⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-26 更新
Semantic Neural Radiance Fields for Multi-Date Satellite Data
Authors:Valentin Wagner, Sebastian Bullinger, Christoph Bodensteiner, Michael Arens
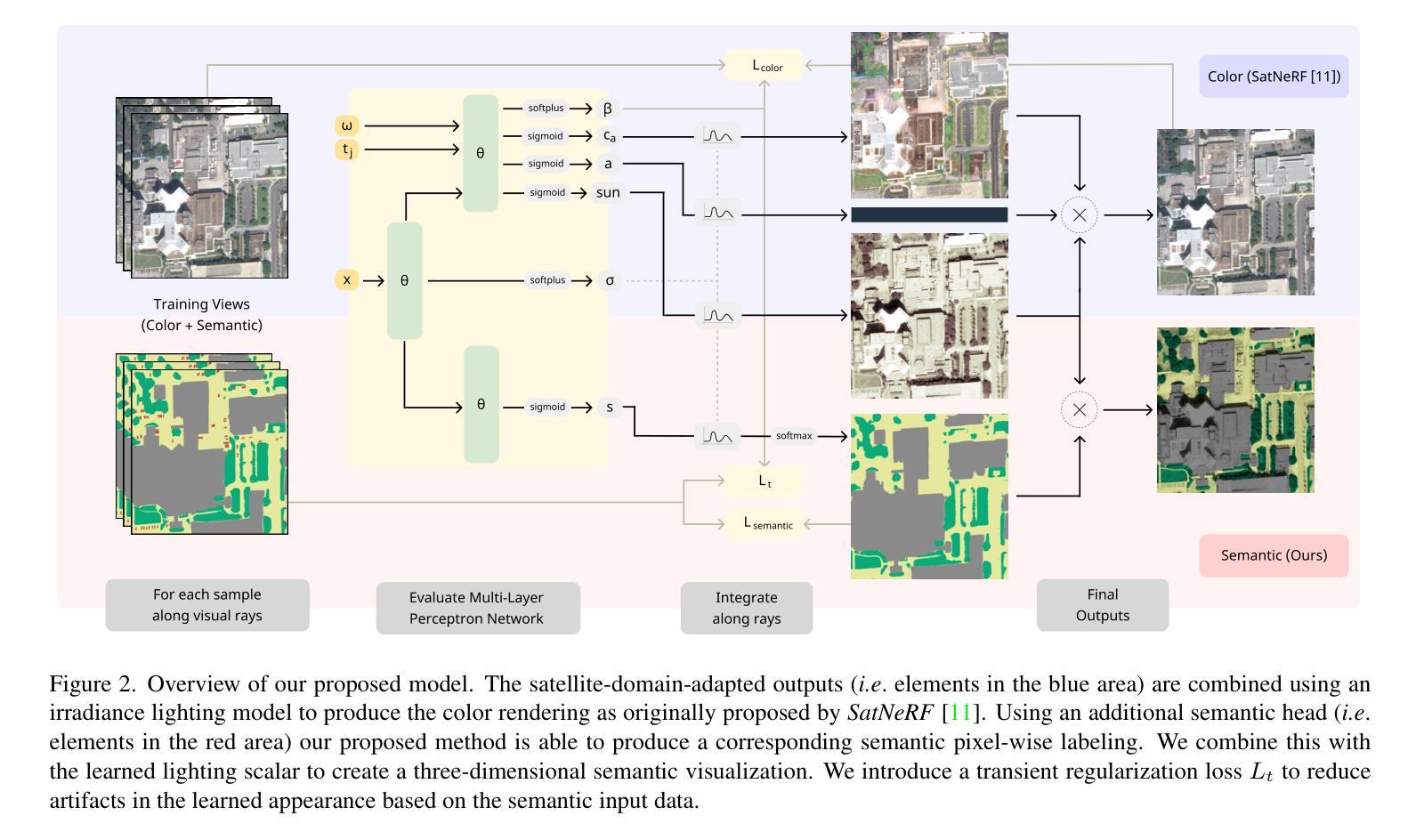
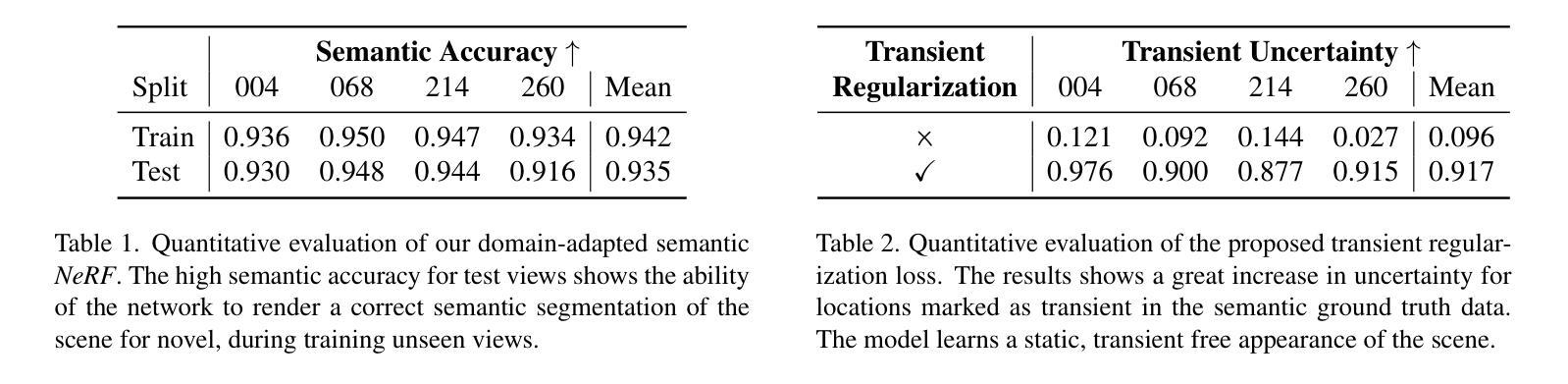
In this work we propose a satellite specific Neural Radiance Fields (NeRF) model capable to obtain a three-dimensional semantic representation (neural semantic field) of the scene. The model derives the output from a set of multi-date satellite images with corresponding pixel-wise semantic labels. We demonstrate the robustness of our approach and its capability to improve noisy input labels. We enhance the color prediction by utilizing the semantic information to address temporal image inconsistencies caused by non-stationary categories such as vehicles. To facilitate further research in this domain, we present a dataset comprising manually generated labels for popular multi-view satellite images. Our code and dataset are available at https://github.com/wagnva/semantic-nerf-for-satellite-data.
在这项工作中,我们提出了一种针对卫星数据的特定Neural Radiance Fields(NeRF)模型,该模型能够获得场景的三维语义表示(神经语义场)。该模型从一系列多时相卫星图像及其对应的像素级语义标签中得出结果。我们展示了该方法的稳健性及其改进输入标签中噪声的能力。我们通过利用语义信息来提高颜色预测,解决由非静止类别(如车辆)引起的图像时间不一致问题。为了促进该领域的研究,我们提供了一组数据集,其中包含针对流行多视角卫星图像的手动生成标签。我们的代码和数据集可在https://github.com/wagnva/semantic-nerf-for-satellite-data找到。
论文及项目相关链接
PDF Accepted at the CV4EO Workshop at WACV 2025
Summary
本文提出了一种针对卫星数据的特定Neural Radiance Fields(NeRF)模型,该模型可从多期卫星图像中获得场景的三维语义表示(神经语义场)。模型利用带有相应像素级语义标签的图像集生成输出,展示出其稳健性,并能在噪声输入标签中改进表现。通过利用语义信息,模型提高了颜色预测的准确性,解决了由非静态类别(如车辆)引起的临时图像不一致问题。为推进该领域的研究,我们提供了一组针对流行多视角卫星图像的手动生成标签数据集。代码和数据集可在链接中找到。
Key Takeaways
- 卫星特定NeRF模型能够获取场景的三维语义表示。
- 模型使用多期卫星图像和相应的像素级语义标签进行训练。
- 该方法展现出稳健性,并能改进噪声输入标签的表现。
- 利用语义信息提高了颜色预测的准确性。
- 模型解决了由非静态类别引起的临时图像不一致问题。
- 为研究提供了包含手动生成标签的流行多视角卫星图像数据集。
点此查看论文截图


ViSNeRF: Efficient Multidimensional Neural Radiance Field Representation for Visualization Synthesis of Dynamic Volumetric Scenes
Authors:Siyuan Yao, Yunfei Lu, Chaoli Wang
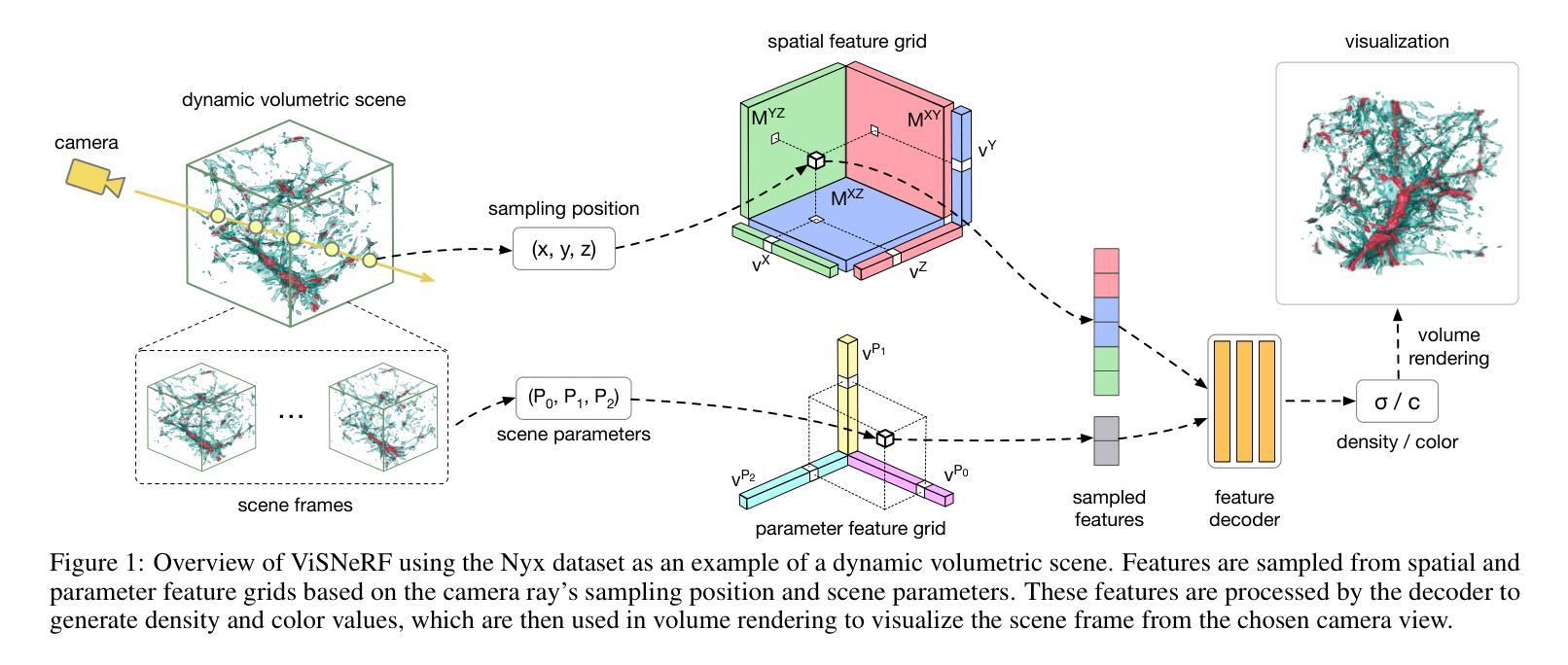
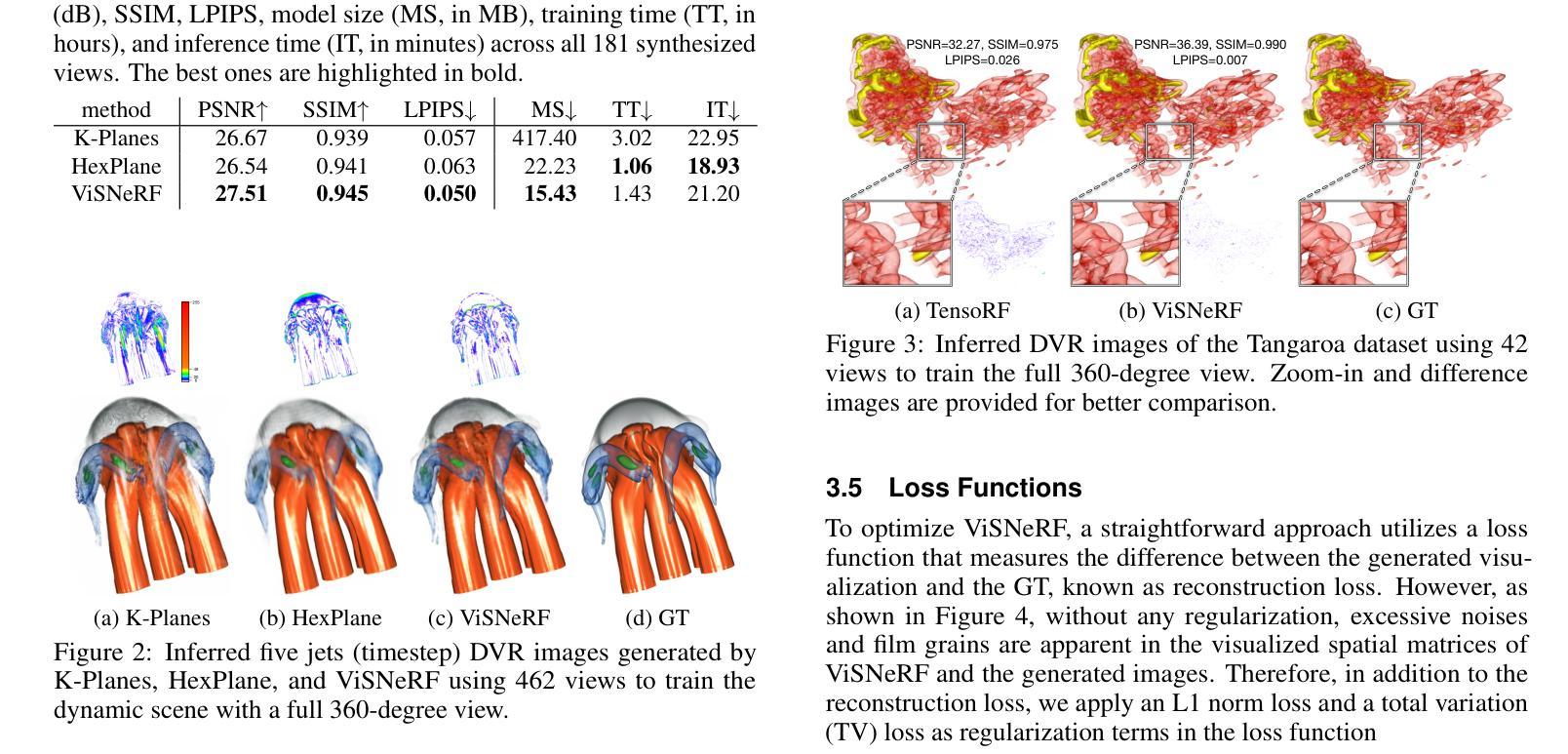
Domain scientists often face I/O and storage challenges when keeping raw data from large-scale simulations. Saving visualization images, albeit practical, is limited to preselected viewpoints, transfer functions, and simulation parameters. Recent advances in scientific visualization leverage deep learning techniques for visualization synthesis by offering effective ways to infer unseen visualizations when only image samples are given during training. However, due to the lack of 3D geometry awareness, existing methods typically require many training images and significant learning time to generate novel visualizations faithfully. To address these limitations, we propose ViSNeRF, a novel 3D-aware approach for visualization synthesis using neural radiance fields. Leveraging a multidimensional radiance field representation, ViSNeRF efficiently reconstructs visualizations of dynamic volumetric scenes from a sparse set of labeled image samples with flexible parameter exploration over transfer functions, isovalues, timesteps, or simulation parameters. Through qualitative and quantitative comparative evaluation, we demonstrate ViSNeRF’s superior performance over several representative baseline methods, positioning it as the state-of-the-art solution. The code is available at https://github.com/JCBreath/ViSNeRF.
领域科学家在保存大规模模拟的原始数据时,经常面临I/O和存储挑战。虽然保存可视化图像是实用的,但它仅限于预选的视角、传输功能和模拟参数。最近的科学可视化进展利用深度学习技术进行可视化合成,提供了一种在仅给训练过程提供图像样本的情况下推断未见可视化的有效方法。然而,由于缺乏3D几何感知能力,现有方法通常需要大量的训练图像和显著的学习时间来生成新的可视化。为了解决这些局限性,我们提出了ViSNeRF,这是一种利用神经辐射场进行可视化合成的新颖3D感知方法。借助多维辐射场表示,ViSNeRF可以从稀疏的标记图像样本集中有效地重建动态体积场景的可视化,并在传输功能、等值、时间步长或模拟参数方面提供灵活的参数探索。通过定性和定量比较评估,我们证明了ViSNeRF相较于几种代表性的基线方法具有卓越性能,使其成为最先进解决方案。代码可在https://github.com/JCBreath/ViSNeRF找到。
论文及项目相关链接
Summary
神经网络辐射场(NeRF)在可视化合成领域的应用,解决了大规模仿真中面临的I/O和存储挑战。ViSNeRF作为一种新型的三维可视化合成方法,利用神经网络辐射场,能够从少量的标记图像样本中高效地重建动态体积场景的可视化。它具备灵活的参数探索能力,可调整传输函数、等值线、时间步长或仿真参数。实验证明,ViSNeRF相较于其他代表性方法,具有卓越的性能表现。
Key Takeaways
- ViSNeRF利用神经网络辐射场(NeRF)解决大规模仿真中的I/O和存储挑战。
- ViSNeRF能够从少量的标记图像样本中重建动态体积场景的可视化。
- ViSNeRF具备灵活的参数探索能力,可调整传输函数、等值线、时间步长等。
- ViSNeRF具备出色的性能表现,相较于其他代表性方法具有优势。
- ViSNeRF方法能够生成高质量的可视化合成,具备潜在的大规模应用前景。
- 代码已公开,方便研究者和开发者使用。
点此查看论文截图




AquaNeRF: Neural Radiance Fields in Underwater Media with Distractor Removal
Authors:Luca Gough, Adrian Azzarelli, Fan Zhang, Nantheera Anantrasirichai
Neural radiance field (NeRF) research has made significant progress in modeling static video content captured in the wild. However, current models and rendering processes rarely consider scenes captured underwater, which are useful for studying and filming ocean life. They fail to address visual artifacts unique to underwater scenes, such as moving fish and suspended particles. This paper introduces a novel NeRF renderer and optimization scheme for an implicit MLP-based NeRF model. Our renderer reduces the influence of floaters and moving objects that interfere with static objects of interest by estimating a single surface per ray. We use a Gaussian weight function with a small offset to ensure that the transmittance of the surrounding media remains constant. Additionally, we enhance our model with a depth-based scaling function to upscale gradients for near-camera volumes. Overall, our method outperforms the baseline Nerfacto by approximately 7.5% and SeaThru-NeRF by 6.2% in terms of PSNR. Subjective evaluation also shows a significant reduction of artifacts while preserving details of static targets and background compared to the state of the arts.
神经辐射场(NeRF)研究在建模野外捕捉的静态视频内容上取得了显著进步。然而,当前模型和渲染过程很少考虑水下场景的捕捉,这对于研究和拍摄海洋生物非常有用。它们无法解决水下场景特有的视觉伪影,如移动的鱼类和悬浮颗粒。本文介绍了一种新型的NeRF渲染器和针对基于隐式多层感知机(MLP)的NeRF模型的优化方案。我们的渲染器通过估算每条射线的单个表面,减少了漂浮物和移动物体对感兴趣静态物体的干扰。我们使用带有小偏移的高斯权重函数,以确保周围介质的透射率保持不变。此外,我们通过基于深度的缩放函数增强我们的模型,以放大近相机体积的梯度。总体而言,我们的方法在峰值信噪比(PSNR)方面比基线Nerfacto高出约7.5%,比SeaThru-NeRF高出6.2%。主观评价还表明,与现有技术相比,我们的方法在减少伪影的同时,保留了静态目标和背景的细节。
论文及项目相关链接
PDF Accepted by 2025 IEEE International Symposium on Circuits and Systems
摘要
NeRF技术在水下场景建模和渲染方面取得了突破。该研究提出了一种新型的NeRF渲染器和优化方案,解决了水下场景特有的视觉伪影问题,如移动生物和悬浮颗粒的影响。通过估算每条射线的单一表面,减少了浮生物和移动物体对静态目标物体的干扰。使用高斯权重函数和小偏移确保了周围介质的透射率保持不变。此外,通过深度基础缩放功能增强模型,以放大近相机体积的梯度。相较于基准的Nerfacto和SeaThru-NeRF,该方法在PSNR上分别提高了约7.5%和6.2%。主观评估显示,该方法在减少伪影的同时,还能保留静态目标和背景的细节。
关键见解
- NeRF技术在水下场景的建模和渲染方面具有显著进展。
- 新型NeRF渲染器和优化方案解决了水下场景特有的视觉伪影问题。
- 通过估算单一表面减少移动生物和悬浮颗粒对静态物体的干扰。
- 利用高斯权重函数确保周围媒体透射率恒定。
- 使用深度基础缩放功能增强模型性能,特别是在近相机区域。
- 与现有技术相比,该方法在PSNR上显著提高。
点此查看论文截图




DualNeRF: Text-Driven 3D Scene Editing via Dual-Field Representation
Authors:Yuxuan Xiong, Yue Shi, Yishun Dou, Bingbing Ni
Recently, denoising diffusion models have achieved promising results in 2D image generation and editing. Instruct-NeRF2NeRF (IN2N) introduces the success of diffusion into 3D scene editing through an “Iterative dataset update” (IDU) strategy. Though achieving fascinating results, IN2N suffers from problems of blurry backgrounds and trapping in local optima. The first problem is caused by IN2N’s lack of efficient guidance for background maintenance, while the second stems from the interaction between image editing and NeRF training during IDU. In this work, we introduce DualNeRF to deal with these problems. We propose a dual-field representation to preserve features of the original scene and utilize them as additional guidance to the model for background maintenance during IDU. Moreover, a simulated annealing strategy is embedded into IDU to endow our model with the power of addressing local optima issues. A CLIP-based consistency indicator is used to further improve the editing quality by filtering out low-quality edits. Extensive experiments demonstrate that our method outperforms previous methods both qualitatively and quantitatively.
最近,去噪扩散模型在2D图像生成和编辑方面取得了有前景的结果。Instruct-NeRF2NeRF(IN2N)通过“迭代数据集更新”(IDU)策略,将扩散的成功引入3D场景编辑。尽管取得了令人着迷的结果,但IN2N仍存在背景模糊和陷入局部最优的问题。第一个问题是由IN2N对背景维护缺乏有效指导所造成的,而第二个问题则源于图像编辑和NeRF训练在IDU过程中的相互作用。在这项工作中,我们引入DualNeRF来解决这些问题。我们提出了一种双场表示法来保留原始场景的特征,并将其作为附加指导,用于在IDU期间进行背景维护。此外,将模拟退火策略嵌入到IDU中,使我们的模型具有解决局部最优问题的能力。使用基于CLIP的一致性指标,进一步提高了编辑质量,通过过滤掉低质量的编辑。大量实验表明,我们的方法在定性和定量上均优于以前的方法。
论文及项目相关链接
Summary
本文介绍了Instruct-NeRF2NeRF(IN2N)在三维场景编辑中应用扩散模型的尝试及其所面临的背景模糊和陷入局部最优的问题。为解决这些问题,本文提出了DualNeRF方法,采用双场表示法保留原始场景特征,作为模型在迭代数据集更新(IDU)过程中的背景维护的额外指导。同时,将模拟退火策略融入IDU,以解决局部最优问题。使用CLIP基于一致性指标进一步提高编辑质量,通过过滤低质量编辑来改善效果。实验证明,该方法在质量和数量上均优于之前的方法。
Key Takeaways
- Instruct-NeRF2NeRF (IN2N) 引入扩散模型至 3D 场景编辑,通过 “迭代数据集更新” (IDU) 策略取得成果。
- IN2N 存在背景模糊和陷入局部最优的问题。
- DualNeRF 引入双场表示法,旨在保留原始场景特征,作为模型在 IDU 过程中的背景维护指导。
- DualNeRF 采用模拟退火策略融入 IDU,解决局部最优问题。
- 使用 CLIP 基于一致性指标提高编辑质量,通过过滤低质量编辑改善效果。
- 实验证明 DualNeRF 在质量和数量上均优于之前的方法。
点此查看论文截图




Para-Lane: Multi-Lane Dataset Registering Parallel Scans for Benchmarking Novel View Synthesis
Authors:Ziqian Ni, Sicong Du, Zhenghua Hou, Chenming Wu, Sheng Yang
To evaluate end-to-end autonomous driving systems, a simulation environment based on Novel View Synthesis (NVS) techniques is essential, which synthesizes photo-realistic images and point clouds from previously recorded sequences under new vehicle poses, particularly in cross-lane scenarios. Therefore, the development of a multi-lane dataset and benchmark is necessary. While recent synthetic scene-based NVS datasets have been prepared for cross-lane benchmarking, they still lack the realism of captured images and point clouds. To further assess the performance of existing methods based on NeRF and 3DGS, we present the first multi-lane dataset registering parallel scans specifically for novel driving view synthesis dataset derived from real-world scans, comprising 25 groups of associated sequences, including 16,000 front-view images, 64,000 surround-view images, and 16,000 LiDAR frames. All frames are labeled to differentiate moving objects from static elements. Using this dataset, we evaluate the performance of existing approaches in various testing scenarios at different lanes and distances. Additionally, our method provides the solution for solving and assessing the quality of multi-sensor poses for multi-modal data alignment for curating such a dataset in real-world. We plan to continually add new sequences to test the generalization of existing methods across different scenarios. The dataset is released publicly at the project page: https://nizqleo.github.io/paralane-dataset/.
为了评估端到端的自动驾驶系统,基于新型视图合成(NVS)技术的模拟环境至关重要。该环境能够在新车辆姿态下,从先前记录的序列中合成逼真的图像和点云,特别是在跨车道场景中。因此,开发多车道数据集和基准测试是必要的。虽然最近已经为跨车道基准测试准备了基于合成场景 的NVS数据集,但它们仍然缺乏捕获的图像和点云的逼真性。为了进一步优化基于NeRF和3DGS的现有方法的性能评估,我们首次推出了多车道数据集注册并行扫描,专门针对从真实世界扫描中派生的新型驾驶视图合成数据集。该数据集包含25组相关序列,包括16,000张前视图图像、64,000张环绕视图图像和16,000张激光雷达帧。所有帧都进行了标记,以区分移动物体和静态元素。使用该数据集,我们在不同车道和距离的各种测试场景中评估了现有方法的性能。此外,我们的方法还提供了解决和评估多传感器姿态质量的解决方案,用于此类数据集的多模态数据对齐在真实世界中的实现。我们计划不断添加新的序列,以测试不同场景下现有方法的泛化能力。该数据集已在项目页面公开发布:https://nizqleo.github.io/paralane-dataset/。
论文及项目相关链接
PDF Accepted by International Conference on 3D Vision (3DV) 2025
Summary
基于Novel View Synthesis(NVS)技术的模拟环境对于评估端到端的自动驾驶系统至关重要,它能合成逼真的图像和点云,从新车辆姿态下记录的序列中生成。为此,开发一个多车道数据集和基准测试是必要的。虽然已有基于合成场景的NVS数据集用于车道间基准测试,但它们仍缺乏捕获图像的逼真性。为了评估基于NeRF和3DGS的方法的性能,我们首次提出了一个注册平行扫描的多车道数据集,专为新型驾驶视图合成数据集而设计,源于真实世界扫描。数据集包含25组相关序列,包括1.6万张前视图图像、6.4万张环绕视图图像和1.6万张激光雷达帧。所有帧都进行了标记,以区分移动物体和静态元素。使用此数据集,我们评估了不同车道和距离的各种测试场景中现有方法的性能。此外,我们的方法还提供解决方案,以解决和评估多传感器姿态的质量,用于多模态数据对齐,以创建此类真实世界数据集。
Key Takeaways
- NVS技术对于评估自动驾驶系统的端到端性能至关重要,可以合成逼真的图像和点云。
- 多车道数据集和基准测试对于评估自动驾驶系统的跨车道性能是必要的。
- 当前合成场景数据集缺乏真实感,难以准确评估自动驾驶系统性能。
- 提出首个基于真实世界扫描的多车道数据集,包含多种视图图像和激光雷达帧。
- 数据集用于评估不同车道和距离下现有方法的性能。
- 该方法提供解决方案来解决多传感器姿态的质量问题,实现多模态数据对齐。
点此查看论文截图





Hier-SLAM++: Neuro-Symbolic Semantic SLAM with a Hierarchically Categorical Gaussian Splatting
Authors:Boying Li, Vuong Chi Hao, Peter J. Stuckey, Ian Reid, Hamid Rezatofighi
We propose Hier-SLAM++, a comprehensive Neuro-Symbolic semantic 3D Gaussian Splatting SLAM method with both RGB-D and monocular input featuring an advanced hierarchical categorical representation, which enables accurate pose estimation as well as global 3D semantic mapping. The parameter usage in semantic SLAM systems increases significantly with the growing complexity of the environment, making scene understanding particularly challenging and costly. To address this problem, we introduce a novel and general hierarchical representation that encodes both semantic and geometric information in a compact form into 3D Gaussian Splatting, leveraging the capabilities of large language models (LLMs) as well as the 3D generative model. By utilizing the proposed hierarchical tree structure, semantic information is symbolically represented and learned in an end-to-end manner. We further introduce a novel semantic loss designed to optimize hierarchical semantic information through both inter-level and cross-level optimization. Additionally, we propose an improved SLAM system to support both RGB-D and monocular inputs using a feed-forward model. To the best of our knowledge, this is the first semantic monocular Gaussian Splatting SLAM system, significantly reducing sensor requirements for 3D semantic understanding and broadening the applicability of semantic Gaussian SLAM system. We conduct experiments on both synthetic and real-world datasets, demonstrating superior or on-par performance with state-of-the-art NeRF-based and Gaussian-based SLAM systems, while significantly reducing storage and training time requirements.
我们提出了Hier-SLAM++,这是一种全面的神经符号语义3D高斯拼接SLAM方法,它支持RGB-D和单目输入,并具备先进的层次化类别表示能力,能够实现准确的姿态估计和全局3D语义映射。随着环境复杂性的增加,语义SLAM系统中的参数使用量也显著增加,这使得场景理解变得特别具有挑战性和成本高昂。为了解决这一问题,我们引入了一种新颖且通用的层次化表示方法,以紧凑的形式将语义和几何信息编码到3D高斯拼接中,利用大型语言模型和3D生成模型的强大功能。通过利用所提出的层次树结构,语义信息以符号形式表示并以端到端的方式进行学习。我们进一步设计了一种新型语义损失,旨在通过跨级别优化来优化层次化语义信息。此外,我们提出了一种改进的SLAM系统,支持RGB-D和单目输入,并使用前馈模型。据我们所知,这是第一个语义单目高斯拼接SLAM系统,大大降低了对3D语义理解的传感器要求,并拓宽了语义高斯SLAM系统的应用范围。我们在合成和真实数据集上进行了实验,证明了与最新的基于NeRF和高斯的SLAM系统相比具有卓越或相当的性能,同时显著降低了存储和训练时间要求。
论文及项目相关链接
PDF 15 pages. Under review
Summary
基于层次结构的高级语义映射技术改进研究:本文提出了一种先进的综合神经符号语义的SLAM方法——Hier-SLAM++。此方法结合RGB-D和单目输入,具有高级层次类别表示功能,能进行准确的姿态估计和全局三维语义地图构建。此方法利用神经网络模型的紧凑三维高斯拼图结构进行高级语义表示学习,利用大型语言模型的优势与3D生成模型实现强大的语言生成和模型应用潜力。引入一种新型的语义损失,优化层次语义信息。支持RGB-D和单目输入的新型SLAM系统首次实现了对单目高斯拼图的语义理解,显著降低了对三维语义理解的传感器要求,并扩大了高斯SLAM系统的应用范围。实验表明,该方法与现有领先的基于NeRF的SLAM系统在性能和参数要求方面有所突破。通过精确控制和广泛评估各种方法和技术的核心元素以及对该领域最前沿的深度分析,进一步推进了该领域的认知界限。总结来说,该研究实现了语义理解的高效和准确性提升。
Key Takeaways
- Hier-SLAM++是一个结合了RGB-D和单目输入的综合神经符号语义的三维高斯Splatting SLAM方法,可实现精确姿态估计和全局三维语义映射。
- 利用大型语言模型和三维生成模型的优势,实现层次结构和语义信息的紧凑表示学习。
- 引入了一种新型的语义损失机制,优化了层次结构中的语义信息优化。这一创新策略为改进高级特征映射提供了一种有效方法。
- 该方法支持RGB-D和单目输入的新型SLAM系统首次实现了单目高斯拼图的语义理解,显著降低了传感器需求。
- 实验表明,该方法在性能上优于或相当于是现有领先的基于NeRF的SLAM系统,同时在存储和训练时间方面有所减少。这标志着在三维语义理解领域的重大进步。
- 通过层次结构的利用和紧凑表示学习,该方法有望推动计算机视觉领域的发展,特别是在场景理解和地图构建方面。
点此查看论文截图



HumanGif: Single-View Human Diffusion with Generative Prior
Authors:Shoukang Hu, Takuya Narihira, Kazumi Fukuda, Ryosuke Sawata, Takashi Shibuya, Yuki Mitsufuji
Previous 3D human creation methods have made significant progress in synthesizing view-consistent and temporally aligned results from sparse-view images or monocular videos. However, it remains challenging to produce perpetually realistic, view-consistent, and temporally coherent human avatars from a single image, as limited information is available in the single-view input setting. Motivated by the success of 2D character animation, we propose HumanGif, a single-view human diffusion model with generative prior. Specifically, we formulate the single-view-based 3D human novel view and pose synthesis as a single-view-conditioned human diffusion process, utilizing generative priors from foundational diffusion models to complement the missing information. To ensure fine-grained and consistent novel view and pose synthesis, we introduce a Human NeRF module in HumanGif to learn spatially aligned features from the input image, implicitly capturing the relative camera and human pose transformation. Furthermore, we introduce an image-level loss during optimization to bridge the gap between latent and image spaces in diffusion models. Extensive experiments on RenderPeople and DNA-Rendering datasets demonstrate that HumanGif achieves the best perceptual performance, with better generalizability for novel view and pose synthesis.
之前的3D人物创建方法在从稀疏视图图像或单目视频中合成视角一致和时间上对齐的结果方面取得了显著进展。然而,从单张图像中生成永久逼真的、视角一致和时间上连贯的人物化身仍然是一个挑战,因为在单视图输入设置中可用信息有限。受到二维角色动画成功的启发,我们提出了HumanGif,这是一个带有生成先验的单视图人类扩散模型。具体来说,我们将基于单视图的3D人物新颖视图和姿态合成制定为受单视图条件约束的人类扩散过程,利用基础扩散模型的生成先验来补充缺失信息。为了确保精细且一致的全新视图和姿态合成,我们在HumanGif中引入了Human NeRF模块,从输入图像中学习空间对齐的特征,隐式捕获相对相机和人物姿态变换。此外,我们在优化过程中引入了图像级损失,以弥合扩散模型中潜在空间和图像空间之间的差距。在RenderPeople和DNA-Rendering数据集上的大量实验表明,HumanGif在感知性能上表现最佳,对于新颖视图和姿态合成具有更好的泛化能力。
论文及项目相关链接
PDF Project page: https://skhu101.github.io/HumanGif/
Summary
本文提出了一种基于单视角的扩散模型HumanGif,用于创建人类角色动画。该模型利用生成先验信息来补充单视角输入中的缺失信息,实现了从单张图像生成高质量、逼真、视角一致且时间连贯的人类角色动画。通过引入Human NeRF模块,该模型能够学习输入图像中的空间对齐特征,并隐式捕获相对相机和人类姿态的变换。此外,通过优化过程中的图像级损失,缩小了潜在空间和图像空间之间的差距。在RenderPeople和DNA-Rendering数据集上的实验表明,HumanGif在感知性能上取得了最佳表现,并在新视角和姿态合成方面表现出更好的泛化能力。
Key Takeaways
- HumanGif是一种基于单视角的扩散模型,用于创建人类角色动画。
- 该模型利用生成先验信息补充单视角输入中的缺失信息。
- 通过引入Human NeRF模块,实现了高质量、逼真、视角一致且时间连贯的人类角色动画合成。
- 该模型隐式捕获相对相机和人类姿态的变换,保证合成的新视角和姿态更为精细和一致。
- 优化过程中的图像级损失有助于缩小潜在空间和图像空间之间的差距。
- 在RenderPeople和DNA-Rendering数据集上的实验表明HumanGif的优异表现。
点此查看论文截图



Bringing NeRFs to the Latent Space: Inverse Graphics Autoencoder
Authors:Antoine Schnepf, Karim Kassab, Jean-Yves Franceschi, Laurent Caraffa, Flavian Vasile, Jeremie Mary, Andrew Comport, Valerie Gouet-Brunet
While pre-trained image autoencoders are increasingly utilized in computer vision, the application of inverse graphics in 2D latent spaces has been under-explored. Yet, besides reducing the training and rendering complexity, applying inverse graphics in the latent space enables a valuable interoperability with other latent-based 2D methods. The major challenge is that inverse graphics cannot be directly applied to such image latent spaces because they lack an underlying 3D geometry. In this paper, we propose an Inverse Graphics Autoencoder (IG-AE) that specifically addresses this issue. To this end, we regularize an image autoencoder with 3D-geometry by aligning its latent space with jointly trained latent 3D scenes. We utilize the trained IG-AE to bring NeRFs to the latent space with a latent NeRF training pipeline, which we implement in an open-source extension of the Nerfstudio framework, thereby unlocking latent scene learning for its supported methods. We experimentally confirm that Latent NeRFs trained with IG-AE present an improved quality compared to a standard autoencoder, all while exhibiting training and rendering accelerations with respect to NeRFs trained in the image space. Our project page can be found at https://ig-ae.github.io .
虽然预训练的图像自编码器在计算机视觉中得到了越来越多的应用,但在二维潜在空间中应用反向图形技术却尚未得到充分探索。然而,除了在训练和渲染方面降低复杂性之外,在潜在空间中应用反向图形技术还实现了与其他基于潜在空间的二维方法的宝贵互操作性。主要挑战是反向图形无法直接应用于这种图像潜在空间,因为它们缺乏基本的三维几何结构。在本文中,我们提出了一种专门解决此问题的反向图形自编码器(IG-AE)。为此,我们通过使图像自编码器的潜在空间与联合训练的潜在三维场景对齐来对其进行了三维几何正则化。我们利用训练好的IG-AE将NeRF带入潜在空间,并使用我们在Nerfstudio框架的开源扩展中实现的潜在NeRF训练管道来实现这一点,从而为所支持的方法解锁了潜在场景学习。通过实验,我们证实了与标准自编码器相比,使用IG-AE训练的潜在NeRF呈现出更高的质量,同时在图像空间训练的NeRF方面表现出训练和渲染的加速。我们的项目页面位于https://ig-ae.github.io。
论文及项目相关链接
PDF Accepted at ICLR 2025. Available at https://openreview.net/forum?id=LTDtjrv02Y
Summary
预训练图像自编码器在计算机视觉领域应用广泛,但其在二维潜在空间内对逆向图形学的应用尚未得到充分探索。本文将逆向图形学与图像潜在空间相结合,以减少训练和渲染复杂度,并与其他潜在空间的二维方法实现良好的互操作性。主要挑战在于逆向图形学无法直接应用于缺乏三维几何的图像潜在空间。针对此问题,本文提出了一种逆向图形自编码器(IG-AE),通过用三维几何对图像自编码器进行正则化,使其潜在空间与联合训练的潜在三维场景对齐。利用训练的IG-AE将NeRF引入潜在空间,实现了一种潜在NeRF训练管道,我们在Nerfstudio框架的开源扩展中实现了这一方法,从而解锁了其支持方法的潜在场景学习。实验证实,与标准自编码器相比,使用IG-AE训练的潜在NeRF呈现出更高的质量,同时在图像空间训练的NeRF具有训练和渲染加速的优势。
Key Takeaways
- 预训练图像自编码器广泛应用于计算机视觉领域,逆向图形学在二维潜在空间的应用尚未充分探索。
- 逆向图形学不能直接应用于缺乏三维几何的图像潜在空间是主要挑战。
- 本文提出的逆向图形自编码器(IG-AE)解决了这一问题,通过正则化图像自编码器与三维几何对齐。
- IG-AE被用于将NeRF引入潜在空间,实现潜在NeRF训练管道。
- 相比标准自编码器,使用IG-AE训练的潜在NeRF具有更高的质量。
- 潜在NeRF具有训练和渲染加速的优势。
点此查看论文截图




Rethinking Open-Vocabulary Segmentation of Radiance Fields in 3D Space
Authors:Hyunjee Lee, Youngsik Yun, Jeongmin Bae, Seoha Kim, Youngjung Uh
Understanding the 3D semantics of a scene is a fundamental problem for various scenarios such as embodied agents. While NeRFs and 3DGS excel at novel-view synthesis, previous methods for understanding their semantics have been limited to incomplete 3D understanding: their segmentation results are rendered as 2D masks that do not represent the entire 3D space. To address this limitation, we redefine the problem to segment the 3D volume and propose the following methods for better 3D understanding. We directly supervise the 3D points to train the language embedding field, unlike previous methods that anchor supervision at 2D pixels. We transfer the learned language field to 3DGS, achieving the first real-time rendering speed without sacrificing training time or accuracy. Lastly, we introduce a 3D querying and evaluation protocol for assessing the reconstructed geometry and semantics together. Code, checkpoints, and annotations are available at the project page.
理解场景的3D语义是各种场景(如实体代理)中的基本问题。虽然NeRF和3DGS在新型视图合成方面表现出色,但之前对于理解其语义的方法仅限于不完整的3D理解:他们的分割结果呈现为2D遮罩,并不能代表整个3D空间。为了解决这个问题,我们重新定义了分割3D体积的问题,并提出了以下方法来更好地进行3D理解。我们直接监督3D点来训练语言嵌入场,不同于以前的方法只在2D像素上进行监督。我们将学到的语言场转移到3DGS,在不牺牲训练时间或准确度的情况下,实现了首次实时渲染速度。最后,我们引入了一个3D查询和评估协议,以共同评估重建的几何和语义。代码、检查点和注释可在项目页面找到。
论文及项目相关链接
PDF AAAI 2025. Project page: https://hyunji12.github.io/Open3DRF
Summary
本文为了解决现有NeRF模型在理解场景三维语义方面存在的局限性,提出了一系列改进方法。首先,对问题进行了重新定义,以实现对三维体积的分割,进而提高三维理解能力。通过直接监督三维点来训练语言嵌入场,而非像之前的方法那样在二维像素上进行锚点监督。将学习到的语言场转移到3DGS,实现了在不牺牲训练时间和准确性的情况下实时渲染速度的提升。最后,引入了一个三维查询和评估协议,以评估重建的几何结构和语义。
Key Takeaways
- 重新定义了问题以实现对三维体积的分割,以提高对场景的三维理解能力。
- 通过直接监督三维点来训练语言嵌入场,而不是在二维像素上进行锚点监督。
- 将学习到的语言场转移到3DGS,实现了实时渲染速度的提升,同时不牺牲训练时间和准确性。
- 引入了一个三维查询和评估协议,用于评估重建的几何结构和语义。
- 现有方法仅能提供不完整的三维理解,而本文方法可以更全面地理解场景的三维语义。
- 本文方法解决了以往方法在场景三维语义理解方面的局限性,如新型视图合成等应用场景中的问题。
点此查看论文截图








