⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-26 更新
MaxGlaViT: A novel lightweight vision transformer-based approach for early diagnosis of glaucoma stages from fundus images
Authors:Mustafa Yurdakul, Kubra Uyar, Sakir Tasdemir
Glaucoma is a prevalent eye disease that progresses silently without symptoms. If not detected and treated early, it can cause permanent vision loss. Computer-assisted diagnosis systems play a crucial role in timely and efficient identification. This study introduces MaxGlaViT, a lightweight model based on the restructured Multi-Axis Vision Transformer (MaxViT) for early glaucoma detection. First, MaxViT was scaled to optimize block and channel numbers, resulting in a lighter architecture. Second, the stem was enhanced by adding attention mechanisms (CBAM, ECA, SE) after convolution layers to improve feature learning. Third, MBConv structures in MaxViT blocks were replaced by advanced DL blocks (ConvNeXt, ConvNeXtV2, InceptionNeXt). The model was evaluated using the HDV1 dataset, containing fundus images of different glaucoma stages. Additionally, 40 CNN and 40 ViT models were tested on HDV1 to validate MaxGlaViT’s efficiency. Among CNN models, EfficientB6 achieved the highest accuracy (84.91%), while among ViT models, MaxViT-Tiny performed best (86.42%). The scaled MaxViT reached 87.93% accuracy. Adding ECA to the stem block increased accuracy to 89.01%. Replacing MBConv with ConvNeXtV2 further improved it to 89.87%. Finally, integrating ECA in the stem and ConvNeXtV2 in MaxViT blocks resulted in 92.03% accuracy. Testing 80 DL models for glaucoma stage classification, this study presents a comprehensive and comparative analysis. MaxGlaViT outperforms experimental and state-of-the-art models, achieving 92.03% accuracy, 92.33% precision, 92.03% recall, 92.13% f1-score, and 87.12% Cohen’s kappa score.
青光眼是一种普遍且无声进展的眼病。如果早期未被发现和治疗,它可能导致永久性视力丧失。计算机辅助诊断系统在及时有效的识别中起着至关重要的作用。本研究介绍了一种基于重构的多轴视觉转换器(MaxViT)的轻量级模型MaxGlaViT,用于早期青光眼的检测。首先,对MaxViT进行缩放以优化块和通道数量,从而得到更轻的结构。其次,通过在卷积层之后添加注意力机制(CBAM、ECA、SE)来增强主干,以提高特征学习能力。第三,将MaxViT块中的MBConv结构替换为先进的DL块(ConvNeXt、ConvNeXtV2、InceptionNeXt)。该模型使用HDV1数据集进行评估,该数据集包含不同青光眼阶段的眼底图像。另外,还在HDV1上测试了40个CNN和40个ViT模型,以验证MaxGlaViT的效率。在CNN模型中,EfficientB6的准确率最高(84.91%),而在ViT模型中,MaxViT-Tiny的表现最佳(86.42%)。缩放的MaxViT达到了87.93%的准确率。在主干块中添加ECA将准确率提高到89.01%。将MBConv替换为ConvNeXtV2进一步提高了准确率至89.87%。最后,在主干中集成ECA,并在MaxViT块中使用ConvNeXtV2,准确率达到了92.03%。本研究对80个用于青光眼分期分类的DL模型进行了综合比较和分析。MaxGlaViT表现优于实验和最新模型,达到了92.03%的准确率、92.33%的精确度、92.03%的召回率、92.13%的f1得分和87.12%的Cohen Kappa得分。
论文及项目相关链接
Summary
该研究提出一种基于重构的多轴视觉转换器(MaxViT)的轻量级模型MaxGlaViT,用于早期青光眼检测。通过优化块和通道数量,增强主干并替换MBConv结构,MaxGlaViT在HDV1数据集上的表现优于其他80种用于青光眼分期分类的深度模型,具有92.03%的准确性。
Key Takeaways
- 青光眼是一种普遍且无声进展的眼疾,早期检测和治疗至关重要。
- 计算机辅助诊断系统在及时有效识别青光眼中起关键作用。
- MaxGlaViT是一个基于重结构的多轴视觉转换器(MaxViT)的轻量级模型,用于早期青光眼检测。
- MaxGlaViT通过优化块和通道数量、增强主干并替换MBConv结构来提高性能。
- 在HDV1数据集上,MaxGlaViT表现出较高的准确性(92.03%),优于其他40种CNN和40种ViT模型。
- 集成ECA和ConvNeXtV2进一步提高了模型的准确性。
点此查看论文截图

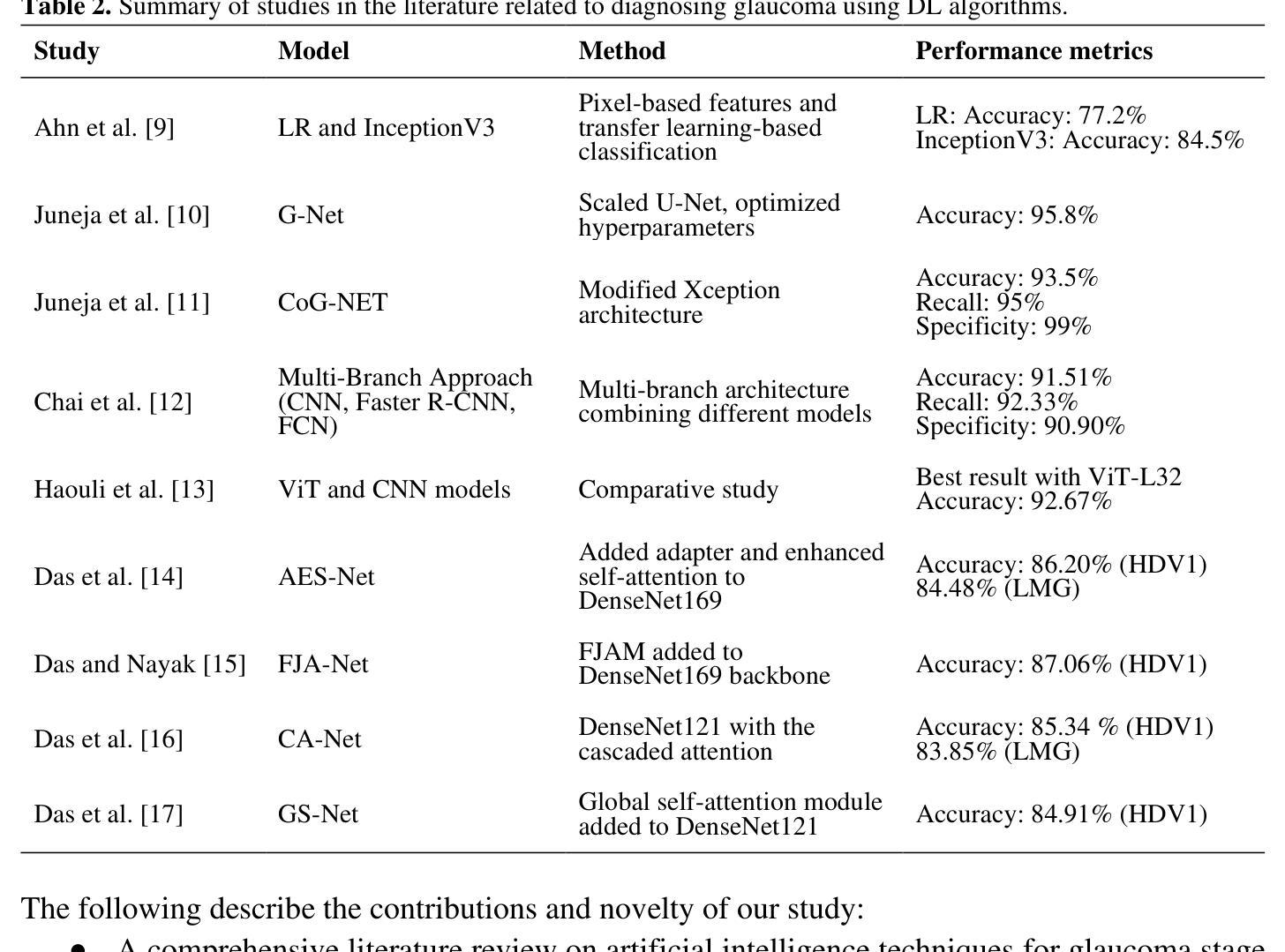
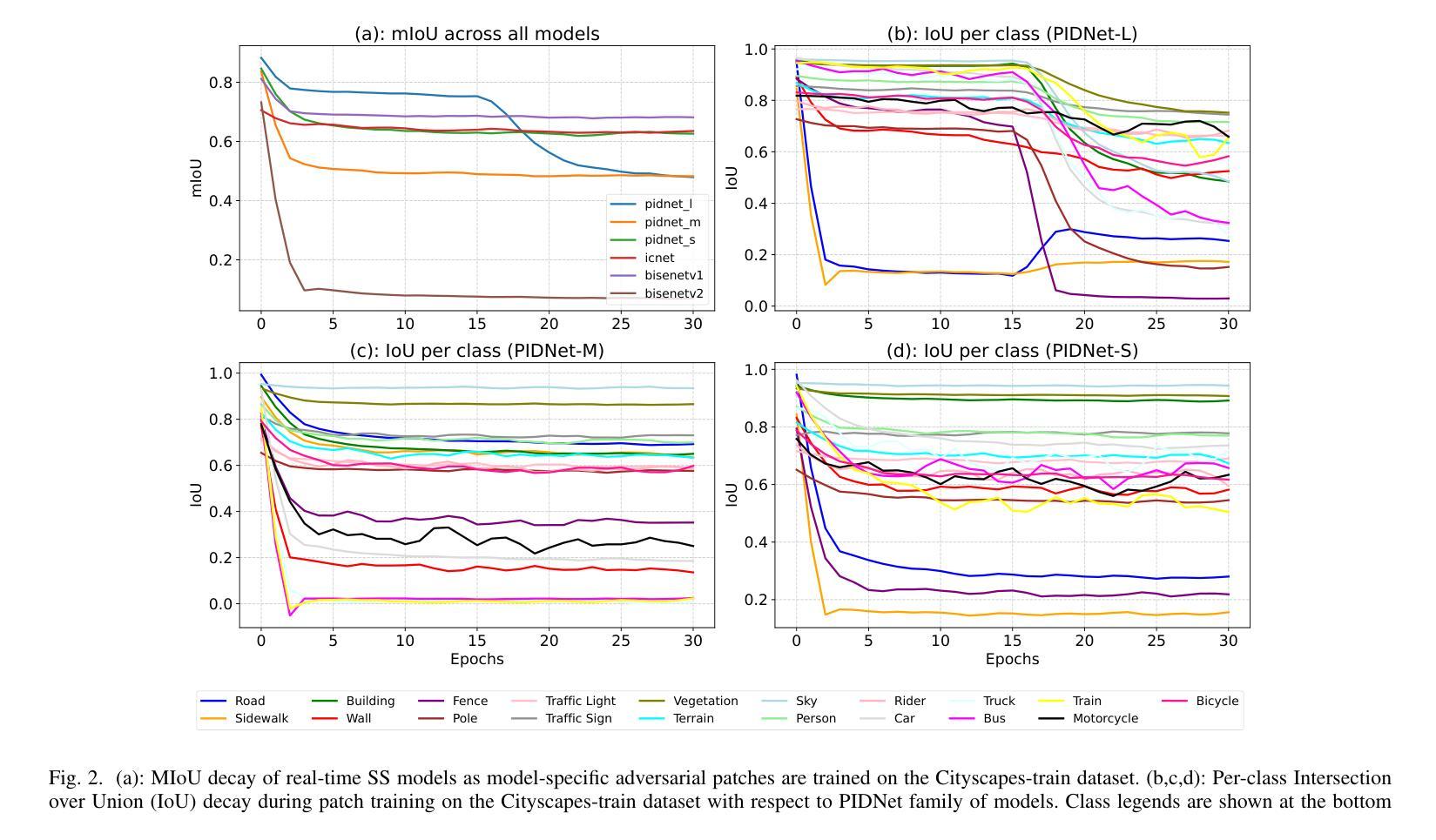
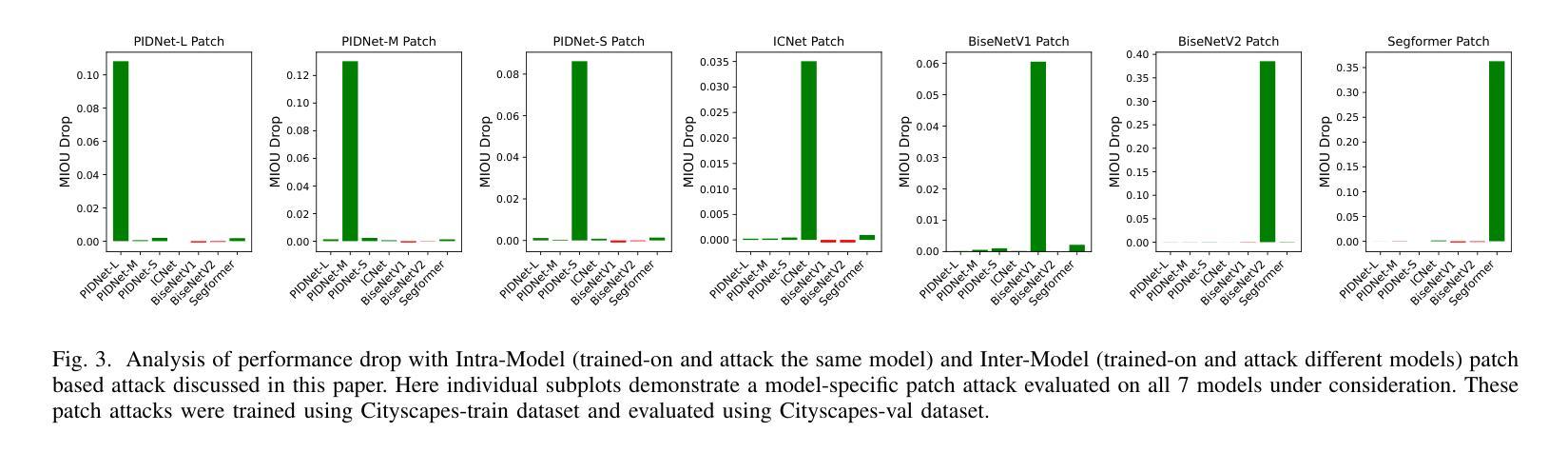
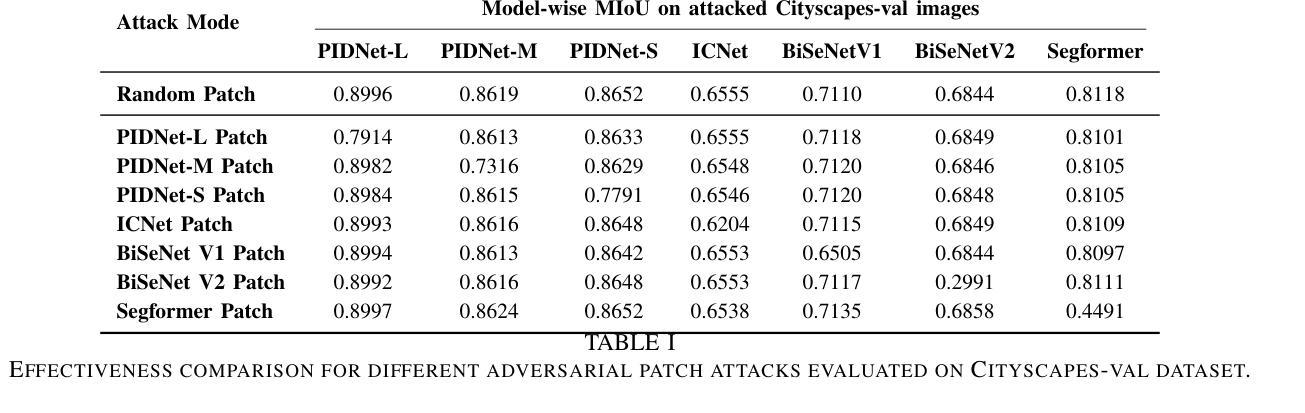
Cross-Model Transferability of Adversarial Patches in Real-time Segmentation for Autonomous Driving
Authors:Prashant Shekhar, Bidur Devkota, Dumindu Samaraweera, Laxima Niure Kandel, Manoj Babu
Adversarial attacks pose a significant threat to deep learning models, particularly in safety-critical applications like healthcare and autonomous driving. Recently, patch based attacks have demonstrated effectiveness in real-time inference scenarios owing to their ‘drag and drop’ nature. Following this idea for Semantic Segmentation (SS), here we propose a novel Expectation Over Transformation (EOT) based adversarial patch attack that is more realistic for autonomous vehicles. To effectively train this attack we also propose a ‘simplified’ loss function that is easy to analyze and implement. Using this attack as our basis, we investigate whether adversarial patches once optimized on a specific SS model, can fool other models or architectures. We conduct a comprehensive cross-model transferability analysis of adversarial patches trained on SOTA Convolutional Neural Network (CNN) models such PIDNet-S, PIDNet-M and PIDNet-L, among others. Additionally, we also include the Segformer model to study transferability to Vision Transformers (ViTs). All of our analysis is conducted on the widely used Cityscapes dataset. Our study reveals key insights into how model architectures (CNN vs CNN or CNN vs. Transformer-based) influence attack susceptibility. In particular, we conclude that although the transferability (effectiveness) of attacks on unseen images of any dimension is really high, the attacks trained against one particular model are minimally effective on other models. And this was found to be true for both ViT and CNN based models. Additionally our results also indicate that for CNN-based models, the repercussions of patch attacks are local, unlike ViTs. Per-class analysis reveals that simple-classes like ‘sky’ suffer less misclassification than others. The code for the project is available at: https://github.com/p-shekhar/adversarial-patch-transferability
对抗性攻击对深度学习模型构成重大威胁,特别是在医疗和自动驾驶等安全关键应用中。最近,基于“拖放”特性的补丁攻击在实时推理场景中表现出了有效性。在此基础上,针对语义分割(SS),我们提出了一种基于期望转换(EOT)的对抗性补丁攻击,对于自动驾驶车辆而言更为现实。为了有效地训练这种攻击,我们还提出了一个易于分析和实现的“简化”损失函数。以这种攻击为基础,我们研究了经过优化的对抗补丁是否可以在特定的SS模型上欺骗其他模型或架构。我们对在诸如PIDNet-S、PIDNet-M和PIDNet-L等最先进的卷积神经网络(CNN)模型上训练的对抗补丁进行了全面的跨模型可传输性分析,另外还包含了针对视觉变压器(ViT)的可转移性研究。我们的所有分析都是在广泛使用的Cityscapes数据集上进行的。我们的研究揭示了模型架构(CNN与CNN或CNN与基于Transformer的架构)如何影响攻击的易感性。特别是,我们得出结论,尽管针对任何尺寸的未见图像的攻击的传输性(有效性)非常高,但针对特定模型训练的攻击对其他模型的效力微乎其微。这一发现在ViT和CNN模型中均成立。此外,我们的结果还表明,对于基于CNN的模型而言,补丁攻击的后果是局部的,与ViT不同。按类别分析表明,“天空”等简单类别遭受的误分类较少。该项目的代码可在:https://github.com/p-shekhar/adversarial-patch-transferability找到。
论文及项目相关链接
Summary
本文提出一种基于期望转换(EOT)的对抗补丁攻击,针对自动驾驶的语义分割模型,更加真实有效。同时,为了有效训练该攻击,还提出了一种易于分析和实现的简化损失函数。研究还进行了跨模型的对抗补丁转移性分析,涉及先进的卷积神经网络(CNN)模型和视觉转换器(ViT)。分析揭示模型架构对攻击易感性的影响,并发现虽然攻击在不同维度图像上的迁移性很高,但对不同模型的攻击效果有限。另外,对于CNN模型,补丁攻击的影响较为局部,与ViT不同。简单类别的误分类程度较低。
Key Takeaways
- 提出了基于期望转换(EOT)的对抗补丁攻击,针对自动驾驶语义分割模型更为真实有效。
- 引入了一种简化损失函数,便于攻击的训练、分析和实施。
- 进行了广泛的跨模型对抗补丁迁移性分析,包括卷积神经网络(CNN)和视觉转换器(ViT)。
- 发现虽然攻击迁移性高,但对不同模型的攻击效果有限。
- 对抗补丁攻击在CNN模型上的影响较为局部,与ViT有所不同。
- 简单类别的误分类程度较低。
点此查看论文截图

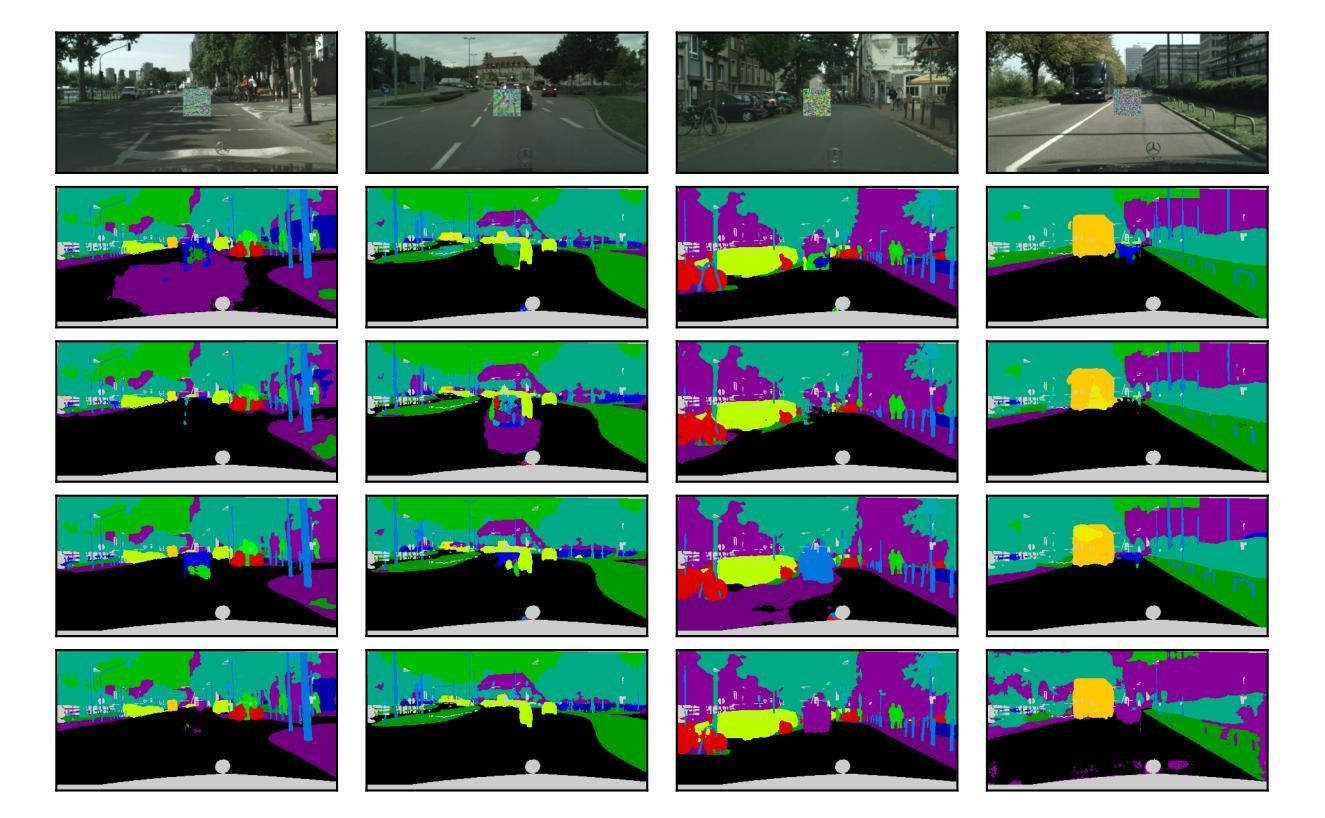
ELIP: Enhanced Visual-Language Foundation Models for Image Retrieval
Authors:Guanqi Zhan, Yuanpei Liu, Kai Han, Weidi Xie, Andrew Zisserman
The objective in this paper is to improve the performance of text-to-image retrieval. To this end, we introduce a new framework that can boost the performance of large-scale pre-trained vision-language models, so that they can be used for text-to-image re-ranking. The approach, Enhanced Language-Image Pre-training (ELIP), uses the text query to predict a set of visual prompts to condition the ViT image encoding. ELIP can easily be applied to the commonly used CLIP/SigLIP and the state-of-the-art BLIP-2 architectures. To train the architecture with limited computing resources, we develop a ‘student friendly’ best practice involving global hard sample mining, and selection and curation of a large-scale dataset. On the evaluation side, we set up two new out-of-distribution benchmarks, Occluded COCO and ImageNet-R, to assess the zero-shot generalisation of the models to different domains. Benefiting from the novel architecture and data curation, experiments show our enhanced network significantly boosts CLIP/SigLIP performance and outperforms the state-of-the-art BLIP-2 model on text-to-image retrieval.
本文的目标是提升文本到图像检索的性能。为此,我们引入了一种能够提升大规模预训练视觉语言模型性能的新框架,使其可用于文本到图像的重新排序。该方法称为增强语言图像预训练(ELIP),它使用文本查询来预测一系列视觉提示,以调节ViT图像编码。ELIP可轻松应用于常用的CLIP/SigLIP和先进的BLIP-2架构。为了使用有限的计算资源进行训练,我们开发了一种“学生友好型”的最佳实践方法,包括全局硬样本挖掘以及大规模数据集的选择和筛选。在评估方面,我们建立了两个新的离群分布基准测试,即遮挡COCO和ImageNet-R,以评估模型在不同领域的零样本泛化能力。受益于新型架构和数据筛选,实验表明,我们的增强网络显著提升了CLIP/SigLIP的性能,并在文本到图像检索方面超越了最先进的BLIP-2模型。
论文及项目相关链接
Summary
文本介绍了通过引入新的框架Enhanced Language-Image Pre-training (ELIP)来提高大规模预训练视觉语言模型在文本到图像检索任务中的性能。该框架利用文本查询预测一组视觉提示来影响图像编码,并可以轻松地应用于常见的CLIP/SigLIP和先进的BLIP-2架构。此外,通过全球硬样本挖掘以及大规模数据集的选择和筛选来以有限的计算资源训练架构。在评估方面,为了评估模型在不同领域的零样本泛化能力,设置了两个新的超出分布范围的基准测试,即遮挡COCO和ImageNet-R。实验表明,得益于新的架构和数据筛选,增强后的网络显著提高了CLIP/SigLIP的性能,并在文本到图像检索任务上超越了最先进的BLIP-2模型。
Key Takeaways
- 论文目标是提高文本到图像检索的性能。
- 引入了一种新的框架Enhanced Language-Image Pre-training (ELIP),用于增强大规模预训练视觉语言模型的能力。
- ELIP框架利用文本查询预测视觉提示来影响图像编码。
- ELIP可应用于CLIP/SigLIP和BLIP-2等架构。
- 通过全球硬样本挖掘和大规模数据集的选择与筛选,使用有限的计算资源进行训练。
- 论文设置了两个新的评估基准测试:Occluded COCO和ImageNet-R,用于评估模型在不同领域的零样本泛化能力。
点此查看论文截图


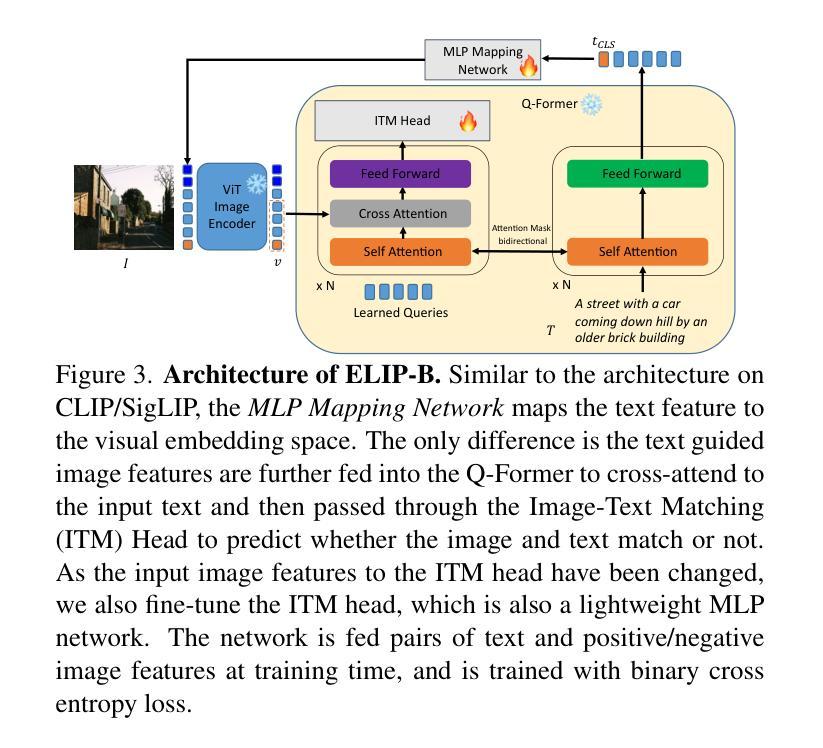

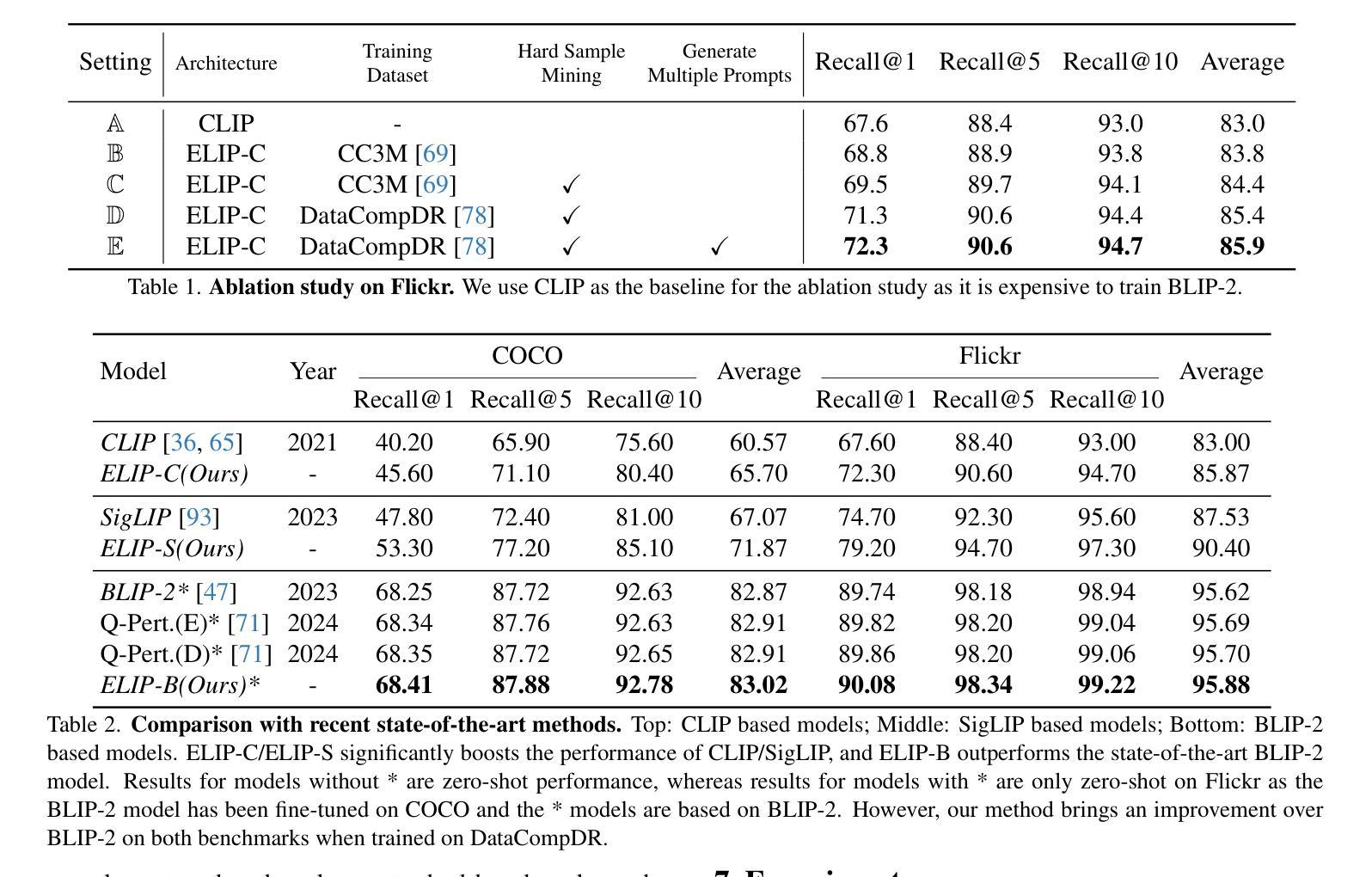
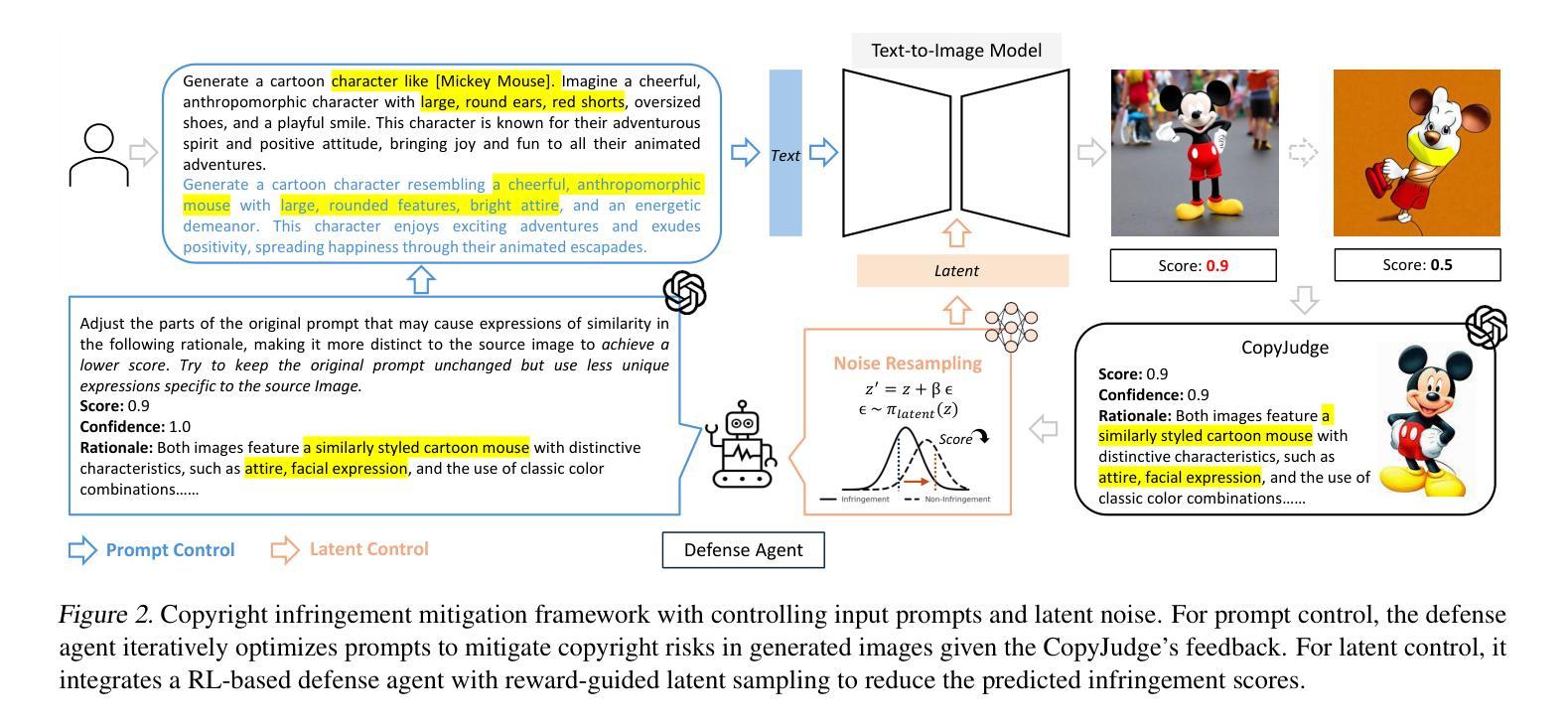
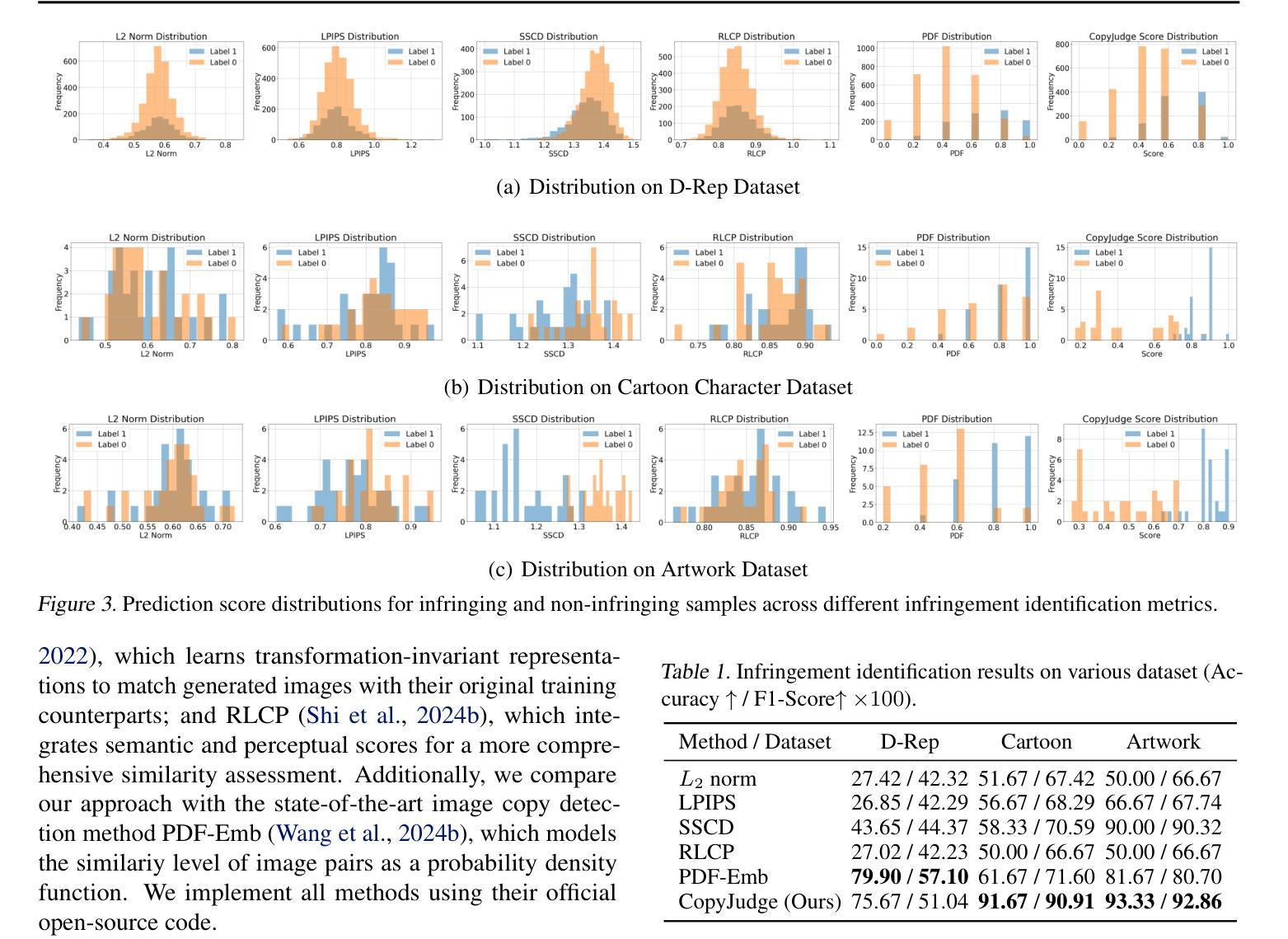
CopyJudge: Automated Copyright Infringement Identification and Mitigation in Text-to-Image Diffusion Models
Authors:Shunchang Liu, Zhuan Shi, Lingjuan Lyu, Yaochu Jin, Boi Faltings
Assessing whether AI-generated images are substantially similar to copyrighted works is a crucial step in resolving copyright disputes. In this paper, we propose CopyJudge, an automated copyright infringement identification framework that leverages large vision-language models (LVLMs) to simulate practical court processes for determining substantial similarity between copyrighted images and those generated by text-to-image diffusion models. Specifically, we employ an abstraction-filtration-comparison test framework with multi-LVLM debate to assess the likelihood of infringement and provide detailed judgment rationales. Based on the judgments, we further introduce a general LVLM-based mitigation strategy that automatically optimizes infringing prompts by avoiding sensitive expressions while preserving the non-infringing content. Besides, our approach can be enhanced by exploring non-infringing noise vectors within the diffusion latent space via reinforcement learning, even without modifying the original prompts. Experimental results show that our identification method achieves comparable state-of-the-art performance, while offering superior generalization and interpretability across various forms of infringement, and that our mitigation method could more effectively mitigate memorization and IP infringement without losing non-infringing expressions.
评估人工智能生成的图像是否与受版权保护的作品存在实质性相似,是解决版权纠纷的重要步骤。在本文中,我们提出了CopyJudge,这是一个自动版权侵权识别框架,它利用大型视觉语言模型(LVLMs)来模拟实际的法庭流程,以确定受版权保护的图像与文本生成的扩散模型生成的图像之间的实质性相似性。具体来说,我们采用抽象过滤比较测试框架和多LVLM辩论来评估侵权的可能性,并提供详细的判断依据。基于这些判断,我们进一步引入了一种通用的基于LVLM的缓解策略,该策略通过避免敏感表达来自动优化侵权提示,同时保留非侵权内容。此外,通过强化学习探索扩散潜在空间中的非侵权噪声向量,甚至在不修改原始提示的情况下,我们的方法可以得到增强。实验结果表明,我们的识别方法达到了与最新技术相当的性能,同时在各种形式的侵权问题上提供了卓越的一般化和可解释性;我们的缓解方法能更有效地减轻记忆和知识产权侵权问题,同时不损失非侵权表达。
论文及项目相关链接
PDF 17pages, 8 figures
Summary
版权判断AI生成的图像是否实质性相似于版权作品是解决版权纠纷的关键步骤。本文提出CopyJudge框架,利用大型视觉语言模型模拟实际法庭流程,评估侵权可能性并提供详细的判断依据。此外,引入基于LVLM的缓解策略,优化侵权提示并探索非侵权噪声向量。实验结果表明,该方法性能优越,具有更好的泛化和解释性。
Key Takeaways
- CopyJudge框架用于评估AI生成的图像是否侵犯版权。
- 利用大型视觉语言模型模拟实际法庭流程进行侵权判断。
- 通过抽象过滤比较测试框架和多LVLM辩论进行实质性相似性评估。
- 提供详细的判断依据。
- 引入基于LVLM的缓解策略,优化侵权提示并避免敏感表达。
- 在扩散潜在空间内探索非侵权噪声向量,通过强化学习增强方法。
点此查看论文截图

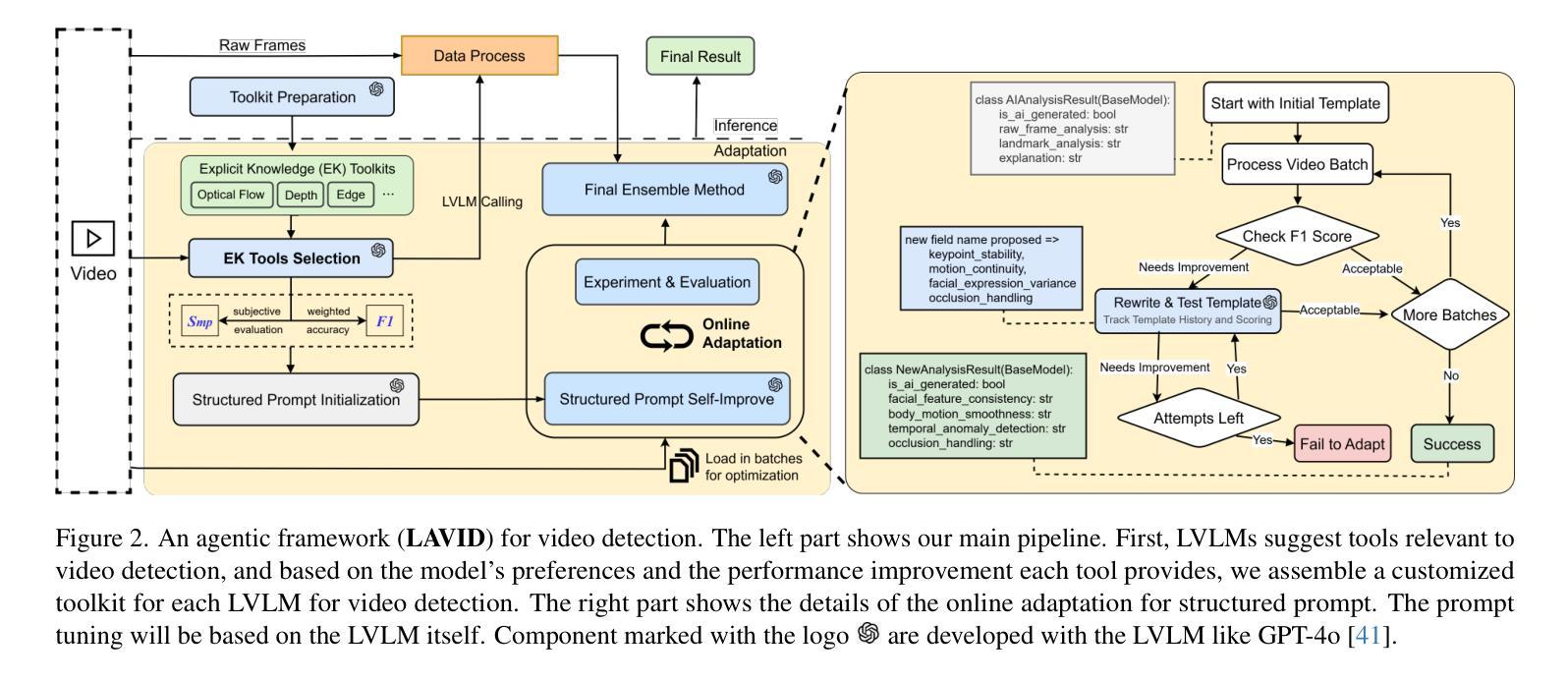
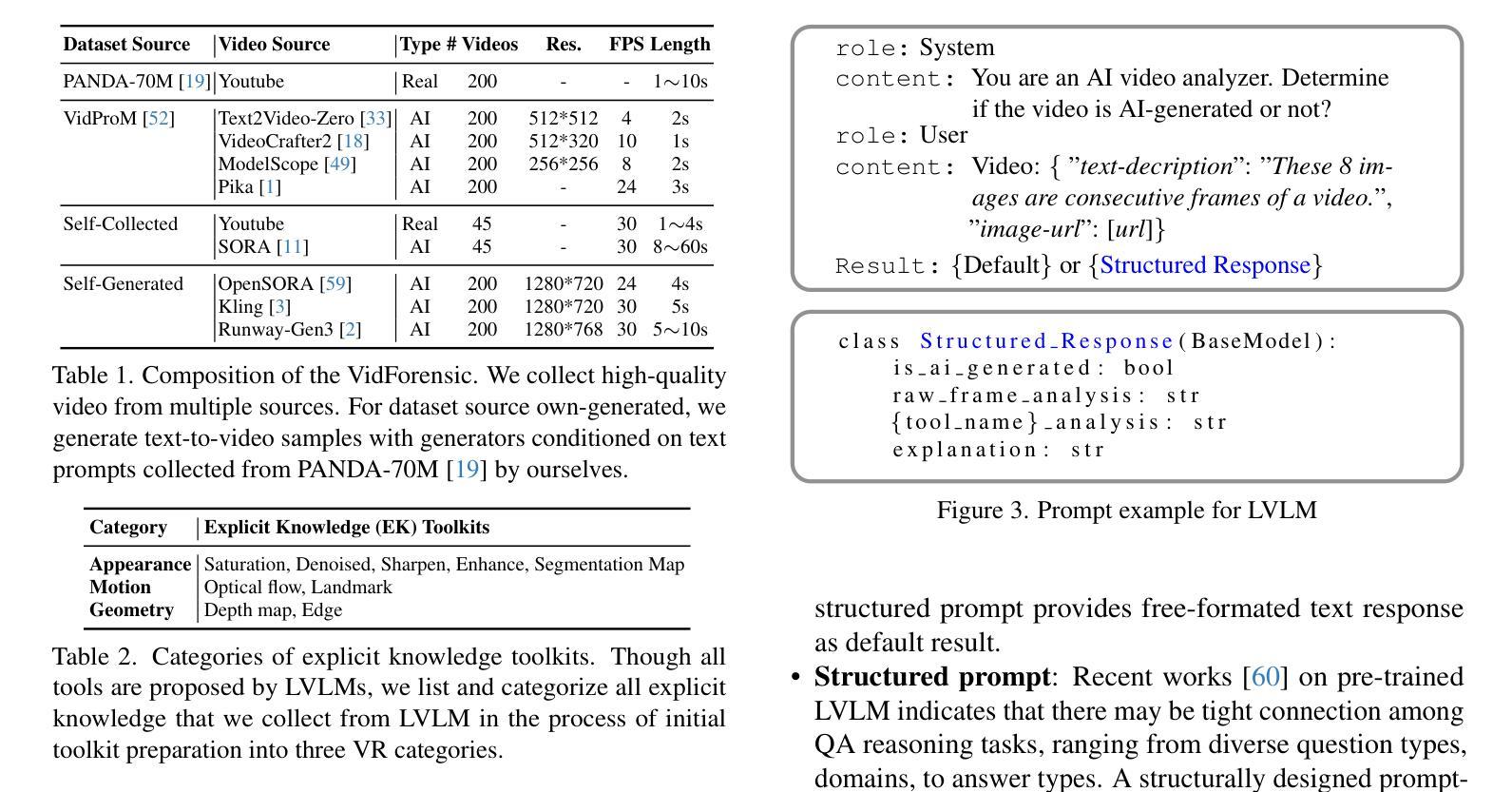
LAVID: An Agentic LVLM Framework for Diffusion-Generated Video Detection
Authors:Qingyuan Liu, Yun-Yun Tsai, Ruijian Zha, Victoria Li, Pengyuan Shi, Chengzhi Mao, Junfeng Yang
The impressive achievements of generative models in creating high-quality videos have raised concerns about digital integrity and privacy vulnerabilities. Recent works of AI-generated content detection have been widely studied in the image field (e.g., deepfake), yet the video field has been unexplored. Large Vision Language Model (LVLM) has become an emerging tool for AI-generated content detection for its strong reasoning and multimodal capabilities. It breaks the limitations of traditional deep learning based methods faced with like lack of transparency and inability to recognize new artifacts. Motivated by this, we propose LAVID, a novel LVLMs-based ai-generated video detection with explicit knowledge enhancement. Our insight list as follows: (1) The leading LVLMs can call external tools to extract useful information to facilitate its own video detection task; (2) Structuring the prompt can affect LVLM’s reasoning ability to interpret information in video content. Our proposed pipeline automatically selects a set of explicit knowledge tools for detection, and then adaptively adjusts the structure prompt by self-rewriting. Different from prior SOTA that trains additional detectors, our method is fully training-free and only requires inference of the LVLM for detection. To facilitate our research, we also create a new benchmark \vidfor with high-quality videos generated from multiple sources of video generation tools. Evaluation results show that LAVID improves F1 scores by 6.2 to 30.2% over the top baselines on our datasets across four SOTA LVLMs.
生成模型在创建高质量视频方面取得了令人印象深刻的成就,这引发了人们对数字完整性和隐私漏洞的担忧。尽管人工智能生成内容的检测在图像领域(例如深度伪造)已经得到了广泛的研究,但视频领域尚未被探索。大型视觉语言模型(LVLM)已成为人工智能生成内容检测的新兴工具,因其强大的推理和多模态能力。它突破了传统基于深度学习的方法所面临的局限性,如缺乏透明度和无法识别新伪造的物品。受此启发,我们提出了LAVID,这是一种基于LVLM的新型人工智能生成视频检测,具有明确的知识增强功能。我们的见解如下:(1)领先的LVLM可以调用外部工具来提取有用信息,以辅助其自身的视频检测任务;(2)结构化提示会影响LVLM解释视频内容中的信息的能力。我们提出的管道会自动选择一组明确的知识工具进行检测,然后通过自我重写自适应地调整结构提示。与先前需要训练附加检测器的方法不同,我们的方法完全无需训练,只需要利用LVLM进行推理检测。为了推动我们的研究,我们还创建了一个新的基准测试\vidfor,该测试使用来自多个视频生成工具的高质量视频。评估结果表明,在我们的数据集上,LAVID在四个最先进的LVLM上的F1分数提高了6.2%至30.2%。
论文及项目相关链接
Summary
本文关注AI生成视频内容的检测问题,提出一种基于大型视觉语言模型(LVLM)的AI生成视频检测新方法LAVID,具有明确的知识增强功能。该方法突破了传统深度学习方法的局限,无需额外训练检测器,仅通过LVLM的推理即可完成检测任务。为推进研究,还建立了新的视频生成工具生成的高质量视频数据集\vidfor。
Key Takeaways
- AI生成视频内容的检测成为研究热点,因担忧数字完整性和隐私漏洞。
- 大型视觉语言模型(LVLM)在AI生成内容检测方面展现出强大的推理和多模态能力。
- LAVID方法基于LVLM,可调用外部工具提取有用信息,促进视频检测任务。
- 结构化的提示会影响LVLM对视频内容信息的理解能力。
- LAVID方法自适应调整结构提示并通过自我重写实现。
- 与现有先进技术相比,LAVID无需额外训练检测器,仅通过LVLM推理进行检测。
- 为推进研究,建立了新的高质量视频数据集\vidfor。
点此查看论文截图

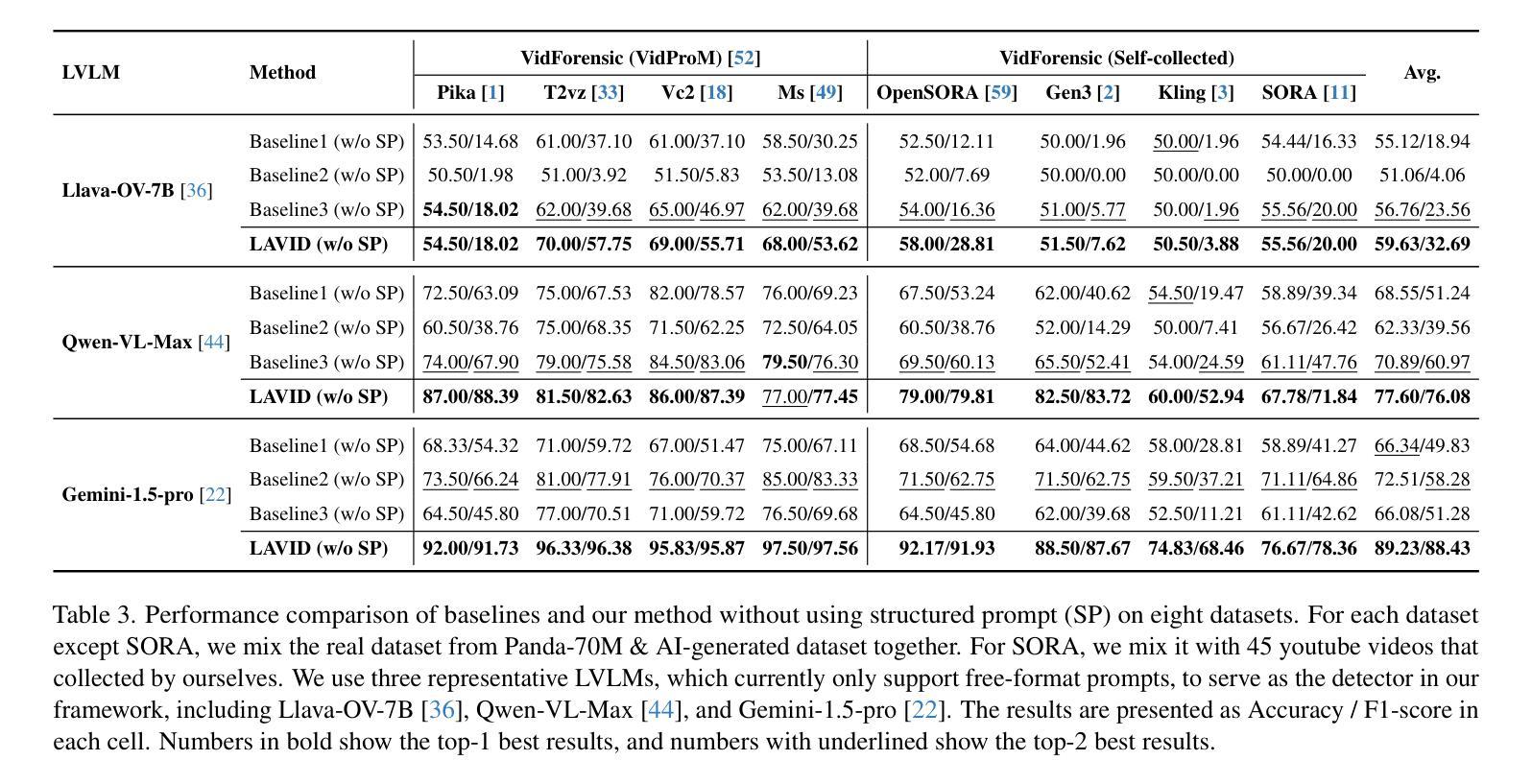
Vision Foundation Models in Medical Image Analysis: Advances and Challenges
Authors:Pengchen Liang, Bin Pu, Haishan Huang, Yiwei Li, Hualiang Wang, Weibo Ma, Qing Chang
The rapid development of Vision Foundation Models (VFMs), particularly Vision Transformers (ViT) and Segment Anything Model (SAM), has sparked significant advances in the field of medical image analysis. These models have demonstrated exceptional capabilities in capturing long-range dependencies and achieving high generalization in segmentation tasks. However, adapting these large models to medical image analysis presents several challenges, including domain differences between medical and natural images, the need for efficient model adaptation strategies, and the limitations of small-scale medical datasets. This paper reviews the state-of-the-art research on the adaptation of VFMs to medical image segmentation, focusing on the challenges of domain adaptation, model compression, and federated learning. We discuss the latest developments in adapter-based improvements, knowledge distillation techniques, and multi-scale contextual feature modeling, and propose future directions to overcome these bottlenecks. Our analysis highlights the potential of VFMs, along with emerging methodologies such as federated learning and model compression, to revolutionize medical image analysis and enhance clinical applications. The goal of this work is to provide a comprehensive overview of current approaches and suggest key areas for future research that can drive the next wave of innovation in medical image segmentation.
视觉基础模型(VFMs)的快速发展,特别是视觉转换器(ViT)和任何分割模型(SAM),已经推动了医学图像分析领域的重大进步。这些模型在捕捉长距离依赖关系和实现分割任务的高泛化方面表现出卓越的能力。然而,将这些大型模型适应于医学图像分析面临着一些挑战,包括医学图像和自然图像领域之间的差异、对有效的模型适应策略的需求以及小型医学数据集的局限性。本文综述了将VFMs适应于医学图像分割的最新研究,重点关注领域适应、模型压缩和联邦学习的挑战。我们讨论了基于适配器的改进、知识蒸馏技术和多尺度上下文特征建模的最新发展,并提出了克服这些瓶颈的未来方向。我们的分析强调了VFMs的潜力,以及与联邦学习和模型压缩等新兴方法相结合,有望革新医学图像分析并增强临床应用。这项工作的目标是提供当前方法的全面概述,并建议未来研究的关键领域,以推动医学图像分割领域的创新浪潮。
论文及项目相关链接
PDF 17 pages, 1 figure
Summary
本文探讨了Vision Foundation Models(VFMs)在医学图像分析领域的最新进展与挑战。文章重点介绍了Vision Transformers(ViT)和Segment Anything Model(SAM)在医学图像分割任务中的优异表现,并指出了将这些大型模型应用于医学图像分析所面临的挑战,如领域差异、模型适配策略和有限的小规模医学数据集等。本文综述了当前将VFMs适配于医学图像分割的最新研究,讨论了领域适配、模型压缩和联邦学习等挑战,并探讨了未来的研究方向。本文强调了VFMs的潜力,以及联邦学习和模型压缩等新兴方法,这些有望推动医学图像分析的革新并提升临床应用。
Key Takeaways
- Vision Foundation Models (VFMs) 在医学图像分析领域取得显著进展。
- Vision Transformers (ViT) 和 Segment Anything Model (SAM) 在医学图像分割任务中表现出卓越性能。
- 将大型模型应用于医学图像分析面临领域差异、模型适配策略和有限数据集等挑战。
- 适配器改进、知识蒸馏技术和多尺度上下文特征建模是当前的最新发展。
- 联邦学习和模型压缩等新兴方法有望推动医学图像分析的革新。
- 该综述提供了对当前研究方法的全面概述,为医学图像分割的未来研究提供了关键方向。
点此查看论文截图

Fully Automatic Content-Aware Tiling Pipeline for Pathology Whole Slide Images
Authors:Falah Jabar, Lill-Tove Rasmussen Busund, Biagio Ricciuti, Masoud Tafavvoghi, Mette Pøhl, Sigve Andersen, Tom Donnem, David J. Kwiatkowski, Mehrdad Rakaee
In recent years, the use of deep learning (DL) methods, including convolutional neural networks (CNNs) and vision transformers (ViTs), has significantly advanced computational pathology, enhancing both diagnostic accuracy and efficiency. Hematoxylin and Eosin (H&E) Whole Slide Images (WSI) plays a crucial role by providing detailed tissue samples for the analysis and training of DL models. However, WSIs often contain regions with artifacts such as tissue folds, blurring, as well as non-tissue regions (background), which can negatively impact DL model performance. These artifacts are diagnostically irrelevant and can lead to inaccurate results. This paper proposes a fully automatic supervised DL pipeline for WSI Quality Assessment (WSI-QA) that uses a fused model combining CNNs and ViTs to detect and exclude WSI regions with artifacts, ensuring that only qualified WSI regions are used to build DL-based computational pathology applications. The proposed pipeline employs a pixel-based segmentation model to classify WSI regions as either qualified or non-qualified based on the presence of artifacts. The proposed model was trained on a large and diverse dataset and validated with internal and external data from various human organs, scanners, and H&E staining procedures. Quantitative and qualitative evaluations demonstrate the superiority of the proposed model, which outperforms state-of-the-art methods in WSI artifact detection. The proposed model consistently achieved over 95% accuracy, precision, recall, and F1 score across all artifact types. Furthermore, the WSI-QA pipeline shows strong generalization across different tissue types and scanning conditions.
近年来,深度学习(DL)方法,包括卷积神经网络(CNN)和视觉变压器(ViT)的应用,在计算病理学领域取得了重大进展,提高了诊断和效率。苏木精和伊红(H&E)全幻灯片图像(WSI)在提供详细的组织样本以供深度学习模型分析和训练方面发挥着至关重要的作用。然而,WSI经常包含具有组织褶皱、模糊以及非组织区域(背景)等伪影区域,这些伪影会对深度学习模型的性能产生负面影响。这些伪影在诊断中无关紧要是导致结果不准确的原因。本文提出了一种全自动监督深度学习管道,用于WSI质量评估(WSI-QA),该管道使用融合模型结合CNN和ViT来检测和排除具有伪影的WSI区域,确保仅使用合格的WSI区域来构建基于深度学习的计算病理学应用程序。该管道采用基于像素的分割模型,根据是否存在伪影将WSI区域分类为合格或非合格。该模型经过大量且多样化的数据集训练,并使用来自不同器官、扫描仪和H&E染色程序的内部和外部数据进行验证。定量和定性评估证明了该模型的优越性,该模型在WSI伪影检测方面优于最先进的方法。该模型在所有伪影类型上的准确率、精确度、召回率和F1分数均达到超过9T的水平。此外,WSI-QA管道在不同组织类型和扫描条件下表现出强大的泛化能力。
论文及项目相关链接
PDF Submitted to Medical Image Analysis journal, February 2025
Summary
该论文提出了一种全自动的基于深度学习的病理切片图像质量评估(WSI-QA)管道,该管道结合了卷积神经网络(CNNs)和视觉变压器(ViTs)的混合模型,用于检测和排除含有伪影的病理切片图像区域。该模型确保了只有合格的区域被用于建立基于深度学习的计算病理学应用。实验证明,该模型在WSI伪影检测方面优于现有技术,并在各种伪影类型上实现了超过95%的准确性、精确度、召回率和F1分数。该管道在不同组织类型和扫描条件下表现出强大的泛化能力。
Key Takeaways
- 深度学习方法在计算病理学领域的应用已显著提高诊断准确性和效率。
- 论文提出了一个全自动的WSI质量评估(WSI-QA)管道,用于检测和排除含有伪影的病理切片图像区域。
- 该管道结合了卷积神经网络(CNNs)和视觉变压器(ViTs)的混合模型以确保仅使用合格的WSI区域进行诊断。
- 该模型经过大规模多样化数据集的训练,并通过内外部数据验证,对各种器官、扫描仪和染色程序具有良好的适用性。
- 实验证明该模型在WSI伪影检测方面表现出卓越的性能,准确率高,达到或超过95%。
- 模型对各种组织类型和扫描条件具有良好的泛化能力。
点此查看论文截图

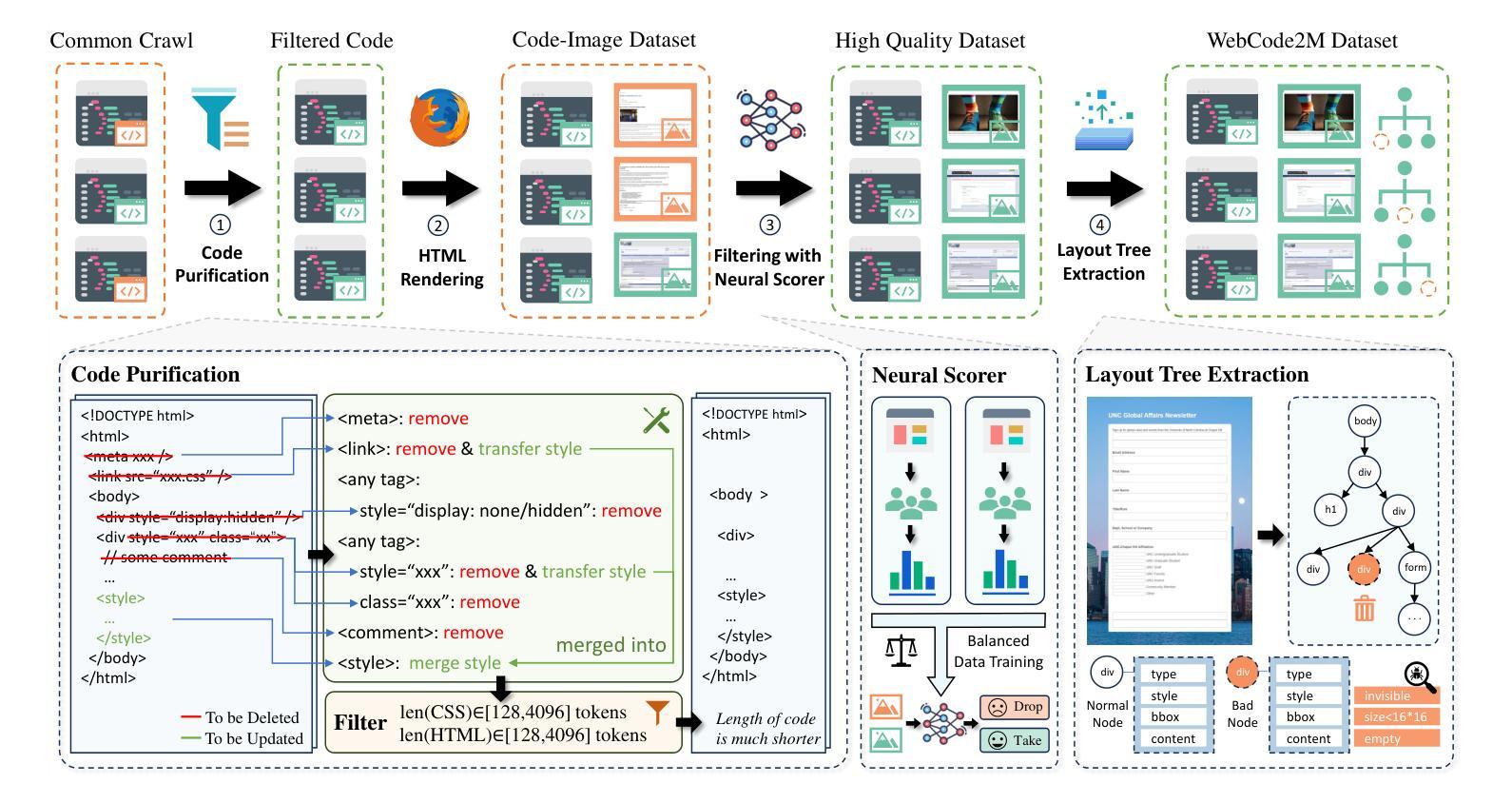
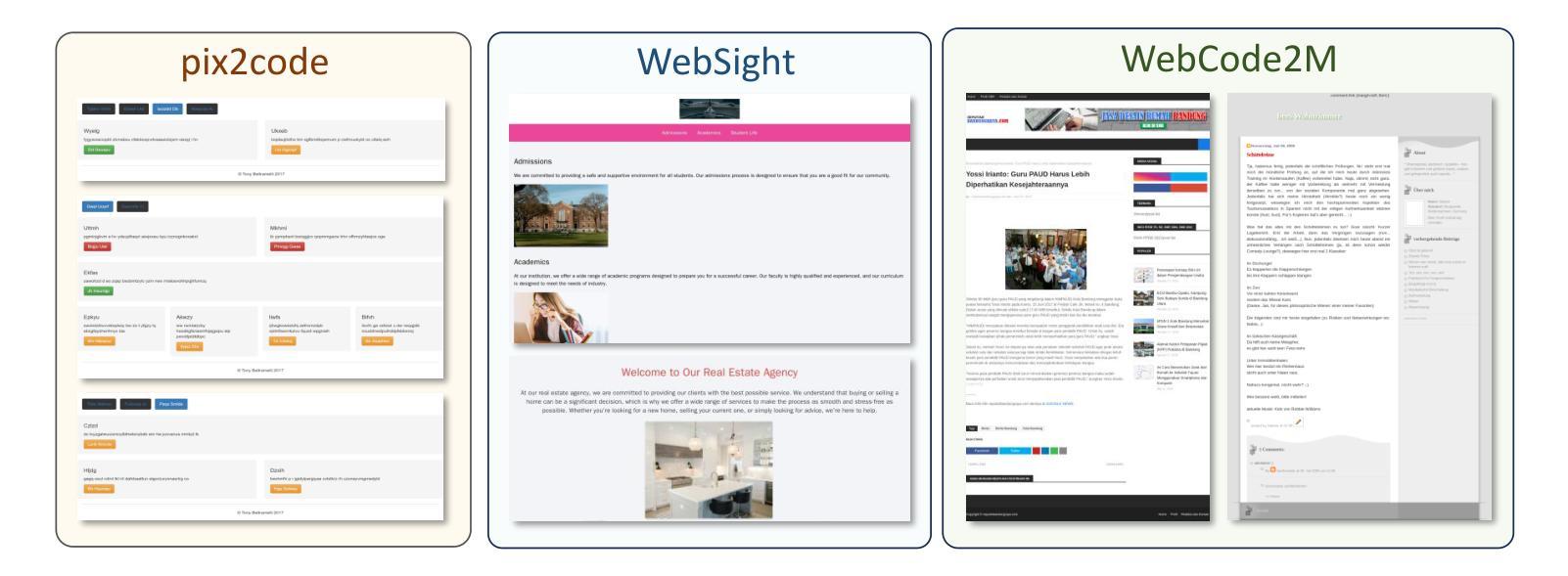
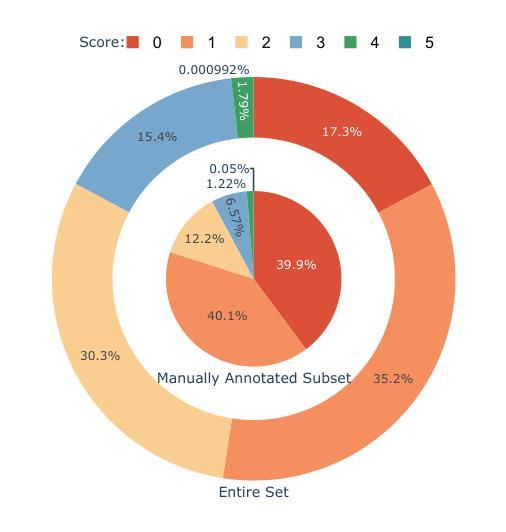
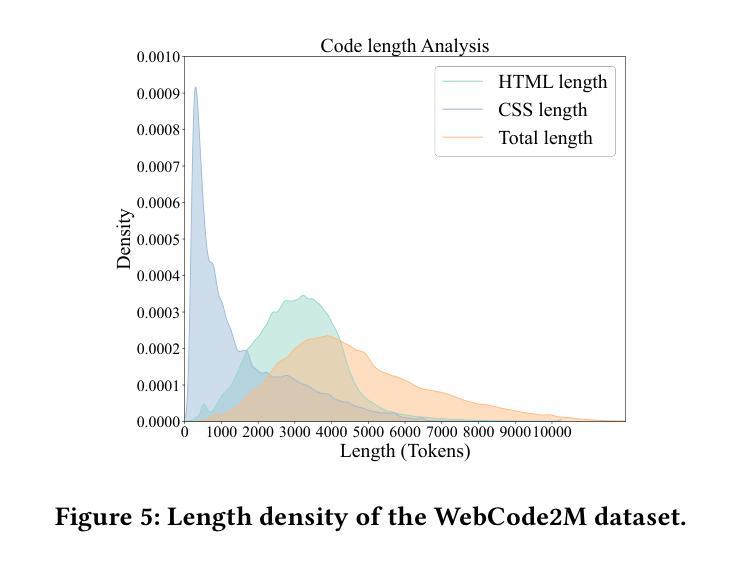
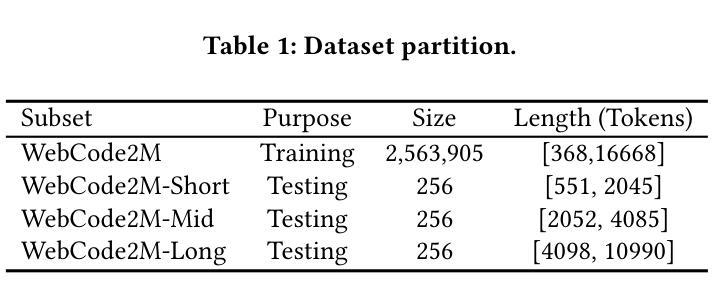
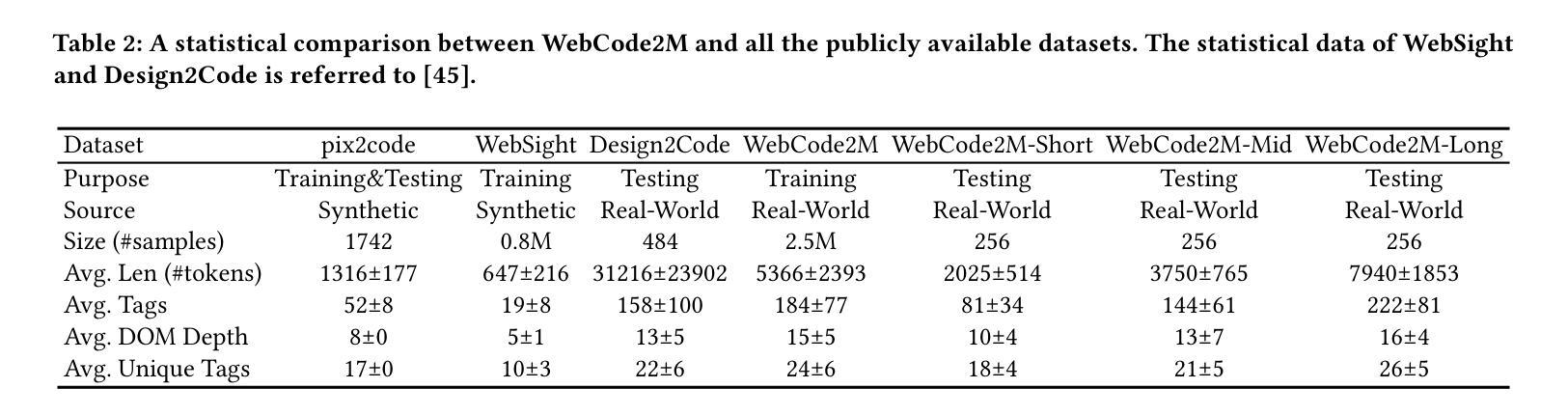
WebCode2M: A Real-World Dataset for Code Generation from Webpage Designs
Authors:Yi Gui, Zhen Li, Yao Wan, Yemin Shi, Hongyu Zhang, Yi Su, Bohua Chen, Dongping Chen, Siyuan Wu, Xing Zhou, Wenbin Jiang, Hai Jin, Xiangliang Zhang
Automatically generating webpage code from webpage designs can significantly reduce the workload of front-end developers, and recent Multimodal Large Language Models (MLLMs) have shown promising potential in this area. However, our investigation reveals that most existing MLLMs are constrained by the absence of high-quality, large-scale, real-world datasets, resulting in inadequate performance in automated webpage code generation. To fill this gap, this paper introduces WebCode2M, a new dataset comprising 2.56 million instances, each containing a design image along with the corresponding webpage code and layout details. Sourced from real-world web resources, WebCode2M offers a rich and valuable dataset for webpage code generation across a variety of applications. The dataset quality is ensured by a scoring model that filters out instances with aesthetic deficiencies or other incomplete elements. To validate the effectiveness of WebCode2M, we introduce a baseline model based on the Vision Transformer (ViT), named WebCoder, and establish a benchmark for fair comparison. Additionally, we introduce a new metric, TreeBLEU, to measure the structural hierarchy recall. The benchmarking results demonstrate that our dataset significantly improves the ability of MLLMs to generate code from webpage designs, confirming its effectiveness and usability for future applications in front-end design tools. Finally, we highlight several practical challenges introduced by our dataset, calling for further research. The code and dataset are publicly available at our project homepage: https://webcode2m.github.io.
自动根据网页设计生成网页代码能够极大地减轻前端开发人员的工作量,而最近的多模态大型语言模型(MLLMs)在这一领域展现出了巨大的潜力。然而,我们的调查发现,大多数现有的MLLMs受限于缺乏高质量、大规模、真实世界的数据集,导致在自动网页代码生成方面的性能不足。为了填补这一空白,本文介绍了WebCode2M数据集,这是一个包含256万个实例的新数据集,每个实例都包含设计图像以及相应的网页代码和布局细节。源于真实世界网络资源,WebCode2M为各种应用的网页代码生成提供了一个丰富而宝贵的数据集。数据集的质量通过评分模型来保证,该模型能够筛选出具有美学缺陷或其他不完整元素的实例。为了验证WebCode2M的有效性,我们基于视觉转换器(ViT)引入了一个名为WebCoder的基线模型,并建立了一个公平的基准测试平台。此外,我们还引入了一个新的指标——TreeBLEU,来衡量结构层次召回率。基准测试结果表明,我们的数据集显著提高了MLLMs从网页设计生成代码的能力,证实了其在前端设计工具未来应用中的有效性和实用性。最后,我们强调了我们数据集所带来的几个实际挑战,呼吁进一步的研究。代码和数据集可在我们的项目主页公开获取:https://webcode2m.github.io。
论文及项目相关链接
PDF WWW’25
Summary
本文介绍了一项新技术,该技术通过引入WebCode2M数据集,显著提高了多模态大型语言模型在自动网页代码生成方面的性能。该数据集包含真实的网页设计和代码信息,有效地解决了之前模型的局限性问题。为验证数据集的实用性,本研究基于视觉转换器提出了一个名为WebCoder的基线模型,并引入了新的度量标准TreeBLEU来衡量生成代码的结构层次召回率。研究结果表明,WebCode2M数据集显著提高了MLLMs从网页设计中生成代码的能力,并强调了该数据集在实际应用中面临的挑战。数据集和代码已公开发布。
Key Takeaways
- 自动生成网页代码可显著减少前端开发人员的工作量。
- 多模态大型语言模型在自动化网页代码生成方面展现潜力。
- 缺乏高质量的大规模数据集是现有模型面临的主要挑战。
- 引入WebCode2M数据集,包含真实世界网页设计与其对应的代码和布局细节。
- 采用评分模型确保数据集质量。
- 基于视觉转换器提出基线模型WebCoder并建立基准测试标准。
点此查看论文截图


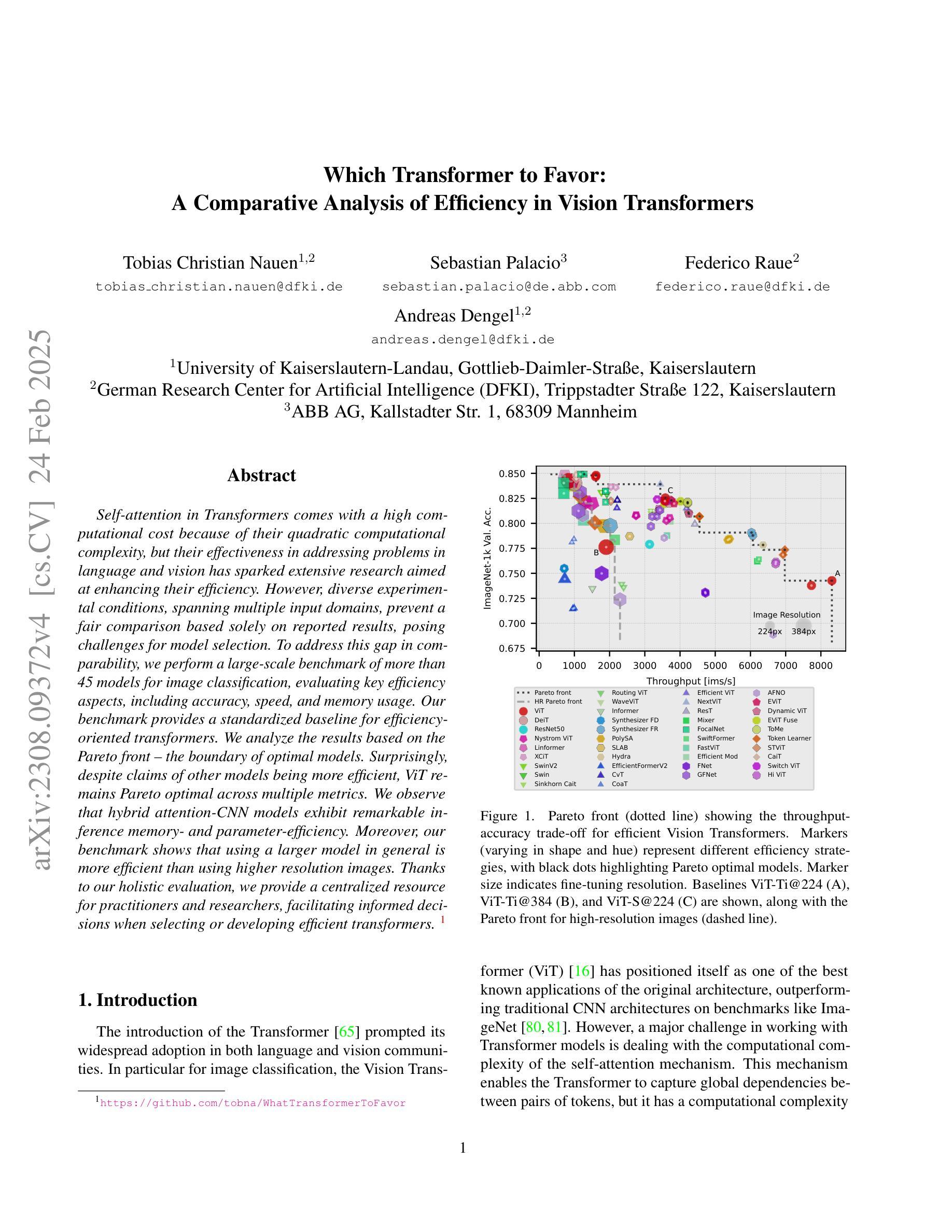
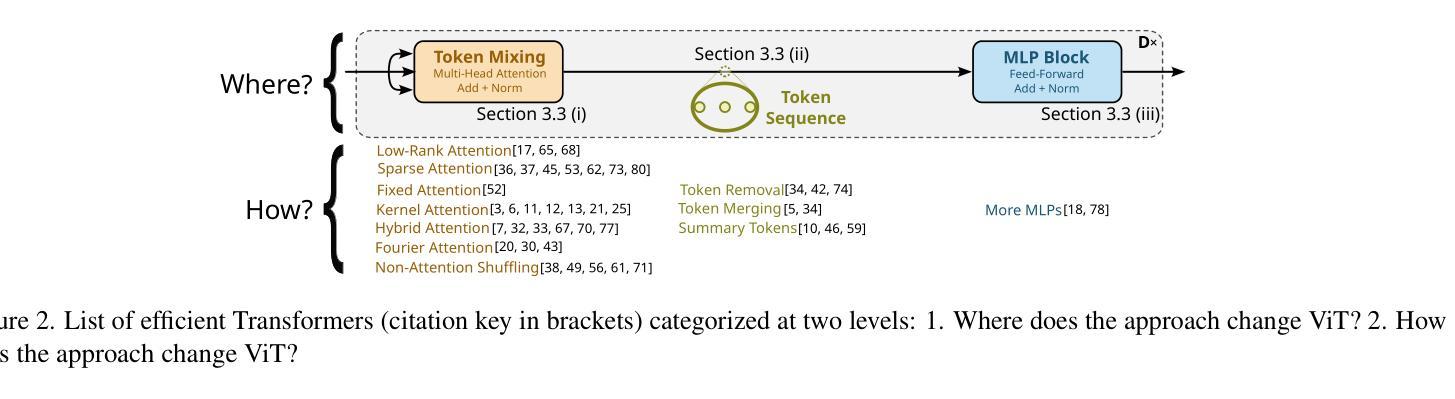
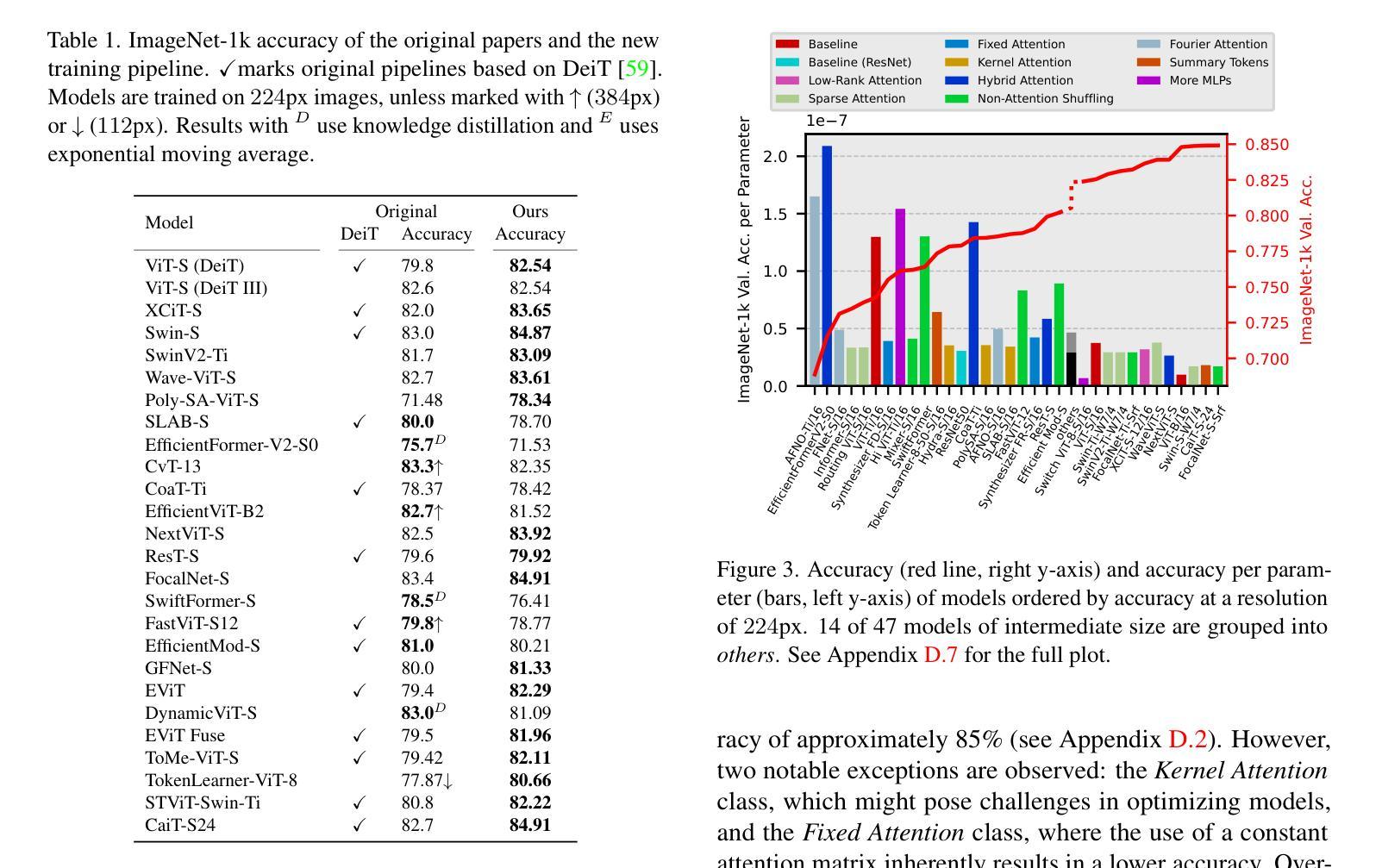
Which Transformer to Favor: A Comparative Analysis of Efficiency in Vision Transformers
Authors:Tobias Christian Nauen, Sebastian Palacio, Federico Raue, Andreas Dengel
Self-attention in Transformers comes with a high computational cost because of their quadratic computational complexity, but their effectiveness in addressing problems in language and vision has sparked extensive research aimed at enhancing their efficiency. However, diverse experimental conditions, spanning multiple input domains, prevent a fair comparison based solely on reported results, posing challenges for model selection. To address this gap in comparability, we perform a large-scale benchmark of more than 45 models for image classification, evaluating key efficiency aspects, including accuracy, speed, and memory usage. Our benchmark provides a standardized baseline for efficiency-oriented transformers. We analyze the results based on the Pareto front – the boundary of optimal models. Surprisingly, despite claims of other models being more efficient, ViT remains Pareto optimal across multiple metrics. We observe that hybrid attention-CNN models exhibit remarkable inference memory- and parameter-efficiency. Moreover, our benchmark shows that using a larger model in general is more efficient than using higher resolution images. Thanks to our holistic evaluation, we provide a centralized resource for practitioners and researchers, facilitating informed decisions when selecting or developing efficient transformers.
Transformer中的自注意力机制由于其二次方的计算复杂度而伴随着较高的计算成本,但其在语言和视觉问题处理中的有效性引发了大量旨在提高其效率的研究。然而,跨越多个输入领域的不同实验条件仅基于报告结果而无法进行公平比较,为模型选择带来了挑战。为了解决可比性方面的这一空白,我们对超过42个模型进行了大规模图像分类基准测试,评估了准确性、速度和内存使用等关键效率方面。我们的基准测试提供了一个面向效率的标准化基线。我们根据帕累托前沿(最优模型的边界)分析结果显示,尽管其他模型声称效率更高,但ViT在多指标方面仍是帕累托最优。我们发现混合注意力CNN模型在推理内存和参数效率方面表现出色。此外,我们的基准测试显示,在大多数情况下使用更大的模型比使用更高分辨率的图像更为高效。得益于我们的全面评估,我们为从业者和研究人员提供了一个集中资源,在选择或开发高效变压器时做出明智决策。
论文及项目相关链接
PDF v3: new models, analysis of scaling behaviors; v4: WACV 2025 camera ready version, appendix added
Summary
本文研究了Transformer自注意力机制的计算成本问题,及其在不同输入域下的效率问题。为弥补模型选择的比较缺失,对超过45种模型进行了大规模图像分类基准测试,涵盖了准确度、速度和内存使用等方面的评估。通过帕累托最优模型分析,发现尽管有其他模型声称更高效,但ViT在多指标上仍是帕累托最优。此外,还发现混合注意力与CNN模型展现出卓越的推理内存和参数效率,使用更大的模型通常比提高图像分辨率更有效率。本文的综合评估为从业者和研究人员提供了集中资源,便于选择或开发高效Transformer时的决策参考。
Key Takeaways
- Transformer的自注意力机制存在高计算成本问题,研究旨在提高其效率。
- 对超过45种模型进行大规模基准测试,涵盖图像分类,评估关键效率方面如准确度、速度和内存使用。
- 通过帕累托最优分析,发现ViT模型在多指标上表现最佳。
- 混合注意力与CNN模型展现出卓越的推理内存和参数效率。
- 使用更大的模型通常比提高图像分辨率更有效率。
- 基准测试为从业者和研究人员提供了决策参考。
点此查看论文截图