⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-01 更新
UIFace: Unleashing Inherent Model Capabilities to Enhance Intra-Class Diversity in Synthetic Face Recognition
Authors:Xiao Lin, Yuge Huang, Jianqing Xu, Yuxi Mi, Shuigeng Zhou, Shouhong Ding
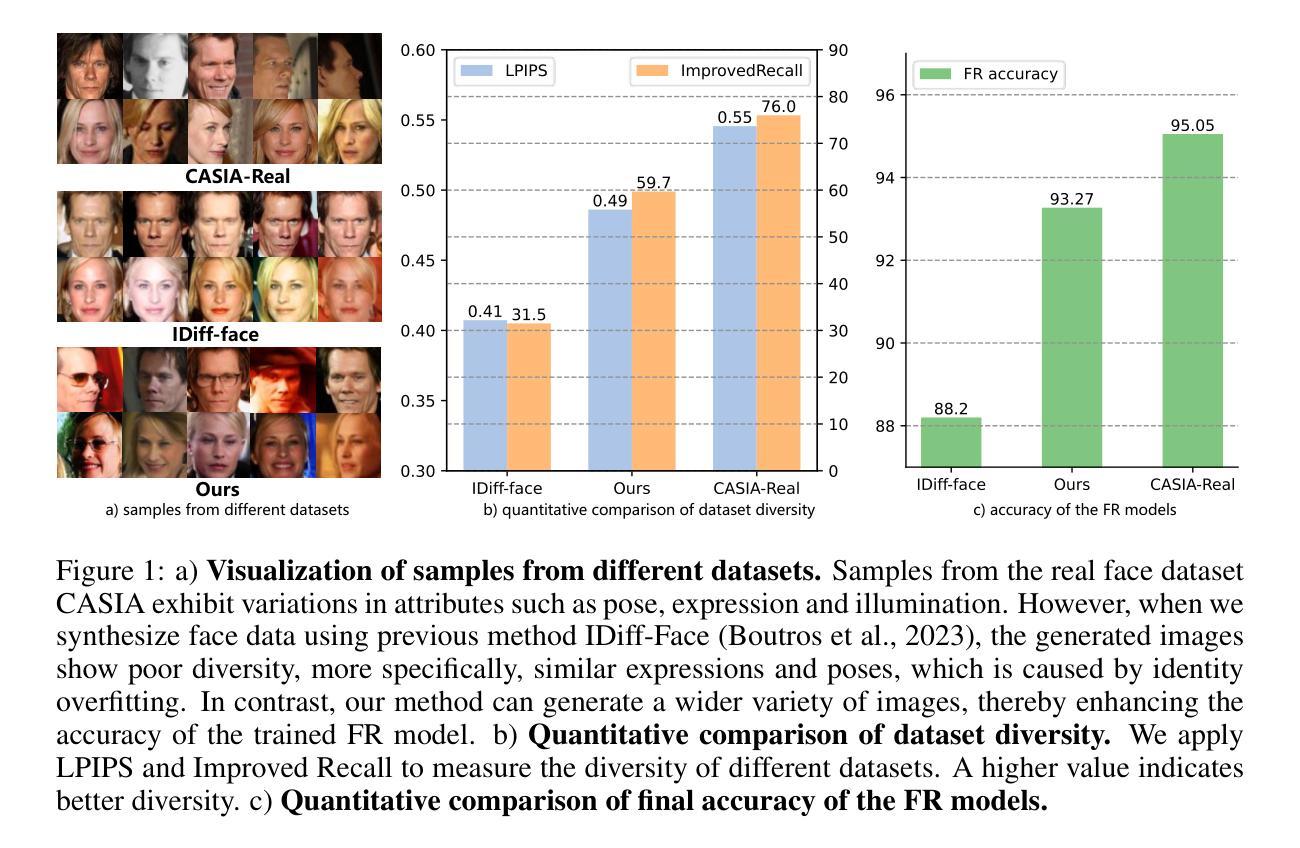
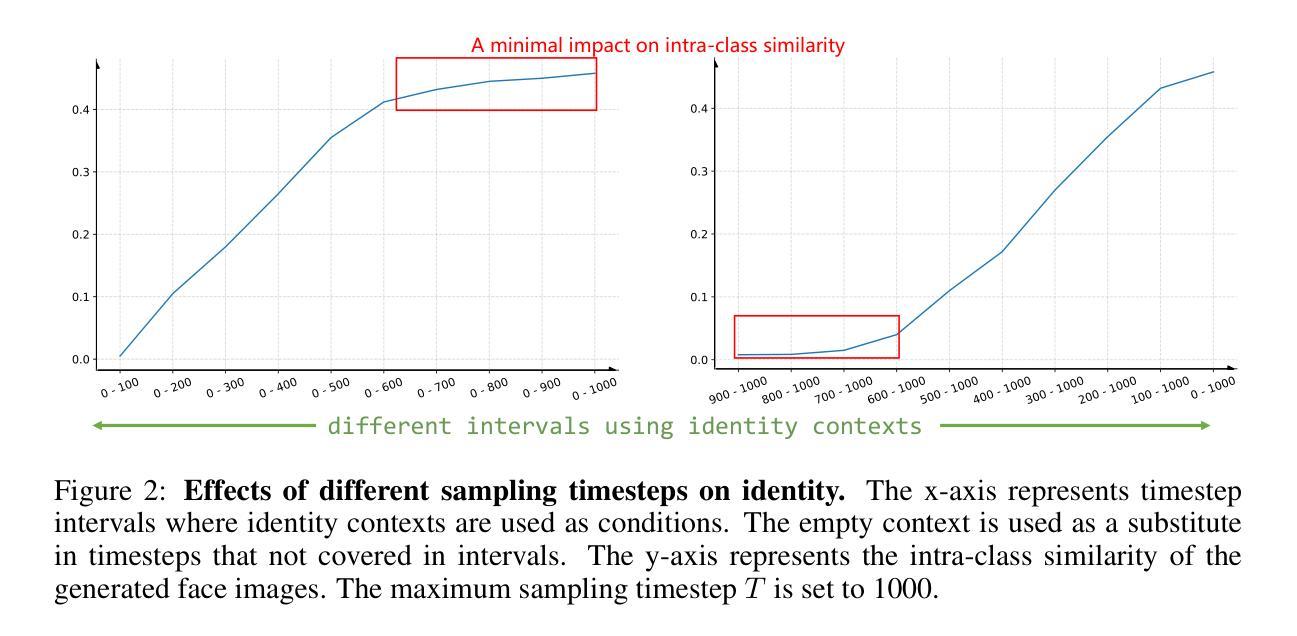
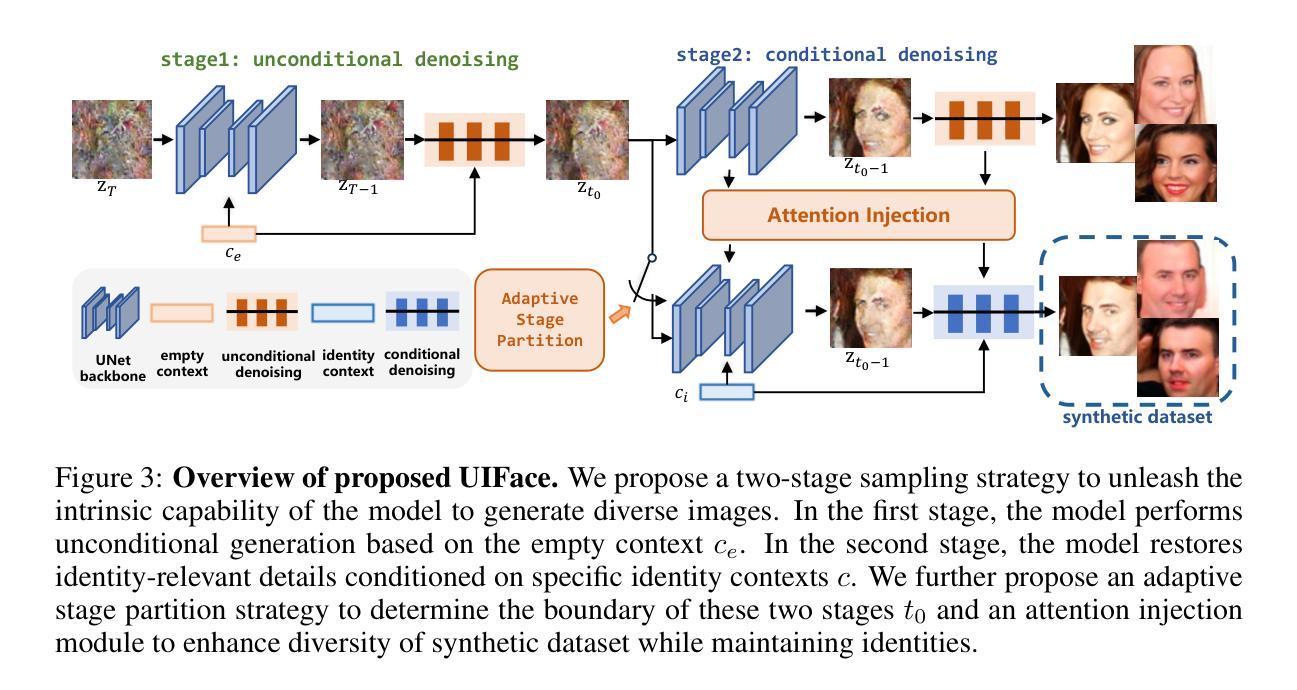
Face recognition (FR) stands as one of the most crucial applications in computer vision. The accuracy of FR models has significantly improved in recent years due to the availability of large-scale human face datasets. However, directly using these datasets can inevitably lead to privacy and legal problems. Generating synthetic data to train FR models is a feasible solution to circumvent these issues. While existing synthetic-based face recognition methods have made significant progress in generating identity-preserving images, they are severely plagued by context overfitting, resulting in a lack of intra-class diversity of generated images and poor face recognition performance. In this paper, we propose a framework to Unleash Inherent capability of the model to enhance intra-class diversity for synthetic face recognition, shortened as UIFace. Our framework first trains a diffusion model that can perform sampling conditioned on either identity contexts or a learnable empty context. The former generates identity-preserving images but lacks variations, while the latter exploits the model’s intrinsic ability to synthesize intra-class-diversified images but with random identities. Then we adopt a novel two-stage sampling strategy during inference to fully leverage the strengths of both types of contexts, resulting in images that are diverse as well as identitypreserving. Moreover, an attention injection module is introduced to further augment the intra-class variations by utilizing attention maps from the empty context to guide the sampling process in ID-conditioned generation. Experiments show that our method significantly surpasses previous approaches with even less training data and half the size of synthetic dataset. The proposed UIFace even achieves comparable performance with FR models trained on real datasets when we further increase the number of synthetic identities.
人脸识别(FR)是计算机视觉领域最重要的应用之一。由于大规模人脸数据集的可用性,FR模型的准确性在近年来得到了显著提高。然而,直接使用这些数据集不可避免地会引发隐私和法律问题。生成合成数据来训练FR模型是避免这些问题的可行解决方案。虽然现有的基于合成的人脸识别方法已经在生成身份保留图像方面取得了显著进展,但它们受到上下文过拟合的严重影响,导致生成的图像缺乏类内多样性和人脸识别性能较差。在本文中,我们提出了一个框架来释放模型的内在能力,以提高合成人脸识别的类内多样性,简称为UIFace。我们的框架首先训练一个扩散模型,该模型可以在身份上下文或可学习的空上下文条件下进行采样。前者可以生成身份保留的图像,但缺乏变化;后者则利用模型合成类内多样化图像的内在能力,但具有随机身份。然后,我们在推理过程中采用了新型的两阶段采样策略,以充分利用两种类型的上下文的优点,从而生成既多样化又保留身份的图像。此外,还引入了一个注意力注入模块,通过利用空上下文中的注意力图来指导ID条件生成中的采样过程,从而进一步增加类内变化。实验表明,我们的方法即使使用更少的训练数据和一半大小的合成数据集也显著超越了以前的方法。当我们进一步增加合成身份的数量时,所提出的UIFace甚至实现了与在真实数据集上训练的FR模型相当的性能。
论文及项目相关链接
PDF ICLR2025
摘要
人脸识别(FR)是计算机视觉领域最重要的应用之一。近年来,由于大规模人脸数据集的可用性,FR模型的准确性得到了显著提高。然而,直接使用这些数据集不可避免地会引发隐私和法律问题。生成合成数据来训练FR模型是解决这些问题的可行解决方案。虽然现有的基于合成的人脸识别方法已经在生成身份保留图像方面取得了重大进展,但它们受到上下文过拟合的严重困扰,导致生成的图像缺乏类内多样性和人脸识别性能下降。本文提出了一个框架,旨在释放模型的内在能力以增强合成人脸识别的类内多样性,简称为UIFace。我们的框架首先训练一个扩散模型,该模型可以在身份上下文或可学习的空上下文条件下进行采样。前者可以生成身份保留的图像,但缺乏变化;而后者则利用模型固有的合成类内多样化图像的能力,但具有随机身份。然后,我们在推理过程中采用了新型的两阶段采样策略,充分结合了两种类型上下文的优势,从而生成了既多样化又保留身份的图像。此外,还引入了一个注意力注入模块,利用空上下文中的注意力图来指导采样过程,进一步增强了类内变化。实验表明,我们的方法显著优于使用更少训练数据和一半大小合成数据集的前人方法。当我们进一步增加合成身份的数量时,所提出的UIFace甚至实现了与在真实数据集上训练的FR模型相当的性能。
关键见解
- 人脸识别(FR)是计算机视觉领域的重要应用,近年来由于大规模数据集的可用性,FR模型的准确性有所提高。
- 直接使用大规模人脸数据集可能引发隐私和法律问题。
- 现有基于合成的方法在生成人脸识别图像时面临上下文过拟合问题,导致类内多样性不足。
- 本文提出了一个框架UIFace,结合扩散模型和两阶段采样策略,旨在增强合成人脸识别的类内多样性。
- UIFace框架通过训练扩散模型在身份上下文和空上下文条件下进行采样,以生成既多样化又保留身份图像。
- 引入注意力注入模块,利用空上下文中的注意力图增强类内变化。
点此查看论文截图