⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-26 更新
Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis
Authors:Zhen Ye, Xinfa Zhu, Chi-Min Chan, Xinsheng Wang, Xu Tan, Jiahe Lei, Yi Peng, Haohe Liu, Yizhu Jin, Zheqi Dai, Hongzhan Lin, Jianyi Chen, Xingjian Du, Liumeng Xue, Yunlin Chen, Zhifei Li, Lei Xie, Qiuqiang Kong, Yike Guo, Wei Xue
Recent advances in text-based large language models (LLMs), particularly in the GPT series and the o1 model, have demonstrated the effectiveness of scaling both training-time and inference-time compute. However, current state-of-the-art TTS systems leveraging LLMs are often multi-stage, requiring separate models (e.g., diffusion models after LLM), complicating the decision of whether to scale a particular model during training or testing. This work makes the following contributions: First, we explore the scaling of train-time and inference-time compute for speech synthesis. Second, we propose a simple framework Llasa for speech synthesis that employs a single-layer vector quantizer (VQ) codec and a single Transformer architecture to fully align with standard LLMs such as Llama. Our experiments reveal that scaling train-time compute for Llasa consistently improves the naturalness of synthesized speech and enables the generation of more complex and accurate prosody patterns. Furthermore, from the perspective of scaling inference-time compute, we employ speech understanding models as verifiers during the search, finding that scaling inference-time compute shifts the sampling modes toward the preferences of specific verifiers, thereby improving emotional expressiveness, timbre consistency, and content accuracy. In addition, we released the checkpoint and training code for our TTS model (1B, 3B, 8B) and codec model publicly available.
最近,基于文本的的大型语言模型(LLM),特别是GPT系列和o1模型,在训练和推理时间的计算扩展方面展现了有效性。然而,当前最先进的利用LLM的TTS系统通常是多阶段的,需要单独的模型(例如LLM之后的扩散模型),这使得在训练或测试期间扩展特定模型变得复杂。本文做出了以下贡献:首先,我们探索了语音合成中的训练时间和推理时间计算的扩展。其次,我们提出了一个用于语音合成的简单框架Llasa,它采用单层向量量化(VQ)编码器和单一的Transformer架构,与Llama等标准LLM完全对齐。我们的实验表明,扩展Llasa的训练时间计算可以持续提高合成语音的自然度,并生成更复杂和准确的语言韵律模式。此外,从扩展推理时间计算的角度来看,我们在搜索过程中使用了语音理解模型作为验证器,发现扩展推理时间计算可以使采样模式转向特定验证器的偏好,从而提高情感表现力、音色一致性和内容准确性。另外,我们公开发布了TTS模型(1B、3B、8B)和编码器模型的检查点和训练代码。
论文及项目相关链接
摘要
近期文本大型语言模型(LLM)的进步,特别是在GPT系列和O1模型上,证明了扩展训练和推理时间的计算的有效性。然而,当前最先进的利用LLM的TTS系统通常是多阶段的,需要单独模型(如LLM之后的扩散模型),这使得在训练或测试期间扩展特定模型变得复杂。本文做出了以下贡献:首先,我们探索了语音合成中训练和推理时间计算的扩展。其次,我们提出了一个用于语音合成的简单框架Llasa,它采用单层向量量化编解码器和与标准LLM(如Llama)相匹配的单一Transformer架构。我们的实验表明,扩展Llasa的训练时间计算可以持续改善合成语音的自然性,并能够生成更复杂和准确的语调模式。此外,从扩展推理时间计算的角度来看,我们在搜索过程中使用了语音理解模型作为验证器,发现扩展推理时间计算会使采样模式转向特定验证器的偏好,从而提高情感表现力、音色一致性和内容准确性。此外,我们公开提供了TTS模型(1B、3B、8B)和编解码器模型的检查点和训练代码。
关键见解
- 近期大型语言模型(LLM)在文本领域的进步证明了扩展训练和推理计算的有效性。
- 当前TTS系统利用LLM通常涉及多阶段和单独模型,使得决策复杂化。
- 本文探索了语音合成中训练和推理计算的扩展。
- 提出了Llasa框架,采用单一Transformer架构和单层向量量化编解码器,与标准LLM对齐。
- 扩展训练时间计算可改善合成语音的自然性并生成更复杂的语调模式。
- 扩展推理时间计算可使采样模式更符合特定验证器的偏好,提高情感表达、音色一致性和内容准确性。
- 公开提供了TTS模型的检查点和训练代码。
点此查看论文截图


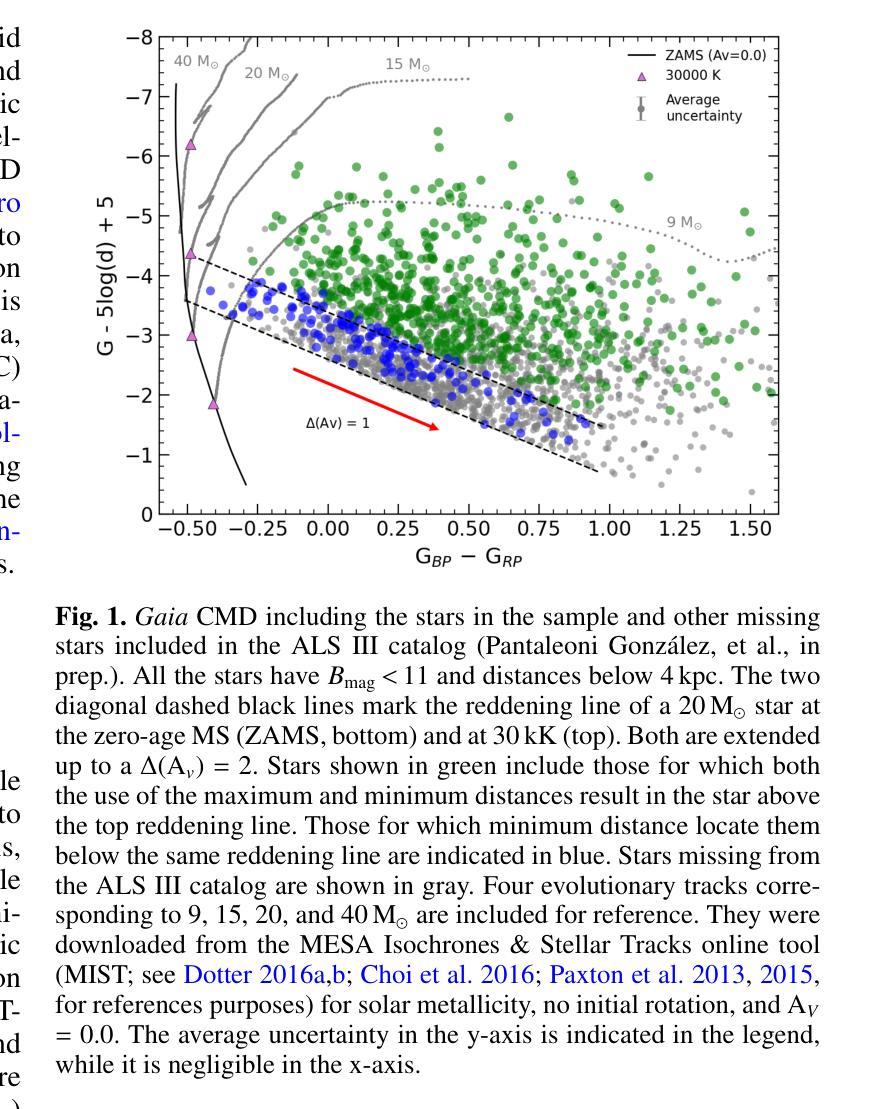
The IACOB project XIV. New clues on the location of the TAMS in the massive star domain
Authors:A. de Burgos, S. Simón-Díaz, M. A. Urbaneja, G. Holgado, S. Ekström, M. C. Ramírez-Tannus, E. Zari
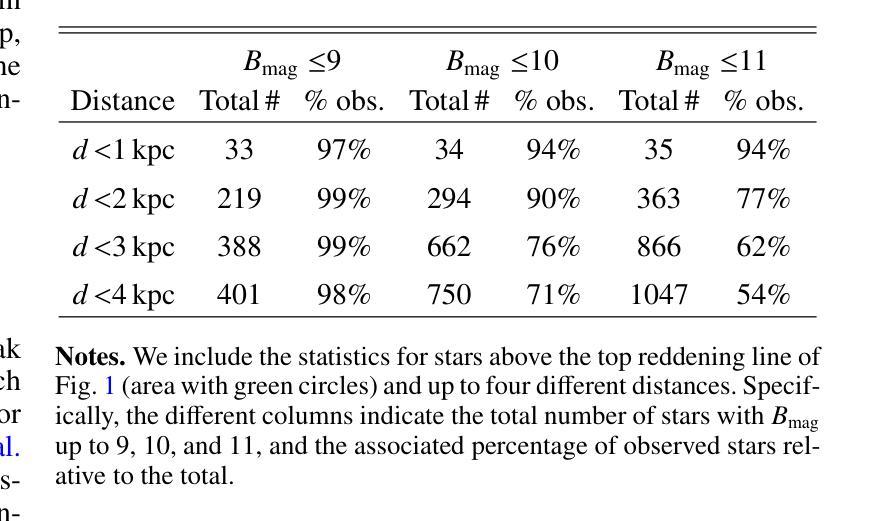
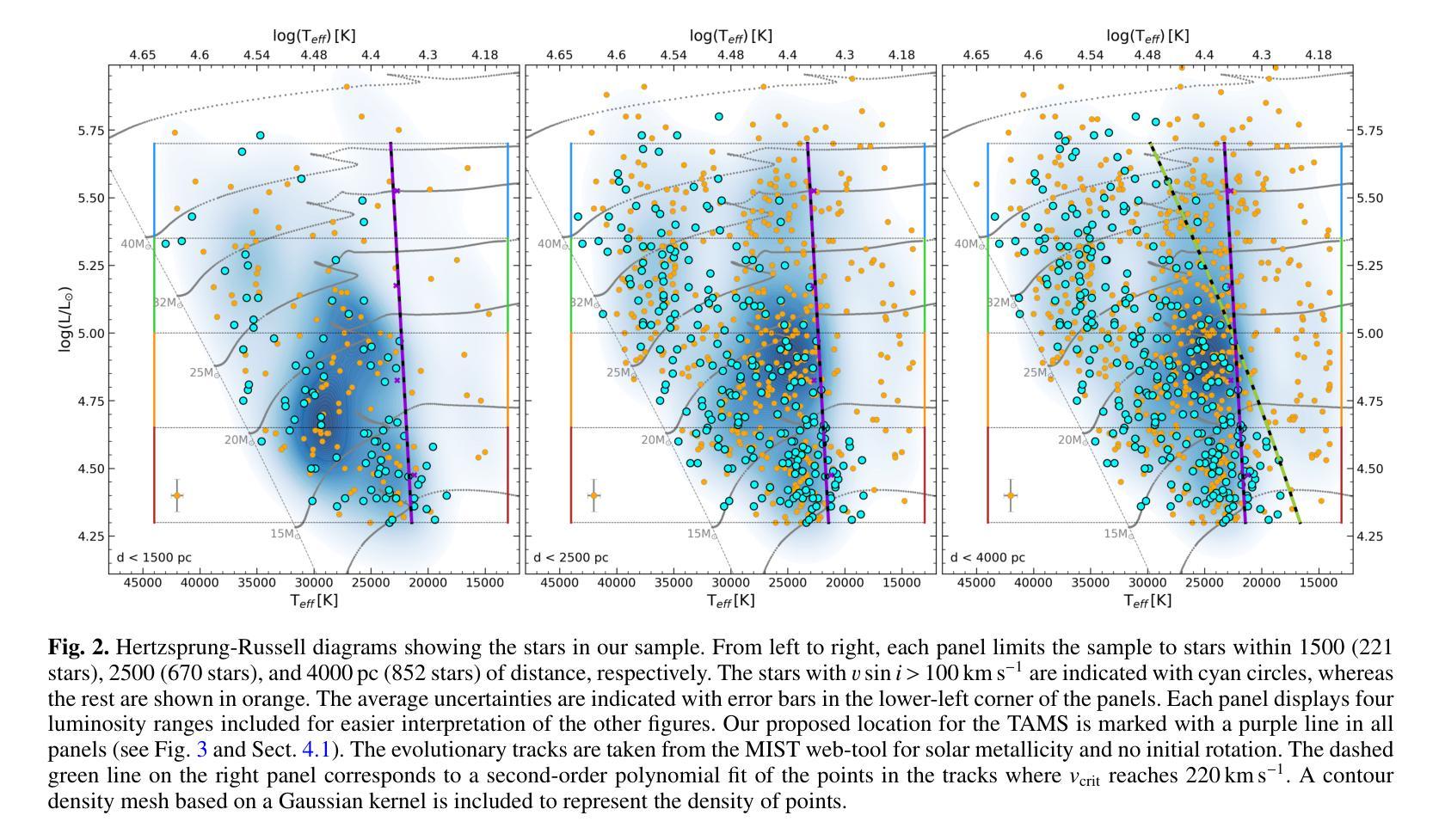
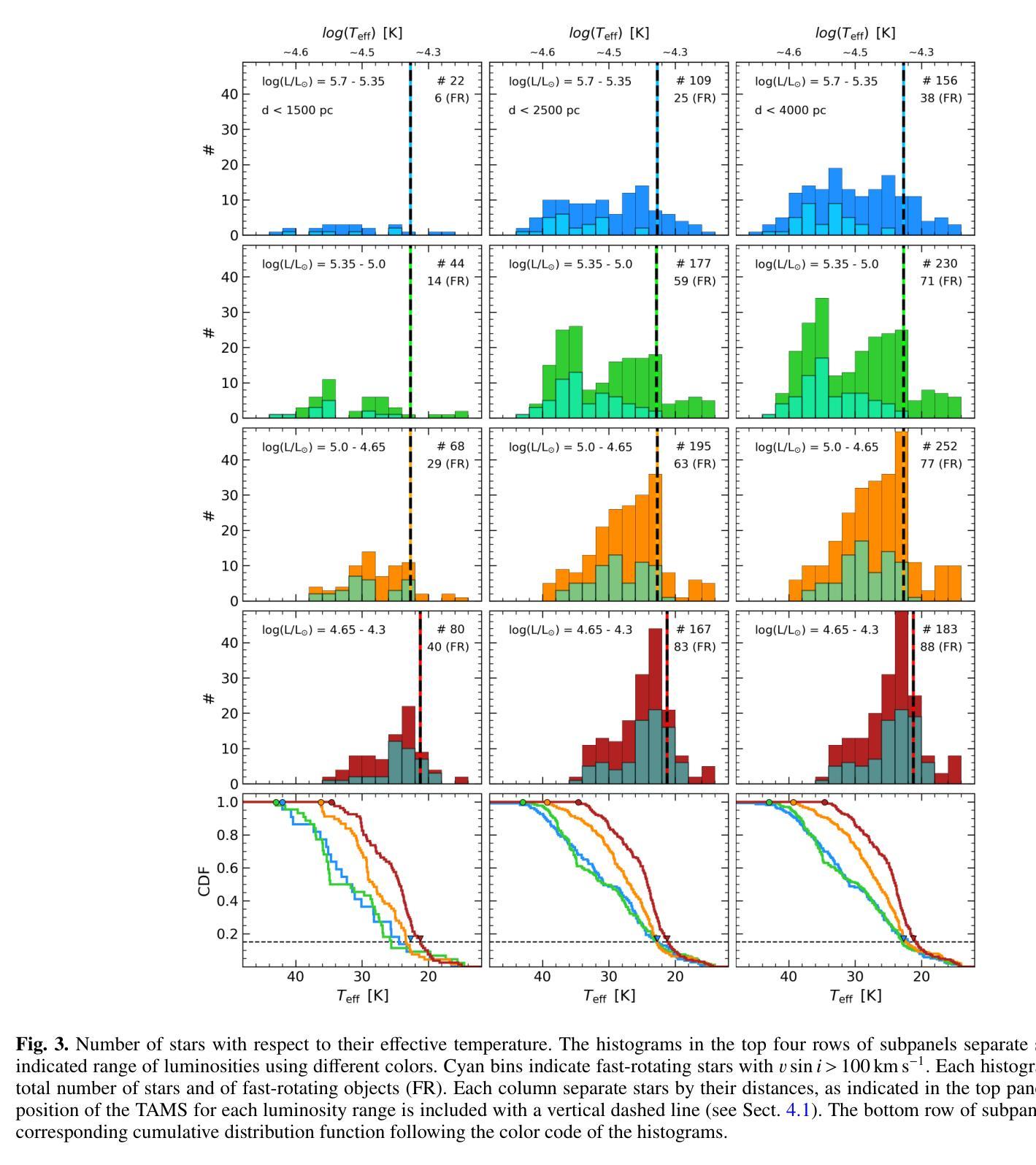
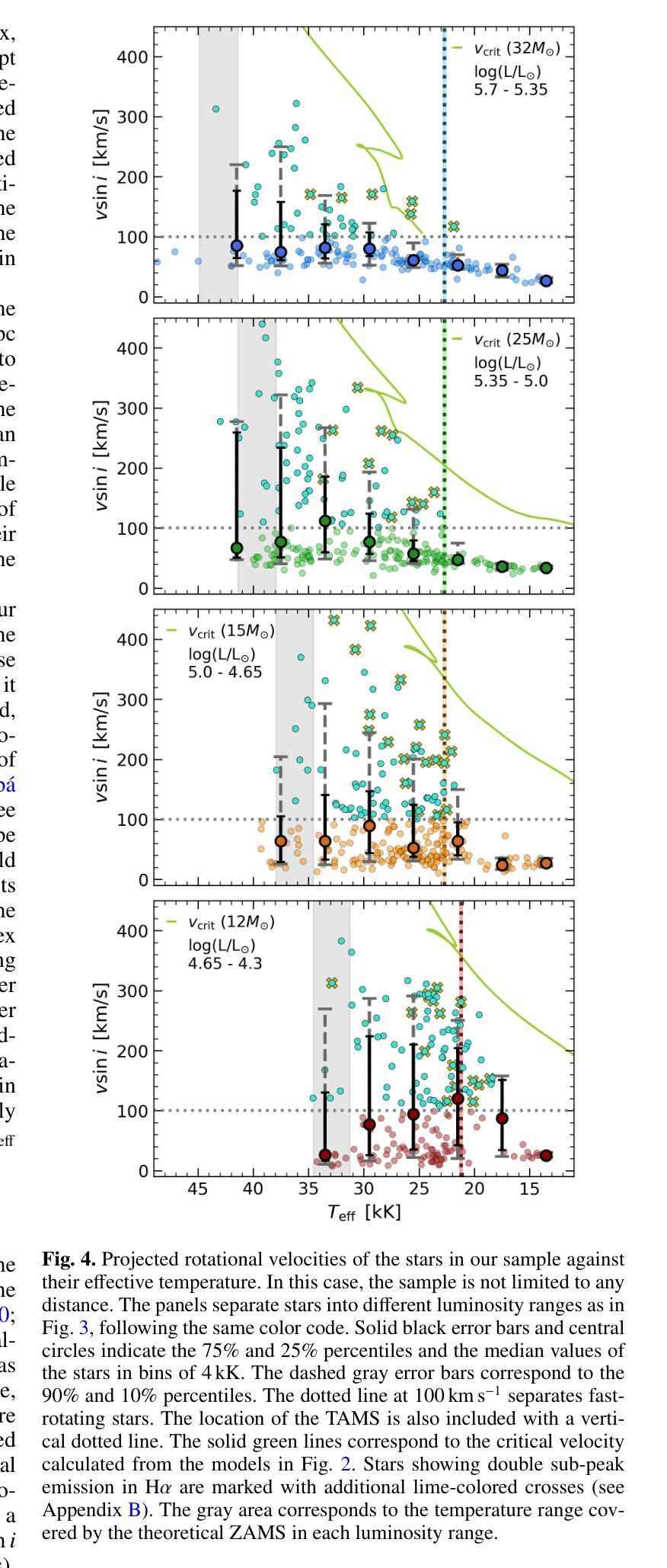
Massive stars play a very important role in many astrophysical fields. Yet, some fundamental aspects of their evolution remain poorly constrained. In this regard, there is an open debate on the width of the main-sequence (MS) phase. We aim to create an updated Hertzsprung-Russell (HR) diagram that includes a volume-limited and statistically significant sample of massive stars. Our goal is to use this sample to investigate the extension of the MS, including information about projected rotational velocities ($v\sin i$) and the spectroscopic binary status. We combine spectroscopic parameters derived with FASTWIND stellar atmosphere code and Gaia distances to obtain stellar parameters for 876 Galactic luminous O- and B-type stars gathered within the IACOB project. We use the ${\tt iacob-broad}$ tool to derive $v\sin i$ estimates and multi-epoch spectra to identify single/double-line spectroscopic binaries (SB1/SB2). We present an HR diagram for 670 stars located within 2500pc balancing completeness and number. We evaluate the extension of the MS in terms of the drop in the relative number of stars as a function of effective temperature ($T_{\rm eff}$). We find a consistent boundary at $\approx$22.5kK within the full range of luminosities that we use to delineate the terminal-age main sequence (TAMS). We obtain a smooth decrease of the highest $v\sin i$ with $T_{\rm eff}$ along the MS, likely limited by the critical velocity. We consider this effect combined with a lower expected fraction of stars beyond the MS as the best explanation for the lack of fast-rotating objects in the post-MS region. Our results favor low to mild initial rotation for the full sample and a binary past for the tail of fast-rotating stars. The prominence of SB1/SB2 systems in the MS, and the 25% decrease in the relative fraction of SB1 systems when crossing the TAMS can further delineate its location.
大规模恒星在许多天体物理领域中都扮演着非常重要的角色。然而,关于它们的演化,仍有一些基本方面没有得到很好的约束。在这方面,关于主序(MS)阶段的宽度存在公开的争论。我们的目标是创建一个更新的赫罗图(HR图),其中包含数量有限且统计意义重大的大规模恒星样本。我们的目标是用这个样本来研究MS的扩展,包括关于投影旋转速度(vsin i)和光谱双星状态的信息。我们结合使用FASTWIND恒星大气代码得出的光谱参数和Gaia距离,以获得IA COB项目中收集的876颗银河明亮O型和B型恒星的恒星参数。我们使用iacob-broad工具来推导vsin i的估计值,并使用多时期光谱来识别单线/双线光谱双星(SB1/SB2)。我们为位于2500pc内的670颗恒星提供了一个平衡的完整性和数量的HR图。我们根据有效温度(T eff)下恒星相对数量的下降来评估MS的扩展。我们在使用的全亮度范围内发现了一个大约22.5kK的一致边界,我们用它来划定终端主序(TAMS)。我们发现最高vsin i随着有效温度沿MS平滑下降,这可能受到临界速度的限制。我们认为这种效应与MS之后缺乏快速旋转物体的最佳解释是,随着MS的结束,恒星的旋转速度逐渐减慢。我们的研究结果支持整个样本的初始旋转速度较低至适中,以及快速旋转恒星尾部具有二进制过去。SB1/SB2系统在MS中的突出地位,以及在跨过TAMS时SB1系统相对比例下降25%,可以进一步划定其位置。
论文及项目相关链接
PDF 16 pages, 9 figures, accepted for publication in A&A
Summary
本文研究了质量恒星在天文物理学领域的重要作用,特别是其主序阶段的延伸问题。文章通过更新赫兹普朗-罗素图,以体积限制和统计显著的样本为基础,探讨了主序的扩展情况。研究使用了包括投影旋转速度(vsin i)和光谱二进制状态在内的信息,对收集自IACOB项目的876颗明亮的O型和B型恒星进行了参数测定。通过平衡完整性和数量,为位于2500秒差距内的670颗恒星呈现了赫兹普朗图。在有效温度(T有效)的范围内,评估了主序的扩展情况,并发现了一个边界约处于22.5kK的温度,以此来划定终端主序。研究发现最高投影旋转速度与主序的有效温度之间有着平稳的下降趋势,这可能与临界速度有关。此外,还探讨了旋转与二进制过去对恒星演化的影响,发现光谱二元系统在主序阶段的突出表现以及跨越终端主序时SB1系统相对比例的下降。总的来说,这项研究为理解质量恒星的演化提供了新的见解。
Key Takeaways
- 规模巨大的恒星在天文学领域具有重要的作用,但它们演化过程中的某些基础方面仍不明确。
- 更新后的赫兹普朗-罗素图包含了大量的质量恒星样本,有助于研究主序阶段的延伸情况。
- 通过研究投影旋转速度(vsin i)和光谱二元状态等信息,对质量恒星的演化有了更深入的了解。
- 研究发现主序的边界约处于22.5kK的温度,并据此确定了终端主序的位置。
- 投影旋转速度与有效温度在主序上的关系表明存在一个平稳的下降趋势,这可能与恒星的临界速度有关。
- 光谱二元系统在主序阶段较为突出,跨越终端主序时SB1系统的相对比例有所下降。
点此查看论文截图

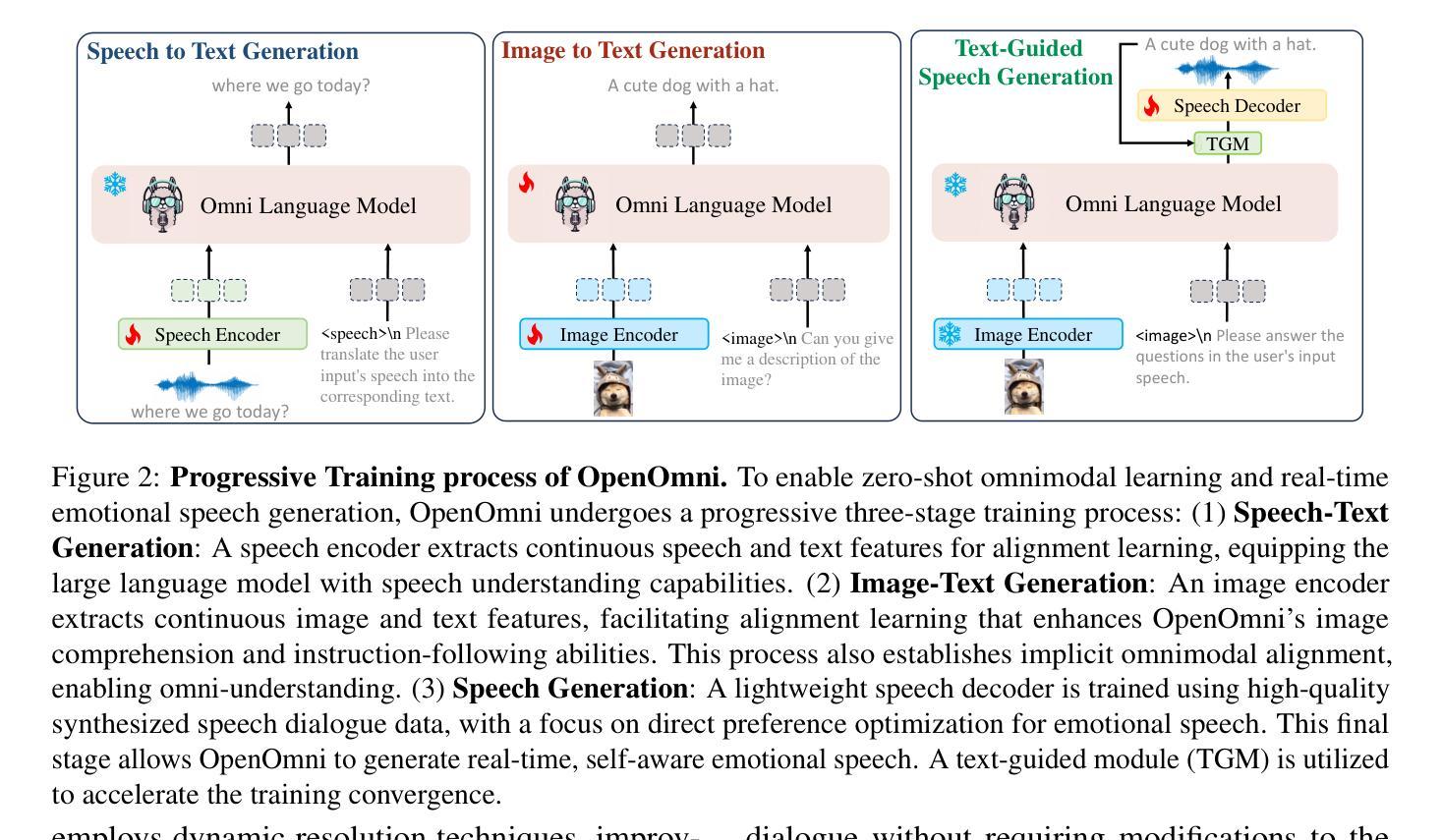
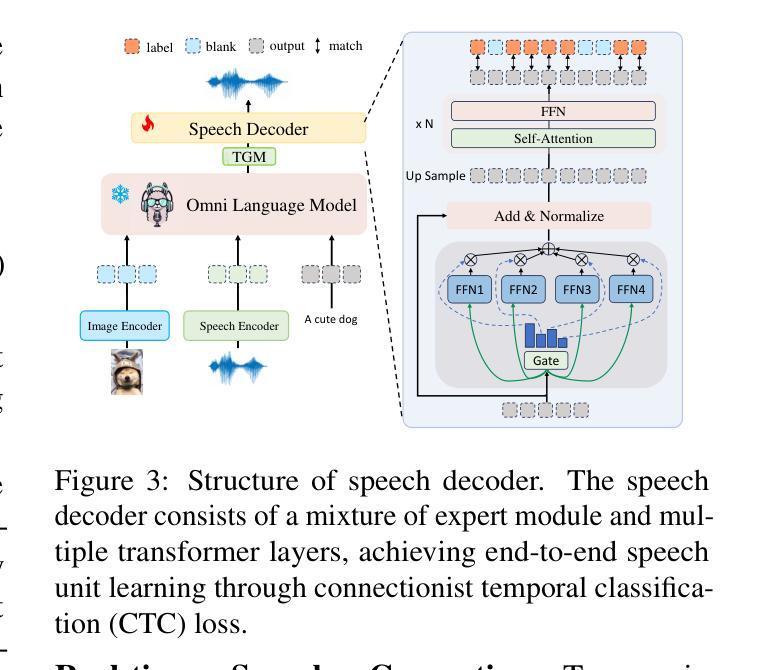
OpenOmni: Advancing Open-Source Omnimodal Large Language Models with Progressive Multimodal Alignment and Real-Time Self-Aware Emotional Speech Synthesis
Authors:Run Luo, Ting-En Lin, Haonan Zhang, Yuchuan Wu, Xiong Liu, Min Yang, Yongbin Li, Longze Chen, Jiaming Li, Lei Zhang, Yangyi Chen, Hamid Alinejad-Rokny, Fei Huang
Recent advancements in omnimodal learning have significantly improved understanding and generation across images, text, and speech, yet these developments remain predominantly confined to proprietary models. The lack of high-quality omnimodal datasets and the challenges of real-time emotional speech synthesis have notably hindered progress in open-source research. To address these limitations, we introduce \name, a two-stage training framework that integrates omnimodal alignment and speech generation to develop a state-of-the-art omnimodal large language model. In the alignment phase, a pre-trained speech model undergoes further training on text-image tasks, enabling (near) zero-shot generalization from vision to speech, outperforming models trained on tri-modal datasets. In the speech generation phase, a lightweight decoder is trained on speech tasks with direct preference optimization, enabling real-time emotional speech synthesis with high fidelity. Experiments show that \name surpasses state-of-the-art models across omnimodal, vision-language, and speech-language benchmarks. It achieves a 4-point absolute improvement on OmniBench over the leading open-source model VITA, despite using 5x fewer training samples and a smaller model size (7B vs. 7x8B). Additionally, \name achieves real-time speech generation with <1s latency at non-autoregressive mode, reducing inference time by 5x compared to autoregressive methods, and improves emotion classification accuracy by 7.7%
最近的多模态学习进展在图像、文本和语音的理解与生成方面取得了显著的提升,但这些发展主要局限于专有模型。高质量多模态数据集的缺乏以及实时情感语音合成的挑战显著地阻碍了开源研究的进步。为了解决这些局限性,我们引入了名为“name”的两阶段训练框架,它集成了多模态对齐和语音生成,以开发先进的多模态大型语言模型。在对齐阶段,预训练的语音模型在文本-图像任务上接受进一步训练,实现了从视觉到语音的(接近)零样本泛化,超越了那些在三元模态数据集上训练的模型。在语音生成阶段,一个轻量级的解码器在语音任务上进行直接偏好优化训练,能够实现高保真度的实时情感语音合成。实验表明,“name”在多模态、视觉语言和语音语言基准测试中均超过了最先进的模型。尽管使用的训练样本数量比领先的开源模型VITA少五倍且模型规模较小(7B对7x8B),但在OmniBench上仍实现了领先最优模型四点的绝对提升。此外,“name”在非自回归模式下实现了小于1秒的实时语音生成延迟,与自回归方法相比减少了五倍的推理时间,并提高了7.7%的情感分类准确率。
论文及项目相关链接
Summary
最新的多模态学习进展极大地提高了图像、文本和语音的理解和生成能力,但主要局限于专有模型。缺乏高质量的多模态数据集以及实时情感语音合成的挑战显著阻碍了开源研究的进展。为解决这些限制,我们推出了名为“名字”的两阶段训练框架,它融合了多模态对齐和语音生成,以开发先进的多模态大型语言模型。“名字”首先进行对齐训练,预训练的语音模型在文本-图像任务上接受进一步训练,实现了从视觉到语音的零样本或近乎零样本泛化,超越了那些在三种模态数据集上训练的模型。接着是语音生成阶段,我们训练了一个轻量级的解码器进行语音任务,通过直接偏好优化实现实时高保真情感语音合成。实验表明,“名字”在多模态、视觉语言和语音语言基准测试中超越了现有模型。相较于领先的开源模型VITA,“名字”在OmniBench上实现了4个点的绝对提升,并且使用更少样本和更小的模型大小。同时,“名字”实现了非自回归模式下的实时语音生成,推理时间缩短为原来的五分之一,情感分类准确率提高了7.7%。
Key Takeaways
- 近期多模态学习的进展主要局限于专有模型的应用,制约了开源研究的进展。
- 缺乏高质量的多模态数据集和实时情感语音合成的挑战是制约开源研究的关键因素。
- 提出的名为“名字”的两阶段训练框架结合了多模态对齐和语音生成技术。
- 对齐阶段通过文本-图像任务的进一步训练实现了从视觉到语音的零样本泛化。
- 语音生成阶段采用轻量级解码器进行语音任务,实现了实时高保真情感语音合成。
- “名字”在多模态基准测试中表现优异,相较于其他模型有显著的提升。
点此查看论文截图