⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-26 更新
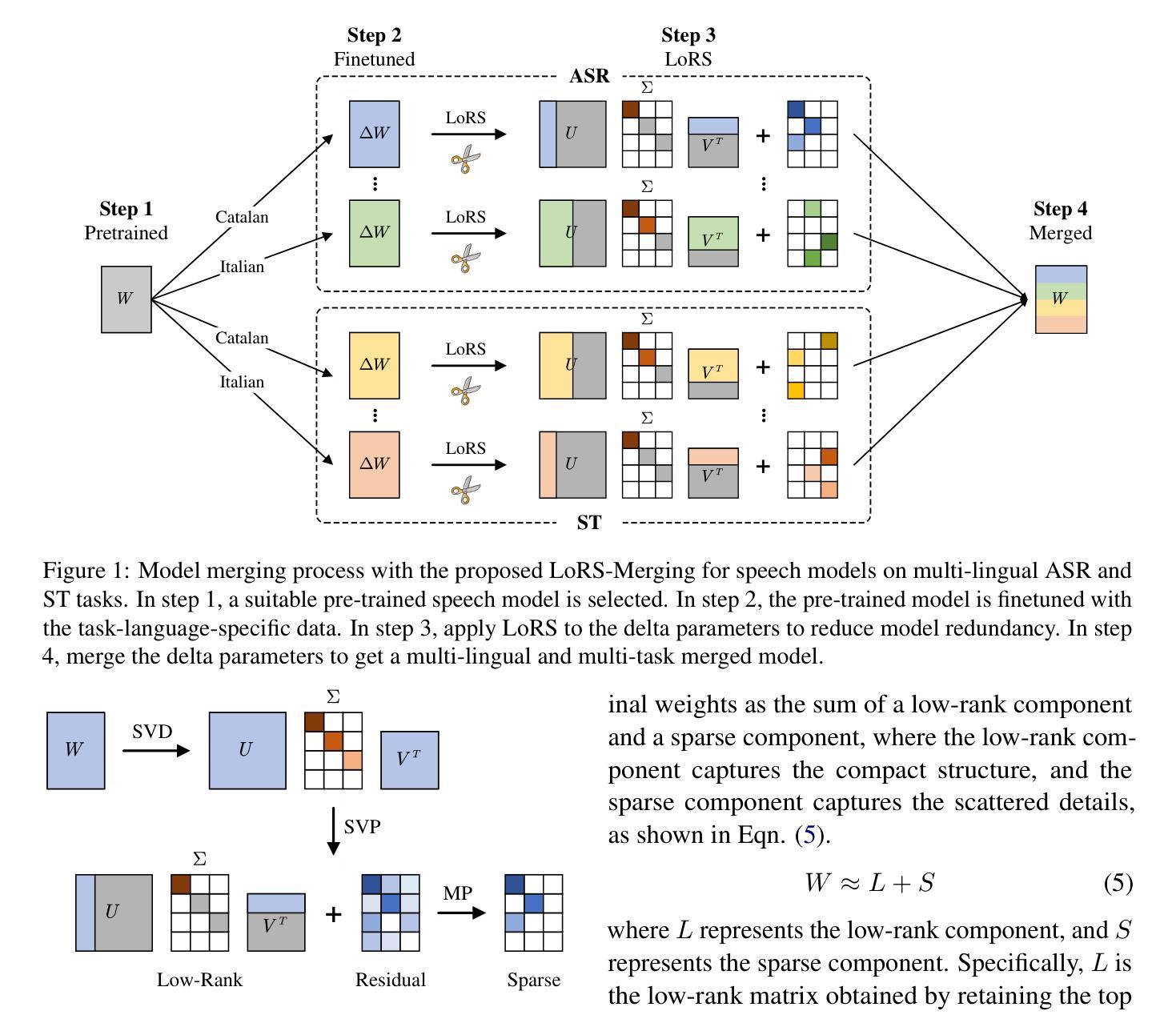
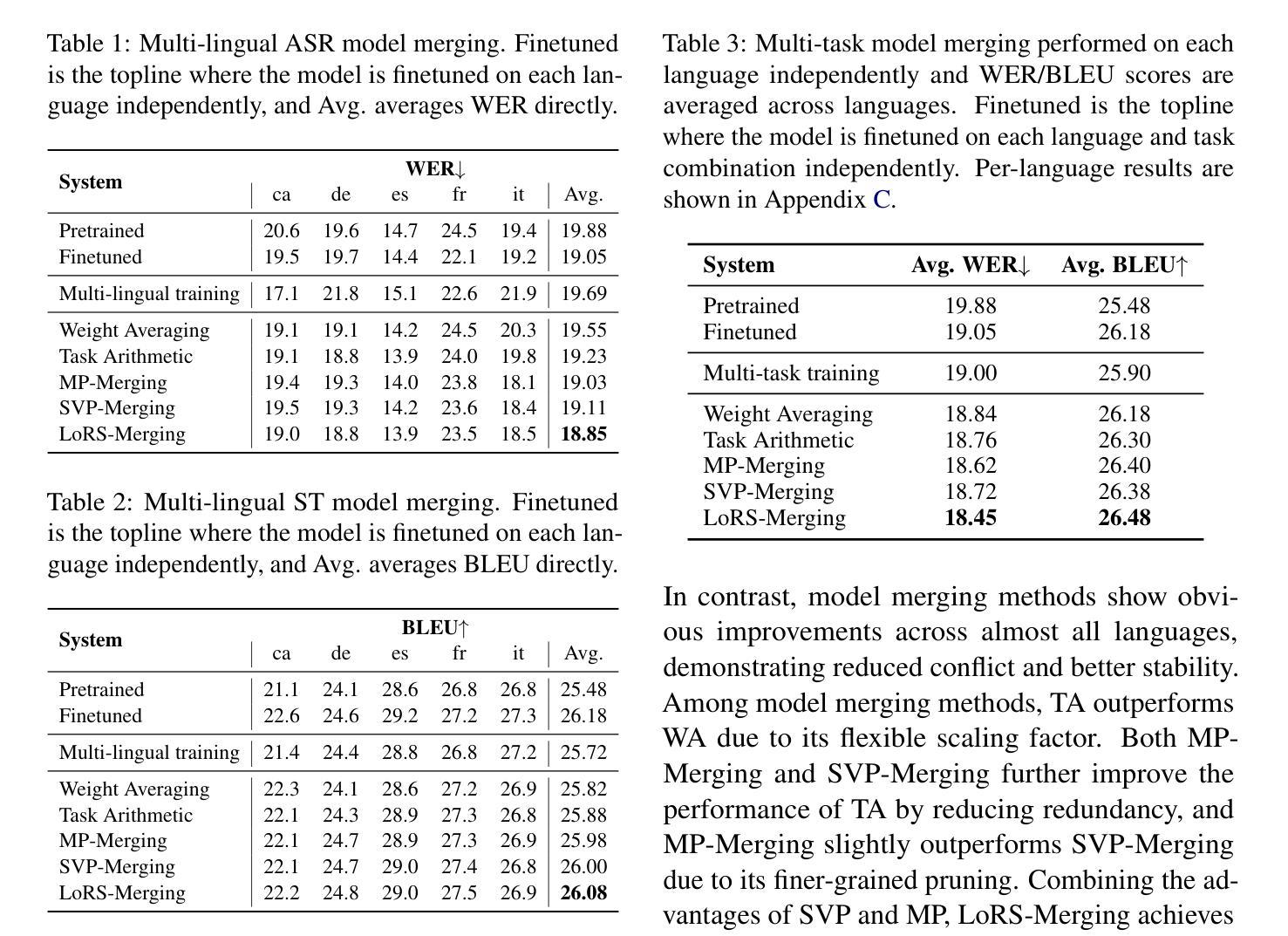
Low-Rank and Sparse Model Merging for Multi-Lingual Speech Recognition and Translation
Authors:Qiuming Zhao, Guangzhi Sun, Chao Zhang, Mingxing Xu, Thomas Fang Zheng
Language diversity presents a significant challenge in speech-to-text (S2T) tasks, such as automatic speech recognition and translation. Traditional multi-task training approaches aim to address this by jointly optimizing multiple speech recognition and translation tasks across various languages. While models like Whisper, built on these strategies, demonstrate strong performance, they still face issues of high computational cost, language interference, suboptimal training configurations, and limited extensibility. To overcome these challenges, we introduce LoRS-Merging (low-rank and sparse model merging), a novel technique designed to efficiently integrate models trained on different languages or tasks while preserving performance and reducing computational overhead. LoRS-Merging combines low-rank and sparse pruning to retain essential structures while eliminating redundant parameters, mitigating language and task interference, and enhancing extensibility. Experimental results across a range of languages demonstrate that LoRS-Merging significantly outperforms conventional multi-lingual multi-task training baselines. Our findings suggest that model merging, particularly LoRS-Merging, is a scalable and effective complement to traditional multi-lingual training strategies for S2T applications.
语言多样性在语音识别到文本(S2T)的任务中,如自动语音识别和翻译,构成了一大挑战。传统多任务训练的方法旨在通过联合优化多种语言的语音识别和翻译任务来解决这一问题。虽然基于这些策略的模型,如whisper,表现出了强大的性能,但它们仍然面临计算成本高、语言干扰、训练配置不佳和扩展性有限的诸多问题。为了克服这些挑战,我们引入了LoRS-Merging(低秩和稀疏模型合并),这是一种旨在高效集成在不同语言或任务上训练的模型的新技术,同时保留性能并降低计算开销。LoRS-Merging结合了低秩和稀疏剪枝,以保留关键结构并消除冗余参数,减轻语言和任务干扰,提高扩展性。跨多种语言的实验结果表明,LoRS-Merging显著优于传统多语种多任务训练基线。我们的研究结果表明,模型合并,尤其是LoRS-Merging,是S2T应用中传统多语种训练策略的可扩展和有效的补充。
论文及项目相关链接
PDF 13 pages, submitted to ACL 2025
Summary
语言多样性在语音转文本(S2T)任务中是一大挑战,如自动语音识别和翻译。传统多任务训练旨在通过联合优化多种语言和翻译任务来解决这一问题。虽然基于这些策略构建的模型如Whisper表现出强大的性能,但它们仍面临计算成本高、语言干扰、训练配置不佳和扩展性有限等问题。为了克服这些挑战,我们引入了LoRS-Merging(低秩和稀疏模型合并),这是一种设计用于高效集成不同语言或任务训练模型的新技术,同时保持性能并降低计算开销。LoRS-Merging结合低秩和稀疏剪枝,保留关键结构,消除冗余参数,减轻语言和任务干扰,提高扩展性。跨多种语言的实验结果表明,LoRS-Merging显著优于传统多语言多任务训练基线。我们的研究结果表明,模型合并,尤其是LoRS-Merging,是S2T应用中传统多语言训练策略的可扩展和有效的补充。
Key Takeaways
- 语言多样性在语音转文本任务中构成重大挑战。
- 传统多任务训练策略旨在通过联合优化多种语言和翻译任务来解决这一挑战。
- 虽然现有模型如Whisper性能强大,但仍存在计算成本高、语言干扰和扩展性有限等问题。
- LoRS-Merging技术旨在通过高效集成不同语言或任务的训练模型来克服这些挑战。
- LoRS-Merging结合低秩和稀疏剪枝,以保留关键结构并消除冗余参数。
- LoRS-Merging能减轻语言和任务间的干扰,提高模型的扩展性。
点此查看论文截图

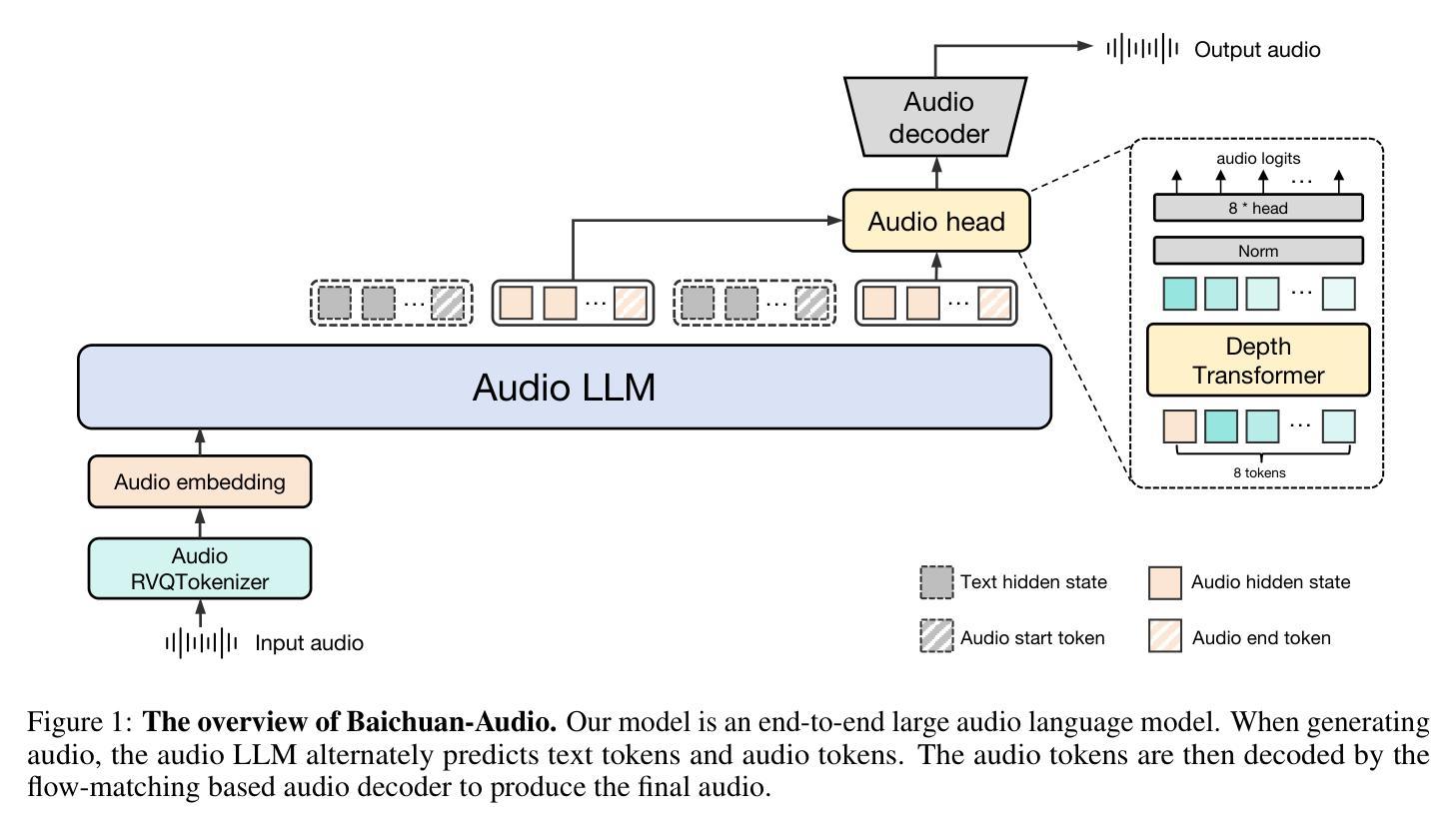
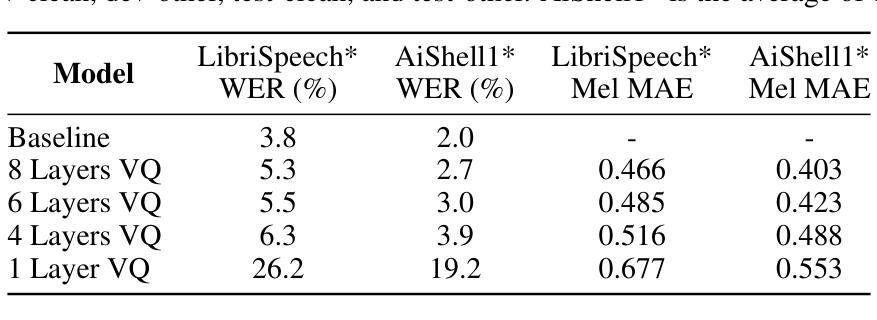
Baichuan-Audio: A Unified Framework for End-to-End Speech Interaction
Authors:Tianpeng Li, Jun Liu, Tao Zhang, Yuanbo Fang, Da Pan, Mingrui Wang, Zheng Liang, Zehuan Li, Mingan Lin, Guosheng Dong, Jianhua Xu, Haoze Sun, Zenan Zhou, Weipeng Chen
We introduce Baichuan-Audio, an end-to-end audio large language model that seamlessly integrates audio understanding and generation. It features a text-guided aligned speech generation mechanism, enabling real-time speech interaction with both comprehension and generation capabilities. Baichuan-Audio leverages a pre-trained ASR model, followed by multi-codebook discretization of speech at a frame rate of 12.5 Hz. This multi-codebook setup ensures that speech tokens retain both semantic and acoustic information. To further enhance modeling, an independent audio head is employed to process audio tokens, effectively capturing their unique characteristics. To mitigate the loss of intelligence during pre-training and preserve the original capabilities of the LLM, we propose a two-stage pre-training strategy that maintains language understanding while enhancing audio modeling. Following alignment, the model excels in real-time speech-based conversation and exhibits outstanding question-answering capabilities, demonstrating its versatility and efficiency. The proposed model demonstrates superior performance in real-time spoken dialogue and exhibits strong question-answering abilities. Our code, model and training data are available at https://github.com/baichuan-inc/Baichuan-Audio
我们推出百川音频(Baichuan-Audio)——端到端的音频大语言模型,它无缝集成了音频理解和生成。该模型具备文本引导的对齐语音生成机制,能够实现具有理解和生成能力的实时语音交互。百川音频利用预训练的语音识别模型,随后以12.5Hz的帧率进行多代码簿离散化语音。这种多代码簿设置确保语音标记保留语义和声音信息。为了进一步提高建模效果,采用独立的音频头来处理音频标记,有效地捕捉其独特特征。为了减轻预训练过程中的智力损失并保留大语言模型的原始能力,我们提出了两阶段预训练策略,既保持语言理解又增强音频建模。对齐后,该模型在实时语音对话中表现出色,具有出色的问答能力,体现了其通用性和效率。所提出的模型在实时口语对话中表现出卓越性能,展现出强大的问答能力。我们的代码、模型和训练数据可在 https://github.com/baichuan-inc/Baichuan-Audio 找到。
论文及项目相关链接
Summary
巴川音频模型是一个端到端的音频大语言模型,融合了音频理解和生成能力,实现实时语音交互。模型具备文本指导对齐的语音生成机制和多码本离散化技术,能有效捕捉语音的语义和声音信息。采用独立音频头处理音频标记,并采用两阶段预训练策略增强建模效果并维护语言理解功能。模型具有优秀的实时对话性能,展现了强大的问答能力。
Key Takeaways
- 巴川音频模型是一个端到端的音频大语言模型,融合了音频理解和生成能力。
- 模型具备文本指导对齐的语音生成机制,实现实时语音交互。
- 多码本离散化技术确保语音标记捕捉语义和声音信息。
- 独立音频头处理音频标记,提升模型性能。
- 采用两阶段预训练策略增强建模效果,同时维护语言理解功能。
- 模型在实时对话中表现出优秀的性能,具备强大的问答能力。
点此查看论文截图

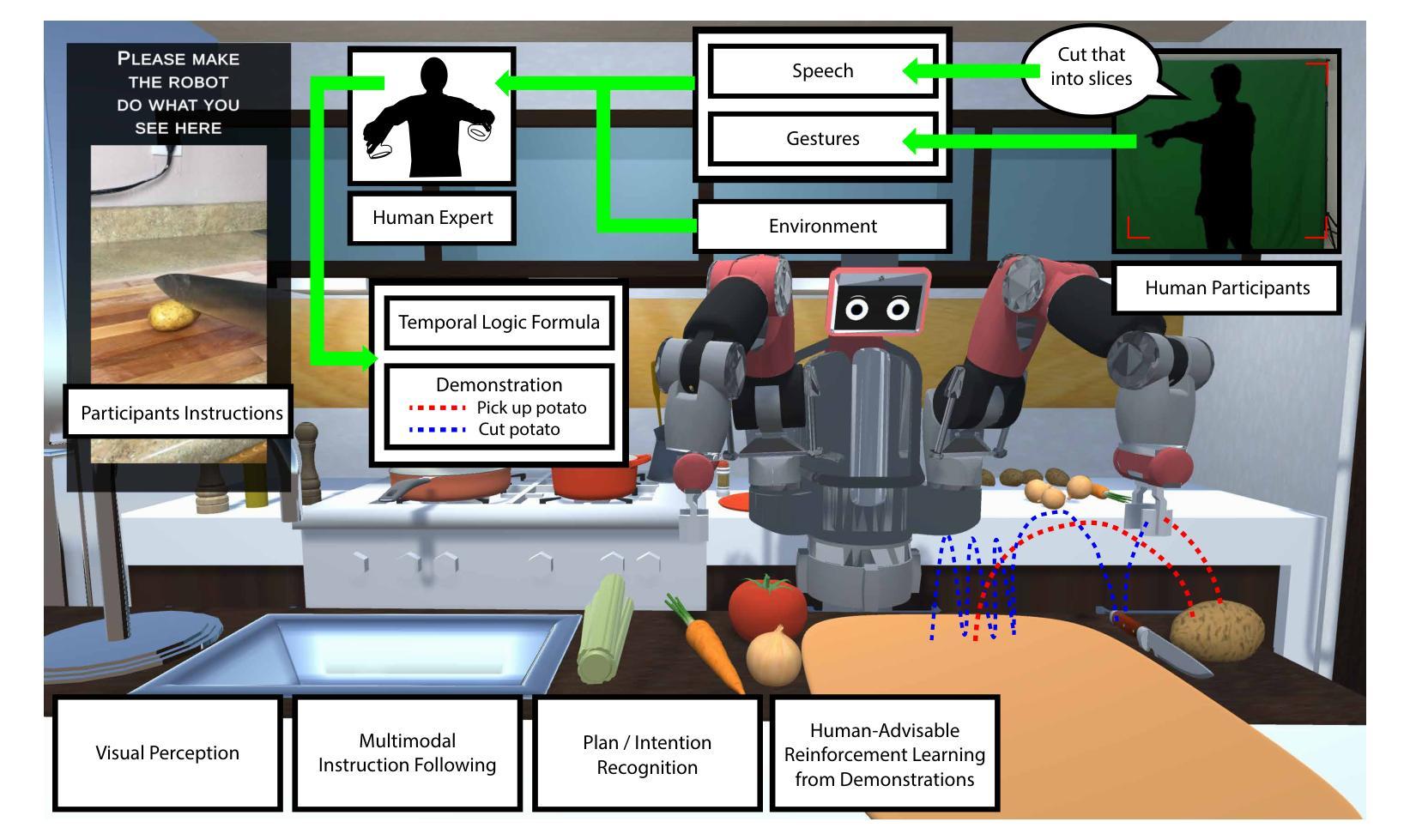
NatSGLD: A Dataset with Speech, Gesture, Logic, and Demonstration for Robot Learning in Natural Human-Robot Interaction
Authors:Snehesh Shrestha, Yantian Zha, Saketh Banagiri, Ge Gao, Yiannis Aloimonos, Cornelia Fermüller
Recent advances in multimodal Human-Robot Interaction (HRI) datasets emphasize the integration of speech and gestures, allowing robots to absorb explicit knowledge and tacit understanding. However, existing datasets primarily focus on elementary tasks like object pointing and pushing, limiting their applicability to complex domains. They prioritize simpler human command data but place less emphasis on training robots to correctly interpret tasks and respond appropriately. To address these gaps, we present the NatSGLD dataset, which was collected using a Wizard of Oz (WoZ) method, where participants interacted with a robot they believed to be autonomous. NatSGLD records humans’ multimodal commands (speech and gestures), each paired with a demonstration trajectory and a Linear Temporal Logic (LTL) formula that provides a ground-truth interpretation of the commanded tasks. This dataset serves as a foundational resource for research at the intersection of HRI and machine learning. By providing multimodal inputs and detailed annotations, NatSGLD enables exploration in areas such as multimodal instruction following, plan recognition, and human-advisable reinforcement learning from demonstrations. We release the dataset and code under the MIT License at https://www.snehesh.com/natsgld/ to support future HRI research.
近期多模态人机互动(HRI)数据集的进步强调语音和手势的整合,让机器人能够吸收明确的知识和隐含的理解。然而,现有的数据集主要专注于基本的任务,如指向物体和推动物体,限制了它们在复杂领域的应用。它们优先处理更简单的人类命令数据,但较少强调训练机器人正确解释任务并适当回应。为了解决这些空白,我们推出了NatSGLD数据集,该数据集是采用“奥兹巫师”(WoZ)方法收集的,参与者与他们认为具有自主性的机器人进行了互动。NatSGLD记录了人类的多模态命令(语音和手势),每个命令都与演示轨迹和线性时序逻辑(LTL)公式配对,为命令任务提供了真实地面的解释。该数据集是HRI和机器学习交叉研究的基础资源。通过提供多模态输入和详细注释,NatSGLD可以在多模态指令跟踪、计划识别和基于演示的人类可建议强化学习等领域进行探索。我们在https://www.snehesh.com/natsgld/下以MIT许可证的形式发布数据集和代码,以支持未来的人机互动研究。
论文及项目相关链接
PDF arXiv admin note: substantial text overlap with arXiv:2403.02274
Summary
近期多模态人机交互(HRI)数据集的发展强调了语音和手势的集成,使机器人能够吸收显性知识和隐性理解。然而,现有数据集主要关注基础任务,如指向和推动物体,限制了它们在复杂领域的应用。NatSGLD数据集的推出解决了这一问题,它采用参与者误以为机器人是自主的“Wizard of Oz”(WoZ)方法收集而成。NatSGLD记录了人类的多模态命令(包括语音和手势),每个命令都配有演示轨迹和线性时序逻辑(LTL)公式,为命令任务提供了真实解读。该数据集为HRI和机器学习交叉领域的研究提供了基础资源,通过提供多模态输入和详细注释,支持对多模态指令跟踪、计划识别和人类可指导的强化学习等领域的探索。
Key Takeaways
- 多模态HRI数据集融合语音和手势,增强机器人对知识的吸收和理解。
- 现有数据集多关注基础任务,限制了其在复杂场景的应用。
- NatSGLD数据集采用WoZ方法收集,包含人类多模态命令、演示轨迹和LTL公式。
- NatSGLD为HRI和机器学习研究提供基础资源。
- 数据集支持多模态指令跟踪、计划识别和强化学习等领域的探索。
- NatSGLD数据集和代码已发布在https://www.snehesh.com/natsgld/,供未来HRI研究使用。
点此查看论文截图


MemeIntel: Explainable Detection of Propagandistic and Hateful Memes
Authors:Mohamed Bayan Kmainasi, Abul Hasnat, Md Arid Hasan, Ali Ezzat Shahroor, Firoj Alam
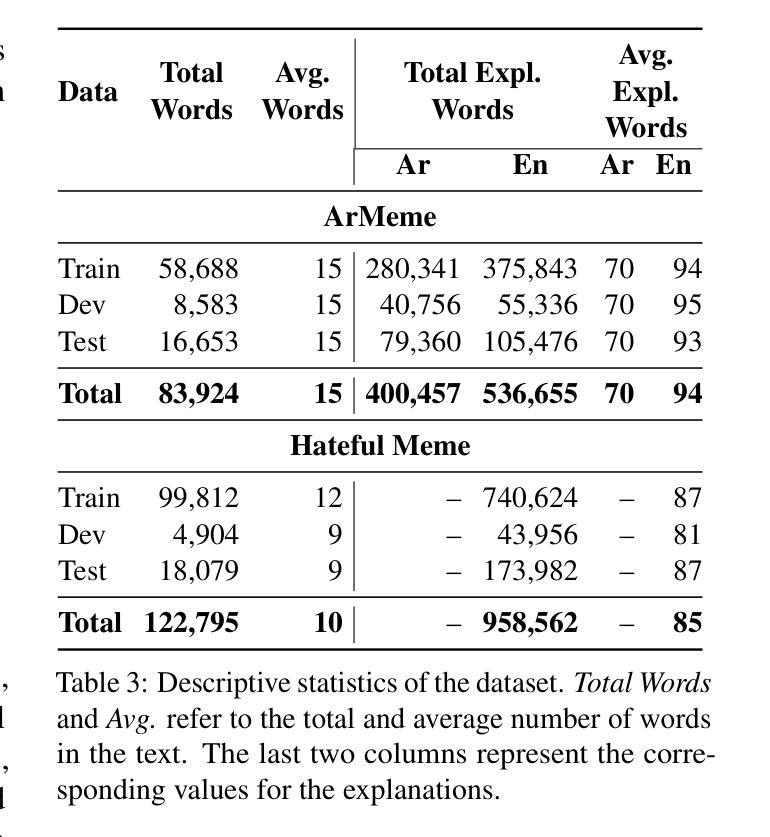
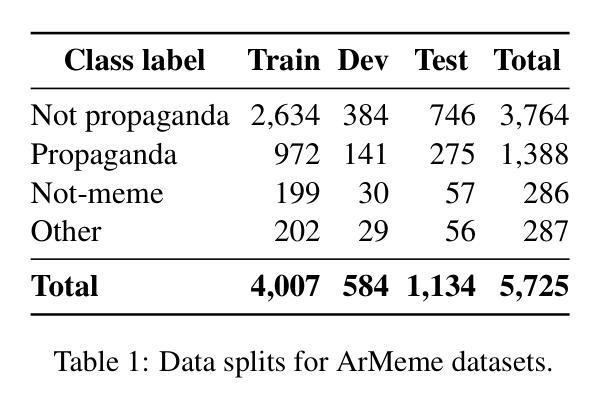
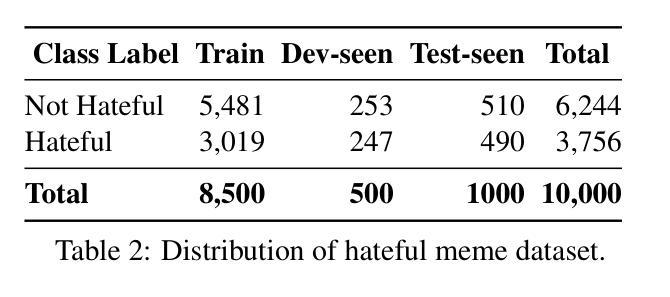
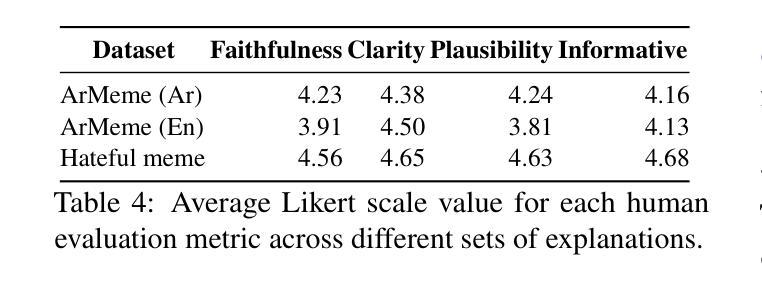
The proliferation of multimodal content on social media presents significant challenges in understanding and moderating complex, context-dependent issues such as misinformation, hate speech, and propaganda. While efforts have been made to develop resources and propose new methods for automatic detection, limited attention has been given to label detection and the generation of explanation-based rationales for predicted labels. To address this challenge, we introduce MemeIntel, an explanation-enhanced dataset for propaganda memes in Arabic and hateful memes in English, making it the first large-scale resource for these tasks. To solve these tasks, we propose a multi-stage optimization approach and train Vision-Language Models (VLMs). Our results demonstrate that this approach significantly improves performance over the base model for both \textbf{label detection} and explanation generation, outperforming the current state-of-the-art with an absolute improvement of ~3% on ArMeme and ~7% on Hateful Memes. For reproducibility and future research, we aim to make the MemeIntel dataset and experimental resources publicly available.
社交媒体上多模态内容的激增,为理解和调节复杂、依赖于情境的议题(如虚假信息、仇恨言论和宣传等)带来了重大挑战。虽然已有人努力开发资源和提出自动检测的新方法,但对标签检测以及基于预测的标签生成解释理由的关注有限。为了应对这一挑战,我们推出了MemeIntel,这是一个针对阿拉伯语的宣传标语和英文的仇恨言论标签增强的数据集,成为这些任务的首个大规模资源。为了解决这些任务,我们提出了多阶段优化方法并训练了视觉语言模型(VLMs)。我们的结果表明,这种方法在标签检测和解释生成方面都显著提高了基础模型的性能,相较于当前最先进的技术,在ArMeme上绝对提高了约3%,在仇恨言论标签上提高了约7%。为了可复制性和未来研究,我们计划将MemeIntel数据集和实验资源公开提供。
论文及项目相关链接
PDF disinformation, misinformation, factuality, harmfulness, fake news, propaganda, hateful meme, multimodality, text, images
Summary
社交媒体上多模态内容的普及,给理解和调控诸如虚假信息、仇恨言论和宣传等复杂、依赖情境的议题带来了重大挑战。尽管已有资源和新方法的开发用于自动检测,但在标签检测和预测标签的解释性依据生成方面关注有限。为应对这一挑战,我们推出了MemeIntel数据集,包含阿拉伯语的宣传标语和英文的仇恨标语解释增强功能,成为首个大规模资源用于这些任务。我们采用多阶段优化方法和训练视觉语言模型(VLMs)来解决这些任务。结果表明,该方法在标签检测和解释生成方面较基础模型有显著提升,相较于当前最前沿技术,在ArMeme上绝对提升约3%,在仇恨标语上提升约7%。我们旨在将MemeIntel数据集和实验资源公开,以供复制和未来研究使用。
Key Takeaways
- 社交媒体多模态内容带来理解和调控复杂、依赖情境的议题的挑战。
- 当前自动检测方面存在标签检测和解释性依据生成的关注不足。
- 引入MemeIntel数据集,包含阿拉伯语和英语的宣传标语和仇恨标语解释增强功能。
- 采用多阶段优化方法和训练视觉语言模型(VLMs)解决相关任务。
- 方法在标签检测和解释生成方面较基础模型有显著提升。
- 与当前最前沿技术相比,在ArMeme和仇恨标语方面取得显著进步。
点此查看论文截图

Speech Enhancement Using Continuous Embeddings of Neural Audio Codec
Authors:Haoyang Li, Jia Qi Yip, Tianyu Fan, Eng Siong Chng
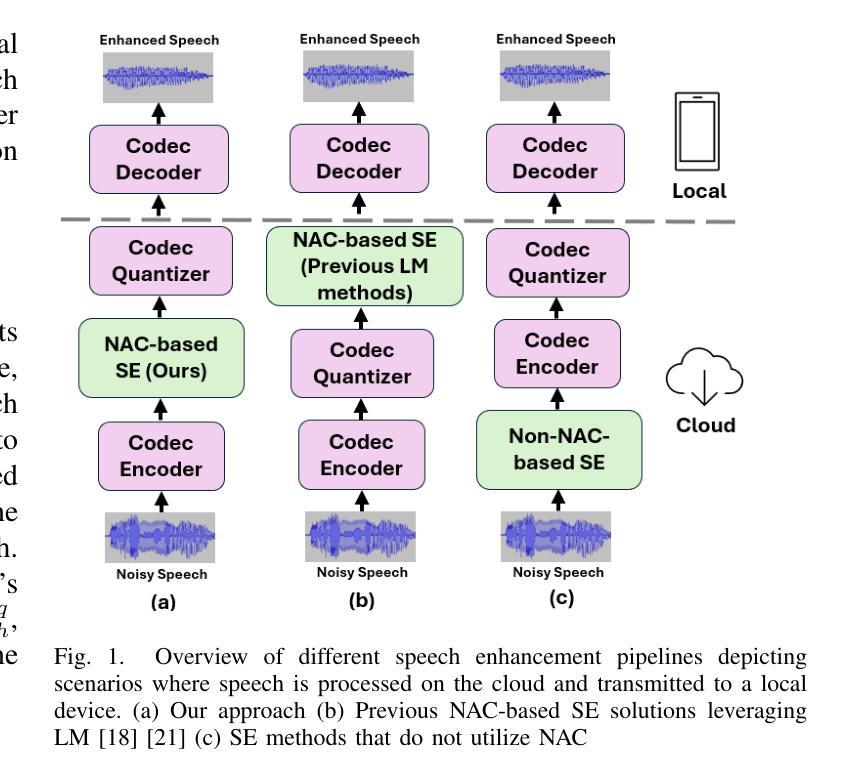
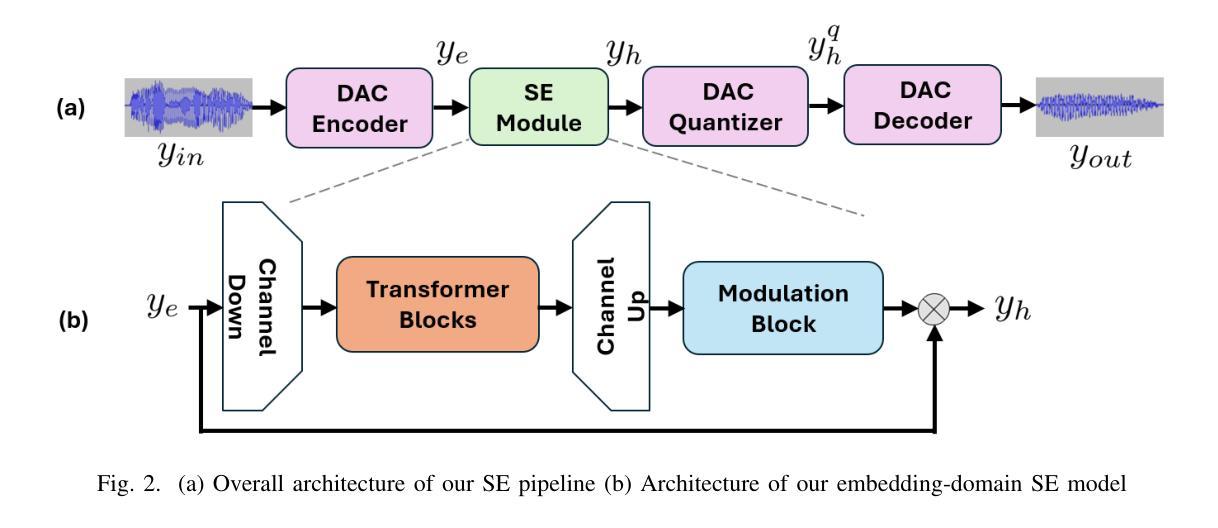
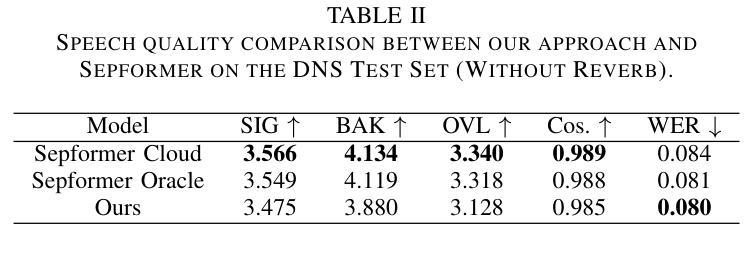
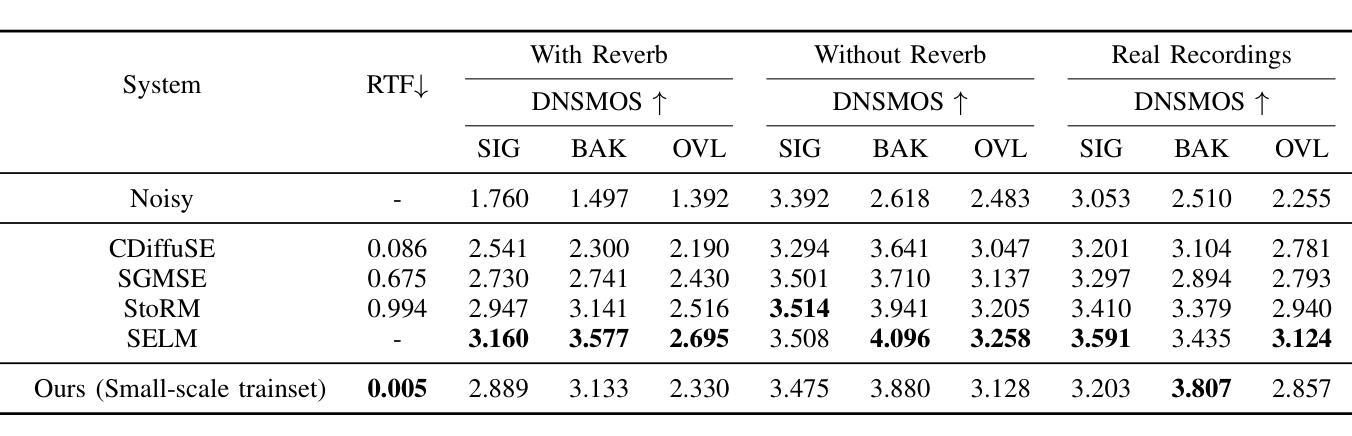
Recent advancements in Neural Audio Codec (NAC) models have inspired their use in various speech processing tasks, including speech enhancement (SE). In this work, we propose a novel, efficient SE approach by leveraging the pre-quantization output of a pretrained NAC encoder. Unlike prior NAC-based SE methods, which process discrete speech tokens using Language Models (LMs), we perform SE within the continuous embedding space of the pretrained NAC, which is highly compressed along the time dimension for efficient representation. Our lightweight SE model, optimized through an embedding-level loss, delivers results comparable to SE baselines trained on larger datasets, with a significantly lower real-time factor of 0.005. Additionally, our method achieves a low GMAC of 3.94, reducing complexity 18-fold compared to Sepformer in a simulated cloud-based audio transmission environment. This work highlights a new, efficient NAC-based SE solution, particularly suitable for cloud applications where NAC is used to compress audio before transmission. Copyright 20XX IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works.
近期神经网络音频编解码器(NAC)模型的进展激发了其在各种语音处理任务中的应用,包括语音增强(SE)。在这项工作中,我们提出了一种利用预训练NAC编码器的预量化输出进行高效SE的新方法。与以前基于NAC的SE方法不同,后者使用语言模型(LM)处理离散的语音标记,我们在预训练的NAC的连续嵌入空间内执行SE,该嵌入空间在时间维度上进行了高度压缩以进行有效表示。我们的轻量级SE模型通过嵌入层损失进行优化,其结果表明即使与在更大数据集上训练的SE基线相比,也能取得相当的结果,实时因子为0.005。此外,我们的方法在模拟的云音频传输环境中实现了较低的GMAC值3.94,与Sepformer相比复杂度降低了18倍。这项工作是首次展示了适用于使用NAC进行音频压缩和传输的云应用程序的高效解决方案。版权声明:本论文版权归IEEE所有。允许个人使用本材料。如需用于其他用途(无论当前还是未来媒体),包括但不限于为广告或宣传目的重印或重新发布本材料、创建新的集体作品、转售或重新分发到服务器或列表、或在其他作品中使用本受版权保护作品的任何部分,都必须获得IEEE的许可。
论文及项目相关链接
PDF Accepted to ICASSP 2025
摘要
近期神经网络音频编码(NAC)模型的进展为其在语音处理任务中的应用提供了可能,包括语音增强(SE)。本研究提出了一种新的高效SE方法,该方法利用预训练NAC的预量化输出。与先前基于NAC的SE方法不同,我们不在离散语音标记上使用语言模型(LMs)进行处理,而是在预训练NAC的连续嵌入空间内执行SE,该空间在时间维度上高度压缩以实现高效表示。我们的轻量化SE模型通过嵌入级损失进行优化,可提供与在更大数据集上训练的SE基线相当的结果,并且实时因子低得多,为0.005。此外,我们的方法在模拟的云基于音频传输环境中实现了3.94的GMAC,与Sepformer相比减少了18倍复杂性。本研究强调了新的高效NAC-基于SE解决方案,尤其适合在NAC用于音频传输前压缩的云应用程序中使用。
要点
- NAC模型最新进展为语音增强等语音处理任务提供了新的应用可能性。
- 提出一种高效SE方法,利用预训练NAC的预量化输出进行语音增强。
- 与传统方法不同,本方法不在离散语音标记上使用语言模型处理,而是在连续嵌入空间内执行SE。
- 模型优化通过嵌入级损失进行,实时因子低(0.005),性能与大型数据集训练的SE基线相当。
- 该方法在模拟的云环境中实现低GMAC(3.94),相较于Sepformer减少了复杂性。
- 本研究适用于云应用程序中的音频压缩和传输场景。
点此查看论文截图

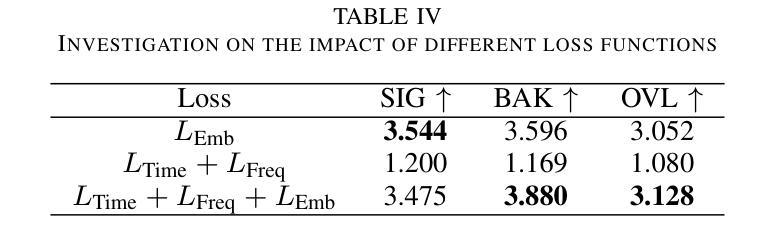
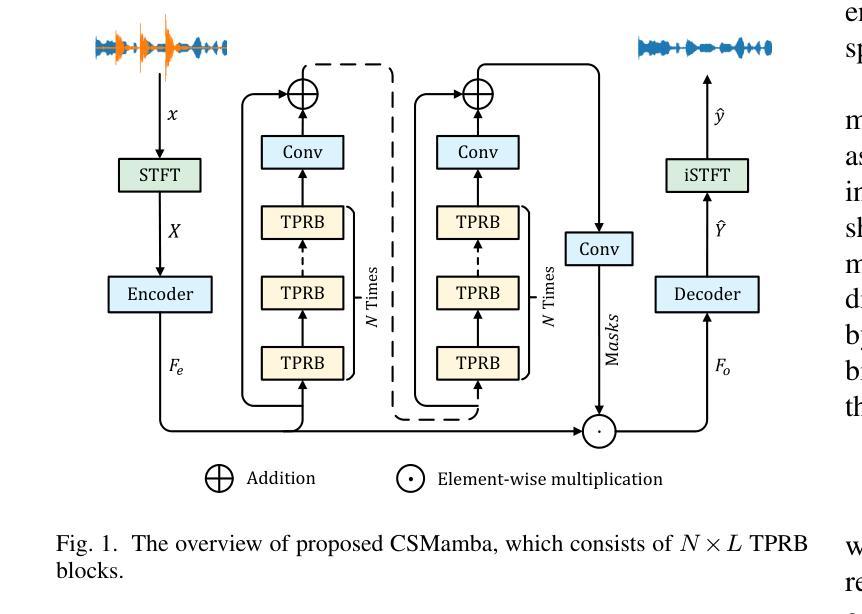
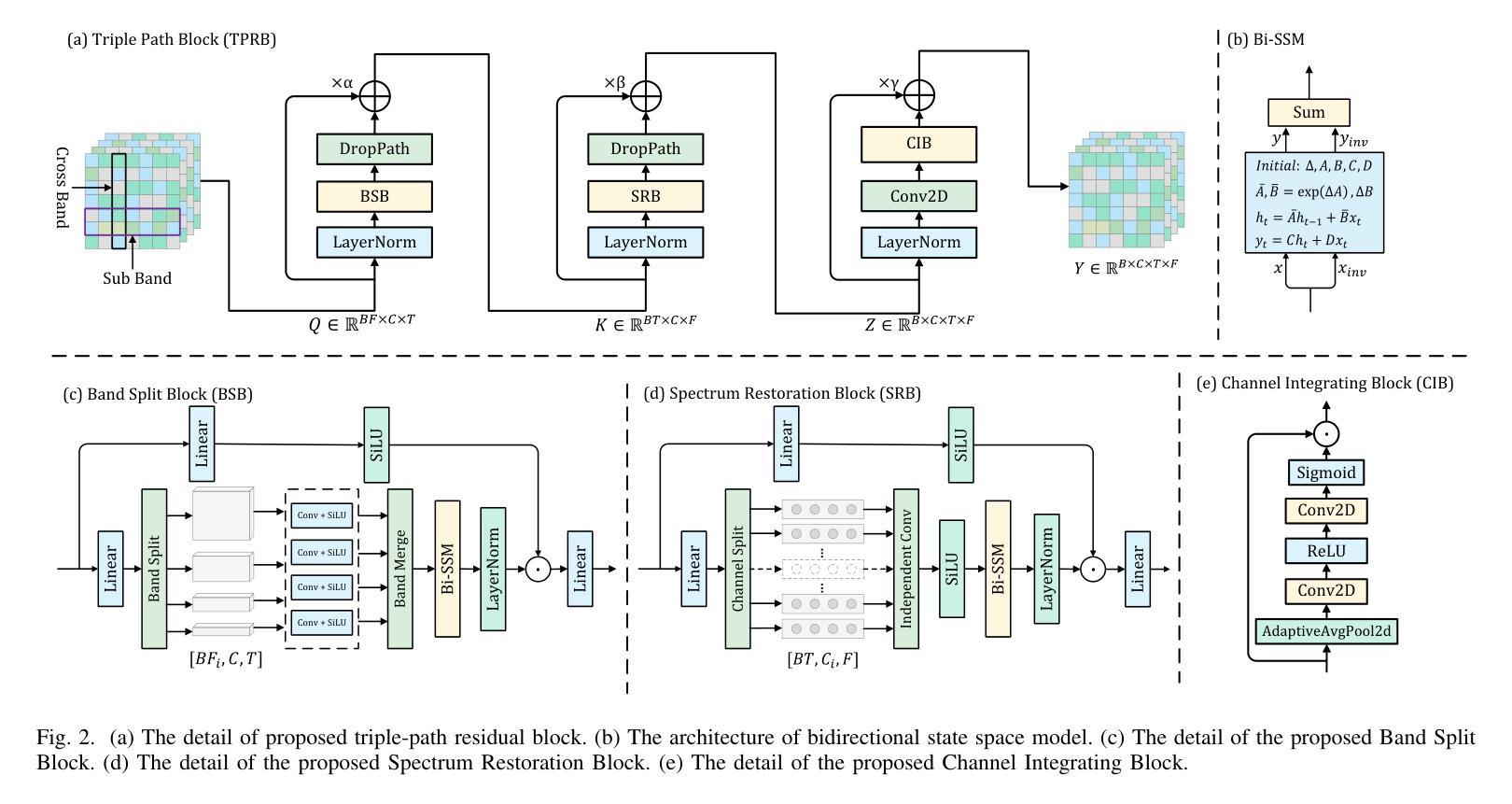
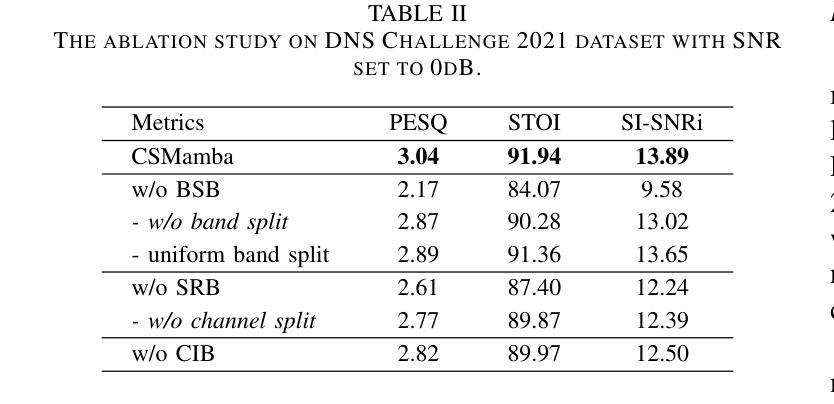
Improving Speech Enhancement by Cross- and Sub-band Processing with State Space Model
Authors:Jizhen Li, Weiping Tu, Yuhong Yang, Xinmeng Xu, Yiqun Zhang, Yanzhen Ren
Recently, the state space model (SSM) represented by Mamba has shown remarkable performance in long-term sequence modeling tasks, including speech enhancement. However, due to substantial differences in sub-band features, applying the same SSM to all sub-bands limits its inference capability. Additionally, when processing each time frame of the time-frequency representation, the SSM may forget certain high-frequency information of low energy, making the restoration of structure in the high-frequency bands challenging. For this reason, we propose Cross- and Sub-band Mamba (CSMamba). To assist the SSM in handling different sub-band features flexibly, we propose a band split block that splits the full-band into four sub-bands with different widths based on their information similarity. We then allocate independent weights to each sub-band, thereby reducing the inference burden on the SSM. Furthermore, to mitigate the forgetting of low-energy information in the high-frequency bands by the SSM, we introduce a spectrum restoration block that enhances the representation of the cross-band features from multiple perspectives. Experimental results on the DNS Challenge 2021 dataset demonstrate that CSMamba outperforms several state-of-the-art (SOTA) speech enhancement methods in three objective evaluation metrics with fewer parameters.
最近,以Mamba为代表的状态空间模型(SSM)在长期序列建模任务中,包括语音增强,都表现出了显著的性能。然而,由于子带特征之间存在巨大差异,将相同的SSM应用于所有子带会限制其推理能力。此外,在处理时频表示的每个时间帧时,SSM可能会忘记某些低能量的高频信息,使得恢复高频带中的结构具有挑战性。因此,我们提出了跨带和子带Mamba(CSMamba)。为了帮助SSM灵活处理不同的子带特征,我们提出了一个带分割块,该块根据信息相似性将全频带分割成四个不同宽度的子带。然后我们对每个子带分配独立权重,从而减轻SSM的推理负担。此外,为了减轻SSM在高频带中忘记低能量信息的问题,我们引入了一个频谱恢复块,该块从多个角度增强了跨带特征的表现。在DNS Challenge 2021数据集上的实验结果表明,CSMamba在三个客观评价指标上优于几种最先进的语音增强方法,且参数更少。
论文及项目相关链接
Summary
Mamba代表的州空间模型(SSM)在长期序列建模任务中表现优异,包括语音增强。但应用同一SSM处理所有子带存在局限性。为此,提出跨带和子带Mamba(CSMamba),通过带分割块将全频带分为不同宽度的子带,并为每个子带分配独立权重,减轻SSM的推理负担。同时,通过频谱恢复块增强跨带特征表示,减少SSM在高频带中遗忘低能量信息的问题。在DNS Challenge 2021数据集上的实验结果表明,CSMamba在三个客观评价指标上优于多种最新语音增强方法,且参数更少。
Key Takeaways
- Mamba代表的州空间模型(SSM)在语音增强等长期序列建模任务中表现出色。
- 应用同一SSM处理所有子带存在局限性,因为子带特征差异显著。
- 提出CSMamba模型,通过带分割块将全频带分为不同宽度的子带。
- 为每个子带分配独立权重,以减轻SSM的推理负担。
- 频谱恢复块用于增强跨带特征表示,减少SSM在高频带中遗忘低能量信息的问题。
- 实验结果表明,CSMamba在客观评价指标上优于多种最新语音增强方法。
点此查看论文截图

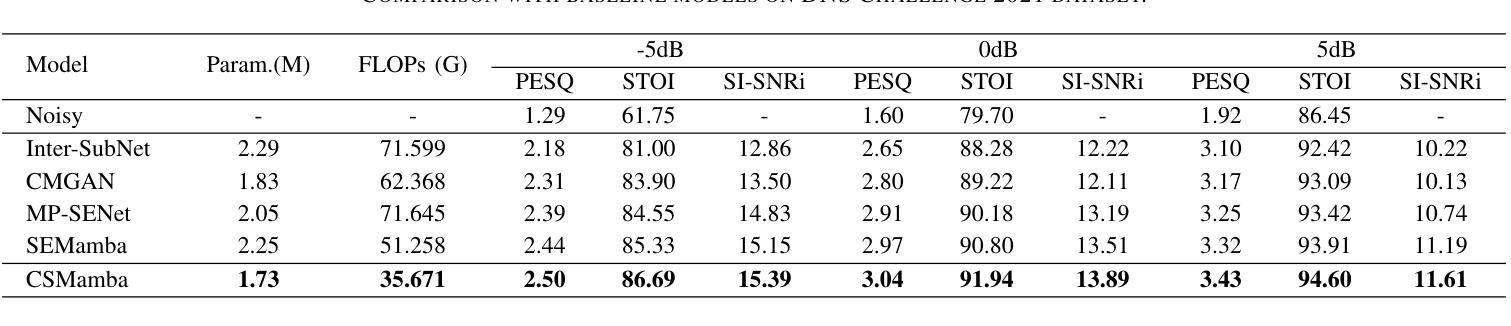
Understanding Zero-shot Rare Word Recognition Improvements Through LLM Integration
Authors:Haoxuan Wang
In this study, we investigate the integration of a large language model (LLM) with an automatic speech recognition (ASR) system, specifically focusing on enhancing rare word recognition performance. Using a 190,000-hour dataset primarily sourced from YouTube, pre-processed with Whisper V3 pseudo-labeling, we demonstrate that the LLM-ASR architecture outperforms traditional Zipformer-Transducer models in the zero-shot rare word recognition task, after training on a large dataset. Our analysis reveals that the LLM contributes significantly to improvements in rare word error rate (R-WER), while the speech encoder primarily determines overall transcription performance (Orthographic Word Error Rate, O-WER, and Normalized Word Error Rate, N-WER). Through extensive ablation studies, we highlight the importance of adapter integration in aligning speech encoder outputs with the LLM’s linguistic capabilities. Furthermore, we emphasize the critical role of high-quality labeled data in achieving optimal performance. These findings provide valuable insights into the synergy between LLM-based ASR architectures, paving the way for future advancements in large-scale LLM-based speech recognition systems.
在这项研究中,我们探究了大型语言模型(LLM)与自动语音识别(ASR)系统的融合,特别关注提高罕见词识别性能。我们使用主要来源于YouTube的19万小时数据集,经过Whisper V3伪标签进行预处理,证明在大型数据集训练后,LLM-ASR架构在零样本罕见词识别任务中优于传统的Zipformer-Transducer模型。我们的分析表明,LLM对降低罕见词错误率(R-WER)做出了显著贡献,而语音编码器主要决定整体转录性能(正字法词错误率、O-WER和归一化词错误率、N-WER)。通过广泛的消融研究,我们强调了适配器集成在将语音编码器输出与LLM的语言能力对齐中的重要性。此外,我们强调了高质量标记数据在实现最佳性能中的关键作用。这些发现揭示了LLM为基础的ASR架构之间的协同价值,为未来大规模LLM为基础的语音识别系统的进步铺平了道路。
论文及项目相关链接
Summary
本研究探讨了大型语言模型(LLM)与自动语音识别(ASR)系统的融合,特别是在提高罕见词识别性能方面的应用。通过使用主要来自YouTube的190,000小时数据集,结合Whisper V3伪标签进行预处理,研究证明LLM-ASR架构在零样本罕见词识别任务中优于传统的Zipformer-Transducer模型。分析显示LLM对降低罕见词错误率(R-WER)有显著贡献,而语音编码器主要决定整体转录性能(包括正字法词错误率(O-WER)和归一化词错误率(N-WER)。通过广泛的消融研究,强调了适配器集成在将语音编码器输出与LLM的语言能力对齐中的重要性。同时,研究强调了高质量标记数据在实现最佳性能方面的关键作用。这些发现对于理解LLM在ASR架构中的协同作用具有重要意义,为大规模LLM语音识别系统的未来发展铺平了道路。
Key Takeaways
- LLM与ASR系统的结合能显著提高罕见词的识别性能。
- 使用YouTuBe数据的190,000小时大型数据集进行训练有助于LLM-ASR架构的表现。
- LLM对降低罕见词错误率有重要贡献。
- 语音编码器在决定整体转录性能中起关键作用。
- 适配器集成在LLM和语音编码器之间发挥重要作用。
- 高质量的标记数据对于实现最佳性能至关重要。
点此查看论文截图

Generative AI Framework for 3D Object Generation in Augmented Reality
Authors:Majid Behravan
This thesis presents a framework that integrates state-of-the-art generative AI models for real-time creation of three-dimensional (3D) objects in augmented reality (AR) environments. The primary goal is to convert diverse inputs, such as images and speech, into accurate 3D models, enhancing user interaction and immersion. Key components include advanced object detection algorithms, user-friendly interaction techniques, and robust AI models like Shap-E for 3D generation. Leveraging Vision Language Models (VLMs) and Large Language Models (LLMs), the system captures spatial details from images and processes textual information to generate comprehensive 3D objects, seamlessly integrating virtual objects into real-world environments. The framework demonstrates applications across industries such as gaming, education, retail, and interior design. It allows players to create personalized in-game assets, customers to see products in their environments before purchase, and designers to convert real-world objects into 3D models for real-time visualization. A significant contribution is democratizing 3D model creation, making advanced AI tools accessible to a broader audience, fostering creativity and innovation. The framework addresses challenges like handling multilingual inputs, diverse visual data, and complex environments, improving object detection and model generation accuracy, as well as loading 3D models in AR space in real-time. In conclusion, this thesis integrates generative AI and AR for efficient 3D model generation, enhancing accessibility and paving the way for innovative applications and improved user interactions in AR environments.
本论文提出了一个集成最新生成式人工智能模型的框架,用于在增强现实(AR)环境中实时创建三维(3D)对象。主要目标是将图像和语音等多样化的输入转化为准确的三维模型,增强用户交互和沉浸感。关键组件包括先进的物体检测算法、用户友好的交互技术以及用于三维生成的三维模型(如Shap-E)。通过利用视觉语言模型(VLMs)和大型语言模型(LLMs),该系统能够捕捉图像中的空间细节,处理文本信息以生成全面的三维物体,无缝地将虚拟物体集成到真实世界环境中。该框架展示了在游戏、教育、零售和室内设计等行业的应用。它允许玩家创建个性化的游戏资产,让客户在购买前看到产品在环境中的效果,设计师将现实世界物体转化为三维模型进行实时可视化。一个重要的贡献是使三维模型创建民主化,使更广泛的受众能够使用先进的AI工具,促进创造力和创新。该框架解决了处理多语言输入、多样化的视觉数据和复杂环境等挑战,提高了物体检测和模型生成的准确性,以及实时在AR空间中加载三维模型的能力。总之,本论文将生成式人工智能和AR技术相结合,实现高效的三维模型生成,提高可访问性,为AR环境中的创新应用和增强用户交互铺平道路。
论文及项目相关链接
摘要
该论文提出一个融合最前沿生成式人工智能模型的框架,用于在增强现实环境中实时创建三维物体。主要目标是将图像和语音等多样化输入转化为精确的三维模型,增强用户互动与沉浸感。关键组件包括高级物体检测算法、用户友好互动技术和强大的三维生成人工智能模型,如Shap-E。借助视觉语言模型和大语言模型,系统捕捉图像的空间细节并处理文本信息,以生成综合三维物体,无缝集成虚拟物体到真实环境。该框架展示了在游戏、教育、零售和室内设计等行业的应用。它允许玩家创建个性化游戏资产,客户在购买前看到产品在环境中的样子,以及设计师将真实世界物体转化为三维模型进行实时可视化。一个重大贡献是使三维模型创建民主化,使先进的AI工具对更广泛的受众群体可用,促进创造力和创新。该框架解决了处理多语言输入、多样化的视觉数据和复杂环境等挑战,提高了物体检测和模型生成的准确性,以及实时在AR空间中加载三维模型的能力。总之,该论文成功整合生成式人工智能和增强现实技术,实现高效的三维模型生成,提高可及性并为创新应用和增强现实环境中的用户互动铺平道路。
关键见解
- 论文提出了一个整合最前沿生成式AI模型的框架,用于在AR环境中实时创建三维物体。
- 框架的主要目标是将多样化的输入(如图像和语音)转化为精确的三维模型。
- 框架包括高级物体检测算法、用户友好互动技术和强大的三维生成AI模型。
- 利用视觉语言模型和大语言模型,实现虚拟物体与真实环境的无缝集成。
- 框架展示了在游戏、教育、零售和室内设计等多个行业的应用潜力。
- 该框架有助于民主化三维模型创建,使先进的AI工具对更广泛的用户群体可用。
点此查看论文截图

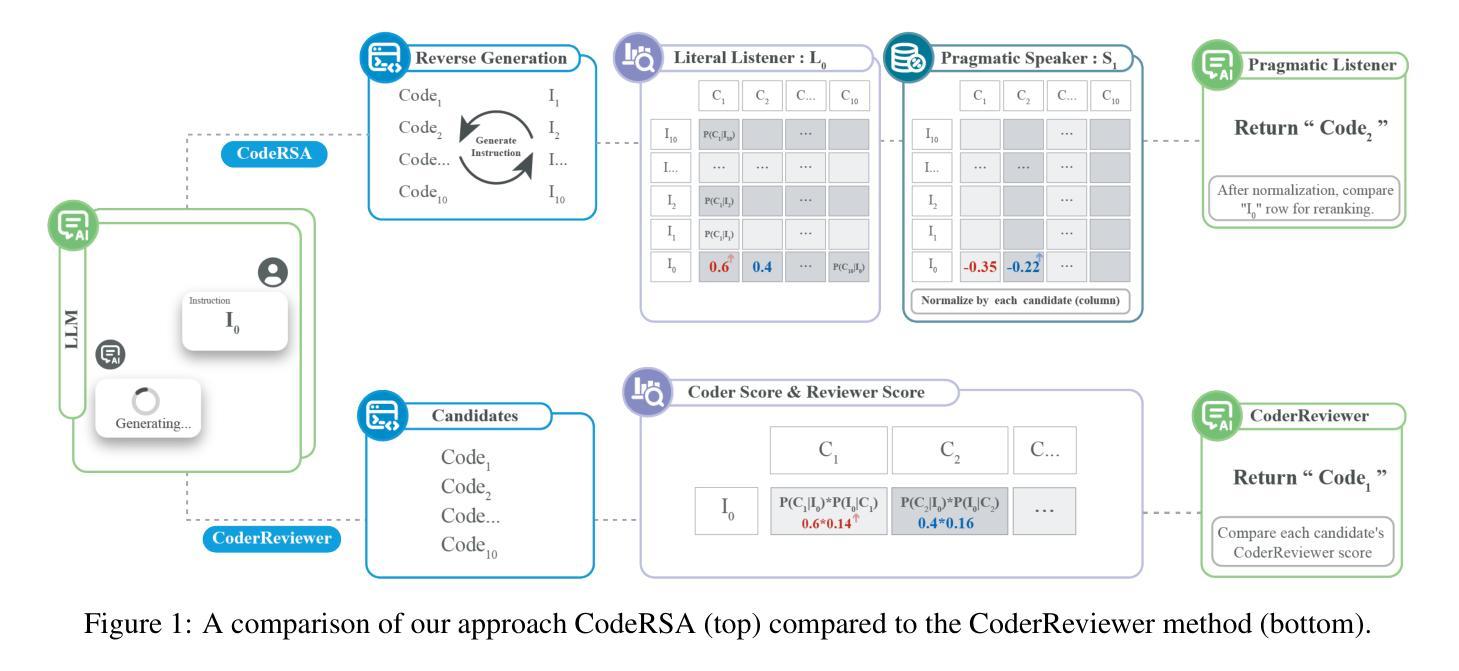
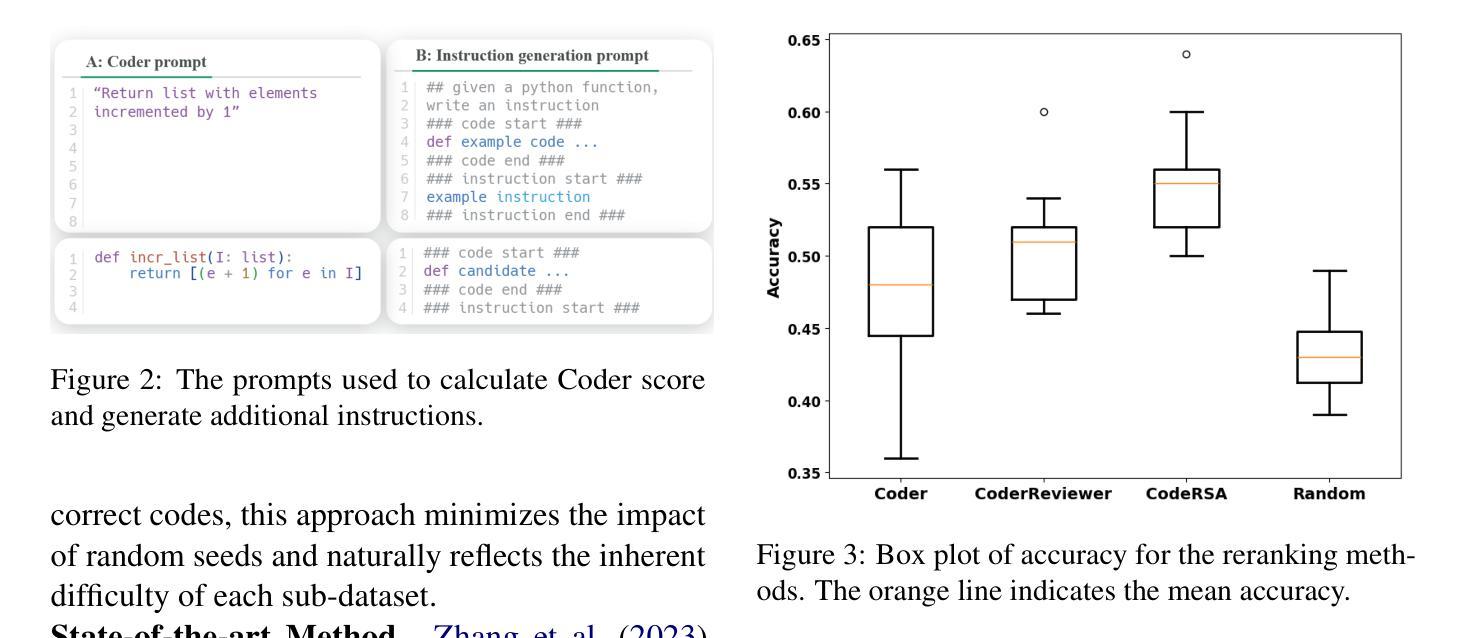
Pragmatic Reasoning improves LLM Code Generation
Authors:Zhuchen Cao, Sven Apel, Adish Singla, Vera Demberg
Large Language Models (LLMs) have demonstrated impressive potential in translating natural language (NL) instructions into program code. However, user instructions often contain inherent ambiguities, making it challenging for LLMs to generate code that accurately reflects the user’s true intent. To address this challenge, researchers have proposed to produce multiple candidates of the program code and then rerank them to identify the best solution. In this paper, we propose CodeRSA, a novel code candidate reranking mechanism built upon the Rational Speech Act (RSA) framework, designed to guide LLMs toward more comprehensive pragmatic reasoning about user intent. We evaluate CodeRSA using one of the latest LLMs on a popular code generation dataset. Our experiment results show that CodeRSA consistently outperforms common baselines, surpasses the state-of-the-art approach in most cases, and demonstrates robust overall performance. These findings underscore the effectiveness of integrating pragmatic reasoning into code candidate reranking, offering a promising direction for enhancing code generation quality in LLMs.
大型语言模型(LLM)在将自然语言(NL)指令翻译成程序代码方面表现出了令人印象深刻的潜力。然而,用户指令通常包含固有的歧义性,这使得对于大型语言模型来说,生成准确反映用户真实意图的代码具有挑战性。为了应对这一挑战,研究人员建议生成多个程序代码候选,然后对它们进行重新排序以找出最佳解决方案。在本文中,我们提出了CodeRSA,这是一种基于理性言语行为(RSA)框架的新型代码候选重新排序机制,旨在引导大型语言模型对用户意图进行更全面、实用主义的推理。我们使用最新的大型语言模型之一在一个流行的代码生成数据集上评估了CodeRSA。实验结果表明,CodeRSA在大多数情况下均表现优异,并且在多数情况下优于最先进的方法,显示出稳健的整体性能。这些发现强调了将实用主义推理整合到代码候选重新排序中的有效性,为提升大型语言模型中的代码生成质量提供了有前景的方向。
论文及项目相关链接
Summary
大型语言模型(LLM)在将自然语言指令翻译成程序代码方面展现出巨大潜力,但用户指令中常存在固有歧义,使LLM难以准确反映用户真实意图地生成代码。为解决此挑战,研究者提议生成程序代码的多重候选,并运用CodeRSA这一基于理性言语行为(RSA)框架的新型代码候选重排机制对候选进行排序以找到最佳解决方案。评估实验结果表明,CodeRSA在多数情况下表现优于常规基准和最新前沿方法,展现出稳健的整体性能。这表明将语用推理融入代码候选重排可有效提升LLM的代码生成质量。
Key Takeaways
- 大型语言模型(LLM)在自然语言翻译代码方面展现出潜力。
- 用户指令中的歧义给LLM准确生成代码带来挑战。
- 为解决这一挑战,研究者提议生成代码的多重候选并进行排序。
- CodeRSA是一种基于理性言语行为(RSA)框架的新型代码候选重排机制。
- CodeRSA在评估实验中表现优异,超越常规基准和前沿方法。
- 实验结果证明了将语用推理融入代码候选重排的有效性。
点此查看论文截图

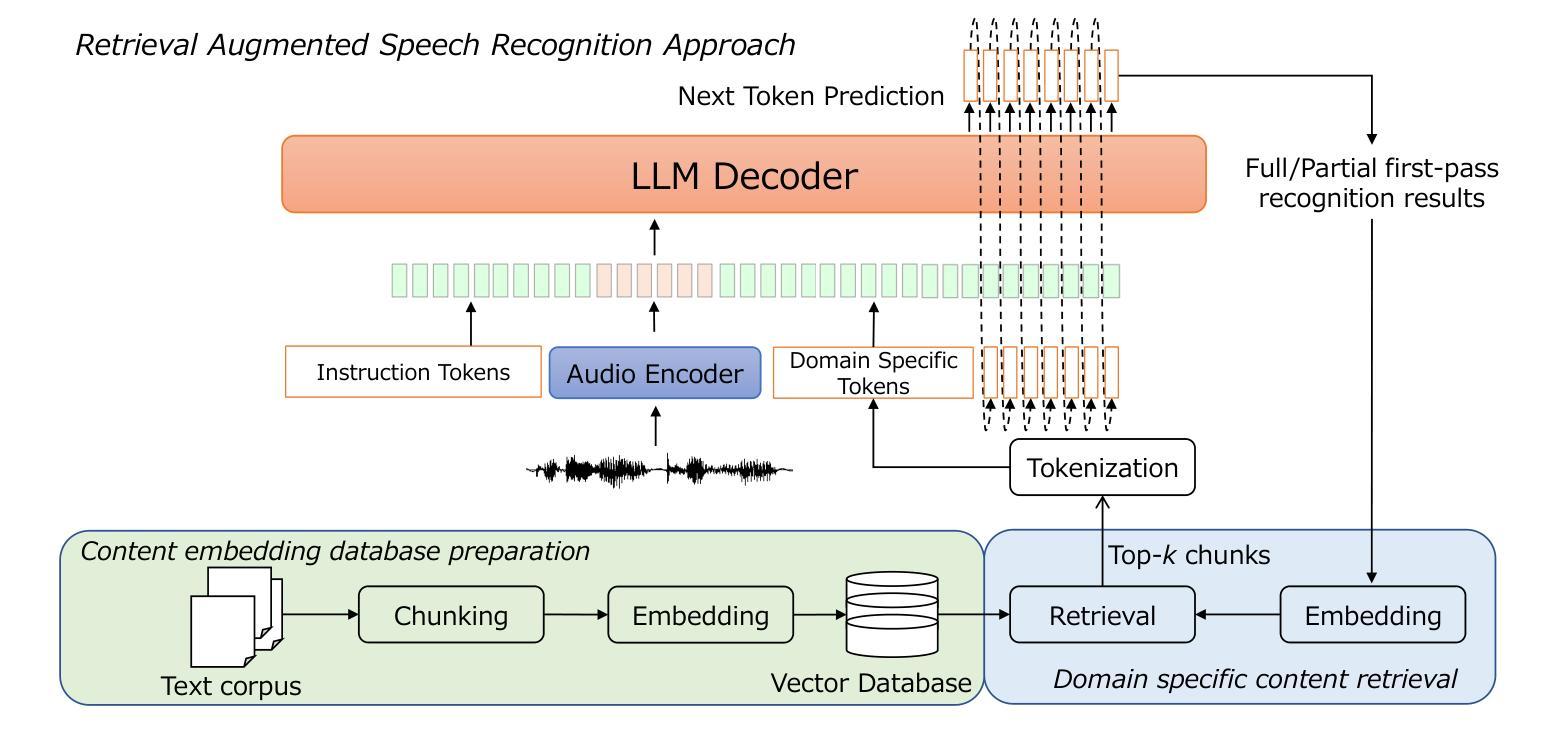
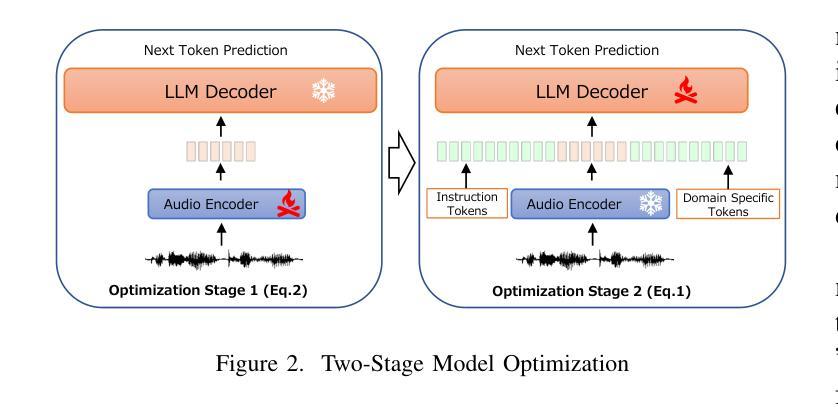
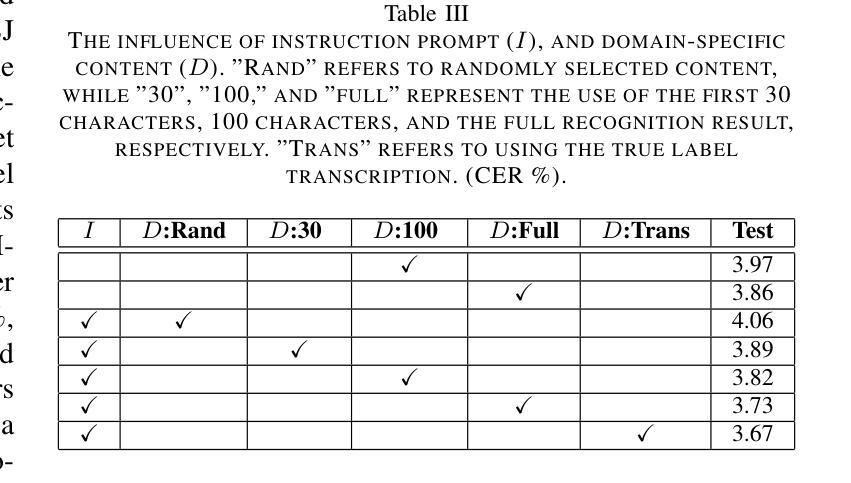
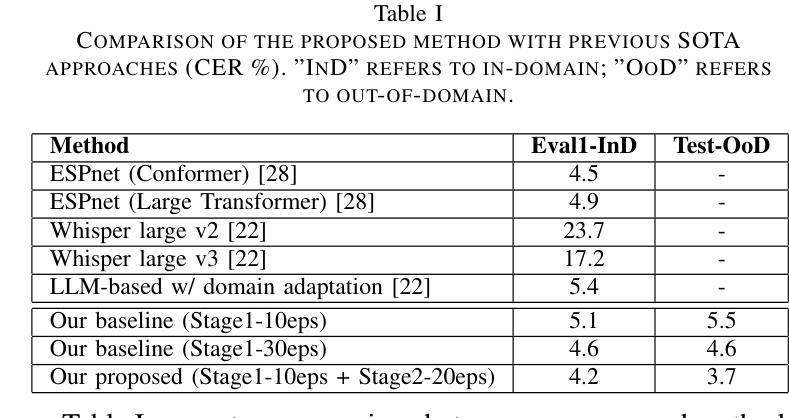
Retrieval-Augmented Speech Recognition Approach for Domain Challenges
Authors:Peng Shen, Xugang Lu, Hisashi Kawai
Speech recognition systems often face challenges due to domain mismatch, particularly in real-world applications where domain-specific data is unavailable because of data accessibility and confidentiality constraints. Inspired by Retrieval-Augmented Generation (RAG) techniques for large language models (LLMs), this paper introduces a LLM-based retrieval-augmented speech recognition method that incorporates domain-specific textual data at the inference stage to enhance recognition performance. Rather than relying on domain-specific textual data during the training phase, our model is trained to learn how to utilize textual information provided in prompts for LLM decoder to improve speech recognition performance. Benefiting from the advantages of the RAG retrieval mechanism, our approach efficiently accesses locally available domain-specific documents, ensuring a convenient and effective process for solving domain mismatch problems. Experiments conducted on the CSJ database demonstrate that the proposed method significantly improves speech recognition accuracy and achieves state-of-the-art results on the CSJ dataset, even without relying on the full training data.
语音识别系统经常面临因领域不匹配而带来的挑战,特别是在现实应用中,由于数据可访问性和保密性约束,往往无法获得特定领域的语音数据。受大型语言模型(LLM)的检索增强生成(RAG)技术的启发,本文介绍了一种基于LLM的检索增强语音识别方法,该方法在推理阶段结合特定领域的文本数据,以提高识别性能。与其他方法不同,我们的模型不是在训练阶段依赖特定领域的文本数据,而是学习如何利用提示中的文本信息,以促使LLM解码器提高语音识别性能。得益于RAG检索机制的优势,我们的方法能够有效地访问本地可用的特定领域文档,确保解决领域不匹配问题的过程既方便又高效。在CSJ数据库上进行的实验表明,该方法显著提高了语音识别精度,在CSJ数据集上达到了最先进的识别效果,甚至在不依赖全部训练数据的情况下也是如此。
论文及项目相关链接
Summary:
本文提出了一种基于大语言模型(LLM)的检索增强语音识别方法,该方法在推理阶段融入领域特定文本数据,以提高语音识别性能。该方法无需在训练阶段依赖领域特定文本数据,而是学习如何利用提示中的文本信息,改善语音识别效果。实验证明,该方法能显著提高语音识别准确率,达到CSJ数据集上的最新水平,且无需依赖全部训练数据。
Key Takeaways:
- 该论文解决了语音识别系统中的领域不匹配问题,特别是在数据获取和保密性受限的现实中。
- 通过结合大语言模型(LLM)和检索增强生成(RAG)技术,论文提出了一种新的语音识别方法。
- 该方法在推理阶段融入领域特定文本数据,而不是在训练阶段。
- 方法的核心在于学习如何利用提示中的文本信息,改善语音识别效果。
- 论文采用RAG检索机制,能高效访问本地可用的领域特定文档。
- 实验证明,该方法能显著提高语音识别准确率,达到最新水平。
点此查看论文截图

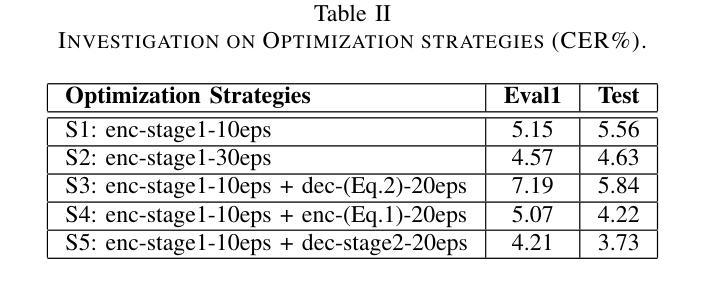
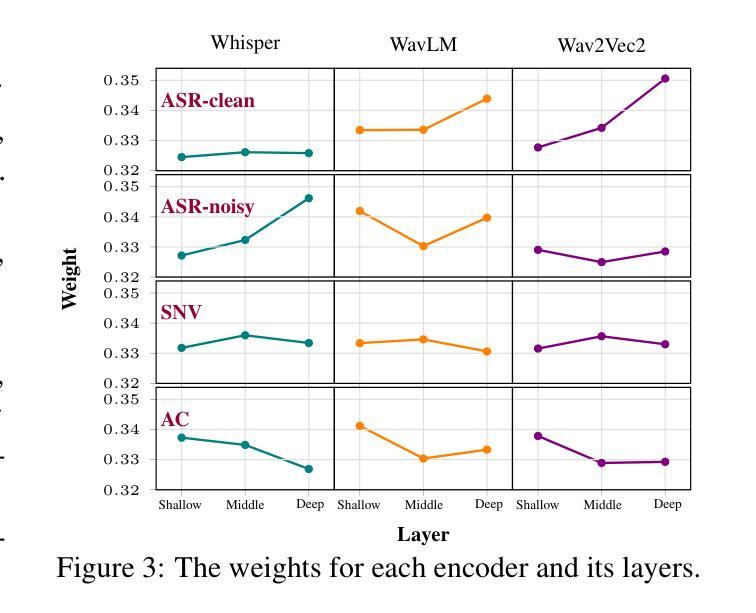
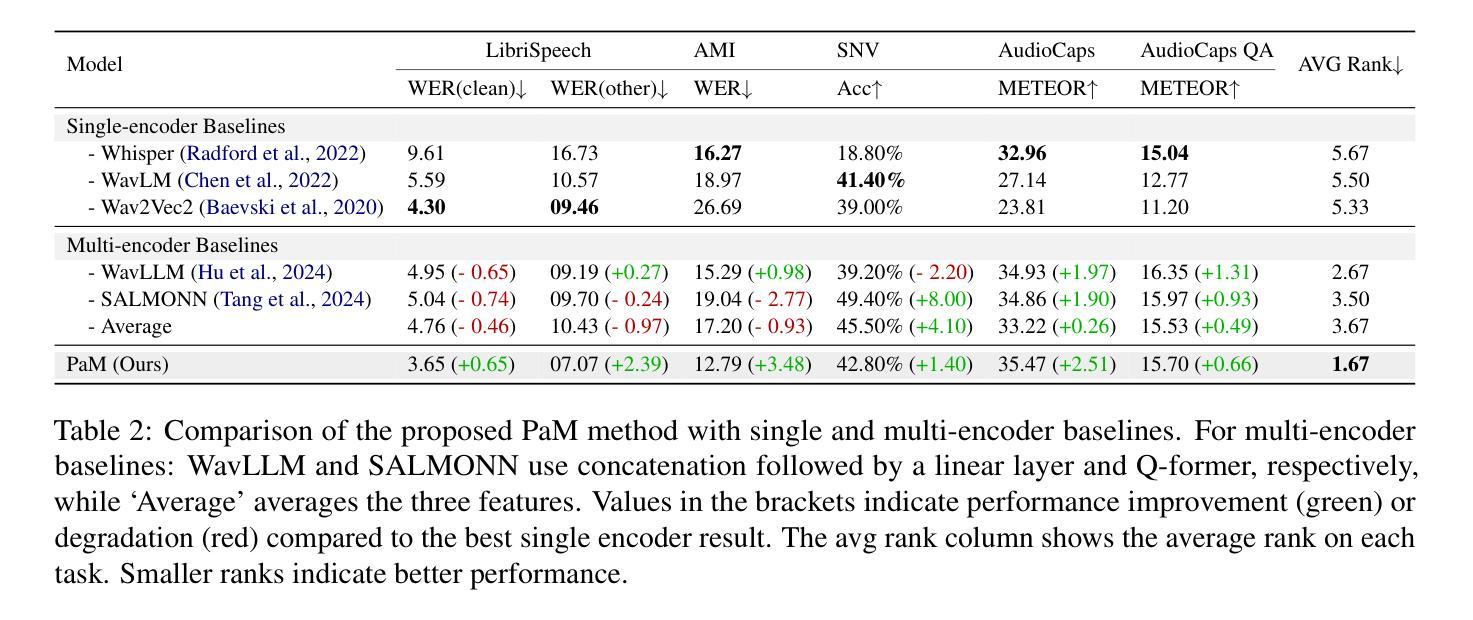
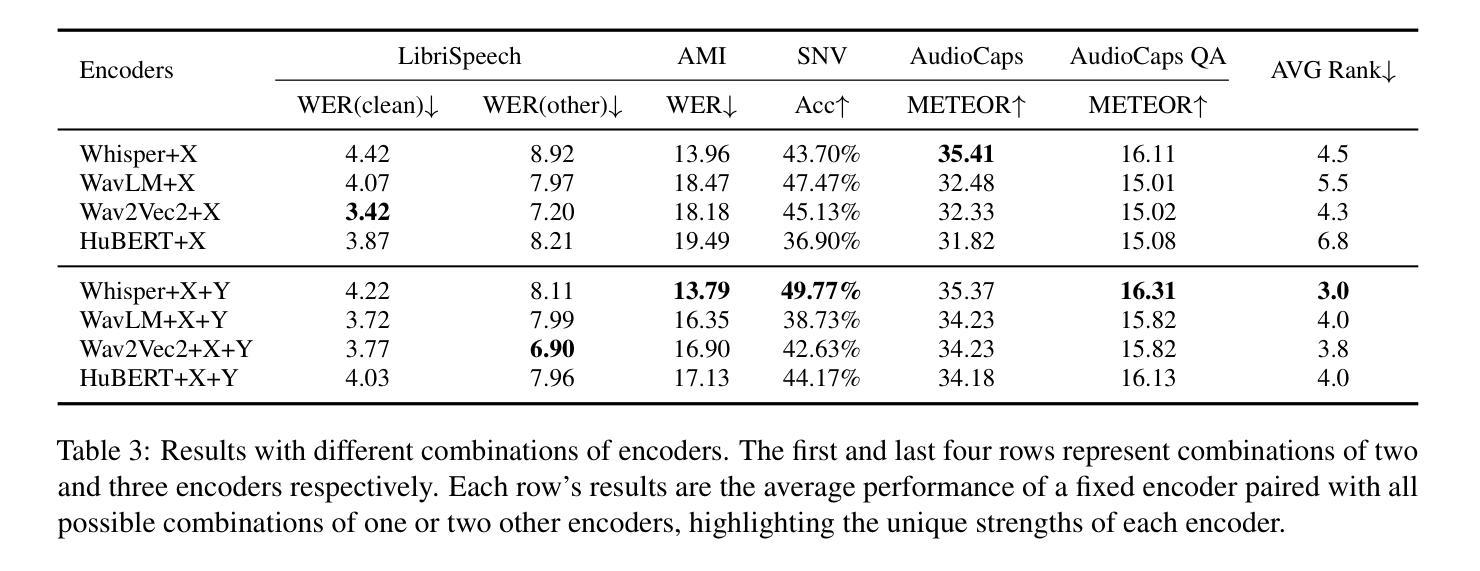
Enhancing Speech Large Language Models with Prompt-Aware Mixture of Audio Encoders
Authors:Weiqiao Shan, Yuang Li, Yuhao Zhang, Yingfeng Luo, Chen Xu, Xiaofeng Zhao, Long Meng, Yunfei Lu, Min Zhang, Hao Yang, Tong Xiao, Jingbo Zhu
Connecting audio encoders with large language models (LLMs) allows the LLM to perform various audio understanding tasks, such as automatic speech recognition (ASR) and audio captioning (AC). Most research focuses on training an adapter layer to generate a unified audio feature for the LLM. However, different tasks may require distinct features that emphasize either semantic or acoustic aspects, making task-specific audio features more desirable. In this paper, we propose Prompt-aware Mixture (PaM) to enhance the Speech LLM that uses multiple audio encoders. Our approach involves using different experts to extract different features based on the prompt that indicates different tasks. Experiments demonstrate that with PaM, only one Speech LLM surpasses the best performances achieved by all single-encoder Speech LLMs on ASR, Speaker Number Verification, and AC tasks. PaM also outperforms other feature fusion baselines, such as concatenation and averaging.
将音频编码器与大型语言模型(LLM)相连接,可以使LLM执行各种音频理解任务,例如自动语音识别(ASR)和音频描述(AC)。大多数研究集中于训练适配器层以生成用于LLM的统一音频特征。然而,不同的任务可能需要强调语义或声学方面的不同特征,这使得任务特定的音频特征更为理想。在本文中,我们提出使用提示感知混合(PaM)技术增强使用多个音频编码器的语音LLM。我们的方法包括根据提示使用不同的专家来提取不同的特征,这些提示表明了不同的任务。实验表明,使用PaM的单一语音LLM在ASR、说话人数量验证和AC任务上的表现超过了所有单编码器语音LLM的最佳性能。PaM还优于其他特征融合基线方法,如拼接和平均化方法。
论文及项目相关链接
PDF 12 pages,4 figures, 7 tables
Summary
基于大型语言模型(LLM)的音频编码器连接使得LLM能够进行音频理解任务,如语音识别(ASR)和音频描述(AC)。尽管大多数研究集中在训练一个统一的音频特征生成适配器层,但不同的任务可能需要强调语义或声学方面的不同特征,因此任务特定的音频特征更为理想。本文提出了基于提示感知混合(PaM)的语音LLM增强方法,该方法使用多个音频编码器提取不同的特征,根据提示针对不同的任务使用不同的专家。实验表明,采用PaM的单一语音LLM在ASR、说话人数验证和AC任务上的性能超过了所有单一编码器语音LLM的最佳性能,并优于其他特征融合基线方法,如拼接和平均。
Key Takeaways
- 音频编码器与大型语言模型的结合使得语言模型能够执行多种音频理解任务,如语音识别和音频描述。
- 大多数研究集中在训练适配器层以生成统一的音频特征,但任务特定音频特征的重要性被忽视。
- 本文提出一种基于提示感知混合(PaM)的方法,以增强语音LLM的性能。
- PaM使用多个音频编码器,根据任务提示提取不同的特征。
- 实验表明,使用PaM的语音LLM在多个任务上超越了最佳的单编码器语音LLM性能。
- PaM方法优于其他特征融合方法,如简单的拼接和平均。
点此查看论文截图
Unveiling Reasoning Thresholds in Language Models: Scaling, Fine-Tuning, and Interpretability through Attention Maps
Authors:Yen-Che Hsiao, Abhishek Dutta
This study investigates the in-context learning capabilities of various decoder-only transformer-based language models with different model sizes and training data, including GPT2, SmolLM2, OpenELM, TinyLlama, Stable LM, and Gemma 2. We identify a critical parameter threshold (~1.6 billion), beyond which reasoning performance improves significantly in tasks such as commonsense reasoning in multiple-choice question answering and deductive reasoning. Specifically, models above this threshold achieve better success rates in chain-of-thought (CoT) prompting for deductive reasoning tasks, especially those requiring longer reasoning chains, such as proof by contradiction and disjunction elimination. To address limitations in sub-threshold models, we demonstrate that fine-tuning with task-specific exemplars substantially enhances reasoning performance, enabling accurate CoT generation even without additional exemplars in the prompt for tasks with shorter reasoning chains. Finally, our analysis of attention maps reveals that models capable of generating correct CoTs exhibit higher token-level attention scores on subsequent correct tokens and the correct parts of speech, providing interpretability insights into reasoning processes. These findings collectively advance understanding of reasoning capabilities in decoder-only transformer-based models. The code is available at: https://github.com/AnnonymousForPapers/CoT_Reasoning_Test.
本研究调查了不同规模的解码器专用基于转换器的语言模型以及使用不同训练数据的模型在各种上下文学习功能方面的表现,包括GPT2、SmolLM2、OpenELM、TinyLlama、Stable LM和Gemma 2。我们确定了临界参数阈值(约1.6亿),超出该阈值后,在多选问答中的常识推理和演绎推理等任务中的推理性能会显著提高。具体来说,超过此阈值的模型在演绎推理任务的思维链提示中取得了更高的成功率,特别是在需要较长推理链的任务中,如反证法和析取消除法。为了解决低于阈值模型的局限性,我们证明使用特定任务的示例进行微调可以大大提高推理性能,即使在没有额外的简短推理链提示中也能准确生成思维链。最后,通过对注意力地图的分析,我们发现能够生成正确思维链的模型在随后的正确令牌和正确的词性方面表现出更高的令牌级注意力得分,这为理解推理过程提供了可解释性洞察。这些发现共同推动了我们对基于解码器的转换器模型推理能力的理解。代码可用在:https://github.com/AnnonymousForPapers/CoT_Reasoning_Test。
论文及项目相关链接
Summary
本研究探讨了不同规模与训练数据的解码器只变压器语言模型的上下文学习能力,包括GPT2、SmolLM2、OpenELM等模型。研究发现一个关键参数阈值(约1.6亿),超过此阈值的模型在多选问答与演绎推理等任务中的常识推理性能显著提升。特别是通过思维链提示法,超过阈值的模型在需要较长推理链的任务中表现优异。对于未达到阈值的模型,通过特定任务的微调可以极大地增强推理性能。此外,通过分析注意力地图发现,能正确生成思维链的模型在后续正确令牌和正确词类上的令牌级别注意力得分更高,为理解推理过程提供了可解释性洞察。
Key Takeaways
- 研究涉及多种解码器只变压器语言模型,包括GPT2等,探讨了它们的上下文学习能力。
- 发现模型性能的关键参数阈值(约1.6亿),超过此阈值的模型在常识推理任务中表现更优秀。
- 思维链提示法在需要较长推理链的任务中特别有效。
- 对未达到性能阈值的模型进行特定任务微调可以显著提高推理性能。
- 分析注意力地图发现正确生成思维链的模型展现出更高的令牌级别注意力得分。
- 研究提供了对解码器只变压器模型的推理能力的深入理解。
点此查看论文截图

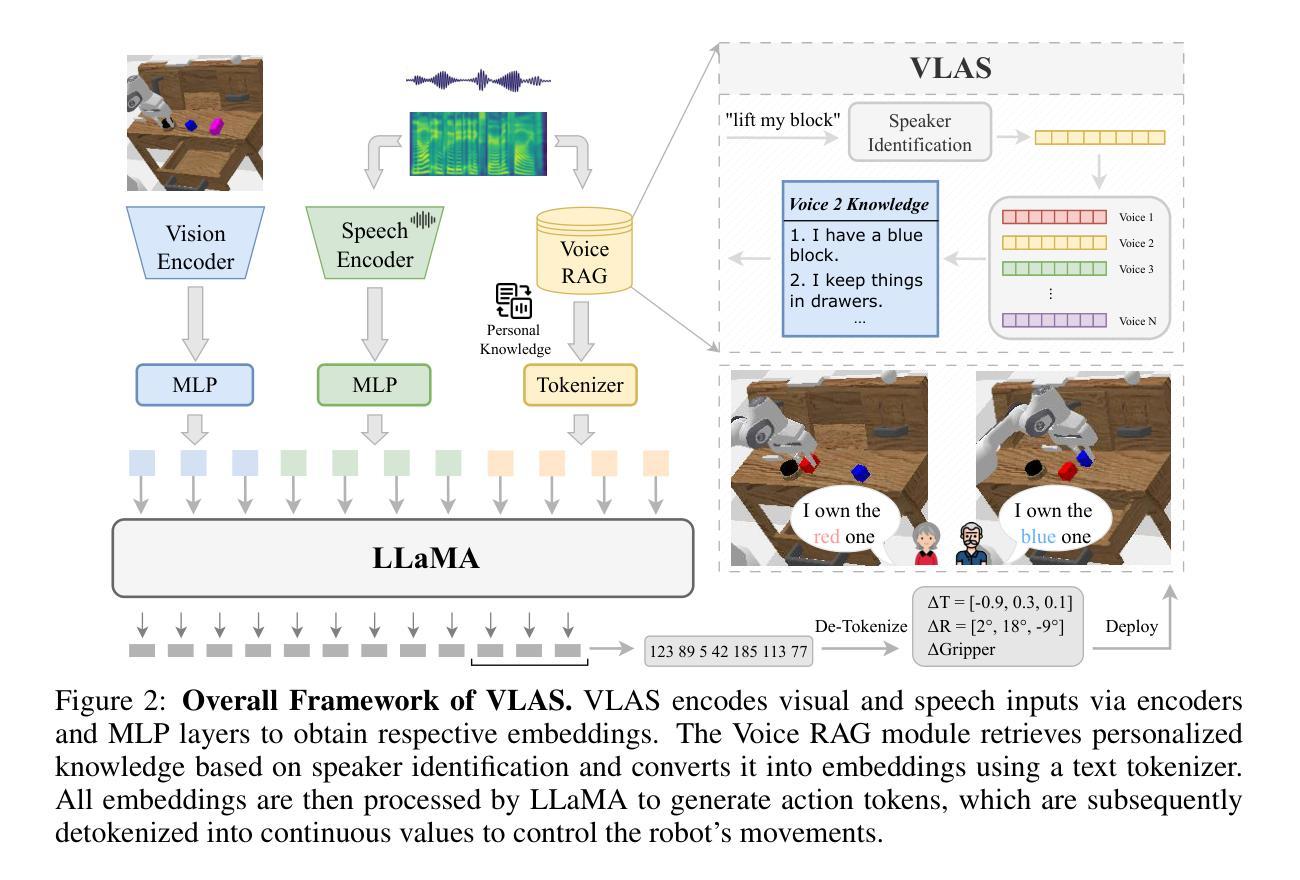
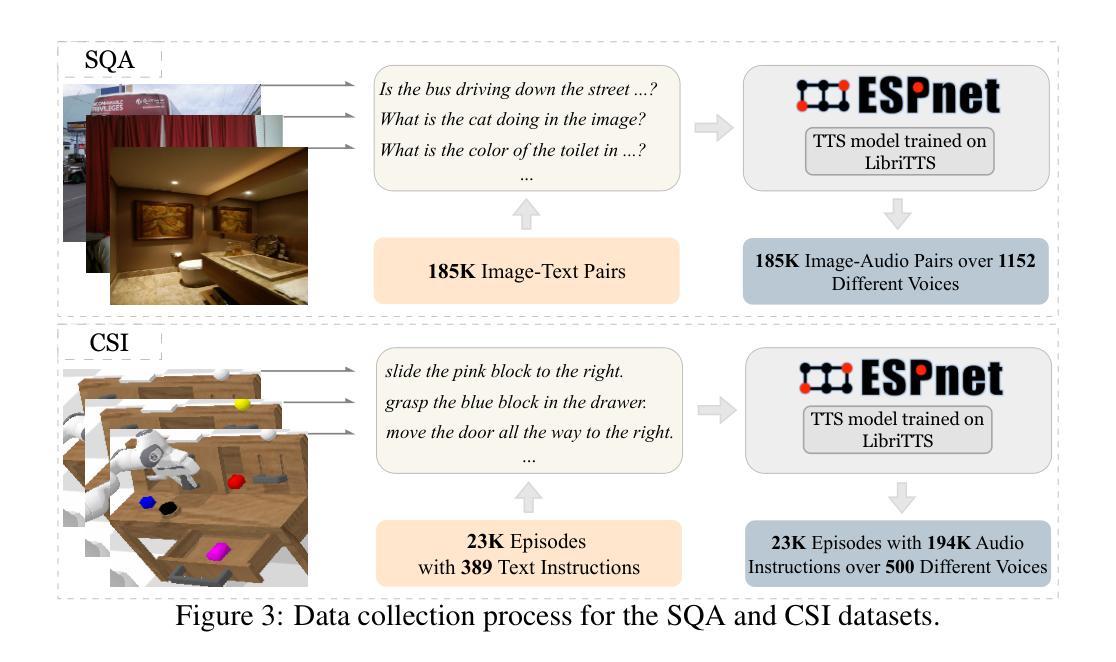
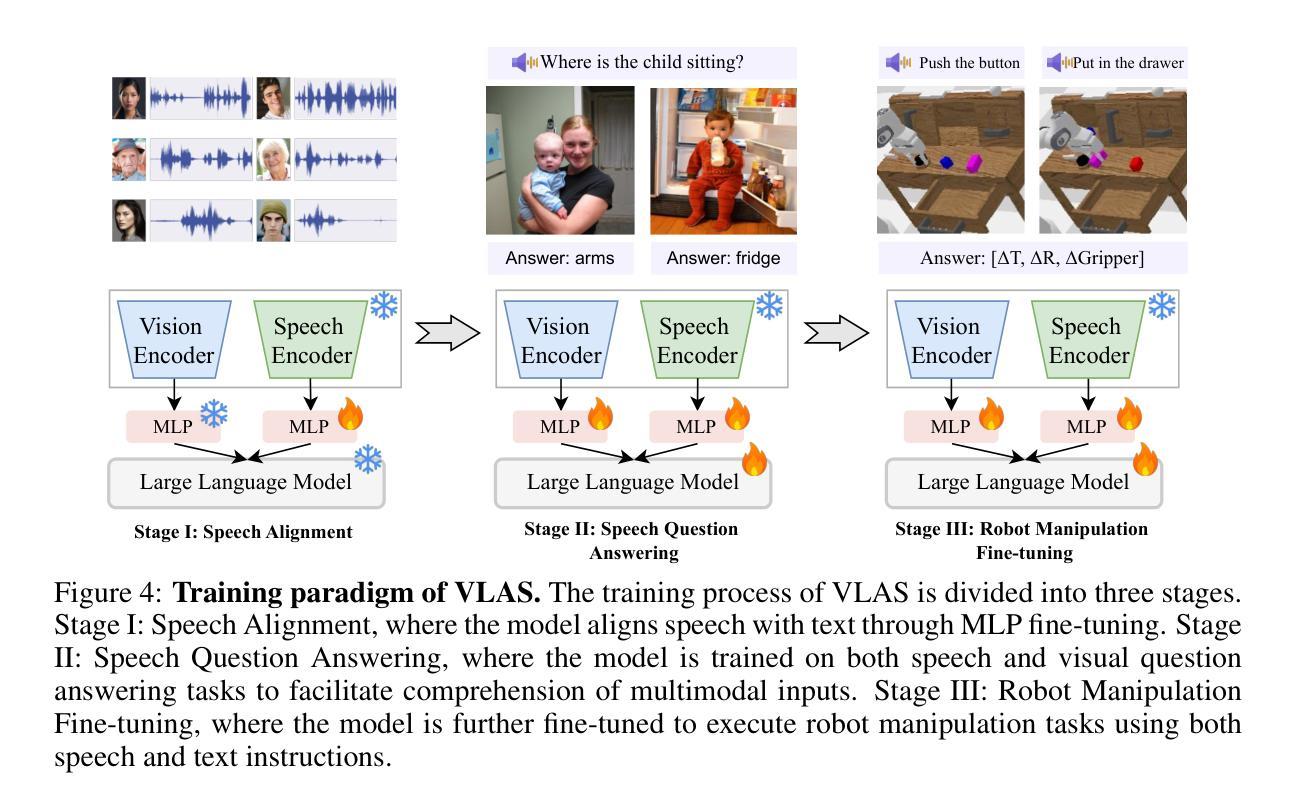
VLAS: Vision-Language-Action Model With Speech Instructions For Customized Robot Manipulation
Authors:Wei Zhao, Pengxiang Ding, Min Zhang, Zhefei Gong, Shuanghao Bai, Han Zhao, Donglin Wang
Vision-language-action models (VLAs) have become increasingly popular in robot manipulation for their end-to-end design and remarkable performance. However, existing VLAs rely heavily on vision-language models (VLMs) that only support text-based instructions, neglecting the more natural speech modality for human-robot interaction. Traditional speech integration methods usually involves a separate speech recognition system, which complicates the model and introduces error propagation. Moreover, the transcription procedure would lose non-semantic information in the raw speech, such as voiceprint, which may be crucial for robots to successfully complete customized tasks. To overcome above challenges, we propose VLAS, a novel end-to-end VLA that integrates speech recognition directly into the robot policy model. VLAS allows the robot to understand spoken commands through inner speech-text alignment and produces corresponding actions to fulfill the task. We also present two new datasets, SQA and CSI, to support a three-stage tuning process for speech instructions, which empowers VLAS with the ability of multimodal interaction across text, image, speech, and robot actions. Taking a step further, a voice retrieval-augmented generation (RAG) paradigm is designed to enable our model to effectively handle tasks that require individual-specific knowledge. Our extensive experiments show that VLAS can effectively accomplish robot manipulation tasks with diverse speech commands, offering a seamless and customized interaction experience.
视觉语言行动模型(VLAs)因其端到端的设计和卓越性能而在机器人操作领域越来越受欢迎。然而,现有的VLAs严重依赖于仅支持文本指令的视觉语言模型(VLMs),忽视了人类与机器人交互中更自然的语音模式。传统的语音集成方法通常需要一个独立的语音识别系统,这增加了模型的复杂性并引入了误差传播。此外,转录过程会丢失原始语音中的非语义信息,如声纹,这对于机器人成功完成定制任务可能是至关重要的。为了克服上述挑战,我们提出了VLAS,这是一种新型的端到端VLA,它直接将语音识别集成到机器人策略模型中。VLAS允许机器人通过内部语音文本对齐理解口头命令,并产生相应的行动来完成任务。我们还推出了两个新数据集SQA和CSI,以支持语音指令的三阶段调整过程,这使VLAS具备文本、图像、语音和机器人行动之间的跨模态交互能力。更进一步的是,设计了一种声音检索增强生成(RAG)范式,使我们的模型能够有效处理需要个人特定知识的任务。我们的广泛实验表明,VLAS可以有效地完成具有多种语音命令的机器人操作任务,提供无缝且定制化的交互体验。
论文及项目相关链接
PDF Accepted as a conference paper at ICLR 2025
Summary
本文介绍了视觉语言行动模型(VLAs)在机器人操作中的最新应用。针对现有VLAs主要依赖文本指令而忽视语音模式的问题,提出了一种新型端到端的VLA模型VLAS,将语音识别直接集成到机器人策略模型中。VLAS能通过内部语音文本对齐理解口语指令,并产生相应的行动来完成任务。此外,还推出了两个新数据集SQA和CSI,支持语音指令的三阶段调整过程,使VLAS具备跨文本、图像、语音和机器人行动的多媒体交互能力。最后,通过引入声音检索增强生成(RAG)范式,使模型能够处理需要个性化知识的任务。
Key Takeaways
- 视觉语言行动模型(VLAs)在机器人操作中的应用日益普及,具有端到端的设计和卓越性能。
- 现有VLAs主要依赖文本指令,忽视了更自然的语音模式的人机交互方式。
- 新型VLAS模型将语音识别直接集成到机器人策略模型中,理解口语指令并产生相应行动。
- VLAS通过内部语音文本对齐实现口语指令理解。
- 推出了SQA和CSI两个新数据集,支持语音指令的三阶段调整过程,增强VLAS的多媒体交互能力。
- VLAS能够处理需要个性化知识的任务,引入声音检索增强生成(RAG)范式。
点此查看论文截图

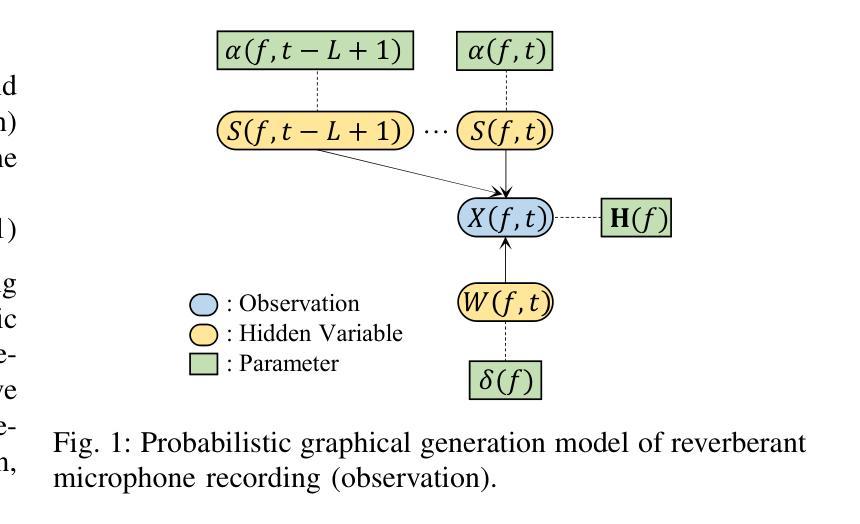
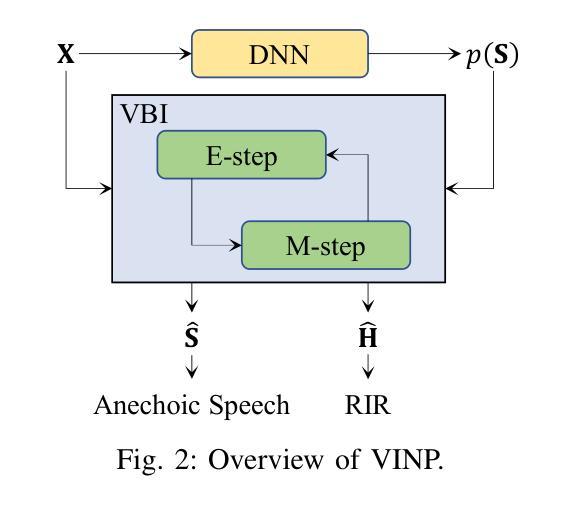
VINP: Variational Bayesian Inference with Neural Speech Prior for Joint ASR-Effective Speech Dereverberation and Blind RIR Identification
Authors:Pengyu Wang, Ying Fang, Xiaofei Li
Reverberant speech, denoting the speech signal degraded by the process of reverberation, contains crucial knowledge of both anechoic source speech and room impulse response (RIR). This work proposes a variational Bayesian inference (VBI) framework with neural speech prior (VINP) for joint speech dereverberation and blind RIR identification. In VINP, a probabilistic signal model is constructed in the time-frequency (T-F) domain based on convolution transfer function (CTF) approximation. For the first time, we propose using an arbitrary discriminative dereverberation deep neural network (DNN) to predict the prior distribution of anechoic speech within a probabilistic model. By integrating both reverberant speech and the anechoic speech prior, VINP yields the maximum a posteriori (MAP) and maximum likelihood (ML) estimations of the anechoic speech spectrum and CTF filter, respectively. After simple transformations, the waveforms of anechoic speech and RIR are estimated. Moreover, VINP is effective for automatic speech recognition (ASR) systems, which sets it apart from most deep learning (DL)-based single-channel dereverberation approaches. Experiments on single-channel speech dereverberation demonstrate that VINP reaches an advanced level in most metrics related to human perception and displays unquestionable state-of-the-art (SOTA) performance in ASR-related metrics. For blind RIR identification, experiments indicate that VINP attains the SOTA level in blind estimation of reverberation time at 60 dB (RT60) and direct-to-reverberation ratio (DRR). Codes and audio samples are available online.
带有混响的语音信号包含了关于无混响源语音和房间冲击响应(RIR)的关键知识。本研究提出了一种基于神经语音先验(VINP)的变贝叶斯推断(VBI)框架,用于联合语音去混响和盲RIR识别。在VINP中,基于卷积传递函数(CTF)近似值在时频(T-F)域中构建概率信号模型。我们首次提出使用任意判别去混响深度神经网络(DNN)在概率模型中预测无混响语音的先验分布。通过整合混响语音和无混响语音先验,VINP得到无混响语音谱和CTF滤波器的最大后验(MAP)和最大似然(ML)估计。经过简单变换,可以估算出无混响语音和RIR的波形。此外,VINP对于自动语音识别(ASR)系统也有效,这与大多数基于深度学习的单通道去混响方法相区别。在单通道语音去混响方面的实验表明,VINP在大多数与人类感知相关的指标中达到了先进水平,并且在与ASR相关的指标中表现出了无可争议的最先进性能。对于盲RIR识别,实验表明,VINP在60分贝(RT60)的混响时间盲估计和直接混响比(DRR)方面达到了最先进水平。代码和音频样本可在网上获得。
论文及项目相关链接
PDF Submitted to IEEE/ACM Trans. on TASLP
摘要
基于神经语音先验的变分贝叶斯推理框架被提出,用于联合语音去混响和盲房间脉冲响应识别。该框架在时频域构建了基于卷积传递函数近似的概率信号模型。本研究首次提出使用任意判别去混响深度神经网络来预测概率模型中的无混响语音先验分布。通过结合混响语音和无混响语音先验,该框架提供了无混响语音谱和卷积传递函数滤波器的最大后验和最大似然估计。经过简单变换,可估算出无混响语音和房间脉冲响应的波形。此外,该框架对于自动语音识别系统也有效,使其有别于大多数基于深度学习的单通道去混响方法。实验表明,该框架在人类感知相关的大多数指标上达到了先进水平和自动语音识别相关指标的最新性能。对于盲房间脉冲响应识别,实验表明该框架在盲估计混响时间直接比在(DRR)和房间脉冲响应的混响时间(RT60)方面达到了最新水平。相关代码和音频样本可在网上获取。
关键见解
- 提出的变分贝叶斯推理框架结合了神经语音先验,用于联合语音去混响和盲房间脉冲响应识别。
- 构建了基于卷积传递函数近似的概率信号模型,在时频域进行分析。
- 使用任意判别去混响深度神经网络预测无混响语音的先验分布。
- 该方法提供了无混响语音谱和卷积传递函数滤波器的最大后验和最大似然估计。
- 框架对自动语音识别系统有效,区别于大多数单通道去混响的深度学习方法。
- 实验表明,该框架在人类感知相关指标上达到先进水平,且在自动语音识别相关指标上表现最佳。
点此查看论文截图


Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis
Authors:Zhen Ye, Xinfa Zhu, Chi-Min Chan, Xinsheng Wang, Xu Tan, Jiahe Lei, Yi Peng, Haohe Liu, Yizhu Jin, Zheqi Dai, Hongzhan Lin, Jianyi Chen, Xingjian Du, Liumeng Xue, Yunlin Chen, Zhifei Li, Lei Xie, Qiuqiang Kong, Yike Guo, Wei Xue
Recent advances in text-based large language models (LLMs), particularly in the GPT series and the o1 model, have demonstrated the effectiveness of scaling both training-time and inference-time compute. However, current state-of-the-art TTS systems leveraging LLMs are often multi-stage, requiring separate models (e.g., diffusion models after LLM), complicating the decision of whether to scale a particular model during training or testing. This work makes the following contributions: First, we explore the scaling of train-time and inference-time compute for speech synthesis. Second, we propose a simple framework Llasa for speech synthesis that employs a single-layer vector quantizer (VQ) codec and a single Transformer architecture to fully align with standard LLMs such as Llama. Our experiments reveal that scaling train-time compute for Llasa consistently improves the naturalness of synthesized speech and enables the generation of more complex and accurate prosody patterns. Furthermore, from the perspective of scaling inference-time compute, we employ speech understanding models as verifiers during the search, finding that scaling inference-time compute shifts the sampling modes toward the preferences of specific verifiers, thereby improving emotional expressiveness, timbre consistency, and content accuracy. In addition, we released the checkpoint and training code for our TTS model (1B, 3B, 8B) and codec model publicly available.
最近,基于文本的大型语言模型(LLM)的最新进展,特别是GPT系列和O1模型,证明了在训练时间和推理时间计算方面的可扩展性非常有效。然而,当前利用LLM的最先进TTS系统通常是多阶段的,需要单独模型(例如LLM之后的扩散模型),这使得在训练或测试期间扩展特定模型变得更加复杂决策。这项工作做出了以下贡献:首先,我们探索了语音合成的训练时间和推理时间计算的可扩展性。其次,我们提出了一种用于语音合成的简单框架Llasa,它采用单层向量量化(VQ)编解码器和单一Transformer架构,以完全符合Llama等标准LLM。我们的实验表明,扩大Llasa的训练时间计算始终提高了合成语音的自然度,并可以生成更复杂和准确的声音模式。此外,从扩展推理时间计算的角度来看,我们在搜索过程中采用了语音理解模型作为验证器,发现扩大推理时间计算使采样模式转向特定验证器的偏好,从而提高情感表现力、音色一致性和内容准确性。另外,我们公开发布了TTS模型(1B、3B、8B)和编解码器模型的检查点和训练代码。
论文及项目相关链接
Summary
本文探讨了基于文本的大型语言模型(LLMs)在语音合成中的训练和推理时间计算规模化的研究。提出了一种名为Llasa的语音合成框架,采用单层向量量化编码器和单一的Transformer架构,与标准LLMs如Llama完全对齐。实验表明,增加训练时间计算规模可以提高合成语音的自然度,并生成更复杂、更准确的语调模式。从推理时间计算规模的角度来看,采用语音理解模型作为验证器进行搜索,发现增加推理时间计算规模会使采样模式转向特定验证器的偏好,从而提高情感表达、音色一致性和内容准确性。
Key Takeaways
- 文本介绍了LLMs在语音合成中的最新进展,特别是GPT系列和o1模型的有效性。
- 当前先进的TTS系统利用LLMs通常是多阶段的,需要单独模型(如扩散模型后的LLM),这使得在训练和测试期间选择模型规模变得复杂。
- 提出了一个名为Llasa的语音合成框架,采用单一层向量量化编码器和单一的Transformer架构与标准LLMs对齐。
- 增加训练时间计算规模可以提高合成语音的自然度和生成更复杂、更准确的语调模式。
- 从推理时间计算规模的角度来看,增加计算规模会使采样模式更符合特定语音理解模型的偏好,提高情感表达、音色一致性和内容准确性。
- 公开提供了TTS模型(1B、3B、8B)和编码器模型的检查点和训练代码。
- 整体而言,该研究为语音合成的计算规模化和性能优化提供了新的见解和工具。
点此查看论文截图

ToxiLab: How Well Do Open-Source LLMs Generate Synthetic Toxicity Data?
Authors:Zheng Hui, Zhaoxiao Guo, Hang Zhao, Juanyong Duan, Lin Ai, Yinheng Li, Julia Hirschberg, Congrui Huang
Effective toxic content detection relies heavily on high-quality and diverse data, which serve as the foundation for robust content moderation models. Synthetic data has become a common approach for training models across various NLP tasks. However, its effectiveness remains uncertain for highly subjective tasks like hate speech detection, with previous research yielding mixed results. This study explores the potential of open-source LLMs for harmful data synthesis, utilizing controlled prompting and supervised fine-tuning techniques to enhance data quality and diversity. We systematically evaluated 6 open source LLMs on 5 datasets, assessing their ability to generate diverse, high-quality harmful data while minimizing hallucination and duplication. Our results show that Mistral consistently outperforms other open models, and supervised fine-tuning significantly enhances data reliability and diversity. We further analyze the trade-offs between prompt-based vs. fine-tuned toxic data synthesis, discuss real-world deployment challenges, and highlight ethical considerations. Our findings demonstrate that fine-tuned open source LLMs provide scalable and cost-effective solutions to augment toxic content detection datasets, paving the way for more accessible and transparent content moderation tools.
有效的有毒内容检测在很大程度上依赖于高质量和多样化的数据,这些数据为构建稳健的内容管理模型提供了基础。合成数据已成为各种NLP任务中训练模型的常见方法。然而,对于像仇恨言论检测这样的高度主观任务,其有效性尚不确定,之前的研究结果喜忧参半。本研究探讨了开源大型语言模型在有害数据合成方面的潜力,利用受控提示和监督微调技术来提高数据的质量和多样性。我们在五个数据集上系统地评估了六个开源大型语言模型,评估它们生成多样化、高质量的有害数据的能力,同时尽量减少幻觉和重复。我们的结果表明,Mistral始终优于其他开放模型,监督微调显著提高了数据的可靠性和多样性。我们进一步分析了基于提示与微调有毒数据合成的权衡,讨论了现实部署挑战,并强调了伦理考量。我们的研究结果表明,经过微调后的开源大型语言模型为增强有毒内容检测数据集提供了可扩展且经济实惠的解决方案,为更可访问和透明的内容管理工具的铺设道路。
论文及项目相关链接
PDF 14 pages
Summary
本文探讨了开源大型语言模型(LLMs)在合成有害数据方面的潜力,研究通过受控提示和监督微调技术提高数据质量和多样性。实验评估了6个开源LLMs在5个数据集上的表现,结果显示Mistral表现最佳,监督微调可显著提高数据可靠性和多样性。研究还分析了提示与微调之间的权衡,并讨论了实际部署的挑战和伦理考量。研究结果表明,微调的开源LLMs为增强有毒内容检测数据集提供了可扩展且经济实惠的解决方案。
Key Takeaways
- 高质量和多样化的数据是建立稳健内容审核模型的基础。
- 合成数据在NLP任务中广泛使用,但在主观任务如仇恨言论检测中的有效性尚不确定。
- 开源LLMs在有害数据合成方面具有潜力。
- 通过受控提示和监督微调技术可以提高数据质量和多样性。
- Mistral在评估中表现最佳。
- 监督微调可显著提高数据可靠性和多样性。
点此查看论文截图

Just KIDDIN: Knowledge Infusion and Distillation for Detection of INdecent Memes
Authors:Rahul Garg, Trilok Padhi, Hemang Jain, Ugur Kursuncu, Ponnurangam Kumaraguru
Toxicity identification in online multimodal environments remains a challenging task due to the complexity of contextual connections across modalities (e.g., textual and visual). In this paper, we propose a novel framework that integrates Knowledge Distillation (KD) from Large Visual Language Models (LVLMs) and knowledge infusion to enhance the performance of toxicity detection in hateful memes. Our approach extracts sub-knowledge graphs from ConceptNet, a large-scale commonsense Knowledge Graph (KG) to be infused within a compact VLM framework. The relational context between toxic phrases in captions and memes, as well as visual concepts in memes enhance the model’s reasoning capabilities. Experimental results from our study on two hate speech benchmark datasets demonstrate superior performance over the state-of-the-art baselines across AU-ROC, F1, and Recall with improvements of 1.1%, 7%, and 35%, respectively. Given the contextual complexity of the toxicity detection task, our approach showcases the significance of learning from both explicit (i.e. KG) as well as implicit (i.e. LVLMs) contextual cues incorporated through a hybrid neurosymbolic approach. This is crucial for real-world applications where accurate and scalable recognition of toxic content is critical for creating safer online environments.
在多模态在线环境中进行毒性识别仍然是一项具有挑战性的任务,因为跨不同模态(例如文本和视觉)的上下文连接复杂性。在本文中,我们提出了一种新型框架,该框架结合了来自大型视觉语言模型(LVLMs)的知识蒸馏(KD)和知识注入,以提高仇恨性meme中的毒性检测性能。我们的方法从ConceptNet(一个大规模常识知识图谱(KG))中提取子知识图谱,并将其注入紧凑的VLM框架中。标题和meme中毒性短语之间的关系上下文以及meme中的视觉概念增强了模型的推理能力。我们在两个仇恨言论基准数据集上进行的实验结果表明,我们的方法在AU-ROC、F1和召回率方面的性能均优于最新基线,分别提高了1.1%、7%和35%。考虑到毒性检测任务的上下文复杂性,我们的方法展示了从显式(即KG)和隐式(即LVLMs)的上下文线索中学习的重要性,这些上下文线索通过混合神经符号方法进行集成。这对于现实世界的应用至关重要,因为在其中准确且可扩展地识别有毒内容对于创建更安全的在线环境至关重要。
论文及项目相关链接
Summary
本文提出一种结合知识蒸馏(KD)和大视觉语言模型(LVLMs)知识注入的新框架,用于增强在仇恨言论检测中的有毒内容识别性能。该框架从ConceptNet中提取子知识图谱,注入紧凑的VLM框架内。有毒短语与标语和标语中的视觉概念的关联上下文增强了模型的推理能力。实验结果表明,与最先进的基线相比,我们的方法在AU-ROC、F1和召回率方面表现出卓越的性能,分别提高了1.1%、7%和35%。这表明结合显性和隐性上下文线索,通过混合神经符号方法学习的重要性。对于需要准确和可扩展地识别有毒内容的现实世界应用至关重要。
Key Takeaways
- 提出了一种结合知识蒸馏和知识注入的新框架,用于增强有毒内容识别的性能。
- 利用ConceptNet提取子知识图谱,并将其注入紧凑的VLM框架内。
- 有毒短语与标语和视觉概念的关联上下文增强了模型的推理能力。
- 实验结果表明,该方法在AU-ROC、F1和召回率方面优于现有技术。
- 与最先进的基线相比,该方法的性能提升显著,特别是在召回率方面。
- 该方法对于现实世界应用至关重要,需要准确和可扩展地识别有毒内容以创建更安全的在线环境。
点此查看论文截图

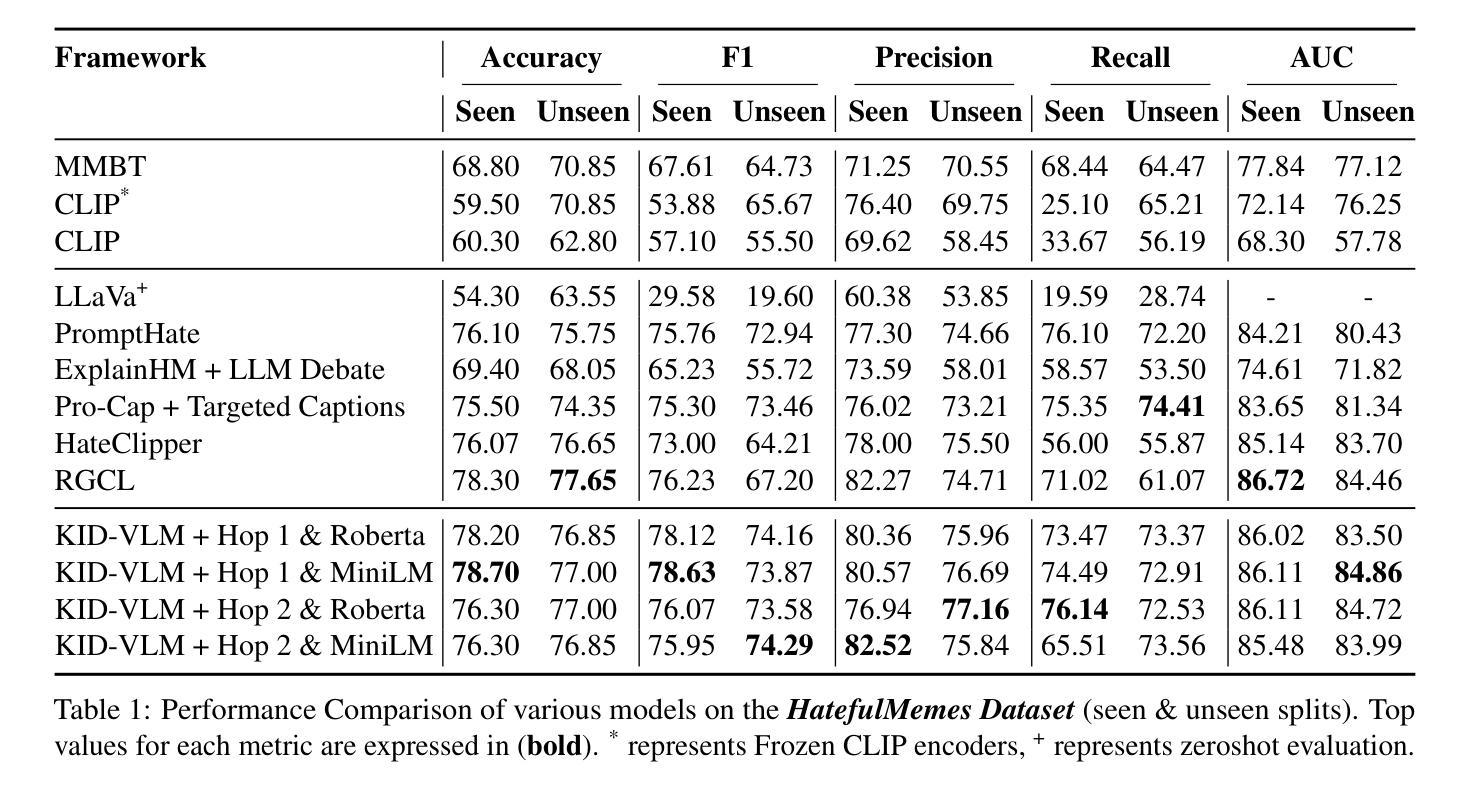
Simultaneous Diarization and Separation of Meetings through the Integration of Statistical Mixture Models
Authors:Tobias Cord-Landwehr, Christoph Boeddeker, Reinhold Haeb-Umbach
We propose an approach for simultaneous diarization and separation of meeting data. It consists of a complex Angular Central Gaussian Mixture Model (cACGMM) for speech source separation, and a von-Mises-Fisher Mixture Model (VMFMM) for diarization in a joint statistical framework. Through the integration, both spatial and spectral information are exploited for diarization and separation. We also develop a method for counting the number of active speakers in a segment of a meeting to support block-wise processing. While the total number of speakers in a meeting may be known, it is usually not known on a per-segment level. With the proposed speaker counting, joint diarization and source separation can be done segment-by-segment, and the permutation problem across segments is solved, thus allowing for block-online processing in the future. Experimental results on the LibriCSS meeting corpus show that the integrated approach outperforms a cascaded approach of diarization and speech enhancement in terms of WER, both on a per-segment and on a per-meeting level.
我们提出了一种同时进行会议数据分化和分离的方法。它包含一个复杂的角中心高斯混合模型(cACGMM)用于语音源分离,以及一个冯·米塞斯·费舍尔混合模型(VMFMM)用于联合统计框架中的分化。通过整合,利用空间和频谱信息进行分化和分离。我们还开发了一种方法,用于计算会议片段中的活动发言人数,以支持分块处理。虽然会议的发言人数总数可能是已知的,但在每一段中通常并不知道。通过提出的发言人计数方法,可以分段进行联合分化和源分离,并解决跨段的排列问题,从而实现在未来的分块在线处理。在LibriCSS会议语料库上的实验结果表明,该集成方法相较于在分段和会议级别上的级联分化与语音增强方法在词错误率(WER)方面表现更优。
论文及项目相关链接
PDF Accepted at ICASSP2025
Summary
本文提出了一种同时进行会议数据分离与日程记录的方法。它采用复杂的角中心高斯混合模型(cACGMM)进行语音源分离,并采用冯米塞斯费希尔混合模型(VMFMM)进行联合统计框架中的日程安排。通过整合,利用空间和频谱信息进行日程安排和分离。此外,还开发了一种方法用于计算会议片段中的活动说话人数,以支持分块处理。实验结果表明,该方法在LibriCSS会议语料库上的表现优于级联的日程安排和语音增强方法,无论是在每段还是整个会议层面,词错误率(WER)都有所降低。
Key Takeaways
- 提出了同时实现会议数据分离与日程记录的方法。
- 采用了复杂的角中心高斯混合模型(cACGMM)进行语音源分离。
- 采用了冯米塞斯费希尔混合模型(VMFMM)进行日程安排。
- 通过整合,该方法能够利用空间和频谱信息。
- 开发了一种计算会议片段中活动说话人数的方法,支持分块处理。
- 该方法解决了跨片段的排列问题,为未来分块在线处理提供了可能。
- 在LibriCSS会议语料库上的实验表明,该方法优于级联的日程安排和语音增强方法。
点此查看论文截图

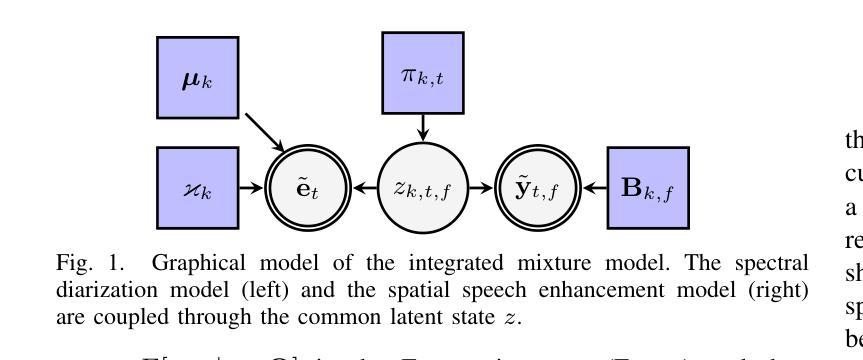
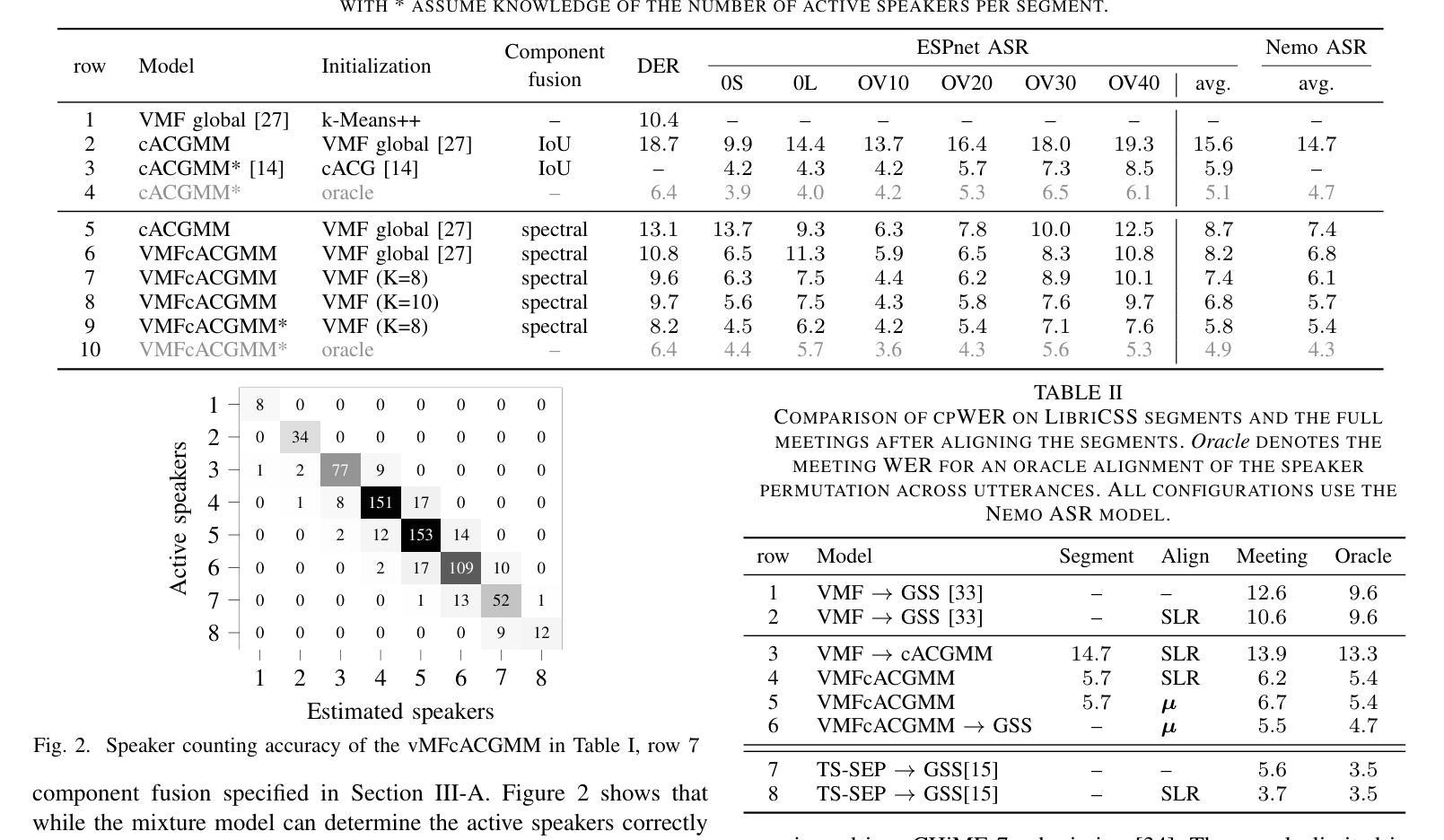
Three-in-One: Fast and Accurate Transducer for Hybrid-Autoregressive ASR
Authors:Hainan Xu, Travis M. Bartley, Vladimir Bataev, Boris Ginsburg
We present Hybrid-Autoregressive INference TrANsducers (HAINAN), a novel architecture for speech recognition that extends the Token-and-Duration Transducer (TDT) model. Trained with randomly masked predictor network outputs, HAINAN supports both autoregressive inference with all network components and non-autoregressive inference without the predictor. Additionally, we propose a novel semi-autoregressive inference paradigm that first generates an initial hypothesis using non-autoregressive inference, followed by refinement steps where each token prediction is regenerated using parallelized autoregression on the initial hypothesis. Experiments on multiple datasets across different languages demonstrate that HAINAN achieves efficiency parity with CTC in non-autoregressive mode and with TDT in autoregressive mode. In terms of accuracy, autoregressive HAINAN outperforms TDT and RNN-T, while non-autoregressive HAINAN significantly outperforms CTC. Semi-autoregressive inference further enhances the model’s accuracy with minimal computational overhead, and even outperforms TDT results in some cases. These results highlight HAINAN’s flexibility in balancing accuracy and speed, positioning it as a strong candidate for real-world speech recognition applications.
我们提出了混合自回归推理转换器(Hybrid-Autoregressive INference TrANsducers,简称HAINAN),这是一种用于语音识别的新型架构,它扩展了Token-and-Duration Transducer(TDT)模型。通过训练带有随机掩码的预测器网络输出,HAINAN支持包含所有网络组件的自回归推理和非自回归推理(无需预测器)。此外,我们还提出了一种新型半自回归推理范式,首先使用非自回归推理生成初始假设,然后通过并行自回归对初始假设进行精细化处理,重新生成每个符号的预测。在多语言数据集上的实验表明,HAINAN在非自回归模式下与CTC的效率相当,在自回归模式下与TDT的效率相当。在准确性方面,自回归的HAINAN优于TDT和RNN-T,而非自回归的HAINAN则显著优于CTC。半自回归推理进一步提高了模型的准确性,且计算开销最小,在某些情况下甚至超过了TDT的结果。这些结果凸显了HAINAN在平衡准确性和速度方面的灵活性,使其成为现实世界中语音识别应用的有力候选者。
论文及项目相关链接
Summary
本文介绍了Hybrid-Autoregressive INference TrANsducers(HAINAN)这一新型语音识别架构。HAINAN扩展了Token-and-Duration Transducer(TDT)模型,通过随机屏蔽预测网络输出来进行训练。它支持自回归推理和非自回归推理,并提出了半自回归推理新范式。实验表明,HAINAN在效率和准确性方面表现出色,具有在平衡准确率和速度方面的灵活性,适用于真实世界的语音识别应用。
Key Takeaways
- HAINAN是一种新型的语音识别架构,基于Token-and-Duration Transducer(TDT)模型进行扩展。
- HAINAN通过随机屏蔽预测网络输出来进行训练。
- HAINAN支持自回归和非自回归两种推理模式。
- 提出了半自回归推理新范式,首先使用非自回归推理生成初步假设,然后进行基于并行自回归的精细化预测。
- 实验结果表明,HAINAN在效率和准确性方面表现出色。
- 自回归HAINAN在准确性方面优于TDT和RNN-T,非自回归HAINAN则显著优于CTC。
点此查看论文截图




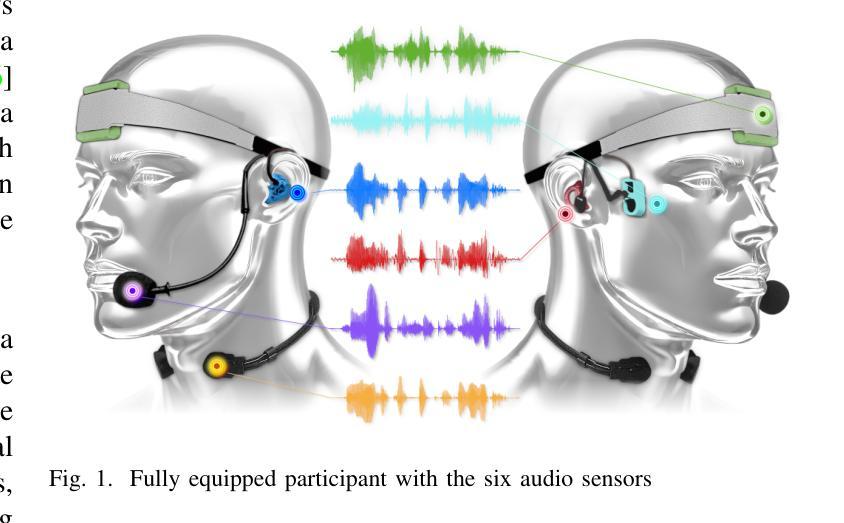
Vibravox: A Dataset of French Speech Captured with Body-conduction Audio Sensors
Authors:Julien Hauret, Malo Olivier, Thomas Joubaud, Christophe Langrenne, Sarah Poirée, Véronique Zimpfer, Éric Bavu
Vibravox is a dataset compliant with the General Data Protection Regulation (GDPR) containing audio recordings using five different body-conduction audio sensors : two in-ear microphones, two bone conduction vibration pickups and a laryngophone. The dataset also includes audio data from an airborne microphone used as a reference. The Vibravox corpus contains 45 hours of speech samples and physiological sounds recorded by 188 participants under different acoustic conditions imposed by an high order ambisonics 3D spatializer. Annotations about the recording conditions and linguistic transcriptions are also included in the corpus. We conducted a series of experiments on various speech-related tasks, including speech recognition, speech enhancement and speaker verification. These experiments were carried out using state-of-the-art models to evaluate and compare their performances on signals captured by the different audio sensors offered by the Vibravox dataset, with the aim of gaining a better grasp of their individual characteristics.
Vibravox是一个符合通用数据保护条例(GDPR)要求的数据集,其中包含使用五种不同的身体传导音频传感器录制的音频记录:两个入耳式麦克风,两个骨传导振动拾音器和一个喉头麦克风。该数据集还包括作为参考的空气传播麦克风的音频数据。Vibravox语料库包含由188名参与者在由高级三维空间定位器施加的不同声学条件下录制的45小时语音样本和生理声音。语料库还包括关于录音条件的注释和语言转录。我们在各种语音相关任务上进行了一系列实验,包括语音识别、语音增强和说话人验证。这些实验使用最前沿的模型进行,旨在评估并比较这些模型在Vibravox数据集提供的不同音频传感器捕获的信号上的性能,从而更好地了解它们各自的特性。
论文及项目相关链接
PDF 23 pages, 42 figures
总结
Vibravox是一个符合通用数据保护条例(GDPR)规定的音频数据集,包含使用五种不同的身体传导音频传感器录制的音频记录,如两个入耳式麦克风、两个骨传导振动拾音器和一个喉头电话。该数据集还包括作为参考的空气传播麦克风的音频数据。Vibravox语料库包含由188名参与者在由高级三维空间化技术设定的高阶环境噪声条件下录制的45小时语音样本和生理声音。语料库还包括关于录音条件和语言转录的注释。我们进行了一系列关于各种语音相关任务的实验,包括语音识别、语音增强和说话人验证,以评估不同音频传感器在Vibravox数据集上的性能并比较其性能,目的是为了更好地了解它们各自的特性。
要点分析
- Vibravox是一个符合GDPR规定的音频数据集。
- 数据集使用了五种不同的身体传导音频传感器进行音频录制。
- 数据集包含45小时的语音样本和生理声音记录。
- 录音来自188名参与者,在不同的声学条件下进行。
- 语料库包含关于录音条件和语言转录的注释。
- 进行了一系列语音相关任务的实验,包括语音识别、语音增强和说话人验证。
- 实验的目的是评估并比较不同音频传感器的性能,以了解它们各自的特性。
点此查看论文截图