⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-26 更新
GLCF: A Global-Local Multimodal Coherence Analysis Framework for Talking Face Generation Detection
Authors:Xiaocan Chen, Qilin Yin, Jiarui Liu, Wei Lu, Xiangyang Luo, Jiantao Zhou
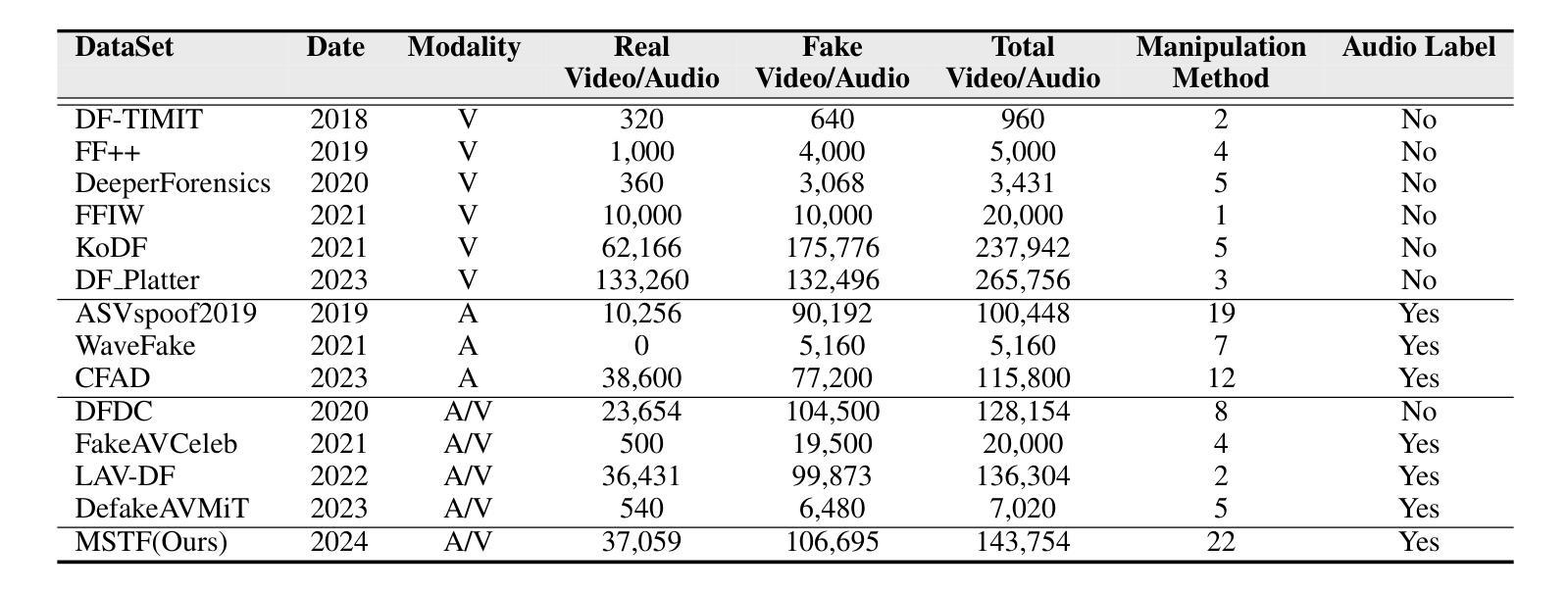
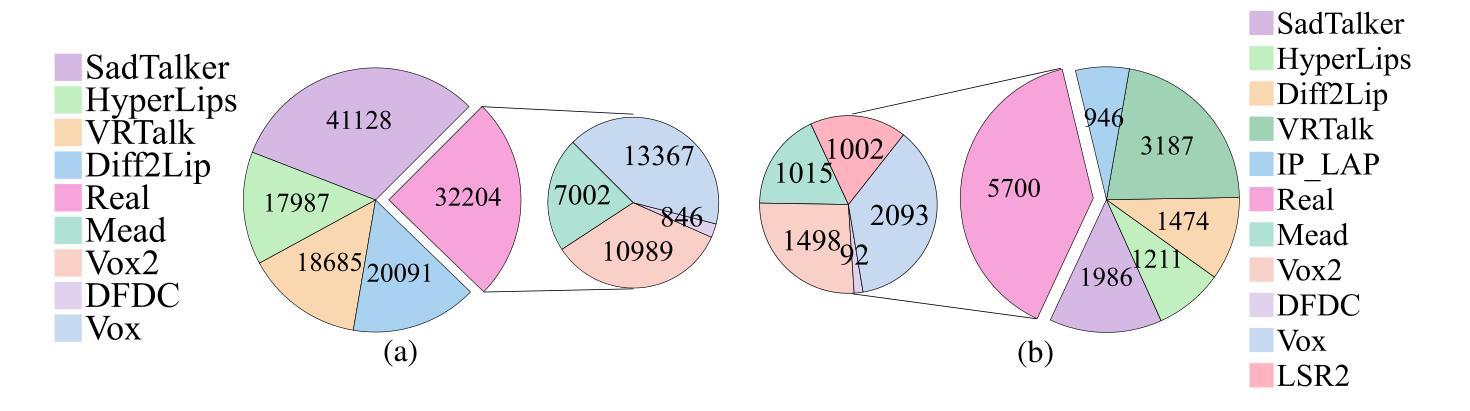
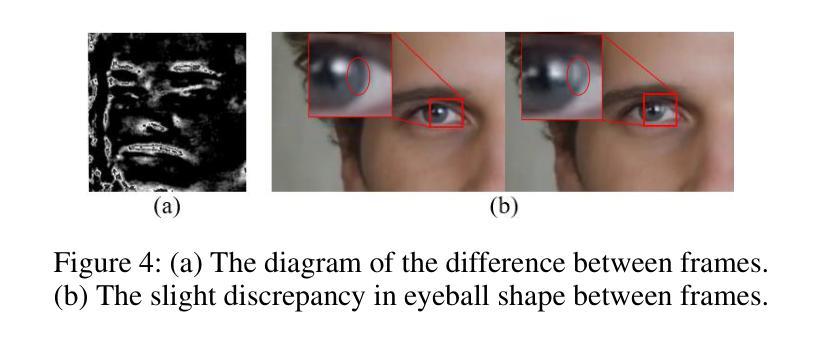
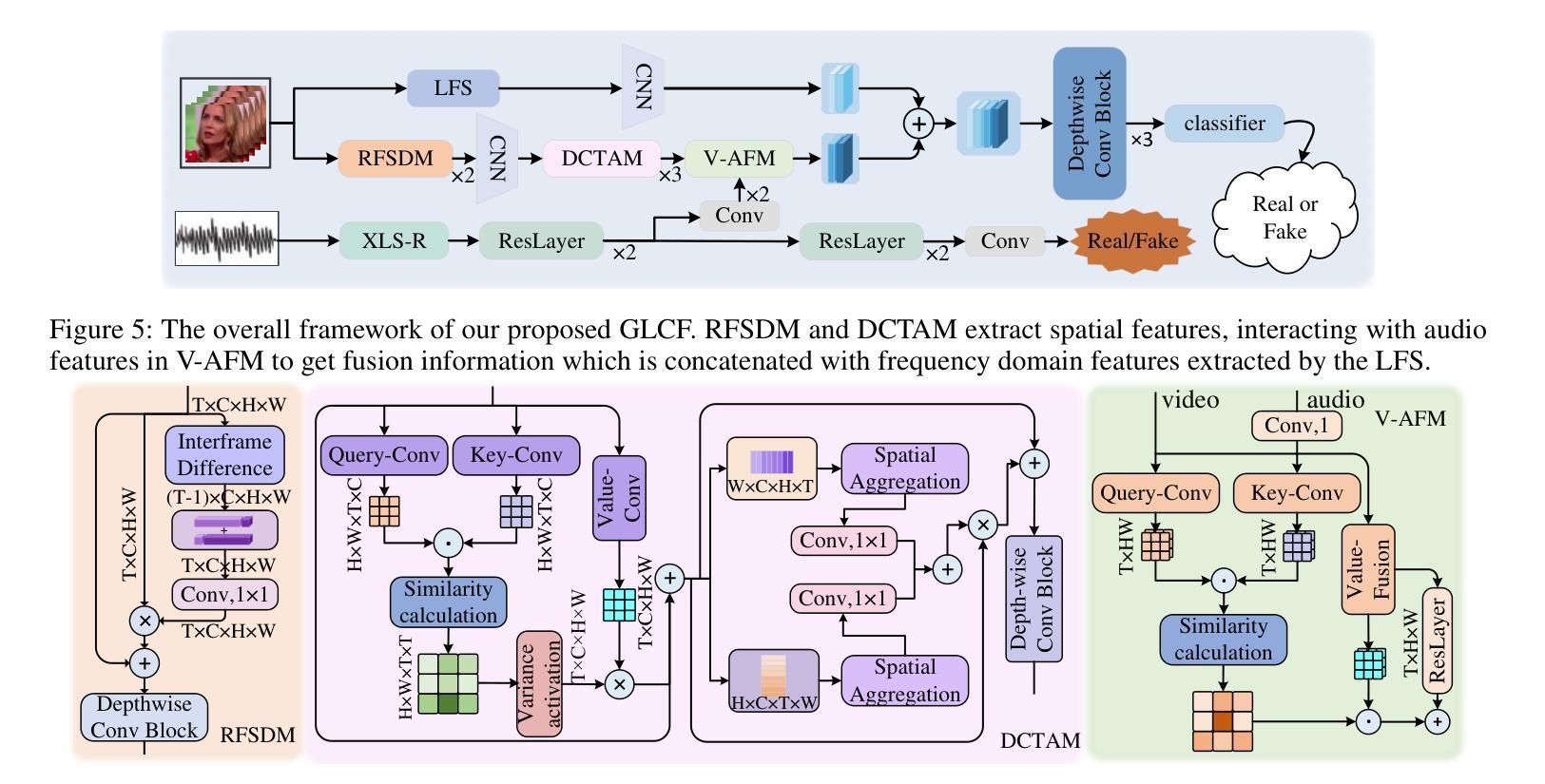
Talking face generation (TFG) allows for producing lifelike talking videos of any character using only facial images and accompanying text. Abuse of this technology could pose significant risks to society, creating the urgent need for research into corresponding detection methods. However, research in this field has been hindered by the lack of public datasets. In this paper, we construct the first large-scale multi-scenario talking face dataset (MSTF), which contains 22 audio and video forgery techniques, filling the gap of datasets in this field. The dataset covers 11 generation scenarios and more than 20 semantic scenarios, closer to the practical application scenario of TFG. Besides, we also propose a TFG detection framework, which leverages the analysis of both global and local coherence in the multimodal content of TFG videos. Therefore, a region-focused smoothness detection module (RSFDM) and a discrepancy capture-time frame aggregation module (DCTAM) are introduced to evaluate the global temporal coherence of TFG videos, aggregating multi-grained spatial information. Additionally, a visual-audio fusion module (V-AFM) is designed to evaluate audiovisual coherence within a localized temporal perspective. Comprehensive experiments demonstrate the reasonableness and challenges of our datasets, while also indicating the superiority of our proposed method compared to the state-of-the-art deepfake detection approaches.
面部谈话生成(TFG)技术仅使用面部图像和伴随文本就可以生成任何角色的逼真谈话视频。这项技术的滥用可能会给社会带来重大风险,因此迫切需要研究相应的检测方法。然而,这个领域的研究受到了公开数据集缺乏的限制。在本文中,我们构建了第一个大规模多场景面部谈话数据集(MSTF),包含了22种音频和视频伪造技术,填补了该领域的数据集空白。该数据集涵盖了11种生成场景和超过20种语义场景,更接近于TFG的实际应用场景。
论文及项目相关链接
Summary
生成对话头像(TFG)技术能利用人物面部图像和文本信息制作出逼真的动态视频。技术的滥用可能对社会构成重大风险,因此亟需研究相应的检测方法。然而,该领域的研究因缺乏公共数据集而受到阻碍。本文构建了首个大规模多场景对话头像数据集(MSTF),包含22种音视频伪造技术,填补了该领域的空白。数据集涵盖11种生成场景和超过20种语义场景,更贴近TFG的实际应用场景。此外,本文还提出了一种TFG检测框架,该框架利用对TFG视频的多模态内容的全局和局部一致性的分析。因此,引入了区域重点平滑检测模块(RSFDM)和差异捕获时间帧聚合模块(DCTAM)来评估TFG视频的全局时间一致性,并聚合多粒度空间信息。同时,设计了一个视觉-音频融合模块(V-AFM)来评估局部时间视角下的视听一致性。综合实验验证了数据集的合理性及挑战,同时表明本文提出的方法相较于最新的深度伪造检测方法具有优越性。
Key Takeaways
- 生成对话头像(TFG)技术能够利用面部图像和文本生成逼真视频。
- TFG技术的滥用对社会存在重大风险,需要研究相应的检测方法。
- 当前领域缺乏公共数据集,本文构建了首个大规模多场景对话头像数据集(MSTF)。
- MSTF数据集包含多种音视频伪造技术,涵盖多种生成和语义场景,更接近实际应用。
- 本文提出一种TFG检测框架,通过评估全局和局部一致性来检测伪造。
- 检测框架包括区域重点平滑检测模块、差异捕获时间帧聚合模块和视觉-音频融合模块。
点此查看论文截图