⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-03-01 更新
Do generative video models understand physical principles?
Authors:Saman Motamed, Laura Culp, Kevin Swersky, Priyank Jaini, Robert Geirhos
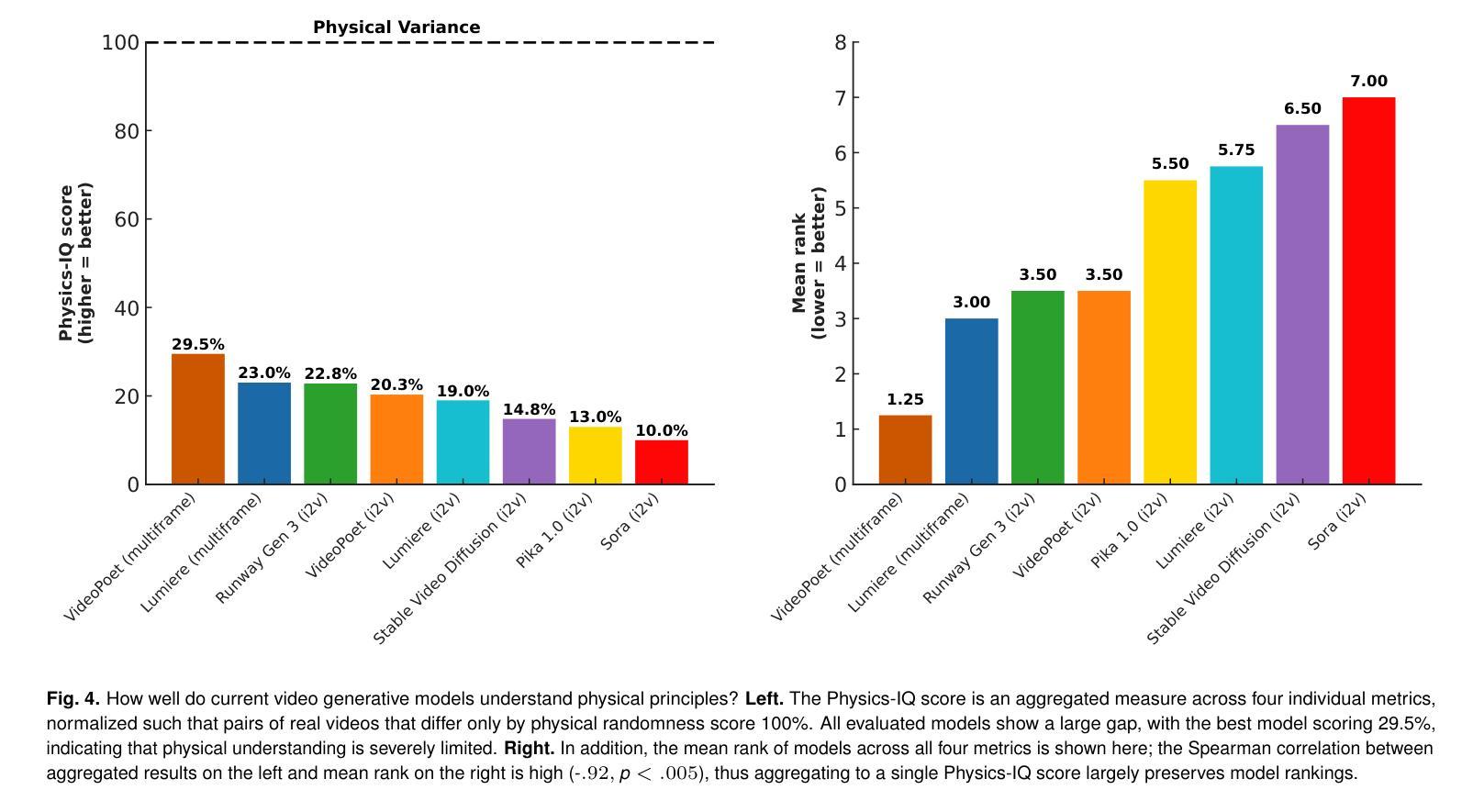
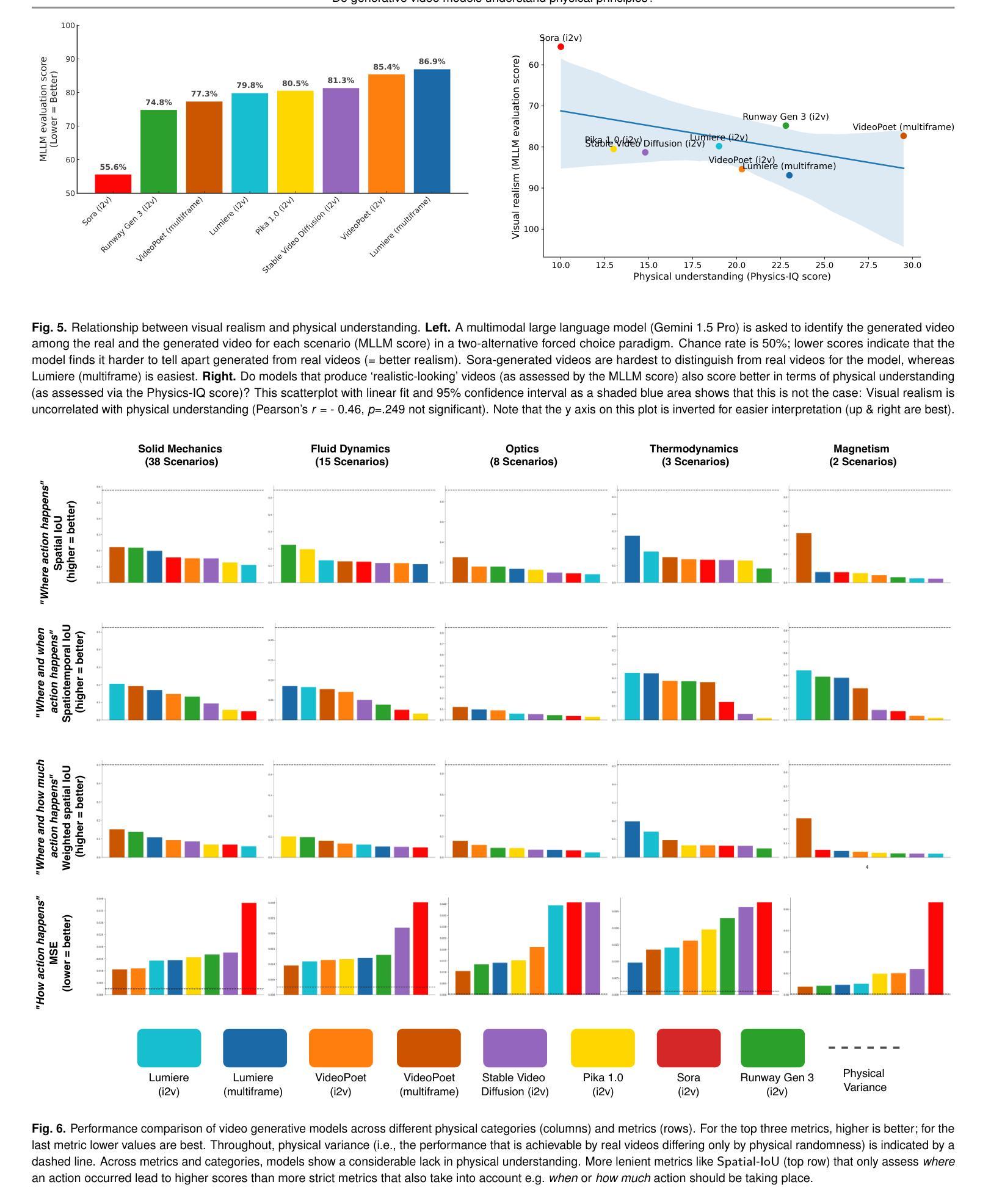
AI video generation is undergoing a revolution, with quality and realism advancing rapidly. These advances have led to a passionate scientific debate: Do video models learn “world models” that discover laws of physics – or, alternatively, are they merely sophisticated pixel predictors that achieve visual realism without understanding the physical principles of reality? We address this question by developing Physics-IQ, a comprehensive benchmark dataset that can only be solved by acquiring a deep understanding of various physical principles, like fluid dynamics, optics, solid mechanics, magnetism and thermodynamics. We find that across a range of current models (Sora, Runway, Pika, Lumiere, Stable Video Diffusion, and VideoPoet), physical understanding is severely limited, and unrelated to visual realism. At the same time, some test cases can already be successfully solved. This indicates that acquiring certain physical principles from observation alone may be possible, but significant challenges remain. While we expect rapid advances ahead, our work demonstrates that visual realism does not imply physical understanding. Our project page is at https://physics-iq.github.io; code at https://github.com/google-deepmind/physics-IQ-benchmark.
人工智能视频生成正在经历一场革命,其质量和逼真度迅速提升。这些进步引发了一场激烈的科学辩论:视频模型是否学习“世界模型”,发现物理定律——或者,它们是否仅仅是复杂的像素预测器,能在不了解现实物理原理的情况下实现视觉逼真?我们通过开发Physics-IQ来解决这个问题,这是一个综合基准数据集,只能通过深入理解和掌握各种物理原理(如流体力学、光学、固体力学、磁学和热力学)来解决。我们发现,在当前的各类模型(Sora、Runway、Pika、Lumiere、稳定视频扩散和视频诗人)中,物理理解严重受限,与视觉逼真度无关。同时,一些测试用例已经可以成功解决。这表明仅通过观察就有可能掌握某些物理原理,但仍存在重大挑战。虽然我们预期未来会有快速进步,但我们的工作表明,视觉逼真度并不意味着对物理的理解。我们的项目页面为:https://physics-iq.github.io;代码页面为:https://github.com/google-deepmind/physics-IQ-benchmark。
论文及项目相关链接
Summary
人工智能视频生成技术正在经历一场革命,质量和逼真度迅速提升。然而,关于视频模型是否学习物理定律的问题引发了一场激烈的辩论。为解决这一问题,我们推出了Physics-IQ数据集作为基准测试平台,它能够测试模型对各种物理原理的深度理解,如流体动力学、光学等。我们发现当前模型对物理原理的理解有限,且与视觉逼真度无关。但部分测试案例已成功解决,暗示仅通过观察可能掌握某些物理原理。视觉逼真度并不代表对物理原理的理解,未来仍有诸多挑战待解决。详情访问:https://physics-iq.github.io。
Key Takeaways
- AI视频生成技术发展迅速,引发关于模型是否理解物理定律的辩论。
- 开发Physics-IQ数据集用于评估模型对物理原理的理解。
- 当前模型对物理原理的理解有限,与视觉逼真度无关。
- 成功解决部分测试案例暗示仅通过观察可能掌握某些物理原理。
- 视觉逼真并不代表对物理原理的深入理解。
- 未来仍存在许多挑战需要解决以提高模型对物理原理的理解能力。
点此查看论文截图



Ego-VPA: Egocentric Video Understanding with Parameter-efficient Adaptation
Authors:Tz-Ying Wu, Kyle Min, Subarna Tripathi, Nuno Vasconcelos
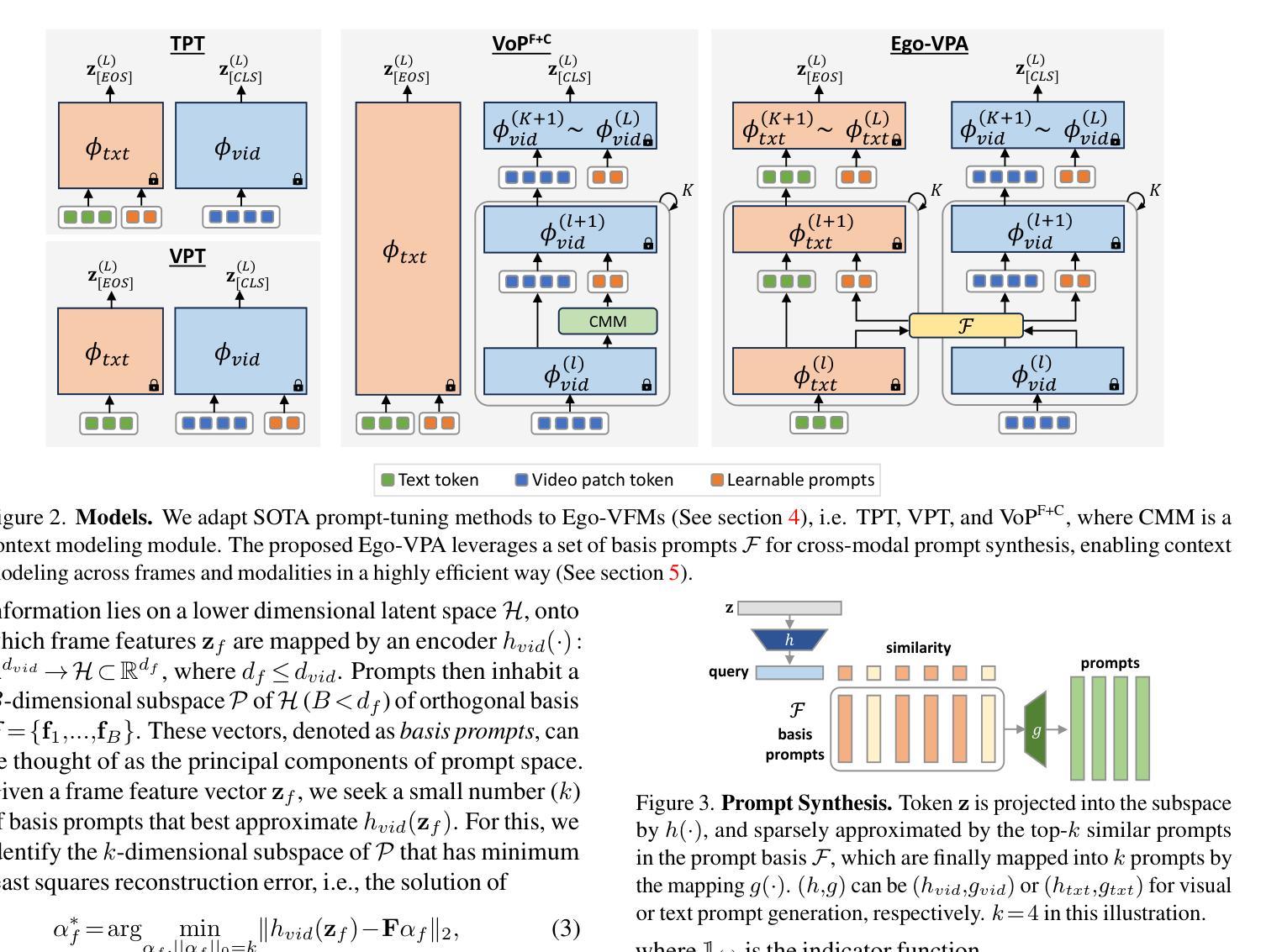
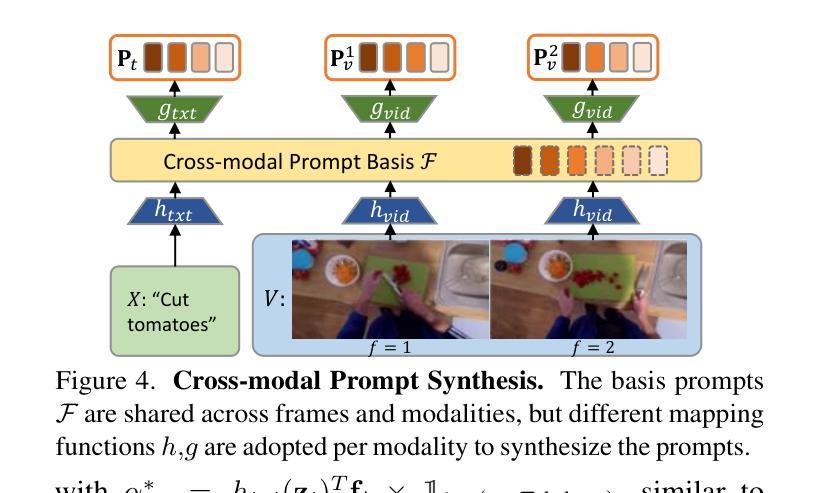
Video understanding typically requires fine-tuning the large backbone when adapting to new domains. In this paper, we leverage the egocentric video foundation models (Ego-VFMs) based on video-language pre-training and propose a parameter-efficient adaptation for egocentric video tasks, namely Ego-VPA. It employs a local sparse approximation for each video frame/text feature using the basis prompts, and the selected basis prompts are used to synthesize video/text prompts. Since the basis prompts are shared across frames and modalities, it models context fusion and cross-modal transfer in an efficient fashion. Experiments show that Ego-VPA excels in lightweight adaptation (with only 0.84% learnable parameters), largely improving over baselines and reaching the performance of full fine-tuning.
视频理解通常需要在新领域进行精细调整大型主干网络。在本文中,我们利用基于视频语言预训练的以自我为中心的视频基础模型(Ego-VFMs),并为以自我为中心的视频任务提出了参数高效的适应方法,即Ego-VPA。它采用基础提示点对每帧视频/文本特征进行局部稀疏近似,所选的基础提示点用于合成视频/文本提示。由于基础提示点跨帧和模态共享,因此以高效的方式对上下文融合和跨模态转换进行建模。实验表明,Ego-VPA在轻量级适应方面表现出色(只有0.84%的可学习参数),大大超过了基线,并达到了完全精细调整的性能。
论文及项目相关链接
PDF Accepted to WACV 2025
Summary
本文介绍了针对第一人称视频任务的一种参数高效适应方法(Ego-VPA)。该方法基于视频语言预训练的自我中心视频基础模型(Ego-VFMs),通过局部稀疏近似为每个视频帧/文本特征使用基础提示,选定的基础提示用于合成视频/文本提示。由于基础提示在帧和模态之间是共享的,因此可以有效地进行上下文融合和跨模态转换。实验表明,Ego-VPA在轻量级适应方面表现出色(只有0.84%的可学习参数),大大提高了基线性能,并达到了完全微调的性能。
Key Takeaways
- 本研究利用基于视频语言预训练的自我中心视频基础模型(Ego-VFMs)。
- 提出了一种针对第一人称视频任务的参数高效适应方法(Ego-VPA)。
- Ego-VPA使用局部稀疏近似为每个视频帧/文本特征生成基础提示。
- 基础提示在帧和模态之间是共享的,以实现上下文融合和跨模态转换。
- 实验结果显示,Ego-VPA在轻量级适应方面具有出色的性能。
- Ego-VPA提高了基线性能,并达到了完全微调的水平,仅使用少量的可学习参数(0.84%)。
点此查看论文截图

MAMBA4D: Efficient Long-Sequence Point Cloud Video Understanding with Disentangled Spatial-Temporal State Space Models
Authors:Jiuming Liu, Jinru Han, Lihao Liu, Angelica I. Aviles-Rivero, Chaokang Jiang, Zhe Liu, Hesheng Wang
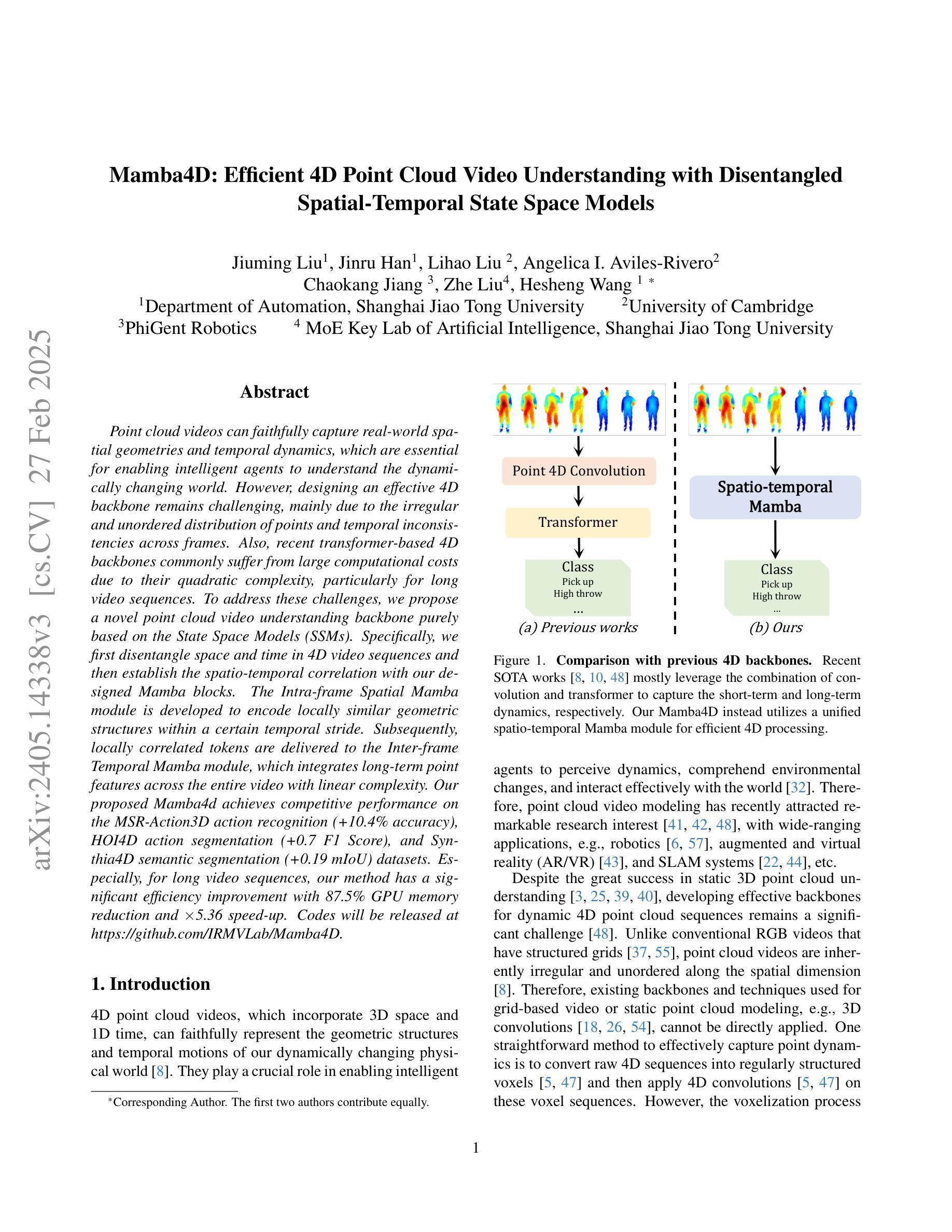
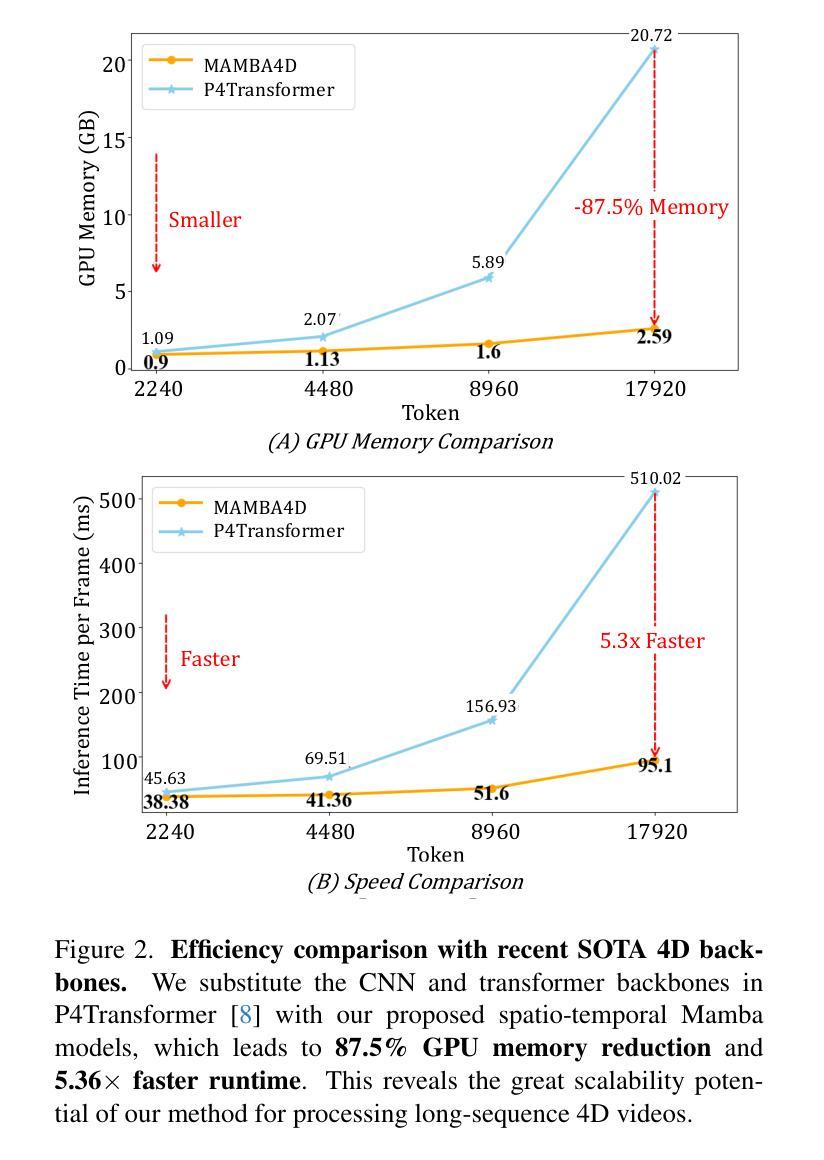
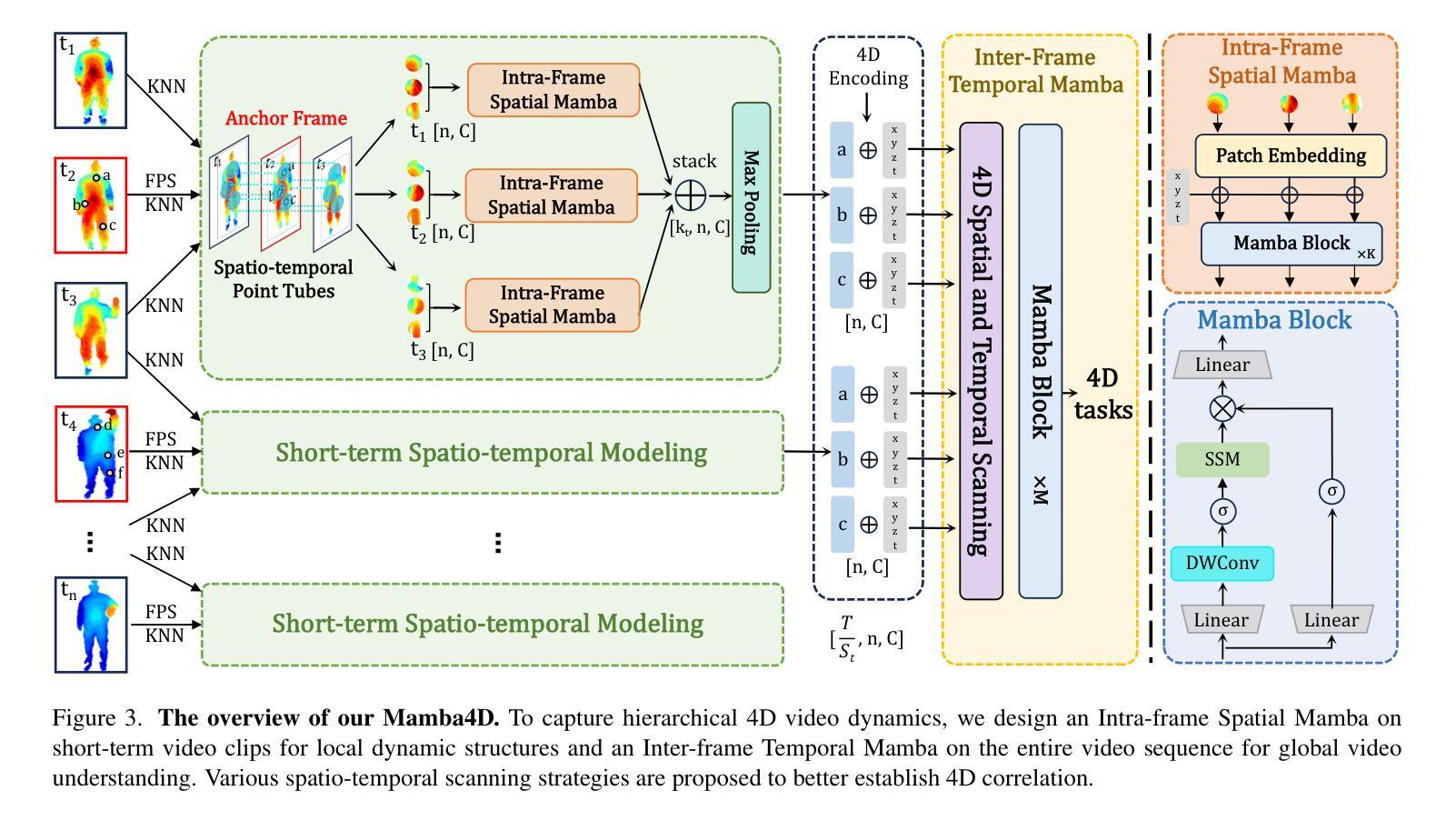
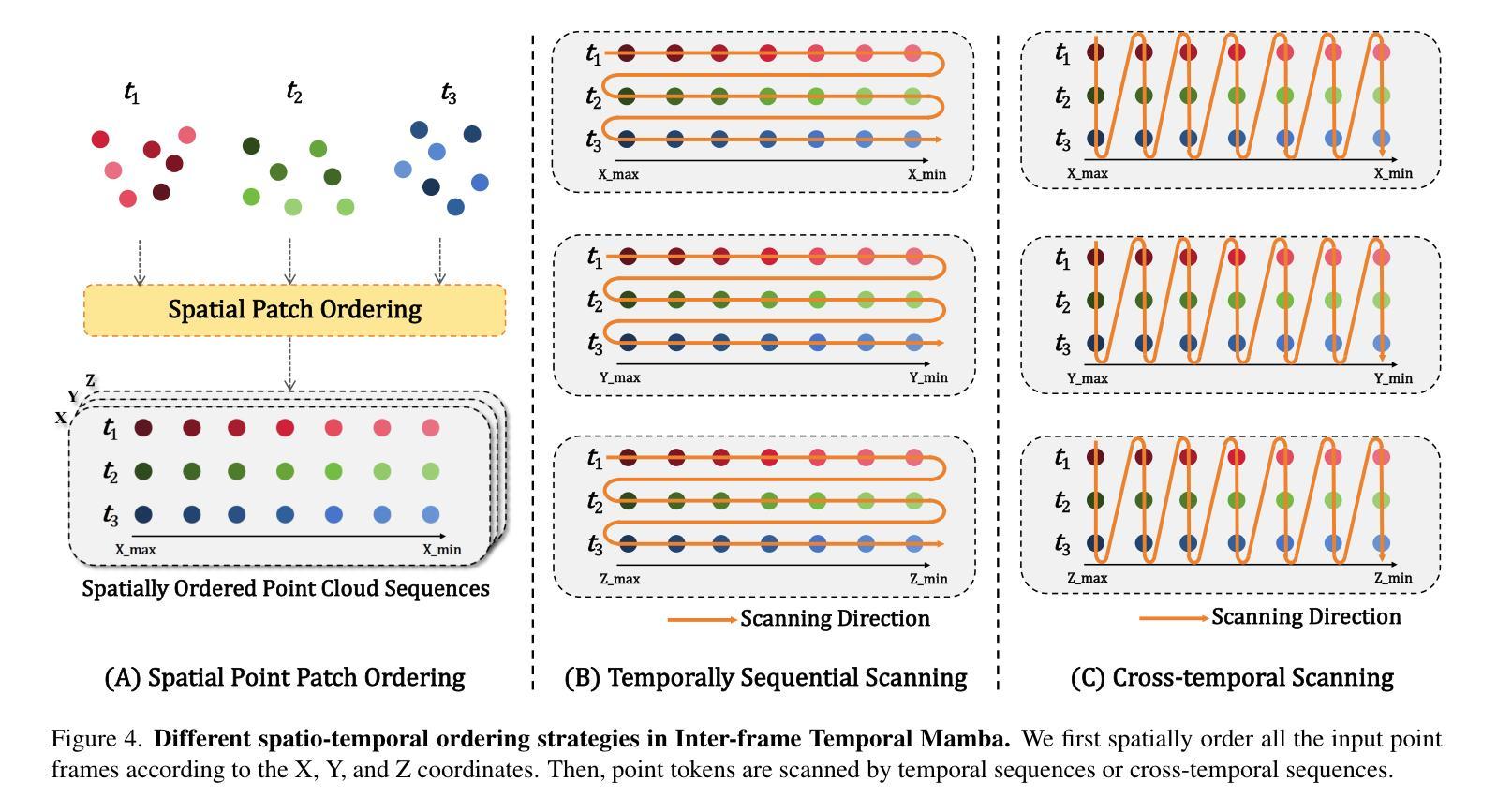
Point cloud videos can faithfully capture real-world spatial geometries and temporal dynamics, which are essential for enabling intelligent agents to understand the dynamically changing world. However, designing an effective 4D backbone remains challenging, mainly due to the irregular and unordered distribution of points and temporal inconsistencies across frames. Also, recent transformer-based 4D backbones commonly suffer from large computational costs due to their quadratic complexity, particularly for long video sequences. To address these challenges, we propose a novel point cloud video understanding backbone purely based on the State Space Models (SSMs). Specifically, we first disentangle space and time in 4D video sequences and then establish the spatio-temporal correlation with our designed Mamba blocks. The Intra-frame Spatial Mamba module is developed to encode locally similar geometric structures within a certain temporal stride. Subsequently, locally correlated tokens are delivered to the Inter-frame Temporal Mamba module, which integrates long-term point features across the entire video with linear complexity. Our proposed Mamba4d achieves competitive performance on the MSR-Action3D action recognition (+10.4% accuracy), HOI4D action segmentation (+0.7 F1 Score), and Synthia4D semantic segmentation (+0.19 mIoU) datasets. Especially, for long video sequences, our method has a significant efficiency improvement with 87.5% GPU memory reduction and 5.36 times speed-up. Codes will be released at https://github.com/IRMVLab/Mamba4D.
点云视频能够忠实捕捉现实世界中的空间几何和时态动态,这对于智能主体理解动态变化的世界至关重要。然而,设计有效的4D主干网络仍然是一个挑战,主要是由于点的分布不规则且无序,以及帧之间的时态不一致性。此外,最近的基于变压器的4D主干网络由于其二次复杂性而面临巨大的计算成本,特别是对于长视频序列。为了解决这些挑战,我们提出了一种全新的点云视频理解主干网络,该网络纯粹基于状态空间模型(SSMs)。具体来说,我们首先解开4D视频序列中的空间和时间,然后利用我们设计的Mamba块建立时空相关性。我们开发了帧内空间Mamba模块,以编码特定时间步长内局部相似的几何结构。随后,局部相关令牌被传递给帧间时间Mamba模块,该模块以线性复杂度整合整个视频的点特征。我们提出的Mamba4d在MSR-Action3D动作识别(提高10.4%的准确性)、HOI4D动作分割(提高0.7的F1分数)和Synthia4D语义分割(提高0.19的mIoU)数据集上实现了具有竞争力的性能。特别是对于长视频序列,我们的方法在GPU内存方面有了显著的效率提升,减少了87.5%的GPU内存使用,并加快了5.36倍的速度。代码将在https://github.com/IRMVLab/Mamba4D发布。
论文及项目相关链接
PDF Accepted by CVPR 2025. The first two authors contribute equally
Summary
点云视频能够捕捉真实世界的空间几何和时态动态,为智能主体理解动态变化的世界提供了可能。然而,设计有效的4D主干网络仍面临挑战,主要是由于点的分布不规则、无序以及跨帧的时态不一致性。为应对这些挑战,我们提出了基于状态空间模型(SSMs)的点云视频理解主干网络。通过解构4D视频序列中的空间和时态,我们建立了时空关联,并设计了Mamba模块。该模块包括帧内空间Mamba模块和帧间时态Mamba模块,分别用于编码局部相似几何结构和整合长期点特征。Mamba4d在MSR-Action3D动作识别、HOI4D动作分割和Synthia4D语义分割数据集上取得了具有竞争力的性能,尤其在长视频序列中,该方法在GPU内存使用和计算速度上具有显著优势。
Key Takeaways
- 点云视频能捕捉真实世界的空间几何和时态动态。
- 设计有效的4D主干网络具有挑战性,因为点的分布不规则、无序,以及跨帧的时态不一致性。
- 提出了基于状态空间模型(SSMs)的点云视频理解主干网络。
- 通过Mamba模块建立时空关联。
- Mamba模块包括帧内空间Mamba模块和帧间时态Mamba模块,分别处理局部几何和长期点特征。
- Mamba4d在多个数据集上表现优秀。
点此查看论文截图