⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-27 更新
Task Graph Maximum Likelihood Estimation for Procedural Activity Understanding in Egocentric Videos
Authors:Luigi Seminara, Giovanni Maria Farinella, Antonino Furnari
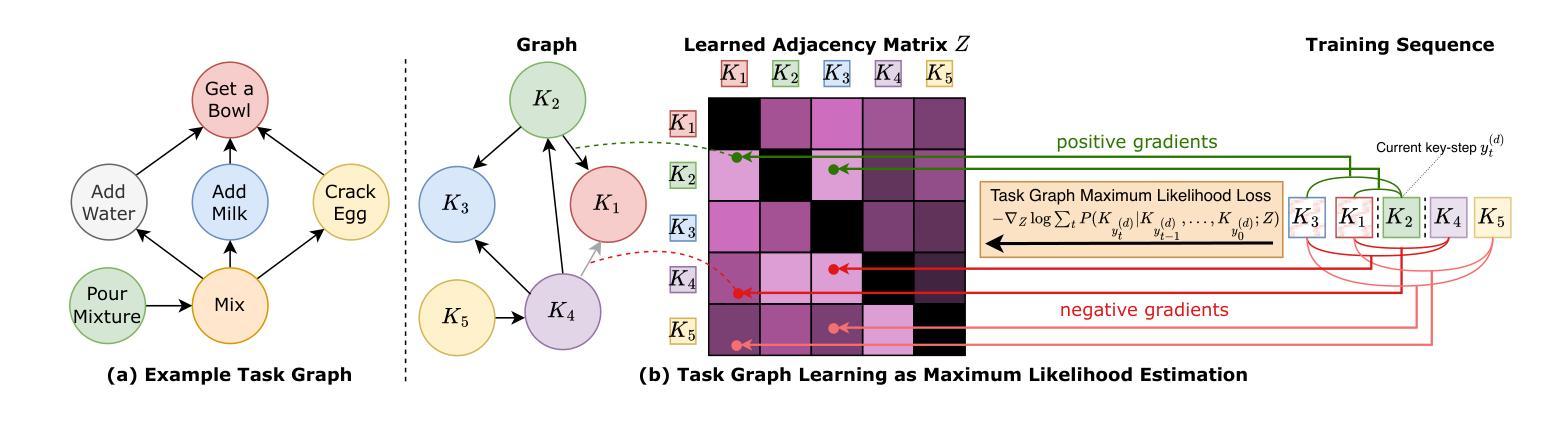
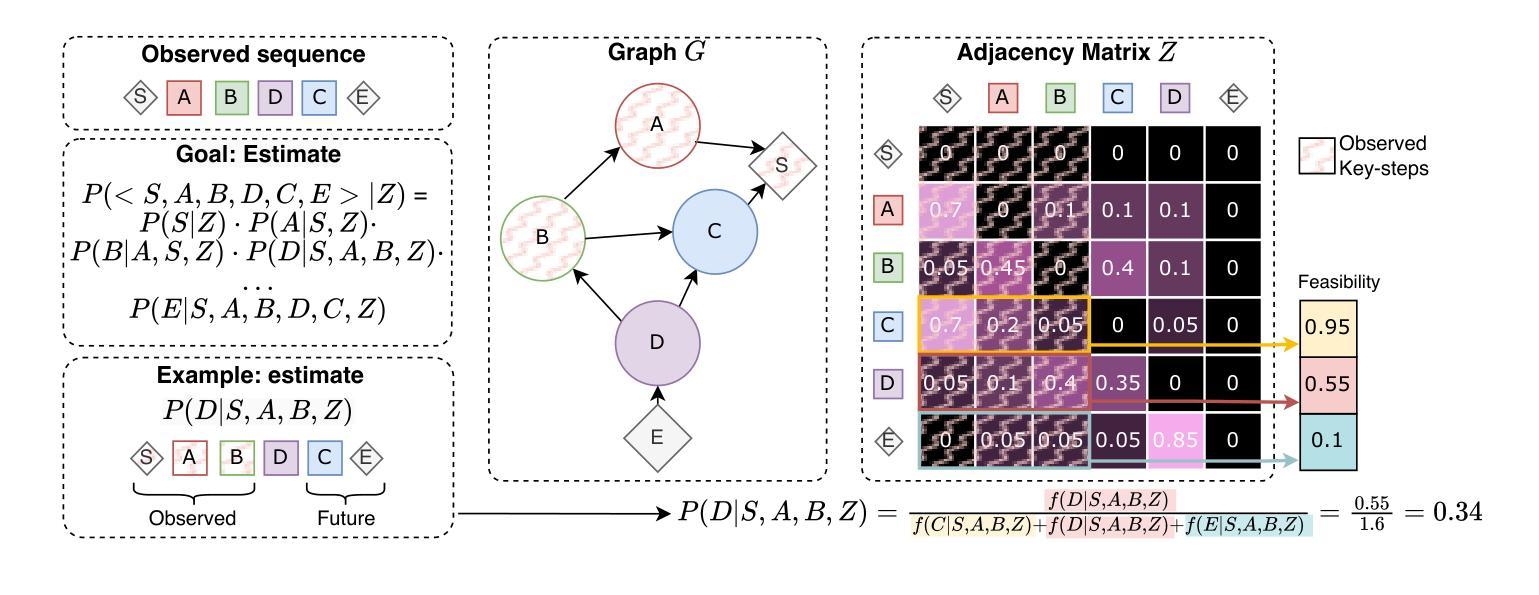
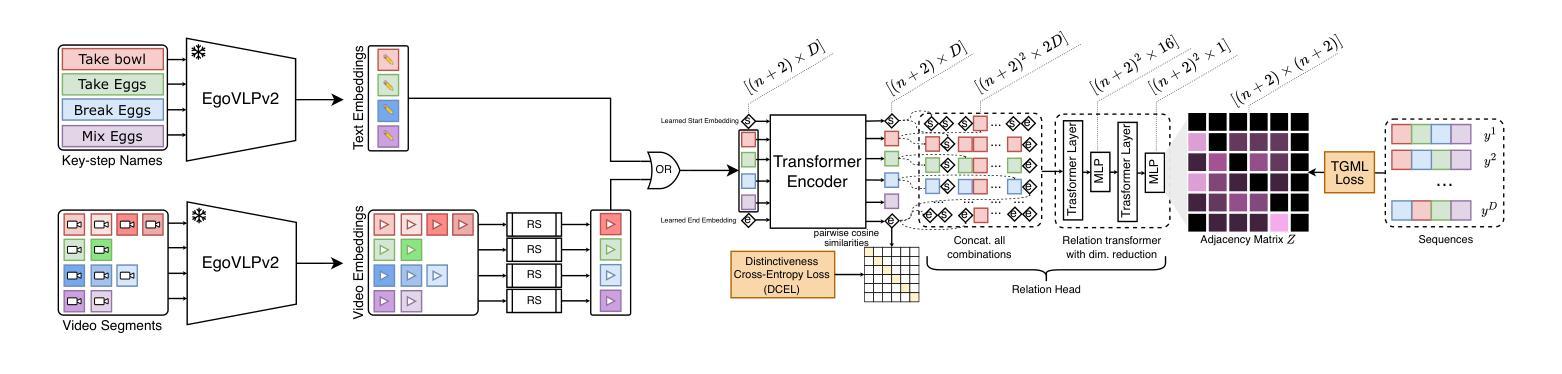
We introduce a gradient-based approach for learning task graphs from procedural activities, improving over hand-crafted methods. Our method directly optimizes edge weights via maximum likelihood, enabling integration into neural architectures. We validate our approach on CaptainCook4D, EgoPER, and EgoProceL, achieving +14.5%, +10.2%, and +13.6% F1-score improvements. Our feature-based approach for predicting task graphs from textual/video embeddings demonstrates emerging video understanding abilities. We also achieved top performance on the procedure understanding benchmark on Ego-Exo4D and significantly improved online mistake detection (+19.8% on Assembly101-O, +6.4% on EPIC-Tent-O). Code: https://github.com/fpv-iplab/Differentiable-Task-Graph-Learning.
我们引入了一种基于梯度的学习方法,用于从程序活动中学习任务图,改进了手工方法。我们的方法通过最大可能性直接优化边缘权重,能够实现与神经网络架构的融合。我们在CaptainCook4D、EgoPER和EgoProceL上验证了我们的方法,分别实现了+14.5%、+10.2%和+13.6%的F1分数提升。我们从文本/视频嵌入中预测任务图的特征方法展示了新兴的视频理解能力。我们在Ego-Exo4D的过程理解基准测试上也取得了顶尖表现,并且在在线错误检测方面取得了显著改进(Assembly101-O上提高了+19.8%,EPIC-Tent-O上提高了+6.4%)。代码地址:https://github.com/fpv-iplab/Differentiable-Task-Graph-Learning。
论文及项目相关链接
PDF arXiv admin note: text overlap with arXiv:2406.01486
Summary
摘要:该研究介绍了一种基于梯度学习的方法,用于从过程活动中学习任务图,改进了手工方法。该方法通过最大可能性直接优化边缘权重,可融入神经网络架构。在CaptainCook4D、EgoPER和EgoProceL等数据集上验证了其方法,F1得分提高了+14.5%、+10.2%和+13.6%。此外,该研究还展示了从文本/视频嵌入预测任务图的特征提取能力,显示出在视频理解方面的优势。在Ego-Exo4D上的过程理解基准测试中也取得了最佳性能,并在Assembly101-O和EPIC-Tent-O上显著提高了在线错误检测能力(+19.8%和+6.4%)。代码已公开在GitHub上。
Key Takeaways
关键要点:
- 研究提出了一种基于梯度学习的方法,用于从过程活动中学习任务图。
- 方法通过最大可能性直接优化边缘权重,可融入神经网络架构。
- 在多个数据集上验证了方法的性能,包括CaptainCook4D、EgoPER和EgoProceL等,F1得分显著提高。
- 通过特征提取预测任务图的能力显示出视频理解的潜力。
- 在过程理解基准测试上取得了最佳性能。
- 显著提高了在线错误检测能力。
点此查看论文截图