, Hong Yu
Objective: OpenNotes enables patients to access EHR notes, but medical jargon can hinder comprehension. To improve understanding, we evaluated closed- and open-source LLMs for extracting and prioritizing key medical terms using prompting, fine-tuning, and data augmentation. Materials and Methods: We assessed LLMs on 106 expert-annotated EHR notes, experimenting with (i) general vs. structured prompts, (ii) zero-shot vs. few-shot prompting, (iii) fine-tuning, and (iv) data augmentation. To enhance open-source models in low-resource settings, we used ChatGPT for data augmentation and applied ranking techniques. We incrementally increased the augmented dataset size (10 to 10,000) and conducted 5-fold cross-validation, reporting F1 score and Mean Reciprocal Rank (MRR). Results and Discussion: Fine-tuning and data augmentation improved performance over other strategies. GPT-4 Turbo achieved the highest F1 (0.433), while Mistral7B with data augmentation had the highest MRR (0.746). Open-source models, when fine-tuned or augmented, outperformed closed-source models. Notably, the best F1 and MRR scores did not always align. Few-shot prompting outperformed zero-shot in vanilla models, and structured prompts yielded different preferences across models. Fine-tuning improved zero-shot performance but sometimes degraded few-shot performance. Data augmentation performed comparably or better than other methods. Conclusion: Our evaluation highlights the effectiveness of prompting, fine-tuning, and data augmentation in improving model performance for medical jargon extraction in low-resource scenarios.
目标:OpenNotes让患者能够访问电子健康记录(EHR)笔记,但医疗术语可能会妨碍理解。为了改善患者的理解,我们评估了用于提取和优先排序关键医学术语的闭源和开源的大型语言模型(LLMs),采用提示、微调和数据增强等方法。材料和方法:我们在106份专家注释的EHR笔记上评估了LLMs,尝试了(i)通用提示与结构化提示,(ii)零样本提示与少样本提示,(iii)微调,以及(iv)数据增强。为了在低资源环境中增强开源模型的效果,我们利用ChatGPT进行数据增强,并应用排序技术。我们逐步增加了增强数据集的大小(从10到10,000),进行了5倍交叉验证,并报告了F1分数和平均倒数排名(MRR)。结果和讨论:相较于其他策略,微调和数据增强提高了性能。GPT-4 Turbo获得了最高的F1分数(0.433),而Mistral7B通过数据增强获得了最高的MRR(0.746)。当开源模型经过微调或增强时,其性能超过了闭源模型。值得注意的是,最佳的F1分数和MRR并不总是对齐。少样本提示在原始模型中表现优于零样本提示,结构化提示在不同模型中产生不同的偏好。微调提高了零样本性能,但有时会降低少样本性能。数据增强的表现与其他方法相当或更好。结论:我们的评估强调了提示、微调和数据增强在改进低资源场景中医学术语提取模型性能的有效性。
论文及项目相关链接
PDF 21pages, 5 figures, 4 tables
Summary
本文探讨了OpenNotes系统下患者获取电子健康记录(EHR)笔记时遇到的医学术语理解难题。研究团队评估了闭源和开源的大型语言模型(LLMs)在提取和优先排序关键医学术语方面的表现,具体采用了提示、微调、数据增强等方法。结果显示,微调和数据增强能提高模型性能,GPT-4 Turbo在F1分数上表现最佳,而Mistral7B在平均倒数排名(MRR)上表现最佳。此外,开源模型在微调或数据增强后表现优于闭源模型。研究还发现,少样本提示通常优于零样本,结构化提示在不同模型中有不同偏好,微调虽能提高零样本性能但有时会降低少样本性能。总体而言,提示、微调、数据增强等方法在医学术语提取方面效果显著,特别是在资源有限的场景下。
Key Takeaways
- OpenNotes允许患者访问电子健康记录(EHR)笔记,但医学术语的复杂性可能阻碍理解。
- 研究评估了闭源和开源的大型语言模型(LLMs)在提取和排序关键医学术语方面的表现。
- 使用了提示、微调、数据增强等方法来改善模型性能。
- GPT-4 Turbo在F1分数上表现最佳,而Mistral7B在平均倒数排名(MRR)上领先。
- 开源模型在微调或数据增强后表现优于闭源模型。
- 少样本提示通常比零样本提示更有效,结构化提示能提高模型性能但不同模型表现不同。
点此查看论文截图

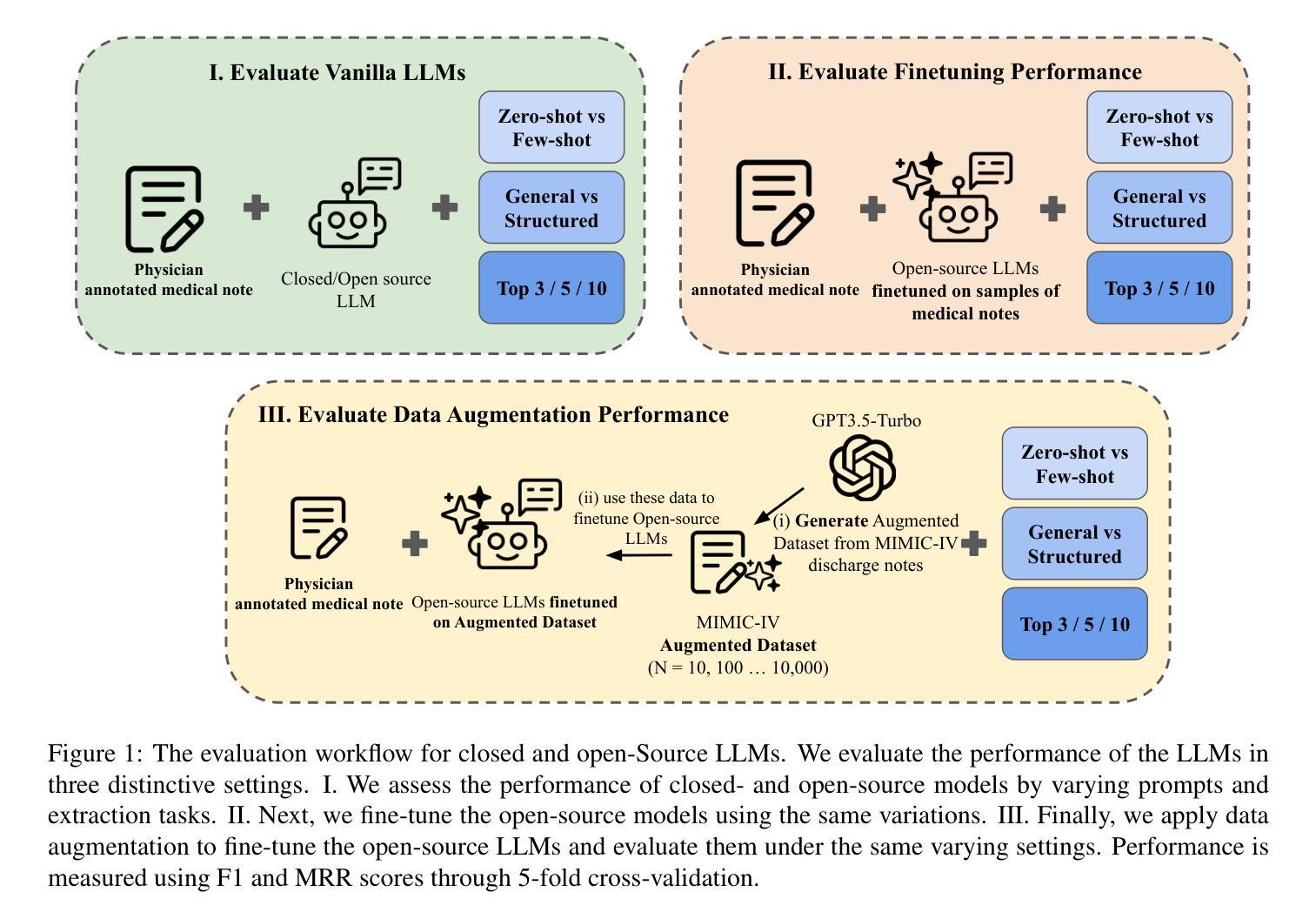

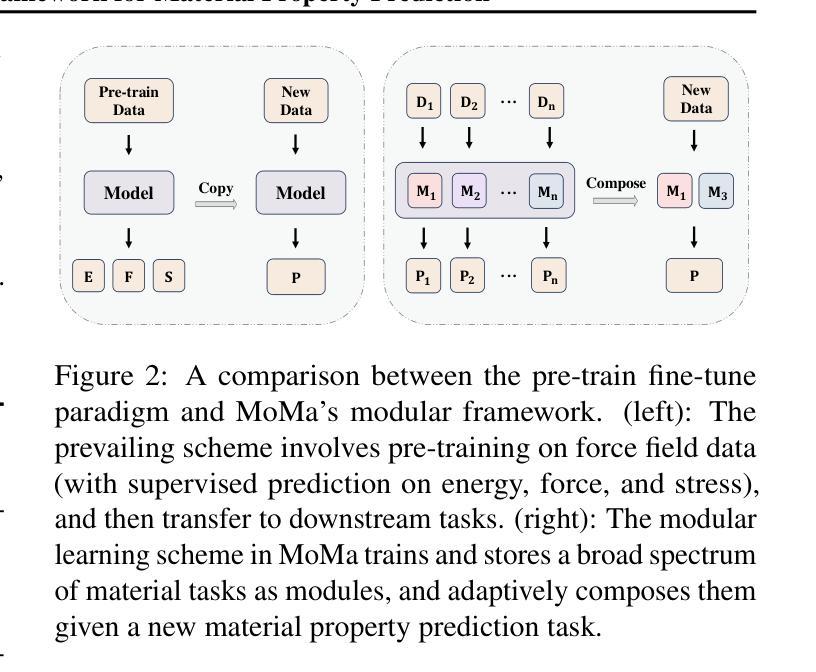
MoMa: A Modular Deep Learning Framework for Material Property Prediction
Authors:Botian Wang, Yawen Ouyang, Yaohui Li, Yiqun Wang, Haorui Cui, Jianbing Zhang, Xiaonan Wang, Wei-Ying Ma, Hao Zhou
Deep learning methods for material property prediction have been widely explored to advance materials discovery. However, the prevailing pre-train then fine-tune paradigm often fails to address the inherent diversity and disparity of material tasks. To overcome these challenges, we introduce MoMa, a Modular framework for Materials that first trains specialized modules across a wide range of tasks and then adaptively composes synergistic modules tailored to each downstream scenario. Evaluation across 17 datasets demonstrates the superiority of MoMa, with a substantial 14% average improvement over the strongest baseline. Few-shot and continual learning experiments further highlight MoMa’s potential for real-world applications. Pioneering a new paradigm of modular material learning, MoMa will be open-sourced to foster broader community collaboration.
深度学习在材料属性预测方面的应用已得到广泛探索,以推动材料发现的发展。然而,流行的预训练微调模式往往无法解决材料任务的固有多样性和差异性。为了克服这些挑战,我们引入了MoMa,这是一个面向材料的模块化框架,它首先训练适用于各种任务的专用模块,然后自适应地组合针对每个下游场景的协同模块。在17个数据集上的评估证明了MoMa的优越性,相较于最强的基线模型,其平均改进了高达14%。小样本和持续学习的实验进一步突显了MoMa在现实世界应用中的潜力。作为模块化材料学习的新范式先驱,MoMa将开源以促进更广泛的社区合作。
论文及项目相关链接
Summary
材料属性预测的深度学习方法在推动材料发现方面得到了广泛的研究。然而,当前先预训练再微调的模式往往无法应对材料任务的内在多样性和差异性。为了克服这些挑战,我们推出MoMa模块化的材料学习框架,该框架首先对各种任务进行专业化模块训练,然后针对每种下游场景自适应地组合协同模块。在多个数据集上的评估显示MoMa的优越性,相对于最强基线有平均提高百分之十四的效果。少样本和持续学习的实验进一步凸显了MoMa在现实世界应用中的潜力。MoMa开创了模块化材料学习的新范式,并将开源以促进更广泛的社区合作。
Key Takeaways
- 当前预训练微调模型在材料学习任务中的表现有待提高。
- MoMa是一个全新的材料学习框架,采用模块化设计以适应不同的材料任务。
- MoMa通过训练专业模块并自适应组合协同模块来提高性能。
- 在多个数据集上的评估显示MoMa相对于现有方法具有显著优势。
- MoMa在少样本和持续学习方面的表现突出其实际应用潜力。
- MoMa将开源以促进更广泛的社区合作和进一步发展。
点此查看论文截图


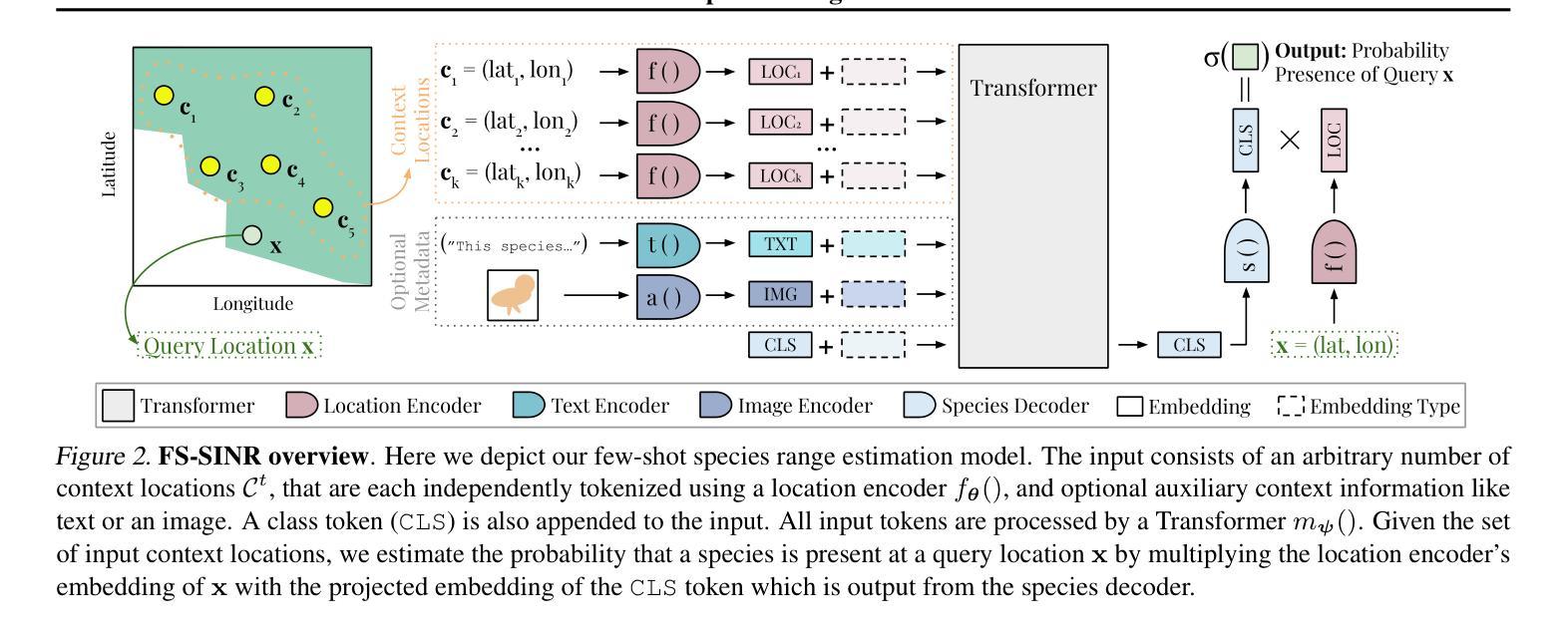
Few-shot Species Range Estimation
Authors:Christian Lange, Max Hamilton, Elijah Cole, Alexander Shepard, Samuel Heinrich, Angela Zhu, Subhransu Maji, Grant Van Horn, Oisin Mac Aodha
Knowing where a particular species can or cannot be found on Earth is crucial for ecological research and conservation efforts. By mapping the spatial ranges of all species, we would obtain deeper insights into how global biodiversity is affected by climate change and habitat loss. However, accurate range estimates are only available for a relatively small proportion of all known species. For the majority of the remaining species, we often only have a small number of records denoting the spatial locations where they have previously been observed. We outline a new approach for few-shot species range estimation to address the challenge of accurately estimating the range of a species from limited data. During inference, our model takes a set of spatial locations as input, along with optional metadata such as text or an image, and outputs a species encoding that can be used to predict the range of a previously unseen species in feed-forward manner. We validate our method on two challenging benchmarks, where we obtain state-of-the-art range estimation performance, in a fraction of the compute time, compared to recent alternative approaches.
了解特定物种在地球上可以或不能被发现的位置对于生态研究和保护工作至关重要。通过绘制所有物种的空间分布范围图,我们将更深入地了解全球生物多样性如何受到气候变化和栖息地丧失的影响。然而,准确的范围估计仅适用于已知物种中的一小部分。对于大多数剩余物种,我们通常只有少数记录标注了它们之前观察到的空间位置。我们概述了一种新的少量物种范围估计方法,以解决从有限数据中准确估计物种范围的挑战。在推理过程中,我们的模型以一组空间位置作为输入,以及可选的元数据,如文本或图像,并输出一个物种编码,该编码可用于以前所未见的物种的范围预测。我们在两个具有挑战性的基准测试上验证了我们的方法,与使用最近的替代方法相比,我们在计算时间上大大缩短,并获得了最先进的范围估计性能。
论文及项目相关链接
摘要
该文指出物种空间分布映射对生态研究和保护工作的重要性。然而,目前准确的物种分布范围数据只涵盖了一小部分已知物种。对于大多数物种,我们只有少数记录表明它们曾在哪些地点出现过。因此,文章提出了一种基于少量数据的物种分布范围估计新方法,该方法能够通过接收空间位置和可选元数据(如文本或图像)作为输入,输出一个物种编码,以预测未见物种的分布范围。在两项具有挑战性的基准测试中,该方法在运算时间大幅减少的情况下,仍取得了最先进的范围估计性能。
要点
- 物种空间分布对生态研究和保护至关重要。
- 目前准确的物种分布范围数据仅限于一小部分已知物种。
- 对于大多数物种,只有少数记录表明它们曾在哪些地点出现过。
- 提出了一种基于少量数据的物种分布范围估计新方法。
- 该方法通过接收空间位置和可选元数据作为输入,输出一个物种编码。
- 方法能够在预测未见物种的分布范围时,以预测推断的方式进行应用。
点此查看论文截图

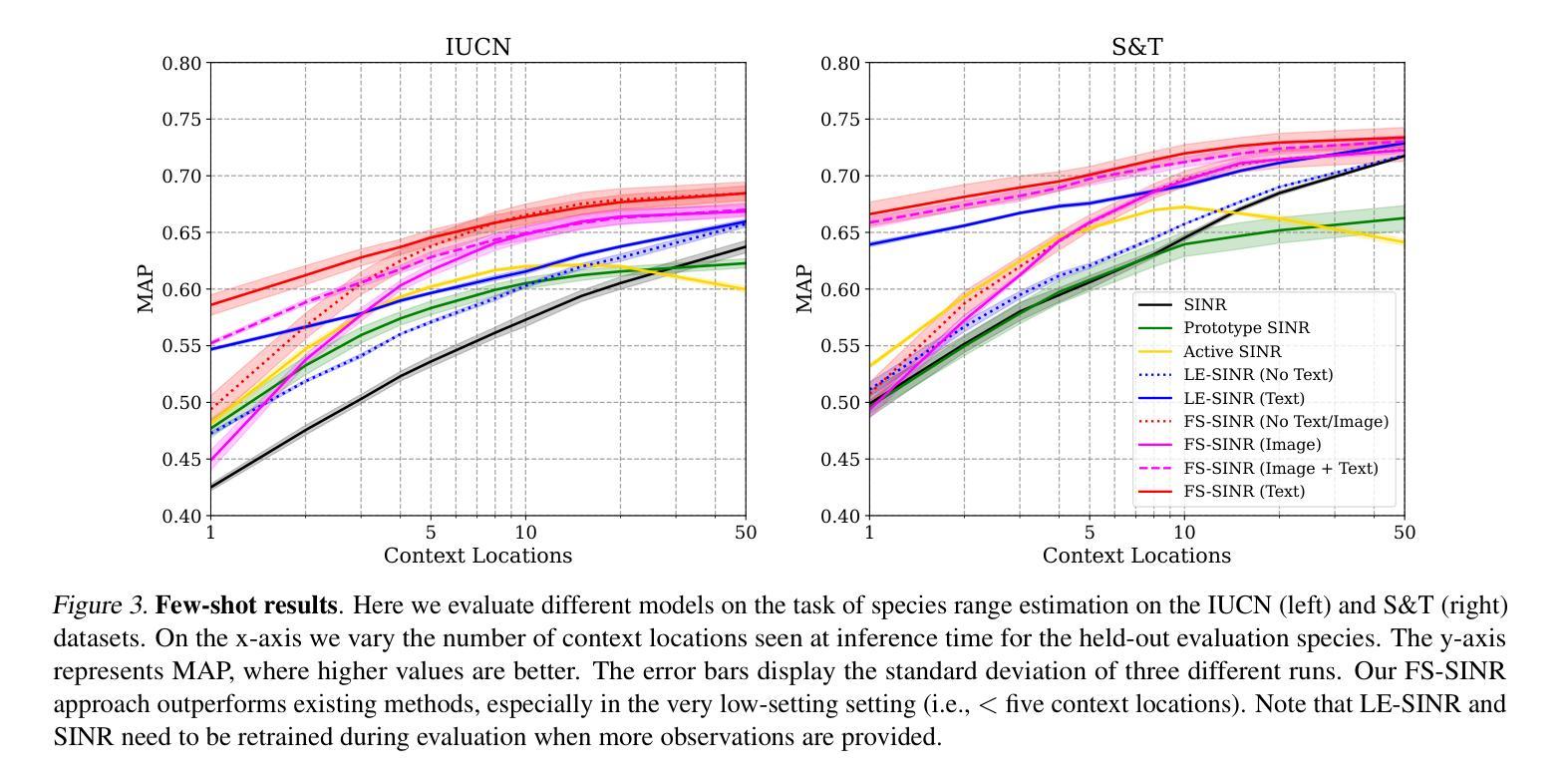

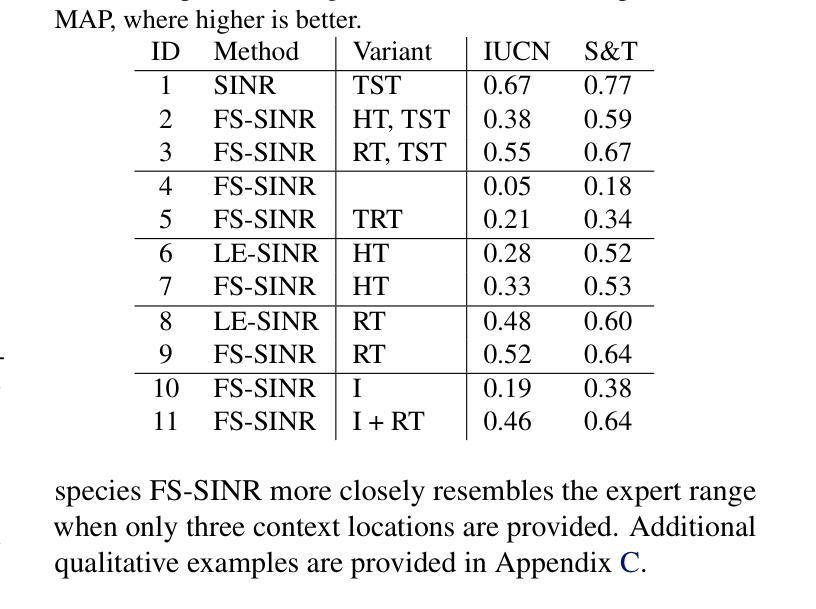
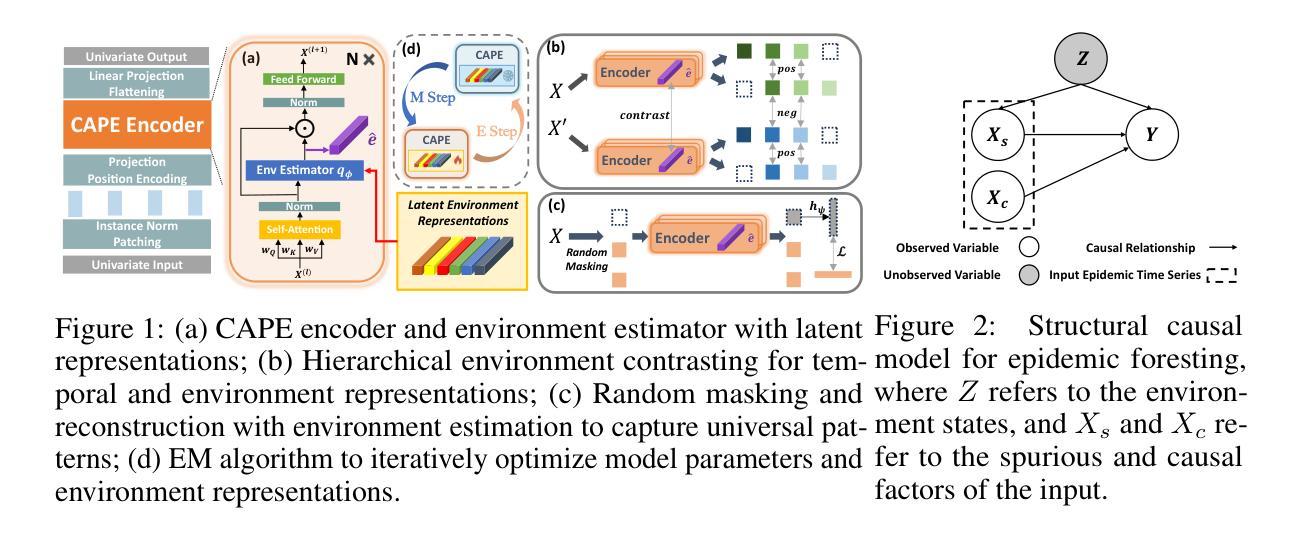
CAPE: Covariate-Adjusted Pre-Training for Epidemic Time Series Forecasting
Authors:Zewen Liu, Juntong Ni, Max S. Y. Lau, Wei Jin
Accurate forecasting of epidemic infection trajectories is crucial for safeguarding public health. However, limited data availability during emerging outbreaks and the complex interaction between environmental factors and disease dynamics present significant challenges for effective forecasting. In response, we introduce CAPE, a novel epidemic pre-training framework designed to harness extensive disease datasets from diverse regions and integrate environmental factors directly into the modeling process for more informed decision-making on downstream diseases. Based on a covariate adjustment framework, CAPE utilizes pre-training combined with hierarchical environment contrasting to identify universal patterns across diseases while estimating latent environmental influences. We have compiled a diverse collection of epidemic time series datasets and validated the effectiveness of CAPE under various evaluation scenarios, including full-shot, few-shot, zero-shot, cross-location, and cross-disease settings, where it outperforms the leading baseline by an average of 9.9% in full-shot and 14.3% in zero-shot settings. The code will be released upon acceptance.
传染病感染轨迹的准确预测对于保障公共卫生至关重要。然而,在新型疫情爆发期间数据可用性的有限性以及环境因子与疾病动态之间的复杂交互,为有效的预测带来了重大挑战。为了应对这些挑战,我们引入了CAPE,这是一个新型传染病预训练框架,旨在利用来自不同地区的广泛疾病数据集,并将环境因子直接整合到建模过程中,以为下游疾病的决策提供更有依据的决策。基于协变量调整框架,CAPE利用预训练结合分层环境对比,以识别疾病之间的通用模式,同时估计潜在的环境影响。我们已编译了多种传染病时间序列数据集,并在各种评估场景下验证了CAPE的有效性,包括全数据、小数据、零数据、跨地点和跨疾病设置。在全数据设置中,它比领先基线高出9.9%;在零数据设置中,高出14.3%。代码将在接受后发布。
论文及项目相关链接
Summary
CAPE是一个新型流行病预训练框架,旨在利用来自不同地区的丰富疾病数据集,并将环境因素直接纳入建模过程中,为下游疾病的决策提供更有根据的预测。CAPE基于协变量调整框架,采用预训练和层次环境对比技术,识别疾病间的通用模式,同时评估潜在环境影响。在多种评估场景中,CAPE表现优异,平均超出领先基线9.9%(全数据场景)和14.3%(零数据场景)。
Key Takeaways
- CAPE是一个流行病预训练框架,用于预测感染轨迹。
- 它结合了来自不同地区的丰富疾病数据集。
- CAPE将环境因素直接纳入建模过程。
- 基于协变量调整框架,CAPE采用预训练和层次环境对比技术。
- CAPE在不同评估场景中表现优异,包括全数据、少数据、零数据、跨地点和跨疾病设置。
- 与领先基线相比,CAPE在全数据场景中平均表现超出9.9%,在零数据场景中平均超出14.3%。
- 代码将在接受后发布。
点此查看论文截图

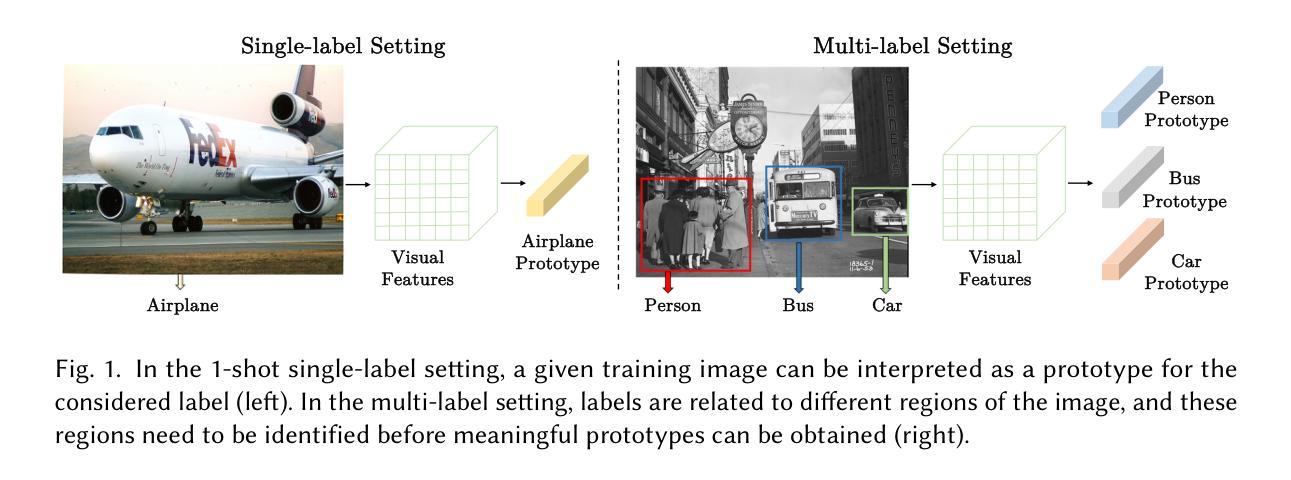
Modeling Multi-modal Cross-interaction for Multi-label Few-shot Image Classification Based on Local Feature Selection
Authors:Kun Yan, Zied Bouraoui, Fangyun Wei, Chang Xu, Ping Wang, Shoaib Jameel, Steven Schockaert
The aim of multi-label few-shot image classification (ML-FSIC) is to assign semantic labels to images, in settings where only a small number of training examples are available for each label. A key feature of the multi-label setting is that an image often has several labels, which typically refer to objects appearing in different regions of the image. When estimating label prototypes, in a metric-based setting, it is thus important to determine which regions are relevant for which labels, but the limited amount of training data and the noisy nature of local features make this highly challenging. As a solution, we propose a strategy in which label prototypes are gradually refined. First, we initialize the prototypes using word embeddings, which allows us to leverage prior knowledge about the meaning of the labels. Second, taking advantage of these initial prototypes, we then use a Loss Change Measurement (LCM) strategy to select the local features from the training images (i.e. the support set) that are most likely to be representative of a given label. Third, we construct the final prototype of the label by aggregating these representative local features using a multi-modal cross-interaction mechanism, which again relies on the initial word embedding-based prototypes. Experiments on COCO, PASCAL VOC, NUS-WIDE, and iMaterialist show that our model substantially improves the current state-of-the-art.
多标签少样本图像分类(ML-FSIC)的目标是在每个标签只有少量训练样本的情况下,为图像分配语义标签。多标签设置的一个关键特征是图像通常具有多个标签,这些标签通常指代图像不同区域中出现的对象。在基于度量的环境中估计标签原型时,确定哪些区域与哪些标签相关非常重要,但训练数据的有限性和局部特征的噪声性质使得这极具挑战性。为解决这一问题,我们提出了一种逐步优化标签原型的策略。首先,我们使用词嵌入初始化原型,以便利用有关标签含义的先验知识。其次,利用这些初始原型,我们使用损失变化测量(LCM)策略从训练图像(即支持集)中选择最可能代表给定标签的局部特征。最后,我们通过多模态交叉交互机制聚合这些代表性局部特征来构建标签的最终原型,这同样依赖于最初的基于词嵌入的原型。在COCO、PASCAL VOC、NUS-WIDE和iMaterialist上的实验表明,我们的模型大大改进了当前的最佳水平。
论文及项目相关链接
PDF In Transactions on Multimedia Computing Communications and Applications. arXiv admin note: text overlap with arXiv:2112.01037
Summary
本文介绍了多标签少样本图像分类(ML-FSIC)的目标,即在每个标签只有少量训练样本的情况下,为图像分配语义标签。文章提出了一种逐步优化标签原型的方法,首先利用词嵌入初始化原型,然后使用局部特征选择策略(Loss Change Measurement,LCM)选择最有可能代表给定标签的局部特征,最后通过多模态交叉交互机制构建最终的标签原型。实验结果表明,该方法在COCO、PASCAL VOC、NUS-WIDE和iMaterialist等多个数据集上均显著提高了当前技术水平。
Key Takeaways
- 多标签少样本图像分类(ML-FSIC)的目标是在少量训练样本的情况下,为图像分配多个语义标签。
- 图像通常具有多个标签,这些标签通常指代图像中不同区域的物体。
- 在估计标签原型时,需要确定哪些区域与哪些标签相关,但由于训练数据有限和局部特征的噪声性质,这具有挑战性。
- 提出了一种逐步优化标签原型的方法,包括使用词嵌入初始化原型、利用Loss Change Measurement(LCM)策略选择局部特征和构建最终标签原型。
- 词嵌入允许利用标签的先验知识,LCM策略有助于选择最可能代表给定标签的局部特征。
- 多模态交叉交互机制用于聚合代表性局部特征,进一步依赖于初始的词嵌入原型。
点此查看论文截图

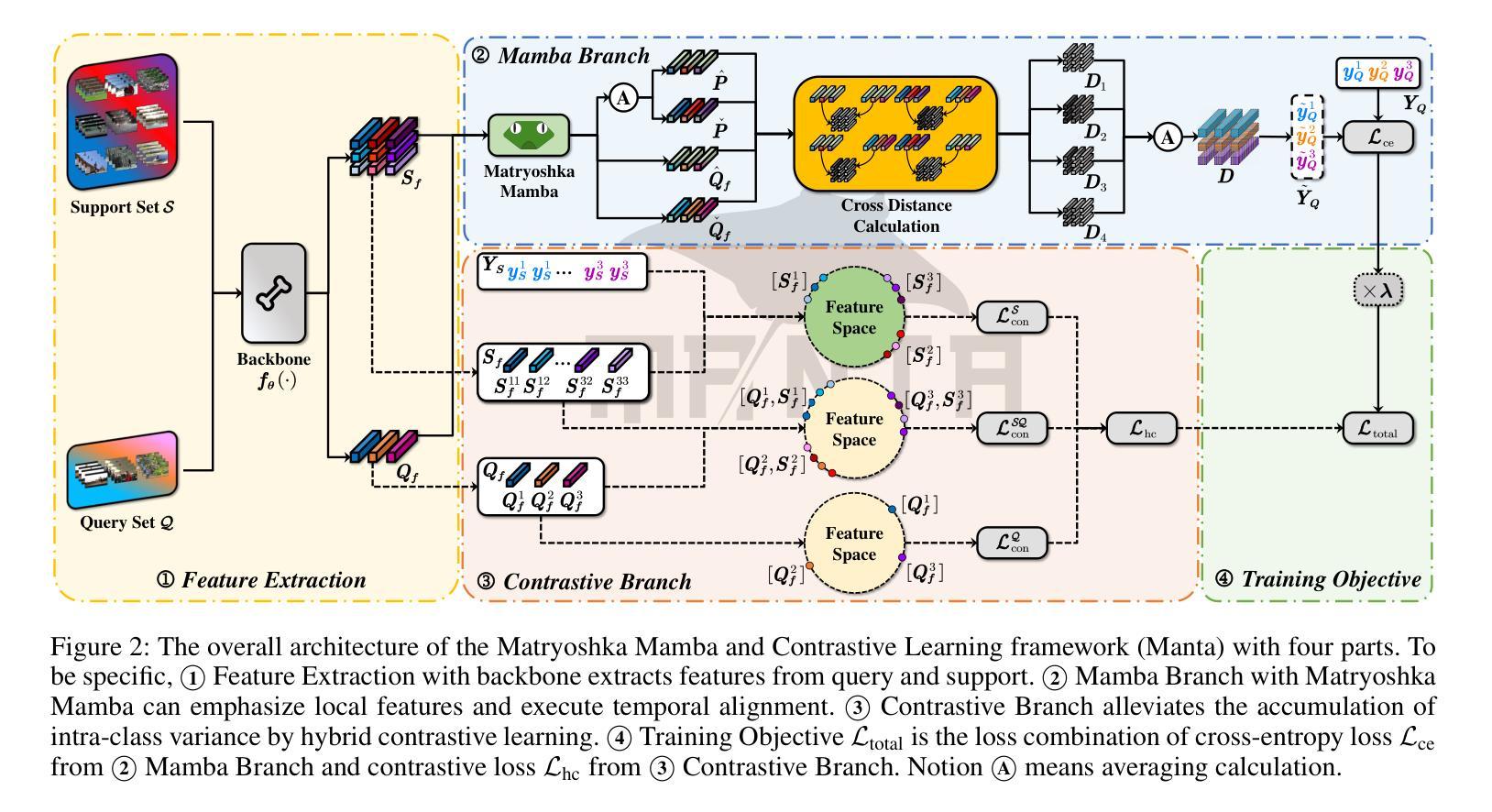
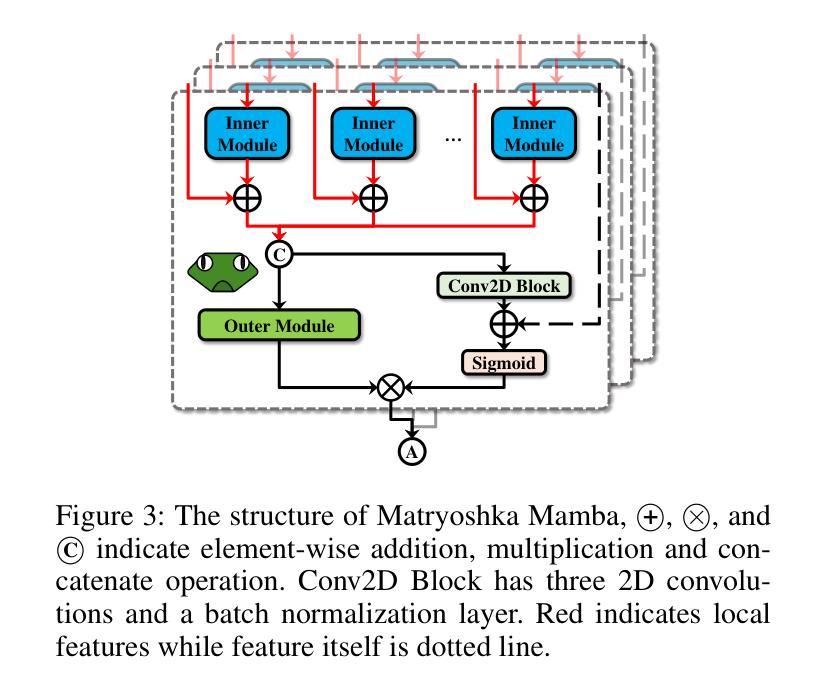
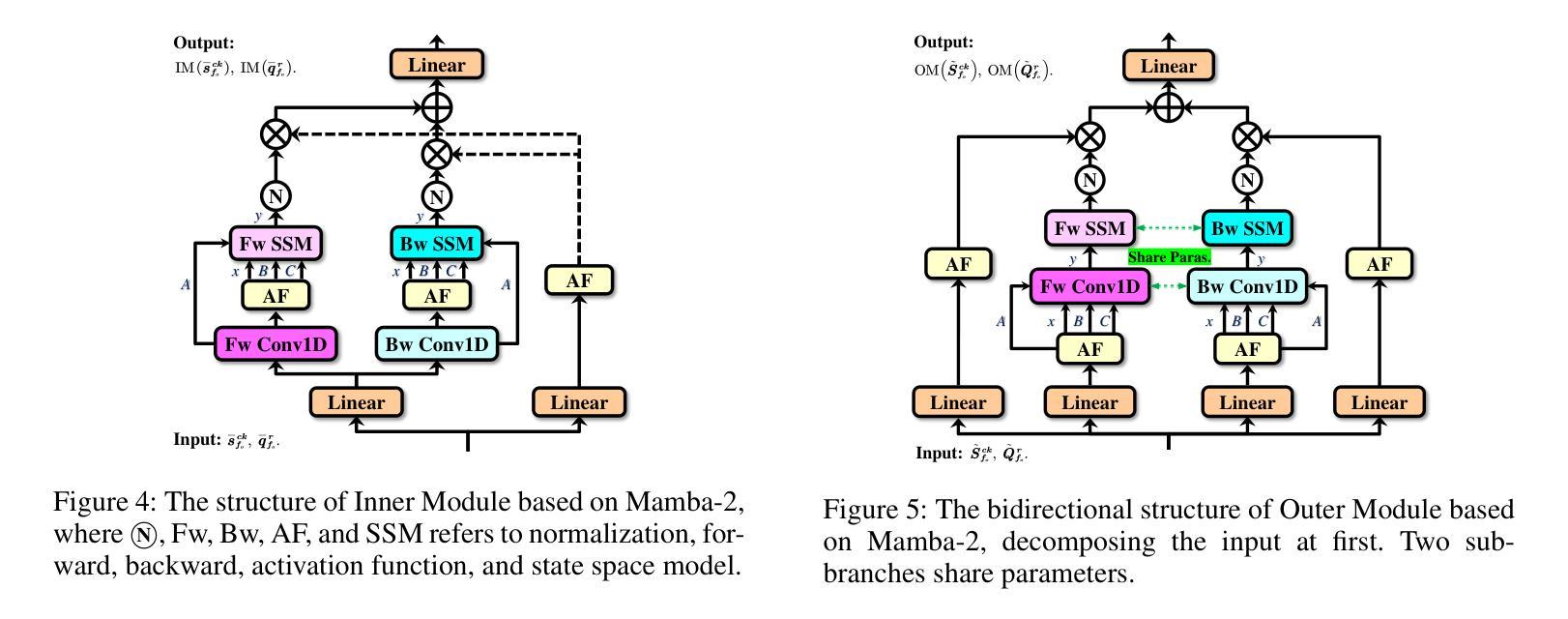
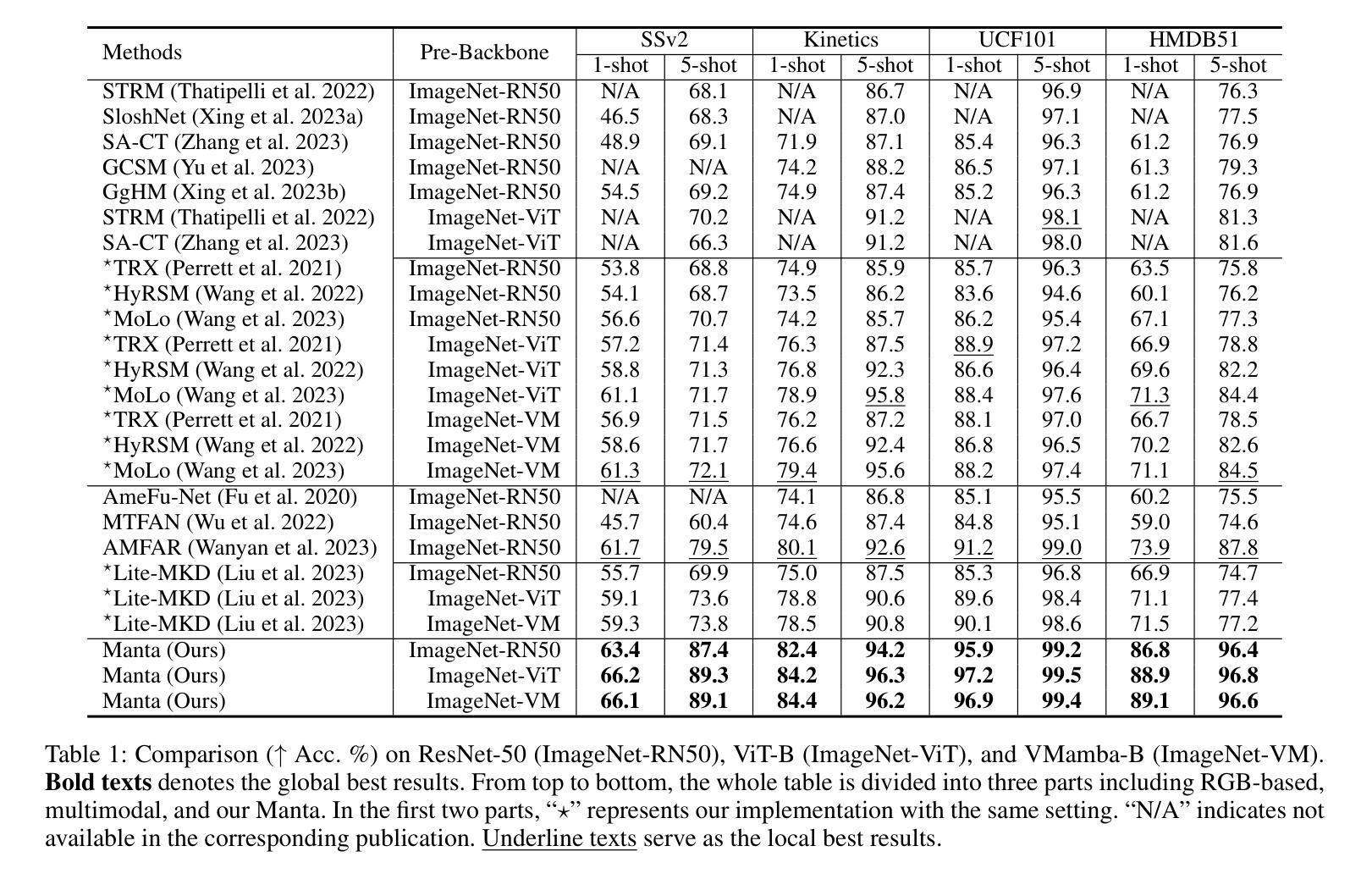
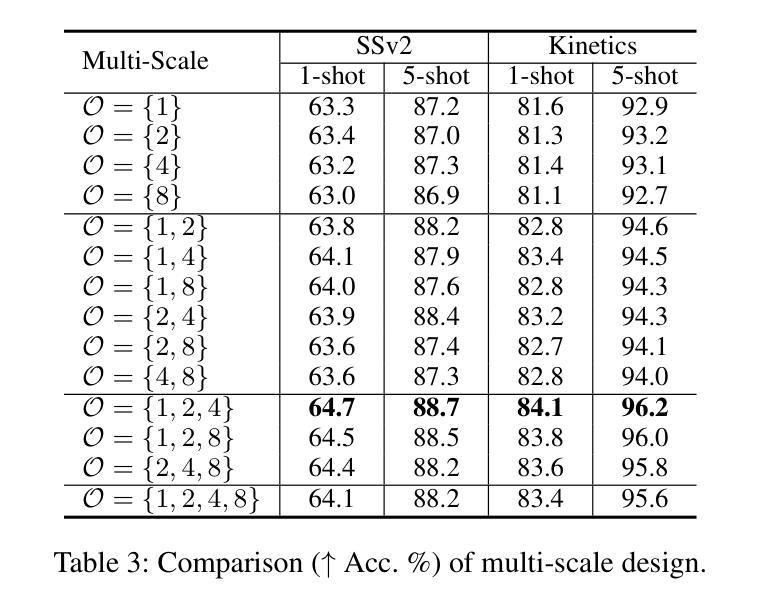
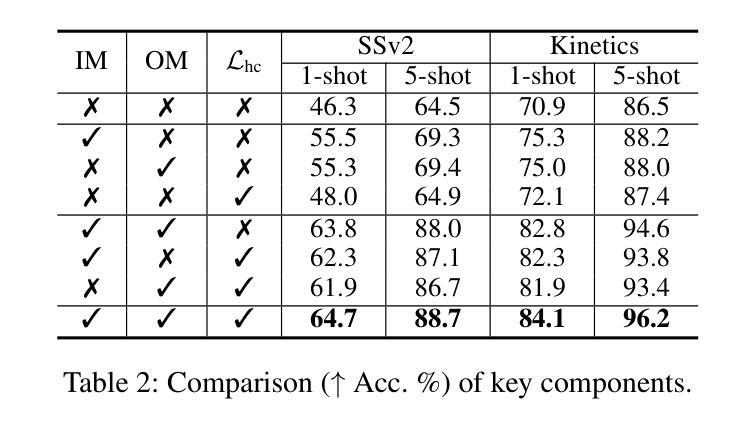
Manta: Enhancing Mamba for Few-Shot Action Recognition of Long Sub-Sequence
Authors:Wenbo Huang, Jinghui Zhang, Guang Li, Lei Zhang, Shuoyuan Wang, Fang Dong, Jiahui Jin, Takahiro Ogawa, Miki Haseyama
In few-shot action recognition (FSAR), long sub-sequences of video naturally express entire actions more effectively. However, the high computational complexity of mainstream Transformer-based methods limits their application. Recent Mamba demonstrates efficiency in modeling long sequences, but directly applying Mamba to FSAR overlooks the importance of local feature modeling and alignment. Moreover, long sub-sequences within the same class accumulate intra-class variance, which adversely impacts FSAR performance. To solve these challenges, we propose a Matryoshka MAmba and CoNtrasTive LeArning framework (Manta). Firstly, the Matryoshka Mamba introduces multiple Inner Modules to enhance local feature representation, rather than directly modeling global features. An Outer Module captures dependencies of timeline between these local features for implicit temporal alignment. Secondly, a hybrid contrastive learning paradigm, combining both supervised and unsupervised methods, is designed to mitigate the negative effects of intra-class variance accumulation. The Matryoshka Mamba and the hybrid contrastive learning paradigm operate in two parallel branches within Manta, enhancing Mamba for FSAR of long sub-sequence. Manta achieves new state-of-the-art performance on prominent benchmarks, including SSv2, Kinetics, UCF101, and HMDB51. Extensive empirical studies prove that Manta significantly improves FSAR of long sub-sequence from multiple perspectives.
在少样本动作识别(FSAR)中,视频的长子序列更自然地表达了整个动作。然而,主流基于Transformer的方法的高计算复杂度限制了其应用。最近的Mamba在建模长序列方面展示了效率,但直接将Mamba应用于FSAR忽略了局部特征建模和对齐的重要性。此外,同一类别内的长子序列会累积类内方差,这对FSAR性能产生不利影响。为了解决这些挑战,我们提出了Matryoshka Mamba和对比学习框架(Manta)。首先,Matryoshka Mamba引入了多个内部模块来增强局部特征表示,而不是直接建模全局特征。外部模块捕获这些局部特征之间时间线的依赖性,以进行隐式时间对齐。其次,结合有监督和无监督方法的混合对比学习范式旨在减轻类内方差累积的负面影响。Matryoshka Mamba和混合对比学习范式在Manta的两个并行分支中运行,增强了Mamba对长子序列的FSAR能力。Manta在SSv2、Kinetics、UCF101和HMDB51等主流基准测试上达到了最新水平,广泛的实证研究证明,Manta从多个角度显著提高了长子序列的FSAR性能。
论文及项目相关链接
PDF Accepted by AAAI 2025
Summary
基于少数镜头动作识别的研究背景,本文主要针对主流Transformer方法在建模长序列视频时的高计算复杂度问题,提出了一个名为Manta的新框架。Manta通过引入Matryoshka Mamba和混合对比学习范式来解决现有方法的局限性。Matryoshka Mamba设计有多个内部模块来增强局部特征表示,而非直接建模全局特征,同时通过外部模块捕捉这些局部特征的时间线依赖性以实现隐式时间对齐。混合对比学习范式结合了监督和无监督方法,以减轻同一类别内方差积累对少数镜头动作识别性能的负面影响。Manta在多个基准测试集上实现了卓越的性能。
Key Takeaways
- 少数镜头动作识别中,长子序列视频更有效表达完整动作。
- 主流Transformer方法在计算复杂度上存在问题,难以应用于长子序列的建模。
- Mamba虽在建模长序列上有效率,但忽略局部特征建模和对齐的重要性。
- 同类长子序列的累积会造成类内方差,影响识别性能。
- Matryoshka Mamba通过引入多个内部模块增强局部特征表示,外部模块实现时间对齐。
- 混合对比学习范式结合监督和无监督方法,减轻类内方差积累的负面影响。
点此查看论文截图

GraphCLIP: Enhancing Transferability in Graph Foundation Models for Text-Attributed Graphs
Authors:Yun Zhu, Haizhou Shi, Xiaotang Wang, Yongchao Liu, Yaoke Wang, Boci Peng, Chuntao Hong, Siliang Tang
Recently, research on Text-Attributed Graphs (TAGs) has gained significant attention due to the prevalence of free-text node features in real-world applications and the advancements in Large Language Models (LLMs) that bolster TAG methodologies. However, current TAG approaches face two primary challenges: (i) Heavy reliance on label information and (ii) Limited cross-domain zero/few-shot transferability. These issues constrain the scaling of both data and model size, owing to high labor costs and scaling laws, complicating the development of graph foundation models with strong transferability. In this work, we propose the GraphCLIP framework to address these challenges by learning graph foundation models with strong cross-domain zero/few-shot transferability through a self-supervised contrastive graph-summary pretraining method. Specifically, we generate and curate large-scale graph-summary pair data with the assistance of LLMs, and introduce a novel graph-summary pretraining method, combined with invariant learning, to enhance graph foundation models with strong cross-domain zero-shot transferability. For few-shot learning, we propose a novel graph prompt tuning technique aligned with our pretraining objective to mitigate catastrophic forgetting and minimize learning costs. Extensive experiments show the superiority of GraphCLIP in both zero-shot and few-shot settings, while evaluations across various downstream tasks confirm the versatility of GraphCLIP. Our code is available at: https://github.com/ZhuYun97/GraphCLIP
近期,关于文本属性图(TAGs)的研究受到了广泛关注,这是由于现实世界应用中自由文本节点特征的普及以及支持TAG方法的大型语言模型(LLMs)的进展。然而,当前的TAG方法面临两个主要挑战:(i)严重依赖标签信息;(ii)跨域零/少样本迁移能力有限。这些问题由于高昂的人工成本和规模扩展定律而限制了数据和模型规模的扩展,从而加剧了具有强大迁移能力的图基础模型的开发难度。在这项工作中,我们提出GraphCLIP框架来解决这些挑战,通过自监督对比图摘要预训练方法来学习具有强大跨域零/少样本迁移能力的图基础模型。具体来说,我们借助LLMs生成和精选大规模图摘要配对数据,并引入一种新型的图摘要预训练方法与不变学习相结合,以增强图基础模型的跨域零样本迁移能力。对于少样本学习,我们提出了一种与预训练目标对齐的图提示调整技术,以减轻灾难性遗忘并最小化学习成本。大量实验表明,GraphCLIP在零样本和少样本设置中都表现出卓越性能,而在各种下游任务上的评估则证实了GraphCLIP的通用性。我们的代码可用在:https://github.com/ZhuYun97/GraphCLIP。
论文及项目相关链接
PDF Accepted to WWW’25
Summary
本文介绍了针对文本属性图(TAGs)的研究进展及其面临的挑战,包括对数据标签的过度依赖和跨域零/少样本迁移能力有限的问题。为应对这些挑战,提出了GraphCLIP框架,通过自监督对比图摘要预训练方法,学习具有强大跨域零/少样本迁移能力的图基础模型。利用大型语言模型生成和筛选大规模图摘要对数据,结合不变学习,增强模型的零样本迁移能力。针对少样本学习,提出了一种与预训练目标对齐的图提示调整技术,以减轻灾难性遗忘并减少学习成本。实验证明GraphCLIP在零样本和少样本设置中的优越性,并在各种下游任务中的评估确认了其通用性。
Key Takeaways
- Text-Attributed Graphs (TAGs)研究受到关注,但面临依赖标签信息和跨域迁移能力有限两大挑战。
- GraphCLIP框架通过自监督对比图摘要预训练方法解决这些问题,提高模型的迁移能力。
- 利用大型语言模型生成和筛选大规模图摘要对数据,增强模型的零样本迁移能力。
- GraphCLIP结合不变学习来提升模型的性能。
- 针对少样本学习,GraphCLIP提出图提示调整技术,减轻灾难性遗忘并减少学习成本。
- 实验证明GraphCLIP在零样本和少样本设置中的优越性。
- GraphCLIP在各种下游任务中的评估结果证明了其通用性。
点此查看论文截图


Packet Inspection Transformer: A Self-Supervised Journey to Unseen Malware Detection with Few Samples
Authors:Kyle Stein, Arash Mahyari, Guillermo Francia III, Eman El-Sheikh
As networks continue to expand and become more interconnected, the need for novel malware detection methods becomes more pronounced. Traditional security measures are increasingly inadequate against the sophistication of modern cyber attacks. Deep Packet Inspection (DPI) has been pivotal in enhancing network security, offering an in-depth analysis of network traffic that surpasses conventional monitoring techniques. DPI not only examines the metadata of network packets, but also dives into the actual content being carried within the packet payloads, providing a comprehensive view of the data flowing through networks. While the integration of advanced deep learning techniques with DPI has introduced modern methodologies into malware detection and network traffic classification, state-of-the-art supervised learning approaches are limited by their reliance on large amounts of annotated data and their inability to generalize to novel, unseen malware threats. To address these limitations, this paper leverages the recent advancements in self-supervised learning (SSL) and few-shot learning (FSL). Our proposed self-supervised approach trains a transformer via SSL to learn the embedding of packet content, including payload, from vast amounts of unlabeled data by masking portions of packets, leading to a learned representation that generalizes to various downstream tasks. Once the representation is extracted from the packets, they are used to train a malware detection algorithm. The representation obtained from the transformer is then used to adapt the malware detector to novel types of attacks using few-shot learning approaches. Our experimental results demonstrate that our method achieves classification accuracies of up to 94.76% on the UNSW-NB15 dataset and 83.25% on the CIC-IoT23 dataset.
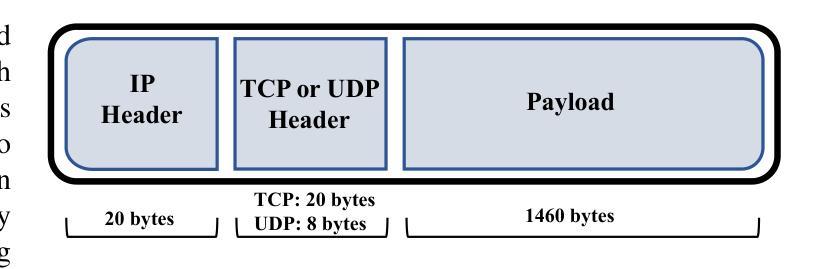
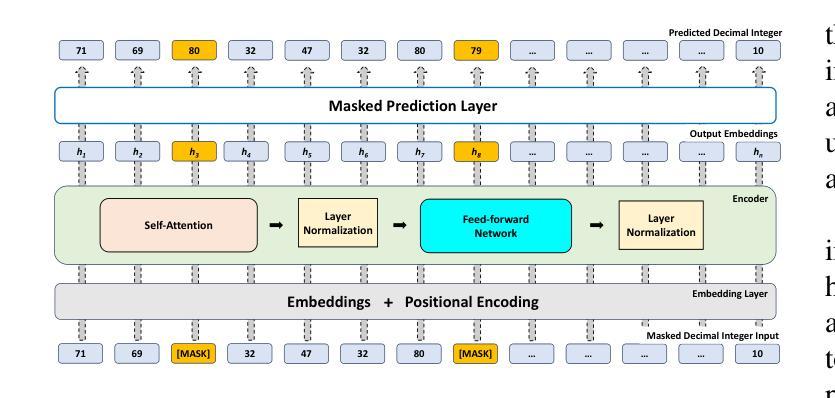
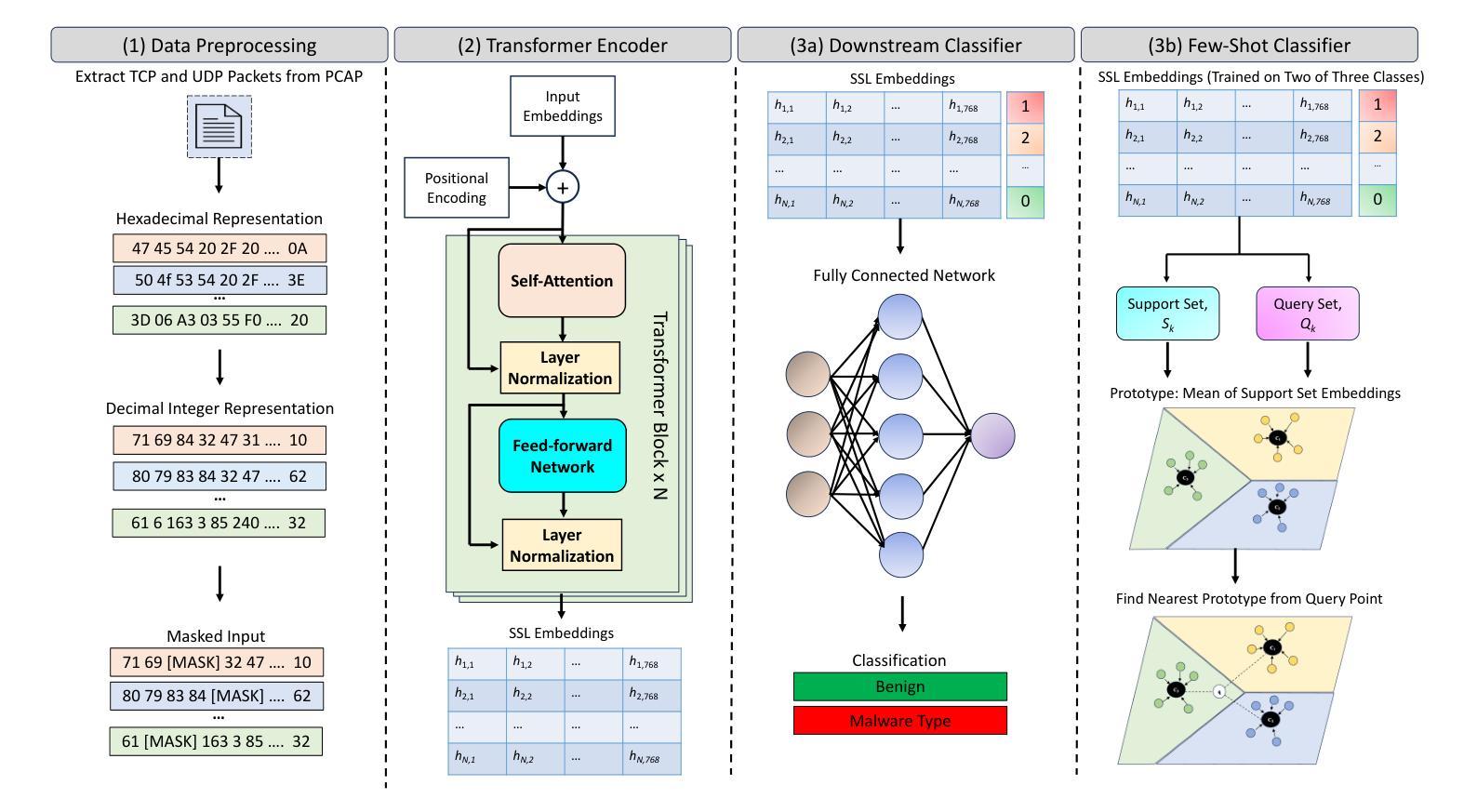
随着网络的不断扩张和相互连接,对新型恶意软件检测方法的需要变得更加迫切。传统的安全措施越来越难以应对现代网络攻击的复杂性。深度包检测(DPI)在增强网络安全方面发挥了关键作用,提供了一种对网络流量进行深入分析的技术,超越了传统监控技术。DPI不仅检查网络包的元数据,还深入研究包有效负载中的实际内容,提供了通过网络流动的数据的全面视图。虽然将先进的深度学习技术与DPI相结合已经为恶意软件检测和网络流量分类引入了现代方法,但最先进的监督学习方法受限于它们对大量注释数据的依赖以及它们对新型未见恶意威胁的泛化能力。为了解决这个问题,本文利用自我监督学习(SSL)和少镜头学习(FSL)的最新进展。我们提出的自我监督方法通过SSL训练一个变压器,学习包括有效负载在内的数据包内容的嵌入,通过掩盖数据包的部分内容,从大量无标签数据中学习表示,这有助于适应各种下游任务。一旦从数据包中提取出表示形式,它们就被用来训练恶意软件检测算法。从变压器获得的表示形式然后被用于利用少镜头学习方法适应新型攻击。我们的实验结果表明,我们的方法在UNSW-NB15数据集上达到了高达94.76%的分类精度,在CIC-IoT23数据集上达到了83.25%的分类精度。
论文及项目相关链接
Summary:随着网络不断扩展和相互连接,新型恶意软件检测方法的必要性更加突出。深度包检测(DPI)对于增强网络安全性至关重要,它提供了对网络流量的深入分析,超越了传统监控技术。本文利用自我监督学习和少样本学习的最新进展,通过自我监督方法训练一个变压器来学习数据包内容的嵌入,包括负载,通过掩盖部分数据包从大量未标记的数据中学习表示,然后将该表示用于训练恶意软件检测算法。实验结果表明,该方法在UNSW-NB15数据集上达到了94.76%的分类准确率,在CIC-IoT23数据集上达到了83.25%的分类准确率。
Key Takeaways:
- 网络互联性的增强凸显了新型恶意软件检测方法的必要性。
- 传统安全措施对现代网络攻击的复杂性越来越不足够应对。
- 深度包检测(DPI)是一种增强网络安全的关键技术,能够深入分析网络流量。
- DPI不仅分析网络包的元数据,还深入实际内容,提供全面的网络数据流视图。
- 深度学习和DPI的结合为恶意软件检测和流量分类提供了现代方法。
- 当前最先进的监督学习方法受限于需要大量标注数据和无法泛化到新型威胁。
点此查看论文截图

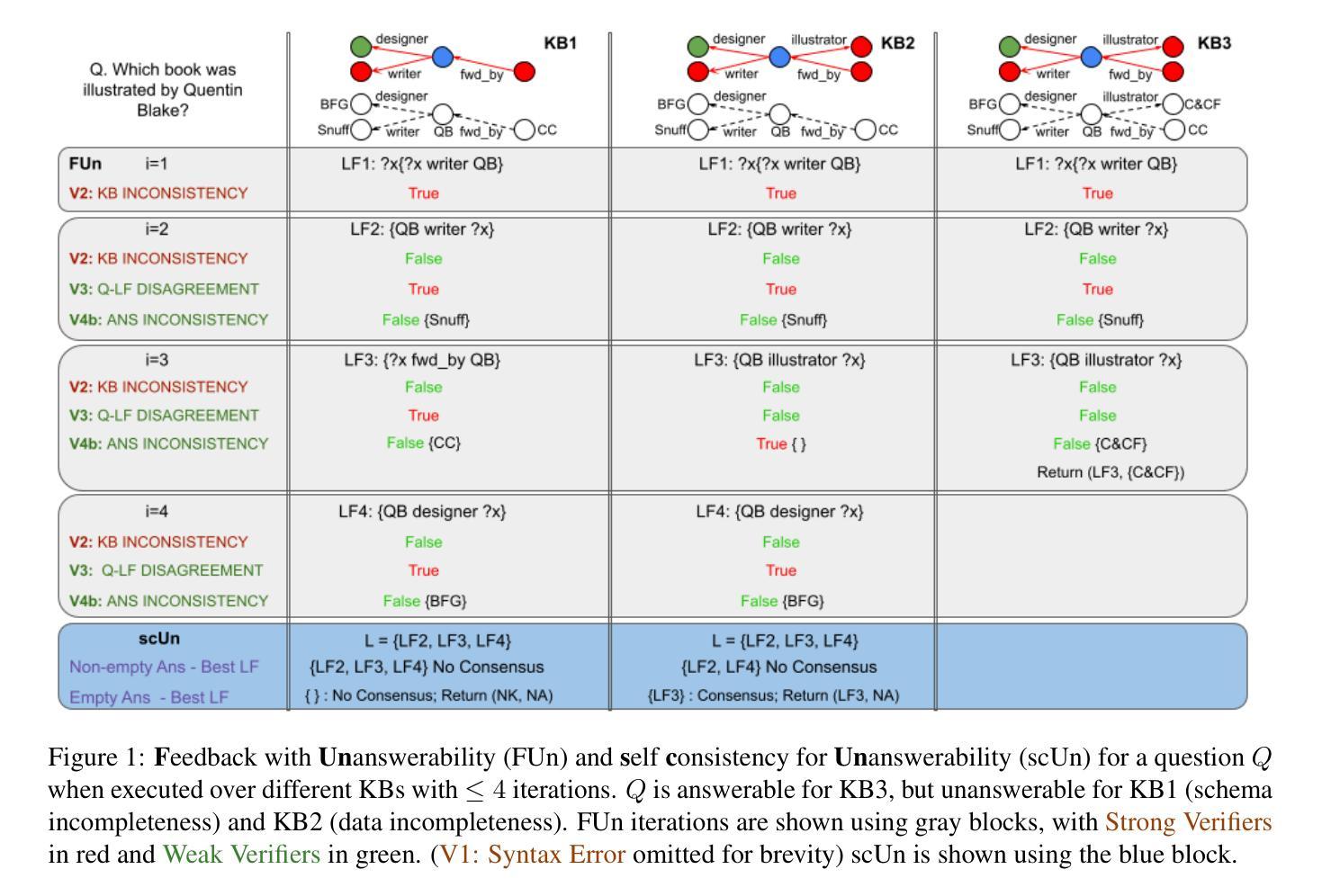
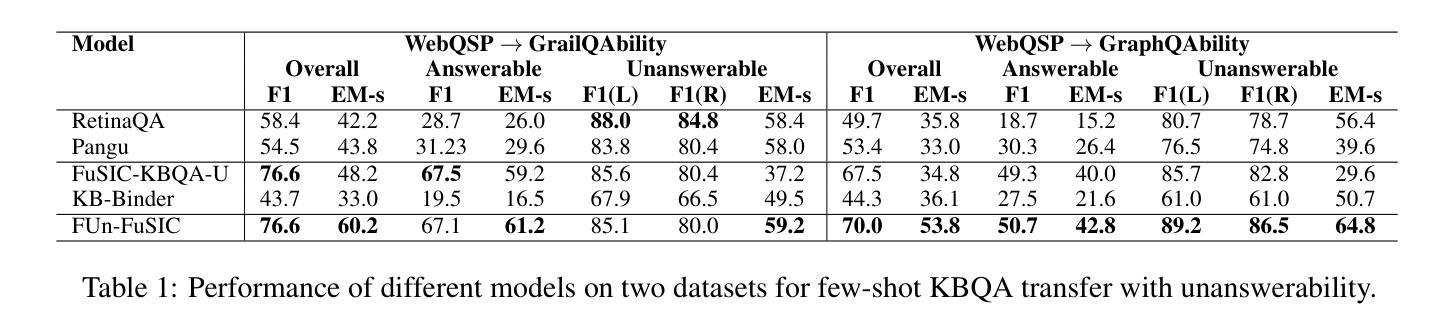
Iterative Repair with Weak Verifiers for Few-shot Transfer in KBQA with Unanswerability
Authors:Riya Sawhney, Samrat Yadav, Indrajit Bhattacharya, Mausam
Real-world applications of KBQA require models to handle unanswerable questions with a limited volume of in-domain labeled training data. We propose the novel task of few-shot transfer for KBQA with unanswerable questions and contribute two new datasets for performance evaluation. We present FUn-FuSIC - a novel solution for our task that extends FuSIC KBQA, the state-of-the-art few-shot transfer model for answerable-only KBQA. We first note that FuSIC-KBQA’s iterative repair makes a strong assumption that all questions are unanswerable. As a remedy, we propose Feedback for Unanswerability (FUn), which uses iterative repair using feedback from a suite of strong and weak verifiers, and an adaptation of self consistency for unanswerabilty to better assess the answerability of a question. Our experiments show that FUn-FuSIC significantly outperforms suitable adaptations of multiple LLM based and supervised SoTA models on our task, while establishing a new SoTA for answerable few-shot transfer as well.
现实世界中的KBQA应用要求模型能够处理无法回答的问题,并且在领域内部只有有限量的标记训练数据。我们针对无法回答的KBQA提出了新颖的小样本迁移任务,并为性能评估贡献了两个新数据集。我们介绍了FUN-FuSIC——一种针对我们任务的新型解决方案,它扩展了FuSIC KBQA(针对仅可回答KBQA的最先进的小样本迁移模型)。我们首先注意到,FuSIC-KBQA的迭代修复假设所有问题都是无法回答的,这是一个很强的假设。作为补救措施,我们提出了针对无法回答的问题的反馈(FUN),它使用来自一系列强验证器和弱验证器的反馈进行迭代修复,并自适应地调整自我一致性以更好地评估问题的可回答性。我们的实验表明,FUN-FuSIC在我们的任务上显著优于多个基于大型语言模型和监督的当前最佳模型(SoTA)的适当改编版本,同时为我们建立了新的可回答的小样本迁移的当前最佳水平。
论文及项目相关链接
摘要
针对KBQA(知识库问答)的实际应用,需要模型处理不可回答的问题,并在有限的领域内标签训练数据下工作。本文提出了针对KBQA不可回答问题进行少样本迁移的新任务,并贡献了两个新的数据集用于性能评估。我们提出了FUN-FuSIC的新解决方案,它是FuSIC KBQA的扩展,适用于仅回答问题的少样本迁移模型。我们发现FuSIC-KBQA的迭代修复假设所有问题都是不可回答的,这存在局限性。为解决这一问题,我们提出了针对不可回答性的反馈(FUN),利用一系列强验证器和弱验证器的反馈进行迭代修复,并自适应地调整自我一致性以更好地评估问题的可回答性。实验表明,FUN-FuSIC在我们的任务上显著优于多个大型语言模型(LLM)和当前最佳监督模型的适应性版本,同时为可回答问题的少样本迁移建立了新的最佳性能。
关键见解
- 针对KBQA的不可回答问题,提出了少样本迁移的新任务。
- 贡献了两个新的数据集用于评估该任务的性能。
- 扩展了FuSIC KBQA模型,提出了FUN-FuSIC解决方案来处理不可回答问题的少样本迁移。
- 指出FuSIC-KBQA的迭代修复假设存在局限性。
- 提出了针对不可回答性的反馈(FUN),通过利用一系列强验证器和弱验证器的反馈进行迭代修复。
- 通过实验验证了FUN-FuSIC在任务上的优越性,同时建立了新的少样本迁移最佳性能。
点此查看论文截图


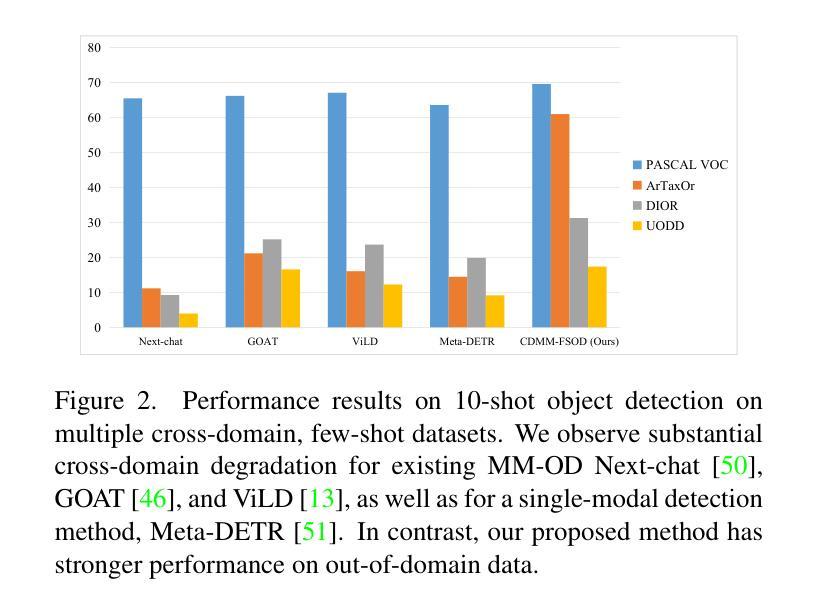
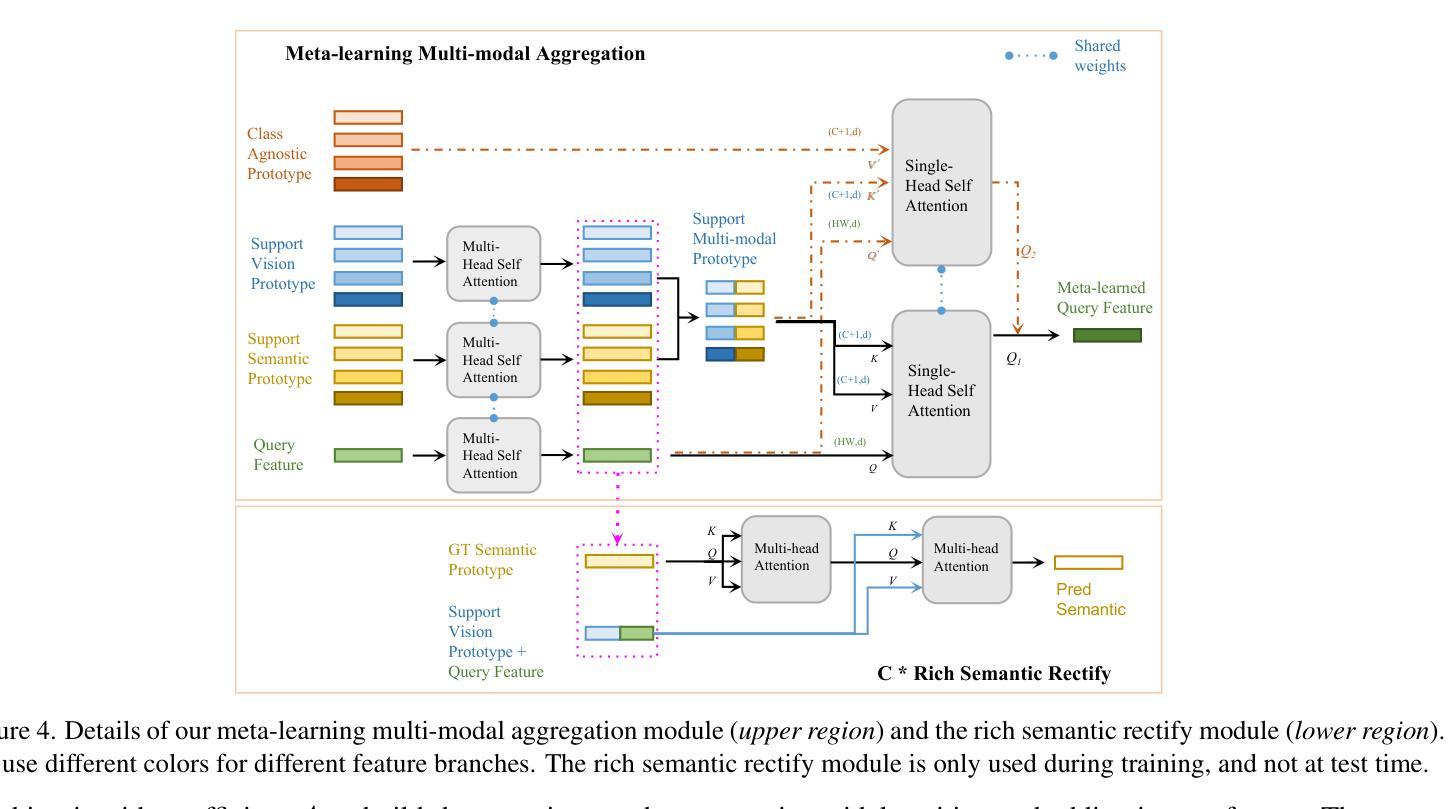
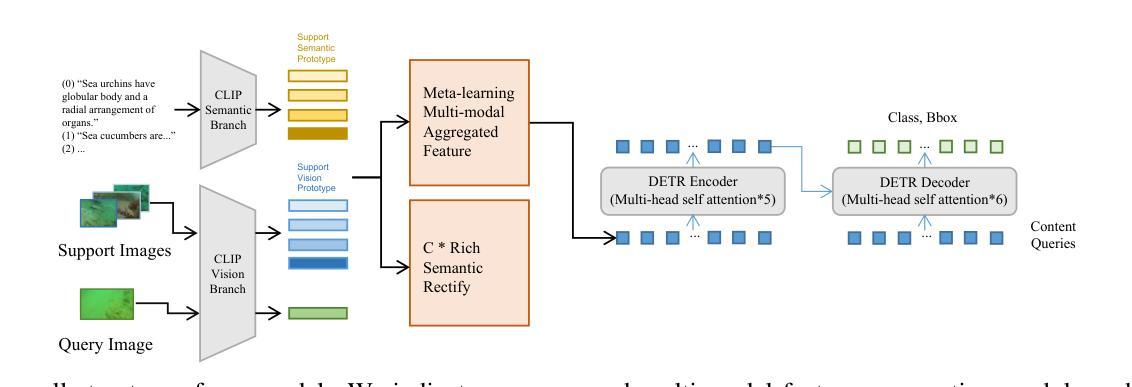
Cross-domain Multi-modal Few-shot Object Detection via Rich Text
Authors:Zeyu Shangguan, Daniel Seita, Mohammad Rostami
Cross-modal feature extraction and integration have led to steady performance improvements in few-shot learning tasks due to generating richer features. However, existing multi-modal object detection (MM-OD) methods degrade when facing significant domain-shift and are sample insufficient. We hypothesize that rich text information could more effectively help the model to build a knowledge relationship between the vision instance and its language description and can help mitigate domain shift. Specifically, we study the Cross-Domain few-shot generalization of MM-OD (CDMM-FSOD) and propose a meta-learning based multi-modal few-shot object detection method that utilizes rich text semantic information as an auxiliary modality to achieve domain adaptation in the context of FSOD. Our proposed network contains (i) a multi-modal feature aggregation module that aligns the vision and language support feature embeddings and (ii) a rich text semantic rectify module that utilizes bidirectional text feature generation to reinforce multi-modal feature alignment and thus to enhance the model’s language understanding capability. We evaluate our model on common standard cross-domain object detection datasets and demonstrate that our approach considerably outperforms existing FSOD methods.
跨模态特征提取和融合由于生成了更丰富的特征,在少样本学习任务中带来了稳定的性能提升。然而,当面临显著的领域迁移和样本不足时,现有的多模态目标检测(MM-OD)方法会性能下降。我们假设丰富的文本信息可以更有效地帮助模型建立视觉实例与其语言描述之间的知识关系,并有助于缓解领域迁移。具体来说,我们研究了跨域少样本泛化的MM-OD(CDMM-FSOD),并提出了一种基于元学习的多模态少样本目标检测方法,利用丰富的文本语义信息作为辅助模态来实现FSOD领域的自适应。我们提出的网络包含(i)一种多模态特征聚合模块,用于对齐视觉和语言支持特征嵌入;(ii)一种丰富的文本语义校正模块,利用双向文本特征生成来加强多模态特征对齐,从而提高模型的语言理解能力和跨领域适应能力。我们在常见的标准跨域目标检测数据集上评估了我们的模型,结果表明我们的方法显著优于现有的FSOD方法。
论文及项目相关链接
Summary
本文探讨了跨模态特征提取与融合在少样本学习任务中的持续性能提升,并指出多模态目标检测(MM-OD)方法在面临显著领域偏移和样本不足时的局限性。研究假设丰富文本信息能有效帮助模型建立视觉实例与语言描述之间的知识关系,并有助于缓解领域偏移问题。文章研究了跨域少样本泛化的多模态目标检测(CDMM-FSOD),并提出一种基于元学习的多模态少样本目标检测方法,利用丰富文本语义信息作为辅助模态来实现领域适应,针对FSOD。所提网络包括多模态特征聚合模块和丰富文本语义校正模块,前者对齐视觉和语言支持特征嵌入,后者利用双向文本特征生成强化多模态特征对齐,提高模型的语言理解力。在跨域目标检测数据集上的评估显示,该方法显著优于现有FSOD方法。
Key Takeaways
- 跨模态特征提取与融合在少样本学习任务中持续推动性能提升。
- 多模态目标检测(MM-OD)方法在面临显著领域偏移和样本不足时性能下降。
- 丰富文本信息能有效帮助模型建立视觉实例与语言描述之间的知识关系。
- 文章研究了跨域少样本泛化的多模态目标检测(CDMM-FSOD)。
- 提出一种基于元学习的多模态少样本目标检测方法,结合丰富文本语义信息作为辅助模态实现领域适应。
- 所提网络包括多模态特征聚合模块,用于对齐视觉和语言特征嵌入。
点此查看论文截图

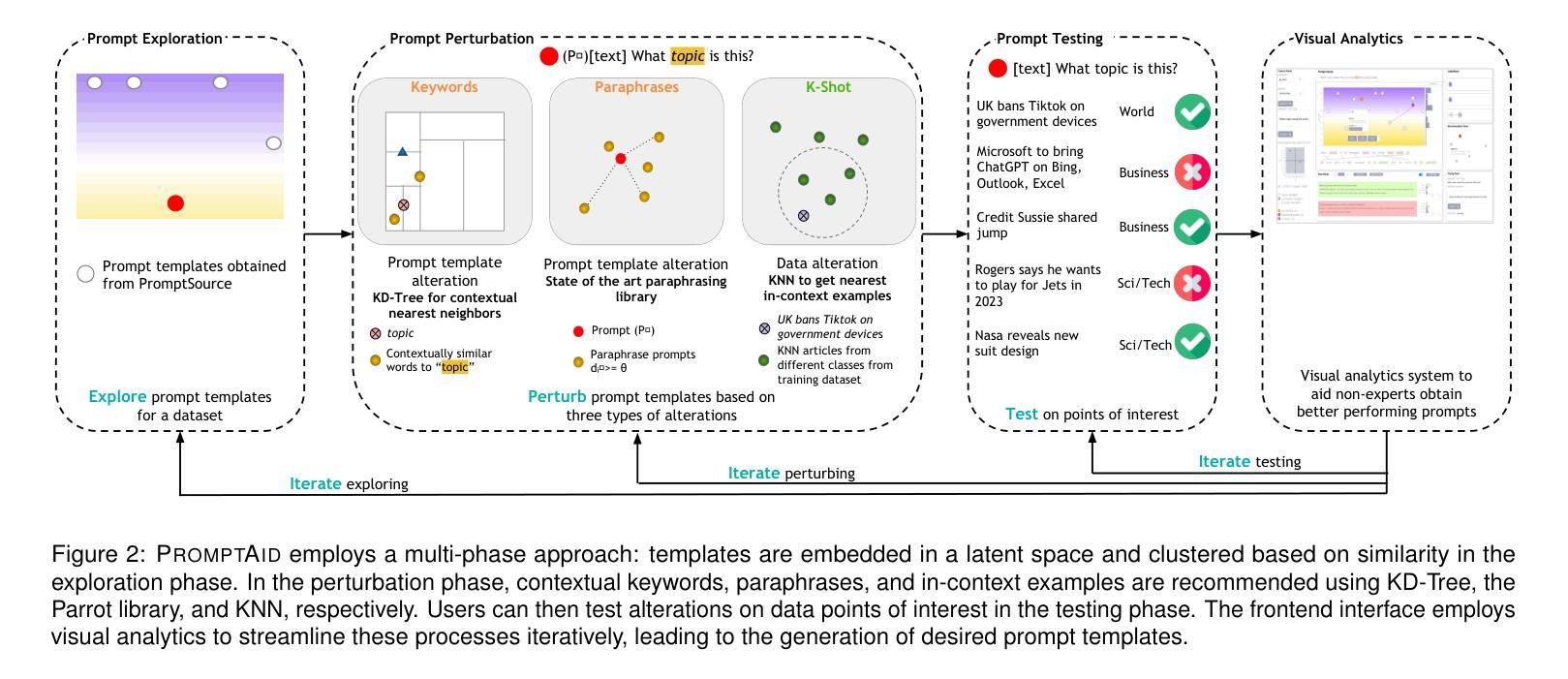
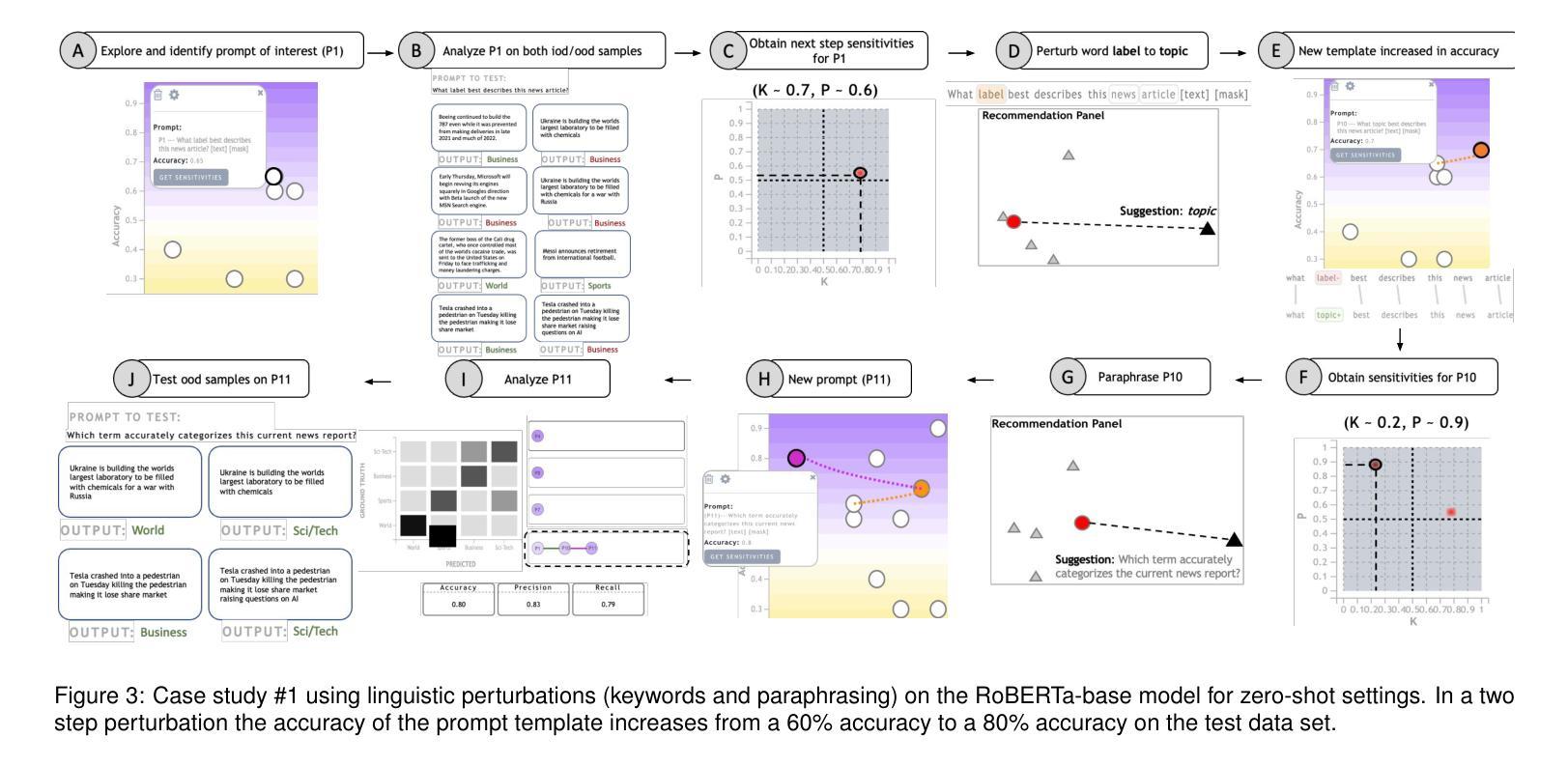
PromptAid: Prompt Exploration, Perturbation, Testing and Iteration using Visual Analytics for Large Language Models
Authors:Aditi Mishra, Utkarsh Soni, Anjana Arunkumar, Jinbin Huang, Bum Chul Kwon, Chris Bryan
Large Language Models (LLMs) have gained widespread popularity due to their ability to perform ad-hoc Natural Language Processing (NLP) tasks with a simple natural language prompt. Part of the appeal for LLMs is their approachability to the general public, including individuals with no prior technical experience in NLP techniques. However, natural language prompts can vary significantly in terms of their linguistic structure, context, and other semantics. Modifying one or more of these aspects can result in significant differences in task performance. Non-expert users may find it challenging to identify the changes needed to improve a prompt, especially when they lack domain-specific knowledge and lack appropriate feedback. To address this challenge, we present PromptAid, a visual analytics system designed to interactively create, refine, and test prompts through exploration, perturbation, testing, and iteration. PromptAid uses multiple, coordinated visualizations which allow users to improve prompts by using the three strategies: keyword perturbations, paraphrasing perturbations, and obtaining the best set of in-context few-shot examples. PromptAid was designed through an iterative prototyping process involving NLP experts and was evaluated through quantitative and qualitative assessments for LLMs. Our findings indicate that PromptAid helps users to iterate over prompt template alterations with less cognitive overhead, generate diverse prompts with help of recommendations, and analyze the performance of the generated prompts while surpassing existing state-of-the-art prompting interfaces in performance.
大型语言模型(LLM)因其能够通过简单的自然语言提示执行专项自然语言处理(NLP)任务而广受欢迎。LLM的吸引力之一在于它们对普通大众的亲和力,包括那些没有先前NLP技术经验的人。然而,自然语言的提示在它们的语言结构、上下文和其他语义方面可能存在很大差异。修改这些方面的一个或多个因素可能会导致任务性能的重大差异。非专业用户可能会发现很难确定改进提示所需的更改,尤其是在他们缺乏特定领域知识和适当的反馈时。为了应对这一挑战,我们推出了PromptAid,一个视觉分析系统,旨在通过探索、扰动、测试和迭代来交互式地创建、完善和调整提示。PromptAid使用多个协调的可视化提示,允许用户通过三种策略改进提示:关键词扰动、同义替换扰动和获取最佳的上下文少量示例。PromptAid的设计过程是通过涉及NLP专家的迭代原型制作过程完成的,并通过针对LLM的定量和定性评估进行了评估。我们的研究结果表明,PromptAid有助于用户减少认知负担地迭代调整提示模板,借助推荐生成多样化的提示,并分析生成的提示的性能,同时在性能上超越了现有的先进提示界面。
论文及项目相关链接
Summary
大型语言模型(LLM)通过自然语言提示执行即兴的自然语言处理(NLP)任务的能力而广受欢迎。LLM的吸引力在于它对公众的亲和力,包括没有NLP技术经验的个人。然而,自然语言的提示在语言表达和结构上有很大的差异,可能导致任务执行效果的不同。非专业用户可能难以识别需要改进的提示变化,特别是在缺乏特定领域知识和适当反馈的情况下。为解决此挑战,我们推出了PromptAid,一个视觉分析系统,旨在通过探索、微调、测试和迭代的方式,以交互方式创建和细化提示。PromptAid利用多种协调可视化工具,使用户能够通过三种策略改进提示:关键字扰动、同义替换扰动和获取最佳的上下文少量示例。PromptAid的设计经过了NLP专家的迭代原型制作过程,并通过定量和定性评估进行验证,表明其能帮助用户通过更少的认知负担来迭代提示模板的修改,借助推荐生成多样化的提示并分析生成提示的性能表现,超越了现有的先进提示界面在性能方面的表现。
Key Takeaways
- 大型语言模型(LLMs)由于其使用自然语言提示执行NLP任务的能力而受到广泛欢迎。
- 自然语言提示的差异(如语言结构、上下文和语义)可能导致任务执行效果的显著不同。
- 非专业用户在改进语言提示方面面临挑战,特别是在缺乏领域知识和反馈的情况下。
- PromptAid是一个视觉分析系统,旨在通过交互方式帮助用户创建、细化和测试语言提示。
- PromptAid利用多种协调可视化工具,支持三种改进提示的策略:关键字扰动、同义替换扰动和获取最佳上下文少量示例。
- PromptAid的设计经过了NLP专家的迭代原型制作过程,并通过定量和定性评估验证其有效性。
点此查看论文截图