⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-02-27 更新
Learning Structure-Supporting Dependencies via Keypoint Interactive Transformer for General Mammal Pose Estimation
Authors:Tianyang Xu, Jiyong Rao, Xiaoning Song, Zhenhua Feng, Xiao-Jun Wu
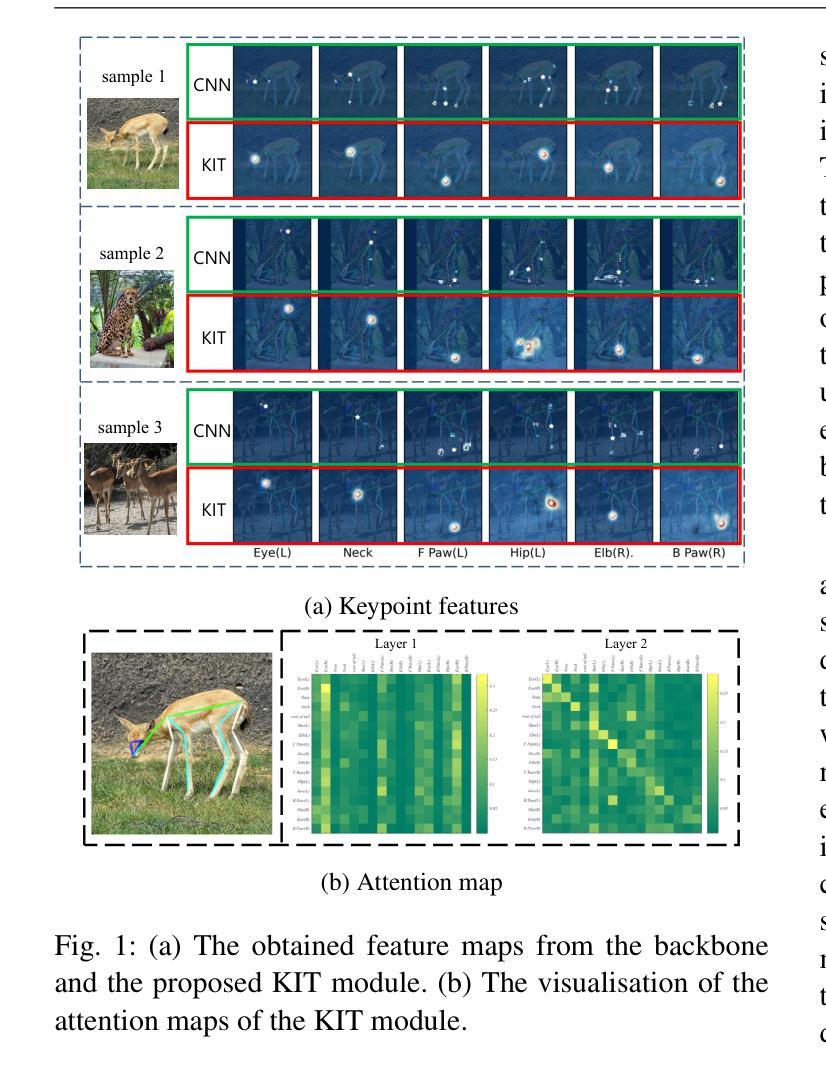
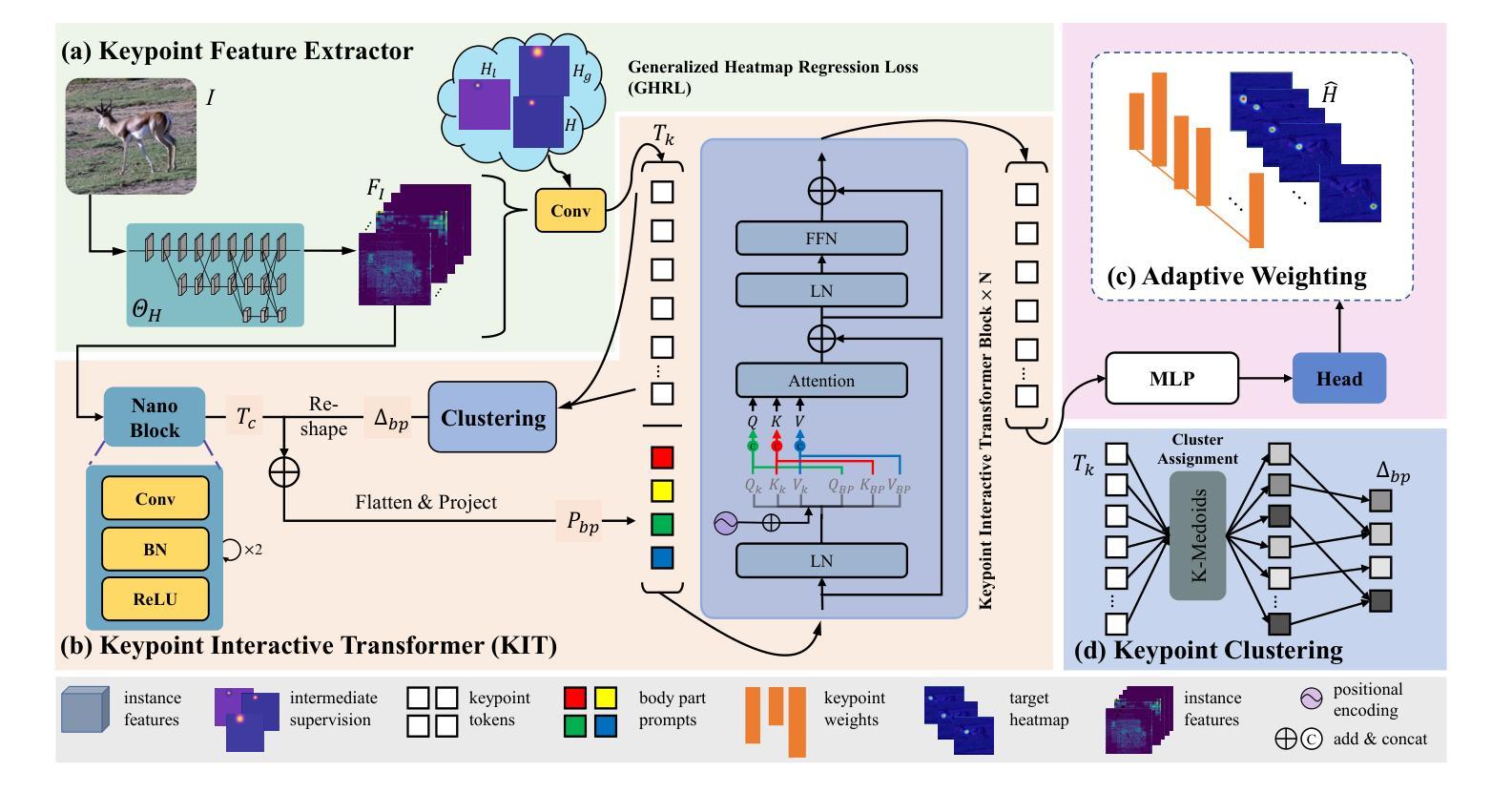
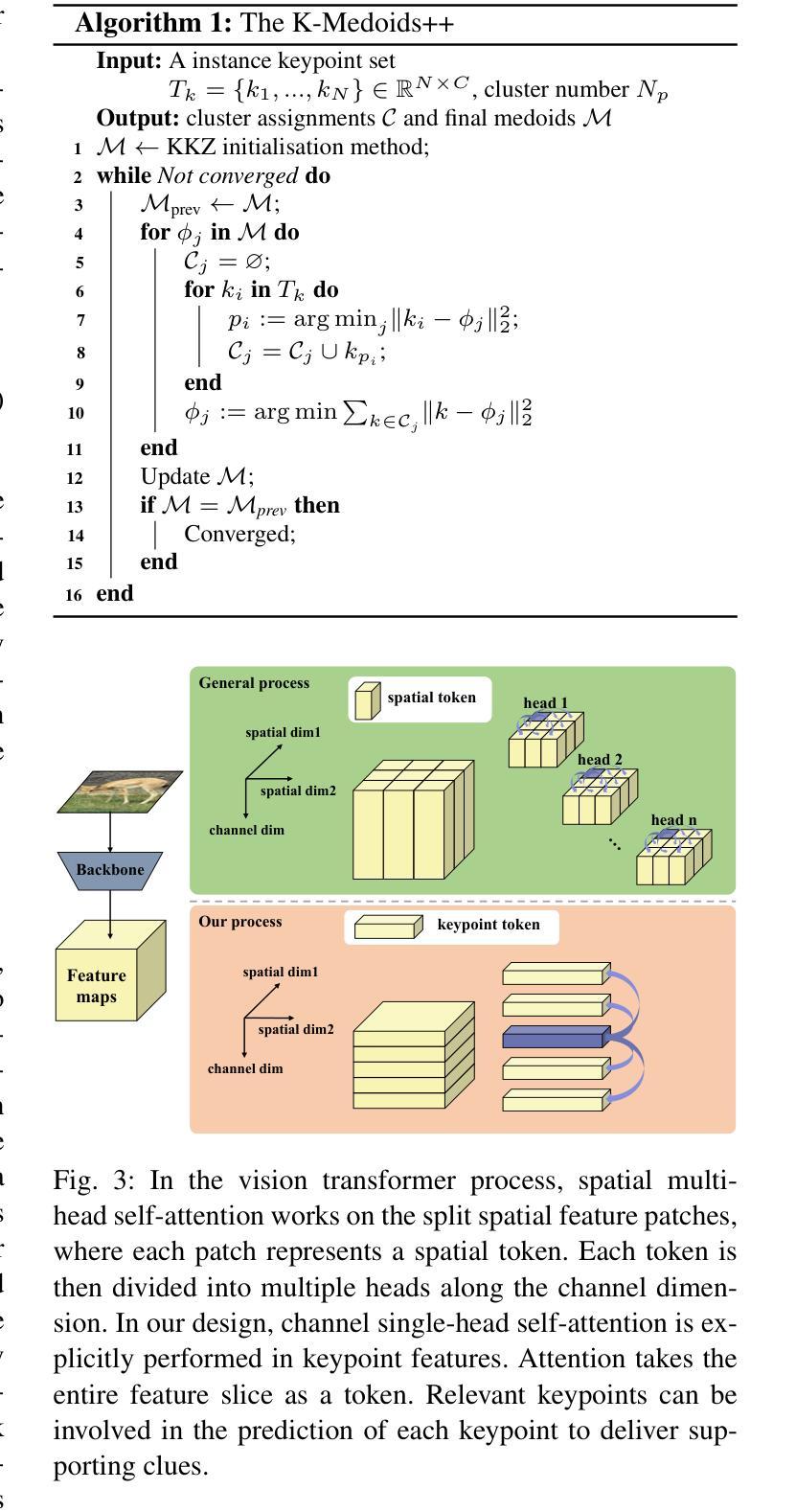
General mammal pose estimation is an important and challenging task in computer vision, which is essential for understanding mammal behaviour in real-world applications. However, existing studies are at their preliminary research stage, which focus on addressing the problem for only a few specific mammal species. In principle, from specific to general mammal pose estimation, the biggest issue is how to address the huge appearance and pose variances for different species. We argue that given appearance context, instance-level prior and the structural relation among keypoints can serve as complementary evidence. To this end, we propose a Keypoint Interactive Transformer (KIT) to learn instance-level structure-supporting dependencies for general mammal pose estimation. Specifically, our KITPose consists of two coupled components. The first component is to extract keypoint features and generate body part prompts. The features are supervised by a dedicated generalised heatmap regression loss (GHRL). Instead of introducing external visual/text prompts, we devise keypoints clustering to generate body part biases, aligning them with image context to generate corresponding instance-level prompts. Second, we propose a novel interactive transformer that takes feature slices as input tokens without performing spatial splitting. In addition, to enhance the capability of the KIT model, we design an adaptive weight strategy to address the imbalance issue among different keypoints.
哺乳动物姿态估计在计算机视觉领域是一项重要且具有挑战性的任务,对于理解哺乳动物在现实世界应用中的行为至关重要。然而,现有的研究尚处于初步研究阶段,主要关注如何解决少数特定哺乳动物物种的问题。从特定到一般哺乳动物姿态估计,最大的问题是如何应对不同物种的巨大外观和姿态差异。我们主张,给定外观上下文、实例级先验知识和关键点之间的结构关系可以作为补充证据。为此,我们提出了一种Keypoint Interactive Transformer(KIT)来学习实例级结构支持依赖关系,用于一般哺乳动物姿态估计。具体来说,我们的KITPose由两个耦合的组件构成。第一个组件用于提取关键点特征并生成身体部位提示。这些特征受到专用通用热图回归损失(GHRL)的监督。我们没有使用外部视觉或文本提示,而是设计了关键点聚类来生成身体部位偏见,将它们与图像上下文对齐,生成相应的实例级提示。其次,我们提出了一种新型交互式变压器,它以特征切片作为输入令牌,无需进行空间分割。此外,为了提高KIT模型的能力,我们设计了一种自适应权重策略来解决不同关键点之间的不平衡问题。
论文及项目相关链接
PDF accepted by IJCV 2025
Summary
针对哺乳动物姿态估计这一计算机视觉中的关键且具有挑战性的任务,现有研究尚处于初步阶段,主要关注少数特定哺乳动物物种的姿态估计。从特定到一般哺乳动物姿态估计,最大的问题是如何处理不同物种的外观和姿态的巨大差异。本文提出一种Keypoint Interactive Transformer(KIT)来学习实例级别的结构支持依赖关系,用于一般哺乳动物姿态估计。KITPose包括两个耦合组件:提取关键点特征并生成身体部位提示,以及提出一种新型交互式变压器,以特征切片为输入令牌,无需进行空间分割。
Key Takeaways
- 哺乳动物姿态估计是一个重要且具有挑战性的任务,对于理解真实世界中的哺乳动物行为至关重要。
- 当前研究主要关注少数特定哺乳动物物种的姿态估计,从特定到一般的转变中面临处理不同物种外观和姿态巨大差异的问题。
- 本文提出Keypoint Interactive Transformer(KIT)模型,用于一般哺乳动物姿态估计,该模型能够学习实例级别的结构支持依赖关系。
- KITPose包括两个主要组件:提取关键点特征并生成身体部位提示,以及一种新的交互式变压器。
- 该模型采用广义热图回归损失(GHRL)进行特征监督,通过关键点聚类生成身体部位偏差,与图像上下文对齐,生成相应的实例级别提示。
- 模型采用特征切片作为输入令牌,无需进行空间分割,提高了模型的效能。
点此查看论文截图

Escaping The Big Data Paradigm in Self-Supervised Representation Learning
Authors:Carlos Vélez García, Miguel Cazorla, Jorge Pomares
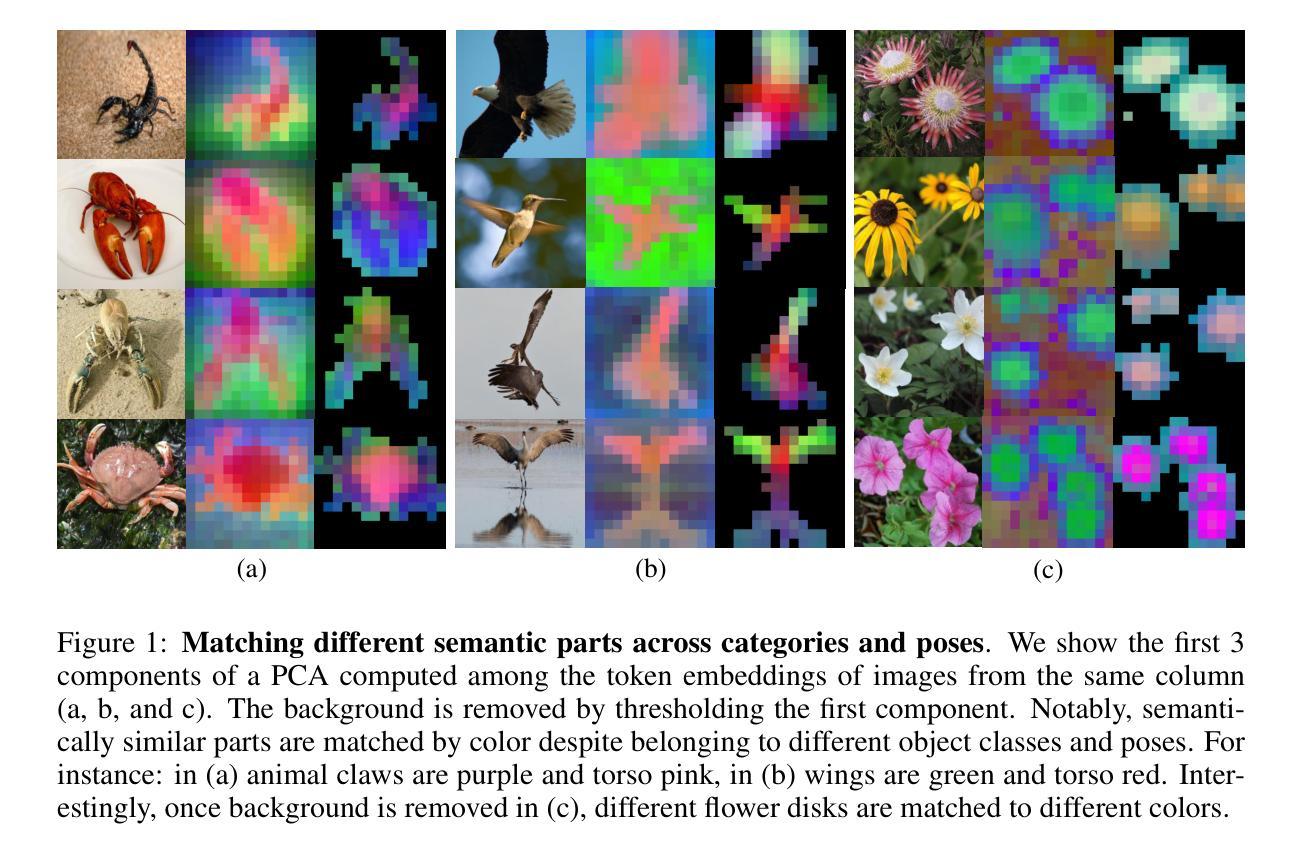
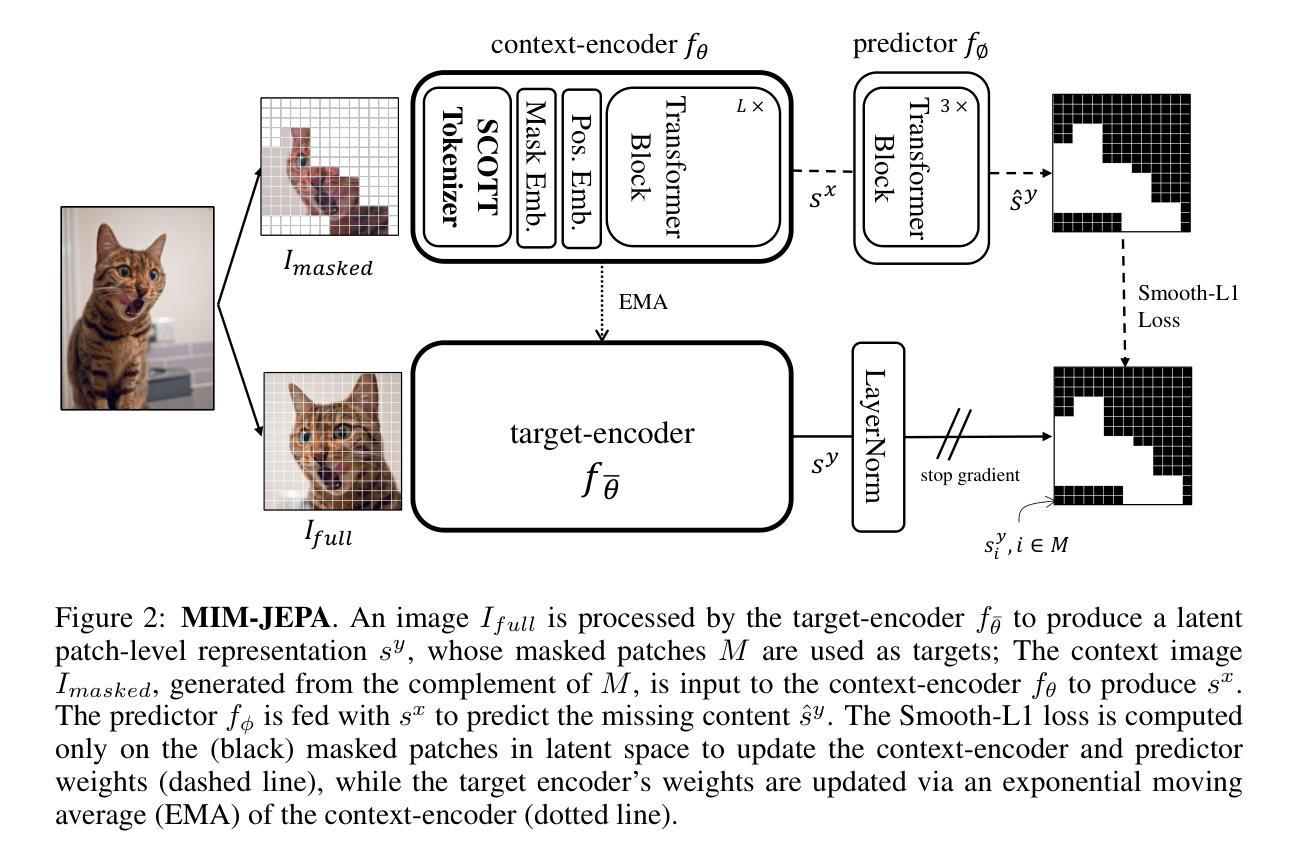
The reliance on large-scale datasets and extensive computational resources has become a major barrier to advancing representation learning in vision, especially in data-scarce domains. In this paper, we address the critical question: Can we escape the big data paradigm in self-supervised representation learning from images? We introduce SCOTT (Sparse Convolutional Tokenizer for Transformers), a shallow tokenization architecture that is compatible with Masked Image Modeling (MIM) tasks. SCOTT injects convolutional inductive biases into Vision Transformers (ViTs), enhancing their efficacy in small-scale data regimes. Alongside, we propose to train on a Joint-Embedding Predictive Architecture within a MIM framework (MIM-JEPA), operating in latent representation space to capture more semantic features. Our approach enables ViTs to be trained from scratch on datasets orders of magnitude smaller than traditionally required –without relying on massive external datasets for pretraining. We validate our method on three small-size, standard-resoultion, fine-grained datasets: Oxford Flowers-102, Oxford IIIT Pets-37, and ImageNet-100. Despite the challenges of limited data and high intra-class similarity, frozen SCOTT models pretrained with MIM-JEPA significantly outperform fully supervised methods and achieve competitive results with SOTA approaches that rely on large-scale pretraining, complex image augmentations and bigger model sizes. By demonstrating that robust off-the-shelf representations can be learned with limited data, compute, and model sizes, our work paves the way for computer applications in resource constrained environments such as medical imaging or robotics. Our findings challenge the prevailing notion that vast amounts of data are indispensable for effective representation learning in vision, offering a new pathway toward more accessible and inclusive advancements in the field.
对大规模数据集和大量计算资源的依赖已成为推进视觉表示学习的主要障碍,特别是在数据稀缺领域。在这篇论文中,我们提出了一个重要问题:我们能否摆脱在自监督表示学习中对大规模数据的依赖?我们引入了SCOTT(用于Transformer的稀疏卷积标记器),这是一种与掩码图像建模(MIM)任务兼容的浅标记化架构。SCOTT将卷积归纳偏置注入视觉转换器(ViT),提高其在小规模数据情况下的效率。同时,我们建议在MIM框架内采用联合嵌入预测架构(MIM-JEPA)进行训练,在潜在表示空间中进行操作以捕获更多语义特征。我们的方法使ViT能够在传统要求所需数据量的小数倍的数据集上进行从头开始训练,而无需依赖大规模外部数据集进行预训练。我们在三个小尺寸、标准分辨率、细粒度数据集上验证了我们的方法:牛津花-102、牛津IIIT宠物-37和ImageNet-100。尽管面临数据有限和高类内相似性的挑战,但使用MIM-JEPA进行预训练的冻结SCOTT模型显著优于完全监督的方法,并且在依赖于大规模预训练、复杂图像增强和更大模型大小的最先进方法上取得了具有竞争力的结果。通过证明可以使用有限的数据、计算和模型大小来学习稳健的现成表示,我们的工作为资源受限环境(如医学成像或机器人技术)中的计算机应用程序铺平了道路。我们的研究挑战了目前普遍认为的大量数据对于视觉有效表示学习不可或缺的观念,为领域内的更可访问和包容性进步提供了新的途径。
论文及项目相关链接
PDF Code and implementation available at: https://github.com/inescopresearch/scott
摘要
本文探讨了在图像自监督表示学习中是否可以摆脱大数据范式的问题。研究团队引入了名为SCOTT(用于Transformer的稀疏卷积令牌化器)的浅令牌化架构,该架构与Masked Image Modeling(MIM)任务兼容。SCOTT将卷积归纳偏见注入到视觉Transformer(ViT)中,提高了其在小规模数据情况下的效率。同时,研究团队提出了在MIM框架内运行的联合嵌入预测架构(MIM-JEPA),在潜在表示空间中进行操作以捕获更多语义特征。此方法使ViT能够在不使用大规模外部数据集进行预训练的情况下,从少量数据中从头开始训练。在牛津花卉-102、牛津IIIT宠物-37和ImageNet-100三个小规模、标准分辨率、细粒度数据集上验证了该方法的有效性。尽管面临数据有限和高类内相似性的挑战,使用MIM-JEPA进行预训练的冻结SCOTT模型显著优于完全监督的方法,并且在依赖于大规模预训练、复杂图像增强和更大模型大小的最先进方法中取得了具有竞争力的结果。通过证明可以使用有限的数据、计算和模型大小来学习稳健的即用型表示形式,这项工作为资源受限的环境中的计算机应用程序(如医学成像或机器人技术)铺平了道路。研究挑战了现有观念,即大量数据对于有效的视觉表示学习是必不可少的,为计算机视觉领域的更普及和包容性发展提供了新途径。
要点
以下是关键洞察点的七点摘要:
- 该论文提出了SCOTT架构,这是一个适用于Masked Image Modeling(MIM)任务的浅令牌化架构。
- SCOTT将卷积归纳偏见注入到视觉Transformer中,提高了在小规模数据上的效率。
- 研究团队引入了MIM框架内的联合嵌入预测架构(MIM-JEPA),以捕获更多的语义特征。
- 这些方法使得视觉Transformer可以在不使用大规模外部数据集进行预训练的情况下,仅使用少量数据从头开始训练。
- 在三个小规模数据集上的实验结果表明,使用MIM-JEPA预训练的模型表现优越,甚至超过了一些依赖大规模预训练、复杂图像增强和更大模型的最先进方法。
- 该研究挑战了需要大规模数据才能进行视觉表示学习的观念。
点此查看论文截图

Arrhythmia Classification from 12-Lead ECG Signals Using Convolutional and Transformer-Based Deep Learning Models
Authors:Andrei Apostol, Maria Nutu
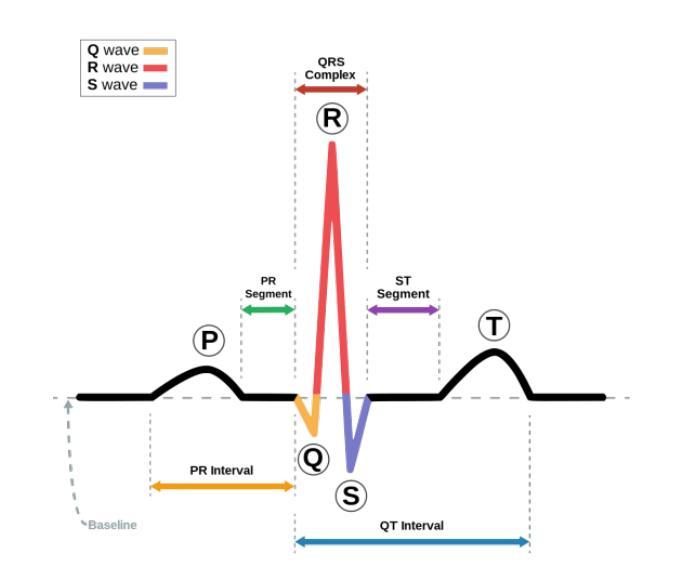
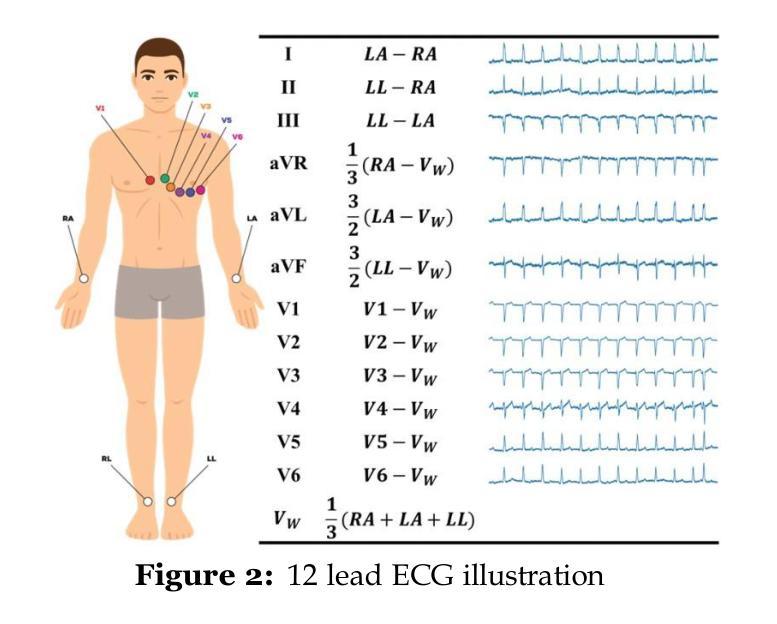
In Romania, cardiovascular problems are the leading cause of death, accounting for nearly one-third of annual fatalities. The severity of this situation calls for innovative diagnosis method for cardiovascular diseases. This article aims to explore efficient, light-weight and rapid methods for arrhythmia diagnosis, in resource-constrained healthcare settings. Due to the lack of Romanian public medical data, we trained our systems using international public datasets, having in mind that the ECG signals are the same regardless the patients’ nationality. Within this purpose, we combined multiple datasets, usually used in the field of arrhythmias classification: PTB-XL electrocardiography dataset , PTB Diagnostic ECG Database, China 12-Lead ECG Challenge Database, Georgia 12-Lead ECG Challenge Database, and St. Petersburg INCART 12-lead Arrhythmia Database. For the input data, we employed ECG signal processing methods, specifically a variant of the Pan-Tompkins algorithm, useful in arrhythmia classification because it provides a robust and efficient method for detecting QRS complexes in ECG signals. Additionally, we used machine learning techniques, widely used for the task of classification, including convolutional neural networks (1D CNNs, 2D CNNs, ResNet) and Vision Transformers (ViTs). The systems were evaluated in terms of accuracy and F1 score. We annalysed our dataset from two perspectives. First, we fed the systems with the ECG signals and the GRU-based 1D CNN model achieved the highest accuracy of 93.4% among all the tested architectures. Secondly, we transformed ECG signals into images and the CNN2D model achieved an accuracy of 92.16%.
在罗马尼亚,心血管问题是导致死亡的主要原因,占年度死亡人数的近三分之一。这种情况的严重性要求对心血管疾病进行创新的诊断方法。本文旨在探索在资源有限的情况下,高效、轻便、快速的心律失常诊断方法。由于缺乏罗马尼亚公共医疗数据,我们使用国际公共数据集来训练我们的系统,考虑到心电图信号与患者的国籍无关。在这一目标下,我们结合了多个通常用于心律失常分类的数据集:PTB-XL心电图数据集、PTB诊断心电图数据库、中国12导联心电图挑战赛数据库、乔治亚州心电图挑战赛数据库和圣彼得堡INCART心律失常数据库。对于输入数据,我们采用心电图信号处理方法,特别是用于心律失常分类的潘汤姆金斯算法的一种变体。这种算法提供了检测和提取心电图信号中QRS复合波的有效且高效的方法。此外,我们还使用了广泛应用于分类任务的机器学习技术,包括卷积神经网络(一维CNN、二维CNN、ResNet)和视觉转换器(ViTs)。系统的评估是基于准确性和F1分数进行的。我们从两个角度对我们的数据集进行了分析。首先,我们用系统输入心电图信号后得出了一维CNN模型的准确率最高,达到所有测试架构中的最高值93.4%。其次,我们将心电图信号转换为图像后,二维CNN模型的准确率为92.16%。
论文及项目相关链接
PDF 34 pages, 17 figures
Summary
罗马尼亚心血管疾病问题严峻,成为主要死亡原因。本研究旨在探索资源受限的医疗环境中高效、轻便、快速的心律失常诊断方法。研究使用国际公开数据集训练模型,结合心电图信号处理方法与机器学习技术,包括一维卷积神经网络(1D CNN)、二维卷积神经网络(2D CNN)、ResNet以及Vision Transformer(ViT)。结果显示,基于GRU的一维卷积神经网络模型准确率最高,达93.4%。当将心电图信号转化为图像时,二维卷积神经网络模型准确率为92.16%。
Key Takeaways
- 心血管疾病在罗马尼亚是主要的死亡原因,占比近三分之一。
- 研究旨在探索资源受限环境下高效、轻便、快速的心律失常诊断方法。
- 研究使用了多个国际公开数据集进行模型训练,包括PTB-XL心电图数据库等。
- 结合心电图信号处理方法,特别是Pan-Tompkins算法,用于心律失常分类。
- 采用机器学习技术,包括一维和二维卷积神经网络、ResNet和Vision Transformer(ViT)。
- 基于GRU的一维卷积神经网络模型表现出最高准确率,达到93.4%。
点此查看论文截图

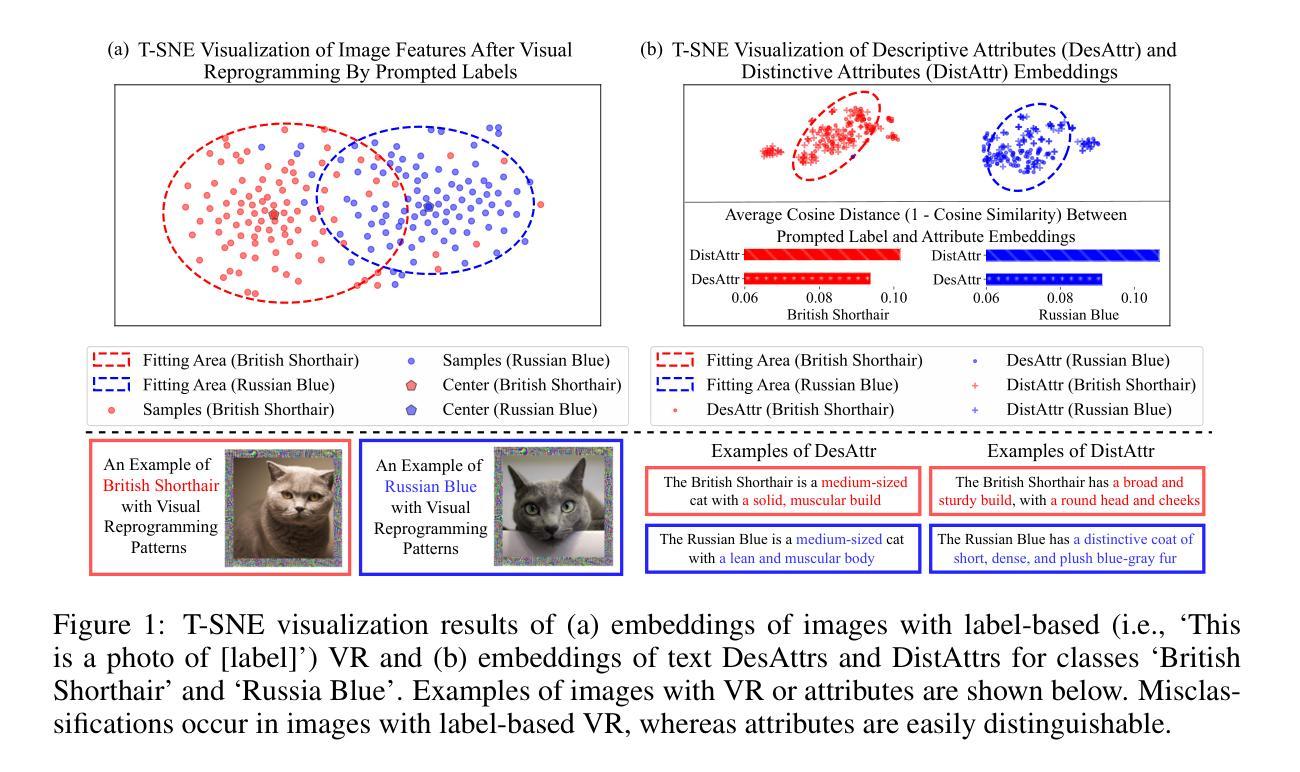
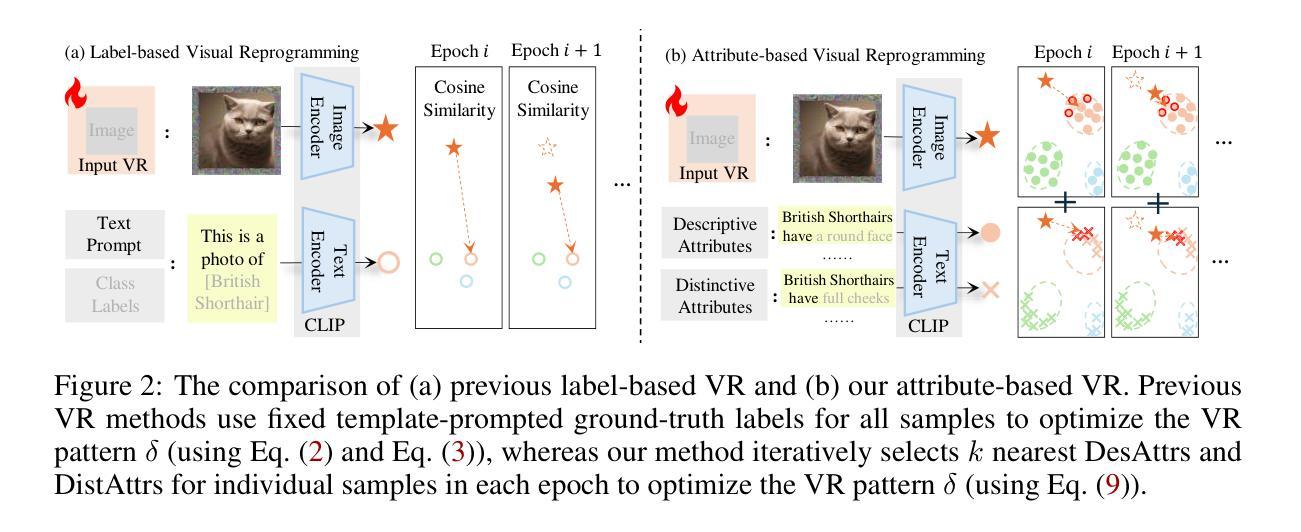
Attribute-based Visual Reprogramming for Vision-Language Models
Authors:Chengyi Cai, Zesheng Ye, Lei Feng, Jianzhong Qi, Feng Liu
Visual reprogramming (VR) reuses pre-trained vision models for downstream image classification tasks by adding trainable noise patterns to inputs. When applied to vision-language models (e.g., CLIP), existing VR approaches follow the same pipeline used in vision models (e.g., ResNet, ViT), where ground-truth class labels are inserted into fixed text templates to guide the optimization of VR patterns. This label-based approach, however, overlooks the rich information and diverse attribute-guided textual representations that CLIP can exploit, which may lead to the misclassification of samples. In this paper, we propose Attribute-based Visual Reprogramming (AttrVR) for CLIP, utilizing descriptive attributes (DesAttrs) and distinctive attributes (DistAttrs), which respectively represent common and unique feature descriptions for different classes. Besides, as images of the same class may reflect different attributes after VR, AttrVR iteratively refines patterns using the $k$-nearest DesAttrs and DistAttrs for each image sample, enabling more dynamic and sample-specific optimization. Theoretically, AttrVR is shown to reduce intra-class variance and increase inter-class separation. Empirically, it achieves superior performance in 12 downstream tasks for both ViT-based and ResNet-based CLIP. The success of AttrVR facilitates more effective integration of VR from unimodal vision models into vision-language models. Our code is available at https://github.com/tmlr-group/AttrVR.
视觉重编程(VR)通过向输入添加可训练的噪声模式,重复使用预训练的视觉模型来进行下游图像分类任务。当应用于视觉语言模型(例如CLIP)时,现有的VR方法遵循与视觉模型(例如ResNet、ViT)相同的管道,将真实标签插入固定文本模板中以引导VR模式的优化。然而,这种基于标签的方法忽视了CLIP可以利用的丰富信息和多样化的属性导向文本表示,这可能导致样本的错误分类。在本文中,我们提出了用于CLIP的属性基视觉重编程(AttrVR),它利用描述性属性(DesAttrs)和区别性属性(DistAttrs),分别代表不同类别的通用和独特特征描述。此外,同一类别的图像在VR后可能会反映出不同的属性,AttrVR迭代地使用每个图像样本的k个最近DesAttrs和DistAttrs来优化模式,从而实现更动态和样本特定的优化。理论上,AttrVR被证明可以减少类内方差并增加类间分离。实际上,它在基于ViT和基于ResNet的CLIP的12个下游任务中实现了卓越的性能。AttrVR的成功促进了从单模态视觉模型到视觉语言模型的VR的更有效集成。我们的代码可在https://github.com/tmlr-group/AttrVR处获得。
论文及项目相关链接
Summary
本文提出了一种基于属性的视觉重编程(AttrVR)方法,用于CLIP模型。该方法利用描述性属性和区别性属性,对同一类别的图像样本进行迭代优化,减少类内差异,增加类间分离。在多个下游任务中,AttrVR实现了对基于ViT和基于ResNet的CLIP模型的优越性能。
Key Takeaways
- Visual Reprogramming (VR)技术通过给输入添加可训练的噪声模式来重用预训练的视觉模型进行下游图像分类任务。
- 现有VR方法在应用至视觉语言模型(如CLIP)时,遵循与视觉模型相同的流程,使用固定的文本模板插入真实标签来指导优化VR模式。
- 本文提出了一种新的方法——Attribute-based Visual Reprogramming (AttrVR),利用描述性属性(DesAttrs)和区别性属性(DistAttrs)来代表不同类别的通用和独特特征描述。
- AttrVR通过迭代使用k近邻法细化每个图像样本的DesAttrs和DistAttrs模式,实现了更动态和样本特定的优化。
- 理论分析表明,AttrVR能减少类内差异,增加类间分离。
- 实证结果显示,AttrVR在基于ViT和基于ResNet的CLIP模型的12个下游任务中实现了优越的性能。
点此查看论文截图