⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-26 更新
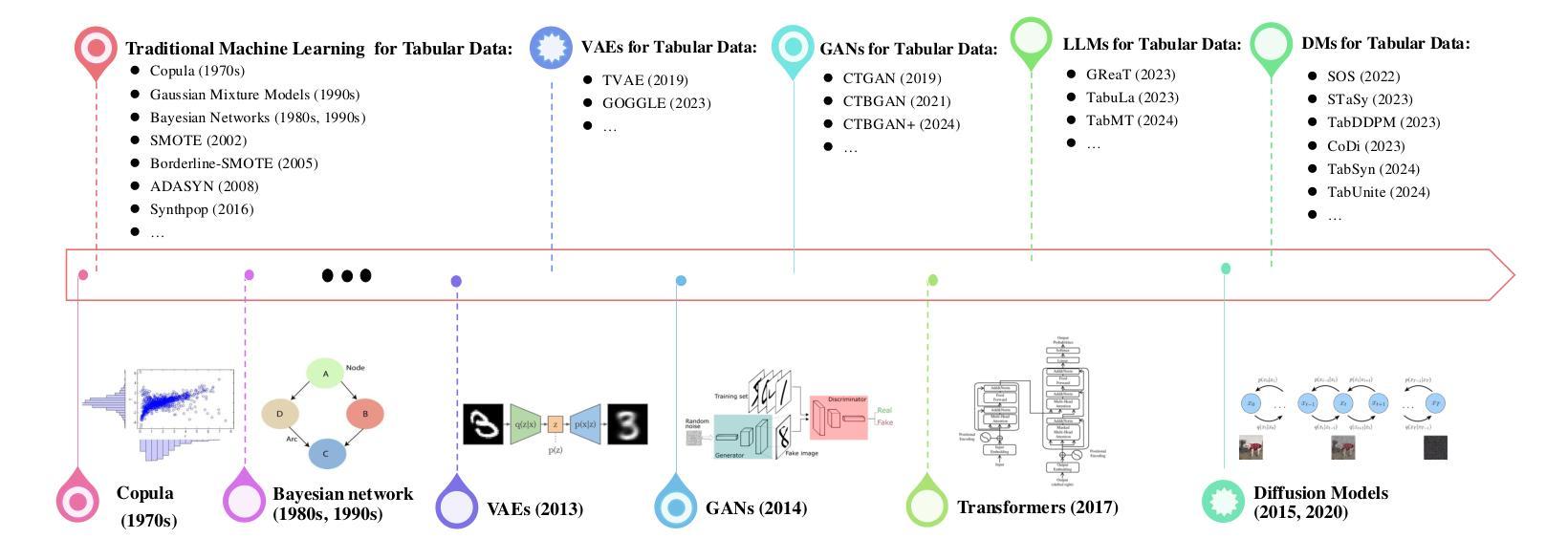
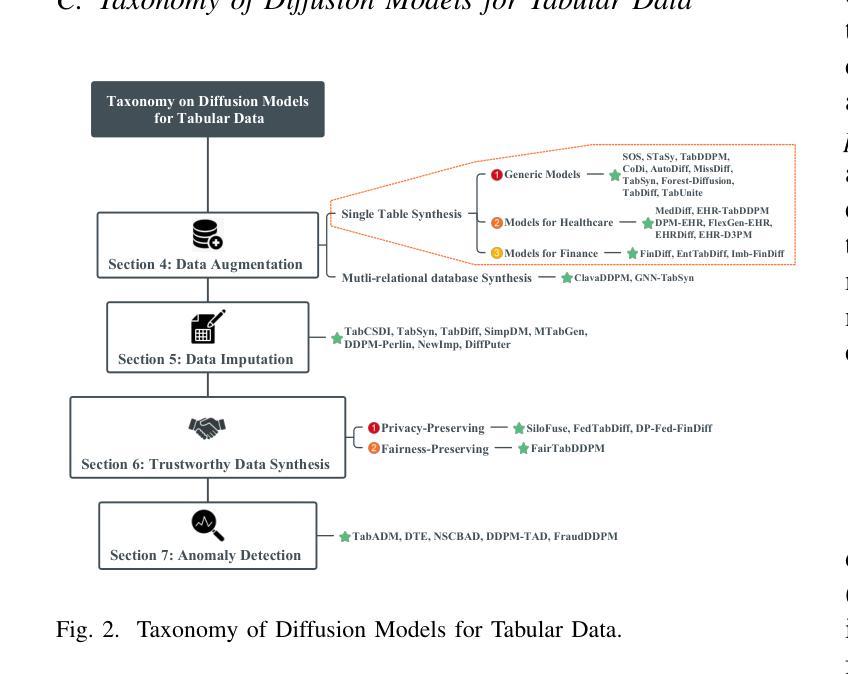
Diffusion Models for Tabular Data: Challenges, Current Progress, and Future Directions
Authors:Zhong Li, Qi Huang, Lincen Yang, Jiayang Shi, Zhao Yang, Niki van Stein, Thomas Bäck, Matthijs van Leeuwen
In recent years, generative models have achieved remarkable performance across diverse applications, including image generation, text synthesis, audio creation, video generation, and data augmentation. Diffusion models have emerged as superior alternatives to Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) by addressing their limitations, such as training instability, mode collapse, and poor representation of multimodal distributions. This success has spurred widespread research interest. In the domain of tabular data, diffusion models have begun to showcase similar advantages over GANs and VAEs, achieving significant performance breakthroughs and demonstrating their potential for addressing unique challenges in tabular data modeling. However, while domains like images and time series have numerous surveys summarizing advancements in diffusion models, there remains a notable gap in the literature for tabular data. Despite the increasing interest in diffusion models for tabular data, there has been little effort to systematically review and summarize these developments. This lack of a dedicated survey limits a clear understanding of the challenges, progress, and future directions in this critical area. This survey addresses this gap by providing a comprehensive review of diffusion models for tabular data. Covering works from June 2015, when diffusion models emerged, to December 2024, we analyze nearly all relevant studies, with updates maintained in a \href{https://github.com/Diffusion-Model-Leiden/awesome-diffusion-models-for-tabular-data}{GitHub repository}. Assuming readers possess foundational knowledge of statistics and diffusion models, we employ mathematical formulations to deliver a rigorous and detailed review, aiming to promote developments in this emerging and exciting area.
近年来,生成模型已在各种应用中取得了显著成效,包括图像生成、文本合成、音频创建、视频生成和数据增强。扩散模型通过解决生成对抗网络(GANs)和变分自编码器(VAEs)存在的局限性,如训练不稳定、模式崩溃以及多模态分布表示不佳等问题,已成为它们的优秀替代方案。这种成功激起了广泛的研究兴趣。在表格数据领域,扩散模型开始显示出对GANs和VAEs的类似优势,在性能上取得了重大突破,并显示出解决表格数据建模中的独特挑战潜力。尽管图像和时间序列等领域有众多关于扩散模型的进展总结调查,但在表格数据的文献中仍存在明显空白。尽管表格数据的扩散模型日益受到关注,但很少有人系统地回顾和总结这些发展。缺乏专门的调查限制了对此关键领域的挑战、进展和未来方向的清晰理解。本调查通过提供对表格数据扩散模型的全面回顾来弥补这一空白。我们从2015年6月扩散模型出现起至2024年12月的工作进行梳理,分析了几乎所有相关研究,更新内容维护在GitHub仓库中。我们假设读者具备统计学和扩散模型的基础知识,采用数学公式进行严谨详细的评论,旨在促进这一新兴和激动人心领域的发展。
论文及项目相关链接
Summary
近年来,生成模型在图像生成、文本合成、音频创建、视频生成和数据增强等多样化应用中取得了显著成效。扩散模型作为生成对抗网络(GANs)和变分自编码器(VAEs)的替代方案,解决了它们的局限性,如训练不稳定、模式崩溃和多模态分布表示不佳等问题,并展现了其潜力。在表格数据领域,扩散模型开始显示其优势,并在表格数据建模中应对独特挑战时取得了显著成果。然而,尽管图像和时间序列等领域有众多关于扩散模型的进展调查,但表格数据领域的文献中仍存在显著差距。这篇综述旨在通过提供表格数据扩散模型的全面回顾来填补这一空白,涵盖了从2015年6月到最新进展的内容。
Key Takeaways
- 生成模型在多个应用领域中表现卓越,包括图像、文本、音频、视频和数据增强。
- 扩散模型作为GANs和VAEs的替代方案,解决了它们的局限性。
- 扩散模型在表格数据领域开始展现优势,并取得显著性能突破。
- 目前关于表格数据扩散模型的文献仍存在显著差距。
- 这篇综述旨在全面回顾表格数据扩散模型的研究进展,并填补文献中的空白。
- 综述涵盖了从2015年6月到最新进展的所有相关研究。
点此查看论文截图


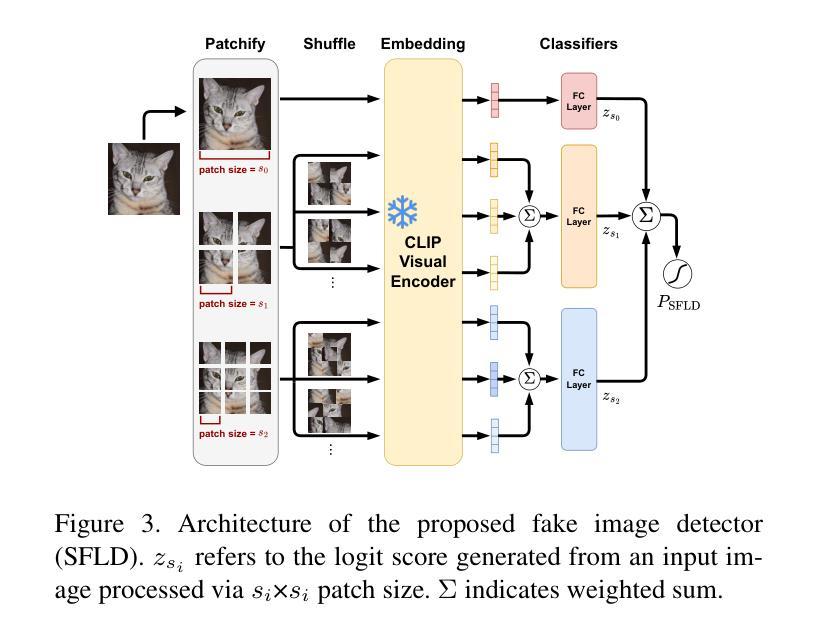
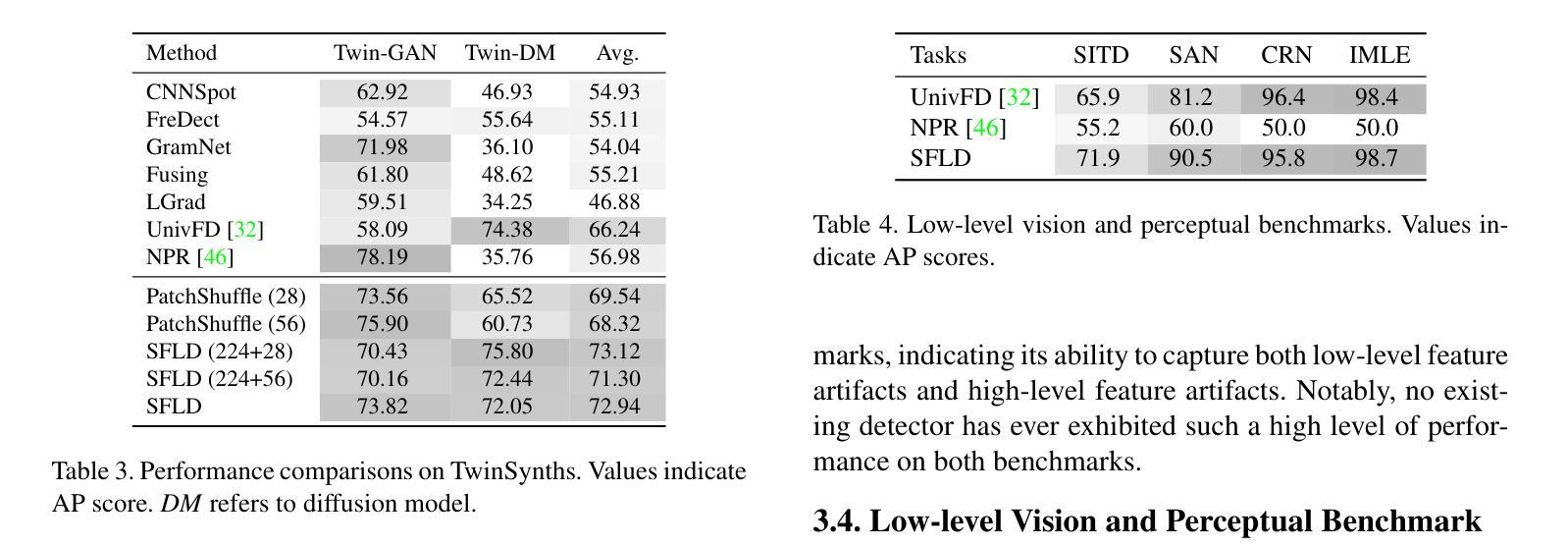
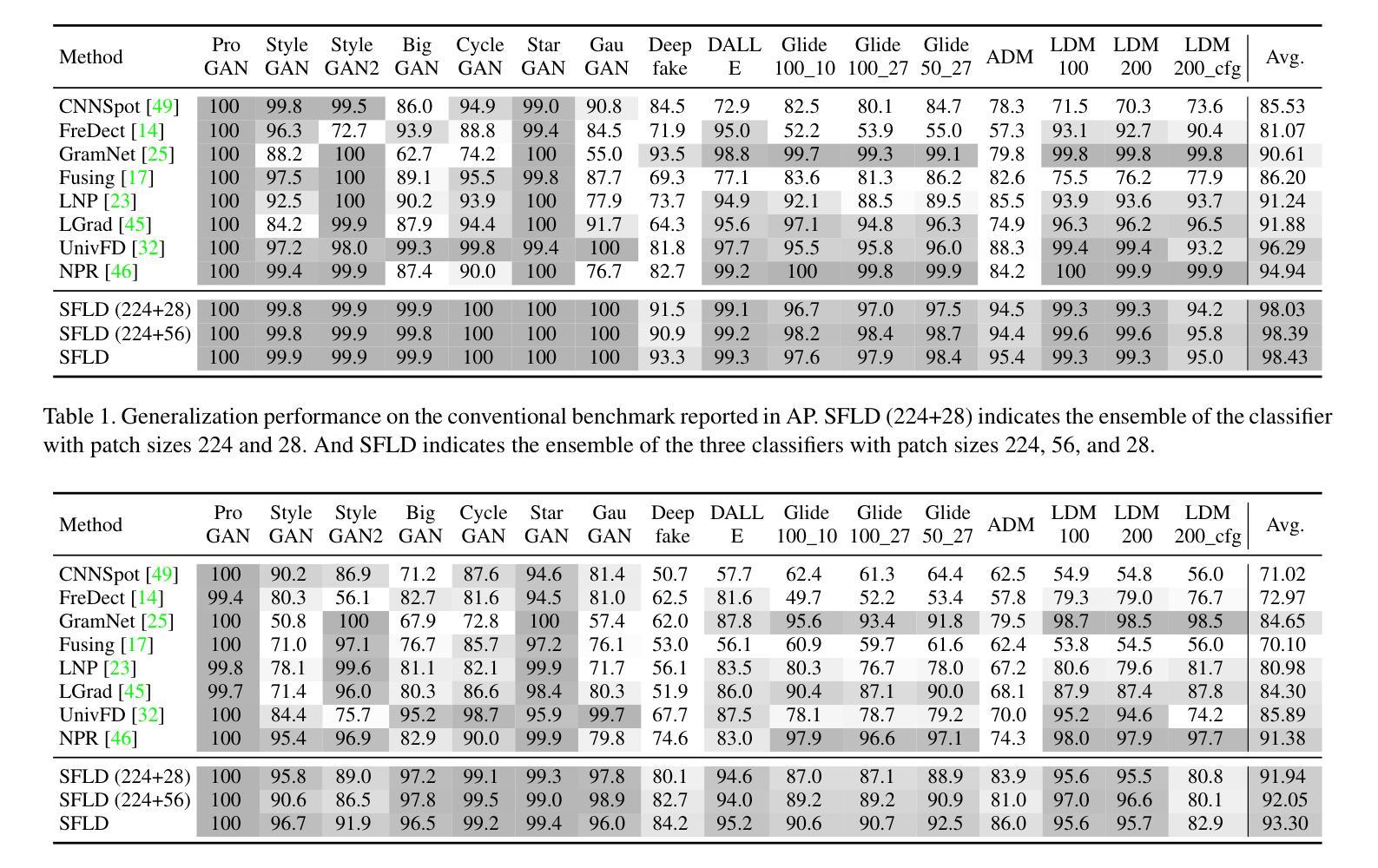
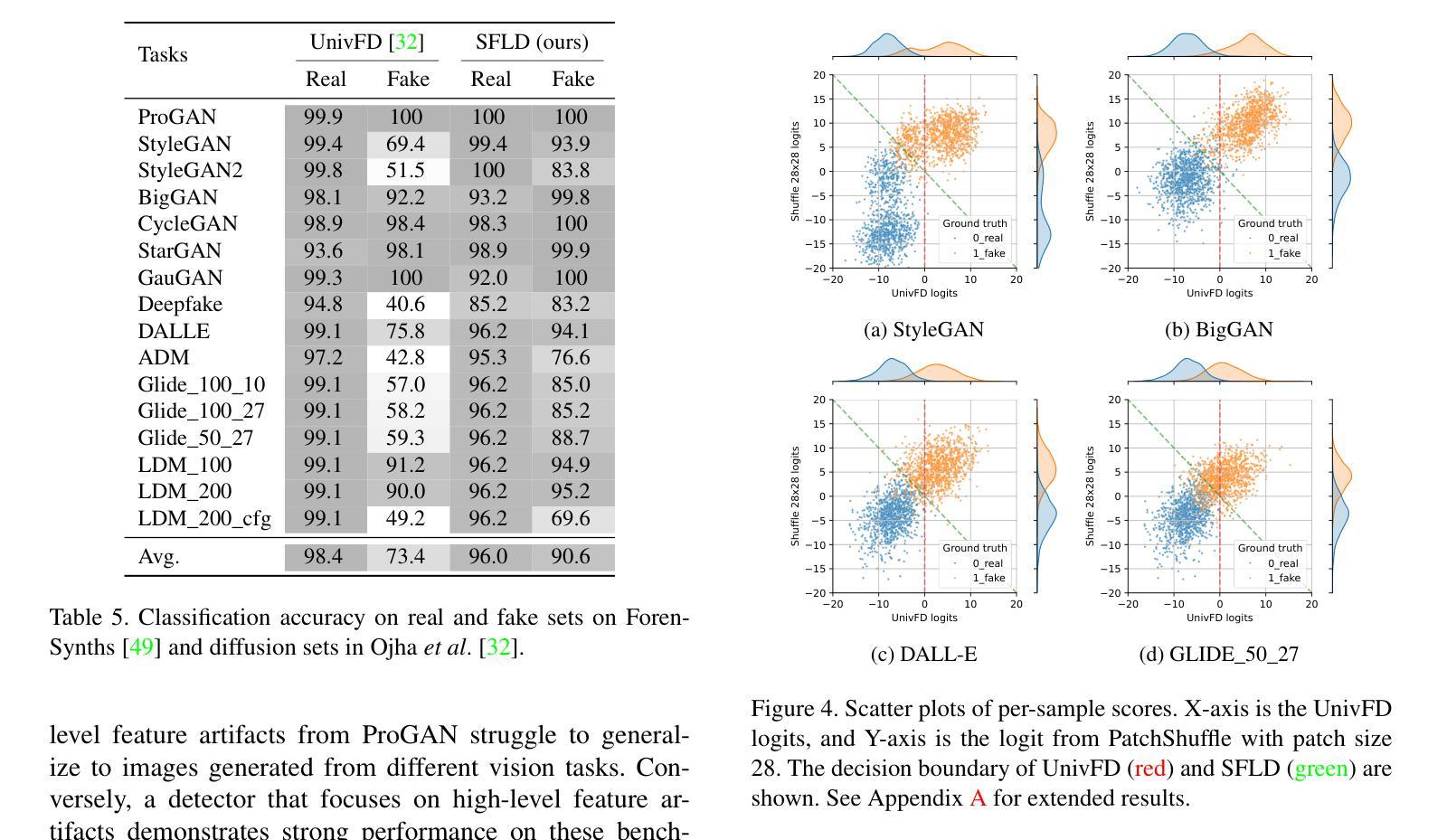
SFLD: Reducing the content bias for AI-generated Image Detection
Authors:Seoyeon Gye, Junwon Ko, Hyounguk Shon, Minchan Kwon, Junmo Kim
Identifying AI-generated content is critical for the safe and ethical use of generative AI. Recent research has focused on developing detectors that generalize to unknown generators, with popular methods relying either on high-level features or low-level fingerprints. However, these methods have clear limitations: biased towards unseen content, or vulnerable to common image degradations, such as JPEG compression. To address these issues, we propose a novel approach, SFLD, which incorporates PatchShuffle to integrate high-level semantic and low-level textural information. SFLD applies PatchShuffle at multiple levels, improving robustness and generalization across various generative models. Additionally, current benchmarks face challenges such as low image quality, insufficient content preservation, and limited class diversity. In response, we introduce TwinSynths, a new benchmark generation methodology that constructs visually near-identical pairs of real and synthetic images to ensure high quality and content preservation. Our extensive experiments and analysis show that SFLD outperforms existing methods on detecting a wide variety of fake images sourced from GANs, diffusion models, and TwinSynths, demonstrating the state-of-the-art performance and generalization capabilities to novel generative models.
识别人工智能生成的内容对于人工智能生成技术的安全和道德使用至关重要。最近的研究主要集中在开发能够推广到未知生成器的检测器上,流行的方法依赖于高级特征或低级指纹。然而,这些方法有明显的局限性:它们偏向于未见过的内容,或容易受到常见图像退化(如JPEG压缩)的影响。为了解决这些问题,我们提出了一种新的方法SFLD,它结合了PatchShuffle来整合高级语义和低级纹理信息。SFLD在多级应用PatchShuffle,提高了在各种生成模型上的鲁棒性和通用性。此外,当前的标准面临诸如图像质量低、内容保存不足和类别多样性有限等挑战。作为回应,我们引入了新的基准生成方法TwinSynths,它构建视觉上几乎相同的真实和合成图像对,以确保高质量和内容保存。我们的广泛实验和分析表明,SFLD在检测来自GAN、扩散模型和TwinSynths的各种虚假图像方面优于现有方法,证明了其在最新性能和推广到新型生成模型方面的能力。
论文及项目相关链接
PDF IEEE/CVF WACV 2025, Oral
Summary
针对人工智能生成内容的识别对于人工智能的安全和伦理使用至关重要。研究集中在开发能够推广到未知生成器的检测器上,但现有方法存在偏向未见内容或易受图像退化(如JPEG压缩)的影响等局限性。为此,我们提出了一种结合PatchShuffle的新方法SFLD,旨在融合高级语义和低级纹理信息。SFLD在多级别应用PatchShuffle,提高了对各种生成模型的稳健性和泛化能力。此外,我们还引入了新的基准测试生成方法TwinSynths,确保生成图像的高质量和内容保留。实验表明,SFLD在检测来自GANs、扩散模型和TwinSynths的虚假图像方面优于现有方法,展示了其在新型生成模型上的卓越性能和泛化能力。
Key Takeaways
- AI生成内容的识别对AI的安全和伦理使用至关重要。
- 现有检测器方法存在对未知内容的偏见和易受图像退化影响的问题。
- 提出的SFLD方法结合PatchShuffle,旨在融合高级语义和低级纹理信息。
- SFLD在多级别应用PatchShuffle,提高对各种生成模型的稳健性和泛化能力。
- 引入新的基准测试生成方法TwinSynths,确保图像的高质量和内容保留。
- 实验表明SFLD在检测各种虚假图像方面优于现有方法。
点此查看论文截图


Methods and Trends in Detecting Generated Images: A Comprehensive Review
Authors:Arpan Mahara, Naphtali Rishe
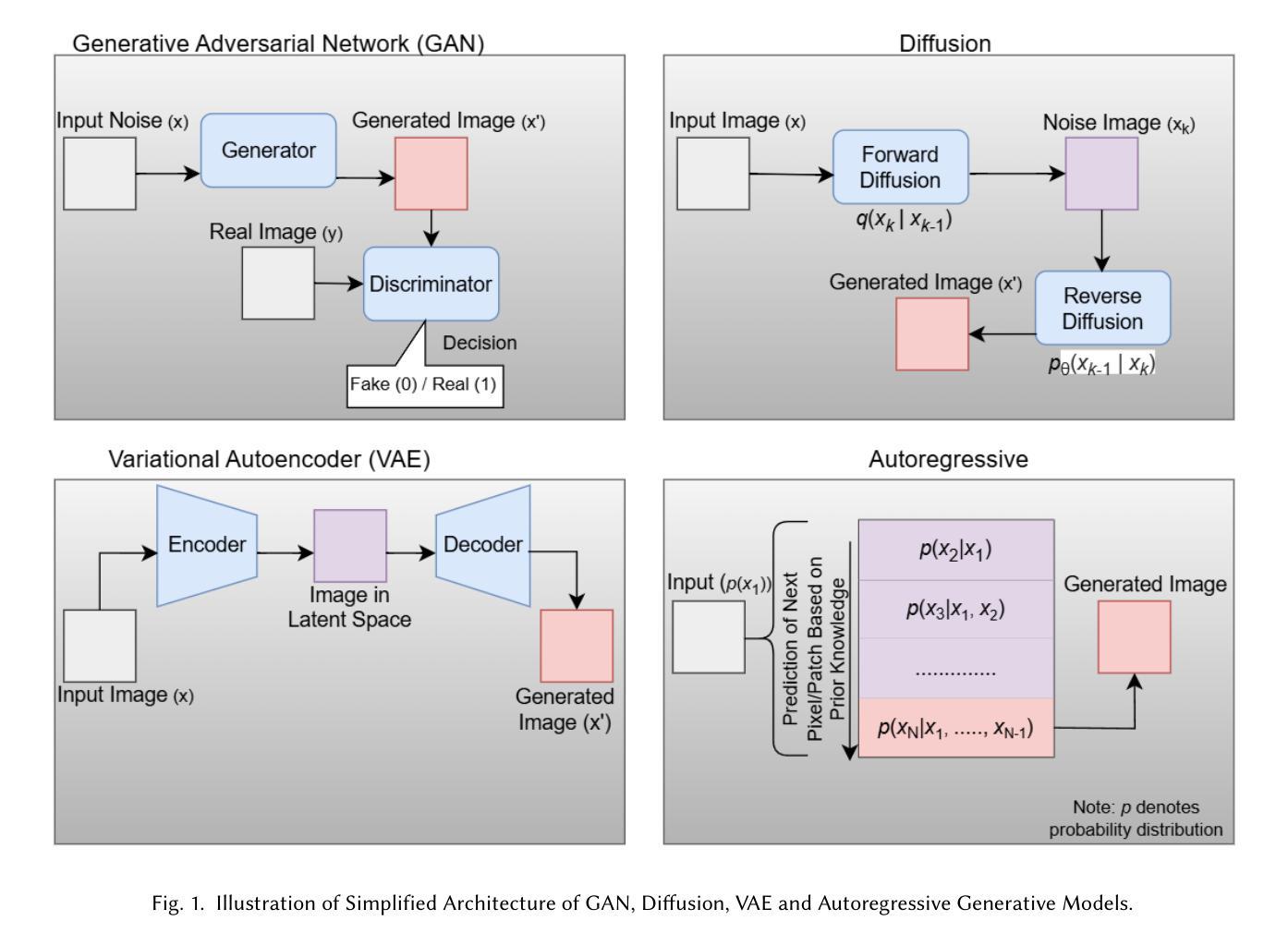
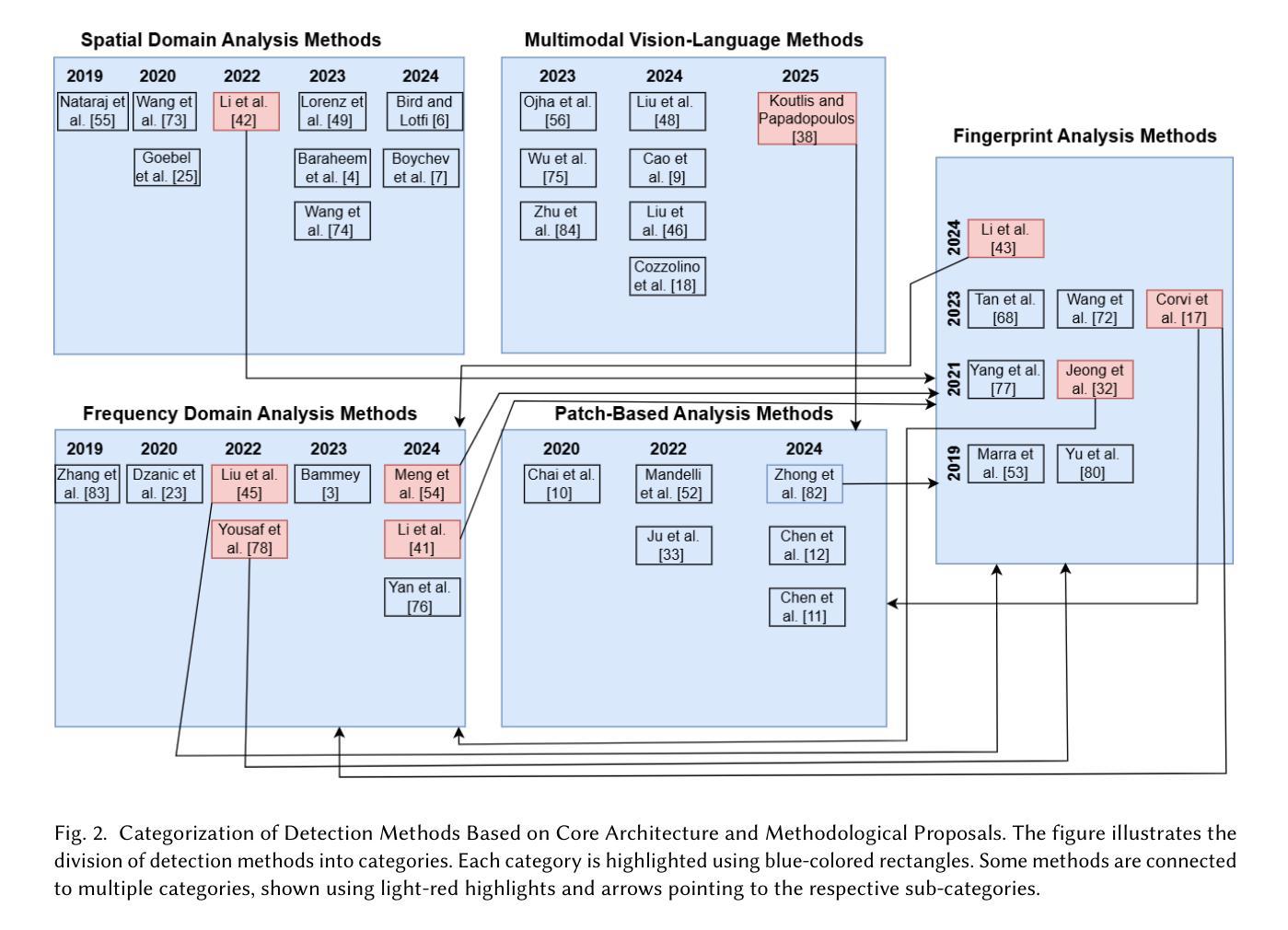
The proliferation of generative models, such as Generative Adversarial Networks (GANs), Diffusion Models, and Variational Autoencoders (VAEs), has enabled the synthesis of high-quality multimedia data. However, these advancements have also raised significant concerns regarding adversarial attacks, unethical usage, and societal harm. Recognizing these challenges, researchers have increasingly focused on developing methodologies to detect synthesized data effectively, aiming to mitigate potential risks. Prior reviews have primarily focused on deepfake detection and often lack coverage of recent advancements in synthetic image detection, particularly methods leveraging multimodal frameworks for improved forensic analysis. To address this gap, the present survey provides a comprehensive review of state-of-the-art methods for detecting and classifying synthetic images generated by advanced generative AI models. This review systematically examines core detection methodologies, identifies commonalities among approaches, and categorizes them into meaningful taxonomies. Furthermore, given the crucial role of large-scale datasets in this field, we present an overview of publicly available datasets that facilitate further research and benchmarking in synthetic data detection.
生成对抗网络(GANs)、扩散模型和变分自编码器(VAEs)等生成模型的普及,使得合成高质量多媒体数据成为可能。然而,这些进步也引发了关于对抗性攻击、不道德使用和社会危害等重大担忧。认识到这些挑战,研究人员越来越关注开发有效的方法来检测合成数据,以减轻潜在风险。之前的审查主要集中在深度伪造检测上,往往缺乏对最近合成图像检测进展的覆盖,特别是利用多模式框架改进法医分析的方法。为了解决这一空白,本综述提供了全面审查最先进的方法检测和分类由先进生成式人工智能模型生成的合成图像。本综述系统地研究了核心的检测方法,识别了各种方法之间的共性,并将其分类为有意义的分类学。此外,鉴于大规模数据集在该领域的关键作用,我们概述了公开可用的数据集,以促进合成数据检测方面的进一步研究和基准测试。
论文及项目相关链接
PDF 30 pages, 4 Figures, 10 Tables
Summary
新一代生成模型如GANs、扩散模型和变分自编码器的发展促进了高质量多媒体数据的合成,但也带来了对抗性攻击、不道德使用和社会危害的担忧。因此,研究人员致力于开发有效的检测合成数据的方法以减轻潜在风险。当前综述主要关注深度伪造检测,缺乏对先进生成AI模型生成图像检测的最新进展,尤其是利用多模态框架提高取证分析的方法。为解决这一空白,本文全面综述了检测分类由先进生成AI模型生成的合成图像的最前沿方法,系统考察核心检测方法论,识别各方法间的共性,并将其分类到有意义的分类学中。此外,鉴于大规模数据集在此领域的关键作用,我们还概述了可用的公开数据集,以促进合成数据检测的进一步研究和基准测试。
Key Takeaways
- 生成模型如GANs等促进了高质量多媒体数据的合成。
- 生成模型的进步同时引发了对抗性攻击、不道德使用和社会危害的担忧。
- 目前对于检测合成数据的检测方法研究日益增多,以减轻潜在风险。
- 现有的综述主要关注深度伪造检测,缺乏对于更先进的生成AI模型生成图像的全面检测方法的综述。
- 当前的检测方法正在越来越多地利用多模态框架以提高检测效率和准确性。
- 综述涵盖了最新的核心检测方法论,并识别了不同方法之间的共性。
点此查看论文截图

Ambient Denoising Diffusion Generative Adversarial Networks for Establishing Stochastic Object Models from Noisy Image Data
Authors:Xichen Xu, Wentao Chen, Weimin Zhou
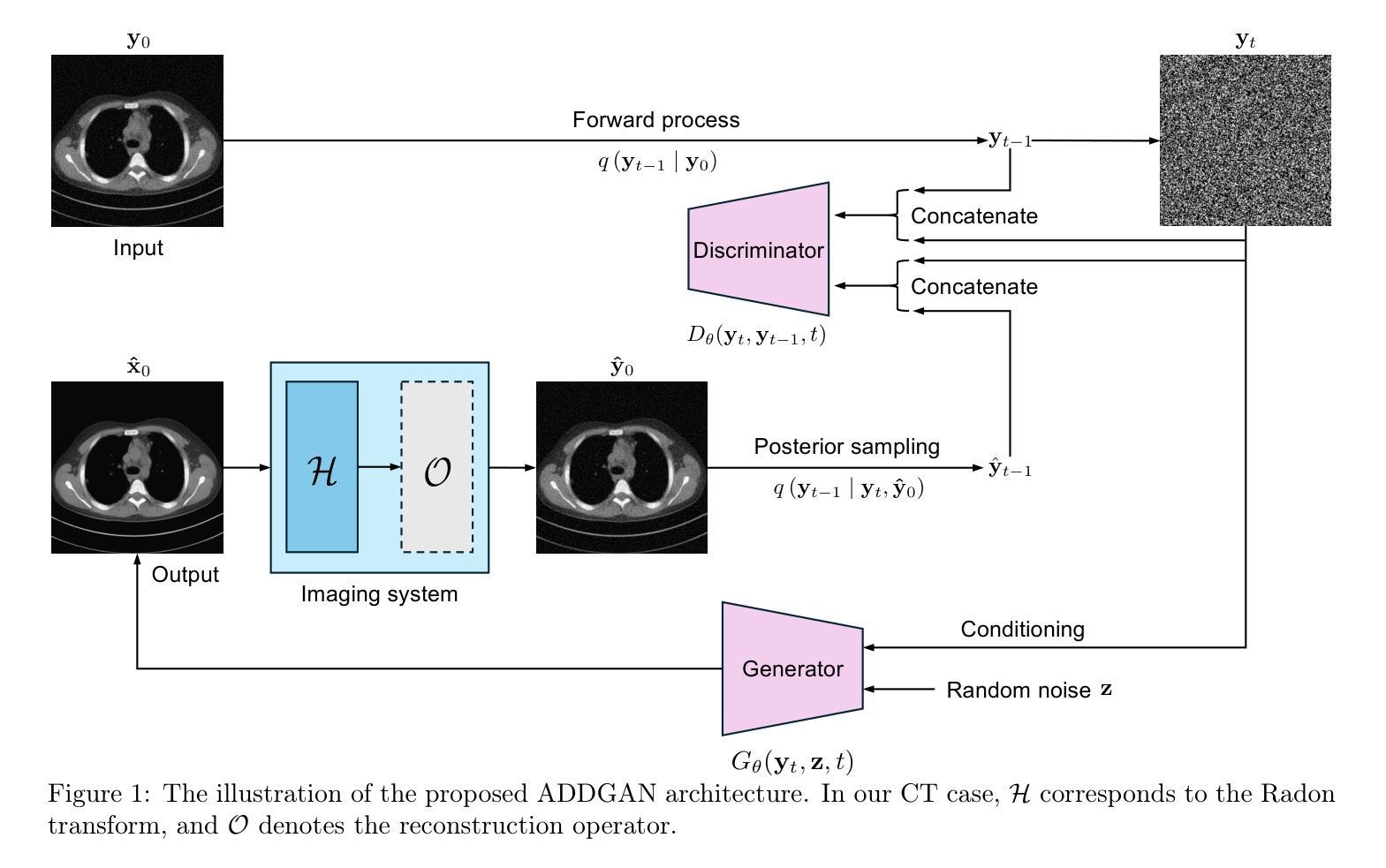
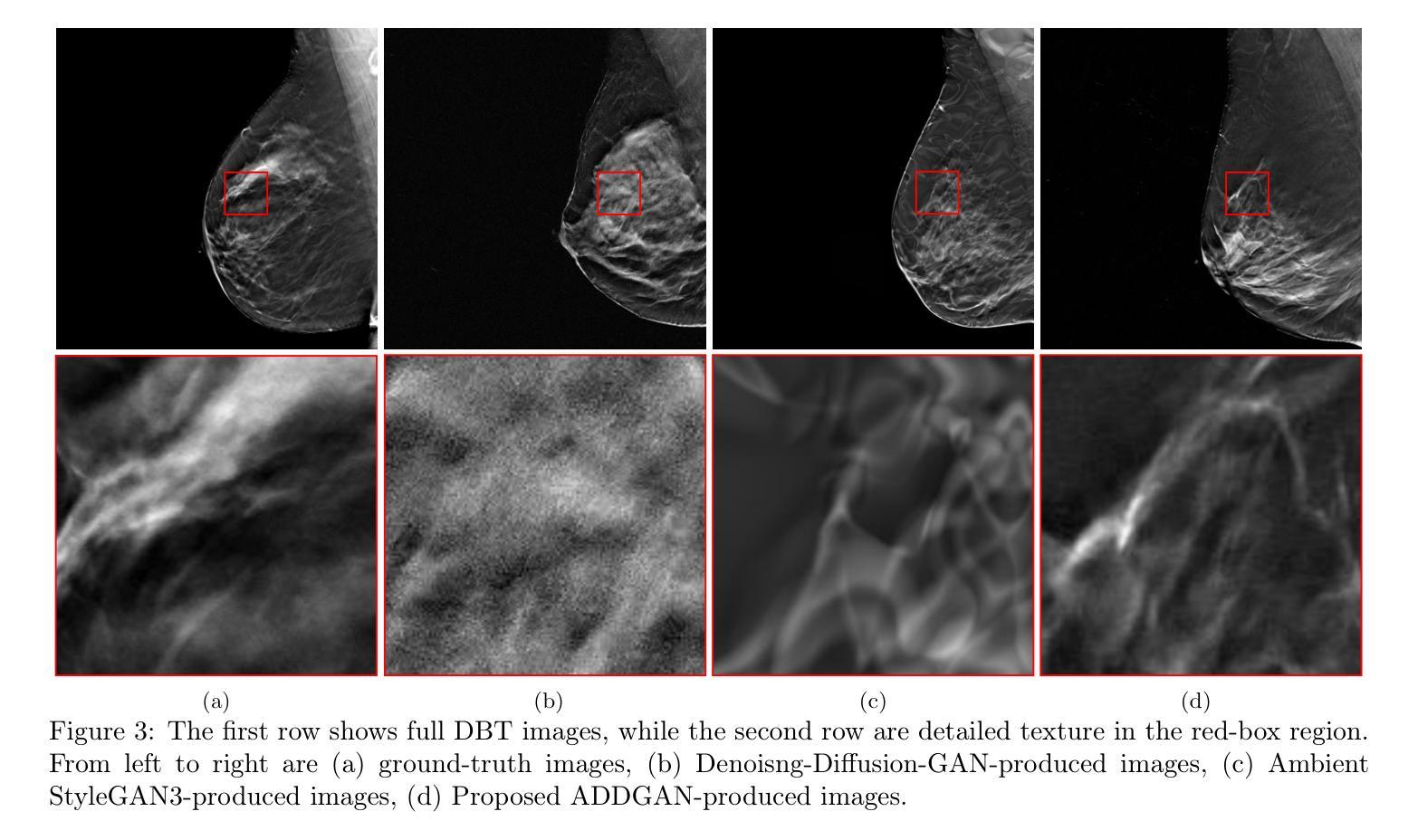
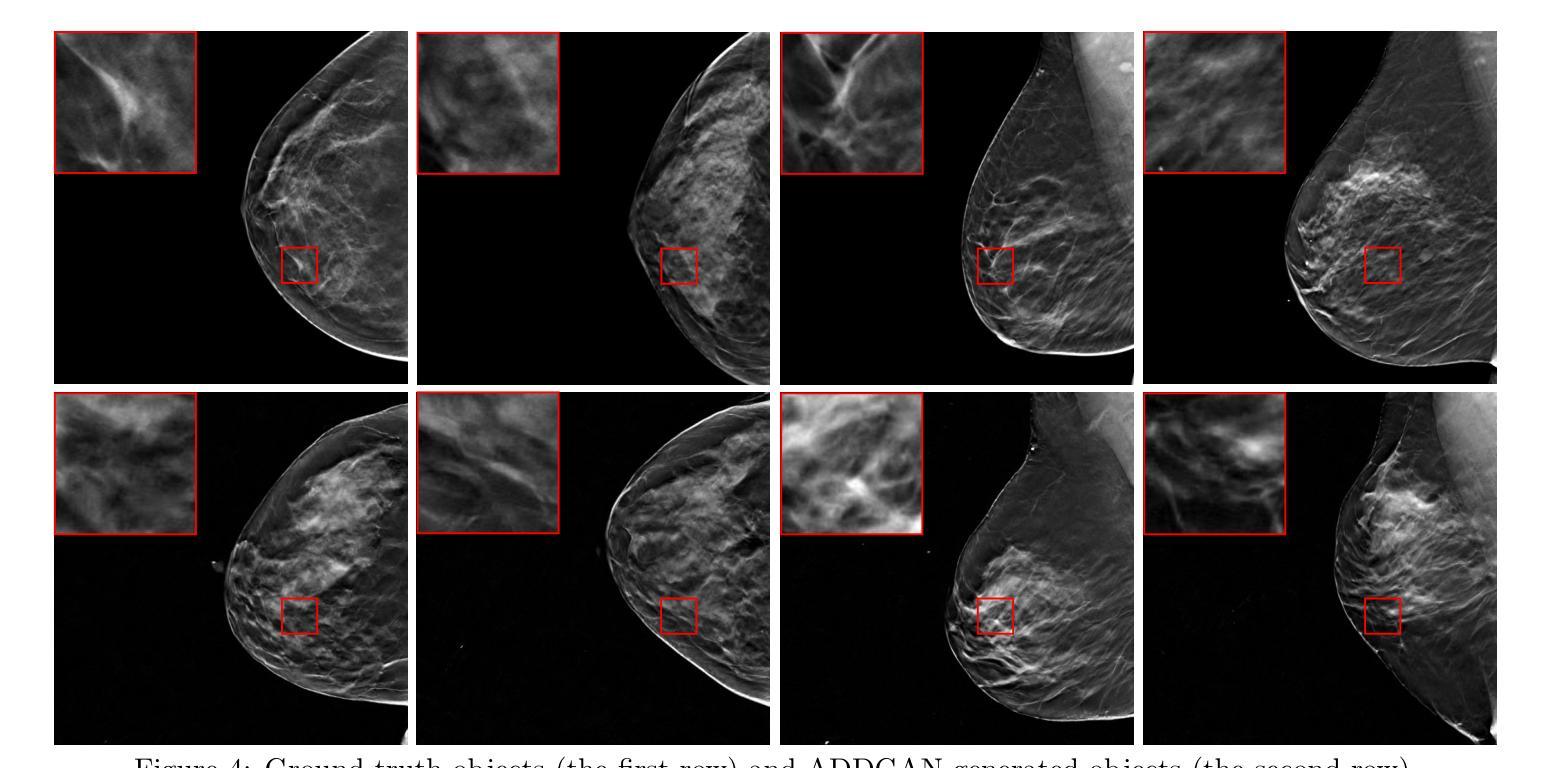
It is widely accepted that medical imaging systems should be objectively assessed via task-based image quality (IQ) measures that ideally account for all sources of randomness in the measured image data, including the variation in the ensemble of objects to be imaged. Stochastic object models (SOMs) that can randomly draw samples from the object distribution can be employed to characterize object variability. To establish realistic SOMs for task-based IQ analysis, it is desirable to employ experimental image data. However, experimental image data acquired from medical imaging systems are subject to measurement noise. Previous work investigated the ability of deep generative models (DGMs) that employ an augmented generative adversarial network (GAN), AmbientGAN, for establishing SOMs from noisy measured image data. Recently, denoising diffusion models (DDMs) have emerged as a leading DGM for image synthesis and can produce superior image quality than GANs. However, original DDMs possess a slow image-generation process because of the Gaussian assumption in the denoising steps. More recently, denoising diffusion GAN (DDGAN) was proposed to permit fast image generation while maintain high generated image quality that is comparable to the original DDMs. In this work, we propose an augmented DDGAN architecture, Ambient DDGAN (ADDGAN), for learning SOMs from noisy image data. Numerical studies that consider clinical computed tomography (CT) images and digital breast tomosynthesis (DBT) images are conducted. The ability of the proposed ADDGAN to learn realistic SOMs from noisy image data is demonstrated. It has been shown that the ADDGAN significantly outperforms the advanced AmbientGAN models for synthesizing high resolution medical images with complex textures.
普遍认为,医学成像系统应通过基于任务的图像质量(IQ)措施进行客观评估,这些措施理想情况下应考虑到测量图像数据中所有随机性的来源,包括要成像的物体集合的变异。可以随机从物体分布中抽取样本的随机物体模型(SOMs)可用于表征物体变异性。为了为基于任务的IQ分析建立现实的SOMs,采用实验图像数据是理想的。然而,从医学成像系统获得的实验图像数据会受到测量噪声的影响。先前的研究调查了使用增强生成对抗网络(GAN)的深层生成模型(DGM)在建立来自噪声测量图像数据的SOMs方面的能力。最近,去噪扩散模型(DDM)作为图像合成的领先DGM出现,并能够产生比GAN更高的图像质量。然而,原始DDMs由于去噪步骤中的高斯假设而具有较慢的图像生成过程。最近,提出了去噪扩散GAN(DDGAN),它能够实现快速图像生成并保持与原始DDMs相当的高质量图像。在这项工作中,我们提出了一种增强的DDGAN架构,即环境DDGAN(ADDGAN),用于从噪声图像数据中学习SOMs。我们对临床计算机断层扫描(CT)图像和数字乳腺断层合成(DBT)图像进行了数值研究。所提出ADDGAN从噪声图像数据中学习现实SOMs的能力得到了证明。结果表明,在合成具有复杂纹理的高分辨率医学图像方面,ADDGAN显著优于先进的AmbientGAN模型。
论文及项目相关链接
PDF SPIE Medical Imaging 2025
摘要
本文探讨了使用增强的去噪扩散生成对抗网络(DDGAN)从带有噪声的图像数据中学习随机对象模型(SOM)的方法。作者提出了一个增强的DDGAN架构——Ambient DDGAN(ADDGAN),并通过对临床计算机断层扫描(CT)图像和数字乳腺断层合成(DBT)图像进行数值研究,展示了其从带噪声的图像数据中学习现实SOM的能力。结果显示,ADDGAN在合成具有复杂纹理的高分辨率医学图像方面显著优于先进的AmbientGAN模型。
关键见解
- 医学成像系统的客观评估需要通过基于任务的图像质量(IQ)度量来进行,这应考虑测量图像数据中的所有随机性的来源,包括要成像的物体集合的变异。
- 随机对象模型(SOMs)可以从物体分布中随机抽取样本,用于表征物体变异性。
- 使用实验图像数据建立现实SOM对于基于任务的IQ分析是理想的,但这些数据会受到来自医学成像系统的测量噪声的影响。
- 增强的生成对抗网络(GAN)被称为环境GAN(AmbientGAN)的深度生成模型(DGM)已被用于从带有噪声的测量图像数据中建立SOMs。
- 去噪扩散模型(DDM)是一种领先的图像合成DGM,能够产生比GAN更高的图像质量。
- 最近提出的去噪扩散GAN(DDGAN)允许快速图像生成,同时保持与原始DDM相当的高质量图像生成。
点此查看论文截图