⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-01 更新
MITracker: Multi-View Integration for Visual Object Tracking
Authors:Mengjie Xu, Yitao Zhu, Haotian Jiang, Jiaming Li, Zhenrong Shen, Sheng Wang, Haolin Huang, Xinyu Wang, Qing Yang, Han Zhang, Qian Wang
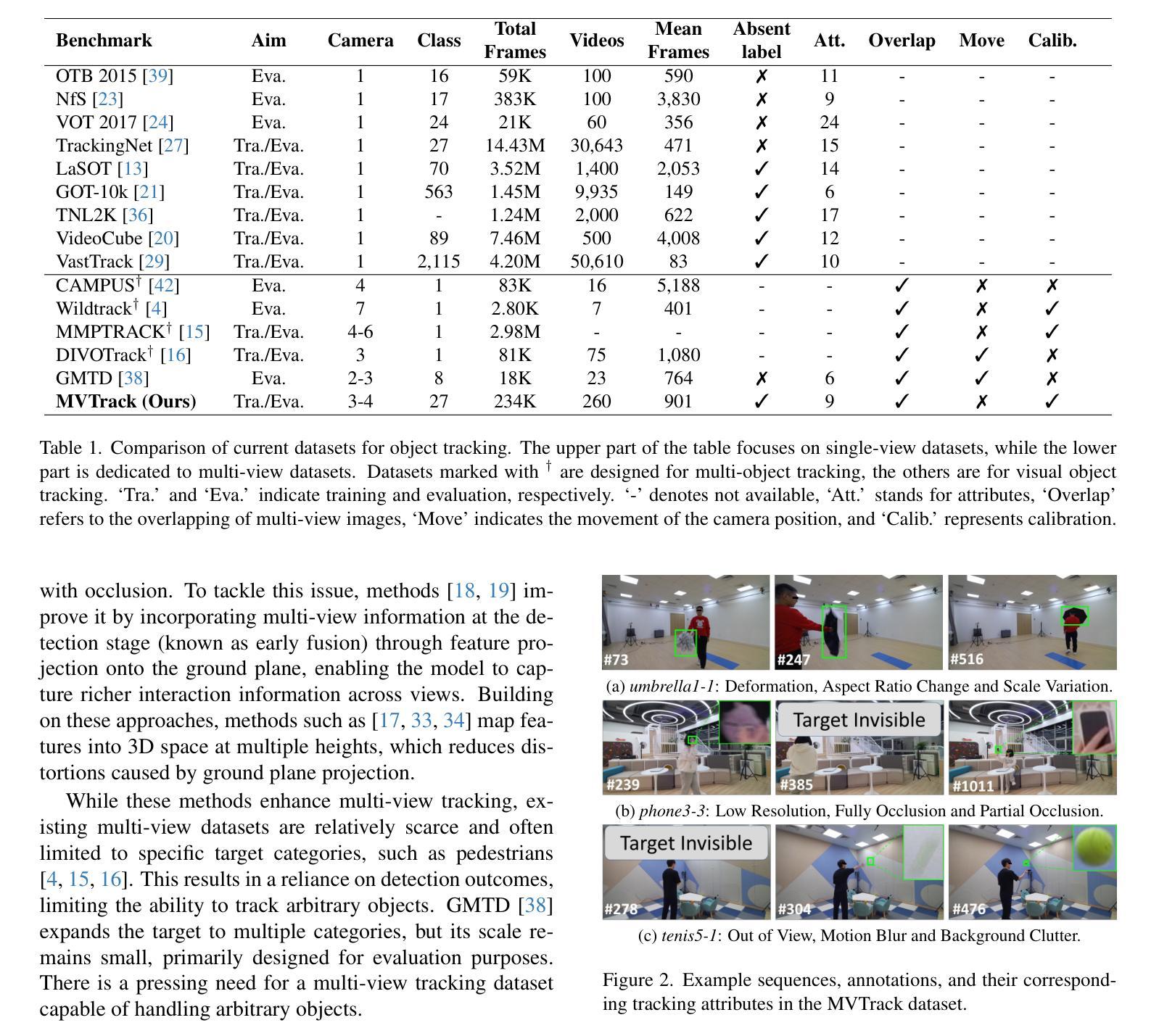
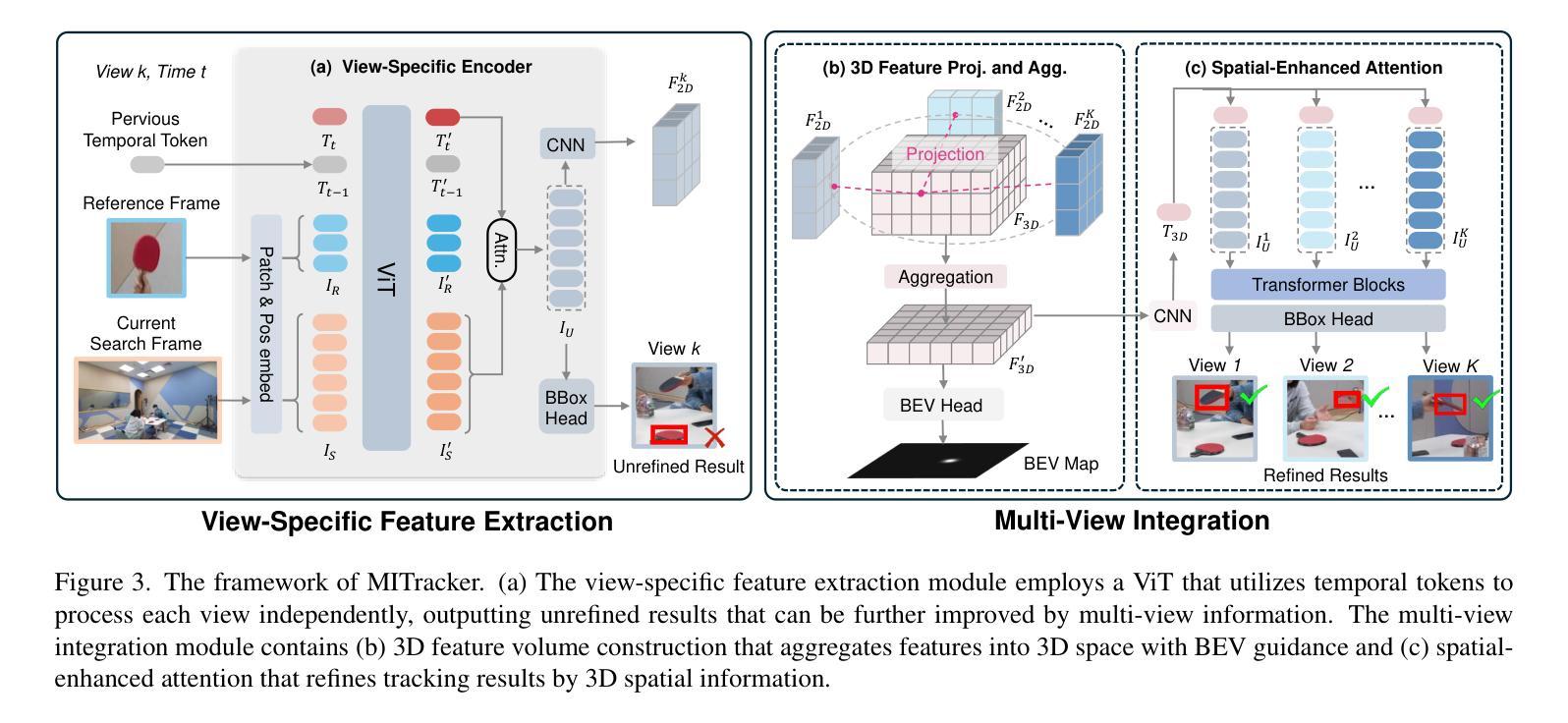
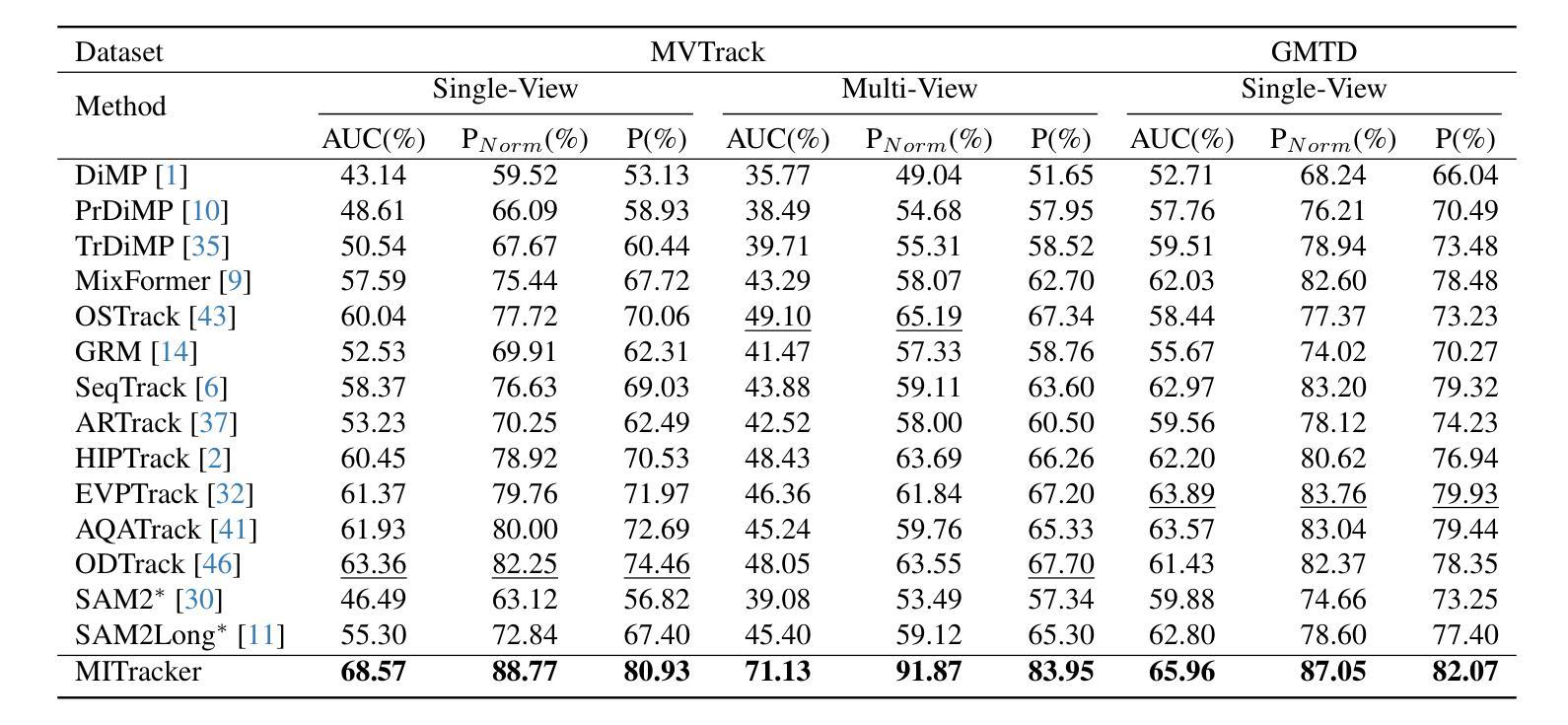
Multi-view object tracking (MVOT) offers promising solutions to challenges such as occlusion and target loss, which are common in traditional single-view tracking. However, progress has been limited by the lack of comprehensive multi-view datasets and effective cross-view integration methods. To overcome these limitations, we compiled a Multi-View object Tracking (MVTrack) dataset of 234K high-quality annotated frames featuring 27 distinct objects across various scenes. In conjunction with this dataset, we introduce a novel MVOT method, Multi-View Integration Tracker (MITracker), to efficiently integrate multi-view object features and provide stable tracking outcomes. MITracker can track any object in video frames of arbitrary length from arbitrary viewpoints. The key advancements of our method over traditional single-view approaches come from two aspects: (1) MITracker transforms 2D image features into a 3D feature volume and compresses it into a bird’s eye view (BEV) plane, facilitating inter-view information fusion; (2) we propose an attention mechanism that leverages geometric information from fused 3D feature volume to refine the tracking results at each view. MITracker outperforms existing methods on the MVTrack and GMTD datasets, achieving state-of-the-art performance. The code and the new dataset will be available at https://mii-laboratory.github.io/MITracker/.
多视角目标跟踪(MVOT)为解决遮挡和目标丢失等在传统单视角跟踪中常见的问题提供了有前景的解决方案。然而,由于缺乏全面的多视角数据集和有效的跨视角集成方法,研究进展受到限制。为了克服这些局限性,我们编译了一个多视角目标跟踪(MVTrack)数据集,包含23.4万个高质量注释帧,涵盖各种场景中的27个不同对象。结合此数据集,我们引入了一种新的MVOT方法,即多视角集成跟踪器(MITracker),以有效地整合多视角目标特征,并提供稳定的跟踪结果。MITracker可以从任意视角跟踪视频帧中任意长度的任何对象。我们的方法与传统的单视角方法相比,关键进步体现在两个方面:(1)MITracker将2D图像特征转换为3D特征体积,并将其压缩到鸟瞰图(BEV)平面,促进了跨视图信息融合;(2)我们提出了一种注意力机制,利用融合3D特征体积的几何信息来优化每个视图的跟踪结果。MITracker在MVTrack和GMTD数据集上的表现优于现有方法,达到了最先进的性能。代码和新数据集将在https://mii-laboratory.github.io/MITracker/上提供。
论文及项目相关链接
Summary
多视角目标跟踪(MVOT)面临遮挡和目标丢失等挑战。为了克服缺乏综合多视角数据集和有效的跨视角集成方法的限制,我们编译了MVTrack数据集,并引入了一种新的MVOT方法——Multi-View Integration Tracker(MITracker)。MITracker将多视角目标特征有效地集成在一起,提供稳定的目标跟踪结果。它将二维图像特征转换为三维特征体积,并压缩到鸟瞰图(BEV)平面上,实现跨视角信息融合。此外,我们还提出了一种注意力机制,利用融合后的三维特征体积的几何信息来优化每个视角的跟踪结果。MITracker在MVTrack和GMTD数据集上的表现优于现有方法,达到了最先进的性能。
Key Takeaways
- 多视角目标跟踪(MVOT)面临遮挡和目标丢失的挑战。
- 缺乏综合多视角数据集和有效的跨视角集成方法是限制MVOT进展的主要原因。
- 为了解决这些问题,我们编译了MVTrack数据集,包含234K个高质量注释帧和27种不同对象。
- 引入了一种新的MVOT方法——Multi-View Integration Tracker(MITracker)。
- MITracker将二维图像特征转换为三维特征体积,并压缩到鸟瞰图(BEV)平面,有助于跨视角信息融合。
- MITracker采用注意力机制,利用三维特征体积的几何信息优化跟踪结果。
点此查看论文截图

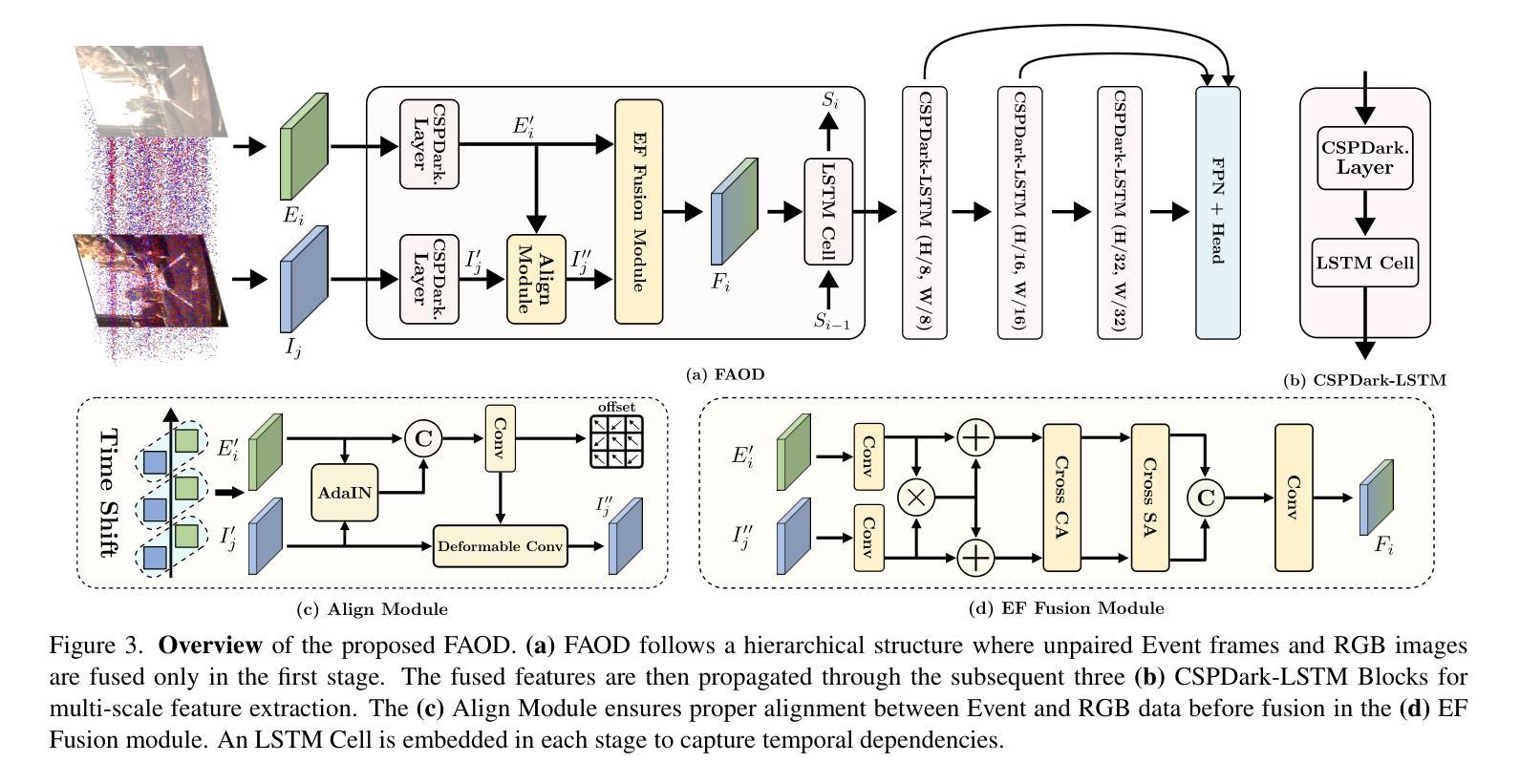
Frequency-Adaptive Low-Latency Object Detection Using Events and Frames
Authors:Haitian Zhang, Xiangyuan Wang, Chang Xu, Xinya Wang, Fang Xu, Huai Yu, Lei Yu, Wen Yang
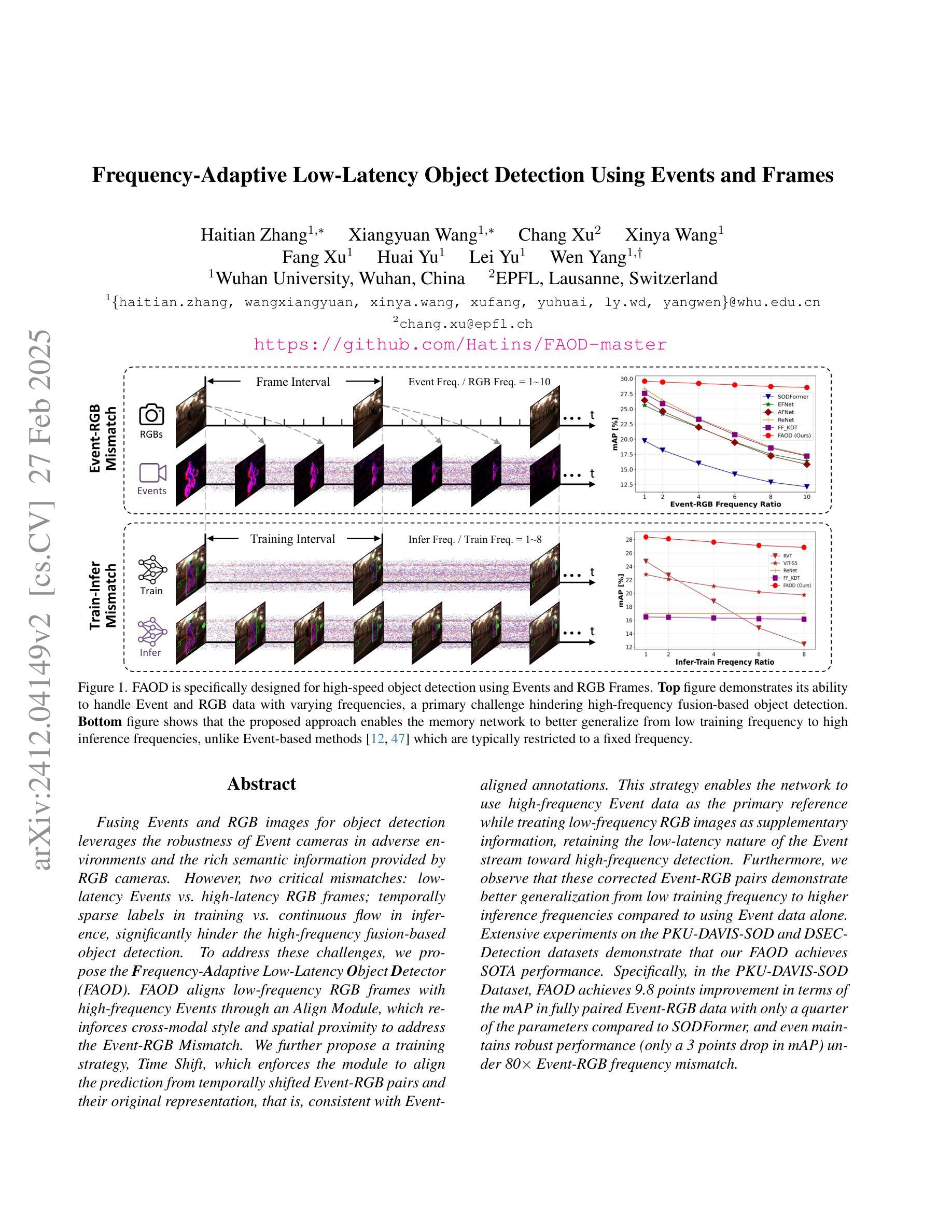
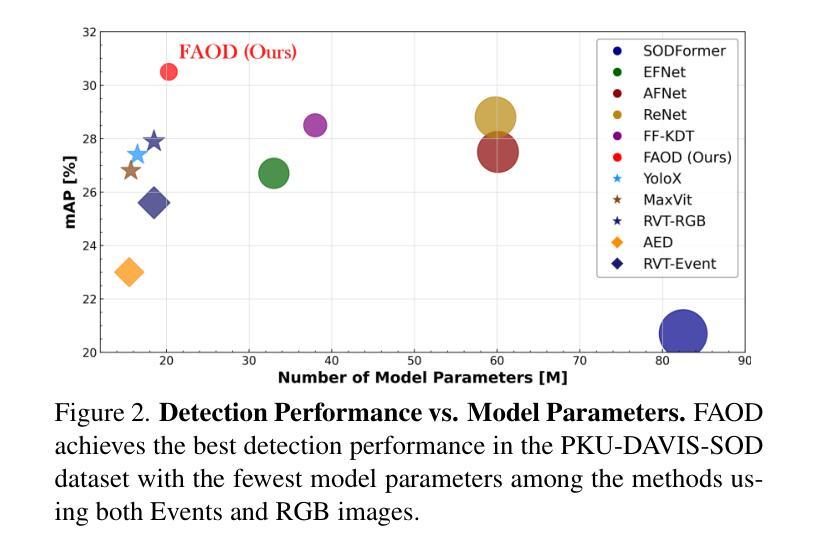
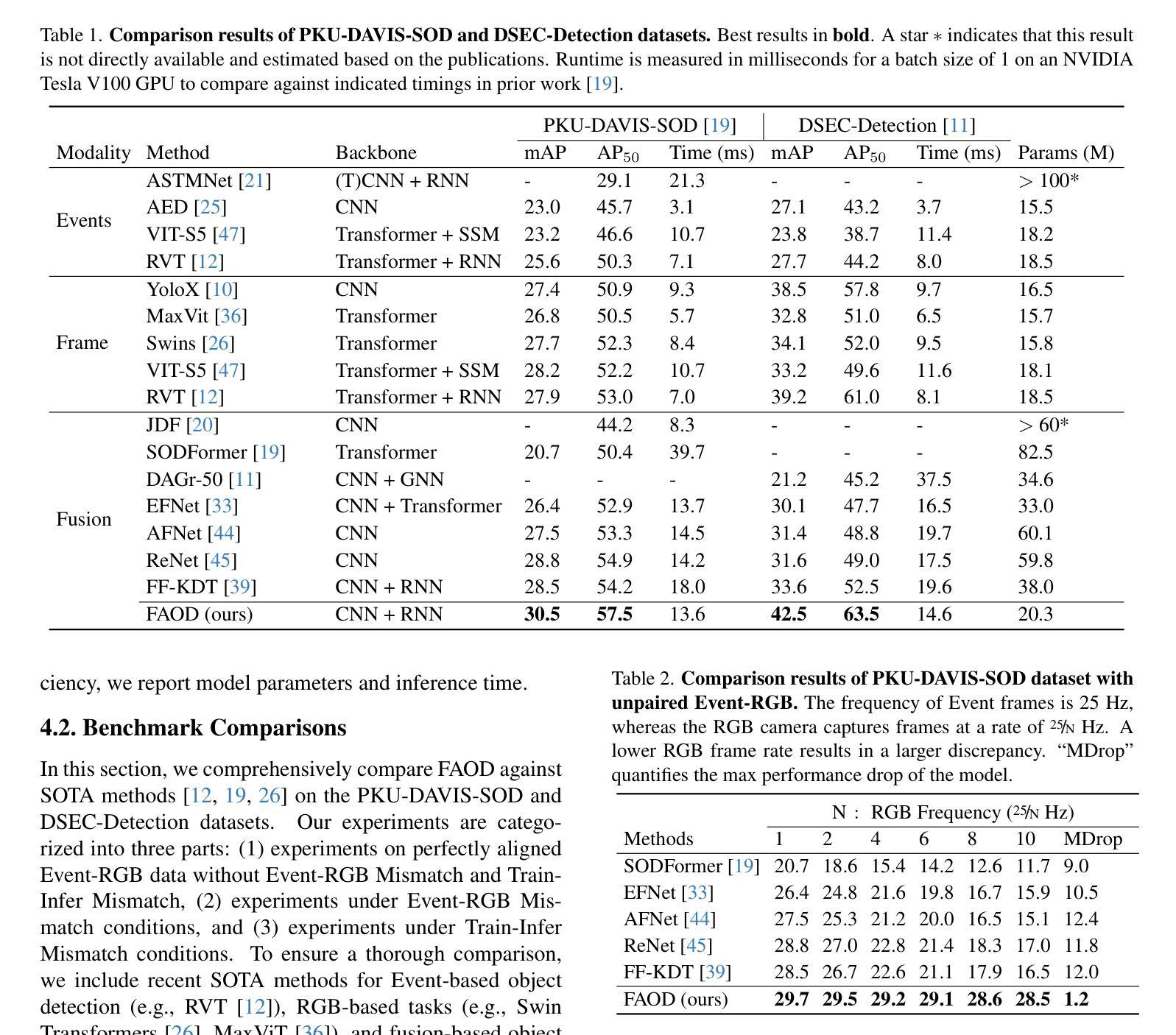
Fusing Events and RGB images for object detection leverages the robustness of Event cameras in adverse environments and the rich semantic information provided by RGB cameras. However, two critical mismatches: low-latency Events \textit{vs.}high-latency RGB frames; temporally sparse labels in training \textit{vs.}continuous flow in inference, significantly hinder the high-frequency fusion-based object detection. To address these challenges, we propose the \textbf{F}requency-\textbf{A}daptive Low-Latency \textbf{O}bject \textbf{D}etector (FAOD). FAOD aligns low-frequency RGB frames with high-frequency Events through an Align Module, which reinforces cross-modal style and spatial proximity to address the Event-RGB Mismatch. We further propose a training strategy, Time Shift, which enforces the module to align the prediction from temporally shifted Event-RGB pairs and their original representation, that is, consistent with Event-aligned annotations. This strategy enables the network to use high-frequency Event data as the primary reference while treating low-frequency RGB images as supplementary information, retaining the low-latency nature of the Event stream toward high-frequency detection. Furthermore, we observe that these corrected Event-RGB pairs demonstrate better generalization from low training frequency to higher inference frequencies compared to using Event data alone. Extensive experiments on the PKU-DAVIS-SOD and DSEC-Detection datasets demonstrate that our FAOD achieves SOTA performance. Specifically, in the PKU-DAVIS-SOD Dataset, FAOD achieves 9.8 points improvement in terms of the mAP in fully paired Event-RGB data with only a quarter of the parameters compared to SODFormer, and even maintains robust performance (only a 3 points drop in mAP) under 80$\times$ Event-RGB frequency mismatch.
融合事件和RGB图像进行目标检测,充分利用了事件相机在恶劣环境中的稳健性和RGB相机提供的丰富语义信息。然而,两个关键不匹配问题:低延迟事件与高通量RGB帧之间的不匹配;训练中的时间稀疏标签与推理中的连续流的不匹配,显著阻碍了基于高频融合的目标检测。为了应对这些挑战,我们提出了频率自适应低延迟对象检测器(FAOD)。FAOD通过一个对齐模块,将低频的RGB帧与高频的事件进行对齐,该模块加强了跨模态风格和空间邻近性,以解决事件-RGB不匹配问题。我们还提出了一种名为时间偏移的训练策略,该策略强制模块对齐时间偏移的事件-RGB对与其原始表示,即与事件对齐的注释保持一致。该策略使网络能够使用高频事件数据作为主要参考,而将低频RGB图像视为辅助信息,保持事件流的低延迟特性以实现高频检测。此外,我们观察到,这些校正后的事件-RGB对在低训练频率到较高推理频率的推广方面表现得更好,与仅使用事件数据相比。在PKU-DAVIS-SOD和DSEC-Detection数据集上的大量实验表明,我们的FAOD达到了最先进的表现。具体来说,在PKU-DAVIS-SOD数据集上,FAOD在全配对事件-RGB数据中的mAP提高了9.8点,与SODFormer相比,参数仅使用了四分之一,甚至在事件-RGB频率不匹配达到80倍的情况下,mAP仅下降3点,仍然保持稳健的性能。
论文及项目相关链接
Summary
该文本介绍了融合事件和RGB图像进行物体检测的技术。为提高在恶劣环境下的稳健性和语义信息的丰富性,该技术融合了事件相机和RGB相机的数据。针对低频事件与高频RGB帧以及训练中的时间稀疏标签与推理中的连续流之间的不匹配问题,提出了频率自适应低延迟物体检测器(FAOD)。FAOD通过对齐模块解决事件与RGB的不匹配问题,并通过时间偏移训练策略提高网络性能。使用高频事件数据作为主要参考,低频RGB图像作为辅助信息,保持事件流的低延迟特性以实现高频检测。实验结果表明,在PKU-DAVIS-SOD和DSEC-Detection数据集上,FAOD达到领先水平。特别是在PKU-DAVIS-SOD数据集上,FAOD在完全配对的事件RGB数据中实现了mAP的9.8点提升,并且在事件RGB频率不匹配的情况下仍能保持稳健性能。
Key Takeaways
- 事件相机与RGB相机融合检测:结合事件相机的稳健性和RGB相机的丰富语义信息。
- 事件与RGB帧的低高频差异:处理低频事件与高频RGB帧之间的不匹配问题。
- 对齐模块:通过Align Module解决事件与RGB的不匹配问题,增强跨模态风格和空间邻近性。
- 时间偏移训练策略:使用此策略来训练模型以对齐事件RGB对及其原始表示,使模型能在不同频率下表现良好。
- 高频事件数据作为主要参考:利用高频事件数据作为检测的主要依据,同时利用低频RGB图像作为补充信息。
- 保持低延迟特性:保持事件流的低延迟特性以实现高频检测。
点此查看论文截图
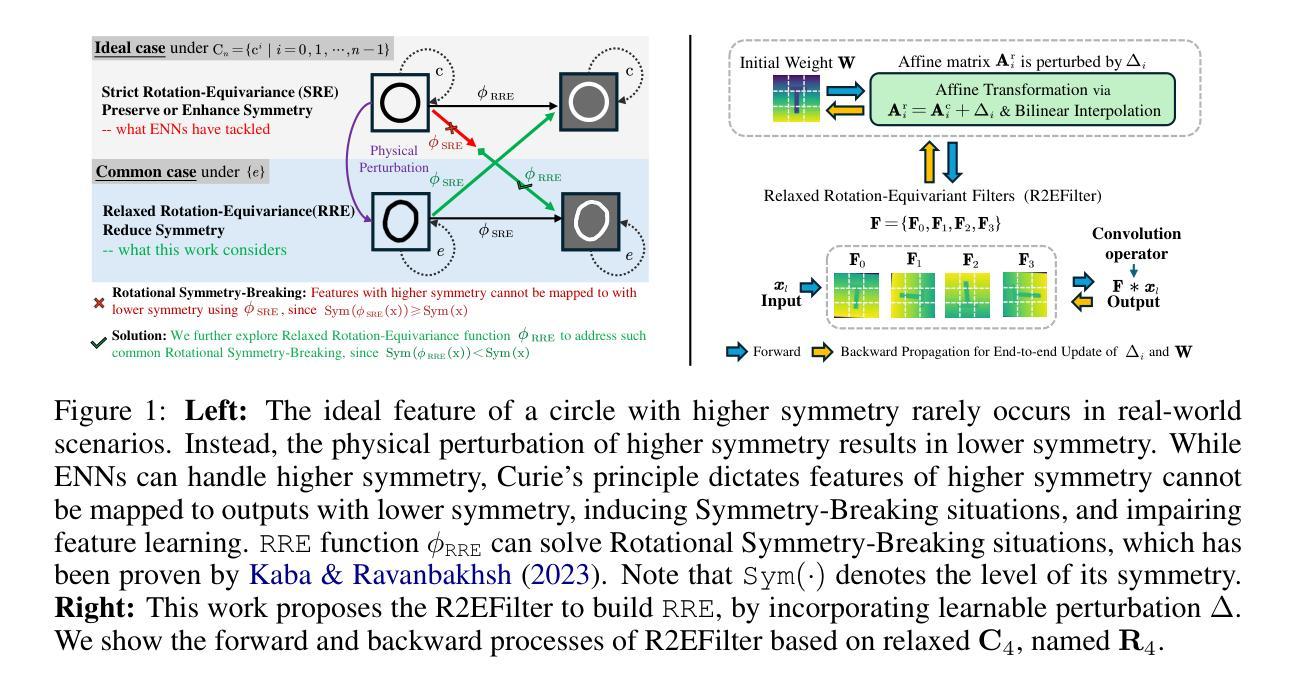
R2Det: Exploring Relaxed Rotation Equivariance in 2D object detection
Authors:Zhiqiang Wu, Yingjie Liu, Hanlin Dong, Xuan Tang, Jian Yang, Bo Jin, Mingsong Chen, Xian Wei
Group Equivariant Convolution (GConv) empowers models to explore underlying symmetry in data, improving performance. However, real-world scenarios often deviate from ideal symmetric systems caused by physical permutation, characterized by non-trivial actions of a symmetry group, resulting in asymmetries that affect the outputs, a phenomenon known as Symmetry Breaking. Traditional GConv-based methods are constrained by rigid operational rules within group space, assuming data remains strictly symmetry after limited group transformations. This limitation makes it difficult to adapt to Symmetry-Breaking and non-rigid transformations. Motivated by this, we mainly focus on a common scenario: Rotational Symmetry-Breaking. By relaxing strict group transformations within Strict Rotation-Equivariant group $\mathbf{C}_n$, we redefine a Relaxed Rotation-Equivariant group $\mathbf{R}_n$ and introduce a novel Relaxed Rotation-Equivariant GConv (R2GConv) with only a minimal increase of $4n$ parameters compared to GConv. Based on R2GConv, we propose a Relaxed Rotation-Equivariant Network (R2Net) as the backbone and develop a Relaxed Rotation-Equivariant Object Detector (R2Det) for 2D object detection. Experimental results demonstrate the effectiveness of the proposed R2GConv in natural image classification, and R2Det achieves excellent performance in 2D object detection with improved generalization capabilities and robustness. The code is available in \texttt{https://github.com/wuer5/r2det}.
群等价卷积(GConv)使模型能够探索数据中的潜在对称性,从而提高性能。然而,现实世界的情况往往与理想的对称系统存在偏差,这是由于物理排列导致的对称组的非平凡动作,从而产生影响输出的不对称性,这种现象被称为对称破坏。传统的基于GConv的方法受到组空间内严格操作规则的约束,假设在有限的群变换之后数据仍然严格对称。这种局限性使得它难以适应对称破坏和非刚性变换。受此启发,我们主要关注一种常见情景:旋转对称破坏。通过放宽严格旋转等价组$\mathbf{C}_n$内的严格群变换,我们重新定义了松弛旋转等价组$\mathbf{R}_n$,并引入了一种新型的松弛旋转等价GConv(R2GConv),与GConv相比,参数仅增加最小的$4n$个。基于R2GConv,我们提出一种松弛旋转等价网络(R2Net)作为主干,并开发了一种用于二维目标检测的松弛旋转等价对象检测器(R2Det)。实验结果表明,在自然图像分类中提出的R2GConv的有效性,以及R2Det在二维目标检测中实现了卓越的性能,提高了通用性和鲁棒性。代码可用在\href{https://github.com/wuer5/r2det}{https://github.com/wuer5/r2det}。
论文及项目相关链接
Summary:
本文介绍了群组等变卷积(GConv)在探索数据潜在对称性方面的优势,但现实世界的场景往往由于物理排列的非对称问题导致的对称性破裂(Symmetry Breaking)而偏离理想对称系统。为应对这一问题,文章提出了一种新型的松弛旋转等变卷积(R2GConv),并基于此构建了松弛旋转等变网络(R2Net)和对象检测器(R2Det)。实验结果表明,R2GConv在自然图像分类中表现有效,R2Det在二维对象检测方面表现出良好的泛化能力和鲁棒性。
Key Takeaways:
- 群组等变卷积(GConv)有助于探索数据的潜在对称性,提升模型性能。
- 现实场景中的对称性破裂(Symmetry Breaking)会影响模型的性能。
- 为应对对称性破裂和非刚性变换,提出了新型的松弛旋转等变卷积(R2GConv)。
- R2GConv相较于传统的GConv,参数仅增加了4n。
- 基于R2GConv构建了松弛旋转等变网络(R2Net)。
- R2Net被用作二维对象检测器的骨干网,提出了松弛旋转等变对象检测器(R2Det)。
点此查看论文截图


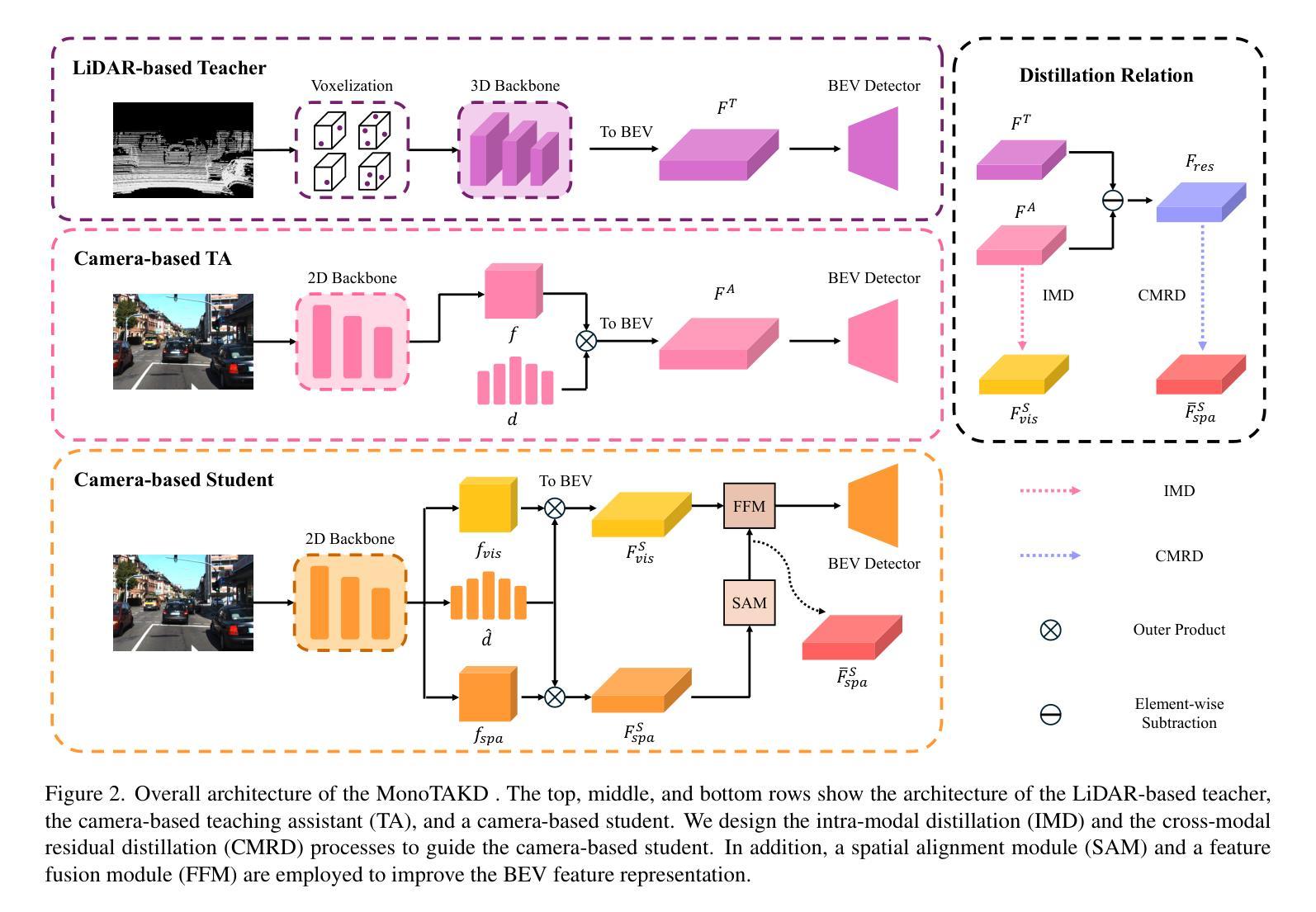
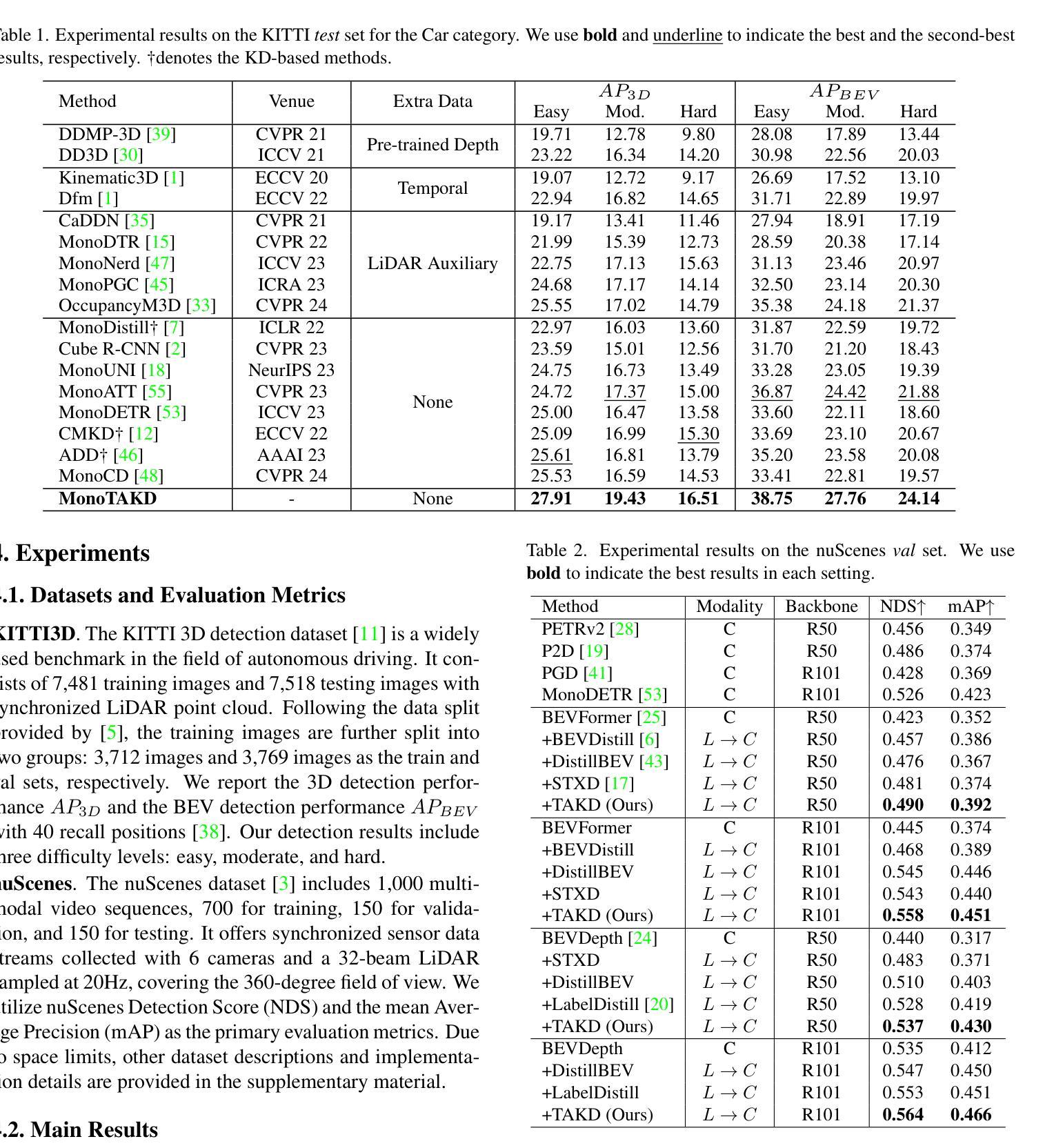
MonoTAKD: Teaching Assistant Knowledge Distillation for Monocular 3D Object Detection
Authors:Hou-I Liu, Christine Wu, Jen-Hao Cheng, Wenhao Chai, Shian-Yun Wang, Gaowen Liu, Jenq-Neng Hwang, Hong-Han Shuai, Wen-Huang Cheng
Monocular 3D object detection (Mono3D) holds noteworthy promise for autonomous driving applications owing to the cost-effectiveness and rich visual context of monocular camera sensors. However, depth ambiguity poses a significant challenge, as it requires extracting precise 3D scene geometry from a single image, resulting in suboptimal performance when transferring knowledge from a LiDAR-based teacher model to a camera-based student model. To address this issue, we introduce {\em Monocular Teaching Assistant Knowledge Distillation (MonoTAKD)} to enhance 3D perception in Mono3D. Our approach presents a robust camera-based teaching assistant model that effectively bridges the representation gap between different modalities for teacher and student models, addressing the challenge of inaccurate depth estimation. By defining 3D spatial cues as residual features that capture the differences between the teacher and the teaching assistant models, we leverage these cues into the student model, improving its 3D perception capabilities. Experimental results show that our MonoTAKD achieves state-of-the-art performance on the KITTI3D dataset. Additionally, we evaluate the performance on nuScenes and KITTI raw datasets to demonstrate the generalization of our model to multi-view 3D and unsupervised data settings. Our code will be available at https://github.com/hoiliu-0801/MonoTAKD.
单目3D对象检测(Mono3D)在自动驾驶应用中具有显著潜力,得益于单目相机传感器的成本效益和丰富的视觉上下文。然而,深度模糊是一个重大挑战,因为它需要从单张图像中提取精确的3D场景几何结构,导致从激光雷达教师模型向相机学生模型转移知识时性能不佳。为了解决这一问题,我们引入了单目教学辅助知识蒸馏(MonoTAKD)来增强Mono3D中的3D感知能力。我们的方法提出了一个稳健的基于相机的教学辅助模型,有效地弥合了不同模态教师模型和学生模型之间的表示差距,解决了深度估计不准确的问题。通过将三维空间线索定义为捕捉教师和教学辅助模型之间差异的残差特征,我们将其融入学生模型中,提高了其三维感知能力。实验结果表明,我们的MonoTAKD在KITTI3D数据集上达到了最先进的性能。此外,我们在nuscenes和KITTI原始数据集上评估了性能,以展示我们的模型在多视图3D和无监督数据设置中的泛化能力。我们的代码将在https://github.com/hoiliu-0801/MonoTAKD上提供。
论文及项目相关链接
PDF Accepted by CVPR 2025. Our code will be available at https://github.com/hoiliu-0801/MonoTAKD
Summary
单目三维物体检测(Mono3D)在自动驾驶应用方面展现出巨大潜力,因单目相机传感器的成本效益和丰富的视觉上下文。然而,深度歧义是一个重大挑战,需要从单张图像中提取精确的3D场景几何结构。为解决这一问题,我们提出单目教学助理知识蒸馏(MonoTAKD)以增强Mono3D中的三维感知能力。通过构建基于相机的教学助理模型,有效弥合了不同模态教师模型与学生模型之间的表征差距,解决了深度估计不准确的问题。实验结果显示,在KITTI3D数据集上,我们的MonoTAKD取得了最先进的性能表现。同时,我们在nuScenes和KITTI原始数据集上评估了模型的性能,证明了模型在多视角三维和无监督数据设置下的泛化能力。
Key Takeaways
- Monocular 3D object detection (Mono3D)具有成本效益和丰富的视觉上下文优势,在自动驾驶领域有广泛应用前景。
- 深度歧义是Mono3D的主要挑战,需要从单张图像中提取精确的3D场景几何结构。
- 引入Monocular Teaching Assistant Knowledge Distillation (MonoTAKD)方法,通过构建基于相机的教学助理模型增强三维感知能力。
- MonoTAKD有效弥合了不同模态教师模型与学生模型之间的表征差距,解决深度估计不准确问题。
- MonoTAKD在KITTI3D数据集上实现最先进的性能表现。
- 模型在nuScenes和KITTI原始数据集上的评估证明了其泛化能力。
点此查看论文截图