⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-27 更新
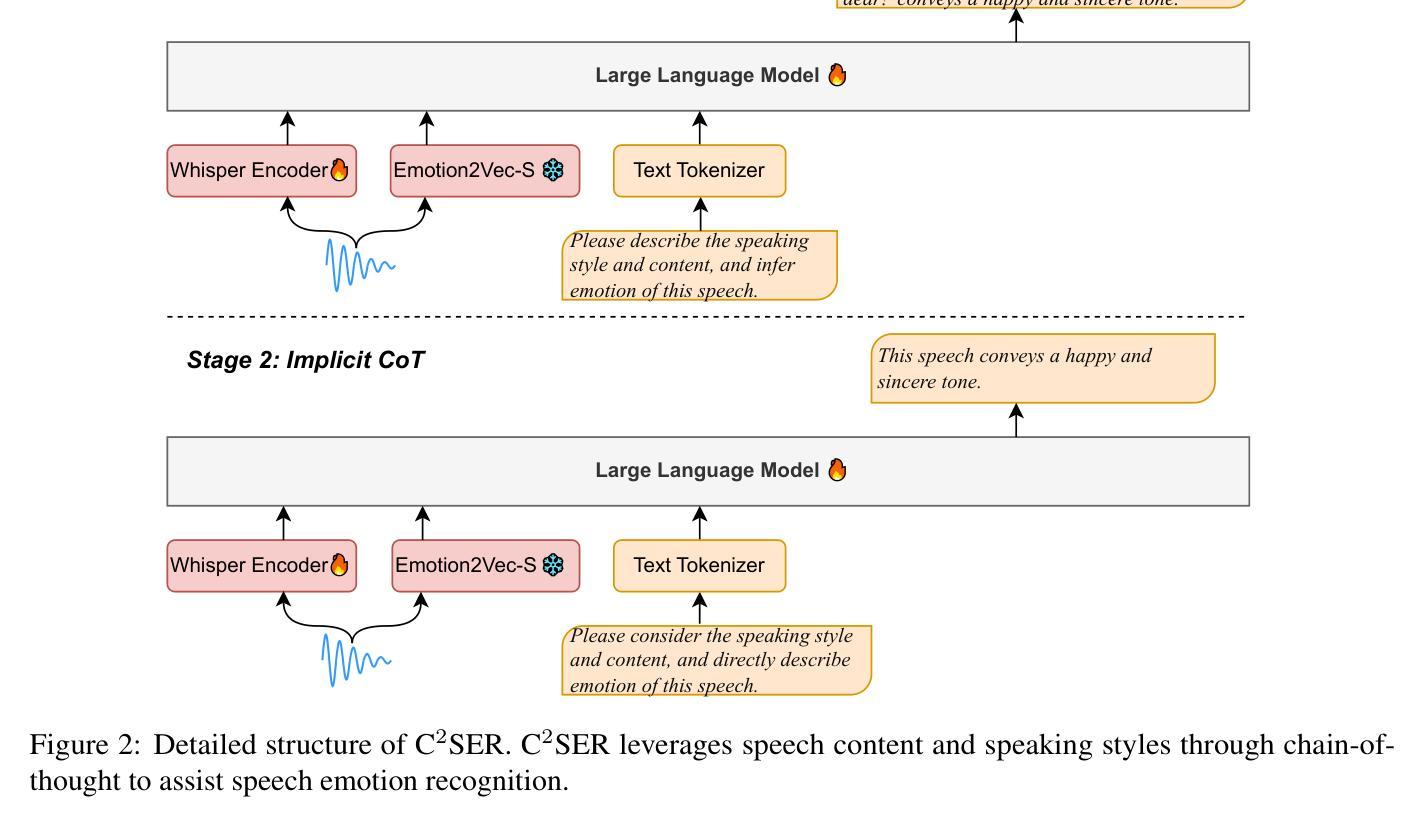
Steering Language Model to Stable Speech Emotion Recognition via Contextual Perception and Chain of Thought
Authors:Zhixian Zhao, Xinfa Zhu, Xinsheng Wang, Shuiyuan Wang, Xuelong Geng, Wenjie Tian, Lei Xie
Large-scale audio language models (ALMs), such as Qwen2-Audio, are capable of comprehending diverse audio signal, performing audio analysis and generating textual responses. However, in speech emotion recognition (SER), ALMs often suffer from hallucinations, resulting in misclassifications or irrelevant outputs. To address these challenges, we propose C$^2$SER, a novel ALM designed to enhance the stability and accuracy of SER through Contextual perception and Chain of Thought (CoT). C$^2$SER integrates the Whisper encoder for semantic perception and Emotion2Vec-S for acoustic perception, where Emotion2Vec-S extends Emotion2Vec with semi-supervised learning to enhance emotional discrimination. Additionally, C$^2$SER employs a CoT approach, processing SER in a step-by-step manner while leveraging speech content and speaking styles to improve recognition. To further enhance stability, C$^2$SER introduces self-distillation from explicit CoT to implicit CoT, mitigating error accumulation and boosting recognition accuracy. Extensive experiments show that C$^2$SER outperforms existing popular ALMs, such as Qwen2-Audio and SECap, delivering more stable and precise emotion recognition. We release the training code, checkpoints, and test sets to facilitate further research.
大规模音频语言模型(ALM),如Qwen2-Audio,能够理解多样的音频信号,执行音频分析并生成文本响应。然而,在语音情感识别(SER)中,ALM常常出现幻觉,导致误分类或无关输出。为了解决这些挑战,我们提出了C$^2$SER,这是一种新型ALM,旨在通过上下文感知和思维链(CoT)增强SER的稳定性和准确性。C$^2$SER集成了Whisper编码器进行语义感知和Emotion2Vec-S进行声音感知,其中Emotion2Vec-S通过半监督学习扩展了Emotion2Vec,以增强情感辨别能力。此外,C$^2$SER采用CoT方法,逐步处理SER,并利用语音内容和说话风格来提高识别率。为了进一步提高稳定性,C$^2$SER从明确的CoT引入自我蒸馏到隐式的CoT,减轻错误累积,提高识别准确性。大量实验表明,C$^2$SER优于现有的流行ALM,如Qwen2-Audio和SECap,实现了更稳定和精确的情感识别。我们发布了训练代码、检查点和测试集,以促进进一步研究。
论文及项目相关链接
Summary
大规模音频语言模型(ALM)在语音情感识别(SER)方面存在挑战,如误分类和不相关输出。为解决这些问题,我们提出了C$^2$SER,一种新型的ALM,通过上下文感知和思维链(CoT)增强SER的稳定性和准确性。C$^2$SER整合了Whisper编码器进行语义感知和Emotion2Vec-S进行声音感知,并采用从显性思维链到隐性思维链的自我蒸馏技术,减少错误累积并提高识别准确性。实验表明,C$^2$SER在性能上优于其他流行的ALM,提供更稳定和精确的情感识别。
Key Takeaways
- 大规模音频语言模型(ALM)如Qwen2-Audio能够处理多样的音频信号,但在语音情感识别(SER)方面面临挑战。
- C$^2$SER是一种新型的ALM,旨在通过上下文感知和思维链(CoT)增强SER的稳定性和准确性。
- C$^2$SER整合了Whisper编码器进行语义感知和Emotion2Vec-S进行声音感知。
- Emotion2Vec-S通过半监督学习扩展了Emotion2Vec,提高了情感识别的辨别能力。
- C$^2$SER采用一种分步的CoT方法处理SER,利用语音内容和说话风格来提高识别效果。
- C$^2$SER引入了自我蒸馏技术,从显性思维链过渡到隐性思维链,减少了错误累积并提高了识别准确性。
点此查看论文截图

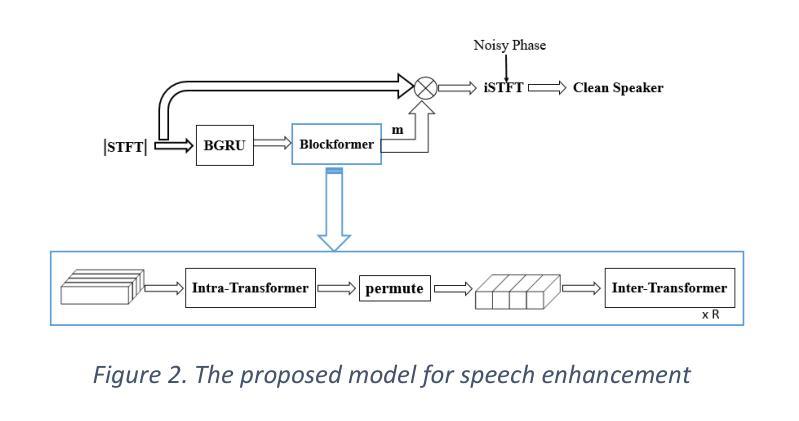
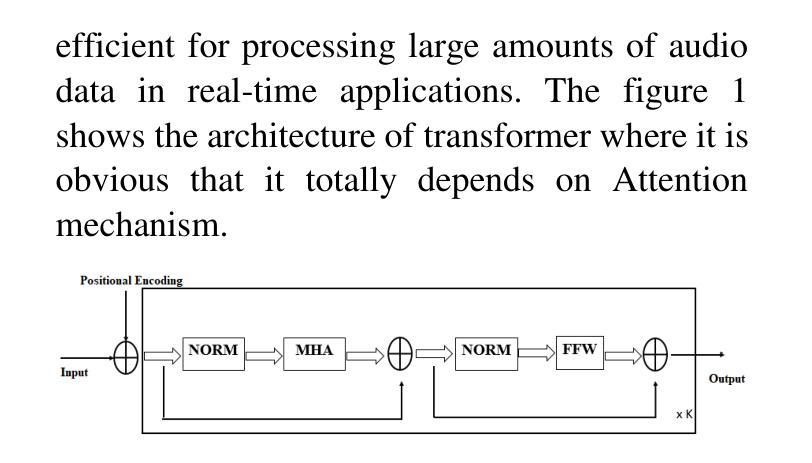
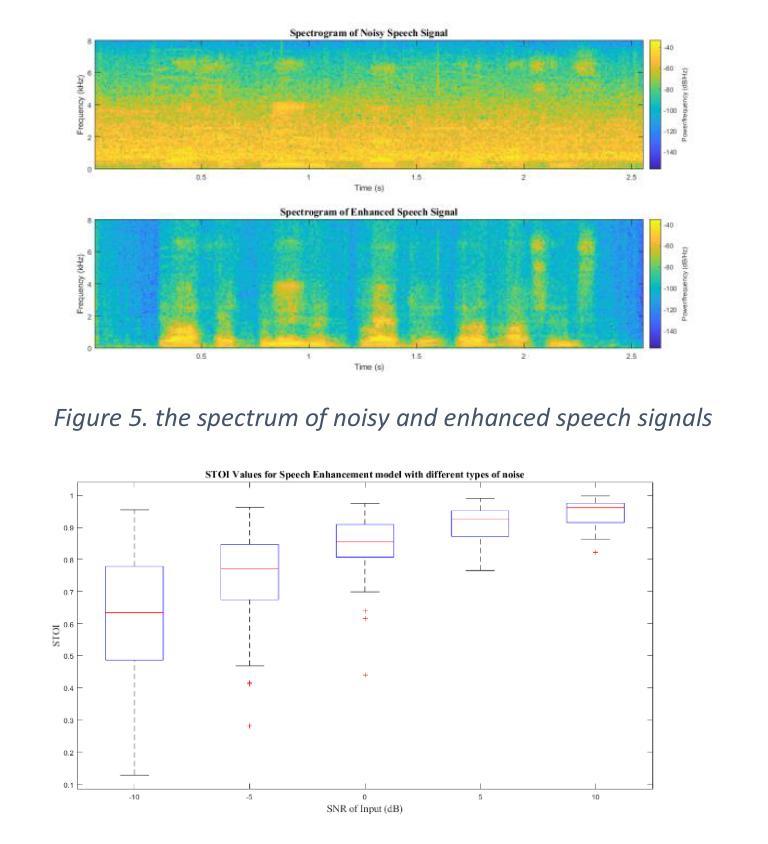
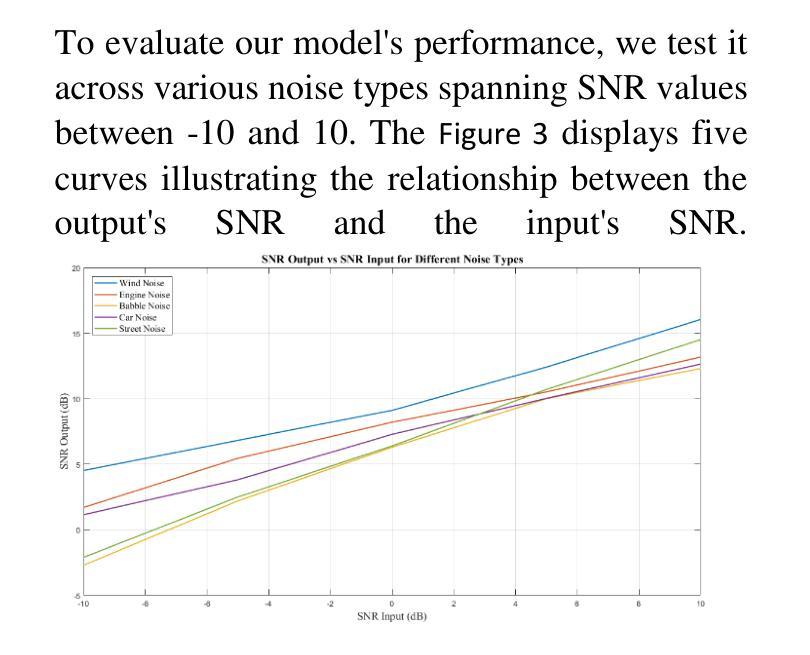
Enhancing Speech Quality through the Integration of BGRU and Transformer Architectures
Authors:Souliman Alghnam, Mohammad Alhussien, Khaled Shaheen
Speech enhancement plays an essential role in improving the quality of speech signals in noisy environments. This paper investigates the efficacy of integrating Bidirectional Gated Recurrent Units (BGRU) and Transformer models for speech enhancement tasks. Through a comprehensive experimental evaluation, our study demonstrates the superiority of this hybrid architecture over traditional methods and standalone models. The combined BGRU-Transformer framework excels in capturing temporal dependencies and learning complex signal patterns, leading to enhanced noise reduction and improved speech quality. Results show significant performance gains compared to existing approaches, highlighting the potential of this integrated model in real-world applications. The seamless integration of BGRU and Transformer architectures not only enhances system robustness but also opens the road for advanced speech processing techniques. This research contributes to the ongoing efforts in speech enhancement technology and sets a solid foundation for future investigations into optimizing model architectures, exploring many application scenarios, and advancing the field of speech processing in noisy environments.
语音增强在改善噪声环境中的语音信号质量方面起着至关重要的作用。本文研究了将双向门控循环单元(BGRU)和Transformer模型集成用于语音增强任务的有效性。通过全面的实验评估,我们的研究表明,该混合架构优于传统方法和独立模型。BGRU-Transformer结合框架在捕捉时间依赖性和学习复杂信号模式方面表现出色,导致噪声减少增强和语音质量提高。与现有方法相比,结果显示了显著的性能提升,突显了这种集成模型在现实世界应用中的潜力。BGRU和Transformer架构的无缝集成不仅提高了系统稳健性,而且为先进的语音处理技术铺平了道路。本研究为语音增强技术的持续努力做出了贡献,并为未来优化模型架构、探索多种应用场景以及推进噪声环境中的语音处理领域的研究奠定了坚实基础。
论文及项目相关链接
摘要
本文主要研究了双向门控循环单元(BGRU)与Transformer模型在语音增强任务中的集成效果。实验证明,该混合架构相较于传统方法和独立模型具有优越性,尤其擅长捕捉时间依赖性和学习复杂信号模式,能够有效提高降噪效果和改善语音质量。相较于现有方法,该集成模型表现出显著的性能提升,展示了其在真实应用中的潜力。BGRU与Transformer架构的无缝集成不仅提高了系统的稳健性,还为先进的语音处理技术开辟了道路。该研究为语音增强技术的持续努力做出了贡献,并为未来优化模型架构、探索多种应用场景和推进噪声环境下语音处理领域的研究奠定了坚实基础。
要点总结
- 双向门控循环单元(BGRU)与Transformer模型的集成在语音增强任务中表现出优异性能。
- 混合架构通过捕捉时间依赖性和学习复杂信号模式,有效提高降噪效果和改善语音质量。
- 与传统方法和独立模型相比,该集成模型表现出显著的性能提升。
- 该研究为语音增强技术的贡献在于其提高了系统的稳健性并为先进的语音处理技术提供了机会。
- 无缝集成BGRU与Transformer架构为未来的模型优化和场景应用探索提供了坚实的基础。
- 该研究有助于推进噪声环境下语音处理领域的发展。
- 该论文的实验结果和研究结论为未来的研究提供了有价值的参考和启示。
点此查看论文截图

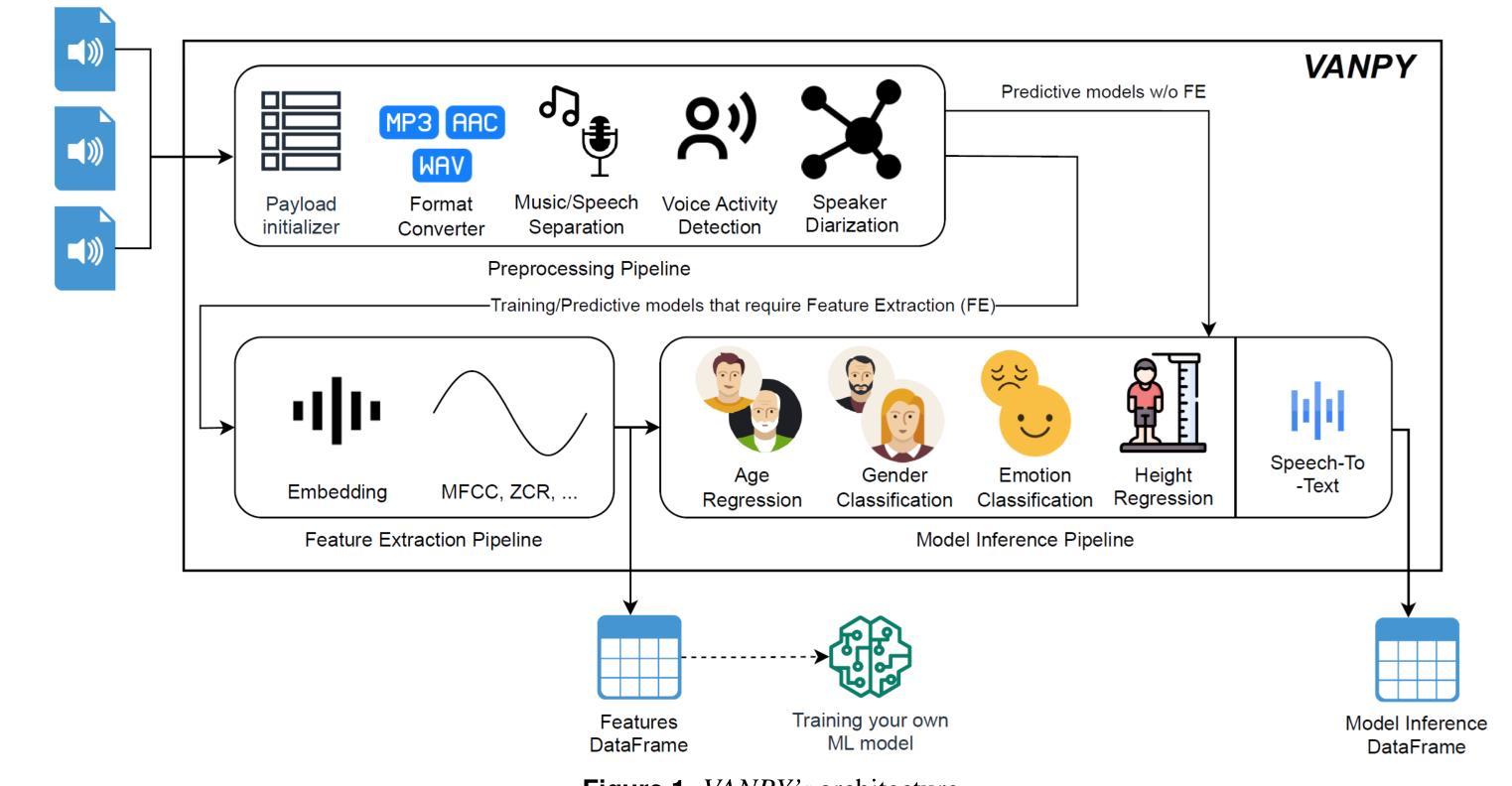
VANPY: Voice Analysis Framework
Authors:Gregory Koushnir, Michael Fire, Galit Fuhrmann Alpert, Dima Kagan
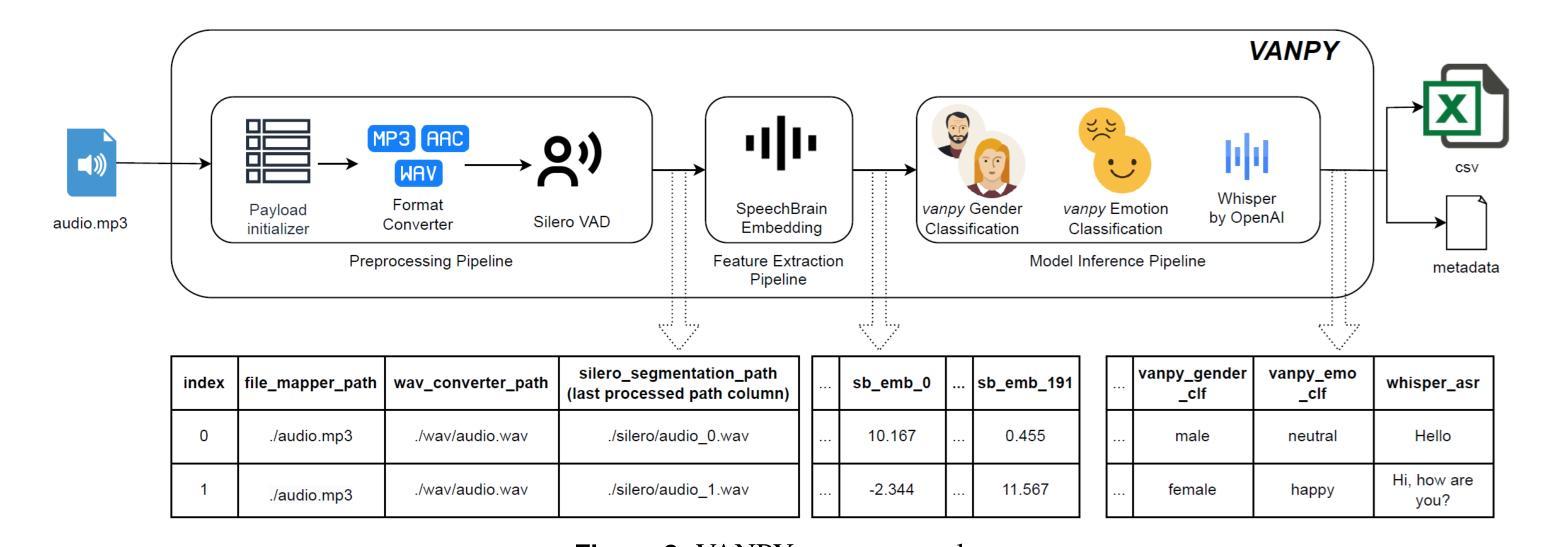
Voice data is increasingly being used in modern digital communications, yet there is still a lack of comprehensive tools for automated voice analysis and characterization. To this end, we developed the VANPY (Voice Analysis in Python) framework for automated pre-processing, feature extraction, and classification of voice data. The VANPY is an open-source end-to-end comprehensive framework that was developed for the purpose of speaker characterization from voice data. The framework is designed with extensibility in mind, allowing for easy integration of new components and adaptation to various voice analysis applications. It currently incorporates over fifteen voice analysis components - including music/speech separation, voice activity detection, speaker embedding, vocal feature extraction, and various classification models. Four of the VANPY’s components were developed in-house and integrated into the framework to extend its speaker characterization capabilities: gender classification, emotion classification, age regression, and height regression. The models demonstrate robust performance across various datasets, although not surpassing state-of-the-art performance. As a proof of concept, we demonstrate the framework’s ability to extract speaker characteristics on a use-case challenge of analyzing character voices from the movie “Pulp Fiction.” The results illustrate the framework’s capability to extract multiple speaker characteristics, including gender, age, height, emotion type, and emotion intensity measured across three dimensions: arousal, dominance, and valence.
语音数据在现代数字通信中的应用越来越广泛,然而,缺乏全面的自动化语音分析和表征工具。为此,我们开发了用于自动化预处理、特征提取和语音分类的VANPY(Python中的语音分析)框架。VANPY是一个开源的端到端综合框架,旨在从语音数据中实现说话人表征。该框架设计时考虑了可扩展性,可轻松集成新组件并适应各种语音分析应用。它目前集成了超过十五种语音分析组件,包括音乐/语音分离、语音活动检测、说话人嵌入、语音特征提取和各种分类模型。为了扩展其说话人表征能力,我们自主开发了四种VANPY组件并将其集成到框架中:性别分类、情感分类、年龄回归和身高回归。虽然模型的性能还未达到最新技术性能的水平,但它在不同的数据集上都展现了稳健的性能。作为概念验证,我们展示了该框架在分析电影《低俗小说》中的角色声音的应用能力。结果表明,该框架能够提取多个说话人的特征,包括性别、年龄、身高、情感类型和情感强度,这通过三个维度来衡量:唤醒度、支配力和效价。
论文及项目相关链接
Summary:
随着语音数据在现代数字通信中的广泛应用,缺乏全面的自动化语音分析和表征工具。为此,我们开发了VANPY(Python语音分析)框架,用于自动化预处理、特征提取和语音分类。该框架是一个开源的端到端综合框架,旨在从语音数据中实现说话人表征。框架设计具有可扩展性,可轻松集成新组件并适应各种语音分析应用。目前集成了超过十五种语音分析组件,包括音乐/语音分离、语音活动检测、说话人嵌入、语音特征提取和各种分类模型。此外,还开发了四个内部组件并将其集成到框架中,以扩展其说话人表征能力:性别分类、情感分类、年龄回归和身高回归。模型在多个数据集上表现出稳健的性能,尽管未超过最新技术水平。作为概念验证,我们展示了该框架在分析电影《低俗小说》中的角色声音方面的能力,结果表明该框架能够提取多个说话人的特征,包括性别、年龄、身高、情感类型和情感强度。通过对唤醒度、主导权和价值这三个维度的衡量来衡量情感强度。
Key Takeaways:
- 语音数据在现代数字通信中越来越受欢迎,但需要全面的自动化语音分析和表征工具。
- VANPY是一个开源的端到端综合框架,用于从语音数据中实现说话人表征。
- 该框架设计具有可扩展性,易于集成新组件并适应各种语音分析应用。
- 目前集成了超过十五种语音分析组件,包括音乐/语音分离、语音活动检测等。
- 开发并集成了四个内部组件以扩展其说话人表征能力,包括性别分类、情感分类等。
- 模型在多个数据集上表现出稳健的性能,具有广泛的应用潜力。
点此查看论文截图


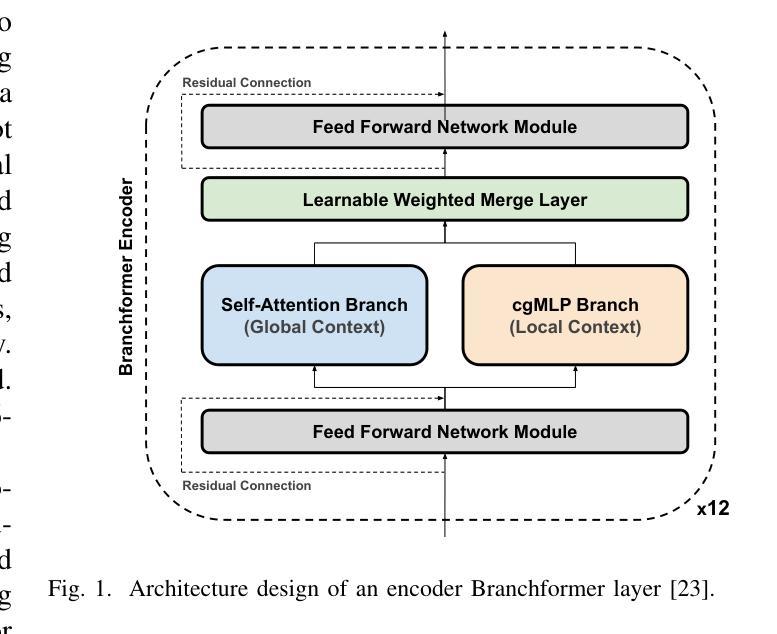
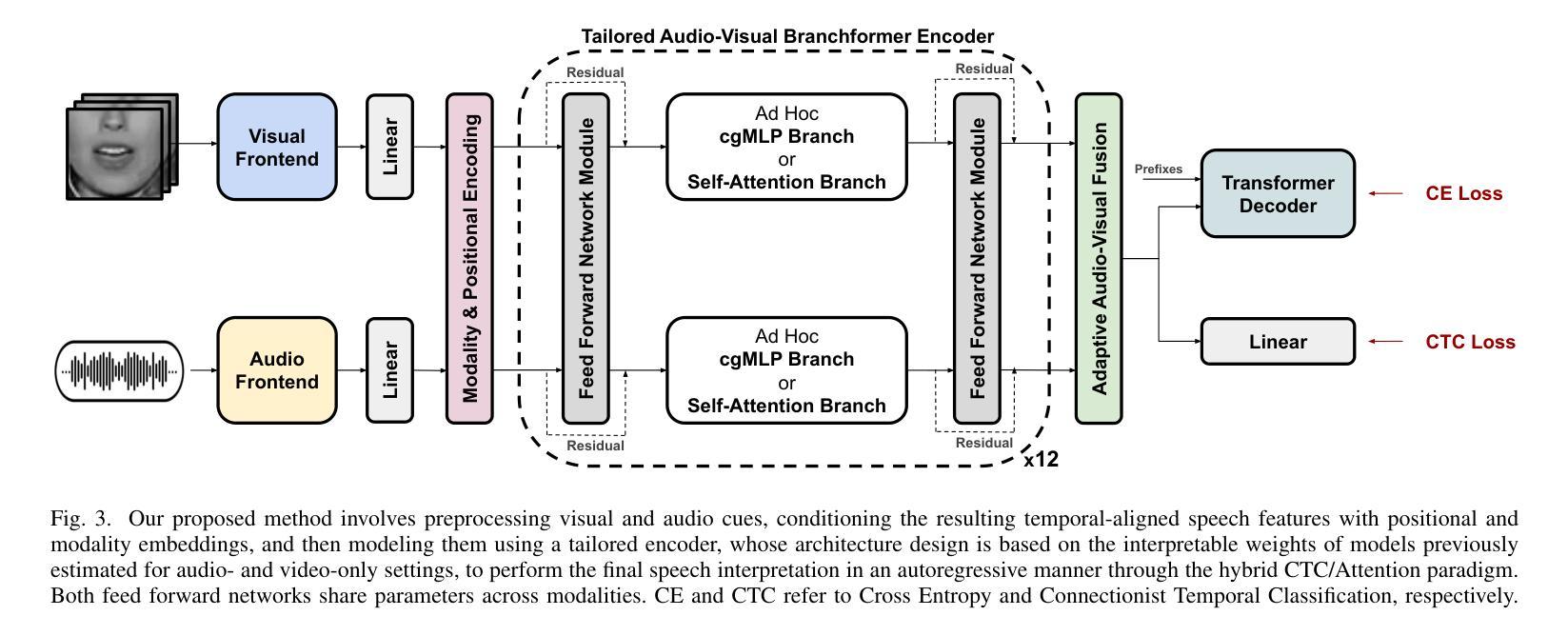
Tailored Design of Audio-Visual Speech Recognition Models using Branchformers
Authors:David Gimeno-Gómez, Carlos-D. Martínez-Hinarejos
Recent advances in Audio-Visual Speech Recognition (AVSR) have led to unprecedented achievements in the field, improving the robustness of this type of system in adverse, noisy environments. In most cases, this task has been addressed through the design of models composed of two independent encoders, each dedicated to a specific modality. However, while recent works have explored unified audio-visual encoders, determining the optimal cross-modal architecture remains an ongoing challenge. Furthermore, such approaches often rely on models comprising vast amounts of parameters and high computational cost training processes. In this paper, we aim to bridge this research gap by introducing a novel audio-visual framework. Our proposed method constitutes, to the best of our knowledge, the first attempt to harness the flexibility and interpretability offered by encoder architectures, such as the Branchformer, in the design of parameter-efficient AVSR systems. To be more precise, the proposed framework consists of two steps: first, estimating audio- and video-only systems, and then designing a tailored audio-visual unified encoder based on the layer-level branch scores provided by the modality-specific models. Extensive experiments on English and Spanish AVSR benchmarks covering multiple data conditions and scenarios demonstrated the effectiveness of our proposed method. Even when trained on a moderate scale of data, our models achieve competitive word error rates (WER) of approximately 2.5% for English and surpass existing approaches for Spanish, establishing a new benchmark with an average WER of around 9.1%. These results reflect how our tailored AVSR system is able to reach state-of-the-art recognition rates while significantly reducing the model complexity w.r.t. the prevalent approach in the field. Code and pre-trained models are available at https://github.com/david-gimeno/tailored-avsr.
近期在视听语音识别(AVSR)方面的进展为该领域带来了前所未有的成就,提高了此类系统在恶劣、嘈杂环境中的稳健性。在大多数情况下,该问题已通过设计由两个独立编码器组成的模型来解决,每个编码器专门用于一种特定模态。然而,尽管近期作品已经探索了统一的视听编码器,但确定最优跨模态架构仍然是一个挑战。此外,此类方法通常依赖于包含大量参数的模型以及高计算成本的训练过程。本文旨在通过引入一种新的视听框架来缩小这一研究差距。据我们所知,我们提出的方法首次尝试利用编码器架构的灵活性和可解释性,例如Branchformer,来设计参数高效的AVSR系统。更具体地说,所提出的框架分为两个阶段:首先估计仅音频和仅视频系统,然后基于模态特定模型提供的层级分支分数设计定制的视听统一编码器。在英语和西班牙语AVSR基准测试上的大量实验,涵盖了多种数据条件和场景,证明了我们提出的方法的有效性。即使在中等规模的数据上进行训练,我们的模型也实现了约2.5%的英文单词错误率(WER),并超越了现有的西班牙语方法,建立了平均WER约为9.1%的新基准。这些结果反映了我们的定制AVSR系统能够达到最先进的识别率,同时显著降低了模型复杂度,相较于领域中的普遍方法。代码和预训练模型可在https://github.com/david-gimeno/tailored-avsr找到。
论文及项目相关链接
PDF Submitted and under review for the Computer Speech and Language journal of Elsevier
摘要
本研究利用新型音频视觉语音识别框架,结合独立模态的特性,通过设计参数高效的音频视觉统一编码器,提高了音频视觉语音识别系统在恶劣噪声环境下的稳健性。实验证明,该方法在英文和西班牙语的语音识别基准测试中表现优异,即使在中等规模数据训练下,也能达到具有竞争力的词错误率。这一创新系统降低了模型复杂度,同时达到了领域内的最佳识别率。详情可见https://github.com/david-gimeno/tailored-avsr。
关键见解
- 最近音频视觉语音识别的进步已显著提高系统在不同噪声环境下的稳健性。
- 当前方法主要通过设计由两个独立编码器组成的模型来解决此问题,每个编码器专门处理一种模态。
- 虽然最近有探索统一音频视觉编码器的趋势,但确定最佳的跨模态架构仍是一个挑战。
- 当前方法通常依赖于具有大量参数和计算成本高昂的训练过程。
- 本研究提出了一种新型的音频视觉框架,结合模态特定模型的层级分支分数,设计了一个基于Branchformer架构的参数高效音频视觉统一编码器。
- 在多个数据条件和场景下的英语和西班牙语语音识别基准测试中,该方法被证明是有效的。
点此查看论文截图


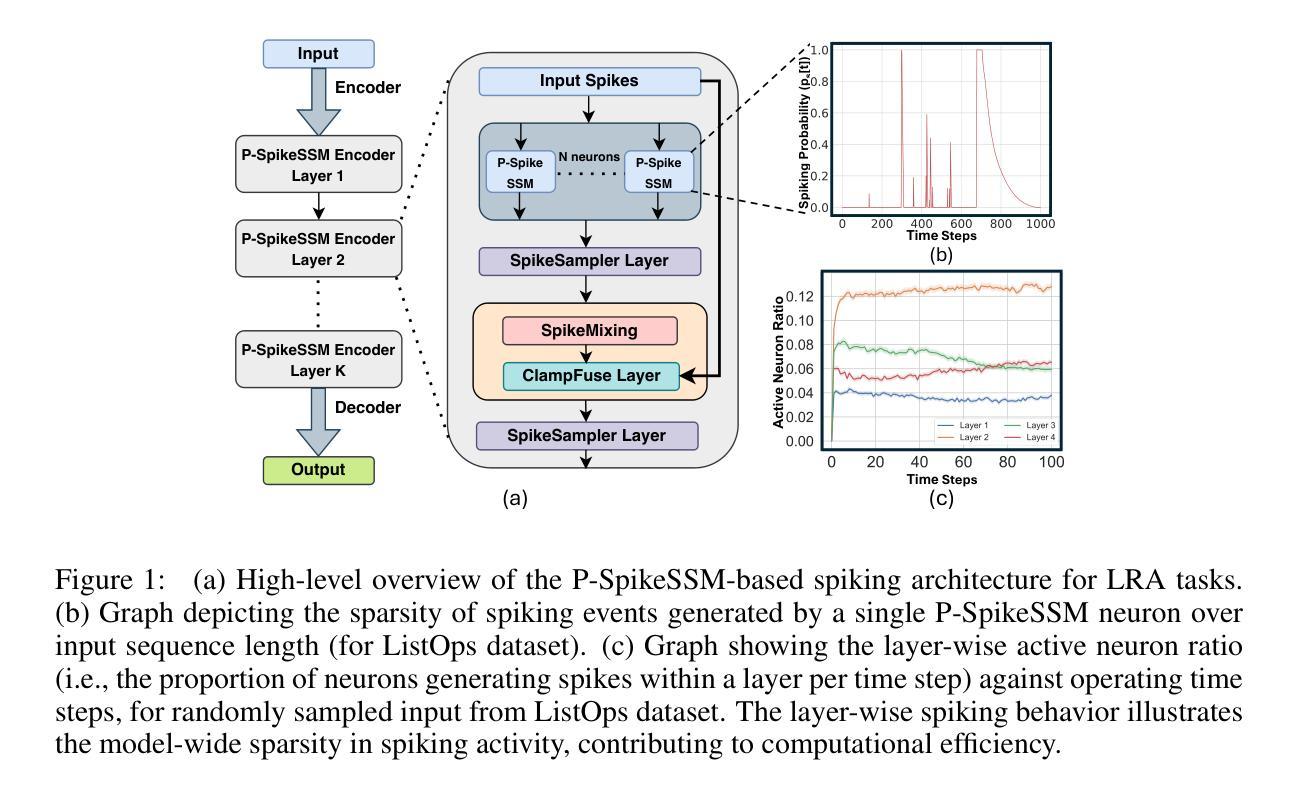
P-SpikeSSM: Harnessing Probabilistic Spiking State Space Models for Long-Range Dependency Tasks
Authors:Malyaban Bal, Abhronil Sengupta
Spiking neural networks (SNNs) are posited as a computationally efficient and biologically plausible alternative to conventional neural architectures, with their core computational framework primarily using the leaky integrate-and-fire (LIF) neuron model. However, the limited hidden state representation of LIF neurons, characterized by a scalar membrane potential, and sequential spike generation process, poses challenges for effectively developing scalable spiking models to address long-range dependencies in sequence learning tasks. In this study, we develop a scalable probabilistic spiking learning framework for long-range dependency tasks leveraging the fundamentals of state space models. Unlike LIF neurons that rely on the deterministic Heaviside function for a sequential process of spike generation, we introduce a SpikeSampler layer that samples spikes stochastically based on an SSM-based neuronal model while allowing parallel computations. To address non-differentiability of the spiking operation and enable effective training, we also propose a surrogate function tailored for the stochastic nature of the SpikeSampler layer. To enhance inter-neuron communication, we introduce the SpikeMixer block, which integrates spikes from neuron populations in each layer. This is followed by a ClampFuse layer, incorporating a residual connection to capture complex dependencies, enabling scalability of the model. Our models attain state-of-the-art performance among SNN models across diverse long-range dependency tasks, encompassing the Long Range Arena benchmark, permuted sequential MNIST, and the Speech Command dataset and demonstrate sparse spiking pattern highlighting its computational efficiency.
脉冲神经网络(Spiking Neural Networks,简称SNNs)被视为传统神经网络架构的计算效率高且生物上合理的替代方案,其核心计算框架主要使用泄漏积分和放电(Leaky Integrate-and-Fire,简称LIF)神经元模型。然而,LIF神经元的隐藏状态表示有限,其特征在于标量膜电位和连续的脉冲生成过程,这给开发有效的可扩展脉冲模型以处理序列学习任务中的远程依赖关系带来了挑战。在本研究中,我们利用状态空间模型的基本原理,为远程依赖任务开发了一个可扩展的脉冲学习框架。不同于依赖确定性海维赛德函数进行脉冲生成的LIF神经元,我们引入了基于SSM的神经元模型的SpikeSampler层,该层可以随机采样脉冲,同时允许并行计算。为了解决脉冲操作的不可微性和实现有效的训练,我们还为SpikeSampler层的随机特性量身定制了一个替代函数。为了增强神经元之间的通信,我们引入了SpikeMixer块,该块可以整合每一层神经元群体的脉冲。随后是ClampFuse层,它结合了残差连接来捕捉复杂的依赖关系,使模型的可扩展性增强。我们的模型在多种远程依赖任务中实现了最先进的性能,包括Long Range Arena基准测试、排列顺序的MNIST和语音命令数据集,并展示了稀疏的脉冲模式,突显了其计算效率。
论文及项目相关链接
PDF Accepted at ICLR 2025
摘要
该研究提出了一种基于状态空间模型的可扩展概率脉冲学习框架,用于处理长距离依赖任务。该框架引入了一种SpikeSampler层,该层基于SSM神经元模型随机采样脉冲,同时允许并行计算。为解决脉冲操作的非可微性和有效训练问题,该研究还提出了一种针对SpikeSampler层随机性的替代函数。此外,该研究引入了SpikeMixer块以增强神经元间的通信,并结合残差连接构建ClampFuse层以捕捉复杂依赖性,实现模型的可扩展性。该模型在不同长距离依赖任务中取得了最先进的性能表现,包括Long Range Arena基准测试、排列顺序MNIST以及语音命令数据集,同时表现出稀疏的脉冲发放模式,突显了其计算效率。
关键见解
- Spiking神经网络(SNNs)被提出作为传统神经网络架构的计算高效且生物上合理的替代方案。
- LIF神经元模型的有限隐藏状态表示和顺序脉冲生成过程对开发针对序列学习任务中的长距离依赖关系的可扩展脉冲模型提出了挑战。
- 研究提出了一种基于状态空间模型的可扩展概率脉冲学习框架,以处理长距离依赖任务。
- SpikeSampler层的引入能够随机采样脉冲,允许并行计算并基于SSM神经元模型。
- 提出了一种针对SpikeSampler层随机性的替代函数,解决脉冲操作的非可微性和有效训练问题。
- SpikeMixer块的引入增强了神经元间的通信,而ClampFuse层结合残差连接以捕捉复杂依赖性并实现模型的可扩展性。
点此查看论文截图