⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-27 更新
UASTrack: A Unified Adaptive Selection Framework with Modality-Customization in Single Object Tracking
Authors:He Wang, Tianyang Xu, Zhangyong Tang, Xiao-Jun Wu, Josef Kittler
Multi-modal tracking is essential in single-object tracking (SOT), as different sensor types contribute unique capabilities to overcome challenges caused by variations in object appearance. However, existing unified RGB-X trackers (X represents depth, event, or thermal modality) either rely on the task-specific training strategy for individual RGB-X image pairs or fail to address the critical importance of modality-adaptive perception in real-world applications. In this work, we propose UASTrack, a unified adaptive selection framework that facilitates both model and parameter unification, as well as adaptive modality discrimination across various multi-modal tracking tasks. To achieve modality-adaptive perception in joint RGB-X pairs, we design a Discriminative Auto-Selector (DAS) capable of identifying modality labels, thereby distinguishing the data distributions of auxiliary modalities. Furthermore, we propose a Task-Customized Optimization Adapter (TCOA) tailored to various modalities in the latent space. This strategy effectively filters noise redundancy and mitigates background interference based on the specific characteristics of each modality. Extensive comparisons conducted on five benchmarks including LasHeR, GTOT, RGBT234, VisEvent, and DepthTrack, covering RGB-T, RGB-E, and RGB-D tracking scenarios, demonstrate our innovative approach achieves comparative performance by introducing only additional training parameters of 1.87M and flops of 1.95G. The code will be available at https://github.com/wanghe/UASTrack.
多模态跟踪在单目标跟踪(SOT)中至关重要,因为不同类型的传感器具有独特的能力,可以克服由目标外观变化带来的挑战。然而,现有的统一RGB-X跟踪器(X代表深度、事件或热模态)要么依赖于针对个别RGB-X图像对的特定任务训练策略,要么未能解决模态自适应感知在现实应用中的关键重要性问题。在这项工作中,我们提出了UASTrack,这是一个统一的自适应选择框架,可以促进模型和参数的统一,以及在各种多模态跟踪任务中进行自适应模态判别。为了实现联合RGB-X对的模态自适应感知,我们设计了一种判别式自动选择器(DAS),能够识别模态标签,从而区分辅助模态的数据分布。此外,我们提出了一种任务定制优化适配器(TCOA),它适用于潜在空间中的各种模态。该策略有效地过滤了噪声冗余,并基于每种模态的特定特征减轻了背景干扰。我们在五个基准测试集上进行了广泛的比较,包括LasHeR、GTOT、RGBT234、VisEvent和DepthTrack,涵盖了RGB-T、RGB-E和RGB-D跟踪场景,结果表明,我们的创新方法通过仅引入187万个额外的训练参数和1.95G的计算量,就实现了相当的性能。代码将在https://github.com/wanghe/UASTrack上提供。
论文及项目相关链接
Summary
本文提出了一种统一自适应选择框架UASTrack,用于多模态目标跟踪中的RGB-X(X代表深度、事件或热模态)跟踪任务。该框架实现了模型和参数的统一,并实现了自适应模态判别。通过设计判别自动选择器(DAS)和任务定制优化适配器(TCOA),UASTrack实现了模态自适应感知,能有效识别模态标签、过滤噪声冗余并减少背景干扰。在五个基准测试上的表现证明了其有效性。
Key Takeaways
- 多模态跟踪在单目标跟踪(SOT)中的重要性:不同传感器类型能克服对象外观变化带来的挑战。
- 现有RGB-X跟踪器的问题:依赖特定任务的训练策略或忽略模态自适应感知在现实世界应用中的重要性。
- UASTrack框架的贡献:实现了模型和参数的统一,以及跨多种多模态跟踪任务的自适应模态判别。
- 判别自动选择器(DAS)的设计:能够识别模态标签,区分辅助模态的数据分布。
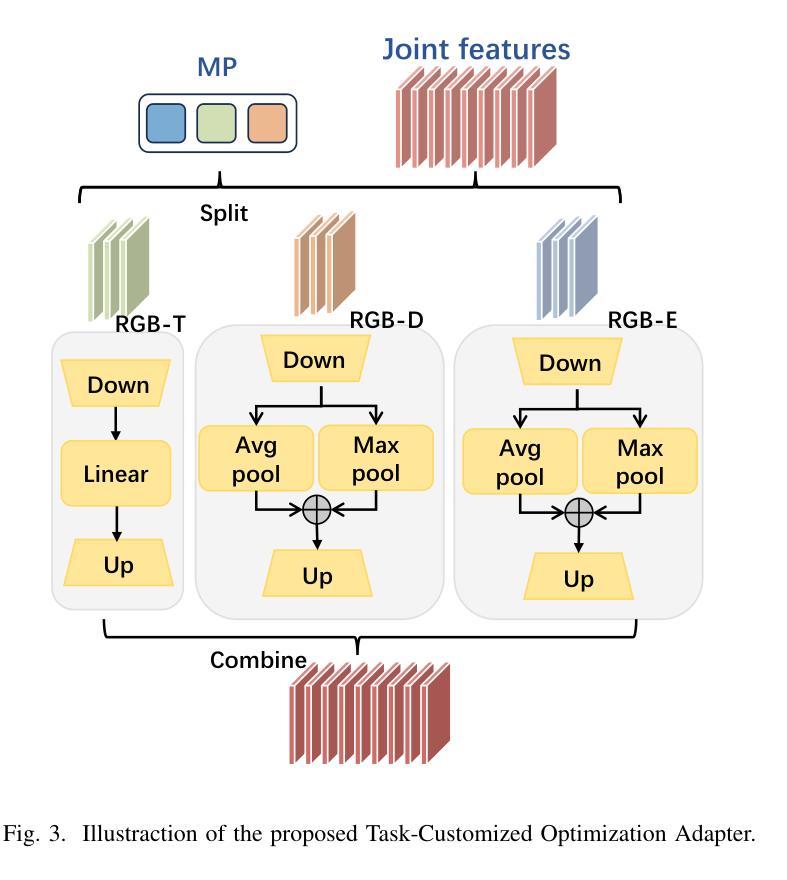
- 任务定制优化适配器(TCOA)的作用:针对各种模态在潜在空间进行定制优化,有效过滤噪声冗余并减少背景干扰。
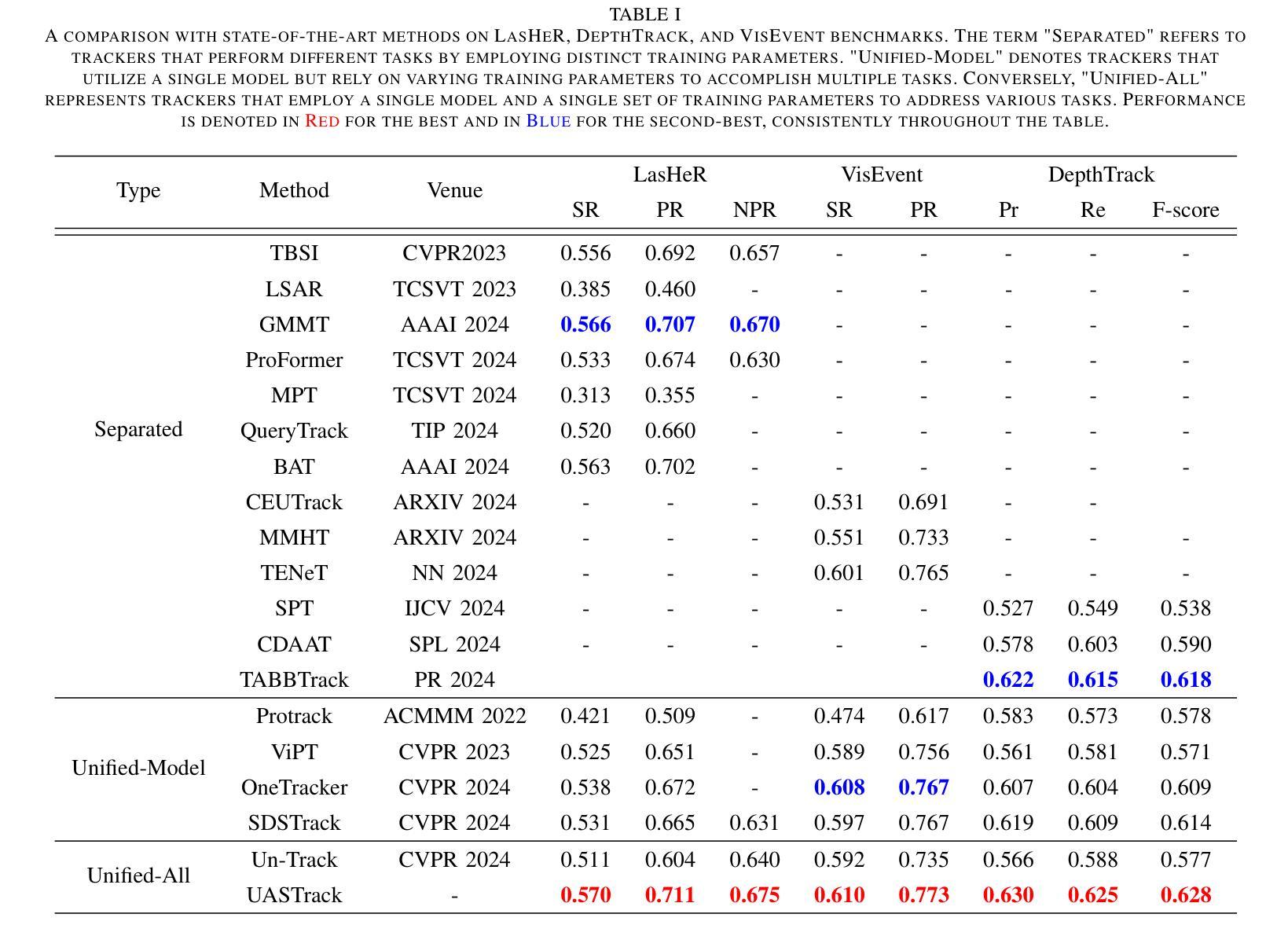
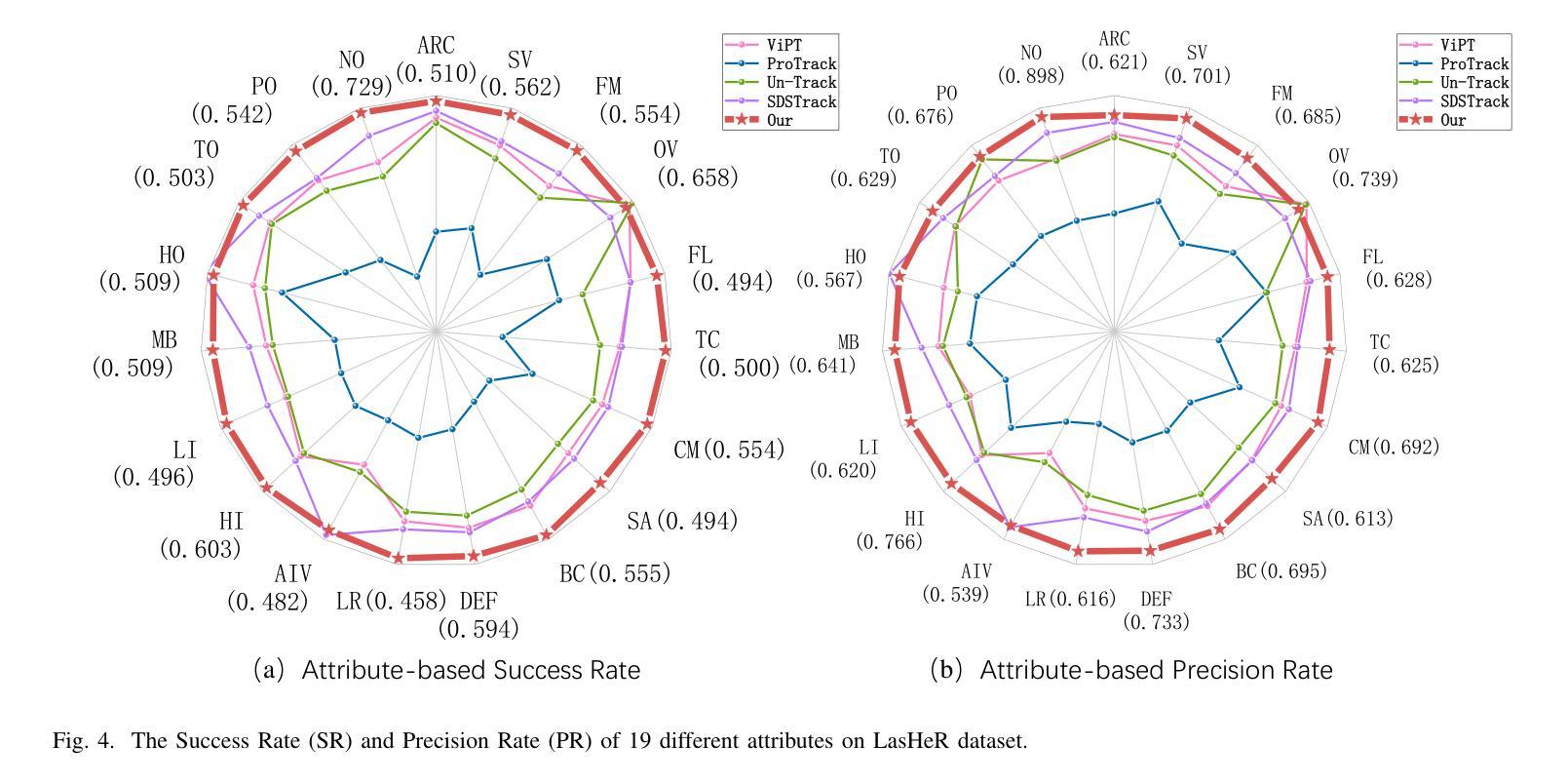
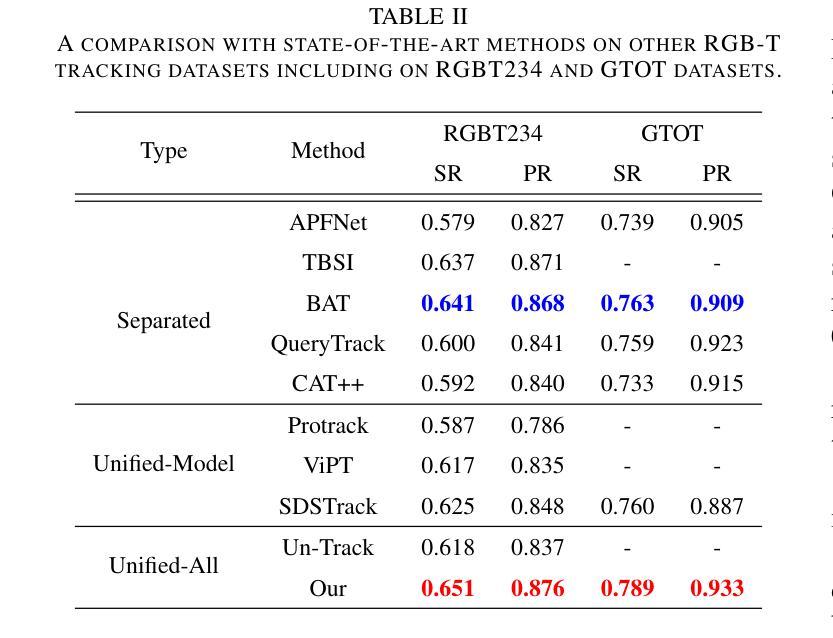
- UASTrack在多个基准测试上的表现:包括LasHeR、GTOT、RGBT234、VisEvent和DepthTrack,覆盖RGB-T、RGB-E和RGB-D跟踪场景,实现比较性能。
点此查看论文截图


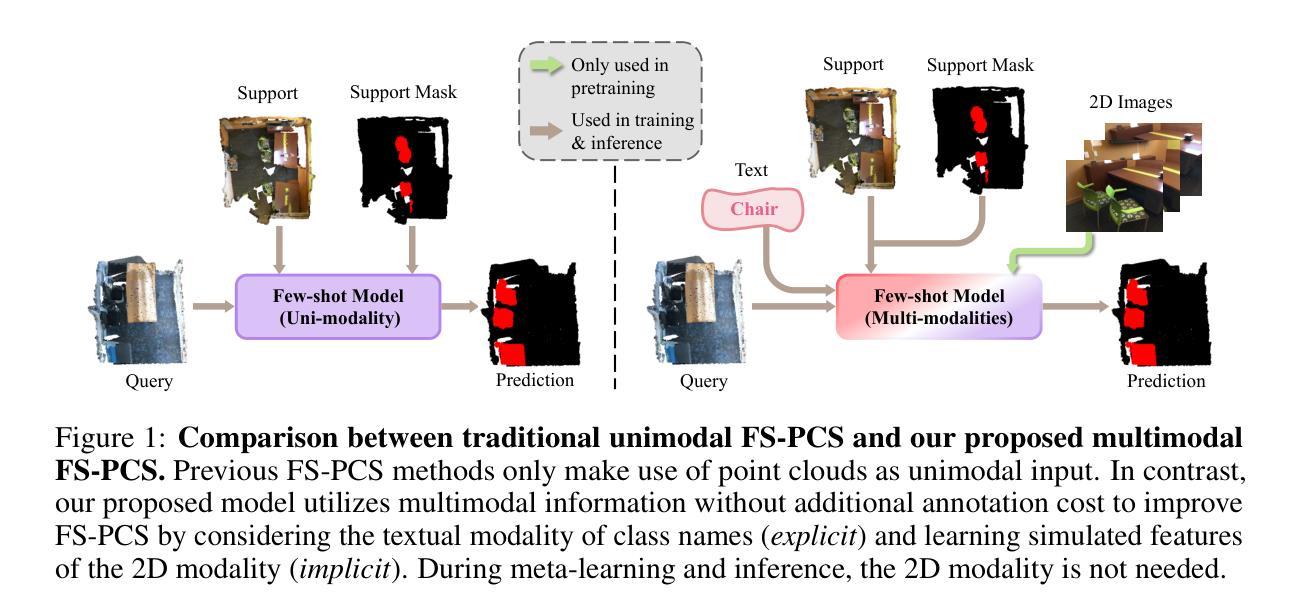
Multimodality Helps Few-shot 3D Point Cloud Semantic Segmentation
Authors:Zhaochong An, Guolei Sun, Yun Liu, Runjia Li, Min Wu, Ming-Ming Cheng, Ender Konukoglu, Serge Belongie
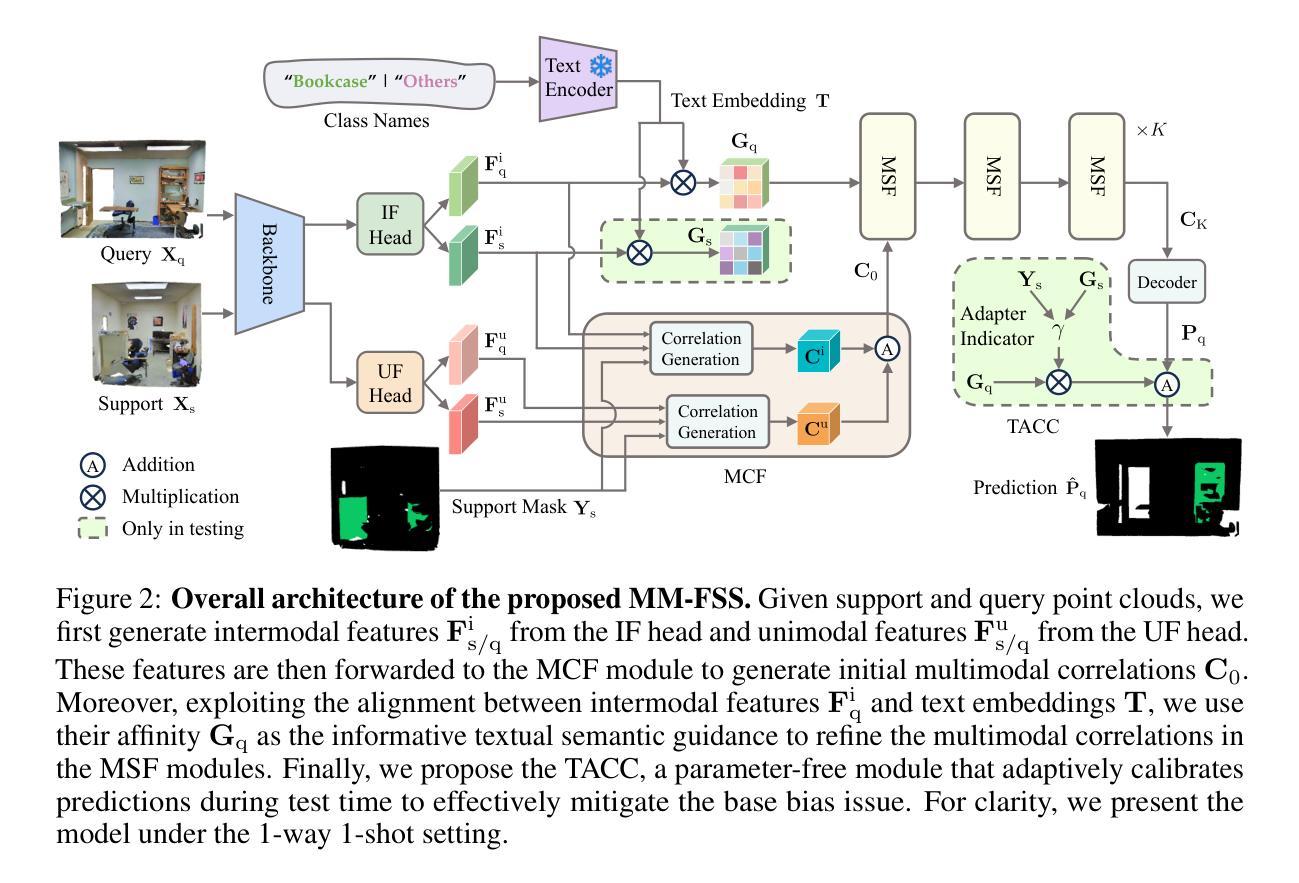
Few-shot 3D point cloud segmentation (FS-PCS) aims at generalizing models to segment novel categories with minimal annotated support samples. While existing FS-PCS methods have shown promise, they primarily focus on unimodal point cloud inputs, overlooking the potential benefits of leveraging multimodal information. In this paper, we address this gap by introducing a multimodal FS-PCS setup, utilizing textual labels and the potentially available 2D image modality. Under this easy-to-achieve setup, we present the MultiModal Few-Shot SegNet (MM-FSS), a model effectively harnessing complementary information from multiple modalities. MM-FSS employs a shared backbone with two heads to extract intermodal and unimodal visual features, and a pretrained text encoder to generate text embeddings. To fully exploit the multimodal information, we propose a Multimodal Correlation Fusion (MCF) module to generate multimodal correlations, and a Multimodal Semantic Fusion (MSF) module to refine the correlations using text-aware semantic guidance. Additionally, we propose a simple yet effective Test-time Adaptive Cross-modal Calibration (TACC) technique to mitigate training bias, further improving generalization. Experimental results on S3DIS and ScanNet datasets demonstrate significant performance improvements achieved by our method. The efficacy of our approach indicates the benefits of leveraging commonly-ignored free modalities for FS-PCS, providing valuable insights for future research. The code is available at https://github.com/ZhaochongAn/Multimodality-3D-Few-Shot
少数样本三维点云分割(FS-PCS)旨在将模型推广到对新型类别的分割,并且只需要极少的标注支持样本。虽然现有的FS-PCS方法在少数样本的三维点云分割上展现出了一定的潜力,但它们主要集中在单模态点云输入上,忽略了利用多模态信息可能带来的潜在好处。为了解决这个问题,本文引入了一种多模态FS-PCS设置,利用文本标签和可能存在的二维图像模态。在这种易于实现的设置下,我们提出了多模态少数样本分割网络(MM-FSS),该模型可以有效地利用多个模态的互补信息。MM-FSS采用共享主干和两个头来提取跨模态和单模态视觉特征,并使用预训练的文本编码器生成文本嵌入。为了充分利用多模态信息,我们提出了多模态关联融合(MCF)模块来生成多模态关联,以及多模态语义融合(MSF)模块来利用文本感知语义指导来完善关联。此外,我们还提出了一种简单有效的测试时间自适应跨模态校准(TACC)技术来缓解训练偏见,进一步提高了模型的泛化能力。在S3DIS和ScanNet数据集上的实验结果表明,我们的方法取得了显著的性能改进。我们的方法的有效性表明了利用通常被忽视的自由模态对于FS-PCS的益处,为未来研究提供了有价值的见解。相关代码可以在https://github.com/ZhaochongAn/Multimodality-3D-Few-Shot 获得。
论文及项目相关链接
PDF Published at ICLR 2025 (Spotlight)
Summary
本文提出了一种利用文本标签和可能的二维图像模态的多模态少样本点云分割方法。通过引入多模态信息,提出了一种名为MultiModal Few-Shot SegNet(MM-FSS)的模型,该模型利用多种模态的互补信息。此外,还提出了多模态关联融合(MCF)和多模态语义融合(MSF)模块以及测试时自适应跨模态校准(TACC)技术,以提高模型的性能。实验结果表明,该方法在S3DIS和ScanNet数据集上取得了显著的性能改进。
Key Takeaways
- 本文旨在解决现有少样本点云分割方法主要依赖单一模态信息的问题,引入多模态信息以提高模型性能。
- 提出了一种名为MM-FSS的模型,该模型利用文本标签和可能的二维图像模态信息,通过共享背景和两个头来提取跨模态和单模态视觉特征。
- 引入了多模态关联融合(MCF)和多模态语义融合(MSF)模块,以充分利用多模态信息并加强语义关联。
- 提出了一种简单的测试时自适应跨模态校准(TACC)技术,以减轻训练偏差,进一步提高模型的泛化能力。
- 在S3DIS和ScanNet数据集上的实验结果表明,该方法显著提高了性能。
- 该方法的有效性表明利用常被忽略的自由模态对于少样本点云分割是有益的,为未来的研究提供了有价值的启示。
点此查看论文截图