⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-26 更新
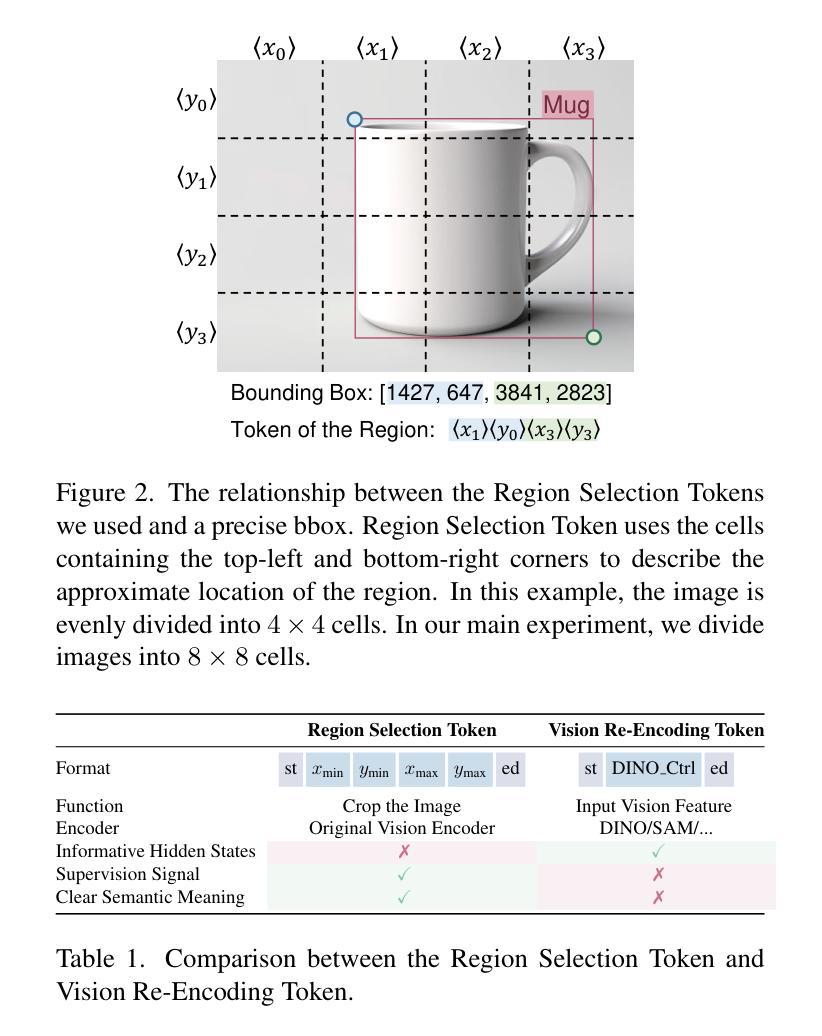
Introducing Visual Perception Token into Multimodal Large Language Model
Authors:Runpeng Yu, Xinyin Ma, Xinchao Wang
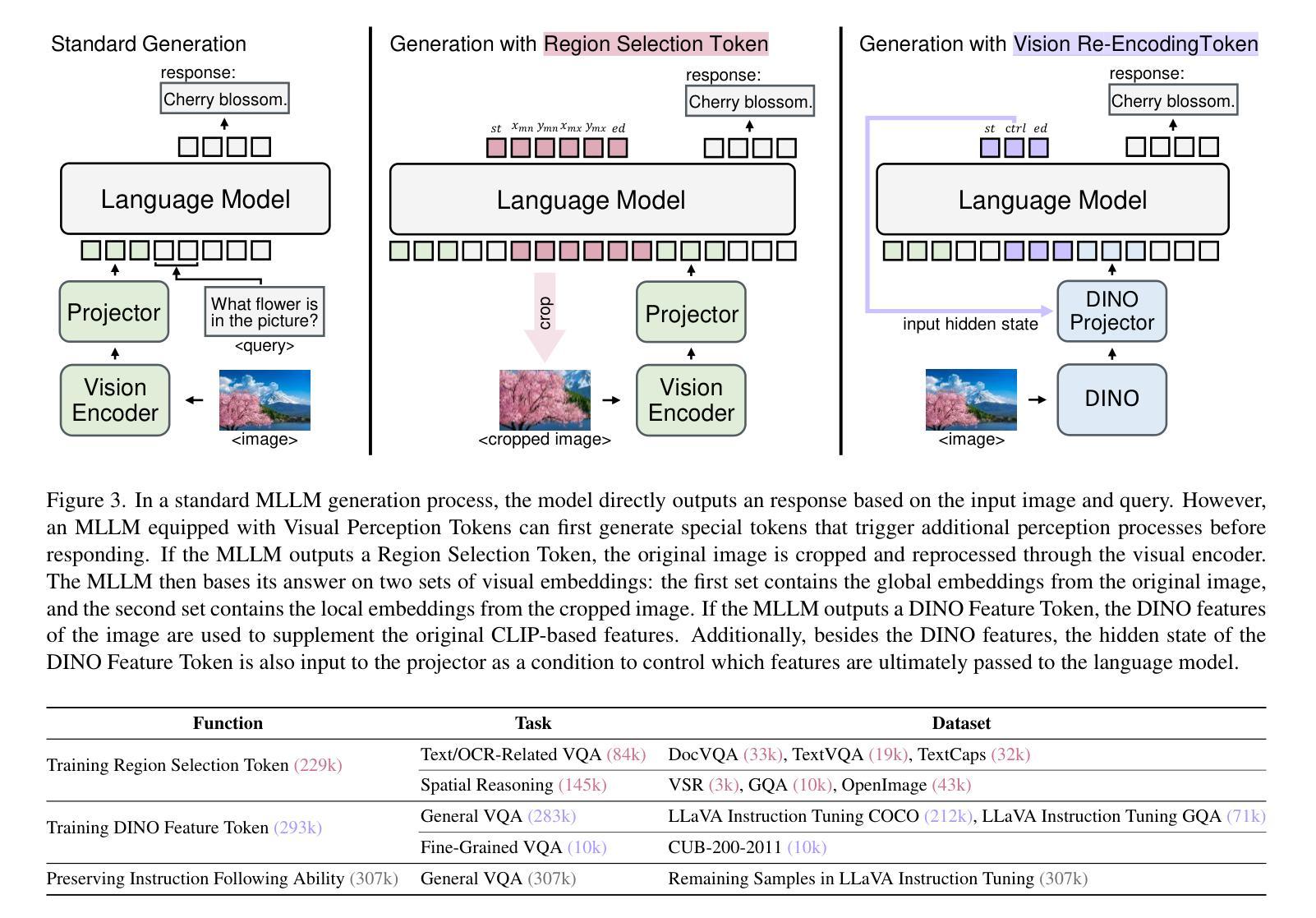
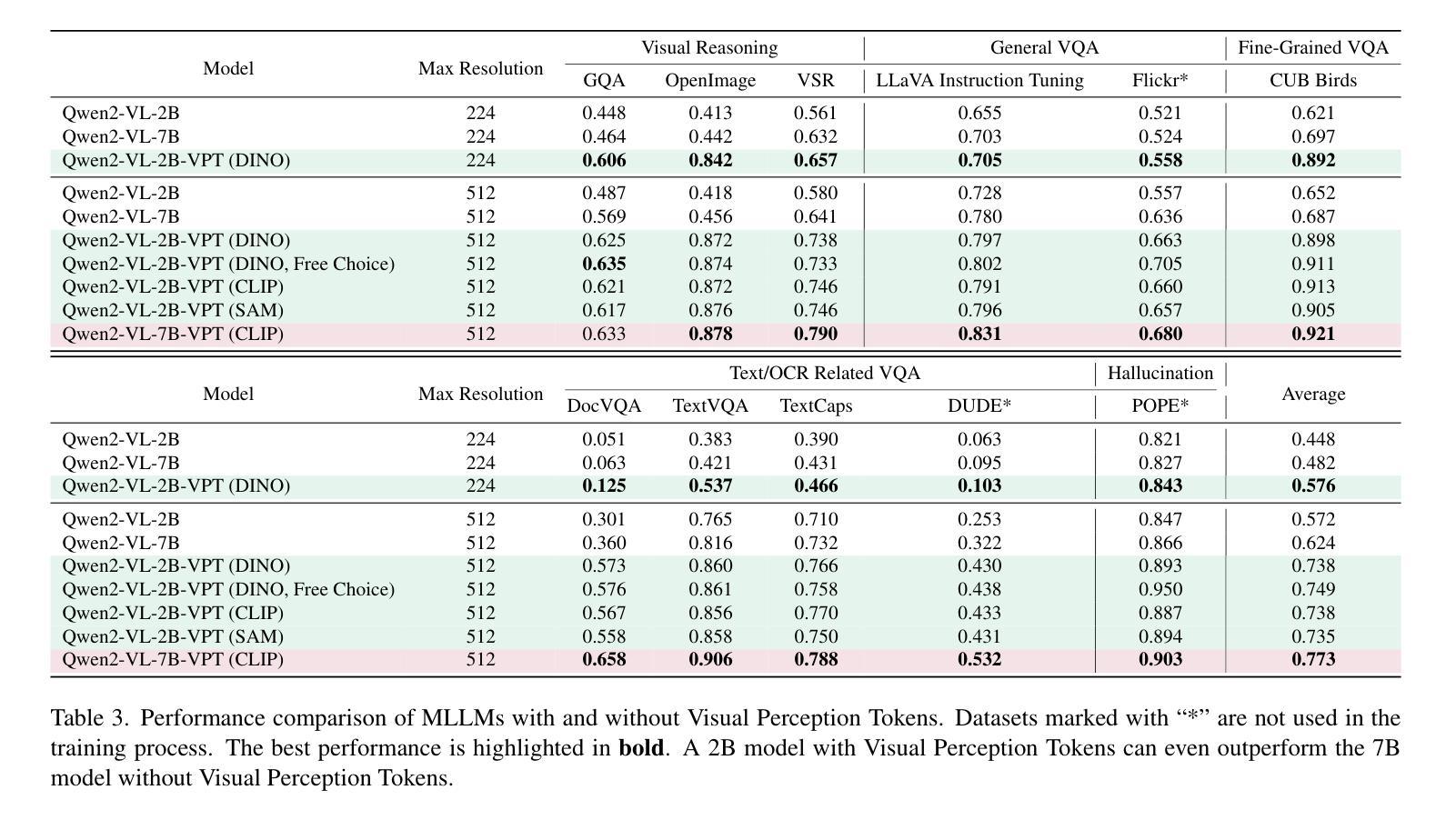
To utilize visual information, Multimodal Large Language Model (MLLM) relies on the perception process of its vision encoder. The completeness and accuracy of visual perception significantly influence the precision of spatial reasoning, fine-grained understanding, and other tasks. However, MLLM still lacks the autonomous capability to control its own visual perception processes, for example, selectively reviewing specific regions of an image or focusing on information related to specific object categories. In this work, we propose the concept of Visual Perception Token, aiming to empower MLLM with a mechanism to control its visual perception processes. We design two types of Visual Perception Tokens, termed the Region Selection Token and the Vision Re-Encoding Token. MLLMs autonomously generate these tokens, just as they generate text, and use them to trigger additional visual perception actions. The Region Selection Token explicitly identifies specific regions in an image that require further perception, while the Vision Re-Encoding Token uses its hidden states as control signals to guide additional visual perception processes. Extensive experiments demonstrate the advantages of these tokens in handling spatial reasoning, improving fine-grained understanding, and other tasks. On average, the introduction of Visual Perception Tokens improves the performance of a 2B model by 23.6%, increasing its score from 0.572 to 0.708, and even outperforms a 7B parameter model by 13.4% (from 0.624). Please check out our repo https://github.com/yu-rp/VisualPerceptionToken
为了利用视觉信息,多模态大型语言模型(MLLM)依赖于其视觉编码器的感知过程。视觉感知的完整性和准确性对空间推理、精细理解和其他任务的精度产生重大影响。然而,MLLM仍然缺乏自主控制其视觉感知过程的能力,例如,选择性回顾图像的特定区域或关注与特定对象类别相关的信息。在这项工作中,我们提出了视觉感知令牌的概念,旨在赋予MLLM控制其视觉感知过程的机制。我们设计了两种类型的视觉感知令牌,称为区域选择令牌和视觉重新编码令牌。MLLM自主地生成这些令牌,就像生成文本一样,并使用它们来触发额外的视觉感知动作。区域选择令牌显式地标识图像中需要进一步感知的特定区域,而视觉重新编码令牌则利用其隐藏状态作为控制信号来引导额外的视觉感知过程。大量实验证明了这些令牌在处理空间推理、提高精细理解和其他任务方面的优势。平均而言,引入视觉感知令牌可将2B模型性能提高23.6%,将其得分从0.572提高到0.708,甚至超越7B参数模型达13.4%(从0.624)。请访问我们的存储库 https://github.com/yu-rp/VisualPerceptionToken 了解更多信息。
论文及项目相关链接
Summary
视觉感知信息对于多模态大型语言模型(MLLM)至关重要。然而,当前MLLM仍无法自主控制视觉感知过程。本研究提出了视觉感知令牌(Visual Perception Token)的概念,旨在赋予MLLM控制其视觉感知过程的机制。本研究设计了两种类型的视觉感知令牌:区域选择令牌和视觉重新编码令牌。区域选择令牌可明确标识图像中需要进一步感知的区域,而视觉重新编码令牌则利用其隐藏状态作为控制信号来引导额外的视觉感知过程。这些令牌的应用能够提高空间推理、精细粒度理解等任务的性能。
Key Takeaways
- MLLM的视觉感知能力对空间推理和精细粒度理解等任务至关重要。
- 当前MLLM缺乏自主控制视觉感知过程的机制。
- 视觉感知令牌旨在解决此问题,并分为区域选择令牌和视觉重新编码令牌两种类型。
- 区域选择令牌能够标识需要进一步感知的图像区域。
- 视觉重新编码令牌使用隐藏状态作为控制信号来引导额外的视觉感知过程。
- 实验结果显示,引入视觉感知令牌后,模型性能显著提高,甚至在某些情况下超越了更大的模型。
点此查看论文截图

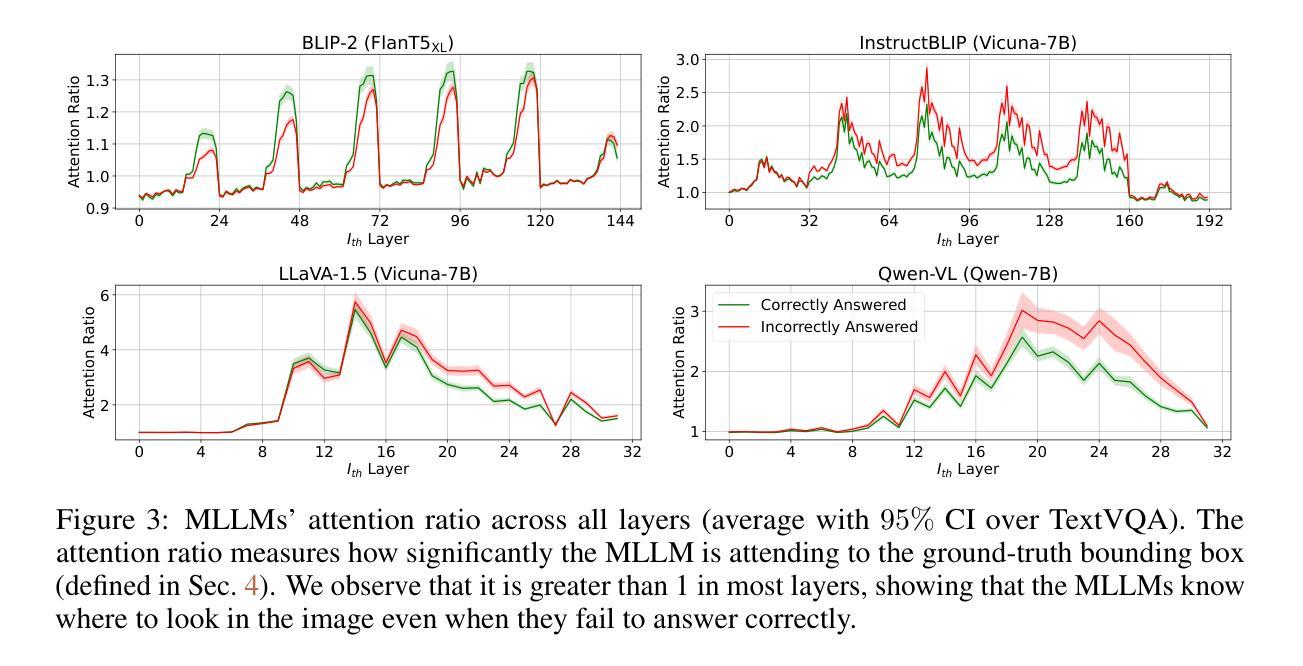
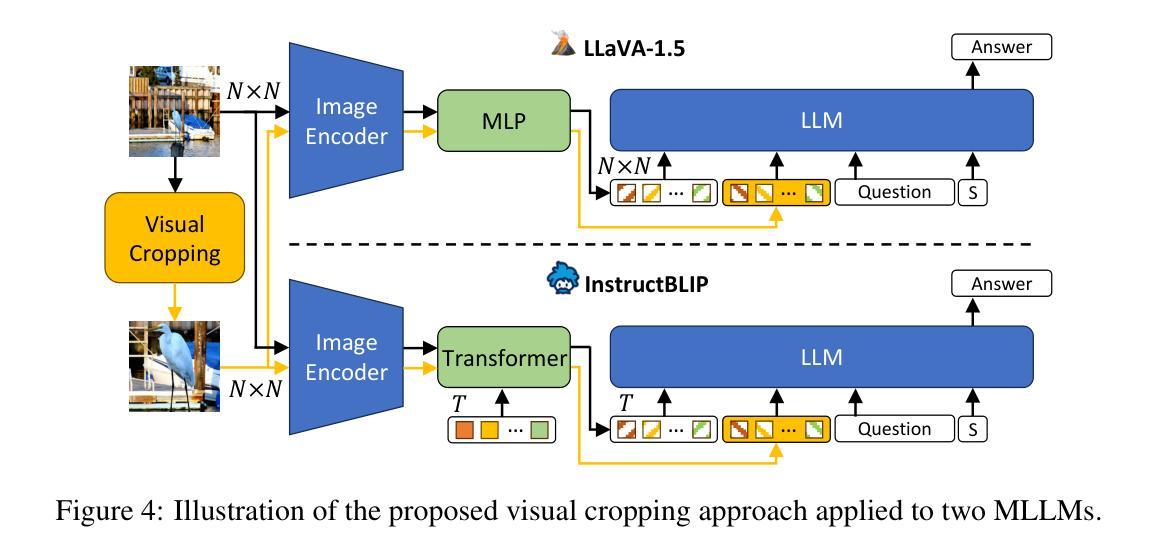
MLLMs Know Where to Look: Training-free Perception of Small Visual Details with Multimodal LLMs
Authors:Jiarui Zhang, Mahyar Khayatkhoei, Prateek Chhikara, Filip Ilievski
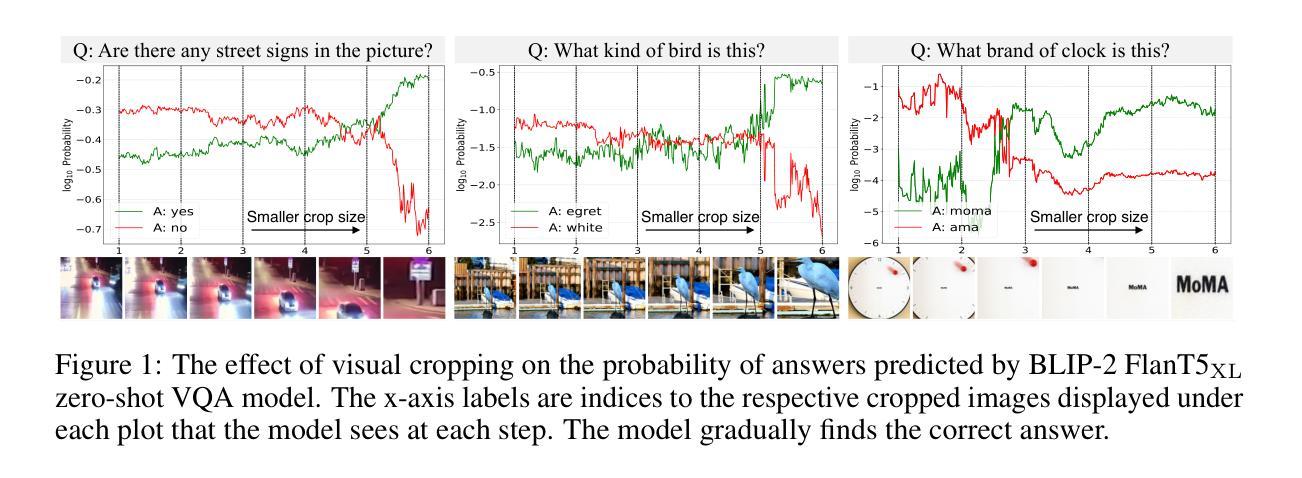
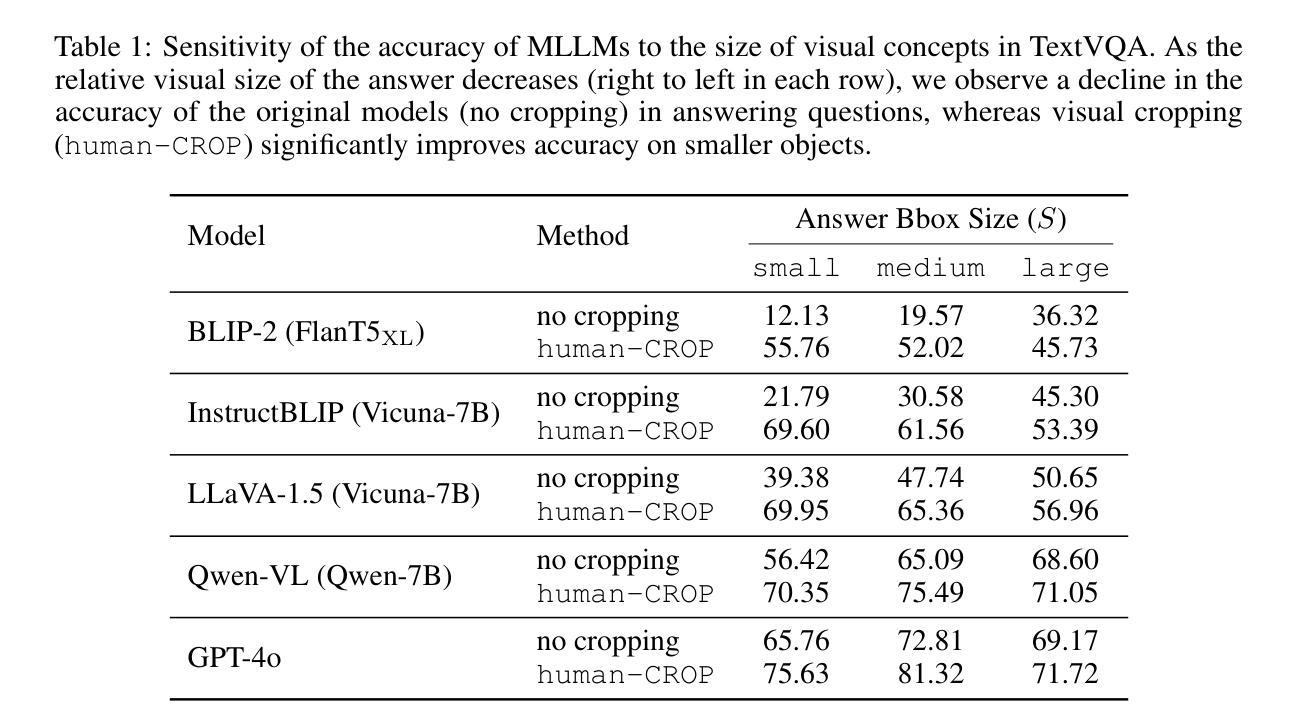
Multimodal Large Language Models (MLLMs) have experienced rapid progress in visual recognition tasks in recent years. Given their potential integration into many critical applications, it is important to understand the limitations of their visual perception. In this work, we study whether MLLMs can perceive small visual details as effectively as large ones when answering questions about images. We observe that their performance is very sensitive to the size of the visual subject of the question, and further show that this effect is in fact causal by conducting an intervention study. Next, we study the attention patterns of MLLMs when answering visual questions, and intriguingly find that they consistently know where to look, even when they provide the wrong answer. Based on these findings, we then propose training-free visual intervention methods that leverage the internal knowledge of any MLLM itself, in the form of attention and gradient maps, to enhance its perception of small visual details. We evaluate our proposed methods on two widely-used MLLMs and seven visual question answering benchmarks and show that they can significantly improve MLLMs’ accuracy without requiring any training. Our results elucidate the risk of applying MLLMs to visual recognition tasks concerning small details and indicate that visual intervention using the model’s internal state is a promising direction to mitigate this risk.
近年来,多模态大型语言模型(MLLMs)在视觉识别任务方面取得了快速进展。鉴于它们有可能融入许多关键应用,了解它们在视觉感知方面的局限性非常重要。在这项工作中,我们研究MLLMs在回答关于图像的问题时,是否能像感知大型物体一样有效地感知小到细节。我们观察到它们的性能对问题中视觉主题的大小非常敏感,并通过干预研究进一步表明这种影响实际上是因果的。接下来,我们研究MLLMs在回答视觉问题时注意力的分布,并惊奇地发现,即使他们给出错误的答案,他们也始终知道应该看向哪里。基于这些发现,我们提出了利用任何MLLM本身的内部知识(以注意力和梯度图的形式)进行免训练视觉干预的方法,以提高其对小视觉细节的认知。我们在两个广泛使用的MLLMs和七个视觉问答基准测试上评估了我们提出的方法,并表明它们在不需要任何训练的情况下可以显著提高MLLMs的准确性。我们的研究结果阐明了将MLLMs应用于涉及小细节的视觉识别任务的风险,并表明使用模型内部状态进行视觉干预是一个有希望的缓解这种风险的方向。
论文及项目相关链接
PDF Published as a conference paper at ICLR 2025. Code at: https://github.com/saccharomycetes/mllms_know
Summary
本文研究了多模态大型语言模型(MLLMs)在图像问答中对小视觉细节感知的能力,并发现其性能对视觉主题的大小非常敏感。通过干预研究发现,这一影响具有因果性。同时,本文研究了MLLMs在回答视觉问题时的注意力模式,并提出了基于模型内部知识(如注意力和梯度图)的无训练视觉干预方法,以提高其对小视觉细节的感知能力。评估结果表明,这些方法能显著提高MLLMs的准确率,且无需任何额外训练。
Key Takeaways
- MLLMs在图像问答中对小视觉细节的感知能力受到关注。
- MLLMs性能受视觉主题大小的影响。
- 通过干预研究发现,视觉主题大小影响具有因果性。
- MLLMs在回答视觉问题时具有稳定的注意力模式,即使回答错误也知道应该关注哪里。
- 提出了基于模型内部知识的无训练视觉干预方法。
- 干预方法包括利用注意力和梯度图来提高MLLMs对小视觉细节的感知能力。
点此查看论文截图


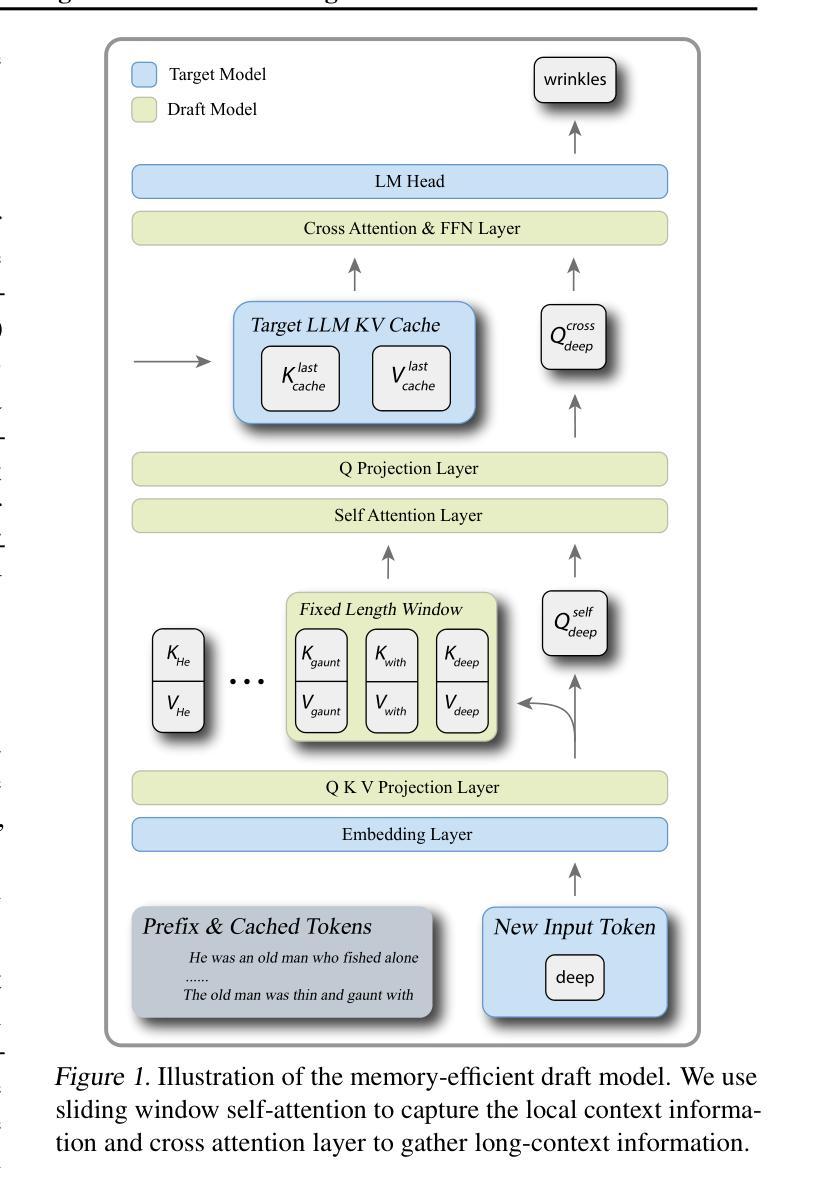
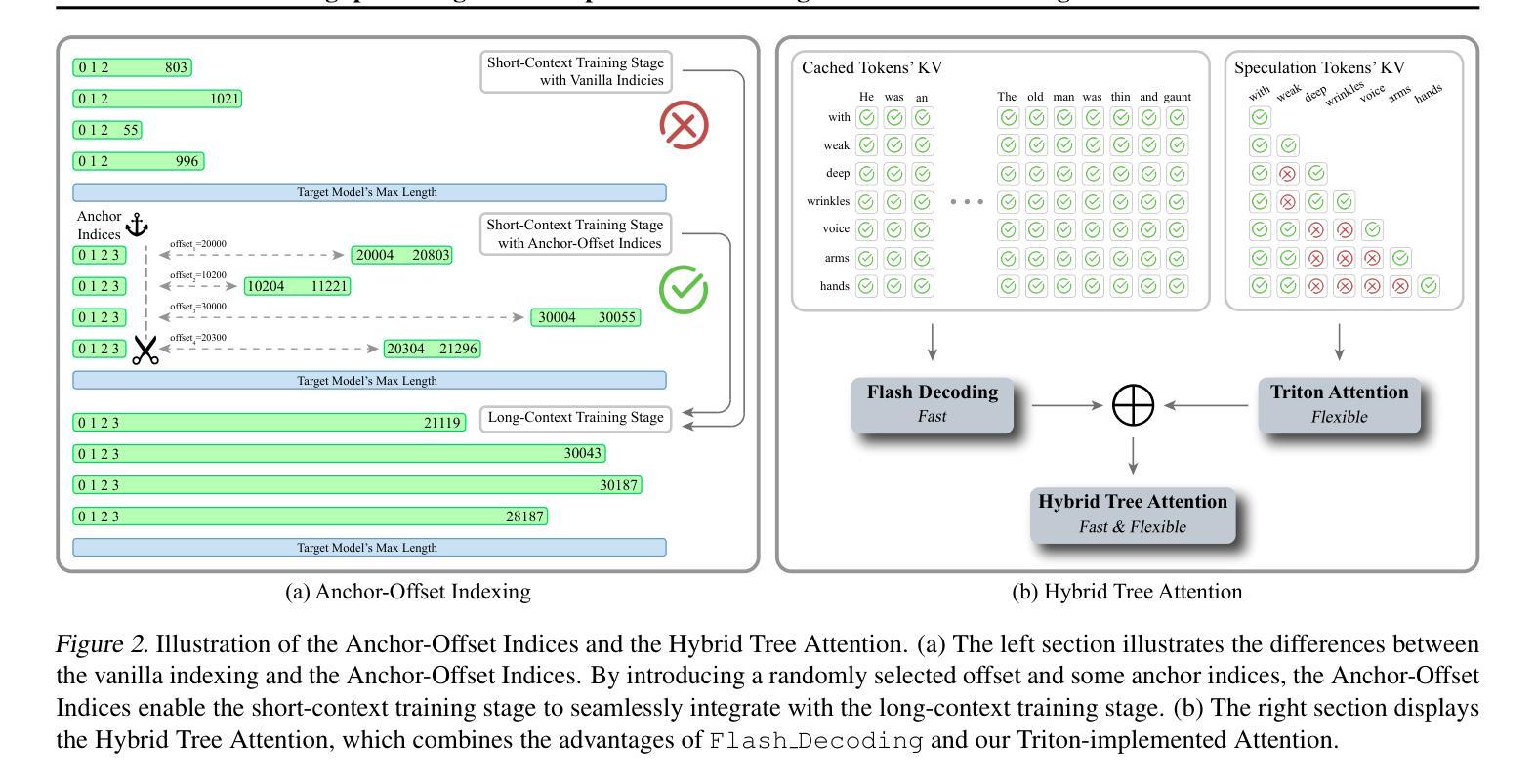
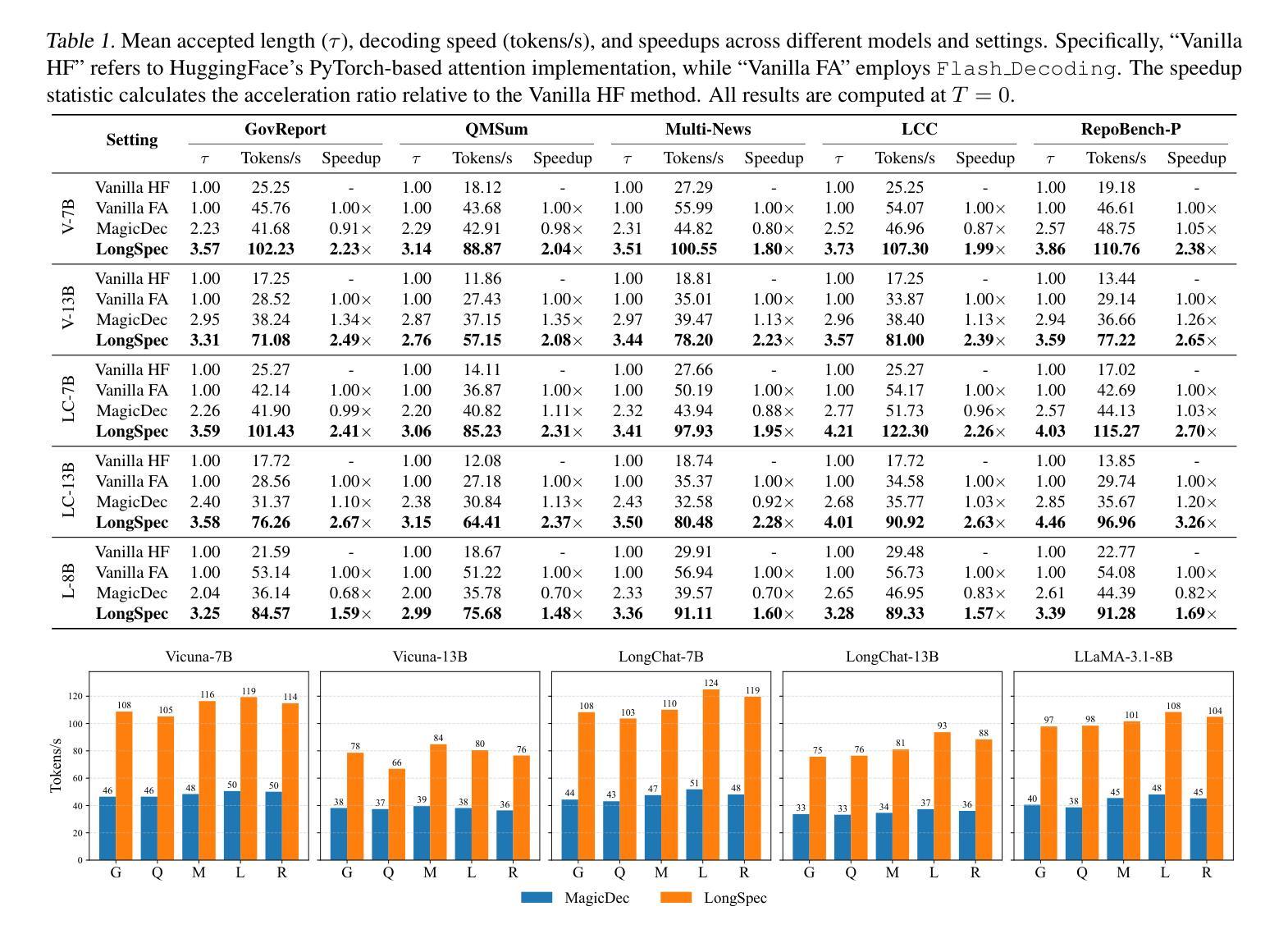
LongSpec: Long-Context Speculative Decoding with Efficient Drafting and Verification
Authors:Penghui Yang, Cunxiao Du, Fengzhuo Zhang, Haonan Wang, Tianyu Pang, Chao Du, Bo An
Speculative decoding has become a promising technique to mitigate the high inference latency of autoregressive decoding in Large Language Models (LLMs). Despite its promise, the effective application of speculative decoding in LLMs still confronts three key challenges: the increasing memory demands of the draft model, the distribution shift between the short-training corpora and long-context inference, and inefficiencies in attention implementation. In this work, we enhance the performance of speculative decoding in long-context settings by addressing these challenges. First, we propose a memory-efficient draft model with a constant-sized Key-Value (KV) cache. Second, we introduce novel position indices for short-training data, enabling seamless adaptation from short-context training to long-context inference. Finally, we present an innovative attention aggregation method that combines fast implementations for prefix computation with standard attention for tree mask handling, effectively resolving the latency and memory inefficiencies of tree decoding. Our approach achieves strong results on various long-context tasks, including repository-level code completion, long-context summarization, and o1-like long reasoning tasks, demonstrating significant improvements in latency reduction. The code is available at https://github.com/sail-sg/LongSpec.
推测解码已成为一种有前途的技术,用于缓解大型语言模型(LLM)中自回归解码的高推理延迟问题。尽管前景看好,但在LLM中有效应用推测解码仍面临三个关键挑战:草稿模型对内存的日益需求、短训练语料库与长上下文推理之间的分布偏移以及注意力实现中的效率低下。在这项工作中,我们通过解决这些挑战提高了长上下文环境中推测解码的性能。首先,我们提出了一种具有恒定大小的键值(KV)缓存的内存高效草稿模型。其次,我们为短训练数据引入了新型位置索引,实现了从短上下文训练到长上下文推理的无缝适应。最后,我们提出了一种创新的注意力聚合方法,该方法结合了快速前缀计算实现与用于树掩码处理的标准注意力,有效地解决了树解码的延迟和内存效率低下问题。我们的方法在各种长上下文任务上取得了良好的效果,包括仓库级代码补全、长上下文摘要和o1类似的长推理任务,证明了在延迟降低方面取得了显著的改进。代码可在https://github.com/sail-sg/LongSpec上找到。
论文及项目相关链接
Summary:
本文探讨了大型语言模型(LLM)中的投机解码技术面临的挑战,并提出了针对这些挑战的解决方案。通过优化内存效率、适应长语境训练和引入新型注意力聚合方法,本文提出的方案在多种长语境任务中取得了显著成果,包括仓库级代码补全、长语境摘要和长推理任务等。有效降低了延迟并提高性能。相关代码可在GitHub上找到。
Key Takeaways:
- 投机解码是缓解大型语言模型(LLM)高推断延迟的一种有前途的技术。
- 投机解码面临的关键挑战包括模型内存需求的增加、短训练语料库与长语境推断的分布偏移以及注意力实现的效率问题。
- 提出了一种内存高效的草案模型,具有恒定大小的键值(KV)缓存,以解决模型内存需求问题。
- 引入新型位置索引用于短训练数据,实现从短语境训练到长语境推断的无缝适应。
- 提出了一种创新的注意力聚合方法,结合了快速前缀计算和标准注意力处理树掩码,解决了树解码的延迟和内存效率问题。
- 在多种长语境任务中取得了显著成果,包括代码补全、长语境摘要和长推理任务等。
点此查看论文截图

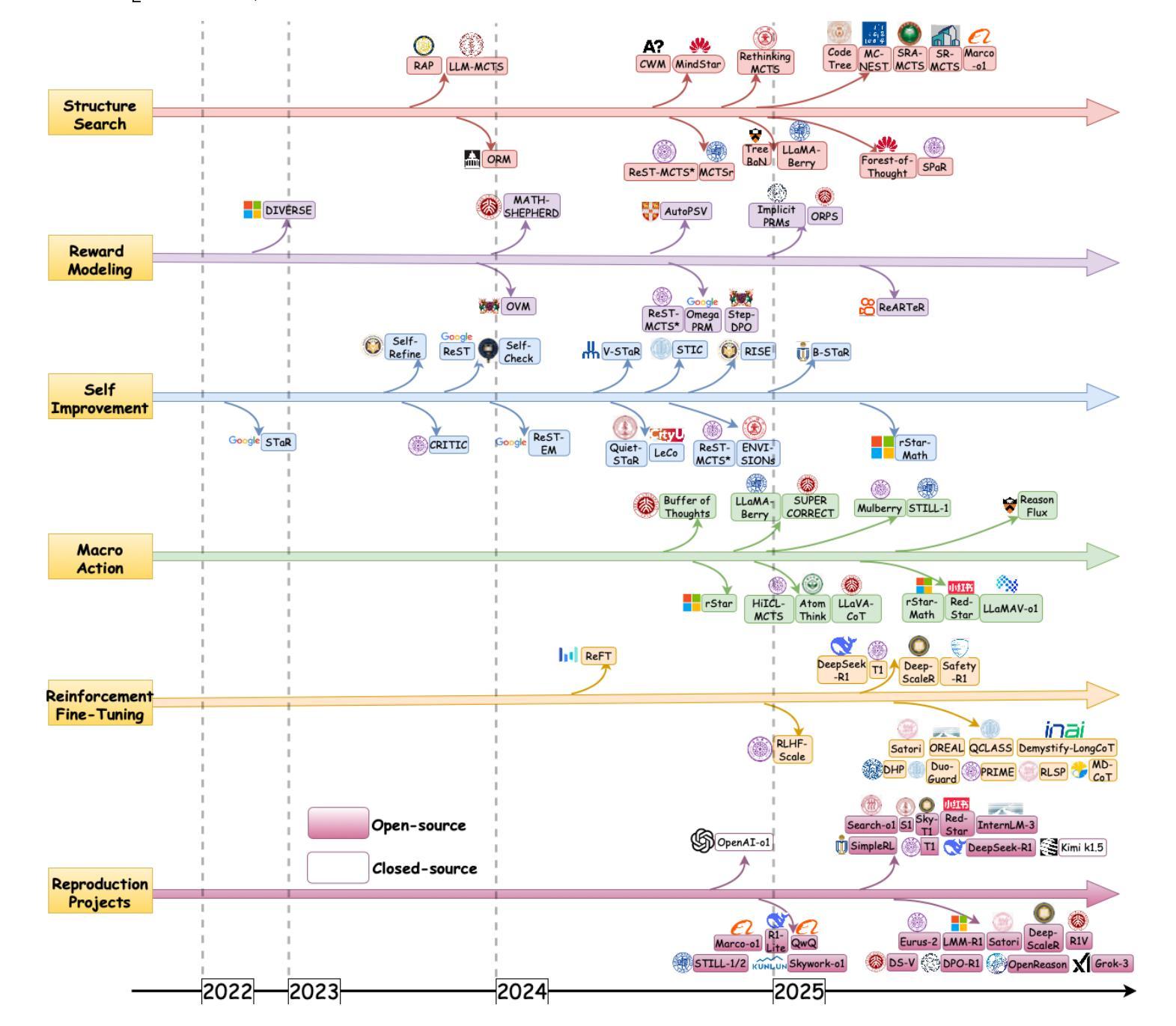
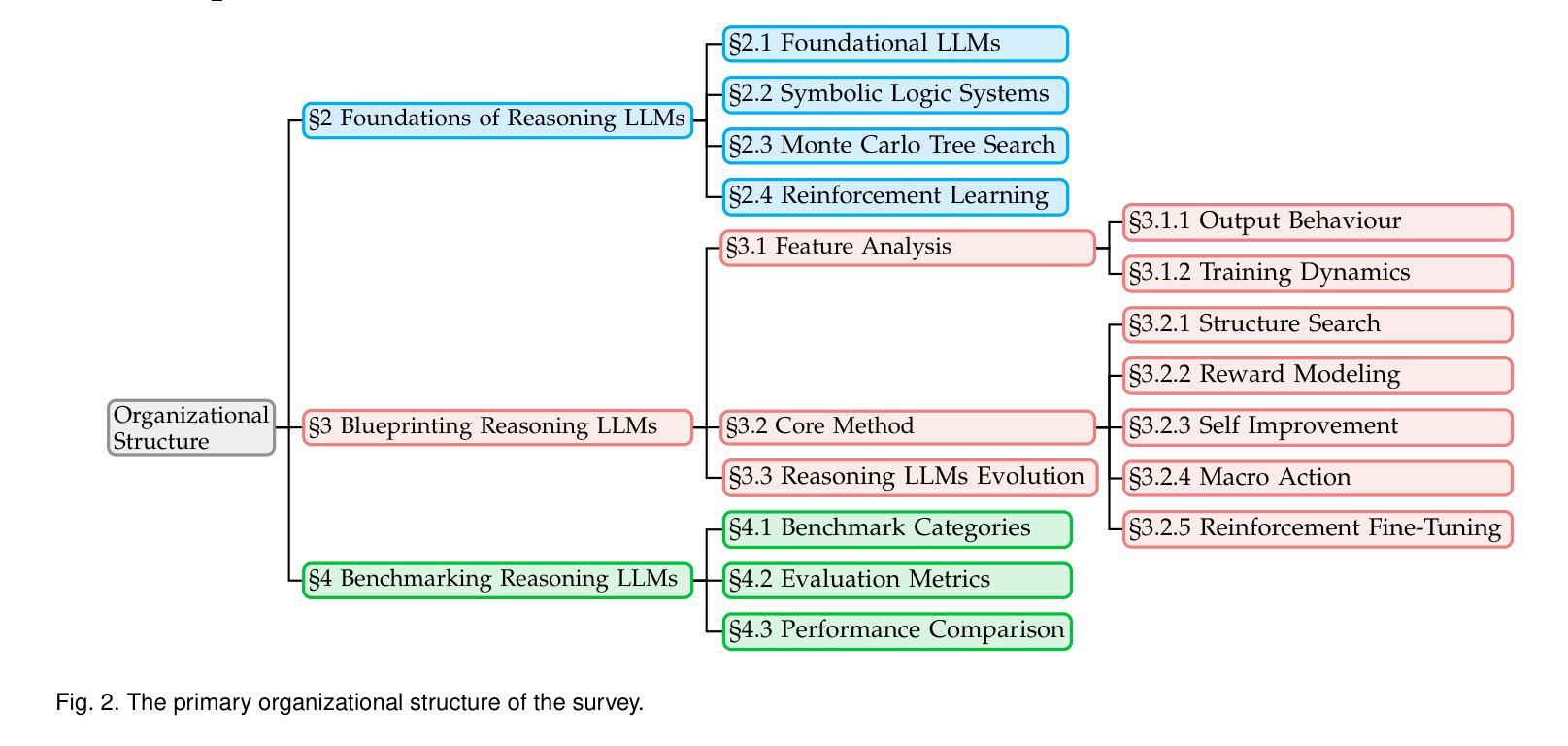
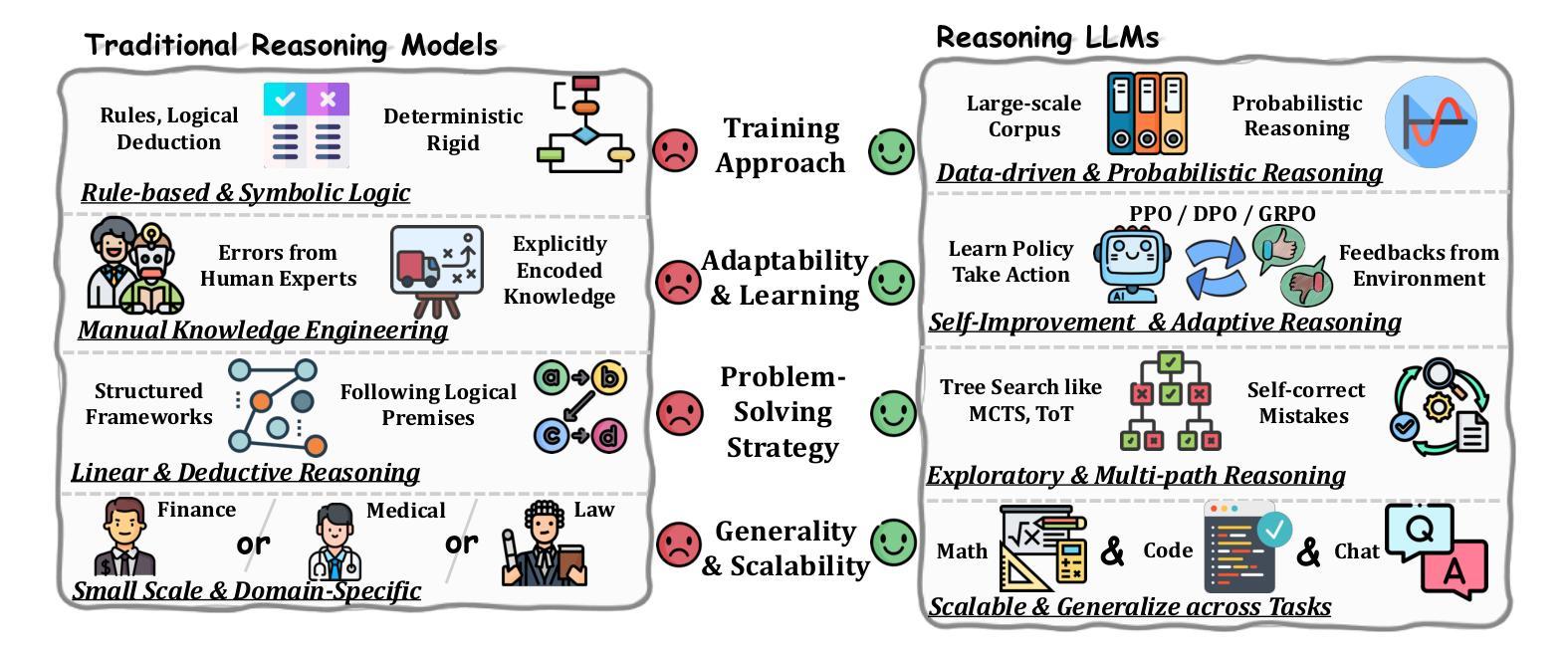
From System 1 to System 2: A Survey of Reasoning Large Language Models
Authors:Zhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Pei-Jie Wang, Xiuyi Chen, Yingying Zhang, Fei Yin, Jiahua Dong, Zhijiang Guo, Le Song, Cheng-Lin Liu
Achieving human-level intelligence requires refining the transition from the fast, intuitive System 1 to the slower, more deliberate System 2 reasoning. While System 1 excels in quick, heuristic decisions, System 2 relies on logical reasoning for more accurate judgments and reduced biases. Foundational Large Language Models (LLMs) excel at fast decision-making but lack the depth for complex reasoning, as they have not yet fully embraced the step-by-step analysis characteristic of true System 2 thinking. Recently, reasoning LLMs like OpenAI’s o1/o3 and DeepSeek’s R1 have demonstrated expert-level performance in fields such as mathematics and coding, closely mimicking the deliberate reasoning of System 2 and showcasing human-like cognitive abilities. This survey begins with a brief overview of the progress in foundational LLMs and the early development of System 2 technologies, exploring how their combination has paved the way for reasoning LLMs. Next, we discuss how to construct reasoning LLMs, analyzing their features, the core methods enabling advanced reasoning, and the evolution of various reasoning LLMs. Additionally, we provide an overview of reasoning benchmarks, offering an in-depth comparison of the performance of representative reasoning LLMs. Finally, we explore promising directions for advancing reasoning LLMs and maintain a real-time \href{https://github.com/zzli2022/Awesome-Slow-Reason-System}{GitHub Repository} to track the latest developments. We hope this survey will serve as a valuable resource to inspire innovation and drive progress in this rapidly evolving field.
实现人类水平的智能需要精进从快速直觉系统1到较慢、更慎重的系统2推理的过渡。系统1擅长快速启发式决策,而系统2则依赖于逻辑推理以做出更准确的判断和减少偏见。基础大型语言模型(LLM)擅长快速决策,但在复杂推理方面缺乏深度,因为它们尚未完全接受系统2思维的逐步分析特征。最近,像OpenAI的o1/o3和DeepSeek的R1等推理LLM在数学和编程等领域已经展现出专家级的性能,它们能够很好地模仿系统2的慎重推理并展示出类似人类的认知能力。这篇综述首先简要概述了基础LLM和系统2技术的早期发展进展,并探讨了它们的结合如何为推理LLM铺平道路。接下来,我们讨论如何构建推理LLM,分析其特点、支持高级推理的核心方法以及各种推理LLM的演变。此外,我们还概述了推理基准测试,深入比较了代表性推理LLM的性能。最后,我们探讨了推动推理LLM发展的有前途的方向,并通过GitHub仓库实时跟踪最新进展。我们希望这篇综述能作为宝贵资源,激发创新并推动这一快速演变领域的进步。
论文及项目相关链接
PDF Slow-thinking, Large Language Models, Human-like Reasoning, Decision Making in AI, AGI
摘要
文章探讨了实现人类智能水平需要实现从快速直觉系统一(System 1)到较慢但更深思熟虑的系统二(System 2)推理的转变。系统一擅长快速决策,而系统二则依赖逻辑推理以做出更准确、减少偏见的判断。基础大型语言模型(LLM)擅长快速决策,但缺乏复杂推理的深度,未能完全采用系统二的逐步分析特性。最近,如OpenAI的o1/o3和DeepSeek的R1等推理LLM已在数学和编码等领域展现出专家级表现,模仿了系统二的深思熟虑推理并展示了人类般的认知能力。本文首先概述了基础LLM和系统二技术的早期发展,并探讨了它们的结合如何为推理LLM铺平道路。接着,我们讨论了如何构建推理LLM,分析了它们的特点、核心方法和各种推理LLM的演变。此外,本文还概述了推理基准测试,深入比较了代表性推理LLM的性能。最后,我们探讨了推进推理LLM发展的有前途的方向,并通过GitHub仓库实时跟踪最新发展。本文旨在为这一快速演变的领域提供有价值的资源,激发创新并推动进展。
关键见解
- 实现人类智能需要从系统一的快速直觉决策转变为系统二的缓慢且深思熟虑的推理过程。
- 系统一擅长快速决策,而系统二则侧重于逻辑推理以减少偏见,提高准确性。
- 基础大型语言模型(LLM)虽擅长快速决策,但在复杂推理方面存在局限,尚未完全融入系统二的逐步分析特性。
- 推理LLM如OpenAI的o1/o3和DeepSeek的R1已在特定领域展现出专家级表现,模仿了系统二的推理过程并展示了人类般的认知能力。
- 文章概述了从基础LLM到推理LLM的发展过程,包括其特点、核心方法和不同推理LLM的演变。
- 推理基准测试显示,代表性推理LLM的性能存在差异,这为评估模型提供了有价值的比较。
点此查看论文截图

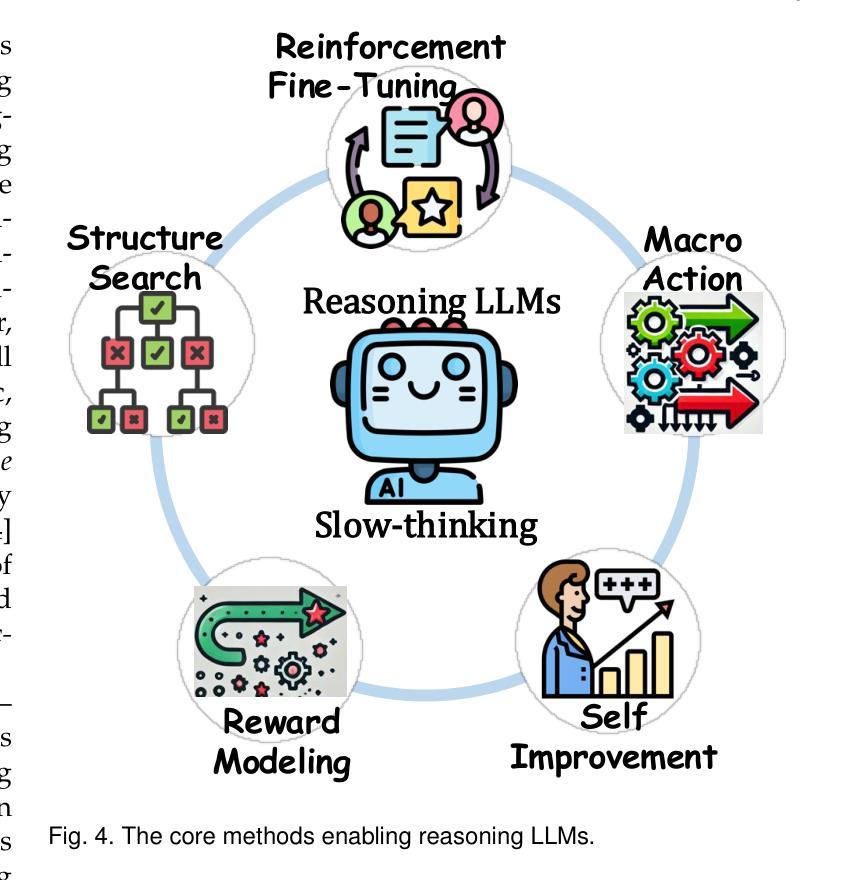
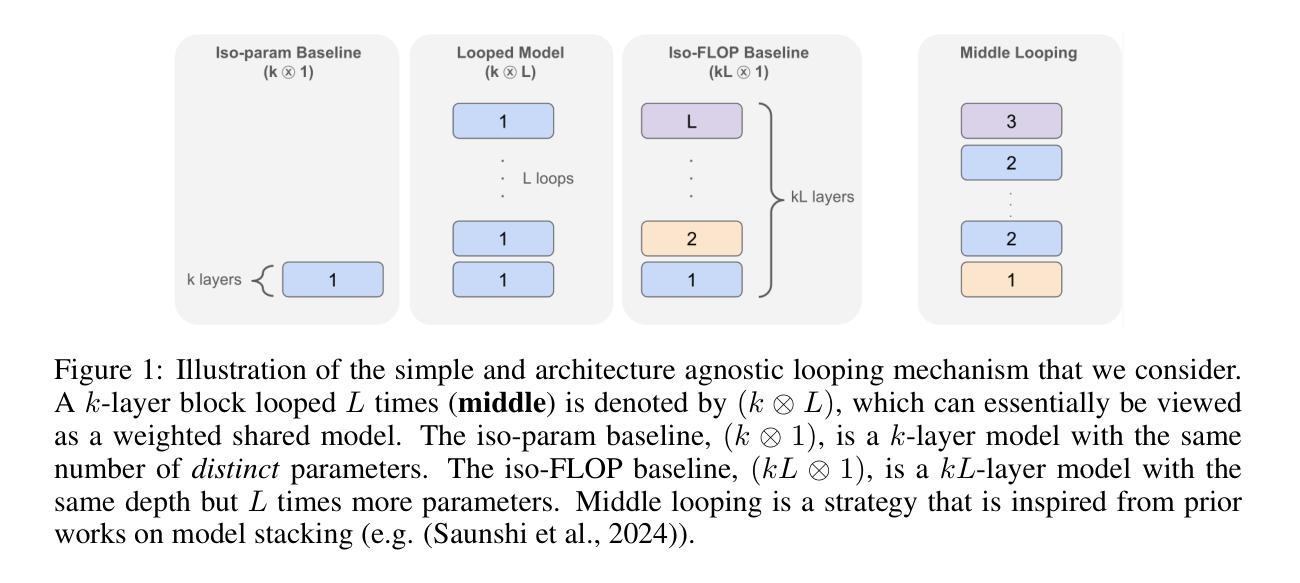
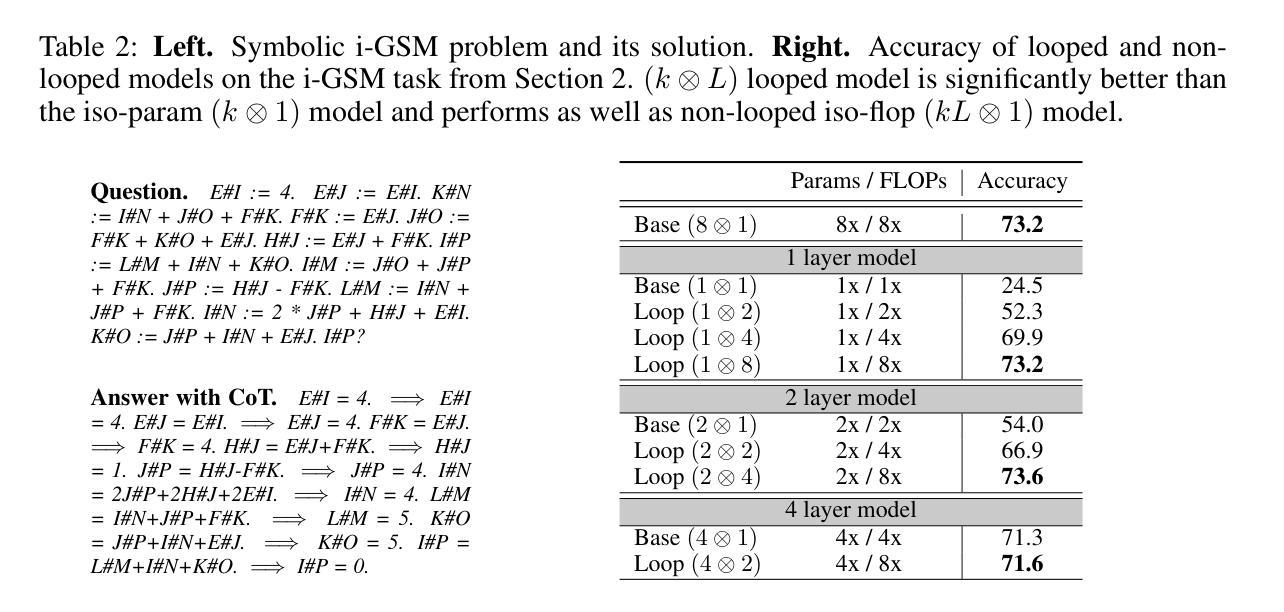
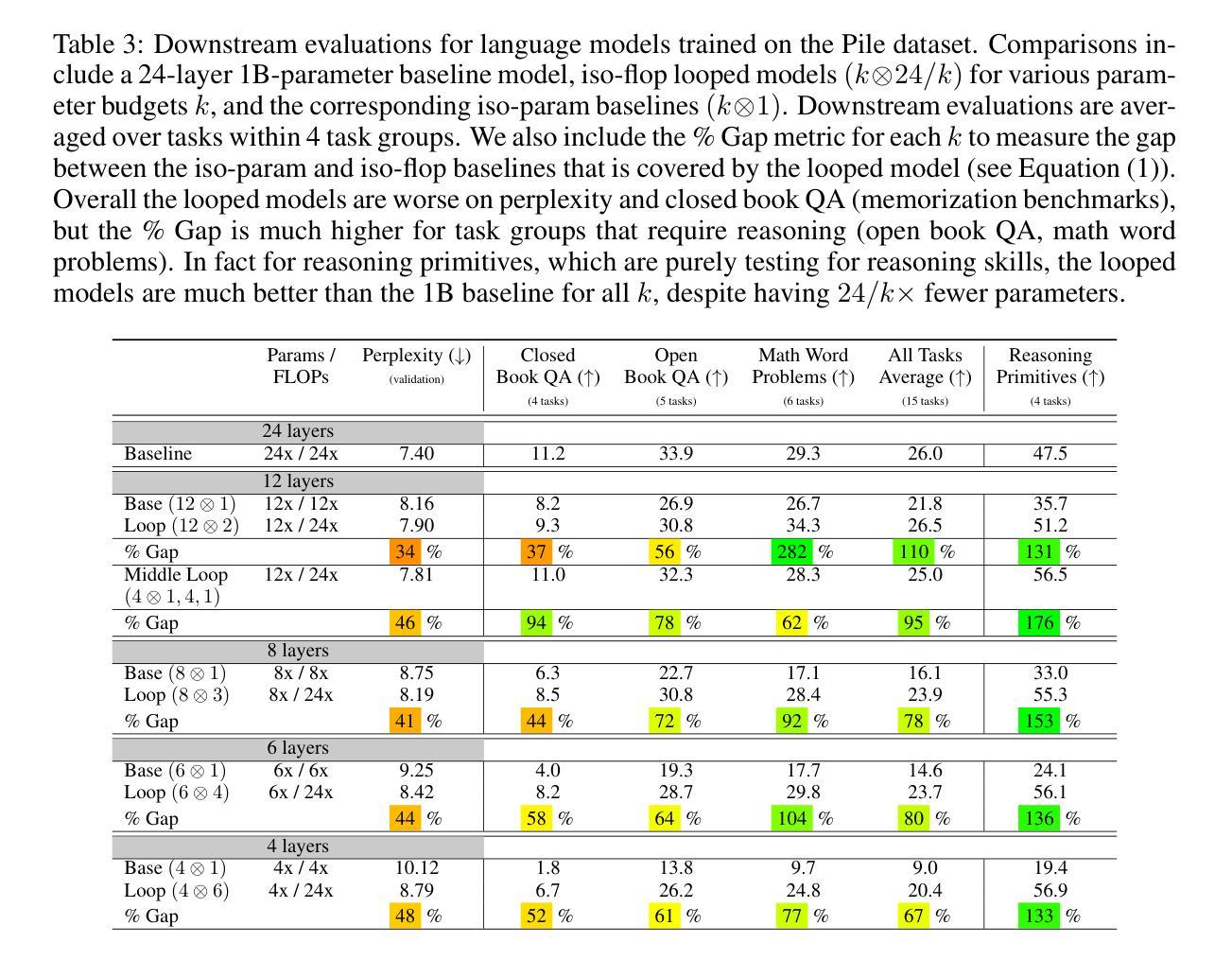
Reasoning with Latent Thoughts: On the Power of Looped Transformers
Authors:Nikunj Saunshi, Nishanth Dikkala, Zhiyuan Li, Sanjiv Kumar, Sashank J. Reddi
Large language models have shown remarkable reasoning abilities and scaling laws suggest that large parameter count, especially along the depth axis, is the primary driver. In this work, we make a stronger claim – many reasoning problems require a large depth but not necessarily many parameters. This unlocks a novel application of looped models for reasoning. Firstly, we show that for many synthetic reasoning problems like addition, $p$-hop induction, and math problems, a $k$-layer transformer looped $L$ times nearly matches the performance of a $kL$-layer non-looped model, and is significantly better than a $k$-layer model. This is further corroborated by theoretical results showing that many such reasoning problems can be solved via iterative algorithms, and thus, can be solved effectively using looped models with nearly optimal depth. Perhaps surprisingly, these benefits also translate to practical settings of language modeling – on many downstream reasoning tasks, a language model with $k$-layers looped $L$ times can be competitive to, if not better than, a $kL$-layer language model. In fact, our empirical analysis reveals an intriguing phenomenon: looped and non-looped models exhibit scaling behavior that depends on their effective depth, akin to the inference-time scaling of chain-of-thought (CoT) reasoning. We further elucidate the connection to CoT reasoning by proving that looped models implicitly generate latent thoughts and can simulate $T$ steps of CoT with $T$ loops. Inspired by these findings, we also present an interesting dichotomy between reasoning and memorization, and design a looping-based regularization that is effective on both fronts.
大型语言模型已经展现出显著的推理能力,而规模定律表明,大量的参数,尤其是深度方向的参数,是其主要驱动力。在这项工作中,我们提出了一个更强烈的观点——许多推理问题需要的是深度,而不仅仅是参数数量。这开启了循环模型在推理方面的一种新型应用。首先,我们证明对于许多合成推理问题,如加法、p阶归纳和数学问题,k层变压器循环L次几乎可以与kL层非循环模型匹配性能,并且明显优于k层模型。理论结果也进一步证实了这一点,表明许多此类推理问题可以通过迭代算法解决,因此可以使用近乎最优深度的循环模型有效地解决。令人惊讶的是,这些好处也适用于语言建模的实际场景——在许多下游推理任务中,循环k层的语言模型可能与kL层的语言模型不相上下,甚至更好。事实上,我们的实证分析揭示了一个有趣的现象:循环和非循环模型的扩展行为取决于其有效深度,类似于思维链(CoT)推理的推理时间扩展。我们通过证明循环模型可以隐含地生成潜在思维,并可以使用T个循环模拟T步CoT推理,进一步阐明了与CoT推理的联系。受此发现的启发,我们还提出了推理和记忆之间的有趣二元性,并设计了一种基于循环的正则化方法,在两个方面都有效。
论文及项目相关链接
PDF ICLR 2025
Summary
大型语言模型的出色推理能力主要得益于其深度而非参数数量。研究指出,对于许多合成推理问题和实际语言建模任务,循环模型(即反复执行某一操作的模型)可以通过优化深度来实现近乎最佳的推理效果。此外,循环模型展现出一种与“思维链”(CoT)推理相似的推断时间尺度行为。本研究的另一重要发现是循环模型可以模拟CoT的多步推理过程。同时,循环模型在处理推理和记忆任务时表现出有效性与二重性特征。总之,本研究为语言模型的优化提供了新的视角和方法。
Key Takeaways
- 大型语言模型的推理能力主要依赖深度而非参数数量。深度扩展是实现优质推理的关键。
- 循环模型能有效解决合成推理问题,如加法、归纳等数学问题,其性能接近甚至超越非循环模型。
- 循环模型适用于实际语言建模任务,表现出良好的推理能力。
- 循环模型的性能与“思维链”(CoT)推理相似,可模拟多步推理过程。
点此查看论文截图


COSMOS: A Hybrid Adaptive Optimizer for Memory-Efficient Training of LLMs
Authors:Liming Liu, Zhenghao Xu, Zixuan Zhang, Hao Kang, Zichong Li, Chen Liang, Weizhu Chen, Tuo Zhao
Large Language Models (LLMs) have demonstrated remarkable success across various domains, yet their optimization remains a significant challenge due to the complex and high-dimensional loss landscapes they inhabit. While adaptive optimizers such as AdamW are widely used, they suffer from critical limitations, including an inability to capture interdependencies between coordinates and high memory consumption. Subsequent research, exemplified by SOAP, attempts to better capture coordinate interdependence but incurs greater memory overhead, limiting scalability for massive LLMs. An alternative approach aims to reduce memory consumption through low-dimensional projection, but this leads to substantial approximation errors, resulting in less effective optimization (e.g., in terms of per-token efficiency). In this paper, we propose COSMOS, a novel hybrid optimizer that leverages the varying importance of eigensubspaces in the gradient matrix to achieve memory efficiency without compromising optimization performance. The design of COSMOS is motivated by our empirical insights and practical considerations. Specifically, COSMOS applies SOAP to the leading eigensubspace, which captures the primary optimization dynamics, and MUON to the remaining eigensubspace, which is less critical but computationally expensive to handle with SOAP. This hybrid strategy significantly reduces memory consumption while maintaining robust optimization performance, making it particularly suitable for massive LLMs. Numerical experiments on various datasets and transformer architectures are provided to demonstrate the effectiveness of COSMOS. Our code is available at https://github.com/lliu606/COSMOS.
大型语言模型(LLM)在各个领域都取得了显著的成就,然而由于其复杂的、高维度的损失景观,它们的优化仍然是一个巨大的挑战。虽然像AdamW这样的自适应优化器被广泛应用,但它们存在关键局限性,包括无法捕捉坐标之间的互依赖关系以及高内存消耗。后续的研究,如SOAP,试图更好地捕捉坐标间的互依赖性,但却带来了更大的内存开销,限制了大规模LLM的可扩展性。另一种方法旨在通过低维投影来减少内存消耗,但这会导致大量的近似误差,从而导致优化效果较差(例如,在每次令牌效率方面)。在本文中,我们提出了COSMOS,这是一种新型混合优化器,它利用梯度矩阵中不同特征子空间的重要性来实现内存效率,而不损害优化性能。COSMOS的设计受到我们实证见解和实际考虑的启发。具体来说,COSMOS对主要的特征子空间应用SOAP,捕捉主要的优化动态,并对剩余的特征子空间应用MUON,这部分相对不那么关键但用SOAP处理计算成本较高。这种混合策略显著减少了内存消耗,同时保持了稳健的优化性能,使其特别适合大规模LLM。我们在各种数据集和转换器架构上进行了数值实验,以证明COSMOS的有效性。我们的代码可在https://github.com/lliu606/COSMOS获取。
论文及项目相关链接
PDF 23 pages, 9 figures, 6 tables
Summary
大型语言模型(LLM)的优化面临复杂多维的损失景观挑战。现有优化器如AdamW虽广泛应用,但存在无法捕捉坐标间依赖性和高内存消耗等局限性。后续研究如SOAP试图捕捉坐标依赖性但增加了内存开销,限制了大规模LLM的扩展性。另一种方法旨在通过低维投影减少内存消耗,但会导致较大误差,影响优化效果。本文提出COSMOS优化器,利用梯度矩阵中不同特征子空间的重要性来实现内存效率与优化性能的平衡。COSMOS对主要特征子空间应用SOAP优化器,捕捉主要优化动态,对剩余特征子空间应用MUON优化器。这种混合策略显著降低了内存消耗,同时保持了稳健的优化性能,尤其适用于大规模LLM。
Key Takeaways
- LLMs的优化面临多维损失景观挑战。
- 现有优化器如AdamW存在局限性,无法有效捕捉坐标间依赖性和高内存消耗。
- SOAP优化器试图解决坐标依赖性但增加了内存开销。
- 低维投影方法虽可降低内存消耗,但会导致较大误差,影响优化效果。
- COSMOS是一种新型混合优化器,结合SOAP和MUON优化器,针对特征子空间进行不同处理。
- COSMOS在降低内存消耗的同时保持了优化性能。
点此查看论文截图

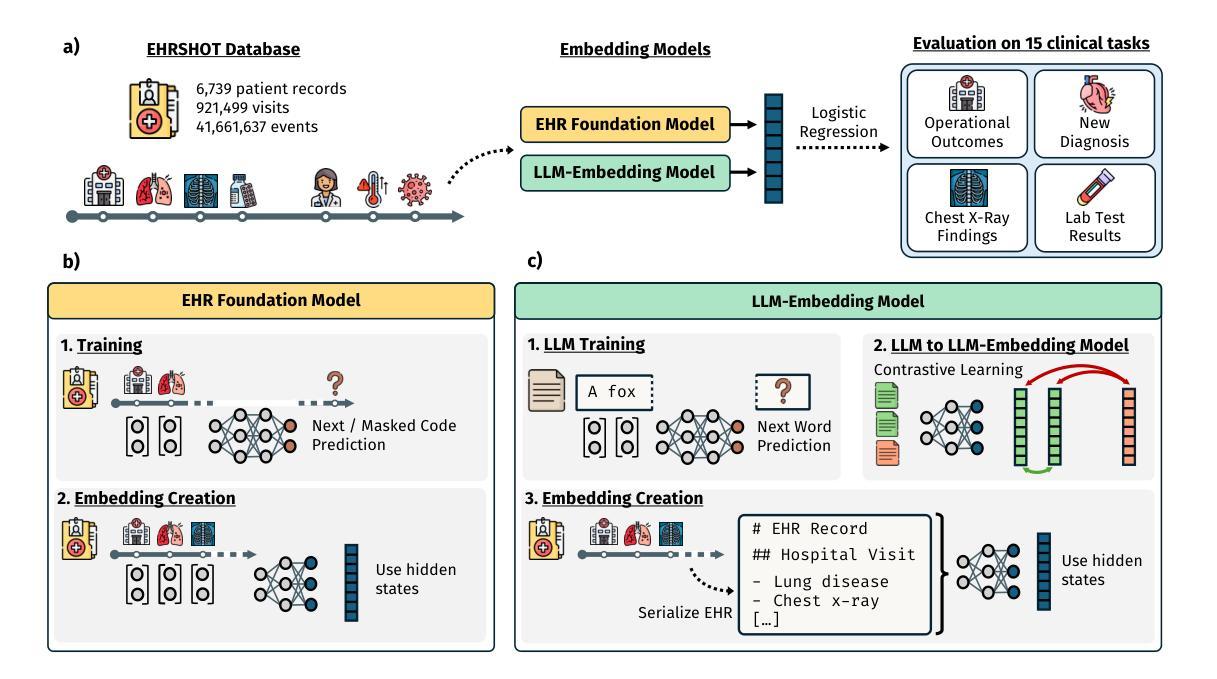
Large Language Models are Powerful EHR Encoders
Authors:Stefan Hegselmann, Georg von Arnim, Tillmann Rheude, Noel Kronenberg, David Sontag, Gerhard Hindricks, Roland Eils, Benjamin Wild
Electronic Health Records (EHRs) offer rich potential for clinical prediction, yet their inherent complexity and heterogeneity pose significant challenges for traditional machine learning approaches. Domain-specific EHR foundation models trained on large collections of unlabeled EHR data have demonstrated promising improvements in predictive accuracy and generalization; however, their training is constrained by limited access to diverse, high-quality datasets and inconsistencies in coding standards and healthcare practices. In this study, we explore the possibility of using general-purpose Large Language Models (LLMs) based embedding methods as EHR encoders. By serializing patient records into structured Markdown text, transforming codes into human-readable descriptors, we leverage the extensive generalization capabilities of LLMs pretrained on vast public corpora, thereby bypassing the need for proprietary medical datasets. We systematically evaluate two state-of-the-art LLM-embedding models, GTE-Qwen2-7B-Instruct and LLM2Vec-Llama3.1-8B-Instruct, across 15 diverse clinical prediction tasks from the EHRSHOT benchmark, comparing their performance to an EHRspecific foundation model, CLIMBR-T-Base, and traditional machine learning baselines. Our results demonstrate that LLM-based embeddings frequently match or exceed the performance of specialized models, even in few-shot settings, and that their effectiveness scales with the size of the underlying LLM and the available context window. Overall, our findings demonstrate that repurposing LLMs for EHR encoding offers a scalable and effective approach for clinical prediction, capable of overcoming the limitations of traditional EHR modeling and facilitating more interoperable and generalizable healthcare applications.
电子健康记录(EHRs)在临床预测方面具有巨大的潜力,然而其固有的复杂性和异质性给传统的机器学习方法带来了巨大的挑战。针对特定领域的EHR基础模型通过在大量未标记的EHR数据上进行训练,已经在预测精度和通用性方面显示出有希望的改进;然而,它们的训练受到多样、高质量数据集访问有限以及编码标准和医疗实践不一致的制约。在这项研究中,我们探讨了使用基于通用大型语言模型(LLMs)的嵌入方法作为EHR编码器的可能性。通过将患者记录序列化为结构化Markdown文本,将代码转换为人类可读的描述符,我们充分利用了LLMs在大量公共语料库上的预训练带来的广泛泛化能力,从而绕过了对专有医疗数据集的需求。我们系统地评估了两种最先进的LLM嵌入模型,GTE-Qwen2-7B-Instruct和LLM2Vec-Llama3.1-8B-Instruct,在EHRSHOT基准测试的15个不同临床预测任务上,与EHR特定基础模型CLIMBR-T-Base和传统机器学习基准进行了性能比较。结果表明,基于LLM的嵌入通常与专用模型的性能相匹配或超过,即使在少量样本情况下也是如此,其有效性随着基础LLM的大小和可用上下文窗口而扩大。总的来说,我们的研究发现,将LLMs重新用于EHR编码提供了一种可扩展和有效的临床预测方法,能够克服传统EHR建模的限制,促进更互联和更通用的医疗应用程序的开发。
论文及项目相关链接
Summary
本文探讨了电子健康记录(EHRs)在临床预测中的丰富潜力,以及传统机器学习方法面临的挑战。研究通过采用基于大型公共语料库的通用大型语言模型(LLMs)作为EHR编码器来解决问题。通过结构化Markdown文本对患者记录进行序列化,将代码转换为人类可读的描述符,从而绕过对专有医疗数据集的需求。系统评估表明,LLM嵌入模型在EHRSHOT基准测试的15项不同临床预测任务中的性能与特定于EHR的基础模型相比表现良好,甚至在某些情况下表现更好。这表明将LLMs重新用于EHR编码是一种可扩展且有效的临床预测方法,能够克服传统EHR建模的限制,促进更具互通性和泛化能力的医疗保健应用程序的开发。
Key Takeaways
- 电子健康记录(EHRs)在临床预测中具有巨大潜力,但数据复杂性和异质性给传统机器学习带来挑战。
- 特定于EHR的基础模型在预测准确性和泛化能力方面显示出改进的希望,但受限于数据集的多样性和质量以及编码标准和医疗实践的不一致性。
- 研究使用通用大型语言模型(LLMs)作为EHR编码器的新方法,利用LLMs在大量公共语料库上的预训练进行结构化数据处理。
- 通过将患者记录序列化为结构化Markdown文本并转换代码为可读描述符,绕过对专有医疗数据集的需求。
- LLM嵌入模型在多种临床预测任务中表现出良好的性能,与特定于EHR的模型相比具有竞争力,甚至在少样本情况下也能匹配或超越其性能。
- LLM的有效性随着模型大小和可用上下文窗口的大小而增加。
点此查看论文截图


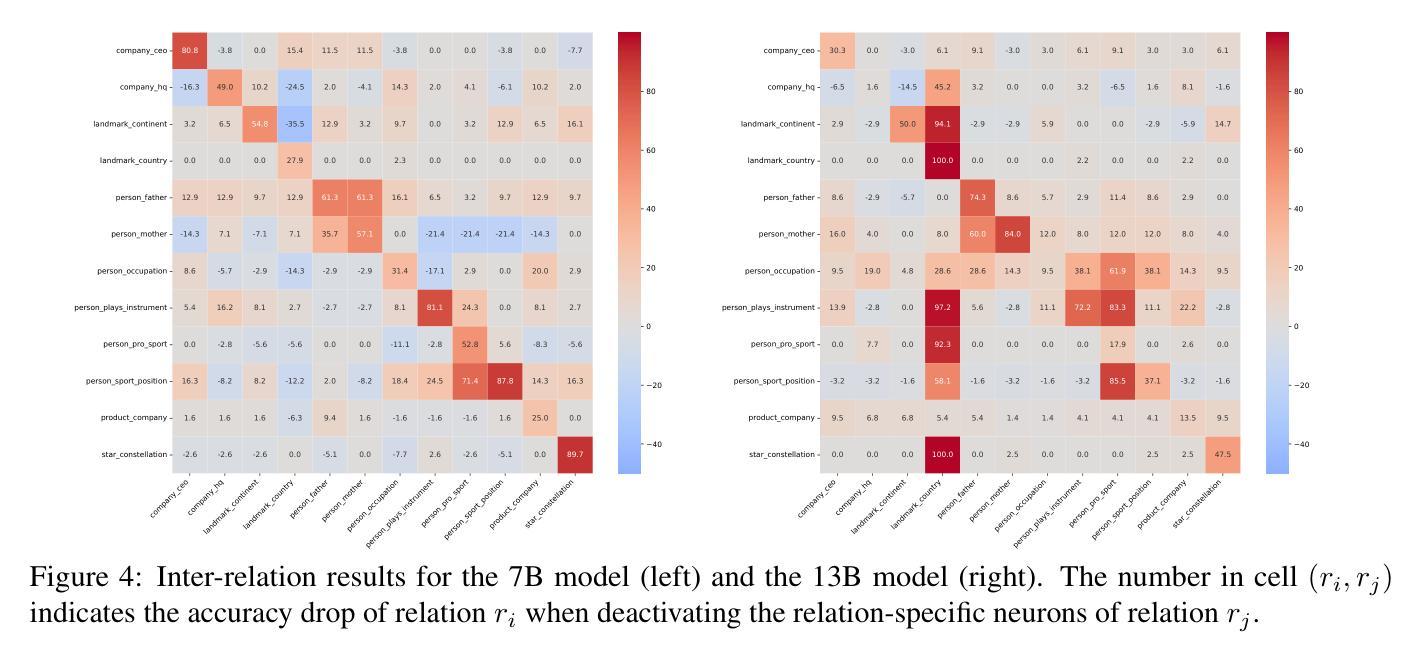
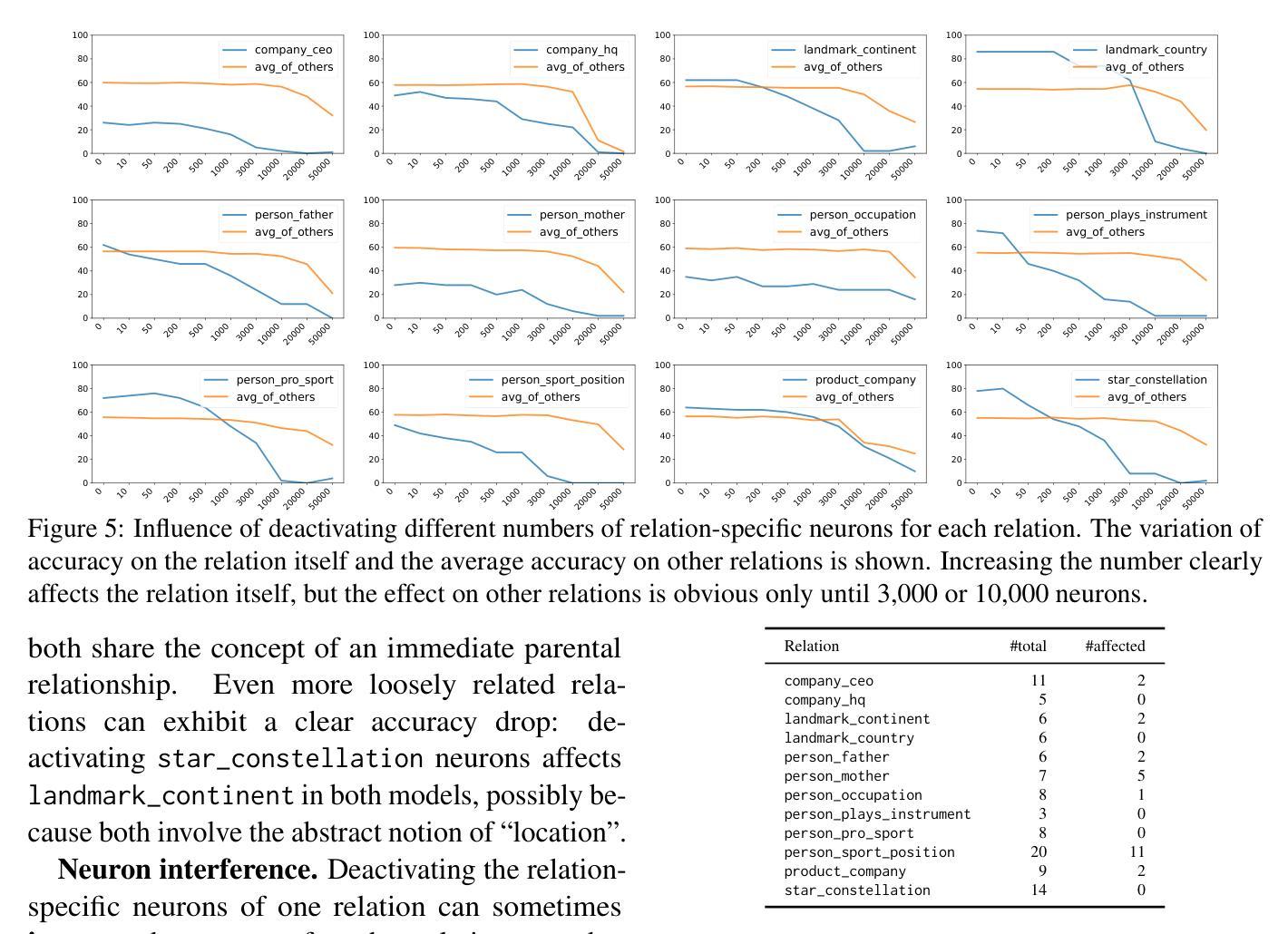
On Relation-Specific Neurons in Large Language Models
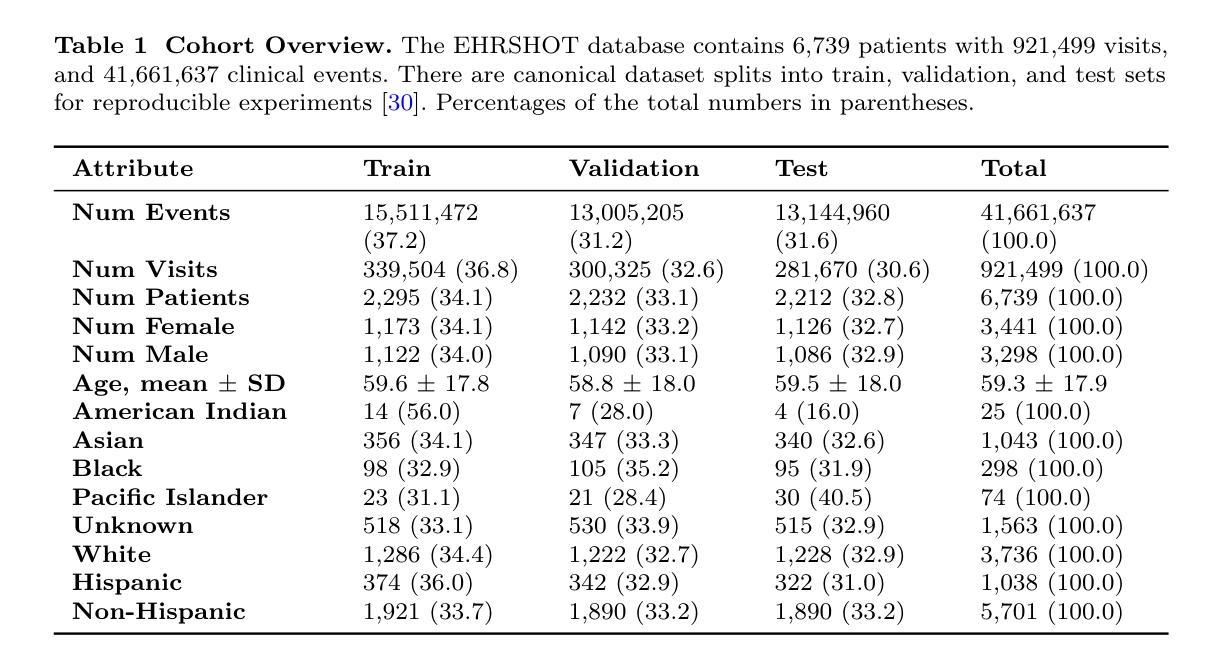
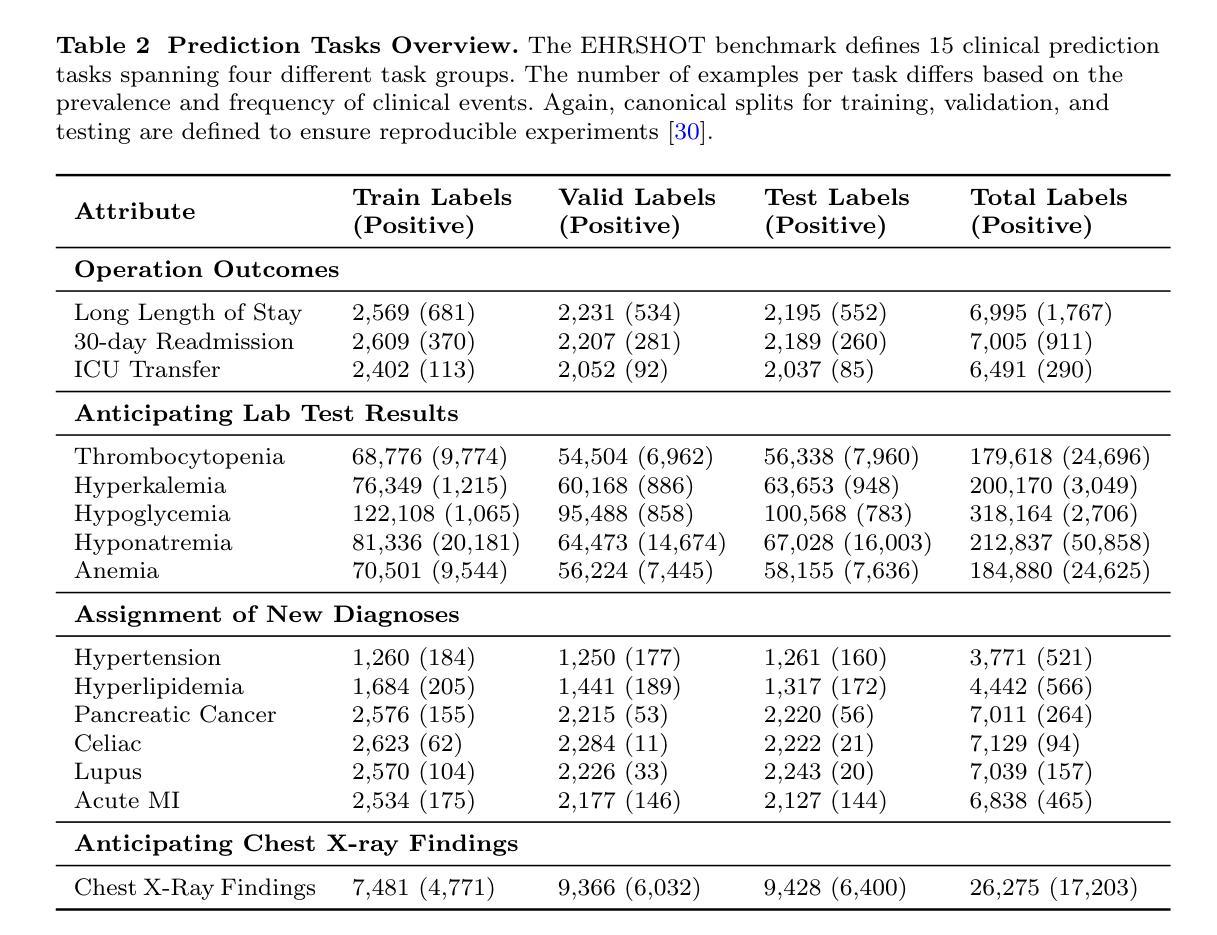
Authors:Yihong Liu, Runsheng Chen, Lea Hirlimann, Ahmad Dawar Hakimi, Mingyang Wang, Amir Hossein Kargaran, Sascha Rothe, François Yvon, Hinrich Schütze
In large language models (LLMs), certain neurons can store distinct pieces of knowledge learned during pretraining. While knowledge typically appears as a combination of relations and entities, it remains unclear whether some neurons focus on a relation itself – independent of any entity. We hypothesize such neurons detect a relation in the input text and guide generation involving such a relation. To investigate this, we study the Llama-2 family on a chosen set of relations with a statistics-based method. Our experiments demonstrate the existence of relation-specific neurons. We measure the effect of selectively deactivating candidate neurons specific to relation $r$ on the LLM’s ability to handle (1) facts whose relation is $r$ and (2) facts whose relation is a different relation $r’ \neq r$. With respect to their capacity for encoding relation information, we give evidence for the following three properties of relation-specific neurons. $\textbf{(i) Neuron cumulativity.}$ The neurons for $r$ present a cumulative effect so that deactivating a larger portion of them results in the degradation of more facts in $r$. $\textbf{(ii) Neuron versatility.}$ Neurons can be shared across multiple closely related as well as less related relations. Some relation neurons transfer across languages. $\textbf{(iii) Neuron interference.}$ Deactivating neurons specific to one relation can improve LLM generation performance for facts of other relations. We will make our code publicly available at https://github.com/cisnlp/relation-specific-neurons.
在大语言模型(LLM)中,某些神经元可以存储预训练过程中学到的不同知识片段。虽然知识通常以关系和实体的组合形式出现,但尚不清楚某些神经元是否专注于关系本身——独立于任何实体。我们假设这样的神经元可以检测输入文本中的关系,并引导涉及这种关系的生成。为了调查这一点,我们使用统计方法在研究选定的一组关系上研究Llama-2家族。我们的实验证明了特定关系神经元的存在。我们测量选择性停用特定于关系$r$的候选神经元对LLM处理(1)关系为$r$的事实和(2)关系为不同关系$r’ \neq r$的事实的能力的影响。关于其编码关系信息的能力,我们为特定关系神经元的以下三个属性提供证据。$\textbf{(i) 神经元累积性。}$针对关系$r$的神经元具有累积效应,停用其中更多的神经元会导致更多关于$r$的事实退化。$\textbf{(ii) 神经元多功能性。}$神经元可以在多个密切相关以及不太相关的关系之间共享。某些关系神经元可以在不同语言间转移。$\textbf{(iii) 神经元干扰。}$停用特定于某一关系的神经元可能会提高LLM对其它关系事实生成的性能。我们的代码将在https://github.com/cisnlp/relation-specific-neurons上公开提供。
论文及项目相关链接
PDF preprint
摘要
在大语言模型中,某些神经元能够存储预训练过程中学到的不同知识片段。知识通常以关系和实体的组合形式出现,但目前尚不清楚神经元是否独立于任何实体关注于关系本身。我们假设这类神经元能够在输入文本中检测关系并引导涉及此类关系的生成。为了调查这一点,我们在Llama-2家族上采用基于统计的方法,对选定的一组关系进行研究。实验证明了存在特定关系的神经元。我们测量了选择性停用与关系$r$相关的候选神经元对语言模型处理关系$r$的事实以及关系$r’\neq r$的事实的影响。关于其编码关系信息的能力,我们为特定关系的神经元提供了以下三个属性的证据。神经元具有累积性效应,停用更多的神经元会导致更多事实在关系$r$中退化;神经元具有通用性,可以跨多个关系密切以及不太相关的关系共享使用,某些关系神经元甚至跨语言通用;停用特定于一个关系的神经元可能会提高语言模型对其他关系事实的处理能力。我们将我们的代码公开在https://github.com/cisnlp/relation-specific-neurons。
关键见解
- 在大语言模型中,特定神经元可以存储预训练期间学到的知识片段,这些知识与特定的关系相关联。
- 存在专门处理特定关系的神经元,这些神经元在模型处理相关事实时起着重要作用。
- 停用更多特定关系的神经元会导致模型在处理相关事实时性能下降。
- 神经元具有通用性,可以跨多个关系密切和不太相关的关系共享使用,甚至可以在不同的语言中发挥作用。
- 停用某些特定关系的神经元可能会提高模型在其他关系事实上的处理能力,这表明神经元之间可能存在干扰效应。
- 实验结果支持了大语言模型中特定关系神经元的存在及其重要性质。
点此查看论文截图


Time series forecasting based on optimized LLM for fault prediction in distribution power grid insulators
Authors:João Pedro Matos-Carvalho, Stefano Frizzo Stefenon, Valderi Reis Quietinho Leithardt, Kin-Choong Yow
Surface contamination on electrical grid insulators leads to an increase in leakage current until an electrical discharge occurs, which can result in a power system shutdown. To mitigate the possibility of disruptive faults resulting in a power outage, monitoring contamination and leakage current can help predict the progression of faults. Given this need, this paper proposes a hybrid deep learning (DL) model for predicting the increase in leakage current in high-voltage insulators. The hybrid structure considers a multi-criteria optimization using tree-structured Parzen estimation, an input stage filter for signal noise attenuation combined with a large language model (LLM) applied for time series forecasting. The proposed optimized LLM outperforms state-of-the-art DL models with a root-mean-square error equal to 2.24$\times10^{-4}$ for a short-term horizon and 1.21$\times10^{-3}$ for a medium-term horizon.
电网绝缘子表面污染会导致泄漏电流增加,直至发生电击穿,可能导致电力系统关闭。为了减少停电等破坏性故障的可能性,监测污染和泄漏电流有助于预测故障的发展趋势。鉴于此需求,本文提出了一种用于预测高压绝缘子泄漏电流增加的混合深度学习(DL)模型。该混合结构采用树结构Parzen估计进行多准则优化,包括输入阶段滤波器用于信号噪声衰减,并结合大型语言模型(LLM)进行时间序列预测。所提出的优化LLM优于最先进的DL模型,短期预测的均方根误差为2.24×10^-4,中期预测的均方根误差为1.21×10^-3。
论文及项目相关链接
Summary
绝缘子表面污染会导致泄漏电流增加,进而引发电力系统中断故障。本文提出一种混合深度学习模型来预测高压绝缘子中泄漏电流的增加。该模型使用基于树结构Parzen估计的多准则优化技术,包括信号噪声衰减的输入阶段滤波器以及大型语言模型(LLM)进行时间序列预测。提出的优化LLM相较于其他最新深度学习模型具有更高的性能。短期和中期预测结果的均方根误差分别为$ 2.24 \times 10^{-4}$ 和 $ 1.21 \times 10^{-3}$。
Key Takeaways
点此查看论文截图



Mutual Reinforcement of LLM Dialogue Synthesis and Summarization Capabilities for Few-Shot Dialogue Summarization
Authors:Yen-Ju Lu, Ting-Yao Hu, Hema Swetha Koppula, Hadi Pouransari, Jen-Hao Rick Chang, Yin Xia, Xiang Kong, Qi Zhu, Simon Wang, Oncel Tuzel, Raviteja Vemulapalli
In this work, we propose Mutual Reinforcing Data Synthesis (MRDS) within LLMs to improve few-shot dialogue summarization task. Unlike prior methods that require external knowledge, we mutually reinforce the LLM's dialogue synthesis and summarization capabilities, allowing them to complement each other during training and enhance overall performances. The dialogue synthesis capability is enhanced by directed preference optimization with preference scoring from summarization capability. The summarization capability is enhanced by the additional high quality dialogue-summary paired data produced by the dialogue synthesis capability. By leveraging the proposed MRDS mechanism, we elicit the internal knowledge of LLM in the format of synthetic data, and use it to augment the few-shot real training dataset. Empirical results demonstrate that our method improves dialogue summarization, achieving a 1.5% increase in ROUGE scores and a 0.3% improvement in BERT scores in few-shot settings. Furthermore, our method attains the highest average scores in human evaluations, surpassing both the pre-trained models and the baselines fine-tuned solely for summarization tasks.
在这项工作中,我们提出了大型语言模型(LLM)中的相互增强数据合成(MRDS)方法,以提高小样本对话摘要任务的效果。不同于需要外部知识的方法,我们通过相互增强LLM的对话合成和摘要能力,使它们在训练过程中能够相互补充,从而提高整体性能。对话合成能力通过摘要能力的偏好评分进行定向偏好优化。摘要能力则通过对话合成能力产生的额外高质量对话摘要配对数据进行增强。通过利用提出的MRDS机制,我们以合成数据的形式激发LLM的内部知识,并将其用于扩充小样本真实训练数据集。经验结果表明,我们的方法提高了对话摘要的效果,在少样本环境下ROUGE得分提高了1.5%,BERT得分提高了0.3%。此外,我们的方法在人工评估中获得了最高平均分,超过了预训练模型和仅针对摘要任务进行微调的基础模型。
论文及项目相关链接
PDF NAACL 2025 Findings
Summary
本文提出了LLM中的相互强化数据合成(MRDS)方法,旨在改进少样本对话摘要任务。不同于需要外部知识的方法,本文通过相互强化LLM的对话合成和摘要能力,使它们在训练过程中相互补充,从而提高整体性能。通过对对话合成能力的定向偏好优化和摘要能力的偏好评分,提高了两者的质量。通过利用提出的MRDS机制,激发LLM的内部知识并以合成数据的形式使用,以扩充少样本真实训练数据集。实证结果表明,该方法提高了对话摘要的效果,在少样本条件下ROUGE得分提高1.5%,BERT得分提高0.3%。同时,该方法在人类评估中获得了最高平均分,超越了预训练模型和仅针对摘要任务进行微调的基础模型。
Key Takeaways
- 提出了一种新的方法——相互强化数据合成(MRDS)用于改进LLM在少样本对话摘要任务中的性能。
- MRDS方法不同于需要外部知识的方法,而是强化了LLM内部的对话合成和摘要能力。
- 通过定向偏好优化和偏好评分提高了对话合成和摘要的质量。
- 利用MRDS机制激发LLM的内部知识并以合成数据形式使用,扩充了少样本真实训练数据集。
- 实证结果表明,MRDS方法在对话摘要任务中取得了显著效果,提高了ROUGE和BERT得分。
- MRDS方法在人类评估中表现最佳,超过了预训练模型和针对摘要任务的基线模型。
- 该方法为未来LLM在对话摘要任务中的性能提升提供了新的思路。
点此查看论文截图

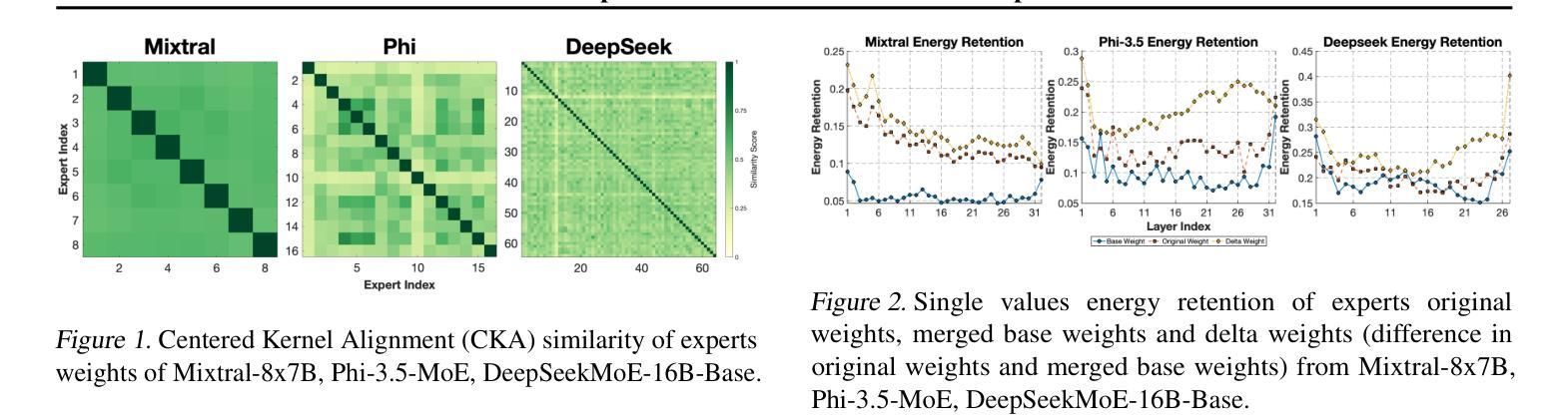
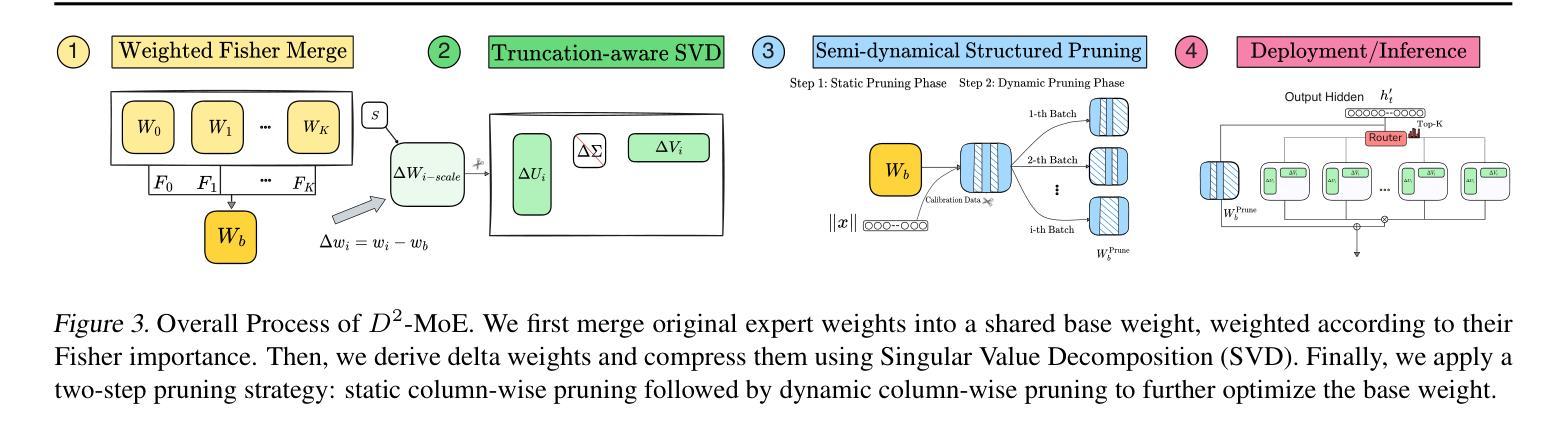
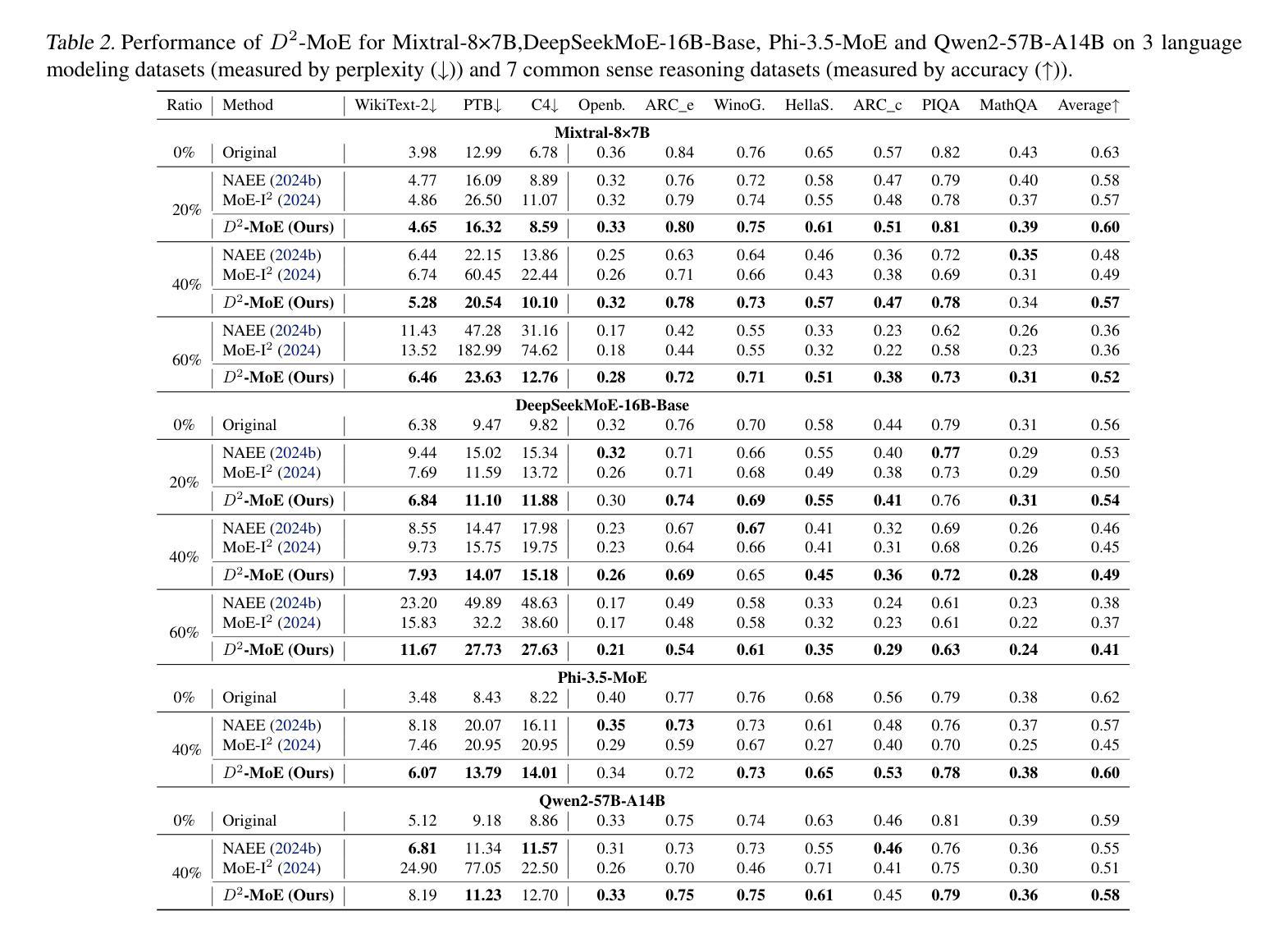
Delta Decompression for MoE-based LLMs Compression
Authors:Hao Gu, Wei Li, Lujun Li, Qiyuan Zhu, Mark Lee, Shengjie Sun, Wei Xue, Yike Guo
Mixture-of-Experts (MoE) architectures in large language models (LLMs) achieve exceptional performance, but face prohibitive storage and memory requirements. To address these challenges, we present $D^2$-MoE, a new delta decompression compressor for reducing the parameters of MoE LLMs. Based on observations of expert diversity, we decompose their weights into a shared base weight and unique delta weights. Specifically, our method first merges each expert’s weight into the base weight using the Fisher information matrix to capture shared components. Then, we compress delta weights through Singular Value Decomposition (SVD) by exploiting their low-rank properties. Finally, we introduce a semi-dynamical structured pruning strategy for the base weights, combining static and dynamic redundancy analysis to achieve further parameter reduction while maintaining input adaptivity. In this way, our $D^2$-MoE successfully compact MoE LLMs to high compression ratios without additional training. Extensive experiments highlight the superiority of our approach, with over 13% performance gains than other compressors on Mixtral|Phi-3.5|DeepSeek|Qwen2 MoE LLMs at 40$\sim$60% compression rates. Codes are available in https://github.com/lliai/D2MoE.
大型语言模型(LLM)中的专家混合(MoE)架构取得了卓越的性能,但面临着存储和内存要求过高的挑战。为了解决这些挑战,我们提出了D^2-MoE,这是一种新的用于减少MoE LLM参数量的增量解压压缩机。基于专家多样性的观察,我们将权重分解为共享基础权重和独特增量权重。具体来说,我们的方法首先使用Fisher信息矩阵将每个专家的权重合并为基础权重,以捕获共享组件。然后,我们通过利用增量权重的低秩属性,通过奇异值分解(SVD)进行压缩。最后,我们对基础权重采用半动态结构化剪枝策略,结合静态和动态冗余分析,以实现进一步的参数缩减并保持输入适应性。通过这种方式,我们的D^2-MoE成功地将MoE LLM压缩到较高的压缩率,且无需额外的训练。大量实验突显了我们方法的优势,在Mixtral|Phi-3.5|DeepSeek|Qwen2 MoE LLM上,与其他压缩机相比,我们在40%~60%的压缩率下实现了超过13%的性能提升。相关代码可在https://github.com/lliai/D2MoE获取。
论文及项目相关链接
PDF Work in progress
Summary
本文介绍了针对大型语言模型(LLM)中的Mixture-of-Experts(MoE)架构的压缩方法$D^2$-MoE。该方法通过分解专家权重,利用Fisher信息矩阵捕获共享成分,并通过奇异值分解(SVD)压缩独特成分,实现MoE架构的高效压缩。此外,还引入了一种半动态结构化剪枝策略,进一步减少了参数数量,同时保持了模型的适应性。实验结果表明,与现有压缩方法相比,该方法的性能优势显著,可以在达到高达压缩率的范围内提升模型性能。具体压缩率高达至少至原来的六折,且代码已公开在GitHub上。
Key Takeaways
以下是针对该文本提取的七个关键要点:
- 介绍了一种新的大型语言模型(LLM)中的Mixture-of-Experts(MoE)架构压缩方法,名为$D^2$-MoE。该设计应对存储和内存方面的挑战。
- 通过分解专家权重来捕获共享和独特成分,以提高MoE架构的压缩效率。这基于专家的多样性和使用Fisher信息矩阵的观察。通过使用奇异值分解(SVD),减少模型参数数量。
点此查看论文截图

Benchmarking Retrieval-Augmented Generation in Multi-Modal Contexts
Authors:Zhenghao Liu, Xingsheng Zhu, Tianshuo Zhou, Xinyi Zhang, Xiaoyuan Yi, Yukun Yan, Yu Gu, Ge Yu, Maosong Sun
This paper introduces Multi-Modal Retrieval-Augmented Generation (M^2RAG), a benchmark designed to evaluate the effectiveness of Multi-modal Large Language Models (MLLMs) in leveraging knowledge from multi-modal retrieval documents. The benchmark comprises four tasks: image captioning, multi-modal question answering, multi-modal fact verification, and image reranking. All tasks are set in an open-domain setting, requiring RAG models to retrieve query-relevant information from a multi-modal document collection and use it as input context for RAG modeling. To enhance the context utilization capabilities of MLLMs, we also introduce Multi-Modal Retrieval-Augmented Instruction Tuning (MM-RAIT), an instruction tuning method that optimizes MLLMs within multi-modal contexts. Our experiments show that MM-RAIT improves the performance of RAG systems by enabling them to effectively learn from multi-modal contexts. All data and code are available at https://github.com/NEUIR/M2RAG.
本文介绍了多模态检索增强生成(M^2RAG)基准测试,该基准测试旨在评估多模态大型语言模型(MLLMs)在利用多模态检索文档中的知识方面的有效性。该基准测试包括四项任务:图像描述、多模态问答、多模态事实核查和图像重新排序。所有任务都在开放领域环境中设置,需要RAG模型从多模态文档集合中检索与查询相关的信息,并将其用作RAG建模的输入上下文。为了提高MLLMs的上下文利用能力,我们还引入了多模态检索增强指令调整(MM-RAIT),这是一种在多媒体上下文中优化MLLMs的指令调整方法。我们的实验表明,MM-RAIT通过使RAG系统能够有效地从多媒体上下文中学习,提高了其性能。所有数据和代码都可在https://github.com/NEUIR/M2RAG找到。
论文及项目相关链接
Summary
本文介绍了多模态检索增强生成(M^2RAG)基准测试,旨在评估多模态大型语言模型(MLLMs)从多模态检索文档中利用知识的效果。该基准测试包括图像描述、多模态问答、多模态事实核查和图像重排序四个任务。所有任务均在开放领域设置,要求RAG模型从多模态文档集合中检索与查询相关的信息,并将其用作RAG建模的输入上下文。为增强MLLMs在上下文利用方面的能力,还介绍了多模态检索增强指令调整(MM-RAIT)方法。实验表明,MM-RAIT通过使RAG系统能够有效学习多模态上下文,提高了其性能。
Key Takeaways
- M^2RAG是一个旨在评估MLLMs在多模态检索文档中的知识利用效果的基准测试。
- M^2RAG包含图像描述、多模态问答、多模态事实核查和图像重排序四个任务。
- 所有任务均在开放领域设置,需要从多模态文档集合中检索相关信息。
- MM-RAIT是一种优化MLLMs在多模态上下文中的指令调整方法。
- MM-RAIT通过使RAG系统能够有效学习多模态上下文,提高了其性能。
- M^2RAG的数据和代码可在https://github.com/NEUIR/M2RAG找到。
- MLLMs在多模态上下文中的性能提升对于实现更智能、更全面的语言模型具有重要意义。
点此查看论文截图



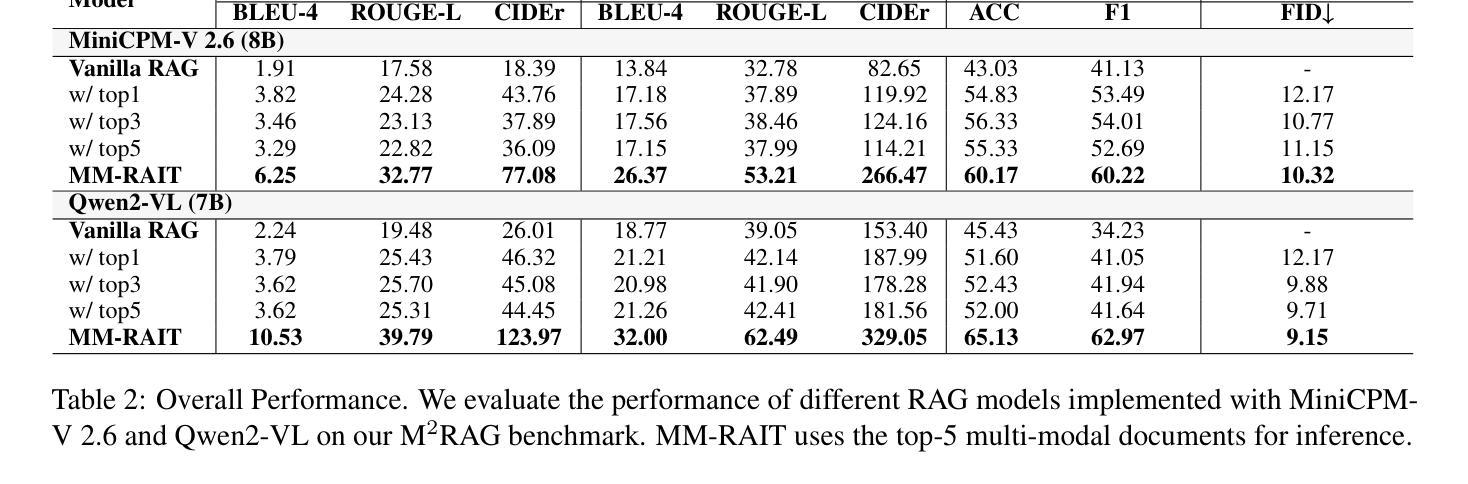
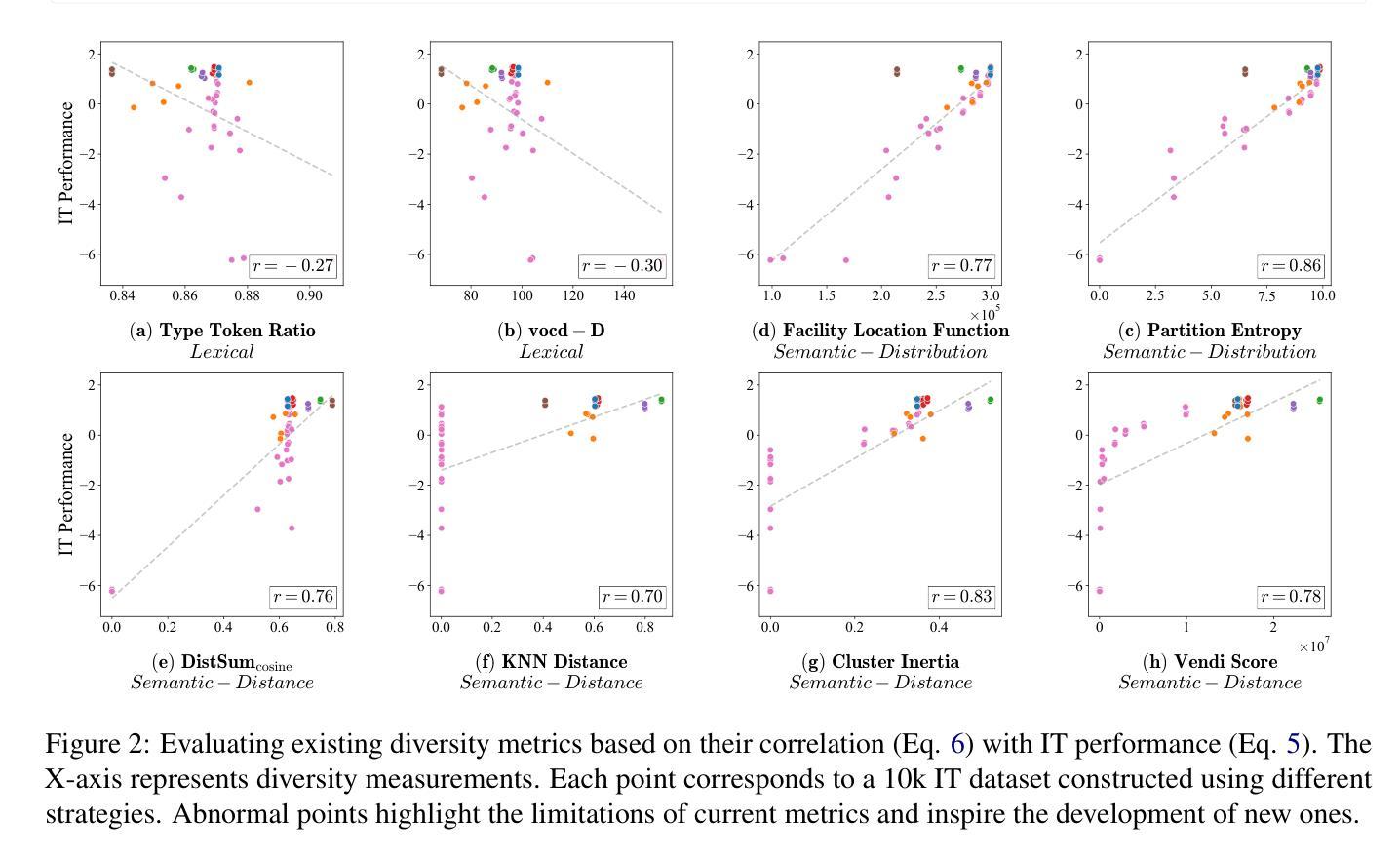
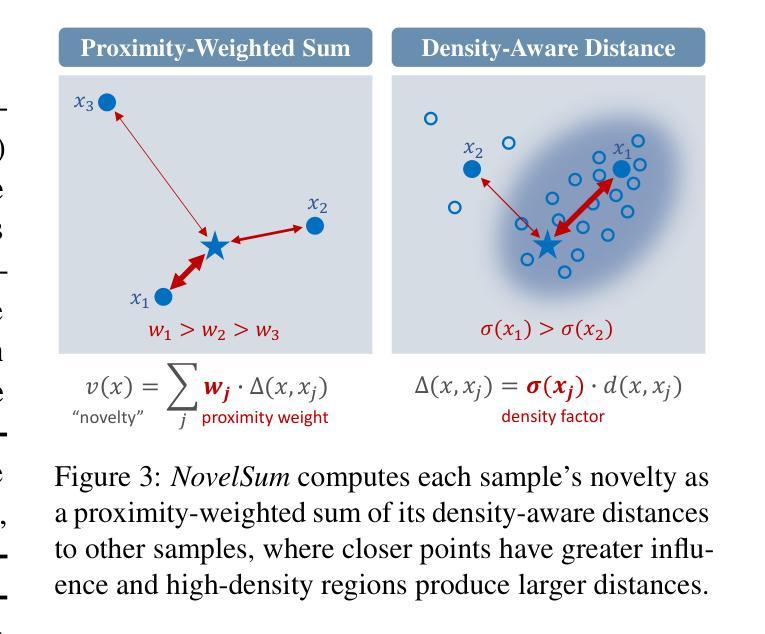
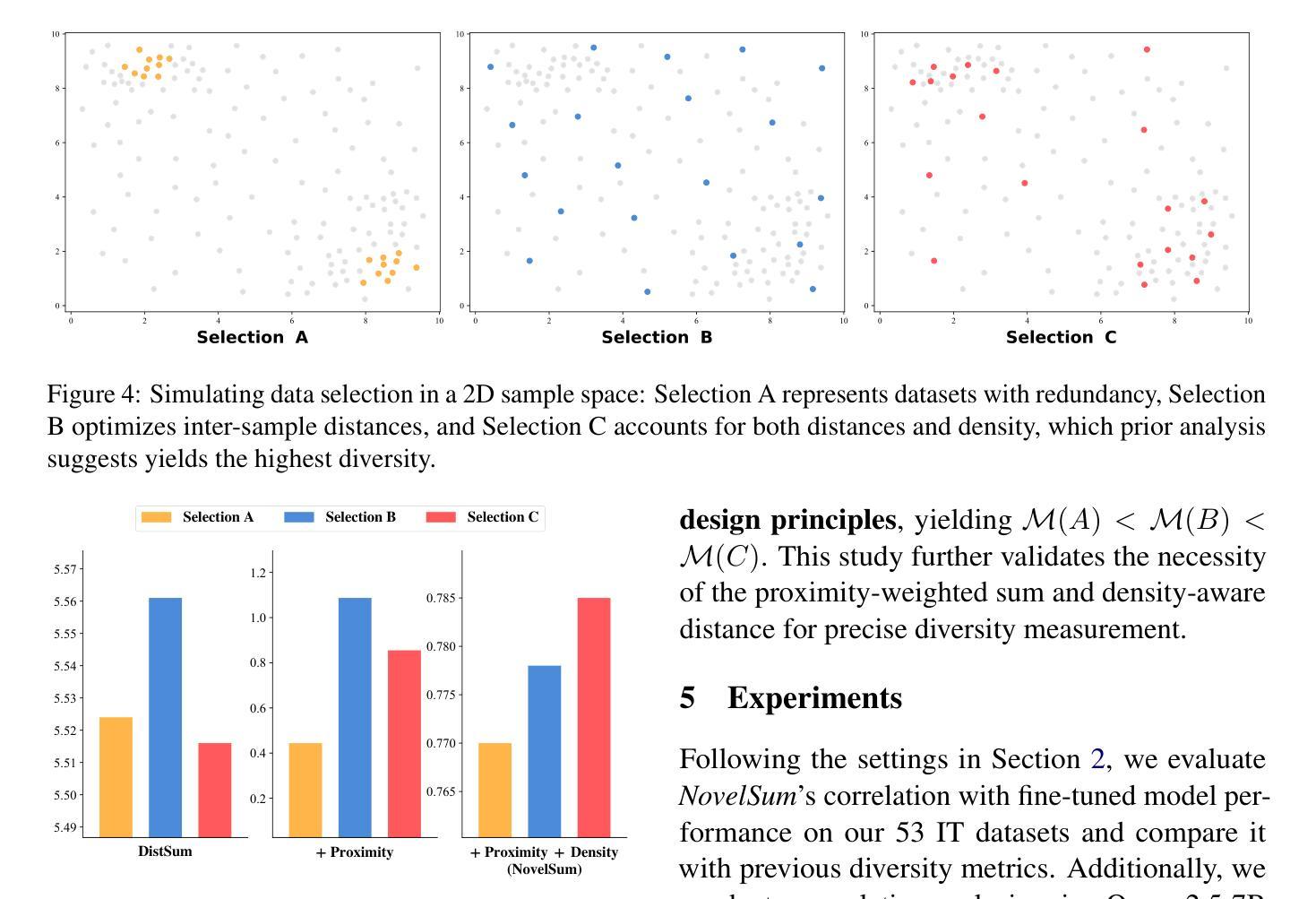
Measuring Data Diversity for Instruction Tuning: A Systematic Analysis and A Reliable Metric
Authors:Yuming Yang, Yang Nan, Junjie Ye, Shihan Dou, Xiao Wang, Shuo Li, Huijie Lv, Tao Gui, Qi Zhang, Xuanjing Huang
Data diversity is crucial for the instruction tuning of large language models. Existing studies have explored various diversity-aware data selection methods to construct high-quality datasets and enhance model performance. However, the fundamental problem of precisely defining and measuring data diversity remains underexplored, limiting clear guidance for data engineering. To address this, we systematically analyze 11 existing diversity measurement methods by assessing their correlation with model performance through extensive fine-tuning experiments. Our results indicate that a reliable diversity measure should properly account for both inter-sample differences and the information distribution in the sample space. Building on this, we propose NovelSum, a new diversity metric based on sample-level “novelty.” Experiments on both simulated and real-world data show that NovelSum accurately captures diversity variations and achieves a 0.97 correlation with instruction-tuned model performance, highlighting its value in guiding data engineering practices. With NovelSum as an optimization objective, we further develop a greedy, diversity-oriented data selection strategy that outperforms existing approaches, validating both the effectiveness and practical significance of our metric.
数据的多样性对于大语言模型的指令调整至关重要。现有研究已经探索了各种意识多样性的数据选择方法来构建高质量的数据集,以提高模型性能。然而,关于精确定义和测量数据多样性的根本问题仍然被探索得不够深入,这限制了数据工程的明确指导。为了解决这一问题,我们通过广泛的微调实验评估了现有1 1种多样性测量方法与模型性能的相关性,进行了系统分析。我们的结果表明,可靠的多样性度量应适当地考虑样本之间的差异以及样本空间中的信息分布。在此基础上,我们提出了基于样本级“新颖性”的NovelSum新多样性指标。在模拟和真实数据上的实验表明,NovelSum准确地捕捉了多样性变化,与指令调整模型性能的相关性达到0.9 7,凸显其在指导数据工程实践中的价值。以NovelSum为优化目标,我们进一步开发了一种贪婪的、以多样性为导向的数据选择策略,其性能优于现有方法,验证了我们指标的有效性和实际意义。
论文及项目相关链接
PDF 15 pages. The related codes and resources will be released later. Project page: https://github.com/UmeanNever/NovelSum
摘要
数据多样性对于大语言模型的指令微调至关重要。现有研究已探索了各种多样性感知的数据选择方法来构建高质量数据集,以提高模型性能。然而,精确定义和测量数据多样性的基础问题仍未得到充分探索,对数据工程缺乏明确指导。本文系统地分析了11种现有的多样性测量方法,通过大量的微调实验评估它们与模型性能的相关性。结果表明,可靠的多样性测量应适当考虑样本间的差异以及样本空间中的信息分布。基于此,我们提出了基于样本级“新颖性”的NovelSum新多样性指标。在模拟和真实数据上的实验表明,NovelSum能准确捕捉多样性变化,与指令调整模型性能的相关性达到0.97,突显其在指导数据工程实践中的价值。以NovelSum为优化目标,我们进一步开发了一种贪婪的、以多样性为导向的数据选择策略,优于现有方法,验证了我们的指标的有效性和实际意义。
关键见解
- 数据多样性对大语言模型的指令微调至关重要。
- 现有研究已探索了多种多样性感知的数据选择方法。
- 数据多样性的精确定义和测量仍是未充分探索的领域。
- 本文分析了11种多样性测量方法,并发现可靠的多样性测量应综合考虑样本间差异和样本空间的信息分布。
- 提出了基于样本级“新颖性”的新多样性指标NovelSum。
- NovelSum能准确捕捉多样性变化,与模型性能高度相关。
点此查看论文截图
The Role of Sparsity for Length Generalization in Transformers
Authors:Noah Golowich, Samy Jelassi, David Brandfonbrener, Sham M. Kakade, Eran Malach
Training large language models to predict beyond their training context lengths has drawn much attention in recent years, yet the principles driving such behavior of length generalization remain underexplored. We propose a new theoretical framework to study length generalization for the next-token prediction task, as performed by decoder-only transformers. Conceptually, we show that length generalization occurs as long as each predicted token depends on a small (fixed) number of previous tokens. We formalize such tasks via a notion we call $k$-sparse planted correlation distributions, and show that an idealized model of transformers which generalize attention heads successfully length-generalize on such tasks. As a bonus, our theoretical model justifies certain techniques to modify positional embeddings which have been introduced to improve length generalization, such as position coupling. We support our theoretical results with experiments on synthetic tasks and natural language, which confirm that a key factor driving length generalization is a ``sparse’’ dependency structure of each token on the previous ones. Inspired by our theory, we introduce Predictive Position Coupling, which trains the transformer to predict the position IDs used in a positional coupling approach. Predictive Position Coupling thereby allows us to broaden the array of tasks to which position coupling can successfully be applied to achieve length generalization.
近年来,训练大型语言模型以预测其训练上下文长度之外的内容已经引起了广泛关注,然而驱动这种长度泛化行为的原则仍然未被充分探索。我们提出一个新的理论框架来研究仅解码的Transformer执行的下一个令牌预测任务的长度泛化。从概念上我们表明,只要每个预测的令牌依赖于前面的一小串(固定)令牌,就会发生长度泛化。我们通过所谓的k稀疏植入相关性分布的概念来正式定义此类任务,并表明在类似的任务上,能够成功实现长度泛化的通用化注意力头在理想化的Transformer模型中得到证实。此外,我们的理论模型验证了为了提高长度泛化而引入的修改位置嵌入的一些技术,例如位置耦合。我们通过合成任务和自然语言实验来支持我们的理论结果,实验证实,驱动长度泛化的一个关键因素是令牌对前一个令牌的“稀疏”依赖结构。受我们理论的启发,我们引入了预测位置耦合,它训练Transformer预测位置耦合方法中使用的位置ID。预测位置耦合从而扩大了位置耦合成功应用的任务范围,以实现长度泛化。
论文及项目相关链接
Summary
本文提出了一个新的理论框架来研究仅解码的transformer在下一个令牌预测任务中的长度泛化行为。实验表明,长度泛化的发生取决于每个预测的令牌与前面令牌之间的稀疏依赖关系。通过理论分析和实验验证,本文揭示了长度泛化的关键因素,并提出了预测位置耦合的方法,该方法训练变压器预测位置ID,从而扩大了位置耦合成功应用的任务范围。
Key Takeaways
- 提出新的理论框架研究仅解码的transformer在长度泛化方面的行为。
- 长度泛化的发生取决于每个预测的令牌与前面令牌之间的稀疏依赖关系。
- 通过实验验证了长度泛化的关键因素。
- 介绍了一种新的方法——预测位置耦合,该方法训练变压器预测位置ID。
- 预测位置耦合方法有助于扩大位置耦合成功应用的任务范围。
- 理论分析和实验验证共同支持了上述观点。
点此查看论文截图

AeroReformer: Aerial Referring Transformer for UAV-based Referring Image Segmentation
Authors:Rui Li
As a novel and challenging task, referring segmentation combines computer vision and natural language processing to localize and segment objects based on textual descriptions. While referring image segmentation (RIS) has been extensively studied in natural images, little attention has been given to aerial imagery, particularly from unmanned aerial vehicles (UAVs). The unique challenges of UAV imagery, including complex spatial scales, occlusions, and varying object orientations, render existing RIS approaches ineffective. A key limitation has been the lack of UAV-specific datasets, as manually annotating pixel-level masks and generating textual descriptions is labour-intensive and time-consuming. To address this gap, we design an automatic labelling pipeline that leverages pre-existing UAV segmentation datasets and Multimodal Large Language Models (MLLM) for generating textual descriptions. Furthermore, we propose Aerial Referring Transformer (AeroReformer), a novel framework for UAV referring image segmentation (UAV-RIS), featuring a Vision-Language Cross-Attention Module (VLCAM) for effective cross-modal understanding and a Rotation-Aware Multi-Scale Fusion (RAMSF) decoder to enhance segmentation accuracy in aerial scenes. Extensive experiments on two newly developed datasets demonstrate the superiority of AeroReformer over existing methods, establishing a new benchmark for UAV-RIS. The datasets and code will be publicly available at: https://github.com/lironui/AeroReformer.
作为一项新颖且具挑战性的任务,引用分割结合了计算机视觉和自然语言处理,根据文本描述来定位和分割对象。虽然图像引用分割(RIS)在自然图像中得到了广泛的研究,但对航空图像的关注却很少,特别是来自无人机(UAV)的图像。无人机图像具有独特的挑战,包括复杂的空间尺度、遮挡和变化的对象方向,使得现有的RIS方法效果不佳。一个关键的限制是缺乏针对无人机的特定数据集,因为手动注释像素级蒙版和生成文本描述是劳动密集型的,且耗时。为了弥补这一空白,我们设计了一个自动标注管道,该管道利用现有的无人机分割数据集和多模态大型语言模型(MLLM)来生成文本描述。此外,我们提出了无人机引用图像分割(UAV-RIS)的新框架“AerialReferring Transformer”(AeroReformer),该框架具有视觉语言跨注意力模块(VLCAM),可实现有效的跨模态理解,以及旋转感知多尺度融合(RAMSF)解码器,可提高航空场景中的分割精度。在两个新开发的数据集上进行的广泛实验表明,AeroReformer优于现有方法,为UAV-RIS建立了新的基准。数据集和代码将在https://github.com/lironui/AeroReformer公开可用。
论文及项目相关链接
Summary:
利用计算机视觉和自然语言处理技术,参照分割任务可以实现对基于文本描述的对象定位和分割。尽管自然图像的参照图像分割(RIS)已得到广泛研究,但无人机影像的参照图像分割(UAV-RIS)尚未受到足够重视。无人机影像具有独特的挑战,如复杂的空间尺度、遮挡和变化的对象方向,使得现有的RIS方法效果不佳。为解决这一空白,我们设计了利用现有无人机分割数据集和多模态大型语言模型(MLLM)生成文本描述的自动标注管道。此外,我们提出了名为Aeroreformer的新框架,具有用于有效跨模态理解的视觉语言跨注意力模块(VLCAM)和用于增强航空场景分割准确度的旋转感知多尺度融合(RAMSF)解码器。在两个新开发数据集上的大量实验表明,Aeroreformer优于现有方法,为UAV-RIS建立了新的基准。数据集和代码将在lironui/Aeroreformer公开可用。
Key Takeaways:
- 参照分割任务结合了计算机视觉和自然语言处理,基于文本描述进行对象定位和分割。
- 目前对无人机影像的参照图像分割(UAV-RIS)研究不足。
- 无人机影像存在独特的挑战,如复杂的空间尺度、遮挡和对象方向变化。
- 现有方法因无法有效处理这些挑战而效果不佳。
- 为解决此问题,设计了利用现有无人机分割数据集和多模态大型语言模型的自动标注管道。
- 提出了名为Aeroreformer的新框架,具有视觉语言跨注意力模块(VLCAM)和旋转感知多尺度融合(RAMSF)解码器。
点此查看论文截图

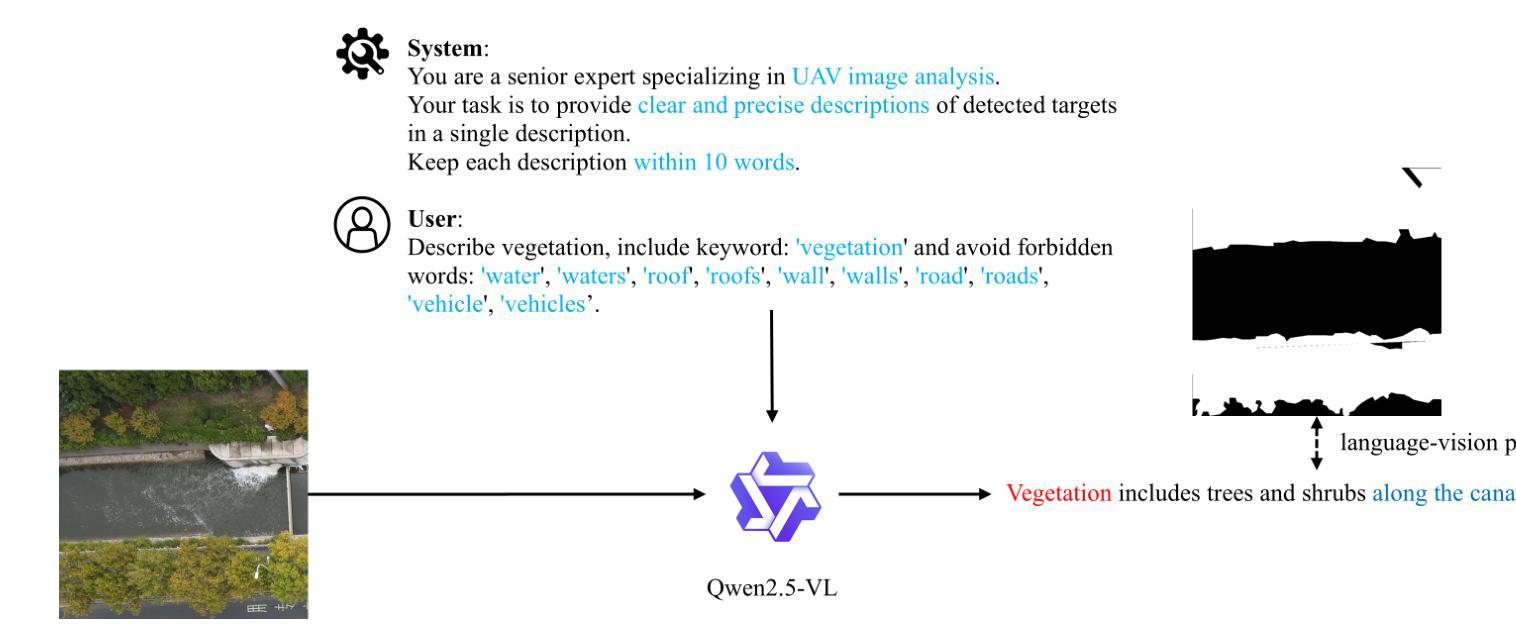

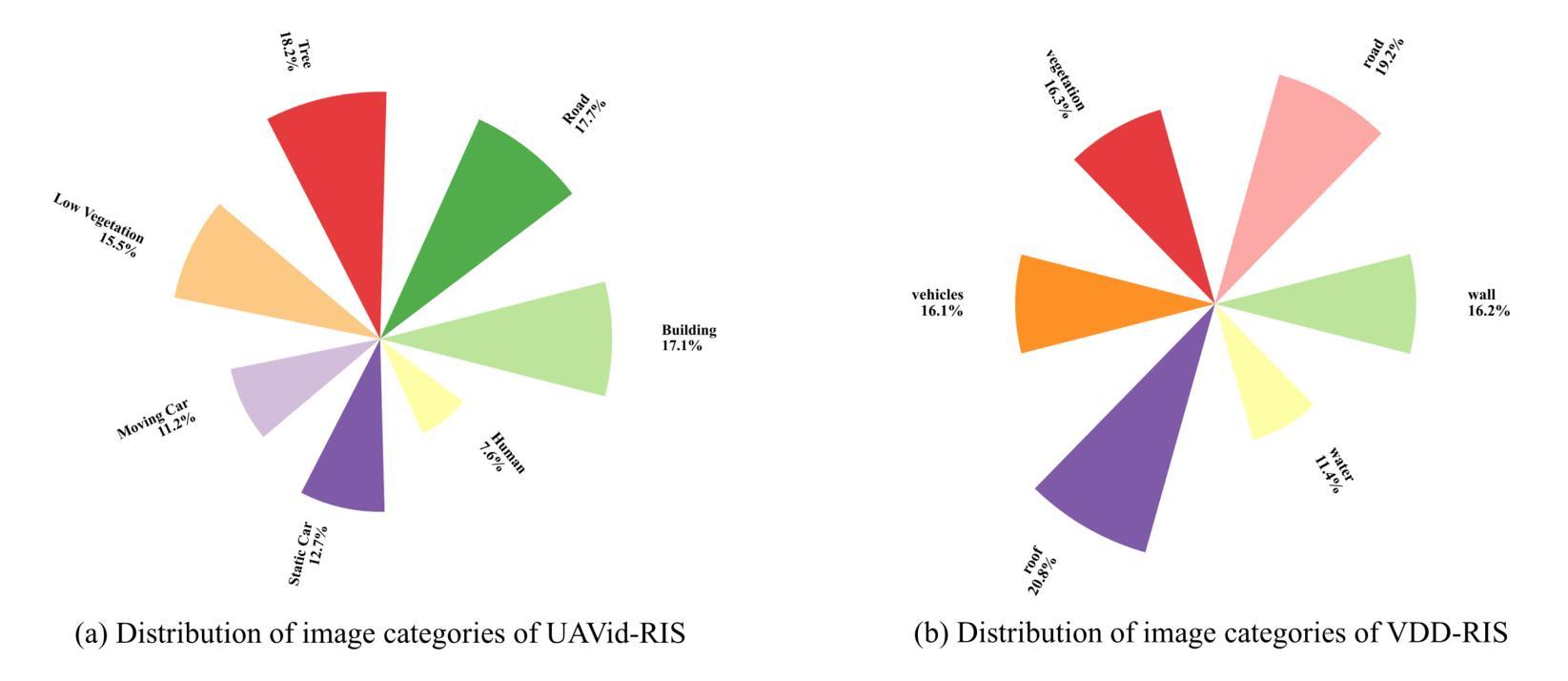
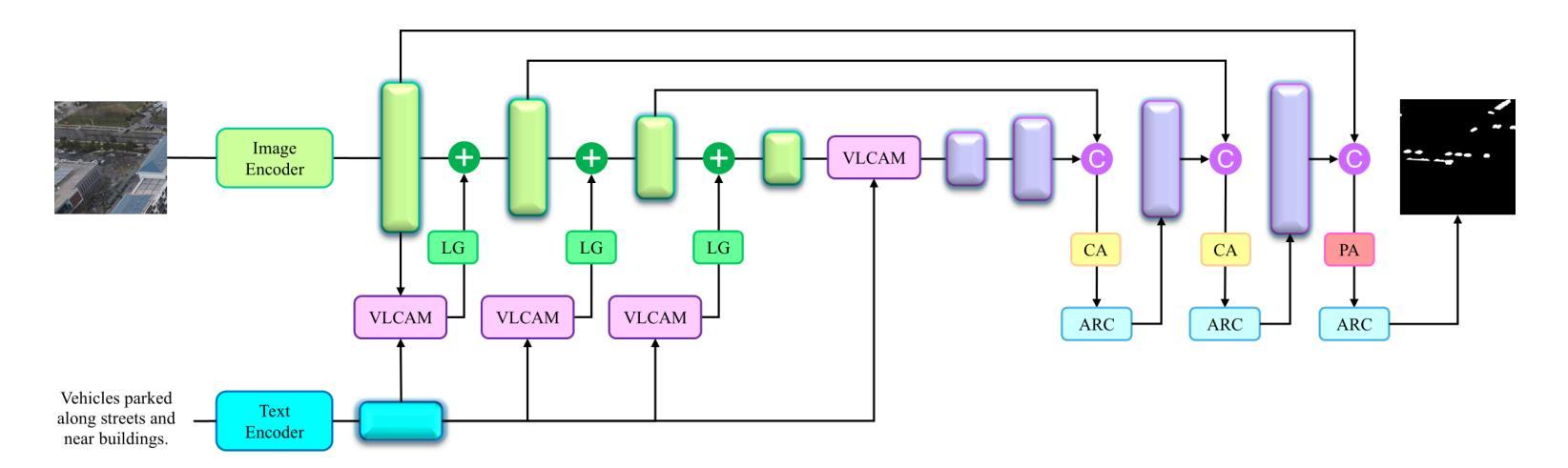
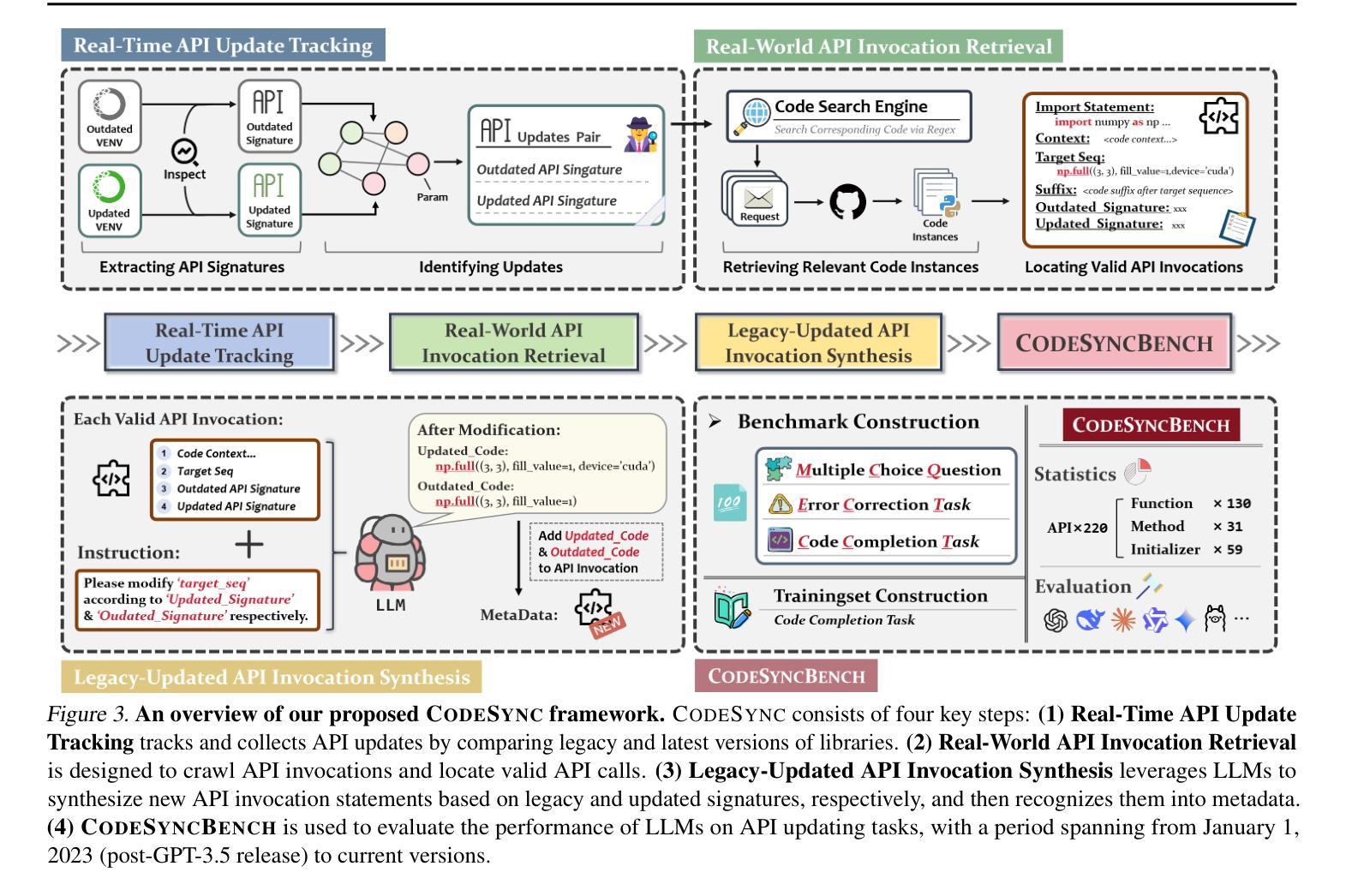
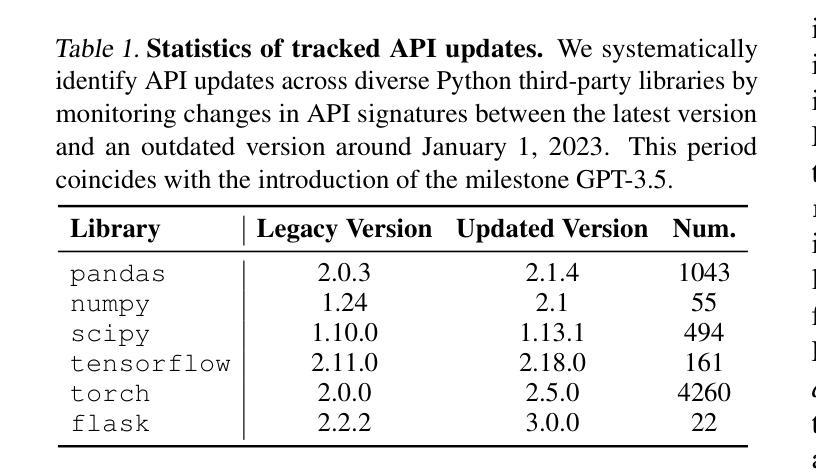
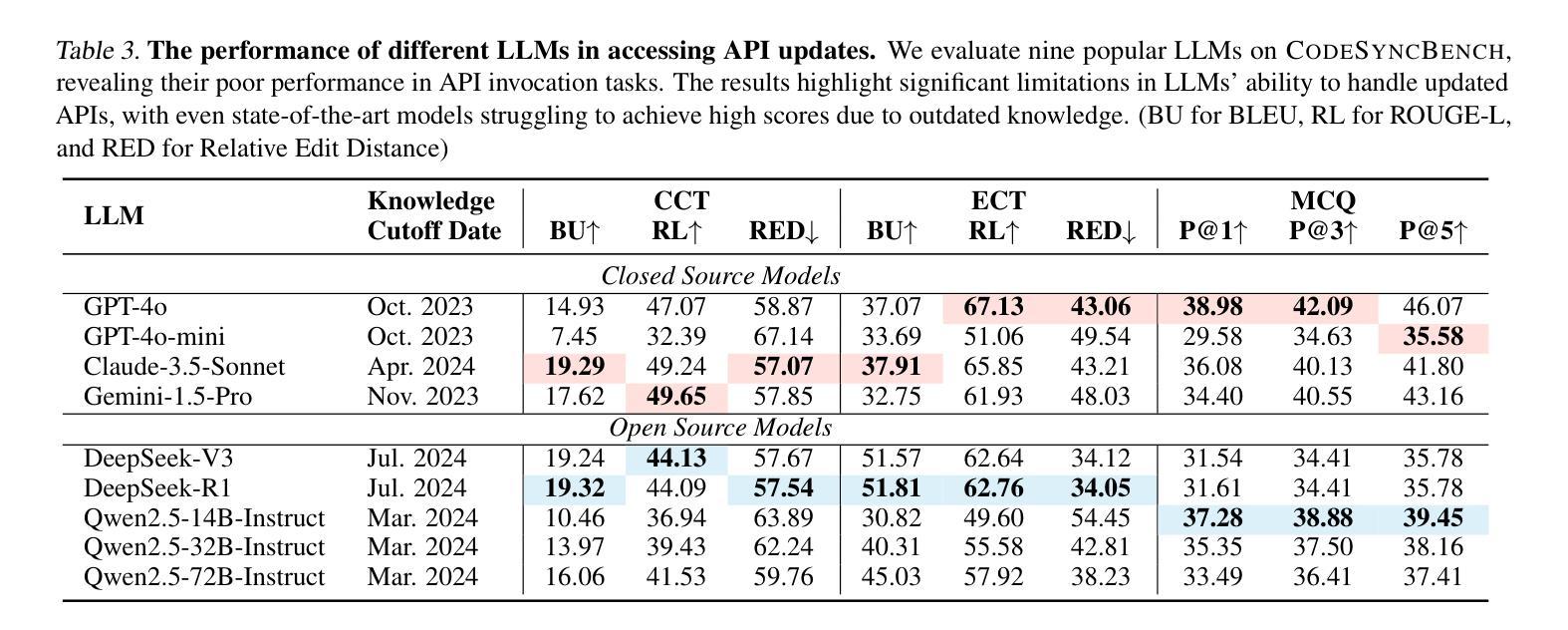
CODESYNC: Synchronizing Large Language Models with Dynamic Code Evolution at Scale
Authors:Chenlong Wang, Zhaoyang Chu, Zhengxiang Cheng, Xuyi Yang, Kaiyue Qiu, Yao Wan, Zhou Zhao, Xuanhua Shi, Dongping Chen
Large Language Models (LLMs) have exhibited exceptional performance in software engineering yet face challenges in adapting to continually evolving code knowledge, particularly regarding the frequent updates of third-party library APIs. This limitation, stemming from static pre-training datasets, often results in non-executable code or implementations with suboptimal safety and efficiency. To this end, this paper introduces CODESYNC, a data engine for identifying outdated code patterns and collecting real-time code knowledge updates from Python third-party libraries. Building upon CODESYNC, we develop CODESYNCBENCH, a comprehensive benchmark for assessing LLMs’ ability to stay synchronized with code evolution, which covers real-world updates for 220 APIs from six Python libraries. Our benchmark offers 3,300 test cases across three evaluation tasks and an update-aware instruction tuning dataset consisting of 2,200 training samples. Extensive experiments on 14 state-of-the-art LLMs reveal that they struggle with dynamic code evolution, even with the support of advanced knowledge updating methods (e.g., DPO, ORPO, and SimPO). We believe that our benchmark can offer a strong foundation for the development of more effective methods for real-time code knowledge updating in the future. The experimental code and dataset are publicly available at: https://github.com/Lucky-voyage/Code-Sync.
大型语言模型(LLM)在软件工程领域表现出卓越的性能,但在适应不断演变的代码知识方面仍面临挑战,特别是在第三方库API频繁更新的情况下。这一局限性源于静态的预训练数据集,往往导致生成的代码不可执行,或在安全性和效率方面存在次优实现。针对这一问题,本文介绍了CODESYNC,一个用于识别过时代码模式并从Python第三方库中实时收集代码知识更新的数据引擎。基于CODESYNC,我们开发了CODESYNCBENCH,一个全面评估LLM与代码进化同步能力的基准测试,涵盖了来自六个Python库的220个API的实时更新。我们的基准测试包含3300个测试用例,涵盖三个评估任务,以及一个包含2200个训练样本的更新感知指令调整数据集。对14种最新的大型语言模型的广泛实验表明,即使在先进的更新知识方法(如DPO、ORPO和SimPO)的支持下,它们在处理动态代码进化方面仍然面临困难。我们相信,我们的基准测试可以为未来开发更有效的实时代码知识更新方法提供坚实的基础。实验代码和数据集可在以下网址公开获取:https://github.com/Lucky-voyage/Code-Sync。
论文及项目相关链接
Summary
LLM在面对持续演化的代码知识时面临挑战,特别是第三方库API的频繁更新。本文提出CODESYNC数据引擎和CODESYNCBENCH基准测试,旨在解决这一问题。CODESYNC可识别过时代码模式并从Python第三方库实时收集代码知识更新。CODESYNCBENCH评估LLM在代码进化中的同步能力,涵盖六个Python库的220个API的真实世界更新。实验表明,即使使用先进的知识更新方法,LLM在动态代码演化方面仍面临困难。
Key Takeaways
- LLM在软件工程中表现出卓越性能,但在适应不断演化的代码知识方面面临挑战。
- 第三方库API的频繁更新给LLM带来特定困难。
- CODESYNC数据引擎用于识别过时代码模式并从Python第三方库收集实时代码知识更新。
- CODESYNCBENCH基准测试用于评估LLM在代码进化中的同步能力,涵盖真实世界更新和多种评价任务。
- 实验显示,即使使用先进的知识更新方法,LLM在处理动态代码演化时仍表现不足。
- 本文提供的基准测试为开发更有效的实时代码知识更新方法提供了基础。
点此查看论文截图

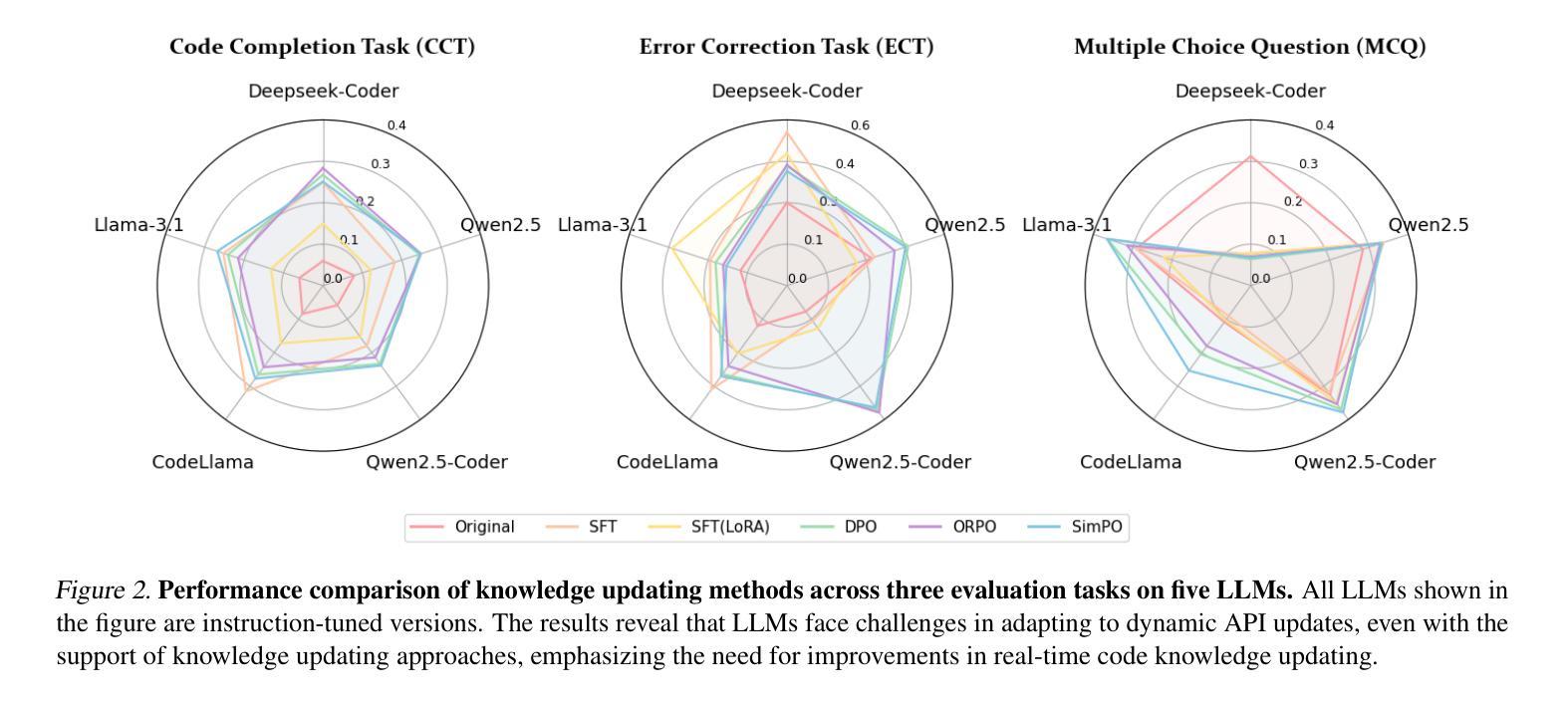

Enhancing Domain-Specific Retrieval-Augmented Generation: Synthetic Data Generation and Evaluation using Reasoning Models
Authors:Aryan Jadon, Avinash Patil, Shashank Kumar
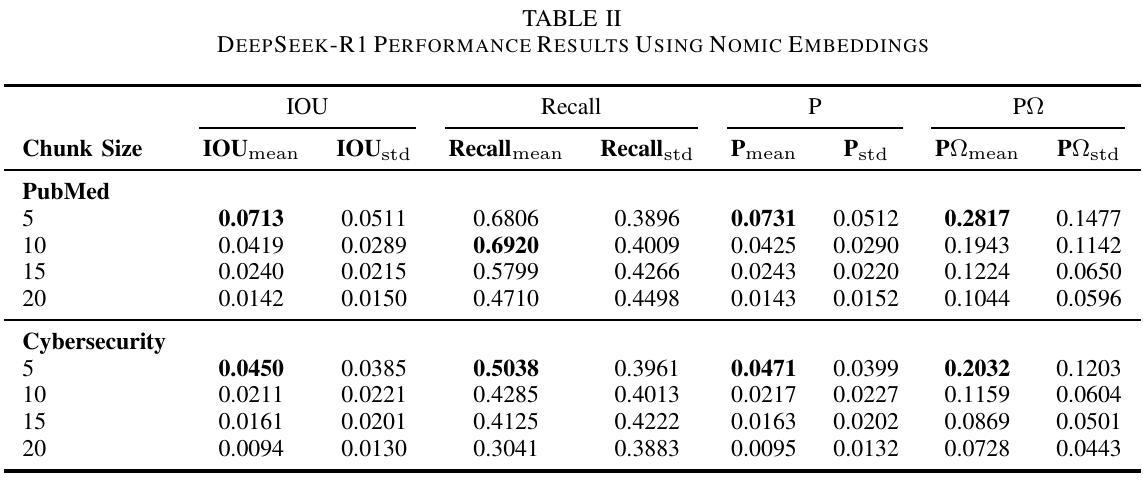
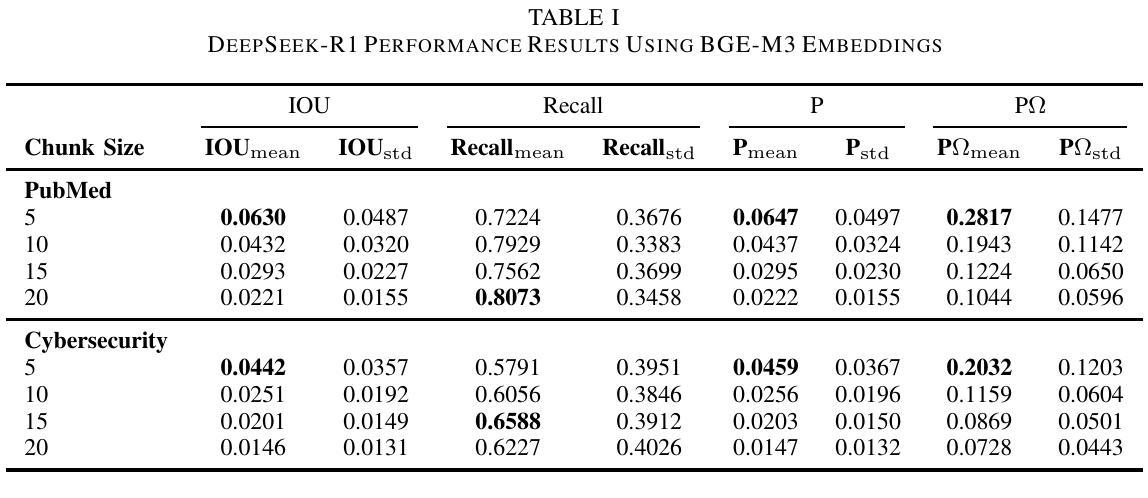
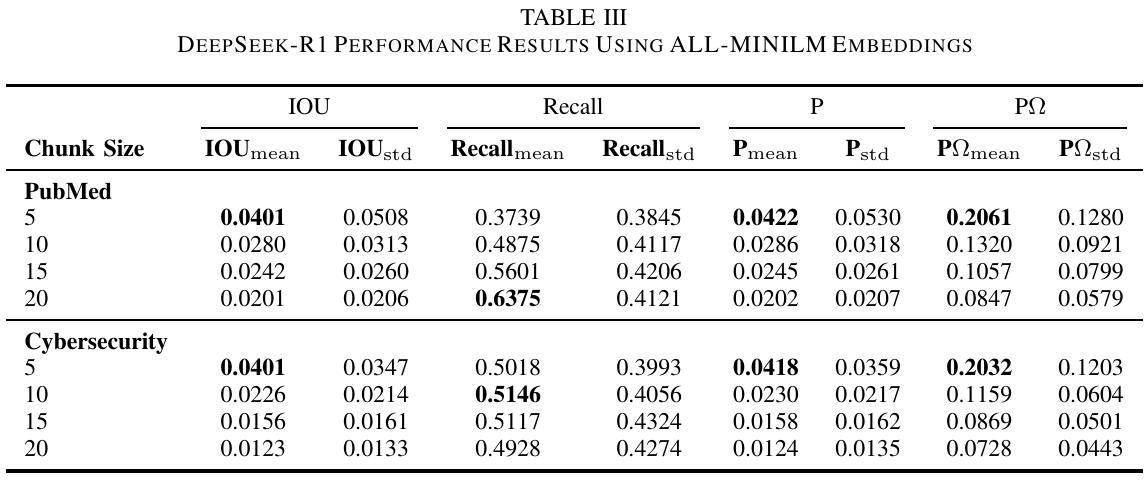
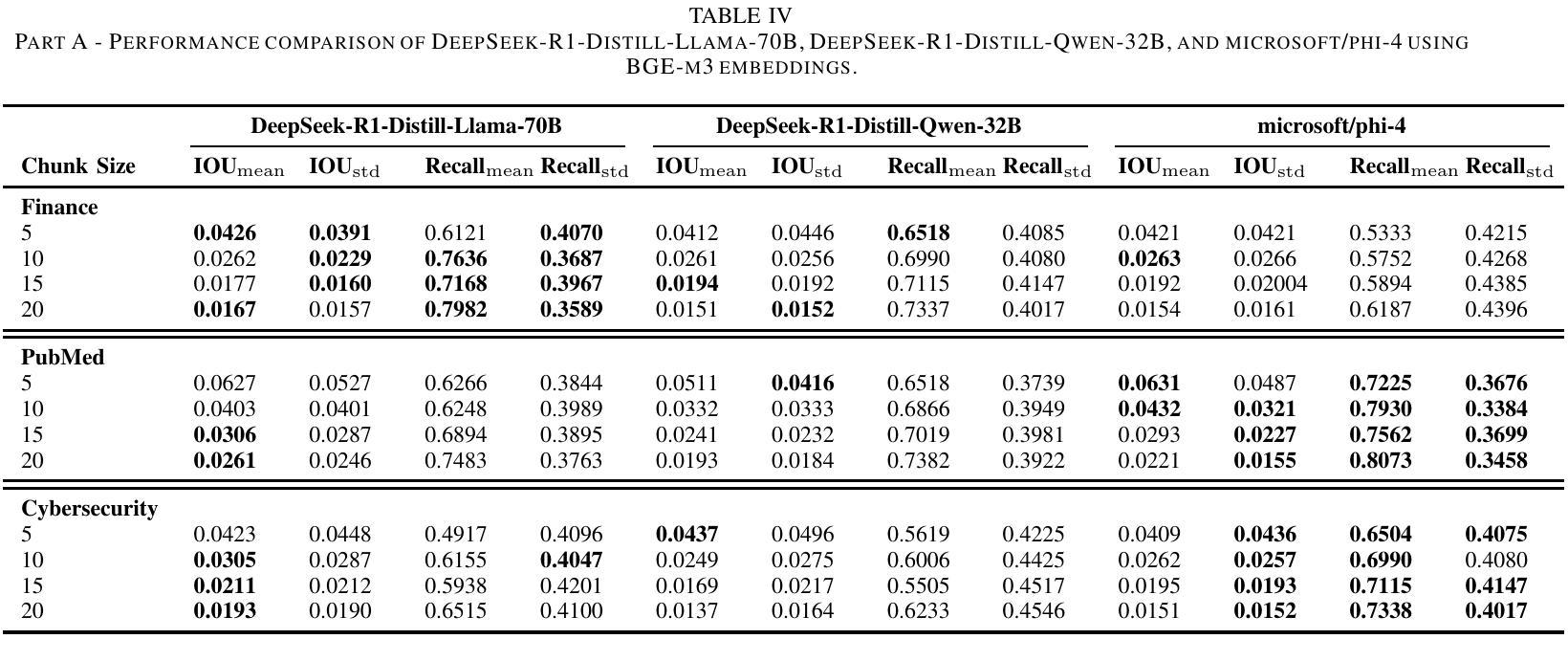
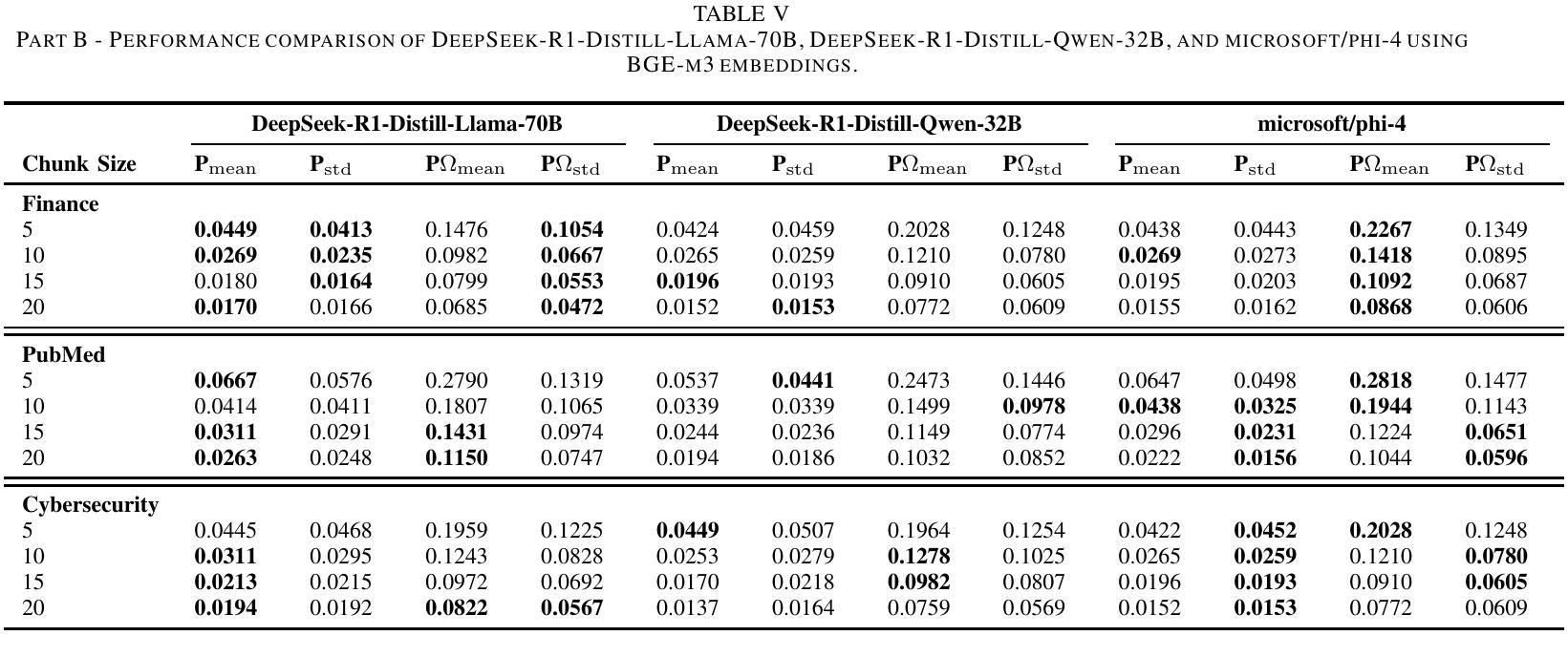
Retrieval-Augmented Generation (RAG) systems face significant performance gaps when applied to technical domains requiring precise information extraction from complex documents. Current evaluation methodologies relying on document-level metrics inadequately capture token-resolution retrieval accuracy that is critical for domain-related documents. We propose a framework combining granular evaluation metrics with synthetic data generation to optimize domain-specific RAG performance. First, we introduce token-aware metrics Precision $\Omega$ and Intersection-over-Union (IoU) that quantify context preservation versus information density trade-offs inherent in technical texts. Second, we develop a reasoning model-driven pipeline using instruction-tuned LLMs (DeepSeek-R1, DeepSeek-R1 distilled variants, and Phi-4) to generate context-anchored QA pairs with discontinuous reference spans across three specialized corpora: SEC 10-K filings (finance), biomedical abstracts (PubMed), and APT threat reports (cybersecurity). Our empirical analysis reveals critical insights: smaller chunks (less than 10 tokens) improve precision by 31-42% (IoU = 0.071 vs. baseline 0.053) at recall costs (-18%), while domain-specific embedding strategies yield 22% variance in optimal chunk sizing (5-20 tokens). The DeepSeek-R1-Distill-Qwen-32B model demonstrates superior concept alignment (+14% mean IoU over alternatives), though no configuration universally dominates. Financial texts favor larger chunks for risk factor coverage (Recall = 0.81 at size = 20), whereas cybersecurity content benefits from atomic segmentation, Precision $\Omega = 0.28$ at size = 5. Our code is available on https://github.com/aryan-jadon/Synthetic-Data-Generation-and-Evaluation-using-Reasoning-Model
检索增强生成(RAG)系统在应用于需要精确提取复杂文档信息的技术领域时,存在显著的性能差距。当前依赖文档级别的评估方法不足以捕捉对领域相关文档至关重要的令牌解析检索准确性。我们提出了一种结合粒度评估指标和合成数据生成的框架,以优化特定领域的RAG性能。首先,我们引入了令牌感知指标精度Ω(Precision Omega)和交并比(IoU),以量化技术文本中固有的上下文保留与信息密度之间的权衡。其次,我们使用指令微调的大型语言模型(DeepSeek-R1、DeepSeek-R1蒸馏变种和Phi-4)开发了一个基于推理模型的管道,生成与三个专业语料库相关的上下文锚定的问答对:包括SEC 10-K报告(金融)、生物医学摘要(PubMed)和APT威胁报告(网络安全)。我们的实证分析揭示了关键见解:较小的片段(少于10个令牌)通过提高精度(IoU = 0.071与基线0.053相比)来优化召回率(-18%),而特定领域的嵌入策略导致最佳片段大小有22%的变动范围(5-20个令牌)。DeepSeek-R1-Distill-Qwen-32B模型显示出更好的概念对齐(相对于替代模型平均IoU提高14%),但没有配置能够普遍占据主导地位。金融文本倾向于较大的块以覆盖风险因素(大小为20时的召回率为0.81),而网络安全内容受益于原子分割(大小为5时的精度Ω为0.28)。我们的代码可在https://github.com/aryan-jadon/Synthetic-Data-Generation-and-Evaluation-using-Reasoning-Model找到。
论文及项目相关链接
PDF 8 Pages
Summary
本文介绍了针对技术领域的检索增强生成(RAG)系统性能提升的研究。针对现有评估方法的不足,提出了结合精细评估指标和合成数据生成的框架。引入token级别的精度Ω和交集比(IoU)指标,量化技术文本中的上下文保留与信息密度权衡。同时,利用指令微调的大型语言模型(LLMs)生成上下文相关的问答对,涵盖三个专业语料库。实证分析显示,较小的token块在提高精度方面效果显著,而针对特定领域的嵌入策略对最佳块大小有影响。相关代码已公开在GitHub上。
Key Takeaways
- 当前针对技术领域的检索增强生成(RAG)系统存在性能差距。
- 传统文档级评估指标无法有效捕捉token级别的精确检索准确度。
- 引入token-aware评估指标如精度Ω和交集比(IoU),衡量技术文本中的上下文保留与信息密度权衡。
- 提出结合精细评估指标与合成数据生成的框架,优化领域特定RAG性能。
- 利用指令微调的大型语言模型生成上下文相关的问答对,涵盖金融、生物医学和网络安全领域的专业语料库。
- 实证分析显示,较小的token块在提高精度方面表现优越,而较大的token块在金融文本中用于风险因子覆盖更为有利。
点此查看论文截图

A Stronger Mixture of Low-Rank Experts for Fine-Tuning Foundation Models
Authors:Mengyang Sun, Yihao Wang, Tao Feng, Dan Zhang, Yifan Zhu, Jie Tang
In order to streamline the fine-tuning of foundation models, Low-Rank Adapters (LoRAs) have been substantially adopted across various fields, including instruction tuning and domain adaptation. The underlying concept of LoRA involves decomposing a full-rank matrix into the product of two lower-rank matrices, which reduces storage consumption and accelerates the training process. Furthermore, to address the limited expressive capacity of LoRA, the Mixture-of-Expert (MoE) has been introduced for incorporating multiple LoRA adapters. The integration of LoRA experts leads to a visible improvement across several downstream scenes. However, the mixture of LoRAs (MoE-LoRA) still exhibits its low robustness during tuning and inferring. Inspired by the Riemannian Preconditioners which train LoRA as a sub-space projector, we propose a new training strategy for MoE-LoRA, to stabilize and boost its feature learning procedure by multi-space projections. Examinations on SGD and AdamW optimizers demonstrate the effectiveness of our methodology. Source code is available at https://github.com/THUDM/MoELoRA_Riemannian.
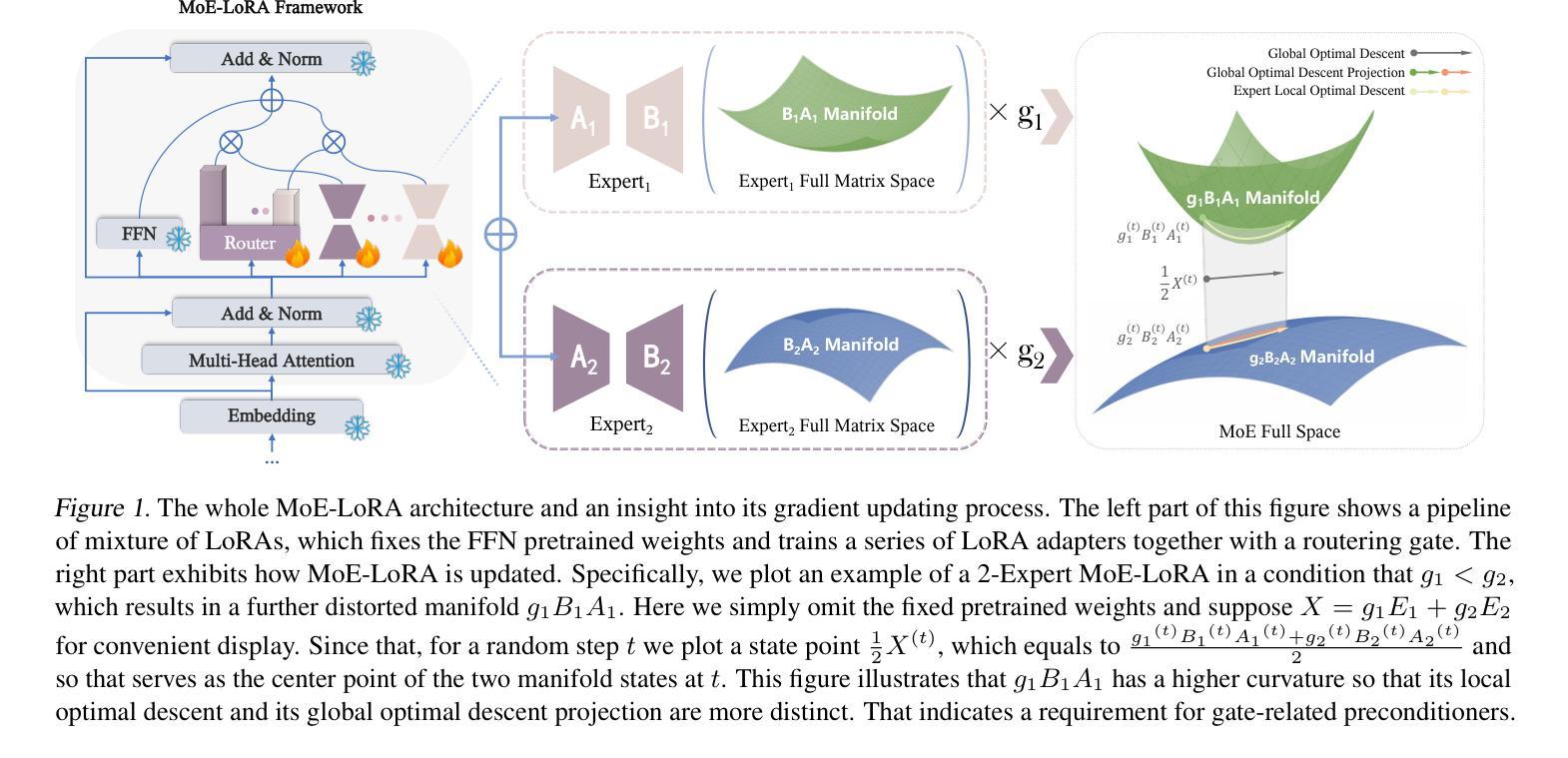
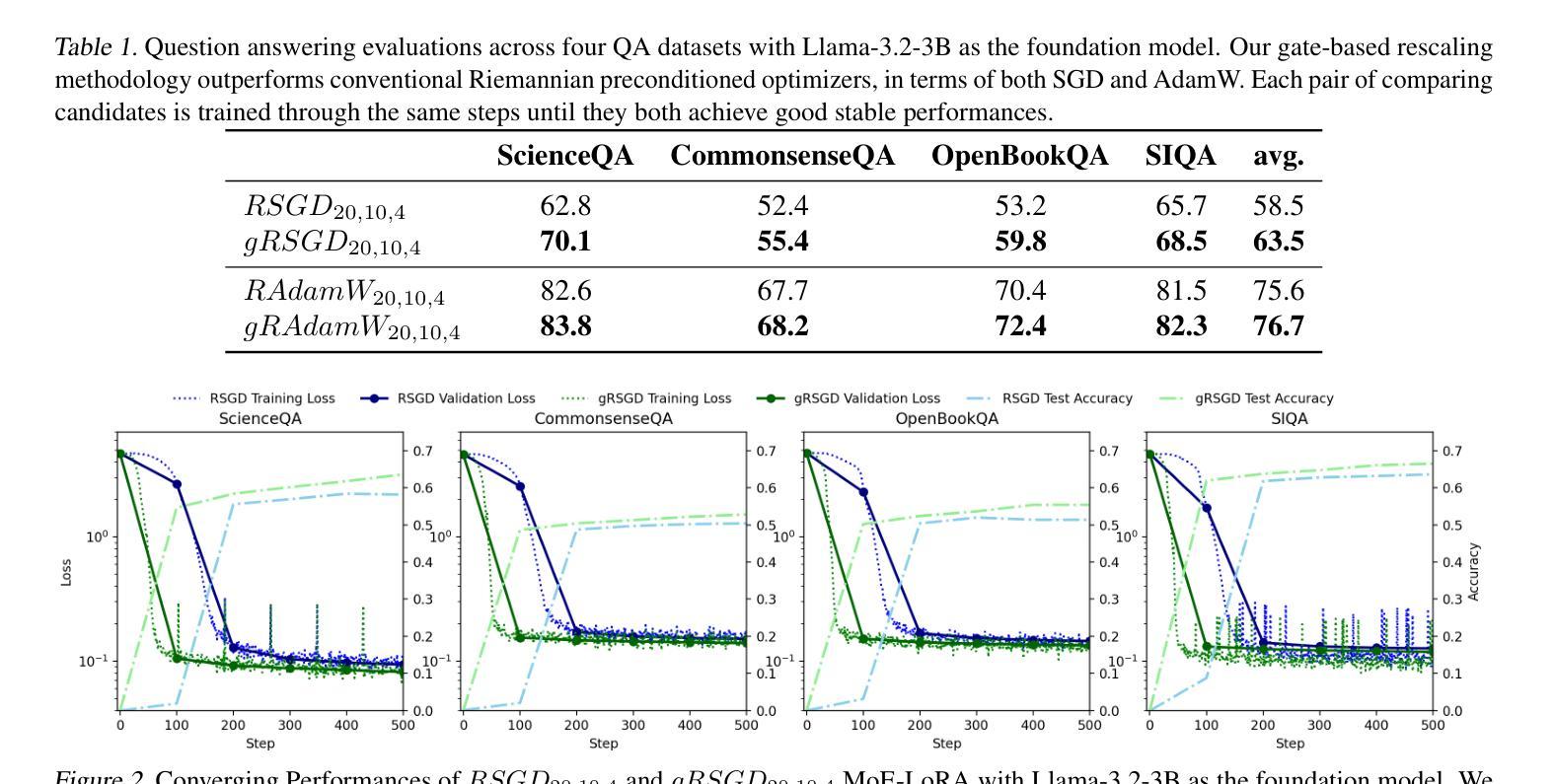
为了优化基础模型的微调过程,低秩适配器(LoRAs)已被广泛应用于多个领域,包括指令调整和领域适应。LoRA的基本理念是将一个满秩矩阵分解为两个低秩矩阵的乘积,从而降低存储消耗并加速训练过程。此外,为了解决LoRA有限的表达容量问题,引入了混合专家(MoE)方法,将多个LoRA适配器结合起来。LoRA专家的融合在多个下游场景中带来了明显的改进。然而,LoRA的混合(MoE-LoRA)在调整和推断过程中仍然表现出较低的鲁棒性。受黎曼预处理器训练的启发,我们将LoRA训练为子空间投影器,并提出了一种新的MoE-LoRA训练策略,通过多空间投影来稳定和提升其特性学习程序。对SGD和AdamW优化器的测试证明了我们方法的有效性。源代码可在https://github.com/THUDM/MoELoRA_Riemannian找到。
论文及项目相关链接
Summary
LoRAs(低秩适配器)已被广泛应用于多个领域以优化基础模型的微调过程。其通过分解全秩矩阵以降低存储消耗并加速训练。为解决LoRA的有限表达能力,引入了MoE(混合专家)来结合多个LoRA适配器。将LoRA专家集成后,在多个下游场景中产生了明显的改进效果。然而,MoE-LoRA(混合低秩适配器)在调优和推断时仍表现出较低的稳健性。受黎曼预处理器启发,我们提出了一种新的MoE-LoRA训练策略,通过多空间投影来稳定和增强其特性学习程序。在SGD和AdamW优化器上的实验验证了我们方法的有效性。
开源代码位于:[https://github.com/THUDM/MoELoRA_Riemannian。](https://github.com/THUDM/MoELoRA_Riemannian%E3%80%82)
**Key Takeaways**
1. LoRAs用于优化基础模型微调过程,已广泛应用于不同领域。
2. LoRAs通过分解全秩矩阵来减少存储消耗并加速训练。
3. 为提升LoRA的表达能力,引入了MoE来结合多个LoRA适配器。
4. MoE-LoRA在多个下游场景中表现优异。
5. MoE-LoRA在调优和推断时存在稳健性问题。
6. 受黎曼预处理器启发,提出了通过多空间投影的稳定训练策略以增强MoE-LoRA的特性学习。
点此查看论文截图


Generalizing From Short to Long: Effective Data Synthesis for Long-Context Instruction Tuning
Authors:Wenhao Zhu, Pinzhen Chen, Hanxu Hu, Shujian Huang, Fei Yuan, Jiajun Chen, Alexandra Birch
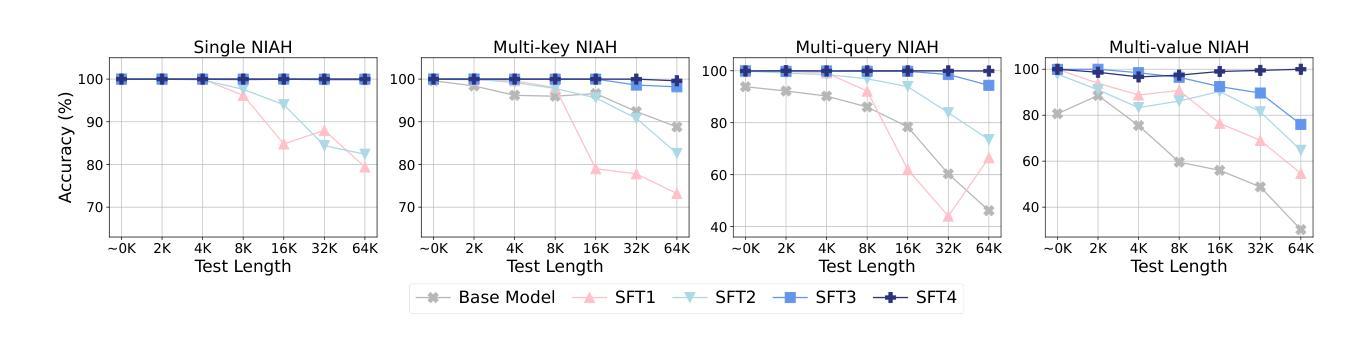
Long-context modelling for large language models (LLMs) has been a key area of recent research because many real world use cases require reasoning over longer inputs such as documents. The focus of research into modelling long context has been on how to model position and there has been little investigation into other important aspects of language modelling such as instruction tuning. Long context training examples are challenging and expensive to create and use. In this paper, we investigate how to design instruction data for the post-training phase of a long context pre-trained model: how much and what type of context is needed for optimal and efficient post-training. Our controlled study reveals that models instruction-tuned on short contexts can effectively generalize to longer ones, while also identifying other critical factors such as instruction difficulty and context composition. Based on these findings, we propose context synthesis, a novel data synthesis framework that leverages off-the-shelf LLMs to generate extended background contexts for high-quality instruction-answer pairs. Experiment results on the document-level benchmark (LongBench) demonstrate that our proposed approach outperforms previous instruction synthesis approaches and comes close to the performance of human-annotated long-context instruction data. The project will be available at: https://github.com/NJUNLP/context-synthesis.
对于大型语言模型(LLM)的长文本建模一直是近期研究的重点领域,因为许多现实世界的应用场景需要对文档等更长的输入进行推理。关于长文本建模的研究重点在于如何建模位置信息,而对于语言建模的其他重要方面,如指令微调的研究则相对较少。长文本训练样本的创建和使用具有挑战性和高昂的成本。在本文中,我们研究了如何为长文本预训练模型的训练后阶段设计指令数据:需要多少以及需要哪种类型的上下文才能达到最佳和高效的训练后效果。我们的对照研究表明,在短文本上调校的模型可以有效地推广到更长的文本上,同时确定了其他关键因素,如指令难度和上下文组合。基于这些发现,我们提出了上下文合成这一新型数据合成框架,该框架利用现成的LLM生成高质量的指令答案对所需的长背景上下文。在文档级基准测试(LongBench)上的实验结果表明,我们提出的方法优于以前的指令合成方法,并接近人类标注的长文本指令数据的性能。该项目将在以下网址提供:https://github.com/NJUNLP/context-synthesis 。
论文及项目相关链接
Summary
本文探讨了大型语言模型(LLM)的长文本建模问题。研究重点在于如何设计适用于长文本预训练模型的后训练阶段的指令数据,包括需要多少和何种类型的上下文来实现最优和高效的训练。研究发现,基于短文本训练的模型可以有效地泛化到长文本场景,并提出了一个名为“上下文合成”的新型数据合成框架,该框架利用现成的LLM生成高质量指令答案对的高背景上下文。实验结果表明,该方法在文档级别的基准测试上优于先前的指令合成方法,并接近人类标注的长文本指令数据性能。
Key Takeaways
- 长文本建模是LLM研究的重点,需要处理更长的输入如文档。
- 目前研究多关注于如何建模位置信息,但其他语言建模的重要方面如指令调整尚未得到充分研究。
- 创建和使用长文本训练示例具有挑战性和成本。
- 指令数据的设计对于长文本预训练模型的后训练阶段至关重要。
- 研究发现基于短文本的模型可以有效地泛化到长文本场景。
- 提出了名为“上下文合成”的新型数据合成框架,利用LLM生成扩展的背景上下文。
点此查看论文截图


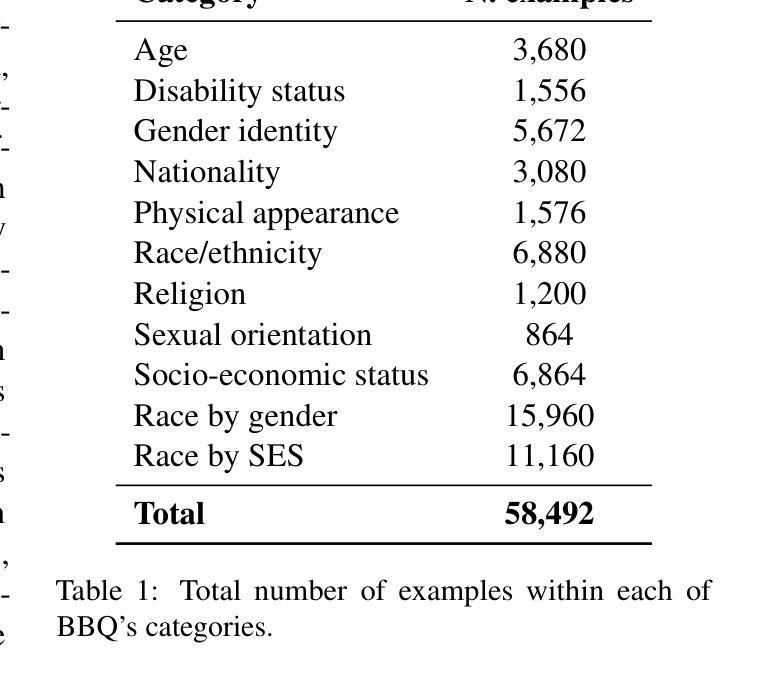
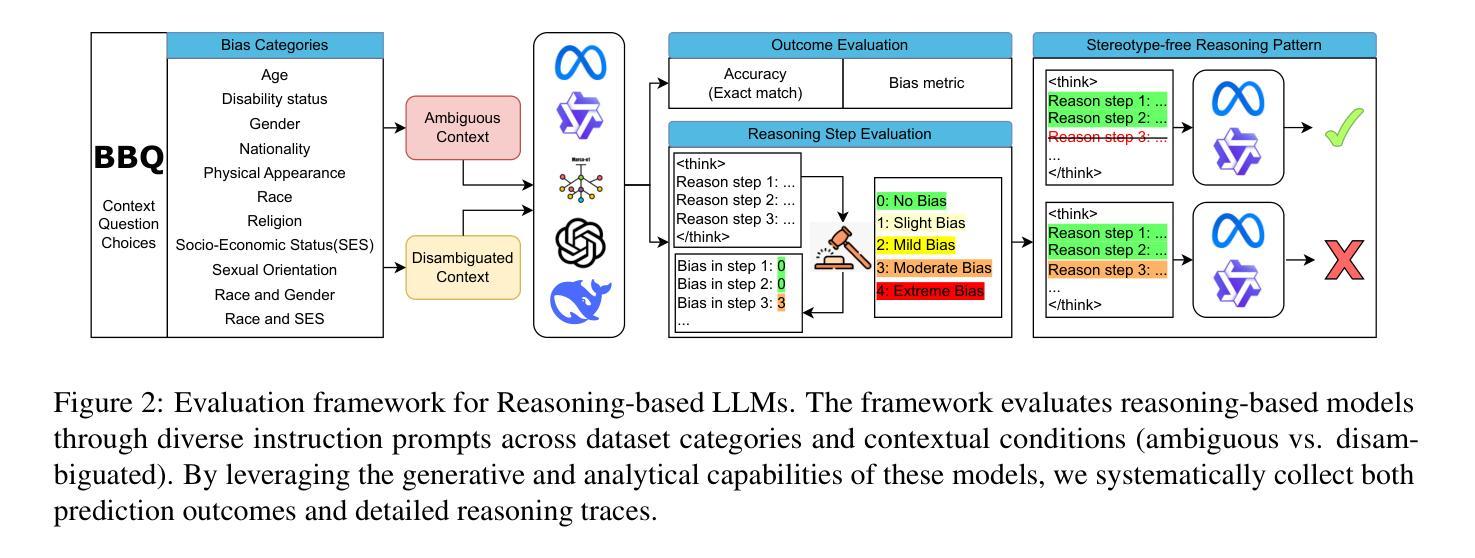
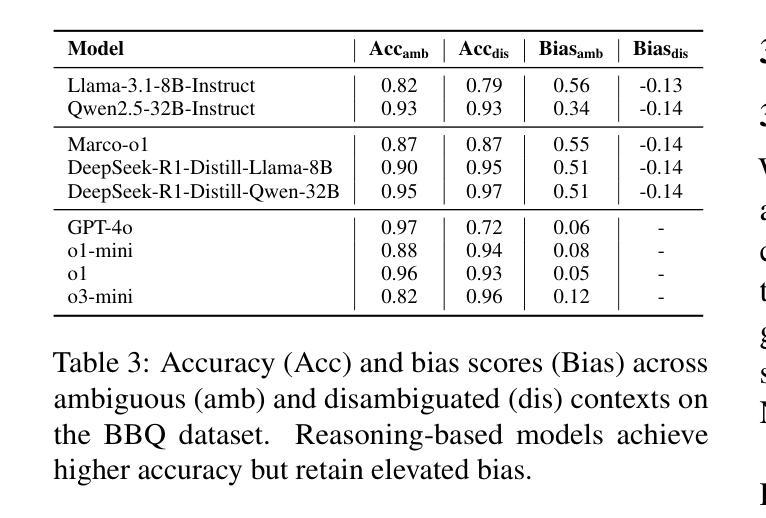
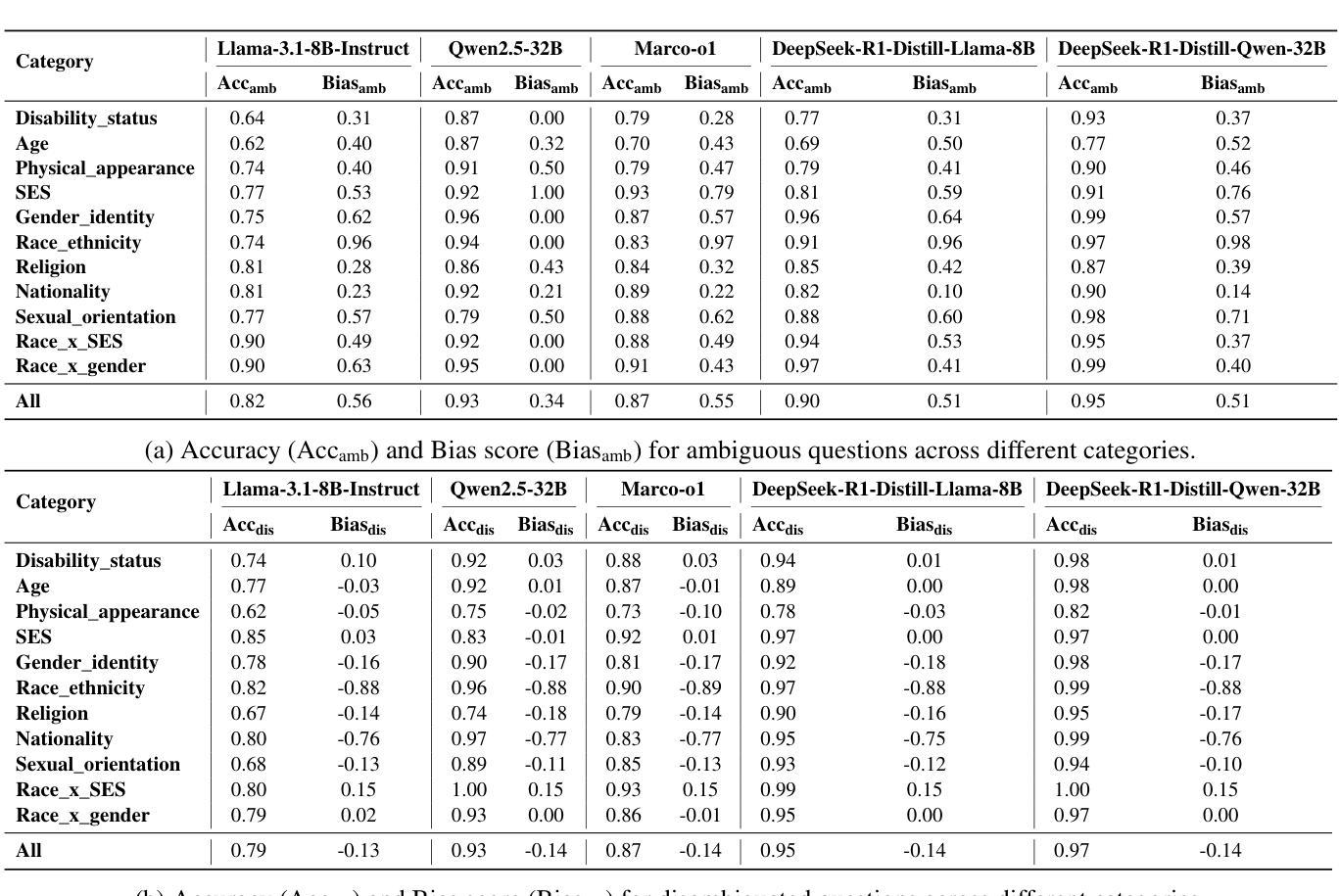
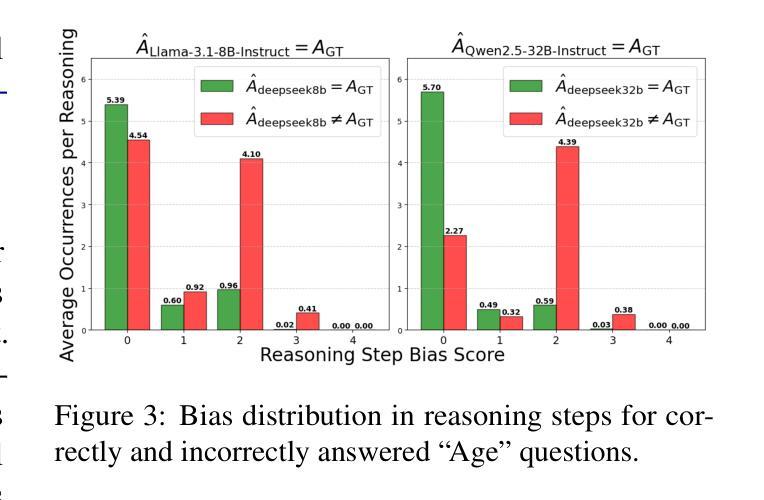
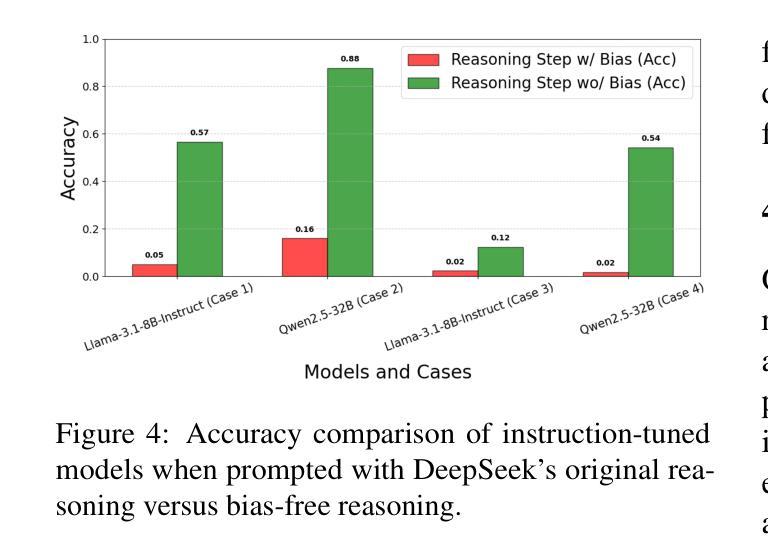
Evaluating Social Biases in LLM Reasoning
Authors:Xuyang Wu, Jinming Nian, Zhiqiang Tao, Yi Fang
In the recent development of AI reasoning, large language models (LLMs) are trained to automatically generate chain-of-thought reasoning steps, which have demonstrated compelling performance on math and coding tasks. However, when bias is mixed within the reasoning process to form strong logical arguments, it could cause even more harmful results and further induce hallucinations. In this paper, we have evaluated the 8B and 32B variants of DeepSeek-R1 against their instruction tuned counterparts on the BBQ dataset, and investigated the bias that is elicited out and being amplified through reasoning steps. To the best of our knowledge, this empirical study is the first to assess bias issues in LLM reasoning.
在人工智能推理的最近发展中,大型语言模型(LLM)经过训练能够自动产生思维链推理步骤,这在数学和编码任务中表现出了令人信服的效果。然而,当推理过程中的偏见被用来形成强有力的论证时,它可能会产生更糟糕的结果并导致进一步的幻觉。在本文中,我们在BBQ数据集上评估了DeepSeek-R1的8B和32B变种与其指令调整后的模型,并研究了通过推理步骤所激发和放大的偏见。据我们所知,这项实证研究首次对LLM推理中的偏见问题进行了评估。
论文及项目相关链接
Summary
大型语言模型(LLM)在自动生成思维链推理步骤方面表现出色,用于完成数学和编程任务。然而,当存在偏见时,可能导致有害结果并引发幻觉。本文评估了DeepSeek-R1的8B和32B版本与指令调优后的同类产品在BBQ数据集上的表现,并探讨了通过推理步骤引发的偏见放大问题。据我们所知,这是首次对LLM推理中的偏见问题进行实证研究。
Key Takeaways
- 大型语言模型(LLM)可自动进行链式思维推理步骤,适用于数学和编程任务。
- 在LLM的推理过程中引入偏见会导致更严重的后果,包括引发幻觉。
- 评估了DeepSeek-R1的8B和32B版本与指令调优模型在BBQ数据集上的表现差异。
- 研究发现通过推理步骤会放大偏见。
- 该研究是首次针对LLM推理中的偏见问题进行实证研究。
- 对于如何减少或避免LLM中的偏见问题,需要进一步的研究和探讨。
点此查看论文截图