⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-01 更新
Enhanced Contrastive Learning with Multi-view Longitudinal Data for Chest X-ray Report Generation
Authors:Kang Liu, Zhuoqi Ma, Xiaolu Kang, Yunan Li, Kun Xie, Zhicheng Jiao, Qiguang Miao
Automated radiology report generation offers an effective solution to alleviate radiologists’ workload. However, most existing methods focus primarily on single or fixed-view images to model current disease conditions, which limits diagnostic accuracy and overlooks disease progression. Although some approaches utilize longitudinal data to track disease progression, they still rely on single images to analyze current visits. To address these issues, we propose enhanced contrastive learning with Multi-view Longitudinal data to facilitate chest X-ray Report Generation, named MLRG. Specifically, we introduce a multi-view longitudinal contrastive learning method that integrates spatial information from current multi-view images and temporal information from longitudinal data. This method also utilizes the inherent spatiotemporal information of radiology reports to supervise the pre-training of visual and textual representations. Subsequently, we present a tokenized absence encoding technique to flexibly handle missing patient-specific prior knowledge, allowing the model to produce more accurate radiology reports based on available prior knowledge. Extensive experiments on MIMIC-CXR, MIMIC-ABN, and Two-view CXR datasets demonstrate that our MLRG outperforms recent state-of-the-art methods, achieving a 2.3% BLEU-4 improvement on MIMIC-CXR, a 5.5% F1 score improvement on MIMIC-ABN, and a 2.7% F1 RadGraph improvement on Two-view CXR.
自动放射学报告生成为解决放射科医生的工作负担提供了有效的解决方案。然而,大多数现有方法主要关注单个或固定视角的图像来建模当前疾病状况,这限制了诊断的准确性并忽略了疾病进展。虽然有些方法利用纵向数据来跟踪疾病进展,但它们仍然依赖单张图像来分析当前就诊情况。为了解决这些问题,我们提出了利用多视角纵向数据的增强对比学习来促进胸部X射线报告生成,命名为MLRG。具体来说,我们引入了一种多视角纵向对比学习方法,该方法结合了当前多视角图像的空间信息和纵向数据的时序信息。该方法还利用放射学报告中的固有时空信息来监督视觉和文本表示的预训练。随后,我们提出了一种标记缺失编码技术,可以灵活地处理特定的患者缺失知识,使模型能够根据可用的先前知识生成更准确的放射学报告。在MIMIC-CXR、MIMIC-ABN和Two-view CXR数据集上的大量实验表明,我们的MLRG超越了最近的最先进方法,在MIMIC-CXR上实现了BLEU-4得分提高2.3%,在MIMIC-ABN上F1得分提高5.5%,在Two-view CXR上F1 RadGraph得分提高2.7%。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
针对放射科医生工作量大且诊断准确度受限的问题,本文提出一种基于多视角纵向数据的对比学习方法的改进方案,旨在优化自动生成的胸部X光报告。该方案结合当前多视角图像的时空信息和历史纵向数据,并利用放射报告的时空信息预训练视觉和文字表达模型。同时,采用一种标记缺失编码技术处理患者特定先验知识的缺失问题,使模型能够在可用的先验知识基础上生成更准确的报告。实验结果证明了其在三个数据集上的性能优于其他先进方法。
Key Takeaways
- 本文旨在解决放射科医生工作量大且诊断准确度受限的问题。
- 提出一种基于多视角纵向对比学习的方法用于自动生成胸部X光报告。
- 结合当前多视角图像的时空信息和历史纵向数据来提高诊断准确性。
- 利用放射报告的时空信息预训练视觉和文字表达模型。
- 采用标记缺失编码技术处理患者特定先验知识的缺失问题。
- 在三个数据集上的实验结果表明,该方法在性能上优于其他先进方法。
点此查看论文截图

Lightweight Contrastive Distilled Hashing for Online Cross-modal Retrieval
Authors:Jiaxing Li, Lin Jiang, Zeqi Ma, Kaihang Jiang, Xiaozhao Fang, Jie Wen
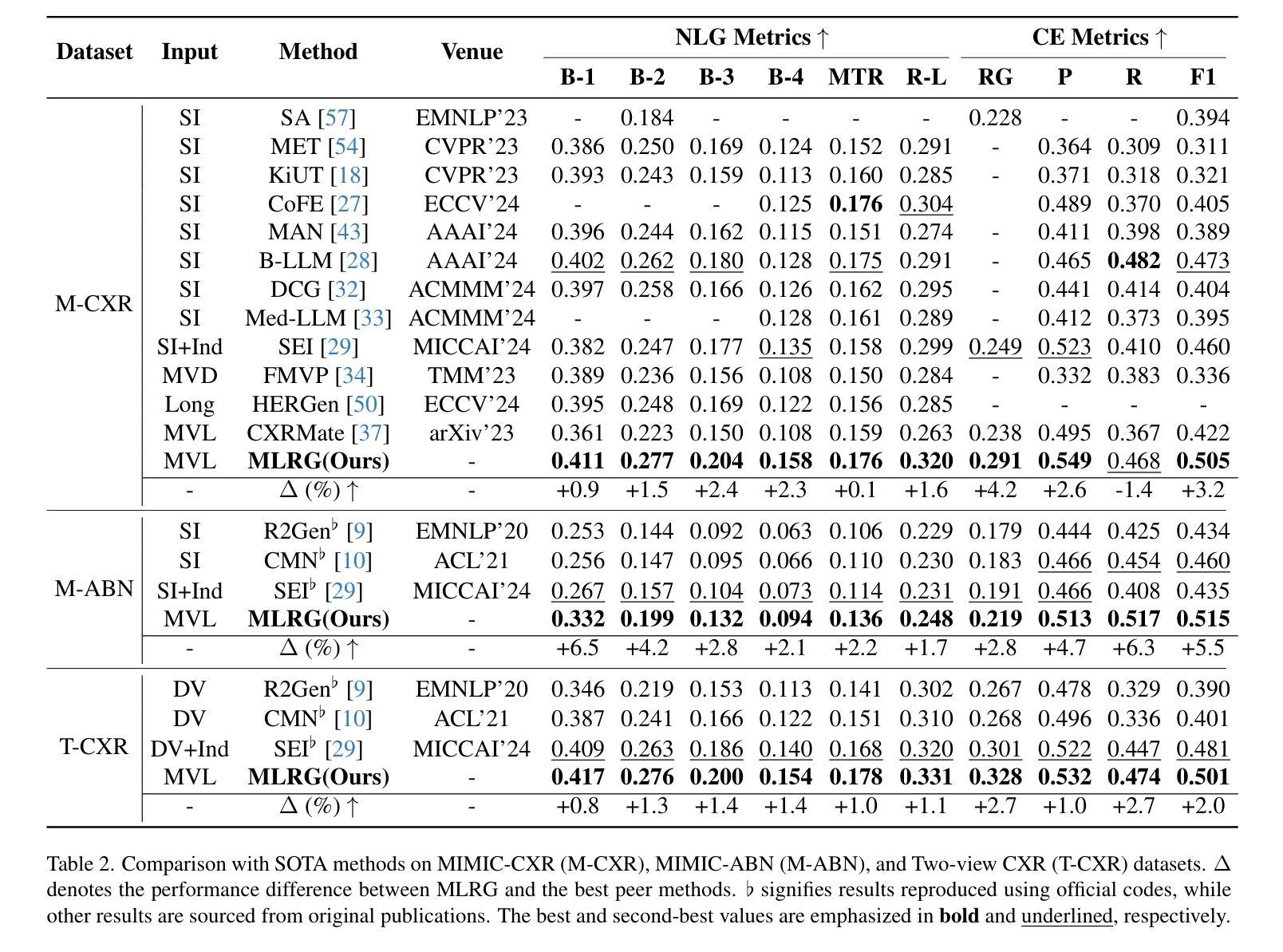
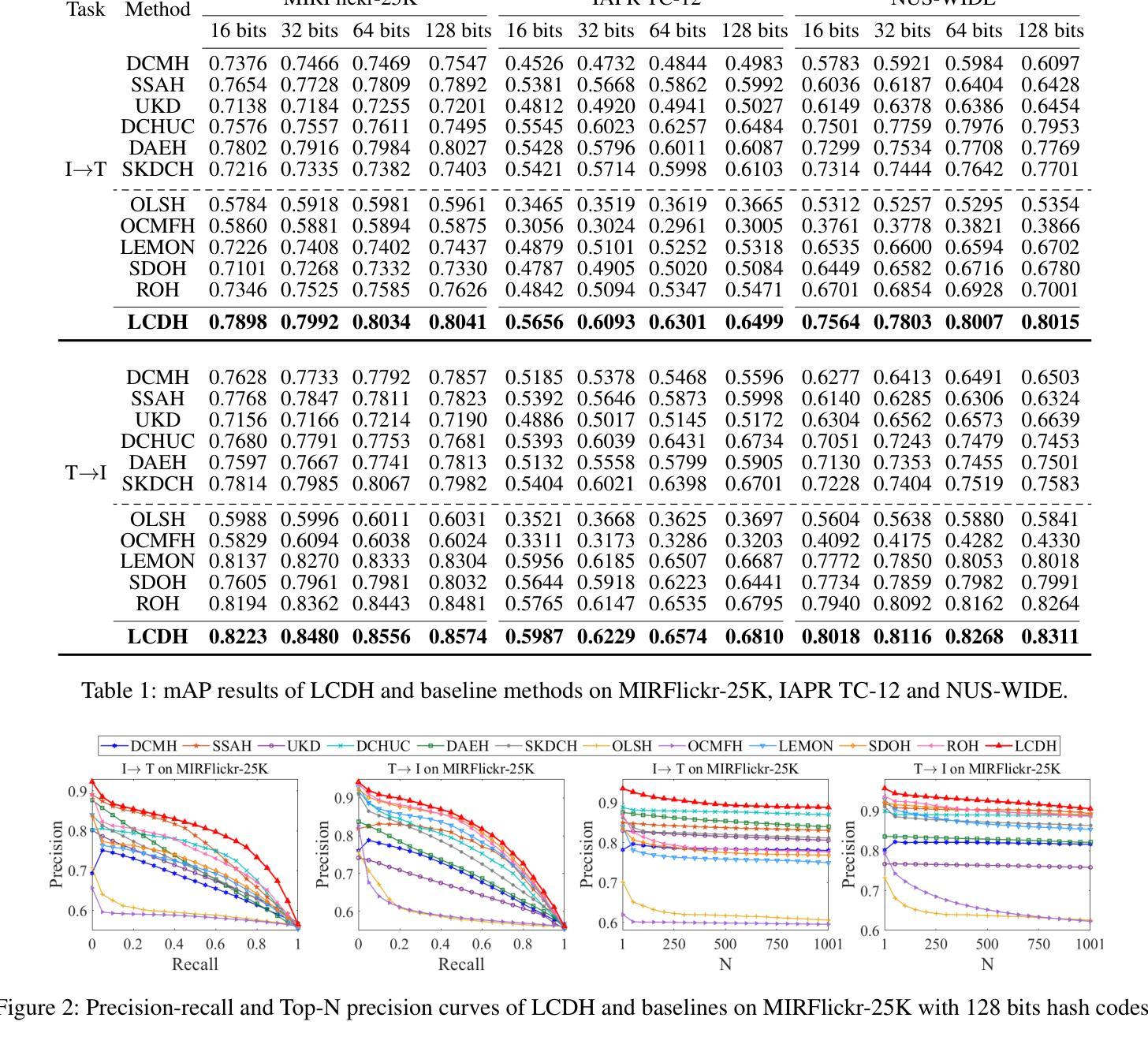
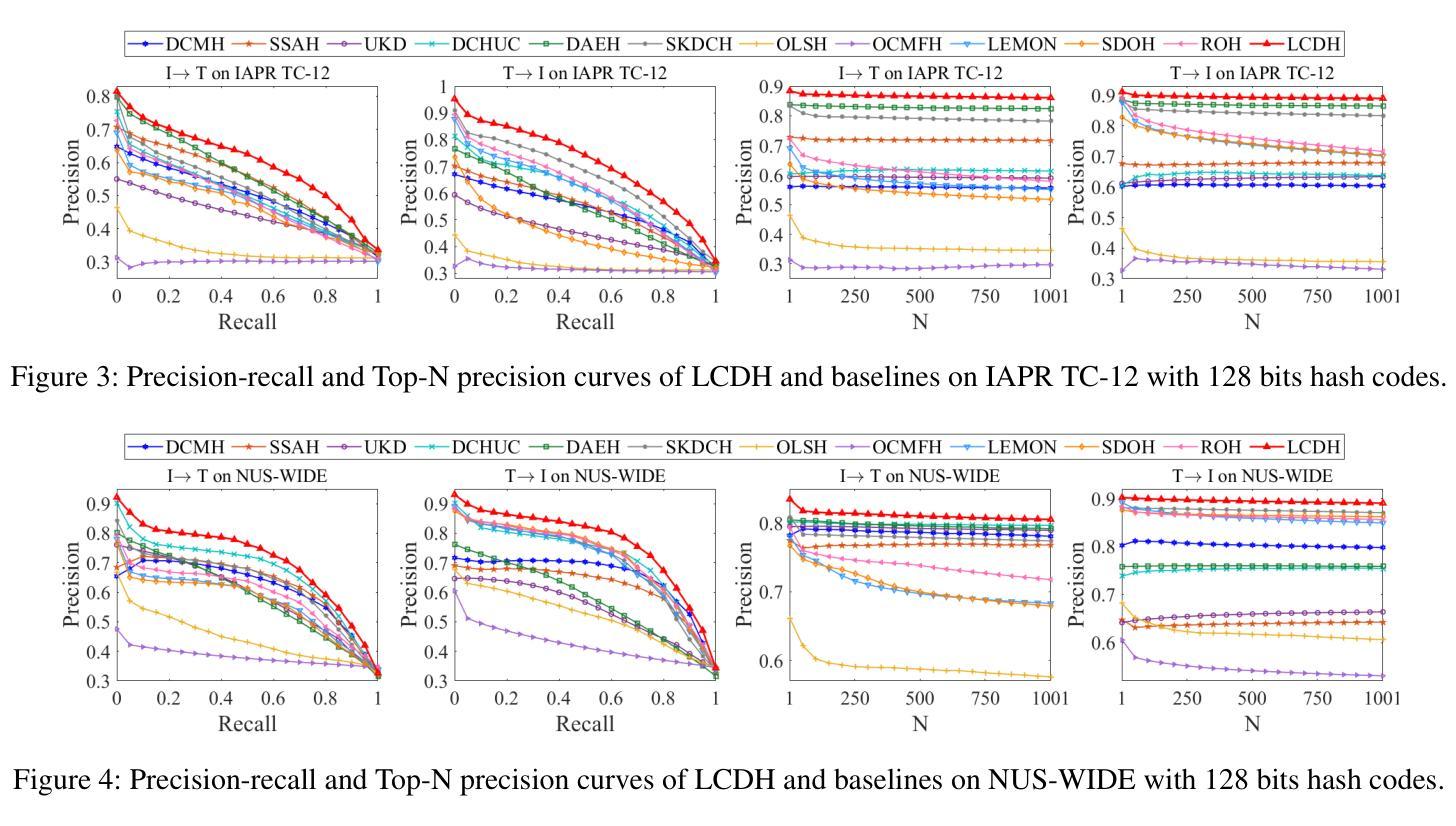
Deep online cross-modal hashing has gained much attention from researchers recently, as its promising applications with low storage requirement, fast retrieval efficiency and cross modality adaptive, etc. However, there still exists some technical hurdles that hinder its applications, e.g., 1) how to extract the coexistent semantic relevance of cross-modal data, 2) how to achieve competitive performance when handling the real time data streams, 3) how to transfer the knowledge learned from offline to online training in a lightweight manner. To address these problems, this paper proposes a lightweight contrastive distilled hashing (LCDH) for cross-modal retrieval, by innovatively bridging the offline and online cross-modal hashing by similarity matrix approximation in a knowledge distillation framework. Specifically, in the teacher network, LCDH first extracts the cross-modal features by the contrastive language-image pre-training (CLIP), which are further fed into an attention module for representation enhancement after feature fusion. Then, the output of the attention module is fed into a FC layer to obtain hash codes for aligning the sizes of similarity matrices for online and offline training. In the student network, LCDH extracts the visual and textual features by lightweight models, and then the features are fed into a FC layer to generate binary codes. Finally, by approximating the similarity matrices, the performance of online hashing in the lightweight student network can be enhanced by the supervision of coexistent semantic relevance that is distilled from the teacher network. Experimental results on three widely used datasets demonstrate that LCDH outperforms some state-of-the-art methods.
深度在线跨模态哈希技术近期受到研究人员的广泛关注,因其具有低存储需求、快速检索效率以及跨模态适应性等潜在应用前景。然而,仍存在一些技术障碍阻碍其应用,例如1)如何提取跨模态数据的共存语义相关性,2)如何处理实时数据流以取得竞争性的性能,以及3)如何将离线学习到的知识以轻便的方式转移到在线训练中。为了解决这些问题,本文提出了一种用于跨模态检索的轻量级对比蒸馏哈希(LCDH),通过知识蒸馏框架中的相似度矩阵近似,创新性地桥接了离线与在线跨模态哈希。具体来说,在教师网络中,LCDH首先通过对比语言图像预训练(CLIP)提取跨模态特征,这些特征在特征融合后进一步输入到注意力模块中进行表示增强。然后,将注意力模块的输出输入到全连接层中以获得哈希码,以对齐在线和离线训练的相似度矩阵大小。在学生网络中,LCDH通过轻量级模型提取视觉和文本特征,然后将特征输入到全连接层中以生成二进制代码。最后,通过近似相似度矩阵,学生网络中在线哈希的性能可以通过从教师网络中提炼出来的共存语义相关性的监督来增强。在三个广泛使用的数据集上的实验结果表明,LCDH优于一些最先进的方法。
论文及项目相关链接
Summary
这篇论文针对深度在线跨模态哈希技术存在的问题,提出了一种轻量级的对比蒸馏哈希(LCDH)方法,用于跨模态检索。该方法通过知识蒸馏框架中的相似度矩阵近似,创新性地连接了离线与在线跨模态哈希。LCDH在老师网络中利用对比语言图像预训练(CLIP)提取跨模态特征,通过注意力模块增强表示后进行特征融合。在学生网络中,使用轻量级模型提取视觉和文本特征,然后通过FC层生成二进制代码。通过近似相似度矩阵,可以提高轻量级学生网络的在线哈希性能,通过老师网络蒸馏出的共现语义相关性进行监督。实验结果表明,LCDH在某些广泛使用的数据集上的性能优于一些最先进的方法。
Key Takeaways
- 深度在线跨模态哈希具有低存储要求、快速检索效率和跨模态适应性等应用前景,但仍存在技术难题。
- LCDH方法通过知识蒸馏和相似度矩阵近似连接离线与在线跨模态哈希。
- LCDH利用对比语言图像预训练(CLIP)提取跨模态特征,并通过注意力模块增强特征表示。
- 在学生网络中,使用轻量级模型处理视觉和文本特征,并通过FC层生成二进制代码。
- 通过近似相似度矩阵,可以提高在线哈希性能,利用老师网络蒸馏出的共现语义相关性进行监督。
- LCDH在三个广泛使用的数据集上的性能优于一些最先进的方法。
点此查看论文截图

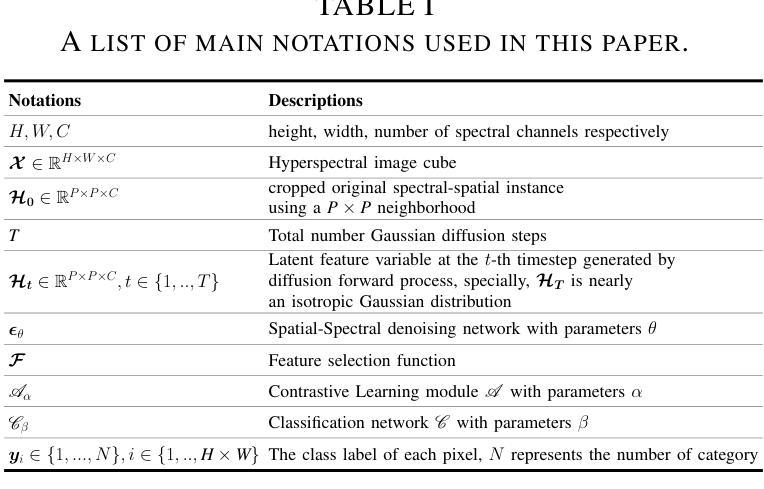
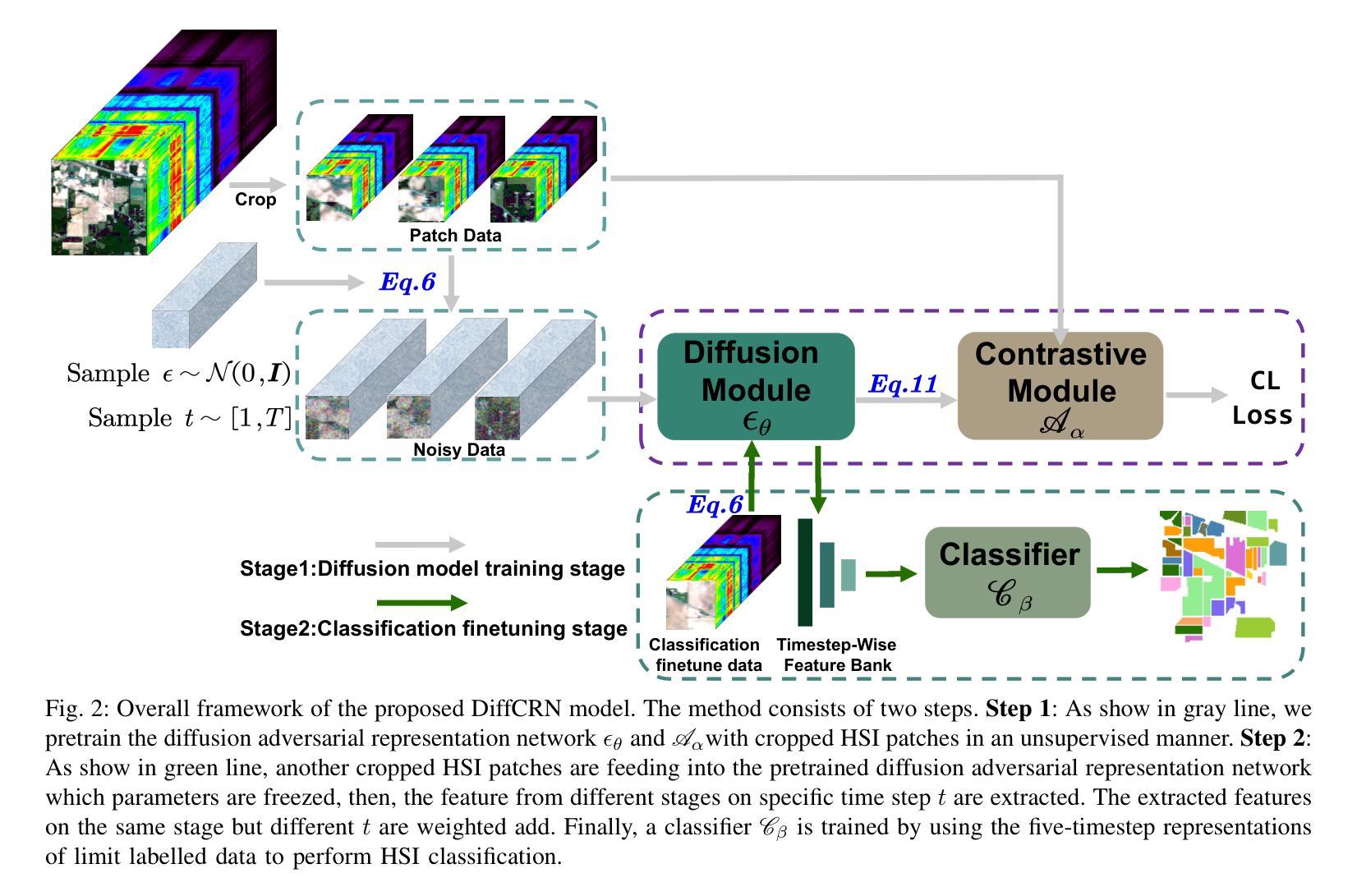
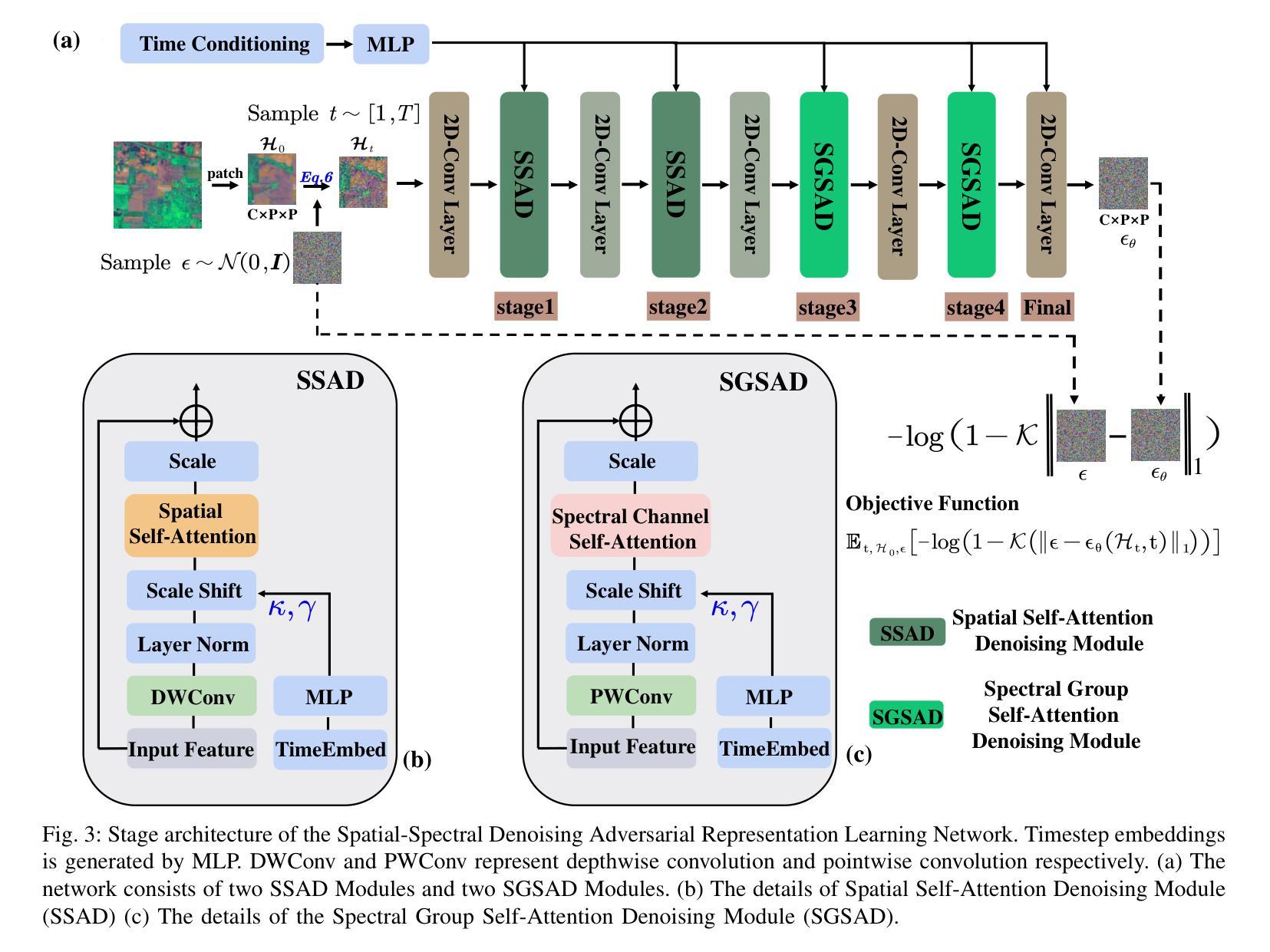
Spatial-Spectral Diffusion Contrastive Representation Network for Hyperspectral Image Classification
Authors:Yimin Zhu, Linlin Xu
Although efficient extraction of discriminative spatial-spectral features is critical for hyperspectral images classification (HSIC), it is difficult to achieve these features due to factors such as the spatial-spectral heterogeneity and noise effect. This paper presents a Spatial-Spectral Diffusion Contrastive Representation Network (DiffCRN), based on denoising diffusion probabilistic model (DDPM) combined with contrastive learning (CL) for HSIC, with the following characteristics. First,to improve spatial-spectral feature representation, instead of adopting the UNets-like structure which is widely used for DDPM, we design a novel staged architecture with spatial self-attention denoising module (SSAD) and spectral group self-attention denoising module (SGSAD) in DiffCRN with improved efficiency for spectral-spatial feature learning. Second, to improve unsupervised feature learning efficiency, we design new DDPM model with logarithmic absolute error (LAE) loss and CL that improve the loss function effectiveness and increase the instance-level and inter-class discriminability. Third, to improve feature selection, we design a learnable approach based on pixel-level spectral angle mapping (SAM) for the selection of time steps in the proposed DDPM model in an adaptive and automatic manner. Last, to improve feature integration and classification, we design an Adaptive weighted addition modul (AWAM) and Cross time step Spectral-Spatial Fusion Module (CTSSFM) to fuse time-step-wise features and perform classification. Experiments conducted on widely used four HSI datasets demonstrate the improved performance of the proposed DiffCRN over the classical backbone models and state-of-the-art GAN, transformer models and other pretrained methods. The source code and pre-trained model will be made available publicly.
虽然高效提取鉴别性空间光谱特征对于高光谱图像分类(HSIC)至关重要,但由于空间光谱异质性和噪声影响等因素,实现这些特征很困难。本文针对HSIC提出了一种基于去噪扩散概率模型(DDPM)和对比学习(CL)的空间光谱扩散对比表示网络(DiffCRN),具有以下特点。首先,为了改进空间光谱特征表示,我们没有采用广泛用于DDPM的UNets类结构,而是设计了带有空间自注意力去噪模块(SSAD)和光谱组自注意力去噪模块(SGSAD)的新型分阶段架构,提高了光谱空间特征学习的效率。其次,为了提升无监督特征学习效率,我们设计了一种新的DDPM模型,结合了对数绝对误差(LAE)损失和CL,提高了损失函数的有效性和实例级别及跨类别间的可区分性。第三,为了改进特征选择,我们设计了一种基于像素级光谱角度映射(SAM)的可学习方法,以自适应和自动的方式选择所提DDPM模型中的时间步长。最后,为了改进特征融合和分类,我们设计了自适应加权添加模块(AWAM)和跨时间步长光谱空间融合模块(CTSSFM),以融合时间步长特征并进行分类。在四个广泛使用的HSI数据集上进行的实验表明,所提出的DiffCRN在经典主干模型和最新的GAN、Transformer模型以及其他预训练方法上表现出了改进的性能。源代码和预训练模型将公开提供。
论文及项目相关链接
Summary
论文提出了一种基于去噪扩散概率模型(DDPM)和对比学习(CL)的空间光谱扩散对比表示网络(DiffCRN),用于高效处理高光谱图像分类问题。通过设计新型的网络架构和改进的损失函数,提高了空间光谱特征表示、无监督特征学习效率、特征选择和特征融合分类能力。在四个广泛使用的HSI数据集上的实验表明,与传统的背景模型、先进的GAN、Transformer模型和其他预训练方法相比,所提出的DiffCRN性能更优。
Key Takeaways
* 该研究利用去噪扩散概率模型(DDPM)和对比学习(CL)构建了一种新的网络架构(DiffCRN),旨在解决高光谱图像分类中的空间光谱特征提取难题。
* 新型的网络架构包括空间自注意力去噪模块(SSAD)和光谱组自注意力去噪模块(SGSAD),提高了谱空间特征学习的效率。
* 通过引入对数绝对误差(LAE)损失和对比学习,改进了无监督特征学习的效率,提高了损失函数的有效性和实例级别及跨类别的可辨别性。
* 采用基于像素级光谱角度映射(SAM)的可学习方法,以自适应和自动的方式选择DDPM模型中的时间步长,改善了特征选择。
* 通过自适应加权添加模块(AWAM)和跨时间步长谱空间融合模块(CTSSFM),融合了时间步长特征,并进行了分类。
点此查看论文截图