⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-27 更新
Contrastive Visual Data Augmentation
Authors:Yu Zhou, Bingxuan Li, Mohan Tang, Xiaomeng Jin, Te-Lin Wu, Kuan-Hao Huang, Heng Ji, Kai-Wei Chang, Nanyun Peng
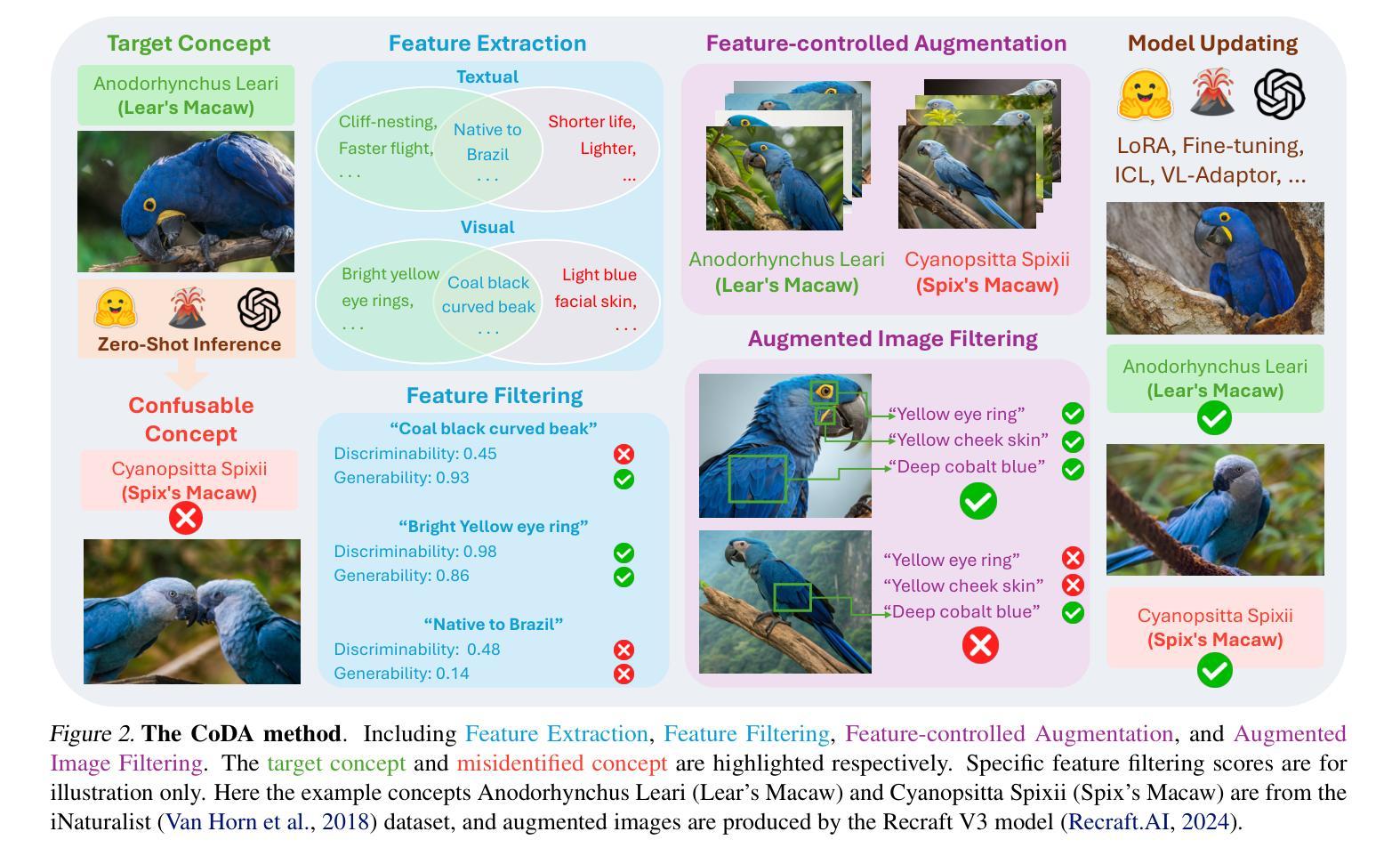
Large multimodal models (LMMs) often struggle to recognize novel concepts, as they rely on pre-trained knowledge and have limited ability to capture subtle visual details. Domain-specific knowledge gaps in training also make them prone to confusing visually similar, commonly misrepresented, or low-resource concepts. To help LMMs better align nuanced visual features with language, improving their ability to recognize and reason about novel or rare concepts, we propose a Contrastive visual Data Augmentation (CoDA) strategy. CoDA extracts key contrastive textual and visual features of target concepts against the known concepts they are misrecognized as, and then uses multimodal generative models to produce targeted synthetic data. Automatic filtering of extracted features and augmented images is implemented to guarantee their quality, as verified by human annotators. We show the effectiveness and efficiency of CoDA on low-resource concept and diverse scene recognition datasets including INaturalist and SUN. We additionally collect NovelSpecies, a benchmark dataset consisting of newly discovered animal species that are guaranteed to be unseen by LMMs. LLaVA-1.6 1-shot updating results on these three datasets show CoDA significantly improves SOTA visual data augmentation strategies by 12.3% (NovelSpecies), 5.1% (SUN), and 6.0% (iNat) absolute gains in accuracy.
大型多模态模型(LMMs)在识别新概念时经常遇到困难,因为它们依赖于预训练知识,并且捕捉细微视觉细节的能力有限。训练中的特定领域知识差距也使得它们容易混淆视觉相似、常见错误表示或资源不足的概念。为了帮助LMMs更好地将细微的视觉特征与语言对齐,提高它们识别和推理新颖或罕见概念的能力,我们提出了一种对比视觉数据增强(CoDA)策略。CoDA针对目标概念与误识别的已知概念之间的关键对比文本和视觉特征进行提取,然后使用多模态生成模型产生有针对性的合成数据。实现了自动过滤提取的特征和增强图像,以保证其质量,并经人类注释者验证。我们在低资源概念和多场景识别数据集(包括INaturalist和SUN)上展示了CoDA的有效性和效率。此外,我们还收集了NovelSpecies,这是一个由新发现的动物物种组成的标准数据集,保证LMMs之前从未见过。在这三个数据集上,LLaVA-1.6的1次拍摄更新结果证明了CoDA显著提高了SOTA的视觉数据增强策略,在准确率上绝对提升了12.3%(NovelSpecies)、5.1%(SUN)和6.0%(iNat)。
论文及项目相关链接
Summary
本文提出了一种名为CoDA的对比视觉数据增强策略,旨在帮助大型多模态模型(LMMs)更好地识别新颖概念。通过提取目标概念与已知概念的对比文本和视觉特征,并使用多模态生成模型产生有针对性的合成数据,从而提高模型的识别和理解能力。实验结果表明,CoDA策略在概念低资源、场景多样的数据集上表现优异,如INaturalist和SUN,以及对新发现动物物种的基准数据集NovelSpecies上显著提高效果。
Key Takeaways
- 大型多模态模型(LMMs)在识别新颖概念时存在困难,因为它们依赖于预训练知识并难以捕捉微妙的视觉细节。
- CoDA策略通过提取目标概念与已知概念的对比文本和视觉特征,帮助LMMs更好地识别和理解新颖或稀有概念。
- CoDA策略使用多模态生成模型产生有针对性的合成数据,以提高模型的识别能力。
- 自动过滤提取的特征和增强的图像,以确保其质量,并经人类注释者验证。
- CoDA策略在概念低资源、场景多样的数据集上的表现优于其他视觉数据增强策略。
- 在包括INaturalist、SUN和新发现动物物种基准数据集NovelSpecies上的实验结果表明,CoDA策略显著提高模型的准确性。
点此查看论文截图