⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-26 更新
Mutual Reinforcement of LLM Dialogue Synthesis and Summarization Capabilities for Few-Shot Dialogue Summarization
Authors:Yen-Ju Lu, Ting-Yao Hu, Hema Swetha Koppula, Hadi Pouransari, Jen-Hao Rick Chang, Yin Xia, Xiang Kong, Qi Zhu, Simon Wang, Oncel Tuzel, Raviteja Vemulapalli
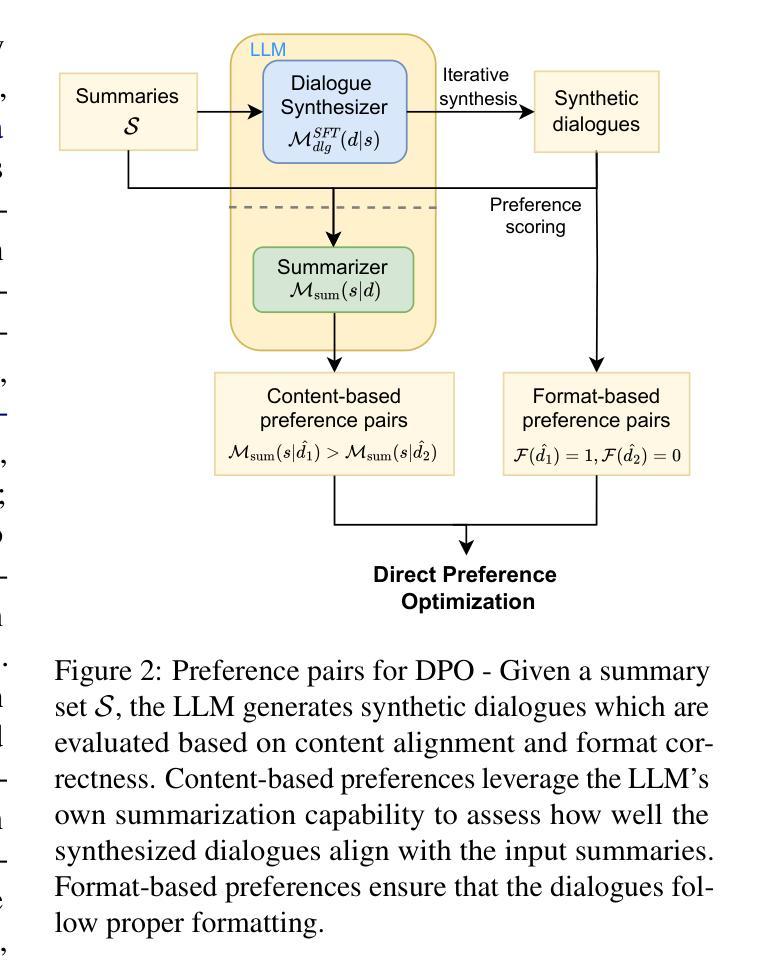
In this work, we propose Mutual Reinforcing Data Synthesis (MRDS) within LLMs to improve few-shot dialogue summarization task. Unlike prior methods that require external knowledge, we mutually reinforce the LLM's dialogue synthesis and summarization capabilities, allowing them to complement each other during training and enhance overall performances. The dialogue synthesis capability is enhanced by directed preference optimization with preference scoring from summarization capability. The summarization capability is enhanced by the additional high quality dialogue-summary paired data produced by the dialogue synthesis capability. By leveraging the proposed MRDS mechanism, we elicit the internal knowledge of LLM in the format of synthetic data, and use it to augment the few-shot real training dataset. Empirical results demonstrate that our method improves dialogue summarization, achieving a 1.5% increase in ROUGE scores and a 0.3% improvement in BERT scores in few-shot settings. Furthermore, our method attains the highest average scores in human evaluations, surpassing both the pre-trained models and the baselines fine-tuned solely for summarization tasks.
在这项工作中,我们提出了大型语言模型(LLM)中的相互增强数据合成(MRDS)方法,以提高小样对话摘要任务的效果。不同于需要外部知识的先前方法,我们通过相互增强LLM的对话合成和摘要能力,使它们在训练过程中能够相互补充,从而提高整体性能。对话合成能力通过来自摘要能力的偏好评分进行定向偏好优化。摘要能力则通过对话合成能力产生的额外高质量对话摘要配对数据进行增强。通过利用提出的MRDS机制,我们以合成数据的形式激发LLM的内部知识,并将其用于扩充小样真实训练数据集。经验结果表明,我们的方法提高了对话摘要的效果,在小样设置下ROUGE得分提高了1.5%,BERT得分提高了0.3%。此外,我们的方法在人工评估中获得了最高平均分,超过了预训练模型和仅针对摘要任务进行微调的基础模型。
论文及项目相关链接
PDF NAACL 2025 Findings
Summary
该工作提出了在大语言模型内部使用相互强化数据合成(MRDS)方法,以提高少样本对话摘要任务的效果。通过相互强化对话合成和摘要能力,无需外部知识,就能在训练过程中相互补充,提高整体性能。对话合成能力通过基于摘要能力的偏好评分进行定向偏好优化增强;摘要能力则通过对话合成产生的额外高质量对话摘要配对数据进行增强。利用MRDS机制激发大语言模型的内部知识,以合成数据的形式加以利用,扩充少样本真实训练数据集。实证结果表明,该方法提高了对话摘要的效果,在ROUGE和BERT得分上分别提高了1.5%和0.3%,并在人类评估中获得了最高平均分,超越了预训练模型和仅针对摘要任务进行微调的基础模型。
Key Takeaways
- 提出了一种新的方法——相互强化数据合成(MRDS),用于提高大语言模型在少样本对话摘要任务的效果。
- MRDS方法通过相互强化对话合成和摘要能力,使两者在训练过程中相互补充。
- 对话合成能力通过基于摘要能力的偏好评分进行定向优化。
- 摘要能力通过对话合成产生的高质量对话摘要配对数据得到增强。
- 利用MRDS机制激发大语言模型的内部知识,以合成数据的形式利用,扩充训练数据集。
- 实证结果表明,该方法在ROUGE和BERT得分上有所提升,并超越了预训练模型和针对摘要任务的基线模型。
点此查看论文截图

MonoTODia: Translating Monologue Requests to Task-Oriented Dialogues
Authors:Sebastian Steindl, Ulrich Schäfer, Bernd Ludwig
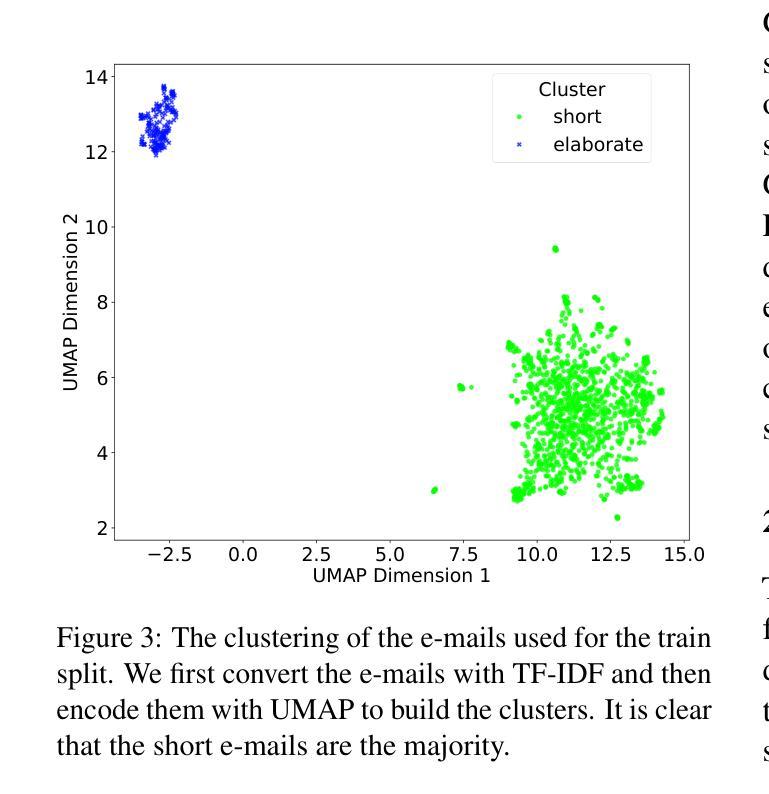
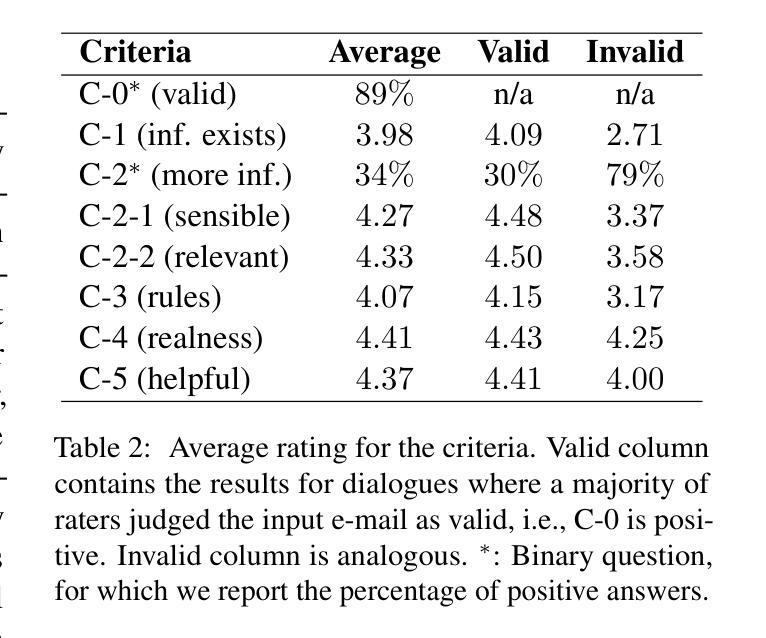
Data scarcity is one of the main problems when it comes to real-world applications of transformer-based models. This is especially evident for task-oriented dialogue (TOD) systems, which require specialized datasets, that are usually not readily available. This can hinder companies from adding TOD systems to their services. This study therefore investigates a novel approach to sourcing annotated dialogues from existing German monologue material. Focusing on a real-world example, we investigate whether these monologues can be transformed into dialogue formats suitable for training TOD systems. We show the approach with the concrete example of a company specializing in travel bookings via e-mail. We fine-tune state-of-the-art Large Language Models for the task of rewriting e-mails as dialogues and annotating them. To ensure the quality and validity of the generated data, we employ crowd workers to evaluate the dialogues across multiple criteria and to provide gold-standard annotations for the test dataset. We further evaluate the usefulness of the dialogues for training TOD systems. Our evaluation shows that the dialogues and annotations are of high quality and can serve as a valuable starting point for training TOD systems. Finally, we make the annotated dataset publicly available to foster future research.
数据稀缺性是变压器模型在现实世界应用中遇到的主要问题之一。这在面向任务的对话(TOD)系统中尤其明显,这些系统需要专门的数据集,而这些数据集通常无法轻易获得。这可能会阻碍公司将TOD系统添加到其服务中。因此,本研究调查了一种从现有的德语独白材料中获取注释对话的新方法。以一个实际例子为重点,我们调查了这些独白是否可以转化为适合训练TOD系统的对话格式。我们以一家专门从事旅行预订的电子邮件公司为例来展示这种方法。我们针对重写电子邮件并将其注释为对话的任务,对最先进的大型语言模型进行了微调。为了确保生成数据的质量和有效性,我们雇佣了众包工作者来根据多个标准对对话进行评估,并为测试数据集提供黄金标准注释。我们进一步评估了对话在训练TOD系统方面的实用性。我们的评估表明,对话和注释质量很高,可以作为训练TOD系统的宝贵起点。最后,我们将注释过的数据集公开提供,以促进未来的研究。
论文及项目相关链接
PDF Accepted at NAACL 2025 (Industry Track)
Summary
本文探讨了在缺乏特定任务导向对话(TOD)系统数据集的情况下,如何从现有的德语独白材料中获取标注对话的新方法。通过实例研究,将独白转化为适合训练TOD系统的对话格式。该研究以一家专注于电子邮件旅行预订的公司为例,对最先进的大型语言模型进行微调,用于重写电子邮件并以对话形式进行标注。为确保生成数据的质量和有效性,该研究雇佣了众包工作者对对话进行多标准评估,并为测试数据集提供黄金标准注释。研究评估表明,这些对话和注释质量高,可作为训练TOD系统的宝贵起点。最后,研究公开了标注数据集以促进未来研究。
Key Takeaways
- 数据稀缺是实际应用中基于转换器模型的主要问题,特别是对于需要专门数据集的任务导向对话(TOD)系统。
- 本研究调查了一种从现有德语独白材料中获取标注对话的新方法。
- 以电子邮件旅行预订公司为例,展示了如何将独白转化为适合训练TOD系统的对话格式。
- 研究微调了先进的大型语言模型,用于重写电子邮件并以对话形式进行标注。
- 采用众包工作者对生成的对话进行多标准评估和黄金标准注释,以确保数据的质量和有效性。
- 研究评估表明,这些对话和注释可作为训练TOD系统的有价值的起点。
点此查看论文截图



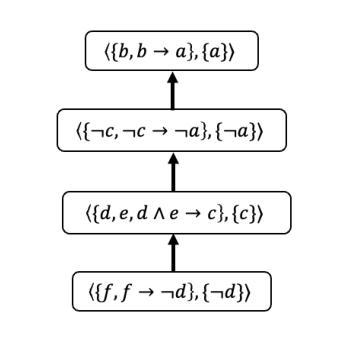
Does Your AI Agent Get You? A Personalizable Framework for Approximating Human Models from Argumentation-based Dialogue Traces
Authors:Yinxu Tang, Stylianos Loukas Vasileiou, William Yeoh
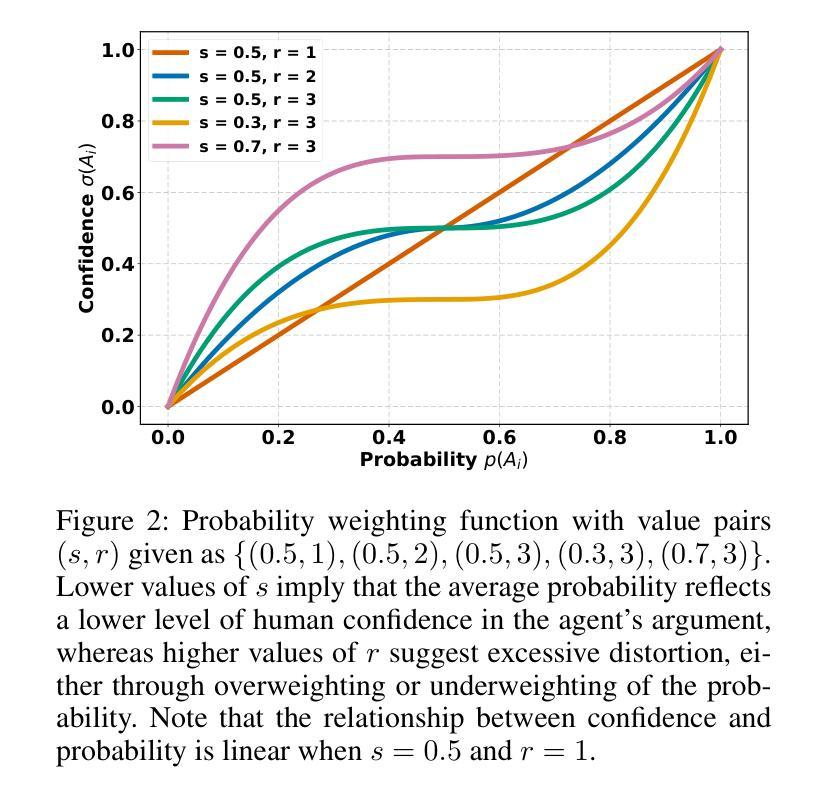
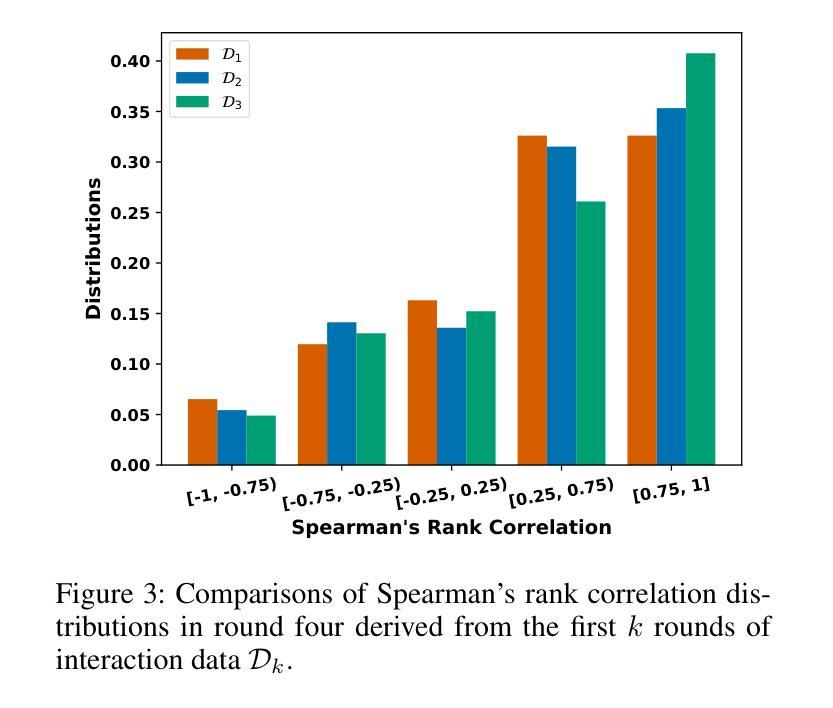
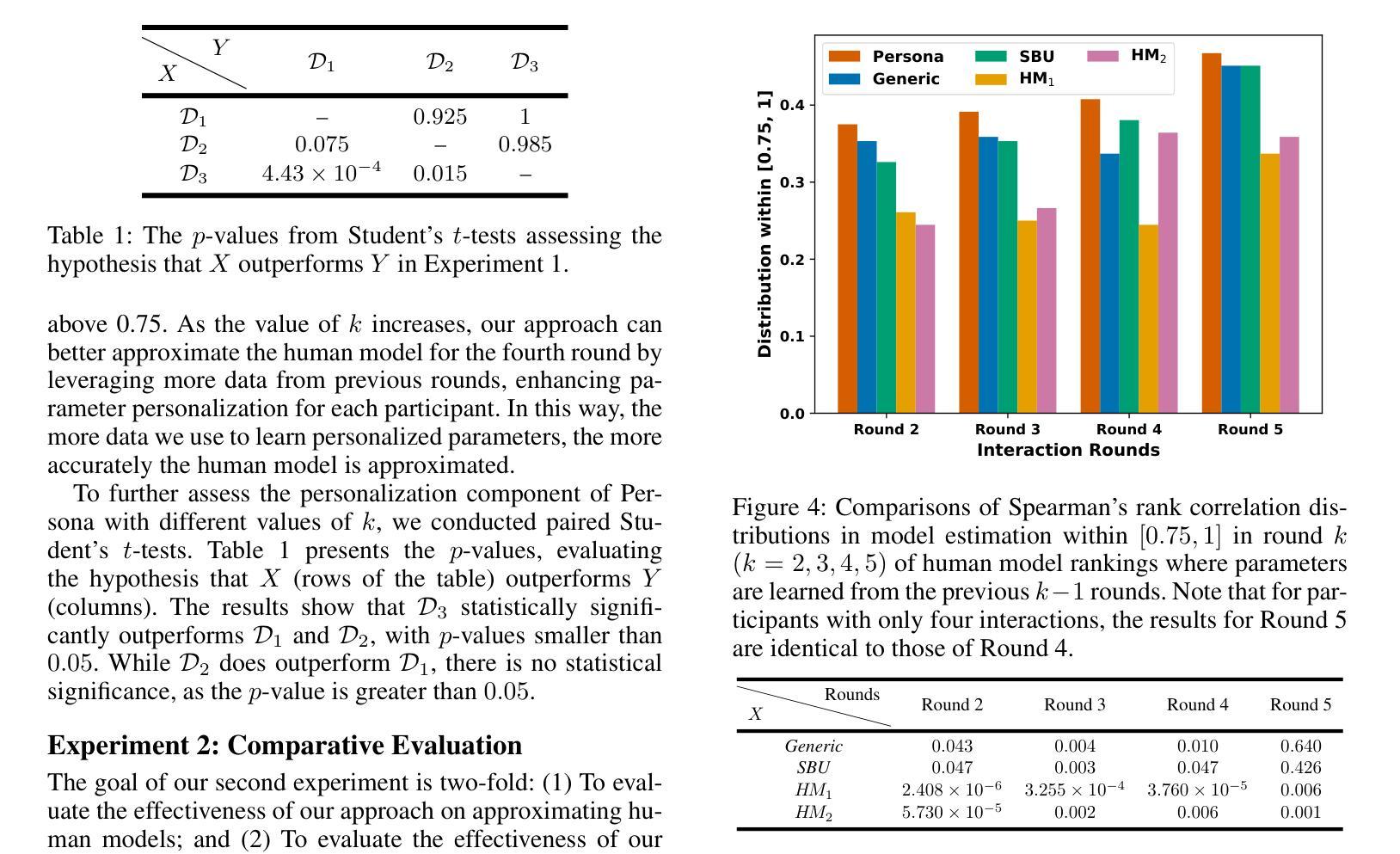
Explainable AI is increasingly employing argumentation methods to facilitate interactive explanations between AI agents and human users. While existing approaches typically rely on predetermined human user models, there remains a critical gap in dynamically learning and updating these models during interactions. In this paper, we present a framework that enables AI agents to adapt their understanding of human users through argumentation-based dialogues. Our approach, called Persona, draws on prospect theory and integrates a probability weighting function with a Bayesian belief update mechanism that refines a probability distribution over possible human models based on exchanged arguments. Through empirical evaluations with human users in an applied argumentation setting, we demonstrate that Persona effectively captures evolving human beliefs, facilitates personalized interactions, and outperforms state-of-the-art methods.
可解释人工智能正在越来越多地采用论证方法,以促进人工智能代理和人类用户之间的交互解释。尽管现有方法通常依赖于预设定的人类用户模型,但在交互过程中动态学习和更新这些模型仍存在关键差距。在本文中,我们提出了一种框架,使人工智能代理能够通过基于论证的对话来了解人类用户。我们的方法称为Persona,它基于前景理论,将概率加权功能与贝叶斯信念更新机制相结合,根据交换的论据对可能的人类模型进行概率分布优化。通过与应用论证环境中的人类用户进行的实证评估表明,Persona有效地捕捉了人类信念的演变,促进了个性化交互,并优于最新方法。
论文及项目相关链接
Summary
本摘要采用论证方法,促进人工智能代理与人类用户之间的交互解释。现有的方法主要依赖于预设的人类用户模型,但缺乏在交互过程中动态学习和更新这些模型的能力。本文提出了一种框架,使人工智能代理能够通过基于论证的对话适应对人类用户的理解。我们的方法称为Persona,它借鉴了前景理论,并整合了一个概率加权函数和贝叶斯信念更新机制,根据交换的论证对可能的人类模型的概率分布进行精炼。通过与人类用户在应用论证环境中的实证评估,我们证明了Persona能够有效地捕捉不断演变的人类信念,促进个性化交互,并优于现有方法。
Key Takeaways
- 该论文利用论证方法来促进人工智能代理和人类用户之间的交互解释。
- 现有方法主要依赖预设的人类用户模型,但缺乏动态学习和更新模型的能力。
- Persona框架通过基于论证的对话使AI代理能够适应对人类用户的理解。
- Persona借鉴了前景理论,并整合了概率加权函数和贝叶斯信念更新机制。
- Persona能够捕捉不断演变的人类信念,促进个性化交互。
- 通过实证评估,Persona在捕捉人类用户信念方面表现出有效性。
点此查看论文截图

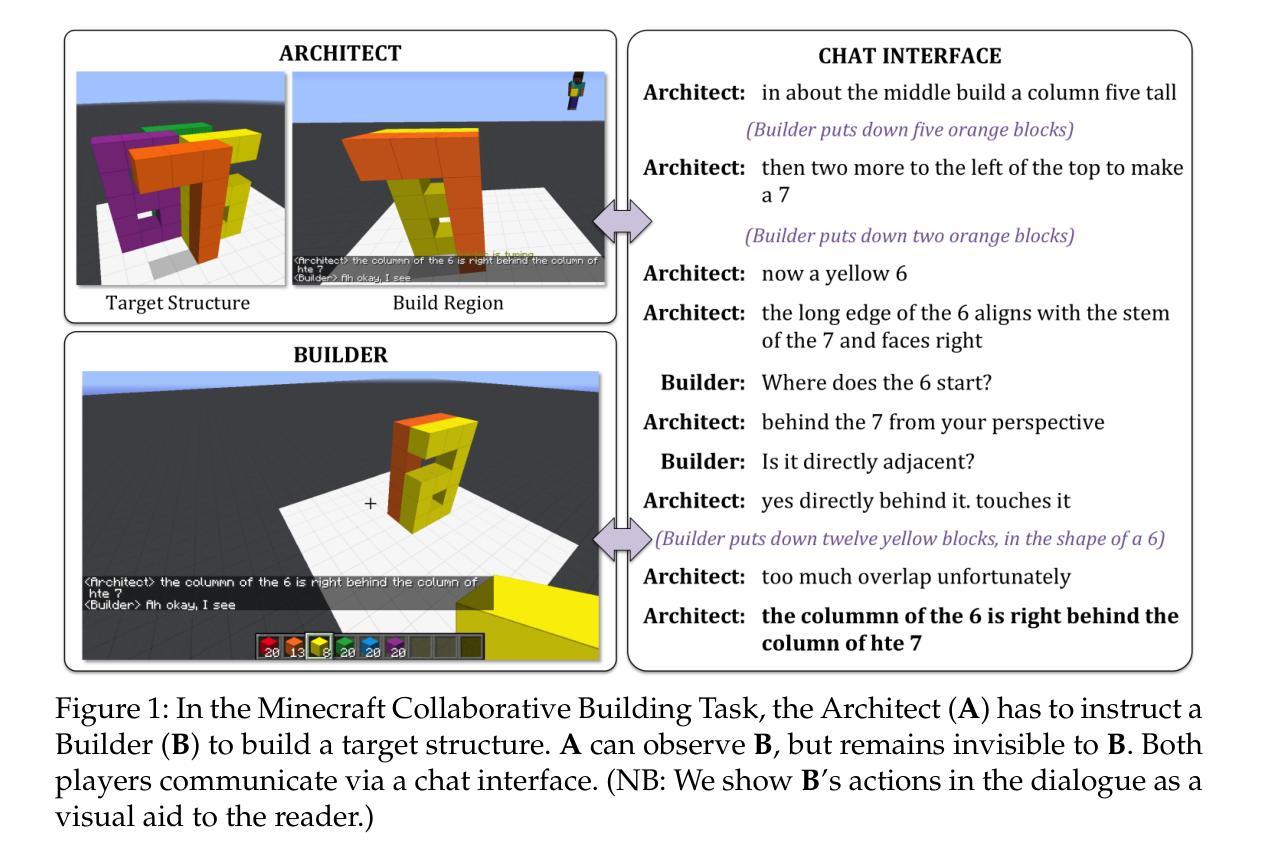
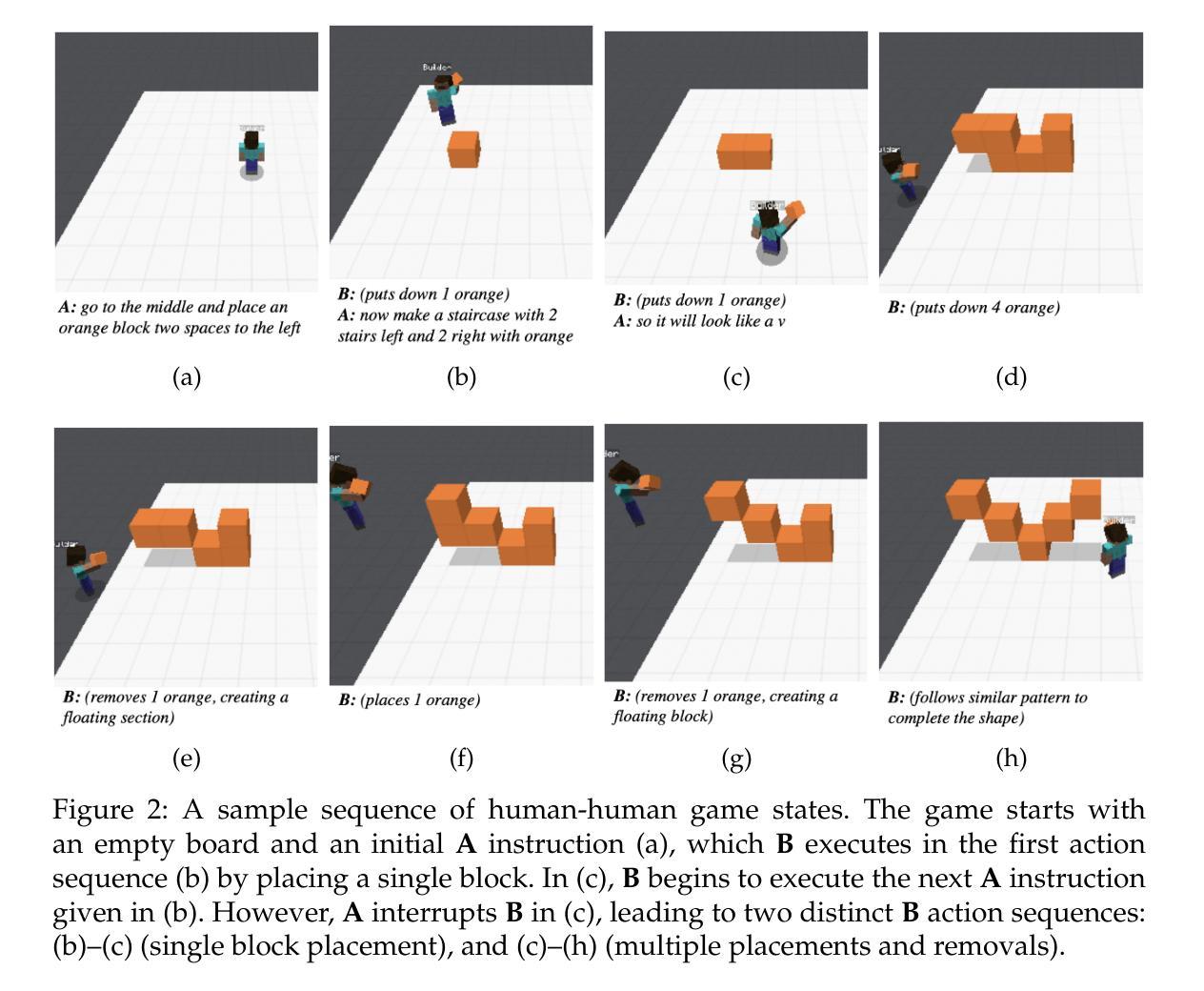
BAP v2: An Enhanced Task Framework for Instruction Following in Minecraft Dialogues
Authors:Prashant Jayannavar, Liliang Ren, Marisa Hudspeth, Charlotte Lambert, Ariel Cordes, Elizabeth Kaplan, Anjali Narayan-Chen, Julia Hockenmaier
Interactive agents capable of understanding and executing instructions in the physical world have long been a central goal in AI research. The Minecraft Collaborative Building Task (MCBT) provides one such setting to work towards this goal (Narayan-Chen, Jayannavar, and Hockenmaier 2019). It is a two-player game in which an Architect (A) instructs a Builder (B) to construct a target structure in a simulated Blocks World Environment. We focus on the challenging Builder Action Prediction (BAP) subtask of predicting correct action sequences in a given multimodal game context with limited training data (Jayannavar, Narayan-Chen, and Hockenmaier 2020). We take a closer look at evaluation and data for the BAP task, discovering key challenges and making significant improvements on both fronts to propose BAP v2, an upgraded version of the task. This will allow future work to make more efficient and meaningful progress on it. It comprises of: (1) an enhanced evaluation benchmark that includes a cleaner test set and fairer, more insightful metrics, and (2) additional synthetic training data generated from novel Minecraft dialogue and target structure simulators emulating the MCBT. We show that the synthetic data can be used to train more performant and robust neural models even with relatively simple training methods. Looking ahead, such data could also be crucial for training more sophisticated, data-hungry deep transformer models and training/fine-tuning increasingly large LLMs. Although modeling is not the primary focus of this work, we also illustrate the impact of our data and training methodologies on a simple LLM- and transformer-based model, thus validating the robustness of our approach, and setting the stage for more advanced architectures and LLMs going forward.
在人工智能研究领域,能够理解和执行物理世界指令的交互代理长期以来都是核心目标之一。Minecraft协作构建任务(MCBT)为实现这一目标提供了一个平台(Narayan-Chen、Jayannavar和Hockenmaier,2019年)。这是一款建筑师(A)向建造者(B)下达指令以在模拟的方块世界环境中构建目标结构的两人游戏。我们重点关注在给定多模式游戏上下文中预测正确动作序列这一极具挑战性的建造者动作预测(BAP)子任务,在有限训练数据的情况下(Jayannavar、Narayan-Chen和Hockenmaier,2020年)。我们对BAP任务的评估和数据进行深入研究,发现了关键挑战,并在两个方面进行了重大改进,提出了BAPv2,即该任务的升级版。这将使未来的工作能够更加高效和有意义地推进。它主要包括:(1)一个增强的评估基准,包括更干净的测试集和更公平、更有洞察力的指标;(2)通过模拟MCBT的Minecraft对话和目标结构而生成额外的合成训练数据。我们表明,即使使用相对简单的训练方法,合成数据也可用于训练性能更高、更稳健的神经网络模型。展望未来,这些数据对于训练更精细、需要大量数据的深度transformer模型以及训练和微调越来越大的大型语言模型也至关重要。虽然建模不是这项工作的重点,但我们也在一个简单的基于大型语言模型和transformer的模型上展示了我们的数据和训练方法的影响,从而验证了我们的方法的稳健性,并为更先进的架构和大型语言模型的发展奠定了基础。
论文及项目相关链接
Summary
人工智能(AI)领域中一个重要的研究目标是构建能够在真实世界中理解和执行指令的互动智能体。《Minecraft合作建筑任务》(MCBT)为此提供了一个重要平台。重点任务之一是预测建筑者在给定多模态游戏环境下的正确动作序列,即建筑行动预测(BAP)。本文对BAP任务的评价和数据进行了深入研究,解决了关键挑战,并推出了BAP v2版本,包含更清洁的测试集和更公正、有洞察力的评价指标,还利用新的Minecraft对话和目标结构模拟器生成了额外的合成训练数据。合成数据证明即使使用简单的训练方法也能训练出性能更高、更稳健的神经网络模型。未来,这些数据可能对训练更复杂、数据需求大的深度转换模型和大型语言模型(LLMs)至关重要。
Key Takeaways
- MCBT为AI领域提供了一个重要的平台,旨在实现互动智能体在真实世界中的理解和执行指令的能力。
- BAP任务是MCBT中的一个重要子任务,旨在预测建筑者在特定游戏环境下的正确动作序列。
- 本文解决了BAP任务的关键挑战,推出了BAP v2版本,包括更清洁的测试集和更公正、有洞察力的评价指标。
- 利用新的Minecraft对话和目标结构模拟器生成了额外的合成训练数据。
- 合成数据证明可以训练出性能更高、更稳健的神经网络模型,即使使用简单的训练方法也是如此。
- 这些合成数据对于训练更复杂、数据需求大的深度转换模型和大型语言模型(LLMs)具有潜在的重要性。
点此查看论文截图

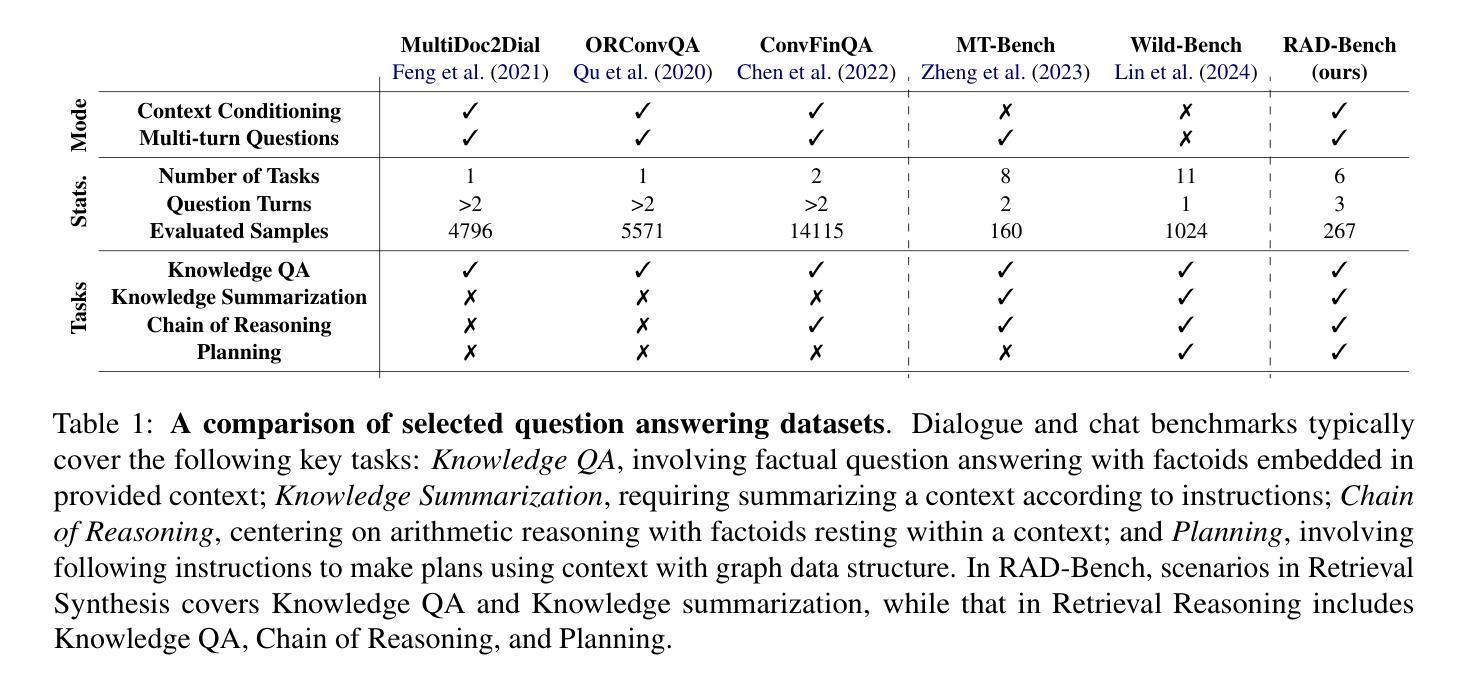
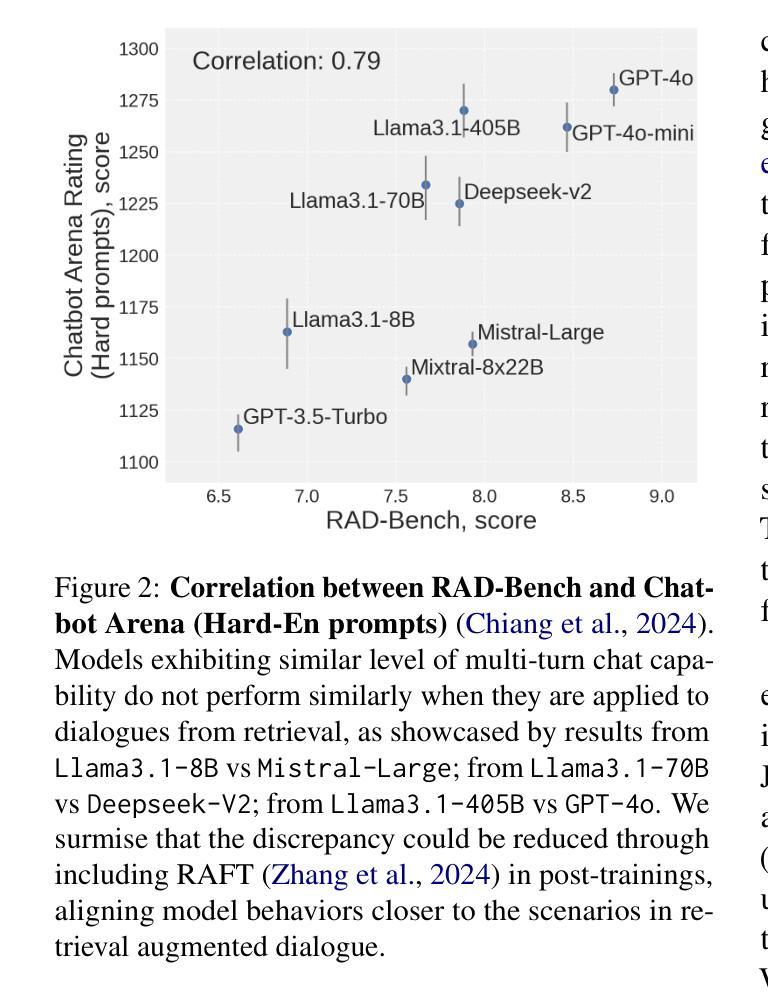
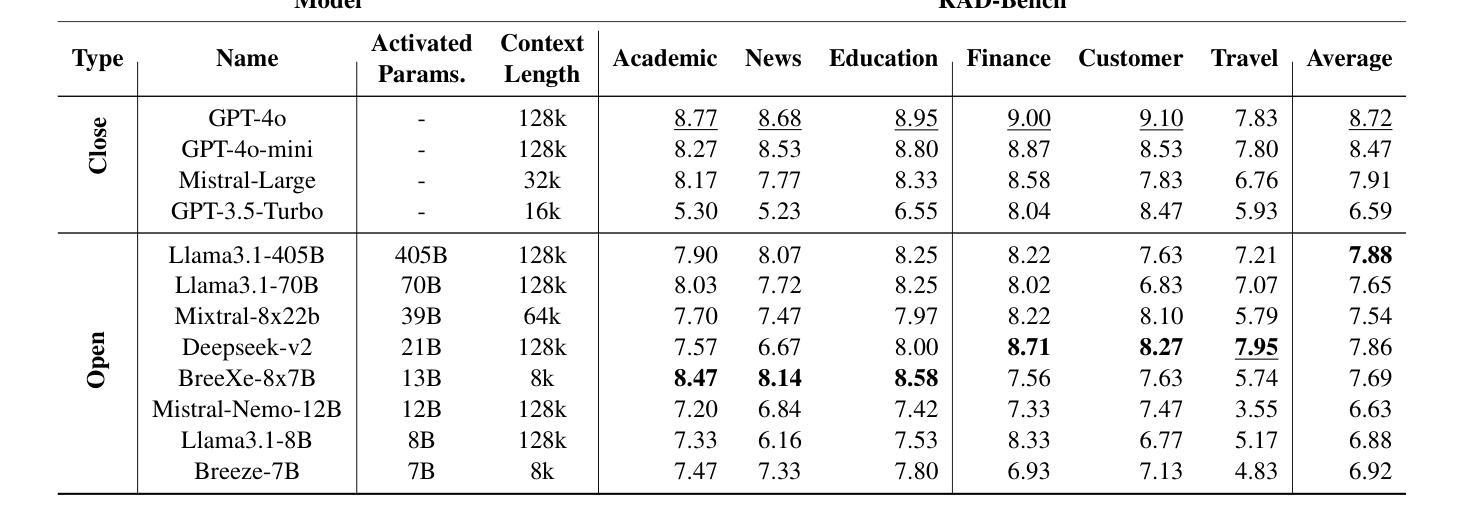
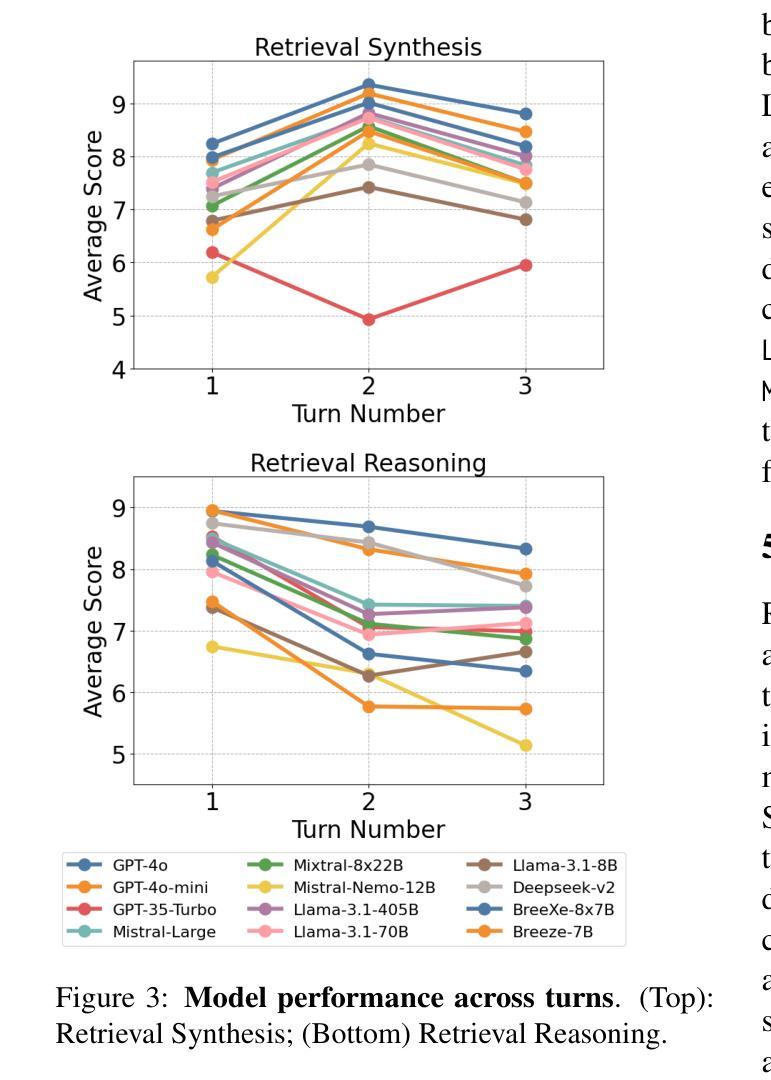
RAD-Bench: Evaluating Large Language Models Capabilities in Retrieval Augmented Dialogues
Authors:Tzu-Lin Kuo, Feng-Ting Liao, Mu-Wei Hsieh, Fu-Chieh Chang, Po-Chun Hsu, Da-Shan Shiu
In real-world applications with Large Language Models (LLMs), external retrieval mechanisms - such as Search-Augmented Generation (SAG), tool utilization, and Retrieval-Augmented Generation (RAG) - are often employed to enhance the quality of augmented generations in dialogues. These approaches often come with multi-turn dialogue, where each interaction is enriched by relevant information retrieved from external sources. Existing benchmarks either assess LLMs’ chat abilities in multi-turn dialogues or their use of retrieval for augmented responses in single-turn settings. However, there is a gap in evaluating LLMs’ ability to leverage retrieval for more precise responses across multiple turns. To address this limitation, we introduce RAD-Bench (Retrieval Augmented Dialogue), a benchmark designed to evaluate LLMs’ capabilities in multi-turn dialogues following retrievals, essential for their deployment in context-rich applications. RAD-Bench evaluates two key abilities of LLMs: Retrieval Synthesis and Retrieval Reasoning. These are measured using discriminative questions and retrieved contexts, and corresponding reference answers, assessing how effectively LLMs integrate and reason with context to maintain and enhance conversation quality over multiple turns. Our evaluation results on commonly used LLMs reveal that model performance deteriorates as additional layers of conditions or constraints are applied across conversation turns, even when accurate retrieved contexts are provided. The data and code are available at https://github.com/mtkresearch/RAD-Bench
在大型语言模型(LLM)的实际应用中,通常会采用外部检索机制,如搜索增强生成(SAG)、工具利用和检索增强生成(RAG),以增强对话中增强生成的质量。这些方法通常伴随着多轮对话,每次互动都通过从外部源检索的相关信息进行丰富。现有的基准测试要么评估LLM在多轮对话中的聊天能力,要么评估它们在单轮设置中利用检索增强回复的能力。然而,在评估LLM利用检索技术跨多轮提供更为精确回复的能力方面存在差距。为了解决这一局限性,我们引入了RAD-Bench(检索增强对话)基准测试,它是专为评估LLM在多轮对话中的检索能力而设计的,这对于将其部署在上下文丰富的应用程序中至关重要。RAD-Bench评估LLM的两个关键能力:检索合成和检索推理。这些能力是通过判别性问题、检索的上下文和相应的参考答案来衡量的,以评估LLM如何有效地整合和推理上下文,在多个回合中保持和增强对话质量。我们在常用LLM上的评估结果表明,即使在提供准确的检索上下文的情况下,随着对话回合中条件和约束的额外层数增加,模型性能也会下降。数据和代码可在https://github.com/mtkresearch/RAD-Bench上找到。
论文及项目相关链接
Summary
本文介绍了在使用大型语言模型(LLMs)进行实际应用时,如何借助外部检索机制(如搜索增强生成(SAG)、工具利用和检索增强生成(RAG))来提高对话中增强生成的质量。文章指出,这些多轮对话中的交互因从外部来源检索到的相关信息而丰富。现有基准测试要么评估LLMs在多轮对话中的聊天能力,要么评估其在单轮设置中利用检索增强回应的能力,但在多轮对话中利用检索来提高回应精确度的能力方面存在评估空白。为解决这一局限,本文引入了RAD-Bench(检索增强对话)基准测试,旨在评估LLMs在多轮对话中利用检索的能力,这对于其在上下文丰富的应用中的部署至关重要。RAD-Bench评估LLMs的两个关键能力:检索合成和检索推理。评估方式使用判别性问题、检索到的上下文和相应的参考答案,评估LLMs如何有效地整合和推理与上下文,以维持并提高对多轮对话的质量。对常用LLMs的评估结果显示,即使在提供准确检索上下文的情况下,随着对话回合中条件的增加或约束的施加,模型性能也会下降。
Key Takeaways
- 大型语言模型(LLMs)在现实世界应用中,常借助外部检索机制如Search-Augmented Generation(SAG)、工具利用和Retrieval-Augmented Generation(RAG)来提高对话质量。
- 当前存在评估LLMs在多轮对话中利用检索能力的空白。
- 引入RAD-Bench基准测试,旨在评估LLMs在多轮对话中的检索合成和检索推理能力。
- RAD-Bench使用判别性问题、检索到的上下文和参考答案进行评估。
- LLMs在整合和推理与上下文方面表现关键,以维持和提高多轮对话质量。
- 常用LLMs在对话回合中的条件或约束增加时,性能会下降。
点此查看论文截图