⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-01 更新
Avat3r: Large Animatable Gaussian Reconstruction Model for High-fidelity 3D Head Avatars
Authors:Tobias Kirschstein, Javier Romero, Artem Sevastopolsky, Matthias Nießner, Shunsuke Saito
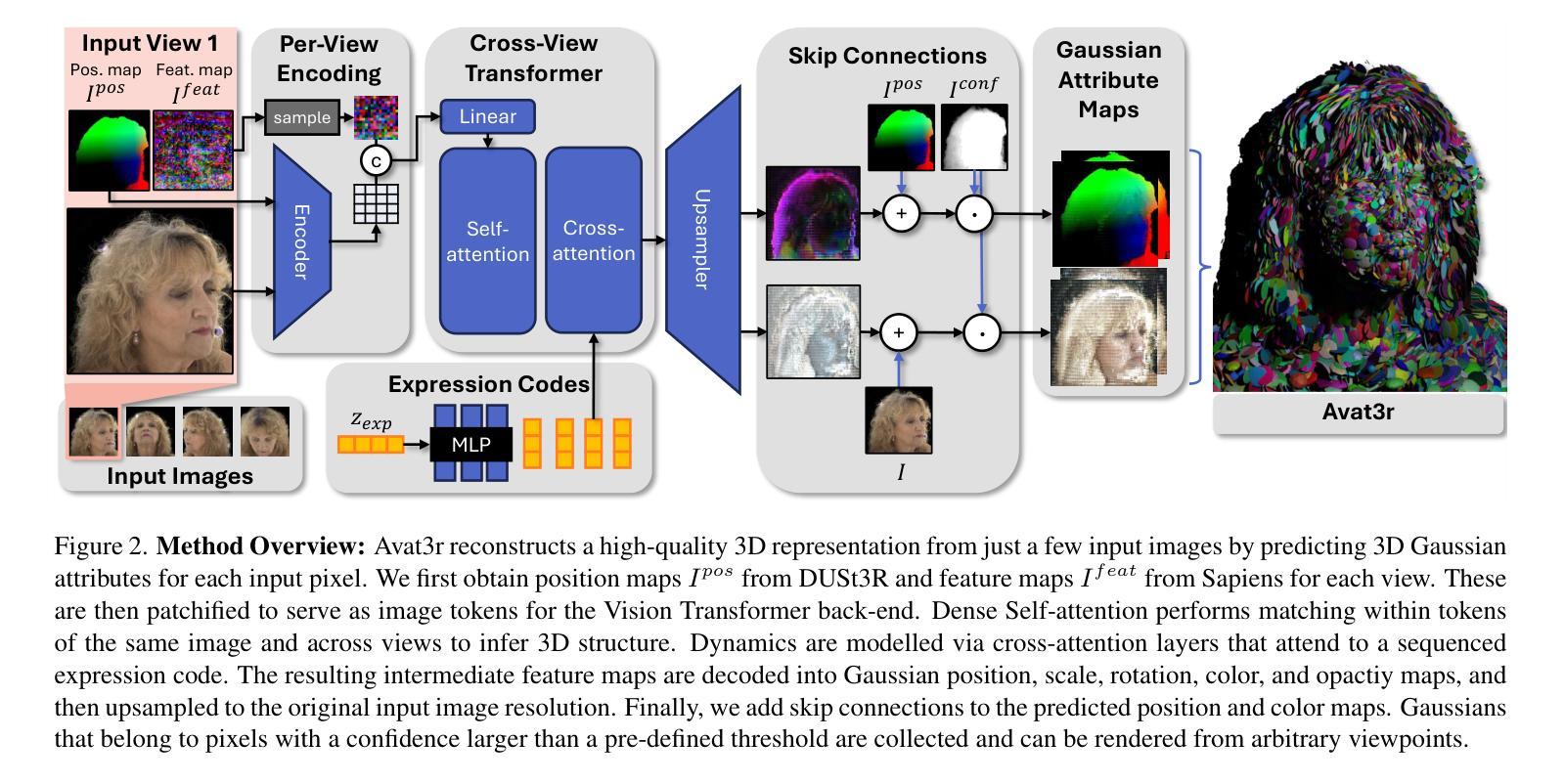
Traditionally, creating photo-realistic 3D head avatars requires a studio-level multi-view capture setup and expensive optimization during test-time, limiting the use of digital human doubles to the VFX industry or offline renderings. To address this shortcoming, we present Avat3r, which regresses a high-quality and animatable 3D head avatar from just a few input images, vastly reducing compute requirements during inference. More specifically, we make Large Reconstruction Models animatable and learn a powerful prior over 3D human heads from a large multi-view video dataset. For better 3D head reconstructions, we employ position maps from DUSt3R and generalized feature maps from the human foundation model Sapiens. To animate the 3D head, our key discovery is that simple cross-attention to an expression code is already sufficient. Finally, we increase robustness by feeding input images with different expressions to our model during training, enabling the reconstruction of 3D head avatars from inconsistent inputs, e.g., an imperfect phone capture with accidental movement, or frames from a monocular video. We compare Avat3r with current state-of-the-art methods for few-input and single-input scenarios, and find that our method has a competitive advantage in both tasks. Finally, we demonstrate the wide applicability of our proposed model, creating 3D head avatars from images of different sources, smartphone captures, single images, and even out-of-domain inputs like antique busts. Project website: https://tobias-kirschstein.github.io/avat3r/
传统上,创建逼真的3D头像需要工作室级别的多角度捕捉设置和昂贵的测试时间优化,这限制了数字人类双胞胎在视觉效果行业或离线渲染中的应用。为了解决这个问题,我们推出了Avat3r,它仅从少数输入图像中回归高质量和可动画的3D头像,大大降低了推理过程中的计算要求。更具体地说,我们使大型重建模型具备动画功能,并从大型多角度视频数据集中学习强大的3D人头的先验知识。为了更好地重建3D头像,我们采用了DUSt3R的位置图和人类基础模型Sapiens的通用特征图。为了动画化3D头像,我们的关键发现是简单的表情编码交叉注意力已经足够。最后,我们在训练期间通过输入具有不同表情的图像来增强模型的稳健性,从而能够从不一致的输入(例如带有意外移动的拍摄不良的手机图像或来自单目视频的画面)重建出3D头像。我们将Avat3r与当前最先进的少输入和单输入场景方法进行了比较,发现我们的方法在两项任务中都具有竞争优势。最后,我们展示了所提出模型的广泛适用性,可从不同来源的图像、智能手机拍摄、单幅图像以及甚至超出域的输入(如古代半身雕像)创建出3D头像。项目网站:https://tobias-kirschstein.github.io/avat3r/
论文及项目相关链接
PDF Project website: https://tobias-kirschstein.github.io/avat3r/, Video: https://youtu.be/P3zNVx15gYs
Summary
本文介绍了一种名为Avat3r的新技术,该技术能够从少量输入图像生成高质量且可动画的3D头像。它解决了传统创建照片级真实感的3D头像需要昂贵的多视角捕捉设备和测试时的优化成本问题,使得数字人类的应用不再局限于VFX行业或离线渲染。Avat3r通过学习强大的3D人头先验知识,采用位置映射和通用特征映射技术,实现更好的3D头像重建。其关键发现是通过简单的表情代码交叉注意力机制,就能够使3D头像动画化。此外,该模型在训练过程中通过输入不同表情的图像增强稳健性,能够从不一致的输入中重建3D头像,如手机拍摄时的意外移动或单目视频中的帧。对比当前先进的方法,Avat3r在少输入和单输入场景中均表现出竞争优势,且能够广泛应用于不同来源的图像、智能手机拍摄、单张图片以及域外输入如古董肖像等。
Key Takeaways
- Avat3r技术能够从少量输入图像创建高质量、可动画的3D头像。
- 解决了传统创建3D头像需要昂贵设备和复杂测试流程的问题。
- 通过学习强大的3D人头先验知识,采用位置映射和通用特征映射技术实现更好的重建。
- 简单的表情代码交叉注意力机制使3D头像动画化。
- 模型在训练过程中通过不同表情的输入图像增强稳健性,适用于不一致的输入。
- Avat3r在少输入和单输入场景中具有竞争优势。
点此查看论文截图



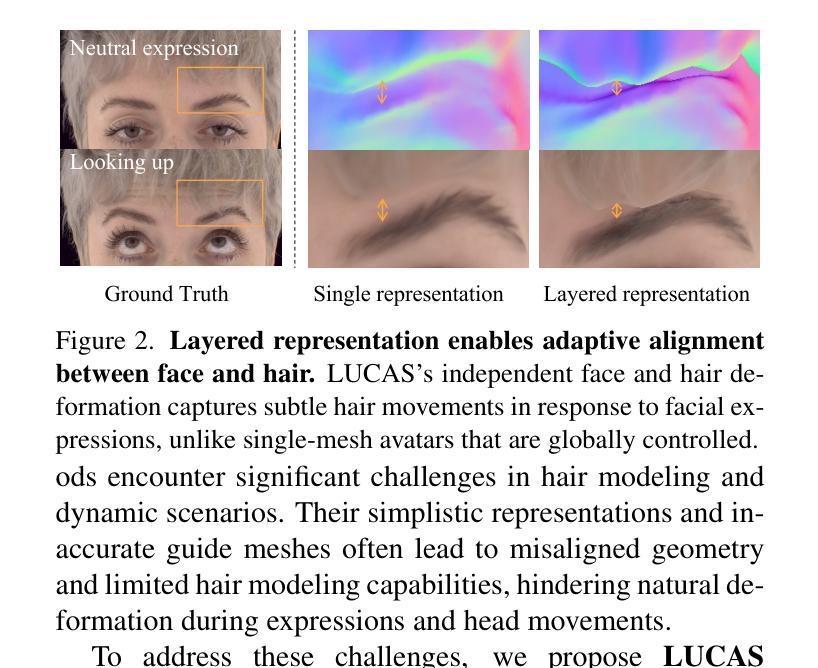
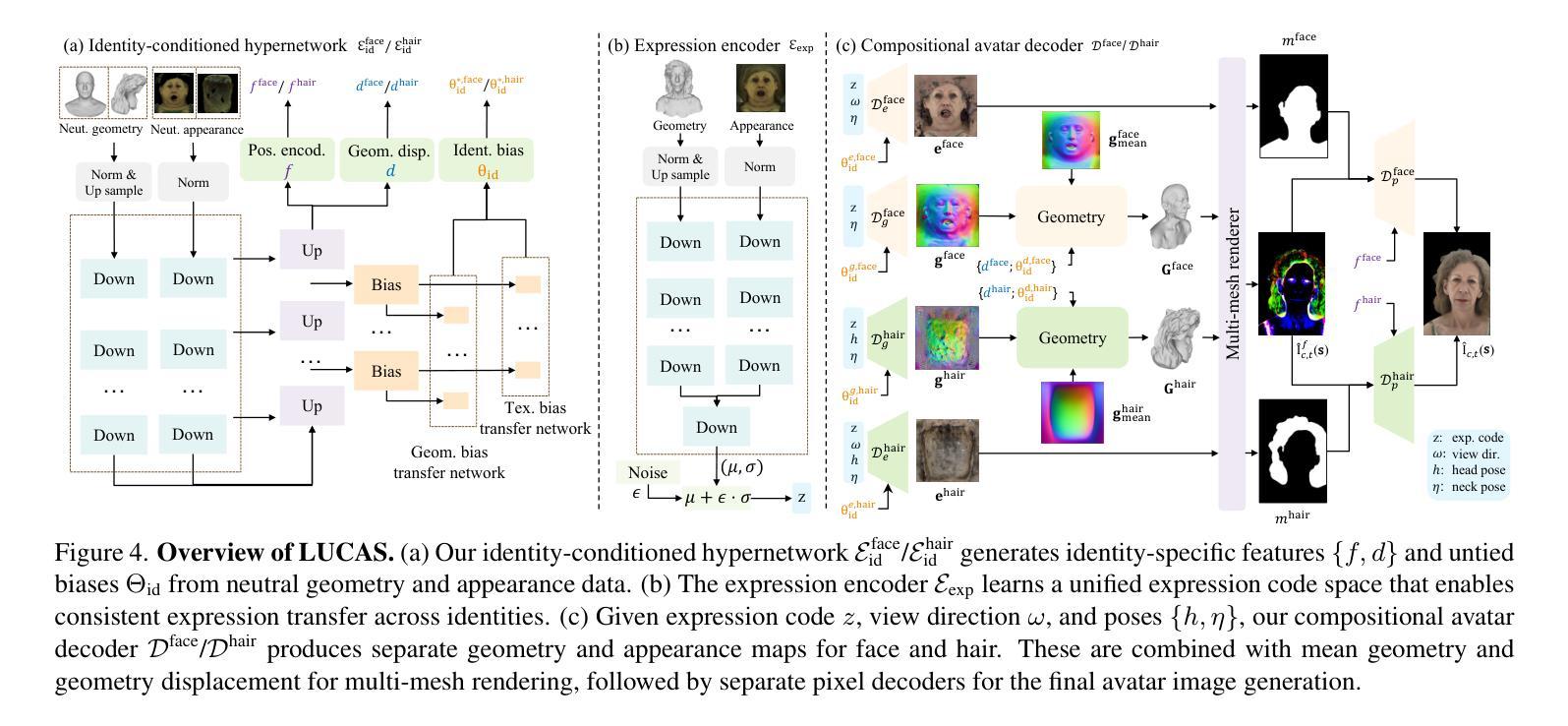
LUCAS: Layered Universal Codec Avatars
Authors:Di Liu, Teng Deng, Giljoo Nam, Yu Rong, Stanislav Pidhorskyi, Junxuan Li, Jason Saragih, Dimitris N. Metaxas, Chen Cao
Photorealistic 3D head avatar reconstruction faces critical challenges in modeling dynamic face-hair interactions and achieving cross-identity generalization, particularly during expressions and head movements. We present LUCAS, a novel Universal Prior Model (UPM) for codec avatar modeling that disentangles face and hair through a layered representation. Unlike previous UPMs that treat hair as an integral part of the head, our approach separates the modeling of the hairless head and hair into distinct branches. LUCAS is the first to introduce a mesh-based UPM, facilitating real-time rendering on devices. Our layered representation also improves the anchor geometry for precise and visually appealing Gaussian renderings. Experimental results indicate that LUCAS outperforms existing single-mesh and Gaussian-based avatar models in both quantitative and qualitative assessments, including evaluations on held-out subjects in zero-shot driving scenarios. LUCAS demonstrates superior dynamic performance in managing head pose changes, expression transfer, and hairstyle variations, thereby advancing the state-of-the-art in 3D head avatar reconstruction.
在逼真3D头部化身重建过程中,模拟动态面部与头发之间的交互以及实现跨身份泛化,特别是在表情和头部运动过程中,面临着严峻挑战。我们提出了LUCAS,这是一种新型通用先验模型(UPM)编解码化身建模方法,它通过分层表示来分离面部和头发。与之前的将头发视为头部整体的UPM不同,我们的方法将无发头部和头发的建模分开成不同的分支。LUCAS是首个引入基于网格的UPM的方法,可在设备上实现实时渲染。我们的分层表示还可以改善锚点几何,以实现精确和视觉吸引力强的高斯渲染。实验结果表明,LUCAS在定量和定性评估上均优于现有的单网格和基于高斯的面容模型,包括对未见过的受试者在零驾驶场景中的评估。LUCAS在头部姿态变化、表情转移和发型变化方面表现出卓越的动态性能,从而推动了3D头部化身重建领域的最新技术。
论文及项目相关链接
Summary
该文章介绍了LUCAS系统,这是一种新型的通用先验模型(UPM),用于对3D头像角色模型进行分层表示,并在建立角色模型时将脸和头发进行分离处理。这种新型的分层处理方式能够提高头发模型和面部模型的精确性和可移植性,使得角色模型在动态表情、头部姿态变化以及发型变化等方面表现出卓越的性能。相较于传统的单网格和基于高斯的角色模型,LUCAS模型在定量和定性评估中都表现出更高的性能。此外,LUCAS模型还首次引入了基于网格的UPM,支持在设备上进行实时渲染。
Key Takeaways
- LUCAS采用新型通用先验模型(UPM)用于对动态角色模型的3D头像重建。
- LUCAS通过分层表示法将面部和头发模型分离处理,以提高模型的精确性和可移植性。
- 与传统的单网格和基于高斯的角色模型相比,LUCAS模型性能更优异,表现在处理头部姿态变化、表情传递和发型变化等方面。
- LUCAS能够应对零样本驱动场景下的性能挑战,适用于广泛的跨身份泛化任务。
- LUCAS模型首次引入了基于网格的UPM,便于实时渲染在设备上的实现。
点此查看论文截图